43 KiB
| title | date | categories | tags | permalink | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Redis 数据类型和应用 | 2020-06-24 10:45:38 |
|
|
/pages/ed757c/ |
Redis 数据类型和应用
Redis 提供了多种数据类型,每种数据类型有丰富的命令支持。
使用 Redis ,不仅要了解其数据类型的特性,还需要根据业务场景,灵活的、高效的使用其数据类型来建模。
一、Redis 基本数据类型
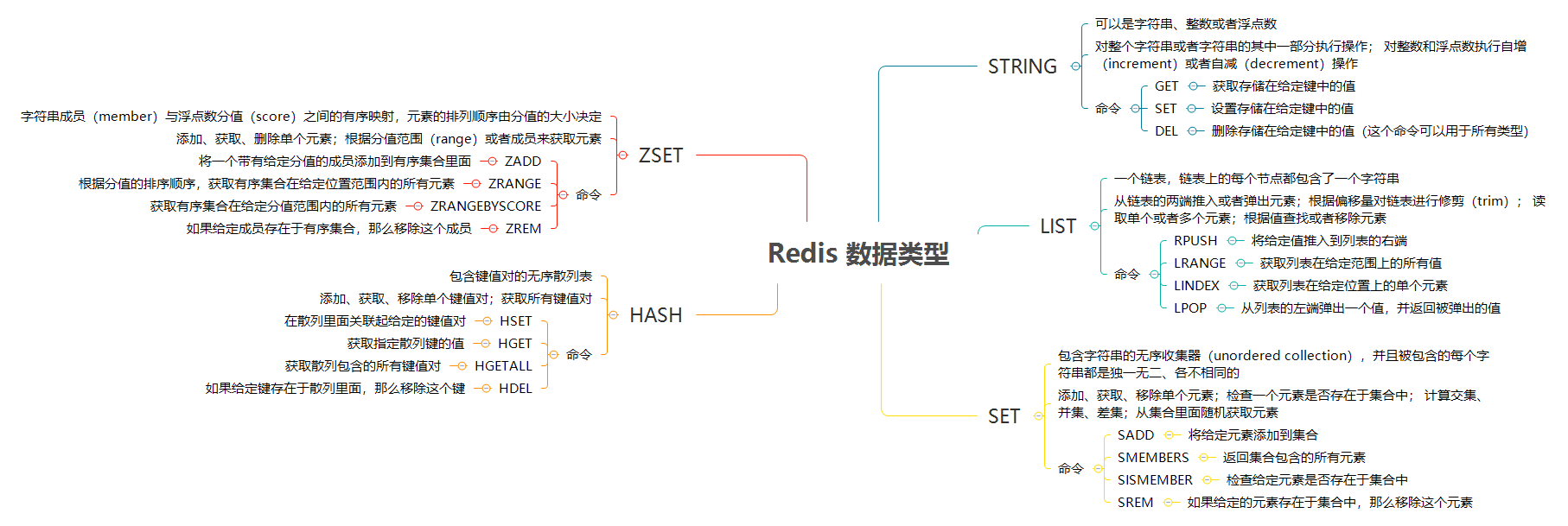
| 数据类型 | 可以存储的值 | 操作 |
|---|---|---|
| STRING | 字符串、整数或者浮点数 | 对整个字符串或者字符串的其中一部分执行操作 对整数和浮点数执行自增或者自减操作 |
| LIST | 列表 | 从两端压入或者弹出元素 读取单个或者多个元素 进行修剪,只保留一个范围内的元素 |
| SET | 无序集合 | 添加、获取、移除单个元素 检查一个元素是否存在于集合中 计算交集、并集、差集 从集合里面随机获取元素 |
| HASH | 包含键值对的无序散列表 | 添加、获取、移除单个键值对 获取所有键值对 检查某个键是否存在 |
| ZSET | 有序集合 | 添加、获取、删除元素 根据分值范围或者成员来获取元素 计算一个键的排名 |
STRING
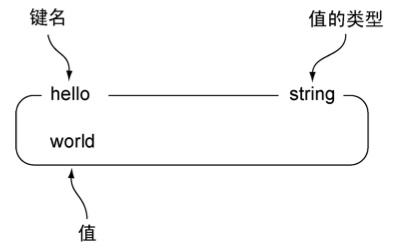
命令:
| 命令 | 行为 |
|---|---|
GET |
获取存储在给定键中的值。 |
SET |
设置存储在给定键中的值。 |
DEL |
删除存储在给定键中的值(这个命令可以用于所有类型)。 |
INCR |
为键 key 储存的数字值加一 |
DECR |
为键 key 储存的数字值减一 |
更多命令请参考:Redis String 类型命令
示例:
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> get hello
"world"
127.0.0.1:6379> del hello
(integer) 1
127.0.0.1:6379> get hello
(nil)
HASH
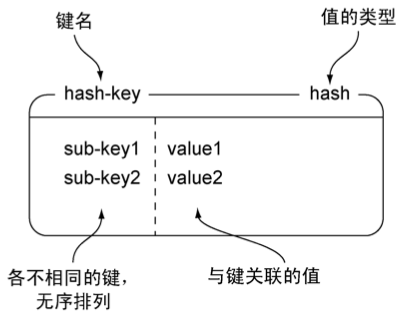
命令:
| 命令 | 行为 |
|---|---|
HSET |
在散列里面关联起给定的键值对。 |
HGET |
获取指定散列键的值。 |
HGETALL |
获取散列包含的所有键值对。 |
HDEL |
如果给定键存在于散列里面,那么移除这个键。 |
更多命令请参考:Redis Hash 类型命令
示例:
127.0.0.1:6379> hset hash-key sub-key1 value1
(integer) 1
127.0.0.1:6379> hset hash-key sub-key2 value2
(integer) 1
127.0.0.1:6379> hset hash-key sub-key1 value1
(integer) 0
127.0.0.1:6379> hset hash-key sub-key3 value2
(integer) 0
127.0.0.1:6379> hgetall hash-key
1) "sub-key1"
2) "value1"
3) "sub-key2"
4) "value2"
127.0.0.1:6379> hdel hash-key sub-key2
(integer) 1
127.0.0.1:6379> hdel hash-key sub-key2
(integer) 0
127.0.0.1:6379> hget hash-key sub-key1
"value1"
127.0.0.1:6379> hgetall hash-key
1) "sub-key1"
2) "value1"
LIST
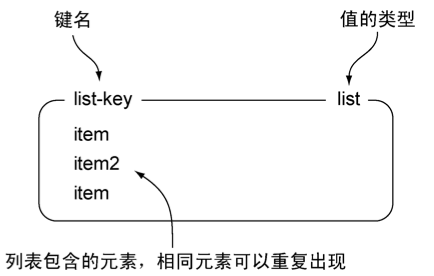
命令:
| 命令 | 行为 |
|---|---|
LPUSH |
将给定值推入列表的右端。 |
RPUSH |
将给定值推入列表的右端。 |
LPOP |
从列表的左端弹出一个值,并返回被弹出的值。 |
RPOP |
从列表的右端弹出一个值,并返回被弹出的值。 |
LRANGE |
获取列表在给定范围上的所有值。 |
LINDEX |
获取列表在给定位置上的单个元素。 |
LREM |
从列表的左端弹出一个值,并返回被弹出的值。 |
LTRIM |
只保留指定区间内的元素,删除其他元素。 |
更多命令请参考:Redis List 类型命令
示例:
127.0.0.1:6379> rpush list-key item
(integer) 1
127.0.0.1:6379> rpush list-key item2
(integer) 2
127.0.0.1:6379> rpush list-key item
(integer) 3
127.0.0.1:6379> lrange list-key 0 -1
1) "item"
2) "item2"
3) "item"
127.0.0.1:6379> lindex list-key 1
"item2"
127.0.0.1:6379> lpop list-key
"item"
127.0.0.1:6379> lrange list-key 0 -1
1) "item2"
2) "item"
SET
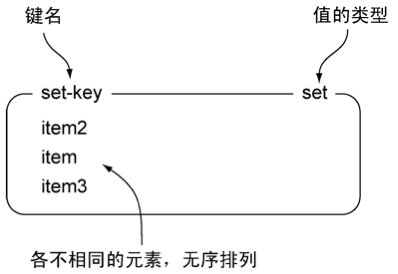
命令:
| 命令 | 行为 |
|---|---|
SADD |
将给定元素添加到集合。 |
SMEMBERS |
返回集合包含的所有元素。 |
SISMEMBER |
检查给定元素是否存在于集合中。 |
SREM |
如果给定的元素存在于集合中,那么移除这个元素。 |
更多命令请参考:Redis Set 类型命令
示例:
127.0.0.1:6379> sadd set-key item
(integer) 1
127.0.0.1:6379> sadd set-key item2
(integer) 1
127.0.0.1:6379> sadd set-key item3
(integer) 1
127.0.0.1:6379> sadd set-key item
(integer) 0
127.0.0.1:6379> smembers set-key
1) "item"
2) "item2"
3) "item3"
127.0.0.1:6379> sismember set-key item4
(integer) 0
127.0.0.1:6379> sismember set-key item
(integer) 1
127.0.0.1:6379> srem set-key item2
(integer) 1
127.0.0.1:6379> srem set-key item2
(integer) 0
127.0.0.1:6379> smembers set-key
1) "item"
2) "item3"
ZSET
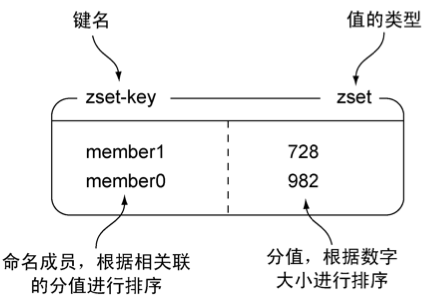
适用场景:由于可以设置 score,且不重复。适合用于存储各种排行数据,如:按评分排序的有序商品集合、按时间排序的有序文章集合。
命令:
| 命令 | 行为 |
|---|---|
ZADD |
将一个带有给定分值的成员添加到有序集合里面。 |
ZRANGE |
根据元素在有序排列中所处的位置,从有序集合里面获取多个元素。 |
ZRANGEBYSCORE |
获取有序集合在给定分值范围内的所有元素。 |
ZREM |
如果给定成员存在于有序集合,那么移除这个成员。 |
更多命令请参考:Redis ZSet 类型命令
示例:
127.0.0.1:6379> zadd zset-key 728 member1
(integer) 1
127.0.0.1:6379> zadd zset-key 982 member0
(integer) 1
127.0.0.1:6379> zadd zset-key 982 member0
(integer) 0
127.0.0.1:6379> zrange zset-key 0 -1 withscores
1) "member1"
2) "728"
3) "member0"
4) "982"
127.0.0.1:6379> zrangebyscore zset-key 0 800 withscores
1) "member1"
2) "728"
127.0.0.1:6379> zrem zset-key member1
(integer) 1
127.0.0.1:6379> zrem zset-key member1
(integer) 0
127.0.0.1:6379> zrange zset-key 0 -1 withscores
1) "member0"
2) "982"
通用命令
排序
Redis 的 SORT 命令可以对 LIST、SET、ZSET 进行排序。
| 命令 | 描述 |
|---|---|
SORT |
`SORT source-key [BY pattern] [LIMIT offset count] [GET pattern [GET pattern ...]] [ASC |
示例:
127.0.0.1:6379[15]> RPUSH 'sort-input' 23 15 110 7
(integer) 4
127.0.0.1:6379[15]> SORT 'sort-input'
1) "7"
2) "15"
3) "23"
4) "110"
127.0.0.1:6379[15]> SORT 'sort-input' alpha
1) "110"
2) "15"
3) "23"
4) "7"
127.0.0.1:6379[15]> HSET 'd-7' 'field' 5
(integer) 1
127.0.0.1:6379[15]> HSET 'd-15' 'field' 1
(integer) 1
127.0.0.1:6379[15]> HSET 'd-23' 'field' 9
(integer) 1
127.0.0.1:6379[15]> HSET 'd-110' 'field' 3
(integer) 1
127.0.0.1:6379[15]> SORT 'sort-input' by 'd-*->field'
1) "15"
2) "110"
3) "7"
4) "23"
127.0.0.1:6379[15]> SORT 'sort-input' by 'd-*->field' get 'd-*->field'
1) "1"
2) "3"
3) "5"
4) "9"
键的过期时间
Redis 的 EXPIRE 命令可以指定一个键的过期时间,当达到过期时间后,Redis 会自动删除该键。
| 命令 | 描述 |
|---|---|
PERSIST |
PERSIST key-name—移除键的过期时间 |
TTL |
TTL key-name—查看给定键距离过期还有多少秒 |
EXPIRE |
EXPIRE key-name seconds—让给定键在指定的秒数之后过期 |
EXPIREAT |
EXPIREAT key-name timestamp—将给定键的过期时间设置为给定的 UNIX 时间戳 |
PTTL |
PTTL key-name—查看给定键距离过期时间还有多少毫秒(这个命令在 Redis 2.6 或以上版本可用) |
PEXPIRE |
PEXPIRE key-name milliseconds—让给定键在指定的毫秒数之后过期(这个命令在 Redis 2.6 或以上版本可用) |
PEXPIREAT |
PEXPIREAT key-name timestamp-milliseconds—将一个毫秒级精度的 UNIX 时间戳设置为给定键的过期时间(这个命令在 Redis 2.6 或以上版本可用) |
示例:
127.0.0.1:6379[15]> SET key value
OK
127.0.0.1:6379[15]> GET key
"value"
127.0.0.1:6379[15]> EXPIRE key 2
(integer) 1
127.0.0.1:6379[15]> GET key
(nil)
二、Redis 高级数据类型
BitMap
BitMap 即位图。BitMap 不是一个真实的数据结构。而是 STRING 类型上的一组面向 bit 操作的集合。由于 STRING 是二进制安全的 blob,并且它们的最大长度是 512m,所以 BitMap 能最大设置 $2^{32}$ 个不同的 bit。
Bitmaps 的最大优点就是存储信息时可以节省大量的空间。例如在一个系统中,不同的用户被一个增长的用户 ID 表示。40 亿($2^{32}=4*1024*1024*1024$ ≈ 40 亿)用户只需要 512M 内存就能记住某种信息,例如用户是否登录过。
BitMap 命令
- SETBIT - 对
key所储存的字符串值,设置或清除指定偏移量上的位(bit)。 - GETBIT - 对
key所储存的字符串值,获取指定偏移量上的位(bit)。 - BITCOUNT - 计算给定字符串中,被设置为
1的比特位的数量。 - BITPOS
- BITOP
- BITFIELD
BitMap 示例
# 对不存在的 key 或者不存在的 offset 进行 GETBIT, 返回 0
redis> EXISTS bit
(integer) 0
redis> GETBIT bit 10086
(integer) 0
# 对已存在的 offset 进行 GETBIT
redis> SETBIT bit 10086 1
(integer) 0
redis> GETBIT bit 10086
(integer) 1
redis> BITCOUNT bit
(integer) 1
BitMap 应用
Bitmap 对于一些特定类型的计算非常有效。例如:使用 bitmap 实现用户上线次数统计。
假设现在我们希望记录自己网站上的用户的上线频率,比如说,计算用户 A 上线了多少天,用户 B 上线了多少天,诸如此类,以此作为数据,从而决定让哪些用户参加 beta 测试等活动 —— 这个模式可以使用 SETBIT key offset value 和 [BITCOUNT key start] [end] 来实现。
比如说,每当用户在某一天上线的时候,我们就使用 SETBIT key offset value ,以用户名作为 key,将那天所代表的网站的上线日作为 offset 参数,并将这个 offset 上的为设置为 1 。
更详细的实现可以参考:
HyperLogLog
HyperLogLog 是用于计算唯一事物的概率数据结构(从技术上讲,这被称为估计集合的基数)。如果统计唯一项,项目越多,需要的内存就越多。因为需要记住过去已经看过的项,从而避免多次统计这些项。
HyperLogLog 命令
- PFADD - 将任意数量的元素添加到指定的 HyperLogLog 里面。
- PFCOUNT - 返回 HyperLogLog 包含的唯一元素的近似数量。
- PFMERGE - 将多个 HyperLogLog 合并(merge)为一个 HyperLogLog , 合并后的 HyperLogLog 的基数接近于所有输入 HyperLogLog 的可见集合(observed set)的并集。合并得出的 HyperLogLog 会被储存在
destkey键里面, 如果该键并不存在, 那么命令在执行之前, 会先为该键创建一个空的 HyperLogLog 。
示例:
redis> PFADD databases "Redis" "MongoDB" "MySQL"
(integer) 1
redis> PFCOUNT databases
(integer) 3
redis> PFADD databases "Redis" # Redis 已经存在,不必对估计数量进行更新
(integer) 0
redis> PFCOUNT databases # 元素估计数量没有变化
(integer) 3
redis> PFADD databases "PostgreSQL" # 添加一个不存在的元素
(integer) 1
redis> PFCOUNT databases # 估计数量增一
4
GEO
这个功能可以将用户给定的地理位置(经度和纬度)信息储存起来,并对这些信息进行操作。
GEO 命令
- GEOADD - 将指定的地理空间位置(纬度、经度、名称)添加到指定的 key 中。
- GEOPOS - 从 key 里返回所有给定位置元素的位置(经度和纬度)。
- GEODIST - 返回两个给定位置之间的距离。
- GEOHASH - 回一个或多个位置元素的标准 Geohash 值,它可以在http://geohash.org/使用。
- GEORADIUS
- GEORADIUSBYMEMBER
三、Redis 数据类型应用
案例-最受欢迎文章
选出最受欢迎文章,需要支持对文章进行评分。
对文章进行投票
(1)使用 HASH 存储文章
使用 HASH 类型存储文章信息。其中:key 是文章 ID;field 是文章的属性 key;value 是属性对应值。

操作:
- 存储文章信息 - 使用
HSET或HMGET命令 - 查询文章信息 - 使用
HGETALL命令 - 添加投票 - 使用
HINCRBY命令
(2)使用 ZSET 针对不同维度集合排序
使用 ZSET 类型分别存储按照时间排序和按照评分排序的文章 ID 集合。
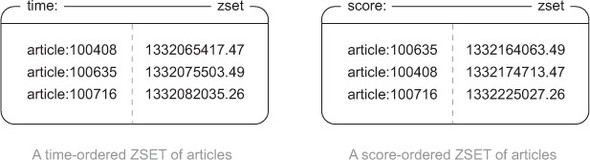
操作:
- 添加记录 - 使用
ZADD命令 - 添加分数 - 使用
ZINCRBY命令 - 取出多篇文章 - 使用
ZREVRANGE命令
(3)为了防止重复投票,使用 SET 类型记录每篇文章 ID 对应的投票集合。

操作:
- 添加投票者 - 使用
SADD命令 - 设置有效期 - 使用
EXPIRE命令
(4)假设 user:115423 给 article:100408 投票,分别需要高更新评分排序集合以及投票集合。

当需要对一篇文章投票时,程序需要用 ZSCORE 命令检查记录文章发布时间的有序集合,判断文章的发布时间是否超过投票有效期(比如:一星期)。
public void articleVote(Jedis conn, String user, String article) {
// 计算文章的投票截止时间。
long cutoff = (System.currentTimeMillis() / 1000) - ONE_WEEK_IN_SECONDS;
// 检查是否还可以对文章进行投票
// (虽然使用散列也可以获取文章的发布时间,
// 但有序集合返回的文章发布时间为浮点数,
// 可以不进行转换直接使用)。
if (conn.zscore("time:", article) < cutoff) {
return;
}
// 从article:id标识符(identifier)里面取出文章的ID。
String articleId = article.substring(article.indexOf(':') + 1);
// 如果用户是第一次为这篇文章投票,那么增加这篇文章的投票数量和评分。
if (conn.sadd("voted:" + articleId, user) == 1) {
conn.zincrby("score:", VOTE_SCORE, article);
conn.hincrBy(article, "votes", 1);
}
}
发布并获取文章
发布文章:
- 添加文章 - 使用
INCR命令计算新的文章 ID,填充文章信息,然后用HSET命令或HMSET命令写入到HASH结构中。 - 将文章作者 ID 添加到投票名单 - 使用
SADD命令添加到代表投票名单的SET结构中。 - 设置投票有效期 - 使用
EXPIRE命令设置投票有效期。
public String postArticle(Jedis conn, String user, String title, String link) {
// 生成一个新的文章ID。
String articleId = String.valueOf(conn.incr("article:"));
String voted = "voted:" + articleId;
// 将发布文章的用户添加到文章的已投票用户名单里面,
conn.sadd(voted, user);
// 然后将这个名单的过期时间设置为一周(第3章将对过期时间作更详细的介绍)。
conn.expire(voted, ONE_WEEK_IN_SECONDS);
long now = System.currentTimeMillis() / 1000;
String article = "article:" + articleId;
// 将文章信息存储到一个散列里面。
HashMap<String, String> articleData = new HashMap<String, String>();
articleData.put("title", title);
articleData.put("link", link);
articleData.put("user", user);
articleData.put("now", String.valueOf(now));
articleData.put("votes", "1");
conn.hmset(article, articleData);
// 将文章添加到根据发布时间排序的有序集合和根据评分排序的有序集合里面。
conn.zadd("score:", now + VOTE_SCORE, article);
conn.zadd("time:", now, article);
return articleId;
}
分页查询最受欢迎文章:
使用 ZINTERSTORE 命令根据页码、每页记录数、排序号,根据评分值从大到小分页查出文章 ID 列表。
public List<Map<String, String>> getArticles(Jedis conn, int page, String order) {
// 设置获取文章的起始索引和结束索引。
int start = (page - 1) * ARTICLES_PER_PAGE;
int end = start + ARTICLES_PER_PAGE - 1;
// 获取多个文章ID。
Set<String> ids = conn.zrevrange(order, start, end);
List<Map<String, String>> articles = new ArrayList<>();
// 根据文章ID获取文章的详细信息。
for (String id : ids) {
Map<String, String> articleData = conn.hgetAll(id);
articleData.put("id", id);
articles.add(articleData);
}
return articles;
}
对文章进行分组
如果文章需要分组,功能需要分为两块:
- 记录文章属于哪个群组
- 负责取出群组里的文章
将文章添加、删除群组:
public void addRemoveGroups(Jedis conn, String articleId, String[] toAdd, String[] toRemove) {
// 构建存储文章信息的键名。
String article = "article:" + articleId;
// 将文章添加到它所属的群组里面。
for (String group : toAdd) {
conn.sadd("group:" + group, article);
}
// 从群组里面移除文章。
for (String group : toRemove) {
conn.srem("group:" + group, article);
}
}
取出群组里的文章:
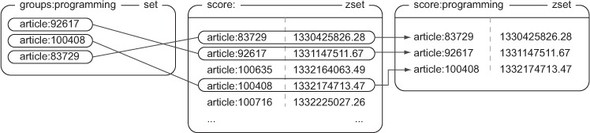
- 通过对存储群组文章的集合和存储文章评分的有序集合执行
ZINTERSTORE命令,可以得到按照文章评分排序的群组文章。 - 通过对存储群组文章的集合和存储文章发布时间的有序集合执行
ZINTERSTORE命令,可以得到按照文章发布时间排序的群组文章。
public List<Map<String, String>> getGroupArticles(Jedis conn, String group, int page, String order) {
// 为每个群组的每种排列顺序都创建一个键。
String key = order + group;
// 检查是否有已缓存的排序结果,如果没有的话就现在进行排序。
if (!conn.exists(key)) {
// 根据评分或者发布时间,对群组文章进行排序。
ZParams params = new ZParams().aggregate(ZParams.Aggregate.MAX);
conn.zinterstore(key, params, "group:" + group, order);
// 让Redis在60秒钟之后自动删除这个有序集合。
conn.expire(key, 60);
}
// 调用之前定义的getArticles函数来进行分页并获取文章数据。
return getArticles(conn, page, key);
}
案例-管理令牌
网站一般会以 Cookie、Session、令牌这类信息存储用户身份信息。
可以将 Cookie/Session/令牌 和用户的映射关系存储在 HASH 结构。
下面以令牌来举例。
查询令牌
public String checkToken(Jedis conn, String token) {
// 尝试获取并返回令牌对应的用户。
return conn.hget("login:", token);
}
更新令牌
- 用户每次访问页面,可以记录下令牌和当前时间戳的映射关系,存入一个
ZSET结构中,以便分析用户是否活跃,继而可以周期性清理最老的令牌,统计当前在线用户数等行为。 - 用户如果正在浏览商品,可以记录到用户最近浏览过的商品有序集合中(集合可以限定数量,超过数量进行裁剪),存入到一个
ZSET结构中,以便分析用户最近可能感兴趣的商品,以便推荐商品。
public void updateToken(Jedis conn, String token, String user, String item) {
// 获取当前时间戳。
long timestamp = System.currentTimeMillis() / 1000;
// 维持令牌与已登录用户之间的映射。
conn.hset("login:", token, user);
// 记录令牌最后一次出现的时间。
conn.zadd("recent:", timestamp, token);
if (item != null) {
// 记录用户浏览过的商品。
conn.zadd("viewed:" + token, timestamp, item);
// 移除旧的记录,只保留用户最近浏览过的25个商品。
conn.zremrangeByRank("viewed:" + token, 0, -26);
conn.zincrby("viewed:", -1, item);
}
}
清理令牌
上一节提到,更新令牌时,将令牌和当前时间戳的映射关系,存入一个 ZSET 结构中。所以可以通过排序得知哪些令牌最老。如果没有清理操作,更新令牌占用的内存会不断膨胀,直到导致机器宕机。
比如:最多允许存储 1000 万条令牌信息,周期性检查,一旦发现记录数超出 1000 万条,将 ZSET 从新到老排序,将超出 1000 万条的记录清除。
public static class CleanSessionsThread extends Thread {
private Jedis conn;
private int limit;
private volatile boolean quit;
public CleanSessionsThread(int limit) {
this.conn = new Jedis("localhost");
this.conn.select(15);
this.limit = limit;
}
public void quit() {
quit = true;
}
@Override
public void run() {
while (!quit) {
// 找出目前已有令牌的数量。
long size = conn.zcard("recent:");
// 令牌数量未超过限制,休眠并在之后重新检查。
if (size <= limit) {
try {
sleep(1000);
} catch (InterruptedException ie) {
Thread.currentThread().interrupt();
}
continue;
}
// 获取需要移除的令牌ID。
long endIndex = Math.min(size - limit, 100);
Set<String> tokenSet = conn.zrange("recent:", 0, endIndex - 1);
String[] tokens = tokenSet.toArray(new String[tokenSet.size()]);
// 为那些将要被删除的令牌构建键名。
ArrayList<String> sessionKeys = new ArrayList<String>();
for (String token : tokens) {
sessionKeys.add("viewed:" + token);
}
// 移除最旧的那些令牌。
conn.del(sessionKeys.toArray(new String[sessionKeys.size()]));
conn.hdel("login:", tokens);
conn.zrem("recent:", tokens);
}
}
}
案例-购物车
可以使用 HASH 结构来实现购物车功能。
每个用户的购物车,存储了商品 ID 和商品数量的映射。
在购物车中添加、删除商品
public void addToCart(Jedis conn, String session, String item, int count) {
if (count <= 0) {
// 从购物车里面移除指定的商品。
conn.hdel("cart:" + session, item);
} else {
// 将指定的商品添加到购物车。
conn.hset("cart:" + session, item, String.valueOf(count));
}
}
清空购物车
在 清理令牌 的基础上,清空会话时,顺便将购物车缓存一并清理。
while (!quit) {
long size = conn.zcard("recent:");
if (size <= limit) {
try {
sleep(1000);
} catch (InterruptedException ie) {
Thread.currentThread().interrupt();
}
continue;
}
long endIndex = Math.min(size - limit, 100);
Set<String> sessionSet = conn.zrange("recent:", 0, endIndex - 1);
String[] sessions = sessionSet.toArray(new String[sessionSet.size()]);
ArrayList<String> sessionKeys = new ArrayList<String>();
for (String sess : sessions) {
sessionKeys.add("viewed:" + sess);
// 新增加的这行代码用于删除旧会话对应用户的购物车。
sessionKeys.add("cart:" + sess);
}
conn.del(sessionKeys.toArray(new String[sessionKeys.size()]));
conn.hdel("login:", sessions);
conn.zrem("recent:", sessions);
}
案例-页面缓存
大部分网页内容并不会经常改变,但是访问时,后台需要动态计算,这可能耗时较多,此时可以使用 STRING 结构存储页面缓存,
public String cacheRequest(Jedis conn, String request, Callback callback) {
// 对于不能被缓存的请求,直接调用回调函数。
if (!canCache(conn, request)) {
return callback != null ? callback.call(request) : null;
}
// 将请求转换成一个简单的字符串键,方便之后进行查找。
String pageKey = "cache:" + hashRequest(request);
// 尝试查找被缓存的页面。
String content = conn.get(pageKey);
if (content == null && callback != null) {
// 如果页面还没有被缓存,那么生成页面。
content = callback.call(request);
// 将新生成的页面放到缓存里面。
conn.setex(pageKey, 300, content);
}
// 返回页面。
return content;
}
案例-数据行缓存
电商网站可能会有促销、特卖、抽奖等活动,这些活动页面只需要从数据库中加载几行数据,如:用户信息、商品信息。
可以使用 STRING 结构来缓存这些数据,使用 JSON 存储结构化的信息。
此外,需要有两个 ZSET 结构来记录更新缓存的时机:
- 第一个为调度有序集合;
- 第二个为延时有序集合。
记录缓存时机:
public void scheduleRowCache(Jedis conn, String rowId, int delay) {
// 先设置数据行的延迟值。
conn.zadd("delay:", delay, rowId);
// 立即缓存数据行。
conn.zadd("schedule:", System.currentTimeMillis() / 1000, rowId);
}
定时更新数据行缓存:
public class CacheRowsThread extends Thread {
private Jedis conn;
private boolean quit;
public CacheRowsThread() {
this.conn = new Jedis("localhost");
this.conn.select(15);
}
public void quit() {
quit = true;
}
@Override
public void run() {
Gson gson = new Gson();
while (!quit) {
// 尝试获取下一个需要被缓存的数据行以及该行的调度时间戳,
// 命令会返回一个包含零个或一个元组(tuple)的列表。
Set<Tuple> range = conn.zrangeWithScores("schedule:", 0, 0);
Tuple next = range.size() > 0 ? range.iterator().next() : null;
long now = System.currentTimeMillis() / 1000;
if (next == null || next.getScore() > now) {
try {
// 暂时没有行需要被缓存,休眠50毫秒后重试。
sleep(50);
} catch (InterruptedException ie) {
Thread.currentThread().interrupt();
}
continue;
}
String rowId = next.getElement();
// 获取下一次调度前的延迟时间。
double delay = conn.zscore("delay:", rowId);
if (delay <= 0) {
// 不必再缓存这个行,将它从缓存中移除。
conn.zrem("delay:", rowId);
conn.zrem("schedule:", rowId);
conn.del("inv:" + rowId);
continue;
}
// 读取数据行。
Inventory row = Inventory.get(rowId);
// 更新调度时间并设置缓存值。
conn.zadd("schedule:", now + delay, rowId);
conn.set("inv:" + rowId, gson.toJson(row));
}
}
}
案例-网页分析
网站可以采集用户的访问、交互、购买行为,再分析用户习惯、喜好,从而判断市场行情和潜在商机等。
那么,简单的,如何记录用户在一定时间内访问的商品页面呢?
参考 更新令牌 代码示例,记录用户访问不同商品的浏览次数,并排序。
判断页面是否需要缓存,根据评分判断商品页面是否热门:
public boolean canCache(Jedis conn, String request) {
try {
URL url = new URL(request);
HashMap<String, String> params = new HashMap<>();
if (url.getQuery() != null) {
for (String param : url.getQuery().split("&")) {
String[] pair = param.split("=", 2);
params.put(pair[0], pair.length == 2 ? pair[1] : null);
}
}
// 尝试从页面里面取出商品ID。
String itemId = extractItemId(params);
// 检查这个页面能否被缓存以及这个页面是否为商品页面。
if (itemId == null || isDynamic(params)) {
return false;
}
// 取得商品的浏览次数排名。
Long rank = conn.zrank("viewed:", itemId);
// 根据商品的浏览次数排名来判断是否需要缓存这个页面。
return rank != null && rank < 10000;
} catch (MalformedURLException mue) {
return false;
}
}
案例-记录日志
可用使用 LIST 结构存储日志数据。
public void logRecent(Jedis conn, String name, String message, String severity) {
String destination = "recent:" + name + ':' + severity;
Pipeline pipe = conn.pipelined();
pipe.lpush(destination, TIMESTAMP.format(new Date()) + ' ' + message);
pipe.ltrim(destination, 0, 99);
pipe.sync();
}
案例-统计数据
更新计数器:
public static final int[] PRECISION = new int[] { 1, 5, 60, 300, 3600, 18000, 86400 };
public void updateCounter(Jedis conn, String name, int count, long now) {
Transaction trans = conn.multi();
for (int prec : PRECISION) {
long pnow = (now / prec) * prec;
String hash = String.valueOf(prec) + ':' + name;
trans.zadd("known:", 0, hash);
trans.hincrBy("count:" + hash, String.valueOf(pnow), count);
}
trans.exec();
}
查看计数器数据:
public List<Pair<Integer>> getCounter(
Jedis conn, String name, int precision) {
String hash = String.valueOf(precision) + ':' + name;
Map<String, String> data = conn.hgetAll("count:" + hash);
List<Pair<Integer>> results = new ArrayList<>();
for (Map.Entry<String, String> entry : data.entrySet()) {
results.add(new Pair<>(
entry.getKey(),
Integer.parseInt(entry.getValue())));
}
Collections.sort(results);
return results;
}
案例-查找 IP 所属地
Redis 实现的 IP 所属地查找比关系型数据实现方式更快。
载入 IP 数据
IP 地址转为整数值:
public int ipToScore(String ipAddress) {
int score = 0;
for (String v : ipAddress.split("\\.")) {
score = score * 256 + Integer.parseInt(v, 10);
}
return score;
}
创建 IP 地址与城市 ID 之间的映射:
public void importIpsToRedis(Jedis conn, File file) {
FileReader reader = null;
try {
// 载入 csv 文件数据
reader = new FileReader(file);
CSVFormat csvFormat = CSVFormat.DEFAULT.withRecordSeparator("\n");
CSVParser csvParser = csvFormat.parse(reader);
int count = 0;
List<CSVRecord> records = csvParser.getRecords();
for (CSVRecord line : records) {
String startIp = line.get(0);
if (startIp.toLowerCase().indexOf('i') != -1) {
continue;
}
// 将 IP 地址转为整数值
int score = 0;
if (startIp.indexOf('.') != -1) {
score = ipToScore(startIp);
} else {
try {
score = Integer.parseInt(startIp, 10);
} catch (NumberFormatException nfe) {
// 略过文件的第一行以及格式不正确的条目
continue;
}
}
// 构建唯一的城市 ID
String cityId = line.get(2) + '_' + count;
// 将城市 ID 及其对应的 IP 地址整数值添加到 ZSET
conn.zadd("ip2cityid:", score, cityId);
count++;
}
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
try {
reader.close();
} catch (Exception e) {
// ignore
}
}
}
存储城市信息:
public void importCitiesToRedis(Jedis conn, File file) {
Gson gson = new Gson();
FileReader reader = null;
try {
// 加载 csv 信息
reader = new FileReader(file);
CSVFormat csvFormat = CSVFormat.DEFAULT.withRecordSeparator("\n");
CSVParser parser = new CSVParser(reader, csvFormat);
// String[] line;
List<CSVRecord> records = parser.getRecords();
for (CSVRecord record : records) {
if (record.size() < 4 || !Character.isDigit(record.get(0).charAt(0))) {
continue;
}
// 将城市地理信息转为 json 结构,存入 HASH 结构中
String cityId = record.get(0);
String country = record.get(1);
String region = record.get(2);
String city = record.get(3);
String json = gson.toJson(new String[] { city, region, country });
conn.hset("cityid2city:", cityId, json);
}
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
try {
reader.close();
} catch (Exception e) {
// ignore
}
}
}
查找 IP 所属城市
操作步骤:
- 将要查找的 IP 地址转为整数值;
- 查找所有分值小于等于要查找的 IP 地址的地址,取出其中最大分值的那个记录;
- 用找到的记录所对应的城市 ID 去检索城市信息。
public String[] findCityByIp(Jedis conn, String ipAddress) {
int score = ipToScore(ipAddress);
Set<String> results = conn.zrevrangeByScore("ip2cityid:", score, 0, 0, 1);
if (results.size() == 0) {
return null;
}
String cityId = results.iterator().next();
cityId = cityId.substring(0, cityId.indexOf('_'));
return new Gson().fromJson(conn.hget("cityid2city:", cityId), String[].class);
}
案例-服务的发现与配置
案例-自动补全
需求:根据用户输入,自动补全信息,如:联系人、商品名等。
- 典型场景一:社交网站后台记录用户最近联系过的 100 个好友,当用户查找好友时,根据输入的关键字自动补全姓名。
- 典型场景二:电商网站后台记录用户最近浏览过的 10 件商品,当用户查找商品是,根据输入的关键字自动补全商品名称。
数据模型:使用 Redis 的 LIST 类型存储最近联系人列表。
构建自动补全列表通常有以下操作:
- 如果指定联系人已经存在于最近联系人列表里,那么从列表里移除他。对应
LREM命令。 - 将指定联系人添加到最近联系人列表的最前面。对应
LPUSH命令。 - 添加操作完成后,如果联系人列表中的数量超过 100 个,进行裁剪操作。对应
LTRIM命令。
案例-广告定向
案例-职位搜索
需求:在一个招聘网站上,求职者有自己的技能清单;用人公司的职位有必要的技能清单。用人公司需要查询满足自己职位要求的求职者;求职者需要查询自己可以投递简历的职位。
关键数据模型:使用 SET 类型存储求职者的技能列表,使用 SET 类型存储职位的技能列表。
关键操作:使用 SDIFF 命令对比两个 SET 的差异,返回 empty 表示匹配要求。
redis cli 示例:
# -----------------------------------------------------------
# Redis 职位搜索数据模型示例
# -----------------------------------------------------------
# (1)职位技能表:使用 set 存储
# job:001 职位添加 4 种技能
SADD job:001 skill:001
SADD job:001 skill:002
SADD job:001 skill:003
SADD job:001 skill:004
# job:002 职位添加 3 种技能
SADD job:002 skill:001
SADD job:002 skill:002
SADD job:002 skill:003
# job:003 职位添加 2 种技能
SADD job:003 skill:001
SADD job:003 skill:003
# 查看
SMEMBERS job:001
SMEMBERS job:002
SMEMBERS job:003
# (2)求职者技能表:使用 set 存储
SADD interviewee:001 skill:001
SADD interviewee:001 skill:003
SADD interviewee:002 skill:001
SADD interviewee:002 skill:002
SADD interviewee:002 skill:003
SADD interviewee:002 skill:004
SADD interviewee:002 skill:005
# 查看
SMEMBERS interviewee:001
SMEMBERS interviewee:002
# (3)求职者遍历查找自己符合要求的职位(返回结果为 empty 表示要求的技能全部命中)
# 比较职位技能清单和求职者技能清单的差异
SDIFF job:001 interviewee:001
SDIFF job:002 interviewee:001
SDIFF job:003 interviewee:001
SDIFF job:001 interviewee:002
SDIFF job:002 interviewee:002
SDIFF job:003 interviewee:002
# (4)用人公司根据遍历查找符合自己职位要求的求职者(返回结果为 empty 表示要求的技能全部命中)
# 比较职位技能清单和求职者技能清单的差异
SDIFF interviewee:001 job:001
SDIFF interviewee:002 job:001
SDIFF interviewee:001 job:002
SDIFF interviewee:002 job:002
SDIFF interviewee:001 job:003
SDIFF interviewee:002 job:003