mirror of https://github.com/dunwu/db-tutorial.git
docs: 文档整理
parent
3feda7eaa4
commit
e551e3019c
|
|
@ -1,6 +1,6 @@
|
|||
<p align="center">
|
||||
<a href="https://dunwu.github.io/db-tutorial/" target="_blank" rel="noopener noreferrer">
|
||||
<img src="http://dunwu.test.upcdn.net/common/logo/dunwu-logo.png" alt="logo" width="150px"/>
|
||||
<img src="https://raw.githubusercontent.com/dunwu/images/dev/common/dunwu-logo-200.png" alt="logo" width="150px"/>
|
||||
</a>
|
||||
</p>
|
||||
|
||||
|
|
@ -31,7 +31,7 @@
|
|||
|
||||
#### [Mysql](docs/sql/mysql) 📚
|
||||
|
||||
|
||||
|
||||
|
||||
- [Mysql 应用指南](docs/sql/mysql/mysql-quickstart.md) ⚡
|
||||
- [Mysql 工作流](docs/sql/mysql/mysql-index.md) - 关键词:`连接`、`缓存`、`语法分析`、`优化`、`执行引擎`、`redo log`、`bin log`、`两阶段提交`
|
||||
|
|
@ -57,7 +57,7 @@
|
|||
|
||||
#### [Redis](docs/nosql/redis) 📚
|
||||
|
||||
|
||||
|
||||
|
||||
- [Redis 面试总结](docs/nosql/redis/redis-interview.md) 💯
|
||||
- [Redis 应用指南](docs/nosql/redis/redis-quickstart.md) ⚡ - 关键词:`内存淘汰`、`事件`、`事务`、`管道`、`发布与订阅`
|
||||
|
|
|
|||
|
|
@ -15,7 +15,7 @@ module.exports = {
|
|||
},
|
||||
},
|
||||
themeConfig: {
|
||||
logo: 'images/dunwu-logo-100.png',
|
||||
logo: 'https://raw.githubusercontent.com/dunwu/images/dev/common/dunwu-logo-200.png',
|
||||
repo: 'dunwu/db-tutorial',
|
||||
repoLabel: 'Github',
|
||||
docsDir: 'docs',
|
||||
|
|
@ -77,6 +77,17 @@ module.exports = {
|
|||
updatePopup: true,
|
||||
},
|
||||
],
|
||||
[
|
||||
'@vuepress/last-updated',
|
||||
{
|
||||
transformer: (timestamp, lang) => {
|
||||
// 不要忘了安装 moment
|
||||
const moment = require('moment')
|
||||
moment.locale(lang)
|
||||
return moment(timestamp).fromNow()
|
||||
},
|
||||
},
|
||||
],
|
||||
['@vuepress/medium-zoom', true],
|
||||
[
|
||||
'container',
|
||||
|
|
|
|||
|
|
@ -1,14 +1,12 @@
|
|||
---
|
||||
home: true
|
||||
heroImage: /images/dunwu-logo-200.png
|
||||
heroImage: https://raw.githubusercontent.com/dunwu/images/dev/common/dunwu-logo-200.png
|
||||
heroText: DB-TUTORIAL
|
||||
tagline: 💾 db-tutorial 是一个数据库教程。
|
||||
actionLink: /
|
||||
footer: CC-BY-SA-4.0 Licensed | Copyright © 2018-Now Dunwu
|
||||
---
|
||||
|
||||
# DB-TUTORIAL
|
||||
|
||||

|
||||

|
||||
|
||||
|
|
@ -32,7 +30,7 @@ footer: CC-BY-SA-4.0 Licensed | Copyright © 2018-Now Dunwu
|
|||
|
||||
#### [Mysql](sql/mysql) 📚
|
||||
|
||||

|
||||

|
||||
|
||||
- [Mysql 应用指南](sql/mysql/mysql-quickstart.md) ⚡
|
||||
- [Mysql 工作流](sql/mysql/mysql-index.md) - 关键词:`连接`、`缓存`、`语法分析`、`优化`、`执行引擎`、`redo log`、`bin log`、`两阶段提交`
|
||||
|
|
@ -58,7 +56,7 @@ footer: CC-BY-SA-4.0 Licensed | Copyright © 2018-Now Dunwu
|
|||
|
||||
#### [Redis](nosql/redis) 📚
|
||||
|
||||

|
||||

|
||||
|
||||
- [Redis 面试总结](nosql/redis/redis-interview.md) 💯
|
||||
- [Redis 应用指南](nosql/redis/redis-quickstart.md) ⚡ - 关键词:`内存淘汰`、`事件`、`事务`、`管道`、`发布与订阅`
|
||||
|
|
|
|||
|
|
@ -386,7 +386,7 @@ migrations 最常用的编写形式就是 SQL。
|
|||
|
||||
为了被 Flyway 自动识别,SQL migrations 的文件命名必须遵循规定的模式:
|
||||
|
||||

|
||||

|
||||
|
||||
- **Prefix** - `V` 代表 versioned migrations (可配置), `U` 代表 undo migrations (可配置)、 `R` 代表 repeatable migrations (可配置)
|
||||
- **Version** - 版本号通过`.`(点)或`_`(下划线)分隔 (repeatable migrations 不需要)
|
||||
|
|
@ -405,7 +405,7 @@ migrations 最常用的编写形式就是 SQL。
|
|||
|
||||
为了被 Flyway 自动识别,JAVA migrations 的文件命名必须遵循规定的模式:
|
||||
|
||||

|
||||

|
||||
|
||||
- **Prefix** - `V` 代表 versioned migrations (可配置), `U` 代表 undo migrations (可配置)、 `R` 代表 repeatable migrations (可配置)
|
||||
- **Version** - 版本号通过`.`(点)或`_`(下划线)分隔 (repeatable migrations 不需要)
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ shardingsphere-jdbc 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供
|
|||
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等。
|
||||
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,Oracle,SQLServer,PostgreSQL 以及任何遵循 SQL92 标准的数据库。
|
||||
|
||||

|
||||
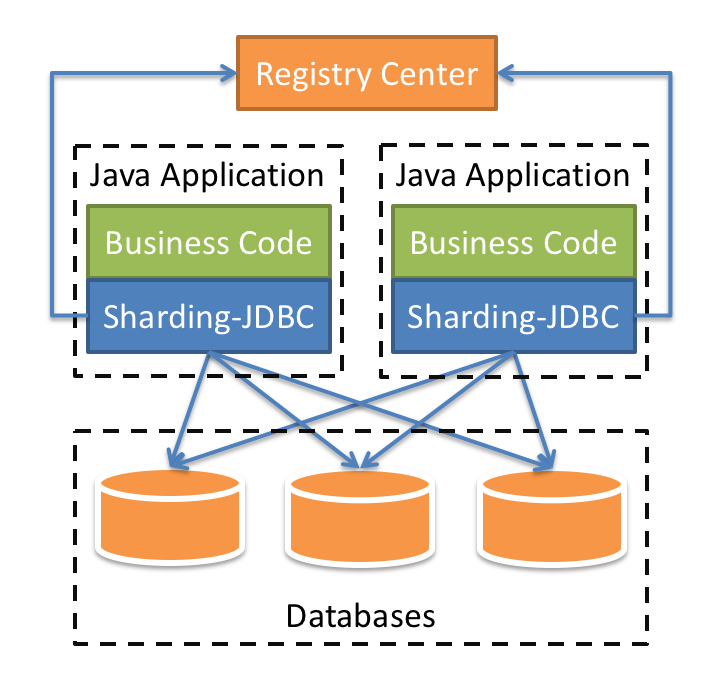
|
||||
|
||||
## 快速入门
|
||||
|
||||
|
|
@ -74,14 +74,14 @@ DataSource dataSource = ShardingSphereDataSourceFactory.createDataSource(dataSou
|
|||
|
||||
ShardingSphere 的 3 个产品的数据分片主要流程是完全一致的。 核心由 `SQL 解析 => 执行器优化 => SQL 路由 => SQL 改写 => SQL 执行 => 结果归并`的流程组成。
|
||||
|
||||

|
||||
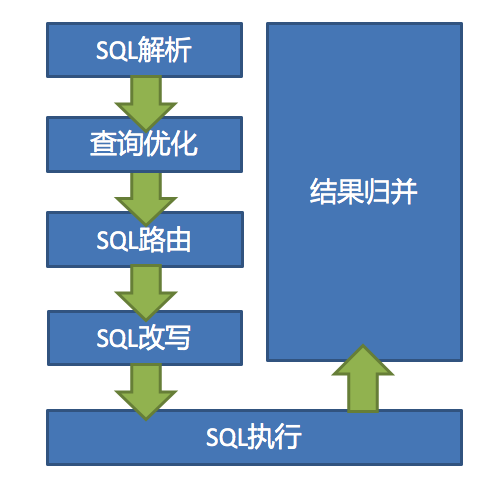
|
||||
|
||||
- QL 解析:分为词法解析和语法解析。 先通过词法解析器将 SQL 拆分为一个个不可再分的单词。再使用语法解析器对 SQL 进行理解,并最终提炼出解析上下文。 解析上下文包括表、选择项、排序项、分组项、聚合函数、分页信息、查询条件以及可能需要修改的占位符的标记。
|
||||
- 执行器优化:合并和优化分片条件,如 OR 等。
|
||||
- SQL 路由:根据解析上下文匹配用户配置的分片策略,并生成路由路径。目前支持分片路由和广播路由。
|
||||
- SQL 改写:将 SQL 改写为在真实数据库中可以正确执行的语句。SQL 改写分为正确性改写和优化改写。
|
||||
- SQL 执行:通过多线程执行器异步执行。
|
||||
- 结果归并:将多个执行结果集归并以便于通过统一的 JDBC 接口输出。结果归并包括流式归并、内存归并和使用装饰者模式的追加归并这几种方式。
|
||||
- 结果归并:将多个执行结果集归并以便于通过统一的 JDBC 接口输出。结果归并包括流式归并、内存归并和使用装饰模式的追加归并这几种方式。
|
||||
|
||||
### 解析引擎
|
||||
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@
|
|||
|
||||
ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar(计划中)这 3 款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
|
||||
|
||||

|
||||
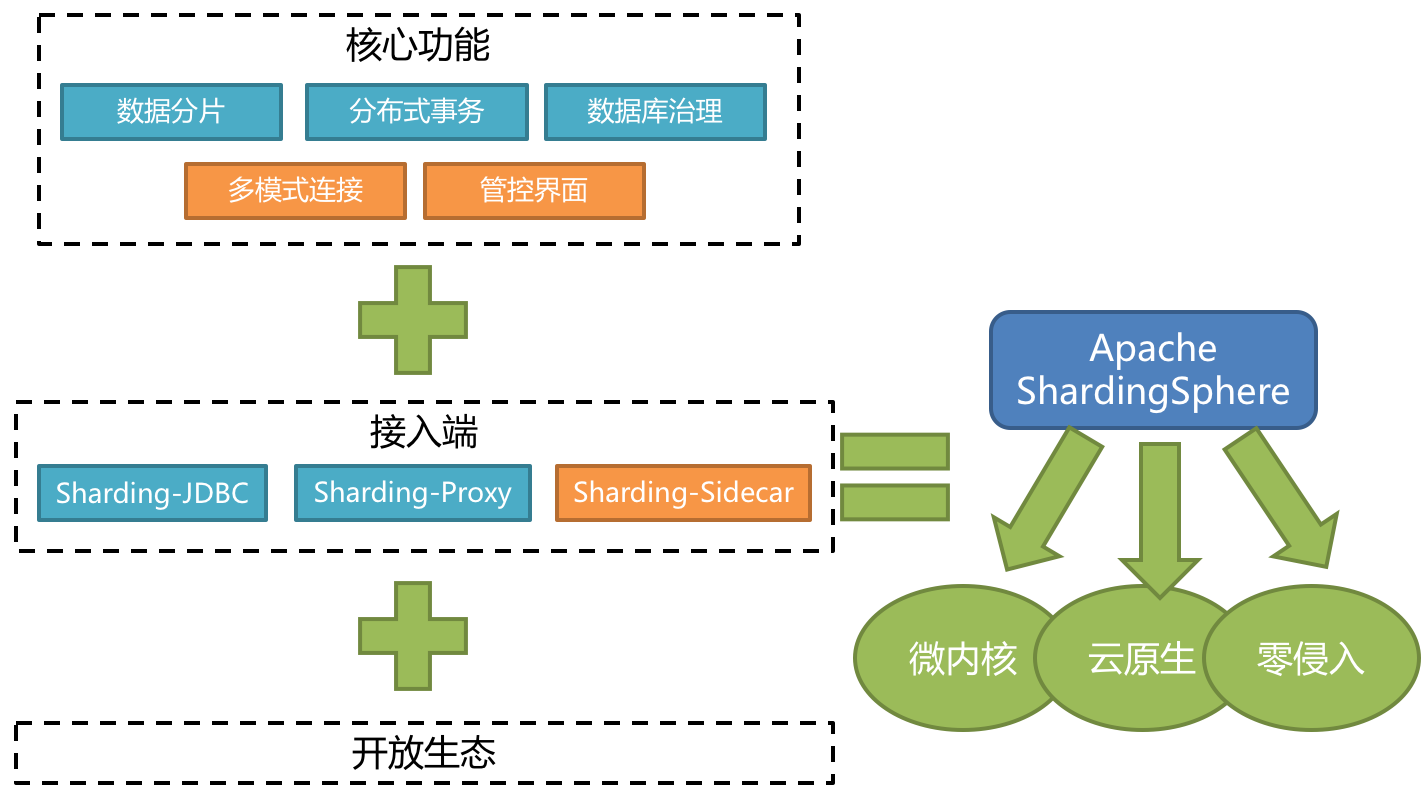
|
||||
|
||||
#### ShardingSphere-JDBC
|
||||
|
||||
|
|
@ -16,7 +16,7 @@ ShardingSphere 是一套开源的分布式数据库中间件解决方案组成
|
|||
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等。
|
||||
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,Oracle,SQLServer,PostgreSQL 以及任何遵循 SQL92 标准的数据库。
|
||||
|
||||

|
||||

|
||||
|
||||
#### Sharding-Proxy
|
||||
|
||||
|
|
@ -25,7 +25,7 @@ ShardingSphere 是一套开源的分布式数据库中间件解决方案组成
|
|||
- 向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用。
|
||||
- 适用于任何兼容 MySQL/PostgreSQL 协议的的客户端。
|
||||
|
||||

|
||||
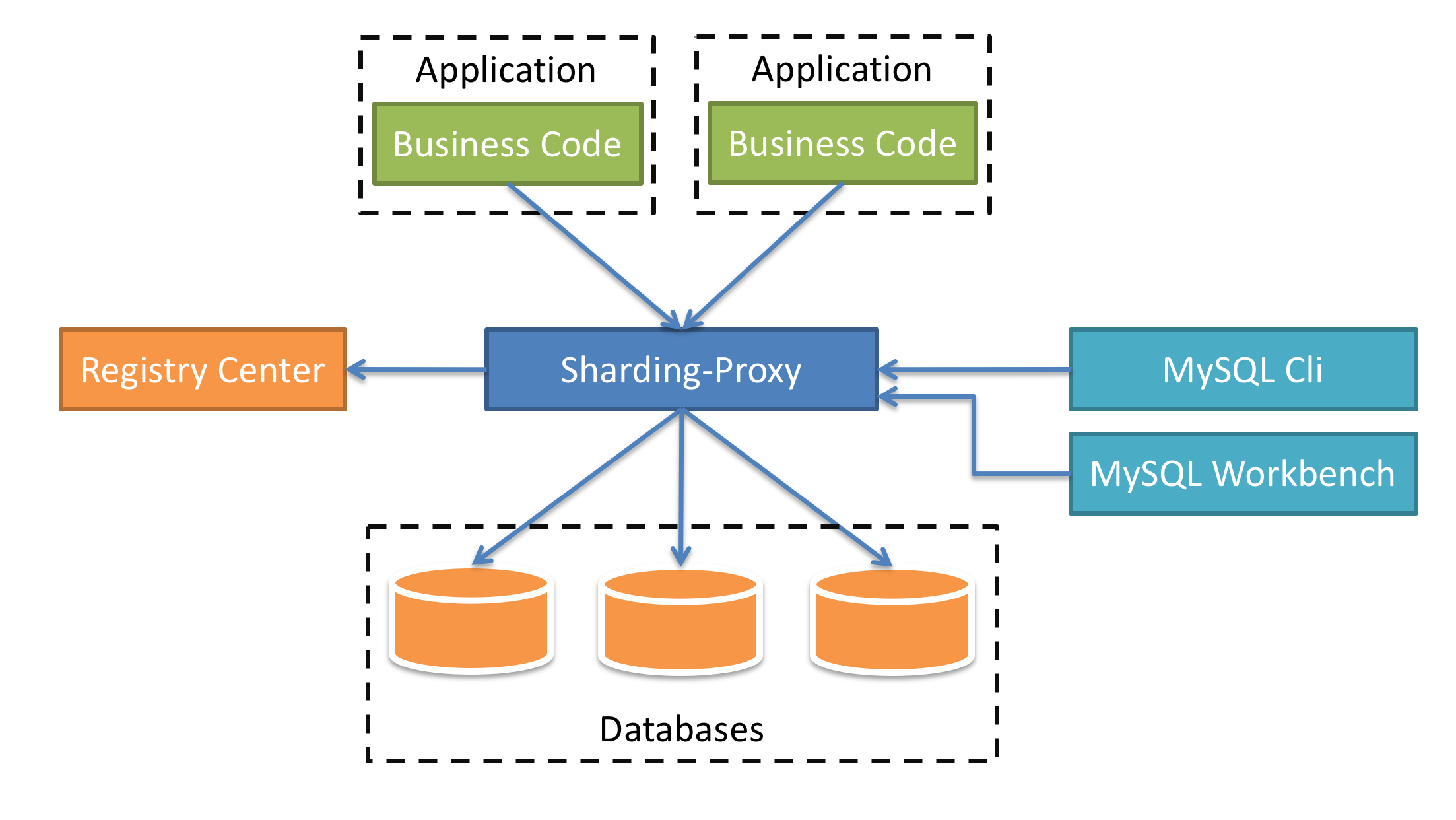
|
||||
|
||||
#### Sharding-Sidecar(TODO)
|
||||
|
||||
|
|
@ -33,7 +33,7 @@ ShardingSphere 是一套开源的分布式数据库中间件解决方案组成
|
|||
|
||||
Database Mesh 的关注重点在于如何将分布式的数据访问应用与数据库有机串联起来,它更加关注的是交互,是将杂乱无章的应用与数据库之间的交互进行有效地梳理。 使用 Database Mesh,访问数据库的应用和数据库终将形成一个巨大的网格体系,应用和数据库只需在网格体系中对号入座即可,它们都是被啮合层所治理的对象。
|
||||
|
||||

|
||||
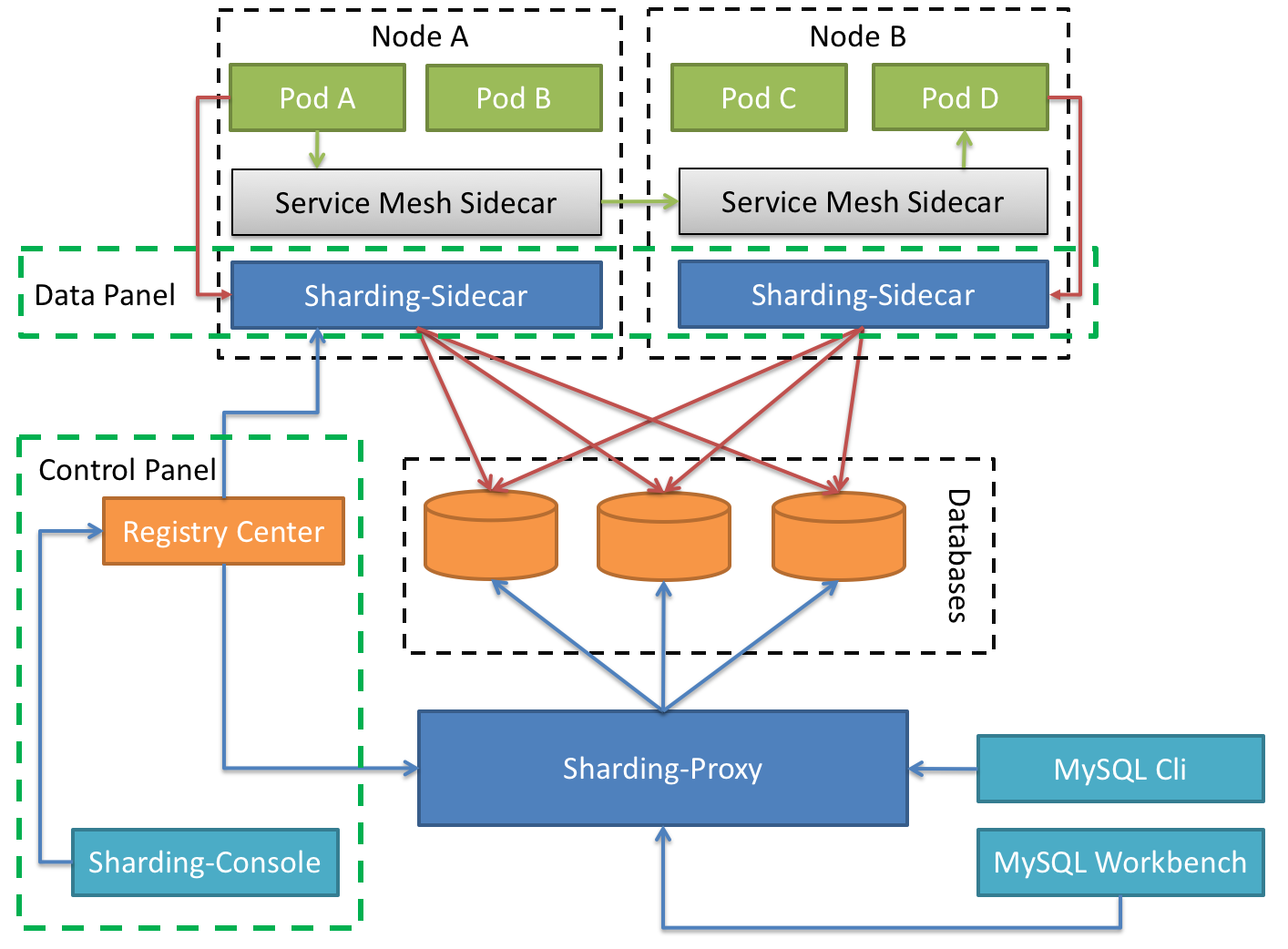
|
||||
|
||||
| _Sharding-JDBC_ | _Sharding-Proxy_ | _Sharding-Sidecar_ | |
|
||||
| :-------------- | :--------------- | :----------------- | ------ |
|
||||
|
|
@ -50,7 +50,7 @@ ShardingSphere-JDBC 采用无中心化架构,适用于 Java 开发的高性能
|
|||
|
||||
Apache ShardingSphere 是多接入端共同组成的生态圈。 通过混合使用 ShardingSphere-JDBC 和 ShardingSphere-Proxy,并采用同一注册中心统一配置分片策略,能够灵活的搭建适用于各种场景的应用系统,使得架构师更加自由地调整适合与当前业务的最佳系统架构。
|
||||
|
||||

|
||||
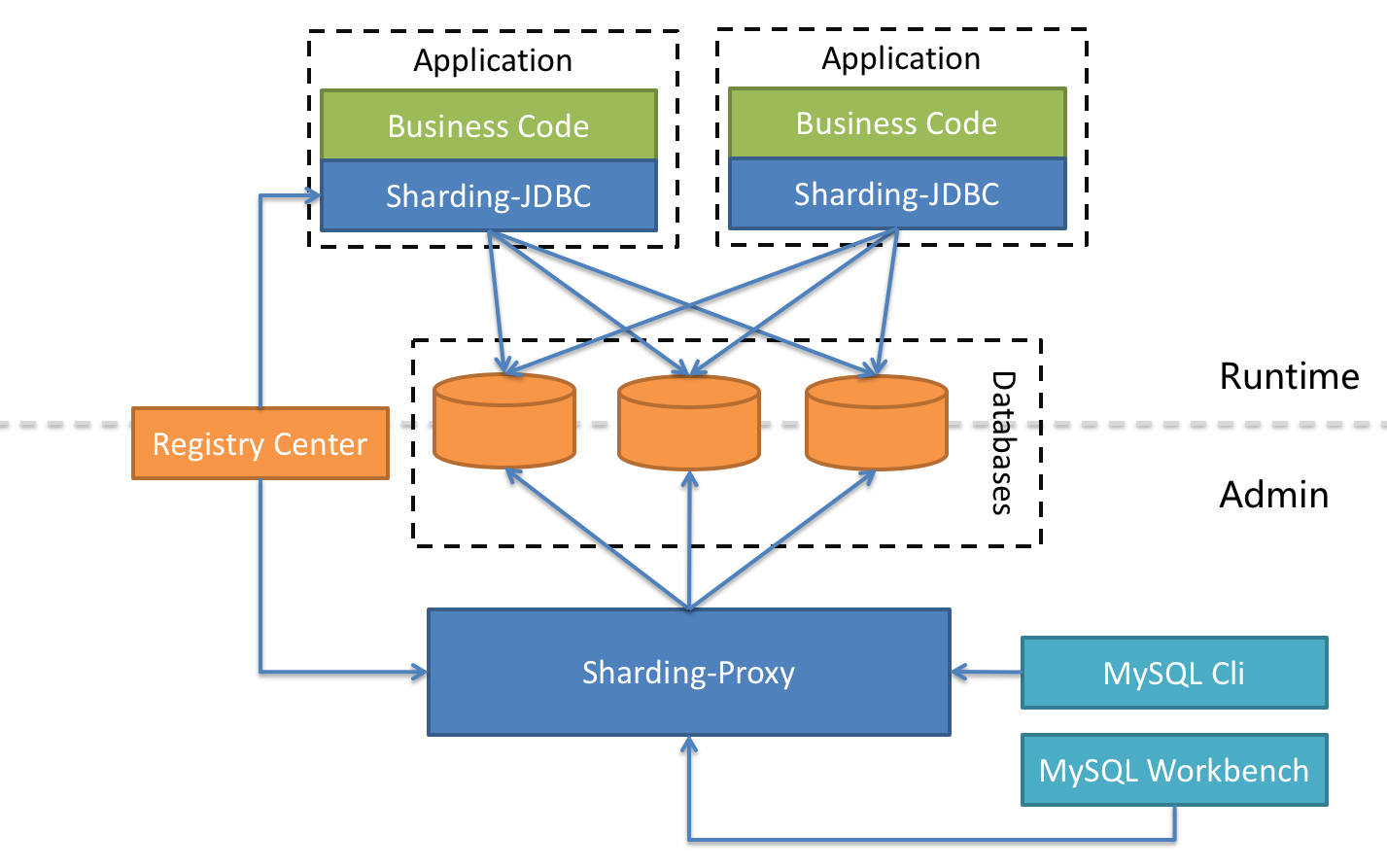
|
||||
|
||||
### 功能列表
|
||||
|
||||
|
|
|
|||
|
|
@ -45,17 +45,17 @@ HBase 表模型结构为:
|
|||
- 列族(column family)是列的集合。
|
||||
- 列(row)是键值对的集合。
|
||||
|
||||

|
||||
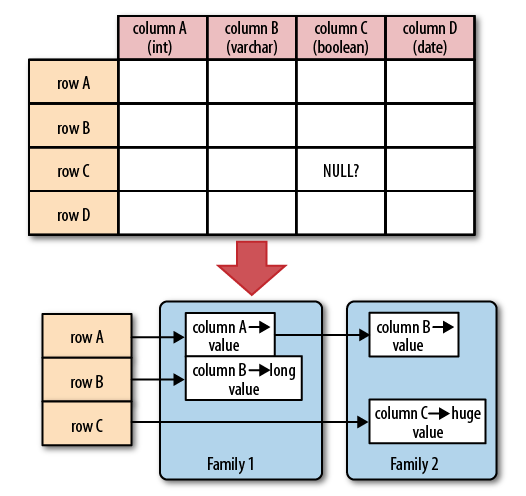
|
||||
|
||||
HBase 表的单元格(cell)由行和列的坐标交叉决定,是有版本的。默认情况下,版本号是自动分配的,为 HBase 插入单元格时的时间戳。单元格的内容是未解释的字节数组。
|
||||
|
||||
行的键也是未解释的字节数组,所以理论上,任何数据都可以通过序列化表示成字符串或二进制,从而存为 HBase 的键值。
|
||||
|
||||

|
||||
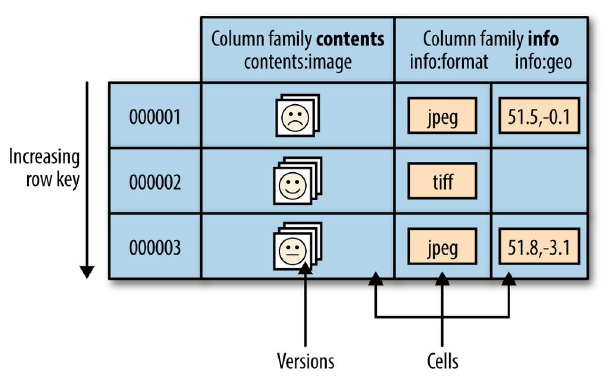
|
||||
|
||||
### HBase 架构
|
||||
|
||||

|
||||
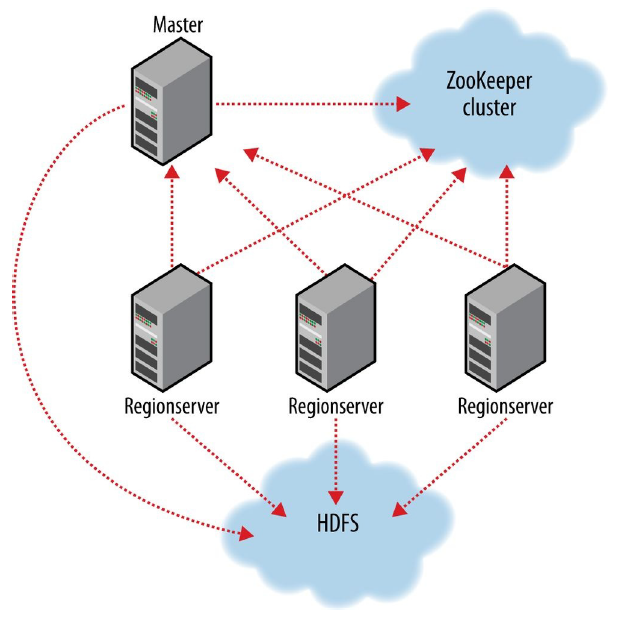
|
||||
|
||||
和 HDFS、YARN 一样,HBase 也采用 master / slave 架构:
|
||||
|
||||
|
|
@ -70,7 +70,7 @@ HBase 表按行键范围水平自动划分为区域(region)。每个区域
|
|||
|
||||
**区域只不过是表被拆分,并分布在区域服务器。**
|
||||
|
||||

|
||||
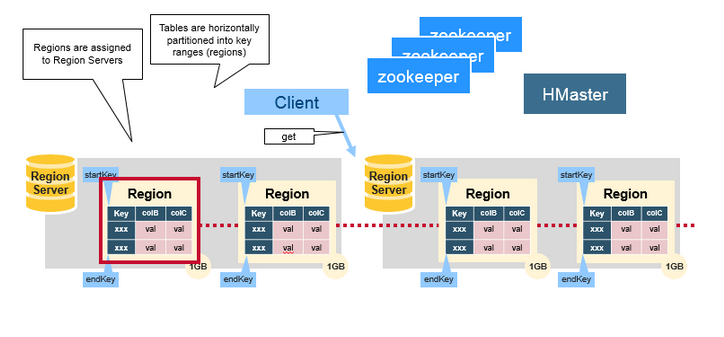
|
||||
|
||||
#### Master 服务器
|
||||
|
||||
|
|
@ -81,7 +81,7 @@ HBase 表按行键范围水平自动划分为区域(region)。每个区域
|
|||
- 监控集群中的所有 region 服务器
|
||||
- 支持 DDL 接口(创建、删除、更新表)
|
||||
|
||||

|
||||
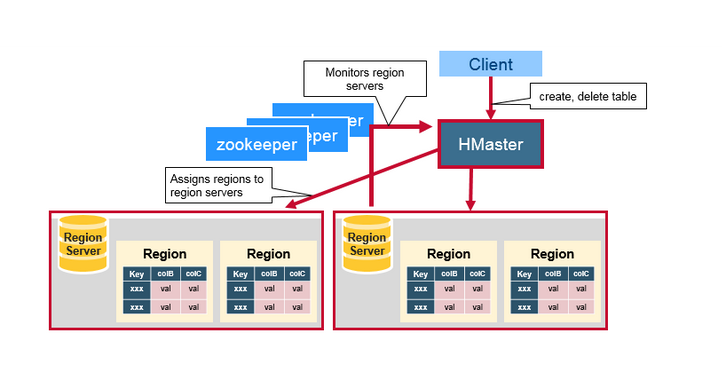
|
||||
|
||||
#### Regin 服务器
|
||||
|
||||
|
|
@ -93,13 +93,13 @@ HBase 表按行键范围水平自动划分为区域(region)。每个区域
|
|||
- `MemStore` - 是写缓存。它存储尚未写入磁盘的新数据。在写入磁盘之前对其进行排序。每个区域每个列族有一个 MemStore。
|
||||
- `Hfiles` - 将行存储为磁盘上的排序键值对。
|
||||
|
||||

|
||||
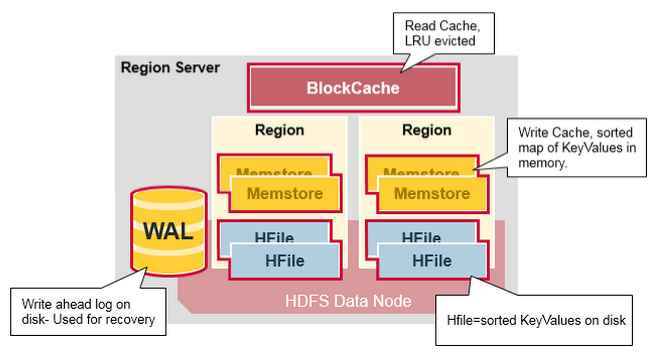
|
||||
|
||||
#### ZooKeeper
|
||||
|
||||
HBase 使用 ZooKeeper 作为分布式协调服务来维护集群中的服务器状态。Zookeeper 维护哪些服务器是活动的和可用的,并提供服务器故障通知。集群至少应该有 3 个节点。
|
||||
|
||||

|
||||
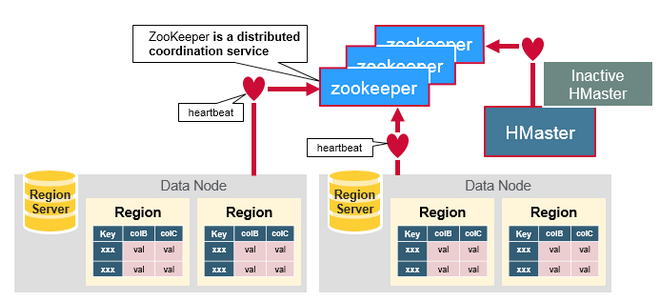
|
||||
|
||||
## HBase 和 RDBMS
|
||||
|
||||
|
|
|
|||
|
|
@ -14,7 +14,7 @@ MongoDB Pipeline 由多个阶段([stages](https://docs.mongodb.com/manual/refe
|
|||
|
||||
同一个阶段可以在 pipeline 中出现多次,但 [`$out`](https://docs.mongodb.com/manual/reference/operator/aggregation/out/#pipe._S_out)、[`$merge`](https://docs.mongodb.com/manual/reference/operator/aggregation/merge/#pipe._S_merge),和 [`$geoNear`](https://docs.mongodb.com/manual/reference/operator/aggregation/geoNear/#pipe._S_geoNear) 阶段除外。所有可用 pipeline 阶段可以参考:[Aggregation Pipeline Stages](https://docs.mongodb.com/manual/reference/operator/aggregation-pipeline/#aggregation-pipeline-operator-reference)。
|
||||
|
||||

|
||||
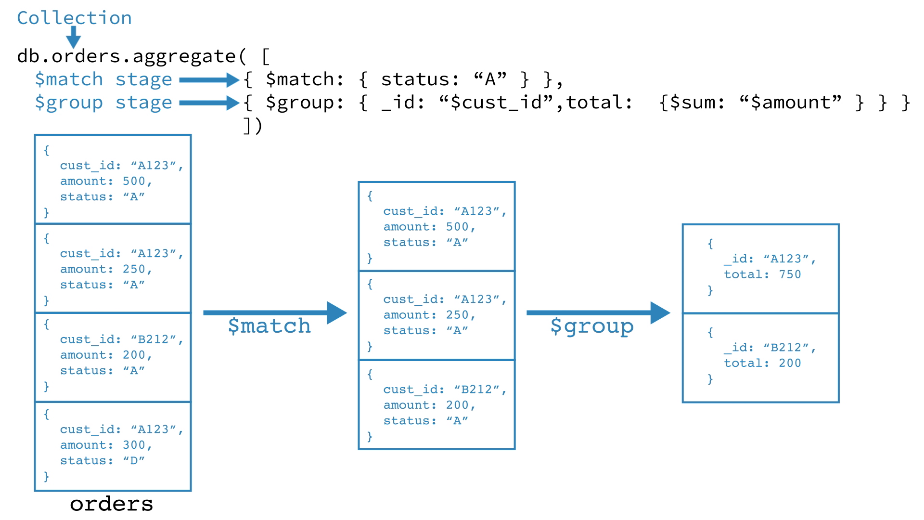
|
||||
|
||||
- 第一阶段:[`$match`](https://docs.mongodb.com/manual/reference/operator/aggregation/match/#pipe._S_match) 阶段按状态字段过滤 document,然后将状态等于“ A”的那些 document 传递到下一阶段。
|
||||
- 第二阶段:[`$group`](https://docs.mongodb.com/manual/reference/operator/aggregation/group/#pipe._S_group) 阶段按 cust_id 字段对 document 进行分组,以计算每个唯一 cust_id 的金额总和。
|
||||
|
|
@ -224,7 +224,7 @@ Pipeline 的内存限制为 100 MB。
|
|||
|
||||
Map-reduce 是一种数据处理范式,用于将大量数据汇总为有用的聚合结果。为了执行 map-reduce 操作,MongoDB 提供了 [`mapReduce`](https://docs.mongodb.com/manual/reference/command/mapReduce/#dbcmd.mapReduce) 数据库命令。
|
||||
|
||||

|
||||

|
||||
|
||||
在上面的操作中,MongoDB 将 map 阶段应用于每个输入 document(即 collection 中与查询条件匹配的 document)。 map 函数分发出多个键-值对。对于具有多个值的那些键,MongoDB 应用 reduce 阶段,该阶段收集并汇总聚合的数据。然后,MongoDB 将结果存储在 collection 中。可选地,reduce 函数的输出可以通过 finalize 函数来进一步汇总聚合结果。
|
||||
|
||||
|
|
@ -240,7 +240,7 @@ MongoDB 支持一下单一目的的聚合操作:
|
|||
|
||||
所有这些操作都汇总了单个 collection 中的 document。尽管这些操作提供了对常见聚合过程的简单访问,但是它们相比聚合 pipeline 和 map-reduce,缺少灵活性和丰富的功能性。
|
||||
|
||||

|
||||

|
||||
|
||||
## SQL 和 MongoDB 聚合对比
|
||||
|
||||
|
|
@ -371,7 +371,7 @@ db.orders.insertMany([
|
|||
|
||||
SQL 和 MongoDB 聚合方式对比:
|
||||
|
||||

|
||||

|
||||
|
||||
## 参考资料
|
||||
|
||||
|
|
|
|||
|
|
@ -17,7 +17,7 @@ MongoDB 提供以下操作向一个 collection 插入 document
|
|||
|
||||
> 注:以上操作都是原子操作。
|
||||
|
||||

|
||||

|
||||
|
||||
插入操作的特性:
|
||||
|
||||
|
|
@ -66,7 +66,7 @@ db.inventory.insertMany([
|
|||
|
||||
MongoDB 提供 [`db.collection.find()`](https://docs.mongodb.com/manual/reference/method/db.collection.find/#db.collection.find) 方法来检索 document。
|
||||
|
||||

|
||||

|
||||
|
||||
### Update 操作
|
||||
|
||||
|
|
@ -82,7 +82,7 @@ MongoDB 提供以下操作来更新 collection 中的 document
|
|||
- [`db.collection.updateMany(<filter>, <update>, <options>)`](https://docs.mongodb.com/manual/reference/method/db.collection.updateMany/#db.collection.updateMany)
|
||||
- [`db.collection.replaceOne(<filter>, <update>, <options>)`](https://docs.mongodb.com/manual/reference/method/db.collection.replaceOne/#db.collection.replaceOne)
|
||||
|
||||

|
||||

|
||||
|
||||
【示例】插入测试数据
|
||||
|
||||
|
|
@ -191,7 +191,7 @@ MongoDB 提供以下操作来删除 collection 中的 document
|
|||
- [`db.collection.deleteOne()`](https://docs.mongodb.com/manual/reference/method/db.collection.deleteOne/#db.collection.deleteOne):删除一条 document
|
||||
- [`db.collection.deleteMany()`](https://docs.mongodb.com/manual/reference/method/db.collection.deleteMany/#db.collection.deleteMany):删除多条 document
|
||||
|
||||

|
||||

|
||||
|
||||
删除操作的特性:
|
||||
|
||||
|
|
|
|||
|
|
@ -12,7 +12,7 @@
|
|||
|
||||
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构。
|
||||
|
||||

|
||||

|
||||
|
||||
### createIndex() 方法
|
||||
|
||||
|
|
|
|||
|
|
@ -371,7 +371,7 @@ review collection 存储所有的评论
|
|||
|
||||
## 树形结构模型
|
||||
|
||||

|
||||

|
||||
|
||||
### 具有父节点的树形结构模型
|
||||
|
||||
|
|
@ -525,7 +525,7 @@ db.categories.insertMany([
|
|||
|
||||
### 具有嵌套集的树形结构模型
|
||||
|
||||

|
||||

|
||||
|
||||
```javascript
|
||||
db.categories.insertMany([
|
||||
|
|
@ -554,7 +554,7 @@ db.categories.find({
|
|||
|
||||
解决方案是:列转行
|
||||
|
||||

|
||||

|
||||
|
||||
### 管理文档不同版本
|
||||
|
||||
|
|
|
|||
|
|
@ -125,7 +125,7 @@ This looks very different from the tabular data structure you started with in St
|
|||
|
||||
嵌入式 document 通过将相关数据存储在单个 document 结构中来捕获数据之间的关系。 MongoDB document 可以将 document 结构嵌入到另一个 document 中的字段或数组中。这些非规范化的数据模型允许应用程序在单个数据库操作中检索和操纵相关数据。
|
||||
|
||||

|
||||

|
||||
|
||||
对于 MongoDB 中的很多场景,非规范化数据模型都是最佳的。
|
||||
|
||||
|
|
@ -137,7 +137,7 @@ This looks very different from the tabular data structure you started with in St
|
|||
|
||||
引用通过包含从一个 document 到另一个 document 的链接或引用来存储数据之间的关系。 应用程序可以解析这些引用以访问相关数据。 广义上讲,这些是规范化的数据模型。
|
||||
|
||||

|
||||
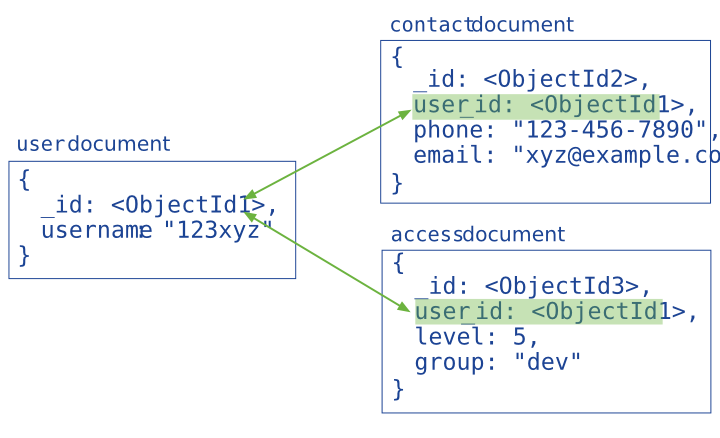
|
||||
|
||||
通常,在以下场景使用引用式的数据模型:
|
||||
|
||||
|
|
|
|||
|
|
@ -28,15 +28,15 @@ MongoDB 中的副本集是一组维护相同数据集的 mongod 进程。一个
|
|||
|
||||
**主节点负责接收所有写操作**。副本集只能有一个主副本,能够以 [`{ w: "majority" }`](https://docs.mongodb.com/manual/reference/write-concern/#writeconcern."majority") 来确认集群中节点的写操作成功情况;尽管在某些情况下,另一个 MongoDB 实例可能会暂时认为自己也是主要的。主节点在其操作日志(即 [oplog](https://docs.mongodb.com/manual/core/replica-set-oplog/))中记录了对其数据集的所有更改。
|
||||
|
||||

|
||||

|
||||
|
||||
**从节点复制主节点的操作日志,并将操作应用于其数据集**,以便同步主节点的数据。如果主节点不可用,则符合条件的从节点将选举新的主节点。
|
||||
|
||||

|
||||

|
||||
|
||||
在某些情况下(例如,有一个主节点和一个从节点,但由于成本限制,禁止添加另一个从节点),您可以选择将 mongod 实例作为仲裁节点添加到副本集。仲裁节点参加选举但不保存数据(即不提供数据冗余)。
|
||||
|
||||

|
||||

|
||||
|
||||
仲裁节点将永远是仲裁节点。在选举期间,主节点可能会降级成为次节点,而次节点可能会升级成为主节点。
|
||||
|
||||
|
|
@ -62,7 +62,7 @@ MongoDB 中的副本集是一组维护相同数据集的 mongod 进程。一个
|
|||
|
||||
当主节点与集群中的其他成员通信的时间超过配置的 `electionTimeoutMillis`(默认为 10 秒)时,符合选举要求的从节点将要求选举,并提名自己为新的主节点。集群尝试完成选举新主节点并恢复正常工作。
|
||||
|
||||

|
||||

|
||||
|
||||
选举完成前,副本集无法处理写入操作。如果将副本集配置为:在主节点处于脱机状态时,在次节点上运行,则副本集可以继续提供读取查询。
|
||||
|
||||
|
|
@ -80,7 +80,7 @@ MongoDB 中的副本集是一组维护相同数据集的 mongod 进程。一个
|
|||
|
||||
默认情况下,客户端从主节点读取数据;但是,客户端可以指定读取首选项,以将读取操作发送到从节点。
|
||||
|
||||

|
||||

|
||||
|
||||
异步复制到从节点意味着向从节点读取数据可能会返回与主节点不一致的数据。
|
||||
|
||||
|
|
|
|||
|
|
@ -36,7 +36,7 @@ MongoDB 分片集群含以下组件:
|
|||
- [mongos](https://docs.mongodb.com/manual/core/sharded-cluster-query-router/):mongos 充当查询路由器,在客户端应用程序和分片集群之间提供接口。从 MongoDB 4.4 开始,mongos 可以支持 [hedged reads](https://docs.mongodb.com/manual/core/sharded-cluster-query-router/#mongos-hedged-reads) 以最大程度地减少延迟。
|
||||
- [config servers](https://docs.mongodb.com/manual/core/sharded-cluster-config-servers/):提供集群元数据存储和分片数据分布的映射。
|
||||
|
||||

|
||||

|
||||
|
||||
### 分片集群的分布
|
||||
|
||||
|
|
@ -48,7 +48,7 @@ MongoDB 数据库可以同时包含分片和未分片的集合的 collection。
|
|||
|
||||
分片和未分片的 collection:
|
||||
|
||||

|
||||

|
||||
|
||||
### 路由节点 mongos
|
||||
|
||||
|
|
@ -56,7 +56,7 @@ MongoDB 数据库可以同时包含分片和未分片的集合的 collection。
|
|||
|
||||
连接 [`mongos`](https://docs.mongodb.com/manual/reference/program/mongos/#bin.mongos) 的方式和连接 [`mongod`](https://docs.mongodb.com/manual/reference/program/mongod/#bin.mongod) 相同,例如通过 [`mongo`](https://docs.mongodb.com/manual/reference/program/mongo/#bin.mongo) shell 或 [MongoDB 驱动程序](https://docs.mongodb.com/drivers/?jump=docs)。
|
||||
|
||||

|
||||

|
||||
|
||||
路由节点的作用:
|
||||
|
||||
|
|
@ -103,7 +103,7 @@ Hash 分片策略会先计算分片 Key 字段值的哈希值;然后,根据
|
|||
|
||||
> 注意:使用哈希索引解析查询时,MongoDB 会自动计算哈希值,应用程序不需要计算哈希。
|
||||
|
||||

|
||||

|
||||
|
||||
尽管分片 Key 范围可能是“接近”的,但它们的哈希值不太可能在同一 [chunk](https://docs.mongodb.com/manual/reference/glossary/#term-chunk) 上。基于 Hash 的数据分发有助于更均匀的数据分布,尤其是在分片 Key 单调更改的数据集中。
|
||||
|
||||
|
|
@ -113,7 +113,7 @@ Hash 分片策略会先计算分片 Key 字段值的哈希值;然后,根据
|
|||
|
||||
范围分片根据分片 Key 值将数据划分为多个范围。然后,根据分片 Key 值为每个 [chunk](https://docs.mongodb.com/manual/reference/glossary/#term-chunk) 分配一个范围。
|
||||
|
||||

|
||||

|
||||
|
||||
值比较近似的一系列分片 Key 更有可能驻留在同一 [chunk](https://docs.mongodb.com/manual/reference/glossary/#term-chunk) 上。范围分片的效率取决于选择的分片 Key。分片 Key 考虑不周全会导致数据分布不均,这可能会削弱分片的某些优势或导致性能瓶颈。
|
||||
|
||||
|
|
@ -125,7 +125,7 @@ Hash 分片策略会先计算分片 Key 字段值的哈希值;然后,根据
|
|||
|
||||
每个区域覆盖一个或多个分片 Key 值范围。区域覆盖的每个范围始终包括其上下边界。
|
||||
|
||||

|
||||

|
||||
|
||||
在定义要覆盖的区域的新范围时,必须使用分片 Key 中包含的字段。如果使用复合分片 Key,则范围必须包含分片 Key 的前缀。
|
||||
|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
# Nosql 技术选型
|
||||
|
||||

|
||||
|
||||
|
||||
[TOC]
|
||||
|
||||
|
|
@ -16,7 +16,7 @@
|
|||
|
||||
随着大数据时代的到来,越来越多的网站、应用系统需要支撑海量数据存储,高并发请求、高可用、高可扩展性等特性要求。传统的关系型数据库在应付这些调整已经显得力不从心,暴露了许多能以克服的问题。由此,各种各样的 NoSQL(Not Only SQL)数据库作为传统关系型数据的一个有力补充得到迅猛发展。
|
||||
|
||||

|
||||

|
||||
|
||||
**NoSQL,泛指非关系型的数据库**,可以理解为 SQL 的一个有力补充。
|
||||
|
||||
|
|
@ -45,7 +45,7 @@
|
|||
|
||||
将表放入存储系统中有两种方法,而我们绝大部分是采用行存储的。 行存储法是将各行放入连续的物理位置,这很像传统的记录和文件系统。 列存储法是将数据按照列存储到数据库中,与行存储类似,下图是两种存储方法的图形化解释:
|
||||
|
||||

|
||||
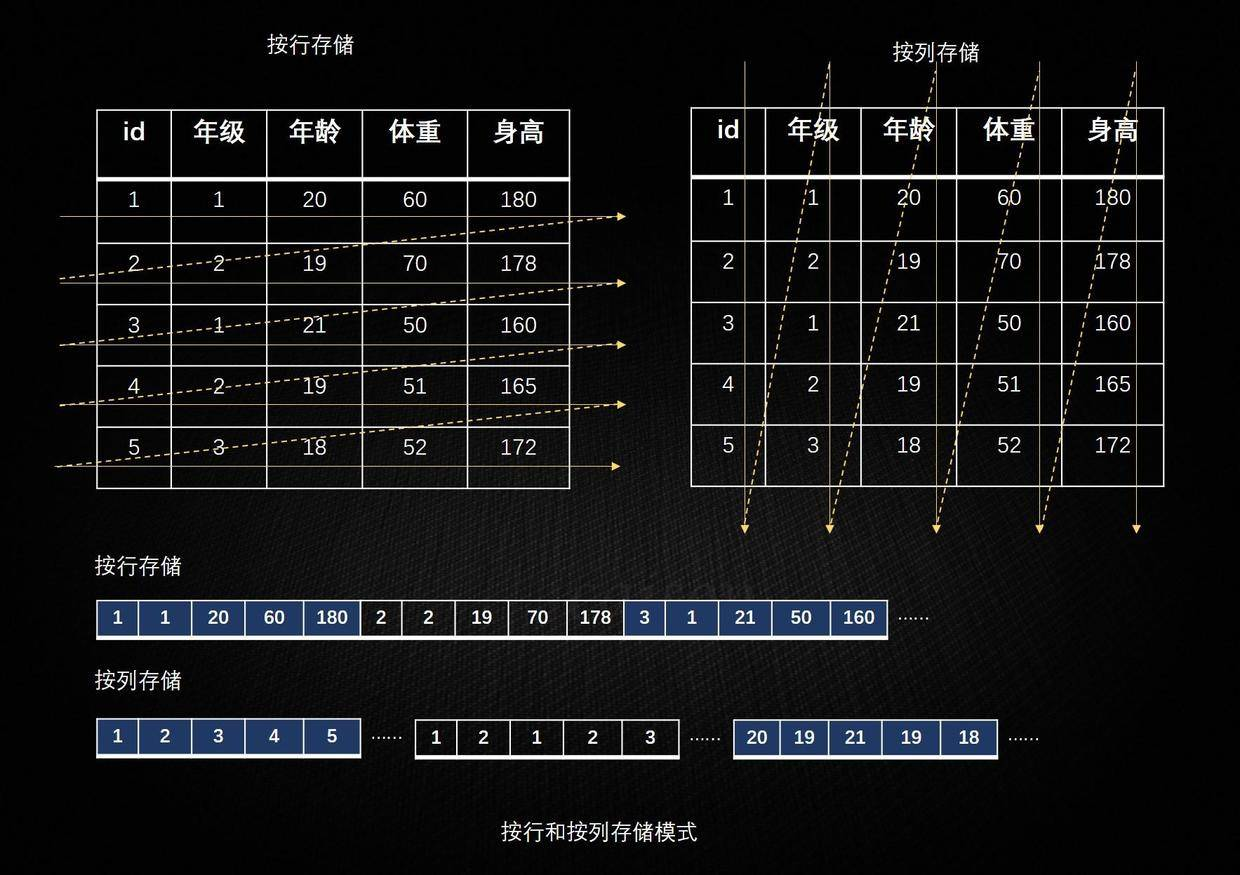
|
||||
|
||||
### 列式数据库产品
|
||||
|
||||
|
|
@ -69,13 +69,13 @@
|
|||
|
||||
列式数据库由于其针对不同列的数据特征而发明的不同算法,使其**往往有比行式数据库高的多的压缩率**,普通的行式数据库一般压缩率在 3:1 到 5:1 左右,而列式数据库的压缩率一般在 8:1 到 30:1 左右。 比较常见的,通过字典表压缩数据: 下面中才是那张表本来的样子。经过字典表进行数据压缩后,表中的字符串才都变成数字了。正因为每个字符串在字典表里只出现一次了,所以达到了压缩的目的(有点像规范化和非规范化 Normalize 和 Denomalize)
|
||||
|
||||

|
||||
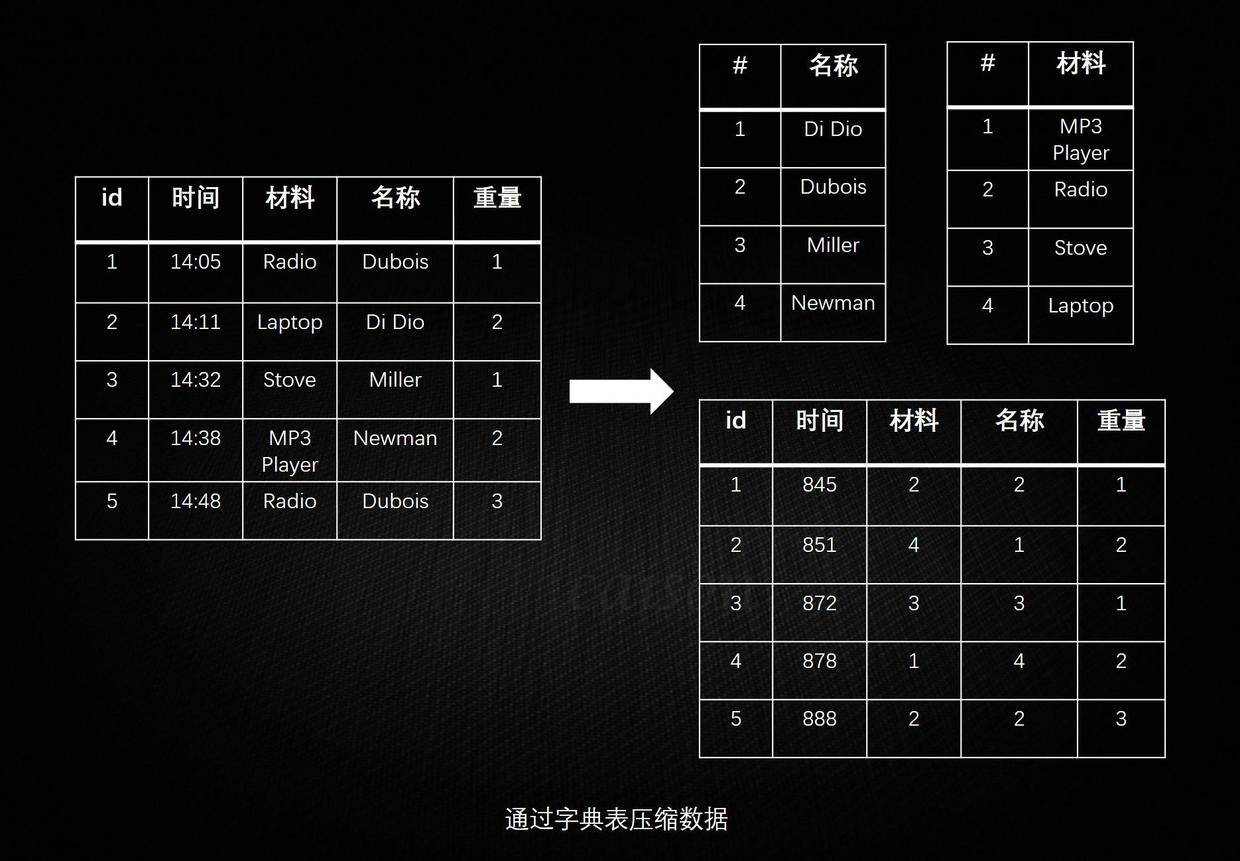
|
||||
|
||||
- **查询效率高**
|
||||
|
||||
读取多条数据的同一列效率高,因为这些列都是存储在一起的,一次磁盘操作可以数据的指定列全部读取到内存中。 下图通过一条查询的执行过程说明列式存储(以及数据压缩)的优点
|
||||
|
||||

|
||||
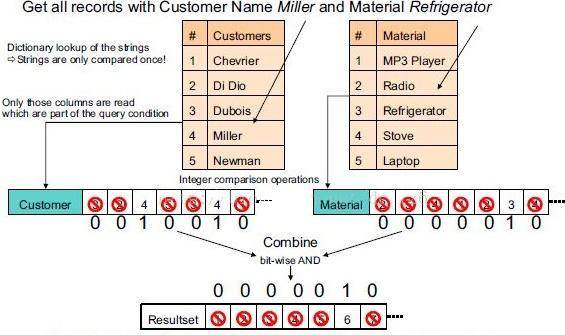
|
||||
|
||||
```
|
||||
执行步骤如下:
|
||||
|
|
@ -116,19 +116,19 @@ KV 存储非常适合存储**不涉及过多数据关系业务关系的数据**
|
|||
|
||||
- Redis
|
||||
|
||||

|
||||

|
||||
|
||||
Redis 是一个使用 ANSI C 编写的开源、支持网络、基于内存、可选持久性的键值对存储数据库。从 2015 年 6 月开始,Redis 的开发由 Redis Labs 赞助,而 2013 年 5 月至 2015 年 6 月期间,其开发由 Pivotal 赞助。在 2013 年 5 月之前,其开发由 VMware 赞助。根据月度排行网站 DB-Engines.com 的数据显示,Redis 是最流行的键值对存储数据库。
|
||||
|
||||
- Cassandra
|
||||
|
||||

|
||||

|
||||
|
||||
Apache Cassandra(社区内一般简称为 C\*)是一套开源分布式 NoSQL 数据库系统。它最初由 Facebook 开发,用于储存收件箱等简单格式数据,集 Google BigTable 的数据模型与 Amazon Dynamo 的完全分布式架构于一身。Facebook 于 2008 将 Cassandra 开源,此后,由于 Cassandra 良好的可扩展性和性能,被 Apple, Comcast,Instagram, Spotify, eBay, Rackspace, Netflix 等知名网站所采用,成为了一种流行的分布式结构化数据存储方案。
|
||||
|
||||
- LevelDB
|
||||
|
||||

|
||||

|
||||
|
||||
LevelDB 是一个由 Google 公司所研发的键/值对(Key/Value Pair)嵌入式数据库管理系统编程库, 以开源的 BSD 许可证发布。
|
||||
|
||||
|
|
@ -165,13 +165,13 @@ KV 存储非常适合存储**不涉及过多数据关系业务关系的数据**
|
|||
|
||||
- MongoDB
|
||||
|
||||

|
||||

|
||||
|
||||
**MongoDB**是一种面向文档的数据库管理系统,由 C++ 撰写而成,以此来解决应用程序开发社区中的大量现实问题。2007 年 10 月,MongoDB 由 10gen 团队所发展。2009 年 2 月首度推出。
|
||||
|
||||
- CouchDB
|
||||
|
||||

|
||||

|
||||
|
||||
Apache CouchDB 是一个开源数据库,专注于易用性和成为"**完全拥抱 web 的数据库**"。它是一个使用 JSON 作为存储格式,JavaScript 作为查询语言,MapReduce 和 HTTP 作为 API 的 NoSQL 数据库。其中一个显著的功能就是多主复制。CouchDB 的第一个版本发布在 2005 年,在 2008 年成为了 Apache 的项目。
|
||||
|
||||
|
|
@ -223,11 +223,11 @@ MongonDB 还是支持多文档事务的 Consistency(一致性)和 Durability(持
|
|||
|
||||
现在有如下文档集合:
|
||||
|
||||

|
||||

|
||||
|
||||
正排索引得到索引如下:
|
||||
|
||||

|
||||
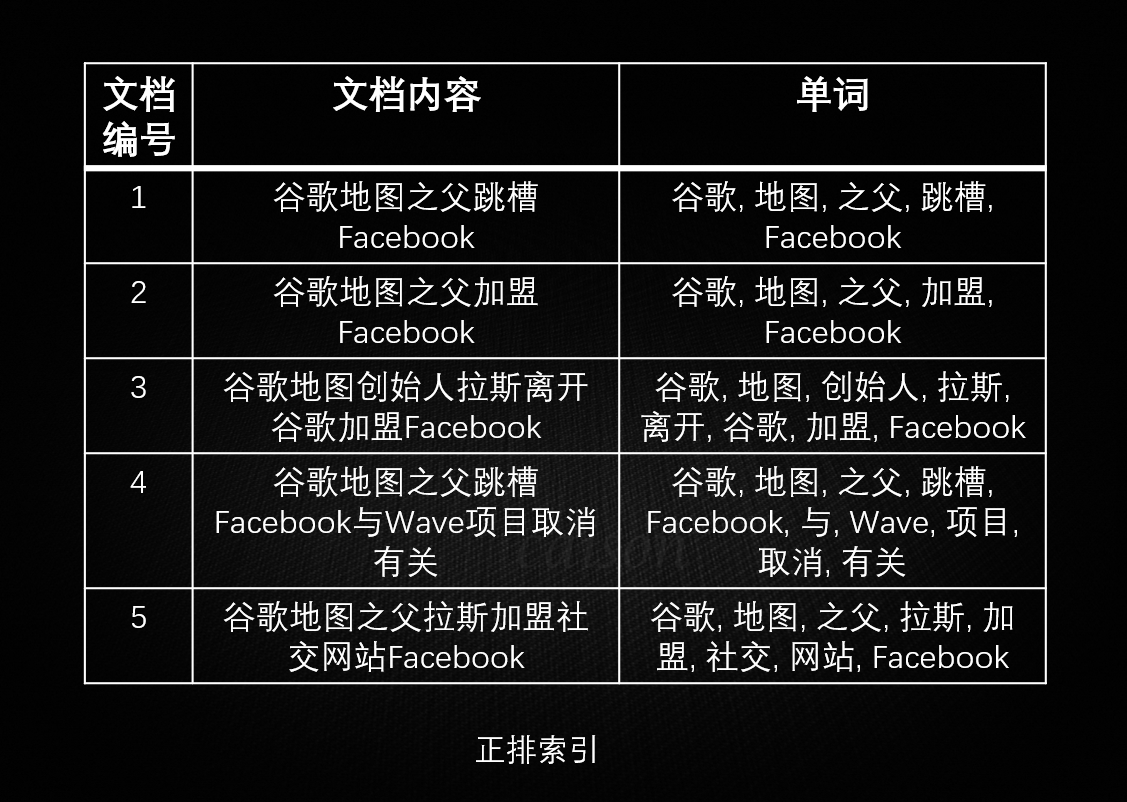
|
||||
|
||||
可见,正排索引适用于根据文档名称查询文档内容
|
||||
|
||||
|
|
@ -237,7 +237,7 @@ MongonDB 还是支持多文档事务的 Consistency(一致性)和 Durability(持
|
|||
|
||||
带有单词频率信息的倒排索引如下:
|
||||
|
||||

|
||||
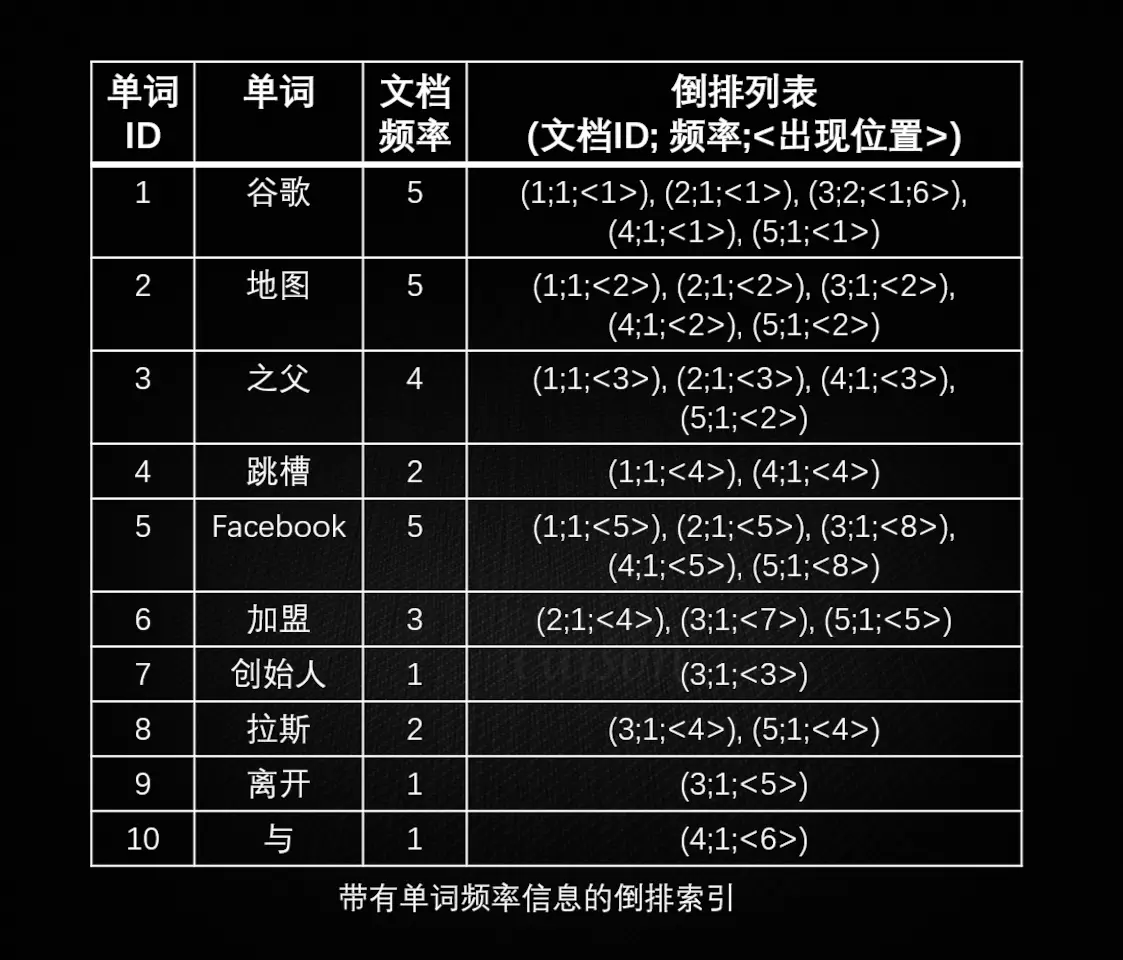
|
||||
|
||||
可见,倒排索引适用于根据关键词来查询文档内容
|
||||
|
||||
|
|
@ -251,7 +251,7 @@ MongonDB 还是支持多文档事务的 Consistency(一致性)和 Durability(持
|
|||
|
||||
- Solr
|
||||
|
||||

|
||||

|
||||
|
||||
Solr 是 Apache Lucene 项目的开源企业搜索平台。其主要功能包括全文检索、命中标示、分面搜索、动态聚类、数据库集成,以及富文本(如 Word、PDF)的处理。Solr 是高度可扩展的,并提供了分布式搜索和索引复制
|
||||
|
||||
|
|
@ -285,7 +285,7 @@ MongonDB 还是支持多文档事务的 Consistency(一致性)和 Durability(持
|
|||
|
||||
## 六、图数据库
|
||||
|
||||

|
||||

|
||||
|
||||
**图形数据库应用图论存储实体之间的关系信息**。最常见例子就是社会网络中人与人之间的关系。关系型数据库用于存储“关系型”数据的效果并不好,其查询复杂、缓慢、超出预期,而图形数据库的独特设计恰恰弥补了这个缺陷,解决关系型数据库存储和处理复杂关系型数据功能较弱的问题。
|
||||
|
||||
|
|
@ -293,19 +293,19 @@ MongonDB 还是支持多文档事务的 Consistency(一致性)和 Durability(持
|
|||
|
||||
- Neo4j
|
||||
|
||||

|
||||

|
||||
|
||||
Neo4j 是由 Neo4j,Inc。开发的图形数据库管理系统。由其开发人员描述为具有原生图存储和处理的符合 ACID 的事务数据库,根据 DB-Engines 排名, Neo4j 是最流行的图形数据库。
|
||||
|
||||
- ArangoDB
|
||||
|
||||

|
||||

|
||||
|
||||
ArangoDB 是由 triAGENS GmbH 开发的原生多模型数据库系统。数据库系统支持三个重要的数据模型(键/值,文档,图形),其中包含一个数据库核心和统一查询语言 AQL(ArangoDB 查询语言)。查询语言是声明性的,允许在单个查询中组合不同的数据访问模式。ArangoDB 是一个 NoSQL 数据库系统,但 AQL 在很多方面与 SQL 类似。
|
||||
|
||||
- Titan
|
||||
|
||||

|
||||

|
||||
|
||||
Titan 是一个可扩展的图形数据库,针对存储和查询包含分布在多机群集中的数百亿个顶点和边缘的图形进行了优化。Titan 是一个事务性数据库,可以支持数千个并发用户实时执行复杂的图形遍历。
|
||||
|
||||
|
|
|
|||
|
|
@ -14,25 +14,25 @@
|
|||
|
||||
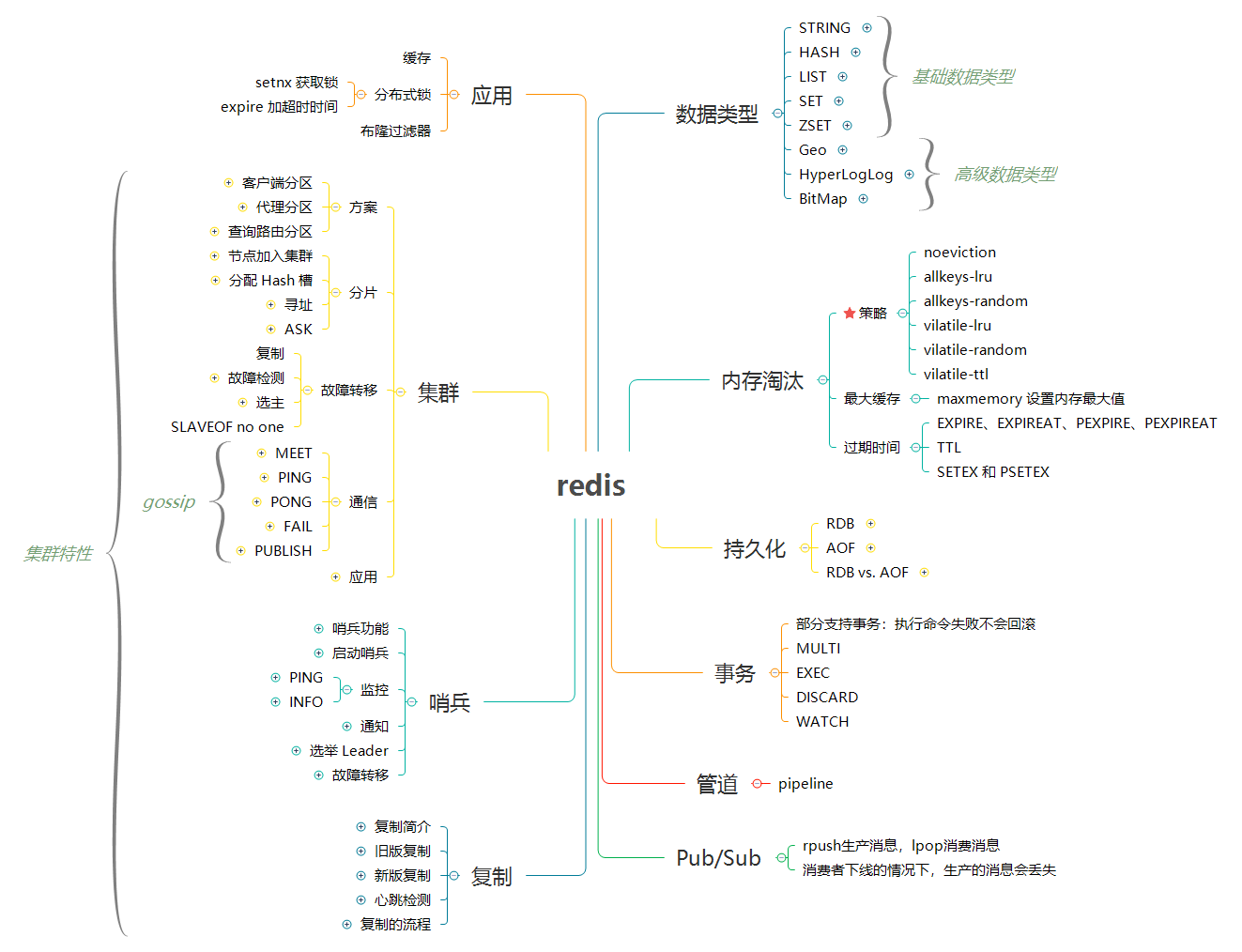
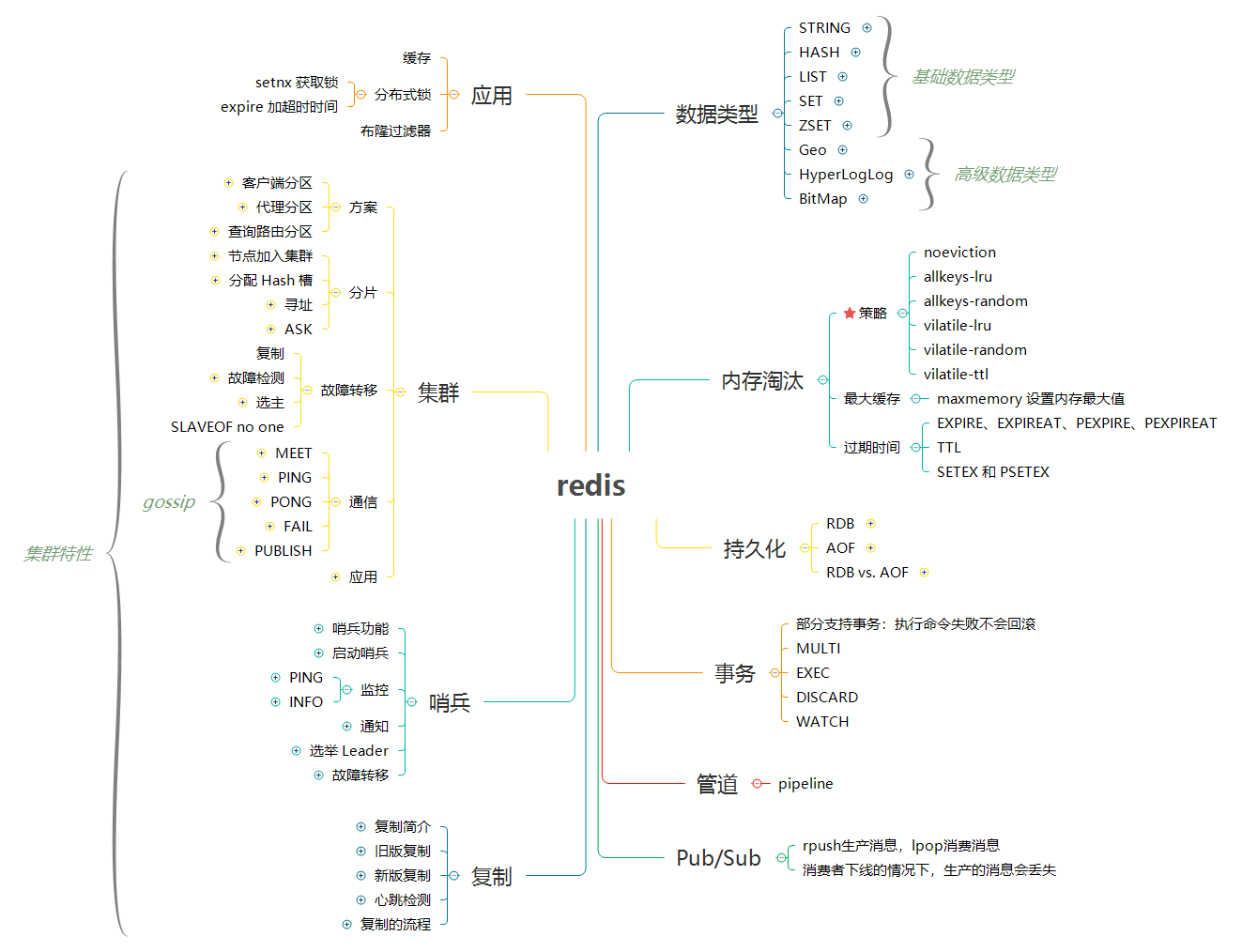
> 关键词:`内存淘汰`、`事件`、`事务`、`管道`、`发布与订阅`
|
||||
|
||||

|
||||

|
||||
|
||||
### [Redis 数据类型和应用](redis-datatype.md)
|
||||
|
||||
> 关键词:`STRING`、`HASH`、`LIST`、`SET`、`ZSET`、`BitMap`、`HyperLogLog`、`Geo`
|
||||
|
||||

|
||||
|
||||
|
||||
### [Redis 持久化](redis-persistence.md)
|
||||
|
||||
> 关键词:`RDB`、`AOF`、`SAVE`、`BGSAVE`、`appendfsync`
|
||||
|
||||

|
||||
|
||||
|
||||
### [Redis 复制](redis-replication.md)
|
||||
|
||||
> 关键词:`SLAVEOF`、`SYNC`、`PSYNC`、`REPLCONF ACK`
|
||||
|
||||

|
||||
|
||||
|
||||
### [Redis 哨兵](redis-sentinel.md)
|
||||
|
||||
|
|
@ -42,13 +42,13 @@
|
|||
>
|
||||
> 关键词:`Sentinel`、`PING`、`INFO`、`Raft`
|
||||
|
||||
|
||||
|
||||
|
||||
### [Redis 集群](redis-cluster.md)
|
||||
|
||||
> 关键词:`CLUSTER MEET`、`Hash slot`、`MOVED`、`ASK`、`SLAVEOF no one`、`redis-trib`
|
||||
|
||||

|
||||
|
||||
|
||||
### [Redis 实战](redis-action.md)
|
||||
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@
|
|||
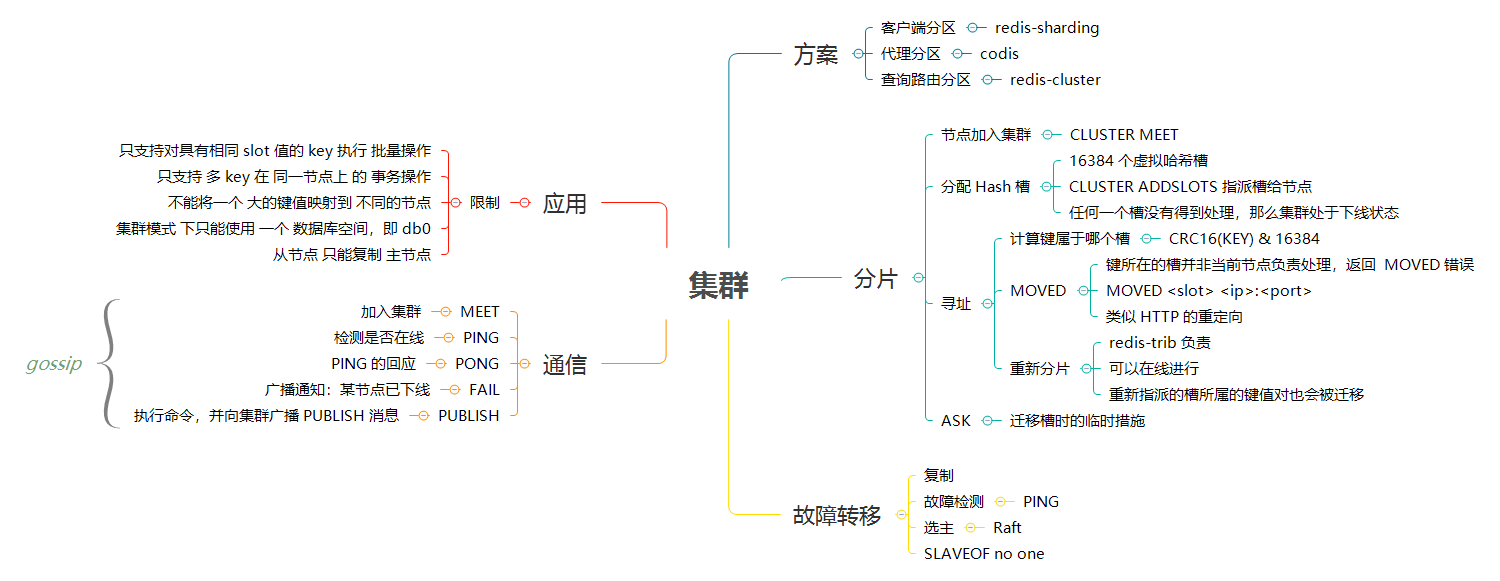
> - Redis 集群采用主从模型,提供复制和故障转移功能,来保证 Redis 集群的高可用。
|
||||
> - 根据 CAP 理论,Consistency、Availability、Partition tolerance 三者不可兼得,而 Redis 集群的选择是 AP。Redis 集群节点间采用异步通信方式,不保证强一致性,尽力达到最终一致性。
|
||||
|
||||

|
||||

|
||||
|
||||
<!-- TOC depthFrom:2 depthTo:3 -->
|
||||
|
||||
|
|
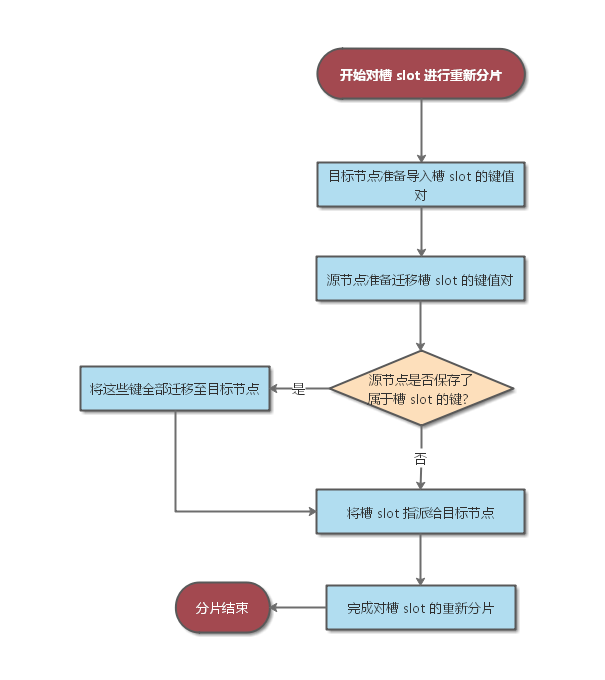
@ -108,7 +108,7 @@ Redis 集群的重新分片操作由 Redis 集群管理软件 **redis-trib** 负
|
|||
|
||||
重新分片的实现原理如下图所示:
|
||||
|
||||

|
||||
|
||||
|
||||
### ASK 错误
|
||||
|
||||
|
|
@ -116,7 +116,7 @@ Redis 集群的重新分片操作由 Redis 集群管理软件 **redis-trib** 负
|
|||
|
||||
判断 ASK 错误的过程如下图所示:
|
||||
|
||||

|
||||
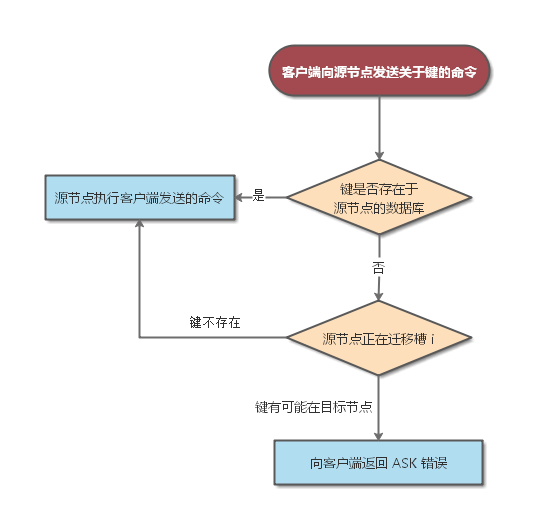
|
||||
|
||||
## 二、Redis Cluster 故障转移
|
||||
|
||||
|
|
|
|||
|
|
@ -37,7 +37,7 @@
|
|||
|
||||
## 一、Redis 基本数据类型
|
||||
|
||||

|
||||

|
||||
|
||||
| 数据类型 | 可以存储的值 | 操作 |
|
||||
| -------- | ---------------------- | ---------------------------------------------------------------------------------------------------------------- |
|
||||
|
|
@ -52,7 +52,7 @@
|
|||
### STRING
|
||||
|
||||
<div align="center">
|
||||
<img src="http://dunwu.test.upcdn.net/cs/database/redis/redis-datatype-string.png" width="400"/>
|
||||
<img src="https://raw.githubusercontent.com/dunwu/images/dev/cs/database/redis/redis-datatype-string.png" width="400"/>
|
||||
</div>
|
||||
**适用场景:缓存、计数器、共享 Session**
|
||||
|
||||
|
|
@ -84,7 +84,7 @@ OK
|
|||
### HASH
|
||||
|
||||
<div align="center">
|
||||
<img src="http://dunwu.test.upcdn.net/cs/database/redis/redis-datatype-hash.png" width="400"/>
|
||||
<img src="https://raw.githubusercontent.com/dunwu/images/dev/cs/database/redis/redis-datatype-hash.png" width="400"/>
|
||||
</div>
|
||||
**适用场景:存储结构化数据**,如一个对象:用户信息、产品信息等。
|
||||
|
||||
|
|
@ -129,7 +129,7 @@ OK
|
|||
### LIST
|
||||
|
||||
<div align="center">
|
||||
<img src="http://dunwu.test.upcdn.net/cs/database/redis/redis-datatype-list.png" width="400"/>
|
||||
<img src="https://raw.githubusercontent.com/dunwu/images/dev/cs/database/redis/redis-datatype-list.png" width="400"/>
|
||||
</div>
|
||||
**适用场景:用于存储列表型数据**。如:粉丝列表、商品列表等。
|
||||
|
||||
|
|
@ -173,7 +173,7 @@ OK
|
|||
### SET
|
||||
|
||||
<div align="center">
|
||||
<img src="http://dunwu.test.upcdn.net/cs/database/redis/redis-datatype-set.png" width="400"/>
|
||||
<img src="https://raw.githubusercontent.com/dunwu/images/dev/cs/database/redis/redis-datatype-set.png" width="400"/>
|
||||
</div>
|
||||
**适用场景:用于存储去重的列表型数据**。
|
||||
|
||||
|
|
@ -219,7 +219,7 @@ OK
|
|||
### ZSET
|
||||
|
||||
<div align="center">
|
||||
<img src="http://dunwu.test.upcdn.net/cs/database/redis/redis-datatype-zset.png" width="400"/>
|
||||
<img src="https://raw.githubusercontent.com/dunwu/images/dev/cs/database/redis/redis-datatype-zset.png" width="400"/>
|
||||
</div>
|
||||
|
||||
适用场景:由于可以设置 score,且不重复。**适合用于存储各种排行数据**,如:按评分排序的有序商品集合、按时间排序的有序文章集合。
|
||||
|
|
@ -448,7 +448,7 @@ redis> PFCOUNT databases # 估计数量增一
|
|||
|
||||
使用 `HASH` 类型存储文章信息。其中:key 是文章 ID;field 是文章的属性 key;value 是属性对应值。
|
||||
|
||||

|
||||

|
||||
|
||||
操作:
|
||||
|
||||
|
|
@ -460,7 +460,7 @@ redis> PFCOUNT databases # 估计数量增一
|
|||
|
||||
使用 `ZSET` 类型分别存储按照时间排序和按照评分排序的文章 ID 集合。
|
||||
|
||||

|
||||
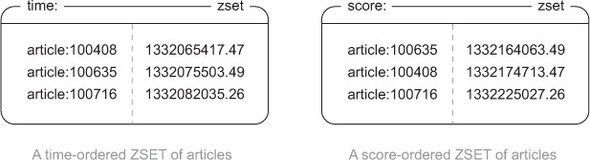
|
||||
|
||||
操作:
|
||||
|
||||
|
|
@ -470,7 +470,7 @@ redis> PFCOUNT databases # 估计数量增一
|
|||
|
||||
(3)为了防止重复投票,使用 `SET` 类型记录每篇文章 ID 对应的投票集合。
|
||||
|
||||

|
||||

|
||||
|
||||
操作:
|
||||
|
||||
|
|
@ -479,7 +479,7 @@ redis> PFCOUNT databases # 估计数量增一
|
|||
|
||||
(4)假设 user:115423 给 article:100408 投票,分别需要高更新评分排序集合以及投票集合。
|
||||
|
||||

|
||||

|
||||
|
||||
当需要对一篇文章投票时,程序需要用 ZSCORE 命令检查记录文章发布时间的有序集合,判断文章的发布时间是否超过投票有效期(比如:一星期)。
|
||||
|
||||
|
|
@ -595,7 +595,7 @@ redis> PFCOUNT databases # 估计数量增一
|
|||
|
||||
取出群组里的文章:
|
||||
|
||||

|
||||
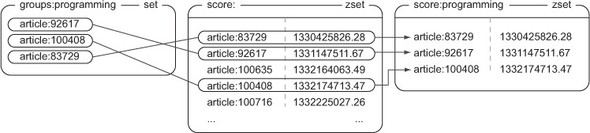
|
||||
|
||||
- 通过对存储群组文章的集合和存储文章评分的有序集合执行 `ZINTERSTORE` 命令,可以得到按照文章评分排序的群组文章。
|
||||
- 通过对存储群组文章的集合和存储文章发布时间的有序集合执行 `ZINTERSTORE` 命令,可以得到按照文章发布时间排序的群组文章。
|
||||
|
|
|
|||
|
|
@ -253,7 +253,7 @@ Redis 集群基于复制特性实现节点间的数据一致性。
|
|||
|
||||
由一个或多个 Sentinel 实例组成的 Sentinel 系统可以监视任意多个主服务器,以及这些主服务器的所有从服务器,并在被监视的主服务器进入下线状态时,自动将下线主服务器的某个从服务器升级为新的主服务器,然后由新的主服务器代替已下线的主服务器继续处理命令请求。
|
||||
|
||||

|
||||
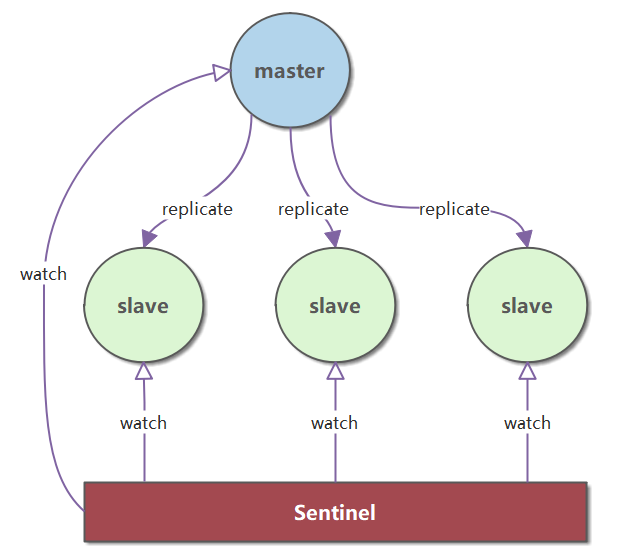
|
||||
|
||||
## Redis vs. Memcached
|
||||
|
||||
|
|
|
|||
|
|
@ -631,11 +631,11 @@ rebalance:表明让 Redis 自动根据节点数进行均衡哈希槽分配。
|
|||
|
||||
--cluster-use-empty-masters:表明
|
||||
|
||||

|
||||
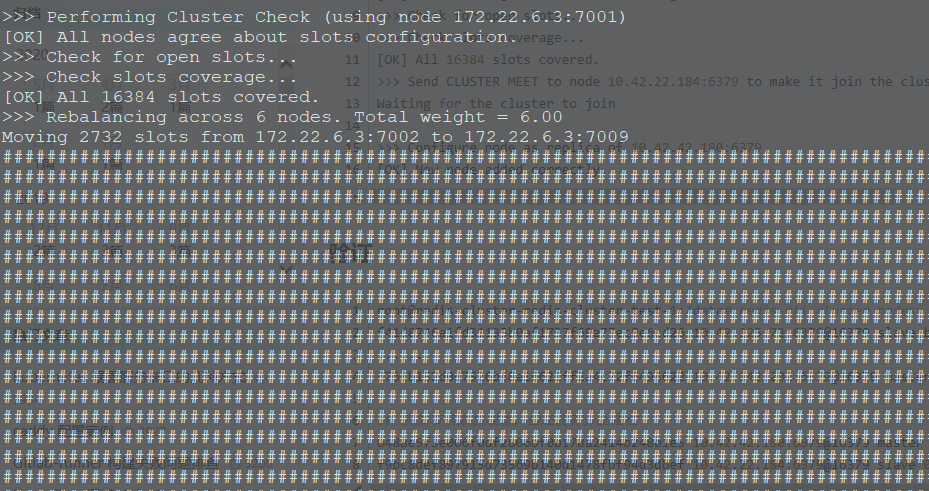
|
||||
|
||||
执行结束后,查看状态:
|
||||
|
||||

|
||||

|
||||
|
||||
## 四、Redis 命令
|
||||
|
||||
|
|
|
|||
|
|
@ -101,7 +101,7 @@ RDB 文件是一个经过压缩的二进制文件,由多个部分组成。
|
|||
|
||||
对于不同类型(STRING、HASH、LIST、SET、SORTED SET)的键值对,RDB 文件会使用不同的方式来保存它们。
|
||||
|
||||

|
||||
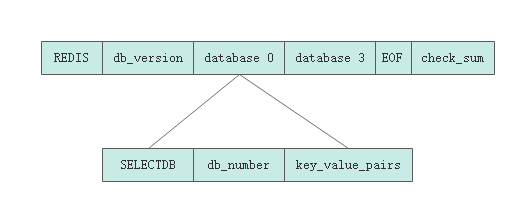
|
||||
|
||||
Redis 本身提供了一个 RDB 文件检查工具 redis-check-dump。
|
||||
|
||||
|
|
@ -181,7 +181,7 @@ AOF 载入过程如下:
|
|||
6. 载入完毕。
|
||||
|
||||
<div align="center">
|
||||
<img src="http://dunwu.test.upcdn.net/cs/database/redis/redis-aof-flow.png" />
|
||||
<img src="https://raw.githubusercontent.com/dunwu/images/dev/cs/database/redis/redis-aof-flow.png" />
|
||||
</div>
|
||||
|
||||
### AOF 的重写
|
||||
|
|
@ -203,7 +203,7 @@ AOF 重写并非读取和分析现有 AOF 文件的内容,而是直接从数
|
|||
- 由于彼此不是在同一个进程中工作,AOF 重写不影响 AOF 写入和同步。当子进程完成创建新 AOF 文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新 AOF 文件的末尾,使得新旧两个 AOF 文件所保存的数据库状态一致。
|
||||
- 最后,服务器用新的 AOF 文件替换就的 AOF 文件,以此来完成 AOF 重写操作。
|
||||
|
||||

|
||||
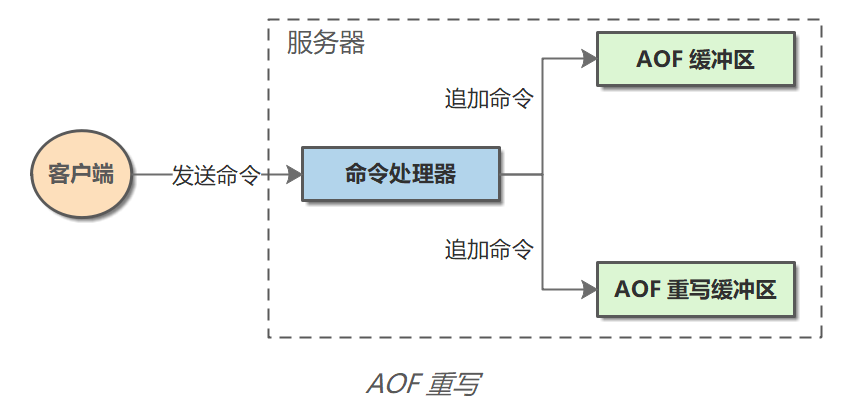
|
||||
|
||||
可以通过设置 `auto-aof-rewrite-percentage` 和 `auto-aof-rewrite-min-size`,使得 Redis 在满足条件时,自动执行 `BGREWRITEAOF`。
|
||||
|
||||
|
|
@ -295,7 +295,7 @@ Redis 的容灾备份基本上就是对数据进行备份,并将这些备份
|
|||
|
||||
## 五、要点总结
|
||||
|
||||

|
||||

|
||||
|
||||
## 参考资料
|
||||
|
||||
|
|
|
|||
|
|
@ -215,7 +215,7 @@ Redis 基于 Reactor 模式开发了自己的网络时间处理器。
|
|||
|
||||
文件事件处理器有四个组成部分:套接字、I/O 多路复用程序、文件事件分派器、事件处理器。
|
||||
|
||||

|
||||
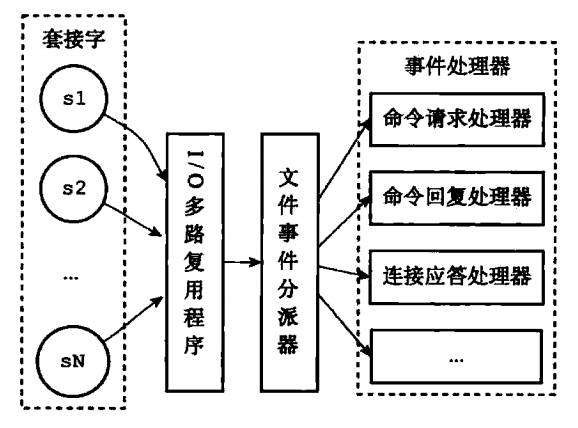
|
||||
|
||||
### 时间事件
|
||||
|
||||
|
|
@ -277,7 +277,7 @@ def main():
|
|||
从事件处理的角度来看,服务器运行流程如下:
|
||||
|
||||
<div align="center">
|
||||
<img src="http://dunwu.test.upcdn.net/cs/database/redis/redis-event.png" />
|
||||
<img src="https://raw.githubusercontent.com/dunwu/images/dev/cs/database/redis/redis-event.png" />
|
||||
</div>
|
||||
|
||||
## 六、Redis 事务
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@
|
|||
>
|
||||
> Redis 2.8 以前的复制不能高效处理断线后重复制的情况,而 Redis 2.8 新添的部分重同步可以解决这个问题。
|
||||
|
||||

|
||||

|
||||
|
||||
<!-- TOC depthFrom:2 depthTo:3 -->
|
||||
|
||||
|
|
@ -68,7 +68,7 @@ Redis 的复制功能分为同步(sync)和命令传播(command propagate
|
|||
3. 主服务器执行 `BGSAVE` 完毕后,主服务器会将生成的 RDB 文件发送给从服务器。从服务器接收并载入 RDB 文件,更新自己的数据库状态。
|
||||
4. 主服务器将记录在缓冲区中的所有写命令发送给从服务器,从服务器执行这些写命令,更新自己的数据库状态。
|
||||
|
||||

|
||||
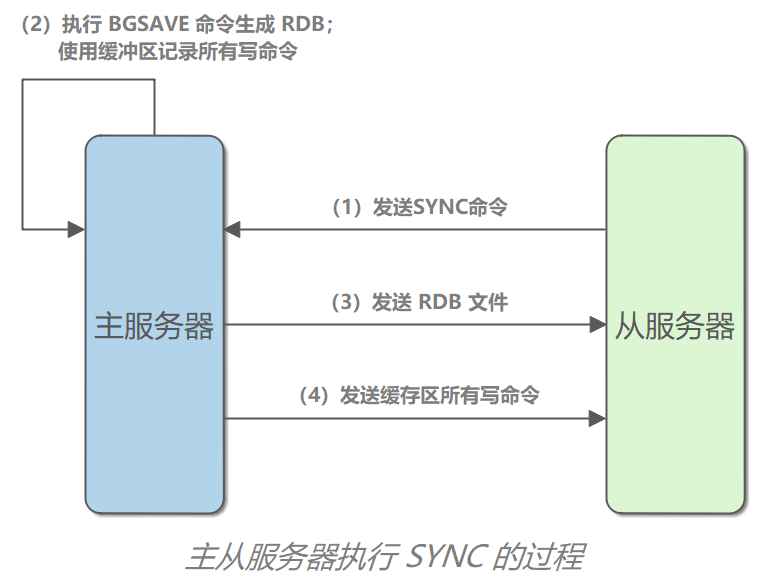
|
||||
|
||||
### 命令传播
|
||||
|
||||
|
|
@ -113,7 +113,7 @@ Redis 的复制功能分为同步(sync)和命令传播(command propagate
|
|||
- 如果主从服务器的复制偏移量相同,则说明二者的数据库状态一致;
|
||||
- 反之,则说明二者的数据库状态不一致。
|
||||
|
||||

|
||||
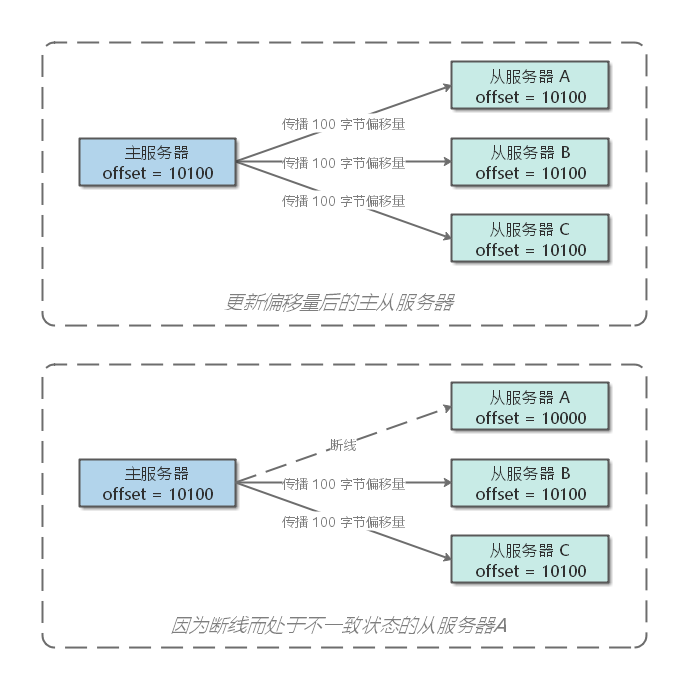
|
||||
|
||||
#### 复制积压缓冲区
|
||||
|
||||
|
|
@ -160,7 +160,7 @@ Redis 的复制功能分为同步(sync)和命令传播(command propagate
|
|||
- 假如主从服务器的 **master run id 相同**,并且**指定的偏移量(offset)在内存缓冲区中还有效**,复制就会从上次中断的点开始继续。
|
||||
- 如果其中一个条件不满足,就会进行完全重新同步(在 2.8 版本之前就是直接进行完全重新同步)。
|
||||
|
||||

|
||||
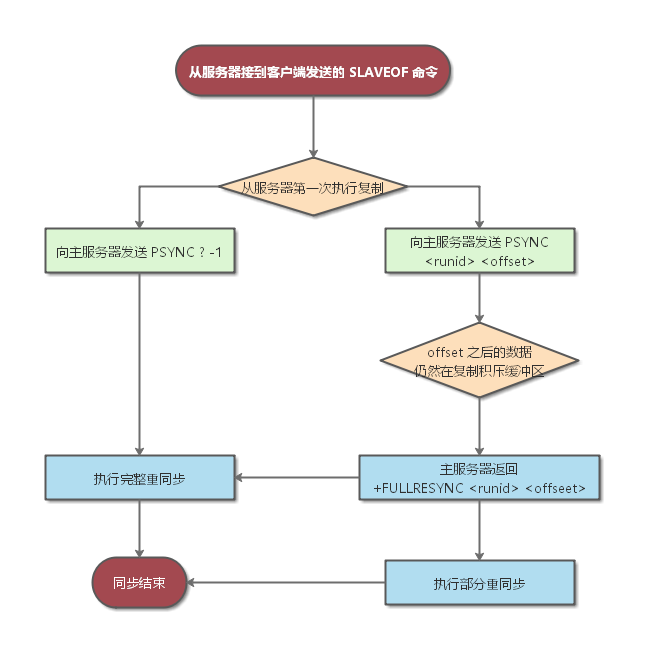
|
||||
|
||||
## 四、心跳检测
|
||||
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@
|
|||
>
|
||||
> Redis 哨兵是 [Raft 算法](https://github.com/dunwu/blog/blob/master/source/_posts/theory/raft.md) 的具体实现。
|
||||
|
||||

|
||||

|
||||
|
||||
<!-- TOC depthFrom:2 depthTo:3 -->
|
||||
|
||||
|
|
@ -26,7 +26,7 @@
|
|||
|
||||
Redis 哨兵(Sentinel)是 Redis 的**高可用性**(Hight Availability)解决方案:由一个或多个 Sentinel 实例组成的 Sentinel 系统可以监视任意多个主服务器,以及这些主服务器的所有从服务器,并在被监视的主服务器进入下线状态时,自动将下线主服务器的某个从服务器升级为新的主服务器,然后由新的主服务器代替已下线的主服务器继续处理命令请求。
|
||||
|
||||

|
||||

|
||||
|
||||
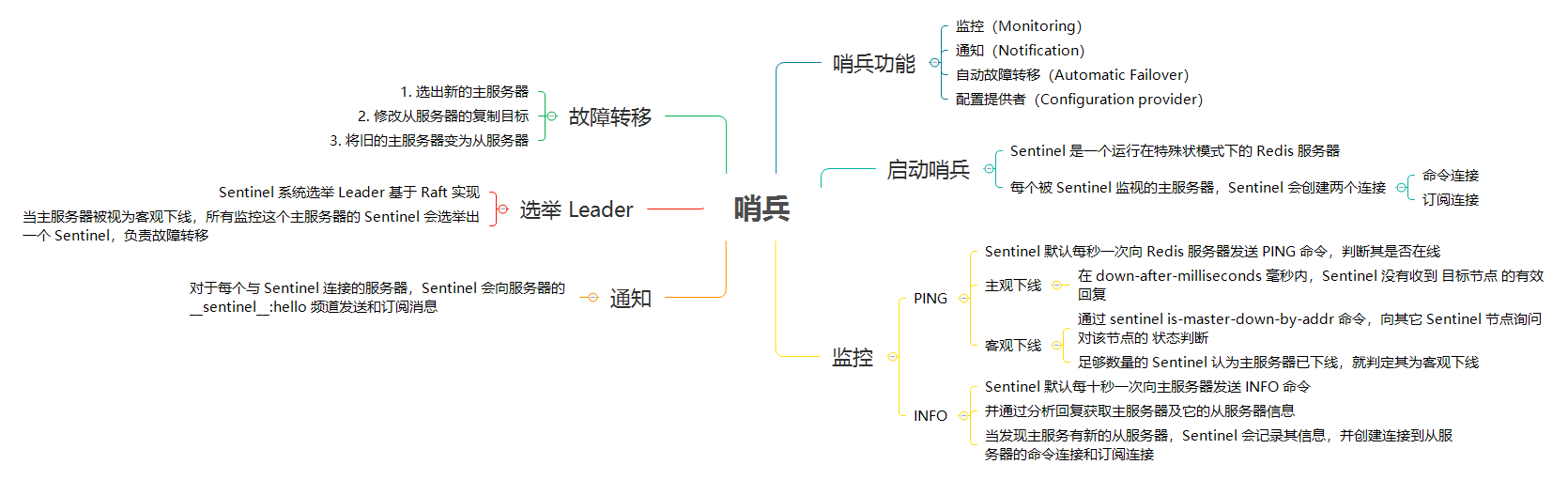
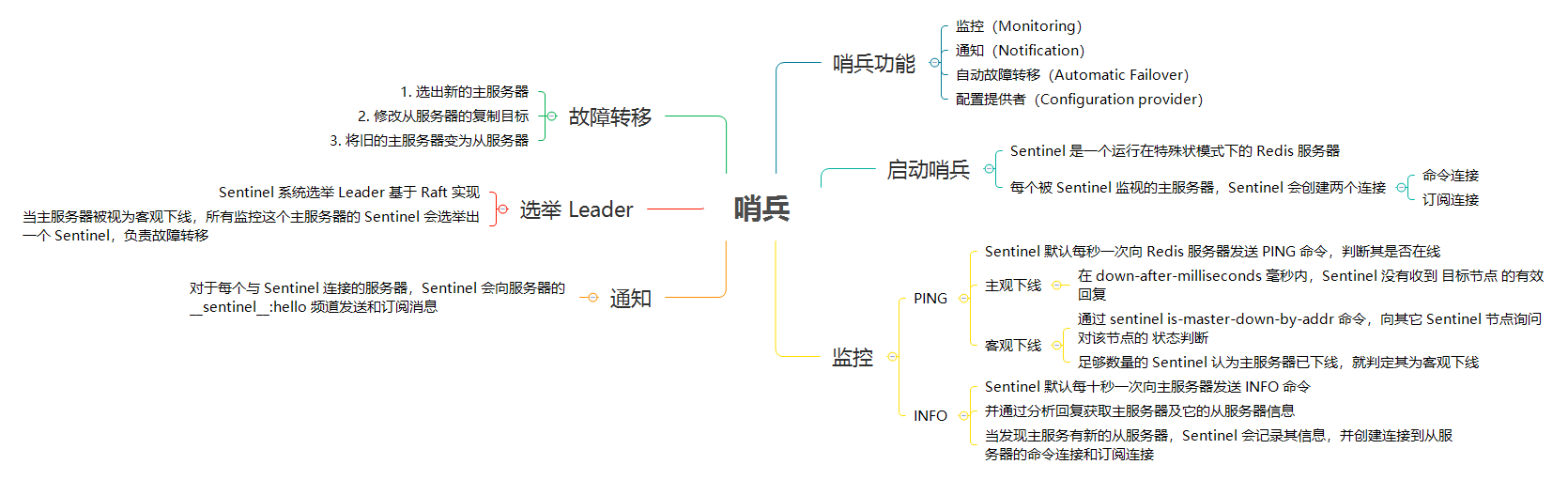
Sentinel 的主要功能如下:
|
||||
|
||||
|
|
@ -86,7 +86,7 @@ Sentinel 模式下 Redis 服务器只支持 `PING`、`SENTINEL`、`INFO`、`SUBS
|
|||
|
||||
对于每个与 Sentinel 连接的服务器,Sentinel 既会向服务器的 `__sentinel__:hello` 频道发送消息,也会订阅服务器的 `__sentinel__:hello` 频道的消息。
|
||||
|
||||

|
||||
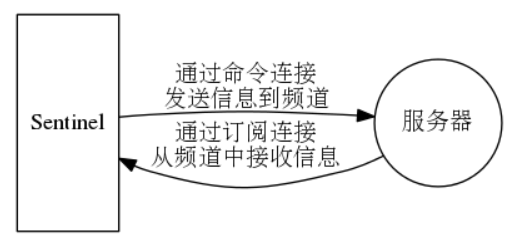
|
||||
|
||||
### 向服务器发送消息
|
||||
|
||||
|
|
|
|||
|
|
@ -6,20 +6,25 @@
|
|||
"clean": "rimraf dist && rimraf .temp",
|
||||
"build": "npm run clean && vuepress build ./ --temp .temp",
|
||||
"start": "vuepress dev ./ --temp .temp",
|
||||
"lint": "markdownlint -c ./.markdownlint.json **/*.md -i node_modules",
|
||||
"lint:fix": "markdownlint -f -c ./.markdownlint.json **/*.md -i node_modules",
|
||||
"help": "vuepress --help"
|
||||
"lint": "markdownlint -r markdownlint-rule-emphasis-style -c ./.markdownlint.json **/*.md -i node_modules",
|
||||
"lint:fix": "markdownlint -f -r markdownlint-rule-emphasis-style -c ./.markdownlint.json **/*.md -i node_modules",
|
||||
"show-help": "vuepress --help",
|
||||
"view-info": "vuepress view-info ./ --temp .temp"
|
||||
},
|
||||
"devDependencies": {
|
||||
"@vuepress/plugin-active-header-links": "^1.5.2",
|
||||
"@vuepress/plugin-back-to-top": "^1.5.0",
|
||||
"@vuepress/plugin-medium-zoom": "^1.5.0",
|
||||
"@vuepress/plugin-pwa": "^1.5.0",
|
||||
"@vuepress/theme-vue": "^1.5.0",
|
||||
"markdownlint-cli": "^0.23.1",
|
||||
"@vuepress/plugin-active-header-links": "^1.8.2",
|
||||
"@vuepress/plugin-back-to-top": "^1.8.2",
|
||||
"@vuepress/plugin-medium-zoom": "^1.8.2",
|
||||
"@vuepress/plugin-pwa": "^1.8.2",
|
||||
"@vuepress/theme-vue": "^1.8.2",
|
||||
"markdownlint-cli": "^0.25.0",
|
||||
"markdownlint-rule-emphasis-style": "^1.0.1",
|
||||
"rimraf": "^3.0.1",
|
||||
"vue-toasted": "^1.1.25",
|
||||
"vuepress": "^1.5.0",
|
||||
"vuepress": "^1.8.2",
|
||||
"vuepress-plugin-flowchart": "^1.4.2"
|
||||
},
|
||||
"dependencies": {
|
||||
"moment": "^2.29.1"
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -13,7 +13,7 @@
|
|||
|
||||
### [Mysql](mysql/README.md)
|
||||
|
||||

|
||||

|
||||
|
||||
- [Mysql 应用指南](mysql/mysql-quickstart.md) ⚡
|
||||
- [Mysql 工作流](mysql/mysql-index.md) - 关键词:`连接`、`缓存`、`语法分析`、`优化`、`执行引擎`、`redo log`、`bin log`、`两阶段提交`
|
||||
|
|
|
|||
|
|
@ -6,11 +6,11 @@
|
|||
|
||||
### [SQL Cheat Sheet](sql-cheat-sheet.md)
|
||||
|
||||

|
||||
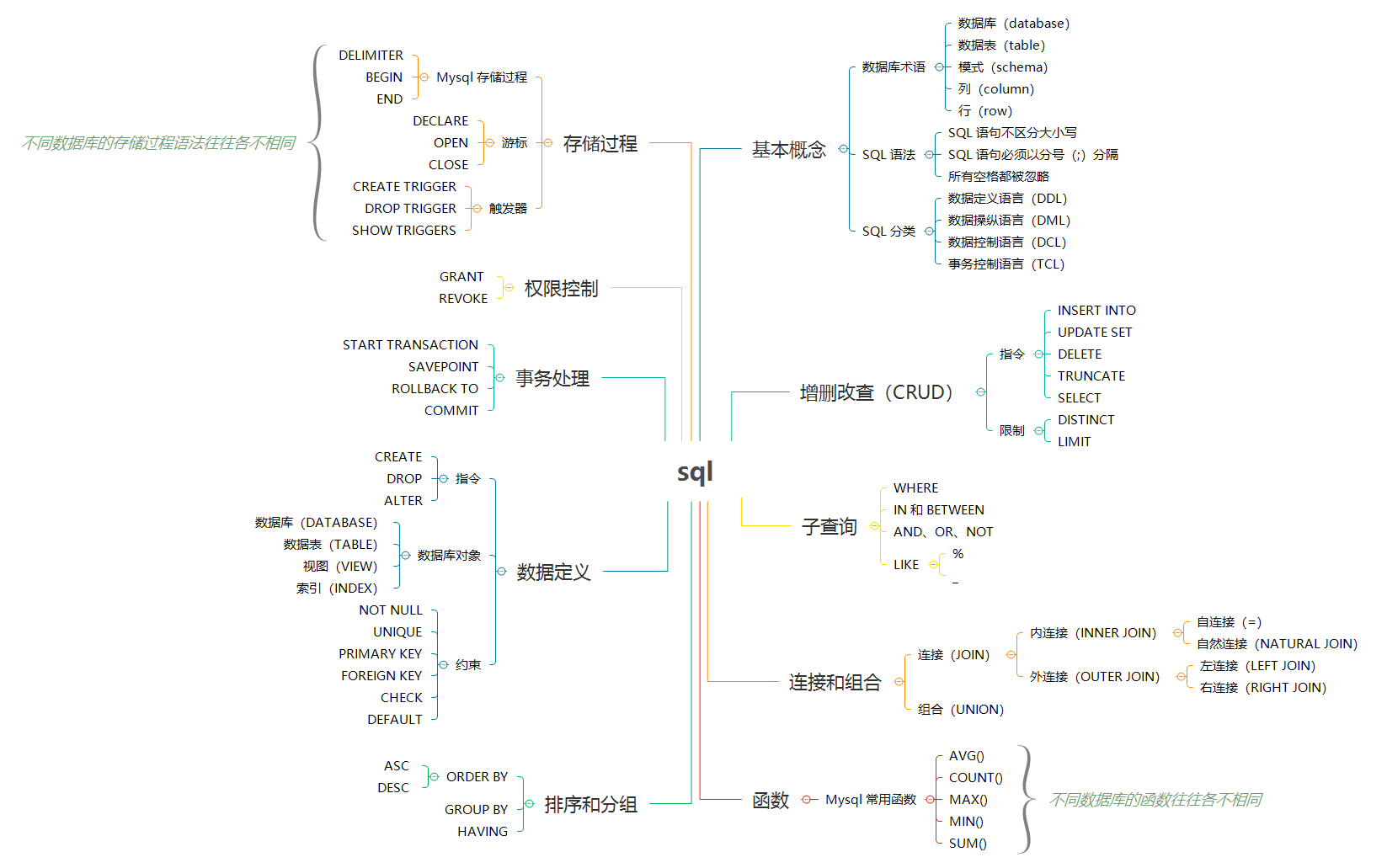
|
||||
|
||||
### [分布式存储基本原理](https://github.com/dunwu/blog/blob/master/source/_posts/theory/distributed-storage.md)
|
||||
|
||||

|
||||

|
||||
|
||||
### [分布式事务基本原理](https://github.com/dunwu/blog/blob/master/source/_posts/theory/distributed-transaction.md)
|
||||
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@
|
|||
>
|
||||
> 本文语法主要针对 Mysql,但大部分的语法对其他关系型数据库也适用。
|
||||
|
||||

|
||||

|
||||
|
||||
## 一、基本概念
|
||||
|
||||
|
|
@ -218,7 +218,7 @@ SELECT * FROM mytable LIMIT 2, 3;
|
|||
- 内部查询首先在其父查询之前执行,以便可以将内部查询的结果传递给外部查询。执行过程可以参考下图:
|
||||
|
||||
<p align="center">
|
||||
<img src="http://dunwu.test.upcdn.net/cs/database/mysql/sql-subqueries.gif!zp" alt="sql-subqueries">
|
||||
<img src="https://raw.githubusercontent.com/dunwu/images/dev/cs/database/mysql/sql-subqueries.gif!zp" alt="sql-subqueries">
|
||||
</p>
|
||||
|
||||
**子查询的子查询**
|
||||
|
|
@ -371,7 +371,7 @@ WHERE prod_name LIKE '__ inch teddy bear';
|
|||
`JOIN` 有两种连接类型:内连接和外连接。
|
||||
|
||||
<div align="center">
|
||||
<img src="http://dunwu.test.upcdn.net/cs/database/mysql/sql-join.png!zp" alt="sql-join">
|
||||
<img src="https://raw.githubusercontent.com/dunwu/images/dev/cs/database/mysql/sql-join.png!zp" alt="sql-join">
|
||||
</div>
|
||||
|
||||
#### 内连接(INNER JOIN)
|
||||
|
|
|
|||
|
|
@ -72,7 +72,7 @@
|
|||
对于任意结点,其内部的关键字 Key 是升序排列的。每个节点中都包含了 data。
|
||||
|
||||
<div align="center">
|
||||
<img src="http://dunwu.test.upcdn.net/cs/database/RDB/B-TREE.png" />
|
||||
<img src="https://raw.githubusercontent.com/dunwu/images/dev/cs/database/RDB/B-TREE.png" />
|
||||
</div>
|
||||
|
||||
对于每个结点,主要包含一个关键字数组 `Key[]`,一个指针数组(指向儿子)`Son[]`。
|
||||
|
|
@ -91,7 +91,7 @@ B+Tree 是 B-Tree 的变种:
|
|||
- 非叶子节点不存储 data,只存储 key;叶子节点不存储指针。
|
||||
|
||||
<div align="center">
|
||||
<img src="http://dunwu.test.upcdn.net/cs/database/RDB/B+TREE.png" />
|
||||
<img src="https://raw.githubusercontent.com/dunwu/images/dev/cs/database/RDB/B+TREE.png" />
|
||||
</div>
|
||||
|
||||
由于并不是所有节点都具有相同的域,因此 B+Tree 中叶节点和内节点一般大小不同。这点与 B-Tree 不同,虽然 B-Tree 中不同节点存放的 key 和指针可能数量不一致,但是每个节点的域和上限是一致的,所以在实现中 B-Tree 往往对每个节点申请同等大小的空间。
|
||||
|
|
@ -101,7 +101,7 @@ B+Tree 是 B-Tree 的变种:
|
|||
一般在数据库系统或文件系统中使用的 B+Tree 结构都在经典 B+Tree 的基础上进行了优化,增加了顺序访问指针。
|
||||
|
||||
<div align="center">
|
||||
<img src="http://dunwu.test.upcdn.net/cs/database/RDB/带有顺序访问指针的B+Tree.png" />
|
||||
<img src="https://raw.githubusercontent.com/dunwu/images/dev/cs/database/RDB/带有顺序访问指针的B+Tree.png" />
|
||||
</div>
|
||||
|
||||
在 B+Tree 的每个叶子节点增加一个指向相邻叶子节点的指针,就形成了带有顺序访问指针的 B+Tree。
|
||||
|
|
@ -327,7 +327,7 @@ MVCC 不能解决幻读问题,**Next-Key 锁就是为了解决幻读问题**
|
|||
|
||||
> 事务简单来说:**一个 Session 中所进行所有的操作,要么同时成功,要么同时失败**。具体来说,事务指的是满足 ACID 特性的一组操作,可以通过 `Commit` 提交一个事务,也可以使用 `Rollback` 进行回滚。
|
||||
|
||||

|
||||
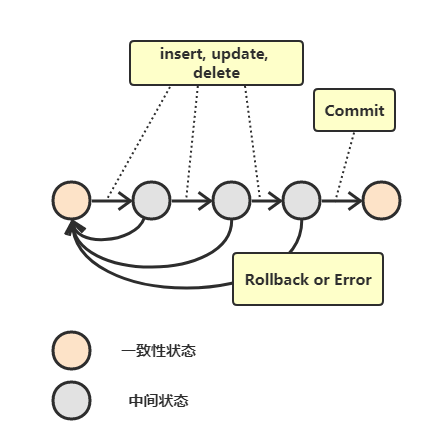
|
||||
|
||||
### ACID
|
||||
|
||||
|
|
@ -340,7 +340,7 @@ ACID — 数据库事务正确执行的四个基本要素:
|
|||
|
||||
**一个支持事务(Transaction)中的数据库系统,必需要具有这四种特性,否则在事务过程(Transaction processing)当中无法保证数据的正确性,交易过程极可能达不到交易。**
|
||||
|
||||

|
||||
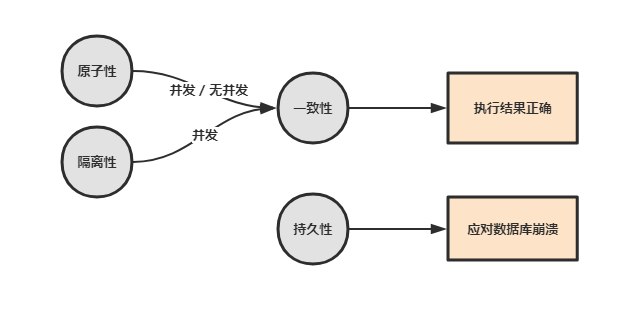
|
||||
|
||||
### 并发一致性问题
|
||||
|
||||
|
|
@ -350,25 +350,25 @@ ACID — 数据库事务正确执行的四个基本要素:
|
|||
|
||||
T<sub>1</sub> 和 T<sub>2</sub> 两个事务都对一个数据进行修改,T<sub>1</sub> 先修改,T<sub>2</sub> 随后修改,T<sub>2</sub> 的修改覆盖了 T<sub>1</sub> 的修改。
|
||||
|
||||

|
||||
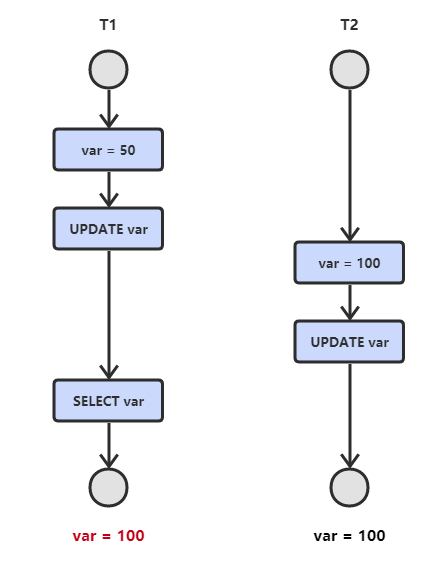
|
||||
|
||||
- **脏读**
|
||||
|
||||
T<sub>1</sub> 修改一个数据,T<sub>2</sub> 随后读取这个数据。如果 T<sub>1</sub> 撤销了这次修改,那么 T<sub>2</sub> 读取的数据是脏数据。
|
||||
|
||||

|
||||
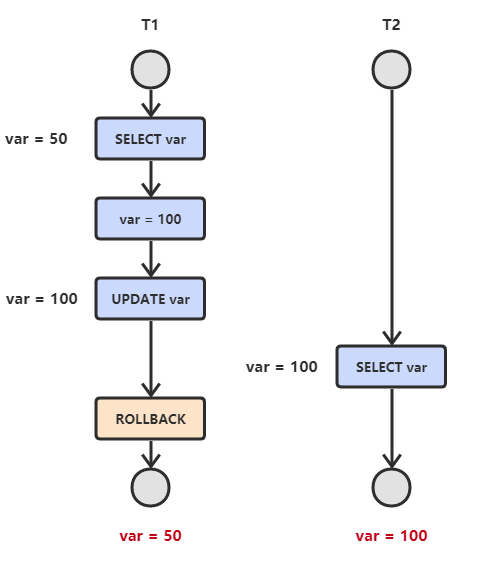
|
||||
|
||||
- **不可重复读**
|
||||
|
||||
T<sub>2</sub> 读取一个数据,T<sub>1</sub> 对该数据做了修改。如果 T<sub>2</sub> 再次读取这个数据,此时读取的结果和第一次读取的结果不同。
|
||||
|
||||

|
||||
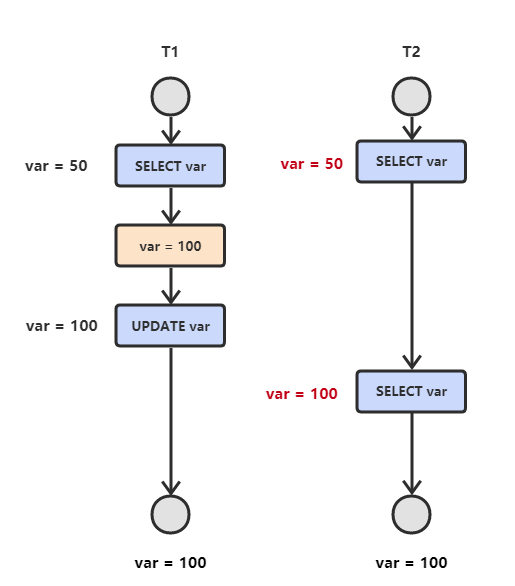
|
||||
|
||||
- **幻读**
|
||||
|
||||
T<sub>1</sub> 读取某个范围的数据,T<sub>2</sub> 在这个范围内插入新的数据,T<sub>1</sub> 再次读取这个范围的数据,此时读取的结果和和第一次读取的结果不同。
|
||||
|
||||

|
||||
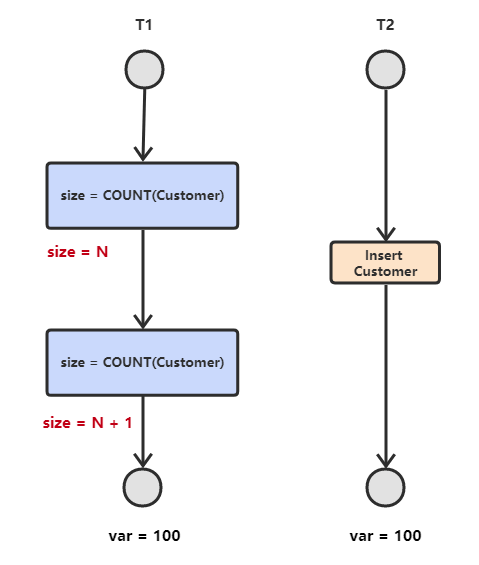
|
||||
|
||||
并发一致性解决方案:
|
||||
|
||||
|
|
@ -448,7 +448,7 @@ T<sub>1</sub> 读取某个范围的数据,T<sub>2</sub> 在这个范围内插
|
|||
|
||||
> **垂直切分**,是 **把一个有很多字段的表给拆分成多个表,或者是多个库上去**。一般来说,会 **将较少的、访问频率较高的字段放到一个表里去**,然后 **将较多的、访问频率较低的字段放到另外一个表里去**。因为数据库是有缓存的,访问频率高的行字段越少,就可以在缓存里缓存更多的行,性能就越好。这个一般在表层面做的较多一些。
|
||||
|
||||
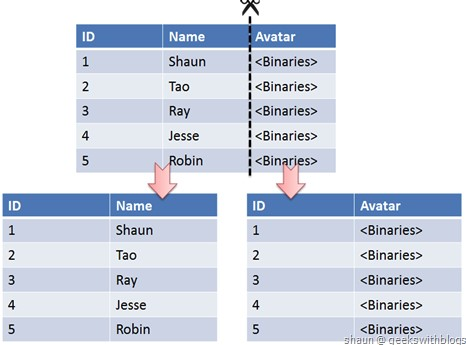
|
||||
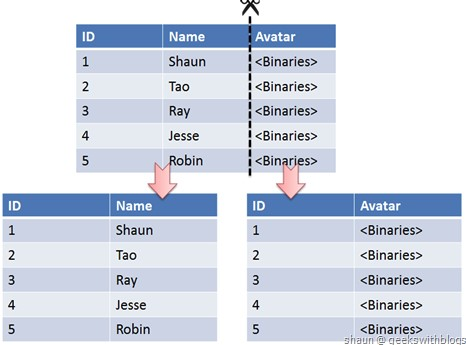
|
||||
|
||||
一般来说,满足下面的条件就可以考虑扩容了:
|
||||
|
||||
|
|
@ -461,7 +461,7 @@ T<sub>1</sub> 读取某个范围的数据,T<sub>2</sub> 在这个范围内插
|
|||
|
||||
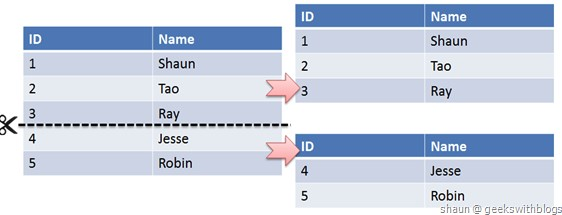
> **水平拆分** 又称为 **Sharding**,它是将同一个表中的记录拆分到多个结构相同的表中。当 **单表数据量太大** 时,会极大影响 **SQL 执行的性能** 。分表是将原来一张表的数据分布到数据库集群的不同节点上,从而缓解单点的压力。
|
||||
|
||||
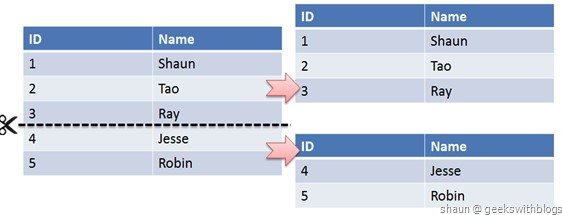
|
||||
|
||||
|
||||
一般来说,**单表有 200 万条数据** 的时候,性能就会相对差一些了,需要考虑分表了。但是,这也要视具体情况而定,可能是 100 万条,也可能是 500 万条,SQL 越复杂,就最好让单表行数越少。
|
||||
|
||||
|
|
@ -580,7 +580,7 @@ Mysql 支持两种复制:基于行的复制和基于语句的复制。
|
|||
- **I/O 线程** :负责从主服务器上读取二进制日志文件,并写入从服务器的日志中。
|
||||
- **SQL 线程** :负责读取日志并执行 SQL 语句以更新数据。
|
||||
|
||||

|
||||
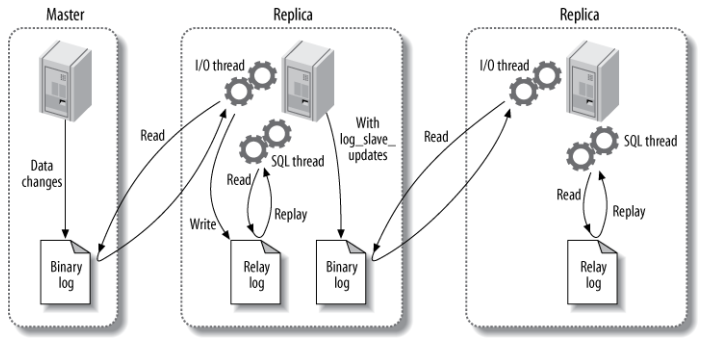
|
||||
|
||||
### 读写分离
|
||||
|
||||
|
|
@ -594,7 +594,7 @@ MySQL 读写分离能提高性能的原因在于:
|
|||
- 从服务器可以配置 `MyISAM` 引擎,提升查询性能以及节约系统开销;
|
||||
- 增加冗余,提高可用性。
|
||||
|
||||

|
||||
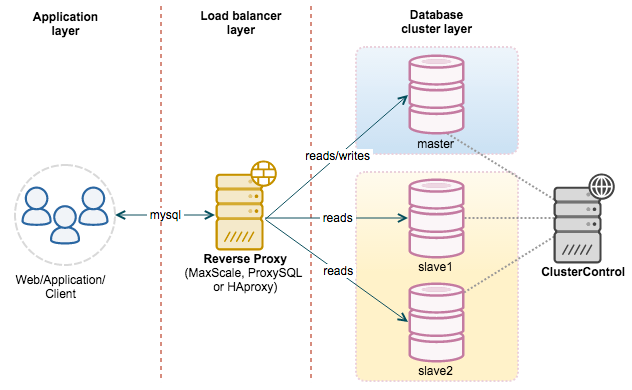
|
||||
|
||||
## 六、数据库优化
|
||||
|
||||
|
|
@ -866,7 +866,7 @@ SQL 关键字尽量大写,如:Oracle 默认会将 SQL 语句中的关键字
|
|||
高级别范式的依赖于低级别的范式,1NF 是最低级别的范式。
|
||||
|
||||
<div align="center">
|
||||
<img src="http://dunwu.test.upcdn.net/cs/database/RDB/数据库范式.png"/>
|
||||
<img src="https://raw.githubusercontent.com/dunwu/images/dev/cs/database/RDB/数据库范式.png"/>
|
||||
</div>
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -14,11 +14,11 @@ H2 允许用户通过浏览器接口方式访问 SQL 数据库。
|
|||
2. 启动方式:在 bin 目录下,双击 jar 包;执行 `java -jar h2*.jar`;执行脚本:`h2.bat` 或 `h2.sh`。
|
||||
3. 在浏览器中访问:`http://localhost:8082`,应该可以看到下图中的页面:
|
||||
|
||||
|
||||
|
||||
|
||||
点击 **Connect** ,可以进入操作界面:
|
||||
|
||||
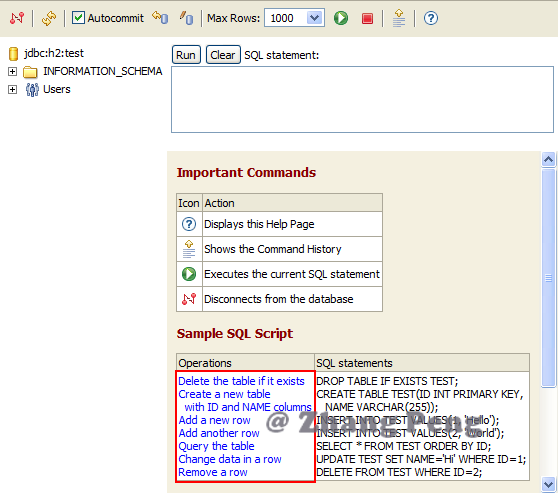
|
||||
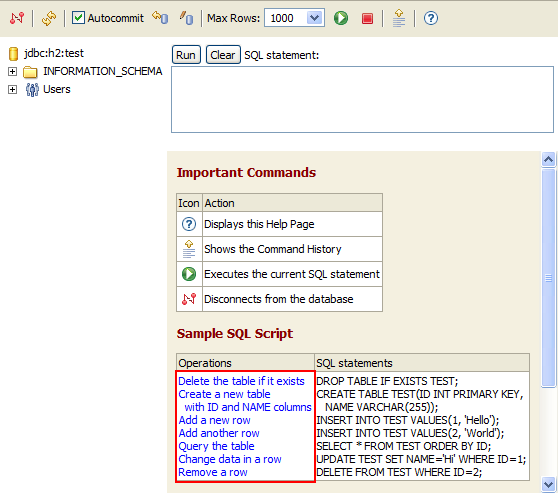
|
||||
|
||||
操作界面十分简单,不一一细说。
|
||||
|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
# Mysql 教程
|
||||
|
||||

|
||||

|
||||
|
||||
## 📖 内容
|
||||
|
||||
|
|
@ -10,19 +10,19 @@
|
|||
|
||||
> 关键词:`Hash`、`B 树`、`聚簇索引`、`回表`
|
||||
|
||||

|
||||
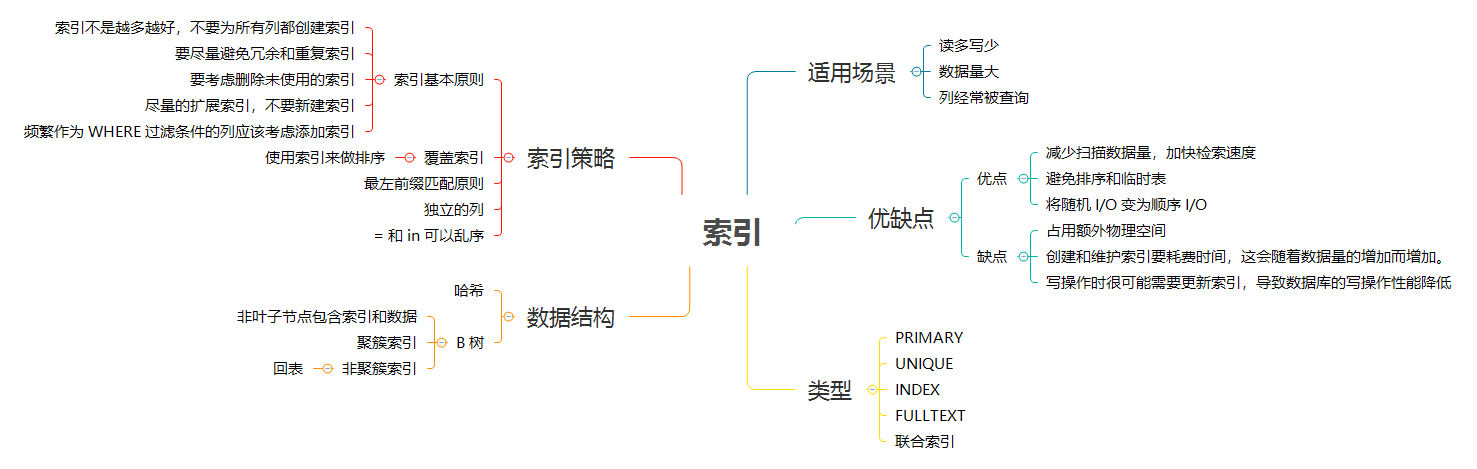
|
||||
|
||||
### [Mysql 锁](mysql-lock.md)
|
||||
|
||||
> 关键词:`乐观锁`、`表级锁`、`行级锁`、`意向锁`、`MVCC`、`Next-key 锁`
|
||||
|
||||

|
||||
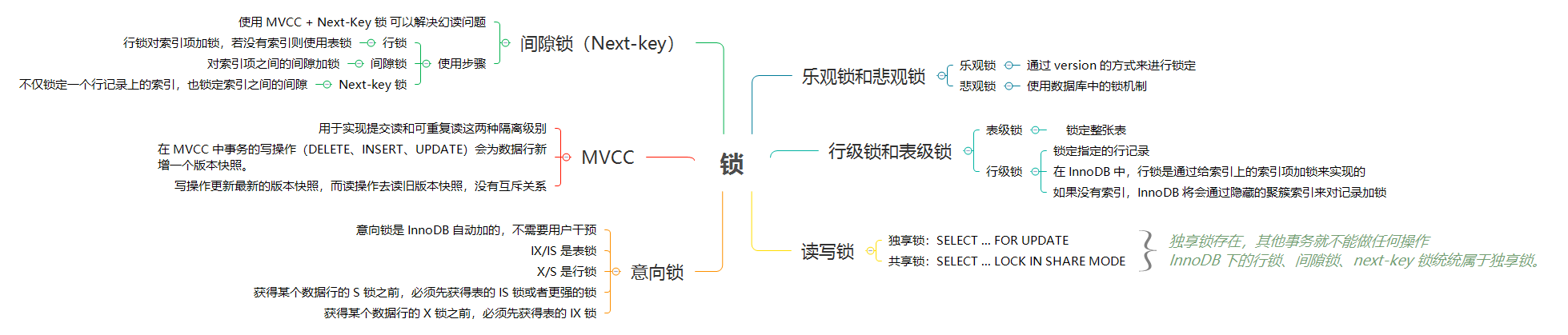
|
||||
|
||||
### [Mysql 事务](mysql-transaction.md)
|
||||
|
||||
> 关键词:`ACID`、`AUTOCOMMIT`、`事务隔离级别`、`死锁`、`分布式事务`
|
||||
|
||||

|
||||
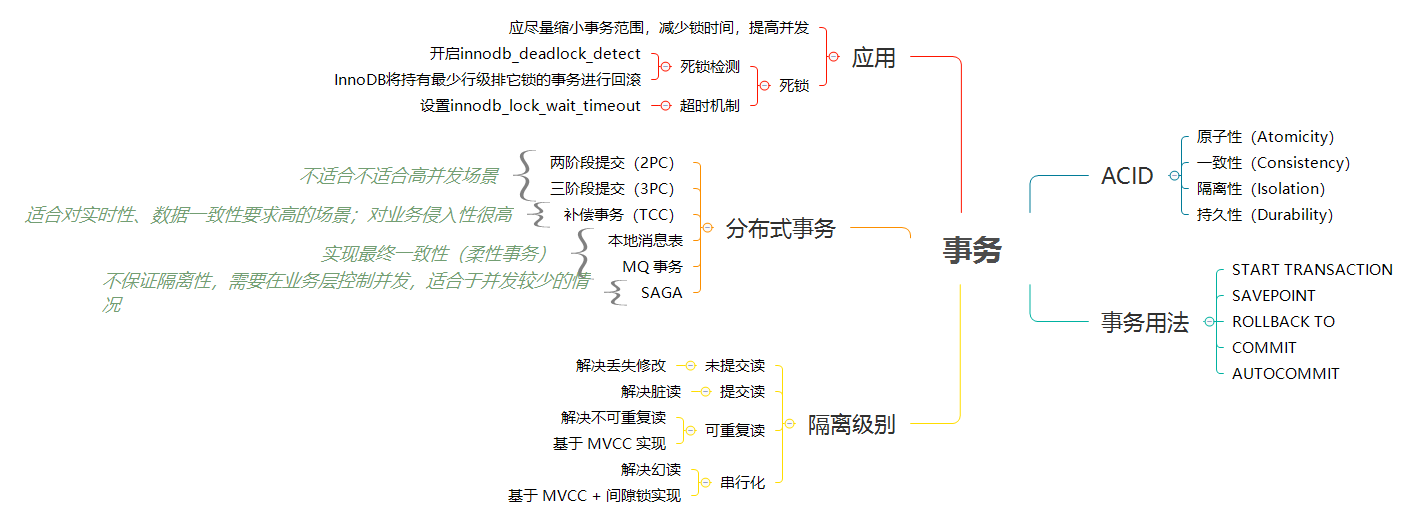
|
||||
|
||||
### [Mysql 性能优化](mysql-optimization.md)
|
||||
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@
|
|||
>
|
||||
> 接下来将向你展示一系列创建高性能索引的策略,以及每条策略其背后的工作原理。但在此之前,先了解与索引相关的一些算法和数据结构,将有助于更好的理解后文的内容。
|
||||
|
||||

|
||||

|
||||
|
||||
<!-- TOC depthFrom:2 depthTo:3 -->
|
||||
|
||||
|
|
@ -120,7 +120,7 @@ B+ 树索引适用于**全键值查找**、**键值范围查找**和**键前缀
|
|||
- 第一,所有的关键字(可以理解为数据)都存储在叶子节点,非叶子节点并不存储真正的数据,所有记录节点都是按键值大小顺序存放在同一层叶子节点上。
|
||||
- 其次,所有的叶子节点由指针连接。如下图为简化了的`B+Tree`。
|
||||
|
||||

|
||||
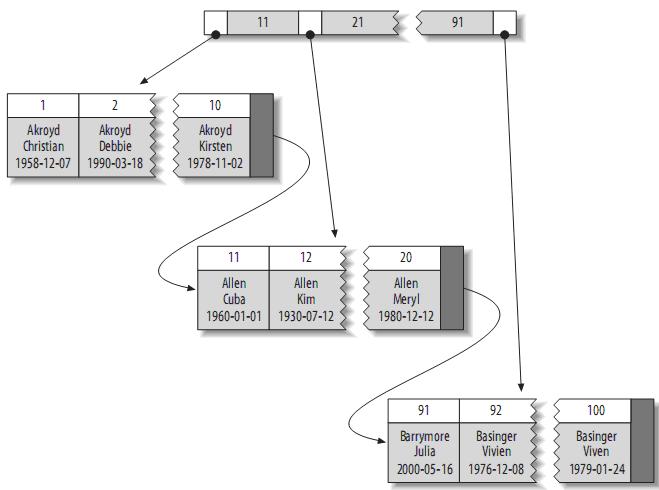
|
||||
|
||||
根据叶子节点的内容,索引类型分为主键索引和非主键索引。
|
||||
|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
# Mysql 锁
|
||||
|
||||

|
||||

|
||||
|
||||
<!-- TOC depthFrom:2 depthTo:3 -->
|
||||
|
||||
|
|
@ -139,7 +139,7 @@ UPDATE t SET x="c" WHERE id=1;
|
|||
|
||||
MVCC 维护了一个一致性读视图 `consistent read view` ,主要包含了当前系统**未提交的事务列表** `TRX_IDs {TRX_ID_1, TRX_ID_2, ...}`,还有该列表的最小值 `TRX_ID_MIN` 和 `TRX_ID_MAX`。
|
||||
|
||||

|
||||
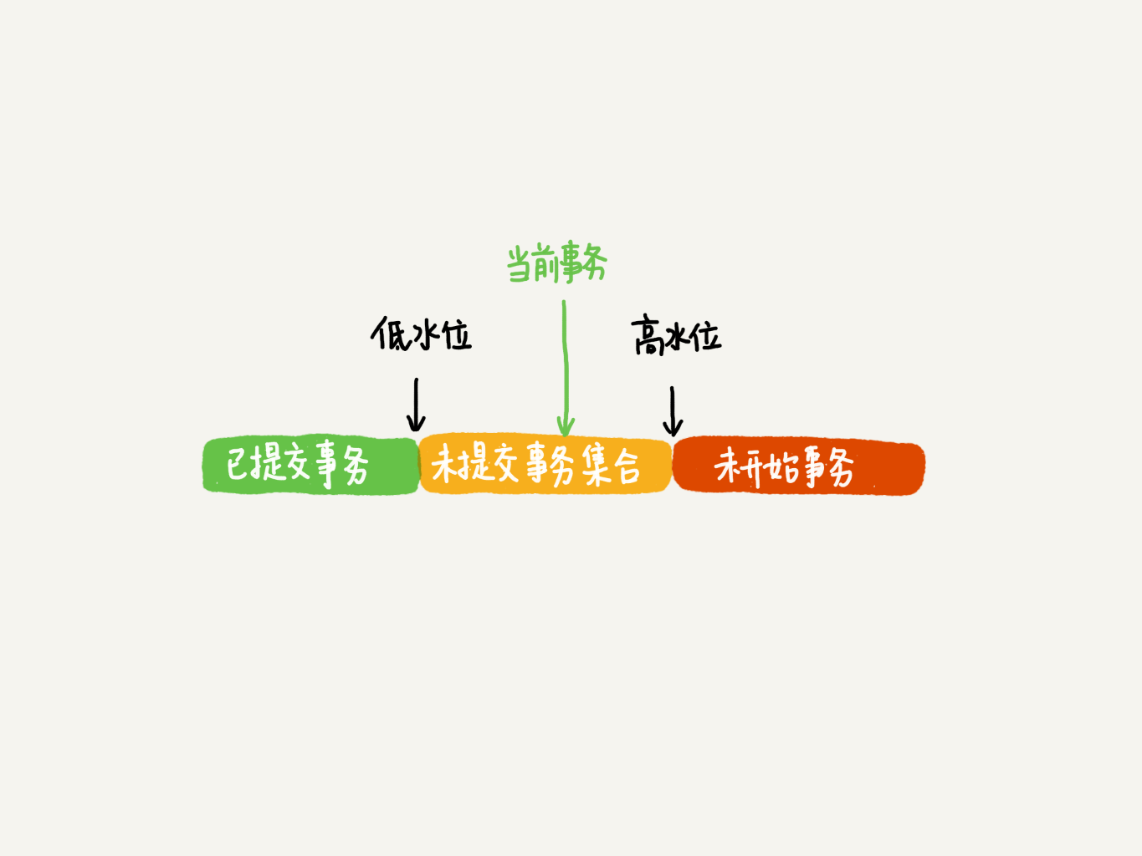
|
||||
|
||||
这样,对于当前事务的启动瞬间来说,一个数据版本的 row trx_id,有以下几种可能:
|
||||
|
||||
|
|
|
|||
|
|
@ -251,7 +251,7 @@ mysql>
|
|||
|
||||
连接完成后,如果你没有后续的动作,这个连接就处于空闲状态,你可以在 `show processlist` 命令中看到它。客户端如果太长时间没动静,连接器就会自动将它断开。这个时间是由参数 `wait_timeout` 控制的,默认值是 8 小时。
|
||||
|
||||

|
||||

|
||||
|
||||
### 2.3. 创建用户
|
||||
|
||||
|
|
|
|||
|
|
@ -209,7 +209,7 @@ Mysql 支持两种复制:基于行的复制和基于语句的复制。
|
|||
- **SQL 线程** :负责读取中继日志并重放其中的 SQL 语句。
|
||||
|
||||
<div align="center">
|
||||
<img src="http://dunwu.test.upcdn.net/cs/database/mysql/master-slave.png" />
|
||||
<img src="https://raw.githubusercontent.com/dunwu/images/dev/cs/database/mysql/master-slave.png" />
|
||||
</div>
|
||||
|
||||
### 8.2. 读写分离
|
||||
|
|
@ -225,7 +225,7 @@ MySQL 读写分离能提高性能的原因在于:
|
|||
- 增加冗余,提高可用性。
|
||||
|
||||
<div align="center">
|
||||
<img src="http://dunwu.test.upcdn.net/cs/database/mysql/master-slave-proxy.png" />
|
||||
<img src="https://raw.githubusercontent.com/dunwu/images/dev/cs/database/mysql/master-slave-proxy.png" />
|
||||
</div>
|
||||
------
|
||||
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@
|
|||
>
|
||||
> 用户可以根据业务是否需要事务处理(事务处理可以保证数据安全,但会增加系统开销),选择合适的存储引擎。
|
||||
|
||||

|
||||

|
||||
|
||||
<!-- TOC depthFrom:2 depthTo:3 -->
|
||||
|
||||
|
|
@ -37,7 +37,7 @@
|
|||
|
||||
> 事务简单来说:**一个 Session 中所进行所有的操作,要么同时成功,要么同时失败**。进一步说,事务指的是满足 ACID 特性的一组操作,可以通过 `Commit` 提交一个事务,也可以使用 `Rollback` 进行回滚。
|
||||
|
||||

|
||||

|
||||
|
||||
**事务就是一组原子性的 SQL 语句**。具体来说,事务指的是满足 ACID 特性的一组操作。
|
||||
|
||||
|
|
@ -49,7 +49,7 @@
|
|||
|
||||
T<sub>1</sub> 和 T<sub>2</sub> 两个线程都对一个数据进行修改,T<sub>1</sub> 先修改,T<sub>2</sub> 随后修改,T<sub>2</sub> 的修改覆盖了 T<sub>1</sub> 的修改。
|
||||
|
||||

|
||||

|
||||
|
||||
## 2. 事务用法
|
||||
|
||||
|
|
@ -155,7 +155,7 @@ ACID 是数据库事务正确执行的四个基本要素。
|
|||
- 在并发的情况下,多个事务并行执行,事务不仅要满足原子性,还需要满足隔离性,才能满足一致性。
|
||||
- 事务满足持久化是为了能应对系统崩溃的情况。
|
||||
|
||||

|
||||

|
||||
|
||||
> MySQL 默认采用自动提交模式(`AUTO COMMIT`)。也就是说,如果不显式使用 `START TRANSACTION` 语句来开始一个事务,那么每个查询操作都会被当做一个事务并自动提交。
|
||||
|
||||
|
|
@ -204,7 +204,7 @@ SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE;
|
|||
|
||||
T<sub>1</sub> 修改一个数据,T<sub>2</sub> 随后读取这个数据。如果 T<sub>1</sub> 撤销了这次修改,那么 T<sub>2</sub> 读取的数据是脏数据。
|
||||
|
||||

|
||||

|
||||
|
||||
### 4.3. 提交读
|
||||
|
||||
|
|
@ -216,7 +216,7 @@ T<sub>1</sub> 修改一个数据,T<sub>2</sub> 随后读取这个数据。如
|
|||
|
||||
T<sub>2</sub> 读取一个数据,T<sub>1</sub> 对该数据做了修改。如果 T<sub>2</sub> 再次读取这个数据,此时读取的结果和第一次读取的结果不同。
|
||||
|
||||

|
||||

|
||||
|
||||
### 4.4. 可重复读
|
||||
|
||||
|
|
@ -228,7 +228,7 @@ T<sub>2</sub> 读取一个数据,T<sub>1</sub> 对该数据做了修改。如
|
|||
|
||||
T<sub>1</sub> 读取某个范围的数据,T<sub>2</sub> 在这个范围内插入新的数据,T<sub>1</sub> 再次读取这个范围的数据,此时读取的结果和和第一次读取的结果不同。
|
||||
|
||||

|
||||

|
||||
|
||||
### 4.5. 串行化
|
||||
|
||||
|
|
@ -280,17 +280,17 @@ T<sub>1</sub> 读取某个范围的数据,T<sub>2</sub> 在这个范围内插
|
|||
|
||||
> INSERT INTO `demo`.`order_record`(`order_no`, `status`, `create_date`) VALUES (5, 1, ‘2019-07-13 10:57:03’);
|
||||
|
||||

|
||||
|
||||
|
||||
**另一个死锁场景**
|
||||
|
||||
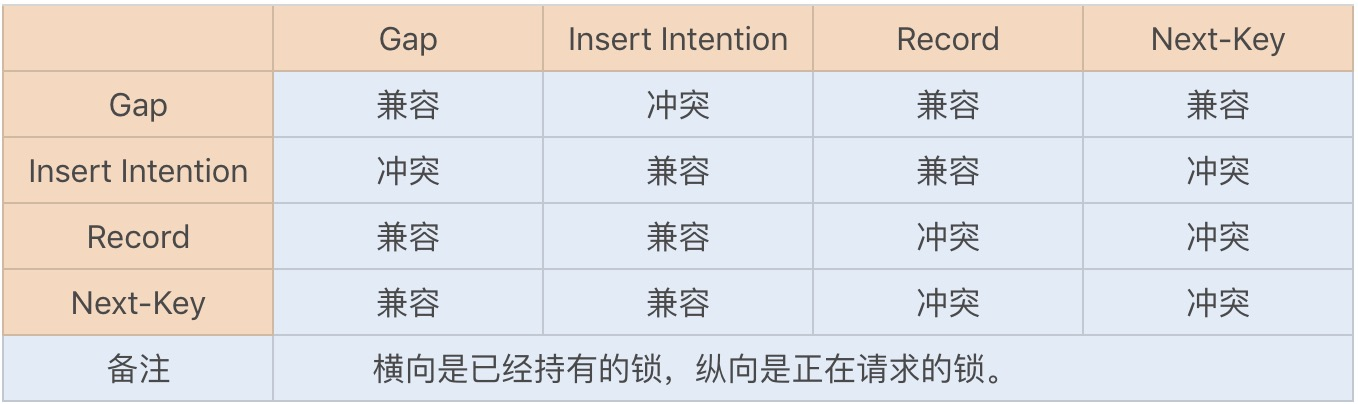
InnoDB 存储引擎的主键索引为聚簇索引,其它索引为辅助索引。如果使用辅助索引来更新数据库,就需要使用聚簇索引来更新数据库字段。如果两个更新事务使用了不同的辅助索引,或一个使用了辅助索引,一个使用了聚簇索引,就都有可能导致锁资源的循环等待。由于本身两个事务是互斥,也就构成了以上死锁的四个必要条件了。
|
||||
|
||||

|
||||

|
||||
|
||||
出现死锁的步骤:
|
||||
|
||||

|
||||
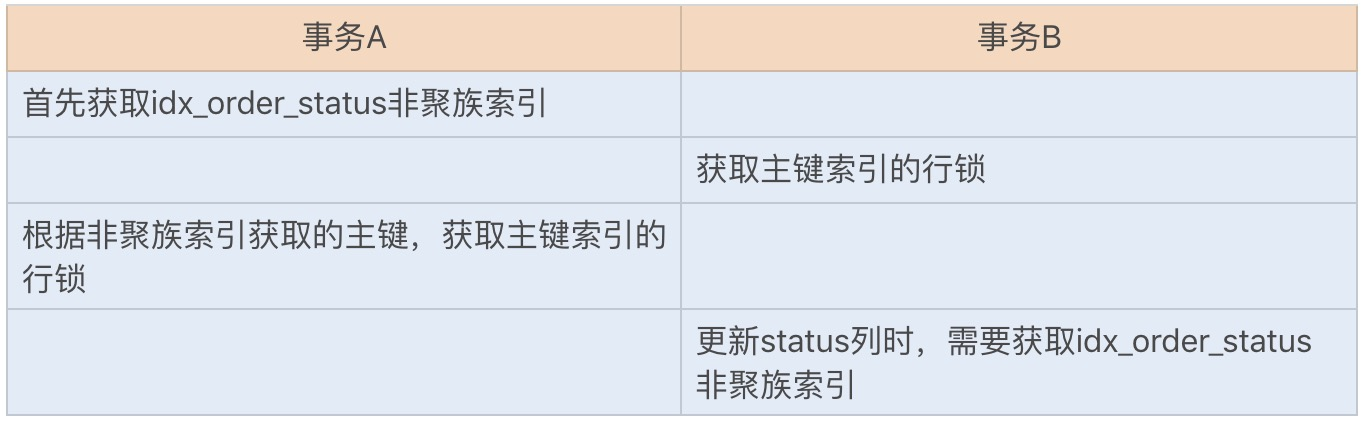
|
||||
|
||||
综上可知,在更新操作时,我们应该尽量使用主键来更新表字段,这样可以有效避免一些不必要的死锁发生。
|
||||
|
||||
|
|
@ -374,7 +374,7 @@ MySQLQueryInterruptedException: Query execution was interrupted
|
|||
|
||||
又因为锁的竞争是不公平的,当多个事务同时对一条记录进行更新时,极端情况下,一个更新操作进去排队系统后,可能会一直拿不到锁,最后因超时被系统打断踢出。
|
||||
|
||||

|
||||
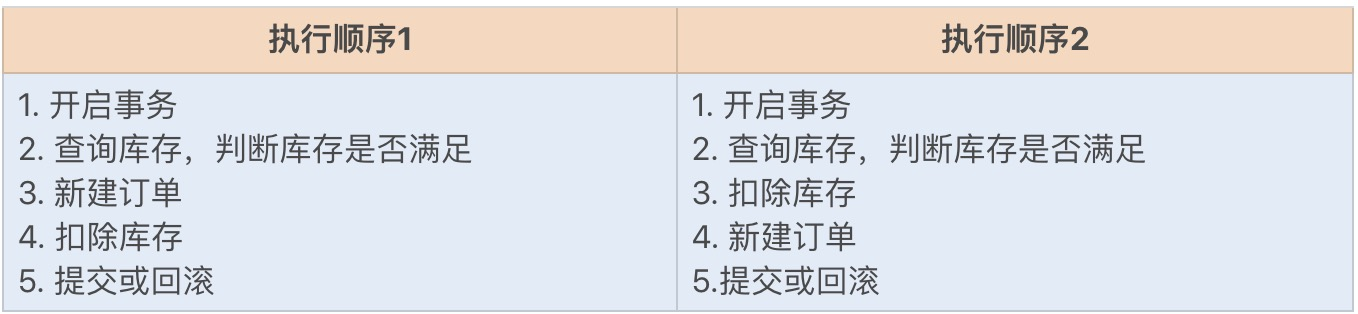
|
||||
|
||||
如上图中的操作,虽然都是在一个事务中,但锁的申请在不同时间,只有当其他操作都执行完,才会释放所有锁。因为扣除库存是更新操作,属于行锁,这将会影响到其他操作该数据的事务,所以我们应该尽量避免长时间地持有该锁,尽快释放该锁。又因为先新建订单和先扣除库存都不会影响业务,所以我们可以将扣除库存操作放到最后,也就是使用执行顺序 1,以此尽量减小锁的持有时间。
|
||||
|
||||
|
|
|
|||
|
|
@ -27,7 +27,7 @@
|
|||
|
||||
**存储引擎层负责数据的存储和提取**。其架构模式是插件式的,支持 InnoDB、MyISAM、Memory 等多个存储引擎。现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始成为了默认存储引擎。
|
||||
|
||||

|
||||
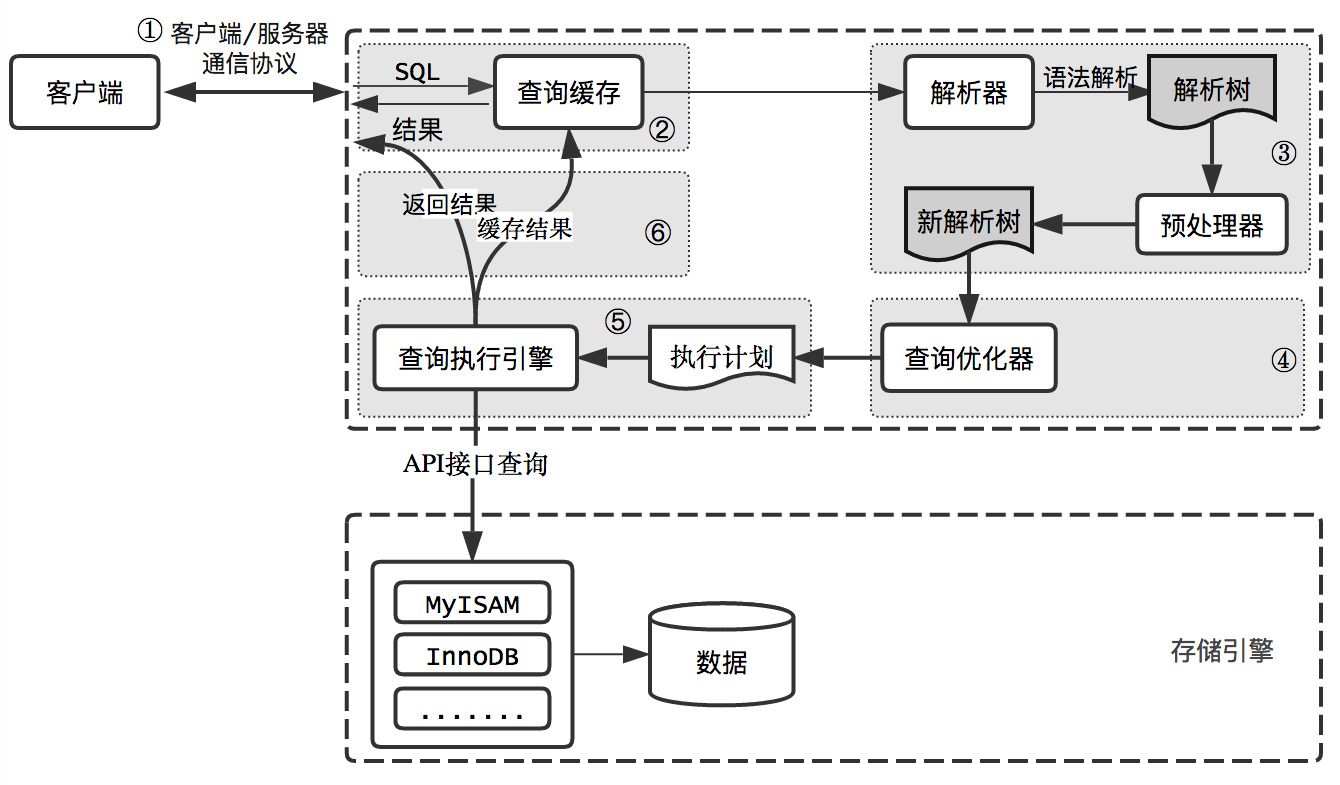
|
||||
|
||||
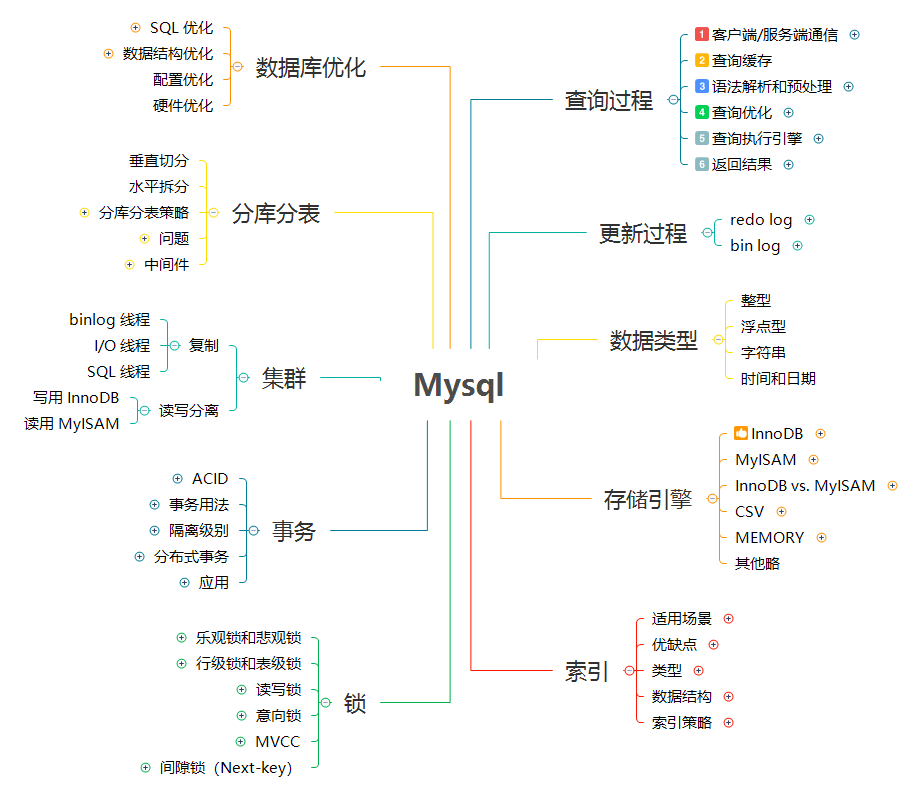
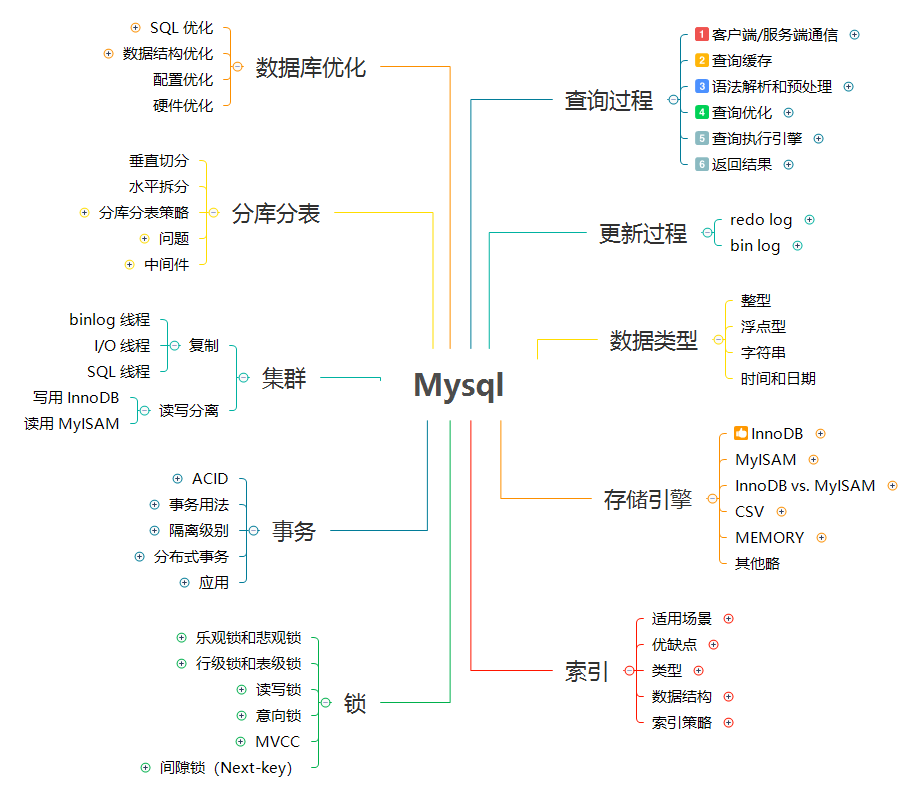
## 2. 查询过程
|
||||
|
||||
|
|
@ -146,7 +146,7 @@ MySQL 更新过程和 MySQL 查询过程类似,也会将流程走一遍。不
|
|||
|
||||
InnoDB 的 redo log 是固定大小的,比如可以配置为一组 4 个文件,每个文件的大小是 1GB,那么这块“粉板”总共就可以记录 4GB 的操作。从头开始写,写到末尾就又回到开头循环写。
|
||||
|
||||

|
||||
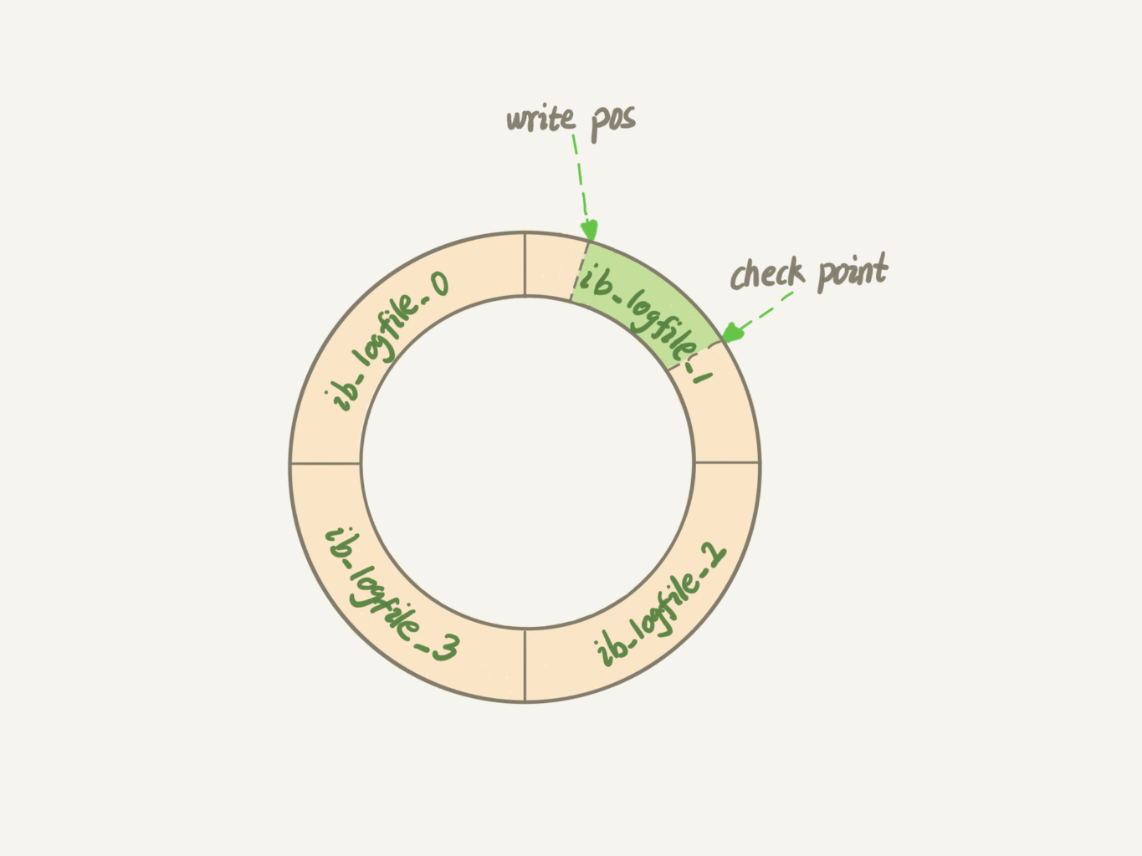
|
||||
|
||||
有了 redo log,InnoDB 就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为**crash-safe**。
|
||||
|
||||
|
|
@ -178,7 +178,7 @@ binlog 是可以追加写入的,即写到一定大小后会切换到下一个
|
|||
|
||||
这里我给出这个 update 语句的执行流程图,图中浅色框表示是在 InnoDB 内部执行的,深色框表示是在执行器中执行的。
|
||||
|
||||

|
||||
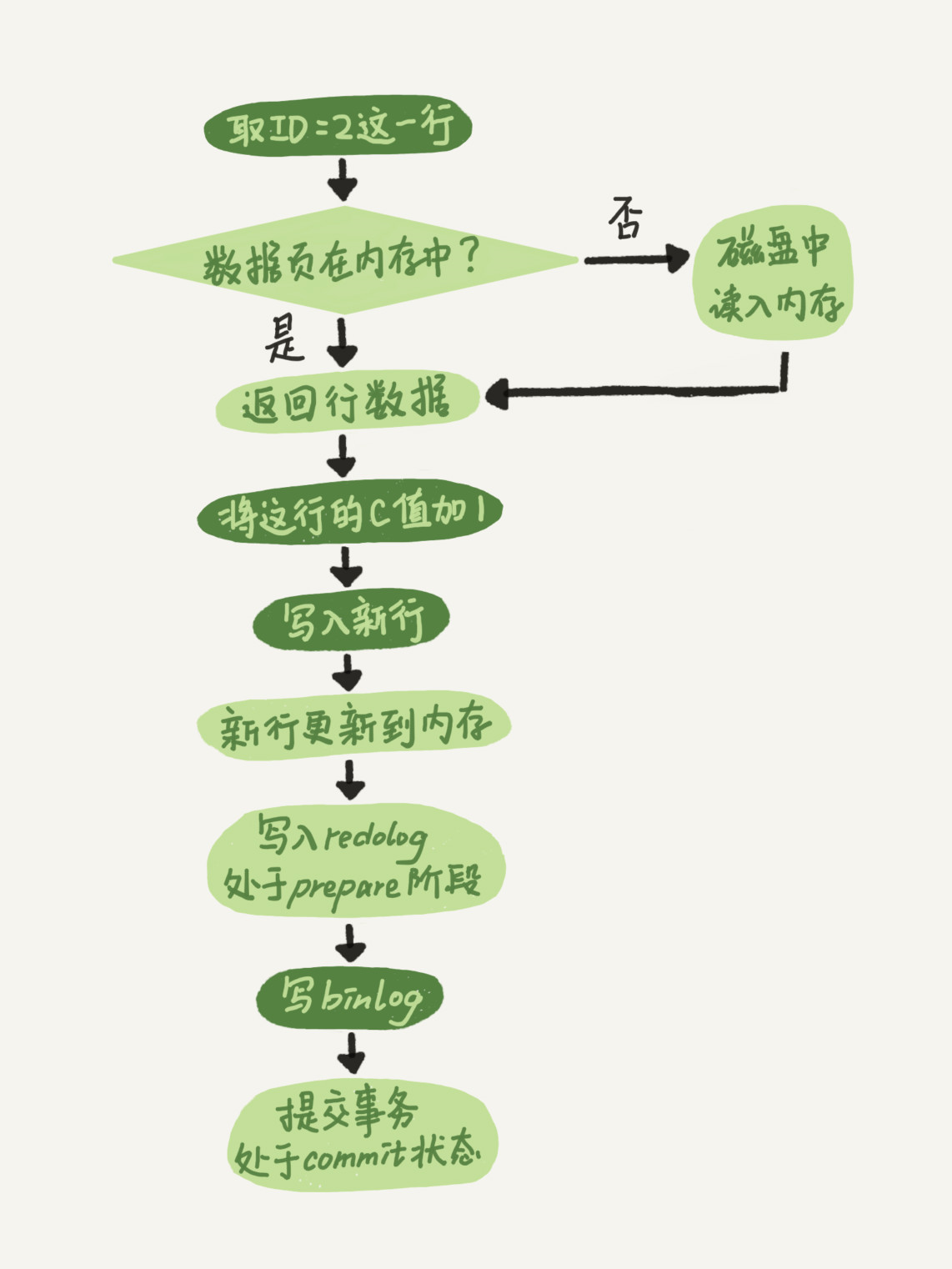
|
||||
|
||||
### 3.4. 两阶段提交
|
||||
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@
|
|||
>
|
||||
> 关键词:Database, RDBM, psql
|
||||
|
||||

|
||||

|
||||
|
||||
## 安装
|
||||
|
||||
|
|
@ -14,7 +14,7 @@
|
|||
|
||||
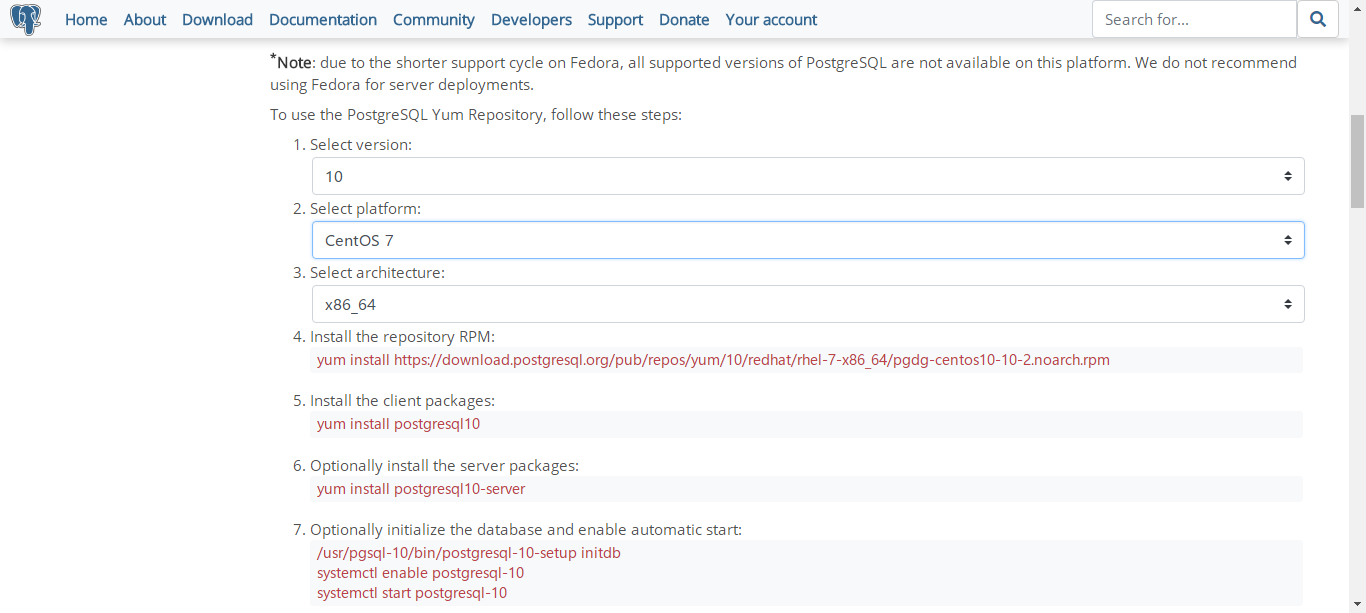
官方下载页面要求用户选择相应版本,然后动态的给出安装提示,如下图所示:
|
||||
|
||||
|
||||
|
||||
|
||||
前 3 步要求用户选择,后 4 步是根据选择动态提示的安装步骤
|
||||
|
||||
|
|
|
|||
Loading…
Reference in New Issue