mirror of https://github.com/dunwu/db-tutorial.git
更新图片路径
parent
766fd3b527
commit
6a21053fdf
|
|
@ -8,7 +8,7 @@ shardingsphere-jdbc 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供
|
||||||
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等。
|
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等。
|
||||||
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,Oracle,SQLServer,PostgreSQL 以及任何遵循 SQL92 标准的数据库。
|
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,Oracle,SQLServer,PostgreSQL 以及任何遵循 SQL92 标准的数据库。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
## 快速入门
|
## 快速入门
|
||||||
|
|
||||||
|
|
@ -74,7 +74,7 @@ DataSource dataSource = ShardingSphereDataSourceFactory.createDataSource(dataSou
|
||||||
|
|
||||||
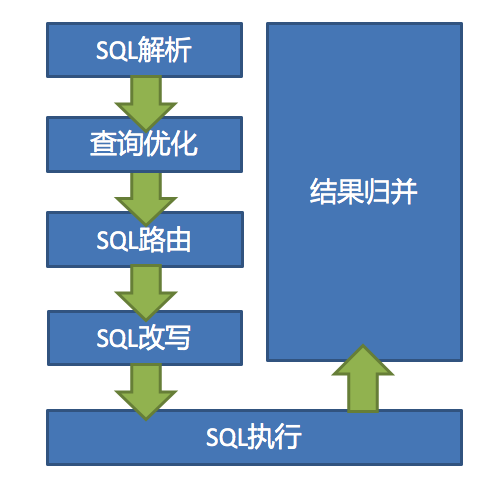
ShardingSphere 的 3 个产品的数据分片主要流程是完全一致的。 核心由 `SQL 解析 => 执行器优化 => SQL 路由 => SQL 改写 => SQL 执行 => 结果归并`的流程组成。
|
ShardingSphere 的 3 个产品的数据分片主要流程是完全一致的。 核心由 `SQL 解析 => 执行器优化 => SQL 路由 => SQL 改写 => SQL 执行 => 结果归并`的流程组成。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
- QL 解析:分为词法解析和语法解析。 先通过词法解析器将 SQL 拆分为一个个不可再分的单词。再使用语法解析器对 SQL 进行理解,并最终提炼出解析上下文。 解析上下文包括表、选择项、排序项、分组项、聚合函数、分页信息、查询条件以及可能需要修改的占位符的标记。
|
- QL 解析:分为词法解析和语法解析。 先通过词法解析器将 SQL 拆分为一个个不可再分的单词。再使用语法解析器对 SQL 进行理解,并最终提炼出解析上下文。 解析上下文包括表、选择项、排序项、分组项、聚合函数、分页信息、查询条件以及可能需要修改的占位符的标记。
|
||||||
- 执行器优化:合并和优化分片条件,如 OR 等。
|
- 执行器优化:合并和优化分片条件,如 OR 等。
|
||||||
|
|
|
||||||
|
|
@ -6,7 +6,7 @@
|
||||||
|
|
||||||
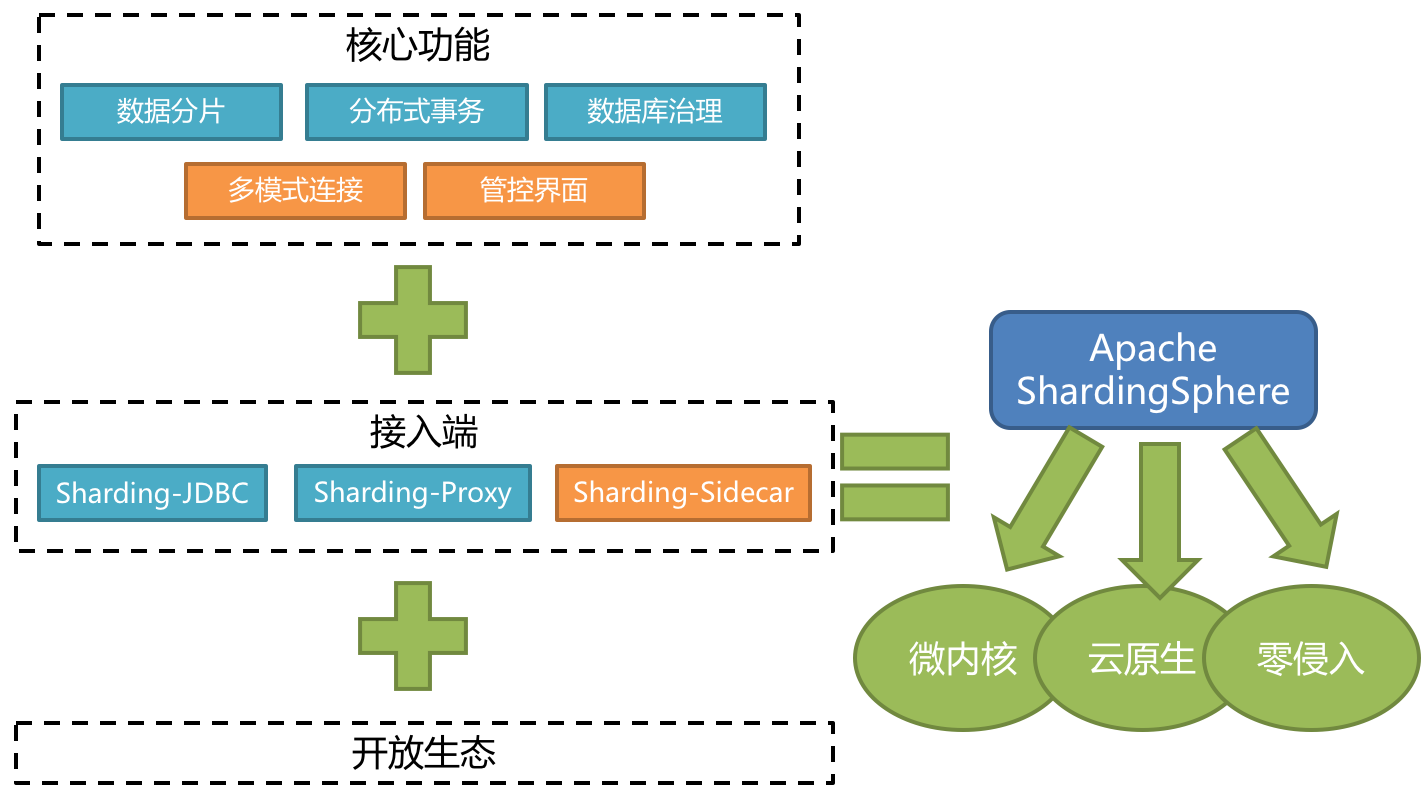
ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar(计划中)这 3 款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
|
ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar(计划中)这 3 款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
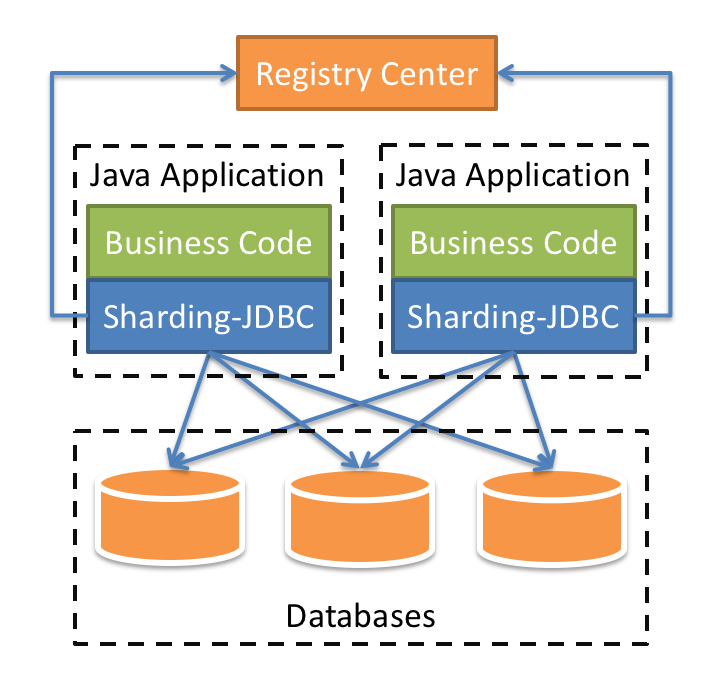
#### ShardingSphere-JDBC
|
#### ShardingSphere-JDBC
|
||||||
|
|
||||||
|
|
@ -16,7 +16,7 @@ ShardingSphere 是一套开源的分布式数据库中间件解决方案组成
|
||||||
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等。
|
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等。
|
||||||
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,Oracle,SQLServer,PostgreSQL 以及任何遵循 SQL92 标准的数据库。
|
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,Oracle,SQLServer,PostgreSQL 以及任何遵循 SQL92 标准的数据库。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
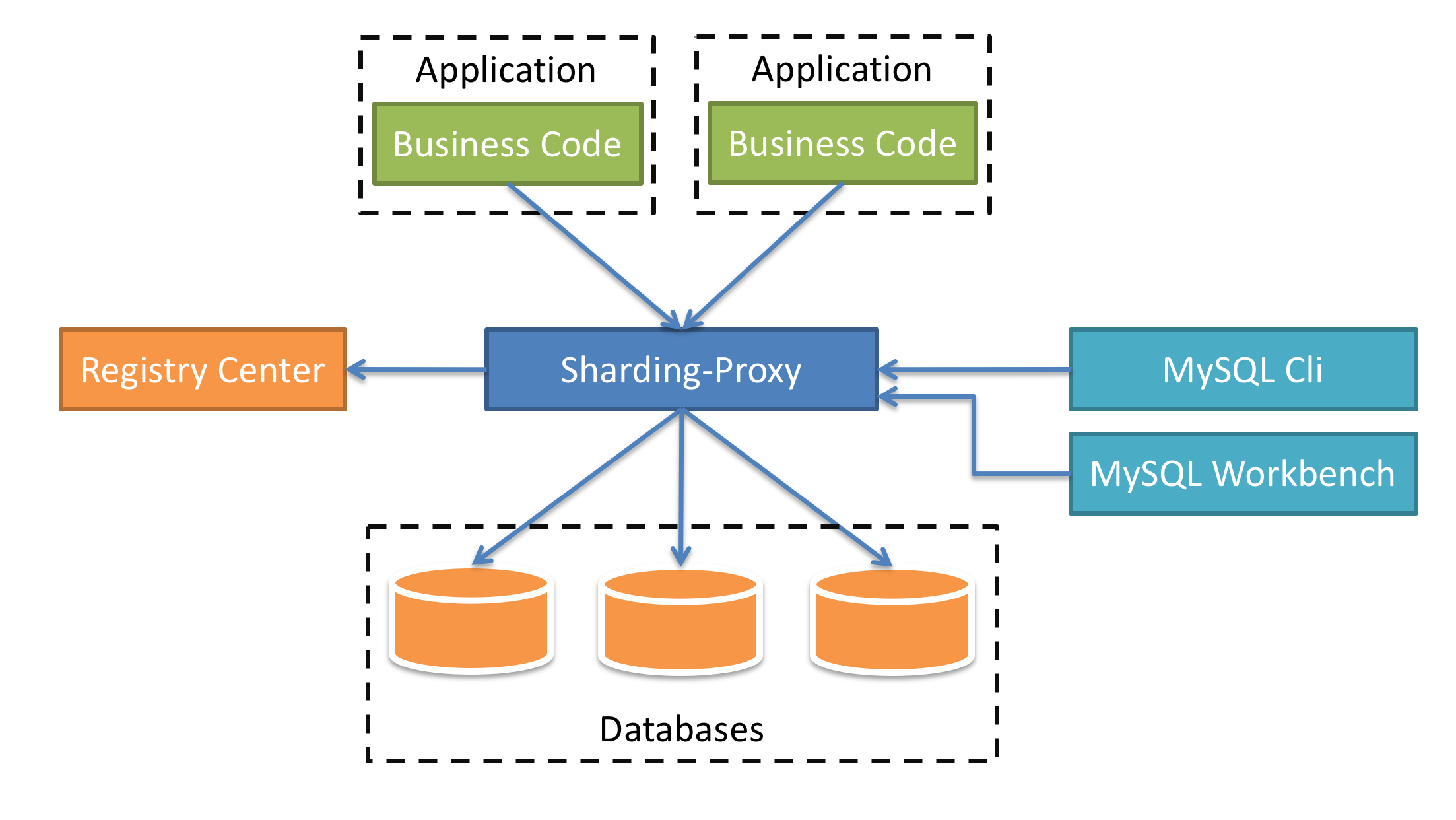
#### Sharding-Proxy
|
#### Sharding-Proxy
|
||||||
|
|
||||||
|
|
@ -25,7 +25,7 @@ ShardingSphere 是一套开源的分布式数据库中间件解决方案组成
|
||||||
- 向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用。
|
- 向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用。
|
||||||
- 适用于任何兼容 MySQL/PostgreSQL 协议的的客户端。
|
- 适用于任何兼容 MySQL/PostgreSQL 协议的的客户端。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
#### Sharding-Sidecar(TODO)
|
#### Sharding-Sidecar(TODO)
|
||||||
|
|
||||||
|
|
@ -33,7 +33,7 @@ ShardingSphere 是一套开源的分布式数据库中间件解决方案组成
|
||||||
|
|
||||||
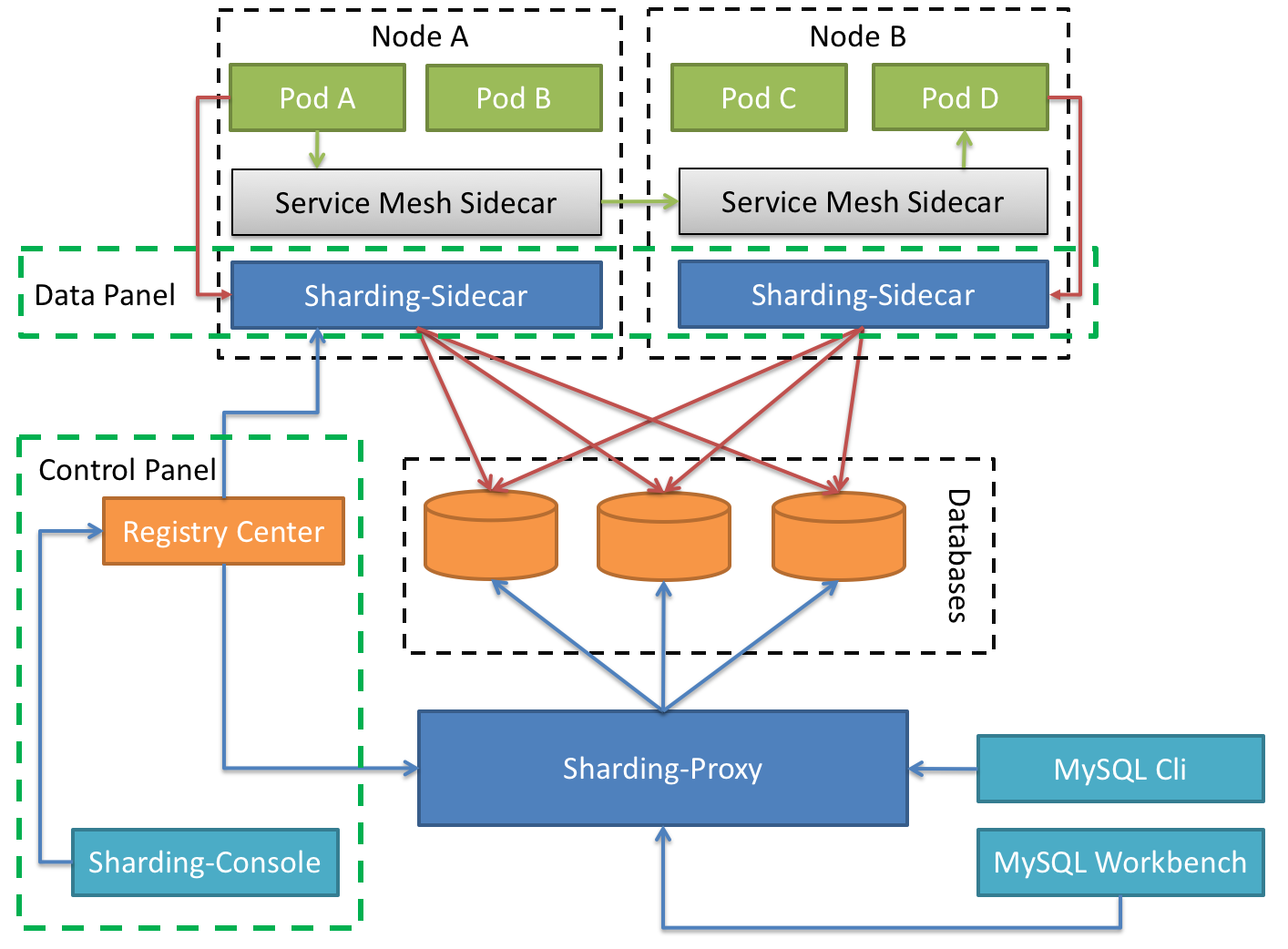
Database Mesh 的关注重点在于如何将分布式的数据访问应用与数据库有机串联起来,它更加关注的是交互,是将杂乱无章的应用与数据库之间的交互进行有效地梳理。 使用 Database Mesh,访问数据库的应用和数据库终将形成一个巨大的网格体系,应用和数据库只需在网格体系中对号入座即可,它们都是被啮合层所治理的对象。
|
Database Mesh 的关注重点在于如何将分布式的数据访问应用与数据库有机串联起来,它更加关注的是交互,是将杂乱无章的应用与数据库之间的交互进行有效地梳理。 使用 Database Mesh,访问数据库的应用和数据库终将形成一个巨大的网格体系,应用和数据库只需在网格体系中对号入座即可,它们都是被啮合层所治理的对象。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
| _Sharding-JDBC_ | _Sharding-Proxy_ | _Sharding-Sidecar_ | |
|
| _Sharding-JDBC_ | _Sharding-Proxy_ | _Sharding-Sidecar_ | |
|
||||||
| :-------------- | :--------------- | :----------------- | ------ |
|
| :-------------- | :--------------- | :----------------- | ------ |
|
||||||
|
|
@ -50,7 +50,7 @@ ShardingSphere-JDBC 采用无中心化架构,适用于 Java 开发的高性能
|
||||||
|
|
||||||
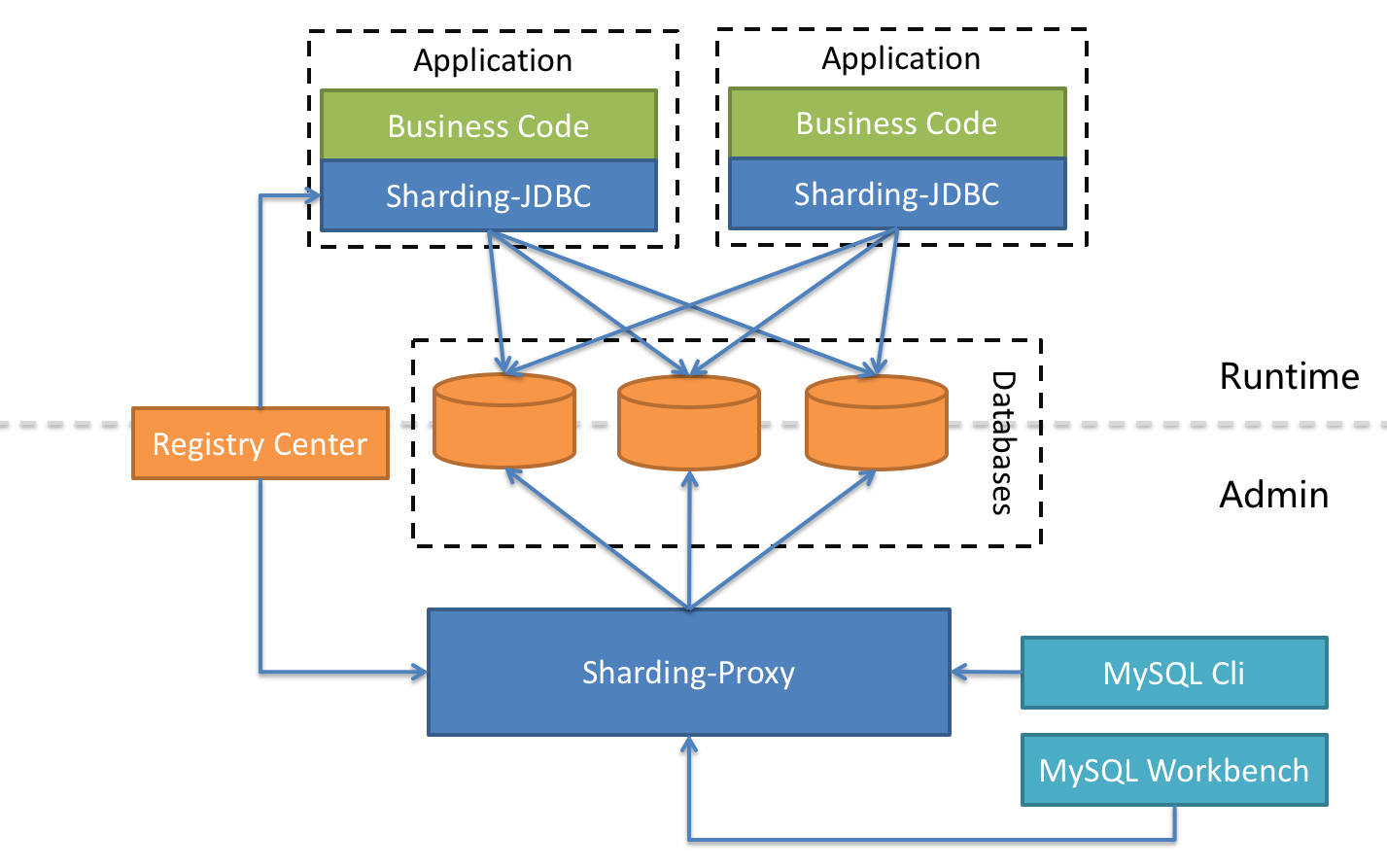
Apache ShardingSphere 是多接入端共同组成的生态圈。 通过混合使用 ShardingSphere-JDBC 和 ShardingSphere-Proxy,并采用同一注册中心统一配置分片策略,能够灵活的搭建适用于各种场景的应用系统,使得架构师更加自由地调整适合与当前业务的最佳系统架构。
|
Apache ShardingSphere 是多接入端共同组成的生态圈。 通过混合使用 ShardingSphere-JDBC 和 ShardingSphere-Proxy,并采用同一注册中心统一配置分片策略,能够灵活的搭建适用于各种场景的应用系统,使得架构师更加自由地调整适合与当前业务的最佳系统架构。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
### 功能列表
|
### 功能列表
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -14,7 +14,7 @@ MongoDB Pipeline 由多个阶段([stages](https://docs.mongodb.com/manual/refe
|
||||||
|
|
||||||
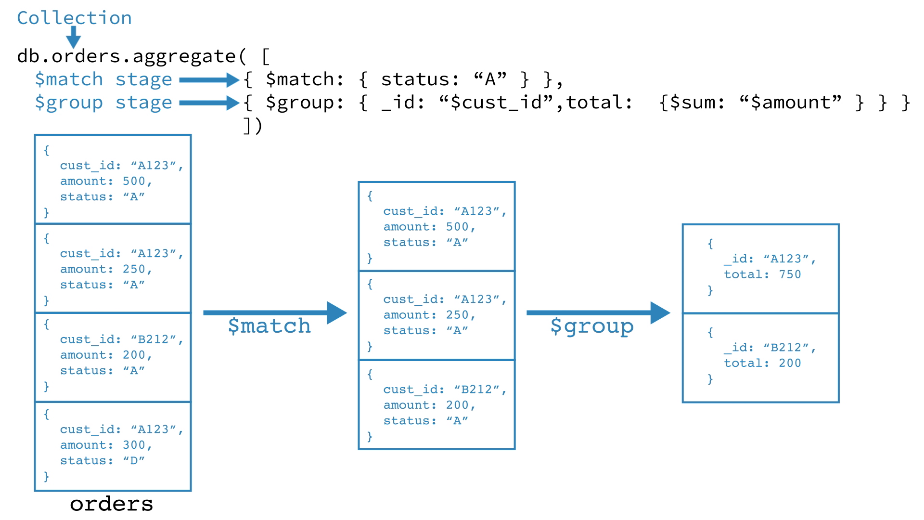
同一个阶段可以在 pipeline 中出现多次,但 [`$out`](https://docs.mongodb.com/manual/reference/operator/aggregation/out/#pipe._S_out)、[`$merge`](https://docs.mongodb.com/manual/reference/operator/aggregation/merge/#pipe._S_merge),和 [`$geoNear`](https://docs.mongodb.com/manual/reference/operator/aggregation/geoNear/#pipe._S_geoNear) 阶段除外。所有可用 pipeline 阶段可以参考:[Aggregation Pipeline Stages](https://docs.mongodb.com/manual/reference/operator/aggregation-pipeline/#aggregation-pipeline-operator-reference)。
|
同一个阶段可以在 pipeline 中出现多次,但 [`$out`](https://docs.mongodb.com/manual/reference/operator/aggregation/out/#pipe._S_out)、[`$merge`](https://docs.mongodb.com/manual/reference/operator/aggregation/merge/#pipe._S_merge),和 [`$geoNear`](https://docs.mongodb.com/manual/reference/operator/aggregation/geoNear/#pipe._S_geoNear) 阶段除外。所有可用 pipeline 阶段可以参考:[Aggregation Pipeline Stages](https://docs.mongodb.com/manual/reference/operator/aggregation-pipeline/#aggregation-pipeline-operator-reference)。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
- 第一阶段:[`$match`](https://docs.mongodb.com/manual/reference/operator/aggregation/match/#pipe._S_match) 阶段按状态字段过滤 document,然后将状态等于“ A”的那些 document 传递到下一阶段。
|
- 第一阶段:[`$match`](https://docs.mongodb.com/manual/reference/operator/aggregation/match/#pipe._S_match) 阶段按状态字段过滤 document,然后将状态等于“ A”的那些 document 传递到下一阶段。
|
||||||
- 第二阶段:[`$group`](https://docs.mongodb.com/manual/reference/operator/aggregation/group/#pipe._S_group) 阶段按 cust_id 字段对 document 进行分组,以计算每个唯一 cust_id 的金额总和。
|
- 第二阶段:[`$group`](https://docs.mongodb.com/manual/reference/operator/aggregation/group/#pipe._S_group) 阶段按 cust_id 字段对 document 进行分组,以计算每个唯一 cust_id 的金额总和。
|
||||||
|
|
@ -224,7 +224,7 @@ Pipeline 的内存限制为 100 MB。
|
||||||
|
|
||||||
Map-reduce 是一种数据处理范式,用于将大量数据汇总为有用的聚合结果。为了执行 map-reduce 操作,MongoDB 提供了 [`mapReduce`](https://docs.mongodb.com/manual/reference/command/mapReduce/#dbcmd.mapReduce) 数据库命令。
|
Map-reduce 是一种数据处理范式,用于将大量数据汇总为有用的聚合结果。为了执行 map-reduce 操作,MongoDB 提供了 [`mapReduce`](https://docs.mongodb.com/manual/reference/command/mapReduce/#dbcmd.mapReduce) 数据库命令。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
在上面的操作中,MongoDB 将 map 阶段应用于每个输入 document(即 collection 中与查询条件匹配的 document)。 map 函数分发出多个键-值对。对于具有多个值的那些键,MongoDB 应用 reduce 阶段,该阶段收集并汇总聚合的数据。然后,MongoDB 将结果存储在 collection 中。可选地,reduce 函数的输出可以通过 finalize 函数来进一步汇总聚合结果。
|
在上面的操作中,MongoDB 将 map 阶段应用于每个输入 document(即 collection 中与查询条件匹配的 document)。 map 函数分发出多个键-值对。对于具有多个值的那些键,MongoDB 应用 reduce 阶段,该阶段收集并汇总聚合的数据。然后,MongoDB 将结果存储在 collection 中。可选地,reduce 函数的输出可以通过 finalize 函数来进一步汇总聚合结果。
|
||||||
|
|
||||||
|
|
@ -240,7 +240,7 @@ MongoDB 支持一下单一目的的聚合操作:
|
||||||
|
|
||||||
所有这些操作都汇总了单个 collection 中的 document。尽管这些操作提供了对常见聚合过程的简单访问,但是它们相比聚合 pipeline 和 map-reduce,缺少灵活性和丰富的功能性。
|
所有这些操作都汇总了单个 collection 中的 document。尽管这些操作提供了对常见聚合过程的简单访问,但是它们相比聚合 pipeline 和 map-reduce,缺少灵活性和丰富的功能性。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
## SQL 和 MongoDB 聚合对比
|
## SQL 和 MongoDB 聚合对比
|
||||||
|
|
||||||
|
|
@ -371,7 +371,7 @@ db.orders.insertMany([
|
||||||
|
|
||||||
SQL 和 MongoDB 聚合方式对比:
|
SQL 和 MongoDB 聚合方式对比:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
## 参考资料
|
## 参考资料
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -17,7 +17,7 @@ MongoDB 提供以下操作向一个 collection 插入 document
|
||||||
|
|
||||||
> 注:以上操作都是原子操作。
|
> 注:以上操作都是原子操作。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
插入操作的特性:
|
插入操作的特性:
|
||||||
|
|
||||||
|
|
@ -66,7 +66,7 @@ db.inventory.insertMany([
|
||||||
|
|
||||||
MongoDB 提供 [`db.collection.find()`](https://docs.mongodb.com/manual/reference/method/db.collection.find/#db.collection.find) 方法来检索 document。
|
MongoDB 提供 [`db.collection.find()`](https://docs.mongodb.com/manual/reference/method/db.collection.find/#db.collection.find) 方法来检索 document。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
### Update 操作
|
### Update 操作
|
||||||
|
|
||||||
|
|
@ -82,7 +82,7 @@ MongoDB 提供以下操作来更新 collection 中的 document
|
||||||
- [`db.collection.updateMany(<filter>, <update>, <options>)`](https://docs.mongodb.com/manual/reference/method/db.collection.updateMany/#db.collection.updateMany)
|
- [`db.collection.updateMany(<filter>, <update>, <options>)`](https://docs.mongodb.com/manual/reference/method/db.collection.updateMany/#db.collection.updateMany)
|
||||||
- [`db.collection.replaceOne(<filter>, <update>, <options>)`](https://docs.mongodb.com/manual/reference/method/db.collection.replaceOne/#db.collection.replaceOne)
|
- [`db.collection.replaceOne(<filter>, <update>, <options>)`](https://docs.mongodb.com/manual/reference/method/db.collection.replaceOne/#db.collection.replaceOne)
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
【示例】插入测试数据
|
【示例】插入测试数据
|
||||||
|
|
||||||
|
|
@ -191,7 +191,7 @@ MongoDB 提供以下操作来删除 collection 中的 document
|
||||||
- [`db.collection.deleteOne()`](https://docs.mongodb.com/manual/reference/method/db.collection.deleteOne/#db.collection.deleteOne):删除一条 document
|
- [`db.collection.deleteOne()`](https://docs.mongodb.com/manual/reference/method/db.collection.deleteOne/#db.collection.deleteOne):删除一条 document
|
||||||
- [`db.collection.deleteMany()`](https://docs.mongodb.com/manual/reference/method/db.collection.deleteMany/#db.collection.deleteMany):删除多条 document
|
- [`db.collection.deleteMany()`](https://docs.mongodb.com/manual/reference/method/db.collection.deleteMany/#db.collection.deleteMany):删除多条 document
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
删除操作的特性:
|
删除操作的特性:
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -12,7 +12,7 @@
|
||||||
|
|
||||||
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构。
|
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
### createIndex() 方法
|
### createIndex() 方法
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -371,7 +371,7 @@ review collection 存储所有的评论
|
||||||
|
|
||||||
## 树形结构模型
|
## 树形结构模型
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
### 具有父节点的树形结构模型
|
### 具有父节点的树形结构模型
|
||||||
|
|
||||||
|
|
@ -525,7 +525,7 @@ db.categories.insertMany([
|
||||||
|
|
||||||
### 具有嵌套集的树形结构模型
|
### 具有嵌套集的树形结构模型
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
```javascript
|
```javascript
|
||||||
db.categories.insertMany([
|
db.categories.insertMany([
|
||||||
|
|
|
||||||
|
|
@ -125,7 +125,7 @@ This looks very different from the tabular data structure you started with in St
|
||||||
|
|
||||||
嵌入式 document 通过将相关数据存储在单个 document 结构中来捕获数据之间的关系。 MongoDB document 可以将 document 结构嵌入到另一个 document 中的字段或数组中。这些非规范化的数据模型允许应用程序在单个数据库操作中检索和操纵相关数据。
|
嵌入式 document 通过将相关数据存储在单个 document 结构中来捕获数据之间的关系。 MongoDB document 可以将 document 结构嵌入到另一个 document 中的字段或数组中。这些非规范化的数据模型允许应用程序在单个数据库操作中检索和操纵相关数据。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
对于 MongoDB 中的很多场景,非规范化数据模型都是最佳的。
|
对于 MongoDB 中的很多场景,非规范化数据模型都是最佳的。
|
||||||
|
|
||||||
|
|
@ -137,7 +137,7 @@ This looks very different from the tabular data structure you started with in St
|
||||||
|
|
||||||
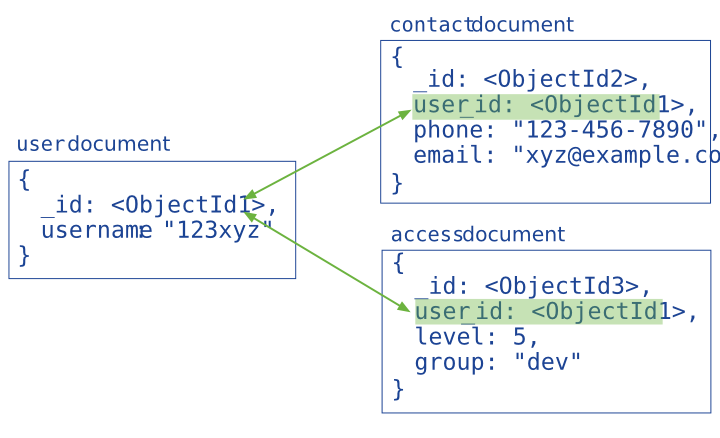
引用通过包含从一个 document 到另一个 document 的链接或引用来存储数据之间的关系。 应用程序可以解析这些引用以访问相关数据。 广义上讲,这些是规范化的数据模型。
|
引用通过包含从一个 document 到另一个 document 的链接或引用来存储数据之间的关系。 应用程序可以解析这些引用以访问相关数据。 广义上讲,这些是规范化的数据模型。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
通常,在以下场景使用引用式的数据模型:
|
通常,在以下场景使用引用式的数据模型:
|
||||||
|
|
||||||
|
|
|
||||||
Loading…
Reference in New Issue