22 KiB
| title | date | categories | tags | permalink | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mysql 索引 | 2020-07-16 11:14:07 |
|
|
/pages/fcb19c/ |
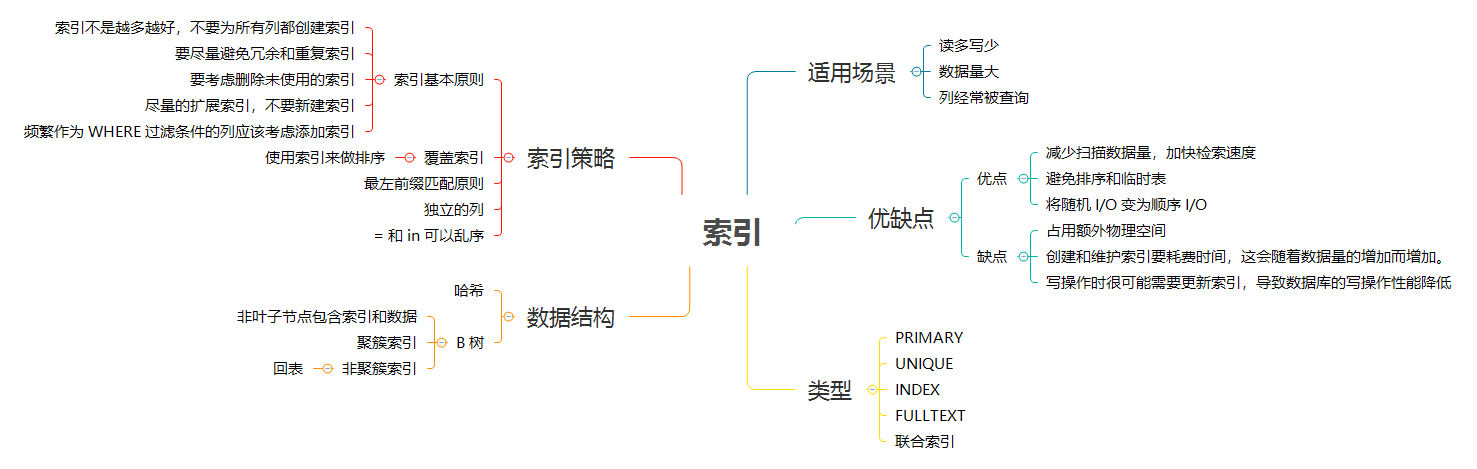
Mysql 索引
索引是提高 MySQL 查询性能的一个重要途径,但过多的索引可能会导致过高的磁盘使用率以及过高的内存占用,从而影响应用程序的整体性能。应当尽量避免事后才想起添加索引,因为事后可能需要监控大量的 SQL 才能定位到问题所在,而且添加索引的时间肯定是远大于初始添加索引所需要的时间,可见索引的添加也是非常有技术含量的。
接下来将向你展示一系列创建高性能索引的策略,以及每条策略其背后的工作原理。但在此之前,先了解与索引相关的一些算法和数据结构,将有助于更好的理解后文的内容。
1. 索引简介
索引是数据库为了提高查找效率的一种数据结构。
索引对于良好的性能非常关键,在数据量小且负载较低时,不恰当的索引对于性能的影响可能还不明显;但随着数据量逐渐增大,性能则会急剧下降。因此,索引优化应该是查询性能优化的最有效手段。
1.1. 索引的优缺点
B 树是最常见的索引,按照顺序存储数据,所以 Mysql 可以用来做 ORDER BY 和 GROUP BY 操作。因为数据是有序的,所以 B 树也就会将相关的列值都存储在一起。最后,因为索引中存储了实际的列值,所以某些查询只使用索引就能够完成全部查询。
✔ 索引的优点:
- 索引大大减少了服务器需要扫描的数据量,从而加快检索速度。
- 索引可以帮助服务器避免排序和临时表。
- 索引可以将随机 I/O 变为顺序 I/O。
- 支持行级锁的数据库,如 InnoDB 会在访问行的时候加锁。使用索引可以减少访问的行数,从而减少锁的竞争,提高并发。
- 唯一索引可以确保每一行数据的唯一性,通过使用索引,可以在查询的过程中使用优化隐藏器,提高系统的性能。
❌ 索引的缺点:
- 创建和维护索引要耗费时间,这会随着数据量的增加而增加。
- 索引需要占用额外的物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立组合索引那么需要的空间就会更大。
- 写操作(
INSERT/UPDATE/DELETE)时很可能需要更新索引,导致数据库的写操作性能降低。
1.2. 何时使用索引
索引能够轻易将查询性能提升几个数量级。
✔ 什么情况适用索引:
- 频繁读操作(
SELECT) - 表的数据量比较大。
- 列名经常出现在
WHERE或连接(JOIN)条件中。
❌ 什么情况不适用索引:
- 频繁写操作(
INSERT/UPDATE/DELETE),也就意味着需要更新索引。 - 列名不经常出现在
WHERE或连接(JOIN)条件中,也就意味着索引会经常无法命中,没有意义,还增加空间开销。 - 非常小的表,对于非常小的表,大部分情况下简单的全表扫描更高效。
- 特大型的表,建立和使用索引的代价将随之增长。可以考虑使用分区技术或 Nosql。
2. 索引的数据结构
在 Mysql 中,索引是在存储引擎层而不是服务器层实现的。所以,并没有统一的索引标准;不同存储引擎的索引的数据结构也不相同。
数组
数组是用连续的内存空间来存储数据,并且支持随机访问。
有序数组可以使用二分查找法,其时间复杂度为 O(log n),无论是等值查询还是范围查询,都非常高效。
但数组有两个重要限制:
- 数组的空间大小固定,如果要扩容只能采用复制数组的方式。
- 插入、删除时间复杂度为
O(n)。
这意味着,如果使用数组作为索引,如果要保证数组有序,其更新操作代价高昂。
2.1. 哈希索引
哈希表是一种以键 - 值(key-value)对形式存储数据的结构,我们只要输入待查找的值即 key,就可以找到其对应的值即 Value。
哈希表 使用 哈希函数 组织数据,以支持快速插入和搜索的数据结构。哈希表的本质是一个数组,其思路是:使用 Hash 函数将 Key 转换为数组下标,利用数组的随机访问特性,使得我们能在 O(1) 的时间代价内完成检索。
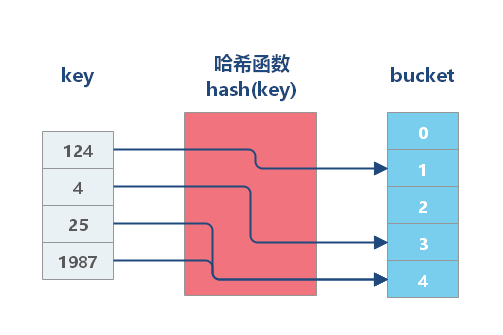
有两种不同类型的哈希表:哈希集合 和 哈希映射。
- 哈希集合 是集合数据结构的实现之一,用于存储非重复值。
- 哈希映射 是映射 数据结构的实现之一,用于存储键值对。
哈希索引基于哈希表实现,只适用于等值查询。对于每一行数据,哈希索引都会将所有的索引列计算一个哈希码(hashcode),哈希码是一个较小的值。哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针。
在 Mysql 中,只有 Memory 存储引擎显示支持哈希索引。
✔ 哈希索引的优点:
- 因为索引数据结构紧凑,所以查询速度非常快。
❌ 哈希索引的缺点:
- 哈希索引值包含哈希值和行指针,而不存储字段值,所以不能使用索引中的值来避免读取行。不过,访问内存中的行的速度很快,所以大部分情况下这一点对性能影响不大。
- 哈希索引数据不是按照索引值顺序存储的,所以无法用于排序。
- 哈希索引不支持部分索引匹配查找,因为哈希索引时使用索引列的全部内容来进行哈希计算的。如,在数据列 (A,B) 上建立哈希索引,如果查询只有数据列 A,无法使用该索引。
- 哈希索引只支持等值比较查询,包括
=、IN()、<=>;不支持任何范围查询,如WHERE price > 100。 - 哈希索引有可能出现哈希冲突
- 出现哈希冲突时,必须遍历链表中所有的行指针,逐行比较,直到找到符合条件的行。
- 如果哈希冲突多的话,维护索引的代价会很高。
因为种种限制,所以哈希索引只适用于特定的场合。而一旦使用哈希索引,则它带来的性能提升会非常显著。
2.2. B 树索引
通常我们所说的索引是指B-Tree索引,它是目前关系型数据库中查找数据最为常用和有效的索引,大多数存储引擎都支持这种索引。使用B-Tree这个术语,是因为 MySQL 在CREATE TABLE或其它语句中使用了这个关键字,但实际上不同的存储引擎可能使用不同的数据结构,比如 InnoDB 就是使用的B+Tree。
B+Tree中的 B 是指balance,意为平衡。需要注意的是,B+树索引并不能找到一个给定键值的具体行,它找到的只是被查找数据行所在的页,接着数据库会把页读入到内存,再在内存中进行查找,最后得到要查找的数据。
二叉搜索树
二叉搜索树的特点是:每个节点的左儿子小于父节点,父节点又小于右儿子。其查询时间复杂度是 $O(log(N))$。
当然为了维持 $O(log(N))的查询复杂度,你就需要保持这棵树是平衡二叉树。为了做这个保证,更新的时间复杂度也是O(log(N))$。
随着数据库中数据的增加,索引本身大小随之增加,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘 I/O 消耗,相对于内存存取,I/O 存取的消耗要高几个数量级。可以想象一下一棵几百万节点的二叉树的深度是多少?如果将这么大深度的一颗二叉树放磁盘上,每读取一个节点,需要一次磁盘的 I/O 读取,整个查找的耗时显然是不能够接受的。那么如何减少查找过程中的 I/O 存取次数?
一种行之有效的解决方法是减少树的深度,将二叉树变为 N 叉树(多路搜索树),而 B+ 树就是一种多路搜索树。
B+ 树
B+ 树索引适用于全键值查找、键值范围查找和键前缀查找,其中键前缀查找只适用于最左前缀查找。
理解B+Tree时,只需要理解其最重要的两个特征即可:
- 第一,所有的关键字(可以理解为数据)都存储在叶子节点,非叶子节点并不存储真正的数据,所有记录节点都是按键值大小顺序存放在同一层叶子节点上。
- 其次,所有的叶子节点由指针连接。如下图为简化了的
B+Tree。
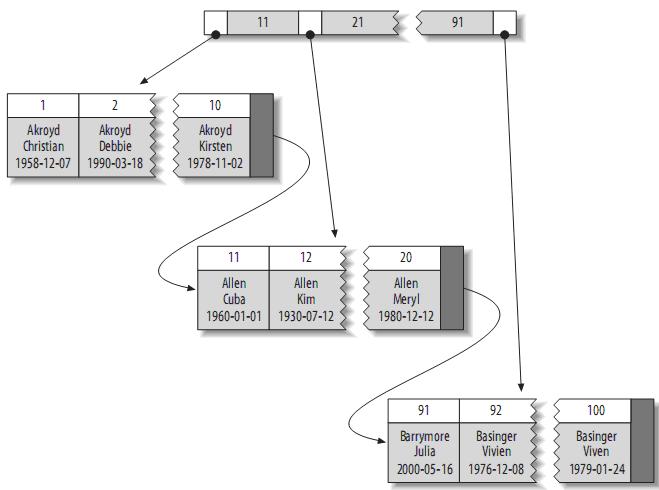
根据叶子节点的内容,索引类型分为主键索引和非主键索引。
- 聚簇索引(clustered):又称为主键索引,其叶子节点存的是整行数据。因为无法同时把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引。InnoDB 的聚簇索引实际是在同一个结构中保存了 B 树的索引和数据行。
- 非主键索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为二级索引(secondary)。数据存储在一个位置,索引存储在另一个位置,索引中包含指向数据存储位置的指针。可以有多个,小于 249 个。
聚簇表示数据行和相邻的键值紧凑地存储在一起,因为数据紧凑,所以访问快。因为无法同时把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引。
聚簇索引和非聚簇索引的查询有什么区别
- 如果语句是
select * from T where ID=500,即聚簇索引查询方式,则只需要搜索 ID 这棵 B+ 树; - 如果语句是
select * from T where k=5,即非聚簇索引查询方式,则需要先搜索 k 索引树,得到 ID 的值为 500,再到 ID 索引树搜索一次。这个过程称为回表。
也就是说,基于非聚簇索引的查询需要多扫描一棵索引树。因此,我们在应用中应该尽量使用主键查询。
显然,主键长度越小,非聚簇索引的叶子节点就越小,非聚簇索引占用的空间也就越小。
自增主键是指自增列上定义的主键,在建表语句中一般是这么定义的: NOT NULL PRIMARY KEY AUTO_INCREMENT。从性能和存储空间方面考量,自增主键往往是更合理的选择。有没有什么场景适合用业务字段直接做主键的呢?还是有的。比如,有些业务的场景需求是这样的:
- 只有一个索引;
- 该索引必须是唯一索引。
由于没有其他索引,所以也就不用考虑其他索引的叶子节点大小的问题。
这时候我们就要优先考虑上一段提到的“尽量使用主键查询”原则,直接将这个索引设置为主键,可以避免每次查询需要搜索两棵树。
2.3. 全文索引
MyISAM 存储引擎支持全文索引,用于查找文本中的关键词,而不是直接比较是否相等。查找条件使用 MATCH AGAINST,而不是普通的 WHERE。
全文索引一般使用倒排索引实现,它记录着关键词到其所在文档的映射。
InnoDB 存储引擎在 MySQL 5.6.4 版本中也开始支持全文索引。
2.4. 空间数据索引
MyISAM 存储引擎支持空间数据索引(R-Tree),可以用于地理数据存储。空间数据索引会从所有维度来索引数据,可以有效地使用任意维度来进行组合查询。
必须使用 GIS 相关的函数来维护数据。
3. 索引的类型
主流的关系型数据库一般都支持以下索引类型:
3.1. 主键索引(PRIMARY)
主键索引:一种特殊的唯一索引,不允许有空值。一个表只能有一个主键(在 InnoDB 中本质上即聚簇索引),一般是在建表的时候同时创建主键索引。
CREATE TABLE `table` (
`id` int(11) NOT NULL AUTO_INCREMENT,
...
PRIMARY KEY (`id`)
)
3.2. 唯一索引(UNIQUE)
唯一索引:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
CREATE TABLE `table` (
...
UNIQUE indexName (title(length))
)
3.3. 普通索引(INDEX)
普通索引:最基本的索引,没有任何限制。
CREATE TABLE `table` (
...
INDEX index_name (title(length))
)
3.4. 全文索引(FULLTEXT)
全文索引:主要用来查找文本中的关键字,而不是直接与索引中的值相比较。
全文索引跟其它索引大不相同,它更像是一个搜索引擎,而不是简单的 WHERE 语句的参数匹配。全文索引配合 match against 操作使用,而不是一般的 WHERE 语句加 LIKE。它可以在 CREATE TABLE,ALTER TABLE ,CREATE INDEX 使用,不过目前只有 char、varchar,text 列上可以创建全文索引。值得一提的是,在数据量较大时候,现将数据放入一个没有全局索引的表中,然后再用 CREATE INDEX 创建全文索引,要比先为一张表建立全文索引然后再将数据写入的速度快很多。
CREATE TABLE `table` (
`content` text CHARACTER NULL,
...
FULLTEXT (content)
)
3.5. 联合索引
组合索引:多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀集合。
CREATE TABLE `table` (
...
INDEX index_name (title(length), title(length), ...)
)
4. 索引的策略
假设有以下表:
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`city` varchar(16) NOT NULL,
`name` varchar(16) NOT NULL,
`age` int(11) NOT NULL,
`addr` varchar(128) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `city` (`city`)
) ENGINE=InnoDB;
4.1. 索引基本原则
- 索引不是越多越好,不要为所有列都创建索引。要考虑到索引的维护代价、空间占用和查询时回表的代价。索引一定是按需创建的,并且要尽可能确保足够轻量。一旦创建了多字段的联合索引,我们要考虑尽可能利用索引本身完成数据查询,减少回表的成本。
- 要尽量避免冗余和重复索引。
- 要考虑删除未使用的索引。
- 尽量的扩展索引,不要新建索引。
- 频繁作为
WHERE过滤条件的列应该考虑添加索引。
4.2. 独立的列
“独立的列” 是指索引列不能是表达式的一部分,也不能是函数的参数。
对索引字段做函数操作,可能会破坏索引值的有序性,因此优化器就决定放弃走树搜索功能。
如果查询中的列不是独立的列,则数据库不会使用索引。
❌ 错误示例:
SELECT actor_id FROM actor WHERE actor_id + 1 = 5;
SELECT ... WHERE TO_DAYS(current_date) - TO_DAYS(date_col) <= 10;
4.3. 覆盖索引
覆盖索引是指,索引上的信息足够满足查询请求,不需要回表查询数据。
【示例】范围查询
create table T (
ID int primary key,
k int NOT NULL DEFAULT 0,
s varchar(16) NOT NULL DEFAULT '',
index k(k))
engine=InnoDB;
insert into T values(100,1, 'aa'),(200,2,'bb'),(300,3,'cc'),(500,5,'ee'),(600,6,'ff'),(700,7,'gg');
select * from T where k between 3 and 5
需要执行几次树的搜索操作,会扫描多少行?
- 在 k 索引树上找到 k=3 的记录,取得 ID = 300;
- 再到 ID 索引树查到 ID=300 对应的 R3;
- 在 k 索引树取下一个值 k=5,取得 ID=500;
- 再回到 ID 索引树查到 ID=500 对应的 R4;
- 在 k 索引树取下一个值 k=6,不满足条件,循环结束。
在这个过程中,回到主键索引树搜索的过程,我们称为回表。可以看到,这个查询过程读了 k 索引树的 3 条记录(步骤 1、3 和 5),回表了两次(步骤 2 和 4)。
如果执行的语句是 select ID from T where k between 3 and 5,这时只需要查 ID 的值,而 ID 的值已经在 k 索引树上了,因此可以直接提供查询结果,不需要回表。索引包含所有需要查询的字段的值,称为覆盖索引。
由于覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段。
4.4. 使用索引来排序
Mysql 有两种方式可以生成排序结果:通过排序操作;或者按索引顺序扫描。
索引最好既满足排序,又用于查找行。这样,就可以通过命中覆盖索引直接将结果查出来,也就不再需要排序了。
这样整个查询语句的执行流程就变成了:
- 从索引 (city,name,age) 找到第一个满足 city='杭州’条件的记录,取出其中的 city、name 和 age 这三个字段的值,作为结果集的一部分直接返回;
- 从索引 (city,name,age) 取下一个记录,同样取出这三个字段的值,作为结果集的一部分直接返回;
- 重复执行步骤 2,直到查到第 1000 条记录,或者是不满足 city='杭州’条件时循环结束。
4.5. 前缀索引
有时候需要索引很长的字符列,这会让索引变得大且慢。
这时,可以使用前缀索引,即只索引开始的部分字符,这样可以大大节约索引空间,从而提高索引效率。但这样也会降低索引的选择性。对于 BLOB/TEXT/VARCHAR 这种文本类型的列,必须使用前缀索引,因为数据库往往不允许索引这些列的完整长度。
索引的选择性是指:不重复的索引值和数据表记录总数的比值。最大值为 1,此时每个记录都有唯一的索引与其对应。选择性越高,查询效率也越高。如果存在多条命中前缀索引的情况,就需要依次扫描,直到最终找到正确记录。
使用前缀索引,定义好长度,就可以做到既节省空间,又不用额外增加太多的查询成本。
那么,如何确定前缀索引合适的长度呢?
可以使用下面这个语句,算出这个列上有多少个不同的值:
select count(distinct email) as L from SUser;
然后,依次选取不同长度的前缀来看这个值,比如我们要看一下 4~7 个字节的前缀索引,可以用这个语句:
select
count(distinct left(email,4))as L4,
count(distinct left(email,5))as L5,
count(distinct left(email,6))as L6,
count(distinct left(email,7))as L7,
from SUser;
当然,使用前缀索引很可能会损失区分度,所以你需要预先设定一个可以接受的损失比例,比如 5%。然后,在返回的 L4~L7 中,找出不小于 L * 95% 的值,假设这里 L6、L7 都满足,你就可以选择前缀长度为 6。
此外,order by 无法使用前缀索引,无法把前缀索引用作覆盖索引。
4.6. 最左前缀匹配原则
不只是索引的全部定义,只要满足最左前缀,就可以利用索引来加速检索。这个最左前缀可以是联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符。
MySQL 会一直向右匹配直到遇到范围查询 (>,<,BETWEEN,LIKE) 就停止匹配。
- 索引可以简单如一个列(a),也可以复杂如多个列(a, b, c, d),即联合索引。
- 如果是联合索引,那么 key 也由多个列组成,同时,索引只能用于查找 key 是否存在(相等),遇到范围查询(>、<、between、like 左匹配)等就不能进一步匹配了,后续退化为线性查找。
- 因此,列的排列顺序决定了可命中索引的列数。
不要为每个列都创建独立索引。
将选择性高的列或基数大的列优先排在多列索引最前列。但有时,也需要考虑 WHERE 子句中的排序、分组和范围条件等因素,这些因素也会对查询性能造成较大影响。
例如:a = 1 and b = 2 and c > 3 and d = 4,如果建立(a,b,c,d)顺序的索引,d 是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d 的顺序可以任意调整。
让选择性最强的索引列放在前面,索引的选择性是指:不重复的索引值和记录总数的比值。最大值为 1,此时每个记录都有唯一的索引与其对应。选择性越高,查询效率也越高。
例如下面显示的结果中 customer_id 的选择性比 staff_id 更高,因此最好把 customer_id 列放在多列索引的前面。
SELECT COUNT(DISTINCT staff_id)/COUNT(*) AS staff_id_selectivity,
COUNT(DISTINCT customer_id)/COUNT(*) AS customer_id_selectivity,
COUNT(*)
FROM payment;
staff_id_selectivity: 0.0001
customer_id_selectivity: 0.0373
COUNT(*): 16049
4.7. = 和 in 可以乱序
不需要考虑 =、IN 等的顺序,Mysql 会自动优化这些条件的顺序,以匹配尽可能多的索引列。
【示例】如有索引 (a, b, c, d),查询条件 c > 3 and b = 2 and a = 1 and d < 4 与 a = 1 and c > 3 and b = 2 and d < 4 等顺序都是可以的,MySQL 会自动优化为 a = 1 and b = 2 and c > 3 and d < 4,依次命中 a、b、c、d。
5. 索引最佳实践
创建了索引,并非一定有效。比如不满足前缀索引、最左前缀匹配原则、查询条件涉及函数计算等情况都无法使用索引。此外,即使 SQL 本身符合索引的使用条件,MySQL 也会通过评估各种查询方式的代价,来决定是否走索引,以及走哪个索引。
因此,在尝试通过索引进行 SQL 性能优化的时候,务必通过执行计划(EXPLAIN)或实际的效果来确认索引是否能有效改善性能问题,否则增加了索引不但没解决性能问题,还增加了数据库增删改的负担。如果对 EXPLAIN 给出的执行计划有疑问的话,你还可以利用 optimizer_trace 查看详细的执行计划做进一步分析。