to clean some pics
|
|
@ -1,91 +0,0 @@
|
||||||
## heapster
|
|
||||||
|
|
||||||
`Heapster` 监控整个集群资源的过程:首先kubelet内置的cAdvisor收集本node节点的容器资源占用情况,然后heapster从kubelet提供的api采集节点和容器的资源占用,最后heapster 持久化数据存储到`influxdb`中(也可以是其他的存储后端,Google Cloud Monitoring等)。
|
|
||||||
|
|
||||||
`Grafana` 则通过配置数据源指向上述 `influxdb`,从而界面化显示监控信息。
|
|
||||||
|
|
||||||
### 部署
|
|
||||||
|
|
||||||
访问 [heapster release](https://github.com/kubernetes/heapster)页面下载最新 release 1.4.3,参考目录`heapster-1.3.0/deploy/kube-config/influxdb`,因为这个官方release 在k8s1.8.4使用还是有不少问题,请在参考的基础上使用本项目提供的yaml文件
|
|
||||||
|
|
||||||
1. [grafana](../../manifests/heapster/grafana.yaml)
|
|
||||||
1. [heapster](../../manifests/heapster/heapster.yaml)
|
|
||||||
1. [influxdb](../../manifests/heapster/influxdb.yaml)
|
|
||||||
|
|
||||||
安装比较简单 `kubectl create -f /etc/ansible/manifests/heapster/`,主要讲一下注意事项
|
|
||||||
|
|
||||||
#### grafana.yaml配置
|
|
||||||
|
|
||||||
+ 修改`heapster-grafana-amd64`镜像,v4.2.0版本修改成 v4.4.3版本,否则 grafana pod无法起来,报`CrashLoopBackOff`错误,详见[ISSUE](https://github.com/kubernetes/heapster/issues/1806)
|
|
||||||
+ 参数`- name: GF_SERVER_ROOT_URL`的设置要根据后续访问grafana的方式确定,如果使用 NodePort方式访问,必须设置成:`value: /`;如果使用apiserver proxy方式,必须设置成`value: /api/v1/namespaces/kube-system/services/monitoring-grafana/proxy/`,注意官方文件中预设的`value: /api/v1/proxy/namespaces/kube-system/services/monitoring-grafana/`已经不适合k8s 1.8.0版本了,
|
|
||||||
+ `kubernetes.io/cluster-service: 'true'` 和 `type: NodePort` 根据上述的访问方式设置,建议使用apiserver 方式,可以增加安全控制
|
|
||||||
|
|
||||||
#### heapster.yaml配置
|
|
||||||
|
|
||||||
+ 需要配置 RBAC 把 ServiceAccount `heapster` 与集群预定义的集群角色 `system:heapster` 绑定,这样heapster pod才有相应权限去访问 apiserver
|
|
||||||
|
|
||||||
#### influxdb.yaml配置
|
|
||||||
|
|
||||||
+ influxdb 官方建议使用命令行或 HTTP API 接口来查询数据库,从 v1.1.0 版本开始默认关闭 admin UI,这里参考[opsnull](https://github.com/opsnull/follow-me-install-kubernetes-cluster/blob/master/10-%E9%83%A8%E7%BD%B2Heapster%E6%8F%92%E4%BB%B6.md)给出的方法,增加ConfigMap配置,然后挂载到容器中,覆盖默认配置
|
|
||||||
+ 注意influxdb 这个版本只能使用 NodePort方式访问它的admin UI,才能正确连接数据库
|
|
||||||
|
|
||||||
### 验证
|
|
||||||
|
|
||||||
``` bash
|
|
||||||
$ kubectl get pods -n kube-system | grep -E 'heapster|monitoring'
|
|
||||||
heapster-3273315324-tmxbg 1/1 Running 0 11m
|
|
||||||
monitoring-grafana-2255110352-94lpn 1/1 Running 0 11m
|
|
||||||
monitoring-influxdb-884893134-3vb6n 1/1 Running 0 11m
|
|
||||||
```
|
|
||||||
扩展检查Pods日志:
|
|
||||||
``` bash
|
|
||||||
$ kubectl logs heapster-3273315324-tmxbg -n kube-system
|
|
||||||
$ kubectl logs monitoring-grafana-2255110352-94lpn -n kube-system
|
|
||||||
$ kubectl logs monitoring-influxdb-884893134-3vb6n -n kube-system
|
|
||||||
```
|
|
||||||
部署完heapster,使用上一步介绍方法查看kubernets dashboard 界面,就可以看到各 Nodes、Pods 的 CPU、内存、负载等利用率曲线图,如果 dashboard上还无法看到利用率图,使用以下命令重启 dashboard pod:
|
|
||||||
+ 首先删除 `kubectl scale deploy kubernetes-dashboard --replicas=0 -n kube-system`
|
|
||||||
+ 然后新建 `kubectl scale deploy kubernetes-dashboard --replicas=1 -n kube-system`
|
|
||||||
|
|
||||||
### 访问 grafana
|
|
||||||
|
|
||||||
#### 1.通过apiserver 访问(建议的方式)
|
|
||||||
|
|
||||||
``` bash
|
|
||||||
kubectl cluster-info | grep grafana
|
|
||||||
monitoring-grafana is running at https://x.x.x.x:6443/api/v1/namespaces/kube-system/services/monitoring-grafana/proxy
|
|
||||||
```
|
|
||||||
请参考上一步 [访问dashboard](dashboard.md)同样的方式,使用证书或者密码认证(参照hosts文件配置,默认:用户admin 密码test1234),访问`https://x.x.x.x:6443/api/v1/namespaces/kube-system/services/monitoring-grafana/proxy`即可,如图可以点击[Home]选择查看 `Cluster` `Pods`的监控图形
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
#### 2.通过NodePort 访问
|
|
||||||
|
|
||||||
+ 修改 `Service` 允许 type: NodePort
|
|
||||||
+ 修改 `Deployment`中参数`- name: GF_SERVER_ROOT_URL`为 `value: /`
|
|
||||||
+ 如果之前grafana已经运行,使用 `kubectl replace --force -f /etc/ansible/manifests/heapster/grafana.yaml` 重启 grafana插件
|
|
||||||
|
|
||||||
``` bash
|
|
||||||
kubectl get svc -n kube-system|grep grafana
|
|
||||||
monitoring-grafana NodePort 10.68.135.50 <none> 80:5855/TCP 11m
|
|
||||||
```
|
|
||||||
然后用浏览器访问 http://NodeIP:5855
|
|
||||||
|
|
||||||
### 访问 influxdb
|
|
||||||
|
|
||||||
官方建议使用命令行或 HTTP API 接口来查询`influxdb`数据库,如非必要就跳过此步骤
|
|
||||||
|
|
||||||
目前根据测试 k8s v1.8.4 使用 NodePort 方式访问 admin 界面后才能正常连接数据库
|
|
||||||
|
|
||||||
``` bash
|
|
||||||
kubectl get svc -n kube-system|grep influxdb
|
|
||||||
monitoring-influxdb NodePort 10.68.195.193 <none> 8086:3382/TCP,8083:7651/TCP 12h
|
|
||||||
```
|
|
||||||
+ 如上例子,8083是管理页面端口,对外暴露的端口为7651
|
|
||||||
+ 8086 是数据连接端口,对外暴露的端口为3382
|
|
||||||
|
|
||||||
使用浏览器访问 http://NodeIP:7651,如图在页面的 “Connection Settings” 的 Host 中输入 node IP, Port 中输入 3382(由8086对外暴露的端口),点击 “Save” 即可
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
@ -1,167 +0,0 @@
|
||||||
## 第一部分:heapster
|
|
||||||
|
|
||||||
+ 本文档基于heapster 1.5.1和k8s 1.9.x,旧版文档请看[heapster 1.4.3](heapster.1.4.3.md)
|
|
||||||
|
|
||||||
`Heapster` 监控整个集群资源的过程:首先kubelet内置的cAdvisor收集本node节点的容器资源占用情况,然后heapster从kubelet提供的api采集节点和容器的资源占用,最后heapster 持久化数据存储到`influxdb`中(也可以是其他的存储后端,Google Cloud Monitoring等)。
|
|
||||||
|
|
||||||
`Grafana` 则通过配置数据源指向上述 `influxdb`,从而界面化显示监控信息。
|
|
||||||
|
|
||||||
### 部署
|
|
||||||
|
|
||||||
访问 [heapster release](https://github.com/kubernetes/heapster)页面下载最新 release 1.5.1,参考目录`heapster-1.5.1/deploy/kube-config/influxdb`,请在参考官方yaml文件的基础上使用本项目提供的yaml文件
|
|
||||||
|
|
||||||
1. [grafana](../../manifests/heapster/grafana.yaml)
|
|
||||||
1. [heapster](../../manifests/heapster/heapster.yaml)
|
|
||||||
1. [influxdb](../../manifests/heapster/influxdb.yaml)
|
|
||||||
|
|
||||||
安装比较简单 `kubectl create -f /etc/ansible/manifests/heapster/`,主要讲一下注意事项
|
|
||||||
|
|
||||||
#### grafana.yaml配置
|
|
||||||
|
|
||||||
+ 参数`- name: GF_SERVER_ROOT_URL`的设置要根据后续访问grafana的方式确定,如果使用 NodePort方式访问,必须设置成:`value: /`;如果使用apiserver proxy方式,必须设置成`value: /api/v1/namespaces/kube-system/services/monitoring-grafana/proxy/`
|
|
||||||
+ `kubernetes.io/cluster-service: 'true'` 和 `type: NodePort` 根据上述的访问方式设置,建议使用apiserver 方式,可以增加安全控制
|
|
||||||
|
|
||||||
#### heapster.yaml配置
|
|
||||||
|
|
||||||
+ 需要配置 RBAC 把 ServiceAccount `heapster` 与集群预定义的集群角色 `system:heapster` 绑定,这样heapster pod才有相应权限去访问 apiserver
|
|
||||||
|
|
||||||
#### influxdb.yaml配置
|
|
||||||
|
|
||||||
+ influxdb 官方建议使用命令行或 HTTP API 接口来查询数据库,从 v1.1.0 版本开始默认关闭 admin UI, 从 v1.3.3 版本开始已经移除 admin UI 插件,如果你因特殊原因需要访问admin UI,请使用 v1.1.1 版本并使用configMap 配置开启它。参考[heapster 1.4.3](heapster.1.4.3.md),具体配置yaml文件参考[influxdb v1.1.1](../../manifests/heapster/influxdb-v1.1.1/influxdb.yaml)
|
|
||||||
|
|
||||||
### 验证
|
|
||||||
|
|
||||||
``` bash
|
|
||||||
$ kubectl get pods -n kube-system | grep -E 'heapster|monitoring'
|
|
||||||
heapster-3273315324-tmxbg 1/1 Running 0 11m
|
|
||||||
monitoring-grafana-2255110352-94lpn 1/1 Running 0 11m
|
|
||||||
monitoring-influxdb-884893134-3vb6n 1/1 Running 0 11m
|
|
||||||
```
|
|
||||||
检查Pods日志:
|
|
||||||
``` bash
|
|
||||||
$ kubectl logs heapster-3273315324-tmxbg -n kube-system
|
|
||||||
$ kubectl logs monitoring-grafana-2255110352-94lpn -n kube-system
|
|
||||||
$ kubectl logs monitoring-influxdb-884893134-3vb6n -n kube-system
|
|
||||||
```
|
|
||||||
部署完heapster,使用上一步介绍方法查看kubernets dashboard 界面,就可以看到各 Nodes、Pods 的 CPU、内存、负载等利用率曲线图,如果 dashboard上还无法看到利用率图,使用以下命令重启 dashboard pod:
|
|
||||||
+ 首先删除 `kubectl scale deploy kubernetes-dashboard --replicas=0 -n kube-system`
|
|
||||||
+ 然后新建 `kubectl scale deploy kubernetes-dashboard --replicas=1 -n kube-system`
|
|
||||||
|
|
||||||
部署完heapster,直接使用 `kubectl` 客户端工具查看资源使用
|
|
||||||
|
|
||||||
``` bash
|
|
||||||
# 查看node 节点资源使用情况
|
|
||||||
$ kubectl top node
|
|
||||||
# 查看各pod 的资源使用情况
|
|
||||||
$ kubectl top pod --all-namespaces
|
|
||||||
```
|
|
||||||
|
|
||||||
### 访问 grafana
|
|
||||||
|
|
||||||
#### 1.通过apiserver 访问(建议的方式)
|
|
||||||
|
|
||||||
``` bash
|
|
||||||
kubectl cluster-info | grep grafana
|
|
||||||
monitoring-grafana is running at https://x.x.x.x:6443/api/v1/namespaces/kube-system/services/monitoring-grafana/proxy
|
|
||||||
```
|
|
||||||
请参考上一步 [访问dashboard](dashboard.md)同样的方式,使用证书或者密码认证(参照hosts文件配置,默认:用户admin 密码test1234),访问`https://x.x.x.x:6443/api/v1/namespaces/kube-system/services/monitoring-grafana/proxy`即可,如图可以点击[Home]选择查看 `Cluster` `Pods`的监控图形
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
#### 2.通过NodePort 访问
|
|
||||||
|
|
||||||
+ 修改 `Service` 允许 type: NodePort
|
|
||||||
+ 修改 `Deployment`中参数`- name: GF_SERVER_ROOT_URL`为 `value: /`
|
|
||||||
+ 如果之前grafana已经运行,使用 `kubectl replace --force -f /etc/ansible/manifests/heapster/grafana.yaml` 重启 grafana插件
|
|
||||||
|
|
||||||
``` bash
|
|
||||||
kubectl get svc -n kube-system|grep grafana
|
|
||||||
monitoring-grafana NodePort 10.68.135.50 <none> 80:5855/TCP 11m
|
|
||||||
```
|
|
||||||
然后用浏览器访问 http://NodeIP:5855
|
|
||||||
|
|
||||||
|
|
||||||
## 第二部分:heapster 之监控数据持久化
|
|
||||||
|
|
||||||
我们知道监控数据是存储到`influxdb`中的,但是默认情况下`influxdb.yaml`文件中存储使用的是`emptyDir`类型,所以当influxdb POD被删除时,监控数据也就丢失了,以下是使用nfs持久化保存监控数据的例子。
|
|
||||||
|
|
||||||
### 前提
|
|
||||||
环境准备一个nfs服务器,如果没有可以参考[nfs-server](nfs-server.md)创建。
|
|
||||||
|
|
||||||
### 创建 PV
|
|
||||||
PersistentVolume (PV) 和 PersistentVolumeClaim (PVC) 提供了方便的持久化卷;`PV` 是集群的存储资源,就像 `node`是集群的计算资源,PV 可以静态或动态创建,这里使用静态方式创建;`PVC` 就是用来申请`PV` 资源,它可以直接挂载在`POD` 里面使用。更多知识请访问[官网](https://kubernetes.io/docs/concepts/storage/persistent-volumes/#persistentvolumeclaims)。根据你监控日志的多少和需保存时间需求创>建固定大小的`PV` 资源,例子:
|
|
||||||
|
|
||||||
``` bash
|
|
||||||
apiVersion: v1
|
|
||||||
kind: PersistentVolume
|
|
||||||
metadata:
|
|
||||||
name: pv-influxdb
|
|
||||||
spec:
|
|
||||||
capacity:
|
|
||||||
storage: 5Gi
|
|
||||||
accessModes:
|
|
||||||
- ReadWriteMany
|
|
||||||
volumeMode: Filesystem
|
|
||||||
persistentVolumeReclaimPolicy: Recycle
|
|
||||||
storageClassName: slow
|
|
||||||
nfs:
|
|
||||||
# 根据实际共享目录修改
|
|
||||||
path: /share
|
|
||||||
# 根据实际 nfs服务器地址修改
|
|
||||||
server: 192.168.1.208
|
|
||||||
```
|
|
||||||
|
|
||||||
### 修改influxdb 存储卷
|
|
||||||
使用PVC 替换 volumes `emptyDir:{}`,创建PVC 如下:
|
|
||||||
|
|
||||||
``` bash
|
|
||||||
kind: PersistentVolumeClaim
|
|
||||||
apiVersion: v1
|
|
||||||
metadata:
|
|
||||||
name: influxdb-claim
|
|
||||||
namespace: kube-system
|
|
||||||
spec:
|
|
||||||
accessModes:
|
|
||||||
- ReadWriteMany
|
|
||||||
volumeMode: Filesystem
|
|
||||||
resources:
|
|
||||||
requests:
|
|
||||||
storage: 3Gi
|
|
||||||
storageClassName: slow
|
|
||||||
```
|
|
||||||
+ 注意`PV` 是不区分namespace,而`PVC` 是区分namespace的
|
|
||||||
|
|
||||||
### 安装持久化influxdb
|
|
||||||
|
|
||||||
如果之前已经安装本项目创建了`heapster`,请使用如下删除 `influxdb POD`:
|
|
||||||
|
|
||||||
``` bash
|
|
||||||
kubectl delete -f /etc/ansible/manifests/heapster/influxdb.yaml
|
|
||||||
```
|
|
||||||
|
|
||||||
然后使用如下命令新建持久化的 `influxdb POD` :
|
|
||||||
|
|
||||||
``` bash
|
|
||||||
kubectl create -f /etc/ansible/manifests/heapster/influxdb-with-pv/
|
|
||||||
```
|
|
||||||
|
|
||||||
### 验证监控数据的持久性
|
|
||||||
|
|
||||||
+ 1.查看集群 `pv` `pvc` 情况
|
|
||||||
|
|
||||||
``` bash
|
|
||||||
$ kubectl get pv
|
|
||||||
$ kubectl get pvc --all-namespaces
|
|
||||||
```
|
|
||||||
|
|
||||||
+ 2.手动删除 `influxdb`,半小时后再次创建,登录grafana 确认历史数据是否还在。
|
|
||||||
|
|
||||||
``` bash
|
|
||||||
# 删除 influxdb deploy
|
|
||||||
kubectl delete -f /etc/ansible/manifests/heapster/influxdb-with-pv/influxdb.yaml
|
|
||||||
|
|
||||||
# 等待半小时后重新创建
|
|
||||||
kubectl create -f /etc/ansible/manifests/heapster/influxdb-with-pv/influxdb.yaml
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
@ -140,7 +140,7 @@ spec:
|
||||||
|
|
||||||
#### 拒绝其他namespaces访问服务
|
#### 拒绝其他namespaces访问服务
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
+ 场景1:你的k8s集群应用按照namespaces区分生产、测试环境,你要确保生产环境不会受到测试环境错误访问影响
|
+ 场景1:你的k8s集群应用按照namespaces区分生产、测试环境,你要确保生产环境不会受到测试环境错误访问影响
|
||||||
+ 场景2:你的k8s集群有多租户应用采用namespaces区分的,你要确保多租户之间的应用隔离
|
+ 场景2:你的k8s集群有多租户应用采用namespaces区分的,你要确保多租户之间的应用隔离
|
||||||
|
|
@ -165,7 +165,7 @@ spec:
|
||||||
|
|
||||||
+ 场景:暴露特定Pod的特定端口给外部访问
|
+ 场景:暴露特定Pod的特定端口给外部访问
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
``` bash
|
``` bash
|
||||||
# 创建示例应用待暴露服务
|
# 创建示例应用待暴露服务
|
||||||
|
|
|
||||||
|
|
@ -1,6 +1,6 @@
|
||||||
## 开始使用 cilium
|
## 开始使用 cilium
|
||||||
|
|
||||||
以下为简要翻译 `cilium doc`上的一个应用示例[原文](http://docs.cilium.io/en/stable/gettingstarted/minikube/#step-2-deploy-the-demo-application),部署在单节点k8s 环境的实践。
|
以下为简要翻译 `cilium doc`上的一个应用示例[原文](https://docs.cilium.io/en/stable/gettingstarted/http/),部署在单节点k8s 环境的实践。
|
||||||
|
|
||||||
### 部署示例应用
|
### 部署示例应用
|
||||||
|
|
||||||
|
|
@ -10,7 +10,7 @@
|
||||||
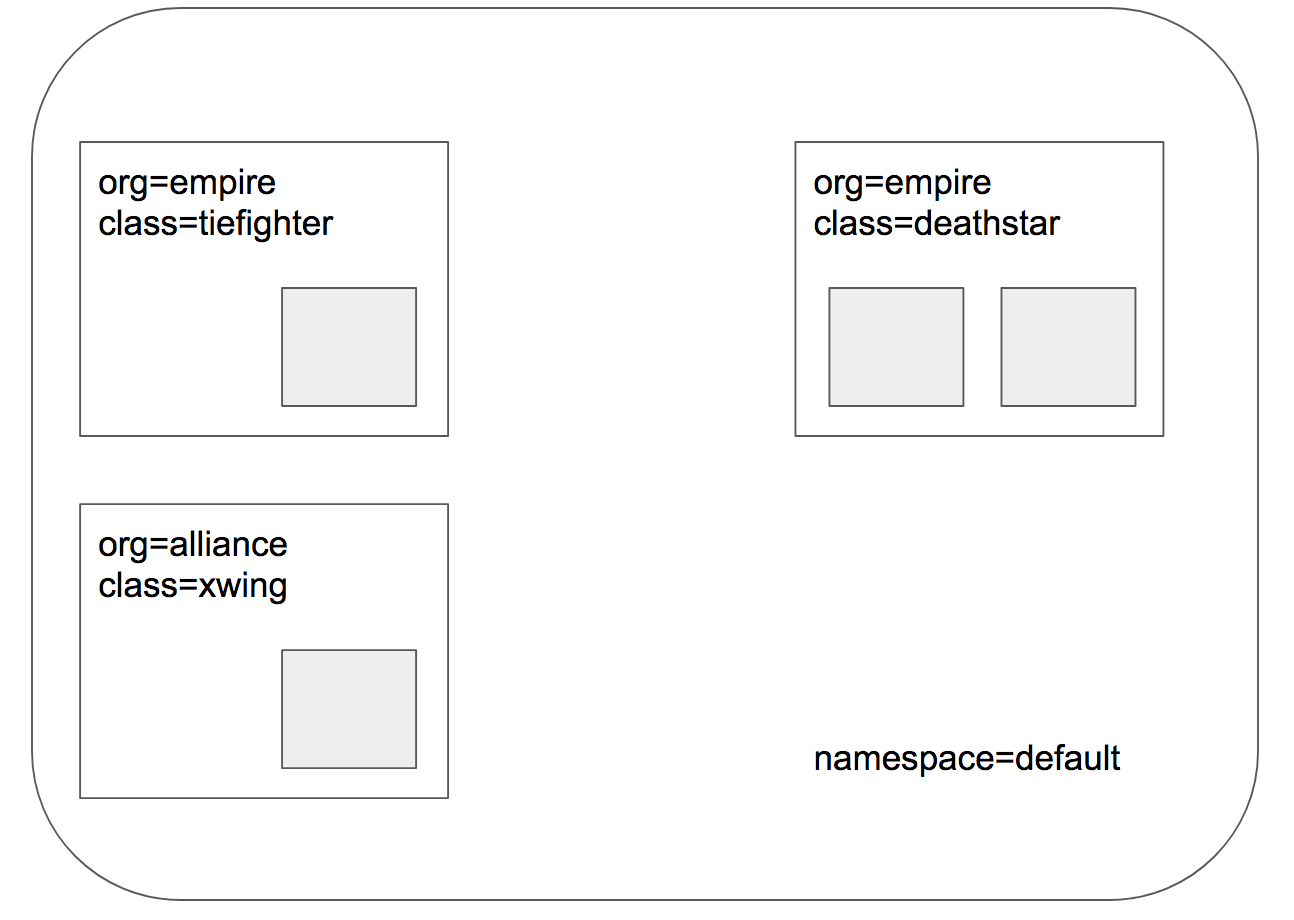
- pod/tiefighter:作为“帝国”方的常规战斗飞船,它会调用上述 HTTP 接口,请求登陆“死星”;
|
- pod/tiefighter:作为“帝国”方的常规战斗飞船,它会调用上述 HTTP 接口,请求登陆“死星”;
|
||||||
- pod/xwing:作为“盟军”方的飞行舰,它也尝试调用 HTTP 接口,请求登陆“死星”;
|
- pod/xwing:作为“盟军”方的飞行舰,它也尝试调用 HTTP 接口,请求登陆“死星”;
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
根据文件[http-sw-app.yaml](../../../roles/cilium/files/star_war_example/http-sw-app.yaml) 创建 `$ kubectl create -f http-sw-app.yaml` 后,验证如下:
|
根据文件[http-sw-app.yaml](../../../roles/cilium/files/star_war_example/http-sw-app.yaml) 创建 `$ kubectl create -f http-sw-app.yaml` 后,验证如下:
|
||||||
|
|
||||||
|
|
@ -66,7 +66,7 @@ Ship landed # 成功着陆
|
||||||
|
|
||||||
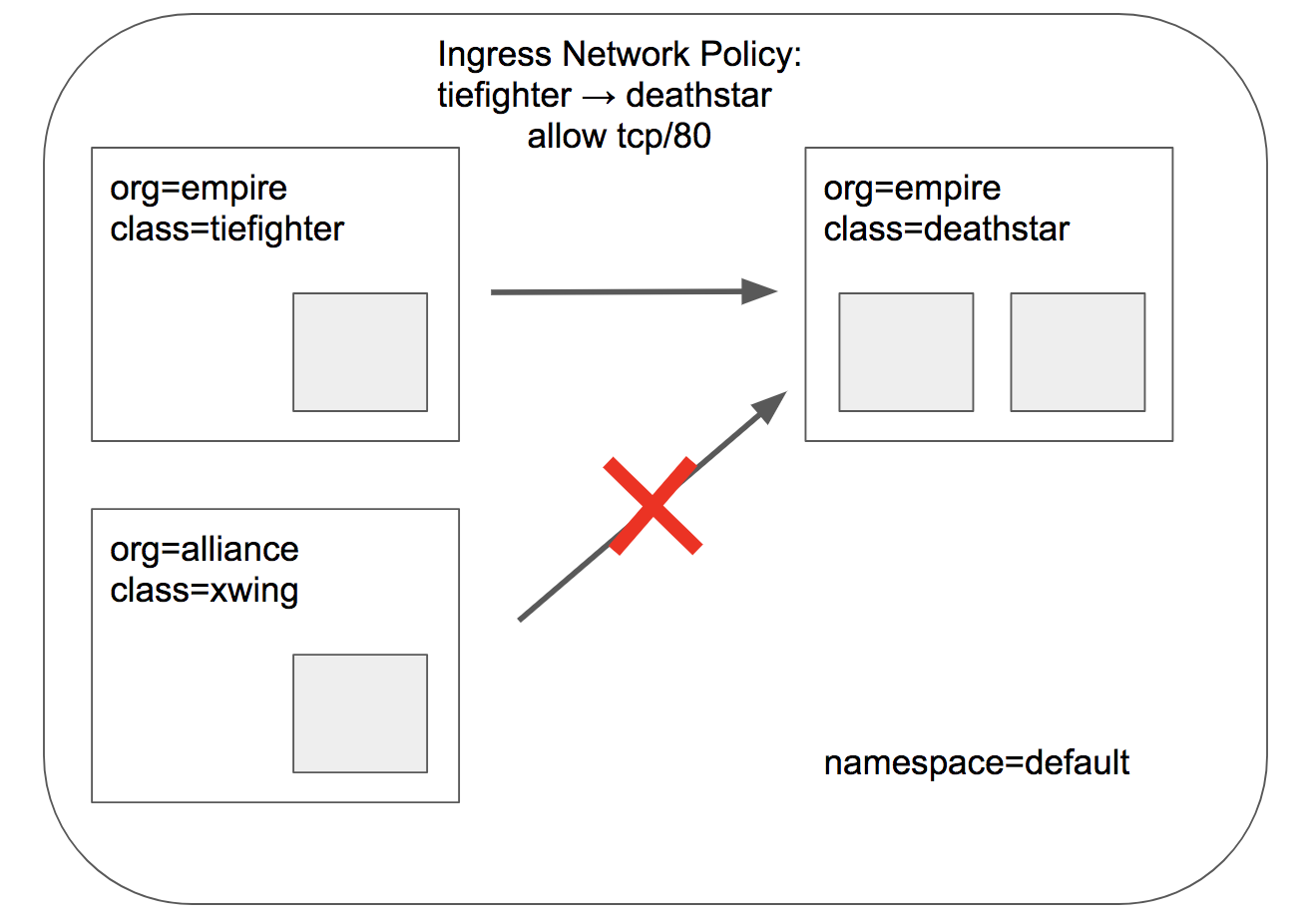
现在我们应用策略,仅让带有标签 `org=empire`的飞船登陆“死星”;那么带有标签 `org=alliance`的“联盟”飞船将禁止登陆;这个就是我们熟悉的传统L3/L4 防火墙策略,并跟踪连接(会话)状态;
|
现在我们应用策略,仅让带有标签 `org=empire`的飞船登陆“死星”;那么带有标签 `org=alliance`的“联盟”飞船将禁止登陆;这个就是我们熟悉的传统L3/L4 防火墙策略,并跟踪连接(会话)状态;
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
根据文件[sw_l3_l4_policy.yaml](../../../roles/cilium/files/star_war_example/sw_l3_l4_policy.yaml) 创建 `$ kubectl apply -f sw_l3_l4_policy.yaml` 后,验证如下:
|
根据文件[sw_l3_l4_policy.yaml](../../../roles/cilium/files/star_war_example/sw_l3_l4_policy.yaml) 创建 `$ kubectl apply -f sw_l3_l4_policy.yaml` 后,验证如下:
|
||||||
|
|
||||||
|
|
@ -126,7 +126,7 @@ main.main()
|
||||||
temp/main.go:5 +0x85
|
temp/main.go:5 +0x85
|
||||||
```
|
```
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
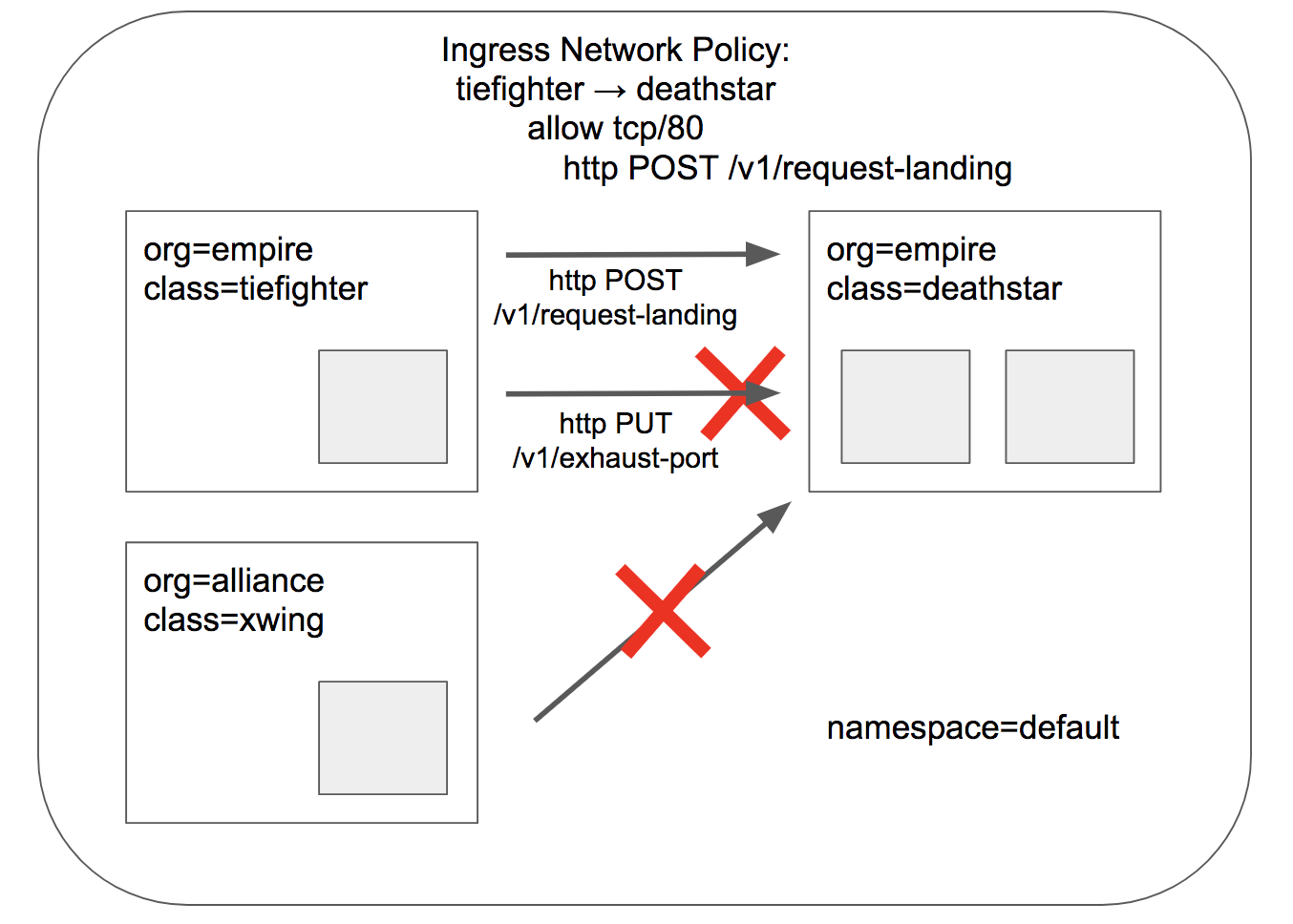
限制L7 的安全策略,根据文件[sw_l3_l4_l7_policy.yaml](../../../roles/cilium/files/star_war_example/sw_l3_l4_l7_policy.yaml) 创建 `$ kubectl apply -f sw_l3_l4_l7_policy.yaml` 后,验证如下:
|
限制L7 的安全策略,根据文件[sw_l3_l4_l7_policy.yaml](../../../roles/cilium/files/star_war_example/sw_l3_l4_l7_policy.yaml) 创建 `$ kubectl apply -f sw_l3_l4_l7_policy.yaml` 后,验证如下:
|
||||||
|
|
||||||
|
|
|
||||||
{kind=link}
|
Before Width: | Height: | Size: 140 KiB |
{kind=link}
|
Before Width: | Height: | Size: 22 KiB |
{kind=link}
|
Before Width: | Height: | Size: 28 KiB |
{kind=link}
|
Before Width: | Height: | Size: 33 KiB |
{kind=link}
|
Before Width: | Height: | Size: 118 KiB |
BIN
pics/grafana.png
{kind=link}
|
Before Width: | Height: | Size: 39 KiB |
{kind=link}
|
Before Width: | Height: | Size: 28 KiB |
{kind=link}
|
Before Width: | Height: | Size: 8.4 KiB |