mirror of https://github.com/dunwu/db-tutorial.git
docs: 更新文档
parent
4090bf9621
commit
651a6dbac0
101
README.md
101
README.md
|
|
@ -31,56 +31,37 @@
|
|||
> - 🔁 项目同步维护:[Github](https://github.com/dunwu/db-tutorial/) | [Gitee](https://gitee.com/turnon/db-tutorial/)
|
||||
> - 📖 电子书阅读:[Github Pages](https://dunwu.github.io/db-tutorial/) | [Gitee Pages](https://turnon.gitee.io/db-tutorial/)
|
||||
|
||||
## 分布式
|
||||
|
||||
### 分布式综合
|
||||
|
||||
- [分布式面试总结](https://dunwu.github.io/blog/pages/f9209d/)
|
||||
|
||||
### 分布式理论
|
||||
|
||||
- [分布式理论](https://dunwu.github.io/blog/pages/286bb3/) - 关键词:`拜占庭将军`、`CAP`、`BASE`、`错误的分布式假设`
|
||||
- [共识性算法 Paxos](https://dunwu.github.io/blog/pages/0276bb/) - 关键词:`共识性算法`
|
||||
- [共识性算法 Raft](https://dunwu.github.io/blog/pages/4907dc/) - 关键词:`共识性算法`
|
||||
- [分布式算法 Gossip](https://dunwu.github.io/blog/pages/71539a/) - 关键词:`数据传播`
|
||||
|
||||
### 分布式关键技术
|
||||
|
||||
- 集群
|
||||
- 复制
|
||||
- 分区
|
||||
- 选主
|
||||
|
||||
#### 流量调度
|
||||
|
||||
- [流量控制](https://dunwu.github.io/blog/pages/60bb6d/) - 关键词:`限流`、`熔断`、`降级`、`计数器法`、`时间窗口法`、`令牌桶法`、`漏桶法`
|
||||
- [负载均衡](https://dunwu.github.io/blog/pages/98a1c1/) - 关键词:`轮询`、`随机`、`最少连接`、`源地址哈希`、`一致性哈希`、`虚拟 hash 槽`
|
||||
- [服务路由](https://dunwu.github.io/blog/pages/3915e8/) - 关键词:`路由`、`条件路由`、`脚本路由`、`标签路由`
|
||||
- 服务网关
|
||||
- [分布式会话](https://dunwu.github.io/blog/pages/95e45f/) - 关键词:`粘性 Session`、`Session 复制共享`、`基于缓存的 session 共享`
|
||||
|
||||
#### 数据调度
|
||||
|
||||
- [数据缓存](https://dunwu.github.io/blog/pages/fd0aaa/) - 关键词:`进程内缓存`、`分布式缓存`、`缓存雪崩`、`缓存穿透`、`缓存击穿`、`缓存更新`、`缓存预热`、`缓存降级`
|
||||
- [读写分离](https://dunwu.github.io/blog/pages/3faf18/)
|
||||
- [分库分表](https://dunwu.github.io/blog/pages/e1046e/) - 关键词:`分片`、`路由`、`迁移`、`扩容`、`双写`、`聚合`
|
||||
- [分布式 ID](https://dunwu.github.io/blog/pages/3ae455/) - 关键词:`UUID`、`自增序列`、`雪花算法`、`Leaf`
|
||||
- [分布式事务](https://dunwu.github.io/blog/pages/e1881c/) - 关键词:`2PC`、`3PC`、`TCC`、`本地消息表`、`MQ 消息`、`SAGA`
|
||||
- [分布式锁](https://dunwu.github.io/blog/pages/40ac64/) - 关键词:`数据库`、`Redis`、`ZooKeeper`、`互斥`、`可重入`、`死锁`、`容错`、`自旋尝试`
|
||||
|
||||
#### 资源调度
|
||||
|
||||
- 弹性伸缩
|
||||
|
||||
#### 服务治理
|
||||
|
||||
- [服务注册和发现](https://dunwu.github.io/blog/pages/1a90aa/)
|
||||
- [服务容错](https://dunwu.github.io/blog/pages/e32c7e/)
|
||||
- 服务编排
|
||||
- 服务版本管理
|
||||
|
||||
## 数据库综合
|
||||
|
||||
### 分布式存储原理
|
||||
|
||||
#### 分布式理论
|
||||
|
||||
- [分布式一致性](https://dunwu.github.io/blog/pages/dac0e2/)
|
||||
- [深入剖析共识性算法 Paxos](https://dunwu.github.io/blog/pages/874539/)
|
||||
- [深入剖析共识性算法 Raft](https://dunwu.github.io/blog/pages/e40812/)
|
||||
- [分布式算法 Gossip](https://dunwu.github.io/blog/pages/d15993/)
|
||||
|
||||
#### 分布式关键技术
|
||||
|
||||
##### 流量调度
|
||||
|
||||
- [流量控制](https://dunwu.github.io/blog/pages/282676/)
|
||||
- [负载均衡](https://dunwu.github.io/blog/pages/98a1c1/)
|
||||
- [服务路由](https://dunwu.github.io/blog/pages/d04ece/)
|
||||
- [分布式会话基本原理](https://dunwu.github.io/blog/pages/3e66c2/)
|
||||
|
||||
##### 数据调度
|
||||
|
||||
- [缓存基本原理](https://dunwu.github.io/blog/pages/471208/)
|
||||
- [读写分离基本原理](https://dunwu.github.io/blog/pages/7da6ca/)
|
||||
- [分库分表基本原理](https://dunwu.github.io/blog/pages/103382/)
|
||||
- [分布式 ID 基本原理](https://dunwu.github.io/blog/pages/0b2e59/)
|
||||
- [分布式事务基本原理](https://dunwu.github.io/blog/pages/910bad/)
|
||||
- [分布式锁基本原理](https://dunwu.github.io/blog/pages/69360c/)
|
||||
|
||||
### 其他
|
||||
|
||||
- [Nosql 技术选型](docs/12.数据库/01.数据库综合/01.Nosql技术选型.md)
|
||||
- [数据结构与数据库索引](docs/12.数据库/01.数据库综合/02.数据结构与数据库索引.md)
|
||||
|
||||
|
|
@ -94,11 +75,13 @@
|
|||
|
||||
> [关系型数据库](docs/12.数据库/03.关系型数据库) 整理主流关系型数据库知识点。
|
||||
|
||||
### 公共知识
|
||||
### 关系型数据库综合
|
||||
|
||||
- [关系型数据库面试总结](docs/12.数据库/03.关系型数据库/01.综合/01.关系型数据库面试.md) 💯
|
||||
- [SQL Cheat Sheet](docs/12.数据库/03.关系型数据库/01.综合/02.SqlCheatSheet.md) 是一个 SQL 入门教程。
|
||||
- [扩展 SQL](docs/12.数据库/03.关系型数据库/01.综合/03.扩展SQL.md) 是一个 SQL 入门教程。
|
||||
- [SQL 语法基础特性](docs/12.数据库/03.关系型数据库/01.综合/02.SQL语法基础特性.md)
|
||||
- [SQL 语法高级特性](docs/12.数据库/03.关系型数据库/01.综合/03.SQL语法高级特性.md)
|
||||
- [扩展 SQL](docs/12.数据库/03.关系型数据库/01.综合/03.扩展SQL.md)
|
||||
- [SQL Cheat Sheet](docs/12.数据库/03.关系型数据库/01.综合/99.SqlCheatSheet.md)
|
||||
|
||||
### Mysql
|
||||
|
||||
|
|
@ -161,12 +144,16 @@
|
|||
|
||||
### HBase
|
||||
|
||||
> [HBase](https://dunwu.github.io/bigdata-tutorial/hbase) 📚 因为常用于大数据项目,所以将其文档和源码整理在 [bigdata-tutorial](https://dunwu.github.io/bigdata-tutorial/) 项目中。
|
||||
|
||||
- [HBase 原理](https://github.com/dunwu/bigdata-tutorial/blob/master/docs/hbase/HBase原理.md) ⚡
|
||||
- [HBase 命令](https://github.com/dunwu/bigdata-tutorial/blob/master/docs/hbase/HBase命令.md)
|
||||
- [HBase 应用](https://github.com/dunwu/bigdata-tutorial/blob/master/docs/hbase/HBase应用.md)
|
||||
- [HBase 运维](https://github.com/dunwu/bigdata-tutorial/blob/master/docs/hbase/HBase运维.md)
|
||||
- [HBase 快速入门](docs/12.数据库/06.列式数据库/01.HBase/01.HBase快速入门.md)
|
||||
- [HBase 数据模型](docs/12.数据库/06.列式数据库/01.HBase/02.HBase数据模型.md)
|
||||
- [HBase Schema 设计](docs/12.数据库/06.列式数据库/01.HBase/03.HBaseSchema设计.md)
|
||||
- [HBase 架构](docs/12.数据库/06.列式数据库/01.HBase/04.HBase架构.md)
|
||||
- [HBase Java API 基础特性](docs/12.数据库/06.列式数据库/01.HBase/10.HBaseJavaApi基础特性.md)
|
||||
- [HBase Java API 高级特性之过滤器](docs/12.数据库/06.列式数据库/01.HBase/11.HBaseJavaApi高级特性之过滤器.md)
|
||||
- [HBase Java API 高级特性之协处理器](docs/12.数据库/06.列式数据库/01.HBase/12.HBaseJavaApi高级特性之协处理器.md)
|
||||
- [HBase Java API 其他高级特性](docs/12.数据库/06.列式数据库/01.HBase/13.HBaseJavaApi其他高级特性.md)
|
||||
- [HBase 运维](docs/12.数据库/06.列式数据库/01.HBase/21.HBase运维.md)
|
||||
- [HBase 命令](docs/12.数据库/06.列式数据库/01.HBase/22.HBase命令.md)
|
||||
|
||||
## 搜索引擎数据库
|
||||
|
||||
|
|
|
|||
|
|
@ -8,12 +8,13 @@ categories:
|
|||
tags:
|
||||
- 数据库
|
||||
- 关系型数据库
|
||||
- 面试
|
||||
permalink: /pages/9bb28f/
|
||||
---
|
||||
|
||||
# 关系型数据库面试
|
||||
|
||||
## 一、索引和约束
|
||||
## 索引和约束
|
||||
|
||||
### 什么是索引
|
||||
|
||||
|
|
@ -252,7 +253,7 @@ MySQL 会一直向右匹配直到遇到范围查询 `(>,<,BETWEEN,LIKE)` 就停
|
|||
- `FOREIGN KEY` - 在一个表中存在的另一个表的主键称此表的外键。用于预防破坏表之间连接的动作,也能防止非法数据插入外键列,因为它必须是它指向的那个表中的值之一。
|
||||
- `CHECK` - 用于控制字段的值范围。
|
||||
|
||||
## 二、并发控制
|
||||
## 并发控制
|
||||
|
||||
### 乐观锁和悲观锁
|
||||
|
||||
|
|
@ -336,7 +337,7 @@ MVCC 不能解决幻读问题,**Next-Key 锁就是为了解决幻读问题**
|
|||
|
||||
当两个事务同时执行,一个锁住了主键索引,在等待其他相关索引。另一个锁定了非主键索引,在等待主键索引。这样就会发生死锁。发生死锁后,`InnoDB` 一般都可以检测到,并使一个事务释放锁回退,另一个获取锁完成事务。
|
||||
|
||||
## 三、事务
|
||||
## 事务
|
||||
|
||||
> 事务简单来说:**一个 Session 中所进行所有的操作,要么同时成功,要么同时失败**。具体来说,事务指的是满足 ACID 特性的一组操作,可以通过 `Commit` 提交一个事务,也可以使用 `Rollback` 进行回滚。
|
||||
|
||||
|
|
@ -441,7 +442,7 @@ T<sub>1</sub> 读取某个范围的数据,T<sub>2</sub> 在这个范围内插
|
|||
| 并发性能 | 无影响 | 严重衰退 | 略微衰退 |
|
||||
| 适合场景 | 业务方处理不一致 | 短事务 & 低并发 | 长事务 & 高并发 |
|
||||
|
||||
## 四、分库分表
|
||||
## 分库分表
|
||||
|
||||
### 什么是分库分表
|
||||
|
||||
|
|
@ -577,7 +578,7 @@ T<sub>1</sub> 读取某个范围的数据,T<sub>2</sub> 在这个范围内插
|
|||
|
||||
来自淘宝综合业务平台团队,它利用对 2 的倍数取余具有向前兼容的特性(如对 4 取余得 1 的数对 2 取余也是 1)来分配数据,避免了行级别的数据迁移,但是依然需要进行表级别的迁移,同时对扩容规模和分表数量都有限制。总得来说,这些方案都不是十分的理想,多多少少都存在一些缺点,这也从一个侧面反映出了 Sharding 扩容的难度。
|
||||
|
||||
## 五、集群
|
||||
## 集群
|
||||
|
||||
> 这个专题需要根据熟悉哪个数据库而定,但是主流、成熟的数据库都会实现一些基本功能,只是实现方式、策略上有所差异。由于本人较为熟悉 Mysql,所以下面主要介绍 Mysql 系统架构问题。
|
||||
|
||||
|
|
@ -609,7 +610,7 @@ MySQL 读写分离能提高性能的原因在于:
|
|||
|
||||
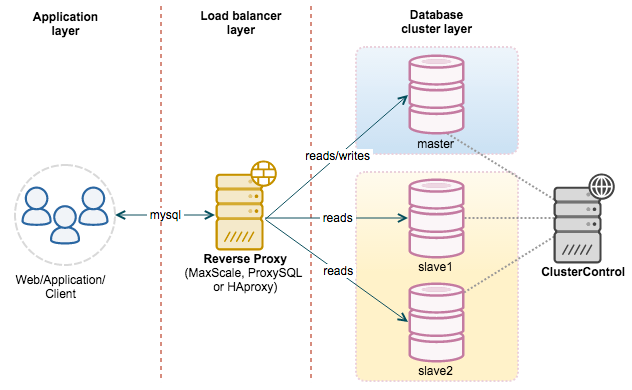
|
||||
|
||||
## 六、数据库优化
|
||||
## 数据库优化
|
||||
|
||||
数据库优化的路线一般为:SQL 优化、结构优化、配置优化、硬件优化。前两个方向一般是普通开发的考量点,而后两个方向一般是 DBA 的考量点。
|
||||
|
||||
|
|
@ -842,7 +843,7 @@ SQL 关键字尽量大写,如:Oracle 默认会将 SQL 语句中的关键字
|
|||
|
||||
数据库扩容、使用高配设备等等。核心就是一个字:钱。
|
||||
|
||||
## 七、数据库理论
|
||||
## 数据库理论
|
||||
|
||||
### 函数依赖
|
||||
|
||||
|
|
@ -960,7 +961,7 @@ Sname, Sdept 和 Mname 都部分依赖于键码,当一个学生选修了多门
|
|||
| 学院-1 | 院长-1 |
|
||||
| 学院-2 | 院长-2 |
|
||||
|
||||
## 八、Mysql 存储引擎
|
||||
## 存储引擎
|
||||
|
||||
Mysql 有多种存储引擎,**不同的存储引擎保存数据和索引的方式是不同的,但表的定义则是在 Mysql 服务层统一处理的**。
|
||||
|
||||
|
|
@ -986,7 +987,7 @@ InnoDB 和 MyISAM 是目前使用的最多的两种 Mysql 存储引擎。
|
|||
- InnoDB 支持故障恢复。
|
||||
- MyISAM 不支持故障恢复。
|
||||
|
||||
## 九、数据库比较
|
||||
## 数据库比较
|
||||
|
||||
### 常见数据库比较
|
||||
|
||||
|
|
@ -1070,6 +1071,78 @@ where rr>5 and rr<=10;
|
|||
|
||||
> 数据类型对比表摘自 [SQL 通用数据类型](https://www.runoob.com/sql/sql-datatypes-general.html)、[SQL 用于各种数据库的数据类型](https://www.runoob.com/sql/sql-datatypes.html)
|
||||
|
||||
## SQL FAQ
|
||||
|
||||
### SELECT COUNT(\*)、SELECT COUNT(1) 和 SELECT COUNT(具体字段) 性能有差别吗?
|
||||
|
||||
在 MySQL InnoDB 存储引擎中,`COUNT(*)` 和 `COUNT(1)` 都是对所有结果进行 `COUNT`。因此`COUNT(*)`和`COUNT(1)`本质上并没有区别,执行的复杂度都是 `O(N)`,也就是采用全表扫描,进行循环 + 计数的方式进行统计。
|
||||
|
||||
如果是 MySQL MyISAM 存储引擎,统计数据表的行数只需要`O(1)`的复杂度,这是因为每张 MyISAM 的数据表都有一个 meta 信息存储了`row_count`值,而一致性则由表级锁来保证。因为 InnoDB 支持事务,采用行级锁和 MVCC 机制,所以无法像 MyISAM 一样,只维护一个`row_count`变量,因此需要采用扫描全表,进行循环 + 计数的方式来完成统计。
|
||||
|
||||
需要注意的是,在实际执行中,`COUNT(*)`和`COUNT(1)`的执行时间可能略有差别,不过你还是可以把它俩的执行效率看成是相等的。
|
||||
|
||||
另外在 InnoDB 引擎中,如果采用`COUNT(*)`和`COUNT(1)`来统计数据行数,要尽量采用二级索引。因为主键采用的索引是聚簇索引,聚簇索引包含的信息多,明显会大于二级索引(非聚簇索引)。对于`COUNT(*)`和`COUNT(1)`来说,它们不需要查找具体的行,只是统计行数,系统会自动采用占用空间更小的二级索引来进行统计。
|
||||
|
||||
然而如果想要查找具体的行,那么采用主键索引的效率更高。如果有多个二级索引,会使用 key_len 小的二级索引进行扫描。当没有二级索引的时候,才会采用主键索引来进行统计。
|
||||
|
||||
这里我总结一下:
|
||||
|
||||
1. 一般情况下,三者执行的效率为 `COUNT(*)`= `COUNT(1)`> `COUNT(字段)`。我们尽量使用`COUNT(*)`,当然如果你要统计的是某个字段的非空数据行数,则另当别论,毕竟比较执行效率的前提是结果一样才可以。
|
||||
2. 如果要统计`COUNT(*)`,尽量在数据表上建立二级索引,系统会自动采用`key_len`小的二级索引进行扫描,这样当我们使用`SELECT COUNT(*)`的时候效率就会提升,有时候可以提升几倍甚至更高。
|
||||
|
||||
> ——摘自[极客时间 - SQL 必知必会](https://time.geekbang.org/column/intro/192)
|
||||
|
||||
### ORDER BY 是对分的组排序还是对分组中的记录排序呢?
|
||||
|
||||
ORDER BY 就是对记录进行排序。如果你在 ORDER BY 前面用到了 GROUP BY,实际上这是一种分组的聚合方式,已经把一组的数据聚合成为了一条记录,再进行排序的时候,相当于对分的组进行了排序。
|
||||
|
||||
### SELECT 语句内部的执行步骤
|
||||
|
||||
一条完整的 SELECT 语句内部的执行顺序是这样的:
|
||||
|
||||
1. FROM 子句组装数据(包括通过 ON 进行连接);
|
||||
2. WHERE 子句进行条件筛选;
|
||||
3. GROUP BY 分组 ;
|
||||
4. 使用聚集函数进行计算;
|
||||
5. HAVING 筛选分组;
|
||||
6. 计算所有的表达式;
|
||||
7. SELECT 的字段;
|
||||
8. ORDER BY 排序;
|
||||
9. LIMIT 筛选。
|
||||
|
||||
> ——摘自[极客时间 - SQL 必知必会](https://time.geekbang.org/column/intro/192)
|
||||
|
||||
### 解哪种情况下应该使用 EXISTS,哪种情况应该用 IN
|
||||
|
||||
索引是个前提,其实选择与否还是要看表的大小。你可以将选择的标准理解为小表驱动大表。在这种方式下效率是最高的。
|
||||
|
||||
比如下面这样:
|
||||
|
||||
```
|
||||
SELECT * FROM A WHERE cc IN (SELECT cc FROM B)
|
||||
SELECT * FROM A WHERE EXISTS (SELECT cc FROM B WHERE B.cc=A.cc)
|
||||
```
|
||||
|
||||
当 A 小于 B 时,用 EXISTS。因为 EXISTS 的实现,相当于外表循环,实现的逻辑类似于:
|
||||
|
||||
```
|
||||
for i in A
|
||||
for j in B
|
||||
if j.cc == i.cc then ...
|
||||
```
|
||||
|
||||
当 B 小于 A 时用 IN,因为实现的逻辑类似于:
|
||||
|
||||
```
|
||||
for i in B
|
||||
for j in A
|
||||
if j.cc == i.cc then ...
|
||||
```
|
||||
|
||||
哪个表小就用哪个表来驱动,A 表小就用 EXISTS,B 表小就用 IN。
|
||||
|
||||
> ——摘自[极客时间 - SQL 必知必会](https://time.geekbang.org/column/intro/192)
|
||||
|
||||
## 参考资料
|
||||
|
||||
- [数据库面试题(开发者必看)](https://juejin.im/post/5a9ca0d6518825555c1d1acd)
|
||||
|
|
|
|||
|
|
@ -0,0 +1,601 @@
|
|||
---
|
||||
title: SQL 语法基础特性
|
||||
date: 2018-06-15 16:07:17
|
||||
categories:
|
||||
- 数据库
|
||||
- 关系型数据库
|
||||
- 综合
|
||||
tags:
|
||||
- 数据库
|
||||
- 关系型数据库
|
||||
- SQL
|
||||
permalink: /pages/b71c9e/
|
||||
---
|
||||
|
||||
# SQL 语法基础特性
|
||||
|
||||
> 本文针对关系型数据库的基本语法。限于篇幅,本文侧重说明用法,不会展开讲解特性、原理。
|
||||
>
|
||||
> 本文语法主要针对 Mysql,但大部分的语法对其他关系型数据库也适用。
|
||||
|
||||
|
||||
|
||||
## SQL 简介
|
||||
|
||||
### 数据库术语
|
||||
|
||||
- `数据库(database)` - 保存有组织的数据的容器(通常是一个文件或一组文件)。
|
||||
- `数据表(table)` - 某种特定类型数据的结构化清单。
|
||||
- `模式(schema)` - 关于数据库和表的布局及特性的信息。模式定义了数据在表中如何存储,包含存储什么样的数据,数据如何分解,各部分信息如何命名等信息。数据库和表都有模式。
|
||||
- `列(column)` - 表中的一个字段。所有表都是由一个或多个列组成的。
|
||||
- `行(row)` - 表中的一个记录。
|
||||
- `主键(primary key)` - 一列(或一组列),其值能够唯一标识表中每一行。
|
||||
|
||||
### SQL 语法
|
||||
|
||||
> SQL(Structured Query Language),标准 SQL 由 ANSI 标准委员会管理,从而称为 ANSI SQL。各个 DBMS 都有自己的实现,如 PL/SQL、Transact-SQL 等。
|
||||
|
||||
#### SQL 语法结构
|
||||
|
||||
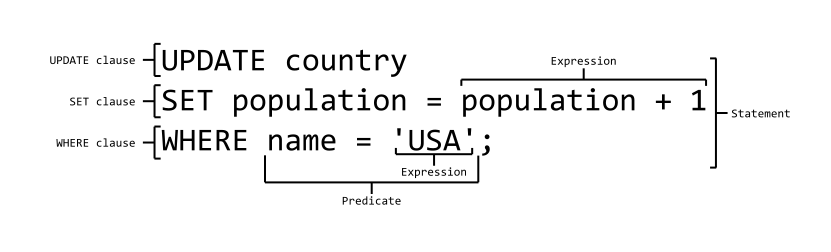
|
||||
|
||||
SQL 语法结构包括:
|
||||
|
||||
- **`子句`** - 是语句和查询的组成成分。(在某些情况下,这些都是可选的。)
|
||||
- **`表达式`** - 可以产生任何标量值,或由列和行的数据库表
|
||||
- **`谓词`** - 给需要评估的 SQL 三值逻辑(3VL)(true/false/unknown)或布尔真值指定条件,并限制语句和查询的效果,或改变程序流程。
|
||||
- **`查询`** - 基于特定条件检索数据。这是 SQL 的一个重要组成部分。
|
||||
- **`语句`** - 可以持久地影响纲要和数据,也可以控制数据库事务、程序流程、连接、会话或诊断。
|
||||
|
||||
#### SQL 语法要点
|
||||
|
||||
- **SQL 语句不区分大小写**,但是数据库表名、列名和值是否区分,依赖于具体的 DBMS 以及配置。
|
||||
|
||||
例如:`SELECT` 与 `select` 、`Select` 是相同的。
|
||||
|
||||
- **多条 SQL 语句必须以分号(`;`)分隔**。
|
||||
|
||||
- 处理 SQL 语句时,**所有空格都被忽略**。SQL 语句可以写成一行,也可以分写为多行。
|
||||
|
||||
```sql
|
||||
-- 一行 SQL 语句
|
||||
UPDATE user SET username='robot', password='robot' WHERE username = 'root';
|
||||
|
||||
-- 多行 SQL 语句
|
||||
UPDATE user
|
||||
SET username='robot', password='robot'
|
||||
WHERE username = 'root';
|
||||
```
|
||||
|
||||
- SQL 支持三种注释
|
||||
|
||||
```sql
|
||||
## 注释1
|
||||
-- 注释2
|
||||
/* 注释3 */
|
||||
```
|
||||
|
||||
#### SQL 分类
|
||||
|
||||
#### 数据定义语言(DDL)
|
||||
|
||||
数据定义语言(Data Definition Language,DDL)是 SQL 语言集中负责数据结构定义与数据库对象定义的语言。
|
||||
|
||||
DDL 的主要功能是**定义数据库对象**。
|
||||
|
||||
DDL 的核心指令是 `CREATE`、`ALTER`、`DROP`。
|
||||
|
||||
#### 数据操纵语言(DML)
|
||||
|
||||
数据操纵语言(Data Manipulation Language, DML)是用于数据库操作,对数据库其中的对象和数据运行访问工作的编程语句。
|
||||
|
||||
DML 的主要功能是 **访问数据**,因此其语法都是以**读写数据库**为主。
|
||||
|
||||
DML 的核心指令是 `INSERT`、`UPDATE`、`DELETE`、`SELECT`。这四个指令合称 CRUD(Create, Read, Update, Delete),即增删改查。
|
||||
|
||||
#### 事务控制语言(TCL)
|
||||
|
||||
事务控制语言 (Transaction Control Language, TCL) 用于**管理数据库中的事务**。这些用于管理由 DML 语句所做的更改。它还允许将语句分组为逻辑事务。
|
||||
|
||||
TCL 的核心指令是 `COMMIT`、`ROLLBACK`。
|
||||
|
||||
#### 数据控制语言(DCL)
|
||||
|
||||
数据控制语言 (Data Control Language, DCL) 是一种可对数据访问权进行控制的指令,它可以控制特定用户账户对数据表、查看表、预存程序、用户自定义函数等数据库对象的控制权。
|
||||
|
||||
DCL 的核心指令是 `GRANT`、`REVOKE`。
|
||||
|
||||
DCL 以**控制用户的访问权限**为主,因此其指令作法并不复杂,可利用 DCL 控制的权限有:`CONNECT`、`SELECT`、`INSERT`、`UPDATE`、`DELETE`、`EXECUTE`、`USAGE`、`REFERENCES`。
|
||||
|
||||
根据不同的 DBMS 以及不同的安全性实体,其支持的权限控制也有所不同。
|
||||
|
||||
---
|
||||
|
||||
**(以下为 DML 语句用法)**
|
||||
|
||||
## 增删改查(CRUD)
|
||||
|
||||
增删改查,又称为 **`CRUD`**,是数据库基本操作中的基本操作。
|
||||
|
||||
### 插入数据
|
||||
|
||||
> - `INSERT INTO` 语句用于向表中插入新记录。
|
||||
|
||||
#### 插入完整的行
|
||||
|
||||
```sql
|
||||
INSERT INTO user
|
||||
VALUES (10, 'root', 'root', 'xxxx@163.com');
|
||||
```
|
||||
|
||||
#### 插入行的一部分
|
||||
|
||||
```sql
|
||||
INSERT INTO user(username, password, email)
|
||||
VALUES ('admin', 'admin', 'xxxx@163.com');
|
||||
```
|
||||
|
||||
#### 插入查询出来的数据
|
||||
|
||||
```sql
|
||||
INSERT INTO user(username)
|
||||
SELECT name
|
||||
FROM account;
|
||||
```
|
||||
|
||||
### 更新数据
|
||||
|
||||
> - `UPDATE` 语句用于更新表中的记录。
|
||||
|
||||
```sql
|
||||
UPDATE user
|
||||
SET username='robot', password='robot'
|
||||
WHERE username = 'root';
|
||||
```
|
||||
|
||||
### 删除数据
|
||||
|
||||
> - `DELETE` 语句用于删除表中的记录。
|
||||
> - `TRUNCATE TABLE` 可以清空表,也就是删除所有行。
|
||||
|
||||
#### 删除表中的指定数据
|
||||
|
||||
```sql
|
||||
DELETE FROM user WHERE username = 'robot';
|
||||
```
|
||||
|
||||
#### 清空表中的数据
|
||||
|
||||
```sql
|
||||
TRUNCATE TABLE user;
|
||||
```
|
||||
|
||||
### 查询数据
|
||||
|
||||
> - `SELECT` 语句用于从数据库中查询数据。
|
||||
> - `DISTINCT` 用于返回唯一不同的值。它作用于所有列,也就是说所有列的值都相同才算相同。
|
||||
> - `LIMIT` 限制返回的行数。可以有两个参数,第一个参数为起始行,从 0 开始;第二个参数为返回的总行数。
|
||||
> - `ASC` :升序(默认)
|
||||
> - `DESC` :降序
|
||||
|
||||
#### 查询单列
|
||||
|
||||
```sql
|
||||
SELECT prod_name FROM products;
|
||||
```
|
||||
|
||||
#### 查询多列
|
||||
|
||||
```sql
|
||||
SELECT prod_id, prod_name, prod_price FROM products;
|
||||
```
|
||||
|
||||
#### 查询所有列
|
||||
|
||||
```sql
|
||||
SELECT * FROM products;
|
||||
```
|
||||
|
||||
#### 查询不同的值
|
||||
|
||||
```sql
|
||||
SELECT DISTINCT vend_id FROM products;
|
||||
```
|
||||
|
||||
#### 限制查询数量
|
||||
|
||||
```sql
|
||||
-- 返回前 5 行
|
||||
SELECT * FROM products LIMIT 5;
|
||||
SELECT * FROM products LIMIT 0, 5;
|
||||
-- 返回第 3 ~ 5 行
|
||||
SELECT * FROM products LIMIT 2, 3;
|
||||
```
|
||||
|
||||
## 过滤数据(WHERE)
|
||||
|
||||
子查询是嵌套在较大查询中的 SQL 查询。子查询也称为**内部查询**或**内部选择**,而包含子查询的语句也称为**外部查询**或**外部选择**。
|
||||
|
||||
- 子查询可以嵌套在 `SELECT`,`INSERT`,`UPDATE` 或 `DELETE` 语句内或另一个子查询中。
|
||||
|
||||
- 子查询通常会在另一个 `SELECT` 语句的 `WHERE` 子句中添加。
|
||||
|
||||
- 您可以使用比较运算符,如 `>`,`<`,或 `=`。比较运算符也可以是多行运算符,如 `IN`,`ANY` 或 `ALL`。
|
||||
|
||||
- 子查询必须被圆括号 `()` 括起来。
|
||||
|
||||
- 内部查询首先在其父查询之前执行,以便可以将内部查询的结果传递给外部查询。执行过程可以参考下图:
|
||||
|
||||
<p align="center">
|
||||
<img src="https://raw.githubusercontent.com/dunwu/images/dev/cs/database/mysql/sql-subqueries.gif" alt="sql-subqueries">
|
||||
</p>
|
||||
|
||||
**子查询的子查询**
|
||||
|
||||
```sql
|
||||
SELECT cust_name, cust_contact
|
||||
FROM customers
|
||||
WHERE cust_id IN (SELECT cust_id
|
||||
FROM orders
|
||||
WHERE order_num IN (SELECT order_num
|
||||
FROM orderitems
|
||||
WHERE prod_id = 'RGAN01'));
|
||||
```
|
||||
|
||||
### WHERE 子句
|
||||
|
||||
在 SQL 语句中,数据根据 `WHERE` 子句中指定的搜索条件进行过滤。
|
||||
|
||||
`WHERE` 子句的基本格式如下:
|
||||
|
||||
```sql
|
||||
SELECT ……(列名) FROM ……(表名) WHERE ……(子句条件)
|
||||
```
|
||||
|
||||
`WHERE` 子句用于过滤记录,即缩小访问数据的范围。`WHERE` 后跟一个返回 `true` 或 `false` 的条件。
|
||||
|
||||
`WHERE` 可以与 `SELECT`,`UPDATE` 和 `DELETE` 一起使用。
|
||||
|
||||
**`SELECT` 语句中的 `WHERE` 子句**
|
||||
|
||||
```sql
|
||||
SELECT * FROM Customers
|
||||
WHERE cust_name = 'Kids Place';
|
||||
```
|
||||
|
||||
**`UPDATE` 语句中的 `WHERE` 子句**
|
||||
|
||||
```sql
|
||||
UPDATE Customers
|
||||
SET cust_name = 'Jack Jones'
|
||||
WHERE cust_name = 'Kids Place';
|
||||
```
|
||||
|
||||
**`DELETE` 语句中的 `WHERE` 子句**
|
||||
|
||||
```sql
|
||||
DELETE FROM Customers
|
||||
WHERE cust_name = 'Kids Place';
|
||||
```
|
||||
|
||||
可以在 `WHERE` 子句中使用的操作符:
|
||||
|
||||
### 比较操作符
|
||||
|
||||
| 运算符 | 描述 |
|
||||
| ------ | ------------------------------------------------------ |
|
||||
| `=` | 等于 |
|
||||
| `<>` | 不等于。注释:在 SQL 的一些版本中,该操作符可被写成 != |
|
||||
| `>` | 大于 |
|
||||
| `<` | 小于 |
|
||||
| `>=` | 大于等于 |
|
||||
| `<=` | 小于等于 |
|
||||
|
||||
### 范围操作符
|
||||
|
||||
| 运算符 | 描述 |
|
||||
| --------- | -------------------------- |
|
||||
| `BETWEEN` | 在某个范围内 |
|
||||
| `IN` | 指定针对某个列的多个可能值 |
|
||||
|
||||
- `IN` 操作符在 `WHERE` 子句中使用,作用是在指定的几个特定值中任选一个值。
|
||||
|
||||
- `BETWEEN` 操作符在 `WHERE` 子句中使用,作用是选取介于某个范围内的值。
|
||||
|
||||
**IN 示例**
|
||||
|
||||
```sql
|
||||
SELECT *
|
||||
FROM products
|
||||
WHERE vend_id IN ('DLL01', 'BRS01');
|
||||
```
|
||||
|
||||
**BETWEEN 示例**
|
||||
|
||||
```sql
|
||||
SELECT *
|
||||
FROM products
|
||||
WHERE prod_price BETWEEN 3 AND 5;
|
||||
```
|
||||
|
||||
### 逻辑操作符
|
||||
|
||||
| 运算符 | 描述 |
|
||||
| ------ | ---------- |
|
||||
| `AND` | 并且(与) |
|
||||
| `OR` | 或者(或) |
|
||||
| `NOT` | 否定(非) |
|
||||
|
||||
`AND`、`OR`、`NOT` 是用于对过滤条件的逻辑处理指令。
|
||||
|
||||
- `AND` 优先级高于 `OR`,为了明确处理顺序,可以使用 `()`。`AND` 操作符表示左右条件都要满足。
|
||||
- `OR` 操作符表示左右条件满足任意一个即可。
|
||||
|
||||
- `NOT` 操作符用于否定一个条件。
|
||||
|
||||
**AND 示例**
|
||||
|
||||
```sql
|
||||
SELECT prod_id, prod_name, prod_price
|
||||
FROM products
|
||||
WHERE vend_id = 'DLL01' AND prod_price <= 4;
|
||||
```
|
||||
|
||||
**OR 示例**
|
||||
|
||||
```sql
|
||||
SELECT prod_id, prod_name, prod_price
|
||||
FROM products
|
||||
WHERE vend_id = 'DLL01' OR vend_id = 'BRS01';
|
||||
```
|
||||
|
||||
**NOT 示例**
|
||||
|
||||
```sql
|
||||
SELECT *
|
||||
FROM products
|
||||
WHERE prod_price NOT BETWEEN 3 AND 5;
|
||||
```
|
||||
|
||||
### 通配符
|
||||
|
||||
| 运算符 | 描述 |
|
||||
| ------ | -------------------------- |
|
||||
| `LIKE` | 搜索某种模式 |
|
||||
| `%` | 表示任意字符出现任意次数 |
|
||||
| `_` | 表示任意字符出现一次 |
|
||||
| `[]` | 必须匹配指定位置的一个字符 |
|
||||
|
||||
`LIKE` 操作符在 `WHERE` 子句中使用,作用是确定字符串是否匹配模式。只有字段是文本值时才使用 `LIKE`。
|
||||
|
||||
`LIKE` 支持以下通配符匹配选项:
|
||||
|
||||
- `%` 表示任何字符出现任意次数。
|
||||
- `_` 表示任何字符出现一次。
|
||||
- `[]` 必须匹配指定位置的一个字符。
|
||||
|
||||
> 注意:**不要滥用通配符,通配符位于开头处匹配会非常慢**。
|
||||
|
||||
`%` 示例:
|
||||
|
||||
```sql
|
||||
SELECT prod_id, prod_name, prod_price
|
||||
FROM products
|
||||
WHERE prod_name LIKE '%bean bag%';
|
||||
```
|
||||
|
||||
`_` 示例:
|
||||
|
||||
```sql
|
||||
SELECT prod_id, prod_name, prod_price
|
||||
FROM products
|
||||
WHERE prod_name LIKE '__ inch teddy bear';
|
||||
```
|
||||
|
||||
-
|
||||
|
||||
## 排序(ORDER BY)
|
||||
|
||||
> `ORDER BY` 用于对结果集进行排序。
|
||||
|
||||
`ORDER BY` 有两种排序模式:
|
||||
|
||||
- `ASC` :升序(默认)
|
||||
- `DESC` :降序
|
||||
|
||||
可以按多个列进行排序,并且为每个列指定不同的排序方式。
|
||||
|
||||
指定多个列的排序示例:
|
||||
|
||||
```sql
|
||||
SELECT * FROM products
|
||||
ORDER BY prod_price DESC, prod_name ASC;
|
||||
```
|
||||
|
||||
## 数据定义(CREATE、ALTER、DROP)
|
||||
|
||||
> DDL 的主要功能是定义数据库对象(如:数据库、数据表、视图、索引等)。
|
||||
|
||||
### 数据库(DATABASE)
|
||||
|
||||
#### 创建数据库
|
||||
|
||||
```sql
|
||||
CREATE DATABASE IF NOT EXISTS db_tutorial;
|
||||
```
|
||||
|
||||
#### 删除数据库
|
||||
|
||||
```sql
|
||||
DROP DATABASE IF EXISTS db_tutorial;
|
||||
```
|
||||
|
||||
#### 选择数据库
|
||||
|
||||
```sql
|
||||
USE db_tutorial;
|
||||
```
|
||||
|
||||
### 数据表(TABLE)
|
||||
|
||||
#### 删除数据表
|
||||
|
||||
```sql
|
||||
DROP TABLE IF EXISTS user;
|
||||
DROP TABLE IF EXISTS vip_user;
|
||||
```
|
||||
|
||||
#### 创建数据表
|
||||
|
||||
**普通创建**
|
||||
|
||||
```sql
|
||||
CREATE TABLE user (
|
||||
id INT(10) UNSIGNED NOT NULL COMMENT 'Id',
|
||||
username VARCHAR(64) NOT NULL DEFAULT 'default' COMMENT '用户名',
|
||||
password VARCHAR(64) NOT NULL DEFAULT 'default' COMMENT '密码',
|
||||
email VARCHAR(64) NOT NULL DEFAULT 'default' COMMENT '邮箱'
|
||||
) COMMENT ='用户表';
|
||||
```
|
||||
|
||||
**根据已有的表创建新表**
|
||||
|
||||
```sql
|
||||
CREATE TABLE vip_user AS
|
||||
SELECT *
|
||||
FROM user;
|
||||
```
|
||||
|
||||
#### 修改数据表
|
||||
|
||||
##### 添加列
|
||||
|
||||
```sql
|
||||
ALTER TABLE user
|
||||
ADD age int(3);
|
||||
```
|
||||
|
||||
##### 删除列
|
||||
|
||||
```sql
|
||||
ALTER TABLE user
|
||||
DROP COLUMN age;
|
||||
```
|
||||
|
||||
##### 修改列
|
||||
|
||||
```sql
|
||||
ALTER TABLE `user`
|
||||
MODIFY COLUMN age tinyint;
|
||||
```
|
||||
|
||||
### 视图(VIEW)
|
||||
|
||||
> 视图是基于 SQL 语句的结果集的可视化的表。**视图是虚拟的表,本身不存储数据,也就不能对其进行索引操作**。对视图的操作和对普通表的操作一样。
|
||||
|
||||
视图的作用:
|
||||
|
||||
- 简化复杂的 SQL 操作,比如复杂的连接。
|
||||
- 只使用实际表的一部分数据。
|
||||
- 通过只给用户访问视图的权限,保证数据的安全性。
|
||||
- 更改数据格式和表示。
|
||||
|
||||
#### 创建视图
|
||||
|
||||
```sql
|
||||
CREATE VIEW top_10_user_view AS
|
||||
SELECT id, username
|
||||
FROM user
|
||||
WHERE id < 10;
|
||||
```
|
||||
|
||||
#### 删除视图
|
||||
|
||||
```sql
|
||||
DROP VIEW top_10_user_view;
|
||||
```
|
||||
|
||||
### 索引(INDEX)
|
||||
|
||||
> 通过索引可以更加快速高效地查询数据。用户无法看到索引,它们只能被用来加速查询。
|
||||
|
||||
更新一个包含索引的表需要比更新一个没有索引的表花费更多的时间,这是由于索引本身也需要更新。因此,理想的做法是仅仅在常常被搜索的列(以及表)上面创建索引。
|
||||
|
||||
唯一索引:唯一索引表明此索引的每一个索引值只对应唯一的数据记录。
|
||||
|
||||
#### 创建索引
|
||||
|
||||
```sql
|
||||
CREATE INDEX idx_email
|
||||
ON user(email);
|
||||
```
|
||||
|
||||
#### 创建唯一索引
|
||||
|
||||
```sql
|
||||
CREATE UNIQUE INDEX uniq_username
|
||||
ON user(username);
|
||||
```
|
||||
|
||||
#### 删除索引
|
||||
|
||||
```sql
|
||||
ALTER TABLE user
|
||||
DROP INDEX idx_email;
|
||||
ALTER TABLE user
|
||||
DROP INDEX uniq_username;
|
||||
```
|
||||
|
||||
#### 添加主键
|
||||
|
||||
```sql
|
||||
ALTER TABLE user
|
||||
ADD PRIMARY KEY (id);
|
||||
```
|
||||
|
||||
#### 删除主键
|
||||
|
||||
```sql
|
||||
ALTER TABLE user
|
||||
DROP PRIMARY KEY;
|
||||
```
|
||||
|
||||
### 约束
|
||||
|
||||
> SQL 约束用于规定表中的数据规则。
|
||||
|
||||
- 如果存在违反约束的数据行为,行为会被约束终止。
|
||||
- 约束可以在创建表时规定(通过 CREATE TABLE 语句),或者在表创建之后规定(通过 ALTER TABLE 语句)。
|
||||
- 约束类型
|
||||
- `NOT NULL` - 指示某列不能存储 NULL 值。
|
||||
- `UNIQUE` - 保证某列的每行必须有唯一的值。
|
||||
- `PRIMARY KEY` - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
|
||||
- `FOREIGN KEY` - 保证一个表中的数据匹配另一个表中的值的参照完整性。
|
||||
- `CHECK` - 保证列中的值符合指定的条件。
|
||||
- `DEFAULT` - 规定没有给列赋值时的默认值。
|
||||
|
||||
创建表时使用约束条件:
|
||||
|
||||
```sql
|
||||
CREATE TABLE Users (
|
||||
Id INT(10) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自增Id',
|
||||
Username VARCHAR(64) NOT NULL UNIQUE DEFAULT 'default' COMMENT '用户名',
|
||||
Password VARCHAR(64) NOT NULL DEFAULT 'default' COMMENT '密码',
|
||||
Email VARCHAR(64) NOT NULL DEFAULT 'default' COMMENT '邮箱地址',
|
||||
Enabled TINYINT(4) DEFAULT NULL COMMENT '是否有效',
|
||||
PRIMARY KEY (Id)
|
||||
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COMMENT='用户表';
|
||||
```
|
||||
|
||||
## 参考资料
|
||||
|
||||
- [《SQL 必知必会》](https://book.douban.com/subject/35167240/)
|
||||
- [『浅入深出』MySQL 中事务的实现](https://draveness.me/mysql-transaction)
|
||||
- [MySQL 的学习--触发器](https://www.cnblogs.com/CraryPrimitiveMan/p/4206942.html)
|
||||
- [维基百科词条 - SQL](https://zh.wikipedia.org/wiki/SQL)
|
||||
- [https://www.sitesbay.com/sql/index](https://www.sitesbay.com/sql/index)
|
||||
- [SQL Subqueries](https://www.w3resource.com/sql/subqueries/understanding-sql-subqueries.php)
|
||||
- [Quick breakdown of the types of joins](https://stackoverflow.com/questions/6294778/mysql-quick-breakdown-of-the-types-of-joins)
|
||||
- [SQL UNION](https://www.w3resource.com/sql/sql-union.php)
|
||||
- [SQL database security](https://www.w3resource.com/sql/database-security/create-users.php)
|
||||
- [Mysql 中的存储过程](https://www.cnblogs.com/chenpi/p/5136483.html)
|
||||
File diff suppressed because it is too large
Load Diff
|
|
@ -0,0 +1,610 @@
|
|||
---
|
||||
title: SQL 语法高级特性
|
||||
date: 2022-04-27 22:13:55
|
||||
categories:
|
||||
- 数据库
|
||||
- 关系型数据库
|
||||
- 综合
|
||||
tags:
|
||||
- 数据库
|
||||
- 关系型数据库
|
||||
- SQL
|
||||
permalink: /pages/1ae1ca/
|
||||
---
|
||||
|
||||
# SQL 语法高级特性
|
||||
|
||||
> 本文针对关系型数据库的基本语法。限于篇幅,本文侧重说明用法,不会展开讲解特性、原理。
|
||||
>
|
||||
> 本文语法主要针对 Mysql,但大部分的语法对其他关系型数据库也适用。
|
||||
|
||||

|
||||
|
||||
## 连接和组合
|
||||
|
||||
### 连接(JOIN)
|
||||
|
||||
> 连接用于连接多个表,使用 `JOIN` 关键字,并且条件语句使用 `ON` 而不是 `WHERE`。
|
||||
|
||||
如果一个 `JOIN` 至少有一个公共字段并且它们之间存在关系,则该 `JOIN` 可以在两个或多个表上工作。
|
||||
|
||||
`JOIN` 保持基表(结构和数据)不变。**连接可以替换子查询,并且比子查询的效率一般会更快**。
|
||||
|
||||
`JOIN` 有两种连接类型:内连接和外连接。
|
||||
|
||||
<div align="center">
|
||||
<img src="https://raw.githubusercontent.com/dunwu/images/dev/cs/database/mysql/sql-join.png" alt="sql-join">
|
||||
</div>
|
||||
|
||||
#### 内连接(INNER JOIN)
|
||||
|
||||
内连接又称等值连接,**使用 `INNER JOIN` 关键字**。在没有条件语句的情况下**返回笛卡尔积**。
|
||||
|
||||
```sql
|
||||
SELECT vend_name, prod_name, prod_price
|
||||
FROM vendors INNER JOIN products
|
||||
ON vendors.vend_id = products.vend_id;
|
||||
```
|
||||
|
||||
##### 自连接(`=`)
|
||||
|
||||
自连接可以看成内连接的一种,只是**连接的表是自身**而已。**自然连接是把同名列通过 `=` 连接起来**的,同名列可以有多个。
|
||||
|
||||
```sql
|
||||
SELECT c1.cust_id, c1.cust_name, c1.cust_contact
|
||||
FROM customers c1, customers c2
|
||||
WHERE c1.cust_name = c2.cust_name
|
||||
AND c2.cust_contact = 'Jim Jones';
|
||||
```
|
||||
|
||||
##### 自然连接(NATURAL JOIN)
|
||||
|
||||
内连接提供连接的列,而自然连接**自动连接所有同名列**。自然连接使用 `NATURAL JOIN` 关键字。
|
||||
|
||||
```sql
|
||||
SELECT *
|
||||
FROM Products
|
||||
NATURAL JOIN Customers;
|
||||
```
|
||||
|
||||
#### 外连接(OUTER JOIN)
|
||||
|
||||
外连接返回一个表中的所有行,并且仅返回来自此表中满足连接条件的那些行,即两个表中的列是相等的。外连接分为左外连接、右外连接、全外连接(Mysql 不支持)。
|
||||
|
||||
##### 左连接(LEFT JOIN)
|
||||
|
||||
左外连接就是保留左表没有关联的行。
|
||||
|
||||
```sql
|
||||
SELECT customers.cust_id, orders.order_num
|
||||
FROM customers LEFT JOIN orders
|
||||
ON customers.cust_id = orders.cust_id;
|
||||
```
|
||||
|
||||
##### 右连接(RIGHT JOIN)
|
||||
|
||||
右外连接就是保留右表没有关联的行。
|
||||
|
||||
```sql
|
||||
SELECT customers.cust_id, orders.order_num
|
||||
FROM customers RIGHT JOIN orders
|
||||
ON customers.cust_id = orders.cust_id;
|
||||
```
|
||||
|
||||
### 组合(UNION)
|
||||
|
||||
> `UNION` 运算符**将两个或更多查询的结果组合起来,并生成一个结果集**,其中包含来自 `UNION` 中参与查询的提取行。
|
||||
|
||||
`UNION` 基本规则:
|
||||
|
||||
- 所有查询的列数和列顺序必须相同。
|
||||
- 每个查询中涉及表的列的数据类型必须相同或兼容。
|
||||
- 通常返回的列名取自第一个查询。
|
||||
|
||||
默认会去除相同行,如果需要保留相同行,使用 `UNION ALL`。
|
||||
|
||||
只能包含一个 `ORDER BY` 子句,并且必须位于语句的最后。
|
||||
|
||||
应用场景:
|
||||
|
||||
- 在一个查询中从不同的表返回结构数据。
|
||||
- 对一个表执行多个查询,按一个查询返回数据。
|
||||
|
||||
组合查询示例:
|
||||
|
||||
```sql
|
||||
SELECT cust_name, cust_contact, cust_email
|
||||
FROM customers
|
||||
WHERE cust_state IN ('IL', 'IN', 'MI')
|
||||
UNION
|
||||
SELECT cust_name, cust_contact, cust_email
|
||||
FROM customers
|
||||
WHERE cust_name = 'Fun4All';
|
||||
```
|
||||
|
||||
### JOIN vs UNION
|
||||
|
||||
- `JOIN` 中连接表的列可能不同,但在 `UNION` 中,所有查询的列数和列顺序必须相同。
|
||||
- `UNION` 将查询之后的行放在一起(垂直放置),但 `JOIN` 将查询之后的列放在一起(水平放置),即它构成一个笛卡尔积。
|
||||
|
||||
## 函数
|
||||
|
||||
> 🔔 注意:不同数据库的函数往往各不相同,因此不可移植。本节主要以 Mysql 的函数为例。
|
||||
|
||||
### 文本处理
|
||||
|
||||
| 函数 | 说明 |
|
||||
| :------------------: | :--------------------: |
|
||||
| `LEFT()`、`RIGHT()` | 左边或者右边的字符 |
|
||||
| `LOWER()`、`UPPER()` | 转换为小写或者大写 |
|
||||
| `LTRIM()`、`RTIM()` | 去除左边或者右边的空格 |
|
||||
| `LENGTH()` | 长度 |
|
||||
| `SOUNDEX()` | 转换为语音值 |
|
||||
|
||||
其中, **SOUNDEX()** 可以将一个字符串转换为描述其语音表示的字母数字模式。
|
||||
|
||||
```sql
|
||||
SELECT *
|
||||
FROM mytable
|
||||
WHERE SOUNDEX(col1) = SOUNDEX('apple')
|
||||
```
|
||||
|
||||
### 日期和时间处理
|
||||
|
||||
- 日期格式:`YYYY-MM-DD`
|
||||
- 时间格式:`HH:MM:SS`
|
||||
|
||||
| 函 数 | 说 明 |
|
||||
| :-------------: | :----------------------------: |
|
||||
| `AddDate()` | 增加一个日期(天、周等) |
|
||||
| `AddTime()` | 增加一个时间(时、分等) |
|
||||
| `CurDate()` | 返回当前日期 |
|
||||
| `CurTime()` | 返回当前时间 |
|
||||
| `Date()` | 返回日期时间的日期部分 |
|
||||
| `DateDiff()` | 计算两个日期之差 |
|
||||
| `Date_Add()` | 高度灵活的日期运算函数 |
|
||||
| `Date_Format()` | 返回一个格式化的日期或时间串 |
|
||||
| `Day()` | 返回一个日期的天数部分 |
|
||||
| `DayOfWeek()` | 对于一个日期,返回对应的星期几 |
|
||||
| `Hour()` | 返回一个时间的小时部分 |
|
||||
| `Minute()` | 返回一个时间的分钟部分 |
|
||||
| `Month()` | 返回一个日期的月份部分 |
|
||||
| `Now()` | 返回当前日期和时间 |
|
||||
| `Second()` | 返回一个时间的秒部分 |
|
||||
| `Time()` | 返回一个日期时间的时间部分 |
|
||||
| `Year()` | 返回一个日期的年份部分 |
|
||||
|
||||
```sql
|
||||
mysql> SELECT NOW();
|
||||
```
|
||||
|
||||
```
|
||||
2018-4-14 20:25:11
|
||||
```
|
||||
|
||||
### 数值处理
|
||||
|
||||
| 函数 | 说明 |
|
||||
| :----: | :----: |
|
||||
| SIN() | 正弦 |
|
||||
| COS() | 余弦 |
|
||||
| TAN() | 正切 |
|
||||
| ABS() | 绝对值 |
|
||||
| SQRT() | 平方根 |
|
||||
| MOD() | 余数 |
|
||||
| EXP() | 指数 |
|
||||
| PI() | 圆周率 |
|
||||
| RAND() | 随机数 |
|
||||
|
||||
### 汇总
|
||||
|
||||
| 函 数 | 说 明 |
|
||||
| :-------: | :--------------: |
|
||||
| `AVG()` | 返回某列的平均值 |
|
||||
| `COUNT()` | 返回某列的行数 |
|
||||
| `MAX()` | 返回某列的最大值 |
|
||||
| `MIN()` | 返回某列的最小值 |
|
||||
| `SUM()` | 返回某列值之和 |
|
||||
|
||||
`AVG()` 会忽略 NULL 行。
|
||||
|
||||
使用 DISTINCT 可以让汇总函数值汇总不同的值。
|
||||
|
||||
```sql
|
||||
SELECT AVG(DISTINCT col1) AS avg_col
|
||||
FROM mytable
|
||||
```
|
||||
|
||||
## 分组
|
||||
|
||||
### GROUP BY
|
||||
|
||||
> `GROUP BY` 子句将记录分组到汇总行中,`GROUP BY` 为每个组返回一个记录。
|
||||
|
||||
`GROUP BY` 可以按一列或多列进行分组。
|
||||
|
||||
`GROUP BY` 通常还涉及聚合函数:COUNT,MAX,SUM,AVG 等。
|
||||
|
||||
`GROUP BY` 按分组字段进行排序后,`ORDER BY` 可以以汇总字段来进行排序。
|
||||
|
||||
分组示例:
|
||||
|
||||
```sql
|
||||
SELECT cust_name, COUNT(cust_address) AS addr_num
|
||||
FROM Customers GROUP BY cust_name;
|
||||
```
|
||||
|
||||
分组后排序示例:
|
||||
|
||||
```sql
|
||||
SELECT cust_name, COUNT(cust_address) AS addr_num
|
||||
FROM Customers GROUP BY cust_name
|
||||
ORDER BY cust_name DESC;
|
||||
```
|
||||
|
||||
### HAVING
|
||||
|
||||
> `HAVING` 用于对汇总的 `GROUP BY` 结果进行过滤。`HAVING` 要求存在一个 `GROUP BY` 子句。
|
||||
|
||||
`WHERE` 和 `HAVING` 可以在相同的查询中。
|
||||
|
||||
`HAVING` vs `WHERE`:
|
||||
|
||||
- `WHERE` 和 `HAVING` 都是用于过滤。
|
||||
- `HAVING` 适用于汇总的组记录;而 `WHERE` 适用于单个记录。
|
||||
|
||||
使用 `WHERE` 和 `HAVING` 过滤数据示例:
|
||||
|
||||
```sql
|
||||
SELECT cust_name, COUNT(*) AS num
|
||||
FROM Customers
|
||||
WHERE cust_email IS NOT NULL
|
||||
GROUP BY cust_name
|
||||
HAVING COUNT(*) >= 1;
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
**(以下为 DDL 语句用法)**
|
||||
|
||||
## 事务
|
||||
|
||||
不能回退 `SELECT` 语句,回退 `SELECT` 语句也没意义;也不能回退 `CREATE` 和 `DROP` 语句。
|
||||
|
||||
**MySQL 默认采用隐式提交策略(`autocommit`)**,每执行一条语句就把这条语句当成一个事务然后进行提交。当出现 `START TRANSACTION` 语句时,会关闭隐式提交;当 `COMMIT` 或 `ROLLBACK` 语句执行后,事务会自动关闭,重新恢复隐式提交。
|
||||
|
||||
通过 `set autocommit=0` 可以取消自动提交,直到 `set autocommit=1` 才会提交;`autocommit` 标记是针对每个连接而不是针对服务器的。
|
||||
|
||||
事务处理指令:
|
||||
|
||||
- `START TRANSACTION` - 指令用于标记事务的起始点。
|
||||
- `SAVEPOINT` - 指令用于创建保留点。
|
||||
- `ROLLBACK TO` - 指令用于回滚到指定的保留点;如果没有设置保留点,则回退到 `START TRANSACTION` 语句处。
|
||||
- `COMMIT` - 提交事务。
|
||||
- `RELEASE SAVEPOINT`:删除某个保存点。
|
||||
- `SET TRANSACTION`:设置事务的隔离级别。
|
||||
|
||||
事务处理示例:
|
||||
|
||||
```sql
|
||||
-- 开始事务
|
||||
START TRANSACTION;
|
||||
|
||||
-- 插入操作 A
|
||||
INSERT INTO `user`
|
||||
VALUES (1, 'root1', 'root1', 'xxxx@163.com');
|
||||
|
||||
-- 创建保留点 updateA
|
||||
SAVEPOINT updateA;
|
||||
|
||||
-- 插入操作 B
|
||||
INSERT INTO `user`
|
||||
VALUES (2, 'root2', 'root2', 'xxxx@163.com');
|
||||
|
||||
-- 回滚到保留点 updateA
|
||||
ROLLBACK TO updateA;
|
||||
|
||||
-- 提交事务,只有操作 A 生效
|
||||
COMMIT;
|
||||
```
|
||||
|
||||
### ACID
|
||||
|
||||
### 事务隔离级别
|
||||
|
||||
---
|
||||
|
||||
**(以下为 DCL 语句用法)**
|
||||
|
||||
## 权限控制
|
||||
|
||||
`GRANT` 和 `REVOKE` 可在几个层次上控制访问权限:
|
||||
|
||||
- 整个服务器,使用 `GRANT ALL` 和 `REVOKE ALL`;
|
||||
- 整个数据库,使用 ON database.\*;
|
||||
- 特定的表,使用 ON database.table;
|
||||
- 特定的列;
|
||||
- 特定的存储过程。
|
||||
|
||||
新创建的账户没有任何权限。
|
||||
|
||||
账户用 `username@host` 的形式定义,`username@%` 使用的是默认主机名。
|
||||
|
||||
MySQL 的账户信息保存在 mysql 这个数据库中。
|
||||
|
||||
```sql
|
||||
USE mysql;
|
||||
SELECT user FROM user;
|
||||
```
|
||||
|
||||
### 创建账户
|
||||
|
||||
```sql
|
||||
CREATE USER myuser IDENTIFIED BY 'mypassword';
|
||||
```
|
||||
|
||||
### 修改账户名
|
||||
|
||||
```sql
|
||||
UPDATE user SET user='newuser' WHERE user='myuser';
|
||||
FLUSH PRIVILEGES;
|
||||
```
|
||||
|
||||
### 删除账户
|
||||
|
||||
```sql
|
||||
DROP USER myuser;
|
||||
```
|
||||
|
||||
### 查看权限
|
||||
|
||||
```sql
|
||||
SHOW GRANTS FOR myuser;
|
||||
```
|
||||
|
||||
### 授予权限
|
||||
|
||||
```sql
|
||||
GRANT SELECT, INSERT ON *.* TO myuser;
|
||||
```
|
||||
|
||||
### 删除权限
|
||||
|
||||
```sql
|
||||
REVOKE SELECT, INSERT ON *.* FROM myuser;
|
||||
```
|
||||
|
||||
### 更改密码
|
||||
|
||||
```sql
|
||||
SET PASSWORD FOR myuser = 'mypass';
|
||||
```
|
||||
|
||||
## 存储过程
|
||||
|
||||
存储过程的英文是 Stored Procedure。它可以视为一组 SQL 语句的批处理。一旦存储过程被创建出来,使用它就像使用函数一样简单,我们直接通过调用存储过程名即可。
|
||||
|
||||
定义存储过程的语法格式:
|
||||
|
||||
```sql
|
||||
CREATE PROCEDURE 存储过程名称 ([参数列表])
|
||||
BEGIN
|
||||
需要执行的语句
|
||||
END
|
||||
```
|
||||
|
||||
存储过程定义语句类型:
|
||||
|
||||
- `CREATE PROCEDURE` 用于创建存储过程
|
||||
- `DROP PROCEDURE` 用于删除存储过程
|
||||
- `ALTER PROCEDURE` 用于修改存储过程
|
||||
|
||||
### 使用存储过程
|
||||
|
||||
创建存储过程的要点:
|
||||
|
||||
- `DELIMITER` 用于定义语句的结束符
|
||||
- 存储过程的 3 种参数类型:
|
||||
- `IN`:存储过程的入参
|
||||
- `OUT`:存储过程的出参
|
||||
- `INPUT`:既是存储过程的入参,也是存储过程的出参
|
||||
- 流控制语句:
|
||||
- `BEGIN…END`:`BEGIN…END` 中间包含了多个语句,每个语句都以(`;`)号为结束符。
|
||||
- `DECLARE`:`DECLARE` 用来声明变量,使用的位置在于 `BEGIN…END` 语句中间,而且需要在其他语句使用之前进行变量的声明。
|
||||
- `SET`:赋值语句,用于对变量进行赋值。
|
||||
- `SELECT…INTO`:把从数据表中查询的结果存放到变量中,也就是为变量赋值。每次只能给一个变量赋值,不支持集合的操作。
|
||||
- `IF…THEN…ENDIF`:条件判断语句,可以在 `IF…THEN…ENDIF` 中使用 `ELSE` 和 `ELSEIF` 来进行条件判断。
|
||||
- `CASE`:`CASE` 语句用于多条件的分支判断。
|
||||
|
||||
创建存储过程示例:
|
||||
|
||||
```sql
|
||||
DROP PROCEDURE IF EXISTS `proc_adder`;
|
||||
DELIMITER ;;
|
||||
CREATE DEFINER=`root`@`localhost` PROCEDURE `proc_adder`(IN a int, IN b int, OUT sum int)
|
||||
BEGIN
|
||||
DECLARE c int;
|
||||
if a is null then set a = 0;
|
||||
end if;
|
||||
|
||||
if b is null then set b = 0;
|
||||
end if;
|
||||
|
||||
set sum = a + b;
|
||||
END
|
||||
;;
|
||||
DELIMITER ;
|
||||
```
|
||||
|
||||
使用存储过程示例:
|
||||
|
||||
```sql
|
||||
set @b=5;
|
||||
call proc_adder(2,@b,@s);
|
||||
select @s as sum;
|
||||
```
|
||||
|
||||
### 存储过程的利弊
|
||||
|
||||
存储过程的优点:
|
||||
|
||||
- **执行效率高**:一次编译多次使用。
|
||||
- **安全性强**:在设定存储过程的时候可以设置对用户的使用权限,这样就和视图一样具有较强的安全性。
|
||||
- **可复用**:将代码封装,可以提高代码复用。
|
||||
- **性能好**
|
||||
- 由于是预先编译,因此具有很高的性能。
|
||||
- 一个存储过程替代大量 T_SQL 语句 ,可以降低网络通信量,提高通信速率。
|
||||
|
||||
存储过程的缺点:
|
||||
|
||||
- **可移植性差**:存储过程不能跨数据库移植。由于不同数据库的存储过程语法几乎都不一样,十分难以维护(不通用)。
|
||||
- **调试困难**:只有少数 DBMS 支持存储过程的调试。对于复杂的存储过程来说,开发和维护都不容易。
|
||||
- **版本管理困难**:比如数据表索引发生变化了,可能会导致存储过程失效。我们在开发软件的时候往往需要进行版本管理,但是存储过程本身没有版本控制,版本迭代更新的时候很麻烦。
|
||||
- **不适合高并发的场景**:高并发的场景需要减少数据库的压力,有时数据库会采用分库分表的方式,而且对可扩展性要求很高,在这种情况下,存储过程会变得难以维护,增加数据库的压力,显然就不适用了。
|
||||
|
||||
> _综上,存储过程的优缺点都非常突出,是否使用一定要慎重,需要根据具体应用场景来权衡_。
|
||||
|
||||
### 触发器
|
||||
|
||||
> 触发器可以视为一种特殊的存储过程。
|
||||
>
|
||||
> 触发器是一种与表操作有关的数据库对象,当触发器所在表上出现指定事件时,将调用该对象,即表的操作事件触发表上的触发器的执行。
|
||||
|
||||
#### 触发器特性
|
||||
|
||||
可以使用触发器来进行审计跟踪,把修改记录到另外一张表中。
|
||||
|
||||
MySQL 不允许在触发器中使用 `CALL` 语句 ,也就是不能调用存储过程。
|
||||
|
||||
**`BEGIN` 和 `END`**
|
||||
|
||||
当触发器的触发条件满足时,将会执行 `BEGIN` 和 `END` 之间的触发器执行动作。
|
||||
|
||||
> 🔔 注意:在 MySQL 中,分号 `;` 是语句结束的标识符,遇到分号表示该段语句已经结束,MySQL 可以开始执行了。因此,解释器遇到触发器执行动作中的分号后就开始执行,然后会报错,因为没有找到和 BEGIN 匹配的 END。
|
||||
>
|
||||
> 这时就会用到 `DELIMITER` 命令(`DELIMITER` 是定界符,分隔符的意思)。它是一条命令,不需要语句结束标识,语法为:`DELIMITER new_delemiter`。`new_delemiter` 可以设为 1 个或多个长度的符号,默认的是分号 `;`,我们可以把它修改为其他符号,如 `$` - `DELIMITER $` 。在这之后的语句,以分号结束,解释器不会有什么反应,只有遇到了 `$`,才认为是语句结束。注意,使用完之后,我们还应该记得把它给修改回来。
|
||||
|
||||
**`NEW` 和 `OLD`**
|
||||
|
||||
- MySQL 中定义了 `NEW` 和 `OLD` 关键字,用来表示触发器的所在表中,触发了触发器的那一行数据。
|
||||
- 在 `INSERT` 型触发器中,`NEW` 用来表示将要(`BEFORE`)或已经(`AFTER`)插入的新数据;
|
||||
- 在 `UPDATE` 型触发器中,`OLD` 用来表示将要或已经被修改的原数据,`NEW` 用来表示将要或已经修改为的新数据;
|
||||
- 在 `DELETE` 型触发器中,`OLD` 用来表示将要或已经被删除的原数据;
|
||||
- 使用方法: `NEW.columnName` (columnName 为相应数据表某一列名)
|
||||
|
||||
#### 触发器指令
|
||||
|
||||
> 提示:为了理解触发器的要点,有必要先了解一下创建触发器的指令。
|
||||
|
||||
`CREATE TRIGGER` 指令用于创建触发器。
|
||||
|
||||
语法:
|
||||
|
||||
```sql
|
||||
CREATE TRIGGER trigger_name
|
||||
trigger_time
|
||||
trigger_event
|
||||
ON table_name
|
||||
FOR EACH ROW
|
||||
BEGIN
|
||||
trigger_statements
|
||||
END;
|
||||
```
|
||||
|
||||
说明:
|
||||
|
||||
- trigger_name:触发器名
|
||||
- trigger_time: 触发器的触发时机。取值为 `BEFORE` 或 `AFTER`。
|
||||
- trigger_event: 触发器的监听事件。取值为 `INSERT`、`UPDATE` 或 `DELETE`。
|
||||
- table_name: 触发器的监听目标。指定在哪张表上建立触发器。
|
||||
- FOR EACH ROW: 行级监视,Mysql 固定写法,其他 DBMS 不同。
|
||||
- trigger_statements: 触发器执行动作。是一条或多条 SQL 语句的列表,列表内的每条语句都必须用分号 `;` 来结尾。
|
||||
|
||||
创建触发器示例:
|
||||
|
||||
```sql
|
||||
DELIMITER $
|
||||
CREATE TRIGGER `trigger_insert_user`
|
||||
AFTER INSERT ON `user`
|
||||
FOR EACH ROW
|
||||
BEGIN
|
||||
INSERT INTO `user_history`(user_id, operate_type, operate_time)
|
||||
VALUES (NEW.id, 'add a user', now());
|
||||
END $
|
||||
DELIMITER ;
|
||||
```
|
||||
|
||||
查看触发器示例:
|
||||
|
||||
```sql
|
||||
SHOW TRIGGERS;
|
||||
```
|
||||
|
||||
删除触发器示例:
|
||||
|
||||
```sql
|
||||
DROP TRIGGER IF EXISTS trigger_insert_user;
|
||||
```
|
||||
|
||||
## 游标
|
||||
|
||||
> 游标(CURSOR)是一个存储在 DBMS 服务器上的数据库查询,它不是一条 `SELECT` 语句,而是被该语句检索出来的结果集。在存储过程中使用游标可以对一个结果集进行移动遍历。
|
||||
|
||||
游标主要用于交互式应用,其中用户需要对数据集中的任意行进行浏览和修改。
|
||||
|
||||
使用游标的步骤:
|
||||
|
||||
1. **定义游标**:通过 `DECLARE cursor_name CURSOR FOR <语句>` 定义游标。这个过程没有实际检索出数据。
|
||||
2. **打开游标**:通过 `OPEN cursor_name` 打开游标。
|
||||
3. **取出数据**:通过 `FETCH cursor_name INTO var_name ...` 获取数据。
|
||||
4. **关闭游标**:通过 `CLOSE cursor_name` 关闭游标。
|
||||
5. **释放游标**:通过 `DEALLOCATE PREPARE` 释放游标。
|
||||
|
||||
游标使用示例:
|
||||
|
||||
```sql
|
||||
DELIMITER $
|
||||
CREATE PROCEDURE getTotal()
|
||||
BEGIN
|
||||
DECLARE total INT;
|
||||
-- 创建接收游标数据的变量
|
||||
DECLARE sid INT;
|
||||
DECLARE sname VARCHAR(10);
|
||||
-- 创建总数变量
|
||||
DECLARE sage INT;
|
||||
-- 创建结束标志变量
|
||||
DECLARE done INT DEFAULT false;
|
||||
-- 创建游标
|
||||
DECLARE cur CURSOR FOR SELECT id,name,age from cursor_table where age>30;
|
||||
-- 指定游标循环结束时的返回值
|
||||
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = true;
|
||||
SET total = 0;
|
||||
OPEN cur;
|
||||
FETCH cur INTO sid, sname, sage;
|
||||
WHILE(NOT done)
|
||||
DO
|
||||
SET total = total + 1;
|
||||
FETCH cur INTO sid, sname, sage;
|
||||
END WHILE;
|
||||
|
||||
CLOSE cur;
|
||||
SELECT total;
|
||||
END $
|
||||
DELIMITER ;
|
||||
|
||||
-- 调用存储过程
|
||||
call getTotal();
|
||||
```
|
||||
|
||||
## 参考资料
|
||||
|
||||
- [《SQL 必知必会》](https://book.douban.com/subject/35167240/)
|
||||
- [『浅入深出』MySQL 中事务的实现](https://draveness.me/mysql-transaction)
|
||||
- [MySQL 的学习--触发器](https://www.cnblogs.com/CraryPrimitiveMan/p/4206942.html)
|
||||
- [维基百科词条 - SQL](https://zh.wikipedia.org/wiki/SQL)
|
||||
- [https://www.sitesbay.com/sql/index](https://www.sitesbay.com/sql/index)
|
||||
- [SQL Subqueries](https://www.w3resource.com/sql/subqueries/understanding-sql-subqueries.php)
|
||||
- [Quick breakdown of the types of joins](https://stackoverflow.com/questions/6294778/mysql-quick-breakdown-of-the-types-of-joins)
|
||||
- [SQL UNION](https://www.w3resource.com/sql/sql-union.php)
|
||||
- [SQL database security](https://www.w3resource.com/sql/database-security/create-users.php)
|
||||
- [Mysql 中的存储过程](https://www.cnblogs.com/chenpi/p/5136483.html)
|
||||
|
|
@ -14,8 +14,6 @@ permalink: /pages/55e9a7/
|
|||
|
||||
# 扩展 SQL
|
||||
|
||||
> 不同于 [SQL Cheat Sheet](02.SqlCheatSheet.md) 中的一般语法,本文主要整理收集一些高级但是很有用的 SQL
|
||||
|
||||
## 数据库
|
||||
|
||||
## 表
|
||||
|
|
@ -57,6 +55,31 @@ where id <= ?
|
|||
order by id limit 1000;
|
||||
```
|
||||
|
||||
### 修改表的编码格式
|
||||
|
||||
utf8mb4 编码是 utf8 编码的超集,兼容 utf8,并且能存储 4 字节的表情字符。如果表的编码指定为 utf8,在保存 emoji 字段时会报错。
|
||||
|
||||
```sql
|
||||
ALTER TABLE <tableName> CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
|
||||
```
|
||||
|
||||
## 其他
|
||||
|
||||
### 显示哪些线程正在运行
|
||||
|
||||
```sql
|
||||
mysql> show processlist;
|
||||
+----+-----------------+-----------------+------+---------+-------+------------------------+------------------+
|
||||
| Id | User | Host | db | Command | Time | State | Info |
|
||||
+----+-----------------+-----------------+------+---------+-------+------------------------+------------------+
|
||||
| 5 | event_scheduler | localhost | NULL | Daemon | 40230 | Waiting on empty queue | NULL |
|
||||
| 10 | root | localhost:10120 | NULL | Query | 0 | init | show processlist |
|
||||
+----+-----------------+-----------------+------+---------+-------+------------------------+------------------+
|
||||
2 rows in set (0.00 sec)
|
||||
```
|
||||
|
||||
Mysql 连接完成后,如果你没有后续的动作,这个连接就处于空闲状态,你可以在 `show processlist` 命令中看到它。其中的 Command 列显示为“Sleep”的这一行,就表示现在系统里面有一个空闲连接。客户端如果太长时间没动静,连接器就会自动将它断开。这个时间是由参数 wait_timeout 控制的,默认值是 8 小时。
|
||||
|
||||
## 参考资料
|
||||
|
||||
- [《SQL 必知必会》](https://item.jd.com/11232698.html)
|
||||
- [《SQL 必知必会》](https://book.douban.com/subject/35167240/)
|
||||
|
|
@ -0,0 +1,192 @@
|
|||
---
|
||||
title: SQL Cheat Sheet
|
||||
date: 2022-07-16 14:17:08
|
||||
categories:
|
||||
- 数据库
|
||||
- 关系型数据库
|
||||
- 综合
|
||||
tags:
|
||||
- 数据库
|
||||
- 关系型数据库
|
||||
- SQL
|
||||
permalink: /pages/e438a7/
|
||||
---
|
||||
|
||||
# SQL Cheat Sheet
|
||||
|
||||
## 查找数据的查询
|
||||
|
||||
### **SELECT**: 用于从数据库中选择数据
|
||||
|
||||
- `SELECT` \* `FROM` table_name;
|
||||
|
||||
### **DISTINCT**: 用于过滤掉重复的值并返回指定列的行
|
||||
|
||||
- `SELECT DISTINCT` column_name;
|
||||
|
||||
### **WHERE**: 用于过滤记录/行
|
||||
|
||||
- `SELECT` column1, column2 `FROM` table_name `WHERE` condition;
|
||||
- `SELECT` \* `FROM` table_name `WHERE` condition1 `AND` condition2;
|
||||
- `SELECT` \* `FROM` table_name `WHERE` condition1 `OR` condition2;
|
||||
- `SELECT` \* `FROM` table_name `WHERE NOT` condition;
|
||||
- `SELECT` \* `FROM` table_name `WHERE` condition1 `AND` (condition2 `OR` condition3);
|
||||
- `SELECT` \* `FROM` table_name `WHERE EXISTS` (`SELECT` column_name `FROM` table_name `WHERE` condition);
|
||||
|
||||
### **ORDER BY**: 用于结果集的排序,升序(ASC)或者降序(DESC)
|
||||
|
||||
- `SELECT` \* `FROM` table_name `ORDER BY` column;
|
||||
- `SELECT` \* `FROM` table_name `ORDER BY` column `DESC`;
|
||||
- `SELECT` \* `FROM` table_name `ORDER BY` column1 `ASC`, column2 `DESC`;
|
||||
|
||||
### **SELECT TOP**: 用于指定从表顶部返回的记录数
|
||||
|
||||
- `SELECT TOP` number columns_names `FROM` table_name `WHERE` condition;
|
||||
- `SELECT TOP` percent columns_names `FROM` table_name `WHERE` condition;
|
||||
- 并非所有数据库系统都支持`SELECT TOP`。 MySQL 中是`LIMIT`子句
|
||||
- `SELECT` column_names `FROM` table_name `LIMIT` offset, count;
|
||||
|
||||
### **LIKE**: 用于搜索列中的特定模式,WHERE 子句中使用的运算符
|
||||
|
||||
- % (percent sign) 是一个表示零个,一个或多个字符的通配符
|
||||
- \_ (underscore) 是一个表示单个字符通配符
|
||||
- `SELECT` column_names `FROM` table_name `WHERE` column_name `LIKE` pattern;
|
||||
- `LIKE` ‘a%’ (查找任何以“a”开头的值)
|
||||
- `LIKE` ‘%a’ (查找任何以“a”结尾的值)
|
||||
- `LIKE` ‘%or%’ (查找任何包含“or”的值)
|
||||
- `LIKE` ‘\_r%’ (查找任何第二位是“r”的值)
|
||||
- `LIKE` ‘a*%*%’ (查找任何以“a”开头且长度至少为 3 的值)
|
||||
- `LIKE` ‘[a-c]%’(查找任何以“a”或“b”或“c”开头的值)
|
||||
|
||||
### **IN**: 用于在 WHERE 子句中指定多个值的运算符
|
||||
|
||||
- 本质上,IN 运算符是多个 OR 条件的简写
|
||||
- `SELECT` column_names `FROM` table_name `WHERE` column_name `IN` (value1, value2, …);
|
||||
- `SELECT` column_names `FROM` table_name `WHERE` column_name `IN` (`SELECT STATEMENT`);
|
||||
|
||||
### **BETWEEN**: 用于过滤给定范围的值的运算符
|
||||
|
||||
- `SELECT` column_names `FROM` table_name `WHERE` column_name `BETWEEN` value1 `AND` value2;
|
||||
- `SELECT` \* `FROM` Products `WHERE` (column_name `BETWEEN` value1 `AND` value2) `AND NOT` column_name2 `IN` (value3, value4);
|
||||
- `SELECT` \* `FROM` Products `WHERE` column_name `BETWEEN` #01/07/1999# AND #03/12/1999#;
|
||||
|
||||
### **NULL**: 代表一个字段没有值
|
||||
|
||||
- `SELECT` \* `FROM` table_name `WHERE` column_name `IS NULL`;
|
||||
- `SELECT` \* `FROM` table_name `WHERE` column_name `IS NOT NULL`;
|
||||
|
||||
### **AS**: 用于给表或者列分配别名
|
||||
|
||||
- `SELECT` column_name `AS` alias_name `FROM` table_name;
|
||||
- `SELECT` column_name `FROM` table_name `AS` alias_name;
|
||||
- `SELECT` column_name `AS` alias_name1, column_name2 `AS` alias_name2;
|
||||
- `SELECT` column_name1, column_name2 + ‘, ‘ + column_name3 `AS` alias_name;
|
||||
|
||||
### **UNION**: 用于组合两个或者多个 SELECT 语句的结果集的运算符
|
||||
|
||||
- 每个 SELECT 语句必须拥有相同的列数
|
||||
- 列必须拥有相似的数据类型
|
||||
- 每个 SELECT 语句中的列也必须具有相同的顺序
|
||||
- `SELECT` columns_names `FROM` table1 `UNION SELECT` column_name `FROM` table2;
|
||||
- `UNION` 仅允许选择不同的值, `UNION ALL` 允许重复
|
||||
|
||||
### **ANY|ALL**: 用于检查 WHERE 或 HAVING 子句中使用的子查询条件的运算符
|
||||
|
||||
- `ANY` 如果任何子查询值满足条件,则返回 true。
|
||||
- `ALL` 如果所有子查询值都满足条件,则返回 true。
|
||||
- `SELECT` columns_names `FROM` table1 `WHERE` column_name operator (`ANY`|`ALL`) (`SELECT` column_name `FROM` table_name `WHERE` condition);
|
||||
|
||||
### **GROUP BY**: 通常与聚合函数(COUNT,MAX,MIN,SUM,AVG)一起使用,用于将结果集分组为一列或多列
|
||||
|
||||
- `SELECT` column_name1, COUNT(column_name2) `FROM` table_name `WHERE` condition `GROUP BY` column_name1 `ORDER BY` COUNT(column_name2) DESC;
|
||||
|
||||
### **HAVING**: HAVING 子句指定 SELECT 语句应仅返回聚合值满足指定条件的行。它被添加到 SQL 语言中,因为 WHERE 关键字不能与聚合函数一起使用。
|
||||
|
||||
- `SELECT` `COUNT`(column_name1), column_name2 `FROM` table `GROUP BY` column_name2 `HAVING` `COUNT(`column_name1`)` > 5;
|
||||
|
||||
## 修改数据的查询
|
||||
|
||||
### **INSERT INTO**: 用于在表中插入新记录/行
|
||||
|
||||
- `INSERT INTO` table_name (column1, column2) `VALUES` (value1, value2);
|
||||
- `INSERT INTO` table_name `VALUES` (value1, value2 …);
|
||||
|
||||
### **UPDATE**: 用于修改表中的现有记录/行
|
||||
|
||||
- `UPDATE` table_name `SET` column1 = value1, column2 = value2 `WHERE` condition;
|
||||
- `UPDATE` table_name `SET` column_name = value;
|
||||
|
||||
### **DELETE**: 用于删除表中的现有记录/行
|
||||
|
||||
- `DELETE FROM` table_name `WHERE` condition;
|
||||
- `DELETE` \* `FROM` table_name;
|
||||
|
||||
## 聚合查询
|
||||
|
||||
### **COUNT**: 返回出现次数
|
||||
|
||||
- `SELECT COUNT (DISTINCT` column_name`)`;
|
||||
|
||||
### **MIN() and MAX()**: 返回所选列的最小/最大值
|
||||
|
||||
- `SELECT MIN (`column_names`) FROM` table_name `WHERE` condition;
|
||||
- `SELECT MAX (`column_names`) FROM` table_name `WHERE` condition;
|
||||
|
||||
### **AVG()**: 返回数字列的平均值
|
||||
|
||||
- `SELECT AVG (`column_name`) FROM` table_name `WHERE` condition;
|
||||
|
||||
### **SUM()**: 返回数值列的总和
|
||||
|
||||
- `SELECT SUM (`column_name`) FROM` table_name `WHERE` condition;
|
||||
|
||||
## 连接查询
|
||||
|
||||
### **INNER JOIN**: 内连接,返回在两张表中具有匹配值的记录
|
||||
|
||||
- `SELECT` column_names `FROM` table1 `INNER JOIN` table2 `ON` table1.column_name=table2.column_name;
|
||||
- `SELECT` table1.column_name1, table2.column_name2, table3.column_name3 `FROM` ((table1 `INNER JOIN` table2 `ON` relationship) `INNER JOIN` table3 `ON` relationship);
|
||||
|
||||
### **LEFT (OUTER) JOIN**: 左外连接,返回左表(table1)中的所有记录,以及右表中的匹配记录(table2)
|
||||
|
||||
- `SELECT` column_names `FROM` table1 `LEFT JOIN` table2 `ON` table1.column_name=table2.column_name;
|
||||
|
||||
### **RIGHT (OUTER) JOIN**: 右外连接,返回右表(table2)中的所有记录,以及左表(table1)中匹配的记录
|
||||
|
||||
- `SELECT` column_names `FROM` table1 `RIGHT JOIN` table2 `ON` table1.column_name=table2.column_name;
|
||||
|
||||
### **FULL (OUTER) JOIN**: 全外连接,全连接是左右外连接的并集. 连接表包含被连接的表的所有记录, 如果缺少匹配的记录, 以 NULL 填充。
|
||||
|
||||
- `SELECT` column_names `FROM` table1 `FULL OUTER JOIN` table2 `ON` table1.column_name=table2.column_name;
|
||||
|
||||
### **Self JOIN**: 自连接,表自身连接
|
||||
|
||||
- `SELECT` column_names `FROM` table1 T1, table1 T2 `WHERE` condition;
|
||||
|
||||
## 视图查询
|
||||
|
||||
### **CREATE**: 创建视图
|
||||
|
||||
- `CREATE VIEW` view_name `AS SELECT` column1, column2 `FROM` table_name `WHERE` condition;
|
||||
|
||||
### **SELECT**: 检索视图
|
||||
|
||||
- `SELECT` \* `FROM` view_name;
|
||||
|
||||
### **DROP**: 删除视图
|
||||
|
||||
- `DROP VIEW` view_name;
|
||||
|
||||
## 修改表的查询
|
||||
|
||||
### **ADD**: 添加字段
|
||||
|
||||
- `ALTER TABLE` table_name `ADD` column_name column_definition;
|
||||
|
||||
### **MODIFY**: 修改字段数据类型
|
||||
|
||||
- `ALTER TABLE` table_name `MODIFY` column_name column_type;
|
||||
|
||||
### **DROP**: 删除字段
|
||||
|
||||
- `ALTER TABLE` table_name `DROP COLUMN` column_name;
|
||||
|
|
@ -16,17 +16,15 @@ hidden: true
|
|||
|
||||
## 📖 内容
|
||||
|
||||
### [关系型数据库面试题 💯](01.关系型数据库面试.md)
|
||||
### [关系型数据库面试总结](01.关系型数据库面试.md) 💯
|
||||
|
||||
### [SQL Cheat Sheet](02.SqlCheatSheet.md)
|
||||
### [SQL 语法基础特性](02.SQL语法基础特性.md)
|
||||
|
||||

|
||||
### [SQL 语法高级特性](03.SQL语法高级特性.md)
|
||||
|
||||
### [分库分表基本原理](https://dunwu.github.io/blog/pages/e1046e/)
|
||||
### [扩展 SQL](03.扩展SQL.md)
|
||||
|
||||

|
||||
|
||||
### [分布式事务基本原理](https://dunwu.github.io/blog/pages/e1881c/)
|
||||
### [SQL Cheat Sheet](99.SqlCheatSheet.md)
|
||||
|
||||
## 📚 资料
|
||||
|
||||
|
|
@ -36,7 +34,7 @@ hidden: true
|
|||
- [Mysql 官方文档之命令行客户端](https://dev.mysql.com/doc/refman/8.0/en/mysql.html)
|
||||
- **书籍**
|
||||
- [《高性能 MySQL》](https://item.jd.com/11220393.html) - Mysql 经典
|
||||
- [《SQL 必知必会》](https://item.jd.com/11232698.html) - SQL 入门
|
||||
- [《SQL 必知必会》](https://book.douban.com/subject/35167240/) - SQL 入门
|
||||
- **教程**
|
||||
- [runoob.com MySQL 教程](http://www.runoob.com/mymysql-tutorial.html) - 入门级 SQL 教程
|
||||
- [mysql-tutorial](https://github.com/jaywcjlove/mysql-tutorial)
|
||||
|
|
|
|||
|
|
@ -14,17 +14,17 @@ permalink: /pages/5fe0f3/
|
|||
|
||||
# Mysql 应用指南
|
||||
|
||||
## 1. SQL 执行过程
|
||||
## SQL 执行过程
|
||||
|
||||
学习 Mysql,最好是先从宏观上了解 Mysql 工作原理。
|
||||
|
||||
> 参考:[Mysql 工作流](02.MySQL工作流.md)
|
||||
|
||||
## 2. 存储引擎
|
||||
## 存储引擎
|
||||
|
||||
在文件系统中,Mysql 将每个数据库(也可以成为 schema)保存为数据目录下的一个子目录。创建表示,Mysql 会在数据库子目录下创建一个和表同名的 `.frm` 文件保存表的定义。因为 Mysql 使用文件系统的目录和文件来保存数据库和表的定义,大小写敏感性和具体平台密切相关。Windows 中大小写不敏感;类 Unix 中大小写敏感。**不同的存储引擎保存数据和索引的方式是不同的,但表的定义则是在 Mysql 服务层统一处理的。**
|
||||
|
||||
### 2.1. 选择存储引擎
|
||||
### 选择存储引擎
|
||||
|
||||
#### Mysql 内置的存储引擎
|
||||
|
||||
|
|
@ -73,7 +73,7 @@ mysql> SHOW ENGINES;
|
|||
ALTER TABLE mytable ENGINE = InnoDB
|
||||
```
|
||||
|
||||
### 2.2. MyISAM
|
||||
### MyISAM
|
||||
|
||||
MyISAM 设计简单,数据以紧密格式存储。对于只读数据,或者表比较小、可以容忍修复操作,则依然可以使用 MyISAM。
|
||||
|
||||
|
|
@ -81,7 +81,7 @@ MyISAM 引擎使用 B+Tree 作为索引结构,**叶节点的 data 域存放的
|
|||
|
||||
MyISAM 提供了大量的特性,包括:全文索引、压缩表、空间函数等。但是,MyISAM 不支持事务和行级锁。并且 MyISAM 不支持崩溃后的安全恢复。
|
||||
|
||||
### 2.3. InnoDB
|
||||
### InnoDB
|
||||
|
||||
InnoDB 是 MySQL 默认的事务型存储引擎,只有在需要 InnoDB 不支持的特性时,才考虑使用其它存储引擎。
|
||||
|
||||
|
|
@ -95,9 +95,9 @@ InnoDB 是基于聚簇索引建立的,与其他存储引擎有很大不同。
|
|||
|
||||
支持真正的在线热备份。其它存储引擎不支持在线热备份,要获取一致性视图需要停止对所有表的写入,而在读写混合场景中,停止写入可能也意味着停止读取。
|
||||
|
||||
## 3. 数据类型
|
||||
## 数据类型
|
||||
|
||||
### 3.1. 整型
|
||||
### 整型
|
||||
|
||||
`TINYINT`, `SMALLINT`, `MEDIUMINT`, `INT`, `BIGINT` 分别使用 `8`, `16`, `24`, `32`, `64` 位存储空间,一般情况下越小的列越好。
|
||||
|
||||
|
|
@ -105,7 +105,7 @@ InnoDB 是基于聚簇索引建立的,与其他存储引擎有很大不同。
|
|||
|
||||
`INT(11)` 中的数字只是规定了交互工具显示字符的个数,对于存储和计算来说是没有意义的。
|
||||
|
||||
### 3.2. 浮点型
|
||||
### 浮点型
|
||||
|
||||
`FLOAT` 和 `DOUBLE` 为浮点类型。
|
||||
|
||||
|
|
@ -113,7 +113,7 @@ InnoDB 是基于聚簇索引建立的,与其他存储引擎有很大不同。
|
|||
|
||||
`FLOAT`、`DOUBLE` 和 `DECIMAL` 都可以指定列宽,例如 `DECIMAL(18, 9)` 表示总共 18 位,取 9 位存储小数部分,剩下 9 位存储整数部分。
|
||||
|
||||
### 3.3. 字符串
|
||||
### 字符串
|
||||
|
||||
主要有 `CHAR` 和 `VARCHAR` 两种类型,一种是定长的,一种是变长的。
|
||||
|
||||
|
|
@ -121,7 +121,7 @@ InnoDB 是基于聚簇索引建立的,与其他存储引擎有很大不同。
|
|||
|
||||
`VARCHAR` 会保留字符串末尾的空格,而 `CHAR` 会删除。
|
||||
|
||||
### 3.4. 时间和日期
|
||||
### 时间和日期
|
||||
|
||||
MySQL 提供了两种相似的日期时间类型:`DATATIME` 和 `TIMESTAMP`。
|
||||
|
||||
|
|
@ -145,17 +145,17 @@ MySQL 提供了 FROM_UNIXTIME() 函数把 UNIX 时间戳转换为日期,并提
|
|||
|
||||
应该尽量使用 TIMESTAMP,因为它比 DATETIME 空间效率更高。
|
||||
|
||||
### 3.5. BLOB 和 TEXT
|
||||
### BLOB 和 TEXT
|
||||
|
||||
`BLOB` 和 `TEXT` 都是为了存储大的数据而设计,前者存储二进制数据,后者存储字符串数据。
|
||||
|
||||
不能对 `BLOB` 和 `TEXT` 类型的全部内容进行排序、索引。
|
||||
|
||||
### 3.6. 枚举类型
|
||||
### 枚举类型
|
||||
|
||||
大多数情况下没有使用枚举类型的必要,其中一个缺点是:枚举的字符串列表是固定的,添加和删除字符串(枚举选项)必须使用`ALTER TABLE`(如果只只是在列表末尾追加元素,不需要重建表)。
|
||||
|
||||
### 3.7. 类型的选择
|
||||
### 类型的选择
|
||||
|
||||
- 整数类型通常是标识列最好的选择,因为它们很快并且可以使用 `AUTO_INCREMENT`。
|
||||
|
||||
|
|
@ -163,25 +163,25 @@ MySQL 提供了 FROM_UNIXTIME() 函数把 UNIX 时间戳转换为日期,并提
|
|||
- 应该尽量避免用字符串类型作为标识列,因为它们很消耗空间,并且通常比数字类型慢。对于 `MD5`、`SHA`、`UUID` 这类随机字符串,由于比较随机,所以可能分布在很大的空间内,导致 `INSERT` 以及一些 `SELECT` 语句变得很慢。
|
||||
- 如果存储 UUID ,应该移除 `-` 符号;更好的做法是,用 `UNHEX()` 函数转换 UUID 值为 16 字节的数字,并存储在一个 `BINARY(16)` 的列中,检索时,可以通过 `HEX()` 函数来格式化为 16 进制格式。
|
||||
|
||||
## 4. 索引
|
||||
## 索引
|
||||
|
||||
> 详见:[Mysql 索引](05.Mysql索引.md)
|
||||
|
||||
## 5. 锁
|
||||
## 锁
|
||||
|
||||
> 详见:[Mysql 锁](04.Mysql锁.md)
|
||||
|
||||
## 6. 事务
|
||||
## 事务
|
||||
|
||||
> 详见:[Mysql 事务](03.Mysql事务.md)
|
||||
|
||||
## 7. 性能优化
|
||||
## 性能优化
|
||||
|
||||
> 详见:[Mysql 性能优化](06.Mysql性能优化.md)
|
||||
|
||||
## 8. 复制
|
||||
## 复制
|
||||
|
||||
### 8.1. 主从复制
|
||||
### 主从复制
|
||||
|
||||
Mysql 支持两种复制:基于行的复制和基于语句的复制。
|
||||
|
||||
|
|
@ -197,7 +197,7 @@ Mysql 支持两种复制:基于行的复制和基于语句的复制。
|
|||
<img src="https://raw.githubusercontent.com/dunwu/images/dev/cs/database/mysql/master-slave.png" />
|
||||
</div>
|
||||
|
||||
### 8.2. 读写分离
|
||||
### 读写分离
|
||||
|
||||
主服务器用来处理写操作以及实时性要求比较高的读操作,而从服务器用来处理读操作。
|
||||
|
||||
|
|
@ -212,25 +212,14 @@ MySQL 读写分离能提高性能的原因在于:
|
|||
<div align="center">
|
||||
<img src="https://raw.githubusercontent.com/dunwu/images/dev/cs/database/mysql/master-slave-proxy.png" />
|
||||
</div>
|
||||
------
|
||||
|
||||
(分割线)以下为高级特性,也是关系型数据库通用方案
|
||||
|
||||
## 9. 分布式事务
|
||||
|
||||
> 参考:[分布式事务基本原理](https://dunwu.github.io/blog/pages/e1881c/)
|
||||
|
||||
## 10. 分库分表
|
||||
|
||||
> 参考:[分库分表基本原理](https://dunwu.github.io/blog/pages/e1046e/)
|
||||
|
||||
## 11. 参考资料
|
||||
## 参考资料
|
||||
|
||||
- [《高性能 MySQL》](https://book.douban.com/subject/23008813/)
|
||||
- [20+ 条 MySQL 性能优化的最佳经验](https://www.jfox.info/20-tiao-mysql-xing-nen-you-hua-de-zui-jia-jing-yan.html)
|
||||
- [How to create unique row ID in sharded databases?](https://stackoverflow.com/questions/788829/how-to-create-unique-row-id-in-sharded-databases)
|
||||
- [SQL Azure Federation – Introduction](http://geekswithblogs.net/shaunxu/archive/2012/01/07/sql-azure-federation-ndash-introduction.aspx)
|
||||
|
||||
## 12. 传送门
|
||||
## 传送门
|
||||
|
||||
◾ 💧 [钝悟的 IT 知识图谱](https://dunwu.github.io/waterdrop/) ◾ 🎯 [钝悟的博客](https://dunwu.github.io/blog/) ◾
|
||||
|
|
@ -14,7 +14,7 @@ permalink: /pages/8262aa/
|
|||
|
||||
# MySQL 工作流
|
||||
|
||||
## 1. 基础架构
|
||||
## 基础架构
|
||||
|
||||
大体来说,MySQL 可以分为 Server 层和存储引擎层两部分。
|
||||
|
||||
|
|
@ -24,22 +24,22 @@ permalink: /pages/8262aa/
|
|||
|
||||
|
||||
|
||||
## 2. 查询过程
|
||||
## 查询过程
|
||||
|
||||
SQL 语句在 MySQL 中是如何执行的?
|
||||
|
||||
MySQL 整个查询执行过程,总的来说分为 6 个步骤:
|
||||
MySQL 整个查询执行过程,总的来说分为 6 个步骤,分别对应 6 个组件:
|
||||
|
||||
1. 客户端和 MySQL 服务器建立连接;客户端向 MySQL 服务器发送一条查询请求。
|
||||
1. 连接器:客户端和 MySQL 服务器建立连接;连接器负责跟客户端建立连接、获取权限、维持和管理连接。
|
||||
2. MySQL 服务器首先检查查询缓存,如果命中缓存,则立刻返回结果。否则进入下一阶段。
|
||||
3. MySQL 服务器进行 SQL 分析:语法分析、词法分析。
|
||||
4. MySQL 服务器用优化器生成对应的执行计划。
|
||||
5. MySQL 服务器根据执行计划,调用存储引擎的 API 来执行查询。
|
||||
6. MySQL 服务器将结果返回给客户端,同时缓存查询结果。
|
||||
|
||||
### 2.1. (一)连接
|
||||
### (一)连接器
|
||||
|
||||
使用 MySQL 第一步自然是要连接数据库。
|
||||
使用 MySQL 第一步自然是要连接数据库。**连接器负责跟客户端建立连接、获取权限、维持和管理连接**。
|
||||
|
||||
MySQL 客户端/服务端通信是**半双工模式**:即任一时刻,要么是服务端向客户端发送数据,要么是客户端向服务器发送数据。客户端用一个单独的数据包将查询请求发送给服务器,所以当查询语句很长的时候,需要设置`max_allowed_packet`参数。但是需要注意的是,如果查询实在是太大,服务端会拒绝接收更多数据并抛出异常。
|
||||
|
||||
|
|
@ -56,7 +56,7 @@ MySQL 客户端连接命令:`mysql -h<主机> -P<端口> -u<用户名> -p<密
|
|||
- **定期断开长连接**。使用一段时间,或者程序里面判断执行过一个占用内存的大查询后,断开连接,之后要查询再重连。
|
||||
- 如果你用的是 MySQL 5.7 或更新版本,可以在每次执行一个比较大的操作后,通过执行 `mysql_reset_connection` 来重新初始化连接资源。这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完时的状态。
|
||||
|
||||
### 2.2. (二)查询缓存
|
||||
### (二)查询缓存
|
||||
|
||||
> **不建议使用数据库缓存,因为往往弊大于利**。
|
||||
|
||||
|
|
@ -76,14 +76,14 @@ select SQL_CACHE * from T where ID=10;
|
|||
|
||||
> 注意:MySQL 8.0 版本直接将查询缓存的整块功能删掉了。
|
||||
|
||||
### 2.3. (三)语法分析
|
||||
### (三)语法分析
|
||||
|
||||
如果没有命中查询缓存,就要开始真正执行语句了。首先,MySQL 需要知道你要做什么,因此需要对 SQL 语句做解析。MySQL 通过关键字对 SQL 语句进行解析,并生成一颗对应的语法解析树。这个过程中,分析器主要通过语法规则来验证和解析。比如 SQL 中是否使用了错误的关键字或者关键字的顺序是否正确等等。预处理则会根据 MySQL 规则进一步检查解析树是否合法。比如检查要查询的数据表和数据列是否存在等等。
|
||||
|
||||
- 分析器先会先做“**词法分析**”。你输入的是由多个字符串和空格组成的一条 SQL 语句,MySQL 需要识别出里面的字符串分别是什么,代表什么。MySQL 从你输入的"select"这个关键字识别出来,这是一个查询语句。它也要把字符串“T”识别成“表名 T”,把字符串“ID”识别成“列 ID”。
|
||||
- 接下来,要做“**语法分析**”。根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法。如果你的语句不对,就会收到“You have an error in your SQL syntax”的错误提醒,比如下面这个语句 select 少打了开头的字母“s”。
|
||||
|
||||
### 2.4. (四)查询优化
|
||||
### (四)查询优化
|
||||
|
||||
经过了分析器,MySQL 就知道你要做什么了。在开始执行之前,还要先经过优化器的处理。
|
||||
|
||||
|
|
@ -116,11 +116,11 @@ MySQL 的查询优化器是一个非常复杂的部件,它使用了非常多
|
|||
|
||||
随着 MySQL 的不断发展,优化器使用的优化策略也在不断的进化,这里仅仅介绍几个非常常用且容易理解的优化策略,其他的优化策略,大家自行查阅吧。
|
||||
|
||||
### 2.5. (五)查询执行引擎
|
||||
### (五)查询执行引擎
|
||||
|
||||
在完成解析和优化阶段以后,MySQL 会生成对应的执行计划,查询执行引擎根据执行计划给出的指令逐步执行得出结果。整个执行过程的大部分操作均是通过调用存储引擎实现的接口来完成,这些接口被称为`handler API`。查询过程中的每一张表由一个`handler`实例表示。实际上,MySQL 在查询优化阶段就为每一张表创建了一个`handler`实例,优化器可以根据这些实例的接口来获取表的相关信息,包括表的所有列名、索引统计信息等。存储引擎接口提供了非常丰富的功能,但其底层仅有几十个接口,这些接口像搭积木一样完成了一次查询的大部分操作。
|
||||
|
||||
### 2.6. (六)返回结果
|
||||
### (六)返回结果
|
||||
|
||||
查询过程的最后一个阶段就是将结果返回给客户端。即使查询不到数据,MySQL 仍然会返回这个查询的相关信息,比如该查询影响到的行数以及执行时间等等。
|
||||
|
||||
|
|
@ -128,11 +128,11 @@ MySQL 的查询优化器是一个非常复杂的部件,它使用了非常多
|
|||
|
||||
结果集返回客户端是一个增量且逐步返回的过程。有可能 MySQL 在生成第一条结果时,就开始向客户端逐步返回结果集了。这样服务端就无须存储太多结果而消耗过多内存,也可以让客户端第一时间获得返回结果。需要注意的是,结果集中的每一行都会以一个满足 ① 中所描述的通信协议的数据包发送,再通过 TCP 协议进行传输,在传输过程中,可能对 MySQL 的数据包进行缓存然后批量发送。
|
||||
|
||||
## 3. 更新过程
|
||||
## 更新过程
|
||||
|
||||
MySQL 更新过程和 MySQL 查询过程类似,也会将流程走一遍。不一样的是:**更新流程还涉及两个重要的日志模块,:redo log(重做日志)和 binlog(归档日志)**。
|
||||
|
||||
### 3.1. redo log
|
||||
### redo log
|
||||
|
||||
**redo log 是 InnoDB 引擎特有的日志**。**redo log 即重做日志**。redo log 是物理日志,记录的是“在某个数据页上做了什么修改”。
|
||||
|
||||
|
|
@ -144,7 +144,7 @@ InnoDB 的 redo log 是固定大小的,比如可以配置为一组 4 个文件
|
|||
|
||||
有了 redo log,InnoDB 就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为**crash-safe**。
|
||||
|
||||
### 3.2. bin log
|
||||
### bin log
|
||||
|
||||
**bin log 即归档日志**。binlog 是逻辑日志,记录的是这个语句的原始逻辑。
|
||||
|
||||
|
|
@ -154,7 +154,7 @@ binlog 是可以追加写入的,即写到一定大小后会切换到下一个
|
|||
|
||||
`sync_binlog` 这个参数设置成 1 的时候,表示每次事务的 binlog 都持久化到磁盘。这个参数我也建议你设置成 1,这样可以保证 MySQL 异常重启之后 binlog 不丢失。
|
||||
|
||||
### 3.3. redo log vs. bin log
|
||||
### redo log vs. bin log
|
||||
|
||||
这两种日志有以下三点不同。
|
||||
|
||||
|
|
@ -174,7 +174,7 @@ binlog 是可以追加写入的,即写到一定大小后会切换到下一个
|
|||
|
||||
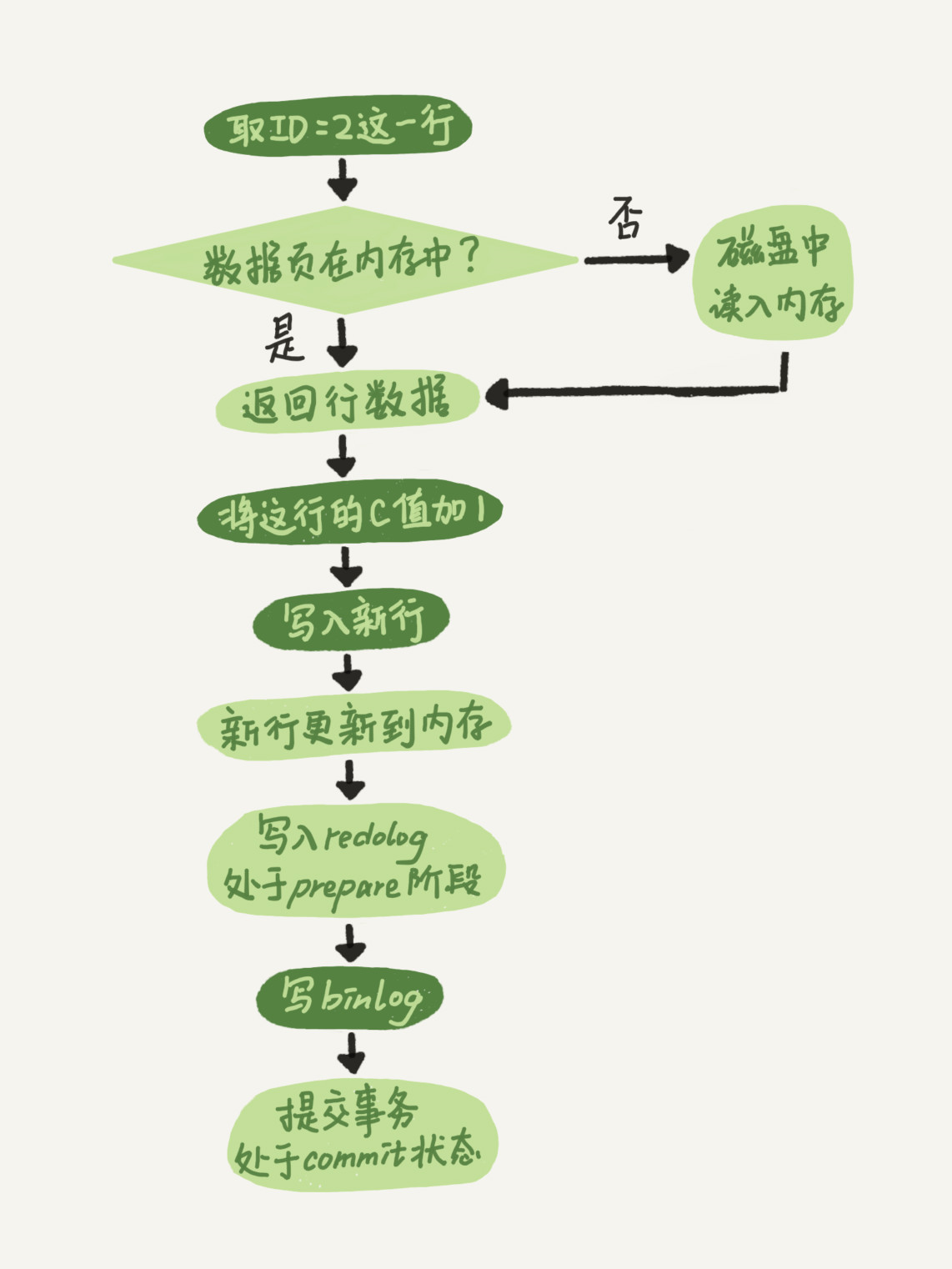
|
||||
|
||||
### 3.4. 两阶段提交
|
||||
### 两阶段提交
|
||||
|
||||
redo log 的写入拆成了两个步骤:prepare 和 commit,这就是"两阶段提交"。为什么日志需要“两阶段提交”。
|
||||
|
||||
|
|
@ -187,7 +187,7 @@ redo log 的写入拆成了两个步骤:prepare 和 commit,这就是"两阶
|
|||
|
||||
可以看到,如果不使用“两阶段提交”,那么数据库的状态就有可能和用它的日志恢复出来的库的状态不一致。
|
||||
|
||||
## 4. 参考资料
|
||||
## 参考资料
|
||||
|
||||
- [《高性能 MySQL》](https://book.douban.com/subject/23008813/)
|
||||
- [MySQL 实战 45 讲](https://time.geekbang.org/column/intro/139)
|
||||
|
|
@ -19,9 +19,9 @@ permalink: /pages/00b04d/
|
|||
>
|
||||
> 用户可以根据业务是否需要事务处理(事务处理可以保证数据安全,但会增加系统开销),选择合适的存储引擎。
|
||||
|
||||
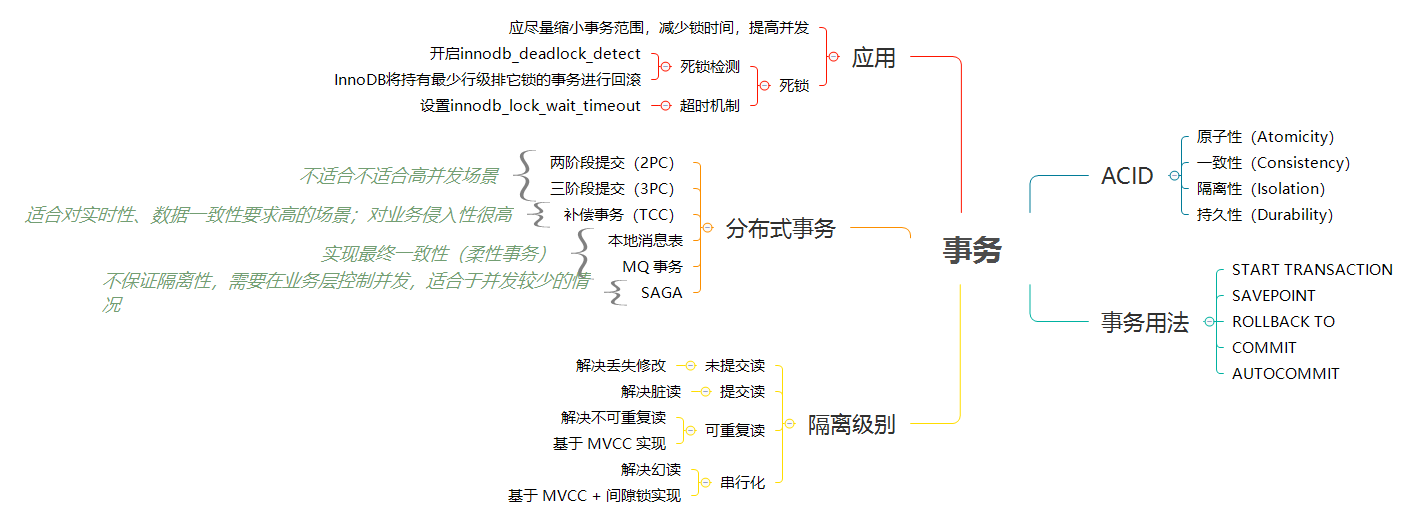
|
||||
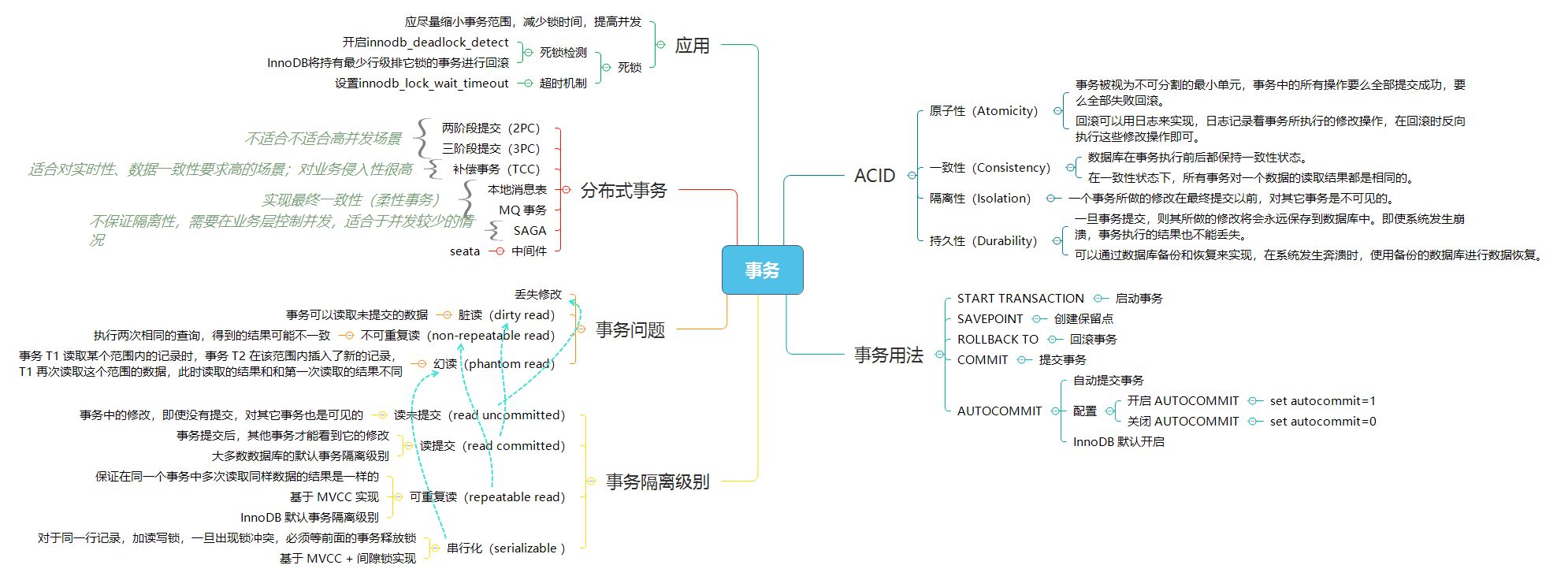
|
||||
|
||||
## 1. 事务简介
|
||||
## 事务简介
|
||||
|
||||
> 事务简单来说:**一个 Session 中所进行所有的操作,要么同时成功,要么同时失败**。进一步说,事务指的是满足 ACID 特性的一组操作,可以通过 `Commit` 提交一个事务,也可以使用 `Rollback` 进行回滚。
|
||||
|
||||
|
|
@ -39,9 +39,9 @@ T<sub>1</sub> 和 T<sub>2</sub> 两个线程都对一个数据进行修改,T<s
|
|||
|
||||
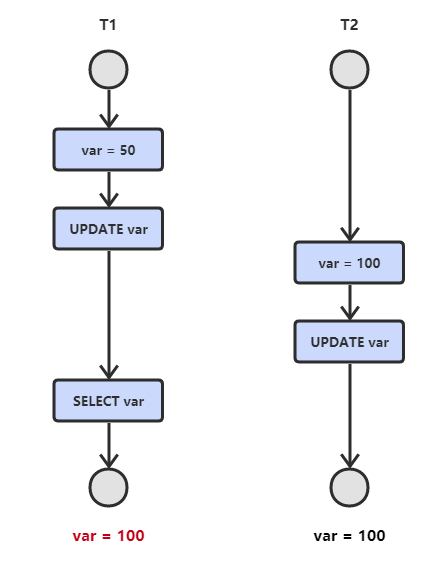
|
||||
|
||||
## 2. 事务用法
|
||||
## 事务用法
|
||||
|
||||
### 2.1. 事务处理指令
|
||||
### 事务处理指令
|
||||
|
||||
Mysql 中,使用 `START TRANSACTION` 语句开始一个事务;使用 `COMMIT` 语句提交所有的修改;使用 `ROLLBACK` 语句撤销所有的修改。不能回退 `SELECT` 语句,回退 `SELECT` 语句也没意义;也不能回退 `CREATE` 和 `DROP` 语句。
|
||||
|
||||
|
|
@ -103,7 +103,7 @@ SELECT * FROM user;
|
|||
1 root1 root1 xxxx@163.com
|
||||
```
|
||||
|
||||
### 2.2. AUTOCOMMIT
|
||||
### AUTOCOMMIT
|
||||
|
||||
**MySQL 默认采用隐式提交策略(`autocommit`)**。每执行一条语句就把这条语句当成一个事务然后进行提交。当出现 `START TRANSACTION` 语句时,会关闭隐式提交;当 `COMMIT` 或 `ROLLBACK` 语句执行后,事务会自动关闭,重新恢复隐式提交。
|
||||
|
||||
|
|
@ -120,7 +120,7 @@ SET autocommit = 0;
|
|||
SET autocommit = 1;
|
||||
```
|
||||
|
||||
## 3. ACID
|
||||
## ACID
|
||||
|
||||
ACID 是数据库事务正确执行的四个基本要素。
|
||||
|
||||
|
|
@ -147,9 +147,9 @@ ACID 是数据库事务正确执行的四个基本要素。
|
|||
|
||||
> MySQL 默认采用自动提交模式(`AUTO COMMIT`)。也就是说,如果不显式使用 `START TRANSACTION` 语句来开始一个事务,那么每个查询操作都会被当做一个事务并自动提交。
|
||||
|
||||
## 4. 事务隔离级别
|
||||
## 事务隔离级别
|
||||
|
||||
### 4.1. 事务隔离简介
|
||||
### 事务隔离简介
|
||||
|
||||
在并发环境下,事务的隔离性很难保证,因此会出现很多并发一致性问题:
|
||||
|
||||
|
|
@ -160,8 +160,8 @@ ACID 是数据库事务正确执行的四个基本要素。
|
|||
|
||||
在 SQL 标准中,定义了四种事务隔离级别(级别由低到高):
|
||||
|
||||
- **未提交读**
|
||||
- **提交读**
|
||||
- **读未提交**
|
||||
- **读提交**
|
||||
- **可重复读**
|
||||
- **串行化**
|
||||
|
||||
|
|
@ -184,63 +184,61 @@ SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
|
|||
SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE;
|
||||
```
|
||||
|
||||
### 4.2. 未提交读
|
||||
### 读未提交
|
||||
|
||||
**`未提交读(READ UNCOMMITTED)` 是指:事务中的修改,即使没有提交,对其它事务也是可见的**。
|
||||
**`读未提交(read uncommitted)` 是指:事务中的修改,即使没有提交,对其它事务也是可见的**。
|
||||
|
||||
未提交读的问题:事务可以读取未提交的数据,也被称为 **脏读(Dirty Read)**。
|
||||
读未提交的问题:事务可以读取未提交的数据,也被称为 **脏读(Dirty Read)**。
|
||||
|
||||
T<sub>1</sub> 修改一个数据,T<sub>2</sub> 随后读取这个数据。如果 T<sub>1</sub> 撤销了这次修改,那么 T<sub>2</sub> 读取的数据是脏数据。
|
||||
|
||||
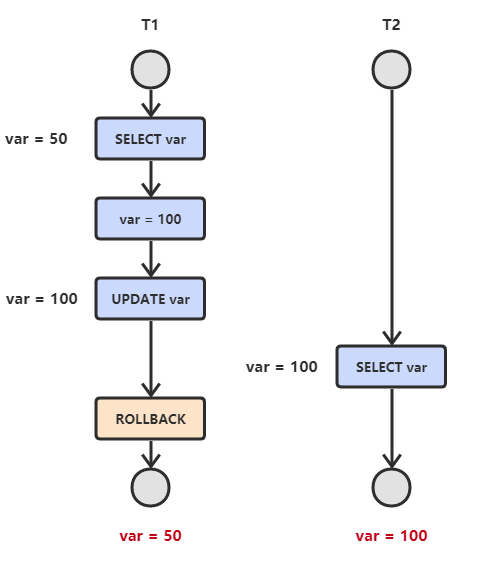
|
||||
|
||||
### 4.3. 提交读
|
||||
### 读提交
|
||||
|
||||
**`提交读(READ COMMITTED)` 是指:事务提交后,其他事务才能看到它的修改**。换句话说,一个事务所做的修改在提交之前对其它事务是不可见的。提交读解决了脏读的问题。
|
||||
**`读提交(read committed)` 是指:事务提交后,其他事务才能看到它的修改**。换句话说,一个事务所做的修改在提交之前对其它事务是不可见的。读提交解决了脏读的问题。
|
||||
|
||||
提交读是大多数数据库的默认事务隔离级别。
|
||||
读提交是大多数数据库的默认事务隔离级别。
|
||||
|
||||
提交读有时也叫不可重复读,它的问题是:执行两次相同的查询,得到的结果可能不一致。
|
||||
读提交有时也叫不可重复读,它的问题是:执行两次相同的查询,得到的结果可能不一致。
|
||||
|
||||
T<sub>2</sub> 读取一个数据,T<sub>1</sub> 对该数据做了修改。如果 T<sub>2</sub> 再次读取这个数据,此时读取的结果和第一次读取的结果不同。
|
||||
|
||||
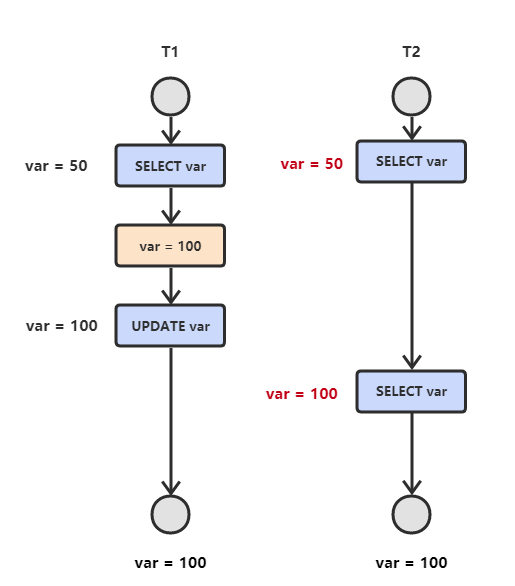
|
||||
|
||||
### 4.4. 可重复读
|
||||
### 可重复读
|
||||
|
||||
**`可重复读(REPEATABLE READ)` 是指:保证在同一个事务中多次读取同样数据的结果是一样的**。可重复读解决了不可重复读问题。
|
||||
|
||||
可重复读是 Mysql 的默认事务隔离级别。
|
||||
|
||||
可重复读的问题:当某个事务读取某个范围内的记录时,另外一个事务又在该范围内插入了新的记录,当之前的事务又再次读取该范围的记录时,会产生 **幻读(Phantom Read)**。
|
||||
|
||||
T<sub>1</sub> 读取某个范围的数据,T<sub>2</sub> 在这个范围内插入新的数据,T<sub>1</sub> 再次读取这个范围的数据,此时读取的结果和和第一次读取的结果不同。
|
||||
可重复读的问题:事务 T1 读取某个范围内的记录时,事务 T2 在该范围内插入了新的记录,T1 再次读取这个范围的数据,此时读取的结果和和第一次读取的结果不同,即为 **幻读(Phantom Read)**。
|
||||
|
||||
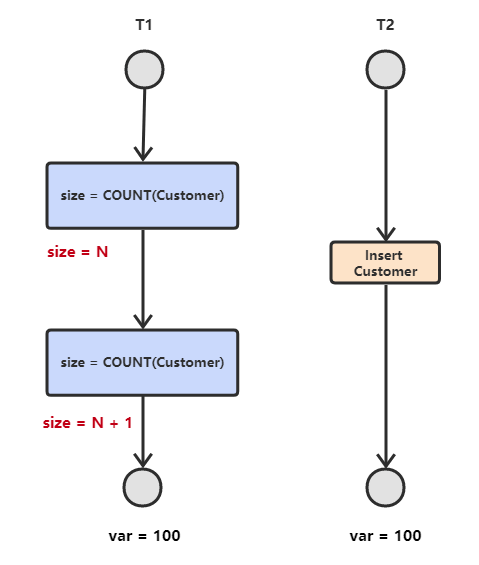
|
||||
|
||||
### 4.5. 串行化
|
||||
### 串行化
|
||||
|
||||
**`串行化(SERIALIXABLE)` 是指:强制事务串行执行**。
|
||||
**`串行化(SERIALIXABLE)` 是指:强制事务串行执行,对于同一行记录,加读写锁,一旦出现锁冲突,必须等前面的事务释放锁**。
|
||||
|
||||
强制事务串行执行,则避免了所有的并发问题。串行化策略会在读取的每一行数据上都加锁,这可能导致大量的超时和锁竞争。这对于高并发应用基本上是不可接受的,所以一般不会采用这个级别。
|
||||
|
||||
### 4.6. 隔离级别小结
|
||||
### 隔离级别小结
|
||||
|
||||
- **`未提交读(READ UNCOMMITTED)`** - 事务中的修改,即使没有提交,对其它事务也是可见的。
|
||||
- **`提交读(READ COMMITTED)`** - 一个事务只能读取已经提交的事务所做的修改。换句话说,一个事务所做的修改在提交之前对其它事务是不可见的。
|
||||
- **`读未提交(READ UNCOMMITTED)`** - 事务中的修改,即使没有提交,对其它事务也是可见的。
|
||||
- **`读提交(READ COMMITTED)`** - 一个事务只能读取已经提交的事务所做的修改。换句话说,一个事务所做的修改在提交之前对其它事务是不可见的。
|
||||
- **`重复读(REPEATABLE READ)`** - 保证在同一个事务中多次读取同样数据的结果是一样的。
|
||||
- **`串行化(SERIALIXABLE)`** - 强制事务串行执行。
|
||||
- **`串行化(SERIALIXABLE)`** - 对于同一行记录,加读写锁,一旦出现锁冲突,必须等前面的事务释放锁。
|
||||
|
||||
数据库隔离级别解决的问题:
|
||||
|
||||
| 隔离级别 | 丢失修改 | 脏读 | 不可重复读 | 幻读 |
|
||||
| :------: | :------: | :--: | :--------: | :--: |
|
||||
| 未提交读 | ✔️ | ❌ | ❌ | ❌ |
|
||||
| 提交读 | ✔️ | ✔️ | ❌ | ❌ |
|
||||
| 读未提交 | ✔️ | ❌ | ❌ | ❌ |
|
||||
| 读提交 | ✔️ | ✔️ | ❌ | ❌ |
|
||||
| 可重复读 | ✔️ | ✔️ | ✔️ | ❌ |
|
||||
| 可串行化 | ✔️ | ✔️ | ✔️ | ✔️ |
|
||||
|
||||
## 5. 死锁
|
||||
## 死锁
|
||||
|
||||
**死锁是指两个或多个事务竞争同一资源,并请求锁定对方占用的资源,从而导致恶性循环的现象**。
|
||||
|
||||
|
|
@ -250,7 +248,7 @@ T<sub>1</sub> 读取某个范围的数据,T<sub>2</sub> 在这个范围内插
|
|||
|
||||
- 多个事务同时锁定同一个资源时,也会产生死锁。
|
||||
|
||||
### 5.1. 死锁的原因
|
||||
### 死锁的原因
|
||||
|
||||
行锁的具体实现算法有三种:record lock、gap lock 以及 next-key lock。record lock 是专门对索引项加锁;gap lock 是对索引项之间的间隙加锁;next-key lock 则是前面两种的组合,对索引项以其之间的间隙加锁。
|
||||
|
||||
|
|
@ -282,7 +280,7 @@ InnoDB 存储引擎的主键索引为聚簇索引,其它索引为辅助索引
|
|||
|
||||
综上可知,在更新操作时,我们应该尽量使用主键来更新表字段,这样可以有效避免一些不必要的死锁发生。
|
||||
|
||||
### 5.2. 避免死锁
|
||||
### 避免死锁
|
||||
|
||||
预防死锁的注意事项:
|
||||
|
||||
|
|
@ -296,7 +294,7 @@ InnoDB 存储引擎的主键索引为聚簇索引,其它索引为辅助索引
|
|||
|
||||
我们还可以使用其它的方式来代替数据库实现幂等性校验。例如,使用 Redis 以及 ZooKeeper 来实现,运行效率比数据库更佳。
|
||||
|
||||
### 5.3. 解决死锁
|
||||
### 解决死锁
|
||||
|
||||
当出现死锁以后,有两种策略:
|
||||
|
||||
|
|
@ -311,7 +309,7 @@ InnoDB 存储引擎的主键索引为聚簇索引,其它索引为辅助索引
|
|||
|
||||
主动死锁检测在发生死锁的时候,是能够快速发现并进行处理的,但是它也是有额外负担的。你可以想象一下这个过程:每当一个事务被锁的时候,就要看看它所依赖的线程有没有被别人锁住,如此循环,最后判断是否出现了循环等待,也就是死锁。
|
||||
|
||||
## 6. 分布式事务
|
||||
## 分布式事务
|
||||
|
||||
在单一数据节点中,事务仅限于对单一数据库资源的访问控制,称之为 **本地事务**。几乎所有的成熟的关系型数据库都提供了对本地事务的原生支持。
|
||||
|
||||
|
|
@ -338,19 +336,19 @@ InnoDB 存储引擎的主键索引为聚簇索引,其它索引为辅助索引
|
|||
|
||||
> 分布式事务详细说明、分析请参考:[分布式事务基本原理](https://dunwu.github.io/blog/pages/e1881c/)
|
||||
|
||||
## 7. 事务最佳实践
|
||||
## 事务最佳实践
|
||||
|
||||
高并发场景下的事务到底该如何调优?
|
||||
|
||||
### 7.1. 尽量使用低级别事务隔离
|
||||
### 尽量使用低级别事务隔离
|
||||
|
||||
结合业务场景,尽量使用低级别事务隔离
|
||||
|
||||
### 7.2. 避免行锁升级表锁
|
||||
### 避免行锁升级表锁
|
||||
|
||||
在 InnoDB 中,行锁是通过索引实现的,如果不通过索引条件检索数据,行锁将会升级到表锁。我们知道,表锁是会严重影响到整张表的操作性能的,所以应该尽力避免。
|
||||
|
||||
### 7.3. 缩小事务范围
|
||||
### 缩小事务范围
|
||||
|
||||
有时候,数据库并发访问量太大,会出现以下异常:
|
||||
|
||||
|
|
@ -370,7 +368,7 @@ MySQLQueryInterruptedException: Query execution was interrupted
|
|||
|
||||
知道了这个设定,对我们使用事务有什么帮助呢?那就是,如果你的事务中需要锁多个行,要把最可能造成锁冲突、最可能影响并发度的锁尽量往后放。
|
||||
|
||||
## 8. 参考资料
|
||||
## 参考资料
|
||||
|
||||
- [《高性能 MySQL》](https://book.douban.com/subject/23008813/)
|
||||
- [《Java 性能调优实战》](https://time.geekbang.org/column/intro/100028001)
|
||||
|
|
|
|||
|
|
@ -17,7 +17,7 @@ permalink: /pages/f1f151/
|
|||
|
||||
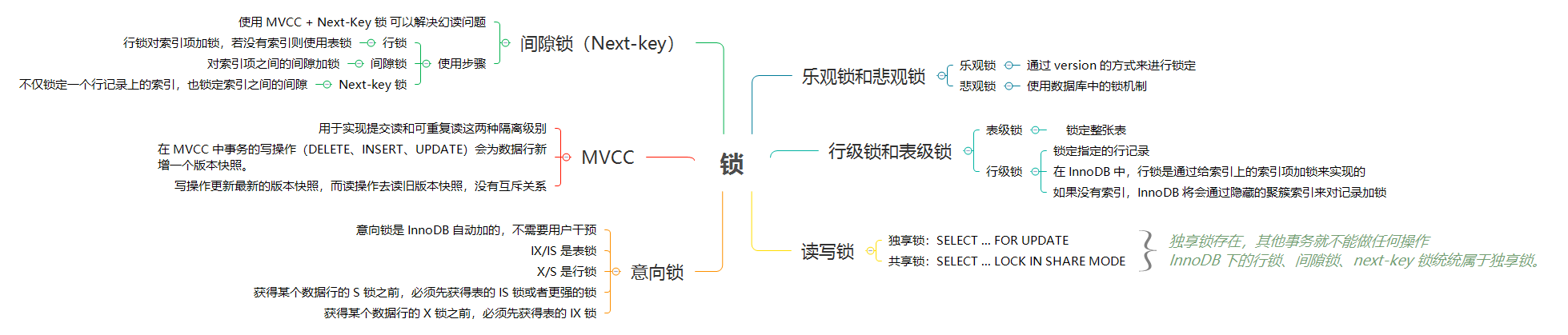
|
||||
|
||||
## 1. 悲观锁和乐观锁
|
||||
## 悲观锁和乐观锁
|
||||
|
||||
确保在多个事务同时存取数据库中同一数据时不破坏事务的隔离性和统一性以及数据库的统一性,**乐观锁和悲观锁是并发控制主要采用的技术手段。**
|
||||
|
||||
|
|
@ -42,7 +42,7 @@ where id=#{id} and version=#{version};
|
|||
|
||||
> 更详细的乐观锁说可以参考:[使用 mysql 乐观锁解决并发问题](https://www.cnblogs.com/laoyeye/p/8097684.html)
|
||||
|
||||
## 2. 表级锁和行级锁
|
||||
## 表级锁和行级锁
|
||||
|
||||
从数据库的锁粒度来看,MySQL 中提供了两种封锁粒度:行级锁和表级锁。
|
||||
|
||||
|
|
@ -55,7 +55,7 @@ where id=#{id} and version=#{version};
|
|||
|
||||
在 `InnoDB` 中,**行锁是通过给索引上的索引项加锁来实现的**。**如果没有索引,`InnoDB` 将会通过隐藏的聚簇索引来对记录加锁**。
|
||||
|
||||
## 3. 读写锁
|
||||
## 读写锁
|
||||
|
||||
- 独享锁(Exclusive),简写为 X 锁,又称写锁。使用方式:`SELECT ... FOR UPDATE;`
|
||||
- 共享锁(Shared),简写为 S 锁,又称读锁。使用方式:`SELECT ... LOCK IN SHARE MODE;`
|
||||
|
|
@ -64,7 +64,7 @@ where id=#{id} and version=#{version};
|
|||
|
||||
**`InnoDB` 下的行锁、间隙锁、next-key 锁统统属于独享锁**。
|
||||
|
||||
## 4. 意向锁
|
||||
## 意向锁
|
||||
|
||||
**当存在表级锁和行级锁的情况下,必须先申请意向锁(表级锁,但不是真的加锁),再获取行级锁**。使用意向锁(Intention Locks)可以更容易地支持多粒度封锁。
|
||||
|
||||
|
|
@ -95,13 +95,13 @@ where id=#{id} and version=#{version};
|
|||
- 任意 IS/IX 锁之间都是兼容的,因为它们只表示想要对表加锁,而不是真正加锁;
|
||||
- 这里兼容关系针对的是表级锁,而表级的 IX 锁和行级的 X 锁兼容,两个事务可以对两个数据行加 X 锁。(事务 T1 想要对数据行 R1 加 X 锁,事务 T2 想要对同一个表的数据行 R2 加 X 锁,两个事务都需要对该表加 IX 锁,但是 IX 锁是兼容的,并且 IX 锁与行级的 X 锁也是兼容的,因此两个事务都能加锁成功,对同一个表中的两个数据行做修改。)
|
||||
|
||||
## 5. MVCC
|
||||
## MVCC
|
||||
|
||||
**多版本并发控制(Multi-Version Concurrency Control, MVCC)可以视为行级锁的一个变种。它在很多情况下都避免了加锁操作,因此开销更低**。不仅是 Mysql,包括 Oracle、PostgreSQL 等其他数据库都实现了各自的 MVCC,实现机制没有统一标准。
|
||||
|
||||
MVCC 是 `InnoDB` 存储引擎实现隔离级别的一种具体方式,**用于实现提交读和可重复读这两种隔离级别**。而未提交读隔离级别总是读取最新的数据行,要求很低,无需使用 MVCC。可串行化隔离级别需要对所有读取的行都加锁,单纯使用 MVCC 无法实现。
|
||||
|
||||
### 5.1. MVCC 思想
|
||||
### MVCC 思想
|
||||
|
||||
加锁能解决多个事务同时执行时出现的并发一致性问题。在实际场景中读操作往往多于写操作,因此又引入了读写锁来避免不必要的加锁操作,例如读和读没有互斥关系。读写锁中读和写操作仍然是互斥的。
|
||||
|
||||
|
|
@ -110,14 +110,14 @@ MVCC 的思想是:
|
|||
- **保存数据在某个时间点的快照,写操作(DELETE、INSERT、UPDATE)更新最新的版本快照;而读操作去读旧版本快照,没有互斥关系**。这一点和 `CopyOnWrite` 类似。
|
||||
- 脏读和不可重复读最根本的原因是**事务读取到其它事务未提交的修改**。在事务进行读取操作时,为了解决脏读和不可重复读问题,**MVCC 规定只能读取已经提交的快照**。当然一个事务可以读取自身未提交的快照,这不算是脏读。
|
||||
|
||||
### 5.2. 版本号
|
||||
### 版本号
|
||||
|
||||
InnoDB 的 MVCC 实现是:在每行记录后面保存两个隐藏列,一个列保存行的创建时间,另一个列保存行的过期时间(这里的时间是指系统版本号)。每开始一个新事务,系统版本号会自动递增,事务开始时刻的系统版本号会作为事务的版本号,用来和查询到的每行记录的版本号进行比较。
|
||||
|
||||
- 系统版本号 `SYS_ID`:是一个递增的数字,每开始一个新的事务,系统版本号就会自动递增。
|
||||
- 事务版本号 `TRX_ID` :事务开始时的系统版本号。
|
||||
|
||||
### 5.3. Undo 日志
|
||||
### Undo 日志
|
||||
|
||||
MVCC 的多版本指的是多个版本的快照,快照存储在 Undo 日志中,该日志通过回滚指针 `ROLL_PTR` 把一个数据行的所有快照连接起来。
|
||||
|
||||
|
|
@ -133,7 +133,7 @@ UPDATE t SET x="c" WHERE id=1;
|
|||
|
||||
`INSERT`、`UPDATE`、`DELETE` 操作会创建一个日志,并将事务版本号 `TRX_ID` 写入。`DELETE` 可以看成是一个特殊的 `UPDATE`,还会额外将 DEL 字段设置为 1。
|
||||
|
||||
### 5.4. ReadView
|
||||
### ReadView
|
||||
|
||||
MVCC 维护了一个一致性读视图 `consistent read view` ,主要包含了当前系统**未提交的事务列表** `TRX_IDs {TRX_ID_1, TRX_ID_2, ...}`,还有该列表的最小值 `TRX_ID_MIN` 和 `TRX_ID_MAX`。
|
||||
|
||||
|
|
@ -157,7 +157,7 @@ MVCC 维护了一个一致性读视图 `consistent read view` ,主要包含了
|
|||
|
||||
在数据行快照不可使用的情况下,需要沿着 Undo Log 的回滚指针 ROLL_PTR 找到下一个快照,再进行上面的判断。
|
||||
|
||||
### 5.5. 快照读与当前读
|
||||
### 快照读与当前读
|
||||
|
||||
快照读
|
||||
|
||||
|
|
@ -184,7 +184,7 @@ SELECT * FROM table WHERE ? lock in share mode;
|
|||
SELECT * FROM table WHERE ? for update;
|
||||
```
|
||||
|
||||
## 6. 行锁
|
||||
## 行锁
|
||||
|
||||
行锁的具体实现算法有三种:record lock、gap lock 以及 next-key lock。
|
||||
|
||||
|
|
@ -200,7 +200,7 @@ MVCC 不能解决幻读问题,**Next-Key 锁就是为了解决幻读问题**
|
|||
|
||||
当两个事务同时执行,一个锁住了主键索引,在等待其他相关索引。另一个锁定了非主键索引,在等待主键索引。这样就会发生死锁。发生死锁后,`InnoDB` 一般都可以检测到,并使一个事务释放锁回退,另一个获取锁完成事务。
|
||||
|
||||
## 7. 参考资料
|
||||
## 参考资料
|
||||
|
||||
- [《高性能 MySQL》](https://book.douban.com/subject/23008813/)
|
||||
- [《Java 性能调优实战》](https://time.geekbang.org/column/intro/100028001)
|
||||
|
|
|
|||
|
|
@ -21,13 +21,13 @@ permalink: /pages/fcb19c/
|
|||
|
||||
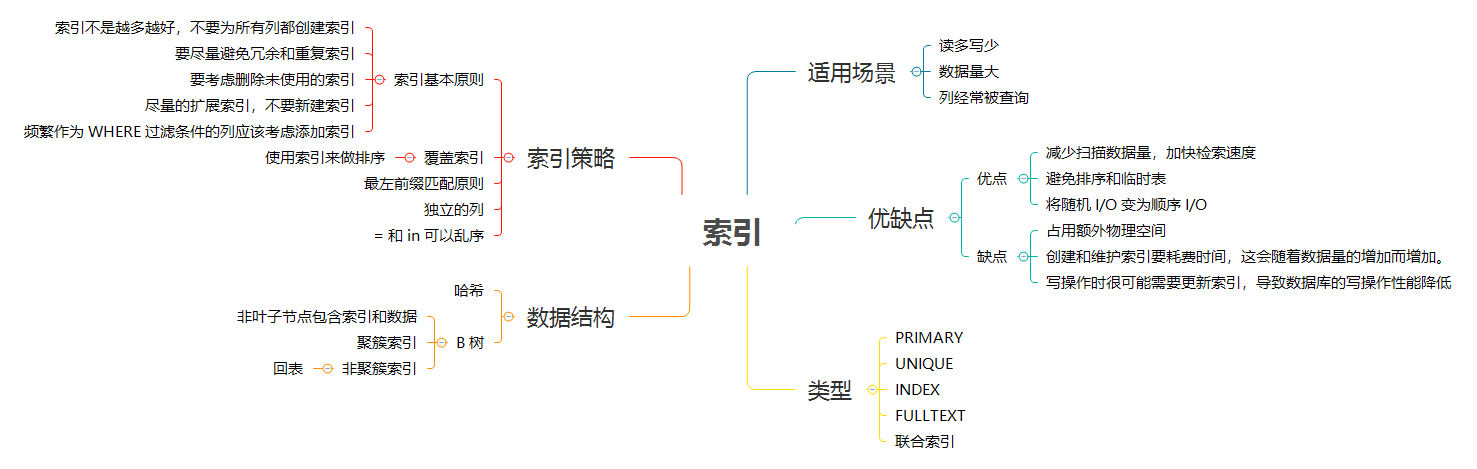
|
||||
|
||||
## 1. 索引简介
|
||||
## 索引简介
|
||||
|
||||
**索引是数据库为了提高查找效率的一种数据结构**。
|
||||
|
||||
索引对于良好的性能非常关键,在数据量小且负载较低时,不恰当的索引对于性能的影响可能还不明显;但随着数据量逐渐增大,性能则会急剧下降。因此,索引优化应该是查询性能优化的最有效手段。
|
||||
|
||||
### 1.1. 索引的优缺点
|
||||
### 索引的优缺点
|
||||
|
||||
B 树是最常见的索引,按照顺序存储数据,所以 Mysql 可以用来做 `ORDER BY` 和 `GROUP BY` 操作。因为数据是有序的,所以 B 树也就会将相关的列值都存储在一起。最后,因为索引中存储了实际的列值,所以某些查询只使用索引就能够完成全部查询。
|
||||
|
||||
|
|
@ -45,7 +45,7 @@ B 树是最常见的索引,按照顺序存储数据,所以 Mysql 可以用
|
|||
- **索引需要占用额外的物理空间**,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立组合索引那么需要的空间就会更大。
|
||||
- **写操作(`INSERT`/`UPDATE`/`DELETE`)时很可能需要更新索引,导致数据库的写操作性能降低**。
|
||||
|
||||
### 1.2. 何时使用索引
|
||||
### 何时使用索引
|
||||
|
||||
> 索引能够轻易将查询性能提升几个数量级。
|
||||
|
||||
|
|
@ -62,7 +62,7 @@ B 树是最常见的索引,按照顺序存储数据,所以 Mysql 可以用
|
|||
- **非常小的表**,对于非常小的表,大部分情况下简单的全表扫描更高效。
|
||||
- **特大型的表**,建立和使用索引的代价将随之增长。可以考虑使用分区技术或 Nosql。
|
||||
|
||||
## 2. 索引的数据结构
|
||||
## 索引的数据结构
|
||||
|
||||
在 Mysql 中,索引是在存储引擎层而不是服务器层实现的。所以,并没有统一的索引标准;不同存储引擎的索引的数据结构也不相同。
|
||||
|
||||
|
|
@ -79,7 +79,7 @@ B 树是最常见的索引,按照顺序存储数据,所以 Mysql 可以用
|
|||
|
||||
这意味着,如果使用数组作为索引,如果要保证数组有序,其更新操作代价高昂。
|
||||
|
||||
### 2.1. 哈希索引
|
||||
### 哈希索引
|
||||
|
||||
哈希表是一种以键 - 值(key-value)对形式存储数据的结构,我们只要输入待查找的值即 key,就可以找到其对应的值即 Value。
|
||||
|
||||
|
|
@ -112,7 +112,7 @@ B 树是最常见的索引,按照顺序存储数据,所以 Mysql 可以用
|
|||
|
||||
> 因为种种限制,所以哈希索引只适用于特定的场合。而一旦使用哈希索引,则它带来的性能提升会非常显著。
|
||||
|
||||
### 2.2. B 树索引
|
||||
### B 树索引
|
||||
|
||||
通常我们所说的索引是指`B-Tree`索引,它是目前关系型数据库中查找数据最为常用和有效的索引,大多数存储引擎都支持这种索引。使用`B-Tree`这个术语,是因为 MySQL 在`CREATE TABLE`或其它语句中使用了这个关键字,但实际上不同的存储引擎可能使用不同的数据结构,比如 InnoDB 就是使用的`B+Tree`。
|
||||
|
||||
|
|
@ -164,7 +164,7 @@ B+ 树索引适用于**全键值查找**、**键值范围查找**和**键前缀
|
|||
|
||||
这时候我们就要优先考虑上一段提到的“尽量使用主键查询”原则,直接将这个索引设置为主键,可以避免每次查询需要搜索两棵树。
|
||||
|
||||
### 2.3. 全文索引
|
||||
### 全文索引
|
||||
|
||||
MyISAM 存储引擎支持全文索引,用于查找文本中的关键词,而不是直接比较是否相等。查找条件使用 MATCH AGAINST,而不是普通的 WHERE。
|
||||
|
||||
|
|
@ -172,17 +172,17 @@ MyISAM 存储引擎支持全文索引,用于查找文本中的关键词,而
|
|||
|
||||
InnoDB 存储引擎在 MySQL 5.6.4 版本中也开始支持全文索引。
|
||||
|
||||
### 2.4. 空间数据索引
|
||||
### 空间数据索引
|
||||
|
||||
MyISAM 存储引擎支持空间数据索引(R-Tree),可以用于地理数据存储。空间数据索引会从所有维度来索引数据,可以有效地使用任意维度来进行组合查询。
|
||||
|
||||
必须使用 GIS 相关的函数来维护数据。
|
||||
|
||||
## 3. 索引的类型
|
||||
## 索引的类型
|
||||
|
||||
主流的关系型数据库一般都支持以下索引类型:
|
||||
|
||||
### 3.1. 主键索引(`PRIMARY`)
|
||||
### 主键索引(`PRIMARY`)
|
||||
|
||||
主键索引:一种特殊的唯一索引,不允许有空值。一个表只能有一个主键(在 InnoDB 中本质上即聚簇索引),一般是在建表的时候同时创建主键索引。
|
||||
|
||||
|
|
@ -194,7 +194,7 @@ CREATE TABLE `table` (
|
|||
)
|
||||
```
|
||||
|
||||
### 3.2. 唯一索引(`UNIQUE`)
|
||||
### 唯一索引(`UNIQUE`)
|
||||
|
||||
唯一索引:**索引列的值必须唯一,但允许有空值**。如果是组合索引,则列值的组合必须唯一。
|
||||
|
||||
|
|
@ -205,7 +205,7 @@ CREATE TABLE `table` (
|
|||
)
|
||||
```
|
||||
|
||||
### 3.3. 普通索引(`INDEX`)
|
||||
### 普通索引(`INDEX`)
|
||||
|
||||
普通索引:最基本的索引,没有任何限制。
|
||||
|
||||
|
|
@ -216,7 +216,7 @@ CREATE TABLE `table` (
|
|||
)
|
||||
```
|
||||
|
||||
### 3.4. 全文索引(`FULLTEXT`)
|
||||
### 全文索引(`FULLTEXT`)
|
||||
|
||||
全文索引:主要用来查找文本中的关键字,而不是直接与索引中的值相比较。
|
||||
|
||||
|
|
@ -230,7 +230,7 @@ CREATE TABLE `table` (
|
|||
)
|
||||
```
|
||||
|
||||
### 3.5. 联合索引
|
||||
### 联合索引
|
||||
|
||||
组合索引:多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀集合。
|
||||
|
||||
|
|
@ -241,7 +241,7 @@ CREATE TABLE `table` (
|
|||
)
|
||||
```
|
||||
|
||||
## 4. 索引的策略
|
||||
## 索引的策略
|
||||
|
||||
假设有以下表:
|
||||
|
||||
|
|
@ -257,7 +257,7 @@ CREATE TABLE `t` (
|
|||
) ENGINE=InnoDB;
|
||||
```
|
||||
|
||||
### 4.1. 索引基本原则
|
||||
### 索引基本原则
|
||||
|
||||
- **索引不是越多越好,不要为所有列都创建索引**。要考虑到索引的维护代价、空间占用和查询时回表的代价。索引一定是按需创建的,并且要尽可能确保足够轻量。一旦创建了多字段的联合索引,我们要考虑尽可能利用索引本身完成数据查询,减少回表的成本。
|
||||
- 要**尽量避免冗余和重复索引**。
|
||||
|
|
@ -265,7 +265,7 @@ CREATE TABLE `t` (
|
|||
- **尽量的扩展索引,不要新建索引**。
|
||||
- **频繁作为 `WHERE` 过滤条件的列应该考虑添加索引**。
|
||||
|
||||
### 4.2. 独立的列
|
||||
### 独立的列
|
||||
|
||||
**“独立的列” 是指索引列不能是表达式的一部分,也不能是函数的参数**。
|
||||
|
||||
|
|
@ -280,7 +280,7 @@ SELECT actor_id FROM actor WHERE actor_id + 1 = 5;
|
|||
SELECT ... WHERE TO_DAYS(current_date) - TO_DAYS(date_col) <= 10;
|
||||
```
|
||||
|
||||
### 4.3. 覆盖索引
|
||||
### 覆盖索引
|
||||
|
||||
**覆盖索引是指,索引上的信息足够满足查询请求,不需要回表查询数据。**
|
||||
|
||||
|
|
@ -313,7 +313,7 @@ select * from T where k between 3 and 5
|
|||
|
||||
**由于覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段。**
|
||||
|
||||
### 4.4. 使用索引来排序
|
||||
### 使用索引来排序
|
||||
|
||||
Mysql 有两种方式可以生成排序结果:通过排序操作;或者按索引顺序扫描。
|
||||
|
||||
|
|
@ -325,7 +325,7 @@ Mysql 有两种方式可以生成排序结果:通过排序操作;或者按
|
|||
2. 从索引 (city,name,age) 取下一个记录,同样取出这三个字段的值,作为结果集的一部分直接返回;
|
||||
3. 重复执行步骤 2,直到查到第 1000 条记录,或者是不满足 city='杭州’条件时循环结束。
|
||||
|
||||
### 4.5. 前缀索引
|
||||
### 前缀索引
|
||||
|
||||
有时候需要索引很长的字符列,这会让索引变得大且慢。
|
||||
|
||||
|
|
@ -358,7 +358,7 @@ from SUser;
|
|||
|
||||
此外,**`order by` 无法使用前缀索引,无法把前缀索引用作覆盖索引**。
|
||||
|
||||
### 4.6. 最左前缀匹配原则
|
||||
### 最左前缀匹配原则
|
||||
|
||||
不只是索引的全部定义,只要满足最左前缀,就可以利用索引来加速检索。这个最左前缀可以是联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符。
|
||||
|
||||
|
|
@ -391,19 +391,19 @@ customer_id_selectivity: 0.0373
|
|||
COUNT(*): 16049
|
||||
```
|
||||
|
||||
### 4.7. = 和 in 可以乱序
|
||||
### = 和 in 可以乱序
|
||||
|
||||
**不需要考虑 `=`、`IN` 等的顺序**,Mysql 会自动优化这些条件的顺序,以匹配尽可能多的索引列。
|
||||
|
||||
【示例】如有索引 (a, b, c, d),查询条件 `c > 3 and b = 2 and a = 1 and d < 4` 与 `a = 1 and c > 3 and b = 2 and d < 4` 等顺序都是可以的,MySQL 会自动优化为 a = 1 and b = 2 and c > 3 and d < 4,依次命中 a、b、c、d。
|
||||
|
||||
## 5. 索引最佳实践
|
||||
## 索引最佳实践
|
||||
|
||||
创建了索引,并非一定有效。比如不满足前缀索引、最左前缀匹配原则、查询条件涉及函数计算等情况都无法使用索引。此外,即使 SQL 本身符合索引的使用条件,MySQL 也会通过评估各种查询方式的代价,来决定是否走索引,以及走哪个索引。
|
||||
|
||||
因此,在尝试通过索引进行 SQL 性能优化的时候,务必通过执行计划(`EXPLAIN`)或实际的效果来确认索引是否能有效改善性能问题,否则增加了索引不但没解决性能问题,还增加了数据库增删改的负担。如果对 EXPLAIN 给出的执行计划有疑问的话,你还可以利用 `optimizer_trace` 查看详细的执行计划做进一步分析。
|
||||
|
||||
## 6. 参考资料
|
||||
## 参考资料
|
||||
|
||||
- [《高性能 MySQL》](https://book.douban.com/subject/23008813/)
|
||||
- [数据库两大神器【索引和锁】](https://juejin.im/post/5b55b842f265da0f9e589e79)
|
||||
|
|
|
|||
|
|
@ -15,11 +15,11 @@ permalink: /pages/396816/
|
|||
|
||||
# Mysql 性能优化
|
||||
|
||||
## 1. 数据结构优化
|
||||
## 数据结构优化
|
||||
|
||||
良好的逻辑设计和物理设计是高性能的基石。
|
||||
|
||||
### 1.1. 数据类型优化
|
||||
### 数据类型优化
|
||||
|
||||
#### 数据类型优化基本原则
|
||||
|
||||
|
|
@ -38,7 +38,7 @@ permalink: /pages/396816/
|
|||
- 应该尽量避免用字符串类型作为标识列,因为它们很消耗空间,并且通常比数字类型慢。对于 `MD5`、`SHA`、`UUID` 这类随机字符串,由于比较随机,所以可能分布在很大的空间内,导致 `INSERT` 以及一些 `SELECT` 语句变得很慢。
|
||||
- 如果存储 UUID ,应该移除 `-` 符号;更好的做法是,用 `UNHEX()` 函数转换 UUID 值为 16 字节的数字,并存储在一个 `BINARY(16)` 的列中,检索时,可以通过 `HEX()` 函数来格式化为 16 进制格式。
|
||||
|
||||
### 1.2. 表设计
|
||||
### 表设计
|
||||
|
||||
应该避免的设计问题:
|
||||
|
||||
|
|
@ -47,7 +47,7 @@ permalink: /pages/396816/
|
|||
- **枚举** - 尽量不要用枚举,因为添加和删除字符串(枚举选项)必须使用 `ALTER TABLE`。
|
||||
- 尽量避免 `NULL`
|
||||
|
||||
### 1.3. 范式和反范式
|
||||
### 范式和反范式
|
||||
|
||||
**范式化目标是尽量减少冗余,而反范式化则相反**。
|
||||
|
||||
|
|
@ -63,7 +63,7 @@ permalink: /pages/396816/
|
|||
|
||||
在真实世界中,很少会极端地使用范式化或反范式化。实际上,应该权衡范式和反范式的利弊,混合使用。
|
||||
|
||||
### 1.4. 索引优化
|
||||
### 索引优化
|
||||
|
||||
> 索引优化应该是查询性能优化的最有效手段。
|
||||
>
|
||||
|
|
@ -92,7 +92,7 @@ permalink: /pages/396816/
|
|||
- **覆盖索引**
|
||||
- **自增字段作主键**
|
||||
|
||||
## 2. SQL 优化
|
||||
## SQL 优化
|
||||
|
||||
使用 `EXPLAIN` 命令查看当前 SQL 是否使用了索引,优化后,再通过执行计划(`EXPLAIN`)来查看优化效果。
|
||||
|
||||
|
|
@ -106,7 +106,7 @@ SQL 优化基本思路:
|
|||
|
||||
- **使用索引来覆盖查询**
|
||||
|
||||
### 2.1. 优化 `COUNT()` 查询
|
||||
### 优化 `COUNT()` 查询
|
||||
|
||||
`COUNT()` 有两种作用:
|
||||
|
||||
|
|
@ -130,7 +130,7 @@ FROM world.city WHERE id <= 5;
|
|||
|
||||
有时候某些业务场景并不需要完全精确的统计值,可以用近似值来代替,`EXPLAIN` 出来的行数就是一个不错的近似值,而且执行 `EXPLAIN` 并不需要真正地去执行查询,所以成本非常低。通常来说,执行 `COUNT()` 都需要扫描大量的行才能获取到精确的数据,因此很难优化,MySQL 层面还能做得也就只有覆盖索引了。如果不还能解决问题,只有从架构层面解决了,比如添加汇总表,或者使用 Redis 这样的外部缓存系统。
|
||||
|
||||
### 2.2. 优化关联查询
|
||||
### 优化关联查询
|
||||
|
||||
在大数据场景下,表与表之间通过一个冗余字段来关联,要比直接使用 `JOIN` 有更好的性能。
|
||||
|
||||
|
|
@ -167,11 +167,11 @@ while(outer_row) {
|
|||
|
||||
可以看到,最外层的查询是根据`A.xx`列来查询的,`A.c`上如果有索引的话,整个关联查询也不会使用。再看内层的查询,很明显`B.c`上如果有索引的话,能够加速查询,因此只需要在关联顺序中的第二张表的相应列上创建索引即可。
|
||||
|
||||
### 2.3. 优化 `GROUP BY` 和 `DISTINCT`
|
||||
### 优化 `GROUP BY` 和 `DISTINCT`
|
||||
|
||||
Mysql 优化器会在内部处理的时候相互转化这两类查询。它们都**可以使用索引来优化,这也是最有效的优化方法**。
|
||||
|
||||
### 2.4. 优化 `LIMIT`
|
||||
### 优化 `LIMIT`
|
||||
|
||||
当需要分页操作时,通常会使用 `LIMIT` 加上偏移量的办法实现,同时加上合适的 `ORDER BY` 字句。**如果有对应的索引,通常效率会不错,否则,MySQL 需要做大量的文件排序操作**。
|
||||
|
||||
|
|
@ -204,13 +204,13 @@ SELECT id FROM t WHERE id > 10000 LIMIT 10;
|
|||
|
||||
其他优化的办法还包括使用预先计算的汇总表,或者关联到一个冗余表,冗余表中只包含主键列和需要做排序的列。
|
||||
|
||||
### 2.5. 优化 UNION
|
||||
### 优化 UNION
|
||||
|
||||
MySQL 总是通过创建并填充临时表的方式来执行 `UNION` 查询。因此很多优化策略在`UNION`查询中都没有办法很好的时候。经常需要手动将`WHERE`、`LIMIT`、`ORDER BY`等字句“下推”到各个子查询中,以便优化器可以充分利用这些条件先优化。
|
||||
|
||||
除非确实需要服务器去重,否则就一定要使用`UNION ALL`,如果没有`ALL`关键字,MySQL 会给临时表加上`DISTINCT`选项,这会导致整个临时表的数据做唯一性检查,这样做的代价非常高。当然即使使用 ALL 关键字,MySQL 总是将结果放入临时表,然后再读出,再返回给客户端。虽然很多时候没有这个必要,比如有时候可以直接把每个子查询的结果返回给客户端。
|
||||
|
||||
### 2.6. 优化查询方式
|
||||
### 优化查询方式
|
||||
|
||||
#### 切分大查询
|
||||
|
||||
|
|
@ -251,7 +251,7 @@ SELECT * FROM tag_post WHERE tag_id=1234;
|
|||
SELECT * FROM post WHERE post.id IN (123,456,567,9098,8904);
|
||||
```
|
||||
|
||||
## 3. 执行计划(`EXPLAIN`)
|
||||
## 执行计划(`EXPLAIN`)
|
||||
|
||||
如何判断当前 SQL 是否使用了索引?如何检验修改后的 SQL 确实有优化效果?
|
||||
|
||||
|
|
@ -304,7 +304,7 @@ possible_keys: PRIMARY
|
|||
|
||||
> 更多内容请参考:[MySQL 性能优化神器 Explain 使用分析](https://segmentfault.com/a/1190000008131735)
|
||||
|
||||
## 4. optimizer trace
|
||||
## optimizer trace
|
||||
|
||||
在 MySQL 5.6 及之后的版本中,我们可以使用 optimizer trace 功能查看优化器生成执行计划的整个过程。有了这个功能,我们不仅可以了解优化器的选择过程,更可以了解每一个执行环节的成本,然后依靠这些信息进一步优化查询。
|
||||
|
||||
|
|
@ -317,14 +317,14 @@ SELECT * FROM information_schema.OPTIMIZER_TRACE;
|
|||
SET optimizer_trace="enabled=off";
|
||||
```
|
||||
|
||||
## 5. 数据模型和业务
|
||||
## 数据模型和业务
|
||||
|
||||
- 表字段比较复杂、易变动、结构难以统一的情况下,可以考虑使用 Nosql 来代替关系数据库表存储,如 ElasticSearch、MongoDB。
|
||||
- 在高并发情况下的查询操作,可以使用缓存(如 Redis)代替数据库操作,提高并发性能。
|
||||
- 数据量增长较快的表,需要考虑水平分表或分库,避免单表操作的性能瓶颈。
|
||||
- 除此之外,我们应该通过一些优化,尽量避免比较复杂的 JOIN 查询操作,例如冗余一些字段,减少 JOIN 查询;创建一些中间表,减少 JOIN 查询。
|
||||
|
||||
## 6. 参考资料
|
||||
## 参考资料
|
||||
|
||||
- [《高性能 MySQL》](https://book.douban.com/subject/23008813/)
|
||||
- [《Java 性能调优实战》](https://time.geekbang.org/column/intro/100028001)
|
||||
|
|
|
|||
|
|
@ -17,9 +17,9 @@ permalink: /pages/e33b92/
|
|||
|
||||
> 如果你的公司有 DBA,那么我恭喜你,你可以无视 Mysql 运维。如果你的公司没有 DBA,那你就好好学两手 Mysql 基本运维操作,行走江湖,防身必备。
|
||||
|
||||
## 1. 安装部署
|
||||
## 安装部署
|
||||
|
||||
### 1.1. Windows 安装
|
||||
### Windows 安装
|
||||
|
||||
(1)下载 Mysql 5.7 免安装版
|
||||
|
||||
|
|
@ -66,7 +66,7 @@ mysqld -install
|
|||
|
||||
在控制台执行 `net start mysql` 启动服务。
|
||||
|
||||
### 1.2. CentOS 安装
|
||||
### CentOS 安装
|
||||
|
||||
> 本文仅介绍 rpm 安装方式
|
||||
|
||||
|
|
@ -156,7 +156,7 @@ systemctl restart mysqld
|
|||
systemctl stop mysqld
|
||||
```
|
||||
|
||||
### 1.3. 初始化数据库密码
|
||||
### 初始化数据库密码
|
||||
|
||||
查看一下初始密码
|
||||
|
||||
|
|
@ -179,7 +179,7 @@ ALTER user 'root'@'localhost' IDENTIFIED BY '你的密码';
|
|||
|
||||
注:密码强度默认为中等,大小写字母、数字、特殊符号,只有修改成功后才能修改配置再设置更简单的密码
|
||||
|
||||
### 1.4. 配置远程访问
|
||||
### 配置远程访问
|
||||
|
||||
```sql
|
||||
CREATE USER 'root'@'%' IDENTIFIED BY '你的密码';
|
||||
|
|
@ -188,7 +188,7 @@ ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '你的密码';
|
|||
FLUSH PRIVILEGES;
|
||||
```
|
||||
|
||||
### 1.5. 跳过登录认证
|
||||
### 跳过登录认证
|
||||
|
||||
```shell
|
||||
vim /etc/my.cnf
|
||||
|
|
@ -200,9 +200,9 @@ vim /etc/my.cnf
|
|||
|
||||
执行 `systemctl restart mysqld`,重启 mysql
|
||||
|
||||
## 2. 基本运维
|
||||
## 基本运维
|
||||
|
||||
### 2.1. 客户端连接
|
||||
### 客户端连接
|
||||
|
||||
语法:`mysql -h<主机> -P<端口> -u<用户名> -p<密码>`
|
||||
|
||||
|
|
@ -228,13 +228,13 @@ Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
|
|||
mysql>
|
||||
```
|
||||
|
||||
### 2.2. 查看连接
|
||||
### 查看连接
|
||||
|
||||
连接完成后,如果你没有后续的动作,这个连接就处于空闲状态,你可以在 `show processlist` 命令中看到它。客户端如果太长时间没动静,连接器就会自动将它断开。这个时间是由参数 `wait_timeout` 控制的,默认值是 8 小时。
|
||||
|
||||

|
||||
|
||||
### 2.3. 创建用户
|
||||
### 创建用户
|
||||
|
||||
```sql
|
||||
CREATE USER 'username'@'host' IDENTIFIED BY 'password';
|
||||
|
|
@ -260,7 +260,7 @@ CREATE USER 'pig'@'%';
|
|||
>
|
||||
> 所以,需要加上 `IDENTIFIED WITH mysql_native_password`,例如:`CREATE USER 'slave'@'%' IDENTIFIED WITH mysql_native_password BY '123456';`
|
||||
|
||||
### 2.4. 查看用户
|
||||
### 查看用户
|
||||
|
||||
```sql
|
||||
-- 查看所有用户
|
||||
|
|
@ -268,7 +268,7 @@ SELECT DISTINCT CONCAT('User: ''', user, '''@''', host, ''';') AS query
|
|||
FROM mysql.user;
|
||||
```
|
||||
|
||||
### 2.5. 授权
|
||||
### 授权
|
||||
|
||||
命令:
|
||||
|
||||
|
|
@ -301,7 +301,7 @@ GRANT privileges ON databasename.tablename TO 'username'@'host' WITH GRANT OPTIO
|
|||
GRANT ALL ON *.* TO 'root'@'%' IDENTIFIED BY '密码' WITH GRANT OPTION;
|
||||
```
|
||||
|
||||
### 2.6. 撤销授权
|
||||
### 撤销授权
|
||||
|
||||
命令:
|
||||
|
||||
|
|
@ -325,14 +325,14 @@ REVOKE SELECT ON *.* FROM 'pig'@'%';
|
|||
|
||||
具体信息可以用命令`SHOW GRANTS FOR 'pig'@'%';` 查看。
|
||||
|
||||
### 2.7. 查看授权
|
||||
### 查看授权
|
||||
|
||||
```SQL
|
||||
-- 查看用户权限
|
||||
SHOW GRANTS FOR 'root'@'%';
|
||||
```
|
||||
|
||||
### 2.8. 更改用户密码
|
||||
### 更改用户密码
|
||||
|
||||
```sql
|
||||
SET PASSWORD FOR 'username'@'host' = PASSWORD('newpassword');
|
||||
|
|
@ -350,7 +350,7 @@ SET PASSWORD = PASSWORD("newpassword");
|
|||
SET PASSWORD FOR 'pig'@'%' = PASSWORD("123456");
|
||||
```
|
||||
|
||||
### 2.9. 备份与恢复
|
||||
### 备份与恢复
|
||||
|
||||
Mysql 备份数据使用 mysqldump 命令。
|
||||
|
||||
|
|
@ -401,7 +401,7 @@ mysql -h <host> -P<port> -u<username> -p<database> < backup.sql
|
|||
mysql -u<username> -p --all-databases < backup.sql
|
||||
```
|
||||
|
||||
### 2.10. 卸载
|
||||
### 卸载
|
||||
|
||||
(1)查看已安装的 mysql
|
||||
|
||||
|
|
@ -421,7 +421,7 @@ mysql-community-libs-8.0.12-1.el7.x86_64
|
|||
yum remove mysql-community-server.x86_64
|
||||
```
|
||||
|
||||
### 2.11. 主从节点部署
|
||||
### 主从节点部署
|
||||
|
||||
假设需要配置一个主从 Mysql 服务器环境
|
||||
|
||||
|
|
@ -627,13 +627,57 @@ mysql> show global variables like "%read_only%";
|
|||
|
||||
> 注:设置 slave 服务器为只读,并不影响主从同步。
|
||||
|
||||
## 3. 服务器配置
|
||||
### 慢查询
|
||||
|
||||
查看慢查询是否开启
|
||||
|
||||
```sql
|
||||
show variables like '%slow_query_log';
|
||||
```
|
||||
|
||||
可以通过 `set global slow_query_log` 命令设置慢查询是否开启:ON 表示开启;OFF 表示关闭。
|
||||
|
||||
```sql
|
||||
set global slow_query_log='ON';
|
||||
```
|
||||
|
||||
查看慢查询时间阈值
|
||||
|
||||
```sql
|
||||
show variables like '%long_query_time%';
|
||||
```
|
||||
|
||||
设置慢查询阈值
|
||||
|
||||
```sql
|
||||
set global long_query_time = 3;
|
||||
```
|
||||
|
||||
### 隔离级别
|
||||
|
||||
查看隔离级别:
|
||||
|
||||
```sql
|
||||
mysql> show variables like 'transaction_isolation';
|
||||
|
||||
+-----------------------+----------------+
|
||||
|
||||
| Variable_name | Value |
|
||||
|
||||
+-----------------------+----------------+
|
||||
|
||||
| transaction_isolation | READ-COMMITTED |
|
||||
|
||||
+-----------------------+----------------+
|
||||
```
|
||||
|
||||
## 服务器配置
|
||||
|
||||
> **_大部分情况下,默认的基本配置已经足够应付大多数场景,不要轻易修改 Mysql 服务器配置,除非你明确知道修改项是有益的。_**
|
||||
>
|
||||
> 尽量不要使用 Mysql 的缓存功能,因为其要求每次请求参数完全相同,才能命中缓存。这种方式实际上并不高效,还会增加额外开销,实际业务场景中一般使用 Redis 等 key-value 存储来解决缓存问题,性能远高于 Mysql 的查询缓存。
|
||||
|
||||
### 3.1. 配置文件路径
|
||||
### 配置文件路径
|
||||
|
||||
配置 Mysql 首先要确定配置文件在哪儿。
|
||||
|
||||
|
|
@ -649,7 +693,7 @@ Default options are read from the following files in the given order:
|
|||
/etc/my.cnf /etc/mysql/my.cnf /usr/etc/my.cnf ~/.my.cnf
|
||||
```
|
||||
|
||||
### 3.2. 配置项语法
|
||||
### 配置项语法
|
||||
|
||||
**Mysql 配置项设置都使用小写,单词之间用下划线或横线隔开(二者是等价的)。**
|
||||
|
||||
|
|
@ -661,7 +705,7 @@ Default options are read from the following files in the given order:
|
|||
/usr/sbin/mysqld --auto_increment_offset=5
|
||||
```
|
||||
|
||||
### 3.3. 常用配置项说明
|
||||
### 常用配置项说明
|
||||
|
||||
> 这里介绍比较常用的基本配置,更多配置项说明可以参考:[Mysql 服务器配置说明](21.Mysql配置.md)
|
||||
|
||||
|
|
@ -760,9 +804,9 @@ port = 3306
|
|||
- 注意:仍然可能出现报错信息 Can't create a new thread;此时观察系统 `cat /proc/mysql` 进程号/limits,观察进程 ulimit 限制情况
|
||||
- 过小的话,考虑修改系统配置表,`/etc/security/limits.conf` 和 `/etc/security/limits.d/90-nproc.conf`
|
||||
|
||||
## 4. 常见问题
|
||||
## 常见问题
|
||||
|
||||
### 4.1. Too many connections
|
||||
### Too many connections
|
||||
|
||||
**现象**
|
||||
|
||||
|
|
@ -833,7 +877,7 @@ mysql soft nofile 65535
|
|||
|
||||
如果是使用 rpm 方式安装 mysql,检查 **mysqld.service** 文件中的 `LimitNOFILE` 是否配置的太小。
|
||||
|
||||
### 4.2. 时区(time_zone)偏差
|
||||
### 时区(time_zone)偏差
|
||||
|
||||
**现象**
|
||||
|
||||
|
|
@ -874,7 +918,7 @@ Query OK, 0 rows affected (0.00 sec)
|
|||
|
||||
修改 `my.cnf` 文件,在 `[mysqld]` 节下增加 `default-time-zone='+08:00'` ,然后重启。
|
||||
|
||||
### 4.3. 数据表损坏如何修复
|
||||
### 数据表损坏如何修复
|
||||
|
||||
使用 myisamchk 来修复,具体步骤:
|
||||
|
||||
|
|
@ -884,7 +928,7 @@ Query OK, 0 rows affected (0.00 sec)
|
|||
|
||||
使用 repair table 或者 OPTIMIZE table 命令来修复,REPAIR TABLE table_name 修复表 OPTIMIZE TABLE table_name 优化表 REPAIR TABLE 用于修复被破坏的表。 OPTIMIZE TABLE 用于回收闲置的数据库空间,当表上的数据行被删除时,所占据的磁盘空间并没有立即被回收,使用了 OPTIMIZE TABLE 命令后这些空间将被回收,并且对磁盘上的数据行进行重排(注意:是磁盘上,而非数据库)
|
||||
|
||||
### 4.4. 数据结构
|
||||
### 数据结构
|
||||
|
||||
> 问题现象:ERROR 1071: Specified key was too long; max key length is 767 bytes
|
||||
|
||||
|
|
@ -892,14 +936,14 @@ Query OK, 0 rows affected (0.00 sec)
|
|||
|
||||
解决方法:优化索引结构,索引字段不宜过长。
|
||||
|
||||
## 5. 脚本
|
||||
## 脚本
|
||||
|
||||
这里推荐我写的几个一键运维脚本,非常方便,欢迎使用:
|
||||
|
||||
- [Mysql 安装脚本](https://github.com/dunwu/linux-tutorial/tree/master/codes/linux/soft/mysql-install.sh)
|
||||
- [Mysql 备份脚本](https://github.com/dunwu/linux-tutorial/tree/master/codes/linux/soft/mysql-backup.sh)
|
||||
|
||||
## 6. 参考资料
|
||||
## 参考资料
|
||||
|
||||
- [《高性能 MySQL》](https://book.douban.com/subject/23008813/)
|
||||
- https://www.cnblogs.com/xiaopotian/p/8196464.html
|
||||
|
|
|
|||
|
|
@ -17,7 +17,7 @@ permalink: /pages/5da42d/
|
|||
|
||||
> 版本:
|
||||
|
||||
## 1. 基本配置
|
||||
## 基本配置
|
||||
|
||||
```ini
|
||||
[mysqld]
|
||||
|
|
@ -62,7 +62,7 @@ socket = /var/lib/mysql/mysql.sock
|
|||
port = 3306
|
||||
```
|
||||
|
||||
## 2. 配置项说明
|
||||
## 配置项说明
|
||||
|
||||
```ini
|
||||
[client]
|
||||
|
|
@ -260,7 +260,8 @@ max_binlog_size = 1000M
|
|||
# 关于 binlog 日志格式问题,请查阅网络资料
|
||||
binlog_format = row
|
||||
|
||||
# 默认值 N=1,使 binlog 在每 N 次 binlog 写入后与硬盘同步,ps:1 最慢
|
||||
# 表示每 N 次写入 binlog 后,持久化到磁盘,默认值 N=1
|
||||
# 建议设置成 1,这样可以保证 MySQL 异常重启之后 binlog 不丢失。
|
||||
# sync_binlog = 1
|
||||
|
||||
# MyISAM 引擎配置
|
||||
|
|
@ -419,8 +420,9 @@ innodb_flush_log_at_timeout = 1
|
|||
|
||||
# 说明:参数可设为 0,1,2;
|
||||
# 参数 0:表示每秒将 log buffer 内容刷新到系统 buffer 中,再调用系统 flush 操作写入磁盘文件。
|
||||
# 参数 1:表示每次事物提交,将 log buffer 内容刷新到系统 buffer 中,再调用系统 flush 操作写入磁盘文件。
|
||||
# 参数 2:表示每次事物提交,将 log buffer 内容刷新到系统 buffer 中,隔 1 秒后再调用系统 flush 操作写入磁盘文件。
|
||||
# 参数 1:表示每次事务提交,redo log 都直接持久化到磁盘。
|
||||
# 参数 2:表示每次事务提交,隔 1 秒后再将 redo log 持久化到磁盘。
|
||||
# 建议设置成 1,这样可以保证 MySQL 异常重启之后数据不丢失。
|
||||
innodb_flush_log_at_trx_commit = 1
|
||||
|
||||
# 说明:限制 Innodb 能打开的表的数据,如果库里的表特别多的情况,请增加这个。
|
||||
|
|
@ -484,7 +486,7 @@ auto-rehash
|
|||
socket = /var/lib/mysql/mysql.sock
|
||||
```
|
||||
|
||||
## 3. 参考资料
|
||||
## 参考资料
|
||||
|
||||
- [《高性能 MySQL》](https://item.jd.com/11220393.html)
|
||||
- [Mysql 配置文件/etc/my.cnf 解析](https://www.jianshu.com/p/5f39c486561b)
|
||||
|
|
@ -17,7 +17,7 @@ permalink: /pages/7b0caf/
|
|||
|
||||
> **📦 本文以及示例源码已归档在 [db-tutorial](https://github.com/dunwu/db-tutorial/)**
|
||||
|
||||
## 1. 为什么表数据删掉一半,表文件大小不变
|
||||
## 为什么表数据删掉一半,表文件大小不变
|
||||
|
||||
【问题】数据库占用空间太大,我把一个最大的表删掉了一半的数据,怎么表文件的大小还是没变?
|
||||
|
||||
|
|
@ -43,7 +43,7 @@ permalink: /pages/7b0caf/
|
|||
|
||||
要达到收缩空洞的目的,可以使用重建表的方式。
|
||||
|
||||
## 2. 参考资料
|
||||
## 参考资料
|
||||
|
||||
- [《高性能 MySQL》](https://book.douban.com/subject/23008813/)
|
||||
- [MySQL 实战 45 讲](https://time.geekbang.org/column/intro/139)
|
||||
|
|
@ -27,7 +27,7 @@ hidden: true
|
|||
|
||||
> 关键词:`ACID`、`AUTOCOMMIT`、`事务隔离级别`、`死锁`、`分布式事务`
|
||||
|
||||

|
||||

|
||||
|
||||
### [Mysql 锁](04.Mysql锁.md)
|
||||
|
||||
|
|
@ -49,14 +49,6 @@ hidden: true
|
|||
|
||||
### [Mysql 常见问题](99.Mysql常见问题)
|
||||
|
||||
---
|
||||
|
||||
相关扩展知识:
|
||||
|
||||
- [关系型数据库面试总结](https://github.com/dunwu/db-tutorial/blob/master/docs/sql/sql-interview.md) 💯
|
||||
- [SQL Cheat Sheet](https://github.com/dunwu/db-tutorial/blob/master/docs/sql/sql-cheat-sheet.md)
|
||||
- [分布式事务基本原理](https://dunwu.github.io/blog/pages/e1881c/)
|
||||
|
||||
## 📚 资料
|
||||
|
||||
- **官方**
|
||||
|
|
|
|||
|
|
@ -14,10 +14,16 @@ permalink: /pages/bdcd7e/
|
|||
|
||||
# SQLite
|
||||
|
||||
> SQLite 是一个实现了自给自足的、无服务器的、零配置的、事务性的 SQL 数据库引擎。
|
||||
> :point_right: [完整示例源码](https://github.com/dunwu/db-tutorial/tree/master/codes/javadb/javadb-sqlite)
|
||||
> SQLite 是一个无服务器的、零配置的、事务性的的开源数据库引擎。
|
||||
> 💻 [完整示例源码](https://github.com/dunwu/db-tutorial/tree/master/codes/javadb/javadb-sqlite)
|
||||
|
||||
## 简介
|
||||
## SQLite 简介
|
||||
|
||||
SQLite 是一个C语言编写的轻量级、全功能、无服务器、零配置的的开源数据库引擎。
|
||||
|
||||
SQLite 的设计目标是嵌入式的数据库,很多嵌入式产品中都使用了它。SQLite 十分轻量,占用资源非常的低,在嵌入式设备中,可能只需要几百K的内存就够了。SQLite 能够支持Windows/Linux/Unix等等主流的操作系统,同时能够跟很多程序语言相结合,同样比起Mysql、PostgreSQL这两款开源的世界著名数据库管理系统来讲,它的处理速度比他们都快。
|
||||
|
||||
SQLite 大小只有 3M 左右,可以将整个 SQLite 嵌入到应用中,而不用采用传统的客户端/服务器(Client/Server)的架构。这样做的好处就是非常轻便,在许多智能设备和应用中都可以使用 SQLite,比如微信就采用了 SQLite 作为本地聊天记录的存储。
|
||||
|
||||
### 优点
|
||||
|
||||
|
|
@ -47,11 +53,11 @@ Sqlite 可在 UNIX(Linux, Mac OS-X, Android, iOS)和 Windows(Win32, WinCE,
|
|||
|
||||
一般,Linux 和 Mac 上会预安装 sqlite。如果没有安装,可以在[官方下载地址](https://www.sqlite.org/download.html)下载合适安装版本,自行安装。
|
||||
|
||||
## 语法
|
||||
## SQLite 语法
|
||||
|
||||
> 这里不会详细列举所有 SQL 语法,仅列举 SQLite 除标准 SQL 以外的,一些自身特殊的 SQL 语法。
|
||||
>
|
||||
> :point_right: 扩展阅读:[标准 SQL 基本语法](https://github.com/dunwu/blog/blob/master/docs/database/sql/sql.md)
|
||||
> 📖 扩展阅读:[标准 SQL 基本语法](https://github.com/dunwu/blog/blob/master/docs/database/sql/sql.md)
|
||||
|
||||
### 大小写敏感
|
||||
|
||||
|
|
@ -143,7 +149,7 @@ sqlite3 test.db .dump > /home/test.sql
|
|||
sqlite3 test.db < test.sql
|
||||
```
|
||||
|
||||
## 数据类型
|
||||
## SQLite 数据类型
|
||||
|
||||
SQLite 使用一个更普遍的动态类型系统。在 SQLite 中,值的数据类型与值本身是相关的,而不是与它的容器相关。
|
||||
|
||||
|
|
@ -296,7 +302,7 @@ goodbye|20
|
|||
$
|
||||
```
|
||||
|
||||
## JAVA Client
|
||||
## SQLite JAVA Client
|
||||
|
||||
(1)在[官方下载地址](https://bitbucket.org/xerial/sqlite-jdbc/downloads)下载 sqlite-jdbc-(VERSION).jar ,然后将 jar 包放在项目中的 classpath。
|
||||
|
||||
|
|
@ -377,6 +383,7 @@ Connection connection = DriverManager.getConnection("jdbc:sqlite::memory:");
|
|||
## 参考资料
|
||||
|
||||
- [SQLite 官网](https://www.sqlite.org/index.html)
|
||||
- [SQLite Github](https://github.com/sqlite/sqlite)
|
||||
- [SQLite 官方文档](https://www.sqlite.org/docs.html)
|
||||
- [SQLite 官方命令行手册](https://www.sqlite.org/cli.html)
|
||||
- http://www.runoob.com/sqlite/sqlite-commands.html
|
||||
|
|
|
|||
|
|
@ -15,11 +15,13 @@ hidden: true
|
|||
|
||||
## 📖 内容
|
||||
|
||||
### 公共知识
|
||||
### 关系型数据库综合
|
||||
|
||||
- [关系型数据库面试总结](01.综合/01.关系型数据库面试.md) 💯
|
||||
- [SQL Cheat Sheet](01.综合/02.SqlCheatSheet.md) 是一个 SQL 入门教程。
|
||||
- [扩展 SQL](01.综合/03.扩展SQL.md) 是一个 SQL 入门教程。
|
||||
- [SQL 语法基础特性](01.综合/02.SQL语法基础特性.md)
|
||||
- [SQL 语法高级特性](01.综合/03.SQL语法高级特性.md)
|
||||
- [扩展 SQL](01.综合/03.扩展SQL.md)
|
||||
- [SQL Cheat Sheet](01.综合/99.SqlCheatSheet.md)
|
||||
|
||||
### Mysql
|
||||
|
||||
|
|
@ -46,7 +48,7 @@ hidden: true
|
|||
### 综合
|
||||
|
||||
- [《数据库的索引设计与优化》](https://book.douban.com/subject/26419771/)
|
||||
- [《SQL 必知必会》](https://book.douban.com/subject/35167240/) - SQL 的基本概念和语法【入门】
|
||||
- [《SQL 必知必会》](https://book.douban.com/subject/35167240/) - SQL 入门经典
|
||||
|
||||
### Mysql
|
||||
|
||||
|
|
@ -56,7 +58,7 @@ hidden: true
|
|||
- [Mysql 官方文档之命令行客户端](https://dev.mysql.com/doc/refman/8.0/en/mysql.html)
|
||||
- **书籍**
|
||||
- [《高性能 MySQL》](https://book.douban.com/subject/23008813/) - 经典,适合 DBA 或作为开发者的参考手册
|
||||
- [《MySQL 必知必会》](https://book.douban.com/subject/3354490/) - 适合入门者
|
||||
- [《MySQL 必知必会》](https://book.douban.com/subject/3354490/) - MySQL 入门经典
|
||||
- **教程**
|
||||
- [MySQL 实战 45 讲](https://time.geekbang.org/column/intro/139)
|
||||
- [runoob.com MySQL 教程](http://www.runoob.com/mysql/mysql-tutorial.html)
|
||||
|
|
|
|||
|
|
@ -0,0 +1,292 @@
|
|||
---
|
||||
title: HBase 快速入门
|
||||
date: 2020-02-10 14:27:39
|
||||
categories:
|
||||
- 数据库
|
||||
- 列式数据库
|
||||
- HBase
|
||||
tags:
|
||||
- 数据库
|
||||
- 列式数据库
|
||||
- 大数据
|
||||
- HBase
|
||||
permalink: /pages/7ab03c/
|
||||
---
|
||||
|
||||
# HBase 快速入门
|
||||
|
||||
## HBase 简介
|
||||
|
||||
### 为什么需要 HBase
|
||||
|
||||
在介绍 HBase 之前,我们不妨先了解一下为什么需要 HBase,或者说 HBase 是为了达到什么目的而产生。
|
||||
|
||||
在 HBase 诞生之前,Hadoop 可以通过 HDFS 来存储结构化、半结构甚至非结构化的数据,它是传统数据库的补充,是海量数据存储的最佳方法,它针对大文件的存储,批量访问和流式访问都做了优化,同时也通过多副本解决了容灾问题。
|
||||
|
||||
Hadoop 的缺陷在于:它只能执行批处理,并且只能以顺序方式访问数据。这意味着即使是最简单的工作,也必须搜索整个数据集,即:**Hadoop 无法实现对数据的随机访问**。实现数据的随机访问是传统的关系型数据库所擅长的,但它们却不能用于海量数据的存储。在这种情况下,必须有一种新的方案来**同时解决海量数据存储和随机访问的问题**,HBase 就是其中之一 (HBase,Cassandra,couchDB,Dynamo 和 MongoDB 都能存储海量数据并支持随机访问)。
|
||||
|
||||
> 注:数据结构分类:
|
||||
>
|
||||
> - 结构化数据:即以关系型数据库表形式管理的数据;
|
||||
> - 半结构化数据:非关系模型的,有基本固定结构模式的数据,例如日志文件、XML 文档、JSON 文档、Email 等;
|
||||
> - 非结构化数据:没有固定模式的数据,如 WORD、PDF、PPT、EXL,各种格式的图片、视频等。
|
||||
|
||||
### 什么是 HBase
|
||||
|
||||
**HBase 是一个构建在 HDFS(Hadoop 文件系统)之上的列式数据库**。
|
||||
|
||||
HBase 是一种类似于 `Google’s Big Table` 的数据模型,它是 Hadoop 生态系统的一部分,它将数据存储在 HDFS 上,客户端可以通过 HBase 实现对 HDFS 上数据的随机访问。
|
||||
|
||||
|
||||
|
||||
HBase 的**核心特性**如下:
|
||||
|
||||
- **分布式**
|
||||
- **伸缩性**:支持通过增减机器进行水平扩展,以提升整体容量和性能
|
||||
- **高可用**:支持 RegionServers 之间的自动故障转移
|
||||
- **自动分区**:Region 分散在集群中,当行数增长的时候,Region 也会自动的分区再均衡
|
||||
- **超大数据集**:HBase 被设计用来读写超大规模的数据集(数十亿行至数百亿行的表)
|
||||
- **支持结构化、半结构化和非结构化的数据**:由于 HBase 基于 HDFS 构建,所以和 HDFS 一样,支持结构化、半结构化和非结构化的数据
|
||||
- **非关系型数据库**
|
||||
- **不支持标准 SQL 语法**
|
||||
- **没有真正的索引**
|
||||
- **不支持复杂的事务**:只支持行级事务,即单行数据的读写都是原子性的
|
||||
|
||||
HBase 的其他特性
|
||||
|
||||
- 读写操作遵循强一致性
|
||||
- 过滤器支持谓词下推
|
||||
- 易于使用的 Java 客户端 API
|
||||
- 它支持线性和模块化可扩展性。
|
||||
- HBase 表支持 Hadoop MapReduce 作业的便捷基类
|
||||
- 很容易使用 Java API 进行客户端访问
|
||||
- 为实时查询提供块缓存 BlockCache 和布隆过滤器
|
||||
- 它通过服务器端过滤器提供查询谓词下推
|
||||
|
||||
### 什么时候使用 HBase
|
||||
|
||||
根据上一节对于 HBase 特性的介绍,我们可以梳理出 HBase 适用、不适用的场景:
|
||||
|
||||
HBase 不适用场景:
|
||||
|
||||
- 需要索引
|
||||
- 需要复杂的事务
|
||||
- 数据量较小(比如:数据量不足几百万行)
|
||||
|
||||
HBase 适用场景:
|
||||
|
||||
- 能存储海量数据并支持随机访问(比如:数据量级达到十亿级至百亿级)
|
||||
- 存储结构化、半结构化数据
|
||||
- 硬件资源充足
|
||||
|
||||
> 一言以蔽之——HBase 适用的场景是:**实时地随机访问超大数据集**。
|
||||
|
||||
HBase 的典型应用场景
|
||||
|
||||
- 存储监控数据
|
||||
- 存储用户/车辆 GPS 信息
|
||||
- 存储用户行为数据
|
||||
- 存储各种日志数据,如:访问日志、操作日志、推送日志等。
|
||||
- 存储短信、邮件等消息类数据
|
||||
- 存储网页数据
|
||||
|
||||
### HBase 数据模型简介
|
||||
|
||||
前面已经提及,HBase 是一个列式数据库,其数据模型和关系型数据库有所不同。其数据模型的关键术语如下:
|
||||
|
||||
- Table:HBase 表由多行组成。
|
||||
- Row:HBase 中的一行由一个行键和一个或多个列以及与之关联的值组成。 行在存储时按行键的字母顺序排序。 为此,行键的设计非常重要。 目标是以相关行彼此靠近的方式存储数据。 常见的行键模式是网站域。 如果您的行键是域,您应该将它们反向存储(org.apache.www、org.apache.mail、org.apache.jira)。 这样,所有 Apache 域在表中彼此靠近,而不是根据子域的第一个字母展开。
|
||||
- Column:HBase 中的列由列族和列限定符组成,它们由 :(冒号)字符分隔。
|
||||
- Column Family:通常出于性能原因,列族在物理上将一组列及其值放在一起。 每个列族都有一组存储属性,例如它的值是否应该缓存在内存中,它的数据是如何压缩的,它的行键是如何编码的,等等。 表中的每一行都有相同的列族,尽管给定的行可能不在给定的列族中存储任何内容。
|
||||
- 列限定符:将列限定符添加到列族以提供给定数据片段的索引。 给定列族内容,列限定符可能是 content:html,另一个可能是 content:pdf。 尽管列族在表创建时是固定的,但列限定符是可变的,并且行之间可能有很大差异。
|
||||
- Cell:单元格是行、列族和列限定符的组合,包含一个值和一个时间戳,代表值的版本。
|
||||
- Timestamp:时间戳写在每个值旁边,是给定版本值的标识符。 默认情况下,时间戳表示写入数据时 RegionServer 上的时间,但您可以在将数据放入单元格时指定不同的时间戳值。
|
||||
|
||||
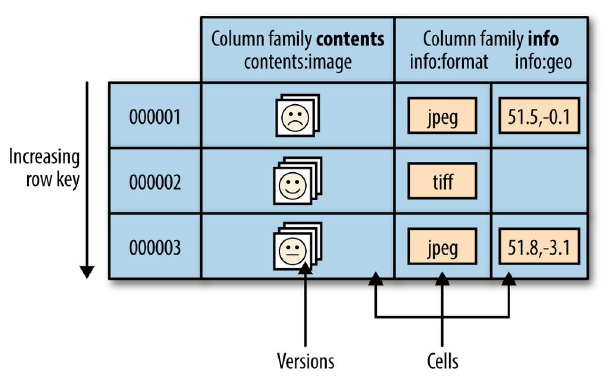
|
||||
|
||||
### 特性比较
|
||||
|
||||
#### HBase vs. RDBMS
|
||||
|
||||
| RDBMS | HBase |
|
||||
| ---------------------------------------- | -------------------------------------------------- |
|
||||
| RDBMS 有它的模式,描述表的整体结构的约束 | HBase 无模式,它不具有固定列模式的概念;仅定义列族 |
|
||||
| 支持的文件系统有 FAT、NTFS 和 EXT | 支持的文件系统只有 HDFS |
|
||||
| 使用提交日志来存储日志 | 使用预写日志 (WAL) 来存储日志 |
|
||||
| 使用特定的协调系统来协调集群 | 使用 ZooKeeper 来协调集群 |
|
||||
| 存储的都是中小规模的数据表 | 存储的是超大规模的数据表,并且适合存储宽表 |
|
||||
| 通常支持复杂的事务 | 仅支持行级事务 |
|
||||
| 适用于结构化数据 | 适用于半结构化、结构化数据 |
|
||||
| 使用主键 | 使用 row key |
|
||||
|
||||
#### HBase vs. HDFS
|
||||
|
||||
| HDFS | HBase |
|
||||
| ----------------------------------------- | ---------------------------------------------------- |
|
||||
| HDFS 提供了一个用于分布式存储的文件系统。 | HBase 提供面向表格列的数据存储。 |
|
||||
| HDFS 为大文件提供优化存储。 | HBase 为表格数据提供了优化。 |
|
||||
| HDFS 使用块文件。 | HBase 使用键值对数据。 |
|
||||
| HDFS 数据模型不灵活。 | HBase 提供了一个灵活的数据模型。 |
|
||||
| HDFS 使用文件系统和处理框架。 | HBase 使用带有内置 Hadoop MapReduce 支持的表格存储。 |
|
||||
| HDFS 主要针对一次写入多次读取进行了优化。 | HBase 针对读/写许多进行了优化。 |
|
||||
|
||||
#### 行式数据库 vs. 列式数据库
|
||||
|
||||
| 行式数据库 | 列式数据库 |
|
||||
| ------------------------------ | ------------------------------ |
|
||||
| 对于添加/修改操作更高效 | 对于读取操作更高效 |
|
||||
| 读取整行数据 | 仅读取必要的列数据 |
|
||||
| 最适合在线事务处理系统(OLTP) | 不适合在线事务处理系统(OLTP) |
|
||||
| 将行数据存储在连续的页内存中 | 将列数据存储在非连续的页内存中 |
|
||||
|
||||
列式数据库的优点:
|
||||
|
||||
- 支持数据压缩
|
||||
- 支持快速数据检索
|
||||
- 简化了管理和配置
|
||||
- 有利于聚合查询(例如 COUNT、SUM、AVG、MIN 和 MAX)的高性能
|
||||
- 分区效率很高,因为它提供了自动分片机制的功能,可以将较大的区域分配给较小的区域
|
||||
|
||||
列式数据库的缺点:
|
||||
|
||||
- JOIN 查询和来自多个表的数据未优化
|
||||
- 必须为频繁的删除和更新创建拆分,因此降低了存储效率
|
||||
- 由于非关系数据库的特性,分区和索引的设计非常困难
|
||||
|
||||
## HBase 安装
|
||||
|
||||
- [独立模式](https://hbase.apache.org/book.html#quickstart)
|
||||
- [伪分布式模式](https://hbase.apache.org/book.html#quickstart_pseudo)
|
||||
- [全分布式模式](https://hbase.apache.org/book.html#quickstart_fully_distributed)
|
||||
- [Docker 部署](https://github.com/big-data-europe/docker-hbase)
|
||||
|
||||
## HBase Hello World 示例
|
||||
|
||||
1. 连接 HBase
|
||||
|
||||
在 HBase 安装目录的 `/bin` 目录下执行 `hbase shell` 命令进入 HBase 控制台。
|
||||
|
||||
```shell
|
||||
$ ./bin/hbase shell
|
||||
hbase(main):001:0>
|
||||
```
|
||||
|
||||
2. 输入 `help` 可以查看 HBase Shell 命令。
|
||||
|
||||
3. 创建表
|
||||
|
||||
可以使用 `create` 命令创建一张新表。必须要指定表名和 Column Family。
|
||||
|
||||
```shell
|
||||
hbase(main):001:0> create 'test', 'cf'
|
||||
0 row(s) in 0.4170 seconds
|
||||
|
||||
=> Hbase::Table - test
|
||||
```
|
||||
|
||||
4. 列出表信息
|
||||
|
||||
使用 `list` 命令来确认新建的表已存在。
|
||||
|
||||
```shell
|
||||
hbase(main):002:0> list 'test'
|
||||
TABLE
|
||||
test
|
||||
1 row(s) in 0.0180 seconds
|
||||
|
||||
=> ["test"]
|
||||
```
|
||||
|
||||
可以使用 `describe` 命令可以查看表的细节信息,包括配置信息
|
||||
|
||||
```shell
|
||||
hbase(main):003:0> describe 'test'
|
||||
Table test is ENABLED
|
||||
test
|
||||
COLUMN FAMILIES DESCRIPTION
|
||||
{NAME => 'cf', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE =>
|
||||
'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'f
|
||||
alse', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE
|
||||
=> '65536'}
|
||||
1 row(s)
|
||||
Took 0.9998 seconds
|
||||
```
|
||||
|
||||
5. 向表中写数据
|
||||
|
||||
可以使用 `put` 命令向 HBase 表中写数据。
|
||||
|
||||
```shell
|
||||
hbase(main):003:0> put 'test', 'row1', 'cf:a', 'value1'
|
||||
0 row(s) in 0.0850 seconds
|
||||
|
||||
hbase(main):004:0> put 'test', 'row2', 'cf:b', 'value2'
|
||||
0 row(s) in 0.0110 seconds
|
||||
|
||||
hbase(main):005:0> put 'test', 'row3', 'cf:c', 'value3'
|
||||
0 row(s) in 0.0100 seconds
|
||||
```
|
||||
|
||||
6. 一次性扫描表的所有数据
|
||||
|
||||
使用 `scan` 命令来扫描表数据。
|
||||
|
||||
```shell
|
||||
hbase(main):006:0> scan 'test'
|
||||
ROW COLUMN+CELL
|
||||
row1 column=cf:a, timestamp=1421762485768, value=value1
|
||||
row2 column=cf:b, timestamp=1421762491785, value=value2
|
||||
row3 column=cf:c, timestamp=1421762496210, value=value3
|
||||
3 row(s) in 0.0230 seconds
|
||||
```
|
||||
|
||||
7. 查看一行数据
|
||||
|
||||
使用 `get` 命令可以查看一行表数据。
|
||||
|
||||
```shell
|
||||
hbase(main):007:0> get 'test', 'row1'
|
||||
COLUMN CELL
|
||||
cf:a timestamp=1421762485768, value=value1
|
||||
1 row(s) in 0.0350 seconds
|
||||
```
|
||||
|
||||
8. 禁用表
|
||||
|
||||
如果想要删除表或修改表设置,必须先使用 `disable` 命令禁用表。如果想再次启用表,可以使用 `enable` 命令。
|
||||
|
||||
```shell
|
||||
hbase(main):008:0> disable 'test'
|
||||
0 row(s) in 1.1820 seconds
|
||||
|
||||
hbase(main):009:0> enable 'test'
|
||||
0 row(s) in 0.1770 seconds
|
||||
```
|
||||
|
||||
9. 删除表
|
||||
|
||||
使用 `drop` 命令可以删除表。
|
||||
|
||||
```shell
|
||||
hbase(main):011:0> drop 'test'
|
||||
0 row(s) in 0.1370 seconds
|
||||
```
|
||||
|
||||
10. 退出 HBase Shell
|
||||
|
||||
使用 `quit` 命令,就能退出 HBase Shell 控制台。
|
||||
|
||||
## 参考资料
|
||||
|
||||
- **官方**
|
||||
- [HBase 官网](http://hbase.apache.org/)
|
||||
- [HBase 官方文档](https://hbase.apache.org/book.html)
|
||||
- [HBase 官方文档中文版](http://abloz.com/hbase/book.html)
|
||||
- **书籍**
|
||||
- [Hadoop 权威指南](https://book.douban.com/subject/27600204/)
|
||||
- **文章**
|
||||
- [Bigtable: A Distributed Storage System for Structured Data](https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/bigtable-osdi06.pdf)
|
||||
- [An In-Depth Look at the HBase Architecture](https://mapr.com/blog/in-depth-look-hbase-architecture)
|
||||
- **教程**
|
||||
- https://github.com/heibaiying/BigData-Notes
|
||||
- https://www.cloudduggu.com/hbase/introduction/
|
||||
|
|
@ -0,0 +1,84 @@
|
|||
---
|
||||
title: HBase 数据模型
|
||||
date: 2023-03-16 15:58:10
|
||||
categories:
|
||||
- 数据库
|
||||
- 列式数据库
|
||||
- HBase
|
||||
tags:
|
||||
- 数据库
|
||||
- 列式数据库
|
||||
- 大数据
|
||||
- HBase
|
||||
permalink: /pages/c8cfeb/
|
||||
---
|
||||
|
||||
# HBase 数据模型
|
||||
|
||||
HBase 是一个面向 `列` 的数据库管理系统,这里更为确切的而说,HBase 是一个面向 `列族` 的数据库管理系统。表 schema 仅定义列族,表具有多个列族,每个列族可以包含任意数量的列,列由多个单元格(cell)组成,单元格可以存储多个版本的数据,多个版本数据以时间戳进行区分。
|
||||
|
||||
## HBase 逻辑存储结构
|
||||
|
||||
- **`Table`**:Table 由 Row 和 Column 组成。
|
||||
- **`Row`**:Row 是列族(Column Family)的集合。
|
||||
- **`Row Key`**:**`Row Key` 是用来检索记录的主键**。
|
||||
- `Row Key` 是未解释的字节数组,所以理论上,任何数据都可以通过序列化表示成字符串或二进制,从而存为 HBase 的键值。
|
||||
- 表中的行,是按照 `Row Key` 的字典序进行排序。这里需要注意以下两点:
|
||||
- 因为字典序对 Int 排序的结果是 1,10,100,11,12,13,14,15,16,17,18,19,2,20,21,…,9,91,92,93,94,95,96,97,98,99。如果你使用整型的字符串作为行键,那么为了保持整型的自然序,行键必须用 0 作左填充。
|
||||
- 行的一次读写操作是原子性的 (不论一次读写多少列)。
|
||||
- 所有对表的访问都要通过 Row Key,有以下三种方式:
|
||||
- 通过指定的 `Row Key` 进行访问;
|
||||
- 通过 `Row Key` 的 range 进行访问,即访问指定范围内的行;
|
||||
- 进行全表扫描。
|
||||
- **`Column Family`**:即列族。HBase 表中的每个列,都归属于某个列族。列族是表的 Schema 的一部分,所以列族需要在创建表时进行定义。
|
||||
- 一个表的列族必须作为表模式定义的一部分预先给出,但是新的列族成员可以随后按需加入。
|
||||
- 同一个列族的所有成员具有相同的前缀,例如 `info:format`,`info:geo` 都属于 `info` 这个列族。
|
||||
- **`Column Qualifier`**:列限定符。可以理解为是具体的列名,例如 `info:format`,`info:geo` 都属于 `info` 这个列族,它们的列限定符分别是 `format` 和 `geo`。列族和列限定符之间始终以冒号分隔。需要注意的是列限定符不是表 Schema 的一部分,你可以在插入数据的过程中动态创建列。
|
||||
- **`Column`**:HBase 中的列由列族和列限定符组成,由 `:`(冒号) 进行分隔,即一个完整的列名应该表述为 `列族名 :列限定符`。
|
||||
- **`Cell`**:`Cell` 是行,列族和列限定符的组合,并包含值和时间戳。HBase 中通过 `row key` 和 `column` 确定的为一个存储单元称为 `Cell`,你可以等价理解为关系型数据库中由指定行和指定列确定的一个单元格,但不同的是 HBase 中的一个单元格是由多个版本的数据组成的,每个版本的数据用时间戳进行区分。
|
||||
- `Cell` 由行和列的坐标交叉决定,是有版本的。默认情况下,版本号是自动分配的,为 HBase 插入 `Cell` 时的时间戳。`Cell` 的内容是未解释的字节数组。
|
||||
-
|
||||
- **`Timestamp`**:`Cell` 的版本通过时间戳来索引,时间戳的类型是 64 位整型,时间戳可以由 HBase 在数据写入时自动赋值,也可以由客户显式指定。每个 `Cell` 中,不同版本的数据按照时间戳倒序排列,即最新的数据排在最前面。
|
||||
|
||||

|
||||
|
||||
## HBase 物理存储结构
|
||||
|
||||
HBase 自动将表水平划分成区域(Region)。每个 Region 由表中 Row 的子集构成。每个 Region 由它所属的表的起始范围来表示(包含的第一行和最后一行)。初始时,一个表只有一个 Region,随着 Region 膨胀,当超过一定阈值时,会在某行的边界上分裂成两个大小基本相同的新 Region。在第一次划分之前,所有加载的数据都放在原始 Region 所在的那台服务器上。随着表变大,Region 个数也会逐渐增加。Region 是在 HBase 集群上分布数据的最小单位。
|
||||
|
||||
## HBase 数据模型示例
|
||||
|
||||
下图为 HBase 中一张表的:
|
||||
|
||||
- RowKey 为行的唯一标识,所有行按照 RowKey 的字典序进行排序;
|
||||
- 该表具有两个列族,分别是 personal 和 office;
|
||||
- 其中列族 personal 拥有 name、city、phone 三个列,列族 office 拥有 tel、addres 两个列。
|
||||
|
||||
|
||||
|
||||
> _图片引用自 : HBase 是列式存储数据库吗_ *https://www.iteblog.com/archives/2498.html*
|
||||
|
||||
## HBase 表特性
|
||||
|
||||
Hbase 的表具有以下特点:
|
||||
|
||||
- **容量大**:一个表可以有数十亿行,上百万列;
|
||||
- **面向列**:数据是按照列存储,每一列都单独存放,数据即索引,在查询时可以只访问指定列的数据,有效地降低了系统的 I/O 负担;
|
||||
- **稀疏性**:空 (null) 列并不占用存储空间,表可以设计的非常稀疏 ;
|
||||
- **数据多版本**:每个单元中的数据可以有多个版本,按照时间戳排序,新的数据在最上面;
|
||||
- **存储类型**:所有数据的底层存储格式都是字节数组 (byte[])。
|
||||
|
||||
## 参考资料
|
||||
|
||||
- **官方**
|
||||
- [HBase 官网](http://hbase.apache.org/)
|
||||
- [HBase 官方文档](https://hbase.apache.org/book.html)
|
||||
- [HBase 官方文档中文版](http://abloz.com/hbase/book.html)
|
||||
- **书籍**
|
||||
- [Hadoop 权威指南](https://book.douban.com/subject/27600204/)
|
||||
- **文章**
|
||||
- [Bigtable: A Distributed Storage System for Structured Data](https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/bigtable-osdi06.pdf)
|
||||
- [An In-Depth Look at the HBase Architecture](https://mapr.com/blog/in-depth-look-hbase-architecture)
|
||||
- **教程**
|
||||
- https://github.com/heibaiying/BigData-Notes
|
||||
- https://www.cloudduggu.com/hbase/introduction/
|
||||
|
|
@ -0,0 +1,229 @@
|
|||
---
|
||||
title: HBase Schema 设计
|
||||
date: 2023-03-15 20:28:32
|
||||
categories:
|
||||
- 数据库
|
||||
- 列式数据库
|
||||
- HBase
|
||||
tags:
|
||||
- 大数据
|
||||
- HBase
|
||||
permalink: /pages/a69528/
|
||||
---
|
||||
|
||||
# HBase Schema 设计
|
||||
|
||||
## HBase Schema 设计要素
|
||||
|
||||
- 这个表应该有多少 Column Family
|
||||
- Column Family 使用什么数据
|
||||
- 每个 Column Family 有有多少列
|
||||
- 列名是什么,尽管列名不必在建表时定义,但读写数据是要知道的
|
||||
- 单元应该存放什么数据
|
||||
- 每个单元存储多少时间版本
|
||||
- 行健(rowKey)结构是什么,应该包含什么信息
|
||||
|
||||
## Row Key 设计
|
||||
|
||||
### Row Key 的作用
|
||||
|
||||
在 HBase 中,所有对表的访问都要通过 Row Key,有三种访问方式:
|
||||
|
||||
- 使用 `get` 命令,查询指定的 Row Key,即精确查找。
|
||||
- 使用 scan 命令,根据 Row Key 进行范围查找。
|
||||
- 全表扫描,即直接扫描表中所有行记录。
|
||||
|
||||
此外,在 HBase 中,表中的行,是按照 Row Key 的字典序进行排序的。
|
||||
|
||||
由此,可见,Row Key 的良好设计对于 HBase CRUD 的性能至关重要。
|
||||
|
||||
### Row Key 的设计原则
|
||||
|
||||
**长度原则**
|
||||
|
||||
RowKey 是一个二进制码流,可以是任意字符串,最大长度为 64kb,实际应用中一般为 10-100byte,以 byte[]形式保存,一般设计成定长。建议越短越好,不要超过 16 个字节,原因如下:
|
||||
|
||||
1. 数据的持久化文件 HFile 中时按照 Key-Value 存储的,如果 RowKey 过长,例如超过 100byte,那么 1000w 行的记录,仅 RowKey 就需占用近 1GB 的空间。这样会极大影响 HFile 的存储效率。
|
||||
2. MemStore 会缓存部分数据到内存中,若 RowKey 字段过长,内存的有效利用率就会降低,就不能缓存更多的数据,从而降低检索效率。
|
||||
3. 目前操作系统都是 64 位系统,内存 8 字节对齐,控制在 16 字节,8 字节的整数倍利用了操作系统的最佳特性。
|
||||
|
||||
**唯一原则**
|
||||
|
||||
必须在设计上保证 RowKey 的唯一性。由于在 HBase 中数据存储是 Key-Value 形式,若向 HBase 中同一张表插入相同 RowKey 的数据,则原先存在的数据会被新的数据覆盖。
|
||||
|
||||
**排序原则**
|
||||
|
||||
HBase 的 RowKey 是按照 ASCII 有序排序的,因此我们在设计 RowKey 的时候要充分利用这点。
|
||||
|
||||
**散列原则**
|
||||
|
||||
设计的 RowKey 应均匀的分布在各个 HBase 节点上。
|
||||
|
||||
### 热点问题
|
||||
|
||||
Region 是在 HBase 集群上分布数据的最小单位。每个 Region 由它所属的表的起始范围来表示(即起始 Row Key 和结束 Row Key)。
|
||||
|
||||
如果,Row Key 使用单调递增的整数或时间戳,就会产生一个问题:因为 Hbase 的 Row Key 是就近存储的,这会导致一段时间内大部分读写集中在某一个 Region 或少数 Region 上(根据二八原则,最近产生的数据,往往是读写频率最高的数据),即所谓 **热点问题**。
|
||||
|
||||
#### 反转(Reversing)
|
||||
|
||||
第一种咱们要分析的方法是反转,顾名思义它就是把固定长度或者数字格式的 RowKey 进行反转,反转分为一般数据反转和时间戳反转,其中以时间戳反转较常见。
|
||||
|
||||
- **反转固定格式的数值** - 以手机号为例,手机号的前缀变化比较少(如 `152、185` 等),但后半部分变化很多。如果将它反转过来,可以有效地避免热点。不过其缺点就是失去了有序性。
|
||||
- **反转时间** - 如果数据访问以查找最近的数据为主,可以将时间戳存储为反向时间戳(例如: `timestamp = Long.MAX_VALUE – timestamp`),这样有利于扫描最近的数据。
|
||||
|
||||
#### 加盐(Salting)
|
||||
|
||||
这里的“加盐”与密码学中的“加盐”不是一回事。它是指在 RowKey 的前面增加一些前缀,加盐的前缀种类越多,RowKey 就被打得越散。
|
||||
|
||||
需要注意的是分配的随机前缀的种类数量应该和我们想把数据分散到的那些 region 的数量一致。只有这样,加盐之后的 rowkey 才会根据随机生成的前缀分散到各个 region 中,避免了热点现象。
|
||||
|
||||
#### 哈希(Hashing)
|
||||
|
||||
其实哈希和加盐的适用场景类似,但我们前缀不可以是随机的,因为必须要让客户端能够完整地重构 RowKey。所以一般会拿原 RowKey 或其一部分计算 Hash 值,然后再对 Hash 值做运算作为前缀。
|
||||
|
||||
## HBase Schema 设计规则
|
||||
|
||||
### Column Family 设计
|
||||
|
||||
HBase 不能很好处理 2 ~ 3 个以上的 Column Family,所以 **HBase 表应尽可能减少 Column Family 数**。如果可以,请只使用一个列族,只有需要经常执行 Column 范围查询时,才引入多列族。也就是说,尽量避免同时查询多个列族。
|
||||
|
||||
- **Column Family 数量多,会影响数据刷新**。HBase 的数据刷新是在每个 Region 的基础上完成的。因此,如果一个 Column Family 携带大量导致刷新的数据,那么相邻的列族即使携带的数据量很小,也会被刷新。当存在许多 Column Family 时,刷新交互会导致一堆不必要的 IO。 此外,在表/区域级别的压缩操作也会在每个存储中发生。
|
||||
- **Column Family 数量多,会影响查找效率**。如:Column Family A 有 100 万行,Column Family B 有 10 亿行,那么 Column Family A 的数据可能会分布在很多很多区域(和 RegionServers)。 这会降低 Column Family A 的批量扫描效率。
|
||||
|
||||
Column Family 名尽量简短,最好是一个字符。Column Family 会在列限定符中被频繁使用,缩短长度有利于节省空间并提升效率。
|
||||
|
||||
### Row 设计
|
||||
|
||||
**HBase 中的 Row 按 Row Key 的字典顺序排序**。
|
||||
|
||||
- **不要将 Row Key 设计为单调递增的**,例如:递增的整数或时间戳
|
||||
|
||||
- 问题:因为 Hbase 的 Row Key 是就近存储的,这样会导致一段时间内大部分写入集中在某一个 Region 上,即所谓热点问题。
|
||||
|
||||
- 解决方法一、加盐:这里的不是指密码学的加盐,而是指将随机分配的前缀添加到行键的开头。这么做是为了避免相同前缀的 Row Key 数据被存储在相邻位置,从而导致热点问题。示例如下:
|
||||
|
||||
- ```
|
||||
foo0001
|
||||
foo0002
|
||||
foo0003
|
||||
foo0004
|
||||
|
||||
改为
|
||||
|
||||
a-foo0003
|
||||
b-foo0001
|
||||
c-foo0003
|
||||
c-foo0004
|
||||
d-foo0002
|
||||
```
|
||||
|
||||
- 解决方法二、Hash:Row Key 的前缀使用 Hash
|
||||
|
||||
- **尽量减少行和列的长度**
|
||||
|
||||
- **反向时间戳**:反向时间戳可以极大地帮助快速找到值的最新版本。
|
||||
|
||||
- **行健不能改变**:唯一可以改变的方式是先删除后插入。
|
||||
|
||||
- **Row Key 和 Column Family**:Row Key 从属于 Column Family,因此,相同的 Row Key 可以存在每一个 Column Family 中而不会出现冲突。
|
||||
|
||||
### Version 设计
|
||||
|
||||
最大、最小 Row 版本号:表示 HBase 会保留的版本号数的上下限。均可以通过 HColumnDescriptor 对每个列族进行配置
|
||||
|
||||
Row 版本号过大,会大大增加 StoreFile 的大小;所以,最大 Row 版本号应按需设置。HBase 会在主要压缩时,删除多余的版本。
|
||||
|
||||
### TTL 设计
|
||||
|
||||
Column Family 会设置一个以秒为单位的 TTL,一旦达到 TTL 时,HBase 会自动删除行记录。
|
||||
|
||||
仅包含过期行的存储文件在次要压缩时被删除。 将 hbase.store.delete.expired.storefile 设置为 false 会禁用此功能。将最小版本数设置为 0 以外的值也会禁用此功能。
|
||||
|
||||
在较新版本的 HBase 上,还支持在 Cell 上设置 TTL,与 Column Family 的 TTL 不同的是,单位是毫秒。
|
||||
|
||||
### Column Family 属性配置
|
||||
|
||||
- HFile 数据块,默认是 64KB,数据库的大小影响数据块索引的大小。数据块大的话一次加载进内存的数据越多,扫描查询效果越好。但是数据块小的话,随机查询性能更好
|
||||
|
||||
```
|
||||
> create 'mytable',{NAME => 'cf1', BLOCKSIZE => '65536'}
|
||||
复制代码
|
||||
```
|
||||
|
||||
- 数据块缓存,数据块缓存默认是打开的,如果一些比较少访问的数据可以选择关闭缓存
|
||||
|
||||
```
|
||||
> create 'mytable',{NAME => 'cf1', BLOCKCACHE => 'FALSE'}
|
||||
复制代码
|
||||
```
|
||||
|
||||
- 数据压缩,压缩会提高磁盘利用率,但是会增加 CPU 的负载,看情况进行控制
|
||||
|
||||
```
|
||||
> create 'mytable',{NAME => 'cf1', COMPRESSION => 'SNAPPY'}
|
||||
复制代码
|
||||
```
|
||||
|
||||
Hbase 表设计是和需求相关的,但是遵守表设计的一些硬性指标对性能的提升还是很有帮助的,这里整理了一些设计时用到的要点。
|
||||
|
||||
## Schema 设计案例
|
||||
|
||||
### 案例:日志数据和时序数据
|
||||
|
||||
假设采集以下数据
|
||||
|
||||
- Hostname
|
||||
- Timestamp
|
||||
- Log event
|
||||
- Value/message
|
||||
|
||||
应该如何设计 Row Key?
|
||||
|
||||
(1)Timestamp 在 Row Key 头部
|
||||
|
||||
如果 Row Key 设计为 `[timestamp][hostname][log-event]` 形式,会出现热点问题。
|
||||
|
||||
如果针对时间的扫描很重要,可以采用时间戳分桶策略,即
|
||||
|
||||
```
|
||||
bucket = timestamp % bucketNum
|
||||
```
|
||||
|
||||
计算出桶号后,将 Row Key 指定为:`[bucket][timestamp][hostname][log-event]`
|
||||
|
||||
如上所述,要为特定时间范围选择数据,需要对每个桶执行扫描。 例如,100 个桶将在键空间中提供广泛的分布,但需要 100 次扫描才能获取单个时间戳的数据,因此需要权衡取舍。
|
||||
|
||||
(2)Hostname 在 Row Key 头部
|
||||
|
||||
如果主机样本量很大,将 Row Key 设计为 `[hostname][log-event][timestamp]`,这样有利于扫描 hostname。
|
||||
|
||||
(3)Timestamp 还是反向 Timestamp
|
||||
|
||||
如果数据访问以查找最近的数据为主,可以将时间戳存储为反向时间戳(例如: `timestamp = Long.MAX_VALUE – timestamp`),这样有利于扫描最近的数据。
|
||||
|
||||
(4)Row Key 是可变长度还是固定长度
|
||||
|
||||
拼接 Row Key 的关键字长度不一定是固定的,例如 hostname 有可能很长,也有可能很短。如果想要统一长度,可以参考以下做法:
|
||||
|
||||
- 将关键字 Hash 编码:使用某种 Hash 算法计算关键字,并取固定长度的值(例如:8 位或 16 位)。
|
||||
- 使用数字替代关键字:例如:使用事件类型 Code 替换事件类型;hostname 如果是 IP,可以转换为 long
|
||||
- 截取关键字:截取后的关键字需要有足够的辨识度,长度大小根据具体情况权衡。
|
||||
|
||||
(5)时间分片
|
||||
|
||||
```
|
||||
[hostname][log-event][timestamp1]
|
||||
[hostname][log-event][timestamp2]
|
||||
[hostname][log-event][timestamp3]
|
||||
```
|
||||
|
||||
上面的例子中,每个详细事件都有单独的行键,可以重写如下,即每个时间段存储一次:
|
||||
|
||||
```
|
||||
[hostname][log-event][timerange]
|
||||
```
|
||||
|
||||
## 参考资料
|
||||
|
||||
- [HBase 官方文档之 HBase and Schema Design](https://hbase.apache.org/book.html#schema)
|
||||
|
|
@ -0,0 +1,160 @@
|
|||
---
|
||||
title: HBase 架构
|
||||
date: 2020-07-24 06:52:07
|
||||
categories:
|
||||
- 数据库
|
||||
- 列式数据库
|
||||
- HBase
|
||||
tags:
|
||||
- 大数据
|
||||
- HBase
|
||||
permalink: /pages/62f8d9/
|
||||
---
|
||||
|
||||
# HBase 架构
|
||||
|
||||
> **_HBase 是一个在 HDFS 上开发的面向列的分布式数据库。_**
|
||||
|
||||
## HBase 存储架构
|
||||
|
||||
> 在 HBase 中,表被分割成多个更小的块然后分散的存储在不同的服务器上,这些小块叫做 Regions,存放 Regions 的地方叫做 RegionServer。Master 进程负责处理不同的 RegionServer 之间的 Region 的分发。
|
||||
|
||||
### 概览
|
||||
|
||||
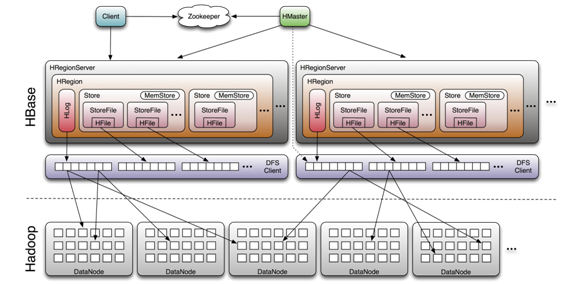
|
||||
|
||||
HBase 主要处理两种文件:预写日志(WAL)和实际数据文件 HFile。一个基本的流程是客户端首先联系 ZooKeeper 集群查找行键。上述过程是通过 ZooKeeper 获取欧含有 `-ROOT-` 的 region 服务器来完成的。通过含有 `-ROOT-` 的 region 服务器可以查询到含有 `.META.` 表中对应的 region 服务器名,其中包含请求的行键信息。这两种内容都会被缓存下来,并且只查询一次。最终,通过查询 .META. 服务器来获取客户端查询的行键数据所在 region 的服务器名。
|
||||
|
||||
### Region
|
||||
|
||||
HBase Table 中的所有行按照 `Row Key` 的字典序排列。HBase Table 根据 Row Key 的范围分片,每个分片叫做 `Region`。一个 `Region` 包含了在 start key 和 end key 之间的所有行。
|
||||
|
||||
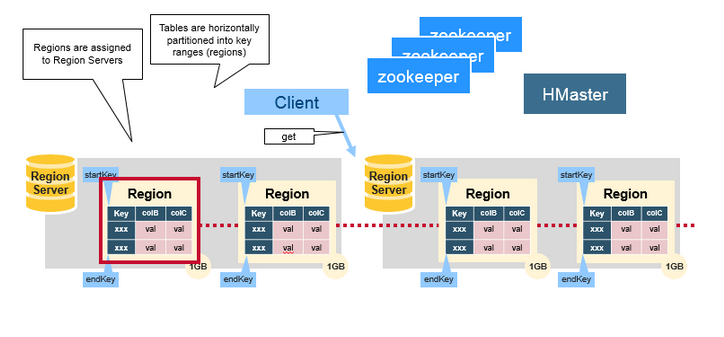
|
||||
|
||||
**HBase 支持自动分区**:每个表初始只有一个 `Region`,随着数据不断增加,`Region` 会不断增大,当增大到一个阀值的时候,`Region` 就会分裂为两个新的 `Region`。当 Table 中的行不断增多,就会有越来越多的 `Region`。
|
||||
|
||||
`Region` 是 HBase 中**分布式存储和负载均衡的最小单元**。这意味着不同的 `Region` 可以分布在不同的 `Region Server` 上。但一个 `Region` 是不会拆分到多个 Server 上的。
|
||||
|
||||
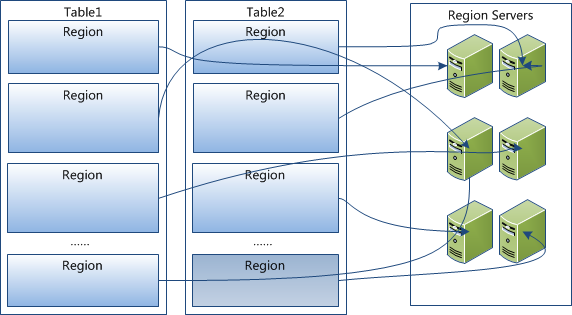
|
||||
|
||||
### Region Server
|
||||
|
||||
`Region` 只不过是表被拆分,并分布在 Region Server。
|
||||
|
||||
`Region Server` 运行在 HDFS 的 DataNode 上。它具有以下组件:
|
||||
|
||||
- **WAL(Write Ahead Log,预写日志)**:用于存储尚未进持久化存储的数据记录,以便在发生故障时进行恢复。如果写 WAL 失败了,那么修改数据的完整操作就是失败的。
|
||||
- 通常情况,每个 RegionServer 只有一个 WAL 实例。在 2.0 之前,WAL 的实现叫做 HLog
|
||||
- WAL 位于 `/hbase/WALs/` 目录下
|
||||
- 如果每个 RegionServer 只有一个 WAL,由于 HDFS 必须是连续的,导致必须写 WAL 连续的,然后出现性能问题。MultiWAL 可以让 RegionServer 同时写多个 WAL 并行的,通过 HDFS 底层的多管道,最终提升总的吞吐量,但是不会提升单个 Region 的吞吐量。
|
||||
- **BlockCache**:**读缓存**。它将频繁读取的数据存储在内存中,如果存储不足,它将按照 `最近最少使用原则` 清除多余的数据。
|
||||
- **MemStore**:**写缓存**。它存储尚未写入磁盘的新数据,并会在数据写入磁盘之前对其进行排序。每个 Region 上的每个列族都有一个 MemStore。
|
||||
- **HFile**:**将行数据按照 Key/Values 的形式存储在文件系统上**。HFile 是 HBase 在 HDFS 中存储数据的格式,它包含多层的索引,这样在 HBase 检索数据的时候就不用完全的加载整个文件。HFile 存储的根目录默认为为 `/hbase`。索引的大小(keys 的大小,数据量的大小)影响 block 的大小,在大数据集的情况下,block 的大小设置为每个 RegionServer 1GB 也是常见的。
|
||||
- 起初,HFile 中并没有任何 Block,数据还存在于 MemStore 中。
|
||||
- Flush 发生时,创建 HFile Writer,第一个空的 Data Block 出现,初始化后的 Data Block 中为 Header 部分预留了空间,Header 部分用来存放一个 Data Block 的元数据信息。
|
||||
- 而后,位于 MemStore 中的 KeyValues 被一个个 append 到位于内存中的第一个 Data Block 中:
|
||||
|
||||
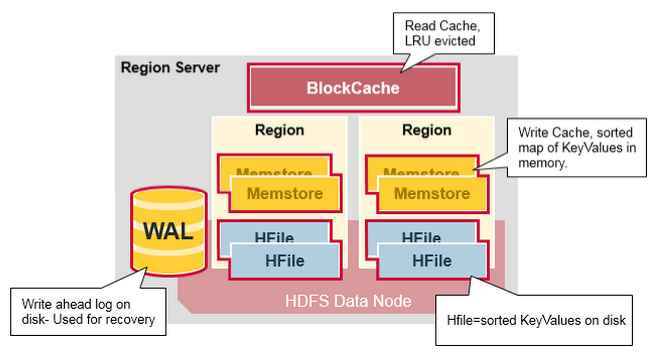
|
||||
|
||||
Region Server 存取一个子表时,会创建一个 Region 对象,然后对表的每个列族创建一个 `Store` 实例,每个 `Store` 会有 0 个或多个 `StoreFile` 与之对应,每个 `StoreFile` 则对应一个 `HFile`,HFile 就是实际存储在 HDFS 上的文件。
|
||||
|
||||
## HBase 系统架构
|
||||
|
||||
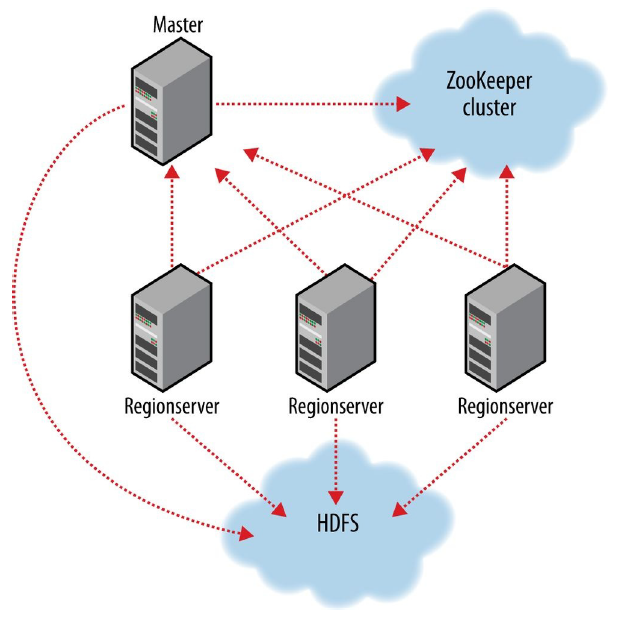
|
||||
|
||||
和 HDFS、YARN 一样,**HBase 也遵循 master / slave 架构**:
|
||||
|
||||
- HBase 有一个 master 节点。**master 节点负责协调管理 region server 节点**。
|
||||
- master 负责将 region 分配给 region server 节点;
|
||||
- master 负责恢复 region server 节点的故障。
|
||||
- HBase 有多个 region server 节点。**region server 节点负责零个或多个 region 的管理并响应客户端的读写请求。region server 节点还负责 region 的划分并通知 master 节点有了新的子 region**。
|
||||
- HBase 依赖 ZooKeeper 来实现故障恢复。
|
||||
|
||||
### Master Server
|
||||
|
||||
**Master Server 负责协调 Region Server**。具体职责如下:
|
||||
|
||||
- 为 Region Server 分配 Region ;
|
||||
- 负责 Region Server 的负载均衡 ;
|
||||
- 发现失效的 Region Server 并重新分配其上的 Region;
|
||||
- GFS 上的垃圾文件回收;
|
||||
- 处理 Schema 的更新请求。
|
||||
|
||||
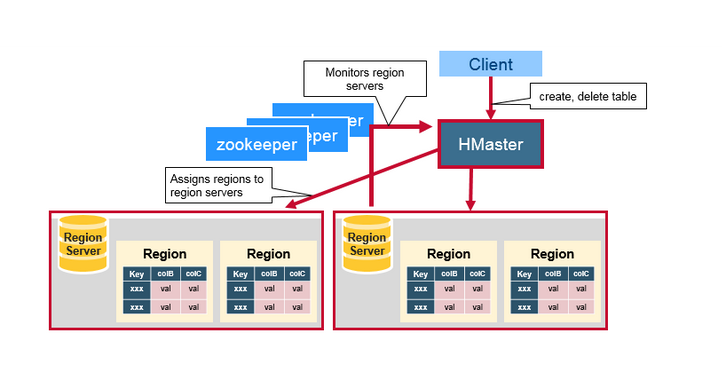
|
||||
|
||||
### Region Server
|
||||
|
||||
- Region Server 负责维护 Master Server 分配给它的 Region,并处理发送到 Region 上的 IO 请求;
|
||||
- 当 Region 过大,Region Server 负责自动分区,并通知 Master Server 记录更新。
|
||||
|
||||
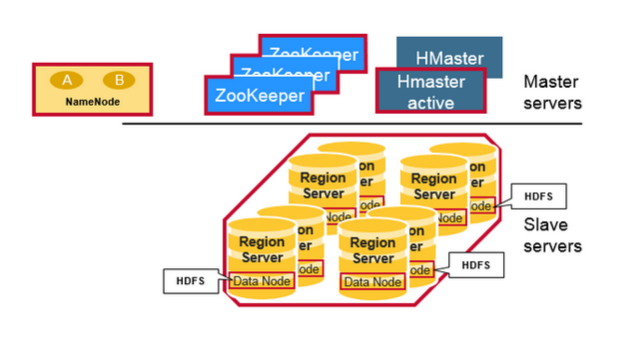
|
||||
|
||||
### ZooKeeper
|
||||
|
||||
**HBase 依赖 ZooKeeper 作为分布式协调服务来维护集群中的服务器状态**。Zookeeper 维护哪些服务器是活动的和可用的,并提供服务器故障通知。集群至少应该有 3 个节点。
|
||||
|
||||
ZooKeeper 的作用:
|
||||
|
||||
- 保证任何时候,集群中只有一个 Master;
|
||||
- 存储所有 Region 的寻址入口;
|
||||
- 实时监控 Region Server 的状态,将 Region Server 的上线和下线信息实时通知给 Master;
|
||||
- 存储 HBase 的 Schema,包括有哪些 Table,每个 Table 有哪些 Column Family 等信息。
|
||||
|
||||
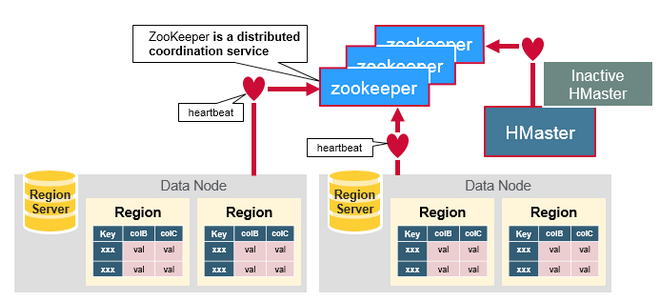
|
||||
|
||||
以上,最重要的一点是 ZooKeeper 如何保证 HBase 集群中只有一个 Master Server 的呢?
|
||||
|
||||
- 所有 Master Server 会竞争 Zookeeper 的 znode 锁(一个临时节点),只有一个 Master Server 能够创建成功,此时该 Master 就是主 Master。
|
||||
- 主 Master 会定期向 Zookeeper 发送心跳。从 Master 则通过 Watcher 机制对主 Master 所在节点进行监听。
|
||||
- 如果,主 Master 未能及时发送心跳,则其持有的 ZooKeeper 会话会过期,相应的 znode 锁(一个临时节点)会被自动删除。这会触发定义在该节点上的 Watcher 事件,所有从 Master 会得到通知,并再次开始竞争 znode 锁,直到完成主 Master 的选举。
|
||||
|
||||
HBase 内部保留名为 hbase:meta 的特殊目录表(catalog table)。它维护着当前集群上所有 region 的列表、状态和位置。hbase:meta 表中的项使用 region 作为键。region 名由所属的表名、region 的起始行、region的创建时间以及基于整体计算得出的 MD5 组成。
|
||||
|
||||
## HBase 读写流程
|
||||
|
||||
### 写入数据的流程
|
||||
|
||||
1. Client 向 Region Server 提交写请求;
|
||||
2. Region Server 找到目标 Region;
|
||||
3. Region 检查数据是否与 Schema 一致;
|
||||
4. 如果客户端没有指定版本,则获取当前系统时间作为数据版本;
|
||||
5. 将更新写入 WAL Log;
|
||||
6. 将更新写入 Memstore;
|
||||
7. 判断 Memstore 存储是否已满,如果存储已满则需要 flush 为 Store Hfile 文件。
|
||||
|
||||
> 更为详细写入流程可以参考:[HBase - 数据写入流程解析](http://hbasefly.com/2016/03/23/hbase_writer/)
|
||||
|
||||
### 读取数据的流程
|
||||
|
||||
以下是客户端首次读写 HBase 上数据的流程:
|
||||
|
||||
1. 客户端从 Zookeeper 获取 `META` 表所在的 Region Server;
|
||||
2. 客户端访问 `META` 表所在的 Region Server,从 `META` 表中查询到访问行键所在的 Region Server,之后客户端将缓存这些信息以及 `META` 表的位置;
|
||||
3. 客户端从行键所在的 Region Server 上获取数据。
|
||||
|
||||
如果再次读取,客户端将从缓存中获取行键所在的 Region Server。这样客户端就不需要再次查询 `META` 表,除非 Region 移动导致缓存失效,这样的话,则将会重新查询并更新缓存。
|
||||
|
||||
注:`META` 表是 HBase 中一张特殊的表,它保存了所有 Region 的位置信息,META 表自己的位置信息则存储在 ZooKeeper 上。
|
||||
|
||||
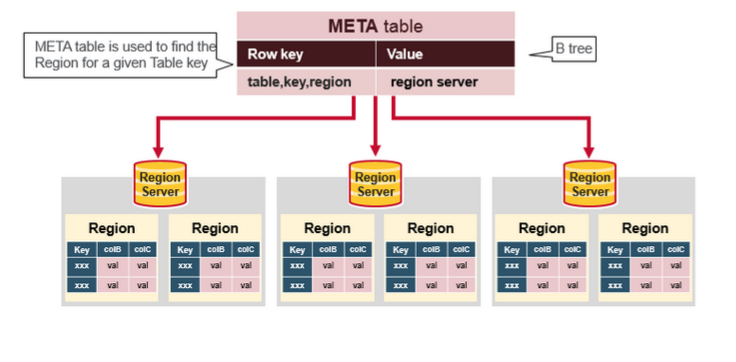
|
||||
|
||||
> 更为详细读取数据流程参考:
|
||||
>
|
||||
> [HBase 原理-数据读取流程解析](http://hbasefly.com/2016/12/21/hbase-getorscan/)
|
||||
>
|
||||
> [HBase 原理-迟到的‘数据读取流程部分细节](http://hbasefly.com/2017/06/11/hbase-scan-2/)
|
||||
|
||||
## 参考资料
|
||||
|
||||
- **官方**
|
||||
- [HBase 官网](http://hbase.apache.org/)
|
||||
- [HBase 官方文档](https://hbase.apache.org/book.html)
|
||||
- [HBase 官方文档中文版](http://abloz.com/hbase/book.html)
|
||||
- [HBase API](https://hbase.apache.org/apidocs/index.html)
|
||||
- **教程**
|
||||
- [BigData-Notes](https://github.com/heibaiying/BigData-Notes)
|
||||
- **文章**
|
||||
- [Bigtable: A Distributed Storage System for Structured Data](https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/bigtable-osdi06.pdf)
|
||||
- [An In-Depth Look at the HBase Architecture](https://mapr.com/blog/in-depth-look-hbase-architecture/)
|
||||
- [入门 HBase,看这一篇就够了](https://juejin.im/post/5c666cc4f265da2da53eb714)
|
||||
- https://bighadoop.wordpress.com/tag/hbase/
|
||||
|
|
@ -0,0 +1,555 @@
|
|||
---
|
||||
title: HBase Java API 基础特性
|
||||
date: 2023-03-15 20:28:32
|
||||
categories:
|
||||
- 数据库
|
||||
- 列式数据库
|
||||
- HBase
|
||||
tags:
|
||||
- 大数据
|
||||
- HBase
|
||||
permalink: /pages/a8cad3/
|
||||
---
|
||||
|
||||
# HBase Java API 基础特性
|
||||
|
||||
## HBase Client API
|
||||
|
||||
### HBase Java API 示例
|
||||
|
||||
引入依赖
|
||||
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>org.apache.hbase</groupId>
|
||||
<artifactId>hbase-client</artifactId>
|
||||
<version>2.1.4</version>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
示例
|
||||
|
||||
```java
|
||||
public class HBaseUtils {
|
||||
|
||||
private static Connection connection;
|
||||
|
||||
static {
|
||||
Configuration configuration = HBaseConfiguration.create();
|
||||
configuration.set("hbase.zookeeper.property.clientPort", "2181");
|
||||
// 如果是集群 则主机名用逗号分隔
|
||||
configuration.set("hbase.zookeeper.quorum", "hadoop001");
|
||||
try {
|
||||
connection = ConnectionFactory.createConnection(configuration);
|
||||
} catch (IOException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* 创建 HBase 表
|
||||
*
|
||||
* @param tableName 表名
|
||||
* @param columnFamilies 列族的数组
|
||||
*/
|
||||
public static boolean createTable(String tableName, List<String> columnFamilies) {
|
||||
try {
|
||||
HBaseAdmin admin = (HBaseAdmin) connection.getAdmin();
|
||||
if (admin.tableExists(TableName.valueOf(tableName))) {
|
||||
return false;
|
||||
}
|
||||
TableDescriptorBuilder tableDescriptor = TableDescriptorBuilder.newBuilder(TableName.valueOf(tableName));
|
||||
columnFamilies.forEach(columnFamily -> {
|
||||
ColumnFamilyDescriptorBuilder cfDescriptorBuilder = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(columnFamily));
|
||||
cfDescriptorBuilder.setMaxVersions(1);
|
||||
ColumnFamilyDescriptor familyDescriptor = cfDescriptorBuilder.build();
|
||||
tableDescriptor.setColumnFamily(familyDescriptor);
|
||||
});
|
||||
admin.createTable(tableDescriptor.build());
|
||||
} catch (IOException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
return true;
|
||||
}
|
||||
|
||||
|
||||
/**
|
||||
* 删除 hBase 表
|
||||
*
|
||||
* @param tableName 表名
|
||||
*/
|
||||
public static boolean deleteTable(String tableName) {
|
||||
try {
|
||||
HBaseAdmin admin = (HBaseAdmin) connection.getAdmin();
|
||||
// 删除表前需要先禁用表
|
||||
admin.disableTable(TableName.valueOf(tableName));
|
||||
admin.deleteTable(TableName.valueOf(tableName));
|
||||
} catch (Exception e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
return true;
|
||||
}
|
||||
|
||||
/**
|
||||
* 插入数据
|
||||
*
|
||||
* @param tableName 表名
|
||||
* @param rowKey 唯一标识
|
||||
* @param columnFamilyName 列族名
|
||||
* @param qualifier 列标识
|
||||
* @param value 数据
|
||||
*/
|
||||
public static boolean putRow(String tableName, String rowKey, String columnFamilyName, String qualifier,
|
||||
String value) {
|
||||
try {
|
||||
Table table = connection.getTable(TableName.valueOf(tableName));
|
||||
Put put = new Put(Bytes.toBytes(rowKey));
|
||||
put.addColumn(Bytes.toBytes(columnFamilyName), Bytes.toBytes(qualifier), Bytes.toBytes(value));
|
||||
table.put(put);
|
||||
table.close();
|
||||
} catch (IOException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
return true;
|
||||
}
|
||||
|
||||
|
||||
/**
|
||||
* 插入数据
|
||||
*
|
||||
* @param tableName 表名
|
||||
* @param rowKey 唯一标识
|
||||
* @param columnFamilyName 列族名
|
||||
* @param pairList 列标识和值的集合
|
||||
*/
|
||||
public static boolean putRow(String tableName, String rowKey, String columnFamilyName, List<Pair<String, String>> pairList) {
|
||||
try {
|
||||
Table table = connection.getTable(TableName.valueOf(tableName));
|
||||
Put put = new Put(Bytes.toBytes(rowKey));
|
||||
pairList.forEach(pair -> put.addColumn(Bytes.toBytes(columnFamilyName), Bytes.toBytes(pair.getKey()), Bytes.toBytes(pair.getValue())));
|
||||
table.put(put);
|
||||
table.close();
|
||||
} catch (IOException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
return true;
|
||||
}
|
||||
|
||||
|
||||
/**
|
||||
* 根据 rowKey 获取指定行的数据
|
||||
*
|
||||
* @param tableName 表名
|
||||
* @param rowKey 唯一标识
|
||||
*/
|
||||
public static Result getRow(String tableName, String rowKey) {
|
||||
try {
|
||||
Table table = connection.getTable(TableName.valueOf(tableName));
|
||||
Get get = new Get(Bytes.toBytes(rowKey));
|
||||
return table.get(get);
|
||||
} catch (IOException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
return null;
|
||||
}
|
||||
|
||||
|
||||
/**
|
||||
* 获取指定行指定列 (cell) 的最新版本的数据
|
||||
*
|
||||
* @param tableName 表名
|
||||
* @param rowKey 唯一标识
|
||||
* @param columnFamily 列族
|
||||
* @param qualifier 列标识
|
||||
*/
|
||||
public static String getCell(String tableName, String rowKey, String columnFamily, String qualifier) {
|
||||
try {
|
||||
Table table = connection.getTable(TableName.valueOf(tableName));
|
||||
Get get = new Get(Bytes.toBytes(rowKey));
|
||||
if (!get.isCheckExistenceOnly()) {
|
||||
get.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(qualifier));
|
||||
Result result = table.get(get);
|
||||
byte[] resultValue = result.getValue(Bytes.toBytes(columnFamily), Bytes.toBytes(qualifier));
|
||||
return Bytes.toString(resultValue);
|
||||
} else {
|
||||
return null;
|
||||
}
|
||||
|
||||
} catch (IOException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
return null;
|
||||
}
|
||||
|
||||
|
||||
/**
|
||||
* 检索全表
|
||||
*
|
||||
* @param tableName 表名
|
||||
*/
|
||||
public static ResultScanner getScanner(String tableName) {
|
||||
try {
|
||||
Table table = connection.getTable(TableName.valueOf(tableName));
|
||||
Scan scan = new Scan();
|
||||
return table.getScanner(scan);
|
||||
} catch (IOException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
return null;
|
||||
}
|
||||
|
||||
|
||||
/**
|
||||
* 检索表中指定数据
|
||||
*
|
||||
* @param tableName 表名
|
||||
* @param filterList 过滤器
|
||||
*/
|
||||
|
||||
public static ResultScanner getScanner(String tableName, FilterList filterList) {
|
||||
try {
|
||||
Table table = connection.getTable(TableName.valueOf(tableName));
|
||||
Scan scan = new Scan();
|
||||
scan.setFilter(filterList);
|
||||
return table.getScanner(scan);
|
||||
} catch (IOException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
return null;
|
||||
}
|
||||
|
||||
/**
|
||||
* 检索表中指定数据
|
||||
*
|
||||
* @param tableName 表名
|
||||
* @param startRowKey 起始 RowKey
|
||||
* @param endRowKey 终止 RowKey
|
||||
* @param filterList 过滤器
|
||||
*/
|
||||
|
||||
public static ResultScanner getScanner(String tableName, String startRowKey, String endRowKey,
|
||||
FilterList filterList) {
|
||||
try {
|
||||
Table table = connection.getTable(TableName.valueOf(tableName));
|
||||
Scan scan = new Scan();
|
||||
scan.withStartRow(Bytes.toBytes(startRowKey));
|
||||
scan.withStopRow(Bytes.toBytes(endRowKey));
|
||||
scan.setFilter(filterList);
|
||||
return table.getScanner(scan);
|
||||
} catch (IOException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
return null;
|
||||
}
|
||||
|
||||
/**
|
||||
* 删除指定行记录
|
||||
*
|
||||
* @param tableName 表名
|
||||
* @param rowKey 唯一标识
|
||||
*/
|
||||
public static boolean deleteRow(String tableName, String rowKey) {
|
||||
try {
|
||||
Table table = connection.getTable(TableName.valueOf(tableName));
|
||||
Delete delete = new Delete(Bytes.toBytes(rowKey));
|
||||
table.delete(delete);
|
||||
} catch (IOException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
return true;
|
||||
}
|
||||
|
||||
|
||||
/**
|
||||
* 删除指定行指定列
|
||||
*
|
||||
* @param tableName 表名
|
||||
* @param rowKey 唯一标识
|
||||
* @param familyName 列族
|
||||
* @param qualifier 列标识
|
||||
*/
|
||||
public static boolean deleteColumn(String tableName, String rowKey, String familyName,
|
||||
String qualifier) {
|
||||
try {
|
||||
Table table = connection.getTable(TableName.valueOf(tableName));
|
||||
Delete delete = new Delete(Bytes.toBytes(rowKey));
|
||||
delete.addColumn(Bytes.toBytes(familyName), Bytes.toBytes(qualifier));
|
||||
table.delete(delete);
|
||||
table.close();
|
||||
} catch (IOException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
return true;
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
## 数据库连接
|
||||
|
||||
在上面的代码中,在类加载时就初始化了 Connection 连接,并且之后的方法都是复用这个 Connection,这时我们可能会考虑是否可以使用自定义连接池来获取更好的性能表现?实际上这是没有必要的。
|
||||
|
||||
首先官方对于 `Connection` 的使用说明如下:
|
||||
|
||||
```
|
||||
Connection Pooling For applications which require high-end multithreaded
|
||||
access (e.g., web-servers or application servers that may serve many
|
||||
application threads in a single JVM), you can pre-create a Connection,
|
||||
as shown in the following example:
|
||||
|
||||
对于高并发多线程访问的应用程序(例如,在单个 JVM 中存在的为多个线程服务的 Web 服务器或应用程序服务器),
|
||||
您只需要预先创建一个 Connection。例子如下:
|
||||
|
||||
// Create a connection to the cluster.
|
||||
Configuration conf = HBaseConfiguration.create();
|
||||
try (Connection connection = ConnectionFactory.createConnection(conf);
|
||||
Table table = connection.getTable(TableName.valueOf(tablename))) {
|
||||
// use table as needed, the table returned is lightweight
|
||||
}
|
||||
```
|
||||
|
||||
之所以能这样使用,这是因为 Connection 并不是一个简单的 socket 连接,[接口文档](https://hbase.apache.org/apidocs/org/apache/hadoop/hbase/client/Connection.html) 中对 Connection 的表述是:
|
||||
|
||||
```
|
||||
A cluster connection encapsulating lower level individual connections to actual servers and a
|
||||
connection to zookeeper. Connections are instantiated through the ConnectionFactory class.
|
||||
The lifecycle of the connection is managed by the caller, who has to close() the connection
|
||||
to release the resources.
|
||||
|
||||
Connection 是一个集群连接,封装了与多台服务器(Matser/Region Server)的底层连接以及与 zookeeper 的连接。
|
||||
连接通过 ConnectionFactory 类实例化。连接的生命周期由调用者管理,调用者必须使用 close() 关闭连接以释放资源。
|
||||
```
|
||||
|
||||
之所以封装这些连接,是因为 HBase 客户端需要连接三个不同的服务角色:
|
||||
|
||||
- **Zookeeper** :主要用于获取 `meta` 表的位置信息,Master 的信息;
|
||||
- **HBase Master** :主要用于执行 HBaseAdmin 接口的一些操作,例如建表等;
|
||||
- **HBase RegionServer** :用于读、写数据。
|
||||
|
||||
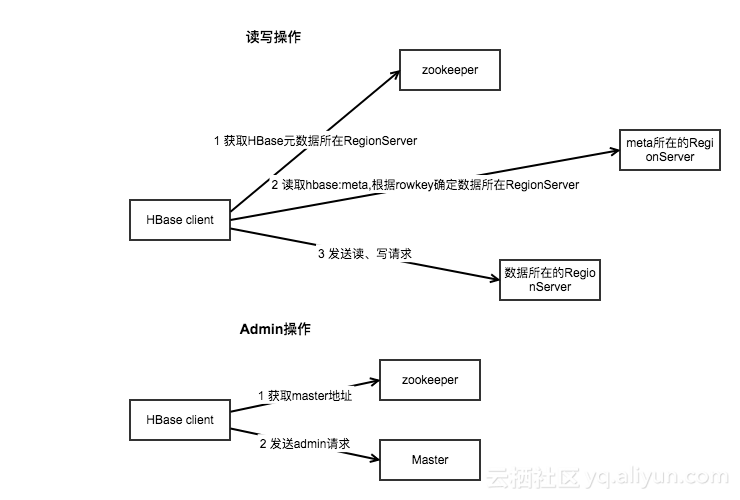
|
||||
|
||||
Connection 对象和实际的 Socket 连接之间的对应关系如下图:
|
||||
|
||||
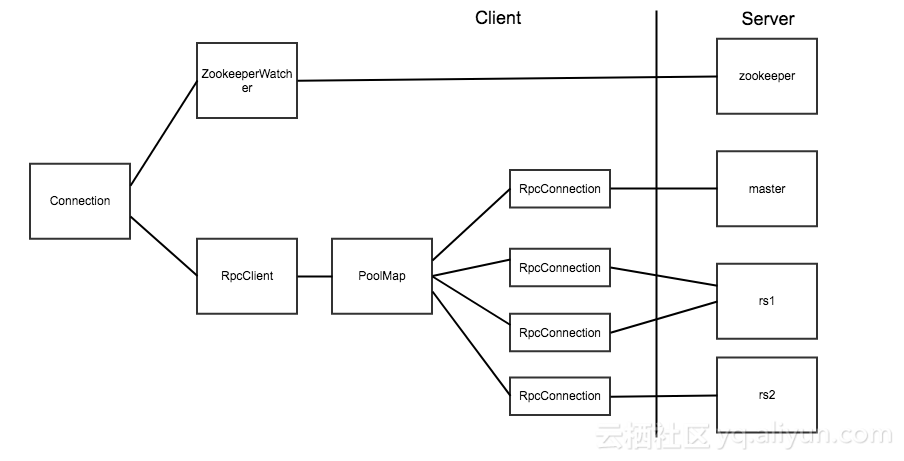
|
||||
|
||||
在 HBase 客户端代码中,真正对应 Socket 连接的是 `RpcConnection` 对象。HBase 使用 `PoolMap` 这种数据结构来存储客户端到 HBase 服务器之间的连接。`PoolMap` 的内部有一个 `ConcurrentHashMap` 实例,其 key 是 `ConnectionId`(封装了服务器地址和用户 ticket),value 是一个 `RpcConnection` 对象的资源池。当 HBase 需要连接一个服务器时,首先会根据 `ConnectionId` 找到对应的连接池,然后从连接池中取出一个连接对象。
|
||||
|
||||
```
|
||||
@InterfaceAudience.Private
|
||||
public class PoolMap<K, V> implements Map<K, V> {
|
||||
private PoolType poolType;
|
||||
|
||||
private int poolMaxSize;
|
||||
|
||||
private Map<K, Pool<V>> pools = new ConcurrentHashMap<>();
|
||||
|
||||
public PoolMap(PoolType poolType) {
|
||||
this.poolType = poolType;
|
||||
}
|
||||
.....
|
||||
```
|
||||
|
||||
HBase 中提供了三种资源池的实现,分别是 `Reusable`,`RoundRobin` 和 `ThreadLocal`。具体实现可以通 `hbase.client.ipc.pool.type` 配置项指定,默认为 `Reusable`。连接池的大小也可以通过 `hbase.client.ipc.pool.size` 配置项指定,默认为 1,即每个 Server 1 个连接。也可以通过修改配置实现:
|
||||
|
||||
```
|
||||
config.set("hbase.client.ipc.pool.type",...);
|
||||
config.set("hbase.client.ipc.pool.size",...);
|
||||
connection = ConnectionFactory.createConnection(config);
|
||||
```
|
||||
|
||||
由此可以看出 HBase 中 Connection 类已经实现了对连接的管理功能,所以我们不必在 Connection 上在做额外的管理。
|
||||
|
||||
另外,Connection 是线程安全的,但 Table 和 Admin 却不是线程安全的,因此正确的做法是一个进程共用一个 Connection 对象,而在不同的线程中使用单独的 Table 和 Admin 对象。Table 和 Admin 的获取操作 `getTable()` 和 `getAdmin()` 都是轻量级,所以不必担心性能的消耗,同时建议在使用完成后显示的调用 `close()` 方法来关闭它们。
|
||||
|
||||
## 概述
|
||||
|
||||
HBase 的主要客户端操作是由 `org.apache.hadoop.hbase.client.HTable` 提供的。创建 HTable 实例非常耗时,所以,建议每个线程只创建一次 HTable 实例。
|
||||
|
||||
HBase 所有修改数据的操作都保证了行级别的原子性。要么读到最新的修改,要么等待系统允许写入改行修改
|
||||
|
||||
用户要尽量使用批处理(batch)更新来减少单独操作同一行数据的次数
|
||||
|
||||
写操作中设计的列的数目并不会影响该行数据的原子性,行原子性会同时保护到所有列
|
||||
|
||||
创建 HTable 实例(指的是在 java 中新建该类),每个实例都要扫描.META. 表,以检查该表是否存在,推荐用户只创建一次 HTable 实例,而且是每个线程创建一个
|
||||
|
||||
如果用户需要多个 HTable 实例,建议使用 HTablePool 类(类似连接池)
|
||||
|
||||
## CRUD 操作
|
||||
|
||||
### put
|
||||
|
||||
`Table` 接口提供了两个 `put` 方法
|
||||
|
||||
```java
|
||||
// 写入单行 put
|
||||
void put(Put put) throws IOException;
|
||||
// 批量写入 put
|
||||
void put(List<Put> puts) throws IOException;
|
||||
```
|
||||
|
||||
Put 类提供了多种构造器方法用来初始化实例。
|
||||
|
||||
Put 类还提供了一系列有用的方法:
|
||||
|
||||
多个 `add` 方法:用于添加指定的列数据。
|
||||
|
||||
`has` 方法:用于检查是否存在特定的单元格,而不需要遍历整个集合
|
||||
|
||||
`getFamilyMap` 方法:可以遍历 Put 实例中每一个可用的 KeyValue 实例
|
||||
|
||||
getRow 方法:用于获取 rowkey
|
||||
Put.heapSize() 可以计算当前 Put 实例所需的堆大小,既包含其中的数据,也包含内部数据结构所需的空间
|
||||
|
||||
#### KeyValue 类
|
||||
|
||||
特定单元格的数据以及坐标,坐标包括行键、列族名、列限定符以及时间戳
|
||||
`KeyValue(byte[] row, int roffset, int rlength, byte[] family, int foffoset, int flength, byte[] qualifier, int qoffset, int qlength, long timestamp, Type type, byte[] value, int voffset, int vlength)`
|
||||
每一个字节数组都有一个 offset 参数和一个 length 参数,允许用户提交一个已经存在的字节数组进行字节级别操作。
|
||||
行目前来说指的是行键,即 Put 构造器里的 row 参数。
|
||||
|
||||
#### 客户端的写缓冲区
|
||||
|
||||
每一个 put 操作实际上都是一个 RPC 操作,它将客户端数据传送到服务器然后返回。
|
||||
|
||||
HBase 的 API 配备了一个客户端的写缓冲区,缓冲区负责收集 put 操作,然后调用 RPC 操作一次性将 put 送往服务器。
|
||||
|
||||
```java
|
||||
void setAutoFlush(boolean autoFlush)
|
||||
boolean isAutoFlush()
|
||||
```
|
||||
|
||||
默认情况下,客户端缓冲区是禁用的。可以通过 `table.setAutoFlush(false)` 来激活缓冲区。
|
||||
|
||||
#### Put 列表
|
||||
|
||||
批量提交 `put` 列表:
|
||||
|
||||
```java
|
||||
void put(List<Put> puts) throws IOException
|
||||
```
|
||||
|
||||
注意:批量提交可能会有部分修改失败。
|
||||
|
||||
#### 原子性操作 compare-and-set
|
||||
|
||||
`checkAndPut` 方法提供了 CAS 机制来保证 put 操作的原子性。
|
||||
|
||||
### get
|
||||
|
||||
```
|
||||
Result get(Get get) throws IOException
|
||||
```
|
||||
|
||||
```csharp
|
||||
Get(byte[] row)
|
||||
Get(byte[] row, RowLock rowLock)
|
||||
Get addColumn(byte[] family, byte[] qualifier)
|
||||
Get addFamily(byte[] family)
|
||||
```
|
||||
|
||||
#### Result 类
|
||||
|
||||
当用户使用 `get()` 方法获取数据,HBase 返回的结果包含所有匹配的单元格数据,这些数据被封装在一个 `Result` 实例中返回给用户。
|
||||
|
||||
Result 类提供的方法如下:
|
||||
|
||||
```java
|
||||
byte[] getValue(byte[] family, byte[] qualifier)
|
||||
byte[] value()
|
||||
byte[] getRow()
|
||||
int size()
|
||||
boolean isEmpty()
|
||||
KeyValue[] raw()
|
||||
List<KeyValue> list()
|
||||
```
|
||||
|
||||
## delete
|
||||
|
||||
```
|
||||
void delete(Delete delete) throws IOException
|
||||
```
|
||||
|
||||
```csharp
|
||||
Delte(byte[] row)
|
||||
Delete(byte[] row, long timestamp, RowLock rowLock)
|
||||
```
|
||||
|
||||
```csharp
|
||||
Delete deleteFamily(byte[] family)
|
||||
Delete deleteFamily(byte[] family, long timestamp)
|
||||
Delete deleteColumns(byte[] family, byte[] qualifier)
|
||||
Delete deleteColumn(byte[] family, byte[] qualifier) // 只删除最新版本
|
||||
```
|
||||
|
||||
## 批处理操作
|
||||
|
||||
Row 是 Put、Get、Delete 的父类。
|
||||
|
||||
```java
|
||||
void batch(List<Row> actions, Object[] results) throws IOException, InterruptedException
|
||||
Object batch(List<Row> actions) throws IOException, InterruptedException
|
||||
```
|
||||
|
||||
## 行锁
|
||||
|
||||
region 服务器提供了行锁特性,这个特性保证了只有一个客户端能获取一行数据相应的锁,同时对该行进行修改。
|
||||
|
||||
如果不显示指定锁,服务器会隐式加锁。
|
||||
|
||||
## 扫描
|
||||
|
||||
scan,类似数据库系统中的 cursor,利用了 HBase 提供的底层顺序存储的数据结构。
|
||||
|
||||
调用 HTable 的 getScanner 就可以返回扫描器
|
||||
|
||||
```java
|
||||
ResultScanner getScanner(Scan scan) throws IOException
|
||||
ResultScanner getScanner(byte[] family) throws IOException
|
||||
```
|
||||
|
||||
Scan 类构造器可以有 startRow,区间一般为 [startRow, stopRow)
|
||||
|
||||
```csharp
|
||||
Scan(byte[] startRow, Filter filter)
|
||||
Scan(byte[] startRow)
|
||||
```
|
||||
|
||||
### ResultScanner
|
||||
|
||||
以行为单位进行返回
|
||||
|
||||
```java
|
||||
Result next() throws IOException
|
||||
Result[] next(int nbRows) throws IOException
|
||||
void close()
|
||||
```
|
||||
|
||||
### 缓存与批量处理
|
||||
|
||||
每一个 next()调用都会为每行数据生成一个单独的 RPC 请求
|
||||
|
||||
可以设置扫描器缓存
|
||||
|
||||
```cpp
|
||||
void setScannerCaching(itn scannerCaching)
|
||||
int getScannerCaching()
|
||||
```
|
||||
|
||||
缓存是面向行一级操作,批量是面向列一级操作
|
||||
|
||||
```cpp
|
||||
void setBatch(int batch)
|
||||
int getBatch
|
||||
```
|
||||
|
||||
RPC 请求的次数=(行数\*每行列数)/Min(每行的列数,批量大小)/扫描器缓存
|
||||
|
||||
## 各种特性
|
||||
|
||||
`Bytes` 类提供了一系列将原生 Java 类型和字节数组互转的方法。
|
||||
|
||||
## 参考资料
|
||||
|
||||
- [《HBase 权威指南》](https://item.jd.com/11321037.html)
|
||||
- [《HBase 权威指南》官方源码](https://github.com/larsgeorge/hbase-book)
|
||||
|
|
@ -0,0 +1,382 @@
|
|||
---
|
||||
title: HBase Java API 高级特性之过滤器
|
||||
date: 2023-03-16 09:45:10
|
||||
categories:
|
||||
- 数据库
|
||||
- 列式数据库
|
||||
- HBase
|
||||
tags:
|
||||
- 大数据
|
||||
- HBase
|
||||
- API
|
||||
permalink: /pages/a3347e/
|
||||
---
|
||||
|
||||
# HBase Java API 高级特性之过滤器
|
||||
|
||||
HBase 中两种主要的数据读取方法是 `get()` 和 `scan()`,它们都支持直接访问数据和通过指定起止 row key 访问数据。此外,可以指定列族、列、时间戳和版本号来进行条件查询。它们的缺点是不支持细粒度的筛选功能。为了弥补这种不足,`Get` 和 `Scan` 支持通过过滤器(`Filter`)对 row key、列或列值进行过滤。
|
||||
|
||||
HBase 提供了一些内置过滤器,也允许用户通过继承 `Filter` 类来自定义过滤器。所有的过滤器都在服务端生效,称为 **谓词下推**。这样可以保证被过滤掉的数据不会被传到客户端。
|
||||
|
||||
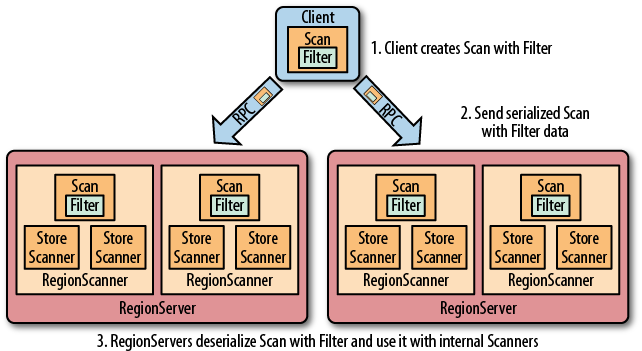
|
||||
|
||||
_图片来自 HBase 权威指南_
|
||||
|
||||
HBase 过滤器层次结构的最底层是 `Filter` 接口和 `FilterBase` 抽象类。大部分过滤器都直接继承自 `FilterBase`。
|
||||
|
||||
## 比较过滤器
|
||||
|
||||
所有比较过滤器均继承自 `CompareFilter`。`CompareFilter` 比 `FilterBase` 多了一个 `compare()` 方法,它需要传入参数定义比较操作的过程:比较运算符和比较器。
|
||||
|
||||
创建一个比较过滤器需要两个参数,分别是**比较运算符**和**比较器实例**。
|
||||
|
||||
```
|
||||
public CompareFilter(final CompareOp compareOp,final ByteArrayComparable comparator) {
|
||||
this.compareOp = compareOp;
|
||||
this.comparator = comparator;
|
||||
}
|
||||
```
|
||||
|
||||
### 比较运算符
|
||||
|
||||
- LESS (<)
|
||||
- LESS_OR_EQUAL (<=)
|
||||
- EQUAL (=)
|
||||
- NOT_EQUAL (!=)
|
||||
- GREATER_OR_EQUAL (>=)
|
||||
- GREATER (>)
|
||||
- NO_OP (排除所有符合条件的值)
|
||||
|
||||
比较运算符均定义在枚举类 `CompareOperator` 中
|
||||
|
||||
```
|
||||
@InterfaceAudience.Public
|
||||
public enum CompareOperator {
|
||||
LESS,
|
||||
LESS_OR_EQUAL,
|
||||
EQUAL,
|
||||
NOT_EQUAL,
|
||||
GREATER_OR_EQUAL,
|
||||
GREATER,
|
||||
NO_OP,
|
||||
}
|
||||
```
|
||||
|
||||
> 注意:在 1.x 版本的 HBase 中,比较运算符定义在 `CompareFilter.CompareOp` 枚举类中,但在 2.0 之后这个类就被标识为 @deprecated ,并会在 3.0 移除。所以 2.0 之后版本的 HBase 需要使用 `CompareOperator` 这个枚举类。
|
||||
|
||||
### 比较器
|
||||
|
||||
所有比较器均继承自 `ByteArrayComparable` 抽象类,常用的有以下几种:
|
||||
|
||||
- **BinaryComparator** : 使用 `Bytes.compareTo(byte [],byte [])` 按字典序比较指定的字节数组。
|
||||
- **BinaryPrefixComparator** : 按字典序与指定的字节数组进行比较,但只比较到这个字节数组的长度。
|
||||
- **RegexStringComparator** : 使用给定的正则表达式与指定的字节数组进行比较。仅支持 `EQUAL` 和 `NOT_EQUAL` 操作。
|
||||
- **SubStringComparator** : 测试给定的子字符串是否出现在指定的字节数组中,比较不区分大小写。仅支持 `EQUAL` 和 `NOT_EQUAL` 操作。
|
||||
- **NullComparator** :判断给定的值是否为空。
|
||||
- **BitComparator** :按位进行比较。
|
||||
|
||||
`BinaryPrefixComparator` 和 `BinaryComparator` 的区别不是很好理解,这里举例说明一下:
|
||||
|
||||
在进行 `EQUAL` 的比较时,如果比较器传入的是 `abcd` 的字节数组,但是待比较数据是 `abcdefgh`:
|
||||
|
||||
- 如果使用的是 `BinaryPrefixComparator` 比较器,则比较以 `abcd` 字节数组的长度为准,即 `efgh` 不会参与比较,这时候认为 `abcd` 与 `abcdefgh` 是满足 `EQUAL` 条件的;
|
||||
- 如果使用的是 `BinaryComparator` 比较器,则认为其是不相等的。
|
||||
|
||||
### 比较过滤器种类
|
||||
|
||||
比较过滤器共有五个(Hbase 1.x 版本和 2.x 版本相同):
|
||||
|
||||
- **RowFilter** :基于行键来过滤数据;
|
||||
- **FamilyFilterr** :基于列族来过滤数据;
|
||||
- **QualifierFilterr** :基于列限定符(列名)来过滤数据;
|
||||
- **ValueFilterr** :基于单元格 (cell) 的值来过滤数据;
|
||||
- **DependentColumnFilter** :指定一个参考列来过滤其他列的过滤器,过滤的原则是基于参考列的时间戳来进行筛选 。
|
||||
|
||||
前四种过滤器的使用方法相同,均只要传递比较运算符和运算器实例即可构建,然后通过 `setFilter` 方法传递给 `scan`:
|
||||
|
||||
```
|
||||
Filter filter = new RowFilter(CompareOperator.LESS_OR_EQUAL,
|
||||
new BinaryComparator(Bytes.toBytes("xxx")));
|
||||
scan.setFilter(filter);
|
||||
```
|
||||
|
||||
`DependentColumnFilter` 的使用稍微复杂一点,这里单独做下说明。
|
||||
|
||||
### DependentColumnFilter
|
||||
|
||||
可以把 `DependentColumnFilter` 理解为**一个 valueFilter 和一个时间戳过滤器的组合**。`DependentColumnFilter` 有三个带参构造器,这里选择一个参数最全的进行说明:
|
||||
|
||||
```
|
||||
DependentColumnFilter(final byte [] family, final byte[] qualifier,
|
||||
final boolean dropDependentColumn, final CompareOperator op,
|
||||
final ByteArrayComparable valueComparator)
|
||||
```
|
||||
|
||||
- **family** :列族
|
||||
- **qualifier** :列限定符(列名)
|
||||
- **dropDependentColumn** :决定参考列是否被包含在返回结果内,为 true 时表示参考列被返回,为 false 时表示被丢弃
|
||||
- **op** :比较运算符
|
||||
- **valueComparator** :比较器
|
||||
|
||||
这里举例进行说明:
|
||||
|
||||
```
|
||||
DependentColumnFilter dependentColumnFilter = new DependentColumnFilter(
|
||||
Bytes.toBytes("student"),
|
||||
Bytes.toBytes("name"),
|
||||
false,
|
||||
CompareOperator.EQUAL,
|
||||
new BinaryPrefixComparator(Bytes.toBytes("xiaolan")));
|
||||
```
|
||||
|
||||
- 首先会去查找 `student:name` 中值以 `xiaolan` 开头的所有数据获得 `参考数据集`,这一步等同于 valueFilter 过滤器;
|
||||
- 其次再用参考数据集中所有数据的时间戳去检索其他列,获得时间戳相同的其他列的数据作为 `结果数据集`,这一步等同于时间戳过滤器;
|
||||
- 最后如果 `dropDependentColumn` 为 true,则返回 `参考数据集`+`结果数据集`,若为 false,则抛弃参考数据集,只返回 `结果数据集`。
|
||||
|
||||
## 专用过滤器
|
||||
|
||||
专用过滤器通常直接继承自 `FilterBase`,用于更特定的场景。
|
||||
|
||||
### 单列列值过滤器 (SingleColumnValueFilter)
|
||||
|
||||
基于某列(参考列)的值决定某行数据是否被过滤。其实例有以下方法:
|
||||
|
||||
- **setFilterIfMissing(boolean filterIfMissing)** :默认值为 false,即如果该行数据不包含参考列,其依然被包含在最后的结果中;设置为 true 时,则不包含;
|
||||
- **setLatestVersionOnly(boolean latestVersionOnly)** :默认为 true,即只检索参考列的最新版本数据;设置为 false,则检索所有版本数据。
|
||||
|
||||
```
|
||||
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter(
|
||||
"student".getBytes(),
|
||||
"name".getBytes(),
|
||||
CompareOperator.EQUAL,
|
||||
new SubstringComparator("xiaolan"));
|
||||
singleColumnValueFilter.setFilterIfMissing(true);
|
||||
scan.setFilter(singleColumnValueFilter);
|
||||
```
|
||||
|
||||
### 单列列值排除器 (SingleColumnValueExcludeFilter)
|
||||
|
||||
`SingleColumnValueExcludeFilter` 继承自上面的 `SingleColumnValueFilter`,过滤行为与其相反。
|
||||
|
||||
### 行键前缀过滤器 (PrefixFilter)
|
||||
|
||||
基于 RowKey 值决定某行数据是否被过滤。
|
||||
|
||||
```
|
||||
PrefixFilter prefixFilter = new PrefixFilter(Bytes.toBytes("xxx"));
|
||||
scan.setFilter(prefixFilter);
|
||||
```
|
||||
|
||||
### 列名前缀过滤器 (ColumnPrefixFilter)
|
||||
|
||||
基于列限定符(列名)决定某行数据是否被过滤。
|
||||
|
||||
```
|
||||
ColumnPrefixFilter columnPrefixFilter = new ColumnPrefixFilter(Bytes.toBytes("xxx"));
|
||||
scan.setFilter(columnPrefixFilter);
|
||||
```
|
||||
|
||||
### 分页过滤器 (PageFilter)
|
||||
|
||||
可以使用这个过滤器实现对结果按行进行分页,创建 PageFilter 实例的时候需要传入每页的行数。
|
||||
|
||||
```
|
||||
public PageFilter(final long pageSize) {
|
||||
Preconditions.checkArgument(pageSize >= 0, "must be positive %s", pageSize);
|
||||
this.pageSize = pageSize;
|
||||
}
|
||||
```
|
||||
|
||||
下面的代码体现了客户端实现分页查询的主要逻辑,这里对其进行一下解释说明:
|
||||
|
||||
客户端进行分页查询,需要传递 `startRow`(起始 RowKey),知道起始 `startRow` 后,就可以返回对应的 pageSize 行数据。这里唯一的问题就是,对于第一次查询,显然 `startRow` 就是表格的第一行数据,但是之后第二次、第三次查询我们并不知道 `startRow`,只能知道上一次查询的最后一条数据的 RowKey(简单称之为 `lastRow`)。
|
||||
|
||||
我们不能将 `lastRow` 作为新一次查询的 `startRow` 传入,因为 scan 的查询区间是[startRow,endRow) ,即前开后闭区间,这样 `startRow` 在新的查询也会被返回,这条数据就重复了。
|
||||
|
||||
同时在不使用第三方数据库存储 RowKey 的情况下,我们是无法通过知道 `lastRow` 的下一个 RowKey 的,因为 RowKey 的设计可能是连续的也有可能是不连续的。
|
||||
|
||||
由于 Hbase 的 RowKey 是按照字典序进行排序的。这种情况下,就可以在 `lastRow` 后面加上 `0` ,作为 `startRow` 传入,因为按照字典序的规则,某个值加上 `0` 后的新值,在字典序上一定是这个值的下一个值,对于 HBase 来说下一个 RowKey 在字典序上一定也是等于或者大于这个新值的。
|
||||
|
||||
所以最后传入 `lastRow`+`0`,如果等于这个值的 RowKey 存在就从这个值开始 scan,否则从字典序的下一个 RowKey 开始 scan。
|
||||
|
||||
> 25 个字母以及数字字符,字典排序如下:
|
||||
>
|
||||
> ```
|
||||
> '0' < '1' < '2' < ... < '9' < 'a' < 'b' < ... < 'z'
|
||||
> ```
|
||||
|
||||
分页查询主要实现逻辑:
|
||||
|
||||
```
|
||||
byte[] POSTFIX = new byte[] { 0x00 };
|
||||
Filter filter = new PageFilter(15);
|
||||
|
||||
int totalRows = 0;
|
||||
byte[] lastRow = null;
|
||||
while (true) {
|
||||
Scan scan = new Scan();
|
||||
scan.setFilter(filter);
|
||||
if (lastRow != null) {
|
||||
// 如果不是首行 则 lastRow + 0
|
||||
byte[] startRow = Bytes.add(lastRow, POSTFIX);
|
||||
System.out.println("start row: " +
|
||||
Bytes.toStringBinary(startRow));
|
||||
scan.withStartRow(startRow);
|
||||
}
|
||||
ResultScanner scanner = table.getScanner(scan);
|
||||
int localRows = 0;
|
||||
Result result;
|
||||
while ((result = scanner.next()) != null) {
|
||||
System.out.println(localRows++ + ": " + result);
|
||||
totalRows++;
|
||||
lastRow = result.getRow();
|
||||
}
|
||||
scanner.close();
|
||||
//最后一页,查询结束
|
||||
if (localRows == 0) break;
|
||||
}
|
||||
System.out.println("total rows: " + totalRows);
|
||||
```
|
||||
|
||||
> 需要注意的是在多台 Regin Services 上执行分页过滤的时候,由于并行执行的过滤器不能共享它们的状态和边界,所以有可能每个过滤器都会在完成扫描前获取了 PageCount 行的结果,这种情况下会返回比分页条数更多的数据,分页过滤器就有失效的可能。
|
||||
|
||||
### 时间戳过滤器 (TimestampsFilter)
|
||||
|
||||
```
|
||||
List<Long> list = new ArrayList<>();
|
||||
list.add(1554975573000L);
|
||||
TimestampsFilter timestampsFilter = new TimestampsFilter(list);
|
||||
scan.setFilter(timestampsFilter);
|
||||
```
|
||||
|
||||
### 首次行键过滤器 (FirstKeyOnlyFilter)
|
||||
|
||||
`FirstKeyOnlyFilter` 只扫描每行的第一列,扫描完第一列后就结束对当前行的扫描,并跳转到下一行。相比于全表扫描,其性能更好,通常用于行数统计的场景,因为如果某一行存在,则行中必然至少有一列。
|
||||
|
||||
```
|
||||
FirstKeyOnlyFilter firstKeyOnlyFilter = new FirstKeyOnlyFilter();
|
||||
scan.set(firstKeyOnlyFilter);
|
||||
```
|
||||
|
||||
## 包装过滤器
|
||||
|
||||
包装过滤器就是通过包装其他过滤器以实现某些拓展的功能。
|
||||
|
||||
### SkipFilter 过滤器
|
||||
|
||||
`SkipFilter` 包装一个过滤器,当被包装的过滤器遇到一个需要过滤的 KeyValue 实例时,则拓展过滤整行数据。下面是一个使用示例:
|
||||
|
||||
```
|
||||
// 定义 ValueFilter 过滤器
|
||||
Filter filter1 = new ValueFilter(CompareOperator.NOT_EQUAL,
|
||||
new BinaryComparator(Bytes.toBytes("xxx")));
|
||||
// 使用 SkipFilter 进行包装
|
||||
Filter filter2 = new SkipFilter(filter1);
|
||||
```
|
||||
|
||||
### WhileMatchFilter 过滤器
|
||||
|
||||
`WhileMatchFilter` 包装一个过滤器,当被包装的过滤器遇到一个需要过滤的 KeyValue 实例时,`WhileMatchFilter` 则结束本次扫描,返回已经扫描到的结果。下面是其使用示例:
|
||||
|
||||
```
|
||||
Filter filter1 = new RowFilter(CompareOperator.NOT_EQUAL,
|
||||
new BinaryComparator(Bytes.toBytes("rowKey4")));
|
||||
|
||||
Scan scan = new Scan();
|
||||
scan.setFilter(filter1);
|
||||
ResultScanner scanner1 = table.getScanner(scan);
|
||||
for (Result result : scanner1) {
|
||||
for (Cell cell : result.listCells()) {
|
||||
System.out.println(cell);
|
||||
}
|
||||
}
|
||||
scanner1.close();
|
||||
|
||||
System.out.println("--------------------");
|
||||
|
||||
// 使用 WhileMatchFilter 进行包装
|
||||
Filter filter2 = new WhileMatchFilter(filter1);
|
||||
|
||||
scan.setFilter(filter2);
|
||||
ResultScanner scanner2 = table.getScanner(scan);
|
||||
for (Result result : scanner1) {
|
||||
for (Cell cell : result.listCells()) {
|
||||
System.out.println(cell);
|
||||
}
|
||||
}
|
||||
scanner2.close();
|
||||
rowKey0/student:name/1555035006994/Put/vlen=8/seqid=0
|
||||
rowKey1/student:name/1555035007019/Put/vlen=8/seqid=0
|
||||
rowKey2/student:name/1555035007025/Put/vlen=8/seqid=0
|
||||
rowKey3/student:name/1555035007037/Put/vlen=8/seqid=0
|
||||
rowKey5/student:name/1555035007051/Put/vlen=8/seqid=0
|
||||
rowKey6/student:name/1555035007057/Put/vlen=8/seqid=0
|
||||
rowKey7/student:name/1555035007062/Put/vlen=8/seqid=0
|
||||
rowKey8/student:name/1555035007068/Put/vlen=8/seqid=0
|
||||
rowKey9/student:name/1555035007073/Put/vlen=8/seqid=0
|
||||
--------------------
|
||||
rowKey0/student:name/1555035006994/Put/vlen=8/seqid=0
|
||||
rowKey1/student:name/1555035007019/Put/vlen=8/seqid=0
|
||||
rowKey2/student:name/1555035007025/Put/vlen=8/seqid=0
|
||||
rowKey3/student:name/1555035007037/Put/vlen=8/seqid=0
|
||||
```
|
||||
|
||||
可以看到被包装后,只返回了 `rowKey4` 之前的数据。
|
||||
|
||||
## FilterList
|
||||
|
||||
以上都是讲解单个过滤器的作用,当需要多个过滤器共同作用于一次查询的时候,就需要使用 `FilterList`。`FilterList` 支持通过构造器或者 `addFilter` 方法传入多个过滤器。
|
||||
|
||||
```
|
||||
// 构造器传入
|
||||
public FilterList(final Operator operator, final List<Filter> filters)
|
||||
public FilterList(final List<Filter> filters)
|
||||
public FilterList(final Filter... filters)
|
||||
|
||||
// 方法传入
|
||||
public void addFilter(List<Filter> filters)
|
||||
public void addFilter(Filter filter)
|
||||
```
|
||||
|
||||
多个过滤器组合的结果由 `operator` 参数定义 ,其可选参数定义在 `Operator` 枚举类中。只有 `MUST_PASS_ALL` 和 `MUST_PASS_ONE` 两个可选的值:
|
||||
|
||||
- **MUST_PASS_ALL** :相当于 AND,必须所有的过滤器都通过才认为通过;
|
||||
- **MUST_PASS_ONE** :相当于 OR,只有要一个过滤器通过则认为通过。
|
||||
|
||||
```
|
||||
@InterfaceAudience.Public
|
||||
public enum Operator {
|
||||
/** !AND */
|
||||
MUST_PASS_ALL,
|
||||
/** !OR */
|
||||
MUST_PASS_ONE
|
||||
}
|
||||
```
|
||||
|
||||
使用示例如下:
|
||||
|
||||
```
|
||||
List<Filter> filters = new ArrayList<Filter>();
|
||||
|
||||
Filter filter1 = new RowFilter(CompareOperator.GREATER_OR_EQUAL,
|
||||
new BinaryComparator(Bytes.toBytes("XXX")));
|
||||
filters.add(filter1);
|
||||
|
||||
Filter filter2 = new RowFilter(CompareOperator.LESS_OR_EQUAL,
|
||||
new BinaryComparator(Bytes.toBytes("YYY")));
|
||||
filters.add(filter2);
|
||||
|
||||
Filter filter3 = new QualifierFilter(CompareOperator.EQUAL,
|
||||
new RegexStringComparator("ZZZ"));
|
||||
filters.add(filter3);
|
||||
|
||||
FilterList filterList = new FilterList(filters);
|
||||
|
||||
Scan scan = new Scan();
|
||||
scan.setFilter(filterList);
|
||||
```
|
||||
|
||||
## 参考资料
|
||||
|
||||
- [《HBase 权威指南》](https://item.jd.com/11321037.html)
|
||||
- [《HBase 权威指南》官方源码](https://github.com/larsgeorge/hbase-book)
|
||||
|
|
@ -0,0 +1,24 @@
|
|||
---
|
||||
title: HBase Java API 高级特性之协处理器
|
||||
date: 2023-03-16 09:46:37
|
||||
categories:
|
||||
- 数据库
|
||||
- 列式数据库
|
||||
- HBase
|
||||
tags:
|
||||
- 大数据
|
||||
- HBase
|
||||
- API
|
||||
permalink: /pages/5f1bc3/
|
||||
---
|
||||
|
||||
# HBase Java API 高级特性之协处理器
|
||||
|
||||
## 简述
|
||||
|
||||
在使用 HBase 时,如果你的数据量达到了数十亿行或数百万列,此时能否在查询中返回大量数据将受制于网络的带宽,即便网络状况允许,但是客户端的计算处理也未必能够满足要求。在这种情况下,协处理器(Coprocessors)应运而生。它允许你将业务计算代码放入在 RegionServer 的协处理器中,将处理好的数据再返回给客户端,这可以极大地降低需要传输的数据量,从而获得性能上的提升。同时协处理器也允许用户扩展实现 HBase 目前所不具备的功能,如权限校验、二级索引、完整性约束等。
|
||||
|
||||
## 参考资料
|
||||
|
||||
- [《HBase 权威指南》](https://item.jd.com/11321037.html)
|
||||
- [《HBase 权威指南》官方源码](https://github.com/larsgeorge/hbase-book)
|
||||
|
|
@ -0,0 +1,157 @@
|
|||
---
|
||||
title: HBase Java API 其他高级特性
|
||||
date: 2023-03-31 16:20:27
|
||||
categories:
|
||||
- 数据库
|
||||
- 列式数据库
|
||||
- HBase
|
||||
tags:
|
||||
- 大数据
|
||||
- HBase
|
||||
- API
|
||||
permalink: /pages/ce5ca0/
|
||||
---
|
||||
|
||||
# HBase Java API 其他高级特性
|
||||
|
||||
## 计数器
|
||||
|
||||
HBase 提供了一种高级功能:计数器(counter)。**HBase 计数器可以用于实时统计,无需延时较高的批量处理操作**。HBase 有一种机制可以将列当作计数器:即读取并修改(其实就是一种 CAS 模式),其保证了在一次操作中的原子性。否则,用户需要对一行数据加锁,然后读取数据,再对当前数据做加法,最后写回 HBase 并释放行锁,这一系列操作会引起大量的资源竞争问题。
|
||||
|
||||
早期的 HBase 版本会在每次计数器更新操作调用一次 RPC 请求,新版本中可以在一次 RPC 请求中完成多个计数器的更新操作,但是多个计数器必须在同一行。
|
||||
|
||||
### 计数器使用 Shell 命令行
|
||||
|
||||
计数器不需要初始化,创建一个新列时初始值为 0,第一次 `incr` 操作返回 1。
|
||||
|
||||
计数器使用 `incr` 命令,增量可以是正数也可以是负数,但是必须是长整数 Long:
|
||||
|
||||
```bash
|
||||
incr '<table>','<row>','<column>',['<increment-value>']
|
||||
```
|
||||
|
||||
计数器使用的例子:
|
||||
|
||||
```python
|
||||
hbase(main):001:0> create 'counters','daily','weekly','monthly'
|
||||
0 row(s) in 1.2260 seconds
|
||||
|
||||
hbase(main):002:0> incr 'counters','20190301','daily:hites',1
|
||||
COUNTER VALUE = 1
|
||||
|
||||
hbase(main):003:0> incr'counters','20190301','daily:hites',1
|
||||
COUNTER VALUE = 2
|
||||
|
||||
hbase(main):004:0> get_counter 'counters','20190301','daily:hites'
|
||||
COUNTER VALUE = 2
|
||||
```
|
||||
|
||||
需要注意的是,增加的参数必须是长整型 Long,如果按照错误的格式更新了计数器(如字符串格式),下次调用 `incr` 会得到错误的结果:
|
||||
|
||||
```python
|
||||
hbase(main):005:0> put 'counters','20190301','daily:clicks','1'
|
||||
0 row(s) in 1.3250 seconds
|
||||
|
||||
hbase(main):006:0> incr'counters','20190301','daily:clicks',1
|
||||
COUNTER VALUE = 3530822107858468865
|
||||
```
|
||||
|
||||
### 单计数器
|
||||
|
||||
操作一个计数器,类似 shell 命令 `incr`
|
||||
|
||||
```java
|
||||
HTable table = new HTable(conf, "counters");
|
||||
|
||||
long cnt1 = table.incrementColumnValue(Bytes.toBytes("20190301"),
|
||||
Bytes.toBytes("daily"),
|
||||
Bytes.toBytes("hits"),
|
||||
1L);
|
||||
|
||||
long cnt2 = table.incrementColumnValue(Bytes.toBytes("20190301"),
|
||||
Bytes.toBytes("daily"),
|
||||
Bytes.toBytes("hits"),
|
||||
1L);
|
||||
|
||||
long current = table.incrementColumnValue(Bytes.toBytes("20190301"),
|
||||
Bytes.toBytes("daily"),
|
||||
Bytes.toBytes("hits"),
|
||||
0);
|
||||
```
|
||||
|
||||
### 多计数器
|
||||
|
||||
使用 `Table` 的 `increment()` 方法可以操作一行的多个计数器,需要构建 `Increment` 实例,并且指定行键:
|
||||
|
||||
```cpp
|
||||
HTable table = new HTable(conf, "counters");
|
||||
|
||||
Increment incr1 = new Increment(Bytes.toBytes("20190301"));
|
||||
incr1.addColumn(Bytes.toBytes("daily"), Bytes.toBytes("clicks"),1);
|
||||
incr1.addColumn(Bytes.toBytes("daily"), Bytes.toBytes("hits"), 1);
|
||||
incr1.addColumn(Bytes.toBytes("weekly"), Bytes.toBytes("clicks"), 2);
|
||||
incr1.addColumn(Bytes.toBytes("weekly"), Bytes.toBytes("hits"), 2);
|
||||
|
||||
Result result = table.increment(incr1);
|
||||
for(Cell cell : result.rawCells()) {
|
||||
// ...
|
||||
}
|
||||
```
|
||||
|
||||
Increment 类还有一种构造器:
|
||||
|
||||
```csharp
|
||||
Increment(byte[] row, RowLock rowLock)
|
||||
```
|
||||
|
||||
`rowLock` 参数可选,可以设置用户自定义锁,可以限制其他写程序操作此行,但是不保证读的操作性。
|
||||
|
||||
## 连接管理
|
||||
|
||||
### 连接管理简介
|
||||
|
||||
在 HBase Java API 中,`Connection` 类代表了一个集群连接,封装了与多台服务器(Matser/Region Server)的底层连接以及与 zookeeper 的连接。`Connection` 通过 `ConnectionFactory` 类实例化,而连接的生命周期则由调用者管理,调用者必须显示调用 `close()` 来释放连接。`Connection` 是线程安全的。创建 `Connection` 实例的开销很高,因此一个进程只需要实例化一个 `Connection` 即可。
|
||||
|
||||
`Table` 接口用于对指定的 HBase 表进行 CRUD 操作。一般,通过 `Connection` 获取 `Table` 实例,用完后,调用 `close()` 释放连接。
|
||||
|
||||
`Admin` 接口主要用于创建、删除、查看、启用/禁用 HBase 表,以及一些其他管理操作。一般,通过 `Connection` 获取 `Admin` 实例,用完后,调用 `close()` 释放连接。
|
||||
|
||||
`Table` 和 `Admin` 实例都是轻量级且并非线程安全的。建议每个线程只实例化一个 `Table` 或 `Admin` 实例。
|
||||
|
||||
### 连接池
|
||||
|
||||
问题:HBase 为什么没有提供 `Connection` 的连接池来获取更好的性能?是否需要自定义 `Connection` 连接池?
|
||||
|
||||
答:不需要。官方对于 `Connection` 的使用说明中,明确指出:对于高并发多线程访问的应用程序,一个进程中只需要预先创建一个 `Connection`。
|
||||
|
||||
问题:HBase 老版本中 `HTablePool` 为什么废弃?是否需要自定义 Table 的连接池?
|
||||
|
||||
答:不需要。Table 和 Admin 的连接本质上是复用 Connection,实例化是一个较为轻量级的操作,因此,并不需要缓存或池化。实际上,HBase Java API 官方就是这么建议的。
|
||||
|
||||
下面是管理 HBase 连接的一个正确编程模型
|
||||
|
||||
```java
|
||||
// 所有进程共用一个 connection 对象
|
||||
connection = ConnectionFactory.createConnection(config);
|
||||
|
||||
// 每个线程使用单独的 table 对象
|
||||
Table table = connection.getTable(TableName.valueOf("tableName"));
|
||||
try {
|
||||
...
|
||||
} finally {
|
||||
table.close();
|
||||
}
|
||||
|
||||
Admin admin = connection.getAdmin();
|
||||
try {
|
||||
...
|
||||
} finally {
|
||||
admin.close();
|
||||
}
|
||||
```
|
||||
|
||||
## 参考资料
|
||||
|
||||
- [《HBase 权威指南》](https://item.jd.com/11321037.html)
|
||||
- [《HBase 权威指南》官方源码](https://github.com/larsgeorge/hbase-book)
|
||||
- [连接 HBase 的正确姿势](https://developer.aliyun.com/article/581702)
|
||||
|
|
@ -0,0 +1,124 @@
|
|||
---
|
||||
title: HBase Java API 管理功能
|
||||
date: 2023-04-13 16:36:48
|
||||
categories:
|
||||
- 数据库
|
||||
- 列式数据库
|
||||
- HBase
|
||||
tags:
|
||||
- 大数据
|
||||
- HBase
|
||||
- API
|
||||
permalink: /pages/b59ba2/
|
||||
---
|
||||
|
||||
# HBase Java API 管理功能
|
||||
|
||||
## 初始化 Admin 实例
|
||||
|
||||
```java
|
||||
Configuration conf = HBaseConfiguration.create();
|
||||
Connection connection = ConnectionFactory.createConnection(conf);
|
||||
Admin admin = connection.getAdmin();
|
||||
```
|
||||
|
||||
## 管理命名空间
|
||||
|
||||
### 查看命名空间
|
||||
|
||||
```java
|
||||
TableName[] tableNames = admin.listTableNamesByNamespace("test");
|
||||
for (TableName tableName : tableNames) {
|
||||
System.out.println(tableName.getName());
|
||||
}
|
||||
```
|
||||
|
||||
### 创建命名空间
|
||||
|
||||
```java
|
||||
NamespaceDescriptor namespace = NamespaceDescriptor.create("test").build();
|
||||
admin.createNamespace(namespace);
|
||||
```
|
||||
|
||||
### 修改命名空间
|
||||
|
||||
```java
|
||||
NamespaceDescriptor namespace = NamespaceDescriptor.create("test")
|
||||
.addConfiguration("Description", "Test Namespace")
|
||||
.build();
|
||||
admin.modifyNamespace(namespace);
|
||||
```
|
||||
|
||||
### 删除命名空间
|
||||
|
||||
```java
|
||||
admin.deleteNamespace("test");
|
||||
```
|
||||
|
||||
## 管理表
|
||||
|
||||
### 创建表
|
||||
|
||||
```java
|
||||
TableName tableName = TableName.valueOf("test:test");
|
||||
HTableDescriptor tableDescriptor = new HTableDescriptor(tableName);
|
||||
HColumnDescriptor columnDescriptor = new HColumnDescriptor(Bytes.toBytes("cf"));
|
||||
tableDescriptor.addFamily(columnDescriptor);
|
||||
admin.createTable(tableDescriptor);
|
||||
```
|
||||
|
||||
### 删除表
|
||||
|
||||
```java
|
||||
admin.deleteTable(TableName.valueOf("test:test"));
|
||||
```
|
||||
|
||||
### 修改表
|
||||
|
||||
```java
|
||||
// 原始表
|
||||
TableName tableName = TableName.valueOf("test:test");
|
||||
HColumnDescriptor columnDescriptor = new HColumnDescriptor("cf1");
|
||||
HTableDescriptor tableDescriptor = new HTableDescriptor(tableName)
|
||||
.addFamily(columnDescriptor)
|
||||
.setValue("Description", "Original Table");
|
||||
admin.createTable(tableDescriptor, Bytes.toBytes(1L), Bytes.toBytes(10000L), 50);
|
||||
|
||||
// 修改表
|
||||
HTableDescriptor newTableDescriptor = admin.getTableDescriptor(tableName);
|
||||
HColumnDescriptor newColumnDescriptor = new HColumnDescriptor("cf2");
|
||||
newTableDescriptor.addFamily(newColumnDescriptor)
|
||||
.setMaxFileSize(1024 * 1024 * 1024L)
|
||||
.setValue("Description", "Modified Table");
|
||||
|
||||
// 修改表必须先禁用再想修改
|
||||
admin.disableTable(tableName);
|
||||
admin.modifyTable(tableName, newTableDescriptor);
|
||||
```
|
||||
|
||||
### 禁用表
|
||||
|
||||
需要注意:HBase 表在删除前,必须先禁用。
|
||||
|
||||
```java
|
||||
admin.disableTable(TableName.valueOf("test:test"));
|
||||
```
|
||||
|
||||
### 启用表
|
||||
|
||||
```
|
||||
admin.enableTable(TableName.valueOf("test:test"));
|
||||
```
|
||||
|
||||
### 查看表是否有效
|
||||
|
||||
```java
|
||||
boolean isOk = admin.isTableAvailable(tableName);
|
||||
System.out.println("Table available: " + isOk);
|
||||
```
|
||||
|
||||
## 参考资料
|
||||
|
||||
- [《HBase 权威指南》](https://item.jd.com/11321037.html)
|
||||
- [《HBase 权威指南》官方源码](https://github.com/larsgeorge/hbase-book)
|
||||
- [连接 HBase 的正确姿势](https://developer.aliyun.com/article/581702)
|
||||
|
|
@ -0,0 +1,83 @@
|
|||
---
|
||||
title: HBase 运维
|
||||
date: 2019-05-07 20:19:25
|
||||
categories:
|
||||
- 数据库
|
||||
- 列式数据库
|
||||
- HBase
|
||||
tags:
|
||||
- 大数据
|
||||
- HBase
|
||||
- 运维
|
||||
permalink: /pages/f808fc/
|
||||
---
|
||||
|
||||
# HBase 运维
|
||||
|
||||
## 配置文件
|
||||
|
||||
- `backup-masters` - 默认情况下不存在。列出主服务器应在其上启动备份主进程的主机,每行一个主机。
|
||||
- `hadoop-metrics2-hbase.properties` - 用于连接 HBase Hadoop 的 Metrics2 框架。
|
||||
- `hbase-env.cmd` and hbase-env.sh - 用于 Windows 和 Linux / Unix 环境的脚本,用于设置 HBase 的工作环境,包括 Java,Java 选项和其他环境变量的位置。
|
||||
- `hbase-policy.xml` - RPC 服务器用于对客户端请求进行授权决策的默认策略配置文件。仅在启用 HBase 安全性时使用。
|
||||
- `hbase-site.xml` - 主要的 HBase 配置文件。此文件指定覆盖 HBase 默认配置的配置选项。您可以在 docs / hbase-default.xml 中查看(但不要编辑)默认配置文件。您还可以在 HBase Web UI 的 HBase 配置选项卡中查看群集的整个有效配置(默认值和覆盖)。
|
||||
- `log4j.properties` - log4j 日志配置。
|
||||
- `regionservers` - 包含应在 HBase 集群中运行 RegionServer 的主机列表。默认情况下,此文件包含单个条目 localhost。它应包含主机名或 IP 地址列表,每行一个,并且如果群集中的每个节点将在其 localhost 接口上运行 RegionServer,则应仅包含 localhost。
|
||||
|
||||
## 环境要求
|
||||
|
||||
- Java
|
||||
- HBase 2.0+ 要求 JDK8+
|
||||
- HBase 1.2+ 要求 JDK7+
|
||||
- SSH - 环境要支持 SSH
|
||||
- DNS - 环境中要在 hosts 配置本机 hostname 和本机 IP
|
||||
- NTP - HBase 集群的时间要同步,可以配置统一的 NTP
|
||||
- 平台 - 生产环境不推荐部署在 Windows 系统中
|
||||
- Hadoop - 依赖 Hadoop 配套版本
|
||||
- Zookeeper - 依赖 Zookeeper 配套版本
|
||||
|
||||
## 运行模式
|
||||
|
||||
### 单点
|
||||
|
||||
hbase-site.xml 配置如下:
|
||||
|
||||
```xml
|
||||
<configuration>
|
||||
<property>
|
||||
<name>hbase.rootdir</name>
|
||||
<value>hdfs://namenode.example.org:8020/hbase</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>hbase.cluster.distributed</name>
|
||||
<value>false</value>
|
||||
</property>
|
||||
</configuration>
|
||||
```
|
||||
|
||||
### 分布式
|
||||
|
||||
hbase-site.xm 配置如下:
|
||||
|
||||
```xml
|
||||
<configuration>
|
||||
<property>
|
||||
<name>hbase.rootdir</name>
|
||||
<value>hdfs://namenode.example.org:8020/hbase</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>hbase.cluster.distributed</name>
|
||||
<value>true</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>hbase.zookeeper.quorum</name>
|
||||
<value>node-a.example.com,node-b.example.com,node-c.example.com</value>
|
||||
</property>
|
||||
</configuration>
|
||||
```
|
||||
|
||||
## 引用和引申
|
||||
|
||||
### 扩展阅读
|
||||
|
||||
- [Apache HBase Configuration](http://hbase.apache.org/book.html#configuration)
|
||||
|
|
@ -0,0 +1,205 @@
|
|||
---
|
||||
title: HBase 命令
|
||||
date: 2020-06-02 22:28:18
|
||||
categories:
|
||||
- 数据库
|
||||
- 列式数据库
|
||||
- HBase
|
||||
tags:
|
||||
- 大数据
|
||||
- HBase
|
||||
permalink: /pages/263c40/
|
||||
---
|
||||
|
||||
# HBase 命令
|
||||
|
||||
> 进入 HBase Shell 控制台:`./bin/hbase shell`
|
||||
>
|
||||
> 如果有 kerberos 认证,需要事先使用相应的 keytab 进行一下认证(使用 kinit 命令),认证成功之后再使用 hbase shell 进入可以使用 whoami 命令可查看当前用户.
|
||||
|
||||
## 基本命令
|
||||
|
||||
- 获取帮助信息:`help`
|
||||
- 获取命令的详细帮助信息:`help 'status'`
|
||||
- 查看服务器状态:`status`
|
||||
- 查看版本信息:`version`
|
||||
- 查看当前登录用户:`whoami`
|
||||
|
||||
## DDL
|
||||
|
||||
### 创建表
|
||||
|
||||
【语法】`create '表名称','列族名称 1','列族名称 2','列名称 N'`
|
||||
|
||||
【示例】
|
||||
|
||||
```shell
|
||||
# 创建一张名为 test 的表,columnFamliy1、columnFamliy2 是 table1 表的列族。
|
||||
create 'test','columnFamliy1','columnFamliy2'
|
||||
```
|
||||
|
||||
### 启用、禁用表
|
||||
|
||||
- 启用表:`enable 'test'`
|
||||
- 禁用表:`disable 'test'`
|
||||
- 检查表是否被启用:`is_enabled 'test'`
|
||||
- 检查表是否被禁用:`is_disabled 'test'`
|
||||
|
||||
### 删除表
|
||||
|
||||
注意:删除表前需要先禁用表
|
||||
|
||||
```shell
|
||||
disable 'test'
|
||||
drop 'test'
|
||||
```
|
||||
|
||||
### 修改表
|
||||
|
||||
#### 添加列族
|
||||
|
||||
**命令格式**: alter '表名', '列族名'
|
||||
|
||||
```shell
|
||||
alter 'test', 'teacherInfo'
|
||||
```
|
||||
|
||||
#### 删除列族
|
||||
|
||||
**命令格式**:alter '表名', {NAME => '列族名', METHOD => 'delete'}
|
||||
|
||||
```shell
|
||||
alter 'test', {NAME => 'teacherInfo', METHOD => 'delete'}
|
||||
```
|
||||
|
||||
#### 更改列族存储版本的限制
|
||||
|
||||
默认情况下,列族只存储一个版本的数据,如果需要存储多个版本的数据,则需要修改列族的属性。修改后可通过 `desc` 命令查看。
|
||||
|
||||
```shell
|
||||
alter 'test',{NAME=>'columnFamliy1',VERSIONS=>3}
|
||||
```
|
||||
|
||||
### 查看表
|
||||
|
||||
- 查看所有表:`list`
|
||||
- 查看表的详细信息:`describe 'test'`
|
||||
- 检查表是否存在:`exists 'test'`
|
||||
|
||||
## 增删改
|
||||
|
||||
### 插入数据
|
||||
|
||||
**命令格式**:`put '表名', '行键','列族:列','值'`
|
||||
|
||||
**注意:如果新增数据的行键值、列族名、列名与原有数据完全相同,则相当于更新操作**
|
||||
|
||||
```shell
|
||||
put 'test', 'rowkey1', 'columnFamliy1:a', 'valueA'
|
||||
put 'test', 'rowkey1', 'columnFamliy1:b', 'valueB'
|
||||
put 'test', 'rowkey1', 'columnFamliy1:c', 'valueC'
|
||||
|
||||
put 'test', 'rowkey2', 'columnFamliy1:a', 'valueA'
|
||||
put 'test', 'rowkey2', 'columnFamliy1:b', 'valueB'
|
||||
put 'test', 'rowkey2', 'columnFamliy1:c', 'valueC'
|
||||
|
||||
put 'test', 'rowkey3', 'columnFamliy1:a', 'valueA'
|
||||
put 'test', 'rowkey3', 'columnFamliy1:b', 'valueB'
|
||||
put 'test', 'rowkey3', 'columnFamliy1:c', 'valueC'
|
||||
|
||||
put 'test', 'rowkey1', 'columnFamliy2:a', 'valueA'
|
||||
put 'test', 'rowkey1', 'columnFamliy2:b', 'valueB'
|
||||
put 'test', 'rowkey1', 'columnFamliy2:c', 'valueC'
|
||||
```
|
||||
|
||||
### 获取指定行、列族、列
|
||||
|
||||
- 获取指定行中所有列的数据信息:`get 'test','rowkey2'`
|
||||
- 获取指定行中指定列族下所有列的数据信息:`get 'test','rowkey2','columnFamliy1'`
|
||||
- 获取指定行中指定列的数据信息:`get 'test','rowkey2','columnFamliy1:a'`
|
||||
|
||||
### 删除指定行、列
|
||||
|
||||
- 删除指定行:`delete 'test','rowkey2'`
|
||||
- 删除指定行中指定列的数据:`delete 'test','rowkey2','columnFamliy1:a'`
|
||||
|
||||
## 查询
|
||||
|
||||
hbase 中访问数据有两种基本的方式:
|
||||
|
||||
- 按指定 rowkey 获取数据:`get` 方法;
|
||||
- 按指定条件获取数据:`scan` 方法。
|
||||
|
||||
`scan` 可以设置 begin 和 end 参数来访问一个范围内所有的数据。get 本质上就是 begin 和 end 相等的一种特殊的 scan。
|
||||
|
||||
### get 查询
|
||||
|
||||
- 获取指定行中所有列的数据信息:`get 'test','rowkey2'`
|
||||
- 获取指定行中指定列族下所有列的数据信息:`get 'test','rowkey2','columnFamliy1'`
|
||||
- 获取指定行中指定列的数据信息:`get 'test','rowkey2','columnFamliy1:a'`
|
||||
|
||||
### scan 查询
|
||||
|
||||
#### 查询整表数据
|
||||
|
||||
```shell
|
||||
scan 'test'
|
||||
```
|
||||
|
||||
#### 查询指定列簇的数据
|
||||
|
||||
```shell
|
||||
scan 'test', {COLUMN=>'columnFamliy1'}
|
||||
```
|
||||
|
||||
#### 条件查询
|
||||
|
||||
```shell
|
||||
# 查询指定列的数据
|
||||
scan 'test', {COLUMNS=> 'columnFamliy1:a'}
|
||||
```
|
||||
|
||||
除了列 `(COLUMNS)` 修饰词外,HBase 还支持 `Limit`(限制查询结果行数),`STARTROW`(`ROWKEY` 起始行,会先根据这个 `key` 定位到 `region`,再向后扫描)、`STOPROW`(结束行)、`TIMERANGE`(限定时间戳范围)、`VERSIONS`(版本数)、和 `FILTER`(按条件过滤行)等。
|
||||
|
||||
如下代表从 `rowkey2` 这个 `rowkey` 开始,查找下两个行的最新 3 个版本的 name 列的数据:
|
||||
|
||||
```shell
|
||||
scan 'test', {COLUMNS=> 'columnFamliy1:a',STARTROW => 'rowkey2',STOPROW => 'rowkey3',LIMIT=>2, VERSIONS=>3}
|
||||
```
|
||||
|
||||
#### 条件过滤
|
||||
|
||||
Filter 可以设定一系列条件来进行过滤。如我们要查询值等于 24 的所有数据:
|
||||
|
||||
```shell
|
||||
scan 'test', FILTER=>"ValueFilter(=,'binary:24')"
|
||||
```
|
||||
|
||||
值包含 valueA 的所有数据:
|
||||
|
||||
```shell
|
||||
scan 'test', FILTER=>"ValueFilter(=,'substring:valueA')"
|
||||
```
|
||||
|
||||
列名中的前缀为 b 的:
|
||||
|
||||
```shell
|
||||
scan 'test', FILTER=>"ColumnPrefixFilter('b')"
|
||||
```
|
||||
|
||||
FILTER 中支持多个过滤条件通过括号、AND 和 OR 进行组合:
|
||||
|
||||
```shell
|
||||
# 列名中的前缀为 b 且列值中包含1998的数据
|
||||
scan 'test', FILTER=>"ColumnPrefixFilter('b') AND ValueFilter ValueFilter(=,'substring:A')"
|
||||
```
|
||||
|
||||
`PrefixFilter` 用于对 Rowkey 的前缀进行判断:
|
||||
|
||||
```shell
|
||||
scan 'test', FILTER=>"PrefixFilter('wr')"
|
||||
```
|
||||
|
||||
## 参考资料
|
||||
|
||||
- [Hbase 常用 Shell 命令](https://github.com/heibaiying/BigData-Notes/blob/master/notes/Hbase_Shell.md)
|
||||
|
|
@ -0,0 +1,50 @@
|
|||
---
|
||||
title: HBase 教程
|
||||
date: 2020-09-09 17:53:08
|
||||
categories:
|
||||
- 数据库
|
||||
- 列式数据库
|
||||
- HBase
|
||||
tags:
|
||||
- 大数据
|
||||
- HBase
|
||||
permalink: /pages/417be6/
|
||||
hidden: true
|
||||
---
|
||||
|
||||
# HBase 教程
|
||||
|
||||
## 📖 内容
|
||||
|
||||
- [HBase 快速入门](01.HBase快速入门.md)
|
||||
- [HBase 数据模型](02.HBase数据模型.md)
|
||||
- [HBase Schema 设计](03.HBaseSchema设计.md)
|
||||
- [HBase 架构](04.HBase架构.md)
|
||||
- [HBase Java API 基础特性](10.HBaseJavaApi基础特性.md)
|
||||
- [HBase Java API 高级特性之过滤器](11.HBaseJavaApi高级特性之过滤器.md)
|
||||
- [HBase Java API 高级特性之协处理器](12.HBaseJavaApi高级特性之协处理器.md)
|
||||
- [HBase Java API 其他高级特性](13.HBaseJavaApi其他高级特性.md)
|
||||
- [HBase 运维](21.HBase运维.md)
|
||||
- [HBase 命令](22.HBase命令.md)
|
||||
- HBase 配置
|
||||
- HBase 灾备
|
||||
|
||||
## 📚 资料
|
||||
|
||||
- **官方**
|
||||
- [HBase 官网](http://hbase.apache.org/)
|
||||
- [HBase 官方文档](https://hbase.apache.org/book.html)
|
||||
- [HBase 官方文档中文版](http://abloz.com/hbase/book.html)
|
||||
- [HBase API](https://hbase.apache.org/apidocs/index.html)
|
||||
- **教程**
|
||||
- [BigData-Notes](https://github.com/heibaiying/BigData-Notes)
|
||||
- **书籍**
|
||||
- [《Hadoop 权威指南(第四版)》](https://item.jd.com/12109713.html)
|
||||
- **文章**
|
||||
- [Bigtable: A Distributed Storage System for Structured Data](https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/bigtable-osdi06.pdf)
|
||||
- [Intro to HBase](https://www.slideshare.net/alexbaranau/intro-to-hbase)
|
||||
- [深入理解 Hbase 架构](https://segmentfault.com/a/1190000019959411)
|
||||
|
||||
## 🚪 传送
|
||||
|
||||
◾ 💧 [钝悟的 IT 知识图谱](https://dunwu.github.io/waterdrop/) ◾ 🎯 [钝悟的博客](https://dunwu.github.io/blog/) ◾
|
||||
|
|
@ -1,139 +0,0 @@
|
|||
---
|
||||
title: Hbase
|
||||
date: 2020-02-10 14:27:39
|
||||
categories:
|
||||
- 数据库
|
||||
- 列式数据库
|
||||
tags:
|
||||
- 数据库
|
||||
- 列式数据库
|
||||
- Hbase
|
||||
permalink: /pages/7ab03c/
|
||||
---
|
||||
|
||||
# HBase
|
||||
|
||||
## 简介
|
||||
|
||||
HBase 是建立在 HDFS 基础上的面向列的分布式数据库。
|
||||
|
||||
- HBase 参考了谷歌的 BigTable 建模,实现的编程语言为 Java。
|
||||
- 它是 Hadoop 项目的子项目,运行于 HDFS 文件系统之上。
|
||||
|
||||
HBase 适用场景:实时地随机访问超大数据集。
|
||||
|
||||
在 [CAP 理论](https://zh.wikipedia.org/wiki/CAP%E5%AE%9A%E7%90%86)中,HBase 属于 CP 类型的系统。
|
||||
|
||||
## 基础
|
||||
|
||||
[HBase 维护](HBase运维.md)
|
||||
|
||||
## 原理
|
||||
|
||||
### 数据模型
|
||||
|
||||
HBase 是一个面向列的数据库,在表中它由行排序。
|
||||
|
||||
HBase 表模型结构为:
|
||||
|
||||
- 表(table)是行的集合。
|
||||
- 行(row)是列族的集合。
|
||||
- 列族(column family)是列的集合。
|
||||
- 列(row)是键值对的集合。
|
||||
|
||||
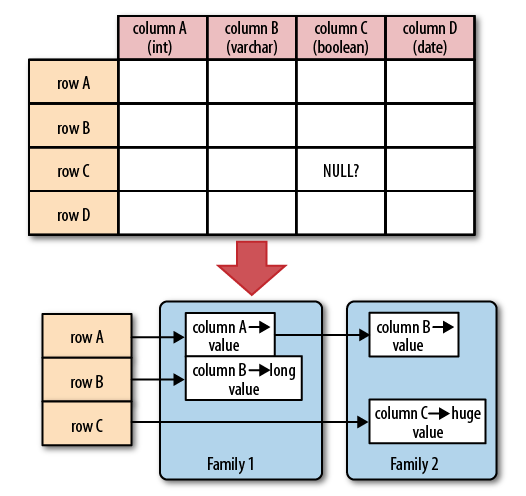
|
||||
|
||||
HBase 表的单元格(cell)由行和列的坐标交叉决定,是有版本的。默认情况下,版本号是自动分配的,为 HBase 插入单元格时的时间戳。单元格的内容是未解释的字节数组。
|
||||
|
||||
行的键也是未解释的字节数组,所以理论上,任何数据都可以通过序列化表示成字符串或二进制,从而存为 HBase 的键值。
|
||||
|
||||

|
||||
|
||||
### HBase 架构
|
||||
|
||||

|
||||
|
||||
和 HDFS、YARN 一样,HBase 也采用 master / slave 架构:
|
||||
|
||||
- HBase 有一个 master 节点。master 节点负责将区域(region)分配给 region 节点;恢复 region 节点的故障。
|
||||
- HBase 有多个 region 节点。region 节点负责零个或多个区域(region)的管理并相应客户端的读写请求。region 节点还负责区域的划分并通知 master 节点有了新的子区域。
|
||||
|
||||
HBase 依赖 ZooKeeper 来实现故障恢复。
|
||||
|
||||
#### Regin
|
||||
|
||||
HBase 表按行键范围水平自动划分为区域(region)。每个区域由表中行的子集构成。每个区域由它所属的表、它所含的第一行及最后一行来表示。
|
||||
|
||||
**区域只不过是表被拆分,并分布在区域服务器。**
|
||||
|
||||

|
||||
|
||||
#### Master 服务器
|
||||
|
||||
区域分配、DDL(create、delete)操作由 HBase master 服务器处理。
|
||||
|
||||
- master 服务器负责协调 region 服务器
|
||||
- 协助区域启动,出现故障恢复或负载均衡情况时,重新分配 region 服务器
|
||||
- 监控集群中的所有 region 服务器
|
||||
- 支持 DDL 接口(创建、删除、更新表)
|
||||
|
||||

|
||||
|
||||
#### Regin 服务器
|
||||
|
||||
区域服务器运行在 HDFS 数据节点上,具有以下组件
|
||||
|
||||
- `WAL` - Write Ahead Log 是 HDFS 上的文件。WAL 存储尚未持久存储到永久存储的新数据,它用于在发生故障时进行恢复。
|
||||
|
||||
- `BlockCache` - 是读缓存。它将频繁读取的数据存储在内存中。至少最近使用的数据在完整时被逐出。
|
||||
- `MemStore` - 是写缓存。它存储尚未写入磁盘的新数据。在写入磁盘之前对其进行排序。每个区域每个列族有一个 MemStore。
|
||||
- `Hfiles` - 将行存储为磁盘上的排序键值对。
|
||||
|
||||

|
||||
|
||||
#### ZooKeeper
|
||||
|
||||
HBase 使用 ZooKeeper 作为分布式协调服务来维护集群中的服务器状态。Zookeeper 维护哪些服务器是活动的和可用的,并提供服务器故障通知。集群至少应该有 3 个节点。
|
||||
|
||||

|
||||
|
||||
## HBase 和 RDBMS
|
||||
|
||||
| HBase | RDBMS |
|
||||
| --------------------------------------------------- | ------------------------------------------ |
|
||||
| HBase 无模式,它不具有固定列模式的概念;仅定义列族。 | RDBMS 有它的模式,描述表的整体结构的约束。 |
|
||||
| 它专门创建为宽表。 HBase 是横向扩展。 | 这些都是细而专为小表。很难形成规模。 |
|
||||
| 没有任何事务存在于 HBase。 | RDBMS 是事务性的。 |
|
||||
| 它反规范化的数据。 | 它具有规范化的数据。 |
|
||||
| 它用于半结构以及结构化数据是非常好的。 | 用于结构化数据非常好。 |
|
||||
|
||||
## API
|
||||
|
||||
Java API 归纳总结在这里:[HBase 应用](hbase-api-java.md)
|
||||
|
||||
## 附录
|
||||
|
||||
### 命令行
|
||||
|
||||
HBase 命令行可以参考这里:[HBase 命令行](HBase命令.md)
|
||||
|
||||
## 更多内容
|
||||
|
||||
### 扩展阅读
|
||||
|
||||
- [HBase 命令](HBase命令.md)
|
||||
- [HBase 运维](HBase运维.md)
|
||||
|
||||
### 参考资料
|
||||
|
||||
#### 官方
|
||||
|
||||
- [HBase 官网](http://hbase.apache.org/)
|
||||
- [HBase 官方文档](https://hbase.apache.org/book.html)
|
||||
- [HBase 官方文档中文版](http://abloz.com/hbase/book.html)
|
||||
- [HBase API](https://hbase.apache.org/apidocs/index.html)
|
||||
|
||||
#### 文章
|
||||
|
||||
- [Bigtable: A Distributed Storage System for Structured Data](https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/bigtable-osdi06.pdf)
|
||||
- [An In-Depth Look at the HBase Architecture](https://mapr.com/blog/in-depth-look-hbase-architecture)
|
||||
|
|
@ -48,28 +48,28 @@ hidden: true
|
|||
|
||||
#### 分布式理论
|
||||
|
||||
- [分布式理论](https://dunwu.github.io/design/pages/367308/)
|
||||
- [深入剖析共识性算法 Paxos](https://dunwu.github.io/design/pages/874539/)
|
||||
- [深入剖析共识性算法 Raft](https://dunwu.github.io/design/pages/e40812/)
|
||||
- [分布式算法 Gossip](https://dunwu.github.io/design/pages/d15993/)
|
||||
- [分布式一致性](https://dunwu.github.io/blog/pages/dac0e2/)
|
||||
- [深入剖析共识性算法 Paxos](https://dunwu.github.io/blog/pages/874539/)
|
||||
- [深入剖析共识性算法 Raft](https://dunwu.github.io/blog/pages/e40812/)
|
||||
- [分布式算法 Gossip](https://dunwu.github.io/blog/pages/d15993/)
|
||||
|
||||
#### 分布式关键技术
|
||||
|
||||
##### 流量调度
|
||||
|
||||
- [流量控制](https://dunwu.github.io/design/pages/282676/)
|
||||
- [流量控制](https://dunwu.github.io/blog/pages/282676/)
|
||||
- [负载均衡](https://dunwu.github.io/blog/pages/98a1c1/)
|
||||
- [服务路由](https://dunwu.github.io/design/pages/d04ece/)
|
||||
- [分布式会话基本原理](https://dunwu.github.io/design/pages/3e66c2/)
|
||||
- [服务路由](https://dunwu.github.io/blog/pages/d04ece/)
|
||||
- [分布式会话基本原理](https://dunwu.github.io/blog/pages/3e66c2/)
|
||||
|
||||
##### 数据调度
|
||||
|
||||
- [缓存基本原理](https://dunwu.github.io/design/pages/471208/)
|
||||
- [读写分离基本原理](https://dunwu.github.io/design/pages/7da6ca/)
|
||||
- [分库分表基本原理](https://dunwu.github.io/design/pages/103382/)
|
||||
- [分布式 ID 基本原理](https://dunwu.github.io/design/pages/0b2e59/)
|
||||
- [分布式事务基本原理](https://dunwu.github.io/design/pages/910bad/)
|
||||
- [分布式锁基本原理](https://dunwu.github.io/design/pages/69360c/)
|
||||
- [缓存基本原理](https://dunwu.github.io/blog/pages/471208/)
|
||||
- [读写分离基本原理](https://dunwu.github.io/blog/pages/7da6ca/)
|
||||
- [分库分表基本原理](https://dunwu.github.io/blog/pages/103382/)
|
||||
- [分布式 ID 基本原理](https://dunwu.github.io/blog/pages/0b2e59/)
|
||||
- [分布式事务基本原理](https://dunwu.github.io/blog/pages/910bad/)
|
||||
- [分布式锁基本原理](https://dunwu.github.io/blog/pages/69360c/)
|
||||
|
||||
### 其他
|
||||
|
||||
|
|
@ -86,11 +86,13 @@ hidden: true
|
|||
|
||||
> [关系型数据库](03.关系型数据库) 整理主流关系型数据库知识点。
|
||||
|
||||
### 公共知识
|
||||
### 关系型数据库综合
|
||||
|
||||
- [关系型数据库面试总结](03.关系型数据库/01.综合/01.关系型数据库面试.md) 💯
|
||||
- [SQL Cheat Sheet](03.关系型数据库/01.综合/02.SqlCheatSheet.md) 是一个 SQL 入门教程。
|
||||
- [扩展 SQL](03.关系型数据库/01.综合/03.扩展SQL.md) 是一个 SQL 入门教程。
|
||||
- [SQL 语法基础特性](03.关系型数据库/01.综合/02.SQL语法基础特性.md)
|
||||
- [SQL 语法高级特性](03.关系型数据库/01.综合/03.SQL语法高级特性.md)
|
||||
- [扩展 SQL](03.关系型数据库/01.综合/03.扩展SQL.md)
|
||||
- [SQL Cheat Sheet](03.关系型数据库/01.综合/99.SqlCheatSheet.md)
|
||||
|
||||
### Mysql
|
||||
|
||||
|
|
@ -153,12 +155,16 @@ hidden: true
|
|||
|
||||
### HBase
|
||||
|
||||
> [HBase](https://dunwu.github.io/bigdata-tutorial/hbase) 📚 因为常用于大数据项目,所以将其文档和源码整理在 [bigdata-tutorial](https://dunwu.github.io/bigdata-tutorial/) 项目中。
|
||||
|
||||
- [HBase 原理](https://github.com/dunwu/bigdata-tutorial/blob/master/docs/hbase/HBase原理.md) ⚡
|
||||
- [HBase 命令](https://github.com/dunwu/bigdata-tutorial/blob/master/docs/hbase/HBase命令.md)
|
||||
- [HBase 应用](https://github.com/dunwu/bigdata-tutorial/blob/master/docs/hbase/HBase应用.md)
|
||||
- [HBase 运维](https://github.com/dunwu/bigdata-tutorial/blob/master/docs/hbase/HBase运维.md)
|
||||
- [HBase 快速入门](06.列式数据库/01.HBase/01.HBase快速入门.md)
|
||||
- [HBase 数据模型](06.列式数据库/01.HBase/02.HBase数据模型.md)
|
||||
- [HBase Schema 设计](06.列式数据库/01.HBase/03.HBaseSchema设计.md)
|
||||
- [HBase 架构](06.列式数据库/01.HBase/04.HBase架构.md)
|
||||
- [HBase Java API 基础特性](06.列式数据库/01.HBase/10.HBaseJavaApi基础特性.md)
|
||||
- [HBase Java API 高级特性之过滤器](06.列式数据库/01.HBase/11.HBaseJavaApi高级特性之过滤器.md)
|
||||
- [HBase Java API 高级特性之协处理器](06.列式数据库/01.HBase/12.HBaseJavaApi高级特性之协处理器.md)
|
||||
- [HBase Java API 其他高级特性](06.列式数据库/01.HBase/13.HBaseJavaApi其他高级特性.md)
|
||||
- [HBase 运维](06.列式数据库/01.HBase/21.HBase运维.md)
|
||||
- [HBase 命令](06.列式数据库/01.HBase/22.HBase命令.md)
|
||||
|
||||
## 搜索引擎数据库
|
||||
|
||||
|
|
|
|||
101
docs/README.md
101
docs/README.md
|
|
@ -33,56 +33,37 @@ footer: CC-BY-SA-4.0 Licensed | Copyright © 2018-Now Dunwu
|
|||
> - 🔁 项目同步维护:[Github](https://github.com/dunwu/db-tutorial/) | [Gitee](https://gitee.com/turnon/db-tutorial/)
|
||||
> - 📖 电子书阅读:[Github Pages](https://dunwu.github.io/db-tutorial/) | [Gitee Pages](https://turnon.gitee.io/db-tutorial/)
|
||||
|
||||
## 分布式
|
||||
|
||||
### 分布式综合
|
||||
|
||||
- [分布式面试总结](https://dunwu.github.io/blog/pages/f9209d/)
|
||||
|
||||
### 分布式理论
|
||||
|
||||
- [分布式理论](https://dunwu.github.io/blog/pages/286bb3/) - 关键词:`拜占庭将军`、`CAP`、`BASE`、`错误的分布式假设`
|
||||
- [共识性算法 Paxos](https://dunwu.github.io/blog/pages/0276bb/) - 关键词:`共识性算法`
|
||||
- [共识性算法 Raft](https://dunwu.github.io/blog/pages/4907dc/) - 关键词:`共识性算法`
|
||||
- [分布式算法 Gossip](https://dunwu.github.io/blog/pages/71539a/) - 关键词:`数据传播`
|
||||
|
||||
### 分布式关键技术
|
||||
|
||||
- 集群
|
||||
- 复制
|
||||
- 分区
|
||||
- 选主
|
||||
|
||||
#### 流量调度
|
||||
|
||||
- [流量控制](https://dunwu.github.io/blog/pages/60bb6d/) - 关键词:`限流`、`熔断`、`降级`、`计数器法`、`时间窗口法`、`令牌桶法`、`漏桶法`
|
||||
- [负载均衡](https://dunwu.github.io/blog/pages/98a1c1/) - 关键词:`轮询`、`随机`、`最少连接`、`源地址哈希`、`一致性哈希`、`虚拟 hash 槽`
|
||||
- [服务路由](https://dunwu.github.io/blog/pages/3915e8/) - 关键词:`路由`、`条件路由`、`脚本路由`、`标签路由`
|
||||
- 服务网关
|
||||
- [分布式会话](https://dunwu.github.io/blog/pages/95e45f/) - 关键词:`粘性 Session`、`Session 复制共享`、`基于缓存的 session 共享`
|
||||
|
||||
#### 数据调度
|
||||
|
||||
- [数据缓存](https://dunwu.github.io/blog/pages/fd0aaa/) - 关键词:`进程内缓存`、`分布式缓存`、`缓存雪崩`、`缓存穿透`、`缓存击穿`、`缓存更新`、`缓存预热`、`缓存降级`
|
||||
- [读写分离](https://dunwu.github.io/blog/pages/3faf18/)
|
||||
- [分库分表](https://dunwu.github.io/blog/pages/e1046e/) - 关键词:`分片`、`路由`、`迁移`、`扩容`、`双写`、`聚合`
|
||||
- [分布式 ID](https://dunwu.github.io/blog/pages/3ae455/) - 关键词:`UUID`、`自增序列`、`雪花算法`、`Leaf`
|
||||
- [分布式事务](https://dunwu.github.io/blog/pages/e1881c/) - 关键词:`2PC`、`3PC`、`TCC`、`本地消息表`、`MQ 消息`、`SAGA`
|
||||
- [分布式锁](https://dunwu.github.io/blog/pages/40ac64/) - 关键词:`数据库`、`Redis`、`ZooKeeper`、`互斥`、`可重入`、`死锁`、`容错`、`自旋尝试`
|
||||
|
||||
#### 资源调度
|
||||
|
||||
- 弹性伸缩
|
||||
|
||||
#### 服务治理
|
||||
|
||||
- [服务注册和发现](https://dunwu.github.io/blog/pages/1a90aa/)
|
||||
- [服务容错](https://dunwu.github.io/blog/pages/e32c7e/)
|
||||
- 服务编排
|
||||
- 服务版本管理
|
||||
|
||||
## 数据库综合
|
||||
|
||||
### 分布式存储原理
|
||||
|
||||
#### 分布式理论
|
||||
|
||||
- [分布式一致性](https://dunwu.github.io/blog/pages/dac0e2/)
|
||||
- [深入剖析共识性算法 Paxos](https://dunwu.github.io/blog/pages/874539/)
|
||||
- [深入剖析共识性算法 Raft](https://dunwu.github.io/blog/pages/e40812/)
|
||||
- [分布式算法 Gossip](https://dunwu.github.io/blog/pages/d15993/)
|
||||
|
||||
#### 分布式关键技术
|
||||
|
||||
##### 流量调度
|
||||
|
||||
- [流量控制](https://dunwu.github.io/blog/pages/282676/)
|
||||
- [负载均衡](https://dunwu.github.io/blog/pages/98a1c1/)
|
||||
- [服务路由](https://dunwu.github.io/blog/pages/d04ece/)
|
||||
- [分布式会话基本原理](https://dunwu.github.io/blog/pages/3e66c2/)
|
||||
|
||||
##### 数据调度
|
||||
|
||||
- [缓存基本原理](https://dunwu.github.io/blog/pages/471208/)
|
||||
- [读写分离基本原理](https://dunwu.github.io/blog/pages/7da6ca/)
|
||||
- [分库分表基本原理](https://dunwu.github.io/blog/pages/103382/)
|
||||
- [分布式 ID 基本原理](https://dunwu.github.io/blog/pages/0b2e59/)
|
||||
- [分布式事务基本原理](https://dunwu.github.io/blog/pages/910bad/)
|
||||
- [分布式锁基本原理](https://dunwu.github.io/blog/pages/69360c/)
|
||||
|
||||
### 其他
|
||||
|
||||
- [Nosql 技术选型](12.数据库/01.数据库综合/01.Nosql技术选型.md)
|
||||
- [数据结构与数据库索引](12.数据库/01.数据库综合/02.数据结构与数据库索引.md)
|
||||
|
||||
|
|
@ -96,11 +77,13 @@ footer: CC-BY-SA-4.0 Licensed | Copyright © 2018-Now Dunwu
|
|||
|
||||
> [关系型数据库](12.数据库/03.关系型数据库) 整理主流关系型数据库知识点。
|
||||
|
||||
### 公共知识
|
||||
### 关系型数据库综合
|
||||
|
||||
- [关系型数据库面试总结](12.数据库/03.关系型数据库/01.综合/01.关系型数据库面试.md) 💯
|
||||
- [SQL Cheat Sheet](12.数据库/03.关系型数据库/01.综合/02.SqlCheatSheet.md) 是一个 SQL 入门教程。
|
||||
- [扩展 SQL](12.数据库/03.关系型数据库/01.综合/03.扩展SQL.md) 是一个 SQL 入门教程。
|
||||
- [SQL 语法基础特性](12.数据库/03.关系型数据库/01.综合/02.SQL语法基础特性.md)
|
||||
- [SQL 语法高级特性](12.数据库/03.关系型数据库/01.综合/03.SQL语法高级特性.md)
|
||||
- [扩展 SQL](12.数据库/03.关系型数据库/01.综合/03.扩展SQL.md)
|
||||
- [SQL Cheat Sheet](12.数据库/03.关系型数据库/01.综合/99.SqlCheatSheet.md)
|
||||
|
||||
### Mysql
|
||||
|
||||
|
|
@ -163,12 +146,16 @@ footer: CC-BY-SA-4.0 Licensed | Copyright © 2018-Now Dunwu
|
|||
|
||||
### HBase
|
||||
|
||||
> [HBase](https://dunwu.github.io/bigdata-tutorial/hbase) 📚 因为常用于大数据项目,所以将其文档和源码整理在 [bigdata-tutorial](https://dunwu.github.io/bigdata-tutorial/) 项目中。
|
||||
|
||||
- [HBase 原理](https://github.com/dunwu/bigdata-tutorial/blob/master/docs/hbase/HBase原理.md) ⚡
|
||||
- [HBase 命令](https://github.com/dunwu/bigdata-tutorial/blob/master/docs/hbase/HBase命令.md)
|
||||
- [HBase 应用](https://github.com/dunwu/bigdata-tutorial/blob/master/docs/hbase/HBase应用.md)
|
||||
- [HBase 运维](https://github.com/dunwu/bigdata-tutorial/blob/master/docs/hbase/HBase运维.md)
|
||||
- [HBase 快速入门](12.数据库/06.列式数据库/01.HBase/01.HBase快速入门.md)
|
||||
- [HBase 数据模型](12.数据库/06.列式数据库/01.HBase/02.HBase数据模型.md)
|
||||
- [HBase Schema 设计](12.数据库/06.列式数据库/01.HBase/03.HBaseSchema设计.md)
|
||||
- [HBase 架构](12.数据库/06.列式数据库/01.HBase/04.HBase架构.md)
|
||||
- [HBase Java API 基础特性](12.数据库/06.列式数据库/01.HBase/10.HBaseJavaApi基础特性.md)
|
||||
- [HBase Java API 高级特性之过滤器](12.数据库/06.列式数据库/01.HBase/11.HBaseJavaApi高级特性之过滤器.md)
|
||||
- [HBase Java API 高级特性之协处理器](12.数据库/06.列式数据库/01.HBase/12.HBaseJavaApi高级特性之协处理器.md)
|
||||
- [HBase Java API 其他高级特性](12.数据库/06.列式数据库/01.HBase/13.HBaseJavaApi其他高级特性.md)
|
||||
- [HBase 运维](12.数据库/06.列式数据库/01.HBase/21.HBase运维.md)
|
||||
- [HBase 命令](12.数据库/06.列式数据库/01.HBase/22.HBase命令.md)
|
||||
|
||||
## 搜索引擎数据库
|
||||
|
||||
|
|
|
|||
Loading…
Reference in New Issue