2.7 KiB
Mesos 基本原理与架构
首先,Mesos 自身只是一个资源调度框架,并非一整套完整的应用管理平台,本身是不能干活的。但是它可以比较容易的跟各种应用管理或者中间件平台整合,一起工作,提高资源使用效率。
架构
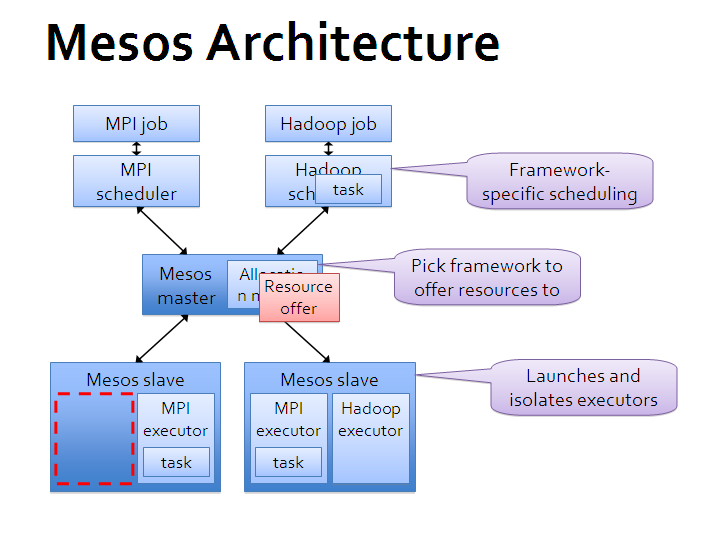 master-slave 架构,master 使用 zookeeper 来做 HA。
master-slave 架构,master 使用 zookeeper 来做 HA。
master 单独运行在管理节点上,slave 运行在各个计算任务节点上。
各种具体任务的管理平台,即 framework 跟 master 交互,来申请资源。
基本单元
master
负责整体的资源调度和逻辑控制。
slave
负责汇报本节点上的资源给 master,并负责隔离资源来执行具体的任务。
隔离机制当然就是各种容器机制了。
framework
framework 是实际干活的,包括两个主要组件:
- scheduler:注册到主节点,等待分配资源;
- executor:在 slave 节点上执行本framework 的任务。
framework 分两种:一种是对资源需求可以 scale up 或者 down 的(Hadoop、Spark);一种是对资源需求大小是固定的(MPI)。
调度
对于一个资源调度框架来说,最核心的就是调度机制,怎么能快速高效的完成对某个 framework 资源的分配(最好是能猜到它的实际需求)。
两层调度算法:
master 先调度一大块资源给某个 framework,framework 自己再实现内部的细粒度调度。
调度机制支持插件。默认是 DRF。
基本调度过程
调度通过 offer 方式交互:
- master 提供一个 offer(一组资源) 给 framework;
- framework 可以决定要不要,如果接受的话,返回一个描述,说明自己希望如何使用和分配这些资源(可以说明只希望使用部分资源,则多出来的会被 master 收回);
- master 则根据 framework 的分配情况发送给 slave,以使用 framework 的 executor 来按照分配的资源策略执行任务。
过滤器
framework 可以通过过滤器机制告诉 master 它的资源偏好,比如希望分配过来的 offer 有哪个资源,或者至少有多少资源。
主要是为了加速资源分配的交互过程。
回头机制
master 可以通过回收计算节点上的任务来动态调整长期任务和短期任务的分布。
HA
master
master 节点存在单点失效问题,所以肯定要上 HA,目前主要是使用 zookpeer 来热备份。
同时 master 节点可以通过 slave 和 framework 发来的消息重建内部状态(具体能有多快呢?这里不使用数据库可能是避免引入复杂度。)。
framework 通知
framework 中相关的失效,master 将发给它的 scheduler 来通知。