13 KiB
Long-Term Roadmap for Torch-MLIR
Overview
Latest update: 2022Q4
Torch-MLIR is about one year old now, and has successfully delivered a lot of value to the community. In this document we outline the major architectural changes that will make Torch-MLIR more robust, accessible, and useful to the community on a 1-2 year timeline.
First, let's recap the goals of Torch-MLIR.
Technically, the goal of Torch-MLIR is to bridge the PyTorch and MLIR ecosystems. That's vague, but it captures a very important property: Torch-MLIR is not in the business of "innovating" either on the frontend or backend sides. The project scope is to be an enabling connector between the two systems.
Non-technically, Torch-MLIR's goal is not to be an end-to-end product, but a reliable piece of "off the shelf" infrastructure that system designers use as part of their larger end-to-end flows. The main users are expected to be "integrators", not end-users writing Python. This has the following facets:
- Community: Users of Torch-MLIR should feel empowered to participate in the community to get their questions resolved, or propose (and even implement) changes needed for their use cases.
- Ecosystem alignment: Users of Torch-MLIR should feel that the project is aligned with all of the projects that it collaborates with, making it safe to bet on for the long term.
- Ease of use: Users of Torch-MLIR should feel that it "Just Works", or that when it fails, it fails in a way that is easy to understand, debug, and fix.
- Development: Torch-MLIR should be easy and convenient to develop.
Today, much of the design space and the main problems have been identified, but larger-scale architectural and cross-project changes are needed to realize the right long-term design. This will allow us to reach a steady-state that best meets the goals above.
The main architectural changes
As described in architecture.md, Torch-MLIR can be split into two main parts: the "frontend" and the "backend".
The main sources of brittleness, maintenance cost, and duplicated work across the ecosystem are:
- The frontend work required to lower TorchScript to the backend contract.
- The irregular support surface area of the large number of PyTorch ops across the Linalg, TOSA, and StableHLO backends.
Most of this document describes long-term ecosystem changes that will address these, drastically improving Torch-MLIR's ability to meet its goals.
Roadmap
Refactoring the frontend
The primary way to make the frontend more reliable is to leverage new PyTorch infrastructure that bridges from the PyTorch eager world into compiler-land. PyTorch has two main projects that together cover almost all user use cases and provide a technically sound, high quality-of-implementation path from user programs into the compiler.
- TorchDynamo - TorchDynamo uses tracing-JIT-like techniques and program slicing to extract traces of tensor operations, which can then be passed to lower-level compilers. It works seamlessly with unmodified user programs.
- FuncTorch - FuncTorch is basically JAX
for PyTorch. It requires manual program tracing and slicing, but that is
actually important for users since it gives them direct control over various
important transformations, such as
gradandvmap.
These are both being heavily-invested-in by PyTorch core developers, and are generally seen as the next generation of compiler technology for the project, blending PyTorch's famous usability with excellent compiler integration opportunities. Torch-MLIR works with these technologies as they exist today, but significant work remains to enable wholesale deleting the high-maintenance parts of Torch-MLIR. In the future, we expect the block diagram of Torch-MLIR to be greatly simplified, as shown in the diagram below. Note that in the "Future" side, PyTorch directly gives us IR in a form satisfying the backend contract.
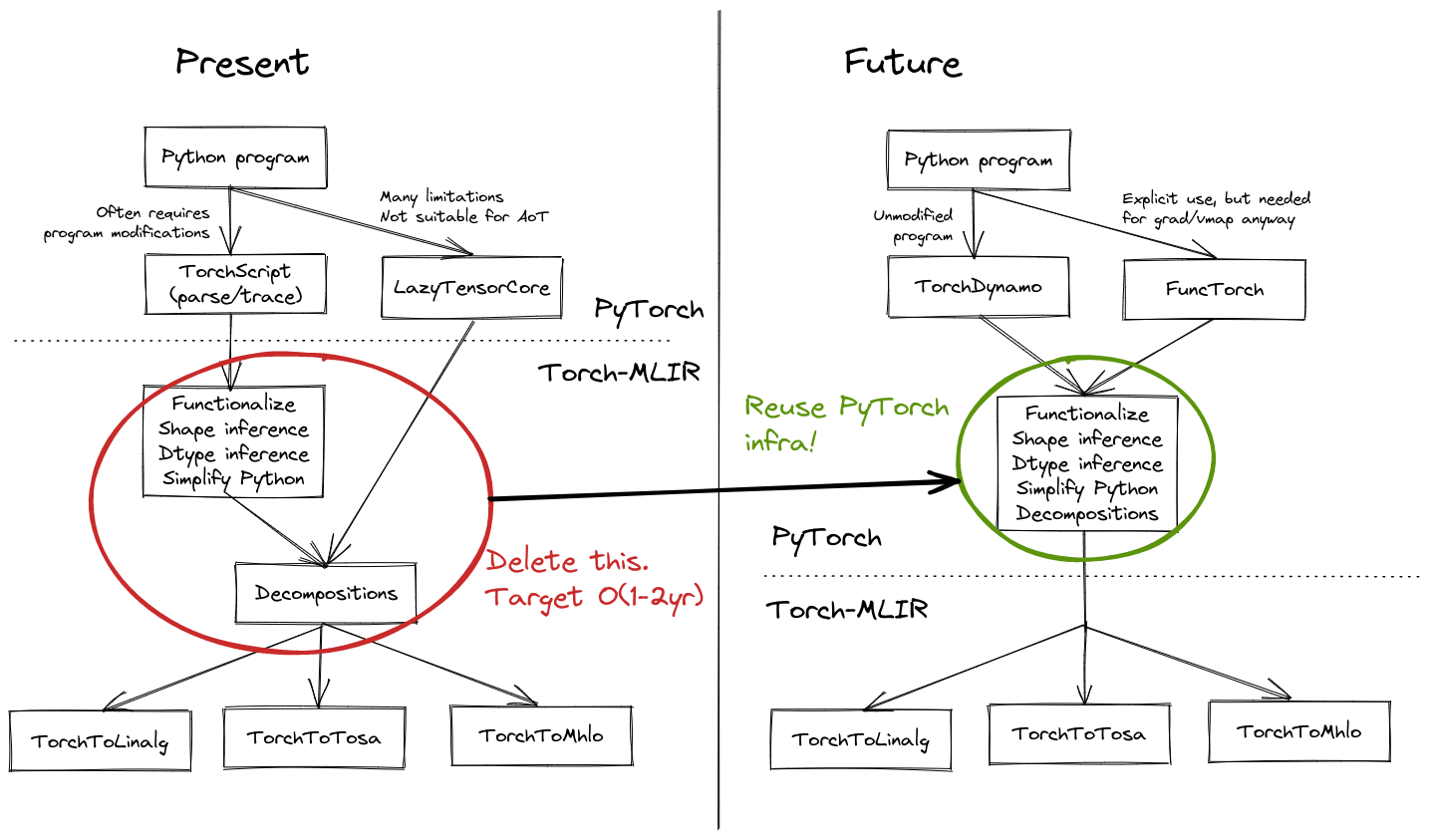
The primary functional requirement of Torch-MLIR which remains unaddressed by today's incarnation of TorchDynamo and FuncTorch is the support for dynamic shapes. PyTorch core devs are heavily investing in this area, and both TorchDynamo and FuncTorch are being upgraded as PyTorch rolls out its new symbolic shape infrastructure.
Smaller blockers are related to general API stability and usability of the various pieces of PyTorch infra.
These blockers are expected to be addressed by the PyTorch core devs over time. Torch-MLIR's role here is to communicate our requirements to PyTorch core and align their roadmap and ours. We do this by maintaining connections with the PyTorch core developers and being "good-citizen power users" of their latest technology (i.e. trying things out, surfacing bugs, providing feedback, etc.).
Note: Because both TorchDynamo and FuncTorch are TorchFX-based, we could write a direct TorchFX -> MLIR importer, and delete the TorchScript importer. This would remove the need for Torch-MLIR to build its own custom Python extension -- Torch-MLIR would be a pure-Python user of the standard MLIR Python bindings. There is no immediate rush for this though, since TorchFX can be converted to TorchScript (this may become lossy as the dynamic shape support in PyTorch gets more advanced).
Refactoring the backend
Today in Torch-MLIR, we support 3 backends out of the box: Linalg-on-Tensors, TOSA, and StableHLO. These backends take IR in the backend contract form (see architecture.md) and lowers them to the respective dialects. Today, each backend is implemented completely independently. This leads to duplication and irregularity across the backends.
Moving forward, we would like for the backends to share more code and for their op support to be more aligned with each other. Since the backend contract today includes "all" of PyTorch's operators, it is very costly to duplicate the lowering of so many ops across backends. Additionally, there are 3 forward-looking efforts that intersect with this effort:
- StableHLO - this is a dialect initially forked from MHLO. MHLO is a fairly complete op set, so it is very attractive to have "almost all" models bottleneck through a stable interface like StableHLO. StableHLO is currently under relatively early development, but already delivers on many of the goals of stability.
- TCP - this is a dialect which could serve a role very similar to MHLO, while providing community ownership. TCP is still in early planning phases, but there is strong alignment with the StableHLO effort. One byproduct of TCP that is expected to be very valuable is to incorporate the robust dynamic shape strategy from Linalg into an MHLO-like dialect, and there is a strong desire from StableHLO developers to adopt this once proven in TCP.
- PrimTorch - this is an effort on the PyTorch side to decompose PyTorch operators into a smaller set of primitive ops. This effort could effectively reduce the op surface area at the Torch-MLIR level a lot, which would make the duplication across backends less of an issue. But it still leaves open a lot of questions, such as how to control decompositions.
This is overall less important than the frontend refactor, because it is "just more work" for us as Torch-MLIR developers to support things in the current infrastructure, while the frontend refactor directly affects the user experience.
As the above efforts progress, we will need to make decisions about how to adopt the various technologies. The main goal is consolidating the bottleneck point where the O(100s-1000s) of ops in PyTorch are reduced to a more tractable O(100) ops. There are two main ways to accomplish this:
- Future A: We concentrate the bottleneck step in the "Backend contract -> StableHLO/MHLO/TCP" lowering path. This gets us a stable output for most things. The cascaded/transitive lowerings then let us do O(100) lowerings from then on down. (exact details are not worked out yet, and depend on e.g. TCP adoption, etc.)
- Future B: PrimTorch concentrates the bottleneck step on the PyTorch side.
These two efforts synergize, but the need for cascaded lowerings is much less if PrimTorch solves the decomposition problem on the PyTorch side.
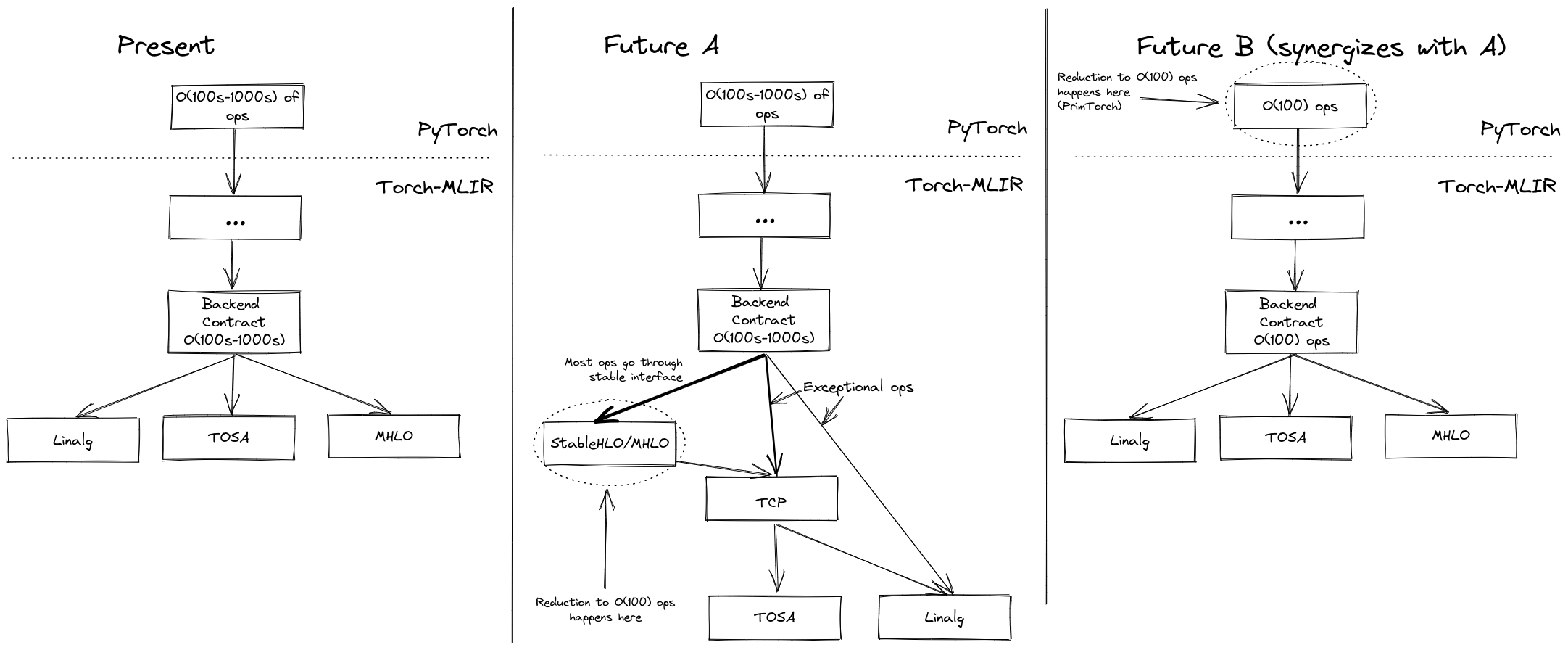
One of the main blockers for doing cascaded lowerings today is the irregular
support for dynamic shapes across TOSA and MHLO. MHLO is much more complete, but
the use of tensor<Nxindex> to model shapes results in brittleness of the
system. A dynamic shape model like that being adopted in TCP (and presumably
StableHLO in time) would simplify this. Hence TCP is strategically important for
proving out a design for a "dynamically shaped MHLO-like thing" that doesn't
have this drawback.
Tools for advanced AoT deployments
PyTorch's future direction is towards TorchDynamo and FuncTorch, which are tracing-based systems. This means that they inherently struggle to capture control flow and non-tensor computations. Many deployments, especially Ahead-of-Time compiled ones such as for edge, require non-tensor computations. It is extremely costly for people deploying such models to manually stitch together graphs of traced functions with custom per-model code with existing tools, and it is also very error-prone. We are awaiting movement on this front from the PyTorch core team. There is some inspiration from systems like IREE-JAX in the JAX space for how to do this, but ultimately this will depend on what the PyTorch core team decides on for edge deployments. It is our responsibility to stay connected with them and make sure that what they are building suits our needs.
Project Governance / Structure
Torch-MLIR is currently an LLVM Incubator. This has had the advantage of being organizationally close to MLIR Core. However, the long-term direction is likely for Torch-MLIR to live under the PyTorch umbrella, for a few reasons:
- As discussed in the other parts of this document, the long-term direction is for Torch-MLIR to be a quite thin component, with much of the code being obsoleted by infra in PyTorch core.
- The move towards more stable backend output formats will generally reduce variance on the MLIR side. This means that MLIR will be the "more frozen" of the two major dependencies (PyTorch and MLIR).
- We would like Torch-MLIR to be hooked into the PyTorch CI systems, and generally be more tightly integrated with the PyTorch development process (this includes things like packaging as well).
Co-design
Many users of MLIR are developing advanced hardware or software systems, and often these require information from the frontend beyond what PyTorch provides today. Torch-MLIR should always be a "follower" of the features available in the frontends and backends it connects to. We want to enable co-design, of course, but new features such as quantization, sparsity, distribution, etc. should be viewed from the lens of "the frontend can give us X information, the backend needs Y information -- how do we connect them?".
To satisfy those needs, we want to focus on existing extensibility mechanisms in the frontend rather than inventing new ones. We intend to explore using existing frontend concepts, such as custom ops, to enable this co-design.
If it proves to be absolutely necessary to add new concepts to the frontend (e.g. new data types), it should be considered very carefully since supporting such features is a major scope increase to the Torch-MLIR project. It is likely to be better done in a separate project, with a carefully thought-out integration with Torch-MLIR that avoids putting the maintenance burden on the side of Torch-MLIR for the exploratory new frontend concept.
LazyTensorCore support in Torch-MLIR
Today, Torch-MLIR supports LazyTensorCore. But as mentioned
here,
on the 1-2yr time horizon LTC will be more an implementation detail under
TorchDynamo for users that already have compilers written using LTC. That is,
LTC is basically just a way to convert a TorchDynamo FX graph into LTC graphs,
for users that have toolchains written against LTC graphs. But that won't make
much technical sense for Torch-MLIR, because we convert to MLIR in the end no
matter what. That is, in the future going
TorchDynamo FX graph -> LTC Graph -> MLIR can just be replaced by the direct
TorchDynamo FX graph -> MLIR path. So in the 1-2yr time horizon, LTC will not
make technical sense in Torch-MLIR.
There will still be non-technical blockers, such as if end-users have
device='lazy' hardcoded into their code. That will require a migration plan
for current LTC-based toolchains onto TorchDynamo. This migration will improve
the end-user experience since TorchDynamo is more seamless, but it is a
end-user-impacting migration nonetheless and we will want to phase it
appropriately with the community.