mirror of https://github.com/dunwu/db-tutorial.git
feat: 更新文档
parent
9f69c6f192
commit
61edc8b97d
199
README.md
199
README.md
|
|
@ -31,75 +31,94 @@
|
||||||
> - 🔁 项目同步维护:[Github](https://github.com/dunwu/db-tutorial/) | [Gitee](https://gitee.com/turnon/db-tutorial/)
|
> - 🔁 项目同步维护:[Github](https://github.com/dunwu/db-tutorial/) | [Gitee](https://gitee.com/turnon/db-tutorial/)
|
||||||
> - 📖 电子书阅读:[Github Pages](https://dunwu.github.io/db-tutorial/) | [Gitee Pages](https://turnon.gitee.io/db-tutorial/)
|
> - 📖 电子书阅读:[Github Pages](https://dunwu.github.io/db-tutorial/) | [Gitee Pages](https://turnon.gitee.io/db-tutorial/)
|
||||||
|
|
||||||
|
## 分布式
|
||||||
|
|
||||||
|
### 分布式综合
|
||||||
|
|
||||||
|
- [分布式面试总结](https://dunwu.github.io/waterdrop/pages/f9209d/)
|
||||||
|
|
||||||
|
### 分布式理论
|
||||||
|
|
||||||
|
- [分布式理论](https://dunwu.github.io/waterdrop/pages/286bb3/) - 关键词:`拜占庭将军`、`CAP`、`BASE`、`错误的分布式假设`
|
||||||
|
- [共识性算法 Paxos](https://dunwu.github.io/waterdrop/pages/0276bb/) - 关键词:`共识性算法`
|
||||||
|
- [共识性算法 Raft](https://dunwu.github.io/waterdrop/pages/4907dc/) - 关键词:`共识性算法`
|
||||||
|
- [分布式算法 Gossip](https://dunwu.github.io/waterdrop/pages/71539a/) - 关键词:`数据传播`
|
||||||
|
|
||||||
|
### 分布式关键技术
|
||||||
|
|
||||||
|
- 集群
|
||||||
|
- 复制
|
||||||
|
- 分区
|
||||||
|
- 选主
|
||||||
|
|
||||||
|
#### 流量调度
|
||||||
|
|
||||||
|
- [流量控制](https://dunwu.github.io/waterdrop/pages/60bb6d/) - 关键词:`限流`、`熔断`、`降级`、`计数器法`、`时间窗口法`、`令牌桶法`、`漏桶法`
|
||||||
|
- [负载均衡](https://dunwu.github.io/waterdrop/pages/98a1c1/) - 关键词:`轮询`、`随机`、`最少连接`、`源地址哈希`、`一致性哈希`、`虚拟 hash 槽`
|
||||||
|
- [服务路由](https://dunwu.github.io/waterdrop/pages/3915e8/) - 关键词:`路由`、`条件路由`、`脚本路由`、`标签路由`
|
||||||
|
- 服务网关
|
||||||
|
- [分布式会话](https://dunwu.github.io/waterdrop/pages/95e45f/) - 关键词:`粘性 Session`、`Session 复制共享`、`基于缓存的 session 共享`
|
||||||
|
|
||||||
|
#### 数据调度
|
||||||
|
|
||||||
|
- [数据缓存](https://dunwu.github.io/waterdrop/pages/fd0aaa/) - 关键词:`进程内缓存`、`分布式缓存`、`缓存雪崩`、`缓存穿透`、`缓存击穿`、`缓存更新`、`缓存预热`、`缓存降级`
|
||||||
|
- [读写分离](https://dunwu.github.io/waterdrop/pages/3faf18/)
|
||||||
|
- [分库分表](https://dunwu.github.io/waterdrop/pages/e1046e/) - 关键词:`分片`、`路由`、`迁移`、`扩容`、`双写`、`聚合`
|
||||||
|
- [分布式 ID](https://dunwu.github.io/waterdrop/pages/3ae455/) - 关键词:`UUID`、`自增序列`、`雪花算法`、`Leaf`
|
||||||
|
- [分布式事务](https://dunwu.github.io/waterdrop/pages/e1881c/) - 关键词:`2PC`、`3PC`、`TCC`、`本地消息表`、`MQ 消息`、`SAGA`
|
||||||
|
- [分布式锁](https://dunwu.github.io/waterdrop/pages/40ac64/) - 关键词:`数据库`、`Redis`、`ZooKeeper`、`互斥`、`可重入`、`死锁`、`容错`、`自旋尝试`
|
||||||
|
|
||||||
|
#### 资源调度
|
||||||
|
|
||||||
|
- 弹性伸缩
|
||||||
|
|
||||||
|
#### 服务治理
|
||||||
|
|
||||||
|
- [服务注册和发现](https://dunwu.github.io/waterdrop/pages/1a90aa/)
|
||||||
|
- [服务容错](https://dunwu.github.io/waterdrop/pages/e32c7e/)
|
||||||
|
- 服务编排
|
||||||
|
- 服务版本管理
|
||||||
|
|
||||||
## 数据库综合
|
## 数据库综合
|
||||||
|
|
||||||
### 分布式存储原理
|
- [Nosql 技术选型](docs/01.计算机科学/02.数据库/01.数据库综合/01.Nosql技术选型.md)
|
||||||
|
- [数据结构与数据库索引](docs/01.计算机科学/02.数据库/01.数据库综合/02.数据结构与数据库索引.md)
|
||||||
#### 分布式理论
|
|
||||||
|
|
||||||
- [分布式理论](https://dunwu.github.io/design/pages/367308/)
|
|
||||||
- [深入剖析共识性算法 Paxos](https://dunwu.github.io/design/pages/874539/)
|
|
||||||
- [深入剖析共识性算法 Raft](https://dunwu.github.io/design/pages/e40812/)
|
|
||||||
- [分布式算法 Gossip](https://dunwu.github.io/design/pages/d15993/)
|
|
||||||
|
|
||||||
#### 分布式关键技术
|
|
||||||
|
|
||||||
##### 流量调度
|
|
||||||
|
|
||||||
- [流量控制](https://dunwu.github.io/design/pages/282676/)
|
|
||||||
- [深入浅出负载均衡](https://dunwu.github.io/design/pages/b7ca44/)
|
|
||||||
- [服务路由](https://dunwu.github.io/design/pages/d04ece/)
|
|
||||||
- [分布式会话基本原理](https://dunwu.github.io/design/pages/3e66c2/)
|
|
||||||
|
|
||||||
##### 数据调度
|
|
||||||
|
|
||||||
- [缓存基本原理](https://dunwu.github.io/design/pages/471208/)
|
|
||||||
- [读写分离基本原理](https://dunwu.github.io/design/pages/7da6ca/)
|
|
||||||
- [分库分表基本原理](https://dunwu.github.io/design/pages/103382/)
|
|
||||||
- [分布式 ID 基本原理](https://dunwu.github.io/design/pages/0b2e59/)
|
|
||||||
- [分布式事务基本原理](https://dunwu.github.io/design/pages/910bad/)
|
|
||||||
- [分布式锁基本原理](https://dunwu.github.io/design/pages/69360c/)
|
|
||||||
|
|
||||||
### 其他
|
|
||||||
|
|
||||||
- [Nosql 技术选型](docs/01.数据库综合/01.Nosql技术选型.md)
|
|
||||||
- [数据结构与数据库索引](docs/01.数据库综合/02.数据结构与数据库索引.md)
|
|
||||||
|
|
||||||
## 数据库中间件
|
## 数据库中间件
|
||||||
|
|
||||||
- [ShardingSphere 简介](docs/02.数据库中间件/01.Shardingsphere/01.ShardingSphere简介.md)
|
- [ShardingSphere 简介](docs/01.计算机科学/02.数据库/02.数据库中间件/01.Shardingsphere/01.ShardingSphere简介.md)
|
||||||
- [ShardingSphere Jdbc](docs/02.数据库中间件/01.Shardingsphere/02.ShardingSphereJdbc.md)
|
- [ShardingSphere Jdbc](docs/01.计算机科学/02.数据库/02.数据库中间件/01.Shardingsphere/02.ShardingSphereJdbc.md)
|
||||||
- [版本管理中间件 Flyway](docs/02.数据库中间件/02.Flyway.md)
|
- [版本管理中间件 Flyway](docs/01.计算机科学/02.数据库/02.数据库中间件/02.Flyway.md)
|
||||||
|
|
||||||
## 关系型数据库
|
## 关系型数据库
|
||||||
|
|
||||||
> [关系型数据库](docs/03.关系型数据库) 整理主流关系型数据库知识点。
|
> [关系型数据库](docs/01.计算机科学/02.数据库/03.关系型数据库) 整理主流关系型数据库知识点。
|
||||||
|
|
||||||
### 公共知识
|
### 公共知识
|
||||||
|
|
||||||
- [关系型数据库面试总结](docs/03.关系型数据库/01.综合/01.关系型数据库面试.md) 💯
|
- [关系型数据库面试总结](docs/01.计算机科学/02.数据库/03.关系型数据库/01.综合/01.关系型数据库面试.md) 💯
|
||||||
- [SQL Cheat Sheet](docs/03.关系型数据库/01.综合/02.SqlCheatSheet.md) 是一个 SQL 入门教程。
|
- [SQL Cheat Sheet](docs/01.计算机科学/02.数据库/03.关系型数据库/01.综合/02.SqlCheatSheet.md) 是一个 SQL 入门教程。
|
||||||
- [扩展 SQL](docs/03.关系型数据库/01.综合/03.扩展SQL.md) 是一个 SQL 入门教程。
|
- [扩展 SQL](docs/01.计算机科学/02.数据库/03.关系型数据库/01.综合/03.扩展SQL.md) 是一个 SQL 入门教程。
|
||||||
|
|
||||||
### Mysql
|
### Mysql
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
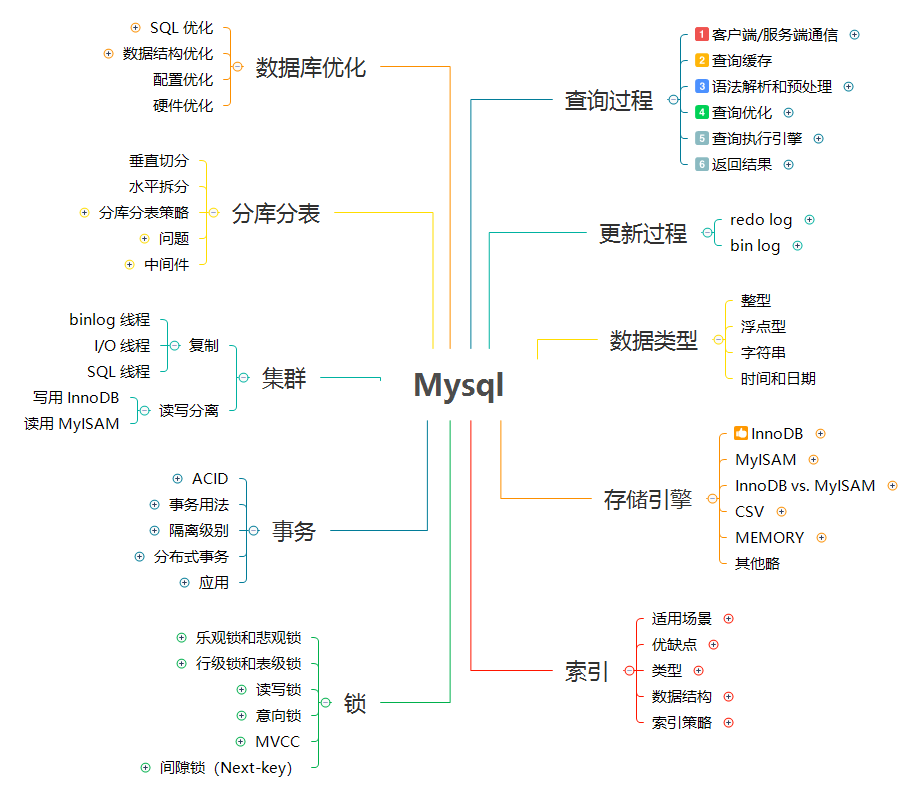
- [Mysql 应用指南](docs/03.关系型数据库/02.Mysql/01.Mysql应用指南.md) ⚡
|
- [Mysql 应用指南](docs/01.计算机科学/02.数据库/03.关系型数据库/02.Mysql/01.Mysql应用指南.md) ⚡
|
||||||
- [Mysql 工作流](docs/03.关系型数据库/02.Mysql/02.MySQL工作流.md) - 关键词:`连接`、`缓存`、`语法分析`、`优化`、`执行引擎`、`redo log`、`bin log`、`两阶段提交`
|
- [Mysql 工作流](docs/01.计算机科学/02.数据库/03.关系型数据库/02.Mysql/02.MySQL工作流.md) - 关键词:`连接`、`缓存`、`语法分析`、`优化`、`执行引擎`、`redo log`、`bin log`、`两阶段提交`
|
||||||
- [Mysql 事务](docs/03.关系型数据库/02.Mysql/03.Mysql事务.md) - 关键词:`ACID`、`AUTOCOMMIT`、`事务隔离级别`、`死锁`、`分布式事务`
|
- [Mysql 事务](docs/01.计算机科学/02.数据库/03.关系型数据库/02.Mysql/03.Mysql事务.md) - 关键词:`ACID`、`AUTOCOMMIT`、`事务隔离级别`、`死锁`、`分布式事务`
|
||||||
- [Mysql 锁](docs/03.关系型数据库/02.Mysql/04.Mysql锁.md) - 关键词:`乐观锁`、`表级锁`、`行级锁`、`意向锁`、`MVCC`、`Next-key 锁`
|
- [Mysql 锁](docs/01.计算机科学/02.数据库/03.关系型数据库/02.Mysql/04.Mysql锁.md) - 关键词:`乐观锁`、`表级锁`、`行级锁`、`意向锁`、`MVCC`、`Next-key 锁`
|
||||||
- [Mysql 索引](docs/03.关系型数据库/02.Mysql/05.Mysql索引.md) - 关键词:`Hash`、`B 树`、`聚簇索引`、`回表`
|
- [Mysql 索引](docs/01.计算机科学/02.数据库/03.关系型数据库/02.Mysql/05.Mysql索引.md) - 关键词:`Hash`、`B 树`、`聚簇索引`、`回表`
|
||||||
- [Mysql 性能优化](docs/03.关系型数据库/02.Mysql/06.Mysql性能优化.md)
|
- [Mysql 性能优化](docs/01.计算机科学/02.数据库/03.关系型数据库/02.Mysql/06.Mysql性能优化.md)
|
||||||
- [Mysql 运维](docs/03.关系型数据库/02.Mysql/20.Mysql运维.md) 🔨
|
- [Mysql 运维](docs/01.计算机科学/02.数据库/03.关系型数据库/02.Mysql/20.Mysql运维.md) 🔨
|
||||||
- [Mysql 配置](docs/03.关系型数据库/02.Mysql/21.Mysql配置.md) 🔨
|
- [Mysql 配置](docs/01.计算机科学/02.数据库/03.关系型数据库/02.Mysql/21.Mysql配置.md) 🔨
|
||||||
- [Mysql 问题](docs/03.关系型数据库/02.Mysql/99.Mysql常见问题.md)
|
- [Mysql 问题](docs/01.计算机科学/02.数据库/03.关系型数据库/02.Mysql/99.Mysql常见问题.md)
|
||||||
|
|
||||||
### 其他
|
### 其他
|
||||||
|
|
||||||
- [PostgreSQL 应用指南](docs/03.关系型数据库/99.其他/01.PostgreSQL.md)
|
- [PostgreSQL 应用指南](docs/01.计算机科学/02.数据库/03.关系型数据库/99.其他/01.PostgreSQL.md)
|
||||||
- [H2 应用指南](docs/03.关系型数据库/99.其他/02.H2.md)
|
- [H2 应用指南](docs/01.计算机科学/02.数据库/03.关系型数据库/99.其他/02.H2.md)
|
||||||
- [SqLite 应用指南](docs/03.关系型数据库/99.其他/03.Sqlite.md)
|
- [SqLite 应用指南](docs/01.计算机科学/02.数据库/03.关系型数据库/99.其他/03.Sqlite.md)
|
||||||
|
|
||||||
## 文档数据库
|
## 文档数据库
|
||||||
|
|
||||||
|
|
@ -111,16 +130,16 @@
|
||||||
>
|
>
|
||||||
> MongoDB 最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
|
> MongoDB 最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
|
||||||
|
|
||||||
- [MongoDB 应用指南](docs/04.文档数据库/01.MongoDB/01.MongoDB应用指南.md)
|
- [MongoDB 应用指南](docs/01.计算机科学/02.数据库/04.文档数据库/01.MongoDB/01.MongoDB应用指南.md)
|
||||||
- [MongoDB 的 CRUD 操作](docs/04.文档数据库/01.MongoDB/02.MongoDB的CRUD操作.md)
|
- [MongoDB 的 CRUD 操作](docs/01.计算机科学/02.数据库/04.文档数据库/01.MongoDB/02.MongoDB的CRUD操作.md)
|
||||||
- [MongoDB 聚合操作](docs/04.文档数据库/01.MongoDB/03.MongoDB的聚合操作.md)
|
- [MongoDB 聚合操作](docs/01.计算机科学/02.数据库/04.文档数据库/01.MongoDB/03.MongoDB的聚合操作.md)
|
||||||
- [MongoDB 事务](docs/04.文档数据库/01.MongoDB/04.MongoDB事务.md)
|
- [MongoDB 事务](docs/01.计算机科学/02.数据库/04.文档数据库/01.MongoDB/04.MongoDB事务.md)
|
||||||
- [MongoDB 建模](docs/04.文档数据库/01.MongoDB/05.MongoDB建模.md)
|
- [MongoDB 建模](docs/01.计算机科学/02.数据库/04.文档数据库/01.MongoDB/05.MongoDB建模.md)
|
||||||
- [MongoDB 建模示例](docs/04.文档数据库/01.MongoDB/06.MongoDB建模示例.md)
|
- [MongoDB 建模示例](docs/01.计算机科学/02.数据库/04.文档数据库/01.MongoDB/06.MongoDB建模示例.md)
|
||||||
- [MongoDB 索引](docs/04.文档数据库/01.MongoDB/07.MongoDB索引.md)
|
- [MongoDB 索引](docs/01.计算机科学/02.数据库/04.文档数据库/01.MongoDB/07.MongoDB索引.md)
|
||||||
- [MongoDB 复制](docs/04.文档数据库/01.MongoDB/08.MongoDB复制.md)
|
- [MongoDB 复制](docs/01.计算机科学/02.数据库/04.文档数据库/01.MongoDB/08.MongoDB复制.md)
|
||||||
- [MongoDB 分片](docs/04.文档数据库/01.MongoDB/09.MongoDB分片.md)
|
- [MongoDB 分片](docs/01.计算机科学/02.数据库/04.文档数据库/01.MongoDB/09.MongoDB分片.md)
|
||||||
- [MongoDB 运维](docs/04.文档数据库/01.MongoDB/20.MongoDB运维.md)
|
- [MongoDB 运维](docs/01.计算机科学/02.数据库/04.文档数据库/01.MongoDB/20.MongoDB运维.md)
|
||||||
|
|
||||||
## KV 数据库
|
## KV 数据库
|
||||||
|
|
||||||
|
|
@ -128,15 +147,15 @@
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
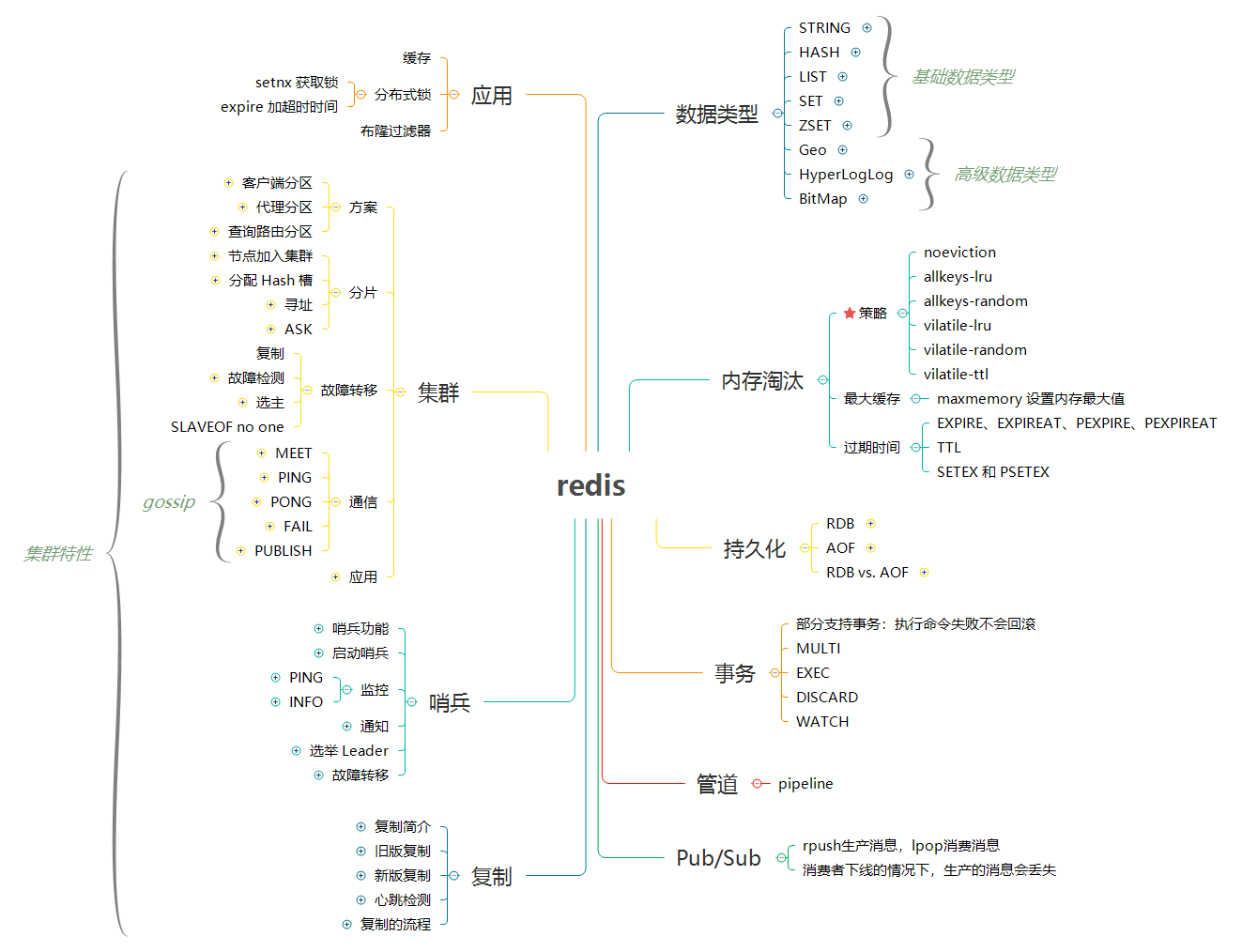
- [Redis 面试总结](docs/05.KV数据库/01.Redis/01.Redis面试总结.md) 💯
|
- [Redis 面试总结](docs/01.计算机科学/02.数据库/05.KV数据库/01.Redis/01.Redis面试总结.md) 💯
|
||||||
- [Redis 应用指南](docs/05.KV数据库/01.Redis/02.Redis应用指南.md) ⚡ - 关键词:`内存淘汰`、`事件`、`事务`、`管道`、`发布与订阅`
|
- [Redis 应用指南](docs/01.计算机科学/02.数据库/05.KV数据库/01.Redis/02.Redis应用指南.md) ⚡ - 关键词:`内存淘汰`、`事件`、`事务`、`管道`、`发布与订阅`
|
||||||
- [Redis 数据类型和应用](docs/05.KV数据库/01.Redis/03.Redis数据类型和应用.md) - 关键词:`STRING`、`HASH`、`LIST`、`SET`、`ZSET`、`BitMap`、`HyperLogLog`、`Geo`
|
- [Redis 数据类型和应用](docs/01.计算机科学/02.数据库/05.KV数据库/01.Redis/03.Redis数据类型和应用.md) - 关键词:`STRING`、`HASH`、`LIST`、`SET`、`ZSET`、`BitMap`、`HyperLogLog`、`Geo`
|
||||||
- [Redis 持久化](docs/05.KV数据库/01.Redis/04.Redis持久化.md) - 关键词:`RDB`、`AOF`、`SAVE`、`BGSAVE`、`appendfsync`
|
- [Redis 持久化](docs/01.计算机科学/02.数据库/05.KV数据库/01.Redis/04.Redis持久化.md) - 关键词:`RDB`、`AOF`、`SAVE`、`BGSAVE`、`appendfsync`
|
||||||
- [Redis 复制](docs/05.KV数据库/01.Redis/05.Redis复制.md) - 关键词:`SLAVEOF`、`SYNC`、`PSYNC`、`REPLCONF ACK`
|
- [Redis 复制](docs/01.计算机科学/02.数据库/05.KV数据库/01.Redis/05.Redis复制.md) - 关键词:`SLAVEOF`、`SYNC`、`PSYNC`、`REPLCONF ACK`
|
||||||
- [Redis 哨兵](docs/05.KV数据库/01.Redis/06.Redis哨兵.md) - 关键词:`Sentinel`、`PING`、`INFO`、`Raft`
|
- [Redis 哨兵](docs/01.计算机科学/02.数据库/05.KV数据库/01.Redis/06.Redis哨兵.md) - 关键词:`Sentinel`、`PING`、`INFO`、`Raft`
|
||||||
- [Redis 集群](docs/05.KV数据库/01.Redis/07.Redis集群.md) - 关键词:`CLUSTER MEET`、`Hash slot`、`MOVED`、`ASK`、`SLAVEOF no one`、`redis-trib`
|
- [Redis 集群](docs/01.计算机科学/02.数据库/05.KV数据库/01.Redis/07.Redis集群.md) - 关键词:`CLUSTER MEET`、`Hash slot`、`MOVED`、`ASK`、`SLAVEOF no one`、`redis-trib`
|
||||||
- [Redis 实战](docs/05.KV数据库/01.Redis/08.Redis实战.md) - 关键词:`缓存`、`分布式锁`、`布隆过滤器`
|
- [Redis 实战](docs/01.计算机科学/02.数据库/05.KV数据库/01.Redis/08.Redis实战.md) - 关键词:`缓存`、`分布式锁`、`布隆过滤器`
|
||||||
- [Redis 运维](docs/05.KV数据库/01.Redis/20.Redis运维.md) 🔨 - 关键词:`安装`、`命令`、`集群`、`客户端`
|
- [Redis 运维](docs/01.计算机科学/02.数据库/05.KV数据库/01.Redis/20.Redis运维.md) 🔨 - 关键词:`安装`、`命令`、`集群`、`客户端`
|
||||||
|
|
||||||
## 列式数据库
|
## 列式数据库
|
||||||
|
|
||||||
|
|
@ -155,30 +174,30 @@
|
||||||
|
|
||||||
> Elasticsearch 是一个基于 Lucene 的搜索和数据分析工具,它提供了一个分布式服务。Elasticsearch 是遵从 Apache 开源条款的一款开源产品,是当前主流的企业级搜索引擎。
|
> Elasticsearch 是一个基于 Lucene 的搜索和数据分析工具,它提供了一个分布式服务。Elasticsearch 是遵从 Apache 开源条款的一款开源产品,是当前主流的企业级搜索引擎。
|
||||||
|
|
||||||
- [Elasticsearch 面试总结](docs/07.搜索引擎数据库/01.Elasticsearch/01.Elasticsearch面试总结.md) 💯
|
- [Elasticsearch 面试总结](docs/01.计算机科学/02.数据库/07.搜索引擎数据库/01.Elasticsearch/01.Elasticsearch面试总结.md) 💯
|
||||||
- [Elasticsearch 快速入门](docs/07.搜索引擎数据库/01.Elasticsearch/02.Elasticsearch快速入门.md)
|
- [Elasticsearch 快速入门](docs/01.计算机科学/02.数据库/07.搜索引擎数据库/01.Elasticsearch/02.Elasticsearch快速入门.md)
|
||||||
- [Elasticsearch 简介](docs/07.搜索引擎数据库/01.Elasticsearch/03.Elasticsearch简介.md)
|
- [Elasticsearch 简介](docs/01.计算机科学/02.数据库/07.搜索引擎数据库/01.Elasticsearch/03.Elasticsearch简介.md)
|
||||||
- [Elasticsearch 索引](docs/07.搜索引擎数据库/01.Elasticsearch/04.Elasticsearch索引.md)
|
- [Elasticsearch 索引](docs/01.计算机科学/02.数据库/07.搜索引擎数据库/01.Elasticsearch/04.Elasticsearch索引.md)
|
||||||
- [Elasticsearch 查询](docs/07.搜索引擎数据库/01.Elasticsearch/05.Elasticsearch查询.md)
|
- [Elasticsearch 查询](docs/01.计算机科学/02.数据库/07.搜索引擎数据库/01.Elasticsearch/05.Elasticsearch查询.md)
|
||||||
- [Elasticsearch 高亮](docs/07.搜索引擎数据库/01.Elasticsearch/06.Elasticsearch高亮.md)
|
- [Elasticsearch 高亮](docs/01.计算机科学/02.数据库/07.搜索引擎数据库/01.Elasticsearch/06.Elasticsearch高亮.md)
|
||||||
- [Elasticsearch 排序](docs/07.搜索引擎数据库/01.Elasticsearch/07.Elasticsearch排序.md)
|
- [Elasticsearch 排序](docs/01.计算机科学/02.数据库/07.搜索引擎数据库/01.Elasticsearch/07.Elasticsearch排序.md)
|
||||||
- [Elasticsearch 聚合](docs/07.搜索引擎数据库/01.Elasticsearch/08.Elasticsearch聚合.md)
|
- [Elasticsearch 聚合](docs/01.计算机科学/02.数据库/07.搜索引擎数据库/01.Elasticsearch/08.Elasticsearch聚合.md)
|
||||||
- [Elasticsearch 分析器](docs/07.搜索引擎数据库/01.Elasticsearch/09.Elasticsearch分析器.md)
|
- [Elasticsearch 分析器](docs/01.计算机科学/02.数据库/07.搜索引擎数据库/01.Elasticsearch/09.Elasticsearch分析器.md)
|
||||||
- [Elasticsearch 性能优化](docs/07.搜索引擎数据库/01.Elasticsearch/10.Elasticsearch性能优化.md)
|
- [Elasticsearch 性能优化](docs/01.计算机科学/02.数据库/07.搜索引擎数据库/01.Elasticsearch/10.Elasticsearch性能优化.md)
|
||||||
- [Elasticsearch Rest API](docs/07.搜索引擎数据库/01.Elasticsearch/11.ElasticsearchRestApi.md)
|
- [Elasticsearch Rest API](docs/01.计算机科学/02.数据库/07.搜索引擎数据库/01.Elasticsearch/11.ElasticsearchRestApi.md)
|
||||||
- [ElasticSearch Java API 之 High Level REST Client](docs/07.搜索引擎数据库/01.Elasticsearch/12.ElasticsearchHighLevelRestJavaApi.md)
|
- [ElasticSearch Java API 之 High Level REST Client](docs/01.计算机科学/02.数据库/07.搜索引擎数据库/01.Elasticsearch/12.ElasticsearchHighLevelRestJavaApi.md)
|
||||||
- [Elasticsearch 集群和分片](docs/07.搜索引擎数据库/01.Elasticsearch/13.Elasticsearch集群和分片.md)
|
- [Elasticsearch 集群和分片](docs/01.计算机科学/02.数据库/07.搜索引擎数据库/01.Elasticsearch/13.Elasticsearch集群和分片.md)
|
||||||
- [Elasticsearch 运维](docs/07.搜索引擎数据库/01.Elasticsearch/20.Elasticsearch运维.md)
|
- [Elasticsearch 运维](docs/01.计算机科学/02.数据库/07.搜索引擎数据库/01.Elasticsearch/20.Elasticsearch运维.md)
|
||||||
|
|
||||||
### Elastic
|
### Elastic
|
||||||
|
|
||||||
- [Elastic 快速入门](docs/07.搜索引擎数据库/02.Elastic/01.Elastic快速入门.md)
|
- [Elastic 快速入门](docs/01.计算机科学/02.数据库/07.搜索引擎数据库/02.Elastic/01.Elastic快速入门.md)
|
||||||
- [Elastic 技术栈之 Filebeat](docs/07.搜索引擎数据库/02.Elastic/02.Elastic技术栈之Filebeat.md)
|
- [Elastic 技术栈之 Filebeat](docs/01.计算机科学/02.数据库/07.搜索引擎数据库/02.Elastic/02.Elastic技术栈之Filebeat.md)
|
||||||
- [Filebeat 运维](docs/07.搜索引擎数据库/02.Elastic/03.Filebeat运维.md)
|
- [Filebeat 运维](docs/01.计算机科学/02.数据库/07.搜索引擎数据库/02.Elastic/03.Filebeat运维.md)
|
||||||
- [Elastic 技术栈之 Kibana](docs/07.搜索引擎数据库/02.Elastic/04.Elastic技术栈之Kibana.md)
|
- [Elastic 技术栈之 Kibana](docs/01.计算机科学/02.数据库/07.搜索引擎数据库/02.Elastic/04.Elastic技术栈之Kibana.md)
|
||||||
- [Kibana 运维](docs/07.搜索引擎数据库/02.Elastic/05.Kibana运维.md)
|
- [Kibana 运维](docs/01.计算机科学/02.数据库/07.搜索引擎数据库/02.Elastic/05.Kibana运维.md)
|
||||||
- [Elastic 技术栈之 Logstash](docs/07.搜索引擎数据库/02.Elastic/06.Elastic技术栈之Logstash.md)
|
- [Elastic 技术栈之 Logstash](docs/01.计算机科学/02.数据库/07.搜索引擎数据库/02.Elastic/06.Elastic技术栈之Logstash.md)
|
||||||
- [Logstash 运维](docs/07.搜索引擎数据库/02.Elastic/07.Logstash运维.md)
|
- [Logstash 运维](docs/01.计算机科学/02.数据库/07.搜索引擎数据库/02.Elastic/07.Logstash运维.md)
|
||||||
|
|
||||||
## 资料 📚
|
## 资料 📚
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -12,15 +12,15 @@ module.exports = {
|
||||||
// 注入到页面<head> 中的标签,格式[tagName, { attrName: attrValue }, innerHTML?]
|
// 注入到页面<head> 中的标签,格式[tagName, { attrName: attrValue }, innerHTML?]
|
||||||
['link', { rel: 'icon', href: '/img/favicon.ico' }], //favicons,资源放在public文件夹
|
['link', { rel: 'icon', href: '/img/favicon.ico' }], //favicons,资源放在public文件夹
|
||||||
['meta', { name: 'keywords', content: 'vuepress,theme,blog,vdoing' }],
|
['meta', { name: 'keywords', content: 'vuepress,theme,blog,vdoing' }],
|
||||||
['meta', { name: 'theme-color', content: '#11a8cd' }], // 移动浏览器主题颜色
|
['meta', { name: 'theme-color', content: '#11a8cd' }] // 移动浏览器主题颜色
|
||||||
],
|
],
|
||||||
markdown: {
|
markdown: {
|
||||||
// lineNumbers: true,
|
// lineNumbers: true,
|
||||||
extractHeaders: ['h2', 'h3', 'h4', 'h5', 'h6'], // 提取标题到侧边栏的级别,默认['h2', 'h3']
|
extractHeaders: ['h2', 'h3', 'h4', 'h5', 'h6'], // 提取标题到侧边栏的级别,默认['h2', 'h3']
|
||||||
externalLinks: {
|
externalLinks: {
|
||||||
target: '_blank',
|
target: '_blank',
|
||||||
rel: 'noopener noreferrer',
|
rel: 'noopener noreferrer'
|
||||||
},
|
}
|
||||||
},
|
},
|
||||||
// 主题配置
|
// 主题配置
|
||||||
themeConfig: {
|
themeConfig: {
|
||||||
|
|
@ -33,24 +33,24 @@ module.exports = {
|
||||||
items: [
|
items: [
|
||||||
{ text: '综合', link: '/03.关系型数据库/01.综合/' },
|
{ text: '综合', link: '/03.关系型数据库/01.综合/' },
|
||||||
{ text: 'Mysql', link: '/03.关系型数据库/02.Mysql/' },
|
{ text: 'Mysql', link: '/03.关系型数据库/02.Mysql/' },
|
||||||
{ text: '其他', link: '/03.关系型数据库/99.其他/' },
|
{ text: '其他', link: '/03.关系型数据库/99.其他/' }
|
||||||
],
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
text: '文档数据库',
|
text: '文档数据库',
|
||||||
items: [{ text: 'MongoDB', link: '/04.文档数据库/01.MongoDB/' }],
|
items: [{ text: 'MongoDB', link: '/04.文档数据库/01.MongoDB/' }]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
text: 'KV数据库',
|
text: 'KV数据库',
|
||||||
items: [{ text: 'Redis', link: '/05.KV数据库/01.Redis/' }],
|
items: [{ text: 'Redis', link: '/05.KV数据库/01.Redis/' }]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
text: '搜索引擎数据库',
|
text: '搜索引擎数据库',
|
||||||
items: [
|
items: [
|
||||||
{ text: 'Elasticsearch', link: '/07.搜索引擎数据库/01.Elasticsearch/' },
|
{ text: 'Elasticsearch', link: '/07.搜索引擎数据库/01.Elasticsearch/' },
|
||||||
{ text: 'Elastic技术栈', link: '/07.搜索引擎数据库/02.Elastic/' },
|
{ text: 'Elastic技术栈', link: '/07.搜索引擎数据库/02.Elastic/' }
|
||||||
],
|
]
|
||||||
},
|
}
|
||||||
],
|
],
|
||||||
sidebarDepth: 2, // 侧边栏显示深度,默认1,最大2(显示到h3标题)
|
sidebarDepth: 2, // 侧边栏显示深度,默认1,最大2(显示到h3标题)
|
||||||
logo: 'https://raw.githubusercontent.com/dunwu/images/dev/common/dunwu-logo.png', // 导航栏logo
|
logo: 'https://raw.githubusercontent.com/dunwu/images/dev/common/dunwu-logo.png', // 导航栏logo
|
||||||
|
|
@ -68,7 +68,7 @@ module.exports = {
|
||||||
// sidebarOpen: false, // 初始状态是否打开侧边栏,默认true
|
// sidebarOpen: false, // 初始状态是否打开侧边栏,默认true
|
||||||
updateBar: {
|
updateBar: {
|
||||||
// 最近更新栏
|
// 最近更新栏
|
||||||
showToArticle: true, // 显示到文章页底部,默认true
|
showToArticle: true // 显示到文章页底部,默认true
|
||||||
// moreArticle: '/archives' // “更多文章”跳转的页面,默认'/archives'
|
// moreArticle: '/archives' // “更多文章”跳转的页面,默认'/archives'
|
||||||
},
|
},
|
||||||
// titleBadge: false, // 文章标题前的图标是否显示,默认true
|
// titleBadge: false, // 文章标题前的图标是否显示,默认true
|
||||||
|
|
@ -93,7 +93,7 @@ module.exports = {
|
||||||
author: {
|
author: {
|
||||||
// 文章默认的作者信息,可在md文件中单独配置此信息 String | {name: String, href: String}
|
// 文章默认的作者信息,可在md文件中单独配置此信息 String | {name: String, href: String}
|
||||||
name: 'dunwu', // 必需
|
name: 'dunwu', // 必需
|
||||||
href: 'https://github.com/dunwu', // 可选的
|
href: 'https://github.com/dunwu' // 可选的
|
||||||
},
|
},
|
||||||
social: {
|
social: {
|
||||||
// 社交图标,显示于博主信息栏和页脚栏
|
// 社交图标,显示于博主信息栏和页脚栏
|
||||||
|
|
@ -102,21 +102,21 @@ module.exports = {
|
||||||
{
|
{
|
||||||
iconClass: 'icon-youjian',
|
iconClass: 'icon-youjian',
|
||||||
title: '发邮件',
|
title: '发邮件',
|
||||||
link: 'mailto:forbreak@163.com',
|
link: 'mailto:forbreak@163.com'
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
iconClass: 'icon-github',
|
iconClass: 'icon-github',
|
||||||
title: 'GitHub',
|
title: 'GitHub',
|
||||||
link: 'https://github.com/dunwu',
|
link: 'https://github.com/dunwu'
|
||||||
},
|
}
|
||||||
],
|
]
|
||||||
},
|
},
|
||||||
footer: {
|
footer: {
|
||||||
// 页脚信息
|
// 页脚信息
|
||||||
createYear: 2019, // 博客创建年份
|
createYear: 2019, // 博客创建年份
|
||||||
copyrightInfo: '钝悟(dunwu) | CC-BY-SA-4.0', // 博客版权信息,支持a标签
|
copyrightInfo: '钝悟(dunwu) | CC-BY-SA-4.0' // 博客版权信息,支持a标签
|
||||||
},
|
},
|
||||||
htmlModules,
|
htmlModules
|
||||||
},
|
},
|
||||||
|
|
||||||
// 插件
|
// 插件
|
||||||
|
|
@ -126,8 +126,8 @@ module.exports = {
|
||||||
{
|
{
|
||||||
// 鼠标点击爱心特效
|
// 鼠标点击爱心特效
|
||||||
color: '#11a8cd', // 爱心颜色,默认随机色
|
color: '#11a8cd', // 爱心颜色,默认随机色
|
||||||
excludeClassName: 'theme-vdoing-content', // 要排除元素的class, 默认空''
|
excludeClassName: 'theme-vdoing-content' // 要排除元素的class, 默认空''
|
||||||
},
|
}
|
||||||
],
|
],
|
||||||
|
|
||||||
['fulltext-search'], // 全文搜索
|
['fulltext-search'], // 全文搜索
|
||||||
|
|
@ -157,8 +157,8 @@ module.exports = {
|
||||||
copySelector: ['div[class*="language-"] pre', 'div[class*="aside-code"] aside'], // String or Array
|
copySelector: ['div[class*="language-"] pre', 'div[class*="aside-code"] aside'], // String or Array
|
||||||
copyMessage: '复制成功', // default is 'Copy successfully and then paste it for use.'
|
copyMessage: '复制成功', // default is 'Copy successfully and then paste it for use.'
|
||||||
duration: 1000, // prompt message display time.
|
duration: 1000, // prompt message display time.
|
||||||
showInMobile: false, // whether to display on the mobile side, default: false.
|
showInMobile: false // whether to display on the mobile side, default: false.
|
||||||
},
|
}
|
||||||
],
|
],
|
||||||
[
|
[
|
||||||
'demo-block',
|
'demo-block',
|
||||||
|
|
@ -170,18 +170,18 @@ module.exports = {
|
||||||
// vue: 'https://cdn.jsdelivr.net/npm/vue/dist/vue.min.js', // 在线示例中的vue依赖
|
// vue: 'https://cdn.jsdelivr.net/npm/vue/dist/vue.min.js', // 在线示例中的vue依赖
|
||||||
jsfiddle: false, // 是否显示 jsfiddle 链接
|
jsfiddle: false, // 是否显示 jsfiddle 链接
|
||||||
codepen: true, // 是否显示 codepen 链接
|
codepen: true, // 是否显示 codepen 链接
|
||||||
horizontal: false, // 是否展示为横向样式
|
horizontal: false // 是否展示为横向样式
|
||||||
},
|
}
|
||||||
},
|
}
|
||||||
],
|
],
|
||||||
[
|
[
|
||||||
'vuepress-plugin-zooming', // 放大图片
|
'vuepress-plugin-zooming', // 放大图片
|
||||||
{
|
{
|
||||||
selector: '.theme-vdoing-content img:not(.no-zoom)',
|
selector: '.theme-vdoing-content img:not(.no-zoom)',
|
||||||
options: {
|
options: {
|
||||||
bgColor: 'rgba(0,0,0,0.6)',
|
bgColor: 'rgba(0,0,0,0.6)'
|
||||||
},
|
}
|
||||||
},
|
}
|
||||||
],
|
],
|
||||||
[
|
[
|
||||||
'@vuepress/last-updated', // "上次更新"时间格式
|
'@vuepress/last-updated', // "上次更新"时间格式
|
||||||
|
|
@ -189,11 +189,30 @@ module.exports = {
|
||||||
transformer: (timestamp, lang) => {
|
transformer: (timestamp, lang) => {
|
||||||
const dayjs = require('dayjs') // https://day.js.org/
|
const dayjs = require('dayjs') // https://day.js.org/
|
||||||
return dayjs(timestamp).format('YYYY/MM/DD, HH:mm:ss')
|
return dayjs(timestamp).format('YYYY/MM/DD, HH:mm:ss')
|
||||||
},
|
}
|
||||||
},
|
}
|
||||||
],
|
],
|
||||||
|
[
|
||||||
|
'vuepress-plugin-comment', // 评论
|
||||||
|
{
|
||||||
|
choosen: 'gitalk',
|
||||||
|
options: {
|
||||||
|
clientID: '7dd8c87a20cff437d2ed',
|
||||||
|
clientSecret: '4e28d81a9a0280796b2b45ce2944424c6f2c1531',
|
||||||
|
repo: 'db-tutorial', // GitHub 仓库
|
||||||
|
owner: 'dunwu', // GitHub仓库所有者
|
||||||
|
admin: ['dunwu'], // 对仓库有写权限的人
|
||||||
|
// distractionFreeMode: true,
|
||||||
|
pagerDirection: 'last', // 'first'正序 | 'last'倒序
|
||||||
|
id: '<%- (frontmatter.permalink || frontmatter.to.path).slice(-16) %>', // 页面的唯一标识,长度不能超过50
|
||||||
|
title: '「评论」<%- frontmatter.title %>', // GitHub issue 的标题
|
||||||
|
labels: ['Gitalk', 'Comment'], // GitHub issue 的标签
|
||||||
|
body: '页面:<%- window.location.origin + (frontmatter.to.path || window.location.pathname) %>' // GitHub issue 的内容
|
||||||
|
}
|
||||||
|
}
|
||||||
|
]
|
||||||
],
|
],
|
||||||
|
|
||||||
// 监听文件变化并重新构建
|
// 监听文件变化并重新构建
|
||||||
extraWatchFiles: ['.vuepress/config.js', '.vuepress/config/htmlModules.js'],
|
extraWatchFiles: ['.vuepress/config.js', '.vuepress/config/htmlModules.js']
|
||||||
}
|
}
|
||||||
|
|
|
||||||
|
|
@ -1,113 +1,9 @@
|
||||||
/**
|
// import vue from 'vue/dist/vue.esm.browser'
|
||||||
* to主题使用者:你可以去掉本文件的所有代码
|
|
||||||
*/
|
|
||||||
export default ({
|
export default ({
|
||||||
Vue, // VuePress 正在使用的 Vue 构造函数
|
Vue, // VuePress 正在使用的 Vue 构造函数
|
||||||
options, // 附加到根实例的一些选项
|
options, // 附加到根实例的一些选项
|
||||||
router, // 当前应用的路由实例
|
router, // 当前应用的路由实例
|
||||||
siteData, // 站点元数据
|
siteData // 站点元数据
|
||||||
isServer, // 当前应用配置是处于 服务端渲染 还是 客户端
|
|
||||||
}) => {
|
}) => {
|
||||||
// 用于监控在路由变化时检查广告拦截器 (to主题使用者:你可以去掉本文件的所有代码)
|
// window.Vue = vue // 使页面中可以使用Vue构造函数 (使页面中的vue demo生效)
|
||||||
if (!isServer) {
|
|
||||||
router.afterEach(() => {
|
|
||||||
//check if wwads' fire function was blocked after document is ready with 3s timeout (waiting the ad loading)
|
|
||||||
docReady(function () {
|
|
||||||
// setTimeout(function () {
|
|
||||||
// if (window._AdBlockInit === undefined) {
|
|
||||||
// ABDetected()
|
|
||||||
// }
|
|
||||||
// }, 3000)
|
|
||||||
})
|
|
||||||
|
|
||||||
// 删除事件改为隐藏事件
|
|
||||||
setTimeout(() => {
|
|
||||||
const pageB = document.querySelector('.pageB')
|
|
||||||
if (!pageB) return
|
|
||||||
const btnEl = pageB.querySelector('.wwads-hide')
|
|
||||||
if (btnEl) {
|
|
||||||
btnEl.onclick = () => {
|
|
||||||
pageB.style.display = 'none'
|
|
||||||
}
|
|
||||||
}
|
|
||||||
// 显示广告模块
|
|
||||||
pageB.style.display = 'flex'
|
|
||||||
|
|
||||||
integrateGitalk(router)
|
|
||||||
}, 0)
|
|
||||||
})
|
|
||||||
}
|
|
||||||
try {
|
|
||||||
document && integrateGitalk(router)
|
|
||||||
} catch (e) {
|
|
||||||
console.error(e.message)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
function ABDetected() {
|
|
||||||
const h =
|
|
||||||
"<style>.wwads-horizontal,.wwads-vertical{background-color:#f4f8fa;padding:5px;min-height:120px;margin-top:20px;box-sizing:border-box;border-radius:3px;font-family:sans-serif;display:flex;min-width:150px;position:relative;overflow:hidden;}.wwads-horizontal{flex-wrap:wrap;justify-content:center}.wwads-vertical{flex-direction:column;align-items:center;padding-bottom:32px}.wwads-horizontal a,.wwads-vertical a{text-decoration:none}.wwads-horizontal .wwads-img,.wwads-vertical .wwads-img{margin:5px}.wwads-horizontal .wwads-content,.wwads-vertical .wwads-content{margin:5px}.wwads-horizontal .wwads-content{flex:130px}.wwads-vertical .wwads-content{margin-top:10px}.wwads-horizontal .wwads-text,.wwads-content .wwads-text{font-size:14px;line-height:1.4;color:#0e1011;-webkit-font-smoothing:antialiased}.wwads-horizontal .wwads-poweredby,.wwads-vertical .wwads-poweredby{display:block;font-size:11px;color:#a6b7bf;margin-top:1em}.wwads-vertical .wwads-poweredby{position:absolute;left:10px;bottom:10px}.wwads-horizontal .wwads-poweredby span,.wwads-vertical .wwads-poweredby span{transition:all 0.2s ease-in-out;margin-left:-1em}.wwads-horizontal .wwads-poweredby span:first-child,.wwads-vertical .wwads-poweredby span:first-child{opacity:0}.wwads-horizontal:hover .wwads-poweredby span,.wwads-vertical:hover .wwads-poweredby span{opacity:1;margin-left:0}.wwads-horizontal .wwads-hide,.wwads-vertical .wwads-hide{position:absolute;right:-23px;bottom:-23px;width:46px;height:46px;border-radius:23px;transition:all 0.3s ease-in-out;cursor:pointer;}.wwads-horizontal .wwads-hide:hover,.wwads-vertical .wwads-hide:hover{background:rgb(0 0 0 /0.05)}.wwads-horizontal .wwads-hide svg,.wwads-vertical .wwads-hide svg{position:absolute;left:10px;top:10px;fill:#a6b7bf}.wwads-horizontal .wwads-hide:hover svg,.wwads-vertical .wwads-hide:hover svg{fill:#3E4546}</style><a href='https://wwads.cn/page/whitelist-wwads' class='wwads-img' target='_blank' rel='nofollow'><img src='https://cdn.jsdelivr.net/gh/xugaoyi/image_store@master/blog/wwads.2a3pidhlh4ys.webp' width='130'></a><div class='wwads-content'><a href='https://wwads.cn/page/whitelist-wwads' class='wwads-text' target='_blank' rel='nofollow'>为了本站的长期运营,请将我们的网站加入广告拦截器的白名单,感谢您的支持!<span style='color: #11a8cd'>如何添加白名单?</span></a><a href='https://wwads.cn/page/end-user-privacy' class='wwads-poweredby' title='万维广告 ~ 让广告更优雅,且有用' target='_blank'><span>万维</span><span>广告</span></a></div><a class='wwads-hide' onclick='parentNode.remove()' title='隐藏广告'><svg xmlns='http://www.w3.org/2000/svg' width='6' height='7'><path d='M.879.672L3 2.793 5.121.672a.5.5 0 11.707.707L3.708 3.5l2.12 2.121a.5.5 0 11-.707.707l-2.12-2.12-2.122 2.12a.5.5 0 11-.707-.707l2.121-2.12L.172 1.378A.5.5 0 01.879.672z'></path></svg></a>"
|
|
||||||
const wwadsEl = document.getElementsByClassName('wwads-cn')
|
|
||||||
const wwadsContentEl = document.querySelector('.wwads-content')
|
|
||||||
if (wwadsEl[0] && !wwadsContentEl) {
|
|
||||||
wwadsEl[0].innerHTML = h
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
//check document ready
|
|
||||||
function docReady(t) {
|
|
||||||
'complete' === document.readyState || 'interactive' === document.readyState
|
|
||||||
? setTimeout(t, 1)
|
|
||||||
: document.addEventListener('DOMContentLoaded', t)
|
|
||||||
}
|
|
||||||
|
|
||||||
// 集成 Gitalk 评论插件
|
|
||||||
function integrateGitalk(router) {
|
|
||||||
const linkGitalk = document.createElement('link')
|
|
||||||
linkGitalk.href = 'https://cdn.jsdelivr.net/npm/gitalk@1/dist/gitalk.css'
|
|
||||||
linkGitalk.rel = 'stylesheet'
|
|
||||||
document.body.appendChild(linkGitalk)
|
|
||||||
const scriptGitalk = document.createElement('script')
|
|
||||||
scriptGitalk.src = 'https://cdn.jsdelivr.net/npm/gitalk@1/dist/gitalk.min.js'
|
|
||||||
document.body.appendChild(scriptGitalk)
|
|
||||||
|
|
||||||
router.afterEach((to) => {
|
|
||||||
if (scriptGitalk.onload) {
|
|
||||||
loadGitalk(to)
|
|
||||||
} else {
|
|
||||||
scriptGitalk.onload = () => {
|
|
||||||
loadGitalk(to)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
})
|
|
||||||
|
|
||||||
function loadGitalk(to) {
|
|
||||||
let commentsContainer = document.getElementById('gitalk-container')
|
|
||||||
if (!commentsContainer) {
|
|
||||||
commentsContainer = document.createElement('div')
|
|
||||||
commentsContainer.id = 'gitalk-container'
|
|
||||||
commentsContainer.classList.add('content')
|
|
||||||
}
|
|
||||||
const $page = document.querySelector('.page')
|
|
||||||
if ($page) {
|
|
||||||
$page.appendChild(commentsContainer)
|
|
||||||
if (typeof Gitalk !== 'undefined' && Gitalk instanceof Function) {
|
|
||||||
renderGitalk(to.fullPath)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
function renderGitalk(fullPath) {
|
|
||||||
console.info(fullPath)
|
|
||||||
const gitalk = new Gitalk({
|
|
||||||
clientID: '7dd8c87a20cff437d2ed',
|
|
||||||
clientSecret: '4e28d81a9a0280796b2b45ce2944424c6f2c1531', // come from github development
|
|
||||||
repo: 'blog',
|
|
||||||
owner: 'dunwu',
|
|
||||||
admin: ['dunwu'],
|
|
||||||
id: 'comment',
|
|
||||||
distractionFreeMode: false,
|
|
||||||
language: 'zh-CN',
|
|
||||||
})
|
|
||||||
gitalk.render('gitalk-container')
|
|
||||||
}
|
|
||||||
}
|
}
|
||||||
|
|
|
||||||
|
|
@ -2,13 +2,14 @@
|
||||||
title: Nosql技术选型
|
title: Nosql技术选型
|
||||||
date: 2020-02-09 02:18:58
|
date: 2020-02-09 02:18:58
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 数据库综合
|
- 数据库综合
|
||||||
tags:
|
tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- 综合
|
- 综合
|
||||||
- Nosql
|
- Nosql
|
||||||
permalink: /pages/4a5e3f/
|
permalink: /pages/0e1012/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Nosql 技术选型
|
# Nosql 技术选型
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: 数据结构与数据库索引
|
title: 数据结构与数据库索引
|
||||||
date: 2022-03-27 23:39:10
|
date: 2022-03-27 23:39:10
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 数据库综合
|
- 数据库综合
|
||||||
tags:
|
tags:
|
||||||
|
|
@ -9,7 +10,7 @@ tags:
|
||||||
- 综合
|
- 综合
|
||||||
- 数据结构
|
- 数据结构
|
||||||
- 索引
|
- 索引
|
||||||
permalink: /pages/4702da/
|
permalink: /pages/d7cd88/
|
||||||
---
|
---
|
||||||
|
|
||||||
# 数据结构与数据库索引
|
# 数据结构与数据库索引
|
||||||
|
|
@ -2,12 +2,14 @@
|
||||||
title: 数据库综合
|
title: 数据库综合
|
||||||
date: 2022-04-11 16:52:35
|
date: 2022-04-11 16:52:35
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 数据库综合
|
- 数据库综合
|
||||||
tags:
|
tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- 综合
|
- 综合
|
||||||
permalink: /pages/6ed13e/
|
permalink: /pages/3c3c45/
|
||||||
|
hidden: true
|
||||||
---
|
---
|
||||||
|
|
||||||
# 数据库综合
|
# 数据库综合
|
||||||
|
|
@ -39,4 +41,4 @@ permalink: /pages/6ed13e/
|
||||||
|
|
||||||
## 🚪 传送
|
## 🚪 传送
|
||||||
|
|
||||||
◾ 🏠 [DB-TUTORIAL 首页](https://github.com/dunwu/db-tutorial) ◾ 🎯 [我的博客](https://github.com/dunwu/blog) ◾
|
◾ 💧 [我的IT知识图谱](https://dunwu.github.io/waterdrop/) ◾ 🎯 [我的博客](https://dunwu.github.io/blog/) ◾
|
||||||
|
|
@ -2,13 +2,15 @@
|
||||||
title: ShardingSphere 简介
|
title: ShardingSphere 简介
|
||||||
date: 2020-10-08 20:30:30
|
date: 2020-10-08 20:30:30
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 数据库中间件
|
- 数据库中间件
|
||||||
|
- Shardingsphere
|
||||||
tags:
|
tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- 中间件
|
- 中间件
|
||||||
- 分库分表
|
- 分库分表
|
||||||
permalink: /pages/560051/
|
permalink: /pages/5ed2a2/
|
||||||
---
|
---
|
||||||
|
|
||||||
# ShardingSphere 简介
|
# ShardingSphere 简介
|
||||||
|
|
@ -2,13 +2,15 @@
|
||||||
title: ShardingSphere Jdbc
|
title: ShardingSphere Jdbc
|
||||||
date: 2020-12-28 00:01:28
|
date: 2020-12-28 00:01:28
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 数据库中间件
|
- 数据库中间件
|
||||||
|
- Shardingsphere
|
||||||
tags:
|
tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- 中间件
|
- 中间件
|
||||||
- 分库分表
|
- 分库分表
|
||||||
permalink: /pages/a9584d/
|
permalink: /pages/8448de/
|
||||||
---
|
---
|
||||||
|
|
||||||
# ShardingSphere Jdbc
|
# ShardingSphere Jdbc
|
||||||
|
|
@ -2,13 +2,14 @@
|
||||||
title: 版本管理中间件 Flyway
|
title: 版本管理中间件 Flyway
|
||||||
date: 2019-08-22 09:02:39
|
date: 2019-08-22 09:02:39
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 数据库中间件
|
- 数据库中间件
|
||||||
tags:
|
tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- 中间件
|
- 中间件
|
||||||
- 版本管理
|
- 版本管理
|
||||||
permalink: /pages/9f8daf/
|
permalink: /pages/e2648c/
|
||||||
---
|
---
|
||||||
|
|
||||||
# 版本管理中间件 Flyway
|
# 版本管理中间件 Flyway
|
||||||
|
|
@ -2,12 +2,14 @@
|
||||||
title: 数据库中间件和代理
|
title: 数据库中间件和代理
|
||||||
date: 2022-04-11 16:52:35
|
date: 2022-04-11 16:52:35
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 数据库中间件
|
- 数据库中间件
|
||||||
tags:
|
tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- 中间件
|
- 中间件
|
||||||
permalink: /pages/02d9f1/
|
permalink: /pages/addb05/
|
||||||
|
hidden: true
|
||||||
---
|
---
|
||||||
|
|
||||||
# 数据库中间件和代理
|
# 数据库中间件和代理
|
||||||
|
|
@ -29,4 +31,4 @@ permalink: /pages/02d9f1/
|
||||||
|
|
||||||
## 🚪 传送
|
## 🚪 传送
|
||||||
|
|
||||||
◾ 🏠 [DB-TUTORIAL 首页](https://github.com/dunwu/db-tutorial) ◾ 🎯 [我的博客](https://github.com/dunwu/blog) ◾
|
◾ 💧 [我的IT知识图谱](https://dunwu.github.io/waterdrop/) ◾ 🎯 [我的博客](https://dunwu.github.io/blog/) ◾
|
||||||
|
|
@ -2,12 +2,14 @@
|
||||||
title: 关系型数据库面试
|
title: 关系型数据库面试
|
||||||
date: 2020-01-15 23:21:02
|
date: 2020-01-15 23:21:02
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
|
- 综合
|
||||||
tags:
|
tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
permalink: /pages/c798e3/
|
permalink: /pages/9bb28f/
|
||||||
---
|
---
|
||||||
|
|
||||||
# 关系型数据库面试
|
# 关系型数据库面试
|
||||||
|
|
@ -2,13 +2,15 @@
|
||||||
title: sql-cheat-sheet
|
title: sql-cheat-sheet
|
||||||
date: 2018-06-15 16:07:17
|
date: 2018-06-15 16:07:17
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
|
- 综合
|
||||||
tags:
|
tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
- SQL
|
- SQL
|
||||||
permalink: /pages/f1c77c/
|
permalink: /pages/b71c9e/
|
||||||
---
|
---
|
||||||
|
|
||||||
# SQL Cheat Sheet
|
# SQL Cheat Sheet
|
||||||
|
|
@ -231,7 +233,7 @@ SELECT * FROM mytable LIMIT 2, 3;
|
||||||
- 内部查询首先在其父查询之前执行,以便可以将内部查询的结果传递给外部查询。执行过程可以参考下图:
|
- 内部查询首先在其父查询之前执行,以便可以将内部查询的结果传递给外部查询。执行过程可以参考下图:
|
||||||
|
|
||||||
<p align="center">
|
<p align="center">
|
||||||
<img src="https://raw.githubusercontent.com/dunwu/images/dev/cs/database/mysql/sql-subqueries.gif!zp" alt="sql-subqueries">
|
<img src="https://raw.githubusercontent.com/dunwu/images/dev/cs/database/mysql/sql-subqueries.gif" alt="sql-subqueries">
|
||||||
</p>
|
</p>
|
||||||
|
|
||||||
**子查询的子查询**
|
**子查询的子查询**
|
||||||
|
|
@ -2,13 +2,15 @@
|
||||||
title: 扩展 SQL
|
title: 扩展 SQL
|
||||||
date: 2020-10-10 19:03:05
|
date: 2020-10-10 19:03:05
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
|
- 综合
|
||||||
tags:
|
tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
- SQL
|
- SQL
|
||||||
permalink: /pages/0f3524/
|
permalink: /pages/55e9a7/
|
||||||
---
|
---
|
||||||
|
|
||||||
# 扩展 SQL
|
# 扩展 SQL
|
||||||
|
|
@ -2,12 +2,15 @@
|
||||||
title: 关系型数据库综合知识
|
title: 关系型数据库综合知识
|
||||||
date: 2020-07-16 11:14:07
|
date: 2020-07-16 11:14:07
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
|
- 综合
|
||||||
tags:
|
tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
permalink: /pages/1e2ee7/
|
permalink: /pages/22f2e3/
|
||||||
|
hidden: true
|
||||||
---
|
---
|
||||||
|
|
||||||
# 关系型数据库综合知识
|
# 关系型数据库综合知识
|
||||||
|
|
@ -43,4 +46,4 @@ permalink: /pages/1e2ee7/
|
||||||
|
|
||||||
## 🚪 传送
|
## 🚪 传送
|
||||||
|
|
||||||
◾ 🏠 [DB-TUTORIAL 首页](https://github.com/dunwu/db-tutorial) ◾ 🎯 [我的博客](https://github.com/dunwu/blog) ◾
|
◾ 💧 [我的IT知识图谱](https://dunwu.github.io/waterdrop/) ◾ 🎯 [我的博客](https://dunwu.github.io/blog/) ◾
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Mysql 应用指南
|
title: Mysql 应用指南
|
||||||
date: 2020-07-13 10:08:37
|
date: 2020-07-13 10:08:37
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
- Mysql
|
- Mysql
|
||||||
|
|
@ -9,7 +10,7 @@ tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
- Mysql
|
- Mysql
|
||||||
permalink: /pages/0b2452/
|
permalink: /pages/5fe0f3/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Mysql 应用指南
|
# Mysql 应用指南
|
||||||
|
|
@ -233,4 +234,4 @@ MySQL 读写分离能提高性能的原因在于:
|
||||||
|
|
||||||
## 12. 传送门
|
## 12. 传送门
|
||||||
|
|
||||||
◾ 🏠 [DB-TUTORIAL 首页](https://github.com/dunwu/db-tutorial) ◾ 🎯 [我的博客](https://github.com/dunwu/blog) ◾
|
◾ 💧 [我的IT知识图谱](https://dunwu.github.io/waterdrop/) ◾ 🎯 [我的博客](https://dunwu.github.io/blog/) ◾
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: MySQL 工作流
|
title: MySQL 工作流
|
||||||
date: 2020-07-16 11:14:07
|
date: 2020-07-16 11:14:07
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
- Mysql
|
- Mysql
|
||||||
|
|
@ -9,7 +10,7 @@ tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
- Mysql
|
- Mysql
|
||||||
permalink: /pages/0a031b/
|
permalink: /pages/8262aa/
|
||||||
---
|
---
|
||||||
|
|
||||||
# MySQL 工作流
|
# MySQL 工作流
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Mysql 事务
|
title: Mysql 事务
|
||||||
date: 2020-06-03 19:32:09
|
date: 2020-06-03 19:32:09
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
- Mysql
|
- Mysql
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
- Mysql
|
- Mysql
|
||||||
- 事务
|
- 事务
|
||||||
permalink: /pages/f3295c/
|
permalink: /pages/00b04d/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Mysql 事务
|
# Mysql 事务
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Mysql 锁
|
title: Mysql 锁
|
||||||
date: 2020-09-07 07:54:19
|
date: 2020-09-07 07:54:19
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
- Mysql
|
- Mysql
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
- Mysql
|
- Mysql
|
||||||
- 锁
|
- 锁
|
||||||
permalink: /pages/86db3b/
|
permalink: /pages/f1f151/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Mysql 锁
|
# Mysql 锁
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Mysql 索引
|
title: Mysql 索引
|
||||||
date: 2020-07-16 11:14:07
|
date: 2020-07-16 11:14:07
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
- Mysql
|
- Mysql
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
- Mysql
|
- Mysql
|
||||||
- 索引
|
- 索引
|
||||||
permalink: /pages/516ac6/
|
permalink: /pages/fcb19c/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Mysql 索引
|
# Mysql 索引
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Mysql 性能优化
|
title: Mysql 性能优化
|
||||||
date: 2020-06-03 20:16:48
|
date: 2020-06-03 20:16:48
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
- Mysql
|
- Mysql
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
- Mysql
|
- Mysql
|
||||||
- 性能
|
- 性能
|
||||||
permalink: /pages/8c404f/
|
permalink: /pages/396816/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Mysql 性能优化
|
# Mysql 性能优化
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Mysql 运维
|
title: Mysql 运维
|
||||||
date: 2019-11-26 21:37:17
|
date: 2019-11-26 21:37:17
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
- Mysql
|
- Mysql
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
- Mysql
|
- Mysql
|
||||||
- 运维
|
- 运维
|
||||||
permalink: /pages/ada3b2/
|
permalink: /pages/e33b92/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Mysql 运维
|
# Mysql 运维
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Mysql 配置
|
title: Mysql 配置
|
||||||
date: 2020-02-29 22:32:57
|
date: 2020-02-29 22:32:57
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
- Mysql
|
- Mysql
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
- Mysql
|
- Mysql
|
||||||
- 配置
|
- 配置
|
||||||
permalink: /pages/6ed8d9/
|
permalink: /pages/5da42d/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Mysql 配置
|
# Mysql 配置
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Mysql 常见问题
|
title: Mysql 常见问题
|
||||||
date: 2020-09-12 10:43:53
|
date: 2020-09-12 10:43:53
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
- Mysql
|
- Mysql
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
- Mysql
|
- Mysql
|
||||||
- FAQ
|
- FAQ
|
||||||
permalink: /pages/5885bb/
|
permalink: /pages/7b0caf/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Mysql 常见问题
|
# Mysql 常见问题
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Mysql 教程
|
title: Mysql 教程
|
||||||
date: 2020-02-10 14:27:39
|
date: 2020-02-10 14:27:39
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
- Mysql
|
- Mysql
|
||||||
|
|
@ -9,7 +10,8 @@ tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
- Mysql
|
- Mysql
|
||||||
permalink: /pages/a7b923/
|
permalink: /pages/a5b63b/
|
||||||
|
hidden: true
|
||||||
---
|
---
|
||||||
|
|
||||||
# Mysql 教程
|
# Mysql 教程
|
||||||
|
|
@ -74,4 +76,4 @@ permalink: /pages/a7b923/
|
||||||
|
|
||||||
## 🚪 传送
|
## 🚪 传送
|
||||||
|
|
||||||
◾ 🏠 [DB-TUTORIAL 首页](https://github.com/dunwu/db-tutorial) ◾ 🎯 [我的博客](https://github.com/dunwu/blog) ◾
|
◾ 💧 [我的IT知识图谱](https://dunwu.github.io/waterdrop/) ◾ 🎯 [我的博客](https://dunwu.github.io/blog/) ◾
|
||||||
|
|
@ -2,13 +2,15 @@
|
||||||
title: PostgreSQL 应用指南
|
title: PostgreSQL 应用指南
|
||||||
date: 2019-08-22 09:02:39
|
date: 2019-08-22 09:02:39
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
|
- 其他
|
||||||
tags:
|
tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
- PostgreSQL
|
- PostgreSQL
|
||||||
permalink: /pages/1d898b/
|
permalink: /pages/52609d/
|
||||||
---
|
---
|
||||||
|
|
||||||
# PostgreSQL 应用指南
|
# PostgreSQL 应用指南
|
||||||
|
|
@ -2,13 +2,15 @@
|
||||||
title: H2 应用指南
|
title: H2 应用指南
|
||||||
date: 2019-08-22 09:02:39
|
date: 2019-08-22 09:02:39
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
|
- 其他
|
||||||
tags:
|
tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
- H2
|
- H2
|
||||||
permalink: /pages/87d312/
|
permalink: /pages/f27c0c/
|
||||||
---
|
---
|
||||||
|
|
||||||
# H2 应用指南
|
# H2 应用指南
|
||||||
|
|
@ -2,13 +2,15 @@
|
||||||
title: sqlite
|
title: sqlite
|
||||||
date: 2019-08-22 09:02:39
|
date: 2019-08-22 09:02:39
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
|
- 其他
|
||||||
tags:
|
tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
- SQLite
|
- SQLite
|
||||||
permalink: /pages/d024ff/
|
permalink: /pages/bdcd7e/
|
||||||
---
|
---
|
||||||
|
|
||||||
# SQLite
|
# SQLite
|
||||||
|
|
@ -2,12 +2,15 @@
|
||||||
title: 关系型数据库其他知识
|
title: 关系型数据库其他知识
|
||||||
date: 2022-04-11 16:52:35
|
date: 2022-04-11 16:52:35
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
|
- 其他
|
||||||
tags:
|
tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
permalink: /pages/b2560d/
|
permalink: /pages/ca9888/
|
||||||
|
hidden: true
|
||||||
---
|
---
|
||||||
|
|
||||||
# 关系型数据库其他知识
|
# 关系型数据库其他知识
|
||||||
|
|
@ -22,4 +25,4 @@ permalink: /pages/b2560d/
|
||||||
|
|
||||||
## 🚪 传送
|
## 🚪 传送
|
||||||
|
|
||||||
◾ 🏠 [DB-TUTORIAL 首页](https://github.com/dunwu/db-tutorial) ◾ 🎯 [我的博客](https://github.com/dunwu/blog) ◾
|
◾ 💧 [我的IT知识图谱](https://dunwu.github.io/waterdrop/) ◾ 🎯 [我的博客](https://dunwu.github.io/blog/) ◾
|
||||||
|
|
@ -2,12 +2,14 @@
|
||||||
title: 关系型数据库
|
title: 关系型数据库
|
||||||
date: 2022-04-11 16:52:35
|
date: 2022-04-11 16:52:35
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
tags:
|
tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- 关系型数据库
|
- 关系型数据库
|
||||||
permalink: /pages/bdd9ad/
|
permalink: /pages/bb43eb/
|
||||||
|
hidden: true
|
||||||
---
|
---
|
||||||
|
|
||||||
# 关系型数据库
|
# 关系型数据库
|
||||||
|
|
@ -69,4 +71,4 @@ permalink: /pages/bdd9ad/
|
||||||
|
|
||||||
## 🚪 传送
|
## 🚪 传送
|
||||||
|
|
||||||
◾ 🏠 [DB-TUTORIAL 首页](https://github.com/dunwu/db-tutorial) ◾ 🎯 [我的博客](https://github.com/dunwu/blog) ◾
|
◾ 💧 [我的IT知识图谱](https://dunwu.github.io/waterdrop/) ◾ 🎯 [我的博客](https://dunwu.github.io/blog/) ◾
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: MongoDB 应用指南
|
title: MongoDB 应用指南
|
||||||
date: 2020-09-07 07:54:19
|
date: 2020-09-07 07:54:19
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 文档数据库
|
- 文档数据库
|
||||||
- MongoDB
|
- MongoDB
|
||||||
|
|
@ -9,7 +10,7 @@ tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- 文档数据库
|
- 文档数据库
|
||||||
- MongoDB
|
- MongoDB
|
||||||
permalink: /pages/56d5b6/
|
permalink: /pages/3288f3/
|
||||||
---
|
---
|
||||||
|
|
||||||
# MongoDB 应用指南
|
# MongoDB 应用指南
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: MongoDB 的 CRUD 操作
|
title: MongoDB 的 CRUD 操作
|
||||||
date: 2020-09-25 21:23:41
|
date: 2020-09-25 21:23:41
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 文档数据库
|
- 文档数据库
|
||||||
- MongoDB
|
- MongoDB
|
||||||
|
|
@ -9,7 +10,7 @@ tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- 文档数据库
|
- 文档数据库
|
||||||
- MongoDB
|
- MongoDB
|
||||||
permalink: /pages/d69d64/
|
permalink: /pages/7efbac/
|
||||||
---
|
---
|
||||||
|
|
||||||
# MongoDB 的 CRUD 操作
|
# MongoDB 的 CRUD 操作
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: MongoDB 的聚合操作
|
title: MongoDB 的聚合操作
|
||||||
date: 2020-09-21 21:22:57
|
date: 2020-09-21 21:22:57
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 文档数据库
|
- 文档数据库
|
||||||
- MongoDB
|
- MongoDB
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- 文档数据库
|
- 文档数据库
|
||||||
- MongoDB
|
- MongoDB
|
||||||
- 聚合
|
- 聚合
|
||||||
permalink: /pages/2698b2/
|
permalink: /pages/75daa5/
|
||||||
---
|
---
|
||||||
|
|
||||||
# MongoDB 的聚合操作
|
# MongoDB 的聚合操作
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: MongoDB 事务
|
title: MongoDB 事务
|
||||||
date: 2020-09-20 23:12:17
|
date: 2020-09-20 23:12:17
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 文档数据库
|
- 文档数据库
|
||||||
- MongoDB
|
- MongoDB
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- 文档数据库
|
- 文档数据库
|
||||||
- MongoDB
|
- MongoDB
|
||||||
- 事务
|
- 事务
|
||||||
permalink: /pages/3287fa/
|
permalink: /pages/4574fe/
|
||||||
---
|
---
|
||||||
|
|
||||||
# MongoDB 事务
|
# MongoDB 事务
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: MongoDB 建模
|
title: MongoDB 建模
|
||||||
date: 2020-09-09 20:47:14
|
date: 2020-09-09 20:47:14
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 文档数据库
|
- 文档数据库
|
||||||
- MongoDB
|
- MongoDB
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- 文档数据库
|
- 文档数据库
|
||||||
- MongoDB
|
- MongoDB
|
||||||
- 建模
|
- 建模
|
||||||
permalink: /pages/c154c4/
|
permalink: /pages/562f99/
|
||||||
---
|
---
|
||||||
|
|
||||||
# MongoDB 建模
|
# MongoDB 建模
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: MongoDB 建模示例
|
title: MongoDB 建模示例
|
||||||
date: 2020-09-12 10:43:53
|
date: 2020-09-12 10:43:53
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 文档数据库
|
- 文档数据库
|
||||||
- MongoDB
|
- MongoDB
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- 文档数据库
|
- 文档数据库
|
||||||
- MongoDB
|
- MongoDB
|
||||||
- 建模
|
- 建模
|
||||||
permalink: /pages/646187/
|
permalink: /pages/88c7d3/
|
||||||
---
|
---
|
||||||
|
|
||||||
# MongoDB 建模示例
|
# MongoDB 建模示例
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: MongoDB 索引
|
title: MongoDB 索引
|
||||||
date: 2020-09-21 21:22:57
|
date: 2020-09-21 21:22:57
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 文档数据库
|
- 文档数据库
|
||||||
- MongoDB
|
- MongoDB
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- 文档数据库
|
- 文档数据库
|
||||||
- MongoDB
|
- MongoDB
|
||||||
- 索引
|
- 索引
|
||||||
permalink: /pages/1c75d4/
|
permalink: /pages/10c674/
|
||||||
---
|
---
|
||||||
|
|
||||||
# MongoDB 索引
|
# MongoDB 索引
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: MongoDB 复制
|
title: MongoDB 复制
|
||||||
date: 2020-09-20 23:12:17
|
date: 2020-09-20 23:12:17
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 文档数据库
|
- 文档数据库
|
||||||
- MongoDB
|
- MongoDB
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- 文档数据库
|
- 文档数据库
|
||||||
- MongoDB
|
- MongoDB
|
||||||
- 复制
|
- 复制
|
||||||
permalink: /pages/e0b65c/
|
permalink: /pages/505407/
|
||||||
---
|
---
|
||||||
|
|
||||||
# MongoDB 复制
|
# MongoDB 复制
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: MongoDB 分片
|
title: MongoDB 分片
|
||||||
date: 2020-09-20 23:12:17
|
date: 2020-09-20 23:12:17
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 文档数据库
|
- 文档数据库
|
||||||
- MongoDB
|
- MongoDB
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- 文档数据库
|
- 文档数据库
|
||||||
- MongoDB
|
- MongoDB
|
||||||
- 分片
|
- 分片
|
||||||
permalink: /pages/34b182/
|
permalink: /pages/ad08f5/
|
||||||
---
|
---
|
||||||
|
|
||||||
# MongoDB 分片
|
# MongoDB 分片
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: MongoDB 运维
|
title: MongoDB 运维
|
||||||
date: 2020-09-09 20:47:14
|
date: 2020-09-09 20:47:14
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 文档数据库
|
- 文档数据库
|
||||||
- MongoDB
|
- MongoDB
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- 文档数据库
|
- 文档数据库
|
||||||
- MongoDB
|
- MongoDB
|
||||||
- 运维
|
- 运维
|
||||||
permalink: /pages/ce58ab/
|
permalink: /pages/5e3c30/
|
||||||
---
|
---
|
||||||
|
|
||||||
# MongoDB 运维
|
# MongoDB 运维
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: MongoDB 教程
|
title: MongoDB 教程
|
||||||
date: 2020-09-09 20:47:14
|
date: 2020-09-09 20:47:14
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 文档数据库
|
- 文档数据库
|
||||||
- MongoDB
|
- MongoDB
|
||||||
|
|
@ -9,7 +10,8 @@ tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- 文档数据库
|
- 文档数据库
|
||||||
- MongoDB
|
- MongoDB
|
||||||
permalink: /pages/86cece/
|
permalink: /pages/b1a116/
|
||||||
|
hidden: true
|
||||||
---
|
---
|
||||||
|
|
||||||
# MongoDB 教程
|
# MongoDB 教程
|
||||||
|
|
@ -58,4 +60,4 @@ permalink: /pages/86cece/
|
||||||
|
|
||||||
## 🚪 传送
|
## 🚪 传送
|
||||||
|
|
||||||
◾ 🏠 [DB-TUTORIAL 首页](https://github.com/dunwu/db-tutorial) ◾ 🎯 [我的博客](https://github.com/dunwu/blog) ◾
|
◾ 💧 [我的IT知识图谱](https://dunwu.github.io/waterdrop/) ◾ 🎯 [我的博客](https://dunwu.github.io/blog/) ◾
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Redis 面试总结
|
title: Redis 面试总结
|
||||||
date: 2020-07-13 17:03:42
|
date: 2020-07-13 17:03:42
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- KV数据库
|
- KV数据库
|
||||||
- Redis
|
- Redis
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- KV数据库
|
- KV数据库
|
||||||
- Redis
|
- Redis
|
||||||
- 面试
|
- 面试
|
||||||
permalink: /pages/c3ce07/
|
permalink: /pages/451b73/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Redis 面试总结
|
# Redis 面试总结
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Redis 应用指南
|
title: Redis 应用指南
|
||||||
date: 2020-01-30 21:48:57
|
date: 2020-01-30 21:48:57
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- KV数据库
|
- KV数据库
|
||||||
- Redis
|
- Redis
|
||||||
|
|
@ -9,7 +10,7 @@ tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- KV数据库
|
- KV数据库
|
||||||
- Redis
|
- Redis
|
||||||
permalink: /pages/5cd883/
|
permalink: /pages/94e9d6/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Redis 应用指南
|
# Redis 应用指南
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Redis 数据类型和应用
|
title: Redis 数据类型和应用
|
||||||
date: 2020-06-24 10:45:38
|
date: 2020-06-24 10:45:38
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- KV数据库
|
- KV数据库
|
||||||
- Redis
|
- Redis
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- KV数据库
|
- KV数据库
|
||||||
- Redis
|
- Redis
|
||||||
- 数据类型
|
- 数据类型
|
||||||
permalink: /pages/5d2de2/
|
permalink: /pages/ed757c/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Redis 数据类型和应用
|
# Redis 数据类型和应用
|
||||||
|
|
@ -255,7 +256,7 @@ OK
|
||||||
Redis 的 `SORT` 命令可以对 `LIST`、`SET`、`ZSET` 进行排序。
|
Redis 的 `SORT` 命令可以对 `LIST`、`SET`、`ZSET` 进行排序。
|
||||||
|
|
||||||
| 命令 | 描述 |
|
| 命令 | 描述 |
|
||||||
| ------ | --------------------------------------------------------------------------------------- |
|
| ------ | --------------------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------- |
|
||||||
| `SORT` | `SORT source-key [BY pattern] [LIMIT offset count] [GET pattern [GET pattern ...]] [ASC | DESC] [ALPHA] [STORE dest-key]`—根据给定选项,对输入 `LIST`、`SET`、`ZSET` 进行排序,然后返回或存储排序的结果。 |
|
| `SORT` | `SORT source-key [BY pattern] [LIMIT offset count] [GET pattern [GET pattern ...]] [ASC | DESC] [ALPHA] [STORE dest-key]`—根据给定选项,对输入 `LIST`、`SET`、`ZSET` 进行排序,然后返回或存储排序的结果。 |
|
||||||
|
|
||||||
示例:
|
示例:
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Redis 持久化
|
title: Redis 持久化
|
||||||
date: 2020-06-24 10:45:38
|
date: 2020-06-24 10:45:38
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- KV数据库
|
- KV数据库
|
||||||
- Redis
|
- Redis
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- KV数据库
|
- KV数据库
|
||||||
- Redis
|
- Redis
|
||||||
- 持久化
|
- 持久化
|
||||||
permalink: /pages/d61faa/
|
permalink: /pages/4de901/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Redis 持久化
|
# Redis 持久化
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Redis 复制
|
title: Redis 复制
|
||||||
date: 2020-06-24 10:45:38
|
date: 2020-06-24 10:45:38
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- KV数据库
|
- KV数据库
|
||||||
- Redis
|
- Redis
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- KV数据库
|
- KV数据库
|
||||||
- Redis
|
- Redis
|
||||||
- 复制
|
- 复制
|
||||||
permalink: /pages/0de16b/
|
permalink: /pages/379cd8/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Redis 复制
|
# Redis 复制
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Redis 哨兵
|
title: Redis 哨兵
|
||||||
date: 2020-06-24 10:45:38
|
date: 2020-06-24 10:45:38
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- KV数据库
|
- KV数据库
|
||||||
- Redis
|
- Redis
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- KV数据库
|
- KV数据库
|
||||||
- Redis
|
- Redis
|
||||||
- 哨兵
|
- 哨兵
|
||||||
permalink: /pages/5e23fc/
|
permalink: /pages/615afe/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Redis 哨兵
|
# Redis 哨兵
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Redis 集群
|
title: Redis 集群
|
||||||
date: 2020-06-24 10:45:38
|
date: 2020-06-24 10:45:38
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- KV数据库
|
- KV数据库
|
||||||
- Redis
|
- Redis
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- KV数据库
|
- KV数据库
|
||||||
- Redis
|
- Redis
|
||||||
- 集群
|
- 集群
|
||||||
permalink: /pages/6b0eb1/
|
permalink: /pages/77dfbe/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Redis 集群
|
# Redis 集群
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Redis 实战
|
title: Redis 实战
|
||||||
date: 2020-06-24 10:45:38
|
date: 2020-06-24 10:45:38
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- KV数据库
|
- KV数据库
|
||||||
- Redis
|
- Redis
|
||||||
|
|
@ -9,7 +10,7 @@ tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- KV数据库
|
- KV数据库
|
||||||
- Redis
|
- Redis
|
||||||
permalink: /pages/199c5a/
|
permalink: /pages/1fc9c4/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Redis 实战
|
# Redis 实战
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Redis 运维
|
title: Redis 运维
|
||||||
date: 2020-06-24 10:45:38
|
date: 2020-06-24 10:45:38
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- KV数据库
|
- KV数据库
|
||||||
- Redis
|
- Redis
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- KV数据库
|
- KV数据库
|
||||||
- Redis
|
- Redis
|
||||||
- 运维
|
- 运维
|
||||||
permalink: /pages/8f1824/
|
permalink: /pages/537098/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Redis 运维
|
# Redis 运维
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Redis 教程
|
title: Redis 教程
|
||||||
date: 2020-02-10 14:27:39
|
date: 2020-02-10 14:27:39
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- KV数据库
|
- KV数据库
|
||||||
- Redis
|
- Redis
|
||||||
|
|
@ -9,7 +10,8 @@ tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- KV数据库
|
- KV数据库
|
||||||
- Redis
|
- Redis
|
||||||
permalink: /pages/b2487a/
|
permalink: /pages/fe3808/
|
||||||
|
hidden: true
|
||||||
---
|
---
|
||||||
|
|
||||||
# Redis 教程
|
# Redis 教程
|
||||||
|
|
@ -99,4 +101,4 @@ permalink: /pages/b2487a/
|
||||||
|
|
||||||
## 🚪 传送
|
## 🚪 传送
|
||||||
|
|
||||||
◾ 🏠 [DB-TUTORIAL 首页](https://github.com/dunwu/db-tutorial) ◾ 🎯 [我的博客](https://github.com/dunwu/blog) ◾
|
◾ 💧 [我的IT知识图谱](https://dunwu.github.io/waterdrop/) ◾ 🎯 [我的博客](https://dunwu.github.io/blog/) ◾
|
||||||
|
|
@ -2,13 +2,14 @@
|
||||||
title: Hbase
|
title: Hbase
|
||||||
date: 2020-02-10 14:27:39
|
date: 2020-02-10 14:27:39
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 列式数据库
|
- 列式数据库
|
||||||
tags:
|
tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- 列式数据库
|
- 列式数据库
|
||||||
- Hbase
|
- Hbase
|
||||||
permalink: /pages/b570af/
|
permalink: /pages/7ab03c/
|
||||||
---
|
---
|
||||||
|
|
||||||
# HBase
|
# HBase
|
||||||
|
|
@ -2,13 +2,14 @@
|
||||||
title: Cassandra
|
title: Cassandra
|
||||||
date: 2019-08-22 09:02:39
|
date: 2019-08-22 09:02:39
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 列式数据库
|
- 列式数据库
|
||||||
tags:
|
tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- 列式数据库
|
- 列式数据库
|
||||||
- Cassandra
|
- Cassandra
|
||||||
permalink: /pages/4c58c2/
|
permalink: /pages/ca3ca5/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Cassandra
|
# Cassandra
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Elasticsearch 面试总结
|
title: Elasticsearch 面试总结
|
||||||
date: 2020-06-16 07:10:44
|
date: 2020-06-16 07:10:44
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
- 面试
|
- 面试
|
||||||
permalink: /pages/1f9edc/
|
permalink: /pages/0cb563/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Elasticsearch 面试总结
|
# Elasticsearch 面试总结
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Elasticsearch 快速入门
|
title: Elasticsearch 快速入门
|
||||||
date: 2020-06-16 07:10:44
|
date: 2020-06-16 07:10:44
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
|
|
@ -9,7 +10,7 @@ tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
permalink: /pages/37b739/
|
permalink: /pages/98c3a5/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Elasticsearch 快速入门
|
# Elasticsearch 快速入门
|
||||||
|
|
@ -20,7 +21,7 @@ permalink: /pages/37b739/
|
||||||
>
|
>
|
||||||
> _以下简称 ES_。
|
> _以下简称 ES_。
|
||||||
|
|
||||||
## 一、Elasticsearch 简介
|
## Elasticsearch 简介
|
||||||
|
|
||||||
### 什么是 Elasticsearch
|
### 什么是 Elasticsearch
|
||||||
|
|
||||||
|
|
@ -105,7 +106,7 @@ Document 使用 JSON 格式表示,下面是一个例子。
|
||||||
| type | 数据表 |
|
| type | 数据表 |
|
||||||
| docuemnt | 一行数据 |
|
| docuemnt | 一行数据 |
|
||||||
|
|
||||||
## 二、ElasticSearch 基本原理
|
## ElasticSearch 基本原理
|
||||||
|
|
||||||
### ES 写数据过程
|
### ES 写数据过程
|
||||||
|
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Elasticsearch 简介
|
title: Elasticsearch 简介
|
||||||
date: 2022-02-22 21:01:01
|
date: 2022-02-22 21:01:01
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
|
|
@ -9,7 +10,7 @@ tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
permalink: /pages/6f7391/
|
permalink: /pages/0fb506/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Elasticsearch 简介
|
# Elasticsearch 简介
|
||||||
|
|
@ -23,31 +24,14 @@ Elasticsearch 是一个基于 Lucene 的搜索和数据分析工具,它提供
|
||||||
- StackOverflow 结合全文搜索与地理位置查询,以及**more-like-this**功能来找到相关的问题和答案。
|
- StackOverflow 结合全文搜索与地理位置查询,以及**more-like-this**功能来找到相关的问题和答案。
|
||||||
- Github 使用 Elasticsearch 检索 1300 亿行的代码。
|
- Github 使用 Elasticsearch 检索 1300 亿行的代码。
|
||||||
|
|
||||||
<!-- TOC depthFrom:2 depthTo:3 -->
|
## Elasticsearch 特点
|
||||||
|
|
||||||
- [1. Elasticsearch 特点](#1-elasticsearch-特点)
|
|
||||||
- [2. Elasticsearch 发展历史](#2-elasticsearch-发展历史)
|
|
||||||
- [3. Elasticsearch 概念](#3-elasticsearch-概念)
|
|
||||||
- [3.1. 近实时(NRT)](#31-近实时nrt)
|
|
||||||
- [3.2. 索引(Index)](#32-索引index)
|
|
||||||
- [3.3. ~~类型(Type)~~](#33-类型type)
|
|
||||||
- [3.4. 文档(Document)](#34-文档document)
|
|
||||||
- [3.5. 节点(Node)](#35-节点node)
|
|
||||||
- [3.6. 集群(Cluster)](#36-集群cluster)
|
|
||||||
- [3.7. 分片(Shards)](#37-分片shards)
|
|
||||||
- [3.8. 副本(Replicas)](#38-副本replicas)
|
|
||||||
- [4. 参考资料](#4-参考资料)
|
|
||||||
|
|
||||||
<!-- /TOC -->
|
|
||||||
|
|
||||||
## 1. Elasticsearch 特点
|
|
||||||
|
|
||||||
- 分布式的实时文件存储,每个字段都被索引并可被搜索;
|
- 分布式的实时文件存储,每个字段都被索引并可被搜索;
|
||||||
- 分布式的实时分析搜索引擎;
|
- 分布式的实时分析搜索引擎;
|
||||||
- 可弹性扩展到上百台服务器规模,处理 PB 级结构化或非结构化数据;
|
- 可弹性扩展到上百台服务器规模,处理 PB 级结构化或非结构化数据;
|
||||||
- 开箱即用(安装即可使用),它提供了许多合理的缺省值,并对初学者隐藏了复杂的搜索引擎理论。只需很少的学习既可在生产环境中使用。
|
- 开箱即用(安装即可使用),它提供了许多合理的缺省值,并对初学者隐藏了复杂的搜索引擎理论。只需很少的学习既可在生产环境中使用。
|
||||||
|
|
||||||
## 2. Elasticsearch 发展历史
|
## Elasticsearch 发展历史
|
||||||
|
|
||||||
- 2010 年 2 月 8 日,Elasticsearch 第一个公开版本发布。
|
- 2010 年 2 月 8 日,Elasticsearch 第一个公开版本发布。
|
||||||
|
|
||||||
|
|
@ -103,15 +87,15 @@ Elasticsearch 是一个基于 Lucene 的搜索和数据分析工具,它提供
|
||||||
- 引入了真正的内存断路器,它可以更精准地检测出无法处理的请求,并防止它们使单个节点不稳定;
|
- 引入了真正的内存断路器,它可以更精准地检测出无法处理的请求,并防止它们使单个节点不稳定;
|
||||||
- Zen2 是 Elasticsearch 的全新集群协调层,提高了可靠性、性能和用户体验,变得更快、更安全,并更易于使用。
|
- Zen2 是 Elasticsearch 的全新集群协调层,提高了可靠性、性能和用户体验,变得更快、更安全,并更易于使用。
|
||||||
|
|
||||||
## 3. Elasticsearch 概念
|
## Elasticsearch 概念
|
||||||
|
|
||||||
下列有一些概念是 Elasticsearch 的核心。从一开始就理解这些概念将极大地帮助简化学习 Elasticsearch 的过程。
|
下列有一些概念是 Elasticsearch 的核心。从一开始就理解这些概念将极大地帮助简化学习 Elasticsearch 的过程。
|
||||||
|
|
||||||
### 3.1. 近实时(NRT)
|
### 近实时(NRT)
|
||||||
|
|
||||||
Elasticsearch 是一个近乎实时的搜索平台。这意味着**从索引文档到可搜索文档的时间有一点延迟**(通常是一秒)。
|
Elasticsearch 是一个近乎实时的搜索平台。这意味着**从索引文档到可搜索文档的时间有一点延迟**(通常是一秒)。
|
||||||
|
|
||||||
### 3.2. 索引(Index)
|
### 索引(Index)
|
||||||
|
|
||||||
索引在不同语境,有着不同的含义
|
索引在不同语境,有着不同的含义
|
||||||
|
|
||||||
|
|
@ -302,13 +286,13 @@ GET my_index/_search?q=full_name:John
|
||||||
DELETE my_index
|
DELETE my_index
|
||||||
```
|
```
|
||||||
|
|
||||||
### 3.3. ~~类型(Type)~~
|
### ~~类型(Type)~~
|
||||||
|
|
||||||
~~type 是一个逻辑意义上的分类或者叫分区,允许在同一索引中建立多个 type。本质是相当于一个过滤条件,高版本将会废弃 type 概念。~~
|
~~type 是一个逻辑意义上的分类或者叫分区,允许在同一索引中建立多个 type。本质是相当于一个过滤条件,高版本将会废弃 type 概念。~~
|
||||||
|
|
||||||
> ~~**6.0.0 版本及之后,废弃 type**~~
|
> ~~**6.0.0 版本及之后,废弃 type**~~
|
||||||
|
|
||||||
### 3.4. 文档(Document)
|
### 文档(Document)
|
||||||
|
|
||||||
Elasticsearch 是面向文档的,**文档是所有可搜索数据的最小单位**。
|
Elasticsearch 是面向文档的,**文档是所有可搜索数据的最小单位**。
|
||||||
|
|
||||||
|
|
@ -352,7 +336,7 @@ Elasticsearch 使用 [_JSON_](http://en.wikipedia.org/wiki/Json) 作为文档的
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 3.5. 节点(Node)
|
### 节点(Node)
|
||||||
|
|
||||||
#### 节点简介
|
#### 节点简介
|
||||||
|
|
||||||
|
|
@ -390,7 +374,7 @@ Elasticsearch 实例本质上是一个 Java 进程。一台机器上可以运行
|
||||||
>
|
>
|
||||||
> 开发环境中一个节点可以承担多种角色。但是,在生产环境中,节点应该设置为单一角色。
|
> 开发环境中一个节点可以承担多种角色。但是,在生产环境中,节点应该设置为单一角色。
|
||||||
|
|
||||||
### 3.6. 集群(Cluster)
|
### 集群(Cluster)
|
||||||
|
|
||||||
#### 集群简介
|
#### 集群简介
|
||||||
|
|
||||||
|
|
@ -434,7 +418,7 @@ Elasticsearch 的集群监控信息中包含了许多的统计数据,其中最
|
||||||
- **`yellow`**:所有的主分片都正常运行,但不是所有的副本分片都正常运行。
|
- **`yellow`**:所有的主分片都正常运行,但不是所有的副本分片都正常运行。
|
||||||
- **`red`**:有主分片没能正常运行。
|
- **`red`**:有主分片没能正常运行。
|
||||||
|
|
||||||
### 3.7. 分片(Shards)
|
### 分片(Shards)
|
||||||
|
|
||||||
#### 分片简介
|
#### 分片简介
|
||||||
|
|
||||||
|
|
@ -470,7 +454,7 @@ Elasticsearch 是利用分片将数据分发到集群内各处的。分片是数
|
||||||
- 影响搜索结果的相关性打分,影响统计结果的准确性
|
- 影响搜索结果的相关性打分,影响统计结果的准确性
|
||||||
- 单节点上过多的分片,会导致资源浪费,同时也会影响性能
|
- 单节点上过多的分片,会导致资源浪费,同时也会影响性能
|
||||||
|
|
||||||
### 3.8. 副本(Replicas)
|
### 副本(Replicas)
|
||||||
|
|
||||||
副本主要是针对主分片(Shards)的复制,Elasticsearch 中主分片可以拥有 0 个或多个的副本。
|
副本主要是针对主分片(Shards)的复制,Elasticsearch 中主分片可以拥有 0 个或多个的副本。
|
||||||
|
|
||||||
|
|
@ -483,7 +467,7 @@ Elasticsearch 是利用分片将数据分发到集群内各处的。分片是数
|
||||||
|
|
||||||
> 每个 Elasticsearch 分片都是 Lucene 索引。单个 Lucene 索引中可以包含最大数量的文档。截止 LUCENE-5843,限制是 2,147,483,519(= `Integer.MAX_VALUE` - 128)文档。您可以使用\_cat/shardsAPI 监控分片大小。
|
> 每个 Elasticsearch 分片都是 Lucene 索引。单个 Lucene 索引中可以包含最大数量的文档。截止 LUCENE-5843,限制是 2,147,483,519(= `Integer.MAX_VALUE` - 128)文档。您可以使用\_cat/shardsAPI 监控分片大小。
|
||||||
|
|
||||||
## 4. 参考资料
|
## 参考资料
|
||||||
|
|
||||||
- [Elasticsearch 官网](https://www.elastic.co/)
|
- [Elasticsearch 官网](https://www.elastic.co/)
|
||||||
- [Elasticsearch 简介](https://www.knowledgedict.com/tutorial/elasticsearch-intro.html)
|
- [Elasticsearch 简介](https://www.knowledgedict.com/tutorial/elasticsearch-intro.html)
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Elasticsearch 索引
|
title: Elasticsearch 索引
|
||||||
date: 2022-02-22 21:01:01
|
date: 2022-02-22 21:01:01
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
|
|
@ -10,16 +11,16 @@ tags:
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
- 索引
|
- 索引
|
||||||
permalink: /pages/5291b4/
|
permalink: /pages/293175/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Elasticsearch 索引
|
# Elasticsearch 索引
|
||||||
|
|
||||||
## 1. 索引管理操作
|
## 索引管理操作
|
||||||
|
|
||||||
Elasticsearch 索引管理主要包括如何进行索引的创建、索引的删除、副本的更新、索引读写权限、索引别名的配置等等内容。
|
Elasticsearch 索引管理主要包括如何进行索引的创建、索引的删除、副本的更新、索引读写权限、索引别名的配置等等内容。
|
||||||
|
|
||||||
### 1.1. 索引删除
|
### 索引删除
|
||||||
|
|
||||||
ES 索引删除操作向 ES 集群的 http 接口发送指定索引的 delete http 请求即可,可以通过 curl 命令,具体如下:
|
ES 索引删除操作向 ES 集群的 http 接口发送指定索引的 delete http 请求即可,可以通过 curl 命令,具体如下:
|
||||||
|
|
||||||
|
|
@ -41,7 +42,7 @@ curl -X DELETE http://10.10.10.66:9200/my_index?pretty
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 1.2. 索引别名
|
### 索引别名
|
||||||
|
|
||||||
ES 的索引别名就是给一个索引或者多个索引起的另一个名字,典型的应用场景是针对索引使用的平滑切换。
|
ES 的索引别名就是给一个索引或者多个索引起的另一个名字,典型的应用场景是针对索引使用的平滑切换。
|
||||||
|
|
||||||
|
|
@ -79,7 +80,7 @@ POST /_aliases
|
||||||
|
|
||||||
ES 索引别名有个典型的应用场景是平滑切换,更多细节可以查看 [Elasticsearch(ES)索引零停机(无需重启)无缝平滑切换的方法](https://www.knowledgedict.com/tutorial/elasticsearch-index-smooth-shift.html)。
|
ES 索引别名有个典型的应用场景是平滑切换,更多细节可以查看 [Elasticsearch(ES)索引零停机(无需重启)无缝平滑切换的方法](https://www.knowledgedict.com/tutorial/elasticsearch-index-smooth-shift.html)。
|
||||||
|
|
||||||
## 2. Settings 详解
|
## Settings 详解
|
||||||
|
|
||||||
Elasticsearch 索引的配置项主要分为**静态配置属性**和**动态配置属性**,静态配置属性是索引创建后不能修改,而动态配置属性则可以随时修改。
|
Elasticsearch 索引的配置项主要分为**静态配置属性**和**动态配置属性**,静态配置属性是索引创建后不能修改,而动态配置属性则可以随时修改。
|
||||||
|
|
||||||
|
|
@ -171,13 +172,13 @@ PUT /my_index
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 2.1. 固定属性
|
### 固定属性
|
||||||
|
|
||||||
- **_`index.creation_date`_**:顾名思义索引的创建时间戳。
|
- **_`index.creation_date`_**:顾名思义索引的创建时间戳。
|
||||||
- **_`index.uuid`_**:索引的 uuid 信息。
|
- **_`index.uuid`_**:索引的 uuid 信息。
|
||||||
- **_`index.version.created`_**:索引的版本号。
|
- **_`index.version.created`_**:索引的版本号。
|
||||||
|
|
||||||
### 2.2. 索引静态配置
|
### 索引静态配置
|
||||||
|
|
||||||
- **_`index.number_of_shards`_**:索引的主分片数,默认值是 **_`5`_**。这个配置在索引创建后不能修改;在 es 层面,可以通过 **_`es.index.max_number_of_shards`_** 属性设置索引最大的分片数,默认为 **_`1024`_**。
|
- **_`index.number_of_shards`_**:索引的主分片数,默认值是 **_`5`_**。这个配置在索引创建后不能修改;在 es 层面,可以通过 **_`es.index.max_number_of_shards`_** 属性设置索引最大的分片数,默认为 **_`1024`_**。
|
||||||
- **_`index.codec`_**:数据存储的压缩算法,默认值为 **_`LZ4`_**,可选择值还有 **_`best_compression`_**,它比 LZ4 可以获得更好的压缩比(即占据较小的磁盘空间,但存储性能比 LZ4 低)。
|
- **_`index.codec`_**:数据存储的压缩算法,默认值为 **_`LZ4`_**,可选择值还有 **_`best_compression`_**,它比 LZ4 可以获得更好的压缩比(即占据较小的磁盘空间,但存储性能比 LZ4 低)。
|
||||||
|
|
@ -194,12 +195,12 @@ PUT /my_index
|
||||||
- **_`filter`_**:定义新的 token filter,如同义词 filter。
|
- **_`filter`_**:定义新的 token filter,如同义词 filter。
|
||||||
- **_`analyzer`_**:配置新的分析器,一般是 char_filter、tokenizer 和一些 token filter 的组合。
|
- **_`analyzer`_**:配置新的分析器,一般是 char_filter、tokenizer 和一些 token filter 的组合。
|
||||||
|
|
||||||
### 2.3. 索引动态配置
|
### 索引动态配置
|
||||||
|
|
||||||
- **_`index.number_of_replicas`_**:索引主分片的副本数,默认值是 **_`1`_**,该值必须大于等于 0,这个配置可以随时修改。
|
- **_`index.number_of_replicas`_**:索引主分片的副本数,默认值是 **_`1`_**,该值必须大于等于 0,这个配置可以随时修改。
|
||||||
- **_`index.refresh_interval`_**:执行新索引数据的刷新操作频率,该操作使对索引的最新更改对搜索可见,默认为 **_`1s`_**。也可以设置为 **_`-1`_** 以禁用刷新。更详细信息参考 [Elasticsearch 动态修改 refresh_interval 刷新间隔设置](https://www.knowledgedict.com/tutorial/elasticsearch-refresh_interval-settings.html)。
|
- **_`index.refresh_interval`_**:执行新索引数据的刷新操作频率,该操作使对索引的最新更改对搜索可见,默认为 **_`1s`_**。也可以设置为 **_`-1`_** 以禁用刷新。更详细信息参考 [Elasticsearch 动态修改 refresh_interval 刷新间隔设置](https://www.knowledgedict.com/tutorial/elasticsearch-refresh_interval-settings.html)。
|
||||||
|
|
||||||
## 3. Mapping 详解
|
## Mapping 详解
|
||||||
|
|
||||||
在 Elasticsearch 中,**`Mapping`**(映射),用来定义一个文档以及其所包含的字段如何被存储和索引,可以在映射中事先定义字段的数据类型、字段的权重、分词器等属性,就如同在关系型数据库中创建数据表时会设置字段的类型。
|
在 Elasticsearch 中,**`Mapping`**(映射),用来定义一个文档以及其所包含的字段如何被存储和索引,可以在映射中事先定义字段的数据类型、字段的权重、分词器等属性,就如同在关系型数据库中创建数据表时会设置字段的类型。
|
||||||
|
|
||||||
|
|
@ -211,7 +212,7 @@ Mapping 会把 json 文档映射成 Lucene 所需要的扁平格式
|
||||||
- 一个 Type 有一个 Mapping 定义
|
- 一个 Type 有一个 Mapping 定义
|
||||||
- 7.0 开始,不需要在 Mapping 定义中指定 type 信息
|
- 7.0 开始,不需要在 Mapping 定义中指定 type 信息
|
||||||
|
|
||||||
### 3.1. 映射分类
|
### 映射分类
|
||||||
|
|
||||||
在 Elasticsearch 中,映射可分为静态映射和动态映射。在关系型数据库中写入数据之前首先要建表,在建表语句中声明字段的属性,在 Elasticsearch 中,则不必如此,Elasticsearch 最重要的功能之一就是让你尽可能快地开始探索数据,文档写入 Elasticsearch 中,它会根据字段的类型自动识别,这种机制称为**动态映射**,而**静态映射**则是写入数据之前对字段的属性进行手工设置。
|
在 Elasticsearch 中,映射可分为静态映射和动态映射。在关系型数据库中写入数据之前首先要建表,在建表语句中声明字段的属性,在 Elasticsearch 中,则不必如此,Elasticsearch 最重要的功能之一就是让你尽可能快地开始探索数据,文档写入 Elasticsearch 中,它会根据字段的类型自动识别,这种机制称为**动态映射**,而**静态映射**则是写入数据之前对字段的属性进行手工设置。
|
||||||
|
|
||||||
|
|
@ -308,7 +309,7 @@ PUT books/it/1
|
||||||
- **`false`**:忽略新的字段。
|
- **`false`**:忽略新的字段。
|
||||||
- **`strict`**:严格模式,发现新的字段抛出异常。
|
- **`strict`**:严格模式,发现新的字段抛出异常。
|
||||||
|
|
||||||
### 3.2. 基础类型
|
### 基础类型
|
||||||
|
|
||||||
| 类型 | 关键字 |
|
| 类型 | 关键字 |
|
||||||
| :--------- | :------------------------------------------------------------------ |
|
| :--------- | :------------------------------------------------------------------ |
|
||||||
|
|
@ -319,7 +320,7 @@ PUT books/it/1
|
||||||
| 二进制类型 | binary |
|
| 二进制类型 | binary |
|
||||||
| 范围类型 | range |
|
| 范围类型 | range |
|
||||||
|
|
||||||
### 3.3. 复杂类型
|
### 复杂类型
|
||||||
|
|
||||||
| 类型 | 关键字 |
|
| 类型 | 关键字 |
|
||||||
| :------- | :----- |
|
| :------- | :----- |
|
||||||
|
|
@ -327,7 +328,7 @@ PUT books/it/1
|
||||||
| 对象类型 | object |
|
| 对象类型 | object |
|
||||||
| 嵌套类型 | nested |
|
| 嵌套类型 | nested |
|
||||||
|
|
||||||
### 3.4. 特殊类型
|
### 特殊类型
|
||||||
|
|
||||||
| 类型 | 关键字 |
|
| 类型 | 关键字 |
|
||||||
| :----------- | :---------- |
|
| :----------- | :---------- |
|
||||||
|
|
@ -339,7 +340,7 @@ PUT books/it/1
|
||||||
| 附件类型 | attachment |
|
| 附件类型 | attachment |
|
||||||
| 抽取类型 | percolator |
|
| 抽取类型 | percolator |
|
||||||
|
|
||||||
### 3.5. Mapping 属性
|
### Mapping 属性
|
||||||
|
|
||||||
Elasticsearch 的 mapping 中的字段属性非常多,具体如下表格:
|
Elasticsearch 的 mapping 中的字段属性非常多,具体如下表格:
|
||||||
|
|
||||||
|
|
@ -357,9 +358,9 @@ Elasticsearch 的 mapping 中的字段属性非常多,具体如下表格:
|
||||||
| **_`search_analyzer`_** | 指定搜索时的分析器,搜索时的优先级最高。 |
|
| **_`search_analyzer`_** | 指定搜索时的分析器,搜索时的优先级最高。 |
|
||||||
| **_`null_value`_** | 用于需要对 Null 值实现搜索的场景,只有 Keyword 类型支持此配置。 |
|
| **_`null_value`_** | 用于需要对 Null 值实现搜索的场景,只有 Keyword 类型支持此配置。 |
|
||||||
|
|
||||||
## 4. 索引查询
|
## 索引查询
|
||||||
|
|
||||||
### 4.1. 多个 index、多个 type 查询
|
### 多个 index、多个 type 查询
|
||||||
|
|
||||||
Elasticsearch 的搜索 api 支持**一个索引(index)的多个类型(type)查询**以及**多个索引(index)**的查询。
|
Elasticsearch 的搜索 api 支持**一个索引(index)的多个类型(type)查询**以及**多个索引(index)**的查询。
|
||||||
|
|
||||||
|
|
@ -393,7 +394,7 @@ GET /_all/_search?q=tag:wow
|
||||||
GET /_search?q=tag:wow
|
GET /_search?q=tag:wow
|
||||||
```
|
```
|
||||||
|
|
||||||
### 4.2. URI 搜索
|
### URI 搜索
|
||||||
|
|
||||||
Elasticsearch 支持用 uri 搜索,可用 get 请求里面拼接相关的参数,并用 curl 相关的命令就可以进行测试。
|
Elasticsearch 支持用 uri 搜索,可用 get 请求里面拼接相关的参数,并用 curl 相关的命令就可以进行测试。
|
||||||
|
|
||||||
|
|
@ -460,13 +461,13 @@ URI 中允许的参数:
|
||||||
| search_type | 搜索的方式,可以是*dfs_query_then_fetch*或*query_then_fetch*。默认为*query_then_fetch* |
|
| search_type | 搜索的方式,可以是*dfs_query_then_fetch*或*query_then_fetch*。默认为*query_then_fetch* |
|
||||||
| allow_partial_search_results | 是否可以返回部分结果。如设置为 false,表示如果请求产生部分结果,则设置为返回整体故障;默认为 true,表示允许请求在超时或部分失败的情况下获得部分结果 |
|
| allow_partial_search_results | 是否可以返回部分结果。如设置为 false,表示如果请求产生部分结果,则设置为返回整体故障;默认为 true,表示允许请求在超时或部分失败的情况下获得部分结果 |
|
||||||
|
|
||||||
### 4.3. 查询流程
|
### 查询流程
|
||||||
|
|
||||||
在 Elasticsearch 中,查询是一个比较复杂的执行模式,因为我们不知道那些 document 会被匹配到,任何一个 shard 上都有可能,所以一个 search 请求必须查询一个索引或多个索引里面的所有 shard 才能完整的查询到我们想要的结果。
|
在 Elasticsearch 中,查询是一个比较复杂的执行模式,因为我们不知道那些 document 会被匹配到,任何一个 shard 上都有可能,所以一个 search 请求必须查询一个索引或多个索引里面的所有 shard 才能完整的查询到我们想要的结果。
|
||||||
|
|
||||||
找到所有匹配的结果是查询的第一步,来自多个 shard 上的数据集在分页返回到客户端之前会被合并到一个排序后的 list 列表,由于需要经过一步取 top N 的操作,所以 search 需要进过两个阶段才能完成,分别是 query 和 fetch。
|
找到所有匹配的结果是查询的第一步,来自多个 shard 上的数据集在分页返回到客户端之前会被合并到一个排序后的 list 列表,由于需要经过一步取 top N 的操作,所以 search 需要进过两个阶段才能完成,分别是 query 和 fetch。
|
||||||
|
|
||||||
## 5. 参考资料
|
## 参考资料
|
||||||
|
|
||||||
- [Elasticsearch 官网](https://www.elastic.co/)
|
- [Elasticsearch 官网](https://www.elastic.co/)
|
||||||
- [Elasticsearch 索引映射类型及 mapping 属性详解](https://www.knowledgedict.com/tutorial/elasticsearch-index-mapping.html)
|
- [Elasticsearch 索引映射类型及 mapping 属性详解](https://www.knowledgedict.com/tutorial/elasticsearch-index-mapping.html)
|
||||||
|
|
@ -0,0 +1,355 @@
|
||||||
|
---
|
||||||
|
title: Elasticsearch 映射
|
||||||
|
date: 2022-05-16 19:54:24
|
||||||
|
categories:
|
||||||
|
- 计算机科学
|
||||||
|
- 数据库
|
||||||
|
- 搜索引擎数据库
|
||||||
|
- Elasticsearch
|
||||||
|
tags:
|
||||||
|
- 数据库
|
||||||
|
- 搜索引擎数据库
|
||||||
|
- Elasticsearch
|
||||||
|
- 索引
|
||||||
|
permalink: /pages/d1bae4/
|
||||||
|
---
|
||||||
|
|
||||||
|
# Elasticsearch 映射
|
||||||
|
|
||||||
|
在 Elasticsearch 中,**`Mapping`**(映射),用来定义一个文档以及其所包含的字段如何被存储和索引,可以在映射中事先定义字段的数据类型、字段的权重、分词器等属性,就如同在关系型数据库中创建数据表时会设置字段的类型。
|
||||||
|
|
||||||
|
Mapping 会把 JSON 文档映射成 Lucene 所需要的扁平格式
|
||||||
|
|
||||||
|
一个 Mapping 属于一个索引的 Type
|
||||||
|
|
||||||
|
- 每个文档都属于一个 Type
|
||||||
|
- 一个 Type 有一个 Mapping 定义
|
||||||
|
- 7.0 开始,不需要在 Mapping 定义中指定 type 信息
|
||||||
|
|
||||||
|
每个 `document` 都是 `field` 的集合,每个 `field` 都有自己的数据类型。映射数据时,可以创建一个 `mapping`,其中包含与 `document` 相关的 `field` 列表。映射定义还包括元数据 `field`,例如 `_source` ,它自定义如何处理 `document` 的关联元数据。
|
||||||
|
|
||||||
|
## 映射方式
|
||||||
|
|
||||||
|
在 Elasticsearch 中,映射可分为静态映射和动态映射。在关系型数据库中写入数据之前首先要建表,在建表语句中声明字段的属性,在 Elasticsearch 中,则不必如此,Elasticsearch 最重要的功能之一就是让你尽可能快地开始探索数据,文档写入 Elasticsearch 中,它会根据字段的类型自动识别,这种机制称为**动态映射**,而**静态映射**则是写入数据之前对字段的属性进行手工设置。
|
||||||
|
|
||||||
|
### 静态映射
|
||||||
|
|
||||||
|
ES 官方将静态映射称为**显式映射([Explicit mapping](https://www.elastic.co/guide/en/elasticsearch/reference/current/explicit-mapping.html))**。**静态映射**是在创建索引时显示的指定索引映射。静态映射和 SQL 中在建表语句中指定字段属性类似。相比动态映射,通过静态映射可以添加更详细、更精准的配置信息。例如:
|
||||||
|
|
||||||
|
- 哪些字符串字段应被视为全文字段。
|
||||||
|
- 哪些字段包含数字、日期或地理位置。
|
||||||
|
- 日期值的格式。
|
||||||
|
- 用于控制动态添加字段的自定义规则。
|
||||||
|
|
||||||
|
【示例】创建索引时,显示指定 mapping
|
||||||
|
|
||||||
|
```javascript
|
||||||
|
PUT /my-index-000001
|
||||||
|
{
|
||||||
|
"mappings": {
|
||||||
|
"properties": {
|
||||||
|
"age": { "type": "integer" },
|
||||||
|
"email": { "type": "keyword" },
|
||||||
|
"name": { "type": "text" }
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
【示例】在已存在的索引中,指定一个 field 的属性
|
||||||
|
|
||||||
|
```javascript
|
||||||
|
PUT /my-index-000001/_mapping
|
||||||
|
{
|
||||||
|
"properties": {
|
||||||
|
"employee-id": {
|
||||||
|
"type": "keyword",
|
||||||
|
"index": false
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
【示例】查看 mapping
|
||||||
|
|
||||||
|
```
|
||||||
|
GET /my-index-000001/_mapping
|
||||||
|
```
|
||||||
|
|
||||||
|
【示例】查看指定 field 的 mapping
|
||||||
|
|
||||||
|
```
|
||||||
|
GET /my-index-000001/_mapping/field/employee-id
|
||||||
|
```
|
||||||
|
|
||||||
|
### 动态映射
|
||||||
|
|
||||||
|
动态映射机制,允许用户不手动定义映射,Elasticsearch 会自动识别字段类型。在实际项目中,如果遇到的业务在导入数据之前不确定有哪些字段,也不清楚字段的类型是什么,使用动态映射非常合适。当 Elasticsearch 在文档中碰到一个以前没见过的字段时,它会利用动态映射来决定该字段的类型,并自动把该字段添加到映射中。
|
||||||
|
|
||||||
|
示例:创建一个名为 `data` 的索引、其 `mapping` 类型为 `_doc`,并且有一个类型为 `long` 的字段 `count`。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
PUT data/_doc/1
|
||||||
|
{ "count": 5 }
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 动态字段映射
|
||||||
|
|
||||||
|
动态字段映射([Dynamic field mappings](https://www.elastic.co/guide/en/elasticsearch/reference/current/dynamic-field-mapping.html))是用于管理动态字段检测的规则。当 Elasticsearch 在文档中检测到新字段时,默认情况下会动态将该字段添加到类型映射中。
|
||||||
|
|
||||||
|
在 mapping 中可以通过将 [`dynamic`](https://www.elastic.co/guide/en/elasticsearch/reference/current/dynamic.html) 参数设置为 `true` 或 `runtime` 来开启动态映射。
|
||||||
|
|
||||||
|
[`dynamic`](https://www.elastic.co/guide/en/elasticsearch/reference/current/dynamic.html) 不同设置的作用:
|
||||||
|
|
||||||
|
| 可选值 | 说明 |
|
||||||
|
| --------- | ------------------------------------------------------------------------------------------------------------------- |
|
||||||
|
| `true` | 新字段被添加到 mapping 中。mapping 的默认设置。 |
|
||||||
|
| `runtime` | 新字段被添加到 mapping 中并作为运行时字段——这些字段不会被索引,但是可以在查询时出现在 `_source` 中。 |
|
||||||
|
| `false` | 新字段不会被索引或搜索,但仍会出现在返回匹配的 `_source` 字段中。这些字段不会添加到映射中,并且必须显式添加新字段。 |
|
||||||
|
| `strict` | 如果检测到新字段,则会抛出异常并拒绝文档。必须将新字段显式添加到映射中。 |
|
||||||
|
|
||||||
|
> 需要注意的是:对已有字段,一旦已经有数据写入,就不再支持修改字段定义。如果希望改变字段类型,必须重建索引。这是由于 Lucene 实现的倒排索引,一旦生成后,就不允许修改。如果修改了字段的数据类型,会导致已被索引的字段无法被搜索。
|
||||||
|
|
||||||
|
启用动态字段映射后,Elasticsearch 使用内置规则来确定如何映射每个字段的数据类型。规则如下:
|
||||||
|
|
||||||
|
| **JSON 数据类型** | **`"dynamic":"true"`** | **`"dynamic":"runtime"`** |
|
||||||
|
| ------------------------------------------------------------------------------------------------------------------------------------ | --------------------------------------- | --------------------------- |
|
||||||
|
| `null` | 没有字段被添加 | 没有字段被添加 |
|
||||||
|
| `true` or `false` | `boolean` 类型 | `boolean` 类型 |
|
||||||
|
| 浮点型数字 | `float` 类型 | `double` 类型 |
|
||||||
|
| 数字 | 数字型 | `long` 类型 |
|
||||||
|
| JSON 对象 | `object` 类型 | 没有字段被添加 |
|
||||||
|
| 数组 | 由数组中第一个非空值决定 | 由数组中第一个非空值决定 |
|
||||||
|
| 开启[日期检测](https://www.elastic.co/guide/en/elasticsearch/reference/current/dynamic-field-mapping.html#date-detection)的字符串 | `date` 类型 | `date` 类型 |
|
||||||
|
| 开启[数字检测](https://www.elastic.co/guide/en/elasticsearch/reference/current/dynamic-field-mapping.html#numeric-detection)的字符串 | `float` 类型或 `long`类型 | `double` 类型或 `long` 类型 |
|
||||||
|
| 什么也没开启的字符串 | 带有 `.keyword` 子 field 的 `text` 类型 | `keyword` 类型 |
|
||||||
|
|
||||||
|
下面举一个例子认识动态 mapping,在 Elasticsearch 中创建一个新的索引并查看它的 mapping,命令如下:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
PUT books
|
||||||
|
GET books/_mapping
|
||||||
|
```
|
||||||
|
|
||||||
|
此时 books 索引的 mapping 是空的,返回结果如下:
|
||||||
|
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"books": {
|
||||||
|
"mappings": {}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
再往 books 索引中写入一条文档,命令如下:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
PUT books/it/1
|
||||||
|
{
|
||||||
|
"id": 1,
|
||||||
|
"publish_date": "2019-11-10",
|
||||||
|
"name": "master Elasticsearch"
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
文档写入完成之后,再次查看 mapping,返回结果如下:
|
||||||
|
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"books": {
|
||||||
|
"mappings": {
|
||||||
|
"properties": {
|
||||||
|
"id": {
|
||||||
|
"type": "long"
|
||||||
|
},
|
||||||
|
"name": {
|
||||||
|
"type": "text",
|
||||||
|
"fields": {
|
||||||
|
"keyword": {
|
||||||
|
"type": "keyword",
|
||||||
|
"ignore_above": 256
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"publish_date": {
|
||||||
|
"type": "date"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
动态映射有时可能会错误的识别字段类型,这种情况下,可能会导致一些功能无法正常使用,如 Range 查询。所以,使用动态 mapping 要结合实际业务需求来综合考虑,如果将 Elasticsearch 当作主要的数据存储使用,并且希望出现未知字段时抛出异常来提醒你注意这一问题,那么开启动态 mapping 并不适用。
|
||||||
|
|
||||||
|
#### 动态模板
|
||||||
|
|
||||||
|
**动态模板([dynamic templates](https://www.elastic.co/guide/en/elasticsearch/reference/current/dynamic-templates.html))**是用于给 `mapping` 动态添加字段的自定义规则。
|
||||||
|
|
||||||
|
动态模板可以设置匹配条件,只有匹配的情况下才使用动态模板:
|
||||||
|
|
||||||
|
- `match_mapping_type` 对 Elasticsearch 检测到的数据类型进行操作
|
||||||
|
- `match` 和 `unmatch` 使用模式匹配字段名称
|
||||||
|
- `path_match` 和 `path_unmatch` 对字段的完整虚线路径进行操作
|
||||||
|
- 如果动态模板没有定义 `match_mapping_type`、`match` 或 `path_match`,则不会匹配任何字段。您仍然可以在批量请求的 `dynamic_templates` 部分按名称引用模板。
|
||||||
|
|
||||||
|
【示例】当设置 `'dynamic':'true'` 时,Elasticsearch 会将字符串字段映射为带有关键字子字段的文本字段。如果只是索引结构化内容并且对全文搜索不感兴趣,可以让 Elasticsearch 仅将字段映射为关键字字段。这种情况下,只有完全匹配才能搜索到这些字段。
|
||||||
|
|
||||||
|
```javascript
|
||||||
|
PUT my-index-000001
|
||||||
|
{
|
||||||
|
"mappings": {
|
||||||
|
"dynamic_templates": [
|
||||||
|
{
|
||||||
|
"strings_as_keywords": {
|
||||||
|
"match_mapping_type": "string",
|
||||||
|
"mapping": {
|
||||||
|
"type": "keyword"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
## 运行时字段
|
||||||
|
|
||||||
|
运行时字段是在查询时评估的字段。运行时字段有以下作用:
|
||||||
|
|
||||||
|
- 在不重新索引数据的情况下,向现有文档添加字段
|
||||||
|
- 在不了解数据结构的情况下,也可以处理数据
|
||||||
|
- 在查询时覆盖从索引字段返回的值
|
||||||
|
- 为特定用途定义字段而不修改底层架构
|
||||||
|
|
||||||
|
检索 Elasticsearch 时,运行时字段和其他字段并没有什么不同。
|
||||||
|
|
||||||
|
需要注意的是:使用 `_search` API 上的 `fields` 参数来检索运行时字段的值。运行时字段不会显示在 `_source` 中,但 `fields` API 适用于所有字段,即使是那些未作为原始 `_source` 的一部分发送的字段。
|
||||||
|
|
||||||
|
运行时字段在处理日志数据时很有用,尤其是当日志是不确定的数据结构时:这种情况下,会降低搜索速度,但您的索引大小要小得多,您可以更快地处理日志,而无需为它们设置索引。
|
||||||
|
|
||||||
|
### 运行时字段的优点
|
||||||
|
|
||||||
|
因为**运行时字段没有被索引**,所以添加运行时字段不会增加索引大小。用户可以直接在 mapping 中定义运行时字段,从而节省存储成本并提高采集数据的速度。定义了运行时字段后,可以立即在搜索请求、聚合、过滤和排序中使用它。
|
||||||
|
|
||||||
|
如果将运行时字段设为索引字段,则无需修改任何引用运行时字段的查询。更好的是,您可以引用字段是运行时字段的一些索引,以及字段是索引字段的其他索引。您可以灵活地选择要索引哪些字段以及保留哪些字段作为运行时字段。
|
||||||
|
|
||||||
|
就其核心而言,运行时字段最重要的好处是能够在您提取字段后将字段添加到文档中。此功能简化了映射决策,因为您不必预先决定如何解析数据,并且可以使用运行时字段随时修改映射。使用运行时字段允许更小的索引和更快的摄取时间,这结合使用更少的资源并降低您的运营成本。
|
||||||
|
|
||||||
|
## 字段数据类型
|
||||||
|
|
||||||
|
在 Elasticsearch 中,每个字段都有一个字段数据类型或字段类型,用于指示字段包含的数据类型(例如字符串或布尔值)及其预期用途。字段类型按系列分组。同一族中的类型具有完全相同的搜索行为,但可能具有不同的空间使用或性能特征。
|
||||||
|
|
||||||
|
Elasticsearch 提供了非常丰富的数据类型,官方将其分为以下几类:
|
||||||
|
|
||||||
|
- **普通类型**
|
||||||
|
- [`binary`](https://www.elastic.co/guide/en/elasticsearch/reference/current/binary.html):编码为 Base64 字符串的二进制值。
|
||||||
|
- [`boolean`](https://www.elastic.co/guide/en/elasticsearch/reference/current/boolean.html):布尔类型,值为 true 或 false。
|
||||||
|
- [Keywords](https://www.elastic.co/guide/en/elasticsearch/reference/current/keyword.html):keyword 族类型,包括 `keyword`、`constant_keyword` 和 `wildcard`。
|
||||||
|
- [Numbers](https://www.elastic.co/guide/en/elasticsearch/reference/current/number.html):数字类型,如 `long` 和 `double`
|
||||||
|
- **Dates**:日期类型,包括 [`date`](https://www.elastic.co/guide/en/elasticsearch/reference/current/date.html) 和 [`date_nanos`](https://www.elastic.co/guide/en/elasticsearch/reference/current/date_nanos.html)。
|
||||||
|
- [`alias`](https://www.elastic.co/guide/en/elasticsearch/reference/current/field-alias.html):用于定义存在字段的别名。
|
||||||
|
- **对象类型**
|
||||||
|
- [`object`](https://www.elastic.co/guide/en/elasticsearch/reference/current/object.html):JSON 对象
|
||||||
|
- [`flattened`](https://www.elastic.co/guide/en/elasticsearch/reference/current/flattened.html):整个 JSON 对象作为单个字段值。
|
||||||
|
- [`nested`](https://www.elastic.co/guide/en/elasticsearch/reference/current/nested.html):保留其子字段之间关系的 JSON 对象。
|
||||||
|
- [`join`](https://www.elastic.co/guide/en/elasticsearch/reference/current/parent-join.html):为同一索引中的文档定义父/子关系。
|
||||||
|
- **结构化数据类型**
|
||||||
|
|
||||||
|
- [Range](https://www.elastic.co/guide/en/elasticsearch/reference/current/range.html):范围类型,例如:`long_range`、`double_range`、`date_range` 和 `ip_range`。
|
||||||
|
- [`ip`](https://www.elastic.co/guide/en/elasticsearch/reference/current/ip.html):IPv4 和 IPv6 地址。
|
||||||
|
- [`version`](https://www.elastic.co/guide/en/elasticsearch/reference/current/version.html):版本号。支持 [Semantic Versioning](https://semver.org/) 优先规则。
|
||||||
|
- [`murmur3`](https://www.elastic.co/guide/en/elasticsearch/plugins/8.2/mapper-murmur3.html):计算并存储 hash 值。
|
||||||
|
|
||||||
|
- **聚合数据类型**
|
||||||
|
|
||||||
|
- [`aggregate_metric_double`](https://www.elastic.co/guide/en/elasticsearch/reference/current/aggregate-metric-double.html):预先聚合的指标值
|
||||||
|
- [`histogram`](https://www.elastic.co/guide/en/elasticsearch/reference/current/histogram.html):直方图式的预聚合数值。
|
||||||
|
|
||||||
|
- **文本搜索类型**
|
||||||
|
- [`text` fields](https://www.elastic.co/guide/en/elasticsearch/reference/current/text.html):text 族类型,包括 `text` 和 `match_only_text`。
|
||||||
|
- [`annotated-text`](https://www.elastic.co/guide/en/elasticsearch/plugins/8.2/mapper-annotated-text.html):包含特殊标记的文本。用于识别命名实体。
|
||||||
|
- [`completion`](https://www.elastic.co/guide/en/elasticsearch/reference/current/search-suggesters.html#completion-suggester):用于自动补全。
|
||||||
|
- [`search_as_you_type`](https://www.elastic.co/guide/en/elasticsearch/reference/current/search-as-you-type.html):键入时完成的类似文本的类型。
|
||||||
|
- [`token_count`](https://www.elastic.co/guide/en/elasticsearch/reference/current/token-count.html):文本中标记的计数。
|
||||||
|
- **文档排名类型**
|
||||||
|
- [`dense_vector`](https://www.elastic.co/guide/en/elasticsearch/reference/current/dense-vector.html):记录浮点数的密集向量。
|
||||||
|
- [`rank_feature`](https://www.elastic.co/guide/en/elasticsearch/reference/current/rank-feature.html):记录一个数字特征,为了在查询时提高命中率。
|
||||||
|
- [`rank_features`](https://www.elastic.co/guide/en/elasticsearch/reference/current/rank-features.html):记录多个数字特征,为了在查询时提高命中率。
|
||||||
|
- **空间数据类型**
|
||||||
|
|
||||||
|
- [`geo_point`](https://www.elastic.co/guide/en/elasticsearch/reference/current/geo-point.html):地理经纬度
|
||||||
|
- [`geo_shape`](https://www.elastic.co/guide/en/elasticsearch/reference/current/geo-shape.html):复杂的形状,例如多边形
|
||||||
|
- [`point`](https://www.elastic.co/guide/en/elasticsearch/reference/current/point.html):任意笛卡尔点
|
||||||
|
- [`shape`](https://www.elastic.co/guide/en/elasticsearch/reference/current/shape.html):任意笛卡尔几何形状
|
||||||
|
|
||||||
|
- **其他类型**
|
||||||
|
- [`percolator`](https://www.elastic.co/guide/en/elasticsearch/reference/current/percolator.html):使用 [Query DSL](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html) 编写的索引查询
|
||||||
|
|
||||||
|
## 元数据字段
|
||||||
|
|
||||||
|
一个文档中,不仅仅包含数据 ,也包含**元数据**。元数据是用于描述文档的信息。
|
||||||
|
|
||||||
|
- **标识元数据字段**
|
||||||
|
- [`_index`](https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-index-field.html):文档所属的索引。
|
||||||
|
- [`_id`](https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-id-field.html):文档的 ID。
|
||||||
|
- **文档 source 元数据字段**
|
||||||
|
- [`_source`](https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-source-field.html):文档正文的原始 JSON。
|
||||||
|
- [`_size`](https://www.elastic.co/guide/en/elasticsearch/plugins/8.2/mapper-size.html):`_source` 字段的大小(以字节为单位),由 [`mapper-size`](https://www.elastic.co/guide/en/elasticsearch/plugins/8.2/mapper-size.html) 插件提供。
|
||||||
|
- **文档计数元数据字段**
|
||||||
|
- [`_doc_count`](https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-doc-count-field.html):当文档表示预聚合数据时,用于存储文档计数的自定义字段。
|
||||||
|
- **索引元数据字段**
|
||||||
|
- [`_field_names`](https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-field-names-field.html):文档中的所有非空字段。
|
||||||
|
- [`_ignored`](https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-ignored-field.html):文档中所有的由于 [`ignore_malformed`](https://www.elastic.co/guide/en/elasticsearch/reference/current/ignore-malformed.html) 而在索引时被忽略的字段。
|
||||||
|
- **路由元数据字段**
|
||||||
|
- [`_routing`](https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-routing-field.html):将文档路由到特定分片的自定义路由值。
|
||||||
|
- **其他元数据字段**
|
||||||
|
- [`_meta`](https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-meta-field.html):应用程序特定的元数据。
|
||||||
|
- [`_tier`](https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-tier-field.html):文档所属索引的当前数据层首选项。
|
||||||
|
|
||||||
|
## 映射参数
|
||||||
|
|
||||||
|
Elasticsearch 提供了以下映射参数:
|
||||||
|
|
||||||
|
- [`analyzer`](https://www.elastic.co/guide/en/elasticsearch/reference/current/analyzer.html):指定在索引或搜索文本字段时用于文本分析的分析器。
|
||||||
|
- [`coerce`](https://www.elastic.co/guide/en/elasticsearch/reference/current/coerce.html):如果开启,Elasticsearch 将尝试清理脏数据以适应字段的数据类型。
|
||||||
|
- [`copy_to`](https://www.elastic.co/guide/en/elasticsearch/reference/current/copy-to.html):允许将多个字段的值复制到一个组字段中,然后可以将其作为单个字段进行查询。
|
||||||
|
- [`doc_values`](https://www.elastic.co/guide/en/elasticsearch/reference/current/doc-values.html):默认情况下,所有字段都是被
|
||||||
|
- [`dynamic`](https://www.elastic.co/guide/en/elasticsearch/reference/current/dynamic.html):是否开启动态映射。
|
||||||
|
- [`eager_global_ordinals`](https://www.elastic.co/guide/en/elasticsearch/reference/current/eager-global-ordinals.html):当在global ordinals的时候,refresh以后下一次查询字典就需要重新构建,在追求查询的场景下很影响查询性能。可以使用eager_global_ordinals,即在每次refresh以后即可更新字典,字典常驻内存,减少了查询的时候构建字典的耗时。
|
||||||
|
- [`enabled`](https://www.elastic.co/guide/en/elasticsearch/reference/current/enabled.html):只能应用于顶级 mapping 定义和 `object` 字段。设置为 `false` 后,Elasticsearch 解析时,会完全跳过该字段。
|
||||||
|
- [`fielddata`](https://www.elastic.co/guide/en/elasticsearch/reference/current/fielddata.html):默认情况下, `text` 字段是可搜索的,但不可用于聚合、排序或脚本。如果为字段设置 `fielddata=true`,就会通过反转倒排索引将 fielddata 加载到内存中。请注意,这可能会占用大量内存。如果想对 `text` 字段进行聚合、排序或脚本操作,fielddata 是唯一方法。
|
||||||
|
- [`fields`](https://www.elastic.co/guide/en/elasticsearch/reference/current/multi-fields.html):有时候,同一个字段需要以不同目的进行索引,此时可以通过 `fields` 进行配置。
|
||||||
|
- [`format`](https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-date-format.html):用于格式化日期类型。
|
||||||
|
- [`ignore_above`](https://www.elastic.co/guide/en/elasticsearch/reference/current/ignore-above.html):字符串长度大于 `ignore_above` 所设,则不会被索引或存储。
|
||||||
|
- [`ignore_malformed`](https://www.elastic.co/guide/en/elasticsearch/reference/current/ignore-malformed.html):有时候,同一个字段,可能会存储不同的数据类型。默认情况下,Elasticsearch 解析字段数据类型失败时,会引发异常,并拒绝整个文档。 如果设置 `ignore_malformed` 为 `true`,则允许忽略异常。这种情况下,格式错误的字段不会被索引,但文档中的其他字段可以正常处理。
|
||||||
|
- [`index_options`](https://www.elastic.co/guide/en/elasticsearch/reference/current/index-options.html) 用于控制将哪些信息添加到倒排索引以进行搜索和突出显示。只有 `text` 和 `keyword` 等基于术语(term)的字段类型支持此配置。
|
||||||
|
- [`index_phrases`](https://www.elastic.co/guide/en/elasticsearch/reference/current/index-phrases.html):如果启用,两个词的组合(shingles)将被索引到一个单独的字段中。这允许以更大的索引为代价,更有效地运行精确的短语查询(无 slop)。请注意,当停用词未被删除时,此方法效果最佳,因为包含停用词的短语将不使用辅助字段,并将回退到标准短语查询。接受真或假(默认)。
|
||||||
|
- [`index_prefixes`](https://www.elastic.co/guide/en/elasticsearch/reference/current/index-prefixes.html):index_prefixes 参数启用 term 前缀索引以加快前缀搜索。
|
||||||
|
- [`index`](https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-index.html):`index` 选项控制字段值是否被索引。默认为 true。
|
||||||
|
- [`meta`](https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-field-meta.html):附加到字段的元数据。此元数据对 Elasticsearch 是不透明的,它仅适用于多个应用共享相同索引的元数据信息,例如:单位。
|
||||||
|
- [`normalizer`](https://www.elastic.co/guide/en/elasticsearch/reference/current/normalizer.html):`keyword` 字段的 `normalizer` 属性类似于 [`analyzer`](https://www.elastic.co/guide/en/elasticsearch/reference/current/analyzer.html) ,只是它保证分析链只产生单个标记。 `normalizer` 在索引 `keyword` 之前应用,以及在搜索时通过查询解析器(例如匹配查询)或通过术语级别查询(例如术语查询)搜索关键字字段时应用。
|
||||||
|
- [`norms`](https://www.elastic.co/guide/en/elasticsearch/reference/current/norms.html):`norms` 存储在查询时使用的各种规范化因子,以便计算文档的相关性评分。
|
||||||
|
- [`null_value`](https://www.elastic.co/guide/en/elasticsearch/reference/current/null-value.html):null 值无法被索引和搜索。当一个字段被设为 null,则被视为没有值。`null_value` 允许将空值替换为指定值,以便对其进行索引和搜索。
|
||||||
|
- [`position_increment_gap`](https://www.elastic.co/guide/en/elasticsearch/reference/current/position-increment-gap.html):分析的文本字段会考虑术语位置,以便能够支持邻近或短语查询。当索引具有多个值的文本字段时,值之间会添加一个“假”间隙,以防止大多数短语查询在值之间匹配。此间隙的大小使用 `position_increment_gap` 配置,默认为 100。
|
||||||
|
- [`properties`](https://www.elastic.co/guide/en/elasticsearch/reference/current/properties.html):类型映射、对象字段和嵌套字段包含的子字段,都称为属性。这些属性可以是任何数据类型,包括对象和嵌套。
|
||||||
|
- [`search_analyzer`](https://www.elastic.co/guide/en/elasticsearch/reference/current/search-analyzer.html):通常,在索引时和搜索时应使用相同的分析器,以确保查询中的术语与倒排索引中的术语格式相同。但是,有时在搜索时使用不同的分析器可能是有意义的,例如使用 [`edge_ngram`](https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-edgengram-tokenizer.html) 标记器实现自动补全或使用同义词搜索时。
|
||||||
|
- [`similarity`](https://www.elastic.co/guide/en/elasticsearch/reference/current/similarity.html):Elasticsearch 允许为每个字段配置文本评分算法或相似度。相似度设置提供了一种选择文本相似度算法的简单方法,而不是默认的 BM25,例如布尔值。只有 `text` 和 `keyword` 等基于文本的字段类型支持此配置。
|
||||||
|
- [`store`](https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-store.html):默认情况下,对字段值进行索引以使其可搜索,但不会存储它们。这意味着可以查询该字段,但无法检索原始字段值。通常这不重要,字段值已经是默认存储的 `_source` 字段的一部分。如果您只想检索单个字段或几个字段的值,而不是整个 `_source`,则可以通过 [source filtering](https://www.elastic.co/guide/en/elasticsearch/reference/current/search-fields.html#source-filtering) 来实现。
|
||||||
|
- [`term_vector`](https://www.elastic.co/guide/en/elasticsearch/reference/current/term-vector.html):term_vector 包含有关分析过程产生的术语的信息,包括:
|
||||||
|
- 术语列表
|
||||||
|
- 每个 term 的位置(或顺序)
|
||||||
|
- 起始和结束字符偏移量,用于将 term 和原始字符串进行映射
|
||||||
|
- 有效负载(如果可用) - 用户定义的,与 term 位置相关的二进制数据
|
||||||
|
|
||||||
|
## 映射配置
|
||||||
|
|
||||||
|
- `index.mapping.total_fields.limit`:索引中的最大字段数。字段和对象映射以及字段别名计入此限制。默认值为 `1000`。
|
||||||
|
- `index.mapping.depth.limit`:字段的最大深度,以内部对象的数量来衡量。例如,如果所有字段都在根对象级别定义,则深度为 `1`。如果有一个对象映射,则深度为 `2`,以此类推。默认值为 `20`。
|
||||||
|
- `index.mapping.nested_fields.limit`:索引中不同 `nested` 映射的最大数量。 `nested` 类型只应在特殊情况下使用,即需要相互独立地查询对象数组。为了防止设计不佳的映射,此设置限制了每个索引的唯一 `nested` 类型的数量。默认值为 `50`。
|
||||||
|
- `index.mapping.nested_objects.limit`:单个文档中,所有 `nested` 类型中包含的最大嵌套 JSON 对象数。当文档包含太多 `nested` 对象时,此限制有助于防止出现内存溢出。默认值为 `10000`。
|
||||||
|
- `index.mapping.field_name_length.limit`:设置字段名称的最大长度。默认为 Long.MAX_VALUE(无限制)。
|
||||||
|
|
||||||
|
## 参考资料
|
||||||
|
|
||||||
|
- [Elasticsearch 官方文档之 Mapping](https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping.html)
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Elasticsearch 查询
|
title: Elasticsearch 查询
|
||||||
date: 2022-01-18 08:01:08
|
date: 2022-01-18 08:01:08
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
|
|
@ -10,18 +11,18 @@ tags:
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
- 查询
|
- 查询
|
||||||
permalink: /pages/478bb5/
|
permalink: /pages/83bd15/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Elasticsearch 查询
|
# Elasticsearch 查询
|
||||||
|
|
||||||
Elasticsearch 查询语句采用基于 RESTful 风格的接口封装成 JSON 格式的对象,称之为 Query DSL。Elasticsearch 查询分类大致分为**全文查询**、**词项查询**、**复合查询**、**嵌套查询**、**位置查询**、**特殊查询**。Elasticsearch 查询从机制分为两种,一种是根据用户输入的查询词,通过排序模型计算文档与查询词之间的**相关度**,并根据评分高低排序返回;另一种是**过滤机制**,只根据过滤条件对文档进行过滤,不计算评分,速度相对较快。
|
Elasticsearch 查询语句采用基于 RESTful 风格的接口封装成 JSON 格式的对象,称之为 Query DSL。Elasticsearch 查询分类大致分为**全文查询**、**词项查询**、**复合查询**、**嵌套查询**、**位置查询**、**特殊查询**。Elasticsearch 查询从机制分为两种,一种是根据用户输入的查询词,通过排序模型计算文档与查询词之间的**相关度**,并根据评分高低排序返回;另一种是**过滤机制**,只根据过滤条件对文档进行过滤,不计算评分,速度相对较快。
|
||||||
|
|
||||||
## 1. 全文查询
|
## 全文查询
|
||||||
|
|
||||||
ES 全文查询主要用于在全文字段上,主要考虑查询词与文档的相关性(Relevance)。
|
ES 全文查询主要用于在全文字段上,主要考虑查询词与文档的相关性(Relevance)。
|
||||||
|
|
||||||
### 1.1. intervals query
|
### intervals query
|
||||||
|
|
||||||
[**`intervals query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-intervals-query.html) 根据匹配词的顺序和近似度返回文档。
|
[**`intervals query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-intervals-query.html) 根据匹配词的顺序和近似度返回文档。
|
||||||
|
|
||||||
|
|
@ -63,7 +64,7 @@ POST _search
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 1.2. match query
|
### match query
|
||||||
|
|
||||||
[**`match query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-match-query.html) **用于搜索单个字段**,首先会针对查询语句进行解析(经过 analyzer),主要是对查询语句进行分词,分词后查询语句的任何一个词项被匹配,文档就会被搜到,默认情况下相当于对分词后词项进行 or 匹配操作。
|
[**`match query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-match-query.html) **用于搜索单个字段**,首先会针对查询语句进行解析(经过 analyzer),主要是对查询语句进行分词,分词后查询语句的任何一个词项被匹配,文档就会被搜到,默认情况下相当于对分词后词项进行 or 匹配操作。
|
||||||
|
|
||||||
|
|
@ -178,7 +179,7 @@ GET /_search
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 1.3. match_bool_prefix query
|
### match_bool_prefix query
|
||||||
|
|
||||||
[**`match_bool_prefix query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-match-bool-prefix-query.html) 分析其输入并根据这些词构造一个布尔查询。除了最后一个术语之外的每个术语都用于术语查询。最后一个词用于 `prefix query`。
|
[**`match_bool_prefix query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-match-bool-prefix-query.html) 分析其输入并根据这些词构造一个布尔查询。除了最后一个术语之外的每个术语都用于术语查询。最后一个词用于 `prefix query`。
|
||||||
|
|
||||||
|
|
@ -216,7 +217,7 @@ GET /_search
|
||||||
|
|
||||||
上面的示例 `match_bool_prefix query` 查询可以匹配包含 `quick brown fox` 的字段,但它也可以快速匹配 `brown fox`。它还可以匹配包含 `quick`、`brown` 和以 `f` 开头的字段,出现在任何位置。
|
上面的示例 `match_bool_prefix query` 查询可以匹配包含 `quick brown fox` 的字段,但它也可以快速匹配 `brown fox`。它还可以匹配包含 `quick`、`brown` 和以 `f` 开头的字段,出现在任何位置。
|
||||||
|
|
||||||
### 1.4. match_phrase query
|
### match_phrase query
|
||||||
|
|
||||||
[**`match_phrase query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-match-query-phrase.html) 即短语匹配,首先会把 query 内容分词,分词器可以自定义,同时文档还要满足以下两个条件才会被搜索到:
|
[**`match_phrase query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-match-query-phrase.html) 即短语匹配,首先会把 query 内容分词,分词器可以自定义,同时文档还要满足以下两个条件才会被搜索到:
|
||||||
|
|
||||||
|
|
@ -253,7 +254,7 @@ GET demo/_search
|
||||||
> - are 的位置应该比 How 的位置大 1 。
|
> - are 的位置应该比 How 的位置大 1 。
|
||||||
> - you 的位置应该比 How 的位置大 2 。
|
> - you 的位置应该比 How 的位置大 2 。
|
||||||
|
|
||||||
### 1.5. match_phrase_prefix query
|
### match_phrase_prefix query
|
||||||
|
|
||||||
[**`match_phrase_prefix query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-match-query-phrase-prefix.html) 和 [**`match_phrase query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-match-query-phrase.html) 类似,只不过 [**`match_phrase_prefix query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-match-query-phrase-prefix.html) 最后一个 term 会被作为前缀匹配。
|
[**`match_phrase_prefix query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-match-query-phrase-prefix.html) 和 [**`match_phrase query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-match-query-phrase.html) 类似,只不过 [**`match_phrase_prefix query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-match-query-phrase-prefix.html) 最后一个 term 会被作为前缀匹配。
|
||||||
|
|
||||||
|
|
@ -268,7 +269,7 @@ GET demo/_search
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 1.6. multi_match query
|
### multi_match query
|
||||||
|
|
||||||
[**`multi_match query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-multi-match-query.html) 是 **`match query`** 的升级,**用于搜索多个字段**。
|
[**`multi_match query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-multi-match-query.html) 是 **`match query`** 的升级,**用于搜索多个字段**。
|
||||||
|
|
||||||
|
|
@ -325,7 +326,7 @@ GET kibana_sample_data_ecommerce/_search
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 1.7. combined_fields query
|
### combined_fields query
|
||||||
|
|
||||||
[**`combined_fields query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-combined-fields-query.html) 支持搜索多个文本字段,就好像它们的内容已被索引到一个组合字段中一样。该查询会生成以 term 为中心的输入字符串视图:首先它将查询字符串解析为独立的 term,然后在所有字段中查找每个 term。当匹配结果可能跨越多个文本字段时,此查询特别有用,例如文章的标题、摘要和正文:
|
[**`combined_fields query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-combined-fields-query.html) 支持搜索多个文本字段,就好像它们的内容已被索引到一个组合字段中一样。该查询会生成以 term 为中心的输入字符串视图:首先它将查询字符串解析为独立的 term,然后在所有字段中查找每个 term。当匹配结果可能跨越多个文本字段时,此查询特别有用,例如文章的标题、摘要和正文:
|
||||||
|
|
||||||
|
|
@ -346,7 +347,7 @@ GET /_search
|
||||||
|
|
||||||
字段前缀权重根据组合字段模型进行计算。例如,如果 title 字段的权重为 2,则匹配度打分时会将 title 中的每个 term 形成的组合字段,按出现两次进行打分。
|
字段前缀权重根据组合字段模型进行计算。例如,如果 title 字段的权重为 2,则匹配度打分时会将 title 中的每个 term 形成的组合字段,按出现两次进行打分。
|
||||||
|
|
||||||
### 1.8. common_terms query
|
### common_terms query
|
||||||
|
|
||||||
> 7.3.0 废弃
|
> 7.3.0 废弃
|
||||||
|
|
||||||
|
|
@ -399,7 +400,7 @@ GET books/_search
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 1.9. query_string query
|
### query_string query
|
||||||
|
|
||||||
[**`query_string query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-query-string-query.html) 是与 Lucene 查询语句的语法结合非常紧密的一种查询,允许在一个查询语句中使用多个特殊条件关键字(如:AND | OR | NOT)对多个字段进行查询,建议熟悉 Lucene 查询语法的用户去使用。
|
[**`query_string query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-query-string-query.html) 是与 Lucene 查询语句的语法结合非常紧密的一种查询,允许在一个查询语句中使用多个特殊条件关键字(如:AND | OR | NOT)对多个字段进行查询,建议熟悉 Lucene 查询语法的用户去使用。
|
||||||
|
|
||||||
|
|
@ -419,7 +420,7 @@ GET /_search
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 1.10. simple_query_string query
|
### simple_query_string query
|
||||||
|
|
||||||
[**`simple_query_string query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-simple-query-string-query.html) 是一种适合直接暴露给用户,并且具有非常完善的查询语法的查询语句,接受 Lucene 查询语法,解析过程中发生错误不会抛出异常。
|
[**`simple_query_string query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-simple-query-string-query.html) 是一种适合直接暴露给用户,并且具有非常完善的查询语法的查询语句,接受 Lucene 查询语法,解析过程中发生错误不会抛出异常。
|
||||||
|
|
||||||
|
|
@ -453,7 +454,7 @@ GET /_search
|
||||||
|
|
||||||
注意:要使用上面的字符,请使用反斜杠 `/` 对其进行转义。
|
注意:要使用上面的字符,请使用反斜杠 `/` 对其进行转义。
|
||||||
|
|
||||||
### 1.11. 全文查询完整示例
|
### 全文查询完整示例
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
#设置 position_increment_gap
|
#设置 position_increment_gap
|
||||||
|
|
@ -501,7 +502,7 @@ POST groups/_search
|
||||||
DELETE groups
|
DELETE groups
|
||||||
```
|
```
|
||||||
|
|
||||||
## 2. 词项查询
|
## 词项查询
|
||||||
|
|
||||||
**`Term`(词项)是表达语意的最小单位**。搜索和利用统计语言模型进行自然语言处理都需要处理 Term。
|
**`Term`(词项)是表达语意的最小单位**。搜索和利用统计语言模型进行自然语言处理都需要处理 Term。
|
||||||
|
|
||||||
|
|
@ -522,7 +523,7 @@ DELETE groups
|
||||||
- **[`type` query](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-type-query.html)**
|
- **[`type` query](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-type-query.html)**
|
||||||
- **[`wildcard` query](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-wildcard-query.html)**
|
- **[`wildcard` query](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-wildcard-query.html)**
|
||||||
|
|
||||||
### 2.1. exists query
|
### exists query
|
||||||
|
|
||||||
[**`exists query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-exists-query.html) 会返回字段中至少有一个非空值的文档。
|
[**`exists query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-exists-query.html) 会返回字段中至少有一个非空值的文档。
|
||||||
|
|
||||||
|
|
@ -561,7 +562,7 @@ GET kibana_sample_data_ecommerce/_search
|
||||||
- `{ "user" : [null] }` 虽然有 user 字段,但是值为空。
|
- `{ "user" : [null] }` 虽然有 user 字段,但是值为空。
|
||||||
- `{ "foo" : "bar" }` 没有 user 字段。
|
- `{ "foo" : "bar" }` 没有 user 字段。
|
||||||
|
|
||||||
### 2.2. fuzzy query
|
### fuzzy query
|
||||||
|
|
||||||
[**`fuzzy query`**(模糊查询)](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-fuzzy-query.html)返回包含与搜索词相似的词的文档。ES 使用 [Levenshtein edit distance(Levenshtein 编辑距离)](https://en.wikipedia.org/wiki/Levenshtein_distance)测量相似度或模糊度。
|
[**`fuzzy query`**(模糊查询)](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-fuzzy-query.html)返回包含与搜索词相似的词的文档。ES 使用 [Levenshtein edit distance(Levenshtein 编辑距离)](https://en.wikipedia.org/wiki/Levenshtein_distance)测量相似度或模糊度。
|
||||||
|
|
||||||
|
|
@ -594,7 +595,7 @@ GET books/_search
|
||||||
|
|
||||||
注意:如果配置了 [`search.allow_expensive_queries`](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html#query-dsl-allow-expensive-queries) ,则 fuzzy query 不能执行。
|
注意:如果配置了 [`search.allow_expensive_queries`](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html#query-dsl-allow-expensive-queries) ,则 fuzzy query 不能执行。
|
||||||
|
|
||||||
### 2.3. ids query
|
### ids query
|
||||||
|
|
||||||
[**`ids query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-ids-query.html) 根据 ID 返回文档。 此查询使用存储在 `_id` 字段中的文档 ID。
|
[**`ids query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-ids-query.html) 根据 ID 返回文档。 此查询使用存储在 `_id` 字段中的文档 ID。
|
||||||
|
|
||||||
|
|
@ -609,7 +610,7 @@ GET /_search
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 2.4. prefix query
|
### prefix query
|
||||||
|
|
||||||
[**`prefix query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-prefix-query.html#prefix-query-ex-request) 用于查询某个字段中包含指定前缀的文档。
|
[**`prefix query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-prefix-query.html#prefix-query-ex-request) 用于查询某个字段中包含指定前缀的文档。
|
||||||
|
|
||||||
|
|
@ -628,7 +629,7 @@ GET /_search
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 2.5. range query
|
### range query
|
||||||
|
|
||||||
[**`range query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-range-query.html) 即范围查询,用于匹配在某一范围内的数值型、日期类型或者字符串型字段的文档。比如搜索哪些书籍的价格在 50 到 100 之间、哪些书籍的出版时间在 2015 年到 2019 年之间。**使用 range 查询只能查询一个字段,不能作用在多个字段上**。
|
[**`range query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-range-query.html) 即范围查询,用于匹配在某一范围内的数值型、日期类型或者字符串型字段的文档。比如搜索哪些书籍的价格在 50 到 100 之间、哪些书籍的出版时间在 2015 年到 2019 年之间。**使用 range 查询只能查询一个字段,不能作用在多个字段上**。
|
||||||
|
|
||||||
|
|
@ -685,7 +686,7 @@ GET kibana_sample_data_ecommerce/_search
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 2.6. regexp query
|
### regexp query
|
||||||
|
|
||||||
[**`regexp query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-regexp-query.html) 返回与正则表达式相匹配的 term 所属的文档。
|
[**`regexp query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-regexp-query.html) 返回与正则表达式相匹配的 term 所属的文档。
|
||||||
|
|
||||||
|
|
@ -712,7 +713,7 @@ GET /_search
|
||||||
|
|
||||||
> 注意:如果配置了[`search.allow_expensive_queries`](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html#query-dsl-allow-expensive-queries) ,则 [**`regexp query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-regexp-query.html) 会被禁用。
|
> 注意:如果配置了[`search.allow_expensive_queries`](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html#query-dsl-allow-expensive-queries) ,则 [**`regexp query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-regexp-query.html) 会被禁用。
|
||||||
|
|
||||||
### 2.7. term query
|
### term query
|
||||||
|
|
||||||
[**`term query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-term-query.html) 用来查找指定字段中包含给定单词的文档,term 查询不被解析,只有查询词和文档中的词精确匹配才会被搜索到,应用场景为查询人名、地名等需要精准匹配的需求。
|
[**`term query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-term-query.html) 用来查找指定字段中包含给定单词的文档,term 查询不被解析,只有查询词和文档中的词精确匹配才会被搜索到,应用场景为查询人名、地名等需要精准匹配的需求。
|
||||||
|
|
||||||
|
|
@ -766,7 +767,7 @@ DELETE my-index-000001
|
||||||
>
|
>
|
||||||
> 要搜索 text 字段值,需改用 match 查询。
|
> 要搜索 text 字段值,需改用 match 查询。
|
||||||
|
|
||||||
### 2.8. terms query
|
### terms query
|
||||||
|
|
||||||
[**`terms query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-terms-query.html) 与 [**`term query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-term-query.html) 相同,但可以搜索多个值。
|
[**`terms query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-terms-query.html) 与 [**`term query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-term-query.html) 相同,但可以搜索多个值。
|
||||||
|
|
||||||
|
|
@ -823,7 +824,7 @@ GET my-index-000001/_search?pretty
|
||||||
DELETE my-index-000001
|
DELETE my-index-000001
|
||||||
```
|
```
|
||||||
|
|
||||||
### 2.9. type query
|
### type query
|
||||||
|
|
||||||
> 7.0.0 后废弃
|
> 7.0.0 后废弃
|
||||||
|
|
||||||
|
|
@ -842,7 +843,7 @@ GET /_search
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 2.10. wildcard query
|
### wildcard query
|
||||||
|
|
||||||
[**`wildcard query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-wildcard-query.html) 即通配符查询,返回与通配符模式匹配的文档。
|
[**`wildcard query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-wildcard-query.html) 即通配符查询,返回与通配符模式匹配的文档。
|
||||||
|
|
||||||
|
|
@ -867,7 +868,7 @@ GET /_search
|
||||||
|
|
||||||
> 注意:如果配置了[`search.allow_expensive_queries`](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html#query-dsl-allow-expensive-queries) ,则[**`wildcard query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-wildcard-query.html) 会被禁用。
|
> 注意:如果配置了[`search.allow_expensive_queries`](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html#query-dsl-allow-expensive-queries) ,则[**`wildcard query`**](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-wildcard-query.html) 会被禁用。
|
||||||
|
|
||||||
### 2.11. 词项查询完整示例
|
### 词项查询完整示例
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
DELETE products
|
DELETE products
|
||||||
|
|
@ -951,11 +952,11 @@ POST /products/_search
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
## 3. 复合查询
|
## 复合查询
|
||||||
|
|
||||||
复合查询就是把一些简单查询组合在一起实现更复杂的查询需求,除此之外,复合查询还可以控制另外一个查询的行为。
|
复合查询就是把一些简单查询组合在一起实现更复杂的查询需求,除此之外,复合查询还可以控制另外一个查询的行为。
|
||||||
|
|
||||||
### 3.1. bool query
|
### bool query
|
||||||
|
|
||||||
bool 查询可以把任意多个简单查询组合在一起,使用 must、should、must_not、filter 选项来表示简单查询之间的逻辑,每个选项都可以出现 0 次到多次,它们的含义如下:
|
bool 查询可以把任意多个简单查询组合在一起,使用 must、should、must_not、filter 选项来表示简单查询之间的逻辑,每个选项都可以出现 0 次到多次,它们的含义如下:
|
||||||
|
|
||||||
|
|
@ -1003,7 +1004,7 @@ GET books/_search
|
||||||
|
|
||||||
有关布尔查询更详细的信息参考 [bool query(组合查询)详解](https://www.knowledgedict.com/tutorial/elasticsearch-query-bool.html)。
|
有关布尔查询更详细的信息参考 [bool query(组合查询)详解](https://www.knowledgedict.com/tutorial/elasticsearch-query-bool.html)。
|
||||||
|
|
||||||
### 3.2. boosting query
|
### boosting query
|
||||||
|
|
||||||
boosting 查询用于需要对两个查询的评分进行调整的场景,boosting 查询会把两个查询封装在一起并降低其中一个查询的评分。
|
boosting 查询用于需要对两个查询的评分进行调整的场景,boosting 查询会把两个查询封装在一起并降低其中一个查询的评分。
|
||||||
|
|
||||||
|
|
@ -1034,7 +1035,7 @@ GET books/_search
|
||||||
|
|
||||||
boosting 查询中指定了抑制因子为 0.2,publish_time 的值在 2015-01-01 之后的文档得分不变,publish_time 的值在 2015-01-01 之前的文档得分为原得分的 0.2 倍。
|
boosting 查询中指定了抑制因子为 0.2,publish_time 的值在 2015-01-01 之后的文档得分不变,publish_time 的值在 2015-01-01 之前的文档得分为原得分的 0.2 倍。
|
||||||
|
|
||||||
### 3.3. constant_score query
|
### constant_score query
|
||||||
|
|
||||||
constant*score query 包装一个 filter query,并返回匹配过滤器查询条件的文档,且它们的相关性评分都等于 \_boost* 参数值(可以理解为原有的基于 tf-idf 或 bm25 的相关分固定为 1.0,所以最终评分为 _1.0 \* boost_,即等于 _boost_ 参数值)。下面的查询语句会返回 title 字段中含有关键词 _elasticsearch_ 的文档,所有文档的评分都是 1.8:
|
constant*score query 包装一个 filter query,并返回匹配过滤器查询条件的文档,且它们的相关性评分都等于 \_boost* 参数值(可以理解为原有的基于 tf-idf 或 bm25 的相关分固定为 1.0,所以最终评分为 _1.0 \* boost_,即等于 _boost_ 参数值)。下面的查询语句会返回 title 字段中含有关键词 _elasticsearch_ 的文档,所有文档的评分都是 1.8:
|
||||||
|
|
||||||
|
|
@ -1054,7 +1055,7 @@ GET books/_search
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 3.4. dis_max query
|
### dis_max query
|
||||||
|
|
||||||
dis_max query 与 bool query 有一定联系也有一定区别,dis_max query 支持多并发查询,可返回与任意查询条件子句匹配的任何文档类型。与 bool 查询可以将所有匹配查询的分数相结合使用的方式不同,dis_max 查询只使用最佳匹配查询条件的分数。请看下面的例子:
|
dis_max query 与 bool query 有一定联系也有一定区别,dis_max query 支持多并发查询,可返回与任意查询条件子句匹配的任何文档类型。与 bool 查询可以将所有匹配查询的分数相结合使用的方式不同,dis_max 查询只使用最佳匹配查询条件的分数。请看下面的例子:
|
||||||
|
|
||||||
|
|
@ -1081,7 +1082,7 @@ GET books/_search
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 3.5. function_score query
|
### function_score query
|
||||||
|
|
||||||
function_score query 可以修改查询的文档得分,这个查询在有些情况下非常有用,比如通过评分函数计算文档得分代价较高,可以改用过滤器加自定义评分函数的方式来取代传统的评分方式。
|
function_score query 可以修改查询的文档得分,这个查询在有些情况下非常有用,比如通过评分函数计算文档得分代价较高,可以改用过滤器加自定义评分函数的方式来取代传统的评分方式。
|
||||||
|
|
||||||
|
|
@ -1127,7 +1128,7 @@ GET books/_search
|
||||||
|
|
||||||
关于 function_score 的更多详细内容请查看 [Elasticsearch function_score 查询最强详解](https://www.knowledgedict.com/tutorial/elasticsearch-function_score.html)。
|
关于 function_score 的更多详细内容请查看 [Elasticsearch function_score 查询最强详解](https://www.knowledgedict.com/tutorial/elasticsearch-function_score.html)。
|
||||||
|
|
||||||
### 3.6. indices query
|
### indices query
|
||||||
|
|
||||||
indices query 适用于需要在多个索引之间进行查询的场景,它允许指定一个索引名字列表和内部查询。indices query 中有 query 和 no_match_query 两部分,query 中用于搜索指定索引列表中的文档,no_match_query 中的查询条件用于搜索指定索引列表之外的文档。下面的查询语句实现了搜索索引 books、books2 中 title 字段包含关键字 javascript,其他索引中 title 字段包含 basketball 的文档,查询语句如下:
|
indices query 适用于需要在多个索引之间进行查询的场景,它允许指定一个索引名字列表和内部查询。indices query 中有 query 和 no_match_query 两部分,query 中用于搜索指定索引列表中的文档,no_match_query 中的查询条件用于搜索指定索引列表之外的文档。下面的查询语句实现了搜索索引 books、books2 中 title 字段包含关键字 javascript,其他索引中 title 字段包含 basketball 的文档,查询语句如下:
|
||||||
|
|
||||||
|
|
@ -1152,7 +1153,7 @@ GET books/_search
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
## 4. 嵌套查询
|
## 嵌套查询
|
||||||
|
|
||||||
在 Elasticsearch 这样的分布式系统中执行全 SQL 风格的连接查询代价昂贵,是不可行的。相应地,为了实现水平规模地扩展,Elasticsearch 提供了以下两种形式的 join:
|
在 Elasticsearch 这样的分布式系统中执行全 SQL 风格的连接查询代价昂贵,是不可行的。相应地,为了实现水平规模地扩展,Elasticsearch 提供了以下两种形式的 join:
|
||||||
|
|
||||||
|
|
@ -1164,7 +1165,7 @@ GET books/_search
|
||||||
|
|
||||||
父子关系可以存在单个的索引的两个类型的文档之间。has_child 查询将返回其子文档能满足特定查询的父文档,而 has_parent 则返回其父文档能满足特定查询的子文档。
|
父子关系可以存在单个的索引的两个类型的文档之间。has_child 查询将返回其子文档能满足特定查询的父文档,而 has_parent 则返回其父文档能满足特定查询的子文档。
|
||||||
|
|
||||||
### 4.1. nested query
|
### nested query
|
||||||
|
|
||||||
文档中可能包含嵌套类型的字段,这些字段用来索引一些数组对象,每个对象都可以作为一条独立的文档被查询出来(用嵌套查询)。
|
文档中可能包含嵌套类型的字段,这些字段用来索引一些数组对象,每个对象都可以作为一条独立的文档被查询出来(用嵌套查询)。
|
||||||
|
|
||||||
|
|
@ -1183,7 +1184,7 @@ PUT /my_index
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 4.2. has_child query
|
### has_child query
|
||||||
|
|
||||||
文档的父子关系创建索引时在映射中声明,这里以员工(employee)和工作城市(branch)为例,它们属于不同的类型,相当于数据库中的两张表,如果想把员工和他们工作的城市关联起来,需要告诉 Elasticsearch 文档之间的父子关系,这里 employee 是 child type,branch 是 parent type,在映射中声明,执行命令:
|
文档的父子关系创建索引时在映射中声明,这里以员工(employee)和工作城市(branch)为例,它们属于不同的类型,相当于数据库中的两张表,如果想把员工和他们工作的城市关联起来,需要告诉 Elasticsearch 文档之间的父子关系,这里 employee 是 child type,branch 是 parent type,在映射中声明,执行命令:
|
||||||
|
|
||||||
|
|
@ -1275,7 +1276,7 @@ GET company/branch/_search?pretty
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 4.3. has_parent query
|
### has_parent query
|
||||||
|
|
||||||
通过父文档查询子文档使用 has_parent 查询。比如,搜索哪些 employee 工作在 UK,查询命令如下:
|
通过父文档查询子文档使用 has_parent 查询。比如,搜索哪些 employee 工作在 UK,查询命令如下:
|
||||||
|
|
||||||
|
|
@ -1293,7 +1294,7 @@ GET company/employee/_search
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
## 5. 位置查询
|
## 位置查询
|
||||||
|
|
||||||
Elasticsearch 可以对地理位置点 geo_point 类型和地理位置形状 geo_shape 类型的数据进行搜索。为了学习方便,这里准备一些城市的地理坐标作为测试数据,每一条文档都包含城市名称和地理坐标这两个字段,这里的坐标点取的是各个城市中心的一个位置。首先把下面的内容保存到 geo.json 文件中:
|
Elasticsearch 可以对地理位置点 geo_point 类型和地理位置形状 geo_shape 类型的数据进行搜索。为了学习方便,这里准备一些城市的地理坐标作为测试数据,每一条文档都包含城市名称和地理坐标这两个字段,这里的坐标点取的是各个城市中心的一个位置。首先把下面的内容保存到 geo.json 文件中:
|
||||||
|
|
||||||
|
|
@ -1338,7 +1339,7 @@ PUT geo
|
||||||
curl -XPOST "http://localhost:9200/_bulk?pretty" --data-binary @geo.json
|
curl -XPOST "http://localhost:9200/_bulk?pretty" --data-binary @geo.json
|
||||||
```
|
```
|
||||||
|
|
||||||
### 5.1. geo_distance query
|
### geo_distance query
|
||||||
|
|
||||||
geo_distance query 可以查找在一个中心点指定范围内的地理点文档。例如,查找距离天津 200km 以内的城市,搜索结果中会返回北京,命令如下:
|
geo_distance query 可以查找在一个中心点指定范围内的地理点文档。例如,查找距离天津 200km 以内的城市,搜索结果中会返回北京,命令如下:
|
||||||
|
|
||||||
|
|
@ -1385,7 +1386,7 @@ GET geo/_search
|
||||||
|
|
||||||
其中 location 对应的经纬度字段;unit 为 `km` 表示将距离以 `km` 为单位写入到每个返回结果的 sort 键中;distance_type 为 `plane` 表示使用快速但精度略差的 `plane` 计算方式。
|
其中 location 对应的经纬度字段;unit 为 `km` 表示将距离以 `km` 为单位写入到每个返回结果的 sort 键中;distance_type 为 `plane` 表示使用快速但精度略差的 `plane` 计算方式。
|
||||||
|
|
||||||
### 5.2. geo_bounding_box query
|
### geo_bounding_box query
|
||||||
|
|
||||||
geo_bounding_box query 用于查找落入指定的矩形内的地理坐标。查询中由两个点确定一个矩形,然后在矩形区域内查询匹配的文档。
|
geo_bounding_box query 用于查找落入指定的矩形内的地理坐标。查询中由两个点确定一个矩形,然后在矩形区域内查询匹配的文档。
|
||||||
|
|
||||||
|
|
@ -1416,7 +1417,7 @@ GET geo/_search
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 5.3. geo_polygon query
|
### geo_polygon query
|
||||||
|
|
||||||
geo_polygon query 用于查找在指定**多边形**内的地理点。例如,呼和浩特、重庆、上海三地组成一个三角形,查询位置在该三角形区域内的城市,命令如下:
|
geo_polygon query 用于查找在指定**多边形**内的地理点。例如,呼和浩特、重庆、上海三地组成一个三角形,查询位置在该三角形区域内的城市,命令如下:
|
||||||
|
|
||||||
|
|
@ -1449,7 +1450,7 @@ GET geo/_search
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 5.4. geo_shape query
|
### geo_shape query
|
||||||
|
|
||||||
geo_shape query 用于查询 geo_shape 类型的地理数据,地理形状之间的关系有相交、包含、不相交三种。创建一个新的索引用于测试,其中 location 字段的类型设为 geo_shape 类型。
|
geo_shape query 用于查询 geo_shape 类型的地理数据,地理形状之间的关系有相交、包含、不相交三种。创建一个新的索引用于测试,其中 location 字段的类型设为 geo_shape 类型。
|
||||||
|
|
||||||
|
|
@ -1518,9 +1519,9 @@ GET geoshape/_search
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
## 6. 特殊查询
|
## 特殊查询
|
||||||
|
|
||||||
### 6.1. more_like_this query
|
### more_like_this query
|
||||||
|
|
||||||
more_like_this query 可以查询和提供文本类似的文档,通常用于近似文本的推荐等场景。查询命令如下:
|
more_like_this query 可以查询和提供文本类似的文档,通常用于近似文本的推荐等场景。查询命令如下:
|
||||||
|
|
||||||
|
|
@ -1555,7 +1556,7 @@ GET books/_search
|
||||||
- include 是否把输入文档作为结果返回。
|
- include 是否把输入文档作为结果返回。
|
||||||
- boost 整个 query 的权重,默认为 1.0。
|
- boost 整个 query 的权重,默认为 1.0。
|
||||||
|
|
||||||
### 6.2. script query
|
### script query
|
||||||
|
|
||||||
Elasticsearch 支持使用脚本进行查询。例如,查询价格大于 180 的文档,命令如下:
|
Elasticsearch 支持使用脚本进行查询。例如,查询价格大于 180 的文档,命令如下:
|
||||||
|
|
||||||
|
|
@ -1573,7 +1574,7 @@ GET books/_search
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 6.3. percolate query
|
### percolate query
|
||||||
|
|
||||||
一般情况下,我们是先把文档写入到 Elasticsearch 中,通过查询语句对文档进行搜索。percolate query 则是反其道而行之的做法,它会先注册查询条件,根据文档来查询 query。例如,在 my-index 索引中有一个 laptop 类型,文档有 price 和 name 两个字段,在映射中声明一个 percolator 类型的 query,命令如下:
|
一般情况下,我们是先把文档写入到 Elasticsearch 中,通过查询语句对文档进行搜索。percolate query 则是反其道而行之的做法,它会先注册查询条件,根据文档来查询 query。例如,在 my-index 索引中有一个 laptop 类型,文档有 price 和 name 两个字段,在映射中声明一个 percolator 类型的 query,命令如下:
|
||||||
|
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Elasticsearch 高亮搜索及显示
|
title: Elasticsearch 高亮搜索及显示
|
||||||
date: 2022-02-22 21:01:01
|
date: 2022-02-22 21:01:01
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
|
|
@ -10,14 +11,14 @@ tags:
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
- 高亮
|
- 高亮
|
||||||
permalink: /pages/4ae35a/
|
permalink: /pages/e1b769/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Elasticsearch 高亮搜索及显示
|
# Elasticsearch 高亮搜索及显示
|
||||||
|
|
||||||
Elasticsearch 的高亮(highlight)可以让您从搜索结果中的一个或多个字段中获取突出显示的摘要,以便向用户显示查询匹配的位置。当您请求突出显示(即高亮)时,响应结果的 highlight 字段中包括高亮的字段和高亮的片段。Elasticsearch 默认会用 `<em></em>` 标签标记关键字。
|
Elasticsearch 的高亮(highlight)可以让您从搜索结果中的一个或多个字段中获取突出显示的摘要,以便向用户显示查询匹配的位置。当您请求突出显示(即高亮)时,响应结果的 highlight 字段中包括高亮的字段和高亮的片段。Elasticsearch 默认会用 `<em></em>` 标签标记关键字。
|
||||||
|
|
||||||
## 1. 高亮参数
|
## 高亮参数
|
||||||
|
|
||||||
ES 提供了如下高亮参数:
|
ES 提供了如下高亮参数:
|
||||||
|
|
||||||
|
|
@ -45,7 +46,7 @@ ES 提供了如下高亮参数:
|
||||||
| `tags_schema` | 设置为使用内置标记模式的样式。 |
|
| `tags_schema` | 设置为使用内置标记模式的样式。 |
|
||||||
| `type` | 使用的高亮模式,可选项为**_`unified`_**、**_`plain`_**或**_`fvh`_**。默认为 _`unified`_。 |
|
| `type` | 使用的高亮模式,可选项为**_`unified`_**、**_`plain`_**或**_`fvh`_**。默认为 _`unified`_。 |
|
||||||
|
|
||||||
## 2. 自定义高亮片段
|
## 自定义高亮片段
|
||||||
|
|
||||||
如果我们想使用自定义标签,在高亮属性中给需要高亮的字段加上 `pre_tags` 和 `post_tags` 即可。例如,搜索 title 字段中包含关键词 javascript 的书籍并使用自定义 HTML 标签高亮关键词,查询语句如下:
|
如果我们想使用自定义标签,在高亮属性中给需要高亮的字段加上 `pre_tags` 和 `post_tags` 即可。例如,搜索 title 字段中包含关键词 javascript 的书籍并使用自定义 HTML 标签高亮关键词,查询语句如下:
|
||||||
|
|
||||||
|
|
@ -66,7 +67,7 @@ GET /books/_search
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
## 3. 多字段高亮
|
## 多字段高亮
|
||||||
|
|
||||||
关于搜索高亮,还需要掌握如何设置多字段搜索高亮。比如,搜索 title 字段的时候,我们期望 description 字段中的关键字也可以高亮,这时候就需要把 `require_field_match` 属性的取值设置为 `fasle`。`require_field_match` 的默认值为 `true`,只会高亮匹配的字段。多字段高亮的查询语句如下:
|
关于搜索高亮,还需要掌握如何设置多字段搜索高亮。比如,搜索 title 字段的时候,我们期望 description 字段中的关键字也可以高亮,这时候就需要把 `require_field_match` 属性的取值设置为 `fasle`。`require_field_match` 的默认值为 `true`,只会高亮匹配的字段。多字段高亮的查询语句如下:
|
||||||
|
|
||||||
|
|
@ -86,7 +87,7 @@ GET /books/_search
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
## 4. 高亮性能分析
|
## 高亮性能分析
|
||||||
|
|
||||||
Elasticsearch 提供了三种高亮器,分别是**默认的 highlighter 高亮器**、**postings-highlighter 高亮器**和 **fast-vector-highlighter 高亮器**。
|
Elasticsearch 提供了三种高亮器,分别是**默认的 highlighter 高亮器**、**postings-highlighter 高亮器**和 **fast-vector-highlighter 高亮器**。
|
||||||
|
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Elasticsearch 排序
|
title: Elasticsearch 排序
|
||||||
date: 2022-01-19 22:49:16
|
date: 2022-01-19 22:49:16
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
|
|
@ -10,20 +11,20 @@ tags:
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
- 排序
|
- 排序
|
||||||
permalink: /pages/44ca8e/
|
permalink: /pages/24baff/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Elasticsearch 排序
|
# Elasticsearch 排序
|
||||||
|
|
||||||
在 Elasticsearch 中,默认排序是**按照相关性的评分(\_score)**进行降序排序,也可以按照**字段的值排序**、**多级排序**、**多值字段排序、基于 geo(地理位置)排序以及自定义脚本排序**,除此之外,对于相关性的评分也可以用 rescore 二次、三次打分,它可以限定重新打分的窗口大小(window size),并针对作用范围内的文档修改其得分,从而达到精细化控制结果相关性的目的。
|
在 Elasticsearch 中,默认排序是**按照相关性的评分(\_score)**进行降序排序,也可以按照**字段的值排序**、**多级排序**、**多值字段排序、基于 geo(地理位置)排序以及自定义脚本排序**,除此之外,对于相关性的评分也可以用 rescore 二次、三次打分,它可以限定重新打分的窗口大小(window size),并针对作用范围内的文档修改其得分,从而达到精细化控制结果相关性的目的。
|
||||||
|
|
||||||
## 1. 默认相关性排序
|
## 默认相关性排序
|
||||||
|
|
||||||
在 Elasticsearch 中,默认情况下,文档是按照相关性得分倒序排列的,其对应的相关性得分字段用 `_score` 来表示,它是浮点数类型,`_score` 评分越高,相关性越高。评分模型的选择可以通过 `similarity` 参数在映射中指定。
|
在 Elasticsearch 中,默认情况下,文档是按照相关性得分倒序排列的,其对应的相关性得分字段用 `_score` 来表示,它是浮点数类型,`_score` 评分越高,相关性越高。评分模型的选择可以通过 `similarity` 参数在映射中指定。
|
||||||
|
|
||||||
相似度算法可以按字段指定,只需在映射中为不同字段选定即可,如果要修改已有字段的相似度算法,只能通过为数据重新建立索引来达到目的。关于更多 es 相似度算法可以参考 [深入理解 es 相似度算法(相关性得分计算)](https://www.knowledgedict.com/tutorial/elasticsearch-similarity.html)。
|
相似度算法可以按字段指定,只需在映射中为不同字段选定即可,如果要修改已有字段的相似度算法,只能通过为数据重新建立索引来达到目的。关于更多 es 相似度算法可以参考 [深入理解 es 相似度算法(相关性得分计算)](https://www.knowledgedict.com/tutorial/elasticsearch-similarity.html)。
|
||||||
|
|
||||||
### 1.1. TF-IDF 模型
|
### TF-IDF 模型
|
||||||
|
|
||||||
Elasticsearch 在 5.4 版本以前,text 类型的字段,默认采用基于 tf-idf 的向量空间模型。
|
Elasticsearch 在 5.4 版本以前,text 类型的字段,默认采用基于 tf-idf 的向量空间模型。
|
||||||
|
|
||||||
|
|
@ -55,11 +56,11 @@ Elasticsearch 在 5.4 版本以前,text 类型的字段,默认采用基于 t
|
||||||
|
|
||||||
一旦词频 TF 和逆文档频率 IDF 计算完成,就可以使用 TF-IDF 公式来计算文档的得分。
|
一旦词频 TF 和逆文档频率 IDF 计算完成,就可以使用 TF-IDF 公式来计算文档的得分。
|
||||||
|
|
||||||
### 1.2. BM25 模型
|
### BM25 模型
|
||||||
|
|
||||||
Elasticsearch 在 5.4 版本之后,针对 text 类型的字段,默认采用的是 BM25 评分模型,而不是基于 tf-idf 的向量空间模型,评分模型的选择可以通过 `similarity` 参数在映射中指定。
|
Elasticsearch 在 5.4 版本之后,针对 text 类型的字段,默认采用的是 BM25 评分模型,而不是基于 tf-idf 的向量空间模型,评分模型的选择可以通过 `similarity` 参数在映射中指定。
|
||||||
|
|
||||||
## 2. 字段的值排序
|
## 字段的值排序
|
||||||
|
|
||||||
在 Elasticsearch 中按照字段的值排序,可以利用 `sort` 参数实现。
|
在 Elasticsearch 中按照字段的值排序,可以利用 `sort` 参数实现。
|
||||||
|
|
||||||
|
|
@ -112,7 +113,7 @@ GET books/_search
|
||||||
|
|
||||||
从如上返回结果,可以看出,`max_score` 和 `_score` 字段都返回 `null`,返回字段多出 `sort` 字段,包含排序字段的分值。计算 \_`score` 的花销巨大,如果不根据相关性排序,记录 \_`score` 是没有意义的。如果无论如何都要计算 \_`score`,可以将 `track_scores` 参数设置为 `true`。
|
从如上返回结果,可以看出,`max_score` 和 `_score` 字段都返回 `null`,返回字段多出 `sort` 字段,包含排序字段的分值。计算 \_`score` 的花销巨大,如果不根据相关性排序,记录 \_`score` 是没有意义的。如果无论如何都要计算 \_`score`,可以将 `track_scores` 参数设置为 `true`。
|
||||||
|
|
||||||
## 3. 多字段排序
|
## 多字段排序
|
||||||
|
|
||||||
如果我们想要结合使用 price、date 和 \_score 进行查询,并且匹配的结果首先按照价格排序,然后按照日期排序,最后按照相关性排序,具体示例如下:
|
如果我们想要结合使用 price、date 和 \_score 进行查询,并且匹配的结果首先按照价格排序,然后按照日期排序,最后按照相关性排序,具体示例如下:
|
||||||
|
|
||||||
|
|
@ -150,7 +151,7 @@ GET books/_search
|
||||||
|
|
||||||
多级排序并不一定包含 `_score`。你可以根据一些不同的字段进行排序,如地理距离或是脚本计算的特定值。
|
多级排序并不一定包含 `_score`。你可以根据一些不同的字段进行排序,如地理距离或是脚本计算的特定值。
|
||||||
|
|
||||||
## 4. 多值字段的排序
|
## 多值字段的排序
|
||||||
|
|
||||||
一种情形是字段有多个值的排序,需要记住这些值并没有固有的顺序;一个多值的字段仅仅是多个值的包装,这时应该选择哪个进行排序呢?
|
一种情形是字段有多个值的排序,需要记住这些值并没有固有的顺序;一个多值的字段仅仅是多个值的包装,这时应该选择哪个进行排序呢?
|
||||||
|
|
||||||
|
|
@ -165,7 +166,7 @@ GET books/_search
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
## 5. 地理位置上的距离排序
|
## 地理位置上的距离排序
|
||||||
|
|
||||||
es 的地理位置排序使用 **`_geo_distance`** 来进行距离排序,如下示例:
|
es 的地理位置排序使用 **`_geo_distance`** 来进行距离排序,如下示例:
|
||||||
|
|
||||||
|
|
@ -198,6 +199,6 @@ _\_geo_distance_ 的选项具体如下:
|
||||||
- **_`ignore_unmapped`_**:未映射字段时,是否忽略处理,可选项有 **_`true`_** 和 **_`false`_**;默认为 _false_,表示如果未映射字段,查询将引发异常;若设置 _true_,将忽略未映射的字段,并且不匹配此查询的任何文档。
|
- **_`ignore_unmapped`_**:未映射字段时,是否忽略处理,可选项有 **_`true`_** 和 **_`false`_**;默认为 _false_,表示如果未映射字段,查询将引发异常;若设置 _true_,将忽略未映射的字段,并且不匹配此查询的任何文档。
|
||||||
- **_`validation_method`_**:指定检验经纬度数据的方式,可选项有 **_`IGNORE_MALFORMED`_**、**_`COERCE`_** 和 **_`STRICT`_**;_IGNORE_MALFORMED_ 表示可接受纬度或经度无效的地理点,即忽略数据;_COERCE_ 表示另外尝试并推断正确的地理坐标;_STRICT_ 为默认值,表示遇到不正确的地理坐标直接抛出异常。
|
- **_`validation_method`_**:指定检验经纬度数据的方式,可选项有 **_`IGNORE_MALFORMED`_**、**_`COERCE`_** 和 **_`STRICT`_**;_IGNORE_MALFORMED_ 表示可接受纬度或经度无效的地理点,即忽略数据;_COERCE_ 表示另外尝试并推断正确的地理坐标;_STRICT_ 为默认值,表示遇到不正确的地理坐标直接抛出异常。
|
||||||
|
|
||||||
## 6. 参考资料
|
## 参考资料
|
||||||
|
|
||||||
- [Elasticsearch 教程](https://www.knowledgedict.com/tutorial/elasticsearch-intro.html)
|
- [Elasticsearch 教程](https://www.knowledgedict.com/tutorial/elasticsearch-intro.html)
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Elasticsearch 聚合
|
title: Elasticsearch 聚合
|
||||||
date: 2022-01-19 22:49:16
|
date: 2022-01-19 22:49:16
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
|
|
@ -10,37 +11,14 @@ tags:
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
- 聚合
|
- 聚合
|
||||||
permalink: /pages/93fa2a/
|
permalink: /pages/f89f66/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Elasticsearch 聚合
|
# Elasticsearch 聚合
|
||||||
|
|
||||||
Elasticsearch 是一个分布式的全文搜索引擎,索引和搜索是 Elasticsearch 的基本功能。事实上,Elasticsearch 的聚合(Aggregations)功能也十分强大,允许在数据上做复杂的分析统计。Elasticsearch 提供的聚合分析功能主要有**指标聚合(metrics aggregations)**、**桶聚合(bucket aggregations)**、**管道聚合(pipeline aggregations)** 和 **矩阵聚合(matrix aggregations)** 四大类,管道聚合和矩阵聚合官方说明是在试验阶段,后期会完全更改或者移除,这里不再对管道聚合和矩阵聚合进行讲解。
|
Elasticsearch 是一个分布式的全文搜索引擎,索引和搜索是 Elasticsearch 的基本功能。事实上,Elasticsearch 的聚合(Aggregations)功能也十分强大,允许在数据上做复杂的分析统计。Elasticsearch 提供的聚合分析功能主要有**指标聚合(metrics aggregations)**、**桶聚合(bucket aggregations)**、**管道聚合(pipeline aggregations)** 和 **矩阵聚合(matrix aggregations)** 四大类,管道聚合和矩阵聚合官方说明是在试验阶段,后期会完全更改或者移除,这里不再对管道聚合和矩阵聚合进行讲解。
|
||||||
|
|
||||||
<!-- TOC depthFrom:2 depthTo:3 -->
|
## 聚合的具体结构
|
||||||
|
|
||||||
- [1. 聚合的具体结构](#1-聚合的具体结构)
|
|
||||||
- [2. 指标聚合](#2-指标聚合)
|
|
||||||
- [2.1. Max Aggregation](#21-max-aggregation)
|
|
||||||
- [2.2. Min Aggregation](#22-min-aggregation)
|
|
||||||
- [2.3. Avg Aggregation](#23-avg-aggregation)
|
|
||||||
- [2.4. Sum Aggregation](#24-sum-aggregation)
|
|
||||||
- [2.5. Value Count Aggregation](#25-value-count-aggregation)
|
|
||||||
- [2.6. Cardinality Aggregation](#26-cardinality-aggregation)
|
|
||||||
- [2.7. Stats Aggregation](#27-stats-aggregation)
|
|
||||||
- [2.8. Extended Stats Aggregation](#28-extended-stats-aggregation)
|
|
||||||
- [2.9. Percentiles Aggregation](#29-percentiles-aggregation)
|
|
||||||
- [2.10. Percentiles Ranks Aggregation](#210-percentiles-ranks-aggregation)
|
|
||||||
- [3. 桶聚合](#3-桶聚合)
|
|
||||||
- [3.1. Terms Aggregation](#31-terms-aggregation)
|
|
||||||
- [3.2. Filter Aggregation](#32-filter-aggregation)
|
|
||||||
- [3.3. Filters Aggregation](#33-filters-aggregation)
|
|
||||||
- [3.4. Range Aggregation](#34-range-aggregation)
|
|
||||||
- [4. 参考资料](#4-参考资料)
|
|
||||||
|
|
||||||
<!-- /TOC -->
|
|
||||||
|
|
||||||
## 1. 聚合的具体结构
|
|
||||||
|
|
||||||
所有的聚合,无论它们是什么类型,都遵从以下的规则。
|
所有的聚合,无论它们是什么类型,都遵从以下的规则。
|
||||||
|
|
||||||
|
|
@ -95,13 +73,13 @@ POST /player/_search?size=0
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
## 2. 指标聚合
|
## 指标聚合
|
||||||
|
|
||||||
指标聚合(又称度量聚合)主要从不同文档的分组中提取统计数据,或者,从来自其他聚合的文档桶来提取统计数据。
|
指标聚合(又称度量聚合)主要从不同文档的分组中提取统计数据,或者,从来自其他聚合的文档桶来提取统计数据。
|
||||||
|
|
||||||
这些统计数据通常来自数值型字段,如最小或者平均价格。用户可以单独获取每项统计数据,或者也可以使用 stats 聚合来同时获取它们。更高级的统计数据,如平方和或者是标准差,可以通过 extended stats 聚合来获取。
|
这些统计数据通常来自数值型字段,如最小或者平均价格。用户可以单独获取每项统计数据,或者也可以使用 stats 聚合来同时获取它们。更高级的统计数据,如平方和或者是标准差,可以通过 extended stats 聚合来获取。
|
||||||
|
|
||||||
### 2.1. Max Aggregation
|
### Max Aggregation
|
||||||
|
|
||||||
Max Aggregation 用于最大值统计。例如,统计 sales 索引中价格最高的是哪本书,并且计算出对应的价格的 2 倍值,查询语句如下:
|
Max Aggregation 用于最大值统计。例如,统计 sales 索引中价格最高的是哪本书,并且计算出对应的价格的 2 倍值,查询语句如下:
|
||||||
|
|
||||||
|
|
@ -144,7 +122,7 @@ GET /sales/_search?size=0
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 2.2. Min Aggregation
|
### Min Aggregation
|
||||||
|
|
||||||
Min Aggregation 用于最小值统计。例如,统计 sales 索引中价格最低的是哪本书,查询语句如下:
|
Min Aggregation 用于最小值统计。例如,统计 sales 索引中价格最低的是哪本书,查询语句如下:
|
||||||
|
|
||||||
|
|
@ -174,7 +152,7 @@ GET /sales/_search?size=0
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 2.3. Avg Aggregation
|
### Avg Aggregation
|
||||||
|
|
||||||
Avg Aggregation 用于计算平均值。例如,统计 exams 索引中考试的平均分数,如未存在分数,默认为 60 分,查询语句如下:
|
Avg Aggregation 用于计算平均值。例如,统计 exams 索引中考试的平均分数,如未存在分数,默认为 60 分,查询语句如下:
|
||||||
|
|
||||||
|
|
@ -209,7 +187,7 @@ GET /exams/_search?size=0
|
||||||
|
|
||||||
除了常规的平均值聚合计算外,elasticsearch 还提供了加权平均值的聚合计算,详情参见 [Elasticsearch 指标聚合之 Weighted Avg Aggregation](https://www.knowledgedict.com/tutorial/elasticsearch-aggregations-metrics-weighted-avg-aggregation.html)。
|
除了常规的平均值聚合计算外,elasticsearch 还提供了加权平均值的聚合计算,详情参见 [Elasticsearch 指标聚合之 Weighted Avg Aggregation](https://www.knowledgedict.com/tutorial/elasticsearch-aggregations-metrics-weighted-avg-aggregation.html)。
|
||||||
|
|
||||||
### 2.4. Sum Aggregation
|
### Sum Aggregation
|
||||||
|
|
||||||
Sum Aggregation 用于计算总和。例如,统计 sales 索引中 type 字段中匹配 hat 的价格总和,查询语句如下:
|
Sum Aggregation 用于计算总和。例如,统计 sales 索引中 type 字段中匹配 hat 的价格总和,查询语句如下:
|
||||||
|
|
||||||
|
|
@ -244,7 +222,7 @@ GET /exams/_search?size=0
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 2.5. Value Count Aggregation
|
### Value Count Aggregation
|
||||||
|
|
||||||
Value Count Aggregation 可按字段统计文档数量。例如,统计 books 索引中包含 author 字段的文档数量,查询语句如下:
|
Value Count Aggregation 可按字段统计文档数量。例如,统计 books 索引中包含 author 字段的文档数量,查询语句如下:
|
||||||
|
|
||||||
|
|
@ -272,7 +250,7 @@ GET /books/_search?size=0
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 2.6. Cardinality Aggregation
|
### Cardinality Aggregation
|
||||||
|
|
||||||
Cardinality Aggregation 用于基数统计,其作用是先执行类似 SQL 中的 distinct 操作,去掉集合中的重复项,然后统计去重后的集合长度。例如,在 books 索引中对 language 字段进行 cardinality 操作可以统计出编程语言的种类数,查询语句如下:
|
Cardinality Aggregation 用于基数统计,其作用是先执行类似 SQL 中的 distinct 操作,去掉集合中的重复项,然后统计去重后的集合长度。例如,在 books 索引中对 language 字段进行 cardinality 操作可以统计出编程语言的种类数,查询语句如下:
|
||||||
|
|
||||||
|
|
@ -308,7 +286,7 @@ GET /books/_search?size=0
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 2.7. Stats Aggregation
|
### Stats Aggregation
|
||||||
|
|
||||||
Stats Aggregation 用于基本统计,会一次返回 count、max、min、avg 和 sum 这 5 个指标。例如,在 exams 索引中对 grade 字段进行分数相关的基本统计,查询语句如下:
|
Stats Aggregation 用于基本统计,会一次返回 count、max、min、avg 和 sum 这 5 个指标。例如,在 exams 索引中对 grade 字段进行分数相关的基本统计,查询语句如下:
|
||||||
|
|
||||||
|
|
@ -340,7 +318,7 @@ GET /exams/_search?size=0
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 2.8. Extended Stats Aggregation
|
### Extended Stats Aggregation
|
||||||
|
|
||||||
Extended Stats Aggregation 用于高级统计,和基本统计功能类似,但是会比基本统计多出以下几个统计结果,sum_of_squares(平方和)、variance(方差)、std_deviation(标准差)、std_deviation_bounds(平均值加/减两个标准差的区间)。在 exams 索引中对 grade 字段进行分数相关的高级统计,查询语句如下:
|
Extended Stats Aggregation 用于高级统计,和基本统计功能类似,但是会比基本统计多出以下几个统计结果,sum_of_squares(平方和)、variance(方差)、std_deviation(标准差)、std_deviation_bounds(平均值加/减两个标准差的区间)。在 exams 索引中对 grade 字段进行分数相关的高级统计,查询语句如下:
|
||||||
|
|
||||||
|
|
@ -379,7 +357,7 @@ GET /exams/_search?size=0
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 2.9. Percentiles Aggregation
|
### Percentiles Aggregation
|
||||||
|
|
||||||
Percentiles Aggregation 用于百分位统计。百分位数是一个统计学术语,如果将一组数据从大到小排序,并计算相应的累计百分位,某一百分位所对应数据的值就称为这一百分位的百分位数。默认情况下,累计百分位为 [ 1, 5, 25, 50, 75, 95, 99 ]。以下例子给出了在 latency 索引中对 load_time 字段进行加载时间的百分位统计,查询语句如下:
|
Percentiles Aggregation 用于百分位统计。百分位数是一个统计学术语,如果将一组数据从大到小排序,并计算相应的累计百分位,某一百分位所对应数据的值就称为这一百分位的百分位数。默认情况下,累计百分位为 [ 1, 5, 25, 50, 75, 95, 99 ]。以下例子给出了在 latency 索引中对 load_time 字段进行加载时间的百分位统计,查询语句如下:
|
||||||
|
|
||||||
|
|
@ -437,7 +415,7 @@ GET latency/_search
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 2.10. Percentiles Ranks Aggregation
|
### Percentiles Ranks Aggregation
|
||||||
|
|
||||||
Percentiles Ranks Aggregation 与 Percentiles Aggregation 统计恰恰相反,就是想看当前数值处在什么范围内(百分位), 假如你查一下当前值 500 和 600 所处的百分位,发现是 90.01 和 100,那么说明有 90.01 % 的数值都在 500 以内,100 % 的数值在 600 以内。
|
Percentiles Ranks Aggregation 与 Percentiles Aggregation 统计恰恰相反,就是想看当前数值处在什么范围内(百分位), 假如你查一下当前值 500 和 600 所处的百分位,发现是 90.01 和 100,那么说明有 90.01 % 的数值都在 500 以内,100 % 的数值在 600 以内。
|
||||||
|
|
||||||
|
|
@ -514,7 +492,7 @@ GET latency/_search
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
## 3. 桶聚合
|
## 桶聚合
|
||||||
|
|
||||||
bucket 可以理解为一个桶,它会遍历文档中的内容,凡是符合某一要求的就放入一个桶中,分桶相当于 SQL 中的 group by。从另外一个角度,可以将指标聚合看成单桶聚合,即把所有文档放到一个桶中,而桶聚合是多桶型聚合,它根据相应的条件进行分组。
|
bucket 可以理解为一个桶,它会遍历文档中的内容,凡是符合某一要求的就放入一个桶中,分桶相当于 SQL 中的 group by。从另外一个角度,可以将指标聚合看成单桶聚合,即把所有文档放到一个桶中,而桶聚合是多桶型聚合,它根据相应的条件进行分组。
|
||||||
|
|
||||||
|
|
@ -532,7 +510,7 @@ bucket 可以理解为一个桶,它会遍历文档中的内容,凡是符合
|
||||||
| 空值聚合(Missing Aggregation) | 空值聚合,可以把文档集中所有缺失字段的文档分到一个桶中。 |
|
| 空值聚合(Missing Aggregation) | 空值聚合,可以把文档集中所有缺失字段的文档分到一个桶中。 |
|
||||||
| 地理点范围聚合(Geo Distance Aggregation) | 用于对地理点(geo point)做范围统计。 |
|
| 地理点范围聚合(Geo Distance Aggregation) | 用于对地理点(geo point)做范围统计。 |
|
||||||
|
|
||||||
### 3.1. Terms Aggregation
|
### Terms Aggregation
|
||||||
|
|
||||||
Terms Aggregation 用于词项的分组聚合。最为经典的用例是获取 X 中最频繁(top frequent)的项目,其中 X 是文档中的某个字段,如用户的名称、标签或分类。由于 terms 聚集统计的是每个词条,而不是整个字段值,因此通常需要在一个非分析型的字段上运行这种聚集。原因是, 你期望“big data”作为词组统计,而不是“big”单独统计一次,“data”再单独统计一次。
|
Terms Aggregation 用于词项的分组聚合。最为经典的用例是获取 X 中最频繁(top frequent)的项目,其中 X 是文档中的某个字段,如用户的名称、标签或分类。由于 terms 聚集统计的是每个词条,而不是整个字段值,因此通常需要在一个非分析型的字段上运行这种聚集。原因是, 你期望“big data”作为词组统计,而不是“big”单独统计一次,“data”再单独统计一次。
|
||||||
|
|
||||||
|
|
@ -622,7 +600,7 @@ Terms Aggregation 用于词项的分组聚合。最为经典的用例是获取 X
|
||||||
|
|
||||||
默认情况下返回按文档计数从高到低的前 10 个分组,可以通过 size 参数指定返回的分组数。
|
默认情况下返回按文档计数从高到低的前 10 个分组,可以通过 size 参数指定返回的分组数。
|
||||||
|
|
||||||
### 3.2. Filter Aggregation
|
### Filter Aggregation
|
||||||
|
|
||||||
Filter Aggregation 是过滤器聚合,可以把符合过滤器中的条件的文档分到一个桶中,即是单分组聚合。
|
Filter Aggregation 是过滤器聚合,可以把符合过滤器中的条件的文档分到一个桶中,即是单分组聚合。
|
||||||
|
|
||||||
|
|
@ -643,7 +621,7 @@ Filter Aggregation 是过滤器聚合,可以把符合过滤器中的条件的
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 3.3. Filters Aggregation
|
### Filters Aggregation
|
||||||
|
|
||||||
Filters Aggregation 是多过滤器聚合,可以把符合多个过滤条件的文档分到不同的桶中,即每个分组关联一个过滤条件,并收集所有满足自身过滤条件的文档。
|
Filters Aggregation 是多过滤器聚合,可以把符合多个过滤条件的文档分到不同的桶中,即每个分组关联一个过滤条件,并收集所有满足自身过滤条件的文档。
|
||||||
|
|
||||||
|
|
@ -683,7 +661,7 @@ Filters Aggregation 是多过滤器聚合,可以把符合多个过滤条件的
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 3.4. Range Aggregation
|
### Range Aggregation
|
||||||
|
|
||||||
Range Aggregation 范围聚合是一个基于多组值来源的聚合,可以让用户定义一系列范围,每个范围代表一个分组。在聚合执行的过程中,从每个文档提取出来的值都会检查每个分组的范围,并且使相关的文档落入分组中。注意,范围聚合的每个范围内包含 from 值但是排除 to 值。
|
Range Aggregation 范围聚合是一个基于多组值来源的聚合,可以让用户定义一系列范围,每个范围代表一个分组。在聚合执行的过程中,从每个文档提取出来的值都会检查每个分组的范围,并且使相关的文档落入分组中。注意,范围聚合的每个范围内包含 from 值但是排除 to 值。
|
||||||
|
|
||||||
|
|
@ -754,6 +732,6 @@ Range Aggregation 范围聚合是一个基于多组值来源的聚合,可以
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
## 4. 参考资料
|
## 参考资料
|
||||||
|
|
||||||
- [Elasticsearch 教程](https://www.knowledgedict.com/tutorial/elasticsearch-intro.html)
|
- [Elasticsearch 教程](https://www.knowledgedict.com/tutorial/elasticsearch-intro.html)
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Elasticsearch 分析器
|
title: Elasticsearch 分析器
|
||||||
date: 2022-02-22 21:01:01
|
date: 2022-02-22 21:01:01
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
|
|
@ -9,43 +10,27 @@ tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
- 分析器
|
- 分词
|
||||||
permalink: /pages/c04143/
|
permalink: /pages/a5a001/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Elasticsearch 分析器
|
# Elasticsearch 分析器
|
||||||
|
|
||||||
在 ES 中,不管是索引任务还是搜索工作,都需要使用 analyzer(分析器)。分析器,分为**内置分析器**和**自定义的分析器**。
|
文本分析是把全文本转换为一系列单词(term/token)的过程,也叫分词。在 Elasticsearch 中,分词是通过 analyzer(分析器)来完成的,不管是索引还是搜索,都需要使用 analyzer(分析器)。分析器,分为**内置分析器**和**自定义的分析器**。
|
||||||
|
|
||||||
分析器进一步由**字符过滤器**(**Character Filters**)、**分词器**(**Tokenizer**)和**词元过滤器**(**Token Filters**)三部分组成。它的执行顺序如下:
|
分析器可以进一步细分为**字符过滤器**(**Character Filters**)、**分词器**(**Tokenizer**)和**词元过滤器**(**Token Filters**)三部分。它的执行顺序如下:
|
||||||
|
|
||||||
**_character filters_** -> **_tokenizer_** -> **_token filters_**
|
**_character filters_** -> **_tokenizer_** -> **_token filters_**
|
||||||
|
|
||||||
<!-- TOC depthFrom:2 depthTo:3 -->
|
## 字符过滤器(Character Filters)
|
||||||
|
|
||||||
- [1. 字符过滤器(Character Filters)](#1-字符过滤器character-filters)
|
character filter 的输入是原始的文本 text,如果配置了多个,它会按照配置的顺序执行,目前 ES 自带的 character filter 主要有如下 3 类:
|
||||||
- [1.1. HTML strip character filter](#11-html-strip-character-filter)
|
|
||||||
- [1.2. Mapping character filter](#12-mapping-character-filter)
|
|
||||||
- [1.3. Pattern Replace character filter](#13-pattern-replace-character-filter)
|
|
||||||
- [2. 分词器(Tokenizer)](#2-分词器tokenizer)
|
|
||||||
- [2.1. elasticsearch-plugin 使用](#21-elasticsearch-plugin-使用)
|
|
||||||
- [2.2. elasticsearch-analysis-ik 安装](#22-elasticsearch-analysis-ik-安装)
|
|
||||||
- [2.3. elasticsearch-analysis-ik 使用](#23-elasticsearch-analysis-ik-使用)
|
|
||||||
- [3. 词元过滤器(Token Filters)](#3-词元过滤器token-filters)
|
|
||||||
- [3.1. 同义词](#31-同义词)
|
|
||||||
- [4. 参考资料](#4-参考资料)
|
|
||||||
|
|
||||||
<!-- /TOC -->
|
1. **html strip character filter**:从文本中剥离 HTML 元素,并用其解码值替换 HTML 实体(如,将 **_`&amp;`_** 替换为 **_`&`_**)。
|
||||||
|
2. **mapping character filter**:自定义一个 map 映射,可以进行一些自定义的替换,如常用的大写变小写也可以在该环节设置。
|
||||||
|
3. **pattern replace character filter**:使用 java 正则表达式来匹配应替换为指定替换字符串的字符,此外,替换字符串可以引用正则表达式中的捕获组。
|
||||||
|
|
||||||
## 1. 字符过滤器(Character Filters)
|
### HTML strip character filter
|
||||||
|
|
||||||
character filter 的输入是原始的文本 text,如果配置了多个,它会按照配置的顺序执行,目前 ES 自带的 character filter 主要由如下 3 类:
|
|
||||||
|
|
||||||
1. html strip character filter:从文本中剥离 HTML 元素,并用其解码值替换 HTML 实体(如,将 **_`&amp;`_** 替换为 **_`&`_**)。
|
|
||||||
2. mapping character filter:自定义一个 map 映射,可以进行一些自定义的替换,如常用的大写变小写也可以在该环节设置。
|
|
||||||
3. pattern replace character filter:使用 java 正则表达式来匹配应替换为指定替换字符串的字符,此外,替换字符串可以引用正则表达式中的捕获组。
|
|
||||||
|
|
||||||
### 1.1. HTML strip character filter
|
|
||||||
|
|
||||||
HTML strip 如下示例:
|
HTML strip 如下示例:
|
||||||
|
|
||||||
|
|
@ -66,7 +51,7 @@ GET /_analyze
|
||||||
[ \nI'm so happy!\n ]
|
[ \nI'm so happy!\n ]
|
||||||
```
|
```
|
||||||
|
|
||||||
### 1.2. Mapping character filter
|
### Mapping character filter
|
||||||
|
|
||||||
Mapping character filter 接收键和值映射(key => value)作为配置参数,每当在预处理过程中遇到与键值映射中的键相同的字符串时,就会使用该键对应的值去替换它。
|
Mapping character filter 接收键和值映射(key => value)作为配置参数,每当在预处理过程中遇到与键值映射中的键相同的字符串时,就会使用该键对应的值去替换它。
|
||||||
|
|
||||||
|
|
@ -112,7 +97,7 @@ GET /_analyze
|
||||||
[ My license plate is 25015 ]
|
[ My license plate is 25015 ]
|
||||||
```
|
```
|
||||||
|
|
||||||
### 1.3. Pattern Replace character filter
|
### Pattern Replace character filter
|
||||||
|
|
||||||
Pattern Replace character filter 支持如下三个参数:
|
Pattern Replace character filter 支持如下三个参数:
|
||||||
|
|
||||||
|
|
@ -135,7 +120,7 @@ Pattern Replace character filter 支持如下三个参数:
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
## 2. 分词器(Tokenizer)
|
## 分词器(Tokenizer)
|
||||||
|
|
||||||
tokenizer 即分词器,也是 analyzer 最重要的组件,它对文本进行分词;**一个 analyzer 必需且只可包含一个 tokenizer**。
|
tokenizer 即分词器,也是 analyzer 最重要的组件,它对文本进行分词;**一个 analyzer 必需且只可包含一个 tokenizer**。
|
||||||
|
|
||||||
|
|
@ -145,7 +130,7 @@ ES 自带默认的分词器是 standard tokenizer,标准分词器提供基于
|
||||||
|
|
||||||
ES 默认提供的分词器 standard 对中文分词不优化,效果差,一般会安装第三方中文分词插件,通常首先 [elasticsearch-analysis-ik](https://github.com/medcl/elasticsearch-analysis-ik) 插件,它其实是 ik 针对的 ES 的定制版。
|
ES 默认提供的分词器 standard 对中文分词不优化,效果差,一般会安装第三方中文分词插件,通常首先 [elasticsearch-analysis-ik](https://github.com/medcl/elasticsearch-analysis-ik) 插件,它其实是 ik 针对的 ES 的定制版。
|
||||||
|
|
||||||
### 2.1. elasticsearch-plugin 使用
|
### elasticsearch-plugin 使用
|
||||||
|
|
||||||
在安装 elasticsearch-analysis-ik 第三方之前,我们首先要了解 es 的插件管理工具 **_`elasticsearch-plugin`_** 的使用。
|
在安装 elasticsearch-analysis-ik 第三方之前,我们首先要了解 es 的插件管理工具 **_`elasticsearch-plugin`_** 的使用。
|
||||||
|
|
||||||
|
|
@ -178,7 +163,7 @@ elasticsearch-plugin remove {plugin_name}
|
||||||
|
|
||||||
> 在安装插件时,要保证安装的插件与 ES 版本一致。
|
> 在安装插件时,要保证安装的插件与 ES 版本一致。
|
||||||
|
|
||||||
### 2.2. elasticsearch-analysis-ik 安装
|
### elasticsearch-analysis-ik 安装
|
||||||
|
|
||||||
在确定要安装的 ik 版本之后,执行如下命令:
|
在确定要安装的 ik 版本之后,执行如下命令:
|
||||||
|
|
||||||
|
|
@ -194,7 +179,7 @@ libexec/plugins/analysis-ik/
|
||||||
libexec/config/analysis-ik/
|
libexec/config/analysis-ik/
|
||||||
```
|
```
|
||||||
|
|
||||||
### 2.3. elasticsearch-analysis-ik 使用
|
### elasticsearch-analysis-ik 使用
|
||||||
|
|
||||||
ES 5.X 版本开始安装完的 elasticsearch-analysis-ik 提供了两个分词器,分别对应名称是 **_ik_max_word_** 和 **_ik_smart_**,ik_max_word 是索引侧的分词器,走全切模式,ik_smart 是搜索侧的分词器,走智能分词,属于搜索模式。
|
ES 5.X 版本开始安装完的 elasticsearch-analysis-ik 提供了两个分词器,分别对应名称是 **_ik_max_word_** 和 **_ik_smart_**,ik_max_word 是索引侧的分词器,走全切模式,ik_smart 是搜索侧的分词器,走智能分词,属于搜索模式。
|
||||||
|
|
||||||
|
|
@ -311,7 +296,7 @@ elasticsearch-analysis-ik 配置文件为 `IKAnalyzer.cfg.xml`,它位于 `libe
|
||||||
|
|
||||||
> 当然,如果开发者认为 ik 默认的词表有问题,也可以进行调整,文件都在 `libexec/config/analysis-ik` 下,如 main.dic 为主词典,stopword.dic 为停用词表。
|
> 当然,如果开发者认为 ik 默认的词表有问题,也可以进行调整,文件都在 `libexec/config/analysis-ik` 下,如 main.dic 为主词典,stopword.dic 为停用词表。
|
||||||
|
|
||||||
## 3. 词元过滤器(Token Filters)
|
## 词元过滤器(Token Filters)
|
||||||
|
|
||||||
token filters 叫词元过滤器,或词项过滤器,对 tokenizer 分出的词进行过滤处理。常用的有转小写、停用词处理、同义词处理等等。**一个 analyzer 可包含 0 个或多个词项过滤器,按配置顺序进行过滤**。
|
token filters 叫词元过滤器,或词项过滤器,对 tokenizer 分出的词进行过滤处理。常用的有转小写、停用词处理、同义词处理等等。**一个 analyzer 可包含 0 个或多个词项过滤器,按配置顺序进行过滤**。
|
||||||
|
|
||||||
|
|
@ -346,7 +331,7 @@ PUT /test_index
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 3.1. 同义词
|
### 同义词
|
||||||
|
|
||||||
Elasticsearch 同义词通过专有的同义词过滤器(synonym token filter)来进行工作,它允许在分析(analysis)过程中方便地处理同义词,一般是通过配置文件配置同义词。此外,同义词可以再建索引时(index-time synonyms)或者检索时(search-time synonyms)使用。
|
Elasticsearch 同义词通过专有的同义词过滤器(synonym token filter)来进行工作,它允许在分析(analysis)过程中方便地处理同义词,一般是通过配置文件配置同义词。此外,同义词可以再建索引时(index-time synonyms)或者检索时(search-time synonyms)使用。
|
||||||
|
|
||||||
|
|
@ -417,6 +402,6 @@ elasticsearch 的同义词有如下两种形式:
|
||||||
|
|
||||||
此时,elasticsearch 中不会将“土豆”和“potato”视为同义词关系,所以多个同义词要写在一起,这往往是开发中经常容易疏忽的点。
|
此时,elasticsearch 中不会将“土豆”和“potato”视为同义词关系,所以多个同义词要写在一起,这往往是开发中经常容易疏忽的点。
|
||||||
|
|
||||||
## 4. 参考资料
|
## 参考资料
|
||||||
|
|
||||||
- [Elasticsearch 教程](https://www.knowledgedict.com/tutorial/elasticsearch-intro.html)
|
- [Elasticsearch 教程](https://www.knowledgedict.com/tutorial/elasticsearch-intro.html)
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Elasticsearch 性能优化
|
title: Elasticsearch 性能优化
|
||||||
date: 2022-01-21 19:54:43
|
date: 2022-01-21 19:54:43
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
|
|
@ -10,18 +11,18 @@ tags:
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
- 性能
|
- 性能
|
||||||
permalink: /pages/dc6b0f/
|
permalink: /pages/2d95ce/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Elasticsearch 性能优化
|
# Elasticsearch 性能优化
|
||||||
|
|
||||||
Elasticsearch 是当前流行的企业级搜索引擎,设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。作为一个开箱即用的产品,在生产环境上线之后,我们其实不一定能确保其的性能和稳定性。如何根据实际情况提高服务的性能,其实有很多技巧。这章我们分享从实战经验中总结出来的 elasticsearch 性能优化,主要从硬件配置优化、索引优化设置、查询方面优化、数据结构优化、集群架构优化等方面讲解。
|
Elasticsearch 是当前流行的企业级搜索引擎,设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。作为一个开箱即用的产品,在生产环境上线之后,我们其实不一定能确保其的性能和稳定性。如何根据实际情况提高服务的性能,其实有很多技巧。这章我们分享从实战经验中总结出来的 elasticsearch 性能优化,主要从硬件配置优化、索引优化设置、查询方面优化、数据结构优化、集群架构优化等方面讲解。
|
||||||
|
|
||||||
## 1. 硬件配置优化
|
## 硬件配置优化
|
||||||
|
|
||||||
升级硬件设备配置一直都是提高服务能力最快速有效的手段,在系统层面能够影响应用性能的一般包括三个因素:CPU、内存和 IO,可以从这三方面进行 ES 的性能优化工作。
|
升级硬件设备配置一直都是提高服务能力最快速有效的手段,在系统层面能够影响应用性能的一般包括三个因素:CPU、内存和 IO,可以从这三方面进行 ES 的性能优化工作。
|
||||||
|
|
||||||
### 1.1. CPU 配置
|
### CPU 配置
|
||||||
|
|
||||||
一般说来,CPU 繁忙的原因有以下几个:
|
一般说来,CPU 繁忙的原因有以下几个:
|
||||||
|
|
||||||
|
|
@ -31,7 +32,7 @@ Elasticsearch 是当前流行的企业级搜索引擎,设计用于云计算中
|
||||||
|
|
||||||
大多数 Elasticsearch 部署往往对 CPU 要求不高。因此,相对其它资源,具体配置多少个(CPU)不是那么关键。你应该选择具有多个内核的现代处理器,常见的集群使用 2 到 8 个核的机器。**如果你要在更快的 CPUs 和更多的核数之间选择,选择更多的核数更好**。多个内核提供的额外并发远胜过稍微快一点点的时钟频率。
|
大多数 Elasticsearch 部署往往对 CPU 要求不高。因此,相对其它资源,具体配置多少个(CPU)不是那么关键。你应该选择具有多个内核的现代处理器,常见的集群使用 2 到 8 个核的机器。**如果你要在更快的 CPUs 和更多的核数之间选择,选择更多的核数更好**。多个内核提供的额外并发远胜过稍微快一点点的时钟频率。
|
||||||
|
|
||||||
### 1.2. 内存配置
|
### 内存配置
|
||||||
|
|
||||||
如果有一种资源是最先被耗尽的,它可能是内存。排序和聚合都很耗内存,所以有足够的堆空间来应付它们是很重要的。即使堆空间是比较小的时候,也能为操作系统文件缓存提供额外的内存。因为 Lucene 使用的许多数据结构是基于磁盘的格式,Elasticsearch 利用操作系统缓存能产生很大效果。
|
如果有一种资源是最先被耗尽的,它可能是内存。排序和聚合都很耗内存,所以有足够的堆空间来应付它们是很重要的。即使堆空间是比较小的时候,也能为操作系统文件缓存提供额外的内存。因为 Lucene 使用的许多数据结构是基于磁盘的格式,Elasticsearch 利用操作系统缓存能产生很大效果。
|
||||||
|
|
||||||
|
|
@ -59,7 +60,7 @@ Elasticsearch 是当前流行的企业级搜索引擎,设计用于云计算中
|
||||||
|
|
||||||
保持线程池的现有设置,目前 ES 的线程池较 1.X 有了较多优化设置,保持现状即可;默认线程池大小等于 CPU 核心数。如果一定要改,按公式 ( ( CPU 核心数 \* 3 ) / 2 ) + 1 设置;不能超过 CPU 核心数的 2 倍;但是不建议修改默认配置,否则会对 CPU 造成硬伤。
|
保持线程池的现有设置,目前 ES 的线程池较 1.X 有了较多优化设置,保持现状即可;默认线程池大小等于 CPU 核心数。如果一定要改,按公式 ( ( CPU 核心数 \* 3 ) / 2 ) + 1 设置;不能超过 CPU 核心数的 2 倍;但是不建议修改默认配置,否则会对 CPU 造成硬伤。
|
||||||
|
|
||||||
### 1.3. 磁盘
|
### 磁盘
|
||||||
|
|
||||||
硬盘对所有的集群都很重要,对大量写入的集群更是加倍重要(例如那些存储日志数据的)。硬盘是服务器上最慢的子系统,这意味着那些写入量很大的集群很容易让硬盘饱和,使得它成为集群的瓶颈。
|
硬盘对所有的集群都很重要,对大量写入的集群更是加倍重要(例如那些存储日志数据的)。硬盘是服务器上最慢的子系统,这意味着那些写入量很大的集群很容易让硬盘饱和,使得它成为集群的瓶颈。
|
||||||
|
|
||||||
|
|
@ -79,11 +80,11 @@ Elasticsearch 是当前流行的企业级搜索引擎,设计用于云计算中
|
||||||
|
|
||||||
**最后,避免使用网络附加存储(NAS)**。人们常声称他们的 NAS 解决方案比本地驱动器更快更可靠。除却这些声称,我们从没看到 NAS 能配得上它的大肆宣传。NAS 常常很慢,显露出更大的延时和更宽的平均延时方差,而且它是单点故障的。
|
**最后,避免使用网络附加存储(NAS)**。人们常声称他们的 NAS 解决方案比本地驱动器更快更可靠。除却这些声称,我们从没看到 NAS 能配得上它的大肆宣传。NAS 常常很慢,显露出更大的延时和更宽的平均延时方差,而且它是单点故障的。
|
||||||
|
|
||||||
## 2. 索引优化设置
|
## 索引优化设置
|
||||||
|
|
||||||
索引优化主要是在 Elasticsearch 的插入层面优化,Elasticsearch 本身索引速度其实还是蛮快的,具体数据,我们可以参考官方的 benchmark 数据。我们可以根据不同的需求,针对索引优化。
|
索引优化主要是在 Elasticsearch 的插入层面优化,Elasticsearch 本身索引速度其实还是蛮快的,具体数据,我们可以参考官方的 benchmark 数据。我们可以根据不同的需求,针对索引优化。
|
||||||
|
|
||||||
### 2.1. 批量提交
|
### 批量提交
|
||||||
|
|
||||||
当有大量数据提交的时候,建议采用批量提交(Bulk 操作);此外使用 bulk 请求时,每个请求不超过几十 M,因为太大会导致内存使用过大。
|
当有大量数据提交的时候,建议采用批量提交(Bulk 操作);此外使用 bulk 请求时,每个请求不超过几十 M,因为太大会导致内存使用过大。
|
||||||
|
|
||||||
|
|
@ -93,7 +94,7 @@ Elasticsearch 是当前流行的企业级搜索引擎,设计用于云计算中
|
||||||
|
|
||||||
如果在提交过程中,遇到 EsRejectedExecutionException 异常的话,则说明集群的索引性能已经达到极限了。这种情况,要么提高服务器集群的资源,要么根据业务规则,减少数据收集速度,比如只收集 Warn、Error 级别以上的日志。
|
如果在提交过程中,遇到 EsRejectedExecutionException 异常的话,则说明集群的索引性能已经达到极限了。这种情况,要么提高服务器集群的资源,要么根据业务规则,减少数据收集速度,比如只收集 Warn、Error 级别以上的日志。
|
||||||
|
|
||||||
### 2.2. 增加 Refresh 时间间隔
|
### 增加 Refresh 时间间隔
|
||||||
|
|
||||||
为了提高索引性能,Elasticsearch 在写入数据的时候,采用延迟写入的策略,即数据先写到内存中,当超过默认 1 秒(index.refresh_interval)会进行一次写入操作,就是将内存中 segment 数据刷新到磁盘中,此时我们才能将数据搜索出来,所以这就是为什么 Elasticsearch 提供的是近实时搜索功能,而不是实时搜索功能。
|
为了提高索引性能,Elasticsearch 在写入数据的时候,采用延迟写入的策略,即数据先写到内存中,当超过默认 1 秒(index.refresh_interval)会进行一次写入操作,就是将内存中 segment 数据刷新到磁盘中,此时我们才能将数据搜索出来,所以这就是为什么 Elasticsearch 提供的是近实时搜索功能,而不是实时搜索功能。
|
||||||
|
|
||||||
|
|
@ -101,7 +102,7 @@ Elasticsearch 是当前流行的企业级搜索引擎,设计用于云计算中
|
||||||
|
|
||||||
> 在加载大量数据时候可以暂时不用 refresh 和 repliccas,index.refresh_interval 设置为-1,index.number_of_replicas 设置为 0。
|
> 在加载大量数据时候可以暂时不用 refresh 和 repliccas,index.refresh_interval 设置为-1,index.number_of_replicas 设置为 0。
|
||||||
|
|
||||||
### 2.3. 修改 index_buffer_size 的设置
|
### 修改 index_buffer_size 的设置
|
||||||
|
|
||||||
索引缓冲的设置可以控制多少内存分配给索引进程。这是一个全局配置,会应用于一个节点上所有不同的分片上。
|
索引缓冲的设置可以控制多少内存分配给索引进程。这是一个全局配置,会应用于一个节点上所有不同的分片上。
|
||||||
|
|
||||||
|
|
@ -112,7 +113,7 @@ indices.memory.min_index_buffer_size: 48mb
|
||||||
|
|
||||||
`indices.memory.index_buffer_size` 接受一个百分比或者一个表示字节大小的值。默认是 10%,意味着分配给节点的总内存的 10%用来做索引缓冲的大小。这个数值被分到不同的分片(shards)上。如果设置的是百分比,还可以设置 `min_index_buffer_size` (默认 48mb)和 `max_index_buffer_size`(默认没有上限)。
|
`indices.memory.index_buffer_size` 接受一个百分比或者一个表示字节大小的值。默认是 10%,意味着分配给节点的总内存的 10%用来做索引缓冲的大小。这个数值被分到不同的分片(shards)上。如果设置的是百分比,还可以设置 `min_index_buffer_size` (默认 48mb)和 `max_index_buffer_size`(默认没有上限)。
|
||||||
|
|
||||||
### 2.4. 修改 translog 相关的设置
|
### 修改 translog 相关的设置
|
||||||
|
|
||||||
一是控制数据从内存到硬盘的操作频率,以减少硬盘 IO。可将 sync_interval 的时间设置大一些。默认为 5s。
|
一是控制数据从内存到硬盘的操作频率,以减少硬盘 IO。可将 sync_interval 的时间设置大一些。默认为 5s。
|
||||||
|
|
||||||
|
|
@ -126,29 +127,29 @@ index.translog.sync_interval: 5s
|
||||||
index.translog.flush_threshold_size: 512mb
|
index.translog.flush_threshold_size: 512mb
|
||||||
```
|
```
|
||||||
|
|
||||||
### 2.5. 注意 \_id 字段的使用
|
### 注意 \_id 字段的使用
|
||||||
|
|
||||||
\_id 字段的使用,应尽可能避免自定义 \_id,以避免针对 ID 的版本管理;建议使用 ES 的默认 ID 生成策略或使用数字类型 ID 做为主键。
|
\_id 字段的使用,应尽可能避免自定义 \_id,以避免针对 ID 的版本管理;建议使用 ES 的默认 ID 生成策略或使用数字类型 ID 做为主键。
|
||||||
|
|
||||||
### 2.6. 注意 \_all 字段及 \_source 字段的使用
|
### 注意 \_all 字段及 \_source 字段的使用
|
||||||
|
|
||||||
**\_**all 字段及 \_source 字段的使用,应该注意场景和需要,\_all 字段包含了所有的索引字段,方便做全文检索,如果无此需求,可以禁用;\_source 存储了原始的 document 内容,如果没有获取原始文档数据的需求,可通过设置 includes、excludes 属性来定义放入 \_source 的字段。
|
**\_**all 字段及 \_source 字段的使用,应该注意场景和需要,\_all 字段包含了所有的索引字段,方便做全文检索,如果无此需求,可以禁用;\_source 存储了原始的 document 内容,如果没有获取原始文档数据的需求,可通过设置 includes、excludes 属性来定义放入 \_source 的字段。
|
||||||
|
|
||||||
### 2.7. 合理的配置使用 index 属性
|
### 合理的配置使用 index 属性
|
||||||
|
|
||||||
合理的配置使用 index 属性,analyzed 和 not_analyzed,根据业务需求来控制字段是否分词或不分词。只有 groupby 需求的字段,配置时就设置成 not_analyzed,以提高查询或聚类的效率。
|
合理的配置使用 index 属性,analyzed 和 not_analyzed,根据业务需求来控制字段是否分词或不分词。只有 groupby 需求的字段,配置时就设置成 not_analyzed,以提高查询或聚类的效率。
|
||||||
|
|
||||||
### 2.8. 减少副本数量
|
### 减少副本数量
|
||||||
|
|
||||||
Elasticsearch 默认副本数量为 3 个,虽然这样会提高集群的可用性,增加搜索的并发数,但是同时也会影响写入索引的效率。
|
Elasticsearch 默认副本数量为 3 个,虽然这样会提高集群的可用性,增加搜索的并发数,但是同时也会影响写入索引的效率。
|
||||||
|
|
||||||
在索引过程中,需要把更新的文档发到副本节点上,等副本节点生效后在进行返回结束。使用 Elasticsearch 做业务搜索的时候,建议副本数目还是设置为 3 个,但是像内部 ELK 日志系统、分布式跟踪系统中,完全可以将副本数目设置为 1 个。
|
在索引过程中,需要把更新的文档发到副本节点上,等副本节点生效后在进行返回结束。使用 Elasticsearch 做业务搜索的时候,建议副本数目还是设置为 3 个,但是像内部 ELK 日志系统、分布式跟踪系统中,完全可以将副本数目设置为 1 个。
|
||||||
|
|
||||||
## 3. 查询方面优化
|
## 查询方面优化
|
||||||
|
|
||||||
Elasticsearch 作为业务搜索的近实时查询时,查询效率的优化显得尤为重要。
|
Elasticsearch 作为业务搜索的近实时查询时,查询效率的优化显得尤为重要。
|
||||||
|
|
||||||
### 3.1. 路由优化
|
### 路由优化
|
||||||
|
|
||||||
当我们查询文档的时候,Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?它其实是通过下面这个公式来计算出来的。
|
当我们查询文档的时候,Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?它其实是通过下面这个公式来计算出来的。
|
||||||
|
|
||||||
|
|
@ -171,7 +172,7 @@ routing 默认值是文档的 id,也可以采用自定义值,比如用户 ID
|
||||||
|
|
||||||
向上面自定义的用户查询,如果 routing 设置为 userid 的话,就可以直接查询出数据来,效率提升很多。
|
向上面自定义的用户查询,如果 routing 设置为 userid 的话,就可以直接查询出数据来,效率提升很多。
|
||||||
|
|
||||||
### 3.2. Filter VS Query
|
### Filter VS Query
|
||||||
|
|
||||||
尽可能使用过滤器上下文(Filter)替代查询上下文(Query)
|
尽可能使用过滤器上下文(Filter)替代查询上下文(Query)
|
||||||
|
|
||||||
|
|
@ -180,7 +181,7 @@ routing 默认值是文档的 id,也可以采用自定义值,比如用户 ID
|
||||||
|
|
||||||
Elasticsearch 针对 Filter 查询只需要回答「是」或者「否」,不需要像 Query 查询一样计算相关性分数,同时 Filter 结果可以缓存。
|
Elasticsearch 针对 Filter 查询只需要回答「是」或者「否」,不需要像 Query 查询一样计算相关性分数,同时 Filter 结果可以缓存。
|
||||||
|
|
||||||
### 3.3. 深度翻页
|
### 深度翻页
|
||||||
|
|
||||||
在使用 Elasticsearch 过程中,应尽量避免大翻页的出现。
|
在使用 Elasticsearch 过程中,应尽量避免大翻页的出现。
|
||||||
|
|
||||||
|
|
@ -190,15 +191,15 @@ Elasticsearch 针对 Filter 查询只需要回答「是」或者「否」,不
|
||||||
|
|
||||||
也可以结合实际业务特点,文档 id 大小如果和文档创建时间是一致有序的,可以以文档 id 作为分页的偏移量,并将其作为分页查询的一个条件。
|
也可以结合实际业务特点,文档 id 大小如果和文档创建时间是一致有序的,可以以文档 id 作为分页的偏移量,并将其作为分页查询的一个条件。
|
||||||
|
|
||||||
### 3.4. 脚本(script)合理使用
|
### 脚本(script)合理使用
|
||||||
|
|
||||||
我们知道脚本使用主要有 3 种形式,内联动态编译方式、\_script 索引库中存储和文件脚本存储的形式;一般脚本的使用场景是粗排,尽量用第二种方式先将脚本存储在 \_script 索引库中,起到提前编译,然后通过引用脚本 id,并结合 params 参数使用,即可以达到模型(逻辑)和数据进行了分离,同时又便于脚本模块的扩展与维护。具体 ES 脚本的深入内容请参考 [Elasticsearch 脚本模块的详解](https://www.knowledgedict.com/tutorial/elasticsearch-script.html)。
|
我们知道脚本使用主要有 3 种形式,内联动态编译方式、\_script 索引库中存储和文件脚本存储的形式;一般脚本的使用场景是粗排,尽量用第二种方式先将脚本存储在 \_script 索引库中,起到提前编译,然后通过引用脚本 id,并结合 params 参数使用,即可以达到模型(逻辑)和数据进行了分离,同时又便于脚本模块的扩展与维护。具体 ES 脚本的深入内容请参考 [Elasticsearch 脚本模块的详解](https://www.knowledgedict.com/tutorial/elasticsearch-script.html)。
|
||||||
|
|
||||||
## 4. 数据结构优化
|
## 数据结构优化
|
||||||
|
|
||||||
基于 Elasticsearch 的使用场景,文档数据结构尽量和使用场景进行结合,去掉没用及不合理的数据。
|
基于 Elasticsearch 的使用场景,文档数据结构尽量和使用场景进行结合,去掉没用及不合理的数据。
|
||||||
|
|
||||||
### 4.1. 尽量减少不需要的字段
|
### 尽量减少不需要的字段
|
||||||
|
|
||||||
如果 Elasticsearch 用于业务搜索服务,一些不需要用于搜索的字段最好不存到 ES 中,这样即节省空间,同时在相同的数据量下,也能提高搜索性能。
|
如果 Elasticsearch 用于业务搜索服务,一些不需要用于搜索的字段最好不存到 ES 中,这样即节省空间,同时在相同的数据量下,也能提高搜索性能。
|
||||||
|
|
||||||
|
|
@ -212,7 +213,7 @@ index.mapping.total_fields.limit: 1000
|
||||||
index.mapping.depth.limit: 20
|
index.mapping.depth.limit: 20
|
||||||
```
|
```
|
||||||
|
|
||||||
### 4.2. Nested Object vs Parent/Child
|
### Nested Object vs Parent/Child
|
||||||
|
|
||||||
尽量避免使用 nested 或 parent/child 的字段,能不用就不用;nested query 慢,parent/child query 更慢,比 nested query 慢上百倍;因此能在 mapping 设计阶段搞定的(大宽表设计或采用比较 smart 的数据结构),就不要用父子关系的 mapping。
|
尽量避免使用 nested 或 parent/child 的字段,能不用就不用;nested query 慢,parent/child query 更慢,比 nested query 慢上百倍;因此能在 mapping 设计阶段搞定的(大宽表设计或采用比较 smart 的数据结构),就不要用父子关系的 mapping。
|
||||||
|
|
||||||
|
|
@ -228,17 +229,17 @@ index.mapping.nested_fields.limit: 50
|
||||||
| 缺点 | 更新父文档或子文档时需要更新整个文档 | 为了维护 join 关系,需要占用部分内存,读取性能较差 |
|
| 缺点 | 更新父文档或子文档时需要更新整个文档 | 为了维护 join 关系,需要占用部分内存,读取性能较差 |
|
||||||
| 场景 | 子文档偶尔更新,查询频繁 | 子文档更新频繁 |
|
| 场景 | 子文档偶尔更新,查询频繁 | 子文档更新频繁 |
|
||||||
|
|
||||||
### 4.3. 选择静态映射,非必需时,禁止动态映射
|
### 选择静态映射,非必需时,禁止动态映射
|
||||||
|
|
||||||
尽量避免使用动态映射,这样有可能会导致集群崩溃,此外,动态映射有可能会带来不可控制的数据类型,进而有可能导致在查询端出现相关异常,影响业务。
|
尽量避免使用动态映射,这样有可能会导致集群崩溃,此外,动态映射有可能会带来不可控制的数据类型,进而有可能导致在查询端出现相关异常,影响业务。
|
||||||
|
|
||||||
此外,Elasticsearch 作为搜索引擎时,主要承载 query 的匹配和排序的功能,那数据的存储类型基于这两种功能的用途分为两类,一是需要匹配的字段,用来建立倒排索引对 query 匹配用,另一类字段是用做粗排用到的特征字段,如 ctr、点击数、评论数等等。
|
此外,Elasticsearch 作为搜索引擎时,主要承载 query 的匹配和排序的功能,那数据的存储类型基于这两种功能的用途分为两类,一是需要匹配的字段,用来建立倒排索引对 query 匹配用,另一类字段是用做粗排用到的特征字段,如 ctr、点击数、评论数等等。
|
||||||
|
|
||||||
## 5. 集群架构设计
|
## 集群架构设计
|
||||||
|
|
||||||
合理的部署 Elasticsearch 有助于提高服务的整体可用性。
|
合理的部署 Elasticsearch 有助于提高服务的整体可用性。
|
||||||
|
|
||||||
### 5.1. 主节点、数据节点和协调节点分离
|
### 主节点、数据节点和协调节点分离
|
||||||
|
|
||||||
Elasticsearch 集群在架构拓朴时,采用主节点、数据节点和负载均衡节点分离的架构,在 5.x 版本以后,又可将数据节点再细分为“Hot-Warm”的架构模式。
|
Elasticsearch 集群在架构拓朴时,采用主节点、数据节点和负载均衡节点分离的架构,在 5.x 版本以后,又可将数据节点再细分为“Hot-Warm”的架构模式。
|
||||||
|
|
||||||
|
|
@ -288,23 +289,23 @@ node.attr.box_type: warm
|
||||||
- node.master:true 和 node.data:false,该 node 服务器只作为一个主节点,但不存储任何索引数据,该 node 服务器将使用自身空闲的资源,来协调各种创建索引请求或者查询请求,并将这些请求合理分发到相关的 node 服务器上。
|
- node.master:true 和 node.data:false,该 node 服务器只作为一个主节点,但不存储任何索引数据,该 node 服务器将使用自身空闲的资源,来协调各种创建索引请求或者查询请求,并将这些请求合理分发到相关的 node 服务器上。
|
||||||
- node.master:false 和 node.data:false,该 node 服务器即不会被选作主节点,也不会存储任何索引数据。该服务器主要用于查询负载均衡。在查询的时候,通常会涉及到从多个 node 服务器上查询数据,并将请求分发到多个指定的 node 服务器,并对各个 node 服务器返回的结果进行一个汇总处理,最终返回给客户端。
|
- node.master:false 和 node.data:false,该 node 服务器即不会被选作主节点,也不会存储任何索引数据。该服务器主要用于查询负载均衡。在查询的时候,通常会涉及到从多个 node 服务器上查询数据,并将请求分发到多个指定的 node 服务器,并对各个 node 服务器返回的结果进行一个汇总处理,最终返回给客户端。
|
||||||
|
|
||||||
### 5.2. 关闭 data 节点服务器中的 http 功能
|
### 关闭 data 节点服务器中的 http 功能
|
||||||
|
|
||||||
针对 Elasticsearch 集群中的所有数据节点,不用开启 http 服务。将其中的配置参数这样设置,`http.enabled:false`,同时也不要安装 head, bigdesk, marvel 等监控插件,这样保证 data 节点服务器只需处理创建/更新/删除/查询索引数据等操作。
|
针对 Elasticsearch 集群中的所有数据节点,不用开启 http 服务。将其中的配置参数这样设置,`http.enabled:false`,同时也不要安装 head, bigdesk, marvel 等监控插件,这样保证 data 节点服务器只需处理创建/更新/删除/查询索引数据等操作。
|
||||||
|
|
||||||
http 功能可以在非数据节点服务器上开启,上述相关的监控插件也安装到这些服务器上,用于监控 Elasticsearch 集群状态等数据信息。这样做一来出于数据安全考虑,二来出于服务性能考虑。
|
http 功能可以在非数据节点服务器上开启,上述相关的监控插件也安装到这些服务器上,用于监控 Elasticsearch 集群状态等数据信息。这样做一来出于数据安全考虑,二来出于服务性能考虑。
|
||||||
|
|
||||||
### 5.3. 一台服务器上最好只部署一个 node
|
### 一台服务器上最好只部署一个 node
|
||||||
|
|
||||||
一台物理服务器上可以启动多个 node 服务器节点(通过设置不同的启动 port),但一台服务器上的 CPU、内存、硬盘等资源毕竟有限,从服务器性能考虑,不建议一台服务器上启动多个 node 节点。
|
一台物理服务器上可以启动多个 node 服务器节点(通过设置不同的启动 port),但一台服务器上的 CPU、内存、硬盘等资源毕竟有限,从服务器性能考虑,不建议一台服务器上启动多个 node 节点。
|
||||||
|
|
||||||
### 5.4. 集群分片设置
|
### 集群分片设置
|
||||||
|
|
||||||
ES 一旦创建好索引后,就无法调整分片的设置,而在 ES 中,一个分片实际上对应一个 lucene 索引,而 lucene 索引的读写会占用很多的系统资源,因此,分片数不能设置过大;所以,在创建索引时,合理配置分片数是非常重要的。一般来说,我们遵循一些原则:
|
ES 一旦创建好索引后,就无法调整分片的设置,而在 ES 中,一个分片实际上对应一个 lucene 索引,而 lucene 索引的读写会占用很多的系统资源,因此,分片数不能设置过大;所以,在创建索引时,合理配置分片数是非常重要的。一般来说,我们遵循一些原则:
|
||||||
|
|
||||||
1. 控制每个分片占用的硬盘容量不超过 ES 的最大 JVM 的堆空间设置(一般设置不超过 32 G,参考上面的 JVM 内存设置原则),因此,如果索引的总容量在 500 G 左右,那分片大小在 16 个左右即可;当然,最好同时考虑原则 2。
|
1. 控制每个分片占用的硬盘容量不超过 ES 的最大 JVM 的堆空间设置(一般设置不超过 32 G,参考上面的 JVM 内存设置原则),因此,如果索引的总容量在 500 G 左右,那分片大小在 16 个左右即可;当然,最好同时考虑原则 2。
|
||||||
2. 考虑一下 node 数量,一般一个节点有时候就是一台物理机,如果分片数过多,大大超过了节点数,很可能会导致一个节点上存在多个分片,一旦该节点故障,即使保持了 1 个以上的副本,同样有可能会导致数据丢失,集群无法恢复。所以,**一般都设置分片数不超过节点数的 3 倍**。
|
2. 考虑一下 node 数量,一般一个节点有时候就是一台物理机,如果分片数过多,大大超过了节点数,很可能会导致一个节点上存在多个分片,一旦该节点故障,即使保持了 1 个以上的副本,同样有可能会导致数据丢失,集群无法恢复。所以,**一般都设置分片数不超过节点数的 3 倍**。
|
||||||
|
|
||||||
## 6. 参考资料
|
## 参考资料
|
||||||
|
|
||||||
- [Elasticsearch 教程](https://www.knowledgedict.com/tutorial/elasticsearch-intro.html)
|
- [Elasticsearch 教程](https://www.knowledgedict.com/tutorial/elasticsearch-intro.html)
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Elasticsearch Rest API
|
title: Elasticsearch Rest API
|
||||||
date: 2020-06-16 07:10:44
|
date: 2020-06-16 07:10:44
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
- API
|
- API
|
||||||
permalink: /pages/1edd27/
|
permalink: /pages/4b1907/
|
||||||
---
|
---
|
||||||
|
|
||||||
# ElasticSearch Rest API
|
# ElasticSearch Rest API
|
||||||
|
|
@ -23,7 +24,7 @@ permalink: /pages/1edd27/
|
||||||
>
|
>
|
||||||
> REST API 最详尽的文档应该参考:[ES 官方 REST API](https://www.elastic.co/guide/en/elasticsearch/reference/current/rest-apis.html)
|
> REST API 最详尽的文档应该参考:[ES 官方 REST API](https://www.elastic.co/guide/en/elasticsearch/reference/current/rest-apis.html)
|
||||||
|
|
||||||
## 1. ElasticSearch Rest API 语法格式
|
## ElasticSearch Rest API 语法格式
|
||||||
|
|
||||||
向 Elasticsearch 发出的请求的组成部分与其它普通的 HTTP 请求是一样的:
|
向 Elasticsearch 发出的请求的组成部分与其它普通的 HTTP 请求是一样的:
|
||||||
|
|
||||||
|
|
@ -39,11 +40,24 @@ curl -X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>'
|
||||||
- `QUERY_STRING`:一些可选的查询请求参数,例如?pretty 参数将使请求返回更加美观易读的 JSON 数据
|
- `QUERY_STRING`:一些可选的查询请求参数,例如?pretty 参数将使请求返回更加美观易读的 JSON 数据
|
||||||
- `BODY`:一个 JSON 格式的请求主体(如果请求需要的话)
|
- `BODY`:一个 JSON 格式的请求主体(如果请求需要的话)
|
||||||
|
|
||||||
## 2. 索引 API
|
ElasticSearch Rest API 分为两种:
|
||||||
|
|
||||||
|
- **URI Search**:在 URL 中使用查询参数
|
||||||
|
- **Request Body Search**:基于 JSON 格式的、更加完备的 DSL
|
||||||
|
|
||||||
|
URI Search 示例:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Request Body Search 示例:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## 索引 API
|
||||||
|
|
||||||
> 参考资料:[Elasticsearch 官方之 cat 索引 API](https://www.elastic.co/guide/en/elasticsearch/reference/current/cat-indices.html)
|
> 参考资料:[Elasticsearch 官方之 cat 索引 API](https://www.elastic.co/guide/en/elasticsearch/reference/current/cat-indices.html)
|
||||||
|
|
||||||
### 2.1. 创建索引
|
### 创建索引
|
||||||
|
|
||||||
新建 Index,可以直接向 ES 服务器发出 `PUT` 请求。
|
新建 Index,可以直接向 ES 服务器发出 `PUT` 请求。
|
||||||
|
|
||||||
|
|
@ -87,7 +101,7 @@ PUT /user
|
||||||
action.auto_create_index: false
|
action.auto_create_index: false
|
||||||
```
|
```
|
||||||
|
|
||||||
### 2.2. 删除索引
|
### 删除索引
|
||||||
|
|
||||||
然后,我们可以通过发送 `DELETE` 请求,删除这个 Index。
|
然后,我们可以通过发送 `DELETE` 请求,删除这个 Index。
|
||||||
|
|
||||||
|
|
@ -102,7 +116,7 @@ DELETE /index_one,index_two
|
||||||
DELETE /index_*
|
DELETE /index_*
|
||||||
```
|
```
|
||||||
|
|
||||||
### 2.3. 查看索引
|
### 查看索引
|
||||||
|
|
||||||
可以通过 GET 请求查看索引信息
|
可以通过 GET 请求查看索引信息
|
||||||
|
|
||||||
|
|
@ -133,7 +147,7 @@ GET /_cat/indices/kibana*?pri&v&h=health,index,pri,rep,docs.count,mt
|
||||||
GET /_cat/indices?v&h=i,tm&s=tm:desc
|
GET /_cat/indices?v&h=i,tm&s=tm:desc
|
||||||
```
|
```
|
||||||
|
|
||||||
### 2.4. 索引别名
|
### 索引别名
|
||||||
|
|
||||||
ES 的索引别名就是给一个索引或者多个索引起的另一个名字,典型的应用场景是针对索引使用的平滑切换。
|
ES 的索引别名就是给一个索引或者多个索引起的另一个名字,典型的应用场景是针对索引使用的平滑切换。
|
||||||
|
|
||||||
|
|
@ -171,7 +185,7 @@ POST /_aliases
|
||||||
|
|
||||||
ES 索引别名有个典型的应用场景是平滑切换,更多细节可以查看 [Elasticsearch(ES)索引零停机(无需重启)无缝平滑切换的方法](https://www.knowledgedict.com/tutorial/elasticsearch-index-smooth-shift.html)。
|
ES 索引别名有个典型的应用场景是平滑切换,更多细节可以查看 [Elasticsearch(ES)索引零停机(无需重启)无缝平滑切换的方法](https://www.knowledgedict.com/tutorial/elasticsearch-index-smooth-shift.html)。
|
||||||
|
|
||||||
### 2.5. 打开/关闭索引
|
### 打开/关闭索引
|
||||||
|
|
||||||
通过在 `POST` 中添加 `_close` 或 `_open` 可以打开、关闭索引。
|
通过在 `POST` 中添加 `_close` 或 `_open` 可以打开、关闭索引。
|
||||||
|
|
||||||
|
|
@ -184,7 +198,7 @@ POST kibana_sample_data_ecommerce/_open
|
||||||
POST kibana_sample_data_ecommerce/_close
|
POST kibana_sample_data_ecommerce/_close
|
||||||
```
|
```
|
||||||
|
|
||||||
## 3. 文档
|
## 文档
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
############Create Document############
|
############Create Document############
|
||||||
|
|
@ -340,7 +354,7 @@ DELETE test
|
||||||
DELETE test2
|
DELETE test2
|
||||||
```
|
```
|
||||||
|
|
||||||
### 3.1. 创建文档
|
### 创建文档
|
||||||
|
|
||||||
#### 指定 ID
|
#### 指定 ID
|
||||||
|
|
||||||
|
|
@ -384,7 +398,7 @@ POST /user/_doc
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 3.2. 删除文档
|
### 删除文档
|
||||||
|
|
||||||
语法格式:
|
语法格式:
|
||||||
|
|
||||||
|
|
@ -398,7 +412,7 @@ DELETE /_index/_doc/_id
|
||||||
DELETE /user/_doc/1
|
DELETE /user/_doc/1
|
||||||
```
|
```
|
||||||
|
|
||||||
### 3.3. 更新文档
|
### 更新文档
|
||||||
|
|
||||||
#### 先删除,再写入
|
#### 先删除,再写入
|
||||||
|
|
||||||
|
|
@ -438,7 +452,7 @@ POST /user/_update/1
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 3.4. 查询文档
|
### 查询文档
|
||||||
|
|
||||||
#### 指定 ID 查询
|
#### 指定 ID 查询
|
||||||
|
|
||||||
|
|
@ -531,7 +545,7 @@ $ curl 'localhost:9200/user/admin/_search?pretty'
|
||||||
|
|
||||||
返回的记录中,每条记录都有一个`_score`字段,表示匹配的程序,默认是按照这个字段降序排列。
|
返回的记录中,每条记录都有一个`_score`字段,表示匹配的程序,默认是按照这个字段降序排列。
|
||||||
|
|
||||||
### 3.5. 全文搜索
|
### 全文搜索
|
||||||
|
|
||||||
ES 的查询非常特别,使用自己的[查询语法](https://www.elastic.co/guide/en/elasticsearch/reference/5.5/query-dsl.html),要求 GET 请求带有数据体。
|
ES 的查询非常特别,使用自己的[查询语法](https://www.elastic.co/guide/en/elasticsearch/reference/5.5/query-dsl.html),要求 GET 请求带有数据体。
|
||||||
|
|
||||||
|
|
@ -598,7 +612,7 @@ $ curl 'localhost:9200/user/admin/_search' -d '
|
||||||
|
|
||||||
上面代码指定,从位置 1 开始(默认是从位置 0 开始),只返回一条结果。
|
上面代码指定,从位置 1 开始(默认是从位置 0 开始),只返回一条结果。
|
||||||
|
|
||||||
### 3.6. 逻辑运算
|
### 逻辑运算
|
||||||
|
|
||||||
如果有多个搜索关键字, Elastic 认为它们是`or`关系。
|
如果有多个搜索关键字, Elastic 认为它们是`or`关系。
|
||||||
|
|
||||||
|
|
@ -627,7 +641,7 @@ $ curl -H 'Content-Type: application/json' 'localhost:9200/user/admin/_search?pr
|
||||||
}'
|
}'
|
||||||
```
|
```
|
||||||
|
|
||||||
### 3.7. 批量执行
|
### 批量执行
|
||||||
|
|
||||||
支持在一次 API 调用中,对不同的索引进行操作
|
支持在一次 API 调用中,对不同的索引进行操作
|
||||||
|
|
||||||
|
|
@ -655,7 +669,7 @@ POST _bulk
|
||||||
|
|
||||||
> 说明:上面的示例如果执行多次,执行结果都不一样。
|
> 说明:上面的示例如果执行多次,执行结果都不一样。
|
||||||
|
|
||||||
### 3.8. 批量读取
|
### 批量读取
|
||||||
|
|
||||||
读多个索引
|
读多个索引
|
||||||
|
|
||||||
|
|
@ -717,7 +731,7 @@ GET /_mget
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 3.9. 批量查询
|
### 批量查询
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
POST kibana_sample_data_ecommerce/_msearch
|
POST kibana_sample_data_ecommerce/_msearch
|
||||||
|
|
@ -727,7 +741,7 @@ POST kibana_sample_data_ecommerce/_msearch
|
||||||
{"query" : {"match_all" : {}},"size":2}
|
{"query" : {"match_all" : {}},"size":2}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 3.10. URI Search 查询语义
|
### URI Search 查询语义
|
||||||
|
|
||||||
Elasticsearch URI Search 遵循 QueryString 查询语义,其形式如下:
|
Elasticsearch URI Search 遵循 QueryString 查询语义,其形式如下:
|
||||||
|
|
||||||
|
|
@ -876,7 +890,7 @@ GET /movies/_search?q=title:"Lord Rings"~2
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 3.11. Request Body & DSL
|
### Request Body & DSL
|
||||||
|
|
||||||
Elasticsearch 除了 URI Search 查询方式,还支持将查询语句通过 Http Request Body 发起查询。
|
Elasticsearch 除了 URI Search 查询方式,还支持将查询语句通过 Http Request Body 发起查询。
|
||||||
|
|
||||||
|
|
@ -1016,7 +1030,7 @@ POST movies/_search
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
## 4. 集群 API
|
## 集群 API
|
||||||
|
|
||||||
> [Elasticsearch 官方之 Cluster API](https://www.elastic.co/guide/en/elasticsearch/reference/current/cluster.html)
|
> [Elasticsearch 官方之 Cluster API](https://www.elastic.co/guide/en/elasticsearch/reference/current/cluster.html)
|
||||||
|
|
||||||
|
|
@ -1060,7 +1074,7 @@ GET /_nodes/ra*:2
|
||||||
GET /_nodes/ra*:2*
|
GET /_nodes/ra*:2*
|
||||||
```
|
```
|
||||||
|
|
||||||
### 4.1. 集群健康 API
|
### 集群健康 API
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
GET /_cluster/health
|
GET /_cluster/health
|
||||||
|
|
@ -1069,7 +1083,7 @@ GET /_cluster/health/kibana_sample_data_ecommerce,kibana_sample_data_flights
|
||||||
GET /_cluster/health/kibana_sample_data_flights?level=shards
|
GET /_cluster/health/kibana_sample_data_flights?level=shards
|
||||||
```
|
```
|
||||||
|
|
||||||
### 4.2. 集群状态 API
|
### 集群状态 API
|
||||||
|
|
||||||
集群状态 API 返回表示整个集群状态的元数据。
|
集群状态 API 返回表示整个集群状态的元数据。
|
||||||
|
|
||||||
|
|
@ -1077,7 +1091,7 @@ GET /_cluster/health/kibana_sample_data_flights?level=shards
|
||||||
GET /_cluster/state
|
GET /_cluster/state
|
||||||
```
|
```
|
||||||
|
|
||||||
## 5. 节点 API
|
## 节点 API
|
||||||
|
|
||||||
> [Elasticsearch 官方之 cat Nodes API](https://www.elastic.co/guide/en/elasticsearch/reference/current/cat-nodes.html)——返回有关集群节点的信息。
|
> [Elasticsearch 官方之 cat Nodes API](https://www.elastic.co/guide/en/elasticsearch/reference/current/cat-nodes.html)——返回有关集群节点的信息。
|
||||||
|
|
||||||
|
|
@ -1088,7 +1102,7 @@ GET /_cat/nodes?v=true
|
||||||
GET /_cat/nodes?v=true&h=id,ip,port,v,m
|
GET /_cat/nodes?v=true&h=id,ip,port,v,m
|
||||||
```
|
```
|
||||||
|
|
||||||
## 6. 分片 API
|
## 分片 API
|
||||||
|
|
||||||
> [Elasticsearch 官方之 cat Shards API](https://www.elastic.co/guide/en/elasticsearch/reference/current/cat-shards.html)——shards 命令是哪些节点包含哪些分片的详细视图。它会告诉你它是主还是副本、文档数量、它在磁盘上占用的字节数以及它所在的节点。
|
> [Elasticsearch 官方之 cat Shards API](https://www.elastic.co/guide/en/elasticsearch/reference/current/cat-shards.html)——shards 命令是哪些节点包含哪些分片的详细视图。它会告诉你它是主还是副本、文档数量、它在磁盘上占用的字节数以及它所在的节点。
|
||||||
|
|
||||||
|
|
@ -1101,7 +1115,7 @@ GET /_cat/shards/my-index-*
|
||||||
GET /_cat/shards?h=index,shard,prirep,state,unassigned.reason
|
GET /_cat/shards?h=index,shard,prirep,state,unassigned.reason
|
||||||
```
|
```
|
||||||
|
|
||||||
## 7. 监控 API
|
## 监控 API
|
||||||
|
|
||||||
Elasticsearch 中集群相关的健康、统计等相关的信息都是围绕着 `cat` API 进行的。
|
Elasticsearch 中集群相关的健康、统计等相关的信息都是围绕着 `cat` API 进行的。
|
||||||
|
|
||||||
|
|
@ -1140,7 +1154,7 @@ GET /_cat
|
||||||
/_cat/templates
|
/_cat/templates
|
||||||
```
|
```
|
||||||
|
|
||||||
## 8. 参考资料
|
## 参考资料
|
||||||
|
|
||||||
- **官方**
|
- **官方**
|
||||||
- [Elasticsearch 官网](https://www.elastic.co/cn/products/elasticsearch)
|
- [Elasticsearch 官网](https://www.elastic.co/cn/products/elasticsearch)
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: ElasticSearch Java API 之 High Level REST Client
|
title: ElasticSearch Java API 之 High Level REST Client
|
||||||
date: 2022-03-01 18:55:46
|
date: 2022-03-01 18:55:46
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
|
|
@ -10,16 +11,16 @@ tags:
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
- API
|
- API
|
||||||
permalink: /pages/baf137/
|
permalink: /pages/201e43/
|
||||||
---
|
---
|
||||||
|
|
||||||
# ElasticSearch Java API 之 High Level REST Client
|
# ElasticSearch Java API 之 High Level REST Client
|
||||||
|
|
||||||
> Elasticsearch 官方的 High Level REST Client 在 7.1.5.0 版本废弃。所以本文中的 API 不推荐使用。
|
> Elasticsearch 官方的 High Level REST Client 在 7.1.5.0 版本废弃。所以本文中的 API 不推荐使用。
|
||||||
|
|
||||||
## 1. 快速开始
|
## 快速开始
|
||||||
|
|
||||||
### 1.1. 引入依赖
|
### 引入依赖
|
||||||
|
|
||||||
在 pom.xml 中引入以下依赖:
|
在 pom.xml 中引入以下依赖:
|
||||||
|
|
||||||
|
|
@ -31,7 +32,7 @@ permalink: /pages/baf137/
|
||||||
</dependency>
|
</dependency>
|
||||||
```
|
```
|
||||||
|
|
||||||
### 1.2. 创建连接和关闭
|
### 创建连接和关闭
|
||||||
|
|
||||||
```java
|
```java
|
||||||
// 创建连接
|
// 创建连接
|
||||||
|
|
@ -44,9 +45,9 @@ RestHighLevelClient client = new RestHighLevelClient(
|
||||||
client.close();
|
client.close();
|
||||||
```
|
```
|
||||||
|
|
||||||
## 2. 索引 API
|
## 索引 API
|
||||||
|
|
||||||
### 2.1. 测试准备
|
### 测试准备
|
||||||
|
|
||||||
```java
|
```java
|
||||||
public static final String INDEX = "mytest";
|
public static final String INDEX = "mytest";
|
||||||
|
|
@ -65,7 +66,7 @@ public static final String MAPPING_JSON =
|
||||||
private RestHighLevelClient client;
|
private RestHighLevelClient client;
|
||||||
```
|
```
|
||||||
|
|
||||||
### 2.2. 创建索引
|
### 创建索引
|
||||||
|
|
||||||
```java
|
```java
|
||||||
// 创建索引
|
// 创建索引
|
||||||
|
|
@ -85,7 +86,7 @@ CreateIndexRequest createIndexRequest = new CreateIndexRequest(INDEX);
|
||||||
Assertions.assertTrue(createIndexResponse.isAcknowledged());
|
Assertions.assertTrue(createIndexResponse.isAcknowledged());
|
||||||
```
|
```
|
||||||
|
|
||||||
### 2.3. 删除索引
|
### 删除索引
|
||||||
|
|
||||||
```java
|
```java
|
||||||
// 删除索引
|
// 删除索引
|
||||||
|
|
@ -94,7 +95,7 @@ DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest(INDEX);
|
||||||
Assertions.assertTrue(deleteResponse.isAcknowledged());
|
Assertions.assertTrue(deleteResponse.isAcknowledged());
|
||||||
```
|
```
|
||||||
|
|
||||||
### 2.4. 判断索引是否存在
|
### 判断索引是否存在
|
||||||
|
|
||||||
```java
|
```java
|
||||||
GetIndexRequest getIndexRequest = new GetIndexRequest(INDEX);
|
GetIndexRequest getIndexRequest = new GetIndexRequest(INDEX);
|
||||||
|
|
@ -103,9 +104,9 @@ GetIndexRequest getIndexRequest = new GetIndexRequest(INDEX);
|
||||||
Assertions.assertTrue(client.indices().exists(getIndexAliasRequest, RequestOptions.DEFAULT));
|
Assertions.assertTrue(client.indices().exists(getIndexAliasRequest, RequestOptions.DEFAULT));
|
||||||
```
|
```
|
||||||
|
|
||||||
## 3. 文档 API
|
## 文档 API
|
||||||
|
|
||||||
### 3.1. 文档测试准备
|
### 文档测试准备
|
||||||
|
|
||||||
```java
|
```java
|
||||||
public static final String INDEX = "mytest";
|
public static final String INDEX = "mytest";
|
||||||
|
|
@ -158,7 +159,7 @@ public void destroy() throws IOException {
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 3.2. 创建文档
|
### 创建文档
|
||||||
|
|
||||||
RestHighLevelClient Api 使用 `IndexRequest` 来构建创建文档的请求参数。
|
RestHighLevelClient Api 使用 `IndexRequest` 来构建创建文档的请求参数。
|
||||||
|
|
||||||
|
|
@ -198,7 +199,7 @@ public void onFailure(Exception e) {
|
||||||
});
|
});
|
||||||
```
|
```
|
||||||
|
|
||||||
### 3.3. 删除文档
|
### 删除文档
|
||||||
|
|
||||||
RestHighLevelClient Api 使用 `DeleteRequest` 来构建删除文档的请求参数。
|
RestHighLevelClient Api 使用 `DeleteRequest` 来构建删除文档的请求参数。
|
||||||
|
|
||||||
|
|
@ -231,7 +232,7 @@ public void onFailure(Exception e) {
|
||||||
});
|
});
|
||||||
```
|
```
|
||||||
|
|
||||||
### 3.4. 更新文档
|
### 更新文档
|
||||||
|
|
||||||
RestHighLevelClient Api 使用 `UpdateRequest` 来构建更新文档的请求参数。
|
RestHighLevelClient Api 使用 `UpdateRequest` 来构建更新文档的请求参数。
|
||||||
|
|
||||||
|
|
@ -270,7 +271,7 @@ public void onFailure(Exception e) {
|
||||||
});
|
});
|
||||||
```
|
```
|
||||||
|
|
||||||
### 3.5. 查看文档
|
### 查看文档
|
||||||
|
|
||||||
RestHighLevelClient Api 使用 `GetRequest` 来构建查看文档的请求参数。
|
RestHighLevelClient Api 使用 `GetRequest` 来构建查看文档的请求参数。
|
||||||
|
|
||||||
|
|
@ -302,7 +303,7 @@ public void onFailure(Exception e) {
|
||||||
});
|
});
|
||||||
```
|
```
|
||||||
|
|
||||||
### 3.6. 获取匹配条件的记录总数
|
### 获取匹配条件的记录总数
|
||||||
|
|
||||||
```java
|
```java
|
||||||
@Test
|
@Test
|
||||||
|
|
@ -321,7 +322,7 @@ public void count() throws IOException {
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 3.7. 分页查询
|
### 分页查询
|
||||||
|
|
||||||
```java
|
```java
|
||||||
@ParameterizedTest
|
@ParameterizedTest
|
||||||
|
|
@ -350,7 +351,7 @@ public void pageTest(int page) throws IOException {
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 3.8. 条件查询
|
### 条件查询
|
||||||
|
|
||||||
```java
|
```java
|
||||||
@Test
|
@Test
|
||||||
|
|
@ -375,7 +376,7 @@ public void matchPhraseQuery() throws IOException {
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
## 4. 参考资料
|
## 参考资料
|
||||||
|
|
||||||
- **官方**
|
- **官方**
|
||||||
- [Java High Level REST Client](https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high.html)
|
- [Java High Level REST Client](https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high.html)
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Elasticsearch 集群和分片
|
title: Elasticsearch 集群和分片
|
||||||
date: 2022-03-01 20:52:25
|
date: 2022-03-01 20:52:25
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
|
|
@ -11,39 +12,14 @@ tags:
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
- 集群
|
- 集群
|
||||||
- 分片
|
- 分片
|
||||||
permalink: /pages/d894ac/
|
permalink: /pages/9a2546/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Elasticsearch 集群和分片
|
# Elasticsearch 集群和分片
|
||||||
|
|
||||||
<!-- TOC depthFrom:2 depthTo:3 -->
|
## 集群
|
||||||
|
|
||||||
- [1. 集群](#1-集群)
|
### 空集群
|
||||||
- [1.1. 空集群](#11-空集群)
|
|
||||||
- [1.2. 集群健康](#12-集群健康)
|
|
||||||
- [1.3. 添加索引](#13-添加索引)
|
|
||||||
- [1.4. 添加故障转移](#14-添加故障转移)
|
|
||||||
- [1.5. 水平扩容](#15-水平扩容)
|
|
||||||
- [1.6. 更多的扩容](#16-更多的扩容)
|
|
||||||
- [1.7. 应对故障](#17-应对故障)
|
|
||||||
- [2. 分片](#2-分片)
|
|
||||||
- [2.1. 使文本可被搜索](#21-使文本可被搜索)
|
|
||||||
- [2.2. 不变性](#22-不变性)
|
|
||||||
- [2.3. 动态更新索引](#23-动态更新索引)
|
|
||||||
- [2.4. 删除和更新](#24-删除和更新)
|
|
||||||
- [2.5. 近实时搜索](#25-近实时搜索)
|
|
||||||
- [2.6. refresh API](#26-refresh-api)
|
|
||||||
- [2.7. 持久化变更](#27-持久化变更)
|
|
||||||
- [2.8. flush API](#28-flush-api)
|
|
||||||
- [2.9. 段合并](#29-段合并)
|
|
||||||
- [2.10. optimize API](#210-optimize-api)
|
|
||||||
- [3. 参考资料](#3-参考资料)
|
|
||||||
|
|
||||||
<!-- /TOC -->
|
|
||||||
|
|
||||||
## 1. 集群
|
|
||||||
|
|
||||||
### 1.1. 空集群
|
|
||||||
|
|
||||||
如果我们启动了一个单独的节点,里面不包含任何的数据和索引,那我们的集群看起来就是一个包含空内容节点的集群。
|
如果我们启动了一个单独的节点,里面不包含任何的数据和索引,那我们的集群看起来就是一个包含空内容节点的集群。
|
||||||
|
|
||||||
|
|
@ -59,7 +35,7 @@ permalink: /pages/d894ac/
|
||||||
|
|
||||||
作为用户,我们可以将请求发送到集群中的任何节点,包括主节点。 每个节点都知道任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点。 无论我们将请求发送到哪个节点,它都能负责从各个包含我们所需文档的节点收集回数据,并将最终结果返回給客户端。 Elasticsearch 对这一切的管理都是透明的。
|
作为用户,我们可以将请求发送到集群中的任何节点,包括主节点。 每个节点都知道任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点。 无论我们将请求发送到哪个节点,它都能负责从各个包含我们所需文档的节点收集回数据,并将最终结果返回給客户端。 Elasticsearch 对这一切的管理都是透明的。
|
||||||
|
|
||||||
### 1.2. 集群健康
|
### 集群健康
|
||||||
|
|
||||||
Elasticsearch 的集群监控信息中包含了许多的统计数据,其中最为重要的一项就是 _集群健康_ , 它在 `status` 字段中展示为 `green` 、 `yellow` 或者 `red` 。
|
Elasticsearch 的集群监控信息中包含了许多的统计数据,其中最为重要的一项就是 _集群健康_ , 它在 `status` 字段中展示为 `green` 、 `yellow` 或者 `red` 。
|
||||||
|
|
||||||
|
|
@ -90,7 +66,7 @@ GET /_cluster/health
|
||||||
- **`yellow`**:所有的主分片都正常运行,但不是所有的副本分片都正常运行。
|
- **`yellow`**:所有的主分片都正常运行,但不是所有的副本分片都正常运行。
|
||||||
- **`red`**:有主分片没能正常运行。
|
- **`red`**:有主分片没能正常运行。
|
||||||
|
|
||||||
### 1.3. 添加索引
|
### 添加索引
|
||||||
|
|
||||||
我们往 Elasticsearch 添加数据时需要用到 _索引_ —— 保存相关数据的地方。索引实际上是指向一个或者多个物理分片的逻辑命名空间 。
|
我们往 Elasticsearch 添加数据时需要用到 _索引_ —— 保存相关数据的地方。索引实际上是指向一个或者多个物理分片的逻辑命名空间 。
|
||||||
|
|
||||||
|
|
@ -153,7 +129,7 @@ PUT /blogs
|
||||||
|
|
||||||
当前我们的集群是正常运行的,但是在硬件故障时有丢失数据的风险。
|
当前我们的集群是正常运行的,但是在硬件故障时有丢失数据的风险。
|
||||||
|
|
||||||
### 1.4. 添加故障转移
|
### 添加故障转移
|
||||||
|
|
||||||
当集群中只有一个节点在运行时,意味着会有一个单点故障问题——没有冗余。 幸运的是,我们只需再启动一个节点即可防止数据丢失。
|
当集群中只有一个节点在运行时,意味着会有一个单点故障问题——没有冗余。 幸运的是,我们只需再启动一个节点即可防止数据丢失。
|
||||||
|
|
||||||
|
|
@ -197,7 +173,7 @@ PUT /blogs
|
||||||
|
|
||||||
我们的集群现在不仅仅是正常运行的,并且还处于 _始终可用_ 的状态。
|
我们的集群现在不仅仅是正常运行的,并且还处于 _始终可用_ 的状态。
|
||||||
|
|
||||||
### 1.5. 水平扩容
|
### 水平扩容
|
||||||
|
|
||||||
怎样为我们的正在增长中的应用程序按需扩容呢? 当启动了第三个节点,我们的集群将拥有三个节点的集群——为了分散负载而对分片进行重新分配。
|
怎样为我们的正在增长中的应用程序按需扩容呢? 当启动了第三个节点,我们的集群将拥有三个节点的集群——为了分散负载而对分片进行重新分配。
|
||||||
|
|
||||||
|
|
@ -209,7 +185,7 @@ PUT /blogs
|
||||||
|
|
||||||
分片是一个功能完整的搜索引擎,它拥有使用一个节点上的所有资源的能力。 我们这个拥有 6 个分片(3 个主分片和 3 个副本分片)的索引可以最大扩容到 6 个节点,每个节点上存在一个分片,并且每个分片拥有所在节点的全部资源。
|
分片是一个功能完整的搜索引擎,它拥有使用一个节点上的所有资源的能力。 我们这个拥有 6 个分片(3 个主分片和 3 个副本分片)的索引可以最大扩容到 6 个节点,每个节点上存在一个分片,并且每个分片拥有所在节点的全部资源。
|
||||||
|
|
||||||
### 1.6. 更多的扩容
|
### 更多的扩容
|
||||||
|
|
||||||
但是如果我们想要扩容超过 6 个节点怎么办呢?
|
但是如果我们想要扩容超过 6 个节点怎么办呢?
|
||||||
|
|
||||||
|
|
@ -234,7 +210,7 @@ PUT /blogs/_settings
|
||||||
>
|
>
|
||||||
> 但是更多的副本分片数提高了数据冗余量:按照上面的节点配置,我们可以在失去 2 个节点的情况下不丢失任何数据。
|
> 但是更多的副本分片数提高了数据冗余量:按照上面的节点配置,我们可以在失去 2 个节点的情况下不丢失任何数据。
|
||||||
|
|
||||||
### 1.7. 应对故障
|
### 应对故障
|
||||||
|
|
||||||
我们之前说过 Elasticsearch 可以应对节点故障,接下来让我们尝试下这个功能。 如果我们关闭第一个节点,这时集群的状态为关闭了一个节点后的集群。
|
我们之前说过 Elasticsearch 可以应对节点故障,接下来让我们尝试下这个功能。 如果我们关闭第一个节点,这时集群的状态为关闭了一个节点后的集群。
|
||||||
|
|
||||||
|
|
@ -254,7 +230,7 @@ PUT /blogs/_settings
|
||||||
|
|
||||||
到目前为止,你应该对分片如何使得 Elasticsearch 进行水平扩容以及数据保障等知识有了一定了解。 接下来我们将讲述关于分片生命周期的更多细节。
|
到目前为止,你应该对分片如何使得 Elasticsearch 进行水平扩容以及数据保障等知识有了一定了解。 接下来我们将讲述关于分片生命周期的更多细节。
|
||||||
|
|
||||||
## 2. 分片
|
## 分片
|
||||||
|
|
||||||
> - 为什么搜索是 _近_ 实时的?
|
> - 为什么搜索是 _近_ 实时的?
|
||||||
> - 为什么文档的 CRUD (创建-读取-更新-删除) 操作是 _实时_ 的?
|
> - 为什么文档的 CRUD (创建-读取-更新-删除) 操作是 _实时_ 的?
|
||||||
|
|
@ -262,7 +238,7 @@ PUT /blogs/_settings
|
||||||
> - 为什么删除文档不会立刻释放空间?
|
> - 为什么删除文档不会立刻释放空间?
|
||||||
> - `refresh`, `flush`, 和 `optimize` API 都做了什么, 你什么情况下应该使用他们?
|
> - `refresh`, `flush`, 和 `optimize` API 都做了什么, 你什么情况下应该使用他们?
|
||||||
|
|
||||||
### 2.1. 使文本可被搜索
|
### 使文本可被搜索
|
||||||
|
|
||||||
必须解决的第一个挑战是如何使文本可被搜索。 传统的数据库每个字段存储单个值,但这对全文检索并不够。文本字段中的每个单词需要被搜索,对数据库意味着需要单个字段有索引多值(这里指单词)的能力。
|
必须解决的第一个挑战是如何使文本可被搜索。 传统的数据库每个字段存储单个值,但这对全文检索并不够。文本字段中的每个单词需要被搜索,对数据库意味着需要单个字段有索引多值(这里指单词)的能力。
|
||||||
|
|
||||||
|
|
@ -285,7 +261,7 @@ the | X | | X | ...
|
||||||
|
|
||||||
早期的全文检索会为整个文档集合建立一个很大的倒排索引并将其写入到磁盘。 一旦新的索引就绪,旧的就会被其替换,这样最近的变化便可以被检索到。
|
早期的全文检索会为整个文档集合建立一个很大的倒排索引并将其写入到磁盘。 一旦新的索引就绪,旧的就会被其替换,这样最近的变化便可以被检索到。
|
||||||
|
|
||||||
### 2.2. 不变性
|
### 不变性
|
||||||
|
|
||||||
倒排索引被写入磁盘后是 _不可改变_ 的:它永远不会修改。 不变性有重要的价值:
|
倒排索引被写入磁盘后是 _不可改变_ 的:它永远不会修改。 不变性有重要的价值:
|
||||||
|
|
||||||
|
|
@ -296,7 +272,7 @@ the | X | | X | ...
|
||||||
|
|
||||||
当然,一个不变的索引也有不好的地方。主要事实是它是不可变的! 你不能修改它。如果你需要让一个新的文档 可被搜索,你需要重建整个索引。这要么对一个索引所能包含的数据量造成了很大的限制,要么对索引可被更新的频率造成了很大的限制。
|
当然,一个不变的索引也有不好的地方。主要事实是它是不可变的! 你不能修改它。如果你需要让一个新的文档 可被搜索,你需要重建整个索引。这要么对一个索引所能包含的数据量造成了很大的限制,要么对索引可被更新的频率造成了很大的限制。
|
||||||
|
|
||||||
### 2.3. 动态更新索引
|
### 动态更新索引
|
||||||
|
|
||||||
下一个需要被解决的问题是怎样在保留不变性的前提下实现倒排索引的更新?答案是: 用更多的索引。
|
下一个需要被解决的问题是怎样在保留不变性的前提下实现倒排索引的更新?答案是: 用更多的索引。
|
||||||
|
|
||||||
|
|
@ -330,7 +306,7 @@ Elasticsearch 基于 Lucene, 这个 java 库引入了 按段搜索 的概念。
|
||||||
|
|
||||||
当一个查询被触发,所有已知的段按顺序被查询。词项统计会对所有段的结果进行聚合,以保证每个词和每个文档的关联都被准确计算。 这种方式可以用相对较低的成本将新文档添加到索引。
|
当一个查询被触发,所有已知的段按顺序被查询。词项统计会对所有段的结果进行聚合,以保证每个词和每个文档的关联都被准确计算。 这种方式可以用相对较低的成本将新文档添加到索引。
|
||||||
|
|
||||||
### 2.4. 删除和更新
|
### 删除和更新
|
||||||
|
|
||||||
段是不可改变的,所以既不能从把文档从旧的段中移除,也不能修改旧的段来进行反映文档的更新。 取而代之的是,每个提交点会包含一个 `.del` 文件,文件中会列出这些被删除文档的段信息。
|
段是不可改变的,所以既不能从把文档从旧的段中移除,也不能修改旧的段来进行反映文档的更新。 取而代之的是,每个提交点会包含一个 `.del` 文件,文件中会列出这些被删除文档的段信息。
|
||||||
|
|
||||||
|
|
@ -340,7 +316,7 @@ Elasticsearch 基于 Lucene, 这个 java 库引入了 按段搜索 的概念。
|
||||||
|
|
||||||
在 [段合并](https://www.elastic.co/guide/cn/elasticsearch/guide/current/merge-process.html) , 我们展示了一个被删除的文档是怎样被文件系统移除的。
|
在 [段合并](https://www.elastic.co/guide/cn/elasticsearch/guide/current/merge-process.html) , 我们展示了一个被删除的文档是怎样被文件系统移除的。
|
||||||
|
|
||||||
### 2.5. 近实时搜索
|
### 近实时搜索
|
||||||
|
|
||||||
随着按段(per-segment)搜索的发展,一个新的文档从索引到可被搜索的延迟显著降低了。新文档在几分钟之内即可被检索,但这样还是不够快。
|
随着按段(per-segment)搜索的发展,一个新的文档从索引到可被搜索的延迟显著降低了。新文档在几分钟之内即可被检索,但这样还是不够快。
|
||||||
|
|
||||||
|
|
@ -360,7 +336,7 @@ Lucene 允许新段被写入和打开—使其包含的文档在未进行一次
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
### 2.6. refresh API
|
### refresh API
|
||||||
|
|
||||||
在 Elasticsearch 中,写入和打开一个新段的轻量的过程叫做 _refresh_ 。 默认情况下每个分片会每秒自动刷新一次。这就是为什么我们说 Elasticsearch 是 _近_ 实时搜索: 文档的变化并不是立即对搜索可见,但会在一秒之内变为可见。
|
在 Elasticsearch 中,写入和打开一个新段的轻量的过程叫做 _refresh_ 。 默认情况下每个分片会每秒自动刷新一次。这就是为什么我们说 Elasticsearch 是 _近_ 实时搜索: 文档的变化并不是立即对搜索可见,但会在一秒之内变为可见。
|
||||||
|
|
||||||
|
|
@ -406,7 +382,7 @@ PUT /my_logs/_settings
|
||||||
|
|
||||||
> `refresh_interval` 需要一个 _持续时间_ 值, 例如 `1s` (1 秒) 或 `2m` (2 分钟)。 一个绝对值 _1_ 表示的是 _1 毫秒_ --无疑会使你的集群陷入瘫痪。
|
> `refresh_interval` 需要一个 _持续时间_ 值, 例如 `1s` (1 秒) 或 `2m` (2 分钟)。 一个绝对值 _1_ 表示的是 _1 毫秒_ --无疑会使你的集群陷入瘫痪。
|
||||||
|
|
||||||
### 2.7. 持久化变更
|
### 持久化变更
|
||||||
|
|
||||||
如果没有用 `fsync` 把数据从文件系统缓存刷(flush)到硬盘,我们不能保证数据在断电甚至是程序正常退出之后依然存在。为了保证 Elasticsearch 的可靠性,需要确保数据变化被持久化到磁盘。
|
如果没有用 `fsync` 把数据从文件系统缓存刷(flush)到硬盘,我们不能保证数据在断电甚至是程序正常退出之后依然存在。为了保证 Elasticsearch 的可靠性,需要确保数据变化被持久化到磁盘。
|
||||||
|
|
||||||
|
|
@ -453,7 +429,7 @@ translog 也被用来提供实时 CRUD 。当你试着通过 ID 查询、更新
|
||||||
|
|
||||||
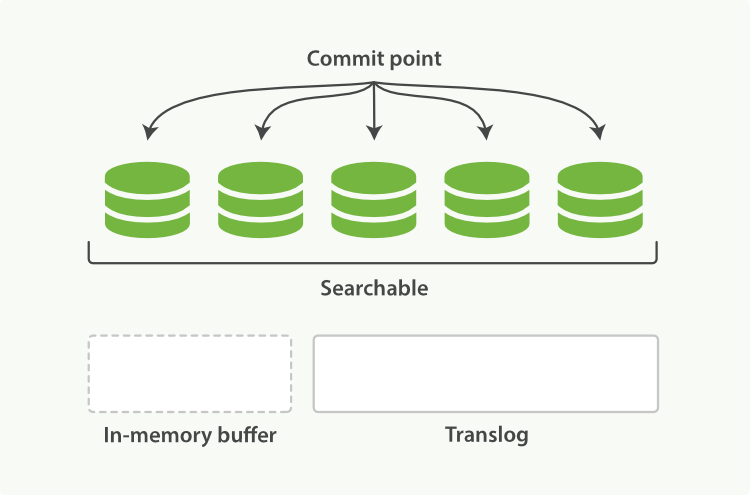
|

|
||||||
|
|
||||||
### 2.8. flush API
|
### flush API
|
||||||
|
|
||||||
这个执行一个提交并且截断 translog 的行为在 Elasticsearch 被称作一次 _flush_ 。 分片每 30 分钟被自动刷新(flush),或者在 translog 太大的时候也会刷新。请查看 [`translog` 文档](https://www.elastic.co/guide/en/elasticsearch/reference/2.4/index-modules-translog.html#_translog_settings) 来设置,它可以用来 控制这些阈值:
|
这个执行一个提交并且截断 translog 的行为在 Elasticsearch 被称作一次 _flush_ 。 分片每 30 分钟被自动刷新(flush),或者在 translog 太大的时候也会刷新。请查看 [`translog` 文档](https://www.elastic.co/guide/en/elasticsearch/reference/2.4/index-modules-translog.html#_translog_settings) 来设置,它可以用来 控制这些阈值:
|
||||||
|
|
||||||
|
|
@ -493,7 +469,7 @@ POST /_flush?wait_for_ongoing
|
||||||
>
|
>
|
||||||
> 如果你不确定这个行为的后果,最好是使用默认的参数( `"index.translog.durability": "request"` )来避免数据丢失。
|
> 如果你不确定这个行为的后果,最好是使用默认的参数( `"index.translog.durability": "request"` )来避免数据丢失。
|
||||||
|
|
||||||
### 2.9. 段合并
|
### 段合并
|
||||||
|
|
||||||
由于自动刷新流程每秒会创建一个新的段 ,这样会导致短时间内的段数量暴增。而段数目太多会带来较大的麻烦。 每一个段都会消耗文件句柄、内存和 cpu 运行周期。更重要的是,每个搜索请求都必须轮流检查每个段;所以段越多,搜索也就越慢。
|
由于自动刷新流程每秒会创建一个新的段 ,这样会导致短时间内的段数量暴增。而段数目太多会带来较大的麻烦。 每一个段都会消耗文件句柄、内存和 cpu 运行周期。更重要的是,每个搜索请求都必须轮流检查每个段;所以段越多,搜索也就越慢。
|
||||||
|
|
||||||
|
|
@ -523,7 +499,7 @@ Elasticsearch 通过在后台进行段合并来解决这个问题。小的段被
|
||||||
|
|
||||||
合并大的段需要消耗大量的 I/O 和 CPU 资源,如果任其发展会影响搜索性能。Elasticsearch 在默认情况下会对合并流程进行资源限制,所以搜索仍然 有足够的资源很好地执行。
|
合并大的段需要消耗大量的 I/O 和 CPU 资源,如果任其发展会影响搜索性能。Elasticsearch 在默认情况下会对合并流程进行资源限制,所以搜索仍然 有足够的资源很好地执行。
|
||||||
|
|
||||||
### 2.10. optimize API
|
### optimize API
|
||||||
|
|
||||||
`optimize` API 大可看做是 _强制合并_ API。它会将一个分片强制合并到 `max_num_segments` 参数指定大小的段数目。 这样做的意图是减少段的数量(通常减少到一个),来提升搜索性能。
|
`optimize` API 大可看做是 _强制合并_ API。它会将一个分片强制合并到 `max_num_segments` 参数指定大小的段数目。 这样做的意图是减少段的数量(通常减少到一个),来提升搜索性能。
|
||||||
|
|
||||||
|
|
@ -541,6 +517,6 @@ POST /logstash-2014-10/_optimize?max_num_segments=1
|
||||||
|
|
||||||
> 请注意,使用 `optimize` API 触发段合并的操作不会受到任何资源上的限制。这可能会消耗掉你节点上全部的 I/O 资源, 使其没有余裕来处理搜索请求,从而有可能使集群失去响应。 如果你想要对索引执行 `optimize`,你需要先使用分片分配(查看 [迁移旧索引](https://www.elastic.co/guide/cn/elasticsearch/guide/current/retiring-data.html#migrate-indices))把索引移到一个安全的节点,再执行。
|
> 请注意,使用 `optimize` API 触发段合并的操作不会受到任何资源上的限制。这可能会消耗掉你节点上全部的 I/O 资源, 使其没有余裕来处理搜索请求,从而有可能使集群失去响应。 如果你想要对索引执行 `optimize`,你需要先使用分片分配(查看 [迁移旧索引](https://www.elastic.co/guide/cn/elasticsearch/guide/current/retiring-data.html#migrate-indices))把索引移到一个安全的节点,再执行。
|
||||||
|
|
||||||
## 3. 参考资料
|
## 参考资料
|
||||||
|
|
||||||
- [Elasticsearch 官方文档之 集群内的原理](https://www.elastic.co/guide/cn/elasticsearch/guide/current/distributed-cluster.html)
|
- [Elasticsearch 官方文档之 集群内的原理](https://www.elastic.co/guide/cn/elasticsearch/guide/current/distributed-cluster.html)
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Elasticsearch 运维
|
title: Elasticsearch 运维
|
||||||
date: 2020-06-16 07:10:44
|
date: 2020-06-16 07:10:44
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
|
|
@ -10,14 +11,14 @@ tags:
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
- 运维
|
- 运维
|
||||||
permalink: /pages/805d11/
|
permalink: /pages/fdaf15/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Elasticsearch 运维
|
# Elasticsearch 运维
|
||||||
|
|
||||||
> [Elasticsearch](https://github.com/elastic/elasticsearch) 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。 作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
|
> [Elasticsearch](https://github.com/elastic/elasticsearch) 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。 作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
|
||||||
|
|
||||||
## 1. Elasticsearch 安装
|
## Elasticsearch 安装
|
||||||
|
|
||||||
> [Elasticsearch 官方下载安装说明](https://www.elastic.co/cn/downloads/elasticsearch)
|
> [Elasticsearch 官方下载安装说明](https://www.elastic.co/cn/downloads/elasticsearch)
|
||||||
|
|
||||||
|
|
@ -33,7 +34,7 @@ permalink: /pages/805d11/
|
||||||
|
|
||||||
执行 `curl http://localhost:9200/` 测试服务是否启动
|
执行 `curl http://localhost:9200/` 测试服务是否启动
|
||||||
|
|
||||||
## 2. Elasticsearch 集群规划
|
## Elasticsearch 集群规划
|
||||||
|
|
||||||
ElasticSearch 集群需要根据业务实际情况去合理规划。
|
ElasticSearch 集群需要根据业务实际情况去合理规划。
|
||||||
|
|
||||||
|
|
@ -50,7 +51,7 @@ ElasticSearch 集群需要根据业务实际情况去合理规划。
|
||||||
- 我们 es 集群的日增量数据大概是 2000 万条,每天日增量数据大概是 500MB,每月增量数据大概是 6 亿,15G。目前系统已经运行了几个月,现在 es 集群里数据总量大概是 100G 左右。
|
- 我们 es 集群的日增量数据大概是 2000 万条,每天日增量数据大概是 500MB,每月增量数据大概是 6 亿,15G。目前系统已经运行了几个月,现在 es 集群里数据总量大概是 100G 左右。
|
||||||
- 目前线上有 5 个索引(这个结合你们自己业务来,看看自己有哪些数据可以放 es 的),每个索引的数据量大概是 20G,所以这个数据量之内,我们每个索引分配的是 8 个 shard,比默认的 5 个 shard 多了 3 个 shard。
|
- 目前线上有 5 个索引(这个结合你们自己业务来,看看自己有哪些数据可以放 es 的),每个索引的数据量大概是 20G,所以这个数据量之内,我们每个索引分配的是 8 个 shard,比默认的 5 个 shard 多了 3 个 shard。
|
||||||
|
|
||||||
## 3. Elasticsearch 配置
|
## Elasticsearch 配置
|
||||||
|
|
||||||
ES 的默认配置文件为 `config/elasticsearch.yml`
|
ES 的默认配置文件为 `config/elasticsearch.yml`
|
||||||
|
|
||||||
|
|
@ -124,9 +125,9 @@ discovery.zen.ping.unicast.hosts: ['host1', 'host2:port', 'host3[portX-portY]']
|
||||||
#设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点。
|
#设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点。
|
||||||
```
|
```
|
||||||
|
|
||||||
## 4. Elasticsearch FAQ
|
## Elasticsearch FAQ
|
||||||
|
|
||||||
### 4.1. elasticsearch 不允许以 root 权限来运行
|
### elasticsearch 不允许以 root 权限来运行
|
||||||
|
|
||||||
**问题:**在 Linux 环境中,elasticsearch 不允许以 root 权限来运行。
|
**问题:**在 Linux 环境中,elasticsearch 不允许以 root 权限来运行。
|
||||||
|
|
||||||
|
|
@ -149,7 +150,7 @@ chown -R elk:elk /opt # 假设你的 elasticsearch 安装在 opt 目录下
|
||||||
su elk
|
su elk
|
||||||
```
|
```
|
||||||
|
|
||||||
### 4.2. vm.max_map_count 不低于 262144
|
### vm.max_map_count 不低于 262144
|
||||||
|
|
||||||
**问题:**`vm.max_map_count` 表示虚拟内存大小,它是一个内核参数。elasticsearch 默认要求 `vm.max_map_count` 不低于 262144。
|
**问题:**`vm.max_map_count` 表示虚拟内存大小,它是一个内核参数。elasticsearch 默认要求 `vm.max_map_count` 不低于 262144。
|
||||||
|
|
||||||
|
|
@ -178,7 +179,7 @@ sysctl -p
|
||||||
>
|
>
|
||||||
> 这种情况下,你只能选择直接修改宿主机上的参数了。
|
> 这种情况下,你只能选择直接修改宿主机上的参数了。
|
||||||
|
|
||||||
### 4.3. nofile 不低于 65536
|
### nofile 不低于 65536
|
||||||
|
|
||||||
**问题:** `nofile` 表示进程允许打开的最大文件数。elasticsearch 进程要求可以打开的最大文件数不低于 65536。
|
**问题:** `nofile` 表示进程允许打开的最大文件数。elasticsearch 进程要求可以打开的最大文件数不低于 65536。
|
||||||
|
|
||||||
|
|
@ -195,7 +196,7 @@ echo "* soft nofile 65536" > /etc/security/limits.conf
|
||||||
echo "* hard nofile 131072" > /etc/security/limits.conf
|
echo "* hard nofile 131072" > /etc/security/limits.conf
|
||||||
```
|
```
|
||||||
|
|
||||||
### 4.4. nproc 不低于 2048
|
### nproc 不低于 2048
|
||||||
|
|
||||||
**问题:** `nproc` 表示最大线程数。elasticsearch 要求最大线程数不低于 2048。
|
**问题:** `nproc` 表示最大线程数。elasticsearch 要求最大线程数不低于 2048。
|
||||||
|
|
||||||
|
|
@ -212,7 +213,7 @@ echo "* soft nproc 2048" > /etc/security/limits.conf
|
||||||
echo "* hard nproc 4096" > /etc/security/limits.conf
|
echo "* hard nproc 4096" > /etc/security/limits.conf
|
||||||
```
|
```
|
||||||
|
|
||||||
## 5. 参考资料
|
## 参考资料
|
||||||
|
|
||||||
- [Elasticsearch 官方下载安装说明](https://www.elastic.co/cn/downloads/elasticsearch)
|
- [Elasticsearch 官方下载安装说明](https://www.elastic.co/cn/downloads/elasticsearch)
|
||||||
- [Install Elasticsearch with RPM](https://www.elastic.co/guide/en/elasticsearch/reference/current/rpm.html#rpm)
|
- [Install Elasticsearch with RPM](https://www.elastic.co/guide/en/elasticsearch/reference/current/rpm.html#rpm)
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Elasticsearch 教程
|
title: Elasticsearch 教程
|
||||||
date: 2022-04-11 16:52:35
|
date: 2022-04-11 16:52:35
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
|
|
@ -9,7 +10,8 @@ tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elasticsearch
|
- Elasticsearch
|
||||||
permalink: /pages/7324df/
|
permalink: /pages/74675e/
|
||||||
|
hidden: true
|
||||||
---
|
---
|
||||||
|
|
||||||
# Elasticsearch 教程
|
# Elasticsearch 教程
|
||||||
|
|
@ -24,12 +26,10 @@ permalink: /pages/7324df/
|
||||||
|
|
||||||
### [Elasticsearch 简介](03.Elasticsearch简介.md)
|
### [Elasticsearch 简介](03.Elasticsearch简介.md)
|
||||||
|
|
||||||
### [Elasticsearch Rest API](11.ElasticsearchRestApi.md)
|
|
||||||
|
|
||||||
### [ElasticSearch Java API 之 High Level REST Client](12.ElasticsearchHighLevelRestJavaApi.md)
|
|
||||||
|
|
||||||
### [Elasticsearch 索引管理](04.Elasticsearch索引.md)
|
### [Elasticsearch 索引管理](04.Elasticsearch索引.md)
|
||||||
|
|
||||||
|
### [Elasticsearch 映射](05.Elasticsearch映射.md)
|
||||||
|
|
||||||
### [Elasticsearch 查询](05.Elasticsearch查询.md)
|
### [Elasticsearch 查询](05.Elasticsearch查询.md)
|
||||||
|
|
||||||
### [Elasticsearch 高亮](06.Elasticsearch高亮.md)
|
### [Elasticsearch 高亮](06.Elasticsearch高亮.md)
|
||||||
|
|
@ -40,12 +40,16 @@ permalink: /pages/7324df/
|
||||||
|
|
||||||
### [Elasticsearch 分析器](09.Elasticsearch分析器.md)
|
### [Elasticsearch 分析器](09.Elasticsearch分析器.md)
|
||||||
|
|
||||||
|
### [Elasticsearch 性能优化](10.Elasticsearch性能优化.md)
|
||||||
|
|
||||||
|
### [Elasticsearch Rest API](11.ElasticsearchRestApi.md)
|
||||||
|
|
||||||
|
### [ElasticSearch Java API 之 High Level REST Client](12.ElasticsearchHighLevelRestJavaApi.md)
|
||||||
|
|
||||||
### [Elasticsearch 集群和分片](13.Elasticsearch集群和分片.md)
|
### [Elasticsearch 集群和分片](13.Elasticsearch集群和分片.md)
|
||||||
|
|
||||||
### [Elasticsearch 运维](20.Elasticsearch运维.md)
|
### [Elasticsearch 运维](20.Elasticsearch运维.md)
|
||||||
|
|
||||||
### [Elasticsearch 性能优化](10.Elasticsearch性能优化.md)
|
|
||||||
|
|
||||||
## 📚 资料
|
## 📚 资料
|
||||||
|
|
||||||
- **官方**
|
- **官方**
|
||||||
|
|
@ -71,4 +75,4 @@ permalink: /pages/7324df/
|
||||||
|
|
||||||
## 🚪 传送
|
## 🚪 传送
|
||||||
|
|
||||||
◾ 🏠 [DB-TUTORIAL 首页](https://github.com/dunwu/db-tutorial) ◾ 🎯 [我的博客](https://github.com/dunwu/blog) ◾
|
◾ 💧 [我的 IT 知识图谱](https://dunwu.github.io/waterdrop/) ◾ 🎯 [我的博客](https://dunwu.github.io/blog/) ◾
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Elastic 快速入门
|
title: Elastic 快速入门
|
||||||
date: 2020-06-16 07:10:44
|
date: 2020-06-16 07:10:44
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elastic
|
- Elastic
|
||||||
|
|
@ -9,7 +10,7 @@ tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elastic
|
- Elastic
|
||||||
permalink: /pages/d5bdd0/
|
permalink: /pages/553160/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Elastic 快速入门
|
# Elastic 快速入门
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Elastic 技术栈之 Filebeat
|
title: Elastic 技术栈之 Filebeat
|
||||||
date: 2020-06-16 07:10:44
|
date: 2020-06-16 07:10:44
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elastic
|
- Elastic
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elastic
|
- Elastic
|
||||||
- Filebeat
|
- Filebeat
|
||||||
permalink: /pages/3efdd8/
|
permalink: /pages/b7f079/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Elastic 技术栈之 Filebeat
|
# Elastic 技术栈之 Filebeat
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Filebeat 运维
|
title: Filebeat 运维
|
||||||
date: 2020-06-16 07:10:44
|
date: 2020-06-16 07:10:44
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elastic
|
- Elastic
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elastic
|
- Elastic
|
||||||
- Filebeat
|
- Filebeat
|
||||||
permalink: /pages/43db0b/
|
permalink: /pages/7c067f/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Filebeat 运维
|
# Filebeat 运维
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Elastic 技术栈之 Kibana
|
title: Elastic 技术栈之 Kibana
|
||||||
date: 2020-06-16 07:10:44
|
date: 2020-06-16 07:10:44
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elastic
|
- Elastic
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elastic
|
- Elastic
|
||||||
- Kibana
|
- Kibana
|
||||||
permalink: /pages/507fcc/
|
permalink: /pages/002159/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Elastic 技术栈之 Kibana
|
# Elastic 技术栈之 Kibana
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Kibana 运维
|
title: Kibana 运维
|
||||||
date: 2020-06-16 07:10:44
|
date: 2020-06-16 07:10:44
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elastic
|
- Elastic
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elastic
|
- Elastic
|
||||||
- Kibana
|
- Kibana
|
||||||
permalink: /pages/8d96f6/
|
permalink: /pages/fc47af/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Kibana 运维
|
# Kibana 运维
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Elastic 技术栈之 Logstash
|
title: Elastic 技术栈之 Logstash
|
||||||
date: 2020-06-16 07:10:44
|
date: 2020-06-16 07:10:44
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elastic
|
- Elastic
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elastic
|
- Elastic
|
||||||
- Logstash
|
- Logstash
|
||||||
permalink: /pages/0da19c/
|
permalink: /pages/55ce99/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Elastic 技术栈之 Logstash
|
# Elastic 技术栈之 Logstash
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Logstash 运维
|
title: Logstash 运维
|
||||||
date: 2020-06-16 07:10:44
|
date: 2020-06-16 07:10:44
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elastic
|
- Elastic
|
||||||
|
|
@ -10,7 +11,7 @@ tags:
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elastic
|
- Elastic
|
||||||
- Logstash
|
- Logstash
|
||||||
permalink: /pages/ec3c6f/
|
permalink: /pages/92df30/
|
||||||
---
|
---
|
||||||
|
|
||||||
# Logstash 运维
|
# Logstash 运维
|
||||||
|
|
@ -2,6 +2,7 @@
|
||||||
title: Elastic 技术栈
|
title: Elastic 技术栈
|
||||||
date: 2022-04-11 16:52:35
|
date: 2022-04-11 16:52:35
|
||||||
categories:
|
categories:
|
||||||
|
- 计算机科学
|
||||||
- 数据库
|
- 数据库
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elastic
|
- Elastic
|
||||||
|
|
@ -9,7 +10,8 @@ tags:
|
||||||
- 数据库
|
- 数据库
|
||||||
- 搜索引擎数据库
|
- 搜索引擎数据库
|
||||||
- Elastic
|
- Elastic
|
||||||
permalink: /pages/976ee9/
|
permalink: /pages/7bf7f7/
|
||||||
|
hidden: true
|
||||||
---
|
---
|
||||||
|
|
||||||
# Elastic 技术栈
|
# Elastic 技术栈
|
||||||
|
|
@ -54,4 +56,4 @@ permalink: /pages/976ee9/
|
||||||
|
|
||||||
## 🚪 传送
|
## 🚪 传送
|
||||||
|
|
||||||
◾ 🏠 [DB-TUTORIAL 首页](https://github.com/dunwu/db-tutorial) ◾ 🎯 [我的博客](https://github.com/dunwu/blog) ◾
|
◾ 💧 [我的IT知识图谱](https://dunwu.github.io/waterdrop/) ◾ 🎯 [我的博客](https://dunwu.github.io/blog/) ◾
|
||||||
|
|
@ -0,0 +1,430 @@
|
||||||
|
---
|
||||||
|
title: 数据库
|
||||||
|
date: 2022-02-22 21:01:01
|
||||||
|
categories:
|
||||||
|
- 计算机科学
|
||||||
|
- 数据库
|
||||||
|
tags:
|
||||||
|
- 数据库
|
||||||
|
permalink: /pages/012488/
|
||||||
|
hidden: true
|
||||||
|
---
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
<a href="https://dunwu.github.io/db-tutorial/" target="_blank" rel="noopener noreferrer">
|
||||||
|
<img src="https://raw.githubusercontent.com/dunwu/images/dev/common/dunwu-logo.png" alt="logo" width="150px"/>
|
||||||
|
</a>
|
||||||
|
</p>
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
|
||||||
|
<a href="https://github.com/dunwu/db-tutorial">
|
||||||
|
<img alt="star" class="no-zoom" src="https://img.shields.io/github/stars/dunwu/db-tutorial?style=for-the-badge">
|
||||||
|
</a>
|
||||||
|
|
||||||
|
<a href="https://github.com/dunwu/db-tutorial">
|
||||||
|
<img alt="fork" class="no-zoom" src="https://img.shields.io/github/forks/dunwu/db-tutorial?style=for-the-badge">
|
||||||
|
</a>
|
||||||
|
|
||||||
|
<a href="https://github.com/dunwu/db-tutorial/commits/master">
|
||||||
|
<img alt="commit" class="no-zoom" src="https://img.shields.io/github/workflow/status/dunwu/db-tutorial/CI?style=for-the-badge">
|
||||||
|
</a>
|
||||||
|
|
||||||
|
<a href="https://creativecommons.org/licenses/by-nc-sa/4.0/deed.zh">
|
||||||
|
<img alt="code style" class="no-zoom" src="https://img.shields.io/github/license/dunwu/db-tutorial?style=for-the-badge">
|
||||||
|
</a>
|
||||||
|
|
||||||
|
</p>
|
||||||
|
|
||||||
|
<h1 align="center">DB-TUTORIAL</h1>
|
||||||
|
|
||||||
|
> 💾 **db-tutorial** 是一个数据库教程。
|
||||||
|
>
|
||||||
|
> - 🔁 项目同步维护:[Github](https://github.com/dunwu/db-tutorial/) | [Gitee](https://gitee.com/turnon/db-tutorial/)
|
||||||
|
> - 📖 电子书阅读:[Github Pages](https://dunwu.github.io/db-tutorial/) | [Gitee Pages](https://turnon.gitee.io/db-tutorial/)
|
||||||
|
|
||||||
|
## 数据库综合
|
||||||
|
|
||||||
|
### 分布式存储原理
|
||||||
|
|
||||||
|
#### 分布式理论
|
||||||
|
|
||||||
|
- [分布式理论](https://dunwu.github.io/design/pages/367308/)
|
||||||
|
- [深入剖析共识性算法 Paxos](https://dunwu.github.io/design/pages/874539/)
|
||||||
|
- [深入剖析共识性算法 Raft](https://dunwu.github.io/design/pages/e40812/)
|
||||||
|
- [分布式算法 Gossip](https://dunwu.github.io/design/pages/d15993/)
|
||||||
|
|
||||||
|
#### 分布式关键技术
|
||||||
|
|
||||||
|
##### 流量调度
|
||||||
|
|
||||||
|
- [流量控制](https://dunwu.github.io/design/pages/282676/)
|
||||||
|
- [深入浅出负载均衡](https://dunwu.github.io/design/pages/b7ca44/)
|
||||||
|
- [服务路由](https://dunwu.github.io/design/pages/d04ece/)
|
||||||
|
- [分布式会话基本原理](https://dunwu.github.io/design/pages/3e66c2/)
|
||||||
|
|
||||||
|
##### 数据调度
|
||||||
|
|
||||||
|
- [缓存基本原理](https://dunwu.github.io/design/pages/471208/)
|
||||||
|
- [读写分离基本原理](https://dunwu.github.io/design/pages/7da6ca/)
|
||||||
|
- [分库分表基本原理](https://dunwu.github.io/design/pages/103382/)
|
||||||
|
- [分布式 ID 基本原理](https://dunwu.github.io/design/pages/0b2e59/)
|
||||||
|
- [分布式事务基本原理](https://dunwu.github.io/design/pages/910bad/)
|
||||||
|
- [分布式锁基本原理](https://dunwu.github.io/design/pages/69360c/)
|
||||||
|
|
||||||
|
### 其他
|
||||||
|
|
||||||
|
- [Nosql 技术选型](01.数据库综合/01.Nosql技术选型.md)
|
||||||
|
- [数据结构与数据库索引](01.数据库综合/02.数据结构与数据库索引.md)
|
||||||
|
|
||||||
|
## 数据库中间件
|
||||||
|
|
||||||
|
- [ShardingSphere 简介](02.数据库中间件/01.Shardingsphere/01.ShardingSphere简介.md)
|
||||||
|
- [ShardingSphere Jdbc](02.数据库中间件/01.Shardingsphere/02.ShardingSphereJdbc.md)
|
||||||
|
- [版本管理中间件 Flyway](02.数据库中间件/02.Flyway.md)
|
||||||
|
|
||||||
|
## 关系型数据库
|
||||||
|
|
||||||
|
> [关系型数据库](03.关系型数据库) 整理主流关系型数据库知识点。
|
||||||
|
|
||||||
|
### 公共知识
|
||||||
|
|
||||||
|
- [关系型数据库面试总结](03.关系型数据库/01.综合/01.关系型数据库面试.md) 💯
|
||||||
|
- [SQL Cheat Sheet](03.关系型数据库/01.综合/02.SqlCheatSheet.md) 是一个 SQL 入门教程。
|
||||||
|
- [扩展 SQL](03.关系型数据库/01.综合/03.扩展SQL.md) 是一个 SQL 入门教程。
|
||||||
|
|
||||||
|
### Mysql
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
- [Mysql 应用指南](03.关系型数据库/02.Mysql/01.Mysql应用指南.md) ⚡
|
||||||
|
- [Mysql 工作流](03.关系型数据库/02.Mysql/02.MySQL工作流.md) - 关键词:`连接`、`缓存`、`语法分析`、`优化`、`执行引擎`、`redo log`、`bin log`、`两阶段提交`
|
||||||
|
- [Mysql 事务](03.关系型数据库/02.Mysql/03.Mysql事务.md) - 关键词:`ACID`、`AUTOCOMMIT`、`事务隔离级别`、`死锁`、`分布式事务`
|
||||||
|
- [Mysql 锁](03.关系型数据库/02.Mysql/04.Mysql锁.md) - 关键词:`乐观锁`、`表级锁`、`行级锁`、`意向锁`、`MVCC`、`Next-key 锁`
|
||||||
|
- [Mysql 索引](03.关系型数据库/02.Mysql/05.Mysql索引.md) - 关键词:`Hash`、`B 树`、`聚簇索引`、`回表`
|
||||||
|
- [Mysql 性能优化](03.关系型数据库/02.Mysql/06.Mysql性能优化.md)
|
||||||
|
- [Mysql 运维](03.关系型数据库/02.Mysql/20.Mysql运维.md) 🔨
|
||||||
|
- [Mysql 配置](03.关系型数据库/02.Mysql/21.Mysql配置.md) 🔨
|
||||||
|
- [Mysql 问题](03.关系型数据库/02.Mysql/99.Mysql常见问题.md)
|
||||||
|
|
||||||
|
### 其他
|
||||||
|
|
||||||
|
- [PostgreSQL 应用指南](03.关系型数据库/99.其他/01.PostgreSQL.md)
|
||||||
|
- [H2 应用指南](03.关系型数据库/99.其他/02.H2.md)
|
||||||
|
- [SqLite 应用指南](03.关系型数据库/99.其他/03.Sqlite.md)
|
||||||
|
|
||||||
|
## 文档数据库
|
||||||
|
|
||||||
|
### MongoDB
|
||||||
|
|
||||||
|
> MongoDB 是一个基于文档的分布式数据库,由 C++ 语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。
|
||||||
|
>
|
||||||
|
> MongoDB 是一个介于关系型数据库和非关系型数据库之间的产品。它是非关系数据库当中功能最丰富,最像关系数据库的。它支持的数据结构非常松散,是类似 json 的 bson 格式,因此可以存储比较复杂的数据类型。
|
||||||
|
>
|
||||||
|
> MongoDB 最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
|
||||||
|
|
||||||
|
- [MongoDB 应用指南](04.文档数据库/01.MongoDB/01.MongoDB应用指南.md)
|
||||||
|
- [MongoDB 的 CRUD 操作](04.文档数据库/01.MongoDB/02.MongoDB的CRUD操作.md)
|
||||||
|
- [MongoDB 聚合操作](04.文档数据库/01.MongoDB/03.MongoDB的聚合操作.md)
|
||||||
|
- [MongoDB 事务](04.文档数据库/01.MongoDB/04.MongoDB事务.md)
|
||||||
|
- [MongoDB 建模](04.文档数据库/01.MongoDB/05.MongoDB建模.md)
|
||||||
|
- [MongoDB 建模示例](04.文档数据库/01.MongoDB/06.MongoDB建模示例.md)
|
||||||
|
- [MongoDB 索引](04.文档数据库/01.MongoDB/07.MongoDB索引.md)
|
||||||
|
- [MongoDB 复制](04.文档数据库/01.MongoDB/08.MongoDB复制.md)
|
||||||
|
- [MongoDB 分片](04.文档数据库/01.MongoDB/09.MongoDB分片.md)
|
||||||
|
- [MongoDB 运维](04.文档数据库/01.MongoDB/20.MongoDB运维.md)
|
||||||
|
|
||||||
|
## KV 数据库
|
||||||
|
|
||||||
|
### Redis
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
- [Redis 面试总结](05.KV数据库/01.Redis/01.Redis面试总结.md) 💯
|
||||||
|
- [Redis 应用指南](05.KV数据库/01.Redis/02.Redis应用指南.md) ⚡ - 关键词:`内存淘汰`、`事件`、`事务`、`管道`、`发布与订阅`
|
||||||
|
- [Redis 数据类型和应用](05.KV数据库/01.Redis/03.Redis数据类型和应用.md) - 关键词:`STRING`、`HASH`、`LIST`、`SET`、`ZSET`、`BitMap`、`HyperLogLog`、`Geo`
|
||||||
|
- [Redis 持久化](05.KV数据库/01.Redis/04.Redis持久化.md) - 关键词:`RDB`、`AOF`、`SAVE`、`BGSAVE`、`appendfsync`
|
||||||
|
- [Redis 复制](05.KV数据库/01.Redis/05.Redis复制.md) - 关键词:`SLAVEOF`、`SYNC`、`PSYNC`、`REPLCONF ACK`
|
||||||
|
- [Redis 哨兵](05.KV数据库/01.Redis/06.Redis哨兵.md) - 关键词:`Sentinel`、`PING`、`INFO`、`Raft`
|
||||||
|
- [Redis 集群](05.KV数据库/01.Redis/07.Redis集群.md) - 关键词:`CLUSTER MEET`、`Hash slot`、`MOVED`、`ASK`、`SLAVEOF no one`、`redis-trib`
|
||||||
|
- [Redis 实战](05.KV数据库/01.Redis/08.Redis实战.md) - 关键词:`缓存`、`分布式锁`、`布隆过滤器`
|
||||||
|
- [Redis 运维](05.KV数据库/01.Redis/20.Redis运维.md) 🔨 - 关键词:`安装`、`命令`、`集群`、`客户端`
|
||||||
|
|
||||||
|
## 列式数据库
|
||||||
|
|
||||||
|
### HBase
|
||||||
|
|
||||||
|
> [HBase](https://dunwu.github.io/bigdata-tutorial/hbase) 📚 因为常用于大数据项目,所以将其文档和源码整理在 [bigdata-tutorial](https://dunwu.github.io/bigdata-tutorial/) 项目中。
|
||||||
|
|
||||||
|
- [HBase 原理](https://github.com/dunwu/bigdata-tutorial/blob/master/docs/hbase/HBase原理.md) ⚡
|
||||||
|
- [HBase 命令](https://github.com/dunwu/bigdata-tutorial/blob/master/docs/hbase/HBase命令.md)
|
||||||
|
- [HBase 应用](https://github.com/dunwu/bigdata-tutorial/blob/master/docs/hbase/HBase应用.md)
|
||||||
|
- [HBase 运维](https://github.com/dunwu/bigdata-tutorial/blob/master/docs/hbase/HBase运维.md)
|
||||||
|
|
||||||
|
## 搜索引擎数据库
|
||||||
|
|
||||||
|
### Elasticsearch
|
||||||
|
|
||||||
|
> Elasticsearch 是一个基于 Lucene 的搜索和数据分析工具,它提供了一个分布式服务。Elasticsearch 是遵从 Apache 开源条款的一款开源产品,是当前主流的企业级搜索引擎。
|
||||||
|
|
||||||
|
- [Elasticsearch 面试总结](07.搜索引擎数据库/01.Elasticsearch/01.Elasticsearch面试总结.md) 💯
|
||||||
|
- [Elasticsearch 快速入门](07.搜索引擎数据库/01.Elasticsearch/02.Elasticsearch快速入门.md)
|
||||||
|
- [Elasticsearch 简介](07.搜索引擎数据库/01.Elasticsearch/03.Elasticsearch简介.md)
|
||||||
|
- [Elasticsearch 索引](07.搜索引擎数据库/01.Elasticsearch/04.Elasticsearch索引.md)
|
||||||
|
- [Elasticsearch 查询](07.搜索引擎数据库/01.Elasticsearch/05.Elasticsearch查询.md)
|
||||||
|
- [Elasticsearch 高亮](07.搜索引擎数据库/01.Elasticsearch/06.Elasticsearch高亮.md)
|
||||||
|
- [Elasticsearch 排序](07.搜索引擎数据库/01.Elasticsearch/07.Elasticsearch排序.md)
|
||||||
|
- [Elasticsearch 聚合](07.搜索引擎数据库/01.Elasticsearch/08.Elasticsearch聚合.md)
|
||||||
|
- [Elasticsearch 分析器](07.搜索引擎数据库/01.Elasticsearch/09.Elasticsearch分析器.md)
|
||||||
|
- [Elasticsearch 性能优化](07.搜索引擎数据库/01.Elasticsearch/10.Elasticsearch性能优化.md)
|
||||||
|
- [Elasticsearch Rest API](07.搜索引擎数据库/01.Elasticsearch/11.ElasticsearchRestApi.md)
|
||||||
|
- [ElasticSearch Java API 之 High Level REST Client](07.搜索引擎数据库/01.Elasticsearch/12.ElasticsearchHighLevelRestJavaApi.md)
|
||||||
|
- [Elasticsearch 集群和分片](07.搜索引擎数据库/01.Elasticsearch/13.Elasticsearch集群和分片.md)
|
||||||
|
- [Elasticsearch 运维](07.搜索引擎数据库/01.Elasticsearch/20.Elasticsearch运维.md)
|
||||||
|
|
||||||
|
### Elastic
|
||||||
|
|
||||||
|
- [Elastic 快速入门](07.搜索引擎数据库/02.Elastic/01.Elastic快速入门.md)
|
||||||
|
- [Elastic 技术栈之 Filebeat](07.搜索引擎数据库/02.Elastic/02.Elastic技术栈之Filebeat.md)
|
||||||
|
- [Filebeat 运维](07.搜索引擎数据库/02.Elastic/03.Filebeat运维.md)
|
||||||
|
- [Elastic 技术栈之 Kibana](07.搜索引擎数据库/02.Elastic/04.Elastic技术栈之Kibana.md)
|
||||||
|
- [Kibana 运维](07.搜索引擎数据库/02.Elastic/05.Kibana运维.md)
|
||||||
|
- [Elastic 技术栈之 Logstash](07.搜索引擎数据库/02.Elastic/06.Elastic技术栈之Logstash.md)
|
||||||
|
- [Logstash 运维](07.搜索引擎数据库/02.Elastic/07.Logstash运维.md)
|
||||||
|
|
||||||
|
## 资料 📚
|
||||||
|
|
||||||
|
### 数据库综合资料
|
||||||
|
|
||||||
|
- [DB-Engines](https://db-engines.com/en/ranking) - 数据库流行度排名
|
||||||
|
- **书籍**
|
||||||
|
- [《数据密集型应用系统设计》](https://book.douban.com/subject/30329536/) - 这可能是目前最好的分布式存储书籍,强力推荐【进阶】
|
||||||
|
- **教程**
|
||||||
|
- [CMU 15445 数据库基础课程](https://15445.courses.cs.cmu.edu/fall2019/schedule.html)
|
||||||
|
- [CMU 15721 数据库高级课程](https://15721.courses.cs.cmu.edu/spring2020/schedule.html)
|
||||||
|
- [检索技术核心 20 讲](https://time.geekbang.org/column/intro/100048401) - 极客教程【进阶】
|
||||||
|
- [后端存储实战课](https://time.geekbang.org/column/intro/100046801) - 极客教程【入门】:讲解存储在电商领域的种种应用和一些基本特性
|
||||||
|
- **论文**
|
||||||
|
- [Efficiency in the Columbia Database Query Optimizer](https://15721.courses.cs.cmu.edu/spring2018/papers/15-optimizer1/xu-columbia-thesis1998.pdf)
|
||||||
|
- [How Good Are Query Optimizers, Really?](http://www.vldb.org/pvldb/vol9/p204-leis.pdf)
|
||||||
|
- [Architecture of a Database System](https://dsf.berkeley.edu/papers/fntdb07-architecture.pdf)
|
||||||
|
- [Data Structures for Databases](https://www.cise.ufl.edu/~mschneid/Research/papers/HS05BoCh.pdf)
|
||||||
|
- **文章**
|
||||||
|
- [Data Structures and Algorithms for Big Databases](https://people.csail.mit.edu/bradley/BenderKuszmaul-tutorial-xldb12.pdf)
|
||||||
|
|
||||||
|
### 关系型数据库资料
|
||||||
|
|
||||||
|
- **综合资料**
|
||||||
|
- [《数据库的索引设计与优化》](https://book.douban.com/subject/26419771/)
|
||||||
|
- [《SQL 必知必会》](https://book.douban.com/subject/35167240/) - SQL 的基本概念和语法【入门】
|
||||||
|
- **Oracle 资料**
|
||||||
|
- [《Oracle Database 9i/10g/11g 编程艺术》](https://book.douban.com/subject/5402711/)
|
||||||
|
|
||||||
|
#### Mysql 资料
|
||||||
|
|
||||||
|
- **官方**
|
||||||
|
- [Mysql 官网](https://www.mysql.com/)
|
||||||
|
- [Mysql 官方文档](https://dev.mysql.com/doc/)
|
||||||
|
- **官方 PPT**
|
||||||
|
- [How to Analyze and Tune MySQL Queries for Better Performance](https://www.mysql.com/cn/why-mysql/presentations/tune-mysql-queries-performance/)
|
||||||
|
- [MySQL Performance Tuning 101](https://www.mysql.com/cn/why-mysql/presentations/mysql-performance-tuning101/)
|
||||||
|
- [MySQL Performance Schema & Sys Schema](https://www.mysql.com/cn/why-mysql/presentations/mysql-performance-sys-schema/)
|
||||||
|
- [MySQL Performance: Demystified Tuning & Best Practices](https://www.mysql.com/cn/why-mysql/presentations/mysql-performance-tuning-best-practices/)
|
||||||
|
- [MySQL Security Best Practices](https://www.mysql.com/cn/why-mysql/presentations/mysql-security-best-practices/)
|
||||||
|
- [MySQL Cluster Deployment Best Practices](https://www.mysql.com/cn/why-mysql/presentations/mysql-cluster-deployment-best-practices/)
|
||||||
|
- [MySQL High Availability with InnoDB Cluster](https://www.mysql.com/cn/why-mysql/presentations/mysql-high-availability-innodb-cluster/)
|
||||||
|
- **书籍**
|
||||||
|
- [《高性能 MySQL》](https://book.douban.com/subject/23008813/) - 经典,适合 DBA 或作为开发者的参考手册【进阶】
|
||||||
|
- [《MySQL 技术内幕:InnoDB 存储引擎》](https://book.douban.com/subject/24708143/)
|
||||||
|
- [《MySQL 必知必会》](https://book.douban.com/subject/3354490/) - Mysql 的基本概念和语法【入门】
|
||||||
|
- **教程**
|
||||||
|
- [runoob.com MySQL 教程](http://www.runoob.com/mysql/mysql-tutorial.html) - 入门级 SQL 教程
|
||||||
|
- [mysql-tutorial](https://github.com/jaywcjlove/mysql-tutorial)
|
||||||
|
- **文章**
|
||||||
|
- [MySQL 索引背后的数据结构及算法原理](http://blog.codinglabs.org/articles/theory-of-mysql-index.html)
|
||||||
|
- [Some study on database storage internals](https://medium.com/@kousiknath/data-structures-database-storage-internals-1f5ed3619d43)
|
||||||
|
- [Sharding Pinterest: How we scaled our MySQL fleet](https://medium.com/@Pinterest_Engineering/sharding-pinterest-how-we-scaled-our-mysql-fleet-3f341e96ca6f)
|
||||||
|
- [Guide to MySQL High Availability](https://www.mysql.com/cn/why-mysql/white-papers/mysql-guide-to-high-availability-solutions/)
|
||||||
|
- [Choosing MySQL High Availability Solutions](https://dzone.com/articles/choosing-mysql-high-availability-solutions)
|
||||||
|
- [High availability with MariaDB TX: The definitive guide](https://mariadb.com/sites/default/files/content/Whitepaper_High_availability_with_MariaDB-TX.pdf)
|
||||||
|
- Mysql 相关经验
|
||||||
|
- [Booking.com: Evolution of MySQL System Design](https://www.percona.com/live/mysql-conference-2015/sessions/bookingcom-evolution-mysql-system-design) ,Booking.com 的 MySQL 数据库使用的演化,其中有很多不错的经验分享,我相信也是很多公司会遇到的的问题。
|
||||||
|
- [Tracking the Money - Scaling Financial Reporting at Airbnb](https://medium.com/airbnb-engineering/tracking-the-money-scaling-financial-reporting-at-airbnb-6d742b80f040) ,Airbnb 的数据库扩展的经验分享。
|
||||||
|
- [Why Uber Engineering Switched from Postgres to MySQL](https://eng.uber.com/mysql-migration/) ,无意比较两个数据库谁好谁不好,推荐这篇 Uber 的长文,主要是想让你从中学习到一些经验和技术细节,这是一篇很不错的文章。
|
||||||
|
- Mysql 集群复制
|
||||||
|
- [Monitoring Delayed Replication, With A Focus On MySQL](https://engineering.imvu.com/2013/01/09/monitoring-delayed-replication-with-a-focus-on-mysql/)
|
||||||
|
- [Mitigating replication lag and reducing read load with freno](https://githubengineering.com/mitigating-replication-lag-and-reducing-read-load-with-freno/)
|
||||||
|
- [Better Parallel Replication for MySQL](https://medium.com/booking-com-infrastructure/better-parallel-replication-for-mysql-14e2d7857813)
|
||||||
|
- [Evaluating MySQL Parallel Replication Part 2: Slave Group Commit](https://medium.com/booking-com-infrastructure/evaluating-mysql-parallel-replication-part-2-slave-group-commit-459026a141d2)
|
||||||
|
- [Evaluating MySQL Parallel Replication Part 3: Benchmarks in Production](https://medium.com/booking-com-infrastructure/evaluating-mysql-parallel-replication-part-3-benchmarks-in-production-db5811058d74)
|
||||||
|
- [Evaluating MySQL Parallel Replication Part 4: More Benchmarks in Production](https://medium.com/booking-com-infrastructure/evaluating-mysql-parallel-replication-part-4-more-benchmarks-in-production-49ee255043ab)
|
||||||
|
- [Evaluating MySQL Parallel Replication Part 4, Annex: Under the Hood](https://medium.com/booking-com-infrastructure/evaluating-mysql-parallel-replication-part-4-annex-under-the-hood-eb456cf8b2fb)
|
||||||
|
- Mysql 数据分区
|
||||||
|
- [StackOverflow: MySQL sharding approaches?](https://stackoverflow.com/questions/5541421/mysql-sharding-approaches)
|
||||||
|
- [Why you don’t want to shard](https://www.percona.com/blog/2009/08/06/why-you-dont-want-to-shard/)
|
||||||
|
- [How to Scale Big Data Applications](https://www.percona.com/sites/default/files/presentations/How to Scale Big Data Applications.pdf)
|
||||||
|
- [MySQL Sharding with ProxySQL](https://www.percona.com/blog/2016/08/30/mysql-sharding-with-proxysql/)
|
||||||
|
- 各公司的 Mysql 数据分区经验分享
|
||||||
|
- [MailChimp: Using Shards to Accommodate Millions of Users](https://devs.mailchimp.com/blog/using-shards-to-accommodate-millions-of-users/)
|
||||||
|
- [Uber: Code Migration in Production: Rewriting the Sharding Layer of Uber’s Schemaless Datastore](https://eng.uber.com/schemaless-rewrite/)
|
||||||
|
- [Sharding & IDs at Instagram](https://instagram-engineering.com/sharding-ids-at-instagram-1cf5a71e5a5c)
|
||||||
|
- [Airbnb: How We Partitioned Airbnb’s Main Database in Two Weeks](https://medium.com/airbnb-engineering/how-we-partitioned-airbnb-s-main-database-in-two-weeks-55f7e006ff21)
|
||||||
|
- **更多资源**
|
||||||
|
- [awesome-mysql](https://github.com/jobbole/awesome-mysql-cn) - MySQL 的资源列表
|
||||||
|
|
||||||
|
### Nosql 数据库综合
|
||||||
|
|
||||||
|
- Martin Fowler 在 YouTube 上分享的 NoSQL 介绍 [Introduction To NoSQL](https://youtu.be/qI_g07C_Q5I), 以及他参与编写的 [NoSQL Distilled - NoSQL 精粹](https://book.douban.com/subject/25662138/),这本书才 100 多页,是本难得的关于 NoSQL 的书,很不错,非常易读。
|
||||||
|
- [NoSQL Databases: a Survey and Decision Guidance](https://medium.com/baqend-blog/nosql-databases-a-survey-and-decision-guidance-ea7823a822d#.nhzop4d23),这篇文章可以带你自上而下地从 CAP 原理到开始了解 NoSQL 的种种技术,是一篇非常不错的文章。
|
||||||
|
- [Distribution, Data, Deployment: Software Architecture Convergence in Big Data Systems](https://resources.sei.cmu.edu/asset_files/WhitePaper/2014_019_001_90915.pdf),这是卡内基·梅隆大学的一篇讲分布式大数据系统的论文。其中主要讨论了在大数据时代下的软件工程中的一些关键点,也说到了 NoSQL 数据库。
|
||||||
|
- [No Relation: The Mixed Blessings of Non-Relational Databases](http://ianvarley.com/UT/MR/Varley_MastersReport_Full_2009-08-07.pdf),这篇论文虽然有点年代久远。但这篇论文是 HBase 的基础,你花上一点时间来读读,就可以了解到,对各种非关系型数据存储优缺点的一个很好的比较。
|
||||||
|
- [NoSQL Data Modeling Techniques](https://highlyscalable.wordpress.com/2012/03/01/nosql-data-modeling-techniques/) ,NoSQL 建模技术。这篇文章我曾经翻译在了 CoolShell 上,标题为 [NoSQL 数据建模技术](https://coolshell.cn/articles/7270.htm),供你参考。
|
||||||
|
- [MongoDB - Data Modeling Introduction](https://docs.mongodb.com/manual/core/data-modeling-introduction/) ,虽然这是 MongoDB 的数据建模介绍,但是其很多观点可以用于其它的 NoSQL 数据库。
|
||||||
|
- [Firebase - Structure Your Database](https://firebase.google.com/docs/database/android/structure-data) ,Google 的 Firebase 数据库使用 JSON 建模的一些最佳实践。
|
||||||
|
- 因为 CAP 原理,所以当你需要选择一个 NoSQL 数据库的时候,你应该看看这篇文档 [Visual Guide to NoSQL Systems](http://blog.nahurst.com/visual-guide-to-nosql-systems)。
|
||||||
|
|
||||||
|
选 SQL 还是 NoSQL,这里有两篇文章,值得你看看。
|
||||||
|
|
||||||
|
- [SQL vs. NoSQL Databases: What’s the Difference?](https://www.upwork.com/hiring/data/sql-vs-nosql-databases-whats-the-difference/)
|
||||||
|
- [Salesforce: SQL or NoSQL](https://engineering.salesforce.com/sql-or-nosql-9eaf1d92545b)
|
||||||
|
|
||||||
|
### 列式数据库资料
|
||||||
|
|
||||||
|
#### Cassandra 资料
|
||||||
|
|
||||||
|
- 沃尔玛实验室有两篇文章值得一读。
|
||||||
|
- [Avoid Pitfalls in Scaling Cassandra Cluster at Walmart](https://medium.com/walmartlabs/avoid-pitfalls-in-scaling-your-cassandra-cluster-lessons-and-remedies-a71ca01f8c04)
|
||||||
|
- [Storing Images in Cassandra at Walmart](https://medium.com/walmartlabs/building-object-store-storing-images-in-cassandra-walmart-scale-a6b9c02af593)
|
||||||
|
- [Yelp: How We Scaled Our Ad Analytics with Apache Cassandra](https://engineeringblog.yelp.com/2016/08/how-we-scaled-our-ad-analytics-with-cassandra.html) ,Yelp 的这篇博客也有一些相关的经验和教训。
|
||||||
|
- [Discord: How Discord Stores Billions of Messages](https://blog.discordapp.com/how-discord-stores-billions-of-messages-7fa6ec7ee4c7) ,Discord 公司分享的一个如何存储十亿级消息的技术文章。
|
||||||
|
- [Cassandra at Instagram](https://www.slideshare.net/DataStax/cassandra-at-instagram-2016) ,Instagram 的一个 PPT,其中介绍了 Instagram 中是怎么使用 Cassandra 的。
|
||||||
|
- [Netflix: Benchmarking Cassandra Scalability on AWS - Over a million writes per second](https://medium.com/netflix-techblog/benchmarking-cassandra-scalability-on-aws-over-a-million-writes-per-second-39f45f066c9e) ,Netflix 公司在 AWS 上给 Cassandra 做的一个 Benchmark。
|
||||||
|
|
||||||
|
#### HBase 资料
|
||||||
|
|
||||||
|
- [Imgur Notification: From MySQL to HBASE](https://medium.com/imgur-engineering/imgur-notifications-from-mysql-to-hbase-9dba6fc44183)
|
||||||
|
- [Pinterest: Improving HBase Backup Efficiency](https://medium.com/@Pinterest_Engineering/improving-hbase-backup-efficiency-at-pinterest-86159da4b954)
|
||||||
|
- [IBM : Tuning HBase performance](https://www.ibm.com/support/knowledgecenter/en/SSPT3X_2.1.2/com.ibm.swg.im.infosphere.biginsights.analyze.doc/doc/bigsql_TuneHbase.html)
|
||||||
|
- [HBase File Locality in HDFS](http://www.larsgeorge.com/2010/05/hbase-file-locality-in-hdfs.html)
|
||||||
|
- [Apache Hadoop Goes Realtime at Facebook](http://borthakur.com/ftp/RealtimeHadoopSigmod2011.pdf)
|
||||||
|
- [Storage Infrastructure Behind Facebook Messages: Using HBase at Scale](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.294.8459&rep=rep1&type=pdf)
|
||||||
|
- [GitHub: Awesome HBase](https://github.com/rayokota/awesome-hbase)
|
||||||
|
|
||||||
|
针对于 HBase 有两本书你可以考虑一下。
|
||||||
|
|
||||||
|
- 首先,先推荐两本书,一本是偏实践的《[HBase 实战](https://book.douban.com/subject/25706541/)》,另一本是偏大而全的手册型的《[HBase 权威指南](https://book.douban.com/subject/10748460/)》。
|
||||||
|
- 当然,你也可以看看官方的 [The Apache HBase™ Reference Guide](http://hbase.apache.org/0.94/book/book.html)
|
||||||
|
- 另外两个列数据库:
|
||||||
|
- [ClickHouse - Open Source Distributed Column Database at Yandex](https://clickhouse.yandex/)
|
||||||
|
- [Scaling Redshift without Scaling Costs at GIPHY](https://engineering.giphy.com/scaling-redshift-without-scaling-costs/)
|
||||||
|
|
||||||
|
### KV 数据库资料
|
||||||
|
|
||||||
|
#### Redis 资料
|
||||||
|
|
||||||
|
- **官网**
|
||||||
|
- [Redis 官网](https://redis.io/)
|
||||||
|
- [Redis github](https://github.com/antirez/redis)
|
||||||
|
- [Redis 官方文档中文版](http://redis.cn/)
|
||||||
|
- [Redis 命令参考](http://redisdoc.com/)
|
||||||
|
- **书籍**
|
||||||
|
- [《Redis 实战》](https://item.jd.com/11791607.html)
|
||||||
|
- [《Redis 设计与实现》](https://item.jd.com/11486101.html)
|
||||||
|
- **源码**
|
||||||
|
- [《Redis 实战》配套 Python 源码](https://github.com/josiahcarlson/redis-in-action)
|
||||||
|
- **资源汇总**
|
||||||
|
- [awesome-redis](https://github.com/JamzyWang/awesome-redis)
|
||||||
|
- **Redis Client**
|
||||||
|
- [spring-data-redis 官方文档](https://docs.spring.io/spring-data/redis/docs/1.8.13.RELEASE/reference/html/)
|
||||||
|
- [redisson 官方文档(中文,略有滞后)](https://github.com/redisson/redisson/wiki/%E7%9B%AE%E5%BD%95)
|
||||||
|
- [redisson 官方文档(英文)](https://github.com/redisson/redisson/wiki/Table-of-Content)
|
||||||
|
- [CRUG | Redisson PRO vs. Jedis: Which Is Faster? 翻译](https://www.jianshu.com/p/82f0d5abb002)
|
||||||
|
- [redis 分布锁 Redisson 性能测试](https://blog.csdn.net/everlasting_188/article/details/51073505)
|
||||||
|
- **文章**
|
||||||
|
- [Learn Redis the hard way (in production) at Trivago](http://tech.trivago.com/2017/01/25/learn-redis-the-hard-way-in-production/)
|
||||||
|
- [Twitter: How Twitter Uses Redis To Scale - 105TB RAM, 39MM QPS, 10,000+ Instances](http://highscalability.com/blog/2014/9/8/how-twitter-uses-redis-to-scale-105tb-ram-39mm-qps-10000-ins.html)
|
||||||
|
- [Slack: Scaling Slack’s Job Queue - Robustly Handling Billions of Tasks in Milliseconds Using Kafka and Redis](https://slack.engineering/scaling-slacks-job-queue-687222e9d100)
|
||||||
|
- [GitHub: Moving persistent data out of Redis at GitHub](https://githubengineering.com/moving-persistent-data-out-of-redis/)
|
||||||
|
- [Instagram: Storing Hundreds of Millions of Simple Key-Value Pairs in Redis](https://engineering.instagram.com/storing-hundreds-of-millions-of-simple-key-value-pairs-in-redis-1091ae80f74c)
|
||||||
|
- [Redis in Chat Architecture of Twitch (from 27:22)](https://www.infoq.com/presentations/twitch-pokemon)
|
||||||
|
- [Deliveroo: Optimizing Session Key Storage in Redis](https://deliveroo.engineering/2016/10/07/optimising-session-key-storage.html)
|
||||||
|
- [Deliveroo: Optimizing Redis Storage](https://deliveroo.engineering/2017/01/19/optimising-membership-queries.html)
|
||||||
|
- [GitHub: Awesome Redis](https://github.com/JamzyWang/awesome-redis)
|
||||||
|
|
||||||
|
### 文档数据库资料
|
||||||
|
|
||||||
|
- [Couchbase Ecosystem at LinkedIn](https://engineering.linkedin.com/blog/2017/12/couchbase-ecosystem-at-linkedin)
|
||||||
|
- [SimpleDB at Zendesk](https://medium.com/zendesk-engineering/resurrecting-amazon-simpledb-9404034ec506)
|
||||||
|
- [Data Points - What the Heck Are Document Databases?](https://msdn.microsoft.com/en-us/magazine/hh547103.aspx)
|
||||||
|
|
||||||
|
#### MongoDB 资料
|
||||||
|
|
||||||
|
- **官方**
|
||||||
|
- [MongoDB 官网](https://www.mongodb.com/)
|
||||||
|
- [MongoDB Github](https://github.com/mongodb/mongo)
|
||||||
|
- [MongoDB 官方免费教程](https://university.mongodb.com/)
|
||||||
|
- **教程**
|
||||||
|
- [MongoDB 教程](https://www.runoob.com/mongodb/mongodb-tutorial.html)
|
||||||
|
- [MongoDB 高手课](https://time.geekbang.org/course/intro/100040001)
|
||||||
|
- **数据**
|
||||||
|
- [mongodb-json-files](https://github.com/ozlerhakan/mongodb-json-files)
|
||||||
|
- **文章**
|
||||||
|
- [Introduction to MongoDB](https://www.slideshare.net/mdirolf/introduction-to-mongodb)
|
||||||
|
- [eBay: Building Mission-Critical Multi-Data Center Applications with MongoDB](https://www.mongodb.com/blog/post/ebay-building-mission-critical-multi-data-center-applications-with-mongodb)
|
||||||
|
- [The AWS and MongoDB Infrastructure of Parse: Lessons Learned](https://medium.baqend.com/parse-is-gone-a-few-secrets-about-their-infrastructure-91b3ab2fcf71)
|
||||||
|
- [Migrating Mountains of Mongo Data](https://medium.com/build-addepar/migrating-mountains-of-mongo-data-63e530539952)
|
||||||
|
- **更多资源**
|
||||||
|
- [Github: Awesome MongoDB](https://github.com/ramnes/awesome-mongodb)
|
||||||
|
|
||||||
|
### 搜索引擎数据库资料
|
||||||
|
|
||||||
|
#### ElasticSearch
|
||||||
|
|
||||||
|
- **官方**
|
||||||
|
- [Elasticsearch 官网](https://www.elastic.co/cn/products/elasticsearch)
|
||||||
|
- [Elasticsearch Github](https://github.com/elastic/elasticsearch)
|
||||||
|
- [Elasticsearch 官方文档](https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html)
|
||||||
|
- [Elasticsearch: The Definitive Guide](https://www.elastic.co/guide/en/elasticsearch/guide/master/index.html) - ElasticSearch 官方学习资料
|
||||||
|
- **书籍**
|
||||||
|
- [《Elasticsearch 实战》](https://book.douban.com/subject/30380439/)
|
||||||
|
- **教程**
|
||||||
|
- [ELK Stack 权威指南](https://github.com/chenryn/logstash-best-practice-cn)
|
||||||
|
- [Elasticsearch 教程](https://www.knowledgedict.com/tutorial/elasticsearch-intro.html)
|
||||||
|
- **文章**
|
||||||
|
- [Elasticsearch+Logstash+Kibana 教程](https://www.cnblogs.com/xing901022/p/4704319.html)
|
||||||
|
- [ELK(Elasticsearch、Logstash、Kibana)安装和配置](https://github.com/judasn/Linux-Tutorial/blob/master/ELK-Install-And-Settings.md)
|
||||||
|
- **性能调优相关**的工程实践
|
||||||
|
- [Elasticsearch Performance Tuning Practice at eBay](https://www.ebayinc.com/stories/blogs/tech/elasticsearch-performance-tuning-practice-at-ebay/)
|
||||||
|
- [Elasticsearch at Kickstarter](https://kickstarter.engineering/elasticsearch-at-kickstarter-db3c487887fc)
|
||||||
|
- [9 tips on ElasticSearch configuration for high performance](https://www.loggly.com/blog/nine-tips-configuring-elasticsearch-for-high-performance/)
|
||||||
|
- [Elasticsearch In Production - Deployment Best Practices](https://medium.com/@abhidrona/elasticsearch-deployment-best-practices-d6c1323b25d7)
|
||||||
|
- **更多资源**
|
||||||
|
- [GitHub: Awesome ElasticSearch](https://github.com/dzharii/awesome-elasticsearch)
|
||||||
|
|
||||||
|
### 图数据库
|
||||||
|
|
||||||
|
- 首先是 IBM Devloperworks 上的两个简介性的 PPT。
|
||||||
|
- [Intro to graph databases, Part 1, Graph databases and the CRUD operations](https://www.ibm.com/developerworks/library/cl-graph-database-1/cl-graph-database-1-pdf.pdf)
|
||||||
|
- [Intro to graph databases, Part 2, Building a recommendation engine with a graph database](https://www.ibm.com/developerworks/library/cl-graph-database-2/cl-graph-database-2-pdf.pdf)
|
||||||
|
- 然后是一本免费的电子书《[Graph Database](http://graphdatabases.com)》。
|
||||||
|
- 接下来是一些图数据库的介绍文章。
|
||||||
|
- [Handling Billions of Edges in a Graph Database](https://www.infoq.com/presentations/graph-database-scalability)
|
||||||
|
- [Neo4j case studies with Walmart, eBay, AirBnB, NASA, etc](https://neo4j.com/customers/)
|
||||||
|
- [FlockDB: Distributed Graph Database for Storing Adjacency Lists at Twitter](https://blog.twitter.com/engineering/en_us/a/2010/introducing-flockdb.html)
|
||||||
|
- [JanusGraph: Scalable Graph Database backed by Google, IBM and Hortonworks](https://architecht.io/google-ibm-back-new-open-source-graph-database-project-janusgraph-1d74fb78db6b)
|
||||||
|
- [Amazon Neptune](https://aws.amazon.com/neptune/)
|
||||||
|
|
||||||
|
### 时序数据库
|
||||||
|
|
||||||
|
- [What is Time-Series Data & Why We Need a Time-Series Database](https://blog.timescale.com/what-the-heck-is-time-series-data-and-why-do-i-need-a-time-series-database-dcf3b1b18563)
|
||||||
|
- [Time Series Data: Why and How to Use a Relational Database instead of NoSQL](https://blog.timescale.com/time-series-data-why-and-how-to-use-a-relational-database-instead-of-nosql-d0cd6975e87c)
|
||||||
|
- [Beringei: High-performance Time Series Storage Engine @Facebook](https://code.facebook.com/posts/952820474848503/beringei-a-high-performance-time-series-storage-engine/)
|
||||||
|
- [Introducing Atlas: Netflix’s Primary Telemetry Platform @Netflix](https://medium.com/netflix-techblog/introducing-atlas-netflixs-primary-telemetry-platform-bd31f4d8ed9a)
|
||||||
|
- [Building a Scalable Time Series Database on PostgreSQL](https://blog.timescale.com/when-boring-is-awesome-building-a-scalable-time-series-database-on-postgresql-2900ea453ee2)
|
||||||
|
- [Scaling Time Series Data Storage - Part I @Netflix](https://medium.com/netflix-techblog/scaling-time-series-data-storage-part-i-ec2b6d44ba39)
|
||||||
|
- [Design of a Cost Efficient Time Series Store for Big Data](https://medium.com/@leventov/design-of-a-cost-efficient-time-series-store-for-big-data-88c5dc41af8e)
|
||||||
|
- [GitHub: Awesome Time-Series Database](https://github.com/xephonhq/awesome-time-series-database)
|
||||||
|
|
||||||
|
## 传送 🚪
|
||||||
|
|
||||||
|
◾ 💧 [我的IT知识图谱](https://dunwu.github.io/waterdrop/) ◾ 🎯 [我的博客](https://dunwu.github.io/blog/) ◾
|
||||||
215
docs/README.md
215
docs/README.md
|
|
@ -33,75 +33,94 @@ footer: CC-BY-SA-4.0 Licensed | Copyright © 2018-Now Dunwu
|
||||||
> - 🔁 项目同步维护:[Github](https://github.com/dunwu/db-tutorial/) | [Gitee](https://gitee.com/turnon/db-tutorial/)
|
> - 🔁 项目同步维护:[Github](https://github.com/dunwu/db-tutorial/) | [Gitee](https://gitee.com/turnon/db-tutorial/)
|
||||||
> - 📖 电子书阅读:[Github Pages](https://dunwu.github.io/db-tutorial/) | [Gitee Pages](https://turnon.gitee.io/db-tutorial/)
|
> - 📖 电子书阅读:[Github Pages](https://dunwu.github.io/db-tutorial/) | [Gitee Pages](https://turnon.gitee.io/db-tutorial/)
|
||||||
|
|
||||||
|
## 分布式
|
||||||
|
|
||||||
|
### 分布式综合
|
||||||
|
|
||||||
|
- [分布式面试总结](https://dunwu.github.io/waterdrop/pages/f9209d/)
|
||||||
|
|
||||||
|
### 分布式理论
|
||||||
|
|
||||||
|
- [分布式理论](https://dunwu.github.io/waterdrop/pages/286bb3/) - 关键词:`拜占庭将军`、`CAP`、`BASE`、`错误的分布式假设`
|
||||||
|
- [共识性算法 Paxos](https://dunwu.github.io/waterdrop/pages/0276bb/) - 关键词:`共识性算法`
|
||||||
|
- [共识性算法 Raft](https://dunwu.github.io/waterdrop/pages/4907dc/) - 关键词:`共识性算法`
|
||||||
|
- [分布式算法 Gossip](https://dunwu.github.io/waterdrop/pages/71539a/) - 关键词:`数据传播`
|
||||||
|
|
||||||
|
### 分布式关键技术
|
||||||
|
|
||||||
|
- 集群
|
||||||
|
- 复制
|
||||||
|
- 分区
|
||||||
|
- 选主
|
||||||
|
|
||||||
|
#### 流量调度
|
||||||
|
|
||||||
|
- [流量控制](https://dunwu.github.io/waterdrop/pages/60bb6d/) - 关键词:`限流`、`熔断`、`降级`、`计数器法`、`时间窗口法`、`令牌桶法`、`漏桶法`
|
||||||
|
- [负载均衡](https://dunwu.github.io/waterdrop/pages/98a1c1/) - 关键词:`轮询`、`随机`、`最少连接`、`源地址哈希`、`一致性哈希`、`虚拟 hash 槽`
|
||||||
|
- [服务路由](https://dunwu.github.io/waterdrop/pages/3915e8/) - 关键词:`路由`、`条件路由`、`脚本路由`、`标签路由`
|
||||||
|
- 服务网关
|
||||||
|
- [分布式会话](https://dunwu.github.io/waterdrop/pages/95e45f/) - 关键词:`粘性 Session`、`Session 复制共享`、`基于缓存的 session 共享`
|
||||||
|
|
||||||
|
#### 数据调度
|
||||||
|
|
||||||
|
- [数据缓存](https://dunwu.github.io/waterdrop/pages/fd0aaa/) - 关键词:`进程内缓存`、`分布式缓存`、`缓存雪崩`、`缓存穿透`、`缓存击穿`、`缓存更新`、`缓存预热`、`缓存降级`
|
||||||
|
- [读写分离](https://dunwu.github.io/waterdrop/pages/3faf18/)
|
||||||
|
- [分库分表](https://dunwu.github.io/waterdrop/pages/e1046e/) - 关键词:`分片`、`路由`、`迁移`、`扩容`、`双写`、`聚合`
|
||||||
|
- [分布式 ID](https://dunwu.github.io/waterdrop/pages/3ae455/) - 关键词:`UUID`、`自增序列`、`雪花算法`、`Leaf`
|
||||||
|
- [分布式事务](https://dunwu.github.io/waterdrop/pages/e1881c/) - 关键词:`2PC`、`3PC`、`TCC`、`本地消息表`、`MQ 消息`、`SAGA`
|
||||||
|
- [分布式锁](https://dunwu.github.io/waterdrop/pages/40ac64/) - 关键词:`数据库`、`Redis`、`ZooKeeper`、`互斥`、`可重入`、`死锁`、`容错`、`自旋尝试`
|
||||||
|
|
||||||
|
#### 资源调度
|
||||||
|
|
||||||
|
- 弹性伸缩
|
||||||
|
|
||||||
|
#### 服务治理
|
||||||
|
|
||||||
|
- [服务注册和发现](https://dunwu.github.io/waterdrop/pages/1a90aa/)
|
||||||
|
- [服务容错](https://dunwu.github.io/waterdrop/pages/e32c7e/)
|
||||||
|
- 服务编排
|
||||||
|
- 服务版本管理
|
||||||
|
|
||||||
## 数据库综合
|
## 数据库综合
|
||||||
|
|
||||||
### 分布式存储原理
|
- [Nosql 技术选型](01.计算机科学/02.数据库/01.数据库综合/01.Nosql技术选型.md)
|
||||||
|
- [数据结构与数据库索引](01.计算机科学/02.数据库/01.数据库综合/02.数据结构与数据库索引.md)
|
||||||
#### 分布式理论
|
|
||||||
|
|
||||||
- [分布式理论](https://dunwu.github.io/design/pages/367308/)
|
|
||||||
- [深入剖析共识性算法 Paxos](https://dunwu.github.io/design/pages/874539/)
|
|
||||||
- [深入剖析共识性算法 Raft](https://dunwu.github.io/design/pages/e40812/)
|
|
||||||
- [分布式算法 Gossip](https://dunwu.github.io/design/pages/d15993/)
|
|
||||||
|
|
||||||
#### 分布式关键技术
|
|
||||||
|
|
||||||
##### 流量调度
|
|
||||||
|
|
||||||
- [流量控制](https://dunwu.github.io/design/pages/282676/)
|
|
||||||
- [深入浅出负载均衡](https://dunwu.github.io/design/pages/b7ca44/)
|
|
||||||
- [服务路由](https://dunwu.github.io/design/pages/d04ece/)
|
|
||||||
- [分布式会话基本原理](https://dunwu.github.io/design/pages/3e66c2/)
|
|
||||||
|
|
||||||
##### 数据调度
|
|
||||||
|
|
||||||
- [缓存基本原理](https://dunwu.github.io/design/pages/471208/)
|
|
||||||
- [读写分离基本原理](https://dunwu.github.io/design/pages/7da6ca/)
|
|
||||||
- [分库分表基本原理](https://dunwu.github.io/design/pages/103382/)
|
|
||||||
- [分布式 ID 基本原理](https://dunwu.github.io/design/pages/0b2e59/)
|
|
||||||
- [分布式事务基本原理](https://dunwu.github.io/design/pages/910bad/)
|
|
||||||
- [分布式锁基本原理](https://dunwu.github.io/design/pages/69360c/)
|
|
||||||
|
|
||||||
### 其他
|
|
||||||
|
|
||||||
- [Nosql 技术选型](01.数据库综合/01.Nosql技术选型.md)
|
|
||||||
- [数据结构与数据库索引](01.数据库综合/02.数据结构与数据库索引.md)
|
|
||||||
|
|
||||||
## 数据库中间件
|
## 数据库中间件
|
||||||
|
|
||||||
- [ShardingSphere 简介](02.数据库中间件/01.Shardingsphere/01.ShardingSphere简介.md)
|
- [ShardingSphere 简介](01.计算机科学/02.数据库/02.数据库中间件/01.Shardingsphere/01.ShardingSphere简介.md)
|
||||||
- [ShardingSphere Jdbc](02.数据库中间件/01.Shardingsphere/02.ShardingSphereJdbc.md)
|
- [ShardingSphere Jdbc](01.计算机科学/02.数据库/02.数据库中间件/01.Shardingsphere/02.ShardingSphereJdbc.md)
|
||||||
- [版本管理中间件 Flyway](02.数据库中间件/02.Flyway.md)
|
- [版本管理中间件 Flyway](01.计算机科学/02.数据库/02.数据库中间件/02.Flyway.md)
|
||||||
|
|
||||||
## 关系型数据库
|
## 关系型数据库
|
||||||
|
|
||||||
> [关系型数据库](03.关系型数据库) 整理主流关系型数据库知识点。
|
> [关系型数据库](01.计算机科学/02.数据库/03.关系型数据库) 整理主流关系型数据库知识点。
|
||||||
|
|
||||||
### 公共知识
|
### 公共知识
|
||||||
|
|
||||||
- [关系型数据库面试总结](03.关系型数据库/01.综合/01.关系型数据库面试.md) 💯
|
- [关系型数据库面试总结](01.计算机科学/02.数据库/03.关系型数据库/01.综合/01.关系型数据库面试.md) 💯
|
||||||
- [SQL Cheat Sheet](03.关系型数据库/01.综合/02.SqlCheatSheet.md) 是一个 SQL 入门教程。
|
- [SQL Cheat Sheet](01.计算机科学/02.数据库/03.关系型数据库/01.综合/02.SqlCheatSheet.md) 是一个 SQL 入门教程。
|
||||||
- [扩展 SQL](03.关系型数据库/01.综合/03.扩展SQL.md) 是一个 SQL 入门教程。
|
- [扩展 SQL](01.计算机科学/02.数据库/03.关系型数据库/01.综合/03.扩展SQL.md) 是一个 SQL 入门教程。
|
||||||
|
|
||||||
### Mysql
|
### Mysql
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
- [Mysql 应用指南](03.关系型数据库/02.Mysql/01.Mysql应用指南.md) ⚡
|
- [Mysql 应用指南](01.计算机科学/02.数据库/03.关系型数据库/02.Mysql/01.Mysql应用指南.md) ⚡
|
||||||
- [Mysql 工作流](03.关系型数据库/02.Mysql/02.MySQL工作流.md) - 关键词:`连接`、`缓存`、`语法分析`、`优化`、`执行引擎`、`redo log`、`bin log`、`两阶段提交`
|
- [Mysql 工作流](01.计算机科学/02.数据库/03.关系型数据库/02.Mysql/02.MySQL工作流.md) - 关键词:`连接`、`缓存`、`语法分析`、`优化`、`执行引擎`、`redo log`、`bin log`、`两阶段提交`
|
||||||
- [Mysql 事务](03.关系型数据库/02.Mysql/03.Mysql事务.md) - 关键词:`ACID`、`AUTOCOMMIT`、`事务隔离级别`、`死锁`、`分布式事务`
|
- [Mysql 事务](01.计算机科学/02.数据库/03.关系型数据库/02.Mysql/03.Mysql事务.md) - 关键词:`ACID`、`AUTOCOMMIT`、`事务隔离级别`、`死锁`、`分布式事务`
|
||||||
- [Mysql 锁](03.关系型数据库/02.Mysql/04.Mysql锁.md) - 关键词:`乐观锁`、`表级锁`、`行级锁`、`意向锁`、`MVCC`、`Next-key 锁`
|
- [Mysql 锁](01.计算机科学/02.数据库/03.关系型数据库/02.Mysql/04.Mysql锁.md) - 关键词:`乐观锁`、`表级锁`、`行级锁`、`意向锁`、`MVCC`、`Next-key 锁`
|
||||||
- [Mysql 索引](03.关系型数据库/02.Mysql/05.Mysql索引.md) - 关键词:`Hash`、`B 树`、`聚簇索引`、`回表`
|
- [Mysql 索引](01.计算机科学/02.数据库/03.关系型数据库/02.Mysql/05.Mysql索引.md) - 关键词:`Hash`、`B 树`、`聚簇索引`、`回表`
|
||||||
- [Mysql 性能优化](03.关系型数据库/02.Mysql/06.Mysql性能优化.md)
|
- [Mysql 性能优化](01.计算机科学/02.数据库/03.关系型数据库/02.Mysql/06.Mysql性能优化.md)
|
||||||
- [Mysql 运维](03.关系型数据库/02.Mysql/20.Mysql运维.md) 🔨
|
- [Mysql 运维](01.计算机科学/02.数据库/03.关系型数据库/02.Mysql/20.Mysql运维.md) 🔨
|
||||||
- [Mysql 配置](03.关系型数据库/02.Mysql/21.Mysql配置.md) 🔨
|
- [Mysql 配置](01.计算机科学/02.数据库/03.关系型数据库/02.Mysql/21.Mysql配置.md) 🔨
|
||||||
- [Mysql 问题](03.关系型数据库/02.Mysql/99.Mysql常见问题.md)
|
- [Mysql 问题](01.计算机科学/02.数据库/03.关系型数据库/02.Mysql/99.Mysql常见问题.md)
|
||||||
|
|
||||||
### 其他
|
### 其他
|
||||||
|
|
||||||
- [PostgreSQL 应用指南](03.关系型数据库/99.其他/01.PostgreSQL.md)
|
- [PostgreSQL 应用指南](01.计算机科学/02.数据库/03.关系型数据库/99.其他/01.PostgreSQL.md)
|
||||||
- [H2 应用指南](03.关系型数据库/99.其他/02.H2.md)
|
- [H2 应用指南](01.计算机科学/02.数据库/03.关系型数据库/99.其他/02.H2.md)
|
||||||
- [SqLite 应用指南](03.关系型数据库/99.其他/03.Sqlite.md)
|
- [SqLite 应用指南](01.计算机科学/02.数据库/03.关系型数据库/99.其他/03.Sqlite.md)
|
||||||
|
|
||||||
## 文档数据库
|
## 文档数据库
|
||||||
|
|
||||||
|
|
@ -113,16 +132,16 @@ footer: CC-BY-SA-4.0 Licensed | Copyright © 2018-Now Dunwu
|
||||||
>
|
>
|
||||||
> MongoDB 最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
|
> MongoDB 最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
|
||||||
|
|
||||||
- [MongoDB 应用指南](04.文档数据库/01.MongoDB/01.MongoDB应用指南.md)
|
- [MongoDB 应用指南](01.计算机科学/02.数据库/04.文档数据库/01.MongoDB/01.MongoDB应用指南.md)
|
||||||
- [MongoDB 的 CRUD 操作](04.文档数据库/01.MongoDB/02.MongoDB的CRUD操作.md)
|
- [MongoDB 的 CRUD 操作](01.计算机科学/02.数据库/04.文档数据库/01.MongoDB/02.MongoDB的CRUD操作.md)
|
||||||
- [MongoDB 聚合操作](04.文档数据库/01.MongoDB/03.MongoDB的聚合操作.md)
|
- [MongoDB 聚合操作](01.计算机科学/02.数据库/04.文档数据库/01.MongoDB/03.MongoDB的聚合操作.md)
|
||||||
- [MongoDB 事务](04.文档数据库/01.MongoDB/04.MongoDB事务.md)
|
- [MongoDB 事务](01.计算机科学/02.数据库/04.文档数据库/01.MongoDB/04.MongoDB事务.md)
|
||||||
- [MongoDB 建模](04.文档数据库/01.MongoDB/05.MongoDB建模.md)
|
- [MongoDB 建模](01.计算机科学/02.数据库/04.文档数据库/01.MongoDB/05.MongoDB建模.md)
|
||||||
- [MongoDB 建模示例](04.文档数据库/01.MongoDB/06.MongoDB建模示例.md)
|
- [MongoDB 建模示例](01.计算机科学/02.数据库/04.文档数据库/01.MongoDB/06.MongoDB建模示例.md)
|
||||||
- [MongoDB 索引](04.文档数据库/01.MongoDB/07.MongoDB索引.md)
|
- [MongoDB 索引](01.计算机科学/02.数据库/04.文档数据库/01.MongoDB/07.MongoDB索引.md)
|
||||||
- [MongoDB 复制](04.文档数据库/01.MongoDB/08.MongoDB复制.md)
|
- [MongoDB 复制](01.计算机科学/02.数据库/04.文档数据库/01.MongoDB/08.MongoDB复制.md)
|
||||||
- [MongoDB 分片](04.文档数据库/01.MongoDB/09.MongoDB分片.md)
|
- [MongoDB 分片](01.计算机科学/02.数据库/04.文档数据库/01.MongoDB/09.MongoDB分片.md)
|
||||||
- [MongoDB 运维](04.文档数据库/01.MongoDB/20.MongoDB运维.md)
|
- [MongoDB 运维](01.计算机科学/02.数据库/04.文档数据库/01.MongoDB/20.MongoDB运维.md)
|
||||||
|
|
||||||
## KV 数据库
|
## KV 数据库
|
||||||
|
|
||||||
|
|
@ -130,15 +149,15 @@ footer: CC-BY-SA-4.0 Licensed | Copyright © 2018-Now Dunwu
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
- [Redis 面试总结](05.KV数据库/01.Redis/01.Redis面试总结.md) 💯
|
- [Redis 面试总结](01.计算机科学/02.数据库/05.KV数据库/01.Redis/01.Redis面试总结.md) 💯
|
||||||
- [Redis 应用指南](05.KV数据库/01.Redis/02.Redis应用指南.md) ⚡ - 关键词:`内存淘汰`、`事件`、`事务`、`管道`、`发布与订阅`
|
- [Redis 应用指南](01.计算机科学/02.数据库/05.KV数据库/01.Redis/02.Redis应用指南.md) ⚡ - 关键词:`内存淘汰`、`事件`、`事务`、`管道`、`发布与订阅`
|
||||||
- [Redis 数据类型和应用](05.KV数据库/01.Redis/03.Redis数据类型和应用.md) - 关键词:`STRING`、`HASH`、`LIST`、`SET`、`ZSET`、`BitMap`、`HyperLogLog`、`Geo`
|
- [Redis 数据类型和应用](01.计算机科学/02.数据库/05.KV数据库/01.Redis/03.Redis数据类型和应用.md) - 关键词:`STRING`、`HASH`、`LIST`、`SET`、`ZSET`、`BitMap`、`HyperLogLog`、`Geo`
|
||||||
- [Redis 持久化](05.KV数据库/01.Redis/04.Redis持久化.md) - 关键词:`RDB`、`AOF`、`SAVE`、`BGSAVE`、`appendfsync`
|
- [Redis 持久化](01.计算机科学/02.数据库/05.KV数据库/01.Redis/04.Redis持久化.md) - 关键词:`RDB`、`AOF`、`SAVE`、`BGSAVE`、`appendfsync`
|
||||||
- [Redis 复制](05.KV数据库/01.Redis/05.Redis复制.md) - 关键词:`SLAVEOF`、`SYNC`、`PSYNC`、`REPLCONF ACK`
|
- [Redis 复制](01.计算机科学/02.数据库/05.KV数据库/01.Redis/05.Redis复制.md) - 关键词:`SLAVEOF`、`SYNC`、`PSYNC`、`REPLCONF ACK`
|
||||||
- [Redis 哨兵](05.KV数据库/01.Redis/06.Redis哨兵.md) - 关键词:`Sentinel`、`PING`、`INFO`、`Raft`
|
- [Redis 哨兵](01.计算机科学/02.数据库/05.KV数据库/01.Redis/06.Redis哨兵.md) - 关键词:`Sentinel`、`PING`、`INFO`、`Raft`
|
||||||
- [Redis 集群](05.KV数据库/01.Redis/07.Redis集群.md) - 关键词:`CLUSTER MEET`、`Hash slot`、`MOVED`、`ASK`、`SLAVEOF no one`、`redis-trib`
|
- [Redis 集群](01.计算机科学/02.数据库/05.KV数据库/01.Redis/07.Redis集群.md) - 关键词:`CLUSTER MEET`、`Hash slot`、`MOVED`、`ASK`、`SLAVEOF no one`、`redis-trib`
|
||||||
- [Redis 实战](05.KV数据库/01.Redis/08.Redis实战.md) - 关键词:`缓存`、`分布式锁`、`布隆过滤器`
|
- [Redis 实战](01.计算机科学/02.数据库/05.KV数据库/01.Redis/08.Redis实战.md) - 关键词:`缓存`、`分布式锁`、`布隆过滤器`
|
||||||
- [Redis 运维](05.KV数据库/01.Redis/20.Redis运维.md) 🔨 - 关键词:`安装`、`命令`、`集群`、`客户端`
|
- [Redis 运维](01.计算机科学/02.数据库/05.KV数据库/01.Redis/20.Redis运维.md) 🔨 - 关键词:`安装`、`命令`、`集群`、`客户端`
|
||||||
|
|
||||||
## 列式数据库
|
## 列式数据库
|
||||||
|
|
||||||
|
|
@ -157,30 +176,30 @@ footer: CC-BY-SA-4.0 Licensed | Copyright © 2018-Now Dunwu
|
||||||
|
|
||||||
> Elasticsearch 是一个基于 Lucene 的搜索和数据分析工具,它提供了一个分布式服务。Elasticsearch 是遵从 Apache 开源条款的一款开源产品,是当前主流的企业级搜索引擎。
|
> Elasticsearch 是一个基于 Lucene 的搜索和数据分析工具,它提供了一个分布式服务。Elasticsearch 是遵从 Apache 开源条款的一款开源产品,是当前主流的企业级搜索引擎。
|
||||||
|
|
||||||
- [Elasticsearch 面试总结](07.搜索引擎数据库/01.Elasticsearch/01.Elasticsearch面试总结.md) 💯
|
- [Elasticsearch 面试总结](01.计算机科学/02.数据库/07.搜索引擎数据库/01.Elasticsearch/01.Elasticsearch面试总结.md) 💯
|
||||||
- [Elasticsearch 快速入门](07.搜索引擎数据库/01.Elasticsearch/02.Elasticsearch快速入门.md)
|
- [Elasticsearch 快速入门](01.计算机科学/02.数据库/07.搜索引擎数据库/01.Elasticsearch/02.Elasticsearch快速入门.md)
|
||||||
- [Elasticsearch 简介](07.搜索引擎数据库/01.Elasticsearch/03.Elasticsearch简介.md)
|
- [Elasticsearch 简介](01.计算机科学/02.数据库/07.搜索引擎数据库/01.Elasticsearch/03.Elasticsearch简介.md)
|
||||||
- [Elasticsearch 索引](07.搜索引擎数据库/01.Elasticsearch/04.Elasticsearch索引.md)
|
- [Elasticsearch 索引](01.计算机科学/02.数据库/07.搜索引擎数据库/01.Elasticsearch/04.Elasticsearch索引.md)
|
||||||
- [Elasticsearch 查询](07.搜索引擎数据库/01.Elasticsearch/05.Elasticsearch查询.md)
|
- [Elasticsearch 查询](01.计算机科学/02.数据库/07.搜索引擎数据库/01.Elasticsearch/05.Elasticsearch查询.md)
|
||||||
- [Elasticsearch 高亮](07.搜索引擎数据库/01.Elasticsearch/06.Elasticsearch高亮.md)
|
- [Elasticsearch 高亮](01.计算机科学/02.数据库/07.搜索引擎数据库/01.Elasticsearch/06.Elasticsearch高亮.md)
|
||||||
- [Elasticsearch 排序](07.搜索引擎数据库/01.Elasticsearch/07.Elasticsearch排序.md)
|
- [Elasticsearch 排序](01.计算机科学/02.数据库/07.搜索引擎数据库/01.Elasticsearch/07.Elasticsearch排序.md)
|
||||||
- [Elasticsearch 聚合](07.搜索引擎数据库/01.Elasticsearch/08.Elasticsearch聚合.md)
|
- [Elasticsearch 聚合](01.计算机科学/02.数据库/07.搜索引擎数据库/01.Elasticsearch/08.Elasticsearch聚合.md)
|
||||||
- [Elasticsearch 分析器](07.搜索引擎数据库/01.Elasticsearch/09.Elasticsearch分析器.md)
|
- [Elasticsearch 分析器](01.计算机科学/02.数据库/07.搜索引擎数据库/01.Elasticsearch/09.Elasticsearch分析器.md)
|
||||||
- [Elasticsearch 性能优化](07.搜索引擎数据库/01.Elasticsearch/10.Elasticsearch性能优化.md)
|
- [Elasticsearch 性能优化](01.计算机科学/02.数据库/07.搜索引擎数据库/01.Elasticsearch/10.Elasticsearch性能优化.md)
|
||||||
- [Elasticsearch Rest API](07.搜索引擎数据库/01.Elasticsearch/11.ElasticsearchRestApi.md)
|
- [Elasticsearch Rest API](01.计算机科学/02.数据库/07.搜索引擎数据库/01.Elasticsearch/11.ElasticsearchRestApi.md)
|
||||||
- [ElasticSearch Java API 之 High Level REST Client](07.搜索引擎数据库/01.Elasticsearch/12.ElasticsearchHighLevelRestJavaApi.md)
|
- [ElasticSearch Java API 之 High Level REST Client](01.计算机科学/02.数据库/07.搜索引擎数据库/01.Elasticsearch/12.ElasticsearchHighLevelRestJavaApi.md)
|
||||||
- [Elasticsearch 集群和分片](07.搜索引擎数据库/01.Elasticsearch/13.Elasticsearch集群和分片.md)
|
- [Elasticsearch 集群和分片](01.计算机科学/02.数据库/07.搜索引擎数据库/01.Elasticsearch/13.Elasticsearch集群和分片.md)
|
||||||
- [Elasticsearch 运维](07.搜索引擎数据库/01.Elasticsearch/20.Elasticsearch运维.md)
|
- [Elasticsearch 运维](01.计算机科学/02.数据库/07.搜索引擎数据库/01.Elasticsearch/20.Elasticsearch运维.md)
|
||||||
|
|
||||||
### Elastic
|
### Elastic
|
||||||
|
|
||||||
- [Elastic 快速入门](07.搜索引擎数据库/02.Elastic/01.Elastic快速入门.md)
|
- [Elastic 快速入门](01.计算机科学/02.数据库/07.搜索引擎数据库/02.Elastic/01.Elastic快速入门.md)
|
||||||
- [Elastic 技术栈之 Filebeat](07.搜索引擎数据库/02.Elastic/02.Elastic技术栈之Filebeat.md)
|
- [Elastic 技术栈之 Filebeat](01.计算机科学/02.数据库/07.搜索引擎数据库/02.Elastic/02.Elastic技术栈之Filebeat.md)
|
||||||
- [Filebeat 运维](07.搜索引擎数据库/02.Elastic/03.Filebeat运维.md)
|
- [Filebeat 运维](01.计算机科学/02.数据库/07.搜索引擎数据库/02.Elastic/03.Filebeat运维.md)
|
||||||
- [Elastic 技术栈之 Kibana](07.搜索引擎数据库/02.Elastic/04.Elastic技术栈之Kibana.md)
|
- [Elastic 技术栈之 Kibana](01.计算机科学/02.数据库/07.搜索引擎数据库/02.Elastic/04.Elastic技术栈之Kibana.md)
|
||||||
- [Kibana 运维](07.搜索引擎数据库/02.Elastic/05.Kibana运维.md)
|
- [Kibana 运维](01.计算机科学/02.数据库/07.搜索引擎数据库/02.Elastic/05.Kibana运维.md)
|
||||||
- [Elastic 技术栈之 Logstash](07.搜索引擎数据库/02.Elastic/06.Elastic技术栈之Logstash.md)
|
- [Elastic 技术栈之 Logstash](01.计算机科学/02.数据库/07.搜索引擎数据库/02.Elastic/06.Elastic技术栈之Logstash.md)
|
||||||
- [Logstash 运维](07.搜索引擎数据库/02.Elastic/07.Logstash运维.md)
|
- [Logstash 运维](01.计算机科学/02.数据库/07.搜索引擎数据库/02.Elastic/07.Logstash运维.md)
|
||||||
|
|
||||||
## 资料 📚
|
## 资料 📚
|
||||||
|
|
||||||
|
|
@ -360,11 +379,11 @@ footer: CC-BY-SA-4.0 Licensed | Copyright © 2018-Now Dunwu
|
||||||
- [mongodb-json-files](https://github.com/ozlerhakan/mongodb-json-files)
|
- [mongodb-json-files](https://github.com/ozlerhakan/mongodb-json-files)
|
||||||
- **文章**
|
- **文章**
|
||||||
- [Introduction to MongoDB](https://www.slideshare.net/mdirolf/introduction-to-mongodb)
|
- [Introduction to MongoDB](https://www.slideshare.net/mdirolf/introduction-to-mongodb)
|
||||||
- [eBay: Building Mission-Critical Multi-Data Center Applications with MongoDB](https://www.mongodb.com/blog/post/ebay-building-mission-critical-multi-data-center-applications-with-mongodb)
|
- [eBay: Building Mission-Critical Multi-Data Center Applications with MongoDB](https://www.mongodb.com/blog/post/ebay-building-mission-critical-multi-data-center-applications-with-mongodb)
|
||||||
- [The AWS and MongoDB Infrastructure of Parse: Lessons Learned](https://medium.baqend.com/parse-is-gone-a-few-secrets-about-their-infrastructure-91b3ab2fcf71)
|
- [The AWS and MongoDB Infrastructure of Parse: Lessons Learned](https://medium.baqend.com/parse-is-gone-a-few-secrets-about-their-infrastructure-91b3ab2fcf71)
|
||||||
- [Migrating Mountains of Mongo Data](https://medium.com/build-addepar/migrating-mountains-of-mongo-data-63e530539952)
|
- [Migrating Mountains of Mongo Data](https://medium.com/build-addepar/migrating-mountains-of-mongo-data-63e530539952)
|
||||||
- **更多资源**
|
- **更多资源**
|
||||||
- [Github: Awesome MongoDB](https://github.com/ramnes/awesome-mongodb)
|
- [Github: Awesome MongoDB](https://github.com/ramnes/awesome-mongodb)
|
||||||
|
|
||||||
### 搜索引擎数据库资料
|
### 搜索引擎数据库资料
|
||||||
|
|
||||||
|
|
@ -384,10 +403,10 @@ footer: CC-BY-SA-4.0 Licensed | Copyright © 2018-Now Dunwu
|
||||||
- [Elasticsearch+Logstash+Kibana 教程](https://www.cnblogs.com/xing901022/p/4704319.html)
|
- [Elasticsearch+Logstash+Kibana 教程](https://www.cnblogs.com/xing901022/p/4704319.html)
|
||||||
- [ELK(Elasticsearch、Logstash、Kibana)安装和配置](https://github.com/judasn/Linux-Tutorial/blob/master/ELK-Install-And-Settings.md)
|
- [ELK(Elasticsearch、Logstash、Kibana)安装和配置](https://github.com/judasn/Linux-Tutorial/blob/master/ELK-Install-And-Settings.md)
|
||||||
- **性能调优相关**的工程实践
|
- **性能调优相关**的工程实践
|
||||||
- [Elasticsearch Performance Tuning Practice at eBay](https://www.ebayinc.com/stories/blogs/tech/elasticsearch-performance-tuning-practice-at-ebay/)
|
- [Elasticsearch Performance Tuning Practice at eBay](https://www.ebayinc.com/stories/blogs/tech/elasticsearch-performance-tuning-practice-at-ebay/)
|
||||||
- [Elasticsearch at Kickstarter](https://kickstarter.engineering/elasticsearch-at-kickstarter-db3c487887fc)
|
- [Elasticsearch at Kickstarter](https://kickstarter.engineering/elasticsearch-at-kickstarter-db3c487887fc)
|
||||||
- [9 tips on ElasticSearch configuration for high performance](https://www.loggly.com/blog/nine-tips-configuring-elasticsearch-for-high-performance/)
|
- [9 tips on ElasticSearch configuration for high performance](https://www.loggly.com/blog/nine-tips-configuring-elasticsearch-for-high-performance/)
|
||||||
- [Elasticsearch In Production - Deployment Best Practices](https://medium.com/@abhidrona/elasticsearch-deployment-best-practices-d6c1323b25d7)
|
- [Elasticsearch In Production - Deployment Best Practices](https://medium.com/@abhidrona/elasticsearch-deployment-best-practices-d6c1323b25d7)
|
||||||
- **更多资源**
|
- **更多资源**
|
||||||
- [GitHub: Awesome ElasticSearch](https://github.com/dzharii/awesome-elasticsearch)
|
- [GitHub: Awesome ElasticSearch](https://github.com/dzharii/awesome-elasticsearch)
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -20,6 +20,7 @@
|
||||||
"json2yaml": "^1.1.0",
|
"json2yaml": "^1.1.0",
|
||||||
"vuepress": "1.9.2",
|
"vuepress": "1.9.2",
|
||||||
"vuepress-plugin-baidu-tongji": "^1.0.1",
|
"vuepress-plugin-baidu-tongji": "^1.0.1",
|
||||||
|
"vuepress-plugin-comment": "^0.7.3",
|
||||||
"vuepress-plugin-demo-block": "^0.7.2",
|
"vuepress-plugin-demo-block": "^0.7.2",
|
||||||
"vuepress-plugin-fulltext-search": "^2.2.1",
|
"vuepress-plugin-fulltext-search": "^2.2.1",
|
||||||
"vuepress-plugin-one-click-copy": "^1.0.2",
|
"vuepress-plugin-one-click-copy": "^1.0.2",
|
||||||
|
|
|
||||||
|
|
@ -1,7 +0,0 @@
|
||||||
/**
|
|
||||||
* @see https://prettier.io/docs/en/options.html
|
|
||||||
* @see https://prettier.io/docs/en/configuration.html
|
|
||||||
*/
|
|
||||||
module.exports = {
|
|
||||||
tabWidth: 2, semi: false, singleQuote: true
|
|
||||||
}
|
|
||||||
Loading…
Reference in New Issue