更新文档
parent
4fe80b5df6
commit
03b62e5505
103
README.md
103
README.md
|
|
@ -1,6 +1,12 @@
|
|||
# OS
|
||||
|
||||
## 内容
|
||||
> 作为研发工程师,谁还没干过点运维的活?:joy:
|
||||
>
|
||||
> 搞运维,怎么着也得懂点操作系统相关。
|
||||
>
|
||||
> 本项目,就是本人在日常学习工作中,对于操作系统、运维部署等相关知识的整理。
|
||||
|
||||
## :books: 内容
|
||||
|
||||
### [Linux](docs/linux/README.md)
|
||||
|
||||
|
|
@ -22,55 +28,70 @@
|
|||
|
||||
### [Vim](docs/vim.md)
|
||||
|
||||
### [Git](docs/git/README.md)
|
||||
|
||||
- [快速指南(quickstart)](docs/git/git-quickstart.md)
|
||||
|
||||
#### git 基础篇(basics)
|
||||
|
||||
- [安装(installation)](docs/git/basics/git-installation.md)
|
||||
- [配置(configuration)](docs/git/basics/git-configuration.md)
|
||||
|
||||
#### git 进阶篇(advanced)
|
||||
|
||||
- [git-flow 工作流](docs/git/advanced/git-flow.md)
|
||||
|
||||
#### git 附录(appendix)
|
||||
|
||||
- [常见问题(faq)](docs/git/appendix/git-faq.md)
|
||||
- [命令(command)](docs/git/appendix/git-command.md)
|
||||
- [资源(resource)](docs/git/appendix/git-resource.md)
|
||||
|
||||
### [Docker](docs/docker/README.md)
|
||||
|
||||
### Windows
|
||||
|
||||
- [Windows 工具](docs/windows/Windows工具.md)
|
||||
|
||||
## 部署
|
||||
## :hammer_and_pick: 常见软件安装/配置/使用指南
|
||||
|
||||
> 这里总结了各种软件的安装、配置。并提供基本安装、运行的脚本。
|
||||
> :bulb: **说明**
|
||||
>
|
||||
> 这里总结了多种常用研发软件的安装、配置、使用指南。并提供基本安装、运行的脚本。
|
||||
>
|
||||
> [环境部署工具](codes/deploy/README.md) :适合开发、运维人员,在 [CentOS](https://www.centos.org/) 机器上安装常用命令工具或开发软件。
|
||||
>
|
||||
> - *`Scripts`:安装配置脚本,按照说明安装使用即可。*
|
||||
> - *`Docs`: 安装配置文档,说明安装的方法以及一些注意事项。*
|
||||
> - *`Tutorial`: 教程文档。*
|
||||
|
||||
### 常见软件安装配置详述
|
||||
#### 研发环境
|
||||
|
||||
> _`CODES`:安装配置脚本,按照说明安装使用即可。_
|
||||
>
|
||||
> _`DOCS`: 安装配置文档,说明安装的方法以及一些注意事项。_
|
||||
- JDK
|
||||
- | [**`Scripts`**](codes/deploy/tool/jdk) | [**`Docs`**](docs/tool/install-jdk.md) |
|
||||
- Maven
|
||||
- | [**`Scripts`**](codes/deploy/tool/maven) | [**`Docs`**](docs/tool/install-maven.md) |
|
||||
- Nginx
|
||||
- | [**`Scripts`**](codes/deploy/tool/nginx) | [**`Docs`**](docs/tool/install-nginx.md) | [**`Tutorial`**](https://github.com/dunwu/nginx-tutorial) |
|
||||
- Nodejs
|
||||
- | [**`Scripts`**](codes/deploy/tool/nodejs) | [**`Docs`**](docs/tool/install-nodejs.md) |
|
||||
- Tomcat
|
||||
- | [**`Scripts`**](codes/deploy/tool/tomcat) | [**`Docs`**](docs/tool/install-tomcat.md) |
|
||||
- Zookeeper
|
||||
- | [**`Scripts`**](codes/deploy/tool/zookeeper) | [**`Docs`**](docs/tool/install-zookeeper.md) |
|
||||
|
||||
- JDK 安装和配置:| [CODES](codes/deploy/tool/jdk) | [DOCS](docs/deploy/tool/install-jdk.md) |
|
||||
- Jenkins 安装和配置:| [CODES](codes/deploy/tool/jenkins) | [DOCS](docs/deploy/tool/install-jenkins.md) |
|
||||
- Kafka 安装和配置:| [CODES](codes/deploy/tool/kafka) | [DOCS](docs/deploy/tool/install-kafka.md) |
|
||||
- Maven 安装和配置:| [CODES](codes/deploy/tool/maven) | [DOCS](docs/deploy/tool/install-maven.md) |
|
||||
- Mongodb 安装和配置:| [CODES](codes/deploy/tool/mongodb) | [DOCS](https://github.com/dunwu/database/blob/master/docs/mongodb/install-mongodb.md) |
|
||||
- Mysql 安装和配置:| [DOCS](https://github.com/dunwu/database/blob/master/docs/mysql/install-mysql.md) |
|
||||
- Nexus 安装和配置:| [DOCS](docs/deploy/tool/install-nexus.md) |
|
||||
- Nginx 安装和配置:| [CODES](codes/deploy/tool/nginx) | [DOCS](docs/deploy/tool/install-nginx.md) |
|
||||
- Nodejs 安装和配置:| [CODES](codes/deploy/tool/nodejs) | [DOCS](docs/deploy/tool/install-nodejs.md) |
|
||||
- PostgreSQL 安装和配置:| [DOCS](https://github.com/dunwu/database/blob/master/docs/postgresql.md#安装) |
|
||||
- Redis 安装和配置:| [CODES](codes/deploy/tool/redis) | [DOCS](https://github.com/dunwu/database/blob/master/docs/redis/install-redis.md) |
|
||||
- RocketMQ 安装和配置:| [CODES](codes/deploy/tool/rocketmq) | [DOCS](docs/deploy/tool/install-rocketmq.md) |
|
||||
- Svn 安装和配置:| [DOCS](docs/deploy/tool/install-svn.md) |
|
||||
- Tomcat 安装和配置:| [CODES](codes/deploy/tool/tomcat) | [DOCS](docs/deploy/tool/install-tomcat.md) |
|
||||
- Zookeeper 安装和配置:| [CODES](codes/deploy/tool/zookeeper) | [DOCS](docs/deploy/tool/install-zookeeper.md) |
|
||||
#### 研发工具
|
||||
|
||||
- Nexus - Maven 私服。
|
||||
- | [**`Docs`**](docs/tool/install-nexus.md) |
|
||||
- Gitlab - Git 代码管理平台。
|
||||
- Jenkins - 持续集成和持续交付平台。
|
||||
- | [**`Scripts`**](codes/deploy/tool/jenkins) | [**`Docs`**](docs/tool/install-jenkins.md) |
|
||||
- Elastic - 常被称为 `ELK` ,是 Java 世界最流行的分布式日志解决方案 。 `ELK` 是 Elastic 公司旗下三款产品 [ElasticSearch](https://www.elastic.co/products/elasticsearch) 、[Logstash](https://www.elastic.co/products/logstash) 、[Kibana](https://www.elastic.co/products/kibana) 的首字母组合。
|
||||
- | [**`Tutorial`**](docs/tool/elastic/README.md) |
|
||||
|
||||
#### 版本控制
|
||||
|
||||
- Git
|
||||
- | [**`Tutorial`**](docs/git/README.md) |
|
||||
- Svn
|
||||
- | [**`Docs`**](docs/tool/install-svn.md) |
|
||||
|
||||
#### 消息中间件
|
||||
|
||||
- Kafka - 应该是 Java 世界最流行的消息中间件了吧。
|
||||
- | [**`Scripts`**](codes/deploy/tool/kafka) | [**`Docs`**](docs/tool/install-kafka.md) |
|
||||
- RocketMQ - 阿里巴巴开源的消息中间件。
|
||||
- | [**`Scripts`**](codes/deploy/tool/rocketmq) | [**`Docs`**](docs/tool/install-rocketmq.md) |
|
||||
|
||||
#### 数据库
|
||||
|
||||
- Mysql - 关系型数据库
|
||||
- | [**`Docs`**](https://github.com/dunwu/database/blob/master/docs/mysql/install-mysql.md) |
|
||||
- PostgreSQL - 关系型数据库
|
||||
- | [**`Docs`**](https://github.com/dunwu/database/blob/master/docs/postgresql.md#安装) |
|
||||
- Mongodb - Nosql
|
||||
- | [**`Scripts`**](codes/deploy/tool/mongodb) | [**`Docs`**](https://github.com/dunwu/database/blob/master/docs/mongodb/install-mongodb.md) |
|
||||
- Redis - Nosql
|
||||
- | [**`Scripts`**](codes/deploy/tool/redis) | [**`Docs`**](https://github.com/dunwu/database/blob/master/docs/redis/install-redis.md) |
|
||||
|
|
|
|||
|
|
@ -0,0 +1,41 @@
|
|||
# Elastic 技术栈
|
||||
|
||||
> **Elastic 技术栈通常被用来作为日志中心。**
|
||||
>
|
||||
> ELK 是 elastic 公司旗下三款产品 [ElasticSearch](https://www.elastic.co/products/elasticsearch) 、[Logstash](https://www.elastic.co/products/logstash) 、[Kibana](https://www.elastic.co/products/kibana) 的首字母组合。
|
||||
>
|
||||
> [ElasticSearch](https://www.elastic.co/products/elasticsearch) 是一个基于 [Lucene](http://lucene.apache.org/core/documentation.html) 构建的开源,分布式,RESTful 搜索引擎。
|
||||
>
|
||||
> [Logstash](https://www.elastic.co/products/logstash) 传输和处理你的日志、事务或其他数据。
|
||||
>
|
||||
> [Kibana](https://www.elastic.co/products/kibana) 将 Elasticsearch 的数据分析并渲染为可视化的报表。
|
||||
>
|
||||
> Elastic 技术栈,在 ELK 的基础上扩展了一些新的产品,如:[Beats](https://www.elastic.co/products/beats) 、[X-Pack](https://www.elastic.co/products/x-pack) 。
|
||||
|
||||
## 目录
|
||||
|
||||
[Elastic 技术栈之快速指南](elastic-quickstart.md)
|
||||
|
||||
[Elastic 技术栈之 Logstash 基础](elastic-logstash.md)
|
||||
|
||||
## 资源
|
||||
|
||||
**官方资源**
|
||||
|
||||
[Elastic 官方文档](https://www.elastic.co/guide/index.html)
|
||||
|
||||
**第三方工具**
|
||||
|
||||
[logstash-logback-encoder](https://github.com/logstash/logstash-logback-encoder)
|
||||
|
||||
**教程**
|
||||
|
||||
[Elasticsearch 权威指南(中文版)](https://es.xiaoleilu.com/index.html)
|
||||
|
||||
[ELK Stack权威指南](https://github.com/chenryn/logstash-best-practice-cn)
|
||||
|
||||
**博文**
|
||||
|
||||
[Elasticsearch+Logstash+Kibana教程](https://www.cnblogs.com/xing901022/p/4704319.html)
|
||||
|
||||
[ELK(Elasticsearch、Logstash、Kibana)安装和配置](https://github.com/judasn/Linux-Tutorial/blob/master/ELK-Install-And-Settings.md)
|
||||
|
|
@ -0,0 +1,296 @@
|
|||
---
|
||||
title: Elastic 技术栈之 Filebeat
|
||||
date: 2017-01-03
|
||||
categories:
|
||||
- javatool
|
||||
tags:
|
||||
- java
|
||||
- javatool
|
||||
- log
|
||||
- elastic
|
||||
---
|
||||
|
||||
# Elastic 技术栈之 Filebeat
|
||||
|
||||
## 简介
|
||||
|
||||
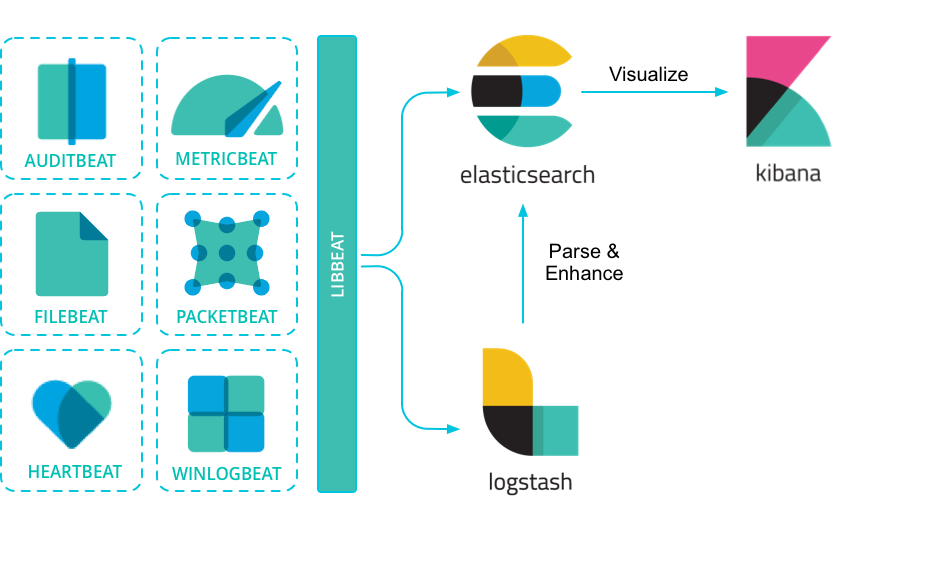
Beats 是安装在服务器上的数据中转代理。
|
||||
|
||||
Beats 可以将数据直接传输到 Elasticsearch 或传输到 Logstash 。
|
||||
|
||||
|
||||
|
||||
Beats 有多种类型,可以根据实际应用需要选择合适的类型。
|
||||
|
||||
常用的类型有:
|
||||
|
||||
- **Packetbeat:**网络数据包分析器,提供有关您的应用程序服务器之间交换的事务的信息。
|
||||
- **Filebeat:**从您的服务器发送日志文件。
|
||||
- **Metricbeat:**是一个服务器监视代理程序,它定期从服务器上运行的操作系统和服务收集指标。
|
||||
- **Winlogbeat:**提供Windows事件日志。
|
||||
|
||||
> **参考**
|
||||
>
|
||||
> 更多 Beats 类型可以参考:[community-beats](https://www.elastic.co/guide/en/beats/libbeat/current/community-beats.html)
|
||||
>
|
||||
> **说明**
|
||||
>
|
||||
> 由于本人工作中只应用了 FileBeat,所以后面内容仅介绍 FileBeat 。
|
||||
|
||||
### FileBeat 的作用
|
||||
|
||||
相比 Logstash,FileBeat 更加轻量化。
|
||||
|
||||
在任何环境下,应用程序都有停机的可能性。 Filebeat 读取并转发日志行,如果中断,则会记住所有事件恢复联机状态时所在位置。
|
||||
|
||||
Filebeat带有内部模块(auditd,Apache,Nginx,System和MySQL),可通过一个指定命令来简化通用日志格式的收集,解析和可视化。
|
||||
|
||||
FileBeat 不会让你的管道超负荷。FileBeat 如果是向 Logstash 传输数据,当 Logstash 忙于处理数据,会通知 FileBeat 放慢读取速度。一旦拥塞得到解决,FileBeat 将恢复到原来的速度并继续传播。
|
||||
|
||||
|
||||
|
||||
## 安装
|
||||
|
||||
Unix / Linux 系统建议使用下面方式安装,因为比较通用。
|
||||
|
||||
```
|
||||
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.1.1-linux-x86_64.tar.gz
|
||||
tar -zxf filebeat-6.1.1-linux-x86_64.tar.gz
|
||||
```
|
||||
|
||||
> **参考**
|
||||
>
|
||||
> 更多内容可以参考:[filebeat-installation](https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-installation.html)
|
||||
|
||||
## 配置
|
||||
|
||||
### 配置文件
|
||||
|
||||
首先,需要知道的是:`filebeat.yml` 是 filebeat 的配置文件。配置文件的路径会因为你安装方式的不同而变化。
|
||||
|
||||
Beat 所有系列产品的配置文件都基于 [YAML](http://www.yaml.org/) 格式,FileBeat 当然也不例外。
|
||||
|
||||
filebeat.yml 部分配置示例:
|
||||
|
||||
```yaml
|
||||
filebeat:
|
||||
prospectors:
|
||||
- type: log
|
||||
paths:
|
||||
- /var/log/*.log
|
||||
multiline:
|
||||
pattern: '^['
|
||||
match: after
|
||||
```
|
||||
|
||||
> **参考**
|
||||
>
|
||||
> 更多 filebeat 配置内容可以参考:[配置 filebeat](https://www.elastic.co/guide/en/beats/filebeat/current/configuring-howto-filebeat.html)
|
||||
>
|
||||
> 更多 filebeat.yml 文件格式内容可以参考:[filebeat.yml 文件格式](https://www.elastic.co/guide/en/beats/libbeat/6.1/config-file-format.html)
|
||||
|
||||
### 重要配置项
|
||||
|
||||
#### filebeat.prospectors
|
||||
|
||||
(文件监视器)用于指定需要关注的文件。
|
||||
|
||||
**示例**
|
||||
|
||||
```yaml
|
||||
filebeat.prospectors:
|
||||
- type: log
|
||||
enabled: true
|
||||
paths:
|
||||
- /var/log/*.log
|
||||
```
|
||||
|
||||
#### output.elasticsearch
|
||||
|
||||
如果你希望使用 filebeat 直接向 elasticsearch 输出数据,需要配置 output.elasticsearch 。
|
||||
|
||||
**示例**
|
||||
|
||||
```yaml
|
||||
output.elasticsearch:
|
||||
hosts: ["192.168.1.42:9200"]
|
||||
```
|
||||
|
||||
#### output.logstash
|
||||
|
||||
如果你希望使用 filebeat 向 logstash输出数据,然后由 logstash 再向elasticsearch 输出数据,需要配置 output.logstash。
|
||||
|
||||
> **注意**
|
||||
>
|
||||
> 相比于向 elasticsearch 输出数据,个人更推荐向 logstash 输出数据。
|
||||
>
|
||||
> 因为 logstash 和 filebeat 一起工作时,如果 logstash 忙于处理数据,会通知 FileBeat 放慢读取速度。一旦拥塞得到解决,FileBeat 将恢复到原来的速度并继续传播。这样,可以减少管道超负荷的情况。
|
||||
|
||||
**示例**
|
||||
|
||||
```yaml
|
||||
output.logstash:
|
||||
hosts: ["127.0.0.1:5044"]
|
||||
```
|
||||
|
||||
此外,还需要在 logstash 的配置文件(如 logstash.conf)中指定 beats input 插件:
|
||||
|
||||
```yaml
|
||||
input {
|
||||
beats {
|
||||
port => 5044 # 此端口需要与 filebeat.yml 中的端口相同
|
||||
}
|
||||
}
|
||||
|
||||
# The filter part of this file is commented out to indicate that it is
|
||||
# optional.
|
||||
# filter {
|
||||
#
|
||||
# }
|
||||
|
||||
output {
|
||||
elasticsearch {
|
||||
hosts => "localhost:9200"
|
||||
manage_template => false
|
||||
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
|
||||
document_type => "%{[@metadata][type]}"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### setup.kibana
|
||||
|
||||
如果打算使用 Filebeat 提供的 Kibana 仪表板,需要配置 setup.kibana 。
|
||||
|
||||
**示例**
|
||||
|
||||
```yaml
|
||||
setup.kibana:
|
||||
host: "localhost:5601"
|
||||
```
|
||||
|
||||
#### setup.template.settings
|
||||
|
||||
在 Elasticsearch 中,[索引模板](https://www.elastic.co/guide/en/elasticsearch/reference/6.1/indices-templates.html)用于定义设置和映射,以确定如何分析字段。
|
||||
|
||||
在 Filebeat 中,setup.template.settings 用于配置索引模板。
|
||||
|
||||
Filebeat 推荐的索引模板文件由 Filebeat 软件包安装。如果您接受 filebeat.yml 配置文件中的默认配置,Filebeat在成功连接到 Elasticsearch 后自动加载模板。
|
||||
|
||||
您可以通过在 Filebeat 配置文件中配置模板加载选项来禁用自动模板加载,或加载自己的模板。您还可以设置选项来更改索引和索引模板的名称。
|
||||
|
||||
> **参考**
|
||||
>
|
||||
> 更多内容可以参考:[filebeat-template](https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-template.html)
|
||||
>
|
||||
> **说明**
|
||||
>
|
||||
> 如无必要,使用 Filebeat 配置文件中的默认索引模板即可。
|
||||
|
||||
#### setup.dashboards
|
||||
|
||||
Filebeat 附带了示例 Kibana 仪表板。在使用仪表板之前,您需要创建索引模式 `filebeat- *`,并将仪表板加载到Kibana 中。为此,您可以运行 `setup` 命令或在 `filebeat.yml` 配置文件中配置仪表板加载。
|
||||
|
||||
为了在 Kibana 中加载 Filebeat 的仪表盘,需要在 `filebeat.yml` 配置中启动开关:
|
||||
|
||||
```
|
||||
setup.dashboards.enabled: true
|
||||
```
|
||||
|
||||
> **参考**
|
||||
>
|
||||
> 更多内容可以参考:[configuration-dashboards](https://www.elastic.co/guide/en/beats/filebeat/current/configuration-dashboards.html)
|
||||
>
|
||||
|
||||
## 命令
|
||||
|
||||
filebeat 提供了一系列命令来完成各种功能。
|
||||
|
||||
执行命令方式:
|
||||
|
||||
```sh
|
||||
./filebeat COMMAND
|
||||
```
|
||||
|
||||
> **参考**
|
||||
>
|
||||
> 更多内容可以参考:[command-line-options](https://www.elastic.co/guide/en/beats/filebeat/current/command-line-options.html)
|
||||
>
|
||||
> **说明**
|
||||
>
|
||||
> 个人认为命令行没有必要一一掌握,因为绝大部分功能都可以通过配置来完成。且通过命令行指定功能这种方式要求每次输入同样参数,不利于固化启动方式。
|
||||
>
|
||||
> 最重要的当然是启动命令 run 了。
|
||||
>
|
||||
> **示例** 指定配置文件启动
|
||||
>
|
||||
> ```sh
|
||||
> ./filebeat run -e -c filebeat.yml -d "publish"
|
||||
> ./filebeat -e -c filebeat.yml -d "publish" # run 可以省略
|
||||
> ```
|
||||
|
||||
## 模块
|
||||
|
||||
Filebeat 提供了一套预构建的模块,让您可以快速实施和部署日志监视解决方案,并附带示例仪表板和数据可视化。这些模块支持常见的日志格式,例如Nginx,Apache2和MySQL 等。
|
||||
|
||||
### 运行模块的步骤
|
||||
|
||||
- 配置 elasticsearch 和 kibana
|
||||
|
||||
```
|
||||
output.elasticsearch:
|
||||
hosts: ["myEShost:9200"]
|
||||
username: "elastic"
|
||||
password: "elastic"
|
||||
setup.kibana:
|
||||
host: "mykibanahost:5601"
|
||||
username: "elastic"
|
||||
password: "elastic
|
||||
```
|
||||
|
||||
> username 和 password 是可选的,如果不需要认证则不填。
|
||||
|
||||
- 初始化环境
|
||||
|
||||
执行下面命令,filebeat 会加载推荐索引模板。
|
||||
|
||||
```
|
||||
./filebeat setup -e
|
||||
```
|
||||
|
||||
- 指定模块
|
||||
|
||||
执行下面命令,指定希望加载的模块。
|
||||
|
||||
```
|
||||
./filebeat -e --modules system,nginx,mysql
|
||||
```
|
||||
|
||||
> **参考**
|
||||
>
|
||||
> 更多内容可以参考: [配置 filebeat 模块](https://www.elastic.co/guide/en/beats/filebeat/current/configuration-filebeat-modules.html) | [filebeat 支持模块](https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-modules.html)
|
||||
|
||||
## 原理
|
||||
|
||||
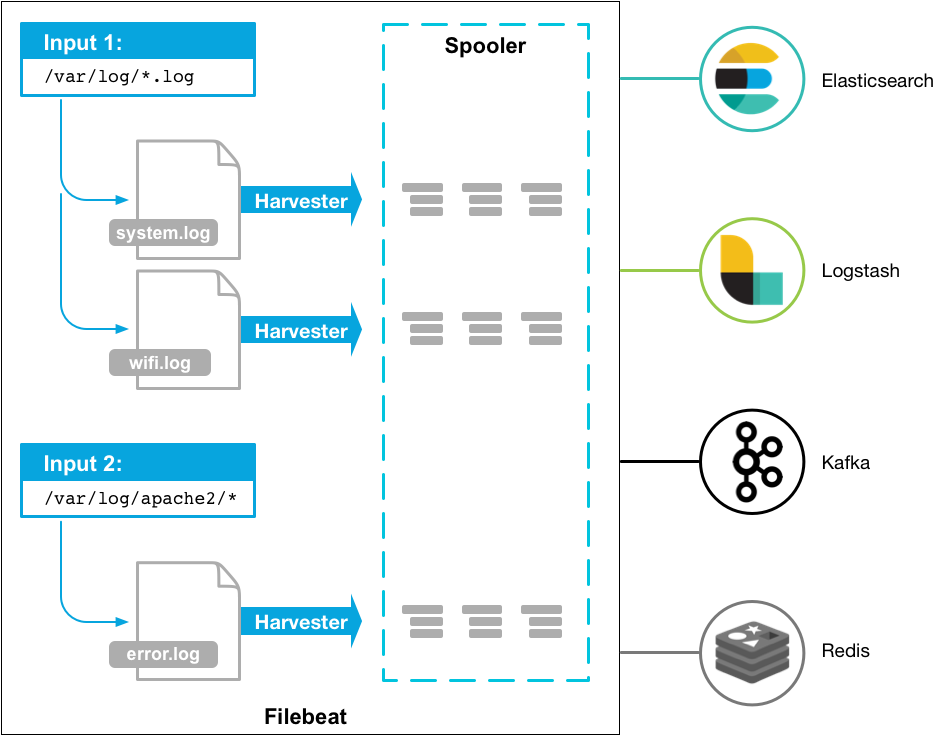
Filebeat 有两个主要组件:
|
||||
|
||||
harvester:负责读取一个文件的内容。它会逐行读取文件内容,并将内容发送到输出目的地。
|
||||
|
||||
prospector:负责管理 harvester 并找到所有需要读取的文件源。比如类型是日志,prospector 就会遍历制定路径下的所有匹配要求的文件。
|
||||
|
||||
```yaml
|
||||
filebeat.prospectors:
|
||||
- type: log
|
||||
paths:
|
||||
- /var/log/*.log
|
||||
- /var/path2/*.log
|
||||
```
|
||||
|
||||
Filebeat保持每个文件的状态,并经常刷新注册表文件中的磁盘状态。状态用于记住 harvester 正在读取的最后偏移量,并确保发送所有日志行。
|
||||
|
||||
Filebeat 将每个事件的传递状态存储在注册表文件中。所以它能保证事件至少传递一次到配置的输出,没有数据丢失。
|
||||
|
||||
## 资料
|
||||
|
||||
[Beats 官方文档](https://www.elastic.co/guide/en/beats/libbeat/current/index.html)
|
||||
|
||||
|
|
@ -0,0 +1,307 @@
|
|||
# Elastic 技术栈之 Kibana
|
||||
|
||||
## Discover
|
||||
|
||||
单击侧面导航栏中的 `Discover` ,可以显示 `Kibana` 的数据查询功能功能。
|
||||
|
||||

|
||||
|
||||
在搜索栏中,您可以输入Elasticsearch查询条件来搜索您的数据。您可以在 `Discover` 页面中浏览结果并在 `Visualize` 页面中创建已保存搜索条件的可视化。
|
||||
|
||||
当前索引模式显示在查询栏下方。索引模式确定提交查询时搜索哪些索引。要搜索一组不同的索引,请从下拉菜单中选择不同的模式。要添加索引模式(index pattern),请转至 `Management/Kibana/Index Patterns` 并单击 `Add New`。
|
||||
|
||||
您可以使用字段名称和您感兴趣的值构建搜索。对于数字字段,可以使用比较运算符,如大于(>),小于(<)或等于(=)。您可以将元素与逻辑运算符 `AND`,`OR` 和 `NOT` 链接,全部使用大写。
|
||||
|
||||
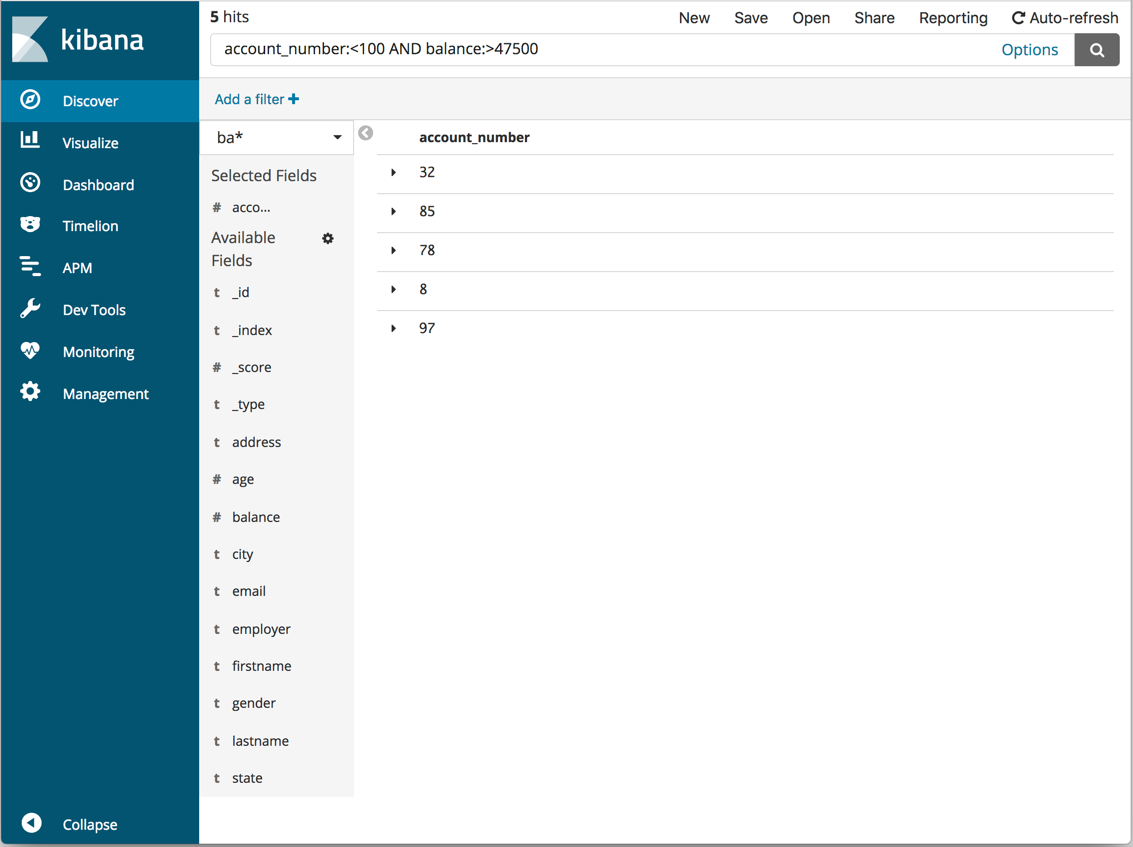
默认情况下,每个匹配文档都显示所有字段。要选择要显示的文档字段,请将鼠标悬停在“可用字段”列表上,然后单击要包含的每个字段旁边的添加按钮。例如,如果只添加account_number,则显示将更改为包含五个帐号的简单列表:
|
||||
|
||||
|
||||
|
||||
### 查询语义
|
||||
|
||||
kibana 的搜索栏遵循 [query-string-syntax](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-query-string-query.html#query-string-syntax) 文档中所说明的查询语义。
|
||||
|
||||
这里说明一些最基本的查询语义。
|
||||
|
||||
查询字符串会被解析为一系列的术语和运算符。一个术语可以是一个单词(如:quick、brown)或用双引号包围的短语(如"quick brown")。
|
||||
|
||||
查询操作允许您自定义搜索 - 下面介绍了可用的选项。
|
||||
|
||||
#### 字段名称
|
||||
|
||||
正如查询字符串查询中所述,将在搜索条件中搜索default_field,但可以在查询语法中指定其他字段:
|
||||
|
||||
例如:
|
||||
|
||||
* 查询 `status` 字段中包含 `active` 关键字
|
||||
|
||||
```
|
||||
status:active
|
||||
```
|
||||
|
||||
* `title` 字段包含 `quick` 或 `brown` 关键字。如果您省略 `OR` 运算符,则将使用默认运算符
|
||||
|
||||
```
|
||||
title:(quick OR brown)
|
||||
title:(quick brown)
|
||||
```
|
||||
|
||||
* author 字段查找精确的短语 "john smith",即精确查找。
|
||||
|
||||
```
|
||||
author:"John Smith"
|
||||
```
|
||||
|
||||
* 任意字段 `book.title`,`book.content` 或 `book.date` 都包含 `quick` 或 `brown`(注意我们需要如何使用 `\*` 表示通配符)
|
||||
|
||||
```
|
||||
book.\*:(quick brown)
|
||||
```
|
||||
|
||||
* title 字段包含任意非 null 值
|
||||
|
||||
```
|
||||
_exists_:title
|
||||
```
|
||||
|
||||
#### 通配符
|
||||
|
||||
ELK 提供了 ? 和 * 两个通配符。
|
||||
|
||||
* `?` 表示任意单个字符;
|
||||
* `*` 表示任意零个或多个字符。
|
||||
|
||||
```
|
||||
qu?ck bro*
|
||||
```
|
||||
|
||||
> **注意:通配符查询会使用大量的内存并且执行性能较为糟糕,所以请慎用。**
|
||||
> **提示**:纯通配符 \* 被写入 [exsits](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-exists-query.html) 查询,从而提高了查询效率。因此,通配符 `field:*` 将匹配包含空值的文档,如:```{“field”:“”}```,但是如果字段丢失或显示将值置为null则不匹配,如:```“field”:null}```
|
||||
> **提示**:在一个单词的开头(例如:`*ing`)使用通配符这种方式的查询量特别大,因为索引中的所有术语都需要检查,以防万一匹配。通过将 `allow_leading_wildcard` 设置为 `false`,可以禁用。
|
||||
|
||||
#### 正则表达式
|
||||
|
||||
可以通过 `/` 将正则表达式包裹在查询字符串中进行查询
|
||||
|
||||
例:
|
||||
|
||||
```
|
||||
name:/joh?n(ath[oa]n)/
|
||||
```
|
||||
|
||||
支持的正则表达式语义可以参考:[Regular expression syntax](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-regexp-query.html#regexp-syntax)
|
||||
|
||||
#### 模糊查询
|
||||
|
||||
我们可以使用 `~` 运算符来进行模糊查询。
|
||||
|
||||
例:
|
||||
|
||||
假设我们实际想查询
|
||||
|
||||
```
|
||||
quick brown forks
|
||||
```
|
||||
|
||||
但是,由于拼写错误,我们的查询关键字变成如下情况,依然可以查到想要的结果。
|
||||
|
||||
```
|
||||
quikc~ brwn~ foks~
|
||||
```
|
||||
|
||||
这种模糊查询使用 Damerau-Levenshtein 距离来查找所有匹配最多两个更改的项。所谓的更改是指单个字符的插入,删除或替换,或者两个相邻字符的换位。
|
||||
|
||||
默认编辑距离为 `2`,但编辑距离为 `1` 应足以捕捉所有人类拼写错误的80%。它可以被指定为:
|
||||
|
||||
```
|
||||
quikc~1
|
||||
```
|
||||
|
||||
#### 近似检索
|
||||
|
||||
尽管短语查询(例如,`john smith`)期望所有的词条都是完全相同的顺序,但是近似查询允许指定的单词进一步分开或以不同的顺序排列。与模糊查询可以为单词中的字符指定最大编辑距离一样,近似搜索也允许我们指定短语中单词的最大编辑距离:
|
||||
|
||||
例
|
||||
|
||||
```
|
||||
"fox quick"~5
|
||||
```
|
||||
|
||||
字段中的文本越接近查询字符串中指定的原始顺序,该文档就越被认为是相关的。当与上面的示例查询相比时,短语 `"quick fox"` 将被认为比 `"quick brown fox"` 更近似查询条件。
|
||||
|
||||
#### 范围
|
||||
|
||||
可以为日期,数字或字符串字段指定范围。闭区间范围用方括号 `[min TO max]` 和开区间范围用花括号 `{min TO max}` 来指定。
|
||||
|
||||
我们不妨来看一些示例。
|
||||
|
||||
* 2012 年的所有日子
|
||||
|
||||
```
|
||||
date:[2012-01-01 TO 2012-12-31]
|
||||
```
|
||||
|
||||
* 数字 1 到 5
|
||||
|
||||
```
|
||||
count:[1 TO 5]
|
||||
```
|
||||
|
||||
* 在 `alpha` 和 `omega` 之间的标签,不包括 `alpha` 和 `omega`
|
||||
|
||||
```
|
||||
tag:{alpha TO omega}
|
||||
```
|
||||
|
||||
* 10 以上的数字
|
||||
|
||||
```
|
||||
count:[10 TO *]
|
||||
```
|
||||
|
||||
* 2012 年以前的所有日期
|
||||
|
||||
```
|
||||
date:{* TO 2012-01-01}
|
||||
```
|
||||
|
||||
此外,开区间和闭区间也可以组合使用
|
||||
|
||||
* 数组 1 到 5,但不包括 5
|
||||
|
||||
```
|
||||
count:[1 TO 5}
|
||||
```
|
||||
|
||||
一边无界的范围也可以使用以下语法:
|
||||
|
||||
```
|
||||
age:>10
|
||||
age:>=10
|
||||
age:<10
|
||||
age:<=10
|
||||
```
|
||||
|
||||
当然,你也可以使用 AND 运算符来得到连个查询结果的交集
|
||||
|
||||
```
|
||||
age:(>=10 AND <20)
|
||||
age:(+>=10 +<20)
|
||||
```
|
||||
|
||||
#### Boosting
|
||||
|
||||
使用操作符 `^` 使一个术语比另一个术语更相关。例如,如果我们想查找所有有关狐狸的文档,但我们对狐狸特别感兴趣:
|
||||
|
||||
```
|
||||
quick^2 fox
|
||||
```
|
||||
|
||||
默认提升值是1,但可以是任何正浮点数。 0到1之间的提升减少了相关性。
|
||||
|
||||
增强也可以应用于短语或组:
|
||||
|
||||
```
|
||||
"john smith"^2 (foo bar)^4
|
||||
```
|
||||
|
||||
#### 布尔操作
|
||||
|
||||
默认情况下,只要一个词匹配,所有词都是可选的。搜索 `foo bar baz` 将查找包含 `foo` 或 `bar` 或 `baz` 中的一个或多个的任何文档。我们已经讨论了上面的`default_operator`,它允许你强制要求所有的项,但也有布尔运算符可以在查询字符串本身中使用,以提供更多的控制。
|
||||
|
||||
首选的操作符是 `+`(此术语必须存在)和 `-` (此术语不得存在)。所有其他条款是可选的。例如,这个查询:
|
||||
|
||||
```
|
||||
quick brown +fox -news
|
||||
```
|
||||
|
||||
这条查询意味着:
|
||||
|
||||
* fox 必须存在
|
||||
* news 必须不存在
|
||||
* quick 和 brown 是可有可无的
|
||||
|
||||
熟悉的运算符 `AND`,`OR` 和 `NOT`(也写成 `&&`,`||` 和 `!`)也被支持。然而,这些操作符有一定的优先级:`NOT` 优先于 `AND`,`AND` 优先于 `OR`。虽然 `+` 和 `-` 仅影响运算符右侧的术语,但 `AND` 和 `OR` 会影响左侧和右侧的术语。
|
||||
|
||||
#### 分组
|
||||
|
||||
多个术语或子句可以用圆括号组合在一起,形成子查询
|
||||
|
||||
```
|
||||
(quick OR brown) AND fox
|
||||
```
|
||||
|
||||
可以使用组来定位特定的字段,或者增强子查询的结果:
|
||||
|
||||
```
|
||||
status:(active OR pending) title:(full text search)^2
|
||||
```
|
||||
|
||||
#### 保留字
|
||||
|
||||
如果你需要使用任何在你的查询本身中作为操作符的字符(而不是作为操作符),那么你应该用一个反斜杠来转义它们。例如,要搜索(1 + 1)= 2,您需要将查询写为 `\(1\+1\)\=2`
|
||||
|
||||
保留字符是:`+ - = && || > < ! ( ) { } [ ] ^ " ~ * ? : \ /`
|
||||
|
||||
无法正确地转义这些特殊字符可能会导致语法错误,从而阻止您的查询运行。
|
||||
|
||||
#### 空查询
|
||||
|
||||
如果查询字符串为空或仅包含空格,则查询将生成一个空的结果集。
|
||||
|
||||
## Visualize
|
||||
|
||||
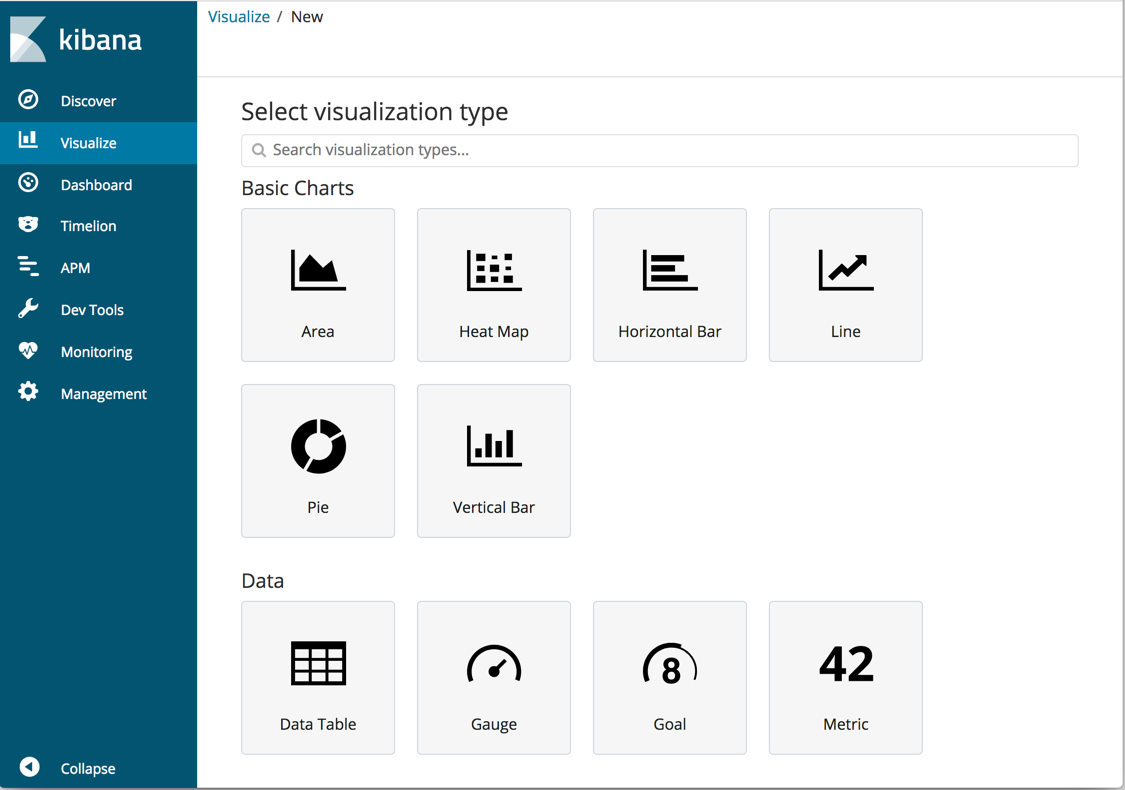
要想使用可视化的方式展示您的数据,请单击侧面导航栏中的 `Visualize`。
|
||||
|
||||
Visualize工具使您能够以多种方式(如饼图、柱状图、曲线图、分布图等)查看数据。要开始使用,请点击蓝色的 `Create a visualization` 或 `+` 按钮。
|
||||
|
||||

|
||||
|
||||
有许多可视化类型可供选择。
|
||||
|
||||
|
||||
|
||||
下面,我们来看创建几个图标示例:
|
||||
|
||||
### Pie
|
||||
|
||||
您可以从保存的搜索中构建可视化文件,也可以输入新的搜索条件。要输入新的搜索条件,首先需要选择一个索引模式来指定要搜索的索引。
|
||||
|
||||
默认搜索匹配所有文档。最初,一个“切片”包含整个饼图:
|
||||
|
||||
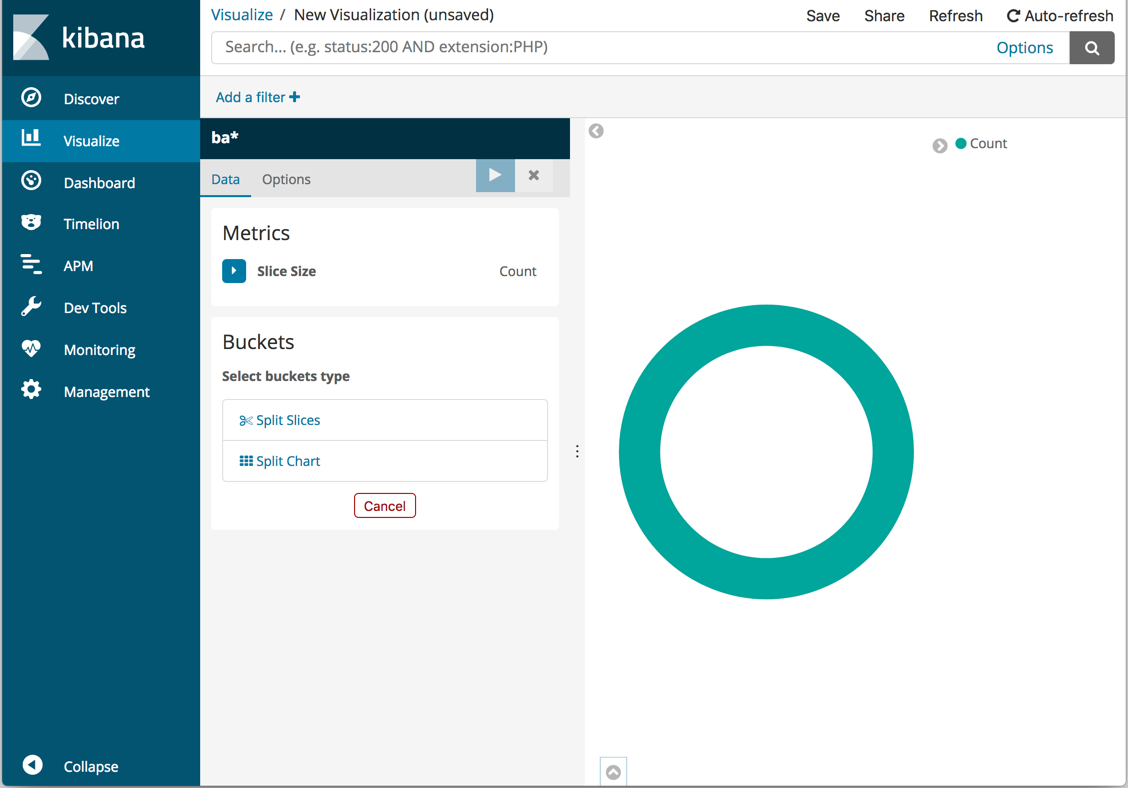
|
||||
|
||||
要指定在图表中展示哪些数据,请使用Elasticsearch存储桶聚合。分组汇总只是将与您的搜索条件相匹配的文档分类到不同的分类中,也称为分组。
|
||||
|
||||
为每个范围定义一个存储桶:
|
||||
|
||||
1. 单击 `Split Slices`。
|
||||
2. 在 `Aggregation` 列表中选择 `Terms`。_注意:这里的 Terms 是 Elk 采集数据时定义好的字段或标签。_
|
||||
3. 在 `Field` 列表中选择 `level.keyword`。
|
||||
4. 点击  按钮来更新图表。
|
||||
|
||||

|
||||
|
||||
完成后,如果想要保存这个图表,可以点击页面最上方一栏中的 `Save` 按钮。
|
||||
|
||||
### Vertical Bar
|
||||
|
||||
我们在展示一下如何创建柱状图。
|
||||
|
||||
1. 点击蓝色的 `Create a visualization` 或 `+` 按钮。选择 `Vertical Bar`
|
||||
2. 选择索引模式。由于您尚未定义任何 bucket ,因此您会看到一个大栏,显示与默认通配符查询匹配的文档总数。
|
||||
3. 指定 Y 轴所代表的字段
|
||||
4. 指定 X 轴所代表的字段
|
||||
5. 点击  按钮来更新图表。
|
||||
|
||||

|
||||
|
||||
完成后,如果想要保存这个图表,可以点击页面最上方一栏中的 `Save` 按钮。
|
||||
|
||||
## Dashboard
|
||||
|
||||
`Dashboard` 可以整合和共享 `Visualize` 集合。
|
||||
|
||||
1. 点击侧面导航栏中的 Dashboard。
|
||||
2. 点击添加显示保存的可视化列表。
|
||||
3. 点击之前保存的 `Visualize`,然后点击列表底部的小向上箭头关闭可视化列表。
|
||||
4. 将鼠标悬停在可视化对象上会显示允许您编辑,移动,删除和调整可视化对象大小的容器控件。
|
||||
|
|
@ -0,0 +1,519 @@
|
|||
---
|
||||
title: Elastic 技术栈之 Logstash 基础
|
||||
date: 2017-12-26
|
||||
categories:
|
||||
- javatool
|
||||
tags:
|
||||
- java
|
||||
- javatool
|
||||
- log
|
||||
- elastic
|
||||
---
|
||||
|
||||
# Elastic 技术栈之 Logstash 基础
|
||||
|
||||
> 本文是 Elastic 技术栈(ELK)的 Logstash 应用。
|
||||
>
|
||||
> 如果不了解 Elastic 的安装、配置、部署,可以参考:[Elastic 技术栈之快速入门](https://github.com/dunwu/JavaStack/blob/master/docs/javatool/elastic/elastic-quickstart.md)
|
||||
|
||||
## 简介
|
||||
|
||||
Logstash 可以传输和处理你的日志、事务或其他数据。
|
||||
|
||||
### 功能
|
||||
|
||||
Logstash 是 Elasticsearch 的最佳数据管道。
|
||||
|
||||
Logstash 是插件式管理模式,在输入、过滤、输出以及编码过程中都可以使用插件进行定制。Logstash 社区有超过 200 种可用插件。
|
||||
|
||||
### 工作原理
|
||||
|
||||
Logstash 有两个必要元素:`input` 和 `output` ,一个可选元素:`filter`。
|
||||
|
||||
这三个元素,分别代表 Logstash 事件处理的三个阶段:输入 > 过滤器 > 输出。
|
||||
|
||||
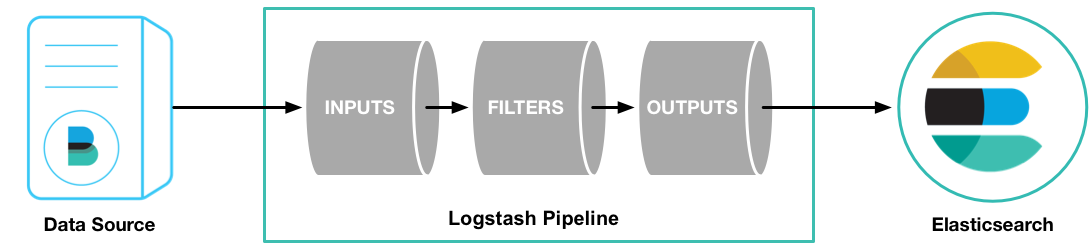
|
||||
|
||||
- input 负责从数据源采集数据。
|
||||
- filter 将数据修改为你指定的格式或内容。
|
||||
- output 将数据传输到目的地。
|
||||
|
||||
在实际应用场景中,通常输入、输出、过滤器不止一个。Logstash 的这三个元素都使用插件式管理方式,用户可以根据应用需要,灵活的选用各阶段需要的插件,并组合使用。
|
||||
|
||||
后面将对插件展开讲解,暂且不表。
|
||||
|
||||
## 设置
|
||||
|
||||
### 设置文件
|
||||
|
||||
- **`logstash.yml`**:logstash 的默认启动配置文件
|
||||
- **`jvm.options`**:logstash 的 JVM 配置文件。
|
||||
- **`startup.options`** (Linux):包含系统安装脚本在 `/usr/share/logstash/bin` 中使用的选项为您的系统构建适当的启动脚本。安装 Logstash 软件包时,系统安装脚本将在安装过程结束时执行,并使用 `startup.options` 中指定的设置来设置用户,组,服务名称和服务描述等选项。
|
||||
|
||||
|
||||
### logstash.yml 设置项
|
||||
|
||||
节选部分设置项,更多项请参考:https://www.elastic.co/guide/en/logstash/current/logstash-settings-file.html
|
||||
|
||||
| 参数 | 描述 | 默认值 |
|
||||
| -------------------------- | ---------------------------------------- | ---------------------------------------- |
|
||||
| `node.name` | 节点名 | 机器的主机名 |
|
||||
| `path.data` | Logstash及其插件用于任何持久性需求的目录。 | `LOGSTASH_HOME/data` |
|
||||
| `pipeline.workers` | 同时执行管道的过滤器和输出阶段的工作任务数量。如果发现事件正在备份,或CPU未饱和,请考虑增加此数字以更好地利用机器处理能力。 | Number of the host’s CPU cores |
|
||||
| `pipeline.batch.size` | 尝试执行过滤器和输出之前,单个工作线程从输入收集的最大事件数量。较大的批量处理大小一般来说效率更高,但是以增加的内存开销为代价。您可能必须通过设置 `LS_HEAP_SIZE` 变量来有效使用该选项来增加JVM堆大小。 | `125` |
|
||||
| `pipeline.batch.delay` | 创建管道事件批处理时,在将一个尺寸过小的批次发送给管道工作任务之前,等待每个事件需要多长时间(毫秒)。 | `5` |
|
||||
| `pipeline.unsafe_shutdown` | 如果设置为true,则即使在内存中仍存在inflight事件时,也会强制Logstash在关闭期间退出。默认情况下,Logstash将拒绝退出,直到所有接收到的事件都被推送到输出。启用此选项可能会导致关机期间数据丢失。 | `false` |
|
||||
| `path.config` | 主管道的Logstash配置路径。如果您指定一个目录或通配符,配置文件将按字母顺序从目录中读取。 | Platform-specific. See [[dir-layout\]](https://github.com/elastic/logstash/blob/6.1/docs/static/settings-file.asciidoc#dir-layout). |
|
||||
| `config.string` | 包含用于主管道的管道配置的字符串。使用与配置文件相同的语法。 | None |
|
||||
| `config.test_and_exit` | 设置为true时,检查配置是否有效,然后退出。请注意,使用此设置不会检查grok模式的正确性。 Logstash可以从目录中读取多个配置文件。如果将此设置与log.level:debug结合使用,则Logstash将记录组合的配置文件,并注掉其源文件的配置块。 | `false` |
|
||||
| `config.reload.automatic` | 设置为true时,定期检查配置是否已更改,并在配置更改时重新加载配置。这也可以通过SIGHUP信号手动触发。 | `false` |
|
||||
| `config.reload.interval` | Logstash 检查配置文件更改的时间间隔。 | `3s` |
|
||||
| `config.debug` | 设置为true时,将完全编译的配置显示为调试日志消息。您还必须设置`log.level:debug`。警告:日志消息将包括任何传递给插件配置作为明文的“密码”选项,并可能导致明文密码出现在您的日志! | `false` |
|
||||
| `config.support_escapes` | 当设置为true时,带引号的字符串将处理转义字符。 | `false` |
|
||||
| `modules` | 配置时,模块必须处于上表所述的嵌套YAML结构中。 | None |
|
||||
| `http.host` | 绑定地址 | `"127.0.0.1"` |
|
||||
| `http.port` | 绑定端口 | `9600` |
|
||||
| `log.level` | 日志级别。有效选项:fatal > error > warn > info > debug > trace | `info` |
|
||||
| `log.format` | 日志格式。json (JSON 格式)或 plain (原对象) | `plain` |
|
||||
| `path.logs` | Logstash 自身日志的存储路径 | `LOGSTASH_HOME/logs` |
|
||||
| `path.plugins` | 在哪里可以找到自定义的插件。您可以多次指定此设置以包含多个路径。 | |
|
||||
|
||||
## 启动
|
||||
|
||||
### 命令行
|
||||
|
||||
通过命令行启动 logstash 的方式如下:
|
||||
|
||||
```
|
||||
bin/logstash [options]
|
||||
```
|
||||
|
||||
其中 [options] 是您可以指定用于控制 Logstash 执行的命令行标志。
|
||||
|
||||
在命令行上设置的任何标志都会覆盖 Logstash 设置文件(`logstash.yml`)中的相应设置,但设置文件本身不会更改。
|
||||
|
||||
> **注**
|
||||
>
|
||||
> 虽然可以通过指定命令行参数的方式,来控制 logstash 的运行方式,但显然这么做很麻烦。
|
||||
>
|
||||
> 建议通过指定配置文件的方式,来控制 logstash 运行,启动命令如下:
|
||||
>
|
||||
> ```
|
||||
> bin/logstash -f logstash.conf
|
||||
> ```
|
||||
> 若想了解更多的命令行参数细节,请参考:https://www.elastic.co/guide/en/logstash/current/running-logstash-command-line.html
|
||||
>
|
||||
|
||||
### 配置文件
|
||||
|
||||
上节,我们了解到,logstash 可以执行 `bin/logstash -f logstash.conf` ,按照配置文件中的参数去覆盖默认设置文件(`logstash.yml`)中的设置。
|
||||
|
||||
这节,我们就来学习一下这个配置文件如何配置参数。
|
||||
|
||||
#### 配置文件结构
|
||||
|
||||
在工作原理一节中,我们已经知道了 Logstash 主要有三个工作阶段 input 、filter、output。而 logstash 配置文件文件结构也与之相对应:
|
||||
|
||||
```
|
||||
input {}
|
||||
|
||||
filter {}
|
||||
|
||||
output {}
|
||||
```
|
||||
|
||||
> 每个部分都包含一个或多个插件的配置选项。如果指定了多个过滤器,则会按照它们在配置文件中的显示顺序应用它们。
|
||||
|
||||
#### 插件配置
|
||||
|
||||
插件的配置由插件名称和插件的一个设置块组成。
|
||||
|
||||
下面的例子中配置了两个输入文件配置:
|
||||
|
||||
```
|
||||
input {
|
||||
file {
|
||||
path => "/var/log/messages"
|
||||
type => "syslog"
|
||||
}
|
||||
|
||||
file {
|
||||
path => "/var/log/apache/access.log"
|
||||
type => "apache"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
您可以配置的设置因插件类型而异。你可以参考: [Input Plugins](https://www.elastic.co/guide/en/logstash/current/input-plugins.html), [Output Plugins](https://www.elastic.co/guide/en/logstash/current/output-plugins.html), [Filter Plugins](https://www.elastic.co/guide/en/logstash/current/filter-plugins.html), 和 [Codec Plugins](https://www.elastic.co/guide/en/logstash/current/codec-plugins.html) 。
|
||||
|
||||
#### 值类型
|
||||
|
||||
一个插件可以要求设置的值是一个特定的类型,比如布尔值,列表或哈希值。以下值类型受支持。
|
||||
|
||||
- Array
|
||||
|
||||
```
|
||||
users => [ {id => 1, name => bob}, {id => 2, name => jane} ]
|
||||
```
|
||||
|
||||
- Lists
|
||||
|
||||
```
|
||||
path => [ "/var/log/messages", "/var/log/*.log" ]
|
||||
uris => [ "http://elastic.co", "http://example.net" ]
|
||||
```
|
||||
|
||||
- Boolean
|
||||
|
||||
```
|
||||
ssl_enable => true
|
||||
```
|
||||
|
||||
- Bytes
|
||||
|
||||
```
|
||||
my_bytes => "1113" # 1113 bytes
|
||||
my_bytes => "10MiB" # 10485760 bytes
|
||||
my_bytes => "100kib" # 102400 bytes
|
||||
my_bytes => "180 mb" # 180000000 bytes
|
||||
```
|
||||
|
||||
- Codec
|
||||
|
||||
```
|
||||
codec => "json"
|
||||
```
|
||||
|
||||
- Hash
|
||||
|
||||
```
|
||||
match => {
|
||||
"field1" => "value1"
|
||||
"field2" => "value2"
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
- Number
|
||||
|
||||
```
|
||||
port => 33
|
||||
```
|
||||
|
||||
- Password
|
||||
|
||||
```
|
||||
my_password => "password"
|
||||
```
|
||||
|
||||
- URI
|
||||
|
||||
```
|
||||
my_uri => "http://foo:bar@example.net"
|
||||
```
|
||||
|
||||
- Path
|
||||
|
||||
```
|
||||
my_path => "/tmp/logstash"
|
||||
```
|
||||
|
||||
- String
|
||||
|
||||
|
||||
- 转义字符
|
||||
|
||||
## 插件
|
||||
|
||||
### input
|
||||
|
||||
> Logstash 支持各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
|
||||
|
||||
#### 常用 input 插件
|
||||
|
||||
- **file**:从文件系统上的文件读取,就像UNIX命令 `tail -0F` 一样
|
||||
- **syslog:**在众所周知的端口514上侦听系统日志消息,并根据RFC3164格式进行解析
|
||||
- **redis:**从redis服务器读取,使用redis通道和redis列表。 Redis经常用作集中式Logstash安装中的“代理”,它将来自远程Logstash“托运人”的Logstash事件排队。
|
||||
- **beats:**处理由Filebeat发送的事件。
|
||||
|
||||
更多详情请见:[Input Plugins](https://www.elastic.co/guide/en/logstash/current/input-plugins.html)
|
||||
|
||||
### filter
|
||||
|
||||
> 过滤器是Logstash管道中的中间处理设备。如果符合特定条件,您可以将条件过滤器组合在一起,对事件执行操作。
|
||||
|
||||
#### 常用 filter 插件
|
||||
|
||||
- **grok:**解析和结构任意文本。 Grok目前是Logstash中将非结构化日志数据解析为结构化和可查询的最佳方法。
|
||||
- **mutate:**对事件字段执行一般转换。您可以重命名,删除,替换和修改事件中的字段。
|
||||
|
||||
- **drop:**完全放弃一个事件,例如调试事件。
|
||||
|
||||
- **clone:**制作一个事件的副本,可能会添加或删除字段。
|
||||
|
||||
- **geoip:**添加有关IP地址的地理位置的信息(也可以在Kibana中显示惊人的图表!)
|
||||
|
||||
|
||||
更多详情请见:[Filter Plugins](https://www.elastic.co/guide/en/logstash/current/filter-plugins.html)
|
||||
|
||||
### output
|
||||
|
||||
> 输出是Logstash管道的最后阶段。一个事件可以通过多个输出,但是一旦所有输出处理完成,事件就完成了执行。
|
||||
|
||||
#### 常用 output 插件
|
||||
|
||||
- **elasticsearch:**将事件数据发送给 Elasticsearch(推荐模式)。
|
||||
- **file:**将事件数据写入文件或磁盘。
|
||||
- **graphite:**将事件数据发送给 graphite(一个流行的开源工具,存储和绘制指标。 http://graphite.readthedocs.io/en/latest/)。
|
||||
- **statsd:**将事件数据发送到 statsd (这是一种侦听统计数据的服务,如计数器和定时器,通过UDP发送并将聚合发送到一个或多个可插入的后端服务)。
|
||||
|
||||
更多详情请见:[Output Plugins](https://www.elastic.co/guide/en/logstash/current/output-plugins.html)
|
||||
|
||||
### codec
|
||||
|
||||
用于格式化对应的内容。
|
||||
|
||||
#### 常用 codec 插件
|
||||
|
||||
- **json:**以JSON格式对数据进行编码或解码。
|
||||
- **multiline:**将多行文本事件(如java异常和堆栈跟踪消息)合并为单个事件。
|
||||
|
||||
更多插件请见:[Codec Plugins](https://www.elastic.co/guide/en/logstash/current/codec-plugins.html)
|
||||
|
||||
## 实战
|
||||
|
||||
前面的内容都是对 Logstash 的介绍和原理说明。接下来,我们来实战一些常见的应用场景。
|
||||
|
||||
### 传输控制台数据
|
||||
|
||||
> stdin input 插件从标准输入读取事件。这是最简单的 input 插件,一般用于测试场景。
|
||||
>
|
||||
|
||||
**应用**
|
||||
|
||||
(1)创建 `logstash-input-stdin.conf` :
|
||||
|
||||
```
|
||||
input { stdin { } }
|
||||
output {
|
||||
elasticsearch { hosts => ["localhost:9200"] }
|
||||
stdout { codec => rubydebug }
|
||||
}
|
||||
```
|
||||
|
||||
更多配置项可以参考:https://www.elastic.co/guide/en/logstash/current/plugins-inputs-stdin.html
|
||||
|
||||
(2)执行 logstash,使用 `-f` 来指定你的配置文件:
|
||||
|
||||
```
|
||||
bin/logstash -f logstash-input-stdin.conf
|
||||
```
|
||||
|
||||
### 传输 logback 日志
|
||||
|
||||
> elk 默认使用的 Java 日志工具是 log4j2 ,并不支持 logback 和 log4j。
|
||||
>
|
||||
> 想使用 logback + logstash ,可以使用 [logstash-logback-encoder](https://github.com/logstash/logstash-logback-encoder) 。[logstash-logback-encoder](https://github.com/logstash/logstash-logback-encoder) 提供了 UDP / TCP / 异步方式来传输日志数据到 logstash。
|
||||
>
|
||||
> 如果你使用的是 log4j ,也不是不可以用这种方式,只要引入桥接 jar 包即可。如果你对 log4j 、logback ,或是桥接 jar 包不太了解,可以参考我的这篇博文:[细说 Java 主流日志工具库](https://github.com/dunwu/JavaStack/blob/master/docs/javalib/java-log.md) 。
|
||||
|
||||
#### TCP 应用
|
||||
|
||||
1. logstash 配置
|
||||
|
||||
(1)创建 `logstash-input-tcp.conf` :
|
||||
|
||||
```
|
||||
input {
|
||||
tcp {
|
||||
port => 9251
|
||||
codec => json_lines
|
||||
mode => server
|
||||
}
|
||||
}
|
||||
output {
|
||||
elasticsearch { hosts => ["localhost:9200"] }
|
||||
stdout { codec => rubydebug }
|
||||
}
|
||||
```
|
||||
|
||||
更多配置项可以参考:https://www.elastic.co/guide/en/logstash/current/plugins-inputs-tcp.html
|
||||
|
||||
(2)执行 logstash,使用 `-f` 来指定你的配置文件:`bin/logstash -f logstash-input-udp.conf`
|
||||
|
||||
|
||||
2. java 应用配置
|
||||
|
||||
(1)在 Java 应用的 pom.xml 中引入 jar 包:
|
||||
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>net.logstash.logback</groupId>
|
||||
<artifactId>logstash-logback-encoder</artifactId>
|
||||
<version>4.11</version>
|
||||
</dependency>
|
||||
|
||||
<!-- logback 依赖包 -->
|
||||
<dependency>
|
||||
<groupId>ch.qos.logback</groupId>
|
||||
<artifactId>logback-core</artifactId>
|
||||
<version>1.2.3</version>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>ch.qos.logback</groupId>
|
||||
<artifactId>logback-classic</artifactId>
|
||||
<version>1.2.3</version>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>ch.qos.logback</groupId>
|
||||
<artifactId>logback-access</artifactId>
|
||||
<version>1.2.3</version>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
(2)接着,在 logback.xml 中添加 appender
|
||||
|
||||
```xml
|
||||
<appender name="ELK-TCP" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
|
||||
<!--
|
||||
destination 是 logstash 服务的 host:port,
|
||||
相当于和 logstash 建立了管道,将日志数据定向传输到 logstash
|
||||
-->
|
||||
<destination>192.168.28.32:9251</destination>
|
||||
<encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder"/>
|
||||
</appender>
|
||||
<logger name="io.github.dunwu.spring" level="TRACE" additivity="false">
|
||||
<appender-ref ref="ELK-TCP" />
|
||||
</logger>
|
||||
```
|
||||
|
||||
(3)接下来,就是 logback 的具体使用 ,如果对此不了解,不妨参考一下我的这篇博文:[细说 Java 主流日志工具库](https://github.com/dunwu/JavaStack/blob/master/docs/javalib/java-log.md) 。
|
||||
|
||||
**实例:**[我的logback.xml](https://github.com/dunwu/JavaStack/blob/master/codes/javatool/src/main/resources/logback.xml)
|
||||
|
||||
#### UDP 应用
|
||||
|
||||
UDP 和 TCP 的使用方式大同小异。
|
||||
|
||||
1. logstash 配置
|
||||
|
||||
(1)创建 `logstash-input-udp.conf` :
|
||||
|
||||
```
|
||||
input {
|
||||
udp {
|
||||
port => 9250
|
||||
codec => json
|
||||
}
|
||||
}
|
||||
output {
|
||||
elasticsearch { hosts => ["localhost:9200"] }
|
||||
stdout { codec => rubydebug }
|
||||
}
|
||||
```
|
||||
|
||||
更多配置项可以参考:https://www.elastic.co/guide/en/logstash/current/plugins-inputs-udp.html
|
||||
|
||||
(2)执行 logstash,使用 `-f` 来指定你的配置文件:`bin/logstash -f logstash-input-udp.conf`
|
||||
|
||||
|
||||
2. java 应用配置
|
||||
|
||||
(1)在 Java 应用的 pom.xml 中引入 jar 包:
|
||||
|
||||
与 **TCP 应用** 一节中的引入依赖包完全相同。
|
||||
|
||||
(2)接着,在 logback.xml 中添加 appender
|
||||
|
||||
```xml
|
||||
<appender name="ELK-UDP" class="net.logstash.logback.appender.LogstashSocketAppender">
|
||||
<host>192.168.28.32</host>
|
||||
<port>9250</port>
|
||||
</appender>
|
||||
<logger name="io.github.dunwu.spring" level="TRACE" additivity="false">
|
||||
<appender-ref ref="ELK-UDP" />
|
||||
</logger>
|
||||
```
|
||||
|
||||
(3)接下来,就是 logback 的具体使用 ,如果对此不了解,不妨参考一下我的这篇博文:[细说 Java 主流日志工具库](https://github.com/dunwu/JavaStack/blob/master/docs/javalib/java-log.md) 。
|
||||
|
||||
**实例:**[我的logback.xml](https://github.com/dunwu/JavaStack/blob/master/codes/javatool/src/main/resources/logback.xml)
|
||||
|
||||
### 传输文件
|
||||
|
||||
> 在 Java Web 领域,需要用到一些重要的工具,例如 Tomcat 、Nginx 、Mysql 等。这些不属于业务应用,但是它们的日志数据对于定位问题、分析统计同样很重要。这时无法使用 logback 方式将它们的日志传输到 logstash。
|
||||
>
|
||||
> 如何采集这些日志文件呢?别急,你可以使用 logstash 的 file input 插件。
|
||||
>
|
||||
> 需要注意的是,传输文件这种方式,必须在日志所在的机器上部署 logstash 。
|
||||
|
||||
**应用**
|
||||
|
||||
logstash 配置
|
||||
|
||||
(1)创建 `logstash-input-file.conf` :
|
||||
|
||||
```
|
||||
input {
|
||||
file {
|
||||
path => ["/var/log/nginx/access.log"]
|
||||
type => "nginx-access-log"
|
||||
start_position => "beginning"
|
||||
}
|
||||
}
|
||||
|
||||
output {
|
||||
if [type] == "nginx-access-log" {
|
||||
elasticsearch {
|
||||
hosts => ["localhost:9200"]
|
||||
index => "nginx-access-log"
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
(2)执行 logstash,使用 `-f` 来指定你的配置文件:`bin/logstash -f logstash-input-file.conf`
|
||||
|
||||
更多配置项可以参考:https://www.elastic.co/guide/en/logstash/current/plugins-inputs-file.html
|
||||
|
||||
## 小技巧
|
||||
|
||||
### 启动、终止应用
|
||||
|
||||
如果你的 logstash 每次都是通过指定配置文件方式启动。不妨建立一个启动脚本。
|
||||
|
||||
```
|
||||
# cd xxx 进入 logstash 安装目录下的 bin 目录
|
||||
logstash -f logstash.conf
|
||||
```
|
||||
|
||||
如果你的 logstash 运行在 linux 系统下,不妨使用 nohup 来启动一个守护进程。这样做的好处在于,即使关闭终端,应用仍会运行。
|
||||
|
||||
**创建 startup.sh**
|
||||
|
||||
```
|
||||
nohup ./logstash -f logstash.conf >> nohup.out 2>&1 &
|
||||
```
|
||||
|
||||
终止应用没有什么好方法,你只能使用 ps -ef | grep logstash ,查出进程,将其kill 。不过,我们可以写一个脚本来干这件事:
|
||||
|
||||
**创建 shutdown.sh**
|
||||
|
||||
脚本不多解释,请自行领会作用。
|
||||
|
||||
```
|
||||
PID=`ps -ef | grep logstash | awk '{ print $2}' | head -n 1`
|
||||
kill -9 ${PID}
|
||||
```
|
||||
|
||||
## 资料
|
||||
|
||||
- [Logstash 官方文档](https://www.elastic.co/guide/en/logstash/current/index.html)
|
||||
- [logstash-logback-encoder](https://github.com/logstash/logstash-logback-encoder)
|
||||
- [ELK Stack权威指南](https://github.com/chenryn/logstash-best-practice-cn)
|
||||
- [ELK(Elasticsearch、Logstash、Kibana)安装和配置](https://github.com/judasn/Linux-Tutorial/blob/master/ELK-Install-And-Settings.md)
|
||||
|
||||
## 推荐阅读
|
||||
|
||||
- [Elastic 技术栈](https://github.com/dunwu/JavaStack/blob/master/docs/javatool/elastic/README.md)
|
||||
- [JavaStack](https://github.com/dunwu/JavaStack)
|
||||
|
|
@ -0,0 +1,289 @@
|
|||
---
|
||||
title: Elastic 技术栈之快速入门
|
||||
date: 2017-12-06
|
||||
categories:
|
||||
- javatool
|
||||
tags:
|
||||
- java
|
||||
- javatool
|
||||
- log
|
||||
- elastic
|
||||
---
|
||||
|
||||
# Elastic 技术栈之快速入门
|
||||
|
||||
## 概念
|
||||
|
||||
### ELK 是什么
|
||||
|
||||
ELK 是 elastic 公司旗下三款产品 [ElasticSearch](https://www.elastic.co/products/elasticsearch) 、[Logstash](https://www.elastic.co/products/logstash) 、[Kibana](https://www.elastic.co/products/kibana) 的首字母组合。
|
||||
|
||||
[ElasticSearch](https://www.elastic.co/products/elasticsearch) 是一个基于 [Lucene](http://lucene.apache.org/core/documentation.html) 构建的开源,分布式,RESTful 搜索引擎。
|
||||
|
||||
[Logstash](https://www.elastic.co/products/logstash) 传输和处理你的日志、事务或其他数据。
|
||||
|
||||
[Kibana](https://www.elastic.co/products/kibana) 将 Elasticsearch 的数据分析并渲染为可视化的报表。
|
||||
|
||||
### 为什么使用 ELK ?
|
||||
|
||||
对于有一定规模的公司来说,通常会很多个应用,并部署在大量的服务器上。运维和开发人员常常需要通过查看日志来定位问题。如果应用是集群化部署,试想如果登录一台台服务器去查看日志,是多么费时费力。
|
||||
|
||||
而通过 ELK 这套解决方案,可以同时实现日志收集、日志搜索和日志分析的功能。
|
||||
|
||||
### Elastic 架构
|
||||
|
||||
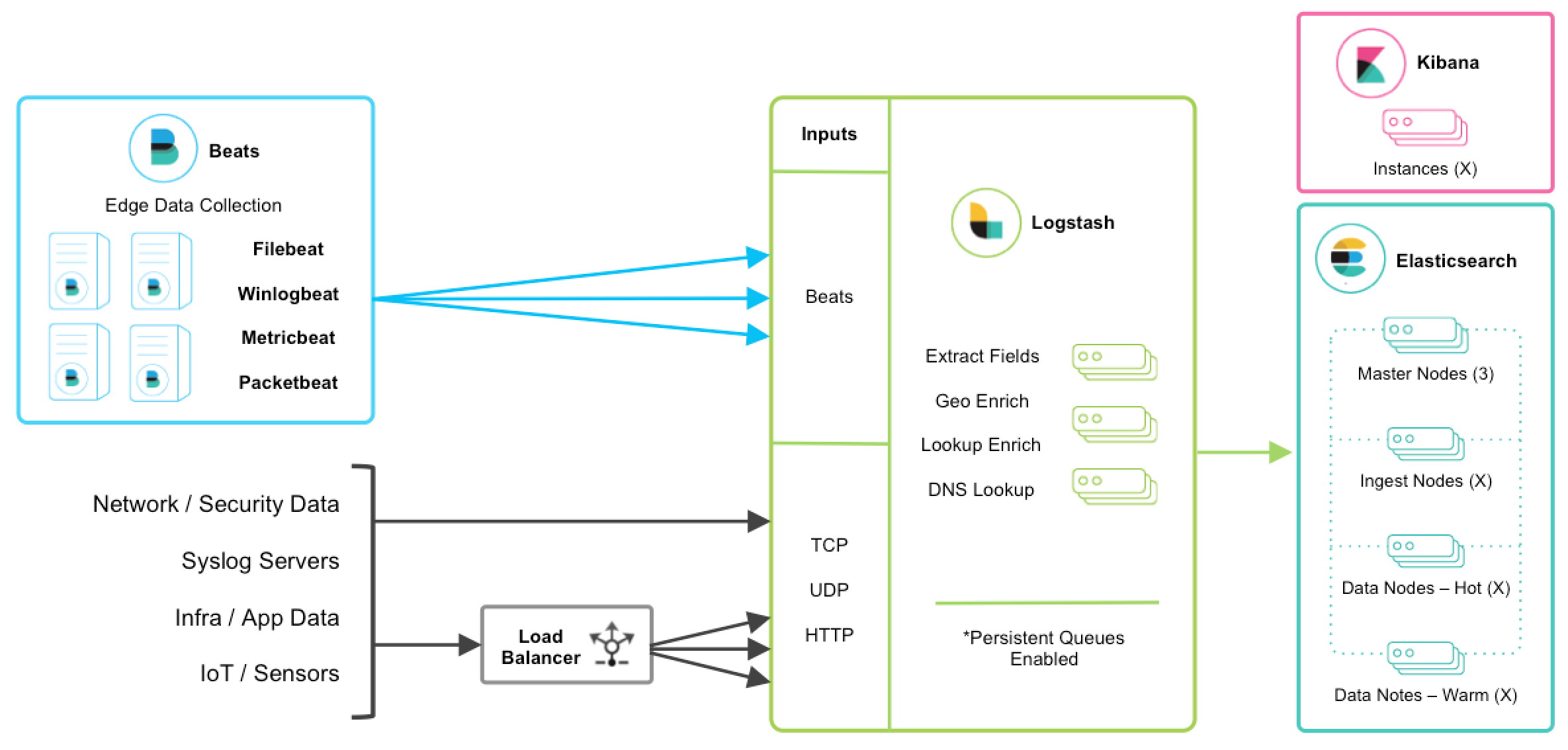
|
||||
|
||||
> **说明**
|
||||
>
|
||||
> 以上是 ELK 技术栈的一个架构图。从图中可以清楚的看到数据流向。
|
||||
>
|
||||
> [Beats](https://www.elastic.co/products/beats) 是单一用途的数据传输平台,它可以将多台机器的数据发送到 Logstash 或 ElasticSearch。但 Beats 并不是不可或缺的一环,所以本文中暂不介绍。
|
||||
>
|
||||
> [Logstash](https://www.elastic.co/products/logstash) 是一个动态数据收集管道。支持以 TCP/UDP/HTTP 多种方式收集数据(也可以接受 Beats 传输来的数据),并对数据做进一步丰富或提取字段处理。
|
||||
>
|
||||
> [ElasticSearch](https://www.elastic.co/products/elasticsearch) 是一个基于 JSON 的分布式的搜索和分析引擎。作为 ELK 的核心,它集中存储数据。
|
||||
>
|
||||
> [Kibana](https://www.elastic.co/products/kibana) 是 ELK 的用户界面。它将收集的数据进行可视化展示(各种报表、图形化数据),并提供配置、管理 ELK 的界面。
|
||||
|
||||
## 安装
|
||||
|
||||
### 准备
|
||||
|
||||
ELK 要求本地环境中安装了 JDK 。如果不确定是否已安装,可使用下面的命令检查:
|
||||
|
||||
```sh
|
||||
java -version
|
||||
```
|
||||
|
||||
> **注意**
|
||||
>
|
||||
> 本文使用的 ELK 是 6.0.0,要求 jdk 版本不低于 JDK8。
|
||||
>
|
||||
> 友情提示:安装 ELK 时,三个应用请选择统一的版本,避免出现一些莫名其妙的问题。例如:由于版本不统一,导致三个应用间的通讯异常。
|
||||
|
||||
### Elasticsearch
|
||||
|
||||
安装步骤如下:
|
||||
|
||||
1. [elasticsearch 官方下载地址](https://www.elastic.co/downloads/elasticsearch)下载所需版本包并解压到本地。
|
||||
2. 运行 `bin/elasticsearch` (Windows 上运行 `bin\elasticsearch.bat`)
|
||||
3. 验证运行成功:linux 上可以执行 `curl http://localhost:9200/` ;windows 上可以用访问 REST 接口的方式来访问 http://localhost:9200/
|
||||
|
||||
> **说明**
|
||||
>
|
||||
> Linux 上可以执行下面的命令来下载压缩包:
|
||||
>
|
||||
> ```
|
||||
> curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.0.0.tar.gz
|
||||
> ```
|
||||
>
|
||||
> Mac 上可以执行以下命令来进行安装:
|
||||
>
|
||||
> ```
|
||||
> brew install elasticsearch
|
||||
> ```
|
||||
>
|
||||
> Windows 上可以选择 MSI 可执行安装程序,将应用安装到本地。
|
||||
|
||||
### Logstash
|
||||
|
||||
安装步骤如下:
|
||||
|
||||
1. 在 [logstash 官方下载地址](https://www.elastic.co/downloads/logstash)下载所需版本包并解压到本地。
|
||||
|
||||
2. 添加一个 `logstash.conf` 文件,指定要使用的插件以及每个插件的设置。举个简单的例子:
|
||||
|
||||
```
|
||||
input { stdin { } }
|
||||
output {
|
||||
elasticsearch { hosts => ["localhost:9200"] }
|
||||
stdout { codec => rubydebug }
|
||||
}
|
||||
```
|
||||
|
||||
3. 运行 `bin/logstash -f logstash.conf` (Windows 上运行`bin/logstash.bat -f logstash.conf`)
|
||||
|
||||
### Kibana
|
||||
|
||||
安装步骤如下:
|
||||
|
||||
1. 在 [kibana 官方下载地址](https://www.elastic.co/downloads/kibana)下载所需版本包并解压到本地。
|
||||
2. 修改 `config/kibana.yml` 配置文件,设置 `elasticsearch.url` 指向 Elasticsearch 实例。
|
||||
3. 运行 `bin/kibana` (Windows 上运行 `bin\kibana.bat`)
|
||||
4. 在浏览器上访问 http://localhost:5601
|
||||
|
||||
### 安装 FAQ
|
||||
|
||||
#### elasticsearch 不允许以 root 权限来运行
|
||||
|
||||
**问题:**在 Linux 环境中,elasticsearch 不允许以 root 权限来运行。
|
||||
|
||||
如果以 root 身份运行 elasticsearch,会提示这样的错误:
|
||||
|
||||
```
|
||||
can not run elasticsearch as root
|
||||
```
|
||||
|
||||
**解决方法:**使用非 root 权限账号运行 elasticsearch
|
||||
|
||||
```sh
|
||||
# 创建用户组
|
||||
groupadd elk
|
||||
# 创建新用户,-g elk 设置其用户组为 elk,-p elk 设置其密码为 elk
|
||||
useradd elk -g elk -p elk
|
||||
# 更改 /opt 文件夹及内部文件的所属用户及组为 elk:elk
|
||||
chown -R elk:elk /opt # 假设你的 elasticsearch 安装在 opt 目录下
|
||||
# 切换账号
|
||||
su elk
|
||||
```
|
||||
|
||||
#### vm.max_map_count 不低于 262144
|
||||
|
||||
**问题:**`vm.max_map_count` 表示虚拟内存大小,它是一个内核参数。elasticsearch 默认要求 `vm.max_map_count` 不低于 262144。
|
||||
|
||||
```
|
||||
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
|
||||
```
|
||||
|
||||
**解决方法:**
|
||||
|
||||
你可以执行以下命令,设置 `vm.max_map_count` ,但是重启后又会恢复为原值。
|
||||
|
||||
```
|
||||
sysctl -w vm.max_map_count=262144
|
||||
```
|
||||
|
||||
持久性的做法是在 `/etc/sysctl.conf` 文件中修改 `vm.max_map_count` 参数:
|
||||
|
||||
```
|
||||
echo "vm.max_map_count=262144" > /etc/sysctl.conf
|
||||
sysctl -p
|
||||
```
|
||||
|
||||
> **注意**
|
||||
>
|
||||
> 如果运行环境为 docker 容器,可能会限制执行 sysctl 来修改内核参数。
|
||||
>
|
||||
> 这种情况下,你只能选择直接修改宿主机上的参数了。
|
||||
|
||||
#### nofile 不低于 65536
|
||||
|
||||
**问题:** `nofile` 表示进程允许打开的最大文件数。elasticsearch 进程要求可以打开的最大文件数不低于 65536。
|
||||
|
||||
```
|
||||
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
|
||||
```
|
||||
|
||||
**解决方法:**
|
||||
|
||||
在 `/etc/security/limits.conf` 文件中修改 `nofile` 参数:
|
||||
|
||||
```
|
||||
echo "* soft nofile 65536" > /etc/security/limits.conf
|
||||
echo "* hard nofile 131072" > /etc/security/limits.conf
|
||||
```
|
||||
|
||||
#### nproc 不低于 2048
|
||||
|
||||
**问题:** `nproc` 表示最大线程数。elasticsearch 要求最大线程数不低于 2048。
|
||||
|
||||
```
|
||||
max number of threads [1024] for user [user] is too low, increase to at least [2048]
|
||||
```
|
||||
|
||||
**解决方法:**
|
||||
|
||||
在 `/etc/security/limits.conf` 文件中修改 `nproc` 参数:
|
||||
|
||||
```
|
||||
echo "* soft nproc 2048" > /etc/security/limits.conf
|
||||
echo "* hard nproc 4096" > /etc/security/limits.conf
|
||||
```
|
||||
|
||||
#### Kibana No Default Index Pattern Warning
|
||||
|
||||
**问题:**安装 ELK 后,访问 kibana 页面时,提示以下错误信息:
|
||||
|
||||
```
|
||||
Warning No default index pattern. You must select or create one to continue.
|
||||
...
|
||||
Unable to fetch mapping. Do you have indices matching the pattern?
|
||||
```
|
||||
|
||||
这就说明 logstash 没有把日志写入到 elasticsearch。
|
||||
|
||||
**解决方法:**
|
||||
|
||||
检查 logstash 与 elasticsearch 之间的通讯是否有问题,一般问题就出在这。
|
||||
|
||||
## 使用
|
||||
|
||||
本人使用的 Java 日志方案为 slf4j + logback,所以这里以 logback 来讲解。
|
||||
|
||||
### Java 应用输出日志到 ELK
|
||||
|
||||
**修改 logstash.conf 配置**
|
||||
|
||||
首先,我们需要修改一下 logstash 服务端 logstash.conf 中的配置
|
||||
|
||||
```
|
||||
input {
|
||||
# stdin { }
|
||||
tcp {
|
||||
# host:port就是上面appender中的 destination,
|
||||
# 这里其实把logstash作为服务,开启9250端口接收logback发出的消息
|
||||
host => "127.0.0.1" port => 9250 mode => "server" tags => ["tags"] codec => json_lines
|
||||
}
|
||||
}
|
||||
output {
|
||||
elasticsearch { hosts => ["localhost:9200"] }
|
||||
stdout { codec => rubydebug }
|
||||
}
|
||||
```
|
||||
|
||||
> **说明**
|
||||
>
|
||||
> 这个 input 中的配置其实是 logstash 服务端监听 9250 端口,接收传递来的日志数据。
|
||||
|
||||
然后,在 Java 应用的 pom.xml 中引入 jar 包:
|
||||
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>net.logstash.logback</groupId>
|
||||
<artifactId>logstash-logback-encoder</artifactId>
|
||||
<version>4.11</version>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
接着,在 logback.xml 中添加 appender
|
||||
|
||||
```xml
|
||||
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
|
||||
<!--
|
||||
destination 是 logstash 服务的 host:port,
|
||||
相当于和 logstash 建立了管道,将日志数据定向传输到 logstash
|
||||
-->
|
||||
<destination>127.0.0.1:9250</destination>
|
||||
<encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder"/>
|
||||
</appender>
|
||||
<logger name="io.github.dunwu.spring" level="TRACE" additivity="false">
|
||||
<appender-ref ref="LOGSTASH" />
|
||||
</logger>
|
||||
```
|
||||
|
||||
大功告成,此后,`io.github.dunwu.spring` 包中的 TRACE 及以上级别的日志信息都会被定向输出到 logstash 服务。
|
||||
|
||||

|
||||
|
||||
## 资料
|
||||
|
||||
- [elastic 官方文档](https://www.elastic.co/guide/index.html)
|
||||
|
||||
- [elasticsearch github](https://github.com/elastic/elasticsearch)
|
||||
|
||||
- [logstash github](https://github.com/elastic/logstash)
|
||||
|
||||
- [kibana github](https://github.com/elastic/kibana)
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,291 @@
|
|||
# Gitlab
|
||||
|
||||
> 环境:
|
||||
>
|
||||
> OS: CentOS7
|
||||
|
||||
<!-- TOC depthFrom:2 depthTo:3 -->
|
||||
|
||||
- [安装 gitlab](#安装-gitlab)
|
||||
- [常规安装 gitlab](#常规安装-gitlab)
|
||||
- [Docker 安装 gitlab](#docker-安装-gitlab)
|
||||
- [安装 gitlab-ci-multi-runner](#安装-gitlab-ci-multi-runner)
|
||||
- [常规安装 gitlab-ci-multi-runner](#常规安装-gitlab-ci-multi-runner)
|
||||
- [Docker 安装 gitlab-ci-multi-runner](#docker-安装-gitlab-ci-multi-runner)
|
||||
- [自签名证书](#自签名证书)
|
||||
- [创建证书](#创建证书)
|
||||
- [gitlab 配置](#gitlab-配置)
|
||||
|
||||
<!-- /TOC -->
|
||||
|
||||
## 安装 gitlab
|
||||
|
||||
### 常规安装 gitlab
|
||||
|
||||
进入官方下载地址:https://about.gitlab.com/install/ ,如下图,选择合适的版本。
|
||||
|
||||
|
||||
|
||||
以 CentOS7 为例:
|
||||
|
||||
#### 安装和配置必要依赖
|
||||
|
||||
在系统防火墙中启用 HTTP 和 SSH
|
||||
|
||||
```
|
||||
sudo yum install -y curl policycoreutils-python openssh-server
|
||||
sudo systemctl enable sshd
|
||||
sudo systemctl start sshd
|
||||
sudo firewall-cmd --permanent --add-service=http
|
||||
sudo systemctl reload firewalld
|
||||
```
|
||||
|
||||
安装 Postfix ,使得 Gitlab 可以发送通知邮件
|
||||
|
||||
```
|
||||
sudo yum install postfix
|
||||
sudo systemctl enable postfix
|
||||
sudo systemctl start postfix
|
||||
```
|
||||
|
||||
#### 添加 Gitlab yum 仓库并安装包
|
||||
|
||||
添加 Gitlab yum 仓库
|
||||
|
||||
```
|
||||
curl https://packages.gitlab.com/install/repositories/gitlab/gitlab-ce/script.rpm.sh | sudo bash
|
||||
```
|
||||
|
||||
通过 yum 安装 gitlab-ce
|
||||
|
||||
```
|
||||
sudo EXTERNAL_URL="http://gitlab.example.com" yum install -y gitlab-ce
|
||||
```
|
||||
|
||||
安装完成后,即可通过默认的 root 账户进行登录。更多细节可以参考:[documentation for detailed instructions on installing and configuration](https://docs.gitlab.com/omnibus/README.html#installation-and-configuration-using-omnibus-package)
|
||||
|
||||
### Docker 安装 gitlab
|
||||
|
||||
拉取镜像
|
||||
|
||||
```
|
||||
docker pull docker.io/gitlab/gitlab-ce
|
||||
```
|
||||
|
||||
启动
|
||||
|
||||
```
|
||||
docker run --detach \
|
||||
--hostname 127.0.0.1 \
|
||||
--publish 8443:443 --publish 80:80 --publish 2222:22 \
|
||||
--name gitlab \
|
||||
--restart always \
|
||||
--volume /home/gitlab/config:/etc/gitlab \
|
||||
--volume /home/gitlab/logs:/var/log/gitlab \
|
||||
--volume /home/gitlab/data:/var/opt/gitlab \
|
||||
docker.io/gitlab/gitlab-ce:latest
|
||||
```
|
||||
|
||||
## 安装 gitlab-ci-multi-runner
|
||||
|
||||
> 参考:https://docs.gitlab.com/runner/install/
|
||||
|
||||
### 常规安装 gitlab-ci-multi-runner
|
||||
|
||||
#### 下载
|
||||
|
||||
```
|
||||
sudo wget -O /usr/local/bin/gitlab-runner https://gitlab-runner-downloads.s3.amazonaws.com/latest/binaries/gitlab-runner-linux-amd64
|
||||
```
|
||||
|
||||
#### 配置执行权限
|
||||
|
||||
```
|
||||
sudo chmod +x /usr/local/bin/gitlab-runner
|
||||
```
|
||||
|
||||
#### 如果想使用 Docker,安装 Docker(可选的)
|
||||
|
||||
```
|
||||
curl -sSL https://get.docker.com/ | sh
|
||||
```
|
||||
|
||||
#### 创建 CI 用户
|
||||
|
||||
```
|
||||
sudo useradd --comment 'GitLab Runner' --create-home gitlab-runner --shell /bin/bash
|
||||
```
|
||||
|
||||
#### 安装并启动服务
|
||||
|
||||
```
|
||||
sudo gitlab-runner install --user=gitlab-runner --working-directory=/home/gitlab-runner
|
||||
sudo gitlab-runner start
|
||||
```
|
||||
|
||||
#### 注册 Runner
|
||||
|
||||
(1)执行命令:
|
||||
|
||||
```
|
||||
sudo gitlab-runner register
|
||||
```
|
||||
|
||||
(2)输入 Gitlab URL 和 令牌
|
||||
|
||||
URL 和令牌信息在 Gitlab 的 Runner 管理页面获取:
|
||||
|
||||
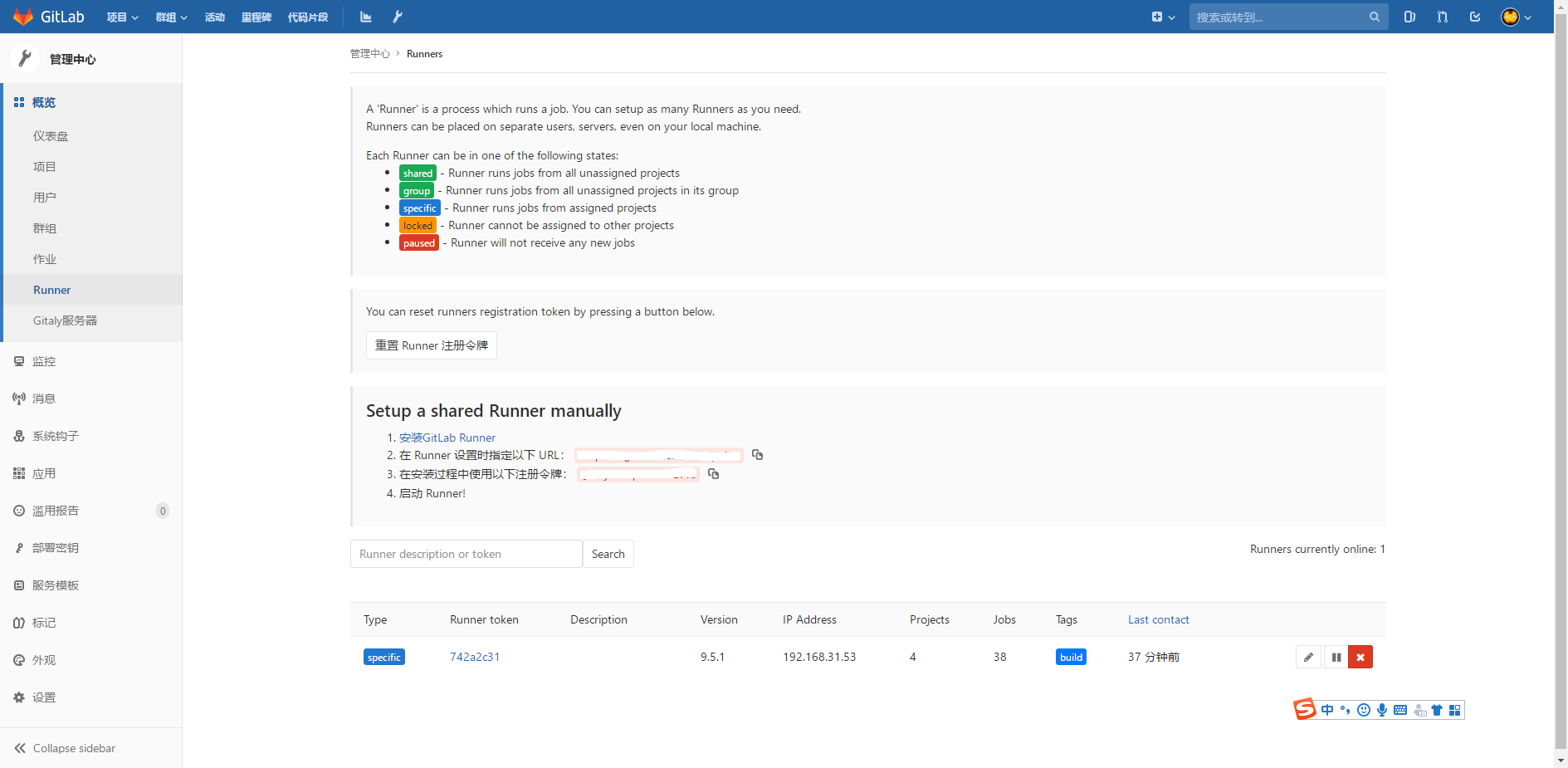
|
||||
|
||||
```
|
||||
Please enter the gitlab-ci coordinator URL (e.g. https://gitlab.com )
|
||||
https://gitlab.com
|
||||
|
||||
Please enter the gitlab-ci token for this runner
|
||||
xxx
|
||||
```
|
||||
|
||||
(3)输入 Runner 的描述
|
||||
|
||||
```
|
||||
Please enter the gitlab-ci description for this runner
|
||||
[hostame] my-runner
|
||||
```
|
||||
|
||||
(4)输入 Runner 相关的标签
|
||||
|
||||
```
|
||||
Please enter the gitlab-ci tags for this runner (comma separated):
|
||||
my-tag,another-tag
|
||||
```
|
||||
|
||||
(5)输入 Runner 执行器
|
||||
|
||||
```
|
||||
Please enter the executor: ssh, docker+machine, docker-ssh+machine, kubernetes, docker, parallels, virtualbox, docker-ssh, shell:
|
||||
docker
|
||||
```
|
||||
|
||||
如果想选择 Docker 作为执行器,你需要指定默认镜像( `.gitlab-ci.yml` 中没有此配置)
|
||||
|
||||
```
|
||||
Please enter the Docker image (eg. ruby:2.1):
|
||||
alpine:latest
|
||||
```
|
||||
|
||||
### Docker 安装 gitlab-ci-multi-runner
|
||||
|
||||
拉取镜像
|
||||
|
||||
```
|
||||
docker pull docker.io/gitlab/gitlab-runner
|
||||
```
|
||||
|
||||
启动
|
||||
|
||||
```
|
||||
docker run -d --name gitlab-runner --restart always \
|
||||
-v /srv/gitlab-runner/config:/etc/gitlab-runner \
|
||||
-v /var/run/docker.sock:/var/run/docker.sock \
|
||||
gitlab/gitlab-runner:latest
|
||||
```
|
||||
|
||||
## 自签名证书
|
||||
|
||||
首先,创建认证目录
|
||||
|
||||
```
|
||||
sudo mkdir -p /etc/gitlab/ssl
|
||||
sudo chmod 700 /etc/gitlab/ssl
|
||||
```
|
||||
|
||||
### 创建证书
|
||||
|
||||
#### 创建 Private Key
|
||||
|
||||
```
|
||||
sudo openssl genrsa -des3 -out /etc/gitlab/ssl/gitlab.domain.com.key 2048
|
||||
```
|
||||
|
||||
会提示输入密码,请记住
|
||||
|
||||
#### 生成 Certificate Request
|
||||
|
||||
```
|
||||
sudo openssl req -new -key /etc/gitlab/ssl/gitlab.domain.com.key -out /etc/gitlab/ssl/gitlab.domain.com.csr
|
||||
```
|
||||
|
||||
根据提示,输入信息
|
||||
|
||||
```
|
||||
Country Name (2 letter code) [XX]:CN
|
||||
State or Province Name (full name) []:JS
|
||||
Locality Name (eg, city) [Default City]:NJ
|
||||
Organization Name (eg, company) [Default Company Ltd]:xxxxx
|
||||
Organizational Unit Name (eg, section) []:
|
||||
Common Name (eg, your name or your server's hostname) []:gitlab.xxxx.io
|
||||
Email Address []:
|
||||
|
||||
Please enter the following 'extra' attributes
|
||||
to be sent with your certificate request
|
||||
A challenge password []:
|
||||
An optional company name []:
|
||||
```
|
||||
|
||||
#### 移除 Private Key 中的密码短语
|
||||
|
||||
```
|
||||
sudo cp -v /etc/gitlab/ssl/gitlab.domain.com.{key,original}
|
||||
sudo openssl rsa -in /etc/gitlab/ssl/gitlab.domain.com.original -out /etc/gitlab/ssl/gitlab.domain.com.key
|
||||
sudo rm -v /etc/gitlab/ssl/gitlab.domain.com.original
|
||||
```
|
||||
|
||||
#### 创建证书
|
||||
|
||||
```
|
||||
sudo openssl x509 -req -days 1460 -in /etc/gitlab/ssl/gitlab.domain.com.csr -signkey /etc/gitlab/ssl/gitlab.domain.com.key -out /etc/gitlab/ssl/gitlab.domain.com.crt
|
||||
```
|
||||
|
||||
#### 移除证书请求文件
|
||||
|
||||
```
|
||||
sudo rm -v /etc/gitlab/ssl/gitlab.domain.com.csr
|
||||
```
|
||||
|
||||
#### 设置文件权限
|
||||
|
||||
```
|
||||
sudo chmod 600 /etc/gitlab/ssl/gitlab.domain.com.*
|
||||
```
|
||||
|
||||
## gitlab 配置
|
||||
|
||||
```
|
||||
sudo vim /etc/gitlab/gitlab.rb
|
||||
external_url 'https://gitlab.domain.com'
|
||||
```
|
||||
|
||||
#### gitlab 网站 https:
|
||||
|
||||
```
|
||||
nginx['redirect_http_to_https'] = true
|
||||
```
|
||||
|
||||
#### gitlab ci 网站 https:
|
||||
|
||||
```
|
||||
ci_nginx['redirect_http_to_https'] = true
|
||||
```
|
||||
|
||||
#### 复制证书到 gitlab 目录:
|
||||
|
||||
```
|
||||
sudo cp /etc/gitlab/ssl/gitlab.domain.com.crt /etc/gitlab/trusted-certs/
|
||||
```
|
||||
|
||||
#### gitlab 重新配置+更新:
|
||||
|
||||
```
|
||||
sudo gitlab-ctl reconfigure
|
||||
sudo gitlab-ctl restart
|
||||
```
|
||||
Loading…
Reference in New Issue