6.7 KiB
人工智能和机器学习概述
所谓“人工智能”通常是泛指让机器具有像人一样的智慧的技术,其目的是让机器像人一样能够感知、思考和解决问题;而“机器学习”通常是指让计算机通过学习现有的数据,实现认知的更新和进步。显然,机器学习是实现人工智能的一种途径,这也是我们的课程要讨论的内容。现如今,“机器学习”和“大数据”可以说是最时髦的两个词汇,而在弱人工智能阶段,无论是“机器学习”还是“大数据”最终要解决的问题本质上是一样的,就是让计算机将纷繁复杂的数据处理成有用的信息,这样就可以发掘出数据带来的意义以及隐藏在数据背后的规律,简单的说就是用现有的数据对将来的状况做出预测和判断。
在讨论机器学习相关内容之前,我们先按照问题的“输入”和“输出”对用计算机求解的问题进行一个分类,如下所示:
- 输入的信息是精确的,要求输出最优解。
- 输入的信息是精确的,无法找到最优解,只能获得满意解。
- 输入的信息是模糊的,要求输出最优解。
- 输入的信息是模糊的,无法找到最优解,只能获得满意解。
在上面的四大类问题中,第1类问题是计算机最擅长解决的,这类问题其实就是“数值计算”和“逻辑推理”方面的问题,而传统意义上的人工智能也就是利用逻辑推理来解决问题(如早期的“人机对弈”)。一直以来,我们都习惯于将计算机称为“电脑”,而基于“冯诺依曼”体系结构的“电脑”实际上只是实现了“人脑”理性思维这部分的功能,而且在这一点上“电脑”的表现通常是优于“人脑”的;但是“人脑”在处理模糊输入信息时表现出来的强大处理能力,在很多场景下“电脑”是难以企及的。所以我们研究机器学习的算法,就是要解决在输入模糊信息时让计算机给出满意解甚至是最优解的问题。
人类通过记忆和归纳这两种方式进行学习,通过记忆可以积累单个事实,使用归纳可以从旧的事实推导出新的事实。所以机器学习其实是一种训练,让计算机通过这种训练能够学会根据数据隐含模式进行合理推断的能力,其基本流程如下所示:
- 观察一组实例,通常称为训练数据,它们可以表示某种统计现象的不完整信息;
- 对观测到的实例进行扩展,并使用推断技术对扩展过程建模;
- 使用这个模型对未知实例进行预测。
基本概念
监督学习和非监督学习
监督学习是从给定的训练数据集中学习得到一个函数,当新的数据到来时,可以根据这个函数预测结果,监督学习的训练集包括输入和输出,也可以说是特征和目标。监督学习的目标是由人来标注的,而非监督学习的数据没有类别信息,训练集也没有人为标注结果,通过无监督学习可以减少数据特征的维度,以便我们可以使用二维或三维图形更加直观地展示数据中的信息 。
特征向量和特征工程
距离度量
- 欧氏距离
d = \sqrt{\sum_{k=1}^n(x_{1k}-x_{2k})^2}
- 曼哈顿距离
d = \sum_{k=1}^n \mid {x_{1k}-x_{2k}} \mid
- 切比雪夫距离
d = max(\mid x_{1k}-x_{2k} \mid)
- 闵可夫斯基距离
- 当
p=1时,就是曼哈顿距离 - 当
p=2时,就是欧式距离 - 当
p \to \infty时,就是切比雪夫距离
- 当
d = \sqrt[p]{\sum_{k=1}^n \mid x_{1k}-x_{2k} \mid ^p}
- 余弦距离
$ cos(\theta) = \frac{\sum_{k=1}^n x_{1k}x_{2k}}{\sqrt{\sum_{k=1}^n x_{1k}^2} \sqrt{\sum_{k=1}^n x_{2k}^2}}
机器学习的定义和应用领域
根据上面的论述,我们可以给“机器学习”下一个正式的定义:机器学习是一门专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身性能的学科。即使对于机器学习这个概念不那么熟悉,但是机器学习的成果已经广泛渗透到了生产生活的各个领域,下面的这些场景对于你来说一定不陌生。
场景1:搜索引擎会根据搜索和使用习惯,优化下一次搜索的结果。
场景2:电商网站会根据你的访问历史自动推荐你可能感兴趣的商品。
场景3:金融类产品会通过你最近的金融活动信息综合评定你的贷款申请。
场景4:视频和直播平台会自动识别图片和视频中有没有不和谐的内容。
场景5:智能家电和智能汽车会根据你的语音指令做出相应的动作。
简单的总结一下,机器学习可以应用到但不限于以下领域:
-
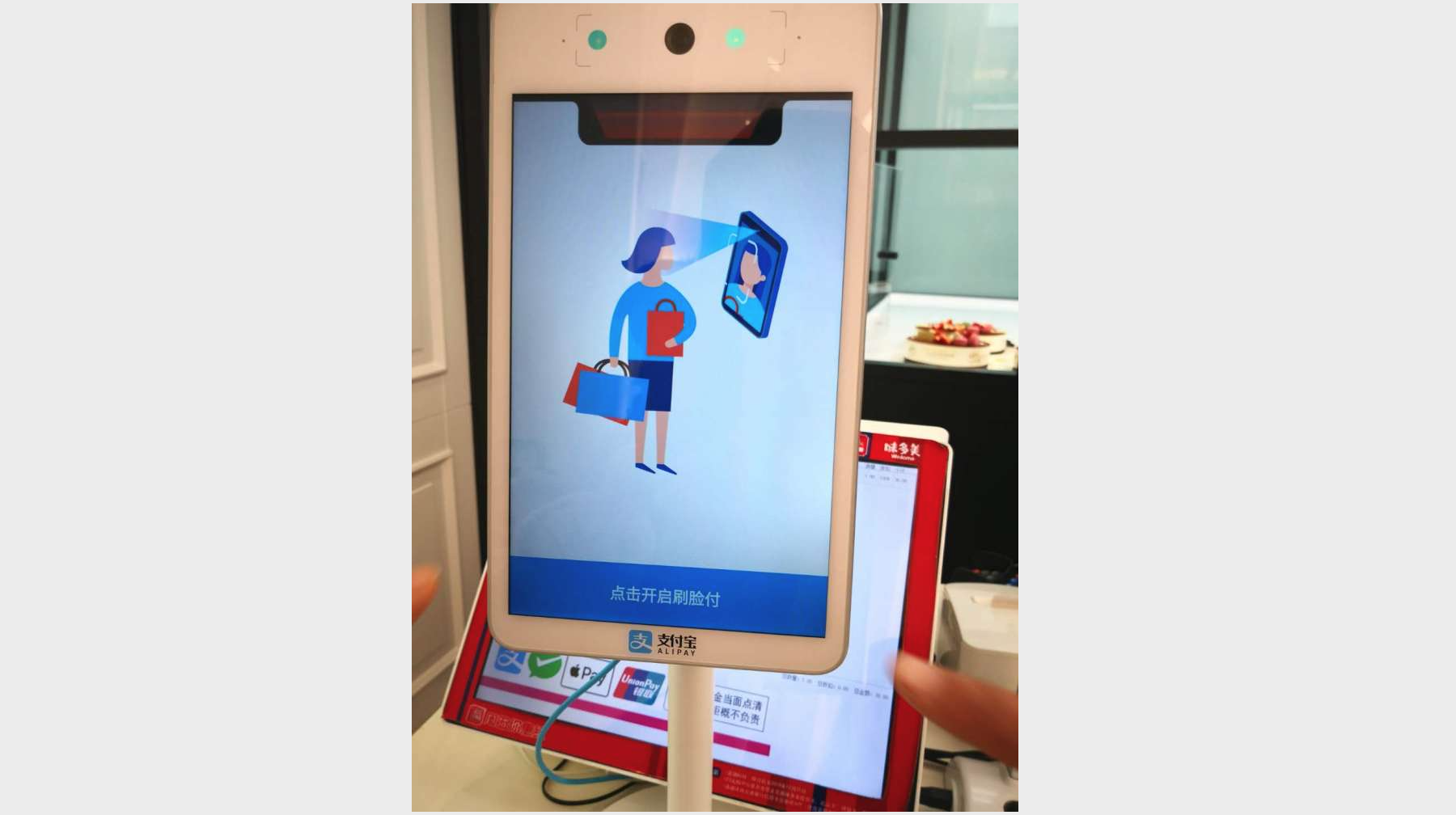
计算机视觉。计算机视觉是指机器感知环境的能力,目前在物体检测和人脸识别这两个领域已经非常成熟且产生了大量的应用。
-
刷脸支付
-

-
-
自然语言处理(NLP)。自然语言处理是目前机器学习中一个非常热门的分支,具体的又可以分为三类应用场景。其中文本挖掘主要是对文本进行分类,包括句法分析、情绪分析和垃圾信息检测等;而机器翻译和语音识别相信不用太多的解释大家也都清楚。
-
文本挖掘
-
机器翻译
-
语音识别

-
-
机器人。机器人可以分为固定机器人和移动机器人两大类。固定机器人通常被用于工业生产,例如用于装配流水线。常见的移动机器人应用有货运机器人、空中机器人和自动载具。机器人需要软硬件的协作才能实现最优的作业,其中硬件包含传感器、反应器和控制器等,而软件主要是实现感知能力,包括定位、测绘、目标检测和识别等。
-
机甲大师

-
扫地机器人

-
机器学习实施步骤
实现机器学习的一般步骤:
- 数据收集
- 数据准备
- 数据分析
- 训练算法
- 测试算法
- 应用算法
Scikit-learn介绍
![]()
Scikit-learn源于Google Summer of Code项目,由David Cournapeau在2007年发起,它提供了机器学习可能用到的工具,包括数据预处理、监督学习(分类、回归)、非监督学习(聚类)、模型选择、降维等。
官网地址:https://scikit-learn.org/stable/index.html
安装方法:pip install scikit-learn