update at 2024-04-12 16:19:36
parent
9735479315
commit
0eedaca203
|
|
@ -1,3 +0,0 @@
|
|||
# Kubernetes 排障案例
|
||||
|
||||
记录本人多年积累的 Kubernetes 相关的排障案例。
|
||||
|
|
@ -1,76 +0,0 @@
|
|||
# 误删 rancher 的 namespace 导致 node 被清空
|
||||
|
||||
## 问题描述
|
||||
|
||||
集群的节点突然全都不见了 (`kubectl get node` 为空),导致集群瘫痪,但实际上节点对应的虚拟机都还在。因为集群没开审计,所以也不太好查 node 是被什么删除的。
|
||||
|
||||
## 快速恢复
|
||||
|
||||
由于只是 k8s node 资源被删除,实际的机器都还在,我们可以批量重启节点,自动拉起 kubelet 重新注册 node,即可恢复。
|
||||
|
||||
## 可疑操作
|
||||
|
||||
发现在节点消失前,有个可疑的操作: 有同学发现在另外一个集群里有许多乱七八糟的 namespace (比如 `c-dxkxf`),查看这些 namespace 中没有运行任何工作负载,可能是其它人之前创建的测试 namespace,就将其删除掉了。
|
||||
|
||||
## 分析
|
||||
|
||||
删除 namespace 的集群中安装了 rancher,怀疑被删除的 namespace 是 rancher 自动创建的。
|
||||
|
||||
rancher 管理了其它 k8s 集群,架构图:
|
||||
|
||||

|
||||
|
||||
猜想: 删除的 namespace 是 rancher 创建的,删除时清理了 rancher 的资源,也触发了 rancher 清理 node 的逻辑。
|
||||
|
||||
## 模拟复现
|
||||
|
||||
尝试模拟复现,验证猜想:
|
||||
1. 创建一个 k8s 集群,作为 rancher 的 root cluster,并将 rancher 安装进去。
|
||||
2. 进入 rancher web 界面,创建一个 cluster,使用 import 方式:
|
||||
|
||||

|
||||
|
||||
3. 输入 cluster name:
|
||||
|
||||
|
||||
|
||||
4. 弹出提示,让在另一个集群执行下面的 kubectl 命令将其导入到 rancher:
|
||||
|
||||

|
||||
|
||||
5. 创建另一个 k8s 集群作为被 rancher 管理的集群,并将 kubeconfig 导入本地以便后续使用 kubectl 操作。
|
||||
6. 导入 kubeconfig 并切换 context 后,执行 rancher 提供的 kubectl 命令将集群导入 rancher:
|
||||
|
||||

|
||||
|
||||
可以看到在被管理的 TKE 集群中自动创建了 cattle-system 命名空间,并运行一些 rancher 的 agent:
|
||||
|
||||

|
||||
|
||||
7. 将 context 切换到安装 rancher 的集群 (root cluster),可以发现添加集群后,自动创建了一些 namespace: 1 个 `c-` 开头的,2 个 `p-` 开头的:
|
||||
|
||||

|
||||
|
||||
猜想是 `c-` 开头的 namespace 被 rancher 用来存储所添加的 `cluster` 的相关信息;`p-` 用于存储 `project` 相关的信息,官方也说了会自动为每个 cluster 创建 2 个 project:
|
||||
|
||||

|
||||
|
||||
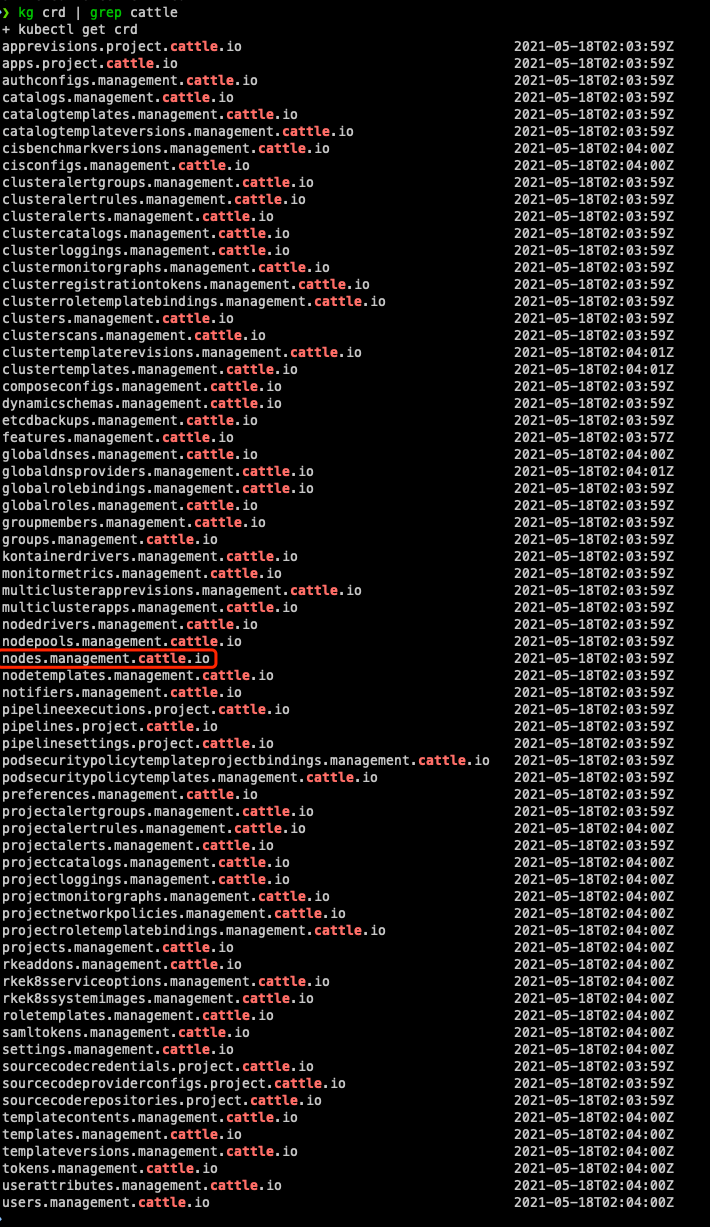
8. 查看有哪些 rancher 的 crd,有个 `nodes.management.cattle.io` 比较显眼,明显用于存储 cluster 的 node 信息:
|
||||
|
||||
|
||||
|
||||
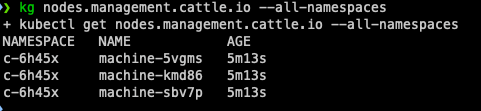
9. 看下 node 存储在哪个 namespace (果然在 `c-` 开头的 namespace 中):
|
||||
|
||||
|
||||
|
||||
10. 尝试删除 `c-` 开头的 namesapce,并切换 context 到被添加的集群,执行 `kubectl get node`:
|
||||
|
||||

|
||||
|
||||
节点被清空,问题复现。
|
||||
|
||||
## 结论
|
||||
|
||||
实验证明,rancher 的 `c-` 开头的 namespace 保存了所添加集群的 node 信息,如果删除了这种 namespace,也就删除了其中所存储的 node 信息,rancher watch 到了就会自动删除所关联集群的 k8s node 资源。
|
||||
|
||||
所以,千万不要轻易去清理 rancher 创建的 namespace,rancher 将一些有状态信息直接存储到了 root cluster 中 (通过 CRD 资源),删除 namespace 可能造成很严重的后果。
|
||||
|
|
@ -1,11 +0,0 @@
|
|||
# kubectl 执行 exec 或 logs 失败
|
||||
|
||||
## 原因
|
||||
|
||||
通常是 `kube-apiserver` 到 `kubelet:10250` 之间的网络不通,10250 是 kubelet 提供接口的端口,`kubectl exec` 和 `kubectl logs` 的原理就是 apiserver 调 kubelet,kubelet 再调运行时 (比如 dockerd) 来实现的。
|
||||
|
||||
## 解决方案
|
||||
|
||||
保证 kubelet 10250 端口对 apiserver 放通。
|
||||
|
||||
检查防火墙、iptables 规则是否对 10250 端口或某些 IP 进行了拦截。
|
||||
|
|
@ -1,173 +0,0 @@
|
|||
# 调度器 cache 快照遗漏部分信息导致 pod pending
|
||||
|
||||
## 问题背景
|
||||
|
||||
新建一个如下的 k8s 集群,有3个master node和1个worker node(worker 和 master在不同的可用区),node信息如下:
|
||||
|
||||
| node | label信息 |
|
||||
|:----|:----|
|
||||
| master-01 | failure-domain.beta.kubernetes.io/region=sh,failure-domain.beta.kubernetes.io/zone=200002 |
|
||||
| master-02 | failure-domain.beta.kubernetes.io/region=sh,failure-domain.beta.kubernetes.io/zone=200002 |
|
||||
| master-03 | failure-domain.beta.kubernetes.io/region=sh,failure-domain.beta.kubernetes.io/zone=200002 |
|
||||
| worker-node-01 | failure-domain.beta.kubernetes.io/region=sh,failure-domain.beta.kubernetes.io/zone=200004 |
|
||||
|
||||
待集群创建好之后,然后创建了一个daemonset对象,就出现了daemonset的某个pod一直卡主pending状态的现象。
|
||||
|
||||
现象如下:
|
||||
|
||||
```bash
|
||||
$ kubectl get pod -o wide
|
||||
NAME READY STATUS RESTARTS AGE NODE
|
||||
debug-4m8lc 1/1 Running 1 89m master-01
|
||||
debug-dn47c 0/1 Pending 0 89m <none>
|
||||
debug-lkmfs 1/1 Running 1 89m master-02
|
||||
debug-qwdbc 1/1 Running 1 89m worker-node-01
|
||||
```
|
||||
|
||||
## 结论先行
|
||||
|
||||
k8s的调度器在调度某个pod时,会从调度器的内部cache中同步一份快照(snapshot),其中保存了pod可以调度的node信息。
|
||||
|
||||
上面问题(daemonset的某个pod实例卡在pending状态)发生的原因就是同步的过程发生了部分node信息丢失,导致了daemonset的部分pod实例无法调度到指定的节点上,出现了pending状态。
|
||||
|
||||
接下来是详细的排查过程。
|
||||
|
||||
## 日志排查
|
||||
|
||||
截图中出现的节点信息(来自用户线上集群):
|
||||
* k8s master节点:ss-stg-ma-01、ss-stg-ma-02、ss-stg-ma-03
|
||||
* k8s worker节点:ss-stg-test-01
|
||||
|
||||
1. 获取调度器的日志
|
||||
|
||||
这里首先是通过动态调大调度器的日志级别,比如,直接调大到`V(10)`,尝试获取一些相关日志。
|
||||
|
||||
当日志级别调大之后,有抓取到一些关键信息,信息如下:
|
||||
|
||||

|
||||
|
||||
* 解释一下,当调度某个pod时,有可能会进入到调度器的抢占`preempt`环节,而上面的日志就是出自于抢占环节。 集群中有4个节点(3个master node和1个worker node),但是日志中只显示了3个节点,缺少了一个master节点。所以,这里暂时怀疑下是调度器内部缓存cache中少了`node info`。
|
||||
|
||||
2. 获取调度器内部cache信息
|
||||
|
||||
k8s v1.18已经支持打印调度器内部的缓存cache信息。打印出来的调度器内部缓存cache信息如下:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
可以看出,调度器的内部缓存cache中的`node info`是完整的(3个master node和1个worker node)。
|
||||
|
||||
通过分析日志,可以得到一个初步结论:调度器内部缓存cache中的`node info`是完整的,但是当调度pod时,缓存cache中又会缺少部分node信息。
|
||||
|
||||
## 问题根因
|
||||
|
||||
在进一步分析之前,我们先一起再熟悉下调度器调度pod的流程(部分展示)和nodeTree数据结构。
|
||||
|
||||
### **pod调度流程(部分展示)**
|
||||
|
||||
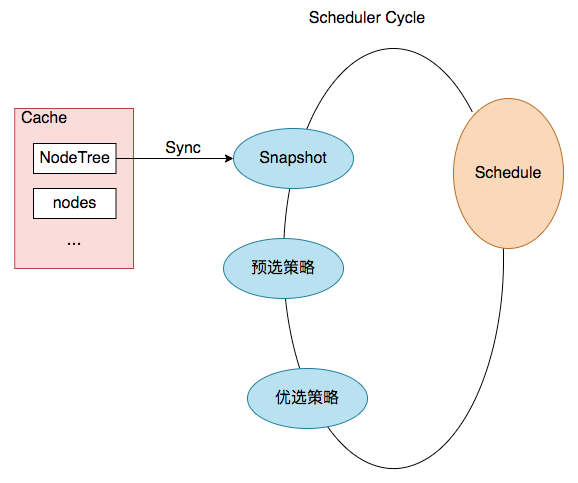
|
||||
|
||||
结合上图,一次pod的调度过程就是一次`Scheduler Cycle`。在这个`Cycle`开始时,第一步就是`update snapshot`。snapshot我们可以理解为cycle内的cache,其中保存了pod调度时所需的`node info`,而`update snapshot`,就是一次nodeTree(调度器内部cache中保存的node信息)到`snapshot`的同步过程。
|
||||
|
||||
而同步过程主要是通过`nodeTree.next()`函数来实现,函数逻辑如下:
|
||||
|
||||
```go
|
||||
// next returns the name of the next node. NodeTree iterates over zones and in each zone iterates
|
||||
// over nodes in a round robin fashion.
|
||||
func (nt *nodeTree) next() string {
|
||||
if len(nt.zones) == 0 {
|
||||
return ""
|
||||
}
|
||||
numExhaustedZones := 0
|
||||
for {
|
||||
if nt.zoneIndex >= len(nt.zones) {
|
||||
nt.zoneIndex = 0
|
||||
}
|
||||
zone := nt.zones[nt.zoneIndex]
|
||||
nt.zoneIndex++
|
||||
// We do not check the exhausted zones before calling next() on the zone. This ensures
|
||||
// that if more nodes are added to a zone after it is exhausted, we iterate over the new nodes.
|
||||
nodeName, exhausted := nt.tree[zone].next()
|
||||
if exhausted {
|
||||
numExhaustedZones++
|
||||
if numExhaustedZones >= len(nt.zones) { // all zones are exhausted. we should reset.
|
||||
nt.resetExhausted()
|
||||
}
|
||||
} else {
|
||||
return nodeName
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
再结合上面排查过程得出的结论,我们可以再进一步缩小问题范围:nodeTree(调度器内部cache)到`snapshot.nodeInfoList`的同步过程丢失了某个节点信息。
|
||||
|
||||
### nodeTree数据结构
|
||||
|
||||
(方便理解,本文使用了链表来展示)
|
||||
|
||||
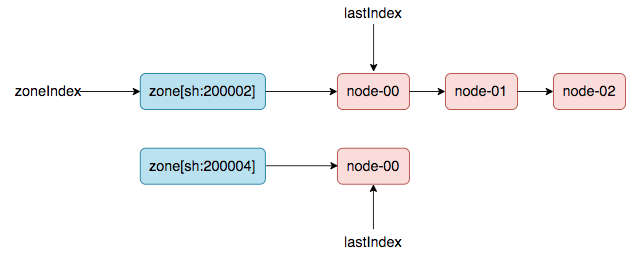
|
||||
|
||||
### 重现问题,定位根因
|
||||
|
||||
创建k8s集群时,会先加入master node,然后再加入worker node(意思是worker node时间上会晚于master node加入集群的时间)。
|
||||
|
||||
第一轮同步:3台master node创建好,然后发生pod调度(比如,cni 插件,以daemonset的方式部署在集群中),会触发一次nodeTree(调度器内部cache)到`snapshot.nodeInfoList`的同步。同步之后,nodeTree的两个游标就变成了如下结果:
|
||||
|
||||
`nodeTree.zoneIndex = 1, nodeTree.nodeArray[sh:200002].lastIndex = 3,`
|
||||
|
||||
第二轮同步:当worker node加入集群中后,然后新建一个daemonset,就会触发第二轮的同步(nodeTree(调度器内部cache)到`snapshot.nodeInfoList`的同步)。
|
||||
|
||||
同步过程如下:
|
||||
|
||||
1. zoneIndex=1, nodeArray[sh:200004].lastIndex=0, we get worker-node-01.
|
||||
|
||||
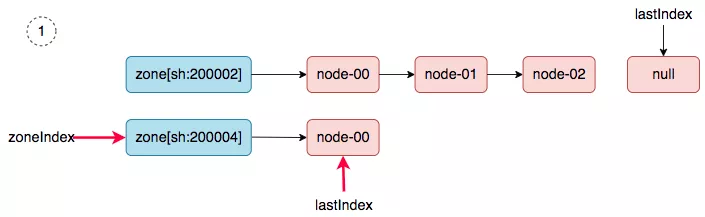
|
||||
|
||||
2. zoneIndex=2 >= len(zones); zoneIndex=0, nodeArray[sh:200002].lastIndex=3, return.
|
||||
|
||||
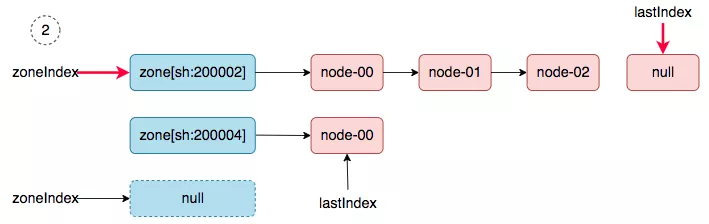
|
||||
|
||||
3. zoneIndex=1, nodeArray[sh:200004].lastIndex=1, return.
|
||||
|
||||
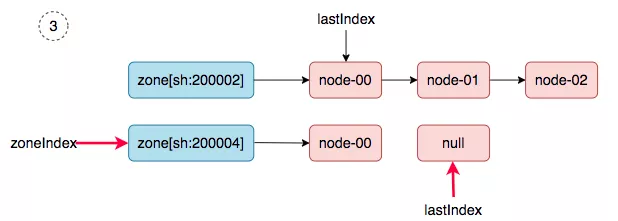
|
||||
|
||||
4. zoneIndex=0, nodeArray[sh:200002].lastIndex=0, we get master-01.
|
||||
|
||||
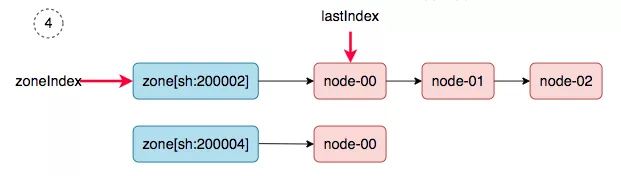
|
||||
|
||||
5. zoneIndex=1, nodeArray[sh:200004].lastIndex=0, we get worker-node-01.
|
||||
|
||||
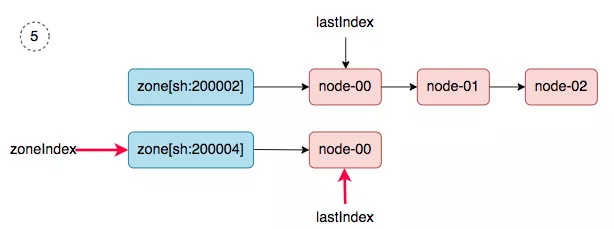
|
||||
|
||||
6. zoneIndex=2 >= len(zones); zoneIndex=0, nodeArray[sh:200002].lastIndex=1, we get master-02.
|
||||
|
||||
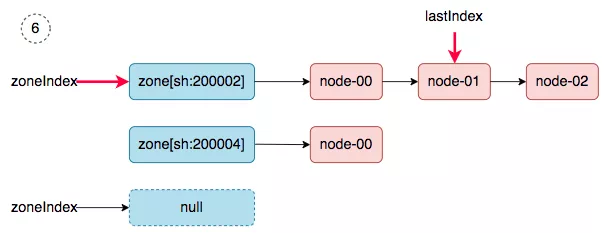
|
||||
|
||||
同步完成之后,调度器的`snapshot.nodeInfoList`得到如下的结果:
|
||||
|
||||
```json
|
||||
[
|
||||
worker-node-01,
|
||||
master-01,
|
||||
worker-node-01,
|
||||
master-02,
|
||||
]
|
||||
```
|
||||
|
||||
master-03去哪了?在第二轮同步的过程中丢了。
|
||||
|
||||
## 解决方案
|
||||
|
||||
从`问题根因`的分析中,可以看出,导致问题发生的原因,在于nodeTree数据结构中的游标zoneIndex 和 lastIndex(zone级别)值被保留了,所以,解决的方案就是在每次同步SYNC时,强制重置游标(归0)。
|
||||
|
||||
## 参考资料
|
||||
|
||||
* [相关 issue](https://github.com/kubernetes/kubernetes/issues/97120)
|
||||
* [相关pr (k8s v1.18)](https://github.com/kubernetes/kubernetes/pull/93387)
|
||||
* [TKE 修复版本 v1.18.4-tke.5](https://cloud.tencent.com/document/product/457/9315#tke-kubernetes-1.18.4-revisions)
|
||||
|
|
@ -1,40 +0,0 @@
|
|||
# 容器磁盘满导致 CPU 飙高
|
||||
|
||||
## 问题描述
|
||||
|
||||
某服务的其中两个副本异常,CPU 飙高。
|
||||
|
||||
## 排查
|
||||
|
||||
1. 查看 `container_cpu_usage_seconds_total` 监控,CPU 飙升,逼近 limit。
|
||||
2. 查看 `container_cpu_cfs_throttled_periods_total` 监控,CPU 飙升伴随 CPU Throttle 飙升,所以服务异常应该是 CPU 被限流导致。
|
||||
3. 查看 `container_cpu_system_seconds_total` 监控,发现 CPU 飙升主要是 CPU system 占用导致,容器内 `pidstat -u -t 5 1` 可以看到进程 `%system` 占用分布情况。
|
||||
4. `perf top` 看 system 占用高主要是 `vfs_write` 写数据导致。
|
||||
|
||||

|
||||
|
||||
5. `iostat -xhd 2` 看 IO 并不高,磁盘利用率也不高,io wait 也不高。
|
||||
6. `sync_inodes_sb` 看起来是写数据时触发了磁盘同步的耗时逻辑
|
||||
7. 深入看内核代码,当磁盘满的时候会调用 flush 刷磁盘所有数据,这个会一直在内核态运行很久,相当于对这个文件系统做 sync。
|
||||
|
||||
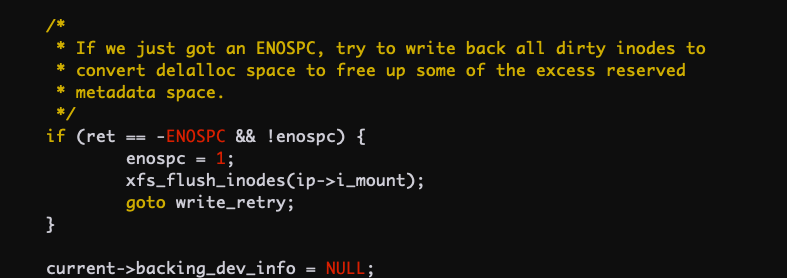
|
||||
|
||||
8. 节点上 `df -h` 看并没有磁盘满。
|
||||
9. 容器内 `df -h` 看根目录空间满了.
|
||||
|
||||

|
||||
|
||||
10. 看到 docker `daemon.json` 配置,限制了容器内 rootfs 最大只能占用 200G
|
||||
|
||||
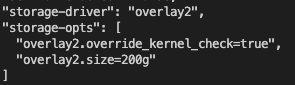
|
||||
|
||||
11. 容器内一级级的 `du -sh *` 排查发现主要是一个 `nohup.log` 文件占满了磁盘。
|
||||
|
||||
|
||||
## 结论
|
||||
|
||||
容器内空间满了继续写数据会导致内核不断刷盘对文件系统同步,会导致内核态 CPU 占用升高,设置了 cpu limit 通常会被 throttle,导致服务处理慢,影响业务。
|
||||
|
||||
## 建议
|
||||
|
||||
对日志进行轮转,或直接打到标准输出,避免写满容器磁盘。
|
||||
|
|
@ -1,17 +0,0 @@
|
|||
# ARP 爆满导致健康检查失败
|
||||
|
||||
## 案例
|
||||
|
||||
一用户某集群节点数 1200+,用户监控方案是 daemonset 部署 node-exporter 暴露节点监控指标,使用 hostNework 方式,statefulset 部署 promethues 且仅有一个实例,落在了一个节点上,promethues 请求所有节点 node-exporter 获取节点监控指标,也就是或扫描所有节点,导致 arp cache 需要存所有 node 的记录,而节点数 1200+,大于了 `net.ipv4.neigh.default.gc_thresh3` 的默认值 1024,这个值是个硬限制,arp cache记录数大于这个就会强制触发 gc,所以会造成频繁gc,当有数据包发送会查本地 arp,如果本地没找到 arp 记录就会判断当前 arp cache 记录数+1是否大于 gc_thresh3,如果没有就会广播 arp 查询 mac 地址,如果大于了就直接报 `arp_cache: neighbor table overflow!`,并且放弃 arp 请求,无法获取 mac 地址也就无法知道探测报文该往哪儿发(即便就在本机某个 veth pair),kubelet 对本机 pod 做存活检查发 arp 查 mac 地址,在 arp cahce 找不到,由于这时 arp cache已经满了,刚要 gc 但还没做所以就只有报错丢包,导致存活检查失败重启 pod。
|
||||
|
||||
## 解决方案
|
||||
|
||||
调整部分节点内核参数,将 arp cache 的 gc 阀值调高 (`/etc/sysctl.conf`):
|
||||
|
||||
``` bash
|
||||
net.ipv4.neigh.default.gc_thresh1 = 80000
|
||||
net.ipv4.neigh.default.gc_thresh2 = 90000
|
||||
net.ipv4.neigh.default.gc_thresh3 = 100000
|
||||
```
|
||||
|
||||
并给 node 打下 label,修改 pod spec,加下 nodeSelector 或者 nodeAffnity,让 pod 只调度到这部分改过内核参数的节点,更多请参考本书 [节点排障: ARP 表爆满](../../troubleshooting/node/arp-cache-overflow)
|
||||
|
|
@ -1,58 +0,0 @@
|
|||
# tcp_tw_recycle 导致跨 VPC 访问 NodePort 超时
|
||||
|
||||
## 现象
|
||||
|
||||
从 VPC a 访问 VPC b 的 TKE 集群的某个节点的 NodePort,有时候正常,有时候会卡住直到超时。
|
||||
|
||||
## 排查
|
||||
|
||||
原因怎么查?
|
||||
|
||||
当然是先抓包看看啦,抓 server 端 NodePort 的包,发现异常时 server 能收到 SYN,但没响应 ACK:
|
||||
|
||||

|
||||
|
||||
反复执行 `netstat -s | grep LISTEN` 发现 SYN 被丢弃数量不断增加:
|
||||
|
||||
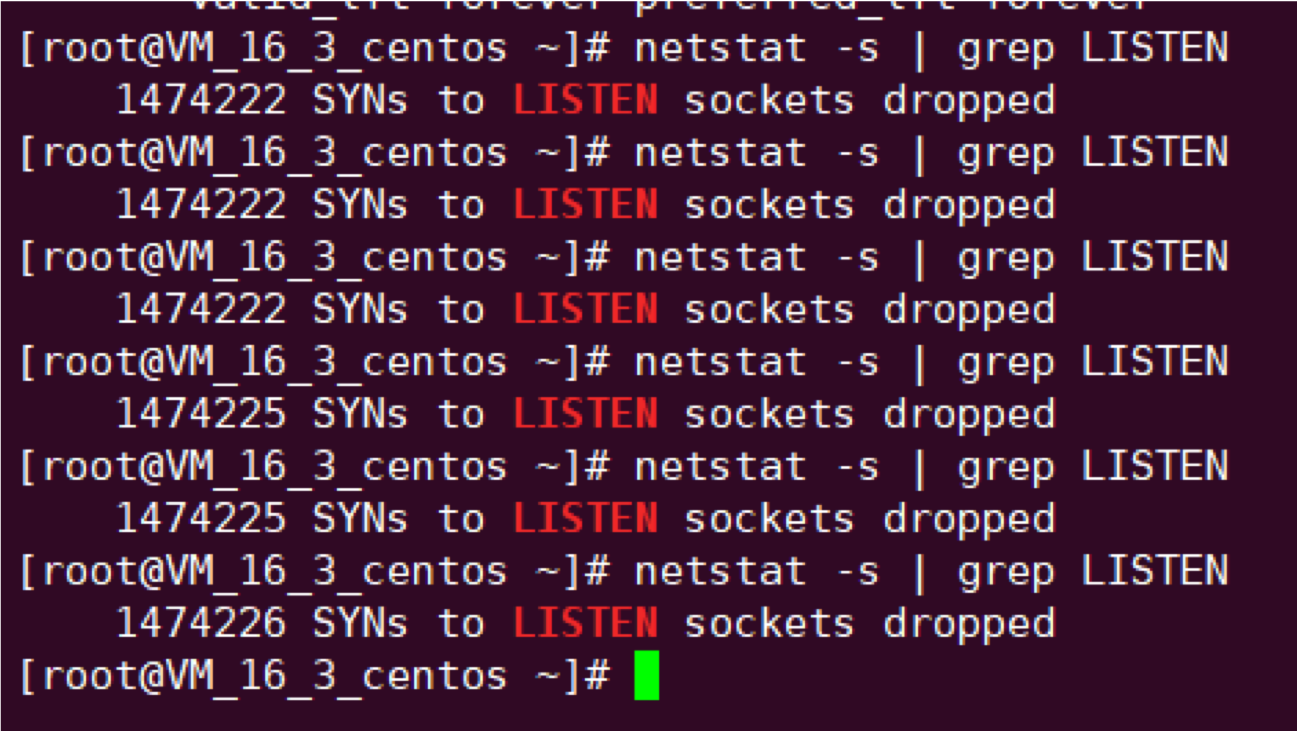
|
||||
|
||||
分析:
|
||||
|
||||
- 两个VPC之间使用对等连接打通的,CVM 之间通信应该就跟在一个内网一样可以互通。
|
||||
- 为什么同一 VPC 下访问没问题,跨 VPC 有问题? 两者访问的区别是什么?
|
||||
|
||||
再仔细看下 client 所在环境,发现 client 是 VPC a 的 TKE 集群节点,捋一下:
|
||||
|
||||
- client 在 VPC a 的 TKE 集群的节点
|
||||
- server 在 VPC b 的 TKE 集群的节点
|
||||
|
||||
因为 TKE 集群中有个叫 `ip-masq-agent` 的 daemonset,它会给 node 写 iptables 规则,默认 SNAT 目的 IP 是 VPC 之外的报文,所以 client 访问 server 会做 SNAT,也就是这里跨 VPC 相比同 VPC 访问 NodePort 多了一次 SNAT,如果是因为多了一次 SNAT 导致的这个问题,直觉告诉我这个应该跟内核参数有关,因为是 server 收到包没回包,所以应该是 server 所在 node 的内核参数问题,对比这个 node 和 普通 TKE node 的默认内核参数,发现这个 node `net.ipv4.tcp_tw_recycle = 1`,这个参数默认是关闭的,跟用户沟通后发现这个内核参数确实在做压测的时候调整过。
|
||||
|
||||
## tcp_tw_recycle 的坑
|
||||
|
||||
解释一下,TCP 主动关闭连接的一方在发送最后一个 ACK 会进入 `TIME_AWAIT` 状态,再等待 2 个 MSL 时间后才会关闭(因为如果 server 没收到 client 第四次挥手确认报文,server 会重发第三次挥手 FIN 报文,所以 client 需要停留 2 MSL的时长来处理可能会重复收到的报文段;同时等待 2 MSL 也可以让由于网络不通畅产生的滞留报文失效,避免新建立的连接收到之前旧连接的报文),了解更详细的过程请参考 TCP 四次挥手。
|
||||
|
||||
参数 `tcp_tw_recycle` 用于快速回收 `TIME_AWAIT` 连接,通常在增加连接并发能力的场景会开启,比如发起大量短连接,快速回收可避免 `tw_buckets` 资源耗尽导致无法建立新连接 (`time wait bucket table overflow`)
|
||||
|
||||
查得 `tcp_tw_recycle` 有个坑,在 RFC1323 有段描述:
|
||||
|
||||
`
|
||||
An additional mechanism could be added to the TCP, a per-host cache of the last timestamp received from any connection. This value could then be used in the PAWS mechanism to reject old duplicate segments from earlier incarnations of the connection, if the timestamp clock can be guaranteed to have ticked at least once since the old connection was open. This would require that the TIME-WAIT delay plus the RTT together must be at least one tick of the sender’s timestamp clock. Such an extension is not part of the proposal of this RFC.
|
||||
`
|
||||
|
||||
大概意思是说 TCP 有一种行为,可以缓存每个连接最新的时间戳,后续请求中如果时间戳小于缓存的时间戳,即视为无效,相应的数据包会被丢弃。
|
||||
|
||||
Linux 是否启用这种行为取决于 `tcp_timestamps` 和 `tcp_tw_recycle`,因为 `tcp_timestamps` 缺省开启,所以当 `tcp_tw_recycle` 被开启后,实际上这种行为就被激活了,当客户端或服务端以 `NAT` 方式构建的时候就可能出现问题。
|
||||
|
||||
当多个客户端通过 NAT 方式联网并与服务端交互时,服务端看到的是同一个 IP,也就是说对服务端而言这些客户端实际上等同于一个,可惜由于这些客户端的时间戳可能存在差异,于是乎从服务端的视角看,便可能出现时间戳错乱的现象,进而直接导致时间戳小的数据包被丢弃。如果发生了此类问题,具体的表现通常是是客户端明明发送的 SYN,但服务端就是不响应 ACK。
|
||||
|
||||
## 真相大白
|
||||
|
||||
回到我们的问题上,client 所在节点上可能也会有其它 pod 访问到 server 所在节点,而它们都被 SNAT 成了 client 所在节点的 NODE IP,但时间戳存在差异,server 就会看到时间戳错乱,因为开启了 `tcp_tw_recycle` 和 `tcp_timestamps` 激活了上述行为,就丢掉了比缓存时间戳小的报文,导致部分 SYN 被丢弃,这也解释了为什么之前我们抓包发现异常时 server 收到了 SYN,但没有响应 ACK,进而说明为什么 client 的请求部分会卡住直到超时。
|
||||
|
||||
由于 `tcp_tw_recycle` 坑太多,在内核 4.12 之后已移除: [remove tcp_tw_recycle](https://github.com/torvalds/linux/commit/4396e46187ca5070219b81773c4e65088dac50cc)
|
||||
|
||||
## 解决方案
|
||||
|
||||
1. 关闭 tcp_tw_recycle。
|
||||
2. 升级内核,启用 `net.ipv4.tcp_tw_reuse`。
|
||||
|
|
@ -1,191 +0,0 @@
|
|||
# DNS 5 秒延时
|
||||
|
||||
## 现象
|
||||
|
||||
用户反馈从 pod 中访问服务时,总是有些请求的响应时延会达到5秒。正常的响应只需要毫秒级别的时延。
|
||||
|
||||
## 抓包
|
||||
|
||||
* [使用 nsenter 进入 netns](../../troubleshooting/skill/enter-netns-with-nsenter),然后使用节点上的 tcpdump 抓 pod 中的包,发现是有的 DNS 请求没有收到响应,超时 5 秒后,再次发送 DNS 请求才成功收到响应。
|
||||
* 在 kube-dns pod 抓包,发现是有 DNS 请求没有到达 kube-dns pod,在中途被丢弃了。
|
||||
|
||||
为什么是 5 秒? `man resolv.conf` 可以看到 glibc 的 resolver 的缺省超时时间是 5s:
|
||||
|
||||
```txt
|
||||
timeout:n
|
||||
Sets the amount of time the resolver will wait for a response from a remote name server before retrying the query via a different name server. Measured in seconds, the default is RES_TIMEOUT (currently 5, see
|
||||
<resolv.h>). The value for this option is silently capped to 30.
|
||||
```
|
||||
|
||||
## 丢包原因
|
||||
|
||||
经过搜索发现这是一个普遍问题。
|
||||
|
||||
根本原因是内核 conntrack 模块的 bug,netfilter 做 NAT 时可能发生资源竞争导致部分报文丢弃。
|
||||
|
||||
Weave works 的工程师 `Martynas Pumputis` 对这个问题做了很详细的分析:[Racy conntrack and DNS lookup timeouts](https://www.weave.works/blog/racy-conntrack-and-dns-lookup-timeouts)
|
||||
|
||||
相关结论:
|
||||
|
||||
* 只有多个线程或进程,并发从同一个 socket 发送相同五元组的 UDP 报文时,才有一定概率会发生
|
||||
* glibc, musl\(alpine linux的libc库\)都使用 "parallel query", 就是并发发出多个查询请求,因此很容易碰到这样的冲突,造成查询请求被丢弃
|
||||
* 由于 ipvs 也使用了 conntrack, 使用 kube-proxy 的 ipvs 模式,并不能避免这个问题
|
||||
|
||||
## 问题的根本解决
|
||||
|
||||
Martynas 向内核提交了两个 patch 来 fix 这个问题,不过他说如果集群中有多个DNS server的情况下,问题并没有完全解决。
|
||||
|
||||
其中一个 patch 已经在 2018-7-18 被合并到 linux 内核主线中: [netfilter: nf\_conntrack: resolve clash for matching conntracks](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=ed07d9a021df6da53456663a76999189badc432a)
|
||||
|
||||
目前只有4.19.rc 版本包含这个patch。
|
||||
|
||||
## 规避办法
|
||||
|
||||
### 规避方案一:使用TCP发送DNS请求
|
||||
|
||||
由于TCP没有这个问题,有人提出可以在容器的resolv.conf中增加`options use-vc`, 强制glibc使用TCP协议发送DNS query。下面是这个man resolv.conf中关于这个选项的说明:
|
||||
|
||||
```text
|
||||
use-vc (since glibc 2.14)
|
||||
Sets RES_USEVC in _res.options. This option forces the
|
||||
use of TCP for DNS resolutions.
|
||||
```
|
||||
|
||||
笔者使用镜像"busybox:1.29.3-glibc" \(libc 2.24\) 做了试验,并没有见到这样的效果,容器仍然是通过UDP发送DNS请求。
|
||||
|
||||
### 规避方案二:避免相同五元组DNS请求的并发
|
||||
|
||||
resolv.conf还有另外两个相关的参数:
|
||||
|
||||
* single-request-reopen \(since glibc 2.9\)
|
||||
* single-request \(since glibc 2.10\)
|
||||
|
||||
man resolv.conf中解释如下:
|
||||
|
||||
```text
|
||||
single-request-reopen (since glibc 2.9)
|
||||
Sets RES_SNGLKUPREOP in _res.options. The resolver
|
||||
uses the same socket for the A and AAAA requests. Some
|
||||
hardware mistakenly sends back only one reply. When
|
||||
that happens the client system will sit and wait for
|
||||
the second reply. Turning this option on changes this
|
||||
behavior so that if two requests from the same port are
|
||||
not handled correctly it will close the socket and open
|
||||
a new one before sending the second request.
|
||||
|
||||
single-request (since glibc 2.10)
|
||||
Sets RES_SNGLKUP in _res.options. By default, glibc
|
||||
performs IPv4 and IPv6 lookups in parallel since
|
||||
version 2.9. Some appliance DNS servers cannot handle
|
||||
these queries properly and make the requests time out.
|
||||
This option disables the behavior and makes glibc
|
||||
perform the IPv6 and IPv4 requests sequentially (at the
|
||||
cost of some slowdown of the resolving process).
|
||||
```
|
||||
|
||||
用自己的话解释下:
|
||||
|
||||
* `single-request-reopen`: 发送 A 类型请求和 AAAA 类型请求使用不同的源端口,这样两个请求在 conntrack 表中不占用同一个表项,从而避免冲突
|
||||
* `single-request`: 避免并发,改为串行发送 A 类型和 AAAA 类型请求,没有了并发,从而也避免了冲突
|
||||
|
||||
要给容器的 `resolv.conf` 加上 options 参数,有几个办法:
|
||||
|
||||
1. 在容器的 "ENTRYPOINT" 或者 "CMD" 脚本中,执行 /bin/echo 'options single-request-reopen' >> /etc/resolv.conf**
|
||||
|
||||
2. 在 pod 的 postStart hook 中:
|
||||
|
||||
```yaml
|
||||
lifecycle:
|
||||
postStart:
|
||||
exec:
|
||||
command:
|
||||
- /bin/sh
|
||||
- -c
|
||||
- "/bin/echo 'options single-request-reopen' >> /etc/resolv.conf"
|
||||
```
|
||||
|
||||
3. 使用 template.spec.dnsConfig (k8s v1.9 及以上才支持):
|
||||
|
||||
```yaml
|
||||
template:
|
||||
spec:
|
||||
dnsConfig:
|
||||
options:
|
||||
- name: single-request-reopen
|
||||
```
|
||||
|
||||
4. 使用 ConfigMap 覆盖 pod 里面的 /etc/resolv.conf:
|
||||
|
||||
configmap:
|
||||
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
data:
|
||||
resolv.conf: |
|
||||
nameserver 1.2.3.4
|
||||
search default.svc.cluster.local svc.cluster.local cluster.local ec2.internal
|
||||
options ndots:5 single-request-reopen timeout:1
|
||||
kind: ConfigMap
|
||||
metadata:
|
||||
name: resolvconf
|
||||
```
|
||||
|
||||
pod spec:
|
||||
|
||||
```yaml
|
||||
volumeMounts:
|
||||
- name: resolv-conf
|
||||
mountPath: /etc/resolv.conf
|
||||
subPath: resolv.conf
|
||||
...
|
||||
|
||||
volumes:
|
||||
- name: resolv-conf
|
||||
configMap:
|
||||
name: resolvconf
|
||||
items:
|
||||
- key: resolv.conf
|
||||
path: resolv.conf
|
||||
```
|
||||
|
||||
5. 使用 MutatingAdmissionWebhook
|
||||
|
||||
[MutatingAdmissionWebhook](https://kubernetes.io/docs/reference/access-authn-authz/admission-controllers/#mutatingadmissionwebhook-beta-in-1-9) 是 1.9 引入的 Controller,用于对一个指定的 Resource 的操作之前,对这个 resource 进行变更。 istio 的自动 sidecar注入就是用这个功能来实现的。 我们也可以通过 MutatingAdmissionWebhook,来自动给所有POD,注入以上3\)或者4\)所需要的相关内容。
|
||||
|
||||
以上方法中, 1 和 2 都需要修改镜像, 3 和 4 则只需要修改 pod 的 spec, 能适用于所有镜像。不过还是有不方便的地方:
|
||||
|
||||
* 每个工作负载的yaml都要做修改,比较麻烦
|
||||
* 对于通过helm创建的工作负载,需要修改helm charts
|
||||
|
||||
方法5\)对集群使用者最省事,照常提交工作负载即可。不过初期需要一定的开发工作量。
|
||||
|
||||
### 最佳实践:使用 LocalDNS
|
||||
|
||||
容器的DNS请求都发往本地的DNS缓存服务 (dnsmasq, nscd 等),不需要走DNAT,也不会发生conntrack冲突。另外还有个好处,就是避免DNS服务成为性能瓶颈。
|
||||
|
||||
使用 LocalDNS 缓存有两种方式:
|
||||
|
||||
* 每个容器自带一个DNS缓存服务
|
||||
* 每个节点运行一个DNS缓存服务,所有容器都把本节点的DNS缓存作为自己的 nameserver
|
||||
|
||||
从资源效率的角度来考虑的话,推荐后一种方式。官方也意识到了这个问题比较常见,给出了 coredns 以 cache 模式作为 daemonset 部署的解决方案: [https://kubernetes.io/docs/tasks/administer-cluster/nodelocaldns/](https://kubernetes.io/docs/tasks/administer-cluster/nodelocaldns/)
|
||||
|
||||
### 实施办法
|
||||
|
||||
条条大路通罗马,不管怎么做,最终到达上面描述的效果即可。
|
||||
|
||||
POD中要访问节点上的DNS缓存服务,可以使用节点的IP。 如果节点上的容器都连在一个虚拟bridge上, 也可以使用这个bridge的三层接口的IP(在TKE中,这个三层接口叫cbr0)。 要确保DNS缓存服务监听这个地址。
|
||||
|
||||
如何把 POD 的 /etc/resolv.conf 中的 nameserver 设置为节点IP呢?
|
||||
|
||||
一个办法,是设置 POD.spec.dnsPolicy 为 "Default", 意思是POD里面的 /etc/resolv.conf, 使用节点上的文件。缺省使用节点上的 /etc/resolv.conf (如果kubelet通过参数--resolv-conf指定了其他文件,则使用--resolv-conf所指定的文件)。
|
||||
|
||||
另一个办法,是给每个节点的kubelet指定不同的--cluster-dns参数,设置为节点的IP,POD.spec.dnsPolicy仍然使用缺省值"ClusterFirst"。 kops项目甚至有个issue在讨论如何在部署集群时设置好--cluster-dns指向节点IP: [https://github.com/kubernetes/kops/issues/5584](https://github.com/kubernetes/kops/issues/5584)
|
||||
|
||||
## 参考资料
|
||||
|
||||
* [Racy conntrack and DNS lookup timeouts](https://www.weave.works/blog/racy-conntrack-and-dns-lookup-timeouts)
|
||||
* [5 – 15s DNS lookups on Kubernetes?](https://blog.quentin-machu.fr/2018/06/24/5-15s-dns-lookups-on-kubernetes/)
|
||||
* [DNS intermittent delays of 5s](https://github.com/kubernetes/kubernetes/issues/56903)
|
||||
* [记一次Docker/Kubernetes上无法解释的连接超时原因探寻之旅](https://mp.weixin.qq.com/s/VYBs8iqf0HsNg9WAxktzYQ)
|
||||
|
||||
|
|
@ -1,95 +0,0 @@
|
|||
# dns id 冲突导致解析异常
|
||||
|
||||
## 现象
|
||||
|
||||
有个用户反馈域名解析有时有问题,看报错是解析超时。
|
||||
|
||||
## 排查
|
||||
|
||||
第一反应当然是看 coredns 的 log:
|
||||
|
||||
``` bash
|
||||
[ERROR] 2 loginspub.xxxxmobile-inc.net.
|
||||
A: unreachable backend: read udp 172.16.0.230:43742->10.225.30.181:53: i/o timeout
|
||||
```
|
||||
|
||||
这是上游 DNS 解析异常了,因为解析外部域名 coredns 默认会请求上游 DNS 来查询,这里的上游 DNS 默认是 coredns pod 所在宿主机的 `resolv.conf` 里面的 nameserver (coredns pod 的 dnsPolicy 为 "Default",也就是会将宿主机里的 `resolv.conf` 里的 nameserver 加到容器里的 `resolv.conf`, coredns 默认配置 `proxy . /etc/resolv.conf`, 意思是非 service 域名会使用 coredns 容器中 `resolv.conf` 文件里的 nameserver 来解析)
|
||||
|
||||
确认了下,超时的上游 DNS 10.225.30.181,并不是期望的 nameserver,VPC 默认 DNS 应该是 180 开头的。看了 coredns 所在节点的 `resolv.conf`,发现确实多出了这个非期望的 nameserver,跟用户确认了下,这个 DNS 不是用户自己加上去的,添加节点时这个 nameserver 本身就在 `resolv.conf` 中。
|
||||
|
||||
根据内部同学反馈, 10.225.30.181 是广州一台年久失修将被撤裁的 DNS,物理网络,没有 VIP,撤掉就没有了,所以如果 coredns 用到了这台 DNS 解析时就可能 timeout。后面我们自己测试,某些 VPC 的集群确实会有这个 nameserver,奇了怪了,哪里冒出来的?
|
||||
|
||||
又试了下直接创建 CVM,不加进 TKE 节点发现没有这个 nameserver,只要一加进 TKE 节点就有了 !!!
|
||||
|
||||
看起来是 TKE 的问题,将 CVM 添加到 TKE 集群会自动重装系统,初始化并加进集群成为 K8S 的 node,确认了初始化过程并不会写 `resolv.conf`,会不会是 TKE 的 OS 镜像问题?尝试搜一下除了 `/etc/resolv.conf` 之外哪里还有这个 nameserver 的 IP,最后发现 `/etc/resolvconf/resolv.conf.d/base` 这里面有。
|
||||
|
||||
看下 `/etc/resolvconf/resolv.conf.d/base` 的作用:Ubuntu 的 `/etc/resolv.conf` 是动态生成的,每次重启都会将 `/etc/resolvconf/resolv.conf.d/base` 里面的内容加到 `/etc/resolv.conf` 里。
|
||||
|
||||
经确认: 这个文件确实是 TKE 的 Ubuntu OS 镜像里自带的,可能发布 OS 镜像时不小心加进去的。
|
||||
|
||||
那为什么有些 VPC 的集群的节点 `/etc/resolv.conf` 里面没那个 IP 呢?它们的 OS 镜像里也都有那个文件那个 IP 呀。
|
||||
|
||||
请教其它部门同学发现:
|
||||
|
||||
- 非 dhcp 子机,cvm 的 cloud-init 会覆盖 `/etc/resolv.conf` 来设置 dns
|
||||
- dhcp 子机,cloud-init 不会设置,而是通过 dhcp 动态下发
|
||||
- 2018 年 4 月 之后创建的 VPC 就都是 dhcp 类型了的,比较新的 VPC 都是 dhcp 类型的
|
||||
|
||||
## 真相大白
|
||||
|
||||
`/etc/resolv.conf` 一开始内容都包含 `/etc/resolvconf/resolv.conf.d/base` 的内容,也就是都有那个不期望的 nameserver,但老的 VPC 由于不是 dhcp 类型,所以 cloud-init 会覆盖 `/etc/resolv.conf`,抹掉了不被期望的 nameserver,而新创建的 VPC 都是 dhcp 类型,cloud-init 不会覆盖 `/etc/resolv.conf`,导致不被期望的 nameserver 残留在了 `/etc/resolv.conf`,而 coredns pod 的 dnsPolicy 为 “Default”,也就是会将宿主机的 `/etc/resolv.conf` 中的 nameserver 加到容器里,coredns 解析集群外的域名默认使用这些 nameserver 来解析,当用到那个将被撤裁的 nameserver 就可能 timeout。
|
||||
|
||||
## 解决方案
|
||||
|
||||
临时解决: 删掉 `/etc/resolvconf/resolv.conf.d/base` 重启。
|
||||
长期解决: 我们重新制作 TKE Ubuntu OS 镜像然后发布更新。
|
||||
|
||||
## 再次出问题
|
||||
|
||||
这下应该没问题了吧,But, 用户反馈还是会偶尔解析有问题,但现象不一样了,这次并不是 dns timeout。
|
||||
|
||||
用脚本跑测试仔细分析现象:
|
||||
|
||||
- 请求 `loginspub.xxxxmobile-inc.net` 时,偶尔提示域名无法解析
|
||||
- 请求 `accounts.google.com` 时,偶尔提示连接失败
|
||||
|
||||
进入 dns 解析偶尔异常的容器的 netns 抓包:
|
||||
|
||||
- dns 请求会并发请求 A 和 AAAA 记录
|
||||
- 测试脚本发请求打印序号,抓包然后 wireshark 分析对比异常时请求序号偏移量,找到异常时的 dns 请求报文,发现异常时 A 和 AAAA 记录的请求 id 冲突,并且 AAAA 响应先返回
|
||||
|
||||

|
||||
|
||||
正常情况下id不会冲突,这里冲突了也就能解释这个 dns 解析异常的现象了:
|
||||
|
||||
- `loginspub.xxxxmobile-inc.net` 没有 AAAA (ipv6) 记录,它的响应先返回告知 client 不存在此记录,由于请求 id 跟 A 记录请求冲突,后面 A 记录响应返回了 client 发现 id 重复就忽略了,然后认为这个域名无法解析
|
||||
- `accounts.google.com` 有 AAAA 记录,响应先返回了,client 就拿这个记录去尝试请求,但当前容器环境不支持 ipv6,所以会连接失败
|
||||
|
||||
## 分析
|
||||
|
||||
那为什么 dns 请求 id 会冲突?
|
||||
|
||||
继续观察发现: 其它节点上的 pod 不会复现这个问题,有问题这个节点上也不是所有 pod 都有这个问题,只有基于 alpine 镜像的容器才有这个问题,在此节点新起一个测试的 `alpine:latest` 的容器也一样有这个问题。
|
||||
|
||||
为什么 alpine 镜像的容器在这个节点上有问题在其它节点上没问题? 为什么其他镜像的容器都没问题?它们跟 alpine 的区别是什么?
|
||||
|
||||
发现一点区别: alpine 使用的底层 c 库是 musl libc,其它镜像基本都是 glibc
|
||||
|
||||
翻 musl libc 源码, 构造 dns 请求时,请求 id 的生成没加锁,而且跟当前时间戳有关 (`network/res_mkquery.c`):
|
||||
|
||||
``` c
|
||||
/* Make a reasonably unpredictable id */
|
||||
clock_gettime(CLOCK_REALTIME, &ts);
|
||||
id = ts.tv_nsec + ts.tv_nsec/65536UL & 0xffff;
|
||||
```
|
||||
|
||||
看注释,作者应该认为这样id基本不会冲突,事实证明,绝大多数情况确实不会冲突,我在网上搜了很久没有搜到任何关于 musl libc 的 dns 请求 id 冲突的情况。这个看起来取决于硬件,可能在某种类型硬件的机器上运行,短时间内生成的 id 就可能冲突。我尝试跟用户在相同地域的集群,添加相同配置相同机型的节点,也复现了这个问题,但后来删除再添加时又不能复现了,看起来后面新建的 cvm 又跑在了另一种硬件的母机上了。
|
||||
|
||||
OK,能解释通了,再底层的细节就不清楚了,我们来看下解决方案:
|
||||
|
||||
- 换基础镜像 (不用alpine)
|
||||
- 完全静态编译业务程序(不依赖底层c库),比如go语言程序编译时可以关闭 cgo (CGO_ENABLED=0),并告诉链接器要静态链接 (`go build` 后面加 `-ldflags '-d'`),但这需要语言和编译工具支持才可以
|
||||
|
||||
## 最终解决方案
|
||||
|
||||
最终建议用户基础镜像换成另一个比较小的镜像: `debian:stretch-slim`。
|
||||
|
|
@ -1,102 +0,0 @@
|
|||
# cgroup 泄露
|
||||
|
||||
## 现象
|
||||
|
||||
创建 Pod 失败,运行时报错 `no space left on device`:
|
||||
|
||||
```txt
|
||||
Dec 24 11:54:31 VM_16_11_centos dockerd[11419]: time="2018-12-24T11:54:31.195900301+08:00" level=error msg="Handler for POST /v1.31/containers/b98d4aea818bf9d1d1aa84079e1688cd9b4218e008c58a8ef6d6c3c106403e7b/start returned error: OCI runtime create failed: container_linux.go:348: starting container process caused \"process_linux.go:279: applying cgroup configuration for process caused \\\"mkdir /sys/fs/cgroup/memory/kubepods/burstable/pod79fe803c-072f-11e9-90ca-525400090c71/b98d4aea818bf9d1d1aa84079e1688cd9b4218e008c58a8ef6d6c3c106403e7b: no space left on device\\\"\": unknown"
|
||||
```
|
||||
|
||||
## 内核 Bug
|
||||
|
||||
`memcg` 是 Linux 内核中用于管理 cgroup 内存的模块,整个生命周期应该是跟随 cgroup 的,但是在低版本内核中\(已知3.10\),一旦给某个 memory cgroup 开启 kmem accounting 中的 `memory.kmem.limit_in_bytes` 就可能会导致不能彻底删除 memcg 和对应的 cssid,也就是说应用即使已经删除了 cgroup \(`/sys/fs/cgroup/memory` 下对应的 cgroup 目录已经删除\), 但在内核中没有释放 cssid,导致内核认为的 cgroup 的数量实际数量不一致,我们也无法得知内核认为的 cgroup 数量是多少。
|
||||
|
||||
关于 cgroup kernel memory,在 [kernel.org](https://www.kernel.org/doc/html/latest/admin-guide/cgroup-v1/memory.html#kernel-memory-extension-config-memcg-kmem) 中有如下描述:
|
||||
|
||||
```
|
||||
2.7 Kernel Memory Extension (CONFIG_MEMCG_KMEM)
|
||||
-----------------------------------------------
|
||||
|
||||
With the Kernel memory extension, the Memory Controller is able to limit
|
||||
the amount of kernel memory used by the system. Kernel memory is fundamentally
|
||||
different than user memory, since it can't be swapped out, which makes it
|
||||
possible to DoS the system by consuming too much of this precious resource.
|
||||
|
||||
Kernel memory accounting is enabled for all memory cgroups by default. But
|
||||
it can be disabled system-wide by passing cgroup.memory=nokmem to the kernel
|
||||
at boot time. In this case, kernel memory will not be accounted at all.
|
||||
|
||||
Kernel memory limits are not imposed for the root cgroup. Usage for the root
|
||||
cgroup may or may not be accounted. The memory used is accumulated into
|
||||
memory.kmem.usage_in_bytes, or in a separate counter when it makes sense.
|
||||
(currently only for tcp).
|
||||
|
||||
The main "kmem" counter is fed into the main counter, so kmem charges will
|
||||
also be visible from the user counter.
|
||||
|
||||
Currently no soft limit is implemented for kernel memory. It is future work
|
||||
to trigger slab reclaim when those limits are reached.
|
||||
```
|
||||
|
||||
这是一个 cgroup memory 的扩展,用于限制对 kernel memory 的使用,但该特性在老于 4.0 版本中是个实验特性,存在泄露问题,在 4.x 较低的版本也还有泄露问题,应该是造成泄露的代码路径没有完全修复,推荐 4.3 以上的内核。
|
||||
|
||||
## 造成容器创建失败
|
||||
|
||||
这个问题可能会导致创建容器失败,因为创建容器为其需要创建 cgroup 来做隔离,而低版本内核有个限制:允许创建的 cgroup 最大数量写死为 65535 \([点我跳转到 commit](https://github.com/torvalds/linux/commit/38460b48d06440de46b34cb778bd6c4855030754#diff-c04090c51d3c6700c7128e84c58b1291R3384)\),如果节点上经常创建和销毁大量容器导致创建很多 cgroup,删除容器但没有彻底删除 cgroup 造成泄露\(真实数量我们无法得知\),到达 65535 后再创建容器就会报创建 cgroup 失败并报错 `no space left on device`,使用 kubernetes 最直观的感受就是 pod 创建之后无法启动成功。
|
||||
|
||||
pod 启动失败,报 event 示例:
|
||||
|
||||
``` bash
|
||||
Events:
|
||||
Type Reason Age From Message
|
||||
---- ------ ---- ---- -------
|
||||
Normal Scheduled 15m default-scheduler Successfully assigned jenkins/jenkins-7845b9b665-nrvks to 10.10.252.4
|
||||
Warning FailedCreatePodContainer 25s (x70 over 15m) kubelet, 10.10.252.4 unable to ensure pod container exists: failed to create container for [kubepods besteffort podc6eeec88-8664-11e9-9524-5254007057ba] : mkdir /sys/fs/cgroup/memory/kubepods/besteffort/podc6eeec88-8664-11e9-9524-5254007057ba: no space left on device
|
||||
```
|
||||
|
||||
dockerd 日志报错示例:
|
||||
|
||||
``` bash
|
||||
Dec 24 11:54:31 VM_16_11_centos dockerd[11419]: time="2018-12-24T11:54:31.195900301+08:00" level=error msg="Handler for POST /v1.31/containers/b98d4aea818bf9d1d1aa84079e1688cd9b4218e008c58a8ef6d6c3c106403e7b/start returned error: OCI runtime create failed: container_linux.go:348: starting container process caused \"process_linux.go:279: applying cgroup configuration for process caused \\\"mkdir /sys/fs/cgroup/memory/kubepods/burstable/pod79fe803c-072f-11e9-90ca-525400090c71/b98d4aea818bf9d1d1aa84079e1688cd9b4218e008c58a8ef6d6c3c106403e7b: no space left on device\\\"\": unknown"
|
||||
```
|
||||
|
||||
kubelet 日志报错示例:
|
||||
|
||||
``` bash
|
||||
Sep 09 18:09:09 VM-0-39-ubuntu kubelet[18902]: I0909 18:09:09.449722 18902 remote_runtime.go:92] RunPodSandbox from runtime service failed: rpc error: code = Unknown desc = failed to start sandbox container for pod "osp-xxx-com-ljqm19-54bf7678b8-bvz9s": Error response from daemon: oci runtime error: container_linux.go:247: starting container process caused "process_linux.go:258: applying cgroup configuration for process caused \"mkdir /sys/fs/cgroup/memory/kubepods/burstable/podf1bd9e87-1ef2-11e8-afd3-fa163ecf2dce/8710c146b3c8b52f5da62e222273703b1e3d54a6a6270a0ea7ce1b194f1b5053: no space left on device\""
|
||||
```
|
||||
|
||||
新版的内核限制为 `2^31` \(可以看成几乎不限制,[点我跳转到代码](https://github.com/torvalds/linux/blob/3120b9a6a3f7487f96af7bd634ec49c87ef712ab/kernel/cgroup/cgroup.c#L5233)\): `cgroup_idr_alloc()` 传入 end 为 0 到 `idr_alloc()`, 再传给 `idr_alloc_u32()`, end 的值最终被三元运算符 `end>0 ? end-1 : INT_MAX` 转成了 `INT_MAX` 常量,即 `2^31`。所以如果新版内核有泄露问题会更难定位,表现形式会是内存消耗严重,幸运的是新版内核已经修复,推荐 4.3 以上。
|
||||
|
||||
### 规避方案
|
||||
|
||||
如果你用的低版本内核\(比如 CentOS 7 v3.10 的内核\)并且不方便升级内核,可以通过不开启 kmem accounting 来实现规避,但会比较麻烦。
|
||||
|
||||
kubelet 和 runc 都会给 memory cgroup 开启 kmem accounting,所以要规避这个问题,就要保证kubelet 和 runc 都别开启 kmem accounting,下面分别进行说明:
|
||||
|
||||
#### runc
|
||||
|
||||
runc 在合并 [这个PR](https://github.com/opencontainers/runc/pull/1350/files) \(2017-02-27\) 之后创建的容器都默认开启了 kmem accounting,后来社区也注意到这个问题,并做了比较灵活的修复, [PR 1921](https://github.com/opencontainers/runc/pull/1921) 给 runc 增加了 "nokmem" 编译选项,缺省的 release 版本没有使用这个选项, 自己使用 nokmem 选项编译 runc 的方法:
|
||||
|
||||
``` bash
|
||||
cd $GO_PATH/src/github.com/opencontainers/runc/
|
||||
make BUILDTAGS="seccomp nokmem"
|
||||
```
|
||||
|
||||
docker-ce v18.09.1 之后的 runc 默认关闭了 kmem accounting,所以也可以直接升级 docker 到这个版本之后。
|
||||
|
||||
#### kubelet
|
||||
|
||||
如果是 1.14 版本及其以上,可以在编译的时候通过 build tag 来关闭 kmem accounting:
|
||||
|
||||
``` bash
|
||||
KUBE_GIT_VERSION=v1.14.1 ./build/run.sh make kubelet GOFLAGS="-tags=nokmem"
|
||||
```
|
||||
|
||||
如果是低版本需要修改代码重新编译。kubelet 在创建 pod 对应的 cgroup 目录时,也会调用 libcontianer 中的代码对 cgroup 做设置,在 `pkg/kubelet/cm/cgroup_manager_linux.go` 的 `Create` 方法中,会调用 `Manager.Apply` 方法,最终调用 `vendor/github.com/opencontainers/runc/libcontainer/cgroups/fs/memory.go` 中的 `MemoryGroup.Apply` 方法,开启 kmem accounting。这里也需要进行处理,可以将这部分代码注释掉然后重新编译 kubelet。
|
||||
|
||||
## 参考资料
|
||||
|
||||
* 一行 kubernetes 1.9 代码引发的血案(与 CentOS 7.x 内核兼容性问题): [http://dockone.io/article/4797](http://dockone.io/article/4797)
|
||||
* Cgroup泄漏--潜藏在你的集群中: [https://tencentcloudcontainerteam.github.io/2018/12/29/cgroup-leaking/](https://tencentcloudcontainerteam.github.io/2018/12/29/cgroup-leaking/)
|
||||
|
|
@ -1,130 +0,0 @@
|
|||
# .Net Core 配置文件无法热加载
|
||||
|
||||
## 问题描述
|
||||
|
||||
在使用 kubernetes 部署应用时, 我使用 `kubernetes` 的 `configmap` 来管理配置文件: `appsettings.json`
|
||||
, 修改configmap 的配置文件后, 我来到了容器里, 通过 `cat /app/config/appsetting.json` 命令查看容器是否已经加载了最新的配置文件, 很幸运的是, 通过命令行查看容器配置发现已经处于最新状态(修改configmap后10-15s 生效), 我尝试请求应用的API, 发现API 在执行过程中使用的配置是老旧的内容, 而不是最新的内容。在本地执行应用时并未出现配置无法热更新的问题。
|
||||
|
||||
```bash
|
||||
# 相关版本
|
||||
kubernetes 版本: 1.14.2
|
||||
# 要求版本大于等于 3.1
|
||||
.Net core: 3.1
|
||||
|
||||
# 容器 os-release (并非 windows)
|
||||
|
||||
NAME="Debian GNU/Linux"
|
||||
VERSION_ID="10"
|
||||
VERSION="10 (buster)"
|
||||
VERSION_CODENAME=buster
|
||||
ID=debian
|
||||
HOME_URL="https://www.debian.org/"
|
||||
SUPPORT_URL="https://www.debian.org/support"
|
||||
BUG_REPORT_URL="https://bugs.debian.org/"
|
||||
|
||||
# 基础镜像:
|
||||
mcr.microsoft.com/dotnet/core/sdk:3.1-buster
|
||||
mcr.microsoft.com/dotnet/core/aspnet:3.1-buster-slim
|
||||
```
|
||||
|
||||
## 问题猜想
|
||||
|
||||
通过命令行排查发现最新的 `configmap` 配置内容已经在容器的指定目录上更新到最新,但是应用仍然使用老旧的配置内容, 这意味着问题发生在: configmap->**容器->应用**, 容器和应用之间, 容器指定目录下的配置更新并没有触发 `.Net` 热加载机制, 那究竟是为什么没有触发配置热加载,需要深挖根本原因, 直觉猜想是: 查看 `.Net Core` 标准库的配置热加载的实现检查触发条件, 很有可能是触发的条件不满足导致应用配置无法重新加载。
|
||||
|
||||
## 问题排查
|
||||
|
||||
猜想方向是热更新的触发条件不满足, 我们熟知使用 `configmap` 挂载文件是使用[symlink](https://en.wikipedia.org/wiki/Symbolic_link)来挂载, 而非常用的物理文件系统, 在修改完 `configmap` , 容器重新加载配置后,这一过程并不会改变文件的修改时间等信息(从容器的角度看)。对此,我们做了一个实验,通过对比configmap修改前和修改后来观察配置( `appsettings.json` )在容器的属性变化(注: 均在容器加载最新配置后对比), 使用 `stat` 命令来佐证了这个细节点。
|
||||
|
||||
**Before:**
|
||||
|
||||
```bash
|
||||
root@app-785bc59df6-gdmnf:/app/Config# stat appsettings.json
|
||||
File: Config/appsettings.json -> ..data/appsettings.json
|
||||
Size: 35 Blocks: 0 IO Block: 4096 symbolic link
|
||||
Device: ca01h/51713d Inode: 27263079 Links: 1
|
||||
Access: (0777/lrwxrwxrwx) Uid: ( 0/ root) Gid: ( 0/ root)
|
||||
Access: 2020-04-25 08:21:18.490453316 +0000
|
||||
Modify: 2020-04-25 08:21:18.490453316 +0000
|
||||
Change: 2020-04-25 08:21:18.490453316 +0000
|
||||
Birth: -
|
||||
```
|
||||
|
||||
**After:**
|
||||
|
||||
```bash
|
||||
root@app-785bc59df6-gdmnf:/app/Config# stat appsettings.json
|
||||
File: appsettings.json -> ..data/appsettings.json
|
||||
Size: 35 Blocks: 0 IO Block: 4096 symbolic link
|
||||
Device: ca01h/51713d Inode: 27263079 Links: 1
|
||||
Access: (0777/lrwxrwxrwx) Uid: ( 0/ root) Gid: ( 0/ root)
|
||||
Access: 2020-04-25 08:21:18.490453316 +0000
|
||||
Modify: 2020-04-25 08:21:18.490453316 +0000
|
||||
Change: 2020-04-25 08:21:18.490453316 +0000
|
||||
Birth: -
|
||||
```
|
||||
|
||||
通过标准库源码发现, `.Net core` 配置热更新机制似乎是基于文件的最后修改日期来触发的, 根据上面的前后对比显而易见, `configmap` 的修改并没有让容器里的指定的文件的最后修改日期改变,也就未触发 `.Net` 应用配置的热加载。
|
||||
|
||||
## 解决办法
|
||||
|
||||
既然猜想基本得到证实, 由于不太熟悉这门语言, 我们尝试在网络上寻找解决办法,很幸运的是我们找到了找到了相关的内容, [fbeltrao](https://github.com/fbeltrao) 开源了一个第三方库([ConfigMapFileProvider](https://github.com/fbeltrao/ConfigMapFileProvider)) 来专门解决这个问题,**通过监听文件内容hash值的变化实现配置热加载**。
|
||||
于是, 我们在修改了项目的代码:
|
||||
|
||||
|
||||
**Before:**
|
||||
|
||||
```csharp
|
||||
// 配置被放在了/app/Config/ 目录下
|
||||
var configPath = Path.Combine(env.ContentRootPath, "Config");
|
||||
config.AddJsonFile(Path.Combine(configPath, "appsettings.json"),
|
||||
optional: false,
|
||||
reloadOnChange: true);
|
||||
```
|
||||
|
||||
**After:**
|
||||
|
||||
```csharp
|
||||
// 配置被放在了/app/Config/ 目录下
|
||||
config.AddJsonFile(ConfigMapFileProvider.FromRelativePath("Config"),
|
||||
"appsettings.json",
|
||||
optional: false,
|
||||
reloadOnChange: true);
|
||||
```
|
||||
|
||||
修改完项目的代码后, 重新构建镜像, 更新部署在 `kubernetes` 上的应用, 然后再次测试, 到此为止, 会出现两种状态:
|
||||
|
||||
1. 一种是你热加载配置完全可用, 非常值得祝贺, 你已经成功修复了这个bug;
|
||||
2. 一种是你的热加载配置功能还存在 bug, 比如: 上一次请求, 配置仍然使用的老旧配置内容, 下一次请求却使用了最新的配置内容,这个时候, 我们需要继续向下排查: `.NET Core` 引入了`Options`模式,使用类来表示相关的设置组,用强类型的类来表达配置项(白话大概表述为: 代码里面有个对象对应配置里的某个字段, 配置里对应的字段更改会触发代码里对象的属性变化), 示例如下:
|
||||
|
||||
**配置示例:**
|
||||
|
||||
```bash
|
||||
$ cat appsettings.json
|
||||
"JwtIssuerOptions": {
|
||||
"Issuer": "test",
|
||||
"Audience": "test",
|
||||
"SecretKey": "test"
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
**代码示例:**
|
||||
|
||||
```csharp
|
||||
services.Configure<JwtIssuerOptions>(Configuration.GetSection("JwtIssuerOptions"));
|
||||
```
|
||||
|
||||
而 Options 模式分为三种:
|
||||
|
||||
1. `IOptions`: Singleton(单例),值一旦生成, 除非通过代码的方式更改,否则它的值不会更新
|
||||
2. `IOptionsMonitor`: Singleton(单例), 通过 `IOptionsChangeTokenSource` 能够和配置文件一起更新,也能通过代码的方式更改值
|
||||
3. `IOptionsSnapshot`: Scoped,配置文件更新的下一次访问,它的值会更新,但是它不能跨范围通过代码的方式更改值,只能在当前范围(请求)内有效。
|
||||
|
||||
在知道这三种模式的意义后,我们已经完全找到了问题的根因, 把 `Options` 模式设置为:`IOptionsMonitor`就能解决完全解决配置热加载的问题。
|
||||
|
||||
## 相关链接
|
||||
|
||||
1. [配置监听ConfigMapFileProvider](https://github.com/fbeltrao/ConfigMapFileProvider)
|
||||
2. [相似的Issue: 1175](https://github.com/dotnet/extensions/issues/1175)
|
||||
3. [官方Options 描述](https://docs.microsoft.com/en-us/aspnet/core/fundamentals/configuration/options?view=aspnetcore-3.1)
|
||||
4. [IOptions、IOptionsMonitor以及IOptionsSnapshot 测试](https://www.cnblogs.com/wenhx/p/ioptions-ioptionsmonitor-and-ioptionssnapshot.html)
|
||||
|
|
@ -1,54 +0,0 @@
|
|||
# 多容器场景下修改 hosts 失效
|
||||
|
||||
## 问题现象
|
||||
|
||||
业务容器启动的逻辑中,修改了 `/etc/hosts` 文件,当 Pod 只存在这一个业务容器时,文件可以修改成功,但存在多个时 (比如注入了 istio 的 sidecar),修改可能会失效。
|
||||
|
||||
## 分析
|
||||
|
||||
1. 容器中的 `/etc/hosts` 是由 kubelet 生成并挂载到 Pod 中所有容器,如果 Pod 有多个容器,它们挂载的 `/etc/hosts` 文件都对应宿主机上同一个文件,路径通常为 `/var/lib/kubelet/pods/<pod-uid>/etc-hosts`。
|
||||
> 如果是 docker 运行时,可以通过 `docker inspect <container-id> -f {{.HostsPath}}` 查看。
|
||||
|
||||
2. kubelet 在启动容器时,都会走如下的调用链(`makeMounts->makeHostsMount->ensureHostsFile`)来给容器挂载 `/etc/hosts`,而在 `ensureHostsFile` 函数中都会重新创建一个新的 `etc-hosts` 文件,导致在其他容器中对 `/etc/hosts` 文件做的任何修改都被还原了。
|
||||
|
||||
所以,当 Pod 中存在多个容器时,容器内修改 `/etc/hosts` 的操作可能会被覆盖回去。
|
||||
|
||||
## 解决方案
|
||||
|
||||
通常不推荐在容器内修改 `/etc/hosts`,应该采用更云原生的做法,参考 [自定义域名解析](../../best-practices/dns/customize-dns-resolution)。
|
||||
|
||||
### 使用 HostAliases
|
||||
|
||||
如果只是某一个 workload 需要 hosts,可以用 HostAliases:
|
||||
|
||||
```yaml
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: host
|
||||
spec:
|
||||
replicas: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: host
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: host
|
||||
spec:
|
||||
hostAliases: # 这下面定义 hosts
|
||||
- ip: "10.10.10.10"
|
||||
hostnames:
|
||||
- "mysql.example.com"
|
||||
containers:
|
||||
- name: nginx
|
||||
image: nginx:latest
|
||||
```
|
||||
|
||||
> 参考官方文档 [Adding entries to Pod /etc/hosts with HostAliases](https://kubernetes.io/docs/tasks/network/customize-hosts-file-for-pods/)。
|
||||
|
||||
### CoreDNS hosts
|
||||
|
||||
如果是多个 workload 都需要共同的 hosts,可以修改集群 CoreDNS 配置,在集群级别增加 hosts:
|
||||
|
||||
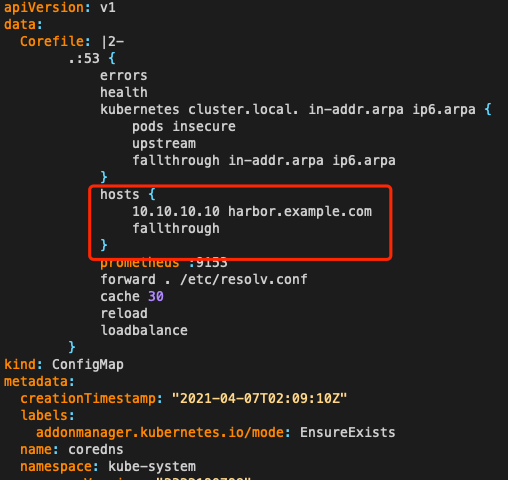
|
||||
|
|
@ -1,15 +0,0 @@
|
|||
# Job 无法被删除
|
||||
|
||||
## 原因
|
||||
|
||||
* 可能是 k8s 的一个bug: [https://github.com/kubernetes/kubernetes/issues/43168](https://github.com/kubernetes/kubernetes/issues/43168)
|
||||
* 本质上是脏数据问题,Running+Succeed != 期望Completions 数量,低版本 kubectl 不容忍,delete job 的时候打开debug(加-v=8),会看到kubectl不断在重试,直到达到timeout时间。新版kubectl会容忍这些,删除job时会删除关联的pod
|
||||
|
||||
## 解决方法
|
||||
|
||||
1. 升级 kubectl 版本,1.12 以上
|
||||
2. 低版本 kubectl 删除 job 时带 `--cascade=false` 参数\(如果job关联的pod没删完,加这个参数不会删除关联的pod\)
|
||||
|
||||
```bash
|
||||
kubectl delete job --cascade=false <job name>
|
||||
```
|
||||
|
|
@ -1,116 +0,0 @@
|
|||
# 系统时间被修改导致 sandbox 冲突
|
||||
|
||||
## 问题描述
|
||||
|
||||
节点重启后,节点上的存量 pod 出现无法正常 running,容器(sandbox)在不断重启的现象。
|
||||
|
||||
查看事件,提示是 sandbox 的 name 存在冲突 (`The container name xxx is already used by yyy`),具体事件如下:
|
||||
|
||||

|
||||
|
||||
## 结论先行
|
||||
|
||||
这个问题的根因是节点的时间问题,节点重启前的系统时间比节点重启后的系统时间提前,影响了 kubelet 内部缓存 cache 中的 sandbox 的排序,导致 kubelet 每次起了一个新 sandbox 之后,都只会拿到旧的 sandbox,导致了 sandbox 的不断创建和 name 冲突。
|
||||
|
||||
## 排查日志
|
||||
|
||||
先来看下 kubelet 的日志,部分截图如下:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
截图上是同一个 pod(kube-proxy)最近的两次 podWorker 逻辑截图,都抛出了同一个提示:`No ready sandbox for pod <pod-name> can be found, Need to start a new one`。这个应该就是造成容器冲突的来源,每次沉浸到 podWorker 的逻辑之后,podWorker 都要尝试去创建一个新的sandbox,进而造成容器冲突。
|
||||
|
||||
疑问:为啥 podWorker 每次都去创建一个新的 sandbox?
|
||||
|
||||
接下来继续调大 kubelet 的日志级别(k8s v1.16已经支持动态调整,这里调大日志级别到V(6)),这里主要是尝试拿到某个 pod 所关联的所有 sandbox,截图如下:
|
||||
|
||||

|
||||
|
||||
通过配合节点上执行 docker inspect(ps)相关命令发现,异常的 pod(kube-proxy)存在两个 sandbox(重启前的+重启后的),并且在 sandboxID 数组中的排序为 `[重启前的sandbox, 重启后的 sandbox]` (这里先 mark 一下)。
|
||||
|
||||
## 相关知识
|
||||
|
||||
在进一步分析之前,我们先介绍下相关背景知识。
|
||||
|
||||
### Pod 创建流程
|
||||
|
||||
先来一起熟悉下 pod 创建流程:
|
||||
|
||||

|
||||
|
||||
### PLEG 组件
|
||||
|
||||
再看下 `PLEG` 的工作流程。kubelet 启动之后,会运行起 `PLEG` 组件,定期的缓存 pod 的信息(包括 pod status)。在 `PLEG` 的每次 relist 逻辑中,会对比 `old pod` 和 `new pod`,检查是否存在变化,如果新旧 pod 之间存在变化,则开始执行下面两个逻辑:
|
||||
1. 生成 event 事件,比如 containerStart 等,最后再投递到 `eventChannel` 中,供 podWorker 来消费。
|
||||
2. 更新内部缓存 cache。在跟新缓存 `updateCache` 的逻辑中,会调用 runtime 的相关接口获取到与 pod 相关的 status 状态信息,然后并缓存到内部缓存 cache中,最后发起通知 ( podWorker 会发起订阅) 。
|
||||
|
||||
podStatus的数据结构如下:
|
||||
|
||||
```go
|
||||
# podStatus
|
||||
type PodStatus struct {
|
||||
// ID of the pod.
|
||||
ID types.UID
|
||||
...
|
||||
...
|
||||
// Only for kuberuntime now, other runtime may keep it nil.
|
||||
SandboxStatuses []*runtimeapi.PodSandboxStatus
|
||||
}
|
||||
|
||||
# SandboxStatus
|
||||
// PodSandboxStatus contains the status of the PodSandbox.
|
||||
type PodSandboxStatus struct {
|
||||
// ID of the sandbox.
|
||||
Id string `protobuf:"bytes,1,opt,name=id,proto3" json:"id,omitempty"`
|
||||
...
|
||||
// Creation timestamp of the sandbox in nanoseconds. Must be > 0.
|
||||
CreatedAt int64 `protobuf:"varint,4,opt,name=created_at,json=createdAt,proto3" json:"created_at,omitempty"`
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
podStatus 会保存 pod 的一些基础信息,再加上 containerStatus 和 sandboxStatus 信息。
|
||||
|
||||
这里重点关注下 SandboxStatus 的排序问题,配合代码可以发现,排序是按照 sandbox 的 Create time 来执行的,并且时间越新,位置越靠前。排序相关的代码部分如下:
|
||||
|
||||
```go
|
||||
// Newest first.
|
||||
type podSandboxByCreated []*runtimeapi.PodSandbox
|
||||
|
||||
func (p podSandboxByCreated) Len() int { return len(p) }
|
||||
func (p podSandboxByCreated) Swap(i, j int) { p[i], p[j] = p[j], p[i] }
|
||||
func (p podSandboxByCreated) Less(i, j int) bool { return p[i].CreatedAt > p[j].CreatedAt }
|
||||
```
|
||||
|
||||
### podWorker 组件
|
||||
|
||||
最后再看下 podWorker 的工作流程。podWorker 的工作就是负责 pod 在节点上的正确运行(比如挂载 volume,新起 sandbox,新起 container 等),一个 pod 对应一个 podWorker,直到 pod 销毁。当节点重启后,kubelet 会收到 `type=ADD` 的事件来创建 pod 对象。
|
||||
|
||||
当 pod 更新之后,会触发 `event=containerStart` 事件的投递,然后 kubelet 就会收到 `type=SYNC` 的事件,来更新 pod 对象。在每次 podWorker 的内部逻辑中(`managePodLoop()`) 中,会存在一个 podStatus(内部缓存)的订阅,如下:
|
||||
|
||||
```go
|
||||
// This is a blocking call that would return only if the cache
|
||||
// has an entry for the pod that is newer than minRuntimeCache
|
||||
// Time. This ensures the worker doesn't start syncing until
|
||||
// after the cache is at least newer than the finished time of
|
||||
// the previous sync.
|
||||
status, err := p.podCache.GetNewerThan(podUID, lastSyncTime)
|
||||
```
|
||||
|
||||
来等待内部 cache 中的 podStatus 更新,然后再操作后续动作(是否重新挂载 volume、是否重建 sandbox,是否重建 container 等)。
|
||||
|
||||
## 复现问题,定位根因
|
||||
|
||||
接下来,我们一起来模拟复现下问题现场。
|
||||
|
||||

|
||||
|
||||
在节点重启之前,由于是新建节点后,所以对于 pod 来说,status 中只有一个命名以 `_0` 结尾的 sandbox。当操作重启节点之后,kubelet 收到 `type=ADD` 的事件,podWorker 开始创建 pod,由于之前以 `_0` 命名结尾的 sandbox 已经 died 了,所以会新建一个新的以 `_1` 命名结尾的 sandbox,当新的以 `_1` 命名结尾的 sandbox 运行之后(containerStarted),就会投递一个 `type=SYNC` 的事件给到 kubelet,然后 podWorker 会被再次触发(内部 cache 也更新了,通知也发出了)。正常情况下,podWorker 会拿到 podStatus 中新的 sandbox(以 `_1` 命名结尾的),就不会再创建 sandbox 了,也就是不会发生 name 冲突的问题。而用户的环境却是,此时拿到了以 `_0` 命名结尾的旧的 sandbox,所以再新一轮的 podWorker 逻辑中,会再次创建一个新的以 `_1` 命名的 sandbox,从而产生冲突。
|
||||
|
||||
而这里的根因就是时间问题,节点重启前的sandbox(以 `_0` 命名结尾的)的 `create time` ,比节点重启后的sandbox(以 `_1` 命名结尾的)的 `create time` 还要提前,所以导致了内部 cache 中 sandbox 的排序发生了错乱,从而触发 name 冲突问题。
|
||||
|
||||
## 解决方案
|
||||
|
||||
根据上面的排查发现,kubelet 的内部缓存中,sandbox 的排序是有系统时间来决定的,所以,尽量保证 k8s 集群中的时间有正确同步,或者不要乱改节点上的时间。
|
||||
|
|
@ -1,53 +0,0 @@
|
|||
# 磁盘 IO 过高导致 Pod 创建超时
|
||||
|
||||
## 问题背景
|
||||
|
||||
在创建 TKE 集群的 worker node 时,用户往往会单独再购买一块云盘,绑到节点上,用于 docker 目录挂载所用(将 docker 目录单独放到数据盘上)。此时,docker 的读写层(RWLayer)就会落到云盘上。
|
||||
|
||||
在该使用场景下,有用户反馈,在创建 Pod 时,会偶现 Pod 创建超时的报错,具体报错如下:
|
||||
|
||||

|
||||
|
||||
## 结论先行
|
||||
|
||||
当单独挂载一块云盘用于 docker 目录挂载使用时,会出现如下情况:云盘的真实使用超过云盘所支持的最大吞吐,导致 pod 创建超时。
|
||||
|
||||
## pod 失败的异常事件
|
||||
|
||||
从报错的事件上来看,可以看到报错是 create sandbox 时,rpc 调用超时了。
|
||||
|
||||
在 create sandbox 时,dockershim 会发起两次dockerd调用,分别是:`POST /containers/create` 和 `POST /containers/start`。而事件上给出的报错,就是 `POST /containers/create` 时的报错。
|
||||
|
||||
## 日志和堆栈分析
|
||||
|
||||
开启dockerd的debug模式后,在异常报错时间段内,能够看到有与 `POST /containers/create` 相关的日志,但是并没有看到与 `POST /containers/start` 相关的日志,说明 docker daemon 有收到 create container 的 rpc 请求,但是并没有在timeout的时间内,完成请求。可以对应到 pod 的异常报错事件。
|
||||
|
||||
当稳定复现问题(rpc timeout)之后,手动尝试在节点上通过curl命令,向docker daemon请求create containber。
|
||||
|
||||
命令如下:
|
||||
|
||||
```bash
|
||||
$ curl --unix-socket /var/run/docker.sock "http://1.38/containers/create?name=test01" -v -X POST -H "Content-Type: application/json" -d '{"Image": "nginx:latest"}'
|
||||
```
|
||||
|
||||
当执行 curl 命令之后,确实要等很长时间(>2min)才返回。
|
||||
|
||||
并抓取 dockerd 的堆栈信息,发现如下:**在问题发生时,有一个 delete container 动作,长时间卡在了 unlinkat 系统调用。**
|
||||
|
||||

|
||||
|
||||
container 的 create 和 delete 请求都会沉浸到 layer store组件,来创建或者删除容器的读写层。
|
||||
|
||||
在 layer store 组件中,维护了一个内部数据结构(layerStore),其中有一个字段 `mounts map[string]*mountedLayer` 用于维护所有容器的读写层信息,并且还配置了一个读写锁用于保护该信息(数据mounts的任何增删操作都需要先获取一个读写锁)。如果某个请求(比如container delete)长时间没有返回,就会阻塞其他 container 的创建或者删除。
|
||||
|
||||

|
||||
|
||||
## 云盘监控
|
||||
|
||||
云盘的相关监控可以重点关注以下三个指标:云盘写流量、IO await、IO %util。
|
||||
|
||||
## 解决方案
|
||||
|
||||
配合业务场景需求,更换更高性能的云盘。
|
||||
|
||||
腾讯云上的云硬盘种类和吞吐指标可以 [官方参考文档](https://cloud.tencent.com/document/product/362/2353) 。
|
||||
|
|
@ -1,286 +0,0 @@
|
|||
# 挂载根目录导致 device or resource busy
|
||||
|
||||
## 现象
|
||||
|
||||
在删除 pod 时,可能会遇到如下事件 `unlinkat xxxxx: device or resource busy`,设备或资源忙导致某个文件无法被删除,进而导致 pod 卡在 Terminating 状态。
|
||||
|
||||
接下来,就单独针对在 **containerd运行时环境** 下,发生的相关报错进行回顾分析,具体的报错现象如下:
|
||||
|
||||
```txt
|
||||
unlinkat /var/run/netns/cni-49ddd103-d374-1f86-7324-13abaeb9c910: device or resource busy
|
||||
```
|
||||
|
||||
## 复现场景
|
||||
|
||||
环境:
|
||||
|
||||
* containerd 运行时
|
||||
* centos 7.6 操作系统
|
||||
|
||||
通过先后创建如下两个服务(sleeping 和 rootfsmount)可以复现问题。
|
||||
|
||||
1. 先创建 sleeping 服务:
|
||||
|
||||
```bash
|
||||
$ cat <<EOF | kubectl apply -f -
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: sleepping
|
||||
spec:
|
||||
replicas: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: sleepping
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: sleepping
|
||||
spec:
|
||||
containers:
|
||||
- name: test
|
||||
image: busybox
|
||||
args: ["sleep", "1h"]
|
||||
EOF
|
||||
```
|
||||
|
||||
2. 再创建 rootfsmount 服务,并且保证 pod 实例调度到与 sleeping 服务相同的节点上。
|
||||
|
||||
```bash
|
||||
$ cat <<EOF | kubectl apply -f -
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: rootfsmount
|
||||
spec:
|
||||
replicas: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: rootfsmount
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: rootfsmount
|
||||
spec:
|
||||
containers:
|
||||
- name: rootfsmount
|
||||
image: busybox
|
||||
args: ["sleep", "1h"]
|
||||
volumeMounts:
|
||||
- mountPath: /rootfs
|
||||
name: host-rootfs
|
||||
volumes:
|
||||
- hostPath:
|
||||
path: /
|
||||
type: ""
|
||||
name: host-rootfs
|
||||
EOF
|
||||
```
|
||||
|
||||
3. 操作删除 sleeping 服务的 pod,此时可以观察到 pod 实例卡在 Terminating 状态。
|
||||
|
||||

|
||||
|
||||
## 相关知识
|
||||
|
||||
在进一步了解之前,先熟悉下几个相关知识
|
||||
|
||||
1. `/run/netns/cni-xxxx` 文件:
|
||||
|
||||
这个文件实际上就是容器的 net nanemspace 的 mount point,可以通过如下命令进入到容器的 net ns 中:
|
||||
|
||||
```bash
|
||||
nsenter --net=/var/run/netns/cni-49ddd103-d374-1f86-7324-13abaeb9c910
|
||||
```
|
||||
|
||||
2. Shared subtrees 技术
|
||||
|
||||
> 此部分为引用说明,详情可见参考链接1
|
||||
|
||||
* 内核特性,用于控制某个挂载点下的子挂载点是否"传播"给其他挂载点,只应用于 bind mount 和 mount namespace 场景中。
|
||||
* Shared subtrees 技术引入了两个概念,分别是 peer group 和 propagation type,接下来一一介绍。
|
||||
|
||||
2.1 peer group
|
||||
|
||||
共享挂载信息的一组挂载点,来源主要两种:
|
||||
* bind mount,此时源和目的挂载点属于同一 peer group,要求源也是挂载点。
|
||||
* 新的 namespace 创建,新的 namespace 会拷贝旧的一份挂载信息,于是,新旧中相同挂载点属于同一 peer group。
|
||||
|
||||
2.2 propagation type
|
||||
|
||||
每个挂载点都有这样的一个元数据(propagation type),用于控制当一个挂载点的下面创建和移除挂载点的时候,是否会传播到属于相同peer group的其他挂载点下去,主要有三种:
|
||||
|
||||
* `MS_SHARED`: 挂载信息在同一个 peer group 里会相互传播。比如把节点上的主目录挂载到容器内的 `/rootfs`,如果节点上的主目录创建了新的挂载点X,则* 在容器内的 `/rootfs` 下面也会出现新的挂载点 `/rootfs/X`。
|
||||
* `MS_PRIVATE`:挂载信息在同一个 peer group 里不会相互传播。比如把节点上的主目录挂载到容器内的 `/rootfs`,如果节点上的主目录创建了新的挂载点X,则容器内的 `/rootfs` 下面不会出现新的挂载点 `/rootfs/X`。
|
||||
* `MS_SLAVE`:挂载信息传播是单向的。比如把节点上的主目录挂载到容器内的 `/rootfs`,如果节点上的主目录创建了新的挂载点 X,则在容器内的 `/rootfs` 下面也会出现新的挂载点 `/rootfs/X` ,反之则不行。
|
||||
|
||||
这个对应到 k8s 中 `Container.volumeMounts` 的 `mountPropagation` 字段,分别是:Bidirectional、None、HostToContainer。
|
||||
|
||||
## 进一步分析
|
||||
|
||||
让我们再回到复现场景中的第二步,创建 rootfsmount 服务时,发生了什么。
|
||||
|
||||
通过命令抓取下 contianerd 的所有 mount 系统调用,发现有如下两个 mount 记录:
|
||||
|
||||
```bash
|
||||
$ strace -f -e trace=mount -p <pid>
|
||||
...
|
||||
[pid 15532] mount("/", "/run/containerd/io.containerd.runtime.v2.task/k8s.io/5b498caf152857cf1c797761e1f52d64c2ce7d4602b72304da7e154ed31043c8/rootfs/rootfs", 0xc0000f7500, MS_BIND|MS_REC, NULL) = 0
|
||||
[pid 15532] mount("", "/run/containerd/io.containerd.runtime.v2.task/k8s.io/5b498caf152857cf1c797761e1f52d64c2ce7d4602b72304da7e154ed31043c8/rootfs/rootfs", 0xc0000f7506, MS_REC|MS_PRIVATE, NULL) = 0
|
||||
...
|
||||
```
|
||||
|
||||
这个就对应于 pod 配置中的 volumeMount,我们再进一步看下 container 中的 mount 信息。
|
||||
|
||||
将节点上的主目录 `/` (挂载点) 挂载到了容器中的 `/rootfs` (挂载点),并且 propagation type 为 rprivate。
|
||||
|
||||
```bash
|
||||
$ crictl inspect <container-id>
|
||||
...
|
||||
{
|
||||
"destination": "/rootfs",
|
||||
"type": "bind",
|
||||
"source": "/",
|
||||
"options": [
|
||||
"rbind",
|
||||
"rprivate",
|
||||
"rw"
|
||||
]
|
||||
},
|
||||
...
|
||||
```
|
||||
|
||||
让我们再看下pod(或者容器内)的挂载情况:
|
||||
|
||||
```bash
|
||||
$ cat /proc/self/mountinfo
|
||||
...
|
||||
# 对应pod的volumeMount设置,将宿主机上的主目录/ 挂载到了容器内的/rootfs目录下
|
||||
651 633 253:1 / /rootfs rw,relatime - ext4 /dev/vda1 rw,data=ordered
|
||||
695 677 0:3 / /rootfs/run/netns/cni-49ddd103-d374-1f86-7324-13abaeb9c910 rw,nosuid,nodev,noexec,relatime - proc proc rw
|
||||
...
|
||||
```
|
||||
|
||||
节点上的挂载点(/var/run/netns/cni-49ddd103-d374-1f86-7324-13abaeb9c910)在容器内,也是挂载点(/rootfs/run/netns/cni-49ddd103-d374-1f86-7324-13abaeb9c910)。
|
||||
|
||||
## 结论
|
||||
|
||||
当测试服务 rootfsmount 的 pod 实例创建时,会把节点上的主目录 `/` 挂载到容器内(比如 `/rootfs`),由于主目录在节点上是一个挂载点,所以节点上的主目录和容器内的/rootfs属于同一个 peer group,并且采用了默认的 propagation type:rprivate。
|
||||
|
||||
当测试服务 sleepping 的 pod 实例销毁时,需要解挂和销毁对应的 netns 文件(/var/run/netns/cni-49ddd103-d374-1f86-7324-13abaeb9c910),由于此时的 propagation type 是 rprivate,节点上主目录下的子挂载点解挂不会传递到容器的 net namespace 内,所以,这个 netns 文件(/rootfs/run/netns/cni-49ddd103-d374-1f86-7324-13abaeb9c910)依然是一个挂载点,导致在销毁 netns 文件时会失败。
|
||||
|
||||
|
||||
## 解决方案
|
||||
|
||||
1. 给 rootfsmount 服务的 volumeMount 配置新增 propagation type,设置为 HostToContainer 或者 Bidirectional。
|
||||
|
||||
```yaml
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: rootfsmount
|
||||
spec:
|
||||
replicas: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: rootfsmount
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: rootfsmount
|
||||
spec:
|
||||
containers:
|
||||
- name: rootfsmount
|
||||
image: busybox
|
||||
args: ["sleep", "1h"]
|
||||
volumeMounts:
|
||||
- mountPath: /rootfs
|
||||
name: host-rootfs
|
||||
mountPropagation: HostToContainer # 这里显示声明mountPropagation为HostToContainer 或者 Bidirectional
|
||||
volumes:
|
||||
- hostPath:
|
||||
path: /
|
||||
type: ""
|
||||
name: host-rootfs
|
||||
```
|
||||
|
||||
|
||||
2. centos 和 redhat 的内核,可以开启如下内核参数:
|
||||
|
||||
```bash
|
||||
echo 1 > /proc/sys/fs/may_detach_mounts
|
||||
```
|
||||
|
||||
## 疑问:为啥 dockerd 运行时没有这个问题?
|
||||
|
||||
这里主要有两点:
|
||||
|
||||
1. dockerd 在启动的时候,开启了内核参数 `fs.may\_detach\_mounts`。
|
||||
|
||||
```go
|
||||
// This is used to allow removal of mountpoints that may be mounted in other
|
||||
// namespaces on RHEL based kernels starting from RHEL 7.4.
|
||||
// Without this setting, removals on these RHEL based kernels may fail with
|
||||
// "device or resource busy".
|
||||
// This setting is not available in upstream kernels as it is not configurable,
|
||||
// but has been in the upstream kernels since 3.15.
|
||||
func setMayDetachMounts() error {
|
||||
f, err := os.OpenFile("/proc/sys/fs/may_detach_mounts", os.O_WRONLY, 0)
|
||||
if err != nil {
|
||||
if os.IsNotExist(err) {
|
||||
return nil
|
||||
}
|
||||
return errors.Wrap(err, "error opening may_detach_mounts kernel config file")
|
||||
}
|
||||
defer f.Close()
|
||||
|
||||
_, err = f.WriteString("1")
|
||||
if os.IsPermission(err) {
|
||||
// Setting may_detach_mounts does not work in an
|
||||
// unprivileged container. Ignore the error, but log
|
||||
// it if we appear not to be in that situation.
|
||||
if !rsystem.RunningInUserNS() {
|
||||
logrus.Debugf("Permission denied writing %q to /proc/sys/fs/may_detach_mounts", "1")
|
||||
}
|
||||
return nil
|
||||
}
|
||||
return err
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
2. dockerd 在挂载目录时,会验证挂载的源目录与 daemon 的 root 目录的关系,如果源目录是 root 目录的子目录或者 root 目录是源目录的子目录,则将 propagation type 设置为 `MS_SLAVE`。
|
||||
|
||||
```go
|
||||
// validateBindDaemonRoot ensures that if a given mountpoint's source is within
|
||||
// the daemon root path, that the propagation is setup to prevent a container
|
||||
// from holding private refereneces to a mount within the daemon root, which
|
||||
// can cause issues when the daemon attempts to remove the mountpoint.
|
||||
func (daemon *Daemon) validateBindDaemonRoot(m mount.Mount) (bool, error) {
|
||||
if m.Type != mount.TypeBind {
|
||||
return false, nil
|
||||
}
|
||||
|
||||
// check if the source is within the daemon root, or if the daemon root is within the source
|
||||
if !strings.HasPrefix(m.Source, daemon.root) && !strings.HasPrefix(daemon.root, m.Source) {
|
||||
return false, nil
|
||||
}
|
||||
|
||||
if m.BindOptions == nil {
|
||||
return true, nil
|
||||
}
|
||||
|
||||
switch m.BindOptions.Propagation {
|
||||
case mount.PropagationRSlave, mount.PropagationRShared, "":
|
||||
return m.BindOptions.Propagation == "", nil
|
||||
default:
|
||||
}
|
||||
|
||||
return false, errdefs.InvalidParameter(errors.Errorf(`invalid mount config: must use either propagation mode "rslave" or "rshared" when mount source is within the daemon root, daemon root: %q, bind mount source: %q, propagation: %q`, daemon.root, m.Source, m.BindOptions.Propagation))
|
||||
}
|
||||
```
|
||||
|
||||
## 参考文档
|
||||
|
||||
* [Shared subtree](https://segmentfault.com/a/1190000006899213)
|
||||
* [Mount Propagation](https://kubernetes.io/zh/docs/concepts/storage/volumes/#mount-propagation)
|
||||
|
|
@ -1,169 +0,0 @@
|
|||
# 高版本 containerd 下载镜像失败
|
||||
|
||||
## 问题描述
|
||||
|
||||
在 containerd 运行时的 kubernetes 线上环境中,出现了镜像无法下载的情况,具体报错如下:
|
||||
|
||||
```txt
|
||||
Failed to pull image ` `"ccr.ccs.tencentyun.com/tkeimages/tke-hpc-controller:v1.0.0"` `: rpc error: code = NotFound desc = failed to pull and unpack image ` `"ccr.ccs.tencentyun.com/tkeimages/tke-hpc-controller:v1.0.0"` `: failed to unpack image on snapshotter overlayfs: failed to extract layer sha256:d72a74c56330b347f7d18b64d2effd93edd695fde25dc301d52c37efbcf4844e: failed to get reader from content store: content digest sha256:2bf487c4beaa6fa7ea6e46ec1ff50029024ebf59f628c065432a16a940792b58: not found
|
||||
```
|
||||
|
||||
containerd 的日志中也有相关日志:
|
||||
|
||||
```txt
|
||||
containerd[136]: time="2020-11-19T16:11:56.975489200Z" level=info msg="PullImage \"redis:2.8.23\""
|
||||
containerd[136]: time="2020-11-19T16:12:00.140053300Z" level=warning msg="reference for unknown type: application/octet-stream" digest="sha256:481995377a044d40ca3358e4203fe95eca1d58b98a1d4c2d9cec51c0c4569613" mediatype=application/octet-stream size=5946
|
||||
```
|
||||
|
||||
## 尝试复现
|
||||
|
||||
分析环境信息:
|
||||
|
||||
* container v1.4.3 运行时。
|
||||
* 基于 1.10 版本的 docker 制作的镜像(比如 dockerhub 镜像仓库中的 redis:2.8.23)。
|
||||
|
||||
然后根据以上版本信息构造相同环境,通过如下命令拉取镜像:
|
||||
|
||||
```bash
|
||||
$ crictl pull docker.io/libraryredis:2.8.23
|
||||
FATA[0001] pulling image failed: rpc error: code = NotFound desc = failed to pull and unpack image "docker.io/library/redis:2.8.23": failed to unpack image on snapshotter overlayfs: failed to extract layer sha256:4dcab49015d47e8f300ec33400a02cebc7b54cadd09c37e49eccbc655279da90: failed to get reader from content store: content digest sha256:51f5c6a04d83efd2d45c5fd59537218924bc46705e3de6ffc8bc07b51481610b: not found
|
||||
```
|
||||
|
||||
问题复现,基本确认跟 containerd 版本与打包镜像的 docker 版本有关。
|
||||
|
||||
## 分析镜像下载的过程
|
||||
|
||||
在 containerd 运行时环境中,完整拉取一个镜像,主要会经历以下几步,如图所示:
|
||||
|
||||

|
||||
|
||||
接下来以 `centos:latest` 镜像的拉取过程为例。
|
||||
|
||||
1. 将镜像名解析成 oci 规范里 descriptor
|
||||
|
||||
主要是 HEAD 请求,并且记录下返回中的 `Content-Type` 和 `Docker-Content-Digest`:
|
||||
|
||||
```bash
|
||||
$ curl -v -X HEAD -H "Accept: application/vnd.docker.distribution.manifest.v2+json, application/vnd.docker.distribution.manifest.list.v2+json, application/vnd.oci.image.manifest.v1+json, application/vnd.oci.image.index.v1+json, */*" https://mirror.ccs.tencentyun.com/v2/library/centos/manifests/latest?ns=docker.io
|
||||
...
|
||||
< HTTP/1.1 200 OK
|
||||
< Date: Mon, 17 May 2021 11:53:29 GMT
|
||||
< Content-Type: application/vnd.docker.distribution.manifest.list.v2+json
|
||||
< Content-Length: 762
|
||||
< Connection: keep-alive
|
||||
< Docker-Content-Digest: sha256:5528e8b1b1719d34604c87e11dcd1c0a20bedf46e83b5632cdeac91b8c04efc1
|
||||
```
|
||||
|
||||
2. 获取镜像的 list 列表:
|
||||
|
||||
```bash
|
||||
$ curl -X GET -H "Accept: application/vnd.docker.distribution.manifest.list.v2+json" https://mirror.ccs.tencentyun.com/v2/library/centos/manifests/sha256:5528e8b1b1719d34604c87e11dcd1c0a20bedf46e83b5632cdeac91b8c04efc1
|
||||
{
|
||||
"manifests":[
|
||||
{
|
||||
"digest":"sha256:dbbacecc49b088458781c16f3775f2a2ec7521079034a7ba499c8b0bb7f86875",
|
||||
"mediaType":"application\/vnd.docker.distribution.manifest.v2+json",
|
||||
"platform":{
|
||||
"architecture":"amd64",
|
||||
"os":"linux"
|
||||
},
|
||||
"size":529
|
||||
},
|
||||
{
|
||||
"digest":"sha256:7723d6b5d15b1c64d0a82ee6298c66cf8c27179e1c8a458e719041ffd08cd091",
|
||||
"mediaType":"application\/vnd.docker.distribution.manifest.v2+json",
|
||||
"platform":{
|
||||
"architecture":"arm64",
|
||||
"os":"linux",
|
||||
"variant":"v8"
|
||||
},
|
||||
"size":529
|
||||
},
|
||||
...
|
||||
"mediaType":"application\/vnd.docker.distribution.manifest.list.v2+json",
|
||||
"schemaVersion":2
|
||||
}
|
||||
```
|
||||
|
||||
3. 获取特定操作系统上的镜像 manifest。由于宿主机的环境是 linux,所以 `containerd` 会选择适合该平台的镜像进行拉取:
|
||||
|
||||
```bash
|
||||
$ curl -X GET -H "Accept: application/vnd.docker.distribution.manifest.v2+json" https://mirror.ccs.tencentyun.com/v2/library/centos/manifests/sha256:dbbacecc49b08458781c16f3775f2a2ec7521079034a7ba499c8b0bb7f86875
|
||||
{
|
||||
"schemaVersion": 2,
|
||||
"mediaType": "application/vnd.docker.distribution.manifest.v2+json",
|
||||
"config": {
|
||||
"mediaType": "application/vnd.docker.container.image.v1+json",
|
||||
"size": 2143,
|
||||
"digest": "sha256:300e315adb2f96afe5f0b2780b87f28ae95231fe3bdd1e16b9ba606307728f55"
|
||||
},
|
||||
"layers": [
|
||||
{
|
||||
"mediaType": "application/vnd.docker.image.rootfs.diff.tar.gzip",
|
||||
"size": 75181999,
|
||||
"digest": "sha256:7a0437f04f83f084b7ed68ad9c4a4947e12fc4e1b006b38129bac89114ec3621"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
5. 拉取镜像的 config 和 layers。最后一步就是解析第三步中获取的 manifest,分别再下载镜像的 config 和 layers 就可以。
|
||||
|
||||
## 关于 mediaType:application/octet-stream
|
||||
|
||||
`mediaType:application/octet-stream` 是 docker 较早(docker v1.10 之前)支持的 `docker/oci` 标准,现在已经不支持了,而社区也任务该 mediaType 也太老了,所以 containerd 后续也就不再支持了 (详情可以参考 PR [#5497](https://github.com/containerd/containerd/pull/5497)) 。
|
||||
|
||||
## 定位根因
|
||||
|
||||
接下来以 `redis:2.8.23` 镜像的拉取过程为例说明一下拉取失败的原因。
|
||||
|
||||
1. 将镜像名解析成 OCI 规范里 descriptor。这里还是 HEAD 请求,但返回中的 `Content-Type` 已经不是 list 类型了,而是 `application/vnd.docker.distribution.manifest.v2+json`:
|
||||
|
||||
```bash
|
||||
$ curl -v -X HEAD -H "Accept: application/vnd.docker.distribution.manifest.v2+json, application/vnd.docker.distribution.manifest.list.v2+json, application/vnd.oci.image.manifest.v1+json, application/vnd.oci.image.index.v1+json, */*" https://mirror.ccs.tencentyun.com/v2/library/redis/manifests/2.8.23?ns=docker.io
|
||||
...
|
||||
< HTTP/1.1 200 OK
|
||||
< Date: Thu, 20 May 2021 02:25:08 GMT
|
||||
< Content-Type: application/vnd.docker.distribution.manifest.v2+json
|
||||
< Content-Length: 1968
|
||||
< Connection: keep-alive
|
||||
< Docker-Content-Digest: sha256:e507029ca6a11b85f8628ff16d7ff73ae54582f16fd757e64431f5ca6d27a13c
|
||||
```
|
||||
|
||||
2. 直接解析 manifest。因为 HEAD 请求中返回的是 manifest 类型,而不是 list 类型,所以这里会直接解析,解析出的 config 的 mediaType 是 `application/octet-stream`:
|
||||
|
||||
```bash
|
||||
$ curl -X GET -H "Accept: application/vnd.docker.distribution.manifest.v2+json" https://mirror.ccs.tencentyun.com/v2/library/redis/manifests/sha256:e507029ca6a11b85f8628ff16d7ff73ae54582f16fd757e64431f5ca6d27a13c
|
||||
{
|
||||
"schemaVersion": 2,
|
||||
"mediaType": "application/vnd.docker.distribution.manifest.v2+json",
|
||||
"config": {
|
||||
"mediaType": "application/octet-stream", # 这里的 mediaType 是 application/octet-stream
|
||||
"size": 5946,
|
||||
"digest": "sha256:481995377a044d40ca3358e4203fe95eca1d58b98a1d4c2d9cec51c0c4569613"
|
||||
},
|
||||
"layers": [
|
||||
{
|
||||
"mediaType": "application/vnd.docker.image.rootfs.diff.tar.gzip",
|
||||
"size": 51356334,
|
||||
"digest": "sha256:51f5c6a04d83efd2d45c5fd59537218924bc46705e3de6ffc8bc07b51481610b"
|
||||
},
|
||||
...
|
||||
]
|
||||
```
|
||||
|
||||
3. containerd 中已经不支持 `mediaType: application/octet-stream`。 在 unpacker 逻辑中, containerd 已经不再支持 `mediaType: application/octet-stream`,导致了不会再下载 layers,故而出错。具体代码在 `containerd/unpacker.go` 中:
|
||||
|
||||
```go
|
||||
case images.MediaTypeDockerSchema2Config, ocispec.MediaTypeImageConfig:
|
||||
```
|
||||
|
||||
## 解决方案
|
||||
|
||||
如果遇到该问题,应基于新的 dockerd 运行时(>= docker v1.11)来重新构建镜像,并推送到镜像仓库中。
|
||||
|
||||
## 疑问:为什么 containerd v1.3.4 版本支持,而新版 v1.4.3 版本却不支持 ?
|
||||
|
||||
在 containerd v1.3.4 的版本中,合进了 [PR #2814:bugfix: support application/octet-stream during pull](https://github.com/containerd/containerd/pull/2814) ,支持了 `mediaType:application/octet-stream` 镜像格式的下载。
|
||||
|
||||
而在 v1.4.3 中,包含 [PR #3870](https://github.com/containerd/containerd/pull/3870) ,又去掉了对 `mediaType:application/octet-stream` 镜像格式的支持,导致了 v1.3.4 和 v1.4.3 版本的行为不一致。
|
||||
|
|
@ -1,91 +0,0 @@
|
|||
import type { SidebarsConfig } from '@docusaurus/plugin-content-docs';
|
||||
|
||||
const sidebars: SidebarsConfig = {
|
||||
troubleshootingSidebar: [
|
||||
'README',
|
||||
{
|
||||
type: 'category',
|
||||
label: '运行时排障',
|
||||
collapsed: false,
|
||||
link: {
|
||||
type: 'generated-index',
|
||||
slug: '/cases/runtime'
|
||||
},
|
||||
items: [
|
||||
'runtime/io-high-load-causing-pod-creation-timeout',
|
||||
'runtime/pull-image-fail-in-high-version-containerd',
|
||||
'runtime/mount-root-causing-device-or-resource-busy',
|
||||
'runtime/broken-system-time-causing-sandbox-conflicts',
|
||||
],
|
||||
},
|
||||
{
|
||||
type: 'category',
|
||||
label: '网络排障',
|
||||
collapsed: false,
|
||||
link: {
|
||||
type: 'generated-index',
|
||||
slug: '/cases/network'
|
||||
},
|
||||
items: [
|
||||
'network/dns-lookup-5s-delay',
|
||||
'network/arp-cache-overflow-causing-healthcheck-failed',
|
||||
'network/cross-vpc-connect-nodeport-timeout',
|
||||
'network/musl-libc-dns-id-conflict-causing-dns-abnormal',
|
||||
],
|
||||
},
|
||||
{
|
||||
type: 'category',
|
||||
label: '高负载',
|
||||
collapsed: false,
|
||||
link: {
|
||||
type: 'generated-index',
|
||||
slug: '/cases/high-load'
|
||||
},
|
||||
items: [
|
||||
'high-load/disk-full-causing-high-cpu',
|
||||
],
|
||||
},
|
||||
{
|
||||
type: 'category',
|
||||
label: '集群故障',
|
||||
collapsed: false,
|
||||
link: {
|
||||
type: 'generated-index',
|
||||
slug: '/cases/cluster'
|
||||
},
|
||||
items: [
|
||||
'cluster/delete-rancher-ns-causing-node-disappear',
|
||||
'cluster/scheduler-snapshot-missing-causing-pod-pending',
|
||||
'cluster/kubectl-exec-or-logs-failed',
|
||||
],
|
||||
},
|
||||
{
|
||||
type: 'category',
|
||||
label: '节点排障',
|
||||
collapsed: false,
|
||||
link: {
|
||||
type: 'generated-index',
|
||||
slug: '/cases/node'
|
||||
},
|
||||
items: [
|
||||
'node/cgroup-leaking',
|
||||
],
|
||||
},
|
||||
{
|
||||
type: 'category',
|
||||
label: '其它排障',
|
||||
collapsed: false,
|
||||
link: {
|
||||
type: 'generated-index',
|
||||
slug: '/cases/others'
|
||||
},
|
||||
items: [
|
||||
'others/failed-to-modify-hosts-in-multiple-container',
|
||||
'others/job-cannot-delete',
|
||||
'others/dotnet-configuration-cannot-auto-reload',
|
||||
],
|
||||
},
|
||||
],
|
||||
};
|
||||
|
||||
export default sidebars;
|
||||
|
|
@ -1,3 +0,0 @@
|
|||
# Kubernetes 排障指南
|
||||
|
||||
云原生老中医,专治疑难杂症。
|
||||
|
|
@ -1,116 +0,0 @@
|
|||
# Namespace 一直 Terminating
|
||||
|
||||
## 概述
|
||||
|
||||
本文分享 namespace 一直卡在 terminating 状态的可能原因与解决方法。
|
||||
|
||||
## Namespace 上存在 Finalizers 且对应软件已卸载
|
||||
|
||||
删除 ns 后,一直卡在 Terminating 状态。通常是存在 finalizers,通过 `kubectl get ns xxx -o yaml` 可以看到是否有 finalizers:
|
||||
|
||||
``` bash
|
||||
$ kubectl get ns -o yaml kube-node-lease
|
||||
apiVersion: v1
|
||||
kind: Namespace
|
||||
metadata:
|
||||
...
|
||||
finalizers:
|
||||
- finalizers.kubesphere.io/namespaces
|
||||
labels:
|
||||
kubesphere.io/workspace: system-workspace
|
||||
name: kube-node-lease
|
||||
ownerReferences:
|
||||
- apiVersion: tenant.kubesphere.io/v1alpha1
|
||||
blockOwnerDeletion: true
|
||||
controller: true
|
||||
kind: Workspace
|
||||
name: system-workspace
|
||||
uid: d4310acd-1fdc-11ea-a370-a2c490b9ae47
|
||||
spec: {}
|
||||
```
|
||||
|
||||
此例是因为之前装过 kubesphere,然后卸载了,但没有清理 finalizers,将其删除就可以了。
|
||||
|
||||
k8s 资源的 metadata 里如果存在 finalizers,那么该资源一般是由某应用创建的,或者是这个资源是此应用关心的。应用会在资源的 metadata 里的 finalizers 加了一个它自己可以识别的标识,这意味着这个资源被删除时需要由此应用来做删除前的清理,清理完了它需要将标识从该资源的 finalizers 中移除,然后才会最终彻底删除资源。比如 Rancher 创建的一些资源就会写入 finalizers 标识。
|
||||
|
||||
如果应用被删除,而finalizer没清理,删除资源时就会一直卡在terminating,可以手动删除finalizer来解决。
|
||||
|
||||
手动删除方法:
|
||||
1. `kubectl edit ns xx` 删除 `spec.finalizers`。
|
||||
2. 如果k8s版本较高会发现方法1行不通,因为高版本更改 namespace finalizers 被移到了 namespace 的 finalize 这个 subresource (参考[官方文档API文档](https://github.com/kubernetes/community/blob/master/contributors/design-proposals/architecture/namespaces.md#rest-api)),并且需要使用 `PUT` 请求,可以先执行 `kubectl proxy` 然后再起一个终端用 curl 模拟请求去删 `finalizers`:
|
||||
``` bash
|
||||
curl -H "Content-Type: application/json" -XPUT -d '{"apiVersion":"v1","kind":"Namespace","metadata":{"name":"delete-me"},"spec":{"finalizers":[]}}' http://localhost:8001/api/v1/namespaces/delete-me/finalize
|
||||
```
|
||||
> 替换 `delete-me` 为你的 namespace 名称
|
||||
|
||||
参考资料:
|
||||
|
||||
* Node Lease 的 Proposal: https://github.com/kubernetes/enhancements/blob/master/keps/sig-node/0009-node-heartbeat.md
|
||||
|
||||
## Namespace 中残留的资源存在 Finalizers 且相应软件已卸载
|
||||
|
||||
查看 namespace yaml:
|
||||
|
||||
```bash
|
||||
$ kubectl get ns istio-system -o yaml
|
||||
...
|
||||
status:
|
||||
conditions:
|
||||
- lastTransitionTime: "2021-12-07T05:07:14Z"
|
||||
message: 'Some resources are remaining: kialis.kiali.io has 1 resource instances'
|
||||
reason: SomeResourcesRemain
|
||||
status: "True"
|
||||
type: NamespaceContentRemaining
|
||||
- lastTransitionTime: "2021-12-07T05:07:14Z"
|
||||
message: 'Some content in the namespace has finalizers remaining: kiali.io/finalizer
|
||||
in 1 resource instances'
|
||||
reason: SomeFinalizersRemain
|
||||
status: "True"
|
||||
type: NamespaceFinalizersRemaining
|
||||
phase: Terminating
|
||||
```
|
||||
|
||||
可以看到 `SomeResourcesRemain` 和 `SomeFinalizersRemain`,对应资源类型是 `kialis.kiali.io`,可以获取看一下:
|
||||
|
||||
```bash
|
||||
$ kubectl -n istio-system get kialis.kiali.io
|
||||
NAME AGE
|
||||
kiali 5d23h
|
||||
```
|
||||
|
||||
这个例子明显看是安装过 kiali,且有 kiali 残留的 crd 资源,但 kiali 已卸载。
|
||||
清理 namespace 时清理 kiali 资源时,发现资源上存在 finilizer,需等待 kiali 本身进一步清理,由于 kiali 已卸载就无法清理,导致一直在等待。
|
||||
|
||||
这个时候我们可以手动删下资源上的 finalizer 即可:
|
||||
|
||||
```bash
|
||||
kubectl -n istio-system edit kialis.kiali.io kiali
|
||||
```
|
||||
|
||||

|
||||
|
||||
## metrics server 被删除
|
||||
|
||||
删除 ns 时,apiserver 会调注册上去的扩展 api 去清理资源,如果扩展 api 对应的服务也被删了,那么就无法清理完成,也就一直卡在 Terminating。
|
||||
|
||||
下面的例子就是使用 prometheus-adapter 注册的 resource metrics api,但 prometheus-adapter 已经被删除了:
|
||||
|
||||
``` bash
|
||||
$ kubectl get apiservice
|
||||
...
|
||||
v1beta1.metrics.k8s.io monitoring/prometheus-adapter False (ServiceNotFound) 75d
|
||||
...
|
||||
```
|
||||
|
||||
## 强删 namespace 方法
|
||||
|
||||
有时候实在找不到原因,也可以强删 namespace,以下是强删方法:
|
||||
|
||||
```bash
|
||||
NAMESPACE=delete-me
|
||||
kubectl get ns $NAMESPACE -o json | jq '.spec.finalizers=[]' > ns.json
|
||||
kubectl proxy --port=8899 &
|
||||
PID=$!
|
||||
curl -X PUT http://localhost:8899/api/v1/namespaces/$NAMESPACE/finalize -H "Content-Type: application/json" --data-binary @ns.json
|
||||
kill $PID
|
||||
```
|
||||
|
|
@ -1,51 +0,0 @@
|
|||
# 排查 CLOSE_WAIT 堆积
|
||||
|
||||
TCP 连接的 `CLOSE_WAIT` 状态,正常情况下是短暂的,如果出现堆积,一般说明应用有问题。
|
||||
|
||||
## CLOSE_WAIT 堆积的危害
|
||||
|
||||
每个 `CLOSE_WAIT` 连接会占据一个文件描述,堆积大量的 `CLOSE_WAIT` 可能造成文件描述符不够用,导致建连或打开文件失败,报错 `too many open files`:
|
||||
|
||||
```txt
|
||||
dial udp 9.215.0.48:9073: socket: too many open files
|
||||
```
|
||||
|
||||
## 如何判断?
|
||||
|
||||
检查系统 `CLOSE_WAIT` 连接数:
|
||||
|
||||
```bash
|
||||
lsof | grep CLOSE_WAIT | wc -l
|
||||
```
|
||||
|
||||
检查指定进程 `CLOSE_WAIT` 连接数:
|
||||
|
||||
```bash
|
||||
lsof -p $PID | grep CLOSE_WAIT | wc -l
|
||||
```
|
||||
|
||||
## 为什么会产生大量 CLOSE_WAIT?
|
||||
|
||||
我们看下 TCP 四次挥手过程:
|
||||
|
||||
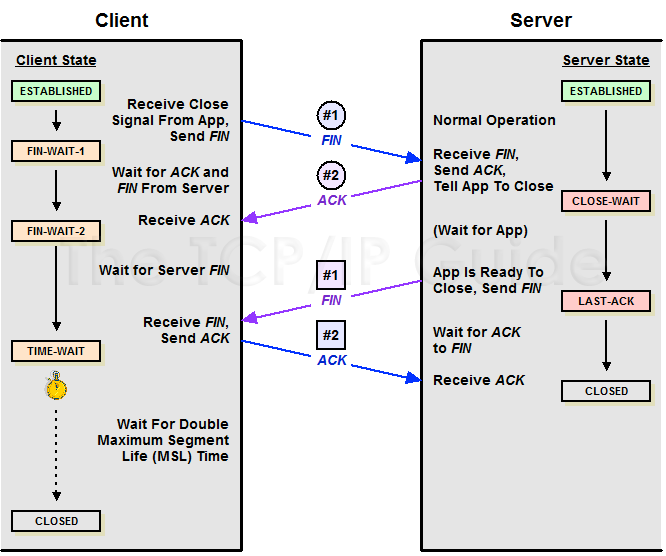
|
||||
|
||||
主动关闭的一方发出 FIN 包,被动关闭的一方响应 ACK 包,此时,被动关闭的一方就进入了 `CLOSE_WAIT` 状态。如果一切正常,稍后被动关闭的一方也会发出 FIN 包,然后迁移到 `LAST_ACK` 状态。
|
||||
|
||||
通常,`CLOSE_WAIT` 状态在服务器停留时间很短,如果你发现大量的 `CLOSE_WAIT` 状态,那么就意味着被动关闭的一方没有及时发出 FIN 包,一般来说都是被动关闭的一方应用程序有问题。
|
||||
|
||||
### 应用没有 Close
|
||||
|
||||
如果 `CLOSE_WAIT` 堆积的量特别大(比如 10w+),甚至导致文件描述符不够用了,一般就是应用没有 Close 连接导致。
|
||||
|
||||
当连接被关闭时,被动关闭方在代码层面没有 close 掉相应的 socket 连接,那么自然不会发出 FIN 包,从而会导致 `CLOSE_WAIT` 堆积。可能是代码里根本没写 Close,也可能是代码不严谨,出现死循环之类的问题,导致即便后面写了 close 也永远执行不到。
|
||||
|
||||
### 应用迟迟不 accept 连接
|
||||
|
||||
如果 `CLOSE_WAIT` 堆积的量不是很大,可能是全连接队列 (accept queue) 堆积了。我们先看下 TCP 连接建立的过程:
|
||||
|
||||
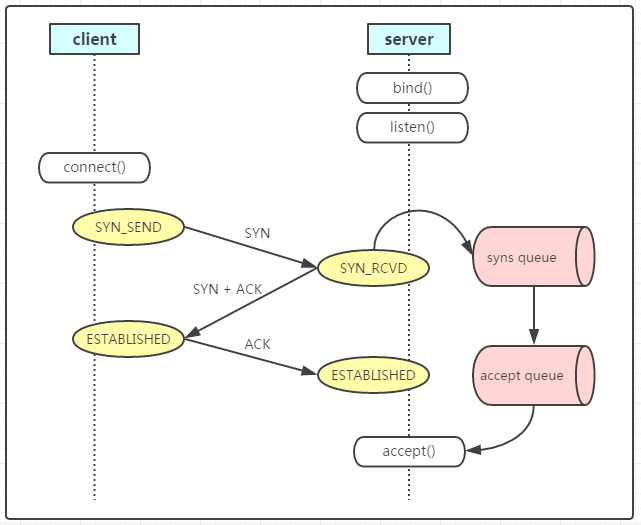
|
||||
|
||||
连接建立好之后会被放入 accept queue,等待应用 accept,如果应用迟迟没有从队列里面去 accept 连接,等到 client 超时时间,主动关闭了连接,这时连接在 server 端仍在全连接队列中,状态变为 `CLOSE_WAIT`。
|
||||
|
||||
如果连接一直不被应用 accept 出来,内核也不会自动响应 ACK 去关闭连接的。不过这种情况的堆积量一般也不高,取决于 accept queue 的大小。
|
||||
|
|
@ -1,86 +0,0 @@
|
|||
# 排查 DNS 解析异常
|
||||
|
||||
## 排查思路
|
||||
|
||||
### 确保集群 DNS 正常运行
|
||||
|
||||
容器内解析 DNS 走的集群 DNS(通常是 CoreDNS),所以首先要确保集群 DNS 运行正常。
|
||||
|
||||
kubelet 启动参数 `--cluster-dns` 可以看到 dns 服务的 cluster ip:
|
||||
|
||||
```bash
|
||||
$ ps -ef | grep kubelet
|
||||
... /usr/bin/kubelet --cluster-dns=172.16.14.217 ...
|
||||
```
|
||||
|
||||
找到 dns 的 service:
|
||||
|
||||
```bash
|
||||
$ kubectl get svc -n kube-system | grep 172.16.14.217
|
||||
kube-dns ClusterIP 172.16.14.217 <none> 53/TCP,53/UDP 47d
|
||||
```
|
||||
|
||||
看是否存在 endpoint:
|
||||
|
||||
```bash
|
||||
$ kubectl -n kube-system describe svc kube-dns | grep -i endpoints
|
||||
Endpoints: 172.16.0.156:53,172.16.0.167:53
|
||||
Endpoints: 172.16.0.156:53,172.16.0.167:53
|
||||
```
|
||||
|
||||
检查 endpoint 的 对应 pod 是否正常:
|
||||
|
||||
```bash
|
||||
$ kubectl -n kube-system get pod -o wide | grep 172.16.0.156
|
||||
kube-dns-898dbbfc6-hvwlr 3/3 Running 0 8d 172.16.0.156 10.0.0.3
|
||||
```
|
||||
|
||||
### 确保 Pod 能与集群 DNS 通信
|
||||
|
||||
检查下 pod 是否能连上集群 dns,可以在 pod 里 telnet 一下 dns 的 53 端口:
|
||||
|
||||
```bash
|
||||
# 连 dns service 的 cluster ip
|
||||
$ telnet 172.16.14.217 53
|
||||
```
|
||||
|
||||
> 如果容器内没有 telnet 等测试工具,可以 [使用 nsenter 进入 netns](../skill/enter-netns-with-nsenter),然后利用宿主机上的 telnet 进行测试。
|
||||
|
||||
如果检查到是网络不通,就需要排查下网络设置:
|
||||
|
||||
* 检查节点的安全组设置,需要放开集群的容器网段。
|
||||
* 检查是否还有防火墙规则,检查 iptables。
|
||||
* 检查 kube-proxy 是否正常运行,集群 DNS 的 IP 是 cluster ip,会经过 kube-proxy 生成的 iptables 或 ipvs 规则进行转发。
|
||||
|
||||
### 抓包
|
||||
|
||||
如果前面检查都没问题,可以考虑抓包看下,如果好复现,可以直接 [使用 nsenter 进入 netns](../skill/enter-netns-with-nsenter) 抓容器内的包:
|
||||
|
||||
```bash
|
||||
tcpdump -i any port 53 -w dns.pcap
|
||||
# tcpdump -i any port 53 -nn -tttt
|
||||
```
|
||||
|
||||
如果还不能分析出来,就在请求链路上的多个点一起抓,比如 Pod 的容器内、宿主机cbr0网桥、宿主机主网卡(eth0)、coredns pod 所在宿主机主网卡、cbr0 以及容器内。等复现拉通对比分析,看看包在哪个点丢的。
|
||||
|
||||
## 现象与可能原因
|
||||
|
||||
### 5 秒延时
|
||||
|
||||
如果DNS查询经常延时5秒才返回,通常是遇到内核 conntrack 冲突导致的丢包,详见 [排障案例: DNS 5秒延时](../../troubleshooting-cases/network/dns-lookup-5s-delay)
|
||||
|
||||
### 解析外部域名超时
|
||||
|
||||
可能原因:
|
||||
|
||||
* 上游 DNS 故障。
|
||||
* 上游 DNS 的 ACL 或防火墙拦截了报文。
|
||||
|
||||
### 所有解析都超时
|
||||
|
||||
如果集群内某个 Pod 不管解析 Service 还是外部域名都失败,通常是 Pod 与集群 DNS 之间通信有问题。
|
||||
|
||||
可能原因:
|
||||
|
||||
* 节点防火墙没放开集群网段,导致如果 Pod 跟集群 DNS 的 Pod 不在同一个节点就无法通信,DNS 请求也就无法被收到。
|
||||
* kube-proxy 异常。
|
||||
|
|
@ -1,27 +0,0 @@
|
|||
# 排查网络不通
|
||||
|
||||
## 排查思路
|
||||
|
||||
TODO
|
||||
|
||||
## 可能原因
|
||||
|
||||
### 端口监听挂掉
|
||||
|
||||
如果容器内的端口已经没有进程监听了,内核就会返回 Reset 包,客户端就会报错连接被拒绝,可以进容器 netns 检查下端口是否存活:
|
||||
|
||||
``` bash
|
||||
netstat -tunlp
|
||||
```
|
||||
|
||||
### iptables 规则问题
|
||||
|
||||
检查报文是否有命中丢弃报文的 iptables 规则:
|
||||
|
||||
```bash
|
||||
iptables -t filter -nvL
|
||||
iptables -t nat -nvL
|
||||
iptables -t raw -nvL
|
||||
iptables -t mangle -nvL
|
||||
iptables-save
|
||||
```
|
||||
|
|
@ -1,168 +0,0 @@
|
|||
# 排查网络丢包
|
||||
|
||||
本文汇总网络丢包相关问题的排查思路与可能原因。
|
||||
|
||||
## 网络丢包的定义与现象
|
||||
|
||||
网络丢包是指部分包正常,部分包被丢弃。
|
||||
|
||||
从现象上看就不是网络一直不通,而是:
|
||||
1. 偶尔不通。
|
||||
2. 速度慢(丢包导致重传)。
|
||||
|
||||
## 排查思路
|
||||
|
||||
TODO
|
||||
|
||||
### 可能原因
|
||||
|
||||
### 高并发 NAT 导致 conntrack 插入冲突
|
||||
|
||||
如果高并发并且做了 NAT,比如使用了 ip-masq-agent,对集群外的网段或公网进行 SNAT,又或者集群内访问 Service 被做了 DNAT,再加上高并发的话,内核就会高并发进行 NAT 和 conntrack 插入,当并发 NAT 后五元组冲突,最终插入的时候只有先插入的那个成功,另外冲突的就会插入失败,然后就丢包了。
|
||||
|
||||
可以通过 `conntrack -S` 确认,如果 `insert_failed` 计数在增加,说明有 conntrack 插入冲突。
|
||||
|
||||
### conntrack 表爆满
|
||||
|
||||
看内核日志:
|
||||
|
||||
``` bash
|
||||
# demsg
|
||||
$ journalctl -k | grep "nf_conntrack: table full"
|
||||
nf_conntrack: nf_conntrack: table full, dropping packet
|
||||
```
|
||||
|
||||
若有以上报错,证明 conntrack 表满了,需要调大 conntrack 表:
|
||||
|
||||
``` bash
|
||||
sysctl -w net.netfilter.nf_conntrack_max=1000000
|
||||
```
|
||||
|
||||
### socket buffer 满导致丢包
|
||||
|
||||
`netstat -s | grep "buffer errors"` 的计数统计在增加,说明流量较大,socket buffer 不够用,需要调大下 buffer 容量:
|
||||
|
||||
```bash
|
||||
net.ipv4.tcp_wmem = 4096 16384 4194304
|
||||
net.ipv4.tcp_rmem = 4096 87380 6291456
|
||||
net.ipv4.tcp_mem = 381462 508616 762924
|
||||
net.core.rmem_default = 8388608
|
||||
net.core.rmem_max = 26214400
|
||||
net.core.wmem_max = 26214400
|
||||
```
|
||||
|
||||
### arp 表爆满
|
||||
|
||||
看内核日志:
|
||||
|
||||
``` bash
|
||||
# demsg
|
||||
$ journalctl -k | grep "neighbor table overflow"
|
||||
arp_cache: neighbor table overflow!
|
||||
```
|
||||
|
||||
若有以上报错,证明 arp 表满了,查看当前 arp 记录数:
|
||||
|
||||
``` bash
|
||||
$ arp -an | wc -l
|
||||
1335
|
||||
```
|
||||
|
||||
查看 arp gc 阀值:
|
||||
|
||||
``` bash
|
||||
$ sysctl -a | grep gc_thresh
|
||||
net.ipv4.neigh.default.gc_thresh1 = 128
|
||||
net.ipv4.neigh.default.gc_thresh2 = 512
|
||||
net.ipv4.neigh.default.gc_thresh3 = 1024
|
||||
```
|
||||
|
||||
调大 arp 表:
|
||||
``` bash
|
||||
sysctl -w net.ipv4.neigh.default.gc_thresh1=80000
|
||||
sysctl -w net.ipv4.neigh.default.gc_thresh2=90000
|
||||
sysctl -w net.ipv4.neigh.default.gc_thresh3=100000
|
||||
```
|
||||
|
||||
更多请参考 [节点排障: Arp 表爆满](../node/arp-cache-overflow.md)。
|
||||
|
||||
### MTU 不一致导致丢包
|
||||
|
||||
如果容器内网卡 MTU 比另一端宿主机内的网卡 MTU 不一致(通常是 CNI 插件问题),数据包就可能被截断导致一些数据丢失:
|
||||
1. 如果容器内的 MTU 更大,发出去的包如果超过 MTU 可能就被丢弃了(通常节点内核不会像交换机那样严谨会分片发送)。
|
||||
2. 同样的,如果容器内的 MTU 更小,进来的包如果超过 MTU 可能就被丢弃。
|
||||
|
||||
> tcp 协商 mss 的时候,主要看的是进程通信两端网卡的 MTU。
|
||||
|
||||
MTU 大小可以通过 `ip address show` 或 `ifconfig` 来确认。
|
||||
|
||||
### QoS 限流丢包
|
||||
|
||||
在云厂商的云主机环境,有可能会在底层会对某些包进行 QoS 限流,比如为了防止公共 DNS 被 DDoS 攻击,限制 UDP 53 端口的包的流量,超过特定速度阈值就丢包,导致部分 DNS 请求丢包而超时。
|
||||
|
||||
### PPS 限速对包
|
||||
|
||||
网卡的速度始终是有上限的,在云环境下,不同机型不同规格的云主机的 PPS 上限也不一样,超过阈值后就不保证能正常转发,可能就丢包了。
|
||||
|
||||
### 连接队列满导致丢包
|
||||
|
||||
对于 TCP 连接,三次握手建立连接,没建连成功前存储在半连接队列,建连成功但还没被应用层 accept 之前,存储在全连接队列。队列大小是有上限的,如果慢了就会丢包:
|
||||
* 如果并发太高或机器负载过高,半连接队列可能会满,新来的 SYN 建连包会被丢包。
|
||||
* 如果应用层 accept 连接过慢,会导致全连接队列堆积,满了就会丢包,通常是并发高、机器负载高或应用 hung 死等原因。
|
||||
|
||||
查看丢包统计:
|
||||
|
||||
```bash
|
||||
netstat -s | grep -E 'drop|overflow'
|
||||
```
|
||||
|
||||
```bash
|
||||
$ cat /proc/net/netstat | awk '/TcpExt/ { print $21,$22 }'
|
||||
ListenOverlows ListenDrops
|
||||
20168 20168
|
||||
```
|
||||
|
||||
> 不同内核版本的列号可能有差别
|
||||
|
||||
如果有现场,还可以观察全连接队列阻塞情况 (`Rec-Q`):
|
||||
|
||||
```bash
|
||||
ss -lnt
|
||||
```
|
||||
|
||||
通过以下内核参数可以调整队列大小 (namespace隔离):
|
||||
|
||||
```bash
|
||||
net.ipv4.tcp_max_syn_backlog = 8096 # 调整半连接队列上限
|
||||
net.core.somaxconn = 32768 # 调整全连接队列上限
|
||||
```
|
||||
|
||||
需要注意的是,`somaxconn` 只是调整了队列最大的上限,但实际队列大小是应用在 `listen` 时传入的 `backlog` 大小,大多编程语言默认会自动读取 `somaxconn` 的值作为 `listen` 系统调用的 `backlog` 参数的大小。
|
||||
|
||||
如果是用 nginx,`backlog` 的值需要在 `nginx.conf` 配置中显示指定,否则会用它自己的默认值 `511`。
|
||||
|
||||
### 源端口耗尽
|
||||
|
||||
当作为 client 发请求,或外部流量从 NodePort 进来时进行 SNAT,会从当前 netns 中选择一个端口作为源端口,端口范围由 `net.ipv4.ip_local_port_range` 这个内核参数决定,如果并发量大,就可能导致源端口耗尽,从而丢包。
|
||||
|
||||
### tcp_tw_recycle 导致丢包
|
||||
|
||||
在低版本内核中(比如 3.10),支持使用 tcp_tw_recycle 内核参数来开启 TIME_WAIT 的快速回收,但如果 client 也开启了 timestamp (一般默认开启),同时也就会导致在 NAT 环境丢包,甚至没有 NAT 时,稍微高并发一点,也会导致 PAWS 校验失败,导致丢包:
|
||||
|
||||
``` bash
|
||||
# 看 SYN 丢包是否全都是 PAWS 校验失败
|
||||
$ cat /proc/net/netstat | grep TcpE| awk '{print $15, $22}'
|
||||
PAWSPassive ListenDrops
|
||||
96305 96305
|
||||
```
|
||||
|
||||
参考资料:
|
||||
|
||||
* https://github.com/torvalds/linux/blob/v3.10/net/ipv4/tcp_ipv4.c#L1465
|
||||
* https://www.freesoft.org/CIE/RFC/1323/13.htm
|
||||
* https://zhuanlan.zhihu.com/p/35684094
|
||||
* https://my.oschina.net/u/4270811/blog/3473655/print
|
||||
|
||||
### listen 了源 port_range 范围内的端口
|
||||
|
||||
比如 `net.ipv4.ip_local_port_range="1024 65535"`,但又 listen 了 `9100` 端口,当作为 client 发请求时,选择一个 port_range 范围内的端口作为源端口,就可能选到 9100,但这个端口已经被 listen 了,就可能会选取失败,导致丢包。
|
||||
|
|
@ -1,30 +0,0 @@
|
|||
# 排查网速差
|
||||
|
||||
网络差是指已经建立的连接,通信慢或期间有断连,本文介绍网络速度差的可能原因。
|
||||
|
||||
## 公网线路丢包
|
||||
|
||||
如果通信经过了公网传输,而公网线路难免有波动,任意一方网络环境差导致丢包都会让网速降下来。
|
||||
|
||||
这时 server 端可以调下拥塞算法,4.19 以上的内核自带了 bbr,在公网丢包情况下,能明显提升网络性能,可以启用观察下:
|
||||
|
||||
```bash
|
||||
sysctl -w net.core.default_qdisc = fq
|
||||
sysctl -w net.ipv4.tcp_available_congestion_control = bbr
|
||||
```
|
||||
|
||||
## 达到带宽或 PPS 上限而被限速
|
||||
|
||||
如果是走公网,一般都有个公网带宽上限,可以看看监控是否达到带宽上限而被限速。
|
||||
|
||||
如果是走内网,也是可能会被限速的;通常云厂商的服务器有各种机型和规格,性能指标各不一样,可以先看下对应机型和规格的 PPS 和内网带宽能力,比如腾讯云可以看 [CVM实例规格](https://cloud.tencent.com/document/product/213/11518),然后再看下监控,是否达到上限。
|
||||
|
||||
## NAT 环境没开启 nf_conntrack_tcp_be_liberal
|
||||
|
||||
容器环境下,不开启这个参数可能造成 NAT 过的 TCP 连接带宽上不去或经常断连。
|
||||
|
||||
现象是有一点时延的 TCP 单流速度慢或经常断连,比如:
|
||||
1. 跨地域专线挂载 nfs ,时延 5ms,下载速度就上不去,只能到 12Mbps 左右。
|
||||
2. 经过公网上传文件经常失败。
|
||||
|
||||
原因是如果流量存在一定时延时,有些包就可能 out of window 了,netfilter 会将 out of window 的包置为 INVALID,如果是 INVALID 状态的包,netfilter 不会对其做 IP 和端口的 NAT 转换,这样协议栈再去根据 ip + 端口去找这个包的连接时,就会找不到,这个时候就会回复一个 RST,但这个 RST 是直接宿主机发出,容器内不知道,导致容器内还以为连接没断不停重试。 所以如果数据包对应的 TCP 连接做过 NAT,在 conntrack 记录了地址转换信息,也有可能部分包因 out of window 不走 conntrack 转换地址,造成一些混乱导致流量速度慢或卡住的现象。
|
||||
|
|
@ -1,50 +0,0 @@
|
|||
# 排查网络超时
|
||||
|
||||
本文记录网络超时的可能原因。
|
||||
|
||||
## 网络完全不通
|
||||
|
||||
如果发现是网络完全不通导致的超时,可以参考 [排查网络不通](network-unreachable.md)。
|
||||
|
||||
## 网络偶尔丢包
|
||||
|
||||
超时也可能是丢包导致的,参考 [排查网络丢包](packet-loss.md) 。
|
||||
|
||||
## cpu 限流 (throttled)
|
||||
|
||||
有以下情况 CPU 会被限流:
|
||||
|
||||
1. Pod 使用的 CPU 超过了 limit,会直接被限流。
|
||||
2. 容器内同时在 running 状态的进程/线程数太多,内核 CFS 调度周期内无法保证容器所在 cgroup 内所有进程都分到足够的时间片运行,部分进程会被限流。
|
||||
3. 内核态 CPU 占用过高也可能会影响到用户态任务执行,触发 cgroup 的 CPU throttle,有些内核态的任务是不可中断的,比如大量创建销毁进程,回收内存等任务,部分核陷入内核态过久,当切回用户态时发现该 CFS 调度周期时间所剩无几,部分进程也无法分到足够时间片从而被限流。
|
||||
|
||||
CPU 被限流后进程就运行变慢了,应用层的表现通常就是超时。
|
||||
|
||||
如果确认?可以查 Promehtues 监控,PromQL 查询语句:
|
||||
|
||||
1. cpu 被限制比例:
|
||||
|
||||
```txt
|
||||
sum by (namespace, pod)(
|
||||
irate(container_cpu_cfs_throttled_periods_total{container!="POD", container!=""}[5m])
|
||||
) /
|
||||
sum by (namespace, pod)(
|
||||
irate(container_cpu_cfs_periods_total{container!="POD", container!=""}[5m])
|
||||
)
|
||||
```
|
||||
|
||||
2. cpu 被限制核数:
|
||||
|
||||
```txt
|
||||
sum by (namespace, pod)(
|
||||
irate(container_cpu_cfs_throttled_periods_total{container!="POD", container!="", cluster="$cluster"}[5m])
|
||||
)
|
||||
```
|
||||
|
||||
如何确认超时就是 CPU throttle 导致的呢?建议:
|
||||
1. 看下 throttle 严不严重,如果只有少了 throttle,可能不会导致超时。
|
||||
2. 拉长监控图时间范围,对比开始超时的时间段与之前正常的时间段,是否都有 throttle,如果是有 throttle 或加重很多后才超时,那很可能是因为 throttle 导致的超时。
|
||||
|
||||
## 节点高负载
|
||||
|
||||
如果节点高负载了,即便没 throttle,进程所分配的 CPU 时间片也不够用,也会导致进程处理慢,从而超时,详见 [节点高负载排查思路](../node/node-high-load.md)
|
||||
|
|
@ -1,26 +0,0 @@
|
|||
# 排查流量激增
|
||||
|
||||
## iftop 纠出大流量 IP
|
||||
|
||||
```bash
|
||||
$ iftop
|
||||
10.21.45.8 => 10.111.100.101 3.35Mb 2.92Mb 2.94Mb
|
||||
<= 194Mb 160Mb 162Mb
|
||||
10.21.45.8 => 10.121.101.22 3.41Mb 2.89Mb 3.04Mb
|
||||
<= 192Mb 159Mb 172Mb
|
||||
10.21.45.8 => 10.22.122.55 279Kb 313Kb 292Kb
|
||||
<= 11.3Kb 12.1Kb 11.9Kb
|
||||
...
|
||||
```
|
||||
|
||||
## netstat 查看大流量 IP 连接
|
||||
|
||||
```bash
|
||||
$ netstat -np | grep 10.121.101.22
|
||||
tcp 0 0 10.21.45.8:48320 10.121.101.22:12002 TIME_WAIT -
|
||||
tcp 0 0 10.21.45.8:59179 10.121.101.22:12002 TIME_WAIT -
|
||||
tcp 0 0 10.21.45.8:55835 10.121.101.22:12002 TIME_WAIT -
|
||||
tcp 0 0 10.21.45.8:49420 10.121.101.22:12002 TIME_WAIT -
|
||||
tcp 0 0 10.21.45.8:55559 10.121.101.22:12002 TIME_WAIT -
|
||||
...
|
||||
```
|
||||
|
|
@ -1,66 +0,0 @@
|
|||
# ARP 表爆满
|
||||
|
||||
## 判断 arp_cache 是否溢出
|
||||
|
||||
内核日志会有有下面的报错:
|
||||
|
||||
``` txt
|
||||
arp_cache: neighbor table overflow!
|
||||
```
|
||||
|
||||
查看当前 arp 记录数:
|
||||
|
||||
``` bash
|
||||
$ arp -an | wc -l
|
||||
1335
|
||||
```
|
||||
|
||||
查看 arp gc 阀值:
|
||||
|
||||
``` bash
|
||||
$ sysctl -a | grep gc_thresh
|
||||
net.ipv4.neigh.default.gc_thresh1 = 128
|
||||
net.ipv4.neigh.default.gc_thresh2 = 512
|
||||
net.ipv4.neigh.default.gc_thresh3 = 1024
|
||||
net.ipv6.neigh.default.gc_thresh1 = 128
|
||||
net.ipv6.neigh.default.gc_thresh2 = 512
|
||||
net.ipv6.neigh.default.gc_thresh3 = 1024
|
||||
```
|
||||
|
||||
当前 arp 记录数接近 `gc_thresh3` 比较容易 overflow,因为当 arp 记录达到 `gc_thresh3` 时会强制触发 gc 清理,当这时又有数据包要发送,并且根据目的 IP 在 arp cache 中没找到 mac 地址,这时会判断当前 arp cache 记录数加 1 是否大于 `gc_thresh3`,如果没有大于就会 时就会报错: `arp_cache: neighbor table overflow!`
|
||||
|
||||
## 解决方案
|
||||
|
||||
调整节点内核参数,将 arp cache 的 gc 阀值调高 (`/etc/sysctl.conf`):
|
||||
|
||||
``` bash
|
||||
net.ipv4.neigh.default.gc_thresh1 = 80000
|
||||
net.ipv4.neigh.default.gc_thresh2 = 90000
|
||||
net.ipv4.neigh.default.gc_thresh3 = 100000
|
||||
```
|
||||
|
||||
分析是否只是部分业务的 Pod 的使用场景需要节点有比较大的 arp 缓存空间。
|
||||
|
||||
如果不是,就需要调整所有节点内核参数。
|
||||
|
||||
如果是,可以将部分 Node 打上标签,比如:
|
||||
|
||||
``` bash
|
||||
kubectl label node host1 arp_cache=large
|
||||
```
|
||||
|
||||
然后用 nodeSelector 或 nodeAffnity 让这部分需要内核有大 arp_cache 容量的 Pod 只调度到这部分节点,推荐使用 nodeAffnity,yaml 示例:
|
||||
|
||||
``` yaml
|
||||
template:
|
||||
spec:
|
||||
affinity:
|
||||
nodeAffinity:
|
||||
requiredDuringSchedulingIgnoredDuringExecution:
|
||||
nodeSelectorTerms:
|
||||
- matchExpressions:
|
||||
- key: arp_cache
|
||||
operator: In
|
||||
values:
|
||||
- large
|
||||
```
|
||||
|
|
@ -1,37 +0,0 @@
|
|||
# cAdvisor 无数据
|
||||
|
||||
## 可能原因
|
||||
|
||||
### 修改容器数据盘后未重启 kubelet
|
||||
|
||||
如果修改过容器数据盘 (docker root),重启了容器运行时,但又没驱逐和重启 kubelet,这时 kubelet 就可能无法正常返回 cAdvisor 数据,日志报错:
|
||||
|
||||
```txt
|
||||
Mar 21 02:59:26 VM-67-101-centos kubelet[714]: E0321 02:59:26.320938 714 manager.go:1086] Failed to create existing container: /kubepods/burstable/podb267f18b-a641-4004-a660-4c6a43b6e520/03164d8f0d1f55a285b50b2117d6fdb2c33d2fa87f46dba0f43b806017607d03: failed to identify the read-write layer ID for container "03164d8f0d1f55a285b50b2117d6fdb2c33d2fa87f46dba0f43b806017607d03". - open /var/lib/docker/image/overlay2/layerdb/mounts/03164d8f0d1f55a285b50b2117d6fdb2c33d2fa87f46dba0f43b806017607d03/mount-id: no such file or directory
|
||||
```
|
||||
|
||||
如何确认?可以看下数据盘是否修改过:
|
||||
|
||||
```bash
|
||||
$ docker info
|
||||
...
|
||||
Docker Root Dir: /data/bcs/service/docker
|
||||
...
|
||||
```
|
||||
|
||||
确认下容器运行时启动时间是否晚于 kubelet:
|
||||
|
||||
```txt
|
||||
● kubelet.service - kubelet
|
||||
Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; vendor preset: disabled)
|
||||
Active: active (running) since Fri 2022-01-14 14:39:52 CST; 2 months 6 days ago
|
||||
|
||||
|
||||
● dockerd.service - dockerd
|
||||
Loaded: loaded (/usr/lib/systemd/system/dockerd.service; enabled; vendor preset: disabled)
|
||||
Active: active (running) since Fri 2022-01-14 14:41:45 CST; 2 months 6 days ago
|
||||
```
|
||||
|
||||
如果都是,可能就是因为修改了容器数据盘路径并且没有重启 kubelet。
|
||||
|
||||
解决方案就是: 对 Node 进行驱逐,让存量旧 Pod 漂移到其它节点,最后重启下 kubelet。
|
||||
|
|
@ -1,92 +0,0 @@
|
|||
# 磁盘爆满
|
||||
|
||||
## 什么情况下磁盘可能会爆满 ?
|
||||
|
||||
kubelet 有 gc 和驱逐机制,通过 `--image-gc-high-threshold`, `--image-gc-low-threshold`, `--eviction-hard`, `--eviction-soft`, `--eviction-minimum-reclaim` 等参数控制 kubelet 的 gc 和驱逐策略来释放磁盘空间,如果配置正确的情况下,磁盘一般不会爆满。
|
||||
|
||||
通常导致爆满的原因可能是配置不正确或者节点上有其它非 K8S 管理的进程在不断写数据到磁盘占用大量空间导致磁盘爆满。
|
||||
|
||||
## 磁盘爆满会有什么影响 ?
|
||||
|
||||
影响 K8S 运行我们主要关注 kubelet 和容器运行时这两个最关键的组件,它们所使用的目录通常不一样,kubelet 一般不会单独挂盘,直接使用系统磁盘,因为通常占用空间不会很大,容器运行时单独挂盘的场景比较多,当磁盘爆满的时候我们也要看 kubelet 和 容器运行时使用的目录是否在这个磁盘,通过 `df` 命令可以查看磁盘挂载点。
|
||||
|
||||
### 容器运行时使用的目录所在磁盘爆满
|
||||
|
||||
如果容器运行时使用的目录所在磁盘空间爆满,可能会造成容器运行时无响应,比如 docker,执行 docker 相关的命令一直 hang 住, kubelet 日志也可以看到 PLEG unhealthy,因为 CRI 调用 timeout,当然也就无法创建或销毁容器,通常表现是 Pod 一直 ContainerCreating 或 一直 Terminating。
|
||||
|
||||
docker 默认使用的目录主要有:
|
||||
|
||||
* `/var/run/docker`: 用于存储容器运行状态,通过 dockerd 的 `--exec-root` 参数指定。
|
||||
* `/var/lib/docker`: 用于持久化容器相关的数据,比如容器镜像、容器可写层数据、容器标准日志输出、通过 docker 创建的 volume 等
|
||||
|
||||
Pod 启动可能报类似下面的事件:
|
||||
|
||||
``` txt
|
||||
Warning FailedCreatePodSandBox 53m kubelet, 172.22.0.44 Failed create pod sandbox: rpc error: code = DeadlineExceeded desc = context deadline exceeded
|
||||
```
|
||||
|
||||
``` txt
|
||||
Warning FailedCreatePodSandBox 2m (x4307 over 16h) kubelet, 10.179.80.31 (combined from similar events): Failed create pod sandbox: rpc error: code = Unknown desc = failed to create a sandbox for pod "apigateway-6dc48bf8b6-l8xrw": Error response from daemon: mkdir /var/lib/docker/aufs/mnt/1f09d6c1c9f24e8daaea5bf33a4230de7dbc758e3b22785e8ee21e3e3d921214-init: no space left on device
|
||||
```
|
||||
|
||||
``` txt
|
||||
Warning Failed 5m1s (x3397 over 17h) kubelet, ip-10-0-151-35.us-west-2.compute.internal (combined from similar events): Error: container create failed: container_linux.go:336: starting container process caused "process_linux.go:399: container init caused \"rootfs_linux.go:58: mounting \\\"/sys\\\" to rootfs \\\"/var/lib/dockerd/storage/overlay/051e985771cc69f3f699895a1dada9ef6483e912b46a99e004af7bb4852183eb/merged\\\" at \\\"/var/lib/dockerd/storage/overlay/051e985771cc69f3f699895a1dada9ef6483e912b46a99e004af7bb4852183eb/merged/sys\\\" caused \\\"no space left on device\\\"\""
|
||||
```
|
||||
|
||||
Pod 删除可能报类似下面的事件:
|
||||
|
||||
``` txt
|
||||
Normal Killing 39s (x735 over 15h) kubelet, 10.179.80.31 Killing container with id docker://apigateway:Need to kill Pod
|
||||
```
|
||||
|
||||
### kubelet 使用的目录所在磁盘爆满
|
||||
|
||||
如果 kubelet 使用的目录所在磁盘空间爆满(通常是系统盘),新建 Pod 时连 Sandbox 都无法创建成功,因为 mkdir 将会失败,通常会有类似这样的 Pod 事件:
|
||||
|
||||
``` txt
|
||||
Warning UnexpectedAdmissionError 44m kubelet, 172.22.0.44 Update plugin resources failed due to failed to write checkpoint file "kubelet_internal_checkpoint": write /var/lib/kubelet/device-plugins/.728425055: no space left on device, which is unexpected.
|
||||
```
|
||||
|
||||
kubelet 默认使用的目录是 `/var/lib/kubelet`, 用于存储插件信息、Pod 相关的状态以及挂载的 volume (比如 `emptyDir`, `ConfigMap`, `Secret`),通过 kubelet 的 `--root-dir` 参数指定。
|
||||
|
||||
## 如何分析磁盘占用 ?
|
||||
|
||||
* 如果运行时使用的是 Docker,请参考本书 排错技巧: 分析 Docker 磁盘占用 (TODO)
|
||||
|
||||
## 如何恢复 ?
|
||||
|
||||
如果容器运行时使用的 Docker,我们无法直接重启 dockerd 来释放一些空间,因为磁盘爆满后 dockerd 无法正常响应,停止的时候也会卡住。我们需要先手动清理一点文件腾出空间好让 dockerd 能够停止并重启。
|
||||
|
||||
可以手动删除一些 docker 的 log 文件或可写层文件,通常删除 log:
|
||||
|
||||
``` bash
|
||||
$ cd /var/lib/docker/containers
|
||||
$ du -sh * # 找到比较大的目录
|
||||
$ cd dda02c9a7491fa797ab730c1568ba06cba74cecd4e4a82e9d90d00fa11de743c
|
||||
$ cat /dev/null > dda02c9a7491fa797ab730c1568ba06cba74cecd4e4a82e9d90d00fa11de743c-json.log.9 # 删除log文件
|
||||
```
|
||||
|
||||
* **注意:** 使用 `cat /dev/null >` 方式删除而不用 `rm`,因为用 rm 删除的文件,docker 进程可能不会释放文件,空间也就不会释放;log 的后缀数字越大表示越久远,先删除旧日志。
|
||||
|
||||
然后将该 node 标记不可调度,并将其已有的 pod 驱逐到其它节点,这样重启 dockerd 就会让该节点的 pod 对应的容器删掉,容器相关的日志(标准输出)与容器内产生的数据文件(没有挂载 volume, 可写层)也会被清理:
|
||||
|
||||
``` bash
|
||||
kubectl drain <node-name>
|
||||
```
|
||||
|
||||
重启 dockerd:
|
||||
|
||||
``` bash
|
||||
systemctl restart dockerd
|
||||
# or systemctl restart docker
|
||||
```
|
||||
|
||||
等重启恢复,pod 调度到其它节点,排查磁盘爆满原因并清理和规避,然后取消节点不可调度标记:
|
||||
|
||||
``` bash
|
||||
kubectl uncordon <node-name>
|
||||
```
|
||||
|
||||
## 如何规避 ?
|
||||
|
||||
正确配置 kubelet gc 和 驱逐相关的参数,即便到达爆满地步,此时节点上的 pod 也都早就自动驱逐到其它节点了,不会存在 Pod 一直 ContainerCreating 或 Terminating 的问题。
|
||||
|
|
@ -1,156 +0,0 @@
|
|||
# IO 高负载
|
||||
|
||||
系统如果出现 IO WAIT 高,说明 IO 设备的速度跟不上 CPU 的处理速度,CPU 需要在那里干等,这里的等待实际也占用了 CPU 时间,导致系统负载升高,可能就会影响业务进程的处理速度,导致业务超时。
|
||||
|
||||
## 如何判断 ?
|
||||
|
||||
使用 `top` 命令看下当前负载:
|
||||
|
||||
```text
|
||||
top - 19:42:06 up 23:59, 2 users, load average: 34.64, 35.80, 35.76
|
||||
Tasks: 679 total, 1 running, 678 sleeping, 0 stopped, 0 zombie
|
||||
Cpu(s): 15.6%us, 1.7%sy, 0.0%ni, 74.7%id, 7.9%wa, 0.0%hi, 0.1%si, 0.0%st
|
||||
Mem: 32865032k total, 30989168k used, 1875864k free, 370748k buffers
|
||||
Swap: 8388604k total, 5440k used, 8383164k free, 7982424k cached
|
||||
|
||||
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
||||
9783 mysql 20 0 17.3g 16g 8104 S 186.9 52.3 3752:33 mysqld
|
||||
5700 nginx 20 0 1330m 66m 9496 S 8.9 0.2 0:20.82 php-fpm
|
||||
6424 nginx 20 0 1330m 65m 8372 S 8.3 0.2 0:04.97 php-fpm
|
||||
```
|
||||
|
||||
`%wa` (wait) 表示 IO WAIT 的 cpu 占用,默认看到的是所有核的平均值,要看每个核的 `%wa` 值需要按下 "1":
|
||||
|
||||
```text
|
||||
top - 19:42:08 up 23:59, 2 users, load average: 34.64, 35.80, 35.76
|
||||
Tasks: 679 total, 1 running, 678 sleeping, 0 stopped, 0 zombie
|
||||
Cpu0 : 29.5%us, 3.7%sy, 0.0%ni, 48.7%id, 17.9%wa, 0.0%hi, 0.1%si, 0.0%st
|
||||
Cpu1 : 29.3%us, 3.7%sy, 0.0%ni, 48.9%id, 17.9%wa, 0.0%hi, 0.1%si, 0.0%st
|
||||
Cpu2 : 26.1%us, 3.1%sy, 0.0%ni, 64.4%id, 6.0%wa, 0.0%hi, 0.3%si, 0.0%st
|
||||
Cpu3 : 25.9%us, 3.1%sy, 0.0%ni, 65.5%id, 5.4%wa, 0.0%hi, 0.1%si, 0.0%st
|
||||
Cpu4 : 24.9%us, 3.0%sy, 0.0%ni, 66.8%id, 5.0%wa, 0.0%hi, 0.3%si, 0.0%st
|
||||
Cpu5 : 24.9%us, 2.9%sy, 0.0%ni, 67.0%id, 4.8%wa, 0.0%hi, 0.3%si, 0.0%st
|
||||
Cpu6 : 24.2%us, 2.7%sy, 0.0%ni, 68.3%id, 4.5%wa, 0.0%hi, 0.3%si, 0.0%st
|
||||
Cpu7 : 24.3%us, 2.6%sy, 0.0%ni, 68.5%id, 4.2%wa, 0.0%hi, 0.3%si, 0.0%st
|
||||
Cpu8 : 23.8%us, 2.6%sy, 0.0%ni, 69.2%id, 4.1%wa, 0.0%hi, 0.3%si, 0.0%st
|
||||
Cpu9 : 23.9%us, 2.5%sy, 0.0%ni, 69.3%id, 4.0%wa, 0.0%hi, 0.3%si, 0.0%st
|
||||
Cpu10 : 23.3%us, 2.4%sy, 0.0%ni, 68.7%id, 5.6%wa, 0.0%hi, 0.0%si, 0.0%st
|
||||
Cpu11 : 23.3%us, 2.4%sy, 0.0%ni, 69.2%id, 5.1%wa, 0.0%hi, 0.0%si, 0.0%st
|
||||
Cpu12 : 21.8%us, 2.4%sy, 0.0%ni, 60.2%id, 15.5%wa, 0.0%hi, 0.0%si, 0.0%st
|
||||
Cpu13 : 21.9%us, 2.4%sy, 0.0%ni, 60.6%id, 15.2%wa, 0.0%hi, 0.0%si, 0.0%st
|
||||
Cpu14 : 21.4%us, 2.3%sy, 0.0%ni, 72.6%id, 3.7%wa, 0.0%hi, 0.0%si, 0.0%st
|
||||
Cpu15 : 21.5%us, 2.2%sy, 0.0%ni, 73.2%id, 3.1%wa, 0.0%hi, 0.0%si, 0.0%st
|
||||
Cpu16 : 21.2%us, 2.2%sy, 0.0%ni, 73.6%id, 3.0%wa, 0.0%hi, 0.0%si, 0.0%st
|
||||
Cpu17 : 21.2%us, 2.1%sy, 0.0%ni, 73.8%id, 2.8%wa, 0.0%hi, 0.0%si, 0.0%st
|
||||
Cpu18 : 20.9%us, 2.1%sy, 0.0%ni, 74.1%id, 2.9%wa, 0.0%hi, 0.0%si, 0.0%st
|
||||
Cpu19 : 21.0%us, 2.1%sy, 0.0%ni, 74.4%id, 2.5%wa, 0.0%hi, 0.0%si, 0.0%st
|
||||
Cpu20 : 20.7%us, 2.0%sy, 0.0%ni, 73.8%id, 3.4%wa, 0.0%hi, 0.0%si, 0.0%st
|
||||
Cpu21 : 20.8%us, 2.0%sy, 0.0%ni, 73.9%id, 3.2%wa, 0.0%hi, 0.0%si, 0.0%st
|
||||
Cpu22 : 20.8%us, 2.0%sy, 0.0%ni, 74.4%id, 2.8%wa, 0.0%hi, 0.0%si, 0.0%st
|
||||
Cpu23 : 20.8%us, 1.9%sy, 0.0%ni, 74.4%id, 2.8%wa, 0.0%hi, 0.0%si, 0.0%st
|
||||
Mem: 32865032k total, 30209248k used, 2655784k free, 370748k buffers
|
||||
Swap: 8388604k total, 5440k used, 8383164k free, 7986552k cached
|
||||
```
|
||||
|
||||
`wa` 通常是 0%,如果经常在 1% 之上,说明存储设备的速度已经太慢,无法跟上 cpu 的处理速度。
|
||||
|
||||
## 如何排查 ?
|
||||
|
||||
### 使用 iostat 检查设备是否 hang 住
|
||||
|
||||
```bash
|
||||
iostat -xhd 2
|
||||
```
|
||||
|
||||
如果有 100% 的 `%util` 的设备,说明该设备基本 hang 住了
|
||||
|
||||

|
||||
|
||||
### 观察高 IO 的磁盘读写情况
|
||||
|
||||
```bash
|
||||
# 捕获 %util 超过 90 时 vdb 盘的读写指标,每秒检查一次
|
||||
while true; do iostat -xhd | grep -A1 vdb | grep -v vdb | awk '{if ($NF > 90){print $0}}'; sleep 1s; done
|
||||
```
|
||||
|
||||
如果读写流量或 IOPS 不高,但 `%util` 不高,通常是磁盘本身有问题了,需要检查下磁盘。 在云上托管的 k8s 集群通常就使用的云厂商的云盘(比如腾讯云CBS),可以拿到磁盘 ID 反馈下。
|
||||
|
||||
如果读写流量或 IOPS 高,继续下面的步骤排查出哪些进程导致的 IO 高负载。
|
||||
|
||||
### 查看哪些进程占住磁盘
|
||||
|
||||
```bash
|
||||
fuser -v -m /dev/vdb
|
||||
```
|
||||
|
||||
### 查找 D 状态的进程
|
||||
|
||||
D 状态 (Disk Sleep) 表示进程正在等待 IO,不可中断,正常情况下不会保持太久,如果进程长时间处于 D 状态,通常是设备故障
|
||||
|
||||
```bash
|
||||
ps -eo pid,ppid,stat,command
|
||||
|
||||
## 捕获 D 状态的进程
|
||||
while true; do ps -eo pid,ppid,stat,command | awk '{if ($3 ~ /D/) {print $0}}'; sleep 0.5s; done
|
||||
```
|
||||
|
||||
### 观察高 IO 进程
|
||||
|
||||
```bash
|
||||
iotop -oP
|
||||
# 展示 I/O 统计,每秒更新一次
|
||||
pidstat -d 1
|
||||
# 只看某个进程
|
||||
pidstat -d 1 -p 3394470
|
||||
```
|
||||
|
||||
## 使用 pidstat 统计
|
||||
|
||||
```bash
|
||||
timeout 10 pidstat -dl 3 > io.txt
|
||||
cat io.txt | awk '{if ($6>2000||$5>2000)print $0}'
|
||||
```
|
||||
|
||||
### 使用 ebpf 抓高 IOPS 进程
|
||||
|
||||
安装 bcc-tools:
|
||||
```bash
|
||||
yum install -y bcc-tools
|
||||
```
|
||||
|
||||
分析:
|
||||
```bash
|
||||
$ cd /usr/share/bcc/tools
|
||||
$ ./biosnoop 5 > io.txt
|
||||
$ cat io.txt | awk '{print $3,$2,$4,$5}' | sort | uniq -c | sort -rn | head -10
|
||||
6850 3356537 containerd vdb R
|
||||
1294 3926934 containerd vdb R
|
||||
864 1670 xfsaild/vdb vdb W
|
||||
578 3953662 kworker/u180:1 vda W
|
||||
496 3540267 logsys_cfg_cli vdb R
|
||||
459 1670 xfsaild/vdb vdb R
|
||||
354 3285936 php-fpm vdb R
|
||||
340 3285934 php-fpm vdb R
|
||||
292 2952592 sap1001 vdb R
|
||||
273 324710 python vdb R
|
||||
$ pstree -apnhs 3356537
|
||||
systemd,1 --switched-root --system --deserialize 22
|
||||
└─containerd,3895
|
||||
└─{containerd},3356537
|
||||
$ timeout 10 strace -fp 3895 > strace.txt 2>&1
|
||||
# vdb 的 IOPS 高,vdb 挂载到了 /data 目录,这里过滤下 "/data"
|
||||
$ grep "/data" strace.txt | tail -10
|
||||
[pid 19562] newfstatat(AT_FDCWD, "/data/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/6974/fs/data/log/monitor/snaps/20211010/ps-2338.log", {st_mode=S_IFREG|0644, st_size=6509, ...}, AT_SYMLINK_NOFOLLOW) = 0
|
||||
[pid 19562] newfstatat(AT_FDCWD, "/data/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/6974/fs/data/log/monitor/snaps/20211010/ps-2339.log", {st_mode=S_IFREG|0644, st_size=6402, ...}, AT_SYMLINK_NOFOLLOW) = 0
|
||||
[pid 19562] newfstatat(AT_FDCWD, "/data/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/6974/fs/data/log/monitor/snaps/20211010/ps-2340.log", {st_mode=S_IFREG|0644, st_size=6509, ...}, AT_SYMLINK_NOFOLLOW) = 0
|
||||
[pid 19562] newfstatat(AT_FDCWD, "/data/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/6974/fs/data/log/monitor/snaps/20211010/ps-2341.log", {st_mode=S_IFREG|0644, st_size=6509, ...}, AT_SYMLINK_NOFOLLOW) = 0
|
||||
[pid 19562] newfstatat(AT_FDCWD, "/data/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/6974/fs/data/log/monitor/snaps/20211010/ps-2342.log", {st_mode=S_IFREG|0644, st_size=6970, ...}, AT_SYMLINK_NOFOLLOW) = 0
|
||||
[pid 19562] newfstatat(AT_FDCWD, "/data/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/6974/fs/data/log/monitor/snaps/20211010/ps-2343.log", {st_mode=S_IFREG|0644, st_size=6509, ...}, AT_SYMLINK_NOFOLLOW) = 0
|
||||
[pid 19562] newfstatat(AT_FDCWD, "/data/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/6974/fs/data/log/monitor/snaps/20211010/ps-2344.log", {st_mode=S_IFREG|0644, st_size=6402, ...}, AT_SYMLINK_NOFOLLOW) = 0
|
||||
[pid 19562] newfstatat(AT_FDCWD, "/data/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/6974/fs/data/log/monitor/snaps/20211010/ps-2345.log", <unfinished ...>
|
||||
[pid 19562] newfstatat(AT_FDCWD, "/data/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/6974/fs/data/log/monitor/snaps/20211010/ps-2346.log", {st_mode=S_IFREG|0644, st_size=7756, ...}, AT_SYMLINK_NOFOLLOW) = 0
|
||||
[pid 19562] newfstatat(AT_FDCWD, "/data/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/6974/fs/data/log/monitor/snaps/20211010/ps-2347.log", Process 3895 detached
|
||||
$ grep "/data" strace.txt > data.txt
|
||||
# 合并且排序,自行用脚本分析下哪些文件操作多
|
||||
$ cat data.txt | awk -F '"' '{print $2}' | sort | uniq -c | sort -n > data-sorted.txt
|
||||
```
|
||||
|
|
@ -1,28 +0,0 @@
|
|||
# IPVS no destination available
|
||||
|
||||
## 现象
|
||||
|
||||
内核日志不停报 `no destination available` 这样的 warning 日志,查看 dmesg:
|
||||
|
||||
```log
|
||||
[23709.680898] IPVS: rr: TCP 192.168.0.52:80 - no destination available
|
||||
[23710.709824] IPVS: rr: TCP 192.168.0.52:80 - no destination available
|
||||
[23832.428700] IPVS: rr: TCP 127.0.0.1:30209 - no destination available
|
||||
[23833.461818] IPVS: rr: TCP 127.0.0.1:30209 - no destination available
|
||||
```
|
||||
|
||||
## 原因
|
||||
|
||||
一般是因为有 Service 用了 `externalTrafficPolicy:Local`,当 Node 上没有该 Service 对应 Pod 时,Node 上的该 Service 对应 NodePort 的 IPVS 规则里,RS 列表为空。当有流量打到这个 Node 的对应 NodePort 上时,由于 RS 列表为空,内核就会报这个 warning 日志。
|
||||
|
||||
在云厂商托管的 K8S 服务里,通常是 LB 会去主动探测 NodePort,发到没有这个 Service 对应 Pod 实例的 Node 时,报文被正常丢弃,从而内核报 warning 日志。
|
||||
|
||||
这个日志不会对服务造成影响,可以忽略不管。如果是在腾讯云 TKE 环境里,并且用的 TencentOS,可以设置一个内核参数来抑制这个 warning 日志输出:
|
||||
|
||||
```bash
|
||||
sysctl -w net.ipv4.vs.ignore_no_rs_error=1
|
||||
```
|
||||
|
||||
## 参考资料
|
||||
|
||||
* Kubernetes Issue: [IPVS error log occupation with externalTrafficPolicy: Local option in Service](https://github.com/kubernetes/kubernetes/issues/100925)
|
||||
|
|
@ -1,19 +0,0 @@
|
|||
# soft lockup (内核软死锁)
|
||||
|
||||
## 内核报错
|
||||
|
||||
``` log
|
||||
Oct 14 15:13:05 VM_1_6_centos kernel: NMI watchdog: BUG: soft lockup - CPU#5 stuck for 22s! [runc:[1:CHILD]:2274]
|
||||
```
|
||||
|
||||
## 原因
|
||||
|
||||
发生这个报错通常是内核繁忙 (扫描、释放或分配大量对象),分不出时间片给用户态进程导致的,也伴随着高负载,如果负载降低报错则会消失。
|
||||
|
||||
## 什么情况下会导致内核繁忙
|
||||
|
||||
* 短时间内创建大量进程 (可能是业务需要,也可能是业务bug或用法不正确导致创建大量进程)
|
||||
|
||||
## 参考资料
|
||||
|
||||
* [What are all these "Bug: soft lockup" messages about](https://www.suse.com/support/kb/doc/?id=7017652)
|
||||
|
|
@ -1,82 +0,0 @@
|
|||
# 内存碎片化
|
||||
|
||||
## 判断是否内存碎片化严重
|
||||
|
||||
内存页分配失败,内核日志报类似下面的错:
|
||||
|
||||
```bash
|
||||
mysqld: page allocation failure. order:4, mode:0x10c0d0
|
||||
```
|
||||
|
||||
* `mysqld` 是被分配的内存的程序
|
||||
* `order` 表示需要分配连续页的数量\(2^order\),这里 4 表示 2^4=16 个连续的页
|
||||
* `mode` 是内存分配模式的标识,定义在内核源码文件 `include/linux/gfp.h` 中,通常是多个标识相与运算的结果,不同版本内核可能不一样,比如在新版内核中 `GFP_KERNEL` 是 `__GFP_RECLAIM | __GFP_IO | __GFP_FS` 的运算结果,而 `__GFP_RECLAIM` 又是 `___GFP_DIRECT_RECLAIM|___GFP_KSWAPD_RECLAIM` 的运算结果
|
||||
|
||||
当 order 为 0 时,说明系统以及完全没有可用内存了,order 值比较大时,才说明内存碎片化了,无法分配连续的大页内存。
|
||||
|
||||
## 内存碎片化造成的问题
|
||||
|
||||
### 容器启动失败
|
||||
|
||||
K8S 会为每个 pod 创建 netns 来隔离 network namespace,内核初始化 netns 时会为其创建 nf\_conntrack 表的 cache,需要申请大页内存,如果此时系统内存已经碎片化,无法分配到足够的大页内存内核就会报错\(`v2.6.33 - v4.6`\):
|
||||
|
||||
```bash
|
||||
runc:[1:CHILD]: page allocation failure: order:6, mode:0x10c0d0
|
||||
```
|
||||
|
||||
Pod 状态将会一直在 ContainerCreating,dockerd 启动容器失败,日志报错:
|
||||
|
||||
```text
|
||||
Jan 23 14:15:31 dc05 dockerd: time="2019-01-23T14:15:31.288446233+08:00" level=error msg="containerd: start container" error="oci runtime error: container_linux.go:247: starting container process caused \"process_linux.go:245: running exec setns process for init caused \\\"exit status 6\\\"\"\n" id=5b9be8c5bb121264899fac8d9d36b02150269d41ce96ba6ad36d70b8640cb01c
|
||||
Jan 23 14:15:31 dc05 dockerd: time="2019-01-23T14:15:31.317965799+08:00" level=error msg="Create container failed with error: invalid header field value \"oci runtime error: container_linux.go:247: starting container process caused \\\"process_linux.go:245: running exec setns process for init caused \\\\\\\"exit status 6\\\\\\\"\\\"\\n\""
|
||||
```
|
||||
|
||||
kubelet 日志报错:
|
||||
|
||||
```text
|
||||
Jan 23 14:15:31 dc05 kubelet: E0123 14:15:31.352386 26037 remote_runtime.go:91] RunPodSandbox from runtime service failed: rpc error: code = 2 desc = failed to start sandbox container for pod "matchdataserver-1255064836-t4b2w": Error response from daemon: {"message":"invalid header field value \"oci runtime error: container_linux.go:247: starting container process caused \\\"process_linux.go:245: running exec setns process for init caused \\\\\\\"exit status 6\\\\\\\"\\\"\\n\""}
|
||||
Jan 23 14:15:31 dc05 kubelet: E0123 14:15:31.352496 26037 kuberuntime_sandbox.go:54] CreatePodSandbox for pod "matchdataserver-1255064836-t4b2w_basic(485fd485-1ed6-11e9-8661-0a587f8021ea)" failed: rpc error: code = 2 desc = failed to start sandbox container for pod "matchdataserver-1255064836-t4b2w": Error response from daemon: {"message":"invalid header field value \"oci runtime error: container_linux.go:247: starting container process caused \\\"process_linux.go:245: running exec setns process for init caused \\\\\\\"exit status 6\\\\\\\"\\\"\\n\""}
|
||||
Jan 23 14:15:31 dc05 kubelet: E0123 14:15:31.352518 26037 kuberuntime_manager.go:618] createPodSandbox for pod "matchdataserver-1255064836-t4b2w_basic(485fd485-1ed6-11e9-8661-0a587f8021ea)" failed: rpc error: code = 2 desc = failed to start sandbox container for pod "matchdataserver-1255064836-t4b2w": Error response from daemon: {"message":"invalid header field value \"oci runtime error: container_linux.go:247: starting container process caused \\\"process_linux.go:245: running exec setns process for init caused \\\\\\\"exit status 6\\\\\\\"\\\"\\n\""}
|
||||
Jan 23 14:15:31 dc05 kubelet: E0123 14:15:31.352580 26037 pod_workers.go:182] Error syncing pod 485fd485-1ed6-11e9-8661-0a587f8021ea ("matchdataserver-1255064836-t4b2w_basic(485fd485-1ed6-11e9-8661-0a587f8021ea)"), skipping: failed to "CreatePodSandbox" for "matchdataserver-1255064836-t4b2w_basic(485fd485-1ed6-11e9-8661-0a587f8021ea)" with CreatePodSandboxError: "CreatePodSandbox for pod \"matchdataserver-1255064836-t4b2w_basic(485fd485-1ed6-11e9-8661-0a587f8021ea)\" failed: rpc error: code = 2 desc = failed to start sandbox container for pod \"matchdataserver-1255064836-t4b2w\": Error response from daemon: {\"message\":\"invalid header field value \\\"oci runtime error: container_linux.go:247: starting container process caused \\\\\\\"process_linux.go:245: running exec setns process for init caused \\\\\\\\\\\\\\\"exit status 6\\\\\\\\\\\\\\\"\\\\\\\"\\\\n\\\"\"}"
|
||||
Jan 23 14:15:31 dc05 kubelet: I0123 14:15:31.372181 26037 kubelet.go:1916] SyncLoop (PLEG): "matchdataserver-1255064836-t4b2w_basic(485fd485-1ed6-11e9-8661-0a587f8021ea)", event: &pleg.PodLifecycleEvent{ID:"485fd485-1ed6-11e9-8661-0a587f8021ea", Type:"ContainerDied", Data:"5b9be8c5bb121264899fac8d9d36b02150269d41ce96ba6ad36d70b8640cb01c"}
|
||||
Jan 23 14:15:31 dc05 kubelet: W0123 14:15:31.372225 26037 pod_container_deletor.go:77] Container "5b9be8c5bb121264899fac8d9d36b02150269d41ce96ba6ad36d70b8640cb01c" not found in pod's containers
|
||||
Jan 23 14:15:31 dc05 kubelet: I0123 14:15:31.678211 26037 kuberuntime_manager.go:383] No ready sandbox for pod "matchdataserver-1255064836-t4b2w_basic(485fd485-1ed6-11e9-8661-0a587f8021ea)" can be found. Need to start a new one
|
||||
```
|
||||
|
||||
查看slab \(后面的0多表示伙伴系统没有大块内存了\):
|
||||
|
||||
```bash
|
||||
$ cat /proc/buddyinfo
|
||||
Node 0, zone DMA 1 0 1 0 2 1 1 0 1 1 3
|
||||
Node 0, zone DMA32 2725 624 489 178 0 0 0 0 0 0 0
|
||||
Node 0, zone Normal 1163 1101 932 222 0 0 0 0 0 0 0
|
||||
```
|
||||
|
||||
### 系统 OOM
|
||||
|
||||
内存碎片化会导致即使当前系统总内存比较多,但由于无法分配足够的大页内存导致给进程分配内存失败,就认为系统内存不够用,需要杀掉一些进程来释放内存,从而导致系统 OOM
|
||||
|
||||
## 解决方法
|
||||
|
||||
* 周期性地或者在发现大块内存不足时,先进行drop\_cache操作:
|
||||
|
||||
```bash
|
||||
echo 3 > /proc/sys/vm/drop_caches
|
||||
```
|
||||
|
||||
* 必要时候进行内存整理,开销会比较大,会造成业务卡住一段时间\(慎用\):
|
||||
|
||||
```bash
|
||||
echo 1 > /proc/sys/vm/compact_memory
|
||||
```
|
||||
|
||||
## 如何防止内存碎片化
|
||||
|
||||
TODO
|
||||
|
||||
## 附录
|
||||
|
||||
相关链接:
|
||||
|
||||
* [https://huataihuang.gitbooks.io/cloud-atlas/content/os/linux/kernel/memory/drop\_caches\_and\_compact\_memory.html](https://huataihuang.gitbooks.io/cloud-atlas/content/os/linux/kernel/memory/drop_caches_and_compact_memory.html)
|
||||
|
||||
|
|
@ -1,85 +0,0 @@
|
|||
# no space left on device
|
||||
|
||||
- 有时候节点 NotReady, kubelet 日志报 `no space left on device`。
|
||||
- 有时候创建 Pod 失败,`describe pod` 看 event 报 `no space left on device`。
|
||||
|
||||
出现这种错误有很多中可能原因,下面我们来根据现象找对应原因。
|
||||
|
||||
## inotify watch 耗尽
|
||||
|
||||
节点 NotReady,kubelet 启动失败,看 kubelet 日志:
|
||||
|
||||
``` bash
|
||||
Jul 18 15:20:58 VM_16_16_centos kubelet[11519]: E0718 15:20:58.280275 11519 raw.go:140] Failed to watch directory "/sys/fs/cgroup/memory/kubepods": inotify_add_watch /sys/fs/cgroup/memory/kubepods/burstable/pod926b7ff4-7bff-11e8-945b-52540048533c/6e85761a30707b43ed874e0140f58839618285fc90717153b3cbe7f91629ef5a: no space left on device
|
||||
```
|
||||
|
||||
系统调用 `inotify_add_watch` 失败,提示 `no space left on device`, 这是因为系统上进程 watch 文件目录的总数超出了最大限制,可以修改内核参数调高限制,详细请参考本书 [inotify watch 耗尽](runnig-out-of-inotify-watches.md)
|
||||
|
||||
## cgroup 泄露
|
||||
|
||||
查看当前 cgroup 数量:
|
||||
|
||||
``` bash
|
||||
$ cat /proc/cgroups | column -t
|
||||
#subsys_name hierarchy num_cgroups enabled
|
||||
cpuset 5 29 1
|
||||
cpu 7 126 1
|
||||
cpuacct 7 126 1
|
||||
memory 9 127 1
|
||||
devices 4 126 1
|
||||
freezer 2 29 1
|
||||
net_cls 6 29 1
|
||||
blkio 10 126 1
|
||||
perf_event 3 29 1
|
||||
hugetlb 11 29 1
|
||||
pids 8 126 1
|
||||
net_prio 6 29 1
|
||||
```
|
||||
|
||||
cgroup 子系统目录下面所有每个目录及其子目录都认为是一个独立的 cgroup,所以也可以在文件系统中统计目录数来获取实际 cgroup 数量,通常跟 `/proc/cgroups` 里面看到的应该一致:
|
||||
|
||||
``` bash
|
||||
$ find -L /sys/fs/cgroup/memory -type d | wc -l
|
||||
127
|
||||
```
|
||||
|
||||
当 cgroup 泄露发生时,这里的数量就不是真实的了,低版本内核限制最大 65535 个 cgroup,并且开启 kmem 删除 cgroup 时会泄露,大量创建删除容器后泄露了许多 cgroup,最终总数达到 65535,新建容器创建 cgroup 将会失败,报 `no space left on device`
|
||||
|
||||
详细请参考本书 [排障案例: cgroup 泄露](../../troubleshooting-cases/node/cgroup-leaking)
|
||||
|
||||
## 磁盘被写满
|
||||
|
||||
Pod 启动失败,状态 `CreateContainerError`:
|
||||
|
||||
``` bash
|
||||
csi-cephfsplugin-27znb 0/2 CreateContainerError 167 17h
|
||||
```
|
||||
|
||||
Pod 事件报错:
|
||||
|
||||
``` bash
|
||||
Warning Failed 5m1s (x3397 over 17h) kubelet, ip-10-0-151-35.us-west-2.compute.internal (combined from similar events): Error: container create failed: container_linux.go:336: starting container process caused "process_linux.go:399: container init caused \"rootfs_linux.go:58: mounting \\\"/sys\\\" to rootfs \\\"/var/lib/containers/storage/overlay/051e985771cc69f3f699895a1dada9ef6483e912b46a99e004af7bb4852183eb/merged\\\" at \\\"/var/lib/containers/storage/overlay/051e985771cc69f3f699895a1dada9ef6483e912b46a99e004af7bb4852183eb/merged/sys\\\" caused \\\"no space left on device\\\"\""
|
||||
```
|
||||
|
||||
## limits 单位错误
|
||||
|
||||
Pod 事件报错:
|
||||
|
||||
```txt
|
||||
Mount Volume.SetUp failed for volume "kube-api-access-j562g" :write /var/lib/kubelet/pods /7c251070
|
||||
-cf3c-4180-97a2-647e858f3f2/volumes/kubernetes.io~projected/kube-api-access-j562g/..2023_07_25_07_25_22.573608539/ca.crt: no space left on device
|
||||
```
|
||||
|
||||
可能是因为定义 requests 和 limits 时忘了写单位,或单位有误:
|
||||
|
||||
```yaml
|
||||
limits:
|
||||
memory: 512mi # 应该大写开头,改成 512Mi
|
||||
```
|
||||
|
||||
```yaml
|
||||
limits:
|
||||
memory: 512 # 没有单位默认为字节,太小,应带上单位
|
||||
```
|
||||
|
||||
根因:可能是因为内存相关的 volume 都受 memory limit 限制 (projected volume, emptydir 等)。
|
||||
|
|
@ -1,28 +0,0 @@
|
|||
# 节点 Crash 与 Vmcore 分析
|
||||
|
||||
本文介绍节点 Crash 后如何分析 vmcore 进行排查。
|
||||
|
||||
## kdump 介绍
|
||||
|
||||
目前大多 Linux 发新版都会默认开启 kdump 服务,以方便在内核崩溃的时候, 可以通过 kdump 服务提供的 kexec 机制快速的启用保留在内存中的第二个内核来收集并转储内核崩溃的日志信息(`vmcore` 等文件), 这种机制需要服务器硬件特性的支持, 不过现今常用的服务器系列均已支持.
|
||||
|
||||
如果没有特别配置 kdump,当发生 crash 时,通常默认会将 vmcore 保存到 `/var/crash` 路径下,也可以查看 `/etc/kdump.conf` 配置来确认:
|
||||
|
||||
```bash
|
||||
$ grep ^path /etc/kdump.conf
|
||||
path /var/crash
|
||||
```
|
||||
|
||||
## 快速查看原因
|
||||
|
||||
在需要快速了解崩溃原因的时候, 可以简单查看崩溃主机(如果重启成功)的 `vmcore-dmesg.txt` 文件, 该文件列出了内核崩溃时的堆栈信息, 有助于我们大致了解崩溃的原因, 方便处理措施的决断. 如下所示为生成的日志文件通常的路径:
|
||||
|
||||
```txt
|
||||
/var/crash/127.0.0.1-2019-11-11-08:40:08/vmcore-dmesg.txt
|
||||
```
|
||||
|
||||
## 参考资料
|
||||
|
||||
* [Linux 系统内核崩溃分析处理简介](https://blog.arstercz.com/brief-intro-to-linux-kernel-crash-analyze/)
|
||||
* [Kernel crash dump guide](https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/kernel_administration_guide/kernel_crash_dump_guide)
|
||||
* [Using kdump and kexec with the Red Hat Enterprise Linux for Real Time Kernel](https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux_for_real_time/7/html/tuning_guide/using_kdump_and_kexec_with_the_rt_kernel)
|
||||
|
|
@ -1,95 +0,0 @@
|
|||
# 节点高负载
|
||||
|
||||
Kubernetes 节点高负载如何排查?本文来盘一盘。
|
||||
|
||||
## 如何判断节点高负载?
|
||||
|
||||
可以通过 `top` 或 `uptime` 来确定 load 大小,如果 load 小于 CPU 数量,属于低负载,如果大于 CPU 数量 2~3 倍,就比较高了,当然也看业务敏感程度,不太敏感的大于 4 倍算高负载。
|
||||
|
||||
## 排查思路
|
||||
|
||||
观察监控:通常不是因为内核 bug 导致的高负载,在卡死之前从监控一般能看出一些问题,可以观察下各项监控指标。
|
||||
|
||||
排查现场:如果没有相关监控或监控维度较少不足以查出问题,就尝试登录节点抓现场分析。有时负载过高通常使用 ssh 登录不上,如果可以用 vnc,可以尝试下使用 vnc 登录。
|
||||
|
||||
## 排查现场思路
|
||||
|
||||
loadavg 可以认为是 R状态线程数和D状态线程数的总和 (R 代表需要 cpu,是 cpu 负载。 D 通常代表需要 IO,是 IO 负载)
|
||||
|
||||
简单判断办法:
|
||||
|
||||
```bash
|
||||
ps -eL -o lwp,pid,ppid,state,comm | grep -E " R | D "
|
||||
```
|
||||
|
||||
然后数一下各种状态多少个进程,看看是 D 住还是 R。
|
||||
|
||||
如果是长时间 D 住,可以进一步查看进程堆栈看看 D 在哪里:
|
||||
|
||||
```bash
|
||||
cat /proc/<PID>/stack
|
||||
```
|
||||
|
||||
如果是大量进程/线程在 R 状态,那就是同时需要 CPU 的进程/线程数过多,CPU 忙不过来了,可以利用 perf 分析程序在忙什么:
|
||||
|
||||
```bash
|
||||
perf -p <PID>
|
||||
```
|
||||
|
||||
## 线程数量过多
|
||||
|
||||
如果 load 高但 CPU 利用率不高,通常是同时 running 的进程/线程数过多,排队等 CPU 切换的进程/线程较多。
|
||||
|
||||
通常在 load 高时执行任何命令都会非常卡,因为执行这些命令也都意味着要创建和执行新的进程,所以下面排查过程中执行命令时需要耐心等待。
|
||||
|
||||
看系统中可创建的进程数实际值:
|
||||
|
||||
```bash
|
||||
cat /proc/sys/kernel/pid_max
|
||||
```
|
||||
|
||||
> 修改方式: sysctl -w kernel.pid_max=65535
|
||||
|
||||
通过以下命令统计当前 PID 数量:
|
||||
|
||||
```bash
|
||||
ps -eLf | wc -l
|
||||
```
|
||||
|
||||
如果数量过多,可以大致扫下有哪些进程,如果有大量重复启动命令的进程,就可能是这个进程对应程序的 bug 导致。
|
||||
|
||||
还可以通过以下命令统计线程数排名:
|
||||
|
||||
```bash
|
||||
printf "NUM\tPID\tCOMMAND\n" && ps -eLf | awk '{$1=null;$3=null;$4=null;$5=null;$6=null;$7=null;$8=null;$9=null;print}' | sort |uniq -c |sort -rn | head -10
|
||||
```
|
||||
|
||||
找出线程数量较多的进程,可能就是某个容器的线程泄漏,导致 PID 耗尽。
|
||||
|
||||
随便取其中一个 PID,用 nsenter 进入进程 netns:
|
||||
|
||||
```bash
|
||||
nsenter -n --target <PID>
|
||||
```
|
||||
|
||||
然后执行 `ip a` 看下 IP 地址,如果不是节点 IP,通常就是 Pod IP,可以通过 `kubectl get pod -o wide -A | grep <IP>` 来反查进程来自哪个 Pod。
|
||||
|
||||
## 陷入内核态过久
|
||||
|
||||
有些时候某些 CPU 可能会执行耗时较长的内核态任务,比如大量创建/销毁进程,回收内存,需要较长时间 reclaim memory,必须要执行完才能切回用户态,虽然内核一般会有 migration 内核线程将这种负载较高的核上的任务迁移到其它核上,但也只能适当缓解,如果这种任务较多,整体的 CPU system 占用就会较高,影响到用户态进程任务的执行,对于业务来说,就是 CPU 不够用,处理就变慢,发生超时。
|
||||
|
||||
CPU 内核态占用的 Prometheus 查询语句:
|
||||
```txt
|
||||
sum(irate(node_cpu_seconds_total{instance="10.10.1.14",mode="system"}[2m]))
|
||||
```
|
||||
|
||||
## IO 高负载
|
||||
|
||||
参考 [IO 高负载](io-high-load.md) 进行排查。
|
||||
|
||||
## FAQ
|
||||
|
||||
### 如果机器完全无法操作怎么办?
|
||||
|
||||
有时候高负载是无法 ssh 登录的,即使通过 vnc 方式登录成功,由于机器太卡也是执行不了任何命令。如通过监控也看不出任何原因,又想要彻查根因,可以从虚拟化底层入手,给虚拟机发信号触发 coredump (无需登录虚拟机),如果用的云产品,可以提工单让虚拟主机的产品售后来排查分析。
|
||||
|
||||
|
|
@ -1,43 +0,0 @@
|
|||
# PID 爆满
|
||||
|
||||
## 如何判断 PID 耗尽
|
||||
|
||||
首先要确认当前的 PID 限制,检查全局 PID 最大限制:
|
||||
|
||||
``` bash
|
||||
cat /proc/sys/kernel/pid_max
|
||||
```
|
||||
|
||||
也检查下线程数限制:
|
||||
|
||||
``` bash
|
||||
cat /proc/sys/kernel/threads-max
|
||||
```
|
||||
|
||||
再检查下当前用户是否还有 `ulimit` 限制最大进程数。
|
||||
|
||||
确认当前实际 PID 数量,检查当前用户的 PID 数量:
|
||||
|
||||
``` bash
|
||||
ps -eLf | wc -l
|
||||
```
|
||||
|
||||
如果发现实际 PID 数量接近最大限制说明 PID 就可能会爆满导致经常有进程无法启动,低版本内核可能报错: `Cannot allocate memory`,这个报错信息不准确,在内核 4.1 以后改进了: https://github.com/torvalds/linux/commit/35f71bc0a09a45924bed268d8ccd0d3407bc476f
|
||||
|
||||
## 如何解决
|
||||
|
||||
临时调大 PID 和线程数限制:
|
||||
|
||||
``` bash
|
||||
echo 65535 > /proc/sys/kernel/pid_max
|
||||
echo 65535 > /proc/sys/kernel/threads-max
|
||||
```
|
||||
|
||||
永久调大 PID 和线程数限制:
|
||||
|
||||
``` bash
|
||||
echo "kernel.pid_max=65535 " >> /etc/sysctl.conf && sysctl -p
|
||||
echo "kernel.threads-max=65535 " >> /etc/sysctl.conf && sysctl -p
|
||||
```
|
||||
|
||||
k8s 1.14 支持了限制 Pod 的进程数量: https://kubernetes.io/blog/2019/04/15/process-id-limiting-for-stability-improvements-in-kubernetes-1.14/
|
||||
|
|
@ -1,108 +0,0 @@
|
|||
# inotify 资源耗尽
|
||||
|
||||
## inotify 耗尽的危害
|
||||
|
||||
如果 inotify 资源耗尽,kubelet 创建容器将会失败:
|
||||
|
||||
```log
|
||||
Failed to watch directory "/sys/fs/cgroup/blkio/system.slice": inotify_add_watch /sys/fs/cgroup/blkio/system.slice/var-lib-kubelet-pods-d111600d\x2dcdf2\x2d11e7\x2d8e6b\x2dfa163ebb68b9-volumes-kubernetes.io\x7esecret-etcd\x2dcerts.mount: no space left on device
|
||||
```
|
||||
|
||||
## 查看 inotify watch 的限制
|
||||
|
||||
每个 linux 进程可以持有多个 fd,每个 inotify 类型的 fd 可以 watch 多个目录,每个用户下所有进程 inotify 类型的 fd 可以 watch 的总目录数有个最大限制,这个限制可以通过内核参数配置: `fs.inotify.max_user_watches`。
|
||||
|
||||
查看最大 inotify watch 数:
|
||||
|
||||
```bash
|
||||
$ cat /proc/sys/fs/inotify/max_user_watches
|
||||
8192
|
||||
```
|
||||
|
||||
## 查看进程的 inotify watch 情况
|
||||
|
||||
使用下面的脚本查看当前有 inotify watch 类型 fd 的进程以及每个 fd watch 的目录数量,降序输出,带总数统计:
|
||||
|
||||
```bash
|
||||
#!/usr/bin/env bash
|
||||
#
|
||||
# Copyright 2019 (c) roc
|
||||
#
|
||||
# This script shows processes holding the inotify fd, alone with HOW MANY directories each inotify fd watches(0 will be ignored).
|
||||
total=0
|
||||
result="EXE PID FD-INFO INOTIFY-WATCHES\n"
|
||||
while read pid fd; do \
|
||||
exe="$(readlink -f /proc/$pid/exe || echo n/a)"; \
|
||||
fdinfo="/proc/$pid/fdinfo/$fd" ; \
|
||||
count="$(grep -c inotify "$fdinfo" || true)"; \
|
||||
if [ $((count)) != 0 ]; then
|
||||
total=$((total+count)); \
|
||||
result+="$exe $pid $fdinfo $count\n"; \
|
||||
fi
|
||||
done <<< "$(lsof +c 0 -n -P -u root|awk '/inotify$/ { gsub(/[urw]$/,"",$4); print $2" "$4 }')" && echo "total $total inotify watches" && result="$(echo -e $result|column -t)\n" && echo -e "$result" | head -1 && echo -e "$result" | sed "1d" | sort -k 4rn;
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```bash
|
||||
total 7882 inotify watches
|
||||
EXE PID FD-INFO INOTIFY-WATCHES
|
||||
/usr/local/qcloud/YunJing/YDEyes/YDService 25813 /proc/25813/fdinfo/8 7077
|
||||
/usr/bin/kubelet 1173 /proc/1173/fdinfo/22 665
|
||||
/usr/bin/ruby2.3 13381 /proc/13381/fdinfo/14 54
|
||||
/usr/lib/policykit-1/polkitd 1458 /proc/1458/fdinfo/9 14
|
||||
/lib/systemd/systemd-udevd 450 /proc/450/fdinfo/9 13
|
||||
/usr/sbin/nscd 7935 /proc/7935/fdinfo/3 6
|
||||
/usr/bin/kubelet 1173 /proc/1173/fdinfo/28 5
|
||||
/lib/systemd/systemd 1 /proc/1/fdinfo/17 4
|
||||
/lib/systemd/systemd 1 /proc/1/fdinfo/18 4
|
||||
/lib/systemd/systemd 1 /proc/1/fdinfo/26 4
|
||||
/lib/systemd/systemd 1 /proc/1/fdinfo/28 4
|
||||
/usr/lib/policykit-1/polkitd 1458 /proc/1458/fdinfo/8 4
|
||||
/usr/local/bin/sidecar-injector 4751 /proc/4751/fdinfo/3 3
|
||||
/usr/lib/accountsservice/accounts-daemon 1178 /proc/1178/fdinfo/7 2
|
||||
/usr/local/bin/galley 8228 /proc/8228/fdinfo/10 2
|
||||
/usr/local/bin/galley 8228 /proc/8228/fdinfo/9 2
|
||||
/lib/systemd/systemd 1 /proc/1/fdinfo/11 1
|
||||
/sbin/agetty 1437 /proc/1437/fdinfo/4 1
|
||||
/sbin/agetty 1440 /proc/1440/fdinfo/4 1
|
||||
/usr/bin/kubelet 1173 /proc/1173/fdinfo/10 1
|
||||
/usr/local/bin/envoy 4859 /proc/4859/fdinfo/5 1
|
||||
/usr/local/bin/envoy 5427 /proc/5427/fdinfo/5 1
|
||||
/usr/local/bin/envoy 6058 /proc/6058/fdinfo/3 1
|
||||
/usr/local/bin/envoy 6893 /proc/6893/fdinfo/3 1
|
||||
/usr/local/bin/envoy 6950 /proc/6950/fdinfo/3 1
|
||||
/usr/local/bin/galley 8228 /proc/8228/fdinfo/3 1
|
||||
/usr/local/bin/pilot-agent 3819 /proc/3819/fdinfo/5 1
|
||||
/usr/local/bin/pilot-agent 4244 /proc/4244/fdinfo/5 1
|
||||
/usr/local/bin/pilot-agent 5901 /proc/5901/fdinfo/3 1
|
||||
/usr/local/bin/pilot-agent 6789 /proc/6789/fdinfo/3 1
|
||||
/usr/local/bin/pilot-agent 6808 /proc/6808/fdinfo/3 1
|
||||
/usr/local/bin/pilot-discovery 6231 /proc/6231/fdinfo/3 1
|
||||
/usr/local/bin/sidecar-injector 4751 /proc/4751/fdinfo/5 1
|
||||
/usr/sbin/acpid 1166 /proc/1166/fdinfo/6 1
|
||||
/usr/sbin/dnsmasq 7572 /proc/7572/fdinfo/8 1
|
||||
```
|
||||
|
||||
## 调整 inotify watch 限制
|
||||
|
||||
如果看到总 watch 数比较大,接近最大限制,可以修改内核参数调高下这个限制。
|
||||
|
||||
临时调整:
|
||||
|
||||
```bash
|
||||
sudo sysctl fs.inotify.max_user_watches=524288
|
||||
```
|
||||
|
||||
永久生效:
|
||||
|
||||
```bash
|
||||
echo "fs.inotify.max_user_watches=524288" >> /etc/sysctl.conf && sysctl -p
|
||||
```
|
||||
|
||||
打开 inotify_add_watch 跟踪,进一步 debug inotify watch 耗尽的原因:
|
||||
|
||||
```bash
|
||||
echo 1 >> /sys/kernel/debug/tracing/events/syscalls/sys_exit_inotify_add_watch/enable
|
||||
```
|
||||
|
||||
|
|
@ -1,78 +0,0 @@
|
|||
# 排查 device or resource busy
|
||||
|
||||
## 背景
|
||||
|
||||
在 kubernetes 环境中,可能会遇到因目录被占用导致 pod 一直 terminating:
|
||||
|
||||
```log
|
||||
Aug 27 15:52:22 VM-244-70-centos kubelet[906978]: E0827 15:52:22.816125 906978 nestedpendingoperations.go:270] Operation for "\"kubernetes.io/secret/b45f3af4-3574-472e-b263-c2b71c3b2ea0-default-token-fltdk\" (\"b45f3af4-3574-472e-b263-c2b71c3b2ea0\")" failed. No retries permitted until 2021-08-27 15:54:24.816098325 +0800 CST m=+108994.575932846 (durationBeforeRetry 2m2s). Error: "UnmountVolume.TearDown failed for volume \"default-token-fltdk\" (UniqueName: \"kubernetes.io/secret/b45f3af4-3574-472e-b263-c2b71c3b2ea0-default-token-fltdk\") pod \"b45f3af4-3574-472e-b263-c2b71c3b2ea0\" (UID: \"b45f3af4-3574-472e-b263-c2b71c3b2ea0\") : unlinkat /var/lib/kubelet/pods/b45f3af4-3574-472e-b263-c2b71c3b2ea0/volumes/kubernetes.io~secret/default-token-fltdk: device or resource busy"
|
||||
```
|
||||
|
||||
本文记录下排查方法。
|
||||
|
||||
## 找出目录被谁占用的
|
||||
|
||||
看下目录哪个进程 mount 了:
|
||||
|
||||
```bash
|
||||
$ find /proc/*/mounts -exec grep /var/lib/kubelet/pods/0104ab85-d0ea-4ac5-a5f9-5bdd12cca589/volumes/kubernetes.io~secret/kube-proxy-token-nvthm {} + 2>/dev/null
|
||||
/proc/6076/mounts:tmpfs /var/lib/kubelet/pods/0104ab85-d0ea-4ac5-a5f9-5bdd12cca589/volumes/kubernetes.io~secret/kube-proxy-token-nvthm tmpfs rw,relatime 0 0
|
||||
```
|
||||
|
||||
根据找出的进程号,看看是谁干的:
|
||||
|
||||
```bash
|
||||
$ ps -ef | grep -v grep | grep 6076
|
||||
root 6076 6057 0 Aug26 ? 00:01:54 /usr/local/loglistener/bin loglistener -c /usr/local/loglistener/etc/loglistener.conf
|
||||
```
|
||||
|
||||
看下完整的进程树:
|
||||
|
||||
```bash
|
||||
$ pstree -apnhs 6076
|
||||
systemd,1 --switched-root --system --deserialize 22
|
||||
└─dockerd,1809 --config-file=/etc/docker/daemon.json
|
||||
└─docker-containe,1868 --config /var/run/docker/containerd/containerd.toml
|
||||
└─docker-containe,6057 -namespace moby -workdir /data/docker/containerd/daemon/io.containerd.runtime.v1.linux/moby/9a8457284ce7078ef838e78b79c87c5b27d8a6682597b44ba7a74d7ec6965365 -address /var/run/docker/containerd/docker-containerd.sock -containerd-binary /usr/bin/docker-containerd -runtime-root ...
|
||||
└─loglistener,6076 loglistener -c /usr/local/loglistener/etc/loglistener.conf
|
||||
├─{loglistener},6108
|
||||
├─{loglistener},6109
|
||||
├─{loglistener},6110
|
||||
├─{loglistener},6111
|
||||
└─{loglistener},6112
|
||||
```
|
||||
|
||||
## 反查 Pod
|
||||
|
||||
如果占住这个目录的进程也是通过 Kubernetes 部署的,我们可以反查出是哪个 Pod 干的。
|
||||
|
||||
通过 nsenter 进入容器的 netns,查看 ip 地址,反查出是哪个 pod:
|
||||
|
||||
```bash
|
||||
$ nsenter -n -t 6076
|
||||
$ ip a
|
||||
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
|
||||
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
|
||||
inet 127.0.0.1/8 scope host lo
|
||||
valid_lft forever preferred_lft forever
|
||||
inet6 ::1/128 scope host
|
||||
valid_lft forever preferred_lft forever
|
||||
2: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 10000
|
||||
link/ether 52:54:00:ca:89:c0 brd ff:ff:ff:ff:ff:ff
|
||||
inet 192.168.244.70/24 brd 192.168.244.255 scope global eth1
|
||||
valid_lft forever preferred_lft forever
|
||||
inet6 fe80::5054:ff:feca:89c0/64 scope link
|
||||
valid_lft forever preferred_lft forever
|
||||
$ kubectl get pod -o wide -A | grep 192.168.244.70
|
||||
log-agent-24nn6 2/2 Running 0 84d 192.168.244.70 10.10.10.22 <none> <none>
|
||||
```
|
||||
|
||||
如果 pod 是 hostNetwork 的,无法通过 ip 来分辨出是哪个 pod,可以提取进程树中出现的容器 id 前几位,然后查出容器名:
|
||||
|
||||
```bash
|
||||
$ docker ps | grep 9a8457284c
|
||||
9a8457284ce7 imroc/loglistener "/usr/local/logliste…" 34 hours ago Up 34 hours k8s_loglistener_log-agent-wd2rp_kube-system_b0dcfe14-1619-43b5-a158-1e2063696138_1
|
||||
```
|
||||
|
||||
Kubernetes 的容器名就可以看出该容器属于哪个 pod。
|
||||
|
||||
|
|
@ -1,38 +0,0 @@
|
|||
# 排查健康检查失败
|
||||
|
||||
* Kubernetes 健康检查包含就绪检查(readinessProbe)和存活检查(livenessProbe)
|
||||
* pod 如果就绪检查失败会将此 pod ip 从 service 中摘除,通过 service 访问,流量将不会被转发给就绪检查失败的 pod
|
||||
* pod 如果存活检查失败,kubelet 将会杀死容器并尝试重启
|
||||
|
||||
健康检查失败的可能原因有多种,除了业务程序BUG导致不能响应健康检查导致 unhealthy,还能有有其它原因,下面我们来逐个排查。
|
||||
|
||||
## 健康检查配置不合理
|
||||
|
||||
`initialDelaySeconds` 或 [StartProbe](https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/#define-startup-probes) 配置的时间太短,容器启动慢,导致容器还没完全启动就开始探测。如果 failureThreshold 是默认值 1,检查失败一次就会被 kill,然后 pod 一直这样被 kill 重启。参考 [健康检查配置](../../best-practices/configure-healthcheck)。
|
||||
|
||||
## 节点负载过高
|
||||
|
||||
cpu 占用高(比如跑满)会导致进程无法正常发包收包,通常会 timeout,导致 kubelet 认为 pod 不健康。参考 [排查节点高负载](../node/node-high-load) 。
|
||||
|
||||
## 容器进程被木马进程杀死
|
||||
|
||||
参考 [使用 systemtap 定位疑难杂症](../skill/use-systemtap-to-locate-problems) 进一步定位。
|
||||
|
||||
## 容器内进程端口监听挂掉
|
||||
|
||||
使用 `netstat -tunlp` 检查端口监听是否还在,如果不在了,抓包可以看到会直接 reset 掉健康检查探测的连接:
|
||||
|
||||
```bash
|
||||
20:15:17.890996 IP 172.16.2.1.38074 > 172.16.2.23.8888: Flags [S], seq 96880261, win 14600, options [mss 1424,nop,nop,sackOK,nop,wscale 7], length 0
|
||||
20:15:17.891021 IP 172.16.2.23.8888 > 172.16.2.1.38074: Flags [R.], seq 0, ack 96880262, win 0, length 0
|
||||
20:15:17.906744 IP 10.0.0.16.54132 > 172.16.2.23.8888: Flags [S], seq 1207014342, win 14600, options [mss 1424,nop,nop,sackOK,nop,wscale 7], length 0
|
||||
20:15:17.906766 IP 172.16.2.23.8888 > 10.0.0.16.54132: Flags [R.], seq 0, ack 1207014343, win 0, length 0
|
||||
```
|
||||
|
||||
连接异常,从而健康检查失败。发生这种情况的原因可能在一个节点上启动了多个使用 `hostNetwork` 监听相同宿主机端口的 Pod,只会有一个 Pod 监听成功,但监听失败的 Pod 的业务逻辑允许了监听失败,并没有退出,Pod 又配了健康检查,kubelet 就会给 Pod 发送健康检查探测报文,但 Pod 由于没有监听所以就会健康检查失败。
|
||||
|
||||
## SYN backlog 设置过小
|
||||
|
||||
SYN backlog 大小即 SYN 队列大小,如果短时间内新建连接比较多,而 SYN backlog 设置太小,就会导致新建连接失败,通过 `netstat -s | grep TCPBacklogDrop` 可以看到有多少是因为 backlog 满了导致丢弃的新连接。
|
||||
|
||||
如果确认是 backlog 满了导致的丢包,建议调高 backlog 的值,内核参数为 `net.ipv4.tcp_max_syn_backlog`。
|
||||
|
|
@ -1,35 +0,0 @@
|
|||
# 排查 Pod 状态异常
|
||||
|
||||
本节分享 Pod 状态异常的排查思路与可能原因。
|
||||
|
||||
## 常见异常状态排查
|
||||
|
||||
- [Terminating](pod-terminating.md)
|
||||
- [Pending](pod-pending.md)
|
||||
- [ContainerCreating 或 Waiting](pod-containercreating-or-waiting.md)
|
||||
- [CrashLoopBackOff](pod-crash.md)
|
||||
- [ImagePullBackOff](pod-imagepullbackoff.md)
|
||||
|
||||
## ImageInspectError
|
||||
|
||||
通常是镜像文件损坏了,可以尝试删除损坏的镜像重新拉取。
|
||||
|
||||
## Error
|
||||
|
||||
通常处于 Error 状态说明 Pod 启动过程中发生了错误。常见的原因包括:
|
||||
|
||||
* 依赖的 ConfigMap、Secret 或者 PV 等不存在。
|
||||
* 请求的资源超过了管理员设置的限制,比如超过了 LimitRange 等。
|
||||
* 违反集群的安全策略,比如违反了 PodSecurityPolicy 等。
|
||||
* 容器无权操作集群内的资源,比如开启 RBAC 后,需要为 ServiceAccount 配置角色绑定。
|
||||
|
||||
## Unknown
|
||||
|
||||
通常是节点失联,没有上报状态给 apiserver,到达阀值后 controller-manager 认为节点失联并将其状态置为 `Unknown`。
|
||||
|
||||
可能原因:
|
||||
|
||||
* 节点高负载导致无法上报。
|
||||
* 节点宕机。
|
||||
* 节点被关机。
|
||||
* 网络不通。
|
||||
|
|
@ -1,142 +0,0 @@
|
|||
# Pod 一直 ContainerCreating 或 Waiting
|
||||
|
||||
## 镜像问题
|
||||
|
||||
* 镜象名称错误。
|
||||
* 错误的镜像标签。
|
||||
* 错误的存储仓库。
|
||||
* 存储仓库需要身份验证。
|
||||
|
||||
## 依赖问题
|
||||
|
||||
在 pod 启动之前,kubelet 将尝试检查与其他 Kubernetes 元素的所有依赖关系。如果无法满足这些依赖项之一,则 pod 将会保持挂起状态。
|
||||
|
||||
依赖主要是挂载相关的:
|
||||
|
||||
1. pvc
|
||||
2. configmap
|
||||
3. secret
|
||||
|
||||
## 挂载 Volume 失败
|
||||
|
||||
Volume 挂载失败也分许多种情况,先列下我这里目前已知的。
|
||||
|
||||
### Pod 漂移没有正常解挂之前的磁盘
|
||||
|
||||
在云尝试托管的 K8S 服务环境下,默认挂载的 Volume 一般是块存储类型的云硬盘,如果某个节点挂了,kubelet 无法正常运行或与 apiserver 通信,到达时间阀值后会触发驱逐,自动在其它节点上启动相同的副本 (Pod 漂移),但是由于被驱逐的 Node 无法正常运行并不知道自己被驱逐了,也就没有正常执行解挂,cloud-controller-manager 也在等解挂成功后再调用云厂商的接口将磁盘真正从节点上解挂,通常会等到一个时间阀值后 cloud-controller-manager 会强制解挂云盘,然后再将其挂载到 Pod 最新所在节点上,这种情况下 ContainerCreating 的时间相对长一点,但一般最终是可以启动成功的,除非云厂商的 cloud-controller-manager 逻辑有 bug。
|
||||
|
||||
### 命中 K8S 挂载 configmap/secret 的 subpath 的 bug
|
||||
|
||||
最近发现如果 Pod 挂载了 configmap 或 secret, 如果后面修改了 configmap 或 secret 的内容,Pod 里的容器又原地重启了(比如存活检查失败被 kill 然后重启拉起),就会触发 K8S 的这个 bug,团队的小伙伴已提 PR: https://github.com/kubernetes/kubernetes/pull/82784
|
||||
|
||||
如果是这种情况,容器会一直启动不成功,可以看到类似以下的报错:
|
||||
|
||||
``` bash
|
||||
$ kubectl -n prod get pod -o yaml manage-5bd487cf9d-bqmvm
|
||||
...
|
||||
lastState: terminated
|
||||
containerID: containerd://e6746201faa1dfe7f3251b8c30d59ebf613d99715f3b800740e587e681d2a903
|
||||
exitCode: 128
|
||||
finishedAt: 2019-09-15T00:47:22Z
|
||||
message: 'failed to create containerd task: OCI runtime create failed: container_linux.go:345:
|
||||
starting container process caused "process_linux.go:424: container init
|
||||
caused \"rootfs_linux.go:58: mounting \\\"/var/lib/kubelet/pods/211d53f4-d08c-11e9-b0a7-b6655eaf02a6/volume-subpaths/manage-config-volume/manage/0\\\"
|
||||
to rootfs \\\"/run/containerd/io.containerd.runtime.v1.linux/k8s.io/e6746201faa1dfe7f3251b8c30d59ebf613d99715f3b800740e587e681d2a903/rootfs\\\"
|
||||
at \\\"/run/containerd/io.containerd.runtime.v1.linux/k8s.io/e6746201faa1dfe7f3251b8c30d59ebf613d99715f3b800740e587e681d2a903/rootfs/app/resources/application.properties\\\"
|
||||
caused \\\"no such file or directory\\\"\"": unknown'
|
||||
```
|
||||
|
||||
### Unable to mount volumes
|
||||
|
||||
如果报类似如下事件:
|
||||
|
||||
```txt
|
||||
Unable to mount volumes for pod "es-0_prod(0f08e3aa-aa56-11ec-ab5b-5254006900dd)": timeout expired waiting for volumes to attach or mount for pod "prod"/"es-0". list of unmounted volumes=[applog]. list of unattached volumes=[applog default-token-m7bf7]
|
||||
```
|
||||
|
||||
参考 [存储排障: Unable to mount volumes](../../storage/unable-to-mount-volumes.md)。
|
||||
|
||||
## 磁盘爆满
|
||||
|
||||
启动 Pod 会调 CRI 接口创建容器,容器运行时创建容器时通常会在数据目录下为新建的容器创建一些目录和文件,如果数据目录所在的磁盘空间满了就会创建失败并报错:
|
||||
|
||||
```bash
|
||||
Events:
|
||||
Type Reason Age From Message
|
||||
---- ------ ---- ---- -------
|
||||
Warning FailedCreatePodSandBox 2m (x4307 over 16h) kubelet, 10.179.80.31 (combined from similar events): Failed create pod sandbox: rpc error: code = Unknown desc = failed to create a sandbox for pod "apigateway-6dc48bf8b6-l8xrw": Error response from daemon: mkdir /var/lib/docker/aufs/mnt/1f09d6c1c9f24e8daaea5bf33a4230de7dbc758e3b22785e8ee21e3e3d921214-init: no space left on device
|
||||
```
|
||||
|
||||
解决方法参考本书 [节点排障:磁盘爆满](../../node/disk-full.md)
|
||||
|
||||
## 节点内存碎片化
|
||||
|
||||
如果节点上内存碎片化严重,缺少大页内存,会导致即使总的剩余内存较多,但还是会申请内存失败,参考 [节点排障: 内存碎片化](../../node/memory-fragmentation.md)
|
||||
|
||||
## limit 设置太小或者单位不对
|
||||
|
||||
如果 limit 设置过小以至于不足以成功运行 Sandbox 也会造成这种状态,常见的是因为 memory limit 单位设置不对造成的 limit 过小,比如误将 memory 的 limit 单位像 request 一样设置为小 `m`,这个单位在 memory 不适用,会被 k8s 识别成 byte, 应该用 `Mi` 或 `M`。,
|
||||
|
||||
举个例子: 如果 memory limit 设为 1024m 表示限制 1.024 Byte,这么小的内存, pause 容器一起来就会被 cgroup-oom kill 掉,导致 pod 状态一直处于 ContainerCreating。
|
||||
|
||||
这种情况通常会报下面的 event:
|
||||
|
||||
``` txt
|
||||
Pod sandbox changed, it will be killed and re-created。
|
||||
```
|
||||
|
||||
kubelet 报错:
|
||||
|
||||
``` txt
|
||||
to start sandbox container for pod ... Error response from daemon: OCI runtime create failed: container_linux.go:348: starting container process caused "process_linux.go:301: running exec setns process for init caused \"signal: killed\"": unknown
|
||||
```
|
||||
|
||||
## 拉取镜像失败
|
||||
|
||||
镜像拉取失败也分很多情况,这里列举下:
|
||||
|
||||
* 配置了错误的镜像
|
||||
* Kubelet 无法访问镜像仓库(比如默认 pause 镜像在 gcr.io 上,国内环境访问需要特殊处理)
|
||||
* 拉取私有镜像的 imagePullSecret 没有配置或配置有误
|
||||
* 镜像太大,拉取超时(可以适当调整 kubelet 的 --image-pull-progress-deadline 和 --runtime-request-timeout 选项)
|
||||
|
||||
## CNI 网络错误
|
||||
|
||||
如果发生 CNI 网络错误通常需要检查下网络插件的配置和运行状态,如果没有正确配置或正常运行通常表现为:
|
||||
|
||||
* 无法配置 Pod 网络
|
||||
* 无法分配 Pod IP
|
||||
|
||||
## controller-manager 异常
|
||||
|
||||
查看 master 上 kube-controller-manager 状态,异常的话尝试重启。
|
||||
|
||||
## 安装 docker 没删干净旧版本
|
||||
|
||||
如果节点上本身有 docker 或者没删干净,然后又安装 docker,比如在 centos 上用 yum 安装:
|
||||
|
||||
``` bash
|
||||
yum install -y docker
|
||||
```
|
||||
|
||||
这样可能会导致 dockerd 创建容器一直不成功,从而 Pod 状态一直 ContainerCreating,查看 event 报错:
|
||||
|
||||
```
|
||||
Type Reason Age From Message
|
||||
---- ------ ---- ---- -------
|
||||
Warning FailedCreatePodSandBox 18m (x3583 over 83m) kubelet, 192.168.4.5 (combined from similar events): Failed create pod sandbox: rpc error: code = Unknown desc = failed to start sandbox container for pod "nginx-7db9fccd9b-2j6dh": Error response from daemon: ttrpc: client shutting down: read unix @->@/containerd-shim/moby/de2bfeefc999af42783115acca62745e6798981dff75f4148fae8c086668f667/shim.sock: read: connection reset by peer: unknown
|
||||
Normal SandboxChanged 3m12s (x4420 over 83m) kubelet, 192.168.4.5 Pod sandbox changed, it will be killed and re-created.
|
||||
```
|
||||
|
||||
可能是因为重复安装 docker 版本不一致导致一些组件之间不兼容,从而导致 dockerd 无法正常创建容器。
|
||||
|
||||
## 存在同名容器
|
||||
|
||||
如果节点上已有同名容器,创建 sandbox 就会失败,event:
|
||||
|
||||
```
|
||||
Warning FailedCreatePodSandBox 2m kubelet, 10.205.8.91 Failed create pod sandbox: rpc error: code = Unknown desc = failed to create a sandbox for pod "lomp-ext-d8c8b8c46-4v8tl": operation timeout: context deadline exceeded
|
||||
Warning FailedCreatePodSandBox 3s (x12 over 2m) kubelet, 10.205.8.91 Failed create pod sandbox: rpc error: code = Unknown desc = failed to create a sandbox for pod "lomp-ext-d8c8b8c46-4v8tl": Error response from daemon: Conflict. The container name "/k8s_POD_lomp-ext-d8c8b8c46-4v8tl_default_65046a06-f795-11e9-9bb6-b67fb7a70bad_0" is already in use by container "30aa3f5847e0ce89e9d411e76783ba14accba7eb7743e605a10a9a862a72c1e2". You have to remove (or rename) that container to be able to reuse that name.
|
||||
```
|
||||
|
||||
关于什么情况下会产生同名容器,这个有待研究。
|
||||
|
|
@ -1,197 +0,0 @@
|
|||
# 排查 Pod CrashLoopBackOff
|
||||
|
||||
Pod 如果处于 `CrashLoopBackOff` 状态说明之前是启动了,只是又异常退出了,只要 Pod 的 [restartPolicy](https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/#restart-policy) 不是 Never 就可能被重启拉起。
|
||||
|
||||
通过 kubectl 可以发现是否有 Pod 发生重启:
|
||||
|
||||
```bash
|
||||
$ kubectl get pod
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
grafana-c9dd59d46-s9dc6 2/2 Running 2 69d
|
||||
```
|
||||
|
||||
当 `RESTARTS` 大于 0 时,说明 Pod 中有容器重启了。
|
||||
|
||||
这时,我们可以先看下容器进程的退出状态码来缩小问题范围。
|
||||
|
||||
## 排查容器退出状态码
|
||||
|
||||
使用 `kubectl describe pod <pod name>` 查看异常 pod 的状态:
|
||||
|
||||
```bash
|
||||
Containers:
|
||||
kubedns:
|
||||
Container ID: docker://5fb8adf9ee62afc6d3f6f3d9590041818750b392dff015d7091eaaf99cf1c945
|
||||
Image: ccr.ccs.tencentyun.com/library/kubedns-amd64:1.14.4
|
||||
Image ID: docker-pullable://ccr.ccs.tencentyun.com/library/kubedns-amd64@sha256:40790881bbe9ef4ae4ff7fe8b892498eecb7fe6dcc22661402f271e03f7de344
|
||||
Ports: 10053/UDP, 10053/TCP, 10055/TCP
|
||||
Host Ports: 0/UDP, 0/TCP, 0/TCP
|
||||
Args:
|
||||
--domain=cluster.local.
|
||||
--dns-port=10053
|
||||
--config-dir=/kube-dns-config
|
||||
--v=2
|
||||
State: Running
|
||||
Started: Tue, 27 Aug 2019 10:58:49 +0800
|
||||
Last State: Terminated
|
||||
Reason: Error
|
||||
Exit Code: 255
|
||||
Started: Tue, 27 Aug 2019 10:40:42 +0800
|
||||
Finished: Tue, 27 Aug 2019 10:58:27 +0800
|
||||
Ready: True
|
||||
Restart Count: 1
|
||||
```
|
||||
|
||||
在容器列表里看 `Last State` 字段,其中 `ExitCode` 即程序上次退出时的状态码,如果不为 0,表示异常退出,我们可以分析下原因。
|
||||
|
||||
### 退出状态码的范围
|
||||
|
||||
* 必须在 0-255 之间。
|
||||
* 0 表示正常退出。
|
||||
* 外界中断将程序退出的时候状态码区间在 129-255,(操作系统给程序发送中断信号,比如 `kill -9` 是 `SIGKILL`,`ctrl+c` 是 `SIGINT`)
|
||||
* 一般程序自身原因导致的异常退出状态区间在 1-128 (这只是一般约定,程序如果一定要用129-255的状态码也是可以的),这时可以用 `kubectl logs -p` 查看容器重启前的标准输出。
|
||||
|
||||
假如写代码指定的退出状态码时不在 0-255 之间,例如: `exit(-1)`,这时会自动做一个转换,最终呈现的状态码还是会在 0-255 之间。 我们把状态码记为 `code`
|
||||
|
||||
* 当指定的退出时状态码为负数,那么转换公式如下:
|
||||
|
||||
```text
|
||||
256 - (|code| % 256)
|
||||
```
|
||||
|
||||
* 当指定的退出时状态码为正数,那么转换公式如下:
|
||||
|
||||
```text
|
||||
code % 256
|
||||
```
|
||||
|
||||
### 常见异常状态码
|
||||
|
||||
**0**
|
||||
|
||||
此状态码表示正常退出,一般是业务进程主动退出了,可以排查下退出前日志,如果日志有打到标准输出,可以通过 `kubectl logs -p` 查看退出前的容器标准输出。
|
||||
|
||||
也可能是存活检查失败被重启,重启时收到 SIGTERM 信号进程正常退出,可以检查事件是否有存活检查失败的日志。
|
||||
|
||||
**137**
|
||||
|
||||
此状态码说名容器是被 `SIGKILL` 信号强制杀死的。可能原因:
|
||||
1. 发生 Cgroup OOM。Pod 中容器使用的内存达到了它的资源限制(`resources.limits`),在 `describe pod` 输出中一般可以看到 Reason 是 `OOMKilled`。
|
||||
2. 发生系统 OOM,内核会选取一些进程杀掉来释放内存,可能刚好选到某些容器的主进程。
|
||||
3. `livenessProbe` (存活检查) 失败,kubelet 重启容器时等待超时,最后发 `SIGKILL` 强制重启。
|
||||
4. 被其它未知进程杀死,比如某些安全组件或恶意木马。
|
||||
|
||||
**1 和 255**
|
||||
|
||||
这种可能是一般错误,具体错误原因只能看业务日志,因为很多程序员写异常退出时习惯用 `exit(1)` 或 `exit(-1)`,-1 会根据转换规则转成 255。
|
||||
|
||||
255 也可能是 Pod 宿主机发生了重启导致的容器重启。
|
||||
|
||||
### 状态码参考
|
||||
|
||||
这里罗列了一些状态码的含义:[Appendix E. Exit Codes With Special Meanings](https://tldp.org/LDP/abs/html/exitcodes.html)
|
||||
|
||||
### Linux 标准中断信号
|
||||
|
||||
Linux 程序被外界中断时会发送中断信号,程序退出时的状态码就是中断信号值加上 128 得到的,比如 `SIGKILL` 的中断信号值为 9,那么程序退出状态码就为 9+128=137。以下是标准信号值参考:
|
||||
|
||||
```text
|
||||
Signal Value Action Comment
|
||||
──────────────────────────────────────────────────────────────────────
|
||||
SIGHUP 1 Term Hangup detected on controlling terminal
|
||||
or death of controlling process
|
||||
SIGINT 2 Term Interrupt from keyboard
|
||||
SIGQUIT 3 Core Quit from keyboard
|
||||
SIGILL 4 Core Illegal Instruction
|
||||
SIGABRT 6 Core Abort signal from abort(3)
|
||||
SIGFPE 8 Core Floating-point exception
|
||||
SIGKILL 9 Term Kill signal
|
||||
SIGSEGV 11 Core Invalid memory reference
|
||||
SIGPIPE 13 Term Broken pipe: write to pipe with no
|
||||
readers; see pipe(7)
|
||||
SIGALRM 14 Term Timer signal from alarm(2)
|
||||
SIGTERM 15 Term Termination signal
|
||||
SIGUSR1 30,10,16 Term User-defined signal 1
|
||||
SIGUSR2 31,12,17 Term User-defined signal 2
|
||||
SIGCHLD 20,17,18 Ign Child stopped or terminated
|
||||
SIGCONT 19,18,25 Cont Continue if stopped
|
||||
SIGSTOP 17,19,23 Stop Stop process
|
||||
SIGTSTP 18,20,24 Stop Stop typed at terminal
|
||||
SIGTTIN 21,21,26 Stop Terminal input for background process
|
||||
SIGTTOU 22,22,27 Stop Terminal output for background process
|
||||
```
|
||||
|
||||
### C/C++ 退出状态码
|
||||
|
||||
`/usr/include/sysexits.h` 试图将退出状态码标准化(仅限 C/C++):
|
||||
|
||||
```text
|
||||
#define EX_OK 0 /* successful termination */
|
||||
|
||||
#define EX__BASE 64 /* base value for error messages */
|
||||
|
||||
#define EX_USAGE 64 /* command line usage error */
|
||||
#define EX_DATAERR 65 /* data format error */
|
||||
#define EX_NOINPUT 66 /* cannot open input */
|
||||
#define EX_NOUSER 67 /* addressee unknown */
|
||||
#define EX_NOHOST 68 /* host name unknown */
|
||||
#define EX_UNAVAILABLE 69 /* service unavailable */
|
||||
#define EX_SOFTWARE 70 /* internal software error */
|
||||
#define EX_OSERR 71 /* system error (e.g., can't fork) */
|
||||
#define EX_OSFILE 72 /* critical OS file missing */
|
||||
#define EX_CANTCREAT 73 /* can't create (user) output file */
|
||||
#define EX_IOERR 74 /* input/output error */
|
||||
#define EX_TEMPFAIL 75 /* temp failure; user is invited to retry */
|
||||
#define EX_PROTOCOL 76 /* remote error in protocol */
|
||||
#define EX_NOPERM 77 /* permission denied */
|
||||
#define EX_CONFIG 78 /* configuration error */
|
||||
|
||||
#define EX__MAX 78 /* maximum listed value */
|
||||
```
|
||||
|
||||
## 可能原因
|
||||
|
||||
以下是一些可能原因。
|
||||
|
||||
### 容器进程主动退出
|
||||
|
||||
如果是容器进程主动退出,退出状态码一般在 0-128 之间,除了可能是业务程序 BUG,还有其它许多可能原因。
|
||||
|
||||
可以通过 `kubectl logs -p` 查看容器退出前的标准输出,如果有采集业务日志,也可以排查下业务日志。
|
||||
|
||||
### 系统 OOM
|
||||
|
||||
如果发生系统 OOM,可以看到 Pod 中容器退出状态码是 137,表示被 `SIGKILL` 信号杀死,同时内核会报错: `Out of memory: Kill process ...`。大概率是节点上部署了其它非 K8S 管理的进程消耗了比较多的内存,或者 kubelet 的 `--kube-reserved` 和 `--system-reserved` 配的比较小,没有预留足够的空间给其它非容器进程,节点上所有 Pod 的实际内存占用总量不会超过 `/sys/fs/cgroup/memory/kubepods` 这里 cgroup 的限制,这个限制等于 `capacity - "kube-reserved" - "system-reserved"`,如果预留空间设置合理,节点上其它非容器进程(kubelet, dockerd, kube-proxy, sshd 等) 内存占用没有超过 kubelet 配置的预留空间是不会发生系统 OOM 的,可以根据实际需求做合理的调整。
|
||||
|
||||
### cgroup OOM
|
||||
|
||||
如果是 cgrou OOM 杀掉的进程,从 Pod 事件的下 `Reason` 可以看到是 `OOMKilled`,说明容器实际占用的内存超过 limit 了,同时内核日志会报: `Memory cgroup out of memory`。 可以根据需求调整下 limit。
|
||||
|
||||
### 健康检查失败
|
||||
|
||||
参考 [Pod 健康检查失败](../healthcheck-failed.md) 进一步定位。
|
||||
|
||||
### 宿主机重启
|
||||
|
||||
Pod 所在宿主机重启会导致容器重启,状态码一般为 255。
|
||||
|
||||
### 节点内存碎片化
|
||||
|
||||
如果节点上内存碎片化严重,缺少大页内存,会导致即使总的剩余内存较多,但还是会申请内存失败,参考 [内存碎片化](../../node/memory-fragmentation.md)。
|
||||
|
||||
### 挂载了 configmap subpath
|
||||
|
||||
K8S 对 configmap subpath 的支持有个问题,如果容器挂载 configmap 指定了 subpath,且后来修改了 configmap 中的内容,当容器重启时会失败,参考 issue [modified subpath configmap mount fails when container restarts](https://github.com/kubernetes/kubernetes/issues/68211)。
|
||||
|
||||
事件日志里可以看出是挂载 subpath 报 `no such file or directory`,describe pod 类似这样:
|
||||
|
||||
```txt
|
||||
Last State: Terminated
|
||||
Reason: StartError
|
||||
Message: failed to create containerd task: OCI runtime create failed: container_linux.go:349: starting container process caused "process_linux.go:449: container init caused \"rootfs_linux.go:58: mounting \\\"/data/kubelet/pods/d6f90d2b-a5c4-11ec-8b09-5254009e5e2e/volume-subpaths/conf/demo-container/2\\\" to rootfs \\\"/run/containerd/io.containerd.runtime.v2.task/k8s.io/f28499d3c81b145ef2e88c31adaade0466ef71cee537377a439bad36707a7e3e/rootfs\\\" at \\\"/run/containerd/io.containerd.runtime.v2.task/k8s.io/f28499d3c81b145ef2e88c31adaade0466ef71cee537377a439bad36707a7e3e/rootfs/app/conf/server.yaml\\\" caused \\\"no such file or directory\\\"\"": unknown
|
||||
Exit Code: 128
|
||||
```
|
||||
|
||||
> 有些平台实现了原地重启的能力,即更新工作负载不会重建 Pod,只是重启,更容易发生类似的问题。
|
||||
|
||||
建议是修改用法,不挂载 subpath。通常使用 subpath 是因为不想覆盖镜像内已有的配置文件,可以将 configmap挂载到其它路径,然后再将镜像内已有的配置文件 include 进来。
|
||||
|
|
@ -1,42 +0,0 @@
|
|||
# 排查 Pod ImagePullBackOff
|
||||
|
||||
## http 类型 registry,地址未加入到 insecure-registry
|
||||
|
||||
dockerd 默认从 https 类型的 registry 拉取镜像,如果使用 https 类型的 registry,则必须将它添加到 insecure-registry 参数中,然后重启或 reload dockerd 生效。
|
||||
|
||||
## https 自签发类型 resitry,没有给节点添加 ca 证书
|
||||
|
||||
如果 registry 是 https 类型,但证书是自签发的,dockerd 会校验 registry 的证书,校验成功才能正常使用镜像仓库,要想校验成功就需要将 registry 的 ca 证书放置到 `/etc/docker/certs.d/<registry:port>/ca.crt` 位置。
|
||||
|
||||
## 私有镜像仓库认证失败
|
||||
|
||||
如果 registry 需要认证,但是 Pod 没有配置 imagePullSecret,配置的 Secret 不存在或者有误都会认证失败。
|
||||
|
||||
## 镜像文件损坏
|
||||
|
||||
如果 push 的镜像文件损坏了,下载下来也用不了,需要重新 push 镜像文件。
|
||||
|
||||
## 镜像拉取超时
|
||||
|
||||
如果节点上新起的 Pod 太多就会有许多可能会造成容器镜像下载排队,如果前面有许多大镜像需要下载很长时间,后面排队的 Pod 就会报拉取超时。
|
||||
|
||||
kubelet 默认串行下载镜像:
|
||||
|
||||
``` txt
|
||||
--serialize-image-pulls Pull images one at a time. We recommend *not* changing the default value on nodes that run docker daemon with version < 1.9 or an Aufs storage backend. Issue #10959 has more details. (default true)
|
||||
```
|
||||
|
||||
也可以开启并行下载并控制并发:
|
||||
|
||||
``` txt
|
||||
--registry-qps int32 If > 0, limit registry pull QPS to this value. If 0, unlimited. (default 5)
|
||||
--registry-burst int32 Maximum size of a bursty pulls, temporarily allows pulls to burst to this number, while still not exceeding registry-qps. Only used if --registry-qps > 0 (default 10)
|
||||
```
|
||||
|
||||
## 镜像不不存在
|
||||
|
||||
kubelet 日志:
|
||||
|
||||
``` bash
|
||||
PullImage "imroc/test:v0.2" from image service failed: rpc error: code = Unknown desc = Error response from daemon: manifest for imroc/test:v0.2 not found
|
||||
```
|
||||
|
|
@ -1,140 +0,0 @@
|
|||
# 排查 Pod 一直 Pending
|
||||
|
||||
Pod 一直 Pending 一般是调度失败,通常我们可以通过 describe 来看下 event 来判断 pending 原因:
|
||||
|
||||
``` bash
|
||||
$ kubectl describe pod tikv-0
|
||||
...
|
||||
Events:
|
||||
Type Reason Age From Message
|
||||
---- ------ ---- ---- -------
|
||||
Warning FailedScheduling 3m (x106 over 33m) default-scheduler 0/4 nodes are available: 1 node(s) had no available volume zone, 2 Insufficient cpu, 3 Insufficient memory.
|
||||
```
|
||||
|
||||
## 任何节点中都没有足够的资源来分配 pod
|
||||
|
||||
Kubernetes 会根据 Pod 的 Request 和所有节点的资源已分配与可分配的情况 (CPU, Memory, GPU, MaxPod 等) 来决定哪些节点可以被调度,如果所有节点都没有足够资源了,Pod 就会一直保持 Pending。
|
||||
|
||||
如果判断某个 Node 资源是否足够? 通过 `kubectl describe node <node-name>` 查看 node 资源情况,关注以下信息:
|
||||
|
||||
* `Allocatable`: 表示此节点能够申请的资源总和
|
||||
* `Allocated resources`: 表示此节点已分配的资源 (Allocatable 减去节点上所有 Pod 总的 Request)
|
||||
|
||||
前者与后者相减,可得出剩余可申请的资源。如果这个值小于 Pod 的 request,就不满足 Pod 的资源要求,Scheduler 在 Predicates (预选) 阶段就会剔除掉这个 Node,也就不会调度上去。
|
||||
|
||||
## 不满足亲和性
|
||||
|
||||
如果 Pod 包含 nodeSelector 指定了节点需要包含的 label,调度器将只会考虑将 Pod 调度到包含这些 label 的 Node 上,如果没有 Node 有这些 label 或者有这些 label 的 Node 其它条件不满足也将会无法调度。参考官方文档:https://kubernetes.io/docs/concepts/configuration/assign-pod-node/#nodeselector
|
||||
|
||||
如果 Pod 包含 affinity(亲和性)的配置,调度器根据调度算法也可能算出没有满足条件的 Node,从而无法调度。affinity 有以下几类:
|
||||
|
||||
* nodeAffinity: 节点亲和性,可以看成是增强版的 nodeSelector,用于限制 Pod 只允许被调度到某一部分 Node。
|
||||
* podAffinity: Pod 亲和性,用于将一些有关联的 Pod 调度到同一个地方,同一个地方可以是指同一个节点或同一个可用区的节点等。
|
||||
* podAntiAffinity: Pod 反亲和性,用于避免将某一类 Pod 调度到同一个地方避免单点故障,比如将集群 DNS 服务的 Pod 副本都调度到不同节点,避免一个节点挂了造成整个集群 DNS 解析失败,使得业务中断。
|
||||
|
||||
## 节点不可调度
|
||||
|
||||
由于节点压力(NotReady)或人为行为(节点封锁),节点可能会变为不可调度的状态,这些节点在状态发生变化之前不会调度任何 pod。
|
||||
|
||||
可以通过 `kubectl get node` 查看节点是否是 `NotReady` 或 `SchedulingDisabled`。
|
||||
|
||||
## 挂载磁盘或固定 IP 导致无法漂移
|
||||
|
||||
如果 Pod 挂载了磁盘(块存储),而一般云盘的实现是不能跨可用区的(时延太高),如果集群中节点分布在多个可用区,当前可用区节点无资源可调度时,Pod 也无法漂移到其它可用区。
|
||||
|
||||
Pod 报类似如下事件日志:
|
||||
|
||||
```txt
|
||||
0/4 nodes are available: 2 node(s) insufficient memory, 2 node(s) had no available volume zone.
|
||||
```
|
||||
|
||||
解决方法:要么删除 pvc 并重建 pod,自动在被调度到的可用区里创建磁盘并挂载;要么在 pod 之前所在可用区内扩容节点以补充资源。
|
||||
|
||||
同理,如果固定了 IP(通过插件或云厂商的网络实现),通常 Pod 就不能漂移到其它子网的节点上去。
|
||||
|
||||
解决方法: 加节点,或取消固定 IP 然后重建。
|
||||
|
||||
## 污点与容忍
|
||||
|
||||
节点如果被打上了污点,Pod 必须要容忍污点才能调度上去:
|
||||
|
||||
```bash
|
||||
0/5 nodes are available: 3 node(s) had taints that the pod didn't tolerate, 2 Insufficient memory.
|
||||
```
|
||||
|
||||
通过 describe node 可以看下 Node 有哪些 Taints:
|
||||
|
||||
``` bash
|
||||
$ kubectl describe nodes host1
|
||||
...
|
||||
Taints: special=true:NoSchedule
|
||||
...
|
||||
```
|
||||
|
||||
如果希望 Pod 可以调度上去,通常解决方法有两个:
|
||||
|
||||
1. 删除污点:
|
||||
|
||||
``` bash
|
||||
kubectl taint nodes host1 special-
|
||||
```
|
||||
|
||||
2. 给 Pod 加上这个污点的容忍:
|
||||
|
||||
``` yaml
|
||||
tolerations:
|
||||
- key: "special"
|
||||
operator: "Equal"
|
||||
value: "true"
|
||||
effect: "NoSchedule"
|
||||
```
|
||||
|
||||
我们通常使用后者的方法来解决。污点既可以是手动添加也可以是被自动添加,下面来深入分析一下。
|
||||
|
||||
### 手动添加的污点
|
||||
|
||||
通过类似以下方式可以给节点添加污点:
|
||||
|
||||
``` bash
|
||||
$ kubectl taint node host1 special=true:NoSchedule
|
||||
node "host1" tainted
|
||||
```
|
||||
|
||||
另外,有些场景下希望新加的节点默认不调度 Pod,直到调整完节点上某些配置才允许调度,就给新加的节点都加上 `node.kubernetes.io/unschedulable` 这个污点。
|
||||
|
||||
### 自动添加的污点
|
||||
|
||||
如果节点运行状态不正常,污点也可以被自动添加,从 v1.12 开始,`TaintNodesByCondition` 特性进入 Beta 默认开启,controller manager 会检查 Node 的 Condition,如果命中条件就自动为 Node 加上相应的污点,这些 Condition 与 Taints 的对应关系如下:
|
||||
|
||||
``` txt
|
||||
Conditon Value Taints
|
||||
-------- ----- ------
|
||||
OutOfDisk True node.kubernetes.io/out-of-disk
|
||||
Ready False node.kubernetes.io/not-ready
|
||||
Ready Unknown node.kubernetes.io/unreachable
|
||||
MemoryPressure True node.kubernetes.io/memory-pressure
|
||||
PIDPressure True node.kubernetes.io/pid-pressure
|
||||
DiskPressure True node.kubernetes.io/disk-pressure
|
||||
NetworkUnavailable True node.kubernetes.io/network-unavailable
|
||||
```
|
||||
|
||||
解释下上面各种条件的意思:
|
||||
|
||||
* OutOfDisk 为 True 表示节点磁盘空间不够了
|
||||
* Ready 为 False 表示节点不健康
|
||||
* Ready 为 Unknown 表示节点失联,在 `node-monitor-grace-period` 这么长的时间内没有上报状态 controller-manager 就会将 Node 状态置为 Unknown (默认 40s)
|
||||
* MemoryPressure 为 True 表示节点内存压力大,实际可用内存很少
|
||||
* PIDPressure 为 True 表示节点上运行了太多进程,PID 数量不够用了
|
||||
* DiskPressure 为 True 表示节点上的磁盘可用空间太少了
|
||||
* NetworkUnavailable 为 True 表示节点上的网络没有正确配置,无法跟其它 Pod 正常通信
|
||||
|
||||
另外,在云环境下,比如腾讯云 TKE,添加新节点会先给这个 Node 加上 `node.cloudprovider.kubernetes.io/uninitialized` 的污点,等 Node 初始化成功后才自动移除这个污点,避免 Pod 被调度到没初始化好的 Node 上。
|
||||
|
||||
## kube-scheduler 没有正常运行
|
||||
|
||||
检查 maser 上的 `kube-scheduler` 是否运行正常,异常的话可以尝试重启临时恢复。
|
||||
|
||||
## 参考资料
|
||||
|
||||
* [Understanding Kubernetes pod pending problems](https://sysdig.com/blog/kubernetes-pod-pending-problems/)
|
||||
* [彻底搞懂 K8S Pod Pending 故障原因及解决方案 ](https://mp.weixin.qq.com/s/SBpnxLfMq4Ubsvg5WH89lA)
|
||||
|
|
@ -1,244 +0,0 @@
|
|||
# 排查 Pod 一直 Terminating
|
||||
|
||||
有时候删除 Pod 一直卡在 Terminating 状态,一直删不掉,本文给出排查思路与可能原因。
|
||||
|
||||
## 分析思路
|
||||
|
||||
Pod 处于 Terminating 状态说明 Pod 是被删除,但一直无法结束。
|
||||
|
||||
Pod 被删除主要可能是:
|
||||
1. 用户主动删除的 Pod。
|
||||
2. 工作负载在滚动更新,自动删除的 Pod。
|
||||
3. 触发了节点驱逐,自动清理的 Pod。
|
||||
4. 节点长时间处于 `NotReady` 状态,Pod 被自动删除以便被重新调度。
|
||||
|
||||
Pod 被删除的流程:
|
||||
1. APIServer 收到删除 Pod 的请求,Pod 被标记删除,处于 `Terminating` 状态。
|
||||
2. 节点上的 kubelet watch 到了 Pod 被删除,开始销毁 Pod。
|
||||
3. Kubelet 调用运行时接口,清理相关容器。
|
||||
4. 所有容器销毁成功,通知 APIServer。
|
||||
5. APIServer 感知到 Pod 成功销毁,检查 metadata 是否还有 `finalizers`,如果有就等待其它控制器清理完,如果没有就直接从 etcd 中删除 Pod 记录。
|
||||
|
||||
可以看出来,删除 Pod 流程涉及到的组件包含: APIServer, etcd, kubelet 与容器运行时 (如 docker、containerd)。
|
||||
|
||||
既然都能看到 Pod 卡在 Terminating 状态,说明 APIServer 能正常响应,也能正常从 etcd 中获取数据,一般不会有什么问题,有问题的地方主要就是节点上的操作。
|
||||
|
||||
通常可以结合事件与上节点排查来分析。
|
||||
|
||||
## 检查 Pod 所在节点是否异常
|
||||
|
||||
可以先用 kubectl 初步检查下节点是否异常:
|
||||
|
||||
```bash
|
||||
# 查找 Terminating 的 Pod 及其所在 Node
|
||||
$ kubectl get pod -o wide | grep Terminating
|
||||
grafana-5d7ff8cb89-8gdtz 1/1 Terminating 1 97d 10.10.7.150 172.20.32.15 <none> <none>
|
||||
|
||||
# 检查 Node 是否异常
|
||||
$ kubectl get node 172.20.32.15
|
||||
NAME STATUS ROLES AGE VERSION
|
||||
172.20.32.15 NotReady <none> 182d v1.20.6
|
||||
|
||||
# 查看 Node 相关事件
|
||||
$ kubectl describe node 172.20.32.15
|
||||
```
|
||||
|
||||
如果有监控,查看下节点相关监控指标,没有监控也可以登上节点去排查。
|
||||
|
||||
### 节点高负载
|
||||
|
||||
如果节点负载过高,分不出足够的 CPU 去销毁 Pod,导致一直无法销毁完成;甚至可能销毁了 Pod,但因负载过高无法与 APIServer 正常通信,一直超时,APIServer 也就无法感知到 Pod 被销毁,导致 Pod 一直无法被彻底删除。
|
||||
|
||||
### 节点被关机
|
||||
|
||||
如果节点关机了,自然无法进行销毁 Pod 的操作。
|
||||
|
||||
### 节点网络异常
|
||||
|
||||
如果节点因网络异常无法与 APIServer 通信,APIServer 也就无法感知到 Pod 被销毁,导致 Pod 一直不会被彻底删除。
|
||||
|
||||
网络异常的原因可能很多,比如:
|
||||
1. iptables 规则有问题。
|
||||
2. 路由配置有问题。
|
||||
3. 网卡被 down。
|
||||
4. BPF 程序问题。
|
||||
|
||||
### 内核异常
|
||||
|
||||
有时候可能触发内核 BUG 导致节点异常,检查下内核日志:
|
||||
|
||||
```bash
|
||||
dmesg
|
||||
# journalctl -k
|
||||
```
|
||||
|
||||
## 分析 kubelet 与容器运行时
|
||||
|
||||
先检查下 kubelet 与容器运行时是否在运行:
|
||||
|
||||
```bash
|
||||
ps -ef | grep kubelet
|
||||
ps -ef | grep containerd
|
||||
# ps -ef | grep dockerd
|
||||
```
|
||||
|
||||
分析 kubelet 日志:
|
||||
|
||||
```bash
|
||||
journalctl -u kubelet --since "3 hours ago" | grep $POD_NAME
|
||||
```
|
||||
|
||||
分析运行时日志:
|
||||
|
||||
```bash
|
||||
journalctl -u containerd
|
||||
# journalctl -u dockerd
|
||||
```
|
||||
|
||||
### 磁盘爆满
|
||||
|
||||
如果容器运行时 (docker 或 containerd 等) 的数据目录所在磁盘被写满,运行时就无法正常无法创建和销毁容器,kubelet 调用运行时去删除容器时就没有反应,看 event 类似这样:
|
||||
|
||||
```bash
|
||||
Normal Killing 39s (x735 over 15h) kubelet, 10.179.80.31 Killing container with id docker://apigateway:Need to kill Pod
|
||||
```
|
||||
|
||||
解决方案:清理磁盘空间
|
||||
|
||||
### 存在 "i" 文件属性
|
||||
|
||||
如果容器的镜像本身或者容器启动后写入的文件存在 "i" 文件属性,此文件就无法被修改删除,而删除 Pod 时会清理容器目录,但里面包含有不可删除的文件,就一直删不了,Pod 状态也将一直保持 Terminating,kubelet 报错:
|
||||
|
||||
``` log
|
||||
Sep 27 14:37:21 VM_0_7_centos kubelet[14109]: E0927 14:37:21.922965 14109 remote_runtime.go:250] RemoveContainer "19d837c77a3c294052a99ff9347c520bc8acb7b8b9a9dc9fab281fc09df38257" from runtime service failed: rpc error: code = Unknown desc = failed to remove container "19d837c77a3c294052a99ff9347c520bc8acb7b8b9a9dc9fab281fc09df38257": Error response from daemon: container 19d837c77a3c294052a99ff9347c520bc8acb7b8b9a9dc9fab281fc09df38257: driver "overlay2" failed to remove root filesystem: remove /data/docker/overlay2/b1aea29c590aa9abda79f7cf3976422073fb3652757f0391db88534027546868/diff/usr/bin/bash: operation not permitted
|
||||
Sep 27 14:37:21 VM_0_7_centos kubelet[14109]: E0927 14:37:21.923027 14109 kuberuntime_gc.go:126] Failed to remove container "19d837c77a3c294052a99ff9347c520bc8acb7b8b9a9dc9fab281fc09df38257": rpc error: code = Unknown desc = failed to remove container "19d837c77a3c294052a99ff9347c520bc8acb7b8b9a9dc9fab281fc09df38257": Error response from daemon: container 19d837c77a3c294052a99ff9347c520bc8acb7b8b9a9dc9fab281fc09df38257: driver "overlay2" failed to remove root filesystem: remove /data/docker/overlay2/b1aea29c590aa9abda79f7cf3976422073fb3652757f0391db88534027546868/diff/usr/bin/bash: operation not permitted
|
||||
```
|
||||
|
||||
通过 `man chattr` 查看 "i" 文件属性描述:
|
||||
|
||||
``` txt
|
||||
A file with the 'i' attribute cannot be modified: it cannot be deleted or renamed, no
|
||||
link can be created to this file and no data can be written to the file. Only the superuser
|
||||
or a process possessing the CAP_LINUX_IMMUTABLE capability can set or clear this attribute.
|
||||
```
|
||||
|
||||
彻底解决当然是不要在容器镜像中或启动后的容器设置 "i" 文件属性,临时恢复方法: 复制 kubelet 日志报错提示的文件路径,然后执行 `chattr -i <file>`:
|
||||
|
||||
``` bash
|
||||
chattr -i /data/docker/overlay2/b1aea29c590aa9abda79f7cf3976422073fb3652757f0391db88534027546868/diff/usr/bin/bash
|
||||
```
|
||||
|
||||
执行完后等待 kubelet 自动重试,Pod 就可以被自动删除了。
|
||||
|
||||
### docker 17 的 bug
|
||||
|
||||
docker hang 住,没有任何响应,看 event:
|
||||
|
||||
```bash
|
||||
Warning FailedSync 3m (x408 over 1h) kubelet, 10.179.80.31 error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
|
||||
```
|
||||
|
||||
怀疑是17版本dockerd的BUG。可通过 `kubectl -n cn-staging delete pod apigateway-6dc48bf8b6-clcwk --force --grace-period=0` 强制删除pod,但 `docker ps` 仍看得到这个容器
|
||||
|
||||
处置建议:
|
||||
|
||||
* 升级到docker 18. 该版本使用了新的 containerd,针对很多bug进行了修复。
|
||||
* 如果出现terminating状态的话,可以提供让容器专家进行排查,不建议直接强行删除,会可能导致一些业务上问题。
|
||||
|
||||
### 低版本 kubelet list-watch 的 bug
|
||||
|
||||
之前遇到过使用 v1.8.13 版本的 k8s,kubelet 有时 list-watch 出问题,删除 pod 后 kubelet 没收到事件,导致 kubelet 一直没做删除操作,所以 pod 状态一直是 Terminating
|
||||
|
||||
### dockerd 与 containerd 的状态不同步
|
||||
|
||||
判断 dockerd 与 containerd 某个容器的状态不同步的方法:
|
||||
|
||||
* describe pod 拿到容器 id
|
||||
* docker ps 查看的容器状态是 dockerd 中保存的状态
|
||||
* 通过 docker-container-ctr 查看容器在 containerd 中的状态,比如:
|
||||
``` bash
|
||||
$ docker-container-ctr --namespace moby --address /var/run/docker/containerd/docker-containerd.sock task ls |grep a9a1785b81343c3ad2093ad973f4f8e52dbf54823b8bb089886c8356d4036fe0
|
||||
a9a1785b81343c3ad2093ad973f4f8e52dbf54823b8bb089886c8356d4036fe0 30639 STOPPED
|
||||
```
|
||||
|
||||
containerd 看容器状态是 stopped 或者已经没有记录,而 docker 看容器状态却是 runing,说明 dockerd 与 containerd 之间容器状态同步有问题,目前发现了 docker 在 aufs 存储驱动下如果磁盘爆满可能发生内核 panic :
|
||||
|
||||
``` txt
|
||||
aufs au_opts_verify:1597:dockerd[5347]: dirperm1 breaks the protection by the permission bits on the lower branch
|
||||
```
|
||||
|
||||
如果磁盘爆满过,dockerd 一般会有下面类似的日志:
|
||||
|
||||
``` log
|
||||
Sep 18 10:19:49 VM-1-33-ubuntu dockerd[4822]: time="2019-09-18T10:19:49.903943652+08:00" level=error msg="Failed to log msg \"\" for logger json-file: write /opt/docker/containers/54922ec8b1863bcc504f6dac41e40139047f7a84ff09175d2800100aaccbad1f/54922ec8b1863bcc504f6dac41e40139047f7a84ff09175d2800100aaccbad1f-json.log: no space left on device"
|
||||
```
|
||||
|
||||
随后可能发生状态不同步,已提issue: https://github.com/docker/for-linux/issues/779
|
||||
|
||||
* 临时恢复: 执行 `docker container prune` 或重启 dockerd
|
||||
* 长期方案: 运行时推荐直接使用 containerd,绕过 dockerd 避免 docker 本身的各种 BUG
|
||||
|
||||
### Daemonset Controller 的 BUG
|
||||
|
||||
有个 k8s 的 bug 会导致 daemonset pod 无限 terminating,1.10 和 1.11 版本受影响,原因是 daemonset controller 复用 scheduler 的 predicates 逻辑,里面将 nodeAffinity 的 nodeSelector 数组做了排序(传的指针),spec 就会跟 apiserver 中的不一致,daemonset controller 又会为 rollingUpdate类型计算 hash (会用到spec),用于版本控制,造成不一致从而无限启动和停止的循环。
|
||||
|
||||
* issue: https://github.com/kubernetes/kubernetes/issues/66298
|
||||
* 修复的PR: https://github.com/kubernetes/kubernetes/pull/66480
|
||||
|
||||
升级集群版本可以彻底解决,临时规避可以给 rollingUpdate 类型 daemonset 不使用 nodeAffinity,改用 nodeSelector。
|
||||
|
||||
### mount 的目录被其它进程占用
|
||||
|
||||
dockerd 报错 `device or resource busy`:
|
||||
|
||||
``` bash
|
||||
May 09 09:55:12 VM_0_21_centos dockerd[6540]: time="2020-05-09T09:55:12.774467604+08:00" level=error msg="Handler for DELETE /v1.38/containers/b62c3796ea2ed5a0bd0eeed0e8f041d12e430a99469dd2ced6f94df911e35905 returned error: container b62c3796ea2ed5a0bd0eeed0e8f041d12e430a99469dd2ced6f94df911e35905: driver \"overlay2\" failed to remove root filesystem: remove /data/docker/overlay2/8bde3ec18c5a6915f40dd8adc3b2f296c1e40cc1b2885db4aee0a627ff89ef59/merged: device or resource busy"
|
||||
```
|
||||
|
||||
查找还有谁在"霸占"此目录:
|
||||
|
||||
``` bash
|
||||
$ grep 8bde3ec18c5a6915f40dd8adc3b2f296c1e40cc1b2885db4aee0a627ff89ef59 /proc/*/mountinfo
|
||||
/proc/27187/mountinfo:4500 4415 0:898 / /var/lib/docker/overlay2/8bde3ec18c5a6915f40dd8adc3b2f296c1e40cc1b2885db4aee0a627ff89ef59/merged rw,relatime - overlay overlay rw,lowerdir=/data/docker/overlay2/l/DNQH6VPJHFFANI36UDKS262BZK:/data/docker/overlay2/l/OAYZKUKWNH7GPT4K5MFI6B7OE5:/data/docker/overlay2/l/ANQD5O27DRMTZJG7CBHWUA65YT:/data/docker/overlay2/l/G4HYAKVIRVUXB6YOXRTBYUDVB3:/data/docker/overlay2/l/IRGHNAKBHJUOKGLQBFBQTYFCFU:/data/docker/overlay2/l/6QG67JLGKMFXGVB5VCBG2VYWPI:/data/docker/overlay2/l/O3X5VFRX2AO4USEP2ZOVNLL4ZK:/data/docker/overlay2/l/H5Q5QE6DMWWI75ALCIHARBA5CD:/data/docker/overlay2/l/LFISJNWBKSRTYBVBPU6PH3YAAZ:/data/docker/overlay2/l/JSF6H5MHJEC4VVAYOF5PYIMIBQ:/data/docker/overlay2/l/7D2F45I5MF2EHDOARROYPXCWHZ:/data/docker/overlay2/l/OUJDAGNIZXVBKBWNYCAUI5YSGG:/data/docker/overlay2/l/KZLUO6P3DBNHNUH2SNKPTFZOL7:/data/docker/overlay2/l/O2BPSFNCVXTE4ZIWGYSRPKAGU4,upperdir=/data/docker/overlay2/8bde3ec18c5a6915f40dd8adc3b2f296c1e40cc1b2885db4aee0a627ff89ef59/diff,workdir=/data/docker/overlay2/8bde3ec18c5a6915f40dd8adc3b2f296c1e40cc1b2885db4aee0a627ff89ef59/work
|
||||
/proc/27187/mountinfo:4688 4562 0:898 / /var/lib/docker/overlay2/81c322896bb06149c16786dc33c83108c871bb368691f741a1e3a9bfc0a56ab2/merged/data/docker/overlay2/8bde3ec18c5a6915f40dd8adc3b2f296c1e40cc1b2885db4aee0a627ff89ef59/merged rw,relatime - overlay overlay rw,lowerdir=/data/docker/overlay2/l/DNQH6VPJHFFANI36UDKS262BZK:/data/docker/overlay2/l/OAYZKUKWNH7GPT4K5MFI6B7OE5:/data/docker/overlay2/l/ANQD5O27DRMTZJG7CBHWUA65YT:/data/docker/overlay2/l/G4HYAKVIRVUXB6YOXRTBYUDVB3:/data/docker/overlay2/l/IRGHNAKBHJUOKGLQBFBQTYFCFU:/data/docker/overlay2/l/6QG67JLGKMFXGVB5VCBG2VYWPI:/data/docker/overlay2/l/O3X5VFRX2AO4USEP2ZOVNLL4ZK:/data/docker/overlay2/l/H5Q5QE6DMWWI75ALCIHARBA5CD:/data/docker/overlay2/l/LFISJNWBKSRTYBVBPU6PH3YAAZ:/data/docker/overlay2/l/JSF6H5MHJEC4VVAYOF5PYIMIBQ:/data/docker/overlay2/l/7D2F45I5MF2EHDOARROYPXCWHZ:/data/docker/overlay2/l/OUJDAGNIZXVBKBWNYCAUI5YSGG:/data/docker/overlay2/l/KZLUO6P3DBNHNUH2SNKPTFZOL7:/data/docker/overlay2/l/O2BPSFNCVXTE4ZIWGYSRPKAGU4,upperdir=/data/docker/overlay2/8bde3ec18c5a6915f40dd8adc3b2f296c1e40cc1b2885db4aee0a627ff89ef59/diff,workdir=/data/docker/overlay2/8bde3ec18c5a6915f40dd8adc3b2f296c1e40cc1b2885db4aee0a627ff89ef59/work
|
||||
```
|
||||
|
||||
> 自行替换容器 id
|
||||
|
||||
找到进程号后查看此进程更多详细信息:
|
||||
|
||||
``` bash
|
||||
ps -f 27187
|
||||
```
|
||||
|
||||
> 更多请参考 [排查 device or resource busy](../device-or-resource-busy)。
|
||||
|
||||
## 检查 Finalizers
|
||||
|
||||
k8s 资源的 metadata 里如果存在 `finalizers`,那么该资源一般是由某程序创建的,并且在其创建的资源的 metadata 里的 `finalizers` 加了一个它的标识,这意味着这个资源被删除时需要由创建资源的程序来做删除前的清理,清理完了它需要将标识从该资源的 `finalizers` 中移除,然后才会最终彻底删除资源。比如 Rancher 创建的一些资源就会写入 `finalizers` 标识。
|
||||
|
||||
处理建议:`kubectl edit` 手动编辑资源定义,删掉 `finalizers`,这时再看下资源,就会发现已经删掉了。
|
||||
|
||||
## 检查 terminationGracePeriodSeconds 是否过大
|
||||
|
||||
如果满足以下条件:
|
||||
1. Pod 配置了 `terminationGracePeriodSeconds` 且值非常大(比如 86400)。
|
||||
2. 主进程没有处理 SIGTERM 信号(比如主进程是 shell 或 systemd)。
|
||||
|
||||
就会导致删除 Pod 不能立即退出,需要等到超时阈值(`terminationGracePeriodSeconds`)后强杀进程,而超时时间非常长,看起来就像一直卡在 Terminating 中。
|
||||
|
||||
解决方案:
|
||||
1. 等待超时时间自动删除。
|
||||
2. 使用 kubectl 强删:
|
||||
```bash
|
||||
kubectl delete pod --force --grace-period=0 POD_NAME
|
||||
```
|
||||
## propagation type 问题
|
||||
|
||||
Pod 事件报错:
|
||||
|
||||
```txt
|
||||
unlinkat /var/run/netns/cni-49ddd103-d374-1f86-7324-13abaeb9c910: device or resource busy
|
||||
```
|
||||
|
||||
原因与解决方案参考: [挂载根目录导致 device or resource busy](../../../troubleshooting-cases/runtime/mount-root-causing-device-or-resource-busy)。
|
||||
|
|
@ -1,15 +0,0 @@
|
|||
# SDK 排障
|
||||
|
||||
## python SDK 报证书 hostname 不匹配
|
||||
|
||||
使用 kubernetes 的 [python SDK](https://github.com/kubernetes-client/python),报错:
|
||||
|
||||
```txt
|
||||
hostname '10.10.36.196' doesn't match either of 'cls-bx5o9kt5-apiserver-service', 'kubernetes', 'kubernetes.default', 'kubernetes.default.svc', 'kubernetes.default.svc.cluster.local', 'localhost'
|
||||
```
|
||||
|
||||
一般原因是 python 的依赖包版本不符合要求,主要关注:
|
||||
* urllib3>=1.24.2
|
||||
* ipaddress>=1.0.17
|
||||
|
||||
参考 [官方文档说明](https://github.com/kubernetes-client/python/blob/master/README.md#hostname-doesnt-match)。
|
||||
|
|
@ -1,123 +0,0 @@
|
|||
import type { SidebarsConfig } from '@docusaurus/plugin-content-docs';
|
||||
|
||||
const sidebars: SidebarsConfig = {
|
||||
troubleshootingSidebar: [
|
||||
'README',
|
||||
{
|
||||
type: 'category',
|
||||
label: '排障技能',
|
||||
collapsed: false,
|
||||
link: {
|
||||
type: 'generated-index',
|
||||
slug: '/skill'
|
||||
},
|
||||
items: [
|
||||
'skill/linux',
|
||||
'skill/enter-netns-with-nsenter',
|
||||
'skill/remote-capture-with-ksniff',
|
||||
'skill/use-systemtap-to-locate-problems',
|
||||
'skill/tcpdump',
|
||||
'skill/wireshark',
|
||||
],
|
||||
},
|
||||
{
|
||||
type: 'category',
|
||||
label: 'Pod 排障',
|
||||
collapsed: false,
|
||||
link: {
|
||||
type: 'generated-index',
|
||||
slug: '/pod'
|
||||
},
|
||||
items: [
|
||||
'pod/healthcheck-failed',
|
||||
'pod/device-or-resource-busy',
|
||||
{
|
||||
type: 'category',
|
||||
label: 'Pod 状态异常',
|
||||
collapsed: true,
|
||||
link: {
|
||||
type: 'generated-index',
|
||||
slug: '/pod/status'
|
||||
},
|
||||
items: [
|
||||
'pod/status/intro',
|
||||
'pod/status/pod-terminating',
|
||||
'pod/status/pod-pending',
|
||||
'pod/status/pod-containercreating-or-waiting',
|
||||
'pod/status/pod-crash',
|
||||
'pod/status/pod-imagepullbackoff',
|
||||
],
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
type: 'category',
|
||||
label: '节点排障',
|
||||
collapsed: false,
|
||||
link: {
|
||||
type: 'generated-index',
|
||||
slug: '/node'
|
||||
},
|
||||
items: [
|
||||
'node/node-crash-and-vmcore',
|
||||
'node/node-high-load',
|
||||
'node/io-high-load',
|
||||
'node/memory-fragmentation',
|
||||
'node/disk-full',
|
||||
'node/pid-full',
|
||||
'node/arp-cache-overflow',
|
||||
'node/runnig-out-of-inotify-watches',
|
||||
'node/kernel-solft-lockup',
|
||||
'node/no-space-left-on-device',
|
||||
'node/ipvs-no-destination-available',
|
||||
'node/cadvisor-no-data',
|
||||
],
|
||||
},
|
||||
{
|
||||
type: 'category',
|
||||
label: '网络排障',
|
||||
collapsed: false,
|
||||
link: {
|
||||
type: 'generated-index',
|
||||
slug: '/network'
|
||||
},
|
||||
items: [
|
||||
'network/timeout',
|
||||
'network/packet-loss',
|
||||
'network/network-unreachable',
|
||||
'network/slow-network-traffic',
|
||||
'network/dns-exception',
|
||||
'network/close-wait-stacking',
|
||||
'network/traffic-surge',
|
||||
],
|
||||
},
|
||||
{
|
||||
type: 'category',
|
||||
label: '存储排障',
|
||||
collapsed: false,
|
||||
link: {
|
||||
type: 'generated-index',
|
||||
slug: '/storage'
|
||||
},
|
||||
items: [
|
||||
'storage/unable-to-mount-volumes',
|
||||
'storage/setup-failed-for-volume',
|
||||
],
|
||||
},
|
||||
{
|
||||
type: 'category',
|
||||
label: '集群排障',
|
||||
collapsed: false,
|
||||
link: {
|
||||
type: 'generated-index',
|
||||
slug: '/cluster'
|
||||
},
|
||||
items: [
|
||||
'cluster/namespace-terminating',
|
||||
],
|
||||
},
|
||||
"sdk",
|
||||
],
|
||||
};
|
||||
|
||||
export default sidebars;
|
||||
|
|
@ -1,81 +0,0 @@
|
|||
# 使用 nsenter 进入 netns 抓包
|
||||
|
||||
## 背景
|
||||
|
||||
我们使用 Kubernetes 时难免发生一些网络问题,往往需要进入容器的网络命名空间 (netns) 中,进行一些网络调试来定位问题,本文介绍如何进入容器的 netns。
|
||||
|
||||
## 获取容器 ID
|
||||
|
||||
使用 kubectl 获取 pod 中任意 cotnainer 的 id:
|
||||
|
||||
```bash
|
||||
kubectl -n test describe pod debug-685b48bcf5-ggn5d
|
||||
```
|
||||
|
||||
输出示例片段1 (containerd运行时):
|
||||
|
||||
```txt
|
||||
Containers:
|
||||
debug:
|
||||
Container ID: containerd://529bbd5c935562a9ba66fc9b9ffa95d486c6324f26d8253d744ffe3dfd728289
|
||||
```
|
||||
|
||||
输出示例片段2 (dockerd运行时):
|
||||
|
||||
```txt
|
||||
Containers:
|
||||
debug:
|
||||
Container ID: docker://e64939086488a9302821566b0c1f193b755c805f5ff5370d5ce5e6f154ffc648
|
||||
```
|
||||
|
||||
## 获取 PID
|
||||
|
||||
拿到 container id 后,我们登录到 pod 所在节点上去获取其主进程 pid。
|
||||
|
||||
containerd 运行时使用 crictl 命令获取:
|
||||
|
||||
```bash
|
||||
$ crictl inspect 529bbd5c935562a9ba66fc9b9ffa95d486c6324f26d8253d744ffe3dfd728289 | grep -i pid
|
||||
"pid": 2266462,
|
||||
"pid": 1
|
||||
"type": "pid"
|
||||
```
|
||||
|
||||
> 此例中 pid 为 2266462
|
||||
|
||||
dockerd 运行时使用 docker 命令获取:
|
||||
|
||||
```bash
|
||||
$ docker inspect e64939086488a9302821566b0c1f193b755c805f5ff5370d5ce5e6f154ffc648 | grep -i pid
|
||||
"Pid": 910351,
|
||||
"PidMode": "",
|
||||
"PidsLimit": 0,
|
||||
```
|
||||
|
||||
> 此例中 pid 为 910351
|
||||
|
||||
## 使用 nsenter 进入容器 netns
|
||||
|
||||
在节点上使用 nsenter 进入 pod 的 netns:
|
||||
|
||||
```bash
|
||||
nsenter -n --target 910351
|
||||
```
|
||||
|
||||
## 调试网络
|
||||
|
||||
成功进入容器的 netns,可以使用节点上的网络工具进行调试网络,可以首先使用 `ip a` 验证下 ip 地址是否为 pod ip:
|
||||
|
||||
```bash
|
||||
$ ip a
|
||||
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
|
||||
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
|
||||
inet 127.0.0.1/8 scope host lo
|
||||
valid_lft forever preferred_lft forever
|
||||
3: eth0@if8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
|
||||
link/ether 6a:c6:6f:67:dd:6c brd ff:ff:ff:ff:ff:ff link-netnsid 0
|
||||
inet 172.18.0.67/26 brd 172.18.0.127 scope global eth0
|
||||
valid_lft forever preferred_lft forever
|
||||
```
|
||||
|
||||
如果要抓包也可以利用节点上的 tcpdump 工具抓包。
|
||||
|
|
@ -1,261 +0,0 @@
|
|||
# Linux 常用排查命令
|
||||
|
||||
## 查看 socket buffer
|
||||
|
||||
查看是否阻塞:
|
||||
|
||||
```bash
|
||||
$ netstat -antup | awk '{if($2>100||$3>100){print $0}}'
|
||||
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
|
||||
tcp 2066 36 9.134.55.160:8000 10.35.16.97:63005 ESTABLISHED 1826655/nginx
|
||||
```
|
||||
|
||||
* `Recv-Q` 是接收队列,如果持续有堆积,可能是高负载,应用处理不过来,也可能是程序的 bug,卡住了,导致没有从 buffer 中取数据,可以看看对应 pid 的 stack 卡在哪里了(`cat /proc/$PID/stack`)。
|
||||
|
||||
查看是否有 UDP buffer 满导致丢包:
|
||||
|
||||
```bash
|
||||
# 使用 netstat 查看统计
|
||||
$ netstat -s | grep "buffer errors"
|
||||
429469 receive buffer errors
|
||||
23568 send buffer errors
|
||||
|
||||
# 也可以用 nstat 查看计数器
|
||||
$ nstat -az | grep -E 'UdpRcvbufErrors|UdpSndbufErrors'
|
||||
UdpRcvbufErrors 429469 0.0
|
||||
UdpSndbufErrors 23568 0.0
|
||||
```
|
||||
|
||||
对于 TCP,发送 buffer 慢不会导致丢包,只是会让程序发送数据包时卡住,等待缓冲区有足够空间释放出来,而接收 buffer 满了会导致丢包,可以通过计数器查看:
|
||||
|
||||
```bash
|
||||
$ nstat -az | grep TcpExtTCPRcvQDrop
|
||||
TcpExtTCPRcvQDrop 264324 0.0
|
||||
```
|
||||
|
||||
查看当前 UDP buffer 的情况:
|
||||
|
||||
```bash
|
||||
$ ss -nump
|
||||
Recv-Q Send-Q Local Address:Port Peer Address:Port Process
|
||||
0 0 10.10.4.26%eth0:68 10.10.4.1:67 users:(("NetworkManager",pid=960,fd=22))
|
||||
skmem:(r0,rb212992,t0,tb212992,f0,w0,o640,bl0,d0)
|
||||
```
|
||||
|
||||
* rb212992 表示 UDP 接收缓冲区大小是 212992 字节,tb212992 表示 UDP 发送缓存区大小是 212992 字节。
|
||||
* Recv-Q 和 Send-Q 分别表示当前接收和发送缓冲区中的数据包字节数。
|
||||
|
||||
查看当前 TCP buffer 的情况:
|
||||
|
||||
```bash
|
||||
$ ss -ntmp
|
||||
ESTAB 0 0 [::ffff:109.244.190.163]:9988 [::ffff:10.10.4.26]:54440 users:(("xray",pid=3603,fd=20))
|
||||
skmem:(r0,rb12582912,t0,tb12582912,f0,w0,o0,bl0,d0)
|
||||
```
|
||||
|
||||
* rb12582912 表示 TCP 接收缓冲区大小是 12582912 字节,tb12582912 表示 TCP 发送缓存区大小是 12582912 字节。
|
||||
* Recv-Q 和 Send-Q 分别表示当前接收和发送缓冲区中的数据包字节数。
|
||||
|
||||
## 查看监听队列
|
||||
|
||||
```bash
|
||||
$ ss -lnt
|
||||
State Recv-Q Send-Q Local Address:Port Peer Address:Port
|
||||
LISTEN 129 128 *:80 *:*
|
||||
```
|
||||
|
||||
> `Recv-Q` 表示 accept queue 中的连接数,如果满了(`Recv-Q`的值比`Send-Q`大1),要么是并发太大,或负载太高,程序处理不过来;要么是程序 bug,卡住了,导致没有从 accept queue 中取连接,可以看看对应 pid 的 stack 卡在哪里了(`cat /proc/$PID/stack`)。
|
||||
|
||||
## 查看网络计数器
|
||||
|
||||
```bash
|
||||
$ nstat -az
|
||||
...
|
||||
TcpExtListenOverflows 12178939 0.0
|
||||
TcpExtListenDrops 12247395 0.0
|
||||
...
|
||||
```
|
||||
|
||||
```bash
|
||||
netstat -s | grep -E 'drop|overflow'
|
||||
```
|
||||
|
||||
> 如果有 overflow,意味着 accept queue 有满过,可以查看监听队列看是否有现场。
|
||||
|
||||
## 查看 conntrack
|
||||
|
||||
```bash
|
||||
$ conntrack -S
|
||||
cpu=0 found=770 invalid=3856 ignore=42570125 insert=0 insert_failed=0 drop=0 early_drop=0 error=0 search_restart=746284
|
||||
cpu=1 found=784 invalid=3647 ignore=41988392 insert=0 insert_failed=0 drop=0 early_drop=0 error=0 search_restart=718963
|
||||
cpu=2 found=25588 invalid=71264 ignore=243330690 insert=0 insert_failed=0 drop=0 early_drop=0 error=0 search_restart=2319295
|
||||
cpu=3 found=25706 invalid=70168 ignore=242616824 insert=0 insert_failed=0 drop=0 early_drop=0 error=18 search_restart=2320376
|
||||
```
|
||||
|
||||
* 若有 `insert_failed`,表示存在 conntrack 插入失败,会导致丢包。
|
||||
|
||||
## 查看连接数
|
||||
|
||||
如果有 ss 命令,可以使用 `ss -s` 统计:
|
||||
|
||||
```bash
|
||||
$ ss -s
|
||||
Total: 470
|
||||
TCP: 220 (estab 47, closed 150, orphaned 0, timewait 71)
|
||||
|
||||
Transport Total IP IPv6
|
||||
RAW 0 0 0
|
||||
UDP 63 60 3
|
||||
TCP 70 55 15
|
||||
INET 133 115 18
|
||||
FRAG 0 0 0
|
||||
```
|
||||
|
||||
如果没有 `ss`,也可以尝试用脚本统计当前各种状态的 TCP 连接数:
|
||||
|
||||
```bash
|
||||
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```txt
|
||||
ESTABLISHED 18
|
||||
TIME_WAIT 457
|
||||
```
|
||||
|
||||
或者直接手动统计 `/proc`:
|
||||
|
||||
```bash
|
||||
cat /proc/net/tcp* | wc -l
|
||||
```
|
||||
|
||||
## 测试网络连通性
|
||||
|
||||
不断 telnet 查看网络是否能通:
|
||||
|
||||
```bash
|
||||
while true; do echo "" | telnet 10.0.0.3 443; sleep 0.1; done
|
||||
```
|
||||
|
||||
* `ctrl+c` 终止测试
|
||||
* 替换 `10.0.0.3` 与 `443` 为需要测试的 IP/域名 和端口
|
||||
|
||||
没有安装 telnet,也可以使用 nc 测试:
|
||||
|
||||
```bash
|
||||
$ nc -vz 10.0.0.3 443
|
||||
```
|
||||
|
||||
## 排查流量激增
|
||||
|
||||
### iftop 纠出大流量 IP
|
||||
|
||||
```bash
|
||||
$ iftop
|
||||
10.21.45.8 => 10.111.100.101 3.35Mb 2.92Mb 2.94Mb
|
||||
<= 194Mb 160Mb 162Mb
|
||||
10.21.45.8 => 10.121.101.22 3.41Mb 2.89Mb 3.04Mb
|
||||
<= 192Mb 159Mb 172Mb
|
||||
10.21.45.8 => 10.22.122.55 279Kb 313Kb 292Kb
|
||||
<= 11.3Kb 12.1Kb 11.9Kb
|
||||
...
|
||||
```
|
||||
|
||||
### netstat 查看大流量 IP 连接
|
||||
|
||||
```bash
|
||||
$ netstat -np | grep 10.121.101.22
|
||||
tcp 0 0 10.21.45.8:48320 10.121.101.22:12002 TIME_WAIT -
|
||||
tcp 0 0 10.21.45.8:59179 10.121.101.22:12002 TIME_WAIT -
|
||||
tcp 0 0 10.21.45.8:55835 10.121.101.22:12002 TIME_WAIT -
|
||||
tcp 0 0 10.21.45.8:49420 10.121.101.22:12002 TIME_WAIT -
|
||||
tcp 0 0 10.21.45.8:55559 10.121.101.22:12002 TIME_WAIT -
|
||||
...
|
||||
```
|
||||
|
||||
## 排查资源占用
|
||||
|
||||
### 文件被占用
|
||||
|
||||
看某个文件在被哪些进程读写:
|
||||
|
||||
```bash
|
||||
lsof <文件名>
|
||||
```
|
||||
|
||||
看某个进程打开了哪些文件:
|
||||
|
||||
```bash
|
||||
lsof -p <pid>
|
||||
```
|
||||
|
||||
### 端口占用
|
||||
|
||||
查看 22 端口被谁占用:
|
||||
|
||||
```bash
|
||||
lsof -i :22
|
||||
```
|
||||
|
||||
```bash
|
||||
netstat -tunlp | grep 22
|
||||
```
|
||||
|
||||
## 查看进程树
|
||||
|
||||
```bash
|
||||
$ pstree -apnhs 3356537
|
||||
systemd,1 --switched-root --system --deserialize 22
|
||||
└─containerd,3895
|
||||
└─{containerd},3356537
|
||||
```
|
||||
|
||||
## 测试对比 CPU 性能
|
||||
|
||||
看计算圆周率耗时,耗时越短说明 CPU 性能越强:
|
||||
|
||||
```bash
|
||||
time echo "scale=5000; 4*a(1)"| bc -l -q
|
||||
```
|
||||
|
||||
## 查看证书内容
|
||||
|
||||
查看 secret 里的证书内容:
|
||||
|
||||
```bash
|
||||
kubectl get secret test-crt-secret -o jsonpath='{.data.tls\.crt}' | base64 -d | openssl x509 -noout -text
|
||||
```
|
||||
|
||||
查看证书文件内容:
|
||||
|
||||
```bash
|
||||
openssl x509 -noout -text -in test.crt
|
||||
```
|
||||
|
||||
查看远程地址的证书内容:
|
||||
|
||||
```bash
|
||||
echo | openssl s_client -connect imroc.cc:443 2>/dev/null | openssl x509 -noout -text
|
||||
```
|
||||
|
||||
## 磁盘占用
|
||||
|
||||
### 空间占用
|
||||
|
||||
```bash
|
||||
df -h
|
||||
```
|
||||
|
||||
### inode 占用
|
||||
|
||||
```bash
|
||||
# df -i
|
||||
Filesystem Inodes IUsed IFree IUse% Mounted on
|
||||
/dev/vda1 6553600 283895 6269705 5% /
|
||||
/dev/vdb1 26214400 62421 26151979 1% /data
|
||||
|
||||
$ tune2fs -l /dev/vda1 | grep -i inode
|
||||
Inode count: 6553600
|
||||
Free inodes: 6465438
|
||||
```
|
||||
|
|
@ -1,87 +0,0 @@
|
|||
# 使用 ksniff 远程抓包
|
||||
|
||||
## 概述
|
||||
|
||||
Kubernetes 环境中遇到网络问题需要抓包排查怎么办?传统做法是登录 Pod 所在节点,然后 [使用 nsenter 进入 Pod netns 抓包](enter-netns-with-nsenter),最后使用节点上 tcpdump 工具进行抓包。整个过程比较繁琐,好在社区出现了 [ksniff](https://github.com/eldadru/ksniff) 这个小工具,它是一个 kubectl 插件,可以让我们在 Kubernetes 中抓包变得更简单快捷。
|
||||
|
||||
本文将介绍如何使用 ksniff 这个工具来对 Pod 进行抓包。
|
||||
|
||||
## 安装
|
||||
|
||||
ksniff 一般使用 [krew](https://github.com/kubernetes-sigs/krew) 这个 kubectl 包管理器进行安装:
|
||||
|
||||
```bash
|
||||
kubectl krew install sniff
|
||||
```
|
||||
## 使用 wireshark 实时分析
|
||||
|
||||
抓取指定 Pod 所有网卡数据包,自动弹出本地安装的 wireshark 并实时捕获:
|
||||
|
||||
```bash
|
||||
kubectl -n test sniff website-7d7d96cdbf-6v4p6
|
||||
```
|
||||
|
||||
可以使用 wireshark 的过滤器实时过滤分析哟:
|
||||
|
||||
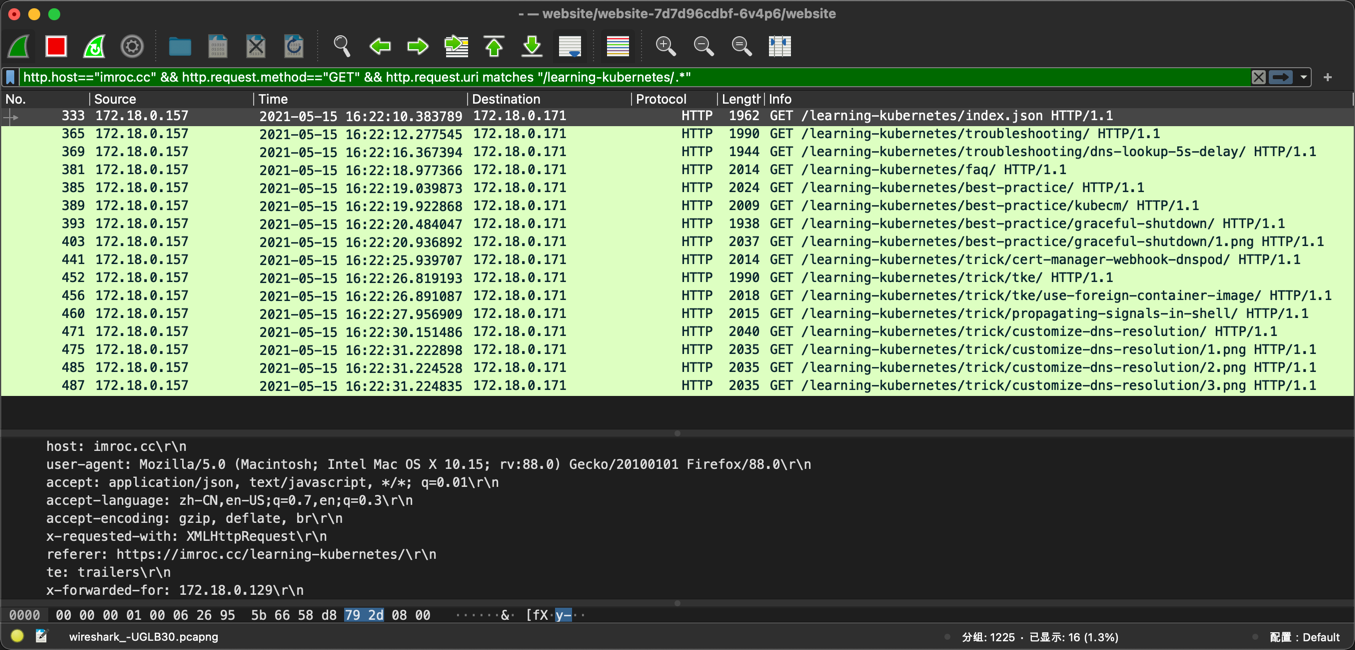
|
||||
|
||||
## 保存抓包文件
|
||||
|
||||
有时在生产环境我们可能无法直接在本地执行 kubectl,需要经过跳板机,这个时候我们可以将抓到的包保存成文件,然后再拷到本地使用 wireshark 分析。
|
||||
|
||||
只需加一个 `-o` 参数指定下保存的文件路径即可:
|
||||
|
||||
```bash
|
||||
kubectl -n test sniff website-7d7d96cdbf-6v4p6 -o test.pcap
|
||||
```
|
||||
|
||||
## 特权模式
|
||||
|
||||
ksniff 默认通过上传 tcpdump 二进制文件到目标 Pod 的一个容器里,然后执行二进制来实现抓包。但该方式依赖容器是以 root 用户启动的,如果不是就无法抓包。
|
||||
|
||||
这个时候我们可以加一个 `-p` 参数,表示会在 Pod 所在节点新起一个 privileged 的 Pod,然后该 Pod 会调用容器运行时 (dockerd 或 containerd 等),新起一个以 root 身份启动的 container,并 attach 到目标 Pod 的 netns,然后执行 container 中的 tcpdump 二进制来实现抓包。
|
||||
|
||||
用法示例:
|
||||
|
||||
```bash
|
||||
kubectl -n test sniff website-7d7d96cdbf-6v4p6 -p
|
||||
```
|
||||
|
||||
## 查看明文
|
||||
|
||||
如果数据包内容很多都是明文 (比如 HTTP),只希望大概看下明文内容,可以指定 `-o -` 将抓包内容直接打印到标准输出 (stdout):
|
||||
|
||||
```bash
|
||||
kubectl -n test sniff website-7d7d96cdbf-6v4p6 -o -
|
||||
```
|
||||
## 抓取时过滤
|
||||
|
||||
有时数据量很大,如果在抓取时不过滤,可能会对 apiserver 造成较大压力 (数据传输经过 apiserver),这种情况我们最好在抓取时就指定 tcpdump 过滤条件,屏蔽掉不需要的数据,避免数据量过大。
|
||||
|
||||
加 `-f` 参数即可指定过滤条件,示例:
|
||||
|
||||
```bash
|
||||
kubectl -n test sniff website-7d7d96cdbf-6v4p6 -f "port 80"
|
||||
```
|
||||
|
||||
## FAQ
|
||||
|
||||
### wireshark 报 unknown
|
||||
|
||||
打开抓包文件时,报错 `pcap: network type 276 unknown or unsupported`:
|
||||
|
||||
|
||||
|
||||
通常是因为 wireshark 版本低导致的,升级到最新版就行。
|
||||
|
||||
### 抓包时报 No such file or directory
|
||||
|
||||
使用 kubectl sniff 抓包时,报错 `ls: cannot access '/tmp/static-tcpdump': No such file or directory` 然后退出:
|
||||
|
||||

|
||||
|
||||
这是笔者在 mac 上安装当时最新的 ksniff v1.6.0 版本遇到的问题。该问题明显是一个 bug,static-tcpdump 二进制没有上传成功就去执行导致的,考虑三种解决方案:
|
||||
|
||||
1. 手动使用 kubectl cp 将二进制拷到目标 Pod 再执行 kubectl sniff 抓包。
|
||||
2. kubectl sniff 指定 `-p` 参数使用特权模式 (亲测有效)。
|
||||
3. 编译最新的 ksniff,替换当前 kubectl-sniff 二进制,这也是笔者目前的使用方式。
|
||||
|
|
@ -1,52 +0,0 @@
|
|||
# 使用 tcpdump 抓包与分析
|
||||
|
||||
## 抓包基础
|
||||
|
||||
```bash
|
||||
# 抓包内容实时显示到控制台
|
||||
tcpdump -i eth0 host 10.0.0.10 -nn -tttt
|
||||
tcpdump -i any host 10.0.0.10 -nn -tttt
|
||||
tcpdump -i any host 10.0.0.10 and port 8088 -nn -tttt
|
||||
# 抓包存到文件
|
||||
tcpdump -i eth0 -w test.pcap
|
||||
# 读取抓包内容
|
||||
tcpdump -r test.pcap -nn -tttt
|
||||
```
|
||||
|
||||
常用参数:
|
||||
|
||||
* `-r`: 指定包文件。
|
||||
* `-nn`: 显示数字ip和端口,不转换成名字。
|
||||
* `-tttt`: 显示时间戳格式: `2006-01-02 15:04:05.999999`。
|
||||
|
||||
## 轮转抓包
|
||||
|
||||
```bash
|
||||
# 每100M轮转一次,最多保留200个文件 (推荐,文件大小可控,可通过文件修改时间判断报文时间范围)
|
||||
tcpdump -i eth0 port 8880 -w cvm.pcap -C 100 -W 200
|
||||
|
||||
# 每2分钟轮转一次,后缀带上时间
|
||||
tcpdump -i eth0 port 31780 -w node-10.70.10.101-%Y-%m%d-%H%M-%S.pcap -G 120
|
||||
```
|
||||
|
||||
## 过滤连接超时的包(reset)
|
||||
|
||||
一般如果有连接超时发生,一般 client 会发送 reset 包,可以过滤下:
|
||||
|
||||
```bash
|
||||
tcpdump -r test.pcap 'tcp[tcpflags] & (tcp-rst) != 0' -nn -ttt
|
||||
```
|
||||
|
||||
## 统计流量源IP
|
||||
|
||||
```bash
|
||||
tcpdump -i eth0 dst port 60002 -c 10000|awk '{print $3}'|awk -F. -v OFS="." '{print $1,$2,$3,$4}'|sort |uniq -c|sort -k1 -n
|
||||
```
|
||||
|
||||
统计效果:
|
||||
|
||||
```txt
|
||||
321 169.254.128.100
|
||||
409 10.0.0.175
|
||||
2202 10.0.226.49
|
||||
```
|
||||
|
|
@ -1,151 +0,0 @@
|
|||
# 使用 Systemtap 定位疑难杂症
|
||||
|
||||
## 安装
|
||||
|
||||
### Ubuntu
|
||||
|
||||
安装 systemtap:
|
||||
|
||||
```bash
|
||||
apt install -y systemtap
|
||||
```
|
||||
|
||||
运行 `stap-prep` 检查还有什么需要安装:
|
||||
|
||||
```bash
|
||||
$ stap-prep
|
||||
Please install linux-headers-4.4.0-104-generic
|
||||
You need package linux-image-4.4.0-104-generic-dbgsym but it does not seem to be available
|
||||
Ubuntu -dbgsym packages are typically in a separate repository
|
||||
Follow https://wiki.ubuntu.com/DebuggingProgramCrash to add this repository
|
||||
|
||||
apt install -y linux-headers-4.4.0-104-generic
|
||||
```
|
||||
|
||||
提示需要 dbgsym 包但当前已有软件源中并不包含,需要使用第三方软件源安装,下面是 dbgsym 安装方法\(参考官方wiki: [https://wiki.ubuntu.com/Kernel/Systemtap](https://wiki.ubuntu.com/Kernel/Systemtap)\):
|
||||
|
||||
```bash
|
||||
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys C8CAB6595FDFF622
|
||||
|
||||
codename=$(lsb_release -c | awk '{print $2}')
|
||||
sudo tee /etc/apt/sources.list.d/ddebs.list << EOF
|
||||
deb http://ddebs.ubuntu.com/ ${codename} main restricted universe multiverse
|
||||
deb http://ddebs.ubuntu.com/ ${codename}-security main restricted universe multiverse
|
||||
deb http://ddebs.ubuntu.com/ ${codename}-updates main restricted universe multiverse
|
||||
deb http://ddebs.ubuntu.com/ ${codename}-proposed main restricted universe multiverse
|
||||
EOF
|
||||
|
||||
sudo apt-get update
|
||||
```
|
||||
|
||||
配置好源后再运行下 `stap-prep`:
|
||||
|
||||
```bash
|
||||
$ stap-prep
|
||||
Please install linux-headers-4.4.0-104-generic
|
||||
Please install linux-image-4.4.0-104-generic-dbgsym
|
||||
```
|
||||
|
||||
提示需要装这两个包,我们安装一下:
|
||||
|
||||
```bash
|
||||
apt install -y linux-image-4.4.0-104-generic-dbgsym
|
||||
apt install -y linux-headers-4.4.0-104-generic
|
||||
```
|
||||
|
||||
### CentOS
|
||||
|
||||
安装 systemtap:
|
||||
|
||||
```bash
|
||||
yum install -y systemtap
|
||||
```
|
||||
|
||||
默认没装 `debuginfo`,我们需要装一下,添加软件源 `/etc/yum.repos.d/CentOS-Debug.repo`:
|
||||
|
||||
```bash
|
||||
[debuginfo]
|
||||
name=CentOS-$releasever - DebugInfo
|
||||
baseurl=http://debuginfo.centos.org/$releasever/$basearch/
|
||||
gpgcheck=0
|
||||
enabled=1
|
||||
protect=1
|
||||
priority=1
|
||||
```
|
||||
|
||||
执行 `stap-prep` \(会安装 `kernel-debuginfo`\)
|
||||
|
||||
最后检查确保 `kernel-debuginfo` 和 `kernel-devel` 均已安装并且版本跟当前内核版本相同,如果有多个版本,就删除跟当前内核版本不同的包\(通过`uname -r`查看当前内核版本\)。
|
||||
|
||||
重点检查是否有多个版本的 `kernel-devel`:
|
||||
|
||||
```bash
|
||||
$ rpm -qa | grep kernel-devel
|
||||
kernel-devel-3.10.0-327.el7.x86_64
|
||||
kernel-devel-3.10.0-514.26.2.el7.x86_64
|
||||
kernel-devel-3.10.0-862.9.1.el7.x86_64
|
||||
```
|
||||
|
||||
如果存在多个,保证只留跟当前内核版本相同的那个,假设当前内核版本是 `3.10.0-862.9.1.el7.x86_64`,那么使用 rpm 删除多余的版本:
|
||||
|
||||
```bash
|
||||
rpm -e kernel-devel-3.10.0-327.el7.x86_64 kernel-devel-3.10.0-514.26.2.el7.x86_64
|
||||
```
|
||||
|
||||
## 使用 systemtap 揪出杀死容器的真凶
|
||||
|
||||
Pod 莫名其妙被杀死? 可以使用 systemtap 来监视进程的信号发送,原理是 systemtap 将脚本翻译成 C 代码然后调用 gcc 编译成 linux 内核模块,再通过 `modprobe` 加载到内核,根据脚本内容在内核做各种 hook,在这里我们就 hook 一下信号的发送,找出是谁 kill 掉了容器进程。
|
||||
|
||||
首先,找到被杀死的 pod 又自动重启的容器的当前 pid,describe 一下 pod:
|
||||
|
||||
```bash
|
||||
......
|
||||
Container ID: docker://5fb8adf9ee62afc6d3f6f3d9590041818750b392dff015d7091eaaf99cf1c945
|
||||
......
|
||||
Last State: Terminated
|
||||
Reason: Error
|
||||
Exit Code: 137
|
||||
Started: Thu, 05 Sep 2019 19:22:30 +0800
|
||||
Finished: Thu, 05 Sep 2019 19:33:44 +0800
|
||||
```
|
||||
|
||||
拿到容器 id 反查容器的主进程 pid:
|
||||
|
||||
```bash
|
||||
$ docker inspect -f "{{.State.Pid}}" 5fb8adf9ee62afc6d3f6f3d9590041818750b392dff015d7091eaaf99cf1c945
|
||||
7942
|
||||
```
|
||||
|
||||
通过 `Exit Code` 可以看出容器上次退出的状态码,如果进程是被外界中断信号杀死的,退出状态码将在 129-255 之间,137 表示进程是被 SIGKILL 信号杀死的,但我们从这里并不能看出是被谁杀死的。
|
||||
|
||||
如果问题可以复现,我们可以使用下面的 systemtap 脚本来监视容器是被谁杀死的\(保存为`sg.stp`\):
|
||||
|
||||
```bash
|
||||
global target_pid = 7942
|
||||
probe signal.send{
|
||||
if (sig_pid == target_pid) {
|
||||
printf("%s(%d) send %s to %s(%d)\n", execname(), pid(), sig_name, pid_name, sig_pid);
|
||||
printf("parent of sender: %s(%d)\n", pexecname(), ppid())
|
||||
printf("task_ancestry:%s\n", task_ancestry(pid2task(pid()), 1));
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
* 变量 `pid` 的值替换为查到的容器主进程 pid
|
||||
|
||||
运行脚本:
|
||||
|
||||
```bash
|
||||
stap sg.stp
|
||||
```
|
||||
|
||||
当容器进程被杀死时,脚本捕捉到事件,执行输出:
|
||||
|
||||
```text
|
||||
pkill(23549) send SIGKILL to server(7942)
|
||||
parent of sender: bash(23495)
|
||||
task_ancestry:swapper/0(0m0.000000000s)=>systemd(0m0.080000000s)=>vGhyM0(19491m2.579563677s)=>sh(33473m38.074571885s)=>bash(33473m38.077072025s)=>bash(33473m38.081028267s)=>bash(33475m4.817798337s)=>pkill(33475m5.202486630s)
|
||||
```
|
||||
|
||||
通过观察 `task_ancestry` 可以看到杀死进程的所有父进程,在这里可以看到有个叫 `vGhyM0` 的奇怪进程名,通常是中了木马,需要安全专家介入继续排查。
|
||||
|
||||
|
|
@ -1,73 +0,0 @@
|
|||
# 使用 wireshark 分析数据包
|
||||
|
||||
## 分析 DNS 异常
|
||||
|
||||
### 找出没有收到响应的 dns 请求
|
||||
|
||||
```txt
|
||||
dns && (dns.flags.response == 0) && ! dns.response_in
|
||||
```
|
||||
|
||||
### 根据 dns 请求 id 过滤
|
||||
|
||||
```txt
|
||||
dns.id == 0xff0b
|
||||
```
|
||||
|
||||
### 找出慢响应
|
||||
|
||||
超过 100 ms 的响应:
|
||||
|
||||
```txt
|
||||
dns.flags.rcode eq 0 and dns.time gt .1
|
||||
```
|
||||
|
||||
### 过滤 NXDomain 的响应
|
||||
|
||||
所有 `No such name` 的响应:
|
||||
|
||||
```txt
|
||||
dns.flags.rcode == 3
|
||||
```
|
||||
|
||||
排除集群内部 service:
|
||||
|
||||
```txt
|
||||
((dns.flags.rcode == 3) && !(dns.qry.name contains ".local") && !(dns.qry.name contains ".svc") && !(dns.qry.name contains ".cluster"))
|
||||
```
|
||||
|
||||
指定某个外部域名:
|
||||
|
||||
```txt
|
||||
((dns.flags.rcode == 3) && (dns.qry.name == "imroc.cc")
|
||||
```
|
||||
|
||||
## 分析 TCP 异常
|
||||
|
||||
### 找出连接超时的请求
|
||||
|
||||
客户端连接超时,如果不是因为 dns 解析超时,那就是因为 tcp 握手超时了,通常是服务端没响应 SYNACK 或响应太慢。
|
||||
|
||||
超时的时候客户端一般会发 RST 给服务端,过滤出握手超时的包:
|
||||
|
||||
```txt
|
||||
(tcp.flags.reset eq 1) and (tcp.flags.ack eq 0)
|
||||
```
|
||||
|
||||
过滤出服务端握手时响应 SYNACK 慢的包:
|
||||
|
||||
```txt
|
||||
tcp.flags eq 0x012 && tcp.time_delta gt 0.0001
|
||||
```
|
||||
|
||||
还可以将 `Time since previous frame in this TCP stream` 添加为一列:
|
||||
|
||||
|
||||
|
||||
点击列名降序排列可查出慢包 (可加更多条件过滤调不需要希望展示的包):
|
||||
|
||||

|
||||
|
||||
找出可疑包后使用 `Conversation Filter` 过滤出完整连接的完整会话内容:
|
||||
|
||||
|
||||
|
|
@ -1,22 +0,0 @@
|
|||
# MountVolume.SetUp failed for volume
|
||||
|
||||
## failed to sync secret cache: timed out waiting for the condition
|
||||
|
||||
Pod 报如下的 warning 事件:
|
||||
|
||||
```txt
|
||||
Events:
|
||||
Type Reason Age From Message
|
||||
---- ------ ---- ---- -------
|
||||
Warning FailedMount 41m kubelet MountVolume.SetUp failed for volume "default-token-bgg5p" : failed to sync secret cache: timed out waiting for the condition
|
||||
```
|
||||
|
||||
如果只是偶现,很快自动恢复,这个是正常的,不必担心。通常是因为节点上 kubelet 调 apiserver 接口获取 configmap 或 secret 的内容时超时了,超时原因可能是:
|
||||
1. 被 apiserver 限速 (节点上pod多,或同时启动很多pod,对apiserver发起的调用多,导致被临时限速了一下),一般很快可以自动恢复。
|
||||
2. 被 kubelet 限速 (默认单节点向apiserver发送读请求每秒上限5个,所有类型请求每秒上限10个)。
|
||||
```txt
|
||||
--kube-api-burst int32 Burst to use while talking with kubernetes apiserver. Doesn't cover events and node heartbeat apis which rate limiting is controlled by a different set of flags (default 10)
|
||||
--kube-api-qps int32 QPS to use while talking with kubernetes apiserver. Doesn't cover events and node heartbeat apis which rate limiting is controlled by a different set of flags (default 5)
|
||||
```
|
||||
|
||||
如果是一直报这个,排查下 RBAC 设置。
|
||||
|
|
@ -1,67 +0,0 @@
|
|||
# Unable to mount volumes
|
||||
|
||||
## 问题现象
|
||||
|
||||
Pod 一直 Pending,有类似如下 Warning 事件:
|
||||
|
||||
```txt
|
||||
Unable to mount volumes for pod "es-0_prod(0f08e3aa-aa56-11ec-ab5b-5254006900dd)": timeout expired waiting for volumes to attach or mount for pod "prod"/"es-0". list of unmounted volumes=[applog]. list of unattached volumes=[applog default-token-m7bf7]
|
||||
```
|
||||
|
||||
## 快速排查
|
||||
|
||||
首选根据 Pod 事件日志的提示进行快速排查,观察下 Pod 事件日志,除了 `Unable to mount volumes` 是否还有其它相关日志。
|
||||
|
||||
### MountVolume.WaitForAttach failed
|
||||
|
||||
Pod 报类似如下事件日志:
|
||||
|
||||
```txt
|
||||
MountVolume.WaitForAttach failed for volume "pvc-067327ac-00ec-11ec-bdce-5254001a6990" : Could not find attached disk("disk-68i8q1gq"). Timeout waiting for mount paths to be created.
|
||||
```
|
||||
|
||||
说明磁盘正在等待被 attach 到节点上,这个操作通常是云厂商的 provisioner 组件去调用磁盘相关 API 来实现的 (挂载磁盘到虚拟机)。可以检查下节点是否有被挂载该磁盘,云上一般是在云控制台查看云服务器的磁盘挂载情况。
|
||||
|
||||
出现这种一般是没有挂载上,可以先自查一下是否遇上了这种场景:
|
||||
1. pod 原地重启,detach 磁盘时超时。
|
||||
2. 容器原地快速重启,controller-manager 误以为已经 attach 就没调用 CSI 去 attach 磁盘,并标记 node 为 attached,记录到 node status 里。
|
||||
3. kubelet watch 到 node 已经 attach 了,取出磁盘信息准备拿来 mount,但是发现对应盘符找不到,最后报错。
|
||||
|
||||
如果是,只有重建 pod 使其调度到其它节点上,重新挂载。
|
||||
|
||||
如果不是,有可能是 CSI 插件本身的问题,可以反馈给相关技术人员。
|
||||
|
||||
## 排查思路
|
||||
|
||||
如果无法通过事件快速排查,可以尝试从头开始一步步查,这里分享排查思路。
|
||||
|
||||
1. 查看 pod 定义,看看有哪些 volume:
|
||||
```bash
|
||||
kubectl get pod $POD_NAME -o jsonpath='{.spec.volumes}' | jq
|
||||
```
|
||||
```json
|
||||
[
|
||||
{
|
||||
"name": "applog",
|
||||
"persistentVolumeClaim": {
|
||||
"claimName": "applog-es-0"
|
||||
}
|
||||
},
|
||||
{
|
||||
"name": "default-token-m7bf7",
|
||||
"secret": {
|
||||
"defaultMode": 420,
|
||||
"secretName": "default-token-m7bf7"
|
||||
}
|
||||
}
|
||||
]
|
||||
```
|
||||
2. 检查事件中 `list of unmounted volumes` 对应的 volume 是哪个,通常是对应一个 pvc,拿到对应 pvc 名称。
|
||||
3. 检查 pvc 状态是否为 `Bound`:
|
||||
```bash
|
||||
$ kubectl get pvc applog-es-0
|
||||
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
|
||||
applog-es-0 Bound pvc-067327ac-00ec-11ec-bdce-5254001a6990 100Gi RWO cbs-stata 215d
|
||||
```
|
||||
4. 如果没有 `Bound`,说明还没有可用的 PV 能绑定,如果 PV 是手动创建,需要创建下,如果是用 `StorageClass` 自动创建而没有创建出来,可以 describe 一下 pvc,看下事件日志的提示,应该就可能看出原因,如果还不能看出来,就看下对应 provisoner 组件的日志。
|
||||
5. 如果是 `Bound` 状态,说明存储已经准备好了,出问题的是挂载,要么是 attach 失败,要么是 mount 失败。如果是 attach 失败,可以结合 `controller-manager` 和 CSI 插件相关日志来分析,如果是 mount 失败,可以排查下 kubelet 的日志。
|
||||
|
|
@ -82,36 +82,6 @@ const config: Config = {
|
|||
`https://github.com/imroc/kubernetes-guide/edit/main/content/best-practices/${docPath}`,
|
||||
}),
|
||||
],
|
||||
[
|
||||
/** @type {import('@docusaurus/plugin-content-docs').PluginOptions} */
|
||||
'@docusaurus/plugin-content-docs',
|
||||
({
|
||||
id: 'troubleshooting',
|
||||
path: 'content/troubleshooting',
|
||||
// 文档的路由前缀
|
||||
routeBasePath: '/troubleshooting',
|
||||
// 左侧导航栏的配置
|
||||
sidebarPath: require.resolve('./content/troubleshooting/sidebars.ts'),
|
||||
// 每个文档左下角 "编辑此页" 的链接
|
||||
editUrl: ({ docPath }) =>
|
||||
`https://github.com/imroc/kubernetes-guide/edit/main/content/troubleshooting/${docPath}`,
|
||||
}),
|
||||
],
|
||||
[
|
||||
/** @type {import('@docusaurus/plugin-content-docs').PluginOptions} */
|
||||
'@docusaurus/plugin-content-docs',
|
||||
({
|
||||
id: 'troubleshooting-cases',
|
||||
path: 'content/troubleshooting-cases',
|
||||
// 文档的路由前缀
|
||||
routeBasePath: '/troubleshooting-cases',
|
||||
// 左侧导航栏的配置
|
||||
sidebarPath: require.resolve('./content/troubleshooting-cases/sidebars.ts'),
|
||||
// 每个文档左下角 "编辑此页" 的链接
|
||||
editUrl: ({ docPath }) =>
|
||||
`https://github.com/imroc/kubernetes-guide/edit/main/content/troubleshooting-cases/${docPath}`,
|
||||
}),
|
||||
],
|
||||
[
|
||||
/** @type {import('@docusaurus/plugin-content-docs').PluginOptions} */
|
||||
'@docusaurus/plugin-content-docs',
|
||||
|
|
@ -197,21 +167,16 @@ const config: Config = {
|
|||
position: 'right',
|
||||
to: '/cases',
|
||||
},
|
||||
{
|
||||
label: '排障指南',
|
||||
position: 'right',
|
||||
to: '/troubleshooting',
|
||||
},
|
||||
{
|
||||
label: '排障案例',
|
||||
position: 'right',
|
||||
to: '/troubleshooting-cases',
|
||||
},
|
||||
{
|
||||
label: '附录',
|
||||
position: 'right',
|
||||
to: '/appendix',
|
||||
},
|
||||
{
|
||||
label: 'Kubernetes 排障指南',
|
||||
position: 'right',
|
||||
href: 'https://imroc.cc/kubernetes/troubleshooting',
|
||||
},
|
||||
{
|
||||
href: 'https://github.com/imroc/kubernetes-guide', // 改成自己的仓库地址
|
||||
label: 'GitHub',
|
||||
|
|
@ -226,6 +191,10 @@ const config: Config = {
|
|||
{
|
||||
title: '相关电子书',
|
||||
items: [
|
||||
{
|
||||
label: 'Kubernetes 排障指南',
|
||||
href: 'https://imroc.cc/kubernetes/troubleshooting',
|
||||
},
|
||||
{
|
||||
label: 'istio 实践指南',
|
||||
href: 'https://imroc.cc/istio',
|
||||
|
|
|
|||
Loading…
Reference in New Issue