11 KiB
| title | date | categories | tags | permalink | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Elastic 技术栈之 Kibana | 2020-06-16 07:10:44 |
|
|
/pages/002159/ |
Elastic 技术栈之 Kibana
Discover
单击侧面导航栏中的 Discover ,可以显示 Kibana 的数据查询功能功能。

在搜索栏中,您可以输入 Elasticsearch 查询条件来搜索您的数据。您可以在 Discover 页面中浏览结果并在 Visualize 页面中创建已保存搜索条件的可视化。
当前索引模式显示在查询栏下方。索引模式确定提交查询时搜索哪些索引。要搜索一组不同的索引,请从下拉菜单中选择不同的模式。要添加索引模式(index pattern),请转至 Management/Kibana/Index Patterns 并单击 Add New。
您可以使用字段名称和您感兴趣的值构建搜索。对于数字字段,可以使用比较运算符,如大于(>),小于(<)或等于(=)。您可以将元素与逻辑运算符 AND,OR 和 NOT 链接,全部使用大写。
默认情况下,每个匹配文档都显示所有字段。要选择要显示的文档字段,请将鼠标悬停在“可用字段”列表上,然后单击要包含的每个字段旁边的添加按钮。例如,如果只添加 account_number,则显示将更改为包含五个帐号的简单列表:
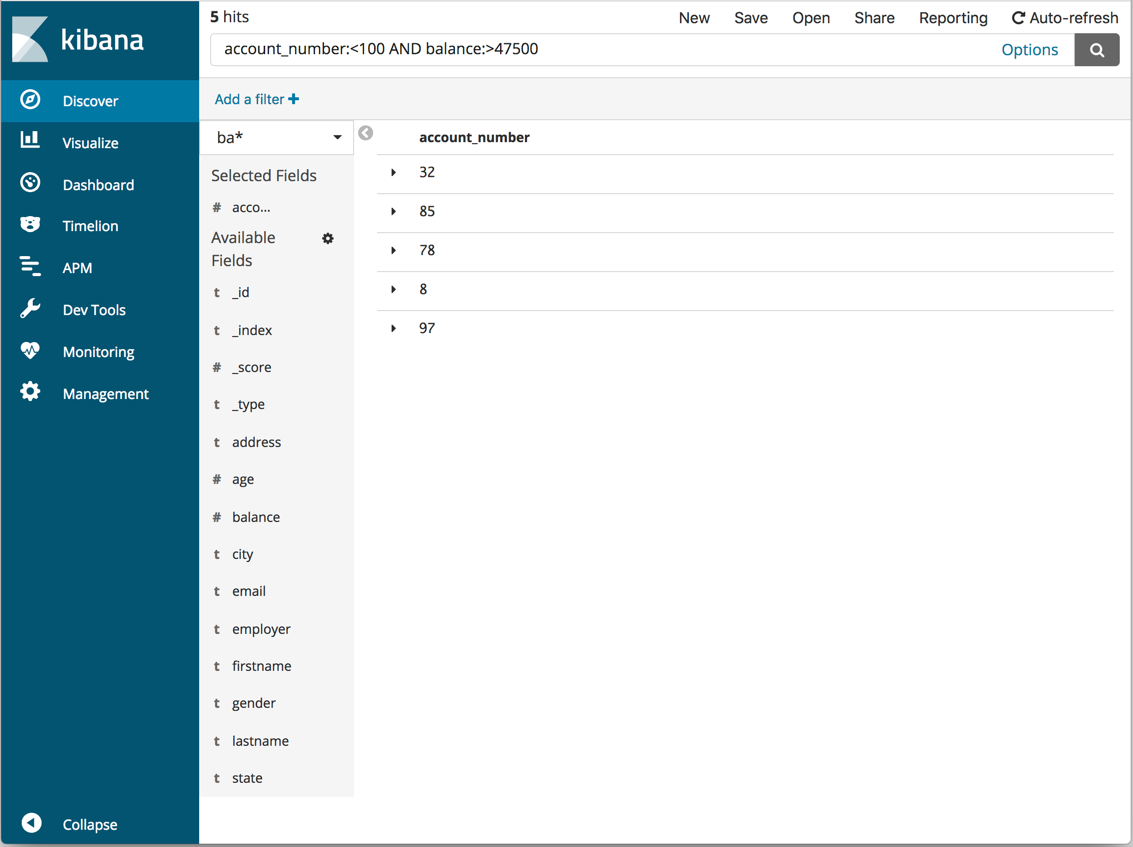
查询语义
kibana 的搜索栏遵循 query-string-syntax 文档中所说明的查询语义。
这里说明一些最基本的查询语义。
查询字符串会被解析为一系列的术语和运算符。一个术语可以是一个单词(如:quick、brown)或用双引号包围的短语(如"quick brown")。
查询操作允许您自定义搜索 - 下面介绍了可用的选项。
字段名称
正如查询字符串查询中所述,将在搜索条件中搜索 default_field,但可以在查询语法中指定其他字段:
例如:
- 查询
status字段中包含active关键字
status:active
title字段包含quick或brown关键字。如果您省略OR运算符,则将使用默认运算符
title:(quick OR brown)
title:(quick brown)
- author 字段查找精确的短语 "john smith",即精确查找。
author:"John Smith"
- 任意字段
book.title,book.content或book.date都包含quick或brown(注意我们需要如何使用\*表示通配符)
book.\*:(quick brown)
- title 字段包含任意非 null 值
_exists_:title
通配符
ELK 提供了 ? 和 * 两个通配符。
?表示任意单个字符;*表示任意零个或多个字符。
qu?ck bro*
注意:通配符查询会使用大量的内存并且执行性能较为糟糕,所以请慎用。 > 提示:纯通配符
*被写入 exsits 查询,从而提高了查询效率。因此,通配符field:*将匹配包含空值的文档,如:{“field”:“”},但是如果字段丢失或显示将值置为 null 则不匹配,如:“field”:null}> 提示:在一个单词的开头(例如:*ing)使用通配符这种方式的查询量特别大,因为索引中的所有术语都需要检查,以防万一匹配。通过将allow_leading_wildcard设置为false,可以禁用。
正则表达式
可以通过 / 将正则表达式包裹在查询字符串中进行查询
例:
name:/joh?n(ath[oa]n)/
支持的正则表达式语义可以参考:Regular expression syntax
模糊查询
我们可以使用 ~ 运算符来进行模糊查询。
例:
假设我们实际想查询
quick brown forks
但是,由于拼写错误,我们的查询关键字变成如下情况,依然可以查到想要的结果。
quikc\~ brwn\~ foks\~
这种模糊查询使用 Damerau-Levenshtein 距离来查找所有匹配最多两个更改的项。所谓的更改是指单个字符的插入,删除或替换,或者两个相邻字符的换位。
默认编辑距离为 2,但编辑距离为 1 应足以捕捉所有人类拼写错误的 80%。它可以被指定为:
quikc\~1
近似检索
尽管短语查询(例如,john smith)期望所有的词条都是完全相同的顺序,但是近似查询允许指定的单词进一步分开或以不同的顺序排列。与模糊查询可以为单词中的字符指定最大编辑距离一样,近似搜索也允许我们指定短语中单词的最大编辑距离:
例
"fox quick"\~5
字段中的文本越接近查询字符串中指定的原始顺序,该文档就越被认为是相关的。当与上面的示例查询相比时,短语 "quick fox" 将被认为比 "quick brown fox" 更近似查询条件。
范围
可以为日期,数字或字符串字段指定范围。闭区间范围用方括号 [min TO max] 和开区间范围用花括号 {min TO max} 来指定。
我们不妨来看一些示例。
- 2012 年的所有日子
date:[2012-01-01 TO 2012-12-31]
- 数字 1 到 5
count:[1 TO 5]
- 在
alpha和omega之间的标签,不包括alpha和omega
tag:{alpha TO omega}
- 10 以上的数字
count:[10 TO *]
- 2012 年以前的所有日期
date:{* TO 2012-01-01}
此外,开区间和闭区间也可以组合使用
- 数组 1 到 5,但不包括 5
count:[1 TO 5}
一边无界的范围也可以使用以下语法:
age:>10
age:>=10
age:<10
age:<=10
当然,你也可以使用 AND 运算符来得到连个查询结果的交集
age:(>=10 AND <20)
age:(+>=10 +<20)
Boosting
使用操作符 ^ 使一个术语比另一个术语更相关。例如,如果我们想查找所有有关狐狸的文档,但我们对狐狸特别感兴趣:
quick^2 fox
默认提升值是 1,但可以是任何正浮点数。 0 到 1 之间的提升减少了相关性。
增强也可以应用于短语或组:
"john smith"^2 (foo bar)^4
布尔操作
默认情况下,只要一个词匹配,所有词都是可选的。搜索 foo bar baz 将查找包含 foo 或 bar 或 baz 中的一个或多个的任何文档。我们已经讨论了上面的default_operator,它允许你强制要求所有的项,但也有布尔运算符可以在查询字符串本身中使用,以提供更多的控制。
首选的操作符是 +(此术语必须存在)和 - (此术语不得存在)。所有其他条款是可选的。例如,这个查询:
quick brown +fox -news
这条查询意味着:
- fox 必须存在
- news 必须不存在
- quick 和 brown 是可有可无的
熟悉的运算符 AND,OR 和 NOT(也写成 &&,|| 和 !)也被支持。然而,这些操作符有一定的优先级:NOT 优先于 AND,AND 优先于 OR。虽然 + 和 - 仅影响运算符右侧的术语,但 AND 和 OR 会影响左侧和右侧的术语。
分组
多个术语或子句可以用圆括号组合在一起,形成子查询
(quick OR brown) AND fox
可以使用组来定位特定的字段,或者增强子查询的结果:
status:(active OR pending) title:(full text search)^2
保留字
如果你需要使用任何在你的查询本身中作为操作符的字符(而不是作为操作符),那么你应该用一个反斜杠来转义它们。例如,要搜索(1 + 1)= 2,您需要将查询写为 \(1\+1\)\=2
保留字符是:+ - = && || > < ! ( ) { } [ ] ^ " ~ * ? : \ /
无法正确地转义这些特殊字符可能会导致语法错误,从而阻止您的查询运行。
空查询
如果查询字符串为空或仅包含空格,则查询将生成一个空的结果集。
Visualize
要想使用可视化的方式展示您的数据,请单击侧面导航栏中的 Visualize。
Visualize 工具使您能够以多种方式(如饼图、柱状图、曲线图、分布图等)查看数据。要开始使用,请点击蓝色的 Create a visualization 或 + 按钮。

有许多可视化类型可供选择。
下面,我们来看创建几个图标示例:
Pie
您可以从保存的搜索中构建可视化文件,也可以输入新的搜索条件。要输入新的搜索条件,首先需要选择一个索引模式来指定要搜索的索引。
默认搜索匹配所有文档。最初,一个“切片”包含整个饼图:
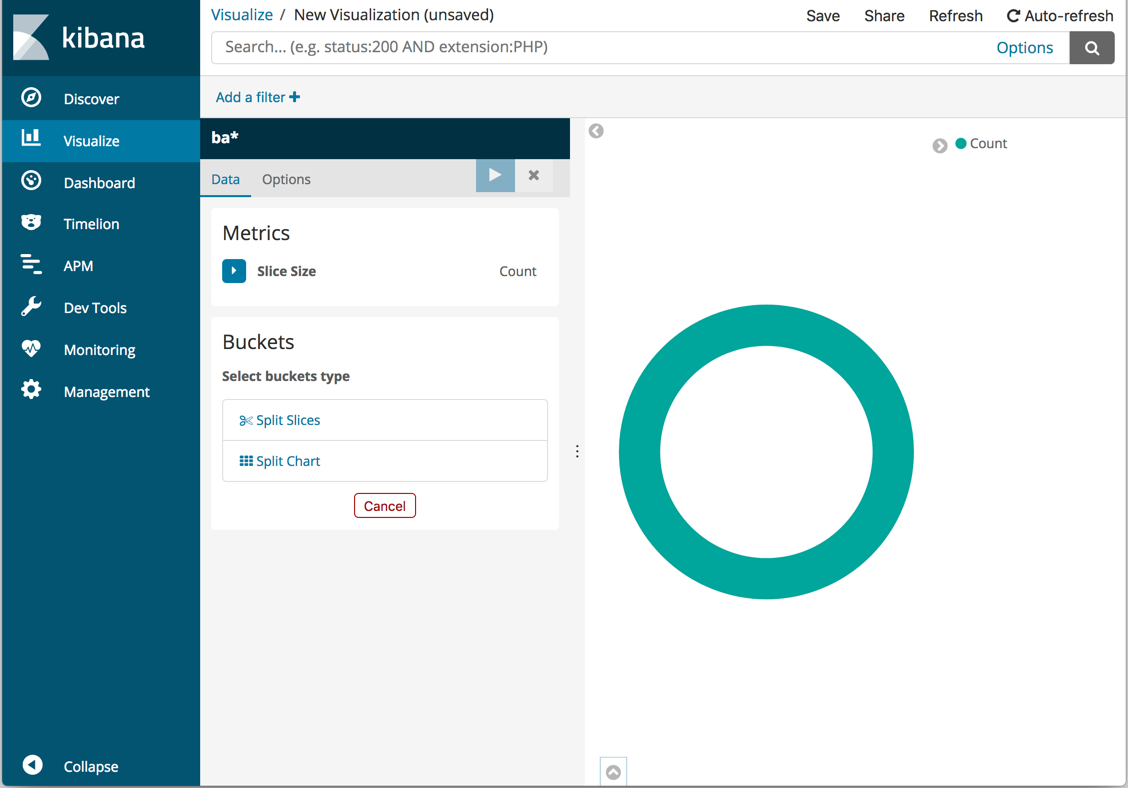
要指定在图表中展示哪些数据,请使用 Elasticsearch 存储桶聚合。分组汇总只是将与您的搜索条件相匹配的文档分类到不同的分类中,也称为分组。
为每个范围定义一个存储桶:
- 单击
Split Slices。 - 在
Aggregation列表中选择Terms。注意:这里的 Terms 是 Elk 采集数据时定义好的字段或标签。 - 在
Field列表中选择level.keyword。 - 点击
 按钮来更新图表。
按钮来更新图表。

完成后,如果想要保存这个图表,可以点击页面最上方一栏中的 Save 按钮。
Vertical Bar
我们在展示一下如何创建柱状图。
- 点击蓝色的
Create a visualization或+按钮。选择Vertical Bar - 选择索引模式。由于您尚未定义任何 bucket ,因此您会看到一个大栏,显示与默认通配符查询匹配的文档总数。
- 指定 Y 轴所代表的字段
- 指定 X 轴所代表的字段
- 点击 按钮来更新图表。

完成后,如果想要保存这个图表,可以点击页面最上方一栏中的 Save 按钮。
Dashboard
Dashboard 可以整合和共享 Visualize 集合。
- 点击侧面导航栏中的 Dashboard。
- 点击添加显示保存的可视化列表。
- 点击之前保存的
Visualize,然后点击列表底部的小向上箭头关闭可视化列表。 - 将鼠标悬停在可视化对象上会显示允许您编辑,移动,删除和调整可视化对象大小的容器控件。