mirror of https://github.com/dunwu/db-tutorial.git
更新文档
parent
e1f862a770
commit
b48d14643b
Binary file not shown.
|
|
@ -1,136 +0,0 @@
|
||||||
# 数据结构在数据库中的应用
|
|
||||||
|
|
||||||
> 关键词:链表、数组、散列表、红黑树、B+ 树、LSM 树、跳表
|
|
||||||
|
|
||||||
## 引言
|
|
||||||
|
|
||||||
从本质来看,数据库只负责两件事:读数据、写数据。
|
|
||||||
|
|
||||||
数据结构的核心就是合理组织数据,尽可能提升读、写数据的效率。
|
|
||||||
|
|
||||||
所以,数据结构是实现数据库的基石。
|
|
||||||
|
|
||||||
## 索引
|
|
||||||
|
|
||||||
索引是基于原始数据衍生的扩展数据结构。它的主要作用是缩小检索的数据范围,提升查询性能。
|
|
||||||
|
|
||||||
很多数据库允许单独添加和删除索引,而不影响数据库的内容,它只会影响查询性能。维护额外的结构势必会引入开销,特别是在新数据写入时。对于写人,它很难超过简单地追加文件方式的性能,因为那已经是最简单的写操作了。由于每次写数据时,需要更新索引,因此任何类型的索引通常都会降低写的速度。
|
|
||||||
|
|
||||||
### 数组和链表
|
|
||||||
|
|
||||||
数组和链表分别代表了连续空间和不连续空间的存储方式,它们是线性表(Linear List)的典型代表。其他所有的数据结构,比如栈、队列、二叉树、B+ 树等,实际上都是这两者的结合和变化。
|
|
||||||
|
|
||||||
数组**支持随机访问**。根据下标随机访问的时间复杂度为 `O(1)`。但这并不代表数组的查找时间复杂度也是 `O(1)`。
|
|
||||||
|
|
||||||
- 对于无序数组,只能顺序查找,其时间复杂度为 `O(n)`。
|
|
||||||
- 对于有序数组,可以应用二分查找法,其时间复杂度为 `O(log n)`。
|
|
||||||
|
|
||||||
在有序数组上应用二分查找法如此高效,为什么几乎没有数据库直接使用数组作为索引?这是因为它的限制条件:数据有序。为了保证数据有序,每次添加、删除数组数据时,都必须要进行数据调整,来保证其有序。此外,由于数组空间大小固定,每次扩容只能采用复制数组的方式。数组的这些特性,决定了它不适合用于数据频繁变化的应用场景。
|
|
||||||
|
|
||||||
### 散列表
|
|
||||||
|
|
||||||
散列表的思路是:使用 Hash 函数将 Key 转换为数组下标。
|
|
||||||
|
|
||||||
哈希表的本质是一个数组,它通过 Hash 函数将查询的 Key 转为数组下标,利用数组的随机访问特性,使得我们能在 `O(1)` 的时间代价内完成检索。
|
|
||||||
|
|
||||||
#### 位图和布隆过滤器
|
|
||||||
|
|
||||||
在海量数据中,快速判断一个对象是否存在。相比于有序数组、二叉检索树和哈希表这三种方案,位图和布隆过滤器其实更适合解决这类状态检索的问题。这是因为,在不要求 100% 判断正确的情况下,使用位图和布隆过滤器可以达到 `O(1)` 时间代价的检索效率,同时空间使用率也非常高效。
|
|
||||||
|
|
||||||
为了判断一个很大的数据范围中,某数值是否存在,可以将这个范围的数据存为数组,其数组值为布尔型(true 或 false)。由于很多语言中,布尔类型需要 1 个字节,而二进制位(bit)的值 0 或 1 也可以表示 true 或 false,并且占用空间更小,所以更加合适。而这种基于位运算的哈希结构,即为位图。
|
|
||||||
|
|
||||||
布隆过滤器最大的特点,就是对一个对象使用多个哈希函数。如果我们使用了 k 个哈希函数,就会得到 k 个哈希值,也就是 k 个下标,我们会把数组中对应下标位置的值都置为 1。布隆过滤器和位图最大的区别就在于,我们不再使用一位来表示一个对象,而是使用 k 位来表示一个对象。这样两个对象的 k 位都相同的概率就会大大降低,从而能够解决哈希冲突的问题了。
|
|
||||||
|
|
||||||
布隆过滤器的误判有一个特点,那就是,它只会对存在的情况有误判。如果某个数字经过布隆过滤器判断不存在,那说明这个数字真的不存在,不会发生误判;如果某个数字经过布隆过滤器判断存在,这个时候才会有可能误判,有可能并不存在。不过,只要我们调整哈希函数的个数、位图大小跟要存储数字的个数之间的比例,那就可以将这种误判的概率降到非常低。
|
|
||||||
|
|
||||||
布隆过滤器过滤器适用于对误判有一定容忍度的场景。
|
|
||||||
|
|
||||||
### B+ 树
|
|
||||||
|
|
||||||
内存是半导体元件。对于内存而言,只要给出了内存地址,我们就可以直接访问该地址取出数据。这个过程具有高效的随机访问特性,因此内存也叫随机访问存储器(Random Access Memory,即 RAM)。内存的访问速度很快,但是价格相对较昂贵,因此一般的计算机内存空间都相对较小。
|
|
||||||
|
|
||||||
而磁盘是机械器件。磁盘访问数据时,需要等磁盘盘片旋转到磁头下,才能读取相应的数据。尽管磁盘的旋转速度很快,但是和内存的随机访问相比,性能差距非常大。一般来说,如果是随机读写,会有 10 万到 100 万倍左右的差距。但如果是顺序访问大批量数据的话,磁盘的性能和内存就是一个数量级的。
|
|
||||||
|
|
||||||
磁盘的最小读写单位是扇区,较早期的磁盘一个扇区是 **`512`** 字节。随着磁盘技术的发展,目前常见的磁盘扇区是 **`4K`** 个字节。操作系统一次会读写多个扇区,所以操作系统的最小读写单位是块(Block),也叫作簇(Cluster)。当我们要从磁盘中读取一个数据时,操作系统会一次性将整个块都读出来。因此,对于大批量的顺序读写来说,磁盘的效率会比随机读写高许多。
|
|
||||||
|
|
||||||
假设有一个有序数组存储在硬盘中,如果它足够大,那么它会存储在多个块中。当我们要对这个数组使用二分查找时,需要先找到中间元素所在的块,将这个块从磁盘中读到内存里,然后在内存中进行二分查找。如果下一步要读的元素在其他块中,则需要再将相应块从磁盘中读入内存。直到查询结束,这个过程可能会多次访问磁盘。我们可以看到,这样的检索性能非常低。
|
|
||||||
|
|
||||||
由于磁盘相对于内存而言访问速度实在太慢,因此,对于磁盘上数据的高效检索,我们有一个极其重要的原则:对磁盘的访问次数要尽可能的少!
|
|
||||||
|
|
||||||
将索引和数据分离就是一种常见的设计思路。在数据频繁变化的场景中,有序数组并不是一个最好的选择,二叉检索树或者哈希表往往更有普适性。但是,哈希表由于缺乏范围检索的能力,在一些场合也不适用。因此,二叉检索树这种树形结构是许多常见检索系统的实施方案。
|
|
||||||
|
|
||||||
随着索引数据越来越大,直到无法完全加载到内存中,这是需要将索引数据也存入磁盘中。B+ 树给出了将树形索引的所有节点都存在磁盘上的高效检索方案。操作系统对磁盘数据的访问是以块为单位的。因此,如果我们想将树型索引的一个节点从磁盘中读出,即使该节点的数据量很小(比如说只有几个字节),但磁盘依然会将整个块的数据全部读出来,而不是只读这一小部分数据,这会让有效读取效率很低。B+ 树的一个关键设计,就是让一个节点的大小等于一个块的大小。节点内存储的数据,不是一个元素,而是一个可以装 m 个元素的有序数组。这样一来,我们就可以将磁盘一次读取的数据全部利用起来,使得读取效率最大化。
|
|
||||||
|
|
||||||
B+ 树还有另一个设计,就是将所有的节点分为内部节点和叶子节点。内部节点仅存储 key 和维持树形结构的指针,并不存储 key 对应的数据(无论是具体数据还是文件位置信息)。这样内部节点就能存储更多的索引数据,我们也就可以使用最少的内部节点,将所有数据组织起来了。而叶子节点仅存储 key 和对应数据,不存储维持树形结构的指针。通过这样的设计,B+ 树就能做到节点的空间利用率最大化。此外,B+ 树还将同一层的所有节点串成了有序的双向链表,这样一来,B+ 树就同时具备了良好的范围查询能力和灵活调整的能力了。
|
|
||||||
|
|
||||||
因此,B+ 树是一棵完全平衡的 m 阶多叉树。所谓的 m 阶,指的是每个节点最多有 m 个子节点,并且每个节点里都存了一个紧凑的可包含 m 个元素的数组。
|
|
||||||
|
|
||||||
即使是复杂的 B+ 树,我们将它拆解开来,其实也是由简单的数组、链表和树组成的,而且 B+ 树的检索过程其实也是二分查找。因此,如果 B+ 树完全加载在内存中的话,它的检索效率其实并不会比有序数组或者二叉检索树更
|
|
||||||
高,也还是二分查找的 log(n) 的效率。并且,它还比数组和二叉检索树更加复杂,还会带来额外的开销。
|
|
||||||
|
|
||||||
另外,这一节还有一个很重要的设计思想需要你掌握,那就是将索引和数据分离。通过这样的方式,我们能将索引的数组大小保持在一个较小的范围内,让它能加载在内存中。在许多大规模系统中,都是使用这个设计思想来精简索引的。而且,B+ 树的内部节点和叶子节点的区分,其实也是索引和数据分离的一次实践。
|
|
||||||
|
|
||||||
MySQL 中的 B+ 树实现其实有两种,一种是 MyISAM 引擎,另一种是 InnoDB 引擎。它们的核心区别就在于,数据和索引是否是分离的。
|
|
||||||
|
|
||||||
在 MyISAM 引擎中,B+ 树的叶子节点仅存储了数据的位置指针,这是一种索引和数据分离的设计方案,叫作非聚集索引。如果要保证 MyISAM 的数据一致性,那我们需要在表级别上进行加锁处理。
|
|
||||||
|
|
||||||
在 InnoDB 中,B+ 树的叶子节点直接存储了具体数据,这是一种索引和数据一体的方案。叫作聚集索引。由于数据直接就存在索引的叶子节点中,因此 InnoDB 不需要给全表加锁来保证一致性,它只需要支持行级的锁就可以了。
|
|
||||||
|
|
||||||
### LSM 树
|
|
||||||
|
|
||||||
B+ 树的数据都存储在叶子节点中,而叶子节点一般都存储在磁盘中。因此,每次插入的新数据都需要随机写入磁盘,而随机写入的性能非常慢。如果是一个日志系统,每秒钟要写入上千条甚至上万条数据,这样的磁盘操作代价会使得系统性能急剧下降,甚至无法使用。
|
|
||||||
|
|
||||||
操作系统对磁盘的读写是以块为单位的,我们能否以块为单位写入,而不是每次插入一个数据都要随机写入磁盘呢?这样是不是就可以大幅度减少写入操作了呢?解决方案就是:**LSM 树**(Log Structured Merge Trees)。
|
|
||||||
|
|
||||||
LSM 树就是根据这个思路设计了这样一个机制:当数据写入时,延迟写磁盘,将数据先存放在内存中的树里,进行常规的存储和查询。当内存中的树持续变大达到阈值时,再批量地以块为单位写入磁盘的树中。因此,LSM 树至少需要由两棵树组成,一棵是存储在内存中较小的 C0 树,另一棵是存储在磁盘中较大的 C1 树。
|
|
||||||
|
|
||||||
LSM 树具有以下 3 个特点:
|
|
||||||
|
|
||||||
1. 将索引分为内存和磁盘两部分,并在内存达到阈值时启动树合并(Merge Trees);
|
|
||||||
2. 用批量写入代替随机写入,并且用预写日志 WAL 技术(Write AheadLog,预写日志技术)保证内存数据,在系统崩溃后可以被恢复;
|
|
||||||
3. 数据采取类似日志追加写的方式写入(Log Structured)磁盘,以顺序写的方式提高写
|
|
||||||
入效率。
|
|
||||||
|
|
||||||
LSM 树的这些特点,使得它相对于 B+ 树,在写入性能上有大幅提升。所以,许多 NoSQL 系统都使用 LSM 树作为检索引擎,而且还对 LSM 树进行了优化以提升检索性能。
|
|
||||||
|
|
||||||
### 倒排索引
|
|
||||||
|
|
||||||
倒排索引的核心其实并不复杂,它的具体实现其实是哈希表,只是它不是将文档 ID 或者题目作为 key,而是反过来,通过将内容或者属性作为 key 来存储对应的文档列表,使得我们能在 O(1) 的时间代价内完成查询。
|
|
||||||
|
|
||||||
尽管原理并不复杂,但是倒排索引是许多检索引擎的核心。比如说,数据库的全文索引功能、搜索引擎的索引、广告引擎和推荐引擎,都使用了倒排索引技术来实现检索功能。
|
|
||||||
|
|
||||||
### 索引的维护
|
|
||||||
|
|
||||||
#### 创建索引
|
|
||||||
|
|
||||||
- **数据压缩**:一个是尽可能地将数据加载到内存中,因为内存的检索效率大大高于磁盘。那为了将数据更多地加载到内存中,索引压缩是一个重要的研究方向。
|
|
||||||
- **分支处理**:另一个是将大数据集合拆成多个小数据集合来处理。这其实就是分布式系统的核心思想。
|
|
||||||
|
|
||||||
#### 更新索引
|
|
||||||
|
|
||||||
(1)Double Buffer(双缓冲)机制
|
|
||||||
|
|
||||||
就是在内存中同时保存两份一样的索引,一个是索引 A,一个是索引 B。两个索引保持一个读、一个写,并且来回切换,最终完成高性能的索引更新。
|
|
||||||
|
|
||||||
优点:简单高效
|
|
||||||
|
|
||||||
缺点:达到一定数据量级后,会带来翻倍的内存开销,甚至有些索引存储在磁盘上的情况下,更是无法使用此机制。
|
|
||||||
|
|
||||||
(2)全量索引和增量索引
|
|
||||||
|
|
||||||
将新接收到的数据单独建立一个可以存在内存中的倒排索引,也就是增量索引。当查询发生的时候,我们会同时查询全量索引和增量索引,将合并的结果作为总的结果输出。
|
|
||||||
|
|
||||||
因为增量索引相对全量索引而言会小很多,内存资源消耗在可承受范围,所以我们可以使用 Double Buffer 机制
|
|
||||||
对增量索引进行索引更新。这样一来,增量索引就可以做到无锁访问。而全量索引本身就是只读的,也不需要加锁。因此,整个检索过程都可以做到无锁访问,也就提高了系统的检索效率。
|
|
||||||
|
|
||||||
## 参考资料
|
|
||||||
|
|
||||||
- **书籍**
|
|
||||||
- [《数据密集型应用系统设计》](https://book.douban.com/subject/30329536/)
|
|
||||||
- **教程**
|
|
||||||
- [数据结构与算法之美](https://time.geekbang.org/column/intro/100017301)
|
|
||||||
- [检索技术核心 20 讲](https://time.geekbang.org/column/intro/100048401)
|
|
||||||
- **论文**
|
|
||||||
- [Data Structures for Databases](https://www.cise.ufl.edu/~mschneid/Research/papers/HS05BoCh.pdf)
|
|
||||||
- **文章**
|
|
||||||
- [Data Structures and Algorithms for Big Databases](https://people.csail.mit.edu/bradley/BenderKuszmaul-tutorial-xldb12.pdf)
|
|
||||||
|
|
@ -0,0 +1,203 @@
|
||||||
|
# 数据结构与数据库索引
|
||||||
|
|
||||||
|
> 关键词:链表、数组、散列表、红黑树、B+ 树、LSM 树、跳表
|
||||||
|
|
||||||
|
## 引言
|
||||||
|
|
||||||
|
**数据库**是“按照 **数据结构** 来组织、存储和管理数据的仓库”。是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。
|
||||||
|
|
||||||
|
——上面这句定义对数据库的定义来自百度百科。通过这个定义,我们也能明显看出数据结构是实现数据库的基石。
|
||||||
|
|
||||||
|
从本质来看,数据库只负责两件事:读数据、写数据;而数据结构研究的是如何合理组织数据,尽可能提升读、写数据的效率,这恰好是数据库的核心问题。因此,数据结构与数据库这两个领域有非常多的交集。其中,数据库索引最能体现二者的紧密关联。
|
||||||
|
|
||||||
|
**索引是数据库为了提高查找效率的一种数据结构**。索引基于原始数据衍生而来,它的主要作用是缩小检索的数据范围,提升查询性能。通俗来说,索引在数据库中的作用就像是一本书的目录索引。索引对于良好的性能非常关键,在数据量小且负载较低时,不恰当的索引对于性能的影响可能还不明显;但随着数据量逐渐增大,性能则会急剧下降。因此,**索引优化应该是查询性能优化的最有效手段**。
|
||||||
|
|
||||||
|
很多数据库允许单独添加和删除索引,而不影响数据库的内容,它只会影响查询性能。维护额外的结构势必会引入开销,特别是在新数据写入时。对于写入,它很难超过简单地追加文件方式的性能,因为那已经是最简单的写操作了。由于每次写数据时,需要更新索引,因此任何类型的索引通常都会降低写的速度。
|
||||||
|
|
||||||
|
本文以一些常见的数据库为例,分析它们的索引采用了什么样的数据结构,有什么利弊,为何如此设计。
|
||||||
|
|
||||||
|
## 数组和链表
|
||||||
|
|
||||||
|
数组和链表分别代表了连续空间和不连续空间的存储方式,它们是线性表(Linear List)的典型代表。其他所有的数据结构,比如栈、队列、二叉树、B+ 树等,实际上都是这两者的结合和变化。
|
||||||
|
|
||||||
|
**数组用连续的内存空间来存储数据**。数组**支持随机访问,根据下标随机访问的时间复杂度为 `O(1)`**。但这并不代表数组的查找时间复杂度也是 `O(1)`。
|
||||||
|
|
||||||
|
- **对于无序数组,只能顺序查找,其时间复杂度为 `O(n)`**。
|
||||||
|
- **对于有序数组,可以应用二分查找法,其时间复杂度为 `O(log n)`**。
|
||||||
|
|
||||||
|
在有序数组上应用二分查找法如此高效,为什么几乎没有数据库直接使用数组作为索引?这是因为它的限制条件:**数据有序**——为了保证数据有序,每次添加、删除数组数据时,都必须要进行数据调整,来保证其有序,而 **数组的插入/删除操作,时间复杂度为 `O(n)`**。此外,由于数组空间大小固定,每次扩容只能采用复制数组的方式。数组的这些特性,决定了它不适合用于数据频繁变化的应用场景。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
**链表用不连续的内存空间来存储数据;并通过一个指针按顺序将这些空间串起来,形成一条链**。
|
||||||
|
|
||||||
|
区别于数组,链表中的元素不是存储在内存中连续的一片区域,链表中的数据存储在每一个称之为「结点」复合区域里,在每一个结点除了存储数据以外,还保存了到下一个节点的指针(Pointer)。由于不必按顺序存储,**链表的插入/删除操作,时间复杂度为 `O(1)`**,但是,链表只支持顺序访问,其 **查找时间复杂度为 `O(n)`**。其低效的查找方式,决定了链表不适合作为索引。
|
||||||
|
|
||||||
|
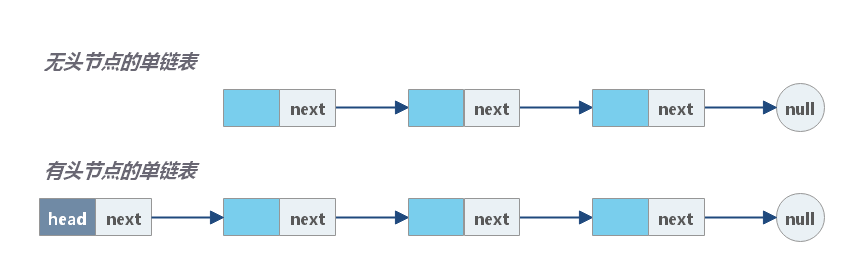
|
||||||
|
|
||||||
|
## 哈希索引
|
||||||
|
|
||||||
|
哈希表是一种以键 - 值(key-value)对形式存储数据的结构,我们只要输入待查找的值即 key,就可以找到其对应的值即 Value。
|
||||||
|
|
||||||
|
**哈希表** 使用 **哈希函数** 组织数据,以支持快速插入和搜索的数据结构。哈希表的本质是一个数组,其思路是:使用 Hash 函数将 Key 转换为数组下标,利用数组的随机访问特性,使得我们能在 `O(1)` 的时间代价内完成检索。
|
||||||
|
|
||||||
|
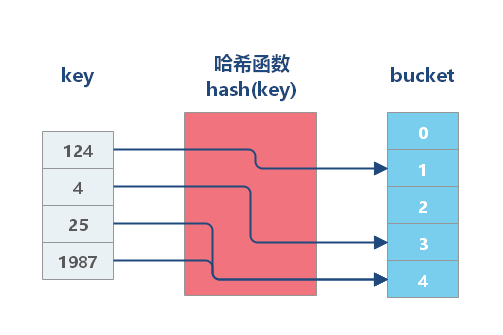
|
||||||
|
|
||||||
|
有两种不同类型的哈希表:**哈希集合** 和 **哈希映射**。
|
||||||
|
|
||||||
|
- **哈希集合** 是集合数据结构的实现之一,用于存储非重复值。
|
||||||
|
- **哈希映射** 是映射 数据结构的实现之一,用于存储键值对。
|
||||||
|
|
||||||
|
哈希索引基于哈希表实现,**只适用于等值查询**。对于每一行数据,哈希索引都会将所有的索引列计算一个哈希码(`hashcode`),哈希码是一个较小的值。哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针。
|
||||||
|
|
||||||
|
✔ 哈希索引的**优点**:
|
||||||
|
|
||||||
|
- 因为索引数据结构紧凑,所以**查询速度非常快**。
|
||||||
|
|
||||||
|
❌ 哈希索引的**缺点**:
|
||||||
|
|
||||||
|
- 哈希索引值包含哈希值和行指针,而不存储字段值,所以不能使用索引中的值来避免读取行。不过,访问内存中的行的速度很快,所以大部分情况下这一点对性能影响不大。
|
||||||
|
- **哈希索引数据不是按照索引值顺序存储的**,所以**无法用于排序**。
|
||||||
|
- 哈希索引**不支持部分索引匹配查找**,因为哈希索引时使用索引列的全部内容来进行哈希计算的。如,在数据列 (A,B) 上建立哈希索引,如果查询只有数据列 A,无法使用该索引。
|
||||||
|
- 哈希索引**只支持等值比较查询**,包括 `=`、`IN()`、`<=>`;不支持任何范围查询,如 `WHERE price > 100`。
|
||||||
|
- 哈希索引有**可能出现哈希冲突**
|
||||||
|
- 出现哈希冲突时,必须遍历链表中所有的行指针,逐行比较,直到找到符合条件的行。
|
||||||
|
- 如果哈希冲突多的话,维护索引的代价会很高。
|
||||||
|
|
||||||
|
> 因为种种限制,所以哈希索引只适用于特定的场合。而一旦使用哈希索引,则它带来的性能提升会非常显著。例如,Mysql 中的 Memory 存储引擎就显示的支持哈希索引。
|
||||||
|
|
||||||
|
## B-Tree 索引
|
||||||
|
|
||||||
|
通常我们所说的 B 树索引是指 `B-Tree` 索引,它是目前关系型数据库中查找数据最为常用和有效的索引,大多数存储引擎都支持这种索引。使用 `B-Tree` 这个术语,是因为 MySQL 在 `CREATE TABLE` 或其它语句中使用了这个关键字,但实际上不同的存储引擎可能使用不同的数据结构,比如 InnoDB 使用的是 `B+Tree `索引;而 MyISAM 使用的是 `B-Tree `索引。
|
||||||
|
|
||||||
|
`B-Tree` 索引中的 B 是指 `balance`,意为平衡。需要注意的是,`B-Tree` 索引并不能找到一个给定键值的具体行,它找到的只是被查找数据行所在的页,接着数据库会把页读入到内存,再在内存中进行查找,最后得到要查找的数据。
|
||||||
|
|
||||||
|
### 二叉搜索树
|
||||||
|
|
||||||
|
二叉搜索树的特点是:每个节点的左儿子小于父节点,父节点又小于右儿子。其查询时间复杂度是 `O(log n)`。
|
||||||
|
|
||||||
|
当然为了维持 `O(log n)` 的查询复杂度,你就需要保持这棵树是平衡二叉树。为了做这个保证,更新的时间复杂度也是 `O(log n)`。
|
||||||
|
|
||||||
|
随着数据库中数据的增加,索引本身大小随之增加,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘 I/O 消耗,相对于内存存取,I/O 存取的消耗要高几个数量级。可以想象一下一棵几百万节点的二叉树的深度是多少?如果将这么大深度的一颗二叉树放磁盘上,每读取一个节点,需要一次磁盘的 I/O 读取,整个查找的耗时显然是不能够接受的。那么如何减少查找过程中的 I/O 存取次数?
|
||||||
|
|
||||||
|
一种行之有效的解决方法是减少树的深度,将**二叉树变为 N 叉树**(多路搜索树),而 **B+ 树就是一种多路搜索树**。
|
||||||
|
|
||||||
|
### `B+Tree` 索引
|
||||||
|
|
||||||
|
B+ 树索引适用于**全键值查找**、**键值范围查找**和**键前缀查找**,其中键前缀查找只适用于最左前缀查找。
|
||||||
|
|
||||||
|
理解 `B+Tree`,只需要理解其最重要的两个特征即可:
|
||||||
|
|
||||||
|
- 第一,所有的关键字(可以理解为数据)都存储在叶子节点,非叶子节点并不存储真正的数据,所有记录节点都是按键值大小顺序存放在同一层叶子节点上。
|
||||||
|
- 其次,所有的叶子节点由指针连接。如下图为简化了的`B+Tree`。
|
||||||
|
|
||||||
|
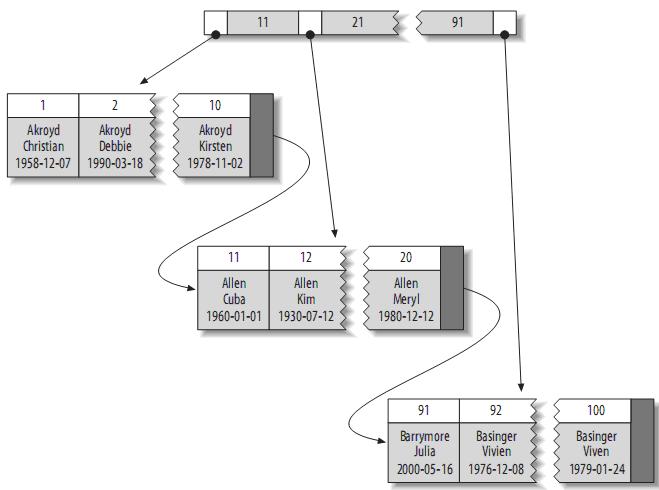
|
||||||
|
|
||||||
|
根据叶子节点的内容,索引类型分为主键索引和非主键索引。
|
||||||
|
|
||||||
|
- **聚簇索引(clustered)**:又称为主键索引,其叶子节点存的是整行数据。因为无法同时把数据行存放在两个不同的地方,所以**一个表只能有一个聚簇索引**。**InnoDB 的聚簇索引实际是在同一个结构中保存了 B 树的索引和数据行**。
|
||||||
|
- 非主键索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为**二级索引(secondary)**。数据存储在一个位置,索引存储在另一个位置,索引中包含指向数据存储位置的指针。可以有多个,小于 249 个。
|
||||||
|
|
||||||
|
**聚簇表示数据行和相邻的键值紧凑地存储在一起,因为数据紧凑,所以访问快**。因为无法同时把数据行存放在两个不同的地方,所以**一个表只能有一个聚簇索引**。
|
||||||
|
|
||||||
|
**聚簇索引和非聚簇索引的查询有什么区别**
|
||||||
|
|
||||||
|
- 如果语句是 `select * from T where ID=500`,即聚簇索引查询方式,则只需要搜索 ID 这棵 B+ 树;
|
||||||
|
- 如果语句是 `select * from T where k=5`,即非聚簇索引查询方式,则需要先搜索 k 索引树,得到 ID 的值为 500,再到 ID 索引树搜索一次。这个过程称为**回表**。
|
||||||
|
|
||||||
|
也就是说,**基于非聚簇索引的查询需要多扫描一棵索引树**。因此,我们在应用中应该尽量使用主键查询。
|
||||||
|
|
||||||
|
**显然,主键长度越小,非聚簇索引的叶子节点就越小,非聚簇索引占用的空间也就越小。**
|
||||||
|
|
||||||
|
自增主键是指自增列上定义的主键,在建表语句中一般是这么定义的: NOT NULL PRIMARY KEY AUTO_INCREMENT。从性能和存储空间方面考量,自增主键往往是更合理的选择。有没有什么场景适合用业务字段直接做主键的呢?还是有的。比如,有些业务的场景需求是这样的:
|
||||||
|
|
||||||
|
- 只有一个索引;
|
||||||
|
- 该索引必须是唯一索引。
|
||||||
|
|
||||||
|
由于没有其他索引,所以也就不用考虑其他索引的叶子节点大小的问题。这时候我们就要优先考虑上一段提到的“尽量使用主键查询”原则,直接将这个索引设置为主键,可以避免每次查询需要搜索两棵树。
|
||||||
|
|
||||||
|
------
|
||||||
|
|
||||||
|
内存是半导体元件。对于内存而言,只要给出了内存地址,我们就可以直接访问该地址取出数据。这个过程具有高效的随机访问特性,因此内存也叫随机访问存储器(Random Access Memory,即 RAM)。内存的访问速度很快,但是价格相对较昂贵,因此一般的计算机内存空间都相对较小。
|
||||||
|
|
||||||
|
而磁盘是机械器件。磁盘访问数据时,需要等磁盘盘片旋转到磁头下,才能读取相应的数据。尽管磁盘的旋转速度很快,但是和内存的随机访问相比,性能差距非常大。一般来说,如果是随机读写,会有 10 万到 100 万倍左右的差距。但如果是顺序访问大批量数据的话,磁盘的性能和内存就是一个数量级的。
|
||||||
|
|
||||||
|
磁盘的最小读写单位是扇区,较早期的磁盘一个扇区是 **`512`** 字节。随着磁盘技术的发展,目前常见的磁盘扇区是 **`4K`** 个字节。操作系统一次会读写多个扇区,所以操作系统的最小读写单位是块(Block),也叫作簇(Cluster)。当我们要从磁盘中读取一个数据时,操作系统会一次性将整个块都读出来。因此,对于大批量的顺序读写来说,磁盘的效率会比随机读写高许多。
|
||||||
|
|
||||||
|
假设有一个有序数组存储在硬盘中,如果它足够大,那么它会存储在多个块中。当我们要对这个数组使用二分查找时,需要先找到中间元素所在的块,将这个块从磁盘中读到内存里,然后在内存中进行二分查找。如果下一步要读的元素在其他块中,则需要再将相应块从磁盘中读入内存。直到查询结束,这个过程可能会多次访问磁盘。我们可以看到,这样的检索性能非常低。
|
||||||
|
|
||||||
|
由于磁盘相对于内存而言访问速度实在太慢,因此,对于磁盘上数据的高效检索,我们有一个极其重要的原则:对磁盘的访问次数要尽可能的少!
|
||||||
|
|
||||||
|
将索引和数据分离就是一种常见的设计思路。在数据频繁变化的场景中,有序数组并不是一个最好的选择,二叉检索树或者哈希表往往更有普适性。但是,哈希表由于缺乏范围检索的能力,在一些场合也不适用。因此,二叉检索树这种树形结构是许多常见检索系统的实施方案。
|
||||||
|
|
||||||
|
随着索引数据越来越大,直到无法完全加载到内存中,这是需要将索引数据也存入磁盘中。B+ 树给出了将树形索引的所有节点都存在磁盘上的高效检索方案。操作系统对磁盘数据的访问是以块为单位的。因此,如果我们想将树型索引的一个节点从磁盘中读出,即使该节点的数据量很小(比如说只有几个字节),但磁盘依然会将整个块的数据全部读出来,而不是只读这一小部分数据,这会让有效读取效率很低。B+ 树的一个关键设计,就是让一个节点的大小等于一个块的大小。节点内存储的数据,不是一个元素,而是一个可以装 m 个元素的有序数组。这样一来,我们就可以将磁盘一次读取的数据全部利用起来,使得读取效率最大化。
|
||||||
|
|
||||||
|
B+ 树还有另一个设计,就是将所有的节点分为内部节点和叶子节点。内部节点仅存储 key 和维持树形结构的指针,并不存储 key 对应的数据(无论是具体数据还是文件位置信息)。这样内部节点就能存储更多的索引数据,我们也就可以使用最少的内部节点,将所有数据组织起来了。而叶子节点仅存储 key 和对应数据,不存储维持树形结构的指针。通过这样的设计,B+ 树就能做到节点的空间利用率最大化。此外,B+ 树还将同一层的所有节点串成了有序的双向链表,这样一来,B+ 树就同时具备了良好的范围查询能力和灵活调整的能力了。
|
||||||
|
|
||||||
|
因此,B+ 树是一棵完全平衡的 m 阶多叉树。所谓的 m 阶,指的是每个节点最多有 m 个子节点,并且每个节点里都存了一个紧凑的可包含 m 个元素的数组。
|
||||||
|
|
||||||
|
即使是复杂的 B+ 树,我们将它拆解开来,其实也是由简单的数组、链表和树组成的,而且 B+ 树的检索过程其实也是二分查找。因此,如果 B+ 树完全加载在内存中的话,它的检索效率其实并不会比有序数组或者二叉检索树更
|
||||||
|
高,也还是二分查找的 log(n) 的效率。并且,它还比数组和二叉检索树更加复杂,还会带来额外的开销。
|
||||||
|
|
||||||
|
另外,这一节还有一个很重要的设计思想需要你掌握,那就是将索引和数据分离。通过这样的方式,我们能将索引的数组大小保持在一个较小的范围内,让它能加载在内存中。在许多大规模系统中,都是使用这个设计思想来精简索引的。而且,B+ 树的内部节点和叶子节点的区分,其实也是索引和数据分离的一次实践。
|
||||||
|
|
||||||
|
MySQL 中的 B+ 树实现其实有两种,一种是 MyISAM 引擎,另一种是 InnoDB 引擎。它们的核心区别就在于,数据和索引是否是分离的。
|
||||||
|
|
||||||
|
在 MyISAM 引擎中,B+ 树的叶子节点仅存储了数据的位置指针,这是一种索引和数据分离的设计方案,叫作非聚集索引。如果要保证 MyISAM 的数据一致性,那我们需要在表级别上进行加锁处理。
|
||||||
|
|
||||||
|
在 InnoDB 中,B+ 树的叶子节点直接存储了具体数据,这是一种索引和数据一体的方案。叫作聚集索引。由于数据直接就存在索引的叶子节点中,因此 InnoDB 不需要给全表加锁来保证一致性,它只需要支持行级的锁就可以了。
|
||||||
|
|
||||||
|
## LSM 树
|
||||||
|
|
||||||
|
B+ 树的数据都存储在叶子节点中,而叶子节点一般都存储在磁盘中。因此,每次插入的新数据都需要随机写入磁盘,而随机写入的性能非常慢。如果是一个日志系统,每秒钟要写入上千条甚至上万条数据,这样的磁盘操作代价会使得系统性能急剧下降,甚至无法使用。
|
||||||
|
|
||||||
|
操作系统对磁盘的读写是以块为单位的,我们能否以块为单位写入,而不是每次插入一个数据都要随机写入磁盘呢?这样是不是就可以大幅度减少写入操作了呢?解决方案就是:**LSM 树**(Log Structured Merge Trees)。
|
||||||
|
|
||||||
|
LSM 树就是根据这个思路设计了这样一个机制:当数据写入时,延迟写磁盘,将数据先存放在内存中的树里,进行常规的存储和查询。当内存中的树持续变大达到阈值时,再批量地以块为单位写入磁盘的树中。因此,LSM 树至少需要由两棵树组成,一棵是存储在内存中较小的 C0 树,另一棵是存储在磁盘中较大的 C1 树。
|
||||||
|
|
||||||
|
LSM 树具有以下 3 个特点:
|
||||||
|
|
||||||
|
1. 将索引分为内存和磁盘两部分,并在内存达到阈值时启动树合并(Merge Trees);
|
||||||
|
2. 用批量写入代替随机写入,并且用预写日志 WAL 技术(Write AheadLog,预写日志技术)保证内存数据,在系统崩溃后可以被恢复;
|
||||||
|
3. 数据采取类似日志追加写的方式写入(Log Structured)磁盘,以顺序写的方式提高写
|
||||||
|
入效率。
|
||||||
|
|
||||||
|
LSM 树的这些特点,使得它相对于 B+ 树,在写入性能上有大幅提升。所以,许多 NoSQL 系统都使用 LSM 树作为检索引擎,而且还对 LSM 树进行了优化以提升检索性能。
|
||||||
|
|
||||||
|
## 倒排索引
|
||||||
|
|
||||||
|
倒排索引的核心其实并不复杂,它的具体实现其实是哈希表,只是它不是将文档 ID 或者题目作为 key,而是反过来,通过将内容或者属性作为 key 来存储对应的文档列表,使得我们能在 O(1) 的时间代价内完成查询。
|
||||||
|
|
||||||
|
尽管原理并不复杂,但是倒排索引是许多检索引擎的核心。比如说,数据库的全文索引功能、搜索引擎的索引、广告引擎和推荐引擎,都使用了倒排索引技术来实现检索功能。
|
||||||
|
|
||||||
|
## 索引的维护
|
||||||
|
|
||||||
|
### 创建索引
|
||||||
|
|
||||||
|
- **数据压缩**:一个是尽可能地将数据加载到内存中,因为内存的检索效率大大高于磁盘。那为了将数据更多地加载到内存中,索引压缩是一个重要的研究方向。
|
||||||
|
- **分支处理**:另一个是将大数据集合拆成多个小数据集合来处理。这其实就是分布式系统的核心思想。
|
||||||
|
|
||||||
|
### 更新索引
|
||||||
|
|
||||||
|
(1)Double Buffer(双缓冲)机制
|
||||||
|
|
||||||
|
就是在内存中同时保存两份一样的索引,一个是索引 A,一个是索引 B。两个索引保持一个读、一个写,并且来回切换,最终完成高性能的索引更新。
|
||||||
|
|
||||||
|
优点:简单高效
|
||||||
|
|
||||||
|
缺点:达到一定数据量级后,会带来翻倍的内存开销,甚至有些索引存储在磁盘上的情况下,更是无法使用此机制。
|
||||||
|
|
||||||
|
(2)全量索引和增量索引
|
||||||
|
|
||||||
|
将新接收到的数据单独建立一个可以存在内存中的倒排索引,也就是增量索引。当查询发生的时候,我们会同时查询全量索引和增量索引,将合并的结果作为总的结果输出。
|
||||||
|
|
||||||
|
因为增量索引相对全量索引而言会小很多,内存资源消耗在可承受范围,所以我们可以使用 Double Buffer 机制
|
||||||
|
对增量索引进行索引更新。这样一来,增量索引就可以做到无锁访问。而全量索引本身就是只读的,也不需要加锁。因此,整个检索过程都可以做到无锁访问,也就提高了系统的检索效率。
|
||||||
|
|
||||||
|
## 参考资料
|
||||||
|
|
||||||
|
- [《数据密集型应用系统设计》](https://book.douban.com/subject/30329536/)
|
||||||
|
- [数据结构与算法之美](https://time.geekbang.org/column/intro/100017301)
|
||||||
|
- [检索技术核心 20 讲](https://time.geekbang.org/column/intro/100048401)
|
||||||
|
- [Data Structures for Databases](https://www.cise.ufl.edu/~mschneid/Research/papers/HS05BoCh.pdf)
|
||||||
|
- [Data Structures and Algorithms for Big Databases](https://people.csail.mit.edu/bradley/BenderKuszmaul-tutorial-xldb12.pdf)
|
||||||
|
|
@ -37,25 +37,27 @@
|
||||||
|
|
||||||
## 1. 索引简介
|
## 1. 索引简介
|
||||||
|
|
||||||
**_索引优化应该是查询性能优化的最有效手段_**。
|
**索引是数据库为了提高查找效率的一种数据结构**。
|
||||||
|
|
||||||
|
索引对于良好的性能非常关键,在数据量小且负载较低时,不恰当的索引对于性能的影响可能还不明显;但随着数据量逐渐增大,性能则会急剧下降。因此,索引优化应该是查询性能优化的最有效手段。
|
||||||
|
|
||||||
### 1.1. 索引的优缺点
|
### 1.1. 索引的优缺点
|
||||||
|
|
||||||
B+ 树索引,按照顺序存储数据,所以 Mysql 可以用来做 ORDER BY 和 GROUP BY 操作。因为数据是有序的,所以 B+ 树也就会将相关的列值都存储在一起。最后,因为索引中存储了实际的列值,所以某些查询只使用索引就能够完成全部查询。
|
B 树是最常见的索引,按照顺序存储数据,所以 Mysql 可以用来做 `ORDER BY` 和 `GROUP BY` 操作。因为数据是有序的,所以 B 树也就会将相关的列值都存储在一起。最后,因为索引中存储了实际的列值,所以某些查询只使用索引就能够完成全部查询。
|
||||||
|
|
||||||
✔ 索引的优点:
|
✔ 索引的优点:
|
||||||
|
|
||||||
- 索引大大减少了服务器需要扫描的数据量,从而加快检索速度。
|
- **索引大大减少了服务器需要扫描的数据量**,从而加快检索速度。
|
||||||
- 支持行级锁的数据库,如 InnoDB 会在访问行的时候加锁。使用索引可以减少访问的行数,从而减少锁的竞争,提高并发。
|
- **索引可以帮助服务器避免排序和临时表**。
|
||||||
- 索引可以帮助服务器避免排序和临时表。
|
- **索引可以将随机 I/O 变为顺序 I/O**。
|
||||||
- 索引可以将随机 I/O 变为顺序 I/O。
|
- 支持行级锁的数据库,如 InnoDB 会在访问行的时候加锁。**使用索引可以减少访问的行数,从而减少锁的竞争,提高并发**。
|
||||||
- 唯一索引可以确保每一行数据的唯一性,通过使用索引,可以在查询的过程中使用优化隐藏器,提高系统的性能。
|
- 唯一索引可以确保每一行数据的唯一性,通过使用索引,可以在查询的过程中使用优化隐藏器,提高系统的性能。
|
||||||
|
|
||||||
❌ 索引的缺点:
|
❌ 索引的缺点:
|
||||||
|
|
||||||
- 创建和维护索引要耗费时间,这会随着数据量的增加而增加。
|
- **创建和维护索引要耗费时间**,这会随着数据量的增加而增加。
|
||||||
- **索引需要占用额外的物理空间**,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立组合索引那么需要的空间就会更大。
|
- **索引需要占用额外的物理空间**,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立组合索引那么需要的空间就会更大。
|
||||||
- 写操作(`INSERT`/`UPDATE`/`DELETE`)时很可能需要更新索引,导致数据库的写操作性能降低。
|
- **写操作(`INSERT`/`UPDATE`/`DELETE`)时很可能需要更新索引,导致数据库的写操作性能降低**。
|
||||||
|
|
||||||
### 1.2. 何时使用索引
|
### 1.2. 何时使用索引
|
||||||
|
|
||||||
|
|
@ -63,37 +65,67 @@ B+ 树索引,按照顺序存储数据,所以 Mysql 可以用来做 ORDER BY
|
||||||
|
|
||||||
✔ 什么情况**适用**索引:
|
✔ 什么情况**适用**索引:
|
||||||
|
|
||||||
- 表经常进行 `SELECT` 操作;
|
- **频繁读操作( `SELECT` )**
|
||||||
- 表的数据量比较大;
|
- **表的数据量比较大**。
|
||||||
- 列名经常出现在 `WHERE` 或连接(`JOIN`)条件中
|
- **列名经常出现在 `WHERE` 或连接(`JOIN`)条件中**。
|
||||||
|
|
||||||
❌ 什么情况**不适用**索引:
|
❌ 什么情况**不适用**索引:
|
||||||
|
|
||||||
- **频繁写操作**( `INSERT`/`UPDATE`/`DELETE` )- 需要更新索引空间;
|
- **频繁写操作**( `INSERT`/`UPDATE`/`DELETE` ),也就意味着需要更新索引。
|
||||||
- **非常小的表** - 对于非常小的表,大部分情况下简单的全表扫描更高效。
|
- **列名不经常出现在 `WHERE` 或连接(`JOIN`)条件中**,也就意味着索引会经常无法命中,没有意义,还增加空间开销。
|
||||||
- 列名不经常出现在 `WHERE` 或连接(`JOIN`)条件中 - 索引就会经常不命中,没有意义,还增加空间开销。
|
- **非常小的表**,对于非常小的表,大部分情况下简单的全表扫描更高效。
|
||||||
- 对于特大型表,建立和使用索引的代价将随之增长。可以考虑使用分区技术或 Nosql。
|
- **特大型的表**,建立和使用索引的代价将随之增长。可以考虑使用分区技术或 Nosql。
|
||||||
|
|
||||||
## 2. 索引的数据结构
|
## 2. 索引的数据结构
|
||||||
|
|
||||||
|
在 Mysql 中,索引是在存储引擎层而不是服务器层实现的。所以,并没有统一的索引标准;不同存储引擎的索引的数据结构也不相同。
|
||||||
|
|
||||||
|
### 数组
|
||||||
|
|
||||||
|
数组是用连续的内存空间来存储数据,并且支持随机访问。
|
||||||
|
|
||||||
|
有序数组可以使用二分查找法,其时间复杂度为 `O(log n)`,无论是等值查询还是范围查询,都非常高效。
|
||||||
|
|
||||||
|
但数组有两个重要限制:
|
||||||
|
|
||||||
|
- 数组的空间大小固定,如果要扩容只能采用复制数组的方式。
|
||||||
|
- 插入、删除时间复杂度为 `O(n)`。
|
||||||
|
|
||||||
|
这意味着,如果使用数组作为索引,如果要保证数组有序,其更新操作代价高昂。
|
||||||
|
|
||||||
### 2.1. 哈希索引
|
### 2.1. 哈希索引
|
||||||
|
|
||||||
> Hash 索引只有精确匹配索引所有列的查询才有效。
|
哈希表是一种以键 - 值(key-value)对形式存储数据的结构,我们只要输入待查找的值即 key,就可以找到其对应的值即 Value。
|
||||||
|
|
||||||
哈希表是一种以键 - 值(key-value)存储数据的结构,我们只要输入待查找的值即 key,就可以找到其对应的值即 Value。哈希的思路很简单,把值放在数组里,用一个哈希函数把 key 换算成一个确定的位置,然后把 value 放在数组的这个位置。
|
**哈希表** 使用 **哈希函数** 组织数据,以支持快速插入和搜索的数据结构。哈希表的本质是一个数组,其思路是:使用 Hash 函数将 Key 转换为数组下标,利用数组的随机访问特性,使得我们能在 `O(1)` 的时间代价内完成检索。
|
||||||
|
|
||||||
对于每一行数据,对所有的索引列计算一个 `hashcode`。哈希索引将所有的 `hashcode` 存储在索引中,同时在 Hash 表中保存指向每个数据行的指针。
|

|
||||||
|
|
||||||
哈希索引的**优点**:
|
有两种不同类型的哈希表:**哈希集合** 和 **哈希映射**。
|
||||||
|
|
||||||
|
- **哈希集合** 是集合数据结构的实现之一,用于存储非重复值。
|
||||||
|
- **哈希映射** 是映射 数据结构的实现之一,用于存储键值对。
|
||||||
|
|
||||||
|
哈希索引基于哈希表实现,**只适用于等值查询**。对于每一行数据,哈希索引都会将所有的索引列计算一个哈希码(`hashcode`),哈希码是一个较小的值。哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针。
|
||||||
|
|
||||||
|
在 Mysql 中,只有 Memory 存储引擎显示支持哈希索引。
|
||||||
|
|
||||||
|
✔ 哈希索引的**优点**:
|
||||||
|
|
||||||
- 因为索引数据结构紧凑,所以**查询速度非常快**。
|
- 因为索引数据结构紧凑,所以**查询速度非常快**。
|
||||||
|
|
||||||
哈希索引的**缺点**:
|
❌ 哈希索引的**缺点**:
|
||||||
|
|
||||||
- 哈希索引数据不是按照索引值顺序存储的,所以**无法用于排序**。
|
- 哈希索引值包含哈希值和行指针,而不存储字段值,所以不能使用索引中的值来避免读取行。不过,访问内存中的行的速度很快,所以大部分情况下这一点对性能影响不大。
|
||||||
- 哈希索引**不支持部分索引匹配查找**。如,在数据列 (A,B) 上建立哈希索引,如果查询只有数据列 A,无法使用该索引。
|
- **哈希索引数据不是按照索引值顺序存储的**,所以**无法用于排序**。
|
||||||
- 哈希索引**只支持等值比较查询**,不支持任何范围查询,如 `WHERE price > 100`。
|
- 哈希索引**不支持部分索引匹配查找**,因为哈希索引时使用索引列的全部内容来进行哈希计算的。如,在数据列 (A,B) 上建立哈希索引,如果查询只有数据列 A,无法使用该索引。
|
||||||
- 哈希索引有**可能出现哈希冲突**,出现哈希冲突时,必须遍历链表中所有的行指针,逐行比较,直到找到符合条件的行。
|
- 哈希索引**只支持等值比较查询**,包括 `=`、`IN()`、`<=>`;不支持任何范围查询,如 `WHERE price > 100`。
|
||||||
|
- 哈希索引有**可能出现哈希冲突**
|
||||||
|
- 出现哈希冲突时,必须遍历链表中所有的行指针,逐行比较,直到找到符合条件的行。
|
||||||
|
- 如果哈希冲突多的话,维护索引的代价会很高。
|
||||||
|
|
||||||
|
|
||||||
|
> 因为种种限制,所以哈希索引只适用于特定的场合。而一旦使用哈希索引,则它带来的性能提升会非常显著。
|
||||||
|
|
||||||
### 2.2. B 树索引
|
### 2.2. B 树索引
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -208,7 +208,7 @@ T<sub>1</sub> 修改一个数据,T<sub>2</sub> 随后读取这个数据。如
|
||||||
|
|
||||||
### 4.3. 提交读
|
### 4.3. 提交读
|
||||||
|
|
||||||
**`提交读(READ COMMITTED)` 是指:一个事务只能读取已经提交的事务所做的修改**。换句话说,一个事务所做的修改在提交之前对其它事务是不可见的。提交读解决了脏读的问题。
|
**`提交读(READ COMMITTED)` 是指:事务提交后,其他事务才能看到它的修改**。换句话说,一个事务所做的修改在提交之前对其它事务是不可见的。提交读解决了脏读的问题。
|
||||||
|
|
||||||
提交读是大多数数据库的默认事务隔离级别。
|
提交读是大多数数据库的默认事务隔离级别。
|
||||||
|
|
||||||
|
|
@ -245,12 +245,12 @@ T<sub>1</sub> 读取某个范围的数据,T<sub>2</sub> 在这个范围内插
|
||||||
|
|
||||||
数据库隔离级别解决的问题:
|
数据库隔离级别解决的问题:
|
||||||
|
|
||||||
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|
| 隔离级别 | 丢失修改 | 脏读 | 不可重复读 | 幻读 |
|
||||||
| :------: | :--: | :--------: | :--: |
|
| :------: | :--: | :--------: | :--: | :--: |
|
||||||
| 未提交读 | ❌ | ❌ | ❌ |
|
| 未提交读 | ✔️ | ❌ | ❌ | ❌ |
|
||||||
| 提交读 | ✔️ | ❌ | ❌ |
|
| 提交读 | ✔️ | ✔️ | ❌ | ❌ |
|
||||||
| 可重复读 | ✔️ | ✔️ | ❌ |
|
| 可重复读 | ✔️ | ✔️ | ✔️ | ❌ |
|
||||||
| 可串行化 | ✔️ | ✔️ | ✔️ |
|
| 可串行化 | ✔️ | ✔️ | ✔️ | ✔️ |
|
||||||
|
|
||||||
## 5. 死锁
|
## 5. 死锁
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -69,8 +69,7 @@ MySQL 客户端连接命令:`mysql -h<主机> -P<端口> -u<用户名> -p<密
|
||||||
|
|
||||||
MySQL 将缓存存放在一个引用表(不要理解成`table`,可以认为是类似于`HashMap`的数据结构),通过一个哈希值索引,这个哈希值通过查询本身、当前要查询的数据库、客户端协议版本号等一些可能影响结果的信息计算得来。所以两个查询在任何字符上的不同(例如:空格、注释),都会导致缓存不会命中。
|
MySQL 将缓存存放在一个引用表(不要理解成`table`,可以认为是类似于`HashMap`的数据结构),通过一个哈希值索引,这个哈希值通过查询本身、当前要查询的数据库、客户端协议版本号等一些可能影响结果的信息计算得来。所以两个查询在任何字符上的不同(例如:空格、注释),都会导致缓存不会命中。
|
||||||
|
|
||||||
**如果查询中包含任何用户自定义函数、存储函数、用户变量、临时表、mysql 库中的系统表,其查询结果**
|
**如果查询中包含任何用户自定义函数、存储函数、用户变量、临时表、mysql 库中的系统表,其查询结果都不会被缓存**。比如函数`NOW()`或者`CURRENT_DATE()`会因为不同的查询时间,返回不同的查询结果,再比如包含`CURRENT_USER`或者`CONNECION_ID()`的查询语句会因为不同的用户而返回不同的结果,将这样的查询结果缓存起来没有任何的意义。
|
||||||
**都不会被缓存**。比如函数`NOW()`或者`CURRENT_DATE()`会因为不同的查询时间,返回不同的查询结果,再比如包含`CURRENT_USER`或者`CONNECION_ID()`的查询语句会因为不同的用户而返回不同的结果,将这样的查询结果缓存起来没有任何的意义。
|
|
||||||
|
|
||||||
**不建议使用数据库缓存,因为往往弊大于利**。查询缓存的失效非常频繁,只要有对一个表的更新,这个表上所有的查询缓存都会被清空。因此很可能你费劲地把结果存起来,还没使用呢,就被一个更新全清空了。对于更新压力大的数据库来说,查询缓存的命中率会非常低。除非你的业务就是有一张静态表,很长时间才会更新一次。比如,一个系统配置表,那这张表上的查询才适合使用查询缓存。
|
**不建议使用数据库缓存,因为往往弊大于利**。查询缓存的失效非常频繁,只要有对一个表的更新,这个表上所有的查询缓存都会被清空。因此很可能你费劲地把结果存起来,还没使用呢,就被一个更新全清空了。对于更新压力大的数据库来说,查询缓存的命中率会非常低。除非你的业务就是有一张静态表,很长时间才会更新一次。比如,一个系统配置表,那这张表上的查询才适合使用查询缓存。
|
||||||
|
|
||||||
|
|
|
||||||
Loading…
Reference in New Issue