mirror of https://github.com/dunwu/db-tutorial.git
update docs
parent
1bb72a6185
commit
093e96c675
|
|
@ -90,8 +90,12 @@
|
|||
#### [MongoDB](docs/nosql/mongodb) 📚
|
||||
|
||||
- [MongoDB 应用指南](docs/nosql/mongodb/mongodb-quickstart.md)
|
||||
- [MongoDB 聚合操作](docs/nosql/mongodb/mongodb-aggregation.md)
|
||||
- [MongoDB 建模](docs/nosql/mongodb/mongodb-model.md)
|
||||
- [MongoDB 建模示例](docs/nosql/mongodb/mongodb-model-example.md)
|
||||
- [MongoDB 索引](docs/nosql/mongodb/mongodb-index.md)
|
||||
- [MongoDB 复制](docs/nosql/mongodb/mongodb-replication.md)
|
||||
- [MongoDB 分片](docs/nosql/mongodb/mongodb-sharding.md)
|
||||
- [MongoDB 运维](docs/nosql/mongodb/mongodb-ops.md)
|
||||
|
||||
### 中间件
|
||||
|
|
|
|||
|
|
@ -93,8 +93,12 @@ footer: CC-BY-SA-4.0 Licensed | Copyright © 2018-Now Dunwu
|
|||
> [MongoDB](nosql/mongodb) 📚
|
||||
|
||||
- [MongoDB 应用指南](nosql/mongodb/mongodb-quickstart.md)
|
||||
- [MongoDB 聚合操作](nosql/mongodb/mongodb-aggregation.md)
|
||||
- [MongoDB 建模](nosql/mongodb/mongodb-model.md)
|
||||
- [MongoDB 建模示例](nosql/mongodb/mongodb-model-example.md)
|
||||
- [MongoDB 索引](nosql/mongodb/mongodb-index.md)
|
||||
- [MongoDB 复制](nosql/mongodb/mongodb-replication.md)
|
||||
- [MongoDB 分片](nosql/mongodb/mongodb-sharding.md)
|
||||
- [MongoDB 运维](nosql/mongodb/mongodb-ops.md)
|
||||
|
||||
### 中间件
|
||||
|
|
|
|||
|
|
@ -1,13 +1,23 @@
|
|||
# MongoDB 教程
|
||||
|
||||
> MongoDB 是一个基于文档的分布式数据库,由 C++ 语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。
|
||||
>
|
||||
> MongoDB 是一个介于关系型数据库和非关系型数据库之间的产品。它是非关系数据库当中功能最丰富,最像关系数据库的。它支持的数据结构非常松散,是类似 json 的 bson 格式,因此可以存储比较复杂的数据类型。
|
||||
>
|
||||
> MongoDB 最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
|
||||
|
||||
## 📖 内容
|
||||
|
||||
### [MongoDB 应用指南](mongodb-quickstart.md)
|
||||
|
||||
### [MongoDB 聚合操作](mongodb-aggregation.md)
|
||||
|
||||
### [MongoDB 建模](mongodb-model.md)
|
||||
|
||||
### [MongoDB 建模示例](mongodb-model-example.md)
|
||||
|
||||
### [MongoDB 索引](mongodb-index.md)
|
||||
|
||||
### [MongoDB 复制](mongodb-replication.md)
|
||||
|
||||
### [MongoDB 分片](mongodb-sharding.md)
|
||||
|
|
|
|||
|
|
@ -0,0 +1,384 @@
|
|||
# MongoDB 聚合操作
|
||||
|
||||
聚合操作处理数据记录并返回计算结果。聚合操作将来自多个 document 的值分组,并可以对分组的数据执行各种操作以返回单个结果。 MongoDB 提供了三种执行聚合的方式:聚合管道,map-reduce 函数和单一目的聚合方法。
|
||||
|
||||
## Pipeline
|
||||
|
||||
### Pipeline 简介
|
||||
|
||||
MongoDB 的聚合框架以数据处理管道(Pipeline)的概念为模型。
|
||||
|
||||
**MongoDB 通过 [`db.collection.aggregate()`](https://docs.mongodb.com/manual/reference/method/db.collection.aggregate/#db.collection.aggregate) 方法支持聚合操作**。并提供了 [`aggregate`](https://docs.mongodb.com/manual/reference/command/aggregate/#dbcmd.aggregate) 命令来执行 pipeline。
|
||||
|
||||
MongoDB Pipeline 由多个阶段([stages](https://docs.mongodb.com/manual/reference/operator/aggregation-pipeline/#aggregation-pipeline-operator-reference))组成。每个阶段在 document 通过 pipeline 时都会对其进行转换。pipeline 阶段不需要为每个输入 document 都生成一个输出 document。例如,某些阶段可能会生成新 document 或过滤 document。
|
||||
|
||||
同一个阶段可以在 pipeline 中出现多次,但 [`$out`](https://docs.mongodb.com/manual/reference/operator/aggregation/out/#pipe._S_out)、[`$merge`](https://docs.mongodb.com/manual/reference/operator/aggregation/merge/#pipe._S_merge),和 [`$geoNear`](https://docs.mongodb.com/manual/reference/operator/aggregation/geoNear/#pipe._S_geoNear) 阶段除外。所有可用 pipeline 阶段可以参考:[Aggregation Pipeline Stages](https://docs.mongodb.com/manual/reference/operator/aggregation-pipeline/#aggregation-pipeline-operator-reference)。
|
||||
|
||||
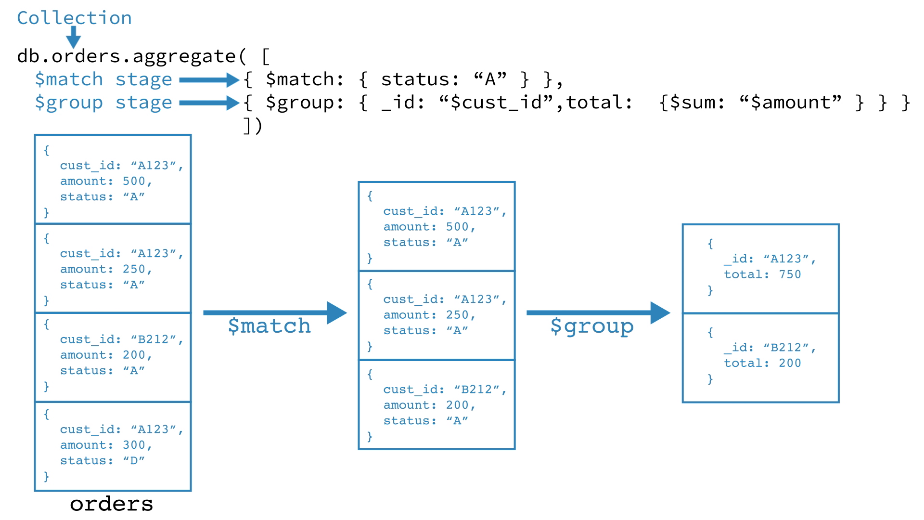
|
||||
|
||||
- 第一阶段:[`$match`](https://docs.mongodb.com/manual/reference/operator/aggregation/match/#pipe._S_match) 阶段按状态字段过滤 document,然后将状态等于“ A”的那些 document 传递到下一阶段。
|
||||
- 第二阶段:[`$group`](https://docs.mongodb.com/manual/reference/operator/aggregation/group/#pipe._S_group) 阶段按 cust_id 字段对 document 进行分组,以计算每个唯一 cust_id 的金额总和。
|
||||
|
||||
最基本的管道阶段提供过滤器,其操作类似于查询和 document 转换(修改输出 document 形式)。
|
||||
|
||||
其他管道操作提供了用于按特定字段对 document 进行分组和排序的工具,以及用于汇总数组(包括 document 数组)内容的工具。另外,管道阶段可以将运算符用于诸如计算平均值或连接字符串之类的任务。
|
||||
|
||||
聚合管道也可以在分片 collection 上操作。
|
||||
|
||||
### Pipeline 优化
|
||||
|
||||
#### 投影优化
|
||||
|
||||
Pipeline 可以确定是否仅需要 document 中必填字段即可获得结果。
|
||||
|
||||
#### Pipeline 串行优化
|
||||
|
||||
(`$project`、`$unset`、`$addFields`、`$set`) + `$match` 串行优化
|
||||
|
||||
对于包含投影阶段([`$project`](https://docs.mongodb.com/manual/reference/operator/aggregation/project/#pipe._S_project) 或 [`$unset`](https://docs.mongodb.com/manual/reference/operator/aggregation/unset/#pipe._S_unset) 或 [`$addFields`](https://docs.mongodb.com/manual/reference/operator/aggregation/addFields/#pipe._S_addFields) 或 [`$set`](https://docs.mongodb.com/manual/reference/operator/aggregation/set/#pipe._S_set)),且后续跟随着 [`$match`](https://docs.mongodb.com/manual/reference/operator/aggregation/match/#pipe._S_match) 阶段的 Pipeline ,MongoDB 会将所有 [`$match`](https://docs.mongodb.com/manual/reference/operator/aggregation/match/#pipe._S_match) 阶段中不需要在投影阶段中计算出的值的过滤器,移动一个在投影阶段之前的新 [`$match`](https://docs.mongodb.com/manual/reference/operator/aggregation/match/#pipe._S_match) 阶段。
|
||||
|
||||
如果 Pipeline 包含多个投影阶段 和 / 或 [`$match`](https://docs.mongodb.com/manual/reference/operator/aggregation/match/#pipe._S_match) 阶段,则 MongoDB 将为每个 [`$match`](https://docs.mongodb.com/manual/reference/operator/aggregation/match/#pipe._S_match) 阶段执行此优化,将每个 [`$match`](https://docs.mongodb.com/manual/reference/operator/aggregation/match/#pipe._S_match) 过滤器移动到该过滤器不依赖的所有投影阶段之前。
|
||||
|
||||
【示例】Pipeline 串行优化示例
|
||||
|
||||
优化前:
|
||||
|
||||
```javascript
|
||||
{ $addFields: {
|
||||
maxTime: { $max: "$times" },
|
||||
minTime: { $min: "$times" }
|
||||
} },
|
||||
{ $project: {
|
||||
_id: 1, name: 1, times: 1, maxTime: 1, minTime: 1,
|
||||
avgTime: { $avg: ["$maxTime", "$minTime"] }
|
||||
} },
|
||||
{ $match: {
|
||||
name: "Joe Schmoe",
|
||||
maxTime: { $lt: 20 },
|
||||
minTime: { $gt: 5 },
|
||||
avgTime: { $gt: 7 }
|
||||
} }
|
||||
```
|
||||
|
||||
优化后:
|
||||
|
||||
```javascript
|
||||
{ $match: { name: "Joe Schmoe" } },
|
||||
{ $addFields: {
|
||||
maxTime: { $max: "$times" },
|
||||
minTime: { $min: "$times" }
|
||||
} },
|
||||
{ $match: { maxTime: { $lt: 20 }, minTime: { $gt: 5 } } },
|
||||
{ $project: {
|
||||
_id: 1, name: 1, times: 1, maxTime: 1, minTime: 1,
|
||||
avgTime: { $avg: ["$maxTime", "$minTime"] }
|
||||
} },
|
||||
{ $match: { avgTime: { $gt: 7 } } }
|
||||
```
|
||||
|
||||
说明:
|
||||
|
||||
`{ name: "Joe Schmoe" }` 不需要计算任何投影阶段的值,所以可以放在最前面。
|
||||
|
||||
`{ avgTime: { $gt: 7 } }` 依赖 [`$project`](https://docs.mongodb.com/manual/reference/operator/aggregation/project/#pipe._S_project) 阶段的 `avgTime` 字段,所以不能移动。
|
||||
|
||||
`maxTime` 和 `minTime` 字段被 [`$addFields`](https://docs.mongodb.com/manual/reference/operator/aggregation/addFields/#pipe._S_addFields) 阶段所依赖,但自身不依赖其他,所以会新建一个 [`$match`](https://docs.mongodb.com/manual/reference/operator/aggregation/match/#pipe._S_match) 阶段,并将其置于 [`$project`](https://docs.mongodb.com/manual/reference/operator/aggregation/project/#pipe._S_project) 阶段之前。
|
||||
|
||||
#### Pipeline 并行优化
|
||||
|
||||
如果可能,优化阶段会将 Pipeline 阶段合并到其前身。通常,合并发生在任意序列重新排序优化之后。
|
||||
|
||||
##### `$sort` + `$limit`
|
||||
|
||||
当 [`$sort`](https://docs.mongodb.com/manual/reference/operator/aggregation/sort/#pipe._S_sort) 在 [`$limit`](https://docs.mongodb.com/manual/reference/operator/aggregation/limit/#pipe._S_limit) 之前时,如果没有中间阶段修改文档数量(例如 [`$unwind`](https://docs.mongodb.com/manual/reference/operator/aggregation/unwind/#pipe._S_unwind)、[`$group`](https://docs.mongodb.com/manual/reference/operator/aggregation/group/#pipe._S_group)),则优化程序可以将 [`$limit`](https://docs.mongodb.com/manual/reference/operator/aggregation/limit/#pipe._S_limit) 合并到 [`$sort`](https://docs.mongodb.com/manual/reference/operator/aggregation/sort/#pipe._S_sort) 中。如果有管道阶段更改了 [`$sort`](https://docs.mongodb.com/manual/reference/operator/aggregation/sort/#pipe._S_sort) 和 [`$limit`](https://docs.mongodb.com/manual/reference/operator/aggregation/limit/#pipe._S_limit) 阶段之间的文档数,则 MongoDB 不会将 [`$limit`](https://docs.mongodb.com/manual/reference/operator/aggregation/limit/#pipe._S_limit) 合并到 [`$sort`](https://docs.mongodb.com/manual/reference/operator/aggregation/sort/#pipe._S_sort) 中。
|
||||
|
||||
【示例】`$sort` + `$limit`
|
||||
|
||||
优化前:
|
||||
|
||||
```javascript
|
||||
{ $sort : { age : -1 } },
|
||||
{ $project : { age : 1, status : 1, name : 1 } },
|
||||
{ $limit: 5 }
|
||||
```
|
||||
|
||||
优化后:
|
||||
|
||||
```javascript
|
||||
{
|
||||
"$sort" : {
|
||||
"sortKey" : {
|
||||
"age" : -1
|
||||
},
|
||||
"limit" : NumberLong(5)
|
||||
}
|
||||
},
|
||||
{ "$project" : {
|
||||
"age" : 1,
|
||||
"status" : 1,
|
||||
"name" : 1
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
##### `$limit` + `$limit`
|
||||
|
||||
如果一个 [`$limit`](https://docs.mongodb.com/manual/reference/operator/aggregation/limit/#pipe._S_limit) 紧随另一个 [`$limit`](https://docs.mongodb.com/manual/reference/operator/aggregation/limit/#pipe._S_limit),那么它们可以合并为一。
|
||||
|
||||
优化前:
|
||||
|
||||
```javascript
|
||||
{ $limit: 100 },
|
||||
{ $limit: 10 }
|
||||
```
|
||||
|
||||
优化后:
|
||||
|
||||
```javascript
|
||||
{
|
||||
$limit: 10
|
||||
}
|
||||
```
|
||||
|
||||
##### `$skip` + `$skip`
|
||||
|
||||
如果一个 [`$skip`](https://docs.mongodb.com/manual/reference/operator/aggregation/skip/#pipe._S_skip) 紧随另一个 [`$skip`](https://docs.mongodb.com/manual/reference/operator/aggregation/skip/#pipe._S_skip) ,那么它们可以合并为一。
|
||||
|
||||
优化前:
|
||||
|
||||
```javascript
|
||||
{ $skip: 5 },
|
||||
{ $skip: 2 }
|
||||
```
|
||||
|
||||
优化后:
|
||||
|
||||
```javascript
|
||||
{
|
||||
$skip: 7
|
||||
}
|
||||
```
|
||||
|
||||
##### `$match` + `$match`
|
||||
|
||||
如果一个 [`$skip`](https://docs.mongodb.com/manual/reference/operator/aggregation/skip/#pipe._S_skip) 紧随另一个 [`$skip`](https://docs.mongodb.com/manual/reference/operator/aggregation/skip/#pipe._S_skip) ,那么它们可以通过 [`$and`](https://docs.mongodb.com/manual/reference/operator/aggregation/and/#exp._S_and) 合并为一。
|
||||
|
||||
优化前:
|
||||
|
||||
```javascript
|
||||
{ $match: { year: 2014 } },
|
||||
{ $match: { status: "A" } }
|
||||
```
|
||||
|
||||
优化后:
|
||||
|
||||
```javascript
|
||||
{
|
||||
$match: {
|
||||
$and: [{ year: 2014 }, { status: 'A' }]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
##### `$lookup` + `$unwind`
|
||||
|
||||
如果一个 [`$unwind`](https://docs.mongodb.com/manual/reference/operator/aggregation/unwind/#pipe._S_unwind) 紧随另一个 [`$lookup`](https://docs.mongodb.com/manual/reference/operator/aggregation/lookup/#pipe._S_lookup),并且 [`$unwind`](https://docs.mongodb.com/manual/reference/operator/aggregation/unwind/#pipe._S_unwind) 在 [`$lookup`](https://docs.mongodb.com/manual/reference/operator/aggregation/lookup/#pipe._S_lookup) 的 as 字段上运行时,优化程序可以将 [`$unwind`](https://docs.mongodb.com/manual/reference/operator/aggregation/unwind/#pipe._S_unwind) 合并到 [`$lookup`](https://docs.mongodb.com/manual/reference/operator/aggregation/lookup/#pipe._S_lookup) 阶段。这样可以避免创建较大的中间文档。
|
||||
|
||||
优化前:
|
||||
|
||||
```javascript
|
||||
{
|
||||
$lookup: {
|
||||
from: "otherCollection",
|
||||
as: "resultingArray",
|
||||
localField: "x",
|
||||
foreignField: "y"
|
||||
}
|
||||
},
|
||||
{ $unwind: "$resultingArray"}
|
||||
```
|
||||
|
||||
优化后:
|
||||
|
||||
```javascript
|
||||
{
|
||||
$lookup: {
|
||||
from: "otherCollection",
|
||||
as: "resultingArray",
|
||||
localField: "x",
|
||||
foreignField: "y",
|
||||
unwinding: { preserveNullAndEmptyArrays: false }
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Pipeline 限制
|
||||
|
||||
结果集中的每个文档均受 BSON 文档大小限制(当前为 16 MB)
|
||||
|
||||
Pipeline 的内存限制为 100 MB。
|
||||
|
||||
## Map-Reduce
|
||||
|
||||
> 聚合 pipeline 比 map-reduce 提供更好的性能和更一致的接口。
|
||||
|
||||
Map-reduce 是一种数据处理范式,用于将大量数据汇总为有用的聚合结果。为了执行 map-reduce 操作,MongoDB 提供了 [`mapReduce`](https://docs.mongodb.com/manual/reference/command/mapReduce/#dbcmd.mapReduce) 数据库命令。
|
||||
|
||||

|
||||
|
||||
在上面的操作中,MongoDB 将 map 阶段应用于每个输入 document(即 collection 中与查询条件匹配的 document)。 map 函数分发出多个键-值对。对于具有多个值的那些键,MongoDB 应用 reduce 阶段,该阶段收集并汇总聚合的数据。然后,MongoDB 将结果存储在 collection 中。可选地,reduce 函数的输出可以通过 finalize 函数来进一步汇总聚合结果。
|
||||
|
||||
MongoDB 中的所有 map-reduce 函数都是 JavaScript,并在 mongod 进程中运行。 Map-reduce 操作将单个 collection 的 document 作为输入,并且可以在开始 map 阶段之前执行任意排序和限制。 mapReduce 可以将 map-reduce 操作的结果作为 document 返回,也可以将结果写入 collection。
|
||||
|
||||
## 单一目的聚合方法
|
||||
|
||||
MongoDB 支持一下单一目的的聚合操作:
|
||||
|
||||
- [`db.collection.estimatedDocumentCount()`](https://docs.mongodb.com/manual/reference/method/db.collection.estimatedDocumentCount/#db.collection.estimatedDocumentCount)
|
||||
- [`db.collection.count()`](https://docs.mongodb.com/manual/reference/method/db.collection.count/#db.collection.count)
|
||||
- [`db.collection.distinct()`](https://docs.mongodb.com/manual/reference/method/db.collection.distinct/#db.collection.distinct)
|
||||
|
||||
所有这些操作都汇总了单个 collection 中的 document。尽管这些操作提供了对常见聚合过程的简单访问,但是它们相比聚合 pipeline 和 map-reduce,缺少灵活性和丰富的功能性。
|
||||
|
||||

|
||||
|
||||
## SQL 和 MongoDB 聚合对比
|
||||
|
||||
MongoDB pipeline 提供了许多等价于 SQL 中常见聚合语句的操作。
|
||||
|
||||
下表概述了常见的 SQL 聚合语句或函数和 MongoDB 聚合操作的映射表:
|
||||
|
||||
| SQL Terms, Functions, and Concepts | MongoDB Aggregation Operators |
|
||||
| :--------------------------------- | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| `WHERE` | [`$match`](https://docs.mongodb.com/manual/reference/operator/aggregation/match/#pipe._S_match) |
|
||||
| `GROUP BY` | [`$group`](https://docs.mongodb.com/manual/reference/operator/aggregation/group/#pipe._S_group) |
|
||||
| `HAVING` | [`$match`](https://docs.mongodb.com/manual/reference/operator/aggregation/match/#pipe._S_match) |
|
||||
| `SELECT` | [`$project`](https://docs.mongodb.com/manual/reference/operator/aggregation/project/#pipe._S_project) |
|
||||
| `ORDER BY` | [`$sort`](https://docs.mongodb.com/manual/reference/operator/aggregation/sort/#pipe._S_sort) |
|
||||
| `LIMIT` | [`$limit`](https://docs.mongodb.com/manual/reference/operator/aggregation/limit/#pipe._S_limit) |
|
||||
| `SUM()` | [`$sum`](https://docs.mongodb.com/manual/reference/operator/aggregation/sum/#grp._S_sum) |
|
||||
| `COUNT()` | [`$sum`](https://docs.mongodb.com/manual/reference/operator/aggregation/sum/#grp._S_sum)[`$sortByCount`](https://docs.mongodb.com/manual/reference/operator/aggregation/sortByCount/#pipe._S_sortByCount) |
|
||||
| `JOIN` | [`$lookup`](https://docs.mongodb.com/manual/reference/operator/aggregation/lookup/#pipe._S_lookup) |
|
||||
| `SELECT INTO NEW_TABLE` | [`$out`](https://docs.mongodb.com/manual/reference/operator/aggregation/out/#pipe._S_out) |
|
||||
| `MERGE INTO TABLE` | [`$merge`](https://docs.mongodb.com/manual/reference/operator/aggregation/merge/#pipe._S_merge) (Available starting in MongoDB 4.2) |
|
||||
| `UNION ALL` | [`$unionWith`](https://docs.mongodb.com/manual/reference/operator/aggregation/unionWith/#pipe._S_unionWith) (Available starting in MongoDB 4.4) |
|
||||
|
||||
【示例】
|
||||
|
||||
```javascript
|
||||
db.orders.insertMany([
|
||||
{
|
||||
_id: 1,
|
||||
cust_id: 'Ant O. Knee',
|
||||
ord_date: new Date('2020-03-01'),
|
||||
price: 25,
|
||||
items: [
|
||||
{ sku: 'oranges', qty: 5, price: 2.5 },
|
||||
{ sku: 'apples', qty: 5, price: 2.5 },
|
||||
],
|
||||
status: 'A',
|
||||
},
|
||||
{
|
||||
_id: 2,
|
||||
cust_id: 'Ant O. Knee',
|
||||
ord_date: new Date('2020-03-08'),
|
||||
price: 70,
|
||||
items: [
|
||||
{ sku: 'oranges', qty: 8, price: 2.5 },
|
||||
{ sku: 'chocolates', qty: 5, price: 10 },
|
||||
],
|
||||
status: 'A',
|
||||
},
|
||||
{
|
||||
_id: 3,
|
||||
cust_id: 'Busby Bee',
|
||||
ord_date: new Date('2020-03-08'),
|
||||
price: 50,
|
||||
items: [
|
||||
{ sku: 'oranges', qty: 10, price: 2.5 },
|
||||
{ sku: 'pears', qty: 10, price: 2.5 },
|
||||
],
|
||||
status: 'A',
|
||||
},
|
||||
{
|
||||
_id: 4,
|
||||
cust_id: 'Busby Bee',
|
||||
ord_date: new Date('2020-03-18'),
|
||||
price: 25,
|
||||
items: [{ sku: 'oranges', qty: 10, price: 2.5 }],
|
||||
status: 'A',
|
||||
},
|
||||
{
|
||||
_id: 5,
|
||||
cust_id: 'Busby Bee',
|
||||
ord_date: new Date('2020-03-19'),
|
||||
price: 50,
|
||||
items: [{ sku: 'chocolates', qty: 5, price: 10 }],
|
||||
status: 'A',
|
||||
},
|
||||
{
|
||||
_id: 6,
|
||||
cust_id: 'Cam Elot',
|
||||
ord_date: new Date('2020-03-19'),
|
||||
price: 35,
|
||||
items: [
|
||||
{ sku: 'carrots', qty: 10, price: 1.0 },
|
||||
{ sku: 'apples', qty: 10, price: 2.5 },
|
||||
],
|
||||
status: 'A',
|
||||
},
|
||||
{
|
||||
_id: 7,
|
||||
cust_id: 'Cam Elot',
|
||||
ord_date: new Date('2020-03-20'),
|
||||
price: 25,
|
||||
items: [{ sku: 'oranges', qty: 10, price: 2.5 }],
|
||||
status: 'A',
|
||||
},
|
||||
{
|
||||
_id: 8,
|
||||
cust_id: 'Don Quis',
|
||||
ord_date: new Date('2020-03-20'),
|
||||
price: 75,
|
||||
items: [
|
||||
{ sku: 'chocolates', qty: 5, price: 10 },
|
||||
{ sku: 'apples', qty: 10, price: 2.5 },
|
||||
],
|
||||
status: 'A',
|
||||
},
|
||||
{
|
||||
_id: 9,
|
||||
cust_id: 'Don Quis',
|
||||
ord_date: new Date('2020-03-20'),
|
||||
price: 55,
|
||||
items: [
|
||||
{ sku: 'carrots', qty: 5, price: 1.0 },
|
||||
{ sku: 'apples', qty: 10, price: 2.5 },
|
||||
{ sku: 'oranges', qty: 10, price: 2.5 },
|
||||
],
|
||||
status: 'A',
|
||||
},
|
||||
{
|
||||
_id: 10,
|
||||
cust_id: 'Don Quis',
|
||||
ord_date: new Date('2020-03-23'),
|
||||
price: 25,
|
||||
items: [{ sku: 'oranges', qty: 10, price: 2.5 }],
|
||||
status: 'A',
|
||||
},
|
||||
])
|
||||
```
|
||||
|
||||
SQL 和 MongoDB 聚合方式对比:
|
||||
|
||||

|
||||
|
||||
## 参考资料
|
||||
|
||||
- **官方**
|
||||
- [MongoDB 官网](https://www.mongodb.com/)
|
||||
- [MongoDBGithub](https://github.com/mongodb/mongo)
|
||||
- [MongoDB 官方免费教程](https://university.mongodb.com/)
|
||||
- **教程**
|
||||
- [MongoDB 教程](https://www.runoob.com/mongodb/mongodb-tutorial.html)
|
||||
- [MongoDB 高手课](https://time.geekbang.org/course/intro/100040001)
|
||||
|
|
@ -0,0 +1,56 @@
|
|||
# MongoDB 索引
|
||||
|
||||
## MongoDB 索引简介
|
||||
|
||||
### 索引的作用
|
||||
|
||||
**MongoDB 在 collection 数据级别上定义索引**。
|
||||
|
||||
索引通常能够极大的提高查询的效率。如果**没有索引**,MongoDB 在读取数据时**必须扫描 collection 中的每个 document** 并选取那些符合查询条件的记录。
|
||||
|
||||
这种扫描全集合的查询是非常低效的,特别是在处理大量的数据时。查询可能要花费几十秒甚至几分钟,这种性能开销是不可接受的。
|
||||
|
||||
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构。
|
||||
|
||||

|
||||
|
||||
### createIndex() 方法
|
||||
|
||||
**MongoDB 使用 `createIndex()` 方法来创建索引**。
|
||||
|
||||
`createIndex()` 语法如下:
|
||||
|
||||
```javascript
|
||||
db.collection.createIndex( <key and index type specification>, <options> )
|
||||
```
|
||||
|
||||
`createIndex()` 可选参数列表如下:
|
||||
|
||||
| Parameter | Type | Description |
|
||||
| :----------------- | :------------ | :----------------------------------------------------------- |
|
||||
| background | Boolean | 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 "background" 可选参数。 "background" 默认值为**false**。 |
|
||||
| unique | Boolean | 建立的索引是否唯一。指定为true创建唯一索引。默认值为**false**. |
|
||||
| name | string | 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。 |
|
||||
| dropDups | Boolean | **3.0+版本已废弃。**在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 **false**. |
|
||||
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 **false**. |
|
||||
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。 |
|
||||
| v | index version | 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。 |
|
||||
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
|
||||
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 |
|
||||
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language. |
|
||||
|
||||
【示例】使用 name 作为索引,并且按照降序排序
|
||||
|
||||
```
|
||||
db.collection.createIndex( { name: -1 } )
|
||||
```
|
||||
|
||||
## 参考资料
|
||||
|
||||
- **官方**
|
||||
- [MongoDB 官网](https://www.mongodb.com/)
|
||||
- [MongoDBGithub](https://github.com/mongodb/mongo)
|
||||
- [MongoDB 官方免费教程](https://university.mongodb.com/)
|
||||
- **教程**
|
||||
- [MongoDB 教程](https://www.runoob.com/mongodb/mongodb-tutorial.html)
|
||||
- [MongoDB 高手课](https://time.geekbang.org/course/intro/100040001)
|
||||
Loading…
Reference in New Issue