update at 2024-04-27 11:00:38
parent
da2e3f0f59
commit
ff1ef613d9
|
|
@ -14,6 +14,10 @@
|
|||
1. `Ollama` + `OpenWebUI` 所需 YAML 相对较少,直接根据需要写 YAML 更直接和灵活。
|
||||
2. 不需要研究 `OpenWebUI` 提供的 `kustomize` 和 `helm` 方式的用法。
|
||||
|
||||
## 模型选型
|
||||
|
||||
Llama3 目前主要有 `8b` 和 `70b` 两个模型,分别对应 80 亿和 700 亿规模的参数模型,CPU 和 GPU 都支持,`8b` 是小模型,对配置要求不高,一般处于成本考虑,可以直接使用 CPU 运行,而 `70b` 则是大模型, CPU 肯定吃不消,GPU 的配置低也几乎跑不起来,主要是显存要大才行,经实测,24G 显存跑起来会非常非常慢,32G 的也比较吃力,40G 的相对流畅(比如 Nvdia A100)。
|
||||
|
||||
## 准备 namespace
|
||||
|
||||
准备一个 namespace,用于部署运行 llama3 所需的服务,这里使用 `llama` namespace:
|
||||
|
|
@ -40,7 +44,17 @@ open-webui 是大模型的 web 界面,支持 llama 系列的大模型,通过
|
|||
kubectl -n llama port-forward service/webui 8080:8080
|
||||
```
|
||||
|
||||
浏览器打开:`http://localhost:8080`,创建账号然后进入 web 界面,选择 llama3 的模型,然后开启对话。
|
||||
浏览器打开:`http://localhost:8080`,首次打开需要创建账号,第一个创建的账号为管理员账号。
|
||||
|
||||
## 下载模型
|
||||
|
||||
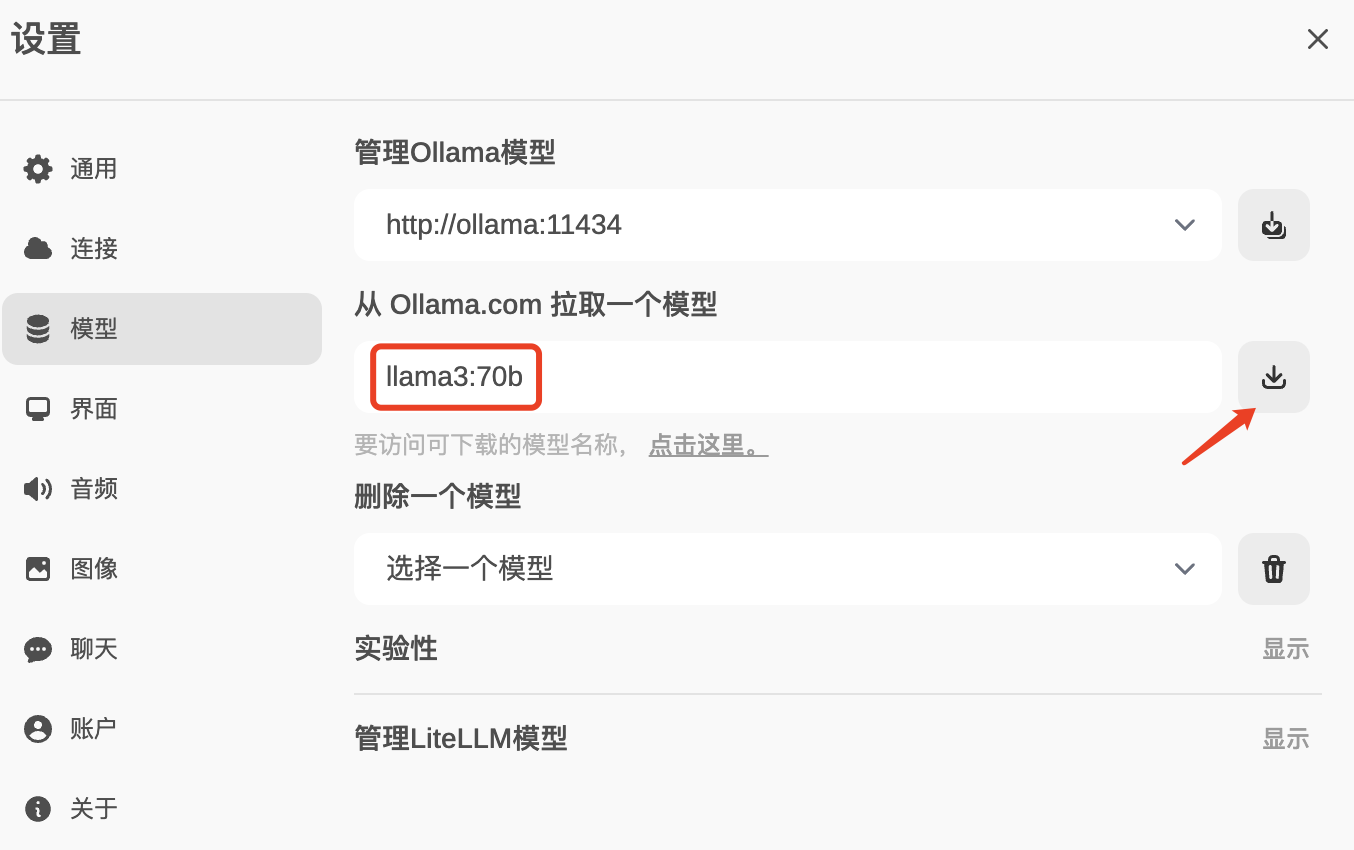
进入 OpenWebUI 并登录后,在 `设置-模型` 里,输出需要下载的 llama3 模型并点击下载按钮(除了基础的模型,还有许多微调的模型,参考 [llama3 可用模型列表](https://ollama.com/library/llama3/tags))。
|
||||
|
||||
|
||||
|
||||
接下来就是等待下载完成:
|
||||
|
||||

|
||||
|
||||
## 常见问题
|
||||
|
||||
|
|
@ -91,6 +105,6 @@ Error: pull model manifest: Get "https://registry.ollama.ai/v2/library/llama3/ma
|
|||
|
||||
## 参考资料
|
||||
|
||||
* Llama3 模型库:https://ollama.com/library/llama3
|
||||
* Llama3 可用模型列表: https://ollama.com/library/llama3/tags
|
||||
* Open WebUI: https://docs.openwebui.com/
|
||||
* Ollama: https://ollama.com/
|
||||
|
|
|
|||
Loading…
Reference in New Issue