diff --git a/docker/docs/ali_docker.md b/docker/docs/ali_docker.md
deleted file mode 100644
index 292d93913..000000000
--- a/docker/docs/ali_docker.md
+++ /dev/null
@@ -1,93 +0,0 @@
-# 阿里超大规模docker化之路
-
-Docker化之前,阿里主要交易业务已经容器化。采用T4做容器化,T4是2011年开发的一套系统,基于LXC开发,在开发T4的过程中,跟业界很大的不同在于,T4更像VM的容器。当用户登进T4后,看起来与标准的KVM等几乎完全一样,对用户来讲是非常透明化的。所以,容器化不是我们推进Docker的原因。
-
- a)触发我们Docker化的主要原因一:Docker最重要的一点是镜像化,可以做到拿着镜像就可以从一台完全空的机器的应用环境搭建起来,可以把单机环境完全从零搭好。Docker化之前,阿里巴巴的应用部署方式主要由Java、C来编写的,不同的业务BU可能采用完全不同的部署方式,没有统一标准。内部尝试通过基线来建立部署标准,定义的基线包括应用依赖的基础环境(OS、JDK版本等)、应用依赖的脚本,基础环境的配置(启动脚本、Nginx配置等)、应用目录结构、应用包、应用依赖的DNS、VIP、ACI等,但不成功。部署标准做不了,直接导致自动化很难做到。
-
- b)触发我们Docker化的主要原因二:DevOps是一个更好的方向,阿里巴巴做了很多运维和研发融合的调整。Docker是帮助DevOps思想真正落地的一种手段,所有的思想最终都体现在工具或框架上,变成一个强制性的手段,Docker会通过Dockerfile的描述,来声明应用的整个运行环境是怎样的,也就意味着在编写Dockerfile过程中,就已经清楚在不同环境中的依赖状况到底是怎样的,而且,这个环境是通过一个团队来维护的。
-
- **Docker化目标**
-
- 2016年7月,阿里巴巴制定了两个Docker化目标:
-
- 交易核心应用100%Docker化;
-
- DB其中一个交易单元全部Docker化。
-
-## Docker化之路
-
- 推进Dcoker之前,我们有一个准备的过程。在准备阶段,我们需要Docker更像VM和更贴合阿里运维体系的Docker,我们将改造过的Docker称为AliDocker;除了AliDocker以外,我们需要支持AliDocker的工具体系,比如编译、镜像库、镜像分发机制,在完成这些准备工作后,我们认为可以一帆风顺地开始大规模的AliDocker上线。但事实并非如此。
-
- **第一轮Docker化**
-
- 我们碰到了很多问题:
-
- 工具不完善,阿里很多应用之前都是在T4容器中,怎样将T4容器转换成AliDocker是首要面临的问题;
-
- 镜像Build后上传,以前阿里一个应用转成多个,很多时候需要在自己的机器上做Build,然后自己上传,导致做应用时很痛苦;
-
- 应用从T4切换成走Docker的链路,链路没有完全准备好,从资源创建到发布,很多需要手工去做,大规模去做效率非常低。
-
- **第二轮Docker化**
-
- 在推进的过程中,我们又遭遇了新的问题。Docker的发布模式是典型的通过镜像,拉到镜像后将原来的容器销毁,重新创建一个容器,把镜像放进去,拉起来。Docker单一化的发布方式支持不了多种发布模式,更改velocity模板发布效率低;有本地内存cache的发布,重启本地内存cache就会消失。怎样在基于镜像模式情况下又能支持多种发布模式呢?
-
- 我们在Docker的镜像模式基础上做出一个crofix的模式,这个模式不是绕开镜像,而是从镜像中拉起我们需要的文件,去做覆盖等动作,这样就可以完成整个发布。Docker化镜像模式是必须坚持的,否则失去了Docker化的意义。
-
- **第三轮Docker化**
-
- 继续推进到很多应用切换到Docker的时候,我们又遇到了更大的问题:
-
- 首先,很多研发人员都有明显的感受,切换到Docker后变慢。第一,编译打包镜像慢,编译打包完应用的压缩包后,还需要把整个环境打包成镜像,这是在原有基础上增加的过程,如果编译时每次都是新机器,以前依赖的所有环境都要重新拉,一个应用Docker的完整镜像通常会很大,因为它包括依赖的所有环境。对此,我们在编译层做了很多优化,尽可能让你每次都在之前编译的基础上进行编译。第二,镜像压缩问题,Go在1.6以前的版本压缩是单线程,意味着压缩整个镜像时效率会非常低,所以我们选择暂时把镜像压缩关闭掉。
-
- 其次是发布问题,Docker的镜像化模式决定了分发一定是镜像分发,使用Docker时不能完全把它当作透明化东西去用,对所有研发人员来说,要非常清楚依赖的环境、Dockerfile中镜像的分层改怎么做,将频繁变化部分与不频繁变化部分做好分层,镜像分层是改变Docker慢的重要方案;阿里制定了镜像分发多机房优化,比如打包后将所有镜像同步到所有机房;阿里也做了发布优化(P2P、镜像预分发、流式发布),还通过Docker Volume将目录绑定到Dockerfile中,可以保证镜像文件每次拉起时不会被删掉。
-
- 在整个Docker化的过程中,我们在“慢”这个问题上遇到了最大的挑战,不管是编译慢还是发布慢,都做了很多突击的改造项目,最后才让整个编译过程、发布过程在可控的响应速度内。
-
- **第四轮Docker化**
-
- 在推进过程中,我们还遇到规模问题:
-
- 由于规模比较大,开源软件很容易碰到支撑规模不够,稳定性差的问题。目前我们使用Swarm来管理,Swarm的规模能力大概可以支撑1000个节点、50000个容器,而我们需要单Swarm实例健康节点数在3W+,对此,我们对Swarm进行了优化。
-
-
-
-
-
-
-
- 规模我们做到从支撑1000到3W+,压力减小了很多。而Swarm的稳定性对我们来讲,最大的问题在HA上,一个Swarm实例如果挂掉,重新拉起需要时间,所以我们在用Swarm时进行了改造。在前面加了一层Proxy,不同业务、不同场景都可以通过Proxy转换到自己不同的Swarm实例上。另外,所有的Swarm节点我们都会用一个备方案在旁边,而且都是不同机房去备。
-
- 通过改造增强HA机制后,可以做到每次切换、简单发布。
-
-## Bugfix和功能增强
-
- 除了上面四轮次比较明显的问题,在整个Docker化过程中,还做了很多的Bugfix和功能增强,具体有以下几方面:
-
- Daemon升级或crash后,所有容器被自动销毁的问题;
-
- Cpuset、cpuacct和CPU子系统mount到一起时CGroup操作错误的bug;
-
- 支持基于目录的磁盘配额功能(依赖内核patch);
-
- 支持制定IP启动容器,支持通过DHCP获取IP;
-
- 支持启动容器前后执行特定脚本;
-
- 支持镜像下载接入各种链式分发和内部mirror的机制;
-
- 增加Docker Build时的各种参数优化效率和适应内部运维环境;
-
- 优化Engine和Registry的交互。
-
- 经历了这么多坎坷,我们终于完成了全部目标,实现双11时交易所有核心应用都AliDocker化,DB其中一个交易单元全部AliDocker化,生产环境共几十万的AliDocker。
-
-## 未来
-
- 容器化的好处是可以把很多对物理机型的强制要求虚拟化,可能也需要Docker在内核层面的改造,对于未来,我们已经做好了准备,希望:
-
- 所有软件AliDocker化;
-
- 和Docker公司紧密合作回馈社区;
-
- AliDocker生态体系逐渐输出到阿里云。
\ No newline at end of file
diff --git a/docker/docs/compose_v2v3.md b/docker/docs/compose_v2v3.md
deleted file mode 100644
index eae634443..000000000
--- a/docker/docs/compose_v2v3.md
+++ /dev/null
@@ -1,24 +0,0 @@
-# Compose文件v3和v2版本的区别
-
-Docker Compose `v3` 和 `v2` 模板文件都采用yaml格式,但是语法上存在一定差距
-
-首先,使用`version: "3"` 或 `version: "3.1"` (Docker 1.13.1) 作为版本声明
-
-其次,由于 Swarm mode 中网络的特殊性,Compose模板中一些声明比如 `expose` 和 `links` 会被忽略。注意:不能再使用 link 定义的网络别名来进行容器互联,可以使用服务名连接。
-
-另外, `volumes_from` 不再支持,只能使用命名数据卷来实现容器数据的持久化和共享;
-
-v3 中引入了 `deploy` 指令,可对Swarm mode中服务部署的进行细粒度控制,包括
-
-- `resources`:定义 `cpu_shares`, `cpu_quota`, `cpuset`, `mem_limit`, `memswap_limit` 等容器资源控制。(v1/v2中相应指令不再支持)
-- `mode`:支持 `global` 和 `replicated` (缺省) 模式的服务;
-- `replicas`:定义 `replicated` 模式的服务的复本数量
-- `placement`:定义服务容器的部署放置约束条件
-- `update_config`:定义服务的更新方式
-- `restart_policy`:定义服务的重启条件 (v1/v2中`restart`指令不再支持)
-- `service`:定义服务的标签
-
-
-虽然 Docker CLI 已经提供了对Docker Compose v3模板的支持。但是 Docker Compose 依然可以作为一个开发工具独立使用,并同时继续支持v1/v2/v2.1等版本已有编排模板。但是当利用 `docker-compose up` 或 `docker-compose run` 来部署v3模板时,模板中的 `deploy` 指令将被忽略
-
-Docker CLI只支持v3模板,但是不支持模板中的 `build` 指令,只允许构建好的镜像来启动服务的容器。
\ No newline at end of file
diff --git a/docker/docs/container_2016.md b/docker/docs/container_2016.md
deleted file mode 100644
index e2de46fbc..000000000
--- a/docker/docs/container_2016.md
+++ /dev/null
@@ -1,139 +0,0 @@
-# 容器技术2016年总结
-
-本文是从容器生态圈的角度来讲述容器技术2016年的发展与变革。
-
-*导读:容器技术已经成了很多公司基础架构一部分,架构师是否已经清楚了解 Docker, Swarm, K8S, Mesos,虚拟化等相关技术的未来走向?*
-
-原文作者:王渊命,技术极客,曾任新浪微博架构师、微米技术总监。2014 年作为联合创始人创立团队协作 IM 服务 Grouk,2016 年加入青云从事容器方面开发,本文仅代表个人观点。
-
-### Docker
-
-提到容器就不能不说 Docker。容器技术虽然存在了很长时间,却因 Docker 而火。很长时间里,很多人的概念里基本 Docker 就代表容器。一次一产品经理朋友问我做什么,我说做容器相关,她表示很不懂,但说是 Docker ,她就明白了,可见 Docker 之火。这一年里,Docker 发布了几个重要版本。我们先回顾下 Docker 本来是什么,再说它的变化。
-
-1. Docker 的镜像机制提供了一种更高级的通用的应用制品(artifact)包,也就是大家说的集装箱能力。原来各种操作系统或编程语言都有各自己的制品机制,Ubuntu 的 deb,RedHat 的 RPM,Java 的 JAR、WAR,各自的依赖管理,制品库都不相同。应用从源码打包,分发到制品库,再部署到服务器,很难抽象出一种通用的流程和机制。而有了 Docker 的镜像以及镜像仓库标准之后,这个流程终于可以标准化了。于是雨后春笋般冒出很多镜像管理仓库,这在以前的制品管理领域是很难想象的,以前貌似也就 Java 领域的 nexus 和 artifactory 略完备些。
-2. Docker 镜像机制以及制作工具,取代了一部分 ansible/puppet 的职能,至少主机上的各种软件栈以及依赖关系的定义和维护被容器替代,运维人员的不可变基础设施的梦想被 Docker 实现。
-3. Docker 对 cgroups/namespace 机制以及网络的封装,使其很容易在本地模拟出多节点运行环境,方便开发人员开发调试复杂的,分布式的软件系统。
-4. Docker 的 daemon 进程,取代了一部分 systemd/supervisor 这样的系统初始化进程管理器的作用,通过 Docker 运行的服务,可以不受 systemd 管理,由 docker daemon 维护其生命周期。
-
-前三点基本上都是容器相关或者延伸的,唯独第四点,深受其他容器编排调度厂商的诟病。任何分布式的管理系统,都会在每个主机上安装一个自己的 agent,由这个 agent 管理该节点上的应用进程。从这点功能上来说,和 Docker daemon 是冲突的,操作系统的 systemd,可以忽略不用就行,但要用 Docker 容器的话,离不开 Docker daemon 。设想一下,如果你老板让你管理一个团队,但任何管理指令都只能通过另外一个人来发出,你也会感觉不爽吧?所以 Docker 和其他容器编排调度系统的冲突从开始就种下了。感觉开始 Docker 团队也没思考这个问题,自己的 Swarm 也是用独立的 agent,但后来发现有点多余,把 Swarm 的 agent 以及调度器内置到 Docker daemon 不就行?何况 Docker daemon 本身已经支持了 remote API,并且这样设计还是一个无中心的对等节点集群模式,部署运维更方便。于是 Docker 的 1.12 内置了 Swarm(准确的说是 SwarmKit),几个命令就将多个单机版本的 Docker daemon 变成一个 cluster,还支持了 service 概念(多个容器实例副本的抽象),1.13 支持了 stack 的概念(多个 service 的组合) 和 Compose(编排定义文件),基本上一个略完备的编排调度系统已经成型。
-
-而这个变化,也表明了和其他容器编排调度系统的决裂。本来 Docker 作为容器的一种,大家都在上面基于容器搭建编排调度系统,还能和平共处。容器相当于轮子,编排调度系统是车,结果有一天造轮子的厂商说自己的几个轮子直接拼接起来就称为一辆车了,造车的厂商不急才怪,这相当于发起了『降维』攻击。
-
-有了编排调度系统,Docker 进而推出 Store 也是顺理成章。服务器端的应用大多不是单个节点或进程的应用,需要将多个服务组装,一直以来大家都在寻找一种方式实现服务器端应用的一键安装和部署。Docker 的应用打包了编排文件以及镜像定义,配合编排调度系统提供的标准环境,再用 Store 作为应用分发,意图已经非常明确。但感觉 Docker 这步走的略匆忙,当前编排调度系统尚未成熟,就着急推出更上一层的应用,可能会拖累后面的演进,不过这也应该是受商业化的压力所致吧。
-
-当然 Docker 出此决策,面临的挑战也是巨大的。容器生态圈的割裂,导致 Docker 得以一己之力重塑自己的生态圈。Docker 推出的容器网络标准(libnetwork)不被其他厂商接受,其他厂商也在降低对 Docker 的依赖程度(整个后面具体分析时会提到)。Swarm 成熟度还不够用在生产环境,它的网络当前只支持 overlay,尚不能支持自己的网络插件标准,编排文件的完备程度也不够。存储方面,去年 Docker 收购了 Infinit (很早就关注 Infinit,它一直宣称要开源,但迟迟没等到源码,就听到了它被 Docker 收购的消息)这家做分布式存储的公司。**如果 Docker 在2017年解决网络和存储两个分布式系统的痛点,Swarm 的前景还是可期。**
-
-作为一个开发者,我自己其实挺喜欢 Docker 的这种设计的,虽然它推出的有点晚。这种模式符合开发团队对容器的渐进式接纳。比如开始可以先将 Docker 当做一种制品包管理工具,网络用 host 模式,这种方式和在主机上维护部署多个应用的进程没有区别,只是接管了依赖以及安装包的维护。然后当开发流程的打包机制改造完毕,开发人员的习惯逐渐改变,这时候就可以引入 Docker 的网络解决方案,先改造应用直接通过容器的网络进行通信,但部署和调度都沿用原来的模式。等这些都改造完,运维也成熟了,然后开启 Swarm 模式,将应用的部署和调度交给 Swarm,基本上完成了应用的容器化改造。**这就像谈恋爱一样,先约约会,牵牵小手,然后(此处省略若干字),然后才是谈婚论嫁,考虑要不要做一辈子的承诺。**而其他编排系统呢,一上来就要用户回答:你准备把你的一切以及后半生交付给我了么?很多人就得犹豫了吧。
-
-总结一下,这一年,Docker 已经不是原来的 Docker,它代表一种容器方案,一个系统软件,也代表一个商标,一个公司,还代表一种容器编排调度系统。容器之战刚刚开始,三足鼎立,胜负未知。但无论最后结果如何,Docker 一初创公司,从开发者工具切入,仅仅三年,火遍全球技术圈,搅动整个服务器端技术栈,进而涉足企业应用市场,携用户以抗巨头,前所未有。传统的企业市场,决策权多在不懂技术的领导,所以解决方案中对开发者是否友好,不是一个关键点,但从 Docker 以及国外最近的一些公司的案例(比如 slack,twilio 等)来看,这一现象正在改变,这表明了开发者群体的成熟和话语权的增加,企业应用对开发者的友好程度将成为一个竞争的关键点。
-
-### Kubernetes
-
-我在 2015 年底分析 Kubernetes 架构的时候,当时 1.2 版本尚未发布。到现在已经发布了 1.6 beta 版本了。去年是 Kubernetes 爆发的一年,从社区文章以及 meetup 就可以看出来。有很多文章已经等不及开始宣布 Kubernetes 赢得了容器之战了。
-
-Kubernetes 的优势是很多概念抽象非常符合理想的分布式调度系统,即便是你自己重新设计这样一个系统,经过不断优化和抽象,最后也会发现,不可避免的慢慢向 Kubernetes 靠近。 比如 Pod,Service,Cluster IP,ReplicationController(新的叫 ReplicaSets ),Label,以及通过 Label 自由选择的 selector 机制,以及去年引入的 DaemonSets 和 StatefulSets。
-
-DaemonSets 用于定义需要每个主机都部署一个,并且不需要动态迁移的服务,比如监控的服务。Swarm 中尚未引入这种概念,不过这种也可能会用另外的实现方式,比如插件机制。通过 DaemonSet 定义的服务可以理解成分调度系统的 agent 扩展插件。
-
-StatefulSets(1.5 版本之前叫 PetSets)主要是为了解决有状态服务部署的问题,它保证 pod 的唯一的网络标志(主要是 pod 的 hostname,ip 是否能保持不变取决于网络实现)的稳定性,不随 pod 迁移重建而变化,另外支持了 PersistentVolume 规范,封装了已有的分布式存储以及 IaaS 云的存储接口。
-
-网络方面,Kubernetes 推出 CNI(Container Network Interface) 网络标准。这个标准比较简单,只是约定了调用命令的参数,如果想扩展自己的实现,只需要写个命令行工具放到系统 path 下,然后根据 CNI 调用的参数来给容器分配网络即可,可以用任何语言实现。它和 Kubernetes 基本没有任何耦合,所以也可以很容易被其他调度系统采用(比如 Mesos)。
-
-从 Kubernetes 的演进可以看出,谷歌对 Kubernetes 的期望在标准制定,最核心的点是描述能力。官方文档 [What is Kubernetes?](undefined) 中有这样一段描述:
-
-> Kubernetes is not a mere “orchestration system”; it eliminates the need for orchestration. The technical definition of “orchestration” is execution of a defined workflow: do A, then B, then C. In contrast, Kubernetes is comprised of a set of independent, composable control processes that continuously drive current state towards the provided desired state. It shouldn’t matter how you get from A to C: make it so.
-
-它的目标不仅仅是一个编排系统,而是提供一个规范,可以让你来描述集群的架构,定义服务的最终状态,它来帮助你的系统达到和维持在这个状态。这个其实和 Puppet/Ansible 等配置管理工具的目的是一致的,只是配置管理工具只能做达到某个状态,没法实现维持到这个状态(没有动态的伸缩以及故障迁移等调度能力),同时配置管理工具的抽象层次也比较低。它之所以选择容器只是因为容器比较容易降低主机和应用的耦合,如果有其他技术能达到这个目的,支持下也不影响它的定位。所以 Kubernetes 去年推出 CRI (Container Runtime Interface) 容器标准,将 Kubernetes 和具体的容器实现进一步解耦,一方面是对 Docker 内嵌 Swarm 的一种反制,另外一方面也是它的目标的必然演进结果。
-
-正因为这样,它让渡出了很大一部分功能给 IaaS 云(比如网络,存储),也不着急推出具体的解决方案,也不着急兼容已有的各种分布式应用,发布两年多还在专心在规范定义以及系统优化上。Kubernetes 系出名门,不担心商业化的问题,大家闺秀不愁嫁,无需迎合别人,自然有人来适应自己。
-
-当然理想是美好的,现实是当前已经有大量的分布式系统,重复实现了许多 Kubernetes 已经实现的功能,或者集群机制是当前的 Kubernetes 的抽象概念没有覆盖到的,当前将这些系统运行到 Kubernetes 还是一件很难的事情(比如 redis cluster,hadoop,etcd,zookeeper,支持主从自动切换的mysql集群等),因为任何抽象都是以损失个性化和特殊化为代价的。这里特别说下,以前分析 Kubernetes 的时候有人反驳我这个说法,我这里不是说 Kubernetes 上不能运行 zookeeper 这样的服务,而是很难实现一键部署并且自动伸缩以及配置自动变更,很多情况下还是需要手动操作接入,比如官方的这个 [zookeeper 例子](undefined)。
-
-CoreOS 为了解决这个问题,推出了 [operator](undefined) 的概念,给不容易通过 Kubernetes 当前的抽象描述的服务(有状态服务或者特殊的集群服务),专门提供一个 operator,operator 通过调用 Kubernetes 的 API 来实现伸缩,恢复,升级备份等功能。这样虽然和 Kubernetes 的声明式理念相冲突,也无法通过 kubectl 直接操作(kubectl 有支持插件机制的提案,未来这种需求可能通过插件实现),也但当前也是一个可行的办法。
-
-另外,Kubernetes 在大数据方面支和 Mesos 还有差距。去年 Kubernetes 支持了 job 概念,job 生成的 pod 执行完成后立刻退出,原来的 service 可以理解成一个死循环的 job。这样,Kubernetes 就具有了分发批量任务的能力,但还缺乏上层的应用接口。理论上,将 Hadoop 的 MapReduce 移植到 Kubernetes,用 Kubernetes 替代底层的 Yarn 的资源调度功能,也是可行的(只是开脑洞,没有具体分析)。有个打算整合 Yarn 和 Kubernetes 的项目已经很久没更新了,这两者的整合我不太看好,两个系统冲突严重,是互相替代的关系,不像 Mesos 和 Kubernetes 的整合(这个后面 Mesos 的段落会分析)。
-
-部署复杂是 Kubernetes 一直被大家诟病一点。2015 年我做测试的时候,部署一套 Kubernetes 是一项很复杂的工作。去年 Kubernetes 推出了 kubeadm,很大程度的降低了部署的复杂度。当前 Kubernetes 除了 kubelet 需要直接在主机上启动,其他的组件都可以通过 Kubernetes 自己托管,一定程度上实现了『自举』,但易用度上和 Swarm 还是有差距。
-
-随着 Kubernetes 的成熟,其他厂商开始制作自己的发行版,比如 CoreOS。CoreOS 原来的容器思路应该是通过自己定制的容器操作系统,以及 etcd ,将多个 CoreOS 主机合并成一个集群,然后通过改造过的 systemd 充当 agent,上面再增加一个调度器,就可以实现容器编排调度,也是一种可行的思路,既然单机的服务进程管理可以通过 systemd,将多个机器的 systemd 连接起来不就是一个分布式的服务进程管理?但后来改变了策略,估计是这种方案采纳成本太高(用户需要同时改变自己主机的操作系统以及应用的部署习惯),所以当前的容器策略变为了定制 Kubernetes,推出 tectonic,CoreOS 改名为 Container Linux(应该是为了避免产品和公司的名称重叠,另外也透露出的一个信息是产品重心的变更),专注于主机操作系统(这个后面的操作系统部分会分析到)。
-
-总结一下,Kubernetes 经过一年快速发展,基本已经非常完备。原来的 kube-proxy 的性能问题(1.2 版本之前),也已经解决。建议原来处于观望状态的用户可以入坑了。不过在应用的最终 package 定义上,Kubernetes 尚未推出自己的解决方案,不确定这个是打算官方来搞,还是让度给发行版厂商,不过可以预计2017年肯定会有相关方案推出。
-
-### Mesos
-
-如果说 Kubernetes 是为了标准而生,那 Mesos 则是为了资源而生。它的理念是:
-
-> define a minimal interface that enables efficient resource sharing across frameworks, and otherwise push control of task scheduling and execution to the frameworks
-
-定义一个最小化的接口来支持跨框架的资源共享,其他的调度以及执行工作都委托给框架自己来控制。
-
-也就是说它的视角是资源视角,目标是资源共享。这个和 Kubernetes 的目标其实是一体两面,一个从定义描述角度一个从资源角度。Mesos 其实是最早切入容器领域的,但它的容器封装的比较简单,只是用来做简单的资源隔离,用户一般没什么感知。有了 Docker 以后,也引入了 Docker,但正如前面我分析的原因,Mesos 上的 Docker 一直有点别扭,于是 Mesos(准确的说应该是 mesosphere DC/OS) 搞了一个 Universal container,改进了 Mesos 原来的容器,支持了 Docker 的镜像格式,这样用户可以在自己的开发环境中使用 Docker,但生产环境中就可以直接切换到 Mesos 自己的容器上,虽然可能有一些兼容性问题,但镜像格式这种变化不会太快,问题在可控范围内。
-
-这也从另外一方面表明了 Docker 的镜像格式基本上已经成了一个事实标准,一个容器解决方案能否切入整个生态圈的关键是是否支持 Docker 镜像格式。当然 Mesos 成员对这点其实也有点抵触,在一些分享里强调 Mesos 也支持部署其他类型的软件包格式,比如gzip等,尤其大规模服务器的场景,从 Docker 仓库拉取镜像有瓶颈。这点个人不太同意,大规模服务器场景,从任何中心节点拉取任何格式的安装包都会有问题,所以 twitter 才搞 p2p 安装包分发,但 Docker 镜像也可以搞成 p2p 分发的,只要有需求,肯定有人能搞出来。
-
-容器网络方面,原来 Mesos 的网络解决方案就是端口映射,应用需要适应 Mesos 做修改,对应用倾入性比较强,通用性较差,所以 Mesos 支持了 Kubernetes 发起的 CNI 网络标准,解决了这个问题。
-
-Mesos 通过 framework 的机制,接管了当前已经存在的分布式系统的一部分职能,让多个分布式系统共享同一个资源池变为可能,容器编排也只是 Mesos 之上的一种应用(Marathon)。这种方式的好处是让整合复杂的分布式系统变为可能,因为 framework 是编程接口,灵活度也比较高,很多不容易跑在 Kubernetes 上的复杂应用,都可以在 Mesos 之上,比如 Hadoop 等大数据相关的系列应用。
-
-正因为 Mesos 和 Kubernetes 的目标正好是一体两面,然后能力也可以互补,所以很早就有人想整合 Kubernetes 和 Mesos,将 Kubernetes 跑在 Mesos 之上,这样 Kubernetes 接管容器编排调度,替代 Marathon,Mesos 解决其他复杂的分布式应用,实现多种应用的资源共享。但 [kubernetes-mesos](undefined) 这个项目后来就不活跃了,一方面是 Kubernetes 变化太快,另外一方面估计是 mesosphere 发现和 Kubernetes 的竞争大于合作吧。后来 IBM 搞了个 [kube-mesos-framework](undefined) 放在 Kubernetes 孵化器里孵化,不过当前尚不能正式使用。个人感觉如果要真的很好整合,对 Kubernetes 和 Mesos 两方都需要做很大改造,但这个项目对生态圈来说是一个大变数,有可能打破三足鼎立的局势。
-
-Mesosphere 的 DC/OS 在 Mesos 基础上搞了一个分布式应用的 package 规范。以前的应用发布都只能发布面向单机操作系统的 package,Mesosphere 通过 Marthon,镜像以及配置文件,定义了一套分布式的 package 规范,用户可以通过一个命令从仓库(repo)上部署复杂的分布式应用到 Mesos。这个和 Docker 的 Store 思路类似。
-
-总结一下,Mesos 的优势是可定制性强,它诞生于 twitter 这样的互联网公司,也比较受互联网公司欢迎。互联网公司的基础设施以及系统大多是自己研发,可以通过规范来要求自己的应用适应调度系统,所以对标准化和抽象能力的的需求不如资源共享强烈。它的缺点是周边生态比较庞杂,接口以及规范设计上,没有 Kubernetes 那么『优雅』。
-
-### Rancher
-
-既然容器之上的编排系统已经三足鼎立了,各有所长了,还有其他机会么?Rancher 尝试了另外一个途径。它自己的定义是一种 IaaS,一种基于容器的 IaaS。首先,它通过容器降低了部署成本,每个只需节点运行一个命令就能部署一套 Rancher 系统,相对于 OpenStack 这种复杂的 IaaS 来说就太容易了。其次,它自己的定位是专门运行容器编排系统的 IaaS,可以在上面一键部署 Kubernetes,Docker Swarm,Mesos。容器编排系统,直接运行到物理机上还是需要一些改造,并且有升级和运维困难的问题,于是 Rancher 出来了,希望抽象出一层非常薄的 IaaS 来解决这个问题。
-
-它的思路是既然现在三家纷争,选哪一方都是一个艰难的决定,那不如选 Rancher 好了。Rancher 一方面可以让几种编排系统共存,另外一方面降低了以后的切换成本,这个艰难的决定可以以后再做。
-
-另外它也推出了自己的应用规范和应用仓库(App Catalogs),它的应用规范也兼容其他的容器编排系统的定义文件,相当于一个容器编排系统应用的一个超集。这样和基础设施相关的应用可以用 Rancher 自己的规范,和业务相关的,变化快需要动态伸缩的应用可以放到容器编排系统中,以后切换也不麻烦。
-
-不过 Rancher 的这个产品假设的问题是,假如以后容器编排调度系统是一家独大,那它的存在空间就会越来越小了。
-
-### 容器平台去向何方?CaaS,IaaS,PaaS,SaaS?
-
-有人把容器服务叫做 CaaS(Container as a Service),类似于当前 IaaS 平台上的数据库服务(RDB as a Service)等,是 IaaS 之上的一种新的应用服务。但个人认为 CaaS 其实是一个伪需求,用户需要的并不是容器,从来也没有人把 IaaS 叫做 VaaS(VM as a Service),容器服务提供的是一种运行环境,并不是具体的服务。
-
-容器编排调度平台首先是一个面向开发者的的工具平台,它上面调度的是应用,这是和当前 IaaS 最大的区别。当前的 IaaS 主要面向的是管理者,调度的是资源,所以 IaaS 的使用入口主要是控制台,虽然有 API,但指令式的 API 使用复杂度要远大于声明式的 API,并且 API 的使用者也多是运维工具,很少有融入业务系统的使用场景。这是由当前 IaaS 云的历史使命决定的。云的第一步是让用户把应用从自己的机房迁移到云上,只有提供可以完全模拟用户物理机房的环境(虚拟机模拟硬件支持全功能的OS,SDN网络,云硬盘存储),对应用无侵入,用户的迁移成本才更低。
-
-但当这一步完成时,用户就会发现,这样虽然省去了硬件的维护成本,但应用的开发维护成本并没有降低,认识到自己本质的需求并不是资源,而是应用的运行环境。这个需求有点像 PaaS,但原来的 PaaS 的问题是对应用的侵入性太强,并且和开发语言绑定,能直接部署的应用有限,用户需要的是一种更通用的 PaaS,可以叫(Generic Platform as a Service),这个词是我生造的,就是一种基本可以部署任何复杂应用的平台服务,正好容器平台可以承担起这样一种职责。
-
-容器平台虽然都有各自的历史背景和侧重点,解决方案也不一样,但最终指向的目标却是一致的,就是屏蔽分布式系统的资源管理细节,提供分布式应用的标准运行环境,同时定义一种分布式应用的 package,对开发者来说降低分布式系统的开发成本,对用户来说降低分布式应用的维护成本,对厂商来说降低分布式应用的分发成本。总结一下,其实就是 DataCenter OS 或 Distributed OS。DC/OS 这个词虽然已经被 Mesosphere 用在自己的产品上了,但个人认为它是所有容器平台的最终目标。当然,这次容器浪潮是否能真的实现这个目标还不好说,但至少现在看来是有希望的。
-
-于是, PaaS 会变成了 DCOS 之上的 devops 工具栈,当前很多 PaaS 平台正向这个方向演进。而 IaaS 就变成了给 DCOS 提供运行环境的服务,DCOS 接管了上层的应用以及基础服务。当然 IaaS 之上还有其他的 SaaS 模式的服务(由于 SaaS,PaaS 的外延并没有精确定义,很多场景下,把面向开发者的 SaaS 模式的中间件叫做 PaaS 组件,我的理解是通过软件实现多租户,完全按量计费的服务都应该属于 SaaS,比如对象存储。这个要细说,估计需要另外一篇文章,这里就不详细分析了),SaaS 模式资源利用率最高,对用户的成本最低,用户一般不会用独立部署的服务去替换。这样一来,格局就变成了用户在 IaaS 之上部署一套 DCOS,需要独立部署的服务以及自己开发的服务都运行在 DCOS 之中,其他的能抽象成标准 SaaS 服务的中间件则优先用 IaaS 提供的。相当于 IaaS 将独立部署的基础设施服务,以及用户自己的服务的部署和调度让渡给了 DCOS。当然,最后 IaaS 本身是否会直接变成一种多租户的 DCOS,由调度资源变成直接调度应用,也不是没可能,但这样调度层会面临非常大的压力,数据中心支撑的节点会受限,暂时看来两层调度的可行性更大些。
-
-这对整个 IaaS 影响很大,所以有人说对 AWS 造成威胁的可能不是 Google Cloud,而是 Kubernets(DCOS)。但即便是 DCOS 成熟,最后如何商业化还是有很大的变数。大家理想中的那个像 Apple 的 AppStore 的服务器端应用市场,最终会是由 DCOS,SaaS,还是 IaaS 服务商提供?DCOS 的优势是掌握了标准可以定义应用规范,SaaS 服务商的优势是直接面向最终用户,可能占据企业应用入口,IaaS 服务商的优势是它掌控了应用的运行环境,无论在计费模式还是反盗版上都有很大优势。但在私有云领域,IaaS 产品会面临 DCOS 更大的冲击。私有云领域如果多租户隔离的需求没那么强烈的情况下,部署一套 DCOS 是一种更简单高效的选择。
-
-### 容器与虚拟机之争
-
-从 Docker 技术成为热门开始,容器与虚拟机的争论就从来没有停止过。但去年一年,大家的注意力逐渐转移到上层,容器和虚拟机的争论算告一段落。这个主要是因为容器本身的外延在变化。
-
-容器,首先它不是一个技术词汇,它是一个抽象概念。顾名思义,就是装东西的器皿,装什么东西呢?应用。
-
-其实 J2EE 领域很早就使用了容器(Container)概念,J2EE 的服务器也叫做 web container 或者 application container,它的目标就是给 Java web 应用提供一种标准化的运行环境,方便开发,部署,分发,只不过这种容器是平台绑定的。
-
-而 Linux 容器自诞生之初,就是一组进程隔离的技术的统称。随着容器领域的竞争与演进,Kubernetes 的 OCI (Open Container Initiative)标准推出,Docker,Unikernels, CoreOS 的 Rocket,Mesos 的 Universal container,Hyper 的 [HyperContainer](undefined)(基于 VM 的容器解决方案) 等百花齐放,容器的概念逐渐清晰,我们这里可以下个定义:
-
-> 容器就是对应用进程的一种标准化封装,无论是采用 linux 的 cgroup namespace 技术,还是使用虚拟化 hypervisor 技术来做这种封装,都不是关键,关键是是目标,容器是为应用标准化而生。
-
-也就是说,最早,大家认为容器是和虚拟机一样的一种隔离技术,所以会拿容器和虚拟机做比较,比较二者的隔离成本,隔离安全性,但现在容器的外延变了,和传统虚拟机的本质差异不在于封装技术,而在于封装的目标,传统虚拟机封装的目标是操作系统,为操作系统提供虚拟化硬件环境,而容器封装的目标是应用进程,其中内嵌的操作系统只是应用的依赖而已。
-
-另外一方面,基于虚拟机的调度系统,比如 OpenStack,也可以将容器作为自己的调度系统的 compute_driver,也就是将容器当虚拟机使用,用来降低虚拟机的隔离成本。所以容器与虚拟机之争本质上是调度理念之争,而不是隔离技术之争。
-
-### 容器对操作系统的影响
-
-Docker 没出现之前,服务器端的操作系统基本是传统 Linux 大厂商的天下,Ubuntu 好不容易通过自己的桌面版的优势赢得一席之地,一个创业公司试图进入这个领域基本是没有机会的,但 Docker 的出现带来了一个契机。这个契机就是一个操作系统需要考虑自己的目标是管理硬件还是管理应用。如果是管理硬件,也就是运行在物理机上的操作系统,目标就是提供内核,管理好硬件(磁盘,网络等),而应用层的事情交给容器,这样硬件层的操作系统不需要考虑各种应用软件栈的兼容问题,降低了操作系统的维护成本。如果是管理应用,那就可以放弃对硬件层的管理,专心维护软件栈。所以这个领域能冒出几家创业公司的产品试水:
-
-1. CoreOS 的 Container Linux 以及 Rancher 的 RancherOS 这两个 OS 的主要目标都是接管硬件,将主机操作系统从复杂的软件栈中解放出来,专心管理硬件和支持容器。传统的 Linux 操作系统为维护上层软件栈的兼容性付出了巨大的成本,发行版的一个优势在于提供全面软件栈的兼容性测试。而当二者解耦后,这个优势不再,竞争的核心在于能否提供更好的支持容器以及系统和内核的升级。
-2. Alpine Linux 这个精简后的 Linux 发行版则是专注于维护软件栈,给容器内的应用提供运行环境。所以它可以做到非常小,默认只有几M大小,即便是包含 bash 进去,也只十多M。所以 Docker 官方默认以它作为镜像的基础系统。
-
-操作系统的演进和更替是一个长期的工程,基本上得伴随着硬件的淘汰,所以至少五到十年的演进,着急不得,但可以期待。
-
-### 关于技术类创业的思考
-
-技术类创业,要思考清楚自己的机会是在市场还是在技术生态圈里占领一席之地。当然前者要比后者容易,后者最终也得变为市场的应用才能盈利,而即便是在技术生态圈中取得地位也不一定能找到商业模式,不过后者的潜力要大于前者。国内的创业一般倾向与前者,而国外则多倾向与后者,所以国内同质化的竞争比较激烈,而在差异化的生态构建方面则缺少建树。主要是因为国内的技术积累以及普及度和国外还有差距,还属于追随者,只有追随并赶超之后才会有创新,这个和 2C 领域的类似,2C 领域最近越来越少 C2C(Copy To China) 模式成功的案例了,2B 领域肯定还需要些年,不过感觉应该也不远。
-
-个人认为,2017 年容器编排调度领域的竞争会上升到应用层面,DCOS 之上的多语言应用框架(比如 微服务框架,Actor 模型框架),各种已有应用和基础设施的容器化,标准化,让已有应用变为云原生(Cloud Native)应用,等等。
-
-当然,理想和现实之间是有鸿沟的。一波一波的技术变革,本质上其实都是在试图将开发和运维人员从琐碎的,重复的,无聊的任务中解放出来,专注于有创意的领域。但变革最难变革的是人的思维方式和做事习惯,以及应对来自组织的阻碍。你说云应该就是按需的,动态的,自服务的,但用户的运维部门就喜欢审批开发人员资源申请,于是云变成了一个虚拟机分配系统。你说资源应该动态调度,应用混合部署有利于提高资源利用率,但用户的安全部门要求应用的业务必须分层,每层必须需要部署到独立的服务器上,跨层调用的端口还需要申请。**所以技术变革最后要落地成商业模式,首先要通过技术理念的传播去改变用户的思维方式以及组织体系,当然这肯定不可能是一蹴而就的,是一个长期的,反复过程**,其次要等待业务需求的驱动,当业务增长导致软件复杂度到一定规模的时候,自然会寻求新技术来解决复杂性。
\ No newline at end of file
diff --git a/docker/docs/convoy.md b/docker/docs/convoy.md
deleted file mode 100644
index 2a7a9a65f..000000000
--- a/docker/docs/convoy.md
+++ /dev/null
@@ -1,18 +0,0 @@
-# Convoy
-
-Convoy是Rancher公司的产品,目前已开源[https://github.com/rancher/convoy](https://github.com/rancher/convoy)
-
-A Docker volume plugin, managing persistent container volumes.
-
-后端存储支持三种方案:
-
-Device Mapper
-Amazon Elastic Block Store
-Virtual File System/Network File System
-Device Mapper
-
-Amazon Elastic Block Store
-
-Virtual File System/Network File System
-
-**该项目Rancher官方已经不维护了。不建议使用,目前使用也有问题,创建的backup无法显示正确的URL地址。目前已知唯品会在使用convoy。**
\ No newline at end of file
diff --git a/docker/docs/cpu_resource_limit.md b/docker/docs/cpu_resource_limit.md
deleted file mode 100644
index c132bb159..000000000
--- a/docker/docs/cpu_resource_limit.md
+++ /dev/null
@@ -1,115 +0,0 @@
-# Docker CPU资源限制
-
-## 一、压测工具
-
-使用 stress 测试。
-
-## 二、CPU 测试
-
-- [Runtime constraints on resources](https://docs.docker.com/engine/reference/run/#runtime-constraints-on-resources)
-- 目前 Docker 支持 CPU 资源限制选项
- - `-c`, `--cpu-shares=0`CPU shares (relative weight)-c 选项将会废弃,推荐使用 `--cpu-shares`
- - `--cpu-period=0`Limit the CPU CFS (Completely Fair Scheduler) period
- - `--cpuset-cpus=""`CPUs in which to allow execution (0-3, 0,1)
- - `--cpuset-mems=""`Memory nodes (MEMs) in which to allow execution (0-3, 0,1). Only effective on NUMA systems.
- - `--cpu-quota=0`Limit the CPU CFS (Completely Fair Scheduler) quota
-
-```
-➜ ~ docker help run | grep cpu
- --cpu-shares CPU shares (relative weight)
- --cpu-period Limit CPU CFS (Completely Fair Scheduler) period
- --cpu-quota Limit CPU CFS (Completely Fair Scheduler) quota
- --cpuset-cpus CPUs in which to allow execution (0-3, 0,1)
- --cpuset-mems MEMs in which to allow execution (0-3, 0,1)
-
-```
-
-### 2.1 CPU share constraint: `-c` or `--cpu-shares`
-
-默认所有的容器对于 CPU 的利用占比都是一样的,`-c` 或者 `--cpu-shares` 可以设置 CPU 利用率权重,默认为 1024,可以设置权重为 2 或者更高(单个 CPU 为 1024,两个为 2048,以此类推)。如果设置选项为 0,则系统会忽略该选项并且使用默认值 1024。通过以上设置,只会在 CPU 密集(繁忙)型运行进程时体现出来。当一个 container 空闲时,其它容器都是可以占用 CPU 的。cpu-shares 值为一个相对值,实际 CPU 利用率则取决于系统上运行容器的数量。
-
-假如一个 1core 的主机运行 3 个 container,其中一个 cpu-shares 设置为 1024,而其它 cpu-shares 被设置成 512。当 3 个容器中的进程尝试使用 100% CPU 的时候「尝试使用 100% CPU 很重要,此时才可以体现设置值」,则设置 1024 的容器会占用 50% 的 CPU 时间。如果又添加一个 cpu-shares 为 1024 的 container,那么两个设置为 1024 的容器 CPU 利用占比为 33%,而另外两个则为 16.5%。简单的算法就是,所有设置的值相加,每个容器的占比就是 CPU 的利用率,如果只有一个容器,那么此时它无论设置 512 或者 1024,CPU 利用率都将是 100%。当然,如果主机是 3core,运行 3 个容器,两个 cpu-shares 设置为 512,一个设置为 1024,则此时每个 container 都能占用其中一个 CPU 为 100%。
-
-测试主机「4core」当只有 1 个 container 时,可以使用任意的 CPU:
-
-```
-➜ ~ docker run -it --rm --cpu-shares 512 ubuntu-stress:latest /bin/bash
-root@4eb961147ba6:/# stress -c 4
-stress: info: [17] dispatching hogs: 4 cpu, 0 io, 0 vm, 0 hdd
-➜ ~ docker stats 4eb961147ba6
-CONTAINER CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O
-4eb961147ba6 398.05% 741.4 kB / 8.297 GB 0.01% 4.88 kB / 648 B 0 B / 0 B
-
-```
-
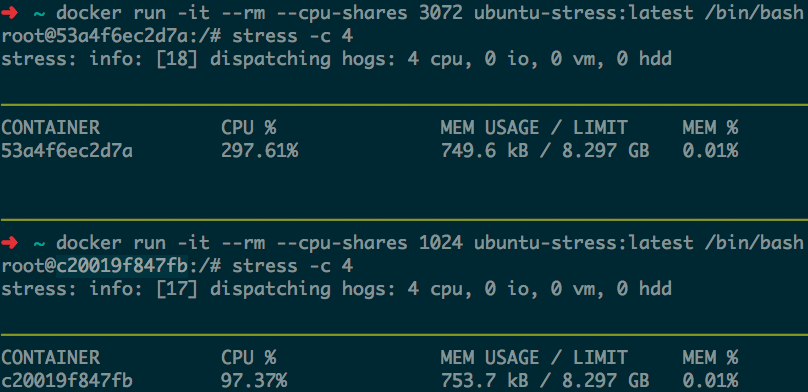
-测试两个 container,一个设置为 3072,一个设置 1024,CPU 占用如下:
-
-
-
-### 2.2 CPU period constraint: `--cpu-period` & `--cpu-quota`
-
-默认的 CPU CFS「Completely Fair Scheduler」period 是 100ms。我们可以通过 `--cpu-period` 值限制容器的 CPU 使用。一般 `--cpu-period` 配合 `--cpu-quota` 一起使用。
-
-设置 cpu-period 为 100ms,cpu-quota 为 200ms,表示最多可以使用 2 个 cpu,如下测试:
-
-```
-➜ ~ docker run -it --rm --cpu-period=100000 --cpu-quota=200000 ubuntu-stress:latest /bin/bash
-root@6b89f2bda5cd:/# stress -c 4 # stress 测试使用 4 个 cpu
-stress: info: [17] dispatching hogs: 4 cpu, 0 io, 0 vm, 0 hdd
-➜ ~ docker stats 6b89f2bda5cd # stats 显示当前容器 CPU 使用率不超过 200%
-CONTAINER CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O
-6b89f2bda5cd 200.68% 745.5 kB / 8.297 GB 0.01% 4.771 kB / 648 B 0 B / 0 B
-
-```
-
-通过以上测试可以得知,`--cpu-period` 结合 `--cpu-quota` 配置是固定的,无论 CPU 是闲还是繁忙,如上配置,容器最多只能使用 2 个 CPU 到 100%。
-
-- [CFS documentation on bandwidth limiting](https://www.kernel.org/doc/Documentation/scheduler/sched-bwc.txt)
-
-### 2.3 Cpuset constraint: `--cpuset-cpus`、`--cpuset-mems`
-
-#### `--cpuset-cpus`
-
-通过 `--cpuset-cpus` 可以绑定指定容器使用指定 CPU:
-
-设置测试容器只能使用 cpu1 和 cpu3,即最多使用 2 个 固定的 CPU 上:
-
-```
-➜ ~ docker run -it --rm --cpuset-cpus="1,3" ubuntu-stress:latest /bin/bash
-root@9f1fc0e11b6f:/# stress -c 4
-stress: info: [17] dispatching hogs: 4 cpu, 0 io, 0 vm, 0 hdd
-➜ ~ docker stats 9f1fc0e11b6f
-CONTAINER CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O
-9f1fc0e11b6f 199.16% 856.1 kB / 8.297 GB 0.01% 4.664 kB / 648 B 0 B / 0 B
-➜ ~ top # 宿主机 CPU 使用情况
-top - 12:43:55 up 3:18, 3 users, load average: 3.20, 2.54, 1.82
-Tasks: 211 total, 3 running, 207 sleeping, 1 stopped, 0 zombie
-%Cpu0 : 0.7 us, 0.3 sy, 0.0 ni, 99.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
-%Cpu1 :100.0 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
-%Cpu2 : 0.7 us, 0.3 sy, 0.0 ni, 99.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
-%Cpu3 :100.0 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
-... ...
-
-```
-
-以下表示容器可以利用 CPU1、CPU2 和 CPU3:
-
-```
-➜ ~ docker run -it --rm --cpuset-cpus="1-3" ubuntu-stress:latest /bin/bash
-
-```
-
-#### `--cpuset-mems`
-
-`--cpuset-mems` 只应用于 NUMA 架构的 CPU 生效,关于这个选项这里不过多介绍。关于 NUMA 架构可以参考这篇文章 [NUMA架构的CPU – 你真的用好了么?](http://cenalulu.github.io/linux/numa/)。
-
-## 三、源码解析
-
-- [github.com/opencontainers/runc/libcontainer/cgroups/fs](https://github.com/opencontainers/runc/tree/master/libcontainer/cgroups/fs)
- - cpu.go
- - cpuset.go
- - cpuacct.go
-
-libcontainer 只是根据设定值写 cgroup 文件,这部分没有什么逻辑性的解释。
-
-From:http://blog.opskumu.com/docker-cpu-limit.html
\ No newline at end of file
diff --git a/docker/docs/crane_usage.md b/docker/docs/crane_usage.md
deleted file mode 100644
index 77b373c87..000000000
--- a/docker/docs/crane_usage.md
+++ /dev/null
@@ -1,112 +0,0 @@
-# Crane的部署和使用
-
-Crane是数人云开源的一款基于swarmkit的容器管理平台。
-
-开源地址:https://github.com/Dataman-Cloud/crane
-
-## 功能##
-
-### 主机管理###
-
-- 节点概览:`id`、`主机名`、`角色`、`可用性`、`状态`、`标签`、`添加时间`等信息
- - id: 集群内的节点id
- - 主机名: 集群内节点主机名
- - 角色: 分为管理节点和工作节点,只有管理节点能调度server及节点角色。目前使用单管理节点。
- - 可用性: 调度开关状态、可用通过`操作`菜单维护。`停止调度`: 节点资源不可用,已经发布的任务会调度到其他可用资源。`暂停调度`: 该节点资源暂时不接受新任务调度,已经发布的任务不受影响。`正常调度`: 节点资源完全放开。
- - 状态:分为`就绪`和`下线`;`就绪`状态指节点状态正常,`下线`状态指节点已经离开群集、资源不可用。
- - 标签:节点的label信息、配合服务发布时的资源调度时使用。
- - 添加时间: 记录节点加入集群时间
-- 节点操作:
- - 连接主机:填写主机ip;点击连接,提示更新主机成功后,点击主机id,即可查询到主机详情。
- - 基本信息:Docker相关信息和主机的基本信息
- - 容器信息:主机上已有的容器统计信息
- - 网络: 主机上现有网络信息
- - 储存卷:主机上Docker的存储卷信息
- - 镜像:节点上已有的Docker镜像
- - 编辑标签:为主机编辑标签,便于服务发布时的策略调度使用。以`key``value`形式创建。
- - 停止调度:节点资源不可用,已经发布的任务会调度到其他可用资源。
- - 暂停调度: 该节点资源暂时不接受新任务调度,已经发布的任务不受影响。
- - 恢复调度: 节点资源恢复使用完全放开。
- - 删除主机:将主机从集群中删除,需要状态为下线状态。
-
-### 应用管理###
-
-目前所有发布的应用都会在应用首页展示,支持对应用的更新、删除、扩展、监控、日志查询、详情查询、连接容器终端等操作。
-
-**应用更新**: 在应用面板处选择待更新的应用,点击应用名称进入`应用详情`--`操作`--`更新`,跳转到`服务更新`界面,修改所需改动的信息,点击`更新`即可完成更新操作。
-
-*注:* 服务的网络模式以及服务模式不可更改,更新时会按照之前设置的更新策略执行,也可以更新`更新策略`。`更新策略`和`容错策略`的变更不会触发容器重启。
-
-**应用扩展**: 在应用面板处选择待更新的应用,点击应用名称进入`应用详情`--`操作`--`修改任务数`,修改的任务数会立即生效。不受更新策略影响。
-
-**应用删除**:
-
-在应用面板处选择待删除的应用,点击应用名称进入`应用详情`,点击`删除应用`,应用会立即被删除,且不能恢复,删除需谨慎 *注:* 若应用内多个服务,不能删除单个服务。
-
-**服务详情**
-
-在应用面板选择应用名称下的服务名称,会跳转到`服务详情`界面。
-
-- 任务列表:展示服务运行到所有任务数,点击每个任务最右侧的`+`,可以展示该任务的历史状态,即使修改过任务数,改处仍然可以找到任务的历史纪录,以及异常原因。
-
- - 容器详情:点击容器的id,可以跳转到`容器详情`界面:
- - 详情界面:展示了容器的`基础信息`、`环境变量`、`端口映射`、`网络配置`、`容器标签`、`存储卷`、`启动命令`等
- - 日志:该容器的实时日志信息。
- - 实时监控:获取容器实时的cpu、内存、网络io的使用情况。
- - 变更:记录容器的层结构变化。
- - 终端webssh:点击该按钮,可用直接连接到该容器内部,无需登录远程主机,无需主机口令,一键进入。
-
- *注:* 监控信息及日志信息实时展示,暂不支持导出。
-
-- 日志:该服务所有容器的实时日志信息的聚合,另外,日志中的关键词如 Error, Warning 会高亮显示。
-
-- 实时监控;服务的监控信息概览,同时显示不同任务的资源使用情况。
-
-- 详情:发布应用时设置的服务信息。
-
-- 入口列表:提供服务的外部访问地址。同时提供nginx的配置信息和haproxy的配置信息,便于用户管理。
-
-- 持续部署:如果该服务需要更新镜像,可以通过该命令直接更新,可用对接内部运维流程;需要保证:镜像地址确定可用。运行命令的主机可用连通服务端。
-
-### 网络管理###
-
-内置 overlay 网络实现应用网络隔离和独立的网络规划能力, 在创建应用时可以为服务指定相应的网络。
-
-### 创建网络
-
-docker1.12默认带有两种overlay网络,`ingress` 和`docker_gwbridge`;
-
-**ingress**
-
-Swarm manager使用`ingress`负载均衡,创建服务时做的端口映射作为service的默认VIP,virtual IP地址作为服务请求的入口。基于virtual IP进行负载均衡.集群内的ingress网络是基于节点端口模式的,集群内的每个监听这个端口的节点,都可以为那个服务路由流量。
-
-需要注意的是,即使指定了自定义网络,做了端口映射的服务也会自动添加ingress网络。
-
-**docker_gwbridge**
-
-`default_gwbridge` 网络只能用在非内部的网络环境下,连接到多主机网络的容器会自动连接到docker_gwbridge网络。这种网络模式让容器可以和集群外产生外部连接,并且在每个worker节点上创建。
-
-**your_own_overlay**
-
-如果有规划网络的需要,容器间做网络隔离,可用通过自定义网络实现。
-
-点击`创建网络`按钮,填写网络信息后`创建`即可。
-
-- 网络名称: 必须为数字或英文
-- 子网:示例:172.20.0.0/16
-- 网关:示例:172.20.10.1
-- ip范围:示例 172.20.10.0/24;可用ip从172.20.10.1~172.20.10.254。
-- 内部网络:如果为是,该网络不提供与集群外的通讯。
-- 标签:设置标签后,在发布新服务时可用通过标签选择网络。
-
-网络管理:
-
-除了`ingress`网络,均可在界面点击`删除`按钮操作。 如果想对已经创建的网络做更新操作,需要删除后重新创建。
-
-## 部署##
-
-1. 请确保 docker 安装版本 >=1.12 并正常运行, 我们可以通过命令 `docker version` 或者 `docker info`来确认 docker 的运行状态(如何安装和配置 docker 请参考 [https://docs.docker.com/engine/installation/)。](https://docs.docker.com/engine/installation/)%E3%80%82)
-2. 请确保 docker-compose 已经正确安装(如何安装 docker-compose 请参考 [https://docs.docker.com/compose/install/)。](https://docs.docker.com/compose/install/)%E3%80%82)
-3. docker,swarm 本身对操作系统还有一些设置需求,譬如主机时钟同步,selinux,docker daemon tcp 服务开启等。这些会在程序安装时自动进行检查, 请在安装时按提醒进行相应设置。
-4. 执行内测邮件中的安装命令,在安装过程中会提醒你输入当前主机的 IP 。
-5. 安装成功后通过浏览器访问 [http://$IP](http://%24ip/) 即可,默认用户名:admin@admin.com 密码:adminadmin
\ No newline at end of file
diff --git a/docker/docs/create_network.md b/docker/docs/create_network.md
deleted file mode 100644
index ed21ac0ff..000000000
--- a/docker/docs/create_network.md
+++ /dev/null
@@ -1,120 +0,0 @@
-# 如何创建docker network?
-
-容器的跨主机网络访问是docker容器集群的基础,我们之前使用的[Shrike](github.com/talkingdata/shrike)实现二层网络,能够使不同主机中的容器和主机的网络互联互通,使容器看上去就像是虚拟机一样,这样做的好处是可以不变动已有的服务,将原有的应用直接封装成一个image启动即可,但这也无法利用上docker1.12+后的service、stack等服务编排、负载均衡、服务发现等功能。我们在此讨论容器的网络模式,暂且忽略自定义网络,会在后面单独谈论它。
-
-## Swarm中已有的network##
-
-安装好docker并启动swarm集群后,会在集群的每个node中找到如下network:
-
-| NETWORK ID | NAME | DRIVER | SCOPE |
-| ------------------ | --------------- | ------------ | ----------- |
-| b1d5859a9439 | bridge | bridge | local |
-| 262ec8634832 | docker_gwbridge | bridge | local |
-| 19c11140a610 | host | host | local |
-| tx49ev228p5l | ingress | overlay | swarm |
-| ~~*c7d82cbc5a33*~~ | ~~*mynet*~~ | ~~*bridge*~~ | ~~*local*~~ |
-| e1a59cb1dc34 | none | null | local |
-
-**(注)**mynet是我们自定义的本地网络,我们暂时不用它,因为我们是以swarm集群模式使用docker,暂时不考虑本地网络;docker_gwbridge作为docker gateway网络,功能比较特殊,负责service的负载均衡和服务发现。
-
-**有两种方式来创建docker network:**
-
-- 使用docker network create命令来创建,只能创建docker内建的网络模式
-- 使用docker plugin,创建自定义网络
-
-## 使用docker命令创建网络##
-
-**Docker中内置的网络模式包括如下几种:**
-
-- bridge 我们基于该网络模式创建了mynet网络
-- host 本地网络模式
-- macvlan 这个模式貌似是最新加的
-- null 无网络
-- overlay 用于swarm集群中容器的跨主机网络访问
-
-**docker create network命令包含以下参数:**
-
-```
-Flag shorthand -h has been deprecated, please use --help
-
-Usage: docker network create [OPTIONS] NETWORK
-
-Create a network
-
-Options:
- --attachable Enable manual container attachment
- --aux-address map Auxiliary IPv4 or IPv6 addresses used by Network driver (default map[])
- -d, --driver string Driver to manage the Network (default "bridge")
- --gateway stringSlice IPv4 or IPv6 Gateway for the master subnet
- --help Print usage
- --internal Restrict external access to the network
- --ip-range stringSlice Allocate container ip from a sub-range
- --ipam-driver string IP Address Management Driver (default "default")
- --ipam-opt map Set IPAM driver specific options (default map[])
- --ipv6 Enable IPv6 networking
- --label list Set metadata on a network (default [])
- -o, --opt map Set driver specific options (default map[])
- --subnet stringSlice Subnet in CIDR format that represents a network segment
-```
-
-创建overlay模式的全局网络,我们可以看到新创建的mynet1的scope是swarm,即集群范围可见的。
-
-```shell
-172.18.0.1:root@sz-pg-oam-docker-test-001:/root]# docker network create -d overlay mynet1
-x81fu4ohqot2ufbpoa2u8vyx3
-172.18.0.1:root@sz-pg-oam-docker-test-001:/root]# docker network ls
-NETWORK ID NAME DRIVER SCOPE
-ad3023f6d324 bridge bridge local
-346c0fe30055 crane_default bridge local
-4da289d8e48a docker_gwbridge bridge local
-3d636dff00da host host local
-tx49ev228p5l ingress overlay swarm
-x81fu4ohqot2 mynet1 overlay swarm
-cc14ee093707 none null local
-172.18.0.1:root@sz-pg-oam-docker-test-001:/root]# docker network inspect mynet1
-[
- {
- "Name": "mynet1",
- "Id": "x81fu4ohqot2ufbpoa2u8vyx3",
- "Created": "0001-01-01T00:00:00Z",
- "Scope": "swarm",
- "Driver": "overlay",
- "EnableIPv6": false,
- "IPAM": {
- "Driver": "default",
- "Options": null,
- "Config": []
- },
- "Internal": false,
- "Attachable": false,
- "Containers": null,
- "Options": {
- "com.docker.network.driver.overlay.vxlanid_list": "4097"
- },
- "Labels": null
- }
-]
-
-```
-
-注意,overlay模式的网络只能在swarm的manager节点上创建,如果在work节点上创建overlay网络会报错:
-
-```shell
-172.18.0.1:root@sz-pg-oam-docker-test-002:/root]# docker network create -d overlay mynet1
-Error response from daemon: Cannot create a multi-host network from a worker node. Please create the network from a manager node.
-```
-
-如果不使用-d指定driver将默认创建本地bridge网络。
-
-## 自定义网络##
-
-创建自定义网络需要设置网络的driver和ipam。
-
-TDB
-
-创建网络需要满足的需求
-
-写一个创建自定义网络的例子
-
-[一步步教你创建一个自定义网络](create_network_step_by_step.md)
-
diff --git a/docker/docs/create_swarm_app.md b/docker/docs/create_swarm_app.md
deleted file mode 100644
index b8f30fbb7..000000000
--- a/docker/docs/create_swarm_app.md
+++ /dev/null
@@ -1,225 +0,0 @@
-# 创建docker swarm应用
-
-下面以docker官网上的创建[vote投票](https://docs.docker.com/engine/getstarted-voting-app/)示例来说明如何创建一个docker swarm的应用。
-
-在进行如下步骤时,你需要保证已经部署并正常运行着一个docker swarm集群。
-
-在这个应用中你将学到
-
-- 通过创建``docker-stack.yml``和使用``docker stack deploy``命令来部署应用
-- 使用``visualizer``来查看应用的运行时
-- 更新``docker-stack.yml``和``vote``镜像重新部署和发布**vote** 应用
-- 使用Compose Version 3
-
-
-
-## 需要使用到的images
-
-| Service | 描述 | Base image |
-| --------- | ---------------------------------------- | ---------------------------------------- |
-| vote | Presents the voting interface via port `5000`. Viewable at `:5000` | Based on a Python image, `dockersamples/examplevotingapp_vote` |
-| result | Displays the voting results via port 5001. Viewable at `:5001` | Based on a Node.js image, `dockersamples/examplevotingapp_result` |
-| visulizer | A web app that shows a map of the deployment of the various services across the available nodes via port `8080`. Viewable at `:8080` | Based on a Node.js image, `dockersamples/visualizer` |
-| redis | Collects raw voting data and stores it in a key/value queue | Based on a `redis` image, `redis:alpine` |
-| db | A PostgreSQL service which provides permanent storage on a host volume | Based on a `postgres` image, `postgres:9.4` |
-| worker | A background service that transfers votes from the queue to permanent storage | Based on a .NET image, `dockersamples/examplevotingapp_worker` |
-
-**用到的镜像有:**
-
-- dockersamples/examplevotingapp_vote:before
-- dockersamples/examplevotingapp_worker
-- dockersamples/examplevotingapp_result:before
-- dockersamples/visualizer:stable
-- postgres:9.4
-- redis:alpine
-
-我们将这些images同步到我们的私有镜像仓库sz-pg-oam-docker-hub-001.tendcloud.com中。
-
-镜像名称分别为:
-
-- sz-pg-oam-docker-hub-001.tendcloud.com/library/examplevotingapp_vote:before
-- sz-pg-oam-docker-hub-001.tendcloud.com/library/examplevotingapp_worker
-- sz-pg-oam-docker-hub-001.tendcloud.com/library/examplevotingapp_result:before
-- sz-pg-oam-docker-hub-001.tendcloud.com/library/visualizer:stable
-- sz-pg-oam-docker-hub-001.tendcloud.com/library/postgres:9.4
-- sz-pg-oam-docker-hub-001.tendcloud.com/library/redis:alpine
-
-## 使用V3版本的compose文件##
-
-[v3版本的compose与v2版本的区别](compose_v2v3.md)
-
-docker-stack.yml配置
-
-```Yaml
-version: "3"
-services:
-
- redis:
- image: sz-pg-oam-docker-hub-001.tendcloud.com/library/redis:alpine
- ports:
- - "6379"
- networks:
- - frontend
- deploy:
- replicas: 2
- update_config:
- parallelism: 2
- delay: 10s
- restart_policy:
- condition: on-failure
- db:
- image: sz-pg-oam-docker-hub-001.tendcloud.com/library/postgres:9.4
- volumes:
- - db-data:/var/lib/postgresql/data
- networks:
- - backend
- deploy:
- placement:
- constraints: [node.role == manager]
- vote:
- image: sz-pg-oam-docker-hub-001.tendcloud.com/library/examplevotingapp_vote:before
- ports:
- - 5000:80
- networks:
- - frontend
- depends_on:
- - redis
- deploy:
- replicas: 2
- update_config:
- parallelism: 2
- restart_policy:
- condition: on-failure
- result:
- image: sz-pg-oam-docker-hub-001.tendcloud.com/library/examplevotingapp_result:before
- ports:
- - 5001:80
- networks:
- - backend
- depends_on:
- - db
- deploy:
- replicas: 2
- update_config:
- parallelism: 2
- delay: 10s
- restart_policy:
- condition: on-failure
-
- worker:
- image: sz-pg-oam-docker-hub-001.tendcloud.com/library/examplevotingapp_worker
- networks:
- - frontend
- - backend
- deploy:
- mode: replicated
- replicas: 1
- labels: [APP=VOTING]
- restart_policy:
- condition: on-failure
- delay: 10s
- max_attempts: 3
- window: 120s
-
- visualizer:
- image: sz-pg-oam-docker-hub-001.tendcloud.com/library/visualizer:stable
- ports:
- - "8080:8080"
- stop_grace_period: 1m30s
- volumes:
- - "/var/run/docker.sock:/var/run/docker.sock"
- deploy:
- placement:
- constraints: [node.role == manager]
-
-networks:
- frontend:
- backend:
-
-volumes:
- db-data:
-```
-
-## 部署##
-
-使用docker stack deploy命令部署vote应用。
-
-```
-$docker stack deploy -c docker-stack.yml vote
-Creating network vote_backend
-Creating network vote_frontend
-Creating network vote_default
-Creating service vote_db
-Creating service vote_vote
-Creating service vote_result
-Creating service vote_worker
-Creating service vote_visualizer
-Creating service vote_redis
-```
-
-使用``docker stack deploy``部署的应用中的images必须是已经在镜像仓库中存在的,而不能像之前的docker-compose up一样,可以通过本地构建镜像后启动。
-
-使用``docker stack service vote``查看应用状态
-
-```
-$docker stack services vote
-ID NAME MODE REPLICAS IMAGE
-5bte3o8e0ta9 vote_result replicated 2/2 sz-pg-oam-docker-hub-001.tendcloud.com/library/examplevotingapp_result:before
-h65a6zakqgq3 vote_worker replicated 1/1 sz-pg-oam-docker-hub-001.tendcloud.com/library/examplevotingapp_worker:latest
-k7xzd0adhh52 vote_db replicated 1/1 sz-pg-oam-docker-hub-001.tendcloud.com/library/postgres:9.4
-pvvi5qqcsnag vote_vote replicated 2/2 sz-pg-oam-docker-hub-001.tendcloud.com/library/examplevotingapp_vote:before
-z4q2gnvoxtpj vote_redis replicated 2/2 sz-pg-oam-docker-hub-001.tendcloud.com/library/redis:alpine
-zgiuxazk4ssc vote_visualizer replicated 1/1 sz-pg-oam-docker-hub-001.tendcloud.com/library/visualizer:stable
-```
-
-使用``docker stack ls``和``docker stack ps vote``查看stack的状态
-
-```
-$docker stack ls
-NAME SERVICES
-vote 6
-$docker stack ps vote
-ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
-tcyy62bs26sp vote_worker.1 sz-pg-oam-docker-hub-001.tendcloud.com/library/examplevotingapp_worker:latest sz-pg-oam-docker-test-003.tendcloud.com Running Running 4 minutes ago
-tfa84y1yz00j vote_redis.1 sz-pg-oam-docker-hub-001.tendcloud.com/library/redis:alpine sz-pg-oam-docker-test-002.tendcloud.com Running Running 5 minutes ago
-4yrp8e2pucnu vote_visualizer.1 sz-pg-oam-docker-hub-001.tendcloud.com/library/visualizer:stable sz-pg-oam-docker-test-001.tendcloud.com Running Running 5 minutes ago
-zv4dan0n9zo3 vote_worker.1 sz-pg-oam-docker-hub-001.tendcloud.com/library/examplevotingapp_worker:latest sz-pg-oam-docker-test-003.tendcloud.com Shutdown Failed 4 minutes ago "task: non-zero exit (1)"
-mhbf683hiugr vote_result.1 sz-pg-oam-docker-hub-001.tendcloud.com/library/examplevotingapp_result:before sz-pg-oam-docker-test-001.tendcloud.com Running Running 5 minutes ago
-slf6je49r4v1 vote_vote.1 sz-pg-oam-docker-hub-001.tendcloud.com/library/examplevotingapp_vote:before sz-pg-oam-docker-test-002.tendcloud.com Running Running 5 minutes ago
-mqypecrgriyq vote_db.1 sz-pg-oam-docker-hub-001.tendcloud.com/library/postgres:9.4 sz-pg-oam-docker-test-001.tendcloud.com Running Running 4 minutes ago
-6n7856nsvavn vote_redis.2 sz-pg-oam-docker-hub-001.tendcloud.com/library/redis:alpine sz-pg-oam-docker-test-003.tendcloud.com Running Running 5 minutes ago
-pcrfnm20jf0r vote_result.2 sz-pg-oam-docker-hub-001.tendcloud.com/library/examplevotingapp_result:before sz-pg-oam-docker-test-002.tendcloud.com Running Running 4 minutes ago
-ydxurw1jnft6 vote_vote.2 sz-pg-oam-docker-hub-001.tendcloud.com/library/examplevotingapp_vote:before sz-pg-oam-docker-test-003.tendcloud.com Running Running 5 minutes ago
-```
-
-## 检查##
-
-当vote应用成功部署后,在浏览器中访问visualizer所部属到的主机的8080端口http://sz-pg-oam-docker-hub-001.tendcloud.com:8080可以看到如下画面:
-
-
-
-Visualizer用于显示服务和主机的状态。
-
-**投票界面**
-
-在浏览器中访问``examplevotingapp_vote``所部属到的主机的5000端口http://sz-pg-oam-docker-hub-001.tendcloud.com:5000可以看到如下画面:
-
-
-
-给猫投一票。
-
-**结果界面**
-
-在浏览器中访问``examplevotingapp_result``所部属到的主机的5001端口http://sz-pg-oam-docker-hub-001.tendcloud.com:5001可以看到如下画面.
-
-
-
-
-
-##总结##
-
-至此整个应用已经完整的部署在docker上了,并验证正常运行。
-
-怎么样,是用docker来部署一个应用是不是很简单?
-
-其实后期的维护、升级、扩展都很简单,后面会详细的说明。
\ No newline at end of file
diff --git a/docker/docs/docker_compile.md b/docker/docs/docker_compile.md
deleted file mode 100644
index cf3c327df..000000000
--- a/docker/docs/docker_compile.md
+++ /dev/null
@@ -1,156 +0,0 @@
-# Docker源码编译和开发环境搭建
-
-官方指导文档:https://docs.docker.com/opensource/code/
-
-设置docker开发环境:https://docs.docker.com/opensource/project/set-up-dev-env/
-
-docker的编译实质上是在docker容器中运行docker。
-
-因此在本地编译docker的前提是需要安装了docker,还需要用git把代码pull下来。
-
-### 创建分支
-
-为了方便以后给docker提交更改,我们从docker官方fork一个分支。
-
-```shell
-git clone https://github.com/rootsongjc/docker.git
-git config --local user.name "Jimmy Song"
-git config --local user.email "rootsongjc@gmail.com"
-git remote add upstream https://github.com/docker/docker.git
-git config --local -l
-git remote -v
-git checkout -b dry-run-test
-touch TEST.md
-vim TEST.md
-git status
-git add TEST.md
-git commit -am "Making a dry run test."
-git push --set-upstream origin dry-run-test
-```
-
-然后就可以在``dry-run-test``这个分支下工作了。
-
-### 配置docker开发环境
-
-[官网](https://docs.docker.com/opensource/project/set-up-dev-env/)上说需要先清空自己电脑上已有的容器和镜像。
-
-docker开发环境本质上是创建一个docker镜像,镜像里包含了docker的所有开发运行环境,本地代码通过挂载的方式放到容器中运行,下面这条命令会自动创建这样一个镜像。
-
-在``dry-run-test``分支下执行
-
-```Shell
-make BIND_DIR=. shell
-```
-
-该命令会自动编译一个docker镜像,From debian:jessie。这一步会上网下载很多依赖包,速度比较慢。如果翻不了墙的话肯定都会失败。因为需要下载的软件和安装包都是在国外服务器上,不翻墙根本就下载不下来,为了不用这么麻烦,推荐直接使用docker官方的dockercore/docker镜像,也不用以前的docker-dev镜像,那个造就废弃了。这个镜像大小有2.31G。
-
-```
-docker pull dockercore/docker
-```
-
-使用方法见这里:https://hub.docker.com/r/dockercore/docker/
-
-然后就可以进入到容器里
-
-```Shell
-docker run --rm -i --privileged -e BUILDFLAGS -e KEEPBUNDLE -e DOCKER_BUILD_GOGC -e DOCKER_BUILD_PKGS -e DOCKER_CLIENTONLY -e DOCKER_DEBUG -e DOCKER_EXPERIMENTAL -e DOCKER_GITCOMMIT -e DOCKER_GRAPHDRIVER=devicemapper -e DOCKER_INCREMENTAL_BINARY -e DOCKER_REMAP_ROOT -e DOCKER_STORAGE_OPTS -e DOCKER_USERLANDPROXY -e TESTDIRS -e TESTFLAGS -e TIMEOUT -v "/Users/jimmy/Workspace/github/rootsongjc/docker/bundles:/go/src/github.com/docker/docker/bundles" -t "dockercore/docker:latest" bash
-```
-
-按照官网的说明make会报错
-
-```
-root@f2753f78bb6d:/go/src/github.com/docker/docker# ./hack/make.sh binary
-
-error: .git directory missing and DOCKER_GITCOMMIT not specified
- Please either build with the .git directory accessible, or specify the
- exact (--short) commit hash you are building using DOCKER_GITCOMMIT for
- future accountability in diagnosing build issues. Thanks!
-```
-
-这是一个[issue-27581](https://github.com/docker/docker/issues/27581),解决方式就是在make的时候手动指定``DOCKER_GITCOMMIT``。
-
-```
-root@f2753f78bb6d:/go/src/github.com/docker/docker# DOCKER_GITCOMMIT=3385658 ./hack/make.sh binary
-
----> Making bundle: binary (in bundles/17.04.0-dev/binary)
-Building: bundles/17.04.0-dev/binary-client/docker-17.04.0-dev
-Created binary: bundles/17.04.0-dev/binary-client/docker-17.04.0-dev
-Building: bundles/17.04.0-dev/binary-daemon/dockerd-17.04.0-dev
-Created binary: bundles/17.04.0-dev/binary-daemon/dockerd-17.04.0-dev
-Copying nested executables into bundles/17.04.0-dev/binary-daemon
-
-```
-
-bundles目录下会生成如下文件结构
-
-```
-.
-├── 17.04.0-dev
-│ ├── binary-client
-│ │ ├── docker -> docker-17.04.0-dev
-│ │ ├── docker-17.04.0-dev
-│ │ ├── docker-17.04.0-dev.md5
-│ │ └── docker-17.04.0-dev.sha256
-│ └── binary-daemon
-│ ├── docker-containerd
-│ ├── docker-containerd-ctr
-│ ├── docker-containerd-ctr.md5
-│ ├── docker-containerd-ctr.sha256
-│ ├── docker-containerd-shim
-│ ├── docker-containerd-shim.md5
-│ ├── docker-containerd-shim.sha256
-│ ├── docker-containerd.md5
-│ ├── docker-containerd.sha256
-│ ├── docker-init
-│ ├── docker-init.md5
-│ ├── docker-init.sha256
-│ ├── docker-proxy
-│ ├── docker-proxy.md5
-│ ├── docker-proxy.sha256
-│ ├── docker-runc
-│ ├── docker-runc.md5
-│ ├── docker-runc.sha256
-│ ├── dockerd -> dockerd-17.04.0-dev
-│ ├── dockerd-17.04.0-dev
-│ ├── dockerd-17.04.0-dev.md5
-│ └── dockerd-17.04.0-dev.sha256
-└── latest -> 17.04.0-dev
-
-4 directories, 26 files
-```
-
-现在可以将docker-daemon和docker-client目录下的docker可以执行文件复制到容器的/usr/bin/目录下了。
-
-启动docker deamon
-
-```Shell
-docker daemon -D&
-```
-
-检查下docker是否可用
-
-```
-root@f2753f78bb6d:/go/src/github.com/docker/docker/bundles/17.04.0-dev# docker version
-DEBU[0048] Calling GET /_ping
-DEBU[0048] Calling GET /v1.27/version
-Client:
- Version: 17.04.0-dev
- API version: 1.27
- Go version: go1.7.5
- Git commit: 3385658
- Built: Mon Mar 6 08:39:06 2017
- OS/Arch: linux/amd64
-
-Server:
- Version: 17.04.0-dev
- API version: 1.27 (minimum version 1.12)
- Go version: go1.7.5
- Git commit: 3385658
- Built: Mon Mar 6 08:39:06 2017
- OS/Arch: linux/amd64
- Experimental: false
-```
-
-到此docker源码编译和开发环境都已经搭建好了。
-
-如果想要修改docker源码,只要在你的IDE、容器里或者你本机上修改docker代码后,再执行上面的hack/make.sh binary命令就可以生成新的docker二进制文件,再替换原来的/usr/bin/目录下的docker二进制文件即可。
\ No newline at end of file
diff --git a/docker/docs/docker_compose.md b/docker/docs/docker_compose.md
deleted file mode 100644
index d6793e8b1..000000000
--- a/docker/docs/docker_compose.md
+++ /dev/null
@@ -1,129 +0,0 @@
-# Docker-compose
-
-docker-compose是一个使用python编写的命令行工具,用于docker应用之间的编排,可以在单主机下使用,也可以使用在docker swarm集群或docker1.12+的swarm mode下。
-
-docker1.13以前docker-compose是一个独立的安装的命令行工具,文档如下https://docs.docker.com/compose/overview/,下面要讲的是compose file,已经在docker1.13种集成了docker的应用编排功能,可以在提供了docker-compose.yml文件的情况下使用docker stack deploy -f docker-compose.yml直接部署应用。
-
-## Compose file
-
-Docker compose file到目前共有3个版本,docker1.13使用的compose file v3版本。官方文档:https://docs.docker.com/compose/compose-file/
-
-Compose file使用[yaml](yaml.org)格式定义,默认名称为docker-compose.yml。
-
-Dockerfile中的``CMD``,``EXPOSE``,``VOLUME``,``ENV``命令可以不必在docker-compose.yml中再定义。
-
-### build
-
-build命令在docker swarm mode下使用docker stack deploy命令时是无效的,只有在本地使用docker-compose命令时才会创建image。
-
-### ARGS
-
-假如Dockerfile中有如下两个变量``$buildno``和``$password``
-
-```dockerfile
-ARG buildno
-ARG password
-
-RUN echo "Build number: $buildno"
-RUN script-requiring-password.sh "$password"
-```
-
-docker-compose.yml中可以使用args来定义这两个变量的值。
-
-```Yaml
-build:
- context: .
- args:
- buildno: 1
- password: secret
-
-build:
- context: .
- args:
- - buildno=1
- - password=secret
-```
-
-使用docker-compose build的时候就会替换这两个变量的值。
-
-也可以忽略这两个变量。
-
-```
-args:
- - buildno
- - password
-```
-
-### command
-
-```
-command: bundle exec thin -p 3000
-```
-
-替换Dockerfile中默认的CMD。
-
-### deploy
-
-Compose file v3才支持的功能,也是重点功能。
-
-```Yaml
-deploy:
- replicas: 6
- update_config:
- parallelism: 2
- delay: 10s
- restart_policy:
- condition: on-failure
-```
-
-**deploy**有如下几个子选项
-
-- **Mode**:可以为global或replicated,global能够规定服务在每台主机一个容器。replicated可以自定义service的容器个数。
-- **replicas**:使用``replicas``定义service的容器个数,只有在replicated mode下可用。
-- **placement**:用来限定容器部署在哪些主机上。使用``constraints``约束。
-- **Update_config**:定义service升级策略。
- - Parrallism:一次性同时升级的容器数
- - delay:两次升级之间的间隔
- - failure_action:升级失败后可以pause或continue,默认pause
- - monitor:升级后监控failure的间隔,格式(ns|us|ms|s|m|h),默认0s
- - max_failure_ratio:可容忍的失败率
-- **resources**:service的资源数量限定,包括如下几个值`cpu_shares`, `cpu_quota`,`cpuset`, `mem_limit`, `memswap_limit`, `mem_swappiness`。
- - **restart_policy**:``condition``:one、on-failure、any默认any,``delay``,``max_attempts``,``window``
- - **labels**:为service打标签
-
-
-### docker-compose.yml还支持的配置有
-
-- **devices**:devices mapping
-- **depends_on**:定义service依赖关系,影响启动顺序
-- **dns**:自定义DNS,可以是单条也可以为列表
-- **dns_search**:自定义DNS搜索域
-- **tmpfs**:挂载临时文件系统
-- **entrypoint**:覆盖dockerfile中国年的entrypoint
-- **env_file**:定义env的文件,可以为一个列表
-- **environment**:定义环境变量
-- **expose**
-- **external_links**:链接外部docker-compose.yml外部启动的容器
-- **extra_hosts**:添加外部hosts
-- **group_add**
-- **healthcheck**:检查service的健康状况
-- **Image**
-- **Isolation**:linux只支持default,windows还有其他选项
-- **labels**:给容器打标签,建议用DNS的反向字符串定义
-- **links**:链接其他service
-- **logging**:日志配置,可以配置日志的driver、地址等
-- **network_mode**
-- **networks**:可以连接的定义网络名称,分配IP地址,设置网络别名,``LINK_LOCAL_IPS``选项可以连接外部非docker管理的IP。还可以定义的选项有driver、driver_opts、enable_ipv6、ipam、internal、labels、external等
-- **pid**
-- **ports**:对外暴露的端口
-- **secret**:定义service可以访问的secret文件
-- **security_opts**
-- **stop_grace_period**
-- **stop_signal**
-- **sysctls**
-- **ulimits**
-- **userns_mode**
-- **volumes**:可以定义driver、driver_opts、external、labels等
-
-
-networks和volumes的子选项比较多,定义的时候请参照详细文档。
\ No newline at end of file
diff --git a/docker/docs/docker_env.md b/docker/docs/docker_env.md
deleted file mode 100644
index d4a207777..000000000
--- a/docker/docs/docker_env.md
+++ /dev/null
@@ -1,42 +0,0 @@
-# Docker环境配置
-
-**软件环境**
-
-- Docker1.13.1
-- docker-compose 1.11.1
-- centos 7.3.1611
-
-如果在Mac上安装后docker后需要从docker hub上下载镜像,建议设置国内的mirror,能够显著增加下载成功率,提高下载速度,~~推荐[daocloud的mirror](https://www.daocloud.io/mirror#accelerator-doc)~~推荐使用阿里云的mirror,速度比较快一些。
-
-设置方式很简单,只需要在Mac版本的docker - preferences - daemon - registry mirrors中增加一条阿里云的加速器地址即可。
-
-**硬件环境**
-
-| Hostname | IP | Role |
-| --------------------------------------- | ------------ | ------------------- |
-| sz-pg-oam-docker-test-001.tendcloud.com | 172.20.0.113 | Swarm leader/worker |
-| sz-pg-oam-docker-test-002.tendcloud.com | 172.20.0.114 | Worker |
-| sz-pg-oam-docker-test-003.tendcloud.com | 172.20.0.115 | Worker |
-
-**网络环境**
-
-- Swarm内置的overlay网络,不需要单独安装
-- *mynet自定义网络(TBD),目前没有在docker中使用*
-
-**Docker配置文件修改**
-
-修改docke让配置文件``/usr/lib/systemd/system/docker.service``
-
-```
-ExecStart=/usr/bin/dockerd --insecure-registry=sz-pg-oam-docker-hub-001.tendcloud.com -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock
-```
-
-修改好后
-
-```
-systemctl daemon-reload
-systemctl restart docker
-```
-
-
-
diff --git a/docker/docs/docker_storage_plugin.md b/docker/docs/docker_storage_plugin.md
deleted file mode 100644
index 58ab575a3..000000000
--- a/docker/docs/docker_storage_plugin.md
+++ /dev/null
@@ -1,27 +0,0 @@
-# Docker存储插件
-
-容器存储的几种形态:
-
-[http://mp.weixin.qq.com/s/cTFkQooDVK8IO7cSJUYiVg](http://mp.weixin.qq.com/s/cTFkQooDVK8IO7cSJUYiVg)
-
-[https://clusterhq.com/2015/12/09/difference-docker-volumes-flocker-volumes/](https://clusterhq.com/2015/12/09/difference-docker-volumes-flocker-volumes/)
-
-目前流行的Docker有状态服务的持久化存储方案有以下几种
-
-- Infinit:[https://infinit.sh](https://infinit.sh/) 2016年11月被Docker公司收购
-- ~~Torus:CoreOS开源的容器分布式存储 [https://github.com/coreos/torus](https://github.com/coreos/torus)~~ **已停止开发**
-- Flocker:Container data volume manager for your Dockerized application [https://clusterhq.com](https://clusterhq.com/)
-- Convoy:Rancher开源的Docker volume plugin [https://github.com/rancher/convoy](https://github.com/rancher/convoy)
-- REX-Ray:运营商无关的存储引擎。[https://github.com/codedellemc/rexray](https://github.com/codedellemc/rexray),只能使用商业存储
-
-对比
-
-| 名称 | 主导公司 | 开源时间 | 是否自建存储 | 是否开源 | 开发语言 | 存储格式 | 环境依赖 |
-| --------- | ---------- | ------------ | ------ | ----- | ------ | ---------------------------------------- | -------- |
-| Infinit | Docker | 2017年开源 | 是 | 否 | C++ | local、Amazon S3、Google Cloud Storage | fuse |
-| ~~Torus~~ | ~~CoreOS~~ | ~~2015年11月~~ | ~~是~~ | ~~是~~ | ~~Go~~ | ~~local~~ | ~~etcd~~ |
-| Convoy | Rancher | 2015年5月 | 否 | 是 | Go | NFS、Amazon EBS、VFS 、Device Mapper | |
-| Flocker | ClusterHQ | 2015年8月 | 否 | 是 | Python | Amazon EBS、OpenStack Cinder、GCE PD、VMware vSphere、Ceph... | |
-| REX-Ray | EMC | 2015年12月 | 否 | 是 | Go | GCE、Amazon EC2、OpenStack | |
-
-Infinit和Torus是一个类型的,都是通过分布式存储来实现容器中数据的持久化,而Convoy和Flocker是通过docker volume plugin实现volume的备份与迁移,需要很多手动操作。
\ No newline at end of file
diff --git a/docker/docs/flocker.md b/docker/docs/flocker.md
deleted file mode 100644
index ffe738f81..000000000
--- a/docker/docs/flocker.md
+++ /dev/null
@@ -1,162 +0,0 @@
-# Flocker
-
-docker Flocker
-
-https://github.com/ClusterHQ/flocker/
-
-文档:
-
-https://docs.clusterhq.com/en/latest/docker-integration/
-
-docker swarm 部署 Flocker
-
-https://docs.clusterhq.com/en/latest/docker-integration/manual-install.html
-
-CentOS 7 安装 flocker-cli
-
-需要 python 2.7
-
-yum install gcc libffi-devel git
-
-[root@swarm-master ~]# git clone https://github.com/ClusterHQ/flocker
-
-[root@swarm-master ~]# cd flocker
-
-[root@swarm-master flocker]# pip install -r requirements/all.txt
-
-[root@swarm-master flocker]# python setup.py install
-
-[root@swarm-master flocker]# flocker-ca --version
-1.14.0+1.g40433b3
-
-
-
-CentOS 7 安装 flocker node 在每个节点中
-
-[root@swarm-node-1 ~]# yum list installed clusterhq-release || yum install -y https://clusterhq-archive.s3.amazonaws.com/centos/clusterhq-release$(rpm -E %dist).noarch.rpm
-[root@swarm-node-1 ~]# yum install -y clusterhq-flocker-node
-[root@swarm-node-1 ~]# yum install -y clusterhq-flocker-docker-plugin
-
-在 管理节点 与 node 节点 创建 flocker 配置目录
-
-mkdir /etc/flocker
-
-[root@swarm-master ~]# cd /etc/flocker
-
-一、生成 flocker 管理服务器 证书
-[root@swarm-master flocker]# flocker-ca initialize cnflocker
-Created cluster.key and cluster.crt. Please keep cluster.key secret, as anyone who can access it will be able to control your cluster.
-
-二、生成 flocker 控制节点 证书
-
-官方 建议使用 hostname, 而不使用IP, 我这里暂时使用 IP
-
-[root@swarm-master flocker]# flocker-ca create-control-certificate 172.16.1.25
-
-
-
-拷贝 control-172.16.1.25.crt control-172.16.1.25.key cluster.crt 三个文件到 控制节点 中
-
-注意:cluster.key 文件为 key 文件,只保存在本机,或者管理服务器 (我这里 管理服务器 与 控制节点 为同一台服务器)
-
-[root@swarm-master flocker]# scp control-172.16.1.25.crt 172.16.1.25:/etc/flocker
-
-[root@swarm-master flocker]# scp control-172.16.1.25.key 172.16.1.25:/etc/flocker
-
-[root@swarm-master flocker]# scp cluster.crt 172.16.1.25:/etc/flocker
-
-重命名 刚复制过来的 control-172.16.1.25.key control-172.16.1.25.crt
-
-[root@swarm-master flocker]# mv control-172.16.1.25.crt control-service.crt
-[root@swarm-master flocker]# mv control-172.16.1.25.key control-service.key
-
-设置 权限
-
-[root@swarm-master flocker]# chmod 0700 /etc/flocker
-[root@swarm-master flocker]# chmod 0600 /etc/flocker/control-service.key
-
-
-
-三、生成 flocker node节点 证书 , 每个节点都必须生成一个不一样的证书
-
-[root@swarm-master flocker]# flocker-ca create-node-certificate
-Created 6cc5713a-4976-4545-bf61-3686f182ae50.crt. Copy it over to /etc/flocker/node.crt on your node machine and make sure to chmod 0600 it.
-
-复制 6cc5713a-4976-4545-bf61-3686f182ae50.crt 6cc5713a-4976-4545-bf61-3686f182ae50.key cluster.crt 到 flocker node 节点 /etc/flocker 目录中
-
-[root@swarm-master flocker]# scp 6cc5713a-4976-4545-bf61-3686f182ae50.crt 172.16.1.28:/etc/flocker
-[root@swarm-master flocker]# scp 6cc5713a-4976-4545-bf61-3686f182ae50.key 172.16.1.28:/etc/flocker
-[root@swarm-master flocker]# scp cluster.crt 172.16.1.28:/etc/flocker
-
-登陆 node 节点 重命名 crt 与 key 文件 为 node.crt node.key
-
-[root@swarm-node-1 flocker]# mv 6cc5713a-4976-4545-bf61-3686f182ae50.crt node.crt
-[root@swarm-node-1 flocker]# mv 6cc5713a-4976-4545-bf61-3686f182ae50.key node.key
-
-[root@swarm-node-1 flocker]# chmod 0700 /etc/flocker
-[root@swarm-node-1 flocker]# chmod 0600 /etc/flocker/node.key
-
-四、生成 Flocker Plugin for Docker 客户端 API
-
-[root@swarm-master flocker]# flocker-ca create-api-certificate plugin
-Created plugin.crt. You can now give it to your API enduser so they can access the control service API.
-
-复制 plugin.crt plugin.key 到 flocker node 节点 /etc/flocker 目录中。
-[root@swarm-master flocker]# scp plugin.crt 172.16.1.28:/etc/flocker/
-[root@swarm-master flocker]# scp plugin.key 172.16.1.28:/etc/flocker/
-
-
-
-五、 控制节点 运行 flocker Service
-
-[root@swarm-master flocker]# systemctl enable flocker-control
-[root@swarm-master flocker]# systemctl start flocker-control
-
-六、 配置 node 节点 以及 后端存储
-
-在每个节点 新增 配置文件
-
-[root@swarm-node-1 flocker]# vi /etc/flocker/agent.yml
-
-\---------------------------------------------------------------------------------------------------
-
-"version": 1
-"control-service":
-"hostname": "172.16.1.25"
-"port": 4524
-
-\# The dataset key below selects and configures a dataset backend (see below: aws/openstack/etc).
-\# # All nodes will be configured to use only one backend
-
-dataset:
-backend: "aws"
-region: ""
-zone: ""
-access_key_id: ""
-secret_access_key: ""
-\---------------------------------------------------------------------------------------------------
-
-
-
-dataset 为后端存储的设置选项。
-
-后端存储支持列表: https://docs.clusterhq.com/en/latest/flocker-features/storage-backends.html#supported-backends
-
-
-
-七、 node 节点 运行 flocker-agent 与 flocker-docker-plugin
-
-[root@swarm-node-1 flocker]# systemctl enable flocker-dataset-agent
-[root@swarm-node-1 flocker]# systemctl start flocker-dataset-agent
-[root@swarm-node-1 flocker]# systemctl enable flocker-container-agent
-[root@swarm-node-1 flocker]# systemctl start flocker-container-agent
-
-[root@swarm-node-1 flocker]# systemctl enable flocker-docker-plugin
-[root@swarm-node-1 flocker]# systemctl restart flocker-docker-plugin
-
-八、 docker volume-driver 测试
-
-[root@swarm-master]# docker run -v apples:/data --volume-driver flocker busybox sh -c "echo hello > /data/file.txt"
-
-[root@swarm-master]# docker run -v apples:/data --volume-driver flocker busybox sh -c "cat /data/file.txt"
-
diff --git a/docker/docs/infinit.md b/docker/docs/infinit.md
deleted file mode 100644
index 78f64d30c..000000000
--- a/docker/docs/infinit.md
+++ /dev/null
@@ -1,114 +0,0 @@
-# Infinit
-
-安装文档[https://infinit.sh/get-started/linux#linux-tarball-install](https://infinit.sh/get-started/linux#linux-tarball-install)
-
-下载压缩包[https://storage.googleapis.com/sh_infinit_releases/linux64/Infinit-x86_64-linux_debian_oldstable-gcc4-0.7.2.tbz](https://storage.googleapis.com/sh_infinit_releases/linux64/Infinit-x86_64-linux_debian_oldstable-gcc4-0.7.2.tbz)
-
-**Infinit还有发布1.0版本,跟他们团队沟通过,好不容易实现了分布式存储,infinit的概念非常好,被docker看中也是有原因的,但是目前使用很不便,严重依赖手敲命令行,user、volume、network的security实在是麻烦,昨天使用的时候在最后一步挂载到docker volume的时候居然还需要联网。给他们提了两个bug,团队去过圣诞假期了,明年1月底才可能发新版本,被docker收购后,发展前景不明.**
-
-**2017-01-04**
-
-**infinit daemon启动的时候--as指定用户后,在挂载docker volume plugin的时候还是需要到Hub上查找用户,这个问题会在下个版本解决。**
-
-依赖fuse,使用yum install -y fuse*安装
-
-解压到/usr/local目录下,
-
-ln -s Infinit-x86_64-linux_debian_oldstable-gcc4-0.7.2 /usr/local/infinit
-
-**172.20.0.113****:root****@****sz-pg-oam-docker-test-001**:/usr/local/infinit]# INFINIT_DATA_HOME=$PWD/share/infinit/filesystem/test/home/ INFINIT_STATE_HOME=/tmp/infinit-demo/ bin/infinit-volume --mount --as demo --name infinit/demo --mountpoint ~/mnt-demo --publish --cache
-
-bin/infinit-volume: /lib64/libc.so.6: version `**GLIBC_2.18**' not found (required by /usr/local/Infinit-x86_64-linux_debian_oldstable-gcc4-0.7.2/bin/../lib/libstdc++.so.6)
-
-CentOS7.2.1511的使用源码安装的时候glibc版本太低,无法使用。
-
-官网上使用的是ubuntu安装,ubuntu的glibc版本比较新,而CentOS比较旧,启动报错。
-
-在Slack上跟人要了个rpm,下载地址:[https://infinit.io/_/37aDi9h#](https://infinit.io/_/37aDi9h#)
-
-Docker镜像地址:[https://hub.docker.com/r/mefyl/infinit](https://hub.docker.com/r/mefyl/infinit)
-
-使用RPM包安装即可,默认安装目录在/opt/infinit下
-
-quick-start文档:[https://infinit.sh/get-started](https://infinit.sh/get-started)
-
-详细参考文档:[https://infinit.sh/documentation/reference](https://infinit.sh/documentation/reference)
-
-slack地址:infinit-sh.slack.com
-
-设置环境变量
-
-**export** LC_ALL=en_US.UTF-8
-
-**创建用户**
-
-虽然可以安装不过需要注册用户才能使用,infinit使用的时候会连接到Internet。
-
-设置环境变量INFINIT_CRASH_REPORTER=0就不会再连接Hub。
-
-create的用户信息会保存在
-
-/opt/infinit/.local
-
-infinit-user --create --name "alice"
-
-**创建网络**
-
-infinit-network --create --as alice --storage local --name my-network
-
-查看网络
-
-infinit-network --list --as alice
-
-启动网络
-
-**infinit**-network --run --daemon --as alice --name my-network --port 11928
-
-必须制定用户,否则会查看root用户的网络,-~~as alice必须放在~~-list动作后面
-
-不要加上--push,否则会push到hub上,又需要连接到网络
-
-创建volume
-
-infinit-volume --create --as alice --network my-network --name my-volume
-
-挂载volume
-
-infinit-volume --mount --as alice --name my-volume --mountpoint ~/mnt-alice-volume --allow-root-creation --async --cache --port 11928
-
-我随意指定的一个端口
-
-不要使用--publish,否则会向Hub注册endpoint
-
-导出user、network、volume
-
-infinit-user --export --as alice --full>alice
-
-infinit-network --export --name my-network --as alice --output my-network
-
-infinit-volume --export --name my-volume --as alice --output my-volume
-
-Device B
-
-导入user、network、volume
-
-infinit-user --import -i alice
-
-infinit-network --import -i my-network
-
-infinit-volume --import -i my-volume
-
-link网络
-
-infinit-network --link --name my-network --as alice
-
-查看网络信息
-
-infinit-journal --stat --network alice/my-network --as alice
-
-挂载volume
-
-infinit-volume --mount --as alice --name my-volume --mountpoint ~/mnt-alice-volume --allow-root-creation --async --cache --peer server_ip:11928
-
-目前状况:B节点无法连接到A
-
diff --git a/docker/docs/io_resource_limit.md b/docker/docs/io_resource_limit.md
deleted file mode 100644
index 3a2421e34..000000000
--- a/docker/docs/io_resource_limit.md
+++ /dev/null
@@ -1,169 +0,0 @@
-# Docker IO资源限制
-
-## 一、压测工具
-
-通过 Linux `dd` 命令测试
-
-## 二、IO 测试
-
-- [Runtime constraints on resources](https://docs.docker.com/engine/reference/run/#runtime-constraints-on-resources)
-- 关于 IO 的限制
- - `--blkio-weight=0`Block IO weight (relative weight) accepts a weight value between 10 and 1000.
- - `--blkio-weight-device=""`Block IO weight (relative device weight, format: `DEVICE_NAME:WEIGHT`)针对特定设备的权重比
- - `--device-read-bps=""`Limit read rate from a device (format: `:[]`). Number is a positive integer. Unit can be one of `kb`, `mb`, or `gb`.按每秒读取块设备的数据量设定上限
- - `--device-write-bps=""`Limit write rate from a device (format: `:[]`). Number is a positive integer. Unit can be one of `kb`, `mb`, or `gb`.按每秒写入块设备的数据量设定上限
- - `--device-read-iops=""`Limit read rate (IO per second) from a device (format: `:`). Number is a positive integer.按照每秒读操作次数设定上限
- - `--device-write-iops=""`Limit write rate (IO per second) from a device (format: `:`). Number is a positive integer.按照每秒写操作次数设定上限
-
-```
-➜ ~ docker help run | grep -E 'bps|IO'
-Usage: docker run [OPTIONS] IMAGE [COMMAND] [ARG...]
- --blkio-weight Block IO (relative weight), between 10 and 1000
- --blkio-weight-device=[] Block IO weight (relative device weight)
- --device-read-bps=[] Limit read rate (bytes per second) from a device
- --device-read-iops=[] Limit read rate (IO per second) from a device
- --device-write-bps=[] Limit write rate (bytes per second) to a device
- --device-write-iops=[] Limit write rate (IO per second) to a device
-➜ ~
-
-```
-
-### 2.1 `--blkio-weight`、`--blkio-weight-device`
-
-- `--blkio-weight`
-
-默认,所有的容器对于 IO 操作「block IO bandwidth – blkio」都拥有相同优先级。可以通过 `--blkio-weight` 修改容器 blkio 权重。`--blkio-weight` 权重值在 10 ~ 1000 之间。
-
-> Note: The blkio weight setting is only available for direct IO. Buffered IO is not currently supported.
-
-使用 blkio weight 还需要注意 IO 的调度必须为 CFQ:
-
-```
-➜ ~ cat /sys/block/sda/queue/scheduler
-noop [deadline] cfq
-➜ ~ sudo sh -c "echo cfq > /sys/block/sda/queue/scheduler"
-➜ ~ cat /sys/block/sda/queue/scheduler
-noop deadline [cfq]
-
-```
-
-按照 Docker 官方文档的介绍测试:
-
-```
-➜ ~ docker run -it --rm --blkio-weight 100 ubuntu-stress:latest /bin/bash
-root@0b6770ee80e0:/#
-➜ ~ docker run -it --rm --blkio-weight 1000 ubuntu-stress:latest /bin/bash
-root@6778b6b39686:/#
-
-```
-
-在运行的容器上同时执行如下命令,统计测试时间:
-
-```
-root@0b6770ee80e0:/# time dd if=/dev/zero of=test.out bs=1M count=1024 oflag=direct
-1024+0 records in
-1024+0 records out
-1073741824 bytes (1.1 GB) copied, 122.442 s, 8.8 MB/s
-
-real 2m2.524s
-user 0m0.008s
-sys 0m0.492s
-root@6778b6b39686:/# time dd if=/dev/zero of=test.out bs=1M count=1024 oflag=direct
-1024+0 records in
-1024+0 records out
-1073741824 bytes (1.1 GB) copied, 122.493 s, 8.8 MB/s
-
-real 2m2.574s
-user 0m0.020s
-sys 0m0.480s
-root@6778b6b39686:/#
-
-```
-
-测试下来,效果不是很理想,没有获得官档的效果,类似的问题可以在相关的 issue 上找到,如 [–blkio-weight doesn’t take effect in docker Docker version 1.8.1 #16173](https://github.com/docker/docker/issues/16173)
-
-官方的测试说明是:
-
-> You’ll find that the proportion of time is the same as the proportion of blkio weights of the two containers.
-
-- `--blkio-weight-device="DEVICE_NAME:WEIGHT"`
-
-`--blkio-weight-device` 可以指定某个设备的权重大小,如果同时指定 `--blkio-weight` 则以 `--blkio-weight` 为全局默认配置,针对指定设备以 `--blkio-weight-device` 指定设备值为主。
-
-```
-➜ ~ docker run -it --rm --blkio-weight-device "/dev/sda:100" ubuntu-stress:latest /bin/bash
-
-```
-
-### 2.2 `--device-read-bps`、`--device-write-bps`
-
-限制容器的写入速度是 1mb「`:[unit]`,单位可以是 kb、mb、gb 正整数」:
-
-```
-➜ ~ docker run -it --rm --device-write-bps /dev/sda:1mb ubuntu-stress:latest /bin/bash
-root@ffa51b81987c:/# dd if=/dev/zero of=test.out bs=1M count=100 oflag=direct
-100+0 records in
-100+0 records out
-104857600 bytes (105 MB) copied, 100.064 s, 1.0 MB/s # 可以得知写入的平均速度是 1.0 MB/s
-
-```
-
-通过 iotop 获取测试过程中的 bps 也是 1.0 MB 为上限:
-
-
-
-读 bps 限制使用方式同写 bps 限制:
-
-```
-➜ ~ docker run -it --rm --device-read-bps /dev/sda:1mb ubuntu-stress:latest /bin/bash
-
-```
-
-### 2.3 `--device-read-iops`、`--device-write-iops`
-
-限制容器 write iops 为 5「`:`,必须为正整数」:
-
-```
-➜ ~ docker run -it --rm --device-write-iops /dev/sda:5 ubuntu-stress:latest /bin/bash
-root@c2a2fa232594:/# dd if=/dev/zero of=test.out bs=1M count=100 oflag=direct
-100+0 records in
-100+0 records out
-104857600 bytes (105 MB) copied, 42.6987 s, 2.5 MB/s
-
-```
-
-通过 `iostat` 监控 tps「此处即为 iops」 基本上持续在 10 左右「会有些偏差」:
-
-```
-➜ ~ iostat 1
-... ...
-avg-cpu: %user %nice %system %iowait %steal %idle
- 1.13 0.00 0.13 23.46 0.00 75.28
-
-Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
-sda 10.00 0.00 2610.00 0 5220
-... ...
-
-```
-
-读 iops 限制使用方式同写 iops 限制:
-
-```
-➜ ~ docker run -it --rm --device-read-iops /dev/sda:5 ubuntu-stress:latest /bin/bash
-
-```
-
-**注:** 在容器中通过 `dd` 测试读速度并没有看到很好的效果,经查没有找到磁盘读操作的好工具,所以文中没有介绍读测试。
-
-## 三、源码解析
-
-- [github.com/opencontainers/runc/libcontainer/cgroups/fs](https://github.com/opencontainers/runc/tree/master/libcontainer/cgroups/fs)blkio.go
-
-libcontainer 主要操作是对 cgroup 下相关文件根据选项写操作,具体更进一步的资源限制操作可以看 cgroup 的实现方式。
-
-## 四、拓展
-
-- [Docker背后的内核知识——cgroups资源限制](http://www.infoq.com/cn/articles/docker-kernel-knowledge-cgroups-resource-isolation)
-- [cgroup 内存、IO、CPU、网络资源管理](http://pan.baidu.com/share/home?uk=1429463486&view=share#category/type=0)
-
-From:http://blog.opskumu.com/docker-io-limit.html
\ No newline at end of file
diff --git a/docker/docs/jd_transform_to_kubernetes.md b/docker/docs/jd_transform_to_kubernetes.md
deleted file mode 100644
index 91cdf48b1..000000000
--- a/docker/docs/jd_transform_to_kubernetes.md
+++ /dev/null
@@ -1,115 +0,0 @@
-# 京东从OpenStack切换到Kubernetes的经验之谈
-
-***京东从2016年底启动从OpenStack切换到Kubernetes的工作,截止目前(2017年2月)已迁移完成20%,预计Q2可以完成全部切换工作。Kubernetes方案与OpenStack方案相比,架构更为简洁。在这个过程中,有这些经验可供业界借鉴。***
-
-## 背景介绍
-
-2016年底,京东新一代容器引擎平台JDOS2.0上线,京东从OpenStack切换到Kubernetes。到目前为止,JDOS2.0集群2w+Pod稳定运行,业务按IDC分布分批迁移到新平台,目前已迁移20%,计划Q2全部切换到Kubernetes上,业务研发人员逐渐适应从基于自动部署上线切换到以镜像为中心的上线方式。JDOS2.0统一提供京东业务,大数据实时离线,机器学习(GPU)计算集群。从OpenStack切换到Kubernetes,这中间又有哪些经验值得借鉴呢?
-
-本文将为读者介绍京东商城研发基础平台部如何从0到JDOS1.0再到JDOS2.0的发展历程和经验总结,主要包括:
-
-- 如何找准痛点作为基础平台系统业务切入点;
-- 如何一边实践一边保持技术视野;
-- 如何运维大规模容器平台;
-- 如何把容器技术与软件定义数据中心结合。
-
-## 集群建设历史
-
-### 物理机时代(2004-2014)
-
-在2014年之前,公司的应用直接部署在物理机上。在物理机时代,应用上线从申请资源到最终分配物理机时间平均为一周。应用混合部署在一起,没有隔离的应用混部难免互相影响。为减少负面影响,在混部的比例平均每台物理机低于9个不同应用的Tomcat实例,因此造成了物理机资源浪费严重,而且调度极不灵活。物理机失效导致的应用实例迁移时间以小时计,自动化的弹性伸缩也难于实现。为提升应用部署效率,公司开发了诸如编译打包、自动部署、日志收集、资源监控等多个配套工具系统。
-
-### 容器化时代(2014-2016)
-
-2014年第三季度,公司首席架构师刘海锋带领基础平台团队对于集群建设进行重新设计规划,Docker容器是主要的选型方案。当时Docker虽然已经逐渐兴起,但是功能略显单薄,而且缺乏生产环境,特别是大规模生产环境的实践。团队对于Docker进行了反复测试,特别是进行了大规模长时间的压力和稳定性测试。根据测试结果,对于Docker进行了定制开发,修复了Device Mapper导致crash、Linux内核等问题,并增加了外挂盘限速、容量管理、镜像构建层级合并等功能。
-
-对于容器的集群管理,团队选择了**OpenStack+nova-docker**的架构,**用管理虚拟机的方式管理容器**,并定义为京东第一代容器引擎平台JDOS1.0(JD DataCenter OS)。JDOS1.0的主要工作是实现了基础设施容器化,应用上线统一使用容器代替原来的物理机。
-
-在应用的运维方面,兼用了之前的配套工具系统。研发上线申请计算资源由之前的一周缩短到分钟级,不管是1台容器还是1千台容器,在经过计算资源池化后可实现秒级供应。同时,应用容器之间的资源使用也得到了有效的隔离,平均部署应用密度提升3倍,物理机使用率提升3倍,带来极大的经济收益。
-
-我们采用多IDC部署方式,使用统一的全局API开放对接到上线系统,支撑业务跨IDC部署。单个OpenStack集群最大是1万台物理计算节点,最小是4K台计算节点,第一代容器引擎平台成功地支撑了2015和2016年的618和双十一的促销活动。至2016年11月,已经有15W+的容器在稳定运行。
-
-在完成的第一代容器引擎落地实践中,团队推动了业务从物理机上迁移到容器中来。在JDOS1.0中,我们使用的IaaS的方式,即使用管理虚拟机的方式来管理容器,因此应用的部署仍然严重依赖于物理机时代的编译打包、自动部署等工具系统。但是JDOS1.0的实践是非常有意义的,其意义在于完成了业务应用的容器化,将容器的网络、存储都逐渐磨合成熟,而这些都为我们后面基于1.0的经验,开发一个全新的应用容器引擎打下了坚实的基础。
-
-## 新一代应用容器引擎(JDOS 2.0)
-
-### 1.0的痛点
-
-JDOS1.0解决了应用容器化的问题,但是依然存在很多不足。
-
-首先是编译打包、自动部署等工具脱胎于物理机时代,与容器的开箱即用理念格格不入,容器启动之后仍然需要配套工具系统为其分发配置、部署应用等等,应用启动的速度受到了制约。
-
-其次,线上线下环境仍然存在不一致的情况,应用运行的操作环境,依赖的软件栈在线下自测时仍然需要进行单独搭建。线上线下环境不一致也造成了一些线上问题难于在线下复现,更无法达到镜像的“一次构建,随处运行”的理想状态。
-
-再次,容器的体量太重,应用需要依赖工具系统进行部署,导致业务的迁移仍然需要工具系统人工运维去实现,难以在通用的平台层实现灵活的扩容缩容与高可用。
-
-另外,容器的调度方式较为单一,只能简单根据物理机剩余资源是否满足要求来进行筛选调度,在提升应用的性能和平台的使用率方面存在天花板,无法做更进一步提升。
-
-### 平台架构
-
-鉴于以上不足,在当JDOS1.0从一千、两千的容器规模,逐渐增长到六万、十万的规模时,我们就已经启动了新一代容器引擎平台(JDOS 2.0)研发。JDOS 2.0的目标不仅仅是一个基础设施的管理平台,更是一个直面应用的容器引擎。JDOS 2.0在原1.0的基础上,围绕Kubernetes,整合了JDOS 1.0的存储、网络,打通了从源码到镜像,再到上线部署的CI/CD全流程,提供从日志、监控、排障、终端、编排等一站式的功能。JDOS 2.0的平台架构如下图所示。
-
-
-
-
-
-在JDOS 2.0中,我们定义了系统与应用两个级别。一个系统包含若干个应用,一个应用包含若干个提供相同服务的容器实例。一般来说,一个大的部门可以申请一个或者多个系统,系统级别直接对应于Kubernetes中的namespace,同一个系统下的所有容器实例会在同一个Kubernetes的namespace中。应用不仅仅提供了容器实例数量的管理,还包括版本管理、域名解析、负载均衡、配置文件等服务。
-
-不仅仅是公司各个业务的应用,大部分的JDOS 2.0组件(Gitlab/Jenkins/Harbor/Logstash/Elastic Search/Prometheus)也实现了容器化,在Kubernetes平台上进行部署。
-
-### 开发者一站式解决方案
-
-JDOS 2.0实现了以镜像为核心的持续集成和持续部署。
-
-
-
-1. 开发者提交代码到源码管理库
-2. 触发Jenkins Master生成构建任务
-3. Jenkins Master使用Kubernetes生成Jenkins Slave Pod
-4. Jenkins Slave拉取源码进行编译打包
-5. 将打包好的文件和Dockerfile发送到构建节点
-6. 在构建节点中构建生成镜像
-7. 将镜像推送到镜像中心Harbor
-8. 根据需要在不同环境生产/更新应用容器
-
-在JDOS 1.0,容器的镜像主要包含了操作系统和应用的运行时软件栈。APP的部署仍然依赖于以往运维的自动部署等工具。在2.0中,我们将应用的部署在镜像的构建过程中完成,镜像包含了APP在内的完整软件栈,真正实现了开箱即用。
-
-
-
-### 网络与外部服务负载均衡
-
-JDOS 2.0继承了JDOS 1.0的方案,采用OpenStack-Neutron的VLAN模式,该方案实现了容器之间的高效通信,非常适合公司内部的集群环境。每个Pod占用Neutron中的一个port,拥有独立的IP。基于CNI标准,我们开发了新的项目Cane,用于将Kubelet和Neutron集成起来。
-
-
-
-同时,Cane负责Kubernetes中service中的LoadBalancer的创建。当有LoadBalancer类型的service创建/删除/修改时,Cane将对应的调用Neutron中创建/删除/修改LBaaS的服务接口,从而实现外部服务负载均衡的管理。另外,Cane项目中的[Hades](https://github.com/ipdcode/hades)京东开源在GitHub上组件为容器提供了内部的DNS解析服务。
-
-### 灵活调度
-
-JDOS 2.0接入了包括大数据、Web应用、深度学习等多种类型的应用,并为每种应用根据类型采用了不同的资源限制方式,并打上了Kubernetes的不同标签。基于多样的标签,我们实现了更为多样和灵活的调度方式,并在部分IDC实验性地混合部署了在线任务和离线任务。相较于1.0,整体资源利用率提升了约30%。
-
-
-
-### 推广与展望
-
-有了1.0的大规模稳定运营作为基础,业务对于使用容器已经给予了相当的信任和支持,但是平台化的容器和基础设施化的容器对于应用的要求也不尽相同。比如,平台化的应用容器IP并不是固定的,因为当一个容器失效,平台会自动启动另一个容器来替代,新的容器IP可能与原IP不同。这就要求服务发现不能再以容器IP作为主要标识,而是需要采用域名,负载均衡或者服务自注册等方式。
-
-因此,在JDOS2.0推广过程中,我们也推动了业务方主要关注应用服务,减少对单个容器等细节的操作,以此自研了全新智能域名解析服务和基于DPDK高性能负载均衡服务,与Kubernetes有效地配合支持。
-
-近两年,随着大数据、人工智能等研发规模的扩大,消耗的计算资源也随之增大。因此,我们将大数据、深度学习等离线计算服务也迁移进入JDOS2.0。目前是主要采用单独划分区域的方式,各自的服务仍然使用相对独立的计算资源,但是已经纳入JDOS2.0平台进行统一管理,并通过机器学习方法,提升计算资源使用效率。
-
-灵活的标签给予了集群调度无限的可能。未来我们将丰富调度算法,并配以节能的相关技术,提高集群整体的ROI,从而为打造一个低能耗、高性能的绿色数据中心打下基础。
-
-## 回望与总结
-
-Kubernetes方案与OpenStack方案相比,架构更为简洁。OpenStack整体运营成本较高,因为牵涉多个项目,每个项目各自有多个不同的组件,组件之间通过RPC(一般使用MQ)进行通讯。为提高可用性和性能,还需要考虑各个组件的扩展和备份等。这些都加剧了整体方案的复杂性,问题的排查和定位难度也相应提升,对于运维人员的要求也相应提高。
-
-与之相比,Kubernetes的组件较少,功能清晰。其核心理念(对于资源和任务的理解)、灵活的设计(标签)和声明式的API是对Google多年来Borg系统的最好总结,而其提供的丰富的功能,使得我们可以投入更多精力在平台的整个生态上,比如网络性能的提升、容器的精准调度上,而不是平台本身。尤其是,副本控制的功能受到了业务线上应用运维工程师的追捧,应用的扩容缩容和高可用实现了秒级完成。JDOS 2.0目前已经接入了约20%的应用,部署有2个集群,目前日常运行的容器有20000个,仍在逐步推广中。
-
-真诚感谢Kubernetes社区和相关开源项目的贡献者,目前京东已经加入CNCF组织,并在社区排名达到TOP30。
-
-## 作者简介
-
-鲍永成,京东基础平台部技术总监,带领基础平台部集群技术团队从2014年上线京东容器引擎平台JDOS1.0到现在的JDOS2.0,作为坚实的统一计算运行平台承载京东全部业务稳定运行。目前主要工作方向是JDOS2.0研发和京东第一代软件定义数据中心建设。
-
-
diff --git a/docker/docs/letv_docker.md b/docker/docs/letv_docker.md
deleted file mode 100644
index 964c13233..000000000
--- a/docker/docs/letv_docker.md
+++ /dev/null
@@ -1,361 +0,0 @@
-# 乐视云基于Kubernetes的PaaS平台建设
-
-### 背景
-
-2014年乐视云开始尝试Docker的推广和使用,我们的团队开始开发第一代容器云平台Harbor (分享网址:
-
-http://dockone.io/article/1091
-
- )。(在这里提醒一下,这与VMware公司中国团队为企业用户设计的Docker Registry erver开源项目Harbor 重名)。
-
-第一代容器云平台可以认为是一个开放的托管平台。开发者可以将自己从公司申请的虚拟机或者物理机添加到Harbor系统中进行托管管理,平台基本包含:镜像自动构建(CI),应用快速扩容、缩容、灰度升级,资源权限管理,多集群主机管理等功能。
-
-由于那时容器才刚刚兴起,刚开始在公司内部推动也有一定的阻力,刚开始给业务线推广的时候,需要首先介绍Docker,介绍容器和虚拟机的区别,然后再介绍平台本身和使用方法,推广成本以及业务线学习成本也比较高。接入Harbor上的业务的大多是业务线自己提供虚拟机,而物理机占少数。不过鉴于Harbor的易用程度,吸引了很多新业务接入。到现在为止Harbor已经完全实现开发自助化。业务自己添加主机,自主管理应用和容器,对应用进行升级、回滚,弹性伸缩,镜像构建,现在已经稳定运行2年多。
-
-#### 第一代容器云平台不足之处
-
-1. 网络方面也是用的最基本的Nat,端口映射模式,存在性能问题。业务必须要知道容器对外映射出来的端口,对业务不透明,不便于报警和运维,也不便于对接负载均衡。
-2. 容器的分发调度全部自己开发,任务量大,当时没有能够做到容器自动迁移。
-3. 不支持应用的全球部署。
-4. Harbor管理的计算资源需要业务线自己申请,计算资源可以是物理机也可以是虚拟机,导致业务线需要关心底层的计算资源,计算资源无法对业务线完全透明。
-5. 为了降低用户对Dockerfile的学习成本,我们对Dockerfile进行了封装,只让用户写Shell脚本,因封装的不合理,导致制作出的镜像太大,尤其Maven项目,需要编译,每次在Docker Build时候,都会重新下载依赖包,导致编译过程长,镜像大,并且容器内服务启动方式不灵活。
-6. 监控报警机制不完善,没有做到容器和应用级别的监控和报警。
-7. 镜像仓库Registry并没有做得到像Docker Hub那样用户权限划分。
-
-随着Kubernetes在越来越多公司开始使用,乐视内部更多的团队和业务线开始接受或者主动了解Docker,同时为了解决第一代平台的存在问题和基于乐视现有服务部署情况,到2015年底,我们团队计划替换掉之前自己写的调度方案,着手尝试使用Kubernetes作为容器的调度引擎,在对比多套网络方案(Calico,Flannel等等)后,结合乐视现有状况,采用Bridge模式,容器大二层网络方案。负载均衡使用Nginx,计算资源全部使用物理机,计算资源完全对业务透明。经过半年多的调研和开发,在2016年10月第二代PaaS平台LeEngine在美国上线,半个月后,北京地区上线。LeEngine现在保持着一月一版本的开发迭代速度,到现在为止已经开发了3个版本。
-
-LeEngine 采用全新的架构,主要面向于无状态或者RPC应用。现在已经承接了乐视云计算,乐视体育章鱼TV,风云直播,乐视网乐看搜索,云相册等近100多个重要业务,使用的客户普遍反映一旦掌握了LeEngine的使用流程,从开发到上线部署,弹性伸缩,升级的效率可成倍增长,极大简化了运维成本。LeEngine拥有极强的用户粘性,吸引了很多业务线主动申请试用LeEngine,现阶段已经不需要再增加额外的精力在公司内部推广。
-
-### 简介
-
-Kubernetes:Google开源的的容器编排工具,在整个2016年,越来越多的公司开始在线上使用Kubernetes,同时Kubernetes具备我们迫切需要的容器自动迁移和高可用功能。关于Kubernetes 的架构在这里我就不多介绍了,虽然架构偏重,但是我们最终决定使用它,并且尽量只使用它的Pod,Replicationtroller和Service功能。
-
-这里首先解释一下几个概念:
-
-用户
-
-:乐视各个产品线下的产品、开发、测试、运维等人员。
-
-Region
-
-:偏向于地理概念,例如北京和洛杉矶是两个Region。 同一个Region内要求内网可达,网络可靠,低延迟。同一个Region共用一套镜像Registry,镜像构建系统,负载均衡系统和监控报警系统,不同Region 共享全局唯一的SDNS和GitLab代码仓库。
-
-Cell
-
-:我们现在使用的Kubernetes 1.2.0版本,理论上能控制1000个计算节点,为谨慎使用,规定一个Kubernetes集群最大计算节点会控制在600个左右。 Cell 概念的引入是为了扩充单个Region下计算节点的规模,偏向于机房的概念,一个Cell 即一个Kubernetes集群,每个Region下可以搭建多个Cell。所有Cell共享本Region下的镜像Registry,镜像构建系统,负载均衡系统和监控系统。为同一个Cell下的容器配置一个或者多个网段,每个网段划分单独的VLAN。同一Cell下的计算节点不会跨机房部署。
-
-LeEngine Registry
-
-:基于Docker Registry 2.0做的部分修改,后端支持乐视云的Ceph存储。并仿照Docker Hub增加权限和认证机制,只有拥有相应权限的用户才能对特定的镜像进行Push和Pull操作。也可以设置镜像公开,公开的镜像任何用户都可以Pull。
-
-计算节点
-
-: 物理机,Kubernetes的Node概念。
-
-应用
-
-: 定义提供相同业务逻辑的一组容器为一个应用,可以认为应用是一个微服务。这类应用要求是无状态Web服务或者RPC类的服务。应用可以部署在多个Cell中。上文提到过,一个Cell可以认为是一个机房。LeEngine在一个Region下会至少部署2个Cell,部署应用时候,我们要求应用至少部署在2个Cell中,这样即使一个机房出现网络故障时,另一个机房的应用容器还能继续对外提供服务。一个应用下可以部署多个版本的容器,因此可以支持应用的灰度升级。访问web类应用时候,我们强制要求这类应用(如果是线上应用)前面必须使用负载均衡,由我们的服务发现系统告诉负载均衡当前应用下有哪些容器IP。从Kubernetes层面讲,我们规定一个应用对应Kubernetes下的一个Namespace,因此在应用的数据库表中会存在一个Namespace的字段,并需要全局唯一,而应用的多个版本对应了在这个Namespace下创建的多个Replicationtroller。
-
-Region、Cell 和kubernetes的关系:
-
-[](http://dockerone.com/uploads/article/20170215/b161c38bc139d5282acd1c8f3e039444.png)
-
-### 架构平台设计
-
-容器直接运行在物理机上,计算节点全部由我们提供,业务线不需要关心,LeEngine可以作为一个企业解决方案对外全套输出,平台架构如下:
-
-[](http://dockerone.com/uploads/article/20170215/51ae1e2c3432f03e936630eefa411152.png)
-
-业务层: 乐视使用容器的各个业务线,是LeEngine的最终用户。
-
-PaaS 层: LeEngine提供的各种服务,主要是完成对应用的弹性伸缩,灰度升级,自动接入负载均衡,监控,报警,快速部署,代码构建等服务。
-
-宿主机资源层:主要指Docker 物理机集群,并包含IP池的管理。
-
-[](http://dockerone.com/uploads/article/20170215/7055c11a130c988b68a34b3e0ee5d343.png)
-
-用户访问部署在LeEngine上的应用时,首先通过SDNS智能解析到对应的Nginx负载均衡集群,然后由Nginx将请求打到对应的容器中。数据库,缓存等有状态的服务并没有在LeEngine体系之内,因为采用大二层网络,容器可以直接连接公司其他团队提供的数据库或者缓存等服务。
-
-下图是为了更好的说明支持多地域,多kubernetes集群的部署。
-
-[](http://dockerone.com/uploads/article/20170215/eb7abcaec90313f5f54a09081acb5c53.png)
-
-单一Region下单Cell部署图:
-
-[](http://dockerone.com/uploads/article/20170215/39608b12c11b1be8a8f4bd16a9756348.png)
-
-我们将计算节点的管理网络和容器网络划分开并给容器网络划分单独的VLAN。
-
-#### 成员、权限管理
-
-LeEngine下面定义了四大资源,应用、镜像、镜像分组和代码构建。为了团队协同操作,这4大资源都增加了成员和权限管理。成员和权限仿照了GitLab进行了设计,成员角色分为:Owner、Master、Developer、Reporter、Guest。 不同的角色针对不同的资源系统都定义了不同的权限。比如应用,只有Owner和Master有权限对应用部署新版本,弹性伸缩等等。 假如一个用户A创建了一个应用A1,那么A就默认是应用A1的Owner,拥有对应用A1所有操作权限,包括部署新版本,弹性伸缩,修改应用,删除应用等所有操作。而用户B此时对应用A1不可见,若想可见,必须由A对这个应用A1执行添加成员的操作,把B添加到A1中,并赋为除Owner以外的任何一个角色,若此时B被赋为Master角色,那B拥有了对应用A1部署新版本,弹性伸缩等权限,反之则没有。
-
-根据上面的权限设计,通过LeEngine的Console界面,不同的用户登录后看到的仅仅是跟自己相关的资源,如下图,在应用中,能看到我创建的以及我参与的应用:
-
-[](http://dockerone.com/uploads/article/20170215/3e8895a01fdd8968fb262ebf2eab4099.png)
-
-在镜像页面,能够看到我创建的以及我参与的镜像,如下图:
-
-[](http://dockerone.com/uploads/article/20170215/6abcb0a147d2ab3d5cf9ac303a701370.png)
-
-帮助文档会提供给用户不同资源的权限说明:
-
-[](http://dockerone.com/uploads/article/20170215/c4e503a90b7dc07df55f9c1343e03d95.png)
-
-[](http://dockerone.com/uploads/article/20170215/adcc568d05035599379bf5f2ba8acaec.png)
-
-#### 用户端和管理端
-
-LeEngine具有面向用户端的Console界面和面向运维管理员的boss界面,在用户端用户可以看到自己创建和参与的4种不同的资源。管理端则主要是对整个LeEngine平台资源进行管理,包括用户可使用最大资源的限制,负载均衡特殊配置,Cell集群下的资源使用情况,操作频率统计等等。
-
-下图是LeEngine测试环境boss系统关于操作频率统计:
-
-[](http://dockerone.com/uploads/article/20170215/463da22aa0b62bfe003090f7a02ab6eb.png)
-
-操作频率包括每天所用应用的部署次数,代码的构建次数,镜像的Push次数,弹性伸缩次数,在一定程度上能展示出业务线对LeEngine平台本身的使用频率。
-
-#### LeEngine-core
-
-LeEngine-core是LeEngine最终对外提供服务的API接口层(beego实现),所有4大资源的操作,包括权限控制,都是通过这一层控制的。LeEngine只提供最原子的API接口,特殊业务线要想有特殊的需求,完全可以在现有API基础上进行二次开发。
-
-#### 容器网络
-
-容器采用大二层网络,因此可以保证外部服务可以直接连通容器,容器也可以直接连通外部服务,比如数据库,缓存等等。采用此种方案可以保证容器横向可连接,纵向可访问。外部想连接容器可以通过容器IP地址直接连接,也可以通过负载均衡方式进行访问。而容器也可以直接访问LeEngine体系外的虚拟,物理机资源,以及MySQL等组件服务。
-
-[](http://dockerone.com/uploads/article/20170215/2017815e75eed5039c9876a450ef526a.png)
-
-我们自己写了CNI插件和CNICTL管理工具,支持添加多个IP段,用来防止IP资源不够的情况。IP段的信息存在了当前Kubernetes集群里的etcd中。我们会为每个Cell即每个Kubernetes集群下都添加至少一个IP段,一般1024个IP地址22子网掩码,单独vlan防止广播风暴,这需要提前跟网络部门规划好IP段。如果这个IP段已经使用完,我们会使用CNICTL工具,重新增加一个新的IP段。
-
-[](http://dockerone.com/uploads/article/20170215/2d0f872b91af43a6fbe72eb959cc80b9.png)
-
-为了进一步保证业务容器在网络方面的稳定性,我们所有的计算节点都是4个网卡,2千兆,2万兆,双双做bond,千兆bond1用来做管理网卡,万兆bond1用来跑业务容器,每个计算节点在交付时候会创建一个OVS网桥,并将bond1挂载上去,上联交换机做堆叠,计算节点尽量打散在多个不同机柜中。
-
-计算节点物理机上的Kubulet在创建Pod的PAUSE容器后,会调用我们自己CNI插件,CNI会创建一个veth pair, 一端扔到这个容器的Namespace中,并命名eth0,一端挂载到OVS网桥上,之后从etcd中大的IP段中找出一个连续16个IP地址的小段给这个计算节点,然后再从这个子段中找一个空闲的IP给这个容器,配置好容器IP,以及路由信息,同时会根据配置来确定是否发送免费ARP信息,之后遵守CNI规范把相应的信息返回给kubelet。当这个计算节点再次创建新的Pod时,会优先从这个子段中选择空间的IP,若没有空闲的IP地址,会重新计算一个子段给这个计算节点用。
-
-现在CNI不能保证Pod删掉重新创建时候IP保持不变,因此应用在每次升级操作后,容器IP地址会变,这就需要我们的服务发现与负载均衡做对接。
-
-不过现在的这套方案也会存在一些问题:比如物理主机突然down掉,或者Docker进程死掉,导致本主机上所有容器挂掉,等kubelet重新启动后,原来死掉的容器所占用的IP并不会释放。我们现在的解决方案是通过我们开发CNICTL命令来进行定期检测。CNICTL提供一个check命令,会检索etcd中所有分配的IP和对应的POD信息,之后调用apiserver获得所有Pod信息,取差值则为没释放的IP地址。收到报警后,人工调用CNICTL的释放IP功能,手动释放IP。
-
-#### 服务发现
-
-我们充分利用了Kubernetes的Service概念,前面已经提过,一个应用对应一个Namespace,一个版本对应一个RC,在用户通过API请求创建应用时候,LeEngine核心API层:LeEngin-core会默认在对应的Kubernetes集群中创建相关联的Namespace,同时默认在这个Namespace下创建一个Service,并创建一个唯一的标签属性,用户在部署新版本(RC)时候,LeEngine会给这个RC添加这个Service的唯一标签。这样就可以通过Service来发现后端的Endpoint。我们用Go写了一个服务发现服务,通过watch api-server的API接口,自动归类发现哪个应用下有IP变动,之后调用我们负载均衡的API接口,动态更改Nginx的后端upstream serverip。
-
-在我们没使用Kubernetes的健康探测功能之前,会有一定的几率出现容器创建完成,服务没有完全启动,这时候容器IP已经加载到负载均衡的情况,如果这时候如果刚好有请求过来,会出现请求失败的现象。之后我们在最新一版中,加入了健康探测功能,用户在给应用部署新版本时,允许用户指定自己服务的监控探测HTTP接口,当容器内服务探测成功后,才会加入到负载均衡中去。而删除容器则不会出现这种情况,执行RC缩容命令后,需要删除的容器首先会立马从负载均衡中删除,之后才会执行容器的删除操作。
-
-#### 负载均衡
-
-我们并没有使用Kubernetes的Proxy作为负载均衡,而是使用Nginx集群作为负载均衡。Nginx我们原则上会部署在同一个Region下的多个机房中,防止因为机房网络故障导致全部的Nginx不可用,支持Nginx横向可扩展,当负载均衡压力过大时候,可以快速横向增加Nginx物理机。为防止单一Nginx集群下代理的Domain数目过多,以及区分不同的业务逻辑,比如公网和内网负载均衡,我们支持创建多个Nginx负载集群。
-
-下图为用户浏览请求路径。
-
-[](http://dockerone.com/uploads/article/20170215/8d636130241f31d7968ecbb5d6fdf9ed.png)
-
-关于如何能够通知Nginx集群自动更新Upstream下的Server IP问题, 我们在Nginx集群外面用beego框架设计了一层API层:slb-core, 专门对外提供API接口,具体结构如下:
-
-[](http://dockerone.com/uploads/article/20170215/e7f0474710a3f261cf0da2daed65e9ad.png)
-
-etcd里面存放每个domain的配置信息。具体key结构如下:
-
-```
-/slb/{groupname or groupid}/domains/{domain_name}/
-
-```
-
-每一台Nginx主机上都会安装一个Agent,每个Agent监控他所属的groupid 的key,比如/slb/2/,这样可监控本Nginx 集群下所有Domain的配置变化,Agent 将变化过的Domain 配置更新到Nginx下的目录下,并判断配置变化是否是更改的upstream下的Server IP还是其他配置,如果发现是其他配置更改,比如location或者增加header,则会reload nginx, 如果发现单纯更改upstream 下Server IP,则直接调用Nginx动态更改upstream ip的接口。
-
-上层的slb-core 则会提供domain动态更改后台upstream ip的接口, 供服务发现调用。
-
-如果多个互相关联,互相调用的业务域名都同时被一个Nginx集群所代理,若其中一个domain需要更改配置,导致需要reload nginx,很可能会出现reload 时间过长的问题。
-
-基于这套架构,后端Nginx主机可以快速扩展,迅速增加到对应集群中。由于增加了nginx test机制,当用户更改domain的配置有语法问题, 也不会影响负载均衡,还会保持上一个正确的配置。现在这套架构已经是乐视负载集群的通用架构,承载了乐视上千个域名的负载均衡。
-
-用户在创建一个应用时候,如果需要负载均衡则需要填写负载均衡域名,Nginx集群等信息, 如下图:
-
-[](http://dockerone.com/uploads/article/20170215/c211f9568db381b6d28b0d97afb8d0f2.png)
-
-创建成功后,通过查看应用的负载均衡导航栏可以知道这个应用负载均衡的CNAME和VIP信息,等业务测试成功后,DNS系统上配置使域名生效。
-
-如下图:
-
-[](http://dockerone.com/uploads/article/20170215/d608cc162e93fcf67854b77beae2a000.png)
-
-下图可以让用户查看负载均衡Nginx配置信息:
-
-[](http://dockerone.com/uploads/article/20170215/ba53fb39e11a46f4d69e3ad3d5c77c53.png)
-
-现阶段Nginx负载均衡集群并没有按照一个应用来进行划分,大多数情况是一个Nginx负载均衡集群代理了多组domain。因此对于用户端,为了防止业务线用户恶意或者无意的随便更改,而导致整个Nginx集群出现问题,现阶段用户端无权更改Nginx配置,如果需要更改特殊配置,需要联系管理员,由管理员进行配置。后续我们会考虑给一个应用分配一组Nginx容器进行负载均衡代理,这样用户就会拥有Nginx配置更改的最高权限。
-
-#### LeEngine registry
-
-LeEngine Registry是我们内部提供的镜像仓库,根据Docker Registry 2.0 版本:docker distribution做了修改,支持乐视Ceph后端存储,同时使用auth-server 以及LeEngine 的权限机制,定义用户和权限划分。允许镜像私有和公开。 公开的镜像任何用户可以执行Pull 操作。私有的镜像可以添加团队成员,不同角色的成员具有不同的Push,Pull, 删除权限。基于以上的设计LeEngine Registry 可以完全独立于LeEngine对外提供镜像仓库服务, 业务线如果不想使用LeEngine的代码构建功能,可以完全使用自己的构建方法,构建出镜像来,之后Push 到LeEngine registry中。
-
-如下图是关于镜像tag的相关操作:
-
-[](http://dockerone.com/uploads/article/20170215/66e492e3c836d85300f27626b22a399e.png)
-
-成员:
-
-[](http://dockerone.com/uploads/article/20170215/31f25fecb49e1eca8c950e8edc572629.png)
-
-动态:
-
-[](http://dockerone.com/uploads/article/20170215/b5d3059446d17e0452781538d97e28b8.png)
-
-LeEngine下4大资源:应用、镜像、镜像组织、代码构建,在每个资源页里都是有动态一栏,用来记录操作记录,方便以后的问题追踪。
-
-#### 代码构建
-
-为了快速将代码构建成Image,并Push到镜像仓库中,LeEngine后面会设置一组专门构建用的Docker物理机集群,用来执行构建任务,每个构建物理机都会安装一个Agent。
-
-LeEngine的代码构建框架如下:
-
-[](http://dockerone.com/uploads/article/20170215/5413a7445a394985b826a2bc75a8cace.png)
-
-每个构建物理机上的agent 启动后,都会将自己的信息定期自动注册到etcd中,表示新增一台构建机,当Agent意外停止或者主机挂掉,etcd中的注册信息会失效,表示已经下线一台构建机。另外Agent会监控自己的任务key,用来接收LeEngine-core下发的构建任务。
-
-当有一个构建请求时会调用LeEngine-core的API,LeEngine-core会从etcd中选出一个合适的构建机(一般按照hash方式,尽量保证一个代码构建在同一台物理机上构建,加快构建速度), 然后将构建任务放到这个构建机的任务key中,对应的Agent监控到key变化后,会执行代码Clone,编译,Build和Push操作。
-
-Etcd在LeEngine中扮演这非常重要的角色,是各个模块通信的消息总线。
-
-鉴于Maven项目,需要编译,在第一代Harbor系统中,编译步骤放在了Docker Build 过程中,由于Maven编译需要大量的mvn依赖,每次编译都需要重新下载依赖,导致编译时间长,编译的镜像多大,因此我们在Build之前,会起一个Container,在Container中对代码进行编译,并将mvn依赖的目录映射到主机上,这样同一个代码构建,在每次构建时候,都会共享同一个mvn依赖,不需要重新下载,加快编译速度,同时还能保证不同的代码构建使用不同的mvn依赖目录,保证编译环境绝对纯净,最后只将编译好的二进制打到镜像中,在一定程度上保证代码不外泄。
-
-代码构建仅限于放在Git上的代码,现阶段并不支持SVN,因此有的业务如果代码在SVN上,可以使用其他工具自己将代码制作成镜像,然后Push到LeEngine Registry上。由于LeEngine Registry上对镜像和镜像仓库做了权限认证,保证了镜像的安全。
-
-代码构建支持手动构建和自动构建,在GitLab上设置相应的Web hook,这样用户只要提交代码,就会自动触发LeEngine的代码构建功能。
-
-下图为创建代码构建的Web页:
-
-[](http://dockerone.com/uploads/article/20170215/c360b0436674f1a6b36de60f1f048df3.png)
-
-使用LeEngine的代码构建,我们要求用户的代码里需要自己写Dockerfile,Dockerfile 里FROM 的根镜像可以使用LeEngine Registry 里公开的镜像,也可以使用Docker Hub里公开的镜像。
-
-如果业务代码需要编译,则可以指定编译环境,编译脚本也是需要放到代码中。
-
-下图为手动构建页面:
-
-[](http://dockerone.com/uploads/article/20170215/b5fc6dab0c2be9d89316886cff7eedb3.png)
-
-tag名如果不写,LeEngine会根据当前分支下的commit号作为镜像tag名。如果选用mvncache,则本次构建就会使用上次构建所下载的mvn依赖,加快构建速度。
-
-下图为构建结果:
-
-[](http://dockerone.com/uploads/article/20170215/b679bb805e1ed84b39edce32a1983880.png)
-
-构建过程:
-
-[](http://dockerone.com/uploads/article/20170215/2f578c3c9a7a2012f54cae5201a4e24a.png)
-
-构建日志中,每一关键环节都记录了耗时时间,以及具体的执行过程。
-
-#### 应用管理
-
-应用支持垮机房部署,多版本灰度升级,弹性伸缩等功能。我们规定一个应用对应一个镜像。
-
-[](http://dockerone.com/uploads/article/20170215/19b5a95258ce6a7954a8575d9efdb6ef.png)
-
-部署版本(一个版本即一个RC)时候,需要指定镜像tag,容器数目,CPU,内存,环境变量,健康检查等等参数,现在的健康检查我们暂时只支持http接口方式:
-
-[](http://dockerone.com/uploads/article/20170215/88414ead04427180ad2515db003269f6.png)
-
-由于大部分的升级,都是更改镜像tag,因此每次部署新版本时候,LeEngine会在新弹出框内,将上一版本的容器数目,CPU,内存,环境变量,健康检查等等参数自动填充到弹出框中,用户只需选择新的镜像tag就可以了。因此最后灰度上线,只需要创建新版本等新版本的容器完全启动,服务自动加入负载均衡后,再将旧版本删除即可。
-
-下图为应用事件查看:
-
-[](http://dockerone.com/uploads/article/20170215/7c7e2438d62cd7817ade92c54abb8047.png)
-
-应用事件主要收集的是应用在Kubernetes集群中的事件信息。
-
-#### 监控、告警系统
-
-监控报警我们分PaaS平台和业务应用两大类。
-
-PaaS平台主要聚焦在基础设施和LeEngine的各个服务组件的监控报警(比如主机CPU,内存,IO,磁盘空间,LeEngine各个服务进程等等),这一类使用公司统一的监控报警机制。
-
-业务应用类,也就是跑在LeEngine上的各个业务线的监控和报警,需要由LeEngine进行对其进行监控和报警,触发报警后,会通知给各个应用的负责人。我们采用了heapster 来收集容器的监控信息和Kubernetes的各种事件。每个Cell集群中都部署一个heapster,监控数据存放到influxdb中。设定了一个应用全局对应一个Kubernetes的Namespace,因此我们能很好的聚合出应用和单个容器的监控数据。
-
-如下图 针对应用的网络流量监控:
-
-[](http://dockerone.com/uploads/article/20170215/4d234595aafecc01393be388e73d7b0f.png)
-
-容器 IP,运行时间和状态:
-
-[](http://dockerone.com/uploads/article/20170215/99890c2c201dbf3a610af8bbda6fe5fa.png)
-
-下图是针对应用下单个容器的监控:
-
-[](http://dockerone.com/uploads/article/20170215/dc7859311da37c17de45909e6b991e36.png)
-
-现在heapster 没法收集容器的磁盘IO数据,后期我们会增加对于磁盘IO的监控收集,同时我们会丰富其他的监控数据(比如请求量等等)。关于报警,我们后期准备使用kapacitor 进行用户自助化报警,让用户自定义设定针对于应用cpu,内存,网络,IO,容器重启,删除等的报警阀值。触发报警后,会调用公司统一的告警平台(电话,邮件,短信三种方式)对相关人员进行报警。默认报警人员为当前应用的Owner和Master角色的成员。此功能已经基本调研完成,计划3月底上线。
-
-#### 日志收集
-
-根据公司具体状况,容器的日志收集暂时还没有纳入LeEngine范围内,全部由业务线自己收集,然后统一收入到公司的日志系统中或者由业务线自己搭建日志存储和检索系统。我们后期会考虑日志统一收集。
-
-### 总结
-
-#### 一键式解决方案
-
-LeEngine提供了代码构建,镜像仓库,应用管理,基本上实现了开发者一键式解决方案:
-
-[](http://dockerone.com/uploads/article/20170215/a03b22ea6f4d4db1b82ddbdaad748d63.png)
-
-各个业务线开发人员只需要提交代码,剩下的就会根据打包和构建规则自动生成特定的镜像版本,测试和运维人员只需要拿着对应的镜像版本进行测试和线上升级即可,极大简化开发运维工作。
-
-#### 减少运维成本
-
-我们建议程序在容器内前台启动,利用Kubernetes的功能,程序死掉后,由kubelet自动拉起,实时保证线上容器实例数。若需要调试,业务或者运维可以直接通过SSH连接到容器内排查问题。由于Kubernetes强大的容器自动迁移功能,即使后端物理主机出现宕机或者网络问题,也不会产生严重的问题,除非后端物理计算资源不够,这在很大程度上减少了运维人员大半夜被叫起处理问题的次数。
-
-##### 计算资源对业务完全透明
-
-底层计算资源完全由我们提供,业务线不用担心资源的问题。
-
-#### 产品化
-
-LeEngine在设计之初,保证尽量少的依赖其他外部资源和服务,整个LeEngine可以作为一个解决方案整体对外输出。
-
-### 存在的问题
-
-任何一款产品不管怎么设计,都有它的不足之处,LeEngine在上线之后,我们也收到了不少反馈和问题。
-
-1. 按照之前的运维习惯,运维人员在排查问题时候,经常会根据IP来进行区分,而LeEngine下的应用每次升级后,容器IP都会变化,这对传统的运维造成一定的冲击。我们现在的解决思路是,如果运维人员一定要通过IP去排查,我们会让运维人员登录LeEngine的Console,查看当前应用下的容器IP列表,之后再去逐个排查。同时有的业务会对IP进行访问限制,针对这种情况,我们只能让这些业务对一个IP段进行限制。
-2. Kubernetes 1.2版本,对容器的swap并没有控制,若业务应用有bug,出现大量的内存泄露,往往会把容器所在物理机的swap吃满,而影响了物理机上其他的容器。 我们现在的解决方案暂时只能通过报警方式,尽快让用户修复问题。
-3. 由于Dockerfile 和编译脚本都要求放在用户Git代码中。会存在用户Git使用不规范,不同分支代码互相merge,导致Dockerfile和编译脚本出现变化,导致构建出的镜像与预期的不一样,从而上线失败。这种问题,我们只能要求业务线规范Git使用规范,LeEngine代码构建本身已经无法控制到这种细粒度。
-4. 现阶段我们还没法做到自动弹性扩容(给应用设定一个最小容器数目和最大容器数目的阀值,根据CPU、内存、IO、请求量或者其他值,自动觉得容器是否需要扩容,缩容)。
-
-### 展望
-
-Docker和Kubernetes也在飞速发展中,相信Kubernetes未来会有更加强劲的功能,我们后续也会考虑把有状态的服务跑到Kubernetes中去,欢迎大家一块探索。
-
-### Q&A
-
-Q:你们的IP管理应该做了很大的开发工作吧?能详细介绍一下?
-
-> A:确实做了很多开发工作,其中很大的一个开发量是关于空闲IP获取这块。
-
-Q:还有你们的灰度发布是用的Kubernetes本身滚动更新功能?还是自己实现的?
-
-> A:灰度发布没用Kubernetes 的滚动更新更能,而是用了不同的RC的相互切换。
-
-Q:多个Region的镜像管理,如何实现镜像同步与更新?
-
-> A: 我们不需要实现镜像的同步。分享中已经提到过,各个Region有自己的镜像仓库。
-
-Q:你好 请问你们大二层网络是用开源方案实现的还是自己根据OVS开发实现的?
-
-> A:是我们自己实现的,我们CNI中调用了OVS,主要是使用了OVS的网桥功能。
-
-Q:应用跨机房部署,我理解也就是可以跨Kubernetes集群部署,Kubernetes里的调度是如何做的?
-
-> A:应用的概念,是在Kubernetes集群之上的,应用可以部署在多个Kubernetes 集群中。
-
-Q:请问贵公司内部服务之间的互相调用是怎么控制的?容器到容器还是容器-Nginx-容器(等同外部)?
-
-> A:1. 容器->容器 2. 外部服务->Nginx->容器 3. 容器->Nginx->容器 4. 容器->外部服务。 这种情况都有,主要看业务场景。
-
-Q:构建服务集群用到什么CI工具,还是自己开发的?etcd在其中有什么作用?
-
-> A:自己开发的,etcd 相当于消息队列,控制层收到构建请求后,etcd中存放了现阶段集群下都有哪些构建机,当来到构建请求后,控制层会寻找一个构建机器,并向构建机器所在的etcd key中发送命令, 对应的构建机器在监控自己的key发生变化后,会执行相应的构建任务。
-
-以上内容根据2017年2月14日晚微信群分享内容整理。分享人
-
-作者:张杰,乐视云计算有限公司PaaS平台LeEngine负责人。毕业于东北大学,专注于云计算领域PaaS平台的技术研究。14年入职乐视,目前从事基于Docker和Kubernetes的企业级PaaS平台的架构设计,研发以及平台落地工作。
\ No newline at end of file
diff --git a/docker/docs/meituan_docker_platform.md b/docker/docs/meituan_docker_platform.md
deleted file mode 100644
index 68765d13f..000000000
--- a/docker/docs/meituan_docker_platform.md
+++ /dev/null
@@ -1,204 +0,0 @@
-# 美团点评容器平台介绍
-
-## 美团点评容器平台简介
-
-本文介绍美团点评的Docker容器集群管理平台(以下简称“容器平台”)。该平台始于2015年,是基于美团云的基础架构和组件而开发的Docker容器集群管理平台。目前该平台为美团点评的外卖、酒店、到店、猫眼等十几个事业部提供容器计算服务,承载线上业务数百个,日均线上请求超过45亿次,业务类型涵盖Web、数据库、缓存、消息队列等。
-
-## 为什么要开发容器管理平台
-
-作为国内大型的O2O互联网公司,美团点评业务发展极为迅速,每天线上发生海量的搜索、推广和在线交易。在容器平台实施之前,美团点评的所有业务都是运行在美团私有云提供的虚拟机之上。随着业务的扩张,除了对线上业务提供极高的稳定性之外,私有云还需要有很高的弹性能力,能够在某个业务高峰时快速创建大量的虚拟机,在业务低峰期将资源回收,分配给其他的业务使用。美团点评大部分的线上业务都是面向消费者和商家的,业务类型多样,弹性的时间、频度也不尽相同,这些都对弹性服务提出了很高的要求。在这一点上,虚拟机已经难以满足需求,主要体现以下两点。
-
-第一,虚拟机弹性能力较弱。使用虚拟机部署业务,在弹性扩容时,需要经过申请虚拟机、创建和部署虚拟机、配置业务环境、启动业务实例这几个步骤。前面的几个步骤属于私有云平台,后面的步骤属于业务工程师。一次扩容需要多部门配合完成,扩容时间以小时计,过程难以实现自动化。如果可以实现自动化“一键快速扩容”,将极大地提高业务弹性效率,释放更多的人力,同时也消除了人工操作导致事故的隐患。
-
-第二,IT成本高。由于虚拟机弹性能力较弱,业务部门为了应对流量高峰和突发流量,普遍采用预留大量机器和服务实例的做法。即先部署好大量的虚拟机或物理机,按照业务高峰时所需资源做预留,一般是非高峰时段资源需求的两倍。资源预留的办法带来非常高的IT成本,在非高峰时段,这些机器资源处于空闲状态,也是巨大的浪费。
-
-由于上述原因,美团点评从2015年开始引入Docker,构建容器集群管理平台,为业务提供高性能的弹性伸缩能力。业界很多公司的做法是采用Docker生态圈的开源组件,例如Kubernetes、Docker Swarm等。我们结合自身的业务需求,基于美团云现有架构和组件,实践出一条自研Docker容器管理平台之路。我们之所以选择自研容器平台,主要出于以下考虑。
-
-#### 快速满足美团点评的多种业务需求
-
-美团点评的业务类型非常广泛,几乎涵盖了互联网公司所有业务类型。每种业务的需求和痛点也不尽相同。例如一些无状态业务(例如Web),对弹性扩容的延迟要求很高;数据库,业务的master节点,需要极高的可用性,而且还有在线调整CPU,内存和磁盘等配置的需求。很多业务需要SSH登陆访问容器以便调优或者快速定位故障原因,这需要容器管理平台提供便捷的调试功能。为了满足不同业务部门的多种需求,容器平台需要大量的迭代开发工作。基于我们所熟悉的现有平台和工具,可以做到“多快好省”地实现开发目标,满足业务的多种需求。
-
-#### 从容器平台稳定性出发,需要对平台和Docker底层技术有更高的把控能力
-
-容器平台承载美团点评大量的线上业务,线上业务对SLA可用性要求非常高,一般要达到99.99%,因此容器平台的稳定性和可靠性是最重要的指标。如果直接引入外界开源组件,我们将面临3个难题:1. 我们需要摸熟开源组件,掌握其接口、评估其性能,至少要达到源码级的理解;2. 构建容器平台,需要对这些开源组件做拼接,从系统层面不断地调优性能瓶颈,消除单点隐患等;3. 在监控、服务治理等方面要和美团点评现有的基础设施整合。这些工作都需要极大的工作量,更重要的是,这样搭建的平台,在短时间内其稳定性和可用性都难以保障。
-
-#### 避免重复建设私有云
-
-美团私有云承载着美团点评所有的在线业务,是国内规模最大的私有云平台之一。经过几年的经营,可靠性经过了公司海量业务的考验。我们不能因为要支持容器,就将成熟稳定的私有云搁置一旁,另起炉灶再重新开发一个新的容器平台。因此从稳定性、成本考虑,基于现有的私有云来建设容器管理平台,对我们来说是最经济的方案。
-
-## 美团点评容器管理平台架构设计
-
-我们将容器管理平台视作一种云计算模式,云计算的架构同样适用于容器。如前所述,容器平台的架构依托于美团私有云现有架构,其中私有云的大部分组件可以直接复用或者经过少量扩展开发。容器平台架构如下图所示。
-
-
-美团点评容器管理平台架构
-
-可以看出,容器平台整体架构自上而下分为业务层、PaaS层、IaaS控制层及宿主机资源层,这与美团云架构基本一致。
-
-**业务层**:代表美团点评使用容器的业务线,他们是容器平台的最终用户。
-**PaaS层**:使用容器平台的HTTP API,完成容器的编排、部署、弹性伸缩,监控、服务治理等功能,对上面的业务层通过HTTP API或者Web的方式提供服务。
-**IaaS控制层**:提供容器平台的API处理、调度、网络、用户鉴权、镜像仓库等管理功能,对PaaS提供HTTP API接口。
-宿主机资源层:Docker宿主机集群,由多个机房,数百个节点组成。每个节点部署HostServer、Docker、监控数据采集模块,Volume管理模块,OVS网络管理模块,Cgroup管理模块等。
-容器平台中的绝大部分组件是基于美团私有云已有组件扩展开发的,例如API,镜像仓库、平台控制器、HostServer、网络管理模块,下面将分别介绍。
-
-#### API
-
-API是容器平台对外提供服务的接口,PaaS层通过API来创建、部署云主机。我们将容器和虚拟机看作两种不同的虚拟化计算模型,可以用统一的API来管理。即虚拟机等同于set(后面将详细介绍),磁盘等同于容器。这个思路有两点好处:1. 业务用户不需要改变云主机的使用逻辑,原来基于虚拟机的业务管理流程同样适用于容器,因此可以无缝地将业务从虚拟机迁移到容器之上;2. 容器平台API不必重新开发,可以复用美团私有云的API处理流程
-创建虚拟机流程较多,一般需要经历调度、准备磁盘、部署配置、启动等多个阶段,平台控制器和Host-SRV之间需要很多的交互过程,带来了一定量的延迟。容器相对简单许多,只需要调度、部署启动两个阶段。因此我们对容器的API做了简化,将准备磁盘、部署配置和启动整合成一步完成,经简化后容器的创建和启动延迟不到3秒钟,基本达到了Docker的启动性能。
-
-#### Host-SRV
-
-Host-SRV是宿主机上的容器进程管理器,负责容器镜像拉取、容器磁盘空间管理、以及容器创建、销毁等运行时的管理工作。
-
-镜像拉取:Host-SRV接到控制器下发的创建请求后,从镜像仓库下载镜像、缓存,然后通过Docker Load接口加载到Docker里。
-
-容器运行时管理:Host-SRV通过本地Unix Socker接口与Docker Daemon通信,对容器生命周期的控制,并支持容器Logs、exec等功能。
-
-容器磁盘空间管理:同时管理容器Rootfs和Volume的磁盘空间,并向控制器上报磁盘使用量,调度器可依据使用量决定容器的调度策略。
-
-Host-SRV和Docker Daemon通过Unix Socket通信,容器进程由Docker-Containerd托管,所以Host-SRV的升级发布不会影响本地容器的运行。
-
-#### 镜像仓库
-
-容器平台有两个镜像仓库:
-
-- **Docker Registry:** 提供Docker Hub的Mirror功能,加速镜像下载,便于业务团队快速构建业务镜像;
-- **Glance:** 基于Openstack组件Glance扩展开发的Docker镜像仓库,用以托管业务部门制作的Docker镜像。
-
-镜像仓库不仅是容器平台的必要组件,也是私有云的必要组件。美团私有云使用Glance作为镜像仓库,在建设容器平台之前,Glance只用来托管虚拟机镜像。每个镜像有一个UUID,使用Glance API和镜像UUID,可以上传、下载虚拟机镜像。Docker镜像实际上是由一组子镜像组成,每个子镜像有独立的ID,并带有一个Parent ID属性,指向其父镜像。我们稍加改造了一下Glance,对每个Glance镜像增加Parent ID的属性,修改了镜像上传和下载的逻辑。经过简单扩展,使Glance具有托管Docker镜像的能力。通过Glance扩展来支持Docker镜像有以下优点:
-
-- 可以使用同一个镜像仓库来托管Docker和虚拟机的镜像,降低运维管理成本;
-- Glance已经十分成熟稳定,使用Glance可以减少在镜像管理上踩坑;
-- 使用Glance可以使Docker镜像仓库和美团私有云“无缝”对接,使用同一套镜像API,可以同时支持虚拟机和Docker镜像上传、下载,支持分布式的存储后端和多租户隔离等特性;
-- Glance UUID和Docker Image ID是一一对应的关系,利用这个特性我们实现了Docker镜像在仓库中的唯一性,避免冗余存储。
-
-可能有人疑问,用Glance做镜像仓库是“重新造轮子”。事实上我们对Glance的改造只有200行左右的代码。Glance简单可靠,我们在很短的时间就完成了镜像仓库的开发上线,目前美团点评已经托管超过16,000多个业务方的Docker镜像,平均上传和下载镜像的延迟都是秒级的。
-
-## 高性能、高弹性的容器网络
-
-网络是十分重要的,又有技术挑战性的领域。一个好的网络架构,需要有高网络传输性能、高弹性、多租户隔离、支持软件定义网络配置等多方面的能力。早期Docker提供的网络方案比较简单,只有None、Bridge、Container和Host这四种网络模式,也没有用户开发接口。2015年Docker在1.9版本集成了Libnetwork作为其网络的解决方案,支持用户根据自身需求,开发相应的网络驱动,实现网络功能自定义的功能,极大地增强了Docker的网络扩展能力。
-
-从容器集群系统来看,只有单宿主机的网络接入是远远不够的,网络还需要提供跨宿主机、机架和机房的能力。从这个需求来看,Docker和虚拟机来说是共通的,没有明显的差异,从理论上也可以用同一套网络架构来满足Docker和虚拟机的网络需求。基于这种理念,容器平台在网络方面复用了美团云网络基础架构和组件。
-
-
-美团点评容器平台网络架构
-
-**数据平面:** 我们采用万兆网卡,结合OVS-DPDK方案,并进一步优化单流的转发性能,将几个CPU核绑定给OVS-DPDK转发使用,只需要少量的计算资源即可提供万兆的数据转发能力。OVS-DPDK和容器所使用的CPU完全隔离,因此也不影响用户的计算资源。
-
-**控制平面:** 我们使用OVS方案。该方案是在每个宿主机上部署一个自研的软件Controller,动态接收网络服务下发的网络规则,并将规则进一步下发至OVS流表,决定是否对某网络流放行。
-
-### MosBridge
-
-在MosBridge之前,我们配置容器网络使用的是None模式。所谓None模式也就是自定义网络的模式,配置网络需要如下几步:
-
-1. 在创建容器时指定—net=None,容器创建启动后没有网络;
-2. 容器启动后,创建eth-pair;
-3. 将eth-pair一端连接到OVS Bridge上;
-4. 使用nsenter这种Namespace工具将eth-pair另一端放到容器的网络Namespace中,然后改名、配置IP地址和路由。
-
-然而,在实践中,我们发现None模式存在一些不足:
-
-- 容器刚启动时是无网络的,一些业务在启动前会检查网络,导致业务启动失败;
-- 网络配置与Docker脱离,容器重启后网络配置丢失;
-- 网络配置由Host-SRV控制,每个网卡的配置流程都是在Host-SRV中实现的。以后网络功能的升级和扩展,例如对容器添加网卡,或者支持VPC,会使Host-SRV越来越难以维护。
-
-为了解决这些问题,我们将眼光投向Docker Libnetwork。Libnetwork为用户提供了可以开发Docker网络的能力,允许用户基于Libnetwork实现网络驱动来自定义其网络配置的行为。就是说,用户可以编写驱动,让Docker按照指定的参数为容器配置IP、网关和路由。基于Libnetwork,我们开发了MosBridge – 适配美团云网络架构的Docker网络驱动。在创建容器时,需要指定容器创建参数—net=mosbridge,并将IP地址、网关、OVS Bridge等参数传给Docker,由MosBridge完成网络的配置过程。有了MosBridge,容器创建启动后便有了网络可以使用。容器的网络配置也持久化在MosBridge中,容器重启后网络配置也不会丢失。更重要的是,MosBridge使Host-SRV和Docker充分解耦,以后网络功能的升级也会更加方便。
-
-## 解决Docker存储隔离性的问题
-
-业界许多公司使用Docker都会面临存储隔离性的问题。就是说Docker提供的数据存储的方案是Volume,通过mount bind的方式将本地磁盘的某个目录挂载到容器中,作为容器的“数据盘”使用。这种本地磁盘Volume的方式无法做到容量限制,任何一个容器都可以不加限制地向Volume写数据,直到占满整个磁盘空间。
-
-
-LVM-Volume方案
-
-针对这一问题,我们开发了LVM Volume方案。该方案是在宿主机上创建一个LVM VG作为Volume的存储后端。创建容器时,从VG中创建一个LV当作一块磁盘,挂载到容器里,这样Volume的容量便由LVM加以强限制。得益于LVM机强大的管理能力,我们可以做到对Volume更精细、更高效的管理。例如,我们可以很方便地调用LVM命令查看Volume使用量,通过打标签的方式实现Volume伪删除和回收站功能,还可以使用LVM命令对Volume做在线扩容。值得一提地是,LVM是基于Linux内核Devicemapper开发的,而Devicemapper在Linux内核的历史悠久,早在内核2.6版本时就已合入,其可靠性和IO性能完全可以信赖。
-
-## 适配多种监控服务的容器状态采集模块
-
-容器监控是容器管理平台极其重要的一环,监控不仅仅要实时得到容器的运行状态,还需要获取容器所占用的资源动态变化。在设计实现容器监控之前,美团点评内部已经有了许多监控服务,例如Zabbix、Falcon和CAT。因此我们不需要重新设计实现一套完整的监控服务,更多地是考虑如何高效地采集容器运行信息,根据运行环境的配置上报到相应的监控服务上。简单来说,我们只需要考虑实现一个高效的Agent,在宿主机上可以采集容器的各种监控数据。这里需要考虑两点:
-
-1. 监控指标多,数据量大,数据采集模块必须高效率;
-2. 监控的低开销,同一个宿主机可以跑几十个,甚至上百个容器,大量的数据采集、整理和上报过程必须低开销。
- 
- 监控数据采集方案
-
-针对业务和运维的监控需求,我们基于Libcontainer开发了**Mos-Docker-Agent**监控模块。该模块从宿主机proc、CGroup等接口采集容器数据,经过加工换算,再通过不同的监控系统driver上报数据。该模块使用GO语言编写,既可以高效率,又可以直接使用Libcontainer。而且监控的数据采集和上报过程不经过Docker Daemon,因此不会加重Daemon的负担。
-
-在监控配置这块,由于监控上报模块是插件式的,可以高度自定义上报的监控服务类型,监控项配置,因此可以很灵活地适应不同的监控场景的需求。
-
-## 支持微服务架构的设计
-
-近几年,微服务架构在互联网技术领域兴起。微服务利用轻量级组件,将一个大型的服务拆解为多个可以独立封装、独立部署的微服务实例,大型服务内在的复杂逻辑由服务之间的交互来实现。
-
-美团点评的很多在线业务是微服务架构的。例如美团点评的服务治理框架,会为每一个在线服务配置一个服务监控Agent,该Agent负责收集上报在线服务的状态信息。类似的微服务还有许多。对于这种微服务架构,使用Docker可以有以下两种封装模式。
-
-1. 将所有微服务进程封装到一个容器中。但这样使服务的更新、部署很不灵活,任何一个微服务的更新都要重新构建容器镜像,这相当于将Docker容器当作虚拟机使用,没有发挥出Docker的优势。
-2. 将每个微服务封装到单独的容器中。Docker具有轻量、环境隔离的优点,很适合用来封装微服务。不过这样可能产生额外的性能问题。一个是大型服务的容器化会产生数倍的计算实例,这对分布式系统的调度和部署带来很大的压力;另一个是性能恶化问题,例如有两个关系紧密的服务,相互通信流量很大,但被部署到不同的机房,会产生相当大的网络开销。
-
-对于支持微服务的问题,Kubernetes的解决方案是Pod。每个Pod由多个容器组成,是服务部署、编排、管理的最小单位,也是调度的最小单位。Pod内的容器相互共享资源,包括网络、Volume、IPC等。因此同一个Pod内的多个容器相互之间可以高效率地通信。
-
-我们借鉴了Pod的思想,在容器平台上开发了面向微服务的容器组,我们内部称之为**set**。一个set逻辑示意如下图所示。
-
-
-Set逻辑示意图
-
-set是容器平台的调度、弹性扩容/缩容的基本单位。每个set由一个BusyBox容器和若干个业务容器组成, BusyBox容器不负责具体业务,只负责管理set的网络、Volume和IPC配置。
-
-
-set的配置json
-
-set内的所有容器共享网络,Volume和IPC。set配置使用一个JSON描述(如图6所示),每一个set实例包含一个Container List,Container的字段描述了该容器运行时的配置,重要的字段有:
-
-- **Index**,容器编号,代表容器的启动顺序;
-- **Image**,Docker镜像在Glance上的name或者ID;
-- **Options**,描述了容器启动时的参数配置。其中CPU和MEM都是百分比,表示这个容器相对于整个set在CPU和内存的分配情况(例如,对于一个4核的set而言,容器CPU:80,表示该容器将最多使用3.2个物理核)。
-
-通过set,我们将美团点评的所有容器业务都做了标准化,即所有的线上业务都是用set描述,容器平台内只有set,调度、部署、启停的单位都是set。
-对于set的实现上我们还做了一些特殊处理:
-
-- Busybox具有Privileged权限,可以自定义一些sysctl内核参数,提升容器性能。
-- 为了稳定性考虑,用户不允许SSH登陆Busybox,只允许登陆其他业务容器。
-- 为了简化Volume管理,每一个set只有一个Volume,并挂载到Busybox下,每个容器相互共享这个Volume。
-
-很多时候一个set内的容器来自不同的团队,镜像更新频度不一,我们在set基础上设计了一个灰度更新的功能。该功能允许业务只更新set中的部分容器镜像,通过一个灰度更新的API,即可将线上的set升级。灰度更新最大的好处是可以在线更新部分容器,并保持线上服务不间断。
-
-## Docker稳定性和特性的解决方案:MosDocker
-
-众所周知,Docker社区非常火热,版本更新十分频繁,大概2~4个月左右会有一个大版本更新,而且每次版本更新都会伴随大量的代码重构。Docker没有一个长期维护的LTS版本,每次更新不可避免地会引入新的Bug。由于时效原因,一般情况下,某个Bug的修复要等到下一个版本。例如1.11引入的Bug,一般要到1.12版才能解决,而如果使用了1.12版,又会引入新的Bug,还要等1.13版。如此一来,Docker的稳定性很难满足生产场景的要求。因此十分有必要维护一个相对稳定的版本,如果发现Bug,可以在此版本基础上,通过自研修复,或者采用社区的BugFix来修复。
-
-除了稳定性的需求之外,我们还需要开发一些功能来满足美团点评的需求。美团点评业务的一些需求来自于我们自己的生产环境,而不属于业界通用的需求。对于这类需求,开源社区通常不会考虑。业界许多公司都存在类似的情况,作为公司基础服务团队就必须通过技术开发来满足这种需求。
-
-基于以上考虑,我们从Docker 1.11版本开始,自研维护一个分支,我们称之为MosDocker。之所以选择从版本1.11开始,是因为从该版本开始,Docker做了几项重大改进:
-Docker Daemon重构为Daemon、Containerd和runC这3个Binary,并解决Daemon的单点失效问题;
-
-- 支持OCI标准,容器由统一的rootfs和spec来定义;
-- 引入了Libnetwork框架,允许用户通过开发接口自定义容器网络;
-- 重构了Docker镜像存储后端,镜像ID由原来的随即字符串转变为基于镜像内容的Hash,使Docker镜像安全性更高。
-
-到目前为止,MosDocker自研的特性主要有:
-
-1. MosBridge,支持美团云网络架构的网络驱动, 基于此特性实现容器多IP,VPC等网络功能;
-2. Cgroup持久化,扩展Docker Update接口,可以使更多的CGroup配置持久化在容器中,保证容器重启后CGroup配置不丢失。
-3. 支持子镜像的Docker Save,可以大幅度提高Docker镜像的上传、下载速度。
-
-总之,维护MosDocker使我们可以将Docker稳定性逐渐控制在自己手里,并且可以按照公司业务的需求做定制开发。
-
-## 在实际业务中的推广应用
-
-在容器平台运行的一年多时间里,已经接入了美团点评多个大型业务部门的业务,业务类型也是多种多样。通过引入Docker技术,为业务部门带来诸多好处,典型的好处包括以下两点。
-
-- 快速部署,快速应对业务突发流量。由于使用Docker,业务的机器申请、部署、业务发布一步完成,业务扩容从原来的小时级缩减为秒级,极大地提高了业务的弹性能力。
-- 节省IT硬件和运维成本。Docker在计算上效率更高,加之高弹性使得业务部门不必预留大量的资源,节省大量的硬件投资。以某业务为例,之前为了应对流量波动和突发流量,预留了32台8核8G的虚拟机。使用容器弹性方案,即3台容器+弹性扩容的方案取代固定32台虚拟机,平均单机QPS提升85%, 平均资源占用率降低44-56%(如图7,8所示)。
-- Docker在线扩容能力,保障服务不中断。一些有状态的业务,例如数据库和缓存,运行时调整CPU、内存和磁盘是常见的需求。之前部署在虚拟机中,调整配置需要重启虚拟机,业务的可用性不可避免地被中断了,成为业务的痛点。Docker对CPU、内存等资源管理是通过Linux的CGroup实现的,调整配置只需要修改容器的CGroup参数,不必重启容器。
-
-
-某业务虚拟机和容器平均单机QPS
-
-
-某业务虚拟机和容器资源使用量
-
-## 结束语
-
-本文介绍了美团点评Docker的实践情况。经过一年的推广实践,从部门内部自己使用,到覆盖公司大部分业务部门和产品线;从单一业务类型到公司线上几十种业务类型,证明了Docker这种容器虚拟化技术在提高运维效率,精简发布流程,降低IT成本等方面的价值。
-
-目前Docker平台还在美团点评深入推广中。在这个过程中,我们发现Docker(或容器技术)本身存在许多问题和不足,例如,Docker存在IO隔离性不强的问题,无法对Buffered IO做限制;偶尔Docker Daemon会卡死,无反应的问题;容器内存OOM导致容器被删除,开启OOM_kill_disabled后可能导致宿主机内核崩溃等问题。因此Docker技术,在我们看来和虚拟机应该是互补的关系,不能指望在所有场景中Docker都可以替代虚拟机,因此只有将Docker和虚拟机并重,才能满足用户的各种场景对云计算的需求。
\ No newline at end of file
diff --git a/docker/docs/memory_resource_limit.md b/docker/docs/memory_resource_limit.md
deleted file mode 100644
index a38464c7c..000000000
--- a/docker/docs/memory_resource_limit.md
+++ /dev/null
@@ -1,305 +0,0 @@
-# Docker内存资源限制
-
-## 一、压测工具
-
-- [stress](http://people.seas.harvard.edu/~apw/stress/)
-
-通过如下 Dockerfile 构建简单的测试镜像
-
-```
-➜ cat Dockerfile
-FROM ubuntu:latest
-
-RUN apt-get update && \
- apt-get install stress
-➜ docker build -t ubuntu-stress:latest .
-```
-
-## 二、内存测试
-
-- [Runtime constraints on resources](https://docs.docker.com/engine/reference/run/#runtime-constraints-on-resources)
-- 目前 Docker 支持内存资源限制选项
- - `-m`, `--memory=""`Memory limit (format: `[]`). Number is a positive integer. Unit can be one of `b`, `k`, `m`, or `g`. Minimum is 4M.
- - `--memory-swap=""`Total memory limit (memory + swap, format: `[]`). Number is a positive integer. Unit can be one of `b`, `k`, `m`, or `g`.
- - `--memory-swappiness=""`Tune a container’s memory swappiness behavior. Accepts an integer between 0 and 100.
- - `--shm-size=""`Size of `/dev/shm`. The format is ``. number must be greater than 0. Unit is optional and can be `b` (bytes), `k` (kilobytes), `m` (megabytes), or `g`(gigabytes). If you omit the unit, the system uses bytes. If you omit the size entirely, the system uses `64m`.根据实际需求设置,这里不作过多的介绍
- - `--memory-reservation=""`Memory soft limit (format: `[]`). Number is a positive integer. Unit can be one of `b`, `k`, `m`, or `g`.
- - `--kernel-memory=""`Kernel memory limit (format: `[]`). Number is a positive integer. Unit can be one of `b`, `k`, `m`, or `g`. Minimum is 4M.kernel memory 没有特殊需求,则无需额外设置
- - `--oom-kill-disable=false`Whether to disable OOM Killer for the container or not.
-
-默认启动一个 container,对于容器的内存是没有任何限制的。
-
-```
-➜ ~ docker help run | grep memory # 测试 docker 版本 1.10.2,宿主系统 Ubuntu 14.04.1
- --kernel-memory Kernel memory limit
- -m, --memory Memory limit
- --memory-reservation Memory soft limit
- --memory-swap Swap limit equal to memory plus swap: '-1' to enable unlimited swap
- --memory-swappiness=-1 Tune container memory swappiness (0 to 100)
-➜ ~
-
-```
-
-### 2.1 `-m ... --memory-swap ...`
-
-- `docker run -it --rm -m 100M --memory-swap -1 ubuntu-stress:latest /bin/bash`
-
-指定限制内存大小并且设置 memory-swap 值为 -1,表示容器程序使用内存受限,而 swap 空间使用不受限制(宿主 swap 支持使用多少则容器即可使用多少。如果 `--memory-swap` 设置小于 `--memory`则设置不生效,使用默认设置)。
-
-```
-➜ ~ docker run -it --rm -m 100M --memory-swap -1 ubuntu-stress:latest /bin/bash
-root@4b61f98e787d:/# stress --vm 1 --vm-bytes 1000M # 通过 stress 工具对容器内存做压测
-stress: info: [14] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd
-
-```
-
-使用 `docker stats` 查看当前容器内存资源使用:
-
-```
-➜ ~ docker stats 4b61f98e787d
-CONTAINER CPU % MEM USAGE/LIMIT MEM % NET I/O
-4b61f98e787d 6.74% 104.8 MB/104.9 MB 99.94% 4.625 kB/648 B
-
-```
-
-通过 `top` 实时监控 stress 进程内存占用:
-
-```
-➜ ~ pgrep stress
-8209
-8210 # 需查看 stress 子进程占用,
-➜ ~ top -p 8210 # 显示可以得知 stress 的 RES 占用为 100m,而 VIRT 占用为 1007m
-top - 17:51:31 up 35 min, 2 users, load average: 1.14, 1.11, 1.06
-Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
-%Cpu(s): 0.2 us, 3.1 sy, 0.0 ni, 74.8 id, 21.9 wa, 0.0 hi, 0.0 si, 0.0 st
-KiB Mem: 8102564 total, 6397064 used, 1705500 free, 182864 buffers
-KiB Swap: 15625212 total, 1030028 used, 14595184 free. 4113952 cached Mem
-
- PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
- 8210 root 20 0 1007.1m 100.3m 0.6m D 13.1 1.3 0:22.59 stress
-
-```
-
-也可以通过如下命令获取 stress 进程的 swap 占用:
-
-```
-➜ ~ for file in /proc/*/status ; do awk '/VmSwap|Name/{printf $2 " " $3}END{ print ""}' $file; done | sort -k 2 -n -r | grep stress
-stress 921716 kB
-stress 96 kB
-➜ ~
-
-```
-
-- `docker run -it --rm -m 100M ubuntu-stress:latest /bin/bash`
-
-按照官方文档的理解,如果指定 `-m` 内存限制时不添加 `--memory-swap` 选项,则表示容器中程序可以使用 100M 内存和 100M swap 内存。默认情况下,`--memory-swap` 会被设置成 memory 的 2倍。
-
-> We set memory limit(300M) only, this means the processes in the container can use 300M memory and 300M swap memory, by default, the total virtual memory size `--memory-swap`will be set as double of memory, in this case, memory + swap would be 2*300M, so processes can use 300M swap memory as well.
-
-如果按照以上方式运行容器提示如下信息:
-
-```
-WARNING: Your kernel does not support swap limit capabilities, memory limited without swap.
-
-```
-
-可参考 [Adjust memory and swap accounting](https://docs.docker.com/engine/installation/linux/ubuntulinux/) 获取解决方案:
-
-- To enable memory and swap on system using GNU GRUB (GNU GRand Unified Bootloader), do the following:
- - Log into Ubuntu as a user with sudo privileges.
- - Edit the /etc/default/grub file.
- - Set the GRUB_CMDLINE_LINUX value as follows:
- - `GRUB_CMDLINE_LINUX="cgroup_enable=memory swapaccount=1"`
- - Save and close the file.
- - Update GRUB.
- - `$ sudo update-grub`
- - Reboot your system.
-
-```
-➜ ~ docker run -it --rm -m 100M ubuntu-stress:latest /bin/bash
-root@ed670cdcb472:/# stress --vm 1 --vm-bytes 200M # 压测 200M,stress 进程会被立即 kill 掉
-stress: info: [17] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd
-stress: FAIL: [17] (416) <-- worker 18 got signal 9
-stress: WARN: [17] (418) now reaping child worker processes
-stress: FAIL: [17] (452) failed run completed in 2s
-root@ed670cdcb472:/# stress --vm 1 --vm-bytes 199M
-
-```
-
-`docker stats` 和 top 获取资源占用情况:
-
-```
-➜ ~ docker stats ed670cdcb472
-CONTAINER CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O
-ed670cdcb472 13.35% 104.3 MB / 104.9 MB 99.48% 6.163 kB / 648 B 26.23 GB / 29.21 GB
-➜ ~ pgrep stress
-16322
-16323
-➜ ~ top -p 16323
-top - 18:12:31 up 56 min, 2 users, load average: 1.07, 1.07, 1.05
-Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
-%Cpu(s): 4.8 us, 4.0 sy, 0.0 ni, 69.6 id, 21.4 wa, 0.0 hi, 0.2 si, 0.0 st
-KiB Mem: 8102564 total, 6403040 used, 1699524 free, 184124 buffers
-KiB Swap: 15625212 total, 149996 used, 15475216 free. 4110440 cached Mem
-
- PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
-16323 root 20 0 206.1m 91.5m 0.6m D 9.9 1.2 0:52.58 stress
-
-```
-
-- `docker run -it -m 100M --memory-swap 400M ubuntu-stress:latest /bin/bash`
-
-```
-➜ ~ docker run -it --rm -m 100M --memory-swap 400M ubuntu-stress:latest /bin/bash
-root@5ed1fd88a1aa:/# stress --vm 1 --vm-bytes 400M # 压测到 400M 程序会被 kill
-stress: info: [24] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd
-stress: FAIL: [24] (416) <-- worker 25 got signal 9
-stress: WARN: [24] (418) now reaping child worker processes
-stress: FAIL: [24] (452) failed run completed in 3s
-root@5ed1fd88a1aa:/# stress --vm 1 --vm-bytes 399M # 压测到 399M 程序刚好可以正常运行(这个值已经处于临界了,不保证不被 kill)
-
-```
-
-`docker stats` 和 top 获取资源占用情况:
-
-```
-➜ ~ docker stats 5ed1fd88a1aa
-CONTAINER CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O
-5ed 12.44% 104.8 MB / 104.9 MB 99.92% 4.861 kB / 648 B 9.138 GB / 10.16 GB
-➜ ~ pgrep stress
-22721
-22722
-➜ ~ top -p 22722
-top - 18:18:58 up 1:02, 2 users, load average: 1.04, 1.04, 1.05
-Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
-%Cpu(s): 1.4 us, 3.3 sy, 0.0 ni, 73.7 id, 21.6 wa, 0.0 hi, 0.1 si, 0.0 st
-KiB Mem: 8102564 total, 6397416 used, 1705148 free, 184608 buffers
-KiB Swap: 15625212 total, 366160 used, 15259052 free. 4102076 cached Mem
-
- PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
-22722 root 20 0 406.1m 84.1m 0.7m D 11.7 1.1 0:08.82 stress
-
-```
-
-根据实际测试可以理解,`-m` 为物理内存上限,而 `--memory-swap` 则是 memory + swap 之和,当压测值是 `--memory-swap` 上限时,则容器中的进程会被直接 OOM kill。
-
-### 2.2 `-m ... --memory-swappiness ...`
-
-swappiness 可以认为是宿主 `/proc/sys/vm/swappiness` 设定:
-
-> Swappiness is a Linux kernel parameter that controls the relative weight given to swapping out runtime memory, as opposed to dropping pages from the system page cache. Swappiness can be set to values between 0 and 100 inclusive. A low value causes the kernel to avoid swapping, a higher value causes the kernel to try to use swap space.[Swappiness](https://en.wikipedia.org/wiki/Swappiness)
-
-`--memory-swappiness=0` 表示禁用容器 swap 功能(这点不同于宿主机,宿主机 swappiness 设置为 0 也不保证 swap 不会被使用):
-
-- `docker run -it --rm -m 100M --memory-swappiness=0 ubuntu-stress:latest /bin/bash`
-
-```
-➜ ~ docker run -it --rm -m 100M --memory-swappiness=0 ubuntu-stress:latest /bin/bash
-root@e3fd6cc73849:/# stress --vm 1 --vm-bytes 100M # 没有任何商量的余地,到达 100M 直接被 kill
-stress: info: [18] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd
-stress: FAIL: [18] (416) <-- worker 19 got signal 9
-stress: WARN: [18] (418) now reaping child worker processes
-stress: FAIL: [18] (452) failed run completed in 0s
-root@e3fd6cc73849:/#
-
-```
-
-### 2.3 `--memory-reservation ...`
-
-`--memory-reservation ...` 选项可以理解为内存的软限制。如果不设置 `-m` 选项,那么容器使用内存可以理解为是不受限的。按照官方的说法,memory reservation 设置可以确保容器不会长时间占用大量内存。
-
-### 2.4 `--oom-kill-disable`
-
-```
-➜ ~ docker run -it --rm -m 100M --memory-swappiness=0 --oom-kill-disable ubuntu-stress:latest /bin/bash
-root@f54f93440a04:/# stress --vm 1 --vm-bytes 200M # 正常情况不添加 --oom-kill-disable 则会直接 OOM kill,加上之后则达到限制内存之后也不会被 kill
-stress: info: [17] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd
-
-```
-
-但是如果是以下的这种没有对容器作任何资源限制的情况,添加 `--oom-kill-disable` 选项就比较 **危险** 了:
-
-```
-$ docker run -it --oom-kill-disable ubuntu:14.04 /bin/bash
-
-```
-
-因为此时容器内存没有限制,并且不会被 oom kill,此时系统则会 kill 系统进程用于释放内存。
-
-### 2.5 `--kernel-memory`
-
-> Kernel memory is fundamentally different than user memory as kernel memory can’t be swapped out. The inability to swap makes it possible for the container to block system services by consuming too much kernel memory. Kernel memory includes:
-
-- stack pages
-- slab pages
-- sockets memory pressure
-- tcp memory pressure
-
-这里直接引用 Docker 官方介绍,如果无特殊需求,kernel-memory 一般无需设置,这里不作过多说明。
-
-## 三、内存资源限制 Docker 源码解析
-
-关于 Docker 资源限制主要是依赖 Linux cgroups 去实现的,关于 cgroups 资源限制实现可以参考:[Docker背后的内核知识——cgroups资源限制](http://www.infoq.com/cn/articles/docker-kernel-knowledge-cgroups-resource-isolation/), libcontainer 配置相关的选项:
-
-- `github.com/opencontainers/runc/libcontainer/cgroups/fs/memory.go`
-
-```
-68 func (s *MemoryGroup) Set(path string, cgroup *configs.Cgroup) error {
-69 if cgroup.Resources.Memory != 0 {
-70 if err := writeFile(path, "memory.limit_in_bytes", strconv.FormatInt(cgroup.Resources.Memory, 10)); err != nil {
-71 return err
-72 }
-73 }
-74 if cgroup.Resources.MemoryReservation != 0 {
-75 if err := writeFile(path, "memory.soft_limit_in_bytes", strconv.FormatInt(cgroup.Resources.MemoryReservation, 10)); err != nil {
-76 return err
-77 }
-78 }
-79 if cgroup.Resources.MemorySwap > 0 {
-80 if err := writeFile(path, "memory.memsw.limit_in_bytes", strconv.FormatInt(cgroup.Resources.MemorySwap, 10)); err != nil {
-81 return err // 如果 MemorySwap 没有设置,则 cgroup 默认设定值是 Memory 2 倍,详见后文测试
-82 }
-83 }
-84 if cgroup.Resources.OomKillDisable {
-85 if err := writeFile(path, "memory.oom_control", "1"); err != nil {
-86 return err
-87 }
-88 }
-89 if cgroup.Resources.MemorySwappiness >= 0 && cgroup.Resources.MemorySwappiness <= 100 {
-90 if err := writeFile(path, "memory.swappiness", strconv.FormatInt(cgroup.Resources.MemorySwappiness, 10)); err != nil {
-91 return err
-92 }
-93 } else if cgroup.Resources.MemorySwappiness == -1 {
-94 return nil // 如果 MemorySwappiness 设置为 -1,则不做任何操作,经测试默认值为 60,后文附测试
-95 } else {
-96 return fmt.Errorf("invalid value:%d. valid memory swappiness range is 0-100", cgroup.Resources.MemorySwappiness)
-97 }
-98
-99 return nil
-100 }
-
-```
-
-附测试:
-
-```
-➜ ~ docker run -it --rm -m 100M --memory-swappiness=-1 ubuntu-stress:latest /bin/bash
-root@fbe9b0abf665:/#
-
-```
-
-查看宿主对应 container cgroup 对应值:
-
-```
-➜ ~ cd /sys/fs/cgroup/memory/docker/fbe9b0abf665b77fff985fd04f85402eae83eb7eb7162a30070b5920d50c5356
-➜ fbe9b0abf665b77fff985fd04f85402eae83eb7eb7162a30070b5920d50c5356 cat memory.swappiness # swappiness 如果设置 -1 则该值默认为 60
-60
-➜ fbe9b0abf665b77fff985fd04f85402eae83eb7eb7162a30070b5920d50c5356 cat memory.memsw.limit_in_bytes # 为设置的 memory 2 倍
-209715200
-➜ fbe9b0abf665b77fff985fd04f85402eae83eb7eb7162a30070b5920d50c5356
-
-```
-
-
-
-from:http://blog.opskumu.com/docker-memory-limit.html
\ No newline at end of file
diff --git a/docker/docs/orchestra_tools.md b/docker/docs/orchestra_tools.md
deleted file mode 100644
index 95cc7cfd4..000000000
--- a/docker/docs/orchestra_tools.md
+++ /dev/null
@@ -1,25 +0,0 @@
-# 容器编排工具#
-
-容器编排工具都有一些共同的特征,如容器配置、发布和发现、系统监控和故障恢复、声明式系统配置以及有关容器布置和性能的规则和约束定义机制。除此之外,有些工具还提供了处理特定需求的特性。
-
-开源编排工具包括Docker Swarm、Kubernetes、Marathon和Nomad。这些工具既可以安装在企业内部你自己的数据中心里,也可以安装在大多数的云上。其中,作为谷歌容器引擎的一部分,Kubernetes还作为托管解决方案提供。它对逻辑单元pods进行调度——pods是一组部署在一起的容器,用来完成特定的任务。Pods可以用于构成更高层次的抽象,如部署。每个pod都提供了标准的监控,也有用户自定义的健康检查。Kubernetes在类似OpenStack这样的项目中也有应用,它得到了社区及供应商的支持。
-
-**Docker Swarm & Kubernetes**
-
-Docker Swarm是Docker的原生编排工具。Docker 1.12新增了“swarm模式”特性,用于跨多个主机进行编排。Docker Swarm仍然是一个独立的产品。可以通过Docker API访问它,也可以用它调用类似docker compose这样的工具,对服务和容器进行声明式编排。Docker Swarm是Docker Datacenter这个更大的产品的一部分,后者是针对企业级容器部署。
-
-Swarm和Kubernetes都使用YAML配置文件。虽然二者都是开源的,但Kubernetes对Docker没有任何依赖,它是Cloud Native Computing Foundation(CNCF)项目的一部分。不过,两种工具都是既可以在本地运行,也可以在类似AWS这样的公有云上运行。
-
-**Marathon**
-
-编排框架Marathon基于Apache Mesos项目。Apache Mesos通过API提供了跨数据中心的资源管理和调度抽象,而这些数据中心可能是物理上分散的。Mesos上的系统可以使用底层的计算、网络和存储资源,就像虚拟机通过虚拟机管理程序使用底层资源一样。Marathon使用了Mesos并在它上面运行,针对长期运行的应用程序提供了容器编排功能。它既支持Mesos容器运行时,也支持Docker容器运行时。
-
-Amazon EC2容器服务(ECS)和Azure容器服务是两个托管解决方案,其中后者是最新的解决方案。ECS仅支持在AWS的基础设施上运行的容器,它可以利用弹性负载均衡、日志工具CloudTrail等AWS特性。ECS任务调度器将任务分组成服务进行编排。对于持久化数据存储,用户可以使用数据卷或者Amazon弹性文件系统(EFS)。Azure的容器服务使用Mesos作为底层集群管理器。用户也可以选用Apache Mesosphere数据中心操作系统(DC/OS)、Kubernetes或者Docker Swarm进行编排。
-
-**[Nomad](nomad.md)**
-
-Hashicorp的Nomad是一个开源产品,可以支持Docker容器、VM和独立应用程序。Nomad基于代理模型,每个代理部署到一台主机上,它会和中央Nomad服务器通信。Nomad服务器负责任务调度,其依据是哪台主机有可用的资源。Nomad可以跨数据中心,而且也可以和其他Hashicorp工具(如Consul)集成。
-
-**总结**
-
-在选择使用哪种编排工具时,其中一个决定性因素是,是否可以接受被锁定到特定的基础设施(如AWS或Azure)。
\ No newline at end of file
diff --git a/docker/docs/plugin_developing.md b/docker/docs/plugin_developing.md
deleted file mode 100644
index c0f26a354..000000000
--- a/docker/docs/plugin_developing.md
+++ /dev/null
@@ -1,131 +0,0 @@
-# docker插件开发示例
-
-[官方示例文档](https://github.com/docker/docker/blob/17.03.x/docs/extend/index.md#developing-a-plugin)
-
-官方以开发一个**sshfs**的volume plugin为例。
-
-```
-$ git clone https://github.com/vieux/docker-volume-sshfs
-$ cd docker-volume-sshfs
-$ go get github.com/docker/go-plugins-helpers/volume
-$ go build -o docker-volume-sshfs main.go
-$ docker build -t rootfsimage .
-$ id=$(docker create rootfsimage true) # id was cd851ce43a403 when the image was created
-$ sudo mkdir -p myplugin/rootfs
-$ sudo docker export "$id" | sudo tar -x -C myplugin/rootfs
-$ docker rm -vf "$id"
-$ docker rmi rootfsimage
-```
-
-我们可以看到**sshfs**的Dockerfile是这样的:
-
-```Dockerfile
-FROM alpine
-
-RUN apk update && apk add sshfs
-
-RUN mkdir -p /run/docker/plugins /mnt/state /mnt/volumes
-
-COPY docker-volume-sshfs docker-volume-sshfs
-
-CMD ["docker-volume-sshfs"]
-```
-
-实际上是讲编译好的可执行文件复制到alpine linux容器中运行。
-
-编译rootfsimage镜像的过程。
-
-```
-docker build -t rootfsimage .
-Sending build context to Docker daemon 11.71 MB
-Step 1/5 : FROM alpine
- ---> 4a415e366388
-Step 2/5 : RUN apk update && apk add sshfs
- ---> Running in 1551ecc1c847
-fetch http://dl-cdn.alpinelinux.org/alpine/v3.5/main/x86_64/APKINDEX.tar.gz
-fetch http://dl-cdn.alpinelinux.org/alpine/v3.5/community/x86_64/APKINDEX.tar.gz
-v3.5.2-2-ge626ce8c3c [http://dl-cdn.alpinelinux.org/alpine/v3.5/main]
-v3.5.1-71-gc7bb9a04f0 [http://dl-cdn.alpinelinux.org/alpine/v3.5/community]
-OK: 7959 distinct packages available
-(1/10) Installing openssh-client (7.4_p1-r0)
-(2/10) Installing fuse (2.9.7-r0)
-(3/10) Installing libffi (3.2.1-r2)
-(4/10) Installing libintl (0.19.8.1-r0)
-(5/10) Installing libuuid (2.28.2-r1)
-(6/10) Installing libblkid (2.28.2-r1)
-(7/10) Installing libmount (2.28.2-r1)
-(8/10) Installing pcre (8.39-r0)
-(9/10) Installing glib (2.50.2-r0)
-(10/10) Installing sshfs (2.8-r0)
-Executing busybox-1.25.1-r0.trigger
-Executing glib-2.50.2-r0.trigger
-OK: 11 MiB in 21 packages
- ---> 1a73c501f431
-Removing intermediate container 1551ecc1c847
-Step 3/5 : RUN mkdir -p /run/docker/plugins /mnt/state /mnt/volumes
- ---> Running in 032af3b2595a
- ---> 30c7e8463e96
-Removing intermediate container 032af3b2595a
-Step 4/5 : COPY docker-volume-sshfs docker-volume-sshfs
- ---> a924c6fcc1e4
-Removing intermediate container ffc5e3c97707
-Step 5/5 : CMD docker-volume-sshfs
- ---> Running in 0dc938fe4f4e
- ---> 0fd2e3d94860
-Removing intermediate container 0dc938fe4f4e
-Successfully built 0fd2e3d94860
-```
-
-编写``config.json``文档
-
-```Json
-{
- "description": "sshFS plugin for Docker",
- "documentation": "https://docs.docker.com/engine/extend/plugins/",
- "entrypoint": ["/go/bin/docker-volume-sshfs"],
- "network": {
- "type": "host"
- },
- "interface" : {
- "types": ["docker.volumedriver/1.0"],
- "socket": "sshfs.sock"
- },
- "linux": {
- "capabilities": ["CAP_SYS_ADMIN"]
- }
-}
-```
-
-该插件使用host网络类型,使用/run/docker/plugins/sshfs.sock接口与docker engine通信。
-
-**创建plugin**
-
-使用``docker plugin create /path/to/plugin/data/``命令创建插件。
-
-具体到sshfs插件,在myplugin目录下使用如下命令创建插件:
-
-```shell
-docker plugin create jimmysong/sshfs:latest .
-```
-
-现在就可以看到刚创建的插件了
-
-```
-docker plugin ls
-ID NAME DESCRIPTION ENABLED
-8aa1f6098fca vieux/sshfs:latest sshFS plugin for Docker true
-```
-
-**push plugin**
-
-先登录你的docker hub账户,然后使用``docker plugin push jimmysong/sshfs:latest``即可以推送docker plugin到docker hub中。
-
-目前推送到**harbor**镜像仓库有问题,报错信息:
-
-```
-c08c951b53b7: Preparing
-denied: requested access to the resource is denied
-```
-
-已给harbor提[issue-1532](https://github.com/vmware/harbor/issues/1532)
-
diff --git a/docker/docs/rancher_network.md b/docker/docs/rancher_network.md
deleted file mode 100644
index 071aacf3f..000000000
--- a/docker/docs/rancher_network.md
+++ /dev/null
@@ -1,164 +0,0 @@
-# Rancher网络探讨和扁平网络实现#
-
-Rancher 1.2之后的版本在很多地方都有更新,容器网络方面除提供IPsec支持之外Rancher增加了对VXLAN支持,同时提供CNI插件管理机制,让用户可以hacking接入其他第三方CNI插件。
-
-本文的主要内容有:
-
-1. 什么是CNI接口
-2. 容器网络基于CNI的实现---IPsec及VXLAN
-3. 容器网络基于CNI的实现---直接路由访问容器
-4. 容器网络介绍
-
-## 1.1 容器的网络类型##
-
-### 1.1.1 原始容器网络###
-
-- Bridge模式
-- HOST模式
-- Container模式
-
-### 1.1.2 容器网络的进化###
-
-- Container Networking Model (CNM)
-- Container Networking Interface (CNI)
-
-## 1.2 CNI和CNM简介 ##
-
-CNM和CNI并不是网络实现而是网络规范和网络体系,CNM和CNI关心的是网络管理的问题。
-
- 这两个模型全都是插件化的,用户可以以插件的形式去插入具体的网络实现。其中CNM由Docker公司自己提出,而CNI则是Google 的Kubernetes主导。总体上说CNM比较不灵活,也不难么开放,但是确是Docker的原生网络实现。而CNI则更具通用性,而且也十分的灵活。目前主流的插件如:Calico、Weave、Mesos基本上是对CNI和CNM两种规范都提供支持。
-
-### 1.2.1 CNM接口:###
-
-CNM是一个被 Docker 提出的规范。现在已经被Cisco Contiv, Kuryr, Open Virtual Networking (OVN), Project Calico, VMware 和 Weave 这些公司和项目所采纳。
-
-
-
-其中Libnetwork是CNM的原生实现。它为Docker daemon和网络驱动程序之间提供了接口。网络控制器负责将驱动和一个网络进行对接。每个驱动程序负责管理它所拥有的网络以及为该网络提供的各种服务,例如IPAM等等。由多个驱动支撑的多个网络可以同时并存。网络驱动可以按提供方被划分为原生驱动(libnetwork内置的或Docker支持的)或者远程驱动 (第三方插件)。原生驱动包括 none, bridge, overlay 以及 MACvlan。驱动也可以被按照适用范围被划分为本地(单主机)的和全局的 (多主机)。
-
-
-
-Network Sandbox:容器内部的网络栈,包含interface、路由表以及DNS等配置,可以看做基于容器网络配置的一个隔离环境(其概念类似“network namespace”)
-
-Endpoint:网络接口,一端在网络容器内,另一端在网络内。一个Endpoints可以加入一个网络。一个容器可以有多个endpoints。
-
-Network:一个endpoints的集合。该集合内的所有endpoints可以互联互通。(其概念类似:Linux bridge、VLAN)
-
-最后,CNM还支持标签(labels)。Lable是以key-value对定义的元数据。用户可以通过定义label这样的元数据来自定义libnetwork和驱动的行为。
-
-### 1.2.2 CNI网络接口
-
-CNI是由Google提出的一个容器网络规范。已采纳改规范的包括Apache Mesos, Cloud Foundry, Kubernetes, Kurma 和 rkt。另外 Contiv Networking, Project Calico 和 Weave这些项目也为CNI提供插件。
-
-
-
-CNI 的规范比较小巧。它规定了一个容器runtime和网络插件之间的简单的契约。这个契约通过JSON的语法定义了CNI插件所需要提供的输入和输出。
-
-一个容器可以被加入到被不同插件所驱动的多个网络之中。一个网络有自己对应的插件和唯一的名称。CNI 插件需要提供两个命令:一个用来将网络接口加入到指定网络,另一个用来将其移除。这两个接口分别在容器被创建和销毁的时候被调用。
-
-在使用CNI接口时容器runtime首先需要分配一个网络命名空间以及一个容器ID。然后连同一些CNI配置参数传给网络驱动。接着网络驱动会将该容器连接到网络并将分配的IP地址以JSON的格式返回给容器runtime。
-
-Mesos 是最新的加入CNI支持的项目。Cloud Foundry的支持也正在开发中。当前的Mesos网络使用宿主机模式,也就是说容器共享了宿主机的IP地址。Mesos正在尝试为每个容器提供一个自己的IP地址。这样做的目的是使得IT人员可以自行选择适合自己的组网方式。
-
-目前,CNI的功能涵盖了IPAM, L2 和 L3。端口映射(L4)则由容器runtime自己负责。CNI也没有规定端口映射的规则。这样比较简化的设计对于Mesos来讲有些问题。端口映射是其中之一。另外一个问题是:当CNI的配置被改变时,容器的行为在规范中是没有定义的。为此,Mesos在CNI agent重启的时候,会使用该容器与CNI关联的配置。
-
-## 2.Rancher的Overlay网络实现 ##
-
-容器网络是容器云平台中很重要的一环,对于不同的规模、不同的安全要求,会有不同的选型。Rancher的默认网络改造成了CNI标准,同时也会支持其他第三方CNI插件,结合Rancher独有的Environment Template功能,用户可以在一个大集群中的每个隔离环境内,创建不同的网络模式,以满足各种业务场景需求,这种管理的灵活性是其他平台没有的。
-
-至于Rancher为什么会选择CNI标准,最开始Rancher也是基于CNM进行了开发,但随着开发的深入,我们不得不转向了CNI,个中原因在本次交流中我们就不做详细说(tu)明(cao)了,大家如果有兴趣可以参阅:[http://blog.kubernetes.io/2016/01/why-Kubernetes-doesnt-use-libnetwork.html](http://blog.kubernetes.io/2016/01/why-Kubernetes-doesnt-use-libnetwork.html)
-
-在之前的Rancher版本上,用户时常抱怨Rancher的网络只有IPsec,没有其他选择。而容器社区的发展是十分迅猛的,各种容器网络插件风起云涌。在Rancher v1.2之后Rancher 全面支持了CNI标准,除在容器网络中实现IPsec之外又实现了呼声比较高的VXLAN网络,同时增加了CNI插件管理机制,让用户可以hacking接入其他第三方CNI插件。随后将和大家一起解读一下Rancher网络的实现。
-
-## 2.1 Rancher-net CNI的IPsec实现 ##
-
-以最简单最快速方式部署Rancher并添加Host,以默认的IPsec网络部署一个简单的应用后,进入应用容器内部看一看网络情况,对比一下之前的Rancher版本:
-
-
-
-最直观的感受便是,网卡名从eth0到eth0@if8有了变化,原先网卡多IP的实现也去掉了,变成了单纯的IPsec网络IP。这其实就引来了我们要探讨的内容,虽然网络实现还是IPsec,但是rancher-net组件实际上是已经基于CNI标准了。最直接的证明就是看一下,rancher-net镜像的Dockerfile:
-
-
-
-熟悉CNI规范的伙伴都知道/opt/cni/bin目录是CNI的插件目录,bridge和loopback也是CNI的默认插件,这里的rancher-bridge实际上和CNI原生的bridge没有太大差别,只是在幂等性健壮性上做了增强。而在IPAM也就是IP地址管理上,Rancher实现了一个自己的rancher-cni-ipam,它的实现非常简单,就是通过访问rancher-metadata来获取系统给容器分配的IP。Rancher实际上Fork了CNI的代码并做了这些修改,[https://github.com/rancher/cni](https://github.com/rancher/cni)。这样看来实际上,rancher-net的IPsec和Vxlan网络其实就是基于CNI的bridge基础上实现的。
-
-在解释rancher-net怎么和CNI融合之前,我们需要了解一下CNI bridge模式是怎么工作的。举个例子,假设有两个容器nginx和mysql,每个容器都有自己的eth0,由于每个容器都是在各自的namespace里面,所以互相之间是无法通信的,这就需要在外部构建一个bridge来做二层转发,容器内的eth0和外部连接在容器上的虚拟网卡构建成对的veth设备,这样容器之间就可以通信了。其实无论是docker的bridge还是cni的bridge,这部分工作原理是差不多的,如图所示:
-
-
-
-那么我们都知道CNI网络在创建时需要有一个配置,这个配置用来定义CNI网络模式,读取哪个CNI插件。在这个场景下也就是cni bridge的信息,这个信息rancher是通过rancher-compose传入metadata来控制的。查看ipsec服务的rancher-compose.yml可以看到,type使用rancher-bridge,ipam使用rancher-cni-ipam,bridge网桥则复用了docker0,有了这个配置我们甚至可以随意定义ipsec网络的CIDR,如下图所示:
-
-
-
-ipsec服务实际上有两个容器:一个是ipsec主容器,内部包含rancher-net服务和ipsec需要的charon服务;另一个sidekick容器是cni-driver,它来控制cni bridge的构建。两端主机通过IPsec隧道网络通信时,数据包到达物理网卡时,需要通过Host内的Iptables规则转发到ipsec容器内,这个Iptables规则管理则是由network-manager组件来完成的,[https://github.com/rancher/plugin-manager](https://github.com/rancher/plugin-manager)。其原理如下图所示(以IPsec为例):
-
-
-
-整体上看cni ipsec的实现比之前的ipsec精进了不少,而且也做了大量的解耦工作,不单纯是走向社区的标准,之前大量的Iptables规则也有了很大的减少,性能上其实也有了很大提升。
-
-## 2.2 Rancher-net vxlan的实现 ##
-
-那么rancher-net的另外一个backend vxlan又是如何实现的呢?我们需要创建一套VXLAN网络环境来一探究竟,默认的Cattle引擎网络是IPsec,如果修改成VXLAN有很多种方式,可以参考我下面使用的方式。
-
-首先,创建一个新的Environment Template,把Rancher IPsec禁用,同时开启Rancher VXLAN,如下图所示:
-
-
-
-然后,我们创建一个新的ENV,并使用刚才创建的模版Cattle-VXLAN,创建完成后,添加Host即可使用。如下图所示:
-
-
-
-以分析IPsec网络实现方式来分析VXLAN,基本上会发现其原理大致相同。同样是基于CNI bridge,使用rancher提供的rancher-cni-bridge 、rancher-cni-ipam,网络配置信息以metadata方式注入。区别就在于rancher-net容器内部,rancher-net激活的是vxlan driver,它会生成一个vtep1042设备,并开启udp 4789端口,这个设备基于udp 4789构建vxlan overlay的两端通信,对于本机的容器通过eth0走bridge通信,对于其他Host的容器,则是通过路由规则转发到vtep1042设备上,再通过overlay到对端主机,由对端主机的bridge转发到相应的容器上。整个过程如图所示:
-
-
-
-## 3.Rancher的扁平网络实现##
-
-为什么需要扁平网络,因为容器目前主流的提供的都是Overlay网络,这个模式的好处是,灵活、容易部署、可以屏蔽网络对应用部署的阻碍,但是对很多用户而言,这样也带了了额外的网络开销,网络管理不可以控制,以及无法与现有SDN网络进行对接。
-
-在实现扁平网络后,容器可以直接分配业务IP,这样访问容器上的应用就类似访问VM里的应用一样,可以直接通过路由直达,不需要进行NAT映射。但偏平网络带来的问题是,会消耗大量的业务段IP地址,同时网络广播也会增多。
-
-## 3.1 扁平网络实现##
-
-在Rancher环境中实现扁平网络需要使用自定义的bridge,同时这个bridge与docker0并没有直接关系。我们可以给容器添加新的网桥mybridge,并把容器通过veth对连接到网桥上mybridge上,如果要实现容器访问宿主机的VM上的服务可以将虚拟机配置的IP也配置到网桥上。进行如上配置后,容器就可以实现IP之间路由直接访问。此图中的vboxnet bridge可以看做是用户环境的上联交互机。
-
-
-
-在VM和物理机的混合场景,所采用的方法也很类型,这边就再多做解释了。
-
-
-
-Rancher CNI网络环境实现扁平网络的工作流如下:
-
-
-
-在实现容器扁平网络的基本配置后,就需要考虑和Rancher的集成,Rancher的Network-plugin的启动依赖于Metadata,而Metadata和DNS server均使用docker0的bridge网络(IP为[169.254.169.250](169.254.169.250))。即,用户配置的扁平网络要能够访问到docker0网络,否则Rancher提供的服务发现与注册以及其它为业务层提供的服务将不可用。目前主要方法如下图所示:
-
-
-
-1. container-1内部有到达[169.254.169.250](169.254.169.250)的一条主机路由,即要访问[169.254.169.250](169.254.169.250)需要先访问[10.43.0.2](10.43.0.2);
-2. 通过veth-cni与veth-doc的链接,CNI bridge下的container-1可以将ARP请求发送到docker0的[10.43.0.2](10.43.0.2)地址上。由于[10.1.0.2](10.1.0.2)的ARP response报文是被veth-cni放行的,于是container-1能够收到来自[10.43.0.2](10.43.0.2)的ARP response报文。
-3. 然后container-1开始发送到[169.254.169.250](169.254.169.250)的IP请求,报文首先被送到docker0的veth-doc上,docker0查询路由表,将报文转到DNS/metadata对应的容器。然后IP报文原路返回,被docker0路由到veth1上往br0发送,由于来自[169.254.169.250](169.254.169.250)的IP报文都是被放行的,因此container-1最终能够收到IP。
-4. 由于属于该network的所有的宿主机的docker0上都需要绑定IP地址[10.43.0.2](10.43.0.2);因此,该IP地址必须被预留,即,在catalog中填写CNI的netconf配置时,不能将其放入IP地址池。
-5. 同时,为了保障该地址对应的ARP请求报文不被发送出主机,从而收到其他主机上对应接口的ARP响应报文,需要对所有请求[10.1.0.2](10.1.0.2)地址的ARP REQUEST报文做限制,不允许其通过br0发送到宿主机网卡。
-
-具体转发规则对应的ebtables规则如下所示:
-
-Drop All traffic from veth-cni except:
-
-1. IP response from [169.254.169.250](169.254.169.250)
-2. ARP response from [10.43.0.2](10.43.0.2)
-
-ebtables -t broute -A BROUTING -i veth-cni -j DROP
-
-ebtables -t broute -I BROUTING -i veth-cni -p ipv4 --ip-source [169.254.169.250](169.254.169.250) -j ACCEPT
-
-ebtables -t broute -I BROUTING -i veth-cni -p arp --arp-opcode 2 --arp-ip-src [10.43.0.2](10.43.0.2) -j ACCEPT
-
-Drop ARP request for [10.43.0.2](10.43.0.2) on eth1
-
-ebtables -t nat -D POSTROUTING -p arp --arp-opcode 1 --arp-ip-dst [10.43.0.2](10.43.0.2) -o eth1 -j DROP
-
-另外也可以在容器所在的主机上将Docker0的bridge和CNI的bridge做三层打通,并使用iptables来进行控制,目前这个方式还在测试中。
-
-
\ No newline at end of file
diff --git a/docker/docs/rancher_usage.md b/docker/docs/rancher_usage.md
deleted file mode 100644
index 9fce1b6e1..000000000
--- a/docker/docs/rancher_usage.md
+++ /dev/null
@@ -1,76 +0,0 @@
-# Rancher的部署和使用
-
-Rancher是一个企业级的容器管理平台,支持Swarm、kubernetes和rancher自研的cattle调度平台。
-
-Rancher可以直接使用容器部署,部署起来非常简单。
-
-在可以联网的主机里直接执行
-
-运行ranche server
-
-```shell
-sudo docker run -d --restart=unless-stopped -p 8080:8080 rancher/server
-```
-
-运行rancher agent
-
-```
-sudo docker run -d --restart=unless-stopped -p 8080:8080 rancher/agent
-```
-
-对于无法联网的主机先将镜像下载到本地然后上传到服务器上。
-
-```Shell
-docker pull rancher/server
-docker pull rancher/agent
-docker image save rancher/server:latest>rancher.tar
-docker image save rancher/agent:latest>rancher.tar
-```
-
-**查看镜像版本**
-
-默认下载和使用的是latest版本的的rancher镜像,想查看具体的镜像版本,可以使用``docker inspect rancher/server|grep VERSION``命令查看server的版本,使用``docker inspect rancher/agent|grep IMAGE``查看agent版本,版本信息是做为镜像的ENV保存的,如:
-
-```
-docker inspect rancher/server|grep VERSION
-"CATTLE_RANCHER_SERVER_VERSION=v1.4.1",
-"CATTLE_RANCHER_COMPOSE_VERSION=v0.12.2",
-"CATTLE_RANCHER_CLI_VERSION=v0.4.1",
-"CATTLE_CATTLE_VERSION=v0.176.9",
-"CATTLE_RANCHER_SERVER_VERSION=v1.4.1",
-"CATTLE_RANCHER_COMPOSE_VERSION=v0.12.2",
-"CATTLE_RANCHER_CLI_VERSION=v0.4.1",
-"CATTLE_CATTLE_VERSION=v0.176.9",
-```
-
-```
-docker inspect rancher/agent|grep IMAGE
-"RANCHER_AGENT_IMAGE=rancher/agent:v1.1.0"
-"ENV RANCHER_AGENT_IMAGE=rancher/agent:v1.1.0"
-"RANCHER_AGENT_IMAGE=rancher/agent:v1.1.0"
-```
-
-我们可以看到rancher server的版本是v1.4.1,默认rancher agent的latest版本是v1.1.0,我们这里使用v1.2.0,所有在pull rancher/agent的时候需要制定版本为v1.2.0 ``docker pull rancher/agent:v1.2.0``
-
-更多资料参考最新版本的Rancher文档:http://docs.rancher.com/rancher/v1.4/en/
-
-**启动Rancher**
-
-在主机sz-pg-oam-docker-test-001.tendcloud.com上执行以下命令启动Rancher server
-
-```Shell
-$ sudo docker run -d --restart=unless-stopped -p 8080:8080 rancher/server
-```
-
-启动完成后可以在浏览器中登录该主机IP:8080看到rancher server的登陆页面,如图:
-
-
-
-
-
-登录后请即使设置access control。
-
-Server启动完成后可以向Rancher中添加主机,
-
-
-
diff --git a/docker/docs/swarm_app_manage.md b/docker/docs/swarm_app_manage.md
deleted file mode 100644
index 273fe076d..000000000
--- a/docker/docs/swarm_app_manage.md
+++ /dev/null
@@ -1,51 +0,0 @@
-# Swarm应用管理
-
-## 应用更新
-
-继续前面的**vote**应用。
-
-加入我们更新了vote应用的result和vote镜像代码重新构建了新镜像,修改``docker-stack.yml``文件,将其中的``sz-pg-oam-docker-hub-001.tendcloud.com/library/examplevotingapp_vote:before``和``sz-pg-oam-docker-hub-001.tendcloud.com/library/examplevotingapp_result:before``分别修改为``sz-pg-oam-docker-hub-001.tendcloud.com/library/examplevotingapp_vote:after``和``sz-pg-oam-docker-hub-001.tendcloud.com/library/examplevotingapp_result:after``,相当于要上线新版本,可以进行如下操作:
-
-```
-$docker stack deploy --compose-file docker-stack.yml vote
-Updating service vote_result (id: 5bte3o8e0ta98mpp80c51ro5z)
-Updating service vote_worker (id: h65a6zakqgq3dd2cfgco1t286)
-Updating service vote_visualizer (id: zgiuxazk4sscyjj0ztcmvqnxf)
-Updating service vote_redis (id: z4q2gnvoxtpjv7e9q4s5p1ovs)
-Updating service vote_db (id: k7xzd0adhh5223fbsspouryxs)
-Updating service vote_vote (id: pvvi5qqcsnaghadu0w6c82pd3)
-```
-
-再次访问投票和结果页面,会看到投票选项已经变成了JAVA、.NET。投票结果页面会显示刚才投票的结果。
-
-官方的完整示例文档地址:https://github.com/docker/labs/blob/master/beginner/chapters/votingapp.md
-
-## 滚动升级
-
-创建service的时候可以指定``—update-delay``参数,可以为10m23s这样写法,表示执行update的间隔是10分钟23秒。也可以用``--update-parallelism``参数指定并发update数量。
-
-```
-$ docker service create \
- --replicas 3 \
- --name redis \
- --update-delay 10s \
- redis:3.0.6
-
-0u6a4s31ybk7yw2wyvtikmu50
-```
-
-update service的时候需要指定镜像名。
-
-```$ docker service update --image redis:3.0.7 redis
-$ docker service update --image redis:3.0.7 redis
-redis
-```
-
-滚动升级的时候也可以指定升级策略,默认是:
-
-- 停止第一个task
-- 调度update task到刚停止的那个task上
-- 启动刚调度的那个task
-- 如果刚调度的那个task返回RUNNING状态,则等到udpate delay时间后停止下一个task
-- 如果每次update都失败,则返回FAILED
-
diff --git a/docker/docs/swarm_mode.md b/docker/docs/swarm_mode.md
deleted file mode 100644
index aa229c10c..000000000
--- a/docker/docs/swarm_mode.md
+++ /dev/null
@@ -1,89 +0,0 @@
-# Swarm mode简介
-
-为了使用 Docker 内置的 swarm 模式,你需要安装 Docker Engine v1.12.0 或者更新版本的 Docker,或者,相应的安装最新的 Docker for Mac, Docker for Windows Beta。
-
-Docker Engine 1.12 内置了 swarm 模式来让用户便捷的管理集群。 通过 Docker CLI 可以创建一个 swarm 集群,部署应用到一个 swarm 集群,或者管理一个 swarm 集群的行为。
-
-如果你正在使用 v1.12.0 以前版本的 Docker ,请参考 [Docker Swarm](https://docs.docker.com/swarm)。
-
-## 主要特性
-
-### 内置于 Docker Engine 的集群管理
-
-可以直接用 Docker Engine CLI 来创建 Swarm 集群,并在该集群上部署服务。你不再需要额外的编排软件来创建或管理 Swarm 集群了。
-
-### 去中心化设计
-
-不同于在部署时就确定节点之间的关系, 新的 Swarm 模式选择在运行时动态地处理这些关系, 你可以用 Docker Engine 部署 manager 和 worker 这两种不同的节点。 这意味着你可以从一个磁盘镜像搭建整个 Swarm 。
-
-### 声明式服务模型
-
-Docker Engine 使用一种声明式方法来定义各种服务的状态。譬如,你可以描述一个由 web 前端服务,消息队列服务和数据库后台组成的应用。
-
-### 服务扩缩
-
-你可以通过 docker service scale 命令轻松地增加或减少某个服务的任务数。
-
-### 集群状态维护
-
-Swarm 管理节点会一直监控集群状态,并依据你给出的期望状态与集群真实状态间的区别来进行调节。譬如,你为一个服务设置了10个任务副本,如果某台运行着该服务两个副本的工作节点停止工作了,管理节点会创建两个新的副本来替掉上述异常终止的副本。 Swarm 管理节点这个新的副本分配到了正常运行的工作节点上。
-
-### 跨主机网络
-
-你可以为你的服务指定一个 overlay 网络。在服务初始化或着更新时,Swarm 管理节点自动的为容器在 overlay 网络上分配地址。
-
-### 服务发现
-
-Swarm 管理节点在集群中自动的为每个服务分配唯一的 DNS name 并为容器配置负载均衡。利用内嵌在 Swarm 中的 DNS 服务器你可以找到每个运行在集群中的容器。
-
-### 负载均衡
-
-你可以把服务的端口暴露给一个集群外部的负载均衡器。 在 Swarm 集群内部你可以决定如何在节点间分发服务的容器。
-
-### 默认 TLS 加密
-
-Swarm 集群中的节点间通信是强制加密的。你可以选择使用自签名的根证书或者来自第三方认证的证书。
-
-### 滚动更新
-
-docker service 允许你自定义更新的间隔时间, 并依次更新你的容器, docker 会按照你设置的更新时间依次更新你的容器, 如果发生了错误, 还可以回滚到之前的状态.
-
-## Swarm
-
-Docker Engine 内置的集群管理和编排功能是利用 SwarmKit 实现的。集群中的 Engine 在 swarm 模式下运行。你可以通过初始化一个 swarm 集群或者加入一个存在的 swarm 集群来激活 Engine 的 swarm 模式。
-
-Swarm 是你部署服务的一个集群。 Docker Engine CLI 已经内置了swarm 管理的相关命令,像添加,删除节点等。 CLI 也内置了在 swarm 上部署服务以及管理服务编排的命令。
-
-在非 swarm mode 下,你只能执行容器命令。在 swarm mode 下,你可以编排服务。
-
-## Node
-
-Node 是 Docker Engine 加入到 swarm 的一个实例。
-
-你可以通过向 manager node 提交一个服务描述来部署应用到 swarm 集群。manager node 调度工作单元--任务,到 worker node。
-
-Manager node 也负责提供维护 swarm 状态所需要的编排和集群管理功能。 Manager node 选举一个 leader 来管理任务编排。
-
-Worker node 接收并执行从 manager node 调度过来的任务。
-
-在默认情况下, manager node 同时也是 worker node,当然你可以配置 manager node 只充当管理角色不参与任务执行。Manager 根据 agent 提供的任务当前状态来维护目标状态。
-
-## Services and tasks
-
-service 指的是在 worker node 上执行的任务的描述。service 是 swarm 系统的中心架构,是用户跟 swarm 交互的基础。
-
-在你创建 service 时, 你需要指定容器镜像,容器里面执行的命令等。
-
-在 replicated service 模式下, swarm 根据你设置的 scale(副本) 数部署在集群中部署指定数量的任务副本。
-
-在 global service 模式下, swarm 在集群每个可用的机器上运行一个 service 的任务。
-
-task 指的是一个 Docker 容器以及需要在该容器内运行的命令。 task 是 swarm 的最小调度单元。 manager node 根据 service scale 的副本数量将 task 分配到 worker node 上。 被分配到一个 node 上的 task 不会被莫名移到另一个 node 上,除非运行失败。
-
-## Load balancing
-
-swarm manager 用 ingress load balancing 来对外暴露 service 。 swarm manager 能够自动的为 service 分配对外端口,当然,你也可以为 service 在 30000-32767 范围内指定端口。
-
-外部组件,譬如公有云的负载均衡器,都可以通过集群中任何主机的上述端口来访问 service ,无论 service 的 task 是否正运行在这个主机上。 swarm 中的所有主机都可以路由 ingress connections 到一个正在运行着的 task 实例上。
-
-Swarm mode 有一个内部的 DNS 组件来自动为每个 service 分配 DNS 入口。 swarm manager 根据 service 在集群中的 DNS name 使用内部负载均衡来分发请求。
\ No newline at end of file
diff --git a/docker/docs/swarm_mode_routing_mesh.md b/docker/docs/swarm_mode_routing_mesh.md
deleted file mode 100644
index 14eb6a29d..000000000
--- a/docker/docs/swarm_mode_routing_mesh.md
+++ /dev/null
@@ -1,110 +0,0 @@
-# Swarm mode路由网络
-
-原文链接:[Use swarm mode routing mesh](https://docs.docker.com/engine/swarm/ingress/)
-
-Swarm mode的``ingress``网络,分布于整个swarm集群,每台swarm node上都有这两个端口:
-
-- 7946 TCP/UDP 容器网络发现
-- 4789 UDP 容器ingress网络
-
-## 服务端口发布
-
-命令格式
-
-```Shell
-$ docker service create \
- --name \
- --publish : \
-
-```
-
-示例
-
-```shell
-$ docker service create \
- --name my-web \
- --publish 9999:80 \
- --replicas 2 \
- nginx
-```
-
-容器内部监听端口80,发布到swarm node的端口是8080。
-
-访问swarm mode任意一个主机的8080端口都可以访问到该serivce。即使这台主机上没有运行``my-web``service的实例,因为有swarm load balancer。如下图所示:
-
-
-
-向已有的service添加publish port。
-
-```Shell
-docker service update --publish-add 9998:80 my-web
-```
-
-添加publish端口后似乎没有什么作用,同时
-
-```
-#docker service update --publish-rm 9999:80 my-web
-Error response from daemon: rpc error: code = 2 desc = update out of sequence
-```
-
-报错。
-
-```shell
-# docker service inspect --format="{{json .Endpoint.Spec.Ports}}" my-web
-[{"Protocol":"tcp","TargetPort":80,"PublishedPort":9998,"PublishMode":"ingress"},{"Protocol":"tcp","TargetPort":80,"PublishedPort":9999,"PublishMode":"ingress"}]
-```
-
-**TODO**似乎是update失败?
-
-再``docker service inspect my-web``会发现
-
-```
- "UpdateStatus": {
- "State": "updating",
- "StartedAt": "2017-02-23T08:00:51.948871008Z",
- "CompletedAt": "1970-01-01T00:00:00Z",
- "Message": "update in progress"
- }
-```
-
-原来的9999端口依然可以访问。
-
-```
-# docker service ps my-web
-ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
-wbzzlq3ajyjq my-web.1 sz-pg-oam-docker-hub-001.tendcloud.com/library/nginx:1.9 sz-pg-oam-docker-test-002.tendcloud.com Running Running 44 minutes ago
-4h2tcxjtgumv my-web.2 sz-pg-oam-docker-hub-001.tendcloud.com/library/nginx:1.9 Running New 39 minutes ago
-w0y1l3x94ox3 \_ my-web.2 sz-pg-oam-docker-hub-001.tendcloud.com/library/nginx:1.9 sz-pg-oam-docker-test-003.tendcloud.com Shutdown Shutdown 39 minutes ago
-```
-
-
-
-## 使用外部Load Balancer
-
-可以使用HAProxy做nginx的负载均衡。
-
-
-
-修改HAProxy的配置文件/etc/haproxy/haproxy.cfg
-
-```
-global
- log /dev/log local0
- log /dev/log local1 notice
-...snip...
-
-# Configure HAProxy to listen on port 80
-frontend http_front
- bind *:80
- stats uri /haproxy?stats
- default_backend http_back
-
-# Configure HAProxy to route requests to swarm nodes on port 8080
-backend http_back
- balance roundrobin
- server node1 192.168.99.100:8080 check
- server node2 192.168.99.101:8080 check
- server node3 192.168.99.102:8080 check
-```
-
-当访问80端口时会自动LB到三台node上。
\ No newline at end of file
diff --git a/docker/docs/tech_resource.md b/docker/docs/tech_resource.md
deleted file mode 100644
index 77d5f6531..000000000
--- a/docker/docs/tech_resource.md
+++ /dev/null
@@ -1,161 +0,0 @@
-# 容器技术工具与资源#
-
-软件容器技术影响着从开发人员、测试人员、运维人员到分析人员的IT团队中的每一个人,它不像虚拟化一样只是系统管理员的工具。容器包的大小和完整性使得团队成员能够在几秒钟内部署完整的环境。
-
-容器是一个很好的工具,同时带来了一系列下游决策,包括使用何种标准、如何存储旧版本和部署镜像、如何在生产中管理这些镜像等等。
-
-但是,该如何正确的组装产品和服务,才能在环境中有效地构建、运行和管理容器?为了回答这个问题,我们调查了各种容器技术产品和服务,以便您可以衡量对比各种容器架构、集群管理和部署、存储、安全、操作系统、部署等方案的优劣。
-
-## 容器运行##
-
-尽管Docker的高人气让其成为了一个事实标准,但市场上的轻量级Linux虚拟化工具众多,Docker也只是众多竞争者中的一个。你有很多选择,包括:
-
-**Docker**
-
-Docker的同名开源容器化引擎适用于大多数后续产品以及许多开源工具。
-
-**Commercially Supported Docker Engine(CSDE)**
-
-Docker公司拥有扩展Docker的所有权。CSDE支持在Windows服务器上运行docker实例。
-
-**Rkt**
-
-rkt的发音为“rocket”,它是由CoreOS开发的。rkt是Docker容器的主要竞争对手。
-
-**Solaris Containers**
-
-Solaris容器架构比Docker更早出现。想必那些已经在Solaris上标准化的IT企业会继续研究它。
-
-**Microsoft容器**
-
-作为Linux的竞争对手,Microsoft Containers可以在非常特定的情况下支持Windows容器。
-
-## 集群管理和部署##
-
-创建镜像、将它们从开发传递到测试并回传,都是容易的事情,但要在生产环境中支持它们就不那么简单了。因为那意味着要注册工件,要将它们作为系统部署到生产中,还要管理服务器和服务器集合,包括云中的服务器集合(即“集群”)。集群管理工具管理工作负载,包括将实例从一个虚拟主机转移到另一个基于负载的虚拟主机上。集群管理工具还负责分配资源,如CPU和内存。
-
-**Kubernetes**
-
-虽然没有集群管理的标准,但Google的开源产品Kubernetes是最受欢迎的。有Amazon的AWS、Google云引擎(GCE)和Microsoft的Azure容器服务的支持,Kubernetes是相对可移植的,这有助于防止供应商锁定,Kubernetes甚至可以在私有云(如OpenStack)上运行。Microsoft、Amazon和Google都提供运行Kubernetes的容器服务,并提供商业支持。
-
-**Apache Mesos**
-
-一个用于抽象计算资源的工具,Apache Mesos可以在同一个集群中同时运行Docker和rkt镜像。DC/OS是在Mesos上构建的平台,用作数据中心操作系统。
-
-**Docker Swarm**
-
-Docker是用于集群管理的免费产品,Swarm从命令行运行,并与Docker 1.12及更高版本捆绑在一起。现在它只用于Docker的原生编排。
-
-**Docker Data Center**
-
-基于Web的dashboard提供对Docker的全部管理,包括控制面板、注册表、监视、日志记录和持续集成,Docker Data Center通过运行Docker Swarm进行集群管理。虽然Docker是免费的,但Data Center是有商业支持的商业产品。当然,Docker Data Center囊括并扩展了公司的免费开源产品:Docker和Swarm。
-
-**Rancher**
-
-严格上说Rancher不属于单纯的集群部署与管理工具,因为它的本质是一个全栈化的容器管理平台,但是Rancher是全球唯一一家同时支持Kubernetes、Mesos和Swarm的容器管理平台。Rancher可以帮用户自动设置并启动Kubernetes、Mesos或Swarm所建立的集群,并同时提高实施访问控制策略和完整易用的用户管理界面。
-
-## 容器存储##
-
-容器从出现伊始就被设计为可互换的、甚至是可替代的,就像货币一样。这对于Web服务器是非常好的,因为这样就根据需求在集群中添加或删除相同的服务器了。另一方面,存储和数据库需要持久性位置来容纳数据,或者至少需要标准的接口层。如果想要迁移到全容器基础架构的组织就需要存储,以下公司及产品已经满足了这一需求。
-
-**ClusterHQ**
-
-这些工具有助于将数据库放入容器中。虽然开发ClusterHQ的供应商在去年12月停业,但它在github.com/ClusterHQ留下了大量的免费/开源软件。
-
-**BlockBridge**
-
-BlockBridge是“弹性存储平台”公司,作为使用Docker的容器提供存储,具有OpenStack选项和软件定义的安全存储。
-
-**EMC/lib存储**
-
-EMC/lib存储系统提供了一个代码库,使得容器存储得以实现,而且这是免费和开放的。
-
-**Docker插件存储**
-
-EMC、NetApp和其他公司已经创建了支持存储的插件Docker Inc.,并且可供下载。
-
-## 容器网络
-
-**Hades**
-
-京东开源的为Kubernetes进行DNS注册管理的插件。
-
-## 容器安全##
-
-对不少想进行容器化的公司而言,单点登录、LDAP集成、审计、入侵检测和预防以及漏洞扫描都存在困难。甚至传统的设备和软件也可能难以或不可能在容器集群上配置。幸运的是,有一些厂商正在努力解决这一需求,但这一领域还很新,有两个新公司尚没有可用的产品。
-
-**Twistlock**
-
-您可以不通过组件(如操作系统、Web服务器或内容管理系统)来构建Docker图像。但问题是,图像上未修补或过时的软件都可能会带来安全风险。Twistlock的漏洞扫描器通过将图像与已知威胁的数据库进行对比来解决这一问题。这是针对不断更新的数据库的自动审核。其它核心功能包括更典型的入侵检测和法规遵从性系统。
-
-**Aqua Container Security**
-
-像Twistlock一样,Aqua专注于创建、监视容器和在容器中实施策略,以及与CI集成,对每个构建运行安全检查。
-
-**StackRox**
-
-由Google的前安全主管、美国总统执行办公室网络安全高级总监Sameer Bhalotra联合创立的StackRox,目前正在准备类似的容器安全产品。虽然创业公司仍处于极低调模式,其网站上也没有产品供应,但该公司是一个值得关注的公司。
-
-**Aporeto**
-
-Aporeto是另一个极低调的创业公司,公司总部位于加利福尼亚州的San Jose,而且Aporeto是Nauge Networks的前CTO。Aporeto表示,公司将提供一个“用于部署和运行现代应用程序的全面的云本地安全解决方案”的微服务和容器。
-
-## 操作系统##
-
-大多数Linux操作系统分发版都是以“方便”为准则,包含体积很大的预安装包,以防用户可能需要它们。相比之下,Docker是为轻量级虚拟化而设计的,以尽可能少的内存、磁盘和CPU运行许多相同的机器。作为回应,不少供应商已经开发了“容器优化型”的Linux构建,尝试在Linux分发版需要的功能与容器需要的极简主义之间达到平衡。以下列出的是市场上最受欢迎的几个:
-
-**RancherOS**
-
-RancherOS仅包含Linux内核和Docker本身,RancherOS系统镜像只需要22 MB的磁盘空间。RancherOS不再将类似systemd这样的服务管理系统内置在大多数版本的Linux中,而是启动Docker Daemon本身作为init或“bootstrap”系统。
-
-**CoreOS Container Linux**
-
-设计为与CoreOS Linux工具和系统配合使用,CoreOS Container Linux已预配置为运行Linux容器。它还带有自动更新打开的功能,操作系统无需人工处理就可以自动更新。
-
-**Ubuntu Snappy**
-
-Canonical是Ubuntu Linux的母公司,又叫Snappy,它能比其他任何Linux分发版多运行七倍多的容器。Snappy性能高,占用空间小,并且能对操作系统和应用程序进行增量(差异)更新,从而保持轻量下载。
-
-**Red Hat Atomic Host**
-
-这些工具将使您可以在最小版本的Red Hat Enterprise Linux中使用Linux容器。那些运行Red Hat enterprise并有意向使用容器的企业,通常希望其主机运行Red Hat Atomic Host操作系统。
-
-**Microsoft Nano Server**
-
-Nano Server是一个小型的、远程管理的命令行操作系统,旨在以容器的形式托管和运行,也可能在云中运行。是的,Microsoft具有创造基于Windows Server的容器的能力,Nano是专门为此而构建的。其他可以使用Windows容器的Microsoft操作系统包括Windows Server 2016和Windows Pro 10 Enterprise。
-
-**VMware Photon**
-
-相较于其它容器操作系统,220MB大小的Photon可谓体积很大了,不过它仍然只是最新版本的Windows的大小的百分之一。这个Linux容器主机旨在与VMware的vSphere虚拟化产品集成。
-
-## 容器相关大会和技术资源##
-
-一旦你真的决定开始使用容器,那么最难的部分一定是实施和支持它们。从行业大会、技术支持论坛到商业支持,这里有你需要的资源。
-
-**DockerCon**
-
-如果您的公司追求的是全Docker架构,并且使用的是Docker Data Center、Swarm和Docker的商业伙伴的其他产品,那DockerCon是必参加的大会之一。DockerCon涵盖的内容从入门教程,到提示、技巧和尖端想法,一应俱全。
-
-**Container Summit**
-
-这个大会规模比DockerCon小,但范围更广。在2016年,Containe Summit在美国召开了两个大型会议和12个小型会议。Container Summit是与正在努力实施和管理容器技术的同行交流的好地方。
-
-**ContainerCon**
-
-这是一个更大的大会,其特别之处在于,参加大会的通常是容器领域的思想领袖,以及各类的供应商。 ContainerCon通常与LinuxCon和CloudOpen同时举办。
-
-**CoreOS Fest**
-
-CoreOS Fest可以视为CoreOS对DockerCon的回答了。参加CoreOS Fest可以获得和rkt/CoreOs技术栈有关的培训与支持信息。
-
-**StackOverflow**
-
-最大的程序员在线问答网站,StackOverflow提供了大量有关在容器中部署应用程序的信息。
-
-**Docker社区网站**
-
-Docker组建的社区网站,提供以Docker为中心的信息和论坛。
-
-**CoreOS社区网站**
-
-CoreOS的社区网站专注于通过聚会和聊天将人们和专家连接起来。
\ No newline at end of file
diff --git a/docker/docs/torus.md b/docker/docs/torus.md
deleted file mode 100644
index 600ea7edc..000000000
--- a/docker/docs/torus.md
+++ /dev/null
@@ -1,12 +0,0 @@
-# Torus
-
-Torus基于ServerSAN和容器生态的kv-store(etcd)打造的容器定义存储Torus,相比单纯的控制面,Torus能够更好的与k8s调度集成,并且具有更快的发放和伸缩能力。 容器定义存储最大的特点在于融合了控制面和数据面能力,并且结合容器特点定制,相对单纯控制面更具优势,产品形态以ServerSAN为主。不足在于存储本身不是cloud-native的,与容器本身还是在两个层面,仍需要解决两层间的调度联动,适配cloud-native的能力。
-
-开源docker-volume-plugin-torus
-
-[https://hub.docker.com/r/steigr/docker-volume-plugin-torus/~/dockerfile/](https://hub.docker.com/r/steigr/docker-volume-plugin-torus/~/dockerfile/)
-
-[https://github.com/steigr/docker-volume-plugin-torus](https://github.com/steigr/docker-volume-plugin-torus)
-
-目前还在POC阶段,暂时还没有验证可行性。
-
diff --git a/docker/imgs/cat.jpg b/docker/imgs/cat.jpg
deleted file mode 100644
index d7e0244e3..000000000
Binary files a/docker/imgs/cat.jpg and /dev/null differ
diff --git a/docker/imgs/jd_app.jpg b/docker/imgs/jd_app.jpg
deleted file mode 100644
index 1478a2da2..000000000
Binary files a/docker/imgs/jd_app.jpg and /dev/null differ
diff --git a/docker/imgs/jd_arch.jpg b/docker/imgs/jd_arch.jpg
deleted file mode 100644
index d4da89fd5..000000000
Binary files a/docker/imgs/jd_arch.jpg and /dev/null differ
diff --git a/docker/imgs/jd_deploy.jpg b/docker/imgs/jd_deploy.jpg
deleted file mode 100644
index 1c794263e..000000000
Binary files a/docker/imgs/jd_deploy.jpg and /dev/null differ
diff --git a/docker/imgs/jd_feature.jpg b/docker/imgs/jd_feature.jpg
deleted file mode 100644
index 247470471..000000000
Binary files a/docker/imgs/jd_feature.jpg and /dev/null differ
diff --git a/docker/imgs/jd_schedule.jpg b/docker/imgs/jd_schedule.jpg
deleted file mode 100644
index 02641ee37..000000000
Binary files a/docker/imgs/jd_schedule.jpg and /dev/null differ
diff --git a/docker/imgs/jd_tor.jpg b/docker/imgs/jd_tor.jpg
deleted file mode 100644
index b4f2d9300..000000000
Binary files a/docker/imgs/jd_tor.jpg and /dev/null differ
diff --git a/docker/imgs/rancher_bridge.png b/docker/imgs/rancher_bridge.png
deleted file mode 100644
index 48815ad99..000000000
Binary files a/docker/imgs/rancher_bridge.png and /dev/null differ
diff --git a/docker/imgs/rancher_cattle.png b/docker/imgs/rancher_cattle.png
deleted file mode 100644
index e07b499bb..000000000
Binary files a/docker/imgs/rancher_cattle.png and /dev/null differ
diff --git a/docker/imgs/rancher_cni_driver.png b/docker/imgs/rancher_cni_driver.png
deleted file mode 100644
index 32962fcf0..000000000
Binary files a/docker/imgs/rancher_cni_driver.png and /dev/null differ
diff --git a/docker/imgs/rancher_cni_workflow.png b/docker/imgs/rancher_cni_workflow.png
deleted file mode 100644
index e7c90d1d7..000000000
Binary files a/docker/imgs/rancher_cni_workflow.png and /dev/null differ
diff --git a/docker/imgs/rancher_cnm.png b/docker/imgs/rancher_cnm.png
deleted file mode 100644
index 74908063a..000000000
Binary files a/docker/imgs/rancher_cnm.png and /dev/null differ
diff --git a/docker/imgs/rancher_cnm_interface.png b/docker/imgs/rancher_cnm_interface.png
deleted file mode 100644
index 4a3e97ffd..000000000
Binary files a/docker/imgs/rancher_cnm_interface.png and /dev/null differ
diff --git a/docker/imgs/rancher_compose.png b/docker/imgs/rancher_compose.png
deleted file mode 100644
index 1db1a5b1f..000000000
Binary files a/docker/imgs/rancher_compose.png and /dev/null differ
diff --git a/docker/imgs/rancher_flat.png b/docker/imgs/rancher_flat.png
deleted file mode 100644
index 674b46916..000000000
Binary files a/docker/imgs/rancher_flat.png and /dev/null differ
diff --git a/docker/imgs/rancher_ipec.png b/docker/imgs/rancher_ipec.png
deleted file mode 100644
index 5493f81cb..000000000
Binary files a/docker/imgs/rancher_ipec.png and /dev/null differ
diff --git a/docker/imgs/rancher_login.jpg b/docker/imgs/rancher_login.jpg
deleted file mode 100644
index b58947c9f..000000000
Binary files a/docker/imgs/rancher_login.jpg and /dev/null differ
diff --git a/docker/imgs/rancher_net.png b/docker/imgs/rancher_net.png
deleted file mode 100644
index 4bca78e99..000000000
Binary files a/docker/imgs/rancher_net.png and /dev/null differ
diff --git a/docker/imgs/rancher_network_plugin.png b/docker/imgs/rancher_network_plugin.png
deleted file mode 100644
index 49220a89f..000000000
Binary files a/docker/imgs/rancher_network_plugin.png and /dev/null differ
diff --git a/docker/imgs/rancher_overlay.png b/docker/imgs/rancher_overlay.png
deleted file mode 100644
index 1bcd40689..000000000
Binary files a/docker/imgs/rancher_overlay.png and /dev/null differ
diff --git a/docker/imgs/rancher_template.png b/docker/imgs/rancher_template.png
deleted file mode 100644
index c4cabed4b..000000000
Binary files a/docker/imgs/rancher_template.png and /dev/null differ
diff --git a/docker/imgs/rancher_version.jpg b/docker/imgs/rancher_version.jpg
deleted file mode 100644
index f353022e0..000000000
Binary files a/docker/imgs/rancher_version.jpg and /dev/null differ
diff --git a/docker/imgs/rancher_vm.png b/docker/imgs/rancher_vm.png
deleted file mode 100644
index 92b7ecec9..000000000
Binary files a/docker/imgs/rancher_vm.png and /dev/null differ
diff --git a/docker/imgs/td_yarn_arch.jpg b/docker/imgs/td_yarn_arch.jpg
deleted file mode 100644
index 9a4705cd6..000000000
Binary files a/docker/imgs/td_yarn_arch.jpg and /dev/null differ
diff --git a/docker/imgs/td_yarn_arch2.jpg b/docker/imgs/td_yarn_arch2.jpg
deleted file mode 100644
index a782a0c7e..000000000
Binary files a/docker/imgs/td_yarn_arch2.jpg and /dev/null differ
diff --git a/docker/imgs/td_yarn_arch3.jpg b/docker/imgs/td_yarn_arch3.jpg
deleted file mode 100644
index 8150445f2..000000000
Binary files a/docker/imgs/td_yarn_arch3.jpg and /dev/null differ
diff --git a/docker/imgs/td_yarn_ci.jpg b/docker/imgs/td_yarn_ci.jpg
deleted file mode 100644
index d5686250e..000000000
Binary files a/docker/imgs/td_yarn_ci.jpg and /dev/null differ
diff --git a/docker/imgs/td_yarn_compare.jpg b/docker/imgs/td_yarn_compare.jpg
deleted file mode 100644
index 05e9b67c5..000000000
Binary files a/docker/imgs/td_yarn_compare.jpg and /dev/null differ
diff --git a/docker/imgs/td_yarn_dockerfile.jpg b/docker/imgs/td_yarn_dockerfile.jpg
deleted file mode 100644
index fa0eded92..000000000
Binary files a/docker/imgs/td_yarn_dockerfile.jpg and /dev/null differ
diff --git a/docker/imgs/td_yarn_ipam.jpg b/docker/imgs/td_yarn_ipam.jpg
deleted file mode 100644
index 1bbe5c14e..000000000
Binary files a/docker/imgs/td_yarn_ipam.jpg and /dev/null differ
diff --git a/docker/imgs/td_yarn_iperf.jpg b/docker/imgs/td_yarn_iperf.jpg
deleted file mode 100644
index a23ccf5a1..000000000
Binary files a/docker/imgs/td_yarn_iperf.jpg and /dev/null differ
diff --git a/docker/imgs/td_yarn_monitor.jpg b/docker/imgs/td_yarn_monitor.jpg
deleted file mode 100644
index eb12df918..000000000
Binary files a/docker/imgs/td_yarn_monitor.jpg and /dev/null differ
diff --git a/docker/imgs/td_yarn_network.jpg b/docker/imgs/td_yarn_network.jpg
deleted file mode 100644
index 0e38dde6e..000000000
Binary files a/docker/imgs/td_yarn_network.jpg and /dev/null differ
diff --git a/docker/imgs/td_yarn_os.jpg b/docker/imgs/td_yarn_os.jpg
deleted file mode 100644
index f0ae603b6..000000000
Binary files a/docker/imgs/td_yarn_os.jpg and /dev/null differ
diff --git a/docker/imgs/td_yarn_shipyard.jpg b/docker/imgs/td_yarn_shipyard.jpg
deleted file mode 100644
index fa93b4e90..000000000
Binary files a/docker/imgs/td_yarn_shipyard.jpg and /dev/null differ
diff --git a/docker/imgs/visualizer.jpg b/docker/imgs/visualizer.jpg
deleted file mode 100644
index b7f226ce3..000000000
Binary files a/docker/imgs/visualizer.jpg and /dev/null differ
diff --git a/docker/imgs/vote-app-diagram.png b/docker/imgs/vote-app-diagram.png
deleted file mode 100644
index 33391c232..000000000
Binary files a/docker/imgs/vote-app-diagram.png and /dev/null differ
diff --git a/docker/imgs/vote_result.jpg b/docker/imgs/vote_result.jpg
deleted file mode 100644
index 9af7b24ea..000000000
Binary files a/docker/imgs/vote_result.jpg and /dev/null differ
diff --git a/docker/imgs/vote_web.jpg b/docker/imgs/vote_web.jpg
deleted file mode 100644
index 8e0b0f1af..000000000
Binary files a/docker/imgs/vote_web.jpg and /dev/null differ
diff --git a/docker/index.md b/docker/index.md
deleted file mode 100644
index ce90cf512..000000000
--- a/docker/index.md
+++ /dev/null
@@ -1,138 +0,0 @@
-# Docker最佳实践
-
-本文档旨在实验Docker1.13新特性和帮助大家了解docker集群的管理和使用。
-
-
-## 环境配置
-
-[Docker1.13环境配置](docs/docker_env.md)
-
-[docker源码编译](docs/docker_compile.md)
-
-
-## 网络管理
-
-网络配置和管理是容器使用中的的一个重点和难点,对比我们之前使用的docker版本是1.11.1,docker1.13中网络模式跟之前的变动比较大,我们会花大力气讲解。
-
-[如何创建docker network](docs/create_network.md)
-
-[Rancher网络探讨和扁平网络实现](docs/rancher_network.md)
-
-[swarm mode的路由网络](docs/swarm_mode_routing_mesh.md)
-
-[docker扁平化网络插件Shrike(基于docker1.11)](https://github.com/TalkingData/shrike)
-
-## 存储管理
-
-[Docker存储插件](docs/docker_storage_plugin.md)
-
-- [infinit](docs/infinit.md) 被docker公司收购的法国团队开发
-- [convoy](docs/convoy.md) rancher开发的docker volume plugin
-- [torus](docs/torus.md) **已废弃**
-- [flocker](docs/flocker.md) ClusterHQ开发
-
-
-
-## 日志管理
-
-Docker提供了一系列[log drivers](https://docs.docker.com/engine/admin/logging/overview/),如fluentd、journald、syslog等。
-
-需要配置docker engine的启动参数。
-
-[docker logging driver](docs/docker_logging_driver.md)
-
-## 创建应用
-
-官方文档:[Docker swarm sample app overview](https://docs.docker.com/engine/getstarted-voting-app/)
-
-[基于docker1.13手把手教你创建swarm app](docs/create_swarm_app.md)
-
-[swarm集群应用管理](docs/swarm_app_manage.md)
-
-[使用docker-compose创建应用](docs/docker_compose.md)
-
-## 集群管理##
-
-我们使用docker内置的swarm来管理docker集群。
-
-[swarm mode介绍](docs/swarm_mode.md)
-
-我们推荐使用开源的docker集群管理配置方案:
-
-- [Crane](https://github.com/Dataman-Cloud/crane):由数人云开源的基于swarmkit的容器管理软件,可以作为docker和go语言开发的一个不错入门项目
-- [Rancher](https://github.com/rancher/rancher):Rancher是一个企业级的容器管理平台,可以使用Kubernetes、swarm和rancher自研的cattle来管理集群。
-
-[Crane的部署和使用](docs/crane_usage.md)
-
-[Rancher的部署和使用](docs/rancher_usage.md)
-
-## 资源限制
-
-[内存资源限制](docs/memory_resource_limit.md)
-
-[CPU资源限制](docs/cpu_resource_limit.md)
-
-[IO资源限制](docs/io_resource_limit.md)
-
-## 服务发现
-
-下面罗列一些列常见的服务发现工具。
-
- Etcd:服务发现/全局分布式键值对存储。这是CoreOS的创建者提供的工具,面向容器和宿主机提供服务发现和全局配置存储功能。它在每个宿主机有基于http协议的API和命令行的客户端。[https://github.com/docker/etcd](https://github.com/docker/etcd)
-
-- [Cousul](https://github.com/hashicorp/consul):服务发现/全局分布式键值对存储。这个服务发现平台有很多高级的特性,使得它能够脱颖而出,例如:配置健康检查、ACL功能、HAProxy配置等等。
-- [Zookeeper](https://github.com/apache/zookeeper):诞生于Hadoop生态系统里的组件,Apache的开源项目。服务发现/全局分布式键值对存储。这个工具较上面两个都比较老,提供一个更加成熟的平台和一些新特性。
-- Crypt:加密etcd条目的项目。Crypt允许组建通过采用公钥加密的方式来保护它们的信息。需要读取数据的组件或被分配密钥,而其他组件则不能读取数据。
-- [Confd](https://github.com/kelseyhightower/confd):观测键值对存储变更和新值的触发器重新配置服务。Confd项目旨在基于服务发现的变化,而动态重新配置任意应用程序。该系统包含了一个工具来检测节点中的变化、一个模版系统能够重新加载受影响的应用。
-- [Vulcand](https://github.com/vulcand/vulcand):vulcand在组件中作为负载均衡使用。它使用etcd作为后端,并基于检测变更来调整它的配置。
-- [Marathon](https://github.com/mesosphere/marathon):虽然marathon主要是调度器,它也实现了一个基本的重新加载HAProxy的功能,当发现变更时,它来协调可用的服务。
-- Frontrunner:这个项目嵌入在marathon中对HAproxy的更新提供一个稳定的解决方案。
-- [Synapse](https://github.com/airbnb/synapse):由Airbnb出品的,Ruby语言开发,这个项目引入嵌入式的HAProxy组件,它能够发送流量给各个组件。[http://bruth.github.io/synapse/docs/](http://bruth.github.io/synapse/docs/)
-- [Nerve](https://github.com/airbnb/nerve):它被用来与synapse结合在一起来为各个组件提供健康检查,如果组件不可用,nerve将更新synapse并将该组件移除出去。
-
-## 插件开发
-
-[插件开发示例-sshfs](docs/plugin_developing.md)
-
-[我的docker插件开发文章](http://rootsongjc.github.io/blogs/docker-plugin-develop/)
-
-[Docker17.03-CE插件开发举例](http://rootsongjc.github.io/blogs/docker-plugin-develop/)
-
-**网络插件**
-
-- [Contiv](http://rootsongjc.github.io/tags/contiv/) 思科出的Docker网络插件,趟坑全记录,目前还无法上生产,1.0正式版还没出,密切关注中。
-- [Calico](github.com/calico) 产品化做的不错,已经有人用在生产上了。
-
-**存储插件**
-
-## 业界使用案例
-
-[京东从OpenStack切换到Kubernetes的经验之谈](docs/jd_transform_to_kubernetes.md)
-
-[美团点评容器平台介绍](docs/meituan_docker_platform.md)
-
-[阿里超大规模docker化之路](docs/ali_docker.md)
-
-[TalkingData-容器技术在大数据场景下的应用Yarn on Docker](docs/td_yarn_on_docker.md)
-
-[乐视云基于Kubernetes的PaaS平台建设](docs/letv_docker.md)
-
-## 资源编排
-
-建议使用kuberentes,虽然比较复杂,但是专业的工具做专业的事情,将编排这么重要的生产特性绑定到docker上的风险还是很大的,我已经转投到kubernetes怀抱了,那么你呢?
-
-[我的kubernetes探险之旅](http://rootsongjc.github.io/tags/kubernetes/)
-
-## 相关资源
-
-[容器技术工具与资源](docs/tech_resource.md)
-
-[容器技术2016年总结](docs/container_2016.md)
-
-## 关于
-
-Author: [Jimmy Song](rootsongjc.github.io/about)
-
-rootsongjc@gmail.com
-
-更多关于**Docker**、**MicroServices**、**Big Data**、**DevOps**、**Deep Learning**的内容请关注[Jimmy Song's Blog](http://rootsongjc.github.io),将不定期更新。
\ No newline at end of file