diff --git a/Day36-40/36.关系型数据库和MySQL概述.md b/Day36-40/36.关系型数据库和MySQL概述.md
new file mode 100644
index 0000000..5bb33a1
--- /dev/null
+++ b/Day36-40/36.关系型数据库和MySQL概述.md
@@ -0,0 +1,388 @@
+## 关系型数据库和MySQL概述
+
+### 关系型数据库概述
+
+1. 数据持久化 - 将数据保存到能够长久保存数据的存储介质中,在掉电的情况下数据也不会丢失。
+
+2. 数据库发展史 - 网状数据库、层次数据库、关系数据库、NoSQL 数据库、NewSQL 数据库。
+
+ > 1970年,IBM的研究员E.F.Codd在*Communication of the ACM*上发表了名为*A Relational Model of Data for Large Shared Data Banks*的论文,提出了**关系模型**的概念,奠定了关系模型的理论基础。后来Codd又陆续发表多篇文章,论述了范式理论和衡量关系系统的12条标准,用数学理论奠定了关系数据库的基础。
+
+3. 关系数据库特点。
+
+ - 理论基础:**关系代数**(关系运算、集合论、一阶谓词逻辑)。
+
+ - 具体表象:用**二维表**(有行和列)组织数据。
+
+ - 编程语言:**结构化查询语言**(SQL)。
+
+4. ER模型(实体关系模型)和概念模型图。
+
+ **ER模型**,全称为**实体关系模型**(Entity-Relationship Model),由美籍华裔计算机科学家陈品山先生提出,是概念数据模型的高层描述方式,如下图所示。
+
+  +
+ - 实体 - 矩形框
+ - 属性 - 椭圆框
+ - 关系 - 菱形框
+ - 重数 - 1:1(一对一) / 1:N(一对多) / M:N(多对多)
+
+ 实际项目开发中,我们可以利用数据库建模工具(如:PowerDesigner)来绘制概念数据模型(其本质就是 ER 模型),然后再设置好目标数据库系统,将概念模型转换成物理模型,最终生成创建二维表的 SQL(很多工具都可以根据我们设计的物理模型图以及设定的目标数据库来导出 SQL 或直接生成数据表)。
+
+ 
+
+5. 关系数据库产品。
+ - [Oracle](https://www.oracle.com/index.html) - 目前世界上使用最为广泛的数据库管理系统,作为一个通用的数据库系统,它具有完整的数据管理功能;作为一个关系数据库,它是一个完备关系的产品;作为分布式数据库,它实现了分布式处理的功能。在 Oracle 最新的 12c 版本中,还引入了多承租方架构,使用该架构可轻松部署和管理数据库云。
+ - [DB2](https://www.ibm.com/analytics/us/en/db2/) - IBM 公司开发的、主要运行于 Unix(包括 IBM 自家的 [AIX](https://zh.wikipedia.org/wiki/AIX))、Linux、以及 Windows 服务器版等系统的关系数据库产品。DB2 历史悠久且被认为是最早使用 SQL 的数据库产品,它拥有较为强大的商业智能功能。
+ - [SQL Server](https://www.microsoft.com/en-us/sql-server/) - 由 Microsoft 开发和推广的关系型数据库产品,最初适用于中小企业的数据管理,但是近年来它的应用范围有所扩展,部分大企业甚至是跨国公司也开始基于它来构建自己的数据管理系统。
+ - [MySQL](https://www.mysql.com/) - MySQL 是开放源代码的,任何人都可以在 GPL(General Public License)的许可下下载并根据个性化的需要对其进行修改。MySQL 因为其速度、可靠性和适应性而备受关注。
+ - [PostgreSQL]() - 在 BSD 许可证下发行的开放源代码的关系数据库产品。
+
+### MySQL 简介
+
+MySQL 最早是由瑞典的 MySQL AB 公司开发的一个开放源码的关系数据库管理系统,该公司于2008年被昇阳微系统公司(Sun Microsystems)收购。在2009年,甲骨文公司(Oracle)收购昇阳微系统公司,因此 MySQL 目前也是 Oracle 旗下产品。
+
+MySQL 在过去由于性能高、成本低、可靠性好,已经成为最流行的开源数据库,因此被广泛地应用于中小型网站开发。随着 MySQL 的不断成熟,它也逐渐被应用于更多大规模网站和应用,比如维基百科、谷歌(Google)、脸书(Facebook)、淘宝网等网站都使用了 MySQL 来提供数据持久化服务。
+
+甲骨文公司收购后昇阳微系统公司,大幅调涨 MySQL 商业版的售价,且甲骨文公司不再支持另一个自由软件项目 [OpenSolaris ](https://zh.wikipedia.org/wiki/OpenSolaris) 的发展,因此导致自由软件社区对于 Oracle 是否还会持续支持 MySQL 社区版(MySQL 的各个发行版本中唯一免费的版本)有所担忧,MySQL 的创始人麦克尔·维德纽斯以 MySQL 为基础,创建了 [MariaDB](https://zh.wikipedia.org/wiki/MariaDB)(以他女儿的名字命名的数据库)分支。有许多原来使用 MySQL 数据库的公司(例如:维基百科)已经陆续完成了从 MySQL 数据库到 MariaDB 数据库的迁移。
+
+### 安装 MySQL
+
+#### Windows 环境
+
+1. 通过[官方网站](https://www.mysql.com/)提供的[下载链接](https://dev.mysql.com/downloads/windows/installer/8.0.html)下载“MySQL社区版服务器”安装程序,如下图所示,建议大家下载离线安装版的MySQL Installer。
+
+
+
+ - 实体 - 矩形框
+ - 属性 - 椭圆框
+ - 关系 - 菱形框
+ - 重数 - 1:1(一对一) / 1:N(一对多) / M:N(多对多)
+
+ 实际项目开发中,我们可以利用数据库建模工具(如:PowerDesigner)来绘制概念数据模型(其本质就是 ER 模型),然后再设置好目标数据库系统,将概念模型转换成物理模型,最终生成创建二维表的 SQL(很多工具都可以根据我们设计的物理模型图以及设定的目标数据库来导出 SQL 或直接生成数据表)。
+
+ 
+
+5. 关系数据库产品。
+ - [Oracle](https://www.oracle.com/index.html) - 目前世界上使用最为广泛的数据库管理系统,作为一个通用的数据库系统,它具有完整的数据管理功能;作为一个关系数据库,它是一个完备关系的产品;作为分布式数据库,它实现了分布式处理的功能。在 Oracle 最新的 12c 版本中,还引入了多承租方架构,使用该架构可轻松部署和管理数据库云。
+ - [DB2](https://www.ibm.com/analytics/us/en/db2/) - IBM 公司开发的、主要运行于 Unix(包括 IBM 自家的 [AIX](https://zh.wikipedia.org/wiki/AIX))、Linux、以及 Windows 服务器版等系统的关系数据库产品。DB2 历史悠久且被认为是最早使用 SQL 的数据库产品,它拥有较为强大的商业智能功能。
+ - [SQL Server](https://www.microsoft.com/en-us/sql-server/) - 由 Microsoft 开发和推广的关系型数据库产品,最初适用于中小企业的数据管理,但是近年来它的应用范围有所扩展,部分大企业甚至是跨国公司也开始基于它来构建自己的数据管理系统。
+ - [MySQL](https://www.mysql.com/) - MySQL 是开放源代码的,任何人都可以在 GPL(General Public License)的许可下下载并根据个性化的需要对其进行修改。MySQL 因为其速度、可靠性和适应性而备受关注。
+ - [PostgreSQL]() - 在 BSD 许可证下发行的开放源代码的关系数据库产品。
+
+### MySQL 简介
+
+MySQL 最早是由瑞典的 MySQL AB 公司开发的一个开放源码的关系数据库管理系统,该公司于2008年被昇阳微系统公司(Sun Microsystems)收购。在2009年,甲骨文公司(Oracle)收购昇阳微系统公司,因此 MySQL 目前也是 Oracle 旗下产品。
+
+MySQL 在过去由于性能高、成本低、可靠性好,已经成为最流行的开源数据库,因此被广泛地应用于中小型网站开发。随着 MySQL 的不断成熟,它也逐渐被应用于更多大规模网站和应用,比如维基百科、谷歌(Google)、脸书(Facebook)、淘宝网等网站都使用了 MySQL 来提供数据持久化服务。
+
+甲骨文公司收购后昇阳微系统公司,大幅调涨 MySQL 商业版的售价,且甲骨文公司不再支持另一个自由软件项目 [OpenSolaris ](https://zh.wikipedia.org/wiki/OpenSolaris) 的发展,因此导致自由软件社区对于 Oracle 是否还会持续支持 MySQL 社区版(MySQL 的各个发行版本中唯一免费的版本)有所担忧,MySQL 的创始人麦克尔·维德纽斯以 MySQL 为基础,创建了 [MariaDB](https://zh.wikipedia.org/wiki/MariaDB)(以他女儿的名字命名的数据库)分支。有许多原来使用 MySQL 数据库的公司(例如:维基百科)已经陆续完成了从 MySQL 数据库到 MariaDB 数据库的迁移。
+
+### 安装 MySQL
+
+#### Windows 环境
+
+1. 通过[官方网站](https://www.mysql.com/)提供的[下载链接](https://dev.mysql.com/downloads/windows/installer/8.0.html)下载“MySQL社区版服务器”安装程序,如下图所示,建议大家下载离线安装版的MySQL Installer。
+
+  +
+2. 运行 Installer,按照下面的步骤进行安装。
+
+ - 选择自定义安装。
+
+
+
+2. 运行 Installer,按照下面的步骤进行安装。
+
+ - 选择自定义安装。
+
+  +
+ - 选择需要安装的组件。
+
+
+
+ - 选择需要安装的组件。
+
+  +
+ - 如果缺少依赖项,需要先安装依赖项。
+
+
+
+ - 如果缺少依赖项,需要先安装依赖项。
+
+  +
+ - 准备开始安装。
+
+
+
+ - 准备开始安装。
+
+  +
+ - 安装完成。
+
+
+
+ - 安装完成。
+
+  +
+ - 准备执行配置向导。
+
+
+
+ - 准备执行配置向导。
+
+  +
+3. 执行安装后的配置向导。
+
+ - 配置服务器类型和网络。
+
+
+
+3. 执行安装后的配置向导。
+
+ - 配置服务器类型和网络。
+
+  +
+ - 配置认证方法(保护密码的方式)。
+
+
+
+ - 配置认证方法(保护密码的方式)。
+
+  +
+ - 配置用户和角色。
+
+
+
+ - 配置用户和角色。
+
+  +
+ - 配置Windows服务名以及是否开机自启。
+
+
+
+ - 配置Windows服务名以及是否开机自启。
+
+  +
+ - 配置日志。
+
+
+
+ - 配置日志。
+
+  +
+ - 配置高级选项。
+
+
+
+ - 配置高级选项。
+
+  +
+ - 应用配置。
+
+
+
+ - 应用配置。
+
+  +
+4. 可以在 Windows 系统的“服务”窗口中启动或停止 MySQL。
+
+
+
+4. 可以在 Windows 系统的“服务”窗口中启动或停止 MySQL。
+
+  +
+5. 配置 PATH 环境变量,以便在命令行提示符窗口使用 MySQL 客户端工具。
+
+ - 打开 Windows 的“系统”窗口并点击“高级系统设置”。
+
+
+
+5. 配置 PATH 环境变量,以便在命令行提示符窗口使用 MySQL 客户端工具。
+
+ - 打开 Windows 的“系统”窗口并点击“高级系统设置”。
+
+  +
+ - 在“系统属性”的“高级”窗口,点击“环境变量”按钮。
+
+
+
+ - 在“系统属性”的“高级”窗口,点击“环境变量”按钮。
+
+  +
+ - 修改PATH环境变量,将MySQL安装路径下的`bin`文件夹的路径配置到PATH环境变量中。
+
+
+
+ - 修改PATH环境变量,将MySQL安装路径下的`bin`文件夹的路径配置到PATH环境变量中。
+
+  +
+ - 配置完成后,可以尝试在“命令提示符”下使用 MySQL 的命令行工具。
+
+
+
+ - 配置完成后,可以尝试在“命令提示符”下使用 MySQL 的命令行工具。
+
+  +
+#### Linux 环境
+
+下面以 CentOS 7.x 环境为例,演示如何安装 MySQL 5.7.x,如果需要在其他 Linux 系统下安装其他版本的 MySQL,请读者自行在网络上查找对应的安装教程。
+
+1. 安装 MySQL。
+
+ 可以在 [MySQL 官方网站]()下载安装文件。首先在下载页面中选择平台和版本,然后找到对应的下载链接,直接下载包含所有安装文件的归档文件,解归档之后通过包管理工具进行安装。
+
+ ```Shell
+ wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.26-1.el7.x86_64.rpm-bundle.tar
+ tar -xvf mysql-5.7.26-1.el7.x86_64.rpm-bundle.tar
+ ```
+
+ 如果系统上有 MariaDB 相关的文件,需要先移除 MariaDB 相关的文件。
+
+ ```Shell
+ yum list installed | grep mariadb | awk '{print $1}' | xargs yum erase -y
+ ```
+
+ 更新和安装可能用到的底层依赖库。
+
+ ```Bash
+ yum update
+ yum install -y libaio libaio-devel
+ ```
+
+ 接下来可以按照如下所示的顺序用 RPM(Redhat Package Manager)工具安装 MySQL。
+
+ ```Shell
+ rpm -ivh mysql-community-common-5.7.26-1.el7.x86_64.rpm
+ rpm -ivh mysql-community-libs-5.7.26-1.el7.x86_64.rpm
+ rpm -ivh mysql-community-libs-compat-5.7.26-1.el7.x86_64.rpm
+ rpm -ivh mysql-community-devel-5.7.26-1.el7.x86_64.rpm
+ rpm -ivh mysql-community-client-5.7.26-1.el7.x86_64.rpm
+ rpm -ivh mysql-community-server-5.7.26-1.el7.x86_64.rpm
+ ```
+
+ 可以使用下面的命令查看已经安装的 MySQL 相关的包。
+
+ ```Shell
+ rpm -qa | grep mysql
+ ```
+
+2. 配置 MySQL。
+
+ MySQL 的配置文件在`/etc`目录下,名为`my.cnf`,默认的配置文件内容如下所示。
+
+ ```Shell
+ cat /etc/my.cnf
+ ```
+
+ ```INI
+ # For advice on how to change settings please see
+ # http://dev.mysql.com/doc/refman/5.7/en/server-configuration-defaults.html
+
+ [mysqld]
+ #
+ # Remove leading # and set to the amount of RAM for the most important data
+ # cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.
+ # innodb_buffer_pool_size = 128M
+ #
+ # Remove leading # to turn on a very important data integrity option: logging
+ # changes to the binary log between backups.
+ # log_bin
+ #
+ # Remove leading # to set options mainly useful for reporting servers.
+ # The server defaults are faster for transactions and fast SELECTs.
+ # Adjust sizes as needed, experiment to find the optimal values.
+ # join_buffer_size = 128M
+ # sort_buffer_size = 2M
+ # read_rnd_buffer_size = 2M
+ datadir=/var/lib/mysql
+ socket=/var/lib/mysql/mysql.sock
+
+ # Disabling symbolic-links is recommended to prevent assorted security risks
+ symbolic-links=0
+
+ log-error=/var/log/mysqld.log
+ pid-file=/var/run/mysqld/mysqld.pid
+ ```
+
+ 通过配置文件,我们可以修改 MySQL 服务使用的端口、字符集、最大连接数、套接字队列大小、最大数据包大小、日志文件的位置、日志过期时间等配置。当然,我们还可以通过修改配置文件来对 MySQL 服务器进行性能调优和安全管控。
+
+3. 启动 MySQL 服务。
+
+ 可以使用下面的命令来启动 MySQL。
+
+ ```Shell
+ service mysqld start
+ ```
+
+ 在 CentOS 7 中,更推荐使用下面的命令来启动 MySQL。
+
+ ```Shell
+ systemctl start mysqld
+ ```
+
+ 启动 MySQL 成功后,可以通过下面的命令来检查网络端口使用情况,MySQL 默认使用`3306`端口。
+
+ ```Shell
+ netstat -ntlp | grep mysql
+ ```
+
+ 也可以使用下面的命令查找是否有名为`mysqld`的进程。
+
+ ```Shell
+ pgrep mysqld
+ ```
+
+4. 使用 MySQL 客户端工具连接服务器。
+
+ 命令行工具:
+
+ ```Shell
+ mysql -u root -p
+ ```
+
+ > 说明:启动客户端时,`-u`参数用来指定用户名,MySQL 默认的超级管理账号为`root`;`-p`表示要输入密码(用户口令);如果连接的是其他主机而非本机,可以用`-h`来指定连接主机的主机名或IP地址。
+
+ 如果是首次安装 MySQL,可以使用下面的命令来找到默认的初始密码。
+
+ ```Shell
+ cat /var/log/mysqld.log | grep password
+ ```
+
+ 上面的命令会查看 MySQL 的日志带有`password`的行,在显示的结果中`root@localhost:`后面的部分就是默认设置的初始密码。
+
+ 进入客户端工具后,可以通过下面的指令来修改超级管理员(root)的访问口令为`123456`。
+
+ ```SQL
+ set global validate_password_policy=0;
+ set global validate_password_length=6;
+ alter user 'root'@'localhost' identified by '123456';
+ ```
+
+ > **说明**:MySQL 较新的版本默认不允许使用弱口令作为用户口令,所以上面的代码修改了验证用户口令的策略和口令的长度。事实上我们不应该使用弱口令,因为存在用户口令被暴力破解的风险。近年来,**攻击数据库窃取数据和劫持数据库勒索比特币**的事件屡见不鲜,要避免这些潜在的风险,最为重要的一点是**不要让数据库服务器暴露在公网上**(最好的做法是将数据库置于内网,至少要做到不向公网开放数据库服务器的访问端口),另外要保管好`root`账号的口令,应用系统需要访问数据库时,通常不使用`root`账号进行访问,而是**创建其他拥有适当权限的账号来访问**。
+
+ 再次使用客户端工具连接 MySQL 服务器时,就可以使用新设置的口令了。在实际开发中,为了方便用户操作,可以选择图形化的客户端工具来连接 MySQL 服务器,包括:
+
+ - MySQL Workbench(官方工具)
+
+
+
+#### Linux 环境
+
+下面以 CentOS 7.x 环境为例,演示如何安装 MySQL 5.7.x,如果需要在其他 Linux 系统下安装其他版本的 MySQL,请读者自行在网络上查找对应的安装教程。
+
+1. 安装 MySQL。
+
+ 可以在 [MySQL 官方网站]()下载安装文件。首先在下载页面中选择平台和版本,然后找到对应的下载链接,直接下载包含所有安装文件的归档文件,解归档之后通过包管理工具进行安装。
+
+ ```Shell
+ wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.26-1.el7.x86_64.rpm-bundle.tar
+ tar -xvf mysql-5.7.26-1.el7.x86_64.rpm-bundle.tar
+ ```
+
+ 如果系统上有 MariaDB 相关的文件,需要先移除 MariaDB 相关的文件。
+
+ ```Shell
+ yum list installed | grep mariadb | awk '{print $1}' | xargs yum erase -y
+ ```
+
+ 更新和安装可能用到的底层依赖库。
+
+ ```Bash
+ yum update
+ yum install -y libaio libaio-devel
+ ```
+
+ 接下来可以按照如下所示的顺序用 RPM(Redhat Package Manager)工具安装 MySQL。
+
+ ```Shell
+ rpm -ivh mysql-community-common-5.7.26-1.el7.x86_64.rpm
+ rpm -ivh mysql-community-libs-5.7.26-1.el7.x86_64.rpm
+ rpm -ivh mysql-community-libs-compat-5.7.26-1.el7.x86_64.rpm
+ rpm -ivh mysql-community-devel-5.7.26-1.el7.x86_64.rpm
+ rpm -ivh mysql-community-client-5.7.26-1.el7.x86_64.rpm
+ rpm -ivh mysql-community-server-5.7.26-1.el7.x86_64.rpm
+ ```
+
+ 可以使用下面的命令查看已经安装的 MySQL 相关的包。
+
+ ```Shell
+ rpm -qa | grep mysql
+ ```
+
+2. 配置 MySQL。
+
+ MySQL 的配置文件在`/etc`目录下,名为`my.cnf`,默认的配置文件内容如下所示。
+
+ ```Shell
+ cat /etc/my.cnf
+ ```
+
+ ```INI
+ # For advice on how to change settings please see
+ # http://dev.mysql.com/doc/refman/5.7/en/server-configuration-defaults.html
+
+ [mysqld]
+ #
+ # Remove leading # and set to the amount of RAM for the most important data
+ # cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.
+ # innodb_buffer_pool_size = 128M
+ #
+ # Remove leading # to turn on a very important data integrity option: logging
+ # changes to the binary log between backups.
+ # log_bin
+ #
+ # Remove leading # to set options mainly useful for reporting servers.
+ # The server defaults are faster for transactions and fast SELECTs.
+ # Adjust sizes as needed, experiment to find the optimal values.
+ # join_buffer_size = 128M
+ # sort_buffer_size = 2M
+ # read_rnd_buffer_size = 2M
+ datadir=/var/lib/mysql
+ socket=/var/lib/mysql/mysql.sock
+
+ # Disabling symbolic-links is recommended to prevent assorted security risks
+ symbolic-links=0
+
+ log-error=/var/log/mysqld.log
+ pid-file=/var/run/mysqld/mysqld.pid
+ ```
+
+ 通过配置文件,我们可以修改 MySQL 服务使用的端口、字符集、最大连接数、套接字队列大小、最大数据包大小、日志文件的位置、日志过期时间等配置。当然,我们还可以通过修改配置文件来对 MySQL 服务器进行性能调优和安全管控。
+
+3. 启动 MySQL 服务。
+
+ 可以使用下面的命令来启动 MySQL。
+
+ ```Shell
+ service mysqld start
+ ```
+
+ 在 CentOS 7 中,更推荐使用下面的命令来启动 MySQL。
+
+ ```Shell
+ systemctl start mysqld
+ ```
+
+ 启动 MySQL 成功后,可以通过下面的命令来检查网络端口使用情况,MySQL 默认使用`3306`端口。
+
+ ```Shell
+ netstat -ntlp | grep mysql
+ ```
+
+ 也可以使用下面的命令查找是否有名为`mysqld`的进程。
+
+ ```Shell
+ pgrep mysqld
+ ```
+
+4. 使用 MySQL 客户端工具连接服务器。
+
+ 命令行工具:
+
+ ```Shell
+ mysql -u root -p
+ ```
+
+ > 说明:启动客户端时,`-u`参数用来指定用户名,MySQL 默认的超级管理账号为`root`;`-p`表示要输入密码(用户口令);如果连接的是其他主机而非本机,可以用`-h`来指定连接主机的主机名或IP地址。
+
+ 如果是首次安装 MySQL,可以使用下面的命令来找到默认的初始密码。
+
+ ```Shell
+ cat /var/log/mysqld.log | grep password
+ ```
+
+ 上面的命令会查看 MySQL 的日志带有`password`的行,在显示的结果中`root@localhost:`后面的部分就是默认设置的初始密码。
+
+ 进入客户端工具后,可以通过下面的指令来修改超级管理员(root)的访问口令为`123456`。
+
+ ```SQL
+ set global validate_password_policy=0;
+ set global validate_password_length=6;
+ alter user 'root'@'localhost' identified by '123456';
+ ```
+
+ > **说明**:MySQL 较新的版本默认不允许使用弱口令作为用户口令,所以上面的代码修改了验证用户口令的策略和口令的长度。事实上我们不应该使用弱口令,因为存在用户口令被暴力破解的风险。近年来,**攻击数据库窃取数据和劫持数据库勒索比特币**的事件屡见不鲜,要避免这些潜在的风险,最为重要的一点是**不要让数据库服务器暴露在公网上**(最好的做法是将数据库置于内网,至少要做到不向公网开放数据库服务器的访问端口),另外要保管好`root`账号的口令,应用系统需要访问数据库时,通常不使用`root`账号进行访问,而是**创建其他拥有适当权限的账号来访问**。
+
+ 再次使用客户端工具连接 MySQL 服务器时,就可以使用新设置的口令了。在实际开发中,为了方便用户操作,可以选择图形化的客户端工具来连接 MySQL 服务器,包括:
+
+ - MySQL Workbench(官方工具)
+
+  +
+ - Navicat for MySQL(界面简单友好)
+
+
+
+ - Navicat for MySQL(界面简单友好)
+
+  +
+
+#### macOS环境
+
+macOS 系统安装 MySQL 是比较简单的,只需要从刚才说到的官方网站下载 DMG 安装文件并运行就可以了,下载的时候需要根据自己使用的是 Intel 的芯片还是苹果的 M1 芯片选择下载链接,如下图所示。
+
+
+
+
+#### macOS环境
+
+macOS 系统安装 MySQL 是比较简单的,只需要从刚才说到的官方网站下载 DMG 安装文件并运行就可以了,下载的时候需要根据自己使用的是 Intel 的芯片还是苹果的 M1 芯片选择下载链接,如下图所示。
+
+ +
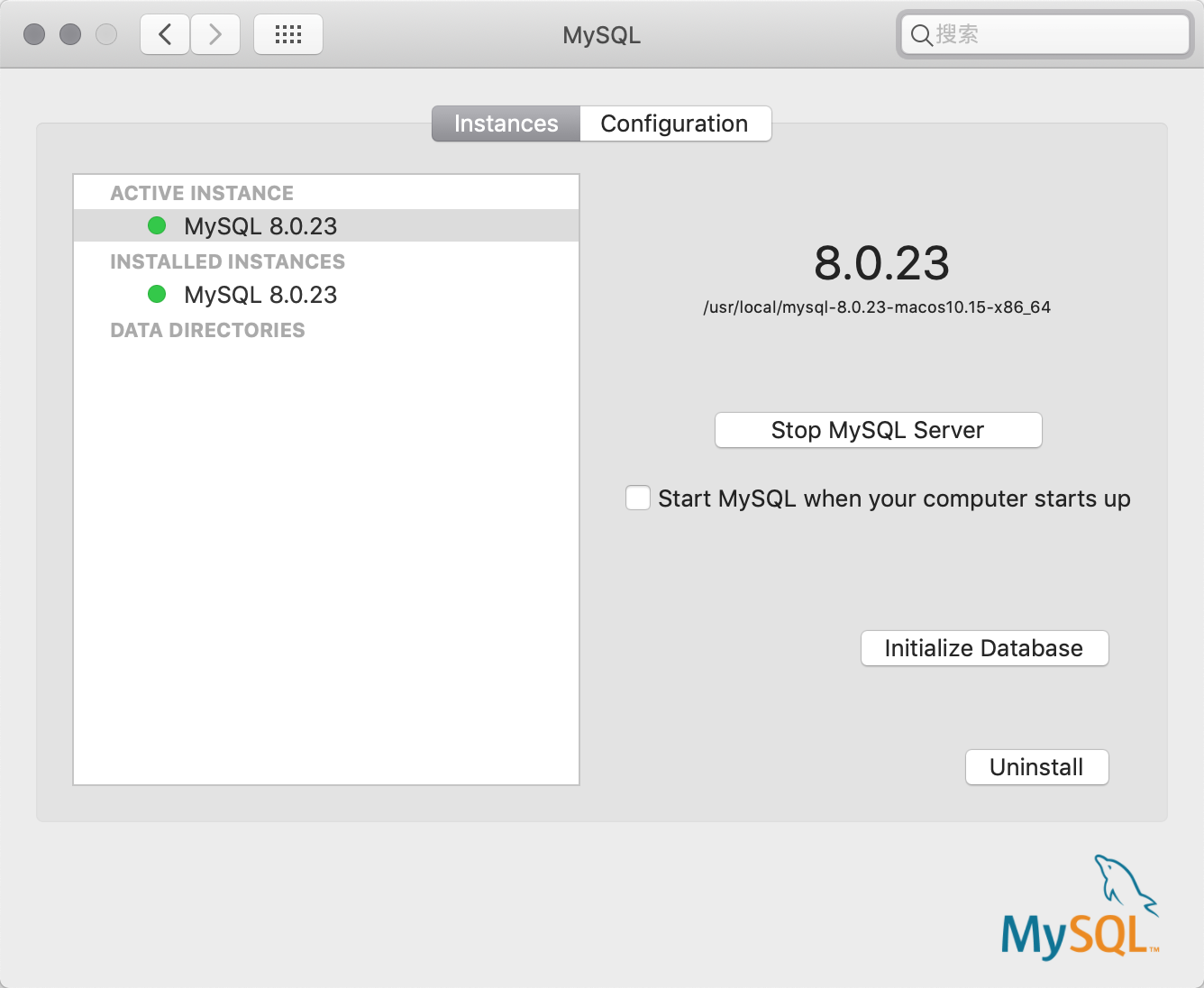
+安装成功后,可以在“系统偏好设置”中找到“MySQL”,在如下所示的画面中,可以启动和停止 MySQL 服务器,也可以对 MySQL 核心文件的路径进行配置。
+
+
+
+安装成功后,可以在“系统偏好设置”中找到“MySQL”,在如下所示的画面中,可以启动和停止 MySQL 服务器,也可以对 MySQL 核心文件的路径进行配置。
+
+ +
+### MySQL 基本命令
+
+#### 查看命令
+
+1. 查看所有数据库
+
+```SQL
+show databases;
+```
+
+2. 查看所有字符集
+
+```SQL
+show character set;
+```
+
+3. 查看所有的排序规则
+
+```SQL
+show collation;
+```
+
+4. 查看所有的引擎
+
+```SQL
+show engines;
+```
+
+5. 查看所有日志文件
+
+```SQL
+show binary logs;
+```
+
+6. 查看数据库下所有表
+
+```SQL
+show tables;
+```
+
+#### 获取帮助
+
+在 MySQL 命令行工具中,可以使用`help`命令或`?`来获取帮助,如下所示。
+
+1. 查看`show`命令的帮助。
+
+ ```MySQL
+ ? show
+ ```
+
+2. 查看有哪些帮助内容。
+
+ ```MySQL
+ ? contents
+ ```
+
+3. 获取函数的帮助。
+
+ ```MySQL
+ ? functions
+ ```
+
+4. 获取数据类型的帮助。
+
+ ```MySQL
+ ? data types
+ ```
+
+#### 其他命令
+
+1. 新建/重建服务器连接 - `connect` / `resetconnection`。
+
+2. 清空当前输入 - `\c`。在输入错误时,可以及时使用`\c`清空当前输入并重新开始。
+
+3. 修改终止符(定界符)- `delimiter`。默认的终止符是`;`,可以使用该命令修改成其他的字符,例如修改为`$`符号,可以用`delimiter $`命令。
+
+4. 打开系统默认编辑器 - `edit`。编辑完成保存关闭之后,命令行会自动执行编辑的内容。
+
+5. 查看服务器状态 - `status`。
+
+6. 修改默认提示符 - `prompt`。
+
+7. 执行系统命令 - `system`。可以将系统命令跟在`system`命令的后面执行,`system`命令也可以缩写为`\!`。
+
+8. 执行 SQL 文件 - `source`。`source`命令后面跟 SQL 文件路径。
+
+9. 重定向输出 - `tee` / `notee`。可以将命令的输出重定向到指定的文件中。
+
+10. 切换数据库 - `use`。
+
+11. 显示警告信息 - `warnings`。
+
+12. 退出命令行 - `quit`或`exit`。
+
+
+
diff --git a/Day36-40/36-38.关系型数据库MySQL.md b/Day36-40/37.SQL和MySQL详解.md
similarity index 72%
rename from Day36-40/36-38.关系型数据库MySQL.md
rename to Day36-40/37.SQL和MySQL详解.md
index 090b1bf..575b580 100644
--- a/Day36-40/36-38.关系型数据库MySQL.md
+++ b/Day36-40/37.SQL和MySQL详解.md
@@ -1,349 +1,4 @@
-## 关系数据库MySQL
-
-### 关系数据库概述
-
-1. 数据持久化 - 将数据保存到能够长久保存数据的存储介质中,在掉电的情况下数据也不会丢失。
-
-2. 数据库发展史 - 网状数据库、层次数据库、关系数据库、NoSQL 数据库、NewSQL 数据库。
-
- > 1970年,IBM的研究员E.F.Codd在*Communication of the ACM*上发表了名为*A Relational Model of Data for Large Shared Data Banks*的论文,提出了**关系模型**的概念,奠定了关系模型的理论基础。后来Codd又陆续发表多篇文章,论述了范式理论和衡量关系系统的12条标准,用数学理论奠定了关系数据库的基础。
-
-3. 关系数据库特点。
-
- - 理论基础:**关系代数**。
-
- - 具体表象:用**二维表**(有行和列)组织数据。
-
- - 编程语言:**结构化查询语言**(SQL)。
-
-4. ER模型(实体关系模型)和概念模型图。
-
- **ER模型**,全称为**实体关系模型**(Entity-Relationship Model),由美籍华裔计算机科学家陈品山先生提出,是概念数据模型的高层描述方式,如下图所示。
-
-
-
- - 实体 - 矩形框
- - 属性 - 椭圆框
- - 关系 - 菱形框
- - 重数 - 1:1(一对一) / 1:N(一对多) / M:N(多对多)
-
- 实际项目开发中,我们可以利用数据库建模工具(如:PowerDesigner)来绘制概念数据模型(其本质就是 ER 模型),然后再设置好目标数据库系统,将概念模型转换成物理模型,最终生成创建二维表的 SQL(很多工具都可以根据我们设计的物理模型图以及设定的目标数据库来导出 SQL 或直接生成数据表)。
-
- 
-
-5. 关系数据库产品。
- - [Oracle](https://www.oracle.com/index.html) - 目前世界上使用最为广泛的数据库管理系统,作为一个通用的数据库系统,它具有完整的数据管理功能;作为一个关系数据库,它是一个完备关系的产品;作为分布式数据库,它实现了分布式处理的功能。在 Oracle 最新的 12c 版本中,还引入了多承租方架构,使用该架构可轻松部署和管理数据库云。
- - [DB2](https://www.ibm.com/analytics/us/en/db2/) - IBM 公司开发的、主要运行于 Unix(包括 IBM 自家的 [AIX](https://zh.wikipedia.org/wiki/AIX))、Linux、以及 Windows 服务器版等系统的关系数据库产品。DB2 历史悠久且被认为是最早使用 SQL 的数据库产品,它拥有较为强大的商业智能功能。
- - [SQL Server](https://www.microsoft.com/en-us/sql-server/) - 由 Microsoft 开发和推广的关系型数据库产品,最初适用于中小企业的数据管理,但是近年来它的应用范围有所扩展,部分大企业甚至是跨国公司也开始基于它来构建自己的数据管理系统。
- - [MySQL](https://www.mysql.com/) - MySQL 是开放源代码的,任何人都可以在 GPL(General Public License)的许可下下载并根据个性化的需要对其进行修改。MySQL 因为其速度、可靠性和适应性而备受关注。
- - [PostgreSQL]() - 在 BSD 许可证下发行的开放源代码的关系数据库产品。
-
-### MySQL 简介
-
-MySQL 最早是由瑞典的 MySQL AB 公司开发的一个开放源码的关系数据库管理系统,该公司于2008年被昇阳微系统公司(Sun Microsystems)收购。在2009年,甲骨文公司(Oracle)收购昇阳微系统公司,因此 MySQL 目前也是 Oracle 旗下产品。
-
-MySQL 在过去由于性能高、成本低、可靠性好,已经成为最流行的开源数据库,因此被广泛地应用于中小型网站开发。随着 MySQL 的不断成熟,它也逐渐被应用于更多大规模网站和应用,比如维基百科、谷歌(Google)、脸书(Facebook)、淘宝网等网站都使用了 MySQL 来提供数据持久化服务。
-
-甲骨文公司收购后昇阳微系统公司,大幅调涨 MySQL 商业版的售价,且甲骨文公司不再支持另一个自由软件项目 [OpenSolaris ](https://zh.wikipedia.org/wiki/OpenSolaris) 的发展,因此导致自由软件社区对于 Oracle 是否还会持续支持 MySQL 社区版(MySQL 的各个发行版本中唯一免费的版本)有所担忧,MySQL 的创始人麦克尔·维德纽斯以 MySQL 为基础,创建了 [MariaDB](https://zh.wikipedia.org/wiki/MariaDB)(以他女儿的名字命名的数据库)分支。有许多原来使用 MySQL 数据库的公司(例如:维基百科)已经陆续完成了从 MySQL 数据库到 MariaDB 数据库的迁移。
-
-### 安装 MySQL
-
-#### Windows 环境
-
-1. 通过[官方网站](https://www.mysql.com/)提供的[下载链接](https://dev.mysql.com/downloads/windows/installer/8.0.html)下载“MySQL社区版服务器”安装程序,如下图所示,建议大家下载离线安装版的MySQL Installer。
-
-
-
-2. 运行 Installer,按照下面的步骤进行安装。
-
- - 选择自定义安装。
-
-
-
- - 选择需要安装的组件。
-
-
-
- - 如果缺少依赖项,需要先安装依赖项。
-
-
-
- - 准备开始安装。
-
-
-
- - 安装完成。
-
-
-
- - 准备执行配置向导。
-
-
-
-3. 执行安装后的配置向导。
-
- - 配置服务器类型和网络。
-
-
-
- - 配置认证方法(保护密码的方式)。
-
-
-
- - 配置用户和角色。
-
-
-
- - 配置Windows服务名以及是否开机自启。
-
-
-
- - 配置日志。
-
-
-
- - 配置高级选项。
-
-
-
- - 应用配置。
-
-
-
-4. 可以在 Windows 系统的“服务”窗口中启动或停止 MySQL。
-
-
-
-5. 配置 PATH 环境变量,以便在命令行提示符窗口使用 MySQL 客户端工具。
-
- - 打开 Windows 的“系统”窗口并点击“高级系统设置”。
-
-
-
- - 在“系统属性”的“高级”窗口,点击“环境变量”按钮。
-
-
-
- - 修改PATH环境变量,将MySQL安装路径下的`bin`文件夹的路径配置到PATH环境变量中。
-
-
-
- - 配置完成后,可以尝试在“命令提示符”下使用 MySQL 的命令行工具。
-
-
-
-#### Linux 环境
-
-下面以 CentOS 7.x 环境为例,演示如何安装 MySQL 5.7.x,如果需要在其他 Linux 系统下安装其他版本的 MySQL,请读者自行在网络上查找对应的安装教程。
-
-1. 安装 MySQL。
-
- 可以在 [MySQL 官方网站]()下载安装文件。首先在下载页面中选择平台和版本,然后找到对应的下载链接,直接下载包含所有安装文件的归档文件,解归档之后通过包管理工具进行安装。
-
- ```Shell
- wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.26-1.el7.x86_64.rpm-bundle.tar
- tar -xvf mysql-5.7.26-1.el7.x86_64.rpm-bundle.tar
- ```
-
- 如果系统上有 MariaDB 相关的文件,需要先移除 MariaDB 相关的文件。
-
- ```Shell
- yum list installed | grep mariadb | awk '{print $1}' | xargs yum erase -y
- ```
-
- 更新和安装可能用到的底层依赖库。
-
- ```Bash
- yum update
- yum install -y libaio libaio-devel
- ```
-
- 接下来可以按照如下所示的顺序用 RPM(Redhat Package Manager)工具安装 MySQL。
-
- ```Shell
- rpm -ivh mysql-community-common-5.7.26-1.el7.x86_64.rpm
- rpm -ivh mysql-community-libs-5.7.26-1.el7.x86_64.rpm
- rpm -ivh mysql-community-libs-compat-5.7.26-1.el7.x86_64.rpm
- rpm -ivh mysql-community-devel-5.7.26-1.el7.x86_64.rpm
- rpm -ivh mysql-community-client-5.7.26-1.el7.x86_64.rpm
- rpm -ivh mysql-community-server-5.7.26-1.el7.x86_64.rpm
- ```
-
- 可以使用下面的命令查看已经安装的 MySQL 相关的包。
-
- ```Shell
- rpm -qa | grep mysql
- ```
-
-2. 配置 MySQL。
-
- MySQL 的配置文件在`/etc`目录下,名为`my.cnf`,默认的配置文件内容如下所示。
-
- ```Shell
- cat /etc/my.cnf
- ```
-
- ```INI
- # For advice on how to change settings please see
- # http://dev.mysql.com/doc/refman/5.7/en/server-configuration-defaults.html
-
- [mysqld]
- #
- # Remove leading # and set to the amount of RAM for the most important data
- # cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.
- # innodb_buffer_pool_size = 128M
- #
- # Remove leading # to turn on a very important data integrity option: logging
- # changes to the binary log between backups.
- # log_bin
- #
- # Remove leading # to set options mainly useful for reporting servers.
- # The server defaults are faster for transactions and fast SELECTs.
- # Adjust sizes as needed, experiment to find the optimal values.
- # join_buffer_size = 128M
- # sort_buffer_size = 2M
- # read_rnd_buffer_size = 2M
- datadir=/var/lib/mysql
- socket=/var/lib/mysql/mysql.sock
-
- # Disabling symbolic-links is recommended to prevent assorted security risks
- symbolic-links=0
-
- log-error=/var/log/mysqld.log
- pid-file=/var/run/mysqld/mysqld.pid
- ```
-
- 通过配置文件,我们可以修改 MySQL 服务使用的端口、字符集、最大连接数、套接字队列大小、最大数据包大小、日志文件的位置、日志过期时间等配置。当然,我们还可以通过修改配置文件来对 MySQL 服务器进行性能调优和安全管控。
-
-3. 启动 MySQL 服务。
-
- 可以使用下面的命令来启动 MySQL。
-
- ```Shell
- service mysqld start
- ```
-
- 在 CentOS 7 中,更推荐使用下面的命令来启动 MySQL。
-
- ```Shell
- systemctl start mysqld
- ```
-
- 启动 MySQL 成功后,可以通过下面的命令来检查网络端口使用情况,MySQL 默认使用`3306`端口。
-
- ```Shell
- netstat -ntlp | grep mysql
- ```
-
- 也可以使用下面的命令查找是否有名为`mysqld`的进程。
-
- ```Shell
- pgrep mysqld
- ```
-
-4. 使用 MySQL 客户端工具连接服务器。
-
- 命令行工具:
-
- ```Shell
- mysql -u root -p
- ```
-
- > 说明:启动客户端时,`-u`参数用来指定用户名,MySQL 默认的超级管理账号为`root`;`-p`表示要输入密码(用户口令);如果连接的是其他主机而非本机,可以用`-h`来指定连接主机的主机名或IP地址。
-
- 如果是首次安装 MySQL,可以使用下面的命令来找到默认的初始密码。
-
- ```Shell
- cat /var/log/mysqld.log | grep password
- ```
-
- 上面的命令会查看 MySQL 的日志带有`password`的行,在显示的结果中`root@localhost:`后面的部分就是默认设置的初始密码。
-
- 进入客户端工具后,可以通过下面的指令来修改超级管理员(root)的访问口令为`123456`。
-
- ```SQL
- set global validate_password_policy=0;
- set global validate_password_length=6;
- alter user 'root'@'localhost' identified by '123456';
- ```
-
- > **说明**:MySQL 较新的版本默认不允许使用弱口令作为用户口令,所以上面的代码修改了验证用户口令的策略和口令的长度。事实上我们不应该使用弱口令,因为存在用户口令被暴力破解的风险。近年来,**攻击数据库窃取数据和劫持数据库勒索比特币**的事件屡见不鲜,要避免这些潜在的风险,最为重要的一点是**不要让数据库服务器暴露在公网上**(最好的做法是将数据库置于内网,至少要做到不向公网开放数据库服务器的访问端口),另外要保管好`root`账号的口令,应用系统需要访问数据库时,通常不使用`root`账号进行访问,而是**创建其他拥有适当权限的账号来访问**。
-
- 再次使用客户端工具连接 MySQL 服务器时,就可以使用新设置的口令了。在实际开发中,为了方便用户操作,可以选择图形化的客户端工具来连接 MySQL 服务器,包括:
-
- - MySQL Workbench(官方工具)
-
-
-
- - Navicat for MySQL(界面简单友好)
-
-
-
- - SQLyog for MySQL(有社区版和商业版)
-
-### MySQL 常用命令
-
- - 查看所有数据库。
-
- ```SQL
- show databases;
- ```
-
- - 查看所有字符集(编码方式)。
-
- ```SQL
- show character set;
- ```
-
- - 查看所有的校对(排序)规则。
-
- ```SQL
- show collation;
- ```
-
- - 查看所有的引擎。
-
- ```SQL
- show engines;
- ```
-
- - 查看所有日志文件。
-
- ```SQL
- show binary logs;
- ```
-
- - 查看数据库下所有表。
-
- ```SQL
- show tables;
- ```
-
- - 获取帮助。
-
- 1. 查看`show`命令的帮助。
-
- ```MySQL
- ? show
- ```
-
- 2. 查看有哪些帮助内容。
-
- ```MySQL
- ? contents
- ```
-
- 3. 获取函数的帮助。
-
- ```MySQL
- ? functions
- ```
-
- 4. 获取数据类型的帮助。
-
- ```MySQL
- ? data types
- ```
+## SQL 和 MySQL 详解
### SQL 详解
@@ -747,6 +402,8 @@ values
(3755, 9999, '2017-09-01', 92);
```
+> **注意**:上面的`insert`语句使用了批处理的方式来插入数据,这种做法插入数据的效率比较高。
+
#### DQL(数据查询语言)
接下来,我们完成如下所示的查询。
@@ -1148,13 +805,19 @@ revoke insert on `school`.* from 'wangdachui'@'%';
> **说明**:创建一个可以允许任意主机登录并且具有超级管理员权限的用户在现实中并不是一个明智的决定,因为一旦该账号的口令泄露或者被破解,数据库将会面临灾难级的风险。
-### 索引
+### MySQL 详解
-索引是关系型数据库中用来提升查询性能最为重要的手段。关系型数据库中的索引就像一本书的目录,我们可以想象一下,如果要从一本书中找出某个知识点,但是这本书没有目录,这将是意见多么可怕的事情(我们估计得一篇一篇的翻下去,才能确定这个知识点到底在什么位置)。创建索引虽然会带来存储空间上的开销,就像一本书的目录会占用一部分的篇幅一样,但是在牺牲空间后换来的查询时间的减少也是非常显著的。
+#### 索引
-MySQL 中,所有数据类型的列都可以被索引,常用的存储引擎 InnoDB 和 MyISAM 能支持每个表创建16个索引。InnoDB 和 MyISAM 使用的索引其底层算法是 B-tree(B树),B-tree 是一种自平衡的树,类似于平衡二叉排序树,能够保持数据有序。这种数据结构能够让查找数据、顺序访问、插入数据及删除的操作都在对数时间内完成。
+索引是关系型数据库中用来提升查询性能最为重要的手段。关系型数据库中的索引就像一本书的目录,我们可以想象一下,如果要从一本书中找出某个知识点,但是这本书没有目录,这将是意见多么可怕的事情!我们估计得一篇一篇的翻下去,才能确定这个知识点到底在什么位置。创建索引虽然会带来存储空间上的开销,就像一本书的目录会占用一部分篇幅一样,但是在牺牲空间后换来的查询时间的减少也是非常显著的。
-接下来我们通过一个简单的例子来说明索引的意义,比如我们要根据学生的姓名来查找学生,这个场景在实际开发中应该经常遇到,就跟通过商品名称查找商品道理是一样的。我们可以使用 MySQL 的`explain`关键字来查看 SQL 的执行计划。
+MySQL 数据库中所有数据类型的列都可以被索引。对于MySQL 8.0 版本的 InnoDB 存储引擎来说,它支持三种类型的索引,分别是 B+ 树索引、全文索引和 R 树索引。这里,我们只介绍使用得最为广泛的 B+ 树索引。使用 B+ 树的原因非常简单,因为它是目前在基于磁盘进行海量数据存储和排序上最有效率的数据结构。B+ 树是一棵[平衡树](https://zh.wikipedia.org/zh-cn/%E5%B9%B3%E8%A1%A1%E6%A0%91),树的高度通常为3或4,但是却可以保存从百万级到十亿级的数据,而从这些数据里面查询一条数据,只需要3次或4次 I/O 操作。
+
+B+ 树由根节点、中间节点和叶子节点构成,其中叶子节点用来保存排序后的数据。由于记录在索引上是排序过的,因此在一个叶子节点内查找数据时可以使用二分查找,这种查找方式效率非常的高。当数据很少的时候,B+ 树只有一个根节点,数据也就保存在根节点上。随着记录越来越多,B+ 树会发生分裂,根节点不再保存数据,而是提供了访问下一层节点的指针,帮助快速确定数据在哪个叶子节点上。
+
+在创建二维表时,我们通常都会为表指定主键列,主键列上默认会创建索引,而对于 MySQL InnoDB 存储引擎来说,因为它使用的是索引组织表这种数据存储结构,所以主键上的索引就是整张表的数据,而这种索引我们也将其称之为**聚集索引**(clustered index)。很显然,一张表只能有一个聚集索引,否则表的数据岂不是要保存多次。我们自己创建的索引都是二级索引(secondary index),更常见的叫法是**非聚集索引**(non-clustered index)。通过我们自定义的非聚集索引只能定位记录的主键,在获取数据时可能需要再通过主键上的聚集索引进行查询,这种现象称为“回表”,因此通过非聚集索引检索数据通常比使用聚集索引检索数据要慢。
+
+接下来我们通过一个简单的例子来说明索引的意义,比如我们要根据学生的姓名来查找学生,这个场景在实际开发中应该经常遇到,就跟通过商品名称查找商品是一个道理。我们可以使用 MySQL 的`explain`关键字来查看 SQL 的执行计划(数据库执行 SQL 语句的具体步骤)。
```SQL
explain select * from tb_student where stuname='林震南'\G
@@ -1271,6 +934,8 @@ alter table tb_student drop index idx_student_name;
drop index idx_student_name on tb_student;
```
+在创建索引时,我们还可以使用复合索引、函数索引(MySQL 5.7 开始支持),用好复合索引可以减少不必要的排序和回表操作,这样就会让查询的性能成倍的提升,有兴趣的读者可以自行研究。
+
我们简单的为大家总结一下索引的设计原则:
1. **最适合**索引的列是出现在**WHERE子句**和连接子句中的列。
@@ -1281,8 +946,7 @@ drop index idx_student_name on tb_student;
最后,还有一点需要说明,InnoDB 使用的 B-tree 索引,数值类型的列除了等值判断时索引会生效之外,使用`>`、`<`、`>=`、`<=`、`BETWEEN...AND... `、`<>`时,索引仍然生效;对于字符串类型的列,如果使用不以通配符开头的模糊查询,索引也是起作用的,但是其他的情况会导致索引失效,这就意味着很有可能会做全表查询。
-
-### 视图
+#### 视图
视图是关系型数据库中将一组查询指令构成的结果集组合成可查询的数据表的对象。简单的说,视图就是虚拟的表,但与数据表不同的是,数据表是一种实体结构,而视图是一种虚拟结构,你也可以将视图理解为保存在数据库中被赋予名字的 SQL 语句。
@@ -1352,7 +1016,48 @@ drop view vw_student_score;
2. 创建视图时可以使用`order by`子句,但如果从视图中检索数据时也使用了`order by`,那么该视图中原先的`order by`会被覆盖。
3. 视图无法使用索引,也不会激发触发器(实际开发中因为性能等各方面的考虑,通常不建议使用触发器,所以我们也不对这个概念进行介绍)的执行。
-### 过程
+#### 函数
+
+MySQL 中的函数跟 Python 中的函数太多的差异,因为函数都是用来封装功能上相对独立且会被重复使用的代码的。如果非要找出一些差别来,那么 MySQL 中的函数是可以执行 SQL 语句的。下面的例子,我们通过自定义函数实现了截断超长字符串的功能。
+
+```SQL
+delimiter $$
+
+create function truncate_string(
+ content varchar(10000),
+ max_length int unsigned
+) returns varchar(10000) no sql
+begin
+ declare result varchar(10000) default content;
+ if char_length(content) > max_length then
+ set result = left(content, max_length);
+ set result = concat(result, '……');
+ end if;
+ return result;
+end $$
+
+delimiter ;
+```
+
+> **说明1**:函数声明后面的`no sql`是声明函数体并没有使用 SQL 语句;如果函数体中需要通过 SQL 读取数据,需要声明为`reads sql data`。
+>
+> **说明2**:定义函数前后的`delimiter`命令是为了修改定界符,因为函数体中的语句都是用`;`表示结束,如果不重新定义定界符,那么遇到的`;`的时候代码就会被截断执行,显然这不是我们想要的效果。
+
+在查询中调用自定义函数。
+
+```SQL
+select truncate_string('和我在成都的街头走一走,直到所有的灯都熄灭了也不停留', 10) as short_string;
+```
+
+```
++--------------------------------------+
+| short_string |
++--------------------------------------+
+| 和我在成都的街头走一…… |
++--------------------------------------+
+```
+
+#### 过程
过程(又称存储过程)是事先编译好存储在数据库中的一组 SQL 的集合,调用过程可以简化应用程序开发人员的工作,减少与数据库服务器之间的通信,对于提升数据操作的性能也是有帮助的。其实迄今为止,我们使用的 SQL 语句都是针对一个或多个表的单条语句,但在实际开发中经常会遇到某个操作需要多条 SQL 语句才能完成的情况。例如,电商网站在受理用户订单时,需要做以下一系列的处理。
@@ -1407,9 +1112,143 @@ select @a as 最高分, @b as 最低分, @c as 平均分;
drop procedure sp_score_stat;
```
-在过程中,我们可以定义变量、条件,可以使用分支和循环语句,可以通过游标操作查询结果,还可以使用事件调度器,这些内容我们暂时不在此处进行介绍。虽然我们说了很多过程的好处,但是在实际开发中,如果过度的使用过程并将大量复杂的运算放到过程中,必然会导致占用数据库服务器的 CPU 资源,造成数据库服务器承受巨大的压力。为此,我们一般会将复杂的运算和处理交给应用服务器,因为很容易部署多台应用服务器来分摊这些压力。
+在过程中,我们可以定义变量、条件,可以使用分支和循环语句,可以通过游标操作查询结果,还可以使用事件调度器,这些内容我们暂时不在此处进行介绍。虽然我们说了很多过程的好处,但是在实际开发中,如果频繁的使用过程并将大量复杂的运算放到过程中,会给据库服务器造成巨大的压力,而数据库往往都是性能瓶颈所在,使用过程无疑是雪上加霜的操作。所以,对于互联网产品开发,我们一般建议让数据库只做好存储,复杂的运算和处理交给应用服务器上的程序去完成,如果应用服务器变得不堪重负了,我们可以比较容易的部署多台应用服务器来分摊这些压力。
-### MySQL8 窗口函数
+如果大家对上面讲到的视图、函数、过程包括我们没有讲到的触发器这些知识有兴趣,建议大家阅读 MySQL 的入门读物[《MySQL必知必会》](https://item.jd.com/12818982.html)进行一般性了解即可,因为这些知识点在大家将来的工作中未必用得上,学了也可能仅仅是为了应付面试而已。
+
+### MySQL 新特性
+
+#### JSON类型
+
+很多开发者在使用关系型数据库做数据持久化的时候,常常感到结构化的存储缺乏灵活性,因为必须事先设计好所有的列以及对应的数据类型。在业务发展和变化的过程中,如果需要修改表结构,这绝对是比较麻烦和难受的事情。从 MySQL 5.7 版本开始,MySQL引入了对 JSON 数据类型的支持(MySQL 8.0 解决了 JSON 的日志性能瓶颈问题),用好 JSON 类型,其实就是打破了关系型数据库和非关系型数据库之间的界限,为数据持久化操作带来了更多的便捷。
+
+JSON 类型主要分为 JSON 对象和 JSON数组两种,如下所示。
+
+1. JSON 对象
+
+```JSON
+{"name": "骆昊", "tel": "13122335566", "QQ": "957658"}
+```
+
+2. JSON 数组
+
+```JSON
+[1, 2, 3]
+```
+
+```JSON
+[{"name": "骆昊", "tel": "13122335566"}, {"name": "王大锤", "QQ": "123456"}]
+```
+
+哪些地方需要用到JSON类型呢?举一个简单的例子,现在很多产品的用户登录都支持多种方式,例如手机号、微信、QQ、新浪微博等,但是一般情况下我们又不会要求用户提供所有的这些信息,那么用传统的设计方式,就需要设计多个列来对应多种登录方式,可能还需要允许这些列存在空值,这显然不是很好的选择;另一方面,如果产品又增加了一种登录方式,那么就必然要修改之前的表结构,这就更让人痛苦了。但是,有了 JSON 类型,刚才的问题就迎刃而解了,我们可以做出如下所示的设计。
+
+```SQL
+create table `tb_test`
+(
+`user_id` bigint unsigned,
+`login_info` json,
+primary key (`user_id`)
+) engine=innodb;
+
+insert into `tb_test` values
+ (1, '{"tel": "13122335566", "QQ": "654321", "wechat": "jackfrued"}'),
+ (2, '{"tel": "13599876543", "weibo": "wangdachui123"}');
+```
+
+如果要查询用户的手机和微信号,可以用如下所示的 SQL 语句。
+
+```SQL
+select
+ `user_id`,
+ json_unquote(json_extract(`login_info`, '$.tel')) as 手机号,
+ json_unquote(json_extract(`login_info`, '$.wechat')) as 微信
+from `tb_test`;
+```
+
+```
++---------+-------------+-----------+
+| user_id | 手机号 | 微信 |
++---------+-------------+-----------+
+| 1 | 13122335566 | jackfrued |
+| 2 | 13599876543 | NULL |
++---------+-------------+-----------+
+```
+
+因为支持 JSON 类型,MySQL 也提供了配套的处理 JSON 数据的函数,就像上面用到的`json_extract`和`json_unquote`。当然,上面的 SQL 还有更为便捷的写法,如下所示。
+
+```SQL
+select
+ `user_id`,
+ `login_info` ->> '$.tel' as 手机号,
+ `login_info` ->> '$.wechat' as 微信
+from `tb_test`;
+```
+
+再举个例子,如果我们的产品要实现用户画像功能(给用户打标签),然后基于用户画像给用户推荐平台的服务或消费品之类的东西,我们也可以使用 JSON 类型来保存用户画像数据,示意代码如下所示。
+
+创建画像标签表。
+
+```SQL
+create table `tb_tags`
+(
+`tag_id` int unsigned not null comment '标签ID',
+`tag_name` varchar(20) not null comment '标签名',
+primary key (`tag_id`)
+) engine=innodb;
+
+insert into `tb_tags` (`tag_id`, `tag_name`)
+values
+ (1, '70后'),
+ (2, '80后'),
+ (3, '90后'),
+ (4, '00后'),
+ (5, '爱运动'),
+ (6, '高学历'),
+ (7, '小资'),
+ (8, '有房'),
+ (9, '有车'),
+ (10, '爱看电影'),
+ (11, '爱网购'),
+ (12, '常点外卖');
+```
+
+为用户打标签。
+
+```SQL
+create table `tb_users_tags`
+(
+`user_id` bigint unsigned not null comment '用户ID',
+`user_tags` json not null comment '用户标签'
+) engine=innodb;
+
+insert into `tb_users_tags` values
+ (1, '[2, 6, 8, 10]'),
+ (2, '[3, 10, 12]'),
+ (3, '[3, 8, 9, 11]');
+```
+
+接下来,我们通过一组查询来了解 JSON 类型的巧妙之处。
+
+1. 查询爱看电影(有`10`这个标签)的用户ID。
+
+ ```SQL
+ select * from `tb_users` where 10 member of (user_tags->'$');
+ ```
+
+2. 查询爱看电影(有`10`这个标签)的80后(有`2`这个标签)用户ID。
+
+ ```
+ select * from `tb_users` where json_contains(user_tags->'$', '[2, 10]');
+
+3. 查询爱看电影或80后或90后的用户ID。
+
+ ```SQL
+ select `user_id` from `tb_users_tags` where json_overlaps(user_tags->'$', '[2, 3, 10]');
+ ```
+
+> **说明**:上面的查询用到了`member of`谓词和两个 JSON 函数,`json_contains`可以检查 JSON 数组是否包含了指定的元素,而`json_overlaps`可以检查 JSON 数组是否与指定的数组有重叠部分。
+
+#### 窗口函数
MySQL 从8.0开始支持窗口函数,大多数商业数据库和一些开源数据库早已提供了对窗口函数的支持,有的也将其称之为 OLAP(联机分析和处理)函数,听名字就知道跟统计和分析相关。为了帮助大家理解窗口函数,我们先说说窗口的概念。
@@ -1541,18 +1380,18 @@ where (
1. 实体完整性 - 每个实体都是独一无二的
- - 主键(primary key) / 唯一约束 / 唯一索引(unique)
+ - 主键(`primary key`) / 唯一约束(`unique`)
2. 引用完整性(参照完整性)- 关系中不允许引用不存在的实体
- - 外键(foreign key)
+ - 外键(`foreign key`)
3. 域(domain)完整性 - 数据是有效的
- 数据类型及长度
- - 非空约束(not null)
+ - 非空约束(`not null`)
- - 默认值约束(default)
+ - 默认值约束(`default`)
- - 检查约束(check)
+ - 检查约束(`check`)
> **说明**:在 MySQL 8.x 以前,检查约束并不起作用。
@@ -1586,183 +1425,44 @@ where (
rollback
```
+4. 查看事务隔离级别
+
+ ```SQL
+ show variables like 'transaction_isolation';
+ ```
+
+ ```
+ +-----------------------+-----------------+
+ | Variable_name | Value |
+ +-----------------------+-----------------+
+ | transaction_isolation | REPEATABLE-READ |
+ +-----------------------+-----------------+
+ ```
+
+ 可以看出,MySQL 默认的事务隔离级别是`REPEATABLE-READ`。
+
+5. 修改(当前会话)事务隔离级别
+
+ ```SQL
+ set session transaction isolation level read committed;
+ ```
+
+ 重新查看事务隔离级别,结果如下所示。
+
+ ```
+ +-----------------------+----------------+
+ | Variable_name | Value |
+ +-----------------------+----------------+
+ | transaction_isolation | READ-COMMITTED |
+ +-----------------------+----------------+
+ ```
+
+关系型数据库的事务是一个很大的话题,因为当存在多个并发事务访问数据时,就有可能出现三类读数据的问题(脏读、不可重复读、幻读)和两类更新数据的问题(第一类丢失更新、第二类丢失更新)。想了解这五类问题的,可以阅读我发布在 CSDN 网站上的[《Java面试题全集(上)》](https://blog.csdn.net/jackfrued/article/details/44921941)一文的第80题。为了避免这些问题,关系型数据库底层是有对应的锁机制的,按锁定对象不同可以分为表级锁和行级锁,按并发事务锁定关系可以分为共享锁和独占锁。然而直接使用锁是非常麻烦的,为此数据库为用户提供了自动锁机制,只要用户指定适当的事务隔离级别,数据库就会通过分析 SQL 语句,然后为事务访问的资源加上合适的锁。此外,数据库还会维护这些锁通过各种手段提高系统的性能,这些对用户来说都是透明的。想了解 MySQL 事务和锁的细节知识,推荐大家阅读进阶读物[《高性能MySQL》](https://item.jd.com/11220393.html),这也是数据库方面的经典书籍。
+
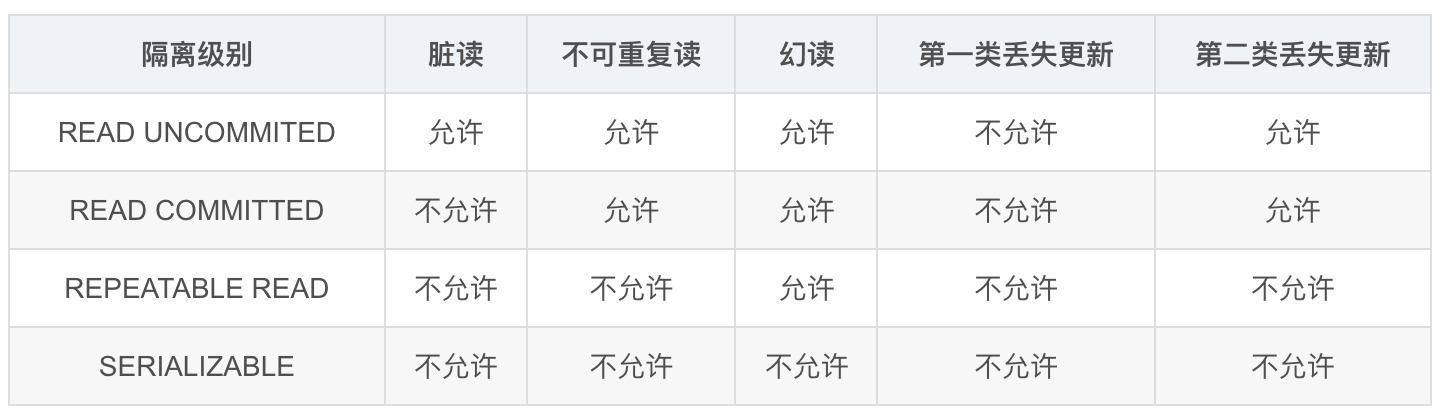
+ANSI/ISO SQL 92标准定义了4个等级的事务隔离级别,如下表所示。需要说明的是,事务隔离级别和数据访问的并发性是对立的,事务隔离级别越高并发性就越差。所以要根据具体的应用来确定到底使用哪种事务隔离级别,这个地方没有万能的原则。
+
+
+
+### MySQL 基本命令
+
+#### 查看命令
+
+1. 查看所有数据库
+
+```SQL
+show databases;
+```
+
+2. 查看所有字符集
+
+```SQL
+show character set;
+```
+
+3. 查看所有的排序规则
+
+```SQL
+show collation;
+```
+
+4. 查看所有的引擎
+
+```SQL
+show engines;
+```
+
+5. 查看所有日志文件
+
+```SQL
+show binary logs;
+```
+
+6. 查看数据库下所有表
+
+```SQL
+show tables;
+```
+
+#### 获取帮助
+
+在 MySQL 命令行工具中,可以使用`help`命令或`?`来获取帮助,如下所示。
+
+1. 查看`show`命令的帮助。
+
+ ```MySQL
+ ? show
+ ```
+
+2. 查看有哪些帮助内容。
+
+ ```MySQL
+ ? contents
+ ```
+
+3. 获取函数的帮助。
+
+ ```MySQL
+ ? functions
+ ```
+
+4. 获取数据类型的帮助。
+
+ ```MySQL
+ ? data types
+ ```
+
+#### 其他命令
+
+1. 新建/重建服务器连接 - `connect` / `resetconnection`。
+
+2. 清空当前输入 - `\c`。在输入错误时,可以及时使用`\c`清空当前输入并重新开始。
+
+3. 修改终止符(定界符)- `delimiter`。默认的终止符是`;`,可以使用该命令修改成其他的字符,例如修改为`$`符号,可以用`delimiter $`命令。
+
+4. 打开系统默认编辑器 - `edit`。编辑完成保存关闭之后,命令行会自动执行编辑的内容。
+
+5. 查看服务器状态 - `status`。
+
+6. 修改默认提示符 - `prompt`。
+
+7. 执行系统命令 - `system`。可以将系统命令跟在`system`命令的后面执行,`system`命令也可以缩写为`\!`。
+
+8. 执行 SQL 文件 - `source`。`source`命令后面跟 SQL 文件路径。
+
+9. 重定向输出 - `tee` / `notee`。可以将命令的输出重定向到指定的文件中。
+
+10. 切换数据库 - `use`。
+
+11. 显示警告信息 - `warnings`。
+
+12. 退出命令行 - `quit`或`exit`。
+
+
+
diff --git a/Day36-40/36-38.关系型数据库MySQL.md b/Day36-40/37.SQL和MySQL详解.md
similarity index 72%
rename from Day36-40/36-38.关系型数据库MySQL.md
rename to Day36-40/37.SQL和MySQL详解.md
index 090b1bf..575b580 100644
--- a/Day36-40/36-38.关系型数据库MySQL.md
+++ b/Day36-40/37.SQL和MySQL详解.md
@@ -1,349 +1,4 @@
-## 关系数据库MySQL
-
-### 关系数据库概述
-
-1. 数据持久化 - 将数据保存到能够长久保存数据的存储介质中,在掉电的情况下数据也不会丢失。
-
-2. 数据库发展史 - 网状数据库、层次数据库、关系数据库、NoSQL 数据库、NewSQL 数据库。
-
- > 1970年,IBM的研究员E.F.Codd在*Communication of the ACM*上发表了名为*A Relational Model of Data for Large Shared Data Banks*的论文,提出了**关系模型**的概念,奠定了关系模型的理论基础。后来Codd又陆续发表多篇文章,论述了范式理论和衡量关系系统的12条标准,用数学理论奠定了关系数据库的基础。
-
-3. 关系数据库特点。
-
- - 理论基础:**关系代数**。
-
- - 具体表象:用**二维表**(有行和列)组织数据。
-
- - 编程语言:**结构化查询语言**(SQL)。
-
-4. ER模型(实体关系模型)和概念模型图。
-
- **ER模型**,全称为**实体关系模型**(Entity-Relationship Model),由美籍华裔计算机科学家陈品山先生提出,是概念数据模型的高层描述方式,如下图所示。
-
-
-
- - 实体 - 矩形框
- - 属性 - 椭圆框
- - 关系 - 菱形框
- - 重数 - 1:1(一对一) / 1:N(一对多) / M:N(多对多)
-
- 实际项目开发中,我们可以利用数据库建模工具(如:PowerDesigner)来绘制概念数据模型(其本质就是 ER 模型),然后再设置好目标数据库系统,将概念模型转换成物理模型,最终生成创建二维表的 SQL(很多工具都可以根据我们设计的物理模型图以及设定的目标数据库来导出 SQL 或直接生成数据表)。
-
- 
-
-5. 关系数据库产品。
- - [Oracle](https://www.oracle.com/index.html) - 目前世界上使用最为广泛的数据库管理系统,作为一个通用的数据库系统,它具有完整的数据管理功能;作为一个关系数据库,它是一个完备关系的产品;作为分布式数据库,它实现了分布式处理的功能。在 Oracle 最新的 12c 版本中,还引入了多承租方架构,使用该架构可轻松部署和管理数据库云。
- - [DB2](https://www.ibm.com/analytics/us/en/db2/) - IBM 公司开发的、主要运行于 Unix(包括 IBM 自家的 [AIX](https://zh.wikipedia.org/wiki/AIX))、Linux、以及 Windows 服务器版等系统的关系数据库产品。DB2 历史悠久且被认为是最早使用 SQL 的数据库产品,它拥有较为强大的商业智能功能。
- - [SQL Server](https://www.microsoft.com/en-us/sql-server/) - 由 Microsoft 开发和推广的关系型数据库产品,最初适用于中小企业的数据管理,但是近年来它的应用范围有所扩展,部分大企业甚至是跨国公司也开始基于它来构建自己的数据管理系统。
- - [MySQL](https://www.mysql.com/) - MySQL 是开放源代码的,任何人都可以在 GPL(General Public License)的许可下下载并根据个性化的需要对其进行修改。MySQL 因为其速度、可靠性和适应性而备受关注。
- - [PostgreSQL]() - 在 BSD 许可证下发行的开放源代码的关系数据库产品。
-
-### MySQL 简介
-
-MySQL 最早是由瑞典的 MySQL AB 公司开发的一个开放源码的关系数据库管理系统,该公司于2008年被昇阳微系统公司(Sun Microsystems)收购。在2009年,甲骨文公司(Oracle)收购昇阳微系统公司,因此 MySQL 目前也是 Oracle 旗下产品。
-
-MySQL 在过去由于性能高、成本低、可靠性好,已经成为最流行的开源数据库,因此被广泛地应用于中小型网站开发。随着 MySQL 的不断成熟,它也逐渐被应用于更多大规模网站和应用,比如维基百科、谷歌(Google)、脸书(Facebook)、淘宝网等网站都使用了 MySQL 来提供数据持久化服务。
-
-甲骨文公司收购后昇阳微系统公司,大幅调涨 MySQL 商业版的售价,且甲骨文公司不再支持另一个自由软件项目 [OpenSolaris ](https://zh.wikipedia.org/wiki/OpenSolaris) 的发展,因此导致自由软件社区对于 Oracle 是否还会持续支持 MySQL 社区版(MySQL 的各个发行版本中唯一免费的版本)有所担忧,MySQL 的创始人麦克尔·维德纽斯以 MySQL 为基础,创建了 [MariaDB](https://zh.wikipedia.org/wiki/MariaDB)(以他女儿的名字命名的数据库)分支。有许多原来使用 MySQL 数据库的公司(例如:维基百科)已经陆续完成了从 MySQL 数据库到 MariaDB 数据库的迁移。
-
-### 安装 MySQL
-
-#### Windows 环境
-
-1. 通过[官方网站](https://www.mysql.com/)提供的[下载链接](https://dev.mysql.com/downloads/windows/installer/8.0.html)下载“MySQL社区版服务器”安装程序,如下图所示,建议大家下载离线安装版的MySQL Installer。
-
-
-
-2. 运行 Installer,按照下面的步骤进行安装。
-
- - 选择自定义安装。
-
-
-
- - 选择需要安装的组件。
-
-
-
- - 如果缺少依赖项,需要先安装依赖项。
-
-
-
- - 准备开始安装。
-
-
-
- - 安装完成。
-
-
-
- - 准备执行配置向导。
-
-
-
-3. 执行安装后的配置向导。
-
- - 配置服务器类型和网络。
-
-
-
- - 配置认证方法(保护密码的方式)。
-
-
-
- - 配置用户和角色。
-
-
-
- - 配置Windows服务名以及是否开机自启。
-
-
-
- - 配置日志。
-
-
-
- - 配置高级选项。
-
-
-
- - 应用配置。
-
-
-
-4. 可以在 Windows 系统的“服务”窗口中启动或停止 MySQL。
-
-
-
-5. 配置 PATH 环境变量,以便在命令行提示符窗口使用 MySQL 客户端工具。
-
- - 打开 Windows 的“系统”窗口并点击“高级系统设置”。
-
-
-
- - 在“系统属性”的“高级”窗口,点击“环境变量”按钮。
-
-
-
- - 修改PATH环境变量,将MySQL安装路径下的`bin`文件夹的路径配置到PATH环境变量中。
-
-
-
- - 配置完成后,可以尝试在“命令提示符”下使用 MySQL 的命令行工具。
-
-
-
-#### Linux 环境
-
-下面以 CentOS 7.x 环境为例,演示如何安装 MySQL 5.7.x,如果需要在其他 Linux 系统下安装其他版本的 MySQL,请读者自行在网络上查找对应的安装教程。
-
-1. 安装 MySQL。
-
- 可以在 [MySQL 官方网站]()下载安装文件。首先在下载页面中选择平台和版本,然后找到对应的下载链接,直接下载包含所有安装文件的归档文件,解归档之后通过包管理工具进行安装。
-
- ```Shell
- wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.26-1.el7.x86_64.rpm-bundle.tar
- tar -xvf mysql-5.7.26-1.el7.x86_64.rpm-bundle.tar
- ```
-
- 如果系统上有 MariaDB 相关的文件,需要先移除 MariaDB 相关的文件。
-
- ```Shell
- yum list installed | grep mariadb | awk '{print $1}' | xargs yum erase -y
- ```
-
- 更新和安装可能用到的底层依赖库。
-
- ```Bash
- yum update
- yum install -y libaio libaio-devel
- ```
-
- 接下来可以按照如下所示的顺序用 RPM(Redhat Package Manager)工具安装 MySQL。
-
- ```Shell
- rpm -ivh mysql-community-common-5.7.26-1.el7.x86_64.rpm
- rpm -ivh mysql-community-libs-5.7.26-1.el7.x86_64.rpm
- rpm -ivh mysql-community-libs-compat-5.7.26-1.el7.x86_64.rpm
- rpm -ivh mysql-community-devel-5.7.26-1.el7.x86_64.rpm
- rpm -ivh mysql-community-client-5.7.26-1.el7.x86_64.rpm
- rpm -ivh mysql-community-server-5.7.26-1.el7.x86_64.rpm
- ```
-
- 可以使用下面的命令查看已经安装的 MySQL 相关的包。
-
- ```Shell
- rpm -qa | grep mysql
- ```
-
-2. 配置 MySQL。
-
- MySQL 的配置文件在`/etc`目录下,名为`my.cnf`,默认的配置文件内容如下所示。
-
- ```Shell
- cat /etc/my.cnf
- ```
-
- ```INI
- # For advice on how to change settings please see
- # http://dev.mysql.com/doc/refman/5.7/en/server-configuration-defaults.html
-
- [mysqld]
- #
- # Remove leading # and set to the amount of RAM for the most important data
- # cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.
- # innodb_buffer_pool_size = 128M
- #
- # Remove leading # to turn on a very important data integrity option: logging
- # changes to the binary log between backups.
- # log_bin
- #
- # Remove leading # to set options mainly useful for reporting servers.
- # The server defaults are faster for transactions and fast SELECTs.
- # Adjust sizes as needed, experiment to find the optimal values.
- # join_buffer_size = 128M
- # sort_buffer_size = 2M
- # read_rnd_buffer_size = 2M
- datadir=/var/lib/mysql
- socket=/var/lib/mysql/mysql.sock
-
- # Disabling symbolic-links is recommended to prevent assorted security risks
- symbolic-links=0
-
- log-error=/var/log/mysqld.log
- pid-file=/var/run/mysqld/mysqld.pid
- ```
-
- 通过配置文件,我们可以修改 MySQL 服务使用的端口、字符集、最大连接数、套接字队列大小、最大数据包大小、日志文件的位置、日志过期时间等配置。当然,我们还可以通过修改配置文件来对 MySQL 服务器进行性能调优和安全管控。
-
-3. 启动 MySQL 服务。
-
- 可以使用下面的命令来启动 MySQL。
-
- ```Shell
- service mysqld start
- ```
-
- 在 CentOS 7 中,更推荐使用下面的命令来启动 MySQL。
-
- ```Shell
- systemctl start mysqld
- ```
-
- 启动 MySQL 成功后,可以通过下面的命令来检查网络端口使用情况,MySQL 默认使用`3306`端口。
-
- ```Shell
- netstat -ntlp | grep mysql
- ```
-
- 也可以使用下面的命令查找是否有名为`mysqld`的进程。
-
- ```Shell
- pgrep mysqld
- ```
-
-4. 使用 MySQL 客户端工具连接服务器。
-
- 命令行工具:
-
- ```Shell
- mysql -u root -p
- ```
-
- > 说明:启动客户端时,`-u`参数用来指定用户名,MySQL 默认的超级管理账号为`root`;`-p`表示要输入密码(用户口令);如果连接的是其他主机而非本机,可以用`-h`来指定连接主机的主机名或IP地址。
-
- 如果是首次安装 MySQL,可以使用下面的命令来找到默认的初始密码。
-
- ```Shell
- cat /var/log/mysqld.log | grep password
- ```
-
- 上面的命令会查看 MySQL 的日志带有`password`的行,在显示的结果中`root@localhost:`后面的部分就是默认设置的初始密码。
-
- 进入客户端工具后,可以通过下面的指令来修改超级管理员(root)的访问口令为`123456`。
-
- ```SQL
- set global validate_password_policy=0;
- set global validate_password_length=6;
- alter user 'root'@'localhost' identified by '123456';
- ```
-
- > **说明**:MySQL 较新的版本默认不允许使用弱口令作为用户口令,所以上面的代码修改了验证用户口令的策略和口令的长度。事实上我们不应该使用弱口令,因为存在用户口令被暴力破解的风险。近年来,**攻击数据库窃取数据和劫持数据库勒索比特币**的事件屡见不鲜,要避免这些潜在的风险,最为重要的一点是**不要让数据库服务器暴露在公网上**(最好的做法是将数据库置于内网,至少要做到不向公网开放数据库服务器的访问端口),另外要保管好`root`账号的口令,应用系统需要访问数据库时,通常不使用`root`账号进行访问,而是**创建其他拥有适当权限的账号来访问**。
-
- 再次使用客户端工具连接 MySQL 服务器时,就可以使用新设置的口令了。在实际开发中,为了方便用户操作,可以选择图形化的客户端工具来连接 MySQL 服务器,包括:
-
- - MySQL Workbench(官方工具)
-
-
-
- - Navicat for MySQL(界面简单友好)
-
-
-
- - SQLyog for MySQL(有社区版和商业版)
-
-### MySQL 常用命令
-
- - 查看所有数据库。
-
- ```SQL
- show databases;
- ```
-
- - 查看所有字符集(编码方式)。
-
- ```SQL
- show character set;
- ```
-
- - 查看所有的校对(排序)规则。
-
- ```SQL
- show collation;
- ```
-
- - 查看所有的引擎。
-
- ```SQL
- show engines;
- ```
-
- - 查看所有日志文件。
-
- ```SQL
- show binary logs;
- ```
-
- - 查看数据库下所有表。
-
- ```SQL
- show tables;
- ```
-
- - 获取帮助。
-
- 1. 查看`show`命令的帮助。
-
- ```MySQL
- ? show
- ```
-
- 2. 查看有哪些帮助内容。
-
- ```MySQL
- ? contents
- ```
-
- 3. 获取函数的帮助。
-
- ```MySQL
- ? functions
- ```
-
- 4. 获取数据类型的帮助。
-
- ```MySQL
- ? data types
- ```
+## SQL 和 MySQL 详解
### SQL 详解
@@ -747,6 +402,8 @@ values
(3755, 9999, '2017-09-01', 92);
```
+> **注意**:上面的`insert`语句使用了批处理的方式来插入数据,这种做法插入数据的效率比较高。
+
#### DQL(数据查询语言)
接下来,我们完成如下所示的查询。
@@ -1148,13 +805,19 @@ revoke insert on `school`.* from 'wangdachui'@'%';
> **说明**:创建一个可以允许任意主机登录并且具有超级管理员权限的用户在现实中并不是一个明智的决定,因为一旦该账号的口令泄露或者被破解,数据库将会面临灾难级的风险。
-### 索引
+### MySQL 详解
-索引是关系型数据库中用来提升查询性能最为重要的手段。关系型数据库中的索引就像一本书的目录,我们可以想象一下,如果要从一本书中找出某个知识点,但是这本书没有目录,这将是意见多么可怕的事情(我们估计得一篇一篇的翻下去,才能确定这个知识点到底在什么位置)。创建索引虽然会带来存储空间上的开销,就像一本书的目录会占用一部分的篇幅一样,但是在牺牲空间后换来的查询时间的减少也是非常显著的。
+#### 索引
-MySQL 中,所有数据类型的列都可以被索引,常用的存储引擎 InnoDB 和 MyISAM 能支持每个表创建16个索引。InnoDB 和 MyISAM 使用的索引其底层算法是 B-tree(B树),B-tree 是一种自平衡的树,类似于平衡二叉排序树,能够保持数据有序。这种数据结构能够让查找数据、顺序访问、插入数据及删除的操作都在对数时间内完成。
+索引是关系型数据库中用来提升查询性能最为重要的手段。关系型数据库中的索引就像一本书的目录,我们可以想象一下,如果要从一本书中找出某个知识点,但是这本书没有目录,这将是意见多么可怕的事情!我们估计得一篇一篇的翻下去,才能确定这个知识点到底在什么位置。创建索引虽然会带来存储空间上的开销,就像一本书的目录会占用一部分篇幅一样,但是在牺牲空间后换来的查询时间的减少也是非常显著的。
-接下来我们通过一个简单的例子来说明索引的意义,比如我们要根据学生的姓名来查找学生,这个场景在实际开发中应该经常遇到,就跟通过商品名称查找商品道理是一样的。我们可以使用 MySQL 的`explain`关键字来查看 SQL 的执行计划。
+MySQL 数据库中所有数据类型的列都可以被索引。对于MySQL 8.0 版本的 InnoDB 存储引擎来说,它支持三种类型的索引,分别是 B+ 树索引、全文索引和 R 树索引。这里,我们只介绍使用得最为广泛的 B+ 树索引。使用 B+ 树的原因非常简单,因为它是目前在基于磁盘进行海量数据存储和排序上最有效率的数据结构。B+ 树是一棵[平衡树](https://zh.wikipedia.org/zh-cn/%E5%B9%B3%E8%A1%A1%E6%A0%91),树的高度通常为3或4,但是却可以保存从百万级到十亿级的数据,而从这些数据里面查询一条数据,只需要3次或4次 I/O 操作。
+
+B+ 树由根节点、中间节点和叶子节点构成,其中叶子节点用来保存排序后的数据。由于记录在索引上是排序过的,因此在一个叶子节点内查找数据时可以使用二分查找,这种查找方式效率非常的高。当数据很少的时候,B+ 树只有一个根节点,数据也就保存在根节点上。随着记录越来越多,B+ 树会发生分裂,根节点不再保存数据,而是提供了访问下一层节点的指针,帮助快速确定数据在哪个叶子节点上。
+
+在创建二维表时,我们通常都会为表指定主键列,主键列上默认会创建索引,而对于 MySQL InnoDB 存储引擎来说,因为它使用的是索引组织表这种数据存储结构,所以主键上的索引就是整张表的数据,而这种索引我们也将其称之为**聚集索引**(clustered index)。很显然,一张表只能有一个聚集索引,否则表的数据岂不是要保存多次。我们自己创建的索引都是二级索引(secondary index),更常见的叫法是**非聚集索引**(non-clustered index)。通过我们自定义的非聚集索引只能定位记录的主键,在获取数据时可能需要再通过主键上的聚集索引进行查询,这种现象称为“回表”,因此通过非聚集索引检索数据通常比使用聚集索引检索数据要慢。
+
+接下来我们通过一个简单的例子来说明索引的意义,比如我们要根据学生的姓名来查找学生,这个场景在实际开发中应该经常遇到,就跟通过商品名称查找商品是一个道理。我们可以使用 MySQL 的`explain`关键字来查看 SQL 的执行计划(数据库执行 SQL 语句的具体步骤)。
```SQL
explain select * from tb_student where stuname='林震南'\G
@@ -1271,6 +934,8 @@ alter table tb_student drop index idx_student_name;
drop index idx_student_name on tb_student;
```
+在创建索引时,我们还可以使用复合索引、函数索引(MySQL 5.7 开始支持),用好复合索引可以减少不必要的排序和回表操作,这样就会让查询的性能成倍的提升,有兴趣的读者可以自行研究。
+
我们简单的为大家总结一下索引的设计原则:
1. **最适合**索引的列是出现在**WHERE子句**和连接子句中的列。
@@ -1281,8 +946,7 @@ drop index idx_student_name on tb_student;
最后,还有一点需要说明,InnoDB 使用的 B-tree 索引,数值类型的列除了等值判断时索引会生效之外,使用`>`、`<`、`>=`、`<=`、`BETWEEN...AND... `、`<>`时,索引仍然生效;对于字符串类型的列,如果使用不以通配符开头的模糊查询,索引也是起作用的,但是其他的情况会导致索引失效,这就意味着很有可能会做全表查询。
-
-### 视图
+#### 视图
视图是关系型数据库中将一组查询指令构成的结果集组合成可查询的数据表的对象。简单的说,视图就是虚拟的表,但与数据表不同的是,数据表是一种实体结构,而视图是一种虚拟结构,你也可以将视图理解为保存在数据库中被赋予名字的 SQL 语句。
@@ -1352,7 +1016,48 @@ drop view vw_student_score;
2. 创建视图时可以使用`order by`子句,但如果从视图中检索数据时也使用了`order by`,那么该视图中原先的`order by`会被覆盖。
3. 视图无法使用索引,也不会激发触发器(实际开发中因为性能等各方面的考虑,通常不建议使用触发器,所以我们也不对这个概念进行介绍)的执行。
-### 过程
+#### 函数
+
+MySQL 中的函数跟 Python 中的函数太多的差异,因为函数都是用来封装功能上相对独立且会被重复使用的代码的。如果非要找出一些差别来,那么 MySQL 中的函数是可以执行 SQL 语句的。下面的例子,我们通过自定义函数实现了截断超长字符串的功能。
+
+```SQL
+delimiter $$
+
+create function truncate_string(
+ content varchar(10000),
+ max_length int unsigned
+) returns varchar(10000) no sql
+begin
+ declare result varchar(10000) default content;
+ if char_length(content) > max_length then
+ set result = left(content, max_length);
+ set result = concat(result, '……');
+ end if;
+ return result;
+end $$
+
+delimiter ;
+```
+
+> **说明1**:函数声明后面的`no sql`是声明函数体并没有使用 SQL 语句;如果函数体中需要通过 SQL 读取数据,需要声明为`reads sql data`。
+>
+> **说明2**:定义函数前后的`delimiter`命令是为了修改定界符,因为函数体中的语句都是用`;`表示结束,如果不重新定义定界符,那么遇到的`;`的时候代码就会被截断执行,显然这不是我们想要的效果。
+
+在查询中调用自定义函数。
+
+```SQL
+select truncate_string('和我在成都的街头走一走,直到所有的灯都熄灭了也不停留', 10) as short_string;
+```
+
+```
++--------------------------------------+
+| short_string |
++--------------------------------------+
+| 和我在成都的街头走一…… |
++--------------------------------------+
+```
+
+#### 过程
过程(又称存储过程)是事先编译好存储在数据库中的一组 SQL 的集合,调用过程可以简化应用程序开发人员的工作,减少与数据库服务器之间的通信,对于提升数据操作的性能也是有帮助的。其实迄今为止,我们使用的 SQL 语句都是针对一个或多个表的单条语句,但在实际开发中经常会遇到某个操作需要多条 SQL 语句才能完成的情况。例如,电商网站在受理用户订单时,需要做以下一系列的处理。
@@ -1407,9 +1112,143 @@ select @a as 最高分, @b as 最低分, @c as 平均分;
drop procedure sp_score_stat;
```
-在过程中,我们可以定义变量、条件,可以使用分支和循环语句,可以通过游标操作查询结果,还可以使用事件调度器,这些内容我们暂时不在此处进行介绍。虽然我们说了很多过程的好处,但是在实际开发中,如果过度的使用过程并将大量复杂的运算放到过程中,必然会导致占用数据库服务器的 CPU 资源,造成数据库服务器承受巨大的压力。为此,我们一般会将复杂的运算和处理交给应用服务器,因为很容易部署多台应用服务器来分摊这些压力。
+在过程中,我们可以定义变量、条件,可以使用分支和循环语句,可以通过游标操作查询结果,还可以使用事件调度器,这些内容我们暂时不在此处进行介绍。虽然我们说了很多过程的好处,但是在实际开发中,如果频繁的使用过程并将大量复杂的运算放到过程中,会给据库服务器造成巨大的压力,而数据库往往都是性能瓶颈所在,使用过程无疑是雪上加霜的操作。所以,对于互联网产品开发,我们一般建议让数据库只做好存储,复杂的运算和处理交给应用服务器上的程序去完成,如果应用服务器变得不堪重负了,我们可以比较容易的部署多台应用服务器来分摊这些压力。
-### MySQL8 窗口函数
+如果大家对上面讲到的视图、函数、过程包括我们没有讲到的触发器这些知识有兴趣,建议大家阅读 MySQL 的入门读物[《MySQL必知必会》](https://item.jd.com/12818982.html)进行一般性了解即可,因为这些知识点在大家将来的工作中未必用得上,学了也可能仅仅是为了应付面试而已。
+
+### MySQL 新特性
+
+#### JSON类型
+
+很多开发者在使用关系型数据库做数据持久化的时候,常常感到结构化的存储缺乏灵活性,因为必须事先设计好所有的列以及对应的数据类型。在业务发展和变化的过程中,如果需要修改表结构,这绝对是比较麻烦和难受的事情。从 MySQL 5.7 版本开始,MySQL引入了对 JSON 数据类型的支持(MySQL 8.0 解决了 JSON 的日志性能瓶颈问题),用好 JSON 类型,其实就是打破了关系型数据库和非关系型数据库之间的界限,为数据持久化操作带来了更多的便捷。
+
+JSON 类型主要分为 JSON 对象和 JSON数组两种,如下所示。
+
+1. JSON 对象
+
+```JSON
+{"name": "骆昊", "tel": "13122335566", "QQ": "957658"}
+```
+
+2. JSON 数组
+
+```JSON
+[1, 2, 3]
+```
+
+```JSON
+[{"name": "骆昊", "tel": "13122335566"}, {"name": "王大锤", "QQ": "123456"}]
+```
+
+哪些地方需要用到JSON类型呢?举一个简单的例子,现在很多产品的用户登录都支持多种方式,例如手机号、微信、QQ、新浪微博等,但是一般情况下我们又不会要求用户提供所有的这些信息,那么用传统的设计方式,就需要设计多个列来对应多种登录方式,可能还需要允许这些列存在空值,这显然不是很好的选择;另一方面,如果产品又增加了一种登录方式,那么就必然要修改之前的表结构,这就更让人痛苦了。但是,有了 JSON 类型,刚才的问题就迎刃而解了,我们可以做出如下所示的设计。
+
+```SQL
+create table `tb_test`
+(
+`user_id` bigint unsigned,
+`login_info` json,
+primary key (`user_id`)
+) engine=innodb;
+
+insert into `tb_test` values
+ (1, '{"tel": "13122335566", "QQ": "654321", "wechat": "jackfrued"}'),
+ (2, '{"tel": "13599876543", "weibo": "wangdachui123"}');
+```
+
+如果要查询用户的手机和微信号,可以用如下所示的 SQL 语句。
+
+```SQL
+select
+ `user_id`,
+ json_unquote(json_extract(`login_info`, '$.tel')) as 手机号,
+ json_unquote(json_extract(`login_info`, '$.wechat')) as 微信
+from `tb_test`;
+```
+
+```
++---------+-------------+-----------+
+| user_id | 手机号 | 微信 |
++---------+-------------+-----------+
+| 1 | 13122335566 | jackfrued |
+| 2 | 13599876543 | NULL |
++---------+-------------+-----------+
+```
+
+因为支持 JSON 类型,MySQL 也提供了配套的处理 JSON 数据的函数,就像上面用到的`json_extract`和`json_unquote`。当然,上面的 SQL 还有更为便捷的写法,如下所示。
+
+```SQL
+select
+ `user_id`,
+ `login_info` ->> '$.tel' as 手机号,
+ `login_info` ->> '$.wechat' as 微信
+from `tb_test`;
+```
+
+再举个例子,如果我们的产品要实现用户画像功能(给用户打标签),然后基于用户画像给用户推荐平台的服务或消费品之类的东西,我们也可以使用 JSON 类型来保存用户画像数据,示意代码如下所示。
+
+创建画像标签表。
+
+```SQL
+create table `tb_tags`
+(
+`tag_id` int unsigned not null comment '标签ID',
+`tag_name` varchar(20) not null comment '标签名',
+primary key (`tag_id`)
+) engine=innodb;
+
+insert into `tb_tags` (`tag_id`, `tag_name`)
+values
+ (1, '70后'),
+ (2, '80后'),
+ (3, '90后'),
+ (4, '00后'),
+ (5, '爱运动'),
+ (6, '高学历'),
+ (7, '小资'),
+ (8, '有房'),
+ (9, '有车'),
+ (10, '爱看电影'),
+ (11, '爱网购'),
+ (12, '常点外卖');
+```
+
+为用户打标签。
+
+```SQL
+create table `tb_users_tags`
+(
+`user_id` bigint unsigned not null comment '用户ID',
+`user_tags` json not null comment '用户标签'
+) engine=innodb;
+
+insert into `tb_users_tags` values
+ (1, '[2, 6, 8, 10]'),
+ (2, '[3, 10, 12]'),
+ (3, '[3, 8, 9, 11]');
+```
+
+接下来,我们通过一组查询来了解 JSON 类型的巧妙之处。
+
+1. 查询爱看电影(有`10`这个标签)的用户ID。
+
+ ```SQL
+ select * from `tb_users` where 10 member of (user_tags->'$');
+ ```
+
+2. 查询爱看电影(有`10`这个标签)的80后(有`2`这个标签)用户ID。
+
+ ```
+ select * from `tb_users` where json_contains(user_tags->'$', '[2, 10]');
+
+3. 查询爱看电影或80后或90后的用户ID。
+
+ ```SQL
+ select `user_id` from `tb_users_tags` where json_overlaps(user_tags->'$', '[2, 3, 10]');
+ ```
+
+> **说明**:上面的查询用到了`member of`谓词和两个 JSON 函数,`json_contains`可以检查 JSON 数组是否包含了指定的元素,而`json_overlaps`可以检查 JSON 数组是否与指定的数组有重叠部分。
+
+#### 窗口函数
MySQL 从8.0开始支持窗口函数,大多数商业数据库和一些开源数据库早已提供了对窗口函数的支持,有的也将其称之为 OLAP(联机分析和处理)函数,听名字就知道跟统计和分析相关。为了帮助大家理解窗口函数,我们先说说窗口的概念。
@@ -1541,18 +1380,18 @@ where (
1. 实体完整性 - 每个实体都是独一无二的
- - 主键(primary key) / 唯一约束 / 唯一索引(unique)
+ - 主键(`primary key`) / 唯一约束(`unique`)
2. 引用完整性(参照完整性)- 关系中不允许引用不存在的实体
- - 外键(foreign key)
+ - 外键(`foreign key`)
3. 域(domain)完整性 - 数据是有效的
- 数据类型及长度
- - 非空约束(not null)
+ - 非空约束(`not null`)
- - 默认值约束(default)
+ - 默认值约束(`default`)
- - 检查约束(check)
+ - 检查约束(`check`)
> **说明**:在 MySQL 8.x 以前,检查约束并不起作用。
@@ -1586,183 +1425,44 @@ where (
rollback
```
+4. 查看事务隔离级别
+
+ ```SQL
+ show variables like 'transaction_isolation';
+ ```
+
+ ```
+ +-----------------------+-----------------+
+ | Variable_name | Value |
+ +-----------------------+-----------------+
+ | transaction_isolation | REPEATABLE-READ |
+ +-----------------------+-----------------+
+ ```
+
+ 可以看出,MySQL 默认的事务隔离级别是`REPEATABLE-READ`。
+
+5. 修改(当前会话)事务隔离级别
+
+ ```SQL
+ set session transaction isolation level read committed;
+ ```
+
+ 重新查看事务隔离级别,结果如下所示。
+
+ ```
+ +-----------------------+----------------+
+ | Variable_name | Value |
+ +-----------------------+----------------+
+ | transaction_isolation | READ-COMMITTED |
+ +-----------------------+----------------+
+ ```
+
+关系型数据库的事务是一个很大的话题,因为当存在多个并发事务访问数据时,就有可能出现三类读数据的问题(脏读、不可重复读、幻读)和两类更新数据的问题(第一类丢失更新、第二类丢失更新)。想了解这五类问题的,可以阅读我发布在 CSDN 网站上的[《Java面试题全集(上)》](https://blog.csdn.net/jackfrued/article/details/44921941)一文的第80题。为了避免这些问题,关系型数据库底层是有对应的锁机制的,按锁定对象不同可以分为表级锁和行级锁,按并发事务锁定关系可以分为共享锁和独占锁。然而直接使用锁是非常麻烦的,为此数据库为用户提供了自动锁机制,只要用户指定适当的事务隔离级别,数据库就会通过分析 SQL 语句,然后为事务访问的资源加上合适的锁。此外,数据库还会维护这些锁通过各种手段提高系统的性能,这些对用户来说都是透明的。想了解 MySQL 事务和锁的细节知识,推荐大家阅读进阶读物[《高性能MySQL》](https://item.jd.com/11220393.html),这也是数据库方面的经典书籍。
+
+ANSI/ISO SQL 92标准定义了4个等级的事务隔离级别,如下表所示。需要说明的是,事务隔离级别和数据访问的并发性是对立的,事务隔离级别越高并发性就越差。所以要根据具体的应用来确定到底使用哪种事务隔离级别,这个地方没有万能的原则。
+
+ +
### 总结
-关于 MySQL 的知识肯定远远不止上面列出的这些,比如 MySQL 的性能优化、管理和维护 MySQL 的相关工具、MySQL 数据的备份和恢复、监控 MySQL、部署高可用架构等问题我们在这里都没有进行讨论。当然,这些内容也都是跟项目开发密切相关的,我们就留到有需要的时候再进行讲解。
-
-### Python数据库编程
-
-在 Python3 中,我们可以使用`mysqlclient`或`pymysql`三方库来实现对 MySQL 数据库的操作,二者的用法完全相同,只是导入的模块名不一样。我们推荐大家使用纯 Python 的三方库`pymysql`,因为它更容易安装成功。下面我们以之前创建的名为`hrs`的数据库为例,为大家演示如何通过 Python 程序操作 MySQL 数据库实现数据持久化操作。
-
-1. 安装 PyMySQL。
-
- ```Shell
- pip install pymysql
- ```
-
-2. 添加一个部门。
-
- ```Python
- import pymysql
-
-
- def main():
- no = int(input('编号: '))
- name = input('名字: ')
- loc = input('所在地: ')
- # 1. 创建数据库连接对象
- con = pymysql.connect(host='localhost', port=3306,
- database='hrs', charset='utf8',
- user='yourname', password='yourpass')
- try:
- # 2. 通过连接对象获取游标
- with con.cursor() as cursor:
- # 3. 通过游标执行SQL并获得执行结果
- result = cursor.execute(
- 'insert into tb_dept values (%s, %s, %s)',
- (no, name, loc)
- )
- if result == 1:
- print('添加成功!')
- # 4. 操作成功提交事务
- con.commit()
- finally:
- # 5. 关闭连接释放资源
- con.close()
-
-
- if __name__ == '__main__':
- main()
- ```
-
-3. 删除一个部门。
-
- ```Python
- import pymysql
-
-
- def main():
- no = int(input('编号: '))
- con = pymysql.connect(host='localhost', port=3306,
- database='hrs', charset='utf8',
- user='yourname', password='yourpass',
- autocommit=True)
- try:
- with con.cursor() as cursor:
- result = cursor.execute(
- 'delete from tb_dept where dno=%s',
- (no, )
- )
- if result == 1:
- print('删除成功!')
- finally:
- con.close()
-
-
- if __name__ == '__main__':
- main()
- ```
-
- > 说明:如果不希望每次 SQL 操作之后手动提交或回滚事务,可以像上面的代码那样,在创建连接的时候多加一个名为`autocommit`的参数并将它的值设置为`True`,表示每次执行 SQL 之后自动提交。如果程序中不需要使用事务环境也不希望手动的提交或回滚就可以这么做。
-
-4. 更新一个部门。
-
- ```Python
- import pymysql
-
-
- def main():
- no = int(input('编号: '))
- name = input('名字: ')
- loc = input('所在地: ')
- con = pymysql.connect(host='localhost', port=3306,
- database='hrs', charset='utf8',
- user='yourname', password='yourpass',
- autocommit=True)
- try:
- with con.cursor() as cursor:
- result = cursor.execute(
- 'update tb_dept set dname=%s, dloc=%s where dno=%s',
- (name, loc, no)
- )
- if result == 1:
- print('更新成功!')
- finally:
- con.close()
-
-
- if __name__ == '__main__':
- main()
- ```
-
-5. 查询所有部门。
-
- ```Python
- import pymysql
- from pymysql.cursors import DictCursor
-
-
- def main():
- con = pymysql.connect(host='localhost', port=3306,
- database='hrs', charset='utf8',
- user='yourname', password='yourpass')
- try:
- with con.cursor(cursor=DictCursor) as cursor:
- cursor.execute('select dno as no, dname as name, dloc as loc from tb_dept')
- results = cursor.fetchall()
- print(results)
- print('编号\t名称\t\t所在地')
- for dept in results:
- print(dept['no'], end='\t')
- print(dept['name'], end='\t')
- print(dept['loc'])
- finally:
- con.close()
-
-
- if __name__ == '__main__':
- main()
- ```
-
-6. 分页查询员工信息。
-
- ```Python
- import pymysql
- from pymysql.cursors import DictCursor
-
-
- class Emp(object):
-
- def __init__(self, no, name, job, sal):
- self.no = no
- self.name = name
- self.job = job
- self.sal = sal
-
- def __str__(self):
- return f'\n编号:{self.no}\n姓名:{self.name}\n职位:{self.job}\n月薪:{self.sal}\n'
-
-
- def main():
- page = int(input('页码: '))
- size = int(input('大小: '))
- con = pymysql.connect(host='localhost', port=3306,
- database='hrs', charset='utf8',
- user='yourname', password='yourpass')
- try:
- with con.cursor() as cursor:
- cursor.execute(
- 'select eno as no, ename as name, job, sal from tb_emp limit %s,%s',
- ((page - 1) * size, size)
- )
- for emp_tuple in cursor.fetchall():
- emp = Emp(*emp_tuple)
- print(emp)
- finally:
- con.close()
-
-
- if __name__ == '__main__':
- main()
- ```
-
+关于 SQL 和 MySQL 的知识肯定远远不止上面列出的这些,比如 SQL 本身的优化、MySQL 性能调优、MySQL 运维相关工具、MySQL 数据的备份和恢复、监控 MySQL 服务、部署高可用架构等,这一系列的问题在这里都没有办法逐一展开来讨论,那就留到有需要的时候再进行讲解吧,各位读者也可以自行探索。
diff --git a/Day36-40/38.Python程序接入MySQL数据库.md b/Day36-40/38.Python程序接入MySQL数据库.md
new file mode 100644
index 0000000..727b31d
--- /dev/null
+++ b/Day36-40/38.Python程序接入MySQL数据库.md
@@ -0,0 +1,295 @@
+## Python程序接入MySQL数据库
+
+在 Python3 中,我们可以使用`mysqlclient`或者`pymysql`三方库来接入 MySQL 数据库并实现数据持久化操作。二者的用法完全相同,只是导入的模块名不一样。我们推荐大家使用纯 Python 的三方库`pymysql`,因为它更容易安装成功。下面我们仍然以之前创建的名为`hrs`的数据库为例,为大家演示如何通过 Python 程序操作 MySQL 数据库实现数据持久化操作。
+
+### 建库建表
+
+```SQL
+-- 创建名为hrs的数据库并指定默认的字符集
+create database `hrs` default character set utf8mb4;
+
+-- 切换到hrs数据库
+use `hrs`;
+
+-- 创建部门表
+create table `tb_dept`
+(
+`dno` int not null comment '编号',
+`dname` varchar(10) not null comment '名称',
+`dloc` varchar(20) not null comment '所在地',
+primary key (`dno`)
+);
+
+-- 插入4个部门
+insert into `tb_dept` values
+ (10, '会计部', '北京'),
+ (20, '研发部', '成都'),
+ (30, '销售部', '重庆'),
+ (40, '运维部', '深圳');
+
+-- 创建员工表
+create table `tb_emp`
+(
+`eno` int not null comment '员工编号',
+`ename` varchar(20) not null comment '员工姓名',
+`job` varchar(20) not null comment '员工职位',
+`mgr` int comment '主管编号',
+`sal` int not null comment '员工月薪',
+`comm` int comment '每月补贴',
+`dno` int not null comment '所在部门编号',
+primary key (`eno`),
+constraint `fk_emp_mgr` foreign key (`mgr`) references tb_emp (`eno`),
+constraint `fk_emp_dno` foreign key (`dno`) references tb_dept (`dno`)
+);
+
+-- 插入14个员工
+insert into `tb_emp` values
+ (7800, '张三丰', '总裁', null, 9000, 1200, 20),
+ (2056, '乔峰', '分析师', 7800, 5000, 1500, 20),
+ (3088, '李莫愁', '设计师', 2056, 3500, 800, 20),
+ (3211, '张无忌', '程序员', 2056, 3200, null, 20),
+ (3233, '丘处机', '程序员', 2056, 3400, null, 20),
+ (3251, '张翠山', '程序员', 2056, 4000, null, 20),
+ (5566, '宋远桥', '会计师', 7800, 4000, 1000, 10),
+ (5234, '郭靖', '出纳', 5566, 2000, null, 10),
+ (3344, '黄蓉', '销售主管', 7800, 3000, 800, 30),
+ (1359, '胡一刀', '销售员', 3344, 1800, 200, 30),
+ (4466, '苗人凤', '销售员', 3344, 2500, null, 30),
+ (3244, '欧阳锋', '程序员', 3088, 3200, null, 20),
+ (3577, '杨过', '会计', 5566, 2200, null, 10),
+ (3588, '朱九真', '会计', 5566, 2500, null, 10);
+```
+
+### 接入MySQL
+
+首先,我们可以在命令行或者 PyCharm 的终端中通过下面的命令安装`pymysql`,如果需要接入 MySQL 8,还需要安装一个名为`cryptography`的三方库来支持 MySQL 8 的密码认证方式。
+
+```Shell
+pip install pymysql cryptography
+```
+
+使用`pymysql`操作 MySQL 的步骤如下所示:
+
+1. 创建连接。MySQL 服务器启动后,提供了基于 TCP (传输控制协议)的网络服务。我们可以通过`pymysql`模块的`connect`函数连接 MySQL 服务器。在调用`connect`函数时,需要指定主机(`host`)、端口(`port`)、用户名(`user`)、口令(`password`)、数据库(`database`)、字符集(`charset`)等参数,该函数会返回一个`Connection`对象。
+2. 获取游标。连接 MySQL 服务器成功后,接下来要做的就是向数据库服务器发送 SQL 语句,MySQL 会执行接收到的 SQL 并将执行结果通过网络返回。要实现这项操作,需要先通过连接对象的`cursor`方法获取游标(`Cursor`)对象。
+3. 发出 SQL。通过游标对象的`execute`方法,我们可以向数据库发出 SQL 语句。
+4. 如果执行`insert`、`delete`或`update`操作,需要根据实际情况提交或回滚事务。因为创建连接时,默认开启了事务环境,在操作完成后,需要使用连接对象的`commit`或`rollback`方法,实现事务的提交或回滚,`rollback`方法通常会放在异常捕获代码块`except`中。如果执行`select`操作,需要通过游标对象抓取查询的结果,对应的方法有三个,分别是:`fetchone`、`fetchmany`和`fetchall`。其中`fetchone`方法会抓取到一条记录,并以元组或字典的方式返回;`fetchmany`和`fetchall`方法会抓取到多条记录,以嵌套元组或列表装字典的方式返回。
+5. 关闭连接。在完成持久化操作后,请不要忘记关闭连接,释放外部资源。我们通常会在`finally`代码块中使用连接对象的`close`方法来关闭连接。
+
+### 代码实操
+
+下面,我们通过代码实操的方式为大家演示上面说的五个步骤。
+
+#### 插入数据
+
+```Python
+import pymysql
+
+no = int(input('部门编号: '))
+name = input('部门名称: ')
+location = input('部门所在地: ')
+
+# 1. 创建连接(Connection)
+conn = pymysql.connect(host='127.0.0.1', port=3306,
+ user='guest', password='Guest.618',
+ database='hrs', charset='utf8mb4')
+try:
+ # 2. 获取游标对象(Cursor)
+ with conn.cursor() as cursor:
+ # 3. 通过游标对象向数据库服务器发出SQL语句
+ affected_rows = cursor.execute(
+ 'insert into `tb_dept` values (%s, %s, %s)',
+ (no, name, location)
+ )
+ if affected_rows == 1:
+ print('新增部门成功!!!')
+ # 4. 提交事务(transaction)
+ conn.commit()
+except pymysql.MySQLError as err:
+ # 4. 回滚事务
+ conn.rollback()
+ print(type(err), err)
+finally:
+ # 5. 关闭连接释放资源
+ conn.close()
+```
+
+> **说明**:上面的`127.0.0.1`称为回环地址,它代表的是本机。下面的`guest`是我提前创建好的用户,该用户拥有对`hrs`数据库的`insert`、`delete`、`update`和`select`权限。我们不建议大家在项目中直接使用`root`超级管理员账号访问数据库,这样做实在是太危险了。我们可以使用下面的命令创建名为`guest`的用户并为其授权。
+>
+> ```SQL
+> create user 'guest'@'%' identified by 'Guest.618';
+> grant insert, delete, update, select on `hrs`.* to 'guest'@'%';
+> ```
+
+如果要插入大量数据,建议使用游标对象的`executemany`方法做批处理(一个`insert`操作后面跟上多组数据),大家可以尝试向一张表插入10000条记录,然后看看不使用批处理一条条的插入和使用批处理有什么差别。游标对象的`executemany`方法第一个参数仍然是 SQL 语句,第二个参数可以是包含多组数据的列表或元组。
+
+#### 删除数据
+
+```Python
+import pymysql
+
+no = int(input('部门编号: '))
+
+# 1. 创建连接(Connection)
+conn = pymysql.connect(host='127.0.0.1', port=3306,
+ user='guest', password='Guest.618',
+ database='hrs', charset='utf8mb4',
+ autocommit=True)
+try:
+ # 2. 获取游标对象(Cursor)
+ with conn.cursor() as cursor:
+ # 3. 通过游标对象向数据库服务器发出SQL语句
+ affected_rows = cursor.execute(
+ 'delete from `tb_dept` where `dno`=%s',
+ (no, )
+ )
+ if affected_rows == 1:
+ print('删除部门成功!!!')
+finally:
+ # 5. 关闭连接释放资源
+ conn.close()
+```
+
+> **说明**:如果不希望每次 SQL 操作之后手动提交或回滚事务,可以`connect`函数中加一个名为`autocommit`的参数并将它的值设置为`True`,表示每次执行 SQL 成功后自动提交。但是我们建议大家手动提交或回滚,这样可以根据实际业务需要来构造事务环境。如果不愿意捕获异常并进行处理,可以在`try`代码块后直接跟`finally`块,省略`except`意味着发生异常时,代码会直接崩溃并将异常栈显示在终端中。
+
+#### 更新数据
+
+```Python
+import pymysql
+
+no = int(input('部门编号: '))
+name = input('部门名称: ')
+location = input('部门所在地: ')
+
+# 1. 创建连接(Connection)
+conn = pymysql.connect(host='127.0.0.1', port=3306,
+ user='guest', password='Guest.618',
+ database='hrs', charset='utf8mb4')
+try:
+ # 2. 获取游标对象(Cursor)
+ with conn.cursor() as cursor:
+ # 3. 通过游标对象向数据库服务器发出SQL语句
+ affected_rows = cursor.execute(
+ 'update `tb_dept` set `dname`=%s, `dloc`=%s where `dno`=%s',
+ (name, location, no)
+ )
+ if affected_rows == 1:
+ print('更新部门信息成功!!!')
+ # 4. 提交事务
+ conn.commit()
+except pymysql.MySQLError as err:
+ # 4. 回滚事务
+ conn.rollback()
+ print(type(err), err)
+finally:
+ # 5. 关闭连接释放资源
+ conn.close()
+```
+
+#### 查询数据
+
+1. 查询部门表的数据。
+
+```Python
+import pymysql
+
+# 1. 创建连接(Connection)
+conn = pymysql.connect(host='127.0.0.1', port=3306,
+ user='guest', password='Guest.618',
+ database='hrs', charset='utf8mb4')
+try:
+ # 2. 获取游标对象(Cursor)
+ with conn.cursor() as cursor:
+ # 3. 通过游标对象向数据库服务器发出SQL语句
+ cursor.execute('select `dno`, `dname`, `dloc` from `tb_dept`')
+ # 4. 通过游标对象抓取数据
+ row = cursor.fetchone()
+ while row:
+ print(row)
+ row = cursor.fetchone()
+except pymysql.MySQLError as err:
+ print(type(err), err)
+finally:
+ # 5. 关闭连接释放资源
+ conn.close()
+```
+>**说明**:上面的代码中,我们通过构造一个`while`循环实现了逐行抓取查询结果的操作。这种方式特别适合查询结果有非常多行的场景。因为如果使用`fetchall`一次性将所有记录抓取到一个嵌套元组中,会造成非常大的内存开销,这在很多场景下并不是一个好主意。如果不愿意使用`while`循环,还可以考虑使用`iter`函数构造一个迭代器来逐行抓取数据,有兴趣的读者可以自行研究。
+
+2. 分页查询员工表的数据。
+
+```Python
+import pymysql
+
+page = int(input('页码: '))
+size = int(input('大小: '))
+
+# 1. 创建连接(Connection)
+con = pymysql.connect(host='127.0.0.1', port=3306,
+ user='guest', password='Guest.618',
+ database='hrs', charset='utf8')
+try:
+ # 2. 获取游标对象(Cursor)
+ with con.cursor(pymysql.cursors.DictCursor) as cursor:
+ # 3. 通过游标对象向数据库服务器发出SQL语句
+ cursor.execute(
+ 'select `eno`, `ename`, `job`, `sal` from `tb_emp` order by `sal` desc limit %s,%s',
+ ((page - 1) * size, size)
+ )
+ # 4. 通过游标对象抓取数据
+ for emp_dict in cursor.fetchall():
+ print(emp_dict)
+finally:
+ # 5. 关闭连接释放资源
+ con.close()
+```
+
+### 案例讲解
+
+下面我们为大家讲解一个将数据库表数据导出到 Excel 文件的例子,我们需要先安装`openpyxl`三方库,命令如下所示。
+
+```Bash
+pip install openpyxl
+```
+
+接下来,我们通过下面的代码实现了将数据库`hrs`中所有员工的编号、姓名、职位、月薪、补贴和部门名称导出到一个 Excel 文件中。
+
+```Python
+import openpyxl
+import pymysql
+
+# 创建工作簿对象
+workbook = openpyxl.Workbook()
+# 获得默认的工作表
+sheet = workbook.active
+# 修改工作表的标题
+sheet.title = '员工基本信息'
+# 给工作表添加表头
+sheet.append(('工号', '姓名', '职位', '月薪', '补贴', '部门'))
+# 创建连接(Connection)
+conn = pymysql.connect(host='127.0.0.1', port=3306,
+ user='guest', password='Guest.618',
+ database='hrs', charset='utf8mb4')
+try:
+ # 获取游标对象(Cursor)
+ with conn.cursor() as cursor:
+ # 通过游标对象执行SQL语句
+ cursor.execute(
+ 'select `eno`, `ename`, `job`, `sal`, coalesce(`comm`, 0), `dname` '
+ 'from `tb_emp` natural join `tb_dept`'
+ )
+ # 通过游标抓取数据
+ row = cursor.fetchone()
+ while row:
+ # 将数据逐行写入工作表中
+ sheet.append(row)
+ row = cursor.fetchone()
+ # 保存工作簿
+ workbook.save('hrs.xlsx')
+except pymysql.MySQLError as err:
+ print(err)
+finally:
+ # 关闭连接释放资源
+ conn.close()
+```
+
+大家可以参考上面的例子,试一试把 Excel 文件的数据导入到指定数据库的指定表中,看看是否可以成功。
\ No newline at end of file
diff --git a/README.md b/README.md
index c4c0605..2e2a3bc 100644
--- a/README.md
+++ b/README.md
@@ -199,7 +199,7 @@ Python在以下领域都有用武之地。
### Day36~40 - [数据库基础和进阶](./Day36-40)
-- [关系型数据库MySQL](./Day36-40/36-38.关系型数据库MySQL.md)
+- [关系型数据库MySQL](./Day36-40/36.关系型数据库和MySQL概述.md)
- 关系型数据库概述
- MySQL的安装和使用
- SQL的使用
diff --git a/更新日志.md b/更新日志.md
index 1e92978..95c69c1 100644
--- a/更新日志.md
+++ b/更新日志.md
@@ -1,5 +1,11 @@
## 更新日志
+### 2021年11月22日
+
+1. 更新了数据库部分的文档和代码。
+2. 修正了网友们指出的文档和代码中的bug。
+3. 更新了README文件中的群信息。
+
### 2021年10月7日
1. 调整了项目目录结构。
+
### 总结
-关于 MySQL 的知识肯定远远不止上面列出的这些,比如 MySQL 的性能优化、管理和维护 MySQL 的相关工具、MySQL 数据的备份和恢复、监控 MySQL、部署高可用架构等问题我们在这里都没有进行讨论。当然,这些内容也都是跟项目开发密切相关的,我们就留到有需要的时候再进行讲解。
-
-### Python数据库编程
-
-在 Python3 中,我们可以使用`mysqlclient`或`pymysql`三方库来实现对 MySQL 数据库的操作,二者的用法完全相同,只是导入的模块名不一样。我们推荐大家使用纯 Python 的三方库`pymysql`,因为它更容易安装成功。下面我们以之前创建的名为`hrs`的数据库为例,为大家演示如何通过 Python 程序操作 MySQL 数据库实现数据持久化操作。
-
-1. 安装 PyMySQL。
-
- ```Shell
- pip install pymysql
- ```
-
-2. 添加一个部门。
-
- ```Python
- import pymysql
-
-
- def main():
- no = int(input('编号: '))
- name = input('名字: ')
- loc = input('所在地: ')
- # 1. 创建数据库连接对象
- con = pymysql.connect(host='localhost', port=3306,
- database='hrs', charset='utf8',
- user='yourname', password='yourpass')
- try:
- # 2. 通过连接对象获取游标
- with con.cursor() as cursor:
- # 3. 通过游标执行SQL并获得执行结果
- result = cursor.execute(
- 'insert into tb_dept values (%s, %s, %s)',
- (no, name, loc)
- )
- if result == 1:
- print('添加成功!')
- # 4. 操作成功提交事务
- con.commit()
- finally:
- # 5. 关闭连接释放资源
- con.close()
-
-
- if __name__ == '__main__':
- main()
- ```
-
-3. 删除一个部门。
-
- ```Python
- import pymysql
-
-
- def main():
- no = int(input('编号: '))
- con = pymysql.connect(host='localhost', port=3306,
- database='hrs', charset='utf8',
- user='yourname', password='yourpass',
- autocommit=True)
- try:
- with con.cursor() as cursor:
- result = cursor.execute(
- 'delete from tb_dept where dno=%s',
- (no, )
- )
- if result == 1:
- print('删除成功!')
- finally:
- con.close()
-
-
- if __name__ == '__main__':
- main()
- ```
-
- > 说明:如果不希望每次 SQL 操作之后手动提交或回滚事务,可以像上面的代码那样,在创建连接的时候多加一个名为`autocommit`的参数并将它的值设置为`True`,表示每次执行 SQL 之后自动提交。如果程序中不需要使用事务环境也不希望手动的提交或回滚就可以这么做。
-
-4. 更新一个部门。
-
- ```Python
- import pymysql
-
-
- def main():
- no = int(input('编号: '))
- name = input('名字: ')
- loc = input('所在地: ')
- con = pymysql.connect(host='localhost', port=3306,
- database='hrs', charset='utf8',
- user='yourname', password='yourpass',
- autocommit=True)
- try:
- with con.cursor() as cursor:
- result = cursor.execute(
- 'update tb_dept set dname=%s, dloc=%s where dno=%s',
- (name, loc, no)
- )
- if result == 1:
- print('更新成功!')
- finally:
- con.close()
-
-
- if __name__ == '__main__':
- main()
- ```
-
-5. 查询所有部门。
-
- ```Python
- import pymysql
- from pymysql.cursors import DictCursor
-
-
- def main():
- con = pymysql.connect(host='localhost', port=3306,
- database='hrs', charset='utf8',
- user='yourname', password='yourpass')
- try:
- with con.cursor(cursor=DictCursor) as cursor:
- cursor.execute('select dno as no, dname as name, dloc as loc from tb_dept')
- results = cursor.fetchall()
- print(results)
- print('编号\t名称\t\t所在地')
- for dept in results:
- print(dept['no'], end='\t')
- print(dept['name'], end='\t')
- print(dept['loc'])
- finally:
- con.close()
-
-
- if __name__ == '__main__':
- main()
- ```
-
-6. 分页查询员工信息。
-
- ```Python
- import pymysql
- from pymysql.cursors import DictCursor
-
-
- class Emp(object):
-
- def __init__(self, no, name, job, sal):
- self.no = no
- self.name = name
- self.job = job
- self.sal = sal
-
- def __str__(self):
- return f'\n编号:{self.no}\n姓名:{self.name}\n职位:{self.job}\n月薪:{self.sal}\n'
-
-
- def main():
- page = int(input('页码: '))
- size = int(input('大小: '))
- con = pymysql.connect(host='localhost', port=3306,
- database='hrs', charset='utf8',
- user='yourname', password='yourpass')
- try:
- with con.cursor() as cursor:
- cursor.execute(
- 'select eno as no, ename as name, job, sal from tb_emp limit %s,%s',
- ((page - 1) * size, size)
- )
- for emp_tuple in cursor.fetchall():
- emp = Emp(*emp_tuple)
- print(emp)
- finally:
- con.close()
-
-
- if __name__ == '__main__':
- main()
- ```
-
+关于 SQL 和 MySQL 的知识肯定远远不止上面列出的这些,比如 SQL 本身的优化、MySQL 性能调优、MySQL 运维相关工具、MySQL 数据的备份和恢复、监控 MySQL 服务、部署高可用架构等,这一系列的问题在这里都没有办法逐一展开来讨论,那就留到有需要的时候再进行讲解吧,各位读者也可以自行探索。
diff --git a/Day36-40/38.Python程序接入MySQL数据库.md b/Day36-40/38.Python程序接入MySQL数据库.md
new file mode 100644
index 0000000..727b31d
--- /dev/null
+++ b/Day36-40/38.Python程序接入MySQL数据库.md
@@ -0,0 +1,295 @@
+## Python程序接入MySQL数据库
+
+在 Python3 中,我们可以使用`mysqlclient`或者`pymysql`三方库来接入 MySQL 数据库并实现数据持久化操作。二者的用法完全相同,只是导入的模块名不一样。我们推荐大家使用纯 Python 的三方库`pymysql`,因为它更容易安装成功。下面我们仍然以之前创建的名为`hrs`的数据库为例,为大家演示如何通过 Python 程序操作 MySQL 数据库实现数据持久化操作。
+
+### 建库建表
+
+```SQL
+-- 创建名为hrs的数据库并指定默认的字符集
+create database `hrs` default character set utf8mb4;
+
+-- 切换到hrs数据库
+use `hrs`;
+
+-- 创建部门表
+create table `tb_dept`
+(
+`dno` int not null comment '编号',
+`dname` varchar(10) not null comment '名称',
+`dloc` varchar(20) not null comment '所在地',
+primary key (`dno`)
+);
+
+-- 插入4个部门
+insert into `tb_dept` values
+ (10, '会计部', '北京'),
+ (20, '研发部', '成都'),
+ (30, '销售部', '重庆'),
+ (40, '运维部', '深圳');
+
+-- 创建员工表
+create table `tb_emp`
+(
+`eno` int not null comment '员工编号',
+`ename` varchar(20) not null comment '员工姓名',
+`job` varchar(20) not null comment '员工职位',
+`mgr` int comment '主管编号',
+`sal` int not null comment '员工月薪',
+`comm` int comment '每月补贴',
+`dno` int not null comment '所在部门编号',
+primary key (`eno`),
+constraint `fk_emp_mgr` foreign key (`mgr`) references tb_emp (`eno`),
+constraint `fk_emp_dno` foreign key (`dno`) references tb_dept (`dno`)
+);
+
+-- 插入14个员工
+insert into `tb_emp` values
+ (7800, '张三丰', '总裁', null, 9000, 1200, 20),
+ (2056, '乔峰', '分析师', 7800, 5000, 1500, 20),
+ (3088, '李莫愁', '设计师', 2056, 3500, 800, 20),
+ (3211, '张无忌', '程序员', 2056, 3200, null, 20),
+ (3233, '丘处机', '程序员', 2056, 3400, null, 20),
+ (3251, '张翠山', '程序员', 2056, 4000, null, 20),
+ (5566, '宋远桥', '会计师', 7800, 4000, 1000, 10),
+ (5234, '郭靖', '出纳', 5566, 2000, null, 10),
+ (3344, '黄蓉', '销售主管', 7800, 3000, 800, 30),
+ (1359, '胡一刀', '销售员', 3344, 1800, 200, 30),
+ (4466, '苗人凤', '销售员', 3344, 2500, null, 30),
+ (3244, '欧阳锋', '程序员', 3088, 3200, null, 20),
+ (3577, '杨过', '会计', 5566, 2200, null, 10),
+ (3588, '朱九真', '会计', 5566, 2500, null, 10);
+```
+
+### 接入MySQL
+
+首先,我们可以在命令行或者 PyCharm 的终端中通过下面的命令安装`pymysql`,如果需要接入 MySQL 8,还需要安装一个名为`cryptography`的三方库来支持 MySQL 8 的密码认证方式。
+
+```Shell
+pip install pymysql cryptography
+```
+
+使用`pymysql`操作 MySQL 的步骤如下所示:
+
+1. 创建连接。MySQL 服务器启动后,提供了基于 TCP (传输控制协议)的网络服务。我们可以通过`pymysql`模块的`connect`函数连接 MySQL 服务器。在调用`connect`函数时,需要指定主机(`host`)、端口(`port`)、用户名(`user`)、口令(`password`)、数据库(`database`)、字符集(`charset`)等参数,该函数会返回一个`Connection`对象。
+2. 获取游标。连接 MySQL 服务器成功后,接下来要做的就是向数据库服务器发送 SQL 语句,MySQL 会执行接收到的 SQL 并将执行结果通过网络返回。要实现这项操作,需要先通过连接对象的`cursor`方法获取游标(`Cursor`)对象。
+3. 发出 SQL。通过游标对象的`execute`方法,我们可以向数据库发出 SQL 语句。
+4. 如果执行`insert`、`delete`或`update`操作,需要根据实际情况提交或回滚事务。因为创建连接时,默认开启了事务环境,在操作完成后,需要使用连接对象的`commit`或`rollback`方法,实现事务的提交或回滚,`rollback`方法通常会放在异常捕获代码块`except`中。如果执行`select`操作,需要通过游标对象抓取查询的结果,对应的方法有三个,分别是:`fetchone`、`fetchmany`和`fetchall`。其中`fetchone`方法会抓取到一条记录,并以元组或字典的方式返回;`fetchmany`和`fetchall`方法会抓取到多条记录,以嵌套元组或列表装字典的方式返回。
+5. 关闭连接。在完成持久化操作后,请不要忘记关闭连接,释放外部资源。我们通常会在`finally`代码块中使用连接对象的`close`方法来关闭连接。
+
+### 代码实操
+
+下面,我们通过代码实操的方式为大家演示上面说的五个步骤。
+
+#### 插入数据
+
+```Python
+import pymysql
+
+no = int(input('部门编号: '))
+name = input('部门名称: ')
+location = input('部门所在地: ')
+
+# 1. 创建连接(Connection)
+conn = pymysql.connect(host='127.0.0.1', port=3306,
+ user='guest', password='Guest.618',
+ database='hrs', charset='utf8mb4')
+try:
+ # 2. 获取游标对象(Cursor)
+ with conn.cursor() as cursor:
+ # 3. 通过游标对象向数据库服务器发出SQL语句
+ affected_rows = cursor.execute(
+ 'insert into `tb_dept` values (%s, %s, %s)',
+ (no, name, location)
+ )
+ if affected_rows == 1:
+ print('新增部门成功!!!')
+ # 4. 提交事务(transaction)
+ conn.commit()
+except pymysql.MySQLError as err:
+ # 4. 回滚事务
+ conn.rollback()
+ print(type(err), err)
+finally:
+ # 5. 关闭连接释放资源
+ conn.close()
+```
+
+> **说明**:上面的`127.0.0.1`称为回环地址,它代表的是本机。下面的`guest`是我提前创建好的用户,该用户拥有对`hrs`数据库的`insert`、`delete`、`update`和`select`权限。我们不建议大家在项目中直接使用`root`超级管理员账号访问数据库,这样做实在是太危险了。我们可以使用下面的命令创建名为`guest`的用户并为其授权。
+>
+> ```SQL
+> create user 'guest'@'%' identified by 'Guest.618';
+> grant insert, delete, update, select on `hrs`.* to 'guest'@'%';
+> ```
+
+如果要插入大量数据,建议使用游标对象的`executemany`方法做批处理(一个`insert`操作后面跟上多组数据),大家可以尝试向一张表插入10000条记录,然后看看不使用批处理一条条的插入和使用批处理有什么差别。游标对象的`executemany`方法第一个参数仍然是 SQL 语句,第二个参数可以是包含多组数据的列表或元组。
+
+#### 删除数据
+
+```Python
+import pymysql
+
+no = int(input('部门编号: '))
+
+# 1. 创建连接(Connection)
+conn = pymysql.connect(host='127.0.0.1', port=3306,
+ user='guest', password='Guest.618',
+ database='hrs', charset='utf8mb4',
+ autocommit=True)
+try:
+ # 2. 获取游标对象(Cursor)
+ with conn.cursor() as cursor:
+ # 3. 通过游标对象向数据库服务器发出SQL语句
+ affected_rows = cursor.execute(
+ 'delete from `tb_dept` where `dno`=%s',
+ (no, )
+ )
+ if affected_rows == 1:
+ print('删除部门成功!!!')
+finally:
+ # 5. 关闭连接释放资源
+ conn.close()
+```
+
+> **说明**:如果不希望每次 SQL 操作之后手动提交或回滚事务,可以`connect`函数中加一个名为`autocommit`的参数并将它的值设置为`True`,表示每次执行 SQL 成功后自动提交。但是我们建议大家手动提交或回滚,这样可以根据实际业务需要来构造事务环境。如果不愿意捕获异常并进行处理,可以在`try`代码块后直接跟`finally`块,省略`except`意味着发生异常时,代码会直接崩溃并将异常栈显示在终端中。
+
+#### 更新数据
+
+```Python
+import pymysql
+
+no = int(input('部门编号: '))
+name = input('部门名称: ')
+location = input('部门所在地: ')
+
+# 1. 创建连接(Connection)
+conn = pymysql.connect(host='127.0.0.1', port=3306,
+ user='guest', password='Guest.618',
+ database='hrs', charset='utf8mb4')
+try:
+ # 2. 获取游标对象(Cursor)
+ with conn.cursor() as cursor:
+ # 3. 通过游标对象向数据库服务器发出SQL语句
+ affected_rows = cursor.execute(
+ 'update `tb_dept` set `dname`=%s, `dloc`=%s where `dno`=%s',
+ (name, location, no)
+ )
+ if affected_rows == 1:
+ print('更新部门信息成功!!!')
+ # 4. 提交事务
+ conn.commit()
+except pymysql.MySQLError as err:
+ # 4. 回滚事务
+ conn.rollback()
+ print(type(err), err)
+finally:
+ # 5. 关闭连接释放资源
+ conn.close()
+```
+
+#### 查询数据
+
+1. 查询部门表的数据。
+
+```Python
+import pymysql
+
+# 1. 创建连接(Connection)
+conn = pymysql.connect(host='127.0.0.1', port=3306,
+ user='guest', password='Guest.618',
+ database='hrs', charset='utf8mb4')
+try:
+ # 2. 获取游标对象(Cursor)
+ with conn.cursor() as cursor:
+ # 3. 通过游标对象向数据库服务器发出SQL语句
+ cursor.execute('select `dno`, `dname`, `dloc` from `tb_dept`')
+ # 4. 通过游标对象抓取数据
+ row = cursor.fetchone()
+ while row:
+ print(row)
+ row = cursor.fetchone()
+except pymysql.MySQLError as err:
+ print(type(err), err)
+finally:
+ # 5. 关闭连接释放资源
+ conn.close()
+```
+>**说明**:上面的代码中,我们通过构造一个`while`循环实现了逐行抓取查询结果的操作。这种方式特别适合查询结果有非常多行的场景。因为如果使用`fetchall`一次性将所有记录抓取到一个嵌套元组中,会造成非常大的内存开销,这在很多场景下并不是一个好主意。如果不愿意使用`while`循环,还可以考虑使用`iter`函数构造一个迭代器来逐行抓取数据,有兴趣的读者可以自行研究。
+
+2. 分页查询员工表的数据。
+
+```Python
+import pymysql
+
+page = int(input('页码: '))
+size = int(input('大小: '))
+
+# 1. 创建连接(Connection)
+con = pymysql.connect(host='127.0.0.1', port=3306,
+ user='guest', password='Guest.618',
+ database='hrs', charset='utf8')
+try:
+ # 2. 获取游标对象(Cursor)
+ with con.cursor(pymysql.cursors.DictCursor) as cursor:
+ # 3. 通过游标对象向数据库服务器发出SQL语句
+ cursor.execute(
+ 'select `eno`, `ename`, `job`, `sal` from `tb_emp` order by `sal` desc limit %s,%s',
+ ((page - 1) * size, size)
+ )
+ # 4. 通过游标对象抓取数据
+ for emp_dict in cursor.fetchall():
+ print(emp_dict)
+finally:
+ # 5. 关闭连接释放资源
+ con.close()
+```
+
+### 案例讲解
+
+下面我们为大家讲解一个将数据库表数据导出到 Excel 文件的例子,我们需要先安装`openpyxl`三方库,命令如下所示。
+
+```Bash
+pip install openpyxl
+```
+
+接下来,我们通过下面的代码实现了将数据库`hrs`中所有员工的编号、姓名、职位、月薪、补贴和部门名称导出到一个 Excel 文件中。
+
+```Python
+import openpyxl
+import pymysql
+
+# 创建工作簿对象
+workbook = openpyxl.Workbook()
+# 获得默认的工作表
+sheet = workbook.active
+# 修改工作表的标题
+sheet.title = '员工基本信息'
+# 给工作表添加表头
+sheet.append(('工号', '姓名', '职位', '月薪', '补贴', '部门'))
+# 创建连接(Connection)
+conn = pymysql.connect(host='127.0.0.1', port=3306,
+ user='guest', password='Guest.618',
+ database='hrs', charset='utf8mb4')
+try:
+ # 获取游标对象(Cursor)
+ with conn.cursor() as cursor:
+ # 通过游标对象执行SQL语句
+ cursor.execute(
+ 'select `eno`, `ename`, `job`, `sal`, coalesce(`comm`, 0), `dname` '
+ 'from `tb_emp` natural join `tb_dept`'
+ )
+ # 通过游标抓取数据
+ row = cursor.fetchone()
+ while row:
+ # 将数据逐行写入工作表中
+ sheet.append(row)
+ row = cursor.fetchone()
+ # 保存工作簿
+ workbook.save('hrs.xlsx')
+except pymysql.MySQLError as err:
+ print(err)
+finally:
+ # 关闭连接释放资源
+ conn.close()
+```
+
+大家可以参考上面的例子,试一试把 Excel 文件的数据导入到指定数据库的指定表中,看看是否可以成功。
\ No newline at end of file
diff --git a/README.md b/README.md
index c4c0605..2e2a3bc 100644
--- a/README.md
+++ b/README.md
@@ -199,7 +199,7 @@ Python在以下领域都有用武之地。
### Day36~40 - [数据库基础和进阶](./Day36-40)
-- [关系型数据库MySQL](./Day36-40/36-38.关系型数据库MySQL.md)
+- [关系型数据库MySQL](./Day36-40/36.关系型数据库和MySQL概述.md)
- 关系型数据库概述
- MySQL的安装和使用
- SQL的使用
diff --git a/更新日志.md b/更新日志.md
index 1e92978..95c69c1 100644
--- a/更新日志.md
+++ b/更新日志.md
@@ -1,5 +1,11 @@
## 更新日志
+### 2021年11月22日
+
+1. 更新了数据库部分的文档和代码。
+2. 修正了网友们指出的文档和代码中的bug。
+3. 更新了README文件中的群信息。
+
### 2021年10月7日
1. 调整了项目目录结构。