5.4 KiB
使用 Prometheus 监控 Kubernetes 集群
我们使用 Giantswarm 开源的 kubernetes-promethues 来监控 kubernetes 集群,所有的 YAML 文件可以在 ../manifests/prometheus 目录下找到。
需要用到的镜像有:
- harbor-001.jimmysong.io/library/prometheus-alertmanager:v0.7.1
- harbor-001.jimmysong.io/library/grafana:4.2.0
- harbor-001.jimmysong.io/library/giantswarm-tiny-tools:latest
- harbor-001.jimmysong.io/library/prom-prometheus:v1.7.0
- harbor-001.jimmysong.io/library/kube-state-metrics:v1.0.1
- harbor-001.jimmysong.io/library/dockermuenster-caddy:0.9.3
- harbor-001.jimmysong.io/library/prom-node-exporter:v0.14.0
注:所有镜像都是从官方镜像仓库下载下。
部署
我将部署时需要用的的配置文件分成了 namespace、serviceaccount、configmaps、clusterrolebinding 和最后的部署 prometheus、grafana 的过程。
## 创建 monitoring namespaece
kubectl create -f prometheus-monitoring-ns.yaml
## 创建 serviceaccount
kubectl create -f prometheus-monitoring-serviceaccount.yaml
## 创建 configmaps
kubectl create -f prometheus-configmaps.yaml
## 创建 clusterrolebinding
kubectl create clusterrolebinding kube-state-metrics --clusterrole=cluster-admin --serviceaccount=monitoring:kube-state-metrics
kubectl create clusterrolebinding prometheus --clusterrole=cluster-admin --serviceaccount=monitoring:prometheus
## 部署 Prometheus
kubectl create -f prometheus-monitoring.yaml
访问 kubernetes 任何一个 node 上的 Grafana service 的 nodeport:
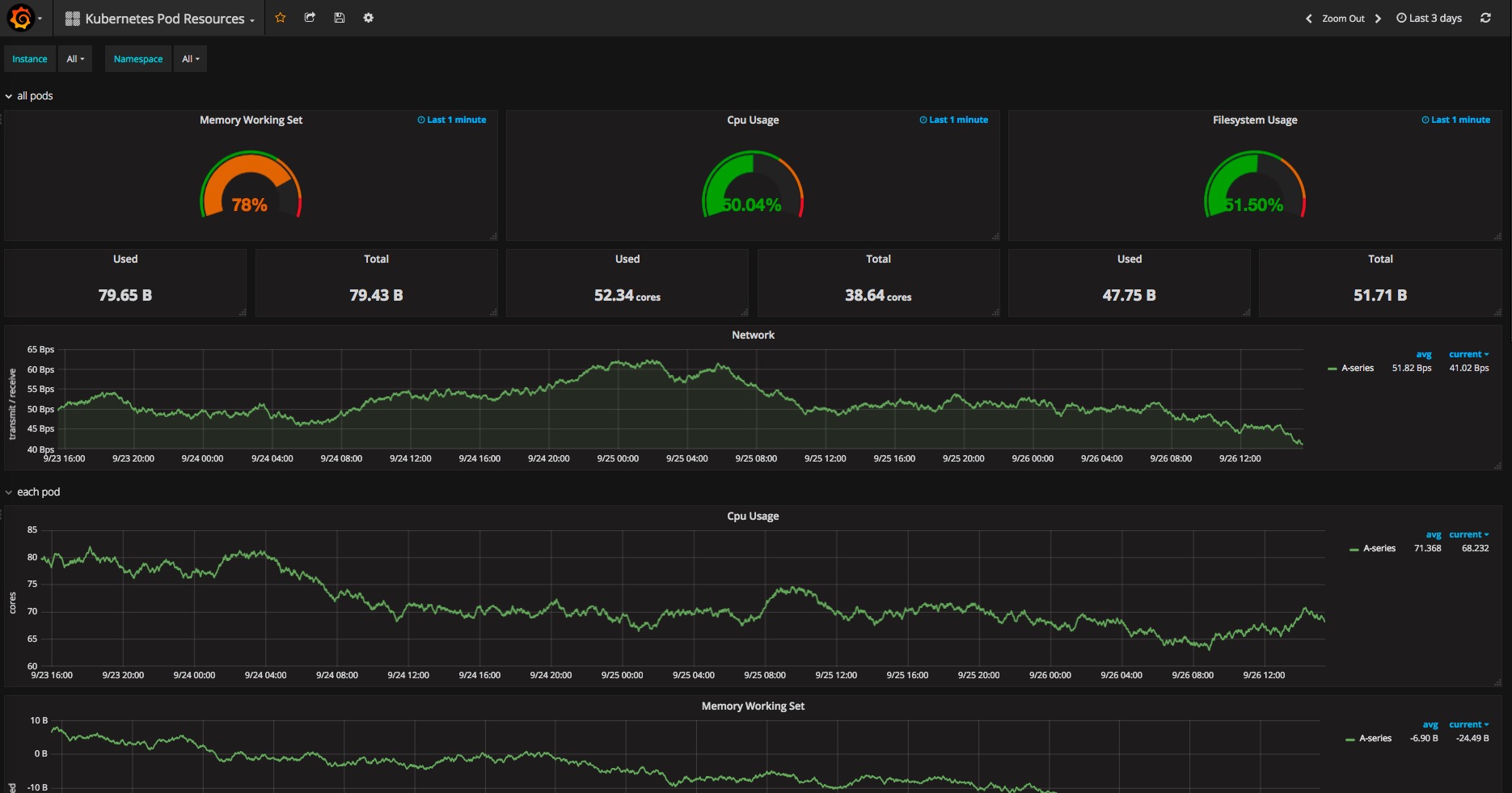
该图中的数据显示明显有问题,还需要修正。
prometheus-monitoring.yaml 文件中有一个 Job 就是用来导入 grafana dashboard 配置信息的,如果该 Job 执行失败,可以单独在在 monitoring 的 namespace 中启动一个容器,将 manifests/prometheus 目录下的 json 文件复制到容器中,然后进入容器 json 文件的目录下执行:
for file in *-datasource.json ; do
if [ -e "$file" ] ; then
echo "importing $file" &&
curl --silent --fail --show-error \
--request POST http://admin:admin@grafana:3000/api/datasources \
--header "Content-Type: application/json" \
--data-binary "@$file" ;
echo "" ;
fi
done ;
for file in *-dashboard.json ; do
if [ -e "$file" ] ; then
echo "importing $file" &&
( echo '{"dashboard":'; \
cat "$file"; \
echo ',"overwrite":true,"inputs":[{"name":"DS_PROMETHEUS","type":"datasource","pluginId":"prometheus","value":"prometheus"}]}' ) \
| jq -c '.' \
| curl --silent --fail --show-error \
--request POST http://admin:admin@grafana:3000/api/dashboards/import \
--header "Content-Type: application/json" \
--data-binary "@-" ;
echo "" ;
fi
done
这样也可以向 grafana 中导入 dashboard。
存在的问题
该项目的代码中存在几个问题。
1. RBAC 角色授权问题
需要用到两个 clusterrolebinding:
kube-state-metrics,对应的serviceaccount是kube-state-metricsprometheus,对应的serviceaccount是prometheus-k8s
在部署 Prometheus 之前应该先创建 serviceaccount、clusterrole、clusterrolebinding 等对象,否则在安装过程中可能因为权限问题而导致各种错误,所以这些配置应该写在一个单独的文件中,而不应该跟其他部署写在一起,即使要写在一个文件中,也应该写在文件的最前面,因为使用 kubectl 部署的时候,kubectl 不会判断 YAML 文件中的资源依赖关系,只是简单的从头部开始执行部署,因此写在文件前面的对象会先部署。
解决方法
也可以绕过复杂的 RBAC 设置,直接使用下面的命令将对应的 serviceaccount 设置成 admin 权限,如下:
kubectl create clusterrolebinding kube-state-metrics --clusterrole=cluster-admin --serviceaccount=monitoring:kube-state-metrics
kubectl create clusterrolebinding prometheus --clusterrole=cluster-admin --serviceaccount=monitoring:prometheus
参考 基于角色的访问控制。
2. API 兼容问题
从 kube-state-metrics 日志中可以看出用户 kube-state-metrics 没有权限访问如下资源类型:
- *v1.Job
- *v1.PersistentVolumeClaim
- *v1beta1.StatefulSet
- *v2alpha1.CronJob
而在我们使用的 kubernetes 1.6.0 版本的集群中 API 路径跟 kube-state-metrics 中不同,无法 list 以上三种资源对象的资源。
3. Job 中的权限认证问题
在 grafana-import-dashboards 这个 job 中有个 init-containers 其中指定的 command 执行错误,应该使用
curl -sX GET -H "Authorization:bearer `cat /var/run/secrets/kubernetes.io/serviceaccount/token`" -k https://kubernetes.default/api/v1/namespaces/monitoring/endpoints/grafana
不需要指定 csr 文件,只需要 token 即可。