commit
a04bca037a
|
|
@ -0,0 +1,36 @@
|
||||||
|
version: 2
|
||||||
|
jobs:
|
||||||
|
lint-gitbook:
|
||||||
|
docker:
|
||||||
|
- image: jimmysong/gitbook-builder:2019-07-31
|
||||||
|
working_directory: ~/gitbook
|
||||||
|
steps:
|
||||||
|
- checkout
|
||||||
|
- run:
|
||||||
|
name: Linting the gitbook
|
||||||
|
command: scripts/lint-gitbook.sh
|
||||||
|
markdown-spell-check:
|
||||||
|
docker:
|
||||||
|
- image: jimmysong/gitbook-builder:2019-07-31
|
||||||
|
working_directory: ~/gitbook
|
||||||
|
steps:
|
||||||
|
- checkout
|
||||||
|
- run:
|
||||||
|
name: Running markdown spell check
|
||||||
|
command: scripts/mdspell-check.sh
|
||||||
|
markdown-style-check:
|
||||||
|
docker:
|
||||||
|
- image: jimmysong/gitbook-builder:2019-07-31
|
||||||
|
working_directory: ~/gitbook
|
||||||
|
steps:
|
||||||
|
- checkout
|
||||||
|
- run:
|
||||||
|
name: Running markdown style check
|
||||||
|
command: scripts/mdl-check.sh
|
||||||
|
workflows:
|
||||||
|
version: 2
|
||||||
|
workflow:
|
||||||
|
jobs:
|
||||||
|
- lint-gitbook
|
||||||
|
- markdown-spell-check
|
||||||
|
- markdown-style-check
|
||||||
|
|
@ -18,3 +18,7 @@ _book
|
||||||
# Github Pages
|
# Github Pages
|
||||||
deploy.sh
|
deploy.sh
|
||||||
.DS_Store
|
.DS_Store
|
||||||
|
|
||||||
|
# IDEA
|
||||||
|
*.iml
|
||||||
|
.idea
|
||||||
|
|
|
||||||
|
|
@ -29,6 +29,19 @@
|
||||||
4. 在浏览器中访问 http://localhost:4000
|
4. 在浏览器中访问 http://localhost:4000
|
||||||
5. 生成的文档在 `_book` 目录下
|
5. 生成的文档在 `_book` 目录下
|
||||||
|
|
||||||
|
**Docker**
|
||||||
|
|
||||||
|
本书提供了 Docker 构建方式。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
make install
|
||||||
|
make build
|
||||||
|
```
|
||||||
|
|
||||||
|
继续运行 `make serve` 即可渲染 gitbook,通过 <http://localhost:4000> 查看。
|
||||||
|
|
||||||
|
注:使用 `docker ps` 找到该容器 ID 后,使用 `docker kill $ID` 可以关掉网站。
|
||||||
|
|
||||||
**下载 PDF/ePub/Mobi 格式文档本地查看**
|
**下载 PDF/ePub/Mobi 格式文档本地查看**
|
||||||
|
|
||||||
访问 [gitbook](https://www.gitbook.com/book/rootsongjc/kubernetes-handbook/details) 可以看到下载地址,可以下载根据最新文档生成的 **PDF/ePub/Mobi** 格式文档(文档的注脚中注明了更新时间),同时也可以直接在 gitbook 中阅读,不过 gitbook 不太稳定打开速度较慢,建议大家直接在 https://jimmysong.io/kubernetes-handbook/ 浏览。
|
访问 [gitbook](https://www.gitbook.com/book/rootsongjc/kubernetes-handbook/details) 可以看到下载地址,可以下载根据最新文档生成的 **PDF/ePub/Mobi** 格式文档(文档的注脚中注明了更新时间),同时也可以直接在 gitbook 中阅读,不过 gitbook 不太稳定打开速度较慢,建议大家直接在 https://jimmysong.io/kubernetes-handbook/ 浏览。
|
||||||
|
|
@ -39,7 +52,7 @@
|
||||||
|
|
||||||
- **On Mac**
|
- **On Mac**
|
||||||
|
|
||||||
在Mac下安装后,使用该命令创建链接
|
在Mac下安装后,使用该命令创建链接:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
ln -s /Applications/calibre.app/Contents/MacOS/ebook-convert /usr/local/bin
|
ln -s /Applications/calibre.app/Contents/MacOS/ebook-convert /usr/local/bin
|
||||||
|
|
@ -51,6 +64,8 @@ ln -s /Applications/calibre.app/Contents/MacOS/ebook-convert /usr/local/bin
|
||||||
gitbook pdf . ./kubernetes-handbook.pdf
|
gitbook pdf . ./kubernetes-handbook.pdf
|
||||||
```
|
```
|
||||||
|
|
||||||
|
**注:因为各种依赖问题,通过 docker 方式暂时无法构建 PDF。**
|
||||||
|
|
||||||
- **On Windows**
|
- **On Windows**
|
||||||
|
|
||||||
需要用到的工具:[calibre](http://calibre-ebook.com/),[phantomjs](http://phantomjs.org/download.html)
|
需要用到的工具:[calibre](http://calibre-ebook.com/),[phantomjs](http://phantomjs.org/download.html)
|
||||||
|
|
|
||||||
526
LICENSE
526
LICENSE
|
|
@ -1,187 +1,395 @@
|
||||||
Apache License
|
Attribution 4.0 International
|
||||||
Version 2.0, January 2004
|
|
||||||
http://www.apache.org/licenses/
|
|
||||||
|
|
||||||
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
=======================================================================
|
||||||
|
|
||||||
1. Definitions.
|
Creative Commons Corporation ("Creative Commons") is not a law firm and
|
||||||
|
does not provide legal services or legal advice. Distribution of
|
||||||
|
Creative Commons public licenses does not create a lawyer-client or
|
||||||
|
other relationship. Creative Commons makes its licenses and related
|
||||||
|
information available on an "as-is" basis. Creative Commons gives no
|
||||||
|
warranties regarding its licenses, any material licensed under their
|
||||||
|
terms and conditions, or any related information. Creative Commons
|
||||||
|
disclaims all liability for damages resulting from their use to the
|
||||||
|
fullest extent possible.
|
||||||
|
|
||||||
"License" shall mean the terms and conditions for use, reproduction,
|
Using Creative Commons Public Licenses
|
||||||
and distribution as defined by Sections 1 through 9 of this document.
|
|
||||||
|
|
||||||
"Licensor" shall mean the copyright owner or entity authorized by
|
Creative Commons public licenses provide a standard set of terms and
|
||||||
the copyright owner that is granting the License.
|
conditions that creators and other rights holders may use to share
|
||||||
|
original works of authorship and other material subject to copyright
|
||||||
|
and certain other rights specified in the public license below. The
|
||||||
|
following considerations are for informational purposes only, are not
|
||||||
|
exhaustive, and do not form part of our licenses.
|
||||||
|
|
||||||
"Legal Entity" shall mean the union of the acting entity and all
|
Considerations for licensors: Our public licenses are
|
||||||
other entities that control, are controlled by, or are under common
|
intended for use by those authorized to give the public
|
||||||
control with that entity. For the purposes of this definition,
|
permission to use material in ways otherwise restricted by
|
||||||
"control" means (i) the power, direct or indirect, to cause the
|
copyright and certain other rights. Our licenses are
|
||||||
direction or management of such entity, whether by contract or
|
irrevocable. Licensors should read and understand the terms
|
||||||
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
and conditions of the license they choose before applying it.
|
||||||
outstanding shares, or (iii) beneficial ownership of such entity.
|
Licensors should also secure all rights necessary before
|
||||||
|
applying our licenses so that the public can reuse the
|
||||||
|
material as expected. Licensors should clearly mark any
|
||||||
|
material not subject to the license. This includes other CC-
|
||||||
|
licensed material, or material used under an exception or
|
||||||
|
limitation to copyright. More considerations for licensors:
|
||||||
|
wiki.creativecommons.org/Considerations_for_licensors
|
||||||
|
|
||||||
"You" (or "Your") shall mean an individual or Legal Entity
|
Considerations for the public: By using one of our public
|
||||||
exercising permissions granted by this License.
|
licenses, a licensor grants the public permission to use the
|
||||||
|
licensed material under specified terms and conditions. If
|
||||||
|
the licensor's permission is not necessary for any reason--for
|
||||||
|
example, because of any applicable exception or limitation to
|
||||||
|
copyright--then that use is not regulated by the license. Our
|
||||||
|
licenses grant only permissions under copyright and certain
|
||||||
|
other rights that a licensor has authority to grant. Use of
|
||||||
|
the licensed material may still be restricted for other
|
||||||
|
reasons, including because others have copyright or other
|
||||||
|
rights in the material. A licensor may make special requests,
|
||||||
|
such as asking that all changes be marked or described.
|
||||||
|
Although not required by our licenses, you are encouraged to
|
||||||
|
respect those requests where reasonable. More_considerations
|
||||||
|
for the public:
|
||||||
|
wiki.creativecommons.org/Considerations_for_licensees
|
||||||
|
|
||||||
"Source" form shall mean the preferred form for making modifications,
|
=======================================================================
|
||||||
including but not limited to software source code, documentation
|
|
||||||
source, and configuration files.
|
|
||||||
|
|
||||||
"Object" form shall mean any form resulting from mechanical
|
Creative Commons Attribution 4.0 International Public License
|
||||||
transformation or translation of a Source form, including but
|
|
||||||
not limited to compiled object code, generated documentation,
|
|
||||||
and conversions to other media types.
|
|
||||||
|
|
||||||
"Work" shall mean the work of authorship, whether in Source or
|
By exercising the Licensed Rights (defined below), You accept and agree
|
||||||
Object form, made available under the License, as indicated by a
|
to be bound by the terms and conditions of this Creative Commons
|
||||||
copyright notice that is included in or attached to the work
|
Attribution 4.0 International Public License ("Public License"). To the
|
||||||
(an example is provided in the Appendix below).
|
extent this Public License may be interpreted as a contract, You are
|
||||||
|
granted the Licensed Rights in consideration of Your acceptance of
|
||||||
|
these terms and conditions, and the Licensor grants You such rights in
|
||||||
|
consideration of benefits the Licensor receives from making the
|
||||||
|
Licensed Material available under these terms and conditions.
|
||||||
|
|
||||||
"Derivative Works" shall mean any work, whether in Source or Object
|
|
||||||
form, that is based on (or derived from) the Work and for which the
|
|
||||||
editorial revisions, annotations, elaborations, or other modifications
|
|
||||||
represent, as a whole, an original work of authorship. For the purposes
|
|
||||||
of this License, Derivative Works shall not include works that remain
|
|
||||||
separable from, or merely link (or bind by name) to the interfaces of,
|
|
||||||
the Work and Derivative Works thereof.
|
|
||||||
|
|
||||||
"Contribution" shall mean any work of authorship, including
|
Section 1 -- Definitions.
|
||||||
the original version of the Work and any modifications or additions
|
|
||||||
to that Work or Derivative Works thereof, that is intentionally
|
|
||||||
submitted to Licensor for inclusion in the Work by the copyright owner
|
|
||||||
or by an individual or Legal Entity authorized to submit on behalf of
|
|
||||||
the copyright owner. For the purposes of this definition, "submitted"
|
|
||||||
means any form of electronic, verbal, or written communication sent
|
|
||||||
to the Licensor or its representatives, including but not limited to
|
|
||||||
communication on electronic mailing lists, source code control systems,
|
|
||||||
and issue tracking systems that are managed by, or on behalf of, the
|
|
||||||
Licensor for the purpose of discussing and improving the Work, but
|
|
||||||
excluding communication that is conspicuously marked or otherwise
|
|
||||||
designated in writing by the copyright owner as "Not a Contribution."
|
|
||||||
|
|
||||||
"Contributor" shall mean Licensor and any individual or Legal Entity
|
a. Adapted Material means material subject to Copyright and Similar
|
||||||
on behalf of whom a Contribution has been received by Licensor and
|
Rights that is derived from or based upon the Licensed Material
|
||||||
subsequently incorporated within the Work.
|
and in which the Licensed Material is translated, altered,
|
||||||
|
arranged, transformed, or otherwise modified in a manner requiring
|
||||||
|
permission under the Copyright and Similar Rights held by the
|
||||||
|
Licensor. For purposes of this Public License, where the Licensed
|
||||||
|
Material is a musical work, performance, or sound recording,
|
||||||
|
Adapted Material is always produced where the Licensed Material is
|
||||||
|
synched in timed relation with a moving image.
|
||||||
|
|
||||||
2. Grant of Copyright License. Subject to the terms and conditions of
|
b. Adapter's License means the license You apply to Your Copyright
|
||||||
this License, each Contributor hereby grants to You a perpetual,
|
and Similar Rights in Your contributions to Adapted Material in
|
||||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
accordance with the terms and conditions of this Public License.
|
||||||
copyright license to reproduce, prepare Derivative Works of,
|
|
||||||
publicly display, publicly perform, sublicense, and distribute the
|
|
||||||
Work and such Derivative Works in Source or Object form.
|
|
||||||
|
|
||||||
3. Grant of Patent License. Subject to the terms and conditions of
|
c. Copyright and Similar Rights means copyright and/or similar rights
|
||||||
this License, each Contributor hereby grants to You a perpetual,
|
closely related to copyright including, without limitation,
|
||||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
performance, broadcast, sound recording, and Sui Generis Database
|
||||||
(except as stated in this section) patent license to make, have made,
|
Rights, without regard to how the rights are labeled or
|
||||||
use, offer to sell, sell, import, and otherwise transfer the Work,
|
categorized. For purposes of this Public License, the rights
|
||||||
where such license applies only to those patent claims licensable
|
specified in Section 2(b)(1)-(2) are not Copyright and Similar
|
||||||
by such Contributor that are necessarily infringed by their
|
Rights.
|
||||||
Contribution(s) alone or by combination of their Contribution(s)
|
|
||||||
with the Work to which such Contribution(s) was submitted. If You
|
|
||||||
institute patent litigation against any entity (including a
|
|
||||||
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
|
||||||
or a Contribution incorporated within the Work constitutes direct
|
|
||||||
or contributory patent infringement, then any patent licenses
|
|
||||||
granted to You under this License for that Work shall terminate
|
|
||||||
as of the date such litigation is filed.
|
|
||||||
|
|
||||||
4. Redistribution. You may reproduce and distribute copies of the
|
d. Effective Technological Measures means those measures that, in the
|
||||||
Work or Derivative Works thereof in any medium, with or without
|
absence of proper authority, may not be circumvented under laws
|
||||||
modifications, and in Source or Object form, provided that You
|
fulfilling obligations under Article 11 of the WIPO Copyright
|
||||||
meet the following conditions:
|
Treaty adopted on December 20, 1996, and/or similar international
|
||||||
|
agreements.
|
||||||
|
|
||||||
(a) You must give any other recipients of the Work or
|
e. Exceptions and Limitations means fair use, fair dealing, and/or
|
||||||
Derivative Works a copy of this License; and
|
any other exception or limitation to Copyright and Similar Rights
|
||||||
|
that applies to Your use of the Licensed Material.
|
||||||
|
|
||||||
(b) You must cause any modified files to carry prominent notices
|
f. Licensed Material means the artistic or literary work, database,
|
||||||
stating that You changed the files; and
|
or other material to which the Licensor applied this Public
|
||||||
|
License.
|
||||||
|
|
||||||
(c) You must retain, in the Source form of any Derivative Works
|
g. Licensed Rights means the rights granted to You subject to the
|
||||||
that You distribute, all copyright, patent, trademark, and
|
terms and conditions of this Public License, which are limited to
|
||||||
attribution notices from the Source form of the Work,
|
all Copyright and Similar Rights that apply to Your use of the
|
||||||
excluding those notices that do not pertain to any part of
|
Licensed Material and that the Licensor has authority to license.
|
||||||
the Derivative Works; and
|
|
||||||
|
|
||||||
(d) If the Work includes a "NOTICE" text file as part of its
|
h. Licensor means the individual(s) or entity(ies) granting rights
|
||||||
distribution, then any Derivative Works that You distribute must
|
under this Public License.
|
||||||
include a readable copy of the attribution notices contained
|
|
||||||
within such NOTICE file, excluding those notices that do not
|
|
||||||
pertain to any part of the Derivative Works, in at least one
|
|
||||||
of the following places: within a NOTICE text file distributed
|
|
||||||
as part of the Derivative Works; within the Source form or
|
|
||||||
documentation, if provided along with the Derivative Works; or,
|
|
||||||
within a display generated by the Derivative Works, if and
|
|
||||||
wherever such third-party notices normally appear. The contents
|
|
||||||
of the NOTICE file are for informational purposes only and
|
|
||||||
do not modify the License. You may add Your own attribution
|
|
||||||
notices within Derivative Works that You distribute, alongside
|
|
||||||
or as an addendum to the NOTICE text from the Work, provided
|
|
||||||
that such additional attribution notices cannot be construed
|
|
||||||
as modifying the License.
|
|
||||||
|
|
||||||
You may add Your own copyright statement to Your modifications and
|
i. Share means to provide material to the public by any means or
|
||||||
may provide additional or different license terms and conditions
|
process that requires permission under the Licensed Rights, such
|
||||||
for use, reproduction, or distribution of Your modifications, or
|
as reproduction, public display, public performance, distribution,
|
||||||
for any such Derivative Works as a whole, provided Your use,
|
dissemination, communication, or importation, and to make material
|
||||||
reproduction, and distribution of the Work otherwise complies with
|
available to the public including in ways that members of the
|
||||||
the conditions stated in this License.
|
public may access the material from a place and at a time
|
||||||
|
individually chosen by them.
|
||||||
|
|
||||||
5. Submission of Contributions. Unless You explicitly state otherwise,
|
j. Sui Generis Database Rights means rights other than copyright
|
||||||
any Contribution intentionally submitted for inclusion in the Work
|
resulting from Directive 96/9/EC of the European Parliament and of
|
||||||
by You to the Licensor shall be under the terms and conditions of
|
the Council of 11 March 1996 on the legal protection of databases,
|
||||||
this License, without any additional terms or conditions.
|
as amended and/or succeeded, as well as other essentially
|
||||||
Notwithstanding the above, nothing herein shall supersede or modify
|
equivalent rights anywhere in the world.
|
||||||
the terms of any separate license agreement you may have executed
|
|
||||||
with Licensor regarding such Contributions.
|
|
||||||
|
|
||||||
6. Trademarks. This License does not grant permission to use the trade
|
k. You means the individual or entity exercising the Licensed Rights
|
||||||
names, trademarks, service marks, or product names of the Licensor,
|
under this Public License. Your has a corresponding meaning.
|
||||||
except as required for reasonable and customary use in describing the
|
|
||||||
origin of the Work and reproducing the content of the NOTICE file.
|
|
||||||
|
|
||||||
7. Disclaimer of Warranty. Unless required by applicable law or
|
|
||||||
agreed to in writing, Licensor provides the Work (and each
|
|
||||||
Contributor provides its Contributions) on an "AS IS" BASIS,
|
|
||||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
|
||||||
implied, including, without limitation, any warranties or conditions
|
|
||||||
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
|
||||||
PARTICULAR PURPOSE. You are solely responsible for determining the
|
|
||||||
appropriateness of using or redistributing the Work and assume any
|
|
||||||
risks associated with Your exercise of permissions under this License.
|
|
||||||
|
|
||||||
8. Limitation of Liability. In no event and under no legal theory,
|
Section 2 -- Scope.
|
||||||
whether in tort (including negligence), contract, or otherwise,
|
|
||||||
unless required by applicable law (such as deliberate and grossly
|
|
||||||
negligent acts) or agreed to in writing, shall any Contributor be
|
|
||||||
liable to You for damages, including any direct, indirect, special,
|
|
||||||
incidental, or consequential damages of any character arising as a
|
|
||||||
result of this License or out of the use or inability to use the
|
|
||||||
Work (including but not limited to damages for loss of goodwill,
|
|
||||||
work stoppage, computer failure or malfunction, or any and all
|
|
||||||
other commercial damages or losses), even if such Contributor
|
|
||||||
has been advised of the possibility of such damages.
|
|
||||||
|
|
||||||
9. Accepting Warranty or Additional Liability. While redistributing
|
a. License grant.
|
||||||
the Work or Derivative Works thereof, You may choose to offer,
|
|
||||||
and charge a fee for, acceptance of support, warranty, indemnity,
|
|
||||||
or other liability obligations and/or rights consistent with this
|
|
||||||
License. However, in accepting such obligations, You may act only
|
|
||||||
on Your own behalf and on Your sole responsibility, not on behalf
|
|
||||||
of any other Contributor, and only if You agree to indemnify,
|
|
||||||
defend, and hold each Contributor harmless for any liability
|
|
||||||
incurred by, or claims asserted against, such Contributor by reason
|
|
||||||
of your accepting any such warranty or additional liability.
|
|
||||||
|
|
||||||
END OF TERMS AND CONDITIONS
|
1. Subject to the terms and conditions of this Public License,
|
||||||
|
the Licensor hereby grants You a worldwide, royalty-free,
|
||||||
|
non-sublicensable, non-exclusive, irrevocable license to
|
||||||
|
exercise the Licensed Rights in the Licensed Material to:
|
||||||
|
|
||||||
APPENDIX: How to apply the Apache License to your work.
|
a. reproduce and Share the Licensed Material, in whole or
|
||||||
|
in part; and
|
||||||
|
|
||||||
To apply the Apache License to your work, attach the following
|
b. produce, reproduce, and Share Adapted Material.
|
||||||
boilerplate notice, with the fields enclosed by brackets "{}"
|
|
||||||
replaced with your own identifying information. (Don't include
|
2. Exceptions and Limitations. For the avoidance of doubt, where
|
||||||
the brackets!) The text should be enclosed in the appropriate
|
Exceptions and Limitations apply to Your use, this Public
|
||||||
comment syntax for the file format. We also recommend that a
|
License does not apply, and You do not need to comply with
|
||||||
file or class name and description of purpose be included on the
|
its terms and conditions.
|
||||||
same "printed page" as the copyright notice for easier
|
|
||||||
identification within third-party archives.
|
3. Term. The term of this Public License is specified in Section
|
||||||
|
6(a).
|
||||||
|
|
||||||
|
4. Media and formats; technical modifications allowed. The
|
||||||
|
Licensor authorizes You to exercise the Licensed Rights in
|
||||||
|
all media and formats whether now known or hereafter created,
|
||||||
|
and to make technical modifications necessary to do so. The
|
||||||
|
Licensor waives and/or agrees not to assert any right or
|
||||||
|
authority to forbid You from making technical modifications
|
||||||
|
necessary to exercise the Licensed Rights, including
|
||||||
|
technical modifications necessary to circumvent Effective
|
||||||
|
Technological Measures. For purposes of this Public License,
|
||||||
|
simply making modifications authorized by this Section 2(a)
|
||||||
|
(4) never produces Adapted Material.
|
||||||
|
|
||||||
|
5. Downstream recipients.
|
||||||
|
|
||||||
|
a. Offer from the Licensor -- Licensed Material. Every
|
||||||
|
recipient of the Licensed Material automatically
|
||||||
|
receives an offer from the Licensor to exercise the
|
||||||
|
Licensed Rights under the terms and conditions of this
|
||||||
|
Public License.
|
||||||
|
|
||||||
|
b. No downstream restrictions. You may not offer or impose
|
||||||
|
any additional or different terms or conditions on, or
|
||||||
|
apply any Effective Technological Measures to, the
|
||||||
|
Licensed Material if doing so restricts exercise of the
|
||||||
|
Licensed Rights by any recipient of the Licensed
|
||||||
|
Material.
|
||||||
|
|
||||||
|
6. No endorsement. Nothing in this Public License constitutes or
|
||||||
|
may be construed as permission to assert or imply that You
|
||||||
|
are, or that Your use of the Licensed Material is, connected
|
||||||
|
with, or sponsored, endorsed, or granted official status by,
|
||||||
|
the Licensor or others designated to receive attribution as
|
||||||
|
provided in Section 3(a)(1)(A)(i).
|
||||||
|
|
||||||
|
b. Other rights.
|
||||||
|
|
||||||
|
1. Moral rights, such as the right of integrity, are not
|
||||||
|
licensed under this Public License, nor are publicity,
|
||||||
|
privacy, and/or other similar personality rights; however, to
|
||||||
|
the extent possible, the Licensor waives and/or agrees not to
|
||||||
|
assert any such rights held by the Licensor to the limited
|
||||||
|
extent necessary to allow You to exercise the Licensed
|
||||||
|
Rights, but not otherwise.
|
||||||
|
|
||||||
|
2. Patent and trademark rights are not licensed under this
|
||||||
|
Public License.
|
||||||
|
|
||||||
|
3. To the extent possible, the Licensor waives any right to
|
||||||
|
collect royalties from You for the exercise of the Licensed
|
||||||
|
Rights, whether directly or through a collecting society
|
||||||
|
under any voluntary or waivable statutory or compulsory
|
||||||
|
licensing scheme. In all other cases the Licensor expressly
|
||||||
|
reserves any right to collect such royalties.
|
||||||
|
|
||||||
|
|
||||||
|
Section 3 -- License Conditions.
|
||||||
|
|
||||||
|
Your exercise of the Licensed Rights is expressly made subject to the
|
||||||
|
following conditions.
|
||||||
|
|
||||||
|
a. Attribution.
|
||||||
|
|
||||||
|
1. If You Share the Licensed Material (including in modified
|
||||||
|
form), You must:
|
||||||
|
|
||||||
|
a. retain the following if it is supplied by the Licensor
|
||||||
|
with the Licensed Material:
|
||||||
|
|
||||||
|
i. identification of the creator(s) of the Licensed
|
||||||
|
Material and any others designated to receive
|
||||||
|
attribution, in any reasonable manner requested by
|
||||||
|
the Licensor (including by pseudonym if
|
||||||
|
designated);
|
||||||
|
|
||||||
|
ii. a copyright notice;
|
||||||
|
|
||||||
|
iii. a notice that refers to this Public License;
|
||||||
|
|
||||||
|
iv. a notice that refers to the disclaimer of
|
||||||
|
warranties;
|
||||||
|
|
||||||
|
v. a URI or hyperlink to the Licensed Material to the
|
||||||
|
extent reasonably practicable;
|
||||||
|
|
||||||
|
b. indicate if You modified the Licensed Material and
|
||||||
|
retain an indication of any previous modifications; and
|
||||||
|
|
||||||
|
c. indicate the Licensed Material is licensed under this
|
||||||
|
Public License, and include the text of, or the URI or
|
||||||
|
hyperlink to, this Public License.
|
||||||
|
|
||||||
|
2. You may satisfy the conditions in Section 3(a)(1) in any
|
||||||
|
reasonable manner based on the medium, means, and context in
|
||||||
|
which You Share the Licensed Material. For example, it may be
|
||||||
|
reasonable to satisfy the conditions by providing a URI or
|
||||||
|
hyperlink to a resource that includes the required
|
||||||
|
information.
|
||||||
|
|
||||||
|
3. If requested by the Licensor, You must remove any of the
|
||||||
|
information required by Section 3(a)(1)(A) to the extent
|
||||||
|
reasonably practicable.
|
||||||
|
|
||||||
|
4. If You Share Adapted Material You produce, the Adapter's
|
||||||
|
License You apply must not prevent recipients of the Adapted
|
||||||
|
Material from complying with this Public License.
|
||||||
|
|
||||||
|
|
||||||
|
Section 4 -- Sui Generis Database Rights.
|
||||||
|
|
||||||
|
Where the Licensed Rights include Sui Generis Database Rights that
|
||||||
|
apply to Your use of the Licensed Material:
|
||||||
|
|
||||||
|
a. for the avoidance of doubt, Section 2(a)(1) grants You the right
|
||||||
|
to extract, reuse, reproduce, and Share all or a substantial
|
||||||
|
portion of the contents of the database;
|
||||||
|
|
||||||
|
b. if You include all or a substantial portion of the database
|
||||||
|
contents in a database in which You have Sui Generis Database
|
||||||
|
Rights, then the database in which You have Sui Generis Database
|
||||||
|
Rights (but not its individual contents) is Adapted Material; and
|
||||||
|
|
||||||
|
c. You must comply with the conditions in Section 3(a) if You Share
|
||||||
|
all or a substantial portion of the contents of the database.
|
||||||
|
|
||||||
|
For the avoidance of doubt, this Section 4 supplements and does not
|
||||||
|
replace Your obligations under this Public License where the Licensed
|
||||||
|
Rights include other Copyright and Similar Rights.
|
||||||
|
|
||||||
|
|
||||||
|
Section 5 -- Disclaimer of Warranties and Limitation of Liability.
|
||||||
|
|
||||||
|
a. UNLESS OTHERWISE SEPARATELY UNDERTAKEN BY THE LICENSOR, TO THE
|
||||||
|
EXTENT POSSIBLE, THE LICENSOR OFFERS THE LICENSED MATERIAL AS-IS
|
||||||
|
AND AS-AVAILABLE, AND MAKES NO REPRESENTATIONS OR WARRANTIES OF
|
||||||
|
ANY KIND CONCERNING THE LICENSED MATERIAL, WHETHER EXPRESS,
|
||||||
|
IMPLIED, STATUTORY, OR OTHER. THIS INCLUDES, WITHOUT LIMITATION,
|
||||||
|
WARRANTIES OF TITLE, MERCHANTABILITY, FITNESS FOR A PARTICULAR
|
||||||
|
PURPOSE, NON-INFRINGEMENT, ABSENCE OF LATENT OR OTHER DEFECTS,
|
||||||
|
ACCURACY, OR THE PRESENCE OR ABSENCE OF ERRORS, WHETHER OR NOT
|
||||||
|
KNOWN OR DISCOVERABLE. WHERE DISCLAIMERS OF WARRANTIES ARE NOT
|
||||||
|
ALLOWED IN FULL OR IN PART, THIS DISCLAIMER MAY NOT APPLY TO YOU.
|
||||||
|
|
||||||
|
b. TO THE EXTENT POSSIBLE, IN NO EVENT WILL THE LICENSOR BE LIABLE
|
||||||
|
TO YOU ON ANY LEGAL THEORY (INCLUDING, WITHOUT LIMITATION,
|
||||||
|
NEGLIGENCE) OR OTHERWISE FOR ANY DIRECT, SPECIAL, INDIRECT,
|
||||||
|
INCIDENTAL, CONSEQUENTIAL, PUNITIVE, EXEMPLARY, OR OTHER LOSSES,
|
||||||
|
COSTS, EXPENSES, OR DAMAGES ARISING OUT OF THIS PUBLIC LICENSE OR
|
||||||
|
USE OF THE LICENSED MATERIAL, EVEN IF THE LICENSOR HAS BEEN
|
||||||
|
ADVISED OF THE POSSIBILITY OF SUCH LOSSES, COSTS, EXPENSES, OR
|
||||||
|
DAMAGES. WHERE A LIMITATION OF LIABILITY IS NOT ALLOWED IN FULL OR
|
||||||
|
IN PART, THIS LIMITATION MAY NOT APPLY TO YOU.
|
||||||
|
|
||||||
|
c. The disclaimer of warranties and limitation of liability provided
|
||||||
|
above shall be interpreted in a manner that, to the extent
|
||||||
|
possible, most closely approximates an absolute disclaimer and
|
||||||
|
waiver of all liability.
|
||||||
|
|
||||||
|
|
||||||
|
Section 6 -- Term and Termination.
|
||||||
|
|
||||||
|
a. This Public License applies for the term of the Copyright and
|
||||||
|
Similar Rights licensed here. However, if You fail to comply with
|
||||||
|
this Public License, then Your rights under this Public License
|
||||||
|
terminate automatically.
|
||||||
|
|
||||||
|
b. Where Your right to use the Licensed Material has terminated under
|
||||||
|
Section 6(a), it reinstates:
|
||||||
|
|
||||||
|
1. automatically as of the date the violation is cured, provided
|
||||||
|
it is cured within 30 days of Your discovery of the
|
||||||
|
violation; or
|
||||||
|
|
||||||
|
2. upon express reinstatement by the Licensor.
|
||||||
|
|
||||||
|
For the avoidance of doubt, this Section 6(b) does not affect any
|
||||||
|
right the Licensor may have to seek remedies for Your violations
|
||||||
|
of this Public License.
|
||||||
|
|
||||||
|
c. For the avoidance of doubt, the Licensor may also offer the
|
||||||
|
Licensed Material under separate terms or conditions or stop
|
||||||
|
distributing the Licensed Material at any time; however, doing so
|
||||||
|
will not terminate this Public License.
|
||||||
|
|
||||||
|
d. Sections 1, 5, 6, 7, and 8 survive termination of this Public
|
||||||
|
License.
|
||||||
|
|
||||||
|
|
||||||
|
Section 7 -- Other Terms and Conditions.
|
||||||
|
|
||||||
|
a. The Licensor shall not be bound by any additional or different
|
||||||
|
terms or conditions communicated by You unless expressly agreed.
|
||||||
|
|
||||||
|
b. Any arrangements, understandings, or agreements regarding the
|
||||||
|
Licensed Material not stated herein are separate from and
|
||||||
|
independent of the terms and conditions of this Public License.
|
||||||
|
|
||||||
|
|
||||||
|
Section 8 -- Interpretation.
|
||||||
|
|
||||||
|
a. For the avoidance of doubt, this Public License does not, and
|
||||||
|
shall not be interpreted to, reduce, limit, restrict, or impose
|
||||||
|
conditions on any use of the Licensed Material that could lawfully
|
||||||
|
be made without permission under this Public License.
|
||||||
|
|
||||||
|
b. To the extent possible, if any provision of this Public License is
|
||||||
|
deemed unenforceable, it shall be automatically reformed to the
|
||||||
|
minimum extent necessary to make it enforceable. If the provision
|
||||||
|
cannot be reformed, it shall be severed from this Public License
|
||||||
|
without affecting the enforceability of the remaining terms and
|
||||||
|
conditions.
|
||||||
|
|
||||||
|
c. No term or condition of this Public License will be waived and no
|
||||||
|
failure to comply consented to unless expressly agreed to by the
|
||||||
|
Licensor.
|
||||||
|
|
||||||
|
d. Nothing in this Public License constitutes or may be interpreted
|
||||||
|
as a limitation upon, or waiver of, any privileges and immunities
|
||||||
|
that apply to the Licensor or You, including from the legal
|
||||||
|
processes of any jurisdiction or authority.
|
||||||
|
|
||||||
|
|
||||||
|
=======================================================================
|
||||||
|
|
||||||
|
Creative Commons is not a party to its public
|
||||||
|
licenses. Notwithstanding, Creative Commons may elect to apply one of
|
||||||
|
its public licenses to material it publishes and in those instances
|
||||||
|
will be considered the "Licensor." The text of the Creative Commons
|
||||||
|
public licenses is dedicated to the public domain under the CC0 Public
|
||||||
|
Domain Dedication. Except for the limited purpose of indicating that
|
||||||
|
material is shared under a Creative Commons public license or as
|
||||||
|
otherwise permitted by the Creative Commons policies published at
|
||||||
|
creativecommons.org/policies, Creative Commons does not authorize the
|
||||||
|
use of the trademark "Creative Commons" or any other trademark or logo
|
||||||
|
of Creative Commons without its prior written consent including,
|
||||||
|
without limitation, in connection with any unauthorized modifications
|
||||||
|
to any of its public licenses or any other arrangements,
|
||||||
|
understandings, or agreements concerning use of licensed material. For
|
||||||
|
the avoidance of doubt, this paragraph does not form part of the
|
||||||
|
public licenses.
|
||||||
|
|
||||||
|
Creative Commons may be contacted at creativecommons.org.
|
||||||
|
|
|
||||||
42
Makefile
42
Makefile
|
|
@ -1,30 +1,36 @@
|
||||||
BOOK_NAME := kubernetes-handbook
|
BOOK_NAME := kubernetes-handbook
|
||||||
BOOK_OUTPUT := _book
|
BOOK_OUTPUT := _book
|
||||||
|
image := jimmysong/gitbook-builder:2019-07-31
|
||||||
|
docker := docker run -t -i --sig-proxy=true --rm -v $(shell pwd):/gitbook -w /gitbook -p 4000:4000 $(image)
|
||||||
|
|
||||||
.PHONY: build
|
.PHONY: build
|
||||||
build:
|
build:
|
||||||
gitbook build . $(BOOK_OUTPUT)
|
@$(docker) scripts/build-gitbook.sh
|
||||||
|
|
||||||
.PHONY: serve
|
.PHONY: lint
|
||||||
serve:
|
lint:
|
||||||
gitbook serve . $(BOOK_OUTPUT)
|
@$(docker) scripts/lint-gitbook.sh
|
||||||
|
htmlproofer --url-ignore "/localhost/,/172.17.8.101/,/172.20.0.113/,/slideshare.net/,/grpc.io/,/kiali.io/,/condiut.io/,/twitter.com/,/facebook.com/,/medium.com/,/google.com/,/jimmysong.io/,/openfaas.com/,/linkerd.io/,/layer5.io/,/thenewstack.io/,/blog.envoyproxy.io/,/blog.openebs.io/,/k8smeetup.github.io/,/blog.heptio.com/,/apigee.com/,/speakerdeck.com/,/download.svcat.sh/,/blog.fabric8.io/,/blog.heptio.com/,/blog.containership.io/,/blog.mobyproject.org/,/blog.spinnaker.io/,/coscale.com/,/zh.wikipedia.org/,/labs.play-with-k8s.com/,/cilium.readthedocs.io/,/azure.microsoft.com/,/storageos.com/,/openid.net/,/prometheus.io/,/coreos.com/,/openwhisk.incubator.apache.org/" $(BOOK_OUTPUT)
|
||||||
.PHONY: epub
|
|
||||||
epub:
|
|
||||||
gitbook epub . $(BOOK_NAME).epub
|
|
||||||
|
|
||||||
.PHONY: pdf
|
|
||||||
pdf:
|
|
||||||
gitbook pdf . $(BOOK_NAME).pdf
|
|
||||||
|
|
||||||
.PHONY: mobi
|
|
||||||
mobi:
|
|
||||||
gitbook mobi . $(BOOK_NAME).mobi
|
|
||||||
|
|
||||||
.PHONY: install
|
.PHONY: install
|
||||||
install:
|
install:
|
||||||
npm install gitbook-cli -g
|
@$(docker) gitbook install
|
||||||
gitbook install
|
|
||||||
|
.PHONY: serve
|
||||||
|
serve:
|
||||||
|
@$(docker) gitbook serve . $(BOOK_OUTPUT)
|
||||||
|
|
||||||
|
.PHONY: epub
|
||||||
|
epub:
|
||||||
|
@$(docker) gitbook epub . $(BOOK_NAME).epub
|
||||||
|
|
||||||
|
.PHONY: pdf
|
||||||
|
pdf:
|
||||||
|
@$(docker) gitbook pdf . $(BOOK_NAME).pdf
|
||||||
|
|
||||||
|
.PHONY: mobi
|
||||||
|
mobi:
|
||||||
|
@$(docker) gitbook mobi . $(BOOK_NAME).mobi
|
||||||
|
|
||||||
.PHONY: clean
|
.PHONY: clean
|
||||||
clean:
|
clean:
|
||||||
|
|
|
||||||
|
|
@ -0,0 +1,48 @@
|
||||||
|
BOOK_NAME := kubernetes-handbook
|
||||||
|
BOOK_OUTPUT := _book
|
||||||
|
|
||||||
|
.PHONY: build
|
||||||
|
build:
|
||||||
|
gitbook build . $(BOOK_OUTPUT)
|
||||||
|
cp images/apple-touch-icon-precomposed-152.png $(BOOK_OUTPUT)/gitbook/images
|
||||||
|
|
||||||
|
.PHONY: lint
|
||||||
|
lint:
|
||||||
|
htmlproofer --url-ignore "/localhost/,/172.17.8.101/,/172.20.0.113/,/slideshare.net/,/grpc.io/,/kiali.io/,/condiut.io/,/twitter.com/,/facebook.com/,/medium.com/,/google.com/,/jimmysong.io/,/openfaas.com/,/linkerd.io/,/layer5.io/,/thenewstack.io/,/blog.envoyproxy.io/,/blog.openebs.io/,/k8smeetup.github.io/,/blog.heptio.com/,/apigee.com/,/speakerdeck.com/,/download.svcat.sh/,/blog.fabric8.io/,/blog.heptio.com/,/blog.containership.io/,/blog.mobyproject.org/,/blog.spinnaker.io/,/coscale.com/,/zh.wikipedia.org/,/labs.play-with-k8s.com/,/cilium.readthedocs.io/,/azure.microsoft.com/,/storageos.com/,/openid.net/,/prometheus.io/,/coreos.com/,/openwhisk.incubator.apache.org/" $(BOOK_OUTPUT)
|
||||||
|
|
||||||
|
.PHONY: serve
|
||||||
|
serve:
|
||||||
|
gitbook serve . $(BOOK_OUTPUT)
|
||||||
|
|
||||||
|
.PHONY: epub
|
||||||
|
epub:
|
||||||
|
gitbook epub . $(BOOK_NAME).epub
|
||||||
|
|
||||||
|
.PHONY: pdf
|
||||||
|
pdf:
|
||||||
|
gitbook pdf . $(BOOK_NAME).pdf
|
||||||
|
|
||||||
|
.PHONY: mobi
|
||||||
|
mobi:
|
||||||
|
gitbook mobi . $(BOOK_NAME).mobi
|
||||||
|
|
||||||
|
.PHONY: install
|
||||||
|
install:
|
||||||
|
npm install gitbook-cli -g
|
||||||
|
gitbook install
|
||||||
|
gem install html-proofer
|
||||||
|
|
||||||
|
.PHONY: clean
|
||||||
|
clean:
|
||||||
|
rm -rf $(BOOK_OUTPUT)
|
||||||
|
|
||||||
|
.PHONY: help
|
||||||
|
help:
|
||||||
|
@echo "Help for make"
|
||||||
|
@echo "make - Build the book"
|
||||||
|
@echo "make build - Build the book"
|
||||||
|
@echo "make serve - Serving the book on localhost:4000"
|
||||||
|
@echo "make install - Install gitbook and plugins"
|
||||||
|
@echo "make epub - Build epub book"
|
||||||
|
@echo "make pdf - Build pdf book"
|
||||||
|
@echo "make clean - Remove generated files"
|
||||||
98
README.md
98
README.md
|
|
@ -1,24 +1,60 @@
|
||||||
# Kubernetes Handbook——Kubernetes中文指南/云原生应用架构实践手册
|
# Kubernetes Handbook——Kubernetes中文指南/云原生应用架构实践手册
|
||||||
|
|
||||||
[Kubernetes](http://kubernetes.io)是Google基于[Borg](https://research.google.com/pubs/pub43438.html)开源的容器编排调度引擎,作为[CNCF](http://cncf.io)(Cloud Native Computing Foundation)最重要的组件之一,它的目标不仅仅是一个编排系统,而是提供一个规范,可以让你来描述集群的架构,定义服务的最终状态,Kubernetes可以帮你将系统自动地达到和维持在这个状态。Kubernetes作为云原生应用的基石,相当于一个云操作系统,其重要性不言而喻。
|
[Kubernetes](http://kubernetes.io)是Google基于[Borg](https://research.google.com/pubs/pub43438.html)开源的容器编排调度引擎,作为[CNCF](https://cncf.io)(Cloud Native Computing Foundation)最重要的组件之一,它的目标不仅仅是一个编排系统,而是提供一个规范,可以让你来描述集群的架构,定义服务的最终状态,Kubernetes可以帮你将系统自动地达到和维持在这个状态。Kubernetes作为云原生应用的基石,相当于一个云操作系统,其重要性不言而喻。
|
||||||
|
|
||||||
本书记录了本人从零开始学习和使用Kubernetes的心路历程,着重于经验分享和总结,同时也会有相关的概念解析,希望能够帮助大家少踩坑,少走弯路,还会指引大家关于关注Kubernetes生态周边,如微服务构建、DevOps、大数据应用、Service Mesh、Cloud Native等领域。
|
云原生技术有利于各组织在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用。云原生的代表技术包括**容器**、**服务网格**、**微服务**、**不可变基础设施**和**声明式API**。这些技术能够构建容错性好、易于管理和便于观察的松耦合系统。结合可靠的自动化手段,云原生技术使工程师能够轻松地对系统作出频繁和可预测的重大变更。——CNCF(云原生计算基金会)。
|
||||||
|
|
||||||
本书的主题不仅限于Kubernetes,还包括以下几大主题:
|
## 关于本书
|
||||||
|
|
||||||
|
<p align="left">
|
||||||
|
<a href="https://circleci.com/gh/rootsongjc/kubernetes-handbook/tree/master">
|
||||||
|
<img src="https://circleci.com/gh/rootsongjc/kubernetes-handbook/tree/master.svg?style=svg" alt="CircleCI"/>
|
||||||
|
</a>
|
||||||
|
</p>
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
<a href="https://jimmysong.io/kubernetes-handbook">
|
||||||
|
<img src="cover.jpg" width="50%" height="50%" alt="Kubernetes Handbook——Kubernetes中文指南/云原生应用架构实践手册 by Jimmy Song(宋净超)">
|
||||||
|
</a>
|
||||||
|
</p>
|
||||||
|
|
||||||
|
本书开源于2017年3月,是第一本系统整理的开源中文版Kubernetes参考资料,记录了本人从零开始学习和使用Kubernetes的历程,着重于总结和资料分享,同时也会有相关的概念解析,希望能够帮助大家少踩坑,少走弯路,还会指引大家关注Kubernetes生态周边,如微服务构建、DevOps、大数据应用、[Service Mesh](https://jimmysong.io/blog/what-is-a-service-mesh/)、Cloud Native等领域。
|
||||||
|
|
||||||
|
### 开始之前
|
||||||
|
|
||||||
|
在阅读本书之前希望您掌握以下知识和准备以下环境:
|
||||||
|
|
||||||
|
- Linux 操作系统原理
|
||||||
|
- Linux 常用命令
|
||||||
|
- Docker 容器原理及基本操作
|
||||||
|
- 一台可以上网的电脑,Mac/Windows/Linux 皆可
|
||||||
|
- 安装 Docker
|
||||||
|
|
||||||
|
### 本书主题
|
||||||
|
|
||||||
|
本书的主题不局限于Kubernetes,还包括以下几大主题:
|
||||||
|
|
||||||
- 云原生开源组件
|
- 云原生开源组件
|
||||||
- 云原生应用与微服务架构
|
- 云原生应用与微服务架构
|
||||||
- 基于Kubernete的Service Mesh架构
|
- 基于Kubernetes的Service Mesh架构
|
||||||
- Kubernetes与微服务结合实践
|
|
||||||
|
|
||||||
起初写作本书时,安装的所有组件、所用示例和操作等皆基于**Kubernetes1.6+** 版本,同时我们也将密切关注kubernetes的版本更新,随着它的版本更新升级,本书中的Kubernetes版本和示例也将随之更新。
|
起初写作本书时,安装的所有组件、所用示例和操作等皆基于 **Kubernetes 1.6+** 版本,同时我们也将密切关注Kubernetes的版本更新,随着它的版本更新升级,本书中的Kubernetes版本和示例也将随之更新。
|
||||||
|
|
||||||
|
### 使用方式
|
||||||
|
|
||||||
|
您可以通过以下方式使用本书:
|
||||||
|
|
||||||
- GitHub地址:https://github.com/rootsongjc/kubernetes-handbook
|
- GitHub地址:https://github.com/rootsongjc/kubernetes-handbook
|
||||||
- Gitbook在线浏览:https://jimmysong.io/kubernetes-handbook/
|
- GitBook在线浏览:https://jimmysong.io/kubernetes-handbook/
|
||||||
|
- 下载本书的发行版:https://github.com/rootsongjc/kubernetes-handbook/releases
|
||||||
|
- 按照[说明](https://github.com/rootsongjc/kubernetes-handbook/blob/master/CODE_OF_CONDUCT.md)自行编译成离线版本
|
||||||
|
- Fork 一份添加你自己的笔记自行维护,有余力者可以一起参与进来
|
||||||
|
|
||||||
|
**注意:Service Mesh 已成立独立的 [istio-handbook](https://www.servicemesher.com/istio-handbook),本书中的 Service Mesh 相关内容已不再维护。**
|
||||||
|
|
||||||
## 快速开始
|
## 快速开始
|
||||||
|
|
||||||
如果您想要学习Kubernetes和云原生应用架构但是又不想自己从头开始搭建和配置一个集群,那么可以直接使用[**kubernetes-vagrant-centos-cluster**](https://github.com/rootsongjc/kubernetes-vagrant-centos-cluster)项目直接在本地部署一个3节点的分布式集群及其他如Heapster、EFK、Istio等可选组件。
|
如果您想要学习Kubernetes和云原生应用架构但是又不想自己从头开始搭建和配置一个集群,那么可以直接使用[kubernetes-vagrant-centos-cluster](https://github.com/rootsongjc/kubernetes-vagrant-centos-cluster)项目直接在本地部署一个3节点的分布式集群及其他如Heapster、EFK、Istio等可选组件,或者使用更加轻量级的[cloud-native-sandbox](https://github.com/rootsongjc/cloud-native-sandbox)在个人电脑上使用Docker运行单节点的Kubernetes、Istio等组件。
|
||||||
|
|
||||||
## 贡献与致谢
|
## 贡献与致谢
|
||||||
|
|
||||||
|
|
@ -28,42 +64,42 @@
|
||||||
- [查看如何贡献](https://github.com/rootsongjc/kubernetes-handbook/blob/master/CONTRIBUTING.md)
|
- [查看如何贡献](https://github.com/rootsongjc/kubernetes-handbook/blob/master/CONTRIBUTING.md)
|
||||||
- [查看文档的组织结构与使用方法](https://github.com/rootsongjc/kubernetes-handbook/blob/master/CODE_OF_CONDUCT.md)
|
- [查看文档的组织结构与使用方法](https://github.com/rootsongjc/kubernetes-handbook/blob/master/CODE_OF_CONDUCT.md)
|
||||||
|
|
||||||
|
## License
|
||||||
|
|
||||||
|
<p align="left">
|
||||||
|
<img src="images/cc4-license.png" alt="CC4 License"/>
|
||||||
|
</p>
|
||||||
|
|
||||||
|
[署名-非商业性使用-相同方式共享 4.0 (CC BY-NC-SA 4.0)](https://creativecommons.org/licenses/by-nc-sa/4.0/deed.zh)
|
||||||
|
|
||||||
## Stargazers over time
|
## Stargazers over time
|
||||||
|
|
||||||
[](https://starcharts.herokuapp.com/rootsongjc/kubernetes-handbook)
|
[](https://starcharts.herokuapp.com/rootsongjc/kubernetes-handbook)
|
||||||
|
|
||||||
## 社区&读者交流
|
## 社区&读者交流
|
||||||
|
|
||||||
- **微信群**:K8S&Cloud Native实战,扫描我的微信二维码,[Jimmy Song](http://jimmysong.io/about),或直接搜索微信号*jimmysong*后拉您入群,请增加备注(姓名-公司/学校/博客/社区/研究所/机构等)。
|
- [云原生社区](https://jimmysong.io/contact/):备注姓名-公司/学校/组织/机构等,并注明加入云原生社区。
|
||||||
- **Slack**:全球中文用户可以加入[Kubernetes官方Slack](http://slack.k8s.io)中文频道**cn-users channel**
|
- [云原生应用架构](https://zhuanlan.zhihu.com/cloud-native):知乎专栏
|
||||||
- **知乎专栏**:[云原生应用架构](https://zhuanlan.zhihu.com/cloud-native)
|
|
||||||
- **微信公众号**:扫描下面的二维码关注微信公众号CloudNativeGo(云原生应用架构)
|
|
||||||
|
|
||||||
<p align="center">
|
|
||||||
<img src="https://github.com/rootsongjc/kubernetes-handbook/blob/master/images/cloud-native-go-wechat-qr-code.jpg?raw=true" alt="云原生应用架构微信公众号二维码"/>
|
|
||||||
</p>
|
|
||||||
|
|
||||||
- **ServiceMesher**:CloudNativeGo的姊妹公众号,旨在加强行业内部交流,促进开源文化构建,推动Service Mesh在企业落地,发布Service Mesh资讯。[加入组织](http://www.servicemesher.com/contact/)。
|
|
||||||
|
|
||||||
<p align="center">
|
|
||||||
<img src="https://ws1.sinaimg.cn/large/00704eQkgy1fshv989hhqj309k09k0t6.jpg" alt="ServiceMesher微信公众号二维码"/>
|
|
||||||
</p>
|
|
||||||
|
|
||||||
## 云原生出版物
|
## 云原生出版物
|
||||||
|
|
||||||
以下为本人翻译出版的图书。
|
以下为本人参与出版的云原生相关图书。
|
||||||
|
|
||||||
- [Cloud Native Go](https://jimmysong.io/posts/cloud-native-go/) - 基于Go和React的web云原生应用构建指南(Kevin Hoffman & Dan Nemeth著 宋净超 吴迎松 徐蓓 马超 译),电子工业出版社,2017年6月出版
|
- [Cloud Native Go](https://jimmysong.io/book/cloud-native-go/) - 基于Go和React的web云原生应用构建指南(Kevin Hoffman & Dan Nemeth著 宋净超 吴迎松 徐蓓 马超 译),电子工业出版社,2017年6月出版
|
||||||
- [Python云原生](https://jimmysong.io/posts/cloud-native-python/) - 使用Python和React构建云原生应用(Manish Sethi著,宋净超译),电子工业出版社,2018年6月出版
|
- [Python云原生](https://jimmysong.io/book/cloud-native-python/) - 使用Python和React构建云原生应用(Manish Sethi著,宋净超译),电子工业出版社,2018年6月出版
|
||||||
- [云原生Java](https://jimmysong.io/posts/cloud-native-java/) - Spring Boot、Spring Cloud与Cloud Foundry弹性系统设计(Josh Long & Kenny Bastani著,张若飞 宋净超译 ),电子工业出版社,2018年7月出版
|
- [云原生Java](https://jimmysong.io/book/cloud-native-java/) - Spring Boot、Spring Cloud与Cloud Foundry弹性系统设计(Josh Long & Kenny Bastani著,张若飞 宋净超译 ),电子工业出版社,2018年7月出版
|
||||||
|
- [未来架构——从服务化到云原生](https://jimmysong.io/book/future-architecture/) - 张亮 吴晟 敖小剑 宋净超 著,电子工业出版社,2019年3月出版
|
||||||
|
|
||||||
|
## 推荐
|
||||||
|
|
||||||
|
- [极客时间专栏《深入剖析 Kubernetes》](https://tva1.sinaimg.cn/large/006y8mN6ly1g7vf4p12rpj30u01hdjwp.jpg):快速入门学习 Kubernetes
|
||||||
|
- [深入浅出云计算](https://time.geekbang.org/column/intro/292?code=EhFrzVKvIro8U06UyaeLCCdmbpk7g010iXprzDxW17I%3D&utm_term=SPoster):云原生时代给开发者和架构师的云计算指南
|
||||||
|
|
||||||
## 支持本书
|
## 支持本书
|
||||||
|
|
||||||
为贡献者加油!为云原生干杯🍻!
|
为云原生干杯🍻!使用微信扫一扫请我喝一杯☕️
|
||||||
|
|
||||||
使用微信扫一扫请贡献者喝一杯☕️
|
|
||||||
|
|
||||||
<p align="center">
|
<p align="center">
|
||||||
<img src="https://github.com/rootsongjc/kubernetes-handbook/blob/master/images/wechat-appreciate-qrcode.jpg?raw=true" alt="微信赞赏码"/>
|
<img src="images/wechat-appreciate-qrcode.jpg" alt="微信赞赏码"/>
|
||||||
</p>
|
</p>
|
||||||
|
|
||||||
64
SUMMARY.md
64
SUMMARY.md
|
|
@ -1,4 +1,4 @@
|
||||||
# Summary
|
# 目录
|
||||||
|
|
||||||
## 前言
|
## 前言
|
||||||
|
|
||||||
|
|
@ -6,11 +6,11 @@
|
||||||
|
|
||||||
## 云原生
|
## 云原生
|
||||||
|
|
||||||
* [云原生的定义](cloud-native/cloud-native-definition.md)
|
* [云原生(Cloud Native)的定义](cloud-native/cloud-native-definition.md)
|
||||||
* [CNCF - 云原生计算基金会简介](cloud-native/cncf.md)
|
* [云原生的设计哲学](cloud-native/cloud-native-philosophy.md)
|
||||||
* [CNCF章程](cloud-native/cncf-charter.md)
|
|
||||||
* [Play with Kubernetes](cloud-native/play-with-kubernetes.md)
|
* [Play with Kubernetes](cloud-native/play-with-kubernetes.md)
|
||||||
* [快速部署一个云原生本地实验环境](cloud-native/cloud-native-local-quick-start.md)
|
* [快速部署一个云原生本地实验环境](cloud-native/cloud-native-local-quick-start.md)
|
||||||
|
* [使用Rancher在阿里云上部署Kubenretes集群](cloud-native/setup-kubernetes-with-rancher-and-aliyun.md)
|
||||||
* [Kubernetes与云原生应用概览](cloud-native/kubernetes-and-cloud-native-app-overview.md)
|
* [Kubernetes与云原生应用概览](cloud-native/kubernetes-and-cloud-native-app-overview.md)
|
||||||
* [云原生应用之路——从Kubernetes到Cloud Native](cloud-native/from-kubernetes-to-cloud-native.md)
|
* [云原生应用之路——从Kubernetes到Cloud Native](cloud-native/from-kubernetes-to-cloud-native.md)
|
||||||
* [云原生编程语言](cloud-native/cloud-native-programming-languages.md)
|
* [云原生编程语言](cloud-native/cloud-native-programming-languages.md)
|
||||||
|
|
@ -30,6 +30,8 @@
|
||||||
* [Kubernetes中的网络](concepts/networking.md)
|
* [Kubernetes中的网络](concepts/networking.md)
|
||||||
* [Kubernetes中的网络解析——以flannel为例](concepts/flannel.md)
|
* [Kubernetes中的网络解析——以flannel为例](concepts/flannel.md)
|
||||||
* [Kubernetes中的网络解析——以calico为例](concepts/calico.md)
|
* [Kubernetes中的网络解析——以calico为例](concepts/calico.md)
|
||||||
|
* [具备API感知的网络和安全性管理开源软件Cilium](concepts/cilium.md)
|
||||||
|
* [Cilium架构设计与概念解析](concepts/cilium-concepts.md)
|
||||||
* [资源对象与基本概念解析](concepts/objects.md)
|
* [资源对象与基本概念解析](concepts/objects.md)
|
||||||
* [Pod状态与生命周期管理](concepts/pod-state-and-lifecycle.md)
|
* [Pod状态与生命周期管理](concepts/pod-state-and-lifecycle.md)
|
||||||
* [Pod概览](concepts/pod-overview.md)
|
* [Pod概览](concepts/pod-overview.md)
|
||||||
|
|
@ -57,6 +59,7 @@
|
||||||
* [CronJob](concepts/cronjob.md)
|
* [CronJob](concepts/cronjob.md)
|
||||||
* [Horizontal Pod Autoscaling](concepts/horizontal-pod-autoscaling.md)
|
* [Horizontal Pod Autoscaling](concepts/horizontal-pod-autoscaling.md)
|
||||||
* [自定义指标HPA](concepts/custom-metrics-hpa.md)
|
* [自定义指标HPA](concepts/custom-metrics-hpa.md)
|
||||||
|
* [准入控制器(Admission Controller)](concepts/admission-controller.md)
|
||||||
* [服务发现](concepts/service-discovery.md)
|
* [服务发现](concepts/service-discovery.md)
|
||||||
* [Service](concepts/service.md)
|
* [Service](concepts/service.md)
|
||||||
* [Ingress](concepts/ingress.md)
|
* [Ingress](concepts/ingress.md)
|
||||||
|
|
@ -75,10 +78,12 @@
|
||||||
* [本地持久化存储](concepts/local-persistent-storage.md)
|
* [本地持久化存储](concepts/local-persistent-storage.md)
|
||||||
* [集群扩展](concepts/extension.md)
|
* [集群扩展](concepts/extension.md)
|
||||||
* [使用自定义资源扩展API](concepts/custom-resource.md)
|
* [使用自定义资源扩展API](concepts/custom-resource.md)
|
||||||
|
* [使用CRD扩展Kubernetes API](concepts/crd.md)
|
||||||
* [Aggregated API Server](concepts/aggregated-api-server.md)
|
* [Aggregated API Server](concepts/aggregated-api-server.md)
|
||||||
* [APIService](concepts/apiservice.md)
|
* [APIService](concepts/apiservice.md)
|
||||||
* [Service Catalog](concepts/service-catalog.md)
|
* [Service Catalog](concepts/service-catalog.md)
|
||||||
* [资源调度](concepts/scheduling.md)
|
* [资源调度](concepts/scheduling.md)
|
||||||
|
* [QoS(服务质量等级)](concepts/qos.md)
|
||||||
|
|
||||||
## 用户指南
|
## 用户指南
|
||||||
|
|
||||||
|
|
@ -89,7 +94,7 @@
|
||||||
* [Secret配置](guide/secret-configuration.md)
|
* [Secret配置](guide/secret-configuration.md)
|
||||||
* [管理namespace中的资源配额](guide/resource-quota-management.md)
|
* [管理namespace中的资源配额](guide/resource-quota-management.md)
|
||||||
* [命令使用](guide/command-usage.md)
|
* [命令使用](guide/command-usage.md)
|
||||||
* [docker用户过度到kubectl命令行指南](guide/docker-cli-to-kubectl.md)
|
* [Docker用户过渡到kubectl命令行指南](guide/docker-cli-to-kubectl.md)
|
||||||
* [kubectl命令概览](guide/using-kubectl.md)
|
* [kubectl命令概览](guide/using-kubectl.md)
|
||||||
* [kubectl命令技巧大全](guide/kubectl-cheatsheet.md)
|
* [kubectl命令技巧大全](guide/kubectl-cheatsheet.md)
|
||||||
* [使用etcdctl访问kubernetes数据](guide/using-etcdctl-to-access-kubernetes-data.md)
|
* [使用etcdctl访问kubernetes数据](guide/using-etcdctl-to-access-kubernetes-data.md)
|
||||||
|
|
@ -131,7 +136,7 @@
|
||||||
* [安装dashboard插件](practice/dashboard-addon-installation.md)
|
* [安装dashboard插件](practice/dashboard-addon-installation.md)
|
||||||
* [安装heapster插件](practice/heapster-addon-installation.md)
|
* [安装heapster插件](practice/heapster-addon-installation.md)
|
||||||
* [安装EFK插件](practice/efk-addon-installation.md)
|
* [安装EFK插件](practice/efk-addon-installation.md)
|
||||||
* [使用kubeadm快速构建测试集群](practice/install-kubernetes-with-kubeadm.md)
|
* [生产级的Kubernetes简化管理工具kubeadm](practice/install-kubernetes-with-kubeadm.md)
|
||||||
* [使用kubeadm在Ubuntu Server 16.04上快速构建测试集群](practice/install-kubernetes-on-ubuntu-server-16.04-with-kubeadm.md)
|
* [使用kubeadm在Ubuntu Server 16.04上快速构建测试集群](practice/install-kubernetes-on-ubuntu-server-16.04-with-kubeadm.md)
|
||||||
* [服务发现与负载均衡](practice/service-discovery-and-loadbalancing.md)
|
* [服务发现与负载均衡](practice/service-discovery-and-loadbalancing.md)
|
||||||
* [安装Traefik ingress](practice/traefik-ingress-installation.md)
|
* [安装Traefik ingress](practice/traefik-ingress-installation.md)
|
||||||
|
|
@ -154,12 +159,13 @@
|
||||||
* [存储管理](practice/storage.md)
|
* [存储管理](practice/storage.md)
|
||||||
* [GlusterFS](practice/glusterfs.md)
|
* [GlusterFS](practice/glusterfs.md)
|
||||||
* [使用GlusterFS做持久化存储](practice/using-glusterfs-for-persistent-storage.md)
|
* [使用GlusterFS做持久化存储](practice/using-glusterfs-for-persistent-storage.md)
|
||||||
* [使用Heketi作为kubernetes的持久存储GlusterFS的external provisioner](practice/using-heketi-gluster-for-persistent-storage.md)
|
* [使用Heketi作为Kubernetes的持久存储GlusterFS的external provisioner](practice/using-heketi-gluster-for-persistent-storage.md)
|
||||||
* [在OpenShift中使用GlusterFS做持久化存储](practice/storage-for-containers-using-glusterfs-with-openshift.md)
|
* [在OpenShift中使用GlusterFS做持久化存储](practice/storage-for-containers-using-glusterfs-with-openshift.md)
|
||||||
* [GlusterD-2.0](practice/glusterd-2.0.md)
|
* [GlusterD-2.0](practice/glusterd-2.0.md)
|
||||||
* [Ceph](practice/ceph.md)
|
* [Ceph](practice/ceph.md)
|
||||||
* [用Helm托管安装Ceph集群并提供后端存储](practice/ceph-helm-install-guide-zh.md)
|
* [用Helm托管安装Ceph集群并提供后端存储](practice/ceph-helm-install-guide-zh.md)
|
||||||
* [使用Ceph做持久化存储](practice/using-ceph-for-persistent-storage.md)
|
* [使用Ceph做持久化存储](practice/using-ceph-for-persistent-storage.md)
|
||||||
|
* [使用rbd-provisioner提供rbd持久化存储](practice/rbd-provisioner.md)
|
||||||
* [OpenEBS](practice/openebs.md)
|
* [OpenEBS](practice/openebs.md)
|
||||||
* [使用OpenEBS做持久化存储](practice/using-openebs-for-persistent-storage.md)
|
* [使用OpenEBS做持久化存储](practice/using-openebs-for-persistent-storage.md)
|
||||||
* [Rook](practice/rook.md)
|
* [Rook](practice/rook.md)
|
||||||
|
|
@ -170,9 +176,12 @@
|
||||||
* [使用Heapster获取集群和对象的metric数据](practice/using-heapster-to-get-object-metrics.md)
|
* [使用Heapster获取集群和对象的metric数据](practice/using-heapster-to-get-object-metrics.md)
|
||||||
* [Prometheus](practice/prometheus.md)
|
* [Prometheus](practice/prometheus.md)
|
||||||
* [使用Prometheus监控kubernetes集群](practice/using-prometheus-to-monitor-kuberentes-cluster.md)
|
* [使用Prometheus监控kubernetes集群](practice/using-prometheus-to-monitor-kuberentes-cluster.md)
|
||||||
|
* [Prometheus查询语言PromQL使用说明](practice/promql.md)
|
||||||
* [使用Vistio监控Istio服务网格中的流量](practice/vistio-visualize-your-istio-mesh.md)
|
* [使用Vistio监控Istio服务网格中的流量](practice/vistio-visualize-your-istio-mesh.md)
|
||||||
|
* [分布式跟踪](practice/distributed-tracing.md)
|
||||||
|
* [OpenTracing](practice/opentracing.md)
|
||||||
* [服务编排管理](practice/services-management-tool.md)
|
* [服务编排管理](practice/services-management-tool.md)
|
||||||
* [使用Helm管理kubernetes应用](practice/helm.md)
|
* [使用Helm管理Kubernetes应用](practice/helm.md)
|
||||||
* [构建私有Chart仓库](practice/create-private-charts-repo.md)
|
* [构建私有Chart仓库](practice/create-private-charts-repo.md)
|
||||||
* [持续集成与发布](practice/ci-cd.md)
|
* [持续集成与发布](practice/ci-cd.md)
|
||||||
* [使用Jenkins进行持续集成与发布](practice/jenkins-ci-cd.md)
|
* [使用Jenkins进行持续集成与发布](practice/jenkins-ci-cd.md)
|
||||||
|
|
@ -189,14 +198,19 @@
|
||||||
* [使用Java构建微服务并发布到Kubernetes平台](usecases/microservices-for-java-developers.md)
|
* [使用Java构建微服务并发布到Kubernetes平台](usecases/microservices-for-java-developers.md)
|
||||||
* [Spring Boot快速开始指南](usecases/spring-boot-quick-start-guide.md)
|
* [Spring Boot快速开始指南](usecases/spring-boot-quick-start-guide.md)
|
||||||
* [Service Mesh 服务网格](usecases/service-mesh.md)
|
* [Service Mesh 服务网格](usecases/service-mesh.md)
|
||||||
|
* [企业级服务网格架构](usecases/the-enterprise-path-to-service-mesh-architectures.md)
|
||||||
|
* [Service Mesh基础](usecases/service-mesh-fundamental.md)
|
||||||
|
* [Service Mesh技术对比](usecases/comparing-service-mesh-technologies.md)
|
||||||
|
* [采纳和演进](usecases/service-mesh-adoption-and-evolution.md)
|
||||||
|
* [定制和集成](usecases/service-mesh-customization-and-integration.md)
|
||||||
|
* [总结](usecases/service-mesh-conclusion.md)
|
||||||
* [Istio](usecases/istio.md)
|
* [Istio](usecases/istio.md)
|
||||||
* [安装并试用Istio service mesh](usecases/istio-installation.md)
|
* [安装并试用Istio service mesh](usecases/istio-installation.md)
|
||||||
* [配置请求的路由规则](usecases/configuring-request-routing.md)
|
|
||||||
* [安装和拓展Istio service mesh](usecases/install-and-expand-istio-mesh.md)
|
|
||||||
* [集成虚拟机](usecases/integrating-vms.md)
|
|
||||||
* [Istio中sidecar的注入规范及示例](usecases/sidecar-spec-in-istio.md)
|
* [Istio中sidecar的注入规范及示例](usecases/sidecar-spec-in-istio.md)
|
||||||
* [如何参与Istio社区及注意事项](usecases/istio-community-tips.md)
|
* [如何参与Istio社区及注意事项](usecases/istio-community-tips.md)
|
||||||
* [Istio教程](usecases/istio-tutorial.md)
|
* [Istio免费学习资源汇总](usecases/istio-tutorials-collection.md)
|
||||||
|
* [Sidecar的注入与流量劫持](usecases/understand-sidecar-injection-and-traffic-hijack-in-istio-service-mesh.md)
|
||||||
|
* [Envoy Sidecar代理的路由转发](usecases/envoy-sidecar-routing-of-istio-service-mesh-deep-dive.md)
|
||||||
* [Linkerd](usecases/linkerd.md)
|
* [Linkerd](usecases/linkerd.md)
|
||||||
* [Linkerd 使用指南](usecases/linkerd-user-guide.md)
|
* [Linkerd 使用指南](usecases/linkerd-user-guide.md)
|
||||||
* [Conduit](usecases/conduit.md)
|
* [Conduit](usecases/conduit.md)
|
||||||
|
|
@ -206,14 +220,15 @@
|
||||||
* [Envoy的架构与基本术语](usecases/envoy-terminology.md)
|
* [Envoy的架构与基本术语](usecases/envoy-terminology.md)
|
||||||
* [Envoy作为前端代理](usecases/envoy-front-proxy.md)
|
* [Envoy作为前端代理](usecases/envoy-front-proxy.md)
|
||||||
* [Envoy mesh教程](usecases/envoy-mesh-in-kubernetes-tutorial.md)
|
* [Envoy mesh教程](usecases/envoy-mesh-in-kubernetes-tutorial.md)
|
||||||
* [SOFAMesh](usecases/sofamesh.md)
|
* [MOSN](usecases/mosn.md)
|
||||||
* [大数据](usecases/big-data.md)
|
* [大数据](usecases/big-data.md)
|
||||||
* [Spark standalone on Kubernetes](usecases/spark-standalone-on-kubernetes.md)
|
* [Spark standalone on Kubernetes](usecases/spark-standalone-on-kubernetes.md)
|
||||||
* [运行支持Kubernetes原生调度的Spark程序](usecases/running-spark-with-kubernetes-native-scheduler.md)
|
* [运行支持Kubernetes原生调度的Spark程序](usecases/running-spark-with-kubernetes-native-scheduler.md)
|
||||||
* [Serverless架构](usecases/serverless.md)
|
* [Serverless架构](usecases/serverless.md)
|
||||||
* [理解Serverless](usecases/understanding-serverless.md)
|
* [理解Serverless](usecases/understanding-serverless.md)
|
||||||
* [FaaS-函数即服务](usecases/faas.md)
|
* [FaaS(函数即服务)](usecases/faas.md)
|
||||||
* [OpenFaaS快速入门指南](usecases/openfaas-quick-start.md)
|
* [OpenFaaS快速入门指南](usecases/openfaas-quick-start.md)
|
||||||
|
* [Knative](usecases/knative.md)
|
||||||
* [边缘计算](usecases/edge-computing.md)
|
* [边缘计算](usecases/edge-computing.md)
|
||||||
* [人工智能](usecases/ai.md)
|
* [人工智能](usecases/ai.md)
|
||||||
|
|
||||||
|
|
@ -222,15 +237,25 @@
|
||||||
* [开发指南概览](develop/index.md)
|
* [开发指南概览](develop/index.md)
|
||||||
* [SIG和工作组](develop/sigs-and-working-group.md)
|
* [SIG和工作组](develop/sigs-and-working-group.md)
|
||||||
* [开发环境搭建](develop/developing-environment.md)
|
* [开发环境搭建](develop/developing-environment.md)
|
||||||
* [本地分布式开发环境搭建(使用Vagrant和Virtualbox)](develop/using-vagrant-and-virtualbox-for-development.md)
|
* [本地分布式开发环境搭建(使用Vagrant和Virtualbox)](develop/using-vagrant-and-virtualbox-for-development.md)
|
||||||
* [单元测试和集成测试](develop/testing.md)
|
* [单元测试和集成测试](develop/testing.md)
|
||||||
* [client-go示例](develop/client-go-sample.md)
|
* [client-go示例](develop/client-go-sample.md)
|
||||||
* [Operator](develop/operator.md)
|
* [Operator](develop/operator.md)
|
||||||
* [operator-sdk](develop/operator-sdk.md)
|
* [operator-sdk](develop/operator-sdk.md)
|
||||||
|
* [kubebuilder](develop/kubebuilder.md)
|
||||||
* [高级开发指南](develop/advance-developer.md)
|
* [高级开发指南](develop/advance-developer.md)
|
||||||
* [社区贡献](develop/contribute.md)
|
* [社区贡献](develop/contribute.md)
|
||||||
* [Minikube](develop/minikube.md)
|
* [Minikube](develop/minikube.md)
|
||||||
|
|
||||||
|
## CNCF(云原生计算基金会)
|
||||||
|
|
||||||
|
* [CNCF - 云原生计算基金会简介](cloud-native/cncf.md)
|
||||||
|
* [CNCF章程](cloud-native/cncf-charter.md)
|
||||||
|
* [CNCF特别兴趣小组(SIG)说明](cloud-native/cncf-sig.md)
|
||||||
|
* [开源项目加入CNCF Sandbox的要求](cloud-native/cncf-sandbox-criteria.md)
|
||||||
|
* [CNCF中的项目治理](cloud-native/cncf-project-governing.md)
|
||||||
|
* [CNCF Ambassador](cloud-native/cncf-ambassador.md)
|
||||||
|
|
||||||
## 附录
|
## 附录
|
||||||
|
|
||||||
* [附录说明](appendix/index.md)
|
* [附录说明](appendix/index.md)
|
||||||
|
|
@ -245,7 +270,14 @@
|
||||||
* [Kubernetes1.9更新日志](appendix/kubernetes-1.9-changelog.md)
|
* [Kubernetes1.9更新日志](appendix/kubernetes-1.9-changelog.md)
|
||||||
* [Kubernetes1.10更新日志](appendix/kubernetes-1.10-changelog.md)
|
* [Kubernetes1.10更新日志](appendix/kubernetes-1.10-changelog.md)
|
||||||
* [Kubernetes1.11更新日志](appendix/kubernetes-1.11-changelog.md)
|
* [Kubernetes1.11更新日志](appendix/kubernetes-1.11-changelog.md)
|
||||||
|
* [Kubernetes1.12更新日志](appendix/kubernetes-1.12-changelog.md)
|
||||||
|
* [Kubernetes1.13更新日志](appendix/kubernetes-1.13-changelog.md)
|
||||||
|
* [Kubernetes1.14更新日志](appendix/kubernetes-1.14-changelog.md)
|
||||||
|
* [Kubernetes1.15更新日志](appendix/kubernetes-1.15-changelog.md)
|
||||||
* [Kubernetes及云原生年度总结及展望](appendix/summary-and-outlook.md)
|
* [Kubernetes及云原生年度总结及展望](appendix/summary-and-outlook.md)
|
||||||
* [Kubernetes与云原生2017年年终总结及2018年展望](appendix/kubernetes-and-cloud-native-summary-in-2017-and-outlook-for-2018.md)
|
* [Kubernetes与云原生2017年年终总结及2018年展望](appendix/kubernetes-and-cloud-native-summary-in-2017-and-outlook-for-2018.md)
|
||||||
|
* [Kubernetes与云原生2018年年终总结及2019年展望](appendix/kubernetes-and-cloud-native-summary-in-2018-and-outlook-for-2019.md)
|
||||||
|
* [CNCF年度报告解读](appendix/cncf-annual-report.md)
|
||||||
|
* [CNCF 2018年年度报告解读](appendix/cncf-annual-report-2018.md)
|
||||||
* [Kubernetes认证服务提供商(KCSP)说明](appendix/about-kcsp.md)
|
* [Kubernetes认证服务提供商(KCSP)说明](appendix/about-kcsp.md)
|
||||||
* [认证Kubernetes管理员(CKA)说明](appendix/about-cka-candidate.md)
|
* [认证Kubernetes管理员(CKA)说明](appendix/about-cka-candidate.md)
|
||||||
|
|
|
||||||
|
|
@ -70,9 +70,6 @@
|
||||||
- 排查工作节点(work node)故障
|
- 排查工作节点(work node)故障
|
||||||
- 排查网络故障
|
- 排查网络故障
|
||||||
|
|
||||||
|
|
||||||
> 参考[课程大纲](https://github.com/cncf/curriculum/blob/master/certified_kubernetes_administrator_exam_V0.9.pdf)
|
|
||||||
|
|
||||||
## 考试说明和checklist
|
## 考试说明和checklist
|
||||||
|
|
||||||
- 注册考试
|
- 注册考试
|
||||||
|
|
@ -139,8 +136,6 @@ kubectl get no −l name=hk8s−node−1 −−context=hk8s
|
||||||
10. 取消和重订
|
10. 取消和重订
|
||||||
> 在预定考试日期前24小时外,取消或重订, 可以获得完整退费
|
> 在预定考试日期前24小时外,取消或重订, 可以获得完整退费
|
||||||
|
|
||||||
> 参考 [CNCF_FAQ](https://www.cncf.io/certification/expert/faq/)
|
|
||||||
|
|
||||||
## 复习资料
|
## 复习资料
|
||||||
|
|
||||||
- [Kubernetes-Learning-Resources](https://github.com/kubernauts/Kubernetes-Learning-Resources)
|
- [Kubernetes-Learning-Resources](https://github.com/kubernauts/Kubernetes-Learning-Resources)
|
||||||
|
|
@ -155,7 +150,7 @@ kubectl get no −l name=hk8s−node−1 −−context=hk8s
|
||||||
|
|
||||||
该课程的课程大纲:
|
该课程的课程大纲:
|
||||||
|
|
||||||
```text
|
```
|
||||||
Welcome & Introduction
|
Welcome & Introduction
|
||||||
Container Orchestration
|
Container Orchestration
|
||||||
Kubernetes
|
Kubernetes
|
||||||
|
|
@ -179,7 +174,7 @@ ps: 个人觉得这个课程可以不用学, 直接看文档就行了 。
|
||||||
|
|
||||||
该课程的课程大纲:
|
该课程的课程大纲:
|
||||||
|
|
||||||
```text
|
```
|
||||||
Kubernetes Fundamentals
|
Kubernetes Fundamentals
|
||||||
Chapter 1. Course Introduction
|
Chapter 1. Course Introduction
|
||||||
Chapter 2. Basics of Kubernetes
|
Chapter 2. Basics of Kubernetes
|
||||||
|
|
@ -204,4 +199,4 @@ ps: 个人觉得这个课程太贵了,为了省点钱 , 仔细研究下
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
From: [Github_hackstoic](https://github.com/hackstoic/kubernetes_practice/blob/master/%E5%85%B3%E4%BA%8EK8S%E7%9B%B8%E5%85%B3%E8%AE%A4%E8%AF%81%E7%9A%84%E8%AF%B4%E6%98%8E.md)
|
From: [Github_hackstoic](https://github.com/hackstoic/kubernetes_practice/blob/master/%E5%85%B3%E4%BA%8EK8S%E7%9B%B8%E5%85%B3%E8%AE%A4%E8%AF%81%E7%9A%84%E8%AF%B4%E6%98%8E.md)
|
||||||
|
|
|
||||||
|
|
@ -29,4 +29,4 @@ KCSP计划的适用对象是通过初审的服务提供商,它们为踏上Kube
|
||||||
|
|
||||||
## 参考
|
## 参考
|
||||||
|
|
||||||
- [CNCF 宣布首批 Kubernetes 认证服务提供商](https://mp.weixin.qq.com/s?__biz=MjM5MzM3NjM4MA==&mid=2654684649&idx=2&sn=4bd259d40d4eb33fc07340c07281e6cf)
|
- [CNCF 宣布首批 Kubernetes 认证服务提供商](https://mp.weixin.qq.com/s?__biz=MjM5MzM3NjM4MA==&mid=2654684649&idx=2&sn=4bd259d40d4eb33fc07340c07281e6cf)
|
||||||
|
|
|
||||||
|
|
@ -0,0 +1,189 @@
|
||||||
|
# CNCF 2018年年度报告解读
|
||||||
|
|
||||||
|
2019年2月初,CNCF 发布了2018年的年度报告,这是 CNCF 继2017年度报告之后,第二次发布年度报告,2017年度的报告只有区区14页,今年的报告长度增长了一倍达31页。下面我将带大家一起来深度解读下这份2018年的年度报告,一窥 CNCF 过去一年里在推广云原生的道路上取得的进展。
|
||||||
|
|
||||||
|
*注:本文最后附上了2017年和2018年度的报告下载地址。*
|
||||||
|
|
||||||
|
## CNCF 年度报告涵盖的范围
|
||||||
|
|
||||||
|
在解读 CNCF 的2018年度报告之前,我们先简单回顾下[2017年度的报告](https://www.cncf.io/wp-content/uploads/2018/03/CNCF-Annual-Report-2017.pdf),因为2017年度报告是 CNCF 的首份年度报告,这样我们也能更好的了解 CNCF 的来龙去脉。
|
||||||
|
|
||||||
|
2017年度报告已经基本确定了 CNCF 每个年度报告所包含的主题:
|
||||||
|
|
||||||
|
- 自我定位
|
||||||
|
- 会员参与情况
|
||||||
|
- 终端用户社区
|
||||||
|
- 项目更新
|
||||||
|
- 会议和活动
|
||||||
|
- 社区
|
||||||
|
- 培训和认证
|
||||||
|
|
||||||
|
以上为 CNCF 主要的市场活动,2017年时其成立的第二年,经过一年时间的筹备,这一年里各种市场活动都已经开始确立并有声有色的开展了起来,包括 KubeCon、成员单位、终端用户都已经发展起来了,以后历年里只是对其不断的发展和完善。
|
||||||
|
|
||||||
|
2018年度报告中又新增了一些主题,这些主题是从2018年开始开展的,包括:
|
||||||
|
|
||||||
|
- **项目更新与满意度调查**
|
||||||
|
- 给 CNCF 项目的维护者发调查问卷询问满意度
|
||||||
|
- [CNCF charter](https://www.cncf.io/about/charter/) 的修订(2018年11月)
|
||||||
|
- 项目更新与发布
|
||||||
|
- 项目服务与支援
|
||||||
|
- 专项活动、文档、网站与博客支持
|
||||||
|
- 本地化、IT 支持和培训
|
||||||
|
- **社区拓展**
|
||||||
|
- 社区奖项
|
||||||
|
- CNCF Meetup
|
||||||
|
- [CNCF Ambassador 计划](https://www.cncf.io/people/ambassadors/)
|
||||||
|
- 卡通吉祥物 Phippy
|
||||||
|
- **生态系统工具**
|
||||||
|
- [devstats](https://devstats.cncf.io/)
|
||||||
|
- [CNCF Landscape](https://landscape.cncf.io) 和路线图
|
||||||
|
- 项目 logo 物料
|
||||||
|
- **测试一致性项目**
|
||||||
|
- **国际化**
|
||||||
|
- 进入中国
|
||||||
|
- 本地化网站
|
||||||
|
|
||||||
|
详情请大家从本文最后的链接下载报告原文以查看详情。
|
||||||
|
|
||||||
|
## CNCF 的定位
|
||||||
|
|
||||||
|
CNCF(云原生计算基金会)成立于2015年12月11日,每届年度报告的开篇都会阐明 CNCF 的定位,CNCF 的自我定位在2018年发生了一次变动,这也说明基金会是跟随市场形势而动,其定位不是一成不变的,其中的变化暗含着 CNCF 战略的转变。
|
||||||
|
|
||||||
|
### CNCF 的2017年度定位
|
||||||
|
|
||||||
|
[2017年度报告](https://www.cncf.io/wp-content/uploads/2018/03/CNCF-Annual-Report-2017.pdf)中是这样正式介绍自己的:
|
||||||
|
|
||||||
|
The Cloud Native Computing Foundation (CNCF) is an open source software foundation dedicated to making cloud-native computing universal and sustainable. Cloud-native computing uses an **open source** software stack to deploy applications as **microservices**, packaging each part into its own **container**, and **dynamically orchestrating** those containers to optimize resource utilization. Cloud-native technologies enable software developers to build great products faster.
|
||||||
|
|
||||||
|
We are a community of open source projects, including Kubernetes, Envoy and Prometheus. Kubernetes and other CNCF projects are some of the highest velocity projects in the history of open source.
|
||||||
|
|
||||||
|
可以看到介绍中的重点技术是:微服务、容器、动态编排。而在2018年 CNCF 对自己进行了重新的定位和包装,增加了新的内容。
|
||||||
|
|
||||||
|
### CNCF 的2018年度定位
|
||||||
|
|
||||||
|
[2018年度报告](https://www.cncf.io/wp-content/uploads/2019/02/CNCF_Annual_Report_2018_FInal.pdf)中 CNCF 对自己的定位是:
|
||||||
|
|
||||||
|
The Cloud Native Computing Foundation (CNCF) is an open source software foundation dedicated to making cloud native computing universal and sustainable. Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. **Containers**, **service meshes**, **microservices**, **immutable infrastructure**, and **declarative APIs** exemplify this approach.
|
||||||
|
|
||||||
|
We are a community of open source projects, including Kubernetes, Prometheus, Envoy, and many others. Kubernetes and other CNCF projects are some of the highest velocity projects in the history of open source.
|
||||||
|
|
||||||
|
我们可以看到其表述中更加注重多云环境,主要涉及的技术比2017年多了Service Mesh(服务网格)、不可变基础设施和声明式 API。
|
||||||
|
|
||||||
|
## 数读报告
|
||||||
|
|
||||||
|
CNCF 年度报告的原文主要是汇报了 CNCF 一年来的所展开的活动和进展,下表示根据 CNCF 2017和2018年度报告整理了关键数据。
|
||||||
|
|
||||||
|
| **Year** | **2016** | **2017** | **2018** |
|
||||||
|
| ------------------------------------------ | -------- | -------- | -------- |
|
||||||
|
| **Members** | 63 | 170 | 365 |
|
||||||
|
| **Contributors** | - | 18687 | 47358 |
|
||||||
|
| **CNCF Meetup Members** | - | 53925 | 89112 |
|
||||||
|
| **Projects** | 4 | 14 | 32 |
|
||||||
|
| **End User Community Members** | - | 32 | 69 |
|
||||||
|
| **Conference and Events Participants** | - | 4085 | - |
|
||||||
|
| **Certified Kubernetes Partners** | - | 44 | - |
|
||||||
|
| **Certified Kubernetes Service Providers** | - | 28 | 74 |
|
||||||
|
| **CNCF Ambassador** | - | - | 65 |
|
||||||
|
| **Kubernetes Training Partners** | - | - | 18 |
|
||||||
|
|
||||||
|
**注**:其中2016年是 CNCF 正式开始工作的第一年,大部分数据因为活动尚未开展而缺失。
|
||||||
|
|
||||||
|
从上表中我们可以看到 CNCF 诞生三年来基金会成员规模、托管项目的贡献者、参加 CNCF 名义的 Meetup 的人数取得较大范围的增长,尤其是2018年,因为基金会成员的爆发式增长(+130%),CNCF 开始给成员分级,会员级别、费用和权益也在 [CNCF 官网](https://www.cncf.io/about/join/)上明码标价。
|
||||||
|
|
||||||
|
2018年 CNCF 组织的 KubeCon&CloudNativeCon 开始固定每年在西欧、北美和中国举行,且2018年是首次进入中国;原来的 Certified Kubernetes Partners 也取消了变成了 Certified Kubernetes Service Providers;CNCF 的 [Ambassador](https://www.cncf.io/people/ambassadors/) 计划拥有了来自15个国家的65位 Ambassador,在世界各地为云原生布道;CNCF 还首次引入了 Kubernetes Training Partner。
|
||||||
|
|
||||||
|
2018 年 CNCF 又推出了一系列新的认证(CKA 为2017年推出),包括:
|
||||||
|
|
||||||
|
- [CKA](https://www.cncf.io/certification/cka/)(Kubernetes 管理员认证):这是 CNCF 最早制定的一个证书,顾名思义,通过该认证证明用户具有管理 Kubernetes 集群的技能、知识和能力。虽然该证书在2017年即推出,但2018年对考试做了更细致的指导。KCSP 要求企业必须有至少三人通过 CKA。
|
||||||
|
- [CKAD](https://www.cncf.io/certification/ckad/)(Kubernetes 应用开发者认证):该认证证明用户可以为 Kubernetes 设计、构建、配置和发布云原生应用程序。经过认证的 Kubernetes Application Developer 可以定义应用程序资源并使用核心原语来构建、监控 Kubernetes 中可伸缩应用程序和排除故障。
|
||||||
|
- [KCSP](https://www.cncf.io/certification/kcsp/)(Kubernetes 服务提供商认证):截止本文发稿时共有74家企业通过该认证。该认证的主体是企业或组织,通过 KCSP 的企业意味着可以为其他组织提供 Kubernetes 支持、咨询、专业服务和培训。通过该认证的中国企业有:灵雀云、阿里云、博云、才云、DaoCloud、EasyStack、易建科技、精灵云、谐云科技、华为、时速云、星号科技、睿云智合、沃趣、元鼎科技、ZTE。
|
||||||
|
- [Certified Kubernetes Conformance](https://www.cncf.io/certification/software-conformance/)(Kubernetes 一致性认证):通过该认证的 Kubernetes 提供商所提供的服务,意味着其可以保证 Kubernetes API 的可移植性及跨云的互操作性;及时更新到最新的 Kubernetes 版本;是否一致是可以通过[运行开源脚本](https://github.com/cncf/k8s-conformance/blob/master/instructions.md)验证的。截止本文发稿通过该认证的中国企业的发行版有:灵雀云(ACE、ACP、AKS)、才云 Compass、华为 FusionStage、酷栈科技 CStack MiaoYun、Daocloud Enterprise、新智认知新氦云、浪潮云、京东 TIG、网易云、七牛云、同方有云、睿云智合 WiseCloud;通过认证的中国企业托管平台有:阿里云、百度云、博云、EasyStack、易建科技、谐云科技、华为云 CCE、腾讯云 TKE、时速云、ZTE TECS。
|
||||||
|
|
||||||
|
以上是 CNCF 提供的主要证书,一般通过 KCSP 的企业都要先通过 Kubernetes 一致性认证,而通过 Kubernetes 一致性认证不一定要同时通过 KCSP,所以我们看到很多通过 Kubernetes 一致性认证的企业就不一定会通过 KCSP,因为 KCSP 的要求更多,至少要成为 CNCF 会员才可以。
|
||||||
|
|
||||||
|
下面将就 CNCF 会员、托管项目的成熟度等级划分、Kubernetes 服务提供商认证和 Kubernetes 提供商认证做详细说明。
|
||||||
|
|
||||||
|
## CNCF 会员
|
||||||
|
|
||||||
|
2018年 CNCF 的会员单位经历了爆发式增长,从170家增长到365家。CNCF 制定了如下的会员等级:
|
||||||
|
|
||||||
|
- Silver Member
|
||||||
|
- Gold Member
|
||||||
|
- Platinum Member
|
||||||
|
- Academic/Nonprofit Member
|
||||||
|
- End User Member
|
||||||
|
|
||||||
|
不同等级的会员需要交纳的年费与权益不同,详情请见 <https://www.cncf.io/about/join/>。
|
||||||
|
|
||||||
|
### 成为 CNCF 会员的好处
|
||||||
|
|
||||||
|
成为 CNCF 会员包括但不限于如下好处:
|
||||||
|
|
||||||
|
- 将可以参与 CNCF 市场委员会、CNCF Webinar、在 CNCF 和 Kubernetes 官网发表博客、博客被 KubeWeekly 收录、
|
||||||
|
- 获得 KubeCon + CloudNativeCon 的门票折扣和参与大会的市场活动
|
||||||
|
- 对于 Kubernetes 系列认证如 KCSP、入选 TOC 也要求必须成为 CNCF 会员才可以获得
|
||||||
|
- End User Case Study
|
||||||
|
- 有机会加入 Ambassador 计划
|
||||||
|
- 在社区里具有更多的话语权,例如 CNCF 在全球范围内组织的活动
|
||||||
|
|
||||||
|
## 项目成熟度等级
|
||||||
|
|
||||||
|
自2015年底 CNCF 创立之初 Kubernetes 成为其首个托管项目以来,截止到2018年底,CNCF 已经托管了[32个开源项目](https://www.cncf.io/projects/),随着越来越多的项目加入到 CNCF,为了更好的管理这些项目,为这些项目划分不同的成熟度等级就成了迫在眉睫的事情。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
根据《Crossing the Chasm》一书中的技术采用生命周期理论,CNCF 将其托管的项目划分为三个等级:
|
||||||
|
|
||||||
|
- Graduated:对应于早期成熟项目。截止到本文发稿时只有 [Kubernetes](https://kubernetes.io/)、[Prometheus](https://prometheus.io/)、[Envoy](https://www.envoyproxy.io/) 和 [CoreDNS](https://coredns.io/) 毕业。
|
||||||
|
- Incubating:对应于早期采用者阶段。截止到本文发稿时有 16 个项目。
|
||||||
|
- Sandbox:对应于创新者阶段。截止到本文发稿时有 12 个项目。
|
||||||
|
|
||||||
|
查看 CNCF 托管的项目列表请访问:https://www.cncf.io/projects/
|
||||||
|
|
||||||
|
CNCF 通过为项目设置成熟度水平是来建议企业应该采用哪些项目。CNCF 中托管的项目通过向 CNCF 的技术监督委员会(TOC)展示其可持续发展性来提高其成熟度:项目的采用率,健康的变化率,有来自多个组织的提交者,采用了 [CNCF 行为准则](https://github.com/cncf/foundation/blob/master/code-of-conduct-languages/zh.md),实现并维护了核心基础设施倡议(Core Infrastructure Initiative)[最佳实践证书](https://bestpractices.coreinfrastructure.org/)。详细信息在 [毕业标准v1.1](https://github.com/cncf/toc/blob/master/process/graduation_criteria.adoc)。
|
||||||
|
|
||||||
|
## Certified Kubernetes Service Provider
|
||||||
|
|
||||||
|
通过 [KCSP](https://www.cncf.io/certification/kcsp/) 意味着企业具有为其他企业或组织提供 Kubernetes 支持、咨询、专业服务和培训的资质。 2018年又有46家企业通过了[KCSP](https://www.cncf.io/certification/kcsp/),通过该认证的企业累计达到76家。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
**如何通过 KCSP**
|
||||||
|
|
||||||
|
要想通过 KCSP 必须满足以下三个条件:
|
||||||
|
|
||||||
|
- 三名或更多工程师通过认证Kubernetes管理员(CKA)考试。*(CKAD考试不计入此要求)*
|
||||||
|
- 支持企业最终用户的商业模式,包括为客户提供驻场工程师
|
||||||
|
- 成为 CNCF 会员
|
||||||
|
|
||||||
|
通过 KCSP 有如下好处:
|
||||||
|
|
||||||
|
- 企业的 logo 会出现在 [Kubernetes Partners](https://kubernetes.io/partners/) 页面
|
||||||
|
- 参加与云原生项目 leader、TOC 成员、CNCF Governing Board 的月度会议
|
||||||
|
- 向终端用户的 leader 寻求帮助
|
||||||
|
|
||||||
|
因为有如上这些好处,为了获得 Kubernetes 项目实施的资质,同时保持与基金会至今的交流,Kubernetes 厂商对该认证都趋之若鹜。
|
||||||
|
|
||||||
|
## Certified Kubernetes offering
|
||||||
|
|
||||||
|
通过 KCSP 认证只代表企业有为他人实施 Kubernetes 项目的资质,而企业自身可能并不对外提供 Kubernetes 平台或服务,这些企业可能只是系统集成商或 ISV,这时候 CNCF 又推出了 Kubernetes 提供商认证。
|
||||||
|
|
||||||
|
Kubernetes 认证的提供商包括 Kubernetes 发行版、托管平台和安装器,通过认证的工具或平台将允许使用 Kubernetes 认证的 Logo,并保证 Kubernetes 一致性认证。
|
||||||
|
|
||||||
|
## 展望 2019
|
||||||
|
|
||||||
|
2018年 Kubernetes 成为 CNCF 孵化的首个毕业项目,根据 CNCF 打造的项目成熟度模型,Prometheus、Envoy、CoreDNS 相继毕业,CNCF 的眼光早已不再仅盯着 Kubernetes 了,[CNCF Landscape](https://landscape.cncf.io) 几乎包揽了所有云计算相关开源项目。可以说 CNCF 早已超出了 Kubernetes 的范畴,而是旨在一个建立在 Kubernetes 为底层资源调度和应用生命周期管理之上的生态系统,CNCF 中还演进出了如 Service Mesh 和 Serverless 之类的分支。
|
||||||
|
|
||||||
|
从 CNCF 2017和2018年度的变化来看,其中已经去掉了”dynamically orchestrating“的字眼,也就意味着 Kubernetes 在容器编排领域已经胜出,进而强调多云环境,同时 CNCF 推动的 Kubernetes 一致性认证也受到众多云厂商的支持,这也意味着 Kubernetes 将成为多云环境 API 一致性的保证。
|
||||||
|
|
||||||
|
CNCF 在2019年的战略将更聚焦于开发者社区,协助尤其是来自终端用户的开发者成为项目的 contributor 和 maintainer,保证终端用户的意见能够在社区里被正确地传达和并最终成功地采纳云原生。
|
||||||
|
|
||||||
|
## 参考
|
||||||
|
|
||||||
|
- [CNCF Annual Report 2017 pdf](https://www.cncf.io/wp-content/uploads/2018/03/CNCF-Annual-Report-2017.pdf)
|
||||||
|
- [CNCF Annual Report 2018 pdf](https://www.cncf.io/wp-content/uploads/2019/02/CNCF_Annual_Report_2018_FInal.pdf)
|
||||||
|
- [CNCF Projects](https://www.cncf.io/projects/)
|
||||||
|
- [CNCF Landscape](https://landscape.cncf.io)
|
||||||
|
- [CNCF Ambassadors](https://www.cncf.io/people/ambassadors/)
|
||||||
|
- [Kubernetes Certified Service Providers](https://www.cncf.io/certification/kcsp/)
|
||||||
|
|
||||||
|
|
@ -0,0 +1,8 @@
|
||||||
|
# CNCF年度报告解读
|
||||||
|
|
||||||
|
CNCF成立于2015年12月11日,自2018年开始每年年初都会发布一次 CNCF Annual Report(CNCF 年度报告),总结 CNCF 去年一年里在推广云原生技术和理念上付出的行动和取得的进展,这一章节将从2018年的年度报告开始每年都会解读一次 CNCF 年度报告,2018年的年度报告延续了2017年年度报告的大体分类,但2017年的报告过于精简(只列举了一些活动与数字),本章不对其解读,而是从2018年的年度报告开始,感兴趣的读者可以下载其报告自行阅览。
|
||||||
|
|
||||||
|
## 参考
|
||||||
|
|
||||||
|
- [CNCF Annual Report 2017 pdf](https://www.cncf.io/wp-content/uploads/2018/03/CNCF-Annual-Report-2017.pdf)
|
||||||
|
- [CNCF Annual Report 2018 pdf](https://www.cncf.io/wp-content/uploads/2019/02/CNCF_Annual_Report_2018_FInal.pdf)
|
||||||
|
|
@ -37,4 +37,4 @@ kubectl logs -f my-pod -c my-container
|
||||||
```bash
|
```bash
|
||||||
kubectl exec my-pod -it /bin/bash
|
kubectl exec my-pod -it /bin/bash
|
||||||
kubectl top pod POD_NAME --containers
|
kubectl top pod POD_NAME --containers
|
||||||
```
|
```
|
||||||
|
|
|
||||||
|
|
@ -5,22 +5,21 @@
|
||||||
|
|
||||||
## 环境配置
|
## 环境配置
|
||||||
|
|
||||||
[Docker1.13环境配置](https://jimmysong.io/docker-handbook/docs/docker_env)
|
- [Docker1.13环境配置](https://jimmysong.io/docker-handbook/docs/docker_env)
|
||||||
|
|
||||||
[docker源码编译](https://jimmysong.io/docker-handbook/docs/docker_compile)
|
- [docker源码编译](https://jimmysong.io/docker-handbook/docs/docker_compile)
|
||||||
|
|
||||||
|
|
||||||
## 网络管理
|
## 网络管理
|
||||||
|
|
||||||
网络配置和管理是容器使用中的的一个重点和难点,对比我们之前使用的docker版本是1.11.1,docker1.13中网络模式跟之前的变动比较大,我们会花大力气讲解。
|
网络配置和管理是容器使用中的的一个重点和难点,对比我们之前使用的docker版本是1.11.1,docker1.13中网络模式跟之前的变动比较大,我们会花大力气讲解。
|
||||||
|
|
||||||
[如何创建docker network](https://jimmysong.io/docker-handbook/docs/create_network)
|
- [如何创建docker network](https://jimmysong.io/docker-handbook/docs/create_network)
|
||||||
|
|
||||||
[Rancher网络探讨和扁平网络实现](https://jimmysong.io/docker-handbook/docs/rancher_network)
|
- [Rancher网络探讨和扁平网络实现](https://jimmysong.io/docker-handbook/docs/rancher_network)
|
||||||
|
|
||||||
[swarm mode的路由网络](https://jimmysong.io/docker-handbook/docs/swarm_mode_routing_mesh)
|
- [swarm mode的路由网络](https://jimmysong.io/docker-handbook/docs/swarm_mode_routing_mesh)
|
||||||
|
|
||||||
[docker扁平化网络插件Shrike(基于docker1.11)](https://github.com/TalkingData/shrike)
|
|
||||||
|
|
||||||
## 存储管理
|
## 存储管理
|
||||||
|
|
||||||
|
|
@ -31,8 +30,6 @@
|
||||||
- [torus](https://jimmysong.io/docker-handbook/docs/torus) **已废弃**
|
- [torus](https://jimmysong.io/docker-handbook/docs/torus) **已废弃**
|
||||||
- [flocker](https://jimmysong.io/docker-handbook/docs/flocker) ClusterHQ开发
|
- [flocker](https://jimmysong.io/docker-handbook/docs/flocker) ClusterHQ开发
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 日志管理
|
## 日志管理
|
||||||
|
|
||||||
Docker提供了一系列[log drivers](https://docs.docker.com/engine/admin/logging/overview/),如fluentd、journald、syslog等。
|
Docker提供了一系列[log drivers](https://docs.docker.com/engine/admin/logging/overview/),如fluentd、journald、syslog等。
|
||||||
|
|
@ -41,13 +38,13 @@ Docker提供了一系列[log drivers](https://docs.docker.com/engine/admin/loggi
|
||||||
|
|
||||||
## 创建应用
|
## 创建应用
|
||||||
|
|
||||||
官方文档:[Docker swarm sample app overview](https://docs.docker.com/engine/getstarted-voting-app/)
|
- 官方文档:[Docker swarm sample app overview](https://docs.docker.com/engine/getstarted-voting-app/)
|
||||||
|
|
||||||
[基于docker1.13手把手教你创建swarm app](https://jimmysong.io/docker-handbook/docs/create_swarm_app)
|
- [基于docker1.13手把手教你创建swarm app](https://jimmysong.io/docker-handbook/docs/create_swarm_app)
|
||||||
|
|
||||||
[swarm集群应用管理](https://jimmysong.io/docker-handbook/docs/swarm_app_manage)
|
- [swarm集群应用管理](https://jimmysong.io/docker-handbook/docs/swarm_app_manage)
|
||||||
|
|
||||||
[使用docker-compose创建应用](https://jimmysong.io/docker-handbook/docs/docker_compose)
|
- [使用docker-compose创建应用](https://jimmysong.io/docker-handbook/docs/docker_compose)
|
||||||
|
|
||||||
## 集群管理##
|
## 集群管理##
|
||||||
|
|
||||||
|
|
@ -60,17 +57,17 @@ Docker提供了一系列[log drivers](https://docs.docker.com/engine/admin/loggi
|
||||||
- [Crane](https://github.com/Dataman-Cloud/crane):由数人云开源的基于swarmkit的容器管理软件,可以作为docker和go语言开发的一个不错入门项目
|
- [Crane](https://github.com/Dataman-Cloud/crane):由数人云开源的基于swarmkit的容器管理软件,可以作为docker和go语言开发的一个不错入门项目
|
||||||
- [Rancher](https://github.com/rancher/rancher):Rancher是一个企业级的容器管理平台,可以使用Kubernetes、swarm和rancher自研的cattle来管理集群。
|
- [Rancher](https://github.com/rancher/rancher):Rancher是一个企业级的容器管理平台,可以使用Kubernetes、swarm和rancher自研的cattle来管理集群。
|
||||||
|
|
||||||
[Crane的部署和使用](https://jimmysong.io/docker-handbook/docs/crane_usage)
|
- [Crane的部署和使用](https://jimmysong.io/docker-handbook/docs/crane_usage)
|
||||||
|
|
||||||
[Rancher的部署和使用](https://jimmysong.io/docker-handbook/docs/rancher_usage)
|
- [Rancher的部署和使用](https://jimmysong.io/docker-handbook/docs/rancher_usage)
|
||||||
|
|
||||||
## 资源限制
|
## 资源限制
|
||||||
|
|
||||||
[内存资源限制](https://jimmysong.io/docker-handbook/docs/memory_resource_limit)
|
- [内存资源限制](https://jimmysong.io/docker-handbook/docs/memory_resource_limit)
|
||||||
|
|
||||||
[CPU资源限制](https://jimmysong.io/docker-handbook/docs/cpu_resource_limit)
|
- [CPU资源限制](https://jimmysong.io/docker-handbook/docs/cpu_resource_limit)
|
||||||
|
|
||||||
[IO资源限制](https://jimmysong.io/docker-handbook/docs/io_resource_limit)
|
- [IO资源限制](https://jimmysong.io/docker-handbook/docs/io_resource_limit)
|
||||||
|
|
||||||
## 服务发现
|
## 服务发现
|
||||||
|
|
||||||
|
|
@ -105,15 +102,15 @@ Docker提供了一系列[log drivers](https://docs.docker.com/engine/admin/loggi
|
||||||
|
|
||||||
## 业界使用案例
|
## 业界使用案例
|
||||||
|
|
||||||
[京东从OpenStack切换到Kubernetes的经验之谈](https://jimmysong.io/docker-handbook/docs/jd_transform_to_kubernetes)
|
- [京东从OpenStack切换到Kubernetes的经验之谈](https://jimmysong.io/docker-handbook/docs/jd_transform_to_kubernetes)
|
||||||
|
|
||||||
[美团点评容器平台介绍](https://jimmysong.io/docker-handbook/docs/meituan_docker_platform)
|
- [美团点评容器平台介绍](https://jimmysong.io/docker-handbook/docs/meituan_docker_platform)
|
||||||
|
|
||||||
[阿里超大规模docker化之路](https://jimmysong.io/docker-handbook/docs/ali_docker)
|
- [阿里超大规模docker化之路](https://jimmysong.io/docker-handbook/docs/ali_docker)
|
||||||
|
|
||||||
[TalkingData-容器技术在大数据场景下的应用Yarn on Docker](http://rootsongjc.github.io/projects/yarn-on-docker/)
|
- [TalkingData-容器技术在大数据场景下的应用Yarn on Docker](https://jimmysong.io/posts/yarn-on-docker/)
|
||||||
|
|
||||||
[乐视云基于Kubernetes的PaaS平台建设](https://jimmysong.io/docker-handbook/docs/letv_docker)
|
- [乐视云基于Kubernetes的PaaS平台建设](https://jimmysong.io/docker-handbook/docs/letv_docker)
|
||||||
|
|
||||||
## 资源编排
|
## 资源编排
|
||||||
|
|
||||||
|
|
@ -123,14 +120,14 @@ Docker提供了一系列[log drivers](https://docs.docker.com/engine/admin/loggi
|
||||||
|
|
||||||
## 相关资源
|
## 相关资源
|
||||||
|
|
||||||
[容器技术工具与资源](https://jimmysong.io/docker-handbook/docs/tech_resource)
|
- [容器技术工具与资源](https://jimmysong.io/docker-handbook/docs/tech_resource)
|
||||||
|
|
||||||
[容器技术2016年总结](https://jimmysong.io/docker-handbook/docs/container_2016)
|
- [容器技术2016年总结](https://jimmysong.io/docker-handbook/docs/container_2016)
|
||||||
|
|
||||||
## 关于
|
## 关于
|
||||||
|
|
||||||
Author: [Jimmy Song](https://jimmysong.io/about)
|
- Author:[Jimmy Song](https://jimmysong.io/about)
|
||||||
|
|
||||||
rootsongjc@gmail.com
|
- Email:rootsongjc@gmail.com
|
||||||
|
|
||||||
更多关于**Docker**、**MicroServices**、**Big Data**、**DevOps**、**Deep Learning**的内容请关注[Jimmy Song's Blog](https://jimmysong.io),将不定期更新。
|
更多关于**Docker**、**MicroServices**、**Big Data**、**DevOps**、**Deep Learning**的内容请关注[Jimmy Song's Blog](https://jimmysong.io),将不定期更新。
|
||||||
|
|
|
||||||
|
|
@ -36,8 +36,6 @@ kubelet启动时报错systemd版本不支持start a slice as transient unit。
|
||||||
|
|
||||||
与[kubeadm init waiting for the control plane to become ready on CentOS 7.2 with kubeadm 1.6.1 #228](https://github.com/kubernetes/kubeadm/issues/228)类似。
|
与[kubeadm init waiting for the control plane to become ready on CentOS 7.2 with kubeadm 1.6.1 #228](https://github.com/kubernetes/kubeadm/issues/228)类似。
|
||||||
|
|
||||||
另外有一个使用systemd管理kubelet的[proposal](https://github.com/kubernetes/community/blob/master/contributors/design-proposals/kubelet-systemd.md)。
|
|
||||||
|
|
||||||
## 4.kube-proxy报错kube-proxy[2241]: E0502 15:55:13.889842 2241 conntrack.go:42] conntrack returned error: error looking for path of conntrack: exec: "conntrack": executable file not found in $PATH
|
## 4.kube-proxy报错kube-proxy[2241]: E0502 15:55:13.889842 2241 conntrack.go:42] conntrack returned error: error looking for path of conntrack: exec: "conntrack": executable file not found in $PATH
|
||||||
|
|
||||||
**导致的现象**
|
**导致的现象**
|
||||||
|
|
@ -126,12 +124,6 @@ kubectl patch deploy --namespace kube-system tiller-deploy -p '{"spec":{"templat
|
||||||
- [Helm: Error: no available release name found - StackOverflow](https://stackoverflow.com/questions/43499971/helm-error-no-available-release-name-found)
|
- [Helm: Error: no available release name found - StackOverflow](https://stackoverflow.com/questions/43499971/helm-error-no-available-release-name-found)
|
||||||
- [Helm 2.2.3 not working properly with kubeadm 1.6.1 default RBAC rules #2224](https://github.com/kubernetes/helm/issues/2224)
|
- [Helm 2.2.3 not working properly with kubeadm 1.6.1 default RBAC rules #2224](https://github.com/kubernetes/helm/issues/2224)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 参考
|
## 参考
|
||||||
|
|
||||||
[Persistent Volume](https://kubernetes.io/docs/concepts/storage/persistent-volumes/)
|
- [Persistent Volume](https://kubernetes.io/docs/concepts/storage/persistent-volumes/)
|
||||||
|
|
||||||
[Resource Design Proposals](https://github.com/kubernetes/community/blob/master/contributors/design-proposals/resources.md)
|
|
||||||
|
|
||||||
[Helm: Error: no available release name found]()
|
|
||||||
|
|
|
||||||
|
|
@ -24,7 +24,3 @@
|
||||||
## 获取
|
## 获取
|
||||||
|
|
||||||
Kubernetes1.10已经可以通过[GitHub下载](https://github.com/kubernetes/kubernetes/releases/tag/v1.10.0)。
|
Kubernetes1.10已经可以通过[GitHub下载](https://github.com/kubernetes/kubernetes/releases/tag/v1.10.0)。
|
||||||
|
|
||||||
## 参考
|
|
||||||
|
|
||||||
[Kubernetes 1.10: Stabilizing Storage, Security, and Networking](http://blog.kubernetes.io/2018/03/kubernetes-1.10-stabilizing-storage-security-networking.html)
|
|
||||||
|
|
@ -30,4 +30,4 @@ CRD不再局限于对单一版本的定制化资源作出定义。如今,利
|
||||||
|
|
||||||
## 参考
|
## 参考
|
||||||
|
|
||||||
- [Kubernetes 1.11: In-Cluster Load Balancing and CoreDNS Plugin Graduate to General Availability](https://kubernetes.io/blog/2018/06/27/kubernetes-1.11-release-announcement/)
|
- [Kubernetes 1.11: In-Cluster Load Balancing and CoreDNS Plugin Graduate to General Availability](https://kubernetes.io/blog/2018/06/27/kubernetes-1.11-release-announcement/)
|
||||||
|
|
|
||||||
|
|
@ -0,0 +1,51 @@
|
||||||
|
# Kubernetes1.12更新日志
|
||||||
|
|
||||||
|
该版本发布继续关注Kubernetes的稳定性,主要是内部改进和一些功能的毕业。该版本中毕业的功能有安全性和Azure的关键功能。此版本中还有两个毕业的值得注意的新增功能:Kubelet TLS Bootstrap和 Azure Virtual Machine Scale Sets(AVMSS)支持。
|
||||||
|
|
||||||
|
这些新功能意味着更高的安全性、可用性、弹性和易用性,可以更快地将生产应用程序推向市场。该版本还表明Kubernetes在开发人员方面日益成熟。
|
||||||
|
|
||||||
|
下面是该版本中的一些关键功能介绍。
|
||||||
|
|
||||||
|
## Kubelet TLS Bootstrap GA
|
||||||
|
|
||||||
|
我们很高兴地宣布[Kubelet TLS Bootstrap GA](https://github.com/kubernetes/features/issues/43)。在Kubernetes 1.4中,我们引入了一个API,用于从集群级证书颁发机构(CA)请求证书。此API的初衷是为kubelet启用TLS客户端证书的配置。此功能允许kubelet将自身引导至TLS安全集群。最重要的是,它可以自动提供和分发签名证书。
|
||||||
|
|
||||||
|
之前,当kubelet第一次运行时,必须在集群启动期间在带外进程中为其提供客户端凭据。负担是运营商提供这些凭证的负担。由于此任务对于手动执行和复杂自动化而言非常繁重,因此许多运营商为所有kubelet部署了具有单个凭证和单一身份的集群。这些设置阻止了节点锁定功能的部署,如节点授权器和NodeRestriction准入控制器。
|
||||||
|
|
||||||
|
为了缓解这个问题,[SIG Auth](https://github.com/kubernetes/community/tree/master/sig-auth)引入了一种方法,让kubelet生成私钥,CSR用于提交到集群级证书签署过程。v1(GA)标识表示生产加固和准备就绪,保证长期向后兼容。
|
||||||
|
|
||||||
|
除此之外,[Kubelet服务器证书引导程序和轮换](https://github.com/kubernetes/features/issues/267)正在转向测试版。目前,当kubelet首次启动时,它会生成一个自签名证书/密钥对,用于接受传入的TLS连接。此功能引入了一个在本地生成密钥,然后向集群API server发出证书签名请求以获取由集群的根证书颁发机构签名的关联证书的过程。此外,当证书接近过期时,将使用相同的机制来请求更新的证书。
|
||||||
|
|
||||||
|
## 稳定支持Azure Virtual Machine Scale Sets(VMSS)和Cluster-Autoscaler
|
||||||
|
|
||||||
|
Azure Virtual Machine Scale Sets(VMSS)允许您创建和管理可以根据需求或设置的计划自动增加或减少的同类VM池。这使您可以轻松管理、扩展和负载均衡多个VM,从而提供高可用性和应用程序弹性,非常适合可作为Kubernetes工作负载运行的大型应用程序。
|
||||||
|
|
||||||
|
凭借这一新的稳定功能,Kubernetes支持[使用Azure VMSS扩展容器化应用程序](https://github.com/kubernetes/features/issues/514),包括[将其与cluster-autoscaler集成的功能](https://github.com/kubernetes/features/issues/513)根据相同的条件自动调整Kubernetes集群的大小。
|
||||||
|
|
||||||
|
## 其他值得注意的功能更新
|
||||||
|
|
||||||
|
- [`RuntimeClass`](https://github.com/kubernetes/features/issues/585)是一个新的集群作用域资源,它将容器运行时属性表示为作为alpha功能发布的控制平面。
|
||||||
|
|
||||||
|
- [Kubernetes和CSI的快照/恢复功能](https://github.com/kubernetes/features/issues/177)正在作为alpha功能推出。这提供了标准化的API设计(CRD),并为CSI卷驱动程序添加了PV快照/恢复支持。
|
||||||
|
|
||||||
|
- [拓扑感知动态配置](https://github.com/kubernetes/features/issues/561)现在处于测试阶段,存储资源现在可以感知自己的位置。这还包括对[AWS EBS](https://github.com/kubernetes/features/issues/567)和[GCE PD](https://github.com/kubernetes/features/issues/558)的beta支持。
|
||||||
|
|
||||||
|
- [可配置的pod进程命名空间共享](https://github.com/kubernetes/features/issues/495)处于测试阶段,用户可以通过在PodSpec中设置选项来配置pod中的容器以共享公共PID命名空间。
|
||||||
|
|
||||||
|
- [根据条件的taint节点](https://github.com/kubernetes/features/issues/382)现在处于测试阶段,用户可以通过使用taint来表示阻止调度的节点条件。
|
||||||
|
|
||||||
|
- Horizontal Pod Autoscaler中的[任意/自定义指标](https://github.com/kubernetes/features/issues/117)正在转向第二个测试版,以测试一些其他增强功能。这项重新设计的Horizontal Pod Autoscaler功能包括对自定义指标和状态条件的支持。
|
||||||
|
|
||||||
|
- 允许[Horizontal Pod Autoscaler更快地达到适当大小](https://github.com/kubernetes/features/issues/591)正在转向测试版。
|
||||||
|
|
||||||
|
- [Pod的垂直缩放](https://github.com/kubernetes/features/issues/21)现在处于测试阶段,使得可以在其生命周期内改变pod上的资源限制。
|
||||||
|
|
||||||
|
- [通过KMS进行静态加密](https://github.com/kubernetes/features/issues/460)目前处于测试阶段。增加了多个加密提供商,包括Google Cloud KMS、Azure Key Vault、AWS KMS和Hashicorp Vault,它们会在数据存储到etcd时对其进行加密。
|
||||||
|
|
||||||
|
## 可用性
|
||||||
|
|
||||||
|
Kubernetes 1.12可以[在GitHub上下载](https://github.com/kubernetes/kubernetes/releases/tag/v1.12.0)。要开始使用Kubernetes,请查看这些[交互式教程](https://kubernetes.io/docs/tutorials/)。您也可以使用[Kubeadm](https://kubernetes.io/docs/setup/independent/create-cluster-kubeadm/)来安装1.12。
|
||||||
|
|
||||||
|
## 参考
|
||||||
|
|
||||||
|
- [Kubernetes 1.12: Kubelet TLS Bootstrap and Azure Virtual Machine Scale Sets (VMSS) Move to General Availability](https://kubernetes.io/blog/2018/09/27/kubernetes-1.12-kubelet-tls-bootstrap-and-azure-virtual-machine-scale-sets-vmss-move-to-general-availability/)
|
||||||
|
|
@ -0,0 +1,25 @@
|
||||||
|
# Kubernetes 1.13 更新日志
|
||||||
|
|
||||||
|
2018年12月3日,Kubernetes 1.13发布,这是2018年发布的第四个也是最后一个大版本。该版本中最显著地改进包括:
|
||||||
|
|
||||||
|
- 使用 [kubeadm](https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm/) 简化集群管理
|
||||||
|
- [CSI](../concepts/csi.md)(容器存储接口),[查看 CSI 规范](https://github.com/container-storage-interface/spec)
|
||||||
|
- [CoreDNS](https://github.com/coredns/coredns) 作为默认的 DNS
|
||||||
|
|
||||||
|
以上功能正式成为 GA(General Available)。
|
||||||
|
|
||||||
|
还有其他一些小的功能更新,例如:
|
||||||
|
|
||||||
|
- 支持第三方设备监控插件成为 alpha 功能。
|
||||||
|
- kubelet 设备插件注册 GA。
|
||||||
|
- 拓扑感知的 Volume 调度进入 stable。
|
||||||
|
- APIServer DryRun 进入 beta。
|
||||||
|
- kubectl diff 进入 beta。
|
||||||
|
- 使用 PV 源的原始块设备进入 beta。
|
||||||
|
|
||||||
|
详细的更新日志请访问 [Kubernetes 1.13: Simplified Cluster Management with Kubeadm, Container Storage Interface (CSI), and CoreDNS as Default DNS are Now Generally Available](https://kubernetes.io/blog/2018/12/03/kubernetes-1-13-release-announcement/)。
|
||||||
|
|
||||||
|
## 参考
|
||||||
|
|
||||||
|
- [Overview of kubeadm](https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm/)
|
||||||
|
- [Kubernetes 1.13: Simplified Cluster Management with Kubeadm, Container Storage Interface (CSI), and CoreDNS as Default DNS are Now Generally Available](https://kubernetes.io/blog/2018/12/03/kubernetes-1-13-release-announcement/)
|
||||||
|
|
@ -0,0 +1,20 @@
|
||||||
|
# Kubernetes 1.14 更新日志
|
||||||
|
|
||||||
|
北京时间2019年3月26日,Kubernetes 1.14发布,这是2019年发布的第一个版本,距离上个版本发布刚好又是三个月的时间。该版本中最显著地改进包括:
|
||||||
|
|
||||||
|
- 对于管理 Windows node 的生产级支持。
|
||||||
|
- 重写了 kubectl 的文档,并为其专门启用新域名 <https://kubectl.docs.kubernetes.io/>,该文档本身类似 Gitbook 的形式,使用 Resource Config 的形式组织,集成了 [kustomize](https://github.com/kubernetes-sigs/kustomize),还有了自己的 logo 和吉祥物 kubee-cuddle。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
- kubectl 插件机制发布稳定版本。
|
||||||
|
- Persistent Local Volume GA。
|
||||||
|
- 限制每个 Pod 的 PID 功能发布 beta 版本。
|
||||||
|
|
||||||
|
详细的更新日志请访问 [Kubernetes 1.14: Production-level support for Windows Nodes, Kubectl Updates, Persistent Local Volumes GA](https://kubernetes.io/blog/2019/03/25/kubernetes-1-14-release-announcement/)。
|
||||||
|
|
||||||
|
## 参考
|
||||||
|
|
||||||
|
- [Kubernetes 1.14: Production-level support for Windows Nodes, Kubectl Updates, Persistent Local Volumes GA - kuberentes.io](https://kubernetes.io/blog/2019/03/25/kubernetes-1-14-release-announcement/)
|
||||||
|
|
@ -0,0 +1,15 @@
|
||||||
|
# Kubernetes 1.15 更新日志
|
||||||
|
|
||||||
|
北京时间 2019 年 6 月 20 日,Kubernetes 1.15 发布,这是 2019 年的第二个版本,距离上个版本发布刚好又是三个月的时间。该版本中最显著地改进包括:
|
||||||
|
|
||||||
|
- CRD
|
||||||
|
- SIG API Machinery 相关的改进
|
||||||
|
- 集群生命周期的稳定性和可用性的改进,kubeadm 管理的证书轮换得到进一步加强,还有了自己的 logo
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
详细的日志请访问:[Kubernetes 1.15: Extensibility and Continuous Improvement](https://kubernetes.io/blog/2019/06/19/kubernetes-1-15-release-announcement/)。
|
||||||
|
|
||||||
|
## 参考
|
||||||
|
|
||||||
|
- [Kubernetes 1.15: Extensibility and Continuous Improvement](https://kubernetes.io/blog/2019/06/19/kubernetes-1-15-release-announcement/)
|
||||||
|
|
@ -15,7 +15,7 @@
|
||||||
- [Network Policy API](https://kubernetes.io/docs/concepts/services-networking/network-policies/) 提升为稳定版本。用户可以通过使用网络插件实现的网络策略来控制哪些Pod之间能够互相通信。
|
- [Network Policy API](https://kubernetes.io/docs/concepts/services-networking/network-policies/) 提升为稳定版本。用户可以通过使用网络插件实现的网络策略来控制哪些Pod之间能够互相通信。
|
||||||
- [节点授权](https://kubernetes.io/docs/admin/authorization/node/)和准入控制插件是新增加的功能,可以用于限制kubelet可以访问的secret、pod和其它基于节点的对象。
|
- [节点授权](https://kubernetes.io/docs/admin/authorization/node/)和准入控制插件是新增加的功能,可以用于限制kubelet可以访问的secret、pod和其它基于节点的对象。
|
||||||
- [加密的Secret](https://kubernetes.io/docs/tasks/administer-cluster/encrypt-data/)和etcd中的其它资源,现在是alpha版本。
|
- [加密的Secret](https://kubernetes.io/docs/tasks/administer-cluster/encrypt-data/)和etcd中的其它资源,现在是alpha版本。
|
||||||
- [Kubelet TLS bootstrapping](https://kubernetes.io/docs/admin/kubelet-tls-bootstrapping/)现在支持客户端和服务器端的证书轮换。
|
- Kubelet TLS bootstrapping 现在支持客户端和服务器端的证书轮换。
|
||||||
- 由API server存储的[审计日志](https://kubernetes.io/docs/tasks/debug-application-cluster/audit/)现在更具可定制性和可扩展性,支持事件过滤和webhook。它们还为系统审计提供更丰富的数据。
|
- 由API server存储的[审计日志](https://kubernetes.io/docs/tasks/debug-application-cluster/audit/)现在更具可定制性和可扩展性,支持事件过滤和webhook。它们还为系统审计提供更丰富的数据。
|
||||||
|
|
||||||
**有状态负载**
|
**有状态负载**
|
||||||
|
|
@ -29,7 +29,7 @@
|
||||||
**可扩展性**
|
**可扩展性**
|
||||||
|
|
||||||
- 运行时的[API聚合](https://kubernetes.io/docs/concepts/api-extension/apiserver-aggregation/)是此版本中最强大的扩展功能,允许高级用户将Kubernetes风格的预先构建的第三方或用户创建的API添加到其集群中。
|
- 运行时的[API聚合](https://kubernetes.io/docs/concepts/api-extension/apiserver-aggregation/)是此版本中最强大的扩展功能,允许高级用户将Kubernetes风格的预先构建的第三方或用户创建的API添加到其集群中。
|
||||||
- [容器运行时接口](https://github.com/kubernetes/community/blob/master/contributors/devel/container-runtime-interface.md)(CRI)已经增强,可以使用新的RPC调用从运行时检索容器度量。 [CRI的验证测试](https://github.com/kubernetes/community/blob/master/contributors/devel/cri-validation.md)已经发布,与[containerd](http://containerd.io/)进行了Alpha集成,现在支持基本的生命周期和镜像管理。参考[深入介绍CRI](http://blog.kubernetes.io/2016/12/container-runtime-interface-cri-in-kubernetes.html)的文章。
|
- 容器运行时接口(CRI)已经增强,可以使用新的RPC调用从运行时检索容器度量。 CRI的验证测试已经发布,与[containerd](http://containerd.io/)进行了Alpha集成,现在支持基本的生命周期和镜像管理。参考[深入介绍CRI](http://blog.kubernetes.io/2016/12/container-runtime-interface-cri-in-kubernetes.html)的文章。
|
||||||
|
|
||||||
**其它功能**
|
**其它功能**
|
||||||
|
|
||||||
|
|
@ -38,10 +38,4 @@
|
||||||
|
|
||||||
**弃用**
|
**弃用**
|
||||||
|
|
||||||
- 第三方资源(TPR)已被自定义资源定义(Custom Resource Definitions,CRD)取代,后者提供了一个更清晰的API,并解决了TPR测试期间引发的问题和案例。如果您使用TPR测试版功能,则建议您[迁移](https://kubernetes.io/docs/tasks/access-kubernetes-api/migrate-third-party-resource/),因为它将在Kubernetes 1.8中被移除。
|
- 第三方资源(TPR)已被自定义资源定义(Custom Resource Definitions,CRD)取代,后者提供了一个更清晰的API,并解决了TPR测试期间引发的问题和案例。如果您使用TPR测试版功能,则建议您迁移,因为它将在Kubernetes 1.8中被移除。
|
||||||
|
|
||||||
以上是Kubernetes1.7中的主要新特性,详细更新文档请查看[Changelog](https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG-1.7.md)。
|
|
||||||
|
|
||||||
## 参考
|
|
||||||
|
|
||||||
[Kuberentes 1.7: Security Hardening, Stateful Application Updates and Extensibility](http://blog.kubernetes.io/2017/06/kubernetes-1.7-security-hardening-stateful-application-extensibility-updates.html)
|
|
||||||
|
|
|
||||||
|
|
@ -6,7 +6,7 @@
|
||||||
|
|
||||||
Kubernetes1.8的[基于角色的访问控制(RBAC)](https://en.wikipedia.org/wiki/Role-based_access_control)成为stable支持。RBAC允许集群管理员[动态定义角色](https://kubernetes.io/docs/admin/authorization/rbac/)对于Kubernetes API的访问策略。通过[网络策略](https://kubernetes.io/docs/concepts/services-networking/network-policies/)筛选出站流量的Beta支持,增强了对入站流量进行过滤的现有支持。 RBAC和网络策略是强化Kubernetes内组织和监管安全要求的两个强大工具。
|
Kubernetes1.8的[基于角色的访问控制(RBAC)](https://en.wikipedia.org/wiki/Role-based_access_control)成为stable支持。RBAC允许集群管理员[动态定义角色](https://kubernetes.io/docs/admin/authorization/rbac/)对于Kubernetes API的访问策略。通过[网络策略](https://kubernetes.io/docs/concepts/services-networking/network-policies/)筛选出站流量的Beta支持,增强了对入站流量进行过滤的现有支持。 RBAC和网络策略是强化Kubernetes内组织和监管安全要求的两个强大工具。
|
||||||
|
|
||||||
Kubelet的传输层安全性(TLS)[证书轮换](https://kubernetes.io/docs/admin/kubelet-tls-bootstrapping/)成为beta版。自动证书轮换减轻了集群安全性运维的负担。
|
Kubelet的传输层安全性(TLS)证书轮换成为beta版。自动证书轮换减轻了集群安全性运维的负担。
|
||||||
|
|
||||||
## 聚焦工作负载支持
|
## 聚焦工作负载支持
|
||||||
|
|
||||||
|
|
@ -25,7 +25,3 @@ Volume快照、PV调整大小、自动taint、pod优先级、kubectl插件等!
|
||||||
除了稳定现有的功能,Kubernetes 1.8还提供了许多预览新功能的alpha版本。
|
除了稳定现有的功能,Kubernetes 1.8还提供了许多预览新功能的alpha版本。
|
||||||
|
|
||||||
社区中的每个特别兴趣小组(SIG)都在继续为所在领域的用户提供更多的功能。有关完整列表,请访问[发行说明](https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG-1.8.md)。
|
社区中的每个特别兴趣小组(SIG)都在继续为所在领域的用户提供更多的功能。有关完整列表,请访问[发行说明](https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG-1.8.md)。
|
||||||
|
|
||||||
## 参考
|
|
||||||
|
|
||||||
[Kubernetes 1.8: Security, Workloads and Feature Depth](http://blog.kubernetes.io/2017/09/kubernetes-18-security-workloads-and.html)
|
|
||||||
|
|
@ -4,13 +4,13 @@
|
||||||
|
|
||||||
## Workloads API GA
|
## Workloads API GA
|
||||||
|
|
||||||
[apps/v1 Workloads API](https://kubernetes.io/docs/reference/workloads-18-19/)成为GA(General Availability),且默认启用。 Apps Workloads API将**DaemonSet**、**Deployment**、**ReplicaSet**和**StatefulSet** API组合在一起,作为Kubernetes中长时间运行的无状态和有状态工作负载的基础。
|
apps/v1 Workloads API成为GA(General Availability),且默认启用。 Apps Workloads API将**DaemonSet**、**Deployment**、**ReplicaSet**和**StatefulSet** API组合在一起,作为Kubernetes中长时间运行的无状态和有状态工作负载的基础。
|
||||||
|
|
||||||
Deployment和ReplicaSet是Kubernetes中最常用的两个对象,经过一年多的实际使用和反馈后,现在已经趋于稳定。[SIG apps](https://github.com/kubernetes/community/tree/master/sig-apps)同时将这些经验应用到另外的两个对象上,使得DaemonSet和StatefulSet也能顺利毕业走向成熟。v1(GA)意味着已经生产可用,并保证长期的向后兼容。
|
Deployment和ReplicaSet是Kubernetes中最常用的两个对象,经过一年多的实际使用和反馈后,现在已经趋于稳定。[SIG apps](https://github.com/kubernetes/community/tree/master/sig-apps)同时将这些经验应用到另外的两个对象上,使得DaemonSet和StatefulSet也能顺利毕业走向成熟。v1(GA)意味着已经生产可用,并保证长期的向后兼容。
|
||||||
|
|
||||||
## Windows支持(beta)
|
## Windows支持(beta)
|
||||||
|
|
||||||
Kubernetes最初是为Linux系统开发的,但是用户逐渐意识到容器编排的好处,我们看到有人需要在Kubernetes上运行Windows工作负载。在12个月前,我们开始认真考虑在Kubernetes上支持Windows Server的工作。 [SIG-Windows](https://github.com/kubernetes/community/tree/master/sig-windows)现在已经将这个功能推广到beta版本,这意味着我们可以评估它的[使用情况](https://kubernetes.io/docs/getting-started-guides/windows/)。
|
Kubernetes最初是为Linux系统开发的,但是用户逐渐意识到容器编排的好处,我们看到有人需要在Kubernetes上运行Windows工作负载。在12个月前,我们开始认真考虑在Kubernetes上支持Windows Server的工作。 [SIG-Windows](https://github.com/kubernetes/community/tree/master/sig-windows)现在已经将这个功能推广到beta版本,这意味着我们可以评估它的使用情况。
|
||||||
|
|
||||||
## 增强存储
|
## 增强存储
|
||||||
|
|
||||||
|
|
@ -37,7 +37,3 @@ kube-proxy的IPVS模式进入beta版,为大型集群提供更好的可扩展
|
||||||
## 获取
|
## 获取
|
||||||
|
|
||||||
Kubernetes1.9已经可以通过[GitHub下载](https://github.com/kubernetes/kubernetes/releases/tag/v1.9.0)。
|
Kubernetes1.9已经可以通过[GitHub下载](https://github.com/kubernetes/kubernetes/releases/tag/v1.9.0)。
|
||||||
|
|
||||||
## 参考
|
|
||||||
|
|
||||||
[Kubernetes 1.9: Apps Workloads GA and Expanded Ecosystem](http://blog.kubernetes.io/2017/12/kubernetes-19-workloads-expanded-ecosystem.html)
|
|
||||||
|
|
@ -12,7 +12,7 @@ Kubernetes是谷歌根据其内部使用的Borg改造成一个通用的容器编
|
||||||
|
|
||||||
### Kubernetes发展历史
|
### Kubernetes发展历史
|
||||||
|
|
||||||
相信凡是关注容器生态圈的人都不会否认,Kubernetes已经成为容器编排调度的实际标准,不论Docker官方还是Mesos都已经支持Kubernetes,Docker公司在今年10月16日至19日举办的DockerCon EU 2017大会上宣布支持Kubernetes调度,就在这不久前Mesos的商业化公司Mesosphere的CTO Tobi Knaup也在官方博客中宣布[Kubernetes on DC/OS](kubectl get --raw=apis/|python -m json.tool)。而回想下2016年时,我们还在为Swarm、Mesos、Kubernetes谁能够在容器编排调度大战中胜出而猜测时,而经过不到一年的发展,Kubernetes就以超过70%的市场占有率(据[TheNewStack](https://www.thenewstack.io)的调研报告)将另外两者遥遥的甩在了身后,其已经在大量的企业中落地,还有一些重量级的客户也宣布将服务迁移到Kubernetes上,比如GitHub(见[Kubernetes at GitHub](https://githubengineering.com/kubernetes-at-github/)),还有eBay、彭博社等。
|
相信凡是关注容器生态圈的人都不会否认,Kubernetes已经成为容器编排调度的实际标准,不论Docker官方还是Mesos都已经支持Kubernetes,Docker公司在今年10月16日至19日举办的DockerCon EU 2017大会上宣布支持Kubernetes调度,就在这不久前Mesos的商业化公司Mesosphere的CTO Tobi Knaup也在官方博客中宣布Kubernetes on DC/OS。而回想下2016年时,我们还在为Swarm、Mesos、Kubernetes谁能够在容器编排调度大战中胜出而猜测时,而经过不到一年的发展,Kubernetes就以超过70%的市场占有率(据[TheNewStack](https://www.thenewstack.io)的调研报告)将另外两者遥遥的甩在了身后,其已经在大量的企业中落地,还有一些重量级的客户也宣布将服务迁移到Kubernetes上,比如GitHub(见[Kubernetes at GitHub](https://githubengineering.com/kubernetes-at-github/)),还有eBay、彭博社等。
|
||||||
|
|
||||||
Kubernetes自2014年由Google开源以来,至今已经发展到了1.9版本,下面是Kubernetes的版本发布路线图:
|
Kubernetes自2014年由Google开源以来,至今已经发展到了1.9版本,下面是Kubernetes的版本发布路线图:
|
||||||
|
|
||||||
|
|
@ -111,4 +111,4 @@ Kubernetes已成为GitHub上参与和讨论人数最多的开源项目,在其
|
||||||
|
|
||||||
2018年的IaaS的运营商将主要提供基础架构服务,如虚拟机、存储和数据库等传统的基础架构和服务,仍然会使用现有的工具如Chef、Terraform、Ansible等来管理;Kubernetes则可能直接运行在裸机上运行,结合CI/CD成为DevOps的得力工具,并成为高级开发人员的应用部署首选;Kubernetes也将成为PaaS层的重要组成部分,为开发者提供应用程序部署的简单方法,但是开发者可能不会直接与Kubernetes或者PaaS交互,实际的应用部署流程很可能落在自动化CI工具如Jenkins上。
|
2018年的IaaS的运营商将主要提供基础架构服务,如虚拟机、存储和数据库等传统的基础架构和服务,仍然会使用现有的工具如Chef、Terraform、Ansible等来管理;Kubernetes则可能直接运行在裸机上运行,结合CI/CD成为DevOps的得力工具,并成为高级开发人员的应用部署首选;Kubernetes也将成为PaaS层的重要组成部分,为开发者提供应用程序部署的简单方法,但是开发者可能不会直接与Kubernetes或者PaaS交互,实际的应用部署流程很可能落在自动化CI工具如Jenkins上。
|
||||||
|
|
||||||
2018年,Kubernetes将更加稳定好用,云原生将会出现更多的落地与最佳实践,这都值得我们期待!
|
2018年,Kubernetes将更加稳定好用,云原生将会出现更多的落地与最佳实践,这都值得我们期待!
|
||||||
|
|
|
||||||
|
|
@ -0,0 +1,163 @@
|
||||||
|
# Kubernetes与云原生2018年年终总结及2019年展望
|
||||||
|
|
||||||
|
去年我写了[Kubernetes与云原生2017年年终总结及2018年展望](kubernetes-and-cloud-native-summary-in-2017-and-outlook-for-2018.md),按照惯例也应该推出2018年的总结和2019年的展望了,写这篇文章的时候已经是2019年的1月末了,如果不写点什么回顾下2018年总觉得这一年过的不完整。
|
||||||
|
|
||||||
|
本文将回顾 Kubernetes 与云原生在2018年的进展,可以说2018年是 Kubernetes 大规模落地,Service Mesh 蓄势待发的一年。
|
||||||
|
|
||||||
|
## 2017年时对2018年的预测
|
||||||
|
|
||||||
|
首先我先带大家回顾下2017年时我对2018年的预测。2017年底我预测2018年的Kubernetes和云原生将向以下方向发展:
|
||||||
|
|
||||||
|
- 服务网格(Service Mesh),在Kubernetes上践行微服务架构进行服务治理所必须的组件;
|
||||||
|
- 无服务器架构(Serverless),以FaaS为代表的无服务器架构将会流行开来;
|
||||||
|
- 加强数据服务承载能力,例如在Kubernetes上运行大数据应用;
|
||||||
|
- 简化应用部署与运维包括云应用的监控与日志收集分析等;
|
||||||
|
|
||||||
|
下面我来分别总结下以上四点预测:
|
||||||
|
|
||||||
|
- 其中服务网格(Service Mesh)是我2018年一直在大力主张和推广的,并创立了[ServiceMesher社区](http://www.servicemesher.com),业界已经对服务网格有了广泛的认知,其在微服务和分布式架构领域将有广阔的前景,2018年7月31日[Istio](https://istio.io)发布1.0,预示着服务网格即将走向成熟;
|
||||||
|
- 无服务器架构的理念提出已久但仍需找到合适的应用场景来大面积铺开,2018年Google、Pivotal等公司新开源的[knative](https://github.com/knative)更加弱化了底层平台的差异,开发者直接定义服务,应用自动打包和部署;
|
||||||
|
- 关于Kubernetes承载大数据计算,已经有很多公司应用它来运行大数据应用,还有一些创业公司提供基于Kubernetes的异构计算平台,在大企业内部也有使用Kubernetes来统一大数据、机器学习、人工智能等平台的需求,大数据行业领先的两家公司Cloudera与Hortonworks的合并势必也会在云原生领域发力;
|
||||||
|
- 随着越来越多的公司选择Kubernetes作为底层的基础设施平台,Kubernetes周边的生态越来越完善,围绕发布部署、监控和APM相关的SaaS类应用层出不穷;
|
||||||
|
|
||||||
|
## CNCF 的毕业项目
|
||||||
|
|
||||||
|
2018年至今按照时间顺序,CNCF中毕业的项目有:
|
||||||
|
|
||||||
|
- 2018年3月:Kubernetes 毕业
|
||||||
|
- 2018年8月,Prometheus 毕业
|
||||||
|
- 2018年11月,Envoy 毕业
|
||||||
|
- 2019年1月,CoreDNS 毕业
|
||||||
|
|
||||||
|
截至本文发稿,已有4个项目毕业,2019将会有更多的项目走向成熟。CNCF 托管的全部项目状态请见:https://www.cncf.io/projects-graduated/
|
||||||
|
|
||||||
|
## Kubernetes在2018年的发展
|
||||||
|
|
||||||
|
2018年3月Kubernetes经过CNCF基金会的投票正式毕业,这意味着它拥有足够多的提交者和贡献人员,并被业界广泛的采纳,已经可以依靠社区的维护健康的发展。关于CNCF项目的毕业标准的详情请参考[CNCF Graduation Criteria v1.1](https://github.com/cncf/toc/blob/master/process/graduation_criteria.adoc)。
|
||||||
|
|
||||||
|
一年里按计划发布了4个版本,详见以下更新日志:
|
||||||
|
|
||||||
|
- [Kubernetes1.10更新日志](../appendix/kubernetes-1.10-changelog.md)
|
||||||
|
- [Kubernetes1.11更新日志](../appendix/kubernetes-1.11-changelog.md)
|
||||||
|
- [Kubernetes1.12更新日志](../appendix/kubernetes-1.12-changelog.md)
|
||||||
|
- [Kubernetes1.13更新日志](../appendix/kubernetes-1.13-changelog.md)
|
||||||
|
|
||||||
|
早在2017年的北美 KubeCon 上就有一种论调说 Kubernetes 正变得 boring,因为它已经越来越成熟,在未来不会出现大的变动,从以上更新日志中也可以看到,大多是一些功能进入 beta 或者 stable 状态,很少有新的功能出现。
|
||||||
|
|
||||||
|
下图是 Google trend 中过去一年来全球搜索 Kubernetes 的趋势图。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
从图中可以看出 Kubernetes 在全球搜索趋势在2018年底已经达到了最巅峰,2019年可能会开始走下降趋势。
|
||||||
|
|
||||||
|
下图是最近5年来 Kubernetes 关键词的百度指数。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
上图来自百度指数,可以大体概括 Kubernetes 关键字在中国的搜索情况,同 Kubernetes 在全球的搜索情况一样,可能已经过了巅峰期。
|
||||||
|
|
||||||
|
## Kubernetes Operator
|
||||||
|
|
||||||
|
以 Kubernetes 为核心来运维上层应用,诞生了一种名为”Kubernetes Native“的新型运维方式,真正践行 DevOps 理念的产物,开发者将于软件的运维逻辑写成代码,利用 Kubernetes 的**控制器模式(Controller Pattern)**和 [CRD](../concepts/crd.md) 来扩展 Kubernetes 的 API,各种 Operator 层出不穷,[awesome-operators](https://github.com/operator-framework/awesome-operators) 列举了目前所有的 Operator。例如我们熟悉的 [Istio](https://istio.io) 中就有50个 CRD。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
CNCF 生态中的诸多应用都已支持 Kubernetes Operator,可以说 Operator 将成为云原生中默认的软件动态运行时管理工具,参考 CoreOS(已被 RedHat 收购,RedHat 已被 IBM 收购) CTO Brandon Philips 的这篇文章 [Introducing the Operator Framework: Building Apps on Kubernetes](https://www.redhat.com/en/blog/introducing-operator-framework-building-apps-kubernetes)。
|
||||||
|
|
||||||
|
## ServiceMesher社区
|
||||||
|
|
||||||
|
下图展示的是 2019 Q1 的软件架构趋势,(图片来自 [Architecture and Design InfoQ Trends Report - January 2019](https://www.infoq.com/articles/architecture-trends-2019))我们可以看到 Service Mesh 还处于创新者阶段,如果从软件生命周期的全阶段来看,它还只是刚刚进入很多人的眼帘,对于这张的新兴技术,在蚂蚁金服的支持的下创办了 [ServiceMesher 社区](http://www.servicemesher.com)。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
既然 Kubernetes 已经开始变得无聊,2018年落地 Kubernetes 已经不是初创公司的事情了,很多大公司甚至传统企业都开始试水或者大规模落地,在 Kubernetes 进一步成熟之时,以 Kubernetes 为基础向上发展,开辟新的战场就能收获更多的业务场景和需求。
|
||||||
|
|
||||||
|
Kubernetes 并不直接对外提供业务能力,而是作为应用运行的底层平台,在应用和平台间还有一个 Gap,这需要中间件的能力来补充。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
- 2018年5月,ServiceMesher 社区由蚂蚁金服发起成立。
|
||||||
|
- 2018年5月30日,[Envoy最新官方文档中文版发布——由Service Mesh爱好者倾情奉献](http://www.servicemesher.com/envoy/)。
|
||||||
|
- 2018年6月21日,[启用新的社区logo](http://mp.weixin.qq.com/s?__biz=MzIwNDIzODExOA==&mid=2650165956&idx=2&sn=8ef0f080fd428b6307389fce4546103a&chksm=8ec1ce8db9b6479b846b37e0fdffbc0f1a6b23c17329032af7e1b9e6dc6412966f42edcf08f9&scene=21#wechat_redirect)。
|
||||||
|
- 2018年6月30日,[开启新域名servicemesher.com](http://www.servicemesher.com)。
|
||||||
|
- 2018年6月30日,举办了第一届 Service Mesh Meetup 杭州站,见[ServiceMesher杭州Meetup圆满完成](http://www.servicemesher.com/blog/hangzhou-meetup-20180630/)。
|
||||||
|
- 2018年7月,ServiceMesher 社区成为 [Istio 社区中国合作伙伴](https://istio.io/about/community/)。
|
||||||
|
- 2018年7月29日,举办了第二届 Service Mesh Meetup 北京站,见[第二届Service Mesh Meetup北京站回顾、视频回放和资料下载](http://www.servicemesher.com/blog/beijing-meetup-20180729/)。
|
||||||
|
- 2018年8月25日,举办了第三届 Service Mesh Meetup 深圳站,见[Service Mesh Meetup深圳站回顾、视频回放及PPT资料分享](http://www.servicemesher.com/blog/service-mesh-meetup-shenzhen-20180825/)。
|
||||||
|
- 2018年9月19日,开始了开源电子书 [istio-handbook](https://github.com/rootsongjc/istio-handbook/) 的创作。
|
||||||
|
- 2018年11月13日,[ServiceMesher社区成员聚首KubeCon&CloudNativeCon上海](https://jimmysong.io/posts/kubecon-cloudnativecon-china-2018/)。
|
||||||
|
- 2018年11月25日,举办了第四届 Service Mesh Meetup 上海站,见[第四届 Service Mesh Meetup 上海站活动回顾与资料下载](http://www.servicemesher.com/blog/service-mesh-meetup-shanghai-20181125/)。
|
||||||
|
- 2019年1月6日,举办了第五届 Service Mesh Meetup 广州站,见[第五届 Service Mesh Meetup 广州站活动回顾与资料下载](http://www.servicemesher.com/blog/service-mesh-meetup-guangzhou-20190106/)。
|
||||||
|
|
||||||
|
|
||||||
|
## Service Mesh Meetup
|
||||||
|
|
||||||
|
这一年 [ServiceMesher 社区](http://www.servicemesher.com)为大家带来5次 Meetup 共 20 次 Topic 分享:
|
||||||
|
|
||||||
|
- 敖小剑(蚂蚁金服):大规模微服务架构下的 Service Mesh 探索之路
|
||||||
|
- 刘超(网易):网易云的 Service Mesh 产品架构和实现
|
||||||
|
- 唐鹏程(才云科技):在 Kubernetes 上搭建高可用 Service Mesh 监控
|
||||||
|
- 徐运元(谐云科技):Service Mesh 结合容器云平台的思考与实践
|
||||||
|
- 张亮(京东金融数据研发负责人):Service Mesh的延伸 —— 论道Database Mesh
|
||||||
|
- 吴晟(Apache SkyWalking创始人):Observability on Service Mesh —— Apache SkyWalking 6.0
|
||||||
|
- 朵晓东(蚂蚁金服,高级技术专家):蚂蚁金服开源的Service Mesh数据平面SOFA MOSN深层揭秘
|
||||||
|
- 丁振凯(新浪微博,微博搜索架构师):微博Service Mesh实践 - WeiboMesh
|
||||||
|
- 张超盟(华为):Kubernetes容器应用基于Istio的灰度发布实践
|
||||||
|
- 朱经惠 (联邦车网):Istio控制平面组件原理解析
|
||||||
|
- 邵俊雄(蚂蚁金服):SOFAMesh 的通用协议扩展
|
||||||
|
- 杨文(JEX):Kubernetes、Service Mesh、CI/CD 实践
|
||||||
|
- 吴晟(Apache SkyWalking 创始人):Observability and Istio telemetry
|
||||||
|
- 敖小剑&张瑜标(蚂蚁金服):蚂蚁金服 Service Mesh 渐进式迁移方案
|
||||||
|
- 徐运元(谐云科技):探讨和实践基于Isito的微服务治理事件监控
|
||||||
|
- 冯玮(七牛容器云平台产品架构师):Envoy、Contour与Kubernetes实践
|
||||||
|
- 郑德惠(唯品会Java资深开发工程师):唯品会的Service Mesh 实践与分享
|
||||||
|
- 陈逸凡(蚂蚁金服):SOFAMosn 持续演进路径及实践案例
|
||||||
|
- 崔秀龙(HPE 软件分析师):在网格的边缘试探——企业 Istio 试水指南
|
||||||
|
- 宋净超(蚂蚁金服):Service Mesh 圆桌讨论
|
||||||
|
|
||||||
|
## Serverless
|
||||||
|
|
||||||
|
我们再看 CNCF 的 [Landscape](https://landscape.cncf.io/),其中右下部分有一个单列的 Serverless 单元,详见 <https://landscape.cncf.io/>。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
我们再看下 Kubernetes、Service Mesh、Serviceless 三者之间的关系:
|
||||||
|
|
||||||
|
- Kubernetes 负责应用的生命周期管理,最小的治理单元是 Pod;
|
||||||
|
- Service Mesh 解决服务间的流量治理,最小的治理单元是 Service(可以类比为 Kubernetes 中 Service 资源);
|
||||||
|
- 而 Serviceless 是更高一层的抽象,最小的治理单元是 APP;
|
||||||
|
|
||||||
|
越向上层就越不关心应用的底层实现,到了 Serverless 开发者只需要关心代码逻辑,其他的一起都是配置,因此 Google 联合 Pivotal 等其他公司于2018年7月创建了 [knative](https://github.com/knative) 这个基于 Kubernetes 和 Istio 的 Serverless 的开源项目。
|
||||||
|
|
||||||
|
## 出版物
|
||||||
|
|
||||||
|
一个繁荣的生态将有大量的开发者支持,有开发者的地方就会有出版物。2018年至本文发稿关于 Kubernetes 和云原生的中文出版物(译作或原著),根据出版时间排序如下:
|
||||||
|
|
||||||
|
- 2018年3月:[《每天5分钟玩转Kubernetes》,CloudMan 著](https://item.jd.com/12329528.html)
|
||||||
|
- 2018年7月:[《Python 云原生——构建应对海量用户数据的高可扩展 Web 应用》,Manish Sathi著,宋净超 译](https://item.jd.com/12365097.html)
|
||||||
|
- 2018年7月:[《云原生 Java——Spring Boot、Spring Cloud 与 Cloud Foundry 弹性系统设计》,Josh Long & Kenny Bastani著,张若飞 宋净超 译](https://item.jd.com/12398618.html)
|
||||||
|
- 2018年8月:[《Kubernetes 权威指南:企业级容器云实战》,闫健勇 龚正 吴治辉 刘晓红 崔秀龙 等 著](https://item.jd.com/12420042.html)
|
||||||
|
- 2018年9月:[《云原生基础架构:构建和管理现代可扩展基础架构的模式及实践》,Justin Garrision & Kris Nova著,孙杰、肖力 译](https://item.jd.com/12432007.html)
|
||||||
|
- 2018年9月:[《基于Kubernetes的容器云平台实战》,陆平 左奇 付光 张晗 著](https://item.jd.com/12433425.html)
|
||||||
|
- 2018年10月:[《Kubernetes经典实例》,Sébastien Goasguen & Michael Hausenblas 著,马晶慧 译](https://item.jd.com/12446081.html)
|
||||||
|
- 2018年11月:[《持续演进的Cloud Native:云原生架构下微服务最佳实践》,王启军 著](https://item.jd.com/12452009.html)
|
||||||
|
- 2018年11月:[《云原生分布式存储基石:etcd深入解析》,华为容器服务团队 杜军 等著](https://item.jd.com/12455265.html)
|
||||||
|
- 2018年12月:[《Kubernetes即学即用》,Kelsey Hightower & Brendan Burns & Joe Beda 著,韩波 译](https://item.jd.com/12476325.html)
|
||||||
|
- 2018年12月:[《Kubernetes 进阶实战》,马永亮 著](https://item.jd.com/12477105.html)
|
||||||
|
- 2018年12月:[《Service Mesh实战:基于Linkerd和Kubernetes的微服务实践》,杨章显 著](https://item.jd.com/12494016.html)
|
||||||
|
- 2019年1月:[《深入浅出 Istio:Service Mesh 快速入门与实践》,崔秀龙 著](https://item.jd.com/12527008.html)
|
||||||
|
- 2019年1月:[《Kubernetes in Action中文版,Marko Luksa著,七牛容器云团队 译](https://item.jd.com/12510666.html)
|
||||||
|
|
||||||
|
**注**:以上仅列举了2018年至本文发稿时已上市发售的书籍,并不代表本人立场推荐以上书籍。
|
||||||
|
|
||||||
|
预告:2019年2月,[《未来架构——从服务化到云原生》张亮 吴晟 敖小剑 宋净超 著](https://jimmysong.io/posts/future-architecture-from-soa-to-cloud-native/)即将上市。
|
||||||
|
|
||||||
|
另外还有很多线上、线下的 Kubernetes 实训课程、电子出版物不胜枚举,例如极客时间出品的[深入剖析 Kubernetes](https://jimmysong.io/posts/kubernetes-tutorial-recommendation/)。
|
||||||
|
|
||||||
|
## 2019年展望
|
||||||
|
|
||||||
|
2019年才开始学 Kubernetes 依然不晚,这可能是影响云计算未来10年的技术,甚至有人预测,未来的开发者可能一上手就是在云上开发,从提交代码、测试到发布一气呵成,直接基于 Git 操作即可完成,完全感受不到 Kubernetes 的存在。展望2019年,我在2017年的预测的趋势依然不变,2019年将更加深化。如果以 Kubernetes 的发展阶段类比,就像2017年时的 Kubernetes 一样,在一部分企业中 Service Mesh 已经开始快速落地,而 Knative 更像 2015 年时的 Kubernetes,一起才刚刚开始,毕竟也是 2018 年中才开源。
|
||||||
|
|
||||||
|
2018年11月 CNCF 在上海举办了第一届中国 KubeCon + CloudNativeCon,2019年6月大会将升级为 KubeCon + CloudNativeCon + Open Source Summit,将进一步推送中国的开源发展与云原生的应用,[查看大会详情](https://www.lfasiallc.com/events/kubecon-cloudnativecon-china-2019/)。
|
||||||
|
|
@ -11,7 +11,10 @@
|
||||||
- 2017年12月15日,[Kubernetes1.9发布](kubernetes-1.9-changelog.md)
|
- 2017年12月15日,[Kubernetes1.9发布](kubernetes-1.9-changelog.md)
|
||||||
- 2018年3月26日,[Kubernetes1.10发布](kubernetes-1.10-changelog.md)
|
- 2018年3月26日,[Kubernetes1.10发布](kubernetes-1.10-changelog.md)
|
||||||
- 2018年6月27日,[Kubernetes1.11发布](kubernetes-1.11-changelog.md)
|
- 2018年6月27日,[Kubernetes1.11发布](kubernetes-1.11-changelog.md)
|
||||||
|
- 2018年9月27日,[Kubernetes1.12发布](kubernetes-1.12-changelog.md)
|
||||||
|
- 2018年12月3日,[Kubernetes1.13发布](kubernetes-1.13-changelog.md)
|
||||||
|
- 2019年3月26日,[Kubernetes 1.14发布](kubernetes-1.14-changelog.md)
|
||||||
|
|
||||||
## 更多
|
## 更多
|
||||||
|
|
||||||
追踪Kubernetes最新特性,请访问互动教学网站提供商 [Katacoda.com](https://katacoda.com) 创建的 [kubernetesstatus.com](http://kubernetesstatus.com/)。
|
追踪Kubernetes最新特性,请访问互动教学网站提供商 [Katacoda.com](https://katacoda.com) 创建的 [kubernetesstatus.com](http://kubernetesstatus.com/)。
|
||||||
|
|
|
||||||
|
|
@ -2,13 +2,26 @@
|
||||||
|
|
||||||
授人以鱼,不如授人以渔。下面的资料将有助于大家了解kubernetes生态圈当前发展状况和发展趋势,我特此整理相关资料如下。
|
授人以鱼,不如授人以渔。下面的资料将有助于大家了解kubernetes生态圈当前发展状况和发展趋势,我特此整理相关资料如下。
|
||||||
|
|
||||||
|
## 社区资源
|
||||||
|
|
||||||
|
Kubernetes 社区的贡献、交流和治理方式相关的内容都保存在 <https://github.com/kubernetes/community> 这个 repo 中,建议参与 Kubernetes 社区前先阅读该 repo 中的资料。
|
||||||
|
|
||||||
|
在这里你可以找到:
|
||||||
|
|
||||||
|
- Kubernetes 的各个 SIG 联系方式、会议记录等
|
||||||
|
- 社区贡献指南
|
||||||
|
- 社区成员的角色分类与职责
|
||||||
|
- 社区贡献的 Kubernetes 资源图标
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
## 生态环境
|
## 生态环境
|
||||||
|
|
||||||
包括kubernetes和cloud native相关的开源软件、工具和全景图。
|
包括kubernetes和cloud native相关的开源软件、工具和全景图。
|
||||||
|
|
||||||
- [awesome-kubernetes](https://github.com/ramitsurana/awesome-kubernetes) - A curated list for awesome kubernetes sources 🚢🎉 [https://ramitsurana.github.io/awesome…](https://ramitsurana.github.io/awesome-kubernetes)
|
- [awesome-kubernetes](https://github.com/ramitsurana/awesome-kubernetes) - A curated list for awesome kubernetes sources 🚢🎉 [https://ramitsurana.github.io/awesome-kubernetes](https://ramitsurana.github.io/awesome-kubernetes)
|
||||||
- [awesome-cloud-native](https://github.com/rootsongjc/awesome-cloud-native/) - A curated list for awesome cloud native architectures <https://jimmysong.io/awesome-cloud-native/>
|
- [awesome-cloud-native](https://github.com/rootsongjc/awesome-cloud-native/) - A curated list for awesome cloud native architectures <https://jimmysong.io/awesome-cloud-native/>
|
||||||
- [cloud native landscape](https://github.com/cncf/landscape) - Cloud Native Landscape [https://cncf.io](https://cncf.io/)
|
- [cloud native landscape](https://github.com/cncf/landscape) - Cloud Native Landscape [https://landscape.cncf.io](https://landscape.cncf.io/)
|
||||||
|
|
||||||
## 开源书籍和教程
|
## 开源书籍和教程
|
||||||
|
|
||||||
|
|
@ -31,16 +44,15 @@ Kubernetes和Cloud Native相关网站、专栏、博客等。
|
||||||
### 网站与专栏
|
### 网站与专栏
|
||||||
|
|
||||||
- [thenewstack.io](https://thenewstack.io/)
|
- [thenewstack.io](https://thenewstack.io/)
|
||||||
- [k8sport.org](http://k8sport.org/)
|
|
||||||
- [giantswarm blog](https://blog.giantswarm.io/)
|
- [giantswarm blog](https://blog.giantswarm.io/)
|
||||||
- [k8smeetup.com](http://www.k8smeetup.com)
|
- [k8smeetup.com](http://www.k8smeetup.com)
|
||||||
- [dockone.io](http://www.dockone.io)
|
- [dockone.io](http://www.dockone.io)
|
||||||
- [Cloud Native知乎专栏](https://zhuanlan.zhihu.com/cloud-native)
|
- [Cloud Native知乎专栏](https://zhuanlan.zhihu.com/cloud-native)
|
||||||
- [kubernetes.org.cn](https://www.kubernetes.org.cn/)
|
- [kubernetes.org.cn](https://www.kubernetes.org.cn/)
|
||||||
|
- [servicemesher.com](https://www.servicemesher.com)
|
||||||
|
|
||||||
### 博客
|
### 博客
|
||||||
|
|
||||||
- [apcera](https://www.apcera.com/blog)
|
|
||||||
- [aporeto](https://www.aporeto.com/blog/)
|
- [aporeto](https://www.aporeto.com/blog/)
|
||||||
- [applatix](https://applatix.com/blog/)
|
- [applatix](https://applatix.com/blog/)
|
||||||
- [apprenda](https://apprenda.com/blog/)
|
- [apprenda](https://apprenda.com/blog/)
|
||||||
|
|
@ -52,7 +64,6 @@ Kubernetes和Cloud Native相关网站、专栏、博客等。
|
||||||
- [containership](https://blog.containership.io/)
|
- [containership](https://blog.containership.io/)
|
||||||
- [coreos](https://coreos.com/blog/)
|
- [coreos](https://coreos.com/blog/)
|
||||||
- [coscale](https://www.coscale.com/blog)
|
- [coscale](https://www.coscale.com/blog)
|
||||||
- [deis](https://deis.com/blog/)
|
|
||||||
- [fabric8](https://blog.fabric8.io/)
|
- [fabric8](https://blog.fabric8.io/)
|
||||||
- [grafana](https://grafana.com/blog/)
|
- [grafana](https://grafana.com/blog/)
|
||||||
- [gravitational](https://gravitational.com/blog/)
|
- [gravitational](https://gravitational.com/blog/)
|
||||||
|
|
@ -68,9 +79,7 @@ Kubernetes和Cloud Native相关网站、专栏、博客等。
|
||||||
- [rancher](https://rancher.com/blog/)
|
- [rancher](https://rancher.com/blog/)
|
||||||
- [sysdig](https://sysdig.com/blog/)
|
- [sysdig](https://sysdig.com/blog/)
|
||||||
- [spinnaker](https://blog.spinnaker.io)
|
- [spinnaker](https://blog.spinnaker.io)
|
||||||
- [supergiant](https://supergiant.io/blog)
|
|
||||||
- [thecodeteam](https://blog.thecodeteam.com/)
|
|
||||||
- [twistlock](https://www.twistlock.com/blog/)
|
- [twistlock](https://www.twistlock.com/blog/)
|
||||||
- [vamp](https://medium.com/vamp-io)
|
- [vamp](https://medium.com/vamp-io)
|
||||||
- [weave](https://www.weave.works/blog/)
|
- [weave](https://www.weave.works/blog/)
|
||||||
- [wercker](http://blog.wercker.com/)
|
- [wercker](http://blog.wercker.com/)
|
||||||
|
|
|
||||||
|
|
@ -1,3 +1,3 @@
|
||||||
# Kubernetes及云原生年度总结及展望
|
# Kubernetes及云原生年度总结及展望
|
||||||
|
|
||||||
本节将聚焦Kubernetes及云原生技术的年度总结并展望下一年的发展。
|
本节将聚焦Kubernetes及云原生技术的年度总结并展望下一年的发展。
|
||||||
|
|
|
||||||
|
|
@ -35,7 +35,7 @@ spec:
|
||||||
|
|
||||||
我们可以在 Pod 中为容器使用 command 为容器指定启动参数:
|
我们可以在 Pod 中为容器使用 command 为容器指定启动参数:
|
||||||
|
|
||||||
```Bash
|
```bash
|
||||||
command: ["/bin/bash","-c","bootstrap.sh"]
|
command: ["/bin/bash","-c","bootstrap.sh"]
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
@ -205,7 +205,7 @@ data:
|
||||||
["8.8.8.8", "8.8.4.4"]
|
["8.8.8.8", "8.8.4.4"]
|
||||||
```
|
```
|
||||||
|
|
||||||
`upstreamNameservers` 即使用的外部DNS,参考:[Configuring Private DNS Zones and Upstream Nameservers in Kubernetes](http://blog.kubernetes.io/2017/04/configuring-private-dns-zones-upstream-nameservers-kubernetes.html)
|
`upstreamNameservers` 即使用的外部DNS。
|
||||||
|
|
||||||
## 8. 创建一个CentOS测试容器
|
## 8. 创建一个CentOS测试容器
|
||||||
|
|
||||||
|
|
|
||||||
24
book.json
24
book.json
|
|
@ -1,17 +1,12 @@
|
||||||
{
|
{
|
||||||
"title": "Kubernetes Handbook - Kubernetes中文指南/云原生应用架构实践手册 by Jimmy Song(宋净超)",
|
"title": "Kubernetes Handbook - Kubernetes中文指南/云原生应用架构实践手册 by Jimmy Song(宋净超)",
|
||||||
"description": "Kubernetes Handbook - Kubernetes中文指南/云原生应用架构实践手册,本书记录了本人从零开始学习和使用Kubernetes的心路历程,着重于经验分享和总结,同时也会有相关的概念解析,希望能够帮助大家少踩坑,少走弯路,还会指引大家关于关注Kubernetes生态周边,如微服务构建、DevOps、大数据应用、Service Mesh、Cloud Native等领域。",
|
"description": "Kubernetes Handbook - Kubernetes中文指南/云原生应用架构实践手册,本书记录了本人从零开始学习和使用Kubernetes的心路历程,着重于经验分享和总结,同时也会有相关的概念解析,希望能够帮助大家少踩坑,少走弯路,还会指引大家关注Kubernetes生态周边,如微服务构建、DevOps、大数据应用、Service Mesh、Cloud Native等领域。",
|
||||||
"language": "zh-hans",
|
"language": "zh-hans",
|
||||||
"author": "Jimmy Song(宋净超)",
|
"author": "Jimmy Song(宋净超)",
|
||||||
"links": {
|
"links": {
|
||||||
"sidebar": {
|
"sidebar": {
|
||||||
"Jimmy Song": "https://jimmysong.io",
|
"回到主页": "https://jimmysong.io",
|
||||||
"Awesome Cloud Native": "https://jimmysong.io/awesome-cloud-native",
|
"Awesome Cloud Native": "https://jimmysong.io/awesome-cloud-native"
|
||||||
"ServiceMesher": "http://www.servicemesher.com",
|
|
||||||
"Awesome Service Mesh": "http://www.servicemesher.com/awesome-servicemesh",
|
|
||||||
"Cloud Native Go - 基于Go和React的web云原生应用构建指南": "https://jimmysong.io/posts/cloud-native-go",
|
|
||||||
"Cloud Native Python(Python云原生) - 使用Python和React构建云原生应用": "https://jimmysong.io/posts/cloud-native-python",
|
|
||||||
"Cloud Native Java(云原生Java)- Spring Boot、Spring Cloud与Cloud Foundry弹性系统设计": "https://jimmysong.io/posts/cloud-native-java"
|
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"plugins": [
|
"plugins": [
|
||||||
|
|
@ -29,7 +24,11 @@
|
||||||
"3-ba",
|
"3-ba",
|
||||||
"theme-default",
|
"theme-default",
|
||||||
"-highlight", "prism", "prism-themes",
|
"-highlight", "prism", "prism-themes",
|
||||||
"sitemap-general"
|
"sitemap-general",
|
||||||
|
"lightbox",
|
||||||
|
"ga",
|
||||||
|
"copy-code-button",
|
||||||
|
"alerts"
|
||||||
],
|
],
|
||||||
"pluginsConfig": {
|
"pluginsConfig": {
|
||||||
"theme-default": {
|
"theme-default": {
|
||||||
|
|
@ -51,8 +50,8 @@
|
||||||
"size": "small"
|
"size": "small"
|
||||||
},
|
},
|
||||||
"tbfed-pagefooter": {
|
"tbfed-pagefooter": {
|
||||||
"copyright": "Copyright © jimmysong.io 2017-2018",
|
"copyright": "<p><a href=https://time.geekbang.org/column/intro/292?code=EhFrzVKvIro8U06UyaeLCCdmbpk7g010iXprzDxW17I%3D&utm_term=SPoster>给开发者和架构师的云计算指南 - 极客时间专栏《深入浅出云计算》</a> | <a href=https://jimmysong.io/contact/>加入云原生社区</a></p>Copyright © 2017-2020 | Distributed under <a href=https://creativecommons.org/licenses/by-nc-sa/4.0/deed.zh>CC BY 4.0</a> | <a href=https://jimmysong.io>jimmysong.io</a>",
|
||||||
"modify_label": "Updated at ",
|
"modify_label": " Updated at ",
|
||||||
"modify_format": "YYYY-MM-DD HH:mm:ss"
|
"modify_format": "YYYY-MM-DD HH:mm:ss"
|
||||||
},
|
},
|
||||||
"favicon": {
|
"favicon": {
|
||||||
|
|
@ -69,6 +68,9 @@
|
||||||
},
|
},
|
||||||
"sitemap-general": {
|
"sitemap-general": {
|
||||||
"prefix": "https://jimmysong.io/kubernetes-handbook/"
|
"prefix": "https://jimmysong.io/kubernetes-handbook/"
|
||||||
|
},
|
||||||
|
"ga": {
|
||||||
|
"token": "UA-93485976-1"
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
|
||||||
|
|
@ -1,4 +1,4 @@
|
||||||
# 云原生的定义
|
# 云原生(Cloud Native)的定义
|
||||||
|
|
||||||
[Pivotal](https://pivotal.io/) 是云原生应用的提出者,并推出了 [Pivotal Cloud Foundry](https://pivotal.io/platform) 云原生应用平台和 [Spring](https://spring.io/) 开源 Java 开发框架,成为云原生应用架构中先驱者和探路者。
|
[Pivotal](https://pivotal.io/) 是云原生应用的提出者,并推出了 [Pivotal Cloud Foundry](https://pivotal.io/platform) 云原生应用平台和 [Spring](https://spring.io/) 开源 Java 开发框架,成为云原生应用架构中先驱者和探路者。
|
||||||
|
|
||||||
|
|
@ -16,7 +16,7 @@
|
||||||
|
|
||||||
## CNCF最初的定义
|
## CNCF最初的定义
|
||||||
|
|
||||||
到了2015年Google主导成了云原生计算基金会(CNCF),起初CNCF对云原生(Cloud Native)的定义包含以下三个方面:
|
到了2015年Google主导成立了云原生计算基金会(CNCF),起初CNCF对云原生(Cloud Native)的定义包含以下三个方面:
|
||||||
|
|
||||||
- 应用容器化
|
- 应用容器化
|
||||||
- 面向微服务架构
|
- 面向微服务架构
|
||||||
|
|
@ -30,14 +30,16 @@
|
||||||
|
|
||||||
> Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach.
|
> Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach.
|
||||||
|
|
||||||
云原生技术帮助公司和机构在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用。云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式API。
|
云原生技术有利于各组织在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用。云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式API。
|
||||||
|
|
||||||
> These techniques enable loosely coupled systems that are resilient, manageable, and observable. Combined with robust automation, they allow engineers to make high-impact changes frequently and predictably with minimal toil.
|
> These techniques enable loosely coupled systems that are resilient, manageable, and observable. Combined with robust automation, they allow engineers to make high-impact changes frequently and predictably with minimal toil.
|
||||||
|
|
||||||
这些技术能够构建容错性好、易于管理和便于观察的松耦合系统。结合可靠的自动化手段,云原生技术可以使开发者轻松地对系统进行频繁并可预测的重大变更。
|
这些技术能够构建容错性好、易于管理和便于观察的松耦合系统。结合可靠的自动化手段,云原生技术使工程师能够轻松地对系统作出频繁和可预测的重大变更。
|
||||||
|
|
||||||
> The Cloud Native Computing Foundation seeks to drive adoption of this paradigm by fostering and sustaining an ecosystem of open source, vendor-neutral projects. We democratize state-of-the-art patterns to make these innovations accessible for everyone.
|
> The Cloud Native Computing Foundation seeks to drive adoption of this paradigm by fostering and sustaining an ecosystem of open source, vendor-neutral projects. We democratize state-of-the-art patterns to make these innovations accessible for everyone.
|
||||||
|
|
||||||
云原生计算基金会(CNCF)致力于培育和维护一个厂商中立的开源生态系统,来推广云原生技术。我们通过将最前沿的模式普惠,让这些创新为大众所用。
|
云原生计算基金会(CNCF)致力于培育和维护一个厂商中立的开源生态系统,来推广云原生技术。我们通过将最前沿的模式民主化,让这些创新为大众所用。
|
||||||
|
|
||||||
**注**:该定义的中文译本还未正式确定,详见[Cloud Native Definition in Chinese](https://docs.google.com/document/d/1-QhD9UeOqEBxaEiXrFP89EhG5K-MFJ4vsfNZOg6E9co/)。
|
## 参考
|
||||||
|
|
||||||
|
- [CNCF Cloud Native Definition v1.0 - github.com](https://github.com/cncf/toc/blob/master/DEFINITION.md)
|
||||||
|
|
@ -2,9 +2,9 @@
|
||||||
|
|
||||||
本文旨在帮助您快速部署一个云原生本地实验环境,让您可以基本不需要任何Kubernetes和云原生技术的基础就可以对云原生环境一探究竟。
|
本文旨在帮助您快速部署一个云原生本地实验环境,让您可以基本不需要任何Kubernetes和云原生技术的基础就可以对云原生环境一探究竟。
|
||||||
|
|
||||||
另外本环境也可以作为一个Kubernetes及其它云原生应用的测试与演示环境。
|
本文中使用[kubernetes-vagrant-centos-cluster](https://github.com/rootsongjc/kubernetes-vagrant-centos-cluster)在本地使用 Vagrant 启动三个虚拟机部署分布式的Kubernetes集群。
|
||||||
|
|
||||||
在GitHub上该repo:https://github.com/rootsongjc/kubernetes-vagrant-centos-cluster
|
如仅需要体验云原生环境和测试服务功能,可以使用更加轻量级的[cloud-native-sandbox](https://github.com/rootsongjc/cloud-native-sandbox),通过个人电脑的Docker部署单节点的Kubernetes、Istio等云原生环境。
|
||||||
|
|
||||||
## 准备环境
|
## 准备环境
|
||||||
|
|
||||||
|
|
@ -121,12 +121,6 @@ kubectl -n kube-system describe secret `kubectl -n kube-system get secret|grep a
|
||||||
|
|
||||||
**注意**:token的值也可以在`vagrant up`的日志的最后看到。
|
**注意**:token的值也可以在`vagrant up`的日志的最后看到。
|
||||||
|
|
||||||
也可以直接使用下面的token:
|
|
||||||
|
|
||||||
```ini
|
|
||||||
eyJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi10b2tlbi1rNzR6YyIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50Lm5hbWUiOiJhZG1pbiIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImY4NzBlZjU0LThiZWUtMTFlOC05NWU0LTUyNTQwMGFkM2I0MyIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDprdWJlLXN5c3RlbTphZG1pbiJ9.CLTKPT-mRYLkAWTIIQlAKE2JWoZY5ZS6jNO0KIN5MZCDkKuyUd8s3dnYmuIL2Qgu_KFXNhUuGLtYW4-xA1r2EqJ2qDMZDOHbgqk0suHI_BbNWMgIFeX5O1ZUOA34FcJl3hpLjyQBSZr07g3MGjM5qeMWqtXErW8v_7iHQg9o1wdhDK57S3rVCngHvjbCNNR6KO2_Eh1EZSvn4WeSzBo1F2yH0CH5kiOd9V-Do7t_ODuwhLmG60x0CqCrYt0jX1WSogdOuV0u2ZFF9RYM36TdV7770nbxY7hYk2tvVs5mxUH01qrj49kRJpoOxUeKTDH92b0aPSB93U7-y_NuVP7Ciw
|
|
||||||
```
|
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
**Heapster监控**
|
**Heapster监控**
|
||||||
|
|
@ -145,7 +139,7 @@ kubectl apply -f addon/heapster/
|
||||||
172.17.8.102 grafana.jimmysong.io
|
172.17.8.102 grafana.jimmysong.io
|
||||||
```
|
```
|
||||||
|
|
||||||
访问Grafana:<http://grafana.jimmysong.io>
|
访问Grafana:`http://grafana.jimmysong.io`
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
|
@ -165,6 +159,8 @@ kubectl apply -f addon/traefik-ingress
|
||||||
|
|
||||||
访问Traefik UI:<http://traefik.jimmysong.io>
|
访问Traefik UI:<http://traefik.jimmysong.io>
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
**EFK**
|
**EFK**
|
||||||
|
|
||||||
使用EFK做日志收集。
|
使用EFK做日志收集。
|
||||||
|
|
@ -211,14 +207,14 @@ istioctl create -f yaml/istio-bookinfo/bookinfo-gateway.yaml
|
||||||
|
|
||||||
| Service | URL |
|
| Service | URL |
|
||||||
| ------------ | ------------------------------------------------------------ |
|
| ------------ | ------------------------------------------------------------ |
|
||||||
| grafana | http://grafana.istio.jimmysong.io |
|
| grafana | `http://grafana.istio.jimmysong.io` |
|
||||||
| servicegraph | http://servicegraph.istio.jimmysong.io/dotviz>, <http://servicegraph.istio.jimmysong.io/graph>,http://servicegraph.istio.jimmysong.io/force/forcegraph.html |
|
| servicegraph | `http://servicegraph.istio.jimmysong.io/dotviz`, `http://servicegraph.istio.jimmysong.io/graph`, `http://servicegraph.istio.jimmysong.io/force/forcegraph.htm` |
|
||||||
| tracing | http://172.17.8.101:$JAEGER_PORT |
|
| tracing | `http://172.17.8.101:$JAEGER_PORT` |
|
||||||
| productpage | http://172.17.8.101:$GATEWAY_PORT/productpage |
|
| productpage | `http://172.17.8.101:$GATEWAY_PORT/productpage` |
|
||||||
|
|
||||||
**注意**:`JAEGER_PORT`可以通过`kubectl -n istio-system get svc tracing -o jsonpath='{.spec.ports[0].nodePort}'`获取,`GATEWAY_PORT`可以通过`kubectl -n istio-system get svc istio-ingressgateway -o jsonpath='{.spec.ports[0].nodePort}'`获取。
|
**注意**:`JAEGER_PORT`可以通过`kubectl -n istio-system get svc tracing -o jsonpath='{.spec.ports[0].nodePort}'`获取,`GATEWAY_PORT`可以通过`kubectl -n istio-system get svc istio-ingressgateway -o jsonpath='{.spec.ports[0].nodePort}'`获取。
|
||||||
|
|
||||||
详细信息请参阅 https://istio.io/docs/guides/bookinfo.html
|

|
||||||
|
|
||||||
### Vistio
|
### Vistio
|
||||||
|
|
||||||
|
|
@ -241,6 +237,44 @@ kubectl -n default port-forward $(kubectl -n default get pod -l app=vistio-web -
|
||||||
|
|
||||||
更多详细内容请参考[Vistio—使用Netflix的Vizceral可视化Istio service mesh](https://servicemesher.github.io/blog/vistio-visualize-your-istio-mesh-using-netflixs-vizceral/)。
|
更多详细内容请参考[Vistio—使用Netflix的Vizceral可视化Istio service mesh](https://servicemesher.github.io/blog/vistio-visualize-your-istio-mesh-using-netflixs-vizceral/)。
|
||||||
|
|
||||||
|
### Kiali
|
||||||
|
|
||||||
|
Kiali是一个用于提供Istio service mesh观察性的项目,更多信息请查看 [https://kiali.io](https://kiali.io/)。
|
||||||
|
|
||||||
|
在本地该项目的根路径下执行下面的命令:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl apply -n istio-system -f addon/kiali
|
||||||
|
```
|
||||||
|
|
||||||
|
Kiali web地址:`http://172.17.8.101:31439`
|
||||||
|
|
||||||
|
用户名/密码:admin/admin
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
**注意**:Kilia使用Jaeger做追踪,请不用屏蔽kilia页面的弹出窗口。
|
||||||
|
|
||||||
|
### Weave scope
|
||||||
|
|
||||||
|
[Weave scope](https://github.com/weaveworks/scope)可用于监控、可视化和管理Docker&Kubernetes集群,详情见 https://www.weave.works/oss/scope/
|
||||||
|
|
||||||
|
在本地该项目的根路径下执行下面的命令:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl apply -f addon/weave-scope
|
||||||
|
```
|
||||||
|
|
||||||
|
在本地的`/etc/hosts`下增加一条记录。
|
||||||
|
|
||||||
|
```
|
||||||
|
172.17.8.102 scope.weave.jimmysong.io
|
||||||
|
```
|
||||||
|
|
||||||
|
现在打开浏览器,访问 `http://scope.weave.jimmysong.io/`
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
## 管理
|
## 管理
|
||||||
|
|
||||||
除了特别说明,以下命令都在当前的repo目录下操作。
|
除了特别说明,以下命令都在当前的repo目录下操作。
|
||||||
|
|
@ -315,5 +349,5 @@ rm -rf .vagrant
|
||||||
|
|
||||||
- [Kubernetes handbook - jimmysong.io](https://jimmysong.io/kubernetes-handbook)
|
- [Kubernetes handbook - jimmysong.io](https://jimmysong.io/kubernetes-handbook)
|
||||||
- [duffqiu/centos-vagrant](https://github.com/duffqiu/centos-vagrant)
|
- [duffqiu/centos-vagrant](https://github.com/duffqiu/centos-vagrant)
|
||||||
- [Kubernetes 1.8 kube-proxy 开启 ipvs](https://mritd.me/2017/10/10/kube-proxy-use-ipvs-on-kubernetes-1.8/#%E4%B8%80%E7%8E%AF%E5%A2%83%E5%87%86%E5%A4%87)
|
- [coredns/deployment](https://github.com/coredns/deployment)
|
||||||
- [Vistio—使用Netflix的Vizceral可视化Istio service mesh](https://servicemesher.github.io/blog/vistio-visualize-your-istio-mesh-using-netflixs-vizceral/)
|
- [Vistio—使用Netflix的Vizceral可视化Istio service mesh](http://www.servicemesher.com/blog/vistio-visualize-your-istio-mesh-using-netflixs-vizceral/)
|
||||||
|
|
|
||||||
|
|
@ -0,0 +1,232 @@
|
||||||
|
# 云原生的设计哲学
|
||||||
|
|
||||||
|
云原生一词已经被过度的采用,很多软件都号称是云原生,很多打着云原生旗号的会议也如雨后春笋般涌现。
|
||||||
|
|
||||||
|
云原生本身甚至不能称为是一种架构,它首先是一种基础设施,运行在其上的应用称作云原生应用,只有符合云原生设计哲学的应用架构才叫云原生应用架构。
|
||||||
|
|
||||||
|
## 云原生的设计理念
|
||||||
|
|
||||||
|
云原生系统的设计理念如下:
|
||||||
|
|
||||||
|
- 面向分布式设计(Distribution):容器、微服务、API 驱动的开发;
|
||||||
|
- 面向配置设计(Configuration):一个镜像,多个环境配置;
|
||||||
|
- 面向韧性设计(Resistancy):故障容忍和自愈;
|
||||||
|
- 面向弹性设计(Elasticity):弹性扩展和对环境变化(负载)做出响应;
|
||||||
|
- 面向交付设计(Delivery):自动拉起,缩短交付时间;
|
||||||
|
- 面向性能设计(Performance):响应式,并发和资源高效利用;
|
||||||
|
- 面向自动化设计(Automation):自动化的 DevOps;
|
||||||
|
- 面向诊断性设计(Diagnosability):集群级别的日志、metric 和追踪;
|
||||||
|
- 面向安全性设计(Security):安全端点、API Gateway、端到端加密;
|
||||||
|
|
||||||
|
以上的设计理念很多都是继承自分布式应用的设计理念。虽然有如此多的理念但是我们仍然无法辨认什么样的设施才是云原生基础设施,不过可以先用排除法,我将解释什么不是云原生基础设施。
|
||||||
|
|
||||||
|
## 什么不是云原生基础设施?
|
||||||
|
|
||||||
|
云原生基础设施不等于在公有云上运行的基础设施。光是租用服务器并不会使您的基础设施云原生化。管理IaaS的流程与运维物理数据中心没什么两样,将现有架构迁移到云上也未必能获得回报。
|
||||||
|
|
||||||
|
云原生不是指在容器中运行应用程序。Netflix率先推出云原生基础设施时,几乎所有应用程序部署在虚拟机中,而不是在容器中。改变应用程序的打包方式并不意味着就会增加自治系统的可扩展性和优势。即使应用程序是通过CI/CD渠道自动构建和部署的,也不意味着您就可以从增强API驱动部署的基础设施中受益。
|
||||||
|
|
||||||
|
这也并不意味着您只能运行容器编排器(例如Kubernetes和Mesos)。容器编排器提供了云原生基础设施所需的许多平台功能,但并未按预期方式使用这些功能,这意味着您的应用程序会在一组服务器上运行,被动态调度。这是一个非常好的起步,但仍有许多工作要做。
|
||||||
|
|
||||||
|
> **调度器与编排器**
|
||||||
|
>
|
||||||
|
> 术语“调度器”和“编排器”通常可以互换使用。
|
||||||
|
>
|
||||||
|
> 在大多数情况下,编排器负责集群中的所有资源利用(例如:存储,网络和CPU)。该术语典型地用于描述执行许多任务的产品,如健康检查和云自动化。
|
||||||
|
|
||||||
|
调度器是编排平台的一个子集,仅负责选择运行在每台服务器上的进程和服务。
|
||||||
|
|
||||||
|
云原生不是微服务或基础设施即代码。微服务意味着更快的开发周期和更小的独特功能,但是单片应用程序可以具有相同的功能,使其能够通过软件有效管理,并且还可以从云原生基础设施中受益。
|
||||||
|
|
||||||
|
基础设施即代码以机器可解析语言或领域特定语言(DSL)定义、自动化您的基础设施。将代码应用于基础架构的传统工具包括配置管理工具(例如Chef和Puppet)。这些工具在自动执行任务和提供一致性方面有很大帮助,但是它们在提供必要的抽象来描述超出单个服务器的基础设施方面存在缺陷。
|
||||||
|
|
||||||
|
配置管理工具一次自动化一台服务器,并依靠人员将服务器提供的功能绑定在一起。这将人类定位为基础设施规模的潜在瓶颈。这些工具也不会使构建完整系统所需的云基础设施(例如存储和网络)的额外部分自动化。
|
||||||
|
|
||||||
|
尽管配置管理工具为操作系统的资源(例如软件包管理器)提供了一些抽象,但它们并没有抽象出足够的底层操作系统来轻松管理它。如果一位工程师想要管理系统中的每个软件包和文件,这将是一个非常艰苦的过程,并且对于每个配置变体都是独一无二的。同样,定义不存在或不正确的资源的配置管理仅消耗系统资源并且不能提供任何价值。
|
||||||
|
|
||||||
|
虽然配置管理工具可以帮助自动化部分基础设施,但它们无法更好地管理应用程序。我们将在后面的章节中通过查看部署,管理,测试和操作基础架构的流程,探讨云原生基础设施的不同之处,但首先,我们将了解哪些应用程序是成功的以及应该何时与原生基础设施一起使用。
|
||||||
|
|
||||||
|
## 云原生应用程序
|
||||||
|
|
||||||
|
就像云改变了业务和基础设施之间的关系一样,云原生应用程序也改变了应用程序和基础设施之间的关系。我们需要了解与传统应用程序相比,云本身有什么不同,因此我们需要了解它们与基础设施的新关系。
|
||||||
|
|
||||||
|
为了写好本书,也为了有一个共享词汇表,我们需要定义“云原生应用程序”是什么意思。云原生与12因素应用程序不同,即使它们可能共享一些类似的特征。如果你想了解更多细节,请阅读Kevin Hoffman撰写的“超越12因素应用程序”(O'Reilly,2012)。
|
||||||
|
|
||||||
|
云原生应用程序被设计为在平台上运行,并设计用于弹性,敏捷性,可操作性和可观察性。弹性包含失败而不是试图阻止它们;它利用了在平台上运行的动态特性。敏捷性允许快速部署和快速迭代。可操作性从应用程序内部控制应用程序生命周期,而不是依赖外部进程和监视器。可观察性提供信息来回答有关应用程序状态的问题。
|
||||||
|
|
||||||
|
> **云原生定义**
|
||||||
|
>
|
||||||
|
> 云原生应用程序的定义仍在发展中。还有像CNCF这样的组织可以提供其他的定义。
|
||||||
|
|
||||||
|
云原生应用程序通过各种方法获取这些特征。它通常取决于应用程序的运行位置以及企业流程和文化。以下是实现云原生应用程序所需特性的常用方法:
|
||||||
|
|
||||||
|
- 微服务
|
||||||
|
- 健康报告
|
||||||
|
- 遥测数据
|
||||||
|
- 弹性
|
||||||
|
- 声明式的,而不是命令式的
|
||||||
|
|
||||||
|
### 微服务
|
||||||
|
|
||||||
|
作为单个实体进行管理和部署的应用程序通常称为单体应用。最初开发应用程序时,单体有很多好处。它们更易于理解,并允许您在不影响其他服务的情况下更改主要功能。
|
||||||
|
|
||||||
|
随着应用程序复杂性的增长,单体应用的益处逐渐减少。它们变得更难理解,而且失去了敏捷性,因为工程师很难推断和修改代码。
|
||||||
|
|
||||||
|
对付复杂性的最好方法之一是将明确定义的功能分成更小的服务,并让每个服务独立迭代。这增加了应用程序的灵活性,允许根据需要更轻松地更改部分应用程序。每个微服务可以由单独的团队进行管理,使用适当的语言编写,并根据需要进行独立扩缩容。
|
||||||
|
|
||||||
|
只要每项服务都遵守强有力的合约,应用程序就可以快速改进和改变。当然,转向微服务架构还有许多其他的考虑因素。其中最不重要的是弹性通信,我们在附录A中有讨论。
|
||||||
|
|
||||||
|
我们无法考虑转向微服务的所有考虑因素。拥有微服务并不意味着您拥有云原生基础设施。如果您想阅读更多,我们推荐Sam Newman的Building Microservices(O'Reilly,2015)。虽然微服务是实现您的应用程序灵活性的一种方式,但正如我们之前所说的,它们不是云原生应用程序的必需条件。
|
||||||
|
|
||||||
|
### 健康报告
|
||||||
|
|
||||||
|
> 停止逆向工程应用程序并开始从内部进行监控。 —— Kelsey Hightower,Monitorama PDX 2016:healthz
|
||||||
|
|
||||||
|
没有人比开发人员更了解应用程序需要什么才能以健康的状态运行。很长一段时间,基础设施管理员都试图从他们负责运行的应用程序中找出“健康”该怎么定义。如果不实际了解应用程序的健康状况,他们尝试在应用程序不健康时进行监控并发出警报,这往往是脆弱和不完整的。
|
||||||
|
|
||||||
|
为了提高云原生应用程序的可操作性,应用程序应该暴露健康检查。开发人员可以将其实施为命令或过程信号,以便应用程序在执行自我检查之后响应,或者更常见的是:通过应用程序提供Web服务,返回HTTP状态码来检查健康状态。
|
||||||
|
|
||||||
|
> **Google Borg示例**
|
||||||
|
>
|
||||||
|
> Google的Borg报告中列出了一个健康报告的例子:
|
||||||
|
>
|
||||||
|
> 几乎每个在Borg下运行的任务都包含一个内置的HTTP服务器,该服务器发布有关任务运行状况和数千个性能指标(如RPC延迟)的信息。Borg会监控运行状况检查URL并重新启动不及时响应或返回HTTP错误代码的任务。其他数据由监控工具跟踪,用于仪表板和服务级别目标(SLO)违规警报。
|
||||||
|
|
||||||
|
将健康责任转移到应用程序中使应用程序更容易管理和自动化。应用程序应该知道它是否正常运行以及它依赖于什么(例如,访问数据库)来提供业务价值。这意味着开发人员需要与产品经理合作来定义应用服务的业务功能并相应地编写测试。
|
||||||
|
|
||||||
|
提供健康检查的应用程序示例包括Zookeeper的ruok命令和etcd的HTTP / 健康端点。
|
||||||
|
|
||||||
|
应用程序不仅仅有健康或不健康的状态。它们将经历一个启动和关闭过程,在这个过程中它们应该通过健康检查,报告它们的状态。如果应用程序可以让平台准确了解它所处的状态,平台将更容易知道如何操作它。
|
||||||
|
|
||||||
|
一个很好的例子就是当平台需要知道应用程序何时可以接收流量。在应用程序启动时,如果它不能正确处理流量,它就应该表现为未准备好。此额外状态将防止应用程序过早终止,因为如果运行状况检查失败,平台可能会认为应用程序不健康,并且会反复停止或重新启动它。
|
||||||
|
|
||||||
|
应用程序健康只是能够自动化应用程序生命周期的一部分。除了知道应用程序是否健康之外,您还需要知道应用程序是否正在进行哪些工作。这些信息来自遥测数据。
|
||||||
|
|
||||||
|
### 遥测数据
|
||||||
|
|
||||||
|
遥测数据是进行决策所需的信息。确实,遥测数据可能与健康报告重叠,但它们有不同的用途。健康报告通知我们应用程序生命周期状态,而遥测数据通知我们应用程序业务目标。
|
||||||
|
|
||||||
|
您测量的指标有时称为服务级指标(SLI)或关键性能指标(KPI)。这些是特定于应用程序的数据,可以确保应用程序的性能处于服务级别目标(SLO)内。如果您需要更多关于这些术语的信息以及它们与您的应用程序、业务需求的关系,我们推荐你阅读来自Site Reliability Engineering(O'Reilly)的第4章。
|
||||||
|
|
||||||
|
遥测和度量标准用于解决以下问题:
|
||||||
|
|
||||||
|
- 应用程序每分钟收到多少请求?
|
||||||
|
- 有没有错误?
|
||||||
|
- 什么是应用程序延迟?
|
||||||
|
- 订购需要多长时间?
|
||||||
|
|
||||||
|
通常会将数据刮取或推送到时间序列数据库(例如Prometheus或InfluxDB)进行聚合。遥测数据的唯一要求是它将被收集数据的系统格式化。
|
||||||
|
|
||||||
|
至少,可能最好实施度量标准的RED方法,该方法收集应用程序的速率,错误和执行时间。
|
||||||
|
|
||||||
|
**请求率**
|
||||||
|
|
||||||
|
收到了多少个请求
|
||||||
|
|
||||||
|
**错误**
|
||||||
|
|
||||||
|
应用程序有多少错误
|
||||||
|
|
||||||
|
**时间**
|
||||||
|
|
||||||
|
多久才能收到回复
|
||||||
|
|
||||||
|
遥测数据应该用于提醒而非健康监测。在动态的、自我修复的环境中,我们更少关注单个应用程序实例的生命周期,更多关注关于整体应用程序SLO的内容。健康报告对于自动应用程序管理仍然很重要,但不应该用于页面工程师。
|
||||||
|
|
||||||
|
如果1个实例或50个应用程序不健康,只要满足应用程序的业务需求,我们可能不会收到警报。度量标准可让您知道您是否符合您的SLO,应用程序的使用方式以及对于您的应用程序来说什么是“正常”。警报有助于您将系统恢复到已知的良好状态。
|
||||||
|
|
||||||
|
> 如果它移动,我们跟踪它。有时候我们会画出一些尚未移动的图形,以防万一它决定为它运行。
|
||||||
|
>
|
||||||
|
> ——Ian Malpass,衡量所有,衡量一切
|
||||||
|
|
||||||
|
警报也不应该与日志记录混淆。记录用于调试,开发和观察模式。它暴露了应用程序的内部功能。度量有时可以从日志(例如错误率)计算,但需要额外的聚合服务(例如ElasticSearch)和处理。
|
||||||
|
|
||||||
|
### 弹性
|
||||||
|
|
||||||
|
一旦你有遥测和监测数据,你需要确保你的应用程序对故障有适应能力。弹性是基础设施的责任,但云原生应用程序也需要承担部分工作。
|
||||||
|
|
||||||
|
基础设施被设计为抵制失败。硬件用于需要多个硬盘驱动器,电源以及全天候监控和部件更换以保持应用程序可用。使用云原生应用程序,应用程序有责任接受失败而不是避免失败。
|
||||||
|
|
||||||
|
> 在任何平台上,尤其是在云中,最重要的特性是其可靠性。
|
||||||
|
>
|
||||||
|
> ——David Rensin,e ARCHITECT Show:来自Google的关于云计算的速成课程
|
||||||
|
|
||||||
|
设计具有弹性的应用程序可能是整本书本身。我们将在云原生应用程序中考虑弹性的两个主要方面:为失败设计和优雅降级。
|
||||||
|
|
||||||
|
#### 为失败设计
|
||||||
|
|
||||||
|
唯一永远不会失败的系统是那些让你活着的系统(例如心脏植入物和刹车系统)。如果您的服务永远不会停止运行,您需要花费太多时间设计它们来抵制故障,并且没有足够的时间增加业务价值。您的SLO确定服务需要多长时间。您花费在工程设计上超出SLO的正常运行时间的任何资源都将被浪费掉。
|
||||||
|
|
||||||
|
您应该为每项服务测量两个值,即平均无故障时间(MTBF)和平均恢复时间(MTTR)。监控和指标可以让您检测您是否符合您的SLO,但运行应用程序的平台是保持高MTBF和低MTTR的关键。
|
||||||
|
|
||||||
|
在任何复杂的系统中,都会有失败。您可以管理硬件中的某些故障(例如,RAID和冗余电源),以及某些基础设施中的故障(例如负载平衡器)。但是因为应用程序知道他们什么时候健康,所以他们也应该尽可能地管理自己的失败。
|
||||||
|
|
||||||
|
设计一个以失败期望为目标的应用程序将比假定可用性的应用程序更具防御性。当故障不可避免时,将会有额外的检查,故障模式和日志内置到应用程序中。
|
||||||
|
|
||||||
|
知道应用程序可能失败的每种方式是不可能的。假设任何事情都可能并且可能会失败,这是一种云原生应用程序的模式。
|
||||||
|
|
||||||
|
您的应用程序的最佳状态是健康状态。第二好的状态是失败状态。其他一切都是非二进制的,难以监控和排除故障。 Honeycomb首席执行官CharityMajors在她的文章“Ops:现在每个人都在工作”中指出:“分布式系统永远不会起作用;它们处于部分退化服务的持续状态。接受失败,设计弹性,保护和缩小关键路径。”
|
||||||
|
|
||||||
|
无论发生什么故障,云原生应用程序都应该是可适应的。他们期望失败,所以他们在检测到时进行调整。
|
||||||
|
|
||||||
|
有些故障不能也不应该被设计到应用程序中(例如,网络分区和可用区故障)。该平台应自主处理未集成到应用程序中的故障域。
|
||||||
|
|
||||||
|
#### 优雅降级
|
||||||
|
|
||||||
|
云原生应用程序需要有一种方法来处理过载,无论它是应用程序还是负载下的相关服务。处理负载的一种方式是优雅降级。 “站点可靠性工程”一书中描述了应用程序的优雅降级,因为它提供的响应在负载过重的情况下“不如正常响应准确或含有较少数据的响应,但计算更容易”。
|
||||||
|
|
||||||
|
减少应用程序负载的某些方面由基础设施处理。智能负载平衡和动态扩展可以提供帮助,但是在某些时候,您的应用程序可能承受的负载比它可以处理的负载更多。云原生应用程序需要知道这种必然性并作出相应的反应。
|
||||||
|
|
||||||
|
优雅降级的重点是允许应用程序始终返回请求的答案。如果应用程序没有足够的本地计算资源,并且依赖服务没有及时返回信息,则这是正确的。依赖于一个或多个其他服务的服务应该可用于应答请求,即使依赖于服务不是。当服务退化时,返回部分答案或使用本地缓存中的旧信息进行答案是可能的解决方案。
|
||||||
|
|
||||||
|
尽管优雅的降级和失败处理都应该在应用程序中实现,但平台的多个层面应该提供帮助。如果采用微服务,则网络基础设施成为需要在提供应用弹性方面发挥积极作用的关键组件。有关构建弹性网络层的更多信息,请参阅附录A。
|
||||||
|
|
||||||
|
> **可用性数学**
|
||||||
|
>
|
||||||
|
> 云原生应用程序需要在基础设施之上建立一个平台,以使基础设施更具弹性。如果您希望将现有应用程序“提升并转移”到云中,则应检查云提供商的服务级别协议(SLA),并考虑在使用多个服务时会发生什么情况。
|
||||||
|
>
|
||||||
|
> 让我们拿运行我们的应用程序的云来进行假设。
|
||||||
|
>
|
||||||
|
> 计算基础设施的典型可用性是每月99.95%的正常运行时间。这意味着您的实例每天可能会缩短到43.2秒,并且仍在您的云服务提供商的SLA中。
|
||||||
|
>
|
||||||
|
> 另外,实例的本地存储(例如EBS卷)也具有99.95%的可用性正常运行时间。如果幸运的话,他们都会同时出现故障,但最糟糕的情况是他们可能会在不同的时间停机,让您的实例只有99.9%的可用性。
|
||||||
|
>
|
||||||
|
> 您的应用程序可能还需要一个数据库,而不是自己安装一个计算可能的停机时间为1分26秒(99.9%可用性)的情况下,选择可靠性为99.95%的更可靠的托管数据库。这使您的应用程序的可靠性达到99.85%,或者每天可能发生2分钟和9秒的宕机时间。
|
||||||
|
>
|
||||||
|
> 将可用性乘到一起可以快速了解为什么应以不同方式处理云。真正不好的部分是,如果云提供商不符合其SLA,它将退还其账单中一定比例的退款。
|
||||||
|
>
|
||||||
|
> 虽然您不必为停机支付费用,但我们并不知道世界上存在云计算信用的单一业务。如果您的应用程序的可用性不足以超过您收到的信用额度,那么您应该真正考虑是否应该运行这个应用程序。
|
||||||
|
|
||||||
|
### 声明式,非反应式
|
||||||
|
|
||||||
|
由于云原生应用程序设计为在云环境中运行,因此它们与基础设施和支持应用程序的交互方式与传统应用程序不同。在云原生应用程序中,与任何事物进行通信的方式都是通过网络进行的。很多时候,网络通信都是通过RESTful HTTP调用完成的,但它也可以通过其他接口(如远程过程调用(RPC))来实现。
|
||||||
|
|
||||||
|
传统的应用程序会通过消息队列,写在共享存储上的文件或触发shell命令的本地脚本来自动执行任务。通信方法对发生的事件作出反应(例如,如果用户单击提交,运行提交脚本)并且通常需要存在于同一物理或虚拟服务器上的信息。
|
||||||
|
|
||||||
|
> **Serverless**
|
||||||
|
>
|
||||||
|
> 无服务器平台是云原生化的,并通过设计对事件做出响应。他们在云中工作得很好的原因是他们通过HTTP API进行通信,是单用途功能,并且在他们所称的功能中声明。该平台还可以通过在云中进行扩展和访问来提供帮助。
|
||||||
|
|
||||||
|
传统应用程序中的反应性通信常常是尝试增强弹性。如果应用程序在磁盘或消息队列中写入文件,然后应用程序死亡,则消息或文件的结果仍可能完成。
|
||||||
|
|
||||||
|
这并不是说不应该使用像消息队列这样的技术,而是说它们不能被依赖于动态和不断发生故障的系统中的唯一弹性层。从根本上讲,应用程序之间的通信应该在云原生环境中改变 - 不仅因为还有其他方法来构建通信弹性(请参阅附录A),还因为在云中复制传统通信方法往往需要更多工作。
|
||||||
|
|
||||||
|
当应用程序可以信任通信的弹性时,他们应该停止反应并开始声明。声明式沟通相信网络将传递消息。它也相信应用程序将返回成功或错误。这并不是说应用程序监视变化并不重要。 Kubernetes的控制器正是这样做到API服务器。但是,一旦发现变更,他们就会声明一个新的状态,并相信API服务器和kubelets会做必要的事情。
|
||||||
|
|
||||||
|
声明式通信模型由于多种原因而变得更加健壮。最重要的是,它规范了通信模型,并且它将功能实现从应用程序转移到远程API或服务端点,从而实现某种状态到达期望状态。这有助于简化应用程序,并使它们彼此的行为更具可预测性。
|
||||||
|
|
||||||
|
### 云原生应用程序如何影响基础设施?
|
||||||
|
|
||||||
|
希望你可以知道云原生应用程序与传统应用程序不同。云原生应用程序不能直接在PaaS上运行或与服务器的操作系统紧密耦合。它们期望在一个拥有大多数自治系统的动态环境中运行。
|
||||||
|
|
||||||
|
云原生基础设施在提供自主应用管理的IaaS之上创建了一个平台。该平台建立在动态创建的基础设施之上,以抽象出单个服务器并促进动态资源分配调度。
|
||||||
|
|
||||||
|
自动化与自治不一样。自动化使人类对他们所采取的行动产生更大的影响。
|
||||||
|
|
||||||
|
云原生是关于不需要人类做出决定的自治系统。它仍然使用自动化,但只有在决定了所需的操作之后。只有在系统不能自动确定正确的事情时才应该通知人。
|
||||||
|
|
||||||
|
具有这些特征的应用程序需要一个能够实际监控,收集度量标准并在发生故障时做出反应的平台。云原生应用程序不依赖于人员设置ping检查或创建Syslog规则。他们需要从选择基本操作系统或软件包管理器的过程中提取自助服务资源,并依靠服务发现和强大的网络通信来提供丰富的功能体验。
|
||||||
|
|
||||||
|
## 参考
|
||||||
|
|
||||||
|
- [“Cloud Native Infrastructure”, a Free O’Reilly eBook](https://blog.heptio.com/i-still-remember-the-first-time-i-logged-into-a-production-server-over-ssh-and-telling-myself-i-53ab1d1e7f46)
|
||||||
|
|
@ -2,7 +2,7 @@
|
||||||
|
|
||||||
当我第一眼看到 [Ballerina](https://ballerina.io) 还真有点惊艳的感觉。Ballerina 这个单词的意思是“芭蕾舞女演员”。我想他们之所以给公司和这们语言起这个名字,可能是希望它成为云原生这个大舞台中,Ballerina 能像一个灵活的芭蕾舞者一样轻松自如吧!
|
当我第一眼看到 [Ballerina](https://ballerina.io) 还真有点惊艳的感觉。Ballerina 这个单词的意思是“芭蕾舞女演员”。我想他们之所以给公司和这们语言起这个名字,可能是希望它成为云原生这个大舞台中,Ballerina 能像一个灵活的芭蕾舞者一样轻松自如吧!
|
||||||
|
|
||||||
Ballerina 是一款开源的编译式的强类型语言,该语言本身的代码可以通过 [GitHub](https://github.com/ballerina-platform/ballerina-lang) 上获取。我们可以通过 Ballerina 官网上的[设计哲学](https://ballerina.io/philosophy/)页面来对这门云原生编程语言一探究竟。
|
Ballerina 是一款开源的编译式的强类型语言,该语言本身的代码可以通过 [GitHub](https://github.com/ballerina-platform/ballerina-lang) 上获取。我们可以通过 Ballerina 官网上的设计哲学页面来对这门云原生编程语言一探究竟。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
|
@ -183,4 +183,4 @@ Ballerina 是一种旨在**集成简化**的语言。基于顺序图的交互,
|
||||||
## 参考
|
## 参考
|
||||||
|
|
||||||
- https://ballerina.io
|
- https://ballerina.io
|
||||||
- [Microservices, Docker, Kubernetes, Serverless, Service Mesh, and Beyond](https://dzone.com/articles/microservices-docker-kubernetes-serverless-service)
|
- [Microservices, Docker, Kubernetes, Serverless, Service Mesh, and Beyond](https://dzone.com/articles/microservices-docker-kubernetes-serverless-service)
|
||||||
|
|
|
||||||
|
|
@ -4,7 +4,7 @@
|
||||||
|
|
||||||
下文部分来自Joe Duffy的博客[Hello, Pulumi](http://joeduffyblog.com/2018/06/18/hello-pulumi/)!
|
下文部分来自Joe Duffy的博客[Hello, Pulumi](http://joeduffyblog.com/2018/06/18/hello-pulumi/)!
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
TL;DR 有了Pulumi,38页的手动操作说明将变成了38行代码。25000行YAML配置变成了使用真实编程语言的500行语句。
|
TL;DR 有了Pulumi,38页的手动操作说明将变成了38行代码。25000行YAML配置变成了使用真实编程语言的500行语句。
|
||||||
|
|
||||||
|
|
@ -151,4 +151,4 @@ $ curl -fsSL https://get.pulumi.com | sh
|
||||||
## 参考
|
## 参考
|
||||||
|
|
||||||
- [Pulumi](https://pulumi.io)
|
- [Pulumi](https://pulumi.io)
|
||||||
- [Hello, Pulumi!](http://joeduffyblog.com/2018/06/18/hello-pulumi/)
|
- [Hello, Pulumi!](http://joeduffyblog.com/2018/06/18/hello-pulumi/)
|
||||||
|
|
|
||||||
|
|
@ -1,6 +1,6 @@
|
||||||
# 云原生编程语言
|
# 云原生编程语言
|
||||||
|
|
||||||
> 以下内容来自Joe Duffy的博客,[Hello, Pulumi!](joeduffyblog.com/2018/06/18/hello-pulumi/)。他说这些是为了说明为什么要创造Pulumi,在此我引用它说明为什么会有云原生编程语言。
|
> 以下内容来自Joe Duffy的博客,[Hello, Pulumi!](http://joeduffyblog.com/2018/06/18/hello-pulumi/)。他说这些是为了说明为什么要创造Pulumi,在此我引用它说明为什么会有云原生编程语言。
|
||||||
|
|
||||||
对于每一个serverless函数来说,我都要写几十行的JSON或者YAML配置。要链接到一个API端点,我还要学习晦涩的概念,执行一系列复制-粘贴的低级工作。如果我想在本机上运行一个小的集群的话,那么Docker还是很棒的,但是如果要在生产上使用的话,那么就要手动管理etcd集群,配置网络和iptables路由表,还有一系列与我的应用程序本身不相干的事情。不过Kubernetes的出现至少让我可以配置一次下次就可以跨云平台重用,但这还是会分散开发人员的精力。
|
对于每一个serverless函数来说,我都要写几十行的JSON或者YAML配置。要链接到一个API端点,我还要学习晦涩的概念,执行一系列复制-粘贴的低级工作。如果我想在本机上运行一个小的集群的话,那么Docker还是很棒的,但是如果要在生产上使用的话,那么就要手动管理etcd集群,配置网络和iptables路由表,还有一系列与我的应用程序本身不相干的事情。不过Kubernetes的出现至少让我可以配置一次下次就可以跨云平台重用,但这还是会分散开发人员的精力。
|
||||||
|
|
||||||
|
|
@ -18,4 +18,4 @@
|
||||||
|
|
||||||
使用这种相同类型的配置表示基于容器的微服务、serverless和细粒度托管服务之间的关系导致了异常的复杂性。将应用程序转变为分布式系统应该是事后的想法。事实证明,云覆盖了您的架构和设计。表达架构和设计的最好的方式是使用代码,使用真正的编程语言编写抽象,重用和优秀的工具。
|
使用这种相同类型的配置表示基于容器的微服务、serverless和细粒度托管服务之间的关系导致了异常的复杂性。将应用程序转变为分布式系统应该是事后的想法。事实证明,云覆盖了您的架构和设计。表达架构和设计的最好的方式是使用代码,使用真正的编程语言编写抽象,重用和优秀的工具。
|
||||||
|
|
||||||
早些时候,Eric和我采访了几十个客户。我们发现,开发人员和DevOps工程师都普遍感到幻灭。我们发现了极端的专业化,即使在同一个团队中,工程师也不会使用同一种语言。最近几周我已经听到了这个消息,我期待有一天会出现NoYAML运动。
|
早些时候,Eric和我采访了几十个客户。我们发现,开发人员和DevOps工程师都普遍感到幻灭。我们发现了极端的专业化,即使在同一个团队中,工程师也不会使用同一种语言。最近几周我已经听到了这个消息,我期待有一天会出现NoYAML运动。
|
||||||
|
|
|
||||||
|
|
@ -0,0 +1,42 @@
|
||||||
|
## CNCF Ambassador
|
||||||
|
|
||||||
|
CNCF Ambassador(CNCF 大使),人员名单详见 <https://www.cncf.io/people/ambassadors/>,笔者很荣幸作为第二位成为 CNCF Ambassador 的中国人。
|
||||||
|
|
||||||
|
## 如何成为 CNCF Ambassador
|
||||||
|
|
||||||
|
可以通过以下方式成为 CNCF Ambassador:
|
||||||
|
|
||||||
|
- 成为 CNCF 会员或对成为某个 CNCF 的项目的贡献者
|
||||||
|
- 以 contributor、blogger、演讲者等身份参与 CNCF 社区项目
|
||||||
|
- 在社区中演讲或撰写博客
|
||||||
|
- 主持云原生社区 meetup
|
||||||
|
|
||||||
|
### 捷径
|
||||||
|
|
||||||
|
只要通过组织和举办推广 CNCF 推广的技术相关的活动即可,具体步骤如下:
|
||||||
|
|
||||||
|
1. 在 [meetup.com](https://www.meetup.com) 上创建一个 group(费用大概半年$42)
|
||||||
|
1. 以策展人名义组织与 CNCF 提倡的云原生主题相关的 meetup
|
||||||
|
1. 将活动加入到 CNCF group(<https://www.meetup.com/pro/cncf>)和为活动申请使用 CNCF logo(<https://github.com/cncf/meetups#how-to-apply>)
|
||||||
|
1. 申请成为 CNCF Ambassador:<https://github.com/cncf/ambassadors> 附上自己最近三个月内举办的 meetup 链接(CNCF 只认 meetup.com 里的活动)
|
||||||
|
|
||||||
|
关于 CNCF meetup 的更多信息请访问:<https://github.com/cncf/meetups/>
|
||||||
|
|
||||||
|
## 成为 CNCF 大使有什么好处?
|
||||||
|
|
||||||
|
这是一个被经常问到的问题,毕竟全球各地的 CNCF 大使推广云原生技术,总得给他们一些甜头。以下是成为 CNCF 大使的好处:
|
||||||
|
|
||||||
|
- 组织社区聚会可以报销 $150/月
|
||||||
|
- 可按年度申请 CNCF 项目的贴纸
|
||||||
|
- CNCF 会议折扣
|
||||||
|
- 免费参加 CNCF CKA/CKAD 考试
|
||||||
|
- 一次在 [CNCF Store](https://store.cncf.io/) 免费购买纪念品的权利
|
||||||
|
- 支持与当地发现演讲者的聚会和活动
|
||||||
|
- 在云原生行业活动中演讲(差旅费用报销,需申请)
|
||||||
|
- 发布博客的机会(CNCF 博客、Kubernetes 博客及其他业界知名平台)
|
||||||
|
- 社交媒体推广支持
|
||||||
|
|
||||||
|
## 参考:
|
||||||
|
|
||||||
|
- <https://github.com/cncf/ambassadors>
|
||||||
|
- <https://www.cncf.io/people/ambassadors/>
|
||||||
|
|
@ -1,12 +1,12 @@
|
||||||
# CNCF章程
|
# CNCF章程
|
||||||
|
|
||||||
CNCF(云原生计算基金会)是Linux基金会旗下的一个基金会,加入CNCF等于同时加入Linux基金会(也意味着你还要交Linux基金会的份子钱),对于想加入CNCF基金会的企业或者组织首先要做的事情就是要了解CNCF的章程(charter),就像是作为一个国家的公民,必须遵守该国家的宪法一样。CNCF之所以能在短短三年的时间内发展壮大到如此规模,很大程度上是与它出色的社区治理和运作模式有关。了解该章程可以帮助我们理解CNCF是如何运作的,也可以当我们自己进行开源项目治理时派上用场。
|
CNCF(云原生计算基金会)是Linux基金会旗下的一个基金会,加入CNCF等于同时加入Linux基金会(也意味着你还要交Linux基金会的份子钱),对于想加入CNCF基金会的企业或者组织首先要做的事情就是要了解CNCF的章程(charter),就像是作为一个国家的公民,必须遵守该国家的宪法一样。CNCF之所以能在短短三年的时间内发展壮大到如此规模,很大程度上是与它出色的社区治理和运作模式有关。了解该章程可以帮助我们理解CNCF是如何运作的,当我们自己进行开源项目治理时也可以派上用场。
|
||||||
|
|
||||||
该章程最后更新于2018年5月15日,详见<https://www.cncf.io/about/charter/>。下文中关于CNCF章程的介绍部分引用自[CNCF 是如何工作的](http://www.ocselected.org/posts/foundation_introduce/how_cncf_works/),有改动。
|
该章程最后更新于2018年5月15日,详见<https://www.cncf.io/about/charter/>。下文中关于CNCF章程的介绍部分引用自[CNCF 是如何工作的](http://www.ocselected.org/posts/foundation_introduce/how_cncf_works/),有改动。
|
||||||
|
|
||||||
下图是我根据CNCF章程绘制的组织架构图。
|
下图是我根据CNCF章程绘制的组织架构图。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
## 1. CNCF的使命
|
## 1. CNCF的使命
|
||||||
|
|
||||||
|
|
@ -42,8 +42,8 @@ d) 通过使技术可访问和可靠来为社区服务
|
||||||
|
|
||||||
CNCF 会极力遵循以下一些原则:
|
CNCF 会极力遵循以下一些原则:
|
||||||
|
|
||||||
1. **快速胜过磨叽**,基金会的初衷之一就是让项目快速的发展,从而支持用户能够积极的使用。
|
1. **快速胜过磨叽**:基金会的初衷之一就是让项目快速的发展,从而支持用户能够积极的使用。
|
||||||
2. **开放!** CNCF 是以开放和高度透明为最高准则的,而且是独立于任何的其它团体进行运作的。CNCF根据贡献的内容和优点接受所有的贡献者,且遵循开源的价值观,CNCF输出的技术是可以让所有人使用和受益的,技术社区及其决策应保持高度透明。
|
2. **开放!**:CNCF 是以开放和高度透明为最高准则的,而且是独立于任何的其它团体进行运作的。CNCF根据贡献的内容和优点接受所有的贡献者,且遵循开源的价值观,CNCF输出的技术是可以让所有人使用和受益的,技术社区及其决策应保持高度透明。
|
||||||
3. **公平**:CNCF 会极力避免那些不好的影响、不良行为、以及“按需付费”的决策。
|
3. **公平**:CNCF 会极力避免那些不好的影响、不良行为、以及“按需付费”的决策。
|
||||||
4. **强大的技术身份**:CNCF 会实现并保持高度的自身技术认同,并将之同步到所有的共享项目中。
|
4. **强大的技术身份**:CNCF 会实现并保持高度的自身技术认同,并将之同步到所有的共享项目中。
|
||||||
5. **清晰的边界**:CNCF 制定明确的目标,并在某些情况下,要确定什么不是基金会的目标,并会帮助整个生态系统的运转,让人们理解新创新的重点所在。
|
5. **清晰的边界**:CNCF 制定明确的目标,并在某些情况下,要确定什么不是基金会的目标,并会帮助整个生态系统的运转,让人们理解新创新的重点所在。
|
||||||
|
|
@ -54,13 +54,13 @@ CNCF 会极力遵循以下一些原则:
|
||||||
|
|
||||||
CNCF中的会员包括白金、金牌、银牌、最终用户、学术和非赢利成员等级别,不同级别的会员在理事会中的投票权不同。
|
CNCF中的会员包括白金、金牌、银牌、最终用户、学术和非赢利成员等级别,不同级别的会员在理事会中的投票权不同。
|
||||||
|
|
||||||
a) **白金会员**:在CNCF理事会中任命1名代表,在理事会的每个次级委员会和活动中任命1名有投票权的代表,在网站可以突出显示;如果也是终端用户成员将继承终端用户成员的所有权利
|
a) **白金会员**:在CNCF理事会中任命1名代表,在理事会的每个次级委员会和活动中任命1名有投票权的代表,在网站可以突出显示;如果也是终端用户成员将继承终端用户成员的所有权利。
|
||||||
|
|
||||||
b) **金牌会员**:基金会中每有5个金牌会员,该级别的会员就可以任命1名代表,最多任命3个;如果也是终端用户成员将继承终端用户成员的所有权利
|
b) **金牌会员**:基金会中每有5个金牌会员,该级别的会员就可以任命1名代表,最多任命3个;如果也是终端用户成员将继承终端用户成员的所有权利。
|
||||||
|
|
||||||
c) **银牌会员**:基金会中每有10个银牌会员,该级别的会员就可以任命1名代表,最多任命3个;如果也是终端用户成员将继承终端用户成员的所有权利
|
c) **银牌会员**:基金会中每有10个银牌会员,该级别的会员就可以任命1名代表,最多任命3个;如果也是终端用户成员将继承终端用户成员的所有权利。
|
||||||
|
|
||||||
d) **终端用户**:参加终端用户咨询社区;向终端用户技术咨询委员会中提名1名代表
|
d) **终端用户**:参加终端用户咨询社区;向终端用户技术咨询委员会中提名1名代表。
|
||||||
|
|
||||||
e) **学术和非赢利会员**:学术和非营利会员分别限于学术和非营利机构,需要理事会批准。学术成员和非营利成员有权将其组织认定为支持CNCF使命的成员以及理事会确定的任何其他权利或利益。
|
e) **学术和非赢利会员**:学术和非营利会员分别限于学术和非营利机构,需要理事会批准。学术成员和非营利成员有权将其组织认定为支持CNCF使命的成员以及理事会确定的任何其他权利或利益。
|
||||||
|
|
||||||
|
|
@ -74,16 +74,16 @@ b) 负责日常事务
|
||||||
2. 商标和版权保护
|
2. 商标和版权保护
|
||||||
3. 市场营销、布道和生态系统建设
|
3. 市场营销、布道和生态系统建设
|
||||||
4. 创建和执行品牌承诺项目,如果需要的话
|
4. 创建和执行品牌承诺项目,如果需要的话
|
||||||
5. 监督运营,业务发展;
|
5. 监督运营,业务发展
|
||||||
6. 募资和财务管理
|
6. 募资和财务管理
|
||||||
|
|
||||||
c) 理事会投票成员由会员代表和社区代表组成:
|
c) 理事会投票成员由会员代表和社区代表组成:
|
||||||
|
|
||||||
1. 成员代表包括:
|
1. 成员代表包括:
|
||||||
- 每名白金会员任命1名代表
|
- 每名白金会员任命1名代表;
|
||||||
- 黄金和银牌成员当选代表
|
- 黄金和银牌成员当选代表。
|
||||||
2. 技术社区代表包括:
|
2. 技术社区代表包括:
|
||||||
- 技术监督委员会主席
|
- 技术监督委员会主席;
|
||||||
- 根据当时在任的理事会批准的程序从CNCF项目中选出两名提交者。
|
- 根据当时在任的理事会批准的程序从CNCF项目中选出两名提交者。
|
||||||
3. 理事会可能会以白金会员比例的价格扩展白金会员资格,对年收入低于5000万美元的创业公司进行长达5年的逐年审计,这些公司被视为理事会的战略技术贡献者。
|
3. 理事会可能会以白金会员比例的价格扩展白金会员资格,对年收入低于5000万美元的创业公司进行长达5年的逐年审计,这些公司被视为理事会的战略技术贡献者。
|
||||||
4. 只有来自一组**关联公司**的人员可以担任会员代表。只有来自一组**关联公司**的人员可以担任技术社区代表。
|
4. 只有来自一组**关联公司**的人员可以担任会员代表。只有来自一组**关联公司**的人员可以担任技术社区代表。
|
||||||
|
|
@ -111,33 +111,33 @@ e) 基金会的收入用途
|
||||||
|
|
||||||
### a) 要求
|
### a) 要求
|
||||||
|
|
||||||
CNCF 技术监督委员会,为了保持中立,则达成了以下共识:
|
CNCF 技术监督委员会,为了保持中立,达成了以下共识:
|
||||||
|
|
||||||
1. 定义和维护CNCF的技术愿景。
|
1. 定义和维护CNCF的技术愿景。
|
||||||
2. 批准由理事会制定的CNCF范围内的新项目,并为项目创建一个概念架构。
|
2. 批准由理事会制定的CNCF范围内的新项目,并为项目创建一个概念架构。
|
||||||
3. 纠正项目的发展方向,决策删除或存档项目。
|
3. 纠正项目的发展方向,决策删除或存档项目。
|
||||||
4. 接受最终用户委员会的反馈并反映在项目中。
|
4. 接受最终用户委员会的反馈并反映在项目中。
|
||||||
5. 在科学管理的情况下调整组件的接口(在代码标准化之前实现参考)
|
5. 在科学管理的情况下调整组件的接口(在代码标准化之前实现参考)。
|
||||||
6. 定义在CNCF项目中实施的常用做法(如果有的话)。
|
6. 定义在CNCF项目中实施的常用做法(如果有的话)。
|
||||||
|
|
||||||
### b) 技术监督委员会的构成
|
### b) 技术监督委员会的构成
|
||||||
|
|
||||||
1. TOC最多由9名成员组成。
|
1. TOC最多由11名成员组成。
|
||||||
2. 选出的TOC成员将涵盖关键的技术领域:容器技术、操作系统、技术运维、分布式系统、用户级应用程序设计等。
|
2. 选出的TOC成员将涵盖关键的技术领域:容器技术、操作系统、技术运维、分布式系统、用户级应用程序设计等。
|
||||||
3. 理事会将选举6名TOC成员,最终用户TAB将选出1名TOC成员,最初的7名TOC成员应另选两名TOC成员。
|
3. 理事会将选举6名TOC成员,最终用户TAB将选出2名TOC成员,非Sandbox项目的Maitainer选出1名TOC成员,TOC成员再选出另外2名TOC成员。每个组都被定义为一个甄选小组(Selecting Group)。
|
||||||
4. 如果超过两名TOC成员来自同一组关联公司,无论是在选举时还是来自后来的工作变更,他们将共同决定谁应该下台,或如果没有协商的依据,则应抽签决定。
|
4. 如果超过2名TOC成员来自同一组关联公司,无论是在选举时还是来自后来的工作变更,他们将共同决定谁应该下台,或如果没有协商的依据,则应抽签决定。
|
||||||
|
|
||||||
### c) 运营模式
|
### c) 运营模式
|
||||||
|
|
||||||
1. TOC 会选举出TOC的主席来,此角色主要负责 TOC 的议程和召集会议。
|
1. TOC 会选举出TOC的主席来,此角色主要负责 TOC 的议程和召集会议。
|
||||||
2. TOC 每个季度会面对面讨论重要的热点问题。
|
2. TOC 期望定期的面对面讨论重要的热点问题。
|
||||||
3. TOC 可能会根据需要开会讨论新出现的问题。 TOC审核可能会提出以下问题:
|
3. TOC 可能会根据需要召开会议以讨论新出现的问题。可能会通过以下方式提出要进行TOC 审查的问题:
|
||||||
- 任何的 TOC 成员
|
- 任何的 TOC 成员
|
||||||
- 任何的理事会成员
|
- 任何的理事会成员
|
||||||
- 建立的CNCF项目的维护者或顶级项目负责人
|
- CNCF项目的维护者或顶级项目负责人
|
||||||
- CNCF 执行董事
|
- CNCF 执行董事
|
||||||
- 最终用户技术咨询委员会获得多数票
|
- 最终用户TAB获得多数票
|
||||||
4. 保持透明:TOC会议、邮件列表、以及会议记录等均是公开可访问的。
|
4. 保持透明:TOC 应举办定期的开放会议,所有项目相关的决定应该在会议、公共邮件列表、公共议题中做出。
|
||||||
5. 简单的TOC问题可以通过简短的讨论和简单的多数表决来解决。TOC讨论可通过电子邮件或TOC会议进行。
|
5. 简单的TOC问题可以通过简短的讨论和简单的多数表决来解决。TOC讨论可通过电子邮件或TOC会议进行。
|
||||||
6. 在对意见和可选虚拟讨论/辩论选项进行审查后,寻求共识并在必要时进行投票。
|
6. 在对意见和可选虚拟讨论/辩论选项进行审查后,寻求共识并在必要时进行投票。
|
||||||
7. 目的是让TOC在TOC和社区内寻找达成共识的途径。满足法定人数要求的会议的TOC决定应以超过TOC成员出席率的50%的方式通过。
|
7. 目的是让TOC在TOC和社区内寻找达成共识的途径。满足法定人数要求的会议的TOC决定应以超过TOC成员出席率的50%的方式通过。
|
||||||
|
|
@ -146,31 +146,29 @@ CNCF 技术监督委员会,为了保持中立,则达成了以下共识:
|
||||||
|
|
||||||
### d) 提名标准
|
### d) 提名标准
|
||||||
|
|
||||||
获得 TOC 提名的开源贡献者应该具备下面条件:
|
获得 TOC 提名应该具备下面条件:
|
||||||
|
|
||||||
1. 承诺有足够的可用可用时间参与CNCF TOC的活动,包括在CNCF成立时相当早期的投入,然后需持续投入时间,而且在季度的 TOC 会议之前要进行充分的准备和审查事宜。
|
1. 承诺有足够的可用时间参与CNCF TOC的活动。
|
||||||
2. 在CNCF范围内展示了高水准的专业经验。
|
2. 在CNCF范围内展示了高水准的专业经验。
|
||||||
3. 证明其有资格能够获得额外的工作人员或社区成员协助其在 TOC 的工作。
|
3. 证明其有资格能够获得额外的工作人员或社区成员协助其在 TOC 的工作。
|
||||||
4. 在讨论中保持中立,并提出CNCF的目标和成功与公司目标或CNCF中的任何特定项目保持平衡。
|
4. 在讨论中保持中立,并提出CNCF的目标和成功与公司目标或CNCF中的任何特定项目保持平衡。
|
||||||
|
|
||||||
### e) TOC成员提名和选举程序
|
### e) TOC成员提名和选举程序
|
||||||
|
|
||||||
1. TOC由9位TOC成员组成:由理事会选出的6位,由最终用户TAB选出的1位和由最初的7位TOC成员选出的2位。
|
2. 提名:甄选小组中的每个人最多可以提名两(2)人,其中最多一(1)个人来自同一组关联公司。每个被提名人必须同意参与才能被添加到提名列表中。
|
||||||
2. 提名:每个有资格提名TOC成员的个人(实体或成员)可以提名至多2名技术代表(来自供应商、最终用户或任何其他领域),其中至多一个可能来自其各自公司。被提名者必须提前同意加入到候选人名单中。
|
- a) 提名需要最多一(1)页的提名议案,其中应包括被提名人的姓名,联系信息和证明被提名人在CNCF领域的经验的支持声明。
|
||||||
- 最初的7名TOC成员(理事会选出的6名成员加上由最终用户TAB选出的1名成员)应使用提名程序提名并选举2名TOC成员。
|
- b) 理事会应确定TOC成员的提名,资格和选举的过程和时间表。
|
||||||
- 提名者需要提供最多一页纸的介绍,其中包括被提名者的姓名,联系信息和支持性陈述,确定了在CNCF领域提名的经验。
|
- c) 在评估期内,至少应保留14个日历日,以便理事会和TOC成员可以与TOC提名人联系。
|
||||||
- 理事会、最终用户TAB和TOC应确定提名、投票和关于TOC选举提名和选举过程的任何其他细节的时间表和日期。
|
2. 资格:在评估期之后,理事会和TOC成员应分别对每位被提名人进行投票,以验证被提名人是否符合资格标准。有效的投票至少需要50%的参与。合格率超过50%的被提名人为合格被提名人。
|
||||||
- 评估期间最少保留14个日历日,TOC 提名者可以联系和/或评估候选人。
|
3. 选举:如果合格提名人的数量等于或小于可供选择的TOC席位的数量,则在提名期结束后应批准合格提名人。如果合格的被提名人数量超过可以选举的TOC席位,则甄选小组应通过Condorcet投票选出TOC成员。Condorcet投票应通过康奈尔在线服务(<http://civs.cs.cornell.edu/>)使用Condorcet-IRV方法运行。
|
||||||
3. 选举:评估期结束后,理事会、最终用户标签和最初的7位TOC成员应分别对每位被候选人进行表决。有效投票需要满足会议法定人数所需的选票数量。每名被候选人均需要支持超过50%的投票人数,以确认被提名者符合资格标准。以多数票通过的候选人应为合格的 TOC 成员。
|
4. TOC选定的席位:TOC选定的TOC成员可以提名并有资格,但在其席位需要选举时不能投票。
|
||||||
4. 如果合格的被提名者的人数等于或少于可选 TOC 席位的数量,则此被提名者应在提名期结束后获得批准。如果有更多的合格被候选人比理事会,最终用户TAB或TOC可选的开放TOC席位多,那么该组应通过Condorcet投票选出TOC成员。Condorcet投票应通过康奈尔在线服务(http://civs.cs.cornell.edu/)使用Condorcet-IRV方法运行。
|
5. 重试。如果合格候选人的数量少于选择小组可以选择的开放式TOC席位,则该小组应发起另一轮提名。
|
||||||
5. 如果理事会,最终用户TAB或TOC可供选举的公开TOC席位的合格被候选人数较少,该小组将启动另一轮提名,每名成员或个人有资格提名至多提名1名候选人。
|
|
||||||
|
|
||||||
### f) 约束条件
|
### f) 约束条件
|
||||||
|
|
||||||
1. TOC 的成员任期为两年,来自理事会选举的最初六名当选TOC成员的任期为3年。由最终用户TAB和TOC选出的TOC成员的初始任期为2年。
|
1. TOC 的成员任期为两年,交错式任期。
|
||||||
2. TOC成员可能会被其他TOC成员的三分之二投票撤除,受影响的个人不能参加投票。
|
2. TOC成员可能会被其他TOC成员的三分之二投票撤除,受影响的个人不能参加投票。
|
||||||
3. 任何TOC成员连续3次连续会议都将被自动暂停投票资格,直至连续参加两次会议。为避免疑义,暂停的TOC成员有资格在连续第二次会议中投票。
|
3. 任何TOC成员连续3次缺席会议都将被自动暂停投票资格,直至连续参加两次会议。为避免疑义,暂停的TOC成员有资格在连续第二次会议中投票。
|
||||||
4. TOC章程、模式、方法、组成等可以由整个理事会的三分之二票通过修改。
|
|
||||||
5. TOC议程将由TOC制定。但是,预计最初的TOC讨论和决定将包括:
|
5. TOC议程将由TOC制定。但是,预计最初的TOC讨论和决定将包括:
|
||||||
- 评估包含在CNCF中的技术
|
- 评估包含在CNCF中的技术
|
||||||
- 确定新技术纳入CNCF的接受标准
|
- 确定新技术纳入CNCF的接受标准
|
||||||
|
|
@ -181,7 +179,7 @@ CNCF 技术监督委员会,为了保持中立,则达成了以下共识:
|
||||||
|
|
||||||
a) CNCF的最终用户成员有权协调和推动CNCF用户作为CNCF设计的消费者的重要活动。任何作为最终用户的成员或非成员,每个“最终用户参与者”均可被邀请参加。最终用户参与者将帮助向技术咨询委员会和CNCF社区就与用户有关的主题提供意见。
|
a) CNCF的最终用户成员有权协调和推动CNCF用户作为CNCF设计的消费者的重要活动。任何作为最终用户的成员或非成员,每个“最终用户参与者”均可被邀请参加。最终用户参与者将帮助向技术咨询委员会和CNCF社区就与用户有关的主题提供意见。
|
||||||
|
|
||||||
b) 最终用户技术咨询委员会是由最终用户社区成员选举所产生。
|
b) 最终用户技术咨询委员会是由最终用户社区成员选举所产生。
|
||||||
|
|
||||||
c) 最终用户社区成员将获得CNCF执行董事的批准,或者 CNCF 执行董事缺席的话,则由 Linux 基金会执行董事来批准。
|
c) 最终用户社区成员将获得CNCF执行董事的批准,或者 CNCF 执行董事缺席的话,则由 Linux 基金会执行董事来批准。
|
||||||
|
|
||||||
|
|
@ -203,8 +201,6 @@ g) 如果最终用户 TAB 有意愿的话,它可以批准小组委员会特别
|
||||||
|
|
||||||
h) 最终用户 TAB 是技术监督委员会的主要输入方,应与技术监督委员会的其他输入方和反馈一起作出决策和计划。这些建议只是建议性的,在任何时候,最终用户TAB的建议都不能用于命令或指导任何TOC或项目参与者采取任何行动或结果。
|
h) 最终用户 TAB 是技术监督委员会的主要输入方,应与技术监督委员会的其他输入方和反馈一起作出决策和计划。这些建议只是建议性的,在任何时候,最终用户TAB的建议都不能用于命令或指导任何TOC或项目参与者采取任何行动或结果。
|
||||||
|
|
||||||
i) 为促进与TOC的双边互动,最终用户技术咨询委员会应选出1名TOC代表。最终用户 TAB 可邀请任何人参加最终用户会议、SIG或其他讨论。
|
|
||||||
|
|
||||||
## 9. CNCF项目
|
## 9. CNCF项目
|
||||||
|
|
||||||
通常情况下,是由CNCF的成员公司、开源社区的成员将项目先是带到CNCF 的技术监督委员会来进行讨论,然后决定是否被CNCF接纳。要贡献给CNCF的项目必须是经过技术监督委员会制定的标准的,之后当然还要经过理事会的批准。CNCF 的目标是希望捐赠给CNCF的项目和CNCF已有的项目在一定程度上是有关联的,而且是可集成的。
|
通常情况下,是由CNCF的成员公司、开源社区的成员将项目先是带到CNCF 的技术监督委员会来进行讨论,然后决定是否被CNCF接纳。要贡献给CNCF的项目必须是经过技术监督委员会制定的标准的,之后当然还要经过理事会的批准。CNCF 的目标是希望捐赠给CNCF的项目和CNCF已有的项目在一定程度上是有关联的,而且是可集成的。
|
||||||
|
|
@ -233,7 +229,7 @@ i) 为促进与TOC的双边互动,最终用户技术咨询委员会应选出1
|
||||||
|
|
||||||
a) 项目或组件完全根据OSI批准的开源许可证进行授权,并且管理良好,并在CNCF中被用作组件。
|
a) 项目或组件完全根据OSI批准的开源许可证进行授权,并且管理良好,并在CNCF中被用作组件。
|
||||||
|
|
||||||
b) 项目并没有由CNCF 来进行市场推广
|
b) 项目并没有由CNCF来进行市场推广
|
||||||
|
|
||||||
c) 项目或组件的开发是由上游社区所开发,而且保持一定的活跃度
|
c) 项目或组件的开发是由上游社区所开发,而且保持一定的活跃度
|
||||||
|
|
||||||
|
|
@ -253,7 +249,7 @@ c) 如果市场委员会变得太大而无法有效运作,市场委员会可
|
||||||
|
|
||||||
## 11. 知识产权政策
|
## 11. 知识产权政策
|
||||||
|
|
||||||
a) 任何加入到CNCF的项目都必须将其拥有的商标和徽标资产转让给Linux基金会的所有权。
|
a) 任何加入到CNCF的项目都必须将其拥有的商标和徽标资产转的所有权让给Linux基金会。
|
||||||
|
|
||||||
b) 每个项目应确定是否需要使用经批准的CNCF CLA。对于选择使用CLA的项目,所有代码贡献者将承担Apache贡献者许可协议中规定的义务,只有在必要时才作出修改,以确定CNCF是捐赠的接受者,并且应由理事会批准。请参阅 <https://github.com/cncf/cla> 上提供的CNCF参与者许可协议。
|
b) 每个项目应确定是否需要使用经批准的CNCF CLA。对于选择使用CLA的项目,所有代码贡献者将承担Apache贡献者许可协议中规定的义务,只有在必要时才作出修改,以确定CNCF是捐赠的接受者,并且应由理事会批准。请参阅 <https://github.com/cncf/cla> 上提供的CNCF参与者许可协议。
|
||||||
|
|
||||||
|
|
@ -265,7 +261,7 @@ e) 所有评估纳入CNCF的项目都必须获得OSI批准的开源许可证的
|
||||||
|
|
||||||
f) 所有文档将由CNCF根据知识共享署名4.0国际许可证来提供。
|
f) 所有文档将由CNCF根据知识共享署名4.0国际许可证来提供。
|
||||||
|
|
||||||
g) 如果需要替代入站或出站许可证以符合杠杆式开放源代码项目的许可证或为实现CNCF的使命而需要其他许可证,理事会可以批准使用替代许可证 对于例外情况下的接受或提供的项目捐赠。
|
g) 如果需要替代入站或出站许可证以符合杠杆式开放源代码项目的许可证或为实现CNCF的使命而需要其他许可证,理事会可以批准使用替代许可证对于例外情况下的接受或提供的项目捐赠。
|
||||||
|
|
||||||
## 12. 反托拉斯指南
|
## 12. 反托拉斯指南
|
||||||
|
|
||||||
|
|
@ -307,7 +303,7 @@ b) 一般和行政(G&A)费用将用于筹集资金以支付财务、会计
|
||||||
|
|
||||||
## 17. 一般规则和操作
|
## 17. 一般规则和操作
|
||||||
|
|
||||||
参与CNCF 应做到:
|
参与 CNCF 应做到:
|
||||||
|
|
||||||
a) 展示与开源项目开发人员社区进行协调的计划和方法,包括关于代表社区的品牌、徽标和其它标志性的主题;
|
a) 展示与开源项目开发人员社区进行协调的计划和方法,包括关于代表社区的品牌、徽标和其它标志性的主题;
|
||||||
|
|
||||||
|
|
@ -319,7 +315,7 @@ d) 参与Linux基金会的所有新闻和分析师关系活动;
|
||||||
|
|
||||||
e) 根据要求,向Linux基金会提供关于项目参与的信息,包括参加项目赞助活动的信息;
|
e) 根据要求,向Linux基金会提供关于项目参与的信息,包括参加项目赞助活动的信息;
|
||||||
|
|
||||||
f) 直接参与到基金会旗下的任何站点。
|
f) 直接参与到基金会旗下的任何站点;
|
||||||
|
|
||||||
g) 根据理事会批准的规则和程序进行运营,前提是这些规则和程序不得与Linux基金会的宗旨和政策不一致,并且不得损害Linux基金会。
|
g) 根据理事会批准的规则和程序进行运营,前提是这些规则和程序不得与Linux基金会的宗旨和政策不一致,并且不得损害Linux基金会。
|
||||||
|
|
||||||
|
|
@ -345,7 +341,7 @@ CNCF社区坚信云原生计算包含三个核心属性:
|
||||||
- 在标准化子系统的边界处定义良好的API
|
- 在标准化子系统的边界处定义良好的API
|
||||||
- 应用程序生命周期管理的最小障碍
|
- 应用程序生命周期管理的最小障碍
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
因为上述时间表已经有些过时了,CNCF成立已经有三年时间了,正在规划新的方案。
|
因为上述时间表已经有些过时了,CNCF成立已经有三年时间了,正在规划新的方案。
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -0,0 +1,102 @@
|
||||||
|
## CNCF中的项目治理
|
||||||
|
|
||||||
|
CNCF 根据“[鸿沟理论](https://www.jianshu.com/p/a305fa93580b)”将其托管的项目分成三个成熟阶段,并设置了项目晋级到更高阶段的标准。
|
||||||
|
|
||||||
|
> “[鸿沟理论](https://www.jianshu.com/p/a305fa93580b)”是由Geoffrey A. Moore提出的高科技产品的市场营销理论。新技术要想跨越鸿沟,必须能够实现一些跨越式的发展,**拥有某一些以前不可能实现的功能**,具有某种内在价值并能够**赢得非技术人员的**青睐。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
目前处于沙箱、孵化中、已毕业项目的数量比例为5:16:13,详见 <https://cncf.io/projects>。其中沙箱(sandbox)项目因为其处于早期阶段并没有直接在上面的链接页面中列出,而是一个单独的 [Sandbox](https://www.cncf.io/sandbox-projects/) 页面,因为 CNCF 为 sandbox 阶段的项目会谨慎背书。
|
||||||
|
|
||||||
|
## 纳入CNCF开源版图的项目需要符合其对云原生的定义
|
||||||
|
|
||||||
|
CNCF 中托管的开源项目要符合云原生定义:
|
||||||
|
|
||||||
|
- 云原生技术有利于各组织在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用。**云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式API**。
|
||||||
|
- 这些技术能够构建容错性好、易于管理和便于观察的松耦合系统。结合可靠的自动化手段,云原生技术使工程师能够轻松地对系统作出频繁和可预测的重大变更。
|
||||||
|
- 云原生计算基金会(CNCF)致力于培育和维护一个厂商中立的开源生态系统,来推广云原生技术。我们通过将最前沿的模式民主化,让这些创新为大众所用。
|
||||||
|
|
||||||
|
## 项目运作流程
|
||||||
|
|
||||||
|
下图演示了开源项目加入 CNCF 后的整个运作流程。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## 开源项目如何加入 CNCF
|
||||||
|
|
||||||
|
1. 开源项目所支持的公司成为 CNCF 会员
|
||||||
|
2. 开源项目满足 CNCF 的要求(见后文)
|
||||||
|
3. 在 GitHub 上提交[proposal](https://github.com/cncf/toc/issues/113)(GitHub Issue)列举项目介绍、现状、目标、license、用户与社区等
|
||||||
|
4. 由 Chris Aniszczyk 安排该项目在某个TOC双月会议上介绍给 TOC 成员
|
||||||
|
5. 1.TOC 会将开源项目指定到某个 [SIG](cncf-sig.md) 中
|
||||||
|
6. 项目获得两个TOC成员的赞成可进入[sandbox](https://github.com/cncf/toc/blob/master/process/sandbox.md)(也可以直接获得2/3多数TOC 投票进入Incubating状态)
|
||||||
|
7. 知识产权转移给 CNCF
|
||||||
|
8. CNCF 安排博客撰写、PR等
|
||||||
|
9. 每年一次评审,晋升到 incubating需要2/3的 TOC 成员投票赞成;至少3家用户成功在生产上使用;通过TOC的尽职调查;贡献者数量健康稳定
|
||||||
|
10. Sandbox 中的项目没有时效性质,可能永远都无法进入incubating 状态,被CNCF谨慎宣传
|
||||||
|
|
||||||
|
## CNCF 开源项目成熟度演进
|
||||||
|
|
||||||
|
CNCF 的开源项目遵循如下图所示的成熟度演进。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
- 加入Sandbox只需要2个TOC成员赞成
|
||||||
|
- 成熟一点的项目可以直接进入incubating阶段,但是 CNCF 会控制不同阶段的项目比例
|
||||||
|
- 晋级到Incubating或Graduated 需要至少2/3的 TOC成员(6名或以上)投票赞成
|
||||||
|
- 每年将评审一次
|
||||||
|
|
||||||
|
## 开源项目加入 CNCF 的最低要求(Sandbox)
|
||||||
|
|
||||||
|
一个开源项目要想加入 CNCF 必须满足以下要求:
|
||||||
|
|
||||||
|
- 项目名称必须在 CNCF 中唯一
|
||||||
|
|
||||||
|
- 项目描述(用途、价值、起源、历史)
|
||||||
|
|
||||||
|
- 与 CNCF 章程一致的声明
|
||||||
|
|
||||||
|
- 来自 TOC 的 sponsor(项目辅导)
|
||||||
|
|
||||||
|
- license(默认为 Apache 2)
|
||||||
|
|
||||||
|
- 源码控制(Github)
|
||||||
|
|
||||||
|
- 网站(英文)
|
||||||
|
|
||||||
|
- 外部依赖(包括 license)
|
||||||
|
|
||||||
|
- 成熟度模型评估(参考 [开源项目加入CNCF Sandbox的要求](cncf-sandbox-criteria.md))
|
||||||
|
- 创始 committer(贡献项目的时长)
|
||||||
|
- 基础设施需求(CI/CNCF集群)
|
||||||
|
- 沟通渠道(slack、irc、邮件列表)
|
||||||
|
- issue 追踪(GitHub)
|
||||||
|
- 发布方法和机制
|
||||||
|
- 社交媒体账号
|
||||||
|
- 社区规模和已有的赞助商
|
||||||
|
- svg 格式的项目 logo
|
||||||
|
|
||||||
|
## 由 Sandbox 升级到 Incubating 的要求
|
||||||
|
|
||||||
|
- 通过 TOC 的[尽职调查](https://github.com/cncf/toc/blob/master/process/due-diligence-guidelines.md)
|
||||||
|
- 至少有 3 个独立的终端用户在在生产上使用该项目:一般在项目的官网列举实际用户
|
||||||
|
- 足够健康数量的贡献者:项目的 GitHub 上有明确的 committer 权限划分、职责说明及成员列表,TOC 将根据项目大小来确认多少committer才算健康
|
||||||
|
- **展示项目在持续进行、良好的发布节奏、贡献频率十分重要**
|
||||||
|
|
||||||
|
|
||||||
|
## 由Incubating升级到Graduated的要求
|
||||||
|
|
||||||
|
- 满足 Sandbox 和 Incubating 的所有要求
|
||||||
|
- **至少有来自两个组织的贡献者**
|
||||||
|
- 明确定义的项目治理及 committer 身份、权限管理
|
||||||
|
- 接受 CNCF 的[行为准则](https://github.com/cncf/foundation/blob/master/code-of-conduct.md),参考[Prometheus](https://bestpractices.coreinfrastructure.org/en/projects/486)
|
||||||
|
- 获得CII 最佳实践徽章
|
||||||
|
- 在项目主库或项目官网有公开的采用者的 logo
|
||||||
|
|
||||||
|
参考归档的 Review:https://github.com/cncf/toc/tree/master/reviews
|
||||||
|
|
||||||
|
## 参考
|
||||||
|
|
||||||
|
- [鸿沟理论 - jianshu.com](https://www.jianshu.com/p/a305fa93580b)
|
||||||
|
- [CNCF Graduation Criteria v1.2 - github.com](https://github.com/cncf/toc/blob/master/process/graduation_criteria.adoc)
|
||||||
|
|
||||||
|
|
@ -0,0 +1,41 @@
|
||||||
|
## 开源项目加入CNCF Sandbox的要求
|
||||||
|
|
||||||
|
[CNCF Project Proposal Process](https://github.com/cncf/toc/blob/master/process/project_proposals.adoc) 中指出开源项目要想加入 CNCF 必须满足以下条件:
|
||||||
|
|
||||||
|
1. 项目名称必须在 CNCF 中唯一
|
||||||
|
2. 项目描述(用途、价值、起源、历史)
|
||||||
|
3. 与 CNCF 章程一致的声明
|
||||||
|
4. 来自 TOC 的 sponsor(项目辅导)
|
||||||
|
5. 成熟度模型评估(参考 [CNCF Graduation Criteria](https://github.com/cncf/toc/blob/master/process/project_proposals.adoc))
|
||||||
|
6. license(默认为 Apache 2)
|
||||||
|
7. 源码控制(Github)
|
||||||
|
8. 外部依赖(包括 license)
|
||||||
|
9. 创始 committer(贡献项目的时长)
|
||||||
|
10. 基础设施需求(CI/CNCF集群)
|
||||||
|
11. 沟通渠道(slack、irc、邮件列表)
|
||||||
|
12. issue 追踪(GitHub)
|
||||||
|
13. 网站
|
||||||
|
14. 发布方法和机制
|
||||||
|
15. 社交媒体账号
|
||||||
|
16. 社区规模和已有的赞助商
|
||||||
|
17. 用户、使用规模、是否用在生产环境,要有证据说明
|
||||||
|
18. svg 格式的项目 logo
|
||||||
|
|
||||||
|
### 项目接纳过程
|
||||||
|
|
||||||
|
整个流程比较复杂,持续时间也不比较久,如 CNCF 提供的这张图所示。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
大体流程如下:
|
||||||
|
|
||||||
|
1. 通过 [GitHub Issue](https://github.com/cncf/toc/issues) 提交 proposal
|
||||||
|
1. TOC 确认项目分类,归类到一个 [CNCF SIG](https://github.com/cncf/toc/blob/master/sigs/cncf-sigs.md) 中(两周)
|
||||||
|
1. SIG 评估(1到 2 个月)
|
||||||
|
1. TOC review
|
||||||
|
1. TOC 拉票,至少 3 票(2 个月)
|
||||||
|
1. 治理和法律问题(CNCF 来处理)
|
||||||
|
|
||||||
|
## 参考
|
||||||
|
|
||||||
|
- [CNCF Project Proposal Process - github.com](https://github.com/cncf/toc/blob/master/process/project_proposals.adoc)
|
||||||
|
|
@ -0,0 +1,173 @@
|
||||||
|
# CNCF特别兴趣小组(SIG)说明
|
||||||
|
|
||||||
|
本文译自 [CNCF Special Interest Groups(SIGs)](https://github.com/cncf/toc/blob/master/sigs/cncf-sigs.md)最终草案v1.0。
|
||||||
|
|
||||||
|
本提案创作于2018年11月至2019年1月期间,由CNCF TOC和”Contributors Primary Author“ Alexis Richardson,Quinton Hoole共同起草。
|
||||||
|
|
||||||
|
## 总体目的
|
||||||
|
|
||||||
|
为了我们的[使命](https://github.com/cncf/foundation/blob/master/charter.md#1-mission-of-the-cloud-native-computing-foundation),在扩展CNCF技术版图、增加用户社区贡献的同时保持其完整性和提高贡献质量。
|
||||||
|
|
||||||
|
## 具体目标
|
||||||
|
|
||||||
|
- 加强项目生态系统建设以满足最终用户和项目贡献者的需求。
|
||||||
|
- 识别CNCF项目组合中的鸿沟(gap),寻找并吸引项目填补这些鸿沟。
|
||||||
|
- 教育和指导用户,为用户提供无偏见、有效且实用的信息。
|
||||||
|
- 将注意力和资源集中在促进CNCF项目的成熟度上。
|
||||||
|
- 明确项目、CNCF项目人员和社区志愿者之间的关系。
|
||||||
|
- 吸引更多社区参与,创建有效的TOC贡献和认可的入口。
|
||||||
|
- 在减少TOC在某些项目上工作量的同时保留选举机构的执行控制和音调完整性。
|
||||||
|
- 避免在供应商之间建立政治平台。
|
||||||
|
|
||||||
|
## 介绍
|
||||||
|
|
||||||
|
CNCF SIG将监督和协调与最终用户和(或)项目需求的逻辑领域相关的利益。这些领域如安全性、测试、可观察性、存储、网络等。通常由一组CNCF项目来满足SIG监督的领域,也可能是多个项目共享的跨领域特征组(如安全性和可观察性)。 SIG是:
|
||||||
|
|
||||||
|
- 是一个长期存在的群体,向技术监督委员会报告
|
||||||
|
- 主要由相关领域的公认专家领导,并得到其他贡献者的支持
|
||||||
|
|
||||||
|
CNCF SIG以Kubernetes SIG为模型,旨在最小化差异以避免混淆——[此处](https://docs.google.com/document/d/1oSGhx5Hw7Hs_qawYB46BvRSPh0ZvFoxvHx-NWaf5Nsc/edit?usp=sharing)描述了两者之间不可避免的差异。
|
||||||
|
|
||||||
|
## SIG的职责与权利
|
||||||
|
|
||||||
|
CNCF SIG在TOC的指导下,提供高质量的专业技术知识、无偏见的信息及其领域内的领导力。TOC作为知情方和高效的执行委员会,利用这一输入来选择和推广适当的CNCF项目与实践,并向最终用户和云原生社区传播高质量的信息。可以很明确的说,SIG对CNCF项目没有直接的权力。特别是,CNCF SIG的创建并没有改变现有已成功实施的[章程](https://github.com/cncf/foundation/blob/master/charter.md)目标,即“项目......轻松地受技术监督委员会管辖”。
|
||||||
|
|
||||||
|
SIG应努力向TOC提供易于理解和可投票的“提议(proposition)”,提议需要有明确的书面证据支持。这些提议可以是:“基于此[书面尽职调查](https://github.com/cncf/toc/blob/master/process/due-diligence-guidelines.md)“或”根据明确的目标和证据来批准这个landscape文件“。SIG提供给TOC的信息和建议必须高度准确和公正,这一点至关重要,这也是受整体上改进CNCF的目标所驱动,而不是使一个项目或公司受益于其他项目或公司。我们相信涨潮会抬升所有船只,这是我们的目标。
|
||||||
|
|
||||||
|
之所以这样设计是考虑到:
|
||||||
|
|
||||||
|
- TOC是仲裁者和撰写者,可能总是会干预和驳回提议。
|
||||||
|
- SIG是受人尊敬的人才。
|
||||||
|
|
||||||
|
SIG可以选择组建有时间限制的集中式工作组来实现某些职责(例如,制作特定的教育白皮书或组合空白分析报告)。工作组应有明确记录的章程、时间表(通常最多几个季度)和一套可交付的成果。一旦时间表过去或成果交付,工作组就会解散重组。
|
||||||
|
|
||||||
|
### 特定SIG责任
|
||||||
|
|
||||||
|
#### 项目处理:
|
||||||
|
|
||||||
|
- 了解并记录该领域内项目的宏观(high-level)路线图,包括CNCF和非CNCF项目。确定项目前景中的差距。
|
||||||
|
- 对于CNCF的项目,执行健康检查(health check)。
|
||||||
|
- 发掘和展出对候选项目。
|
||||||
|
- 帮助候选项目准备向TOC提交。
|
||||||
|
- 每个CNCF项目将由TOC分配给一个合适的SIG。
|
||||||
|
|
||||||
|
#### 最终用户教育(输出)
|
||||||
|
|
||||||
|
- 提供最新、高质量、无偏见且易于使用的材料,帮助最终用户理解并有效采用SIG领域内的云原生技术和实践,例如:
|
||||||
|
- 白皮书、演示文稿、视频或其他形式的培训、阐明术语、比较不同的方法,可用的项目或产品、常见或推荐的做法、趋势、说明性的成功和失败等。
|
||||||
|
- 信息应尽可能基于研究和事实收集,而不是纯粹的营销或推测。
|
||||||
|
|
||||||
|
#### 最终用户输入收集(输入)
|
||||||
|
|
||||||
|
- 收集有用的最终用户输入和有关期望、痛点、主要用例等的反馈。
|
||||||
|
- 将其编译成易于使用的报告和(或)演示文稿,以帮助项目进行功能设计、优先级排序、UX等。
|
||||||
|
|
||||||
|
#### 社区支持
|
||||||
|
|
||||||
|
- SIG是开放式组织,提供会议、会议议程和笔记,邮件列表以及其他公开通信。
|
||||||
|
- SIG的邮件列表、SIG会议日历和其他通信文件将公开发布和维护。
|
||||||
|
|
||||||
|
#### 作为TOC的值得信赖的专家顾问
|
||||||
|
|
||||||
|
- 对新项目和毕业项目进行技术尽职调查,并就调查结果向TOC提出建议。
|
||||||
|
- 参与或定期检查其所在领域的项目,并根据需要或应要求向TOC提供有关健康、状态和措施(如果有)的建议。
|
||||||
|
|
||||||
|
#### SIG章程:
|
||||||
|
|
||||||
|
- 每年正式审核,并由TOC批准。章程必须明确表达:
|
||||||
|
- 哪些属于SIG的范围,哪些不属于;
|
||||||
|
- 与其他CNCF SIG或其他相关团体交流,明确是否有重叠;
|
||||||
|
- 如何运作和管理,具体是否以及如何偏离TOC提供的标准SIG操作指南。不鼓励偏离这些指导原则,除非有TOC批准的对这种分歧的良好且记录良好的原因。
|
||||||
|
|
||||||
|
请参阅[CNCF SIG的责任示例](https://docs.google.com/document/d/1L9dJl5aBFnN5KEf82J689FY0UtnUawnt9ooCq8SkO_w/edit?usp=sharing)。
|
||||||
|
|
||||||
|
## 运营模式
|
||||||
|
|
||||||
|
重要提示:每个SIG都由CNCF执行人员的指定成员提供支持,该成员负责与CNCF执行董事(Executive Director)的联络、SIG的沟通和绩效,并向理事会(Governing Board)和TOC提交季度和年度报告。
|
||||||
|
|
||||||
|
作为起点,我们受到CNCF OSS项目和K8S SIG的启发。这意味着最小的可行治理和基于社区的组织。
|
||||||
|
|
||||||
|
### SIG组建、领导和成员构成
|
||||||
|
|
||||||
|
1. SIG由TOC组建。初始SIG列在下面,并将根据需要随时间进行调整。如果社区成员认为需要增加额外的SIG,应该向TOC提出,并给出明确的理由,最好是由志愿者领导SIG。TOC希望拥有最小的可行SIG数量,并且所有SIG都是高效的(与具有大量相对无效的SIG的“SIG蔓延(SIG sprawl)”相反)。
|
||||||
|
2. SIG有三名联席主席,他们是TOC贡献者,该领域的公认专家,并且有能力共同领导SIG以产生无偏见信息。
|
||||||
|
3. SIG有一名TOC联络员,作为TOC的投票成员,在TOC或SIG主席认为有必要提交TOC时,作为额外的非执行主席。
|
||||||
|
4. SIG拥有多名技术领导者,他们被公认为(1)SIG领域的专家,(2)SIG领域的项目负责人(3)展示了提供产生SIG所需的无偏见信息所需的平衡技术领导能力。采取独立主席和技术主管角色的原因主要是想将行政职能的责任与深层技术职能和相关的时间承诺和技能组合分开。在适当的情况下,个人可以同时担任两种角色(见下文)。
|
||||||
|
5. 强烈鼓励SIG内部的思想和兴趣多样性。为此,TOC将主动阻止绝大多数技术主管来自单一公司、市场细分等的绝大多数(⅔或更多)主席。
|
||||||
|
6. SIG成员是自己任命的,因此一些SIG工作由TOC贡献者和社区的志愿者完成。为了识别随着时间的推移对SIG做出持续和有价值贡献的成员,可以创建SIG定义和分配的角色(例如,抄写员、培训或文档协调员等)。 SIG应该记录这些角色和职责是什么,执行者是谁,并让SIG领导批准。
|
||||||
|
|
||||||
|
### SIG成员角色
|
||||||
|
|
||||||
|
#### 主席
|
||||||
|
|
||||||
|
- 每周/两周/每月轮转的三个活动席位。
|
||||||
|
- 主要执行管理功能,包括收集和编制每周(双周)议程的主题、主持会议、确保发布高质量的会议记录,以及跟踪和解决后续行动。
|
||||||
|
- 如果有人有时间和能力同时担任这两个角色,只要TOC和SIG成员满意,则可以由技术主管兼任。
|
||||||
|
|
||||||
|
#### 技术主管
|
||||||
|
|
||||||
|
- 领导SIG领域的项目。
|
||||||
|
- 是否有时间和能力对项目进行深度技术探索。项目可能包括正式的CNCF项目或SIG所涵盖领域的其他项目。
|
||||||
|
|
||||||
|
#### 其他命名角色
|
||||||
|
|
||||||
|
- 由SIG命名和定义(例如抄写员、公关主管、文档/培训负责人等)
|
||||||
|
- 由绝大多数主席批准。
|
||||||
|
|
||||||
|
#### 其他成员
|
||||||
|
|
||||||
|
- 自我任命
|
||||||
|
- 可能没有明确的角色或职责,也没有正式分配的角色(见上文)。
|
||||||
|
- 除了指定的角色外,不得为公众造成他们在SIG中拥有任何权限或正式职责的印象。
|
||||||
|
|
||||||
|
### 选举
|
||||||
|
|
||||||
|
- TOC提名主席
|
||||||
|
- 在TOC的2/3多数票后,分配了主席
|
||||||
|
- 任期2年但交错排列,使至少有一个席位能够保持连续性
|
||||||
|
- TOC和主席提名技术主管
|
||||||
|
- 技术主管需要获得TOC的2/3多数票和SIG主席的2/3多数票
|
||||||
|
- 在获得TOC的2/3多数票通过后,SIG主席和技术主管可以被随时取消任命
|
||||||
|
|
||||||
|
### 治理
|
||||||
|
|
||||||
|
- 所有SIG都继承并遵循CNCF TOC操作原则。
|
||||||
|
- SIG必须有一个记录在案的治理流程,鼓励社区参与和明确的指导方针,以避免有偏见的决策。
|
||||||
|
- 注意:这里的目标是与CNCF项目的“最小可行”模型保持一致,并且只需要这样的治理,而不是任何过于繁琐的事情
|
||||||
|
- 如果符合CNCF运营原则,他们可能会像OSS项目一样,随着时间的推移逐步实施一系列实践。
|
||||||
|
- 与CNCF项目一样,所有例外和争议均由TOC和CNCF员工帮助处理
|
||||||
|
|
||||||
|
### 预算和资源
|
||||||
|
|
||||||
|
- 此时没有正式的系统预算,除了CNCF执行人员承诺提供指定人员作为联络点。
|
||||||
|
- 正如CNCF项目可能需要通过CNCF提供的“帮助”,SIG可以通过[ServiceDesk](https://github.com/cncf/servicedesk)求人办事。
|
||||||
|
|
||||||
|
## 退休
|
||||||
|
|
||||||
|
- 在SIG无法建立履行职责和(或)定期向TOC报告的情况下,TOC将:
|
||||||
|
- 考虑在3个月后解散(retire)SIG
|
||||||
|
- 必须在6个月后解散SIG
|
||||||
|
- TOC可以通过2/3多数票通过对SIG的“不信任(no confidence)”。 在这种情况下,TOC可以投票解散或重组SIG。
|
||||||
|
|
||||||
|
## 初始SIG
|
||||||
|
|
||||||
|
为了开始该过程,TOC提出以下SIG和分配给每个SIG的项目。显然,所有这些SIG都不会在一夜之间完全形成或立即开始运作,因此TOC本身将履行尚未形成的SIG的职责,直到SIG形成为止。 然而,我们可以立即指定TOC的一个投票成员作为每个SIG的联络员,并优先考虑SIG的组建顺序,立即从最紧迫的SIG开始。
|
||||||
|
|
||||||
|
| 命名(待定) | 领域 | 当前的CNCF项目 |
|
||||||
|
| ------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
|
||||||
|
| Traffic | networking, service discovery, load balancing, service mesh, RPC, pubsub, etc. | Envoy, Linkerd, NATS, gRPC, CoreDNS, CNI |
|
||||||
|
| Observability | monitoring, logging, tracing, profiling, etc. | Prometheus, OpenTracing, Fluentd, Jaeger, Cortex, OpenMetrics, |
|
||||||
|
| Governance | security, authentication, authorization, auditing, policy enforcement, compliance, GDPR, cost management, etc | SPIFFE, SPIRE, Open Policy Agent, Notary, TUF, Falco, |
|
||||||
|
| App Dev, Ops & Testing | PaaS, Serverless, Operators,... CI/CD, Conformance, Chaos Eng, Scalability and Reliability measurement etc. | Helm, CloudEvents, Telepresence, Buildpacks |
|
||||||
|
| Core and Applied Architectures | orchestration, scheduling, container runtimes, sandboxing technologies, packaging and distribution, specialized architectures thereof (e.g. Edge, IoT, Big Data, AI/ML, etc). | Kubernetes, containerd, rkt, Harbor, Dragonfly, Virtual Kubelet |
|
||||||
|
| Storage | Block, File and Object Stores, Databases, Key-Value stores etc. | TiKV, etcd, Vitess, Rook |
|
||||||
|
|
||||||
|
TOC和CNCF工作人员将一起起草一套上述初步章程,并征集/选举合适的席位。
|
||||||
|
|
||||||
|
## 附录A:工作示例 - CNCF治理SIG
|
||||||
|
|
||||||
|
请参阅[单独文档](https://docs.google.com/document/d/18ufx6TjPavfZubwrpyMwz6KkU-YA_aHaHmBBQkplnr0/edit?usp=sharing)。
|
||||||
|
|
||||||
|
## 参考
|
||||||
|
|
||||||
|
- [CNCF Special Interest Groups(SIGs)](https://github.com/cncf/toc/blob/master/sigs/cncf-sigs.md)
|
||||||
|
|
@ -1,16 +1,18 @@
|
||||||
# CNCF - 云原生计算基金会简介
|
# CNCF - 云原生计算基金会简介
|
||||||
|
|
||||||
CNCF,全称Cloud Native Computing Foundation(云原生计算基金会),口号是**坚持和整合开源技术来让编排容器作为微服务架构的一部分**,其作为致力于云原生应用推广和普及的一支重要力量,不论您是云原生应用的开发者、管理者还是研究人员都有必要了解。
|
CNCF,全称Cloud Native Computing Foundation(云原生计算基金会),成立于 2015 年7月21日([于美国波特兰OSCON 2015上宣布](https://www.cncf.io/announcement/2015/06/21/new-cloud-native-computing-foundation-to-drive-alignment-among-container-technologies/)),其最初的口号是**坚持和整合开源技术来让编排容器作为微服务架构的一部分**,其作为致力于云原生应用推广和普及的一支重要力量,不论您是云原生应用的开发者、管理者还是研究人员都有必要了解。
|
||||||
|
|
||||||
CNCF作为一个厂商中立的基金会,致力于Github上的快速成长的开源技术的推广,如Kubernetes、Prometheus、Envoy等,帮助开发人员更快更好的构建出色的产品。
|
CNCF作为一个厂商中立的基金会,致力于Github上的快速成长的开源技术的推广,如Kubernetes、Prometheus、Envoy等,帮助开发人员更快更好的构建出色的产品。
|
||||||
|
|
||||||
下图是CNCF的全景图。
|
下图是CNCF的全景图。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
该全景图不断更新中,原图请见:https://github.com/cncf/landscape
|
||||||
|
|
||||||
其中包含了CNCF中托管的项目,还有很多是非CNCF项目。
|
其中包含了CNCF中托管的项目,还有很多是非CNCF项目。
|
||||||
|
|
||||||
关于CNCF的使命与组织方式请参考[CNCF宪章](https://www.cncf.io/about/charter/),概括的讲CNCF的使命包括以下三点:
|
关于CNCF的使命与组织方式请参考[CNCF章程](https://www.cncf.io/about/charter/),概括的讲CNCF的使命包括以下三点:
|
||||||
|
|
||||||
* 容器化包装。
|
* 容器化包装。
|
||||||
* 通过中心编排系统的动态资源管理。
|
* 通过中心编排系统的动态资源管理。
|
||||||
|
|
@ -33,7 +35,7 @@ CNCF这个角色的作用是推广技术,形成社区,开源项目管理与
|
||||||
|
|
||||||
成熟度级别(Maturity Level)包括以下三种:
|
成熟度级别(Maturity Level)包括以下三种:
|
||||||
|
|
||||||
* inception(初级)
|
* sandbox(初级)
|
||||||
* incubating(孵化中)
|
* incubating(孵化中)
|
||||||
* graduated(毕业)
|
* graduated(毕业)
|
||||||
|
|
||||||
|
|
@ -43,7 +45,7 @@ CNCF这个角色的作用是推广技术,形成社区,开源项目管理与
|
||||||
|
|
||||||
项目所达到相应成熟度需要满足的条件和投票机制见下图:
|
项目所达到相应成熟度需要满足的条件和投票机制见下图:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
## TOC(技术监督委员会)
|
## TOC(技术监督委员会)
|
||||||
|
|
||||||
|
|
@ -52,7 +54,7 @@ TOC(Technical Oversight Committee)作为CNCF中的一个重要组织,它
|
||||||
* 定义和维护技术视野
|
* 定义和维护技术视野
|
||||||
* 审批新项目加入组织,为项目设定概念架构
|
* 审批新项目加入组织,为项目设定概念架构
|
||||||
* 接受最终用户的反馈并映射到项目中
|
* 接受最终用户的反馈并映射到项目中
|
||||||
* 调整组件见的访问接口,协调组件之间兼容性
|
* 调整组件间的访问接口,协调组件之间兼容性
|
||||||
|
|
||||||
TOC成员通过选举产生,见[选举时间表](https://github.com/cncf/toc/blob/master/process/election-schedule.md)。
|
TOC成员通过选举产生,见[选举时间表](https://github.com/cncf/toc/blob/master/process/election-schedule.md)。
|
||||||
|
|
||||||
|
|
@ -61,10 +63,7 @@ TOC成员通过选举产生,见[选举时间表](https://github.com/cncf/toc/b
|
||||||
## 参考
|
## 参考
|
||||||
|
|
||||||
* [https://www.cncf.io](https://www.cncf.io)
|
* [https://www.cncf.io](https://www.cncf.io)
|
||||||
* [https://www.cncf.io/projects/graduation-criteria/](https://www.cncf.io/projects/graduation-criteria/)
|
|
||||||
* [https://www.cncf.io/about/charter/](https://www.cncf.io/about/charter/)
|
* [https://www.cncf.io/about/charter/](https://www.cncf.io/about/charter/)
|
||||||
* [https://github.com/cncf/landscape](https://github.com/cncf/landscape)
|
* [https://github.com/cncf/landscape](https://github.com/cncf/landscape)
|
||||||
* [https://github.com/cncf/toc](https://github.com/cncf/toc)
|
* [https://github.com/cncf/toc](https://github.com/cncf/toc)
|
||||||
|
* [AT&T, Box, Cisco, Cloud Foundry Foundation, CoreOS, Cycle Computing, Docker, eBay, Goldman Sachs, Google, Huawei, IBM, Intel, Joyent, Kismatic, Mesosphere, Red Hat, Switch SUPERNAP, Twitter, Univa, VMware and Weaveworks join new effort to build and maintain cloud native distributed systems - cncf.io](https://www.cncf.io/announcement/2015/06/21/new-cloud-native-computing-foundation-to-drive-alignment-among-container-technologies/)
|
||||||
|
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -10,8 +10,6 @@
|
||||||
|
|
||||||
> 容器——Cloud Native的基石
|
> 容器——Cloud Native的基石
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
容器最初是通过开发者工具而流行,可以使用它来做隔离的开发测试环境和持续集成环境,这些都是因为容器轻量级,易于配置和使用带来的优势,docker和docker-compose这样的工具极大的方便的了应用开发环境的搭建,开发者就像是化学家一样在其中小心翼翼的进行各种调试和开发。
|
容器最初是通过开发者工具而流行,可以使用它来做隔离的开发测试环境和持续集成环境,这些都是因为容器轻量级,易于配置和使用带来的优势,docker和docker-compose这样的工具极大的方便的了应用开发环境的搭建,开发者就像是化学家一样在其中小心翼翼的进行各种调试和开发。
|
||||||
|
|
||||||
随着容器的在开发者中的普及,已经大家对CI流程的熟悉,容器周边的各种工具蓬勃发展,俨然形成了一个小生态,在2016年达到顶峰,下面这张是我画的容器生态图:
|
随着容器的在开发者中的普及,已经大家对CI流程的熟悉,容器周边的各种工具蓬勃发展,俨然形成了一个小生态,在2016年达到顶峰,下面这张是我画的容器生态图:
|
||||||
|
|
@ -24,8 +22,6 @@
|
||||||
|
|
||||||
> Kubernetes——让容器应用进入大规模工业生产。
|
> Kubernetes——让容器应用进入大规模工业生产。
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
**Kubernetes是容器编排系统的事实标准**
|
**Kubernetes是容器编排系统的事实标准**
|
||||||
|
|
||||||
在单机上运行容器,无法发挥它的最大效能,只有形成集群,才能最大程度发挥容器的良好隔离、资源分配与编排管理的优势,而对于容器的编排管理,Swarm、Mesos和Kubernetes的大战已经基本宣告结束,Kubernetes成为了无可争议的赢家。
|
在单机上运行容器,无法发挥它的最大效能,只有形成集群,才能最大程度发挥容器的良好隔离、资源分配与编排管理的优势,而对于容器的编排管理,Swarm、Mesos和Kubernetes的大战已经基本宣告结束,Kubernetes成为了无可争议的赢家。
|
||||||
|
|
@ -48,11 +44,11 @@
|
||||||
|
|
||||||
但就2017年为止,Kubernetes的主要使用场景也主要作为应用开发测试环境、CI/CD和运行Web应用这几个领域,如下图[TheNewStack](http://thenewstack.io)的Kubernetes生态状况调查报告所示。
|
但就2017年为止,Kubernetes的主要使用场景也主要作为应用开发测试环境、CI/CD和运行Web应用这几个领域,如下图[TheNewStack](http://thenewstack.io)的Kubernetes生态状况调查报告所示。
|
||||||
|
|
||||||
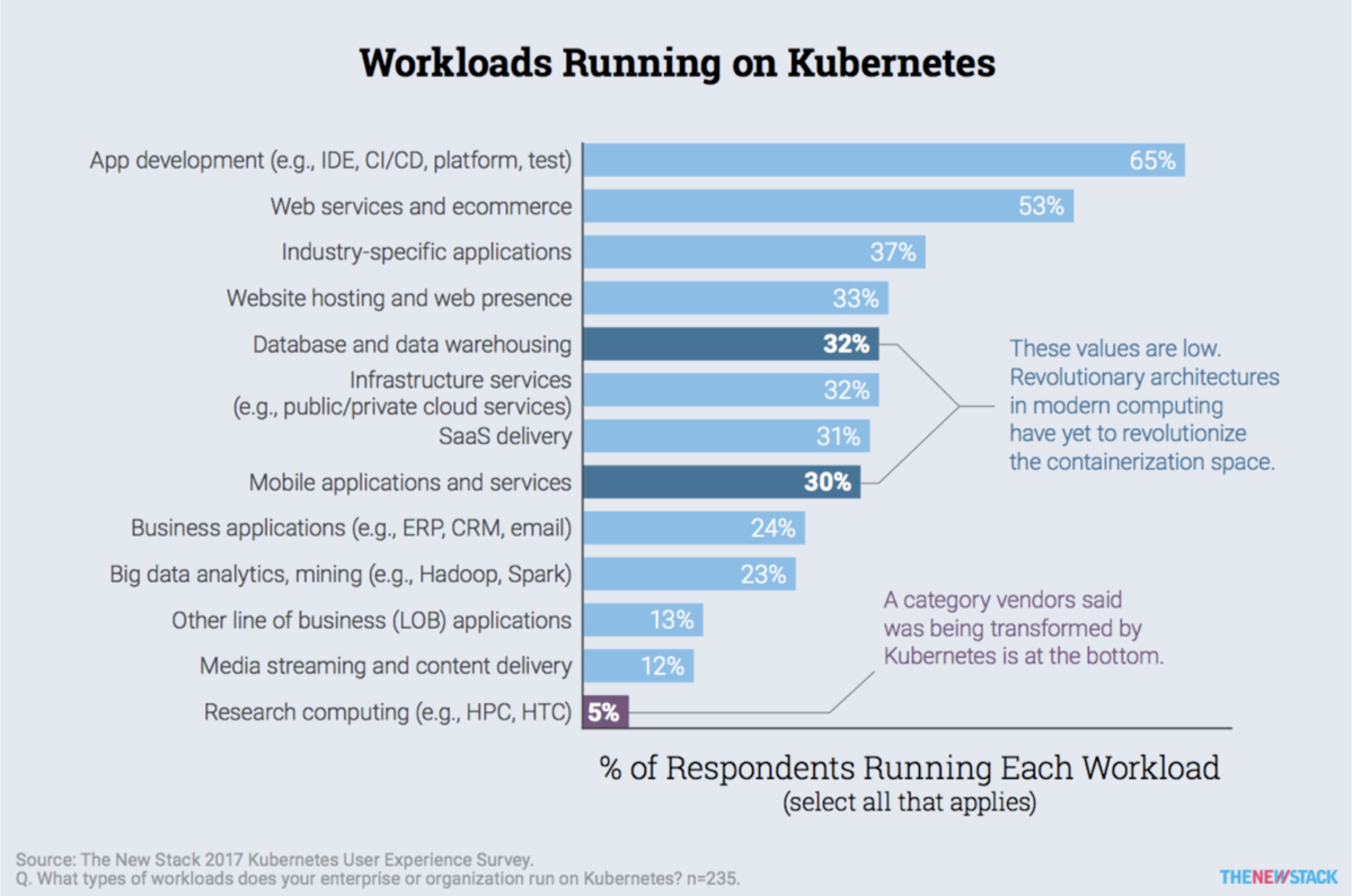
|

|
||||||
|
|
||||||
另外基于Kubernetes的构建PaaS平台和Serverless也处于爆发的准备的阶段,如下图中Gartner的报告中所示:
|
另外基于Kubernetes的构建PaaS平台和Serverless也处于爆发的准备的阶段,如下图中Gartner的报告中所示:
|
||||||
|
|
||||||
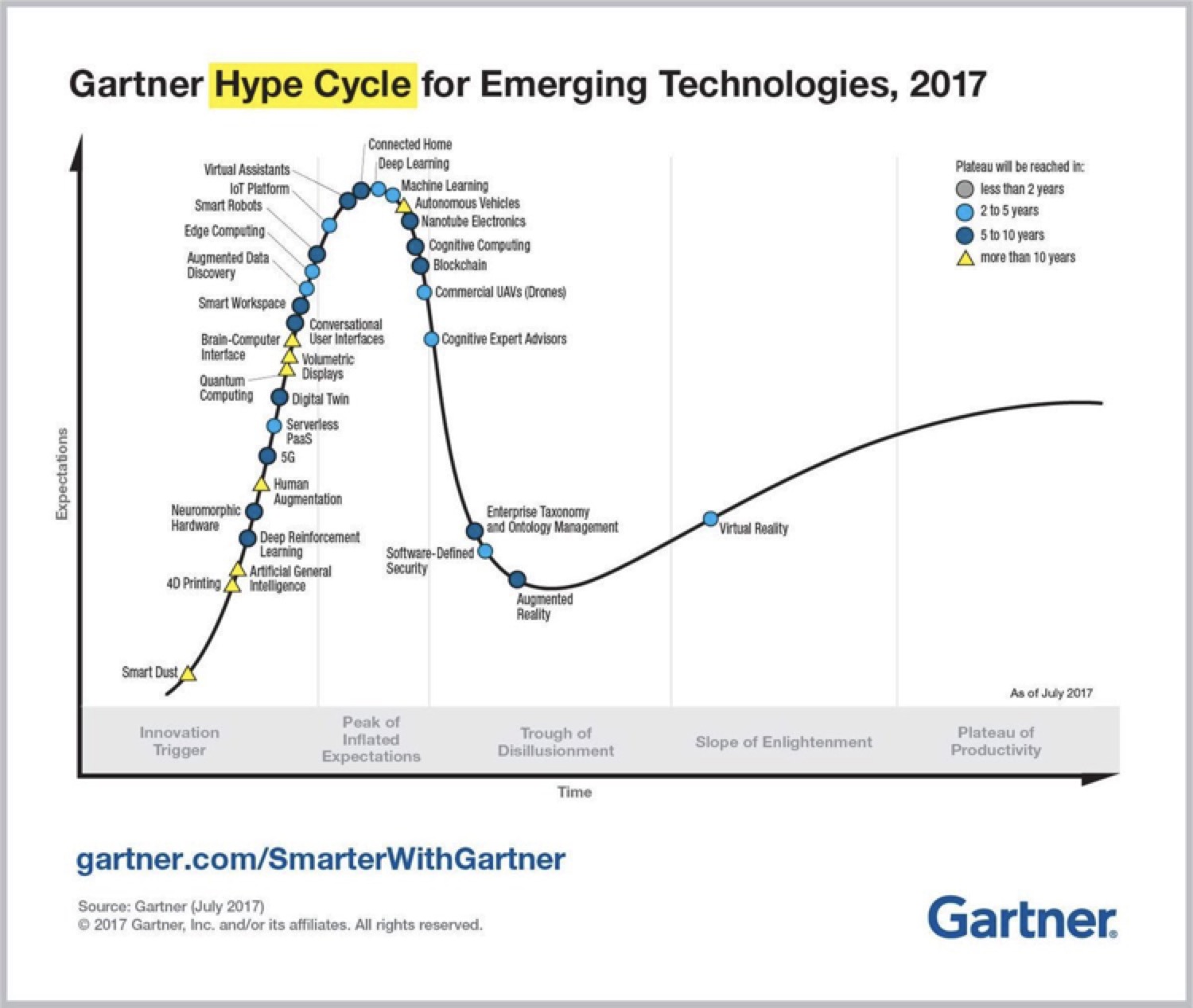
|

|
||||||
|
|
||||||
当前各大公有云如Google GKE、微软Azure ACS、亚马逊EKS(2018年上线)、VMWare、Pivotal、腾讯云、阿里云等都提供了Kubernetes服务。
|
当前各大公有云如Google GKE、微软Azure ACS、亚马逊EKS(2018年上线)、VMWare、Pivotal、腾讯云、阿里云等都提供了Kubernetes服务。
|
||||||
|
|
||||||
|
|
@ -76,8 +72,6 @@
|
||||||
|
|
||||||
> DevOps——通向云原生的云梯
|
> DevOps——通向云原生的云梯
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
CNCF(云原生计算基金会)给出了云原生应用的三大特征:
|
CNCF(云原生计算基金会)给出了云原生应用的三大特征:
|
||||||
|
|
||||||
- **容器化包装**:软件应用的进程应该包装在容器中独立运行。
|
- **容器化包装**:软件应用的进程应该包装在容器中独立运行。
|
||||||
|
|
@ -90,7 +84,7 @@ CNCF(云原生计算基金会)给出了云原生应用的三大特征:
|
||||||
|
|
||||||
[CNCF](https://cncf.io)所托管的应用(目前已达12个),即朝着这个目标发展,其公布的[Cloud Native Landscape](https://github.com/cncf/landscape),给出了云原生生态的参考体系。
|
[CNCF](https://cncf.io)所托管的应用(目前已达12个),即朝着这个目标发展,其公布的[Cloud Native Landscape](https://github.com/cncf/landscape),给出了云原生生态的参考体系。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
**使用Kubernetes构建云原生应用**
|
**使用Kubernetes构建云原生应用**
|
||||||
|
|
||||||
|
|
@ -131,8 +125,6 @@ CNCF(云原生计算基金会)给出了云原生应用的三大特征:
|
||||||
|
|
||||||
> Services for show, meshes for a pro.
|
> Services for show, meshes for a pro.
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Kubernetes中的应用将作为微服务运行,但是Kubernetes本身并没有给出微服务治理的解决方案,比如服务的限流、熔断、良好的灰度发布支持等。
|
Kubernetes中的应用将作为微服务运行,但是Kubernetes本身并没有给出微服务治理的解决方案,比如服务的限流、熔断、良好的灰度发布支持等。
|
||||||
|
|
||||||
**Service Mesh可以用来做什么**
|
**Service Mesh可以用来做什么**
|
||||||
|
|
@ -185,13 +177,11 @@ Linker的部署十分简单,本身就是一个镜像,使用Kubernetes的[Dae
|
||||||
|
|
||||||
> Cloud Native的大规模工业生产
|
> Cloud Native的大规模工业生产
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
**GitOps**
|
**GitOps**
|
||||||
|
|
||||||
给开发者带来最大的配置和上线的灵活性,践行DevOps流程,改善研发效率,下图这样的情况将更少发生。
|
给开发者带来最大的配置和上线的灵活性,践行DevOps流程,改善研发效率,下图这样的情况将更少发生。
|
||||||
|
|
||||||
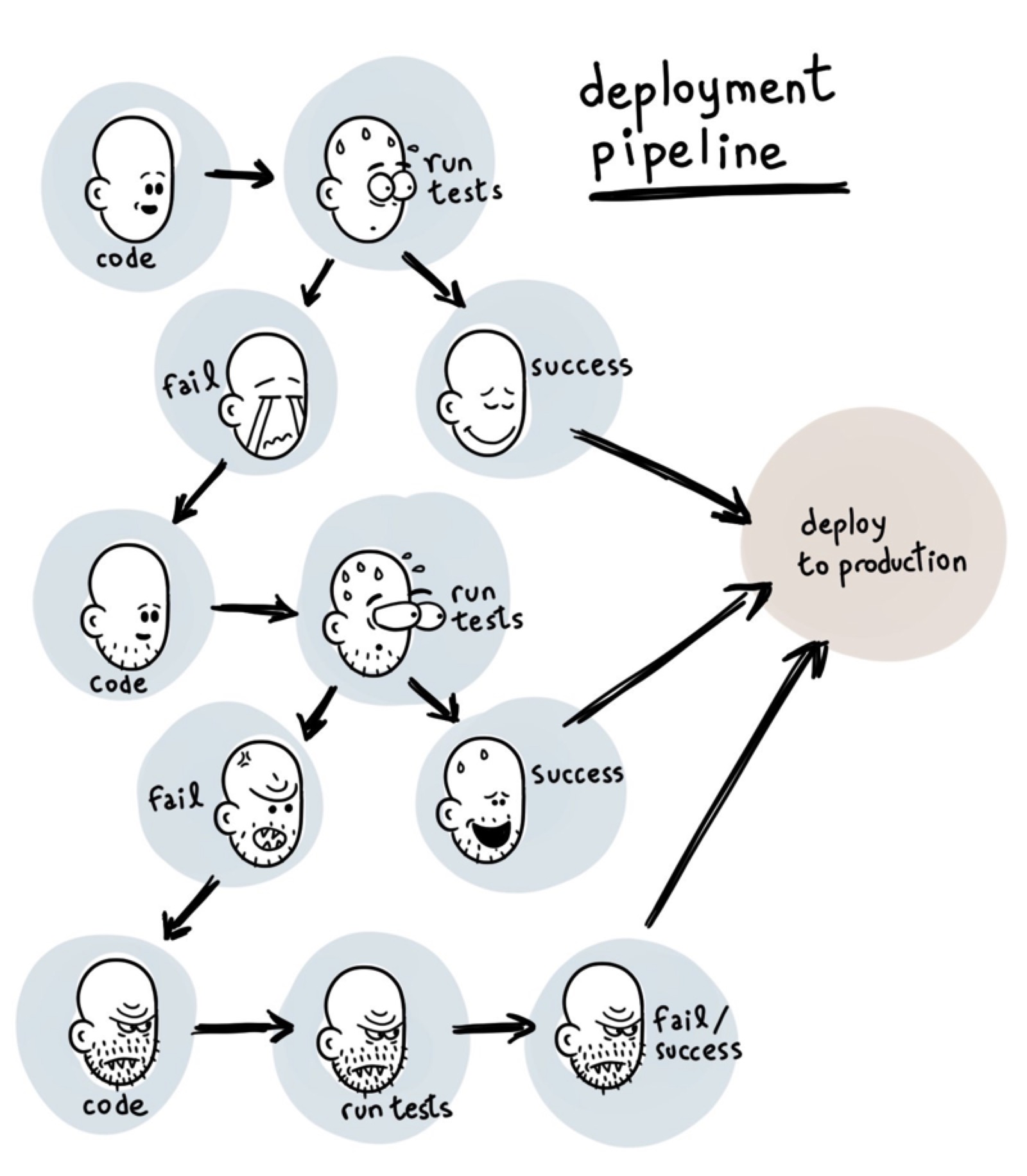
|

|
||||||
|
|
||||||
我们知道Kubernetes中的所有应用的部署都是基于YAML文件的,这实际上就是一种**Infrastructure as code**,完全可以通过Git来管控基础设施和部署环境的变更。
|
我们知道Kubernetes中的所有应用的部署都是基于YAML文件的,这实际上就是一种**Infrastructure as code**,完全可以通过Git来管控基础设施和部署环境的变更。
|
||||||
|
|
||||||
|
|
@ -256,19 +246,19 @@ Spark现在已经非官方支持了基于Kubernetes的原生调度,其具有
|
||||||
|
|
||||||
下图是我们刚调研准备使用Kubernetes时候的调研方案选择。
|
下图是我们刚调研准备使用Kubernetes时候的调研方案选择。
|
||||||
|
|
||||||
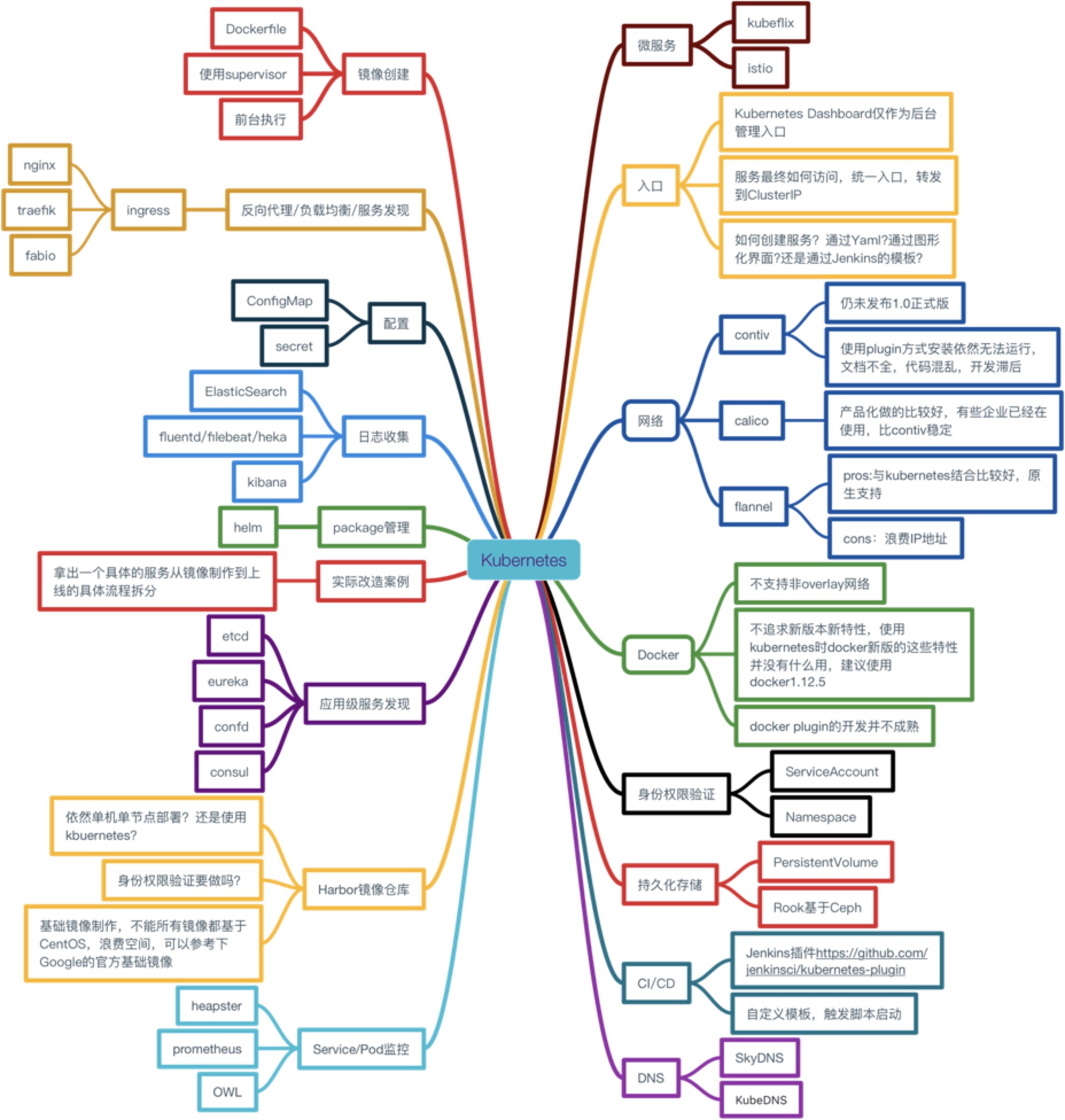
|

|
||||||
|
|
||||||
对于一个初次接触Kubernetes的人来说,看到这样一个庞大的架构选型时会望而生畏,但是Kubernetes的开源社区帮助了我们很多。
|
对于一个初次接触Kubernetes的人来说,看到这样一个庞大的架构选型时会望而生畏,但是Kubernetes的开源社区帮助了我们很多。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
我组建了**K8S&Cloud Native实战**微信群,参与了k8smeetup、KEUC2017、[kubernetes-docs-cn](https://github.com/kubernetes/kubernetes-docs-cn) Kubernetes官方中文文档项目。
|
我组建了**K8S&Cloud Native实战**、**ServiceMesher**微信群,参与了k8smeetup、KEUC2017、[kubernetes-docs-cn](https://github.com/kubernetes/kubernetes-docs-cn) Kubernetes官方中文文档项目。
|
||||||
|
|
||||||
**有用的资料和链接**
|
**有用的资料和链接**
|
||||||
|
|
||||||
- 我的博客: <https://jimmysong.io>
|
- 我的博客: <https://jimmysong.io>
|
||||||
- 微信群:k8s&cloud native实战群(见:<https://jimmysong.io/about>)
|
- 微信群:k8s&cloud native实战群、ServiceMesher(见:<https://jimmysong.io/about>)
|
||||||
- Meetup:k8smeetup
|
- Meetup:k8smeetup、[ServiceMesher](http://www.servicemesher.com)
|
||||||
- Cloud Native Go - 基于Go和React云原生Web应用开发:https://jimmysong.io/cloud-native-go
|
- Cloud Native Go - 基于Go和React云原生Web应用开发:https://jimmysong.io/cloud-native-go
|
||||||
- Gitbook:<https://jimmysong.io/kubernetes-handbook>
|
- Gitbook:<https://jimmysong.io/kubernetes-handbook>
|
||||||
- Cloud native开源生态:<https://jimmysong.io/awesome-cloud-native/>
|
- Cloud native开源生态:<https://jimmysong.io/awesome-cloud-native/>
|
||||||
|
|
|
||||||
|
|
@ -1,6 +1,6 @@
|
||||||
# Kubernetes与云原生应用概览
|
# Kubernetes与云原生应用概览
|
||||||
|
|
||||||
几个月前Mesos已经宣布支持Kubernetes,而在2017年10月份的DockerCon EU上,Docker公司宣布官方同时支持Swarm和Kubernetes容器编排,Kubernetes已然成为容器编排调度的标准。
|
2017年9月,Mesos宣布支持Kubernetes,而在2017年10月份的DockerCon EU上,Docker公司宣布官方同时支持Swarm和Kubernetes容器编排,Kubernetes已然成为容器编排调度的标准。
|
||||||
|
|
||||||
作为全书的开头,首先从历史、生态和应用角度介绍一下Kubernetes与云原生应用,深入浅出,高屋建瓴,没有深入到具体细节,主要是为了给初次接触Kubernetes的小白扫盲,具体细节请参考链接。
|
作为全书的开头,首先从历史、生态和应用角度介绍一下Kubernetes与云原生应用,深入浅出,高屋建瓴,没有深入到具体细节,主要是为了给初次接触Kubernetes的小白扫盲,具体细节请参考链接。
|
||||||
|
|
||||||
|
|
@ -199,7 +199,7 @@ Kubernetes 对象是 “目标性记录” —— 一旦创建对象,Kubernete
|
||||||
|
|
||||||
### 部署Kubernetes集群
|
### 部署Kubernetes集群
|
||||||
|
|
||||||
使用二进制部署 `kubernetes` 集群的所有组件和插件,而不是使用 `kubeadm` 等自动化方式来部署集群,同时开启了集群的TLS安全认证,这样可以帮助我们解系统各组件的交互原理,进而能快速解决实际问题。详见[在CentOS上部署Kubernetes集群](../practice/install-kubernetes-on-centos.md)。
|
使用二进制部署 `kubernetes` 集群的所有组件和插件,而不是使用 `kubeadm` 等自动化方式来部署集群,同时开启了集群的TLS安全认证,这样可以帮助我们了解系统各组件的交互原理,进而能快速解决实际问题。详见[在CentOS上部署Kubernetes集群](../practice/install-kubernetes-on-centos.md)。
|
||||||
|
|
||||||
**集群详情**
|
**集群详情**
|
||||||
|
|
||||||
|
|
@ -267,7 +267,7 @@ Kubernetes在设计之初就充分考虑了针对容器的服务发现与负载
|
||||||
Kubernetes是一个多租户的云平台,因此必须对用户的权限加以限制,对用户空间进行隔离。Kubernetes中的隔离主要包括这几种:
|
Kubernetes是一个多租户的云平台,因此必须对用户的权限加以限制,对用户空间进行隔离。Kubernetes中的隔离主要包括这几种:
|
||||||
|
|
||||||
* 网络隔离:需要使用网络插件,比如[flannel](https://coreos.com/flannel/), [calico](https://www.projectcalico.org/)。
|
* 网络隔离:需要使用网络插件,比如[flannel](https://coreos.com/flannel/), [calico](https://www.projectcalico.org/)。
|
||||||
* 资源隔离:kubernetes原生支持资源隔离,pod就是资源就是隔离和调度的最小单位,同时使用[namespace](https://jimmysong.io/kubernetes-handbook/concepts/namespace.html)限制用户空间和资源限额。
|
* 资源隔离:kubernetes原生支持资源隔离,pod就是资源隔离和调度的最小单位,同时使用[namespace](https://jimmysong.io/kubernetes-handbook/concepts/namespace.html)限制用户空间和资源限额。
|
||||||
* 身份隔离:使用[RBAC-基于角色的访问控制](https://jimmysong.io/kubernetes-handbook/guide/rbac.html),多租户的身份认证和权限控制。
|
* 身份隔离:使用[RBAC-基于角色的访问控制](https://jimmysong.io/kubernetes-handbook/guide/rbac.html),多租户的身份认证和权限控制。
|
||||||
|
|
||||||
## 如何开发Kubernetes原生应用步骤介绍
|
## 如何开发Kubernetes原生应用步骤介绍
|
||||||
|
|
@ -325,11 +325,12 @@ Kubernetes是一个多租户的云平台,因此必须对用户的权限加以
|
||||||
步骤说明:
|
步骤说明:
|
||||||
|
|
||||||
1. 将原有应用拆解为服务
|
1. 将原有应用拆解为服务
|
||||||
2. 容器化、制作镜像
|
2. 定义服务的接口/API通信方式
|
||||||
3. 准备应用配置文件
|
3. 编写启动脚本作为容器的进程入口
|
||||||
4. 准备Kubernetes YAML文件
|
4. 准备应用配置文件
|
||||||
5. 编写bootstarp脚本
|
5. 容器化、制作镜像
|
||||||
6. 创建ConfigMaps
|
6. 准备Kubernetes YAML文件
|
||||||
|
7. 如果有外置配置文件需要创建ConfigMap或Secret存储
|
||||||
|
|
||||||
详见:[迁移传统应用到Kubernetes步骤详解——以Hadoop YARN为例](https://jimmysong.io/posts/migrating-hadoop-yarn-to-kubernetes/)。
|
详见:[迁移传统应用到Kubernetes步骤详解——以Hadoop YARN为例](https://jimmysong.io/posts/migrating-hadoop-yarn-to-kubernetes/)。
|
||||||
|
|
||||||
|
|
@ -337,7 +338,7 @@ Kubernetes是一个多租户的云平台,因此必须对用户的权限加以
|
||||||
|
|
||||||
Service Mesh现在一般被翻译作服务网格,目前主流的Service Mesh有如下几款:
|
Service Mesh现在一般被翻译作服务网格,目前主流的Service Mesh有如下几款:
|
||||||
|
|
||||||
* [Istio](https://istio.io):IBM、Google、Lyft共同开源,详细文档见[Istio官方文档中文版](http://istio.doczh.cn/)
|
* [Istio](https://istio.io):IBM、Google、Lyft共同开源,详细文档见[Istio官方文档](https://istio.io)
|
||||||
* [Linkerd](https://linkerd.io):原Twitter工程师开发,现为[CNCF](https://cncf.io)中的项目之一
|
* [Linkerd](https://linkerd.io):原Twitter工程师开发,现为[CNCF](https://cncf.io)中的项目之一
|
||||||
* [Envoy](https://www.envoyproxy.io/):Lyft开源的,可以在Istio中使用Sidecar模式运行
|
* [Envoy](https://www.envoyproxy.io/):Lyft开源的,可以在Istio中使用Sidecar模式运行
|
||||||
* [Conduit](https://conduit.io):同样由Buoyant开源的轻量级的基于Kubernetes的Service Mesh
|
* [Conduit](https://conduit.io):同样由Buoyant开源的轻量级的基于Kubernetes的Service Mesh
|
||||||
|
|
@ -359,7 +360,7 @@ Service Mesh现在一般被翻译作服务网格,目前主流的Service Mesh
|
||||||
* [微服务管理框架Service Mesh——Linkerd安装试用笔记](https://jimmysong.io/posts/linkerd-user-guide/)
|
* [微服务管理框架Service Mesh——Linkerd安装试用笔记](https://jimmysong.io/posts/linkerd-user-guide/)
|
||||||
* [微服务管理框架Service Mesh——Istio安装试用笔记](https://jimmysong.io/posts/istio-installation/)
|
* [微服务管理框架Service Mesh——Istio安装试用笔记](https://jimmysong.io/posts/istio-installation/)
|
||||||
|
|
||||||
更多关于 Service Mesh 的内容请访问 [Service Mesh 中文网](http://www.servicemesh.cn)。
|
更多关于 Service Mesh 的内容请访问 [ServiceMesher 社区网站](http://www.servicemesher.com)。
|
||||||
|
|
||||||
## 使用案例
|
## 使用案例
|
||||||
|
|
||||||
|
|
@ -386,7 +387,7 @@ Kubernetes作为云原生计算的基本组件之一,开源2年时间以来热
|
||||||
|
|
||||||
**使用Kibana查看日志**
|
**使用Kibana查看日志**
|
||||||
|
|
||||||
日志字段中包括了应用的标签、容器名称、主机名称、宿主机名称、IP地址、时间、
|
日志字段中包括了应用的标签、容器名称、主机名称、宿主机名称、IP地址、时间。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
|
@ -474,5 +475,5 @@ Spark原生支持standalone、mesos和YARN资源调度,现已支持Kubernetes
|
||||||
|
|
||||||
* [迁移到云原生应用架构指南](https://jimmysong.io/migrating-to-cloud-native-application-architectures)
|
* [迁移到云原生应用架构指南](https://jimmysong.io/migrating-to-cloud-native-application-architectures)
|
||||||
* [Cloud Native Go - 已由电子工业出版社出版](https://jimmysong.io/cloud-native-go)
|
* [Cloud Native Go - 已由电子工业出版社出版](https://jimmysong.io/cloud-native-go)
|
||||||
* [Cloud Native Python - 将由电子工业出版社出版](https://jimmysong.io/posts/cloud-native-python)
|
* [Cloud Native Python - 已由电子工业出版社出版](https://jimmysong.io/posts/cloud-native-python)
|
||||||
* [Istio Service Mesh 中文文档](http://istio.doczh.cn/)
|
* [Istio Service Mesh 中文文档 v1.2](https://archive.istio.io/v1.2/zh/)
|
||||||
|
|
|
||||||
|
|
@ -0,0 +1,61 @@
|
||||||
|
# 使用Rancher在阿里云上部署Kubernetes集群
|
||||||
|
|
||||||
|
如果您已经购买了阿里云的 ECS,那么您可以使用 Rancher 很方便的构建起一套 Kubernetes 集群用于测试及小规模使用。使用 Rancher 可以自动和可视化的完成 Kubernetes 集群的安装工作,省去的繁琐的人工安装过程,然您快速投入的业务开发中。下文根据 Rancher 2.x 安装 Kubernetes 集群。
|
||||||
|
|
||||||
|
**注:阿里云上已支持[容器服务 ACK](https://cn.aliyun.com/product/kubernetes),如果您需要高性能、企业级的 Kubernetes 服务不妨考虑一下。**
|
||||||
|
|
||||||
|
## 准备
|
||||||
|
|
||||||
|
要想使用阿里云 ECS 和 Rancher 直接搭建一套 Kubernetes 集群,需要准备以下条件:
|
||||||
|
|
||||||
|
- 开通了公网 IP 的 ECS
|
||||||
|
- ECS 规格建议至少 4C8G
|
||||||
|
- ECS 使用的阿里云的经典网络
|
||||||
|
|
||||||
|
### 安全组规则
|
||||||
|
|
||||||
|
组成 Kubenretes 集群的 ECS 位于阿里云经典网络中,需要为集群配置安全组规则如下:
|
||||||
|
|
||||||
|
- UDP/8472 端口:阿里云默认禁止了 UDP,我们使用的 flannel 网络插件的VXLAN 模式,需要将 ECS 的安全组设置 UDP/8472 端口开放
|
||||||
|
- TCP/6443:Kubernetes API Server
|
||||||
|
- TCP/2379:etcd
|
||||||
|
- TCP/2380:etcd
|
||||||
|
- TCP/80:http
|
||||||
|
- TCP/443:https
|
||||||
|
|
||||||
|
## 步骤
|
||||||
|
|
||||||
|
假设现在我们有两个节点 master 和 node,请参考 [Rancher Quick Start Guide](https://rancher.com/docs/rancher/v2.x/en/quick-start-guide/deployment/quickstart-manual-setup/) 安装 Rancher。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
**Master**
|
||||||
|
|
||||||
|
先在 Master 节点安装 Rancher server、control、etcd 和 worker。
|
||||||
|
|
||||||
|
选择网络组件为 Flannel,同时在自定义主机运行命令中选择主机角色、填写主机的内网和外网 IP。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker run -d --restart=unless-stopped -p 80:80 -p 443:443 rancher/rancher
|
||||||
|
```
|
||||||
|
|
||||||
|
Rancher 将自动创建 Kubernetes 集群,并默认在 80 端口运行 web server。
|
||||||
|
|
||||||
|
**Node**
|
||||||
|
|
||||||
|
添加 Node 节点时只需要在 Rancher 的 web 界面上找到您刚安装的集群并选择【编辑集群】并选择节点角色为 Worker 即可增加一台 Kubenretes 集群节点。
|
||||||
|
|
||||||
|
## 集群交互
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
如果您习惯使用命令行与集群交互可以 Rancher 的 web 上找到集群首页上的 `Kubeconfig File` 下载按钮,将该文件中的内容保存到您自己电脑的 `~/.kube/config` 文件中。然后现在对应 Kubernetes 版本的 `kubectl` 命令并放到 `PATH` 路径下即可。
|
||||||
|
|
||||||
|
如果您没有在本地安装 `kubectl` 工具,也可以通过 Rancher 的集群页面上的 `Launch kubectl` 命令通过 web 来操作集群。
|
||||||
|
|
||||||
|
## 参考
|
||||||
|
|
||||||
|
- [Rancher - rancher.com](https://rancher.com/products/rancher/)
|
||||||
|
- [阿里云容器服务 ACK - aliyun.com](https://cn.aliyun.com/product/kubernetes)
|
||||||
|
|
@ -13,15 +13,17 @@
|
||||||
- DevOps:开发与运维之间的协同,上升到一种文化的层次,能够让应用快速的部署和发布
|
- DevOps:开发与运维之间的协同,上升到一种文化的层次,能够让应用快速的部署和发布
|
||||||
- 微服务:这是应用开发的一种理念,将单体应用拆分为微服务才能更好的实现云原生,才能独立的部署、扩展和更新
|
- 微服务:这是应用开发的一种理念,将单体应用拆分为微服务才能更好的实现云原生,才能独立的部署、扩展和更新
|
||||||
|
|
||||||
一句话解释什么是云原生应用:云原生应用就是为了在云上运行而开发的应用
|
一句话解释什么是云原生应用:云原生应用就是为了在云上运行而开发的应用。
|
||||||
|
|
||||||

|
## Kubernetes:云原生操作系统
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
要运行这样的应用必须有一个操作系统,就像我们运行PC或手机应用一样,而Kubernetes就是一个这样的操作系统。
|
要运行这样的应用必须有一个操作系统,就像我们运行PC或手机应用一样,而Kubernetes就是一个这样的操作系统。
|
||||||
|
|
||||||
我们再来看下操作系统宝库哪些层次。
|
我们再来看下操作系统包括哪些层次。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
- 硬件管理:可以管理CPU、内存、网络和存储
|
- 硬件管理:可以管理CPU、内存、网络和存储
|
||||||
- 设备接口、虚拟化工具、实用工具
|
- 设备接口、虚拟化工具、实用工具
|
||||||
|
|
@ -30,7 +32,7 @@
|
||||||
|
|
||||||
下面是CNCF给出的云原生景观图。
|
下面是CNCF给出的云原生景观图。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
该图中包括云原生的各种层次的提供者和应用,通过该图可以组合出一些列的云原生平台。
|
该图中包括云原生的各种层次的提供者和应用,通过该图可以组合出一些列的云原生平台。
|
||||||
|
|
||||||
|
|
@ -52,7 +54,7 @@ Kubernetes发展已经有3年多的时间了,它已经基本成为了容器编
|
||||||
|
|
||||||
这是KubeVirt的架构图。
|
这是KubeVirt的架构图。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
我们看到图中有两个是Kubernetes原生的组件,API server和kubelet,我们创建了virt-controller就是为了创建CRD的controller,它扩展了kube-controller的功能,用于管理虚拟机的生命周期,同时在每个节点上都用DaemonSet的方式运行一个virt-handler,这个handler是用于创建虚拟机的处理器,每个节点上即可用运行虚拟机也可以运行容器,只要这个节点上有virt-handler就可以运行和调度虚拟机。
|
我们看到图中有两个是Kubernetes原生的组件,API server和kubelet,我们创建了virt-controller就是为了创建CRD的controller,它扩展了kube-controller的功能,用于管理虚拟机的生命周期,同时在每个节点上都用DaemonSet的方式运行一个virt-handler,这个handler是用于创建虚拟机的处理器,每个节点上即可用运行虚拟机也可以运行容器,只要这个节点上有virt-handler就可以运行和调度虚拟机。
|
||||||
|
|
||||||
|
|
@ -64,7 +66,7 @@ Kubernetes的资源隔离也能保证对集群资源的最大化和最优利用
|
||||||
|
|
||||||
下图中展示了Kubernetes中的资源隔离层次。
|
下图中展示了Kubernetes中的资源隔离层次。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
- 容器
|
- 容器
|
||||||
- Pod:命名空间的隔离,共享网络,每个Pod都有独立IP,使用Service Account为Pod赋予账户
|
- Pod:命名空间的隔离,共享网络,每个Pod都有独立IP,使用Service Account为Pod赋予账户
|
||||||
|
|
@ -80,13 +82,13 @@ Kubernetes中的基本资源类型分成了三类:
|
||||||
|
|
||||||
在最近一届的KubeCon & CloudNativeCon上Operator已经变得越来越流行。下面是OpenEBS的一个使用Operator的例子。
|
在最近一届的KubeCon & CloudNativeCon上Operator已经变得越来越流行。下面是OpenEBS的一个使用Operator的例子。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
OpenEBS是一款容器化存储,它基于Ceph构建,容器化存储最大的好处就是复用Kubernetes的资源类型,简化存储应用的部署,将单体的存储拆分为“微服务化”的存储,即每个应用在声明PV的时候才会创建存储,并与PV的生命周期一样都是独立于应用的。
|
OpenEBS是一款容器化存储,它基于Ceph构建,容器化存储最大的好处就是复用Kubernetes的资源类型,简化存储应用的部署,将单体的存储拆分为“微服务化”的存储,即每个应用在声明PV的时候才会创建存储,并与PV的生命周期一样都是独立于应用的。
|
||||||
|
|
||||||
OpenEBS的存储也是分控制平面和数据平面的,下图是OpenEBS的架构图。
|
OpenEBS的存储也是分控制平面和数据平面的,下图是OpenEBS的架构图。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
黄色部分是OpenEBS的组件(除了kube-dashboard),它是使用Kubernetes的各种原语和CRD来创建的,架构跟Kubernetes本身也很类似。
|
黄色部分是OpenEBS的组件(除了kube-dashboard),它是使用Kubernetes的各种原语和CRD来创建的,架构跟Kubernetes本身也很类似。
|
||||||
|
|
||||||
|
|
@ -94,13 +96,13 @@ OpenEBS的存储也是分控制平面和数据平面的,下图是OpenEBS的架
|
||||||
|
|
||||||
上面说到了Operator的一个应用,下面再来看一个我们之前在Kubernetes中部署Hadoop YARN和Spark的例子。
|
上面说到了Operator的一个应用,下面再来看一个我们之前在Kubernetes中部署Hadoop YARN和Spark的例子。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
Kubernetes始于12因素应用的PaaS平台,它是微服务的绝佳部署管理平台,基于它可以应用多种设计模式。它的未来将变成什么样呢?
|
Kubernetes始于12因素应用的PaaS平台,它是微服务的绝佳部署管理平台,基于它可以应用多种设计模式。它的未来将变成什么样呢?
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
- Service Mesh:解决微服务治理问题
|
- Service Mesh:解决微服务治理问题
|
||||||
- Auto Pilot:自动驾驭能力,服务自动扩展,智能运维
|
- Auto Pilot:自动驾驭能力,服务自动扩展,智能运维
|
||||||
|
|
@ -114,7 +116,7 @@ Kubernetes始于12因素应用的PaaS平台,它是微服务的绝佳部署管
|
||||||
|
|
||||||
甚至出现了像ballerina这样的云原生编程语言,它的出现就是为了解决应用开发到服务集成之间的鸿沟的。它有以下几个特点。
|
甚至出现了像ballerina这样的云原生编程语言,它的出现就是为了解决应用开发到服务集成之间的鸿沟的。它有以下几个特点。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
- 使用云原生语义的DSL
|
- 使用云原生语义的DSL
|
||||||
- 注解式配置
|
- 注解式配置
|
||||||
|
|
@ -123,13 +125,13 @@ Kubernetes始于12因素应用的PaaS平台,它是微服务的绝佳部署管
|
||||||
|
|
||||||
要完成云的集成CI/CD,或者用一个词代替来说就是GitOps的需求越来越强烈。
|
要完成云的集成CI/CD,或者用一个词代替来说就是GitOps的需求越来越强烈。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
### Kubernetes没有做什么
|
### Kubernetes没有做什么
|
||||||
|
|
||||||
看下这张图中的两个服务,它们使用的是kube-proxy里基于iptables的原生的负载均衡,并且服务间的流量也没有任何控制。
|
看下这张图中的两个服务,它们使用的是kube-proxy里基于iptables的原生的负载均衡,并且服务间的流量也没有任何控制。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
Kubernetes缺少的最重要的一个功能就是微服务的治理,微服务比起单体服务来说使得部署和运维起来更加复杂,对于微服务的可观测性也有更高的要求,同时CI/CD流程Kubernetes本身也没有提供。
|
Kubernetes缺少的最重要的一个功能就是微服务的治理,微服务比起单体服务来说使得部署和运维起来更加复杂,对于微服务的可观测性也有更高的要求,同时CI/CD流程Kubernetes本身也没有提供。
|
||||||
|
|
||||||
|
|
@ -141,7 +143,7 @@ Service Mesh是一个专用的基础设施层,它能够将微服务的治理
|
||||||
|
|
||||||
这是Istio Service Mesh的架构图。
|
这是Istio Service Mesh的架构图。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
- Pilot:提供用户接口,用户可以通过该接口配置各种路由规则,Pilot还可以通过适配器获取平台上各种服务之间的管理,Evnoy这个使用Sidecar方式部署到每个应用pod中的进程会通过Pilot中的Envoy API获得平台上各个服务之间的管理,同时也会应用用户配置的路由规则。
|
- Pilot:提供用户接口,用户可以通过该接口配置各种路由规则,Pilot还可以通过适配器获取平台上各种服务之间的管理,Evnoy这个使用Sidecar方式部署到每个应用pod中的进程会通过Pilot中的Envoy API获得平台上各个服务之间的管理,同时也会应用用户配置的路由规则。
|
||||||
- Mixer:获取各种平台属性,服务间通讯时会先访问Mixer兼容各平台的属性信息,如quota、访问控制和策略评估,将服务间的访问信息记录后上报到mixer形成遥测报告。
|
- Mixer:获取各种平台属性,服务间通讯时会先访问Mixer兼容各平台的属性信息,如quota、访问控制和策略评估,将服务间的访问信息记录后上报到mixer形成遥测报告。
|
||||||
|
|
@ -149,7 +151,7 @@ Service Mesh是一个专用的基础设施层,它能够将微服务的治理
|
||||||
|
|
||||||
Service Mesh实际上为了解决社会分工问题,它本身是为了解决微服务的治理。
|
Service Mesh实际上为了解决社会分工问题,它本身是为了解决微服务的治理。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
Pilot和控制平面是为了运维人员准备的。
|
Pilot和控制平面是为了运维人员准备的。
|
||||||
|
|
||||||
|
|
@ -157,8 +159,6 @@ Pilot和控制平面是为了运维人员准备的。
|
||||||
|
|
||||||
Isito在每个上下游服务之间部署一个Envoy,Envoy中有几个基本的服务发现服务,监听器即Envoy要转发的流量端口,Endpoint是要转发的目的地,Cluster是一系列Endpoint用来做负载均衡,Route是定义各种路由规则,每个Envoy进程里可以设置多个Listener。
|
Isito在每个上下游服务之间部署一个Envoy,Envoy中有几个基本的服务发现服务,监听器即Envoy要转发的流量端口,Endpoint是要转发的目的地,Cluster是一系列Endpoint用来做负载均衡,Route是定义各种路由规则,每个Envoy进程里可以设置多个Listener。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
---
|
本文根据 [Jimmy Song](https://jimmysong.io) 于2018年5月20日在[第四届南京全球技术周](https://www.bagevent.com/event/1233659)上【互联网技术专场】上的题为【云原生应用的下一站】的演讲的部分内容的文字整理而成。
|
||||||
|
|
||||||
本文根据 [Jimmy Song](https://jimmysong.io) 于2018年5月20日在[第四届南京全球技术周](http://njsd-china.org/)上【互联网技术专场】上的题为【云原生应用的下一站】的演讲的部分内容的文字整理而成。
|
|
||||||
|
|
|
||||||
|
|
@ -0,0 +1,82 @@
|
||||||
|
# 准入控制器(Admission Controller)
|
||||||
|
|
||||||
|
准入控制器(Admission Controller)位于 API Server 中,在对象被持久化之前,准入控制器拦截对 API Server 的请求,一般用来做身份验证和授权。其中包含两个特殊的控制器:`MutatingAdmissionWebhook` 和 `ValidatingAdmissionWebhook`。分别作为配置的变异和验证[准入控制 webhook](https://kubernetes.io/docs/reference/access-authn-authz/extensible-admission-controllers/#admission-webhooks)。
|
||||||
|
|
||||||
|
**变更(Mutating)准入控制**:修改请求的对象
|
||||||
|
|
||||||
|
**验证(Validating)准入控制**:验证请求的对象
|
||||||
|
|
||||||
|
准入控制器是在 API Server 的启动参数重配置的。一个准入控制器可能属于以上两者中的一种,也可能两者都属于。当请求到达 API Server 的时候首先执行变更准入控制,然后再执行验证准入控制。
|
||||||
|
|
||||||
|
我们在部署 Kubernetes 集群的时候都会默认开启一系列准入控制器,如果没有设置这些准入控制器的话可以说你的 Kubernetes 集群就是在裸奔,应该只有集群管理员可以修改集群的准入控制器。
|
||||||
|
|
||||||
|
例如我会默认开启如下的准入控制器。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
--admission-control=ServiceAccount,NamespaceLifecycle,NamespaceExists,LimitRanger,ResourceQuota,MutatingAdmissionWebhook,ValidatingAdmissionWebhook
|
||||||
|
```
|
||||||
|
|
||||||
|
## 准入控制器列表
|
||||||
|
|
||||||
|
Kubernetes 目前支持的准入控制器有:
|
||||||
|
|
||||||
|
- **AlwaysPullImages**:此准入控制器修改每个 Pod 的时候都强制重新拉取镜像。
|
||||||
|
- **DefaultStorageClass**:此准入控制器观察创建`PersistentVolumeClaim`时不请求任何特定存储类的对象,并自动向其添加默认存储类。这样,用户就不需要关注特殊存储类而获得默认存储类。
|
||||||
|
- **DefaultTolerationSeconds**:此准入控制器将Pod的容忍时间`notready:NoExecute`和`unreachable:NoExecute` 默认设置为5分钟。
|
||||||
|
- **DenyEscalatingExec**:此准入控制器将拒绝`exec` 和附加命令到以允许访问宿主机的升级了权限运行的pod。
|
||||||
|
- **EventRateLimit (alpha)**:此准入控制器缓解了 API Server 被事件请求淹没的问题,限制时间速率。
|
||||||
|
- **ExtendedResourceToleration**:此插件有助于创建具有扩展资源的专用节点。
|
||||||
|
- **ImagePolicyWebhook**:此准入控制器允许后端判断镜像拉取策略,例如配置镜像仓库的密钥。
|
||||||
|
- **Initializers (alpha)**:Pod初始化的准入控制器,详情请参考[动态准入控制](https://kubernetes.io/docs/reference/access-authn-authz/extensible-admission-controllers/)。
|
||||||
|
- **LimitPodHardAntiAffinityTopology**:此准入控制器拒绝任何在 `requiredDuringSchedulingRequiredDuringExecution` 的 `AntiAffinity ` 字段中定义除了`kubernetes.io/hostname` 之外的拓扑关键字的 pod 。
|
||||||
|
- **LimitRanger**:此准入控制器将确保所有资源请求不会超过 namespace 的 `LimitRange`。
|
||||||
|
- **MutatingAdmissionWebhook (1.9版本中为beta)**:该准入控制器调用与请求匹配的任何变更 webhook。匹配的 webhook是串行调用的;如果需要,每个人都可以修改对象。
|
||||||
|
- **NamespaceAutoProvision**:此准入控制器检查命名空间资源上的所有传入请求,并检查引用的命名空间是否存在。如果不存在就创建一个命名空间。
|
||||||
|
- **NamespaceExists**:此许可控制器检查除 `Namespace` 其自身之外的命名空间资源上的所有请求。如果请求引用的命名空间不存在,则拒绝该请求。
|
||||||
|
- **NamespaceLifecycle**:此准入控制器强制执行正在终止的命令空间中不能创建新对象,并确保`Namespace`拒绝不存在的请求。此准入控制器还防止缺失三个系统保留的命名空间`default`、`kube-system`、`kube-public`。
|
||||||
|
- **NodeRestriction**:该准入控制器限制了 kubelet 可以修改的`Node`和`Pod`对象。
|
||||||
|
- **OwnerReferencesPermissionEnforcement**:此准入控制器保护对`metadata.ownerReferences`对象的访问,以便只有对该对象具有“删除”权限的用户才能对其进行更改。
|
||||||
|
- **PodNodeSelector**:此准入控制器通过读取命名空间注释和全局配置来限制可在命名空间内使用的节点选择器。
|
||||||
|
- **PodPreset**:此准入控制器注入一个pod,其中包含匹配的PodPreset中指定的字段,详细信息见[Pod Preset](pod-preset.md)。
|
||||||
|
- **PodSecurityPolicy**:此准入控制器用于创建和修改pod,并根据请求的安全上下文和可用的Pod安全策略确定是否应该允许它。
|
||||||
|
- **PodTolerationRestriction**:此准入控制器首先验证容器的容忍度与其命名空间的容忍度之间是否存在冲突,并在存在冲突时拒绝该容器请求。
|
||||||
|
- **Priority**:此控制器使用`priorityClassName`字段并填充优先级的整数值。如果未找到优先级,则拒绝Pod。
|
||||||
|
- **ResourceQuota**:此准入控制器将观察传入请求并确保它不违反命名空间的`ResourceQuota`对象中列举的任何约束。
|
||||||
|
- **SecurityContextDeny**:此准入控制器将拒绝任何试图设置某些升级的[SecurityContext](https://kubernetes.io/docs/user-guide/security-context)字段的pod 。
|
||||||
|
- **ServiceAccount**:此准入控制器实现[serviceAccounts的](https://kubernetes.io/docs/user-guide/service-accounts)自动化。
|
||||||
|
- **用中的存储对象保护**:该`StorageObjectInUseProtection`插件将`kubernetes.io/pvc-protection`或`kubernetes.io/pv-protection`终结器添加到新创建的持久卷声明(PVC)或持久卷(PV)。在用户删除PVC或PV的情况下,PVC或PV不会被移除,直到PVC或PV保护控制器从PVC或PV中移除终结器。有关更多详细信息,请参阅使用中的[存储对象保护](https://kubernetes.io/docs/concepts/storage/persistent-volumes/#storage-object-in-use-protection)。
|
||||||
|
- **ValidatingAdmissionWebhook(1.8版本中为alpha;1.9版本中为beta)**:该准入控制器调用与请求匹配的任何验证webhook。匹配的webhooks是并行调用的;如果其中任何一个拒绝请求,则请求失败。
|
||||||
|
|
||||||
|
## 推荐配置
|
||||||
|
|
||||||
|
**Kubernetes 1.10+**
|
||||||
|
|
||||||
|
对于Kubernetes 1.10及更高版本,我们建议使用`--enable-admission-plugins`标志运行以下一组准入控制器(**顺序无关紧要**)。
|
||||||
|
|
||||||
|
> **注意:** `--admission-control`在1.10中已弃用并替换为`--enable-admission-plugins`。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
--enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,DefaultTolerationSeconds,MutatingAdmissionWebhook,ValidatingAdmissionWebhook,ResourceQuota
|
||||||
|
```
|
||||||
|
|
||||||
|
对于Kubernetes 1.9及更早版本,我们建议使用`--admission-control`标志(**顺序有关**)运行以下一组许可控制器。
|
||||||
|
|
||||||
|
**Kubernetes 1.9**
|
||||||
|
|
||||||
|
```bash
|
||||||
|
--admission-control=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,DefaultTolerationSeconds,MutatingAdmissionWebhook,ValidatingAdmissionWebhook,ResourceQuota
|
||||||
|
```
|
||||||
|
|
||||||
|
值得重申的是,在1.9中,这些发生在变更阶段和验证阶段,并且例如`ResourceQuota`在验证阶段运行,因此是运行的最后一个准入控制器。 `MutatingAdmissionWebhook`在此列表中出现在它之前,因为它在变更阶段运行。
|
||||||
|
|
||||||
|
对于早期版本,没有验证准入控制器和变更准入控制器的概念,并且准入控制器以指定的确切顺序运行。
|
||||||
|
|
||||||
|
**Kubernetes 1.6 - 1.8**
|
||||||
|
|
||||||
|
```bash
|
||||||
|
--admission-control=NamespaceLifecycle,LimitRanger,ServiceAccount,PersistentVolumeLabel,DefaultStorageClass,ResourceQuota,DefaultTolerationSeconds
|
||||||
|
```
|
||||||
|
|
||||||
|
## 参考
|
||||||
|
|
||||||
|
- [Using Admission Controllers - kubernetes.io](https://kubernetes.io/docs/reference/access-authn-authz/admission-controllers/)
|
||||||
|
|
@ -25,4 +25,4 @@ Aggregated(聚合的)API server是为了将原来的API server这个巨石
|
||||||
|
|
||||||
## 参考
|
## 参考
|
||||||
|
|
||||||
[Aggregated API Servers - kuberentes design-proposals](https://github.com/kubernetes/community/blob/master/contributors/design-proposals/api-machinery/aggregated-api-servers.md)
|
[Aggregated API Servers - kuberentes design-proposals](https://github.com/kubernetes/community/blob/master/contributors/design-proposals/api-machinery/aggregated-api-servers.md)
|
||||||
|
|
|
||||||
|
|
@ -75,4 +75,4 @@ spec:
|
||||||
fieldPath: metadata.namespace
|
fieldPath: metadata.namespace
|
||||||
```
|
```
|
||||||
|
|
||||||
`alpha.istio.io/sidecar` 注解就是用来控制是否自动向 pod 中注入 sidecar 的。参考:[安装 Istio sidecar - istio.doczh.cn](http://istio.doczh.cn/docs/setup/kubernetes/sidecar-injection.html)。
|
`alpha.istio.io/sidecar` 注解就是用来控制是否自动向 pod 中注入 sidecar 的。
|
||||||
|
|
|
||||||
|
|
@ -98,7 +98,7 @@ v1beta2.apps 2d
|
||||||
v2beta1.autoscaling 2d
|
v2beta1.autoscaling 2d
|
||||||
```
|
```
|
||||||
|
|
||||||
另外查看当前kubernetes集群支持的API版本还可以使用`kubectl api-version`:
|
另外查看当前kubernetes集群支持的API版本还可以使用`kubectl api-versions`:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
$ kubectl api-versions
|
$ kubectl api-versions
|
||||||
|
|
@ -126,9 +126,3 @@ storage.k8s.io/v1
|
||||||
storage.k8s.io/v1beta1
|
storage.k8s.io/v1beta1
|
||||||
v1
|
v1
|
||||||
```
|
```
|
||||||
|
|
||||||
## 参考
|
|
||||||
|
|
||||||
[API Conventions](https://github.com/kubernetes/community/blob/master/contributors/devel/api-conventions.md#resources)
|
|
||||||
|
|
||||||
[Kuberentes1.8 reference doc](https://kubernetes.io/docs/api-reference/v1.8/#apiservicespec-v1beta1-apiregistration)
|
|
||||||
|
|
@ -1,3 +1,3 @@
|
||||||
# 身份与权限认证
|
# 身份与权限认证
|
||||||
|
|
||||||
Kubernetes中提供了良好的多租户认证管理机制,如RBAC、ServiceAccount还有各种Policy等。
|
Kubernetes中提供了良好的多租户认证管理机制,如RBAC、ServiceAccount还有各种Policy等。
|
||||||
|
|
|
||||||
|
|
@ -1,17 +1,22 @@
|
||||||
# Kubernetes中的网络解析——以calico为例
|
# Kubernetes中的网络解析——以calico为例
|
||||||
|
|
||||||
|
[Calico](https://www.projectcalico.org/) 原意为”有斑点的“,如果说一只猫为 calico cat 的话,就是说这是只花猫,也叫三色猫,所以 calico 的 logo 是只三色猫。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
## 概念
|
## 概念
|
||||||
|
|
||||||
Calico 创建和管理一个扁平的三层网络(不需要overlay),每个容器会分配一个可路由的ip。由于通信时不需要解包和封包,网络性能损耗小,易于排查,且易于水平扩展。
|
Calico创建和管理一个扁平的三层网络(不需要overlay),每个容器会分配一个可路由的IP。由于通信时不需要解包和封包,网络性能损耗小,易于排查,且易于水平扩展。
|
||||||
|
|
||||||
小规模部署时可以通过bgp client直接互联,大规模下可通过指定的BGP route reflector来完成,这样保证所有的数据流量都是通过IP路由的方式完成互联的。
|
小规模部署时可以通过BGP client直接互联,大规模下可通过指定的BGP Route Reflector来完成,这样保证所有的数据流量都是通过IP路由的方式完成互联的。
|
||||||
Calico基于iptables还提供了丰富而灵活的网络Policy,保证通过各个节点上的ACLs来提供Workload的多租户隔离、安全组以及其他可达性限制等功能。
|
|
||||||
|
Calico基于iptables还提供了丰富而灵活的网络Policy,保证通过各个节点上的ACL来提供Workload的多租户隔离、安全组以及其他可达性限制等功能。
|
||||||
|
|
||||||
## Calico架构
|
## Calico架构
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
calico主要由Felix,etcd,BGP client,BGP Route Reflector组成。
|
Calico主要由Felix、etcd、BGP client、BGP Route Reflector组成。
|
||||||
|
|
||||||
- [Etcd](https://docs.projectcalico.org/v3.0/reference/architecture/):负责存储网络信息
|
- [Etcd](https://docs.projectcalico.org/v3.0/reference/architecture/):负责存储网络信息
|
||||||
- [BGP client](https://docs.projectcalico.org/v3.0/reference/architecture/):负责将Felix配置的路由信息分发到其他节点
|
- [BGP client](https://docs.projectcalico.org/v3.0/reference/architecture/):负责将Felix配置的路由信息分发到其他节点
|
||||||
|
|
@ -20,14 +25,16 @@ calico主要由Felix,etcd,BGP client,BGP Route Reflector组成。
|
||||||
|
|
||||||
## 部署
|
## 部署
|
||||||
|
|
||||||
```
|
运行下面的命令可以部署 calico 网络。
|
||||||
|
|
||||||
|
```bash
|
||||||
mkdir /etc/cni/net.d/
|
mkdir /etc/cni/net.d/
|
||||||
|
|
||||||
kubectl apply -f https://docs.projectcalico.org/v3.0/getting-started/kubernetes/installation/rbac.yaml
|
kubectl apply -f https://docs.projectcalico.org/v3.0/getting-started/kubernetes/installation/rbac.yaml
|
||||||
|
|
||||||
wget https://docs.projectcalico.org/v3.0/getting-started/kubernetes/installation/hosted/calico.yaml
|
wget https://docs.projectcalico.org/v3.0/getting-started/kubernetes/installation/hosted/calico.yaml
|
||||||
|
|
||||||
修改etcd_endpoints的值和默认的192.168.0.0/16(不能和已有网段冲突)
|
# 修改etcd_endpoints的值和默认的192.168.0.0/16(不能和已有网段冲突)
|
||||||
|
|
||||||
kubectl apply -f calico.yaml
|
kubectl apply -f calico.yaml
|
||||||
|
|
||||||
|
|
@ -40,6 +47,10 @@ calicoctl get ippool
|
||||||
calicoctl get node
|
calicoctl get node
|
||||||
```
|
```
|
||||||
|
|
||||||
- [部署](https://docs.projectcalico.org/v3.0/usage/calicoctl/install)
|
如果安装时启用应用层策略的话还需要安装 [istio](https://istio.io),详见 [Enabling application layer policy](https://docs.projectcalico.org/v3.4/getting-started/kubernetes/installation/app-layer-policy#about-enabling-application-layer-policy)。
|
||||||
- [calicoctl命令](https://docs.projectcalico.org/v3.0/reference/calicoctl/commands/)
|
|
||||||
- [架构](https://docs.projectcalico.org/v3.0/reference/architecture/)
|
## 参考
|
||||||
|
|
||||||
|
- [安装Calico - docs.projectcalico.org](https://docs.projectcalico.org/v3.4/usage/calicoctl/install)
|
||||||
|
- [calicoctl命令参考 - docs.projectcalico.org](https://docs.projectcalico.org/v3.4/reference/calicoctl/commands/)
|
||||||
|
- [Calico架构 - docs.projectcalico.org](https://docs.projectcalico.org/v3.4/reference/architecture/)
|
||||||
|
|
|
||||||
|
|
@ -0,0 +1,120 @@
|
||||||
|
# Cilium架构设计与概念解析
|
||||||
|
|
||||||
|
Cilium 要求 Linux kernel 版本在 4.8.0 以上,Cilium 官方建议 kernel 版本至少在 4.9.17 以上,高版本的 Ubuntu 发行版中 Linux 内核版本一般在 4.12 以上,如使用 CentOS7 需要升级内核才能运行 Cilium。
|
||||||
|
|
||||||
|
KV 存储数据库用存储以下状态:
|
||||||
|
|
||||||
|
- 策略身份,Label 列表 <=> 服务身份标识
|
||||||
|
- 全局的服务 ID,与 VIP 相关联(可选)
|
||||||
|
- 封装的 VTEP(Vxlan Tunnel End Point)映射(可选)
|
||||||
|
|
||||||
|
为了简单起见,Cilium 一般跟容器编排调度器使用同一个 KV 存储数据库,例如在 Kubernetes 中使用 etcd 存储。
|
||||||
|
|
||||||
|
## 组成
|
||||||
|
|
||||||
|
下图是 Cilium 的组件示意图,Cilium 是位于 Linux kernel 与容器编排系统的中间层。向上可以为容器配置网络,向下可以向 Linux 内核生成 BPF 程序来控制容器的安全性和转发行为。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
管理员通过 Cilium CLI 配置策略信息,这些策略信息将存储在 KV 数据库里,Cilium 使用插件(如 CNI)与容器编排调度系统交互,来实现容器间的联网和容器分配 IP 地址分配,同时 Cilium 还可以获得容器的各种元数据和流量信息,提供监控 API。
|
||||||
|
|
||||||
|
**Cilium Agent**
|
||||||
|
|
||||||
|
Cilium Agent 作为守护进程运行在每个节点上,与容器运行时如 Docker,和容器编排系统交互如 Kubernetes。通常是使用插件的形式(如 Docker plugin)或遵从容器编排标准定义的网络接口(如 [CNI](https://jimmysong.io/kubernetes-handbook/concepts/cni.html))。
|
||||||
|
|
||||||
|
Cilium Agent 的功能有:
|
||||||
|
|
||||||
|
- 暴露 API 给运维和安全团队,可以配置容器间的通信策略。还可以通过这些 API 获取网络监控数据。
|
||||||
|
- 收集容器的元数据,例如 Pod 的 Label,可用于 Cilium 安全策略里的 Endpoint 识别,这个跟 Kubernetes 中的 service 里的 Endpoint 类似。
|
||||||
|
- 与容器管理平台的网络插件交互,实现 IPAM 的功能,用于给容器分配 IP 地址,该功能与 [flannel](https://jimmysong.io/kubernetes-handbook/concepts/flannel.html)、[calico](https://jimmysong.io/kubernetes-handbook/concepts/calico.html) 网络插件类似。
|
||||||
|
- 将其有关容器标识和地址的知识与已配置的安全性和可见性策略相结合,生成高效的 BPF 程序,用于控制容器的网络转发和安全行为。
|
||||||
|
- 使用 clang/LLVM 将 BPF 程序编译为字节码,在容器的虚拟以太网设备中的所有数据包上执行,并将它们传递给 Linux 内核。
|
||||||
|
|
||||||
|
## 命令行工具
|
||||||
|
|
||||||
|
Cilium 提供了管理命令行管理工具,可以与 Cilium Agent API 交互。`cilium` 命令使用方式如下。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Usage:
|
||||||
|
cilium [command]
|
||||||
|
|
||||||
|
Available Commands:
|
||||||
|
bpf 直接访问本地 BPF map
|
||||||
|
cleanup 重置 agent 状态
|
||||||
|
completion bash 自动补全
|
||||||
|
config Cilium 配置选项
|
||||||
|
debuginfo 从 agent 请求可用的调试信息
|
||||||
|
endpoint 管理 endpoint
|
||||||
|
identity 管理安全身份
|
||||||
|
kvstore 直接访问 kvstore
|
||||||
|
map 访问 BPF map
|
||||||
|
monitor 显示 BPF 程序事件
|
||||||
|
node 管理集群节点
|
||||||
|
policy 管理安全策略
|
||||||
|
prefilter 管理 XDP CIDR filter
|
||||||
|
service 管理 service & loadbalancer
|
||||||
|
status 显示 daemon 的状态
|
||||||
|
version 打印版本信息
|
||||||
|
```
|
||||||
|
|
||||||
|
详细使用情况请参考 [Cilium Command Cheatsheet](https://cilium.readthedocs.io/en/stable/cheatsheet/)。
|
||||||
|
|
||||||
|
## 策略控制示例
|
||||||
|
|
||||||
|
使用 docker-compose 安装测试,需要先用 vagrant 启动虚拟机,使用的是 Ubuntu-17.10 的 vagrant box。在下面的示例中,Cilium 是使用 docker network plugin 的方式部署的。Cilium 的一项主要功能——为容器创建网络,使用 `docker inspect` 来查询使用 Cilium 网络的容器配置,可以看到 Cilium 创建的容器网络示例如下。
|
||||||
|
|
||||||
|
```json
|
||||||
|
"Networks": {
|
||||||
|
"cilium-net": {
|
||||||
|
"IPAMConfig": null,
|
||||||
|
"Links": null,
|
||||||
|
"Aliases": [
|
||||||
|
"a08e52d13a38"
|
||||||
|
],
|
||||||
|
"NetworkID": "c4cc3ac444f3c494beb1355e4a9c4bc474d9a84288ceb2030513e8406cdf4e9b",
|
||||||
|
"EndpointID": "2e3e4486525c20fc516d0a9d1c52f84edf9a000f3068803780e23b4c6a1ca3ed",
|
||||||
|
"Gateway": "",
|
||||||
|
"IPAddress": "10.15.125.240",
|
||||||
|
"IPPrefixLen": 32,
|
||||||
|
"IPv6Gateway": "f00d::a0f:0:0:1",
|
||||||
|
"GlobalIPv6Address": "f00d::a0f:0:0:ed50",
|
||||||
|
"GlobalIPv6PrefixLen": 128,
|
||||||
|
"MacAddress": "",
|
||||||
|
"DriverOpts": null
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
- **NetworkID**:每个网络平面的唯一标识
|
||||||
|
- **EndpointID**:每个容器/Pod 的在网络中的唯一标识
|
||||||
|
|
||||||
|
在 docker-compose 安装方式的[快速开始指南](https://cilium.readthedocs.io/en/stable/gettingstarted/docker/)中,演示了如何使用 Label 来选择容器,从而限制两个容器(应用)之间的流量访问权限的。
|
||||||
|
|
||||||
|
策略使用 JSON 格式配置,例如[官方示例](https://cilium.readthedocs.io/en/stable/gettingstarted/docker/)使用 Cilium 直接在 L3/L4 层管理容器间访问策略的方式。例如下面的策略配置具有 `id=app2` 标签的容器可以使用 TCP 协议、80 端口访问具有标签 `id=app1` 标签的容器。
|
||||||
|
|
||||||
|
```json
|
||||||
|
[{
|
||||||
|
"labels": [{"key": "name", "value": "l3-rule"}],
|
||||||
|
"endpointSelector": {"matchLabels":{"id":"app1"}},
|
||||||
|
"ingress": [{
|
||||||
|
"fromEndpoints": [
|
||||||
|
{"matchLabels":{"id":"app2"}}
|
||||||
|
],
|
||||||
|
"toPorts": [{
|
||||||
|
"ports": [{"port": "80", "protocol": "TCP"}]
|
||||||
|
}]
|
||||||
|
}]
|
||||||
|
}]
|
||||||
|
```
|
||||||
|
|
||||||
|
将该配置保存成 JSON 文件,在使用 `cilium policy import` 命令即可应用到 Cilium 网络中。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
如图所示,此时 `id` 标签为其他值的容器就无法访问 `id=app1` 容器,策略配置中的 `toPorts` 中还可以配置 HTTP `method` 和 `path`,实现更细粒度的访问策略控制,详见 [Cilium 官方文档](https://cilium.readthedocs.io/en/stable/gettingstarted/docker/)。
|
||||||
|
|
||||||
|
## 参考
|
||||||
|
|
||||||
|
- [https://cilium.readthedocs.io/en/stable/concepts/](https://cilium.readthedocs.io/en/stable/concepts/)
|
||||||
|
- [https://cilium.readthedocs.io/en/stable/gettingstarted/docker/](https://cilium.readthedocs.io/en/stable/gettingstarted/docker/)
|
||||||
|
|
||||||
|
|
@ -0,0 +1,116 @@
|
||||||
|
# 具备API感知的网络和安全性管理的开源软件Cilium
|
||||||
|
|
||||||
|
Cilium是一个纯开源软件,没有哪家公司提供商业化支持,也不是由某一公司开源,该软件用于透明地保护使用Linux容器管理平台(如Docker和Kubernetes)部署的应用程序服务之间的网络连接。
|
||||||
|
|
||||||
|
Cilium的基础是一种名为BPF的新Linux内核技术,它可以在Linux本身动态插入强大的安全可见性和控制逻辑。由于BPF在Linux内核中运行,因此可以应用和更新Cilium安全策略,而无需对应用程序代码或容器配置进行任何更改。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
基于微服务的应用程序分为小型独立服务,这些服务使用**HTTP**、**gRPC**、**Kafka**等轻量级协议通过API相互通信。但是,现有的Linux网络安全机制(例如iptables)仅在网络和传输层(即IP地址和端口)上运行,并且缺乏对微服务层的可见性。
|
||||||
|
|
||||||
|
Cilium为Linux容器框架(如[**Docker**](https://www.docker.com/)和[**Kubernetes)**](https://kubernetes.io/)带来了API感知网络安全过滤。使用名为**BPF**的新Linux内核技术,Cilium提供了一种基于容器/容器标识定义和实施网络层和应用层安全策略的简单而有效的方法。
|
||||||
|
|
||||||
|
**注**:Cilium中文意思是“纤毛“,它十分细小而又无处不在。
|
||||||
|
|
||||||
|
## BPF
|
||||||
|
|
||||||
|
**柏克莱封包过滤器**(Berkeley Packet Filter,缩写 BPF),是[类Unix](https://zh.wikipedia.org/wiki/%E7%B1%BBUnix)系统上[数据链路层](https://zh.wikipedia.org/wiki/%E6%95%B0%E6%8D%AE%E9%93%BE%E8%B7%AF%E5%B1%82)的一种原始接口,提供原始链路层[封包](https://zh.wikipedia.org/wiki/%E5%B0%81%E5%8C%85)的收发,除此之外,如果网卡驱动支持[洪泛](https://zh.wikipedia.org/wiki/%E6%B4%AA%E6%B3%9B)模式,那么它可以让网卡处于此种模式,这样可以收到[网络](https://zh.wikipedia.org/wiki/%E7%BD%91%E7%BB%9C)上的所有包,不管他们的目的地是不是所在[主机](https://zh.wikipedia.org/wiki/%E4%B8%BB%E6%A9%9F)。参考[维基百科](https://zh.wikipedia.org/wiki/BPF)和[eBPF简史](https://www.ibm.com/developerworks/cn/linux/l-lo-eBPF-history/index.html)。
|
||||||
|
|
||||||
|
## 特性
|
||||||
|
|
||||||
|
以下是Cilium的特性。
|
||||||
|
|
||||||
|
**基于身份的安全性**
|
||||||
|
|
||||||
|
Cilium可见性和安全策略基于容器编排系统的标识(例如,Kubernetes中的Label)。在编写安全策略、审计和故障排查时,再也不用担心网络子网或容器IP地址了。
|
||||||
|
|
||||||
|
**卓越的性能**
|
||||||
|
|
||||||
|
BPF利用Linux底层的强大能力,通过提供Linux内核的沙盒可编程性来实现数据路径,从而提供卓越的性能。
|
||||||
|
|
||||||
|
**API协议可见性+安全性**
|
||||||
|
|
||||||
|
传统防火墙仅根据IP地址和端口等网络标头查看和过滤数据包。Cilium也可以这样做,但也可以理解并过滤单个HTTP、gRPC和Kafka请求,这些请求将微服务拼接在一起。
|
||||||
|
|
||||||
|
**专为扩展而设计**
|
||||||
|
|
||||||
|
Cilium是为扩展而设计的,在部署新pod时不需要节点间交互,并且通过高度可扩展的键值存储进行所有协调。
|
||||||
|
|
||||||
|
## 为什么选择Cilium?
|
||||||
|
|
||||||
|
现代数据中心应用程序的开发已经转向面向服务的体系结构(SOA),通常称为*微服务*,其中大型应用程序被分成小型独立服务,这些服务使用HTTP等轻量级协议通过API相互通信。微服务应用程序往往是高度动态的,作为持续交付的一部分部署的滚动更新期间单个容器启动或销毁,应用程序扩展/缩小以适应负载变化。
|
||||||
|
|
||||||
|
这种向高度动态的微服务的转变过程,给确保微服务之间的连接方面提出了挑战和机遇。传统的Linux网络安全方法(例如iptables)过滤IP地址和TCP/UDP端口,但IP地址经常在动态微服务环境中流失。容器的高度不稳定的生命周期导致这些方法难以与应用程序并排扩展,因为负载均衡表和访问控制列表要不断更新,可能增长成包含数十万条规则。出于安全目的,协议端口(例如,用于HTTP流量的TCP端口80)不能再用于区分应用流量,因为该端口用于跨服务的各种消息。
|
||||||
|
|
||||||
|
另一个挑战是提供准确的可见性,因为传统系统使用IP地址作为主要识别工具,其在微服务架构中的寿命可能才仅仅几秒钟,被大大缩短。
|
||||||
|
|
||||||
|
利用Linux BPF,Cilium保留了透明地插入安全可视性+强制执行的能力,但这种方式基于服务/pod/容器标识(与传统系统中的IP地址识别相反),并且可以根据应用层进行过滤 (例如HTTP)。因此,通过将安全性与寻址分离,Cilium不仅可以在高度动态的环境中应用安全策略,而且除了提供传统的第3层和第4层分割之外,还可以通过在HTTP层运行来提供更强的安全隔离。 。
|
||||||
|
|
||||||
|
BPF的使用使得Cilium能够以高度可扩展的方式实现以上功能,即使对于大规模环境也不例外。
|
||||||
|
|
||||||
|
## 功能概述
|
||||||
|
|
||||||
|
### 透明的保护API
|
||||||
|
|
||||||
|
能够保护现代应用程序协议,如REST/HTTP、gRPC和Kafka。传统防火墙在第3层和第4层运行,在特定端口上运行的协议要么完全受信任,要么完全被阻止。Cilium提供了过滤各个应用程序协议请求的功能,例如:
|
||||||
|
|
||||||
|
- 允许所有带有方法`GET`和路径`/public/.*`的HTTP请求。拒绝所有其他请求。
|
||||||
|
- 允许`service1`在Kafka topic上生成`topic1`,`service2`消费`topic1`。拒绝所有其他Kafka消息。
|
||||||
|
- 要求HTTP标头`X-Token: [0-9]+`出现在所有REST调用中。
|
||||||
|
|
||||||
|
详情请参考[7层协议](http://docs.cilium.io/en/stable/policy/#layer-7)。
|
||||||
|
|
||||||
|
### 基于身份来保护服务间通信
|
||||||
|
|
||||||
|
现代分布式应用程序依赖于诸如容器之类的技术来促进敏捷性并按需扩展。这将导致在短时间内启动大量应用容器。典型的容器防火墙通过过滤源IP地址和目标端口来保护工作负载。这就要求不论在集群中的哪个位置启动容器时都要操作所有服务器上的防火墙。
|
||||||
|
|
||||||
|
为了避免受到规模限制,Cilium为共享相同安全策略的应用程序容器组分配安全标识。然后,该标识与应用程序容器发出的所有网络数据包相关联,从而允许验证接收节点处的身份。使用键值存储执行安全身份管理。
|
||||||
|
|
||||||
|
### 安全访问外部服务
|
||||||
|
|
||||||
|
基于标签的安全性是集群内部访问控制的首选工具。为了保护对外部服务的访问,支持入口(ingress)和出口(egress)的传统基于CIDR的安全策略。这允许限制对应用程序容器的访问以及对特定IP范围的访问。
|
||||||
|
|
||||||
|
### 简单网络
|
||||||
|
|
||||||
|
一个简单的扁平第3层网络能够跨越多个集群连接所有应用程序容器。使用主机范围分配器可以简化IP分配。这意味着每个主机可以在主机之间没有任何协调的情况下分配IP。
|
||||||
|
|
||||||
|
支持以下多节点网络模型:
|
||||||
|
|
||||||
|
- **Overlay**:基于封装的虚拟网络产生所有主机。目前VXLAN和Geneve已经完成,但可以启用Linux支持的所有封装格式。
|
||||||
|
|
||||||
|
何时使用此模式:此模式具有最小的基础架构和集成要求。它几乎适用于任何网络基础架构,唯一的要求是主机之间可以通过IP连接。
|
||||||
|
|
||||||
|
- **本机路由**:使用Linux主机的常规路由表。网络必须能够路由应用程序容器的IP地址。
|
||||||
|
|
||||||
|
何时使用此模式:此模式适用于高级用户,需要了解底层网络基础结构。此模式适用于:
|
||||||
|
|
||||||
|
- 本地IPv6网络
|
||||||
|
- 与云网络路由器配合使用
|
||||||
|
- 如果您已经在运行路由守护进程
|
||||||
|
|
||||||
|
### 负载均衡
|
||||||
|
|
||||||
|
应用程序容器和外部服务之间的流量的分布式负载均衡。负载均衡使用BPF实现,允许几乎无限的规模,并且如果未在源主机上执行负载均衡操作,则支持直接服务器返回(DSR)。
|
||||||
|
|
||||||
|
**注意**:负载均衡需要启用连接跟踪。这是默认值。
|
||||||
|
|
||||||
|
### 监控和故障排除
|
||||||
|
|
||||||
|
可见性和故障排查是任何分布式系统运行的基础。虽然我们喜欢用`tcpdump`和 `ping`,它们很好用,但我们努力为故障排除提供更好的工具。包括以下工具:
|
||||||
|
|
||||||
|
- 使用元数据进行事件监控:当数据包被丢弃时,该工具不仅仅报告数据包的源IP和目标IP,该工具还提供发送方和接收方的完整标签信息等。
|
||||||
|
- 策略决策跟踪:为什么丢弃数据包或拒绝请求。策略跟踪框架允许跟踪运行工作负载和基于任意标签定义的策略决策过程。
|
||||||
|
- 通过Prometheus导出指标:通过Prometheus导出关键指标,以便与现有仪表板集成。
|
||||||
|
|
||||||
|
### 集成
|
||||||
|
|
||||||
|
- 网络插件集成:[CNI](https://github.com/containernetworking/cni)、[libnetwork](https://github.com/docker/libnetwork)
|
||||||
|
- 容器运行时:[containerd](https://github.com/containerd/containerd)
|
||||||
|
- Kubernetes:[NetworkPolicy](https://kubernetes.io/docs/concepts/services-networking/network-policies/)、[Label](https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/)、[Ingress](https://kubernetes.io/docs/concepts/services-networking/ingress/)、[Service](https://kubernetes.io/docs/concepts/services-networking/service/)
|
||||||
|
- 日志记录:syslog、[fluentd](http://www.fluentd.org/)
|
||||||
|
|
||||||
|
## 参考
|
||||||
|
|
||||||
|
- [Cilium官方网站 - cilium.io](https://cilium.io)
|
||||||
|
- [eBPF 简史 - ibm.com](https://www.ibm.com/developerworks/cn/linux/l-lo-eBPF-history/index.html)
|
||||||
|
- [网络层拦截可选项 - zhihu.com](https://zhuanlan.zhihu.com/p/25672552)
|
||||||
|
|
@ -1,3 +1,3 @@
|
||||||
# 集群信息
|
# 集群信息
|
||||||
|
|
||||||
为了管理异构和不同配置的主机,为了便于Pod的运维管理,Kubernetes中提供了很多集群管理的配置和管理功能,通过namespace划分的空间,通过为node节点创建label和taint用于pod的调度等。
|
为了管理异构和不同配置的主机,为了便于Pod的运维管理,Kubernetes中提供了很多集群管理的配置和管理功能,通过namespace划分的空间,通过为node节点创建label和taint用于pod的调度等。
|
||||||
|
|
|
||||||
|
|
@ -1,5 +1,7 @@
|
||||||
# Kubernetes的设计理念
|
# Kubernetes的设计理念
|
||||||
|
|
||||||
|
这一章将介绍 Kubernetes 的设计理念及基本概念。
|
||||||
|
|
||||||
### Kubernetes设计理念与分布式系统
|
### Kubernetes设计理念与分布式系统
|
||||||
|
|
||||||
分析和理解Kubernetes的设计理念可以使我们更深入地了解Kubernetes系统,更好地利用它管理分布式部署的云原生应用,另一方面也可以让我们借鉴其在分布式系统设计方面的经验。
|
分析和理解Kubernetes的设计理念可以使我们更深入地了解Kubernetes系统,更好地利用它管理分布式部署的云原生应用,另一方面也可以让我们借鉴其在分布式系统设计方面的经验。
|
||||||
|
|
@ -8,7 +10,7 @@
|
||||||
|
|
||||||
Kubernetes设计理念和功能其实就是一个类似Linux的分层架构,如下图所示
|
Kubernetes设计理念和功能其实就是一个类似Linux的分层架构,如下图所示
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
* 核心层:Kubernetes最核心的功能,对外提供API构建高层的应用,对内提供插件式应用执行环境
|
* 核心层:Kubernetes最核心的功能,对外提供API构建高层的应用,对内提供插件式应用执行环境
|
||||||
* 应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS解析等)
|
* 应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS解析等)
|
||||||
|
|
@ -52,7 +54,7 @@ Kubernetes中所有的配置都是通过API对象的spec去设置的,也就是
|
||||||
|
|
||||||
Kubernetes有很多技术概念,同时对应很多API对象,最重要的也是最基础的是Pod。Pod是在Kubernetes集群中运行部署应用或服务的最小单元,它是可以支持多容器的。Pod的设计理念是支持多个容器在一个Pod中共享网络地址和文件系统,可以通过进程间通信和文件共享这种简单高效的方式组合完成服务。Pod对多容器的支持是K8最基础的设计理念。比如你运行一个操作系统发行版的软件仓库,一个Nginx容器用来发布软件,另一个容器专门用来从源仓库做同步,这两个容器的镜像不太可能是一个团队开发的,但是他们一块儿工作才能提供一个微服务;这种情况下,不同的团队各自开发构建自己的容器镜像,在部署的时候组合成一个微服务对外提供服务。
|
Kubernetes有很多技术概念,同时对应很多API对象,最重要的也是最基础的是Pod。Pod是在Kubernetes集群中运行部署应用或服务的最小单元,它是可以支持多容器的。Pod的设计理念是支持多个容器在一个Pod中共享网络地址和文件系统,可以通过进程间通信和文件共享这种简单高效的方式组合完成服务。Pod对多容器的支持是K8最基础的设计理念。比如你运行一个操作系统发行版的软件仓库,一个Nginx容器用来发布软件,另一个容器专门用来从源仓库做同步,这两个容器的镜像不太可能是一个团队开发的,但是他们一块儿工作才能提供一个微服务;这种情况下,不同的团队各自开发构建自己的容器镜像,在部署的时候组合成一个微服务对外提供服务。
|
||||||
|
|
||||||
Pod是Kubernetes集群中所有业务类型的基础,可以看作运行在K8集群中的小机器人,不同类型的业务就需要不同类型的小机器人去执行。目前Kubernetes中的业务主要可以分为长期伺服型(long-running)、批处理型(batch)、节点后台支撑型(node-daemon)和有状态应用型(stateful application);分别对应的小机器人控制器为Deployment、Job、DaemonSet和StatefulSet,本文后面会一一介绍。
|
Pod是Kubernetes集群中所有业务类型的基础,可以看作运行在Kubernetes集群中的小机器人,不同类型的业务就需要不同类型的小机器人去执行。目前Kubernetes中的业务主要可以分为长期伺服型(long-running)、批处理型(batch)、节点后台支撑型(node-daemon)和有状态应用型(stateful application);分别对应的小机器人控制器为Deployment、Job、DaemonSet和StatefulSet,本文后面会一一介绍。
|
||||||
|
|
||||||
### 副本控制器(Replication Controller,RC)
|
### 副本控制器(Replication Controller,RC)
|
||||||
|
|
||||||
|
|
@ -80,7 +82,7 @@ Job是Kubernetes用来控制批处理型任务的API对象。批处理业务与
|
||||||
|
|
||||||
### 有状态服务集(StatefulSet)
|
### 有状态服务集(StatefulSet)
|
||||||
|
|
||||||
Kubernetes在1.3版本里发布了Alpha版的PetSet功能,在1.5版本里将PetSet功能升级到了Beta版本,并重新命名为StatefulSet,最终在1.9版本里成为正式GA版本。在云原生应用的体系里,有下面两组近义词;第一组是无状态(stateless)、牲畜(cattle)、无名(nameless)、可丢弃(disposable);第二组是有状态(stateful)、宠物(pet)、有名(having name)、不可丢弃(non-disposable)。RC和RS主要是控制提供无状态服务的,其所控制的Pod的名字是随机设置的,一个Pod出故障了就被丢弃掉,在另一个地方重启一个新的Pod,名字变了、名字和启动在哪儿都不重要,重要的只是Pod总数;而StatefulSet是用来控制有状态服务,StatefulSet中的每个Pod的名字都是事先确定的,不能更改。StatefulSet中Pod的名字的作用,并不是《千与千寻》的人性原因,而是关联与该Pod对应的状态。
|
Kubernetes在1.3版本里发布了Alpha版的PetSet功能,在1.5版本里将PetSet功能升级到了Beta版本,并重新命名为StatefulSet,最终在1.9版本里成为正式GA版本。在云原生应用的体系里,有下面两组近义词;第一组是无状态(stateless)、牲畜(cattle)、无名(nameless)、可丢弃(disposable);第二组是有状态(stateful)、宠物(pet)、有名(having name)、不可丢弃(non-disposable)。RC和RS主要是控制提供无状态服务的,其所控制的Pod的名字是随机设置的,一个Pod出故障了就被丢弃掉,在另一个地方重启一个新的Pod,名字变了。名字和启动在哪儿都不重要,重要的只是Pod总数;而StatefulSet是用来控制有状态服务,StatefulSet中的每个Pod的名字都是事先确定的,不能更改。StatefulSet中Pod的名字的作用,并不是《千与千寻》的人性原因,而是关联与该Pod对应的状态。
|
||||||
|
|
||||||
对于RC和RS中的Pod,一般不挂载存储或者挂载共享存储,保存的是所有Pod共享的状态,Pod像牲畜一样没有分别(这似乎也确实意味着失去了人性特征);对于StatefulSet中的Pod,每个Pod挂载自己独立的存储,如果一个Pod出现故障,从其他节点启动一个同样名字的Pod,要挂载上原来Pod的存储继续以它的状态提供服务。
|
对于RC和RS中的Pod,一般不挂载存储或者挂载共享存储,保存的是所有Pod共享的状态,Pod像牲畜一样没有分别(这似乎也确实意味着失去了人性特征);对于StatefulSet中的Pod,每个Pod挂载自己独立的存储,如果一个Pod出现故障,从其他节点启动一个同样名字的Pod,要挂载上原来Pod的存储继续以它的状态提供服务。
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -320,9 +320,9 @@ spec:
|
||||||
image: harbor-001.jimmysong.io/library/nginx:1.9
|
image: harbor-001.jimmysong.io/library/nginx:1.9
|
||||||
ports:
|
ports:
|
||||||
- containerPort: 80
|
- containerPort: 80
|
||||||
volumeMounts:
|
volumeMounts:
|
||||||
- name: config-volume
|
- name: config-volume
|
||||||
mountPath: /etc/config
|
mountPath: /etc/config
|
||||||
volumes:
|
volumes:
|
||||||
- name: config-volume
|
- name: config-volume
|
||||||
configMap:
|
configMap:
|
||||||
|
|
@ -338,7 +338,7 @@ data:
|
||||||
```
|
```
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
$ kubectl exec `kubectl get pods -l run=my-nginx -o=name|cut -d "/" -f2` cat /tmp/log_level
|
$ kubectl exec `kubectl get pods -l run=my-nginx -o=name|cut -d "/" -f2` cat /etc/config/log_level
|
||||||
INFO
|
INFO
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
@ -359,6 +359,10 @@ DEBUG
|
||||||
|
|
||||||
我们可以看到使用 ConfigMap 方式挂载的 Volume 的文件中的内容已经变成了 `DEBUG`。
|
我们可以看到使用 ConfigMap 方式挂载的 Volume 的文件中的内容已经变成了 `DEBUG`。
|
||||||
|
|
||||||
|
Known Issue:
|
||||||
|
如果使用ConfigMap的**subPath**挂载为Container的Volume,Kubernetes不会做自动热更新:
|
||||||
|
https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/#mounted-configmaps-are-updated-automatically
|
||||||
|
|
||||||
## ConfigMap 更新后滚动更新 Pod
|
## ConfigMap 更新后滚动更新 Pod
|
||||||
|
|
||||||
更新 ConfigMap 目前并不会触发相关 Pod 的滚动更新,可以通过修改 pod annotations 的方式强制触发滚动更新。
|
更新 ConfigMap 目前并不会触发相关 Pod 的滚动更新,可以通过修改 pod annotations 的方式强制触发滚动更新。
|
||||||
|
|
@ -384,4 +388,3 @@ ENV 是在容器启动的时候注入的,启动之后 kubernetes 就不会再
|
||||||
- [ConfigMap | kubernetes handbook - jimmysong.io](https://jimmysong.io/kubernetes-handbook/concepts/configmap.html)
|
- [ConfigMap | kubernetes handbook - jimmysong.io](https://jimmysong.io/kubernetes-handbook/concepts/configmap.html)
|
||||||
- [创建高可用ectd集群 | Kubernetes handbook - jimmysong.io](https://jimmysong.io/kubernetes-handbook/practice/etcd-cluster-installation.html)
|
- [创建高可用ectd集群 | Kubernetes handbook - jimmysong.io](https://jimmysong.io/kubernetes-handbook/practice/etcd-cluster-installation.html)
|
||||||
- [Kubernetes中的服务发现与docker容器间的环境变量传递源码探究](https://jimmysong.io/posts/exploring-kubernetes-env-with-docker/)
|
- [Kubernetes中的服务发现与docker容器间的环境变量传递源码探究](https://jimmysong.io/posts/exploring-kubernetes-env-with-docker/)
|
||||||
- [Automatically Roll Deployments When ConfigMaps or Secrets change](https://github.com/kubernetes/helm/blob/master/docs/charts_tips_and_tricks.md#automatically-roll-deployments-when-configmaps-or-secrets-change)
|
|
||||||
|
|
|
||||||
|
|
@ -4,7 +4,7 @@
|
||||||
|
|
||||||
## ConfigMap概览
|
## ConfigMap概览
|
||||||
|
|
||||||
**ConfigMap API**资源用来保存**key-value pair**配置数据,这个数据可以在**pods**里使用,或者被用来为像**controller**一样的系统组件存储配置数据。虽然ConfigMap跟[Secrets](https://kubernetes.io/docs/user-guide/secrets/)类似,但是ConfigMap更方便的处理不含敏感信息的字符串。 注意:ConfigMaps不是属性配置文件的替代品。ConfigMaps只是作为多个properties文件的引用。你可以把它理解为Linux系统中的`/etc`目录,专门用来存储配置文件的目录。下面举个例子,使用ConfigMap配置来创建Kuberntes Volumes,ConfigMap中的每个data项都会成为一个新文件。
|
**ConfigMap API**资源用来保存**key-value pair**配置数据,这个数据可以在**pods**里使用,或者被用来为像**controller**一样的系统组件存储配置数据。虽然ConfigMap跟[Secrets](https://kubernetes.io/docs/user-guide/secrets/)类似,但是ConfigMap更方便的处理不含敏感信息的字符串。 注意:ConfigMaps不是属性配置文件的替代品。ConfigMaps只是作为多个properties文件的引用。你可以把它理解为Linux系统中的`/etc`目录,专门用来存储配置文件的目录。下面举个例子,使用ConfigMap配置来创建Kubernetes Volumes,ConfigMap中的每个data项都会成为一个新文件。
|
||||||
|
|
||||||
```yaml
|
```yaml
|
||||||
kind: ConfigMap
|
kind: ConfigMap
|
||||||
|
|
@ -54,7 +54,7 @@ kubectl create configmap
|
||||||
|
|
||||||
### 使用目录创建
|
### 使用目录创建
|
||||||
|
|
||||||
比如我们已经有个了包含一些配置文件,其中包含了我们想要设置的ConfigMap的值:
|
比如我们已经有了一些配置文件,其中包含了我们想要设置的ConfigMap的值:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
$ ls docs/user-guide/configmap/kubectl/
|
$ ls docs/user-guide/configmap/kubectl/
|
||||||
|
|
@ -367,4 +367,4 @@ spec:
|
||||||
restartPolicy: Never
|
restartPolicy: Never
|
||||||
```
|
```
|
||||||
|
|
||||||
运行这个Pod后的结果是`very`。
|
运行这个Pod后的结果是`very`。
|
||||||
|
|
|
||||||
|
|
@ -1,3 +1,3 @@
|
||||||
# 控制器
|
# 控制器
|
||||||
|
|
||||||
Kubernetes中内建了很多controller(控制器),这些相当于一个状态机,用来控制Pod的具体状态和行为。
|
Kubernetes中内建了很多controller(控制器),这些相当于一个状态机,用来控制Pod的具体状态和行为。
|
||||||
|
|
|
||||||
|
|
@ -0,0 +1,620 @@
|
||||||
|
# 使用CRD扩展Kubernetes API
|
||||||
|
|
||||||
|
本文是如何创建 CRD 来扩展 Kubernetes API 的教程。CRD 是用来扩展 Kubernetes 最常用的方式,在 Service Mesh 和 Operator 中也被大量使用。因此读者如果想在 Kubernetes 上做扩展和开发的话,是十分有必要了解 CRD 的。
|
||||||
|
|
||||||
|
在阅读本文前您需要先了解[使用自定义资源扩展 API](custom-resource.md), 以下内容译自 [Kubernetes 官方文档](https://kubernetes.io/docs/tasks/access-kubernetes-api/custom-resources/custom-resource-definitions/),有删改,推荐阅读[如何从零开始编写一个 Kubernetes CRD](https://www.servicemesher.com/blog/kubernetes-crd-quick-start/)。
|
||||||
|
|
||||||
|
## 创建 CRD(CustomResourceDefinition)
|
||||||
|
|
||||||
|
创建新的 CustomResourceDefinition(CRD)时,Kubernetes API Server 会为您指定的每个版本创建新的 RESTful 资源路径。CRD 可以是命名空间的,也可以是集群范围的,可以在 CRD `scope` 字段中所指定。与现有的内置对象一样,删除命名空间会删除该命名空间中的所有自定义对象。CustomResourceDefinition 本身是非命名空间的,可供所有命名空间使用。
|
||||||
|
|
||||||
|
参考下面的 CRD,将其配置保存在 `resourcedefinition.yaml` 文件中:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: apiextensions.k8s.io/v1
|
||||||
|
kind: CustomResourceDefinition
|
||||||
|
metadata:
|
||||||
|
# 名称必须符合下面的格式:<plural>.<group>
|
||||||
|
name: crontabs.stable.example.com
|
||||||
|
spec:
|
||||||
|
# REST API使用的组名称:/apis/<group>/<version>
|
||||||
|
group: stable.example.com
|
||||||
|
# REST API使用的版本号:/apis/<group>/<version>
|
||||||
|
versions:
|
||||||
|
- name: v1
|
||||||
|
# 可以通过 served 来开关每个 version
|
||||||
|
served: true
|
||||||
|
# 有且仅有一个 version 开启存储
|
||||||
|
storage: true
|
||||||
|
schema:
|
||||||
|
openAPIV3Schema:
|
||||||
|
type: object
|
||||||
|
properties:
|
||||||
|
spec:
|
||||||
|
type: object
|
||||||
|
properties:
|
||||||
|
cronSpec:
|
||||||
|
type: string
|
||||||
|
image:
|
||||||
|
type: string
|
||||||
|
replicas:
|
||||||
|
type: integer
|
||||||
|
# Namespaced或Cluster
|
||||||
|
scope: Namespaced
|
||||||
|
names:
|
||||||
|
# URL中使用的复数名称: /apis/<group>/<version>/<plural>
|
||||||
|
plural: crontabs
|
||||||
|
# CLI中使用的单数名称
|
||||||
|
singular: crontab
|
||||||
|
# CamelCased格式的单数类型。在清单文件中使用
|
||||||
|
kind: CronTab
|
||||||
|
# CLI中使用的资源简称
|
||||||
|
shortNames:
|
||||||
|
- ct
|
||||||
|
```
|
||||||
|
|
||||||
|
> 此处使用的 apiVersion 版本是 `apiextensions.k8s.io/v1`,跟上一版 `apiextensions.k8s.io/v1beta1` 的最主要区别是改用了 [OpenAPI v3.0 validation schema](https://kubernetes.io/docs/tasks/access-kubernetes-api/extend-api-custom-resource-definitions/#validation)。
|
||||||
|
|
||||||
|
创建该 CRD:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl create -f resourcedefinition.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
访问 RESTful API 端点如 <http://172.20.0.113:8080> 将看到如下 API 端点已创建:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
/apis/stable.example.com/v1/namespaces/*/crontabs/...
|
||||||
|
```
|
||||||
|
|
||||||
|
然后,此端点 URL 可用于创建和管理自定义对象。上面的 CRD 中定义的类型就是 `CronTab`。
|
||||||
|
|
||||||
|
可能需要几秒钟才能创建端点。您可以监控 CustomResourceDefinition 中 `Established` 的状态何时为 true,或者查看 API 资源的发现信息中是否显示了您的资源。
|
||||||
|
|
||||||
|
## 创建自定义对象
|
||||||
|
|
||||||
|
创建 CustomResourceDefinition 对象后,您可以创建自定义对象。自定义对象可包含自定义字段。这些字段可以包含任意 JSON。在以下示例中, `cronSpec` 和 `image` 自定义字段在自定义对象中设置 `CronTab`。`CronTab` 类型来自您在上面创建的 CustomResourceDefinition 对象的规范。
|
||||||
|
|
||||||
|
如果您将以下 YAML 保存到 `my-crontab.yaml`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: "stable.example.com/v1"
|
||||||
|
kind: CronTab
|
||||||
|
metadata:
|
||||||
|
name: my-new-cron-object
|
||||||
|
spec:
|
||||||
|
cronSpec: "* * * * */5"
|
||||||
|
image: my-awesome-cron-image
|
||||||
|
```
|
||||||
|
|
||||||
|
并创建它:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl create -f my-crontab.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
然后,您可以使用 kubectl 管理 CronTab 对象。例如:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl get crontab
|
||||||
|
```
|
||||||
|
|
||||||
|
应该打印这样的列表:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
NAME AGE
|
||||||
|
my-new-cron-object 6s
|
||||||
|
```
|
||||||
|
|
||||||
|
使用 kubectl 时,资源名称不区分大小写,您可以使用 CRD 中定义的单数或复数形式,以及任何短名称。
|
||||||
|
|
||||||
|
您还可以查看原始 YAML 数据:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl get ct -o yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
您应该看到它的 yaml 中的自定义 `cronSpec` 和 `image` 字段:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: v1
|
||||||
|
items:
|
||||||
|
- apiVersion: stable.example.com/v1
|
||||||
|
kind: CronTab
|
||||||
|
metadata:
|
||||||
|
clusterName: ""
|
||||||
|
creationTimestamp: 2017-05-31T12:56:35Z
|
||||||
|
deletionGracePeriodSeconds: null
|
||||||
|
deletionTimestamp: null
|
||||||
|
name: my-new-cron-object
|
||||||
|
namespace: default
|
||||||
|
resourceVersion: "285"
|
||||||
|
selfLink: /apis/stable.example.com/v1/namespaces/default/crontabs/my-new-cron-object
|
||||||
|
uid: 9423255b-4600-11e7-af6a-28d2447dc82b
|
||||||
|
spec:
|
||||||
|
cronSpec: '* * * * */5'
|
||||||
|
image: my-awesome-cron-image
|
||||||
|
kind: List
|
||||||
|
metadata:
|
||||||
|
resourceVersion: ""
|
||||||
|
selfLink: ""
|
||||||
|
```
|
||||||
|
|
||||||
|
## 删除 CustomResourceDefinition
|
||||||
|
|
||||||
|
删除 CustomResourceDefinition 时,服务器将删除 RESTful API 端点并**删除存储在其中的所有自定义对象**。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl delete -f resourcedefinition.yaml
|
||||||
|
kubectl get crontabs
|
||||||
|
Error from server (NotFound): Unable to list "crontabs": the server could not find the requested resource (get crontabs.stable.example.com)
|
||||||
|
```
|
||||||
|
|
||||||
|
如果稍后重新创建相同的 CustomResourceDefinition,它将从空开始。
|
||||||
|
|
||||||
|
## 提供 CRD 的多个版本
|
||||||
|
|
||||||
|
有关提供 CustomResourceDefinition 的多个版本以及将对象从一个版本迁移到另一个[版本](https://kubernetes.io/docs/tasks/access-kubernetes-api/custom-resources/custom-resource-definition-versioning/)的详细信息,请参阅[自定义资源定义版本控制](https://kubernetes.io/docs/tasks/access-kubernetes-api/custom-resources/custom-resource-definition-versioning/)。
|
||||||
|
|
||||||
|
## 高级主题
|
||||||
|
|
||||||
|
### Finalizer(终结器)
|
||||||
|
|
||||||
|
*Finalizer(终结器)*允许控制器实现异步预删除 hook。自定义对象支持终结器,就像内置对象一样。
|
||||||
|
|
||||||
|
您可以将终结器添加到自定义对象,如下所示:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: "stable.example.com/v1"
|
||||||
|
kind: CronTab
|
||||||
|
metadata:
|
||||||
|
finalizers:
|
||||||
|
- finalizer.stable.example.com
|
||||||
|
```
|
||||||
|
|
||||||
|
终结器是任意字符串值,当存在时确保在资源存在时不可能进行硬删除。
|
||||||
|
|
||||||
|
对具有终结器的对象的第一个删除请求设置该`metadata.deletionTimestamp`字段的值, 但不删除它。设置此值后,`finalizer` 只能删除列表中的条目。
|
||||||
|
|
||||||
|
如果设置了 `metadata.deletionTimestamp` 字段,控制器监控对象将执行它们所有的终结器,对该对象轮询更新请求。执行完所有终结器后,将删除该资源。
|
||||||
|
|
||||||
|
值`metadata.deletionGracePeriodSeconds`控制轮询更新之间的间隔。
|
||||||
|
|
||||||
|
每个控制器都有责任从列表中删除其终结器。
|
||||||
|
|
||||||
|
如果终结器列表为空,Kubernetes 最终只会删除该对象,这意味着所有终结器都已执行。
|
||||||
|
|
||||||
|
### Validation(验证)
|
||||||
|
|
||||||
|
**功能状态:** `Kubernetes v1.12` [beta](https://kubernetes.io/docs/tasks/access-kubernetes-api/custom-resources/custom-resource-definitions/#)
|
||||||
|
|
||||||
|
可以通过 [OpenAPI v3 schema](https://github.com/OAI/OpenAPI-Specification/blob/master/versions/3.0.0.md#schemaObject)验证自定义对象是否符合标准 。此外,以下限制适用于 schema:
|
||||||
|
|
||||||
|
- 字段`default`、`nullable`、`discriminator`、`readOnly`、`writeOnly`、`xml`、 `deprecated` 和 `$ref` 不能设置。
|
||||||
|
- 该字段 `uniqueItems` 不能设置为 true。
|
||||||
|
- 该字段 `additionalProperties` 不能设置为 false。
|
||||||
|
|
||||||
|
您可以使用 [kube-apiserver](https://kubernetes.io/docs/admin/kube-apiserver)`CustomResourceValidation` 上的功能门(feature gate)禁用此功能:
|
||||||
|
|
||||||
|
```
|
||||||
|
--feature-gates=CustomResourceValidation=false
|
||||||
|
```
|
||||||
|
|
||||||
|
该 schema 在 CustomResourceDefinition 中定义。在以下示例中,CustomResourceDefinition 对自定义对象应用以下验证:
|
||||||
|
|
||||||
|
- `spec.cronSpec` 必须是字符串,并且必须是正则表达式描述的形式。
|
||||||
|
- `spec.replicas` 必须是整数,且最小值必须为 1,最大值为 10。
|
||||||
|
|
||||||
|
将 CustomResourceDefinition 保存到 `resourcedefinition.yaml`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: apiextensions.k8s.io/v1beta1
|
||||||
|
kind: CustomResourceDefinition
|
||||||
|
metadata:
|
||||||
|
name: crontabs.stable.example.com
|
||||||
|
spec:
|
||||||
|
group: stable.example.com
|
||||||
|
versions:
|
||||||
|
- name: v1
|
||||||
|
served: true
|
||||||
|
storage: true
|
||||||
|
version: v1
|
||||||
|
scope: Namespaced
|
||||||
|
names:
|
||||||
|
plural: crontabs
|
||||||
|
singular: crontab
|
||||||
|
kind: CronTab
|
||||||
|
shortNames:
|
||||||
|
- ct
|
||||||
|
validation:
|
||||||
|
# openAPIV3Schema 适用于验证自定义对象的 schema。
|
||||||
|
openAPIV3Schema:
|
||||||
|
properties:
|
||||||
|
spec:
|
||||||
|
properties:
|
||||||
|
cronSpec:
|
||||||
|
type: string
|
||||||
|
pattern: '^(\d+|\*)(/\d+)?(\s+(\d+|\*)(/\d+)?){4}$'
|
||||||
|
replicas:
|
||||||
|
type: integer
|
||||||
|
minimum: 1
|
||||||
|
maximum: 10
|
||||||
|
```
|
||||||
|
|
||||||
|
并创建它:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl create -f resourcedefinition.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
`CronTab` 如果其字段中存在无效值,则将拒绝创建类型的自定义对象的请求。在以下示例中,自定义对象包含具有无效值的字段:
|
||||||
|
|
||||||
|
- `spec.cronSpec` 与正则表达式不匹配。
|
||||||
|
- `spec.replicas` 大于10。
|
||||||
|
|
||||||
|
如果您将以下YAML保存到`my-crontab.yaml`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: "stable.example.com/v1"
|
||||||
|
kind: CronTab
|
||||||
|
metadata:
|
||||||
|
name: my-new-cron-object
|
||||||
|
spec:
|
||||||
|
cronSpec: "* * * *"
|
||||||
|
image: my-awesome-cron-image
|
||||||
|
replicas: 15
|
||||||
|
```
|
||||||
|
|
||||||
|
并创建它:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl create -f my-crontab.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
你会收到一个错误:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
The CronTab "my-new-cron-object" is invalid: []: Invalid value: map[string]interface {}{"apiVersion":"stable.example.com/v1", "kind":"CronTab", "metadata":map[string]interface {}{"name":"my-new-cron-object", "namespace":"default", "deletionTimestamp":interface {}(nil), "deletionGracePeriodSeconds":(*int64)(nil), "creationTimestamp":"2017-09-05T05:20:07Z", "uid":"e14d79e7-91f9-11e7-a598-f0761cb232d1", "selfLink":"", "clusterName":""}, "spec":map[string]interface {}{"cronSpec":"* * * *", "image":"my-awesome-cron-image", "replicas":15}}:
|
||||||
|
validation failure list:
|
||||||
|
spec.cronSpec in body should match '^(\d+|\*)(/\d+)?(\s+(\d+|\*)(/\d+)?){4}$'
|
||||||
|
spec.replicas in body should be less than or equal to 10
|
||||||
|
```
|
||||||
|
|
||||||
|
如果字段包含有效值,则接受对象创建请求。
|
||||||
|
|
||||||
|
将以下 YAML 保存到 `my-crontab.yaml`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: "stable.example.com/v1"
|
||||||
|
kind: CronTab
|
||||||
|
metadata:
|
||||||
|
name: my-new-cron-object
|
||||||
|
spec:
|
||||||
|
cronSpec: "* * * * */5"
|
||||||
|
image: my-awesome-cron-image
|
||||||
|
replicas: 5
|
||||||
|
```
|
||||||
|
|
||||||
|
并创建它:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl create -f my-crontab.yaml
|
||||||
|
crontab "my-new-cron-object" created
|
||||||
|
```
|
||||||
|
|
||||||
|
### 其他打印列
|
||||||
|
|
||||||
|
从 Kubernetes 1.11 开始,kubectl 使用服务器端打印。服务器决定 `kubectl get` 命令显示哪些列。您可以使用 CustomResourceDefinition 自定义这些列。下面的示例将输出 `Spec`、`Replicas` 和 `Age` 列。
|
||||||
|
|
||||||
|
1. 将 CustomResourceDefinition 保存到 `resourcedefinition.yaml`。
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: apiextensions.k8s.io/v1beta1
|
||||||
|
kind: CustomResourceDefinition
|
||||||
|
metadata:
|
||||||
|
name: crontabs.stable.example.com
|
||||||
|
spec:
|
||||||
|
group: stable.example.com
|
||||||
|
version: v1
|
||||||
|
scope: Namespaced
|
||||||
|
names:
|
||||||
|
plural: crontabs
|
||||||
|
singular: crontab
|
||||||
|
kind: CronTab
|
||||||
|
shortNames:
|
||||||
|
- ct
|
||||||
|
additionalPrinterColumns:
|
||||||
|
- name: Spec
|
||||||
|
type: string
|
||||||
|
description: The cron spec defining the interval a CronJob is run
|
||||||
|
JSONPath: .spec.cronSpec
|
||||||
|
- name: Replicas
|
||||||
|
type: integer
|
||||||
|
description: The number of jobs launched by the CronJob
|
||||||
|
JSONPath: .spec.replicas
|
||||||
|
- name: Age
|
||||||
|
type: date
|
||||||
|
JSONPath: .metadata.creationTimestamp
|
||||||
|
```
|
||||||
|
|
||||||
|
2. 创建 CustomResourceDefinition:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl create -f resourcedefinition.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
3. 使用上一节中的创建的 `my-crontab.yaml` 实例。
|
||||||
|
|
||||||
|
4. 调用服务器端打印:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl get crontab my-new-cron-object
|
||||||
|
```
|
||||||
|
|
||||||
|
请注意 `NAME`、`SPEC`、`REPLICAS` 和 `AGE` 在输出列:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
NAME SPEC REPLICAS AGE
|
||||||
|
my-new-cron-object * * * * * 1 7s
|
||||||
|
```
|
||||||
|
|
||||||
|
`NAME` 列是隐含的,不需要在 CustomResourceDefinition 中定义。
|
||||||
|
|
||||||
|
#### Priority(优先级)
|
||||||
|
|
||||||
|
每列中都包含一个 `priority` 字段。目前,优先级区分标准视图或 wide 视图中显示的列(使用 `-o wide` 标志)。
|
||||||
|
|
||||||
|
- 具有优先级的列 `0` 显示在标准视图中。
|
||||||
|
- 优先级大于 `0` 的列仅在 wide 视图中显示。
|
||||||
|
|
||||||
|
#### Type(类型)
|
||||||
|
|
||||||
|
列中的 `type` 字段可以是以下任何一种(参考 [OpenAPI v3 数据类型](https://github.com/OAI/OpenAPI-Specification/blob/master/versions/3.0.0.md#dataTypes)):
|
||||||
|
|
||||||
|
- `integer` - 非浮点数
|
||||||
|
- `number` - 浮点数
|
||||||
|
- `string` - 字符串
|
||||||
|
- `boolean` - ture 或 false
|
||||||
|
- `date` - 自此时间戳以来的时间差异呈现
|
||||||
|
|
||||||
|
如果 CustomResource 中的值与为列指定的类型不匹配,则省略该值。使用 CustomResource 验证以确保值类型正确。
|
||||||
|
|
||||||
|
#### Format(格式)
|
||||||
|
|
||||||
|
列中的 `format` 字段可以是以下任何一个:
|
||||||
|
|
||||||
|
- `int32`
|
||||||
|
- `int64`
|
||||||
|
- `float`
|
||||||
|
- `double`
|
||||||
|
- `byte`
|
||||||
|
- `date`
|
||||||
|
- `date-time`
|
||||||
|
- `password`
|
||||||
|
|
||||||
|
该列 `format` 控制 `kubectl` 打印值时使用的样式。
|
||||||
|
|
||||||
|
### 子资源
|
||||||
|
|
||||||
|
**功能状态:** `Kubernetes v1.12` [beta](https://kubernetes.io/docs/tasks/access-kubernetes-api/custom-resources/custom-resource-definitions/#)
|
||||||
|
|
||||||
|
自定义资源支持 `/status` 和 `/scale` 子资源。
|
||||||
|
|
||||||
|
您可以使用 [kube-apiserver](https://kubernetes.io/docs/admin/kube-apiserver) `CustomResourceSubresources` 上的功能门(feature gate)禁用此功能:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
--feature-gates=CustomResourceSubresources=false
|
||||||
|
```
|
||||||
|
|
||||||
|
可以通过在 CustomResourceDefinition 中定义它们来选择性地启用 status 和 scale 子资源。
|
||||||
|
|
||||||
|
#### 状态子资源
|
||||||
|
|
||||||
|
启用状态子资源后,将公开自定义资源的子资源 `/status`。
|
||||||
|
|
||||||
|
- 状态和规范节分别由自定义资源内的 JSONPath `.status` 和 `.spec`JSONPath 表示。
|
||||||
|
- `PUT``/status` 对子资源的请求采用自定义资源对象,并忽略除状态节之外的任何更改。
|
||||||
|
- `PUT``/status` 对子资源的请求仅验证自定义资源的状态节。
|
||||||
|
- `PUT`/ `POST`/ `PATCH` 请求自定义资源忽略更改状态节。
|
||||||
|
- 对 spec 节的任何更改都会增加 `.metadata.generation` 的值。
|
||||||
|
- 在 CRD OpenAPI 验证模式的根目录中只允许以下构造:
|
||||||
|
- - Description
|
||||||
|
- Example
|
||||||
|
- ExclusiveMaximum
|
||||||
|
- ExclusiveMinimum
|
||||||
|
- ExternalDocs
|
||||||
|
- Format
|
||||||
|
- Items
|
||||||
|
- Maximum
|
||||||
|
- MaxItems
|
||||||
|
- MaxLength
|
||||||
|
- Minimum
|
||||||
|
- MinItems
|
||||||
|
- MinLength
|
||||||
|
- MultipleOf
|
||||||
|
- Pattern
|
||||||
|
- Properties
|
||||||
|
- Required
|
||||||
|
- Title
|
||||||
|
- Type
|
||||||
|
- UniqueItems
|
||||||
|
|
||||||
|
#### 扩展子资源
|
||||||
|
|
||||||
|
启用 scale 子资源后,将公开自定义资源的子资源 `/scale`。该 `autoscaling/v1.Scale` 对象作为有效负载发送 `/scale`。
|
||||||
|
|
||||||
|
要启用 scale 子资源,CustomResourceDefinition 中需要定义以下值。
|
||||||
|
|
||||||
|
- `SpecReplicasPath` 在与之对应的自定义资源中定义 JSONPath `Scale.Spec.Replicas`。
|
||||||
|
- 这是一个必需的值。
|
||||||
|
- `.spec` 只允许使用带点符号的 JSONPaths 。
|
||||||
|
- 如果 `SpecReplicasPath` 自定义资源中没有值,则 `/scale` 子资源将在GET上返回错误。
|
||||||
|
- `StatusReplicasPath` 在与之对应的自定义资源中定义 JSONPath `Scale.Status.Replicas`。
|
||||||
|
- 这是一个必需的值。
|
||||||
|
- `.stutus` 只允许使用带点符号的 JSONPaths 。
|
||||||
|
- 如果 `StatusReplicasPath` 自定义资源中没有值,则子资源 `/scale` 中的状态副本值将默认为 0。
|
||||||
|
- `LabelSelectorPath `在与之对应的自定义资源中定义 JSONPath `Scale.Status.Selector`。
|
||||||
|
- 这是一个可选值。
|
||||||
|
- 必须将其设置为与 HPA 一起使用。
|
||||||
|
- `.status` 只允许使用带点符号的 JSONPaths 。
|
||||||
|
- 如果 `LabelSelectorPath` 自定义资源中没有值,则子资源 `/scale` 中的状态选择器值将默认为空字符串。
|
||||||
|
|
||||||
|
在以下示例中,启用了status 和 scale 子资源。
|
||||||
|
|
||||||
|
将 CustomResourceDefinition 保存到`resourcedefinition.yaml`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: apiextensions.k8s.io/v1beta1
|
||||||
|
kind: CustomResourceDefinition
|
||||||
|
metadata:
|
||||||
|
name: crontabs.stable.example.com
|
||||||
|
spec:
|
||||||
|
group: stable.example.com
|
||||||
|
versions:
|
||||||
|
- name: v1
|
||||||
|
served: true
|
||||||
|
storage: true
|
||||||
|
scope: Namespaced
|
||||||
|
names:
|
||||||
|
plural: crontabs
|
||||||
|
singular: crontab
|
||||||
|
kind: CronTab
|
||||||
|
shortNames:
|
||||||
|
- ct
|
||||||
|
# subresources describes the subresources for custom resources.
|
||||||
|
subresources:
|
||||||
|
# status enables the status subresource.
|
||||||
|
status: {}
|
||||||
|
# scale enables the scale subresource.
|
||||||
|
scale:
|
||||||
|
# specReplicasPath defines the JSONPath inside of a custom resource that corresponds to Scale.Spec.Replicas.
|
||||||
|
specReplicasPath: .spec.replicas
|
||||||
|
# statusReplicasPath defines the JSONPath inside of a custom resource that corresponds to Scale.Status.Replicas.
|
||||||
|
statusReplicasPath: .status.replicas
|
||||||
|
# labelSelectorPath defines the JSONPath inside of a custom resource that corresponds to Scale.Status.Selector.
|
||||||
|
labelSelectorPath: .status.labelSelector
|
||||||
|
```
|
||||||
|
|
||||||
|
并创建它:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl create -f resourcedefinition.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
创建 CustomResourceDefinition 对象后,您可以创建自定义对象。
|
||||||
|
|
||||||
|
如果您将以下 YAML 保存到 `my-crontab.yaml`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: "stable.example.com/v1"
|
||||||
|
kind: CronTab
|
||||||
|
metadata:
|
||||||
|
name: my-new-cron-object
|
||||||
|
spec:
|
||||||
|
cronSpec: "* * * * */5"
|
||||||
|
image: my-awesome-cron-image
|
||||||
|
replicas: 3
|
||||||
|
```
|
||||||
|
|
||||||
|
并创建它:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl create -f my-crontab.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
然后在以下位置创建新的命名空间 RESTful API 端点:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
/apis/stable.example.com/v1/namespaces/*/crontabs/status
|
||||||
|
```
|
||||||
|
|
||||||
|
和
|
||||||
|
|
||||||
|
```bash
|
||||||
|
/apis/stable.example.com/v1/namespaces/*/crontabs/scale
|
||||||
|
```
|
||||||
|
|
||||||
|
可以使用该 `kubectl scale` 命令缩放自定义资源。例如,以上创建的自定义资源的的 `.spec.replicas` 设置为 5:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl scale --replicas=5 crontabs/my-new-cron-object
|
||||||
|
crontabs "my-new-cron-object" scaled
|
||||||
|
|
||||||
|
kubectl get crontabs my-new-cron-object -o jsonpath='{.spec.replicas}'
|
||||||
|
5
|
||||||
|
```
|
||||||
|
|
||||||
|
### Category(分类)
|
||||||
|
|
||||||
|
类别是自定义资源所属的分组资源的列表(例如 `all`)。您可以使用 `kubectl get <category-name>` 列出属于该类别的资源。此功能是 **beta**,可用于 v1.10 中的自定义资源。
|
||||||
|
|
||||||
|
以下示例添加 `all` CustomResourceDefinition 中的类别列表,并说明如何使用 `kubectl get all` 输出自定义资源 。
|
||||||
|
|
||||||
|
将以下 CustomResourceDefinition 保存到 `resourcedefinition.yaml`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: apiextensions.k8s.io/v1beta1
|
||||||
|
kind: CustomResourceDefinition
|
||||||
|
metadata:
|
||||||
|
name: crontabs.stable.example.com
|
||||||
|
spec:
|
||||||
|
group: stable.example.com
|
||||||
|
versions:
|
||||||
|
- name: v1
|
||||||
|
served: true
|
||||||
|
storage: true
|
||||||
|
scope: Namespaced
|
||||||
|
names:
|
||||||
|
plural: crontabs
|
||||||
|
singular: crontab
|
||||||
|
kind: CronTab
|
||||||
|
shortNames:
|
||||||
|
- ct
|
||||||
|
# categories is a list of grouped resources the custom resource belongs to.
|
||||||
|
categories:
|
||||||
|
- all
|
||||||
|
```
|
||||||
|
|
||||||
|
并创建它:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl create -f resourcedefinition.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
创建 CustomResourceDefinition 对象后,您可以创建自定义对象。
|
||||||
|
|
||||||
|
将以下 YAML 保存到 `my-crontab.yaml`:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
apiVersion: "stable.example.com/v1"
|
||||||
|
kind: CronTab
|
||||||
|
metadata:
|
||||||
|
name: my-new-cron-object
|
||||||
|
spec:
|
||||||
|
cronSpec: "* * * * */5"
|
||||||
|
image: my-awesome-cron-image
|
||||||
|
```
|
||||||
|
|
||||||
|
并创建它:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl create -f my-crontab.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
您可以使用`kubectl get`以下方式指定类别:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl get all
|
||||||
|
```
|
||||||
|
|
||||||
|
它将包括种类的自定义资源`CronTab`:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
NAME AGE
|
||||||
|
crontabs/my-new-cron-object 3s
|
||||||
|
```
|
||||||
|
|
||||||
|
## 参考
|
||||||
|
|
||||||
|
- [Extend the Kubernetes API with CustomResourceDefinitions - kubernetes.io](https://kubernetes.io/docs/tasks/access-kubernetes-api/custom-resources/custom-resource-definitions/)
|
||||||
|
- [如何从零开始编写一个Kubernetes CRD - servicemesher.com](https://www.servicemesher.com/blog/kubernetes-crd-quick-start/)
|
||||||
|
|
@ -1,6 +1,6 @@
|
||||||
# CRI - Container Runtime Interface(容器运行时接口)
|
# CRI - Container Runtime Interface(容器运行时接口)
|
||||||
|
|
||||||
CRI中定义了**容器**和**镜像**的服务的接口,因为容器运行时与镜像的生命周期是彼此隔离的,因此需要定义两个服务。该接口使用[Protocol Buffer](https://developers.google.com/protocol-buffers/),基于[gRPC](https://grpc.io/),在Kubernetes v1.10+版本中是在[pkg/kubelet/apis/cri/runtime/v1alpha2](https://github.com/kubernetes/kubernetes/tree/master/pkg/kubelet/apis/cri/runtime/v1alpha2)的`api.proto`中定义的。
|
CRI中定义了**容器**和**镜像**的服务的接口,因为容器运行时与镜像的生命周期是彼此隔离的,因此需要定义两个服务。该接口使用[Protocol Buffer](https://developers.google.com/protocol-buffers/),基于[gRPC](https://grpc.io/),在Kubernetes v1.10+版本中是在`pkg/kubelet/apis/cri/runtime/v1alpha2`的`api.proto`中定义的。
|
||||||
|
|
||||||
## CRI架构
|
## CRI架构
|
||||||
|
|
||||||
|
|
@ -14,8 +14,6 @@ Container Runtime实现了CRI gRPC Server,包括`RuntimeService`和`ImageServi
|
||||||
|
|
||||||
要想启用CRI只需要在kubelet的启动参数重传入此参数:`--container-runtime-endpoint`远程运行时服务的端点。当前Linux上支持unix socket,windows上支持tcp。例如:`unix:///var/run/dockershim.sock`、 `tcp://localhost:373`,默认是`unix:///var/run/dockershim.sock`,即默认使用本地的docker作为容器运行时。
|
要想启用CRI只需要在kubelet的启动参数重传入此参数:`--container-runtime-endpoint`远程运行时服务的端点。当前Linux上支持unix socket,windows上支持tcp。例如:`unix:///var/run/dockershim.sock`、 `tcp://localhost:373`,默认是`unix:///var/run/dockershim.sock`,即默认使用本地的docker作为容器运行时。
|
||||||
|
|
||||||
关于CRI的详细进展请参考[CRI: the Container Runtime Interface](https://github.com/kubernetes/community/blob/master/contributors/devel/container-runtime-interface.md)。
|
|
||||||
|
|
||||||
## CRI接口
|
## CRI接口
|
||||||
|
|
||||||
Kubernetes 1.9中的CRI接口在`api.proto`中的定义如下:
|
Kubernetes 1.9中的CRI接口在`api.proto`中的定义如下:
|
||||||
|
|
@ -122,21 +120,28 @@ service ImageService {
|
||||||
|
|
||||||
我们最初在使用Kubernetes时通常会默认使用Docker作为容器运行时,其实从Kubernetes 1.5开始已经开始支持CRI,目前是处于Alpha版本,通过CRI接口可以指定使用其它容器运行时作为Pod的后端,目前支持 CRI 的后端有:
|
我们最初在使用Kubernetes时通常会默认使用Docker作为容器运行时,其实从Kubernetes 1.5开始已经开始支持CRI,目前是处于Alpha版本,通过CRI接口可以指定使用其它容器运行时作为Pod的后端,目前支持 CRI 的后端有:
|
||||||
|
|
||||||
- [cri-o](https://github.com/kubernetes-incubator/cri-o):同时兼容OCI和CRI的容器运行时
|
- [cri-o](https://github.com/kubernetes-incubator/cri-o):cri-o是Kubernetes的CRI标准的实现,并且允许Kubernetes间接使用OCI兼容的容器运行时,可以把cri-o看成Kubernetes使用OCI兼容的容器运行时的中间层。
|
||||||
- [cri-containerd](https://github.com/containerd/cri-containerd):基于[Containerd](https://github.com/containerd/containerd)的Kubernetes CRI 实现
|
- [cri-containerd](https://github.com/containerd/cri-containerd):基于[Containerd](https://github.com/containerd/containerd)的Kubernetes CRI 实现
|
||||||
- [rkt](https://coreos.com/rkt/):由于CoreOS主推的用来跟docker抗衡的容器运行时
|
- [rkt](https://coreos.com/rkt/):由CoreOS主推的用来跟docker抗衡的容器运行时
|
||||||
- [frakti](https://github.com/kubernetes/frakti):基于hypervisor的CRI
|
- [frakti](https://github.com/kubernetes/frakti):基于hypervisor的CRI
|
||||||
- [docker](https://www.docker.com):kuberentes最初就开始支持的容器运行时,目前还没完全从kubelet中解耦,docker公司同时推广了[OCI](https://www.opencontainers.org/)标准
|
- [docker](https://www.docker.com):kuberentes最初就开始支持的容器运行时,目前还没完全从kubelet中解耦,docker公司同时推广了[OCI](https://www.opencontainers.org/)标准
|
||||||
- [Clear Containers](https://github.com/clearcontainers):由Intel推出的同时兼容OCI和CRI的容器运行时
|
|
||||||
- [Kata Containers](https://katacontainers.io/):符合OCI规范同时兼容CRI
|
|
||||||
- [gVisor](https://github.com/google/gvisor):由谷歌推出的容器运行时沙箱(Experimental)
|
|
||||||
|
|
||||||
CRI是由[SIG-Node](https://kubernetes.slack.com/archives/sig-node)来维护的。
|
CRI是由[SIG-Node](https://kubernetes.slack.com/archives/sig-node)来维护的。
|
||||||
|
|
||||||
|
## 当前通过CRI-O间接支持CRI的后端
|
||||||
|
|
||||||
|
当前同样存在一些只实现了[OCI](https://www.opencontainers.org/)标准的容器,但是它们可以通过CRI-O来作为Kubernetes的容器运行时。CRI-O是Kubernetes的CRI标准的实现,并且允许Kubernetes间接使用OCI兼容的容器运行时。
|
||||||
|
|
||||||
|
- [Clear Containers](https://github.com/clearcontainers):由Intel推出的兼容OCI容器运行时,可以通过CRI-O来兼容CRI。
|
||||||
|
- [Kata Containers](https://katacontainers.io/):符合OCI规范,可以通过CRI-O或[Containerd CRI Plugin](https://github.com/containerd/cri)来兼容CRI。。
|
||||||
|
- [gVisor](https://github.com/google/gvisor):由谷歌推出的容器运行时沙箱(Experimental),可以通过CRI-O来兼容CRI。
|
||||||
|
|
||||||
|
|
||||||
## 参考
|
## 参考
|
||||||
|
|
||||||
- [Kubernetes CRI and Minikube](https://sreeninet.wordpress.com/2017/02/11/kubernetes-cri-and-minikube/)
|
- [Kubernetes CRI and Minikube](https://sreeninet.wordpress.com/2017/02/11/kubernetes-cri-and-minikube/)
|
||||||
- [Kubernetes container runtime interface](https://feisky.xyz/2016/09/24/Kubernetes-container-runtime-interface/)
|
|
||||||
- [CRI-O and Alternative Runtimes in Kubernetes](https://www.projectatomic.io/blog/2017/02/crio-runtimes/)
|
- [CRI-O and Alternative Runtimes in Kubernetes](https://www.projectatomic.io/blog/2017/02/crio-runtimes/)
|
||||||
- [Docker、Containerd、RunC...:你应该知道的所有](http://www.infoq.com/cn/news/2017/02/Docker-Containerd-RunC)
|
- [Docker、Containerd、RunC...:你应该知道的所有](https://www.infoq.cn/article/2017/02/Docker-Containerd-RunC/)
|
||||||
- [Introducing Container Runtime Interface (CRI) in Kubernetes](http://blog.kubernetes.io/2016/12/container-runtime-interface-cri-in-kubernetes.html)
|
- [Introducing Container Runtime Interface (CRI) in Kubernetes](http://blog.kubernetes.io/2016/12/container-runtime-interface-cri-in-kubernetes.html)
|
||||||
|
- [cri-o](https://cri-o.io/)
|
||||||
|
- [Kata Containers Architecture](https://github.com/kata-containers/documentation/blob/master/design/architecture.md#kubernetes-support)
|
||||||
|
|
|
||||||
|
|
@ -7,9 +7,9 @@
|
||||||
|
|
||||||
一个 CronJob 对象类似于 *crontab* (cron table)文件中的一行。它根据指定的预定计划周期性地运行一个 Job,格式可以参考 [Cron](https://en.wikipedia.org/wiki/Cron) 。
|
一个 CronJob 对象类似于 *crontab* (cron table)文件中的一行。它根据指定的预定计划周期性地运行一个 Job,格式可以参考 [Cron](https://en.wikipedia.org/wiki/Cron) 。
|
||||||
|
|
||||||
### 前提条件
|
## 前提条件
|
||||||
|
|
||||||
当使用的 Kubernetes 集群,版本 >= 1.4(对 ScheduledJob),>= 1.5(对 CronJob),当启动 API Server(参考 [为集群开启或关闭 API 版本](https://kubernetes.io/docs/admin/cluster-management/#turn-on-or-off-an-api-version-for-your-cluster) 获取更多信息)时,通过传递选项 `--runtime-config=batch/v2alpha1=true` 可以开启 batch/v2alpha1 API。
|
当前使用的 Kubernetes 集群,版本 >= 1.8(对 CronJob)。对于先前版本的集群,版本 < 1.8,启动 API Server(参考 [为集群开启或关闭 API 版本](https://kubernetes.io/docs/admin/cluster-management/#turn-on-or-off-an-api-version-for-your-cluster) 获取更多信息)时,通过传递选项 `--runtime-config=batch/v2alpha1=true` 可以开启 batch/v2alpha1 API。
|
||||||
|
|
||||||
典型的用法如下所示:
|
典型的用法如下所示:
|
||||||
|
|
||||||
|
|
@ -36,10 +36,10 @@
|
||||||
|
|
||||||
- `.spec.successfulJobsHistoryLimit` 和 `.spec.failedJobsHistoryLimit` :**历史限制**,是可选的字段。它们指定了可以保留多少完成和失败的 Job。
|
- `.spec.successfulJobsHistoryLimit` 和 `.spec.failedJobsHistoryLimit` :**历史限制**,是可选的字段。它们指定了可以保留多少完成和失败的 Job。
|
||||||
|
|
||||||
默认没有限制,所有成功和失败的 Job 都会被保留。然而,当运行一个 Cron Job 时,Job 可以很快就堆积很多,推荐设置这两个字段的值。设置限制的值为 `0`,相关类型的 Job 完成后将不会被保留。
|
默认情况下,它们分别设置为 `3` 和 `1`。设置限制的值为 `0`,相关类型的 Job 完成后将不会被保留。
|
||||||
|
|
||||||
```yaml
|
```yaml
|
||||||
apiVersion: batch/v2alpha1
|
apiVersion: batch/v1beta1
|
||||||
kind: CronJob
|
kind: CronJob
|
||||||
metadata:
|
metadata:
|
||||||
name: hello
|
name: hello
|
||||||
|
|
@ -59,7 +59,7 @@ spec:
|
||||||
restartPolicy: OnFailure
|
restartPolicy: OnFailure
|
||||||
```
|
```
|
||||||
|
|
||||||
```Bash
|
```bash
|
||||||
$ kubectl create -f cronjob.yaml
|
$ kubectl create -f cronjob.yaml
|
||||||
cronjob "hello" created
|
cronjob "hello" created
|
||||||
```
|
```
|
||||||
|
|
@ -77,12 +77,12 @@ hello */1 * * * * False 0 <none>
|
||||||
$ kubectl get jobs
|
$ kubectl get jobs
|
||||||
NAME DESIRED SUCCESSFUL AGE
|
NAME DESIRED SUCCESSFUL AGE
|
||||||
hello-1202039034 1 1 49s
|
hello-1202039034 1 1 49s
|
||||||
$ pods=$(kubectl get pods --selector=job-name=hello-1202039034 --output=jsonpath={.items..metadata.name} -a)
|
$ pods=$(kubectl get pods --selector=job-name=hello-1202039034 --output=jsonpath={.items..metadata.name})
|
||||||
$ kubectl logs $pods
|
$ kubectl logs $pods
|
||||||
Mon Aug 29 21:34:09 UTC 2016
|
Mon Aug 29 21:34:09 UTC 2016
|
||||||
Hello from the Kubernetes cluster
|
Hello from the Kubernetes cluster
|
||||||
|
|
||||||
# 注意,删除cronjob的时候不会自动删除job,这些job可以用kubectl delete job来删除
|
# 注意,删除 cronjob 的时候不会自动删除 job,这些 job 可以用 kubectl delete job 来删除
|
||||||
$ kubectl delete cronjob hello
|
$ kubectl delete cronjob hello
|
||||||
cronjob "hello" deleted
|
cronjob "hello" deleted
|
||||||
```
|
```
|
||||||
|
|
@ -119,4 +119,4 @@ job "hello-1202039034" deleted
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
一旦 Job 被删除,由 Job 创建的 Pod 也会被删除。注意,所有由名称为 “hello” 的 Cron Job 创建的 Job 会以前缀字符串 “hello-” 进行命名。如果想要删除当前 Namespace 中的所有 Job,可以通过命令 `kubectl delete jobs --all` 立刻删除它们。
|
一旦 Job 被删除,由 Job 创建的 Pod 也会被删除。注意,所有由名称为 “hello” 的 Cron Job 创建的 Job 会以前缀字符串 “hello-” 进行命名。如果想要删除当前 Namespace 中的所有 Job,可以通过命令 `kubectl delete jobs --all` 立刻删除它们。
|
||||||
|
|
|
||||||
|
|
@ -2,7 +2,7 @@
|
||||||
|
|
||||||
CSI 代表[容器存储接口](https://github.com/container-storage-interface/spec/blob/master/spec.md),CSI 试图建立一个行业标准接口的规范,借助 CSI 容器编排系统(CO)可以将任意存储系统暴露给自己的容器工作负载。有关详细信息,请查看[设计方案](https://github.com/kubernetes/community/blob/master/contributors/design-proposals/storage/container-storage-interface.md)。
|
CSI 代表[容器存储接口](https://github.com/container-storage-interface/spec/blob/master/spec.md),CSI 试图建立一个行业标准接口的规范,借助 CSI 容器编排系统(CO)可以将任意存储系统暴露给自己的容器工作负载。有关详细信息,请查看[设计方案](https://github.com/kubernetes/community/blob/master/contributors/design-proposals/storage/container-storage-interface.md)。
|
||||||
|
|
||||||
`csi` 卷类型是一种 in-tree(即跟其它存储插件在同一个代码路径下,随 Kubernetes 的代码同时编译的) 的 CSI 卷插件,用于 Pod 与在同一节点上运行的外部 CSI 卷驱动程序交互。部署 CSI 兼容卷驱动后,用户可以使用 `csi` 作为卷类型来挂载驱动提供的存储。
|
`csi` 卷类型是一种 out-tree(即跟其它存储插件在同一个代码路径下,随 Kubernetes 的代码同时编译的) 的 CSI 卷插件,用于 Pod 与在同一节点上运行的外部 CSI 卷驱动程序交互。部署 CSI 兼容卷驱动后,用户可以使用 `csi` 作为卷类型来挂载驱动提供的存储。
|
||||||
|
|
||||||
CSI 持久化卷支持是在 Kubernetes v1.9 中引入的,作为一个 alpha 特性,必须由集群管理员明确启用。换句话说,集群管理员需要在 apiserver、controller-manager 和 kubelet 组件的 “`--feature-gates =`” 标志中加上 “`CSIPersistentVolume = true`”。
|
CSI 持久化卷支持是在 Kubernetes v1.9 中引入的,作为一个 alpha 特性,必须由集群管理员明确启用。换句话说,集群管理员需要在 apiserver、controller-manager 和 kubelet 组件的 “`--feature-gates =`” 标志中加上 “`CSIPersistentVolume = true`”。
|
||||||
|
|
||||||
|
|
@ -116,15 +116,22 @@ Kubernetes 尽可能少地指定 CSI Volume 驱动程序的打包和部署规范
|
||||||
|
|
||||||
监听 Kubernetes PersistentVolumeClaim 对象的 sidecar 容器,并触发对 CSI 端点的 CreateVolume 和DeleteVolume 操作;
|
监听 Kubernetes PersistentVolumeClaim 对象的 sidecar 容器,并触发对 CSI 端点的 CreateVolume 和DeleteVolume 操作;
|
||||||
|
|
||||||
- [Driver-registrar](https://github.com/kubernetes-csi/driver-registrar)
|
- [Driver-registrar](https://github.com/kubernetes-csi/driver-registrar)(DEPRECATED)
|
||||||
|
|
||||||
使用 Kubelet(将来)注册 CSI 驱动程序的 sidecar 容器,并将 `NodeId` (通过 `GetNodeID` 调用检索到 CSI endpoint)添加到 Kubernetes Node API 对象的 annotation 里面。
|
使用 Kubelet(将来)注册 CSI 驱动程序的 sidecar 容器,并将 `NodeId` (通过 `GetNodeID` 调用检索到 CSI endpoint)添加到 Kubernetes Node API 对象的 annotation 里面。
|
||||||
|
|
||||||
|
- [Cluster Driver Registrar](https://github.com/kubernetes-csi/cluster-driver-registrar)
|
||||||
|
|
||||||
|
创建 CSIDriver 这个集群范围的 CRD 对象。
|
||||||
|
|
||||||
|
- [Node Driver Registrar](https://github.com/kubernetes-csi/node-driver-registrar)
|
||||||
|
|
||||||
|
替代 Driver-registrar。
|
||||||
|
|
||||||
存储供应商完全可以使用这些组件来为其插件构建 Kubernetes Deployment,同时让它们的 CSI 驱动程序完全意识不到 Kubernetes 的存在。
|
存储供应商完全可以使用这些组件来为其插件构建 Kubernetes Deployment,同时让它们的 CSI 驱动程序完全意识不到 Kubernetes 的存在。
|
||||||
|
|
||||||
另外 CSI 驱动完全是由第三方存储供应商自己维护的,在 kubernetes 1.9 版本中 CSI 还处于 alpha 版本。
|
另外 CSI 驱动完全是由第三方存储供应商自己维护的,在 kubernetes 1.9 版本中 CSI 还处于 alpha 版本。
|
||||||
|
|
||||||
## 参考
|
## 参考
|
||||||
|
|
||||||
- [Introducing Container Storage Interface (CSI) Alpha for Kubernetes](http://blog.kubernetes.io/2018/01/introducing-container-storage-interface.html)
|
- [Container Storage Interface (CSI)](https://github.com/container-storage-interface/spec/blob/master/spec.md)
|
||||||
- [Container Storage Interface (CSI)](https://github.com/container-storage-interface/spec/blob/master/spec.md)
|
|
||||||
|
|
|
||||||
|
|
@ -66,4 +66,4 @@ $ kubectl get --raw=apis/custom-metrics.metrics.k8s.io/v1alpha1
|
||||||
- [1.7版本的kubernetes中启用自定义HPA](https://docs.bitnami.com/kubernetes/how-to/configure-autoscaling-custom-metrics/)
|
- [1.7版本的kubernetes中启用自定义HPA](https://docs.bitnami.com/kubernetes/how-to/configure-autoscaling-custom-metrics/)
|
||||||
- [Horizontal Pod Autoscaler Walkthrough](https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/)
|
- [Horizontal Pod Autoscaler Walkthrough](https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/)
|
||||||
- [Kubernetes 1.8: Now with 100% Daily Value of Custom Metrics](https://blog.openshift.com/kubernetes-1-8-now-custom-metrics/)
|
- [Kubernetes 1.8: Now with 100% Daily Value of Custom Metrics](https://blog.openshift.com/kubernetes-1-8-now-custom-metrics/)
|
||||||
- [Arbitrary/Custom Metrics in the Horizontal Pod Autoscaler#117](https://github.com/kubernetes/features/issues/117)
|
- [Arbitrary/Custom Metrics in the Horizontal Pod Autoscaler#117](https://github.com/kubernetes/features/issues/117)
|
||||||
|
|
|
||||||
|
|
@ -20,7 +20,7 @@ Kubernetes1.6版本中包含一个内建的资源叫做TPR(ThirdPartyResource
|
||||||
|
|
||||||
- 你的API是否属于[声明式的](https://kubernetes.io/docs/concepts/api-extension/custom-resources/#declarative-apis)
|
- 你的API是否属于[声明式的](https://kubernetes.io/docs/concepts/api-extension/custom-resources/#declarative-apis)
|
||||||
- 是否想使用kubectl命令来管理
|
- 是否想使用kubectl命令来管理
|
||||||
- 是否要作为kubenretes中的对象类型来管理,同时显示在kuberetes dashboard上
|
- 是否要作为kubenretes中的对象类型来管理,同时显示在kubernetes dashboard上
|
||||||
- 是否可以遵守kubernetes的API规则限制,例如URL和API group、namespace限制
|
- 是否可以遵守kubernetes的API规则限制,例如URL和API group、namespace限制
|
||||||
- 是否可以接受该API只能作用于集群或者namespace范围
|
- 是否可以接受该API只能作用于集群或者namespace范围
|
||||||
- 想要复用kubernetes API的公共功能,比如CRUD、watch、内置的认证和授权等
|
- 想要复用kubernetes API的公共功能,比如CRUD、watch、内置的认证和授权等
|
||||||
|
|
@ -92,9 +92,9 @@ spec:
|
||||||
kubectl create -f resourcedefinition.yaml
|
kubectl create -f resourcedefinition.yaml
|
||||||
```
|
```
|
||||||
|
|
||||||
访问RESTful API端点如http://172.20.0.113:8080将看到如下API端点已创建:
|
访问RESTful API端点如<http://172.20.0.113:8080>将看到如下API端点已创建:
|
||||||
|
|
||||||
```
|
```bash
|
||||||
/apis/stable.example.com/v1/namespaces/*/crontabs/...
|
/apis/stable.example.com/v1/namespaces/*/crontabs/...
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
@ -130,8 +130,6 @@ metadata:
|
||||||
|
|
||||||
详情参考:[Extend the Kubernetes API with CustomResourceDefinitions](https://kubernetes.io/docs/tasks/access-kubernetes-api/extend-api-custom-resource-definitions/)
|
详情参考:[Extend the Kubernetes API with CustomResourceDefinitions](https://kubernetes.io/docs/tasks/access-kubernetes-api/extend-api-custom-resource-definitions/)
|
||||||
|
|
||||||
使用kubernetes1.7及以上版本请参考[Migrate a ThirdPartyResource to CustomResourceDefinition](https://kubernetes.io/docs/tasks/access-kubernetes-api/migrate-third-party-resource/)。
|
|
||||||
|
|
||||||
## 自定义控制器
|
## 自定义控制器
|
||||||
|
|
||||||
单纯设置了自定义资源,并没有什么用,只有跟自定义控制器结合起来,才能将资源对象中的声明式API翻译成用户所期望的状态。自定义控制器可以用来管理任何资源类型,但是一般是跟自定义资源结合使用。
|
单纯设置了自定义资源,并没有什么用,只有跟自定义控制器结合起来,才能将资源对象中的声明式API翻译成用户所期望的状态。自定义控制器可以用来管理任何资源类型,但是一般是跟自定义资源结合使用。
|
||||||
|
|
@ -140,7 +138,7 @@ metadata:
|
||||||
|
|
||||||
## API server聚合
|
## API server聚合
|
||||||
|
|
||||||
Aggregated(聚合的)API server是为了将原来的API server这个巨石(monolithic)应用给拆分成,为了方便用户开发自己的API server集成进来,而不用直接修改kubernetes官方仓库的代码,这样一来也能将API server解耦,方便用户使用实验特性。这些API server可以跟core API server无缝衔接,试用kubectl也可以管理它们。
|
Aggregated(聚合的)API server是为了将原来的API server这个巨石(monolithic)应用给拆分成,为了方便用户开发自己的API server集成进来,而不用直接修改kubernetes官方仓库的代码,这样一来也能将API server解耦,方便用户使用实验特性。这些API server可以跟core API server无缝衔接,使用kubectl也可以管理它们。
|
||||||
|
|
||||||
详情参考[Aggregated API Server](aggregated-api-server.md)。
|
详情参考[Aggregated API Server](aggregated-api-server.md)。
|
||||||
|
|
||||||
|
|
@ -148,4 +146,4 @@ Aggregated(聚合的)API server是为了将原来的API server这个巨石
|
||||||
|
|
||||||
- [Custom Resources](https://kubernetes.io/docs/concepts/api-extension/custom-resources/)
|
- [Custom Resources](https://kubernetes.io/docs/concepts/api-extension/custom-resources/)
|
||||||
- [Extend the Kubernetes API with CustomResourceDefinitions](https://kubernetes.io/docs/tasks/access-kubernetes-api/extend-api-custom-resource-definitions/)
|
- [Extend the Kubernetes API with CustomResourceDefinitions](https://kubernetes.io/docs/tasks/access-kubernetes-api/extend-api-custom-resource-definitions/)
|
||||||
- [Introducing Operators: Putting Operational Knowledge into Software](https://coreos.com/blog/introducing-operators.html)
|
- [Introducing Operators: Putting Operational Knowledge into Software](https://coreos.com/blog/introducing-operators.html)
|
||||||
|
|
|
||||||
|
|
@ -17,9 +17,9 @@
|
||||||
|
|
||||||
### 必需字段
|
### 必需字段
|
||||||
|
|
||||||
和其它所有 Kubernetes 配置一样,DaemonSet 需要 `apiVersion`、`kind` 和 `metadata`字段。有关配置文件的通用信息,详见文档 [部署应用](https://kubernetes.io/docs/user-guide/deploying-applications/)、[配置容器](https://kubernetes.io/docs/user-guide/configuring-containers/) 和 [资源管理](https://kubernetes.io/docs/concepts/tools/kubectl/object-management-overview/) 。
|
和其它所有 Kubernetes 配置一样,DaemonSet 需要 `apiVersion`、`kind` 和 `metadata`字段。有关配置文件的通用信息,详见文档 [部署应用](https://kubernetes.io/docs/user-guide/deploying-applications/)、[配置容器](https://kubernetes.io/docs/user-guide/configuring-containers/) 和资源管理。
|
||||||
|
|
||||||
DaemonSet 也需要一个 [`.spec`](https://git.k8s.io/community/contributors/devel/api-conventions.md#spec-and-status) 配置段。
|
DaemonSet 也需要一个 `.spec`配置段。
|
||||||
|
|
||||||
### Pod 模板
|
### Pod 模板
|
||||||
|
|
||||||
|
|
@ -34,7 +34,7 @@ Pod 除了必须字段外,在 DaemonSet 中的 Pod 模板必须指定合理的
|
||||||
|
|
||||||
### Pod Selector
|
### Pod Selector
|
||||||
|
|
||||||
`.spec.selector` 字段表示 Pod Selector,它与 [Job](https://kubernetes.io/docs/concepts/jobs/run-to-completion-finite-workloads/) 或其它资源的 `.sper.selector` 的原理是相同的。
|
`.spec.selector` 字段表示 Pod Selector,它与 [Job](https://kubernetes.io/docs/concepts/jobs/run-to-completion-finite-workloads/) 或其它资源的 `.spec.selector` 的原理是相同的。
|
||||||
|
|
||||||
`spec.selector` 表示一个对象,它由如下两个字段组成:
|
`spec.selector` 表示一个对象,它由如下两个字段组成:
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -56,13 +56,11 @@ kubectl rollout undo deployment/nginx-deployment
|
||||||
|
|
||||||
## Deployment 结构示意图
|
## Deployment 结构示意图
|
||||||
|
|
||||||
参考:https://kubernetes.io/docs/api-reference/v1.6/#deploymentspec-v1beta1-apps
|
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
## Deployment 概念详细解析
|
## Deployment 概念详细解析
|
||||||
|
|
||||||
本文翻译自kubernetes官方文档:https://kubernetes.io/docs/concepts/workloads/controllers/deployment.md
|
本文翻译自kubernetes官方文档:https://kubernetes.io/docs/concepts/workloads/controllers/deployment
|
||||||
|
|
||||||
根据2017年5月10日的Commit 8481c02 翻译。
|
根据2017年5月10日的Commit 8481c02 翻译。
|
||||||
|
|
||||||
|
|
@ -386,8 +384,6 @@ $ kubectl rollout undo deployment/nginx-deployment --to-revision=2
|
||||||
deployment "nginx-deployment" rolled back
|
deployment "nginx-deployment" rolled back
|
||||||
```
|
```
|
||||||
|
|
||||||
与 rollout 相关的命令详细文档见[kubectl rollout](https://kubernetes.io/docs/user-guide/kubectl/v1.6/#rollout)。
|
|
||||||
|
|
||||||
该 Deployment 现在已经回退到了先前的稳定版本。如您所见,Deployment controller产生了一个回退到revison 2的`DeploymentRollback`的 event。
|
该 Deployment 现在已经回退到了先前的稳定版本。如您所见,Deployment controller产生了一个回退到revison 2的`DeploymentRollback`的 event。
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
|
|
@ -484,10 +480,16 @@ NAME DESIRED CURRENT READY AGE
|
||||||
nginx-deployment-1989198191 7 7 0 7m
|
nginx-deployment-1989198191 7 7 0 7m
|
||||||
nginx-deployment-618515232 11 11 11 7m
|
nginx-deployment-618515232 11 11 11 7m
|
||||||
```
|
```
|
||||||
|
## 删除autoscale
|
||||||
|
|
||||||
|
```bash
|
||||||
|
kubectl get hpa
|
||||||
|
kubectl delete hpa ${name of hpa}
|
||||||
|
```
|
||||||
|
|
||||||
## 暂停和恢复Deployment
|
## 暂停和恢复Deployment
|
||||||
|
|
||||||
您可以在发出一次或多次更新前暂停一个 Deployment,然后再恢复它。这样您就能多次暂停和恢复 Deployment,在此期间进行一些修复工作,而不会发出不必要的 rollout。
|
您可以在发出一次或多次更新前暂停一个 Deployment,然后再恢复它。这样您就能在Deployment暂停期间进行多次修复工作,而不会发出不必要的 rollout。
|
||||||
|
|
||||||
例如使用刚刚创建 Deployment:
|
例如使用刚刚创建 Deployment:
|
||||||
|
|
||||||
|
|
@ -568,7 +570,7 @@ nginx-3926361531 3 3 3 28s
|
||||||
|
|
||||||
## Deployment 状态
|
## Deployment 状态
|
||||||
|
|
||||||
Deployment 在生命周期中有多种状态。在创建一个新的 ReplicaSet 的时候它可以是 [progressing](https://kubernetes.io/docs/concepts/workloads/controllers/deployment.md#progressing-deployment) 状态, [complete](https://kubernetes.io/docs/concepts/workloads/controllers/deployment.md#complete-deployment) 状态,或者 [fail to progress ](https://kubernetes.io/docs/concepts/workloads/controllers/deployment.md#failed-deployment)状态。
|
Deployment 在生命周期中有多种状态。在创建一个新的 ReplicaSet 的时候它可以是 [progressing](https://kubernetes.io/docs/concepts/workloads/controllers/deployment#progressing-deployment) 状态, [complete](https://kubernetes.io/docs/concepts/workloads/controllers/deployment#complete-deployment) 状态,或者 [fail to progress ](https://kubernetes.io/docs/concepts/workloads/controllers/deployment#failed-deployment)状态。
|
||||||
|
|
||||||
### 进行中的 Deployment
|
### 进行中的 Deployment
|
||||||
|
|
||||||
|
|
@ -610,7 +612,7 @@ $ echo $?
|
||||||
- 范围限制
|
- 范围限制
|
||||||
- 程序运行时配置错误
|
- 程序运行时配置错误
|
||||||
|
|
||||||
探测这种情况的一种方式是,在您的 Deployment spec 中指定[`spec.progressDeadlineSeconds`](https://kubernetes.io/docs/concepts/workloads/controllers/deployment.md#progress-deadline-seconds)。`spec.progressDeadlineSeconds` 表示 Deployment controller 等待多少秒才能确定(通过 Deployment status)Deployment进程是卡住的。
|
探测这种情况的一种方式是,在您的 Deployment spec 中指定[`spec.progressDeadlineSeconds`](https://kubernetes.io/docs/concepts/workloads/controllers/deployment#progress-deadline-seconds)。`spec.progressDeadlineSeconds` 表示 Deployment controller 等待多少秒才能确定(通过 Deployment status)Deployment进程是卡住的。
|
||||||
|
|
||||||
下面的`kubectl`命令设置`progressDeadlineSeconds` 使 controller 在 Deployment 在进度卡住10分钟后报告:
|
下面的`kubectl`命令设置`progressDeadlineSeconds` 使 controller 在 Deployment 在进度卡住10分钟后报告:
|
||||||
|
|
||||||
|
|
@ -625,8 +627,6 @@ $ kubectl patch deployment/nginx-deployment -p '{"spec":{"progressDeadlineSecond
|
||||||
- Status=False
|
- Status=False
|
||||||
- Reason=ProgressDeadlineExceeded
|
- Reason=ProgressDeadlineExceeded
|
||||||
|
|
||||||
浏览 [Kubernetes API conventions](https://github.com/kubernetes/community/blob/master/contributors/devel/api-conventions.md#typical-status-properties) 查看关于status conditions的更多信息。
|
|
||||||
|
|
||||||
**注意:** kubernetes除了报告`Reason=ProgressDeadlineExceeded`状态信息外不会对卡住的 Deployment 做任何操作。更高层次的协调器可以利用它并采取相应行动,例如,回滚 Deployment 到之前的版本。
|
**注意:** kubernetes除了报告`Reason=ProgressDeadlineExceeded`状态信息外不会对卡住的 Deployment 做任何操作。更高层次的协调器可以利用它并采取相应行动,例如,回滚 Deployment 到之前的版本。
|
||||||
|
|
||||||
**注意:** 如果您暂停了一个 Deployment,在暂停的这段时间内kubernetnes不会检查您指定的 deadline。您可以在 Deployment 的 rollout 途中安全的暂停它,然后再恢复它,这不会触发超过deadline的状态。
|
**注意:** 如果您暂停了一个 Deployment,在暂停的这段时间内kubernetnes不会检查您指定的 deadline。您可以在 Deployment 的 rollout 途中安全的暂停它,然后再恢复它,这不会触发超过deadline的状态。
|
||||||
|
|
@ -675,7 +675,7 @@ status:
|
||||||
unavailableReplicas: 2
|
unavailableReplicas: 2
|
||||||
```
|
```
|
||||||
|
|
||||||
最终,一旦超过 Deployment 进程的 deadline,kuberentes 会更新状态和导致 Progressing 状态的原因:
|
最终,一旦超过 Deployment 进程的 deadline,kubernetes 会更新状态和导致 Progressing 状态的原因:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
Conditions:
|
Conditions:
|
||||||
|
|
@ -698,7 +698,7 @@ Conditions:
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
`Type=Available`、 `Status=True` 以为这您的Deployment有最小可用性。 最小可用性是在Deployment策略中指定的参数。`Type=Progressing` 、 `Status=True`意味着您的Deployment 或者在部署过程中,或者已经成功部署,达到了期望的最少的可用replica数量(查看特定状态的Reason——在我们的例子中`Reason=NewReplicaSetAvailable` 意味着Deployment已经完成)。
|
`Type=Available`、 `Status=True` 意味着您的Deployment有最小可用性。 最小可用性是在Deployment策略中指定的参数。`Type=Progressing` 、 `Status=True`意味着您的Deployment 或者在部署过程中,或者已经成功部署,达到了期望的最少的可用replica数量(查看特定状态的Reason——在我们的例子中`Reason=NewReplicaSetAvailable` 意味着Deployment已经完成)。
|
||||||
|
|
||||||
您可以使用`kubectl rollout status`命令查看Deployment进程是否失败。当Deployment过程超过了deadline,`kubectl rollout status`将返回非0的exit code。
|
您可以使用`kubectl rollout status`命令查看Deployment进程是否失败。当Deployment过程超过了deadline,`kubectl rollout status`将返回非0的exit code。
|
||||||
|
|
||||||
|
|
@ -728,9 +728,7 @@ $ echo $?
|
||||||
|
|
||||||
## 编写 Deployment Spec
|
## 编写 Deployment Spec
|
||||||
|
|
||||||
在所有的 Kubernetes 配置中,Deployment 也需要`apiVersion`,`kind`和`metadata`这些配置项。配置文件的通用使用说明查看 [部署应用](https://kubernetes.io/docs/tasks/run-application/run-stateless-application-deployment/),配置容器,和 [使用 kubectl 管理资源 ](https://kubernetes.io/docs/tutorials/object-management-kubectl/object-management/) 文档。
|
在所有的 Kubernetes 配置中,Deployment 也需要`apiVersion`,`kind`和`metadata`这些配置项。配置文件的通用使用说明查看 [部署应用](https://kubernetes.io/docs/tasks/run-application/run-stateless-application-deployment/),配置容器,和使用 kubectl 管理资源文档。
|
||||||
|
|
||||||
Deployment也需要 [`.spec` section](https://github.com/kubernetes/community/blob/master/contributors/devel/api-conventions.md#spec-and-status).
|
|
||||||
|
|
||||||
### Pod Template
|
### Pod Template
|
||||||
|
|
||||||
|
|
@ -738,7 +736,7 @@ Deployment也需要 [`.spec` section](https://github.com/kubernetes/community/bl
|
||||||
|
|
||||||
`.spec.template` 是 [pod template](https://kubernetes.io/docs/user-guide/replication-controller/#pod-template). 它跟 [Pod](https://kubernetes.io/docs/user-guide/pods)有一模一样的schema,除了它是嵌套的并且不需要`apiVersion` 和 `kind`字段。
|
`.spec.template` 是 [pod template](https://kubernetes.io/docs/user-guide/replication-controller/#pod-template). 它跟 [Pod](https://kubernetes.io/docs/user-guide/pods)有一模一样的schema,除了它是嵌套的并且不需要`apiVersion` 和 `kind`字段。
|
||||||
|
|
||||||
另外为了划分Pod的范围,Deployment中的pod template必须指定适当的label(不要跟其他controller重复了,参考[selector](https://kubernetes.io/docs/concepts/workloads/controllers/deployment.md#selector))和适当的重启策略。
|
另外为了划分Pod的范围,Deployment中的pod template必须指定适当的label(不要跟其他controller重复了,参考[selector](https://kubernetes.io/docs/concepts/workloads/controllers/deployment#selector))和适当的重启策略。
|
||||||
|
|
||||||
[`.spec.template.spec.restartPolicy`](https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle) 可以设置为 `Always` , 如果不指定的话这就是默认配置。
|
[`.spec.template.spec.restartPolicy`](https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle) 可以设置为 `Always` , 如果不指定的话这就是默认配置。
|
||||||
|
|
||||||
|
|
@ -784,7 +782,7 @@ Deployment也需要 [`.spec` section](https://github.com/kubernetes/community/bl
|
||||||
|
|
||||||
### Progress Deadline Seconds
|
### Progress Deadline Seconds
|
||||||
|
|
||||||
`.spec.progressDeadlineSeconds` 是可选配置项,用来指定在系统报告Deployment的[failed progressing](https://kubernetes.io/docs/concepts/workloads/controllers/deployment.md#failed-deployment) ——表现为resource的状态中`type=Progressing`、`Status=False`、 `Reason=ProgressDeadlineExceeded`前可以等待的Deployment进行的秒数。Deployment controller会继续重试该Deployment。未来,在实现了自动回滚后, deployment controller在观察到这种状态时就会自动回滚。
|
`.spec.progressDeadlineSeconds` 是可选配置项,用来指定在系统报告Deployment的[failed progressing](https://kubernetes.io/docs/concepts/workloads/controllers/deployment#failed-deployment) ——表现为resource的状态中`type=Progressing`、`Status=False`、 `Reason=ProgressDeadlineExceeded`前可以等待的Deployment进行的秒数。Deployment controller会继续重试该Deployment。未来,在实现了自动回滚后, deployment controller在观察到这种状态时就会自动回滚。
|
||||||
|
|
||||||
如果设置该参数,该值必须大于 `.spec.minReadySeconds`。
|
如果设置该参数,该值必须大于 `.spec.minReadySeconds`。
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -1,3 +1,3 @@
|
||||||
# 扩展
|
# 扩展
|
||||||
|
|
||||||
Kubernetes是一个高度开放可扩展的架构,可以通过自定义资源类型CRD来定义自己的类型,还可以自己来扩展API服务,用户的使用方式跟Kubernetes的原生对象无异。
|
Kubernetes是一个高度开放可扩展的架构,可以通过自定义资源类型CRD来定义自己的类型,还可以自己来扩展API服务,用户的使用方式跟Kubernetes的原生对象无异。
|
||||||
|
|
|
||||||
|
|
@ -1,4 +1,4 @@
|
||||||
### Kubernetes中的网络解析——以flannel为例
|
# Kubernetes中的网络解析——以flannel为例
|
||||||
|
|
||||||
我们当初使用[kubernetes-vagrant-centos-cluster](https://github.com/rootsongjc/kubernetes-vagrant-centos-cluster)安装了拥有三个节点的kubernetes集群,节点的状态如下所述。
|
我们当初使用[kubernetes-vagrant-centos-cluster](https://github.com/rootsongjc/kubernetes-vagrant-centos-cluster)安装了拥有三个节点的kubernetes集群,节点的状态如下所述。
|
||||||
|
|
||||||
|
|
@ -382,13 +382,12 @@ Chain KUBE-SERVICES (2 references)
|
||||||
target prot opt source destination
|
target prot opt source destination
|
||||||
```
|
```
|
||||||
|
|
||||||
从上面的iptables中可以看到注入了很多Kuberentes service的规则,请参考[iptables 规则](https://www.cnyunwei.cc/archives/393)获取更多详细信息。
|
从上面的iptables中可以看到注入了很多Kuberentes service的规则。
|
||||||
|
|
||||||
## 参考
|
## 参考
|
||||||
|
|
||||||
- [coreos/flannel - github.com](https://github.com/coreos/flannel)
|
- [coreos/flannel - github.com](https://github.com/coreos/flannel)
|
||||||
- [linux 网络虚拟化: network namespace 简介](http://cizixs.com/2017/02/10/network-virtualization-network-namespace)
|
- [linux 网络虚拟化: network namespace 简介](http://cizixs.com/2017/02/10/network-virtualization-network-namespace)
|
||||||
- [Linux虚拟网络设备之veth](https://segmentfault.com/a/1190000009251098)
|
- [Linux虚拟网络设备之veth](https://segmentfault.com/a/1190000009251098)
|
||||||
- [iptables 规则](https://www.cnyunwei.cc/archives/393)
|
|
||||||
- [flannel host-gw network](http://hustcat.github.io/flannel-host-gw-network/)
|
- [flannel host-gw network](http://hustcat.github.io/flannel-host-gw-network/)
|
||||||
- [flannel - openshift.com](https://docs.openshift.com/container-platform/3.4/architecture/additional_concepts/flannel.html)
|
- [flannel - openshift.com](https://docs.openshift.com/container-platform/3.4/architecture/additional_concepts/flannel.html)
|
||||||
|
|
|
||||||
|
|
@ -88,6 +88,8 @@ metadata:
|
||||||
|
|
||||||
对很多 Controller 资源,包括 ReplicationController、ReplicaSet、StatefulSet、DaemonSet 和 Deployment,默认的垃圾收集策略是 `orphan`。因此,除非指定其它的垃圾收集策略,否则所有 Dependent 对象使用的都是 `orphan` 策略。
|
对很多 Controller 资源,包括 ReplicationController、ReplicaSet、StatefulSet、DaemonSet 和 Deployment,默认的垃圾收集策略是 `orphan`。因此,除非指定其它的垃圾收集策略,否则所有 Dependent 对象使用的都是 `orphan` 策略。
|
||||||
|
|
||||||
|
**注意**:本段所指的默认值是指 REST API 的默认值,并非 kubectl 命令的默认值,kubectl 默认为级联删除,后面会讲到。
|
||||||
|
|
||||||
下面是一个在后台删除 Dependent 对象的例子:
|
下面是一个在后台删除 Dependent 对象的例子:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
|
|
@ -119,7 +121,7 @@ kubectl 也支持级联删除。 通过设置 `--cascade` 为 true,可以使
|
||||||
|
|
||||||
下面是一个例子,使一个 ReplicaSet 的 Dependent 对象成为孤儿 Dependent:
|
下面是一个例子,使一个 ReplicaSet 的 Dependent 对象成为孤儿 Dependent:
|
||||||
|
|
||||||
```Bash
|
```bash
|
||||||
kubectl delete replicaset my-repset --cascade=false
|
kubectl delete replicaset my-repset --cascade=false
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
@ -131,4 +133,4 @@ kubectl delete replicaset my-repset --cascade=false
|
||||||
|
|
||||||
原文地址:https://k8smeetup.github.io/docs/concepts/workloads/controllers/garbage-collection/
|
原文地址:https://k8smeetup.github.io/docs/concepts/workloads/controllers/garbage-collection/
|
||||||
|
|
||||||
译者:[shirdrn](https://github.com/shirdrn)
|
译者:[shirdrn](https://github.com/shirdrn)
|
||||||
|
|
|
||||||
|
|
@ -13,7 +13,7 @@ Kubernetes自1.2版本引入HPA机制,到1.6版本之前一直是通过kubelet
|
||||||
|
|
||||||
## HPA解析
|
## HPA解析
|
||||||
|
|
||||||
Horizontal Pod Autoscaling仅适用于Deployment和ReplicaSet,在V1版本中仅支持根据Pod的CPU利用率扩所容,在v1alpha版本中,支持根据内存和用户自定义的metric扩缩容。
|
Horizontal Pod Autoscaling仅适用于Deployment和ReplicaSet,在v1版本中仅支持根据Pod的CPU利用率扩缩容,在v1alpha版本中,支持根据内存和用户自定义的metric扩缩容。
|
||||||
|
|
||||||
如果你不想看下面的文章可以直接看下面的示例图,组件交互、组件的配置、命令示例,都画在图上了。
|
如果你不想看下面的文章可以直接看下面的示例图,组件交互、组件的配置、命令示例,都画在图上了。
|
||||||
|
|
||||||
|
|
@ -62,7 +62,7 @@ kubectl autoscale (-f FILENAME | TYPE NAME | TYPE/NAME) [--min=MINPODS] --max=MA
|
||||||
kubectl autoscale deployment foo --min=2 --max=5 --cpu-percent=80
|
kubectl autoscale deployment foo --min=2 --max=5 --cpu-percent=80
|
||||||
```
|
```
|
||||||
|
|
||||||
为Deployment foo创建 一个autoscaler,当Pod的CPU利用率达到80%的时候,RC的replica数在2到5之间。该命令的详细使用文档见https://kubernetes.io/docs/user-guide/kubectl/v1.6/#autoscale 。
|
为Deployment foo创建 一个autoscaler,当Pod的CPU利用率达到80%的时候,RC的replica数在2到5之间。
|
||||||
|
|
||||||
**注意** :如果为ReplicaSet创建HPA的话,无法使用rolling update,但是对于Deployment来说是可以的,因为Deployment在执行rolling update的时候会自动创建新的ReplicationController。
|
**注意** :如果为ReplicaSet创建HPA的话,无法使用rolling update,但是对于Deployment来说是可以的,因为Deployment在执行rolling update的时候会自动创建新的ReplicationController。
|
||||||
|
|
||||||
|
|
@ -78,7 +78,7 @@ Horizontal Pod Autoscaler 由一个控制循环实现,循环周期由 controll
|
||||||
|
|
||||||
在每个周期内,controller manager 会查询 HorizontalPodAutoscaler 中定义的 metric 的资源利用率。Controller manager 从 resource metric API(每个 pod 的 resource metric)或者自定义 metric API(所有的metric)中获取 metric。
|
在每个周期内,controller manager 会查询 HorizontalPodAutoscaler 中定义的 metric 的资源利用率。Controller manager 从 resource metric API(每个 pod 的 resource metric)或者自定义 metric API(所有的metric)中获取 metric。
|
||||||
|
|
||||||
- 每个 Pod 的 resource metric(例如 CPU),controller 通过 resource metric API 获取 HorizontalPodAutoscaler 中定义的每个 Pod 中的 metric。然后,如果设置了目标利用率,controller 计算利用的值与每个 Pod 的容器里的 resource request 值的百分比。如果设置了目标原始值,将直接使用该原始 metric 值。然后 controller 计算所有目标 Pod 的利用率或原始值(取决于所指定的目标类型)的平均值,产生一个用于缩放所需 replica 数量的比率。 请注意,如果某些 Pod 的容器没有设置相关的 resource request ,则不会定义 Pod 的 CPU 利用率,并且 Aucoscaler 也不会对该 metric 采取任何操作。 有关自动缩放算法如何工作的更多细节,请参阅 [自动缩放算法设计文档](https://git.k8s.io/community/contributors/design-proposals/horizontal-pod-autoscaler.md#autoscaling-algorithm)。
|
- 每个 Pod 的 resource metric(例如 CPU),controller 通过 resource metric API 获取 HorizontalPodAutoscaler 中定义的每个 Pod 中的 metric。然后,如果设置了目标利用率,controller 计算利用的值与每个 Pod 的容器里的 resource request 值的百分比。如果设置了目标原始值,将直接使用该原始 metric 值。然后 controller 计算所有目标 Pod 的利用率或原始值(取决于所指定的目标类型)的平均值,产生一个用于缩放所需 replica 数量的比率。 请注意,如果某些 Pod 的容器没有设置相关的 resource request ,则不会定义 Pod 的 CPU 利用率,并且 Aucoscaler 也不会对该 metric 采取任何操作。
|
||||||
- 对于每个 Pod 自定义的 metric,controller 功能类似于每个 Pod 的 resource metric,只是它使用原始值而不是利用率值。
|
- 对于每个 Pod 自定义的 metric,controller 功能类似于每个 Pod 的 resource metric,只是它使用原始值而不是利用率值。
|
||||||
- 对于 object metric,获取单个度量(描述有问题的对象),并与目标值进行比较,以产生如上所述的比率。
|
- 对于 object metric,获取单个度量(描述有问题的对象),并与目标值进行比较,以产生如上所述的比率。
|
||||||
|
|
||||||
|
|
@ -86,22 +86,16 @@ HorizontalPodAutoscaler 控制器可以以两种不同的方式获取 metric :
|
||||||
|
|
||||||
当使用直接的 Heapster 访问时,HorizontalPodAutoscaler 直接通过 API 服务器的服务代理子资源查询 Heapster。需要在集群上部署 Heapster 并在 kube-system namespace 中运行。
|
当使用直接的 Heapster 访问时,HorizontalPodAutoscaler 直接通过 API 服务器的服务代理子资源查询 Heapster。需要在集群上部署 Heapster 并在 kube-system namespace 中运行。
|
||||||
|
|
||||||
有关 REST 客户端访问的详细信息,请参阅 [支持自定义度量](https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale.md#prerequisites)。
|
|
||||||
|
|
||||||
Autoscaler 访问相应的 replication controller,deployment 或 replica set 来缩放子资源。
|
Autoscaler 访问相应的 replication controller,deployment 或 replica set 来缩放子资源。
|
||||||
|
|
||||||
Scale 是一个允许您动态设置副本数并检查其当前状态的接口。
|
Scale 是一个允许您动态设置副本数并检查其当前状态的接口。
|
||||||
|
|
||||||
有关缩放子资源的更多细节可以在 [这里](https://git.k8s.io/community/contributors/design-proposals/horizontal-pod-autoscaler.md#scale-subresource) 找到。
|
|
||||||
|
|
||||||
## API Object
|
## API Object
|
||||||
|
|
||||||
Horizontal Pod Autoscaler 是 kubernetes 的 `autoscaling` API 组中的 API 资源。当前的稳定版本中,只支持 CPU 自动扩缩容,可以在`autoscaling/v1` API 版本中找到。
|
Horizontal Pod Autoscaler 是 kubernetes 的 `autoscaling` API 组中的 API 资源。当前的稳定版本中,只支持 CPU 自动扩缩容,可以在`autoscaling/v1` API 版本中找到。
|
||||||
|
|
||||||
在 alpha 版本中支持根据内存和自定义 metric 扩缩容,可以在`autoscaling/v2alpha1` 中找到。`autoscaling/v2alpha1` 中引入的新字段在`autoscaling/v1` 中是做为 annotation 而保存的。
|
在 alpha 版本中支持根据内存和自定义 metric 扩缩容,可以在`autoscaling/v2alpha1` 中找到。`autoscaling/v2alpha1` 中引入的新字段在`autoscaling/v1` 中是做为 annotation 而保存的。
|
||||||
|
|
||||||
关于该 API 对象的更多信息,请参阅 [HorizontalPodAutoscaler Object](https://git.k8s.io/community/contributors/design-proposals/horizontal-pod-autoscaler.md#horizontalpodautoscaler-object)。
|
|
||||||
|
|
||||||
## 在 kubectl 中支持 Horizontal Pod Autoscaling
|
## 在 kubectl 中支持 Horizontal Pod Autoscaling
|
||||||
|
|
||||||
Horizontal Pod Autoscaler 和其他的所有 API 资源一样,通过 `kubectl` 以标准的方式支持。
|
Horizontal Pod Autoscaler 和其他的所有 API 资源一样,通过 `kubectl` 以标准的方式支持。
|
||||||
|
|
@ -116,8 +110,6 @@ Horizontal Pod Autoscaler 和其他的所有 API 资源一样,通过 `kubectl`
|
||||||
|
|
||||||
例如,执行`kubectl autoscale rc foo —min=2 —max=5 —cpu-percent=80`命令将为 replication controller *foo* 创建一个 autoscaler,目标的 CPU 利用率是`80%`,replica 的数量介于 2 和 5 之间。
|
例如,执行`kubectl autoscale rc foo —min=2 —max=5 —cpu-percent=80`命令将为 replication controller *foo* 创建一个 autoscaler,目标的 CPU 利用率是`80%`,replica 的数量介于 2 和 5 之间。
|
||||||
|
|
||||||
关于`kubectl autoscale`的更多信息请参阅 [这里](https://kubernetes.io/docs/user-guide/kubectl/v1.6/#autoscale)。
|
|
||||||
|
|
||||||
## 滚动更新期间的自动扩缩容
|
## 滚动更新期间的自动扩缩容
|
||||||
|
|
||||||
目前在Kubernetes中,可以通过直接管理 replication controller 或使用 deployment 对象来执行 [滚动更新](https://kubernetes.io/docs/tasks/run-application/rolling-update-replication-controller),该 deployment 对象为您管理基础 replication controller。
|
目前在Kubernetes中,可以通过直接管理 replication controller 或使用 deployment 对象来执行 [滚动更新](https://kubernetes.io/docs/tasks/run-application/rolling-update-replication-controller),该 deployment 对象为您管理基础 replication controller。
|
||||||
|
|
@ -150,22 +142,12 @@ Kubernetes 然后查询新的自定义 metric API 来获取相应自定义 metri
|
||||||
|
|
||||||
您可以使用 Heapster 实现 resource metric API,方法是将 `--api-server` 标志设置为 true 并运行 Heapster。 单独的组件必须提供自定义 metric API(有关自定义metric API的更多信息,可从 [k8s.io/metrics repository](https://github.com/kubernetes/metrics) 获得)。
|
您可以使用 Heapster 实现 resource metric API,方法是将 `--api-server` 标志设置为 true 并运行 Heapster。 单独的组件必须提供自定义 metric API(有关自定义metric API的更多信息,可从 [k8s.io/metrics repository](https://github.com/kubernetes/metrics) 获得)。
|
||||||
|
|
||||||
## 进一步阅读
|
|
||||||
|
|
||||||
- 设计文档:[Horizontal Pod Autoscaling](https://git.k8s.io/community/contributors/design-proposals/horizontal-pod-autoscaler.md)
|
|
||||||
- kubectl autoscale 命令:[kubectl autoscale](https://kubernetes.io/docs/user-guide/kubectl/v1.6/#autoscale)
|
|
||||||
- 使用例子: [Horizontal Pod Autoscaler](https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough)
|
|
||||||
|
|
||||||
## 参考
|
## 参考
|
||||||
|
|
||||||
HPA设计文档:https://github.com/kubernetes/community/blob/master/contributors/design-proposals/horizontal-pod-autoscaler.md
|
- HPA说明:https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
|
||||||
|
|
||||||
HPA说明:https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
|
- HPA详解:https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
|
||||||
|
|
||||||
HPA详解:https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
|
- 自定义metrics开发:https://github.com/kubernetes/metrics
|
||||||
|
|
||||||
kubectl autoscale命令详细使用说明:https://kubernetes.io/docs/user-guide/kubectl/v1.6/#autoscale
|
- 1.7版本的kubernetes中启用自定义HPA:[Configure Kubernetes Autoscaling With Custom Metrics in Kubernetes 1.7 - Bitnami](https://docs.bitnami.com/kubernetes/how-to/configure-autoscaling-custom-metrics/)
|
||||||
|
|
||||||
自定义metrics开发:https://github.com/kubernetes/metrics
|
|
||||||
|
|
||||||
1.7版本的kubernetes中启用自定义HPA:[Configure Kubernetes Autoscaling With Custom Metrics in Kubernetes 1.7 - Bitnami](https://docs.bitnami.com/kubernetes/how-to/configure-autoscaling-custom-metrics/)
|
|
||||||
|
|
|
||||||
|
|
@ -19,11 +19,11 @@ Borg主要由BorgMaster、Borglet、borgcfg和Scheduler组成,如下图所示
|
||||||
|
|
||||||
## Kubernetes架构
|
## Kubernetes架构
|
||||||
|
|
||||||
Kubernetes借鉴了Borg的设计理念,比如Pod、Service、Labels和单Pod单IP等。Kubernetes的整体架构跟Borg非常像,如下图所示
|
Kubernetes借鉴了Borg的设计理念,比如Pod、Service、Label和单Pod单IP等。Kubernetes的整体架构跟Borg非常像,如下图所示。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
Kubernetes主要由以下几个核心组件组成:
|
Kubernetes主要由以下几个核心组件组成:
|
||||||
|
|
||||||
- etcd保存了整个集群的状态;
|
- etcd保存了整个集群的状态;
|
||||||
- apiserver提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制;
|
- apiserver提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制;
|
||||||
|
|
@ -33,11 +33,11 @@ Kubernetes主要由以下几个核心组件组成:
|
||||||
- Container runtime负责镜像管理以及Pod和容器的真正运行(CRI);
|
- Container runtime负责镜像管理以及Pod和容器的真正运行(CRI);
|
||||||
- kube-proxy负责为Service提供cluster内部的服务发现和负载均衡;
|
- kube-proxy负责为Service提供cluster内部的服务发现和负载均衡;
|
||||||
|
|
||||||
除了核心组件,还有一些推荐的Add-ons:
|
除了核心组件,还有一些推荐的插件,其中有的已经成为CNCF中的托管项目:
|
||||||
|
|
||||||
- kube-dns负责为整个集群提供DNS服务
|
- CoreDNS负责为整个集群提供DNS服务
|
||||||
- Ingress Controller为服务提供外网入口
|
- Ingress Controller为服务提供外网入口
|
||||||
- Heapster提供资源监控
|
- Prometheus提供资源监控
|
||||||
- Dashboard提供GUI
|
- Dashboard提供GUI
|
||||||
- Federation提供跨可用区的集群
|
- Federation提供跨可用区的集群
|
||||||
|
|
||||||
|
|
@ -64,25 +64,24 @@ Kubernetes主要由以下几个核心组件组成:
|
||||||
|
|
||||||
### 分层架构
|
### 分层架构
|
||||||
|
|
||||||
Kubernetes设计理念和功能其实就是一个类似Linux的分层架构,如下图所示
|
Kubernetes设计理念和功能其实就是一个类似Linux的分层架构,如下图所示。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
* 核心层:Kubernetes最核心的功能,对外提供API构建高层的应用,对内提供插件式应用执行环境
|
* 核心层:Kubernetes最核心的功能,对外提供API构建高层的应用,对内提供插件式应用执行环境
|
||||||
* 应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS解析等)
|
* 应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS解析等)、Service Mesh(部分位于应用层)
|
||||||
* 管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态Provision等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy等)
|
* 管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态Provision等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy等)、Service Mesh(部分位于管理层)
|
||||||
* 接口层:kubectl命令行工具、客户端SDK以及集群联邦
|
* 接口层:kubectl命令行工具、客户端SDK以及集群联邦
|
||||||
* 生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴
|
* 生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴
|
||||||
* Kubernetes外部:日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS应用、ChatOps等
|
* Kubernetes外部:日志、监控、配置管理、CI/CD、Workflow、FaaS、OTS应用、ChatOps、GitOps、SecOps等
|
||||||
* Kubernetes内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等
|
* Kubernetes内部:[CRI](cri.md)、[CNI](cni.md)、[CSI](csi.md)、镜像仓库、Cloud Provider、集群自身的配置和管理等
|
||||||
|
|
||||||
> 关于分层架构,可以关注下Kubernetes社区正在推进的[Kubernetes architectual roadmap](https://docs.google.com/document/d/1XkjVm4bOeiVkj-Xt1LgoGiqWsBfNozJ51dyI-ljzt1o)和[slide](https://docs.google.com/presentation/d/1GpELyzXOGEPY0Y1ft26yMNV19ROKt8eMN67vDSSHglk/edit)。
|
> 关于分层架构,可以关注下Kubernetes社区正在推进的[Kubernetes architectual roadmap](https://docs.google.com/document/d/1XkjVm4bOeiVkj-Xt1LgoGiqWsBfNozJ51dyI-ljzt1o)和[slide](https://docs.google.com/presentation/d/1GpELyzXOGEPY0Y1ft26yMNV19ROKt8eMN67vDSSHglk/edit)。
|
||||||
|
|
||||||
## 参考文档
|
## 参考文档
|
||||||
|
|
||||||
- [Kubernetes design and architecture](https://github.com/kubernetes/community/blob/master/contributors/design-proposals/architecture.md)
|
- [Borg, Omega, and Kubernetes - Lessons learned from three container-management systems over a decade](http://queue.acm.org/detail.cfm?id=2898444)
|
||||||
- <http://queue.acm.org/detail.cfm?id=2898444>
|
- [Paper - Large-scale cluster management at Google with Borg](http://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/43438.pdf)
|
||||||
- <http://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/43438.pdf>
|
- [KUBERNETES: AN OVERVIEW](http://thenewstack.io/kubernetes-an-overview)
|
||||||
- <http://thenewstack.io/kubernetes-an-overview>
|
|
||||||
- [Kubernetes architectual roadmap](https://docs.google.com/document/d/1XkjVm4bOeiVkj-Xt1LgoGiqWsBfNozJ51dyI-ljzt1o)和[slide](https://docs.google.com/presentation/d/1GpELyzXOGEPY0Y1ft26yMNV19ROKt8eMN67vDSSHglk/edit)
|
- [Kubernetes architectual roadmap](https://docs.google.com/document/d/1XkjVm4bOeiVkj-Xt1LgoGiqWsBfNozJ51dyI-ljzt1o)和[slide](https://docs.google.com/presentation/d/1GpELyzXOGEPY0Y1ft26yMNV19ROKt8eMN67vDSSHglk/edit)
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -1,8 +1,6 @@
|
||||||
# Ingress解析
|
# Ingress解析
|
||||||
|
|
||||||
## 前言
|
Ingress 是从Kubernetes集群外部访问集群内部服务的入口,这篇文章部分译自Kubernetes官方文档[Ingress Resource](https://kubernetes.io/docs/concepts/services-networking/ingress/),后面的章节会讲到使用[Traefik](https://github.com/containous/traefik)来做Ingress controller,文章末尾给出了几个相关链接。
|
||||||
|
|
||||||
这是kubernete官方文档中[Ingress Resource](https://kubernetes.io/docs/concepts/services-networking/ingress/)的翻译,后面的章节会讲到使用[Traefik](https://github.com/containous/traefik)来做Ingress controller,文章末尾给出了几个相关链接。
|
|
||||||
|
|
||||||
**术语**
|
**术语**
|
||||||
|
|
||||||
|
|
@ -11,7 +9,7 @@
|
||||||
- 节点:Kubernetes集群中的一台物理机或者虚拟机。
|
- 节点:Kubernetes集群中的一台物理机或者虚拟机。
|
||||||
- 集群:位于Internet防火墙后的节点,这是kubernetes管理的主要计算资源。
|
- 集群:位于Internet防火墙后的节点,这是kubernetes管理的主要计算资源。
|
||||||
- 边界路由器:为集群强制执行防火墙策略的路由器。 这可能是由云提供商或物理硬件管理的网关。
|
- 边界路由器:为集群强制执行防火墙策略的路由器。 这可能是由云提供商或物理硬件管理的网关。
|
||||||
- 集群网络:一组逻辑或物理链接,可根据Kubernetes[网络模型](https://kubernetes.io/docs/admin/networking/)实现群集内的通信。 集群网络的实现包括Overlay模型的 [flannel](https://github.com/coreos/flannel#flannel) 和基于SDN的[OVS](https://kubernetes.io/docs/admin/ovs-networking/)。
|
- 集群网络:一组逻辑或物理链接,可根据Kubernetes[网络模型](https://kubernetes.io/docs/admin/networking/)实现群集内的通信。 集群网络的实现包括Overlay模型的 [flannel](https://github.com/coreos/flannel#flannel) 和基于SDN的OVS。
|
||||||
- 服务:使用标签选择器标识一组pod成为的Kubernetes[服务](https://kubernetes.io/docs/user-guide/services/)。 除非另有说明,否则服务假定在集群网络内仅可通过虚拟IP访问。
|
- 服务:使用标签选择器标识一组pod成为的Kubernetes[服务](https://kubernetes.io/docs/user-guide/services/)。 除非另有说明,否则服务假定在集群网络内仅可通过虚拟IP访问。
|
||||||
|
|
||||||
## 什么是Ingress?
|
## 什么是Ingress?
|
||||||
|
|
@ -41,9 +39,9 @@ Ingress是授权入站连接到达集群服务的规则集合。
|
||||||
|
|
||||||
在使用Ingress resource之前,有必要先了解下面几件事情。Ingress是beta版本的resource,在kubernetes1.1之前还没有。你需要一个`Ingress Controller`来实现`Ingress`,单纯的创建一个`Ingress`没有任何意义。
|
在使用Ingress resource之前,有必要先了解下面几件事情。Ingress是beta版本的resource,在kubernetes1.1之前还没有。你需要一个`Ingress Controller`来实现`Ingress`,单纯的创建一个`Ingress`没有任何意义。
|
||||||
|
|
||||||
GCE/GKE会在master节点上部署一个ingress controller。你可以在一个pod中部署任意个自定义的ingress controller。你必须正确地annotate每个ingress,比如 [运行多个ingress controller](https://git.k8s.io/ingress#running-multiple-ingress-controllers) 和 [关闭glbc](https://git.k8s.io/ingress-gce/BETA_LIMITATIONS.md#disabling-glbc).
|
GCE/GKE会在master节点上部署一个ingress controller。你可以在一个pod中部署任意个自定义的ingress controller。你必须正确地annotate每个ingress,比如 [运行多个ingress controller](https://git.k8s.io/ingress#running-multiple-ingress-controllers) 和 关闭glbc。
|
||||||
|
|
||||||
确定你已经阅读了Ingress controller的[beta版本限制](https://github.com/kubernetes/ingress-gce/blob/master/BETA_LIMITATIONS.md#glbc-beta-limitations)。在非GCE/GKE的环境中,你需要在pod中[部署一个controller](https://git.k8s.io/ingress-nginx/README.md)。
|
确定你已经阅读了Ingress controller的 beta版本限制。在非GCE/GKE的环境中,你需要在pod中[部署一个controller](https://git.k8s.io/ingress-nginx/README.md)。
|
||||||
|
|
||||||
## Ingress Resource
|
## Ingress Resource
|
||||||
|
|
||||||
|
|
@ -68,9 +66,9 @@ GCE/GKE会在master节点上部署一个ingress controller。你可以在一个p
|
||||||
|
|
||||||
**配置说明**
|
**配置说明**
|
||||||
|
|
||||||
**1-4行**:跟Kubernetes的其他配置一样,ingress的配置也需要`apiVersion`,`kind`和`metadata`字段。配置文件的详细说明请查看[部署应用](https://kubernetes.io/docs/user-guide/deploying-applications), [配置容器](https://kubernetes.io/docs/user-guide/configuring-containers)和 [使用resources](https://kubernetes.io/docs/user-guide/working-with-resources).
|
**1-4行**:跟Kubernetes的其他配置一样,ingress的配置也需要`apiVersion`,`kind`和`metadata`字段。配置文件的详细说明请查看[部署应用](https://kubernetes.io/docs/user-guide/deploying-applications), [配置容器](https://kubernetes.io/docs/user-guide/configuring-containers)和使用resources。
|
||||||
|
|
||||||
**5-7行**: Ingress [spec](https://github.com/kubernetes/community/blob/master/contributors/devel/api-conventions.md#spec-and-status) 中包含配置一个loadbalancer或proxy server的所有信息。最重要的是,它包含了一个匹配所有入站请求的规则列表。目前ingress只支持http规则。
|
**5-7行**: Ingress spec 中包含配置一个loadbalancer或proxy server的所有信息。最重要的是,它包含了一个匹配所有入站请求的规则列表。目前ingress只支持http规则。
|
||||||
|
|
||||||
**8-9行**:每条http规则包含以下信息:一个`host`配置项(比如for.bar.com,在这个例子中默认是*),`path`列表(比如:/testpath),每个path都关联一个`backend`(比如test:80)。在loadbalancer将流量转发到backend之前,所有的入站请求都要先匹配host和path。
|
**8-9行**:每条http规则包含以下信息:一个`host`配置项(比如for.bar.com,在这个例子中默认是*),`path`列表(比如:/testpath),每个path都关联一个`backend`(比如test:80)。在loadbalancer将流量转发到backend之前,所有的入站请求都要先匹配host和path。
|
||||||
|
|
||||||
|
|
@ -85,6 +83,7 @@ GCE/GKE会在master节点上部署一个ingress controller。你可以在一个p
|
||||||
- F5(公司)[支持并维护](https://support.f5.com/csp/article/K86859508) [F5 BIG-IP Controller for Kubernetes](http://clouddocs.f5.com/products/connectors/k8s-bigip-ctlr/latest).
|
- F5(公司)[支持并维护](https://support.f5.com/csp/article/K86859508) [F5 BIG-IP Controller for Kubernetes](http://clouddocs.f5.com/products/connectors/k8s-bigip-ctlr/latest).
|
||||||
- [Kong](https://konghq.com/) 同时支持并维护[社区版](https://discuss.konghq.com/c/kubernetes)与[企业版](https://konghq.com/api-customer-success/)的 [Kong Ingress Controller for Kubernetes](https://konghq.com/blog/kubernetes-ingress-controller-for-kong/).
|
- [Kong](https://konghq.com/) 同时支持并维护[社区版](https://discuss.konghq.com/c/kubernetes)与[企业版](https://konghq.com/api-customer-success/)的 [Kong Ingress Controller for Kubernetes](https://konghq.com/blog/kubernetes-ingress-controller-for-kong/).
|
||||||
- [Traefik](https://github.com/containous/traefik) 是功能齐全的 ingress controller([Let’s Encrypt](https://letsencrypt.org/), secrets, http2, websocket…), [Containous](https://containo.us/services) 也对其提供商业支持。
|
- [Traefik](https://github.com/containous/traefik) 是功能齐全的 ingress controller([Let’s Encrypt](https://letsencrypt.org/), secrets, http2, websocket…), [Containous](https://containo.us/services) 也对其提供商业支持。
|
||||||
|
- [Istio](https://istio.io) 使用CRD Gateway来[控制Ingress流量](https://istio.io/docs/tasks/traffic-management/ingress/)。
|
||||||
|
|
||||||
|
|
||||||
## 在你开始前
|
## 在你开始前
|
||||||
|
|
@ -123,7 +122,7 @@ test-ingress - testsvc:80 107.178.254.228
|
||||||
|
|
||||||
### 简单展开
|
### 简单展开
|
||||||
|
|
||||||
如前面描述的那样,kubernete pod中的IP只在集群网络内部可见,我们需要在边界设置一个东西,让它能够接收ingress的流量并将它们转发到正确的端点上。这个东西一般是高可用的loadbalancer。使用Ingress能够允许你将loadbalancer的个数降低到最少,例如,假如你想要创建这样的一个设置:
|
如前面描述的那样,kubernetes pod中的IP只在集群网络内部可见,我们需要在边界设置一个东西,让它能够接收ingress的流量并将它们转发到正确的端点上。这个东西一般是高可用的loadbalancer。使用Ingress能够允许你将loadbalancer的个数降低到最少,例如,假如你想要创建这样的一个设置:
|
||||||
|
|
||||||
```
|
```
|
||||||
foo.bar.com -> 178.91.123.132 -> / foo s1:80
|
foo.bar.com -> 178.91.123.132 -> / foo s1:80
|
||||||
|
|
@ -233,7 +232,7 @@ spec:
|
||||||
|
|
||||||
请注意,各种Ingress controller支持的TLS功能之间存在差距。 请参阅有关[nginx](https://git.k8s.io/ingress-nginx/README.md#https),[GCE](https://git.k8s.io/ingress-gce/README.md#frontend-https)或任何其他平台特定Ingress controller的文档,以了解TLS在你的环境中的工作原理。
|
请注意,各种Ingress controller支持的TLS功能之间存在差距。 请参阅有关[nginx](https://git.k8s.io/ingress-nginx/README.md#https),[GCE](https://git.k8s.io/ingress-gce/README.md#frontend-https)或任何其他平台特定Ingress controller的文档,以了解TLS在你的环境中的工作原理。
|
||||||
|
|
||||||
Ingress controller启动时附带一些适用于所有Ingress的负载平衡策略设置,例如负载均衡算法,后端权重方案等。更高级的负载平衡概念(例如持久会话,动态权重)尚未在Ingress中公开。 你仍然可以通过[service loadbalancer](https://github.com/kubernetes/ingress-nginx/blob/master/docs/ingress-controller-catalog.md)获取这些功能。 随着时间的推移,我们计划将适用于跨平台的负载平衡模式加入到Ingress资源中。
|
Ingress controller启动时附带一些适用于所有Ingress的负载平衡策略设置,例如负载均衡算法,后端权重方案等。更高级的负载平衡概念(例如持久会话,动态权重)尚未在Ingress中公开。 你仍然可以通过service loadbalancer获取这些功能。 随着时间的推移,我们计划将适用于跨平台的负载平衡模式加入到Ingress资源中。
|
||||||
|
|
||||||
还值得注意的是,尽管健康检查不直接通过Ingress公开,但Kubernetes中存在并行概念,例如[准备探查](https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-probes/),可以使你达成相同的最终结果。 请查看特定控制器的文档,以了解他们如何处理健康检查([nginx](https://git.k8s.io/ingress-nginx/README.md),[GCE](https://git.k8s.io/ingress-gce/README.md#health-checks))。
|
还值得注意的是,尽管健康检查不直接通过Ingress公开,但Kubernetes中存在并行概念,例如[准备探查](https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-probes/),可以使你达成相同的最终结果。 请查看特定控制器的文档,以了解他们如何处理健康检查([nginx](https://git.k8s.io/ingress-nginx/README.md),[GCE](https://git.k8s.io/ingress-gce/README.md#health-checks))。
|
||||||
|
|
||||||
|
|
@ -241,7 +240,7 @@ Ingress controller启动时附带一些适用于所有Ingress的负载平衡策
|
||||||
|
|
||||||
假如你想要向已有的ingress中增加一个新的Host,你可以编辑和更新该ingress:
|
假如你想要向已有的ingress中增加一个新的Host,你可以编辑和更新该ingress:
|
||||||
|
|
||||||
```Bash
|
```bash
|
||||||
$ kubectl get ing
|
$ kubectl get ing
|
||||||
NAME RULE BACKEND ADDRESS
|
NAME RULE BACKEND ADDRESS
|
||||||
test - 178.91.123.132
|
test - 178.91.123.132
|
||||||
|
|
@ -288,7 +287,7 @@ test - 178.91.123.132
|
||||||
|
|
||||||
## 跨可用域故障
|
## 跨可用域故障
|
||||||
|
|
||||||
在不通云供应商之间,跨故障域的流量传播技术有所不同。 有关详细信息,请查看相关Ingress controller的文档。 有关在federation集群中部署Ingress的详细信息,请参阅[federation文档]()。
|
在不同云供应商之间,跨故障域的流量传播技术有所不同。 有关详细信息,请查看相关Ingress controller的文档。 有关在federation集群中部署Ingress的详细信息,请参阅federation文档。
|
||||||
|
|
||||||
## 未来计划
|
## 未来计划
|
||||||
|
|
||||||
|
|
@ -310,16 +309,6 @@ test - 178.91.123.132
|
||||||
|
|
||||||
## 参考
|
## 参考
|
||||||
|
|
||||||
[Kubernetes Ingress Resource](https://kubernetes.io/docs/concepts/services-networking/ingress/)
|
- [Kubernetes Ingress Resource](https://kubernetes.io/docs/concepts/services-networking/ingress/)
|
||||||
|
- [使用NGINX Plus负载均衡Kubernetes服务](http://dockone.io/article/957)
|
||||||
[使用NGINX Plus负载均衡Kubernetes服务](http://dockone.io/article/957)
|
- [使用 NGINX 和 NGINX Plus 的 Ingress Controller 进行 Kubernetes 的负载均衡](http://www.cnblogs.com/276815076/p/6407101.html)
|
||||||
|
|
||||||
[使用 NGINX 和 NGINX Plus 的 Ingress Controller 进行 Kubernetes 的负载均衡](http://www.cnblogs.com/276815076/p/6407101.html)
|
|
||||||
|
|
||||||
[Kubernetes : Ingress Controller with Træfɪk and Let's Encrypt](https://blog.osones.com/en/kubernetes-ingress-controller-with-traefik-and-lets-encrypt.html)
|
|
||||||
|
|
||||||
[Kubernetes : Træfɪk and Let's Encrypt at scale](https://blog.osones.com/en/kubernetes-traefik-and-lets-encrypt-at-scale.html)
|
|
||||||
|
|
||||||
[Kubernetes Ingress Controller-Træfɪk](https://docs.traefik.io/user-guide/kubernetes/)
|
|
||||||
|
|
||||||
[Kubernetes 1.2 and simplifying advanced networking with Ingress](http://blog.kubernetes.io/2016/03/Kubernetes-1.2-and-simplifying-advanced-networking-with-Ingress.html)
|
|
||||||
|
|
|
||||||
|
|
@ -1,8 +1,8 @@
|
||||||
# Init 容器
|
# Init 容器
|
||||||
|
|
||||||
该特性在 1.6 版本已经推出 beta 版本。Init 容器可以在 PodSpec 中同应用程序的 `containers` 数组一起来指定。 beta 注解的值将仍需保留,并覆盖 PodSpec 字段值。
|
该特性在自 Kubernetes 1.6 版本推出 beta 版本。Init 容器可以在 PodSpec 中同应用程序的 `containers` 数组一起来指定。此前 beta 注解的值仍将保留,并覆盖 PodSpec 字段值。
|
||||||
|
|
||||||
本文讲解 Init 容器的基本概念,它是一种专用的容器,在应用程序容器启动之前运行,并包括一些应用镜像中不存在的实用工具和安装脚本。
|
本文讲解 Init 容器的基本概念,这是一种专用的容器,在应用程序容器启动之前运行,用来包含一些应用镜像中不存在的实用工具或安装脚本。
|
||||||
|
|
||||||
## 理解 Init 容器
|
## 理解 Init 容器
|
||||||
|
|
||||||
|
|
@ -15,13 +15,13 @@ Init 容器与普通的容器非常像,除了如下两点:
|
||||||
|
|
||||||
如果 Pod 的 Init 容器失败,Kubernetes 会不断地重启该 Pod,直到 Init 容器成功为止。然而,如果 Pod 对应的 `restartPolicy` 为 Never,它不会重新启动。
|
如果 Pod 的 Init 容器失败,Kubernetes 会不断地重启该 Pod,直到 Init 容器成功为止。然而,如果 Pod 对应的 `restartPolicy` 为 Never,它不会重新启动。
|
||||||
|
|
||||||
指定容器为 Init 容器,在 PodSpec 中添加 `initContainers` 字段,以 [v1.Container](https://kubernetes.io/docs/api-reference/v1.6/#container-v1-core) 类型对象的 JSON 数组的形式,还有 app 的 `containers` 数组。 Init 容器的状态在 `status.initContainerStatuses` 字段中以容器状态数组的格式返回(类似 `status.containerStatuses` 字段)。
|
指定容器为 Init 容器,在 PodSpec 中添加 `initContainers` 字段,以 v1.Container 类型对象的 JSON 数组的形式,还有 app 的 `containers` 数组。 Init 容器的状态在 `status.initContainerStatuses` 字段中以容器状态数组的格式返回(类似 `status.containerStatuses` 字段)。
|
||||||
|
|
||||||
### 与普通容器的不同之处
|
### 与普通容器的不同之处
|
||||||
|
|
||||||
Init 容器支持应用容器的全部字段和特性,包括资源限制、数据卷和安全设置。 然而,Init 容器对资源请求和限制的处理稍有不同,在下面 [资源](https://kubernetes.io/docs/concepts/workloads/pods/init-containers/#resources) 处有说明。 而且 Init 容器不支持 Readiness Probe,因为它们必须在 Pod 就绪之前运行完成。
|
Init 容器支持应用容器的全部字段和特性,包括资源限制、数据卷和安全设置。 然而,Init 容器对资源请求和限制的处理稍有不同,在下面 [资源](https://kubernetes.io/docs/concepts/workloads/pods/init-containers/#resources) 处有说明。 而且 Init 容器不支持 Readiness Probe,因为它们必须在 Pod 就绪之前运行完成。
|
||||||
|
|
||||||
如果为一个 Pod 指定了多个 Init 容器,那些容器会按顺序一次运行一个。 每个 Init 容器必须运行成功,下一个才能够运行。 当所有的 Init 容器运行完成时,Kubernetes 初始化 Pod 并像平常一样运行应用容器。
|
如果为一个 Pod 指定了多个 Init 容器,那些容器会按顺序一次运行一个。只有当前面的 Init 容器必须运行成功后,才可以运行下一个 Init 容器。当所有的 Init 容器运行完成后,Kubernetes 才初始化 Pod 和运行应用容器。
|
||||||
|
|
||||||
## Init 容器能做什么?
|
## Init 容器能做什么?
|
||||||
|
|
||||||
|
|
@ -35,20 +35,18 @@ Init 容器支持应用容器的全部字段和特性,包括资源限制、数
|
||||||
|
|
||||||
### 示例
|
### 示例
|
||||||
|
|
||||||
下面是一些如何使用 Init 容器的想法:
|
下面列举了 Init 容器的一些用途:
|
||||||
|
|
||||||
- 等待一个 Service 创建完成,通过类似如下 shell 命令:
|
- 等待一个 Service 创建完成,通过类似如下 shell 命令:
|
||||||
|
|
||||||
```
|
```bash
|
||||||
for i in {1..100}; do sleep 1; if dig myservice; then exit 0; fi; exit 1
|
for i in {1..100}; do sleep 1; if dig myservice; then exit 0; fi; exit 1
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
- 将 Pod 注册到远程服务器,通过在命令中调用 API,类似如下:
|
- 将 Pod 注册到远程服务器,通过在命令中调用 API,类似如下:
|
||||||
|
|
||||||
```
|
```bash
|
||||||
curl -X POST http://$MANAGEMENT_SERVICE_HOST:$MANAGEMENT_SERVICE_PORT/register -d 'instance=$(<POD_NAME>)&ip=$(<POD_IP>)'
|
curl -X POST http://$MANAGEMENT_SERVICE_HOST:$MANAGEMENT_SERVICE_PORT/register -d 'instance=$(<POD_NAME>)&ip=$(<POD_IP>)'
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
- 在启动应用容器之前等一段时间,使用类似 `sleep 60` 的命令。
|
- 在启动应用容器之前等一段时间,使用类似 `sleep 60` 的命令。
|
||||||
|
|
@ -57,7 +55,7 @@ Init 容器支持应用容器的全部字段和特性,包括资源限制、数
|
||||||
|
|
||||||
- 将配置值放到配置文件中,运行模板工具为主应用容器动态地生成配置文件。例如,在配置文件中存放 POD_IP 值,并使用 Jinja 生成主应用配置文件。
|
- 将配置值放到配置文件中,运行模板工具为主应用容器动态地生成配置文件。例如,在配置文件中存放 POD_IP 值,并使用 Jinja 生成主应用配置文件。
|
||||||
|
|
||||||
更多详细用法示例,可以在 [StatefulSet 文档](https://kubernetes.io/docs/concepts/abstractions/controllers/statefulsets/) 和 [生产环境 Pod 指南](https://kubernetes.io/docs/user-guide/production-pods.md#handling-initialization) 中找到。
|
更多详细用法示例,可以在 [StatefulSet 文档](https://kubernetes.io/docs/concepts/abstractions/controllers/statefulsets/) 和 [生产环境 Pod 指南](https://kubernetes.io/docs/concepts/workloads/pods/init-containers/) 中找到。
|
||||||
|
|
||||||
### 使用 Init 容器
|
### 使用 Init 容器
|
||||||
|
|
||||||
|
|
@ -113,9 +111,11 @@ spec:
|
||||||
command: ['sh', '-c', 'until nslookup mydb; do echo waiting for mydb; sleep 2; done;']
|
command: ['sh', '-c', 'until nslookup mydb; do echo waiting for mydb; sleep 2; done;']
|
||||||
```
|
```
|
||||||
|
|
||||||
1.5 版本的语法在 1.6 版本仍然可以使用,但是我们推荐使用 1.6 版本的新语法。 在 Kubernetes 1.6 版本中,Init 容器在 API 中新建了一个字段。 虽然期望使用 beta 版本的 annotation,但在未来发行版将会被废弃掉。
|
> **注意:版本兼容性问题**
|
||||||
|
>
|
||||||
|
> 1.5 版本的语法在 1.6 和 1.7 版本中仍然可以使用,但是我们推荐使用 1.6 版本的新语法。Kubernetes 1.8 以后的版本只支持新语法。在 Kubernetes 1.6 版本中,Init 容器在 API 中新建了一个字段。 虽然期望使用 beta 版本的 annotation,但在未来发行版将会被废弃掉。
|
||||||
|
|
||||||
下面的 yaml 文件展示了 `mydb` 和 `myservice` 两个 Service:
|
下面的 YAML 文件展示了 `mydb` 和 `myservice` 两个 Service:
|
||||||
|
|
||||||
```yaml
|
```yaml
|
||||||
kind: Service
|
kind: Service
|
||||||
|
|
@ -186,7 +186,7 @@ $ kubectl logs myapp-pod -c init-mydb # Inspect the second init container
|
||||||
|
|
||||||
一旦我们启动了 `mydb` 和 `myservice` 这两个 Service,我们能够看到 Init 容器完成,并且 `myapp-pod` 被创建:
|
一旦我们启动了 `mydb` 和 `myservice` 这两个 Service,我们能够看到 Init 容器完成,并且 `myapp-pod` 被创建:
|
||||||
|
|
||||||
```Bash
|
```bash
|
||||||
$ kubectl create -f services.yaml
|
$ kubectl create -f services.yaml
|
||||||
service "myservice" created
|
service "myservice" created
|
||||||
service "mydb" created
|
service "mydb" created
|
||||||
|
|
@ -199,17 +199,17 @@ myapp-pod 1/1 Running 0 9m
|
||||||
|
|
||||||
## 具体行为
|
## 具体行为
|
||||||
|
|
||||||
在 Pod 启动过程中,Init 容器会按顺序在网络和数据卷初始化之后启动。 每个容器必须在下一个容器启动之前成功退出。 如果由于运行时或失败退出,导致容器启动失败,它会根据 Pod 的 `restartPolicy` 指定的策略进行重试。 然而,如果 Pod 的 `restartPolicy` 设置为 Always,Init 容器失败时会使用 `RestartPolicy` 策略。
|
在 Pod 启动过程中,Init 容器会按顺序在网络和数据卷初始化之后启动。每个容器必须在下一个容器启动之前成功退出。如果由于运行时或失败退出,将导致容器启动失败,它会根据 Pod 的 `restartPolicy` 指定的策略进行重试。然而,如果 Pod 的 `restartPolicy` 设置为 Always,Init 容器失败时会使用 `RestartPolicy` 策略。
|
||||||
|
|
||||||
在所有的 Init 容器没有成功之前,Pod 将不会变成 `Ready` 状态。 Init 容器的端口将不会在 Service 中进行聚集。 正在初始化中的 Pod 处于 `Pending` 状态,但应该会将条件 `Initializing` 设置为 true。
|
在所有的 Init 容器没有成功之前,Pod 将不会变成 `Ready` 状态。Init 容器的端口将不会在 Service 中进行聚集。 正在初始化中的 Pod 处于 `Pending` 状态,但应该会将 `Initializing` 状态设置为 true。
|
||||||
|
|
||||||
如果 Pod [重启](https://kubernetes.io/docs/concepts/workloads/pods/init-containers/#pod-restart-reasons),所有 Init 容器必须重新执行。
|
如果 Pod [重启](https://kubernetes.io/docs/concepts/workloads/pods/init-containers/#pod-restart-reasons),所有 Init 容器必须重新执行。
|
||||||
|
|
||||||
对 Init 容器 spec 的修改,被限制在容器 image 字段中。 更改 Init 容器的 image 字段,等价于重启该 Pod。
|
对 Init 容器 spec 的修改被限制在容器 image 字段,修改其他字段都不会生效。更改 Init 容器的 image 字段,等价于重启该 Pod。
|
||||||
|
|
||||||
因为 Init 容器可能会被重启、重试或者重新执行,所以 Init 容器的代码应该是幂等的。 特别地,被写到 `EmptyDirs` 中文件的代码,应该对输出文件可能已经存在做好准备。
|
因为 Init 容器可能会被重启、重试或者重新执行,所以 Init 容器的代码应该是幂等的。特别地当写到 `EmptyDirs` 文件中的代码,应该对输出文件可能已经存在做好准备。
|
||||||
|
|
||||||
Init 容器具有应用容器的所有字段。 除了 `readinessProbe`,因为 Init 容器无法定义不同于完成(completion)的就绪(readiness)的之外的其他状态。 这会在验证过程中强制执行。
|
Init 容器具有应用容器的所有字段。除了 `readinessProbe`,因为 Init 容器无法定义不同于完成(completion)的就绪(readiness)之外的其他状态。这会在验证过程中强制执行。
|
||||||
|
|
||||||
在 Pod 上使用 `activeDeadlineSeconds`,在容器上使用 `livenessProbe`,这样能够避免 Init 容器一直失败。 这就为 Init 容器活跃设置了一个期限。
|
在 Pod 上使用 `activeDeadlineSeconds`,在容器上使用 `livenessProbe`,这样能够避免 Init 容器一直失败。 这就为 Init 容器活跃设置了一个期限。
|
||||||
|
|
||||||
|
|
@ -229,11 +229,11 @@ Init 容器具有应用容器的所有字段。 除了 `readinessProbe`,因为
|
||||||
|
|
||||||
- Pod 的 *有效 QoS 层*,是 Init 容器和应用容器相同的 QoS 层。
|
- Pod 的 *有效 QoS 层*,是 Init 容器和应用容器相同的 QoS 层。
|
||||||
|
|
||||||
基于有效 Pod 请求和限制来应用配额和限制。 Pod 级别的 cgroups 是基于有效 Pod 请求和限制,和调度器相同。
|
基于有效 Pod 请求和限制来应用配额和限制。Pod 级别的 cgroups 是基于有效 Pod 请求和限制,和调度器相同。
|
||||||
|
|
||||||
### Pod 重启的原因
|
### Pod 重启的原因
|
||||||
|
|
||||||
Pod 能够重启,会导致 Init 容器重新执行,主要有如下几个原因:
|
Pod 重启,会导致 Init 容器重新执行,主要有如下几个原因:
|
||||||
|
|
||||||
- 用户更新 PodSpec 导致 Init 容器镜像发生改变。应用容器镜像的变更只会重启应用容器。
|
- 用户更新 PodSpec 导致 Init 容器镜像发生改变。应用容器镜像的变更只会重启应用容器。
|
||||||
- Pod 基础设施容器被重启。这不多见,但某些具有 root 权限可访问 Node 的人可能会这样做。
|
- Pod 基础设施容器被重启。这不多见,但某些具有 root 权限可访问 Node 的人可能会这样做。
|
||||||
|
|
@ -241,8 +241,12 @@ Pod 能够重启,会导致 Init 容器重新执行,主要有如下几个原
|
||||||
|
|
||||||
## 支持与兼容性
|
## 支持与兼容性
|
||||||
|
|
||||||
Apiserver 版本为 1.6 或更高版本的集群,通过使用 `spec.initContainers` 字段来支持 Init 容器。 之前的版本可以使用 alpha 和 beta 注解支持 Init 容器。 `spec.initContainers` 字段也被加入到 alpha 和 beta 注解中,所以 Kubernetes 1.3.0 版本或更高版本可以执行 Init 容器,并且 1.6 版本的 apiserver 能够安全地回退到 1.5.x 版本,而不会使存在的已创建 Pod 失去 Init 容器的功能。
|
API Server 版本为 1.6 或更高版本的集群,通过使用 `spec.initContainers` 字段来支持 Init 容器。之前的版本可以使用 alpha 和 beta 注解支持 Init 容器。`spec.initContainers` 字段也被加入到 alpha 和 beta 注解中,所以 Kubernetes 1.3.0 版本或更高版本可以执行 Init 容器,并且 1.6 版本的 API Server 能够安全地回退到 1.5.x 版本,而不会使已创建的 Pod 失去 Init 容器的功能。
|
||||||
|
|
||||||
原文地址:https://k8smeetup.github.io/docs/concepts/workloads/pods/init-containers/
|
---
|
||||||
|
|
||||||
译者:[shirdrn](https://github.com/shirdrn)
|
> 原文地址:https://k8smeetup.github.io/docs/concepts/workloads/pods/init-containers/
|
||||||
|
>
|
||||||
|
> 译者:[shirdrn](https://github.com/shirdrn)
|
||||||
|
>
|
||||||
|
> 校对:[Jimmy Song](https://github.com/rootsongjc)
|
||||||
|
|
|
||||||
|
|
@ -34,11 +34,10 @@ spec:
|
||||||
$ kubectl create -f ./job.yaml
|
$ kubectl create -f ./job.yaml
|
||||||
job "pi" created
|
job "pi" created
|
||||||
$ pods=$(kubectl get pods --selector=job-name=pi --output=jsonpath={.items..metadata.name})
|
$ pods=$(kubectl get pods --selector=job-name=pi --output=jsonpath={.items..metadata.name})
|
||||||
$ kubectl logs $pods
|
$ kubectl logs $pods -c pi
|
||||||
3.141592653589793238462643383279502...
|
3.141592653589793238462643383279502...
|
||||||
```
|
```
|
||||||
|
|
||||||
## Bare Pods
|
## Bare Pods
|
||||||
|
|
||||||
所谓Bare Pods是指直接用PodSpec来创建的Pod(即不在ReplicaSets或者ReplicationController的管理之下的Pods)。这些Pod在Node重启后不会自动重启,但Job则会创建新的Pod继续任务。所以,推荐使用Job来替代Bare Pods,即便是应用只需要一个Pod。
|
所谓Bare Pods是指直接用PodSpec来创建的Pod(即不在ReplicaSets或者ReplicationController的管理之下的Pods)。这些Pod在Node重启后不会自动重启,但Job则会创建新的Pod继续任务。所以,推荐使用Job来替代Bare Pods,即便是应用只需要一个Pod。
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -102,4 +102,3 @@ selector:
|
||||||
- another-node-label-value
|
- another-node-label-value
|
||||||
```
|
```
|
||||||
|
|
||||||
详见[node selection](https://github.com/kubernetes/kubernetes.github.io/tree/master/docs/user-guide/node-selection)。
|
|
||||||
|
|
@ -226,4 +226,4 @@ spec:
|
||||||
|
|
||||||
## 参考
|
## 参考
|
||||||
|
|
||||||
- [Local Persistent Storage User Guide](https://github.com/kubernetes-incubator/external-storage/tree/master/local-volume)
|
- [Local Persistent Storage User Guide](https://github.com/kubernetes-incubator/external-storage/tree/master/local-volume)
|
||||||
|
|
|
||||||
|
|
@ -1,10 +1,12 @@
|
||||||
# Network Policy
|
# Network Policy
|
||||||
|
|
||||||
网络策略说明一组 `Pod` 之间是如何被允许互相通信,以及如何与其它网络 Endpoint 进行通信。 `NetworkPolicy` 资源使用标签来选择 `Pod`,并定义了一些规则,这些规则指明允许什么流量进入到选中的 `Pod` 上。
|
网络策略说明一组 `Pod` 之间是如何被允许互相通信,以及如何与其它网络 Endpoint 进行通信。 `NetworkPolicy` 资源使用标签来选择 `Pod`,并定义了一些规则,这些规则指明允许什么流量进入到选中的 `Pod` 上。关于 Network Policy 的详细用法请参考 [Kubernetes 官网](https://kubernetes.io/docs/concepts/services-networking/network-policies/)。
|
||||||
|
|
||||||
|
Network Policy 的作用对象是 Pod,也可以应用到 Namespace 和集群的 Ingress、Egress 流量。Network Policy 是作用在 L3/4 层的,即限制的是对 IP 地址和端口的访问,如果需要对应用层做访问限制需要使用如 [Istio](https://istio.io) 这类 Service Mesh。
|
||||||
|
|
||||||
## 前提条件
|
## 前提条件
|
||||||
|
|
||||||
网络策略通过网络插件来实现,所以必须使用一种支持 `NetworkPolicy` 的网络方案 —— 非 Controller 创建的资源,是不起作用的。
|
网络策略通过网络插件来实现,所以必须使用一种支持 `NetworkPolicy` 的网络方案(如 [calico](https://www.projectcalico.org/))—— 非 Controller 创建的资源,是不起作用的。
|
||||||
|
|
||||||
## 隔离的与未隔离的 Pod
|
## 隔离的与未隔离的 Pod
|
||||||
|
|
||||||
|
|
@ -12,8 +14,6 @@
|
||||||
|
|
||||||
## `NetworkPolicy` 资源
|
## `NetworkPolicy` 资源
|
||||||
|
|
||||||
查看 [API参考](https://kubernetes.io/docs/api-reference/v1.7/#networkpolicy-v1-networking) 可以获取该资源的完整定义。
|
|
||||||
|
|
||||||
下面是一个 `NetworkPolicy` 的例子:
|
下面是一个 `NetworkPolicy` 的例子:
|
||||||
|
|
||||||
```yaml
|
```yaml
|
||||||
|
|
@ -26,8 +26,15 @@ spec:
|
||||||
podSelector:
|
podSelector:
|
||||||
matchLabels:
|
matchLabels:
|
||||||
role: db
|
role: db
|
||||||
|
policyTypes:
|
||||||
|
- Ingress
|
||||||
|
- Egress
|
||||||
ingress:
|
ingress:
|
||||||
- from:
|
- from:
|
||||||
|
- ipBlock:
|
||||||
|
cidr: 172.17.0.0/16
|
||||||
|
except:
|
||||||
|
- 172.17.1.0/24
|
||||||
- namespaceSelector:
|
- namespaceSelector:
|
||||||
matchLabels:
|
matchLabels:
|
||||||
project: myproject
|
project: myproject
|
||||||
|
|
@ -37,25 +44,34 @@ spec:
|
||||||
ports:
|
ports:
|
||||||
- protocol: TCP
|
- protocol: TCP
|
||||||
port: 6379
|
port: 6379
|
||||||
|
egress:
|
||||||
|
- to:
|
||||||
|
- ipBlock:
|
||||||
|
cidr: 10.0.0.0/24
|
||||||
|
ports:
|
||||||
|
- protocol: TCP
|
||||||
|
port: 5978
|
||||||
```
|
```
|
||||||
|
|
||||||
*将上面配置 POST 到 API Server 将不起任何作用,除非选择的网络方案支持网络策略。*
|
*将上面配置 POST 到 API Server 将不起任何作用,除非选择的网络方案支持网络策略。*
|
||||||
|
|
||||||
**必选字段**:像所有其它 Kubernetes 配置一样, `NetworkPolicy` 需要 `apiVersion`、`kind` 和 `metadata` 这三个字段,关于如何使用配置文件的基本信息,可以查看 [这里](https://kubernetes.io/docs/user-guide/simple-yaml),[这里](https://kubernetes.io/docs/user-guide/configuring-containers) 和 [这里](https://kubernetes.io/docs/user-guide/working-with-resources)。
|
**必选字段**:像所有其它 Kubernetes 配置一样, `NetworkPolicy` 需要 `apiVersion`、`kind` 和 `metadata` 这三个字段,关于如何使用配置文件的基本信息,可以查看 [这里](https://kubernetes.io/docs/user-guide/configuring-containers)。
|
||||||
|
|
||||||
**spec**:`NetworkPolicy` [spec](https://git.k8s.io/community/contributors/devel/api-conventions.md#spec-and-status) 具有在给定 Namespace 中定义特定网络的全部信息。
|
**spec**:`NetworkPolicy` spec 具有在给定 Namespace 中定义特定网络的全部信息。
|
||||||
|
|
||||||
**podSelector**:每个 `NetworkPolicy` 包含一个 `podSelector`,它可以选择一组应用了网络策略的 Pod。由于 `NetworkPolicy` 当前只支持定义 `ingress` 规则,这个 `podSelector` 实际上为该策略定义了一组 “目标Pod”。示例中的策略选择了标签为 “role=db” 的 Pod。一个空的 `podSelector` 选择了该 Namespace 中的所有 Pod。
|
**podSelector**:每个 `NetworkPolicy` 包含一个 `podSelector`,它可以选择一组应用了网络策略的 Pod。由于 `NetworkPolicy` 当前只支持定义 `ingress` 规则,这个 `podSelector` 实际上为该策略定义了一组 “目标Pod”。示例中的策略选择了标签为 “role=db” 的 Pod。一个空的 `podSelector` 选择了该 Namespace 中的所有 Pod。
|
||||||
|
|
||||||
**ingress**:每个`NetworkPolicy` 包含了一个白名单 `ingress` 规则列表。每个规则只允许能够匹配上 `from` 和 `ports`配置段的流量。示例策略包含了单个规则,它从这两个源中匹配在单个端口上的流量,第一个是通过`namespaceSelector` 指定的,第二个是通过 `podSelector` 指定的。
|
**ingress**:每个`NetworkPolicy` 包含了一个白名单 `ingress` 规则列表。每个规则只允许能够匹配上 `from` 和 `ports`配置段的流量。示例策略包含了单个规则,它从这两个源中匹配在单个端口上的流量,第一个是通过`namespaceSelector` 指定的,第二个是通过 `podSelector` 指定的。
|
||||||
|
|
||||||
|
**egress**:每个`NetworkPolicy` 包含了一个白名单 `ingress` 规则列表。每个规则只允许能够匹配上 `to` 和 `ports`配置段的流量。示例策略包含了单个规则,它匹配目的地 `10.0.0.0/24` 单个端口的流量。
|
||||||
|
|
||||||
因此,上面示例的 NetworkPolicy:
|
因此,上面示例的 NetworkPolicy:
|
||||||
|
|
||||||
1. 在 “default” Namespace中 隔离了标签 “role=db” 的 Pod(如果他们还没有被隔离)
|
1. 在 “default” Namespace中 隔离了标签 “role=db” 的 Pod(如果他们还没有被隔离)
|
||||||
2. 在 “default” Namespace中,允许任何具有 “role=frontend” 的 Pod,连接到标签为 “role=db” 的 Pod 的 TCP 端口 6379
|
2. 在 “default” Namespace中,允许任何具有 “role=frontend” 的 Pod,IP 范围在 172.17.0.0–172.17.0.255 和 172.17.2.0–172.17.255.255(整个 172.17.0.0/16 段, 172.17.1.0/24 除外)连接到标签为 “role=db” 的 Pod 的 TCP 端口 6379
|
||||||
3. 允许在 Namespace 中任何具有标签 “project=myproject” 的 Pod,连接到 “default” Namespace 中标签为 “role=db” 的 Pod 的 TCP 端口 6379
|
3. 允许在 Namespace 中任何具有标签 “project=myproject” ,IP范围在10.0.0.0/24段的 Pod,连接到 “default” Namespace 中标签为 “role=db” 的 Pod 的 TCP 端口 5978
|
||||||
|
|
||||||
查看 [NetworkPolicy 入门指南](https://kubernetes.io/docs/getting-started-guides/network-policy/walkthrough) 给出的更进一步的例子。
|
查看 [NetworkPolicy 入门指南](https://kubernetes.io/docs/getting-started-guides/network-policy/walkthrough)给出的更进一步的例子。
|
||||||
|
|
||||||
## 默认策略
|
## 默认策略
|
||||||
|
|
||||||
|
|
@ -84,6 +100,7 @@ spec:
|
||||||
ingress:
|
ingress:
|
||||||
- {}
|
- {}
|
||||||
```
|
```
|
||||||
原文地址:https://k8smeetup.github.io/docs/concepts/services-networking/network-policies/
|
## 参考
|
||||||
|
|
||||||
译者:[shirdrn](https://github.com/shirdrn)
|
- [Network Policies - k8smeetup.github.io](https://k8smeetup.github.io/docs/concepts/services-networking/network-policies/)
|
||||||
|
- [Network Policies - kubernetes.io](https://kubernetes.io/docs/concepts/services-networking/network-policies/)
|
||||||
|
|
|
||||||
|
|
@ -30,4 +30,4 @@ Kubernetes中的网络可以说对初次接触Kubernetes或者没有网络方面
|
||||||
下面仅以当前最常用的flannel和calico插件为例解析。
|
下面仅以当前最常用的flannel和calico插件为例解析。
|
||||||
|
|
||||||
- [Kubernetes中的网络解析——以flannel为例](flannel.md)
|
- [Kubernetes中的网络解析——以flannel为例](flannel.md)
|
||||||
- [Kubernetes中的网络解析——以calico为例](calico.md)
|
- [Kubernetes中的网络解析——以calico为例](calico.md)
|
||||||
|
|
|
||||||
|
|
@ -13,8 +13,8 @@ Node包括如下状态信息:
|
||||||
- Condition
|
- Condition
|
||||||
- OutOfDisk:磁盘空间不足时为`True`
|
- OutOfDisk:磁盘空间不足时为`True`
|
||||||
- Ready:Node controller 40秒内没有收到node的状态报告为`Unknown`,健康为`True`,否则为`False`。
|
- Ready:Node controller 40秒内没有收到node的状态报告为`Unknown`,健康为`True`,否则为`False`。
|
||||||
- MemoryPressure:当node没有内存压力时为`True`,否则为`False`。
|
- MemoryPressure:当node有内存压力时为`True`,否则为`False`。
|
||||||
- DiskPressure:当node没有磁盘压力时为`True`,否则为`False`。
|
- DiskPressure:当node有磁盘压力时为`True`,否则为`False`。
|
||||||
- Capacity
|
- Capacity
|
||||||
- CPU
|
- CPU
|
||||||
- 内存
|
- 内存
|
||||||
|
|
|
||||||
|
|
@ -24,16 +24,18 @@
|
||||||
- Ingress
|
- Ingress
|
||||||
- ConfigMap
|
- ConfigMap
|
||||||
- Label
|
- Label
|
||||||
- ThirdPartyResources
|
- CustomResourceDefinition
|
||||||
|
- Role
|
||||||
|
- ClusterRole
|
||||||
|
|
||||||
我将它们简单的分类为以下几种资源对象:
|
我将它们简单的分类为以下几种资源对象:
|
||||||
|
|
||||||
| 类别 | 名称 |
|
| 类别 | 名称 |
|
||||||
| :--- | ---------------------------------------- |
|
| :------- | ------------------------------------------------------------ |
|
||||||
| 资源对象 | Pod、ReplicaSet、ReplicationController、Deployment、StatefulSet、DaemonSet、Job、CronJob、HorizontalPodAutoscaling |
|
| 资源对象 | Pod、ReplicaSet、ReplicationController、Deployment、StatefulSet、DaemonSet、Job、CronJob、HorizontalPodAutoscaling、Node、Namespace、Service、Ingress、Label、CustomResourceDefinition |
|
||||||
| 配置对象 | Node、Namespace、Service、Secret、ConfigMap、Ingress、Label、ThirdPartyResource、 ServiceAccount |
|
| 存储对象 | Volume、PersistentVolume、Secret、ConfigMap |
|
||||||
| 存储对象 | Volume、Persistent Volume |
|
| 策略对象 | SecurityContext、ResourceQuota、LimitRange |
|
||||||
| 策略对象 | SecurityContext、ResourceQuota、LimitRange |
|
| 身份对象 | ServiceAccount、Role、ClusterRole |
|
||||||
|
|
||||||
## 理解 kubernetes 中的对象
|
## 理解 kubernetes 中的对象
|
||||||
|
|
||||||
|
|
@ -45,7 +47,7 @@
|
||||||
|
|
||||||
Kubernetes 对象是 “目标性记录” —— 一旦创建对象,Kubernetes 系统将持续工作以确保对象存在。通过创建对象,可以有效地告知 Kubernetes 系统,所需要的集群工作负载看起来是什么样子的,这就是 Kubernetes 集群的 **期望状态**。
|
Kubernetes 对象是 “目标性记录” —— 一旦创建对象,Kubernetes 系统将持续工作以确保对象存在。通过创建对象,可以有效地告知 Kubernetes 系统,所需要的集群工作负载看起来是什么样子的,这就是 Kubernetes 集群的 **期望状态**。
|
||||||
|
|
||||||
与 Kubernetes 对象工作 —— 是否创建、修改,或者删除 —— 需要使用 [Kubernetes API](https://git.k8s.io/community/contributors/devel/api-conventions.md)。当使用 `kubectl` 命令行接口时,比如,CLI 会使用必要的 Kubernetes API 调用,也可以在程序中直接使用 Kubernetes API。为了实现该目标,Kubernetes 当前提供了一个 `golang` [客户端库](https://github.com/kubernetes/client-go) ,其它语言库(例如[Python](https://github.com/kubernetes-incubator/client-python))也正在开发中。
|
与 Kubernetes 对象工作 —— 是否创建、修改,或者删除 —— 需要使用 Kubernetes API。当使用 `kubectl` 命令行接口时,比如,CLI 会使用必要的 Kubernetes API 调用,也可以在程序中直接使用 Kubernetes API。为了实现该目标,Kubernetes 当前提供了一个 `golang` [客户端库](https://github.com/kubernetes/client-go) ,其它语言库(例如[Python](https://github.com/kubernetes-incubator/client-python))也正在开发中。
|
||||||
|
|
||||||
### 对象 Spec 与状态
|
### 对象 Spec 与状态
|
||||||
|
|
||||||
|
|
@ -53,7 +55,7 @@ Kubernetes 对象是 “目标性记录” —— 一旦创建对象,Kubernete
|
||||||
|
|
||||||
例如,Kubernetes Deployment 对象能够表示运行在集群中的应用。当创建 Deployment 时,可能需要设置 Deployment 的 spec,以指定该应用需要有 3 个副本在运行。Kubernetes 系统读取 Deployment spec,启动我们所期望的该应用的 3 个实例 —— 更新状态以与 spec 相匹配。如果那些实例中有失败的(一种状态变更),Kubernetes 系统通过修正来响应 spec 和状态之间的不一致 —— 这种情况,启动一个新的实例来替换。
|
例如,Kubernetes Deployment 对象能够表示运行在集群中的应用。当创建 Deployment 时,可能需要设置 Deployment 的 spec,以指定该应用需要有 3 个副本在运行。Kubernetes 系统读取 Deployment spec,启动我们所期望的该应用的 3 个实例 —— 更新状态以与 spec 相匹配。如果那些实例中有失败的(一种状态变更),Kubernetes 系统通过修正来响应 spec 和状态之间的不一致 —— 这种情况,启动一个新的实例来替换。
|
||||||
|
|
||||||
关于对象 spec、status 和 metadata 更多信息,查看 [Kubernetes API Conventions](https://git.k8s.io/community/contributors/devel/api-conventions.md)。
|
关于对象 spec、status 和 metadata 更多信息,查看 [Kubernetes API Conventions]( https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md)。
|
||||||
|
|
||||||
### 描述 Kubernetes 对象
|
### 描述 Kubernetes 对象
|
||||||
|
|
||||||
|
|
@ -80,7 +82,7 @@ spec:
|
||||||
- containerPort: 80
|
- containerPort: 80
|
||||||
```
|
```
|
||||||
|
|
||||||
一种创建 Deployment 的方式,类似上面使用 `.yaml` 文件,是使用 `kubectl` 命令行接口(CLI)中的 [`kubectl create`](https://kubernetes.io/docs/user-guide/kubectl/v1.7/#create) 命令,传递 `.yaml` 作为参数。下面是一个示例:
|
一种创建 Deployment 的方式,类似上面使用 `.yaml` 文件,是使用 `kubectl` 命令行接口(CLI)中的 `kubectl create` 命令,传递 `.yaml` 作为参数。下面是一个示例:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
$ kubectl create -f docs/user-guide/nginx-deployment.yaml --record
|
$ kubectl create -f docs/user-guide/nginx-deployment.yaml --record
|
||||||
|
|
|
||||||
|
|
@ -18,7 +18,7 @@ Pause容器,是可以自己来定义,官方使用的`gcr.io/google_container
|
||||||
|
|
||||||
## Pause容器的作用
|
## Pause容器的作用
|
||||||
|
|
||||||
我们检查nod节点的时候会发现每个node上都运行了很多的pause容器,例如如下。
|
我们检查node节点的时候会发现每个node上都运行了很多的pause容器,例如如下。
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
$ docker ps
|
$ docker ps
|
||||||
|
|
|
||||||
|
|
@ -28,13 +28,11 @@ PV 属于集群中的资源。PVC 是对这些资源的请求,也作为对资
|
||||||
|
|
||||||
#### 动态
|
#### 动态
|
||||||
|
|
||||||
当管理员创建的静态 PV 都不匹配用户的 `PersistentVolumeClaim` 时,集群可能会尝试动态地为 PVC 创建卷。此配置基于 `StorageClasses`:PVC 必须请求[存储类](https://kubernetes.io/docs/concepts/storage/storage-classes/),并且管理员必须创建并配置该类才能进行动态创建。声明该类为 `""` 可以有效地禁用其动态配置。
|
根据 `StorageClasses`,当管理员创建的静态 PV 都不匹配用户的 `PersistentVolumeClaim` 时,集群可能会尝试动态地为 PVC 创建卷。
|
||||||
|
|
||||||
要启用基于存储级别的动态存储配置,集群管理员需要启用 API server 上的 `DefaultStorageClass` [准入控制器](https://kubernetes.io/docs/admin/admission-controllers/#defaultstorageclass)。例如,通过确保 `DefaultStorageClass` 位于 API server 组件的 `--admission-control` 标志,使用逗号分隔的有序值列表中,可以完成此操作。有关 API server 命令行标志的更多信息,请检查 [kube-apiserver](https://kubernetes.io/docs/admin/kube-apiserver/) 文档。
|
|
||||||
|
|
||||||
### 绑定
|
### 绑定
|
||||||
|
|
||||||
再动态配置的情况下,用户创建或已经创建了具有特定存储量的 `PersistentVolumeClaim` 以及某些访问模式。master 中的控制环路监视新的 PVC,寻找匹配的 PV(如果可能),并将它们绑定在一起。如果为新的 PVC 动态调配 PV,则该环路将始终将该 PV 绑定到 PVC。否则,用户总会得到他们所请求的存储,但是容量可能超出要求的数量。一旦 PV 和 PVC 绑定后,`PersistentVolumeClaim` 绑定是排他性的,不管它们是如何绑定的。 PVC 跟 PV 绑定是一对一的映射。
|
在动态配置的情况下,用户创建或已经创建了具有特定存储量的 `PersistentVolumeClaim` 以及某些访问模式。master 中的控制环路监视新的 PVC,寻找匹配的 PV(如果可能),并将它们绑定在一起。如果为新的 PVC 动态调配 PV,则该环路将始终将该 PV 绑定到 PVC。否则,用户总会得到他们所请求的存储,但是容量可能超出要求的数量。一旦 PV 和 PVC 绑定后,`PersistentVolumeClaim` 绑定是排他性的,不管它们是如何绑定的。 PVC 跟 PV 绑定是一对一的映射。
|
||||||
|
|
||||||
如果没有匹配的卷,声明将无限期地保持未绑定状态。随着匹配卷的可用,声明将被绑定。例如,配置了许多 50Gi PV的集群将不会匹配请求 100Gi 的PVC。将100Gi PV 添加到群集时,可以绑定 PVC。
|
如果没有匹配的卷,声明将无限期地保持未绑定状态。随着匹配卷的可用,声明将被绑定。例如,配置了许多 50Gi PV的集群将不会匹配请求 100Gi 的PVC。将100Gi PV 添加到群集时,可以绑定 PVC。
|
||||||
|
|
||||||
|
|
@ -42,7 +40,7 @@ PV 属于集群中的资源。PVC 是对这些资源的请求,也作为对资
|
||||||
|
|
||||||
Pod 使用声明作为卷。集群检查声明以查找绑定的卷并为集群挂载该卷。对于支持多种访问模式的卷,用户指定在使用声明作为容器中的卷时所需的模式。
|
Pod 使用声明作为卷。集群检查声明以查找绑定的卷并为集群挂载该卷。对于支持多种访问模式的卷,用户指定在使用声明作为容器中的卷时所需的模式。
|
||||||
|
|
||||||
用户进行了声明,并且该声明是绑定的,则只要用户需要,绑定的 PV 就属于该用户。用户通过在 Pod 的 volume 配置中包含 `persistentVolumeClaim` 来调度 Pod 并访问用户声明的 PV。[请参阅下面的语法细节](#claims-as-volumes)。
|
用户进行了声明,并且该声明是绑定的,则只要用户需要,绑定的 PV 就属于该用户。用户通过在 Pod 的 volume 配置中包含 `persistentVolumeClaim` 来调度 Pod 并访问用户声明的 PV。
|
||||||
|
|
||||||
### 持久化卷声明的保护
|
### 持久化卷声明的保护
|
||||||
|
|
||||||
|
|
@ -50,7 +48,7 @@ PVC 保护的目的是确保由 pod 正在使用的 PVC 不会从系统中移除
|
||||||
|
|
||||||
注意:当 pod 状态为 `Pending` 并且 pod 已经分配给节点或 pod 为 `Running` 状态时,PVC 处于活动状态。
|
注意:当 pod 状态为 `Pending` 并且 pod 已经分配给节点或 pod 为 `Running` 状态时,PVC 处于活动状态。
|
||||||
|
|
||||||
当启用[PVC 保护 alpha 功能](https://kubernetes.io/docs/tasks/administer-cluster/pvc-protection/)时,如果用户删除了一个 pod 正在使用的 PVC,则该 PVC 不会被立即删除。PVC 的删除将被推迟,直到 PVC 不再被任何 pod 使用。
|
当启用PVC 保护 alpha 功能时,如果用户删除了一个 pod 正在使用的 PVC,则该 PVC 不会被立即删除。PVC 的删除将被推迟,直到 PVC 不再被任何 pod 使用。
|
||||||
|
|
||||||
您可以看到,当 PVC 的状态为 `Teminatiing` 时,PVC 受到保护,`Finalizers` 列表中包含 `kubernetes.io/pvc-protection`:
|
您可以看到,当 PVC 的状态为 `Teminatiing` 时,PVC 受到保护,`Finalizers` 列表中包含 `kubernetes.io/pvc-protection`:
|
||||||
|
|
||||||
|
|
@ -111,7 +109,7 @@ spec:
|
||||||
|
|
||||||
#### 删除
|
#### 删除
|
||||||
|
|
||||||
对于支持删除回收策略的卷插件,删除操作将从 Kubernetes 中删除 `PersistentVolume` 对象,并删除外部基础架构(如 AWS EBS、GCE PD、Azure Disk 或 Cinder 卷)中的关联存储资产。动态配置的卷继承其 [`StorageClass` 的回收策略](#reclaim-policy),默认为 Delete。管理员应该根据用户的期望来配置 `StorageClass`,否则就必须要在 PV 创建后进行编辑或修补。请参阅[更改 PersistentVolume 的回收策略](https://kubernetes.iohttps://kubernetes.io/docs/tasks/administer-cluster/change-pv-reclaim-policy/)。
|
对于支持删除回收策略的卷插件,删除操作将从 Kubernetes 中删除 `PersistentVolume` 对象,并删除外部基础架构(如 AWS EBS、GCE PD、Azure Disk 或 Cinder 卷)中的关联存储资产。动态配置的卷继承其 `StorageClass`,默认为 Delete。管理员应该根据用户的期望来配置 `StorageClass`,否则就必须要在 PV 创建后进行编辑或修补。请参阅[更改 PersistentVolume 的回收策略](https://kubernetes.io/docs/tasks/administer-cluster/change-pv-reclaim-policy/)。
|
||||||
|
|
||||||
### 扩展持久化卷声明
|
### 扩展持久化卷声明
|
||||||
|
|
||||||
|
|
@ -362,7 +360,7 @@ spec:
|
||||||
|
|
||||||
PVC 不一定要请求类。其 `storageClassName` 设置为 `""` 的 PVC 始终被解释为没有请求类的 PV,因此只能绑定到没有类的 PV(没有注解或 `""`)。没有 `storageClassName` 的 PVC 根据是否打开[`DefaultStorageClass` 准入控制插件](https://kubernetes.io/docs/admin/admission-controllers/#defaultstorageclass),集群对其进行不同处理。
|
PVC 不一定要请求类。其 `storageClassName` 设置为 `""` 的 PVC 始终被解释为没有请求类的 PV,因此只能绑定到没有类的 PV(没有注解或 `""`)。没有 `storageClassName` 的 PVC 根据是否打开[`DefaultStorageClass` 准入控制插件](https://kubernetes.io/docs/admin/admission-controllers/#defaultstorageclass),集群对其进行不同处理。
|
||||||
|
|
||||||
- 如果打开了准入控制插件,管理员可以指定一个默认的 `StorageClass`。所有没有 `StorageClassName` 的 PVC 将被绑定到该默认的 PV。通过在 `StorageClass` 对象中将注解 `storageclassclass.ubernetes.io/is-default-class` 设置为 “true” 来指定默认的 `StorageClass`。如果管理员没有指定缺省值,那么集群会响应 PVC 创建,就好像关闭了准入控制插件一样。如果指定了多个默认值,则准入控制插件将禁止所有 PVC 创建。
|
- 如果打开了准入控制插件,管理员可以指定一个默认的 `StorageClass`。所有没有 `StorageClassName` 的 PVC 将被绑定到该默认的 PV。通过在 `StorageClass` 对象中将注解 `storageclass.kubernetes.io/is-default-class` 设置为 “true” 来指定默认的 `StorageClass`。如果管理员没有指定缺省值,那么集群会响应 PVC 创建,就好像关闭了准入控制插件一样。如果指定了多个默认值,则准入控制插件将禁止所有 PVC 创建。
|
||||||
- 如果准入控制插件被关闭,则没有默认 `StorageClass` 的概念。所有没有 `storageClassName` 的 PVC 只能绑定到没有类的 PV。在这种情况下,没有 `storageClassName` 的 PVC 的处理方式与 `storageClassName` 设置为 `""` 的 PVC 的处理方式相同。
|
- 如果准入控制插件被关闭,则没有默认 `StorageClass` 的概念。所有没有 `storageClassName` 的 PVC 只能绑定到没有类的 PV。在这种情况下,没有 `storageClassName` 的 PVC 的处理方式与 `storageClassName` 设置为 `""` 的 PVC 的处理方式相同。
|
||||||
|
|
||||||
根据安装方法的不同,默认的 `StorageClass` 可以在安装过程中通过插件管理器部署到 Kubernetes 集群。
|
根据安装方法的不同,默认的 `StorageClass` 可以在安装过程中通过插件管理器部署到 Kubernetes 集群。
|
||||||
|
|
@ -483,9 +481,9 @@ spec:
|
||||||
|
|
||||||
## 编写可移植配置
|
## 编写可移植配置
|
||||||
|
|
||||||
如果您正在编写在多种群集上运行并需要持久存储的配置模板或示例,我们建议您使用以下模式:
|
如果您正在编写在多种集群上运行并需要持久存储的配置模板或示例,我们建议您使用以下模式:
|
||||||
|
|
||||||
- 不要在您的在配置组合中包含 `PersistentVolumeClaim` 对象(与 Deployment、ConfigMap等一起)。
|
- 要在您的在配置组合中包含 `PersistentVolumeClaim` 对象(与 Deployment、ConfigMap等一起)。
|
||||||
- 不要在配置中包含 `PersistentVolume` 对象,因为用户实例化配置可能没有创建 `PersistentVolume` 的权限。
|
- 不要在配置中包含 `PersistentVolume` 对象,因为用户实例化配置可能没有创建 `PersistentVolume` 的权限。
|
||||||
- 给用户在实例化模板时提供存储类名称的选项。
|
- 给用户在实例化模板时提供存储类名称的选项。
|
||||||
- 如果用户提供存储类名称,则将该值放入 `persistentVolumeClaim.storageClassName` 字段中。如果集群具有由管理员启用的 StorageClass,这将导致 PVC 匹配正确的存储类别。
|
- 如果用户提供存储类名称,则将该值放入 `persistentVolumeClaim.storageClassName` 字段中。如果集群具有由管理员启用的 StorageClass,这将导致 PVC 匹配正确的存储类别。
|
||||||
|
|
|
||||||
|
|
@ -39,7 +39,7 @@ Pod 不会消失,直到有人(人类或控制器)将其销毁,或者当
|
||||||
|
|
||||||
- 确保您的 pod [请求所需的资源](https://kubernetes.io/docs/tasks/configure-pod-container/assign-cpu-ram-container)。
|
- 确保您的 pod [请求所需的资源](https://kubernetes.io/docs/tasks/configure-pod-container/assign-cpu-ram-container)。
|
||||||
- 如果您需要更高的可用性,请复制您的应用程序。 (了解有关运行复制的[无状态](https://kubernetes.io/docs/tasks/run-application/run-stateless-application-deployment)和[有状态](https://kubernetes.io/docs/tasks/run-application/run-replicated-stateful-application)应用程序的信息。)
|
- 如果您需要更高的可用性,请复制您的应用程序。 (了解有关运行复制的[无状态](https://kubernetes.io/docs/tasks/run-application/run-stateless-application-deployment)和[有状态](https://kubernetes.io/docs/tasks/run-application/run-replicated-stateful-application)应用程序的信息。)
|
||||||
- 为了在运行复制应用程序时获得更高的可用性,请跨机架(使用[反亲和性](https://kubernetes.io/docs/user-guide/node-selection/#inter-pod-affinity-and-anti-affinity-beta-feature))或跨区域(如果使用[多区域集群](https://kubernetes.io/docs/admin/multiple-zones))分布应用程序。
|
- 为了在运行复制应用程序时获得更高的可用性,请跨机架(使用[反亲和性](https://kubernetes.io/docs/user-guide/node-selection/#inter-pod-affinity-and-anti-affinity-beta-feature))或跨区域(如果使用多区域集群)分布应用程序。
|
||||||
|
|
||||||
自愿中断的频率各不相同。在 Kubernetes 集群上,根本没有自愿的中断。但是,您的集群管理员或托管提供商可能会运行一些导致自愿中断的附加服务。例如,节点软件更新可能导致自愿更新。另外,集群(节点)自动缩放的某些实现可能会导致碎片整理和紧缩节点的自愿中断。您的集群管理员或主机提供商应该已经记录了期望的自愿中断级别(如果有的话)。
|
自愿中断的频率各不相同。在 Kubernetes 集群上,根本没有自愿的中断。但是,您的集群管理员或托管提供商可能会运行一些导致自愿中断的附加服务。例如,节点软件更新可能导致自愿更新。另外,集群(节点)自动缩放的某些实现可能会导致碎片整理和紧缩节点的自愿中断。您的集群管理员或主机提供商应该已经记录了期望的自愿中断级别(如果有的话)。
|
||||||
|
|
||||||
|
|
@ -63,7 +63,7 @@ PDB 不能阻止[非自愿中断](https://kubernetes.io/docs/concepts/workloads/
|
||||||
|
|
||||||
由于应用程序的滚动升级而被删除或不可用的 Pod 确实会计入中断预算,但控制器(如 Deployment 和 StatefulSet)在进行滚动升级时不受 PDB 的限制——在应用程序更新期间的故障处理是在控制器的规格(spec)中配置(了解[更新 Deployment](https://kubernetes.io/docs/concepts/cluster-administration/manage-deployment/#updating-your-application-without-a-service-outage))。
|
由于应用程序的滚动升级而被删除或不可用的 Pod 确实会计入中断预算,但控制器(如 Deployment 和 StatefulSet)在进行滚动升级时不受 PDB 的限制——在应用程序更新期间的故障处理是在控制器的规格(spec)中配置(了解[更新 Deployment](https://kubernetes.io/docs/concepts/cluster-administration/manage-deployment/#updating-your-application-without-a-service-outage))。
|
||||||
|
|
||||||
使用驱逐 API 驱逐 pod 时,pod 会被优雅地终止(请参阅 [PodSpec](https://kubernetes.io/docs/resources-reference/v1.6/#podspec-v1-core) 中的 `terminationGracePeriodSeconds`)。
|
使用驱逐 API 驱逐 pod 时,pod 会被优雅地终止(请参阅 PodSpec 中的 `terminationGracePeriodSeconds`)。
|
||||||
|
|
||||||
## PDB 示例
|
## PDB 示例
|
||||||
|
|
||||||
|
|
@ -153,7 +153,7 @@ Pod Disruption Budget(Pod 中断预算) 通过在角色之间提供接口来
|
||||||
|
|
||||||
## 参考
|
## 参考
|
||||||
|
|
||||||
- [Disruptions - kubernetes.io](https://kubernetes.iohttps://kubernetes.io/docs/concepts/workloads/pods/disruptions/)
|
- [Disruptions - kubernetes.io](https://kubernetes.io/docs/concepts/workloads/pods/disruptions/)
|
||||||
|
|
||||||
- 通过配置[Pod Disruption Budget(Pod 中断预算)](https://kubernetes.io/docs/tasks/run-application//configure-pdb)来执行保护应用程序的步骤。
|
- 通过配置[Pod Disruption Budget(Pod 中断预算)](https://kubernetes.io/docs/tasks/run-application//configure-pdb)来执行保护应用程序的步骤。
|
||||||
- 了解更多关于[排空节点](https://kubernetes.io/docs/tasks/administer-cluster//safely-drain-node)的信息。
|
- 了解更多关于[排空节点](https://kubernetes.io/docs/tasks/administer-cluster//safely-drain-node)的信息。
|
||||||
|
|
|
||||||
|
|
@ -33,9 +33,9 @@ spec:
|
||||||
|
|
||||||
## 调试hook
|
## 调试hook
|
||||||
|
|
||||||
Hook调用的日志没有暴露个给Pod的event,所以只能通过`describe`命令来获取,如果有错误将可以看到`FailedPostStartHook`或`FailedPreStopHook`这样的event。
|
Hook调用的日志没有暴露给Pod的event,所以只能通过`describe`命令来获取,如果有错误将可以看到`FailedPostStartHook`或`FailedPreStopHook`这样的event。
|
||||||
|
|
||||||
## 参考
|
## 参考
|
||||||
|
|
||||||
- [Attach Handlers to Container Lifecycle Events](https://kubernetes.io/docs/tasks/configure-pod-container/attach-handler-lifecycle-event/)
|
- [Attach Handlers to Container Lifecycle Events](https://kubernetes.io/docs/tasks/configure-pod-container/attach-handler-lifecycle-event/)
|
||||||
- [Container Lifecycle Hooks](https://kubernetes.io/docs/concepts/containers/container-lifecycle-hooks/)
|
- [Container Lifecycle Hooks](https://kubernetes.io/docs/concepts/containers/container-lifecycle-hooks/)
|
||||||
|
|
|
||||||
|
|
@ -2,7 +2,7 @@
|
||||||
|
|
||||||
## Pod phase
|
## Pod phase
|
||||||
|
|
||||||
Pod 的 `status` 在信息保存在 [PodStatus](https://kubernetes.io/docs/resources-reference/v1.7/#podstatus-v1-core) 中定义,其中有一个 `phase` 字段。
|
Pod 的 `status` 字段是一个 PodStatus 对象,PodStatus中有一个 `phase` 字段。
|
||||||
|
|
||||||
Pod 的相位(phase)是 Pod 在其生命周期中的简单宏观概述。该阶段并不是对容器或 Pod 的综合汇总,也不是为了做为综合状态机。
|
Pod 的相位(phase)是 Pod 在其生命周期中的简单宏观概述。该阶段并不是对容器或 Pod 的综合汇总,也不是为了做为综合状态机。
|
||||||
|
|
||||||
|
|
@ -12,9 +12,9 @@ Pod 相位的数量和含义是严格指定的。除了本文档中列举的状
|
||||||
|
|
||||||
- 挂起(Pending):Pod 已被 Kubernetes 系统接受,但有一个或者多个容器镜像尚未创建。等待时间包括调度 Pod 的时间和通过网络下载镜像的时间,这可能需要花点时间。
|
- 挂起(Pending):Pod 已被 Kubernetes 系统接受,但有一个或者多个容器镜像尚未创建。等待时间包括调度 Pod 的时间和通过网络下载镜像的时间,这可能需要花点时间。
|
||||||
- 运行中(Running):该 Pod 已经绑定到了一个节点上,Pod 中所有的容器都已被创建。至少有一个容器正在运行,或者正处于启动或重启状态。
|
- 运行中(Running):该 Pod 已经绑定到了一个节点上,Pod 中所有的容器都已被创建。至少有一个容器正在运行,或者正处于启动或重启状态。
|
||||||
- 成功(Successed):Pod 中的所有容器都被成功终止,并且不会再重启。
|
- 成功(Succeeded):Pod 中的所有容器都被成功终止,并且不会再重启。
|
||||||
- 失败(Failed):Pod 中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非0状态退出或者被系统终止。
|
- 失败(Failed):Pod 中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非0状态退出或者被系统终止。
|
||||||
- 未知(Unkonwn):因为某些原因无法取得 Pod 的状态,通常是因为与 Pod 所在主机通信失败。
|
- 未知(Unknown):因为某些原因无法取得 Pod 的状态,通常是因为与 Pod 所在主机通信失败。
|
||||||
|
|
||||||
下图是Pod的生命周期示意图,从图中可以看到Pod状态的变化。
|
下图是Pod的生命周期示意图,从图中可以看到Pod状态的变化。
|
||||||
|
|
||||||
|
|
@ -22,15 +22,15 @@ Pod 相位的数量和含义是严格指定的。除了本文档中列举的状
|
||||||
|
|
||||||
## Pod 状态
|
## Pod 状态
|
||||||
|
|
||||||
Pod 有一个 PodStatus 对象,其中包含一个 [PodCondition](https://kubernetes.io/docs/resources-reference/v1.7/#podcondition-v1-core) 数组。 PodCondition 数组的每个元素都有一个 `type` 字段和一个 `status` 字段。`type` 字段是字符串,可能的值有 PodScheduled、Ready、Initialized 和 Unschedulable。`status` 字段是一个字符串,可能的值有 True、False 和 Unknown。
|
Pod 有一个 PodStatus 对象,其中包含一个 PodCondition 数组。 PodCondition 数组的每个元素都有一个 `type` 字段和一个 `status` 字段。`type` 字段是字符串,可能的值有 PodScheduled、Ready、Initialized、Unschedulable和ContainersReady。`status` 字段是一个字符串,可能的值有 True、False 和 Unknown。
|
||||||
|
|
||||||
## 容器探针
|
## 容器探针
|
||||||
|
|
||||||
[探针](https://kubernetes.io/docs/resources-reference/v1.7/#probe-v1-core) 是由 [kubelet](https://kubernetes.io/docs/admin/kubelet/) 对容器执行的定期诊断。要执行诊断,kubelet 调用由容器实现的 [Handler](https://godoc.org/k8s.io/kubernetes/pkg/api/v1#Handler)。有三种类型的处理程序:
|
探针是由 [kubelet](https://kubernetes.io/docs/admin/kubelet/) 对容器执行的定期诊断。要执行诊断,kubelet 调用由容器实现的 [Handler](https://godoc.org/k8s.io/kubernetes/pkg/api/v1#Handler)。有三种类型的处理程序:
|
||||||
|
|
||||||
- [ExecAction](https://kubernetes.io/docs/resources-reference/v1.7/#execaction-v1-core):在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。
|
- ExecAction:在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。
|
||||||
- [TCPSocketAction](https://kubernetes.io/docs/resources-reference/v1.7/#tcpsocketaction-v1-core):对指定端口上的容器的 IP 地址进行 TCP 检查。如果端口打开,则诊断被认为是成功的。
|
- TCPSocketAction:对指定端口上的容器的 IP 地址进行 TCP 检查。如果端口打开,则诊断被认为是成功的。
|
||||||
- [HTTPGetAction](https://kubernetes.io/docs/resources-reference/v1.7/#httpgetaction-v1-core):对指定的端口和路径上的容器的 IP 地址执行 HTTP Get 请求。如果响应的状态码大于等于200 且小于 400,则诊断被认为是成功的。
|
- HTTPGetAction:对指定的端口和路径上的容器的 IP 地址执行 HTTP Get 请求。如果响应的状态码大于等于200 且小于 400,则诊断被认为是成功的。
|
||||||
|
|
||||||
每次探测都将获得以下三种结果之一:
|
每次探测都将获得以下三种结果之一:
|
||||||
|
|
||||||
|
|
@ -57,7 +57,7 @@ Kubelet 可以选择是否执行在容器上运行的两种探针执行和做出
|
||||||
|
|
||||||
## Pod 和容器状态
|
## Pod 和容器状态
|
||||||
|
|
||||||
有关 Pod 容器状态的详细信息,请参阅 [PodStatus](https://kubernetes.io/docs/resources-reference/v1.7/#podstatus-v1-core) 和 [ContainerStatus](https://kubernetes.io/docs/resources-reference/v1.7/#containerstatus-v1-core)。请注意,报告的 Pod 状态信息取决于当前的 [ContainerState](https://kubernetes.io/docs/resources-reference/v1.7/#containerstatus-v1-core)。
|
有关 Pod 容器状态的详细信息,请参阅 PodStatus 和 ContainerStatus。请注意,报告的 Pod 状态信息取决于当前的 ContainerState。
|
||||||
|
|
||||||
## 重启策略
|
## 重启策略
|
||||||
|
|
||||||
|
|
@ -96,7 +96,7 @@ spec:
|
||||||
containers:
|
containers:
|
||||||
- args:
|
- args:
|
||||||
- /server
|
- /server
|
||||||
image: gcr.io/google_containers/liveness
|
image: k8s.gcr.io/liveness
|
||||||
livenessProbe:
|
livenessProbe:
|
||||||
httpGet:
|
httpGet:
|
||||||
# when "host" is not defined, "PodIP" will be used
|
# when "host" is not defined, "PodIP" will be used
|
||||||
|
|
@ -106,8 +106,8 @@ spec:
|
||||||
path: /healthz
|
path: /healthz
|
||||||
port: 8080
|
port: 8080
|
||||||
httpHeaders:
|
httpHeaders:
|
||||||
- name: X-Custom-Header
|
- name: X-Custom-Header
|
||||||
value: Awesome
|
value: Awesome
|
||||||
initialDelaySeconds: 15
|
initialDelaySeconds: 15
|
||||||
timeoutSeconds: 1
|
timeoutSeconds: 1
|
||||||
name: liveness
|
name: liveness
|
||||||
|
|
@ -159,4 +159,4 @@ spec:
|
||||||
|
|
||||||
原文地址:https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/
|
原文地址:https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/
|
||||||
|
|
||||||
翻译:[rootsongjc](https://github.com/rootsongjc)
|
翻译:[rootsongjc](https://github.com/rootsongjc)
|
||||||
|
|
|
||||||
|
|
@ -2,22 +2,22 @@
|
||||||
|
|
||||||
## 理解Pod
|
## 理解Pod
|
||||||
|
|
||||||
Pod是kubernetes中你可以创建和部署的最小也是最简的单位。一个Pod代表着集群中运行的一个进程。
|
Pod是kubernetes中你可以创建和部署的最小也是最简的单位。Pod代表着集群中运行的进程。
|
||||||
|
|
||||||
Pod中封装着应用的容器(有的情况下是好几个容器),存储、独立的网络IP,管理容器如何运行的策略选项。Pod代表着部署的一个单位:kubernetes中应用的一个实例,可能由一个或者多个容器组合在一起共享资源。
|
Pod中封装着应用的容器(有的情况下是好几个容器),存储、独立的网络IP,管理容器如何运行的策略选项。Pod代表着部署的一个单位:kubernetes中应用的一个实例,可能由一个或者多个容器组合在一起共享资源。
|
||||||
|
|
||||||
> [Docker](https://www.docker.com)是kubernetes中最常用的容器运行时,但是Pod也支持其他容器运行时。
|
> [Docker](https://www.docker.com)是kubernetes中最常用的容器运行时,但是Pod也支持其他容器运行时。
|
||||||
|
|
||||||
|
|
||||||
在Kubrenetes集群中Pod有如下两种使用方式:
|
在Kubernetes集群中Pod有如下两种使用方式:
|
||||||
|
|
||||||
- **一个Pod中运行一个容器**。“每个Pod中一个容器”的模式是最常见的用法;在这种使用方式中,你可以把Pod想象成是单个容器的封装,kuberentes管理的是Pod而不是直接管理容器。
|
- **一个Pod中运行一个容器**。“每个Pod中一个容器”的模式是最常见的用法;在这种使用方式中,你可以把Pod想象成是单个容器的封装,kuberentes管理的是Pod而不是直接管理容器。
|
||||||
- **在一个Pod中同时运行多个容器**。一个Pod中也可以同时封装几个需要紧密耦合互相协作的容器,它们之间共享资源。这些在同一个Pod中的容器可以互相协作成为一个service单位——一个容器共享文件,另一个“sidecar”容器来更新这些文件。Pod将这些容器的存储资源作为一个实体来管理。
|
- **在一个Pod中同时运行多个容器**。一个Pod中也可以同时封装几个需要紧密耦合互相协作的容器,它们之间共享资源。这些在同一个Pod中的容器可以互相协作成为一个service单位——一个容器共享文件,另一个“sidecar”容器来更新这些文件。Pod将这些容器的存储资源作为一个实体来管理。
|
||||||
|
|
||||||
[Kubernetes Blog](http://blog.kubernetes.io) 有关于Pod用例的详细信息,查看:
|
[Kubernetes Blog](http://blog.kubernetes.io) 有关于Pod用例的详细信息,查看:
|
||||||
|
|
||||||
- [The Distributed System Toolkit: Patterns for Composite Containers](http://blog.kubernetes.io/2015/06/the-distributed-system-toolkit-patterns.html)
|
- [The Distributed System Toolkit: Patterns for Composite Containers](https://kubernetes.io/blog/2015/06/the-distributed-system-toolkit-patterns/)
|
||||||
- [Container Design Patterns](http://blog.kubernetes.io/2016/06/container-design-patterns.html)
|
- [Container Design Patterns](https://kubernetes.io/blog/2016/06/container-design-patterns/)
|
||||||
|
|
||||||
每个Pod都是应用的一个实例。如果你想平行扩展应用的话(运行多个实例),你应该运行多个Pod,每个Pod都是一个应用实例。在Kubernetes中,这通常被称为replication。
|
每个Pod都是应用的一个实例。如果你想平行扩展应用的话(运行多个实例),你应该运行多个Pod,每个Pod都是一个应用实例。在Kubernetes中,这通常被称为replication。
|
||||||
|
|
||||||
|
|
@ -37,11 +37,11 @@ Pod中可以共享两种资源:网络和存储。
|
||||||
|
|
||||||
#### 存储
|
#### 存储
|
||||||
|
|
||||||
可以Pod指定多个共享的Volume。Pod中的所有容器都可以访问共享的volume。Volume也可以用来持久化Pod中的存储资源,以防容器重启后文件丢失。
|
可以为一个Pod指定多个共享的Volume。Pod中的所有容器都可以访问共享的volume。Volume也可以用来持久化Pod中的存储资源,以防容器重启后文件丢失。
|
||||||
|
|
||||||
## 使用Pod
|
## 使用Pod
|
||||||
|
|
||||||
你很少会直接在kubernetes中创建单个Pod。因为Pod的生命周期是短暂的,用后即焚的实体。当Pod被创建后(不论是由你直接创建还是被其他Controller),都会被Kuberentes调度到集群的Node上。直到Pod的进程终止、被删掉、因为缺少资源而被驱逐、或者Node故障之前这个Pod都会一直保持在那个Node上。
|
你很少会直接在kubernetes中创建单个Pod。因为Pod的生命周期是短暂的,用后即焚的实体。当Pod被创建后(不论是由你直接创建还是被其他Controller),都会被Kubernetes调度到集群的Node上。直到Pod的进程终止、被删掉、因为缺少资源而被驱逐、或者Node故障之前这个Pod都会一直保持在那个Node上。
|
||||||
|
|
||||||
> 注意:重启Pod中的容器跟重启Pod不是一回事。Pod只提供容器的运行环境并保持容器的运行状态,重启容器不会造成Pod重启。
|
> 注意:重启Pod中的容器跟重启Pod不是一回事。Pod只提供容器的运行环境并保持容器的运行状态,重启容器不会造成Pod重启。
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -2,7 +2,7 @@
|
||||||
|
|
||||||
> **注意:**PodPreset 资源对象只有 kubernetes 1.8 以上版本才支持。
|
> **注意:**PodPreset 资源对象只有 kubernetes 1.8 以上版本才支持。
|
||||||
|
|
||||||
Preset 就是预设,有时候想要让一批容器在启动的时候就注入一些信息,比如 secret、volume、volume mount 和环境变量,而又不想一个一个的改这些 Pod 的 tmeplate,这时候就可以用到 PodPreset 这个资源对象了。
|
Preset 就是预设,有时候想要让一批容器在启动的时候就注入一些信息,比如 secret、volume、volume mount 和环境变量,而又不想一个一个的改这些 Pod 的 template,这时候就可以用到 PodPreset 这个资源对象了。
|
||||||
|
|
||||||
本页是关于 PodPreset 的概述,该对象用来在 Pod 创建的时候向 Pod 中注入某些特定信息。该信息可以包括 secret、volume、volume mount 和环境变量。
|
本页是关于 PodPreset 的概述,该对象用来在 Pod 创建的时候向 Pod 中注入某些特定信息。该信息可以包括 secret、volume、volume mount 和环境变量。
|
||||||
|
|
||||||
|
|
@ -45,7 +45,3 @@ Kubernetes 提供了一个准入控制器(`PodPreset`),当其启用时,P
|
||||||
## 更多资料
|
## 更多资料
|
||||||
|
|
||||||
- [使用 PodPreset 向 Pod 中注入数据](https://kubernetes.io/docs/tasks/inject-data-application/podpreset)
|
- [使用 PodPreset 向 Pod 中注入数据](https://kubernetes.io/docs/tasks/inject-data-application/podpreset)
|
||||||
|
|
||||||
本文为 Kubernetes 官方中文文档,地址:https://kubernetes.io/cn/docs/concepts/workloads/pods/podpreset/
|
|
||||||
|
|
||||||
翻译: [rootsongjc](https://github.com/rootsongjc)
|
|
||||||
|
|
@ -183,7 +183,7 @@ podsecuritypolicy "permissive" deleted
|
||||||
|
|
||||||
在 Kubernetes 1.5 或更新版本,可以使用 PodSecurityPolicy 来控制,对基于用户角色和组的已授权容器的访问。访问不同的 PodSecurityPolicy 对象,可以基于认证来控制。基于 Deployment、ReplicaSet 等创建的 Pod,限制访问 PodSecurityPolicy 对象,[Controller Manager](https://kubernetes.io/docs/admin/kube-controller-manager/) 必须基于安全 API 端口运行,并且不能够具有超级用户权限。
|
在 Kubernetes 1.5 或更新版本,可以使用 PodSecurityPolicy 来控制,对基于用户角色和组的已授权容器的访问。访问不同的 PodSecurityPolicy 对象,可以基于认证来控制。基于 Deployment、ReplicaSet 等创建的 Pod,限制访问 PodSecurityPolicy 对象,[Controller Manager](https://kubernetes.io/docs/admin/kube-controller-manager/) 必须基于安全 API 端口运行,并且不能够具有超级用户权限。
|
||||||
|
|
||||||
PodSecurityPolicy 认证使用所有可用的策略,包括创建 Pod 的用户,Pod 上指定的服务账户(service acount)。当 Pod 基于 Deployment、ReplicaSet 创建时,它是创建 Pod 的 Controller Manager,所以如果基于非安全 API 端口运行,允许所有的 PodSecurityPolicy 对象,并且不能够有效地实现细分权限。用户访问给定的 PSP 策略有效,仅当是直接部署 Pod 的情况。更多详情,查看 [PodSecurityPolicy RBAC 示例](https://git.k8s.io/kubernetes/examples/podsecuritypolicy/rbac/README.md),当直接部署 Pod 时,应用 PodSecurityPolicy 控制基于角色和组的已授权容器的访问 。
|
PodSecurityPolicy 认证使用所有可用的策略,包括创建 Pod 的用户,Pod 上指定的服务账户(service acount)。当 Pod 基于 Deployment、ReplicaSet 创建时,它是创建 Pod 的 Controller Manager,所以如果基于非安全 API 端口运行,允许所有的 PodSecurityPolicy 对象,并且不能够有效地实现细分权限。用户访问给定的 PSP 策略有效,仅当是直接部署 Pod 的情况。当直接部署 Pod 时,应用 PodSecurityPolicy 控制基于角色和组的已授权容器的访问 。
|
||||||
|
|
||||||
原文地址:https://k8smeetup.github.io/docs/concepts/policy/pod-security-policy/
|
原文地址:https://k8smeetup.github.io/docs/concepts/policy/pod-security-policy/
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -8,4 +8,4 @@
|
||||||
- Pod的生命周期
|
- Pod的生命周期
|
||||||
- Pod中容器的启动顺序模板定义
|
- Pod中容器的启动顺序模板定义
|
||||||
|
|
||||||
Kubernetes中的基本组件`kube-controller-manager`就是用来控制Pod的状态和生命周期的,在了解各种controller之前我们有必要先了解下Pod本身和其生命周期。
|
Kubernetes中的基本组件`kube-controller-manager`就是用来控制Pod的状态和生命周期的,在了解各种controller之前我们有必要先了解下Pod本身和其生命周期。
|
||||||
|
|
|
||||||
|
|
@ -10,7 +10,7 @@ Pod就像是豌豆荚一样,它由一个或者多个容器组成(例如Docke
|
||||||
|
|
||||||
尽管kubernetes支持多种容器运行时,但是Docker依然是最常用的运行时环境,我们可以使用Docker的术语和规则来定义Pod。
|
尽管kubernetes支持多种容器运行时,但是Docker依然是最常用的运行时环境,我们可以使用Docker的术语和规则来定义Pod。
|
||||||
|
|
||||||
Pod中共享的环境包括Linux的namespace,cgroup和其他可能的隔绝环境,这一点跟Docker容器一致。在Pod的环境中,每个容器中可能还有更小的子隔离环境。
|
Pod中共享的环境包括Linux的namespace、cgroup和其他可能的隔绝环境,这一点跟Docker容器一致。在Pod的环境中,每个容器中可能还有更小的子隔离环境。
|
||||||
|
|
||||||
Pod中的容器共享IP地址和端口号,它们之间可以通过`localhost`互相发现。它们之间可以通过进程间通信,例如[SystemV](https://en.wikipedia.org/wiki/UNIX_System_V)信号或者POSIX共享内存。不同Pod之间的容器具有不同的IP地址,不能直接通过IPC通信。
|
Pod中的容器共享IP地址和端口号,它们之间可以通过`localhost`互相发现。它们之间可以通过进程间通信,例如[SystemV](https://en.wikipedia.org/wiki/UNIX_System_V)信号或者POSIX共享内存。不同Pod之间的容器具有不同的IP地址,不能直接通过IPC通信。
|
||||||
|
|
||||||
|
|
@ -18,7 +18,7 @@ Pod中的容器也有访问共享volume的权限,这些volume会被定义成po
|
||||||
|
|
||||||
根据Docker的结构,Pod中的容器共享namespace和volume,不支持共享PID的namespace。
|
根据Docker的结构,Pod中的容器共享namespace和volume,不支持共享PID的namespace。
|
||||||
|
|
||||||
就像每个应用容器,pod被认为是临时(非持久的)实体。在Pod的生命周期中讨论过,pod被创建后,被分配一个唯一的ID(UID),调度到节点上,并一致维持期望的状态直到被终结(根据重启策略)或者被删除。如果node死掉了,分配到了这个node上的pod,在经过一个超时时间后会被重新调度到其他node节点上。一个给定的pod(如UID定义的)不会被“重新调度”到新的节点上,而是被一个同样的pod取代,如果期望的话甚至可以是相同的名字,但是会有一个新的UID(查看replication controller获取详情)。(未来,一个更高级别的API将支持pod迁移)。
|
就像每个应用容器,pod被认为是临时(非持久的)实体。在Pod的生命周期中讨论过,pod被创建后,被分配一个唯一的ID(UID),调度到节点上,并一致维持期望的状态直到被终结(根据重启策略)或者被删除。如果node死掉了,分配到了这个node上的pod,在经过一个超时时间后会被重新调度到其他node节点上。一个给定的pod(如UID定义的)不会被“重新调度”到新的节点上,而是被一个同样的pod取代,如果期望的话甚至可以是相同的名字,但是会有一个新的UID。
|
||||||
|
|
||||||
Volume跟pod有相同的生命周期(当其UID存在的时候)。当Pod因为某种原因被删除或者被新创建的相同的Pod取代,它相关的东西(例如volume)也会被销毁和再创建一个新的volume。
|
Volume跟pod有相同的生命周期(当其UID存在的时候)。当Pod因为某种原因被删除或者被新创建的相同的Pod取代,它相关的东西(例如volume)也会被销毁和再创建一个新的volume。
|
||||||
|
|
||||||
|
|
@ -26,7 +26,7 @@ Volume跟pod有相同的生命周期(当其UID存在的时候)。当Pod因
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
*A multi-container pod that contains a file puller and a web server that uses a persistent volume for shared storage between the containers.*
|
*一个多容器Pod,包含文件提取程序和Web服务器,该服务器使用持久卷在容器之间共享存储。*
|
||||||
|
|
||||||
## Pod的动机
|
## Pod的动机
|
||||||
|
|
||||||
|
|
@ -46,15 +46,15 @@ Pod中的应用容器可以共享volume。Volume能够保证pod重启时使用
|
||||||
|
|
||||||
Pod也可以用于垂直应用栈(例如LAMP),这样使用的主要动机是为了支持共同调度和协调管理应用程序,例如:
|
Pod也可以用于垂直应用栈(例如LAMP),这样使用的主要动机是为了支持共同调度和协调管理应用程序,例如:
|
||||||
|
|
||||||
- content management systems, file and data loaders, local cache managers, etc.
|
- 内容管理系统、文件和数据加载器、本地换群管理器等。
|
||||||
- log and checkpoint backup, compression, rotation, snapshotting, etc.
|
- 日志和检查点备份、压缩、旋转、快照等。
|
||||||
- data change watchers, log tailers, logging and monitoring adapters, event publishers, etc.
|
- 数据变更观察者、日志和监控适配器、活动发布者等。
|
||||||
- proxies, bridges, and adapters
|
- 代理、桥接和适配器等。
|
||||||
- controllers, managers, configurators, and updaters
|
- 控制器、管理器、配置器、更新器等。
|
||||||
|
|
||||||
通常单个pod中不会同时运行一个应用的多个实例。
|
通常单个pod中不会同时运行一个应用的多个实例。
|
||||||
|
|
||||||
详细说明请看: [The Distributed System ToolKit: Patterns for Composite Containers](http://blog.kubernetes.io/2015/06/the-distributed-system-toolkit-patterns.html).
|
详细说明请看: [The Distributed System ToolKit: Patterns for Composite Containers](https://kubernetes.io/blog/2015/06/the-distributed-system-toolkit-patterns/).
|
||||||
|
|
||||||
## 其他替代选择
|
## 其他替代选择
|
||||||
|
|
||||||
|
|
@ -75,22 +75,22 @@ Pod在设计支持就不是作为持久化实体的。在调度失败、节点
|
||||||
|
|
||||||
通常,用户不需要手动直接创建Pod,而是应该使用controller(例如[Deployments](./deployment.md)),即使是在创建单个Pod的情况下。Controller可以提供集群级别的自愈功能、复制和升级管理。
|
通常,用户不需要手动直接创建Pod,而是应该使用controller(例如[Deployments](./deployment.md)),即使是在创建单个Pod的情况下。Controller可以提供集群级别的自愈功能、复制和升级管理。
|
||||||
|
|
||||||
The use of collective APIs as the primary user-facing primitive is relatively common among cluster scheduling systems, including [Borg](https://research.google.com/pubs/pub43438.html), [Marathon](https://mesosphere.github.io/marathon/docs/rest-api.html), [Aurora](http://aurora.apache.org/documentation/latest/reference/configuration/#job-schema), and [Tupperware](http://www.slideshare.net/Docker/aravindnarayanan-facebook140613153626phpapp02-37588997).
|
使用集合API作为主要的面向用户的原语在集群调度系统中相对常见,包括[Borg](https://research.google.com/pubs/pub43438.html)、[Marathon](https://mesosphere.github.io/marathon/docs/rest-api.html)、[Aurora](http://aurora.apache.org/documentation/latest/reference/configuration/#job-schema)和[Tupperware](https://www.slideshare.net/Docker/aravindnarayanan-facebook140613153626phpapp02-37588997)。
|
||||||
|
|
||||||
Pod is exposed as a primitive in order to facilitate:
|
Pod 原语有利于:
|
||||||
|
|
||||||
- scheduler and controller pluggability
|
- 调度程序和控制器可插拔性
|
||||||
- support for pod-level operations without the need to "proxy" them via controller APIs
|
- 支持pod级操作,无需通过控制器API“代理”它们
|
||||||
- decoupling of pod lifetime from controller lifetime, such as for bootstrapping
|
- 将pod生命周期与控制器生命周期分离,例如用于自举(bootstrap)
|
||||||
- decoupling of controllers and services — the endpoint controller just watches pods
|
- 控制器和服务的分离——端点控制器只是监视pod
|
||||||
- clean composition of Kubelet-level functionality with cluster-level functionality — Kubelet is effectively the "pod controller"
|
- 将集群级功能与Kubelet级功能的清晰组合——Kubelet实际上是“pod控制器”
|
||||||
- high-availability applications, which will expect pods to be replaced in advance of their termination and certainly in advance of deletion, such as in the case of planned evictions, image prefetching, or live pod migration [#3949](http://issue.k8s.io/3949)
|
- 高可用性应用程序,它们可以在终止之前及在删除之前更换pod,例如在计划驱逐、镜像预拉取或实时pod迁移的情况下[#3949](https://github.com/kubernetes/kubernetes/issues/3949)
|
||||||
|
|
||||||
[StatefulSet](statefulset.md) controller(目前还是beta状态)支持有状态的Pod。在1.4版本中被称为PetSet。在kubernetes之前的版本中创建有状态pod的最佳方式是创建一个replica为1的replication controller。
|
[StatefulSet](statefulset.md) 控制器支持有状态的Pod。在1.4版本中被称为PetSet。在kubernetes之前的版本中创建有状态pod的最佳方式是创建一个replica为1的replication controller。
|
||||||
|
|
||||||
## Pod的终止
|
## Pod的终止
|
||||||
|
|
||||||
因为Pod作为在集群的节点上运行的进程,所以在不再需要的时候能够优雅的终止掉是十分必要的(比起使用发送KILL信号这种暴力的方式)。用户需要能够放松删除请求,并且知道它们何时会被终止,是否被正确的删除。用户想终止程序时发送删除pod的请求,在pod可以被强制删除前会有一个宽限期,会发送一个TERM请求到每个容器的主进程。一旦超时,将向主进程发送KILL信号并从API server中删除。如果kubelet或者container manager在等待进程终止的过程中重启,在重启后仍然会重试完整的宽限期。
|
因为Pod作为在集群的节点上运行的进程,所以在不再需要的时候能够优雅的终止掉是十分必要的(比起使用发送KILL信号这种暴力的方式)。用户需要能够发起一个删除 Pod 的请求,并且知道它们何时会被终止,是否被正确的删除。用户想终止程序时发送删除pod的请求,在pod可以被强制删除前会有一个宽限期,会发送一个TERM请求到每个容器的主进程。一旦超时,将向主进程发送KILL信号并从API server中删除。如果kubelet或者container manager在等待进程终止的过程中重启,在重启后仍然会重试完整的宽限期。
|
||||||
|
|
||||||
示例流程如下:
|
示例流程如下:
|
||||||
|
|
||||||
|
|
@ -102,9 +102,10 @@ Pod is exposed as a primitive in order to facilitate:
|
||||||
2. 向Pod中的进程发送TERM信号;
|
2. 向Pod中的进程发送TERM信号;
|
||||||
5. 跟第三步同时,该Pod将从该service的端点列表中删除,不再是replication controller的一部分。关闭的慢的pod将继续处理load balancer转发的流量;
|
5. 跟第三步同时,该Pod将从该service的端点列表中删除,不再是replication controller的一部分。关闭的慢的pod将继续处理load balancer转发的流量;
|
||||||
6. 过了宽限期后,将向Pod中依然运行的进程发送SIGKILL信号而杀掉进程。
|
6. 过了宽限期后,将向Pod中依然运行的进程发送SIGKILL信号而杀掉进程。
|
||||||
7. Kublete会在API server中完成Pod的的删除,通过将优雅周期设置为0(立即删除)。Pod在API中消失,并且在客户端也不可见。
|
7. Kubelet会在API server中完成Pod的的删除,通过将优雅周期设置为0(立即删除)。Pod在API中消失,并且在客户端也不可见。
|
||||||
|
|
||||||
删除宽限期默认是30秒。 `kubectl delete`命令支持 `—grace-period=<seconds>` 选项,允许用户设置自己的宽限期。如果设置为0将强制删除pod。在kubectl>=1.5版本的命令中,你必须同时使用 `--force` 和 `--grace-period=0` 来强制删除pod。
|
删除宽限期默认是30秒。 `kubectl delete`命令支持 `—grace-period=<seconds>` 选项,允许用户设置自己的宽限期。如果设置为0将强制删除pod。在kubectl>=1.5版本的命令中,你必须同时使用 `--force` 和 `--grace-period=0` 来强制删除pod。
|
||||||
|
在 yaml 文件中可以通过 `{{ .spec.spec.terminationGracePeriodSeconds }}` 来修改此值。
|
||||||
|
|
||||||
### 强制删除Pod
|
### 强制删除Pod
|
||||||
|
|
||||||
|
|
@ -114,7 +115,7 @@ Pod的强制删除是通过在集群和etcd中将其定义为删除状态。当
|
||||||
|
|
||||||
## Pod中容器的特权模式
|
## Pod中容器的特权模式
|
||||||
|
|
||||||
从kubernetes1.1版本开始,pod中的容器就可以开启previleged模式,在容器定义文件的 `SecurityContext` 下使用 `privileged` flag。 这在使用Linux的网络操作和访问设备的能力时是很有用的。容器内进程可获得近乎等同于容器外进程的权限。在不需要修改和重新编译kubelet的情况下就可以使用pod来开发节点的网络和存储插件。
|
从Kubernetes1.1版本开始,pod中的容器就可以开启privileged模式,在容器定义文件的 `SecurityContext` 下使用 `privileged` flag。 这在使用Linux的网络操作和访问设备的能力时是很有用的。容器内进程可获得近乎等同于容器外进程的权限。在不需要修改和重新编译kubelet的情况下就可以使用pod来开发节点的网络和存储插件。
|
||||||
|
|
||||||
如果master节点运行的是kuberentes1.1或更高版本,而node节点的版本低于1.1版本,则API server将也可以接受新的特权模式的pod,但是无法启动,pod将处于pending状态。
|
如果master节点运行的是kuberentes1.1或更高版本,而node节点的版本低于1.1版本,则API server将也可以接受新的特权模式的pod,但是无法启动,pod将处于pending状态。
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -0,0 +1,41 @@
|
||||||
|
# QoS(服务质量等级)
|
||||||
|
|
||||||
|
QoS(Quality of Service),大部分译为“服务质量等级”,又译作“服务质量保证”,是作用在 Pod 上的一个配置,当 Kubernetes 创建一个 Pod 时,它就会给这个 Pod 分配一个 QoS 等级,可以是以下等级之一:
|
||||||
|
|
||||||
|
- **Guaranteed**:Pod 里的每个容器都必须有内存/CPU 限制和请求,而且值必须相等。
|
||||||
|
- **Burstable**:Pod 里至少有一个容器有内存或者 CPU 请求且不满足 Guarantee 等级的要求,即内存/CPU 的值设置的不同。
|
||||||
|
- **BestEffort**:容器必须没有任何内存或者 CPU 的限制或请求。
|
||||||
|
|
||||||
|
该配置不是通过一个配置项来配置的,而是通过配置 CPU/内存的 `limits` 与 `requests` 值的大小来确认服务质量等级的。使用 `kubectl get pod -o yaml` 可以看到 pod 的配置输出中有 `qosClass` 一项。该配置的作用是为了给资源调度提供策略支持,调度算法根据不同的服务质量等级可以确定将 pod 调度到哪些节点上。
|
||||||
|
|
||||||
|
例如,下面这个 YAML 配置中的 Pod 资源配置部分设置的服务质量等级就是 `Guarantee`。
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
spec:
|
||||||
|
containers:
|
||||||
|
...
|
||||||
|
resources:
|
||||||
|
limits:
|
||||||
|
cpu: 100m
|
||||||
|
memory: 128Mi
|
||||||
|
requests:
|
||||||
|
cpu: 100m
|
||||||
|
memory: 128Mi
|
||||||
|
```
|
||||||
|
|
||||||
|
下面的 YAML 配置的 Pod 的服务质量等级是 `Burstable`。
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
spec:
|
||||||
|
containers:
|
||||||
|
...
|
||||||
|
resources:
|
||||||
|
limits:
|
||||||
|
memory: "180Mi"
|
||||||
|
requests:
|
||||||
|
memory: "100Mi"
|
||||||
|
```
|
||||||
|
|
||||||
|
## 参考
|
||||||
|
|
||||||
|
- [Configure Quality of Service for Pods](https://kubernetes.io/docs/tasks/configure-pod-container/quality-service-pod/)
|
||||||
|
|
@ -347,15 +347,15 @@ API Server会创建一组默认的`ClusterRole`和`ClusterRoleBinding`对象。
|
||||||
|
|
||||||
### 其它组件角色
|
### 其它组件角色
|
||||||
|
|
||||||
| 默认ClusterRole | 默认ClusterRoleBinding | 描述 |
|
| 默认ClusterRole | 默认ClusterRoleBinding | 描述 |
|
||||||
| ---------------------------------------- | ---------------------------------------- | ---------------------------------------- |
|
| ---------------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
|
||||||
| **system:auth-delegator** | None | 允许委托认证和授权检查。 通常由附加API Server用于统一认证和授权。 |
|
| **system:auth-delegator** | None | 允许委托认证和授权检查。 通常由附加API Server用于统一认证和授权。 |
|
||||||
| **system:heapster** | None | [Heapster](https://github.com/kubernetes/heapster)组件的角色。 |
|
| **system:heapster** | None | [Heapster](https://github.com/kubernetes/heapster)组件的角色。 |
|
||||||
| **system:kube-aggregator** | None | [kube-aggregator](https://github.com/kubernetes/kube-aggregator)组件的角色。 |
|
| **system:kube-aggregator** | None | [kube-aggregator](https://github.com/kubernetes/kube-aggregator)组件的角色。 |
|
||||||
| **system:kube-dns** | **kube-dns** service account in the **kube-system**namespace | [kube-dns](https://k8smeetup.github.io/docs/admin/dns/)组件的角色。 |
|
| **system:kube-dns** | **kube-dns** service account in the **kube-system**namespace | [kube-dns](https://k8smeetup.github.io/docs/admin/dns/)组件的角色。 |
|
||||||
| **system:node-bootstrapper** | None | 允许对执行[Kubelet TLS引导(Kubelet TLS bootstrapping)](https://k8smeetup.github.io/docs/admin/kubelet-tls-bootstrapping/)所需要资源的访问. |
|
| **system:node-bootstrapper** | None | 允许对执行[Kubelet TLS引导(Kubelet TLS bootstrapping)](https://k8smeetup.github.io/docs/admin/kubelet-tls-bootstrapping/)所需要资源的访问. |
|
||||||
| **system:node-problem-detector** | None | [node-problem-detector](https://github.com/kubernetes/node-problem-detector)组件的角色。 |
|
| **system:node-problem-detector** | None | [node-problem-detector](https://github.com/kubernetes/node-problem-detector)组件的角色。 |
|
||||||
| **system:persistent-volume-provisioner** | None | 允许对大部分[动态存储卷创建组件(dynamic volume provisioner)](https://k8smeetup.github.io/docs/user-guide/persistent-volumes/#provisioner)所需要资源的访问。 |
|
| **system:persistent-volume-provisioner** | None | 允许对大部分动态存储卷创建组件(dynamic volume provisioner)所需要资源的访问。 |
|
||||||
|
|
||||||
### 控制器(Controller)角色
|
### 控制器(Controller)角色
|
||||||
|
|
||||||
|
|
@ -583,4 +583,4 @@ kubectl create clusterrolebinding permissive-binding \
|
||||||
--user=admin \
|
--user=admin \
|
||||||
--user=kubelet \
|
--user=kubelet \
|
||||||
--group=system:serviceaccounts
|
--group=system:serviceaccounts
|
||||||
```
|
```
|
||||||
|
|
|
||||||
|
|
@ -8,5 +8,5 @@ Kubernetes中的众多资源类型,例如Deployment、DaemonSet、StatefulSet
|
||||||
|
|
||||||
考虑以下两种情况:
|
考虑以下两种情况:
|
||||||
|
|
||||||
- 集群中有新增节点,想要让集群中的节点的资源利用率比较均衡一些,想要将一些高负载的节点上的pod驱逐到新增节点上,这是kuberentes的scheduer所不支持的,需要使用如[rescheduler](https://github.com/kubernetes-incubator/descheduler)这样的插件来实现。
|
- 集群中有新增节点,想要让集群中的节点的资源利用率比较均衡一些,想要将一些高负载的节点上的pod驱逐到新增节点上,这是kuberentes的scheduler所不支持的,需要使用如[descheduler](https://github.com/kubernetes-incubator/descheduler)这样的插件来实现。
|
||||||
- 想要运行一些大数据应用,设计到资源分片,pod需要与数据分布达到一致均衡,避免个别节点处理大量数据,而其它节点闲置导致整个作业延迟,这时候可以考虑使用[kube-arbitritor](https://github.com/kubernetes-incubator/kube-arbitrator)。
|
- 想要运行一些大数据应用,设计到资源分片,pod需要与数据分布达到一致均衡,避免个别节点处理大量数据,而其它节点闲置导致整个作业延迟,这时候可以考虑使用[kube-batch](https://github.com/kubernetes-incubator/kube-batch)。
|
||||||
|
|
|
||||||
|
|
@ -265,7 +265,7 @@ chmod +x ./kubectl
|
||||||
|
|
||||||
如果不是, 请安装[更新版本的helm CLI](https://github.com/kubernetes/helm#install)并运行`helm init --upgrade`。
|
如果不是, 请安装[更新版本的helm CLI](https://github.com/kubernetes/helm#install)并运行`helm init --upgrade`。
|
||||||
|
|
||||||
有关安装的更多详细信息,请参阅 [Helm安装说明](https://github.com/kubernetes/helm/blob/master/docs/install.md)。
|
有关安装的更多详细信息,请参阅 Helm安装说明。
|
||||||
|
|
||||||
#### Tiller 权限
|
#### Tiller 权限
|
||||||
Tiller是Helm的服务端组件。默认情况下, helm init将Tiller pod安装到kube-system名称空间中,并将Tiller配置为使用default服务帐户(service account)。
|
Tiller是Helm的服务端组件。默认情况下, helm init将Tiller pod安装到kube-system名称空间中,并将Tiller配置为使用default服务帐户(service account)。
|
||||||
|
|
@ -278,9 +278,9 @@ kubectl create clusterrolebinding tiller-cluster-admin \
|
||||||
--serviceaccount=kube-system:default
|
--serviceaccount=kube-system:default
|
||||||
```
|
```
|
||||||
### Helm Repository设置
|
### Helm Repository设置
|
||||||
Service Catalog很容易通过[Helm chart](https://github.com/kubernetes/helm/blob/master/docs/charts.md)安装 。
|
Service Catalog很容易通过 Helm chart 安装 。
|
||||||
|
|
||||||
此chart位于 [chart repository](https://github.com/kubernetes/helm/blob/master/docs/chart_repository.md)中。将此repository添加到本地计算机:
|
此chart位于 chart repository 中。将此repository添加到本地计算机:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
helm repo add svc-cat https://svc-catalog-charts.storage.googleapis.com
|
helm repo add svc-cat https://svc-catalog-charts.storage.googleapis.com
|
||||||
|
|
|
||||||
|
|
@ -1,3 +1,3 @@
|
||||||
# 服务发现
|
# 服务发现
|
||||||
|
|
||||||
Kubernetes中为了实现服务实例间的负载均衡和不同服务间的服务发现,创造了Serivce对象,同时又为从集群外部访问集群创建了Ingress对象。
|
Kubernetes中为了实现服务实例间的负载均衡和不同服务间的服务发现,创造了Serivce对象,同时又为从集群外部访问集群创建了Ingress对象。
|
||||||
|
|
|
||||||
|
|
@ -1,7 +1,7 @@
|
||||||
# Service
|
# Service
|
||||||
|
|
||||||
Kubernetes [`Pod`](https://kubernetes.io/docs/user-guide/pods) 是有生命周期的,它们可以被创建,也可以被销毁,然而一旦被销毁生命就永远结束。
|
Kubernetes [`Pod`](https://kubernetes.io/docs/user-guide/pods) 是有生命周期的,它们可以被创建,也可以被销毁,然而一旦被销毁生命就永远结束。
|
||||||
通过 [`ReplicationController`](https://kubernetes.io/docs/user-guide/replication-controller) 能够动态地创建和销毁 `Pod`(例如,需要进行扩缩容,或者执行 [滚动升级](https://kubernetes.io/docs/user-guide/kubectl/v1.7/#rolling-update))。
|
通过 [`ReplicationController`](https://kubernetes.io/docs/user-guide/replication-controller) 能够动态地创建和销毁 `Pod`。
|
||||||
每个 `Pod` 都会获取它自己的 IP 地址,即使这些 IP 地址不总是稳定可依赖的。
|
每个 `Pod` 都会获取它自己的 IP 地址,即使这些 IP 地址不总是稳定可依赖的。
|
||||||
这会导致一个问题:在 Kubernetes 集群中,如果一组 `Pod`(称为 backend)为其它 `Pod` (称为 frontend)提供服务,那么那些 frontend 该如何发现,并连接到这组 `Pod` 中的哪些 backend 呢?
|
这会导致一个问题:在 Kubernetes 集群中,如果一组 `Pod`(称为 backend)为其它 `Pod` (称为 frontend)提供服务,那么那些 frontend 该如何发现,并连接到这组 `Pod` 中的哪些 backend 呢?
|
||||||
|
|
||||||
|
|
@ -195,7 +195,7 @@ spec:
|
||||||
## 选择自己的 IP 地址
|
## 选择自己的 IP 地址
|
||||||
|
|
||||||
在 `Service` 创建的请求中,可以通过设置 `spec.clusterIP` 字段来指定自己的集群 IP 地址。
|
在 `Service` 创建的请求中,可以通过设置 `spec.clusterIP` 字段来指定自己的集群 IP 地址。
|
||||||
比如,希望替换一个已经已存在的 DNS 条目,或者遗留系统已经配置了一个固定的 IP 且很难重新配置。
|
比如,希望替换一个已经存在的 DNS 条目,或者遗留系统已经配置了一个固定的 IP 且很难重新配置。
|
||||||
用户选择的 IP 地址必须合法,并且这个 IP 地址在 `service-cluster-ip-range` CIDR 范围内,这对 API Server 来说是通过一个标识来指定的。
|
用户选择的 IP 地址必须合法,并且这个 IP 地址在 `service-cluster-ip-range` CIDR 范围内,这对 API Server 来说是通过一个标识来指定的。
|
||||||
如果 IP 地址不合法,API Server 会返回 HTTP 状态码 422,表示值不合法。
|
如果 IP 地址不合法,API Server 会返回 HTTP 状态码 422,表示值不合法。
|
||||||
|
|
||||||
|
|
@ -216,7 +216,7 @@ Kubernetes 支持2种基本的服务发现模式 —— 环境变量和 DNS。
|
||||||
### 环境变量
|
### 环境变量
|
||||||
|
|
||||||
当 `Pod` 运行在 `Node` 上,kubelet 会为每个活跃的 `Service` 添加一组环境变量。
|
当 `Pod` 运行在 `Node` 上,kubelet 会为每个活跃的 `Service` 添加一组环境变量。
|
||||||
它同时支持 [Docker links 兼容](https://docs.docker.com/userguide/dockerlinks/) 变量(查看 [makeLinkVariables](http://releases.k8s.io/{{page.githubbranch}}/pkg/kubelet/envvars/envvars.go#L49))、简单的 `{SVCNAME}_SERVICE_HOST` 和 `{SVCNAME}_SERVICE_PORT` 变量,这里 `Service` 的名称需大写,横线被转换成下划线。
|
它同时支持 [Docker links 兼容](https://docs.docker.com/userguide/dockerlinks/) 变量(查看 makeLinkVariables)、简单的 `{SVCNAME}_SERVICE_HOST` 和 `{SVCNAME}_SERVICE_PORT` 变量,这里 `Service` 的名称需大写,横线被转换成下划线。
|
||||||
|
|
||||||
举个例子,一个名称为 `"redis-master"` 的 Service 暴露了 TCP 端口 6379,同时给它分配了 Cluster IP 地址 10.0.0.11,这个 Service 生成了如下环境变量:
|
举个例子,一个名称为 `"redis-master"` 的 Service 暴露了 TCP 端口 6379,同时给它分配了 Cluster IP 地址 10.0.0.11,这个 Service 生成了如下环境变量:
|
||||||
|
|
||||||
|
|
@ -464,8 +464,8 @@ Kubernetes 最主要的哲学之一,是用户不应该暴露那些能够导致
|
||||||
|
|
||||||
## API 对象
|
## API 对象
|
||||||
|
|
||||||
在 Kubernetes REST API 中,Service 是 top-level 资源。关于 API 对象的更多细节可以查看:[Service API 对象](https://kubernetes.io/docs/api-reference/v1.7/#service-v1-core)。
|
在 Kubernetes REST API 中,Service 是 top-level 资源。
|
||||||
|
|
||||||
## 更多信息
|
## 更多信息
|
||||||
|
|
||||||
- [使用 Service 连接 Frontend 到 Backend](https://kubernetes.io/docs/tutorials/connecting-apps/connecting-frontend-backend/)
|
- [使用 Service 连接 Frontend 到 Backend](https://kubernetes.io/docs/tutorials/connecting-apps/connecting-frontend-backend/)
|
||||||
|
|
|
||||||
|
|
@ -4,7 +4,7 @@ Service Account为Pod中的进程提供身份信息。
|
||||||
|
|
||||||
**注意**:**本文是关于 Service Account 的用户指南,管理指南另见 Service Account 的集群管理指南 。**
|
**注意**:**本文是关于 Service Account 的用户指南,管理指南另见 Service Account 的集群管理指南 。**
|
||||||
|
|
||||||
> 本文档描述的关于 Serivce Account 的行为只有当您按照 Kubernetes 项目建议的方式搭建起集群的情况下才有效。您的集群管理员可能在您的集群中有自定义配置,这种情况下该文档可能并不适用。
|
> 本文档描述的关于 Service Account 的行为只有当您按照 Kubernetes 项目建议的方式搭建起集群的情况下才有效。您的集群管理员可能在您的集群中有自定义配置,这种情况下该文档可能并不适用。
|
||||||
|
|
||||||
当您(真人用户)访问集群(例如使用`kubectl`命令)时,apiserver 会将您认证为一个特定的 User Account(目前通常是`admin`,除非您的系统管理员自定义了集群配置)。Pod 容器中的进程也可以与 apiserver 联系。 当它们在联系 apiserver 的时候,它们会被认证为一个特定的 Service Account(例如`default`)。
|
当您(真人用户)访问集群(例如使用`kubectl`命令)时,apiserver 会将您认证为一个特定的 User Account(目前通常是`admin`,除非您的系统管理员自定义了集群配置)。Pod 容器中的进程也可以与 apiserver 联系。 当它们在联系 apiserver 的时候,它们会被认证为一个特定的 Service Account(例如`default`)。
|
||||||
|
|
||||||
|
|
@ -205,4 +205,4 @@ spec:
|
||||||
|
|
||||||
## 参考
|
## 参考
|
||||||
|
|
||||||
- [Configure Service Accounts for Pods](https://kubernetes.io/docs/tasks/configure-pod-container/configure-service-account/)
|
- [Configure Service Accounts for Pods](https://kubernetes.io/docs/tasks/configure-pod-container/configure-service-account/)
|
||||||
|
|
|
||||||
|
|
@ -41,7 +41,7 @@ StatefulSet 适用于有以下某个或多个需求的应用:
|
||||||
|
|
||||||
- StatefulSet 是 beta 资源,Kubernetes 1.5 以前版本不支持。
|
- StatefulSet 是 beta 资源,Kubernetes 1.5 以前版本不支持。
|
||||||
- 对于所有的 alpha/beta 的资源,您都可以通过在 apiserver 中设置 `--runtime-config` 选项来禁用。
|
- 对于所有的 alpha/beta 的资源,您都可以通过在 apiserver 中设置 `--runtime-config` 选项来禁用。
|
||||||
- 给定 Pod 的存储必须由 [PersistentVolume Provisioner](http://releases.k8s.io/%7B%7Bpage.githubbranch%7D%7D/examples/persistent-volume-provisioning/README.md) 根据请求的 `storage class` 进行配置,或由管理员预先配置。
|
- 给定 Pod 的存储必须由 PersistentVolume Provisioner 根据请求的 `storage class` 进行配置,或由管理员预先配置。
|
||||||
- 删除或 scale StatefulSet 将_不会_删除与 StatefulSet 相关联的 volume。 这样做是为了确保数据安全性,这通常比自动清除所有相关 StatefulSet 资源更有价值。
|
- 删除或 scale StatefulSet 将_不会_删除与 StatefulSet 相关联的 volume。 这样做是为了确保数据安全性,这通常比自动清除所有相关 StatefulSet 资源更有价值。
|
||||||
- StatefulSets 目前要求 [Headless Service](https://kubernetes.io/docs/concepts/services-networking/service/#headless-services) 负责 Pod 的网络身份。 您有责任创建此服务。
|
- StatefulSets 目前要求 [Headless Service](https://kubernetes.io/docs/concepts/services-networking/service/#headless-services) 负责 Pod 的网络身份。 您有责任创建此服务。
|
||||||
|
|
||||||
|
|
@ -114,7 +114,7 @@ StatefulSet Pod 具有唯一的身份,包括序数,稳定的网络身份和
|
||||||
|
|
||||||
StatefulSet 中的每个 Pod 从 StatefulSet 的名称和 Pod 的序数派生其主机名。构造的主机名的模式是`$(statefulset名称)-$(序数)`。 上面的例子将创建三个名为`web-0,web-1,web-2`的 Pod。
|
StatefulSet 中的每个 Pod 从 StatefulSet 的名称和 Pod 的序数派生其主机名。构造的主机名的模式是`$(statefulset名称)-$(序数)`。 上面的例子将创建三个名为`web-0,web-1,web-2`的 Pod。
|
||||||
|
|
||||||
StatefulSet 可以使用 [Headless Service](https://kubernetes.io/docs/concepts/services-networking/service/#headless-services) 来控制其 Pod 的域。此服务管理的域的格式为:`$(服务名称).$(namespace).svc.cluster.local`,其中 “cluster.local” 是 [集群域](http://releases.k8s.io/%7B%7Bpage.githubbranch%7D%7D/cluster/addons/dns/README.md)。
|
StatefulSet 可以使用 [Headless Service](https://kubernetes.io/docs/concepts/services-networking/service/#headless-services) 来控制其 Pod 的域。此服务管理的域的格式为:`$(服务名称).$(namespace).svc.cluster.local`,其中 “cluster.local” 是集群域。
|
||||||
|
|
||||||
在创建每个Pod时,它将获取一个匹配的 DNS 子域,采用以下形式:`$(pod 名称).$(管理服务域)`,其中管理服务由 StatefulSet 上的 `serviceName` 字段定义。
|
在创建每个Pod时,它将获取一个匹配的 DNS 子域,采用以下形式:`$(pod 名称).$(管理服务域)`,其中管理服务由 StatefulSet 上的 `serviceName` 字段定义。
|
||||||
|
|
||||||
|
|
@ -126,7 +126,7 @@ StatefulSet 可以使用 [Headless Service](https://kubernetes.io/docs/concepts/
|
||||||
| cluster.local | foo/nginx | foo/web | nginx.foo.svc.cluster.local | web-{0..N-1}.nginx.foo.svc.cluster.local | web-{0..N-1} |
|
| cluster.local | foo/nginx | foo/web | nginx.foo.svc.cluster.local | web-{0..N-1}.nginx.foo.svc.cluster.local | web-{0..N-1} |
|
||||||
| kube.local | foo/nginx | foo/web | nginx.foo.svc.kube.local | web-{0..N-1}.nginx.foo.svc.kube.local | web-{0..N-1} |
|
| kube.local | foo/nginx | foo/web | nginx.foo.svc.kube.local | web-{0..N-1}.nginx.foo.svc.kube.local | web-{0..N-1} |
|
||||||
|
|
||||||
注意 Cluster Domain 将被设置成 `cluster.local` 除非进行了 [其他配置](http://releases.k8s.io/%7B%7Bpage.githubbranch%7D%7D/cluster/addons/dns/README.md)。
|
注意 Cluster Domain 将被设置成 `cluster.local` 除非进行了其他配置。
|
||||||
|
|
||||||
### 稳定存储
|
### 稳定存储
|
||||||
|
|
||||||
|
|
@ -491,7 +491,7 @@ kubectl expose po zk-1 --port=2181 --target-port=2181 --name=zk-1 --selector=zkI
|
||||||
|
|
||||||
查看`zk-0`这个service可以看到如下结果:
|
查看`zk-0`这个service可以看到如下结果:
|
||||||
|
|
||||||
```
|
```bash
|
||||||
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||||
zk-0 10.254.98.14 <nodes> 2181:31693/TCP 5m
|
zk-0 10.254.98.14 <nodes> 2181:31693/TCP 5m
|
||||||
```
|
```
|
||||||
|
|
@ -500,6 +500,6 @@ zk-0 10.254.98.14 <nodes> 2181:31693/TCP 5m
|
||||||
|
|
||||||
## 参考
|
## 参考
|
||||||
|
|
||||||
https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/
|
- https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/
|
||||||
|
|
||||||
[kubernetes contrib - statefulsets](https://github.com/kubernetes/contrib/tree/master/statefulsets)
|
- [kubernetes contrib - statefulsets](https://github.com/kubernetes/contrib/tree/master/statefulsets)
|
||||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue