mirror of https://github.com/dunwu/db-tutorial.git
update docs
parent
16a41f1520
commit
079b40f1bd
12
README.md
12
README.md
|
|
@ -69,14 +69,14 @@
|
|||
- [Redis 实战](docs/nosql/redis/redis-action.md) - 关键词:`缓存`、`分布式锁`、`布隆过滤器`
|
||||
- [Redis 运维](docs/nosql/redis/redis-ops.md) 🔨 - 关键词:`安装`、`命令`、`集群`、`客户端`
|
||||
|
||||
#### Elasticsearch
|
||||
|
||||
> [Elasticsearch](docs/nosql/elasticsearch) 📚
|
||||
#### [Elasticsearch](docs/nosql/elasticsearch) 📚
|
||||
|
||||
- [Elasticsearch 面试总结](docs/nosql/elasticsearch/elasticsearch-interview.md) 💯
|
||||
- [ElasticSearch 应用指南](docs/nosql/elasticsearch/elasticsearch-quickstart.md)
|
||||
- [ElasticSearch API](docs/nosql/elasticsearch/ElasticSearchRestApi.md)
|
||||
- [ElasticSearch 运维](docs/nosql/elasticsearch/elasticsearch-ops.md)
|
||||
- [Elasticsearch 简介](docs/nosql/elasticsearch/Elasticsearch简介.md)
|
||||
- [Elasticsearch 快速入门](docs/nosql/elasticsearch/Elasticsearch快速入门.md)
|
||||
- [Elasticsearch 基本概念](docs/nosql/elasticsearch/Elasticsearch基本概念.md)
|
||||
- [Elasticsearch Rest API](docs/nosql/elasticsearch/ElasticsearchRestApi.md)
|
||||
- [Elasticsearch 运维](docs/nosql/elasticsearch/Elasticsearch运维.md)
|
||||
|
||||
#### HBase
|
||||
|
||||
|
|
|
|||
|
|
@ -68,14 +68,14 @@ footer: CC-BY-SA-4.0 Licensed | Copyright © 2018-Now Dunwu
|
|||
- [Redis 实战](nosql/redis/redis-action.md) - 关键词:`缓存`、`分布式锁`、`布隆过滤器`
|
||||
- [Redis 运维](nosql/redis/redis-ops.md) 🔨 - 关键词:`安装`、`命令`、`集群`、`客户端`
|
||||
|
||||
#### Elasticsearch
|
||||
|
||||
> [Elasticsearch](nosql/elasticsearch) 📚
|
||||
#### [Elasticsearch](nosql/elasticsearch) 📚
|
||||
|
||||
- [Elasticsearch 面试总结](nosql/elasticsearch/elasticsearch-interview.md) 💯
|
||||
- [ElasticSearch 应用指南](nosql/elasticsearch/elasticsearch-quickstart.md)
|
||||
- [ElasticSearch API](nosql/elasticsearch/ElasticSearchRestApi.md)
|
||||
- [ElasticSearch 运维](nosql/elasticsearch/elasticsearch-ops.md)
|
||||
- [Elasticsearch 简介](nosql/elasticsearch/Elasticsearch简介.md)
|
||||
- [Elasticsearch 快速入门](nosql/elasticsearch/Elasticsearch快速入门.md)
|
||||
- [Elasticsearch 基本概念](nosql/elasticsearch/Elasticsearch基本概念.md)
|
||||
- [Elasticsearch Rest API](nosql/elasticsearch/ElasticsearchRestApi.md)
|
||||
- [Elasticsearch 运维](nosql/elasticsearch/Elasticsearch运维.md)
|
||||
|
||||
#### HBase
|
||||
|
||||
|
|
|
|||
|
|
@ -20,9 +20,11 @@
|
|||
> [Elasticsearch](elasticsearch) 📚
|
||||
|
||||
- [Elasticsearch 面试总结](elasticsearch/elasticsearch-interview.md) 💯
|
||||
- [ElasticSearch 应用指南](elasticsearch/elasticsearch-quickstart.md)
|
||||
- [ElasticSearch API](elasticsearch/elasticsearch-api.md)
|
||||
- [ElasticSearch 运维](elasticsearch/elasticsearch-ops.md)
|
||||
- [Elasticsearch 简介](elasticsearch/Elasticsearch简介.md)
|
||||
- [Elasticsearch 快速入门](elasticsearch/Elasticsearch快速入门.md)
|
||||
- [Elasticsearch 基本概念](elasticsearch/Elasticsearch基本概念.md)
|
||||
- [Elasticsearch Rest API](elasticsearch/ElasticsearchRestApi.md)
|
||||
- [Elasticsearch 运维](elasticsearch/Elasticsearch运维.md)
|
||||
|
||||
### 图数据库
|
||||
|
||||
|
|
|
|||
|
|
@ -666,6 +666,295 @@ POST kibana_sample_data_ecommerce/_msearch
|
|||
{"query" : {"match_all" : {}},"size":2}
|
||||
```
|
||||
|
||||
### URI Search 查询语义
|
||||
|
||||
Elasticsearch URI Search 遵循 QueryString 查询语义,其形式如下:
|
||||
|
||||
```bash
|
||||
GET /movies/_search?q=2012&df=title&sort=year:desc&from=0&size=10&timeout=1s
|
||||
{
|
||||
"profile": true
|
||||
}
|
||||
```
|
||||
|
||||
- **`q`** 指定查询语句,使用 QueryString 语义
|
||||
- **`df`** 默认字段,不指定时
|
||||
- **`sort`** 排序:from 和 size 用于分页
|
||||
- **`profile`** 可以查看查询时如何被执行的
|
||||
|
||||
```bash
|
||||
GET /movies/_search?q=title:2012&sort=year:desc&from=0&size=10&timeout=1s
|
||||
{
|
||||
"profile":"true"
|
||||
}
|
||||
```
|
||||
|
||||
#### Term 和 Phrase
|
||||
|
||||
Beautiful Mind 等效于 Beautiful OR Mind
|
||||
|
||||
"Beautiful Mind" 等效于 Beautiful AND Mind
|
||||
|
||||
```bash
|
||||
# Term 查询
|
||||
GET /movies/_search?q=title:Beautiful Mind
|
||||
{
|
||||
"profile":"true"
|
||||
}
|
||||
|
||||
# 使用引号,Phrase 查询
|
||||
GET /movies/_search?q=title:"Beautiful Mind"
|
||||
{
|
||||
"profile":"true"
|
||||
}
|
||||
```
|
||||
|
||||
#### 分组与引号
|
||||
|
||||
title:(Beautiful AND Mind)
|
||||
|
||||
title="Beautiful Mind"
|
||||
|
||||
#### AND、OR、NOT 或者 &&、||、!
|
||||
|
||||
> 注意:AND、OR、NOT 必须大写
|
||||
|
||||
```bash
|
||||
# 布尔操作符
|
||||
GET /movies/_search?q=title:(Beautiful AND Mind)
|
||||
{
|
||||
"profile":"true"
|
||||
}
|
||||
|
||||
GET /movies/_search?q=title:(Beautiful NOT Mind)
|
||||
{
|
||||
"profile":"true"
|
||||
}
|
||||
```
|
||||
|
||||
#### 范围查询
|
||||
|
||||
- `[]` 表示闭区间
|
||||
- `{}` 表示开区间
|
||||
|
||||
示例:
|
||||
|
||||
```bash
|
||||
# 范围查询 ,区间写法
|
||||
GET /movies/_search?q=title:beautiful AND year:{2010 TO 2018%7D
|
||||
{
|
||||
"profile":"true"
|
||||
}
|
||||
|
||||
GET /movies/_search?q=title:beautiful AND year:[* TO 2018]
|
||||
{
|
||||
"profile":"true"
|
||||
}
|
||||
```
|
||||
|
||||
#### 算数符号
|
||||
|
||||
```bash
|
||||
# 2010 年以后的记录
|
||||
GET /movies/_search?q=year:>2010
|
||||
{
|
||||
"profile":"true"
|
||||
}
|
||||
|
||||
# 2010 年到 2018 年的记录
|
||||
GET /movies/_search?q=year:(>2010 && <=2018)
|
||||
{
|
||||
"profile":"true"
|
||||
}
|
||||
|
||||
# 2010 年到 2018 年的记录
|
||||
GET /movies/_search?q=year:(+>2010 +<=2018)
|
||||
{
|
||||
"profile":"true"
|
||||
}
|
||||
```
|
||||
|
||||
#### 通配符查询
|
||||
|
||||
- `?` 代表 1 个字符
|
||||
- `*` 代表 0 或多个字符
|
||||
|
||||
示例:
|
||||
|
||||
```bash
|
||||
GET /movies/_search?q=title:mi?d
|
||||
{
|
||||
"profile":"true"
|
||||
}
|
||||
|
||||
GET /movies/_search?q=title:b*
|
||||
{
|
||||
"profile":"true"
|
||||
}
|
||||
```
|
||||
|
||||
#### 正则表达式
|
||||
|
||||
title:[bt]oy
|
||||
|
||||
#### 模糊匹配与近似查询
|
||||
|
||||
示例:
|
||||
|
||||
```bash
|
||||
# 相似度在 1 个字符以内
|
||||
GET /movies/_search?q=title:beautifl~1
|
||||
{
|
||||
"profile":"true"
|
||||
}
|
||||
|
||||
# 相似度在 2 个字符以内
|
||||
GET /movies/_search?q=title:"Lord Rings"~2
|
||||
{
|
||||
"profile":"true"
|
||||
}
|
||||
```
|
||||
|
||||
### Request Body & DSL
|
||||
|
||||
Elasticsearch 除了 URI Search 查询方式,还支持将查询语句通过 Http Request Body 发起查询。
|
||||
|
||||
```bash
|
||||
GET /kibana_sample_data_ecommerce/_search?ignore_unavailable=true
|
||||
{
|
||||
"profile":"true",
|
||||
"query": {
|
||||
"match_all": {}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 分页
|
||||
|
||||
```bash
|
||||
GET /kibana_sample_data_ecommerce/_search?ignore_unavailable=true
|
||||
{
|
||||
"profile": "true",
|
||||
"from": 0,
|
||||
"size": 10,
|
||||
"query": {
|
||||
"match_all": {}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 排序
|
||||
|
||||
最好在数字型或日期型字段上排序
|
||||
|
||||
因为对于多值类型或分析过的字段排序,系统会选一个值,无法得知该值
|
||||
|
||||
```bash
|
||||
GET /kibana_sample_data_ecommerce/_search?ignore_unavailable=true
|
||||
{
|
||||
"profile": "true",
|
||||
"sort": [
|
||||
{
|
||||
"order_date": "desc"
|
||||
}
|
||||
],
|
||||
"from": 1,
|
||||
"size": 10,
|
||||
"query": {
|
||||
"match_all": {}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### \_source 过滤
|
||||
|
||||
如果 `_source` 没有存储,那就只返回匹配的文档的元数据
|
||||
|
||||
`_source` 支持使用通配符,如:`_source["name*", "desc*"]`
|
||||
|
||||
示例:
|
||||
|
||||
```bash
|
||||
GET /kibana_sample_data_ecommerce/_search?ignore_unavailable=true
|
||||
{
|
||||
"profile": "true",
|
||||
"_source": [
|
||||
"order_date",
|
||||
"category.keyword"
|
||||
],
|
||||
"from": 1,
|
||||
"size": 10,
|
||||
"query": {
|
||||
"match_all": {}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 脚本字段
|
||||
|
||||
```bash
|
||||
GET /kibana_sample_data_ecommerce/_search?ignore_unavailable=true
|
||||
{
|
||||
"profile": "true",
|
||||
"script_fields": {
|
||||
"new_field": {
|
||||
"script": {
|
||||
"lang": "painless",
|
||||
"source":"doc['order_date'].value+' hello'"
|
||||
}
|
||||
}
|
||||
},
|
||||
"from": 1,
|
||||
"size": 10,
|
||||
"query": {
|
||||
"match_all": {}
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
#### 使用查询表达式 - Match
|
||||
|
||||
```bash
|
||||
POST movies/_search
|
||||
{
|
||||
"query": {
|
||||
"match": {
|
||||
"title": "last christmas"
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
POST movies/_search
|
||||
{
|
||||
"query": {
|
||||
"match": {
|
||||
"title": {
|
||||
"query": "last christmas",
|
||||
"operator": "and"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
#### 短语搜索 - Match Phrase
|
||||
|
||||
```bash
|
||||
POST movies/_search
|
||||
{
|
||||
"query": {
|
||||
"match_phrase": {
|
||||
"title":{
|
||||
"query": "last christmas"
|
||||
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## 集群 API
|
||||
|
||||
> [Elasticsearch 官方之 Cluster API](https://www.elastic.co/guide/en/elasticsearch/reference/current/cluster.html)
|
||||
|
|
|
|||
|
|
@ -52,13 +52,12 @@ Elasticsearch 使用 [_JSON_](http://en.wikipedia.org/wiki/Json) 作为文档的
|
|||
|
||||
索引的 Mapping 和 Setting
|
||||
|
||||
Mapping 定义文档字段的类型
|
||||
|
||||
Setting 定义不同的数据分布
|
||||
- **`Mapping`** 定义文档字段的类型
|
||||
- **`Setting`** 定义不同的数据分布
|
||||
|
||||
示例:
|
||||
|
||||
```
|
||||
```json
|
||||
{
|
||||
"settings": { ... any settings ... },
|
||||
"mappings": {
|
||||
|
|
@ -73,6 +72,166 @@ Setting 定义不同的数据分布
|
|||
|
||||
|
||||
|
||||
## Mapping
|
||||
|
||||
在 Elasticsearch 中,**`Mapping`**(映射),用来定义一个文档以及其所包含的字段如何被存储和索引,可以在映射中事先定义字段的数据类型、字段的权重、分词器等属性,就如同在关系型数据库中创建数据表时会设置字段的类型。
|
||||
|
||||
Mapping 会把 json 文档映射成 Lucene 所需要的扁平格式
|
||||
|
||||
一个 Mapping 属于一个索引的 Type
|
||||
|
||||
- 每个文档都属于一个 Type
|
||||
- 一个 Type 有一个 Mapping 定义
|
||||
- 7.0 开始,不需要在 Mapping 定义中指定 type 信息
|
||||
|
||||
### 映射分类
|
||||
|
||||
在 Elasticsearch 中,映射可分为静态映射和动态映射。
|
||||
|
||||
#### 静态映射
|
||||
|
||||
**静态映射**是在创建索引时手工指定索引映射。静态映射和 SQL 中在建表语句中指定字段属性类似。相比动态映射,通过静态映射可以添加更详细、更精准的配置信息。
|
||||
|
||||
如何定义一个 Mapping
|
||||
|
||||
```bash
|
||||
PUT /books
|
||||
{
|
||||
"mappings": {
|
||||
"type_one": { ... any mappings ... },
|
||||
"type_two": { ... any mappings ... },
|
||||
...
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 动态映射
|
||||
|
||||
**动态映射**是一种偷懒的方式,可直接创建索引并写入文档,文档中字段的类型是 Elasticsearch **自动识别**的,不需要在创建索引的时候设置字段的类型。在实际项目中,如果遇到的业务在导入数据之前不确定有哪些字段,也不清楚字段的类型是什么,使用动态映射非常合适。当 Elasticsearch 在文档中碰到一个以前没见过的字段时,它会利用动态映射来决定该字段的类型,并自动把该字段添加到映射中,根据字段的取值自动推测字段类型的规则见下表:
|
||||
|
||||
| JSON 格式的数据 | 自动推测的字段类型 |
|
||||
| :-------------- | :--------------------------------------------------------------------------------- |
|
||||
| null | 没有字段被添加 |
|
||||
| true or false | boolean 类型 |
|
||||
| 浮点类型数字 | float 类型 |
|
||||
| 数字 | long 类型 |
|
||||
| JSON 对象 | object 类型 |
|
||||
| 数组 | 由数组中第一个非空值决定 |
|
||||
| string | 有可能是 date 类型(若开启日期检测)、double 或 long 类型、text 类型、keyword 类型 |
|
||||
|
||||
下面举一个例子认识动态 mapping,在 Elasticsearch 中创建一个新的索引并查看它的 mapping,命令如下:
|
||||
|
||||
```bash
|
||||
PUT books
|
||||
GET books/_mapping
|
||||
```
|
||||
|
||||
此时 books 索引的 mapping 是空的,返回结果如下:
|
||||
|
||||
```json
|
||||
{
|
||||
"books": {
|
||||
"mappings": {}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
再往 books 索引中写入一条文档,命令如下:
|
||||
|
||||
```bash
|
||||
PUT books/it/1
|
||||
{
|
||||
"id": 1,
|
||||
"publish_date": "2019-11-10",
|
||||
"name": "master Elasticsearch"
|
||||
}
|
||||
```
|
||||
|
||||
文档写入完成之后,再次查看 mapping,返回结果如下:
|
||||
|
||||
```json
|
||||
{
|
||||
"books": {
|
||||
"mappings": {
|
||||
"properties": {
|
||||
"id": {
|
||||
"type": "long"
|
||||
},
|
||||
"name": {
|
||||
"type": "text",
|
||||
"fields": {
|
||||
"keyword": {
|
||||
"type": "keyword",
|
||||
"ignore_above": 256
|
||||
}
|
||||
}
|
||||
},
|
||||
"publish_date": {
|
||||
"type": "date"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
使用动态 mapping 要结合实际业务需求来综合考虑,如果将 Elasticsearch 当作主要的数据存储使用,并且希望出现未知字段时抛出异常来提醒你注意这一问题,那么开启动态 mapping 并不适用。在 mapping 中可以通过 `dynamic` 设置来控制是否自动新增字段,接受以下参数:
|
||||
|
||||
- **`true`**:默认值为 true,自动添加字段。
|
||||
- **`false`**:忽略新的字段。
|
||||
- **`strict`**:严格模式,发现新的字段抛出异常。
|
||||
|
||||
### 基础类型
|
||||
|
||||
| 类型 | 关键字 |
|
||||
| :--------- | :------------------------------------------------------------------ |
|
||||
| 字符串类型 | string、text、keyword |
|
||||
| 数字类型 | long、integer、short、byte、double、float、half_float、scaled_float |
|
||||
| 日期类型 | date |
|
||||
| 布尔类型 | boolean |
|
||||
| 二进制类型 | binary |
|
||||
| 范围类型 | range |
|
||||
|
||||
### 复杂类型
|
||||
|
||||
| 类型 | 关键字 |
|
||||
| :------- | :----- |
|
||||
| 数组类型 | array |
|
||||
| 对象类型 | object |
|
||||
| 嵌套类型 | nested |
|
||||
|
||||
### 特殊类型
|
||||
|
||||
| 类型 | 关键字 |
|
||||
| :----------- | :---------- |
|
||||
| 地理类型 | geo_point |
|
||||
| 地理图形类型 | geo_shape |
|
||||
| IP 类型 | ip |
|
||||
| 范围类型 | completion |
|
||||
| 令牌计数类型 | token_count |
|
||||
| 附件类型 | attachment |
|
||||
| 抽取类型 | percolator |
|
||||
|
||||
### Mapping 属性
|
||||
|
||||
Elasticsearch 的 mapping 中的字段属性非常多,具体如下表格:
|
||||
|
||||
| 属性名 | 描述 |
|
||||
| :---------------------- | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------ |
|
||||
| **_`type`_** | 字段类型,常用的有 text、integer 等等。 |
|
||||
| **_`index`_** | 当前字段是否被作为索引。可选值为 **_`true`_**,默认为 true。 |
|
||||
| **_`store`_** | 是否存储指定字段,可选值为 **_`true`_** | **_`false`_**,设置 true 意味着需要开辟单独的存储空间为这个字段做存储,而且这个存储是独立于 **_`_source`_** 的存储的。 |
|
||||
| **_`norms`_** | 是否使用归一化因子,可选值为 **_`true`_** | **_`false`_**,不需要对某字段进行打分排序时,可禁用它,节省空间;_type_ 为 _text_ 时,默认为 _true_;而 _type_ 为 _keyword_ 时,默认为 _false_。 |
|
||||
| **_`index_options`_** | 索引选项控制添加到倒排索引(Inverted Index)的信息,这些信息用于搜索(Search)和高亮显示:**_`docs`_**:只索引文档编号(Doc Number);**_`freqs`_**:索引文档编号和词频率(term frequency);**_`positions`_**:索引文档编号,词频率和词位置(序号);**_`offsets`_**:索引文档编号,词频率,词偏移量(开始和结束位置)和词位置(序号)。默认情况下,被分析的字符串(analyzed string)字段使用 _positions_,其他字段默认使用 _docs_。此外,需要注意的是 _index_option_ 是 elasticsearch 特有的设置属性;临近搜索和短语查询时,_index_option_ 必须设置为 _offsets_,同时高亮也可使用 postings highlighter。 |
|
||||
| **_`term_vector`_** | 索引选项控制词向量相关信息:**_`no`_**:默认值,表示不存储词向量相关信息;**_`yes`_**:只存储词向量信息;**_`with_positions`_**:存储词项和词项位置;**_`with_offsets`_**:存储词项和字符偏移位置;**_`with_positions_offsets`_**:存储词项、词项位置、字符偏移位置。_term_vector_ 是 lucene 层面的索引设置。 |
|
||||
| **_`similarity`_** | 指定文档相似度算法(也可以叫评分模型):**_`BM25`_**:es 5 之后的默认设置。 |
|
||||
| **_`copy_to`_** | 复制到自定义 \_all 字段,值是数组形式,即表明可以指定多个自定义的字段。 |
|
||||
| **_`analyzer`_** | 指定索引和搜索时的分析器,如果同时指定 _search_analyzer_ 则搜索时会优先使用 _search_analyzer_。 |
|
||||
| **_`search_analyzer`_** | 指定搜索时的分析器,搜索时的优先级最高。 |
|
||||
| **_`null_value`_** | 用于需要对 Null 值实现搜索的场景,只有 Keyword 类型支持此配置。 |
|
||||
|
||||
## 分词
|
||||
|
||||
## 节点
|
||||
|
||||
### 节点简介
|
||||
|
|
@ -165,7 +324,7 @@ Elasticsearch 的集群监控信息中包含了许多的统计数据,其中最
|
|||
|
||||
Elasticsearch 是利用分片将数据分发到集群内各处的。分片是数据的容器,文档保存在分片内,分片又被分配到集群内的各个节点里。 当你的集群规模扩大或者缩小时, Elasticsearch 会自动的在各节点中迁移分片,使得数据仍然均匀分布在集群里。
|
||||
|
||||
### 主分片和副分片
|
||||
### 主分片和副分片
|
||||
|
||||
分片分为主分片(Primary Shard)和副分片(Replica Shard)。
|
||||
|
||||
|
|
@ -195,32 +354,7 @@ Elasticsearch 是利用分片将数据分发到集群内各处的。分片是数
|
|||
|
||||
当集群中只有一个节点运行时,意味着存在单点故障问题——没有冗余。
|
||||
|
||||
---
|
||||
|
||||
文档的基本 CRUD 与批量操作
|
||||
|
||||
倒排索引入门
|
||||
|
||||
通过分析器进行分词
|
||||
|
||||
Search API 概览
|
||||
|
||||
URI Search 详解
|
||||
|
||||
Request Body 与 Query DSL 简介
|
||||
|
||||
Query String & Simple Query String 查询
|
||||
|
||||
Dynamic Mapping 和常见字段类型
|
||||
|
||||
显式 Mapping 设置与常见参数介绍
|
||||
|
||||
多字段特性及 Mapping 中配置自定义 Analyzer
|
||||
|
||||
Index Template 和 Dynamic Template
|
||||
|
||||
Elasticsearch 聚合分析简介
|
||||
|
||||
## 参考资料
|
||||
|
||||
- [Elasticsearch 官网](https://www.elastic.co/)
|
||||
- [Elasticsearch 索引映射类型及 mapping 属性详解](https://www.knowledgedict.com/tutorial/elasticsearch-index-mapping.html)
|
||||
|
|
|
|||
|
|
@ -7,10 +7,11 @@
|
|||
> [Elasticsearch](https://www.elastic.co/products/elasticsearch) 是一个基于 [Lucene](http://lucene.apache.org/core/documentation.html) 构建的开源,分布式,RESTful 搜索引擎。
|
||||
|
||||
- [Elasticsearch 面试总结](elasticsearch-interview.md) 💯
|
||||
- [Elasticsearch 简介](Elasticsearch简介.md)
|
||||
- [Elasticsearch 快速入门](Elasticsearch快速入门.md)
|
||||
- [Elasticsearch 基本概念](Elasticsearch基本概念.md)
|
||||
- [Elasticsearch Rest API](ElasticsearchRestApi.md)
|
||||
- [Elasticsearch 运维](elasticsearch-ops.md)
|
||||
- [Elasticsearch 运维](Elasticsearch运维.md)
|
||||
|
||||
### Elastic 技术栈
|
||||
|
||||
|
|
|
|||
|
|
@ -159,7 +159,7 @@ buffer 每 refresh 一次,就会产生一个 `segment file`,所以默认情
|
|||
| 8 | 拉斯 | 3,5 |
|
||||
| 9 | 离开 | 3 |
|
||||
| 10 | 与 | 4 |
|
||||
| .. | .. | .. |
|
||||
| .. | .. | .. |
|
||||
|
||||
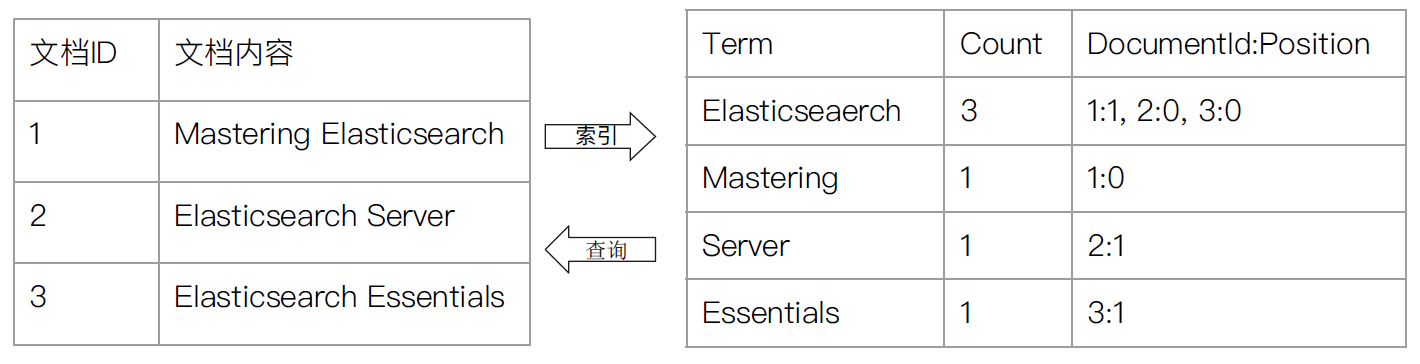
另外,实用的倒排索引还可以记录更多的信息,比如文档频率信息,表示在文档集合中有多少个文档包含某个单词。
|
||||
|
||||
|
|
@ -217,7 +217,7 @@ Beats 有多种类型,可以根据实际应用需要选择合适的类型。
|
|||
|
||||
### 4.1. Filebeat 简介
|
||||
|
||||
> *由于本人仅接触过 Filebeat,所以本文只介绍 Beats 组件中的 Filebeat*。
|
||||
> _由于本人仅接触过 Filebeat,所以本文只介绍 Beats 组件中的 Filebeat_。
|
||||
|
||||
相比 Logstash,FileBeat 更加轻量化。
|
||||
|
||||
|
|
@ -250,7 +250,7 @@ Filebeat 将每个事件的传递状态存储在注册表文件中。所以它
|
|||
|
||||
## 5. 运维
|
||||
|
||||
- [ElasticSearch 运维](nosql/elasticsearch/elasticsearch-ops.md)
|
||||
- [ElasticSearch 运维](nosql/elasticsearch/Elasticsearch运维.md)
|
||||
- [Logstash 运维](nosql/elasticsearch/elastic/elastic-logstash-ops.mdstic/elastic-logstash-ops.md)
|
||||
- [Kibana 运维](nosql/elasticsearch/elastic/elastic-kibana-ops.mdlastic/elastic-kibana-ops.md)
|
||||
- [Beats 运维](nosql/elasticsearch/elastic/elastic-beats-ops.mdelastic/elastic-beats-ops.md)
|
||||
|
|
|
|||
Loading…
Reference in New Issue