initial commit
commit
3c76bdc0b1
|
|
@ -0,0 +1,30 @@
|
||||||
|
---
|
||||||
|
slug: /
|
||||||
|
---
|
||||||
|
|
||||||
|
# Kubernetes 实践指南
|
||||||
|
|
||||||
|
本书将介绍 Kubernetes 相关实战经验与总结,助你成为一名云原生老司机 😎。
|
||||||
|
|
||||||
|
## 关于本书
|
||||||
|
|
||||||
|
本书为电子书形式,内容为本人多年的云原生与 Kubernetes 实战经验进行系统性整理的结果,不废话,纯干货。
|
||||||
|
|
||||||
|
## 阅读方式
|
||||||
|
|
||||||
|
* 在线阅读: [https://imroc.cc/kubernetes/](https://imroc.cc/kubernetes/)
|
||||||
|
* 导出 PDF: 点击右上角打印按钮,可保存为 PDF 文件。
|
||||||
|
|
||||||
|
## 评论与互动
|
||||||
|
|
||||||
|
本书已集成 [giscus](https://giscus.app/zh-CN) 评论系统,欢迎对感兴趣的文章进行评论与交流。
|
||||||
|
|
||||||
|
## 贡献
|
||||||
|
|
||||||
|
本书使用 [mdbook](https://rust-lang.github.io/mdBook/) 构建,已集成 Github Actions 自动构建和发布,欢迎 Fork 并 PR 来贡献干货内容 (点击右上角编辑按钮可快速修改文章)。
|
||||||
|
|
||||||
|
内容使用 markdown 格式,文章在 `src` 目录下。
|
||||||
|
|
||||||
|
## 许可证
|
||||||
|
|
||||||
|
您可以使用 [署名 - 非商业性使用 - 相同方式共享 4.0 (CC BY-NC-SA 4.0)](https://creativecommons.org/licenses/by-nc-sa/4.0/deed.zh) 协议共享。
|
||||||
|
|
@ -0,0 +1,139 @@
|
||||||
|
# kubectl 速查手册
|
||||||
|
|
||||||
|
## 使用 kubectl get --raw
|
||||||
|
|
||||||
|
### 获取节点 cadvisor 指标
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl get --raw=/api/v1/nodes/11.185.19.215/proxy/metrics/cadvisor
|
||||||
|
|
||||||
|
# 查看有哪些指标名
|
||||||
|
kubectl get --raw=/api/v1/nodes/11.185.19.215/proxy/metrics/cadvisor | grep -v "#" | awk -F '{' '{print $1}' | awk '{print $1}' | sort | uniq
|
||||||
|
```
|
||||||
|
|
||||||
|
### 获取节点 kubelet 指标
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl get --raw=/api/v1/nodes/11.185.19.215/proxy/metrics
|
||||||
|
```
|
||||||
|
|
||||||
|
### 获取 node-exporter pod 指标
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl get --raw=/api/v1/namespaces/monitoring/pods/node-exporter-n5rz2:9100/proxy/metrics
|
||||||
|
```
|
||||||
|
|
||||||
|
### 获取节点 summary 数据
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl get --raw=/api/v1/nodes/11.185.19.21/proxy/stats/summary
|
||||||
|
```
|
||||||
|
|
||||||
|
### 测试 Resource Metrics API
|
||||||
|
|
||||||
|
获取指定 namespace 下所有 pod 指标:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/namespaces/ns-prjzbsxs-1391012-production/pods/"
|
||||||
|
```
|
||||||
|
|
||||||
|
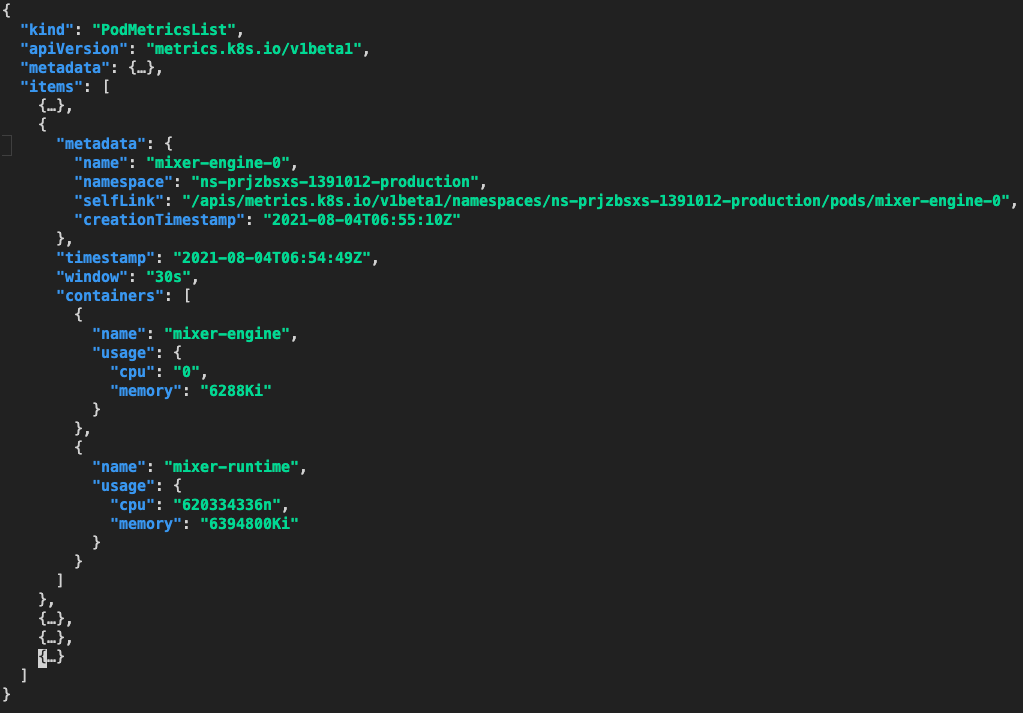
|
||||||
|
|
||||||
|
获取指定 pod 的指标:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/namespaces/ns-prjzbsxs-1391012-production/pods/mixer-engine-0"
|
||||||
|
```
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## Node 相关
|
||||||
|
|
||||||
|
### 表格输出各节点占用的 podCIDR
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
$ kubectl get no -o=custom-columns=INTERNAL-IP:.metadata.name,EXTERNAL-IP:.status.addresses[1].address,CIDR:.spec.podCIDR
|
||||||
|
INTERNAL-IP EXTERNAL-IP CIDR
|
||||||
|
10.100.12.194 152.136.146.157 10.101.64.64/27
|
||||||
|
10.100.16.11 10.100.16.11 10.101.66.224/27
|
||||||
|
```
|
||||||
|
|
||||||
|
### 表格输出各节点总可用资源 (Allocatable)
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
$ kubectl get no -o=custom-columns="NODE:.metadata.name,ALLOCATABLE CPU:.status.allocatable.cpu,ALLOCATABLE MEMORY:.status.allocatable.memory"
|
||||||
|
NODE ALLOCATABLE CPU ALLOCATABLE MEMORY
|
||||||
|
10.0.0.2 3920m 7051692Ki
|
||||||
|
10.0.0.3 3920m 7051816Ki
|
||||||
|
```
|
||||||
|
|
||||||
|
### 输出各节点已分配资源的情况
|
||||||
|
|
||||||
|
所有种类的资源已分配情况概览:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
$ kubectl get nodes --no-headers | awk '{print $1}' | xargs -I {} sh -c "echo {} ; kubectl describe node {} | grep Allocated -A 5 | grep -ve Event -ve Allocated -ve percent -ve --;"
|
||||||
|
10.0.0.2
|
||||||
|
Resource Requests Limits
|
||||||
|
cpu 3040m (77%) 19800m (505%)
|
||||||
|
memory 4843402752 (67%) 15054901888 (208%)
|
||||||
|
10.0.0.3
|
||||||
|
Resource Requests Limits
|
||||||
|
cpu 300m (7%) 1 (25%)
|
||||||
|
memory 250M (3%) 2G (27%)
|
||||||
|
```
|
||||||
|
|
||||||
|
表格输出 cpu 已分配情况:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
$ kubectl get nodes --no-headers | awk '{print $1}' | xargs -I {} sh -c 'echo -ne "{}\t" ; kubectl describe node {} | grep Allocated -A 5 | grep -ve Event -ve Allocated -ve percent -ve -- | grep cpu | awk '\''{print $2$3}'\'';'
|
||||||
|
10.0.0.10 460m(48%)
|
||||||
|
10.0.0.12 235m(25%)
|
||||||
|
```
|
||||||
|
|
||||||
|
表格输出 memory 已分配情况:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
$ kubectl get nodes --no-headers | awk '{print $1}' | xargs -I {} sh -c 'echo -ne "{}\t" ; kubectl describe node {} | grep Allocated -A 5 | grep -ve Event -ve Allocated -ve percent -ve -- | grep memory | awk '\''{print $2$3}'\'';'
|
||||||
|
10.0.0.10 257460608(41%)
|
||||||
|
10.0.0.12 59242880(9%)
|
||||||
|
```
|
||||||
|
|
||||||
|
### 查看节点可用区分布情况
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ kubectl get nodes -o=jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.metadata.labels.failure-domain\.beta\.kubernetes\.io\/zone}{"\n"}{end}'
|
||||||
|
10.83.96.127 100004
|
||||||
|
10.83.96.132 100004
|
||||||
|
10.83.96.139 100004
|
||||||
|
10.83.96.8 100004
|
||||||
|
10.83.96.93 100004
|
||||||
|
```
|
||||||
|
|
||||||
|
## Pod 相关
|
||||||
|
|
||||||
|
### 清理 Evicted 的 pod
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
kubectl get pod -o wide --all-namespaces | awk '{if($4=="Evicted"){cmd="kubectl -n "$1" delete pod "$2; system(cmd)}}'
|
||||||
|
```
|
||||||
|
|
||||||
|
### 清理非 Running 的 pod
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
kubectl get pod -o wide --all-namespaces | awk '{if($4!="Running"){cmd="kubectl -n "$1" delete pod "$2; system(cmd)}}'
|
||||||
|
```
|
||||||
|
|
||||||
|
### 升级镜像
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
export NAMESPACE="kube-system"
|
||||||
|
export WORKLOAD_TYPE="daemonset"
|
||||||
|
export WORKLOAD_NAME="ip-masq-agent"
|
||||||
|
export CONTAINER_NAME="ip-masq-agent"
|
||||||
|
export IMAGE="ccr.ccs.tencentyun.com/library/ip-masq-agent:v2.5.0"
|
||||||
|
```
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
kubectl -n $NAMESPACE patch $WORKLOAD_TYPE $WORKLOAD_NAME --patch '{"spec": {"template": {"spec": {"containers": [{"name": "$CONTAINER_NAME","image": "$IMAGE" }]}}}}'
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,48 @@
|
||||||
|
# TKE Serverless 集群
|
||||||
|
|
||||||
|
```hcl title="main.tf"
|
||||||
|
terraform {
|
||||||
|
required_providers {
|
||||||
|
tencentcloud = {
|
||||||
|
source = "tencentcloudstack/tencentcloud"
|
||||||
|
version = "1.80.4"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
provider "tencentcloud" {
|
||||||
|
secret_id = "************************************" # 云 API 密钥 SecretId
|
||||||
|
secret_key = "********************************" # 云 API 密钥 SecretKey
|
||||||
|
region = "ap-shanghai" # 地域,完整可用地域列表参考: https://cloud.tencent.com/document/product/213/6091
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
data "tencentcloud_vpc_instances" "myvpc" {
|
||||||
|
name = "myvpc" # 指定 VPC 名称
|
||||||
|
}
|
||||||
|
|
||||||
|
data "tencentcloud_vpc_subnets" "mysubnet" {
|
||||||
|
vpc_id = data.tencentcloud_vpc_instances.myvpc.instance_list.0.vpc_id
|
||||||
|
name = "mysubnet" # 指定子网名称
|
||||||
|
}
|
||||||
|
|
||||||
|
resource "tencentcloud_eks_cluster" "myserverless" {
|
||||||
|
cluster_name = "roc-test-serverless" # 指定 serverless 集群名称
|
||||||
|
k8s_version = "1.24.4" # 指定 serverless 集群版本
|
||||||
|
|
||||||
|
public_lb {
|
||||||
|
enabled = true # 打开公网访问 (kubectl 远程操作集群)
|
||||||
|
allow_from_cidrs = ["0.0.0.0/0"]
|
||||||
|
}
|
||||||
|
|
||||||
|
vpc_id = data.tencentcloud_vpc_instances.roctest.instance_list.0.vpc_id
|
||||||
|
subnet_ids = [
|
||||||
|
data.tencentcloud_vpc_subnets.mysubnet.instance_list.0.subnet_id
|
||||||
|
]
|
||||||
|
cluster_desc = "roc test cluster" # 集群描述
|
||||||
|
service_subnet_id = data.tencentcloud_vpc_subnets.mysubnet.instance_list.0.subnet_id
|
||||||
|
enable_vpc_core_dns = true
|
||||||
|
need_delete_cbs = true
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
|
@ -0,0 +1,154 @@
|
||||||
|
# TKE 集群(VPC-CNI)
|
||||||
|
|
||||||
|
```hcl title="main.tf"
|
||||||
|
terraform {
|
||||||
|
required_providers {
|
||||||
|
# highlight-next-line
|
||||||
|
tencentcloud = {
|
||||||
|
source = "tencentcloudstack/tencentcloud"
|
||||||
|
version = "1.81.24"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
variable "secret_id" {
|
||||||
|
default = "************************************" # 替换 secret id
|
||||||
|
}
|
||||||
|
|
||||||
|
variable "secret_key" {
|
||||||
|
default = "********************************" # 替换 secret key
|
||||||
|
}
|
||||||
|
|
||||||
|
variable "region" {
|
||||||
|
default = "ap-shanghai"
|
||||||
|
}
|
||||||
|
|
||||||
|
provider "tencentcloud" {
|
||||||
|
secret_id = var.secret_id # 云 API 密钥 SecretId
|
||||||
|
secret_key = var.secret_key # 云 API 密钥 SecretKey
|
||||||
|
region = var.region # 地域,完整可用地域列表参考: https://cloud.tencent.com/document/product/213/6091
|
||||||
|
}
|
||||||
|
|
||||||
|
variable "availability_zone_first" {
|
||||||
|
default = "ap-shanghai-4" # 替换首选可用区
|
||||||
|
}
|
||||||
|
|
||||||
|
variable "availability_zone_second" {
|
||||||
|
default = "ap-shanghai-2" # 替换备选可用区
|
||||||
|
}
|
||||||
|
|
||||||
|
variable "default_instance_type" {
|
||||||
|
default = "S5.MEDIUM4"
|
||||||
|
}
|
||||||
|
|
||||||
|
variable "vpc_name" {
|
||||||
|
default = "roc-test" # 替换 VPC 名称
|
||||||
|
}
|
||||||
|
|
||||||
|
variable "cluster_name" {
|
||||||
|
default = "roc-test-cluster" # 替换集群名称
|
||||||
|
}
|
||||||
|
|
||||||
|
variable "image_id" {
|
||||||
|
default = "img-1tmhysjj" # TencentOS Server 3.2 with Driver
|
||||||
|
}
|
||||||
|
|
||||||
|
variable "security_group" {
|
||||||
|
default = "sg-616bnwjw" # 替换安全组 ID
|
||||||
|
}
|
||||||
|
|
||||||
|
variable "skey_id" {
|
||||||
|
default = "skey-3t01mlvf" # 替换 ssh 密钥 ID
|
||||||
|
}
|
||||||
|
|
||||||
|
variable "service_cidr" {
|
||||||
|
default = "192.168.6.0/24" # 替换 service 网段
|
||||||
|
}
|
||||||
|
|
||||||
|
data "tencentcloud_vpc_instances" "vpc" {
|
||||||
|
name = var.vpc_name
|
||||||
|
}
|
||||||
|
|
||||||
|
data "tencentcloud_vpc_subnets" "zone_first" {
|
||||||
|
vpc_id = data.tencentcloud_vpc_instances.vpc.instance_list.0.vpc_id
|
||||||
|
availability_zone = var.availability_zone_first
|
||||||
|
}
|
||||||
|
|
||||||
|
data "tencentcloud_vpc_subnets" "zone_second" {
|
||||||
|
vpc_id = data.tencentcloud_vpc_instances.vpc.instance_list.0.vpc_id
|
||||||
|
availability_zone = var.availability_zone_second
|
||||||
|
}
|
||||||
|
|
||||||
|
resource "tencentcloud_kubernetes_cluster" "managed_cluster" {
|
||||||
|
vpc_id = data.tencentcloud_vpc_instances.vpc.instance_list.0.vpc_id
|
||||||
|
cluster_max_pod_num = 256
|
||||||
|
cluster_name = var.cluster_name
|
||||||
|
cluster_desc = "roc test cluster" # 替换集群描述
|
||||||
|
cluster_version = "1.26.1"
|
||||||
|
cluster_max_service_num = 256
|
||||||
|
cluster_internet = true
|
||||||
|
cluster_internet_security_group = var.security_group
|
||||||
|
cluster_deploy_type = "MANAGED_CLUSTER"
|
||||||
|
|
||||||
|
container_runtime = "containerd"
|
||||||
|
kube_proxy_mode = "ipvs"
|
||||||
|
network_type = "VPC-CNI" # 集群网络模式,GR 或 VPC-CNI,推荐用 VPC-CNI。如果用 GR,还需要设置集群网段(cluster_cidr)
|
||||||
|
service_cidr = var.service_cidr
|
||||||
|
eni_subnet_ids = [
|
||||||
|
data.tencentcloud_vpc_subnets.zone_first.instance_list.0.subnet_id,
|
||||||
|
data.tencentcloud_vpc_subnets.zone_second.instance_list.0.subnet_id
|
||||||
|
]
|
||||||
|
worker_config { # 集群创建时自动创建的 cvm worker 节点(非节点池),如果不需要,可以删除此代码块。
|
||||||
|
instance_name = "roc-test" # 替换节点cvm名称
|
||||||
|
count = 1 # 替换初始节点数量
|
||||||
|
availability_zone = var.availability_zone_first
|
||||||
|
instance_type = var.default_instance_type
|
||||||
|
|
||||||
|
system_disk_type = "CLOUD_PREMIUM"
|
||||||
|
system_disk_size = 50
|
||||||
|
internet_charge_type = "TRAFFIC_POSTPAID_BY_HOUR"
|
||||||
|
internet_max_bandwidth_out = 0 # 节点是否需要公网带宽,0 为不需要,1 为需要。
|
||||||
|
public_ip_assigned = false
|
||||||
|
security_group_ids = [var.security_group]
|
||||||
|
subnet_id = data.tencentcloud_vpc_subnets.zone_first.instance_list.0.subnet_id
|
||||||
|
|
||||||
|
enhanced_security_service = false
|
||||||
|
enhanced_monitor_service = false
|
||||||
|
key_ids = [var.skey_id]
|
||||||
|
img_id = var.image_id
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
# 集群初始化时自动创建的节点池,如果不需要,可删除此代码块
|
||||||
|
resource "tencentcloud_kubernetes_node_pool" "mynodepool" {
|
||||||
|
name = "roc-test-pool" # 替换节点池名称
|
||||||
|
cluster_id = tencentcloud_kubernetes_cluster.managed_cluster.id
|
||||||
|
max_size = 6 # 最大节点数量
|
||||||
|
min_size = 0 # 最小节点数量
|
||||||
|
vpc_id = data.tencentcloud_vpc_instances.vpc.instance_list.0.vpc_id
|
||||||
|
subnet_ids = [data.tencentcloud_vpc_subnets.zone_first.instance_list.0.subnet_id]
|
||||||
|
retry_policy = "INCREMENTAL_INTERVALS"
|
||||||
|
desired_capacity = 2 # 节点池的期望节点数量
|
||||||
|
enable_auto_scale = false
|
||||||
|
multi_zone_subnet_policy = "EQUALITY"
|
||||||
|
node_os = "tlinux3.1x86_64"
|
||||||
|
delete_keep_instance = false
|
||||||
|
|
||||||
|
auto_scaling_config {
|
||||||
|
instance_type = var.default_instance_type
|
||||||
|
system_disk_type = "CLOUD_PREMIUM"
|
||||||
|
system_disk_size = "50"
|
||||||
|
orderly_security_group_ids = [var.security_group]
|
||||||
|
|
||||||
|
instance_charge_type = "SPOTPAID"
|
||||||
|
spot_instance_type = "one-time"
|
||||||
|
spot_max_price = "1000"
|
||||||
|
public_ip_assigned = false
|
||||||
|
|
||||||
|
key_ids = [var.skey_id]
|
||||||
|
enhanced_security_service = false
|
||||||
|
enhanced_monitor_service = false
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
|
@ -0,0 +1,267 @@
|
||||||
|
# 实用 YAML
|
||||||
|
|
||||||
|
## RBAC 相关
|
||||||
|
|
||||||
|
### 给 roc 授权 test 命名空间所有权限,istio-system 命名空间的只读权限
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
kind: Role
|
||||||
|
apiVersion: rbac.authorization.k8s.io/v1
|
||||||
|
metadata:
|
||||||
|
name: admin
|
||||||
|
namespace: test
|
||||||
|
rules:
|
||||||
|
- apiGroups: ["*"]
|
||||||
|
resources: ["*"]
|
||||||
|
verbs: ["*"]
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
kind: RoleBinding
|
||||||
|
apiVersion: rbac.authorization.k8s.io/v1
|
||||||
|
metadata:
|
||||||
|
name: admin-to-roc
|
||||||
|
namespace: test
|
||||||
|
subjects:
|
||||||
|
- kind: User
|
||||||
|
name: roc
|
||||||
|
apiGroup: rbac.authorization.k8s.io
|
||||||
|
roleRef:
|
||||||
|
kind: Role
|
||||||
|
name: admin
|
||||||
|
apiGroup: rbac.authorization.k8s.io
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
kind: Role
|
||||||
|
apiVersion: rbac.authorization.k8s.io/v1
|
||||||
|
metadata:
|
||||||
|
name: readonly
|
||||||
|
namespace: istio-system
|
||||||
|
rules:
|
||||||
|
- apiGroups: ["*"]
|
||||||
|
resources: ["*"]
|
||||||
|
verbs: ["get", "watch", "list"]
|
||||||
|
|
||||||
|
---
|
||||||
|
kind: RoleBinding
|
||||||
|
apiVersion: rbac.authorization.k8s.io/v1
|
||||||
|
metadata:
|
||||||
|
name: readonly-to-roc
|
||||||
|
namespace: istio-system
|
||||||
|
subjects:
|
||||||
|
- kind: User
|
||||||
|
name: roc
|
||||||
|
apiGroup: rbac.authorization.k8s.io
|
||||||
|
roleRef:
|
||||||
|
kind: Role
|
||||||
|
name: readonly
|
||||||
|
apiGroup: rbac.authorization.k8s.io
|
||||||
|
```
|
||||||
|
|
||||||
|
### 给 roc 授权整个集群的只读权限
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
kind: ClusterRole
|
||||||
|
apiVersion: rbac.authorization.k8s.io/v1
|
||||||
|
metadata:
|
||||||
|
name: readonly
|
||||||
|
rules:
|
||||||
|
- apiGroups: ["*"]
|
||||||
|
resources: ["*"]
|
||||||
|
verbs: ["get", "watch", "list"]
|
||||||
|
|
||||||
|
---
|
||||||
|
kind: ClusterRoleBinding
|
||||||
|
apiVersion: rbac.authorization.k8s.io/v1
|
||||||
|
metadata:
|
||||||
|
name: readonly-to-roc
|
||||||
|
subjects:
|
||||||
|
- kind: User
|
||||||
|
name: roc
|
||||||
|
apiGroup: rbac.authorization.k8s.io
|
||||||
|
roleRef:
|
||||||
|
kind: ClusterRole
|
||||||
|
name: readonly
|
||||||
|
apiGroup: rbac.authorization.k8s.io
|
||||||
|
```
|
||||||
|
|
||||||
|
### 给 manager 用户组里所有用户授权 secret 读权限
|
||||||
|
|
||||||
|
``` yaml
|
||||||
|
apiVersion: rbac.authorization.k8s.io/v1
|
||||||
|
kind: ClusterRole
|
||||||
|
metadata:
|
||||||
|
name: secret-reader
|
||||||
|
rules:
|
||||||
|
- apiGroups: [""]
|
||||||
|
resources: ["secrets"]
|
||||||
|
verbs: ["get", "watch", "list"]
|
||||||
|
---
|
||||||
|
|
||||||
|
apiVersion: rbac.authorization.k8s.io/v1
|
||||||
|
kind: ClusterRoleBinding
|
||||||
|
metadata:
|
||||||
|
name: read-secrets-global
|
||||||
|
subjects:
|
||||||
|
- kind: Group
|
||||||
|
name: manager
|
||||||
|
apiGroup: rbac.authorization.k8s.io
|
||||||
|
roleRef:
|
||||||
|
kind: ClusterRole
|
||||||
|
name: secret-reader
|
||||||
|
apiGroup: rbac.authorization.k8s.io
|
||||||
|
```
|
||||||
|
|
||||||
|
### 给 roc 授权集群只读权限 (secret读权限除外)
|
||||||
|
|
||||||
|
secret 读权限比较敏感,不要轻易放开,k8s 的 Role/ClusterRole 没有提供类似 "某资源除外" 的能力,secret 在 core group 下,所以只排除 secret 读权限的话需要列举其它所有 core 下面的资源,另外加上其它所有可能的 group 所有资源(包括CRD):
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
kind: ClusterRole
|
||||||
|
apiVersion: rbac.authorization.k8s.io/v1
|
||||||
|
metadata:
|
||||||
|
name: readonly
|
||||||
|
rules:
|
||||||
|
- apiGroups: [""]
|
||||||
|
resources:
|
||||||
|
- bindings
|
||||||
|
- componentstatuses
|
||||||
|
- configmaps
|
||||||
|
- endpoints
|
||||||
|
- events
|
||||||
|
- limitranges
|
||||||
|
- namespaces
|
||||||
|
- nodes
|
||||||
|
- persistentvolumeclaims
|
||||||
|
- persistentvolumes
|
||||||
|
- pods
|
||||||
|
- podtemplates
|
||||||
|
- replicationcontrollers
|
||||||
|
- resourcequotas
|
||||||
|
- serviceaccounts
|
||||||
|
- services
|
||||||
|
verbs: ["get", "list"]
|
||||||
|
- apiGroups:
|
||||||
|
- cert-manager.io
|
||||||
|
- admissionregistration.k8s.io
|
||||||
|
- apiextensions.k8s.io
|
||||||
|
- apiregistration.k8s.io
|
||||||
|
- apps
|
||||||
|
- authentication.k8s.io
|
||||||
|
- autoscaling
|
||||||
|
- batch
|
||||||
|
- certificaterequests.cert-manager.io
|
||||||
|
- certificates.cert-manager.io
|
||||||
|
- certificates.k8s.io
|
||||||
|
- cloud.tencent.com
|
||||||
|
- coordination.k8s.io
|
||||||
|
- discovery.k8s.io
|
||||||
|
- events.k8s.io
|
||||||
|
- extensions
|
||||||
|
- install.istio.io
|
||||||
|
- metrics.k8s.io
|
||||||
|
- monitoring.coreos.com
|
||||||
|
- networking.istio.io
|
||||||
|
- node.k8s.io
|
||||||
|
- policy
|
||||||
|
- rbac.authorization.k8s.io
|
||||||
|
- scheduling.k8s.io
|
||||||
|
- security.istio.io
|
||||||
|
- storage.k8s.io
|
||||||
|
resources: ["*"]
|
||||||
|
verbs: [ "get", "list" ]
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
apiVersion: rbac.authorization.k8s.io/v1
|
||||||
|
kind: ClusterRoleBinding
|
||||||
|
metadata:
|
||||||
|
name: roc
|
||||||
|
roleRef:
|
||||||
|
apiGroup: rbac.authorization.k8s.io
|
||||||
|
kind: ClusterRole
|
||||||
|
name: readonly
|
||||||
|
subjects:
|
||||||
|
- apiGroup: rbac.authorization.k8s.io
|
||||||
|
kind: User
|
||||||
|
name: roc
|
||||||
|
```
|
||||||
|
|
||||||
|
> 可以借助 `kubectl api-resources -o name` 来列举。
|
||||||
|
|
||||||
|
### 限制 ServiceAccount 权限
|
||||||
|
|
||||||
|
授权 `build-robot` 这个 ServiceAccount 读取 build 命名空间中 Pod 的信息和 log 的权限:
|
||||||
|
|
||||||
|
``` yaml
|
||||||
|
apiVersion: v1
|
||||||
|
kind: ServiceAccount
|
||||||
|
metadata:
|
||||||
|
name: build-robot
|
||||||
|
namespace: build
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
apiVersion: rbac.authorization.k8s.io/v1
|
||||||
|
kind: Role
|
||||||
|
metadata:
|
||||||
|
namespace: build
|
||||||
|
name: pod-reader
|
||||||
|
rules:
|
||||||
|
- apiGroups: [""]
|
||||||
|
resources: ["pods", "pods/log"]
|
||||||
|
verbs: ["get", "list"]
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
apiVersion: rbac.authorization.k8s.io/v1
|
||||||
|
kind: RoleBinding
|
||||||
|
metadata:
|
||||||
|
name: read-pods
|
||||||
|
namespace: build
|
||||||
|
subjects:
|
||||||
|
- kind: ServiceAccount
|
||||||
|
name: build-robot
|
||||||
|
namespace: build
|
||||||
|
roleRef:
|
||||||
|
kind: Role
|
||||||
|
name: pod-reader
|
||||||
|
apiGroup: rbac.authorization.k8s.io
|
||||||
|
```
|
||||||
|
|
||||||
|
### ServiceAccount 最高权限
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: v1
|
||||||
|
kind: ServiceAccount
|
||||||
|
metadata:
|
||||||
|
name: cluster-admin
|
||||||
|
namespace: kube-system
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
apiVersion: rbac.authorization.k8s.io/v1
|
||||||
|
kind: ClusterRole
|
||||||
|
metadata:
|
||||||
|
name: cluster-admin
|
||||||
|
rules:
|
||||||
|
- apiGroups: ["*"]
|
||||||
|
resources: ["*"]
|
||||||
|
verbs: ["*"]
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
apiVersion: rbac.authorization.k8s.io/v1
|
||||||
|
kind: ClusterRoleBinding
|
||||||
|
metadata:
|
||||||
|
name: cluster-admin
|
||||||
|
subjects:
|
||||||
|
- kind: ServiceAccount
|
||||||
|
name: cluster-admin
|
||||||
|
namespace: kube-system
|
||||||
|
roleRef:
|
||||||
|
kind: ClusterRole
|
||||||
|
name: cluster-admin
|
||||||
|
apiGroup: rbac.authorization.k8s.io
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,254 @@
|
||||||
|
# 灵活调节 HPA 扩缩容速率
|
||||||
|
## HPA v2beta2 版本开始支持调节扩缩容速率
|
||||||
|
|
||||||
|
在 K8S 1.18 之前,HPA 扩容是无法调整灵敏度的:
|
||||||
|
|
||||||
|
1. 对于缩容,由 `kube-controller-manager` 的 `--horizontal-pod-autoscaler-downscale-stabilization-window` 参数控制缩容时间窗口,默认 5 分钟,即负载减小后至少需要等 5 分钟才会缩容。
|
||||||
|
2. 对于扩容,由 hpa controller 固定的算法、硬编码的常量因子来控制扩容速度,无法自定义。
|
||||||
|
|
||||||
|
这样的设计逻辑导致用户无法自定义 HPA 的扩缩容速率,而不同的业务场景对于扩容容灵敏度要求可能是不一样的,比如:
|
||||||
|
|
||||||
|
1. 对于有流量突发的关键业务,在需要的时候应该快速扩容 (即便可能不需要,以防万一),但缩容要慢 (防止另一个流量高峰)。
|
||||||
|
2. 处理关键数据的应用,数据量飙升时它们应该尽快扩容以减少数据处理时间,数据量降低时应尽快缩小规模以降低成本,数据量的短暂抖动导致不必要的频繁扩缩是可以接受的。
|
||||||
|
3. 处理常规数据/网络流量的业务,不是很重要,它们可能会以一般的方式扩大和缩小规模,以减少抖动。
|
||||||
|
|
||||||
|
HPA 在 K8S 1.18 迎来了一次更新,在之前 v2beta2 版本上新增了扩缩容灵敏度的控制,不过版本号依然保持 v2beta2 不变。
|
||||||
|
## 原理与误区
|
||||||
|
|
||||||
|
HPA 在进行扩缩容时,先是由固定的算法计算出期望副本数:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
期望副本数 = ceil[当前副本数 * (当前指标 / 期望指标)]
|
||||||
|
```
|
||||||
|
|
||||||
|
其中 `当前指标 / 期望指标` 的比例如果接近 1 (在容忍度范围内,默认为 0.1,即比例在 0.9~1.1 之间),则不进行伸缩,避免抖动导致频繁扩缩容。
|
||||||
|
|
||||||
|
> 容忍度是由 `kube-controller-manager` 参数 `--horizontal-pod-autoscaler-tolerance` 决定,默认是 0.1,即 10%。
|
||||||
|
|
||||||
|
本文要介绍的扩缩容速率调节,不是指要调整期望副本数的算法,它并不会加大或缩小扩缩容比例或数量,仅仅是控制扩缩容的速率,实现的效果是: 控制 HPA 在 XX 时间内最大允许扩容/缩容 XX 比例/数量的 Pod。
|
||||||
|
|
||||||
|
## 如何使用
|
||||||
|
|
||||||
|
这次更新实际就是在 HPA Spec 下新增了一个 `behavior` 字段,下面有 `scaleUp` 和 `scaleDown` 两个字段分别控制扩容和缩容的行为,具体可参考 [官方 API 文档](https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.24/#hpascalingrules-v2beta2-autoscaling)。
|
||||||
|
|
||||||
|
使用示例:
|
||||||
|
```yaml
|
||||||
|
apiVersion: autoscaling/v2beta2
|
||||||
|
kind: HorizontalPodAutoscaler
|
||||||
|
metadata:
|
||||||
|
name: web
|
||||||
|
spec:
|
||||||
|
minReplicas: 1
|
||||||
|
maxReplicas: 1000
|
||||||
|
metrics:
|
||||||
|
- pods:
|
||||||
|
metric:
|
||||||
|
name: k8s_pod_rate_cpu_core_used_limit
|
||||||
|
target:
|
||||||
|
averageValue: "80"
|
||||||
|
type: AverageValue
|
||||||
|
type: Pods
|
||||||
|
scaleTargetRef:
|
||||||
|
apiVersion: apps/v1
|
||||||
|
kind: Deployment
|
||||||
|
name: web
|
||||||
|
behavior: # 这里是重点
|
||||||
|
scaleDown:
|
||||||
|
stabilizationWindowSeconds: 300 # 需要缩容时,先观察 5 分钟,如果一直持续需要缩容才执行缩容
|
||||||
|
policies:
|
||||||
|
- type: Percent
|
||||||
|
value: 100 # 允许全部缩掉
|
||||||
|
periodSeconds: 15
|
||||||
|
scaleUp:
|
||||||
|
stabilizationWindowSeconds: 0 # 需要扩容时,立即扩容
|
||||||
|
policies:
|
||||||
|
- type: Percent
|
||||||
|
value: 100
|
||||||
|
periodSeconds: 15 # 每 15s 最大允许扩容当前 1 倍数量的 Pod
|
||||||
|
- type: Pods
|
||||||
|
value: 4
|
||||||
|
periodSeconds: 15 # 每 15s 最大允许扩容 4 个 Pod
|
||||||
|
selectPolicy: Max # 使用以上两种扩容策略中算出来扩容 Pod 数量最大的
|
||||||
|
```
|
||||||
|
|
||||||
|
* 以上 `behavior` 配置是默认的,即如果不配置,会默认加上。
|
||||||
|
* `scaleUp` 和 `scaleDown` 都可以配置1个或多个策略,最终扩缩时用哪个策略,取决于 `selectPolicy`。
|
||||||
|
* `selectPolicy` 默认是 `Max`,即扩缩时,评估多个策略算出来的结果,最终选取扩缩 Pod 数量最多的那个策略的结果。
|
||||||
|
* `stabilizationWindowSeconds` 是稳定窗口时长,即需要指标高于或低于阈值,并持续这个窗口的时长才会真正执行扩缩,以防止抖动导致频繁扩缩容。扩容时,稳定窗口默认为0,即立即扩容;缩容时,稳定窗口默认为5分钟。
|
||||||
|
* `policies` 中定义扩容或缩容策略,`type` 的值可以是 `Pods` 或 `Percent`,表示每 `periodSeconds` 时间范围内,允许扩缩容的最大副本数或比例。
|
||||||
|
|
||||||
|
|
||||||
|
## 场景与示例
|
||||||
|
|
||||||
|
下面给出一些使用场景的示例。
|
||||||
|
### 快速扩容
|
||||||
|
|
||||||
|
当你的应用需要快速扩容时,可以使用类似如下的 HPA 配置:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
behavior:
|
||||||
|
scaleUp:
|
||||||
|
policies:
|
||||||
|
- type: Percent
|
||||||
|
value: 900
|
||||||
|
periodSeconds: 15 # 每 15s 最多允许扩容 9 倍于当前副本数
|
||||||
|
```
|
||||||
|
|
||||||
|
上面的配置表示扩容时最大一次性新增当前 9 倍数量的副本数,当然也不能超过 `maxReplicas` 的限制。
|
||||||
|
|
||||||
|
假如一开始只有 1 个 Pod,如果遭遇流量突发,且指标持续超阈值 9 倍以上,它将以飞快的速度进行扩容,扩容时 Pod 数量变化趋势如下:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
1 -> 10 -> 100 -> 1000
|
||||||
|
```
|
||||||
|
|
||||||
|
没有配置缩容策略,将等待全局默认的缩容时间窗口 (默认5分钟) 后开始缩容。
|
||||||
|
|
||||||
|
### 快速扩容,缓慢缩容
|
||||||
|
|
||||||
|
如果流量高峰过了,并发量骤降,如果用默认的缩容策略,等几分钟后 Pod 数量也会随之骤降,如果 Pod 缩容后突然又来一个流量高峰,虽然可以快速扩容,但扩容的过程毕竟还是需要一定时间的,如果流量高峰足够高,在这段时间内还是可能造成后端处理能力跟不上,导致部分请求失败。这时候我们可以为 HPA 加上缩容策略,HPA `behavior` 配置示例如下:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
behavior:
|
||||||
|
scaleUp:
|
||||||
|
policies:
|
||||||
|
- type: Percent
|
||||||
|
value: 900
|
||||||
|
periodSeconds: 15 # 每 15s 最多允许扩容 9 倍于当前副本数
|
||||||
|
scaleDown:
|
||||||
|
policies:
|
||||||
|
- type: Pods
|
||||||
|
value: 1
|
||||||
|
periodSeconds: 600 # 每 10 分钟最多只允许缩掉 1 个 Pod
|
||||||
|
```
|
||||||
|
|
||||||
|
上面示例中增加了 `scaleDown` 的配置,指定缩容时每 10 分钟才缩掉 1 个 Pod,大大降低了缩容速度,缩容时的 Pod 数量变化趋势如下:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
1000 -> … (10 min later) -> 999
|
||||||
|
```
|
||||||
|
|
||||||
|
这个可以让关键业务在可能有流量突发的情况下保持处理能力,避免流量高峰导致部分请求失败。
|
||||||
|
|
||||||
|
### 缓慢扩容
|
||||||
|
|
||||||
|
如果想要你的应用不太关键,希望扩容时不要太敏感,可以让它扩容平稳缓慢一点,为 HPA 加入下面的 `behavior`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
behavior:
|
||||||
|
scaleUp:
|
||||||
|
policies:
|
||||||
|
- type: Pods
|
||||||
|
value: 1
|
||||||
|
periodSeconds: 300 # 每 5 分钟最多只允许扩容 1 个 Pod
|
||||||
|
```
|
||||||
|
|
||||||
|
假如一开始只有 1 个 Pod,指标一直持续超阈值,扩容时它的 Pod 数量变化趋势如下:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
1 -> 2 -> 3 -> 4
|
||||||
|
```
|
||||||
|
|
||||||
|
### 禁止自动缩容
|
||||||
|
|
||||||
|
如果应用非常关键,希望扩容后不自动缩容,需要人工干预或其它自己开发的 controller 来判断缩容条件,可以使用类型如下的 `behavior` 配置来禁止自动缩容:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
behavior:
|
||||||
|
scaleDown:
|
||||||
|
selectPolicy: Disabled
|
||||||
|
```
|
||||||
|
|
||||||
|
### 延长缩容时间窗口
|
||||||
|
|
||||||
|
缩容默认时间窗口是 5 分钟,如果我们需要延长时间窗口以避免一些流量毛刺造成的异常,可以指定下缩容的时间窗口,`behavior` 配置示例如下:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
behavior:
|
||||||
|
scaleDown:
|
||||||
|
stabilizationWindowSeconds: 600 # 等待 10 分钟再开始缩容
|
||||||
|
policies:
|
||||||
|
- type: Pods
|
||||||
|
value: 5
|
||||||
|
periodSeconds: 600 # 每 10 分钟最多只允许缩掉 5 个 Pod
|
||||||
|
```
|
||||||
|
|
||||||
|
上面的示例表示当负载降下来时,会等待 600s (10 分钟) 再缩容,每 10 分钟最多只允许缩掉 5 个 Pod。
|
||||||
|
|
||||||
|
### 延长扩容时间窗口
|
||||||
|
|
||||||
|
有些应用经常会有数据毛刺导致频繁扩容,而扩容出来的 Pod 其实没太大必要,反而浪费资源。比如数据处理管道的场景,需要的副本数取决于队列中的事件数量,当队列中堆积了大量事件时,我们希望可以快速扩容,但又不希望太灵敏,因为可能只是短时间内的事件堆积,即使不扩容也可以很快处理掉。
|
||||||
|
|
||||||
|
默认的扩容算法会在较短的时间内扩容,针对这种场景我们可以给扩容增加一个时间窗口以避免毛刺导致扩容带来的资源浪费,`behavior` 配置示例如下:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
behavior:
|
||||||
|
scaleUp:
|
||||||
|
stabilizationWindowSeconds: 300 # 扩容前等待 5 分钟的时间窗口
|
||||||
|
policies:
|
||||||
|
- type: Pods
|
||||||
|
value: 20
|
||||||
|
periodSeconds: 60 # 每分钟最多只允许扩容 20 个 Pod
|
||||||
|
```
|
||||||
|
|
||||||
|
上面的示例表示扩容时,需要先等待 5 分钟的时间窗口,如果在这段时间内指标又降下来了就不再扩容,如果一直持续超过阈值才扩容,并且每分钟最多只允许扩容 20 个 Pod。
|
||||||
|
|
||||||
|
## FAQ
|
||||||
|
|
||||||
|
### 为什么我用 v2beta2 创建的 HPA,创建后获取到的 yaml 版本是 v1 或 v2beta1?
|
||||||
|
|
||||||
|
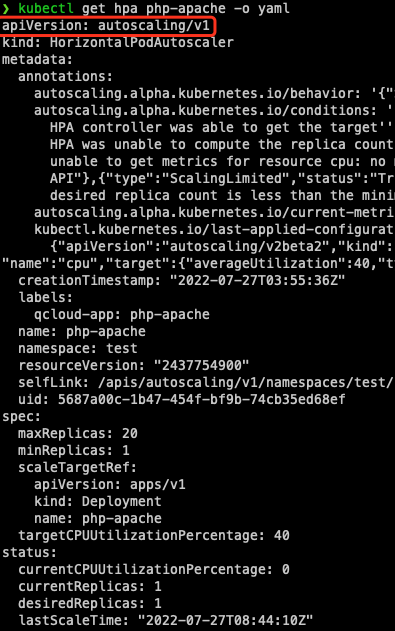
|
||||||
|
|
||||||
|
这是因为 HPA 有多个 apiVersion 版本:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl api-versions | grep autoscaling
|
||||||
|
autoscaling/v1
|
||||||
|
autoscaling/v2beta1
|
||||||
|
autoscaling/v2beta2
|
||||||
|
```
|
||||||
|
|
||||||
|
以任意一种版本创建,都可以以任意版本获取(自动转换)。
|
||||||
|
|
||||||
|
如果是用 kubectl 获取,kubectl 在进行 API discovery 时,会缓存 apiserver 返回的各种资源与版本信息,有些资源存在多个版本,在 get 时如果不指定版本,会使用默认版本获取,对于 HPA,默认是 v1。
|
||||||
|
|
||||||
|
如果是通过一些平台的界面获取,取决于平台的实现方式,比如腾讯云容器服务控制台,默认用 v2beta1 版本展示:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
如何使用 v2beta2 版本获取或编辑?指定包含版本信息的完整资源名即可:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl get horizontalpodautoscaler.v2beta2.autoscaling php-apache -o yaml
|
||||||
|
# kubectl edit horizontalpodautoscaler.v2beta2.autoscaling php-apache
|
||||||
|
```
|
||||||
|
|
||||||
|
### 配置快速扩容,为什么快不起来?
|
||||||
|
|
||||||
|
比如这个配置:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
behavior:
|
||||||
|
scaleUp:
|
||||||
|
policies:
|
||||||
|
- type: Percent
|
||||||
|
value: 900
|
||||||
|
periodSeconds: 10
|
||||||
|
```
|
||||||
|
|
||||||
|
含义是允许每 10 秒最大允许扩出 9 倍于当前数量的 Pod,实测中可能发现压力已经很大了,但扩容却并不快。
|
||||||
|
|
||||||
|
通常原因是计算周期与指标延时:
|
||||||
|
* 期望副本数的计算有个计算周期,默认是 15 秒 (由 `kube-controller-manager` 的 `--horizontal-pod-autoscaler-sync-period` 参数决定)。
|
||||||
|
* 每次计算时,都会通过相应的 metrics API 去获取当前监控指标的值,这个返回的值通常不是实时的,对于腾讯云容器服务而言,监控数据是每分钟上报一次;对于自建的 prometheus + prometheus-adapter 而言,监控数据的更新取决于监控数据抓取间隔,prometheus-adapter 的 `--metrics-relist-interval` 参数决定监控指标刷新周期(从 prometheus 中查询),这两部分时长之和为监控数据更新的最长时间。
|
||||||
|
|
||||||
|
通常都不需要 HPA 极度的灵敏,有一定的延时一般都是可以接受的。如果实在有对灵敏度特别敏感的场景,可以考虑使用 prometheus,缩小监控指标抓取间隔和 prometheus-adapter 的 `--metrics-relist-interval`。
|
||||||
|
|
||||||
|
## 小结
|
||||||
|
|
||||||
|
本文介绍了如何利用 HPA 的新特性来控制扩缩容的速率,以更好的满足各种不同场景对扩容速度的需求,也提供了常见的几种场景与配置示例,可自行根据自己需求对号入座。
|
||||||
|
|
||||||
|
## 参考资料
|
||||||
|
|
||||||
|
* [HPA 官方介绍文档](https://kubernetes.io/zh-cn/docs/tasks/run-application/horizontal-pod-autoscale/)
|
||||||
|
* [控制 HPA 扩容速度的提案](https://github.com/kubernetes/enhancements/tree/master/keps/sig-autoscaling/853-configurable-hpa-scale-velocity)
|
||||||
|
|
@ -0,0 +1,312 @@
|
||||||
|
# HPA 使用自定义指标进行伸缩
|
||||||
|
|
||||||
|
Kubernetes 默认提供 CPU 和内存作为 HPA 弹性伸缩的指标,如果有更复杂的场景需求,比如基于业务单副本 QPS 大小来进行自动扩缩容,可以考虑自行安装 [prometheus-adapter](https://github.com/DirectXMan12/k8s-prometheus-adapter) 来实现基于自定义指标的 Pod 弹性伸缩。
|
||||||
|
|
||||||
|
## 实现原理
|
||||||
|
|
||||||
|
Kubernetes 提供了 [Custom Metrics API](https://github.com/kubernetes/community/blob/master/contributors/design-proposals/instrumentation/custom-metrics-api.md) 与 [External Metrics API](https://github.com/kubernetes/community/blob/master/contributors/design-proposals/instrumentation/external-metrics-api.md) 来对 HPA 的指标进行扩展,让用户能够根据实际需求进行自定义。
|
||||||
|
|
||||||
|
prometheus-adapter 对这两种 API 都有支持,通常使用 Custom Metrics API 就够了,本文也主要针对此 API 来实现使用自定义指标进行弹性伸缩。
|
||||||
|
|
||||||
|
## 前提条件
|
||||||
|
|
||||||
|
* 部署有 Prometheus 并做了相应的自定义指标采集。
|
||||||
|
* 已安装 [helm](https://helm.sh/docs/intro/install/) 。
|
||||||
|
|
||||||
|
## 业务暴露监控指标
|
||||||
|
|
||||||
|
这里以一个简单的 golang 业务程序为例,暴露 HTTP 请求的监控指标:
|
||||||
|
|
||||||
|
``` go
|
||||||
|
package main
|
||||||
|
|
||||||
|
import (
|
||||||
|
"github.com/prometheus/client_golang/prometheus"
|
||||||
|
"github.com/prometheus/client_golang/prometheus/promhttp"
|
||||||
|
"net/http"
|
||||||
|
"strconv"
|
||||||
|
)
|
||||||
|
|
||||||
|
var (
|
||||||
|
HTTPRequests = prometheus.NewCounterVec(
|
||||||
|
prometheus.CounterOpts{
|
||||||
|
Name: "httpserver_requests_total",
|
||||||
|
Help: "Number of the http requests received since the server started",
|
||||||
|
},
|
||||||
|
[]string{"status"},
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
func init() {
|
||||||
|
prometheus.MustRegister(HTTPRequests)
|
||||||
|
}
|
||||||
|
|
||||||
|
func main() {
|
||||||
|
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
|
||||||
|
path := r.URL.Path
|
||||||
|
code := 200
|
||||||
|
switch path {
|
||||||
|
case "/test":
|
||||||
|
w.WriteHeader(200)
|
||||||
|
w.Write([]byte("OK"))
|
||||||
|
case "/metrics":
|
||||||
|
promhttp.Handler().ServeHTTP(w, r)
|
||||||
|
default:
|
||||||
|
w.WriteHeader(404)
|
||||||
|
w.Write([]byte("Not Found"))
|
||||||
|
}
|
||||||
|
HTTPRequests.WithLabelValues(strconv.Itoa(code)).Inc()
|
||||||
|
})
|
||||||
|
http.ListenAndServe(":80", nil)
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
该示例程序暴露了 `httpserver_requests_total` 指标,记录 HTTP 的请求,通过这个指标可以计算出该业务程序的 QPS 值。
|
||||||
|
|
||||||
|
## 部署业务程序
|
||||||
|
|
||||||
|
将前面的程序打包成容器镜像,然后部署到集群,比如使用 Deployment 部署:
|
||||||
|
|
||||||
|
``` yaml
|
||||||
|
apiVersion: apps/v1
|
||||||
|
kind: Deployment
|
||||||
|
metadata:
|
||||||
|
name: httpserver
|
||||||
|
namespace: httpserver
|
||||||
|
spec:
|
||||||
|
replicas: 1
|
||||||
|
selector:
|
||||||
|
matchLabels:
|
||||||
|
app: httpserver
|
||||||
|
template:
|
||||||
|
metadata:
|
||||||
|
labels:
|
||||||
|
app: httpserver
|
||||||
|
spec:
|
||||||
|
containers:
|
||||||
|
- name: httpserver
|
||||||
|
image: registry.imroc.cc/test/httpserver:custom-metrics
|
||||||
|
imagePullPolicy: Always
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
apiVersion: v1
|
||||||
|
kind: Service
|
||||||
|
metadata:
|
||||||
|
name: httpserver
|
||||||
|
namespace: httpserver
|
||||||
|
labels:
|
||||||
|
app: httpserver
|
||||||
|
annotations:
|
||||||
|
prometheus.io/scrape: "true"
|
||||||
|
prometheus.io/path: "/metrics"
|
||||||
|
prometheus.io/port: "http"
|
||||||
|
spec:
|
||||||
|
type: ClusterIP
|
||||||
|
ports:
|
||||||
|
- port: 80
|
||||||
|
protocol: TCP
|
||||||
|
name: http
|
||||||
|
selector:
|
||||||
|
app: httpserver
|
||||||
|
```
|
||||||
|
|
||||||
|
## Prometheus 采集业务监控
|
||||||
|
|
||||||
|
业务部署好了,我们需要让我们的 Promtheus 去采集业务暴露的监控指标。
|
||||||
|
|
||||||
|
### 方式一: 配置 Promtheus 采集规则
|
||||||
|
|
||||||
|
在 Promtheus 的采集规则配置文件添加采集规则:
|
||||||
|
|
||||||
|
``` yaml
|
||||||
|
- job_name: httpserver
|
||||||
|
scrape_interval: 5s
|
||||||
|
kubernetes_sd_configs:
|
||||||
|
- role: endpoints
|
||||||
|
namespaces:
|
||||||
|
names:
|
||||||
|
- httpserver
|
||||||
|
relabel_configs:
|
||||||
|
- action: keep
|
||||||
|
source_labels:
|
||||||
|
- __meta_kubernetes_service_label_app
|
||||||
|
regex: httpserver
|
||||||
|
- action: keep
|
||||||
|
source_labels:
|
||||||
|
- __meta_kubernetes_endpoint_port_name
|
||||||
|
regex: http
|
||||||
|
```
|
||||||
|
|
||||||
|
### 方式二: 配置 ServiceMonitor
|
||||||
|
|
||||||
|
若已安装 prometheus-operator,则可通过创建 ServiceMonitor 的 CRD 对象配置 Prometheus。示例如下:
|
||||||
|
|
||||||
|
``` yaml
|
||||||
|
apiVersion: monitoring.coreos.com/v1
|
||||||
|
kind: ServiceMonitor
|
||||||
|
metadata:
|
||||||
|
name: httpserver
|
||||||
|
spec:
|
||||||
|
endpoints:
|
||||||
|
- port: http
|
||||||
|
interval: 5s
|
||||||
|
namespaceSelector:
|
||||||
|
matchNames:
|
||||||
|
- httpserver
|
||||||
|
selector:
|
||||||
|
matchLabels:
|
||||||
|
app: httpserver
|
||||||
|
```
|
||||||
|
|
||||||
|
## 安装 prometheus-adapter
|
||||||
|
|
||||||
|
我们使用 helm 安装 [prometheus-adapter](https://artifacthub.io/packages/helm/prometheus-community/prometheus-adapter),安装前最重要的是确定并配置自定义指标,按照前面的示例,我们业务中使用 `httpserver_requests_total` 这个指标来记录 HTTP 请求,那么我们可以通过类似下面的 PromQL 计算出每个业务 Pod 的 QPS 监控:
|
||||||
|
|
||||||
|
```
|
||||||
|
sum(rate(http_requests_total[2m])) by (pod)
|
||||||
|
```
|
||||||
|
|
||||||
|
我们需要将其转换为 prometheus-adapter 的配置,准备一个 `values.yaml`:
|
||||||
|
|
||||||
|
``` yaml
|
||||||
|
rules:
|
||||||
|
default: false
|
||||||
|
custom:
|
||||||
|
- seriesQuery: 'httpserver_requests_total'
|
||||||
|
resources:
|
||||||
|
template: <<.Resource>>
|
||||||
|
name:
|
||||||
|
matches: "httpserver_requests_total"
|
||||||
|
as: "httpserver_requests_qps" # PromQL 计算出来的 QPS 指标
|
||||||
|
metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>}[1m])) by (<<.GroupBy>>)
|
||||||
|
prometheus:
|
||||||
|
url: http://prometheus.monitoring.svc.cluster.local # 替换 Prometheus API 的地址 (不写端口)
|
||||||
|
port: 9090u
|
||||||
|
```
|
||||||
|
|
||||||
|
执行 helm 命令进行安装:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
|
||||||
|
helm repo update
|
||||||
|
# Helm 3
|
||||||
|
helm install prometheus-adapter prometheus-community/prometheus-adapter -f values.yaml
|
||||||
|
# Helm 2
|
||||||
|
# helm install --name prometheus-adapter prometheus-community/prometheus-adapter -f values.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
## 测试是否安装正确
|
||||||
|
|
||||||
|
如果安装正确,是可以看到 Custom Metrics API 返回了我们配置的 QPS 相关指标:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
$ kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1
|
||||||
|
{
|
||||||
|
"kind": "APIResourceList",
|
||||||
|
"apiVersion": "v1",
|
||||||
|
"groupVersion": "custom.metrics.k8s.io/v1beta1",
|
||||||
|
"resources": [
|
||||||
|
{
|
||||||
|
"name": "jobs.batch/httpserver_requests_qps",
|
||||||
|
"singularName": "",
|
||||||
|
"namespaced": true,
|
||||||
|
"kind": "MetricValueList",
|
||||||
|
"verbs": [
|
||||||
|
"get"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"name": "pods/httpserver_requests_qps",
|
||||||
|
"singularName": "",
|
||||||
|
"namespaced": true,
|
||||||
|
"kind": "MetricValueList",
|
||||||
|
"verbs": [
|
||||||
|
"get"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"name": "namespaces/httpserver_requests_qps",
|
||||||
|
"singularName": "",
|
||||||
|
"namespaced": false,
|
||||||
|
"kind": "MetricValueList",
|
||||||
|
"verbs": [
|
||||||
|
"get"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
]
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
也能看到业务 Pod 的 QPS 值:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
$ kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1/namespaces/httpserver/pods/*/httpserver_requests_qps
|
||||||
|
{
|
||||||
|
"kind": "MetricValueList",
|
||||||
|
"apiVersion": "custom.metrics.k8s.io/v1beta1",
|
||||||
|
"metadata": {
|
||||||
|
"selfLink": "/apis/custom.metrics.k8s.io/v1beta1/namespaces/httpserver/pods/%2A/httpserver_requests_qps"
|
||||||
|
},
|
||||||
|
"items": [
|
||||||
|
{
|
||||||
|
"describedObject": {
|
||||||
|
"kind": "Pod",
|
||||||
|
"namespace": "httpserver",
|
||||||
|
"name": "httpserver-6f94475d45-7rln9",
|
||||||
|
"apiVersion": "/v1"
|
||||||
|
},
|
||||||
|
"metricName": "httpserver_requests_qps",
|
||||||
|
"timestamp": "2020-11-17T09:14:36Z",
|
||||||
|
"value": "500m",
|
||||||
|
"selector": null
|
||||||
|
}
|
||||||
|
]
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
> 上面示例 QPS 为 `500m`,表示 QPS 值为 0.5
|
||||||
|
|
||||||
|
## 测试 HPA
|
||||||
|
|
||||||
|
假如我们设置每个业务 Pod 的平均 QPS 达到 50,就触发扩容,最小副本为 1 个,最大副本为1000,HPA 可以这么配置:
|
||||||
|
|
||||||
|
``` yaml
|
||||||
|
apiVersion: autoscaling/v2beta2
|
||||||
|
kind: HorizontalPodAutoscaler
|
||||||
|
metadata:
|
||||||
|
name: httpserver
|
||||||
|
namespace: httpserver
|
||||||
|
spec:
|
||||||
|
minReplicas: 1
|
||||||
|
maxReplicas: 1000
|
||||||
|
scaleTargetRef:
|
||||||
|
apiVersion: apps/v1
|
||||||
|
kind: Deployment
|
||||||
|
name: httpserver
|
||||||
|
metrics:
|
||||||
|
- type: Pods
|
||||||
|
pods:
|
||||||
|
metric:
|
||||||
|
name: httpserver_requests_qps
|
||||||
|
target:
|
||||||
|
averageValue: 50
|
||||||
|
type: AverageValue
|
||||||
|
```
|
||||||
|
|
||||||
|
然后对业务进行压测,观察是否扩容:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
$ kubectl get hpa
|
||||||
|
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
|
||||||
|
httpserver Deployment/httpserver 83933m/50 1 1000 2 18h
|
||||||
|
|
||||||
|
$ kubectl get pods
|
||||||
|
NAME READY STATUS RESTARTS AGE
|
||||||
|
httpserver-6f94475d45-47d5w 1/1 Running 0 3m41s
|
||||||
|
httpserver-6f94475d45-7rln9 1/1 Running 0 37h
|
||||||
|
httpserver-6f94475d45-6c5xm 0/1 ContainerCreating 0 1s
|
||||||
|
httpserver-6f94475d45-wl78d 0/1 ContainerCreating 0 1s
|
||||||
|
```
|
||||||
|
|
||||||
|
扩容正常则说明已经实现 HPA 基于业务自定义指标进行弹性伸缩。
|
||||||
|
|
@ -0,0 +1,109 @@
|
||||||
|
# 健康检查配置
|
||||||
|
|
||||||
|
> 本文视频教程: [https://www.bilibili.com/video/BV16q4y1y7B9](https://www.bilibili.com/video/BV16q4y1y7B9)
|
||||||
|
|
||||||
|
本文分享 K8S 健康检查配置的最佳实践,文末也分享配置不当的案例。
|
||||||
|
|
||||||
|
## Kubernetes 健康检查介绍
|
||||||
|
|
||||||
|
K8S 支持三种健康检查:
|
||||||
|
1. 就绪检查(`readinessProbe`): Pod启动后,如果配了就绪检查,要等就绪检查探测成功,Pod Ready 状态变为 True,允许放流量进来;在运行期间如果突然探测失败,Ready 状态变为 False,摘除流量。
|
||||||
|
2. 存活检查(`livenessProbe`): Pod 在运行时,如果存活检查探测失败,会自动重启容器;值得注意的是,存活探测的结果不影响 Pod 的 Ready 状态,这也是许多同学可能误解的地方。
|
||||||
|
3. 启动检查(`startupProbe`): 作用是让存活检查和就绪检查的开始探测时间延后,等启动检查成功后再开始探测,通常用于避免业务进程启动慢导致存活检查失败而被无限重启。
|
||||||
|
|
||||||
|
三种健康检查配置格式都是一样的,以 `readinessProbe` 为例:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
readinessProbe:
|
||||||
|
successThreshold: 1 # 1 次探测成功就认为健康
|
||||||
|
failureThreshold: 2 # 连续 2 次探测失败认为不健康
|
||||||
|
periodSeconds: 3 # 3s 探测一次
|
||||||
|
timeoutSeconds: 2 # 2s 超时还没返回成功就认为不健康
|
||||||
|
httpGet: # 使用 http 接口方式探测,GET 请求 80 端口的 "/healthz" 这个 http 接口,响应状态码在200~399之间视为健康,否则不健康。
|
||||||
|
port: 80
|
||||||
|
path: "/healthz"
|
||||||
|
#exec: # 使用脚本探测,执行容器内 "/check-health.sh" 这个脚本文件,退出状态码等于0视为健康,否则不健康。
|
||||||
|
# command: ["/check-health.sh"]
|
||||||
|
#tcp: # 使用 TCP 探测,看 9000 端口是否监听。
|
||||||
|
# port: 9000
|
||||||
|
```
|
||||||
|
|
||||||
|
## 探测结果一定要真实反应业务健康状态
|
||||||
|
|
||||||
|
### 首选 HTTP 探测
|
||||||
|
|
||||||
|
通常是推荐业务自身提供 http 探测接口,如果业务层面健康就返回 200 状态码;否则,就返回 500。
|
||||||
|
|
||||||
|
### 备选脚本探测
|
||||||
|
|
||||||
|
如果业务还不支持 http 探测接口,或者有探测接口但不是 http 协议,也可以将探测逻辑写到脚本文件里,然后配置脚本方式探测。
|
||||||
|
|
||||||
|
### 尽量避免 TCP 探测
|
||||||
|
|
||||||
|
另外,应尽量避免使用 TCP 探测,因为 TCP 探测实际就是 kubelet 向指定端口发送 TCP SYN 握手包,当端口被监听内核就会直接响应 ACK,探测就会成功:
|
||||||
|
|
||||||
|
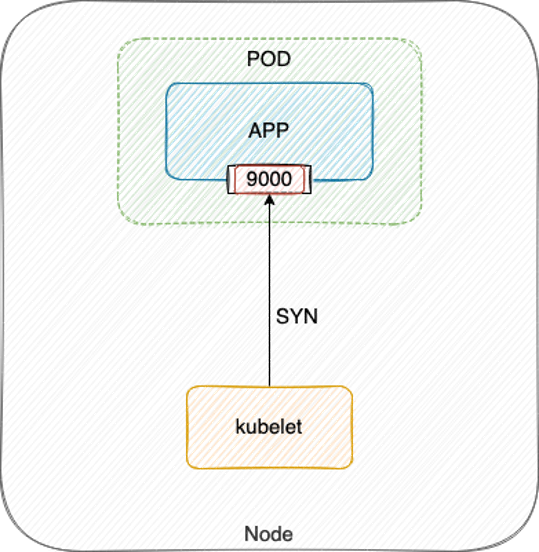
|
||||||
|
|
||||||
|
当程序死锁或 hang 死,这些并不影响端口监听,所以探测结果还是健康,流量打到表面健康但实际不健康的 Pod 上,就无法处理请求,从而引发业务故障。
|
||||||
|
|
||||||
|
## 所有提供服务的 container 都要加上 ReadinessProbe
|
||||||
|
|
||||||
|
如果你的容器对外提供了服务,监听了端口,那么都应该配上 ReadinessProbe,ReadinessProbe 不通过就视为 Pod 不健康,然后会自动将不健康的 Pod 踢出去,避免将业务流量转发给异常 Pod。
|
||||||
|
|
||||||
|
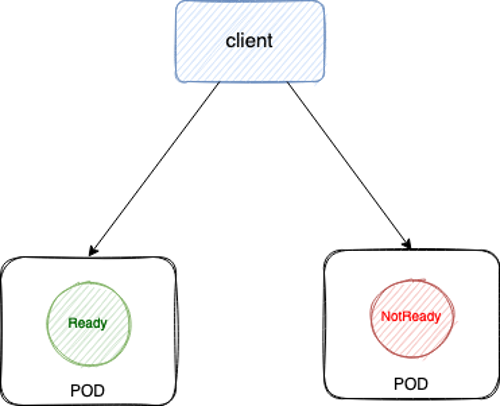
|
||||||
|
|
||||||
|
## 谨慎使用 LivenessProbe
|
||||||
|
|
||||||
|
LivenessProbe 失败会重启 Pod,不要轻易使用,除非你了解后果并且明白为什么你需要它,参考 [Liveness Probes are Dangerous](https://srcco.de/posts/kubernetes-liveness-probes-are-dangerous.html) 。
|
||||||
|
|
||||||
|
### 探测条件要更宽松
|
||||||
|
|
||||||
|
如果使用 LivenessProbe,不要和 ReadinessProbe 设置成一样,需要更宽松一点,避免因抖动导致 Pod 频繁被重启。
|
||||||
|
|
||||||
|
通常是失败阈值 (`failureThreshold`) 设置得更大一点,避免因探测太敏感导致 Pod 很容易被重启。
|
||||||
|
|
||||||
|
另外如果有必要,超时时间 (`timeoutSeconds`) 和探测间隔 (`periodSeconds`) 也可以根据情况适当延长。
|
||||||
|
|
||||||
|
### 保护慢启动容器
|
||||||
|
|
||||||
|
有些应用本身可能启动慢(比如 Java),或者用的富容器,需要起一大堆依赖,导致容器启动需要的较长,如果配置了存活检查,可能会造成启动过程中达到失败阈值被重启,如此循环,无限重启。
|
||||||
|
|
||||||
|
对于这类启动慢的容器,我们需要保护下,等待应用完全启动后才开始探测:
|
||||||
|
|
||||||
|
1. 如果 K8S 版本低于 1.18,可以设置 LivenessProbe 的初始探测延时 (`initialDelaySeconds`)。
|
||||||
|
2. 如果 K8S 版本在 1.18 及其以上,可以配置 [StartProbe](https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/#define-startup-probes),保证等应用完全启动后才开始探测。
|
||||||
|
|
||||||
|
### 避免依赖导致级联故障
|
||||||
|
|
||||||
|
LivenessProbe 探测逻辑里不要有外部依赖 (db, 其它 pod 等),避免抖动导致级联故障。
|
||||||
|
|
||||||
|
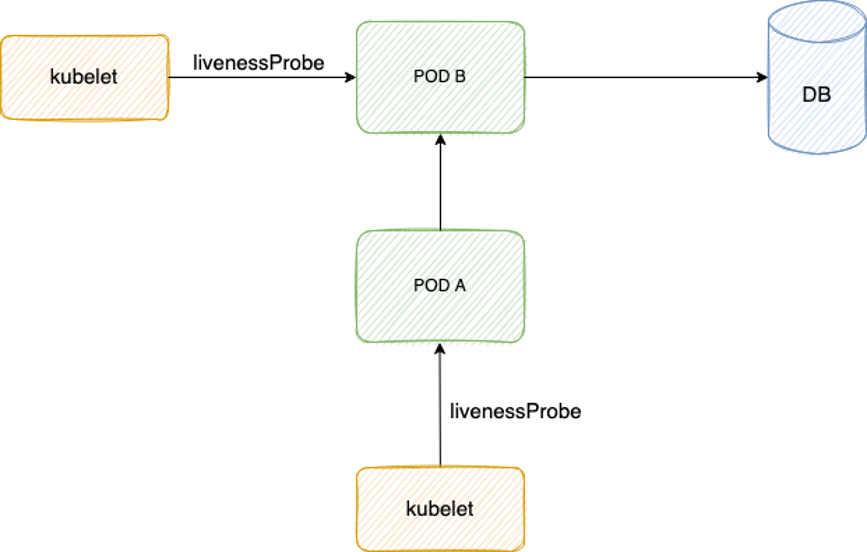
|
||||||
|
|
||||||
|
如上图,Pod B 探测逻辑里查 DB,Pod A 探测逻辑里调用 Pod B,如果 DB 抖动,Pod B 变为不健康,Pod A 调用 Pod B 也失败,也变为不健康,从而级联故障。
|
||||||
|
|
||||||
|
## 反面教材
|
||||||
|
|
||||||
|
### 突然无限重启且流量异常
|
||||||
|
|
||||||
|
故障现象: Pod 突然不断重启,期间有流量进入,这部分流量异常。
|
||||||
|
|
||||||
|
原因:
|
||||||
|
1. Pod 之前所在节点异常,重建漂移到了其它节点去启动。
|
||||||
|
2. Pod 重建后由于基础镜像中依赖的一个服务有问题导致启动较慢,因为同时配置了 ReadinessProbe 与 LivenessProbe,大概率是启动时所有健康检查都失败,达到 LivenessProbe 失败次数阈值,又被重启。
|
||||||
|
3. Pod 配置了 preStop 实现优雅终止,被重启前会先执行 preStop,优雅终止的时长较长,preStop 期间 ReadinessProbe 还会继续探测。
|
||||||
|
4. 探测方式使用的 TCP 探测,进程优雅终止过程中 TCP 探测仍然会成功(没完全退出前端口监听仍然存在),但实际此时进程已不会处理新请求了。
|
||||||
|
5. LivenessProbe 结果不会影响 Pod Ready 状态,是否 Ready 主要取决于 ReadinessProbe 结果,由于 preStop 期间 ReadinessProbe 是成功的,Pod 就变 Ready 了。
|
||||||
|
6. Pod Ready 但实际无法处理请求,业务就会异常。
|
||||||
|
|
||||||
|
总结:
|
||||||
|
1. Pod 慢启动 + 存活探测 导致被无限重启。需要延长 `initialDelaySeconds` 或 [StartProbe](https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/#define-startup-probes) 来保护慢启动容器。
|
||||||
|
2. TCP 探测方式不能完全真实反应业务健康状态,导致在优雅终止过程中,ReadinessProbe 探测成功让流量放进来而业务却不会处理,导致流量异常。需要使用更好的探测方式,建议业务提供 HTTP 探活接口,使用 HTTP 探测业务真实健康状态。
|
||||||
|
|
||||||
|
### netstat 探测超时
|
||||||
|
|
||||||
|
故障现象: 探测脚本经常 2s 超时。
|
||||||
|
|
||||||
|
原因: 使用脚本探测,超时时间为 2s,脚本里使用了 netstat 检测端口是否存活来判断业务进程是否正常,当流量较大时,连接数多,netstat 运行所需时间就较长 (因为 netstat 会遍历 `/proc` 下每个 pid 内容来进行统计,执行时长受连接数波动所影响),所以在业务高峰时往往容易执行超时,从而探测失败。
|
||||||
|
|
||||||
|
总结: 这种探测方式比 TCP 探测方式更原始,强烈不推荐,参考最佳实践优化探测配置。
|
||||||
|
|
||||||
|
|
@ -0,0 +1,48 @@
|
||||||
|
# 在容器中使用 crontab
|
||||||
|
|
||||||
|
## 准备 crontab 配置文件
|
||||||
|
|
||||||
|
新建一个名为 `crontab` 的配置文件,写定时任务规则:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
* * * * * echo "Crontab is working" > /proc/1/fd/1
|
||||||
|
```
|
||||||
|
|
||||||
|
> `/proc/1/fd/1` 表示输出到容器主进程的标准输出,这样我们可以利用 `kubectl logs` 来查看到执行日志。
|
||||||
|
|
||||||
|
## 准备 Dockerfile
|
||||||
|
|
||||||
|
### CentOS 镜像
|
||||||
|
|
||||||
|
```dockerfile
|
||||||
|
FROM docker.io/centos:7
|
||||||
|
|
||||||
|
RUN yum -y install crontabs && rm -rf /etc/cron.*/*
|
||||||
|
|
||||||
|
ADD crontab /etc/crontab
|
||||||
|
RUN chmod 0644 /etc/crontab
|
||||||
|
RUN crontab /etc/crontab
|
||||||
|
|
||||||
|
CMD ["crond", "-n"]
|
||||||
|
```
|
||||||
|
|
||||||
|
### Ubuntu 镜像
|
||||||
|
|
||||||
|
```dockerfile
|
||||||
|
FROM docker.io/ubuntu:20.04
|
||||||
|
|
||||||
|
RUN apt-get update && apt-get install -y cron && rm -rf /etc/cron.*/*
|
||||||
|
|
||||||
|
ADD crontab /etc/crontab
|
||||||
|
RUN chmod 0644 /etc/crontab
|
||||||
|
RUN crontab /etc/crontab
|
||||||
|
|
||||||
|
CMD ["cron", "-f", "-l", "2"]
|
||||||
|
```
|
||||||
|
|
||||||
|
## 打包镜像
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker build -t docker.io/imroc/crontab:latest -f Dockerfile .
|
||||||
|
# podman build -t docker.io/imroc/crontab:latest -f Dockerfile .
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,47 @@
|
||||||
|
# Go 应用容器化
|
||||||
|
|
||||||
|
## 使用多阶段构建编译
|
||||||
|
|
||||||
|
可以使用 golang 的官方镜像进行编译,建议使用静态编译,因为 golang 官方镜像默认使用的基础镜像是 debian,如果使用默认的编译,会依赖依赖一些动态链接库,当业务镜像使用了其它发行版基础镜像,且动态链接库不一样的话 (比如 alpine),就会导致程序启动时发现依赖的动态链接库找不到而无法启动:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
standard_init_linux.go:211: exec user process caused "no such file or directory"
|
||||||
|
```
|
||||||
|
|
||||||
|
以下是多阶段构建静态编译 golang 程序的 Dockerfile 示例:
|
||||||
|
|
||||||
|
```Dockerfile
|
||||||
|
FROM golang:latest as builder
|
||||||
|
|
||||||
|
COPY . /build
|
||||||
|
|
||||||
|
WORKDIR /build
|
||||||
|
|
||||||
|
RUN CGO_ENABLED=0 go build -trimpath -ldflags='-s -w -extldflags=-static' -o /app
|
||||||
|
|
||||||
|
FROM ubuntu:22.10
|
||||||
|
|
||||||
|
COPY --from=builder /app /
|
||||||
|
|
||||||
|
CMD ["/app"]
|
||||||
|
```
|
||||||
|
|
||||||
|
如果希望最小化镜像,可以用空基础镜像,让镜像中只包含一个静态编译后 go 二进制:
|
||||||
|
|
||||||
|
```Dockerfile
|
||||||
|
FROM golang:latest as builder
|
||||||
|
|
||||||
|
COPY . /build
|
||||||
|
|
||||||
|
WORKDIR /build
|
||||||
|
|
||||||
|
RUN CGO_ENABLED=0 go build -trimpath -ldflags='-s -w -extldflags=-static' -o /app
|
||||||
|
|
||||||
|
FROM scratch
|
||||||
|
|
||||||
|
COPY --from=builder /app /
|
||||||
|
|
||||||
|
CMD ["/app"]
|
||||||
|
```
|
||||||
|
|
||||||
|
> 建议 k8s 1.23 及其以上版本使用 scratch 基础镜像,即使镜像中不包含 bash 等调试工具,也可以 [使用临时容器来进行调试](https://kubernetes.io/zh-cn/docs/tasks/debug/debug-application/debug-running-pod/#ephemeral-container)。
|
||||||
|
|
@ -0,0 +1,141 @@
|
||||||
|
# Java 应用容器化
|
||||||
|
|
||||||
|
本文介绍 Java 应用容器化相关注意事项。
|
||||||
|
|
||||||
|
## 避免低版本 JDK
|
||||||
|
|
||||||
|
JDK 低版本对容器不友好,感知不到自己在容器内:
|
||||||
|
1. 不知道被分配了多少内存,很容易造成消耗过多内容而触发 Cgroup OOM 被杀死。
|
||||||
|
2. 不知道被分配了多少 CPU,认为可用 CPU 数量就是宿主机的 CPU 数量,导致 JVM 创建过多线程,容易高负载被 Cgroup CPU 限流(throttle)。
|
||||||
|
|
||||||
|
在高版本的 JDK 中 (JDK10) 对容器进行了很好的支持,同时也 backport 到了低版本 (JDK8):
|
||||||
|
1. 如果使用的 `Oracle JDK`,确保版本大于等于 `8u191`。
|
||||||
|
2. 如果使用的 `OpenJDK`,确保版本大于等于 `8u212`。
|
||||||
|
|
||||||
|
## 常见问题
|
||||||
|
|
||||||
|
### 相同镜像在部分机器上跑有问题
|
||||||
|
|
||||||
|
* 现象: 经常会有人说,我的 java 容器镜像,在 A 机器上跑的好好的,在 B 机器上就有问题,都是用的同一个容器镜像啊。
|
||||||
|
* 根因:java 类加载的顺序问题,如果有不同版本的重复 jar 包,只会加载其中一个,并且不保证顺序。
|
||||||
|
* 解决方案:业务去掉重复的 jar 包。
|
||||||
|
* 类似 case 的分析文章:[关于Jar加载顺序的问题分析](https://www.jianshu.com/p/dcad5330b06f)
|
||||||
|
|
||||||
|
### java 默认线程池的线程数问题
|
||||||
|
|
||||||
|
* 现象:java 应用创建大量线程。
|
||||||
|
* 根因:低版本 jdk,无法正确识别 cgroup 的 limit,所以 cpu 的数量及内存的大小是直接从宿主机获取的,跟 cgroup 里的 limit 不一致。
|
||||||
|
* 解决方案:业务升级 jdk 版本。
|
||||||
|
|
||||||
|
## 使用 Maven 构建 Java 容器镜像
|
||||||
|
本文介绍如果在容器环境将 Maven 项目构建成 Java 容器镜像,完整示例源码请参考 Github [maven-docker-example](https://github.com/imroc/maven-docker-example)。
|
||||||
|
|
||||||
|
### pom.xml
|
||||||
|
|
||||||
|
以下是 maven `pom.xml` 示例:
|
||||||
|
|
||||||
|
```xml
|
||||||
|
<?xml version="1.0" encoding="UTF-8"?>
|
||||||
|
<project xmlns="http://maven.apache.org/POM/4.0.0"
|
||||||
|
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
|
||||||
|
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
|
||||||
|
<modelVersion>4.0.0</modelVersion>
|
||||||
|
|
||||||
|
<groupId>org.example</groupId>
|
||||||
|
<artifactId>http</artifactId>
|
||||||
|
<version>1.0-SNAPSHOT</version>
|
||||||
|
|
||||||
|
<properties>
|
||||||
|
<!-- 指定 maven 编译时用的 jdk 版本,与 maven 基础镜像中的版本一致 -->
|
||||||
|
<maven.compiler.source>11</maven.compiler.source>
|
||||||
|
<maven.compiler.target>11</maven.compiler.target>
|
||||||
|
</properties>
|
||||||
|
|
||||||
|
<build>
|
||||||
|
<!-- 指定项目最终生成的 jar 文件名,建议固定下来,方便在 Dockerfile 中 COPY 固定文件名 -->
|
||||||
|
<finalName>app</finalName>
|
||||||
|
<plugins>
|
||||||
|
<plugin>
|
||||||
|
<!-- 将项目源码编译成一个可执行 jar 包 -->
|
||||||
|
<groupId>org.apache.maven.plugins</groupId>
|
||||||
|
<artifactId>maven-jar-plugin</artifactId>
|
||||||
|
<configuration>
|
||||||
|
<archive>
|
||||||
|
<manifest>
|
||||||
|
<!-- 运行 jar 包时运行的主类,要求类全名 -->
|
||||||
|
<mainClass>org.example.http.HttpTest</mainClass>
|
||||||
|
<!-- 是否指定项目 classpath 下的依赖 -->
|
||||||
|
<addClasspath>true</addClasspath>
|
||||||
|
<!-- 指定依赖的时候声明前缀 -->
|
||||||
|
<classpathPrefix>./lib/</classpathPrefix>
|
||||||
|
<!-- 依赖是否使用带有时间戳的唯一版本号,如:xxx-1.3.0-20121225.012733.jar -->
|
||||||
|
<useUniqueVersions>false</useUniqueVersions>
|
||||||
|
</manifest>
|
||||||
|
</archive>
|
||||||
|
</configuration>
|
||||||
|
</plugin>
|
||||||
|
<plugin>
|
||||||
|
<!-- 利用 maven-dependency-plugin 把当前项目的所有依赖放到 target 目录下的 lib 文件夹下 -->
|
||||||
|
<groupId>org.apache.maven.plugins</groupId>
|
||||||
|
<artifactId>maven-dependency-plugin</artifactId>
|
||||||
|
<executions>
|
||||||
|
<execution>
|
||||||
|
<id>copy</id>
|
||||||
|
<phase>package</phase>
|
||||||
|
<goals>
|
||||||
|
<goal>copy-dependencies</goal>
|
||||||
|
</goals>
|
||||||
|
<configuration>
|
||||||
|
<outputDirectory>${project.build.directory}/lib</outputDirectory>
|
||||||
|
</configuration>
|
||||||
|
</execution>
|
||||||
|
</executions>
|
||||||
|
</plugin>
|
||||||
|
</plugins>
|
||||||
|
</build>
|
||||||
|
|
||||||
|
<dependencies>
|
||||||
|
<dependency>
|
||||||
|
<groupId>org.apache.httpcomponents.client5</groupId>
|
||||||
|
<artifactId>httpclient5</artifactId>
|
||||||
|
<version>5.1.3</version>
|
||||||
|
</dependency>
|
||||||
|
</dependencies>
|
||||||
|
|
||||||
|
</project>
|
||||||
|
```
|
||||||
|
|
||||||
|
关键点:
|
||||||
|
* 利用 `maven-dependency-plugin` 插件将所有依赖 jar 包拷贝到 `./lib` 下。
|
||||||
|
* 利用 `maven-jar-plugin` 插件在打包 jar 时指定 main 函数所在 Class,让 jar 可执行;将依赖包放到 jar 包相对路径的 `./lib` 下并自动加上 `CLASSPATH`。
|
||||||
|
|
||||||
|
### Dockerfile
|
||||||
|
|
||||||
|
以下是用于构建镜像的 `Dockerfile` 示例:
|
||||||
|
|
||||||
|
```dockerfile
|
||||||
|
FROM docker.io/library/maven:3.8-jdk-11 AS build
|
||||||
|
|
||||||
|
COPY src /app/src
|
||||||
|
COPY pom.xml /app
|
||||||
|
|
||||||
|
RUN mvn -f /app/pom.xml clean package
|
||||||
|
|
||||||
|
FROM openjdk:11-jre-slim
|
||||||
|
COPY --from=build /app/target/app.jar /app/app.jar
|
||||||
|
COPY --from=build /app/target/lib /app/lib
|
||||||
|
ENTRYPOINT ["java","-jar","/app/app.jar"]
|
||||||
|
```
|
||||||
|
|
||||||
|
关键点:
|
||||||
|
* 利用多阶段构建,只将生成的 jar 包及其依赖拷贝到最终镜像中,减小镜像体积。
|
||||||
|
* 镜像指定启动命令,给 `java` 指定要运行的 jar 包。
|
||||||
|
|
||||||
|
## 参考资料
|
||||||
|
|
||||||
|
* [JDK 8u191 Update Release Notes ](https://www.oracle.com/java/technologies/javase/8u191-relnotes.html)
|
||||||
|
* [Docker support in Java 8 — finally!](https://blog.softwaremill.com/docker-support-in-new-java-8-finally-fd595df0ca54)
|
||||||
|
* [Better Containerized JVMs in JDK10](http://blog.gilliard.lol/2018/01/10/Java-in-containers-jdk10.html)
|
||||||
|
* [JVM in a Container](https://merikan.com/2019/04/jvm-in-a-container/#java-8u131-and-java-9)
|
||||||
|
* [14 best practices for containerising your Java applications](https://www.tutorialworks.com/docker-java-best-practices/)
|
||||||
|
* [Best Practices: Java Memory Arguments for Containers](https://dzone.com/articles/best-practices-java-memory-arguments-for-container)
|
||||||
|
|
@ -0,0 +1,122 @@
|
||||||
|
# 在容器内使用 systemd
|
||||||
|
|
||||||
|
## 概述
|
||||||
|
|
||||||
|
某些情况下我们需要在容器内使用 systemd 去拉起进程,比如业务历史包袱重,有许多依赖组件,不能仅仅只启动1个业务进程,还有许多其它进程需要启动,短时间内不好改造好,过渡期间使用 systemd 作为主进程拉起所有依赖进程。
|
||||||
|
|
||||||
|
## 安装 systemd
|
||||||
|
|
||||||
|
如果你用的基础镜像是 centos,那么已经内置了 systemd,建议使用 `centos:8`,启动入口是 `/sbin/init`;如果是 ubuntu,那么需要安装一下 systemd,启动入口是 `/usr/sbin/systemd`,Dockerfile 示例:
|
||||||
|
|
||||||
|
```dockerfile
|
||||||
|
FROM ubuntu:22.04
|
||||||
|
RUN apt update -y
|
||||||
|
RUN apt install -y systemd
|
||||||
|
```
|
||||||
|
|
||||||
|
## 示例
|
||||||
|
|
||||||
|
systemd 相比业务进程比较特殊,它运行起来需要以下条件:
|
||||||
|
1. 自己必须是 1 号进程,所以不能启用 `shareProcessNamespace`。
|
||||||
|
2. 需要对 `/run` 和 `/sys/fs/cgroup` 等路径进行挂载,通常需要给到 systemd 容器一定特权。
|
||||||
|
|
||||||
|
最简单的方式是将运行 systemd 的 container 设为特权容器,示例:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: apps/v1
|
||||||
|
kind: Deployment
|
||||||
|
metadata:
|
||||||
|
name: systemd
|
||||||
|
spec:
|
||||||
|
replicas: 1
|
||||||
|
selector:
|
||||||
|
matchLabels:
|
||||||
|
app: systemd
|
||||||
|
template:
|
||||||
|
metadata:
|
||||||
|
labels:
|
||||||
|
app: systemd
|
||||||
|
spec:
|
||||||
|
containers:
|
||||||
|
- name: systemd
|
||||||
|
image: centos:8
|
||||||
|
command:
|
||||||
|
- /sbin/init
|
||||||
|
securityContext:
|
||||||
|
privileged: true # 设置特权
|
||||||
|
```
|
||||||
|
|
||||||
|
如果希望尽量减少特权,可以只读方式挂载 hostPath `/sys/fs/cgroup`,然后 capabilities 给个 `SYS_ADMIN`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: apps/v1
|
||||||
|
kind: Deployment
|
||||||
|
metadata:
|
||||||
|
name: systemd
|
||||||
|
spec:
|
||||||
|
replicas: 1
|
||||||
|
selector:
|
||||||
|
matchLabels:
|
||||||
|
app: systemd
|
||||||
|
template:
|
||||||
|
metadata:
|
||||||
|
labels:
|
||||||
|
app: systemd
|
||||||
|
spec:
|
||||||
|
containers:
|
||||||
|
- name: systemd
|
||||||
|
image: centos:8
|
||||||
|
command:
|
||||||
|
- /sbin/init
|
||||||
|
securityContext:
|
||||||
|
capabilities:
|
||||||
|
add:
|
||||||
|
- SYS_ADMIN # 设置容器权限
|
||||||
|
privileged: false # 非特权
|
||||||
|
volumeMounts:
|
||||||
|
- mountPath: /sys/fs/cgroup
|
||||||
|
name: cgroup
|
||||||
|
readOnly: true # 只读方式挂载 cgroup 目录
|
||||||
|
volumes:
|
||||||
|
- hostPath:
|
||||||
|
path: /sys/fs/cgroup
|
||||||
|
type: ""
|
||||||
|
name: cgroup
|
||||||
|
```
|
||||||
|
|
||||||
|
如果用 ubuntu 安装了 systemd,用法类似的,只是启动入口变成了 `/usr/bin/systemd`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: apps/v1
|
||||||
|
kind: Deployment
|
||||||
|
metadata:
|
||||||
|
name: systemd
|
||||||
|
spec:
|
||||||
|
replicas: 1
|
||||||
|
selector:
|
||||||
|
matchLabels:
|
||||||
|
app: systemd
|
||||||
|
template:
|
||||||
|
metadata:
|
||||||
|
labels:
|
||||||
|
app: systemd
|
||||||
|
spec:
|
||||||
|
containers:
|
||||||
|
- name: systemd
|
||||||
|
image: cr.imroc.cc/library/systemd:ubuntu
|
||||||
|
command:
|
||||||
|
- /usr/bin/systemd
|
||||||
|
securityContext:
|
||||||
|
capabilities:
|
||||||
|
add:
|
||||||
|
- SYS_ADMIN
|
||||||
|
privileged: false
|
||||||
|
volumeMounts:
|
||||||
|
- mountPath: /sys/fs/cgroup
|
||||||
|
name: cgroup
|
||||||
|
volumes:
|
||||||
|
- hostPath:
|
||||||
|
path: /sys/fs/cgroup
|
||||||
|
type: ""
|
||||||
|
name: cgroup
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,17 @@
|
||||||
|
# 解决容器内时区不一致问题
|
||||||
|
|
||||||
|
## 背景
|
||||||
|
|
||||||
|
业务程序在使用时间的时候(比如打印日志),没有指定时区,使用的系统默认时区,而基础镜像一般默认使用 UTC 时间,程序输出时间戳的时候,就与国内的时间相差 8 小时,如何使用国内的时间呢?本文教你如何解决。
|
||||||
|
|
||||||
|
## 最佳实践:使用多阶段构建拷贝时区文件
|
||||||
|
|
||||||
|
centos 基础镜像内置了时区文件,可以将里面国内的时区文件拷贝到业务镜像中的 `/etc/localtime` 路径,表示系统默认时区是国内时区:
|
||||||
|
|
||||||
|
```Dockerfile
|
||||||
|
FROM centos:latest
|
||||||
|
|
||||||
|
FROM ubuntu:22.10
|
||||||
|
|
||||||
|
COPY --from=0 /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,60 @@
|
||||||
|
# 自定义域名解析
|
||||||
|
|
||||||
|
本文介绍在 kubernetes 上如何自定义集群 CoreDNS 的域名解析。
|
||||||
|
|
||||||
|
## 添加全局自定义域名解析
|
||||||
|
|
||||||
|
可以为 coredns 配置 hosts 来实现为 kubernetes 集群添加全局的自定义域名解析:
|
||||||
|
|
||||||
|
编辑 coredns 配置:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl -n kube-system edit configmap coredns
|
||||||
|
```
|
||||||
|
|
||||||
|
加入 hosts:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
hosts {
|
||||||
|
10.10.10.10 harbor.example.com
|
||||||
|
10.10.10.11 grafana.example.com
|
||||||
|
fallthrough
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
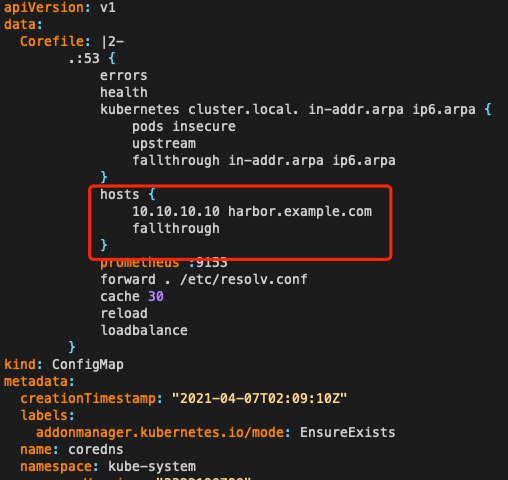
|
||||||
|
|
||||||
|
> 参考 [CoreDNS hosts 插件说明](https://coredns.io/plugins/hosts/)
|
||||||
|
|
||||||
|
如果是想解析到集群内的 Service,也可以配置下 rewrite:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
rewrite name harbor.example.com harbor.harbor.svc.cluster.local
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
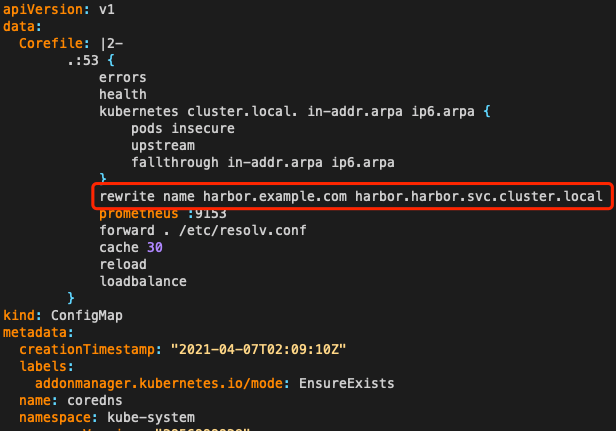
|
||||||
|
|
||||||
|
> 参考 [CoreDNS rewrite 插件说明](https://coredns.io/plugins/rewrite/)
|
||||||
|
|
||||||
|
## 为部分 Pod 添加自定义域名解析
|
||||||
|
|
||||||
|
如果有部分 Pod 对特定的域名解析有依赖,在不希望配置 dns 解析的情况下,可以使用 K8S 提供的 `hostAliases` 来为部分工作负载添加 hosts:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
spec:
|
||||||
|
hostAliases:
|
||||||
|
- hostnames: [ "harbor.example.com" ]
|
||||||
|
ip: "10.10.10.10"
|
||||||
|
```
|
||||||
|
|
||||||
|
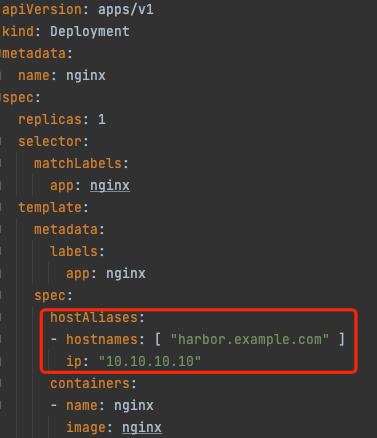
|
||||||
|
|
||||||
|
添加后在容器内可以看到 hosts 被添加到了 `/etc/hosts` 中:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ cat /etc/hosts
|
||||||
|
...
|
||||||
|
# Entries added by HostAliases.
|
||||||
|
10.10.10.10 harboar.example.com
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,83 @@
|
||||||
|
# CoreDNS 性能优化
|
||||||
|
|
||||||
|
CoreDNS 作为 Kubernetes 集群的域名解析组件,如果性能不够可能会影响业务,本文介绍几种 CoreDNS 的性能优化手段。
|
||||||
|
|
||||||
|
## 合理控制 CoreDNS 副本数
|
||||||
|
|
||||||
|
考虑以下几种方式:
|
||||||
|
1. 根据集群规模预估 coredns 需要的副本数,直接调整 coredns deployment 的副本数:
|
||||||
|
```bash
|
||||||
|
kubectl -n kube-system scale --replicas=10 deployment/coredns
|
||||||
|
```
|
||||||
|
2. 为 coredns 定义 HPA 自动扩缩容。
|
||||||
|
3. 安装 [cluster-proportional-autoscaler](https://github.com/kubernetes-sigs/cluster-proportional-autoscaler) 以实现更精确的扩缩容(推荐)。
|
||||||
|
|
||||||
|
## 禁用 ipv6
|
||||||
|
|
||||||
|
如果 K8S 节点没有禁用 IPV6 的话,容器内进程请求 coredns 时的默认行为是同时发起 IPV4 和 IPV6 解析,而通常我们只需要用到 IPV4,当容器请求某个域名时,coredns 解析不到 IPV6 记录,就会 forward 到 upstream 去解析,如果到 upstream 需要经过较长时间(比如跨公网,跨机房专线),就会拖慢整个解析流程的速度,业务层面就会感知 DNS 解析慢。
|
||||||
|
|
||||||
|
CoreDNS 有一个 [template](https://coredns.io/plugins/template/) 的插件,可以用它来禁用 IPV6 的解析,只需要给 CoreDNS 加上如下的配置:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
template ANY AAAA {
|
||||||
|
rcode NXDOMAIN
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
> 这个配置的含义是:给所有 IPV6 的解析请求都响应空记录,即无此域名的 IPV6 记录。
|
||||||
|
|
||||||
|
## 优化 ndots
|
||||||
|
|
||||||
|
默认情况下,Kubernetes 集群中的域名解析往往需要经过多次请求才能解析到。查看 pod 内 的 `/etc/resolv.conf` 可以知道 `ndots` 选项默认为 5:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
意思是: 如果域名中 `.` 的数量小于 5,就依次遍历 `search` 中的后缀并拼接上进行 DNS 查询。
|
||||||
|
|
||||||
|
举个例子,在 debug 命名空间查询 `kubernetes.default.svc.cluster.local` 这个 service:
|
||||||
|
1. 域名中有 4 个 `.`,小于 5,尝试拼接上第一个 search 进行查询,即 `kubernetes.default.svc.cluster.local.debug.svc.cluster.local`,查不到该域名。
|
||||||
|
2. 继续尝试 `kubernetes.default.svc.cluster.local.svc.cluster.local`,查不到该域名。
|
||||||
|
3. 继续尝试 `kubernetes.default.svc.cluster.local.cluster.local`,仍然查不到该域名。
|
||||||
|
4. 尝试不加后缀,即 `kubernetes.default.svc.cluster.local`,查询成功,返回响应的 ClusterIP。
|
||||||
|
|
||||||
|
可以看到一个简单的 service 域名解析需要经过 4 轮解析才能成功,集群中充斥着大量无用的 DNS 请求。
|
||||||
|
|
||||||
|
怎么办呢?我们可以设置较小的 ndots,在 Pod 的 dnsConfig 中可以设置:
|
||||||
|
|
||||||
|
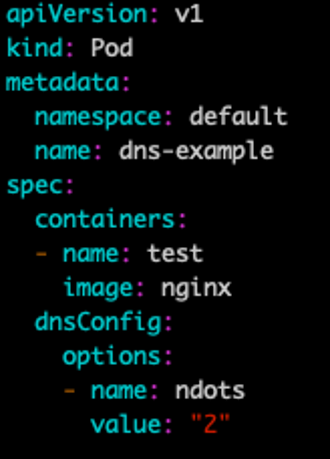
|
||||||
|
|
||||||
|
然后业务发请求时尽量将 service 域名拼完整,这样就不会经过 search 拼接造成大量多余的 DNS 请求。
|
||||||
|
|
||||||
|
不过这样会比较麻烦,有没有更好的办法呢?有的!请看下面的 autopath 方式。
|
||||||
|
|
||||||
|
## 启用 autopath
|
||||||
|
|
||||||
|
启用 CoreDNS 的 autopath 插件可以避免每次域名解析经过多次请求才能解析到,原理是 CoreDNS 智能识别拼接过 search 的 DNS 解析,直接响应 CNAME 并附上相应的 ClusterIP,一步到位,可以极大减少集群内 DNS 请求数量。
|
||||||
|
|
||||||
|
启用方法是修改 CoreDNS 配置:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl -n kube-system edit configmap coredns
|
||||||
|
```
|
||||||
|
|
||||||
|
修改红框中圈出来的配置:
|
||||||
|
|
||||||
|
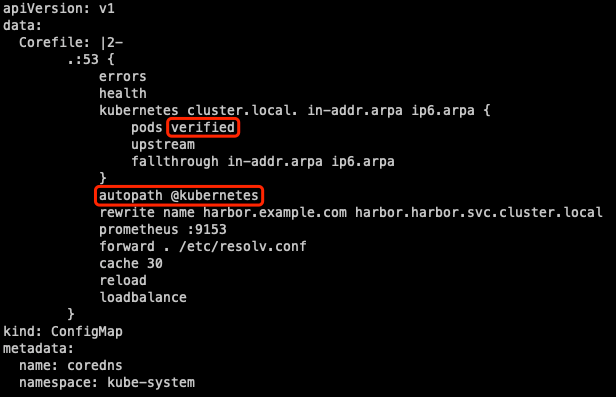
|
||||||
|
|
||||||
|
* 加上 `autopath @kubernetes`。
|
||||||
|
* 默认的 `pods insecure` 改成 `pods verified`。
|
||||||
|
|
||||||
|
需要注意的是,启用 autopath 后,由于 coredns 需要 watch 所有的 pod,会增加 coredns 的内存消耗,根据情况适当调节 coredns 的 memory request 和 limit。
|
||||||
|
|
||||||
|
## 部署 NodeLocal DNSCache
|
||||||
|
|
||||||
|
参考 k8s 官方文档 [Using NodeLocal DNSCache in Kubernetes clusters](https://kubernetes.io/docs/tasks/administer-cluster/nodelocaldns/)
|
||||||
|
|
||||||
|
如果是使用 TKE 并且 kube-proxy 转发模式为 iptables,可以直接在扩展组件中安装此扩展组件,扩展组件说明请参考 [TKE 官方文档](https://cloud.tencent.com/document/product/457/49423);如果使用的 ipvs 模式,可以参考 [TKE IPVS 模式安装 localdns](../../tencent/networking/install-localdns-with-ipvs.md)。
|
||||||
|
|
||||||
|
## 使用 DNSAutoscaler
|
||||||
|
|
||||||
|
社区有开源的 [cluster-proportional-autoscaler](https://github.com/kubernetes-sigs/cluster-proportional-autoscaler) ,可以根据集群规模自动扩缩容,支持比较灵活的扩缩容算法。
|
||||||
|
|
||||||
|
如果使用的是 TKE,已经将其产品化成 `DNSAutoscaler 扩展组件`,在扩展组件中直接安装即可,组件说明请参考 [TKE 官方文档](https://cloud.tencent.com/document/product/457/49305)。
|
||||||
|
|
||||||
|
|
@ -0,0 +1,149 @@
|
||||||
|
# 业务代码处理 SIGTERM 信号
|
||||||
|
|
||||||
|
要实现优雅终止,首先业务代码得支持下优雅终止的逻辑,在业务代码里面处理下 `SIGTERM` 信号,一般主要逻辑就是"排水",即等待存量的任务或连接完全结束,再退出进程。
|
||||||
|
|
||||||
|
本文给出各种语言的代码示例。
|
||||||
|
|
||||||
|
## shell
|
||||||
|
|
||||||
|
```bash
|
||||||
|
#!/bin/sh
|
||||||
|
|
||||||
|
## Redirecting Filehanders
|
||||||
|
ln -sf /proc/$$/fd/1 /log/stdout.log
|
||||||
|
ln -sf /proc/$$/fd/2 /log/stderr.log
|
||||||
|
|
||||||
|
## Pre execution handler
|
||||||
|
pre_execution_handler() {
|
||||||
|
## Pre Execution
|
||||||
|
# TODO: put your pre execution steps here
|
||||||
|
: # delete this nop
|
||||||
|
}
|
||||||
|
|
||||||
|
## Post execution handler
|
||||||
|
post_execution_handler() {
|
||||||
|
## Post Execution
|
||||||
|
# TODO: put your post execution steps here
|
||||||
|
: # delete this nop
|
||||||
|
}
|
||||||
|
|
||||||
|
## Sigterm Handler
|
||||||
|
sigterm_handler() {
|
||||||
|
if [ $pid -ne 0 ]; then
|
||||||
|
# the above if statement is important because it ensures
|
||||||
|
# that the application has already started. without it you
|
||||||
|
# could attempt cleanup steps if the application failed to
|
||||||
|
# start, causing errors.
|
||||||
|
kill -15 "$pid"
|
||||||
|
wait "$pid"
|
||||||
|
post_execution_handler
|
||||||
|
fi
|
||||||
|
exit 143; # 128 + 15 -- SIGTERM
|
||||||
|
}
|
||||||
|
|
||||||
|
## Setup signal trap
|
||||||
|
# on callback execute the specified handler
|
||||||
|
trap 'sigterm_handler' SIGTERM
|
||||||
|
|
||||||
|
## Initialization
|
||||||
|
pre_execution_handler
|
||||||
|
|
||||||
|
## Start Process
|
||||||
|
# run process in background and record PID
|
||||||
|
>/log/stdout.log 2>/log/stderr.log "$@" &
|
||||||
|
pid="$!"
|
||||||
|
# Application can log to stdout/stderr, /log/stdout.log or /log/stderr.log
|
||||||
|
|
||||||
|
## Wait forever until app dies
|
||||||
|
wait "$pid"
|
||||||
|
return_code="$?"
|
||||||
|
|
||||||
|
## Cleanup
|
||||||
|
post_execution_handler
|
||||||
|
# echo the return code of the application
|
||||||
|
exit $return_code
|
||||||
|
```
|
||||||
|
|
||||||
|
## Go
|
||||||
|
|
||||||
|
```go
|
||||||
|
package main
|
||||||
|
|
||||||
|
import (
|
||||||
|
"fmt"
|
||||||
|
"os"
|
||||||
|
"os/signal"
|
||||||
|
"syscall"
|
||||||
|
)
|
||||||
|
|
||||||
|
func main() {
|
||||||
|
|
||||||
|
sigs := make(chan os.Signal, 1)
|
||||||
|
done := make(chan bool, 1)
|
||||||
|
//registers the channel
|
||||||
|
signal.Notify(sigs, syscall.SIGTERM)
|
||||||
|
|
||||||
|
go func() {
|
||||||
|
sig := <-sigs
|
||||||
|
fmt.Println("Caught SIGTERM, shutting down")
|
||||||
|
// Finish any outstanding requests, then...
|
||||||
|
done <- true
|
||||||
|
}()
|
||||||
|
|
||||||
|
fmt.Println("Starting application")
|
||||||
|
// Main logic goes here
|
||||||
|
<-done
|
||||||
|
fmt.Println("exiting")
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
## Python
|
||||||
|
|
||||||
|
```python
|
||||||
|
import signal, time, os
|
||||||
|
|
||||||
|
def shutdown(signum, frame):
|
||||||
|
print('Caught SIGTERM, shutting down')
|
||||||
|
# Finish any outstanding requests, then...
|
||||||
|
exit(0)
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
# Register handler
|
||||||
|
signal.signal(signal.SIGTERM, shutdown)
|
||||||
|
# Main logic goes here
|
||||||
|
```
|
||||||
|
|
||||||
|
## NodeJS
|
||||||
|
|
||||||
|
```js
|
||||||
|
process.on('SIGTERM', () => {
|
||||||
|
console.log('The service is about to shut down!');
|
||||||
|
|
||||||
|
// Finish any outstanding requests, then...
|
||||||
|
process.exit(0);
|
||||||
|
});
|
||||||
|
```
|
||||||
|
|
||||||
|
## Java
|
||||||
|
|
||||||
|
```java
|
||||||
|
import sun.misc.Signal;
|
||||||
|
import sun.misc.SignalHandler;
|
||||||
|
|
||||||
|
public class ExampleSignalHandler {
|
||||||
|
public static void main(String... args) throws InterruptedException {
|
||||||
|
final long start = System.nanoTime();
|
||||||
|
Signal.handle(new Signal("TERM"), new SignalHandler() {
|
||||||
|
public void handle(Signal sig) {
|
||||||
|
System.out.format("\nProgram execution took %f seconds\n", (System.nanoTime() - start) / 1e9f);
|
||||||
|
System.exit(0);
|
||||||
|
}
|
||||||
|
});
|
||||||
|
int counter = 0;
|
||||||
|
while(true) {
|
||||||
|
System.out.println(counter++);
|
||||||
|
Thread.sleep(500);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,7 @@
|
||||||
|
# 优雅终止介绍
|
||||||
|
|
||||||
|
> 本文视频教程: [https://www.bilibili.com/video/BV1fu411m73C](https://www.bilibili.com/video/BV1fu411m73C)
|
||||||
|
|
||||||
|
所谓优雅终止,就是保证在销毁 Pod 的时候保证对业务无损,比如在业务发版时,让工作负载能够平滑滚动更新。 Pod 在销毁时,会停止容器内的进程,通常在停止的过程中我们需要执行一些善后逻辑,比如等待存量请求处理完以避免连接中断,或通知相关依赖进行清理等,从而实现优雅终止目的。
|
||||||
|
|
||||||
|
本节将介绍在 Kubernetes 场景下,实现 Pod 优雅终止的最佳实践。
|
||||||
|
|
@ -0,0 +1,50 @@
|
||||||
|
# LB 直通 Pod 场景
|
||||||
|
|
||||||
|
## 传统 NodePort 场景
|
||||||
|
|
||||||
|
K8S 服务对外暴露传统方案是 LB 绑定 Service 的 NodePort 流量从 LB 打到 NodePort 之后再由 kube-proxy 生成的 ipvs 或 iptables 规则进行转发:
|
||||||
|
|
||||||
|
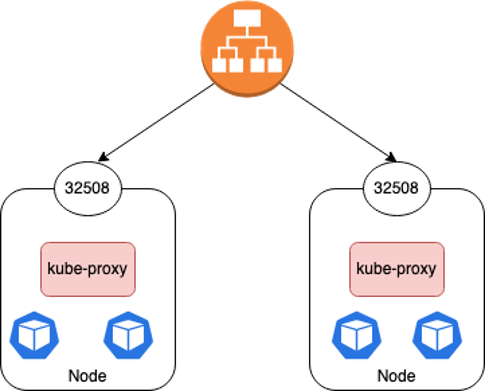
|
||||||
|
|
||||||
|
这样当滚动更新时,LB 绑定的 NodePort 一般无需变动,也就不需要担心 LB 解绑导致对业务有损。
|
||||||
|
|
||||||
|
## LB 直通 Pod 场景
|
||||||
|
|
||||||
|
现在很多云厂商也都支持了 LB 直通 Pod,即 LB 直接将流量转发给 Pod,不需要再经过集群内做一次转发:
|
||||||
|
|
||||||
|
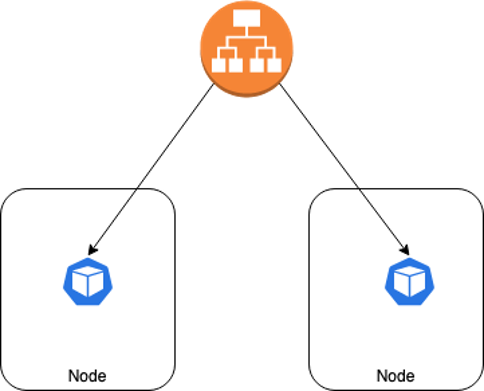
|
||||||
|
|
||||||
|
当滚动更新时,LB 就需要解绑旧 Pod,绑定新 Pod,如果 LB 到旧 Pod 上的存量连接的存量请求还没处理完,直接解绑的话就可能造成请求异常;我们期望的是,等待存量请求处理完,LB 才真正解绑旧 Pod。
|
||||||
|
|
||||||
|
## 解决方案
|
||||||
|
|
||||||
|
### TKE
|
||||||
|
|
||||||
|
腾讯云 TKE 官方针对四层 Service 和七层 Ingress 都提供了解决方案。
|
||||||
|
|
||||||
|
如果是四层 Service,在 Service 上加上这样的注解即可(前提是 Service 用了 CLB 直通 Pod 模式):
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
service.cloud.tencent.com/enable-grace-shutdown: "true"
|
||||||
|
```
|
||||||
|
|
||||||
|
> 参考官方文档 [Service 优雅停机](https://cloud.tencent.com/document/product/457/60064)
|
||||||
|
|
||||||
|
如果是七层 CLB 类型 Ingress,在 Ingress 上加上这样的注解即可(前提是 Service 用了 CLB 直通 Pod 模式):
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
ingress.cloud.tencent.com/enable-grace-shutdown: "true"
|
||||||
|
```
|
||||||
|
|
||||||
|
> 参考官方文档 [Ingress 优雅停机](https://cloud.tencent.com/document/product/457/60065)
|
||||||
|
|
||||||
|
### ACK
|
||||||
|
|
||||||
|
阿里云 ACK 目前只针对四层 Service 提供了解决方案,通过注解开启优雅中断与设置中断超时时间:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-connection-drain: "on"
|
||||||
|
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-connection-drain-timeout: "900"
|
||||||
|
```
|
||||||
|
|
||||||
|
> 参考官方文档 [通过Annotation配置负载均衡](https://help.aliyun.com/document_detail/86531.html)
|
||||||
|
|
@ -0,0 +1,13 @@
|
||||||
|
# 长连接场景
|
||||||
|
|
||||||
|
如果业务是长链接场景,比如游戏、会议、直播等,客户端与服务端会保持着长链接:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
销毁 Pod 时需要的优雅终止的时间通常比较长 (preStop + 业务进程停止超过 30s),有的极端情况甚至可能长达数小时,这时候可以根据实际情况自定义 `terminationGracePeriodSeconds`,避免过早的被 `SIGKILL` 杀死,示例:
|
||||||
|
|
||||||
|
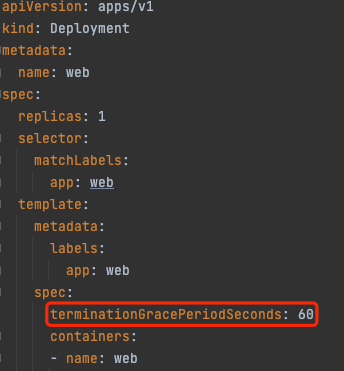
|
||||||
|
|
||||||
|
具体设置多大可以根据业务场景最坏的情况来预估,比如对战类游戏场景,同一房间玩家的客户端都连接的同一个服务端 Pod,一轮游戏最长半个小时,那么我们就设置 `terminationGracePeriodSeconds` 为 1800。
|
||||||
|
|
||||||
|
如果不好预估最坏的情况,最好在业务层面优化下,比如 Pod 销毁时的优雅终止逻辑里面主动通知下客户端,让客户端连到新的后端,然后客户端来保证这两个连接的平滑切换。等旧 Pod 上所有客户端连接都连切换到了新 Pod 上,才最终退出
|
||||||
|
|
@ -0,0 +1,19 @@
|
||||||
|
# Pod 终止流程
|
||||||
|
|
||||||
|
我们先了解下容器在 Kubernetes 环境中的终止流程:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
1. Pod 被删除,状态变为 `Terminating`。从 API 层面看就是 Pod metadata 中的 deletionTimestamp 字段会被标记上删除时间。
|
||||||
|
2. kube-proxy watch 到了就开始更新转发规则,将 Pod 从 service 的 endpoint 列表中摘除掉,新的流量不再转发到该 Pod。
|
||||||
|
3. kubelet watch 到了就开始销毁 Pod。
|
||||||
|
|
||||||
|
3.1. 如果 Pod 中有 container 配置了 [preStop Hook](https://kubernetes.io/docs/concepts/containers/container-lifecycle-hooks/) ,将会执行。
|
||||||
|
|
||||||
|
3.2. 发送 `SIGTERM` 信号给容器内主进程以通知容器进程开始优雅停止。
|
||||||
|
|
||||||
|
3.3. 等待 container 中的主进程完全停止,如果在 `terminationGracePeriodSeconds` 内 (默认 30s) 还未完全停止,就发送 `SIGKILL` 信号将其强制杀死。
|
||||||
|
|
||||||
|
3.4. 所有容器进程终止,清理 Pod 资源。
|
||||||
|
|
||||||
|
3.5. 通知 APIServer Pod 销毁完成,完成 Pod 删除。
|
||||||
|
|
@ -0,0 +1,90 @@
|
||||||
|
# 在 SHELL 中传递信号
|
||||||
|
|
||||||
|
在 Kubernetes 中,Pod 停止时 kubelet 会先给容器中的主进程发 `SIGTERM` 信号来通知进程进行 shutdown 以实现优雅停止,如果超时进程还未完全停止则会使用 `SIGKILL` 来强行终止。
|
||||||
|
|
||||||
|
但有时我们会遇到一种情况: 业务逻辑处理了 `SIGTERM` 信号,但 Pod 停止时好像没收到信号导致优雅停止逻辑不生效。
|
||||||
|
|
||||||
|
通常是因为我们的业务进程是在脚本中启动的,容器的启动入口使用了脚本,所以容器中的主进程并不是我们所希望的业务进程而是 shell 进程,导致业务进程收不到 `SIGTERM` 信号,更详细的原因在上一节我们已经介绍了,下面将介绍几种解决方案。
|
||||||
|
|
||||||
|
## 使用 exec 启动
|
||||||
|
|
||||||
|
在 shell 中启动二进制的命令前加一个 [exec](https://stackoverflow.com/questions/18351198/what-are-the-uses-of-the-exec-command-in-shell-scripts) 即可让该二进制启动的进程代替当前 shell 进程,即让新启动的进程成为主进程:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
#! /bin/bash
|
||||||
|
...
|
||||||
|
|
||||||
|
exec /bin/yourapp # 脚本中执行二进制
|
||||||
|
```
|
||||||
|
|
||||||
|
然后业务进程就可以正常接收所有信号了,实现优雅退出也不在话下。
|
||||||
|
|
||||||
|
## 多进程场景: 使用 trap 传递信号
|
||||||
|
|
||||||
|
通常我们一个容器只会有一个进程,也是 Kubernetes 的推荐做法。但有些时候我们不得不启动多个进程,比如从传统部署迁移到 Kubernetes 的过渡期间,使用了富容器,即单个容器中需要启动多个业务进程,这时也只能通过 shell 启动,但无法使用上面的 `exec` 方式来传递信号,因为 `exec` 只能让一个进程替代当前 shell 成为主进程。
|
||||||
|
|
||||||
|
这个时候我们可以在 shell 中使用 `trap` 来捕获信号,当收到信号后触发回调函数来将信号通过 `kill` 传递给业务进程,脚本示例:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
#! /bin/bash
|
||||||
|
|
||||||
|
/bin/app1 & pid1="$!" # 启动第一个业务进程并记录 pid
|
||||||
|
echo "app1 started with pid $pid1"
|
||||||
|
|
||||||
|
/bin/app2 & pid2="$!" # 启动第二个业务进程并记录 pid
|
||||||
|
echo "app2 started with pid $pid2"
|
||||||
|
|
||||||
|
handle_sigterm() {
|
||||||
|
echo "[INFO] Received SIGTERM"
|
||||||
|
kill -SIGTERM $pid1 $pid2 # 传递 SIGTERM 给业务进程
|
||||||
|
wait $pid1 $pid2 # 等待所有业务进程完全终止
|
||||||
|
}
|
||||||
|
trap handle_sigterm SIGTERM # 捕获 SIGTERM 信号并回调 handle_sigterm 函数
|
||||||
|
|
||||||
|
wait # 等待回调执行完,主进程再退出
|
||||||
|
```
|
||||||
|
|
||||||
|
## 完美方案: 使用 init 系统
|
||||||
|
|
||||||
|
前面一种方案实际是用脚本实现了一个极简的 init 系统 (或 supervisor) 来管理所有子进程,只不过它的逻辑很简陋,仅仅简单的透传指定信号给子进程,其实社区有更完善的方案,[dumb-init](https://github.com/Yelp/dumb-init) 和 [tini](https://github.com/krallin/tini) 都可以作为 init 进程,作为主进程 (PID 1) 在容器中启动,然后它再运行 shell 来执行我们指定的脚本 (shell 作为子进程),shell 中启动的业务进程也成为它的子进程,当它收到信号时会将其传递给所有的子进程,从而也能完美解决 SHELL 无法传递信号问题,并且还有回收僵尸进程的能力。
|
||||||
|
|
||||||
|
这是以 `dumb-init` 为例制作镜像的 `Dockerfile` 示例:
|
||||||
|
|
||||||
|
```dockerfile
|
||||||
|
FROM ubuntu:22.04
|
||||||
|
RUN apt-get update && apt-get install -y dumb-init
|
||||||
|
ADD start.sh /
|
||||||
|
ADD app1 /bin/app1
|
||||||
|
ADD app2 /bin/app2
|
||||||
|
ENTRYPOINT ["dumb-init", "--"]
|
||||||
|
CMD ["/start.sh"]
|
||||||
|
```
|
||||||
|
|
||||||
|
这是以 `tini` 为例制作镜像的 `Dockerfile` 示例:
|
||||||
|
|
||||||
|
```dockerfile
|
||||||
|
FROM ubuntu:22.04
|
||||||
|
ENV TINI_VERSION v0.19.0
|
||||||
|
ADD https://github.com/krallin/tini/releases/download/${TINI_VERSION}/tini /tini
|
||||||
|
COPY entrypoint.sh /entrypoint.sh
|
||||||
|
RUN chmod +x /tini /entrypoint.sh
|
||||||
|
ENTRYPOINT ["/tini", "--"]
|
||||||
|
CMD [ "/start.sh" ]
|
||||||
|
```
|
||||||
|
|
||||||
|
`start.sh` 脚本示例:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
#! /bin/bash
|
||||||
|
/bin/app1 &
|
||||||
|
/bin/app2 &
|
||||||
|
wait
|
||||||
|
```
|
||||||
|
|
||||||
|
## 参考资料
|
||||||
|
|
||||||
|
* [Trapping signals in Docker containers](https://medium.com/@gchudnov/trapping-signals-in-docker-containers-7a57fdda7d86)
|
||||||
|
* [Gracefully Stopping Docker Containers](https://www.ctl.io/developers/blog/post/gracefully-stopping-docker-containers/)
|
||||||
|
* [Why Your Dockerized Application Isn’t Receiving Signals](https://hynek.me/articles/docker-signals/)
|
||||||
|
* [Best practices for propagating signals on Docker](https://www.kaggle.com/residentmario/best-practices-for-propagating-signals-on-docker)
|
||||||
|
* [Graceful shutdowns with ECS](https://aws.amazon.com/cn/blogs/containers/graceful-shutdowns-with-ecs/)
|
||||||
|
|
@ -0,0 +1,26 @@
|
||||||
|
# 合理使用 preStop
|
||||||
|
|
||||||
|
若你的业务代码中没有处理 `SIGTERM` 信号,或者你无法控制使用的第三方库或系统来增加优雅终止的逻辑,也可以尝试为 Pod 配置下 preStop,在这里面实现优雅终止的逻辑,示例:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
lifecycle:
|
||||||
|
preStop:
|
||||||
|
exec:
|
||||||
|
command:
|
||||||
|
- /clean.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
> 参考 [Kubernetes API 文档](https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/pod-v1/#lifecycle-1)
|
||||||
|
|
||||||
|
在某些极端情况下,Pod 被删除的一小段时间内,仍然可能有新连接被转发过来,因为 kubelet 与 kube-proxy 同时 watch 到 pod 被删除,kubelet 有可能在 kube-proxy 同步完规则前就已经停止容器了,这时可能导致一些新的连接被转发到正在删除的 Pod,而通常情况下,当应用受到 `SIGTERM` 后都不再接受新连接,只保持存量连接继续处理,所以就可能导致 Pod 删除的瞬间部分请求失败。
|
||||||
|
|
||||||
|
这种情况下,我们也可以利用 preStop 先 sleep 一小下,等待 kube-proxy 完成规则同步再开始停止容器内进程:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
lifecycle:
|
||||||
|
preStop:
|
||||||
|
exec:
|
||||||
|
command:
|
||||||
|
- sleep
|
||||||
|
- 5s
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,25 @@
|
||||||
|
# 为什么收不到 SIGTERM 信号?
|
||||||
|
|
||||||
|
我们的业务代码通常会捕捉 `SIGTERM` 信号,然后执行停止逻辑以实现优雅终止。在 Kubernetes 环境中,业务发版时经常会对 workload 进行滚动更新,当旧版本 Pod 被删除时,K8S 会对 Pod 中各个容器中的主进程发送 `SIGTERM` 信号,当达到超时时间进程还未完全停止的话,K8S 就会发送 `SIGKILL` 信号将其强制杀死。
|
||||||
|
|
||||||
|
业务在 Kubernetes 环境中实际运行时,有时候可能会发现在滚动更新时,我们业务的优雅终止逻辑并没有被执行,现象是在等了较长时间后,业务进程直接被 `SIGKILL` 强制杀死了。
|
||||||
|
|
||||||
|
## 什么原因?
|
||||||
|
|
||||||
|
通常都是因为容器启动入口使用了 shell,比如使用了类似 `/bin/sh -c my-app` 这样的启动入口。 或者使用 `/entrypoint.sh` 这样的脚本文件作为入口,在脚本中再启动业务进程:
|
||||||
|
|
||||||
|
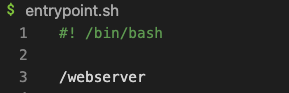
|
||||||
|
|
||||||
|
这就可能就会导致容器内的业务进程收不到 `SIGTERM` 信号,原因是:
|
||||||
|
|
||||||
|
1. 容器主进程是 shell,业务进程是在 shell 中启动的,成为了 shell 进程的子进程。
|
||||||
|
|
||||||
|
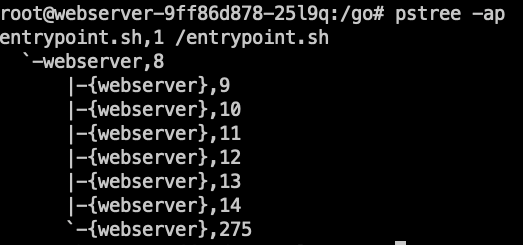
|
||||||
|
2. shell 进程默认不会处理 `SIGTERM` 信号,自己不会退出,也不会将信号传递给子进程,导致业务进程不会触发停止逻辑。
|
||||||
|
3. 当等到 K8S 优雅停止超时时间 (`terminationGracePeriodSeconds`,默认 30s),发送 `SIGKILL` 强制杀死 shell 及其子进程。
|
||||||
|
|
||||||
|
|
||||||
|
## 如何解决?
|
||||||
|
|
||||||
|
1. 如果可以的话,尽量不使用 shell 启动业务进程。
|
||||||
|
2. 如果一定要通过 shell 启动,比如在启动前需要用 shell 进程一些判断和处理,或者需要启动多个进程,那么就需要在 shell 中传递下 SIGTERM 信号了,解决方案请参考 [在 SHELL 中传递信号](propagating-signals-in-shell.md) 。
|
||||||
|
|
@ -0,0 +1,168 @@
|
||||||
|
# Pod 打散调度
|
||||||
|
|
||||||
|
将 Pod 打散调度到不同地方,可避免因软硬件故障、光纤故障、断电或自然灾害等因素导致服务不可用,以实现服务的高可用部署。
|
||||||
|
|
||||||
|
Kubernetes 支持两种方式将 Pod 打散调度:
|
||||||
|
* Pod 反亲和 (Pod Anti-Affinity)
|
||||||
|
* Pod 拓扑分布约束 (Pod Topology Spread Constraints)
|
||||||
|
|
||||||
|
本文介绍两种方式的用法示例与对比总结。
|
||||||
|
|
||||||
|
## 使用 podAntiAffinity
|
||||||
|
|
||||||
|
**将 Pod 强制打散调度到不同节点上(强反亲和),以避免单点故障**:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: apps/v1
|
||||||
|
kind: Deployment
|
||||||
|
metadata:
|
||||||
|
name: nginx
|
||||||
|
spec:
|
||||||
|
replicas: 1
|
||||||
|
selector:
|
||||||
|
matchLabels:
|
||||||
|
app: nginx
|
||||||
|
template:
|
||||||
|
metadata:
|
||||||
|
labels:
|
||||||
|
app: nginx
|
||||||
|
spec:
|
||||||
|
affinity:
|
||||||
|
podAntiAffinity:
|
||||||
|
requiredDuringSchedulingIgnoredDuringExecution:
|
||||||
|
- topologyKey: kubernetes.io/hostname
|
||||||
|
labelSelector:
|
||||||
|
matchLabels:
|
||||||
|
app: nginx
|
||||||
|
containers:
|
||||||
|
- name: nginx
|
||||||
|
image: nginx
|
||||||
|
```
|
||||||
|
|
||||||
|
* `labelSelector.matchLabels` 替换成选中 Pod 实际使用的 label。
|
||||||
|
* `topologyKey`: 节点的某个 label 的 key,能代表节点所处拓扑域,可以用 [Well-Known Labels](https://kubernetes.io/docs/reference/labels-annotations-taints/#failure-domainbetakubernetesioregion),常用的是 `kubernetes.io/hostname` (节点维度)、`topology.kubernetes.io/zone` (可用区/机房 维度)。也可以自行手动为节点打上自定义的 label 来定义拓扑域,比如 `rack` (机架维度)、`machine` (物理机维度)、`switch` (交换机维度)。
|
||||||
|
* 若不希望用强制,可以使用弱反亲和,让 Pod 尽量调度到不同节点:
|
||||||
|
```yaml
|
||||||
|
podAntiAffinity:
|
||||||
|
preferredDuringSchedulingIgnoredDuringExecution:
|
||||||
|
- podAffinityTerm:
|
||||||
|
topologyKey: kubernetes.io/hostname
|
||||||
|
weight: 100
|
||||||
|
```
|
||||||
|
|
||||||
|
**将 Pod 强制打散调度到不同可用区(机房),以实现跨机房容灾**:
|
||||||
|
|
||||||
|
将 `kubernetes.io/hostname` 换成 `topology.kubernetes.io/zone`,其余同上。
|
||||||
|
|
||||||
|
## 使用 topologySpreadConstraints
|
||||||
|
|
||||||
|
**将 Pod 最大程度上均匀的打散调度到各个节点上**:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: apps/v1
|
||||||
|
kind: Deployment
|
||||||
|
metadata:
|
||||||
|
name: nginx
|
||||||
|
spec:
|
||||||
|
replicas: 1
|
||||||
|
selector:
|
||||||
|
matchLabels:
|
||||||
|
app: nginx
|
||||||
|
template:
|
||||||
|
metadata:
|
||||||
|
labels:
|
||||||
|
app: nginx
|
||||||
|
spec:
|
||||||
|
topologySpreadConstraints:
|
||||||
|
- maxSkew: 1
|
||||||
|
topologyKey: kubernetes.io/hostname
|
||||||
|
whenUnsatisfiable: DoNotSchedule
|
||||||
|
labelSelector:
|
||||||
|
- matchLabels:
|
||||||
|
app: nginx
|
||||||
|
containers:
|
||||||
|
- name: nginx
|
||||||
|
image: nginx
|
||||||
|
```
|
||||||
|
|
||||||
|
* `topologyKey`: 与 podAntiAffinity 中配置类似。
|
||||||
|
* `labelSelector`: 与 podAntiAffinity 中配置类似,只是这里可以支持选中多组 pod 的 label。
|
||||||
|
* `maxSkew`: 必须是大于零的整数,表示能容忍不同拓扑域中 Pod 数量差异的最大值。这里的 1 意味着只允许相差 1 个 Pod。
|
||||||
|
* `whenUnsatisfiable`: 指示不满足条件时如何处理。`DoNotSchedule` 不调度 (保持 Pending),类似强反亲和;`ScheduleAnyway` 表示要调度,类似弱反亲和;
|
||||||
|
|
||||||
|
以上配置连起来解释: 将所有 nginx 的 Pod 严格均匀打散调度到不同节点上,不同节点上 nginx 的副本数量最多只能相差 1 个,如果有节点因其它因素无法调度更多的 Pod (比如资源不足),那么就让剩余的 nginx 副本 Pending。
|
||||||
|
|
||||||
|
所以,如果要在所有节点中严格打散,通常不太可取,可以加下 nodeAffinity,只在部分资源充足的节点严格打散:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
spec:
|
||||||
|
affinity:
|
||||||
|
nodeAffinity:
|
||||||
|
requiredDuringSchedulingIgnoredDuringExecution:
|
||||||
|
nodeSelectorTerms:
|
||||||
|
- matchExpressions:
|
||||||
|
- key: io
|
||||||
|
operator: In
|
||||||
|
values:
|
||||||
|
- high
|
||||||
|
topologySpreadConstraints:
|
||||||
|
- maxSkew: 1
|
||||||
|
topologyKey: kubernetes.io/hostname
|
||||||
|
whenUnsatisfiable: DoNotSchedule
|
||||||
|
labelSelector:
|
||||||
|
- matchLabels:
|
||||||
|
app: nginx
|
||||||
|
```
|
||||||
|
|
||||||
|
或者类似弱反亲和, **将 Pod 尽量均匀的打散调度到各个节点上,不强制** (DoNotSchedule 改为 ScheduleAnyway):
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
spec:
|
||||||
|
topologySpreadConstraints:
|
||||||
|
- maxSkew: 1
|
||||||
|
topologyKey: kubernetes.io/hostname
|
||||||
|
whenUnsatisfiable: ScheduleAnyway
|
||||||
|
labelSelector:
|
||||||
|
- matchLabels:
|
||||||
|
app: nginx
|
||||||
|
```
|
||||||
|
|
||||||
|
如果集群节点支持跨可用区,也可以 **将 Pod 尽量均匀的打散调度到各个可用区** 以实现更高级别的高可用 (topologyKey 改为 `topology.kubernetes.io/zone`):
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
spec:
|
||||||
|
topologySpreadConstraints:
|
||||||
|
- maxSkew: 1
|
||||||
|
topologyKey: topology.kubernetes.io/zone
|
||||||
|
whenUnsatisfiable: ScheduleAnyway
|
||||||
|
labelSelector:
|
||||||
|
- matchLabels:
|
||||||
|
app: nginx
|
||||||
|
```
|
||||||
|
|
||||||
|
更进一步地,可以 **将 Pod 尽量均匀的打散调度到各个可用区的同时,在可用区内部各节点也尽量打散**:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
spec:
|
||||||
|
topologySpreadConstraints:
|
||||||
|
- maxSkew: 1
|
||||||
|
topologyKey: topology.kubernetes.io/zone
|
||||||
|
whenUnsatisfiable: ScheduleAnyway
|
||||||
|
labelSelector:
|
||||||
|
- matchLabels:
|
||||||
|
app: nginx
|
||||||
|
- maxSkew: 1
|
||||||
|
topologyKey: kubernetes.io/hostname
|
||||||
|
whenUnsatisfiable: ScheduleAnyway
|
||||||
|
labelSelector:
|
||||||
|
- matchLabels:
|
||||||
|
app: nginx
|
||||||
|
```
|
||||||
|
|
||||||
|
## 小结
|
||||||
|
|
||||||
|
从示例能明显看出,`topologySpreadConstraints` 比 `podAntiAffinity` 功能更强,提供了提供更精细的调度控制,我们可以理解成 `topologySpreadConstraints` 是 `podAntiAffinity` 的升级版。`topologySpreadConstraints` 特性在 K8S v1.18 默认启用,所以建议 v1.18 及其以上的集群使用 `topologySpreadConstraints` 来打散 Pod 的分布以提高服务可用性。
|
||||||
|
|
||||||
|
## 参考资料
|
||||||
|
|
||||||
|
* [Pod Topology Spread Constraints](https://kubernetes.io/docs/concepts/workloads/pods/pod-topology-spread-constraints/)
|
||||||
|
|
@ -0,0 +1,43 @@
|
||||||
|
# 工作负载平滑升级
|
||||||
|
|
||||||
|
解决了服务单点故障和驱逐节点时导致的可用性降低问题后,我们还需要考虑一种可能导致可用性降低的场景,那就是滚动更新。为什么服务正常滚动更新也可能影响服务的可用性呢?别急,下面我来解释下原因。
|
||||||
|
|
||||||
|
## 业务有损滚动更新
|
||||||
|
|
||||||
|
假如集群内存在服务间调用:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
当 server 端发生滚动更新时:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
发生两种尴尬的情况:
|
||||||
|
1. 旧的副本很快销毁,而 client 所在节点 kube-proxy 还没更新完转发规则,仍然将新连接调度给旧副本,造成连接异常,可能会报 "connection refused" (进程停止过程中,不再接受新请求) 或 "no route to host" (容器已经完全销毁,网卡和 IP 已不存在)。
|
||||||
|
2. 新副本启动,client 所在节点 kube-proxy 很快 watch 到了新副本,更新了转发规则,并将新连接调度给新副本,但容器内的进程启动很慢 (比如 Tomcat 这种 java 进程),还在启动过程中,端口还未监听,无法处理连接,也造成连接异常,通常会报 "connection refused" 的错误。
|
||||||
|
|
||||||
|
## 最佳实践
|
||||||
|
|
||||||
|
针对第一种情况,可以给 container 加 preStop,让 Pod 真正销毁前先 sleep 等待一段时间,等待 client 所在节点 kube-proxy 更新转发规则,然后再真正去销毁容器。这样能保证在 Pod Terminating 后还能继续正常运行一段时间,这段时间如果因为 client 侧的转发规则更新不及时导致还有新请求转发过来,Pod 还是可以正常处理请求,避免了连接异常的发生。听起来感觉有点不优雅,但实际效果还是比较好的,分布式的世界没有银弹,我们只能尽量在当前设计现状下找到并实践能够解决问题的最优解。
|
||||||
|
|
||||||
|
针对第二种情况,可以给 container 加 ReadinessProbe (就绪检查),让容器内进程真正启动完成后才更新 Service 的 Endpoint,然后 client 所在节点 kube-proxy 再更新转发规则,让流量进来。这样能够保证等 Pod 完全就绪了才会被转发流量,也就避免了链接异常的发生。
|
||||||
|
|
||||||
|
最佳实践 yaml 示例:
|
||||||
|
|
||||||
|
``` yaml
|
||||||
|
readinessProbe:
|
||||||
|
httpGet:
|
||||||
|
path: /healthz
|
||||||
|
port: 80
|
||||||
|
httpHeaders:
|
||||||
|
- name: X-Custom-Header
|
||||||
|
value: Awesome
|
||||||
|
initialDelaySeconds: 10
|
||||||
|
timeoutSeconds: 1
|
||||||
|
lifecycle:
|
||||||
|
preStop:
|
||||||
|
exec:
|
||||||
|
command: ["/bin/bash", "-c", "sleep 10"]
|
||||||
|
```
|
||||||
|
|
||||||
|
最后,业务本身也需要实现优雅终止,避免被销毁时中断业务,参考 [优雅终止最佳实践](../graceful-shutdown/index.html)
|
||||||
|
|
@ -0,0 +1,38 @@
|
||||||
|
# 日志采集
|
||||||
|
|
||||||
|
本文介绍 Kubernetes 中,日志采集的最佳实践。
|
||||||
|
|
||||||
|
## 落盘文件还是标准输出?
|
||||||
|
|
||||||
|
在上 K8S 的过程中,往往会遇到一个问题:业务日志是输出到日志文件,还是输出到标准输出?哪种方式更好?
|
||||||
|
|
||||||
|
如果输出到日志文件,日志轮转就需要自己去完成,要么业务日志框架支持,要么用其它工具去轮转(比如 sidecar 与业务容器共享日志目录,然后 sidecar 中 crontab + logrotate 之类的工具去轮转)。
|
||||||
|
|
||||||
|
如果输出到标准输出(前提是容器主进程是业务进程),日志轮转则是由 K8S 自动完成,业务不需要关心,对于非 docker 的运行时(比如 containerd),日志轮转由 kubelet 完成,每个容器标准输出的日志轮转规则由 kubelet 以下两个参数决定:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
--container-log-max-files int32 Set the maximum number of container log files that can be present for a container. The number must be >= 2. This flag can only be used with --container-runtime=remote. (default 5)
|
||||||
|
--container-log-max-size string Set the maximum size (e.g. 10Mi) of container log file before it is rotated. This flag can only be used with --container-runtime=remote. (default "10Mi")
|
||||||
|
```
|
||||||
|
|
||||||
|
> 日志默认最多存储 5 个文件,每个最大 10Mi。
|
||||||
|
|
||||||
|
对于 docker 运行时,没有实现 CRI 接口,日志轮转由 docker 自身完成,在配置文件 `/etc/docker/daemon.json` 中配置:
|
||||||
|
|
||||||
|
``` json
|
||||||
|
{
|
||||||
|
"log-driver":"json-file",
|
||||||
|
"log-opts": {"max-size":"500m", "max-file":"3"}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
输出到标准输出还有一些其它好处:
|
||||||
|
|
||||||
|
1. 日志内容可以通过标准 K8S API 获取到,比如使用 `kubectl logs` 或一些 K8S 管理平台的可视化界面查看(比如 Kubernetes Dashboard,KubeSphere, Rancher 以及云厂商的容器服务控制台等)。
|
||||||
|
2. 运维无需关注业务日志文件路径,可以更方便的使用统一的采集规则进行采集,减少运维复杂度。
|
||||||
|
|
||||||
|
**最佳实践**
|
||||||
|
|
||||||
|
如果你的应用已经足够云原生了,符合"单进程模型",不再是富容器,那么应尽量将日志输出到标准输出,业务不需要关心日志轮转,使用日志采集工具采集容器标准输出。有一种例外的情况是,对于非 docker 运行时,如果你有单个容器的日志输出过快,速率持续超过 `30MB/s` 的话,kubelet 在轮转压缩的时候,可能会 "追不上",迟迟读不到 EOF,轮转失败,最终可能导致磁盘爆满,这种情况还是建议输出到日志文件,自行轮转。
|
||||||
|
|
||||||
|
其它情况,可以先将日志落盘到文件,并自行轮转下。
|
||||||
|
|
@ -0,0 +1,34 @@
|
||||||
|
# 长连接服务
|
||||||
|
|
||||||
|
## 负载不均问题
|
||||||
|
|
||||||
|
对于长连接的服务,可能会存在负载不均的问题,下面介绍两种场景。
|
||||||
|
|
||||||
|
### 滚动更新负载不均
|
||||||
|
|
||||||
|
在连接数比较固定或波动不大的情况下,滚动更新时,旧 Pod 上的连接逐渐断掉,重连到新启动的 Pod 上,越先启动的 Pod 所接收到的连接数越多,造成负载不均:
|
||||||
|
|
||||||
|
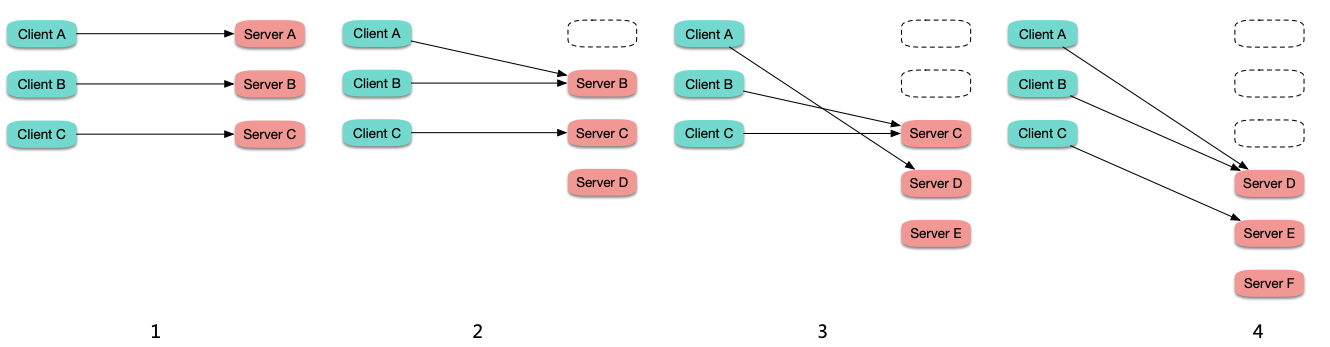
|
||||||
|
|
||||||
|
### rr 策略负载不均
|
||||||
|
|
||||||
|
假如长连接服务的不同连接的保持时长差异很大,而 ipvs 转发时默认是 rr 策略转发,如果某些后端 Pod "运气较差",它们上面的连接保持时间比较较长,而由于是 rr 转发,它们身上累计的连接数就可能较多,节点上通过 `ipvsadm -Ln -t CLUSTER-IP:PORT` 查看某个 service 的转发情况:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
部分 Pod 连接数高,意味着相比连接数低的 Pod 要同时处理更多的连接,着消耗的资源也就相对更多,从而造成负载不均。
|
||||||
|
|
||||||
|
将 kube-proxy 的 ipvs 转发模式设置为 lc (Least-Connection) ,即倾向转发给连接数少的 Pod,可能会有所缓解,但也不一定,因为 ipvs 的负载均衡状态是分散在各个节点的,并没有收敛到一个地方,也就无法在全局层面感知哪个 Pod 上的连接数少,并不能真正做到 lc。可以尝试设置为 sh (Source Hashing),并且这样可以保证即便负载均衡状态没有收敛到同一个地方,也能在全局尽量保持负载均衡。
|
||||||
|
|
||||||
|
## 扩容失效问题
|
||||||
|
|
||||||
|
在连接数比较固定或波动不大的情况下,工作负载在 HPA 自动扩容时,由于是长链接,连接数又比较固定,所有连接都 "固化" 在之前的 Pod 上,新扩出的 Pod 几乎没有连接,造成之前的 Pod 高负载,而扩出来的 Pod 又无法分担压力,导致扩容失效:
|
||||||
|
|
||||||
|
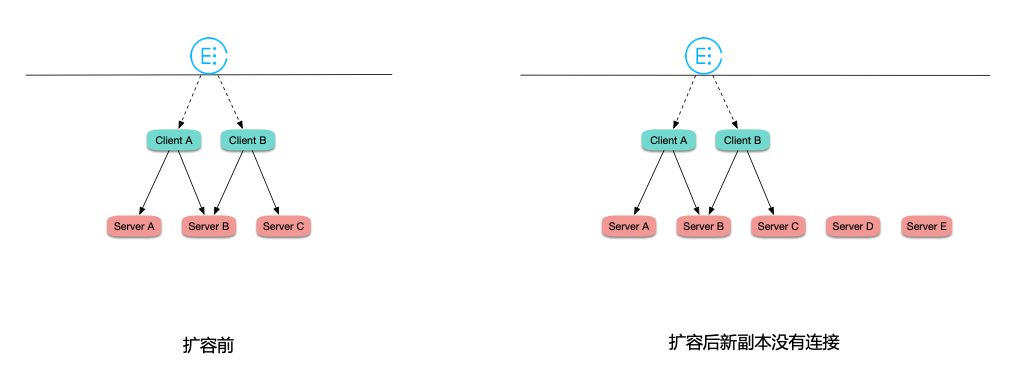
|
||||||
|
|
||||||
|
## 最佳实践
|
||||||
|
|
||||||
|
1. 业务层面自动重连,避免连接 "固化" 到某个后端 Pod 上。比如周期性定时重连,或者一个连接中处理的请求数达到阈值后自动重连。
|
||||||
|
2. 不直接请求后端,通过七层代理访问。比如 gRPC 协议,可以 [使用 nginx ingress 转发 gRPC](https://kubernetes.github.io/ingress-nginx/examples/grpc/),也可以 [使用 istio 转发 gRPC](https://istiobyexample.dev/grpc/),这样对于 gRPC 这样多个请求复用同一个长连接的场景,经过七层代理后,可以自动拆分请求,在请求级别负载均衡。
|
||||||
|
3. kube-proxy 的 ipvs 转发策略设置为 sh (`--ipvs-scheduler=sh`)。如果用的腾讯云 EKS 弹性集群,没有节点,看不到 kube-proxy,可以通过 `eks.tke.cloud.tencent.com/ipvs-scheduler: 'sh'` 这样的注解来设置,另外还支持将端口号也加入到 hash 的 key,更利于负载均衡,需再设置下 `eks.tke.cloud.tencent.com/ipvs-sh-port: "true"`,参考 [EKS 注解](../tencent/appendix/eks-annotations.md#%E8%AE%BE%E7%BD%AE-ipvs-%E5%8F%82%E6%95%B0)。
|
||||||
|
|
||||||
|
|
@ -0,0 +1,90 @@
|
||||||
|
# 使用 Ansible 批量操作节点
|
||||||
|
|
||||||
|
## 原理介绍
|
||||||
|
|
||||||
|
Ansible 是一款流行的开源运维工具,可以直接通过 SSH 协议批量操作机器,无需事先进行手动安装依赖等操作,十分便捷。我们可以针对需要批量操作的节点,使用 ansbile 批量对节点执行指定的脚本。
|
||||||
|
|
||||||
|
## 准备 Ansible 控制节点
|
||||||
|
|
||||||
|
1. 选取实例作为 Ansible 的控制节点,通过此节点批量发起对存量 TKE 节点的操作。可选择与集群所在私有网络 VPC 中任意实例作为控制节点(包括 TKE 节点)。
|
||||||
|
2. 选定控制节点后,选择对应方式安装 Ansible:
|
||||||
|
|
||||||
|
- Ubuntu 操作系统安装方式:
|
||||||
|
```bash
|
||||||
|
sudo apt update && sudo apt install software-properties-common -y && sudo apt-add-repository --yes --update ppa:ansible/ansible && sudo apt install ansible -y
|
||||||
|
```
|
||||||
|
|
||||||
|
- CentOS 操作系统安装方式:
|
||||||
|
```bash
|
||||||
|
sudo yum install ansible -y
|
||||||
|
```
|
||||||
|
|
||||||
|
## 准备配置文件
|
||||||
|
|
||||||
|
将所有需要进行配置操作的节点内网 IP 配置到 `host.ini` 文件中,每行一个 IP。示例如下:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
10.0.3.33
|
||||||
|
10.0.2.4
|
||||||
|
```
|
||||||
|
|
||||||
|
如需操作所有节点,可通过以下命令一键生成 `hosts.ini` 文件。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl get nodes -o jsonpath='{.items[*].status.addresses[?(@.type=="InternalIP")].address}' | tr ' ' '\n' > hosts.ini
|
||||||
|
```
|
||||||
|
|
||||||
|
## 准备批量执行脚本
|
||||||
|
|
||||||
|
将需批量执行的操作写入脚本,并保存为脚本文件,下面举个例子。
|
||||||
|
|
||||||
|
自建镜像仓库后没有权威机构颁发证书,直接使用 HTTP 或 HTTPS 自签发的证书,默认情况下 dockerd 拉取镜像时会报错。此时可通过批量修改节点的 dockerd 配置,将自建仓库地址添加到 dockerd 配置的 `insecure-registries` 中使 dockerd 忽略证书校验。脚本文件 `modify-dockerd.sh` 内容如下:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# yum install -y jq # centos
|
||||||
|
apt install -y jq # ubuntu
|
||||||
|
cat /etc/docker/daemon.json | jq '."insecure-registries" += ["myharbor.com"]' > /tmp/daemon.json
|
||||||
|
cp /tmp/daemon.json /etc/docker/daemon.json
|
||||||
|
systemctl restart dockerd
|
||||||
|
```
|
||||||
|
|
||||||
|
## 使用 Ansible 批量执行脚本
|
||||||
|
|
||||||
|
通常 TKE 节点在新增时均指向一个 SSH 登录密钥或密码。请按照实际情况执行以下操作:
|
||||||
|
|
||||||
|
### 使用密钥
|
||||||
|
|
||||||
|
1. 准备密钥文件,例如 `tke.key`。
|
||||||
|
2. 执行以下命令,授权密钥文件:
|
||||||
|
```bash
|
||||||
|
chmod 0600 tke.key
|
||||||
|
```
|
||||||
|
|
||||||
|
3. 批量执行脚本:
|
||||||
|
- Ubuntu 操作系统节点批量执行示例如下:
|
||||||
|
```bash
|
||||||
|
ansible all -i hosts.ini --ssh-common-args="-o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null" --user ubuntu --become --become-user=root --private-key=tke.key -m script -a "modify-dockerd.sh"
|
||||||
|
```
|
||||||
|
- 其他操作系统节点批量执行示例如下:
|
||||||
|
```bash
|
||||||
|
ansible all -i hosts.ini --ssh-common-args="-o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null" --user root -m script -a "modify-dockerd.sh"
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
### 使用密码
|
||||||
|
|
||||||
|
1. 执行以下命令,将密码输入至 PASS 变量。
|
||||||
|
```bash
|
||||||
|
read -s PASS
|
||||||
|
```
|
||||||
|
|
||||||
|
2. 批量执行脚本:
|
||||||
|
- Ubuntu 操作系统节点的 SSH 用户名默认为 ubuntu,批量执行示例如下:
|
||||||
|
```bash
|
||||||
|
ansible all -i hosts.ini --ssh-common-args="-o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null" --user ubuntu --become --become-user=root -e "ansible_password=$PASS" -m script -a "modify-dockerd.sh"
|
||||||
|
```
|
||||||
|
|
||||||
|
- 其他系统节点的 SSH 用户名默认为 root,批量执行示例如下:
|
||||||
|
```bash
|
||||||
|
ansible all -i hosts.ini --ssh-common-args="-o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null" --user root -e "ansible_password=$PASS" -m script -a "modify-dockerd.sh"
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,52 @@
|
||||||
|
# ETCD 优化
|
||||||
|
|
||||||
|
## 高可用部署
|
||||||
|
|
||||||
|
部署一个高可用 ETCD 集群可以参考官方文档 [Clustering Guide](https://etcd.io/docs/v3.5/op-guide/clustering/)。
|
||||||
|
|
||||||
|
> 如果是 self-host 方式部署的集群,可以用 etcd-operator 部署 etcd 集群;也可以使用另一个小集群专门部署 etcd (使用 etcd-operator)
|
||||||
|
|
||||||
|
## 提高磁盘 IO 性能
|
||||||
|
|
||||||
|
ETCD 对磁盘写入延迟非常敏感,对于负载较重的集群建议磁盘使用 SSD 固态硬盘。可以使用 diskbench 或 fio 测量磁盘实际顺序 IOPS。
|
||||||
|
|
||||||
|
## 提高 ETCD 的磁盘 IO 优先级
|
||||||
|
|
||||||
|
由于 ETCD 必须将数据持久保存到磁盘日志文件中,因此来自其他进程的磁盘活动可能会导致增加写入时间,结果导致 ETCD 请求超时和临时 leader 丢失。当给定高磁盘优先级时,ETCD 服务可以稳定地与这些进程一起运行:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
sudo ionice -c2 -n0 -p $(pgrep etcd)
|
||||||
|
```
|
||||||
|
|
||||||
|
## 提高存储配额
|
||||||
|
|
||||||
|
默认 ETCD 空间配额大小为 2G,超过 2G 将不再写入数据。通过给 ETCD 配置 `--quota-backend-bytes` 参数增大空间配额,最大支持 8G。
|
||||||
|
|
||||||
|
## 分离 events 存储
|
||||||
|
|
||||||
|
集群规模大的情况下,集群中包含大量节点和服务,会产生大量的 event,这些 event 将会对 etcd 造成巨大压力并占用大量 etcd 存储空间,为了在大规模集群下提高性能,可以将 events 存储在单独的 ETCD 集群中。
|
||||||
|
|
||||||
|
配置 kube-apiserver:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
--etcd-servers="http://etcd1:2379,http://etcd2:2379,http://etcd3:2379" --etcd-servers-overrides="/events#http://etcd4:2379,http://etcd5:2379,http://etcd6:2379"
|
||||||
|
```
|
||||||
|
|
||||||
|
## 减小网络延迟
|
||||||
|
|
||||||
|
如果有大量并发客户端请求 ETCD leader 服务,则可能由于网络拥塞而延迟处理 follower 对等请求。在 follower 节点上的发送缓冲区错误消息:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
dropped MsgProp to 247ae21ff9436b2d since streamMsg's sending buffer is full
|
||||||
|
dropped MsgAppResp to 247ae21ff9436b2d since streamMsg's sending buffer is full
|
||||||
|
```
|
||||||
|
|
||||||
|
可以通过在客户端提高 ETCD 对等网络流量优先级来解决这些错误。在 Linux 上,可以使用 tc 对对等流量进行优先级排序:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
$ tc qdisc add dev eth0 root handle 1: prio bands 3
|
||||||
|
$ tc filter add dev eth0 parent 1: protocol ip prio 1 u32 match ip sport 2380 0xffff flowid 1:1
|
||||||
|
$ tc filter add dev eth0 parent 1: protocol ip prio 1 u32 match ip dport 2380 0xffff flowid 1:1
|
||||||
|
$ tc filter add dev eth0 parent 1: protocol ip prio 2 u32 match ip sport 2379 0xffff flowid 1:1
|
||||||
|
$ tc filter add dev eth0 parent 1: protocol ip prio 2 u32 match ip dport 2379 0xffff flowid 1:1
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,125 @@
|
||||||
|
# 大规模集群优化
|
||||||
|
|
||||||
|
Kubernetes 自 v1.6 以来,官方就宣称单集群最大支持 5000 个节点。不过这只是理论上,在具体实践中从 0 到 5000,还是有很长的路要走,需要见招拆招。
|
||||||
|
|
||||||
|
官方标准如下:
|
||||||
|
|
||||||
|
* 不超过 5000 个节点
|
||||||
|
* 不超过 150000 个 pod
|
||||||
|
* 不超过 300000 个容器
|
||||||
|
* 每个节点不超过 100 个 pod
|
||||||
|
|
||||||
|
## Master 节点配置优化
|
||||||
|
|
||||||
|
GCE 推荐配置:
|
||||||
|
|
||||||
|
* 1-5 节点: n1-standard-1
|
||||||
|
* 6-10 节点: n1-standard-2
|
||||||
|
* 11-100 节点: n1-standard-4
|
||||||
|
* 101-250 节点: n1-standard-8
|
||||||
|
* 251-500 节点: n1-standard-16
|
||||||
|
* 超过 500 节点: n1-standard-32
|
||||||
|
|
||||||
|
AWS 推荐配置:
|
||||||
|
|
||||||
|
* 1-5 节点: m3.medium
|
||||||
|
* 6-10 节点: m3.large
|
||||||
|
* 11-100 节点: m3.xlarge
|
||||||
|
* 101-250 节点: m3.2xlarge
|
||||||
|
* 251-500 节点: c4.4xlarge
|
||||||
|
* 超过 500 节点: c4.8xlarge
|
||||||
|
|
||||||
|
对应 CPU 和内存为:
|
||||||
|
|
||||||
|
* 1-5 节点: 1vCPU 3.75G内存
|
||||||
|
* 6-10 节点: 2vCPU 7.5G内存
|
||||||
|
* 11-100 节点: 4vCPU 15G内存
|
||||||
|
* 101-250 节点: 8vCPU 30G内存
|
||||||
|
* 251-500 节点: 16vCPU 60G内存
|
||||||
|
* 超过 500 节点: 32vCPU 120G内存
|
||||||
|
|
||||||
|
## kube-apiserver 优化
|
||||||
|
|
||||||
|
### 高可用
|
||||||
|
|
||||||
|
* 方式一: 启动多个 kube-apiserver 实例通过外部 LB 做负载均衡。
|
||||||
|
* 方式二: 设置 `--apiserver-count` 和 `--endpoint-reconciler-type`,可使得多个 kube-apiserver 实例加入到 Kubernetes Service 的 endpoints 中,从而实现高可用。
|
||||||
|
|
||||||
|
不过由于 TLS 会复用连接,所以上述两种方式都无法做到真正的负载均衡。为了解决这个问题,可以在服务端实现限流器,在请求达到阀值时告知客户端退避或拒绝连接,客户端则配合实现相应负载切换机制。
|
||||||
|
|
||||||
|
### 控制连接数
|
||||||
|
|
||||||
|
kube-apiserver 以下两个参数可以控制连接数:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
--max-mutating-requests-inflight int The maximum number of mutating requests in flight at a given time. When the server exceeds this, it rejects requests. Zero for no limit. (default 200)
|
||||||
|
--max-requests-inflight int The maximum number of non-mutating requests in flight at a given time. When the server exceeds this, it rejects requests. Zero for no limit. (default 400)
|
||||||
|
```
|
||||||
|
|
||||||
|
节点数量在 1000 - 3000 之间时,推荐:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
--max-requests-inflight=1500
|
||||||
|
--max-mutating-requests-inflight=500
|
||||||
|
```
|
||||||
|
|
||||||
|
节点数量大于 3000 时,推荐:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
--max-requests-inflight=3000
|
||||||
|
--max-mutating-requests-inflight=1000
|
||||||
|
```
|
||||||
|
|
||||||
|
## kube-scheduler 与 kube-controller-manager 优化
|
||||||
|
|
||||||
|
### 高可用
|
||||||
|
|
||||||
|
kube-controller-manager 和 kube-scheduler 是通过 leader election 实现高可用,启用时需要添加以下参数:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
--leader-elect=true
|
||||||
|
--leader-elect-lease-duration=15s
|
||||||
|
--leader-elect-renew-deadline=10s
|
||||||
|
--leader-elect-resource-lock=endpoints
|
||||||
|
--leader-elect-retry-period=2s
|
||||||
|
```
|
||||||
|
|
||||||
|
### 控制 QPS
|
||||||
|
|
||||||
|
与 kube-apiserver 通信的 qps 限制,推荐为:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
--kube-api-qps=100
|
||||||
|
```
|
||||||
|
|
||||||
|
## Kubelet 优化
|
||||||
|
|
||||||
|
* 设置 `--image-pull-progress-deadline=30m`
|
||||||
|
* 设置 `--serialize-image-pulls=false`(需要 Docker 使用 overlay2 )
|
||||||
|
* Kubelet 单节点允许运行的最大 Pod 数:`--max-pods=110`(默认是 110,可以根据实际需要设置)
|
||||||
|
|
||||||
|
## 集群 DNS 高可用
|
||||||
|
|
||||||
|
设置反亲和,让集群 DNS (kube-dns 或 coredns) 分散在不同节点,避免单点故障:
|
||||||
|
|
||||||
|
``` yaml
|
||||||
|
affinity:
|
||||||
|
podAntiAffinity:
|
||||||
|
requiredDuringSchedulingIgnoredDuringExecution:
|
||||||
|
- weight: 100
|
||||||
|
labelSelector:
|
||||||
|
matchExpressions:
|
||||||
|
- key: k8s-app
|
||||||
|
operator: In
|
||||||
|
values:
|
||||||
|
- kube-dns
|
||||||
|
topologyKey: kubernetes.io/hostname
|
||||||
|
```
|
||||||
|
|
||||||
|
## ETCD 优化
|
||||||
|
|
||||||
|
参考 [ETCD 优化](etcd-optimization.md)
|
||||||
|
|
||||||
|
## 参考资料
|
||||||
|
|
||||||
|
* [Considerations for large clusters](https://kubernetes.io/docs/setup/best-practices/cluster-large/)
|
||||||
|
|
@ -0,0 +1,53 @@
|
||||||
|
# 安全维护或下线节点
|
||||||
|
|
||||||
|
有时候我们需要对节点进行维护或进行版本升级等操作,操作之前需要对节点执行驱逐 (kubectl drain),驱逐时会将节点上的 Pod 进行删除,以便它们漂移到其它节点上,当驱逐完毕之后,节点上的 Pod 都漂移到其它节点了,这时我们就可以放心的对节点进行操作了。
|
||||||
|
|
||||||
|
## 驱逐存在的问题
|
||||||
|
|
||||||
|
有一个问题就是,驱逐节点是一种有损操作,驱逐的原理:
|
||||||
|
|
||||||
|
1. 封锁节点 (设为不可调度,避免新的 Pod 调度上来)。
|
||||||
|
2. 将该节点上的 Pod 删除。
|
||||||
|
3. ReplicaSet 控制器检测到 Pod 减少,会重新创建一个 Pod,调度到新的节点上。
|
||||||
|
|
||||||
|
这个过程是先删除,再创建,并非是滚动更新,因此更新过程中,如果一个服务的所有副本都在被驱逐的节点上,则可能导致该服务不可用。
|
||||||
|
|
||||||
|
我们再来下什么情况下驱逐会导致服务不可用:
|
||||||
|
|
||||||
|
1. 服务存在单点故障,所有副本都在同一个节点,驱逐该节点时,就可能造成服务不可用。
|
||||||
|
2. 服务没有单点故障,但刚好这个服务涉及的 Pod 全部都部署在这一批被驱逐的节点上,所以这个服务的所有 Pod 同时被删,也会造成服务不可用。
|
||||||
|
3. 服务没有单点故障,也没有全部部署到这一批被驱逐的节点上,但驱逐时造成这个服务的一部分 Pod 被删,短时间内服务的处理能力下降导致服务过载,部分请求无法处理,也就降低了服务可用性。
|
||||||
|
|
||||||
|
## 解决方案
|
||||||
|
|
||||||
|
针对第一点,我们可以使用前面讲的 [Pod 打散调度](../ha/pod-split-up-scheduling.md) 避免单点故障。
|
||||||
|
|
||||||
|
针对第二和第三点,我们可以通过配置 PDB (PodDisruptionBudget) 来避免所有副本同时被删除,驱逐时 K8S 会 "观察" nginx 的当前可用与期望的副本数,根据定义的 PDB 来控制 Pod 删除速率,达到阀值时会等待 Pod 在其它节点上启动并就绪后再继续删除,以避免同时删除太多的 Pod 导致服务不可用或可用性降低,下面给出两个示例。
|
||||||
|
|
||||||
|
示例一 (保证驱逐时 nginx 至少有 90% 的副本可用):
|
||||||
|
|
||||||
|
``` yaml
|
||||||
|
apiVersion: policy/v1beta1
|
||||||
|
kind: PodDisruptionBudget
|
||||||
|
metadata:
|
||||||
|
name: zk-pdb
|
||||||
|
spec:
|
||||||
|
minAvailable: 90%
|
||||||
|
selector:
|
||||||
|
matchLabels:
|
||||||
|
app: zookeeper
|
||||||
|
```
|
||||||
|
|
||||||
|
示例二 (保证驱逐时 zookeeper 最多有一个副本不可用,相当于逐个删除并等待在其它节点完成重建):
|
||||||
|
|
||||||
|
``` yaml
|
||||||
|
apiVersion: policy/v1beta1
|
||||||
|
kind: PodDisruptionBudget
|
||||||
|
metadata:
|
||||||
|
name: zk-pdb
|
||||||
|
spec:
|
||||||
|
maxUnavailable: 1
|
||||||
|
selector:
|
||||||
|
matchLabels:
|
||||||
|
app: zookeeper
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,53 @@
|
||||||
|
# 安全变更容器数据盘路径
|
||||||
|
|
||||||
|
本文介绍如何安全的对容器的数据盘路径进行变更。
|
||||||
|
|
||||||
|
## Docker 运行时
|
||||||
|
|
||||||
|
### 注意事项
|
||||||
|
|
||||||
|
如果节点上容器运行时是 Docker,想要变更 Docker Root Dir,需要谨慎一点。如果操作不慎,可能造成采集不到容器监控数据,因为容器监控数据由 kubelet 的 cadvisor 模块提供,而由于 docker 没有实现 CRI 接口,cadvisor 会对 Docker 有一些特殊处理: 在刚启动时,通过 `docker info` 获取 `Docker Root Dir` 路径,后续逻辑会依赖这个路径。
|
||||||
|
|
||||||
|
如果在 kubelet 运行过程中,改了 `Docker Root Dir`,cadvisor 并不会更新路径,仍然认为路径是之前的,就会造成 kubelet 不能正常返回监控指标并且报类似如下的错:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
Mar 21 02:59:26 VM-67-101-centos kubelet[714]: E0321 02:59:26.320938 714 manager.go:1086] Failed to create existing container: /kubepods/burstable/podb267f18b-a641-4004-a660-4c6a43b6e520/03164d8f0d1f55a285b50b2117d6fdb2c33d2fa87f46dba0f43b806017607d03: failed to identify the read-write layer ID for container "03164d8f0d1f55a285b50b2117d6fdb2c33d2fa87f46dba0f43b806017607d03". - open /var/lib/docker/image/overlay2/layerdb/mounts/03164d8f0d1f55a285b50b2117d6fdb2c33d2fa87f46dba0f43b806017607d03/mount-id: no such file or directory
|
||||||
|
```
|
||||||
|
|
||||||
|
> 参考 [排障案例: cAdvisor 无数据](../../troubleshooting/node/cadvisor-no-data.md)。
|
||||||
|
|
||||||
|
### 变更步骤
|
||||||
|
|
||||||
|
1. 驱逐节点(`kubectl drain NODE`),让存量 Pod 漂移到其它节点上,参考 [安全维护或下线节点](securely-maintain-or-offline-node.md)。
|
||||||
|
2. 修改 dockerd 配置文件 `/etc/docker/daemon.json`:
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"graph": "/data/docker"
|
||||||
|
}
|
||||||
|
```
|
||||||
|
3. 重启 dockerd:
|
||||||
|
```bash
|
||||||
|
systemctl restart docker
|
||||||
|
# systemctl restart dockerd
|
||||||
|
```
|
||||||
|
4. 重启 kubelet
|
||||||
|
```bash
|
||||||
|
systemctl restart kubelet
|
||||||
|
```
|
||||||
|
5. 节点恢复为可调度状态: `kubectl uncordon NODE`。
|
||||||
|
|
||||||
|
## 其它运行时
|
||||||
|
|
||||||
|
其它运行时都实现了 CRI 接口,变更容器 Root Dir 就不需要那么严谨,不过安全起见,还是建议先安全的将节点上存量 Pod 驱逐走(参考 [安全维护或下线节点](securely-maintain-or-offline-node.md)),然后再修改运行时配置并重启容器运行时。
|
||||||
|
|
||||||
|
配置修改方式参考对应运行时的官方文档,这里以常用的 `containerd` 为例:
|
||||||
|
|
||||||
|
1. 修改 `/etc/containerd/config.toml`:
|
||||||
|
```toml
|
||||||
|
root = "/data/containerd"
|
||||||
|
```
|
||||||
|
2. 重启 containerd:
|
||||||
|
```bash
|
||||||
|
systemctl restart containerd
|
||||||
|
```
|
||||||
|
3. 节点恢复为可调度状态: `kubectl uncordon NODE`。
|
||||||
|
|
@ -0,0 +1,97 @@
|
||||||
|
# CPU 绑核
|
||||||
|
|
||||||
|
## 背景
|
||||||
|
|
||||||
|
对于一些计算密集型,或对 CPU 比较敏感的业务,可以开启 CPU 亲和性,即绑核,避免跟其它 Pod 争抢 CPU 降低性能。
|
||||||
|
|
||||||
|
## 操作步骤
|
||||||
|
|
||||||
|
1. 驱逐节点:
|
||||||
|
```bash
|
||||||
|
kubectl drain <NODE_NAME>
|
||||||
|
```
|
||||||
|
2. 停止 kubelet:
|
||||||
|
```bash
|
||||||
|
systemctl stop kubelet
|
||||||
|
```
|
||||||
|
3. 修改 kubelet 参数:
|
||||||
|
```txt
|
||||||
|
--cpu-manager-policy="static"
|
||||||
|
```
|
||||||
|
4. 删除旧的 CPU 管理器状态文件:
|
||||||
|
```bash
|
||||||
|
rm var/lib/kubelet/cpu_manager_state
|
||||||
|
```
|
||||||
|
5. 启动 kubelet
|
||||||
|
```bash
|
||||||
|
systemctl start kubelet
|
||||||
|
```
|
||||||
|
|
||||||
|
## 绑定 NUMA 亲和性
|
||||||
|
|
||||||
|
CPU 规格较大的节点,可能会跨 NUMA,如果 Pod 中业务进程运行的时候,在不同 NUMA 的 CPU 之间切换,会有一定的性能损耗,这种情况可以进一步开启 NUMA 的亲和性,让 Pod 中进程都跑在同一 NUMA 的 CPU 上,减少性能损耗。
|
||||||
|
|
||||||
|
### 前提条件
|
||||||
|
|
||||||
|
* 内核启用 NUMA: 确保 `/etc/default/grub` 中没有 `numa=off`,若有就改为 `numa=on`。
|
||||||
|
* k8s 1.18 版本以上 (依赖特性 TopologyManager 在 1.18 进入 beta 默认开启)。
|
||||||
|
|
||||||
|
### 启用方法
|
||||||
|
|
||||||
|
增加 kubelet 参数:
|
||||||
|
|
||||||
|
* `--cpu-manager-policy=static`
|
||||||
|
* `--topology-manager-policy=single-numa-node`
|
||||||
|
|
||||||
|
### 验证 NUMA 亲和性
|
||||||
|
|
||||||
|
1. 确认节点CPU 分布情况:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
NUMA node0 CPU(s): 0-23,48-71
|
||||||
|
NUMA node1 CPU(s): 24-47,72-95
|
||||||
|
```
|
||||||
|
|
||||||
|
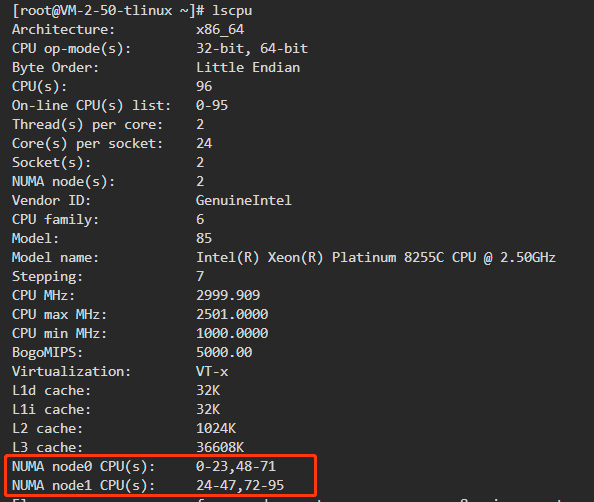
|
||||||
|
|
||||||
|
2. 先后创建三个static类型(request和limit严格一致)的Pod:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
debug1: CPU request==limit==40C
|
||||||
|
debug2: CPU request==limit==40C
|
||||||
|
debug3: CPU request==limit==10C
|
||||||
|
```
|
||||||
|
|
||||||
|
实验预期:
|
||||||
|
* debug1与debug2分布在不同的numa上,各自占用40C CPU资源,numa1与numa2各自剩余8C。
|
||||||
|
* debug3预期需要10C并且都在一个numa上,在debug1和debug2各自占用40C的情况下,总共剩余16C CPU,但每个numa剩余8C<10C,debug3必定调度失败。
|
||||||
|
|
||||||
|
3. 验证
|
||||||
|
debug1上创建40个100%使用CPU的进程,查看进程分布情况:debug1全部分布在numa0上:
|
||||||
|
|
||||||
|
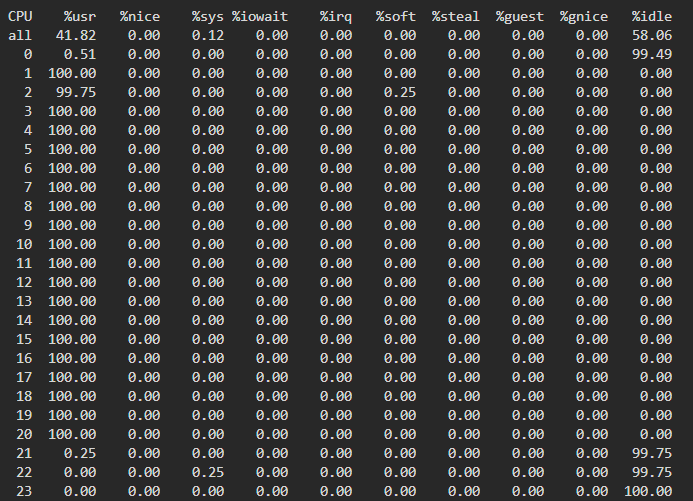
|
||||||
|
|
||||||
|
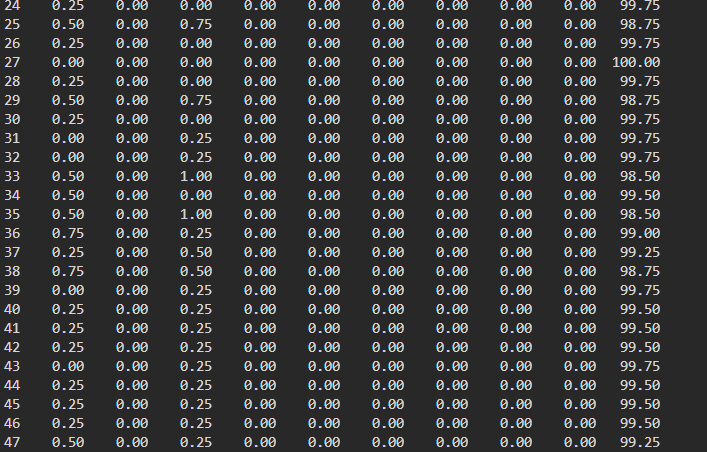
|
||||||
|
|
||||||
|
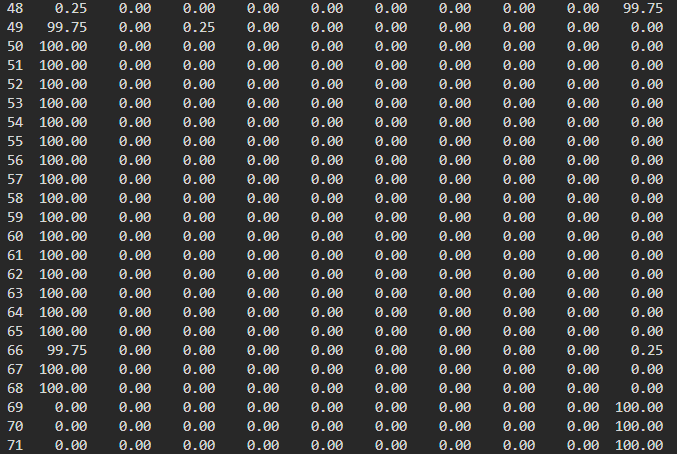
|
||||||
|
|
||||||
|
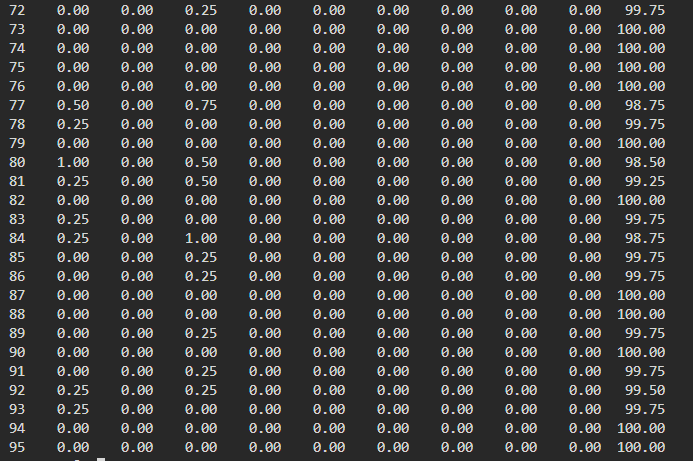
|
||||||
|
|
||||||
|
同样,debug2全部分布在numa1上。
|
||||||
|
|
||||||
|
debug3由于没有numa满足>=10C,调度失败。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
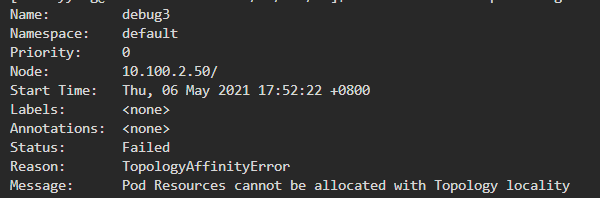
|
||||||
|
|
||||||
|
### 确保Pod内的进程在本numa分配内存
|
||||||
|
|
||||||
|
本质上是通过系统调用(set_mempolicy)设置进程属性,在内核给进程分配内存时,内核只在进程所属numa分配内存。如果业务进程本身没有明显调用set_mempolicy设置内存分配策略,可以通过numactl --localalloc cmd 启动的进程,内核分配内存时会严格保证内存分布在本numa
|
||||||
|
|
||||||
|
## 参考资料
|
||||||
|
|
||||||
|
* [https://docs.qq.com/doc/DSkNYQWt4bHhva0F6](https://docs.qq.com/doc/DSkNYQWt4bHhva0F6)
|
||||||
|
* [https://blog.csdn.net/nicekwell/article/details/9368307](https://blog.csdn.net/nicekwell/article/details/9368307)
|
||||||
|
* [为什么 NUMA 会影响程序的延迟](https://draveness.me/whys-the-design-numa-performance/)
|
||||||
|
* [控制节点上的 CPU 管理策略](https://kubernetes.io/zh-cn/docs/tasks/administer-cluster/cpu-management-policies/)
|
||||||
|
|
@ -0,0 +1,207 @@
|
||||||
|
# 网络性能调优
|
||||||
|
|
||||||
|
本文整理在 K8S 环境中的网络性能调优实践。一些涉及到内核参数的调整,关于如何调整 Pod 内核参数的方法请参考 [为 Pod 设置内核参数](../../trick/deploy/set-sysctl.md)。
|
||||||
|
|
||||||
|
## 高并发场景
|
||||||
|
|
||||||
|
### TIME_WAIT 连接复用
|
||||||
|
|
||||||
|
如果短连接并发量较高,它所在 netns 中 TIME_WAIT 状态的连接就比较多,而 TIME_WAIT 连接默认要等 2MSL 时长才释放,长时间占用源端口,当这种状态连接数量累积到超过一定量之后可能会导致无法新建连接。
|
||||||
|
|
||||||
|
所以建议开启 TIME_WAIT 复用,即允许将 TIME_WAIT 连接重新用于新的 TCP 连接:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
net.ipv4.tcp_tw_reuse=1
|
||||||
|
```
|
||||||
|
|
||||||
|
> 在高版本内核中,`net.ipv4.tcp_tw_reuse` 默认值为 2,表示仅为回环地址开启复用,基本可以粗略的认为没开启复用。
|
||||||
|
|
||||||
|
### 扩大源端口范围
|
||||||
|
|
||||||
|
高并发场景,对于 client 来说会使用大量源端口,源端口范围从 `net.ipv4.ip_local_port_range` 这个内核参数中定义的区间随机选取,在高并发环境下,端口范围小容易导致源端口耗尽,使得部分连接异常。通常 Pod 源端口范围默认是 32768-60999,建议将其扩大,调整为 1024-65535: `sysctl -w net.ipv4.ip_local_port_range="1024 65535"`。
|
||||||
|
|
||||||
|
### 调大最大文件句柄数
|
||||||
|
|
||||||
|
在 linux 中,每个连接都会占用一个文件句柄,所以句柄数量限制同样也会限制最大连接数, 对于像 Nginx 这样的反向代理,对于每个请求,它会与 client 和 upstream server 分别建立一个连接,即占据两个文件句柄,所以理论上来说 Nginx 能同时处理的连接数最多是系统最大文件句柄数限制的一半。
|
||||||
|
|
||||||
|
系统最大文件句柄数由 `fs.file-max` 这个内核参数来控制,一些环境默认值可能为 838860,建议调大:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
fs.file-max=1048576
|
||||||
|
```
|
||||||
|
|
||||||
|
### 调大全连接连接队列的大小
|
||||||
|
|
||||||
|
TCP 全连接队列的长度如果过小,在高并发环境可能导致队列溢出,使得部分连接无法建立。
|
||||||
|
|
||||||
|
如果因全连接队列溢出导致了丢包,从统计的计数上是可以看出来的:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# 用 netstat 查看统计
|
||||||
|
$ netstat -s | grep -E 'overflow|drop'
|
||||||
|
12178939 times the listen queue of a socket overflowed
|
||||||
|
12247395 SYNs to LISTEN sockets dropped
|
||||||
|
|
||||||
|
# 也可以用 nstat 查看计数器
|
||||||
|
$ nstat -az | grep -E 'TcpExtListenOverflows|TcpExtListenDrops'
|
||||||
|
TcpExtListenOverflows 12178939 0.0
|
||||||
|
TcpExtListenDrops 12247395 0.0
|
||||||
|
```
|
||||||
|
|
||||||
|
全连接队列的大小取决于 `net.core.somaxconn` 内核参数以及业务进程调用 listen 时传入的 backlog 参数,取两者中的较小值(`min(backlog,somaxconn)`),一些编程语言通常是默认取 `net.core.somaxconn` 参数的值作为 backlog 参数传入 listen 系统调用(比如Go语言)。
|
||||||
|
|
||||||
|
高并发环境可以考虑将其改到 `65535`:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
sysctl -w net.core.somaxconn=65535
|
||||||
|
```
|
||||||
|
|
||||||
|
如何查看队列大小来验证是否成功调整队列大小?可以执行 `ss -lntp` 看 `Send-Q` 的值。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ ss -lntp
|
||||||
|
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
|
||||||
|
LISTEN 0 65535 0.0.0.0:80 0.0.0.0:* users:(("nginx",pid=347916,fd=6),("nginx",pid=347915,fd=6),("nginx",pid=347887,fd=6))
|
||||||
|
```
|
||||||
|
|
||||||
|
> ss 用 -l 查看 LISTEN 状态连接时,`Recv-Q` 表示的当前已建连但还未被服务端调用 `accept()` 取走的连接数量,即全连接队列中的连接数;`Send-Q` 表示的则是最大的 listen backlog 数值,即全连接队列大小。如果 `Recv-Q` 大小接近 `Send-Q` 的大小时,说明连接队列可能溢出。
|
||||||
|
|
||||||
|
需要注意的是,Nginx 在 listen 时并没有读取 somaxconn 作为 backlog 参数传入,而是在 nginx 配置文件中有自己单独的参数配置:
|
||||||
|
|
||||||
|
```nginx.conf
|
||||||
|
server {
|
||||||
|
listen 80 backlog=1024;
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
如果不设置,backlog 在 linux 上默认为 511:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
backlog=number
|
||||||
|
sets the backlog parameter in the listen() call that limits the maximum length for the queue of pending connections. By default, backlog is set to -1 on FreeBSD, DragonFly BSD, and macOS, and to 511 on other platforms.
|
||||||
|
```
|
||||||
|
|
||||||
|
也就是说,即便你的 `somaxconn` 配的很高,nginx 所监听端口的连接队列最大却也只有 511,高并发场景下还是可能导致连接队列溢出,所以建议配置下 nginx 的 backlog 参数。
|
||||||
|
|
||||||
|
不过如果用的是 Nginx Ingress ,情况又不太一样,因为 Nginx Ingress Controller 会自动读取 somaxconn 的值作为 backlog 参数写到生成的 `nginx.conf` 中,参考 [源码](https://github.com/kubernetes/ingress-nginx/blob/controller-v0.34.1/internal/ingress/controller/nginx.go#L592)。
|
||||||
|
|
||||||
|
## 高吞吐场景
|
||||||
|
|
||||||
|
### 调大 UDP 缓冲区
|
||||||
|
|
||||||
|
UDP socket 的发送和接收缓冲区是有上限的,如果缓冲区较小,高并发环境可能导致缓冲区满而丢包,从网络计数可以看出来:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# 使用 netstat 查看统计
|
||||||
|
$ netstat -s | grep "buffer errors"
|
||||||
|
429469 receive buffer errors
|
||||||
|
23568 send buffer errors
|
||||||
|
|
||||||
|
# 也可以用 nstat 查看计数器
|
||||||
|
$ nstat -az | grep -E 'UdpRcvbufErrors|UdpSndbufErrors'
|
||||||
|
UdpRcvbufErrors 429469 0.0
|
||||||
|
UdpSndbufErrors 23568 0.0
|
||||||
|
```
|
||||||
|
|
||||||
|
还可以使用 `ss -nump` 查看当前缓冲区的情况:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ ss -nump
|
||||||
|
Recv-Q Send-Q Local Address:Port Peer Address:Port Process
|
||||||
|
0 0 10.10.4.26%eth0:68 10.10.4.1:67 users:(("NetworkManager",pid=960,fd=22))
|
||||||
|
skmem:(r0,rb212992,t0,tb212992,f0,w0,o640,bl0,d0)
|
||||||
|
```
|
||||||
|
|
||||||
|
> 1. `rb212992` 表示 UDP 接收缓冲区大小是 `212992` 字节,`tb212992` 表示 UDP 发送缓存区大小是 `212992` 字节。
|
||||||
|
> 2. `Recv-Q` 和 `Send-Q` 分别表示当前接收和发送缓冲区中的数据包字节数。
|
||||||
|
|
||||||
|
UDP 发送缓冲区大小取决于:
|
||||||
|
1. `net.core.wmem_default` 和 `net.core.wmem_max` 这两个内核参数,分别表示缓冲区的默认大小和最大上限。
|
||||||
|
2. 如果程序自己调用 `setsockopt`设置`SO_SNDBUF`来自定义缓冲区大小,最终取值不会超过 `net.core.wmem_max`;如果程序没设置,则会使用 `net.core.wmem_default` 作为缓冲区的大小。
|
||||||
|
|
||||||
|
同理,UDP 接收缓冲区大小取决于:
|
||||||
|
1. `net.core.rmem_default` 和 `net.core.rmem_max` 这两个内核参数,分别表示缓冲区的默认大小和最大上限。
|
||||||
|
2. 如果程序自己调用 `setsockopt`设置`SO_RCVBUF`来自定义缓冲区大小,最终取值不会超过 `net.core.rmem_max`;如果程序没设置,则会使用 `net.core.rmem_default` 作为缓冲区的大小。
|
||||||
|
|
||||||
|
需要注意的是,这些内核参数在容器网络命名空间中是无法设置的,是 Node 级别的参数,需要在节点上修改,建议修改值:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
net.core.rmem_default=26214400 # socket receive buffer 默认值 (25M),如果程序没用 setsockopt 更改 buffer 长度的话,默认用这个值。
|
||||||
|
net.core.wmem_default=26214400 # socket send buffer 默认值 (25M),如果程序没用 setsockopt 更改 buffer 长度的话,默认用这个值。
|
||||||
|
net.core.rmem_max=26214400 # socket receive buffer 上限 (25M),如果程序使用 setsockopt 更改 buffer 长度,最大不能超过此限制。
|
||||||
|
net.core.wmem_max=26214400 # socket send buffer 上限 (25M),如果程序使用 setsockopt 更改 buffer 长度,最大不能超过此限制。
|
||||||
|
```
|
||||||
|
|
||||||
|
如果程序自己有调用 `setsockopt` 去设置 `SO_SNDBUF` 或 `SO_RCVBUF`,建议设置到跟前面内核参数对应的最大上限值。
|
||||||
|
|
||||||
|
### 调大 TCP 缓冲区
|
||||||
|
|
||||||
|
TCP socket 的发送和接收缓冲区也是有上限的,不过对于发送缓冲区,即便满了也是不会丢包的,只是会让程序发送数据包时卡住,等待缓冲区有足够空间释放出来,所以一般不需要优化发送缓冲区。
|
||||||
|
|
||||||
|
对于接收缓冲区,在高并发环境如果较小,可能导致缓冲区满而丢包,从网络计数可以看出来:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ nstat -az | grep TcpExtTCPRcvQDrop
|
||||||
|
TcpExtTCPRcvQDrop 264324 0.0
|
||||||
|
```
|
||||||
|
|
||||||
|
还可以使用 `ss -ntmp` 查看当前缓冲区情况:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ ss -ntmp
|
||||||
|
ESTAB 0 0 [::ffff:109.244.190.163]:9988 [::ffff:10.10.4.26]:54440 users:(("xray",pid=3603,fd=20))
|
||||||
|
skmem:(r0,rb12582912,t0,tb12582912,f0,w0,o0,bl0,d0)
|
||||||
|
```
|
||||||
|
|
||||||
|
> 1. `rb12582912` 表示 TCP 接收缓冲区大小是 `12582912` 字节,`tb12582912` 表示 UDP 发送缓存区大小是 `12582912` 字节。
|
||||||
|
> 2. `Recv-Q` 和 `Send-Q` 分别表示当前接收和发送缓冲区中的数据包字节数。
|
||||||
|
|
||||||
|
如果存在 `net.ipv4.tcp_rmem` 这个参数,对于 TCP 而言,会覆盖 `net.core.rmem_default` 和 `net.core.rmem_max` 的值。这个参数网络命名空间隔离的,而在容器网络命名空间中,一般默认是有配置的,所以如果要调整 TCP 接收缓冲区,需要显式在 Pod 级别配置下内核参数:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
net.ipv4.tcp_rmem="4096 26214400 26214400"
|
||||||
|
```
|
||||||
|
|
||||||
|
> 1. 单位是字节,分别是 min, default, max。
|
||||||
|
> 2. 如果程序没用 setsockopt 更改 buffer 长度,就会使用 default 作为初始 buffer 长度(覆盖 `net.core.rmem_default`),然后根据内存压力在 min 和 max 之间自动调整。
|
||||||
|
> 3. 如果程序使用了 setsockopt 更改 buffer 长度,则使用传入的长度 (仍然受限于 `net.core.rmem_max`)。
|
||||||
|
|
||||||
|
## 内核参数调优配置示例
|
||||||
|
|
||||||
|
调整 Pod 内核参数:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
initContainers:
|
||||||
|
- name: setsysctl
|
||||||
|
image: busybox
|
||||||
|
securityContext:
|
||||||
|
privileged: true
|
||||||
|
command:
|
||||||
|
- sh
|
||||||
|
- -c
|
||||||
|
- |
|
||||||
|
sysctl -w net.core.somaxconn=65535
|
||||||
|
sysctl -w net.ipv4.ip_local_port_range="1024 65535"
|
||||||
|
sysctl -w net.ipv4.tcp_tw_reuse=1
|
||||||
|
sysctl -w fs.file-max=1048576
|
||||||
|
sysctl -w net.ipv4.tcp_rmem="4096 26214400 26214400"
|
||||||
|
```
|
||||||
|
|
||||||
|
调整节点内核参数(修改 `/etc/sysctl.conf` 并执行 `sysctl -p`):
|
||||||
|
|
||||||
|
```bash
|
||||||
|
net.core.rmem_default=26214400
|
||||||
|
net.core.wmem_default=26214400
|
||||||
|
net.core.rmem_max=26214400
|
||||||
|
net.core.wmem_max=26214400
|
||||||
|
```
|
||||||
|
|
||||||
|
如果使用的是 [腾讯云弹性集群 EKS](https://console.cloud.tencent.com/tke2/ecluster) 这种没有节点的 Serverless 类型 K8S(每个 Pod 都是独占虚拟机),可以在 Pod 级别加如下注解来修改 Pod 对应虚拟机中的内核参数:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
eks.tke.cloud.tencent.com/host-sysctls: '[{"name": "net.core.rmem_max","value": "26214400"},{"name": "net.core.wmem_max","value": "26214400"},{"name": "net.core.rmem_default","value": "26214400"},{"name": "net.core.wmem_default","value": "26214400"}]'
|
||||||
|
```
|
||||||
|
|
||||||
|
## 参考资料
|
||||||
|
|
||||||
|
* [云服务器网络访问丢包](https://cloud.tencent.com/document/product/213/57336)
|
||||||
|
|
@ -0,0 +1,88 @@
|
||||||
|
# 合理设置 Request 与 Limit
|
||||||
|
|
||||||
|
如何为容器配置 Request 与 Limit? 这是一个即常见又棘手的问题,这个根据服务类型,需求与场景的不同而不同,没有固定的答案,这里结合生产经验总结了一些最佳实践,可以作为参考。
|
||||||
|
|
||||||
|
## 所有容器都应该设置 request
|
||||||
|
|
||||||
|
request 的值并不是指给容器实际分配的资源大小,它仅仅是给调度器看的,调度器会 "观察" 每个节点可以用于分配的资源有多少,也知道每个节点已经被分配了多少资源。被分配资源的大小就是节点上所有 Pod 中定义的容器 request 之和,它可以计算出节点剩余多少资源可以被分配(可分配资源减去已分配的 request 之和)。如果发现节点剩余可分配资源大小比当前要被调度的 Pod 的 reuqest 还小,那么就不会考虑调度到这个节点,反之,才可能调度。所以,如果不配置 request,那么调度器就不能知道节点大概被分配了多少资源出去,调度器得不到准确信息,也就无法做出合理的调度决策,很容易造成调度不合理,有些节点可能很闲,而有些节点可能很忙,甚至 NotReady。
|
||||||
|
|
||||||
|
所以,建议是给所有容器都设置 request,让调度器感知节点有多少资源被分配了,以便做出合理的调度决策,让集群节点的资源能够被合理的分配使用,避免陷入资源分配不均导致一些意外发生。
|
||||||
|
|
||||||
|
## CPU request 与 limit 的一般性建议
|
||||||
|
|
||||||
|
* 如果不确定应用最佳的 CPU 限制,可以不设置 CPU limit,参考: [Understanding resource limits in kubernetes: cpu time](https://medium.com/@betz.mark/understanding-resource-limits-in-kubernetes-cpu-time-9eff74d3161b)。
|
||||||
|
* 如果要设置 CPU request,大多可以设置到不大于 1 核,除非是 CPU 密集型应用。
|
||||||
|
|
||||||
|
## 老是忘记设置怎么办?
|
||||||
|
|
||||||
|
有时候我们会忘记给部分容器设置 request 与 limit,其实我们可以使用 LimitRange 来设置 namespace 的默认 request 与 limit 值,同时它也可以用来限制最小和最大的 request 与 limit。
|
||||||
|
示例:
|
||||||
|
|
||||||
|
``` yaml
|
||||||
|
apiVersion: v1
|
||||||
|
kind: LimitRange
|
||||||
|
metadata:
|
||||||
|
name: mem-limit-range
|
||||||
|
namespace: test
|
||||||
|
spec:
|
||||||
|
limits:
|
||||||
|
- default:
|
||||||
|
memory: 512Mi
|
||||||
|
cpu: 500m
|
||||||
|
defaultRequest:
|
||||||
|
memory: 256Mi
|
||||||
|
cpu: 100m
|
||||||
|
type: Container
|
||||||
|
```
|
||||||
|
|
||||||
|
## 重要的线上应用该如何设置
|
||||||
|
|
||||||
|
节点资源不足时,会触发自动驱逐,将一些低优先级的 Pod 删除掉以释放资源让节点自愈。没有设置 request,limit 的 Pod 优先级最低,容易被驱逐;request 不等于 limit 的其次; request 等于 limit 的 Pod 优先级较高,不容易被驱逐。所以如果是重要的线上应用,不希望在节点故障时被驱逐导致线上业务受影响,就建议将 request 和 limit 设成一致。
|
||||||
|
|
||||||
|
## 怎样设置才能提高资源利用率?
|
||||||
|
|
||||||
|
如果给给你的应用设置较高的 request 值,而实际占用资源长期远小于它的 request 值,导致节点整体的资源利用率较低。当然这对时延非常敏感的业务除外,因为敏感的业务本身不期望节点利用率过高,影响网络包收发速度。所以对一些非核心,并且资源不长期占用的应用,可以适当减少 request 以提高资源利用率。
|
||||||
|
|
||||||
|
如果你的服务支持水平扩容,单副本的 request 值一般可以设置到不大于 1 核,CPU 密集型应用除外。比如 coredns,设置到 0.1 核就可以,即 100m。
|
||||||
|
|
||||||
|
## 尽量避免使用过大的 request 与 limit
|
||||||
|
|
||||||
|
如果你的服务使用单副本或者少量副本,给很大的 request 与 limit,让它分配到足够多的资源来支撑业务,那么某个副本故障对业务带来的影响可能就比较大,并且由于 request 较大,当集群内资源分配比较碎片化,如果这个 Pod 所在节点挂了,其它节点又没有一个有足够的剩余可分配资源能够满足这个 Pod 的 request 时,这个 Pod 就无法实现漂移,也就不能自愈,加重对业务的影响。
|
||||||
|
|
||||||
|
相反,建议尽量减小 request 与 limit,通过增加副本的方式来对你的服务支撑能力进行水平扩容,让你的系统更加灵活可靠。
|
||||||
|
|
||||||
|
## 避免测试 namespace 消耗过多资源影响生产业务
|
||||||
|
|
||||||
|
若生产集群有用于测试的 namespace,如果不加以限制,可能导致集群负载过高,从而影响生产业务。可以使用 ResourceQuota 来限制测试 namespace 的 request 与 limit 的总大小。
|
||||||
|
示例:
|
||||||
|
|
||||||
|
``` yaml
|
||||||
|
apiVersion: v1
|
||||||
|
kind: ResourceQuota
|
||||||
|
metadata:
|
||||||
|
name: quota-test
|
||||||
|
namespace: test
|
||||||
|
spec:
|
||||||
|
hard:
|
||||||
|
requests.cpu: "1"
|
||||||
|
requests.memory: 1Gi
|
||||||
|
limits.cpu: "2"
|
||||||
|
limits.memory: 2Gi
|
||||||
|
```
|
||||||
|
|
||||||
|
## FAQ
|
||||||
|
|
||||||
|
### 为什么 CPU 利用率远不到 limit 还会被 throttle ?
|
||||||
|
|
||||||
|
CPU 限流是因为内核使用 CFS 调度算法,对于微突发场景,在一个 CPU 调度周期内 (100ms) 所占用的时间超过了 limit 还没执行完,就会强制 "抢走" CPU 使用权(throttle),等待下一个周期再执行,但是时间拉长一点,进程使用 CPU 所占用的时间比例却很低,监控上就看不出来 CPU 有突增,但实际上又被 throttle 了。
|
||||||
|
|
||||||
|
更多详细解释参考 [k8s CPU limit和throttling的迷思](https://zhuanlan.zhihu.com/p/433065108)。
|
||||||
|
|
||||||
|
## 参考资料
|
||||||
|
|
||||||
|
* [Understanding Kubernetes limits and requests by example](https://sysdig.com/blog/kubernetes-limits-requests/)
|
||||||
|
* [Understanding resource limits in kubernetes: cpu time](https://medium.com/@betz.mark/understanding-resource-limits-in-kubernetes-cpu-time-9eff74d3161b)
|
||||||
|
* [Understanding resource limits in kubernetes: memory](https://medium.com/@betz.mark/understanding-resource-limits-in-kubernetes-memory-6b41e9a955f9)
|
||||||
|
* [Kubernetes best practices: Resource requests and limits](https://cloud.google.com/blog/products/gcp/kubernetes-best-practices-resource-requests-and-limits)
|
||||||
|
* [Kubernetes 资源分配之 Request 和 Limit 解析](https://cloud.tencent.com/developer/article/1004976)
|
||||||
|
|
||||||
|
|
@ -0,0 +1,36 @@
|
||||||
|
# k3s 安装实践案例
|
||||||
|
|
||||||
|
## 概述
|
||||||
|
|
||||||
|
本文主要给出一些具体的安装实践案例供大家参考。
|
||||||
|
|
||||||
|
## 安装精简版 k3s
|
||||||
|
|
||||||
|
有时候个人开发者只想用 k3s 来替代容器来部署一些应用,不需要 k8s 很多复杂的功能,此时在安装的时候可以禁用很多不需要的组件,节约服务器资源:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ curl -sfL https://get.k3s.io | sh -s - server \
|
||||||
|
--disable-cloud-controller \
|
||||||
|
--disable-network-policy \
|
||||||
|
--disable-helm-controller \
|
||||||
|
--disable=traefik,local-storage,metrics-server,servicelb
|
||||||
|
```
|
||||||
|
|
||||||
|
### 路由器上安装极简 k3s
|
||||||
|
|
||||||
|
将 k3s 安装在自家路由器上,统一用声明式的 yaml 管理路由器的应用和功能,方便刷机后也能重新一键安装回来:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
INSTALL_K3S_MIRROR=cn curl -sfL https://rancher-mirror.rancher.cn/k3s/k3s-install.sh | sh -s - server \
|
||||||
|
--kubelet-arg="--hostname-override=10.10.10.2" \
|
||||||
|
--disable-kube-proxy \
|
||||||
|
--disable-cloud-controller \
|
||||||
|
--disable-network-policy \
|
||||||
|
--disable-helm-controller \
|
||||||
|
--disable=traefik,local-storage,metrics-server,servicelb,coredns
|
||||||
|
```
|
||||||
|
|
||||||
|
* 国内家庭网络使用 k3s 默认安装脚本网络不通,使用 mirror 脚本替代。
|
||||||
|
* 如果是主路由,公网 ip 每次拨号会变,而 k3s 启动时会获取到外网 ip 作为 hostname,用导出的 kubeconfig 去访问 apiserver 时,会报证书问题(签发时不包含重新拨号之后的外网 ip),可以用 `--kubelet-arg` 强制指定一下路由器使用的静态内网 IP。
|
||||||
|
* 在路由器部署的应用通常只用 HostNetwork,不需要访问 service,可以禁用 kube-proxy 和 coredns。
|
||||||
|
|
||||||
|
|
@ -0,0 +1,104 @@
|
||||||
|
# k3s 国内离线安装方法
|
||||||
|
|
||||||
|
## 步骤
|
||||||
|
|
||||||
|
### 下载离线文件
|
||||||
|
|
||||||
|
进入 [k3s release](https://github.com/k3s-io/k3s/releases) 页面,下载 k3s 二进制和依赖镜像的压缩包:
|
||||||
|
|
||||||
|
* `k3s`: 二进制。
|
||||||
|
* `k3s-airgap-images-amd64.tar`: 镜像压缩包。
|
||||||
|
|
||||||
|
下载安装脚本:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
curl -o install.sh https://get.k3s.io
|
||||||
|
```
|
||||||
|
|
||||||
|
下载完将所有文件放入需要安装 k3s 的机器上。
|
||||||
|
|
||||||
|
### 安装依赖镜像
|
||||||
|
|
||||||
|
```bash
|
||||||
|
sudo mkdir -p /var/lib/rancher/k3s/agent/images/
|
||||||
|
sudo cp ./k3s-airgap-images-amd64.tar /var/lib/rancher/k3s/agent/images/
|
||||||
|
```
|
||||||
|
|
||||||
|
### 安装 k3s 二进制
|
||||||
|
|
||||||
|
```bash
|
||||||
|
chmod +x k3s
|
||||||
|
cp k3s /usr/local/bin/
|
||||||
|
```
|
||||||
|
|
||||||
|
### 执行安装脚本
|
||||||
|
|
||||||
|
```bash
|
||||||
|
chmod +x install.sh
|
||||||
|
INSTALL_K3S_SKIP_DOWNLOAD=true ./install.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
### 验证
|
||||||
|
|
||||||
|
查看 k3s 运行状态:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
systemctl status k3s
|
||||||
|
```
|
||||||
|
|
||||||
|
查看 k3s 日志:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
journalctl -u k3s -f
|
||||||
|
```
|
||||||
|
|
||||||
|
查看 k3s 集群状态:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ k3s kubectl get node
|
||||||
|
NAME STATUS ROLES AGE VERSION
|
||||||
|
vm-55-160-centos Ready control-plane,master 3m22s v1.25.2+k3s1
|
||||||
|
$ k3s kubectl get pod -A
|
||||||
|
NAMESPACE NAME READY STATUS RESTARTS AGE
|
||||||
|
kube-system local-path-provisioner-5b5579c644-6h99x 1/1 Running 0 3m22s
|
||||||
|
kube-system coredns-75fc8f8fff-sjjzs 1/1 Running 0 3m22s
|
||||||
|
kube-system helm-install-traefik-crd-mgffn 0/1 Completed 0 3m22s
|
||||||
|
kube-system metrics-server-74474969b-6bj6r 1/1 Running 0 3m22s
|
||||||
|
kube-system svclb-traefik-0ab06643-6vj96 2/2 Running 0 3m1s
|
||||||
|
kube-system helm-install-traefik-m7wdm 0/1 Completed 2 3m22s
|
||||||
|
kube-system traefik-7d647b7597-dw6b4 1/1 Running 0 3m1s
|
||||||
|
```
|
||||||
|
|
||||||
|
### 获取 kubeconfig
|
||||||
|
|
||||||
|
若希望在本机之外用 kubectl 操作集群,可以将 kubeconfig 导出来:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
k3s kubectl config view --raw > k3s
|
||||||
|
```
|
||||||
|
|
||||||
|
修改其中 server 地址的 IP 为本机 IP,将 kubeconfig 文件放到 kubectl 所在机器上,然后用 [kubecm](https://github.com/sunny0826/kubecm) 合并到本地 kubeconfig:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubecm add --context-name=k3s -cf k3s
|
||||||
|
```
|
||||||
|
|
||||||
|
使用 [kubectx](https://github.com/ahmetb/kubectx) 切换 context:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ kubectl ctx k3s
|
||||||
|
Switched to context "k3s".
|
||||||
|
```
|
||||||
|
|
||||||
|
使用 kubectl 操作 k3s 集群:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ kubectl get node
|
||||||
|
NAME STATUS ROLES AGE VERSION
|
||||||
|
vm-55-160-centos Ready control-plane,master 14m v1.25.2+k3s1
|
||||||
|
```
|
||||||
|
|
||||||
|
## 参考资料
|
||||||
|
|
||||||
|
* [k3s 离线安装官方文档](https://docs.k3s.io/zh/installation/airgap)
|
||||||
|
|
||||||
|
|
@ -0,0 +1,197 @@
|
||||||
|
# 使用 kubespray 搭建集群
|
||||||
|
|
||||||
|
## 原理
|
||||||
|
|
||||||
|
[kubespray](https://github.com/kubernetes-sigs/kubespray) 是利用 [ansible](https://docs.ansible.com/ansible/latest/index.html) 这个工具,通过 SSH 协议批量让指定远程机器执行一系列脚本,安装各种组件,完成 K8S 集群搭建。
|
||||||
|
|
||||||
|
## 准备工作
|
||||||
|
|
||||||
|
下载 kubespray 并拷贝一份配置:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# 下载 kubespray
|
||||||
|
$ git clone --depth=1 https://github.com/kubernetes-sigs/kubespray.git
|
||||||
|
$ cd kubespray
|
||||||
|
# 安装依赖,包括 ansible
|
||||||
|
$ sudo pip3 install -r requirements.txt
|
||||||
|
|
||||||
|
# 复制一份配置文件
|
||||||
|
cp -rfp inventory/sample inventory/mycluster
|
||||||
|
```
|
||||||
|
|
||||||
|
## 修改配置
|
||||||
|
|
||||||
|
需要修改的配置文件列表:
|
||||||
|
|
||||||
|
* `inventory/mycluster/group_vars/all/*.yml`
|
||||||
|
* `inventory/mycluster/group_vars/k8s-cluster/*.yml`
|
||||||
|
|
||||||
|
下面介绍一些需要重点关注的配置,根据自己需求进行修改。
|
||||||
|
|
||||||
|
### 集群网络
|
||||||
|
|
||||||
|
修改配置文件 `inventory/mycluster/group_vars/k8s_cluster/k8s-cluster.yml`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
# 选择网络插件,支持 cilium, calico, weave 和 flannel
|
||||||
|
kube_network_plugin: cilium
|
||||||
|
|
||||||
|
# 设置 Service 网段
|
||||||
|
kube_service_addresses: 10.233.0.0/18
|
||||||
|
|
||||||
|
# 设置 Pod 网段
|
||||||
|
kube_pods_subnet: 10.233.64.0/18
|
||||||
|
```
|
||||||
|
|
||||||
|
其它相关配置文件: `inventory/mycluster/group_vars/k8s_cluster/k8s-net-*.yml`。
|
||||||
|
|
||||||
|
### 运行时
|
||||||
|
|
||||||
|
修改配置文件 `inventory/mycluster/group_vars/k8s_cluster/k8s-cluster.yml`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
# 支持 docker, crio 和 containerd,推荐 containerd.
|
||||||
|
container_manager: containerd
|
||||||
|
|
||||||
|
# 是否开启 kata containers
|
||||||
|
kata_containers_enabled: false
|
||||||
|
```
|
||||||
|
|
||||||
|
其它相关配置文件:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
inventory/mycluster/group_vars/all/containerd.yml
|
||||||
|
inventory/mycluster/group_vars/all/cri-o.yml
|
||||||
|
inventory/mycluster/group_vars/all/docker.yml
|
||||||
|
```
|
||||||
|
|
||||||
|
### 集群证书
|
||||||
|
|
||||||
|
修改配置文件 `inventory/mycluster/group_vars/k8s_cluster/k8s-cluster.yml`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
# 是否开启自动更新证书,推荐开启。
|
||||||
|
auto_renew_certificates: true
|
||||||
|
```
|
||||||
|
|
||||||
|
## 准备机器列表
|
||||||
|
|
||||||
|
拿到集群部署的初始机器内网 ip 列表,修改 `inventory/mycluster/inventory.ini`:
|
||||||
|
|
||||||
|
```ini
|
||||||
|
[all]
|
||||||
|
master1 ansible_host=10.10.10.1
|
||||||
|
master2 ansible_host=10.10.10.2
|
||||||
|
master3 ansible_host=10.10.10.3
|
||||||
|
node1 ansible_host=10.10.10.4
|
||||||
|
node2 ansible_host=10.10.10.5
|
||||||
|
node3 ansible_host=10.10.10.6
|
||||||
|
node4 ansible_host=10.10.10.7
|
||||||
|
node5 ansible_host=10.10.10.8
|
||||||
|
node6 ansible_host=10.10.10.9
|
||||||
|
node7 ansible_host=10.10.10.10
|
||||||
|
|
||||||
|
[kube_control_plane]
|
||||||
|
master1
|
||||||
|
master2
|
||||||
|
master3
|
||||||
|
|
||||||
|
[etcd]
|
||||||
|
master1
|
||||||
|
master2
|
||||||
|
master3
|
||||||
|
|
||||||
|
[kube_node]
|
||||||
|
master1
|
||||||
|
master2
|
||||||
|
master3
|
||||||
|
node1
|
||||||
|
node2
|
||||||
|
node3
|
||||||
|
node4
|
||||||
|
node5
|
||||||
|
node6
|
||||||
|
node7
|
||||||
|
|
||||||
|
[calico_rr]
|
||||||
|
|
||||||
|
[k8s_cluster:children]
|
||||||
|
kube_control_plane
|
||||||
|
kube_node
|
||||||
|
calico_rr
|
||||||
|
```
|
||||||
|
|
||||||
|
> **注:** 务必使用 `ansible_host` 标识节点内网 IP,否则可能导致出现类似 [这个issue](https://github.com/kubernetes-sigs/kubespray/issues/5949) 的问题。
|
||||||
|
|
||||||
|
附上 vim 编辑 inventory,批量加机器的技巧:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## 国内环境安装
|
||||||
|
|
||||||
|
在国内进行安装时,会因 GFW 影响而安装失败,参考 [kubespray 离线安装配置](offline.md)。
|
||||||
|
|
||||||
|
## 部署集群
|
||||||
|
|
||||||
|
```bash
|
||||||
|
ansible-playbook \
|
||||||
|
-i inventory/mycluster/inventory.ini \
|
||||||
|
--private-key=id_rsa \
|
||||||
|
--user=ubuntu -b \
|
||||||
|
cluster.yml
|
||||||
|
```
|
||||||
|
|
||||||
|
## 获取 kubeconfig
|
||||||
|
|
||||||
|
部署完成后,从 master 节点上的 `/root/.kube/config` 路径获取到 kubeconfig,这里以 ansible 的 fetch 功能为例,将 kubeconfig 拷贝下来:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ ansible -i '10.10.6.9,' -b -m fetch --private-key id_rsa --user=ubuntu -a 'src=/root/.kube/config dest=kubeconfig flat=yes' all
|
||||||
|
[WARNING]: Skipping callback plugin 'ara_default', unable to load
|
||||||
|
10.10.6.9 | CHANGED => {
|
||||||
|
"changed": true,
|
||||||
|
"checksum": "190eafeead70a8677b736eaa66d84d77c4a7f8be",
|
||||||
|
"dest": "/root/kubespray/kubeconfig",
|
||||||
|
"md5sum": "ded532f68930c48a53b3b2144b30f7f5",
|
||||||
|
"remote_checksum": "190eafeead70a8677b736eaa66d84d77c4a7f8be",
|
||||||
|
"remote_md5sum": null
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
> `-i` 中的逗号是故意的,意思是不让 ansible 误以为是个 inventory 文件,而是解析为单个 host。
|
||||||
|
|
||||||
|
获取到 kubeconfig 后,可以修改其中的 server 地址,将 `https://127.0.0.1:6443` 改为非 master 节点可以访问的地址,最简单就直接替换 `127.0.0.1` 成其中一台 master 节点的 IP 地址,也可以在 Master 前面挂个负载均衡器,然后替换成负载均衡器的地址。
|
||||||
|
|
||||||
|
## 扩容节点
|
||||||
|
|
||||||
|
如果要扩容节点,可以准备好节点的内网 IP 列表,并追加到之前的 inventory 文件里,然后再次使用 `ansible-playbook` 运行一次,有点不同的是: `cluster.yml` 换成 `scale.yml`:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
ansible-playbook \
|
||||||
|
-i inventory/mycluster/inventory.ini \
|
||||||
|
--private-key=id_rsa \
|
||||||
|
--user=ubuntu -b \
|
||||||
|
scale.yml
|
||||||
|
```
|
||||||
|
|
||||||
|
## 缩容节点
|
||||||
|
|
||||||
|
如果有节点不再需要了,我们可以将其移除集群,通常步骤是:
|
||||||
|
1. `kubectl cordon NODE` 驱逐节点,确保节点上的服务飘到其它节点上去,参考 [安全维护或下线节点](../../best-practices/ops/securely-maintain-or-offline-node.md)。
|
||||||
|
2. 停止节点上的一些 k8s 组件 (kubelet, kube-proxy) 等。
|
||||||
|
3. `kubectl delete NODE` 将节点移出集群。
|
||||||
|
4. 如果节点是虚拟机,并且不需要了,可以直接销毁掉。
|
||||||
|
|
||||||
|
前 3 个步骤,也可以用 kubespray 提供的 `remove-node.yml` 这个 playbook 来一步到位实现:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
ansible-playbook \
|
||||||
|
-i inventory/mycluster/inventory.ini \
|
||||||
|
--private-key=id_rsa \
|
||||||
|
--user=ubuntu -b \
|
||||||
|
--extra-vars "node=node1,node2" \
|
||||||
|
remove-node.yml
|
||||||
|
```
|
||||||
|
|
||||||
|
> `--extra-vars` 里写要移出的节点名列表,如果节点已经卡死,无法通过 SSH 登录,可以在 `--extra-vars` 加个 `reset_nodes=false` 的选项,跳过第二个步骤。
|
||||||
|
|
||||||
|
|
@ -0,0 +1,113 @@
|
||||||
|
# kubespray 离线安装配置
|
||||||
|
|
||||||
|
## 背景
|
||||||
|
|
||||||
|
在国内使用 kubespray 安装 Kubernetes 集群,下载依赖的文件和镜像时,往往会遇到下载失败,这时我们可以利用 kubespray 离线安装配置的能力来部署集群。
|
||||||
|
|
||||||
|
## 准备工作
|
||||||
|
|
||||||
|
要想离线安装,首先做下以下准备:
|
||||||
|
1. 一台不受 GFW 限制的服务器或 PC,用于下载安装 Kubernetes 所依赖的海外文件和镜像。
|
||||||
|
2. 一个用于离线安装的静态服务器,存储安装集群所需的二进制静态文件。通常使用 nginx 搭建静态服务器即可。
|
||||||
|
3. 一个用于离线安装的镜像仓库,存储安装集群所需的依赖镜像。比如自己搭建的 Harbor,只要网络可以通,能够正常拉取到镜像即可。
|
||||||
|
|
||||||
|
## 生成依赖文件和镜像的列表
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ cd contrib/offline
|
||||||
|
$ bash generate_list.sh
|
||||||
|
$ tree temp/
|
||||||
|
temp/
|
||||||
|
├── files.list
|
||||||
|
├── files.list.template
|
||||||
|
├── images.list
|
||||||
|
└── images.list.template
|
||||||
|
```
|
||||||
|
|
||||||
|
* `flies.list` 是依赖文件的列表。
|
||||||
|
* `images.list` 是依赖镜像的列表。
|
||||||
|
|
||||||
|
## 搬运文件
|
||||||
|
|
||||||
|
执行以下命令将依赖的静态文件全部下载到 `temp/files` 目录下:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
wget -x -P temp/files -i temp/files.list
|
||||||
|
```
|
||||||
|
|
||||||
|
将静态文件通过静态服务器暴露出来,比如使用 nginx,根据情况修改 nginx 配置,比如:
|
||||||
|
|
||||||
|
```nginx.conf
|
||||||
|
user root;
|
||||||
|
server {
|
||||||
|
listen 80 default_server;
|
||||||
|
listen [::]:80 default_server;
|
||||||
|
location /k8s/ {
|
||||||
|
alias /root/kubespray/contrib/offline/temp/files/;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
## 搬运镜像
|
||||||
|
|
||||||
|
我们可以使用 [skopeo](https://github.com/containers/skopeo) 将依赖的镜像同步到我们自己的镜像仓库,安装方法参考 [官方安装文档](https://github.com/containers/skopeo/blob/main/install.md)。
|
||||||
|
|
||||||
|
安装好后,登录下自己的镜像仓库:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ skopeo login cr.imroc.cc
|
||||||
|
Username: admin
|
||||||
|
Password:
|
||||||
|
Login Succeeded!
|
||||||
|
```
|
||||||
|
|
||||||
|
然后将所有依赖镜像同步到我们自己的镜像仓库:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
for image in $(cat temp/images.list); do skopeo copy docker://${image} docker://cr.imroc.cc/k8s/${image#*/}; done
|
||||||
|
```
|
||||||
|
|
||||||
|
注意事项:
|
||||||
|
1. 替换成自己的仓库地址。
|
||||||
|
2. 提前创建好仓库,比如用 harbor,提前创建好名为 "k8s" 的项目,以便将所有镜像都同步到 "k8s" 这个项目路径下。
|
||||||
|
3. 如果直接二进制安装 skopeo,需提前创建好配置文件 `/etc/containers/policy.json`,内容可以用默认的,参考 [default-policy.json](https://github.com/containers/skopeo/blob/main/default-policy.json)。
|
||||||
|
|
||||||
|
## 修改 offline.yml
|
||||||
|
|
||||||
|
搬运好了文件和镜像,我们来修改下 kubespray 的地址,让依赖的文件和镜像下载地址使用我们自己的地址,修改 `/root/kubespray/inventory/mycluster/group_vars/all/offline.yml`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
# 替换镜像地址
|
||||||
|
registry_host: "cr.imroc.cc/k8s"
|
||||||
|
kube_image_repo: "{{ registry_host }}"
|
||||||
|
gcr_image_repo: "{{ registry_host }}"
|
||||||
|
github_image_repo: "{{ registry_host }}"
|
||||||
|
docker_image_repo: "{{ registry_host }}"
|
||||||
|
quay_image_repo: "{{ registry_host }}"
|
||||||
|
|
||||||
|
# 替换静态文件地址
|
||||||
|
files_repo: "http://10.10.10.14/k8s"
|
||||||
|
kubeadm_download_url: "{{ files_repo }}/storage.googleapis.com/kubernetes-release/release/{{ kube_version }}/bin/linux/{{ image_arch }}/kubeadm"
|
||||||
|
kubectl_download_url: "{{ files_repo }}/storage.googleapis.com/kubernetes-release/release/{{ kube_version }}/bin/linux/{{ image_arch }}/kubectl"
|
||||||
|
kubelet_download_url: "{{ files_repo }}/storage.googleapis.com/kubernetes-release/release/{{ kube_version }}/bin/linux/{{ image_arch }}/kubelet"
|
||||||
|
cni_download_url: "{{ files_repo }}/github.com/containernetworking/plugins/releases/download/{{ cni_version }}/cni-plugins-linux-{{ image_arch }}-{{ cni_version }}.tgz"
|
||||||
|
crictl_download_url: "{{ files_repo }}/github.com/kubernetes-sigs/cri-tools/releases/download/{{ crictl_version }}/crictl-{{ crictl_version }}-{{ ansible_system | lower }}-{{ image_arch }}.tar.gz"
|
||||||
|
etcd_download_url: "{{ files_repo }}/github.com/etcd-io/etcd/releases/download/{{ etcd_version }}/etcd-{{ etcd_version }}-linux-{{ image_arch }}.tar.gz"
|
||||||
|
calicoctl_download_url: "{{ files_repo }}/github.com/projectcalico/calico/releases/download/{{ calico_ctl_version }}/calicoctl-linux-{{ image_arch }}"
|
||||||
|
calico_crds_download_url: "{{ files_repo }}/github.com/projectcalico/calico/archive/{{ calico_version }}.tar.gz"
|
||||||
|
flannel_cni_download_url: "{{ files_repo }}/github.com/flannel-io/cni-plugin/releases/download/{{ flannel_cni_version }}/flannel-{{ image_arch }}"
|
||||||
|
helm_download_url: "{{ files_repo }}/get.helm.sh/helm-{{ helm_version }}-linux-{{ image_arch }}.tar.gz"
|
||||||
|
crun_download_url: "{{ files_repo }}/github.com/containers/crun/releases/download/{{ crun_version }}/crun-{{ crun_version }}-linux-{{ image_arch }}"
|
||||||
|
kata_containers_download_url: "{{ files_repo }}/github.com/kata-containers/kata-containers/releases/download/{{ kata_containers_version }}/kata-static-{{ kata_containers_version }}-{{ ansible_architecture }}.tar.xz"
|
||||||
|
runc_download_url: "{{ files_repo }}/github.com/opencontainers/runc/releases/download/{{ runc_version }}/runc.{{ image_arch }}"
|
||||||
|
containerd_download_url: "{{ files_repo }}/github.com/containerd/containerd/releases/download/v{{ containerd_version }}/containerd-{{ containerd_version }}-linux-{{ image_arch }}.tar.gz"
|
||||||
|
nerdctl_download_url: "{{ files_repo }}/github.com/containerd/nerdctl/releases/download/v{{ nerdctl_version }}/nerdctl-{{ nerdctl_version }}-{{ ansible_system | lower }}-{{ image_arch }}.tar.gz"
|
||||||
|
krew_download_url: "{{ files_repo }}/github.com/kubernetes-sigs/krew/releases/download/{{ krew_version }}/krew-{{ host_os }}_{{ image_arch }}.tar.gz"
|
||||||
|
cri_dockerd_download_url: "{{ files_repo }}/github.com/Mirantis/cri-dockerd/releases/download/{{ cri_dockerd_version }}/cri-dockerd-{{ cri_dockerd_version }}-linux-{{ image_arch }}.tar.gz"
|
||||||
|
gvisor_runsc_download_url: "{{ files_repo }}/storage.googleapis.com/gvisor/releases/release/{{ gvisor_version }}/{{ ansible_architecture }}/runsc"
|
||||||
|
gvisor_containerd_shim_runsc_download_url: "{{ files_repo }}/storage.googleapis.com/gvisor/releases/release/{{ gvisor_version }}/{{ ansible_architecture }}/containerd-shim-runsc-v1"
|
||||||
|
youki_download_url: "{{ files_repo }}/github.com/containers/youki/releases/download/v{{ youki_version }}/youki_v{{ youki_version | regex_replace('\\.', '_') }}_linux.tar.gz"
|
||||||
|
```
|
||||||
|
|
||||||
|
> `xxx_download_url` 不是直接 uncomment 得到的,是通过 `images.list.template` 里的内容加上 `{{ files_repo }}` 拼接而来。
|
||||||
|
|
||||||
|
|
@ -0,0 +1,64 @@
|
||||||
|
# 使用 Terraform 创建集群
|
||||||
|
|
||||||
|
利用 Terrafrom 可以创建各种云上产品化的 Kubernetes 集群。
|
||||||
|
|
||||||
|
## 准备配置文件
|
||||||
|
|
||||||
|
创建 `main.tf`, 可参考[附录](../appendix/terraform) 中的示例,根据自己需求按照注释提示替换内容
|
||||||
|
|
||||||
|
## 创建集群
|
||||||
|
|
||||||
|
在 `main.tf` 所在目录执行 `terraform init`,然后再执行 `terraform apply`,输入 `yes` 确认执行。
|
||||||
|
|
||||||
|
等待大约1分多钟,会自动打印创建出来的集群 id:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
tencentcloud_eks_cluster.roc-test: Still creating... [1m10s elapsed]
|
||||||
|
tencentcloud_eks_cluster.roc-test: Still creating... [1m20s elapsed]
|
||||||
|
tencentcloud_eks_cluster.roc-test: Creation complete after 1m21s [id=cls-4d2qxcs5]
|
||||||
|
|
||||||
|
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.
|
||||||
|
```
|
||||||
|
|
||||||
|
## 获取 kubeconfig
|
||||||
|
|
||||||
|
集群刚创建好的时候,APIServer 外网访问的 CLB 还没创建好,不知道外网 IP 地址,terraform 本地记录的状态里,kubeconfig 的 server 地址就为空。所以我们先 refresh 一下,将创建好的 server 地址同步到本地:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
terraform refresh
|
||||||
|
```
|
||||||
|
|
||||||
|
然后导出 kubeconfig 文件:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
terraform show -json | jq -r '.values.root_module.resources[] | select(.address | test("tencentcloud_eks_cluster.roc-test")) | .values.kube_config' > eks
|
||||||
|
```
|
||||||
|
|
||||||
|
> 注意替换 `roc-test` 为自己在 `main.tf` 文件中定义的名字。
|
||||||
|
|
||||||
|
使用 [kubecm](../trick/kubectl/merge-kubeconfig-with-kubecm.md) 可以一键导入合并 kubeconfig:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubecm add -f eks
|
||||||
|
```
|
||||||
|
|
||||||
|
使用 [kubectx](../trick/kubectl/quick-switch-with-kubectx.md) 可以切换 context:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl ctx eks
|
||||||
|
```
|
||||||
|
|
||||||
|
然后就可以使用 kubectl 操作集群了。
|
||||||
|
|
||||||
|
## 销毁集群
|
||||||
|
|
||||||
|
在 `main.tf` 所在目录执行:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
terraform destroy
|
||||||
|
```
|
||||||
|
|
||||||
|
## 参考资料
|
||||||
|
|
||||||
|
* [Terrafrom TencentCloud Provider Documentation](https://registry.terraform.io/providers/tencentcloudstack/tencentcloud/latest/docs)
|
||||||
|
|
||||||
|
|
@ -0,0 +1,121 @@
|
||||||
|
# Grafana 高可用部署
|
||||||
|
|
||||||
|
## 概述
|
||||||
|
|
||||||
|
Grafana 默认安装是单副本,非高可用部署,而 Grafana 自身是支持多副本高可用部署的,本文介绍其配置方法以及已经安装的 Grafana 如何迁移到高可用架构。
|
||||||
|
|
||||||
|
## 修改配置
|
||||||
|
|
||||||
|
要让 Grafana 支持高可用,需要对 Grafana 配置文件 (`grafana.ini`) 进行一些关键的修改:
|
||||||
|
|
||||||
|
1. Grafana 默认使用 sqlite3 文件存储数据,多副本共享可能会有数据冲突,可以配置一下 `database` 让多副本共享同一个 mysql 或 postgres 数据库,这样多副本就可以无状态横向伸缩。
|
||||||
|
2. Grafana 多副本运行,如果配置了告警规则,每个副本都会重复告警,配置一下 `ha_peers` 让 Grafana 自行选主只让其中一个副本执行告警。
|
||||||
|
|
||||||
|
```ini
|
||||||
|
[database]
|
||||||
|
url = mysql://root:123456@mysql.db.svc.cluster.local:3306/grafana
|
||||||
|
[unified_alerting]
|
||||||
|
enabled = true
|
||||||
|
ha_peers = monitoring-grafana-headless.svc.monitoring.cluster.local:9094
|
||||||
|
[alerting]
|
||||||
|
enabled = false
|
||||||
|
```
|
||||||
|
|
||||||
|
* `database` 下配置数据库连接信息,包含数据库类型、用户名、密码、数据库地址、端口以及要具体哪个库。
|
||||||
|
* `alerting` 的 `enabled` 置为 false,表示禁用默认的告警方式(每个 Grafana 实例都单独告警)。
|
||||||
|
* `unified_alerting` 的 `enabled` 置为 true,表示开启高可用告警。
|
||||||
|
* `unified_alerting` 的 `ha_peers` 填入 Grafana 所有实例的地址,在 k8s 环境可用 headless service,dns 会自动解析到所有 pod ip 来实现自动发现 Grafana 所有 IP,端口默认是 9094,用于 gossip 协议实现高可用。
|
||||||
|
|
||||||
|
## helm chart 配置示例
|
||||||
|
|
||||||
|
如果 grafana 安装到 Kubernetes,通常使用 helm chart 来安装,一般是 [grafana 官方 chart](https://github.com/grafana/helm-charts/tree/main/charts/grafana),`values.yaml` 配置示例:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
replicas: 2
|
||||||
|
defaultDashboardsTimezone: browser
|
||||||
|
grafana.ini:
|
||||||
|
unified_alerting:
|
||||||
|
enabled: true
|
||||||
|
ha_peers: 'monitoring-grafana-headless.monitoring.svc.cluster.local:9094'
|
||||||
|
alerting:
|
||||||
|
enabled: false
|
||||||
|
database:
|
||||||
|
url: 'mysql://root:123456@mysql.db.svc.cluster.local:3306/grafana'
|
||||||
|
server:
|
||||||
|
root_url: "https://grafana.imroc.cc"
|
||||||
|
paths:
|
||||||
|
data: /var/lib/grafana/
|
||||||
|
logs: /var/log/grafana
|
||||||
|
plugins: /var/lib/grafana/plugins
|
||||||
|
provisioning: /etc/grafana/provisioning
|
||||||
|
analytics:
|
||||||
|
check_for_updates: true
|
||||||
|
log:
|
||||||
|
mode: console
|
||||||
|
grafana_net:
|
||||||
|
url: https://grafana.net
|
||||||
|
```
|
||||||
|
|
||||||
|
* `grafana.ini` 字段用于修改 grafana 配置文件内容,使用 `yaml` 格式定义,会自动转成 `ini`。
|
||||||
|
* `ha_peers` 指向的 headless service 自行提前创建(当前 chart 内置的 headless 没暴露 9094 端口)。
|
||||||
|
|
||||||
|
headless service 示例:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: v1
|
||||||
|
kind: Service
|
||||||
|
metadata:
|
||||||
|
name: monitoring-grafana-headless
|
||||||
|
namespace: monitoring
|
||||||
|
spec:
|
||||||
|
clusterIP: None
|
||||||
|
ports:
|
||||||
|
- name: http-web
|
||||||
|
port: 3000
|
||||||
|
protocol: TCP
|
||||||
|
targetPort: 3000
|
||||||
|
- name: alert
|
||||||
|
port: 9094
|
||||||
|
protocol: TCP
|
||||||
|
targetPort: 9094
|
||||||
|
selector:
|
||||||
|
app.kubernetes.io/instance: monitoring
|
||||||
|
app.kubernetes.io/name: grafana
|
||||||
|
type: ClusterIP
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你使用的 [kube-prometheus-stack](https://github.com/prometheus-community/helm-charts/tree/main/charts/kube-prometheus-stack) 安装,实际也是用的 Grafana 官方的 chart,只不过作为了一个子 chart,写 `values.yaml` 时将上面准备的配置放到 `grafana` 字段下面即可:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
grafana:
|
||||||
|
replicas: 2
|
||||||
|
defaultDashboardsTimezone: browser
|
||||||
|
grafana.ini:
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
## 已安装的 Grafana 如何迁移到高可用架构 ?
|
||||||
|
|
||||||
|
如果你用的默认安装,使用 sqlite3 文件存储数据,可以先按照如下步骤迁移数据:
|
||||||
|
|
||||||
|
1. 拿到 `grafana.db` 文件,使用 Grafana 官方提供的迁移脚本 [sqlitedump.sh](https://github.com/grafana/database-migrator) 将 sqlite3 的数据转换成 sql 文件:
|
||||||
|
```bash
|
||||||
|
sqlitedump.sh grafana.db > grafana.sql
|
||||||
|
```
|
||||||
|
> 确保环境中安装了 sqlite3 命令。
|
||||||
|
2. 停止 Grafana (如果是 K8S 部署,可以修改副本数为 0)。
|
||||||
|
3. 准备好数据库,提前创建好 grafana database:
|
||||||
|
```sql
|
||||||
|
CREATE DATABASE grafana;
|
||||||
|
```
|
||||||
|
4. 替换 Grafana 配置文件,参考前面的配置示例。
|
||||||
|
5. 启动 Grafana,让 Grafana 自动初始化数据库。
|
||||||
|
6. 将 sql 文件导入数据库执行:
|
||||||
|
```bash
|
||||||
|
mysql -h172.16.181.186 -P3306 -uroot -p123456 grafana < grafana.sql
|
||||||
|
```
|
||||||
|
7. 恢复 Grafana 运行。
|
||||||
|
|
||||||
|
## 参考资料
|
||||||
|
|
||||||
|
- [Set up Grafana for high availability](https://grafana.com/docs/grafana/latest/setup-grafana/set-up-for-high-availability/)
|
||||||
|
|
@ -0,0 +1,315 @@
|
||||||
|
# 使用 operator 部署 VictoriaMetrics
|
||||||
|
|
||||||
|
## VictoriaMetrics 架构概览
|
||||||
|
|
||||||
|
以下是 VictoriaMetrics 的核心组件架构图:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
* `vmstorage` 负责存储数据,是有状态组件。
|
||||||
|
* `vmselect` 负责查询数据,Grafana 添加 Prometheus 数据源时使用 `vmselect` 地址,查询数据时,`vmselect` 会调用各个 `vmstorage` 的接口完成数据的查询。
|
||||||
|
* `vminsert` 负责写入数据,采集器将采集到的数据 "吐到" `vminsert`,然后 `vminsert` 会调用各个 `vmstorage` 的接口完成数据的写入。
|
||||||
|
* 各个组件都可以水平伸缩,但不支持自动伸缩,因为伸缩需要修改启动参数。
|
||||||
|
|
||||||
|
## 安装 operator
|
||||||
|
|
||||||
|
使用 helm 安装:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
helm repo add vm https://victoriametrics.github.io/helm-charts
|
||||||
|
helm repo update
|
||||||
|
helm install victoria-operator vm/victoria-metrics-operator
|
||||||
|
```
|
||||||
|
|
||||||
|
检查 operator 是否成功启动:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ kubectl -n monitoring get pod
|
||||||
|
NAME READY STATUS RESTARTS AGE
|
||||||
|
victoria-operator-victoria-metrics-operator-7b886f85bb-jf6ng 1/1 Running 0 20s
|
||||||
|
```
|
||||||
|
|
||||||
|
## 安装 VMSorage, VMSelect 与 VMInsert
|
||||||
|
|
||||||
|
准备 `vmcluster.yaml`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: operator.victoriametrics.com/v1beta1
|
||||||
|
kind: VMCluster
|
||||||
|
metadata:
|
||||||
|
name: vmcluster
|
||||||
|
namespace: monitoring
|
||||||
|
spec:
|
||||||
|
retentionPeriod: "1" # 默认单位是月,参考 https://docs.victoriametrics.com/Single-server-VictoriaMetrics.html#retention
|
||||||
|
vmstorage:
|
||||||
|
replicaCount: 2
|
||||||
|
storage:
|
||||||
|
volumeClaimTemplate:
|
||||||
|
metadata:
|
||||||
|
name: data
|
||||||
|
spec:
|
||||||
|
accessModes: [ "ReadWriteOnce" ]
|
||||||
|
storageClassName: cbs
|
||||||
|
resources:
|
||||||
|
requests:
|
||||||
|
storage: 100Gi
|
||||||
|
vmselect:
|
||||||
|
replicaCount: 2
|
||||||
|
vminsert:
|
||||||
|
replicaCount: 2
|
||||||
|
```
|
||||||
|
|
||||||
|
安装:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ kubectl apply -f vmcluster.yaml
|
||||||
|
vmcluster.operator.victoriametrics.com/vmcluster created
|
||||||
|
```
|
||||||
|
|
||||||
|
检查组件是否启动成功:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ kubectl -n monitoring get pod | grep vmcluster
|
||||||
|
vminsert-vmcluster-77886b8dcb-jqpfw 1/1 Running 0 20s
|
||||||
|
vminsert-vmcluster-77886b8dcb-l5wrg 1/1 Running 0 20s
|
||||||
|
vmselect-vmcluster-0 1/1 Running 0 20s
|
||||||
|
vmselect-vmcluster-1 1/1 Running 0 20s
|
||||||
|
vmstorage-vmcluster-0 1/1 Running 0 20s
|
||||||
|
vmstorage-vmcluster-1 1/1 Running 0 20s
|
||||||
|
```
|
||||||
|
|
||||||
|
## 安装 VMAlertmanager 与 VMAlert
|
||||||
|
|
||||||
|
准备 `vmalertmanager.yaml`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: operator.victoriametrics.com/v1beta1
|
||||||
|
kind: VMAlertmanager
|
||||||
|
metadata:
|
||||||
|
name: vmalertmanager
|
||||||
|
namespace: monitoring
|
||||||
|
spec:
|
||||||
|
replicaCount: 1
|
||||||
|
selectAllByDefault: true
|
||||||
|
```
|
||||||
|
|
||||||
|
安装 `VMAlertmanager`:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ kubectl apply -f vmalertmanager.yaml
|
||||||
|
vmalertmanager.operator.victoriametrics.com/vmalertmanager created
|
||||||
|
```
|
||||||
|
|
||||||
|
准备 `vmalert.yaml`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: operator.victoriametrics.com/v1beta1
|
||||||
|
kind: VMAlert
|
||||||
|
metadata:
|
||||||
|
name: vmalert
|
||||||
|
namespace: monitoring
|
||||||
|
spec:
|
||||||
|
replicaCount: 1
|
||||||
|
selectAllByDefault: true
|
||||||
|
notifier:
|
||||||
|
url: http://vmalertmanager-vmalertmanager:9093
|
||||||
|
resources:
|
||||||
|
requests:
|
||||||
|
cpu: 10m
|
||||||
|
memory: 10Mi
|
||||||
|
remoteWrite:
|
||||||
|
url: http://vminsert-vmcluster:8480/insert/0/prometheus/
|
||||||
|
remoteRead:
|
||||||
|
url: http://vmselect-vmcluster:8481/select/0/prometheus/
|
||||||
|
datasource:
|
||||||
|
url: http://vmselect-vmcluster:8481/select/0/prometheus/
|
||||||
|
```
|
||||||
|
|
||||||
|
安装 `VMAlert`:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ kubectl apply -f vmalert.yaml
|
||||||
|
vmalert.operator.victoriametrics.com/vmalert created
|
||||||
|
```
|
||||||
|
|
||||||
|
检查组件是否启动成功:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ kubectl -n monitoring get pod | grep vmalert
|
||||||
|
vmalert-vmalert-5987fb9d5f-9wt6l 2/2 Running 0 20s
|
||||||
|
vmalertmanager-vmalertmanager-0 2/2 Running 0 40s
|
||||||
|
```
|
||||||
|
|
||||||
|
## 安装 VMAgent
|
||||||
|
|
||||||
|
vmagent 用于采集监控数据并发送给 VictoriaMetrics 进行存储,对于腾讯云容器服务上的容器监控数据采集,需要用自定义的 `additionalScrapeConfigs` 配置,准备自定义采集规则配置文件 `scrape-config.yaml`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: v1
|
||||||
|
kind: Secret
|
||||||
|
type: Opaque
|
||||||
|
metadata:
|
||||||
|
name: additional-scrape-configs
|
||||||
|
namespace: monitoring
|
||||||
|
stringData:
|
||||||
|
additional-scrape-configs.yaml: |-
|
||||||
|
- job_name: "tke-cadvisor"
|
||||||
|
scheme: https
|
||||||
|
metrics_path: /metrics/cadvisor
|
||||||
|
tls_config:
|
||||||
|
insecure_skip_verify: true
|
||||||
|
authorization:
|
||||||
|
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
|
||||||
|
kubernetes_sd_configs:
|
||||||
|
- role: node
|
||||||
|
relabel_configs:
|
||||||
|
- source_labels: [__meta_kubernetes_node_label_node_kubernetes_io_instance_type]
|
||||||
|
regex: eklet
|
||||||
|
action: drop
|
||||||
|
- action: labelmap
|
||||||
|
regex: __meta_kubernetes_node_label_(.+)
|
||||||
|
- job_name: "tke-kubelet"
|
||||||
|
scheme: https
|
||||||
|
metrics_path: /metrics
|
||||||
|
tls_config:
|
||||||
|
insecure_skip_verify: true
|
||||||
|
authorization:
|
||||||
|
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
|
||||||
|
kubernetes_sd_configs:
|
||||||
|
- role: node
|
||||||
|
relabel_configs:
|
||||||
|
- source_labels: [__meta_kubernetes_node_label_node_kubernetes_io_instance_type]
|
||||||
|
regex: eklet
|
||||||
|
action: drop
|
||||||
|
- action: labelmap
|
||||||
|
regex: __meta_kubernetes_node_label_(.+)
|
||||||
|
- job_name: "tke-probes"
|
||||||
|
scheme: https
|
||||||
|
metrics_path: /metrics/probes
|
||||||
|
tls_config:
|
||||||
|
insecure_skip_verify: true
|
||||||
|
authorization:
|
||||||
|
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
|
||||||
|
kubernetes_sd_configs:
|
||||||
|
- role: node
|
||||||
|
relabel_configs:
|
||||||
|
- source_labels: [__meta_kubernetes_node_label_node_kubernetes_io_instance_type]
|
||||||
|
regex: eklet
|
||||||
|
action: drop
|
||||||
|
- action: labelmap
|
||||||
|
regex: __meta_kubernetes_node_label_(.+)
|
||||||
|
- job_name: eks
|
||||||
|
honor_timestamps: true
|
||||||
|
metrics_path: '/metrics'
|
||||||
|
params:
|
||||||
|
collect[]: ['ipvs']
|
||||||
|
# - 'cpu'
|
||||||
|
# - 'meminfo'
|
||||||
|
# - 'diskstats'
|
||||||
|
# - 'filesystem'
|
||||||
|
# - 'load0vg'
|
||||||
|
# - 'netdev'
|
||||||
|
# - 'filefd'
|
||||||
|
# - 'pressure'
|
||||||
|
# - 'vmstat'
|
||||||
|
scheme: http
|
||||||
|
kubernetes_sd_configs:
|
||||||
|
- role: pod
|
||||||
|
relabel_configs:
|
||||||
|
- source_labels: [__meta_kubernetes_pod_annotation_tke_cloud_tencent_com_pod_type]
|
||||||
|
regex: eklet
|
||||||
|
action: keep
|
||||||
|
- source_labels: [__meta_kubernetes_pod_phase]
|
||||||
|
regex: Running
|
||||||
|
action: keep
|
||||||
|
- source_labels: [__meta_kubernetes_pod_ip]
|
||||||
|
separator: ;
|
||||||
|
regex: (.*)
|
||||||
|
target_label: __address__
|
||||||
|
replacement: ${1}:9100
|
||||||
|
action: replace
|
||||||
|
- source_labels: [__meta_kubernetes_pod_name]
|
||||||
|
separator: ;
|
||||||
|
regex: (.*)
|
||||||
|
target_label: pod
|
||||||
|
replacement: ${1}
|
||||||
|
action: replace
|
||||||
|
- source_labels: [__meta_kubernetes_namespace]
|
||||||
|
separator: ;
|
||||||
|
regex: (.*)
|
||||||
|
target_label: namespace
|
||||||
|
replacement: ${1}
|
||||||
|
action: replace
|
||||||
|
metric_relabel_configs:
|
||||||
|
- source_labels: [__name__]
|
||||||
|
separator: ;
|
||||||
|
regex: (container_.*|pod_.*|kubelet_.*)
|
||||||
|
replacement: $1
|
||||||
|
action: keep
|
||||||
|
```
|
||||||
|
|
||||||
|
再准备 `vmagent.yaml`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: operator.victoriametrics.com/v1beta1
|
||||||
|
kind: VMAgent
|
||||||
|
metadata:
|
||||||
|
name: vmagent
|
||||||
|
namespace: monitoring
|
||||||
|
spec:
|
||||||
|
selectAllByDefault: true
|
||||||
|
additionalScrapeConfigs:
|
||||||
|
key: additional-scrape-configs.yaml
|
||||||
|
name: additional-scrape-configs
|
||||||
|
resources:
|
||||||
|
requests:
|
||||||
|
cpu: 10m
|
||||||
|
memory: 10Mi
|
||||||
|
replicaCount: 1
|
||||||
|
remoteWrite:
|
||||||
|
- url: "http://vminsert-vmcluster:8480/insert/0/prometheus/api/v1/write"
|
||||||
|
```
|
||||||
|
|
||||||
|
安装:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ kubectl apply -f scrape-config.yaml
|
||||||
|
secret/additional-scrape-configs created
|
||||||
|
$ kubectl apply -f vmagent.yaml
|
||||||
|
vmagent.operator.victoriametrics.com/vmagent created
|
||||||
|
```
|
||||||
|
|
||||||
|
检查组件是否启动成功:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ kubectl -n monitoring get pod | grep vmagent
|
||||||
|
vmagent-vmagent-cf9bbdbb4-tm4w9 2/2 Running 0 20s
|
||||||
|
vmagent-vmagent-cf9bbdbb4-ija8r 2/2 Running 0 20s
|
||||||
|
```
|
||||||
|
|
||||||
|
## 配置 Grafana
|
||||||
|
|
||||||
|
### 添加数据源
|
||||||
|
|
||||||
|
VictoriaMetrics 兼容 Prometheus,在 Grafana 添加数据源时,使用 Prometheus 类型,如果 Grafana 跟 VictoriaMetrics 安装在同一集群中,可以使用 service 地址,如:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
http://vmselect-vmcluster:8481/select/0/prometheus/
|
||||||
|
```
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 添加 Dashboard
|
||||||
|
|
||||||
|
VictoriaMetrics 官方提供了几个 Grafana Dashboard,id 分别是:
|
||||||
|
1. 11176
|
||||||
|
2. 12683
|
||||||
|
3. 14205
|
||||||
|
|
||||||
|
可以将其导入 Grafana:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
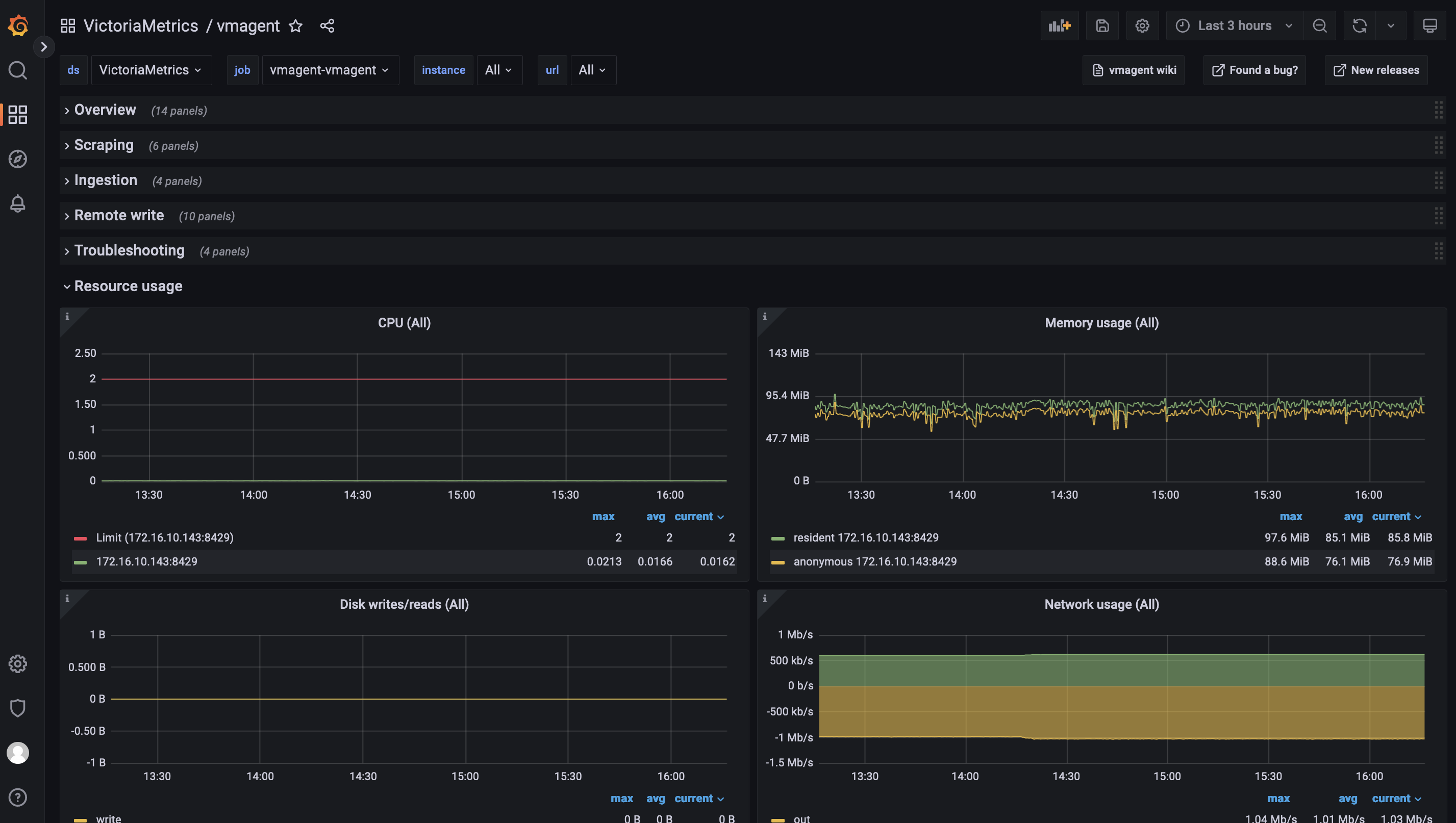
|
||||||
|
|
@ -0,0 +1,58 @@
|
||||||
|
# ipvs 连接复用引发的系列问题
|
||||||
|
|
||||||
|
在 Kubernetes 社区里面有一个讨论已久的 bug ([#81775](https://github.com/kubernetes/kubernetes/issues/81775)),这个问题是当 client 对 service 发起大量新建 TCP 连接时,新的连接被转发到 Terminating 或已完全销毁的旧 Pod 上,导致持续丢包 (报错 `no route to host`),其根因是内核 ipvs 连接复用引发,本文来详细掰扯下。
|
||||||
|
|
||||||
|
## conn_reuse_mode 简介
|
||||||
|
|
||||||
|
在介绍原因之前,我们先介绍下 `conn_reuse_mode` 这个内核参数,它是以下两个 patch 引入的:
|
||||||
|
|
||||||
|
1. year 2015 d752c364571743d696c2a54a449ce77550c35ac5
|
||||||
|
2. year 2016 f719e3754ee2f7275437e61a6afd520181fdd43b
|
||||||
|
|
||||||
|
其目的是:
|
||||||
|
1. 当 `client ip:client port` 复用发生时,对于 `TIME_WAIT` 状态下的 ip_vs_conn,进行重新调度,使得 connection 在 rs 上的分布更均衡,以提高性能。
|
||||||
|
2. 如果该 mode 是 0,则会复用旧 ip_vs_conn 里的 rs,使得连接更不均衡。
|
||||||
|
|
||||||
|
所以当 `conn_reuse_mode` 为 0 表示启用 ipvs 连接复用,为 1 表示不复用,是不是有点反直觉?这个确实也比较有争议。
|
||||||
|
|
||||||
|
## conn_reuse_mode=1 的 bug
|
||||||
|
|
||||||
|
开启这个内核参数 (`conn_reuse_mode=1`) 本意是为了提高新建的性能,实际结果是大幅度降低了性能,实际测试中发现 cps 从 3w 降低到了 1.5K,这也表明内核社区的一些 patch 没有经过严格的性能测试。
|
||||||
|
|
||||||
|
开启这个内核参数实际就表示 ipvs 转发时不做连接复用,每次新建的连接都会重新调度 rs 并新建 ip_vs_conn,但它的实现有个问题: 在新建连接时 (SYN 包),如果 `client ip:client port` 匹配到了 ipvs 旧连接 (`TIME_WIAT` 状态),且使用了 conntrack,就会丢掉第一个 SYN 包,等待重传后 (1s) 才能成功建连,从而导致建连性能急剧下降。
|
||||||
|
|
||||||
|
Kubernetes 社区也发现了这个 bug,所以当 kube-proxy 使用 ipvs 转发模式时,默认将 `conn_reuse_mode` 置为 0 来规避这个问题,详见 PR [#71114](https://github.com/kubernetes/kubernetes/pull/71114) 与 issue [#70747](https://github.com/kubernetes/kubernetes/issues/70747) 。
|
||||||
|
|
||||||
|
## conn_reuse_mode=0 引发的问题
|
||||||
|
|
||||||
|
由于 Kubernetes 为了规避 `conn_reuse_mode=1` 带来的性能问题,在 ipvs 模式下,让 kube-proxy 在启动时将 `conn_reuse_mode` 置为了 0 ,即使用 ipvs 连接复用的能力,但 ipvs 连接复用有两个问题:
|
||||||
|
|
||||||
|
1. 只要有 `client ip:client port` 匹配上 ip_vs_conn (发生复用),就直接转发给对应的 rs,不管 rs 当前是什么状态,即便 rs 的 weight 为 0 (通常是 `TIME_WAIT` 状态) 也会转发,`TIME_WAIT` 的 rs 通常是 Terminating 状态已销毁的 Pod,转发过去的话连接就必然异常。
|
||||||
|
2. 高并发下大量复用,没有为新连接没有调度 rs,直接转发到所复用连接对应的 rs 上,导致很多新连接被 "固化" 到部分 rs 上。
|
||||||
|
|
||||||
|
业务中实际遇到的现象可能有很多种:
|
||||||
|
|
||||||
|
1. **滚动更新连接异常。** 被访问的服务滚动更新时,Pod 有新建有销毁,ipvs 发生连接复用时转发到了已销毁的 Pod 导致连接异常 (`no route to host`)。
|
||||||
|
2. **滚动更新负载不均。** 由于复用时不会重新调度连接,导致新连接也被 "固化" 在某些 Pod 上了。
|
||||||
|
3. **新扩容的 Pod 接收流量少。** 同样也是由于复用时不会重新调度连接,导致很多新连接被 "固化" 在扩容之前的这些 Pod 上了。
|
||||||
|
|
||||||
|
## 规避方案
|
||||||
|
|
||||||
|
我们知道了问题原因,那么在 ipvs 转发模式下该如何规避呢?我们从南北向和东西向分别考虑下。
|
||||||
|
|
||||||
|
### 南北向流量
|
||||||
|
|
||||||
|
1. 使用 LB 直通 Pod。对于南北向流量,通常依赖 NodePort 来暴露,前面的负载均衡器将流量先转到 NodePort 上,然后再通过 ipvs 转发到后端 Pod。现在很多云厂商都支持 LB 直通 Pod,这种模式下负载均衡器直接将请求转发到 Pod,不经过 NodePort,也就没有 ipvs 转发,从而在流量接入层规避这个问题。
|
||||||
|
2. 使用 ingress 转发。在集群中部署 ingress controller (比如 nginx ingress),流量到达 ingress 再向后转时 (转发到集群内的 Pod),不会经过 service 转发,而是直接转发到 service 对应的 `Pod IP:Port`,也就绕过了 ipvs。Ingress controller 本身结合使用前面所说的 LB 直通 Pod 方式部署,效果更佳。
|
||||||
|
|
||||||
|
### 东西向流量
|
||||||
|
|
||||||
|
集群内的服务间调用 (东西向流量),默认还是会走 ipvs 转发。对于有这种高并发场景的业务,我们可以考虑使用 Serivce Mesh (如 istio) 来治理流量,服务间转发由 sidecar 代理,并且不会经过 ipvs。
|
||||||
|
|
||||||
|
## 终极方案: 内核修复
|
||||||
|
|
||||||
|
`conn_reuse_mode=1` 引发性能急需下降的 bug,目前在腾讯云提供的 [TencentOS-kernel](https://github.com/Tencent/TencentOS-kernel) 开源内核已修复,对应 PR [#17](https://github.com/Tencent/TencentOS-kernel/pull/17), [TKE](https://cloud.tencent.com/product/tke) 上的解决方案就是使用这个内核 patch,依赖禁用 ipvs 连接复用 (`conn_reuse_mode=1`),这样同时也就解决了 ipvs 连接复用引发的系列问题,且经过了大规模生产验证。
|
||||||
|
|
||||||
|
不过以上修复并未直接合并到 linux 社区,当前已有两个相关 patch 合并到了 linux 内核主干 (自 v5.9),分别解决 `conn_reuse_mode` 为 0 和 1 时的上述 bug,其中一个也是借鉴了腾讯云修复的思路,详见 k8s issue [#93297](https://github.com/kubernetes/kubernetes/issues/93297) 。
|
||||||
|
|
||||||
|
如果你使用了 v5.9 以上的内核,理论上就没有本文所述的问题了。既然 v5.9 以上的内核已修复上述 bug,那么 kube-proxy 就无需显式去设置 `conn_reuse_mode` 这个内核参数了,这也是 PR [#102122](https://github.com/kubernetes/kubernetes/pull/102122) 所做的事。不过值得注意的是,社区 patch 目前并未看到有大规模的生产验证,试用有风险。
|
||||||
|
|
@ -0,0 +1,44 @@
|
||||||
|
# 为什么要开 bridge-nf-call-iptables?
|
||||||
|
|
||||||
|
Kubernetes 环境中,很多时候都要求节点内核参数开启 `bridge-nf-call-iptables`:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
sysctl -w net.bridge.bridge-nf-call-iptables=1
|
||||||
|
```
|
||||||
|
|
||||||
|
> 参考官方文档 [Network Plugin Requirements](https://kubernetes.io/docs/concepts/extend-kubernetes/compute-storage-net/network-plugins/#network-plugin-requirements)
|
||||||
|
|
||||||
|
如果不开启或中途因某些操作导致参数被关闭了,就可能造成一些奇奇怪怪的网络问题,排查起来非常麻烦。
|
||||||
|
|
||||||
|
为什么要开启呢?本文就来跟你详细掰扯下。
|
||||||
|
|
||||||
|
## 基于网桥的容器网络
|
||||||
|
|
||||||
|
Kubernetes 集群网络有很多种实现,有很大一部分都用到了 Linux 网桥:
|
||||||
|
|
||||||
|
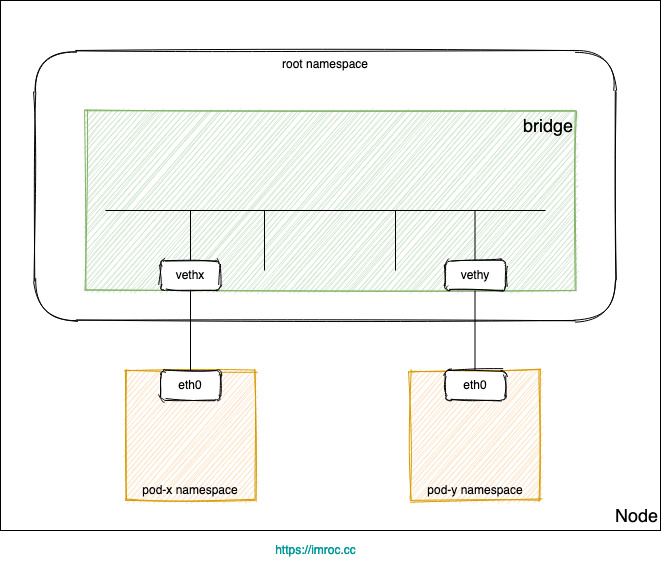
|
||||||
|
|
||||||
|
* 每个 Pod 的网卡都是 veth 设备,veth pair 的另一端连上宿主机上的网桥。
|
||||||
|
* 由于网桥是虚拟的二层设备,同节点的 Pod 之间通信直接走二层转发,跨节点通信才会经过宿主机 eth0。
|
||||||
|
|
||||||
|
## Service 同节点通信问题
|
||||||
|
|
||||||
|
不管是 iptables 还是 ipvs 转发模式,Kubernetes 中访问 Service 都会进行 DNAT,将原本访问 ClusterIP:Port 的数据包 DNAT 成 Service 的某个 Endpoint (PodIP:Port),然后内核将连接信息插入 conntrack 表以记录连接,目的端回包的时候内核从 conntrack 表匹配连接并反向 NAT,这样原路返回形成一个完整的连接链路:
|
||||||
|
|
||||||
|
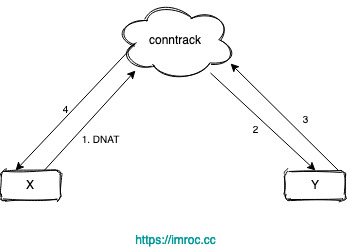
|
||||||
|
|
||||||
|
但是 Linux 网桥是一个虚拟的二层转发设备,而 iptables conntrack 是在三层上,所以如果直接访问同一网桥内的地址,就会直接走二层转发,不经过 conntrack:
|
||||||
|
1. Pod 访问 Service,目的 IP 是 Cluster IP,不是网桥内的地址,走三层转发,会被 DNAT 成 PodIP:Port。
|
||||||
|
2. 如果 DNAT 后是转发到了同节点上的 Pod,目的 Pod 回包时发现目的 IP 在同一网桥上,就直接走二层转发了,没有调用 conntrack,导致回包时没有原路返回 (见下图)。
|
||||||
|
|
||||||
|
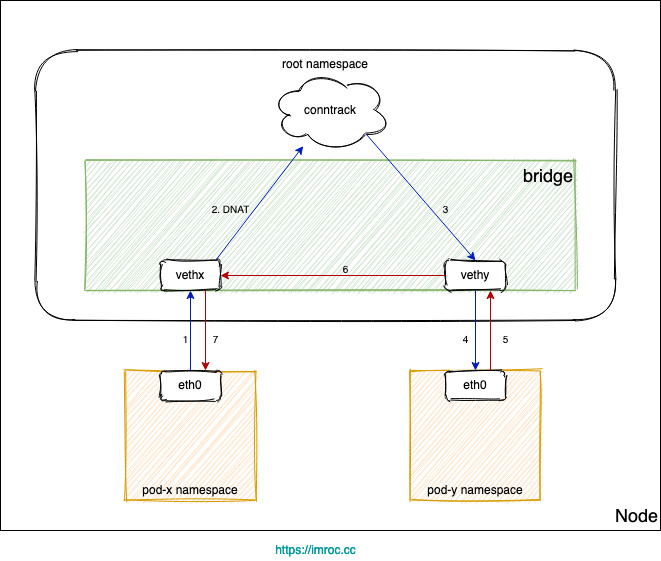
|
||||||
|
|
||||||
|
由于没有原路返回,客户端与服务端的通信就不在一个 "频道" 上,不认为处在同一个连接,也就无法正常通信。
|
||||||
|
|
||||||
|
常见的问题现象就是偶现 DNS 解析失败,当 coredns 所在节点上的 pod 解析 dns 时,dns 请求落到当前节点的 coredns pod 上时,就可能发生这个问题。
|
||||||
|
|
||||||
|
## 开启 bridge-nf-call-iptables
|
||||||
|
|
||||||
|
如果 Kubernetes 环境的网络链路中走了 bridge 就可能遇到上述 Service 同节点通信问题,而 Kubernetes 很多网络实现都用到了 bridge。
|
||||||
|
|
||||||
|
`bridge-nf-call-iptables` 这个内核参数 (置为 1),表示 bridge 设备在二层转发时也去调用 iptables 配置的三层规则 (包含 conntrack),所以开启这个参数就能够解决上述 Service 同节点通信问题,这也是为什么在 Kubernetes 环境中,大多都要求开启 `bridge-nf-call-iptables` 的原因。
|
||||||
|
|
@ -0,0 +1,706 @@
|
||||||
|
/**
|
||||||
|
* Creating a sidebar enables you to:
|
||||||
|
- create an ordered group of docs
|
||||||
|
- render a sidebar for each doc of that group
|
||||||
|
- provide next/previous navigation
|
||||||
|
|
||||||
|
The sidebars can be generated from the filesystem, or explicitly defined here.
|
||||||
|
|
||||||
|
Create as many sidebars as you want.
|
||||||
|
*/
|
||||||
|
|
||||||
|
// @ts-check
|
||||||
|
|
||||||
|
// ref: https://docusaurus.io/docs/sidebar/items
|
||||||
|
/** @type {import('@docusaurus/plugin-content-docs').SidebarsConfig} */
|
||||||
|
const sidebars = {
|
||||||
|
kubernetesSidebar: [
|
||||||
|
'README',
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '集群搭建',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/deploy'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '使用 kubespray 搭建集群',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/deploy/kubespray'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'deploy/kubespray/install',
|
||||||
|
'deploy/kubespray/offline',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '安装 k3s 轻量集群',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/deploy/k3s'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'deploy/k3s/install-cases',
|
||||||
|
'deploy/k3s/offline-installation',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
'deploy/terraform',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '最佳实践',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/best-practices'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '优雅终止',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/best-practices/graceful-shutdown'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'best-practices/graceful-shutdown/intro',
|
||||||
|
'best-practices/graceful-shutdown/pod-termination-proccess',
|
||||||
|
'best-practices/graceful-shutdown/code-example-of-handle-sigterm',
|
||||||
|
'best-practices/graceful-shutdown/why-cannot-receive-sigterm',
|
||||||
|
'best-practices/graceful-shutdown/propagating-signals-in-shell',
|
||||||
|
'best-practices/graceful-shutdown/use-prestop',
|
||||||
|
'best-practices/graceful-shutdown/persistent-connection',
|
||||||
|
'best-practices/graceful-shutdown/lb-to-pod-directly',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: 'DNS',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/best-practices/dns'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'best-practices/dns/customize-dns-resolution',
|
||||||
|
'best-practices/dns/optimize-coredns-performance',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '性能优化',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/best-practices/performance-optimization'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'best-practices/performance-optimization/network',
|
||||||
|
'best-practices/performance-optimization/cpu',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '高可用',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/best-practices/ha'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'best-practices/ha/pod-split-up-scheduling',
|
||||||
|
'best-practices/ha/smooth-upgrade',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '弹性伸缩',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/best-practices/autoscaling'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'best-practices/autoscaling/hpa-velocity',
|
||||||
|
'best-practices/autoscaling/hpa-with-custom-metrics',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '容器化',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/best-practices/containerization'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'best-practices/containerization/systemd-in-container',
|
||||||
|
'best-practices/containerization/java',
|
||||||
|
'best-practices/containerization/golang',
|
||||||
|
'best-practices/containerization/crontab-in-container',
|
||||||
|
'best-practices/containerization/timezone',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '集群运维',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/best-practices/ops'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'best-practices/ops/securely-maintain-or-offline-node',
|
||||||
|
'best-practices/ops/securely-modify-container-root-dir',
|
||||||
|
'best-practices/ops/large-scale-cluster-optimization',
|
||||||
|
'best-practices/ops/etcd-optimization',
|
||||||
|
'best-practices/ops/batch-operate-node-with-ansible',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
'best-practices/configure-healthcheck',
|
||||||
|
'best-practices/request-limit',
|
||||||
|
'best-practices/logging',
|
||||||
|
'best-practices/long-connection',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '监控告警',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/monitoring'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: 'grafana',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/monitoring/grafana'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'monitoring/grafana/ha-setup',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: 'Victoria Metrics',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/monitoring/victoriametrics'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'monitoring/victoriametrics/install-with-operator',
|
||||||
|
],
|
||||||
|
}
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '集群网络',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/networking'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '常见问题',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/networking/faq'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'networking/faq/why-enable-bridge-nf-call-iptables',
|
||||||
|
'networking/faq/ipvs-conn-reuse-mode',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '实用技巧',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/trick'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '高效使用 kubectl',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/trick/kubectl'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'trick/kubectl/kubectl-aliases',
|
||||||
|
'trick/kubectl/quick-switch-with-kubectx',
|
||||||
|
'trick/kubectl/merge-kubeconfig-with-kubecm',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '镜像相关',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/trick/images'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'trick/images/podman',
|
||||||
|
'trick/images/sync-images-with-skopeo',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '部署与配置',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/trick/deploy'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'trick/deploy/set-sysctl',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '证书签发',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/trick/certs'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'trick/certs/sign-certs-with-cfssl',
|
||||||
|
'trick/certs/sign-free-certs-with-cert-manager',
|
||||||
|
'trick/certs/sign-free-certs-for-dnspod',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '用户与权限',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/trick/user-and-permissions'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'trick/user-and-permissions/create-user-using-csr-api',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '故障排查',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/troubleshooting'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '排障技能',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/troubleshooting/skill'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'troubleshooting/skill/linux',
|
||||||
|
'troubleshooting/skill/enter-netns-with-nsenter',
|
||||||
|
'troubleshooting/skill/remote-capture-with-ksniff',
|
||||||
|
'troubleshooting/skill/use-systemtap-to-locate-problems',
|
||||||
|
'troubleshooting/skill/tcpdump',
|
||||||
|
'troubleshooting/skill/wireshark',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: 'Pod 排障',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/troubleshooting/pod'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'troubleshooting/pod/healthcheck-failed',
|
||||||
|
'troubleshooting/pod/device-or-resource-busy',
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: 'Pod 状态异常',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/troubleshooting/pod/status'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'troubleshooting/pod/status/intro',
|
||||||
|
'troubleshooting/pod/status/pod-terminating',
|
||||||
|
'troubleshooting/pod/status/pod-pending',
|
||||||
|
'troubleshooting/pod/status/pod-containercreating-or-waiting',
|
||||||
|
'troubleshooting/pod/status/pod-crash',
|
||||||
|
'troubleshooting/pod/status/pod-imagepullbackoff',
|
||||||
|
],
|
||||||
|
}
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '节点排障',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/troubleshooting/node'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'troubleshooting/node/node-crash-and-vmcore',
|
||||||
|
'troubleshooting/node/node-high-load',
|
||||||
|
'troubleshooting/node/io-high-load',
|
||||||
|
'troubleshooting/node/memory-fragmentation',
|
||||||
|
'troubleshooting/node/disk-full',
|
||||||
|
'troubleshooting/node/pid-full',
|
||||||
|
'troubleshooting/node/arp-cache-overflow',
|
||||||
|
'troubleshooting/node/runnig-out-of-inotify-watches',
|
||||||
|
'troubleshooting/node/kernel-solft-lockup',
|
||||||
|
'troubleshooting/node/no-space-left-on-device',
|
||||||
|
'troubleshooting/node/ipvs-no-destination-available',
|
||||||
|
'troubleshooting/node/cadvisor-no-data',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '网络排障',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/troubleshooting/network'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'troubleshooting/network/timeout',
|
||||||
|
'troubleshooting/network/packet-loss',
|
||||||
|
'troubleshooting/network/network-unreachable',
|
||||||
|
'troubleshooting/network/slow-network-traffic',
|
||||||
|
'troubleshooting/network/dns-exception',
|
||||||
|
'troubleshooting/network/close-wait-stacking',
|
||||||
|
'troubleshooting/network/traffic-surge',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '存储排障',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/troubleshooting/storage'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'troubleshooting/storage/unable-to-mount-volumes',
|
||||||
|
'troubleshooting/storage/setup-failed-for-volume',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '集群排障',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/troubleshooting/cluster'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'troubleshooting/cluster/namespace-terminating',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
"troubleshooting/sdk",
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '排障案例',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/troubleshooting/cases'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '运行时排障',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/troubleshooting/cases/runtime'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'troubleshooting/cases/runtime/io-high-load-causing-pod-creation-timeout',
|
||||||
|
'troubleshooting/cases/runtime/pull-image-fail-in-high-version-containerd',
|
||||||
|
'troubleshooting/cases/runtime/mount-root-causing-device-or-resource-busy',
|
||||||
|
'troubleshooting/cases/runtime/broken-system-time-causing-sandbox-conflicts',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '网络排障',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/troubleshooting/cases/network'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'troubleshooting/cases/network/dns-lookup-5s-delay',
|
||||||
|
'troubleshooting/cases/network/arp-cache-overflow-causing-healthcheck-failed',
|
||||||
|
'troubleshooting/cases/network/cross-vpc-connect-nodeport-timeout',
|
||||||
|
'troubleshooting/cases/network/musl-libc-dns-id-conflict-causing-dns-abnormal',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '高负载',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/troubleshooting/cases/high-load'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'troubleshooting/cases/high-load/disk-full-causing-high-cpu',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '集群故障',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/troubleshooting/cases/cluster'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'troubleshooting/cases/cluster/delete-rancher-ns-causing-node-disappear',
|
||||||
|
'troubleshooting/cases/cluster/scheduler-snapshot-missing-causing-pod-pending',
|
||||||
|
'troubleshooting/cases/cluster/kubectl-exec-or-logs-failed',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '节点排障',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/troubleshooting/cases/node'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'troubleshooting/cases/node/cgroup-leaking',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '其它排障',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/troubleshooting/cases/others'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'troubleshooting/cases/others/failed-to-modify-hosts-in-multiple-container',
|
||||||
|
'troubleshooting/cases/others/job-cannot-delete',
|
||||||
|
'troubleshooting/cases/others/dotnet-configuration-cannot-auto-reload',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
],
|
||||||
|
}
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '腾讯云容器服务',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/tencent'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: 'Serverless 集群与超级节点',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/tencent/serverless'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'tencent/serverless/precautions',
|
||||||
|
'tencent/serverless/why-tke-supernode-rocks',
|
||||||
|
'tencent/serverless/supernode-case-online',
|
||||||
|
'tencent/serverless/supernode-case-offline',
|
||||||
|
'tencent/serverless/large-image-solution',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '网络指南',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/tencent/networking'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'tencent/networking/clb-to-pod-directly',
|
||||||
|
'tencent/networking/how-to-use-eip',
|
||||||
|
'tencent/networking/install-localdns-with-ipvs',
|
||||||
|
'tencent/networking/expose-grpc-with-tcm',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '存储指南',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/tencent/storage'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'tencent/storage/cbs-pvc-expansion',
|
||||||
|
'tencent/storage/readonlymany-pv',
|
||||||
|
'tencent/storage/mount-cfs-with-v3',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '监控告警',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/tencent/monitoring'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'tencent/monitoring/prometheus-scrape-config',
|
||||||
|
'tencent/monitoring/grafana-dashboard-for-supernode-pod',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '镜像与仓库',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/tencent/images'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'tencent/images/use-mirror-in-container',
|
||||||
|
'tencent/images/use-foreign-container-image',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '故障排查',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/tencent/troubleshooting'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'tencent/troubleshooting/public-service-or-ingress-connect-failed',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '常见应用安装与部署',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/tencent/install-apps'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'tencent/install-apps/install-harbor-on-tke',
|
||||||
|
'tencent/install-apps/install-gitlab-on-tke',
|
||||||
|
'tencent/install-apps/install-kubesphere-on-tke',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '常见问题',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/tencent/faq'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'tencent/faq/modify-rp-filter-causing-exception',
|
||||||
|
'tencent/faq/clb-loopback',
|
||||||
|
'tencent/faq/controller-manager-and-scheduler-unhealthy',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '解决方案',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/tencent/solution'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'tencent/solution/multi-account',
|
||||||
|
'tencent/solution/upgrade-inplace',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '附录',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/tencent/appendix'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'tencent/appendix/useful-kubectl-for-tencent-cloud',
|
||||||
|
'tencent/appendix/eks-annotations',
|
||||||
|
'tencent/appendix/ingress-error-code',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
],
|
||||||
|
},
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: '附录',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/appendix'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'appendix/kubectl-cheat-sheet',
|
||||||
|
'appendix/yaml',
|
||||||
|
{
|
||||||
|
type: 'category',
|
||||||
|
label: 'Terrafrom 配置',
|
||||||
|
collapsed: true,
|
||||||
|
link: {
|
||||||
|
type: 'generated-index',
|
||||||
|
slug: '/appendix/terraform'
|
||||||
|
},
|
||||||
|
items: [
|
||||||
|
'appendix/terraform/tke-vpc-cni',
|
||||||
|
'appendix/terraform/tke-serverless',
|
||||||
|
]
|
||||||
|
},
|
||||||
|
]
|
||||||
|
}
|
||||||
|
],
|
||||||
|
};
|
||||||
|
|
||||||
|
module.exports = sidebars;
|
||||||
|
|
@ -0,0 +1,7 @@
|
||||||
|
# EKS 注解
|
||||||
|
|
||||||
|
相关内容已合并到官方文档,相关链接:
|
||||||
|
|
||||||
|
* [EKS Annotation 官方说明文档](https://cloud.tencent.com/document/product/457/44173)
|
||||||
|
* [EKS 全局配置说明](https://cloud.tencent.com/document/product/457/71915)
|
||||||
|
* [EKS 镜像缓存](https://cloud.tencent.com/document/product/457/65908)
|
||||||
|
|
@ -0,0 +1,552 @@
|
||||||
|
# Ingress 错误码
|
||||||
|
|
||||||
|
## E4000 CreateLoadBalancer RequestLimitExceeded
|
||||||
|
|
||||||
|
接口调用出现短时间内出现超频情况,错误会重试。少量出现对服务没有影响。
|
||||||
|
|
||||||
|
## E4003 CreateLoadBalancer LimitExceeded
|
||||||
|
|
||||||
|
故障原因: 负载均衡资源数量受限。
|
||||||
|
|
||||||
|
处理办法: 提交工单申请提高负载均衡的资源数量上限。
|
||||||
|
|
||||||
|
## E4004 CreateListener LimitExceeded
|
||||||
|
|
||||||
|
故障原因: 负载均衡资源下的监听器数量受限。
|
||||||
|
|
||||||
|
处理办法: 提交工单申请提高负载均衡下监听器的资源数量上限。
|
||||||
|
|
||||||
|
## E4005 CreateRule LimitExceeded
|
||||||
|
|
||||||
|
故障原因: 负载均衡资源下的规则数量受限。
|
||||||
|
|
||||||
|
处理办法: 提交工单申请提高负载均衡下的规则的资源数量上限。
|
||||||
|
|
||||||
|
## E4006 DeleteListener Redirection config on the listener
|
||||||
|
|
||||||
|
故障原因: 在 Ingress 管理的监听器下面设置了重定向规则,导致监听器删除失败。
|
||||||
|
|
||||||
|
处理办法: 需要自行处理该重定向规则,Ingress 会在接下来的重试中删除该监听器。
|
||||||
|
|
||||||
|
## E4007 Norm AssumeTkeCredential -8017 | -8032 Record Not Exist
|
||||||
|
|
||||||
|
故障原因: 绝大部分的情况是修改了 `ip-masq-agent-config`,导致访问 Norm 的请求没有进行 IP 伪装,导致 Norm 的鉴权未通过。
|
||||||
|
|
||||||
|
**排查步骤**
|
||||||
|
|
||||||
|
1. 检查当前配置:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl get configmap -n kube-system ip-masq-agent-config
|
||||||
|
```
|
||||||
|
|
||||||
|
```txt
|
||||||
|
nonMasqueradeCIDRs: // 所有pod出去的流量没有进行IP伪装, Norm针对来源IP鉴权(Node)
|
||||||
|
- 0.0.0.0/0
|
||||||
|
|
||||||
|
nonMasqueradeCIDRs: // 正常情况, 这里配置的是集群网络和VPC网络的CIDR
|
||||||
|
- 10.0.0.0/14
|
||||||
|
- 172.16.0.0/16
|
||||||
|
```
|
||||||
|
|
||||||
|
2. 检查`ip-masq-agent` 的重启时间,是不是最近有过更新:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ kubectl get pod -n kube-system -l name=ip-masq-agent
|
||||||
|
NAME READY STATUS RESTARTS AGE
|
||||||
|
ip-masq-agent-n4p9k 1/1 Running 0 4h
|
||||||
|
ip-masq-agent-qj6rk 1/1 Running 0 4h
|
||||||
|
```
|
||||||
|
|
||||||
|
处理办法:
|
||||||
|
* 修改 `ip-masq-agent-config` 中 `的nonMasqueradeCIDRs`,使用一个合理的配置。
|
||||||
|
* 确认 Masq 配置正确后,重启 Ingress Controller 组件。
|
||||||
|
|
||||||
|
## E4008 Norm AssumeTkeCredential -8002 Data is nil
|
||||||
|
|
||||||
|
故障原因: 撤销了对于腾讯云容器服务的授权,导致服务无法运行
|
||||||
|
|
||||||
|
处理办法:
|
||||||
|
* 登录访问管理服务,找到角色 `TKE_QCSRole`(没有则创建)
|
||||||
|
* 创建服务预设角色并授予腾讯云容器服务相关权限
|
||||||
|
|
||||||
|
## E4009 Ingress: xxx secret name is empty
|
||||||
|
|
||||||
|
故障原因: Ingress模板格式错误。spec.tls.secretName 没有填写或为空
|
||||||
|
|
||||||
|
处理办法:
|
||||||
|
* 帮助文档地址: https://kubernetes.io/docs/concepts/services-networking/ingress/#tls
|
||||||
|
* 检查并修改Ingress模板
|
||||||
|
|
||||||
|
## E4010 Secret xxx not found
|
||||||
|
|
||||||
|
故障原因: Ingress模板信息错误。spec.tls.secretName 中填写的Secrets资源不存在
|
||||||
|
|
||||||
|
处理办法:
|
||||||
|
* 帮助文档地址: https://kubernetes.io/docs/concepts/configuration/secret/
|
||||||
|
* 查并修改Ingress模板
|
||||||
|
|
||||||
|
## E4011 Secret xxx has no qcloud cert id
|
||||||
|
|
||||||
|
故障原因: Ingress模板中引用的Secrets内容缺失。或引用的Secrets需要包含qcloud_cert_id字段信息
|
||||||
|
|
||||||
|
处理办法:
|
||||||
|
|
||||||
|
* 参考 K8S 官方文档: https://kubernetes.io/docs/concepts/configuration/secret/
|
||||||
|
* 检查证书配置:
|
||||||
|
```bash
|
||||||
|
$ kubectl get ingress <ingress> -n <namespace> -o yaml
|
||||||
|
apiVersion: extensions/v1beta1
|
||||||
|
kind: Ingress
|
||||||
|
metadata:
|
||||||
|
annotations:
|
||||||
|
qcloud_cert_id: YCOLTUdr <-- 检查这个是不是证书ID
|
||||||
|
spec:
|
||||||
|
tls:
|
||||||
|
- secretName: secret-name <-- 检查配置Secret名称
|
||||||
|
```
|
||||||
|
* 检查Secret配置:
|
||||||
|
```bash
|
||||||
|
$ kubectl get secret <secret-name> -n <namespace> -o yaml
|
||||||
|
apiVersion: v1
|
||||||
|
data:
|
||||||
|
qcloud_cert_id: WUNPTFRVZHI= <-- 检查这个是不是证书ID的Base64编码
|
||||||
|
kind: Secret
|
||||||
|
metadata:
|
||||||
|
name: nginx-service-2
|
||||||
|
namespace: default
|
||||||
|
type: Opaque
|
||||||
|
|
||||||
|
$ echo -n "WUNPTFRVZHI=" | base64 -d
|
||||||
|
YCOLTUdr <-- 证书ID一致
|
||||||
|
```
|
||||||
|
|
||||||
|
* 如何创建Secret:
|
||||||
|
```bash
|
||||||
|
kubectl create secret generic <secret-name> -n <namespace> --from-literal=qcloud_cert_id=YCOLTUdr <-- 证书ID
|
||||||
|
```
|
||||||
|
|
||||||
|
## E4012 CreateListener InvalidParameterValue
|
||||||
|
|
||||||
|
故障原因: 大概率是Ingress模板信息错误。spec.tls.secretName中指定的Secrets资源中描述的qcloud_cert_id不存在。
|
||||||
|
|
||||||
|
排查步骤: 查到错误原因,如果错误原因是Query certificate 'xxxxxxx' failed.,确定是的证书ID填写错误。
|
||||||
|
|
||||||
|
处理办法:
|
||||||
|
* 登录 SSL证书 控制台,检查证书的ID是否正确。
|
||||||
|
* 随后修改Secrets中的证书ID
|
||||||
|
|
||||||
|
## E4013 Ingress rules invalid. 'spec.rules.http' is empty.
|
||||||
|
|
||||||
|
故障原因: Ingress模板不正确,spec.rules.http没有填写实际内容
|
||||||
|
|
||||||
|
处理办法: 修正自己的Ingress模板
|
||||||
|
|
||||||
|
## E4017 负载均衡的标签存在篡改
|
||||||
|
|
||||||
|
故障原因:修改了负载均衡的标签,导致根据标签定位负载均衡资源失败。
|
||||||
|
|
||||||
|
处理办法:
|
||||||
|
* 由于标签或负载均衡资源被删除或篡改,数据可能存在不一致,建议删除负载均衡、或删除负载均衡所有标签,然后重建Ingress资源。
|
||||||
|
|
||||||
|
## E4018 kubernetes.io/ingress.existLbId 中指定的LB资源不存在
|
||||||
|
|
||||||
|
故障原因: Ingress模板不正确,Annotation `kubernetes.io/ingress.existLbId` 中指定的LoadBalance不存在
|
||||||
|
|
||||||
|
排查步骤: 检查日志中给出的LBId, 检查改账号在该地域是否存在此LB资源。
|
||||||
|
|
||||||
|
处理办法:
|
||||||
|
* 如果查询后台系统,确认LB资源的确存在。转交工单到CLB,排查为何资源查询失败。
|
||||||
|
* 如果查询后台系统,确认LB资源不存在。检查模板中定义的LBId是否正确
|
||||||
|
|
||||||
|
## E4019 Can not use lb: created by TKE for ingress: xxx
|
||||||
|
|
||||||
|
故障原因: kubernetes.io/ingress.existLbId中指定的LBId已经被Ingress或是Service使用(资源生命周期由TKE集群管理),不能重复使用
|
||||||
|
|
||||||
|
相关参考: Ingress 的声明周期管理
|
||||||
|
|
||||||
|
处理办法:
|
||||||
|
* 更换其他LB
|
||||||
|
* 删除使用了这个LB资源的Ingress或Service(按以下步骤操作)
|
||||||
|
* 删除LB资源上的tke-createdBy-flag资源
|
||||||
|
* 删除使用了这个LB资源的Ingress或Service。(如果不做第一步,LB资源会被自动销毁)
|
||||||
|
* 指定新的Ingress使用这个LB.
|
||||||
|
* 在该LB资源上打上tke-createdBy-flag=yes的标签. (如果不做这一步,该资源的生命周期将不会被Ingress负责,后续该资源不会自动销毁)
|
||||||
|
|
||||||
|
## E4020 Error lb: used by ingress: xxx
|
||||||
|
|
||||||
|
故障原因: `kubernetes.io/ingress.existLbId` 中指定的LBId已经被Ingress使用,不能重复使用
|
||||||
|
|
||||||
|
相关参考: Ingress 的声明周期管理
|
||||||
|
|
||||||
|
处理办法:
|
||||||
|
* 更换其他LB
|
||||||
|
* 删除使用了这个LB资源的Ingress
|
||||||
|
* 删除LB资源上的tke-createdBy-flag资源(按以下步骤操作)
|
||||||
|
* 删除使用了这个LB资源的Ingress或Service。(如果不做第一步,LB资源会被自动销毁)
|
||||||
|
* 指定新的Ingress使用这个LB.
|
||||||
|
* 在该LB资源上打上tke-createdBy-flag=yes的标签. (如果不做这一步,后续该资源的生命周期将不会被Ingress负责,该资源不会自动销毁)
|
||||||
|
|
||||||
|
## E4021 exist lb: xxx listener not empty
|
||||||
|
|
||||||
|
故障原因: `kubernetes.io/ingress.existLbId` 中指定的LBId中还有监听器没有删除。
|
||||||
|
|
||||||
|
详细描述: 使用已有LB时,如果LB上存在监听器,可能造成LB资源的误操作。所以禁用还存在监听器的存量监听器。
|
||||||
|
|
||||||
|
处理办法:
|
||||||
|
* 更换其他LB
|
||||||
|
* 删除该LB下的所有监听器
|
||||||
|
|
||||||
|
## E4022 Ingress rules invalid.
|
||||||
|
|
||||||
|
故障原因: kubernetes.io/ingress.http-rules 标签的格式解析错误
|
||||||
|
|
||||||
|
详细描述: kubernetes.io/ingress.http-rules 标签内容应该是一个Json格式的字符串,内容不正确时会报错
|
||||||
|
|
||||||
|
处理办法: 检查模板中定义的 http-rules 是否正确
|
||||||
|
|
||||||
|
格式示例:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
kubernetes.io/ingress.http-rules: '[{"path":"/abc","backend":{"serviceName":"nginx-service-2","servicePort":"8080"}}]'
|
||||||
|
```
|
||||||
|
|
||||||
|
## E4023 create lb error: ResourceInsufficient
|
||||||
|
|
||||||
|
故障原因: kubernetes.io/ingress.https-rules 标签的格式解析错误
|
||||||
|
|
||||||
|
详细描述: kubernetes.io/ingress.https-rules 标签内容应该是一个Json格式的字符串,内容不正确时会报错
|
||||||
|
|
||||||
|
处理办法: 检查模板中定义的 https-rules 是否正确
|
||||||
|
|
||||||
|
格式示例:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
kubernetes.io/ingress.https-rules: '[{"path":"/abc","backend":{"serviceName":"nginx-service-2","servicePort":"8080"}}]'
|
||||||
|
```
|
||||||
|
|
||||||
|
## E4024 create lb error: InvalidParameter or InvalidParameterValue
|
||||||
|
|
||||||
|
故障原因: 创建Ingress LB时,通过注解配置的参数有错误。
|
||||||
|
|
||||||
|
详细描述: 注解配置的删除,不合法
|
||||||
|
|
||||||
|
处理办法: 检查注解参数
|
||||||
|
|
||||||
|
## E4025 create lb error: ResourceInsufficient
|
||||||
|
|
||||||
|
故障原因: 创建Ingress LB时,资源不足。
|
||||||
|
|
||||||
|
详细描述: 通常是内网型LB的子网IP数量不足
|
||||||
|
|
||||||
|
处理办法: 检查子网IP是否耗尽
|
||||||
|
|
||||||
|
## E4026 Ingress extensive parameters invalid.
|
||||||
|
|
||||||
|
故障原因: 创建Ingress LB时,kubernetes.io/ingress.extensiveParameters 标签的格式解析错误
|
||||||
|
|
||||||
|
详细描述: 提供的注解内容不是一个合法的JSON字符串
|
||||||
|
|
||||||
|
处理办法:
|
||||||
|
* 修改注解内容,给出一个示例参考:kubernetes.io/ingress.extensiveParameters: '{"AddressIPVersion":"IPv4","ZoneId":"ap-guangzhou-1"}'
|
||||||
|
* 参数参考文档:https://cloud.tencent.com/document/product/214/30692
|
||||||
|
|
||||||
|
## E4027 EnsureCreateLoadBalancer Insufficient Account Balance
|
||||||
|
|
||||||
|
故障原因: 账户欠费
|
||||||
|
|
||||||
|
处理办法: 充钱就好
|
||||||
|
|
||||||
|
## E4030 This interface only support HTTP/HTTPS listener
|
||||||
|
|
||||||
|
故障原因: 通过使用已有LB的方式,使用传统型CLB无法创建七层规则
|
||||||
|
|
||||||
|
处理办法: 需要修改指定的CLB,或删除标签让Ingress主动创建CLB
|
||||||
|
|
||||||
|
## E4031 Ingress rule invalid. Invalid path.
|
||||||
|
|
||||||
|
故障原因: 模板中填写的七层规则,Path的格式不符合规则
|
||||||
|
|
||||||
|
处理办法: 检查路径是否符合以下格式。
|
||||||
|
|
||||||
|
* 默认为 `/`,必须以 `/` 开头,长度限制为 1-120。
|
||||||
|
* 非正则的 URL 路径,以 `/` 开头,支持的字符集如下:`a-z A-Z 0-9 . - / = ?`。
|
||||||
|
|
||||||
|
## E4032 LoadBalancer AddressIPVersion Error
|
||||||
|
|
||||||
|
故障原因: 使用了错误的 `AddressIPVersion` 参数
|
||||||
|
|
||||||
|
详细描述: 目前基于IPv4网络的集群只支持,IPv4和NAT IPv6类型的负载均衡。不支持纯IPv6类型的负载均衡。
|
||||||
|
|
||||||
|
处理办法:
|
||||||
|
* 如果是创建负载均衡的情况。修改一下kubernetes.io/ingress.extensiveParameters参数。
|
||||||
|
* 如果是使用已有负载均衡的情况。不能选用该负载均衡,需要更换其他负载均衡。
|
||||||
|
|
||||||
|
## E4033 LoadBalancer AddressIPVersion do not support
|
||||||
|
|
||||||
|
故障原因: 该地域不支持IPv6类型的负载均衡。
|
||||||
|
|
||||||
|
详细描述: 目前不是所有地域都支持IPv6的负载均衡,有强业务需求的请联系负载均衡提出需求。
|
||||||
|
|
||||||
|
## E4034 Ingress RuleHostEmpty
|
||||||
|
|
||||||
|
故障原因: Ingress规则中没有配置Host
|
||||||
|
|
||||||
|
详细描述: 目前针对IPv4的负载均衡,不配置Host的情况下会使用IPv4的地址作为Host。当使用纯IPv6负载均衡时,默认Host的逻辑不存在,必须指定域名。
|
||||||
|
|
||||||
|
处理办法: 修改 Ingress,补充Ingress的Host字段
|
||||||
|
|
||||||
|
## E4035 LoadBalancer CertificateId Invalid
|
||||||
|
|
||||||
|
故障原因: 证书ID格式不正确。(CertId长度不正确)
|
||||||
|
|
||||||
|
处理办法:
|
||||||
|
* 参考文档:https://cloud.tencent.com/document/product/457/45738
|
||||||
|
* 登录负载均衡控制台,确认证书ID,修改Ingress使用的Secret资源内描述的证书ID。
|
||||||
|
|
||||||
|
## E4036 LoadBalancer CertificateId NotFound
|
||||||
|
|
||||||
|
故障原因: 证书ID不存在。
|
||||||
|
处理办法:
|
||||||
|
* 参考文档:https://cloud.tencent.com/document/product/457/45738
|
||||||
|
* 登录负载均衡控制台,确认证书ID,修改Ingress使用的Secret资源内描述的证书ID。
|
||||||
|
|
||||||
|
## E4037 Annotation 'ingress.cloud.tencent.com/direct-access' Invalid
|
||||||
|
|
||||||
|
故障原因: ingress.cloud.tencent.com/direct-access的合法值是 true 或 false
|
||||||
|
|
||||||
|
处理办法: 检查配置的 `ingress.cloud.tencent.com/direct-access` 注解内容是否是一个合法的 bool 值。
|
||||||
|
|
||||||
|
## E4038 Certificate Type Error
|
||||||
|
|
||||||
|
故障原因: 配置的证书类型,需要是服务端证书。不能使用客户端证书配置单向证书。
|
||||||
|
|
||||||
|
处理办法:
|
||||||
|
* 登录负载均衡控制台,检查使用的证书类型,确认使用的是服务端证书。
|
||||||
|
* 如果确认是客户端证书,需要修改。
|
||||||
|
* 如果确认是服务端证书,联系负载均衡排查证书使用故障。
|
||||||
|
|
||||||
|
## E4038 Certificate Out of Date / E4039 Certificate Out of Date
|
||||||
|
|
||||||
|
故障原因: 配置的证书过期了,检查配置的证书的过期时间。
|
||||||
|
|
||||||
|
处理办法:
|
||||||
|
* 参考文档:https://cloud.tencent.com/document/product/457/45738
|
||||||
|
* 登录负载均衡控制台,检查使用的证书的过期时间。
|
||||||
|
* 更换新的证书,并更新Ingress使用的Secret资源,同步证书。
|
||||||
|
|
||||||
|
## E4040 Certificate Not Found for SNI
|
||||||
|
|
||||||
|
故障原因: Ingress中描述的域名,存在一个或多个没有包含在TLS的域名证书规则中。
|
||||||
|
|
||||||
|
处理办法:
|
||||||
|
* 参考文档:https://cloud.tencent.com/document/product/457/45738
|
||||||
|
* 检查是否有域名没有提供对应的证书Secret资源。
|
||||||
|
|
||||||
|
## E4041 Service Not Found
|
||||||
|
|
||||||
|
故障原因: Ingress中引用的Service不存在
|
||||||
|
处理办法: 检查Ingress中声明使用的所有Service资源是否存在,注意在Service和Ingress需要在同一个命名空间下。
|
||||||
|
|
||||||
|
## E4042 Service Port Not Found
|
||||||
|
|
||||||
|
故障原因: Ingress中引用的Service端口不存在
|
||||||
|
|
||||||
|
处理办法: 检查Ingress中声明使用的所有Service资源及其使用的端口是否存在。
|
||||||
|
|
||||||
|
## E4043 TkeServiceConfig Not Found
|
||||||
|
|
||||||
|
故障原因: Ingress通过"ingress.cloud.tencent.com/tke-service-config"注解引用的TkeServiceConfig资源不存在
|
||||||
|
|
||||||
|
处理办法:
|
||||||
|
* 参考文档: https://cloud.tencent.com/document/product/457/45700
|
||||||
|
* 检查Ingress注解中声明的TkeServiceConfig资源是否存在,注意在同一命名空间中。查询命令:`kubectl get tkeserviceconfigs.cloud.tencent.com -n <namespace> <name>`
|
||||||
|
|
||||||
|
## E4044 Mixed Rule Invalid
|
||||||
|
|
||||||
|
故障原因: Ingress的注解"kubernetes.io/ingress.rule-mix"不是一个合法的JSON字符串。
|
||||||
|
|
||||||
|
处理办法:
|
||||||
|
* https://cloud.tencent.com/document/product/457/45693
|
||||||
|
* 参考文档,编写正确的注解内容。或者通过控制台使用Ingress混合协议功能。
|
||||||
|
|
||||||
|
## E4045 InternetChargeType Invalid
|
||||||
|
|
||||||
|
故障原因: Ingress的注解"kubernetes.io/ingress.internetChargeType"内容不合法。
|
||||||
|
|
||||||
|
处理办法: 参考 InternetChargeType 参数的可选值:https://cloud.tencent.com/document/api/214/30694#InternetAccessible
|
||||||
|
|
||||||
|
## E4046 InternetMaxBandwidthOut Invalid
|
||||||
|
|
||||||
|
故障原因: Ingress的注解"kubernetes.io/ingress.internetMaxBandwidthOut"内容不合法。
|
||||||
|
|
||||||
|
处理办法: 参考 InternetMaxBandwidthOut 参数的可选值:https://cloud.tencent.com/document/api/214/30694#InternetAccessible
|
||||||
|
|
||||||
|
## E4047 Service Type Invalid
|
||||||
|
|
||||||
|
故障原因: 作为Ingress后端引用的Service,类型只能是NodePort或LoadBalancer。
|
||||||
|
处理办法: 检查Service类型,建议使用NodePort或LoadBalancer类型的Service作为Ingress后端。
|
||||||
|
|
||||||
|
## E4048 Default Secret conflict.
|
||||||
|
|
||||||
|
故障原因: Ingress中,TLS声明了多个默认证书,出现冲突
|
||||||
|
|
||||||
|
处理办法:
|
||||||
|
* https://cloud.tencent.com/document/product/457/45738
|
||||||
|
* 检查TLS配置,最多配置一个默认证书。修改更新配置后会自动同步。
|
||||||
|
|
||||||
|
## E4049 SNI Secret conflict.
|
||||||
|
|
||||||
|
故障原因: Ingress中,TLS声明了多个证书对应同一个域名,出现冲突
|
||||||
|
|
||||||
|
处理办法:
|
||||||
|
* https://cloud.tencent.com/document/product/457/45738
|
||||||
|
* 检查TLS配置,最多为单个域名配置一个证书。修改更新配置后会自动同步。
|
||||||
|
|
||||||
|
## E4050 Annotation 'ingress.cloud.tencent.com/tke-service-config-auto' Invalid
|
||||||
|
|
||||||
|
故障原因: ingress.cloud.tencent.com/tke-service-config-auto的合法值是 true 或 false
|
||||||
|
处理办法: 检查配置的 `ingress.cloud.tencent.com/tke-service-config-auto` 注解内容是否是一个合法的 bool 值。
|
||||||
|
|
||||||
|
## E4051 Annotation 'ingress.cloud.tencent.com/tke-service-config' Name Invalid
|
||||||
|
|
||||||
|
故障原因: ingress.cloud.tencent.com/tke-service-config的名称不能以 '-auto-ingress-config' or '-auto-service-config' 为后缀。会和自动同步的配置名称出现冲突。
|
||||||
|
处理办法: 修改注解 ’ingress.cloud.tencent.com/tke-service-config’ ,使用其他名称的TkeServiceConfig资源。
|
||||||
|
|
||||||
|
## E4052 Ingress Host Invalid
|
||||||
|
|
||||||
|
故障原因: 根据K8S的限制,Ingress的Host需要满足正则表达式 "(\*|[a-z0-9]([-a-z0-9]*[a-z0-9])?)(\.[a-z0-9]([-a-z0-9]*[a-z0-9])?)+"
|
||||||
|
|
||||||
|
处理办法: 默认情况下域名都是符合以上要求的。排除一下域名没有 “.”,域名包含特殊字符等情况就可以了。
|
||||||
|
|
||||||
|
## E4053 LoadBalancer Subnet IP Insufficient
|
||||||
|
|
||||||
|
故障原因: 负载均衡所在子网的IP已经用光,无法在配置的子网下创建负载均衡。
|
||||||
|
|
||||||
|
处理办法:
|
||||||
|
* 确定选定子网所使用的注解:“kubernetes.io/ingress.subnetId”。
|
||||||
|
* 建议改用其他子网,或者在该子网下释放一些IP资源。
|
||||||
|
|
||||||
|
## E4091 CreateLoadBalancer Invoke vpc failed: subnet not exists
|
||||||
|
|
||||||
|
故障原因: 创建内网型LB时指定的子网不正确。
|
||||||
|
|
||||||
|
处理办法: 检查Ingress模板中的kubernetes.io/ingress.subnetId字段中描述的子网ID是否正确
|
||||||
|
|
||||||
|
## E5003 CLB InternalError
|
||||||
|
|
||||||
|
故障原因: CLB内部错误
|
||||||
|
|
||||||
|
处理办法: 转至CLB排查原因
|
||||||
|
|
||||||
|
## E5004 CVM InternalError
|
||||||
|
|
||||||
|
故障原因: CVM内部错误
|
||||||
|
|
||||||
|
处理办法: 将工单立刻转至CVM排查后续原因
|
||||||
|
|
||||||
|
## E5005 TAG InternalError
|
||||||
|
|
||||||
|
故障原因: 标签服务内部错误
|
||||||
|
|
||||||
|
处理办法: 将工单立刻转至标签服务排查后续原因
|
||||||
|
|
||||||
|
## E5007 Norm InternalError
|
||||||
|
|
||||||
|
故障原因: 服务内部错误
|
||||||
|
|
||||||
|
处理办法: 将工单立刻转至标签服务排查后续原因
|
||||||
|
|
||||||
|
## E5008 TKE InternalError
|
||||||
|
|
||||||
|
故障原因: 服务内部错误
|
||||||
|
|
||||||
|
处理办法: 将工单立刻转至标签服务排查后续原因
|
||||||
|
|
||||||
|
## E5009 CLB BatchTarget Faild
|
||||||
|
|
||||||
|
故障原因: CLB内部错误, 后端批量绑定、解绑出现部分错误
|
||||||
|
|
||||||
|
处理办法: 将工单立刻转至CLB排查后续原因
|
||||||
|
|
||||||
|
## E6001 Failed to get zone from env: TKE_REGION / E6002 Failed to get vpcId from env: TKE_VPC_ID
|
||||||
|
|
||||||
|
故障原因: 集群资源 configmap tke-config 配置缺失,导致容器启动失败
|
||||||
|
处理办法:
|
||||||
|
* `kubectl get configmap -n kube-system tke-config` 检查configmap是否存在
|
||||||
|
* `kubectl create configmap tke-config -n kube-system --from-literal=TKE_REGION=<ap-shanghai-fsi> --from-literal=TKE_VPC_ID=<vpc-6z0k7g8b>` 创建configmap,region、vpc_id需要根据集群具体信息进行修改
|
||||||
|
* `kubectl edit deployment -n kube-system l7-lb-controller -o yaml` 确保模板内的 env 内容正确。
|
||||||
|
```yaml
|
||||||
|
spec:
|
||||||
|
containers:
|
||||||
|
- args:
|
||||||
|
- --cluster-name=<cls-a0lcxsdm>
|
||||||
|
env:
|
||||||
|
- name: TKE_REGION
|
||||||
|
valueFrom:
|
||||||
|
configMapKeyRef:
|
||||||
|
key: TKE_REGION
|
||||||
|
name: tke-config
|
||||||
|
- name: TKE_VPC_ID
|
||||||
|
valueFrom:
|
||||||
|
configMapKeyRef:
|
||||||
|
key: TKE_VPC_ID
|
||||||
|
name: tke-config
|
||||||
|
```
|
||||||
|
|
||||||
|
## E6006 Error during sync: Post https://clb.internal.tencentcloudapi.com/: dial tcp: i/o timeout
|
||||||
|
|
||||||
|
故障原因 A: CoreDNS对相关API服务的域名解析出现错误
|
||||||
|
|
||||||
|
可能涉及到相同问题的域名:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
lb.api.qcloud.com
|
||||||
|
tag.api.qcloud.com
|
||||||
|
cbs.api.qcloud.com
|
||||||
|
cvm.api.qcloud.com
|
||||||
|
snapshot.api.qcloud.com
|
||||||
|
monitor.api.qcloud.com
|
||||||
|
scaling.api.qcloud.com
|
||||||
|
ccs.api.qcloud.com
|
||||||
|
tke.internal.tencentcloudapi.com
|
||||||
|
clb.internal.tencentcloudapi.com
|
||||||
|
cvm.internal.tencentcloudapi.com
|
||||||
|
```
|
||||||
|
|
||||||
|
处理办法: 对l7-lb-controller追加以下域名解析。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl patch deployment l7-lb-controller -n kube-system --patch '{"spec":{"template":{"spec":{"hostAliases":[{"hostnames":["lb.api.qcloud.com","tag.api.qcloud.com","cbs.api.qcloud.com","cvm.api.qcloud.com","snapshot.api.qcloud.com","monitor.api.qcloud.com","scaling.api.qcloud.com","ccs.api.qcloud.com"],"ip":"169.254.0.28"},{"hostnames":["tke.internal.tencentcloudapi.com","clb.internal.tencentcloudapi.com","cvm.internal.tencentcloudapi.com"],"ip":"169.254.0.95"}]}}}}'
|
||||||
|
```
|
||||||
|
|
||||||
|
故障原因 B: 集群网络问题
|
||||||
|
|
||||||
|
处理办法: 暂无,提工单,并附上日志中的异常栈信息。
|
||||||
|
|
||||||
|
## E6007 | E6009 Ingress InternalError
|
||||||
|
|
||||||
|
故障原因: Ingress 内部错误
|
||||||
|
|
||||||
|
处理办法: 将工单立刻转至misakazhou,并附上日志中的异常栈信息。
|
||||||
|
|
||||||
|
## W1000 Service xxx not found in store
|
||||||
|
|
||||||
|
告警原因: 指定的Service不存在,Ingress规则无法找到对应绑定的后端。
|
||||||
|
处理办法: 检查集群Service资源中是否存在 backend.serviceName 所描述的资源
|
||||||
|
|
||||||
|
## W1001 clean not creatted by TKE loadbalancer: xxx for ingress:
|
||||||
|
|
||||||
|
告警原因: 删除Ingress的时候,Ingress使用的负载均衡没有被删除
|
||||||
|
|
||||||
|
详细描述: Ingress使用的负载均衡资源没有tke-createdBy-flag=yes的标签,生命周期没有在Ingress的管理之下。需要自行手动删除。
|
||||||
|
|
||||||
|
处理办法: 需要的话,可以选择手动删除该负载均衡资源
|
||||||
|
|
||||||
|
## W1002 do not clean listener.
|
||||||
|
|
||||||
|
告警原因: 删除Ingress的时候,Ingress使用的负载均衡下的监听器没有被删除
|
||||||
|
|
||||||
|
详细描述: Ingress使用的负载均衡资源下的监听器名称不是TKE-DEDICATED-LISTENER,该监听器不是Ingress创建的或是被修改,生命周期没有在Ingress的管理之下。需要自行手动删除。
|
||||||
|
|
||||||
|
处理办法: 需要的话,可以选择手动删除该负载均衡资源下的监听器
|
||||||
|
|
@ -0,0 +1,67 @@
|
||||||
|
# 实用 kubectl 脚本
|
||||||
|
|
||||||
|
本文分享腾讯云容器服务相关常用实用 kubectl 脚本。
|
||||||
|
|
||||||
|
## ENI 相关
|
||||||
|
|
||||||
|
查询节点的 eni-ip Allocatable 情况:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl get nodes -o=jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.status.allocatable.tke\.cloud\.tencent\.com\/eni-ip}{"\n"}{end}'
|
||||||
|
```
|
||||||
|
|
||||||
|
指定可用区节点的 eni-ip Allocatable 情况:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl get nodes -o=jsonpath='{range .items[?(@.metadata.labels.failure-domain\.beta\.kubernetes\.io\/zone=="100003")]}{.metadata.name}{"\t"}{.status.allocatable.tke\.cloud\.tencent\.com\/eni-ip}{"\n"}{end}'
|
||||||
|
```
|
||||||
|
|
||||||
|
查看各节点 ENI 的子网网段:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl get nec -o json | jq -r '.items[] | select(.status.eniInfos!=null)| { name: .metadata.name, zone: , subnetCIDR: [.status.eniInfos[].subnetCIDR]|join(",") }| "\(.name)\t\(.subnetCIDR)"'
|
||||||
|
```
|
||||||
|
|
||||||
|
查可以绑指定子网ENI的节点都是在哪个可用区:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# 指定子网
|
||||||
|
subnetCIDR="11.185.48.0/20"
|
||||||
|
# 查询哪些节点可以绑这个子网的 ENI
|
||||||
|
kubectl get nec -o json | jq -r '.items[] | select(.status.eniInfos!=null)| { name: .metadata.name, subnetCIDR: [.status.eniInfos[].subnetCIDR]|join(",") }| "\(.name)\t\(.subnetCIDR)"' | grep $subnetCIDR | awk '{print $1}' > node-cidr.txt
|
||||||
|
# 查询所有节点的可用区
|
||||||
|
kubectl get nodes -o=jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.metadata.labels.failure-domain\.beta\.kubernetes\.io\/zone}{"\n"}{end}' > node-zone.txt
|
||||||
|
# 筛选出可以绑这个子网的节点都是在哪个可用区
|
||||||
|
awk 'BEGIN{while(getline<"node-cidr.txt") a[$1]=1;} {if(a[$1]==1) print $0;}' node-zone.txt
|
||||||
|
|
||||||
|
|
||||||
|
# 合并一下就是
|
||||||
|
subnetCIDR="11.185.48.0/20"
|
||||||
|
kubectl get nec -o json | jq -r '.items[] | select(.status.eniInfos!=null)| { name: .metadata.name, subnetCIDR: [.status.eniInfos[].subnetCIDR]|join(",") }| "\(.name)\t\(.subnetCIDR)"' | grep $subnetCIDR | awk '{print $1}' > node-cidr.txt && kubectl get nodes -o=jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.metadata.labels.failure-domain\.beta\.kubernetes\.io\/zone}{"\n"}{end}' > node-zone.txt && awk 'BEGIN{while(getline<"node-cidr.txt") a[$1]=1;} {if(a[$1]==1) print $0;}' node-zone.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
## EKS 相关
|
||||||
|
|
||||||
|
查看 eks 集群子网剩余 ip 数量:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl get node -o json | jq -r '.items[] | {subnet: .metadata.annotations."eks.tke.cloud.tencent.com/subnet-id", ip: .metadata.labels."eks.tke.cloud.tencent.com/available-ip-count"} | "\(.subnet)\t\(.ip)"'
|
||||||
|
```
|
||||||
|
|
||||||
|
查看指定子网剩余 ip 数量
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# 直接替换子网 id 查
|
||||||
|
kubectl get node -o json | jq -r '.items[] | select(.metadata.annotations."eks.tke.cloud.tencent.com/subnet-id"=="subnet-1p9zhi9g") | {ip: .metadata.labels."eks.tke.cloud.tencent.com/available-ip-count"} | "\(.ip)"'
|
||||||
|
|
||||||
|
# 使用变量查
|
||||||
|
subnet="subnet-1p9zhi9g"
|
||||||
|
kubectl get node -o json | jq -r '.items[] | {subnet: .metadata.annotations."eks.tke.cloud.tencent.com/subnet-id", ip: .metadata.labels."eks.tke.cloud.tencent.com/available-ip-count"} | "\(.subnet)\t\(.ip)"' | grep $subnet | awk '{print $2}'
|
||||||
|
```
|
||||||
|
|
||||||
|
查看指定固定 IP 的 Pod 所在子网剩余 IP 数量:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pod="wedata-lineage-service-test-env-48872523-0"
|
||||||
|
kubectl get cm static-addresses -o json | jq -r ".data.\"${pod}\"" | xargs kubectl get node -o json | jq -r '{ip: .metadata.labels."eks.tke.cloud.tencent.com/available-ip-count"} | "\(.ip)"'
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,60 @@
|
||||||
|
# Serverless 弹性集群注意事项
|
||||||
|
|
||||||
|
## 访问公网
|
||||||
|
|
||||||
|
与 TKE 集群不同的是,EKS 没有节点,无法像 TKE 那样,Pod 可以利用节点自身的公网带宽访问公网。
|
||||||
|
|
||||||
|
EKS 没有节点,要让 Pod 访问公网有两种方式:
|
||||||
|
|
||||||
|
1. [通过 NAT 网关访问外网](https://cloud.tencent.com/document/product/457/48710)
|
||||||
|
2. [通过弹性公网 IP 访问外网](https://cloud.tencent.com/document/product/457/60354)
|
||||||
|
|
||||||
|
大多情况下可以考虑方式一,创建 NAT 网关,在 VPC 路由表里配置路由,如果希望整个 VPC 都默认走这个 NAT 网关出公网,可以修改 default 路由表:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
如果只想让超级节点的 Pod 走这个 NAT 网关,可以新建路由表。
|
||||||
|
|
||||||
|
配置方法是在路由表新建一条路由策略,`0.0.0.0/0` 网段的下一条类型为 `NAT 网关`,且选择前面创建的 NAT 网关实例:
|
||||||
|
|
||||||
|
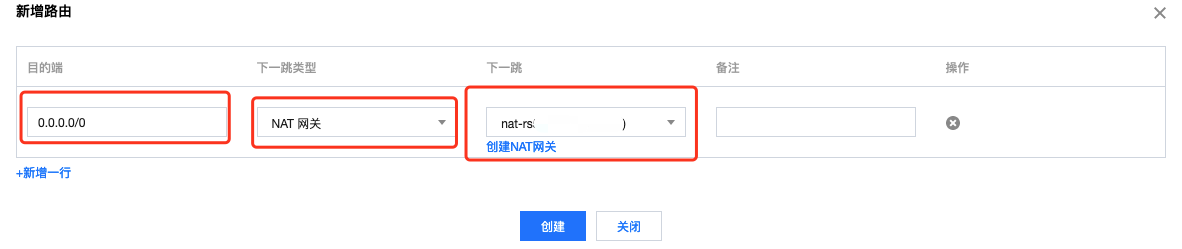
|
||||||
|
|
||||||
|
创建好后,如果不是 default 路由表,需要关联一下超级节点的子网:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## 9100 端口
|
||||||
|
|
||||||
|
EKS 默认会在每个 Pod 的 9100 端口进行监听,暴露 Pod 相关监控指标,如果业务本身也监听 9100,会失败,参考 [9100 端口问题](https://imroc.cc/kubernetes/tencent/appendix/eks-annotations.html#9100-%E7%AB%AF%E5%8F%A3%E9%97%AE%E9%A2%98)。
|
||||||
|
|
||||||
|
## 注意配额限制
|
||||||
|
|
||||||
|
使用 EKS 集群时注意一下配额限制,如果不够,可以提工单调高上限:
|
||||||
|
1. 单集群 Pod 数量上限 (默认200)。
|
||||||
|
2. 安全组绑定实例数量上限 (如果不给 Pod 指定安全组,会使用当前项目当前地域的默认安全组,每个安全组绑定实例数量上限为 2000)。
|
||||||
|
|
||||||
|
## ipvs 超时时间问题
|
||||||
|
|
||||||
|
### istio 场景 dns 超时
|
||||||
|
|
||||||
|
istio 的 sidecar (istio-proxy) 拦截流量借助了 conntrack 来实现连接跟踪,当部分没有拦截的流量 (比如 UDP) 通过 service 访问时,会经过 ipvs 转发,而 ipvs 和 conntrack 对连接都有一个超时时间设置,如果在 ipvs 和 conntrack 中的超时时间不一致,就可能出现 conntrack 中连接还在,但在 ipvs 中已被清理而导致出去的包被 ipvs 调度到新的 rs,而 rs 回包的时候匹配不到 conntrack,不会做反向 SNAT,从而导致进程收不到回包。
|
||||||
|
|
||||||
|
在 EKS 中,ipvs 超时时间当前默认是 5s,而 conntrack 超时时间默认是 120s,如果在 EKS 中使用 TCM 或自行安装 istio,当 coredns 扩容后一段时间,业务解析域名时就可能出现 DNS 超时。
|
||||||
|
|
||||||
|
在产品化解决之前,我们可以给 Pod 加如下注解,将 ipvs 超时时间也设成 120s,与 conntrack 超时时间对齐:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
eks.tke.cloud.tencent.com/ipvs-udp-timeout: "120s"
|
||||||
|
```
|
||||||
|
|
||||||
|
### gRPC 场景 Connection reset by peer
|
||||||
|
|
||||||
|
gRPC 是长连接,Java 版的 gRPC 默认 idle timeout 是 30 分钟,并且没配置 TCP 连接的 keepalive 心跳,而 ipvs 默认的 tcp timeout 是 15 分钟。
|
||||||
|
|
||||||
|
这就会导致一个问题: 业务闲置 15 分钟后,ipvs 断开连接,但是上层应用还认为连接在,还会复用连接发包,而 ipvs 中对应连接已不存在,会直接响应 RST 来将连接断掉,从业务日志来看就是 `Connection reset by peer`。
|
||||||
|
|
||||||
|
这种情况,如果不想改代码来启用 keepalive,可以直接调整下 eks 的 ipvs 的 tcp timeout 时间,与业务 idle timeout 时长保持一致:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
eks.tke.cloud.tencent.com/ipvs-tcp-timeout: "1800s"
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,107 @@
|
||||||
|
# CLB 回环问题
|
||||||
|
|
||||||
|
## 问题描述
|
||||||
|
|
||||||
|
使用 TKE 一些用户,可能会遇到因 CLB 回环问题导致服务访问不通或访问 Ingress 几秒延时的现象,本文就此问题介绍下相关背景、原因以及一些思考与建议。
|
||||||
|
|
||||||
|
## 有哪些现象?
|
||||||
|
|
||||||
|
CLB 回环可能导致的问题现象有:
|
||||||
|
|
||||||
|
1. 不管是 iptables 还是 ipvs 模式,访问本集群内网 Ingress 出现 4 秒延时或不通。
|
||||||
|
1. ipvs 模式下,集群内访问本集群 LoadBanacer 类型的内网 Service 出现完全不通,或者时通时不通。
|
||||||
|
|
||||||
|
## 为什么会回环?
|
||||||
|
|
||||||
|
根本原因在于 CLB 将请求转发到 rs 时,报文的源目的 IP 都在同一节点内,导致数据包在子机内部回环出不去:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
下面我们针对具体场景来分析下。
|
||||||
|
|
||||||
|
### 分析 Ingress 回环
|
||||||
|
|
||||||
|
我们先来分析下 Ingress。使用 TKE 默认自带的 Ingress,会为每个 Ingress 资源创建一个 CLB 以及 80,443 的 7 层监听器规则(HTTP/HTTPS),并为 Ingress 每个 location 绑定对应 TKE 各个节点某个相同的 NodePort 作为 rs (每个 location 对应一个 Service,每个 Service 都通过各个节点的某个相同 NodePort 暴露流量),CLB 根据请求匹配 location 转发到相应的 rs (即 NodePort),流量到了 NodePort 后会再经过 K8S 的 iptables 或 ipvs 转发给对应的后端 Pod。集群中的 Pod 访问本集群的内网 Ingress,CLB 将请求转发给其中一台节点的对应 NodePort:
|
||||||
|
|
||||||
|
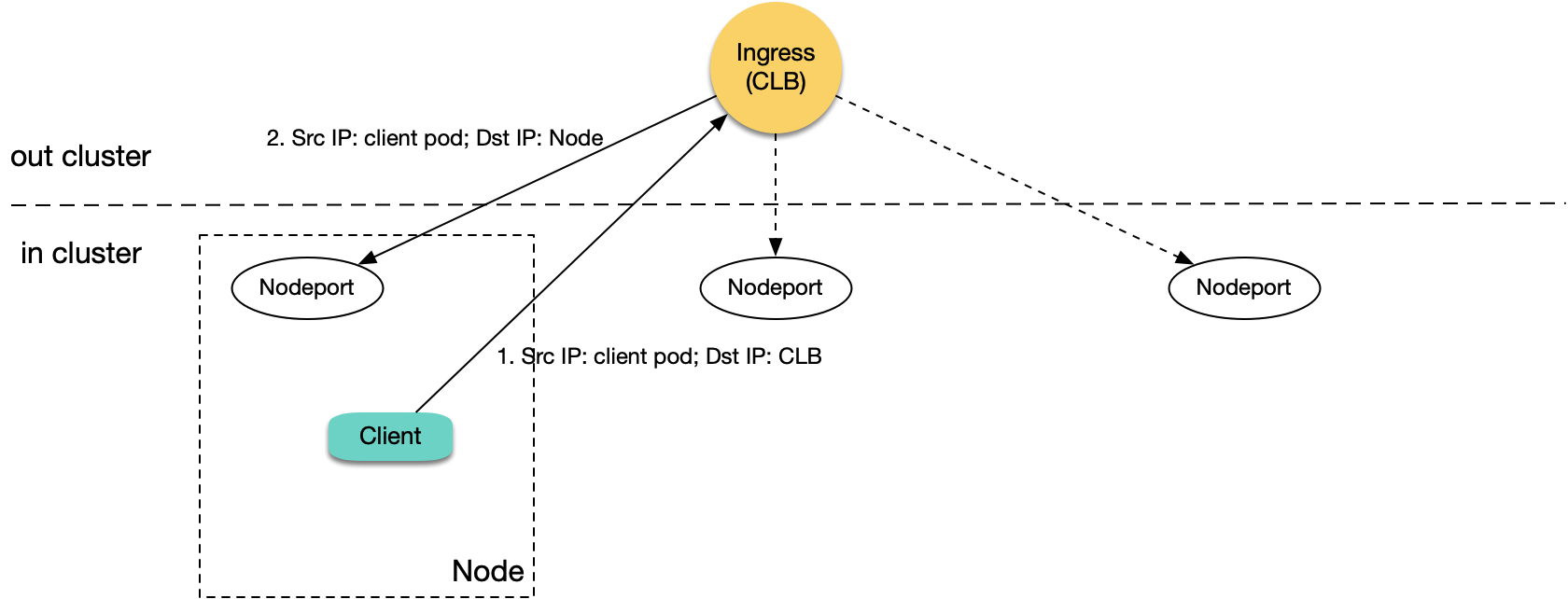
|
||||||
|
|
||||||
|
如图,当被转发的这台节点恰好也是发请求的 client 所在节点时:
|
||||||
|
|
||||||
|
1. 集群中的 Pod 访问 CLB,然后 CLB 将请求转发到任意一台节点的对应 NodePort。
|
||||||
|
1. 报文到 NodePort 时,目的 IP 是节点 IP,源 IP 是 client pod 的真实 IP, 因为 CLB 不做 SNAT,会将真实源 IP 透传过去。
|
||||||
|
1. 由于源 IP 与目的 IP 都在这台机器内,所以就导致了回环,CLB 将收不到来自 rs 的响应。
|
||||||
|
|
||||||
|
|
||||||
|
那为什么访问集群内 Ingress 的故障现象大多是几秒延时呢?因为 7 层 CLB 如果请求 rs 后端超时(大概 4s),会重试下一个 rs,所以如果 client 这侧设置的超时时间较长,出现回环问题的现象就是请求响应慢,有几秒的延时。当然如果集群只有一个节点,CLB 也没得可以重试的 rs,现象就是访问不通了。
|
||||||
|
|
||||||
|
### 分析 LoadBalancer Service 回环
|
||||||
|
|
||||||
|
上面分析了 7 层 CLB 的情况,下面来分析下 4 层 CLB。当使用 LoadBalancer 类型的内网 Service 时暴露服务时,会创建内网 CLB 并创建对应的 4 层监听器(TCP/UDP)。当集群内 Pod 访问 LoadBalancer 类型 Service 的 `EXTERNAL-IP` 时(即 CLB IP),原生 K8S 实际上不会去真正访问 LB,而是直接通过 iptables 或 ipvs 转发到后端 Pod (不经过 CLB):
|
||||||
|
|
||||||
|
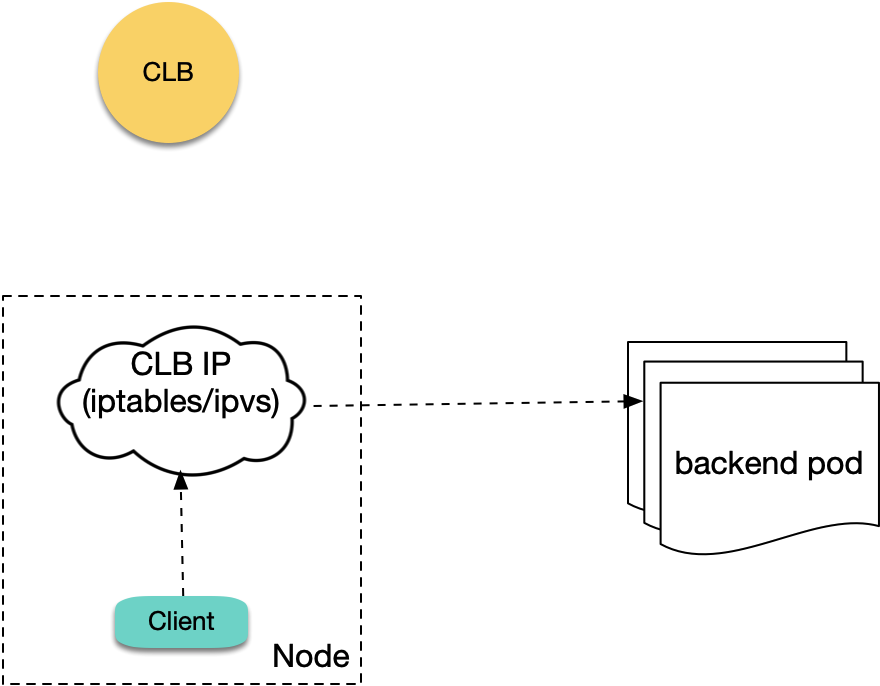
|
||||||
|
|
||||||
|
所以原生 K8S 的逻辑是不会有这个问题的。但在 TKE 的 ipvs 模式下,client 访问 CLB IP 的包会真正到 CLB,所以如果在 ipvs 模式下 Pod 访问本集群 LoadBalancer 类型 Service 的 CLB IP 会遇到回环问题,情况跟前面内网 Ingress 回环类似:
|
||||||
|
|
||||||
|
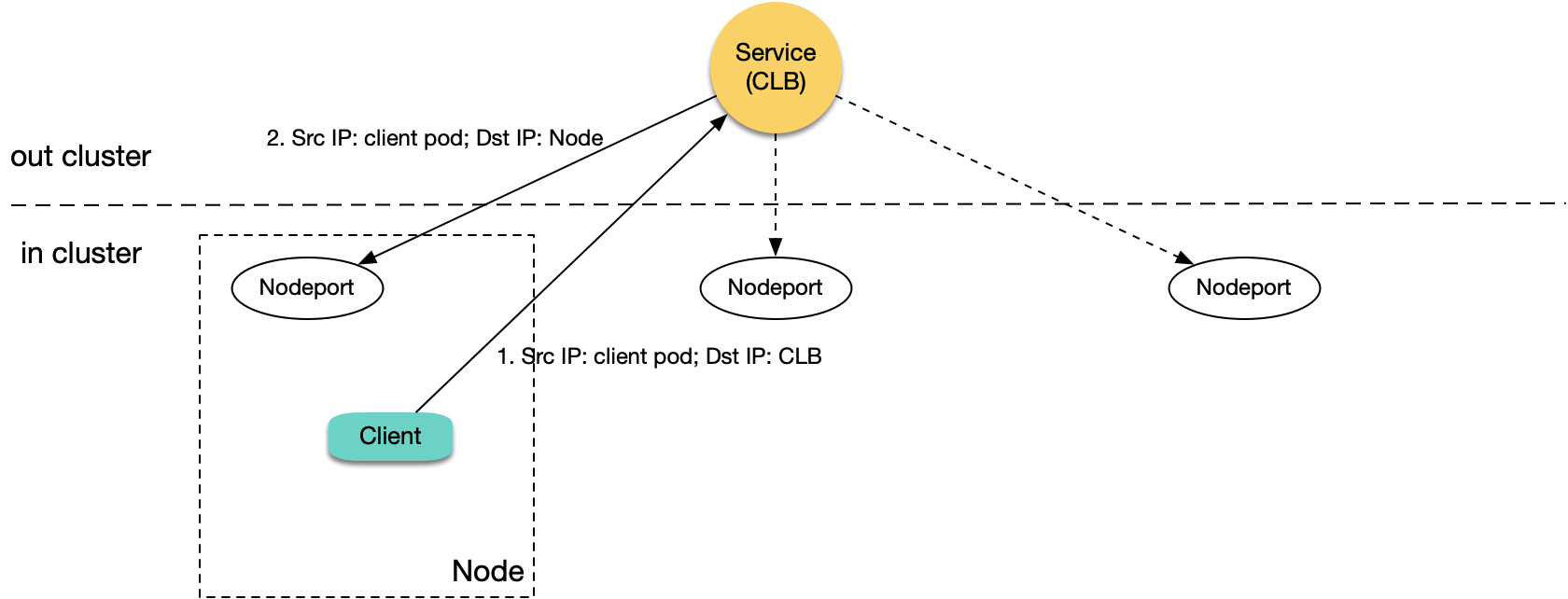
|
||||||
|
|
||||||
|
有一点不同的是,四层 CLB 不会重试下一个 rs,当遇到回环时,现象通常是时通时不通;当然如果集群只有一个节点,也就完全不通。
|
||||||
|
|
||||||
|
那为什么 TKE 的 ipvs 模式不是用原生 K8S 那样的转发逻辑呢(不经过 LB,直接转发到后端 pod)?这个要从我在 19 年 7 月份发现,到目前为止社区都还没解决的问题说起: https://github.com/kubernetes/kubernetes/issues/79783
|
||||||
|
|
||||||
|
这里大概介绍下背景,以前 TKE 的 ipvs 模式集群使用 LoadBalancer 内网 Service 暴露服务,内网 CLB 对后端 NodePort 的健康探测会全部失败,原因是:
|
||||||
|
|
||||||
|
1. ipvs 主要工作在 INPUT 链,需要将要转发的 VIP (Service 的 Cluster IP 和 `EXTERNAL-IP` )当成本机 IP,才好让报文进入 INPUT 链交给 ipvs 处理。
|
||||||
|
2. kube-proxy 的做法是将 Cluster IP 和 `EXTERNAL-IP` 都绑到一个叫 `kube-ipvs0` 的 dummy 网卡,这个网卡仅仅用来绑 VIP (内核自动为其生成 local 路由),不用于接收流量。
|
||||||
|
3. 内网 CLB 对 NodePort 的探测报文源 IP 是 CLB 自身的 VIP,目的 IP 是 Node IP。当探测报文到达节点时,节点发现源 IP 是本机 IP (因为它被绑到了 `kube-ipvs0`),就将其丢掉。所以 CLB 的探测报文永远无法收到响应,也就全部探测失败,虽然 CLB 有全死全活逻辑 (全部探测失败视为全部可以被转发),但也相当于探测就没起到任何作用,在某些情况下会造成一些异常。
|
||||||
|
|
||||||
|
为了解决这个问题,TKE 的修复策略是:ipvs 模式不绑 `EXTERNAL-IP` 到 `kube-ipvs0` 。也就是说,集群内 Pod 访问 CLB IP 的报文不会进入 INPUT 链,而是直接出节点网卡,真正到达 CLB,这样健康探测的报文进入节点时就不会被当成本机 IP 而丢弃,同时探测响应报文也不会进入 INPUT 链导致出不去。
|
||||||
|
|
||||||
|
虽然这种方法修复了 CLB 健康探测失败的问题,但也导致集群内 Pod 访问 CLB 的包真正到了 CLB,由于访问集群内的服务,报文又会被转发回其中一台节点,也就存在了回环的可能性。
|
||||||
|
|
||||||
|
## 为什么公网 CLB 没这个问题?
|
||||||
|
|
||||||
|
使用公网 Ingress 和 LoadBalancer 类型公网 Service 没有回环问题,我的理解主要是公网 CLB 收到的报文源 IP 是子机的出口公网 IP,而子机内部感知不到自己的公网 IP,当报文转发回子机时,不认为公网源 IP 是本机 IP,也就不存在回环。
|
||||||
|
|
||||||
|
## CLB 是否有避免回环机制?
|
||||||
|
|
||||||
|
有。CLB 会判断源 IP,如果发现后端 rs 也有相同 IP,就不考虑转发给这个 rs,而选择其它 rs。但是,源 Pod IP 跟后端 rs IP 并不相同,CLB 也不知道这两个 IP 是在同一节点,所以还是可能会转发过去,也就可能发生回环。
|
||||||
|
|
||||||
|
## client 与 server 反亲和部署能否规避?
|
||||||
|
|
||||||
|
如果我将 client 跟 server 通过反亲和性部署,避免 client 跟 server 部署在同一节点,能否规避这个问题?默认情况下, LB 通过节点 NodePort 绑定 rs,可能转发给任意节点 NodePort,此时不管 client 与 server 是否在同一节点都可能发生回环。但如果给 Service 设置 `externalTrafficPolicy: Local`, LB 就只会转发到有 server pod 的节点,如果 client 与 server 通过反亲和调度在不同节点,此时是不会发生回环的,所以反亲和 + `externalTrafficPolicy: Local` 可以规避此问题(包括内网 Ingress 和 LoadBalancer 类型内网 Service),就是有点麻烦。
|
||||||
|
|
||||||
|
## VPC-CNI 的 LB 直通 Pod 是否也存在这个问题?
|
||||||
|
|
||||||
|
TKE 通常用的 Global Router 网络模式(网桥方案),还有一种是 VPC-CNI (弹性网卡方案)。目前 LB 直通 Pod 只支持 VPC-CNI 的 Pod,即 LB 不绑 NodePort 作为 rs,而是直接绑定后端 Pod 作为 rs:
|
||||||
|
|
||||||
|
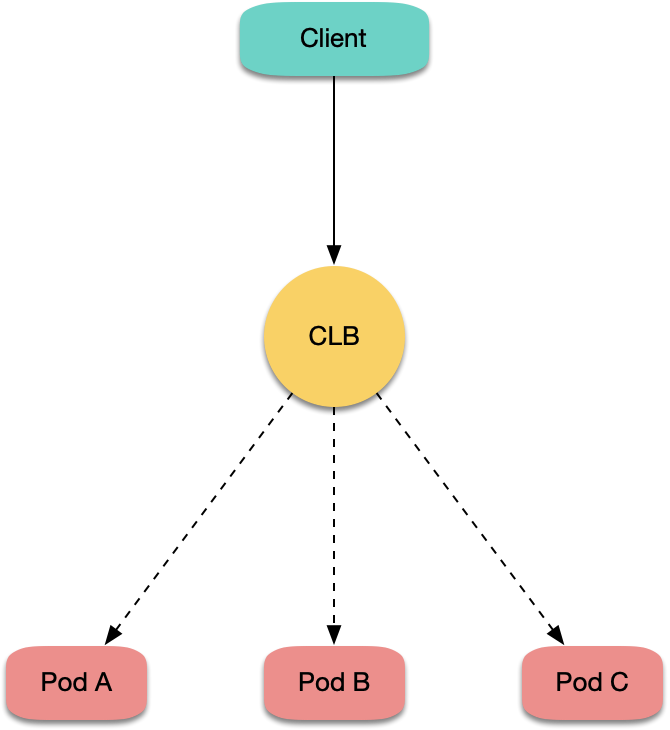
|
||||||
|
|
||||||
|
这样就绕过了 NodePort,不会像之前一样可能会转发给任意节点。但如果 client 与 server 在同一节点,也一样还是可能会发生回环,通过反亲和可以规避。
|
||||||
|
|
||||||
|
## 有什么建议?
|
||||||
|
|
||||||
|
反亲和 与 `externalTrafficPolicy: Local` 的规避方式不太优雅。一般来讲,访问集群内的服务避免访问本集群的 CLB,因为服务本身在集群内部,从 CLB 绕一圈不仅会增加网络链路的长度,还会引发回环问题。
|
||||||
|
|
||||||
|
访问集群内服务尽量用 Service 名称,比如:`server.prod.svc.cluster.local` ,这样就不会经过 CLB,没有回环问题。
|
||||||
|
|
||||||
|
如果业务有耦合域名,不能使用 Service 名称,可以使用 coredns 的 rewrite 插件,将域名指向集群内的 Service,coredns 配置示例:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: v1
|
||||||
|
kind: ConfigMap
|
||||||
|
metadata:
|
||||||
|
name: coredns
|
||||||
|
namespace: kube-system
|
||||||
|
data:
|
||||||
|
Corefile: |2-
|
||||||
|
.:53 {
|
||||||
|
rewrite name roc.oa.com server.prod.svc.cluster.local
|
||||||
|
...
|
||||||
|
|
||||||
|
```
|
||||||
|
如果多个 Service 共用一个域名,可以自行部署 Ingress Controller (如 nginx-ingress),用上面 rewrite 的方法将域名指向自建的 Ingress Controller,然后自建的 Ingress 根据请求 location (域名+路径) 匹配 Service,再转发给后端 Pod,整段链路也是不经过 CLB,也能规避回环问题。
|
||||||
|
|
||||||
|
## 总结
|
||||||
|
|
||||||
|
本文对 TKE 的 CLB 回环问题进行了详细的梳理,介绍了其前因后果以及一些规避的建议。
|
||||||
|
|
||||||
|
|
@ -0,0 +1,37 @@
|
||||||
|
# controller-manager 和 scheduler 状态显示 Unhealthy
|
||||||
|
|
||||||
|
## 背景
|
||||||
|
|
||||||
|
有些地方显示 TKE 集群的 controller-manager 和 scheduler 组件 Unhealthy,比如使用 `kubectl get cs` 查看:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ kubectl get cs
|
||||||
|
NAME STATUS MESSAGE ERROR
|
||||||
|
scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused
|
||||||
|
controller-manager Unhealthy Get "http://127.0.0.1:10252/healthz": dial tcp 127.0.0.1:10252: connect: connection refused
|
||||||
|
etcd-0 Healthy {"health":"true"}
|
||||||
|
```
|
||||||
|
|
||||||
|
或者使用 rancher 查看:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## 原因
|
||||||
|
|
||||||
|
是因为 TKE 托管集群的 master 各个组件都是单独部署的,apiserver 与 controller-manager 和 scheduler 都不在同一台机器,而 controller-manager 和 scheduler 的状态,是 apiserver 来探测的,探测的代码是写死的直接连本机:
|
||||||
|
|
||||||
|
```go
|
||||||
|
func (s componentStatusStorage) serversToValidate() map[string]*componentstatus.Server {
|
||||||
|
serversToValidate := map[string]*componentstatus.Server{
|
||||||
|
"controller-manager": {Addr: "127.0.0.1", Port: ports.InsecureKubeControllerManagerPort, Path: "/healthz"},
|
||||||
|
"scheduler": {Addr: "127.0.0.1", Port: ports.InsecureSchedulerPort, Path: "/healthz"},
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
这个只是显示问题,不影响使用。
|
||||||
|
|
||||||
|
## 相关链接
|
||||||
|
|
||||||
|
* 探测直连本机源码: https://github.com/kubernetes/kubernetes/blob/v1.14.3/pkg/registry/core/rest/storage_core.go#L256
|
||||||
|
* k8s issue: https://github.com/kubernetes/kubernetes/issues/19570
|
||||||
|
* rancher issue: https://github.com/rancher/rancher/issues/11496
|
||||||
|
|
@ -0,0 +1,26 @@
|
||||||
|
# 修改 rp_filter 导致网络异常
|
||||||
|
|
||||||
|
## 背景
|
||||||
|
|
||||||
|
如果在 TKE 使用了 VPC-CNI 网络模式,会关闭节点的 rp_filter:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
net.ipv4.conf.all.rp_filter=0
|
||||||
|
net.ipv4.conf.eth0.rp_filter=0
|
||||||
|
```
|
||||||
|
|
||||||
|
如果因为某种原因,将 rp_filter 打开了(参数置为1),会导致各种异常现象,排查下来就是网络不通,不通的原因就是 rp_filter 被打开了。
|
||||||
|
|
||||||
|
## 什么情况下可能被打开?
|
||||||
|
|
||||||
|
通常有两种原因 给节点加了自定义初始化的脚本,修改了默认的内核参数,将 rp_filter 打开了。
|
||||||
|
2. 使用了[自定义镜像](https://cloud.tencent.com/document/product/457/39563) ,在自定义镜像中自定义了内核参数,打开了 rp_filter。
|
||||||
|
|
||||||
|
## 为什么打开 rp_filter 会不通?
|
||||||
|
|
||||||
|
rp_filter 是控制内核是否开启校验数据包源地址的开关,如果被打开,当数据包发送和接收时的走的路径不太一样时,就会丢弃报文,主要是为了防止 DDoS 或 IP 欺骗。而 TKE VPC-CNI 网络的实现机制,当 Pod 与 VPC 网段之外的 IP 直接通信时,数据包发送走的单独的弹性网卡,接收会走主网卡(eth0),如果开启了 rp_filter,这时就会导致网络不通。
|
||||||
|
|
||||||
|
总结几种常见的场景:
|
||||||
|
1. Pod 访问公网 (公网目的 IP 在 VPC 网段之外)
|
||||||
|
2. 使用了公网 [启用 CLB 直通 Pod](../networking/clb-to-pod-directly.md) (公网源 IP 在 VPC 网段之外)
|
||||||
|
3. Pod 访问 apiserver (169 的 IP 在 VPC 网段之外)
|
||||||
|
|
@ -0,0 +1,55 @@
|
||||||
|
# 使用海外容器镜像
|
||||||
|
|
||||||
|
## 背景
|
||||||
|
|
||||||
|
在 TKE 上部署开源应用时,经常会遇到依赖的镜像拉不下来或非常慢的问题,比如 gcr, quay.io 等境外公开镜像仓库。实际 TKE 已经提供了海外镜像加速的能力,本文介绍如何使用此项能力来部署开源应用。
|
||||||
|
|
||||||
|
## 镜像地址映射
|
||||||
|
|
||||||
|
以下是支持的镜像仓库及其映射地址:
|
||||||
|
|
||||||
|
| 海外镜像仓库地址 | 腾讯云映射地址 |
|
||||||
|
|:----|:----|
|
||||||
|
| quay.io | quay.tencentcloudcr.com |
|
||||||
|
| nvcr.io | nvcr.tencentcloudcr.com |
|
||||||
|
|
||||||
|
## 修改镜像地址
|
||||||
|
|
||||||
|
在部署应用时,修改下镜像地址,将镜像仓库域名替换为腾讯云上的映射地址 (见上方表格),比如将 `quay.io/prometheus/node-exporter:v0.18.1` 改为 `quay.tencentcloudcr.com/prometheus/node-exporter:v0.18.1`,这样拉取镜像时就会走到加速地址。
|
||||||
|
|
||||||
|
## 不想修改镜像地址 ?
|
||||||
|
|
||||||
|
如果镜像太多,嫌修改镜像地址太麻烦 (比如使用 helm 部署,用到了很多镜像),可以利用 containerd 的 mirror 配置来实现无需修改镜像地址 (前提是容器运行时使用的 containerd )。
|
||||||
|
|
||||||
|
> docker 仅支持 docker hub 的 mirror 配置,所以如果容器运行时是 docker 就必须修改镜像地址。
|
||||||
|
|
||||||
|
具体方法是修改 containerd 配置 (`/etc/containerd/config.toml`),将腾讯云映射地址配到 mirrors 里:
|
||||||
|
|
||||||
|
```toml
|
||||||
|
[plugins.cri.registry]
|
||||||
|
[plugins.cri.registry.mirrors]
|
||||||
|
[plugins.cri.registry.mirrors."quay.io"]
|
||||||
|
endpoint = ["https://quay.tencentcloudcr.com"]
|
||||||
|
[plugins.cri.registry.mirrors."nvcr.io"]
|
||||||
|
endpoint = ["https://nvcr.tencentcloudcr.com"]
|
||||||
|
[plugins.cri.registry.mirrors."docker.io"]
|
||||||
|
endpoint = ["https://mirror.ccs.tencentyun.com"]
|
||||||
|
```
|
||||||
|
|
||||||
|
不过每个节点都去手动修改过于麻烦,我们可以在添加节点或创建节点池时指定下自定义数据 (即初始化节点时会运行的自定义脚本) 来自动修改 containerd 配置:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
将下面的脚本粘贴进去:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
sed -i '/\[plugins\.cri\.registry\.mirrors\]/ a\\ \ \ \ \ \ \ \ [plugins.cri.registry.mirrors."quay.io"]\n\ \ \ \ \ \ \ \ \ \ endpoint = ["https://quay.tencentcloudcr.com"]' /etc/containerd/config.toml
|
||||||
|
sed -i '/\[plugins\.cri\.registry\.mirrors\]/ a\\ \ \ \ \ \ \ \ [plugins.cri.registry.mirrors."nvcr.io"]\n\ \ \ \ \ \ \ \ \ \ endpoint = ["https://nvcr.tencentcloudcr.com"]' /etc/containerd/config.toml
|
||||||
|
systemctl restart containerd
|
||||||
|
```
|
||||||
|
|
||||||
|
> 推荐使用节点池,扩容节点时都会自动运行脚本,就不需要每次加节点都去配下自定义数据了。
|
||||||
|
|
||||||
|
## 参考资料
|
||||||
|
|
||||||
|
* [TKE 官方文档: 境外镜像拉取加速](https://cloud.tencent.com/document/product/457/51237)
|
||||||
|
|
@ -0,0 +1,285 @@
|
||||||
|
# 使用软件源加速软件包安装
|
||||||
|
|
||||||
|
## 概述
|
||||||
|
|
||||||
|
在 TKE 环境中,在容器运行中或构建镜像时,如果需要安装一些软件包,通常会使用基础镜像内自带的包管理工具进行安装,而基础镜像内默认的软件源在国内使用往往会比较慢,造成安装过程非常慢。而腾讯云实际本身提供了各个 linux 发行版的软件源,我们将容器内的软件源替换为腾讯云的软件源即可实现加速。
|
||||||
|
|
||||||
|
## 确定 linux 发行版版本
|
||||||
|
|
||||||
|
一般容器镜像都是基于某个基础镜像构建而来,通常查看 Dockerfile 就可以直到基础镜像用的哪个 linux 发行版。
|
||||||
|
|
||||||
|
也可以直接进入运行中的容器,执行 `cat /etc/os-release` 来检查基础镜像的 linux 发行版版本。
|
||||||
|
|
||||||
|
## Ubuntu
|
||||||
|
|
||||||
|
先根据 Ubuntu 发新版替换软件源,然后执行 `apt update -y` 更新软件源,最后再使用 `apt install -y xxx` 来安装需要的软件包。
|
||||||
|
|
||||||
|
**下面是各发行版的软件源替换方法**
|
||||||
|
|
||||||
|
### Ubuntu 20
|
||||||
|
|
||||||
|
```bash
|
||||||
|
cat > /etc/apt/sources.list <<'EOF'
|
||||||
|
deb http://mirrors.tencentyun.com/ubuntu/ focal main restricted universe multiverse
|
||||||
|
deb http://mirrors.tencentyun.com/ubuntu/ focal-security main restricted universe multiverse
|
||||||
|
deb http://mirrors.tencentyun.com/ubuntu/ focal-updates main restricted universe multiverse
|
||||||
|
#deb http://mirrors.tencentyun.com/ubuntu/ focal-proposed main restricted universe multiverse
|
||||||
|
#deb http://mirrors.tencentyun.com/ubuntu/ focal-backports main restricted universe multiverse
|
||||||
|
deb-src http://mirrors.tencentyun.com/ubuntu/ focal main restricted universe multiverse
|
||||||
|
deb-src http://mirrors.tencentyun.com/ubuntu/ focal-security main restricted universe multiverse
|
||||||
|
deb-src http://mirrors.tencentyun.com/ubuntu/ focal-updates main restricted universe multiverse
|
||||||
|
#deb-src http://mirrors.tencentyun.com/ubuntu/ focal-proposed main restricted universe multiverse
|
||||||
|
#deb-src http://mirrors.tencentyun.com/ubuntu/ focal-backports main restricted universe multiverse
|
||||||
|
EOF
|
||||||
|
```
|
||||||
|
|
||||||
|
### Ubuntu 18
|
||||||
|
|
||||||
|
```bash
|
||||||
|
cat > /etc/apt/sources.list <<'EOF'
|
||||||
|
deb http://mirrors.tencentyun.com/ubuntu/ bionic main restricted universe multiverse
|
||||||
|
deb http://mirrors.tencentyun.com/ubuntu/ bionic-security main restricted universe multiverse
|
||||||
|
deb http://mirrors.tencentyun.com/ubuntu/ bionic-updates main restricted universe multiverse
|
||||||
|
#deb http://mirrors.tencentyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
|
||||||
|
#deb http://mirrors.tencentyun.com/ubuntu/ bionic-backports main restricted universe multiverse
|
||||||
|
deb-src http://mirrors.tencentyun.com/ubuntu/ bionic main restricted universe multiverse
|
||||||
|
deb-src http://mirrors.tencentyun.com/ubuntu/ bionic-security main restricted universe multiverse
|
||||||
|
deb-src http://mirrors.tencentyun.com/ubuntu/ bionic-updates main restricted universe multiverse
|
||||||
|
#deb-src http://mirrors.tencentyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
|
||||||
|
#deb-src http://mirrors.tencentyun.com/ubuntu/ bionic-backports main restricted universe multiverse
|
||||||
|
EOF
|
||||||
|
```
|
||||||
|
|
||||||
|
### Ubuntu 16
|
||||||
|
|
||||||
|
```bash
|
||||||
|
cat > /etc/apt/sources.list <<'EOF'
|
||||||
|
deb http://mirrors.tencentyun.com/ubuntu/ xenial main restricted universe multiverse
|
||||||
|
deb http://mirrors.tencentyun.com/ubuntu/ xenial-security main restricted universe multiverse
|
||||||
|
deb http://mirrors.tencentyun.com/ubuntu/ xenial-updates main restricted universe multiverse
|
||||||
|
deb-src http://mirrors.tencentyun.com/ubuntu/ xenial main restricted universe multiverse
|
||||||
|
deb-src http://mirrors.tencentyun.com/ubuntu/ xenial-security main restricted universe multiverse
|
||||||
|
deb-src http://mirrors.tencentyun.com/ubuntu/ xenial-updates main restricted universe multiverse
|
||||||
|
EOF
|
||||||
|
```
|
||||||
|
|
||||||
|
## Debian
|
||||||
|
|
||||||
|
先根据 Debian 发新版替换软件源,然后执行 `apt update -y` 更新软件源,最后再使用 `apt install -y xxx` 安装需要的软件包。
|
||||||
|
|
||||||
|
**下面是各发行版的软件源替换方法**
|
||||||
|
|
||||||
|
### Debian 10
|
||||||
|
```bash
|
||||||
|
cat > /etc/apt/sources.list <<'EOF'
|
||||||
|
deb http://mirrors.tencentyun.com/debian buster main contrib non-free
|
||||||
|
# deb-src http://mirrors.tencentyun.com/debian buster main contrib non-free
|
||||||
|
deb http://mirrors.tencentyun.com/debian buster-updates main contrib non-free
|
||||||
|
# deb-src http://mirrors.tencentyun.com/debian buster-updates main contrib non-free
|
||||||
|
deb http://mirrors.tencentyun.com/debian-security buster/updates main contrib non-free
|
||||||
|
|
||||||
|
# deb-src http://mirrors.tencentyun.com/debian-security buster/updates main contrib non-free
|
||||||
|
# deb http://mirrors.tencentyun.com/debian buster-backports main contrib non-free
|
||||||
|
# deb-src http://mirrors.tencentyun.com/debian buster-backports main contrib non-free
|
||||||
|
# deb http://mirrors.tencentyun.com/debian buster-proposed-updates main contrib non-free
|
||||||
|
# deb-src http://mirrors.tencentyun.com/debian buster-proposed-updates main contrib non-free
|
||||||
|
EOF
|
||||||
|
```
|
||||||
|
|
||||||
|
### Debian 9
|
||||||
|
|
||||||
|
```bash
|
||||||
|
cat > /etc/apt/sources.list <<'EOF'
|
||||||
|
deb http://mirrors.tencentyun.com/debian stretch main contrib non-free
|
||||||
|
deb http://mirrors.tencentyun.com/debian stretch-updates main contrib non-free
|
||||||
|
deb http://mirrors.tencentyun.com/debian-security stretch/updates main
|
||||||
|
#deb http://mirrors.tencentyun.com/debian stretch-backports main contrib non-free
|
||||||
|
#deb http://mirrors.tencentyun.com/debian stretch-proposed-updates main contrib non-free
|
||||||
|
|
||||||
|
deb-src http://mirrors.tencentyun.com/debian stretch main contrib non-free
|
||||||
|
deb-src http://mirrors.tencentyun.com/debian stretch-updates main contrib non-free
|
||||||
|
deb-src http://mirrors.tencentyun.com/debian-security stretch/updates main
|
||||||
|
#deb-src http://mirrors.tencentyun.com/debian stretch-backports main contrib non-free
|
||||||
|
#deb-src http://mirrors.tencentyun.com/debian stretch-proposed-updates main contrib non-free
|
||||||
|
EOF
|
||||||
|
```
|
||||||
|
|
||||||
|
## CentOS
|
||||||
|
|
||||||
|
先删除 CentOS 镜像中所有自带软件源:
|
||||||
|
```bash
|
||||||
|
rm -f /etc/yum.repos.d/*
|
||||||
|
```
|
||||||
|
|
||||||
|
再根据 CentOS 发新版替换软件源,然后执行下面命令更新缓存:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
yum clean all
|
||||||
|
yum makecache
|
||||||
|
```
|
||||||
|
|
||||||
|
最后再使用 `yum install -y xxx` 来安装需要的软件包。
|
||||||
|
|
||||||
|
**下面是各发行版的软件源替换方法**
|
||||||
|
|
||||||
|
### CentOS 8
|
||||||
|
|
||||||
|
```bash
|
||||||
|
cat > /etc/yum.repos.d/CentOS-Base.repo <<'EOF'
|
||||||
|
# Qcloud-Base.repo
|
||||||
|
|
||||||
|
[BaseOS]
|
||||||
|
name=Qcloud-$releasever - BaseOS
|
||||||
|
baseurl=http://mirrors.tencentyun.com/centos/$releasever/BaseOS/$basearch/os/
|
||||||
|
gpgcheck=1
|
||||||
|
enabled=1
|
||||||
|
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-Qcloud-8
|
||||||
|
EOF
|
||||||
|
|
||||||
|
cat > /etc/yum.repos.d/CentOS-Epel.repo <<'EOF'
|
||||||
|
[epel]
|
||||||
|
name=EPEL for redhat/centos $releasever - $basearch
|
||||||
|
baseurl=http://mirrors.tencentyun.com/epel/$releasever/Everything/$basearch
|
||||||
|
failovermethod=priority
|
||||||
|
enabled=1
|
||||||
|
gpgcheck=1
|
||||||
|
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-8
|
||||||
|
EOF
|
||||||
|
|
||||||
|
cat > /etc/yum.repos.d/CentOS-centosplus.repo <<'EOF'
|
||||||
|
# Qcloud-centosplus.repo
|
||||||
|
|
||||||
|
[centosplus]
|
||||||
|
name=Qcloud-$releasever - Plus
|
||||||
|
baseurl=http://mirrors.tencentyun.com/centos/$releasever/centosplus/$basearch/os/
|
||||||
|
gpgcheck=1
|
||||||
|
enabled=0
|
||||||
|
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-Qcloud-8
|
||||||
|
EOF
|
||||||
|
|
||||||
|
cat > /etc/yum.repos.d/Qcloud-Extras.repo <<'EOF'
|
||||||
|
# Qcloud-Extras.repo
|
||||||
|
|
||||||
|
[extras]
|
||||||
|
name=Qcloud-$releasever - Extras
|
||||||
|
baseurl=http://mirrors.tencentyun.com/centos/$releasever/extras/$basearch/os/
|
||||||
|
gpgcheck=1
|
||||||
|
enabled=1
|
||||||
|
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-Qcloud-8
|
||||||
|
EOF
|
||||||
|
|
||||||
|
cat > /etc/yum.repos.d/Qcloud-Devel.repo <<'EOF'
|
||||||
|
# Qcloud-Devel.repo
|
||||||
|
|
||||||
|
[Devel]
|
||||||
|
name=Qcloud-$releasever - Devel WARNING! FOR BUILDROOT USE ONLY!
|
||||||
|
baseurl=http://mirrors.tencentyun.com/$contentdir/$releasever/Devel/$basearch/os/
|
||||||
|
gpgcheck=1
|
||||||
|
enabled=0
|
||||||
|
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-Qcloud-8
|
||||||
|
EOF
|
||||||
|
|
||||||
|
cat > /etc/yum.repos.d/Qcloud-AppStream.repo <<'EOF'
|
||||||
|
# Qcloud-AppStream.repo
|
||||||
|
|
||||||
|
[AppStream]
|
||||||
|
name=Qcloud-$releasever - AppStream
|
||||||
|
baseurl=http://mirrors.tencentyun.com/centos/$releasever/AppStream/$basearch/os/
|
||||||
|
gpgcheck=1
|
||||||
|
enabled=1
|
||||||
|
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-Qcloud-8
|
||||||
|
EOF
|
||||||
|
|
||||||
|
cat > /etc/yum.repos.d/Qcloud-PowerTools.repo <<'EOF'
|
||||||
|
# Qcloud-PowerTools.repo
|
||||||
|
|
||||||
|
[PowerTools]
|
||||||
|
name=Qcloud-$releasever - PowerTools
|
||||||
|
baseurl=http://mirrors.tencentyun.com/centos/$releasever/PowerTools/$basearch/os/
|
||||||
|
gpgcheck=1
|
||||||
|
enabled=0
|
||||||
|
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-Qcloud-8
|
||||||
|
EOF
|
||||||
|
|
||||||
|
cat > /etc/yum.repos.d/Qcloud-HA.repo <<'EOF'
|
||||||
|
# Qcloud-HA.repo
|
||||||
|
|
||||||
|
[HighAvailability]
|
||||||
|
name=Qcloud-$releasever - HA
|
||||||
|
baseurl=http://mirrors.tencentyun.com/$contentdir/$releasever/HighAvailability/$basearch/os/
|
||||||
|
gpgcheck=1
|
||||||
|
enabled=0
|
||||||
|
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-Qcloud-8
|
||||||
|
EOF
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
### CenOS 7
|
||||||
|
|
||||||
|
```bash
|
||||||
|
cat > /etc/yum.repos.d/CentOS-Base.repo <<'EOF'
|
||||||
|
[extras]
|
||||||
|
gpgcheck=1
|
||||||
|
gpgkey=http://mirrors.tencentyun.com/centos/RPM-GPG-KEY-CentOS-7
|
||||||
|
enabled=1
|
||||||
|
baseurl=http://mirrors.tencentyun.com/centos/$releasever/extras/$basearch/
|
||||||
|
name=Qcloud centos extras - $basearch
|
||||||
|
[os]
|
||||||
|
gpgcheck=1
|
||||||
|
gpgkey=http://mirrors.tencentyun.com/centos/RPM-GPG-KEY-CentOS-7
|
||||||
|
enabled=1
|
||||||
|
baseurl=http://mirrors.tencentyun.com/centos/$releasever/os/$basearch/
|
||||||
|
name=Qcloud centos os - $basearch
|
||||||
|
[updates]
|
||||||
|
gpgcheck=1
|
||||||
|
gpgkey=http://mirrors.tencentyun.com/centos/RPM-GPG-KEY-CentOS-7
|
||||||
|
enabled=1
|
||||||
|
baseurl=http://mirrors.tencentyun.com/centos/$releasever/updates/$basearch/
|
||||||
|
name=Qcloud centos updates - $basearch
|
||||||
|
EOF
|
||||||
|
|
||||||
|
cat > /etc/yum.repos.d/CentOS-Epel.repo <<'EOF'
|
||||||
|
[epel]
|
||||||
|
name=EPEL for redhat/centos $releasever - $basearch
|
||||||
|
failovermethod=priority
|
||||||
|
gpgcheck=1
|
||||||
|
gpgkey=http://mirrors.tencentyun.com/epel/RPM-GPG-KEY-EPEL-7
|
||||||
|
enabled=1
|
||||||
|
baseurl=http://mirrors.tencentyun.com/epel/$releasever/$basearch/
|
||||||
|
EOF
|
||||||
|
```
|
||||||
|
|
||||||
|
### CentOS 6
|
||||||
|
|
||||||
|
```bash
|
||||||
|
cat > /etc/yum.repos.d/CentOS-Base.repo <<'EOF'
|
||||||
|
[extras]
|
||||||
|
gpgcheck=1
|
||||||
|
gpgkey=http://mirrors.tencentyun.com/centos/RPM-GPG-KEY-CentOS-6
|
||||||
|
enabled=1
|
||||||
|
baseurl=http://mirrors.tencentyun.com/centos/$releasever/extras/$basearch/
|
||||||
|
name=Qcloud centos extras - $basearch
|
||||||
|
[os]
|
||||||
|
gpgcheck=1
|
||||||
|
gpgkey=http://mirrors.tencentyun.com/centos/RPM-GPG-KEY-CentOS-6
|
||||||
|
enabled=1
|
||||||
|
baseurl=http://mirrors.tencentyun.com/centos/$releasever/os/$basearch/
|
||||||
|
name=Qcloud centos os - $basearch
|
||||||
|
[updates]
|
||||||
|
gpgcheck=1
|
||||||
|
gpgkey=http://mirrors.tencentyun.com/centos/RPM-GPG-KEY-CentOS-6
|
||||||
|
enabled=1
|
||||||
|
baseurl=http://mirrors.tencentyun.com/centos/$releasever/updates/$basearch/
|
||||||
|
name=Qcloud centos updates - $basearch
|
||||||
|
EOF
|
||||||
|
|
||||||
|
cat > /etc/yum.repos.d/CentOS-Epel.repo <<'EOF'
|
||||||
|
[epel]
|
||||||
|
name=epel for redhat/centos $releasever - $basearch
|
||||||
|
failovermethod=priority
|
||||||
|
gpgcheck=1
|
||||||
|
gpgkey=http://mirrors.tencentyun.com/epel/RPM-GPG-KEY-EPEL-6
|
||||||
|
enabled=1
|
||||||
|
baseurl=http://mirrors.tencentyun.com/epel/$releasever/$basearch/
|
||||||
|
EOF
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,453 @@
|
||||||
|
# 自建 Gitlab 代码仓库
|
||||||
|
|
||||||
|
本文介绍如何在腾讯云容器服务上部署 Gitlab 代码仓库。
|
||||||
|
|
||||||
|
## 前提条件
|
||||||
|
|
||||||
|
* 已安装 [Helm](https://helm.sh)。
|
||||||
|
* 已开启集群访问并配置好 kubeconfig,可以通过 kubectl 操作集群(参考[官方文档:连接集群](https://cloud.tencent.com/document/product/457/32191))。
|
||||||
|
|
||||||
|
## 准备 chart
|
||||||
|
|
||||||
|
Gitlab 官方提供了 helm chart,可以下载下来:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
helm repo add gitlab https://charts.gitlab.io/
|
||||||
|
helm fetch gitlab/gitlab --untar
|
||||||
|
helm fetch gitlab/gitlab-runner --untar
|
||||||
|
```
|
||||||
|
|
||||||
|
> 参考 [Gitlab 官方文档: Deployment Guide](https://docs.gitlab.com/charts/installation/deployment.html)
|
||||||
|
|
||||||
|
不过要愉快的部署到腾讯云容器服务,要修改的配置项较多:
|
||||||
|
* 如果存储使用默认的云硬盘(cbs),容量必须是 10Gi 的倍数,官方 chart 有一些 8Gi 的定义,会导致 pvc 一直 pending,pod 也一致 pending,需要修改一下配置。
|
||||||
|
* gitlab 相关组件的容器镜像地址使用的是 gitlab 官方的镜像仓库,在国内拉取可能会失败,需要同步到国内并修改镜像地址。
|
||||||
|
* 很多组件和功能可能用不到,建议是最小化安装,不需要的通通禁用,如 nginx-ingress, cert-manager, prometheus 等。
|
||||||
|
* 服务暴露方式和 TLS 证书管理,不同平台差异比较大,建议是单独管理,helm 安装时只安装应用本身,ingress 和 tls 相关配置禁用掉。
|
||||||
|
|
||||||
|
修改这些配置比较繁琐,我已经维护了一份 Gitlab 适配腾讯云容器服务的 chart 包,相关 gitlab 镜像也做了同步,可以实现一键安装。可以通过 git 拉下来:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git clone https://github.com/tke-apps/gitlab.git
|
||||||
|
cd gitlab
|
||||||
|
```
|
||||||
|
|
||||||
|
## StorageClass 注意事项
|
||||||
|
|
||||||
|
像 gitaly, minio 这些组件,是需要挂载持久化存储的,在腾讯云容器服务,默认使用的是云硬盘(CBS),块存储,通常也建议使用这种,不过在使用之前,建议确保默认 StorageClass 支持磁盘容量在线扩容,这个特性需要确保集群版本在 1.18 以上,且安装了 CBS CSI 插件(Out-of-Tree),新版本集群默认会安装。
|
||||||
|
|
||||||
|
然后找到默认 StorageClass,通常名为 "cbs":
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
编辑 yaml:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
先确保以下两点,如果不满足,可以删除重建:
|
||||||
|
* 默认 StorageClass 的 `is-default-class` 注解为 true。
|
||||||
|
* provisioner 是 `com.tencent.cloud.csi.cbs`。
|
||||||
|
|
||||||
|
如果满足,添加字段 `allowVolumeExpansion: true` 并保存。
|
||||||
|
|
||||||
|
另外,也可以通过 kubectl 修改,先查询 default StorageClass:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
然后使用 `kubectl edit sc <NAME>` 进行修改。
|
||||||
|
|
||||||
|
## 部署 Gitlab
|
||||||
|
|
||||||
|
### 准备配置
|
||||||
|
|
||||||
|
创建 `gitlab.yaml` 配置,分享一下我的配置:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
redis:
|
||||||
|
install: true
|
||||||
|
master:
|
||||||
|
nodeSelector:
|
||||||
|
node.kubernetes.io/instance-type: eklet
|
||||||
|
persistence:
|
||||||
|
enabled: false
|
||||||
|
postgresql:
|
||||||
|
install: false
|
||||||
|
minio:
|
||||||
|
persistence:
|
||||||
|
enabled: true
|
||||||
|
volumeName: gitlab-minio
|
||||||
|
accessMode: ReadWriteMany
|
||||||
|
size: '100Gi'
|
||||||
|
gitlab:
|
||||||
|
gitaly:
|
||||||
|
persistence:
|
||||||
|
enabled: true
|
||||||
|
volumeName: 'gitlab-gitaly'
|
||||||
|
accessMode: ReadWriteMany
|
||||||
|
size: 100Gi
|
||||||
|
global:
|
||||||
|
hosts:
|
||||||
|
domain: imroc.cc
|
||||||
|
https: true
|
||||||
|
gitlab:
|
||||||
|
name: gitlab.imroc.cc
|
||||||
|
https: true
|
||||||
|
nodeSelector:
|
||||||
|
node.kubernetes.io/instance-type: eklet
|
||||||
|
psql:
|
||||||
|
password:
|
||||||
|
useSecret: true
|
||||||
|
secret: gitlab-psql-password-secret
|
||||||
|
key: password
|
||||||
|
host: 'pgsql-postgresql.db'
|
||||||
|
port: 5432
|
||||||
|
username: gitlab
|
||||||
|
database: gitlab
|
||||||
|
```
|
||||||
|
|
||||||
|
* redis 作为缓存,不想持久化数据,降低成本。
|
||||||
|
* postgresql 使用现有的数据库,不安装,配置上数据库连接信息(数据库密码通过secret存储,提前创建好)。
|
||||||
|
* minio 和 gitaly 挂载的存储,使用了 NFS,提前创建好 pv,在 `persistence` 配置里指定 `volumeName` 来绑定 pv。
|
||||||
|
* 我的集群是标准集群,有普通节点和超级节点,我希望 gitlab 所有组件都调度到超级节点,global 和 redis 与 minio 里指定 nodeSelector,强制调度到超级节点。
|
||||||
|
* 服务暴露方式我用的 istio-ingressgateway,证书也配到 gateway 上的,对外访问方式是 https,在 `global.hosts` 下配置对外访问域名,`https` 置为 true(用于页面内的连接跳转,避免https页面跳到http链接)。
|
||||||
|
|
||||||
|
|
||||||
|
`gitlab-psql-password-secret.yaml`(存 postgresql 密码的 secret):
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: v1
|
||||||
|
kind: Secret
|
||||||
|
metadata:
|
||||||
|
name: gitlab-psql-password-secret
|
||||||
|
namespace: gitlab
|
||||||
|
type: Opaque
|
||||||
|
stringData:
|
||||||
|
password: '123456'
|
||||||
|
```
|
||||||
|
|
||||||
|
gitaly 和 minio 挂载的存储我使用 NFS,提前创建好 CFS 实例和相应的文件夹路径,并 `chmod 0777 <DIR>` 修改目录权限,避免因权限问题导致 pod 启动失败。以下分别是它们的 pv yaml 定义:
|
||||||
|
|
||||||
|
`minio-nfs-pv.yaml`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: v1
|
||||||
|
kind: PersistentVolume
|
||||||
|
metadata:
|
||||||
|
name: gitlab-minio
|
||||||
|
spec:
|
||||||
|
accessModes:
|
||||||
|
- ReadWriteMany
|
||||||
|
capacity:
|
||||||
|
storage: 100Gi
|
||||||
|
nfs:
|
||||||
|
path: /gitlab/minio
|
||||||
|
server: 10.10.0.15
|
||||||
|
persistentVolumeReclaimPolicy: Retain
|
||||||
|
volumeMode: Filesystem
|
||||||
|
storageClassName: 'cbs'
|
||||||
|
```
|
||||||
|
|
||||||
|
`gitaly-nfs-pv.yaml`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: v1
|
||||||
|
kind: PersistentVolume
|
||||||
|
metadata:
|
||||||
|
name: gitlab-gitaly
|
||||||
|
spec:
|
||||||
|
accessModes:
|
||||||
|
- ReadWriteMany
|
||||||
|
capacity:
|
||||||
|
storage: 100Gi
|
||||||
|
nfs:
|
||||||
|
path: /gitlab/gitaly
|
||||||
|
server: 10.10.0.15
|
||||||
|
persistentVolumeReclaimPolicy: Retain
|
||||||
|
volumeMode: Filesystem
|
||||||
|
storageClassName: 'cbs'
|
||||||
|
```
|
||||||
|
|
||||||
|
* `storageClassName` 我使用默认的 StorageClass 名称,因为部署配置里没指定 storageClass 会自动给 pvc 加上默认的,如果 pv 跟 pvc 的 `storageClassName` 不匹配,会导致调度失败。
|
||||||
|
|
||||||
|
上述 pv 和 secret 是 gitlab 应用依赖的,需要在部署 gitlab 之前先 apply 到集群:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl apply -f gitlab-psql-password-secret.yaml
|
||||||
|
kubectl apply -f minio-nfs-pv.yaml
|
||||||
|
kubectl apply -f gitaly-nfs-pv.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
### 安装 gitlab
|
||||||
|
|
||||||
|
使用 helm 安装:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
helm upgrade -n gitlab --install gitlab -f gitlab.yaml ./gitlab
|
||||||
|
```
|
||||||
|
|
||||||
|
检查 gitlab 组件是否正常运行:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ kubectl -n gitlab get pod
|
||||||
|
NAME READY STATUS RESTARTS AGE
|
||||||
|
gitlab-gitaly-0 1/1 Running 0 8m
|
||||||
|
gitlab-gitlab-exporter-7bc89d678-d4c7h 1/1 Running 0 8m
|
||||||
|
gitlab-gitlab-shell-77d99c8b45-kbfmd 1/1 Running 0 8m
|
||||||
|
gitlab-kas-549b4cf77c-thjrv 1/1 Running 0 8m
|
||||||
|
gitlab-migrations-1-2pnx7 0/1 Completed 0 8m
|
||||||
|
gitlab-minio-7b57f77ccb-g9mqb 1/1 Running 0 8m
|
||||||
|
gitlab-minio-create-buckets-1-hvz9g 0/1 Completed 0 6m
|
||||||
|
gitlab-redis-master-0 2/2 Running 0 6m
|
||||||
|
gitlab-sidekiq-all-in-1-v2-5f8c64987f-jhtv9 1/1 Running 0 8m
|
||||||
|
gitlab-toolbox-66bbb6d4dc-qff92 1/1 Running 0 8m
|
||||||
|
gitlab-webservice-default-868fbf9fbc-9cb8g 2/2 Running 0 8m
|
||||||
|
```
|
||||||
|
|
||||||
|
> 后续想卸载可使用这个命令: `helm -n gitlab uninstall gitlab`
|
||||||
|
|
||||||
|
### 暴露 Gitlab 服务
|
||||||
|
|
||||||
|
查看 service:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ kubectl -n gitlab get service
|
||||||
|
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||||
|
gitlab-gitaly ClusterIP None <none> 8075/TCP,9236/TCP 8m
|
||||||
|
gitlab-gitlab-exporter ClusterIP 172.16.189.22 <none> 9168/TCP 8m
|
||||||
|
gitlab-gitlab-shell ClusterIP 172.16.251.106 <none> 22/TCP 8m
|
||||||
|
gitlab-kas ClusterIP 172.16.245.70 <none> 8150/TCP,8153/TCP,8154/TCP,8151/TCP 8m
|
||||||
|
gitlab-minio-svc ClusterIP 172.16.187.127 <none> 9000/TCP 8m
|
||||||
|
gitlab-redis-headless ClusterIP None <none> 6379/TCP 8m
|
||||||
|
gitlab-redis-master ClusterIP 172.16.156.40 <none> 6379/TCP 8m
|
||||||
|
gitlab-redis-metrics ClusterIP 172.16.196.188 <none> 9121/TCP 8m
|
||||||
|
gitlab-webservice-default ClusterIP 172.16.143.4 <none> 8080/TCP,8181/TCP,8083/TCP 8m
|
||||||
|
```
|
||||||
|
|
||||||
|
其中带 `webservice` 的 service 是 Gitlab 访问总入口,需要特别注意的是,端口是 8181,不是 8080 那个。
|
||||||
|
|
||||||
|
我使用 istio-ingressgateway,Gateway 本身已提前监听好 443 并挂好证书:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl -n external get gw imroc -o yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: networking.istio.io/v1alpha3
|
||||||
|
kind: Gateway
|
||||||
|
metadata:
|
||||||
|
name: imroc
|
||||||
|
namespace: external
|
||||||
|
spec:
|
||||||
|
selector:
|
||||||
|
app: istio-ingressgateway
|
||||||
|
istio: ingressgateway
|
||||||
|
servers:
|
||||||
|
- port:
|
||||||
|
number: 443
|
||||||
|
name: HTTPS-443-pp0c
|
||||||
|
protocol: HTTPS
|
||||||
|
hosts:
|
||||||
|
- imroc.cc
|
||||||
|
- "*.imroc.cc"
|
||||||
|
tls:
|
||||||
|
mode: SIMPLE
|
||||||
|
credentialName: imroc-cc-crt-secret
|
||||||
|
```
|
||||||
|
|
||||||
|
只需创建一个 VirtualService,将 gitlab 服务与 Gateway 绑定,暴露出去。
|
||||||
|
|
||||||
|
`gitlab-vs.yaml`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: networking.istio.io/v1beta1
|
||||||
|
kind: VirtualService
|
||||||
|
metadata:
|
||||||
|
name: gitlab-imroc-cc
|
||||||
|
namespace: gitlab
|
||||||
|
spec:
|
||||||
|
gateways:
|
||||||
|
- external/imroc
|
||||||
|
hosts:
|
||||||
|
- 'gitlab.imroc.cc'
|
||||||
|
http:
|
||||||
|
- route:
|
||||||
|
- destination:
|
||||||
|
host: gitlab-webservice-default
|
||||||
|
port:
|
||||||
|
number: 8181 # 注意这里端口是 8181,不是 8080
|
||||||
|
```
|
||||||
|
|
||||||
|
执行创建:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl apply -f gitlab-vs.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
除了暴露 https,如果需要通过 ssh 协议来 push 或 pull 代码,需要暴露 22 端口,使用单独的 Gateway 对象来暴露(绑定同一个 ingressgateway),`shell-gw.yaml`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: networking.istio.io/v1alpha3
|
||||||
|
kind: Gateway
|
||||||
|
metadata:
|
||||||
|
name: shell
|
||||||
|
namespace: external
|
||||||
|
spec:
|
||||||
|
selector:
|
||||||
|
app: istio-ingressgateway
|
||||||
|
istio: ingressgateway
|
||||||
|
servers:
|
||||||
|
- port:
|
||||||
|
number: 22
|
||||||
|
name: shell
|
||||||
|
protocol: TCP
|
||||||
|
hosts:
|
||||||
|
- "*"
|
||||||
|
```
|
||||||
|
|
||||||
|
创建 Gateway:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl apply -f shell-gw.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
为 22 端口创建 VirtualService 并绑定 Gateway,`gitlab-shell-vs.yaml`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: networking.istio.io/v1beta1
|
||||||
|
kind: VirtualService
|
||||||
|
metadata:
|
||||||
|
name: gitlab-shell
|
||||||
|
namespace: gitlab
|
||||||
|
spec:
|
||||||
|
gateways:
|
||||||
|
- external/shell
|
||||||
|
hosts:
|
||||||
|
- '*'
|
||||||
|
tcp:
|
||||||
|
- match:
|
||||||
|
- port: 22
|
||||||
|
route:
|
||||||
|
- destination:
|
||||||
|
host: gitlab-gitlab-shell
|
||||||
|
port:
|
||||||
|
number: 22
|
||||||
|
```
|
||||||
|
|
||||||
|
创建 VirutalService:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl apply -f gitlab-shell-vs.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
### 获取 root 初始密码并登录
|
||||||
|
|
||||||
|
服务暴露出来之后,确保 DNS 也正确配置,解析到网关的 IP,我这里则是 istio-ingressgateway 对应的 CLB 的外网 IP。
|
||||||
|
|
||||||
|
在浏览器中打开 gitlab 外部地址:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
自动跳转到登录页面,管理员用户名为 root,密码可通过自动生成的 secret 获取:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ kubectl -n gitlab get secret | grep initial-root-password
|
||||||
|
gitlab-gitlab-initial-root-password Opaque 1 38m
|
||||||
|
$ kubectl -n gitlab get secret gitlab-gitlab-initial-root-password -o jsonpath='{.data.password}' | base64 -d
|
||||||
|
kxe***********************************************************k5
|
||||||
|
```
|
||||||
|
|
||||||
|
拿到密码后输入然后登录即可。
|
||||||
|
|
||||||
|
## 部署并注册 gitlab-runner
|
||||||
|
|
||||||
|
Gitlab 有很强大的 CI 功能,我们可以在集群中也部署一下 gitlab-runner,如果为代码仓库设置了 CI 流程,可以自动将任务分发给 gitlab-runner 去执行 CI 任务,每个任务再创建单独的 Pod 去运行:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
下面介绍 gitlab-runner 的部署与注册方法。
|
||||||
|
|
||||||
|
### 获取注册 token
|
||||||
|
|
||||||
|
在【Admin】-【Overview】-【Runners】 复制注册 token:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
也可以通过 kubectl 获取 secret 得到 token:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ kubectl -n gitlab get secret gitlab-gitlab-runner-secret -o jsonpath='{.data.runner-registration-token}' | base64 -d
|
||||||
|
AF************************************************************kF
|
||||||
|
```
|
||||||
|
|
||||||
|
### 准备配置
|
||||||
|
|
||||||
|
`gitlab-runner.yaml`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
runnerRegistrationToken: AF************************************************************kF
|
||||||
|
gitlabUrl: 'https://gitlab.imroc.cc'
|
||||||
|
runners:
|
||||||
|
locked: false
|
||||||
|
config: |
|
||||||
|
[[runners]]
|
||||||
|
environment = ["FF_USE_LEGACY_KUBERNETES_EXECUTION_STRATEGY=1"]
|
||||||
|
[runners.kubernetes]
|
||||||
|
image = "ubuntu:20.04"
|
||||||
|
```
|
||||||
|
|
||||||
|
注意:
|
||||||
|
* `runnerRegistrationToken` 替换为上一步获取到的 token。
|
||||||
|
* `gitlabUrl` 替换为 gitlab 访问地址。
|
||||||
|
* 超级节点(EKS)的 Pod,不支持 attach,如果 runner 调度到超级节点(EKS) 就会有问题,打开 runer [FF_USE_LEGACY_KUBERNETES_EXECUTION_STRATEGY](https://docs.gitlab.com/runner/configuration/feature-flags.html#available-feature-flags) 的 feature flag 来换成 exec 方式。
|
||||||
|
|
||||||
|
### 安装 gitlab-runner
|
||||||
|
|
||||||
|
使用 helm 安装:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
helm upgrade -n gitlab --install gitlab-runner -f gitlab-runner.yaml ./gitlab-runner
|
||||||
|
```
|
||||||
|
|
||||||
|
检查 runner 是否正常运行:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ kubectl -n gitlab get pod | grep runner
|
||||||
|
gitlab-runner-6fb794bb6b-s6n5h 1/1 Running 0 2m17s
|
||||||
|
```
|
||||||
|
|
||||||
|
> 后续想卸载可使用这个命令: `helm -n gitlab uninstall gitlab-runner`
|
||||||
|
|
||||||
|
### 检查是否注册成功
|
||||||
|
|
||||||
|
进入 Gitlab 【Admin】-【Overview】-【Runners】页面检查 runner 是否注册成功:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## 附录
|
||||||
|
### 测试场景
|
||||||
|
|
||||||
|
如果只是测试下 Gitlab,不长期使用,在不需要的时候可以把所有副本缩为 0 以节约成本:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl get deployments.v1.apps | grep -v NAME | awk '{print $1}' | xargs -I {} kubectl scale deployments.v1.apps/{} --replicas=0
|
||||||
|
kubectl get sts | grep -v NAME | awk '{print $1}' | xargs -I {} kubectl scale sts/{} --replicas=0
|
||||||
|
```
|
||||||
|
|
||||||
|
在需要用的时候置为 1:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl get deployments.v1.apps | grep -v NAME | awk '{print $1}' | xargs -I {} kubectl scale deployments.v1.apps/{} --replicas=1
|
||||||
|
kubectl get sts | grep -v NAME | awk '{print $1}' | xargs -I {} kubectl scale sts/{} --replicas=1
|
||||||
|
```
|
||||||
|
|
||||||
|
如果使用了 `https://github.com/tke-apps/gitlab` 这个仓库,可以直接用以下命令缩0:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
make scale0
|
||||||
|
```
|
||||||
|
|
||||||
|
扩到1:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
make scale1
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,288 @@
|
||||||
|
# 自建 Harbor 镜像仓库
|
||||||
|
|
||||||
|
## 概述
|
||||||
|
|
||||||
|
腾讯云有 [容器镜像服务 TCR](https://cloud.tencent.com/product/tcr),企业级容器镜像仓库,满足绝大多数镜像仓库的需求,如果需要使用镜像仓库,可以首选 TCR,如果是考虑到成本,或想使用 Harbor 的高级功能(如 [Proxy Cache](https://goharbor.io/docs/2.1.0/administration/configure-proxy-cache/)) 等因素,可以考虑自建 Harbor 镜像仓库,本文介绍如何在腾讯云容器服务中部署 Harbor 作为自建的容器镜像仓库。
|
||||||
|
|
||||||
|
## 前提条件
|
||||||
|
|
||||||
|
* 已安装 [Helm](https://helm.sh)。
|
||||||
|
* 已开启集群访问并配置好 kubeconfig,可以通过 kubectl 操作集群(参考[官方文档:连接集群](https://cloud.tencent.com/document/product/457/32191))。
|
||||||
|
|
||||||
|
## 操作步骤
|
||||||
|
|
||||||
|
### 准备 COS 对象存储
|
||||||
|
|
||||||
|
镜像的存储建议是放对象存储,因为容量大,可扩展,成本低,速度还快。腾讯云上的对象存储是 [COS](https://cloud.tencent.com/product/cos),而 harbor 的存储驱动暂不支持 COS,不过 COS 自身兼容 S3,所以可以配置 harbor 使用 S3 存储驱动。
|
||||||
|
|
||||||
|
下面我们登录腾讯云账号,在 [COS 控制台](https://console.cloud.tencent.com/cos/bucket) 创建一个存储桶:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
记录一下如下信息后面用:
|
||||||
|
* `region`: 存储桶所在地域,如 `ap-chengdu`,参考 [地域和可用区](https://cloud.tencent.com/document/product/213/6091)。
|
||||||
|
* `bucket`: 存储桶名称,如 `registry-12*******6` (有 appid 后缀)。
|
||||||
|
* `regionendpoint`: 类似 `https://cos.<REGION>.myqcloud.com` 这种格式的 url,如 `https://cos.ap-chengdu.myqcloud.com`。
|
||||||
|
|
||||||
|
### 创建云 API 密钥
|
||||||
|
|
||||||
|
在 [访问密钥](https://console.cloud.tencent.com/cam/capi) 这里新建密钥:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
> 如果之前已经新建过,可跳过此步骤。
|
||||||
|
|
||||||
|
记录一下生成的 `SecretId` 和 `SecretKey`,后面需要用。
|
||||||
|
|
||||||
|
### 准备 chart
|
||||||
|
|
||||||
|
```bash
|
||||||
|
helm repo add harbor https://helm.goharbor.io
|
||||||
|
helm fetch harbor/harbor --untar
|
||||||
|
```
|
||||||
|
|
||||||
|
* 参考 [Harbor 官方文档: Deploying Harbor with High Availability via Helm](https://goharbor.io/docs/edge/install-config/harbor-ha-helm/)
|
||||||
|
* 查看 `./harbor/values.yaml` 可以看到配置项。
|
||||||
|
|
||||||
|
### 准备配置
|
||||||
|
|
||||||
|
`harbor-values.yaml`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
expose:
|
||||||
|
type: clusterIP
|
||||||
|
tls:
|
||||||
|
enabled: false # 建议关闭 tls,如果对外需要 https 访问,可以将 TLS 放到前面的 7 层代理进行配置。
|
||||||
|
externalURL: https://registry.imroc.cc # 镜像仓库的对外访问地址
|
||||||
|
persistence:
|
||||||
|
imageChartStorage:
|
||||||
|
type: s3
|
||||||
|
s3: # 务必修改! COS 相关配置
|
||||||
|
region: ap-chegndu
|
||||||
|
bucket: harbor-12*******6
|
||||||
|
accesskey: AKI*******************************zv # SecretId
|
||||||
|
secretkey: g5****************************FR # SecretKey
|
||||||
|
regionendpoint: https://cos.ap-chengdu.myqcloud.com
|
||||||
|
rootdirectory: / # 存储桶中存储镜像数据的路径
|
||||||
|
persistentVolumeClaim:
|
||||||
|
registry:
|
||||||
|
existingClaim: 'registry-registry'
|
||||||
|
jobservice:
|
||||||
|
existingClaim: "registry-jobservice"
|
||||||
|
harborAdminPassword: '123456' # 务必修改! harbor 管理员登录密码
|
||||||
|
chartmuseum:
|
||||||
|
enabled: false
|
||||||
|
trivy:
|
||||||
|
enabled: false
|
||||||
|
notary:
|
||||||
|
enabled: false
|
||||||
|
database:
|
||||||
|
type: external
|
||||||
|
external:
|
||||||
|
host: 'pgsql-postgresql.db'
|
||||||
|
username: 'postgres'
|
||||||
|
password: '123456'
|
||||||
|
coreDatabase: 'registry'
|
||||||
|
redis:
|
||||||
|
type: external
|
||||||
|
external:
|
||||||
|
addr: 'redis.db:6379'
|
||||||
|
coreDatabaseIndex: "10"
|
||||||
|
jobserviceDatabaseIndex: "11"
|
||||||
|
registryDatabaseIndex: "12"
|
||||||
|
chartmuseumDatabaseIndex: "13"
|
||||||
|
trivyAdapterIndex: "14"
|
||||||
|
```
|
||||||
|
|
||||||
|
注意事项:
|
||||||
|
* `expose` 配置暴露服务,我这里打算用其它方式暴露(istio-ingress-gateway),不使用 Ingress, LoadBalancer 之类的方式,所以 type 置为 clusterIP (表示仅集群内访问);另外,tls 也不需要,都是在 gateway 上配置就行。
|
||||||
|
* `s3` 配置实为 COS 相关配置,将前面步骤记录的信息填上去。
|
||||||
|
* chartmuseum, trivy, notary 我都不需要,所以 `enabled` 都设为 `false`。
|
||||||
|
* `harborAdminPassword` 是 harbor 管理员登录密码,设置一下。
|
||||||
|
* `database` 是配置 postgresql 数据库,我使用现成的数据库,配置 type 为 external 并写上相关连接配置。
|
||||||
|
* `redis` 是配置 redis 缓存,我使用现成的 redis,配置 type 为 external 并写上相关连接配置。
|
||||||
|
* `persistentVolumeClaim` 配置持久化存储,我这里只有 `registry` 和 `jobservice` 模块需要挂载存储,存储我挂载的 CFS (腾讯云 NFS 服务),指定 `existingClaim` 为提前创建好的 pvc,参考附录【挂载 CFS】。
|
||||||
|
|
||||||
|
### 安装
|
||||||
|
|
||||||
|
```bash
|
||||||
|
helm upgrade --install -n registry -f harbor-values.yaml registry ./harbor
|
||||||
|
```
|
||||||
|
|
||||||
|
> 后续如需卸载可以执行: helm uninstall registry
|
||||||
|
|
||||||
|
检查 pod 是否正常启动:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ kubectl -n registry get pod
|
||||||
|
NAME READY STATUS RESTARTS AGE
|
||||||
|
registry-harbor-core-55d577c7-l9k5j 1/1 Running 0 1m
|
||||||
|
registry-harbor-jobservice-66846c575-dbvdz 1/1 Running 0 1m
|
||||||
|
registry-harbor-nginx-7d94c9446c-z6rkn 1/1 Running 0 1m
|
||||||
|
registry-harbor-portal-d87bc7554-psp2r 1/1 Running 0 1m
|
||||||
|
registry-harbor-registry-66d899c9c9-v2w7r 2/2 Running 0 1m
|
||||||
|
```
|
||||||
|
|
||||||
|
检查自动创建的 service:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ kubectl -n registry get svc
|
||||||
|
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||||
|
harbor ClusterIP 172.16.195.61 <none> 80/TCP 1m
|
||||||
|
registry-harbor-core ClusterIP 172.16.244.174 <none> 80/TCP 1m
|
||||||
|
registry-harbor-jobservice ClusterIP 172.16.219.62 <none> 80/TCP 1m
|
||||||
|
registry-harbor-portal ClusterIP 172.16.216.247 <none> 80/TCP 1m
|
||||||
|
registry-harbor-registry ClusterIP 172.16.146.201 <none> 5000/TCP,8080/TCP 1m
|
||||||
|
```
|
||||||
|
|
||||||
|
### 暴露服务
|
||||||
|
|
||||||
|
我这里使用 istio-ingressgateway 进行暴露,创建 VirtualService 与 Gateway 绑定:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: networking.istio.io/v1beta1
|
||||||
|
kind: VirtualService
|
||||||
|
metadata:
|
||||||
|
name: registry-imroc-cc
|
||||||
|
namespace: registry
|
||||||
|
spec:
|
||||||
|
gateways:
|
||||||
|
- external/imroc
|
||||||
|
hosts:
|
||||||
|
- 'registry.imroc.cc'
|
||||||
|
http:
|
||||||
|
- route:
|
||||||
|
- destination:
|
||||||
|
host: harbor
|
||||||
|
port:
|
||||||
|
number: 80
|
||||||
|
```
|
||||||
|
|
||||||
|
而 Gateway 则是提前创建好的,监听 443,并配置了证书:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: networking.istio.io/v1beta1
|
||||||
|
kind: Gateway
|
||||||
|
metadata:
|
||||||
|
name: imroc
|
||||||
|
namespace: external
|
||||||
|
spec:
|
||||||
|
selector:
|
||||||
|
app: istio-ingressgateway
|
||||||
|
istio: ingressgateway
|
||||||
|
servers:
|
||||||
|
- hosts:
|
||||||
|
- imroc.cc
|
||||||
|
- '*.imroc.cc'
|
||||||
|
port:
|
||||||
|
name: HTTPS-443
|
||||||
|
number: 443
|
||||||
|
protocol: HTTPS
|
||||||
|
tls:
|
||||||
|
credentialName: imroc-cc-crt-secret
|
||||||
|
mode: SIMPLE
|
||||||
|
```
|
||||||
|
|
||||||
|
### 验证服务与 COS 最终一致性问题
|
||||||
|
|
||||||
|
最后,可以登录一下 registry 并 push 下镜像试试:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
以上直接 push 成功是比较幸运的情况,通常往往会报 500 错误:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
什么原因? 是因为 COS 是保证最终一致性,当镜像数据 put 成功后,并不能保证马上能 list 到,导致 harbor 以为没 put 成功,从而报错,参考 [这篇文章](https://cloud.tencent.com/developer/article/1855894)。
|
||||||
|
|
||||||
|
如何解决?可以提工单将指定存储桶改为强一致性。但是由于 COS 底层架构升级的原因,暂时无法后台改配置,预计今年年底后才可以申请,相关工单截图:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
临时规避的方法可以是:上传失败时重试下,直至上传成功。
|
||||||
|
|
||||||
|
## 附录
|
||||||
|
|
||||||
|
### 挂载 CFS
|
||||||
|
|
||||||
|
使用如下 yaml 将 CFS 作为 jobservice 和 registry 模块的持久化存储进行挂载:
|
||||||
|
|
||||||
|
`registry-nfs-pv.yaml`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: v1
|
||||||
|
kind: PersistentVolume
|
||||||
|
metadata:
|
||||||
|
name: registry-registry
|
||||||
|
spec:
|
||||||
|
accessModes:
|
||||||
|
- ReadWriteMany
|
||||||
|
capacity:
|
||||||
|
storage: 10Gi
|
||||||
|
nfs:
|
||||||
|
path: /registry/registry
|
||||||
|
server: 10.10.0.15
|
||||||
|
persistentVolumeReclaimPolicy: Retain
|
||||||
|
storageClassName: ""
|
||||||
|
volumeMode: Filesystem
|
||||||
|
|
||||||
|
---
|
||||||
|
apiVersion: v1
|
||||||
|
kind: PersistentVolumeClaim
|
||||||
|
metadata:
|
||||||
|
name: registry-registry
|
||||||
|
namespace: registry
|
||||||
|
spec:
|
||||||
|
accessModes:
|
||||||
|
- ReadWriteMany
|
||||||
|
resources:
|
||||||
|
requests:
|
||||||
|
storage: 10Gi
|
||||||
|
storageClassName: ""
|
||||||
|
volumeMode: Filesystem
|
||||||
|
volumeName: registry-registry
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
`jobservice-nfs-pv.yaml`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: v1
|
||||||
|
kind: PersistentVolume
|
||||||
|
metadata:
|
||||||
|
name: registry-jobservice
|
||||||
|
spec:
|
||||||
|
accessModes:
|
||||||
|
- ReadWriteMany
|
||||||
|
capacity:
|
||||||
|
storage: 10Gi
|
||||||
|
nfs:
|
||||||
|
path: /registry/jobservice
|
||||||
|
server: 10.10.0.15
|
||||||
|
persistentVolumeReclaimPolicy: Retain
|
||||||
|
storageClassName: ""
|
||||||
|
volumeMode: Filesystem
|
||||||
|
|
||||||
|
---
|
||||||
|
apiVersion: v1
|
||||||
|
kind: PersistentVolumeClaim
|
||||||
|
metadata:
|
||||||
|
name: registry-jobservice
|
||||||
|
namespace: registry
|
||||||
|
spec:
|
||||||
|
accessModes:
|
||||||
|
- ReadWriteMany
|
||||||
|
resources:
|
||||||
|
requests:
|
||||||
|
storage: 10Gi
|
||||||
|
storageClassName: ""
|
||||||
|
volumeMode: Filesystem
|
||||||
|
volumeName: registry-jobservice
|
||||||
|
```
|
||||||
|
|
||||||
|
注意:
|
||||||
|
* 确保创建的 CFS 与 TKE/EKS 集群在同一个 VPC。
|
||||||
|
* nfs 的 server ip 在 [CFS 控制台](https://console.cloud.tencent.com/cfs/fs) 可以查看,替换 yaml 中的 ip 地址。
|
||||||
|
* yaml 中如果指定 path ,确保提前创建好,且 `chmod 0777 <DIR>` 一下,避免因权限问题导致无法启动。
|
||||||
|
|
@ -0,0 +1,174 @@
|
||||||
|
# 安装 KubeSphere
|
||||||
|
|
||||||
|
## 概述
|
||||||
|
|
||||||
|
本文介绍在腾讯云容器服务上如何安装 KubeSphere 及其踩坑与注意事项。
|
||||||
|
|
||||||
|
## 安装步骤
|
||||||
|
|
||||||
|
具体安装步骤参考 KubeSphere 官方文档:[在腾讯云 TKE 安装 KubeSphere](https://kubesphere.io/zh/docs/installing-on-kubernetes/hosted-kubernetes/install-ks-on-tencent-tke/)。
|
||||||
|
|
||||||
|
## 踩坑与注意事项
|
||||||
|
|
||||||
|
### cbs 磁盘容量以 10Gi 为倍数
|
||||||
|
|
||||||
|
腾讯云容器服务默认使用 CBS 云硬盘作为存储,容量只支持 10Gi 的倍数,如果定义 pvc 时指定的容量不是 10Gi 的倍数,就会挂盘失败。
|
||||||
|
|
||||||
|
安装 KubeSphere 时,修改下 `ClusterConfiguration` 中各个组件的 `volumeSize` 配置,确保是 10Gi 的倍数。
|
||||||
|
|
||||||
|
### 卸载卡住与卸载不干净导致重装失败
|
||||||
|
|
||||||
|
有时安装出问题,希望卸载重装,使用 KubeSphere 官方文档 [从 Kubernetes 上卸载 KubeSphere](https://kubesphere.io/zh/docs/installing-on-kubernetes/uninstall-kubesphere-from-k8s/) 中的 `kubesphere-delete.sh` 脚本进行清理,可能会出现卡住的情况。
|
||||||
|
|
||||||
|
通常是有 finalizer 的原因:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
编辑资源删除相应 finalizer 即可。
|
||||||
|
|
||||||
|
如果清理不干净,重装还会报错:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
通常是关联的一些 MutatingWebhookConfiguration,ValidatingWebhookConfiguration, ClusterRole, ClusterRoleBinding 等资源没清理,可以根据 ks-installer 日志定位并清理。
|
||||||
|
|
||||||
|
### 监控不兼容导致看不到超级节点中 Pod 的监控
|
||||||
|
|
||||||
|
KubeSphere 部署完后看工作负载的 Pod 列表,没有超级节点上 Pod 的监控数据:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
是因为 KubeSphere 启用的监控,采集 cadvisor 监控数据的采集规则是,访问所有节点的 10250 端口去拉监控数据,而超级节点的 IP 是个无法路由的 “假” IP,所以拉不到数据。
|
||||||
|
|
||||||
|
解决方案:按照以下步骤增加自定义采集规则。
|
||||||
|
|
||||||
|
1. 准备 secret yaml `scrape-config.yaml`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: v1
|
||||||
|
kind: Secret
|
||||||
|
type: Opaque
|
||||||
|
metadata:
|
||||||
|
name: additional-scrape-configs
|
||||||
|
namespace: kubesphere-monitoring-system
|
||||||
|
stringData:
|
||||||
|
additional-scrape-configs.yaml: |-
|
||||||
|
- job_name: kubelet # eks cadvisor 监控,为兼容 ks 查询,固定 job 名为 kubelet
|
||||||
|
honor_timestamps: true
|
||||||
|
metrics_path: '/metrics'
|
||||||
|
params:
|
||||||
|
collect[]:
|
||||||
|
- 'ipvs'
|
||||||
|
scheme: http
|
||||||
|
kubernetes_sd_configs:
|
||||||
|
- role: pod
|
||||||
|
relabel_configs:
|
||||||
|
- source_labels: [__meta_kubernetes_pod_annotation_tke_cloud_tencent_com_pod_type]
|
||||||
|
regex: eklet
|
||||||
|
action: keep
|
||||||
|
- source_labels: [__meta_kubernetes_pod_phase]
|
||||||
|
regex: Running
|
||||||
|
action: keep
|
||||||
|
- source_labels: [__meta_kubernetes_pod_ip]
|
||||||
|
separator: ;
|
||||||
|
regex: (.*)
|
||||||
|
target_label: __address__
|
||||||
|
replacement: ${1}:9100
|
||||||
|
action: replace
|
||||||
|
- source_labels: [__meta_kubernetes_pod_name]
|
||||||
|
separator: ;
|
||||||
|
regex: (.*)
|
||||||
|
target_label: pod
|
||||||
|
replacement: ${1}
|
||||||
|
action: replace
|
||||||
|
- source_labels: [__meta_kubernetes_namespace]
|
||||||
|
separator: ;
|
||||||
|
regex: (.*)
|
||||||
|
target_label: namespace
|
||||||
|
replacement: ${1}
|
||||||
|
action: replace
|
||||||
|
metric_relabel_configs:
|
||||||
|
- source_labels: [__name__]
|
||||||
|
separator: ;
|
||||||
|
regex: container_.*
|
||||||
|
replacement: $1
|
||||||
|
action: keep
|
||||||
|
- target_label: metrics_path
|
||||||
|
replacement: /metrics/cadvisor
|
||||||
|
action: replace
|
||||||
|
- job_name: eks # eks cadvisor 之外的其它监控
|
||||||
|
honor_timestamps: true
|
||||||
|
metrics_path: '/metrics'
|
||||||
|
params:
|
||||||
|
collect[]:
|
||||||
|
- 'ipvs'
|
||||||
|
scheme: http
|
||||||
|
kubernetes_sd_configs:
|
||||||
|
- role: pod
|
||||||
|
relabel_configs:
|
||||||
|
- source_labels: [__meta_kubernetes_pod_annotation_tke_cloud_tencent_com_pod_type]
|
||||||
|
regex: eklet
|
||||||
|
action: keep
|
||||||
|
- source_labels: [__meta_kubernetes_pod_phase]
|
||||||
|
regex: Running
|
||||||
|
action: keep
|
||||||
|
- source_labels: [__meta_kubernetes_pod_ip]
|
||||||
|
separator: ;
|
||||||
|
regex: (.*)
|
||||||
|
target_label: __address__
|
||||||
|
replacement: ${1}:9100
|
||||||
|
action: replace
|
||||||
|
- source_labels: [__meta_kubernetes_pod_name]
|
||||||
|
separator: ;
|
||||||
|
regex: (.*)
|
||||||
|
target_label: pod
|
||||||
|
replacement: ${1}
|
||||||
|
action: replace
|
||||||
|
- source_labels: [__meta_kubernetes_namespace]
|
||||||
|
separator: ;
|
||||||
|
regex: (.*)
|
||||||
|
target_label: namespace
|
||||||
|
replacement: ${1}
|
||||||
|
action: replace
|
||||||
|
metric_relabel_configs:
|
||||||
|
- source_labels: [__name__]
|
||||||
|
separator: ;
|
||||||
|
regex: (container_.*|pod_.*|kubelet_.*)
|
||||||
|
replacement: $1
|
||||||
|
action: keep
|
||||||
|
```
|
||||||
|
|
||||||
|
2. 创建 secret:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl apply -f scrape-config.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
3. 修改 Prometheus CR:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl -n kubesphere-monitoring-system edit prometheuses.monitoring.coreos.com k8s
|
||||||
|
```
|
||||||
|
|
||||||
|
加入 `additionalScrapeConfigs`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
spec:
|
||||||
|
additionalScrapeConfigs:
|
||||||
|
key: additional-scrape-configs.yaml
|
||||||
|
name: additional-scrape-configs
|
||||||
|
```
|
||||||
|
|
||||||
|
### ks-apiserver 出现 crash
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
一般是 kubesphere 的 chart 包不完善,crd 没装完整,可以手动装一下:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl apply -f https://raw.githubusercontent.com/kubesphere/notification-manager/master/config/bundle.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
> 参考: https://kubesphere.com.cn/forum/d/7610-ks-330-ks-apiserver-crash/3
|
||||||
|
|
@ -0,0 +1,14 @@
|
||||||
|
# ingressgateway 和 egressgateway 日志采集与检索
|
||||||
|
|
||||||
|
##
|
||||||
|
|
||||||
|
2022-08-25T09:28:36.316+0800
|
||||||
|
2022-08-25T01:45:16.897Z
|
||||||
|
%Y-%m-%dT%H:%M:%S.%f%z
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
File diff suppressed because it is too large
Load Diff
|
|
@ -0,0 +1,240 @@
|
||||||
|
# Prometheus 采集配置最佳实践
|
||||||
|
|
||||||
|
使用 Prometheus 采集腾讯云容器服务的监控数据时如何配置采集规则?主要需要注意的是 kubelet 与 cadvisor 的监控指标采集,本文分享为 Prometheus 配置 `scrape_config` 来采集腾讯云容器服务集群的监控数据的方法。
|
||||||
|
|
||||||
|
## 普通节点采集规则
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
- job_name: "tke-cadvisor"
|
||||||
|
scheme: https
|
||||||
|
metrics_path: /metrics/cadvisor # 采集容器 cadvisor 监控数据
|
||||||
|
tls_config:
|
||||||
|
insecure_skip_verify: true # tke 的 kubelet 使用自签证书,忽略证书校验
|
||||||
|
authorization:
|
||||||
|
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
|
||||||
|
kubernetes_sd_configs:
|
||||||
|
- role: node
|
||||||
|
relabel_configs:
|
||||||
|
- source_labels: [__meta_kubernetes_node_label_node_kubernetes_io_instance_type]
|
||||||
|
regex: eklet # 排除超级节点
|
||||||
|
action: drop
|
||||||
|
- action: labelmap
|
||||||
|
regex: __meta_kubernetes_node_label_(.+)
|
||||||
|
- job_name: "tke-kubelet"
|
||||||
|
scheme: https
|
||||||
|
metrics_path: /metrics # 采集 kubelet 自身的监控数据
|
||||||
|
tls_config:
|
||||||
|
insecure_skip_verify: true
|
||||||
|
authorization:
|
||||||
|
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
|
||||||
|
kubernetes_sd_configs:
|
||||||
|
- role: node
|
||||||
|
relabel_configs:
|
||||||
|
- source_labels: [__meta_kubernetes_node_label_node_kubernetes_io_instance_type]
|
||||||
|
regex: eklet
|
||||||
|
action: drop
|
||||||
|
- action: labelmap
|
||||||
|
regex: __meta_kubernetes_node_label_(.+)
|
||||||
|
- job_name: "tke-probes" # 采集容器健康检查健康数据
|
||||||
|
scheme: https
|
||||||
|
metrics_path: /metrics/probes
|
||||||
|
tls_config:
|
||||||
|
insecure_skip_verify: true
|
||||||
|
authorization:
|
||||||
|
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
|
||||||
|
kubernetes_sd_configs:
|
||||||
|
- role: node
|
||||||
|
relabel_configs:
|
||||||
|
- source_labels: [__meta_kubernetes_node_label_node_kubernetes_io_instance_type]
|
||||||
|
regex: eklet
|
||||||
|
action: drop
|
||||||
|
- action: labelmap
|
||||||
|
regex: __meta_kubernetes_node_label_(.+)
|
||||||
|
```
|
||||||
|
|
||||||
|
* 使用节点服务发现 (`kubernetes_sd_configs` 的 role 为 `node`),抓取所有节点 `kubelet:10250` 暴露的几种监控数据。
|
||||||
|
* 如果集群是普通节点与超级节点混用,排除超级节点 (`relabel_configs` 中将带 `node.kubernetes.io/instance-type: eklet` 这种 label 的 node 排除)。
|
||||||
|
* TKE 节点上的 kubelet 证书是自签的,需要忽略证书校验,所以 `insecure_skip_verify` 要置为 true。
|
||||||
|
* kubelet 通过 `/metrics/cadvisor`, `/metrics` 与 `/metrics/probes` 路径分别暴露了容器 cadvisor 监控数据、kubelet 自身监控数据以及容器健康检查健康数据,为这三个不同路径分别配置采集 job 进行采集。
|
||||||
|
|
||||||
|
## 超级节点采集规则
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
- job_name: eks # 采集超级节点监控数据
|
||||||
|
honor_timestamps: true
|
||||||
|
metrics_path: '/metrics' # 所有健康数据都在这个路径
|
||||||
|
params: # 通常需要加参数过滤掉 ipvs 相关的指标,因为可能数据量较大,打高 Pod 负载。
|
||||||
|
collect[]:
|
||||||
|
- 'ipvs'
|
||||||
|
# - 'cpu'
|
||||||
|
# - 'meminfo'
|
||||||
|
# - 'diskstats'
|
||||||
|
# - 'filesystem'
|
||||||
|
# - 'load0vg'
|
||||||
|
# - 'netdev'
|
||||||
|
# - 'filefd'
|
||||||
|
# - 'pressure'
|
||||||
|
# - 'vmstat'
|
||||||
|
scheme: http
|
||||||
|
kubernetes_sd_configs:
|
||||||
|
- role: pod # 超级节点 Pod 的监控数据暴露在 Pod 自身 IP 的 9100 端口,所以使用 Pod 服务发现
|
||||||
|
relabel_configs:
|
||||||
|
- source_labels: [__meta_kubernetes_pod_annotation_tke_cloud_tencent_com_pod_type]
|
||||||
|
regex: eklet # 只采集超级节点的 Pod
|
||||||
|
action: keep
|
||||||
|
- source_labels: [__meta_kubernetes_pod_phase]
|
||||||
|
regex: Running # 非 Running 状态的 Pod 机器资源已释放,不需要采集
|
||||||
|
action: keep
|
||||||
|
- source_labels: [__meta_kubernetes_pod_ip]
|
||||||
|
separator: ;
|
||||||
|
regex: (.*)
|
||||||
|
target_label: __address__
|
||||||
|
replacement: ${1}:9100 # 监控指标暴露在 Pod 的 9100 端口
|
||||||
|
action: replace
|
||||||
|
- source_labels: [__meta_kubernetes_pod_name]
|
||||||
|
separator: ;
|
||||||
|
regex: (.*)
|
||||||
|
target_label: pod # 将 Pod 名字写到 "pod" label
|
||||||
|
replacement: ${1}
|
||||||
|
action: replace
|
||||||
|
- source_labels: [__meta_kubernetes_namespace]
|
||||||
|
separator: ;
|
||||||
|
regex: (.*)
|
||||||
|
target_label: namespace # 将 Pod 所在 namespace 写到 "namespace" label
|
||||||
|
replacement: ${1}
|
||||||
|
action: replace
|
||||||
|
metric_relabel_configs:
|
||||||
|
- source_labels: [__name__]
|
||||||
|
separator: ;
|
||||||
|
regex: (container_.*|pod_.*|kubelet_.*)
|
||||||
|
replacement: $1
|
||||||
|
action: keep
|
||||||
|
```
|
||||||
|
|
||||||
|
* 超级节点的监控数据暴露在每个 Pod 的 9100 端口的 `/metrics` 这个 HTTP API 路径(非 HTTPS),使用 Pod 服务发现(`kubernetes_sd_configs` 的 role 为 `pod`),用一个 job 就可以采集完。
|
||||||
|
* 超级节点的 Pod 支持通过 `collect[]` 这个查询参数来过滤掉不希望采集的指标,这样可以避免指标数据量过大,导致 Pod 负载升高,通常要过滤掉 `ipvs` 的指标。
|
||||||
|
* 如果集群是普通节点与超级节点混用,确保只采集超级节点的 Pod (`relabel_configs` 中只保留有 `tke.cloud.tencent.com/pod-type:eklet` 这个注解的 Pod)。
|
||||||
|
* 如果 Pod 的 phase 不是 Running 也无法采集,可以排除。
|
||||||
|
* `container_` 开头的指标是 cadvisor 监控数据,`pod_` 前缀指标是超级节点 Pod 所在子机的监控数据(相当于将 `node_exporter` 的 `node_` 前缀指标替换成了 `pod_`),`kubelet_` 前缀指标是超级节点 Pod 子机内兼容 kubelet 的指标(主要是 pvc 存储监控)。
|
||||||
|
|
||||||
|
## kube-prometheus-stack 配置
|
||||||
|
|
||||||
|
如今都流行使用 [kube-prometheus-stack](https://github.com/prometheus-community/helm-charts/tree/main/charts/kube-prometheus-stack) 这个 helm chart 来自建 Prometheus,在 `values.yaml` 中进行自定义配置然后安装到集群,其中可以配置 Prometheus 原生的 `scrape_config` (非 CRD),配置方法是将自定义的 `scrape_config` 写到 `prometheus.prometheusSpec.additionalScrapeConfigs` 字段下,下面是示例:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
prometheus:
|
||||||
|
prometheusSpec:
|
||||||
|
additionalScrapeConfigs:
|
||||||
|
- job_name: "tke-cadvisor"
|
||||||
|
scheme: https
|
||||||
|
metrics_path: /metrics/cadvisor
|
||||||
|
tls_config:
|
||||||
|
insecure_skip_verify: true
|
||||||
|
authorization:
|
||||||
|
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
|
||||||
|
kubernetes_sd_configs:
|
||||||
|
- role: node
|
||||||
|
relabel_configs:
|
||||||
|
- source_labels: [__meta_kubernetes_node_label_node_kubernetes_io_instance_type]
|
||||||
|
regex: eklet
|
||||||
|
action: drop
|
||||||
|
- action: labelmap
|
||||||
|
regex: __meta_kubernetes_node_label_(.+)
|
||||||
|
- job_name: "tke-kubelet"
|
||||||
|
scheme: https
|
||||||
|
metrics_path: /metrics
|
||||||
|
tls_config:
|
||||||
|
insecure_skip_verify: true
|
||||||
|
authorization:
|
||||||
|
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
|
||||||
|
kubernetes_sd_configs:
|
||||||
|
- role: node
|
||||||
|
relabel_configs:
|
||||||
|
- source_labels: [__meta_kubernetes_node_label_node_kubernetes_io_instance_type]
|
||||||
|
regex: eklet
|
||||||
|
action: drop
|
||||||
|
- action: labelmap
|
||||||
|
regex: __meta_kubernetes_node_label_(.+)
|
||||||
|
- job_name: "tke-probes"
|
||||||
|
scheme: https
|
||||||
|
metrics_path: /metrics/probes
|
||||||
|
tls_config:
|
||||||
|
insecure_skip_verify: true
|
||||||
|
authorization:
|
||||||
|
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
|
||||||
|
kubernetes_sd_configs:
|
||||||
|
- role: node
|
||||||
|
relabel_configs:
|
||||||
|
- source_labels: [__meta_kubernetes_node_label_node_kubernetes_io_instance_type]
|
||||||
|
regex: eklet
|
||||||
|
action: drop
|
||||||
|
- action: labelmap
|
||||||
|
regex: __meta_kubernetes_node_label_(.+)
|
||||||
|
- job_name: eks
|
||||||
|
honor_timestamps: true
|
||||||
|
metrics_path: '/metrics'
|
||||||
|
params:
|
||||||
|
collect[]: ['ipvs']
|
||||||
|
# - 'cpu'
|
||||||
|
# - 'meminfo'
|
||||||
|
# - 'diskstats'
|
||||||
|
# - 'filesystem'
|
||||||
|
# - 'load0vg'
|
||||||
|
# - 'netdev'
|
||||||
|
# - 'filefd'
|
||||||
|
# - 'pressure'
|
||||||
|
# - 'vmstat'
|
||||||
|
scheme: http
|
||||||
|
kubernetes_sd_configs:
|
||||||
|
- role: pod
|
||||||
|
relabel_configs:
|
||||||
|
- source_labels: [__meta_kubernetes_pod_annotation_tke_cloud_tencent_com_pod_type]
|
||||||
|
regex: eklet
|
||||||
|
action: keep
|
||||||
|
- source_labels: [__meta_kubernetes_pod_phase]
|
||||||
|
regex: Running
|
||||||
|
action: keep
|
||||||
|
- source_labels: [__meta_kubernetes_pod_ip]
|
||||||
|
separator: ;
|
||||||
|
regex: (.*)
|
||||||
|
target_label: __address__
|
||||||
|
replacement: ${1}:9100
|
||||||
|
action: replace
|
||||||
|
- source_labels: [__meta_kubernetes_pod_name]
|
||||||
|
separator: ;
|
||||||
|
regex: (.*)
|
||||||
|
target_label: pod
|
||||||
|
replacement: ${1}
|
||||||
|
action: replace
|
||||||
|
- source_labels: [__meta_kubernetes_namespace]
|
||||||
|
separator: ;
|
||||||
|
regex: (.*)
|
||||||
|
target_label: namespace
|
||||||
|
replacement: ${1}
|
||||||
|
action: replace
|
||||||
|
metric_relabel_configs:
|
||||||
|
- source_labels: [__name__]
|
||||||
|
separator: ;
|
||||||
|
regex: (container_.*|pod_.*|kubelet_.*)
|
||||||
|
replacement: $1
|
||||||
|
action: keep
|
||||||
|
storageSpec:
|
||||||
|
volumeClaimTemplate:
|
||||||
|
spec:
|
||||||
|
accessModes: ["ReadWriteOnce"]
|
||||||
|
resources:
|
||||||
|
requests:
|
||||||
|
storage: 100Gi
|
||||||
|
```
|
||||||
|
|
||||||
|
## FAQ
|
||||||
|
|
||||||
|
### 为什么使用 collect[] 这种奇怪的参数过滤指标?
|
||||||
|
|
||||||
|
超级节点的 Pod 监控指标使用 `collect[]` 查询参数来过滤不需要的监控指标:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
curl ${IP}:9100/metrics?collect[]=ipvs&collect[]=vmstat
|
||||||
|
```
|
||||||
|
|
||||||
|
为什么要使用这么奇怪的参数名?这是因为 `node_exporter` 就是用的这个参数,超级节点的 Pod 内部引用了 `node_exporter` 的逻辑,[这里](https://github.com/prometheus/node_exporter#filtering-enabled-collectors) 是 `node_exporter` 的 `collect[]` 参数用法说明。
|
||||||
|
|
@ -0,0 +1,124 @@
|
||||||
|
# 启用 CLB 直通 Pod
|
||||||
|
|
||||||
|
## 概述
|
||||||
|
|
||||||
|
TKE 提供了 CLB 直通 Pod 的能力,不经过 NodePort,网络链路上少了一跳,带来了一系列好处:
|
||||||
|
|
||||||
|
1. 链路更短,性能会有所提高。
|
||||||
|
2. 没有 SNAT,避免了流量集中可能导致的源端口耗尽、conntrack 插入冲突等问题。
|
||||||
|
3. 不经过 NodePort,也就不会再经过 k8s 的 iptables/ipvs 转发,从而负载均衡状态就都收敛到了 CLB 这一个地方,可避免负载均衡状态分散导致的全局负载不均问题。
|
||||||
|
4. 由于没有 SNAT,天然可以获取真实源 IP,不再需要 `externalTrafficPolicy: Local` 。
|
||||||
|
5. 实现会话保持更简单,只需要让 CLB 开启会话保持即可,不需要设置 Service 的 `sessionAffinity`。
|
||||||
|
|
||||||
|
虽然 CLB 直通 Pod 提供了这么多好处,但默认不会启用,本文介绍如何在 TKE 上启用 CLB 直通 Pod。
|
||||||
|
|
||||||
|
## 前提条件
|
||||||
|
|
||||||
|
1. `Kubernetes`集群版本需要高于 1.12,因为 CLB 直绑 Pod,检查 Pod 是否 Ready,除了看 Pod 是否 Running、是否通过 readinessProbe 外, 还需要看 LB 对 Pod 的健康探测是否通过,这依赖于 `ReadinessGate` 特性,该特性在 Kubernetes 1.12 才开始支持。
|
||||||
|
2. 集群网络模式必须开启 `VPC-CNI` 弹性网卡模式,因为目前 LB 直通 Pod 的实现是基于弹性网卡的,普通的网络模式暂时不支持,这个在未来将会支持。
|
||||||
|
|
||||||
|
## CLB 直通 Pod 启用方法
|
||||||
|
|
||||||
|
启用方法是在创建 Service 或 Ingress 时,声明一下要使用 CLB 直通 Pod。
|
||||||
|
|
||||||
|
### Service 声明 CLB 直通 Pod
|
||||||
|
|
||||||
|
当你用 LoadBalancer 的 Service 暴露服务时,需要声明使用直连模式:
|
||||||
|
|
||||||
|
* 如果通过控制台创建 Service,可以勾选 `采用负载均衡直连Pod模式`:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
* 如果通过 yaml 创建 Service,需要为 Service 加上 `service.cloud.tencent.com/direct-access: "true"` 的 annotation:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: v1
|
||||||
|
kind: Service
|
||||||
|
metadata:
|
||||||
|
annotations:
|
||||||
|
service.cloud.tencent.com/direct-access: "true" # 关键
|
||||||
|
labels:
|
||||||
|
app: nginx
|
||||||
|
name: nginx-service-eni
|
||||||
|
spec:
|
||||||
|
externalTrafficPolicy: Cluster
|
||||||
|
ports:
|
||||||
|
- name: 80-80-no
|
||||||
|
port: 80
|
||||||
|
protocol: TCP
|
||||||
|
targetPort: 80
|
||||||
|
selector:
|
||||||
|
app: nginx
|
||||||
|
sessionAffinity: None
|
||||||
|
type: LoadBalancer
|
||||||
|
```
|
||||||
|
|
||||||
|
### CLB Ingress 声明 CLB 直通 Pod
|
||||||
|
|
||||||
|
当使用 CLB Ingress 暴露服务时,同样也需要声明使用直连模式:
|
||||||
|
|
||||||
|
* 如果通过控制台创建 CLB Ingress,可以勾选 `采用负载均衡直连Pod模式`:
|
||||||
|
|
||||||
|
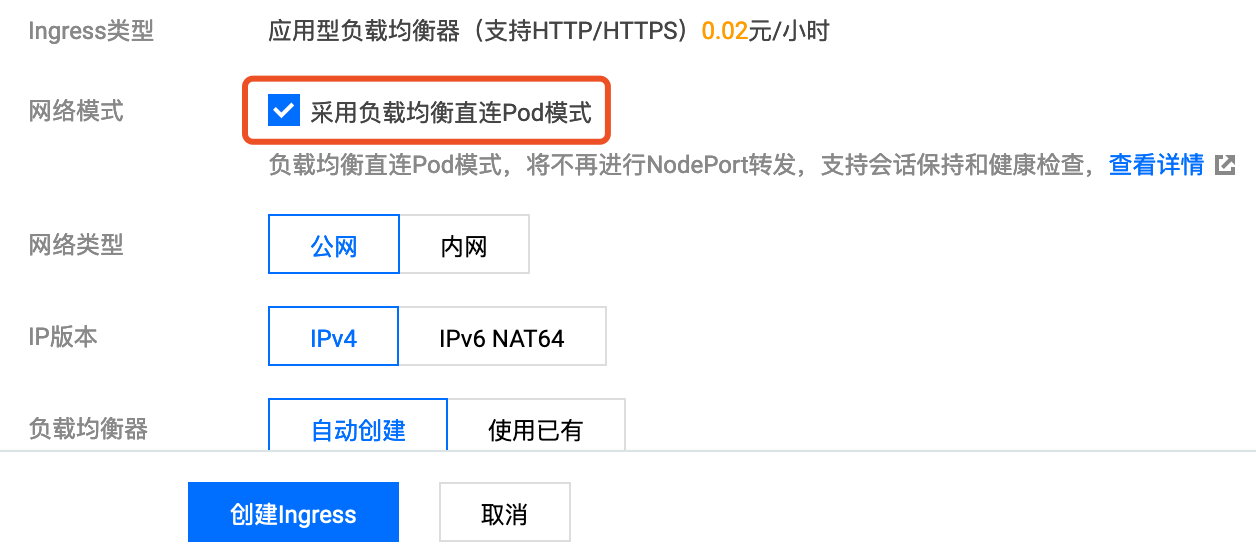
|
||||||
|
|
||||||
|
* 如果通过 yaml 创建 CLB Ingress,需要为 Ingress 加上 `ingress.cloud.tencent.com/direct-access: "true"` 的 annotation:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: networking.k8s.io/v1beta1
|
||||||
|
kind: Ingress
|
||||||
|
metadata:
|
||||||
|
annotations:
|
||||||
|
ingress.cloud.tencent.com/direct-access: "true"
|
||||||
|
kubernetes.io/ingress.class: qcloud
|
||||||
|
name: test-ingress
|
||||||
|
namespace: default
|
||||||
|
spec:
|
||||||
|
rules:
|
||||||
|
- http:
|
||||||
|
paths:
|
||||||
|
- backend:
|
||||||
|
serviceName: nginx
|
||||||
|
servicePort: 80
|
||||||
|
path: /
|
||||||
|
```
|
||||||
|
|
||||||
|
启用方法根据集群网络模式有细微差别,见下文分解。
|
||||||
|
|
||||||
|
### GlobalRouter + VPC-CNI 网络模式混用注意事项
|
||||||
|
|
||||||
|
如果 TKE 集群创建时,网络模式选择的 [GlobalRouter](https://cloud.tencent.com/document/product/457/50354) ,后面再开启的 [VPC-CNI](https://cloud.tencent.com/document/product/457/50355) ,这样集群的网络模式就是 GlobalRouter + VPC-CNI 两种网络模式混用。
|
||||||
|
|
||||||
|
这种集群创建的 Pod 默认没有使用弹性网卡,如果要启用 CLB 直通 Pod,首先在部署工作负载的时候,声明一下 Pod 要使用 VPC-CNI 模式 (弹性网卡),具体操作方法是使用 yaml 创建工作负载 (不通过 TKE 控制台),为 Pod 指定 `tke.cloud.tencent.com/networks: tke-route-eni` 这个 annotation 来声明使用弹性网卡,并且为其中一个容器加上 `tke.cloud.tencent.com/eni-ip: "1"` 这样的 requests 与 limits,示例:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: apps/v1
|
||||||
|
kind: Deployment
|
||||||
|
metadata:
|
||||||
|
labels:
|
||||||
|
app: nginx
|
||||||
|
name: nginx-deployment-eni
|
||||||
|
spec:
|
||||||
|
replicas: 3
|
||||||
|
selector:
|
||||||
|
matchLabels:
|
||||||
|
app: nginx
|
||||||
|
template:
|
||||||
|
metadata:
|
||||||
|
annotations:
|
||||||
|
tke.cloud.tencent.com/networks: tke-route-eni
|
||||||
|
labels:
|
||||||
|
app: nginx
|
||||||
|
spec:
|
||||||
|
containers:
|
||||||
|
- image: nginx
|
||||||
|
name: nginx
|
||||||
|
resources:
|
||||||
|
requests:
|
||||||
|
tke.cloud.tencent.com/eni-ip: "1"
|
||||||
|
limits:
|
||||||
|
tke.cloud.tencent.com/eni-ip: "1"
|
||||||
|
```
|
||||||
|
|
||||||
|
## 参考资料
|
||||||
|
|
||||||
|
* [在 TKE 上使用负载均衡直通 Pod](https://cloud.tencent.com/document/product/457/48793)
|
||||||
|
|
@ -0,0 +1,130 @@
|
||||||
|
# 使用 TCM 对外暴露 gRPC 服务
|
||||||
|
|
||||||
|
## 背景
|
||||||
|
|
||||||
|
gRPC 是长连接服务,而长连接服务负载不均是通病,因为使用四层负载均衡的话,只能在连接调度层面负载均衡,但不能在请求级别负载均衡。不同连接上的请求数量、网络流量、请求耗时、存活时长等可能都不一样,就容易造成不同 Pod 的负载不一样。而 istio 天然支持 gRPC 负载均衡,即在七层进行负载均衡,可以将不同请求转发到不同后端,从而避免负载不均问题,腾讯云容器服务也对 istio 进行了产品化托管,产品叫 [TCM](https://cloud.tencent.com/product/tcm),本文介绍如何使用 TCM 来暴露 gRPC 服务。
|
||||||
|
|
||||||
|
## 创建网格
|
||||||
|
|
||||||
|
进入 [TCM控制台](https://console.cloud.tencent.com/tke2/mesh),新建一个网格,每个网格可以管理多个 TKE/EKS 集群,创建网格的时候就可以关联集群(创建完之后关联也可以):
|
||||||
|
|
||||||
|
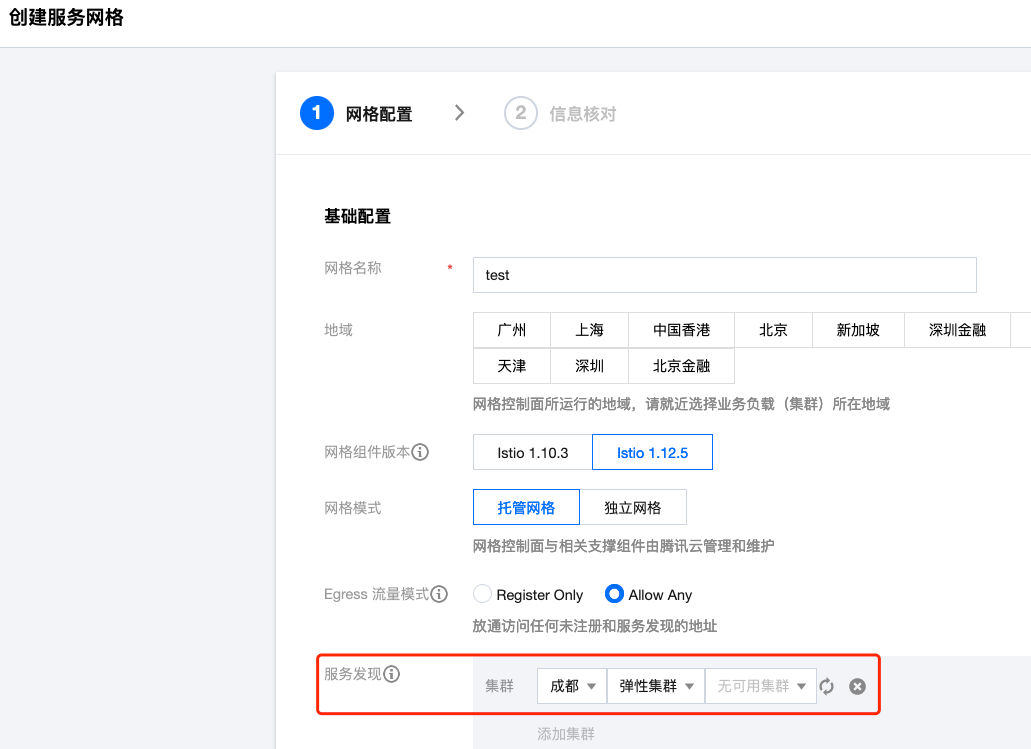
|
||||||
|
|
||||||
|
边缘代理网关通常会启用 Ingress Gateway,即将内部服务通过 CLB 暴露出来:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## 启用 sidecar 自动注入
|
||||||
|
|
||||||
|
网格创建好后,点进去,在 【服务】-【sidecar自动注入】中勾选要启用自动注入的 namespace:
|
||||||
|
|
||||||
|
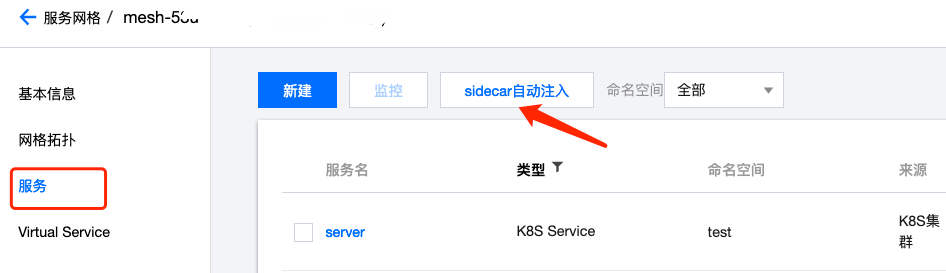
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
gRPC 服务端部署在哪个 namespace 就勾选哪个。
|
||||||
|
|
||||||
|
## 部署 gRPC 服务端
|
||||||
|
|
||||||
|
将 gRPC 服务部署到网格中的一个集群,确保部署的 namespace 开启了sidecar自动注入:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: apps/v1
|
||||||
|
kind: Deployment
|
||||||
|
metadata:
|
||||||
|
name: server
|
||||||
|
namespace: test
|
||||||
|
spec:
|
||||||
|
replicas: 1
|
||||||
|
selector:
|
||||||
|
matchLabels:
|
||||||
|
app: server
|
||||||
|
template:
|
||||||
|
metadata:
|
||||||
|
labels:
|
||||||
|
app: server
|
||||||
|
spec:
|
||||||
|
containers:
|
||||||
|
- name: server
|
||||||
|
image: docker.io/imroc/grpc_server:latest
|
||||||
|
imagePullPolicy: Always
|
||||||
|
```
|
||||||
|
|
||||||
|
如果服务端在开启自动注入之前已经部署了,可以重建下服务端 Pod,重建后会触发自动注入。
|
||||||
|
|
||||||
|
## 创建 Service
|
||||||
|
|
||||||
|
给工作负载关联一个 Service,使用 yaml 创建:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: v1
|
||||||
|
kind: Service
|
||||||
|
metadata:
|
||||||
|
name: server
|
||||||
|
namespace: test
|
||||||
|
labels:
|
||||||
|
app: server
|
||||||
|
spec:
|
||||||
|
type: ClusterIP
|
||||||
|
ports:
|
||||||
|
- port: 8000
|
||||||
|
protocol: TCP
|
||||||
|
targetPort: 50051
|
||||||
|
name: grpc
|
||||||
|
selector:
|
||||||
|
app: server
|
||||||
|
```
|
||||||
|
|
||||||
|
注意:
|
||||||
|
|
||||||
|
- 重点是端口的 name 要以 grpc 开头,也可以直接写 grpc,istio 通过 port name 识别协议类型。
|
||||||
|
- 不通过控制台创建的原因主要是因为控制台创建 Service 不支持为端口指定 name。
|
||||||
|
|
||||||
|
## 创建 Gateway
|
||||||
|
|
||||||
|
如果希望 gRPC 对集群外暴露,istio 需要确保有 Gateway 对象,如果没有创建,可以先创建一个,在 TCM 中这样操作,【Gateway】-【新建】:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
【网关列表】引用最开始创建的 Ingress Gateway,【协议端口】使用GRPC,指定的端口号为 CLB 要监听的端口号,【Hosts】为服务从外部被访问的IP或域名,通配符 `*` 表示匹配所有:
|
||||||
|
|
||||||
|
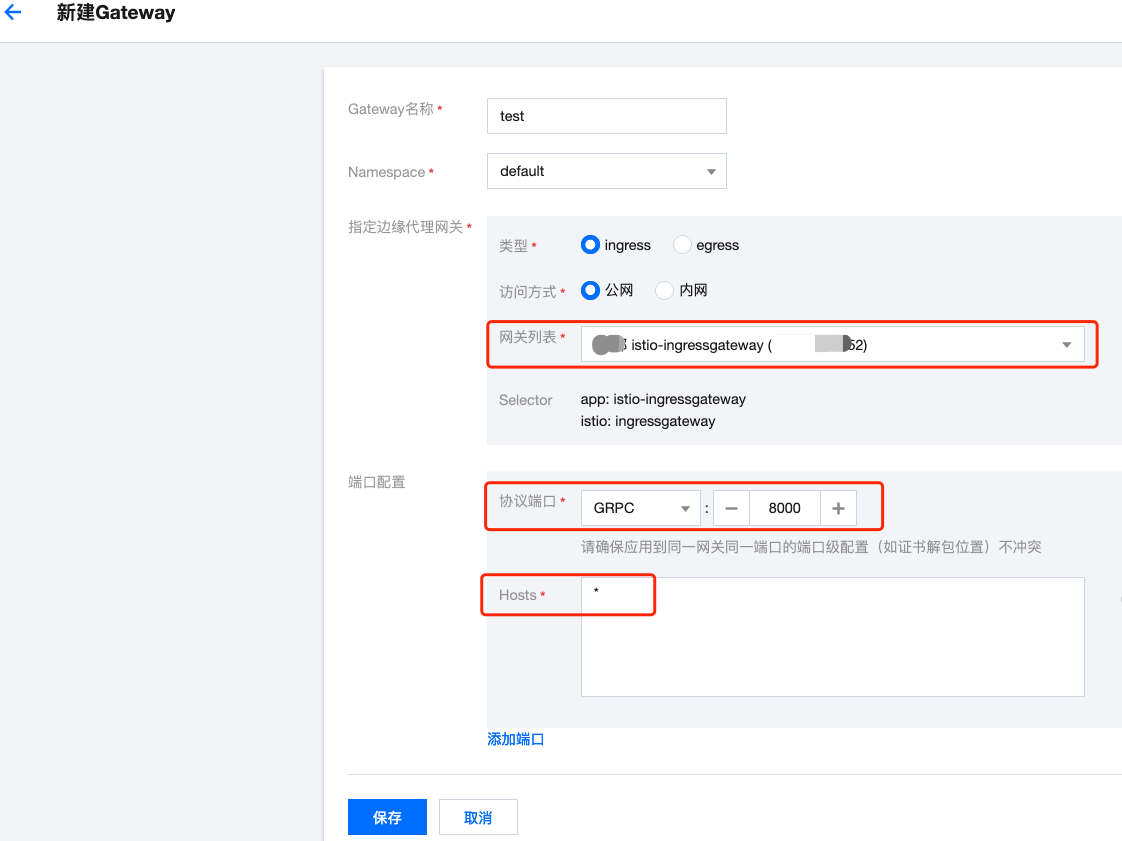
|
||||||
|
|
||||||
|
## 创建 VirtualService
|
||||||
|
|
||||||
|
VirtualService 是 istio 描述服务的基本对象,我们使用 VirtualService 将 gRPC 服务关联到 Gateway 上,就可以将服务暴露出去了,在 TCM 上这样操作,【Virtual Service】-【新建】:
|
||||||
|
|
||||||
|
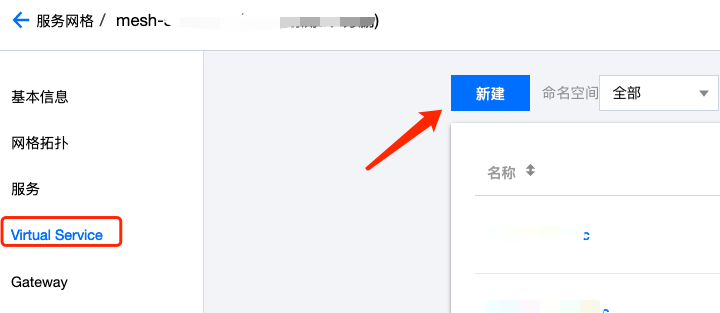
|
||||||
|
|
||||||
|
【名称】随意,【命名空间】为服务端所在命名空间,【关联Hosts】这里可以跟 Gateway 那里的设置保持一致,【挂载Gateway】选择前面创建的 Gateway,【类型】选HTTP(istio中http既可以路由http,也可以用于路由grpc),【匹配条件】删除默认,不写条件,【目的端】选择服务端的 service + port:
|
||||||
|
|
||||||
|
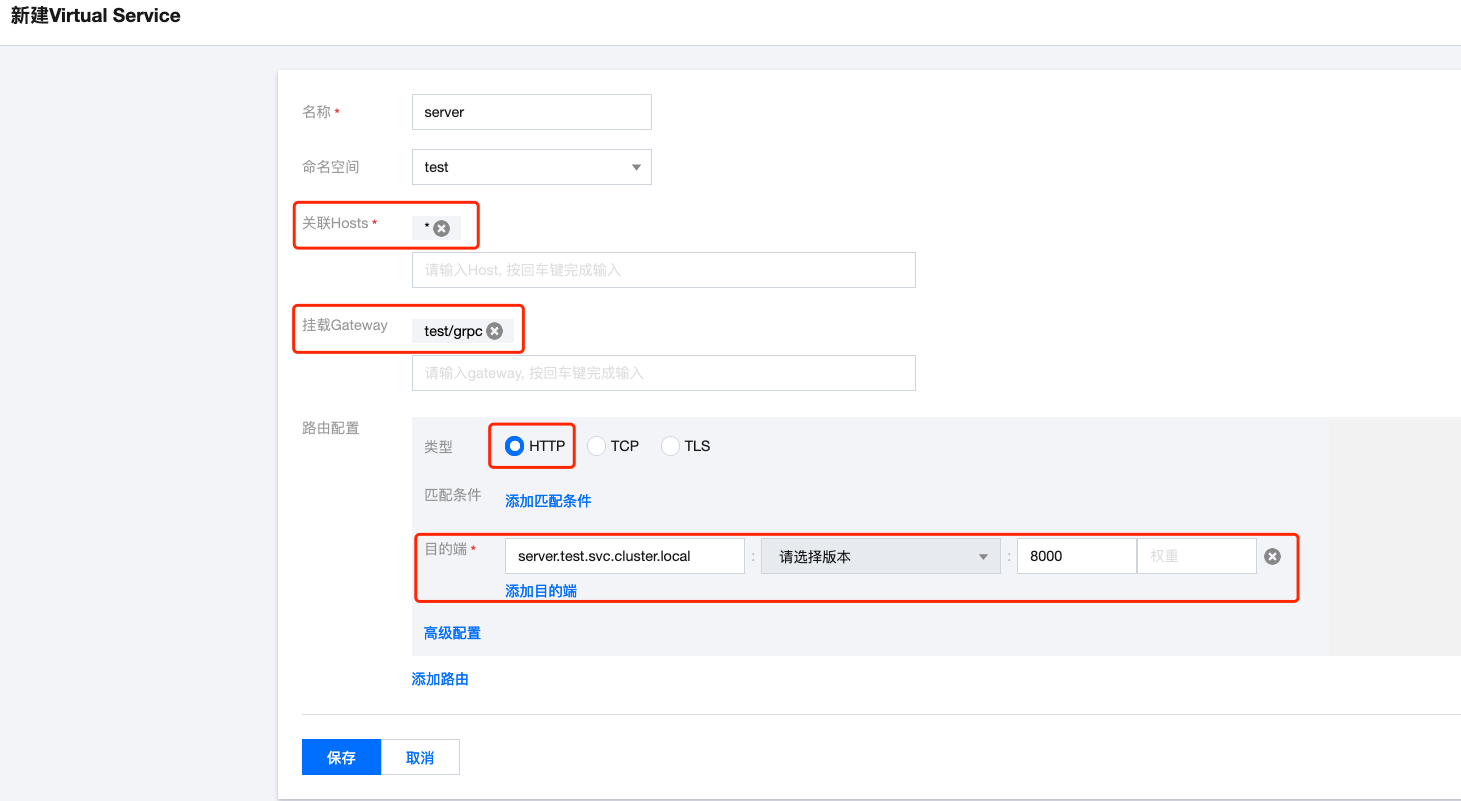
|
||||||
|
|
||||||
|
保存后即可,然后就可以通过 CLB 暴露出来的地址访问 grpc 服务了,并且会自动在请求级别进行负载均衡,CLB 的地址取决于创建出来的 Ingress Gateway 所使用的 CLB,测试一下效果:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Virtual Service 如果通过 yaml 创建,可以参考下面示例:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: networking.istio.io/v1alpha3
|
||||||
|
kind: VirtualService
|
||||||
|
metadata:
|
||||||
|
name: server
|
||||||
|
namespace: test
|
||||||
|
spec:
|
||||||
|
gateways:
|
||||||
|
- test/grpc
|
||||||
|
hosts:
|
||||||
|
- '*'
|
||||||
|
http:
|
||||||
|
- route:
|
||||||
|
- destination:
|
||||||
|
host: server
|
||||||
|
```
|
||||||
|
|
||||||
|
## demo仓库
|
||||||
|
|
||||||
|
包含服务端代码示例、Dockerfile、部署 yaml 等。
|
||||||
|
|
||||||
|
仓库地址:[https://github.com/imroc/grpc-demo](https://github.com/imroc/grpc-demo)
|
||||||
|
|
@ -0,0 +1,110 @@
|
||||||
|
# Pod 绑 EIP
|
||||||
|
|
||||||
|
腾讯云容器服务的 TKE 暂不支持 Pod 绑 EIP,但 EKS 集群(弹性集群) 是支持的,且需要配置 yaml,加上相应的注解,本文给出实例。
|
||||||
|
|
||||||
|
## yaml 示例
|
||||||
|
|
||||||
|
EKS 的 EIP 核心注解是 `eks.tke.cloud.tencent.com/eip-attributes`,内容可以填写创建 EIP 接口的相关的参数,详细参数列表参考 [这里](https://cloud.tencent.com/document/api/215/16699#2.-.E8.BE.93.E5.85.A5.E5.8F.82.E6.95.B0) 。
|
||||||
|
|
||||||
|
下面给出一个简单示例,为每个 Pod 副本都绑定带宽上限 50Mbps,按流量计费的 EIP:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: apps/v1
|
||||||
|
kind: Deployment
|
||||||
|
metadata:
|
||||||
|
name: eip
|
||||||
|
spec:
|
||||||
|
replicas: 1
|
||||||
|
selector:
|
||||||
|
matchLabels:
|
||||||
|
app: eip
|
||||||
|
template:
|
||||||
|
metadata:
|
||||||
|
labels:
|
||||||
|
app: eip
|
||||||
|
annotations:
|
||||||
|
'eks.tke.cloud.tencent.com/eip-attributes': '{"InternetMaxBandwidthOut":50, "InternetChargeType":"TRAFFIC_POSTPAID_BY_HOUR"}'
|
||||||
|
spec:
|
||||||
|
containers:
|
||||||
|
- name: eip
|
||||||
|
image: cr.imroc.cc/library/net-tools:latest
|
||||||
|
command:
|
||||||
|
- sleep
|
||||||
|
- infinity
|
||||||
|
```
|
||||||
|
|
||||||
|
## 如何在容器内获取自身公网 IP ?
|
||||||
|
|
||||||
|
可以利用 K8S 的 [Downward API](https://kubernetes.io/zh/docs/tasks/inject-data-application/environment-variable-expose-pod-information/) ,将 Pod 上的一些字段注入到环境变量或挂载到文件,Pod 的 EIP 信息最终会写到 Pod 的 `tke.cloud.tencent.com/eip-public-ip` 这个 annotation 上,但不会 Pod 创建时就写上,是在启动过程写上去的,所以如果注入到环境变量最终会为空,挂载到文件就没问题,以下是使用方法:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: apps/v1
|
||||||
|
kind: Deployment
|
||||||
|
metadata:
|
||||||
|
name: eip
|
||||||
|
spec:
|
||||||
|
replicas: 1
|
||||||
|
selector:
|
||||||
|
matchLabels:
|
||||||
|
app: eip
|
||||||
|
template:
|
||||||
|
metadata:
|
||||||
|
labels:
|
||||||
|
app: eip
|
||||||
|
spec:
|
||||||
|
containers:
|
||||||
|
- name: eip
|
||||||
|
image: cr.imroc.cc/library/net-tools:latest
|
||||||
|
command:
|
||||||
|
- sleep
|
||||||
|
- infinity
|
||||||
|
volumeMounts:
|
||||||
|
- mountPath: /etc/podinfo
|
||||||
|
name: podinfo
|
||||||
|
volumes:
|
||||||
|
- name: podinfo
|
||||||
|
downwardAPI:
|
||||||
|
items:
|
||||||
|
- path: "labels"
|
||||||
|
fieldRef:
|
||||||
|
fieldPath: metadata.labels
|
||||||
|
- path: "annotations" # 关键
|
||||||
|
fieldRef:
|
||||||
|
fieldPath: metadata.annotations
|
||||||
|
```
|
||||||
|
|
||||||
|
容器内进程启动时可以读取 `/etc/podinfo/annotations` 中的内容来获取 EIP。
|
||||||
|
|
||||||
|
|
||||||
|
## 如何保留 EIP
|
||||||
|
|
||||||
|
需要使用 StatefulSet 部署,且加上 `eks.tke.cloud.tencent.com/eip-claim-delete-policy: "Never"` 这个 annotation:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: apps/v1
|
||||||
|
kind: StatefulSet
|
||||||
|
metadata:
|
||||||
|
labels:
|
||||||
|
app: eip
|
||||||
|
name: eip
|
||||||
|
spec:
|
||||||
|
serviceName: ""
|
||||||
|
replicas: 1
|
||||||
|
selector:
|
||||||
|
matchLabels:
|
||||||
|
app: eip
|
||||||
|
template:
|
||||||
|
metadata:
|
||||||
|
annotations:
|
||||||
|
eks.tke.cloud.tencent.com/eip-attributes: "{}"
|
||||||
|
eks.tke.cloud.tencent.com/eip-claim-delete-policy: "Never" # 关键
|
||||||
|
labels:
|
||||||
|
app: eip
|
||||||
|
spec:
|
||||||
|
containers:
|
||||||
|
- name: eip
|
||||||
|
image: cr.imroc.cc/library/net-tools:latest
|
||||||
|
command:
|
||||||
|
- sleep
|
||||||
|
- infinity
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,313 @@
|
||||||
|
# IPVS 模式安装 localdns
|
||||||
|
|
||||||
|
## 背景
|
||||||
|
|
||||||
|
TKE 对 NodeLocal DNS Cache 进行了产品化支持,直接在扩展组件里面就可以一键安装到集群,参考 [NodeLocalDNSCache 扩展组件说明](https://cloud.tencent.com/document/product/457/49423) ,可是仅仅支持 iptables 转发模式的集群,而目前大多集群都会使用 IPVS 转发模式,无法安装这个扩展组件。
|
||||||
|
|
||||||
|
本文将介绍如何在 TKE IPVS 模式集群中自行安装 NodeLocal DNS Cache。
|
||||||
|
|
||||||
|
|
||||||
|
## 准备 yaml
|
||||||
|
|
||||||
|
复制以下 yaml 到文件 `nodelocaldns.yaml`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
# Copyright 2018 The Kubernetes Authors.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
apiVersion: v1
|
||||||
|
kind: ServiceAccount
|
||||||
|
metadata:
|
||||||
|
name: node-local-dns
|
||||||
|
namespace: kube-system
|
||||||
|
labels:
|
||||||
|
kubernetes.io/cluster-service: "true"
|
||||||
|
addonmanager.kubernetes.io/mode: Reconcile
|
||||||
|
---
|
||||||
|
apiVersion: v1
|
||||||
|
kind: Service
|
||||||
|
metadata:
|
||||||
|
name: kube-dns-upstream
|
||||||
|
namespace: kube-system
|
||||||
|
labels:
|
||||||
|
k8s-app: kube-dns
|
||||||
|
kubernetes.io/cluster-service: "true"
|
||||||
|
addonmanager.kubernetes.io/mode: Reconcile
|
||||||
|
kubernetes.io/name: "KubeDNSUpstream"
|
||||||
|
spec:
|
||||||
|
ports:
|
||||||
|
- name: dns
|
||||||
|
port: 53
|
||||||
|
protocol: UDP
|
||||||
|
targetPort: 53
|
||||||
|
- name: dns-tcp
|
||||||
|
port: 53
|
||||||
|
protocol: TCP
|
||||||
|
targetPort: 53
|
||||||
|
selector:
|
||||||
|
k8s-app: kube-dns
|
||||||
|
---
|
||||||
|
apiVersion: v1
|
||||||
|
kind: ConfigMap
|
||||||
|
metadata:
|
||||||
|
name: node-local-dns
|
||||||
|
namespace: kube-system
|
||||||
|
labels:
|
||||||
|
addonmanager.kubernetes.io/mode: Reconcile
|
||||||
|
data:
|
||||||
|
Corefile: |
|
||||||
|
cluster.local:53 {
|
||||||
|
errors
|
||||||
|
cache {
|
||||||
|
success 9984 30
|
||||||
|
denial 9984 5
|
||||||
|
}
|
||||||
|
reload
|
||||||
|
loop
|
||||||
|
bind 169.254.20.10
|
||||||
|
forward . __PILLAR__CLUSTER__DNS__ {
|
||||||
|
force_tcp
|
||||||
|
}
|
||||||
|
prometheus :9253
|
||||||
|
health 169.254.20.10:8080
|
||||||
|
}
|
||||||
|
in-addr.arpa:53 {
|
||||||
|
errors
|
||||||
|
cache 30
|
||||||
|
reload
|
||||||
|
loop
|
||||||
|
bind 169.254.20.10
|
||||||
|
forward . __PILLAR__CLUSTER__DNS__ {
|
||||||
|
force_tcp
|
||||||
|
}
|
||||||
|
prometheus :9253
|
||||||
|
}
|
||||||
|
ip6.arpa:53 {
|
||||||
|
errors
|
||||||
|
cache 30
|
||||||
|
reload
|
||||||
|
loop
|
||||||
|
bind 169.254.20.10
|
||||||
|
forward . __PILLAR__CLUSTER__DNS__ {
|
||||||
|
force_tcp
|
||||||
|
}
|
||||||
|
prometheus :9253
|
||||||
|
}
|
||||||
|
.:53 {
|
||||||
|
errors
|
||||||
|
cache 30
|
||||||
|
reload
|
||||||
|
loop
|
||||||
|
bind 169.254.20.10
|
||||||
|
forward . __PILLAR__UPSTREAM__SERVERS__
|
||||||
|
prometheus :9253
|
||||||
|
}
|
||||||
|
---
|
||||||
|
apiVersion: apps/v1
|
||||||
|
kind: DaemonSet
|
||||||
|
metadata:
|
||||||
|
name: node-local-dns
|
||||||
|
namespace: kube-system
|
||||||
|
labels:
|
||||||
|
k8s-app: node-local-dns
|
||||||
|
kubernetes.io/cluster-service: "true"
|
||||||
|
addonmanager.kubernetes.io/mode: Reconcile
|
||||||
|
spec:
|
||||||
|
updateStrategy:
|
||||||
|
rollingUpdate:
|
||||||
|
maxUnavailable: 10%
|
||||||
|
selector:
|
||||||
|
matchLabels:
|
||||||
|
k8s-app: node-local-dns
|
||||||
|
template:
|
||||||
|
metadata:
|
||||||
|
labels:
|
||||||
|
k8s-app: node-local-dns
|
||||||
|
annotations:
|
||||||
|
prometheus.io/port: "9253"
|
||||||
|
prometheus.io/scrape: "true"
|
||||||
|
spec:
|
||||||
|
priorityClassName: system-node-critical
|
||||||
|
serviceAccountName: node-local-dns
|
||||||
|
hostNetwork: true
|
||||||
|
dnsPolicy: Default # Don't use cluster DNS.
|
||||||
|
tolerations:
|
||||||
|
- key: "CriticalAddonsOnly"
|
||||||
|
operator: "Exists"
|
||||||
|
- effect: "NoExecute"
|
||||||
|
operator: "Exists"
|
||||||
|
- effect: "NoSchedule"
|
||||||
|
operator: "Exists"
|
||||||
|
containers:
|
||||||
|
- name: node-cache
|
||||||
|
image: cr.imroc.cc/k8s/k8s-dns-node-cache:1.17.0
|
||||||
|
resources:
|
||||||
|
requests:
|
||||||
|
cpu: 25m
|
||||||
|
memory: 5Mi
|
||||||
|
args: [ "-localip", "169.254.20.10", "-conf", "/etc/Corefile", "-upstreamsvc", "kube-dns-upstream" ]
|
||||||
|
securityContext:
|
||||||
|
privileged: true
|
||||||
|
ports:
|
||||||
|
- containerPort: 53
|
||||||
|
name: dns
|
||||||
|
protocol: UDP
|
||||||
|
- containerPort: 53
|
||||||
|
name: dns-tcp
|
||||||
|
protocol: TCP
|
||||||
|
- containerPort: 9253
|
||||||
|
name: metrics
|
||||||
|
protocol: TCP
|
||||||
|
livenessProbe:
|
||||||
|
httpGet:
|
||||||
|
host: 169.254.20.10
|
||||||
|
path: /health
|
||||||
|
port: 8080
|
||||||
|
initialDelaySeconds: 60
|
||||||
|
timeoutSeconds: 5
|
||||||
|
volumeMounts:
|
||||||
|
- mountPath: /run/xtables.lock
|
||||||
|
name: xtables-lock
|
||||||
|
readOnly: false
|
||||||
|
- name: config-volume
|
||||||
|
mountPath: /etc/coredns
|
||||||
|
- name: kube-dns-config
|
||||||
|
mountPath: /etc/kube-dns
|
||||||
|
volumes:
|
||||||
|
- name: xtables-lock
|
||||||
|
hostPath:
|
||||||
|
path: /run/xtables.lock
|
||||||
|
type: FileOrCreate
|
||||||
|
- name: kube-dns-config
|
||||||
|
configMap:
|
||||||
|
name: kube-dns
|
||||||
|
optional: true
|
||||||
|
- name: config-volume
|
||||||
|
configMap:
|
||||||
|
name: node-local-dns
|
||||||
|
items:
|
||||||
|
- key: Corefile
|
||||||
|
path: Corefile.base
|
||||||
|
---
|
||||||
|
# A headless service is a service with a service IP but instead of load-balancing it will return the IPs of our associated Pods.
|
||||||
|
# We use this to expose metrics to Prometheus.
|
||||||
|
apiVersion: v1
|
||||||
|
kind: Service
|
||||||
|
metadata:
|
||||||
|
annotations:
|
||||||
|
prometheus.io/port: "9253"
|
||||||
|
prometheus.io/scrape: "true"
|
||||||
|
labels:
|
||||||
|
k8s-app: node-local-dns
|
||||||
|
name: node-local-dns
|
||||||
|
namespace: kube-system
|
||||||
|
spec:
|
||||||
|
clusterIP: None
|
||||||
|
ports:
|
||||||
|
- name: metrics
|
||||||
|
port: 9253
|
||||||
|
targetPort: 9253
|
||||||
|
selector:
|
||||||
|
k8s-app: node-local-dns
|
||||||
|
```
|
||||||
|
|
||||||
|
## 替换集群 DNS 地址
|
||||||
|
|
||||||
|
获取集群 DNS 的地址并替换 yaml 文件中的 `__PILLAR__CLUSTER__DNS__` 变量:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubedns=`kubectl get svc kube-dns -n kube-system -o jsonpath={.spec.clusterIP}`
|
||||||
|
|
||||||
|
sed -i "s/__PILLAR__CLUSTER__DNS__/$kubedns/g" nodelocaldns.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
> `__PILLAR__UPSTREAM__SERVERS__` 这个变量我们不管,localdns pod 会自行填充。
|
||||||
|
|
||||||
|
|
||||||
|
## 一键安装
|
||||||
|
|
||||||
|
通过以下命令一键安装到集群:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl apply -f nodelocaldns.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
## 修改 kubelet 参数
|
||||||
|
|
||||||
|
IPVS 模式集群由于需要为所有 Service 在 `kube-ipvs0` 这个 dummy 网卡上绑对应的 Cluster IP,以实现 IPVS 转发,所以 localdns 就无法再监听集群 DNS 的 Cluster IP。而 kubelet 的 `--cluster-dns` 默认指向的是集群 DNS 的 Cluster IP 而不是 localdns 监听的地址,安装 localdns 之后集群中的 Pod 默认还是使用的集群 DNS 解析。
|
||||||
|
|
||||||
|
如何让 Pod 默认使用 localdns 进行 DNS 解析呢?需要改每个节点上 kubelet 的 `--cluster-dns` 启动参数:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
--cluster-dns=169.254.20.10
|
||||||
|
```
|
||||||
|
|
||||||
|
可以通过以下脚本进行修改并重启 kubelet 来生效:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
sed -i 's/CLUSTER_DNS.*/CLUSTER_DNS="--cluster-dns=169.254.20.10"/' /etc/kubernetes/kubelet
|
||||||
|
systemctl restart kubelet
|
||||||
|
```
|
||||||
|
|
||||||
|
### 存量节点修改
|
||||||
|
|
||||||
|
如何修改集群中已有节点的 kubelet 参数呢?目前没有产品化解决方案,可以自行通过第三方工具来修改,通常使用 ansible,安装方式参考 [官方文档: Installing Ansible](https://docs.ansible.com/ansible/latest/installation_guide/intro_installation.html) 。
|
||||||
|
|
||||||
|
安装好 ansible 之后,按照以下步骤操作:
|
||||||
|
|
||||||
|
1. 导出所有节点 IP 到 `hosts.ini`:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl get nodes -o jsonpath='{.items[*].status.addresses[?(@.type=="InternalIP")].address}' | tr ' ' '\n' > hosts.ini
|
||||||
|
```
|
||||||
|
|
||||||
|
2. 准备脚本 `modify-kubelet.sh`:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
sed -i 's/CLUSTER_DNS.*/CLUSTER_DNS="--cluster-dns=169.254.20.10"/' /etc/kubernetes/kubelet
|
||||||
|
systemctl restart kubelet
|
||||||
|
```
|
||||||
|
|
||||||
|
3. 准备可以用于节点登录的 ssh 秘钥或密码 (秘钥改名为 key,并执行 `chmod 0600 key`)
|
||||||
|
4. 使用 ansible 在所有节点上运行脚本 `modify-kubelet.sh`:
|
||||||
|
* 使用秘钥的示例:
|
||||||
|
```bash
|
||||||
|
ansible all -i hosts.ini --ssh-common-args="-o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null" --user root --private-key=key -m script -a "mo dify-kubelet.sh"
|
||||||
|
```
|
||||||
|
* 使用密码的示例:
|
||||||
|
```bash
|
||||||
|
ansible all -i hosts.ini --ssh-common-args="-o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null" -m script --extra-vars "ansible_user=root an sible_password=yourpassword" -a "modify-kubelet.sh"
|
||||||
|
```
|
||||||
|
> **注:** 如果节点使用的 ubuntu 系统,默认 user 是 ubuntu,可以自行替换下,另外 ansible 参数再加上 `--become --become-user=root` 以便让 ansible 执行脚本时拥有 root 权限,避免操作失败。
|
||||||
|
|
||||||
|
### 增量节点修改
|
||||||
|
|
||||||
|
如何让新增的节点都默认修改 kubelet 参数呢?可以在加节点时设置【自定义数据】(即自定义初始化脚本),会在节点组件初始化好后执行:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
每个节点都贴一下脚本过于麻烦,一般建议使用节点池,在创建节电池时指定节点的【自定义数据】,这样就可以让节点池里扩容出来的节点都执行下这个脚本,而无需每个节点都单独设置:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## 关于存量 Pod
|
||||||
|
|
||||||
|
集群中正在运行的存量 Pod 还是会使用旧的集群 DNS,等重建后会自动切换到 localdns,新创建的 Pod 也都会默认使用 localdns。
|
||||||
|
|
||||||
|
一般没特别需要的情况下,可以不管存量 Pod,等下次更新, Pod 重建后就会自动切换到 localdns;如果想要立即切换,可以将工作负载滚动更新触发 Pod 重建来实现手动切换。
|
||||||
|
|
||||||
|
## 参考资料
|
||||||
|
|
||||||
|
* [Using NodeLocal DNSCache in Kubernetes clusters](https://kubernetes.io/docs/tasks/administer-cluster/nodelocaldns/)
|
||||||
|
|
@ -0,0 +1,10 @@
|
||||||
|
# 卸载 SSL 证书到 CLB
|
||||||
|
|
||||||
|
## 概述
|
||||||
|
|
||||||
|
本文介绍如何将腾讯云容器服务中部署的服务,通过 CLB 暴露并且将 SSL 卸载到 CLB。
|
||||||
|
|
||||||
|
## 操作步骤
|
||||||
|
|
||||||
|
### 准备证书
|
||||||
|
|
||||||
|
|
@ -0,0 +1,125 @@
|
||||||
|
# 大镜像解决方案
|
||||||
|
|
||||||
|
## 背景
|
||||||
|
|
||||||
|
超级节点(Serverless) 的 Pod,默认分配的系统盘大小是 20GB,当容器镜像非常大的时候(比如镜像中包含大的 AI 模型),拉取镜像会因空间不足而失败:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
Warning Failed 50s eklet Failed to pull image "registry.imroc.cc/test/large:latest": rpc error: code = Unknown desc = failed to pull and unpack image "registry.imroc.cc/test/large:latest": failed to copy: write /var/lib/containerd/io.containerd.content.v1.content/ingest/002e585a6f26fd1a69a59a72588300b909c745455c03e6d99e894d03664d47ce/data: no space left on device
|
||||||
|
```
|
||||||
|
|
||||||
|
针对这种问题,有两种解决方案。
|
||||||
|
|
||||||
|
## 方案一: 使用镜像缓存
|
||||||
|
|
||||||
|
在 [镜像缓存页面](https://console.cloud.tencent.com/tke2/image-cache/list) 新建实例(确保地域与集群所在地域相同):
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
填入大镜像的镜像地址,以及系统盘大小:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
> 如果是私有镜像,也添加下镜像凭证。
|
||||||
|
|
||||||
|
等待实例创建完成:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
最后创建工作负载时,使用 `eks.tke.cloud.tencent.com/use-image-cache: auto` 为 Pod 开启镜像缓存,自动匹配同名镜像的镜像缓存实例,根据快照创建新的磁盘作为 Pod 系统盘,yaml 示例:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: apps/v1
|
||||||
|
kind: Deployment
|
||||||
|
metadata:
|
||||||
|
name: large
|
||||||
|
spec:
|
||||||
|
replicas: 1
|
||||||
|
selector:
|
||||||
|
matchLabels:
|
||||||
|
app: large
|
||||||
|
template:
|
||||||
|
metadata:
|
||||||
|
labels:
|
||||||
|
app: large
|
||||||
|
annotations:
|
||||||
|
eks.tke.cloud.tencent.com/use-image-cache: auto
|
||||||
|
spec:
|
||||||
|
nodeSelector:
|
||||||
|
node.kubernetes.io/instance-type: eklet
|
||||||
|
containers:
|
||||||
|
- name: large
|
||||||
|
image: registry.imroc.cc/test/large:latest
|
||||||
|
command:
|
||||||
|
- "sleep"
|
||||||
|
- "infinity"
|
||||||
|
resources:
|
||||||
|
requests:
|
||||||
|
cpu: '1'
|
||||||
|
memory: '2Gi'
|
||||||
|
limits:
|
||||||
|
cpu: '1'
|
||||||
|
memory: '2Gi'
|
||||||
|
```
|
||||||
|
|
||||||
|
如果是通过控制台 UI 创建工作负载,可以直接勾选下镜像缓存:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
> 通常使用自动匹配即可,更多详情说明参考官方文档 [镜像缓存](https://cloud.tencent.com/document/product/457/65908)。
|
||||||
|
|
||||||
|
工作负载创建好后,从 Pod 事件可以看到类似 ` Image cache imc-al38vsrl used. Disk disk-e8crnrhp attached` 的信息:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
Events:
|
||||||
|
Type Reason Age From Message
|
||||||
|
---- ------ ---- ---- -------
|
||||||
|
Normal Scheduled 79s default-scheduler Successfully assigned test/large-77fb4b647f-rpbm9 to eklet-subnet-ahugkjhr-517773
|
||||||
|
Normal Starting 78s eklet Starting pod sandbox eks-5epp4l7h
|
||||||
|
Normal Starting 42s eklet Sync endpoints
|
||||||
|
Normal ImageCacheUsed 42s eklet Image cache imc-al38vsrl used. Disk disk-e8crnrhp attached
|
||||||
|
Normal Pulling 41s eklet Pulling image "registry.imroc.cc/test/large:latest"
|
||||||
|
Normal Pulled 40s eklet Successfully pulled image "registry.imroc.cc/test/large:latest" in 1.126771639s
|
||||||
|
Normal Created 40s eklet Created container large
|
||||||
|
Normal Started 40s eklet Started container large
|
||||||
|
```
|
||||||
|
|
||||||
|
进容器内部也可以看到根路径容量不止 20GB 了:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
如果有很多工作负载都使用大镜像,不想每个都配,也可以将注解配置到全局,参考 [EKS 全局配置说明](https://cloud.tencent.com/document/product/457/71915)。
|
||||||
|
|
||||||
|
## 方案二: 修改系统盘大小
|
||||||
|
|
||||||
|
Pod 系统盘默认大小为 20GB,如有需要,可以改大,超过 20GB 的部分将会进行计费。
|
||||||
|
|
||||||
|
修改的方式是在 Pod 上加 `eks.tke.cloud.tencent.com/root-cbs-size: “50”` 这样的注解,示例:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: apps/v1
|
||||||
|
kind: Deployment
|
||||||
|
metadata:
|
||||||
|
name: nginx
|
||||||
|
spec:
|
||||||
|
replicas: 1
|
||||||
|
selector:
|
||||||
|
matchLabels:
|
||||||
|
app: nginx
|
||||||
|
template:
|
||||||
|
metadata:
|
||||||
|
labels:
|
||||||
|
app: nginx
|
||||||
|
annotations:
|
||||||
|
eks.tke.cloud.tencent.com/root-cbs-size: "50"
|
||||||
|
spec:
|
||||||
|
containers:
|
||||||
|
- name: nginx
|
||||||
|
image: nginx
|
||||||
|
```
|
||||||
|
|
||||||
|
## 总结
|
||||||
|
|
||||||
|
针对大镜像的场景,可以使用本文介绍的两种解决方案:镜像缓存和自定义系统盘大小。
|
||||||
|
|
||||||
|
使用镜像缓存的优势在于,可以加速大镜像 Pod 的启动;自定义系统盘大小的优势在于,不需要创建镜像缓存实例,比较简单方便。可以根据自身需求选取合适的方案。
|
||||||
|
|
@ -0,0 +1,60 @@
|
||||||
|
# Serverless 弹性集群注意事项
|
||||||
|
|
||||||
|
## 访问公网
|
||||||
|
|
||||||
|
与 TKE 集群不同的是,EKS 没有节点,无法像 TKE 那样,Pod 可以利用节点自身的公网带宽访问公网。
|
||||||
|
|
||||||
|
EKS 没有节点,要让 Pod 访问公网有两种方式:
|
||||||
|
|
||||||
|
1. [通过 NAT 网关访问外网](https://cloud.tencent.com/document/product/457/48710)
|
||||||
|
2. [通过弹性公网 IP 访问外网](https://cloud.tencent.com/document/product/457/60354)
|
||||||
|
|
||||||
|
大多情况下可以考虑方式一,创建 NAT 网关,在 VPC 路由表里配置路由,如果希望整个 VPC 都默认走这个 NAT 网关出公网,可以修改 default 路由表:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
如果只想让超级节点的 Pod 走这个 NAT 网关,可以新建路由表。
|
||||||
|
|
||||||
|
配置方法是在路由表新建一条路由策略,`0.0.0.0/0` 网段的下一条类型为 `NAT 网关`,且选择前面创建的 NAT 网关实例:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
创建好后,如果不是 default 路由表,需要关联一下超级节点的子网:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## 9100 端口
|
||||||
|
|
||||||
|
EKS 默认会在每个 Pod 的 9100 端口进行监听,暴露 Pod 相关监控指标,如果业务本身也监听 9100,会失败,参考 [9100 端口问题](https://imroc.cc/kubernetes/tencent/appendix/eks-annotations.html#9100-%E7%AB%AF%E5%8F%A3%E9%97%AE%E9%A2%98)。
|
||||||
|
|
||||||
|
## 注意配额限制
|
||||||
|
|
||||||
|
使用 EKS 集群时注意一下配额限制,如果不够,可以提工单调高上限:
|
||||||
|
1. 单集群 Pod 数量上限 (默认200)。
|
||||||
|
2. 安全组绑定实例数量上限 (如果不给 Pod 指定安全组,会使用当前项目当前地域的默认安全组,每个安全组绑定实例数量上限为 2000)。
|
||||||
|
|
||||||
|
## ipvs 超时时间问题
|
||||||
|
|
||||||
|
### istio 场景 dns 超时
|
||||||
|
|
||||||
|
istio 的 sidecar (istio-proxy) 拦截流量借助了 conntrack 来实现连接跟踪,当部分没有拦截的流量 (比如 UDP) 通过 service 访问时,会经过 ipvs 转发,而 ipvs 和 conntrack 对连接都有一个超时时间设置,如果在 ipvs 和 conntrack 中的超时时间不一致,就可能出现 conntrack 中连接还在,但在 ipvs 中已被清理而导致出去的包被 ipvs 调度到新的 rs,而 rs 回包的时候匹配不到 conntrack,不会做反向 SNAT,从而导致进程收不到回包。
|
||||||
|
|
||||||
|
在 EKS 中,ipvs 超时时间当前默认是 5s,而 conntrack 超时时间默认是 120s,如果在 EKS 中使用 TCM 或自行安装 istio,当 coredns 扩容后一段时间,业务解析域名时就可能出现 DNS 超时。
|
||||||
|
|
||||||
|
在产品化解决之前,我们可以给 Pod 加如下注解,将 ipvs 超时时间也设成 120s,与 conntrack 超时时间对齐:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
eks.tke.cloud.tencent.com/ipvs-udp-timeout: "120s"
|
||||||
|
```
|
||||||
|
|
||||||
|
### gRPC 场景 Connection reset by peer
|
||||||
|
|
||||||
|
gRPC 是长连接,Java 版的 gRPC 默认 idle timeout 是 30 分钟,并且没配置 TCP 连接的 keepalive 心跳,而 ipvs 默认的 tcp timeout 是 15 分钟。
|
||||||
|
|
||||||
|
这就会导致一个问题: 业务闲置 15 分钟后,ipvs 断开连接,但是上层应用还认为连接在,还会复用连接发包,而 ipvs 中对应连接已不存在,会直接响应 RST 来将连接断掉,从业务日志来看就是 `Connection reset by peer`。
|
||||||
|
|
||||||
|
这种情况,如果不想改代码来启用 keepalive,可以直接调整下 eks 的 ipvs 的 tcp timeout 时间,与业务 idle timeout 时长保持一致:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
eks.tke.cloud.tencent.com/ipvs-tcp-timeout: "1800s"
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,57 @@
|
||||||
|
# 超级节点案例分享: 便捷管理离线任务与大规模压测
|
||||||
|
|
||||||
|
## 概述
|
||||||
|
|
||||||
|
腾讯云容器服务的超级节点有着隔离性强,扩容快,成本低等特点,天然适合离线任务与大规模压测。
|
||||||
|
|
||||||
|
本文分享这种场景的几个真实实践案例。
|
||||||
|
|
||||||
|
## 案例一: CI 系统(某出行客户)
|
||||||
|
|
||||||
|
gitlab-runner 启动 Pod 运行 CI 任务,任务结束即销毁 Pod,使用常驻节点会造成资源利用率低。任务量大时扩容节点时间长,造成部分 CI 任务过慢。
|
||||||
|
|
||||||
|
方案改进: 使用 Serverless 集群(超级节点),无需常驻节点资源,Pod 按量计费,且支持竞价实例,任务结束即停止计费,降低成本。任务量大时也可以快速扩容,提高 CI 效率。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## 案例二: 游戏 AI 训练(某游戏客户)
|
||||||
|
|
||||||
|
使用 GPU Pod 训练游戏 NPC AI 模型,训练完成后,再启动大量 CPU Pod 对模型进行验证。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
使用 TKE 普通节点,持续跑大量任务,Pod 数量规模巨大且扩缩容频繁,导致普通节点经常需要扩容。普通节点扩容慢,导致部分任务过慢。扩容过程可能出错,比如售罄,初始化失败等。
|
||||||
|
|
||||||
|
方案改进: 切换到 Serverless 集群(超级节点),扩缩容速度得到极大提升(超10倍),不再有任务过慢的情况。由于使用超级节点,购买的资源规格取决于 Pod 规格,没有大规格,不容易出现售罄;没有初始化节点过程,也不会发生初始化失败的问题。超级节点支持 Pod 的竞价实例,且任务跑完即释放,极大降低成本。
|
||||||
|
|
||||||
|
## 案例三: 大规模 CronJob 优化 (某教育客户)
|
||||||
|
|
||||||
|
因业务需要,需要启动大规模的 CronJob 跑离线任务,使用 TKE 普通节点,在线业务与离线 CronJob 混部,频繁启停场景下,cgroup 弱隔离带来普通节点稳定性问题。为避免售罄、节点扩容慢问题,购买了大量包年包月常驻节点,低峰期资源利用率低很低。
|
||||||
|
|
||||||
|
方案改进: 添加超级节点,将 CronJob 调度到超级节点,普通节点稳定性大幅提升。无需预留资源,pod 按量计费,定时任务资源成本降低 70% 左右。Job 实现秒级启动(EKS 镜像缓存,pod 启动加速)。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## 案例四: 边缘集群直播案例 (某视频客户)
|
||||||
|
|
||||||
|
问题与困境: 在中心地域部署业务,边缘主播推流延迟大影响体验。每个地域都单独部署一套 K8S 集群,运维压力大。
|
||||||
|
|
||||||
|
Serverless 集群方案: 统一 K8S 接口运维多地域集群,无节点,免运维。弹性转码服务,成本低,扩容灵活。
|
||||||
|
|
||||||
|
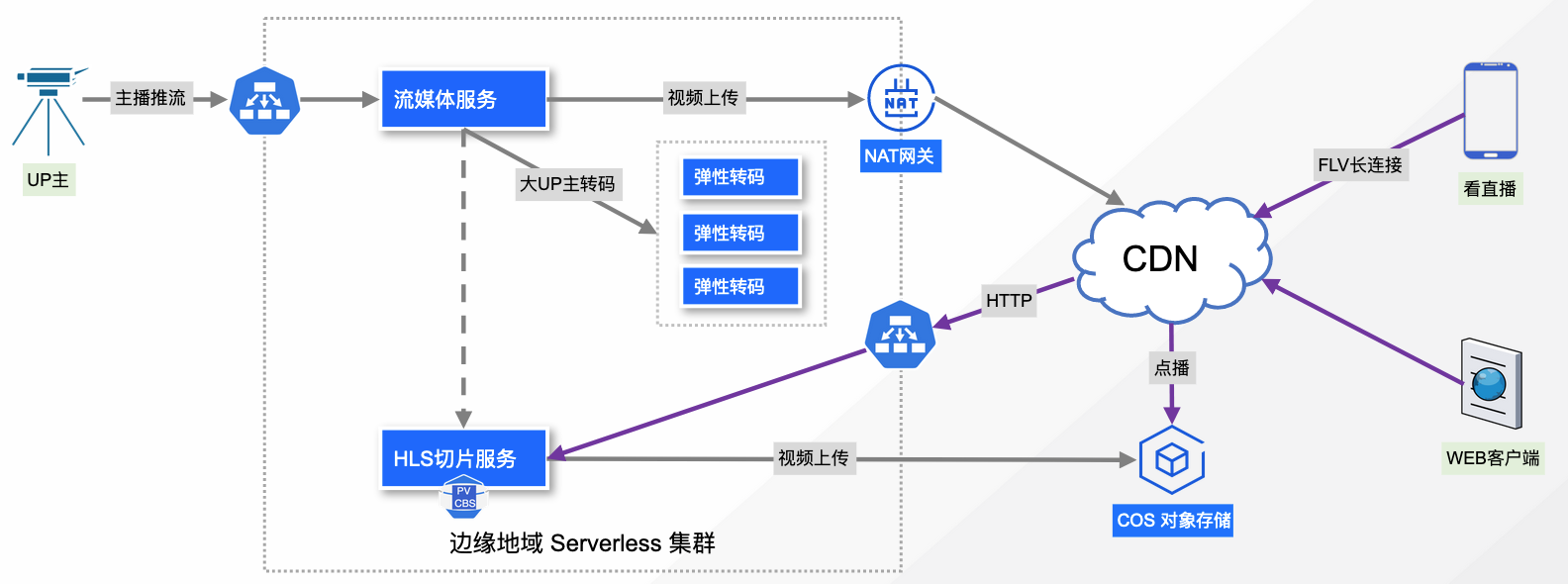
|
||||||
|
|
||||||
|
## 案例五: 日志处理 (某社交平台客户)
|
||||||
|
|
||||||
|
使用 logstash 进行日志清洗,集群规模大,业务高峰期产生日志量特别大,普通节点扩容慢,导致有丢日志的情况发生。高峰期过后,普通节点资源利用率较低。
|
||||||
|
|
||||||
|
方案改进: 高峰期极速扩容,不存在丢日志问题。高峰期过后,平均负载降低,自动缩容,缩掉的 Pod 停止计费,提高资源利用率,降低成本。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## 案例六: 大规模压测 (某社交平台客户)
|
||||||
|
|
||||||
|
TKE 普通节点隔离性弱,压测时需要控制调度策略,避免与在线业务混部,造成干扰。压测时带宽消耗非常大,单节点调度过多压测 Pod 容易达到节点带宽瓶颈而丢包。
|
||||||
|
|
||||||
|
方案改进: 使用 Serverless 集群(超级节点), Pod 之间强隔离,压测 Pod 不会对在线业务造成干扰,无需关心调度策略,解放运维。每个 Pod 独占虚拟机,基本不会因达到带宽瓶颈而丢包。
|
||||||
|
|
||||||
|

|
||||||
|
|
@ -0,0 +1,41 @@
|
||||||
|
# 超级节点案例分享: 轻松应对流量洪峰
|
||||||
|
|
||||||
|
## 概述
|
||||||
|
|
||||||
|
腾讯云容器服务的超级节点可以轻松应对流量洪峰。
|
||||||
|
|
||||||
|
本文分享这种场景的几个真实实践案例。
|
||||||
|
|
||||||
|
## 案例一: 信息流系统(某新闻媒体客户)
|
||||||
|
|
||||||
|
在线业务,购买了包年包月普通节点,在业务高峰期算力不足,扩容节点慢导致部分请求失败。业务高峰时间有时无法预测(可能某个新闻突然就爆火了),扩容慢问题的影响进一步被放大。
|
||||||
|
|
||||||
|
方案改进: 普通节点作为常驻资源池进行兜底,优先调度 Pod 到普通节点,当普通节点资源不足再调度到超级节点。高峰期 HPA 自动扩容 Pod,过程中不会触发扩容节点,不存在扩容慢问题。超级节点上 Pod 缩容后停止计费,降低成本。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## 案例二: 元宇宙案例(某元宇宙客户)
|
||||||
|
|
||||||
|
元宇宙业务,类似在线游戏,全球同服,带宽需求量极大,需要每个 Pod 绑 EIP,且使用的游戏框架依赖读 eth0 公网 IP。做活动时,流量相比平时大很多,大概100倍,需要能够快速扩容。
|
||||||
|
|
||||||
|
Serverless 集群方案: 超级节点的 Pod 支持绑 EIP 和开启 EIP 直通(将公网 IP 地址绑到 eth0 网卡)。使用超级节点+HPC 定时扩容(活动时间可预知),轻松应对活动高峰,活动结束 Pod 销毁释放资源,降低成本。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## 案例三: 医疗场景案例(某医疗客户)
|
||||||
|
|
||||||
|
医生提交任务到系统,利用 GPU 推理来自动生成报告,辅助医生判断病情。
|
||||||
|
|
||||||
|
上午医生上班时间是高峰期,其余时间的量则非常低,常驻的普通节点在低峰期闲置造成浪费。普通节点在高峰期扩容速度太慢,导致一些任务需要等待很久,影响医生工作效率。
|
||||||
|
|
||||||
|
方案改进: 使用 Serverless 集群,GPU Pod 直接按需创建,无需常驻节点,也无需扩容节点,提高资源利用率,降低成本。POD 启动速度快,高峰期任务也能得到及时运行,提高医生工作效率。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## 案例四: 录制与转码(某教育客户)
|
||||||
|
|
||||||
|
在线授课生成视频回看的业务场景,服务端录制有一定时效性,在业务高峰期需快速扩容。转码会消耗大量计算资源,低峰期需求量则非常少,使用普通节点时,一般要保留一些常驻节点兜底,避免售罄时不可用,低峰期造成资源闲置和浪费。
|
||||||
|
|
||||||
|
方案改进: 由于上课时间比较集中,可使用 [HPC 插件](https://cloud.tencent.com/document/product/457/56753) 定时提前扩容录制 Pod,轻松应对高峰期,结合 HPA 快速扩容还可应对预期之外的流量洪峰。Pod 按需创建,销毁立即停止计费,无需预留资源,节约成本。
|
||||||
|
|
||||||
|

|
||||||
|
|
@ -0,0 +1,88 @@
|
||||||
|
# 为什么超级节点这么牛!
|
||||||
|
|
||||||
|
## 概述
|
||||||
|
|
||||||
|
腾讯云容器服务中集群节点有普通节点和超级节点之分,具体怎么选呢?本文告诉你答案。
|
||||||
|
|
||||||
|
## 集群与节点类型
|
||||||
|
|
||||||
|
腾讯云容器服务产品化的 Kubernetes 集群最主要是以下两种:
|
||||||
|
|
||||||
|
- 标准集群
|
||||||
|
- Serverless 集群
|
||||||
|
|
||||||
|
不管哪种集群,都需要添加节点才能运行服务(Pod)。对于标准集群,同时支持添加普通节点与超级节点:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
而对于 Serverless 集群,只支持添加超级节点:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## 普通节点与超级节点的区别
|
||||||
|
|
||||||
|
普通节点都很好理解,就是将虚拟机(CVM)添加到集群中作为 K8S 的一个节点,每台虚拟机(节点)上可以调度多个 Pod 运行。
|
||||||
|
|
||||||
|
那超级节点又是什么呢?可以理解是一种虚拟的节点,每个超级节点代表一个 VPC 的子网,调度到超级节点的 Pod 分配出的 IP 也会在这个子网中,每个 Pod 都独占一台轻量虚拟机,Pod 之间都是强隔离的,跟在哪个超级节点上无关。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
> 更多详细解释请参考 [官方文档: 超级节点概述](https://cloud.tencent.com/document/product/457/74014)。
|
||||||
|
|
||||||
|
所以,调度到超级节点的 Pod,你可以认为它没有节点,自身就是一个独立的虚拟机,超级节点仅仅是一个虚拟的节点概念,并不是指某台机器,一个超级节点能调度的 Pod 数量主要取决于这个超级节点关联的子网的 IP 数量。
|
||||||
|
|
||||||
|
虽然超级节点里的 Pod 独占一台虚拟机,但是很它很轻量,可以快速启动,也不要运维节点了,这种特性也带来了一些相对普通节点非常明显的优势,下面对这些优势详细讲解下。
|
||||||
|
|
||||||
|
## 超级节点的优势
|
||||||
|
|
||||||
|
### 隔离性更强
|
||||||
|
|
||||||
|
Pod 之间是虚拟机级别的强隔离,不存在 Pod 之间干扰问题(如某个 Pod 磁盘 IO 过高影响其它 Pod),也不会因底层故障导致大范围受影响。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 免运维
|
||||||
|
|
||||||
|
无需运维节点:
|
||||||
|
* Pod 重建即可自动升级基础组件或内核到最新版。
|
||||||
|
* 如果 Pod 因高负载或其它原因导致长时间无心跳上报,底层虚拟机也可以自动重建,迁移到新机器并开机运行实现自愈。
|
||||||
|
* 检测到硬件故障自动热迁移实现自愈。
|
||||||
|
* 检测到 GPU 坏卡可自动迁移到正常机器。
|
||||||
|
|
||||||
|
### 弹性更高效
|
||||||
|
|
||||||
|
对于普通节点,扩容比较慢,因为需要各种安装与初始化流程,且固定机型+大规格的节点,有时可能有售罄的风险。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
而超级节点只需扩容 POD,超级节点本身没有安装与初始化流程,可快速扩容应对业务高峰。且 POD 规格相对较小,机型可根据资源情况自动调整,售罄概率很低。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 成本更省
|
||||||
|
|
||||||
|
为避免扩容慢,或者因某机型+规格的机器资源不足导致扩容失败,普通节点往往会预留一些 buffer,在低峰期资源利用率很低,造成资源的闲置和浪费。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
而超级节点可按需使用,POD 销毁立即停止计费,由于 POD 规格一般不大,且机型可根据资源大盘情况自动灵活调整,不容易出现售罄的情况,无需预留 buffer,极大提升资源利用率,降低成本。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## 如何选择?
|
||||||
|
|
||||||
|
### 一般建议
|
||||||
|
|
||||||
|
超级节点在很多场景中优势都比较明显,大多情况下使用超级节点都可以满足需求。
|
||||||
|
|
||||||
|
如果是超级节点没有明显无法满足自身需求的话,可以考虑优先使用 Serverless 集群,只用超级节点。
|
||||||
|
|
||||||
|
如果存在超级节点无法满足需求的情况,可以使用标准集群,添加普通节点,同时也可以添加超级节点来混用,将超级节点无法满足需求的服务只调度到普通节点。
|
||||||
|
|
||||||
|
那哪些情况超级节点无法满足需求呢?参考下面 **适合普通节点的场景**。
|
||||||
|
|
||||||
|
### 适合普通节点的场景
|
||||||
|
|
||||||
|
- 需要定制操作系统,[自定义系统镜像](https://cloud.tencent.com/document/product/457/39563)。
|
||||||
|
- 需要很多小规格的 Pod 来节约成本,比如 0.01 核,或者甚至没有 request 与 limit (通常用于测试环境,需要创建大量 Pod,但资源占用很低)。
|
||||||
|
- 需要对集群配置进行高度自定义,比如修改运行时的一些配置(如 registry mirror)。
|
||||||
|
|
@ -0,0 +1,546 @@
|
||||||
|
# 腾讯云跨账号流量统一接入与治理方案
|
||||||
|
|
||||||
|
## 需求场景
|
||||||
|
|
||||||
|
服务部署在不同腾讯云账号下,想统一在一个腾讯云账号下接入流量,部分流量可能会转发到其它腾讯云账号下的服务。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## 需求分析
|
||||||
|
|
||||||
|
多集群跨 VPC 流量管理,可以通过 [腾讯云服务网格](https://cloud.tencent.com/product/tcm)(TCM) + [云联网](https://cloud.tencent.com/product/ccn)(CCN) 来实现,自动对多个容器集群进行服务发现(Pod IP),利用 isito ingressgateway 统一接入流量,然后直接转发到后端服务的 Pod IP:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
但这里需求关键点是跨账号,虽然跨账号网络也可以用云联网打通,但是 TCM 是无法直接管理其它账号下的集群的,原因很明显,关联集群时只能选择本账号下的集群,没有权限关联其它账号下的集群:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
幸运的是,我们可以利用 [云原生分布式云中心](https://cloud.tencent.com/product/tdcc)(TDCC) 来管理其它账号的集群 (TDCC 目前还在内测中,需提交 [内核申请](https://cloud.tencent.com/apply/p/897g10ltlv6) 进行开通),将其它账号的集群注册到 TDCC 中,然后在 TCM 里添加 TDCC 中注册的集群,TCM 通过关联 TDCC 注册集群来间接对其它账号的集群进行服务发现,以实现多账号下的集群流量统一纳管:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## 注意事项: 其它账号尽量使用独立集群
|
||||||
|
|
||||||
|
istio 注入 sidecar 时需要集群 apiserver 调用 TCM 控制面 webhook:
|
||||||
|
|
||||||
|
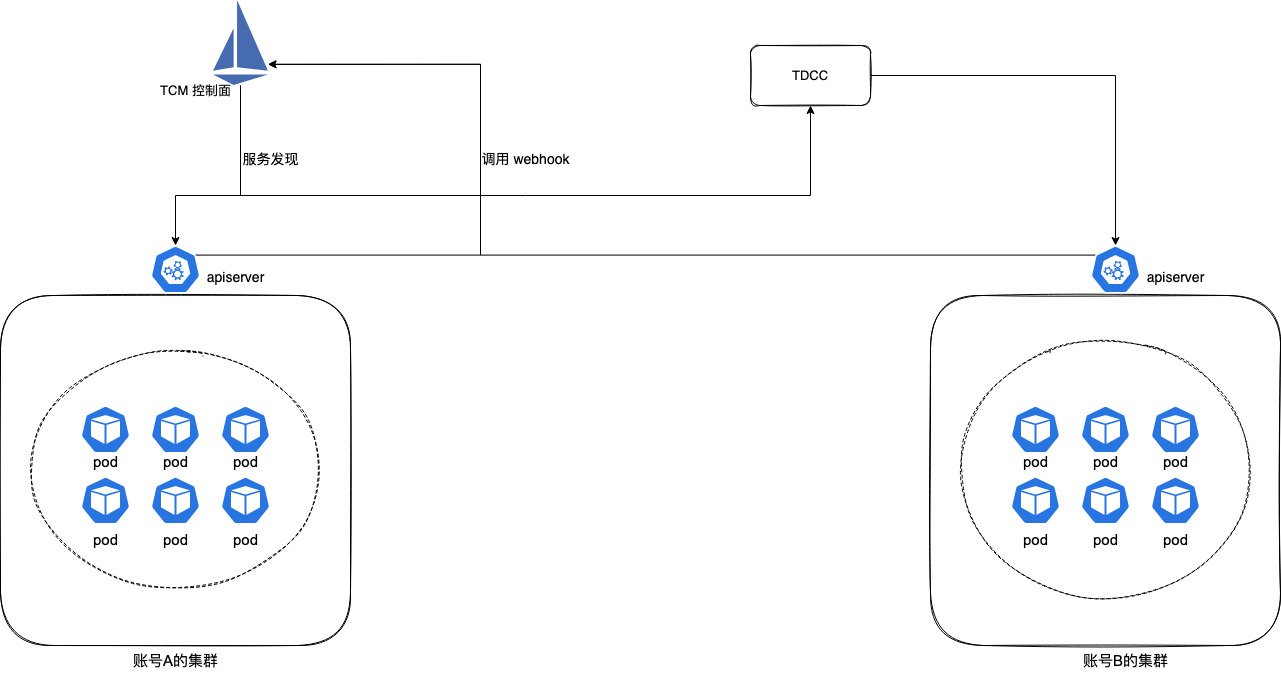
|
||||||
|
|
||||||
|
如果使用托管集群(TKE托管集群或EKS集群),apiserver 是用户不可见的,使用 169 开头的 IP,这个 IP 只在 VPC 内可用。
|
||||||
|
|
||||||
|
所以如果将账号B的托管集群注册到账号A的 TDCC 中,账号B的托管集群 apiserver 也无法调用到账号A的TCM控制面,就会导致无法注入 sidecar,而独立集群没这个问题,因为 apiserver 是部署在用户 CVM 上,使用 CVM 的 IP,打通云联网后网络就可以互通,所以推荐其它账号下的集群使用 TKE 独立集群。
|
||||||
|
|
||||||
|
当然如果能保证完全没有 sidecar 自动注入的需求,不需要账号 B 的服务通过网格的服务发现主动调用账号 A 的服务,这种情况使用托管集群也可以。
|
||||||
|
|
||||||
|
## 操作步骤
|
||||||
|
|
||||||
|
### 准备集群
|
||||||
|
|
||||||
|
在账号A下(用于接入流量的账号),准备好一个或多个 TKE/EKS 集群,在其它账号准备好 TKE 独立集群。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
注意,一定保证所有集群使用的网段互不冲突。
|
||||||
|
|
||||||
|
### 使用云联网打通网络
|
||||||
|
|
||||||
|
登录账号A,进入[云联网控制台](https://console.cloud.tencent.com/vpc/ccn)里,新建一个云联网,然后点击【新增实例】,将需要账号A下需要打通网络的VPC全部关联进来:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
登录其它账号,进入[VPC控制台](https://console.cloud.tencent.com/vpc/vpc),点击进入需要与账号A打通网络的VPC,点【立即关联】:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
选择【其它账号】,输入账号A的ID以及前面创建的云联网的ID以申请加入账号A创建的云联网:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
然后再登录账号A,点进前面创建的云联网,同意其它账号VPC加入云联网的申请:
|
||||||
|
|
||||||
|
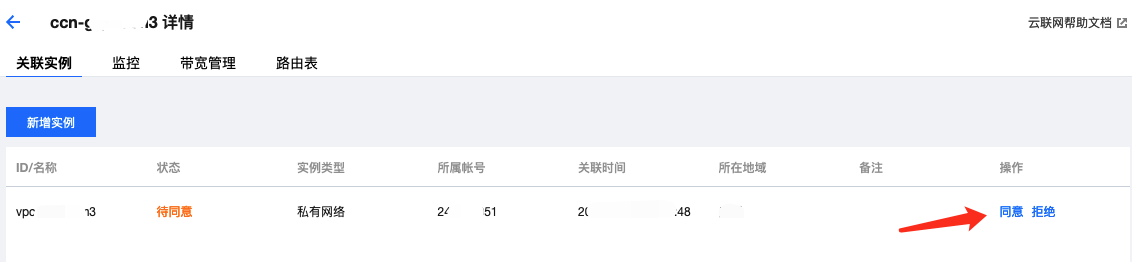
|
||||||
|
|
||||||
|
不出意外,不同账号不同 VPC 成功通过云联网打通网络:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
如果你使用了 TKE 集群的 Global Router 网络模式,在集群基本信息页面,将容器网络注册到云联网的开关打开,以便让 Global Router 网络模式的容器 IP 通过云联网下发给所有其它 VPC:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 开通 TDCC
|
||||||
|
|
||||||
|
登录账号A,进入 [TDCC 控制台](https://console.cloud.tencent.com/tdcc),首次进入需要按流程进行开通操作。
|
||||||
|
|
||||||
|
首先会提示为 TDCC 进行授权:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
点击【同意授权】:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
选择要开通的 TDCC 所在地域以及 VPC 与子网:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
需要注意的是:
|
||||||
|
* TDCC 是多集群的控制面,可以同时管理多个地域的集群,尽量将 TDCC 所在地域选在服务部署的地域,如果服务分散在多个地域,或者 TDCC 还不支持服务所在地域,可以尽量选择离服务近一点的地域,尽量降低 TDCC 控制面到集群之间的时延。
|
||||||
|
* TDCC 与集群如果跨地域,仅仅增加一点控制面之间的时延,不影响数据面。数据面之间的转发时延只取决于集群之间的距离,与 TDCC 无关,比如,集群都在成都地域,但 TDCC 不支持成都,可以将 TDCC 选择广州。
|
||||||
|
* 可以将 TDCC 所在 VPC 也加入到云联网,这样其它账号注册集群到 TDCC 时就可以使用内网方式,网络稳定性更有保障。
|
||||||
|
|
||||||
|
等待 TDCC 的 Hub 集群创建完成:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
完成后,在 [TDCC 集群列表页面](https://console.cloud.tencent.com/tdcc/cluster),点击【注册已有集群】:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
虽然其它账号使用的 TKE 独立集群,但这里一定要选择 【非TKE集群】:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
> 因为如果选 【TKE集群】,只能选到本账号的,其它账号的选不了。
|
||||||
|
|
||||||
|
选择其它账号集群实际所在地域,然后点【完成】,回到集群列表页面,点击【查看注册命令】:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
可以看到自动生成的 yaml,将其下载下来,保存成 `agent.yaml`:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
然后 kubectl 的 context 切换到其它账号中要注册到 TDCC 的集群,使用 kubectl 将 yaml apply 进去:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl apply -f agent.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
不出意外,TDCC 集群列表页面可以看到注册集群状态变为了`运行中`,即将其它账号下的集群成功注册到 TDCC:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 创建服务网格
|
||||||
|
|
||||||
|
登录账号A,进入 [TCM 控制台](https://console.cloud.tencent.com/tke2/mesh),点【新建】来创建一个服务网格:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
推荐选择最高版本 istio,托管网格:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
> 服务发现就是关联集群,可以在创建网格时就关联,也可以等创建完再关联。
|
||||||
|
|
||||||
|
如果将 TDCC 中的注册集群关联进 TCM?在关联集群时,选择 TDCC 所在地域和注册集群类型,然后就可以下拉选择其它账号下注册进来的集群了:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
不出意外,账号A和其它账号的集群都关联到同一个服务网格了:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 创建 Ingress Gateway
|
||||||
|
|
||||||
|
进入账号A创建的网格,在基本信息页面里创建 Ingress Gateway:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
配置一下 Ingress Gateway,`接入集群` 选要统一接入流量的集群:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
创建好后,点进去:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
可以看到创建出来的 CLB IP 地址以及对应的 CLB ID:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
> 如有需要,创建 Ingress Gateway 时也可以选择已有 CLB。
|
||||||
|
|
||||||
|
Ingress Gateway 组件创建好了,再创建一个 Gateway 对象与之关联:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
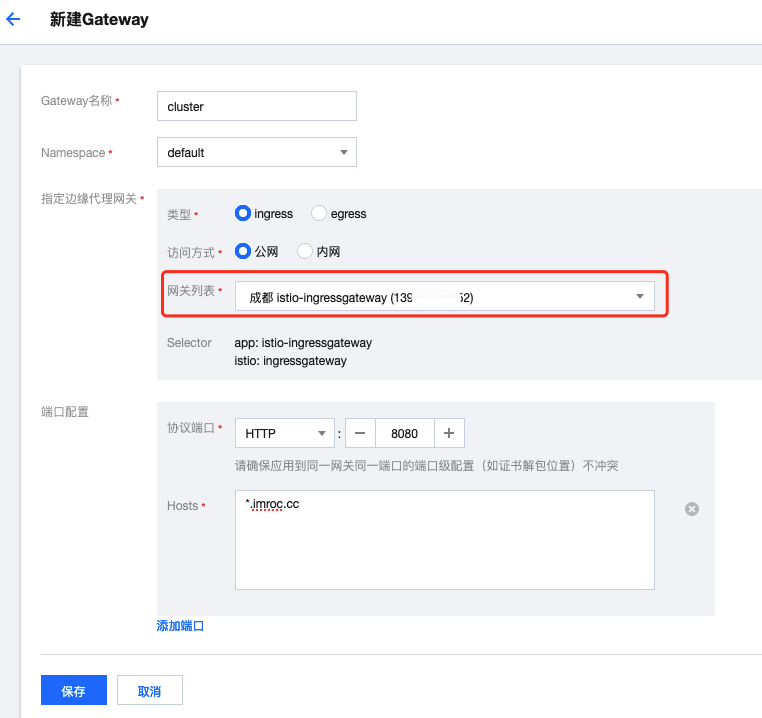
|
||||||
|
|
||||||
|
也可以直接用 yaml 创建:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: networking.istio.io/v1alpha3
|
||||||
|
kind: Gateway
|
||||||
|
metadata:
|
||||||
|
name: cluster
|
||||||
|
namespace: istio-system
|
||||||
|
spec:
|
||||||
|
selector:
|
||||||
|
app: istio-ingressgateway
|
||||||
|
istio: ingressgateway
|
||||||
|
servers:
|
||||||
|
- port:
|
||||||
|
number: 80
|
||||||
|
name: HTTP-80
|
||||||
|
protocol: HTTP
|
||||||
|
hosts:
|
||||||
|
- "*.imroc.cc"
|
||||||
|
```
|
||||||
|
|
||||||
|
### 配置 DNS 解析
|
||||||
|
|
||||||
|
将三个不同的域名都解析到前面创建的 Ingress Gateway 的 CLB IP:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
验证一下是否都正确解析到了同一个 IP:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 部署测试服务
|
||||||
|
|
||||||
|
分别在几个集群部署服务,这里给出一个示例,将 3 个不同服务分别部署在不同集群中,其中一个集群在其它账号下:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
* 3 个服务使用不同域名,但 DNS 都指向同一个 ingressgateway,统一接入流量。
|
||||||
|
* 根据不同域名转发给不同的服务。
|
||||||
|
|
||||||
|
服务部署使用 [prism](https://stoplight.io/open-source/prism),模拟不同服务的返回不同,访问根路径分别返回字符串`cluster1`、`cluster2`与`cluster3`。
|
||||||
|
|
||||||
|
第一个服务的 yaml (`cluster1.yaml`):
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: v1
|
||||||
|
kind: ConfigMap
|
||||||
|
metadata:
|
||||||
|
name: cluster1-conf
|
||||||
|
namespace: test
|
||||||
|
data:
|
||||||
|
mock.yaml: |
|
||||||
|
openapi: 3.0.3
|
||||||
|
info:
|
||||||
|
title: MockServer
|
||||||
|
description: MockServer
|
||||||
|
version: 1.0.0
|
||||||
|
paths:
|
||||||
|
'/':
|
||||||
|
get:
|
||||||
|
responses:
|
||||||
|
'200':
|
||||||
|
content:
|
||||||
|
'text/plain':
|
||||||
|
schema:
|
||||||
|
type: string
|
||||||
|
example: cluster1
|
||||||
|
---
|
||||||
|
apiVersion: v1
|
||||||
|
kind: Service
|
||||||
|
metadata:
|
||||||
|
name: cluster1
|
||||||
|
namespace: test
|
||||||
|
labels:
|
||||||
|
app: cluster1
|
||||||
|
spec:
|
||||||
|
type: ClusterIP
|
||||||
|
ports:
|
||||||
|
- port: 80
|
||||||
|
name: http
|
||||||
|
protocol: TCP
|
||||||
|
targetPort: 80
|
||||||
|
selector:
|
||||||
|
app: cluster1
|
||||||
|
|
||||||
|
---
|
||||||
|
apiVersion: apps/v1
|
||||||
|
kind: Deployment
|
||||||
|
metadata:
|
||||||
|
name: cluster1
|
||||||
|
namespace: test
|
||||||
|
spec:
|
||||||
|
replicas: 1
|
||||||
|
selector:
|
||||||
|
matchLabels:
|
||||||
|
app: cluster1
|
||||||
|
version: v1
|
||||||
|
template:
|
||||||
|
metadata:
|
||||||
|
labels:
|
||||||
|
app: cluster1
|
||||||
|
version: v1
|
||||||
|
spec:
|
||||||
|
containers:
|
||||||
|
- name: cluster1
|
||||||
|
image: stoplight/prism:4
|
||||||
|
args:
|
||||||
|
- mock
|
||||||
|
- -h
|
||||||
|
- 0.0.0.0
|
||||||
|
- -p
|
||||||
|
- "80"
|
||||||
|
- /etc/prism/mock.yaml
|
||||||
|
volumeMounts:
|
||||||
|
- mountPath: /etc/prism
|
||||||
|
name: config
|
||||||
|
volumes:
|
||||||
|
- name: config
|
||||||
|
configMap:
|
||||||
|
name: cluster1-conf
|
||||||
|
```
|
||||||
|
|
||||||
|
将其 apply 到账号 A 的集群1:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl create ns test
|
||||||
|
kubectl apply -f cluster1.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
等待部署成功:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
第二个服务的 yaml (`cluster2.yaml`):
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: v1
|
||||||
|
kind: ConfigMap
|
||||||
|
metadata:
|
||||||
|
name: cluster2-conf
|
||||||
|
namespace: test
|
||||||
|
data:
|
||||||
|
mock.yaml: |
|
||||||
|
openapi: 3.0.3
|
||||||
|
info:
|
||||||
|
title: MockServer
|
||||||
|
description: MockServer
|
||||||
|
version: 1.0.0
|
||||||
|
paths:
|
||||||
|
'/':
|
||||||
|
get:
|
||||||
|
responses:
|
||||||
|
'200':
|
||||||
|
content:
|
||||||
|
'text/plain':
|
||||||
|
schema:
|
||||||
|
type: string
|
||||||
|
example: cluster2
|
||||||
|
---
|
||||||
|
apiVersion: v1
|
||||||
|
kind: Service
|
||||||
|
metadata:
|
||||||
|
name: cluster2
|
||||||
|
namespace: test
|
||||||
|
labels:
|
||||||
|
app: cluster2
|
||||||
|
spec:
|
||||||
|
type: ClusterIP
|
||||||
|
ports:
|
||||||
|
- port: 80
|
||||||
|
name: http
|
||||||
|
protocol: TCP
|
||||||
|
targetPort: 80
|
||||||
|
selector:
|
||||||
|
app: cluster2
|
||||||
|
|
||||||
|
---
|
||||||
|
apiVersion: apps/v1
|
||||||
|
kind: Deployment
|
||||||
|
metadata:
|
||||||
|
name: cluster2
|
||||||
|
namespace: test
|
||||||
|
spec:
|
||||||
|
replicas: 1
|
||||||
|
selector:
|
||||||
|
matchLabels:
|
||||||
|
app: cluster2
|
||||||
|
version: v1
|
||||||
|
template:
|
||||||
|
metadata:
|
||||||
|
labels:
|
||||||
|
app: cluster2
|
||||||
|
version: v1
|
||||||
|
spec:
|
||||||
|
containers:
|
||||||
|
- name: cluster2
|
||||||
|
image: stoplight/prism:4
|
||||||
|
args:
|
||||||
|
- mock
|
||||||
|
- -h
|
||||||
|
- 0.0.0.0
|
||||||
|
- -p
|
||||||
|
- "80"
|
||||||
|
- /etc/prism/mock.yaml
|
||||||
|
volumeMounts:
|
||||||
|
- mountPath: /etc/prism
|
||||||
|
name: config
|
||||||
|
volumes:
|
||||||
|
- name: config
|
||||||
|
configMap:
|
||||||
|
name: cluster2-conf
|
||||||
|
```
|
||||||
|
|
||||||
|
将其 apply 到账号 A 的集群2:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl create ns test
|
||||||
|
kubectl apply -f cluster2.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
类似的,第三个服务的 yaml (`cluster3.yaml`):
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: v1
|
||||||
|
kind: ConfigMap
|
||||||
|
metadata:
|
||||||
|
name: cluster3-conf
|
||||||
|
namespace: test
|
||||||
|
data:
|
||||||
|
mock.yaml: |
|
||||||
|
openapi: 3.0.3
|
||||||
|
info:
|
||||||
|
title: MockServer
|
||||||
|
description: MockServer
|
||||||
|
version: 1.0.0
|
||||||
|
paths:
|
||||||
|
'/':
|
||||||
|
get:
|
||||||
|
responses:
|
||||||
|
'200':
|
||||||
|
content:
|
||||||
|
'text/plain':
|
||||||
|
schema:
|
||||||
|
type: string
|
||||||
|
example: cluster3
|
||||||
|
---
|
||||||
|
apiVersion: v1
|
||||||
|
kind: Service
|
||||||
|
metadata:
|
||||||
|
name: cluster3
|
||||||
|
namespace: test
|
||||||
|
labels:
|
||||||
|
app: cluster3
|
||||||
|
spec:
|
||||||
|
type: ClusterIP
|
||||||
|
ports:
|
||||||
|
- port: 80
|
||||||
|
name: http
|
||||||
|
protocol: TCP
|
||||||
|
targetPort: 80
|
||||||
|
selector:
|
||||||
|
app: cluster3
|
||||||
|
|
||||||
|
---
|
||||||
|
apiVersion: apps/v1
|
||||||
|
kind: Deployment
|
||||||
|
metadata:
|
||||||
|
name: cluster3
|
||||||
|
namespace: test
|
||||||
|
spec:
|
||||||
|
replicas: 1
|
||||||
|
selector:
|
||||||
|
matchLabels:
|
||||||
|
app: cluster3
|
||||||
|
version: v1
|
||||||
|
template:
|
||||||
|
metadata:
|
||||||
|
labels:
|
||||||
|
app: cluster3
|
||||||
|
version: v1
|
||||||
|
spec:
|
||||||
|
containers:
|
||||||
|
- name: cluster3
|
||||||
|
image: stoplight/prism:4
|
||||||
|
args:
|
||||||
|
- mock
|
||||||
|
- -h
|
||||||
|
- 0.0.0.0
|
||||||
|
- -p
|
||||||
|
- "80"
|
||||||
|
- /etc/prism/mock.yaml
|
||||||
|
volumeMounts:
|
||||||
|
- mountPath: /etc/prism
|
||||||
|
name: config
|
||||||
|
volumes:
|
||||||
|
- name: config
|
||||||
|
configMap:
|
||||||
|
name: cluster3-conf
|
||||||
|
```
|
||||||
|
|
||||||
|
将其 apply 到另一个账号的集群:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl create ns test
|
||||||
|
kubectl apply -f cluster3.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
### 配置 VirtualService 规则
|
||||||
|
|
||||||
|
可以在 TCM 控制台可视化操作,也可以用 apply yaml,这里示例使用 yaml。
|
||||||
|
|
||||||
|
首先,为三个不同服务创建对应的 VirtualService 并与 Gateway 关联:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: networking.istio.io/v1beta1
|
||||||
|
kind: VirtualService
|
||||||
|
metadata:
|
||||||
|
name: cluster1-imroc-cc
|
||||||
|
namespace: test
|
||||||
|
spec:
|
||||||
|
gateways:
|
||||||
|
- istio-system/cluster
|
||||||
|
hosts:
|
||||||
|
- 'cluster1.imroc.cc'
|
||||||
|
http:
|
||||||
|
- route:
|
||||||
|
- destination:
|
||||||
|
host: cluster1.test.svc.cluster.local
|
||||||
|
port:
|
||||||
|
number: 80
|
||||||
|
---
|
||||||
|
apiVersion: networking.istio.io/v1beta1
|
||||||
|
kind: VirtualService
|
||||||
|
metadata:
|
||||||
|
name: cluster2-imroc-cc
|
||||||
|
namespace: test
|
||||||
|
spec:
|
||||||
|
gateways:
|
||||||
|
- istio-system/cluster
|
||||||
|
hosts:
|
||||||
|
- 'cluster2.imroc.cc'
|
||||||
|
http:
|
||||||
|
- route:
|
||||||
|
- destination:
|
||||||
|
host: cluster2.test.svc.cluster.local
|
||||||
|
port:
|
||||||
|
number: 80
|
||||||
|
---
|
||||||
|
apiVersion: networking.istio.io/v1beta1
|
||||||
|
kind: VirtualService
|
||||||
|
metadata:
|
||||||
|
name: cluster3-imroc-cc
|
||||||
|
namespace: test
|
||||||
|
spec:
|
||||||
|
gateways:
|
||||||
|
- istio-system/cluster
|
||||||
|
hosts:
|
||||||
|
- cluster3.imroc.cc
|
||||||
|
http:
|
||||||
|
- route:
|
||||||
|
- destination:
|
||||||
|
host: cluster3.test.svc.cluster.local
|
||||||
|
port:
|
||||||
|
number: 80
|
||||||
|
```
|
||||||
|
|
||||||
|
### 测试效果
|
||||||
|
|
||||||
|
使用 curl 请求不同服务的域名,可以看到将请求均正确转发到了对应的集群,并响应了对应不同的结果:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## 总结
|
||||||
|
|
||||||
|
本文给出了在腾讯云上利用 TCM+CCN+TDCC 实现跨账号多集群流量统一接入和治理的方案,示例中的功能相对简单,如有需要,还可以自行配置 istio 规则实现更细粒度的流量治理,比如根据不同 url 路径转发到不同集群的服务,甚至相同 url 同时转发到不同集群,配置流量比例等。
|
||||||
|
|
@ -0,0 +1,109 @@
|
||||||
|
# 原地升级
|
||||||
|
|
||||||
|
## 需求与背景
|
||||||
|
|
||||||
|
Kubernetes 默认不支持原地升级,使用腾讯云容器服务也一样,也没有集成相关插件来支持,可以安装开源的 openkruise 来实现,本文介绍如何在腾讯云容器服务上利用 openkruise 让工作负载进行原地升级。
|
||||||
|
|
||||||
|
## 原地升级的好处
|
||||||
|
|
||||||
|
原地升级的主要好处是,更新更快,并且可以避免更新后底层资源不足导致一直 Pending:
|
||||||
|
|
||||||
|
* 不需要重建 Pod,对于 EKS 来说,都不需要重建虚拟机。
|
||||||
|
* 原地升级实际就是替换容器镜像,重启下容器,对于 EKS 来说,可以避免 Pod 重建后底层没资源调度的情况。
|
||||||
|
* 不需要重新拉取整个镜像,只需要拉取有变化的 layer 即可。
|
||||||
|
|
||||||
|
## 操作步骤
|
||||||
|
|
||||||
|
### 安装 openkruise
|
||||||
|
|
||||||
|
|
||||||
|
```bash
|
||||||
|
helm repo add openkruise https://openkruise.github.io/charts/
|
||||||
|
helm repo update
|
||||||
|
helm install kruise openkruise/kruise
|
||||||
|
```
|
||||||
|
|
||||||
|
> 参考 [官方安装文档](https://openkruise.io/zh/docs/installation)
|
||||||
|
|
||||||
|
### 创建支持原地升级的工作负载
|
||||||
|
|
||||||
|
OpenKruise 中有以下几种工作负载支持原地升级:
|
||||||
|
|
||||||
|
* CloneSet
|
||||||
|
* Advanced StatefulSet
|
||||||
|
* Advanced DaemonSet
|
||||||
|
* SidecarSet
|
||||||
|
|
||||||
|
> 更多原地升级详细文档参考 [官方文档](https://openkruise.io/zh/docs/core-concepts/inplace-update/)
|
||||||
|
|
||||||
|
以下用 `Advanced StatefulSet` 进行演示,准备 `sts.yaml`
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: apps.kruise.io/v1beta1
|
||||||
|
kind: StatefulSet
|
||||||
|
metadata:
|
||||||
|
name: sample
|
||||||
|
spec:
|
||||||
|
replicas: 3
|
||||||
|
serviceName: fake-service
|
||||||
|
selector:
|
||||||
|
matchLabels:
|
||||||
|
app: sample
|
||||||
|
template:
|
||||||
|
metadata:
|
||||||
|
labels:
|
||||||
|
app: sample
|
||||||
|
spec:
|
||||||
|
readinessGates:
|
||||||
|
# A new condition that ensures the pod remains at NotReady state while the in-place update is happening
|
||||||
|
- conditionType: InPlaceUpdateReady
|
||||||
|
containers:
|
||||||
|
- name: main
|
||||||
|
image: nginx:alpine
|
||||||
|
podManagementPolicy: Parallel # allow parallel updates, works together with maxUnavailable
|
||||||
|
updateStrategy:
|
||||||
|
type: RollingUpdate
|
||||||
|
rollingUpdate:
|
||||||
|
# Do in-place update if possible, currently only image update is supported for in-place update
|
||||||
|
podUpdatePolicy: InPlaceIfPossible
|
||||||
|
# Allow parallel updates with max number of unavailable instances equals to 2
|
||||||
|
maxUnavailable: 2
|
||||||
|
```
|
||||||
|
|
||||||
|
部署到集群:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ kubectl apply -f sts.yaml
|
||||||
|
statefulset.apps.kruise.io/sample created
|
||||||
|
```
|
||||||
|
|
||||||
|
检查 pod 是否正常拉起:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ kubectl get pod
|
||||||
|
NAME READY STATUS RESTARTS AGE
|
||||||
|
sample-0 1/1 Running 0 16s
|
||||||
|
sample-1 1/1 Running 0 16s
|
||||||
|
sample-2 1/1 Running 0 16s
|
||||||
|
```
|
||||||
|
|
||||||
|
### 更新镜像
|
||||||
|
|
||||||
|
修改 yaml 中的 image 为 `nginx:latest`,然后再 apply:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ kubectl apply -f sts.yaml
|
||||||
|
statefulset.apps.kruise.io/sample configured
|
||||||
|
```
|
||||||
|
|
||||||
|
观察 pod:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ kubectl get pod
|
||||||
|
NAME READY STATUS RESTARTS AGE
|
||||||
|
sample-0 1/1 Running 1 2m47s
|
||||||
|
sample-1 1/1 Running 1 2m47s
|
||||||
|
sample-2 1/1 Running 1 2m47s
|
||||||
|
```
|
||||||
|
|
||||||
|
可以看到,pod 中的容器只是重启了下,并没重建 pod,至此,原地升级验证成功。
|
||||||
|
|
@ -0,0 +1,106 @@
|
||||||
|
# 扩容 CBS 类型的 PVC
|
||||||
|
|
||||||
|
## 概述
|
||||||
|
|
||||||
|
TKE 中一般使用 PVC 来声明存储容量和类型,自动绑定 PV 并挂载到 Pod,通常都使用 CBS (云硬盘) 存储。当 CBS 的磁盘容量不够用了,如何进行扩容呢?分两种情况,本文会详细介绍。
|
||||||
|
|
||||||
|
## 存储插件类型
|
||||||
|
|
||||||
|
CBS 存储插件在 TKE 中存在两种形式:
|
||||||
|
1. In-Tree: Kubernetes 早期只支持以 In-Tree 的方式扩展存储插件,也就是将插件的逻辑编译进 Kubernetes 的组件中,也是 TKE 集群 1.20 版本之前默认自带的存储插件。
|
||||||
|
2. CSI: Kubernetes 社区发展过程中,引入存储扩展卷的 API,将存储插件实现逻辑从 Kubernetes 代码库中剥离出去,各个存储插件的实现单独维护和部署,无需侵入 Kubernetes 自身组件,也是社区现在推荐的存储扩展方式。TKE 在 1.20 版本之前,如果要使用 CSI 插件,可以在扩展组件中安装 CBS CSI 插件;自 1.20 版本开始,默认安装 CBS CSI 插件,将 In-Tree 插件完全下掉。
|
||||||
|
|
||||||
|
可以检查 PVC 对应 StorageClass 的 yaml,如果 provisioner 是 `cloud.tencent.com/qcloud-cbs`,说明是 In-tree,如果是 `com.tencent.cloud.csi.cbs` 就是 CSI。
|
||||||
|
|
||||||
|
## In-Tree 插件扩容 PVC
|
||||||
|
|
||||||
|
如何符合以下两种情况,说明你的 CBS PVC 用的 In-Tree 插件:
|
||||||
|
1. 如果你的集群版本低于 1.20,并且没有安装 CSI 插件 (默认没有安装),那么你使用的 CBS 类型 PVC 一定用的 In-Tree 插件;
|
||||||
|
2. 如果安装了 CSI 插件,但创建的 PVC 引用的 StorageClass 并没有使用 CSI (如下图)。
|
||||||
|
|
||||||
|
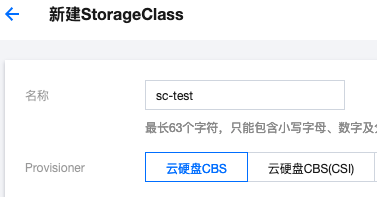
|
||||||
|
|
||||||
|
对 In-Tree 插件的 PVC 进行扩容需要手动操作,比较麻烦,操作步骤如下:
|
||||||
|
|
||||||
|
1. 获取 pvc 所绑定的 pv:
|
||||||
|
```bash
|
||||||
|
$ kubectl -n monitoring get pvc grafana -o jsonpath='{.spec.volumeName}'
|
||||||
|
grafana
|
||||||
|
```
|
||||||
|
|
||||||
|
2. 获取 pv 对应的 cbs id:
|
||||||
|
```bash
|
||||||
|
$ kubectl get pv -o jsonpath="{.spec.qcloudCbs.cbsDiskId}" grafana
|
||||||
|
disk-780nl2of
|
||||||
|
```
|
||||||
|
|
||||||
|
3. 在[云硬盘控制台](https://console.cloud.tencent.com/cvm/cbs/index) 找到对应云盘,进⾏扩容操作:
|
||||||
|
|
||||||
|
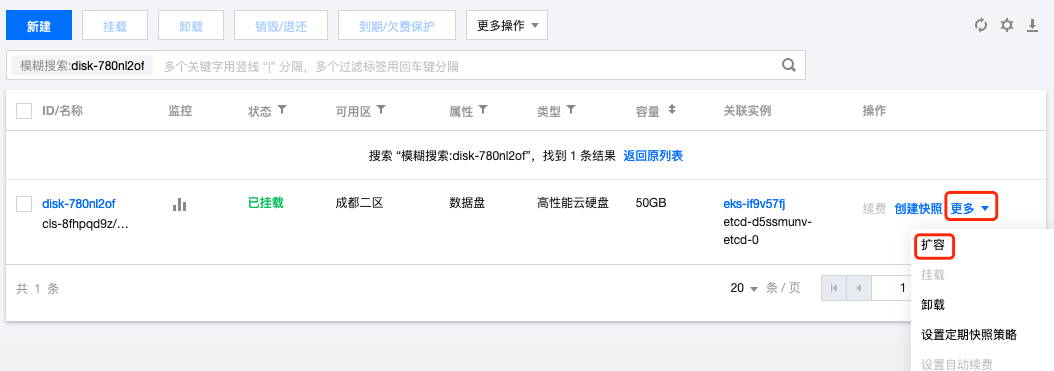
|
||||||
|
|
||||||
|
4. 登录 CBS 挂载的节点 (pod 所在节点),找到这块 cbs 盘对应的设备路径:
|
||||||
|
```bash
|
||||||
|
$ ls -l /dev/disk/by-id/*disk-780nl2of*
|
||||||
|
lrwxrwxrwx 1 root root 9 Jul 18 23:26 /dev/disk/by-id/virtio-disk-780nl2of -> ../../vdc
|
||||||
|
```
|
||||||
|
|
||||||
|
5. 执⾏命令扩容⽂件系统(替换 cbs 设备路径):
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# 对于 ext4 ⽂件系统(通常是这种)
|
||||||
|
resize2fs /dev/vdc
|
||||||
|
# 对于 xfs ⽂件系统
|
||||||
|
xfs_growfs /dev/vdc
|
||||||
|
```
|
||||||
|
|
||||||
|
### FAQ
|
||||||
|
|
||||||
|
**不需要改 PVC 或 PV 吗?**
|
||||||
|
|
||||||
|
不需要,PVC 和 PV 的容量显示也还是会显示扩容之前的⼤⼩,但实际⼤⼩是扩容后的。
|
||||||
|
|
||||||
|
## CSI 插件扩容 PVC
|
||||||
|
|
||||||
|
如果 TKE 集群版本在 1.20 及其以上版本,一定是用的 CSI 插件;如果低于 1.20,安装了 CBS CSI 扩展组件,且 PVC 引用的 StorageClass 是 CBS CSI 类型的,开启了在线扩容能力,那么就可以直接修改 PVC 容量实现自动扩容 PV 的容量。
|
||||||
|
|
||||||
|
所以 CBS CSI 插件扩容 PVC 过于简单,只有修改 PVC 容量一个步骤,这里就先讲下如何确保 PVC 能够在线扩容。
|
||||||
|
|
||||||
|
如果用控制台创建 StorageClass ,确保勾选 【启用在线扩容】(默认就会勾选):
|
||||||
|
|
||||||
|
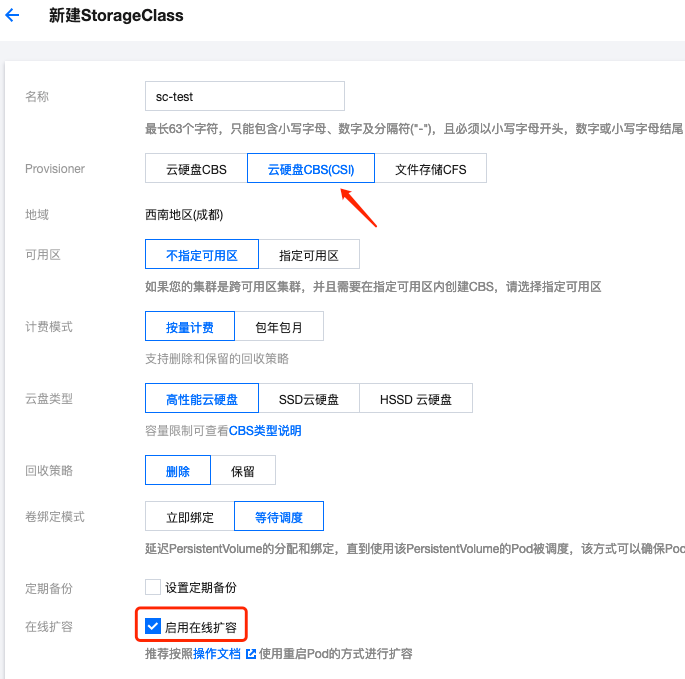
|
||||||
|
|
||||||
|
如果使用 YAML 创建,确保将 `allowVolumeExpansion` 设为 true:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
allowVolumeExpansion: true # 这里是关键
|
||||||
|
apiVersion: storage.k8s.io/v1
|
||||||
|
kind: StorageClass
|
||||||
|
metadata:
|
||||||
|
name: cbs-csi-expand
|
||||||
|
parameters:
|
||||||
|
diskType: CLOUD_PREMIUM
|
||||||
|
provisioner: com.tencent.cloud.csi.cbs
|
||||||
|
reclaimPolicy: Delete
|
||||||
|
volumeBindingMode: WaitForFirstConsumer
|
||||||
|
```
|
||||||
|
|
||||||
|
创建 PVC 时记得选择 CBS CSI 类型且开启了在线扩容的 StorageClass:
|
||||||
|
|
||||||
|
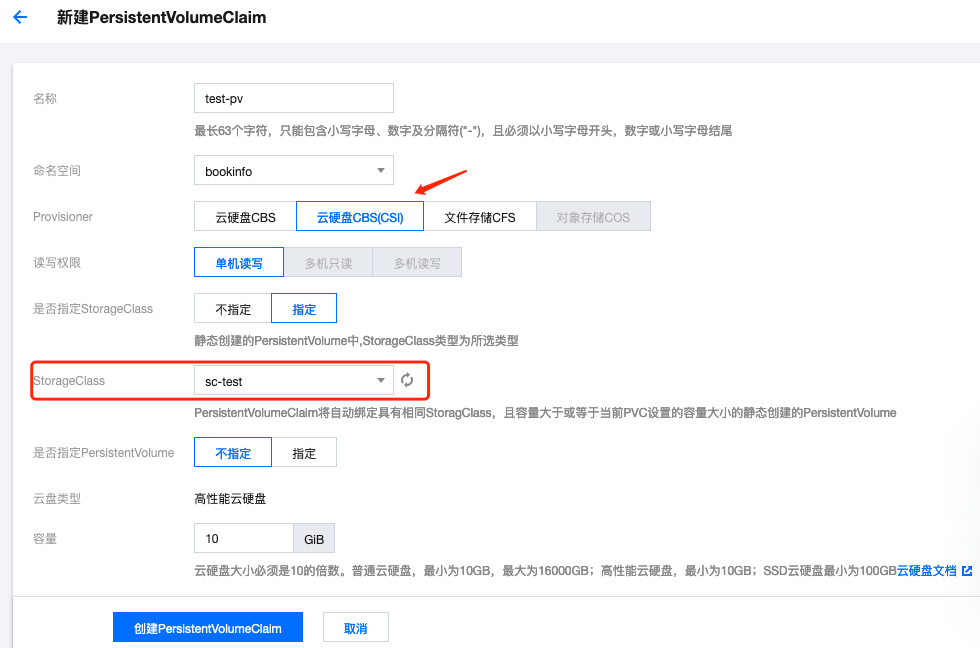
|
||||||
|
|
||||||
|
然后当需要扩容 PVC 的时候,直接修改 PVC 的容量即可:
|
||||||
|
|
||||||
|
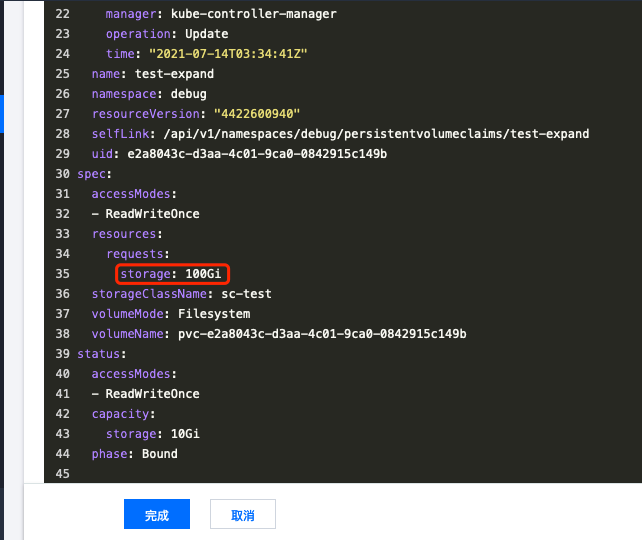
|
||||||
|
|
||||||
|
> 修改完后对应的 CBS 磁盘容量会自动扩容到指定大小 (注意必须是 10Gi 的倍数),可以自行到云硬盘控制台确认。
|
||||||
|
|
||||||
|
### FAQ
|
||||||
|
|
||||||
|
**需要重启 Pod 吗?**
|
||||||
|
|
||||||
|
可以不重启 pod 直接扩容,但,这种情况下被扩容的云盘的文件系统被 mount 在节点上,如果有频繁 I/O 的话,有可能会出现文件系统扩容错误。为了确保文件系统的稳定性,还是推荐先让云盘文件系统处于未 mount 情况下进行扩容,可以将 Pod 副本调为 0 或修改 PV 打上非法的 zone (`kubectl label pv pvc-xxx failure-domain.beta.kubernetes.io/zone=nozone`) 让 Pod 重建后 Pending,然后再修改 PVC 容量进行在线扩容,最后再恢复 Pod Running 以挂载扩容后的磁盘。
|
||||||
|
|
||||||
|
**担心扩容导致数据出问题,如何兜底?**
|
||||||
|
|
||||||
|
可以在扩容前使用快照来备份数据,避免扩容失败导致数据丢失。
|
||||||
|
|
||||||
|
|
@ -0,0 +1,171 @@
|
||||||
|
# 使用 V3 协议挂载 CFS
|
||||||
|
|
||||||
|
## 背景
|
||||||
|
|
||||||
|
腾讯云 CFS 文件存储,同时支持 NFS V3 和 V4 协议,mount 的时候,如果不指定协议,默认是客户端与服务端协商得到版本号,大多情况下会使用 NFS V4 协议,但 CFS 文件存储使用 NFS V4 挂载的话目前存在不稳定的问题,建议是显式指定使用 NFS V3 协议挂载。
|
||||||
|
|
||||||
|
本文分别介绍在腾讯云容器服务 TKE 和 EKS 两种集群中,显式指定使用 NFS V3 协议挂载的方法。
|
||||||
|
|
||||||
|
## 使用 CFS 插件 (仅限 TKE 集群)
|
||||||
|
|
||||||
|
### StorageClass 自动创建 CFS
|
||||||
|
|
||||||
|
如果 TKE 集群安装了 CFS 扩展组件,可以自动创建并挂载 CFS 存储,创建 StorageClass 时协议版本选择 V3:
|
||||||
|
|
||||||
|
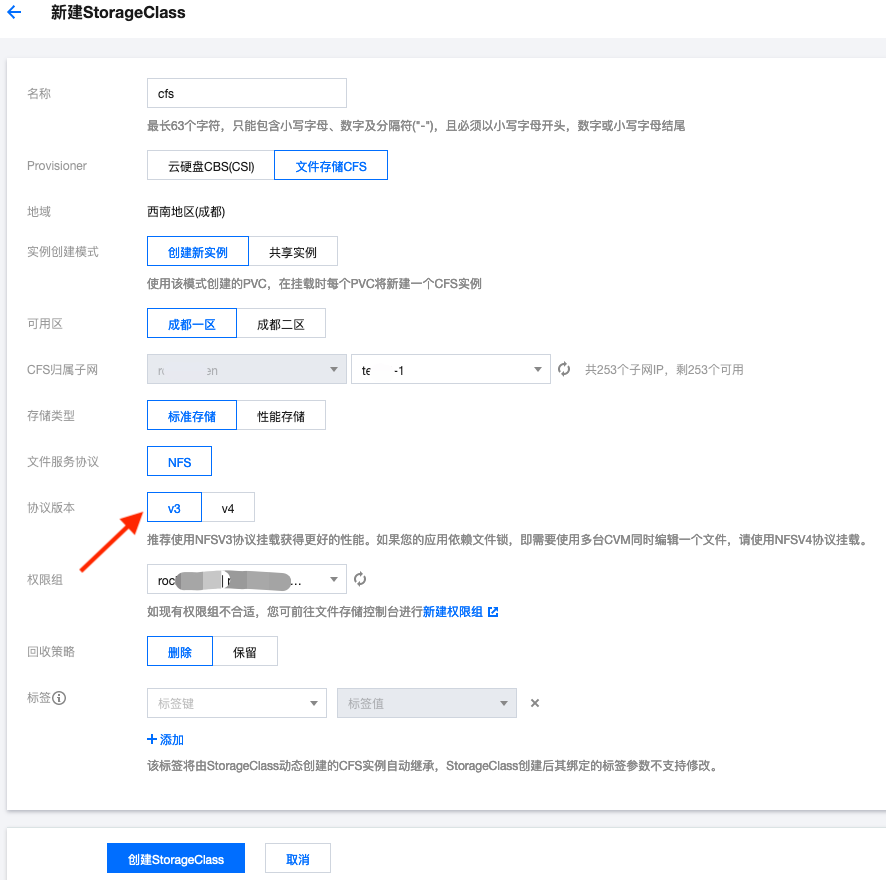
|
||||||
|
|
||||||
|
yaml 示例:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: storage.k8s.io/v1
|
||||||
|
kind: StorageClass
|
||||||
|
metadata:
|
||||||
|
name: cfs
|
||||||
|
parameters:
|
||||||
|
vers: "3" # 关键点:指定协议版本。
|
||||||
|
pgroupid: pgroup-mni3ng8n # 指定自动创建出来的 CFS 的权限组 ID。
|
||||||
|
storagetype: SD # 指定自动创建出来的 CFS 的存储类型。SD 为标准存储,HP 为性能存储。
|
||||||
|
subdir-share: "true" # 是否每个 PVC 都共享同一个 CFS 实例。
|
||||||
|
vpcid: vpc-e8wtynjo # 指定 VPC ID,确保与当前集群 VPC 相同。
|
||||||
|
subnetid: subnet-e7uo51yj # 指定自动创建出来的 CFS 的子网 ID。
|
||||||
|
provisioner: com.tencent.cloud.csi.tcfs.cfs
|
||||||
|
reclaimPolicy: Delete
|
||||||
|
volumeBindingMode: Immediate
|
||||||
|
```
|
||||||
|
|
||||||
|
后续使用 PVC 直接指定前面创建的 StorageClass 即可。
|
||||||
|
|
||||||
|
### 静态创建复用已有 CFS 实例
|
||||||
|
|
||||||
|
如果已经有 CFS 实例了,希望不自动创建而直接复用已有 CFS 实例,可以使用静态创建。
|
||||||
|
|
||||||
|
yaml 实例:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: v1
|
||||||
|
kind: PersistentVolume
|
||||||
|
metadata:
|
||||||
|
name: cfs-pv
|
||||||
|
spec:
|
||||||
|
accessModes:
|
||||||
|
- ReadWriteMany
|
||||||
|
capacity:
|
||||||
|
storage: 10Gi
|
||||||
|
csi:
|
||||||
|
driver: com.tencent.cloud.csi.cfs
|
||||||
|
volumeAttributes:
|
||||||
|
fsid: yemafcez # 指定 fsid,在 CFS 实例控制台页面的挂载点信息里看 NFS 3.0 挂载命令,里面有 fsid。
|
||||||
|
host: 10.10.9.6 # CFS 实例 IP。
|
||||||
|
path: / # 指定要挂载的 CFS 实例的目录。
|
||||||
|
vers: "3" # 关键点:指定协议版本。
|
||||||
|
volumeHandle: cfs-pv
|
||||||
|
persistentVolumeReclaimPolicy: Retain
|
||||||
|
storageClassName: "" # 指定 StorageClass 为空
|
||||||
|
volumeMode: Filesystem
|
||||||
|
---
|
||||||
|
apiVersion: v1
|
||||||
|
kind: PersistentVolumeClaim
|
||||||
|
metadata:
|
||||||
|
name: cfs-pvc
|
||||||
|
spec:
|
||||||
|
accessModes:
|
||||||
|
- ReadWriteMany
|
||||||
|
resources:
|
||||||
|
requests:
|
||||||
|
storage: 10Gi
|
||||||
|
storageClassName: "" # 指定 StorageClass 为空
|
||||||
|
volumeMode: Filesystem
|
||||||
|
volumeName: cfs-pv # PVC 引用 PV 的名称,手动绑定关系。
|
||||||
|
```
|
||||||
|
|
||||||
|
### CSI Inline 方式
|
||||||
|
|
||||||
|
如果不想用 PV,也可以在定义 Volumes 时使用 CSI Inline 的方式,yaml 示例:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
---
|
||||||
|
apiVersion: storage.k8s.io/v1beta1
|
||||||
|
kind: CSIDriver
|
||||||
|
metadata:
|
||||||
|
name: com.tencent.cloud.csi.cfs
|
||||||
|
spec:
|
||||||
|
attachRequired: false
|
||||||
|
podInfoOnMount: false
|
||||||
|
volumeLifecycleModes:
|
||||||
|
- Ephemeral # 告知 CFS 插件启用 inline 的功能,以便让 CSI Inline 定义方式可以正常工作
|
||||||
|
|
||||||
|
---
|
||||||
|
apiVersion: apps/v1
|
||||||
|
kind: Deployment
|
||||||
|
metadata:
|
||||||
|
name: nginx
|
||||||
|
spec:
|
||||||
|
replicas: 1
|
||||||
|
selector:
|
||||||
|
matchLabels:
|
||||||
|
app: nginx
|
||||||
|
template:
|
||||||
|
metadata:
|
||||||
|
labels:
|
||||||
|
app: nginx
|
||||||
|
spec:
|
||||||
|
containers:
|
||||||
|
- name: nginx
|
||||||
|
image: nginx:latest
|
||||||
|
volumeMounts:
|
||||||
|
- mountPath: /test
|
||||||
|
name: cfs
|
||||||
|
volumes:
|
||||||
|
- csi: # 这里定义 CSI Inline
|
||||||
|
driver: com.tencent.cloud.csi.cfs
|
||||||
|
volumeAttributes:
|
||||||
|
fsid: yemafcez
|
||||||
|
host: 10.10.9.6
|
||||||
|
path: /
|
||||||
|
vers: "3"
|
||||||
|
proto: tcp
|
||||||
|
name: cfs
|
||||||
|
```
|
||||||
|
|
||||||
|
## PV 指定 mountOptions (TKE 集群与 EKS 弹性集群通用)
|
||||||
|
|
||||||
|
K8S 原生支持挂载 NFS 存储,而 CFS 本质就是 NFS 存储,可以直接 K8S 原生用法,只是需要在 PV 指定下挂载选项 (mountOptions),具体加哪些,可以在 CFS 实例控制台页面的挂载点信息里看 NFS 3.0 挂载命令。
|
||||||
|
|
||||||
|
这种方式需要自行提前创建好 CFS 示例,然后手动创建 PV/PVC 与 CFS 实例关联,yaml 示例:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: v1
|
||||||
|
kind: PersistentVolume
|
||||||
|
metadata:
|
||||||
|
name: cfs-pv
|
||||||
|
spec:
|
||||||
|
accessModes:
|
||||||
|
- ReadWriteMany
|
||||||
|
capacity:
|
||||||
|
storage: 10Gi
|
||||||
|
nfs:
|
||||||
|
path: /yemafcez # v3 协议这里 path 一定要以 fsid 开头,在 CFS 实例控制台页面的挂载点信息里看 NFS 3.0 挂载命令,里面有 fsid。
|
||||||
|
server: 10.10.9.6 # CFS 实例 IP。
|
||||||
|
mountOptions: # 指定挂载选项,从 CFS 实例控制台挂载点信息里面获取。
|
||||||
|
- vers=3 # 使用 v3 协议
|
||||||
|
- proto=tcp
|
||||||
|
- nolock,noresvport
|
||||||
|
persistentVolumeReclaimPolicy: Retain
|
||||||
|
storageClassName: "" # 指定 StorageClass 为空
|
||||||
|
volumeMode: Filesystem
|
||||||
|
|
||||||
|
---
|
||||||
|
apiVersion: v1
|
||||||
|
kind: PersistentVolumeClaim
|
||||||
|
metadata:
|
||||||
|
name: cfs-pvc
|
||||||
|
spec:
|
||||||
|
accessModes:
|
||||||
|
- ReadWriteMany
|
||||||
|
resources:
|
||||||
|
requests:
|
||||||
|
storage: 10Gi
|
||||||
|
storageClassName: "" # 指定 StorageClass 为空
|
||||||
|
volumeMode: Filesystem
|
||||||
|
volumeName: cfs-pv # PVC 引用 PV 的名称,手动绑定关系。
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,66 @@
|
||||||
|
# 定义 ReadOnlyMany 存储的方法
|
||||||
|
|
||||||
|
## 概述
|
||||||
|
|
||||||
|
要实现 `ReadOnlyMany` (多机只读) 的前提条件是后端存储是共享存储,在腾讯云上有 `COS` (对象存储) 和 `CFS` (文件存储) 两种。本文介绍这两种共享存储在腾讯云容器服务环境里定义成 PV 的使用方法。
|
||||||
|
|
||||||
|
## COS
|
||||||
|
|
||||||
|
1. `accessModes` 指定 `ReadOnlyMany`。
|
||||||
|
2. `csi.volumeAttributes.additional_args` 指定 `-oro`。
|
||||||
|
|
||||||
|
yaml 示例:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: v1
|
||||||
|
kind: PersistentVolume
|
||||||
|
metadata:
|
||||||
|
name: registry
|
||||||
|
spec:
|
||||||
|
accessModes:
|
||||||
|
- ReadOnlyMany
|
||||||
|
capacity:
|
||||||
|
storage: 1Gi
|
||||||
|
csi:
|
||||||
|
readOnly: true
|
||||||
|
driver: com.tencent.cloud.csi.cosfs
|
||||||
|
volumeHandle: registry
|
||||||
|
volumeAttributes:
|
||||||
|
additional_args: "-oro"
|
||||||
|
url: "http://cos.ap-chengdu.myqcloud.com"
|
||||||
|
bucket: "roc-**********"
|
||||||
|
path: /test
|
||||||
|
nodePublishSecretRef:
|
||||||
|
name: cos-secret
|
||||||
|
namespace: kube-system
|
||||||
|
```
|
||||||
|
|
||||||
|
## CFS
|
||||||
|
|
||||||
|
1. `accessModes` 指定 `ReadOnlyMany`。
|
||||||
|
2. `mountOptions` 指定 `ro`。
|
||||||
|
|
||||||
|
yaml 示例:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: v1
|
||||||
|
kind: PersistentVolume
|
||||||
|
metadata:
|
||||||
|
name: test
|
||||||
|
spec:
|
||||||
|
accessModes:
|
||||||
|
- ReadOnlyMany
|
||||||
|
capacity:
|
||||||
|
storage: 10Gi
|
||||||
|
storageClassName: cfs
|
||||||
|
persistentVolumeReclaimPolicy: Retain
|
||||||
|
volumeMode: Filesystem
|
||||||
|
mountOptions:
|
||||||
|
- ro
|
||||||
|
csi:
|
||||||
|
driver: com.tencent.cloud.csi.cfs
|
||||||
|
volumeAttributes:
|
||||||
|
host: 10.10.99.99
|
||||||
|
path: /test
|
||||||
|
volumeHandle: cfs-********
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,31 @@
|
||||||
|
# 排查公网服务不通
|
||||||
|
|
||||||
|
## 问题描述
|
||||||
|
|
||||||
|
部署在 TKE 集群内的服务使用公网对外暴露 (LoadBalancer 类型 Service 或 Ingress),但访问不通。
|
||||||
|
|
||||||
|
## 常见原因
|
||||||
|
|
||||||
|
### 节点安全组没放通 NodePort
|
||||||
|
|
||||||
|
如果服务使用 TKE 默认的公网 Service 或 Ingress 暴露,CLB 会转发流量到 NodePort,流量转发链路是: client –> CLB –> NodePort –> ...
|
||||||
|
|
||||||
|
CLB 转发的数据包不会做 SNAT,所以报文到达节点时源 IP 就是 client 的公网 IP,如果节点安全组入站规则没有放通 client –> NodePort 链路的话,是访问不通的。
|
||||||
|
|
||||||
|
**解决方案1:** 节点安全组入站规则对公网访问 NodePort 区间端口(30000-32768):
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
**解决方案2:** 若担心直接放开整个 NodePort 区间所有端口有安全风险,可以只暴露 service 所用到的 NodePort (比较麻烦)。
|
||||||
|
|
||||||
|
**解决方案3:** 若只允许固定 IP 段的 client 访问 ingressgateway,可以只对这个 IP 段放开整个 NodePort 区间所有端口。
|
||||||
|
|
||||||
|
**解决方案4:** 启用 CLB 直通 Pod,这样流量就不经过 NodePort,所以就没有此安全组问题。启用 CLB 直通 Pod 需要集群网络支持 VPC-CNI,详细请参考 [如何启用 CLB 直通 Pod](https://imroc.cc/k8s/tke/faq/loadblancer-to-pod-directly/) 。
|
||||||
|
|
||||||
|
### 使用了 ClusterIP 类型 Service
|
||||||
|
|
||||||
|
如果使用 TKE 默认的 CLB Ingress 暴露服务,依赖后端 Service 要有 NodePort,如果 Service 是 ClusterIP 类型,将无法转发,也就不通。
|
||||||
|
|
||||||
|
**解决方案1**: Ingress 涉及的后端 Service 改为 NodePort 类型。
|
||||||
|
|
||||||
|
**解决方案2:** 不使用 TKE 默认的 CLB Ingress,其它类型 Ingress,比如 [Nginx Ingress](https://cloud.tencent.com/document/product/457/50502) 。
|
||||||
|
|
@ -0,0 +1,120 @@
|
||||||
|
# 使用 cfssl 生成证书
|
||||||
|
|
||||||
|
搭建各种云原生环境的过程中,经常需要生成证书,比如最常见的 etcd,本文记录使用 cfssl 快速生成证书的方法。
|
||||||
|
|
||||||
|
## 安装 cfssl
|
||||||
|
|
||||||
|
**方法1**: 去 [release](https://github.com/cloudflare/cfssl/releases) 页面下载,然后解压安装。
|
||||||
|
|
||||||
|
**方法2**: 使用 go install 安装:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
go install github.com/cloudflare/cfssl/cmd/cfssl@latest
|
||||||
|
go install github.com/cloudflare/cfssl/cmd/cfssljson@latest
|
||||||
|
```
|
||||||
|
|
||||||
|
## 创建 CA 证书
|
||||||
|
|
||||||
|
由于各个组件都需要配置证书,并且依赖 CA 证书来签发证书,所以我们首先要生成好 CA 证书以及后续的签发配置文件:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
cat > ca-csr.json <<EOF
|
||||||
|
{
|
||||||
|
"CN": "Kubernetes",
|
||||||
|
"key": {
|
||||||
|
"algo": "rsa",
|
||||||
|
"size": 2048
|
||||||
|
},
|
||||||
|
"names": [
|
||||||
|
{
|
||||||
|
"C": "CN",
|
||||||
|
"ST": "SiChuan",
|
||||||
|
"L": "ChengDu",
|
||||||
|
"O": "Kubernetes",
|
||||||
|
"OU": "CA"
|
||||||
|
}
|
||||||
|
]
|
||||||
|
}
|
||||||
|
EOF
|
||||||
|
|
||||||
|
cfssl gencert -initca ca-csr.json | cfssljson -bare ca
|
||||||
|
|
||||||
|
cat > ca-config.json <<EOF
|
||||||
|
{
|
||||||
|
"signing": {
|
||||||
|
"default": {
|
||||||
|
"expiry": "876000h"
|
||||||
|
},
|
||||||
|
"profiles": {
|
||||||
|
"kubernetes": {
|
||||||
|
"usages": [
|
||||||
|
"signing",
|
||||||
|
"key encipherment",
|
||||||
|
"server auth",
|
||||||
|
"client auth"
|
||||||
|
],
|
||||||
|
"expiry": "876000h"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
EOF
|
||||||
|
```
|
||||||
|
|
||||||
|
生成的文件中有下面三个后面会用到:
|
||||||
|
|
||||||
|
* `ca-key.pem`: CA 证书密钥
|
||||||
|
* `ca.pem`: CA 证书
|
||||||
|
* `ca-config.json`: 证书签发配置,用 CA 证书来签发其它证书时需要用
|
||||||
|
|
||||||
|
csr 文件字段解释:
|
||||||
|
|
||||||
|
* `CN`(Common Name): apiserver 从证书中提取该字段作为请求的用户名 (User Name)
|
||||||
|
* `names[].O`(Organization): apiserver 从证书中提取该字段作为请求用户所属的组 (Group)
|
||||||
|
|
||||||
|
> 由于这里是 CA 证书,是签发其它证书的根证书,这个证书密钥不会分发出去作为 client 证书,所有组件使用的 client 证书都是由 CA 证书签发而来,所以 CA 证书的 CN 和 O 的名称并不重要,后续其它签发出来的证书的 CN 和 O 的名称才是有用的。
|
||||||
|
|
||||||
|
## 为 ETCD 签发证书
|
||||||
|
|
||||||
|
这里证书可以只创建一次,所有 etcd 实例都共用这里创建的证书:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
cat > etcd-csr.json <<EOF
|
||||||
|
{
|
||||||
|
"CN": "etcd",
|
||||||
|
"hosts": [
|
||||||
|
"*.karmada-system.svc",
|
||||||
|
"*.karmada-system.svc",
|
||||||
|
"*.karmada-system.svc.cluster",
|
||||||
|
"*.karmada-system.svc.cluster.local"
|
||||||
|
],
|
||||||
|
"key": {
|
||||||
|
"algo": "rsa",
|
||||||
|
"size": 2048
|
||||||
|
},
|
||||||
|
"names": [
|
||||||
|
{
|
||||||
|
"C": "CN",
|
||||||
|
"ST": "SiChuan",
|
||||||
|
"L": "Chengdu",
|
||||||
|
"O": "etcd",
|
||||||
|
"OU": "etcd"
|
||||||
|
}
|
||||||
|
]
|
||||||
|
}
|
||||||
|
EOF
|
||||||
|
|
||||||
|
cfssl gencert \
|
||||||
|
-ca=ca.pem \
|
||||||
|
-ca-key=ca-key.pem \
|
||||||
|
-config=ca-config.json \
|
||||||
|
-profile=kubernetes \
|
||||||
|
etcd-csr.json | cfssljson -bare etcd
|
||||||
|
```
|
||||||
|
|
||||||
|
> hosts 需要包含 etcd 被访问时用到的地址,可以用 IP ,域名或泛域名。
|
||||||
|
|
||||||
|
会生成下面两个重要的文件:
|
||||||
|
|
||||||
|
* `etcd-key.pem`: etcd 密钥。
|
||||||
|
* `etcd.pem`: etcd 证书。
|
||||||
|
|
@ -0,0 +1,156 @@
|
||||||
|
# 为 dnspod 的域名签发免费证书
|
||||||
|
|
||||||
|
如果你的域名使用 [DNSPod](https://docs.dnspod.cn/) 管理,想在 Kubernetes 上为域名自动签发免费证书,可以使用 cert-manager 来实现。
|
||||||
|
|
||||||
|
cert-manager 支持许多 dns provider,但不支持国内的 dnspod,不过 cert-manager 提供了 [Webhook](https://cert-manager.io/docs/concepts/webhook/) 机制来扩展 provider,社区也有 dnspod 的 provider 实现,但没怎么维护了。
|
||||||
|
|
||||||
|
本文将介绍如何结合 cert-manager 与本人开发的 [cert-manager-webhook-dnspod](https://github.com/imroc/cert-manager-webhook-dnspod) 来实现为 dnspod 上的域名自动签发免费证书,支持最新 cert-manager,接入腾讯云API密钥(dnspod 官方推荐方式,不用 `apiID` 和 `apiToken`)。
|
||||||
|
|
||||||
|
## 基础知识
|
||||||
|
|
||||||
|
推荐先阅读 [使用 cert-manager 签发免费证书](sign-free-certs-with-cert-manager.md) 。
|
||||||
|
|
||||||
|
## 创建腾讯云 API 密钥
|
||||||
|
|
||||||
|
登录腾讯云控制台,在 [API密钥管理](https://console.cloud.tencent.com/cam/capi) 中新建密钥,然后复制自动生成的 `SecretId` 和 `SecretKey` 并保存下来,以备后面的步骤使用。
|
||||||
|
|
||||||
|
## 安装 cert-manager-webhook-dnspod
|
||||||
|
|
||||||
|
阅读了前面推荐的文章,假设集群中已经安装了 cert-manager,下面使用 helm 来安装下 cert-manager-webhook-dnspod 。
|
||||||
|
|
||||||
|
首先准备下 helm 配置文件 (`dnspod-webhook-values.yaml`):
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
clusterIssuer:
|
||||||
|
enabled: true
|
||||||
|
name: dnspod # 自动创建的 ClusterIssuer 名称
|
||||||
|
ttl: 600
|
||||||
|
staging: false
|
||||||
|
secretId: 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' # 替换成你的 SecretId
|
||||||
|
secretKey: 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' # 替换成你的 SecretKey
|
||||||
|
email: roc@imroc.cc # 用于接收证书过期的邮件告警。如果cert-manager和webhook都正常工作,证书会自动续期不会过期
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
> 完整配置见 [values.yaml](https://github.com/imroc/cert-manager-webhook-dnspod/blob/master/charts/values.yaml)
|
||||||
|
|
||||||
|
然后使用 helm 进行安装:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
helm repo add roc https://charts.imroc.cc
|
||||||
|
helm upgrade --install -f dnspod-webhook-values.yaml cert-manager-webhook-dnspod roc/cert-manager-webhook-dnspod -n cert-manager
|
||||||
|
```
|
||||||
|
|
||||||
|
## 创建证书
|
||||||
|
|
||||||
|
创建 `Certificate` 对象来签发免费证书:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: cert-manager.io/v1
|
||||||
|
kind: Certificate
|
||||||
|
metadata:
|
||||||
|
name: example-crt
|
||||||
|
namespace: istio-system
|
||||||
|
spec:
|
||||||
|
secretName: example-crt-secret # 证书保存在这个 secret 中
|
||||||
|
issuerRef:
|
||||||
|
name: dnspod # 这里使用自动生成出来的 ClusterIssuer
|
||||||
|
kind: ClusterIssuer
|
||||||
|
group: cert-manager.io
|
||||||
|
dnsNames: # 填入需要签发证书的域名列表,支持泛域名,确保域名是使用 dnspod 管理的
|
||||||
|
- "example.com"
|
||||||
|
- "*.example.com"
|
||||||
|
```
|
||||||
|
|
||||||
|
等待状态变成 Ready 表示签发成功:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ kubectl -n istio-system get certificates.cert-manager.io
|
||||||
|
NAME READY SECRET AGE
|
||||||
|
example-crt True example-crt-secret 25d
|
||||||
|
```
|
||||||
|
|
||||||
|
若签发失败可 describe 一下看下原因:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl -n istio-system describe certificates.cert-manager.io example-crt
|
||||||
|
```
|
||||||
|
|
||||||
|
## 使用证书
|
||||||
|
|
||||||
|
证书签发成功后会保存到我们指定的 secret 中,下面给出一些使用示例。
|
||||||
|
|
||||||
|
在 ingress 中使用:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: networking.k8s.io/v1beta1
|
||||||
|
kind: Ingress
|
||||||
|
metadata:
|
||||||
|
name: test-ingress
|
||||||
|
annotations:
|
||||||
|
kubernetes.io/ingress.class: nginx
|
||||||
|
spec:
|
||||||
|
rules:
|
||||||
|
- host: test.example.com
|
||||||
|
http:
|
||||||
|
paths:
|
||||||
|
- path: /
|
||||||
|
backend:
|
||||||
|
serviceName: web
|
||||||
|
servicePort: 80
|
||||||
|
tls:
|
||||||
|
hosts:
|
||||||
|
- test.example.com
|
||||||
|
secretName: example-crt-secret # 引用证书 secret
|
||||||
|
```
|
||||||
|
|
||||||
|
在 istio 的 ingressgateway 中使用:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: networking.istio.io/v1alpha3
|
||||||
|
kind: Gateway
|
||||||
|
metadata:
|
||||||
|
name: example-gw
|
||||||
|
namespace: istio-system
|
||||||
|
spec:
|
||||||
|
selector:
|
||||||
|
app: istio-ingressgateway
|
||||||
|
istio: ingressgateway
|
||||||
|
servers:
|
||||||
|
- port:
|
||||||
|
number: 80
|
||||||
|
name: HTTP-80
|
||||||
|
protocol: HTTP
|
||||||
|
hosts:
|
||||||
|
- example.com
|
||||||
|
- "*.example.com"
|
||||||
|
tls:
|
||||||
|
httpsRedirect: true # http 重定向 https (强制 https)
|
||||||
|
- port:
|
||||||
|
number: 443
|
||||||
|
name: HTTPS-443
|
||||||
|
protocol: HTTPS
|
||||||
|
hosts:
|
||||||
|
- example.com
|
||||||
|
- "*.example.com"
|
||||||
|
tls:
|
||||||
|
mode: SIMPLE
|
||||||
|
credentialName: example-crt-secret # 引用证书 secret
|
||||||
|
---
|
||||||
|
apiVersion: networking.istio.io/v1beta1
|
||||||
|
kind: VirtualService
|
||||||
|
metadata:
|
||||||
|
name: example-vs
|
||||||
|
namespace: test
|
||||||
|
spec:
|
||||||
|
gateways:
|
||||||
|
- istio-system/example-gw # 转发规则绑定到 ingressgateway,将服务暴露出去
|
||||||
|
hosts:
|
||||||
|
- 'test.example.com'
|
||||||
|
http:
|
||||||
|
- route:
|
||||||
|
- destination:
|
||||||
|
host: example
|
||||||
|
port:
|
||||||
|
number: 80
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,243 @@
|
||||||
|
# 使用 cert-manager 签发免费证书
|
||||||
|
|
||||||
|
随着 HTTPS 不断普及,越来越多的网站都在从 HTTP 升级到 HTTPS,使用 HTTPS 就需要向权威机构申请证书,需要付出一定的成本,如果需求数量多,也是一笔不小的开支。cert-manager 是 Kubernetes 上的全能证书管理工具,如果对安全级别和证书功能要求不高,可以利用 cert-manager 基于 [ACME](https://tools.ietf.org/html/rfc8555X) 协议与 [Let's Encrypt](https://letsencrypt.org/) 来签发免费证书并自动续期,实现永久免费使用证书。
|
||||||
|
|
||||||
|
## cert-manager 工作原理
|
||||||
|
|
||||||
|
cert-manager 部署到 Kubernetes 集群后,它会 watch 它所支持的 CRD 资源,我们通过创建 CRD 资源来指示 cert-manager 为我们签发证书并自动续期:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
解释下几个关键的资源:
|
||||||
|
|
||||||
|
* Issuer/ClusterIssuer: 用于指示 cert-manager 用什么方式签发证书,本文主要讲解签发免费证书的 ACME 方式。ClusterIssuer 与 Issuer 的唯一区别就是 Issuer 只能用来签发自己所在 namespace 下的证书,ClusterIssuer 可以签发任意 namespace 下的证书。
|
||||||
|
* Certificate: 用于告诉 cert-manager 我们想要什么域名的证书以及签发证书所需要的一些配置,包括对 Issuer/ClusterIssuer 的引用。
|
||||||
|
|
||||||
|
## 免费证书签发原理
|
||||||
|
|
||||||
|
Let’s Encrypt 利用 ACME 协议来校验域名是否真的属于你,校验成功后就可以自动颁发免费证书,证书有效期只有 90 天,在到期前需要再校验一次来实现续期,幸运的是 cert-manager 可以自动续期,这样就可以使用永久免费的证书了。如何校验这个域名是否属于你呢?主流的两种校验方式是 HTTP-01 和 DNS-01,详细校验原理可参考 [Let's Encrypt 的运作方式](https://letsencrypt.org/zh-cn/how-it-works/),下面将简单描述下。
|
||||||
|
|
||||||
|
### HTTP-01 校验原理
|
||||||
|
|
||||||
|
HTTP-01 的校验原理是给你域名指向的 HTTP 服务增加一个临时 location ,Let’s Encrypt 会发送 http 请求到 `http://<YOUR_DOMAIN>/.well-known/acme-challenge/<TOKEN>`,`YOUR_DOMAIN` 就是被校验的域名,`TOKEN` 是 ACME 协议的客户端负责放置的文件,在这里 ACME 客户端就是 cert-manager,它通过修改或创建 Ingress 规则来增加这个临时校验路径并指向提供 `TOKEN` 的服务。Let’s Encrypt 会对比 `TOKEN` 是否符合预期,校验成功后就会颁发证书。此方法仅适用于给使用 Ingress 暴露流量的服务颁发证书,并且不支持泛域名证书。
|
||||||
|
|
||||||
|
### DNS-01 校验原理
|
||||||
|
|
||||||
|
DNS-01 的校验原理是利用 DNS 提供商的 API Key 拿到你的 DNS 控制权限, 在 Let’s Encrypt 为 ACME 客户端提供令牌后,ACME 客户端 \(cert-manager\) 将创建从该令牌和您的帐户密钥派生的 TXT 记录,并将该记录放在 `_acme-challenge.<YOUR_DOMAIN>`。 然后 Let’s Encrypt 将向 DNS 系统查询该记录,如果找到匹配项,就可以颁发证书。此方法不需要你的服务使用 Ingress,并且支持泛域名证书。
|
||||||
|
|
||||||
|
## 校验方式对比
|
||||||
|
|
||||||
|
HTTP-01 的校验方式的优点是: 配置简单通用,不管使用哪个 DNS 提供商都可以使用相同的配置方法;缺点是:需要依赖 Ingress,如果你的服务不是用 Ingress 暴露流量的就不适用,而且不支持泛域名证书。
|
||||||
|
|
||||||
|
DNS-01 的校验方式的优点是没有 HTTP-01 校验方式缺点,不依赖 Ingress,也支持泛域名;缺点就是不同 DNS 提供商的配置方式不一样,而且 DNS 提供商有很多,cert-manager 的 Issuer 不可能每个都去支持,不过有一些可以通过部署实现了 cert-manager 的 [Webhook](https://cert-manager.io/docs/concepts/webhook/) 的服务来扩展 Issuer 进行支持,比如 DNSPod 和 阿里 DNS,详细 Webhook 列表请参考: https://cert-manager.io/docs/configuration/acme/dns01/#webhook
|
||||||
|
|
||||||
|
选择哪种方式呢?条件允许的话,建议是尽量用 `DNS-01` 的方式,限制更少,功能更全。
|
||||||
|
|
||||||
|
## 操作步骤
|
||||||
|
|
||||||
|
### 安装 cert-manager
|
||||||
|
|
||||||
|
通常直接使用 yaml 方式一键安装 cert-manager 到集群,参考官网文档 [Installing with regular manifests](https://cert-manager.io/docs/installation/kubernetes/#installing-with-regular-manifests) 。
|
||||||
|
|
||||||
|
### 配置 DNS
|
||||||
|
|
||||||
|
登录你的 DNS 提供商后台,配置域名的 DNS A 记录,指向你需要证书的后端服务对外暴露的 IP 地址,以 cloudflare 为例:
|
||||||
|
|
||||||
|
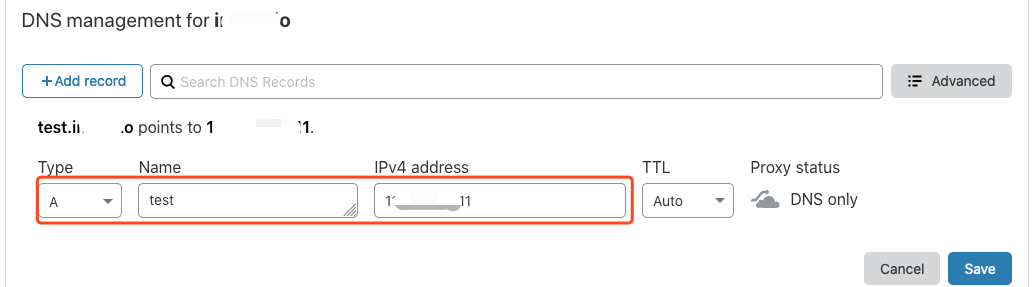
|
||||||
|
|
||||||
|
### HTTP-01 校验方式签发证书
|
||||||
|
|
||||||
|
如果使用 HTTP-01 的校验方式,需要用到 Ingress 来配合校验。cert-manager 会通过自动修改 Ingress 规则或自动新增 Ingress 两种方式之一来实现对外暴露校验所需的临时 HTTP 路径,这个就是在给 Issuer 配置 http01 校验,指定 Ingress 的 `name` 或 `class` 的区别 (见下面的示例)。
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: cert-manager.io/v1
|
||||||
|
kind: Issuer
|
||||||
|
metadata:
|
||||||
|
name: letsencrypt-http01
|
||||||
|
namespace: prod
|
||||||
|
spec:
|
||||||
|
acme:
|
||||||
|
server: https://acme-v02.api.letsencrypt.org/directory
|
||||||
|
privateKeySecretRef:
|
||||||
|
name: letsencrypt-http01-account-key
|
||||||
|
solvers:
|
||||||
|
- http01:
|
||||||
|
ingress:
|
||||||
|
name: web # 指定被自动修改的 Ingress 名称
|
||||||
|
```
|
||||||
|
|
||||||
|
使用上面的 Issuer 签发证书,cert-manager 会自动修改 `prod/web` 这个 Ingress 资源,以暴露校验所需的临时路径,这是自动修改 Ingress 的方式,你也可以使用自动新增 Ingress 的 方式,示例:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: cert-manager.io/v1
|
||||||
|
kind: Issuer
|
||||||
|
metadata:
|
||||||
|
name: letsencrypt-http01
|
||||||
|
namespace: prod
|
||||||
|
spec:
|
||||||
|
acme:
|
||||||
|
server: https://acme-v02.api.letsencrypt.org/directory
|
||||||
|
privateKeySecretRef:
|
||||||
|
name: letsencrypt-http01-account-key
|
||||||
|
solvers:
|
||||||
|
- http01:
|
||||||
|
ingress:
|
||||||
|
class: nginx # 指定自动创建的 Ingress 的 ingress class
|
||||||
|
```
|
||||||
|
|
||||||
|
使用上面的 Issuer 签发证书,cert-manager 会自动创建 Ingress 资源,以暴露校验所需的临时路径。
|
||||||
|
|
||||||
|
有了 Issuer,接下来就可以创建 Certificate 并引用 Issuer 进行签发了,示例:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: cert-manager.io/v1
|
||||||
|
kind: Certificate
|
||||||
|
metadata:
|
||||||
|
name: test-mydomain-com
|
||||||
|
namespace: prod
|
||||||
|
spec:
|
||||||
|
dnsNames:
|
||||||
|
- test.mydomain.com # 要签发证书的域名
|
||||||
|
issuerRef:
|
||||||
|
kind: Issuer
|
||||||
|
name: letsencrypt-http01 # 引用 Issuer,指示采用 http01 方式进行校验
|
||||||
|
secretName: test-mydomain-com-tls # 最终签发出来的证书会保存在这个 Secret 里面
|
||||||
|
```
|
||||||
|
|
||||||
|
### DNS-01 校验方式签发证书
|
||||||
|
|
||||||
|
如果使用 DNS-01 的校验方式,就需要看你使用的哪个 DNS 提供商了,cert-manager 内置了一些 DNS 提供商的支持,详细列表和用法请参考 [Supported DNS01 providers](https://cert-manager.io/docs/configuration/acme/dns01/#supported-dns01-providers),不过 cert-manager 不可能去支持所有的 DNS 提供商,如果没有你所使用的 DNS 提供商怎么办呢?有两种方案:
|
||||||
|
|
||||||
|
* 方案一:设置 Custom Nameserver。在你的 DNS 提供商后台设置 custom nameserver,指向像 cloudflare 这种可以管理其它 DNS 提供商域名的 nameserver 地址,具体地址可登录 cloudflare 后台查看:
|
||||||
|
|
||||||
|
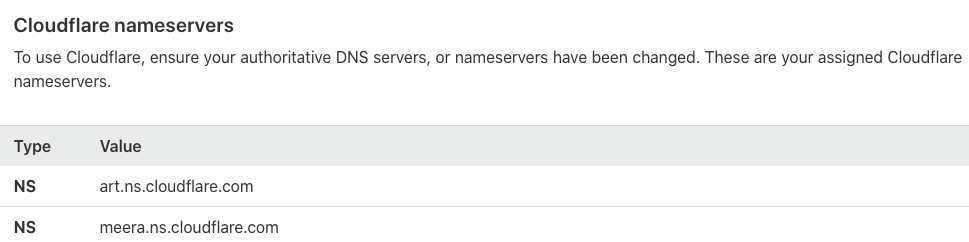
|
||||||
|
|
||||||
|
下面是 namecheap 设置 custom nameserver 的示例:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
最后配置 Issuer 指定 DNS-01 验证时,加上 cloudflare 的一些信息即可(见下文示例)。
|
||||||
|
|
||||||
|
* 方案二:使用 Webhook。使用 cert-manager 的 Webhook 来扩展 cert-manager 的 DNS-01 验证所支持的 DNS 提供商,已经有许多第三方实现,包括国内常用的 DNSPod 与阿里 DNS,详细列表参考: [Webhook](https://cert-manager.io/docs/configuration/acme/dns01/#webhook)。
|
||||||
|
|
||||||
|
下面以 cloudflare 为例来签发证书:
|
||||||
|
|
||||||
|
1. 登录 cloudflare,点到 `My Profile > API Tokens > Create Token` 来创建 Token:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
复制 Token 并妥善保管:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
将 Token 保存到 Secret 中:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: v1
|
||||||
|
kind: Secret
|
||||||
|
metadata:
|
||||||
|
name: cloudflare-api-token-secret
|
||||||
|
namespace: cert-manager
|
||||||
|
type: Opaque
|
||||||
|
stringData:
|
||||||
|
api-token: <API Token> # 粘贴 Token 到这里,不需要 base64 加密。
|
||||||
|
```
|
||||||
|
|
||||||
|
> 如果是要创建 ClusterIssuer,Secret 需要创建在 cert-manager 所在命名空间中,如果是 Issuer,那就创建在 Issuer 所在命名空间中。
|
||||||
|
|
||||||
|
创建 ClusterIssuer:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: cert-manager.io/v1
|
||||||
|
kind: ClusterIssuer
|
||||||
|
metadata:
|
||||||
|
name: letsencrypt-dns01
|
||||||
|
spec:
|
||||||
|
acme:
|
||||||
|
privateKeySecretRef:
|
||||||
|
name: letsencrypt-dns01
|
||||||
|
server: https://acme-v02.api.letsencrypt.org/directory
|
||||||
|
solvers:
|
||||||
|
- dns01:
|
||||||
|
cloudflare:
|
||||||
|
email: my-cloudflare-acc@example.com # 替换成你的 cloudflare 邮箱账号,API Token 方式认证非必需,API Keys 认证是必需
|
||||||
|
apiTokenSecretRef:
|
||||||
|
key: api-token
|
||||||
|
name: cloudflare-api-token-secret # 引用保存 cloudflare 认证信息的 Secret
|
||||||
|
```
|
||||||
|
|
||||||
|
创建 Certificate:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: cert-manager.io/v1
|
||||||
|
kind: Certificate
|
||||||
|
metadata:
|
||||||
|
name: test-mydomain-com
|
||||||
|
namespace: default
|
||||||
|
spec:
|
||||||
|
dnsNames:
|
||||||
|
- test.mydomain.com # 要签发证书的域名
|
||||||
|
issuerRef:
|
||||||
|
kind: ClusterIssuer
|
||||||
|
name: letsencrypt-dns01 # 引用 ClusterIssuer,指示采用 dns01 方式进行校验
|
||||||
|
secretName: test-mydomain-com-tls # 最终签发出来的证书会保存在这个 Secret 里面
|
||||||
|
```
|
||||||
|
|
||||||
|
### 获取和使用证书
|
||||||
|
|
||||||
|
创建好 Certificate 后,等一小会儿,我们可以 kubectl 查看是否签发成功:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ kubectl get certificate -n prod
|
||||||
|
NAME READY SECRET AGE
|
||||||
|
test-mydomain-com True test-mydomain-com-tls 1m
|
||||||
|
```
|
||||||
|
|
||||||
|
如果 `READY` 为 `False` 表示失败,可以通过 describe 查看 event 来排查失败原因:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ kubectl describe certificate test-mydomain-com -n prod
|
||||||
|
```
|
||||||
|
|
||||||
|
如果为 `True` 表示签发成功,证书就保存在我们所指定的 Secret 中 (上面的例子是 `default/test-mydomain-com-tls`),可以通过 kubectl 查看:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ kubectl get secret test-mydomain-com-tls -n default
|
||||||
|
...
|
||||||
|
data:
|
||||||
|
tls.crt: <cert>
|
||||||
|
tls.key: <private key>
|
||||||
|
```
|
||||||
|
|
||||||
|
其中 `tls.crt` 就是证书,`tls.key` 是密钥。
|
||||||
|
|
||||||
|
你可以将它们挂载到你需要证书的应用中,或者使用 Ingress,可以直接在 Ingress 中引用 secret,示例:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: networking.k8s.io/v1beta1
|
||||||
|
kind: Ingress
|
||||||
|
metadata:
|
||||||
|
name: test-ingress
|
||||||
|
annotations:
|
||||||
|
kubernetes.io/Ingress.class: nginx
|
||||||
|
spec:
|
||||||
|
rules:
|
||||||
|
- host: test.mydomain.com
|
||||||
|
http:
|
||||||
|
paths:
|
||||||
|
- path: /web
|
||||||
|
backend:
|
||||||
|
serviceName: web
|
||||||
|
servicePort: 80
|
||||||
|
tls:
|
||||||
|
hosts:
|
||||||
|
- test.mydomain.com
|
||||||
|
secretName: test-mydomain-com-tls
|
||||||
|
```
|
||||||
|
|
||||||
|
## 参考资料
|
||||||
|
|
||||||
|
* [cert-manager 官网](https://cert-manager.io/)
|
||||||
|
* [Let's Encrypt 的运作方式](https://letsencrypt.org/zh-cn/how-it-works/)
|
||||||
|
* [Issuer API 文档](https://cert-manager.io/docs/reference/api-docs/#cert-manager.io/v1.Issuer)
|
||||||
|
* [Certificate API 文档](https://cert-manager.io/docs/reference/api-docs/#cert-manager.io/v1.Certificate)
|
||||||
|
|
@ -0,0 +1,74 @@
|
||||||
|
# 为 Pod 设置内核参数
|
||||||
|
|
||||||
|
本文介绍为 Pod 设置内核参数的几种方式。
|
||||||
|
|
||||||
|
## 在 securityContext 中指定 sysctls
|
||||||
|
|
||||||
|
自 k8s 1.12 起,[sysctls](https://kubernetes.io/docs/tasks/administer-cluster/sysctl-cluster/) 特性 beta 并默认开启,允许用户在 pod 的 `securityContext` 中设置内核参数,用法示例:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: v1
|
||||||
|
kind: Pod
|
||||||
|
metadata:
|
||||||
|
name: sysctl-example
|
||||||
|
spec:
|
||||||
|
securityContext:
|
||||||
|
sysctls:
|
||||||
|
- name: net.core.somaxconn
|
||||||
|
value: "1024"
|
||||||
|
- name: net.core.somaxconn
|
||||||
|
value: "1024"
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
不过使用该方法,默认情况下有些认为是 unsafe 的参数是不能改的,需要将其配到 kubelet 的 `--allowed-unsafe-sysctls` 中才可以用。
|
||||||
|
|
||||||
|
## 使用 initContainers
|
||||||
|
|
||||||
|
如果希望设置内核参数更简单通用,可以在 initContainer 中设置,不过这个要求给 initContainer 打开 `privileged` 权限。示例:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: v1
|
||||||
|
kind: Pod
|
||||||
|
metadata:
|
||||||
|
name: sysctl-example-init
|
||||||
|
spec:
|
||||||
|
initContainers:
|
||||||
|
- image: busybox
|
||||||
|
command:
|
||||||
|
- sh
|
||||||
|
- -c
|
||||||
|
- |
|
||||||
|
sysctl -w net.core.somaxconn=65535
|
||||||
|
sysctl -w net.ipv4.ip_local_port_range="1024 65535"
|
||||||
|
sysctl -w net.ipv4.tcp_tw_reuse=1
|
||||||
|
sysctl -w fs.file-max=1048576
|
||||||
|
imagePullPolicy: Always
|
||||||
|
name: setsysctl
|
||||||
|
securityContext:
|
||||||
|
privileged: true
|
||||||
|
containers:
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
> 这里用了 privileged 容器,只是为了让这个 container 有权限修改当前容器网络命名空间中的内核参数,只要 Pod 没使用 hostNetwork,内核参数的修改是不会影响 Node 上的内核参数的,两者是隔离的,所以不需要担心会影响 Node 上其它 Pod 的内核参数 (hostNetwork 的 Pod 就不要在 Pod 上修改内核参数了)。
|
||||||
|
|
||||||
|
## 使用 tuning CNI 插件统一设置 sysctl
|
||||||
|
|
||||||
|
如果想要为所有 Pod 统一配置某些内核参数,可以使用 [tuning](https://github.com/containernetworking/plugins/tree/master/plugins/meta/tuning) 这个 CNI 插件来做:
|
||||||
|
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"name": "mytuning",
|
||||||
|
"type": "tuning",
|
||||||
|
"sysctl": {
|
||||||
|
"net.core.somaxconn": "500",
|
||||||
|
"net.ipv4.tcp_tw_reuse": "1"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
## 参考资料
|
||||||
|
|
||||||
|
* [Using sysctls in a Kubernetes Cluster](https://kubernetes.io/docs/tasks/administer-cluster/sysctl-cluster/)
|
||||||
|
* [tuning 插件文档](https://www.cni.dev/plugins/current/meta/tuning/)
|
||||||
|
|
@ -0,0 +1,62 @@
|
||||||
|
# 使用 Podman 构建镜像
|
||||||
|
|
||||||
|
## 概述
|
||||||
|
|
||||||
|
[Podman](https://podman.io/) 是一个类似 docker 的工具,可以运行容器,也可以构建镜像,甚至可以像 docker 一样支持构建多平台镜像。如今 Docker Desktop 已经宣布收费,可以考虑使用 Podman 来替代。
|
||||||
|
|
||||||
|
## 安装
|
||||||
|
|
||||||
|
参考 [官方安装文档](https://podman.io/getting-started/installation),我使用的是 Mac,安装很简单:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
brew install podman
|
||||||
|
```
|
||||||
|
|
||||||
|
由于 podman 是基于 Linux 的,安装在 Mac 需要先启动它的虚拟机:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
podman machine init
|
||||||
|
podman machine start
|
||||||
|
```
|
||||||
|
|
||||||
|
最后检查下是否 ok:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
podman info
|
||||||
|
```
|
||||||
|
|
||||||
|
## Podman 构建镜像的背后
|
||||||
|
|
||||||
|
Podman 构建镜像在背后实际是利用了 [Buildah](https://buildah.io/) 这个工具去构建,只是封装了一层,更容易使用了。
|
||||||
|
|
||||||
|
## Podman 构建镜像的方法
|
||||||
|
|
||||||
|
`podman build` 基本兼容 `docker build`,所以你可以像使用 docker 一样去使用 podman 构建镜像。
|
||||||
|
|
||||||
|
## FAQ
|
||||||
|
|
||||||
|
### 未启动虚拟机导致报错
|
||||||
|
|
||||||
|
执行 podman 命令是,遇到 `connect: no such file or directory` 的报错:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ podman build --platform=linux/amd64 . -t imroc/crontab:centos -f centos.Dockerfile
|
||||||
|
Cannot connect to Podman. Please verify your connection to the Linux system using `podman system connection list`, or try `podman machine init` and `podman machine start` to manage a new Linux VM
|
||||||
|
Error: unable to connect to Podman socket: Get "http://d/v4.0.2/libpod/_ping": dial unix ///var/folders/91/dsfxsd7j28z2mxl7vm91mjg40000gn/T/podman-run--1/podman/podman.sock: connect: no such file or directory
|
||||||
|
```
|
||||||
|
|
||||||
|
通常是因为在非 Linux 的系统上,没有启动 podman linux 虚拟机导致的,启动下就可以了。
|
||||||
|
|
||||||
|
### 代理导致拉取镜像失败
|
||||||
|
|
||||||
|
使用 podman 构建镜像或直接拉取镜像的过程中,遇到这种报错:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
Error: error creating build container: initializing source docker://centos:8: pinging container registry registry-1.docker.io: Get "https://registry-1.docker.io/v2/": proxyconnect tcp: dial tcp 127.0.0.1:12639: connect: connection refused
|
||||||
|
```
|
||||||
|
|
||||||
|
通常是因为启动 podman 虚拟机时,终端上有 HTTP 代理的环境变量,可以销毁虚拟机,重新启动,启动前确保当前终端没有 HTTP 代理的环境变量。
|
||||||
|
|
||||||
|
## 参考资料
|
||||||
|
|
||||||
|
* [Migrating from Docker to Podman](https://marcusnoble.co.uk/2021-09-01-migrating-from-docker-to-podman/)
|
||||||
|
|
@ -0,0 +1,81 @@
|
||||||
|
# 使用 skopeo 批量同步 helm chart 依赖镜像
|
||||||
|
|
||||||
|
## skopeo 是什么?
|
||||||
|
|
||||||
|
[skepeo](https://github.com/containers/skopeo) 是一个开源的容器镜像搬运工具,比较通用,各种镜像仓库都支持。
|
||||||
|
|
||||||
|
## 安装 skopeo
|
||||||
|
|
||||||
|
参考官方的 [安装指引](https://github.com/containers/skopeo/blob/main/install.md)。
|
||||||
|
|
||||||
|
## 导出当前 helm 配置依赖哪些镜像
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ helm template -n monitoring -f kube-prometheus-stack.yaml ./kube-prometheus-stack | grep "image:" | awk -F 'image:' '{print $2}' | awk '{$1=$1;print}' | sed -e 's/^"//' -e 's/"$//' > images.txt
|
||||||
|
$ cat images.txt
|
||||||
|
quay.io/prometheus/node-exporter:v1.3.1
|
||||||
|
quay.io/kiwigrid/k8s-sidecar:1.19.2
|
||||||
|
quay.io/kiwigrid/k8s-sidecar:1.19.2
|
||||||
|
grafana/grafana:9.0.2
|
||||||
|
registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.5.0
|
||||||
|
quay.io/prometheus-operator/prometheus-operator:v0.57.0
|
||||||
|
quay.io/prometheus/alertmanager:v0.24.0
|
||||||
|
quay.io/prometheus/prometheus:v2.36.1
|
||||||
|
bats/bats:v1.4.1
|
||||||
|
k8s.gcr.io/ingress-nginx/kube-webhook-certgen:v1.1.1
|
||||||
|
k8s.gcr.io/ingress-nginx/kube-webhook-certgen:v1.1.1
|
||||||
|
```
|
||||||
|
|
||||||
|
* 使用 helm template 渲染 yaml,利用脚本导出所有依赖的容器镜像并记录到 `images.txt`。
|
||||||
|
* 可以检查下 `images.txt` 中哪些不需要同步,删除掉。
|
||||||
|
|
||||||
|
## 准备同步脚本
|
||||||
|
|
||||||
|
准备同步脚本(`sync.sh`):
|
||||||
|
|
||||||
|
```bash
|
||||||
|
#! /bin/bash
|
||||||
|
|
||||||
|
DST_IMAGE_REPO="registry.imroc.cc/prometheus"
|
||||||
|
|
||||||
|
cat images.txt | while read line
|
||||||
|
do
|
||||||
|
while :
|
||||||
|
do
|
||||||
|
skopeo sync --src=docker --dest=docker $line $DST_IMAGE_REPO
|
||||||
|
if [ "$?" == "0" ]; then
|
||||||
|
break
|
||||||
|
fi
|
||||||
|
done
|
||||||
|
done
|
||||||
|
```
|
||||||
|
|
||||||
|
* 修改 `DST_IMAGE_REPO` 为你要同步的目标仓库地址与路径,`images.txt` 中的镜像都会被同步到这个仓库路径下面。
|
||||||
|
|
||||||
|
赋予脚本执行权限:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
chmod +x sync.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
## 登录仓库
|
||||||
|
|
||||||
|
同步镜像时,不管是源和目的,涉及到私有镜像,都需要先登录,不然同步会报错。
|
||||||
|
|
||||||
|
登录方法很简单,跟 `docker login` 一样,指定要登录的镜像仓库地址:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
skopeo login registry.imroc.cc
|
||||||
|
```
|
||||||
|
|
||||||
|
然后输入用户名密码即可。
|
||||||
|
|
||||||
|
## 执行同步
|
||||||
|
|
||||||
|
最后执行 `./sync.sh` 即可将所有镜像一键同步到目标仓库中,中途如果失败会一直重试直到成功。
|
||||||
|
|
||||||
|
## FAQ
|
||||||
|
|
||||||
|
### 为什么不用 skopeo 配置文件方式批量同步?
|
||||||
|
|
||||||
|
因为配置相对复杂和麻烦,不如直接用一个列表文本,每行代表一个镜像,通过脚本读取每一行分别进行同步,这样更简单。
|
||||||
|
|
@ -0,0 +1,35 @@
|
||||||
|
# 使用 kubectl-aliases 缩短命令
|
||||||
|
|
||||||
|
日常使用 kubectl 进行各种操作,每次输入完整命令会比较浪费时间,推荐使用 [kubectl-aliases](https://github.com/ahmetb/kubectl-aliases) 来提升 kubectl 日常操作效率,敲更少的字符完成更多的事。
|
||||||
|
|
||||||
|
## 安装 kubectl-aliases
|
||||||
|
|
||||||
|
参考 [官方安装文档](https://github.com/ahmetb/kubectl-aliases#installation)
|
||||||
|
|
||||||
|
## 查看完整列表
|
||||||
|
|
||||||
|
```bash
|
||||||
|
cat ~/.kubectl_aliases
|
||||||
|
```
|
||||||
|
|
||||||
|
## 高频使用的别名
|
||||||
|
|
||||||
|
```bash
|
||||||
|
ka // kubectl apply --recursive -f
|
||||||
|
kg // kubectl get
|
||||||
|
kgpo // kubectl get pods
|
||||||
|
ksys // kubectl -n kube-system
|
||||||
|
ksysgpo // kubectl -n kube-system get pods
|
||||||
|
kd // kubectl describe
|
||||||
|
kdpo // kubectl describe pod
|
||||||
|
```
|
||||||
|
|
||||||
|
## 自定义
|
||||||
|
|
||||||
|
建议针对自己常用的操作设置下别名,比如经常操作 istio 的话,可以用 `ki` 来代替 `kubectl -n istio-system`。
|
||||||
|
|
||||||
|
编辑 `~/.kubectl_aliases`:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
alias ki='kubectl -n istio-system'
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,42 @@
|
||||||
|
# 使用 kubecm 合并 kubeconfig
|
||||||
|
|
||||||
|
Kubernetes 提供了 kubectl 命令行工具来操作集群,使用 kubeconfig 作为配置文件,默认路径是 `~/.kube/config`,如果想使用 kubectl 对多个集群进行管理和操作,就在 kubeconfig 中配置多个集群的信息即可,通常可以通过编辑 kubeconfig 文件或执行一堆 `kubectl config` 的命令来实现。
|
||||||
|
|
||||||
|
一般情况下,Kubernetes 集群在安装或创建好之后,都会生成 kubeconfig 文件,如何简单高效的将这些 kubeconfig 合并以便让我们通过一个 kubeconfig 就能方便的管理多集群呢?我们可以借助 [kubecm](https://github.com/sunny0826/kubecm) 这个工具,本文将介绍如何利用 `kubecm` 来实现多集群的 kubeconfig 高效管理。
|
||||||
|
|
||||||
|
## 安装 kubecm
|
||||||
|
|
||||||
|
首先需要在管理多集群的机器上安装 `kubecm`,安装方法参考 [官方文档](https://kubecm.cloud/#/zh-cn/install) 。
|
||||||
|
|
||||||
|
## 使用 kubecm 添加访问凭证到 kubeconfig
|
||||||
|
|
||||||
|
首先拿到你集群的 kubeconfig 文件,将其重命名为你想指定的 context 名称,然后通过下面的命令将 kubeconfig 信息合并到 `~/.kube/config`:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
kubecm add --context-name=dev -cf config.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
* `dev` 替换为希望导入后的 context 名称。
|
||||||
|
* `config.yaml` 替换为 kubeconfig 文件名。
|
||||||
|
|
||||||
|
## 查看集群列表
|
||||||
|
|
||||||
|
通过 `kubecm` 添加了要管理和操作的集群后,通过 `kubecm ls` 可查看 kubeconfig 中的集群列表 (星号标识的是当前操作的集群):
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## 切换集群
|
||||||
|
|
||||||
|
当想要切换到其它集群操作时,可使用 `kubecm switch` 进行交互式切换:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
不过还是推荐使用 kubectx 进行切换。
|
||||||
|
|
||||||
|
## 移除集群
|
||||||
|
|
||||||
|
如果想要移除某个集群,可以用 `kubecm delete <context>`:
|
||||||
|
|
||||||
|

|
||||||
|
|
@ -0,0 +1,41 @@
|
||||||
|
# 使用 kubectx 和 kubens 快速切换
|
||||||
|
|
||||||
|
推荐使用 `kubectx` 和 `kubens` 来在多个集群和命名空间之间快速切换。
|
||||||
|
|
||||||
|
## 项目地址
|
||||||
|
|
||||||
|
这两个工具都在同一个项目中: [https://github.com/ahmetb/kubectx](https://github.com/ahmetb/kubectx)
|
||||||
|
|
||||||
|
## 安装
|
||||||
|
|
||||||
|
参考 [官方安装文档](https://github.com/ahmetb/kubectx#installation)。
|
||||||
|
|
||||||
|
推荐使用 kubectl 插件的方式安装:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl krew install ctx
|
||||||
|
kubectl krew install ns
|
||||||
|
```
|
||||||
|
|
||||||
|
> 如果没安装 [krew](https://krew.sigs.k8s.io/),需提前安装下,参考 [krew 安装文档](https://krew.sigs.k8s.io/docs/user-guide/setup/install/)。
|
||||||
|
|
||||||
|
## 使用
|
||||||
|
|
||||||
|
插件方式安装后,使用如下命令切换集群:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl ctx [CLUSTER]
|
||||||
|
```
|
||||||
|
|
||||||
|
切换命名空间:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl ns [NAMESPACE]
|
||||||
|
```
|
||||||
|
|
||||||
|
推荐结合 [使用 kubectl 别名快速执行命令](./kubectl-aliases.md) 来缩短命令:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
k ctx [CLUSTER]
|
||||||
|
k ns [NAMESPACE]
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,114 @@
|
||||||
|
# 使用 CSR API 创建用户
|
||||||
|
|
||||||
|
k8s 支持 CSR API,通过创建 `CertificateSigningRequest` 资源就可以发起 CSR 请求,管理员审批通过之后 `kube-controller-manager` 就会为我们签发证书,确保 `kube-controller-manager` 配了根证书密钥对:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
--cluster-signing-cert-file=/var/lib/kubernetes/ca.pem
|
||||||
|
--cluster-signing-key-file=/var/lib/kubernetes/ca-key.pem
|
||||||
|
```
|
||||||
|
|
||||||
|
## 安装 cfssl
|
||||||
|
|
||||||
|
我们用 cfssl 来创建 key 和 csr 文件,所以需要先安装 cfssl:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
curl -L https://pkg.cfssl.org/R1.2/cfssl_linux-amd64 -o cfssl
|
||||||
|
curl -L https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64 -o cfssljson
|
||||||
|
curl -L https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64 -o cfssl-certinfo
|
||||||
|
|
||||||
|
chmod +x cfssl cfssljson cfssl-certinfo
|
||||||
|
sudo mv cfssl cfssljson cfssl-certinfo /usr/local/bin/
|
||||||
|
```
|
||||||
|
|
||||||
|
> 更多 cfssl 详情参考: [使用 cfssl 生成证书](../certs/sign-certs-with-cfssl.md)。
|
||||||
|
|
||||||
|
## 创建步骤
|
||||||
|
|
||||||
|
指定要创建的用户名:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
USERNAME="roc"
|
||||||
|
```
|
||||||
|
|
||||||
|
再创建 key 和 csr 文件:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
cat <<EOF | cfssl genkey - | cfssljson -bare ${USERNAME}
|
||||||
|
{
|
||||||
|
"CN": "${USERNAME}",
|
||||||
|
"key": {
|
||||||
|
"algo": "rsa",
|
||||||
|
"size": 2048
|
||||||
|
}
|
||||||
|
}
|
||||||
|
EOF
|
||||||
|
```
|
||||||
|
|
||||||
|
生成以下文件:
|
||||||
|
|
||||||
|
```
|
||||||
|
roc.csr
|
||||||
|
roc-key.pem
|
||||||
|
```
|
||||||
|
|
||||||
|
创建 `CertificateSigningRequest`(发起 CSR 请求):
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
cat <<EOF | kubectl apply -f -
|
||||||
|
apiVersion: certificates.k8s.io/v1beta1
|
||||||
|
kind: CertificateSigningRequest
|
||||||
|
metadata:
|
||||||
|
name: ${USERNAME}
|
||||||
|
spec:
|
||||||
|
request: $(cat ${USERNAME}.csr | base64 | tr -d '\n')
|
||||||
|
usages:
|
||||||
|
- digital signature
|
||||||
|
- key encipherment
|
||||||
|
- client auth
|
||||||
|
EOF
|
||||||
|
```
|
||||||
|
|
||||||
|
管理员审批 CSR 请求:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
# 查看 csr
|
||||||
|
# kubectl get csr
|
||||||
|
|
||||||
|
# 审批 csr
|
||||||
|
kubectl certificate approve ${USERNAME}
|
||||||
|
```
|
||||||
|
|
||||||
|
获取证书:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
kubectl get csr ${USERNAME} -o jsonpath={.status.certificate} | base64 --decode > ${USERNAME}.pem
|
||||||
|
```
|
||||||
|
|
||||||
|
得到证书文件:
|
||||||
|
|
||||||
|
```
|
||||||
|
roc.pem
|
||||||
|
```
|
||||||
|
|
||||||
|
至此,我们已经创建好了用户,用户的证书密钥对文件:
|
||||||
|
|
||||||
|
```
|
||||||
|
roc.pem
|
||||||
|
roc-key.pem
|
||||||
|
```
|
||||||
|
|
||||||
|
## 配置 kubeconfig
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
# 增加 user
|
||||||
|
kubectl config set-credentials ${USERNAME} --embed-certs=true --client-certificate=${USERNAME}.pem --client-key=${USERNAME}-key.pem
|
||||||
|
|
||||||
|
# 如果还没配 cluster,可以通过下面命令配一下
|
||||||
|
kubectl config set-cluster <cluster> --server=<apiserver-url> --certificate-authority=<ca-cert-file>
|
||||||
|
|
||||||
|
# 增加 context,绑定 cluster 和 user
|
||||||
|
kubectl config set-context <context> --cluster=<cluster> --user=${USERNAME}
|
||||||
|
|
||||||
|
# 使用刚增加的 context
|
||||||
|
kubectl config use-context <context>
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,76 @@
|
||||||
|
# 误删 rancher 的 namespace 导致 node 被清空
|
||||||
|
|
||||||
|
## 问题描述
|
||||||
|
|
||||||
|
集群的节点突然全都不见了 (`kubectl get node` 为空),导致集群瘫痪,但实际上节点对应的虚拟机都还在。因为集群没开审计,所以也不太好查 node 是被什么删除的。
|
||||||
|
|
||||||
|
## 快速恢复
|
||||||
|
|
||||||
|
由于只是 k8s node 资源被删除,实际的机器都还在,我们可以批量重启节点,自动拉起 kubelet 重新注册 node,即可恢复。
|
||||||
|
|
||||||
|
## 可疑操作
|
||||||
|
|
||||||
|
发现在节点消失前,有个可疑的操作: 有同学发现在另外一个集群里有许多乱七八糟的 namespace (比如 `c-dxkxf`),查看这些 namespace 中没有运行任何工作负载,可能是其它人之前创建的测试 namespace,就将其删除掉了。
|
||||||
|
|
||||||
|
## 分析
|
||||||
|
|
||||||
|
删除 namespace 的集群中安装了 rancher,怀疑被删除的 namespace 是 rancher 自动创建的。
|
||||||
|
|
||||||
|
rancher 管理了其它 k8s 集群,架构图:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
猜想: 删除的 namespace 是 rancher 创建的,删除时清理了 rancher 的资源,也触发了 rancher 清理 node 的逻辑。
|
||||||
|
|
||||||
|
## 模拟复现
|
||||||
|
|
||||||
|
尝试模拟复现,验证猜想:
|
||||||
|
1. 创建一个 k8s 集群,作为 rancher 的 root cluster,并将 rancher 安装进去。
|
||||||
|
2. 进入 rancher web 界面,创建一个 cluster,使用 import 方式:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
3. 输入 cluster name:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
4. 弹出提示,让在另一个集群执行下面的 kubectl 命令将其导入到 rancher:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
5. 创建另一个 k8s 集群作为被 rancher 管理的集群,并将 kubeconfig 导入本地以便后续使用 kubectl 操作。
|
||||||
|
6. 导入 kubeconfig 并切换 context 后,执行 rancher 提供的 kubectl 命令将集群导入 rancher:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
可以看到在被管理的 TKE 集群中自动创建了 cattle-system 命名空间,并运行一些 rancher 的 agent:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
7. 将 context 切换到安装 rancher 的集群 (root cluster),可以发现添加集群后,自动创建了一些 namespace: 1 个 `c-` 开头的,2 个 `p-` 开头的:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
猜想是 `c-` 开头的 namespace 被 rancher 用来存储所添加的 `cluster` 的相关信息;`p-` 用于存储 `project` 相关的信息,官方也说了会自动为每个 cluster 创建 2 个 project:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
8. 查看有哪些 rancher 的 crd,有个 `nodes.management.cattle.io` 比较显眼,明显用于存储 cluster 的 node 信息:
|
||||||
|
|
||||||
|
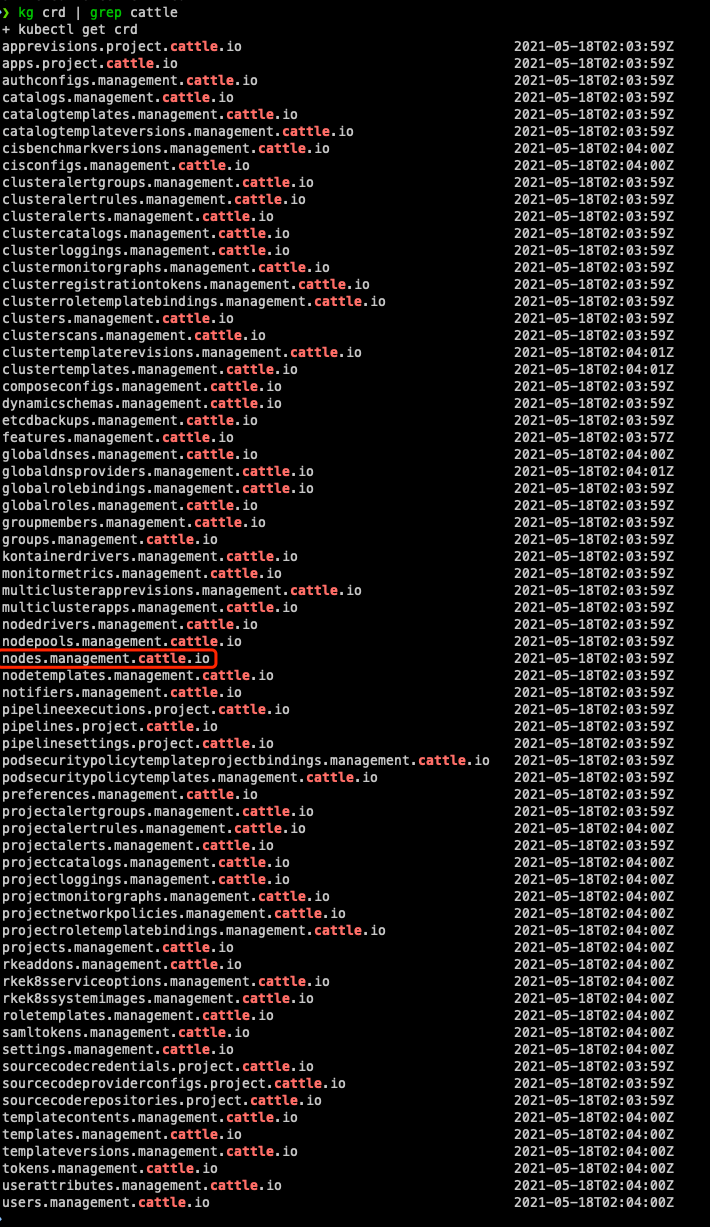
|
||||||
|
|
||||||
|
9. 看下 node 存储在哪个 namespace (果然在 `c-` 开头的 namespace 中):
|
||||||
|
|
||||||
|
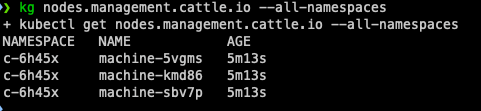
|
||||||
|
|
||||||
|
10. 尝试删除 `c-` 开头的 namesapce,并切换 context 到被添加的集群,执行 `kubectl get node`:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
节点被清空,问题复现。
|
||||||
|
|
||||||
|
## 结论
|
||||||
|
|
||||||
|
实验证明,rancher 的 `c-` 开头的 namespace 保存了所添加集群的 node 信息,如果删除了这种 namespace,也就删除了其中所存储的 node 信息,rancher watch 到了就会自动删除所关联集群的 k8s node 资源。
|
||||||
|
|
||||||
|
所以,千万不要轻易去清理 rancher 创建的 namespace,rancher 将一些有状态信息直接存储到了 root cluster 中 (通过 CRD 资源),删除 namespace 可能造成很严重的后果。
|
||||||
|
|
@ -0,0 +1,11 @@
|
||||||
|
# kubectl 执行 exec 或 logs 失败
|
||||||
|
|
||||||
|
## 原因
|
||||||
|
|
||||||
|
通常是 `kube-apiserver` 到 `kubelet:10250` 之间的网络不通,10250 是 kubelet 提供接口的端口,`kubectl exec` 和 `kubectl logs` 的原理就是 apiserver 调 kubelet,kubelet 再调运行时 (比如 dockerd) 来实现的。
|
||||||
|
|
||||||
|
## 解决方案
|
||||||
|
|
||||||
|
保证 kubelet 10250 端口对 apiserver 放通。
|
||||||
|
|
||||||
|
检查防火墙、iptables 规则是否对 10250 端口或某些 IP 进行了拦截。
|
||||||
|
|
@ -0,0 +1,173 @@
|
||||||
|
# 调度器 cache 快照遗漏部分信息导致 pod pending
|
||||||
|
|
||||||
|
## 问题背景
|
||||||
|
|
||||||
|
新建一个如下的 k8s 集群,有3个master node和1个worker node(worker 和 master在不同的可用区),node信息如下:
|
||||||
|
|
||||||
|
| node | label信息 |
|
||||||
|
|:----|:----|
|
||||||
|
| master-01 | failure-domain.beta.kubernetes.io/region=sh,failure-domain.beta.kubernetes.io/zone=200002 |
|
||||||
|
| master-02 | failure-domain.beta.kubernetes.io/region=sh,failure-domain.beta.kubernetes.io/zone=200002 |
|
||||||
|
| master-03 | failure-domain.beta.kubernetes.io/region=sh,failure-domain.beta.kubernetes.io/zone=200002 |
|
||||||
|
| worker-node-01 | failure-domain.beta.kubernetes.io/region=sh,failure-domain.beta.kubernetes.io/zone=200004 |
|
||||||
|
|
||||||
|
待集群创建好之后,然后创建了一个daemonset对象,就出现了daemonset的某个pod一直卡主pending状态的现象。
|
||||||
|
|
||||||
|
现象如下:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ kubectl get pod -o wide
|
||||||
|
NAME READY STATUS RESTARTS AGE NODE
|
||||||
|
debug-4m8lc 1/1 Running 1 89m master-01
|
||||||
|
debug-dn47c 0/1 Pending 0 89m <none>
|
||||||
|
debug-lkmfs 1/1 Running 1 89m master-02
|
||||||
|
debug-qwdbc 1/1 Running 1 89m worker-node-01
|
||||||
|
```
|
||||||
|
|
||||||
|
## 结论先行
|
||||||
|
|
||||||
|
k8s的调度器在调度某个pod时,会从调度器的内部cache中同步一份快照(snapshot),其中保存了pod可以调度的node信息。
|
||||||
|
|
||||||
|
上面问题(daemonset的某个pod实例卡在pending状态)发生的原因就是同步的过程发生了部分node信息丢失,导致了daemonset的部分pod实例无法调度到指定的节点上,出现了pending状态。
|
||||||
|
|
||||||
|
接下来是详细的排查过程。
|
||||||
|
|
||||||
|
## 日志排查
|
||||||
|
|
||||||
|
截图中出现的节点信息(来自用户线上集群):
|
||||||
|
* k8s master节点:ss-stg-ma-01、ss-stg-ma-02、ss-stg-ma-03
|
||||||
|
* k8s worker节点:ss-stg-test-01
|
||||||
|
|
||||||
|
1. 获取调度器的日志
|
||||||
|
|
||||||
|
这里首先是通过动态调大调度器的日志级别,比如,直接调大到`V(10)`,尝试获取一些相关日志。
|
||||||
|
|
||||||
|
当日志级别调大之后,有抓取到一些关键信息,信息如下:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
* 解释一下,当调度某个pod时,有可能会进入到调度器的抢占`preempt`环节,而上面的日志就是出自于抢占环节。 集群中有4个节点(3个master node和1个worker node),但是日志中只显示了3个节点,缺少了一个master节点。所以,这里暂时怀疑下是调度器内部缓存cache中少了`node info`。
|
||||||
|
|
||||||
|
2. 获取调度器内部cache信息
|
||||||
|
|
||||||
|
k8s v1.18已经支持打印调度器内部的缓存cache信息。打印出来的调度器内部缓存cache信息如下:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
可以看出,调度器的内部缓存cache中的`node info`是完整的(3个master node和1个worker node)。
|
||||||
|
|
||||||
|
通过分析日志,可以得到一个初步结论:调度器内部缓存cache中的`node info`是完整的,但是当调度pod时,缓存cache中又会缺少部分node信息。
|
||||||
|
|
||||||
|
## 问题根因
|
||||||
|
|
||||||
|
在进一步分析之前,我们先一起再熟悉下调度器调度pod的流程(部分展示)和nodeTree数据结构。
|
||||||
|
|
||||||
|
### **pod调度流程(部分展示)**
|
||||||
|
|
||||||
|
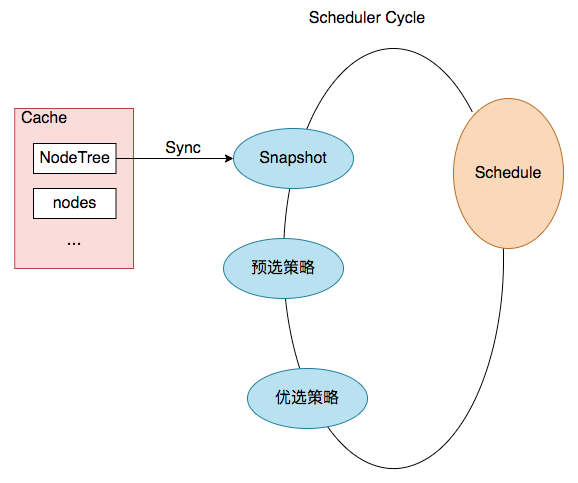
|
||||||
|
|
||||||
|
结合上图,一次pod的调度过程就是一次`Scheduler Cycle`。在这个`Cycle`开始时,第一步就是`update snapshot`。snapshot我们可以理解为cycle内的cache,其中保存了pod调度时所需的`node info`,而`update snapshot`,就是一次nodeTree(调度器内部cache中保存的node信息)到`snapshot`的同步过程。
|
||||||
|
|
||||||
|
而同步过程主要是通过`nodeTree.next()`函数来实现,函数逻辑如下:
|
||||||
|
|
||||||
|
```go
|
||||||
|
// next returns the name of the next node. NodeTree iterates over zones and in each zone iterates
|
||||||
|
// over nodes in a round robin fashion.
|
||||||
|
func (nt *nodeTree) next() string {
|
||||||
|
if len(nt.zones) == 0 {
|
||||||
|
return ""
|
||||||
|
}
|
||||||
|
numExhaustedZones := 0
|
||||||
|
for {
|
||||||
|
if nt.zoneIndex >= len(nt.zones) {
|
||||||
|
nt.zoneIndex = 0
|
||||||
|
}
|
||||||
|
zone := nt.zones[nt.zoneIndex]
|
||||||
|
nt.zoneIndex++
|
||||||
|
// We do not check the exhausted zones before calling next() on the zone. This ensures
|
||||||
|
// that if more nodes are added to a zone after it is exhausted, we iterate over the new nodes.
|
||||||
|
nodeName, exhausted := nt.tree[zone].next()
|
||||||
|
if exhausted {
|
||||||
|
numExhaustedZones++
|
||||||
|
if numExhaustedZones >= len(nt.zones) { // all zones are exhausted. we should reset.
|
||||||
|
nt.resetExhausted()
|
||||||
|
}
|
||||||
|
} else {
|
||||||
|
return nodeName
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
再结合上面排查过程得出的结论,我们可以再进一步缩小问题范围:nodeTree(调度器内部cache)到`snapshot.nodeInfoList`的同步过程丢失了某个节点信息。
|
||||||
|
|
||||||
|
### nodeTree数据结构
|
||||||
|
|
||||||
|
(方便理解,本文使用了链表来展示)
|
||||||
|
|
||||||
|
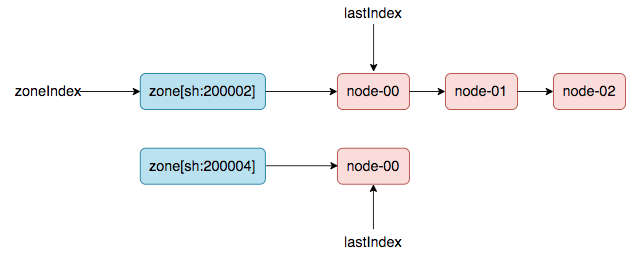
|
||||||
|
|
||||||
|
### 重现问题,定位根因
|
||||||
|
|
||||||
|
创建k8s集群时,会先加入master node,然后再加入worker node(意思是worker node时间上会晚于master node加入集群的时间)。
|
||||||
|
|
||||||
|
第一轮同步:3台master node创建好,然后发生pod调度(比如,cni 插件,以daemonset的方式部署在集群中),会触发一次nodeTree(调度器内部cache)到`snapshot.nodeInfoList`的同步。同步之后,nodeTree的两个游标就变成了如下结果:
|
||||||
|
|
||||||
|
`nodeTree.zoneIndex = 1, nodeTree.nodeArray[sh:200002].lastIndex = 3,`
|
||||||
|
|
||||||
|
第二轮同步:当worker node加入集群中后,然后新建一个daemonset,就会触发第二轮的同步(nodeTree(调度器内部cache)到`snapshot.nodeInfoList`的同步)。
|
||||||
|
|
||||||
|
同步过程如下:
|
||||||
|
|
||||||
|
1. zoneIndex=1, nodeArray[sh:200004].lastIndex=0, we get worker-node-01.
|
||||||
|
|
||||||
|
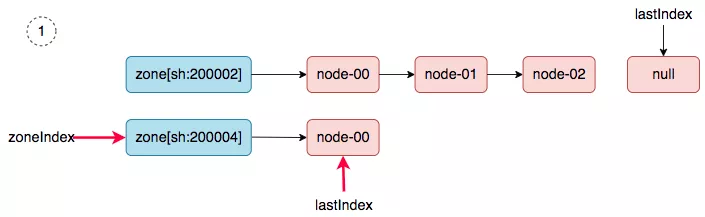
|
||||||
|
|
||||||
|
2. zoneIndex=2 >= len(zones); zoneIndex=0, nodeArray[sh:200002].lastIndex=3, return.
|
||||||
|
|
||||||
|
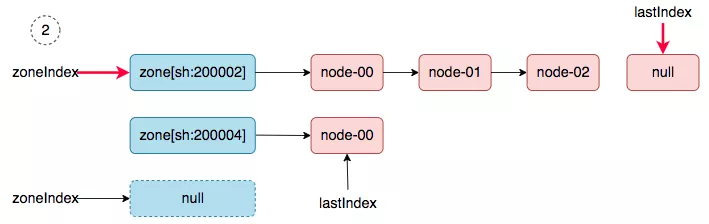
|
||||||
|
|
||||||
|
3. zoneIndex=1, nodeArray[sh:200004].lastIndex=1, return.
|
||||||
|
|
||||||
|
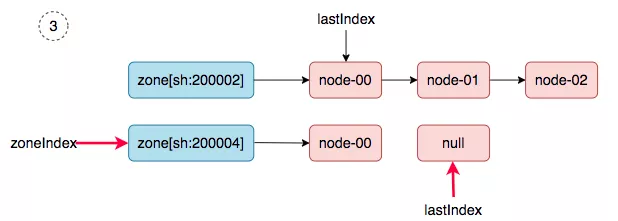
|
||||||
|
|
||||||
|
4. zoneIndex=0, nodeArray[sh:200002].lastIndex=0, we get master-01.
|
||||||
|
|
||||||
|
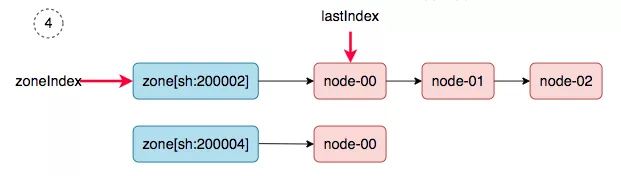
|
||||||
|
|
||||||
|
5. zoneIndex=1, nodeArray[sh:200004].lastIndex=0, we get worker-node-01.
|
||||||
|
|
||||||
|
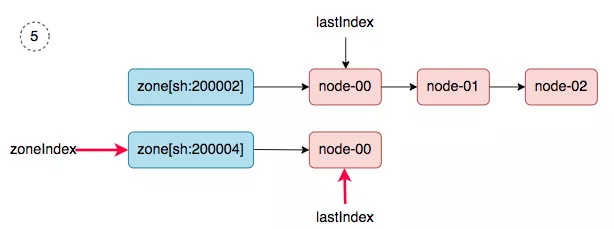
|
||||||
|
|
||||||
|
6. zoneIndex=2 >= len(zones); zoneIndex=0, nodeArray[sh:200002].lastIndex=1, we get master-02.
|
||||||
|
|
||||||
|
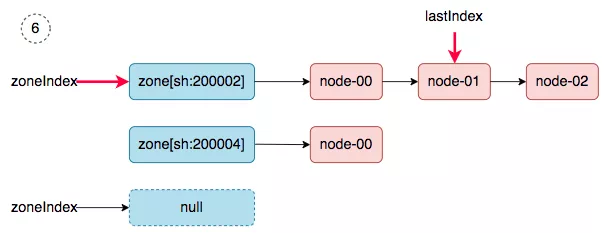
|
||||||
|
|
||||||
|
同步完成之后,调度器的`snapshot.nodeInfoList`得到如下的结果:
|
||||||
|
|
||||||
|
```json
|
||||||
|
[
|
||||||
|
worker-node-01,
|
||||||
|
master-01,
|
||||||
|
worker-node-01,
|
||||||
|
master-02,
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
master-03去哪了?在第二轮同步的过程中丢了。
|
||||||
|
|
||||||
|
## 解决方案
|
||||||
|
|
||||||
|
从`问题根因`的分析中,可以看出,导致问题发生的原因,在于nodeTree数据结构中的游标zoneIndex 和 lastIndex(zone级别)值被保留了,所以,解决的方案就是在每次同步SYNC时,强制重置游标(归0)。
|
||||||
|
|
||||||
|
## 参考资料
|
||||||
|
|
||||||
|
* [相关 issue](https://github.com/kubernetes/kubernetes/issues/97120)
|
||||||
|
* [相关pr (k8s v1.18)](https://github.com/kubernetes/kubernetes/pull/93387)
|
||||||
|
* [TKE 修复版本 v1.18.4-tke.5](https://cloud.tencent.com/document/product/457/9315#tke-kubernetes-1.18.4-revisions)
|
||||||
|
|
@ -0,0 +1,40 @@
|
||||||
|
# 容器磁盘满导致 CPU 飙高
|
||||||
|
|
||||||
|
## 问题描述
|
||||||
|
|
||||||
|
某服务的其中两个副本异常,CPU 飙高。
|
||||||
|
|
||||||
|
## 排查
|
||||||
|
|
||||||
|
1. 查看 `container_cpu_usage_seconds_total` 监控,CPU 飙升,逼近 limit。
|
||||||
|
2. 查看 `container_cpu_cfs_throttled_periods_total` 监控,CPU 飙升伴随 CPU Throttle 飙升,所以服务异常应该是 CPU 被限流导致。
|
||||||
|
3. 查看 `container_cpu_system_seconds_total` 监控,发现 CPU 飙升主要是 CPU system 占用导致,容器内 `pidstat -u -t 5 1` 可以看到进程 `%system` 占用分布情况。
|
||||||
|
4. `perf top` 看 system 占用高主要是 `vfs_write` 写数据导致。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
5. `iostat -xhd 2` 看 IO 并不高,磁盘利用率也不高,io wait 也不高。
|
||||||
|
6. `sync_inodes_sb` 看起来是写数据时触发了磁盘同步的耗时逻辑
|
||||||
|
7. 深入看内核代码,当磁盘满的时候会调用 flush 刷磁盘所有数据,这个会一直在内核态运行很久,相当于对这个文件系统做 sync。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
8. 节点上 `df -h` 看并没有磁盘满。
|
||||||
|
9. 容器内 `df -h` 看根目录空间满了.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
10. 看到 docker `daemon.json` 配置,限制了容器内 rootfs 最大只能占用 200G
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
11. 容器内一级级的 `du -sh *` 排查发现主要是一个 `nohup.log` 文件占满了磁盘。
|
||||||
|
|
||||||
|
|
||||||
|
## 结论
|
||||||
|
|
||||||
|
容器内空间满了继续写数据会导致内核不断刷盘对文件系统同步,会导致内核态 CPU 占用升高,设置了 cpu limit 通常会被 throttle,导致服务处理慢,影响业务。
|
||||||
|
|
||||||
|
## 建议
|
||||||
|
|
||||||
|
对日志进行轮转,或直接打到标准输出,避免写满容器磁盘。
|
||||||
|
|
@ -0,0 +1,17 @@
|
||||||
|
# ARP 爆满导致健康检查失败
|
||||||
|
|
||||||
|
## 案例
|
||||||
|
|
||||||
|
一用户某集群节点数 1200+,用户监控方案是 daemonset 部署 node-exporter 暴露节点监控指标,使用 hostNework 方式,statefulset 部署 promethues 且仅有一个实例,落在了一个节点上,promethues 请求所有节点 node-exporter 获取节点监控指标,也就是或扫描所有节点,导致 arp cache 需要存所有 node 的记录,而节点数 1200+,大于了 `net.ipv4.neigh.default.gc_thresh3` 的默认值 1024,这个值是个硬限制,arp cache记录数大于这个就会强制触发 gc,所以会造成频繁gc,当有数据包发送会查本地 arp,如果本地没找到 arp 记录就会判断当前 arp cache 记录数+1是否大于 gc_thresh3,如果没有就会广播 arp 查询 mac 地址,如果大于了就直接报 `arp_cache: neighbor table overflow!`,并且放弃 arp 请求,无法获取 mac 地址也就无法知道探测报文该往哪儿发(即便就在本机某个 veth pair),kubelet 对本机 pod 做存活检查发 arp 查 mac 地址,在 arp cahce 找不到,由于这时 arp cache已经满了,刚要 gc 但还没做所以就只有报错丢包,导致存活检查失败重启 pod。
|
||||||
|
|
||||||
|
## 解决方案
|
||||||
|
|
||||||
|
调整部分节点内核参数,将 arp cache 的 gc 阀值调高 (`/etc/sysctl.conf`):
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
net.ipv4.neigh.default.gc_thresh1 = 80000
|
||||||
|
net.ipv4.neigh.default.gc_thresh2 = 90000
|
||||||
|
net.ipv4.neigh.default.gc_thresh3 = 100000
|
||||||
|
```
|
||||||
|
|
||||||
|
并给 node 打下 label,修改 pod spec,加下 nodeSelector 或者 nodeAffnity,让 pod 只调度到这部分改过内核参数的节点,更多请参考本书 [节点排障: ARP 表爆满](../../node/arp-cache-overflow.md)
|
||||||
|
|
@ -0,0 +1,58 @@
|
||||||
|
# tcp_tw_recycle 导致跨 VPC 访问 NodePort 超时
|
||||||
|
|
||||||
|
## 现象
|
||||||
|
|
||||||
|
从 VPC a 访问 VPC b 的 TKE 集群的某个节点的 NodePort,有时候正常,有时候会卡住直到超时。
|
||||||
|
|
||||||
|
## 排查
|
||||||
|
|
||||||
|
原因怎么查?
|
||||||
|
|
||||||
|
当然是先抓包看看啦,抓 server 端 NodePort 的包,发现异常时 server 能收到 SYN,但没响应 ACK:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
反复执行 `netstat -s | grep LISTEN` 发现 SYN 被丢弃数量不断增加:
|
||||||
|
|
||||||
|
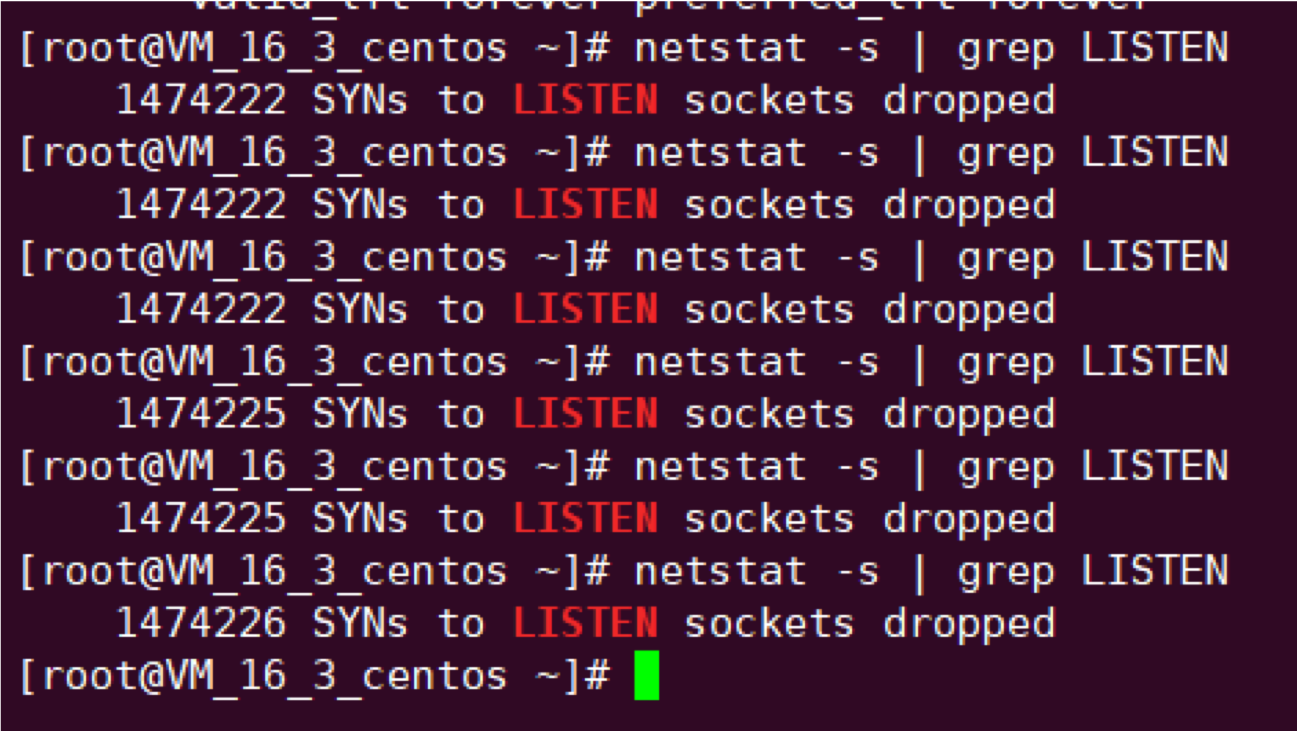
|
||||||
|
|
||||||
|
分析:
|
||||||
|
|
||||||
|
- 两个VPC之间使用对等连接打通的,CVM 之间通信应该就跟在一个内网一样可以互通。
|
||||||
|
- 为什么同一 VPC 下访问没问题,跨 VPC 有问题? 两者访问的区别是什么?
|
||||||
|
|
||||||
|
再仔细看下 client 所在环境,发现 client 是 VPC a 的 TKE 集群节点,捋一下:
|
||||||
|
|
||||||
|
- client 在 VPC a 的 TKE 集群的节点
|
||||||
|
- server 在 VPC b 的 TKE 集群的节点
|
||||||
|
|
||||||
|
因为 TKE 集群中有个叫 `ip-masq-agent` 的 daemonset,它会给 node 写 iptables 规则,默认 SNAT 目的 IP 是 VPC 之外的报文,所以 client 访问 server 会做 SNAT,也就是这里跨 VPC 相比同 VPC 访问 NodePort 多了一次 SNAT,如果是因为多了一次 SNAT 导致的这个问题,直觉告诉我这个应该跟内核参数有关,因为是 server 收到包没回包,所以应该是 server 所在 node 的内核参数问题,对比这个 node 和 普通 TKE node 的默认内核参数,发现这个 node `net.ipv4.tcp_tw_recycle = 1`,这个参数默认是关闭的,跟用户沟通后发现这个内核参数确实在做压测的时候调整过。
|
||||||
|
|
||||||
|
## tcp_tw_recycle 的坑
|
||||||
|
|
||||||
|
解释一下,TCP 主动关闭连接的一方在发送最后一个 ACK 会进入 `TIME_AWAIT` 状态,再等待 2 个 MSL 时间后才会关闭(因为如果 server 没收到 client 第四次挥手确认报文,server 会重发第三次挥手 FIN 报文,所以 client 需要停留 2 MSL的时长来处理可能会重复收到的报文段;同时等待 2 MSL 也可以让由于网络不通畅产生的滞留报文失效,避免新建立的连接收到之前旧连接的报文),了解更详细的过程请参考 TCP 四次挥手。
|
||||||
|
|
||||||
|
参数 `tcp_tw_recycle` 用于快速回收 `TIME_AWAIT` 连接,通常在增加连接并发能力的场景会开启,比如发起大量短连接,快速回收可避免 `tw_buckets` 资源耗尽导致无法建立新连接 (`time wait bucket table overflow`)
|
||||||
|
|
||||||
|
查得 `tcp_tw_recycle` 有个坑,在 RFC1323 有段描述:
|
||||||
|
|
||||||
|
`
|
||||||
|
An additional mechanism could be added to the TCP, a per-host cache of the last timestamp received from any connection. This value could then be used in the PAWS mechanism to reject old duplicate segments from earlier incarnations of the connection, if the timestamp clock can be guaranteed to have ticked at least once since the old connection was open. This would require that the TIME-WAIT delay plus the RTT together must be at least one tick of the sender’s timestamp clock. Such an extension is not part of the proposal of this RFC.
|
||||||
|
`
|
||||||
|
|
||||||
|
大概意思是说 TCP 有一种行为,可以缓存每个连接最新的时间戳,后续请求中如果时间戳小于缓存的时间戳,即视为无效,相应的数据包会被丢弃。
|
||||||
|
|
||||||
|
Linux 是否启用这种行为取决于 `tcp_timestamps` 和 `tcp_tw_recycle`,因为 `tcp_timestamps` 缺省开启,所以当 `tcp_tw_recycle` 被开启后,实际上这种行为就被激活了,当客户端或服务端以 `NAT` 方式构建的时候就可能出现问题。
|
||||||
|
|
||||||
|
当多个客户端通过 NAT 方式联网并与服务端交互时,服务端看到的是同一个 IP,也就是说对服务端而言这些客户端实际上等同于一个,可惜由于这些客户端的时间戳可能存在差异,于是乎从服务端的视角看,便可能出现时间戳错乱的现象,进而直接导致时间戳小的数据包被丢弃。如果发生了此类问题,具体的表现通常是是客户端明明发送的 SYN,但服务端就是不响应 ACK。
|
||||||
|
|
||||||
|
## 真相大白
|
||||||
|
|
||||||
|
回到我们的问题上,client 所在节点上可能也会有其它 pod 访问到 server 所在节点,而它们都被 SNAT 成了 client 所在节点的 NODE IP,但时间戳存在差异,server 就会看到时间戳错乱,因为开启了 `tcp_tw_recycle` 和 `tcp_timestamps` 激活了上述行为,就丢掉了比缓存时间戳小的报文,导致部分 SYN 被丢弃,这也解释了为什么之前我们抓包发现异常时 server 收到了 SYN,但没有响应 ACK,进而说明为什么 client 的请求部分会卡住直到超时。
|
||||||
|
|
||||||
|
由于 `tcp_tw_recycle` 坑太多,在内核 4.12 之后已移除: [remove tcp_tw_recycle](https://github.com/torvalds/linux/commit/4396e46187ca5070219b81773c4e65088dac50cc)
|
||||||
|
|
||||||
|
## 解决方案
|
||||||
|
|
||||||
|
1. 关闭 tcp_tw_recycle。
|
||||||
|
2. 升级内核,启用 `net.ipv4.tcp_tw_reuse`。
|
||||||
|
|
@ -0,0 +1,191 @@
|
||||||
|
# DNS 5 秒延时
|
||||||
|
|
||||||
|
## 现象
|
||||||
|
|
||||||
|
用户反馈从 pod 中访问服务时,总是有些请求的响应时延会达到5秒。正常的响应只需要毫秒级别的时延。
|
||||||
|
|
||||||
|
## 抓包
|
||||||
|
|
||||||
|
* [使用 nsenter 进入 netns](../../skill/enter-netns-with-nsenter.md),然后使用节点上的 tcpdump 抓 pod 中的包,发现是有的 DNS 请求没有收到响应,超时 5 秒后,再次发送 DNS 请求才成功收到响应。
|
||||||
|
* 在 kube-dns pod 抓包,发现是有 DNS 请求没有到达 kube-dns pod,在中途被丢弃了。
|
||||||
|
|
||||||
|
为什么是 5 秒? `man resolv.conf` 可以看到 glibc 的 resolver 的缺省超时时间是 5s:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
timeout:n
|
||||||
|
Sets the amount of time the resolver will wait for a response from a remote name server before retrying the query via a different name server. Measured in seconds, the default is RES_TIMEOUT (currently 5, see
|
||||||
|
<resolv.h>). The value for this option is silently capped to 30.
|
||||||
|
```
|
||||||
|
|
||||||
|
## 丢包原因
|
||||||
|
|
||||||
|
经过搜索发现这是一个普遍问题。
|
||||||
|
|
||||||
|
根本原因是内核 conntrack 模块的 bug,netfilter 做 NAT 时可能发生资源竞争导致部分报文丢弃。
|
||||||
|
|
||||||
|
Weave works的工程师 [Martynas Pumputis](martynas@weave.works) 对这个问题做了很详细的分析:[Racy conntrack and DNS lookup timeouts](https://www.weave.works/blog/racy-conntrack-and-dns-lookup-timeouts)
|
||||||
|
|
||||||
|
相关结论:
|
||||||
|
|
||||||
|
* 只有多个线程或进程,并发从同一个 socket 发送相同五元组的 UDP 报文时,才有一定概率会发生
|
||||||
|
* glibc, musl\(alpine linux的libc库\)都使用 "parallel query", 就是并发发出多个查询请求,因此很容易碰到这样的冲突,造成查询请求被丢弃
|
||||||
|
* 由于 ipvs 也使用了 conntrack, 使用 kube-proxy 的 ipvs 模式,并不能避免这个问题
|
||||||
|
|
||||||
|
## 问题的根本解决
|
||||||
|
|
||||||
|
Martynas 向内核提交了两个 patch 来 fix 这个问题,不过他说如果集群中有多个DNS server的情况下,问题并没有完全解决。
|
||||||
|
|
||||||
|
其中一个 patch 已经在 2018-7-18 被合并到 linux 内核主线中: [netfilter: nf\_conntrack: resolve clash for matching conntracks](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=ed07d9a021df6da53456663a76999189badc432a)
|
||||||
|
|
||||||
|
目前只有4.19.rc 版本包含这个patch。
|
||||||
|
|
||||||
|
## 规避办法
|
||||||
|
|
||||||
|
### 规避方案一:使用TCP发送DNS请求
|
||||||
|
|
||||||
|
由于TCP没有这个问题,有人提出可以在容器的resolv.conf中增加`options use-vc`, 强制glibc使用TCP协议发送DNS query。下面是这个man resolv.conf中关于这个选项的说明:
|
||||||
|
|
||||||
|
```text
|
||||||
|
use-vc (since glibc 2.14)
|
||||||
|
Sets RES_USEVC in _res.options. This option forces the
|
||||||
|
use of TCP for DNS resolutions.
|
||||||
|
```
|
||||||
|
|
||||||
|
笔者使用镜像"busybox:1.29.3-glibc" \(libc 2.24\) 做了试验,并没有见到这样的效果,容器仍然是通过UDP发送DNS请求。
|
||||||
|
|
||||||
|
### 规避方案二:避免相同五元组DNS请求的并发
|
||||||
|
|
||||||
|
resolv.conf还有另外两个相关的参数:
|
||||||
|
|
||||||
|
* single-request-reopen \(since glibc 2.9\)
|
||||||
|
* single-request \(since glibc 2.10\)
|
||||||
|
|
||||||
|
man resolv.conf中解释如下:
|
||||||
|
|
||||||
|
```text
|
||||||
|
single-request-reopen (since glibc 2.9)
|
||||||
|
Sets RES_SNGLKUPREOP in _res.options. The resolver
|
||||||
|
uses the same socket for the A and AAAA requests. Some
|
||||||
|
hardware mistakenly sends back only one reply. When
|
||||||
|
that happens the client system will sit and wait for
|
||||||
|
the second reply. Turning this option on changes this
|
||||||
|
behavior so that if two requests from the same port are
|
||||||
|
not handled correctly it will close the socket and open
|
||||||
|
a new one before sending the second request.
|
||||||
|
|
||||||
|
single-request (since glibc 2.10)
|
||||||
|
Sets RES_SNGLKUP in _res.options. By default, glibc
|
||||||
|
performs IPv4 and IPv6 lookups in parallel since
|
||||||
|
version 2.9. Some appliance DNS servers cannot handle
|
||||||
|
these queries properly and make the requests time out.
|
||||||
|
This option disables the behavior and makes glibc
|
||||||
|
perform the IPv6 and IPv4 requests sequentially (at the
|
||||||
|
cost of some slowdown of the resolving process).
|
||||||
|
```
|
||||||
|
|
||||||
|
用自己的话解释下:
|
||||||
|
|
||||||
|
* `single-request-reopen`: 发送 A 类型请求和 AAAA 类型请求使用不同的源端口,这样两个请求在 conntrack 表中不占用同一个表项,从而避免冲突
|
||||||
|
* `single-request`: 避免并发,改为串行发送 A 类型和 AAAA 类型请求,没有了并发,从而也避免了冲突
|
||||||
|
|
||||||
|
要给容器的 `resolv.conf` 加上 options 参数,有几个办法:
|
||||||
|
|
||||||
|
1. 在容器的 "ENTRYPOINT" 或者 "CMD" 脚本中,执行 /bin/echo 'options single-request-reopen' >> /etc/resolv.conf**
|
||||||
|
|
||||||
|
2. 在 pod 的 postStart hook 中:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
lifecycle:
|
||||||
|
postStart:
|
||||||
|
exec:
|
||||||
|
command:
|
||||||
|
- /bin/sh
|
||||||
|
- -c
|
||||||
|
- "/bin/echo 'options single-request-reopen' >> /etc/resolv.conf"
|
||||||
|
```
|
||||||
|
|
||||||
|
3. 使用 template.spec.dnsConfig (k8s v1.9 及以上才支持):
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
template:
|
||||||
|
spec:
|
||||||
|
dnsConfig:
|
||||||
|
options:
|
||||||
|
- name: single-request-reopen
|
||||||
|
```
|
||||||
|
|
||||||
|
4. 使用 ConfigMap 覆盖 pod 里面的 /etc/resolv.conf:
|
||||||
|
|
||||||
|
configmap:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: v1
|
||||||
|
data:
|
||||||
|
resolv.conf: |
|
||||||
|
nameserver 1.2.3.4
|
||||||
|
search default.svc.cluster.local svc.cluster.local cluster.local ec2.internal
|
||||||
|
options ndots:5 single-request-reopen timeout:1
|
||||||
|
kind: ConfigMap
|
||||||
|
metadata:
|
||||||
|
name: resolvconf
|
||||||
|
```
|
||||||
|
|
||||||
|
pod spec:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
volumeMounts:
|
||||||
|
- name: resolv-conf
|
||||||
|
mountPath: /etc/resolv.conf
|
||||||
|
subPath: resolv.conf
|
||||||
|
...
|
||||||
|
|
||||||
|
volumes:
|
||||||
|
- name: resolv-conf
|
||||||
|
configMap:
|
||||||
|
name: resolvconf
|
||||||
|
items:
|
||||||
|
- key: resolv.conf
|
||||||
|
path: resolv.conf
|
||||||
|
```
|
||||||
|
|
||||||
|
5. 使用 MutatingAdmissionWebhook
|
||||||
|
|
||||||
|
[MutatingAdmissionWebhook](https://kubernetes.io/docs/reference/access-authn-authz/admission-controllers/#mutatingadmissionwebhook-beta-in-1-9) 是 1.9 引入的 Controller,用于对一个指定的 Resource 的操作之前,对这个 resource 进行变更。 istio 的自动 sidecar注入就是用这个功能来实现的。 我们也可以通过 MutatingAdmissionWebhook,来自动给所有POD,注入以上3\)或者4\)所需要的相关内容。
|
||||||
|
|
||||||
|
以上方法中, 1 和 2 都需要修改镜像, 3 和 4 则只需要修改 pod 的 spec, 能适用于所有镜像。不过还是有不方便的地方:
|
||||||
|
|
||||||
|
* 每个工作负载的yaml都要做修改,比较麻烦
|
||||||
|
* 对于通过helm创建的工作负载,需要修改helm charts
|
||||||
|
|
||||||
|
方法5\)对集群使用者最省事,照常提交工作负载即可。不过初期需要一定的开发工作量。
|
||||||
|
|
||||||
|
### 最佳实践:使用 LocalDNS
|
||||||
|
|
||||||
|
容器的DNS请求都发往本地的DNS缓存服务 (dnsmasq, nscd 等),不需要走DNAT,也不会发生conntrack冲突。另外还有个好处,就是避免DNS服务成为性能瓶颈。
|
||||||
|
|
||||||
|
使用 LocalDNS 缓存有两种方式:
|
||||||
|
|
||||||
|
* 每个容器自带一个DNS缓存服务
|
||||||
|
* 每个节点运行一个DNS缓存服务,所有容器都把本节点的DNS缓存作为自己的 nameserver
|
||||||
|
|
||||||
|
从资源效率的角度来考虑的话,推荐后一种方式。官方也意识到了这个问题比较常见,给出了 coredns 以 cache 模式作为 daemonset 部署的解决方案: [https://kubernetes.io/docs/tasks/administer-cluster/nodelocaldns/](https://kubernetes.io/docs/tasks/administer-cluster/nodelocaldns/)
|
||||||
|
|
||||||
|
### 实施办法
|
||||||
|
|
||||||
|
条条大路通罗马,不管怎么做,最终到达上面描述的效果即可。
|
||||||
|
|
||||||
|
POD中要访问节点上的DNS缓存服务,可以使用节点的IP。 如果节点上的容器都连在一个虚拟bridge上, 也可以使用这个bridge的三层接口的IP(在TKE中,这个三层接口叫cbr0)。 要确保DNS缓存服务监听这个地址。
|
||||||
|
|
||||||
|
如何把 POD 的 /etc/resolv.conf 中的 nameserver 设置为节点IP呢?
|
||||||
|
|
||||||
|
一个办法,是设置 POD.spec.dnsPolicy 为 "Default", 意思是POD里面的 /etc/resolv.conf, 使用节点上的文件。缺省使用节点上的 /etc/resolv.conf (如果kubelet通过参数--resolv-conf指定了其他文件,则使用--resolv-conf所指定的文件)。
|
||||||
|
|
||||||
|
另一个办法,是给每个节点的kubelet指定不同的--cluster-dns参数,设置为节点的IP,POD.spec.dnsPolicy仍然使用缺省值"ClusterFirst"。 kops项目甚至有个issue在讨论如何在部署集群时设置好--cluster-dns指向节点IP: [https://github.com/kubernetes/kops/issues/5584](https://github.com/kubernetes/kops/issues/5584)
|
||||||
|
|
||||||
|
## 参考资料
|
||||||
|
|
||||||
|
* [Racy conntrack and DNS lookup timeouts](https://www.weave.works/blog/racy-conntrack-and-dns-lookup-timeouts)
|
||||||
|
* [5 – 15s DNS lookups on Kubernetes?](https://blog.quentin-machu.fr/2018/06/24/5-15s-dns-lookups-on-kubernetes/)
|
||||||
|
* [DNS intermittent delays of 5s](https://github.com/kubernetes/kubernetes/issues/56903)
|
||||||
|
* [记一次Docker/Kubernetes上无法解释的连接超时原因探寻之旅](https://mp.weixin.qq.com/s/VYBs8iqf0HsNg9WAxktzYQ)
|
||||||
|
|
||||||
|
|
@ -0,0 +1,95 @@
|
||||||
|
# dns id 冲突导致解析异常
|
||||||
|
|
||||||
|
## 现象
|
||||||
|
|
||||||
|
有个用户反馈域名解析有时有问题,看报错是解析超时。
|
||||||
|
|
||||||
|
## 排查
|
||||||
|
|
||||||
|
第一反应当然是看 coredns 的 log:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
[ERROR] 2 loginspub.xxxxmobile-inc.net.
|
||||||
|
A: unreachable backend: read udp 172.16.0.230:43742->10.225.30.181:53: i/o timeout
|
||||||
|
```
|
||||||
|
|
||||||
|
这是上游 DNS 解析异常了,因为解析外部域名 coredns 默认会请求上游 DNS 来查询,这里的上游 DNS 默认是 coredns pod 所在宿主机的 `resolv.conf` 里面的 nameserver (coredns pod 的 dnsPolicy 为 "Default",也就是会将宿主机里的 `resolv.conf` 里的 nameserver 加到容器里的 `resolv.conf`, coredns 默认配置 `proxy . /etc/resolv.conf`, 意思是非 service 域名会使用 coredns 容器中 `resolv.conf` 文件里的 nameserver 来解析)
|
||||||
|
|
||||||
|
确认了下,超时的上游 DNS 10.225.30.181,并不是期望的 nameserver,VPC 默认 DNS 应该是 180 开头的。看了 coredns 所在节点的 `resolv.conf`,发现确实多出了这个非期望的 nameserver,跟用户确认了下,这个 DNS 不是用户自己加上去的,添加节点时这个 nameserver 本身就在 `resolv.conf` 中。
|
||||||
|
|
||||||
|
根据内部同学反馈, 10.225.30.181 是广州一台年久失修将被撤裁的 DNS,物理网络,没有 VIP,撤掉就没有了,所以如果 coredns 用到了这台 DNS 解析时就可能 timeout。后面我们自己测试,某些 VPC 的集群确实会有这个 nameserver,奇了怪了,哪里冒出来的?
|
||||||
|
|
||||||
|
又试了下直接创建 CVM,不加进 TKE 节点发现没有这个 nameserver,只要一加进 TKE 节点就有了 !!!
|
||||||
|
|
||||||
|
看起来是 TKE 的问题,将 CVM 添加到 TKE 集群会自动重装系统,初始化并加进集群成为 K8S 的 node,确认了初始化过程并不会写 `resolv.conf`,会不会是 TKE 的 OS 镜像问题?尝试搜一下除了 `/etc/resolv.conf` 之外哪里还有这个 nameserver 的 IP,最后发现 `/etc/resolvconf/resolv.conf.d/base` 这里面有。
|
||||||
|
|
||||||
|
看下 `/etc/resolvconf/resolv.conf.d/base` 的作用:Ubuntu 的 `/etc/resolv.conf` 是动态生成的,每次重启都会将 `/etc/resolvconf/resolv.conf.d/base` 里面的内容加到 `/etc/resolv.conf` 里。
|
||||||
|
|
||||||
|
经确认: 这个文件确实是 TKE 的 Ubuntu OS 镜像里自带的,可能发布 OS 镜像时不小心加进去的。
|
||||||
|
|
||||||
|
那为什么有些 VPC 的集群的节点 `/etc/resolv.conf` 里面没那个 IP 呢?它们的 OS 镜像里也都有那个文件那个 IP 呀。
|
||||||
|
|
||||||
|
请教其它部门同学发现:
|
||||||
|
|
||||||
|
- 非 dhcp 子机,cvm 的 cloud-init 会覆盖 `/etc/resolv.conf` 来设置 dns
|
||||||
|
- dhcp 子机,cloud-init 不会设置,而是通过 dhcp 动态下发
|
||||||
|
- 2018 年 4 月 之后创建的 VPC 就都是 dhcp 类型了的,比较新的 VPC 都是 dhcp 类型的
|
||||||
|
|
||||||
|
## 真相大白
|
||||||
|
|
||||||
|
`/etc/resolv.conf` 一开始内容都包含 `/etc/resolvconf/resolv.conf.d/base` 的内容,也就是都有那个不期望的 nameserver,但老的 VPC 由于不是 dhcp 类型,所以 cloud-init 会覆盖 `/etc/resolv.conf`,抹掉了不被期望的 nameserver,而新创建的 VPC 都是 dhcp 类型,cloud-init 不会覆盖 `/etc/resolv.conf`,导致不被期望的 nameserver 残留在了 `/etc/resolv.conf`,而 coredns pod 的 dnsPolicy 为 “Default”,也就是会将宿主机的 `/etc/resolv.conf` 中的 nameserver 加到容器里,coredns 解析集群外的域名默认使用这些 nameserver 来解析,当用到那个将被撤裁的 nameserver 就可能 timeout。
|
||||||
|
|
||||||
|
## 解决方案
|
||||||
|
|
||||||
|
临时解决: 删掉 `/etc/resolvconf/resolv.conf.d/base` 重启。
|
||||||
|
长期解决: 我们重新制作 TKE Ubuntu OS 镜像然后发布更新。
|
||||||
|
|
||||||
|
## 再次出问题
|
||||||
|
|
||||||
|
这下应该没问题了吧,But, 用户反馈还是会偶尔解析有问题,但现象不一样了,这次并不是 dns timeout。
|
||||||
|
|
||||||
|
用脚本跑测试仔细分析现象:
|
||||||
|
|
||||||
|
- 请求 `loginspub.xxxxmobile-inc.net` 时,偶尔提示域名无法解析
|
||||||
|
- 请求 `accounts.google.com` 时,偶尔提示连接失败
|
||||||
|
|
||||||
|
进入 dns 解析偶尔异常的容器的 netns 抓包:
|
||||||
|
|
||||||
|
- dns 请求会并发请求 A 和 AAAA 记录
|
||||||
|
- 测试脚本发请求打印序号,抓包然后 wireshark 分析对比异常时请求序号偏移量,找到异常时的 dns 请求报文,发现异常时 A 和 AAAA 记录的请求 id 冲突,并且 AAAA 响应先返回
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
正常情况下id不会冲突,这里冲突了也就能解释这个 dns 解析异常的现象了:
|
||||||
|
|
||||||
|
- `loginspub.xxxxmobile-inc.net` 没有 AAAA (ipv6) 记录,它的响应先返回告知 client 不存在此记录,由于请求 id 跟 A 记录请求冲突,后面 A 记录响应返回了 client 发现 id 重复就忽略了,然后认为这个域名无法解析
|
||||||
|
- `accounts.google.com` 有 AAAA 记录,响应先返回了,client 就拿这个记录去尝试请求,但当前容器环境不支持 ipv6,所以会连接失败
|
||||||
|
|
||||||
|
## 分析
|
||||||
|
|
||||||
|
那为什么 dns 请求 id 会冲突?
|
||||||
|
|
||||||
|
继续观察发现: 其它节点上的 pod 不会复现这个问题,有问题这个节点上也不是所有 pod 都有这个问题,只有基于 alpine 镜像的容器才有这个问题,在此节点新起一个测试的 `alpine:latest` 的容器也一样有这个问题。
|
||||||
|
|
||||||
|
为什么 alpine 镜像的容器在这个节点上有问题在其它节点上没问题? 为什么其他镜像的容器都没问题?它们跟 alpine 的区别是什么?
|
||||||
|
|
||||||
|
发现一点区别: alpine 使用的底层 c 库是 musl libc,其它镜像基本都是 glibc
|
||||||
|
|
||||||
|
翻 musl libc 源码, 构造 dns 请求时,请求 id 的生成没加锁,而且跟当前时间戳有关 (`network/res_mkquery.c`):
|
||||||
|
|
||||||
|
``` c
|
||||||
|
/* Make a reasonably unpredictable id */
|
||||||
|
clock_gettime(CLOCK_REALTIME, &ts);
|
||||||
|
id = ts.tv_nsec + ts.tv_nsec/65536UL & 0xffff;
|
||||||
|
```
|
||||||
|
|
||||||
|
看注释,作者应该认为这样id基本不会冲突,事实证明,绝大多数情况确实不会冲突,我在网上搜了很久没有搜到任何关于 musl libc 的 dns 请求 id 冲突的情况。这个看起来取决于硬件,可能在某种类型硬件的机器上运行,短时间内生成的 id 就可能冲突。我尝试跟用户在相同地域的集群,添加相同配置相同机型的节点,也复现了这个问题,但后来删除再添加时又不能复现了,看起来后面新建的 cvm 又跑在了另一种硬件的母机上了。
|
||||||
|
|
||||||
|
OK,能解释通了,再底层的细节就不清楚了,我们来看下解决方案:
|
||||||
|
|
||||||
|
- 换基础镜像 (不用alpine)
|
||||||
|
- 完全静态编译业务程序(不依赖底层c库),比如go语言程序编译时可以关闭 cgo (CGO_ENABLED=0),并告诉链接器要静态链接 (`go build` 后面加 `-ldflags '-d'`),但这需要语言和编译工具支持才可以
|
||||||
|
|
||||||
|
## 最终解决方案
|
||||||
|
|
||||||
|
最终建议用户基础镜像换成另一个比较小的镜像: `debian:stretch-slim`。
|
||||||
|
|
@ -0,0 +1,102 @@
|
||||||
|
# cgroup 泄露
|
||||||
|
|
||||||
|
## 现象
|
||||||
|
|
||||||
|
创建 Pod 失败,运行时报错 `no space left on device`:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
Dec 24 11:54:31 VM_16_11_centos dockerd[11419]: time="2018-12-24T11:54:31.195900301+08:00" level=error msg="Handler for POST /v1.31/containers/b98d4aea818bf9d1d1aa84079e1688cd9b4218e008c58a8ef6d6c3c106403e7b/start returned error: OCI runtime create failed: container_linux.go:348: starting container process caused \"process_linux.go:279: applying cgroup configuration for process caused \\\"mkdir /sys/fs/cgroup/memory/kubepods/burstable/pod79fe803c-072f-11e9-90ca-525400090c71/b98d4aea818bf9d1d1aa84079e1688cd9b4218e008c58a8ef6d6c3c106403e7b: no space left on device\\\"\": unknown"
|
||||||
|
```
|
||||||
|
|
||||||
|
## 内核 Bug
|
||||||
|
|
||||||
|
`memcg` 是 Linux 内核中用于管理 cgroup 内存的模块,整个生命周期应该是跟随 cgroup 的,但是在低版本内核中\(已知3.10\),一旦给某个 memory cgroup 开启 kmem accounting 中的 `memory.kmem.limit_in_bytes` 就可能会导致不能彻底删除 memcg 和对应的 cssid,也就是说应用即使已经删除了 cgroup \(`/sys/fs/cgroup/memory` 下对应的 cgroup 目录已经删除\), 但在内核中没有释放 cssid,导致内核认为的 cgroup 的数量实际数量不一致,我们也无法得知内核认为的 cgroup 数量是多少。
|
||||||
|
|
||||||
|
关于 cgroup kernel memory,在 [kernel.org](https://www.kernel.org/doc/html/latest/admin-guide/cgroup-v1/memory.html#kernel-memory-extension-config-memcg-kmem) 中有如下描述:
|
||||||
|
|
||||||
|
```
|
||||||
|
2.7 Kernel Memory Extension (CONFIG_MEMCG_KMEM)
|
||||||
|
-----------------------------------------------
|
||||||
|
|
||||||
|
With the Kernel memory extension, the Memory Controller is able to limit
|
||||||
|
the amount of kernel memory used by the system. Kernel memory is fundamentally
|
||||||
|
different than user memory, since it can't be swapped out, which makes it
|
||||||
|
possible to DoS the system by consuming too much of this precious resource.
|
||||||
|
|
||||||
|
Kernel memory accounting is enabled for all memory cgroups by default. But
|
||||||
|
it can be disabled system-wide by passing cgroup.memory=nokmem to the kernel
|
||||||
|
at boot time. In this case, kernel memory will not be accounted at all.
|
||||||
|
|
||||||
|
Kernel memory limits are not imposed for the root cgroup. Usage for the root
|
||||||
|
cgroup may or may not be accounted. The memory used is accumulated into
|
||||||
|
memory.kmem.usage_in_bytes, or in a separate counter when it makes sense.
|
||||||
|
(currently only for tcp).
|
||||||
|
|
||||||
|
The main "kmem" counter is fed into the main counter, so kmem charges will
|
||||||
|
also be visible from the user counter.
|
||||||
|
|
||||||
|
Currently no soft limit is implemented for kernel memory. It is future work
|
||||||
|
to trigger slab reclaim when those limits are reached.
|
||||||
|
```
|
||||||
|
|
||||||
|
这是一个 cgroup memory 的扩展,用于限制对 kernel memory 的使用,但该特性在老于 4.0 版本中是个实验特性,存在泄露问题,在 4.x 较低的版本也还有泄露问题,应该是造成泄露的代码路径没有完全修复,推荐 4.3 以上的内核。
|
||||||
|
|
||||||
|
## 造成容器创建失败
|
||||||
|
|
||||||
|
这个问题可能会导致创建容器失败,因为创建容器为其需要创建 cgroup 来做隔离,而低版本内核有个限制:允许创建的 cgroup 最大数量写死为 65535 \([点我跳转到 commit](https://github.com/torvalds/linux/commit/38460b48d06440de46b34cb778bd6c4855030754#diff-c04090c51d3c6700c7128e84c58b1291R3384)\),如果节点上经常创建和销毁大量容器导致创建很多 cgroup,删除容器但没有彻底删除 cgroup 造成泄露\(真实数量我们无法得知\),到达 65535 后再创建容器就会报创建 cgroup 失败并报错 `no space left on device`,使用 kubernetes 最直观的感受就是 pod 创建之后无法启动成功。
|
||||||
|
|
||||||
|
pod 启动失败,报 event 示例:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
Events:
|
||||||
|
Type Reason Age From Message
|
||||||
|
---- ------ ---- ---- -------
|
||||||
|
Normal Scheduled 15m default-scheduler Successfully assigned jenkins/jenkins-7845b9b665-nrvks to 10.10.252.4
|
||||||
|
Warning FailedCreatePodContainer 25s (x70 over 15m) kubelet, 10.10.252.4 unable to ensure pod container exists: failed to create container for [kubepods besteffort podc6eeec88-8664-11e9-9524-5254007057ba] : mkdir /sys/fs/cgroup/memory/kubepods/besteffort/podc6eeec88-8664-11e9-9524-5254007057ba: no space left on device
|
||||||
|
```
|
||||||
|
|
||||||
|
dockerd 日志报错示例:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
Dec 24 11:54:31 VM_16_11_centos dockerd[11419]: time="2018-12-24T11:54:31.195900301+08:00" level=error msg="Handler for POST /v1.31/containers/b98d4aea818bf9d1d1aa84079e1688cd9b4218e008c58a8ef6d6c3c106403e7b/start returned error: OCI runtime create failed: container_linux.go:348: starting container process caused \"process_linux.go:279: applying cgroup configuration for process caused \\\"mkdir /sys/fs/cgroup/memory/kubepods/burstable/pod79fe803c-072f-11e9-90ca-525400090c71/b98d4aea818bf9d1d1aa84079e1688cd9b4218e008c58a8ef6d6c3c106403e7b: no space left on device\\\"\": unknown"
|
||||||
|
```
|
||||||
|
|
||||||
|
kubelet 日志报错示例:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
Sep 09 18:09:09 VM-0-39-ubuntu kubelet[18902]: I0909 18:09:09.449722 18902 remote_runtime.go:92] RunPodSandbox from runtime service failed: rpc error: code = Unknown desc = failed to start sandbox container for pod "osp-xxx-com-ljqm19-54bf7678b8-bvz9s": Error response from daemon: oci runtime error: container_linux.go:247: starting container process caused "process_linux.go:258: applying cgroup configuration for process caused \"mkdir /sys/fs/cgroup/memory/kubepods/burstable/podf1bd9e87-1ef2-11e8-afd3-fa163ecf2dce/8710c146b3c8b52f5da62e222273703b1e3d54a6a6270a0ea7ce1b194f1b5053: no space left on device\""
|
||||||
|
```
|
||||||
|
|
||||||
|
新版的内核限制为 `2^31` \(可以看成几乎不限制,[点我跳转到代码](https://github.com/torvalds/linux/blob/3120b9a6a3f7487f96af7bd634ec49c87ef712ab/kernel/cgroup/cgroup.c#L5233)\): `cgroup_idr_alloc()` 传入 end 为 0 到 `idr_alloc()`, 再传给 `idr_alloc_u32()`, end 的值最终被三元运算符 `end>0 ? end-1 : INT_MAX` 转成了 `INT_MAX` 常量,即 `2^31`。所以如果新版内核有泄露问题会更难定位,表现形式会是内存消耗严重,幸运的是新版内核已经修复,推荐 4.3 以上。
|
||||||
|
|
||||||
|
### 规避方案
|
||||||
|
|
||||||
|
如果你用的低版本内核\(比如 CentOS 7 v3.10 的内核\)并且不方便升级内核,可以通过不开启 kmem accounting 来实现规避,但会比较麻烦。
|
||||||
|
|
||||||
|
kubelet 和 runc 都会给 memory cgroup 开启 kmem accounting,所以要规避这个问题,就要保证kubelet 和 runc 都别开启 kmem accounting,下面分别进行说明:
|
||||||
|
|
||||||
|
#### runc
|
||||||
|
|
||||||
|
runc 在合并 [这个PR](https://github.com/opencontainers/runc/pull/1350/files) \(2017-02-27\) 之后创建的容器都默认开启了 kmem accounting,后来社区也注意到这个问题,并做了比较灵活的修复, [PR 1921](https://github.com/opencontainers/runc/pull/1921) 给 runc 增加了 "nokmem" 编译选项,缺省的 release 版本没有使用这个选项, 自己使用 nokmem 选项编译 runc 的方法:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
cd $GO_PATH/src/github.com/opencontainers/runc/
|
||||||
|
make BUILDTAGS="seccomp nokmem"
|
||||||
|
```
|
||||||
|
|
||||||
|
docker-ce v18.09.1 之后的 runc 默认关闭了 kmem accounting,所以也可以直接升级 docker 到这个版本之后。
|
||||||
|
|
||||||
|
#### kubelet
|
||||||
|
|
||||||
|
如果是 1.14 版本及其以上,可以在编译的时候通过 build tag 来关闭 kmem accounting:
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
KUBE_GIT_VERSION=v1.14.1 ./build/run.sh make kubelet GOFLAGS="-tags=nokmem"
|
||||||
|
```
|
||||||
|
|
||||||
|
如果是低版本需要修改代码重新编译。kubelet 在创建 pod 对应的 cgroup 目录时,也会调用 libcontianer 中的代码对 cgroup 做设置,在 `pkg/kubelet/cm/cgroup_manager_linux.go` 的 `Create` 方法中,会调用 `Manager.Apply` 方法,最终调用 `vendor/github.com/opencontainers/runc/libcontainer/cgroups/fs/memory.go` 中的 `MemoryGroup.Apply` 方法,开启 kmem accounting。这里也需要进行处理,可以将这部分代码注释掉然后重新编译 kubelet。
|
||||||
|
|
||||||
|
## 参考资料
|
||||||
|
|
||||||
|
* 一行 kubernetes 1.9 代码引发的血案(与 CentOS 7.x 内核兼容性问题): [http://dockone.io/article/4797](http://dockone.io/article/4797)
|
||||||
|
* Cgroup泄漏--潜藏在你的集群中: [https://tencentcloudcontainerteam.github.io/2018/12/29/cgroup-leaking/](https://tencentcloudcontainerteam.github.io/2018/12/29/cgroup-leaking/)
|
||||||
|
|
@ -0,0 +1,130 @@
|
||||||
|
# .Net Core 配置文件无法热加载
|
||||||
|
|
||||||
|
## 问题描述
|
||||||
|
|
||||||
|
在使用 kubernetes 部署应用时, 我使用 `kubernetes` 的 `configmap` 来管理配置文件: `appsettings.json`
|
||||||
|
, 修改configmap 的配置文件后, 我来到了容器里, 通过 `cat /app/config/appsetting.json` 命令查看容器是否已经加载了最新的配置文件, 很幸运的是, 通过命令行查看容器配置发现已经处于最新状态(修改configmap后10-15s 生效), 我尝试请求应用的API, 发现API 在执行过程中使用的配置是老旧的内容, 而不是最新的内容。在本地执行应用时并未出现配置无法热更新的问题。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# 相关版本
|
||||||
|
kubernetes 版本: 1.14.2
|
||||||
|
# 要求版本大于等于 3.1
|
||||||
|
.Net core: 3.1
|
||||||
|
|
||||||
|
# 容器 os-release (并非 windows)
|
||||||
|
|
||||||
|
NAME="Debian GNU/Linux"
|
||||||
|
VERSION_ID="10"
|
||||||
|
VERSION="10 (buster)"
|
||||||
|
VERSION_CODENAME=buster
|
||||||
|
ID=debian
|
||||||
|
HOME_URL="https://www.debian.org/"
|
||||||
|
SUPPORT_URL="https://www.debian.org/support"
|
||||||
|
BUG_REPORT_URL="https://bugs.debian.org/"
|
||||||
|
|
||||||
|
# 基础镜像:
|
||||||
|
mcr.microsoft.com/dotnet/core/sdk:3.1-buster
|
||||||
|
mcr.microsoft.com/dotnet/core/aspnet:3.1-buster-slim
|
||||||
|
```
|
||||||
|
|
||||||
|
## 问题猜想
|
||||||
|
|
||||||
|
通过命令行排查发现最新的 `configmap` 配置内容已经在容器的指定目录上更新到最新,但是应用仍然使用老旧的配置内容, 这意味着问题发生在: configmap->**容器->应用**, 容器和应用之间, 容器指定目录下的配置更新并没有触发 `.Net` 热加载机制, 那究竟是为什么没有触发配置热加载,需要深挖根本原因, 直觉猜想是: 查看 `.Net Core` 标准库的配置热加载的实现检查触发条件, 很有可能是触发的条件不满足导致应用配置无法重新加载。
|
||||||
|
|
||||||
|
## 问题排查
|
||||||
|
|
||||||
|
猜想方向是热更新的触发条件不满足, 我们熟知使用 `configmap` 挂载文件是使用[symlink](https://en.wikipedia.org/wiki/Symbolic_link)来挂载, 而非常用的物理文件系统, 在修改完 `configmap` , 容器重新加载配置后,这一过程并不会改变文件的修改时间等信息(从容器的角度看)。对此,我们做了一个实验,通过对比configmap修改前和修改后来观察配置( `appsettings.json` )在容器的属性变化(注: 均在容器加载最新配置后对比), 使用 `stat` 命令来佐证了这个细节点。
|
||||||
|
|
||||||
|
**Before:**
|
||||||
|
|
||||||
|
```bash
|
||||||
|
root@app-785bc59df6-gdmnf:/app/Config# stat appsettings.json
|
||||||
|
File: Config/appsettings.json -> ..data/appsettings.json
|
||||||
|
Size: 35 Blocks: 0 IO Block: 4096 symbolic link
|
||||||
|
Device: ca01h/51713d Inode: 27263079 Links: 1
|
||||||
|
Access: (0777/lrwxrwxrwx) Uid: ( 0/ root) Gid: ( 0/ root)
|
||||||
|
Access: 2020-04-25 08:21:18.490453316 +0000
|
||||||
|
Modify: 2020-04-25 08:21:18.490453316 +0000
|
||||||
|
Change: 2020-04-25 08:21:18.490453316 +0000
|
||||||
|
Birth: -
|
||||||
|
```
|
||||||
|
|
||||||
|
**After:**
|
||||||
|
|
||||||
|
```bash
|
||||||
|
root@app-785bc59df6-gdmnf:/app/Config# stat appsettings.json
|
||||||
|
File: appsettings.json -> ..data/appsettings.json
|
||||||
|
Size: 35 Blocks: 0 IO Block: 4096 symbolic link
|
||||||
|
Device: ca01h/51713d Inode: 27263079 Links: 1
|
||||||
|
Access: (0777/lrwxrwxrwx) Uid: ( 0/ root) Gid: ( 0/ root)
|
||||||
|
Access: 2020-04-25 08:21:18.490453316 +0000
|
||||||
|
Modify: 2020-04-25 08:21:18.490453316 +0000
|
||||||
|
Change: 2020-04-25 08:21:18.490453316 +0000
|
||||||
|
Birth: -
|
||||||
|
```
|
||||||
|
|
||||||
|
通过标准库源码发现, `.Net core` 配置热更新机制似乎是基于文件的最后修改日期来触发的, 根据上面的前后对比显而易见, `configmap` 的修改并没有让容器里的指定的文件的最后修改日期改变,也就未触发 `.Net` 应用配置的热加载。
|
||||||
|
|
||||||
|
## 解决办法
|
||||||
|
|
||||||
|
既然猜想基本得到证实, 由于不太熟悉这门语言, 我们尝试在网络上寻找解决办法,很幸运的是我们找到了找到了相关的内容, [fbeltrao](https://github.com/fbeltrao) 开源了一个第三方库([ConfigMapFileProvider](https://github.com/fbeltrao/ConfigMapFileProvider)) 来专门解决这个问题,**通过监听文件内容hash值的变化实现配置热加载**。
|
||||||
|
于是, 我们在修改了项目的代码:
|
||||||
|
|
||||||
|
|
||||||
|
**Before:**
|
||||||
|
|
||||||
|
```csharp
|
||||||
|
// 配置被放在了/app/Config/ 目录下
|
||||||
|
var configPath = Path.Combine(env.ContentRootPath, "Config");
|
||||||
|
config.AddJsonFile(Path.Combine(configPath, "appsettings.json"),
|
||||||
|
optional: false,
|
||||||
|
reloadOnChange: true);
|
||||||
|
```
|
||||||
|
|
||||||
|
**After:**
|
||||||
|
|
||||||
|
```csharp
|
||||||
|
// 配置被放在了/app/Config/ 目录下
|
||||||
|
config.AddJsonFile(ConfigMapFileProvider.FromRelativePath("Config"),
|
||||||
|
"appsettings.json",
|
||||||
|
optional: false,
|
||||||
|
reloadOnChange: true);
|
||||||
|
```
|
||||||
|
|
||||||
|
修改完项目的代码后, 重新构建镜像, 更新部署在 `kubernetes` 上的应用, 然后再次测试, 到此为止, 会出现两种状态:
|
||||||
|
|
||||||
|
1. 一种是你热加载配置完全可用, 非常值得祝贺, 你已经成功修复了这个bug;
|
||||||
|
2. 一种是你的热加载配置功能还存在 bug, 比如: 上一次请求, 配置仍然使用的老旧配置内容, 下一次请求却使用了最新的配置内容,这个时候, 我们需要继续向下排查: `.NET Core` 引入了`Options`模式,使用类来表示相关的设置组,用强类型的类来表达配置项(白话大概表述为: 代码里面有个对象对应配置里的某个字段, 配置里对应的字段更改会触发代码里对象的属性变化), 示例如下:
|
||||||
|
|
||||||
|
**配置示例:**
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ cat appsettings.json
|
||||||
|
"JwtIssuerOptions": {
|
||||||
|
"Issuer": "test",
|
||||||
|
"Audience": "test",
|
||||||
|
"SecretKey": "test"
|
||||||
|
...
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
**代码示例:**
|
||||||
|
|
||||||
|
```csharp
|
||||||
|
services.Configure<JwtIssuerOptions>(Configuration.GetSection("JwtIssuerOptions"));
|
||||||
|
```
|
||||||
|
|
||||||
|
而 Options 模式分为三种:
|
||||||
|
|
||||||
|
1. `IOptions`: Singleton(单例),值一旦生成, 除非通过代码的方式更改,否则它的值不会更新
|
||||||
|
2. `IOptionsMonitor`: Singleton(单例), 通过 `IOptionsChangeTokenSource` 能够和配置文件一起更新,也能通过代码的方式更改值
|
||||||
|
3. `IOptionsSnapshot`: Scoped,配置文件更新的下一次访问,它的值会更新,但是它不能跨范围通过代码的方式更改值,只能在当前范围(请求)内有效。
|
||||||
|
|
||||||
|
在知道这三种模式的意义后,我们已经完全找到了问题的根因, 把 `Options` 模式设置为:`IOptionsMonitor`就能解决完全解决配置热加载的问题。
|
||||||
|
|
||||||
|
## 相关链接
|
||||||
|
|
||||||
|
1. [配置监听ConfigMapFileProvider](https://github.com/fbeltrao/ConfigMapFileProvider)
|
||||||
|
2. [相似的Issue: 1175](https://github.com/dotnet/extensions/issues/1175)
|
||||||
|
3. [官方Options 描述](https://docs.microsoft.com/en-us/aspnet/core/fundamentals/configuration/options?view=aspnetcore-3.1)
|
||||||
|
4. [IOptions、IOptionsMonitor以及IOptionsSnapshot 测试](https://www.cnblogs.com/wenhx/p/ioptions-ioptionsmonitor-and-ioptionssnapshot.html)
|
||||||
|
|
@ -0,0 +1,54 @@
|
||||||
|
# 多容器场景下修改 hosts 失效
|
||||||
|
|
||||||
|
## 问题现象
|
||||||
|
|
||||||
|
业务容器启动的逻辑中,修改了 `/etc/hosts` 文件,当 Pod 只存在这一个业务容器时,文件可以修改成功,但存在多个时 (比如注入了 istio 的 sidecar),修改可能会失效。
|
||||||
|
|
||||||
|
## 分析
|
||||||
|
|
||||||
|
1. 容器中的 `/etc/hosts` 是由 kubelet 生成并挂载到 Pod 中所有容器,如果 Pod 有多个容器,它们挂载的 `/etc/hosts` 文件都对应宿主机上同一个文件,路径通常为 `/var/lib/kubelet/pods/<pod-uid>/etc-hosts`。
|
||||||
|
> 如果是 docker 运行时,可以通过 `docker inspect <container-id> -f {{.HostsPath}}` 查看。
|
||||||
|
|
||||||
|
2. kubelet 在启动容器时,都会走如下的调用链(`makeMounts->makeHostsMount->ensureHostsFile`)来给容器挂载 `/etc/hosts`,而在 `ensureHostsFile` 函数中都会重新创建一个新的 `etc-hosts` 文件,导致在其他容器中对 `/etc/hosts` 文件做的任何修改都被还原了。
|
||||||
|
|
||||||
|
所以,当 Pod 中存在多个容器时,容器内修改 `/etc/hosts` 的操作可能会被覆盖回去。
|
||||||
|
|
||||||
|
## 解决方案
|
||||||
|
|
||||||
|
通常不推荐在容器内修改 `/etc/hosts`,应该采用更云原生的做法,参考 [自定义域名解析](../../../best-practices/dns/customize-dns-resolution.md)。
|
||||||
|
|
||||||
|
### 使用 HostAliases
|
||||||
|
|
||||||
|
如果只是某一个 workload 需要 hosts,可以用 HostAliases:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: apps/v1
|
||||||
|
kind: Deployment
|
||||||
|
metadata:
|
||||||
|
name: host
|
||||||
|
spec:
|
||||||
|
replicas: 1
|
||||||
|
selector:
|
||||||
|
matchLabels:
|
||||||
|
app: host
|
||||||
|
template:
|
||||||
|
metadata:
|
||||||
|
labels:
|
||||||
|
app: host
|
||||||
|
spec:
|
||||||
|
hostAliases: # 这下面定义 hosts
|
||||||
|
- ip: "10.10.10.10"
|
||||||
|
hostnames:
|
||||||
|
- "mysql.example.com"
|
||||||
|
containers:
|
||||||
|
- name: nginx
|
||||||
|
image: nginx:latest
|
||||||
|
```
|
||||||
|
|
||||||
|
> 参考官方文档 [Adding entries to Pod /etc/hosts with HostAliases](https://kubernetes.io/docs/tasks/network/customize-hosts-file-for-pods/)。
|
||||||
|
|
||||||
|
### CoreDNS hosts
|
||||||
|
|
||||||
|
如果是多个 workload 都需要共同的 hosts,可以修改集群 CoreDNS 配置,在集群级别增加 hosts:
|
||||||
|
|
||||||
|
|
||||||
|
|
@ -0,0 +1,15 @@
|
||||||
|
# Job 无法被删除
|
||||||
|
|
||||||
|
## 原因
|
||||||
|
|
||||||
|
* 可能是 k8s 的一个bug: [https://github.com/kubernetes/kubernetes/issues/43168](https://github.com/kubernetes/kubernetes/issues/43168)
|
||||||
|
* 本质上是脏数据问题,Running+Succeed != 期望Completions 数量,低版本 kubectl 不容忍,delete job 的时候打开debug(加-v=8),会看到kubectl不断在重试,直到达到timeout时间。新版kubectl会容忍这些,删除job时会删除关联的pod
|
||||||
|
|
||||||
|
## 解决方法
|
||||||
|
|
||||||
|
1. 升级 kubectl 版本,1.12 以上
|
||||||
|
2. 低版本 kubectl 删除 job 时带 `--cascade=false` 参数\(如果job关联的pod没删完,加这个参数不会删除关联的pod\)
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl delete job --cascade=false <job name>
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,116 @@
|
||||||
|
# 系统时间被修改导致 sandbox 冲突
|
||||||
|
|
||||||
|
## 问题描述
|
||||||
|
|
||||||
|
节点重启后,节点上的存量 pod 出现无法正常 running,容器(sandbox)在不断重启的现象。
|
||||||
|
|
||||||
|
查看事件,提示是 sandbox 的 name 存在冲突 (`The container name xxx is already used by yyy`),具体事件如下:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## 结论先行
|
||||||
|
|
||||||
|
这个问题的根因是节点的时间问题,节点重启前的系统时间比节点重启后的系统时间提前,影响了 kubelet 内部缓存 cache 中的 sandbox 的排序,导致 kubelet 每次起了一个新 sandbox 之后,都只会拿到旧的 sandbox,导致了 sandbox 的不断创建和 name 冲突。
|
||||||
|
|
||||||
|
## 排查日志
|
||||||
|
|
||||||
|
先来看下 kubelet 的日志,部分截图如下:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
截图上是同一个 pod(kube-proxy)最近的两次 podWorker 逻辑截图,都抛出了同一个提示:`No ready sandbox for pod <pod-name> can be found, Need to start a new one`。这个应该就是造成容器冲突的来源,每次沉浸到 podWorker 的逻辑之后,podWorker 都要尝试去创建一个新的sandbox,进而造成容器冲突。
|
||||||
|
|
||||||
|
疑问:为啥 podWorker 每次都去创建一个新的 sandbox?
|
||||||
|
|
||||||
|
接下来继续调大 kubelet 的日志级别(k8s v1.16已经支持动态调整,这里调大日志级别到V(6)),这里主要是尝试拿到某个 pod 所关联的所有 sandbox,截图如下:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
通过配合节点上执行 docker inspect(ps)相关命令发现,异常的 pod(kube-proxy)存在两个 sandbox(重启前的+重启后的),并且在 sandboxID 数组中的排序为 `[重启前的sandbox, 重启后的 sandbox]` (这里先 mark 一下)。
|
||||||
|
|
||||||
|
## 相关知识
|
||||||
|
|
||||||
|
在进一步分析之前,我们先介绍下相关背景知识。
|
||||||
|
|
||||||
|
### Pod 创建流程
|
||||||
|
|
||||||
|
先来一起熟悉下 pod 创建流程:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### PLEG 组件
|
||||||
|
|
||||||
|
再看下 `PLEG` 的工作流程。kubelet 启动之后,会运行起 `PLEG` 组件,定期的缓存 pod 的信息(包括 pod status)。在 `PLEG` 的每次 relist 逻辑中,会对比 `old pod` 和 `new pod`,检查是否存在变化,如果新旧 pod 之间存在变化,则开始执行下面两个逻辑:
|
||||||
|
1. 生成 event 事件,比如 containerStart 等,最后再投递到 `eventChannel` 中,供 podWorker 来消费。
|
||||||
|
2. 更新内部缓存 cache。在跟新缓存 `updateCache` 的逻辑中,会调用 runtime 的相关接口获取到与 pod 相关的 status 状态信息,然后并缓存到内部缓存 cache中,最后发起通知 ( podWorker 会发起订阅) 。
|
||||||
|
|
||||||
|
podStatus的数据结构如下:
|
||||||
|
|
||||||
|
```go
|
||||||
|
# podStatus
|
||||||
|
type PodStatus struct {
|
||||||
|
// ID of the pod.
|
||||||
|
ID types.UID
|
||||||
|
...
|
||||||
|
...
|
||||||
|
// Only for kuberuntime now, other runtime may keep it nil.
|
||||||
|
SandboxStatuses []*runtimeapi.PodSandboxStatus
|
||||||
|
}
|
||||||
|
|
||||||
|
# SandboxStatus
|
||||||
|
// PodSandboxStatus contains the status of the PodSandbox.
|
||||||
|
type PodSandboxStatus struct {
|
||||||
|
// ID of the sandbox.
|
||||||
|
Id string `protobuf:"bytes,1,opt,name=id,proto3" json:"id,omitempty"`
|
||||||
|
...
|
||||||
|
// Creation timestamp of the sandbox in nanoseconds. Must be > 0.
|
||||||
|
CreatedAt int64 `protobuf:"varint,4,opt,name=created_at,json=createdAt,proto3" json:"created_at,omitempty"`
|
||||||
|
...
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
podStatus 会保存 pod 的一些基础信息,再加上 containerStatus 和 sandboxStatus 信息。
|
||||||
|
|
||||||
|
这里重点关注下 SandboxStatus 的排序问题,配合代码可以发现,排序是按照 sandbox 的 Create time 来执行的,并且时间越新,位置越靠前。排序相关的代码部分如下:
|
||||||
|
|
||||||
|
```go
|
||||||
|
// Newest first.
|
||||||
|
type podSandboxByCreated []*runtimeapi.PodSandbox
|
||||||
|
|
||||||
|
func (p podSandboxByCreated) Len() int { return len(p) }
|
||||||
|
func (p podSandboxByCreated) Swap(i, j int) { p[i], p[j] = p[j], p[i] }
|
||||||
|
func (p podSandboxByCreated) Less(i, j int) bool { return p[i].CreatedAt > p[j].CreatedAt }
|
||||||
|
```
|
||||||
|
|
||||||
|
### podWorker 组件
|
||||||
|
|
||||||
|
最后再看下 podWorker 的工作流程。podWorker 的工作就是负责 pod 在节点上的正确运行(比如挂载 volume,新起 sandbox,新起 container 等),一个 pod 对应一个 podWorker,直到 pod 销毁。当节点重启后,kubelet 会收到 `type=ADD` 的事件来创建 pod 对象。
|
||||||
|
|
||||||
|
当 pod 更新之后,会触发 `event=containerStart` 事件的投递,然后 kubelet 就会收到 `type=SYNC` 的事件,来更新 pod 对象。在每次 podWorker 的内部逻辑中(`managePodLoop()`) 中,会存在一个 podStatus(内部缓存)的订阅,如下:
|
||||||
|
|
||||||
|
```go
|
||||||
|
// This is a blocking call that would return only if the cache
|
||||||
|
// has an entry for the pod that is newer than minRuntimeCache
|
||||||
|
// Time. This ensures the worker doesn't start syncing until
|
||||||
|
// after the cache is at least newer than the finished time of
|
||||||
|
// the previous sync.
|
||||||
|
status, err := p.podCache.GetNewerThan(podUID, lastSyncTime)
|
||||||
|
```
|
||||||
|
|
||||||
|
来等待内部 cache 中的 podStatus 更新,然后再操作后续动作(是否重新挂载 volume、是否重建 sandbox,是否重建 container 等)。
|
||||||
|
|
||||||
|
## 复现问题,定位根因
|
||||||
|
|
||||||
|
接下来,我们一起来模拟复现下问题现场。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在节点重启之前,由于是新建节点后,所以对于 pod 来说,status 中只有一个命名以 `_0` 结尾的 sandbox。当操作重启节点之后,kubelet 收到 `type=ADD` 的事件,podWorker 开始创建 pod,由于之前以 `_0` 命名结尾的 sandbox 已经 died 了,所以会新建一个新的以 `_1` 命名结尾的 sandbox,当新的以 `_1` 命名结尾的 sandbox 运行之后(containerStarted),就会投递一个 `type=SYNC` 的事件给到 kubelet,然后 podWorker 会被再次触发(内部 cache 也更新了,通知也发出了)。正常情况下,podWorker 会拿到 podStatus 中新的 sandbox(以 `_1` 命名结尾的),就不会再创建 sandbox 了,也就是不会发生 name 冲突的问题。而用户的环境却是,此时拿到了以 `_0` 命名结尾的旧的 sandbox,所以再新一轮的 podWorker 逻辑中,会再次创建一个新的以 `_1` 命名的 sandbox,从而产生冲突。
|
||||||
|
|
||||||
|
而这里的根因就是时间问题,节点重启前的sandbox(以 `_0` 命名结尾的)的 `create time` ,比节点重启后的sandbox(以 `_1` 命名结尾的)的 `create time` 还要提前,所以导致了内部 cache 中 sandbox 的排序发生了错乱,从而触发 name 冲突问题。
|
||||||
|
|
||||||
|
## 解决方案
|
||||||
|
|
||||||
|
根据上面的排查发现,kubelet 的内部缓存中,sandbox 的排序是有系统时间来决定的,所以,尽量保证 k8s 集群中的时间有正确同步,或者不要乱改节点上的时间。
|
||||||
|
|
@ -0,0 +1,53 @@
|
||||||
|
# 磁盘 IO 过高导致 Pod 创建超时
|
||||||
|
|
||||||
|
## 问题背景
|
||||||
|
|
||||||
|
在创建 TKE 集群的 worker node 时,用户往往会单独再购买一块云盘,绑到节点上,用于 docker 目录挂载所用(将 docker 目录单独放到数据盘上)。此时,docker 的读写层(RWLayer)就会落到云盘上。
|
||||||
|
|
||||||
|
在该使用场景下,有用户反馈,在创建 Pod 时,会偶现 Pod 创建超时的报错,具体报错如下:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## 结论先行
|
||||||
|
|
||||||
|
当单独挂载一块云盘用于 docker 目录挂载使用时,会出现如下情况:云盘的真实使用超过云盘所支持的最大吞吐,导致 pod 创建超时。
|
||||||
|
|
||||||
|
## pod 失败的异常事件
|
||||||
|
|
||||||
|
从报错的事件上来看,可以看到报错是 create sandbox 时,rpc 调用超时了。
|
||||||
|
|
||||||
|
在 create sandbox 时,dockershim 会发起两次dockerd调用,分别是:`POST /containers/create` 和 `POST /containers/start`。而事件上给出的报错,就是 `POST /containers/create` 时的报错。
|
||||||
|
|
||||||
|
## 日志和堆栈分析
|
||||||
|
|
||||||
|
开启dockerd的debug模式后,在异常报错时间段内,能够看到有与 `POST /containers/create` 相关的日志,但是并没有看到与 `POST /containers/start` 相关的日志,说明 docker daemon 有收到 create container 的 rpc 请求,但是并没有在timeout的时间内,完成请求。可以对应到 pod 的异常报错事件。
|
||||||
|
|
||||||
|
当稳定复现问题(rpc timeout)之后,手动尝试在节点上通过curl命令,向docker daemon请求create containber。
|
||||||
|
|
||||||
|
命令如下:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ curl --unix-socket /var/run/docker.sock "http://1.38/containers/create?name=test01" -v -X POST -H "Content-Type: application/json" -d '{"Image": "nginx:latest"}'
|
||||||
|
```
|
||||||
|
|
||||||
|
当执行 curl 命令之后,确实要等很长时间(>2min)才返回。
|
||||||
|
|
||||||
|
并抓取 dockerd 的堆栈信息,发现如下:**在问题发生时,有一个 delete container 动作,长时间卡在了 unlinkat 系统调用。**
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
container 的 create 和 delete 请求都会沉浸到 layer store组件,来创建或者删除容器的读写层。
|
||||||
|
|
||||||
|
在 layer store 组件中,维护了一个内部数据结构(layerStore),其中有一个字段 `mounts map[string]*mountedLayer` 用于维护所有容器的读写层信息,并且还配置了一个读写锁用于保护该信息(数据mounts的任何增删操作都需要先获取一个读写锁)。如果某个请求(比如container delete)长时间没有返回,就会阻塞其他 container 的创建或者删除。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## 云盘监控
|
||||||
|
|
||||||
|
云盘的相关监控可以重点关注以下三个指标:云盘写流量、IO await、IO %util。
|
||||||
|
|
||||||
|
## 解决方案
|
||||||
|
|
||||||
|
配合业务场景需求,更换更高性能的云盘。
|
||||||
|
|
||||||
|
腾讯云上的云硬盘种类和吞吐指标可以 [官方参考文档](https://cloud.tencent.com/document/product/362/2353) 。
|
||||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue